- 投稿日:2019-12-03T23:16:59+09:00
memory allocation error対策でEC2にスワップ領域を作成する
はじめに
EC2でJenkinsを実行中に微妙にメモリが足りなくて、
memory allocation errorでジョブが失敗することがありました。
稀な実行ジョブのためにインスタンスタイプを変えるのもしゃくなので、スワップ領域を作成して対処することにしました。実施手順
現在のスワップ領域を確認
$ grep Swap /proc/meminfo SwapCached: 0 kB SwapTotal: 0 kB SwapFree: 0 kB1GiBのスワップ領域を作成
$ sudo dd if=/dev/zero of=/swapfile bs=100M count=10スワップファイルの読み書きのアクセス許可を更新
$ sudo chmod 600 /swapfileLinux スワップ領域のセットアップ
$ sudo mkswap /swapfileスワップ領域にスワップファイルを追加して、スワップファイルを即座に使用できるようにする
$ sudo swapon /swapfile手順が正常に完了したか確認
$ sudo swapon -s
/etc/fstabファイルを編集して、起動時にスワップファイルを有効にする$ sudo vi /etc/fstab tmpfs /dev/shm tmpfs defaults 0 0 devpts /dev/pts devpts gid=5,mode=620 0 0 sysfs /sys sysfs defaults 0 0 proc /proc proc defaults 0 0 + /swapfile swap swap defaults 0 0終わったか確認する
grep Swap /proc/meminfo SwapCached: 0 kB SwapTotal: 1023996 kB SwapFree: 1023996 kB以上でした。
- 投稿日:2019-12-03T22:53:13+09:00
Lambda x MySQLでデータを更新してもクエリ結果が変わらない(キャッシュされているような振る舞いをする)
問題
表題の通りだが、Lambda x MySQL(RDS)で、テーブルのデータを変更しても、Lambda上でPythonからDBに対するSELECT結果が変わらないという問題が起きた。その場しのぎとしてLambdaのコードを変更すると、データ変更が反映されるためそれで運用をしのいでいる環境だった(または、少し時間を空けていた)。問題の解消法がわかったので載せておく。ただし原因はわかっていない。
(補足:RDSはサーバレスの部品ではないので、一般的にはDynamoDBを推奨)解消方法
StackOverflowで同様の現象で困っている人がいて、回答の通り、Connection確立時に autocommit=True とすることで問題を解消できた。または各SELECT後にcommitしても解消できるかと思う。
stackoverflow: why is an aws lambda python call to a mysql rds being cached
以下はpymysqlというライブラリの例
query.py# Connect to the database connection = pymysql.connect(host='localhost', user='user', password='passwd', db='db', charset='utf8mb4', cursorclass=pymysql.cursors.DictCursor, autocommit=True) # これを追加考察というか疑問
問題を回避できたのは良いが、今回の問題がLambda起因なのかMySQL起因なのかすらよくわかっていない。
クエリ後にConnectionが切れているのは確認したが、コネクション再開時に依然としてトランザクションが続いているということはありえるのだろうか。もしそうだとすると、Select後にCommitすることで、他のトランザクションの変更が反映されるということであれば理解できる。
(少なくともMySQL(innoDB)のデフォルトの分離性レベルは「REPEATABLE-READ」で、innoDBであればこの分離性レベルであってもファントムリードも起きないほど分離性レベルは高い)pymysqlのgithub issuesでは以下のように書いてあった。
Autocommit off can mean you are seeing a shadowed copy of the data in which case you will not see outside changes until you rollback/commit the transaction
オートコミットがオフであることが意味することは、データのシャドウドコピーを見ることであり、その状況では、コミット/ロールバックしない限り外部の変更を見ることができないだろう、と。
どなたか、何が起きているのか教えてください
参考
- 投稿日:2019-12-03T22:09:39+09:00
チームにAWS セッションマネージャを導入した話
はじめに
こんにちは。
この記事は、FOLIO Advent calendar 2019 7日目の記事です。
私はFOLIOのグロース部というデータ分析業務やダッシュボードや分析基盤の開発・運用をするチームに所属しており、そのなかで私は主に分析基盤の開発・運用を担当しています。
なお、FOLIOには今年の10月からジョインしたばかりです。
思えば去年の今頃は前職のアドベントカレンダーの記事を書いていましたね。。Databricksは大好きなツールなので、普段遣いできなくなってしまったのは転職の心残りの一つです。さて本題。
この記事では、直近AWSのセッションマネージャをチームに導入して、EC2へのSSHログインを廃止した話について書いていきます。AWSセッションマネージャとは
AWSセッションマネージャとは、AWS System Managerの一機能で、平たく言うとEC2サーバに公開鍵認証を経ずにログインし、コマンドを実行できる機能です。
ちなみにSystem managerはその名の通りAWSのリソース管理のための多様な機能を備えていますが、本記事ではそれらには触れません。
興味ある方はこちらの記事なんかがコンパクトに纏まっていて良いと思います。前提となる業務状況と導入の目的
- 複数のサーバを動かしており、分析用のjupyterが動いているサーバ、データパイプラインを動かすための利用しているairflow用のサーバ, EC2にホスティングしているredashサーバなど複数のサーバが動いている
- ちなみにFOLIOでは部署ごとにAWSアカウントが別れているので、アプリケーションに関するリソースは分析メンバーは直接触れません。今回の話はデータ分析周りのAWSリソースのことを扱っているとご理解ください。
- 上記のような状況で、複数サーバにログインするための鍵やアカウントの管理が煩雑になっていた。
こうした状況のため、セッションマネージャの機能を利用してサーバにログインさせることで、シンプルに管理することが導入のモチベーションです。
また、セッションマネージャの良いところはAWSのマネジメントコンソール上からサーバにログインできることにもありますが、セッションマネージャ導入をメンバーに説明した段階で、セッションマネージャを(ブラウザではなく)ターミナル上で使いたいというニーズがあったため、チームメンバーにIAMユーザを払い出してAWS CLIでセッションマネージャを利用する方法を選択しました。具体的に実施したこと
- セッションマネージャを利用するためのIAMポリシーの作成し、それをIAMグループにアタッチし、チームメンバーにそのグループに所属するIAMユーザを払い出した
- EC2サーバ側の準備として、
- セッションマネージャを利用するための、IAMポリシーを作成し、セッションマネージャを利用したいインスタンスのロールにアタッチ
- 各EC2サーバ上で必要に応じてamazon-ssm-agentをインストール(AWSが用意したAMIを使ってる場合、最初からインストールされていますが、一部コミュニティAMIを利用しているサーバには個別にインストールしました)
- ユーザ向けの導入準備として、普段SSHを使ってサーバにログインしているメンバー向けにセッションマネージャのハンズオンを実施。
それぞれの手順について書いていきます。
IAMポリシーの準備
準備したポリシーは、
1. SSMを利用するユーザに付与するポリシー
2. EC2サーバ側のロールにアタッチするポリシー
の2つ。Session manegerは便利なサービスである反面強力なサービスでもあるので、セキュリティホールにもなりえます。1
必要十分なIAMポリシー設計ができると良いですね。
実際に利用しているものとは異なりますが、ポリシーの一例を提示します。
- ユーザに付与するポリシー
ごくシンプルなポリシーですが、工夫した点としては、セッションの終了は「自分が立ち上げたセッションのみ終了を許可している」点です。
ssm-users-policy.json{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "ssm:StartSession", "Resource": [ "<your-ec2-resource-list>" ] }, { "Effect": "Allow", "Action": "ssm:TerminateSession", "Resource": "arn:aws:ssm:*:*:session/${aws:username}-*" } ] }
- EC2サーバに付与するポリシー
AWS管理ポリシーの
AmazonEC2RoleforSSMから先ほどの記事を参考にガッツリ削ってます。
ええ、セッションマネージャからEC2にアクセスするだけならこれだけでも十分なんです。policy-for-ec2-server.json{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ssm:DescribeAssociation", "ssmmessages:*", "ssm:UpdateInstanceInformation", "ec2messages:*" ], "Resource": "*" } ] }EC2サーバ上でSSMエージェントを動作させる
セッションマネージャを用いてEC2にアクセスするには、そのサーバ上でSSMエージェントが動作している必要があります。
前述の通り、そこそこ新しいAWS純正のAMIを使っているインスタンスには最初からインストールおよび起動されているので、インストールは不要です。
もしインストールされていなくても、Amazon Linuxであればyum, Ubuntuであればaptからインストールできます。
ただし、インストールしたのち、EC2にアタッチされているIAMロールに前述のIAMポリシーをアタッチしたあとに追加したポリシーの情報を反映するためにSSMエージェントを再起動する必要があります。ここ、しょうもないポイントながら設定時にハマったので注意です。さて、ここまで終わればEC2側の準備は完了なので、続いてユーザ側の準備を進めます。
ユーザ側の準備
AWS CLIは当然必要なのでインストールした上で、セッションマネージャ用のプラグインをインストールします。
やり方は非常にシンプルです。# インストール用のファイルを落っことしてきて解凍する curl "https://s3.amazonaws.com/session-manager-downloads/plugin/latest/mac/sessionmanager-bundle.zip" -o "sessionmanager-bundle.zip" unzip sessionmanager-bundle.zip # 公式ドキュメント上のインストールコマンドを叩くだけ sudo ./sessionmanager-bundle/install -i /usr/local/sessionmanagerplugin -b /usr/local/bin/session-manager-plugin続いて、AWS CLIでIAMユーザを利用するための準備も進めましょう。
ユーザに配布しているIAMユーザには作業用ファイルを置くS3を操作するためのものなども存在するのですが、前述の理由からセッションマネージャ専用のIAMユーザを払い出すことにしました。
なので、専用のプロファイルを切って、そちらに必要な情報を追加していきましょう。
下の例ではssmというprofile名で必要な情報を格納しています。~/.aws/config[profile ssm] region = <your-region>~/.aws/credentials[ssm] aws_access_key_id = <your_aws_access_key_id> aws_secret_access_key = <your_aws_secret_access_key>接続する際はこんな感じ。接続したいインスタンスのIDを管理コンソールからコピペしてきましょう。
aws ssm start-session --target <your-ec2-instance-id> --profile ssmこのコマンドを実行すると、セッションIDが払い出され、サーバ上でコマンドが実行できます。
Starting session with SessionId: xxxxxxxxxxxxxxxxxxxx(※実際にはここに実際のSessionIdが入ります) $ pwd /var/snap/amazon-ssm-agent/1480 $ whoami ssm-user $ echo "日本語も使える" 日本語も使えるssm-userというユーザでログインされていることがわかりますね。
sudoが使えるので、ここからユーザを切り替えることもできるので、任意の別のユーザとしてコマンドを実行することもできます。
本来ならばユーザも指定したいところではありますが、現在はssm-userでログインしています(そのへんの経緯は後述しているので興味があれば読んでみてください)。まとめ
AWSセッションマネージャを用いて、鍵管理を行うことなくEC2にアクセスできるようになりました。
ターミナル上から操作できるので、さながらSSHを利用しているような使い心地でEC2リソースにアクセスできますね。
また、本記事では直接触れなかったものの、セッションマネージャの実行ログはCloudWatchで監査ログが残せるのもメリットの一つです。あとがき兼FAQ
- 最初にユーザ変えるコマンド打つのだるくない?SSHみたいにユーザ指定できないの?
- ユーザ指定する方法はあります。ただし、今回の業務状況にはマッチしなかったので採用していません。
- セッションマネージャを経由してログインするサーバが単一、もしくは共通のユーザ名を保つ場合には、こちらのドキュメント2のようにセッションマネージャの設定からAWSアカウント単位、IAM role単位で設定することもできますが、前提条件に書いた、複数のサーバにログインする都合上採用できませんでした。
- scpはどうするの?
- セッションマネージャのちょっと残念な点でもあるのですが、 AWS CLIを用いてscpコマンドを実行することもできるのですが、その際に EC2サーバを作成する際に発行された秘密鍵が必要になります。
せっかく鍵管理から解放されたと思ったのに...!ということで、sshを廃止したついでにscpも廃止し、サーバとローカル環境間でファイルをやり取りする際には、作業用のファイルを置く(本番実行に関わるような設定ファイルは置かない)ためのS3バケットを作成し、そこを介してファイルをやり取りすることにしています。- インスタンスID暗記するの辛い
- よくログインするサーバにはエイリアスを張りましょう
- 投稿日:2019-12-03T21:32:58+09:00
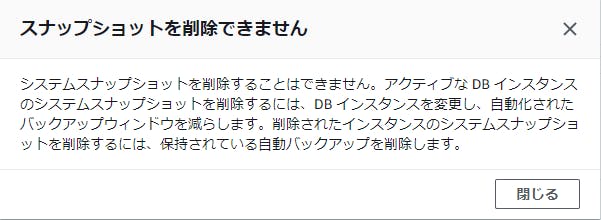
自動取得されたRDSのスナップショットが削除できない場合
自動取得されたRDSのスナップショットを削除しようとしたら、「システムスナップショットを削除することはできません」と言われて困惑している人向け。
状況
OracleのRDS環境を動作確認のために作ったら、知らぬ間に自動スナップショットが取得されていました。
RDSのインスタンスを削除してもそのスナップショットは削除されなかったので、手動で削除しようと思ったらこんなメッセージが出て削除できませんでした。
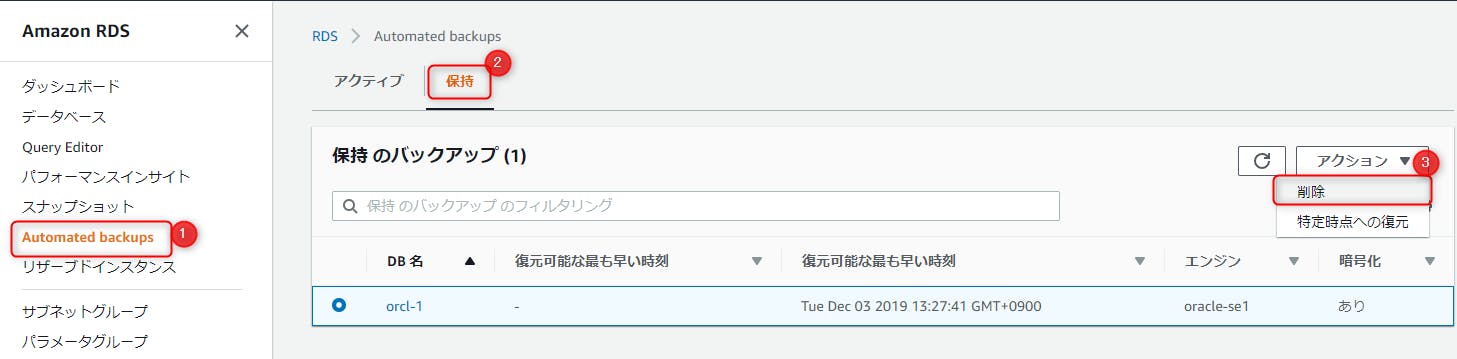
削除方法
左側メニューの「Automated backups」からバックアップを削除すると、連動して削除されます。
よくよく見てみれば、エラーメッセージの末尾にちゃんと書いてありますね。「保持されている自動バックアップを削除します」って。バックアップとスナップショットは別物。
エラーメッセージはちゃんと読みましょうという教訓でした。
- 投稿日:2019-12-03T21:32:19+09:00
【AWS】 fargate間のレスポンスタイムとサイドカー
はじめに
fargateで複数のコンテナ間通信が発生する場合fargate間のレスポンスタイムがどのくらいかかるのか気になったので参考までに測定してみたメモ。
構成
比較用に同一タスク上に複数コンテナ(サイドカー)を構築した場合と別タスクからELB経由でアクセスした際で比較を行った。
計測条件
別タスクのコンテナからELB経由でAPI Serverにアクセスした場合と、
同一タスクのコンテナからlocalhostでAPI Serverにアクセスした場合を
下記curlで測定した(localhostの場合のコマンド例)。curl -kL -s -o /dev/null -w "%{time_total}\n" http://127.0.0.1/api
ここでは
time_totalをレスポンスタイムとするまたそれぞれのコンテナ内で
lscpuを見たところ別ものだったため別インスタンス上に配置されているものとする。計測結果
10回測定し最速と最遅を切り捨て8回の平均値とする。
別タスク 同一タスク 1 82 2 933 8 2 4 9 2 5 8 2 6 8 17 9 1 8 8 2 9 9 1 10 8 1 Ave. 8.4 1.6 (msec)
別タスクにすることで2者間の差である 6.8msec が乗ってくることになる。
スループット
同様に大きめのペイロードサイズ(100MB弱)を転送するときのスループットについても計測
別タスク 同一タスク 1 4,9253862 3,611 379 3 4,484 377 4 2,925 380 5 3,865 353 6 4,205 353 7 2,828359 8 3,944 3529 3,325 363 10 4,353 358 Ave. 3,839 365 (msec)
2者間の差とペイロードサイズ(88,099,412byte)から 約200Mbps 程度と推定される
まとめ
このレイテンシーが許容されるのか否かで同一タスク上に構成すべきか検討材料になるであろう。
ただしスケールさせる場合はタスク単位となるためトレードオフである。
また本計測値はfargateのvCPUタイプやその他構成など条件によって変わってくるため参考値程度にとどめておく。

- 投稿日:2019-12-03T21:01:57+09:00
本当にあったAWSでやらかした話と対策?
概要
みなさんこんにちは?
「フォトリ」という家族写真の撮影サービスを運用している会社でCTOをしてるカイトズズキと申します。この記事では、先日会社のAWSで割と高額の請求が来てしまい?死にたくなる思いをしたので、そのお話についてしていきます。
AWSは便利だけど、お金使いすぎたりしないか不安になりますよね。
特に僕はそんなにAWSには詳しくない人間なので、なおさらドキドキです。この記事を通して、僕がやっちまった失敗をみなさんに知ってもらい、
同じような失敗をする人が1人でも減ることを祈ってます?やらかした話
やらかしレベル
まず、結果としてどれくらいやらかしたかと言うと、
普段の使用料金以外に、
-Lambdaで 10万円 くらい
-S3で 30万円 くらい
の請求が来てしまいました、、、普段は数万円程度で2つのWebサービスを運用しているため、
最初に気づいたときは驚きすぎて理解に苦しみました、、、笑なお、結果的に
Lambdaの方はAWS様にご返金いただきました。
本当に神です、これからも一生ついていきます?何が起きたのか
まず最初に述べたいのは「しょうもないミス」です。
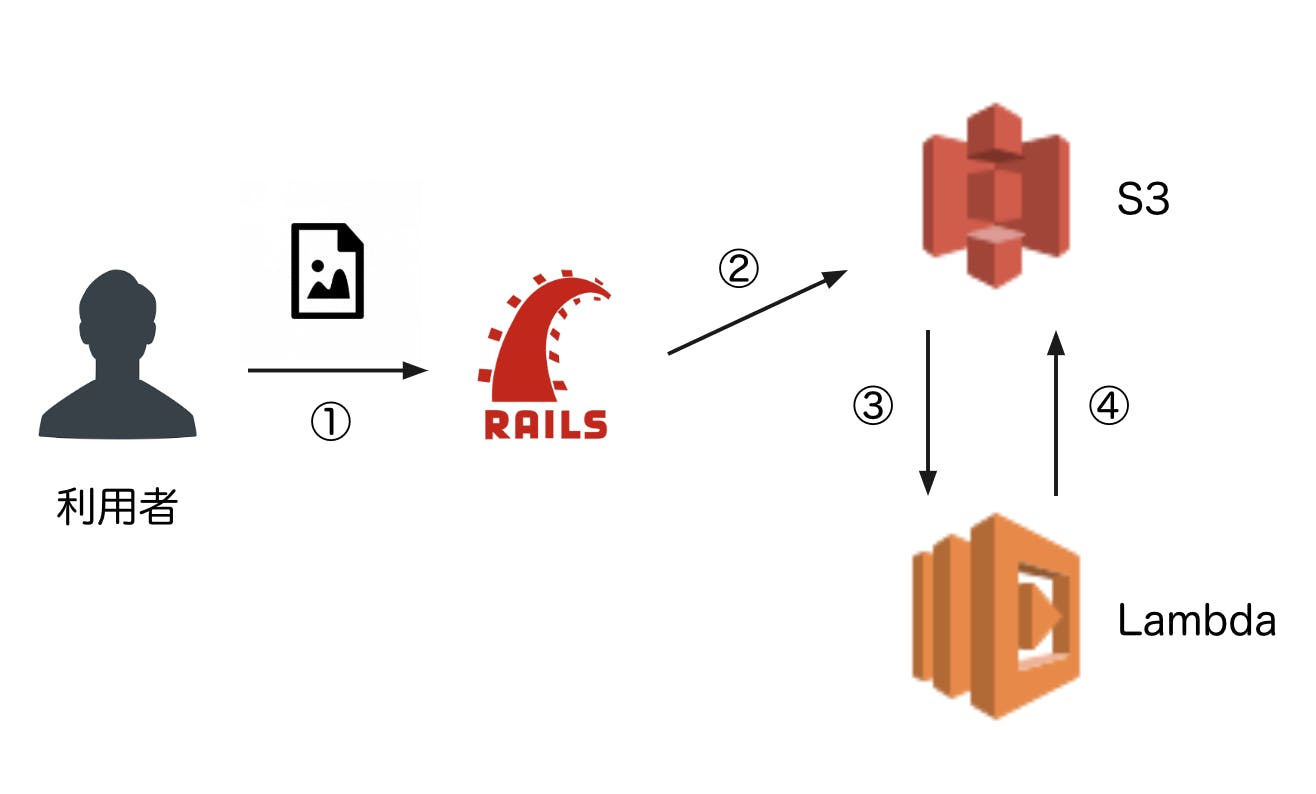
それだけにショックは大きいのですが、基礎が全てですね。まず、今回事件が起きたシステムの概要図です。
- ユーザーが画像を送信
- 送信された画像を受け取り、S3にアップロード
- S3の特定の場所(フォルダA)にファイルがアップロードされたときに、Lambda関数が発火
- 画像を加工し、S3にアップロード(フォルダB)
この一通りの流れで、
- ユーザーがアップした元画像 → フォルダA
- 加工された画像 → フォルダB
という状況が完成します。サービスの仕様上、さまざまな画像ファイルを取り扱うため、
このなんとも便利なシステムを僕らはいろんな場所で活用しておりました。。。しかし!!
ある日事件は起きました。
新しくLambda関数を作成した際に、
フォルダAとフォルダBに、同じフォルダを指定してしまったのです。言い換えると、Lambda内で加工した画像を加工前の画像があるフォルダに再アップする仕様にしてしまったのです。
(分かりにくい日本語ですみません?)
何が起きるかおわかりでしょうか?
先ほどの説明の 4 を実行した後に、再度 3 が実行されてしまい、3 → 4 → 3 → 4 ・・・ という無限ループが起きてしましました。
普通に考えればすぐに気づくことなのですが、、、
これにより
Lambda関数がたくさん実行され、S3にたくさん画像がアップロード/ダウンロードされ(具体的には GET と PUT のリクエストがたくさんされ)、無事に高額の請求がきました?なぜ高額になったのか
ただ、ミスった設定をしたことが問題ではなく、「すぐに対処できなかった」ことが本当の問題でした。
今回の件は、最初の無限ループが始まってから事件発覚までに約1週間もかかりました。それもたまたま今月の請求をチラ見したときに気づいたので、気づくのにもっとかかっていた可能性すらあります。
この後の「対応・対策」の部分で、このあたりを詳しくお話します。
対応・対策
今回の件を経て、いくつか対応や対策をしたので、軽くご紹介します。
皆さんも同じような目に遭わないよう、ちゃんと対策できてるか振り返ってみてください。(他にもこんな対策あるよ!みたいなのあれば是非たくさんコメントください!!)
対応
「対策」の前に「対応」です。
事故後に行った「対応」としては、
- 事故ったLambdaの設定を修正
- AWSに問い合わせ(ごめんなさい返金してくださいお願いします)
といった感じです。
あからさまな自爆で返金してもらうのは本当に申し訳なかったですが、
AWSの中の人に「たぶん返金できるよ」と教えてもらったので、勇気を持ってごめんなさいしました。また、今回の対応をするにあたり、以下の記事を参考に障害報告を作成しました。
エンジニアなら知っておきたい障害報告&再発防止策の考え方 - Qiita
これまでメンバーが数人の会社ということもあり、ほとんどの報告を口頭で行っていましたが、
この記事を参考に報告書を書いてみたところ、状況や思考がうまく整理され、かなりスッキリしました。わざわざ文章書くのはめんどくさく感じますが、
これは今年一番のオススメなので、最近やらかした人もこれからやらかす人も是非参考にしてみてください!対策
今回の諸悪の根源は、「事故ったこと」ではなく「事故に気づかなかったこと」だと思ってます。
なんなら気づくのに時間がかかったからこそ、ちょっとしたミスが事故になった、とも言えます。AWS様にお問い合わせした際、以下のような返事を頂きました。
意図しない課金が発生を防ぐため、
CloudWatch [参考1] にて請求アラートを作成いただき利用状況をモニタリングいただくこと、
AWS Budgets [参考2] を利用いただくことで予想されるコストがお客様の作成した予算を上回る場合や予算を超えた場合にアラートを通知するよう設定いただくことをおすすめしております。お手数ではございますが、下記の参考情報をご確認いただき、ご設定をいただきますようお願い申し上げます。
[参考1] https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/monitor_estimated_charges_with_cloudwatch.html
[参考2] https://docs.aws.amazon.com/ja_jp/awsaccountbilling/latest/aboutv2/budgets-managing-costs.htmlこれらを設定することにより、請求額が異常な値になるその前に気づくようになることができます。
やって当たり前の設定なのですが、それをサボっていたのです。。。
もし僕と同じようにサボっている人は、この機会に是非。また、上記に加えて、
CloudWatchを用いて、Lambda関数の実行回数(Invocations)にしきい値を設定し、実行されまくったときに通知がくるように設定しました。
↑こんな感じ関数毎に値を変えて設定しました。
また、各種通知はメールに送信されるだけでは見落とすリスクがあるため、
Slackの通知用チャンネルにも自動で投稿されるようにしました。(ここまで偉そう?に書いてますが、もろもろ対応を手伝ってくれたインターンS君、ありがとう!)
最後に
拙い文章ですが、最後まで読んでいただきありがとうございます。
事故ったときはショックのあまり夜も眠れない日々でしたが、
一通り振り返ってみて、すごくいい体験ができたな、と思ってます。皆さんも是非、たくさん失敗しながら楽しいAWSライフをお送りください!

- 投稿日:2019-12-03T20:58:38+09:00
AWS CLIを利用した、サービス監視について(Windows)
概要
AWS CLIを利用したWindowsサービス監視について記載します。
CloudWatch Agentでは、プロセス監視が可能ですが、サービス監視を行う事が出来ません。
そこで、Windowsのコマンドでサービスの起動状態を確認し
結果をCloudWatchに出力するといった内容となります。※
※出力=put の意味となります。事前設定
本内容では、下記項目が必要となるので先事前に準備をお願いします。
①CloudWatch メトリクス 出力用 IAMユーザ作成 ※1
②AWS CLIインストール,初期設定(IAMユーザ設定含む) ※1
※1 上記内容は、AWSに公式手順がある為参照してください。設定内容
今回の設定内容については、2フェーズに分け作業を実施します。
★設定フェーズ
①監視サービス名確認作業
②監視サービス確認用バッチファイル作成サービス名確認作業
まず、初めにサービス名の確認を行います。
Windowsのサービスより、対象のサービス一覧を確認して下さい。※2
対象のサービスをダブルクリックし、プロパティ情報を表示してください。
表示完了後、【サービス名】を確認してください。今回サービス名に記載されていないようを利用します。
※本例では、Task Schedulerのサービス確認を実施しています。
※2 ファイル名を指定して実行【services.msc】を起動する事により表示されます。
サービス確認用バッチファイル作成
次にバッチファイルを作成します。
まず、メモ帳を開き下記内容を入力してください。
一部内容は、可変となるため入力をお願いします。win_service.bat@echo off rem AWSインスタンスメタデータ取得 rem 取得後、【instanceid】に代入 for /f "usebackq tokens=*" %%a in (`PowerShell.exe -Command invoke-restmethod -uri http://169.254.169.254/latest/meta-data/instance-id`) do @set incetanceid=%%a rem サービス稼働確認(errorlevel の結果により、Processesの値を変更) sc query 【###確認したサービス名を入力###】 | findstr STATE | findstr RUNNING >null if %errorlevel% == 0 ( echo errorlevel=%errorlevel% set Processes=1 ) else ( echo errorlevel=%errorlevel% set Processes=0 ) echo Processes=%Processes% #Putコマンドを利用し、CloudWatchに送信 aws cloudwatch put-metric-data --metric-name "【###メトリクス名###】" --namespace "【###ネームスペース名###】" --region 【###リージョン名###】 --value %Processes% --unit "Count" --dimensions "InstanceId=%incetanceid%"★スクリプト説明
本スクリプトは、sc queryの結果を確認し正であれば、Processes変数に1を代入
誤であれば0を代入します。その後、CloudWatchにProcessesの値が送信されます。
※稼働しているサービスのみ表示されるので、STOP等の場合は表示されない。すなわち誤となります。後は、タスクスケジューラで繰り返しスクリプトを起動させれば完了です。
結果
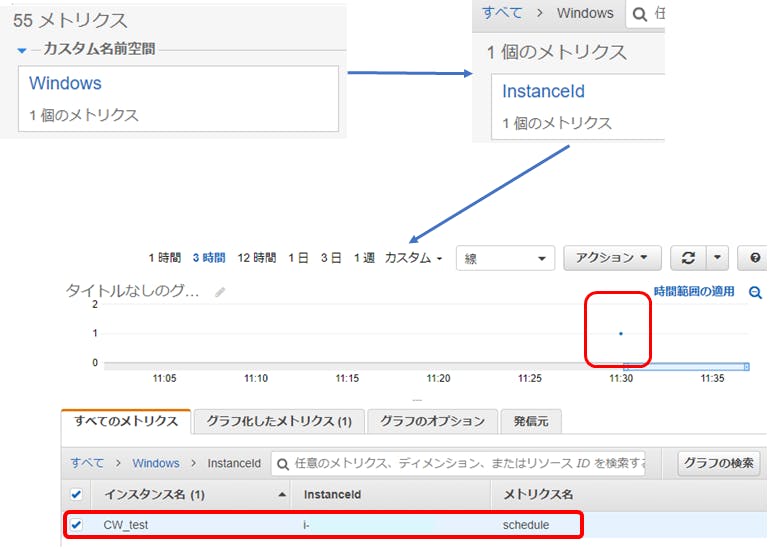
今回は、例として下記設定で実施しました。
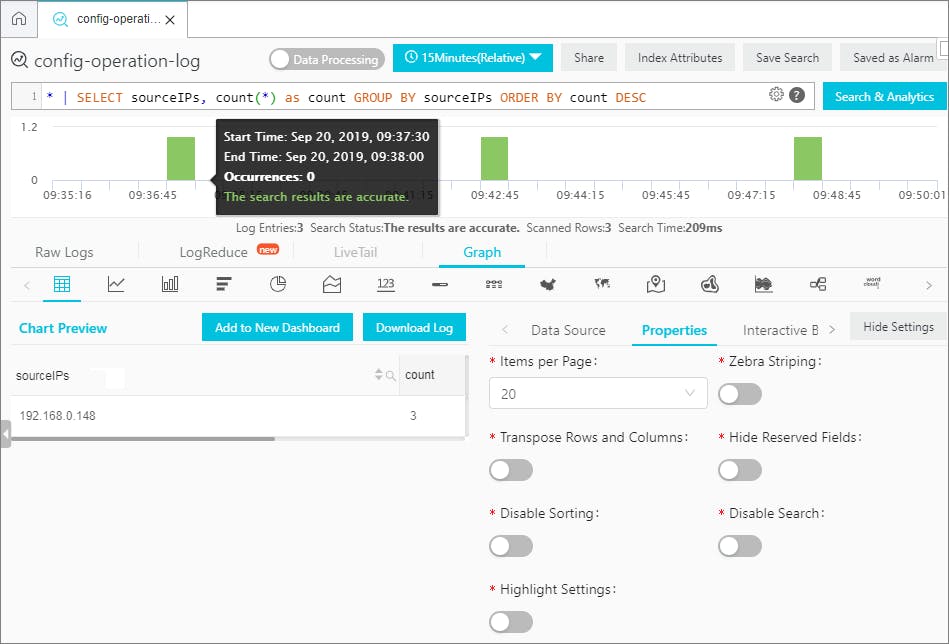
★本例での設定設定内容監視サービス名 "schedule" metric-name "schedule" namespace "Windows"★出力結果(CloudWatch内の出力結果です。)
CloudWatch 内にカスタムメトリクスが作成されています。
後は、本スクリプトを定期間隔で実行すれば完了となります。
※タスクスケジューラによる定期間隔設定方法については、別記事で記載しています。以上が、今回の内容となります。
参考URL
下記内容を参考にし本スクリプトを作成しております。
・CloudWatch メトリクス 出力用IAMユーザ作成方法
(https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/create-iam-roles-for-cloudwatch-agent.html)・Windows AWS CLIインストール
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/install-windows.html

- 投稿日:2019-12-03T20:47:32+09:00
社内chatworkにVIPチャンネルを作った話
がいよう
上記エントリが面白かったのでchatwork版を作りました。
やりたいこと
- 匿名チャンネルと、発言するbotアカウントを用意する。
- botアカウントでChatwork Webhookを使う。
- WebhookをAWS API Gatewayで受け取り、Lambdaを発火する。
- LambdaからChatwork APIを使いbotアカウントで匿名チャンネルへ発言する。
やっていきましょう
Chatworkをやる
匿名チャンネルと、発言するbotアカウントを作ります。
匿名チャンネルには一緒に遊びたいユーザーを全員追加しておきます。
botアカウントを作成したら、ChatWork画面右上のアカウント名 > API設定から
作成したbotアカウントでAPIが利用出来るよう設定しておきます。
※chatworkはAPIを利用する際管理者の許可が必要な場合があります。APIが使えるようになったらまずAPI Tokenを作成します。(後で使います)
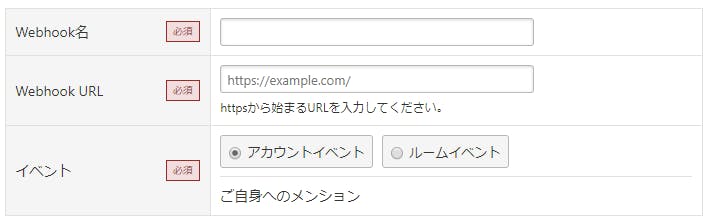
また、新規Webhookを作成しておきます。
URLは後から変えられるのでここでは適当で大丈夫です。
イベントがアカウントイベントになっていればOK。
名前は適当につけてください。AWSをやる
ChatWorkのWebhookから送信されるリクエストをLambdaで検証してみた
まずこれを読みます。読みました。雰囲気を掴むことができます。AWS Lambdaに新規関数を作成します。
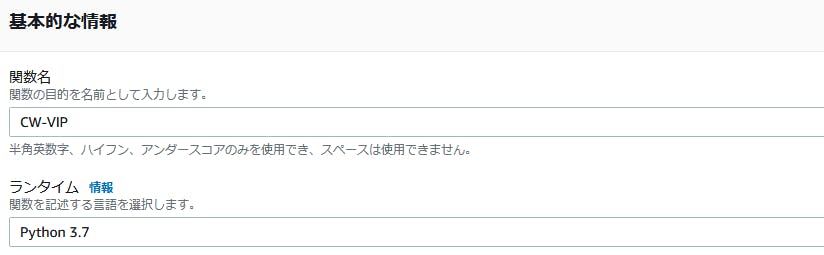
今回はPythonを使いますので、ランタイムはPython3.7等にしておいてください。
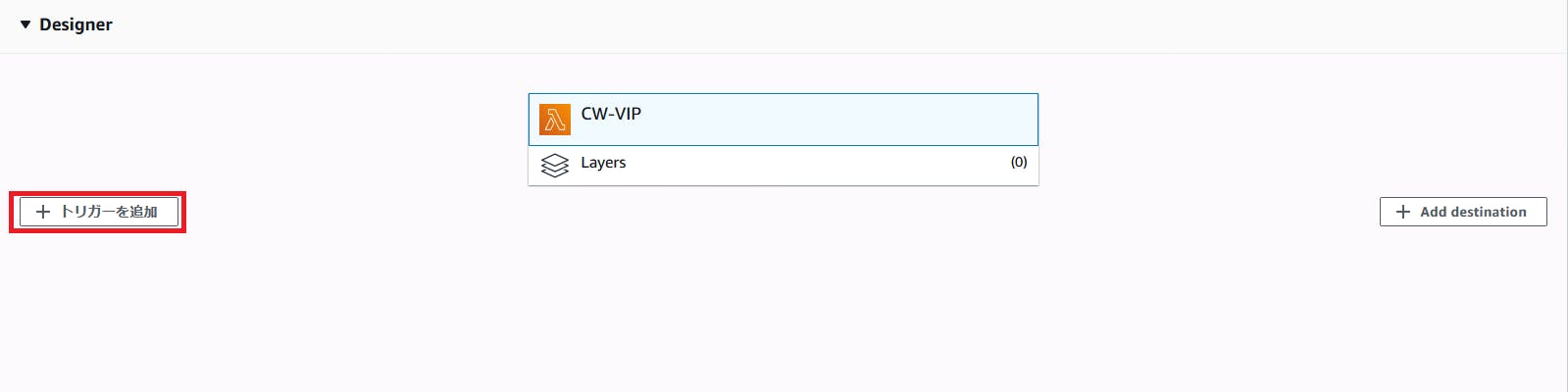
作成したら、トリガーの追加から
API Gatewayを登録します。
こんな感じに設定します。
手っ取り早く動かすためにセキュリティの設定を全て無視していますが、必要に応じて設定してください。ラムダの設定画面に戻ると
画像下部のように、少し下にAPIのエンドポイントが出てると思います。
これをchatworkのWebhook URLへ設定しておきましょう。ところで、脳がrequests以外からPOSTを送出したがらなかったため、ソースコード側の準備として
[検証]LambdaのLayer機能を早速試してみた #reinvent
上記エントリを参考にrequestsモジュールを持つLayerを追加します。
勿論、urllibの使い方を思い出す手段もあります。コストが安いと感じる方を選択してください。関数の作成
import json import os import requests def lambda_handler(event, context): url = f'https://api.chatwork.com/v2/rooms/{os.environ['ROOM_ID']}/messages' headers = {'X-ChatWorkToken': os.environ['CW_KEY']} content = json.loads(event['body']) # eventのbodyは文字列で来るようです content = content['webhook_event']['body'] # アカウントイベントにした場合、ここにメッセージ本文があります content = content.replace('[To:bot_account_id] botアカウント名さん\n', '') # Toで発言された時入ってくる文言を除去 params = {'body': f'{content}'} res = requests.post(url, data=params, headers=headers) return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') }最低限動作太郎です。これをLambdaのエディタ部分に書きます。
本当はWebhookに乗ってくるTOKENを使った認証を入れたり、処理の結果に応じてreturnする内容を変えたりした方がいいです。
これを書いた人はとにかく動かしたかったのでそういうのを端折りました。すみませんエディタ部分のすぐ下に環境変数の入力欄があると思いますので、匿名チャンネルのIDと匿名アカウントのAPI Tokenを設定してください。
チャンネルのIDは、ブラウザでそのチャンネルを開いた時URLに入っている数字を使っています。動かしてみる
動きます。良かったですね。
おわりに
残業の息抜きに作ったので、内容に自信がありません。
もしマサカリを投げたくなったらどんどん投げてください。
あとなんかダメなのあったら指摘して下さい。消しますので。ありがとうございました。

- 投稿日:2019-12-03T20:06:43+09:00
AWS+hls.jsでストリーミング再生(その1)
動画を配信するためにhls.jsを使ってみました。
動画を扱ったのが初めてだったので、まとめておきます。ストリーミング再生?HLS??
ストリーミング再生とは、本当に簡単に言うと「動画ファイルを細切れにして、ちょっとずつ読み込んで再生する方法」です。
動画(でかい)を一括で読み込んで再生すると、データの取得に時間がかかりますし、もし途中で見るのをやめるような場合はその分無駄が生じます。
ストリーミング再生では、細切れにされた動画を順番に取得して再生するので、動画を読み込みながら再生をすることが可能です。見なかった分のデータは取得しないので、一括で動画データを取得する方法と比べると、そういった意味では効率がいいと言えます。HLSはHTTPを使用してストリーミング再生するプロトコルです。
HLSはHTTP Live Streamingの略で、Appleが開発した動画配信のプロトコルです。
HLSはプレイリストファイル(.m3u8)とセグメントファイル(.ts)ファイルで構成されます。
セグメントファイルは動画を細切れにしたもので、プレイリストファイルにはセグメントファイルをどの順番で再生するかなどの情報が書かれています。使ったもの
今回使用したもの
・S3:動画ファイルの置き場所
・Amazon Elastic Transcoder:mp4の動画をHLS形式に変換
・firebase:ストリーミング再生するフロント側の場所1.動画を用意する
動画はmp4形式のものを用意しました(というか作ってもらった)。
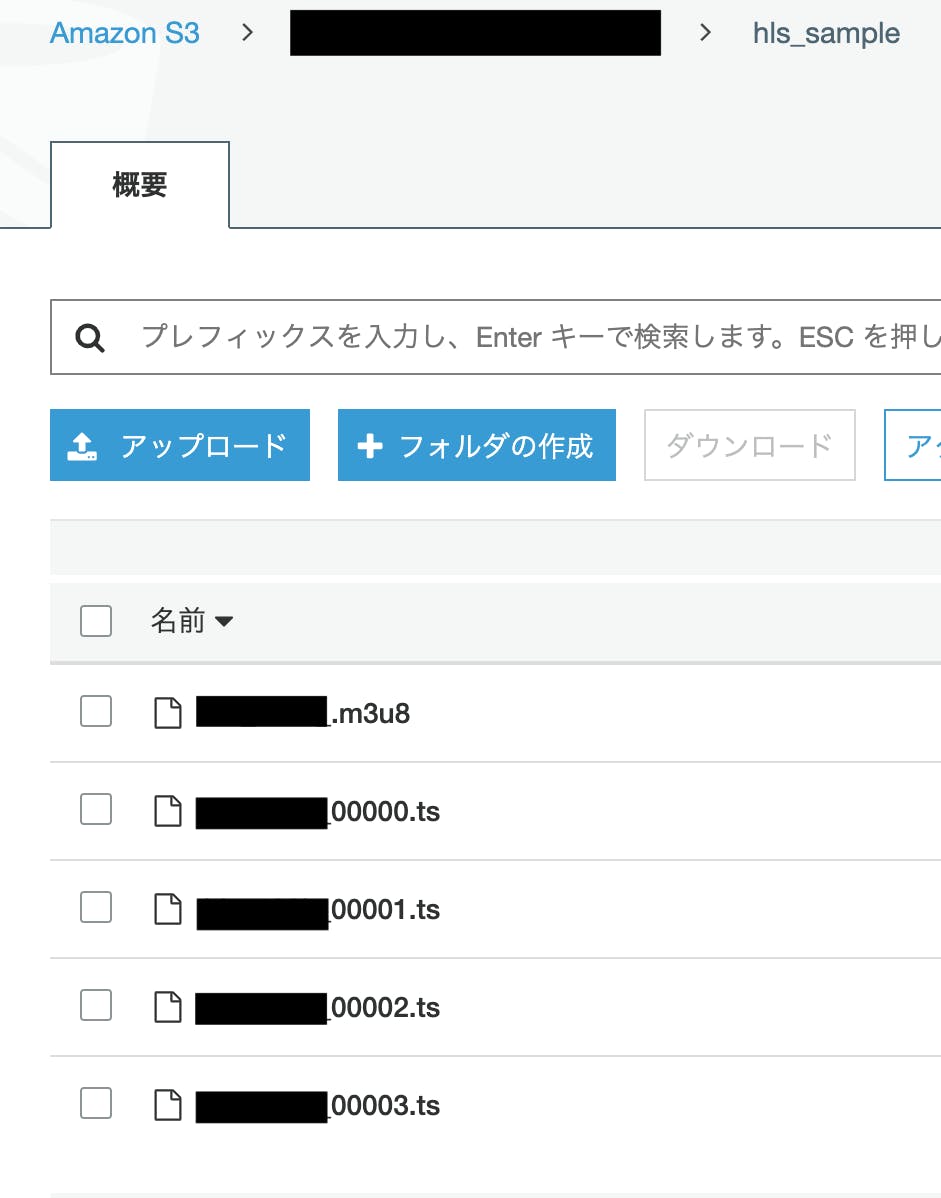
専用のバケットを作成し、動画をアップロードします。
上の画像のhls_sampleというフォルダは、Elastic TranscoderでHLS形式に変換したものを入れる予定です(現段階ではフォルダの中身は空です)。2.HLS形式に変換する
Elastic Transcoderでmp4の動画をHLS形式に変換します。
変換するまでにやることは
1.パイプラインを作成する
2.ジョブを実行する
です。まずはパイプラインの作成から・・・
Elastic TranscoderでCreate New Pipelineをクリックします。
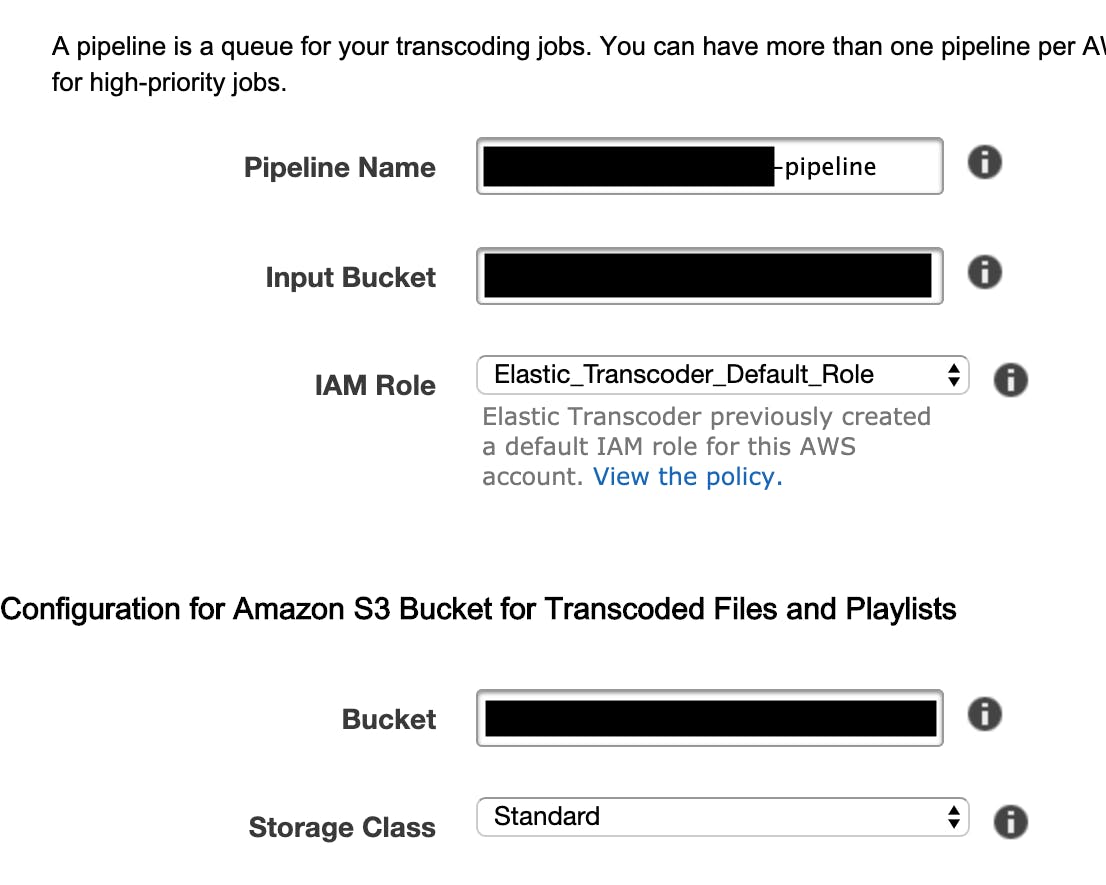
作成するpipelineに関する設定をします。
・Pipeline Name:パイプラインの名前。パッと見て目的がわかるような名前がいいと思います。
・Input Bucket:HLS形式に変換する動画ファイルを格納しているS3バケットの名前。上記1で作成したものを指定します。
・IAM Role:このパイプライン用のロール。特別な事情が無ければ、デフォルトのままでOKです。
Configuration for Amazon S3 Bucket for Transcoded Files and Playlists以下の項目は変換後のファイルに関するものです。
・Bucket:変換したファイルを格納するバケット名。
・Storage Class:S3のストレージクラスを指定します。StandardかReduce Redundancy(低冗長化)から選択できますが、今回はデフォルトのままStandardにしました。
Configuration for Amazon S3 Bucket for Thumbnailsはサムネイルに関する項目です。
・Bucket:パイプラインに送信したジョブのサムネイルを保存する用のS3バケット名を指定します。
・Storage Class:S3のストレージクラスを指定します(上と同じです)。
その他の項目はデフォルトのままです。
詳しくは公式ドキュメントをご覧ください。
ここまで設定した後、右下のCreate Pipelineを押すとパイプラインが作成されます。さて、次はジョブを作ります。
Create New Jobを押します。
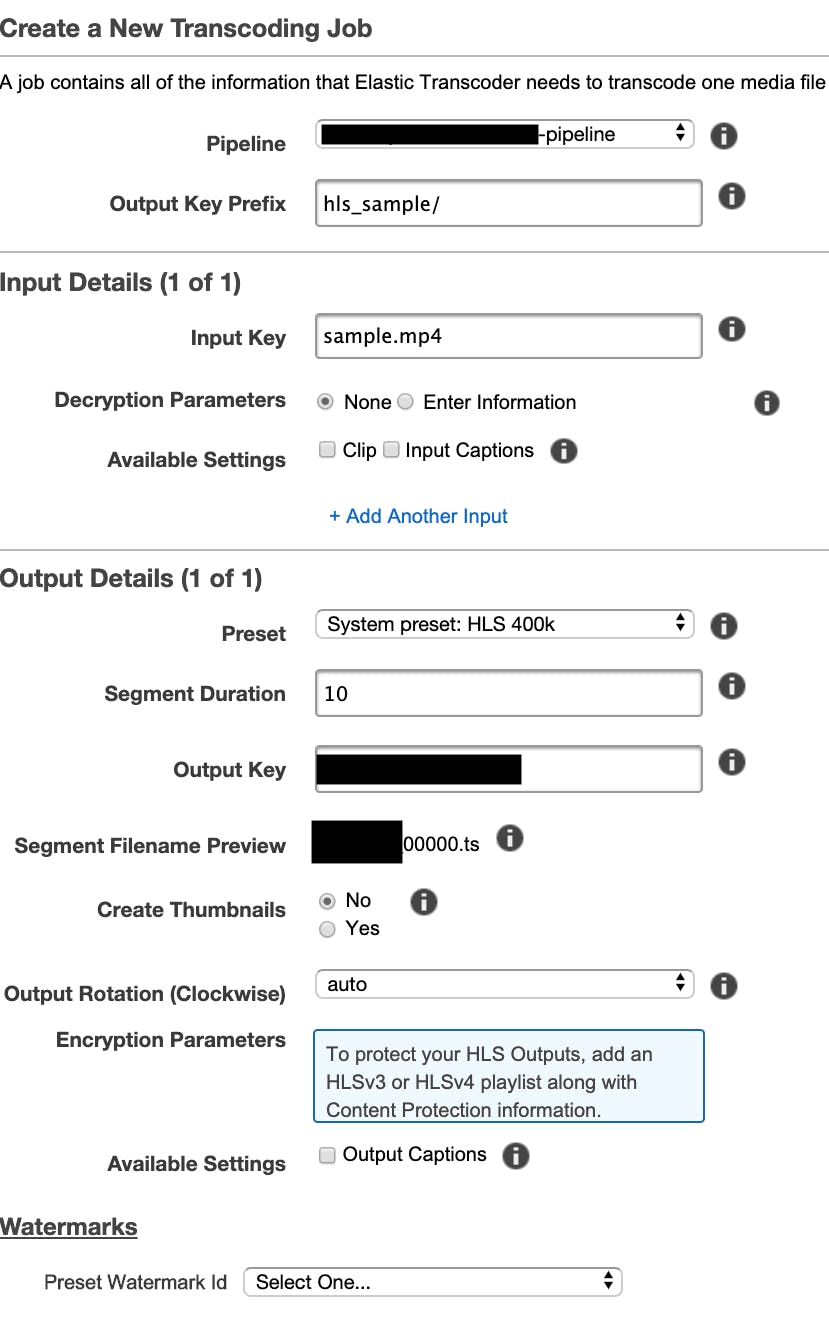
Jobの詳細を設定する画面が表示されるので、
今回はこのように設定しました。
上から順に各項目を見ていくと、
・Pipeline:先ほど作成したパイプラインを指定します。
・Output Key Prefix:Elastic Transcoderが生成するファイル名の先頭につける値です。今回はS3バケット内のhls_sampleというフォルダにHLS形式のファイルを出力したいので、そのように入力しています。
・input Key:S3のバケットにアップロードした、変換したいファイルの名前です。
・Preset:この変換で使用するプリセットです。今回はHLSに変換したいので、HLS_400Kを選びました。
※HLSのエンコーディング等に関することはこちらが参考になりました。
・Segment Duration:セグメントファイルの最長時間です。1~60秒の間の値を指定します。今回は10秒。
・Output Key:出力されるファイル(セグメントファイル、プレイリスト両方)の名前になります。
ただし、セグメントファイルに関しては生成されるファイルが一つではないので、その下の欄のSegment Filename Previewにあるように、Output Key+連番.tsというファイル名で保存されます。その他の値はデフォルトです。
詳しくは公式ドキュメントをご覧ください。ここまで設定できたら、右下のCreate New Jobをクリックします。
少し時間がかかりますが、ステータスがCompleteになれば完了です。
アウトプット先に指定したS3のバケットを確認してみると、
いますね。
プレイリストファイルである.m3u8ファイルと、4つのセグメントファイル(.ts)が作成されました。
これでmp4ファイルからHLS形式のファイルに変換することができました。長くなってしまいそうなので・・・
再生する部分は別の記事に分けます・・・
続きはこちら参考にさせていただいた記事
大変勉強になりました。ありがとうございます。
https://qiita.com/mechamogera/items/a91848b0c3b6fe9f18f5
https://dev.classmethod.jp/references/amazon-elastic-transcoder-hls/



- 投稿日:2019-12-03T19:03:17+09:00
自動テープ起こしを夢見て
先日、Amazon Transcribeが日本語に対応したというニュースを耳にした。Amazon Transcribeとは音声からテキストに変換するサービスである。
アイリッジでは毎月月末に全社員が集まってミーティングが行われる。その際の発言を録音してAmazon Transcribeで文字起こしを行い、適宜編集して全体に公開すればをすれば役に立つのでは、と思い立った。手順
Amazon Transcribeは簡単に使うことができる。
- ミーティングの発言者の近くに録音用のスマートフォン(Pixel 3a)を配置し、録音アプリで録音する。
- 録音音声ファイル(WAV形式)をAmazon Transcribeのコンソールからアップロードする。
- しばらくするとJSON形式のファイルがダウンロードできる。
- 先駆者のスクリプトを参考にしていい感じにHTMLファイルにする。
今回、作成したのは以下のスクリプトである。
import json import sys def confidence_to_color(confidence: float) -> str: """confidenceの値に応じてHTMLの色を指定する""" if confidence == 1: return "black" elif confidence >= 0.9: return "gray" else: return "silver" def main(): input_lines = sys.stdin.readline() data = json.loads(input_lines) print("<!DOCTYPE html>") print("<body>") for item in data['results']['items']: color = confidence_to_color(float(item['alternatives'][0]['confidence'])) content = item['alternatives'][0]['content'] print(f'<span style="color: {color}; ">{content}</span>', end="") print() print("</body>") if __name__ == "__main__": main()このスクリプトファイルを
cli_trans.pyとすると、以下のように使う。(venv)$ cat asrOutput.json | python3 cli_trans.py > result.htmlこれで、簡単に文字起こしができた。
現実と向き合う
Amazon Transcribeで生成されたテキストファイルを適宜編集すればいい、と思っていたが、生成されたものは少し手を入れればいい、という代物ではなく、日本語の文法になんとか従って書かれた奇妙なテキストであった。題材が会社内のミーティングであるためそれを公開できないのが残念であるが、その迫力はなかなかものであり、HTMLファイルを見て「現代芸術である」と答えた人もいた。
どうしてこうなったのか?Amazon Transcribeが誇大広告であったのではなく、音声ファイルの作成方法にその原因があると思われる。今回の録音方法はスマートフォンを配置して録音というもので人間の耳で聞き取る分には十分であるがあまり品質がよい状況ではなかった。Garbage In Garbage Outの通り、品質が悪い音声ファイルからは世にも奇妙なテキストしか生成できないのである。
どうすればよかったのであろうか?まずはきちんとした録音環境を用意することである。例えば、発言者がマイクを使っているのであればマイクから直接音を拾うといった工夫である。例えば、コールセンターにおける会話を録音して文字に起こす、全員がオンライン上でマイクで話す、といった状況ならばよいのかもしれない。おたのしみコーナー
さて、堅苦しい話はここまでにして、Amazon Transcribeで生成された奇妙なテキストの内、筆者の琴線に触れ、かつパブリックにしてもよさそうなものを列挙してみる。
パルプ喋って貰っていいですか
- 「軽く喋ってもらっていいですか」の誤変換。今回のミーティングは出張中の社員でも参加できそうな人はオンラインで参加してもらっていて、動作確認を行うための発言である。
サービス障害動画ができました
- 「サービス紹介動画ができました」の誤変換。サービス障害動画は胃が痛くなるのでお断りしたい。
焼却観測するビジネス
- 物騒なワードが出てきたが、弊社はこんな危ういビジネスはやらないはず。
応援部というキーワード
- 次のビジネスに向けたキーワード...ではないはず。
巻物の共同事業
- 新たなるビジネスキーワード。
結構アドラー的な箱を開ける
- アドラー的という形容詞もよくわからないが、そのような箱とは一体どんな箱なのか。
うんそっかええじゃええなるほどね
- 相槌や口癖を拾ってしまったものであるが、普段は標準語なのにとっさに方言が出てしまったかのような趣がある。
- 投稿日:2019-12-03T18:48:07+09:00
[AWS] ELB知らない人は,本当に危険!!(SAA突破攻略本)
ELBについて解説
こんばんわ.
AWSの少しだけニッチなところをご紹介します.ELBってめっちゃ大事です.
ECサイトやネイティブアプリケーションの運用でかかせません.
大事な勝負日に503エラーなんてしてられないですよね?EC2,S3,Lambda,cloud9あたりはみなさんよく使うと思います.
僕もその辺しか最初は知りませんでした.
S3なんかは覚えたての頃はかなり感動しました.
SNS作るときなんか,オブジェクトURLで保存すれば,DB容量の節約になりますからね.その辺は使っていて直感的に覚えるのがベストでしょう.
さて,本題.
ELBって知ってますか?
マネジメントコンソールに書いてありますが,よくわからず,煙たがっていました.しかし,クラウド運用する方は必須.
また,ソリューションアーキテクトアソシエイトを取るには不可避です.
みなさん嫌いなセキュリティですね.基礎となるVPCに関してはこちら
ELBのド基礎
ELBとは,
仮想ロードバランスサービス
です.なにそれ?
ですよね.
まずはロードバランサーについて,
オンプレでロードバランサーとは,
web鯖やapp鯖など,複数ある場合に通信負荷を軽減するために,通信を分散させる事です.つまり,クラウド版の通信分散をさせる為の割り当て役
とでも定義しておきましょう.
これがオーバーした時に503エラーが返されるのですね.前の記事でも書きましたが,おさらい.
AWSでは,VPCを設定して仮想ネットワークを制御します.ELBはVPC上に位置付けされます.
VPCが正常に動くように,割り当てやヘルスチェックをするものです!!ちなみにヘルスチェックで異常を発見しても
インスタンスへのトラフィック送信を停止するのみです.ELBの種類とその特性
ELBは3種類のロードバランサーが提供されています.
それぞれ特性が違うので,最適な種類を選べるようになりましょう.1.ALB
Application Load Balancer
HTTP,HTTPSをサポートしています.
パスやホストのルーティングサポートをしています.
基本的にこいつ2.NLB
Network load Balancer
TCP,TLSのサポートです.
固定IPアドレスを設定できます.
例えば,クライアントが
「ドメインじゃなくてIPでアクセスしたい」
なんて言ってきたらこいつの出番.3.CLB
Classic Load Balancer
古いです.いりません.
簡単に説明すると,ALBの旧ver .
VPCの前の仮想ネットワークはEC2 Classicってやつでした.
なので,古参のEC2 Classicで構築されている場合はこいつ.
まあ,見ないので,気にしなくていいです.ELBのお仕事
※?このページがエラーというわけじゃ無いですのでご安心を.
負荷が増減すると,
負荷に応じて自動でスケールします.
スケーリングが間に合わないとき503エラーをクライアントに返します.だんだん見えてきました?
でも,例えば
アプリのメンテ明け.
ECサイトでの新商品発売日
なんて日は,トラフィックがかなり増えます.
結果的にサーバー負荷が大きくなるでしょう.そんな時は,
Pre-Warmingです.
上記のように,多くの負荷が予測できる場合,
AWSに申請することが出来ます.
事前にスケーリングさせます.ちなみにAWSコンソールではなく,
AWSサポートに申請が必要です.SSL Termination
外部公開ではSSLはもはや必須です.
公開鍵暗号設定でセキュリティを強化してくれる仕組みですね.
オンプレでも簡単にポチッと押せばssl化してくれます.ELBの"SSL Termination"では,
クライアント,ELB間をhttps通信
ロードバランサーとインスタンス間をhttp通信してくれます.
通信処理の負荷が軽減出来ますただ,利用する時は,ロードバランサーにSSL証明書を構成する必要があります.
スティッキーセッション
セッションを引き継いで,cookieに設定した値を利用しながら動作する時.
例)会員制のサイトなど
ELBによって,毎回reqを同一のインスタンスに送信したいですよね?まさしくそれを可能にするのがスティッキーセッションです.
こちらの実装方法は2つ1.任意の有効期限の間は,同じインスタンスを使用するよ
2.アプリのCookieに従うよCookieを使うアプリなら2でいいです.
この辺覚えてないと,AWSデプロイ後には苦しむかも.
1度ぶち当たると,ELBはめちゃめちゃ大切なことに気付かされた.仮想ネットワークから復習したい方は下の記事も読んでください
[必須]プライベートな仮想ネットワークを制御する



- 投稿日:2019-12-03T18:47:30+09:00
独自ドメインを取得し、Route53 と ELB を使ってEC2上のWebアプリをHTTPS(SSL)通信に対応させてみる
こんにちは。今回は AWS の EC2 で構築しているアプリに HTTPS でアクセスできるようにしてみたいと思います。
前提
- EC2 上でアプリが動作していること
- nginx を使っていること
またすべて自己責任でお願いします。
全体像のイメージ
.
Domainを取得する
僕はこちらのサイトでドメインを取得しました。
使用したいドメインを検索して、利用できるドメインを選択します。

僕は無料のモノにしました。その後、チェックアウトします。チェックアウトが完了したら右上のServicesからMy Domainsを選択します。
.
自分が登録したドメインが表示されていればOKです!
Route53 にドメインを登録する
まずは Route53 に取得したドメインを設定していきます。
AWS のサービスから Route53 を開きます。

左のメニューからホストゾーンを選択し、ホストゾーンの作成をクリック。
取得しておいたドメインをドメイン名に入力して、作成をクリックします。
そうするとこんな感じでドメインが設定されていると思います。
.
タイプがNSになっている4つの値を先ほどドメインを取得したサイトであるfreenom上に設定してあげます。My Domains > Manage Domainをクリック。その後、上のタブバーからManagement Toolsをクリックし、Nameserversを選択する。Route53に表示されていた4つの値をこんな感じで設定してあげます。このときに末尾のピリオドは取り除いてください。
手元のPCのターミナル上から次のようなコマンドを入力して、次のような応答があればOKです。このときまで、IPアドレスは返ってきません。EC2上のアプリとドメインを関連づけていないので。
$ dig sample-domain.gq ; <<>> DiG 9.10.6 <<>> sample-domain.gq ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 29220 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 512 ;; QUESTION SECTION: ;sample-domain.gq. IN A ;; AUTHORITY SECTION: sample-domain.gq. 900 IN SOA ns-951.awsdns-54.net. awsdns-hostmaster.amazon.com. 1 7200 900 1209600 86400 ;; Query time: 213 msec ;; SERVER: 192.168.1.1#53(192.168.1.1) ;; WHEN: Sun Sep 22 17:10:24 JST 2019 ;; MSG SIZE rcvd: 129これでネームサーバーにドメインを設定することができました。
次にドメインとEC2上のアプリを関連づけていきます。
AWSのEC2のダッシュボードを開き、左側のElasticIPをクリックします。
.
左上の新しいアドレスの割り当てをクリックし、割り当てをクリックします。その後、一覧画面に新しく割り当てられたElasticIPが表示されるので、右上のアクションからアドレスの関連付けを選択して、Webアプリを構築しているインスタンスを選択します。
ElasticIPの値をメモしておきます。次の手順でドメインを用いてアクセスすることができます。
再度Route53を開き、レコードセットの作成をクリック。
名前は空で、タイプはA-IPv4アドレスを選択しておきます。
そして値のところに先ほどメモしたElasticIPの値を貼り付けて作成をクリックします。
これでブラウザにそのドメインを入力すると、アクセスすることができると思います。
SSL 証明書の取得
さあ、次にSSL 証明書を取得していきます。
AWS のサービスより Certificate Manager を検索します。
証明書のリクエストをクリックして、パブリック証明書のリクエストを選択します。
次の画面でドメイン名のところにさきほど取得したドメイン名を入力します。
次はDNSの検証を選択して確認をクリックします。
次画面の確定とリクエストをクリックして、続行をクリックするとこんな感じで検証未完了の画面になると思います。
▶︎マークをクリックして、Route53でのレコードの作成をクリックします。
その後、Route53にドメインがCNAMEが追加されます。これをALBを使ってHTTPS通信できるようにしていきます。
EC2のダッシュボードの左側のメニューからロードバランサーを選択し、ロードバランサーの作成をクリックします。
一番左側のApplication Load Balancerを作成します。
リスナーのところにHTTPとHTTPSを設定します。これによりクライアントからのHTTPSとHTTP通信を受け付けます。
アベイラビリティーゾーンのところはすべてチェックします。僕は最初2つしかチェックせずに、このあと作成するターゲットと位置するアベイラビリティーゾーンが事なってしまったため、503エラーに悩まされましたので。。。ターゲットのアベイラビリティーゾーンとロードバランサーのアベイラビリティーゾーンを合わせれば2つでも問題ないかと思います。
証明書の選択のところで先ほど準備した証明書を選択して次へ進みます。
セキュリティグループは新しいセキュリティグループを作成するを選択して次のように設定します。
ターゲットグループは名前のところだけ、適当に入力して次に進みます。
次の画面では下の一覧表に表示されているインスタンスからWebアプリを構築しているインスタンスを選択して、登録済みに追加し、次に進みます。確認画面で問題がなければ作成をクリックします。
ロードバランサーの画面で状態がactiveになっていればOKです!
またターゲットグループ画面のしたのターゲットタブをクリックし、登録済みターゲットのステータスがhealthyになっていることも確認しておきましょう。僕はここがunsetになっていて、503エラーで半日悩んだので。。
インスタンスのセキュリティグループに先ほど作成したロードバランサーのセキュリティグループを追加していきます。
インスタンス一覧から該当のインスタンスを選択して、右スクロールしていくと、セキュリティグループという項目があると思うので、クリックします。下のインバウンドタブを選択して、編集画面をクリックします。
さていよいよ最後です。Route53で取得したドメインにきたリクエストをこのロードバランサーに振り分けてあげるように設定していきます。
Route53の先ほど作成したホストゾーンのページから最初に作成したタイプAのレコードを選択し、
エイリアスをオンにして、ターゲット名の入力のところから、ELB Application Load Balancerのところにある先ほど設定したロードバランサーを選択して、作成をクリックします。
これで
でアクセスしてあげれば表示されるかと思います。
ちなみにhttpでアクセスがきた場合httpsにリダイレクトするにはnginxを次のように設定して上げる必要があります。
/etc/nginx/nginx.conf
if ($http_x_forwarded_proto = 'http'){ return 301 https://$host$request_uri; }https通信に対応するために1日以上かかってしまいましたがなんとかできるようになってよかったです。
参考サイト
「AWSでWebサイトをHTTPS化 その1:ELB(+ACM発行証明書)→EC2編」
https://recipe.kc-cloud.jp/archives/11084「EC2とELBでかんたんhttps環境構築メモ」
http://developers.goalist.co.jp/entry/2018/09/26/170000「AWSで独自ドメインを無料で簡単にSSL化!」
https://daichan.club/aws/78593「AWSでドメイン、SSL証明書の取得、設定 AWS EC2」
https://qiita.com/masch/items/a5ef84998fb7784f9115「ALBのヘルスチェックの豆知識」
http://blog.serverworks.co.jp/tech/2017/02/08/alb-tagert-health-status/
















- 投稿日:2019-12-03T18:13:59+09:00
Alibaba Cloudの特徴� 〜AWSとの比較〜
目的
マルチクラウドの実現に向けて、Alibaba Cloudの特徴および特色をAWSに準じて説明します。
読者に「へーAlibaba Cloudってこんな感じなんだー」と思ってもらうのが目的です。対象
AWSを知ってる人
Alibaba Cloudを知らない人
Alibaba Cloudで何が出来るか知りたい人特徴・特色
AWSと似ている
IaaS製品の名称がほぼ同じです。
ECS - EC2
VPC - VPC
ELB - SLB
EIP - EIPAWSをIaaSとして利用しているユーザは、Alibaba Cloud(以下ALBB)も余裕で使えます。
アジアの領域に強い
日本と中国の間でVPNネットワークを簡単に構築出来ます。Greate Firewallなんて一切気しません。
日米と同じ感覚で、日中を繋げられるのはもはやチートです。加えてアジアリージョンの国数で言っても、ALBBが強いです。
AWS ALBB GCP Azure 東京 ◯ ◯ ◯ ◯ 大阪 △ × ◯ ◯ 中国 ◯ ◯ ◯ ◯ シンガポール ◯ ◯ ◯ ◯ インド ◯ ◯ ◯ ◯ オーストラリア ◯ ◯ ◯ ◯ 韓国 ◯ × × ◯ インドネシア × ◯ × × マレーシア × ◯ × × プロダクトのリリースもまずはアジアから行われます。これが地味に嬉しいです。
SIチックに頑張る文化
ALBBのプロダクトは中国で実際の顧客へ提供したサービスを汎用化させてプロダクト化させています。
この文化は今も健在で、例えば売上規模が大きい場合にはAPIの仕様をカスタマイズした独自APIを、Alibaba Cloud本社にエンジニアに作ってもらい提供してもらえます。AWSではせいぜいパッチを提供してもらう程度です。AI・ビッグデータ関連がヤバイ
シリコンバレーのスタートアップが軒並み卒倒するくらいのプロダクトラインアップがあります。
ImageSearch
オブジェクトストレージに教師用の画像を入れておくだけで、問い合わせ画像をAPIに食わせると、類似画像をミリ秒で返してくれます。
FaceRecognition
人の顔を認識するだけで年齢、表情、人種などの情報を、同一人物の重複排除をしながら得られます。例えば、年齢:28〜29歳 表情:やや怒っている 人物キー:00001という情報を得られます。アジア人以外の精度も高いです。
DataV
CSVやJSONを食わせるだけで簡単にリッチなデザインの可視化が出来ます。例えば、エンドユーザ向けのレポート作成の手間を大幅に省けます。APIで定期的にJSONを発行すれば、それに応じてDataVの画面もリアルタイムで遷移します。
LogService
言うなればCloudWatch logsです。ただOSエージェントやSDK、JDBC等インターフェイス一通り用意されているので、Splunkの代替としても利用できます。
機能としてログ全体にSQLクエリを投げたり、デフォルトの機械学習機能を用いて予兆検知からアラート発砲まで行ってくれます。
LogServiceのSQLクエリ
LogServiceの予兆検知
これらの機能をおおよそ「0.34円/GB」と「3.45円/100万APIコール」で利用できます(詳細)。頭おかしい。
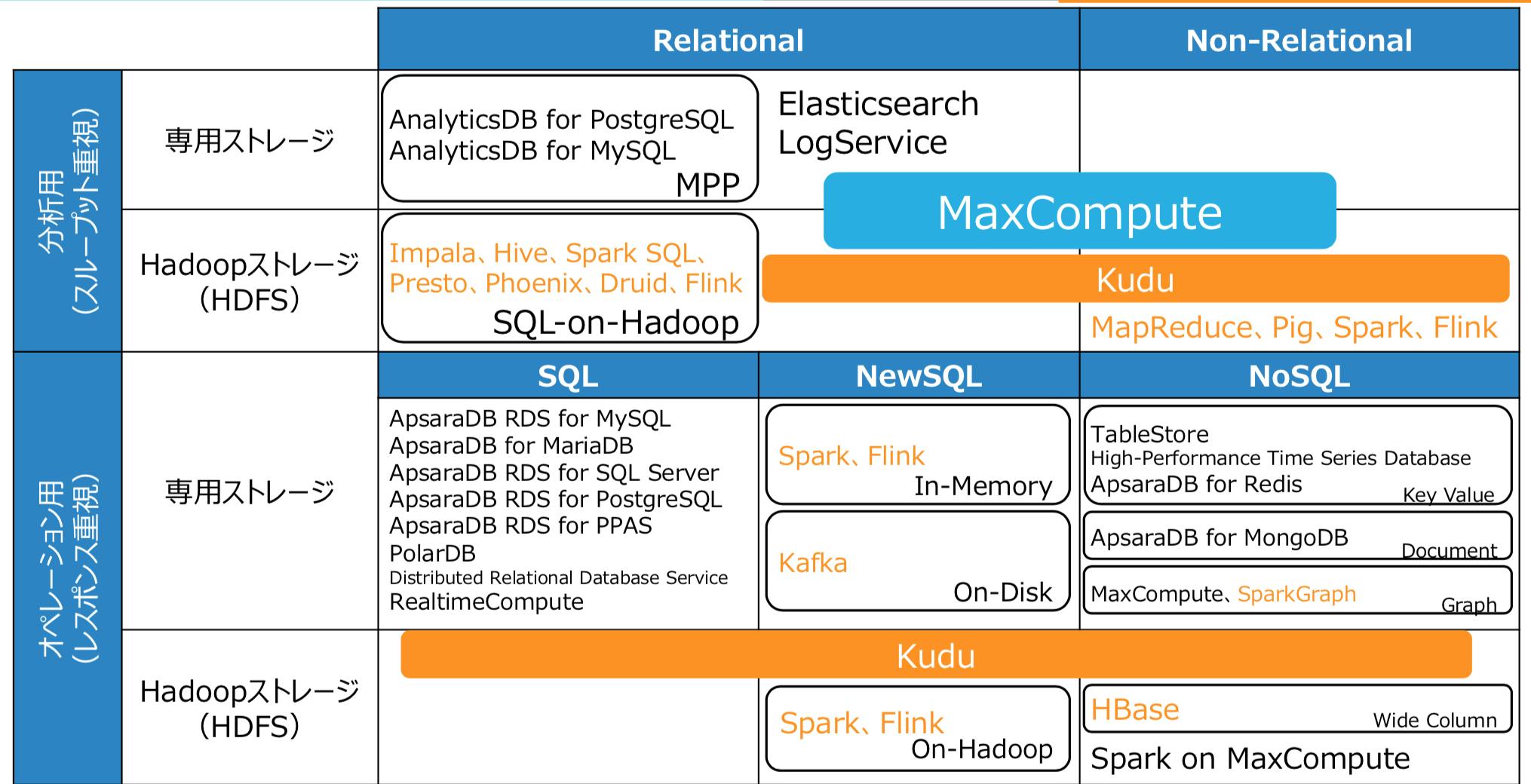
分析系プロダクト
以下の全てがALBBのプロダクトとして利用可能です。つまりGUIからポチーと作れます。
黒色文字と水色がマネージド型のプロダクトで、オレンジ色がHadoopサービスであるE-MapReduce上で稼働するミドルウェアです機械学習
機械学習について、Machine Learning for PAIというプロダクトを展開しており、初心者にも機械学習できる易しい環境を提供しています。
つまりALBBを採用することで、機械学習の最大の課題である人材不足を解決できます。
中国以外での実績に乏しい
少しネガティブな所も記載しておきます。
そもそもAlibaba Cloudは中国で十分に成功しているので、世界に向けての活動はあまり積極的ではなかったです。近年は思考を転換して能動的に動いているといっても、2019年12月現在実績がそこまで多いとは言えません。上記で紹介したサービスでもFace RecognitionとPAIは日本リージョンではまだG/Aされていません。
日本市場の実績を重視する文化の企業では採用が難しいかもしれませんが、逆にいえば、日本市場で活用されていない上記技術を先行利用するチャンスでもあります(無理やりデータは日本にあり、日本法の準拠です。
大手メディアですら未だに誤解して記載していますが、AWSと同様に、Alibaba Cloudのデータ管理は日本準拠法が適用されます。
セキュリティプロダクトがやたら多い
中国国内からの攻撃からも耐えられるように、セキュリティプロダクトがやたら多いです。
ダブルイレブンの恩恵を受けられる
毎年11月11日に意味分からないほど安くなります。
2019年は仮想サーバが条件を満たせば99%オフ、無条件でも50%オフになりました。
勿論サブスクリプションで買えます。例えば、m5.2xlargeが通常の価格だと$230/年、ダブルイレブンだと$165/年になります。安すぎる。まとめ
あれ、ALBBってすごくね?


- 投稿日:2019-12-03T16:41:16+09:00
AWS SAAでのVPCを初心者用でも分かるように簡単に説明
AWS SAA でのVPCが理解しずらい件
どうも.
最近ではオンプレよりも
クラウドが主流化してきましたね.案件もお●前.comやロ●ポップを使って
構築してくれ!なんて案件も偶にありますが,,,
大きい企業になるともっぱらGCP,AWSですね.たまーに,Azureなんてありますが,
Azureは分からないので,AWSに強引に持っていきます.どのクラウドベンダーでも構わないのですが,
アジャイル開発が主流になってきているので
AWS認定なんかあると,
チヤホヤされそうです.ちなみに僕はAWS普段使ってるし受かるだろ〜
的なノリで受けて模試では半分しか点数取れませんでした.本格的に勉強しだしたので,今月中にでもSAAをサクッと受かろうと思います.
自分が勉強していてしっくりこなかった分野は,セキュリティネットワークでしたね.
(あまり実践に関わってこない)それでは,VPC解説していきます.
VPCとは
バーチャルプライベートクラウド
の略です.
一言で言うと,プライベートな仮想ネットワークでしょう.オンプレ時使っていたルータやファイアウォールは必要なくなりました.
VPC設定の流れ
1.VPC作成
ここで重要なのは1点.
「リージョンをまたいでVPC作成はできない」
マネジメントコンソールにリージョン選択する場所がありますが,
そこは選択必須です.という事
2.サブネットを作ろう
サブネットはネットワークの分割区分です.
重要なのは,複数のアベイラビリティゾーンに跨がれない,
と言う事
サブネットには,
・プライベート
・パブリック
がありますが,インターネットへのルートありか無しかだけでございます.CIDRというのはネットワーク状のIPアドレス割り当て数なのですが,
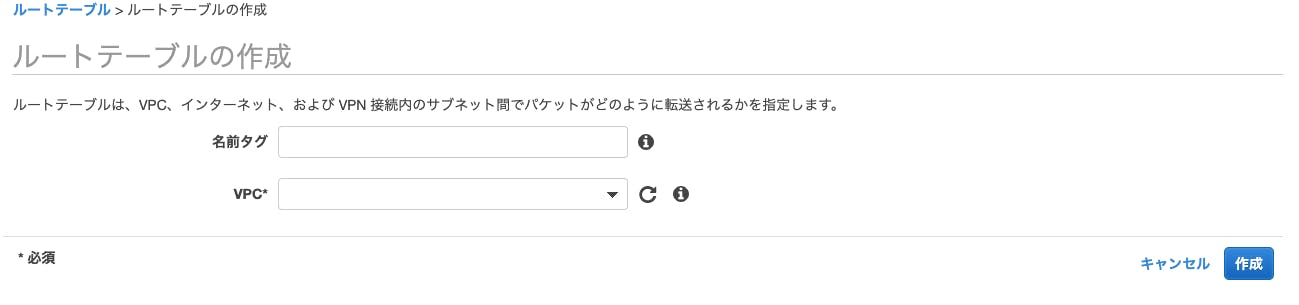
VPCのCIDR範囲>サブネットのCIDR範囲なら平気です.3.ルートテーブルを作ろう
わかりやすく言えば,サブネットのルーティングを規定します.
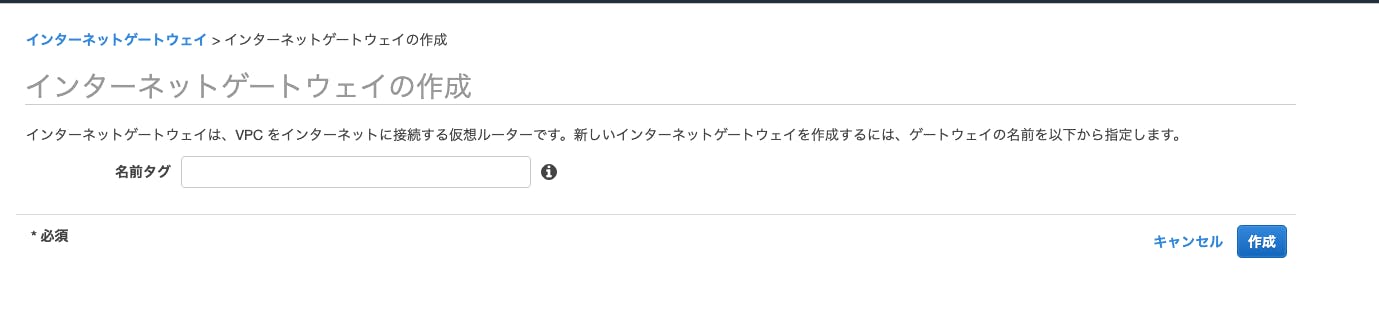
4.ゲートウェイのアタッチ
VPCからインターネットにアクセスをさせる作業です.
これによって,サブネットがパブリック,プライベートが決められます.
ちなみに
初期状態(設定しない)はプライベート .
設定するとパブリックです.5.セキュリティ設定
AWSでは,
ファイアウォール = セキュリティグループ + ネットワークACL(アクセスコントロールリスト)
で設定されます.セキュリティグループとネットワークACLの違いは,
設定単位が違います.前者は,インスタンス
後者は,サブネット単位で制御します.また,模試に出たのは,
セキュリティグループ → ステートフル (現状のデータを持ってる)
ネットワークACL → ステートレス (持ってない)
つまり,ネットワークACLには戻りのトラフィック設定が必要です個別に設定するならセキュリティグループ
一括ならネットワークACL
と覚えましょう
ちなみにIAM管理者なら後から変更可能です.補足
手を動かすと更に分かりますよ.
クライアントにEC2インスタンスにおける
セキュリティをかけるには,
セキュリティグループで通信はSSHだから22で送信先は00.00.00.000!!
(ポート番号
SSH -> 22
https ->443
http -> 80)
のように自由にできるところまで行くと,
SAAのセキュリティは怖く無いです.




- 投稿日:2019-12-03T16:41:16+09:00
AWS SAAでのVPCを初心者でも分かるように簡単に説明
AWS SAA でのVPCが理解しずらい件
どうも.
最近ではオンプレよりも
クラウドが主流化してきましたね.案件もお●前.comやロ●ポップを使って
構築してくれ!なんて案件も偶にありますが,,,
大きい企業になるともっぱらGCP,AWSですね.たまーに,Azureなんてありますが,
Azureは分からないので,AWSに強引に持っていきます.どのクラウドベンダーでも構わないのですが,
アジャイル開発が主流になってきているので
AWS認定なんかあると,
チヤホヤされそうです.ちなみに僕はAWS普段使ってるし受かるだろ〜
的なノリで受けて模試では半分しか点数取れませんでした.本格的に勉強しだしたので,今月中にでもSAAをサクッと受かろうと思います.
自分が勉強していてしっくりこなかった分野は,セキュリティネットワークでしたね.
(あまり実践に関わってこない)それでは,VPC解説していきます.
VPCとは
バーチャルプライベートクラウド
の略です.
一言で言うと,プライベートな仮想ネットワークでしょう.オンプレ時使っていたルータやファイアウォールは必要なくなりました.
VPC設定の流れ
1.VPC作成
ここで重要なのは1点.
「リージョンをまたいでVPC作成はできない」
マネジメントコンソールにリージョン選択する場所がありますが,
そこは選択必須です.という事
2.サブネットを作ろう
サブネットはネットワークの分割区分です.
重要なのは,複数のアベイラビリティゾーンに跨がれない,
と言う事
サブネットには,
・プライベート
・パブリック
がありますが,インターネットへのルートありか無しかだけでございます.CIDRというのはネットワーク状のIPアドレス割り当て数なのですが,
VPCのCIDR範囲>サブネットのCIDR範囲なら平気です.3.ルートテーブルを作ろう
わかりやすく言えば,サブネットのルーティングを規定します.
4.ゲートウェイのアタッチ
VPCからインターネットにアクセスをさせる作業です.
これによって,サブネットがパブリック,プライベートが決められます.
ちなみに
初期状態(設定しない)はプライベート .
設定するとパブリックです.5.セキュリティ設定
AWSでは,
ファイアウォール = セキュリティグループ + ネットワークACL(アクセスコントロールリスト)
で設定されます.セキュリティグループとネットワークACLの違いは,
設定単位が違います.前者は,インスタンス
後者は,サブネット単位で制御します.また,模試に出たのは,
セキュリティグループ → ステートフル (現状のデータを持ってる)
ネットワークACL → ステートレス (持ってない)
つまり,ネットワークACLには戻りのトラフィック設定が必要です個別に設定するならセキュリティグループ
一括ならネットワークACL
と覚えましょう
ちなみにIAM管理者なら後から変更可能です.補足
手を動かすと更に分かりますよ.
クライアントにEC2インスタンスにおける
セキュリティをかけるには,
セキュリティグループで通信はSSHだから22で送信先は00.00.00.000!!
(ポート番号
SSH -> 22
https ->443
http -> 80)
のように自由にできるところまで行くと,
SAAのセキュリティは怖く無いです.
- 投稿日:2019-12-03T16:22:09+09:00
【初心者でも使える】AWSが提供する文書解析サービス「Amazon Comprehend」が日本語対応したので触ってみた!
はじめに
Amazon Comprehendという機械学習のサービスの一つをご紹介致します!
プログラミングもいらず、機械学習の前提知識もいらない、直感的に自然言語処理ができます。
私JJも気軽に挑戦できますね!Amazon Comprehendで何ができるの?
Entities(固有名詞抽出)
属性。データテーブルのようなものですね。
日付やイベント、特定の場所、企業や人、量やタイトル及びその他を抽出できます。
タイプ 説明 日付 曜日、月、時間 場所 国、都市、湖、建物 組織 政府、企業、宗教、チーム 人 個人、グループ、人物 量 通貨、パーセンテージ、数値、バイトなどの定量化された量 タイトル 映画、書籍、歌、作品に付けられた公式名 Key phrases(キーワード抽出)
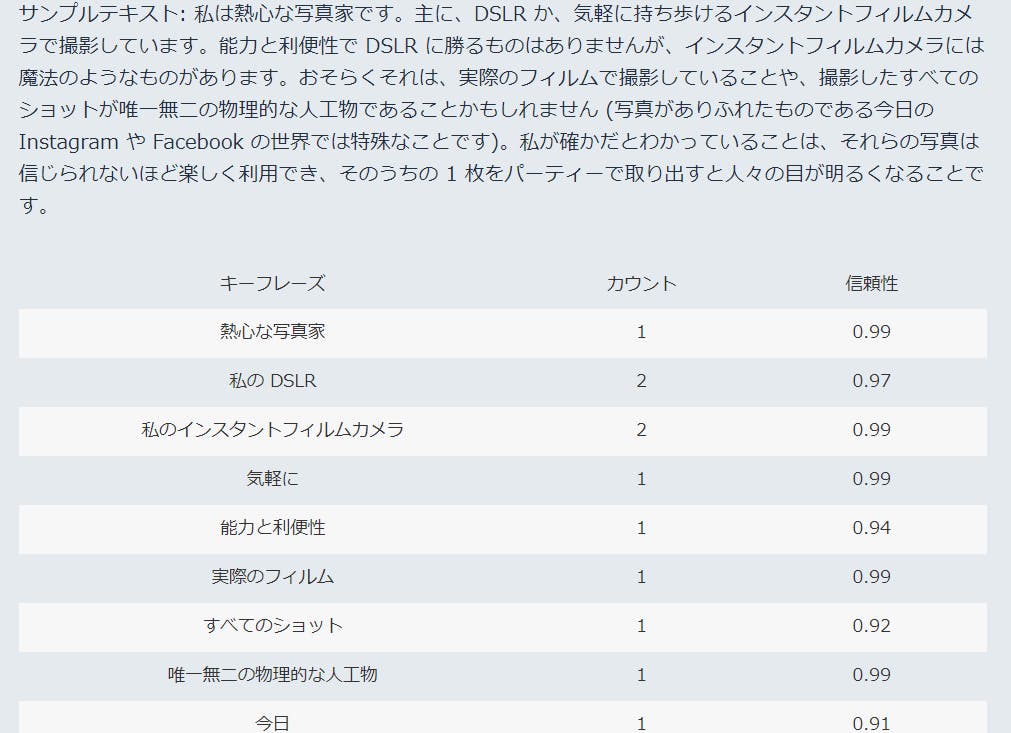
重要なフレーズとなる特徴的な名詞を抽出できます。会話のポイントだったり特徴的なキーフレーズであることを裏付ける信頼性スコア(フレーズの検出がアプリケーションにとって十分に高い信頼性を持っているかどうか)を出してくれます。以下Amazonの資料から。
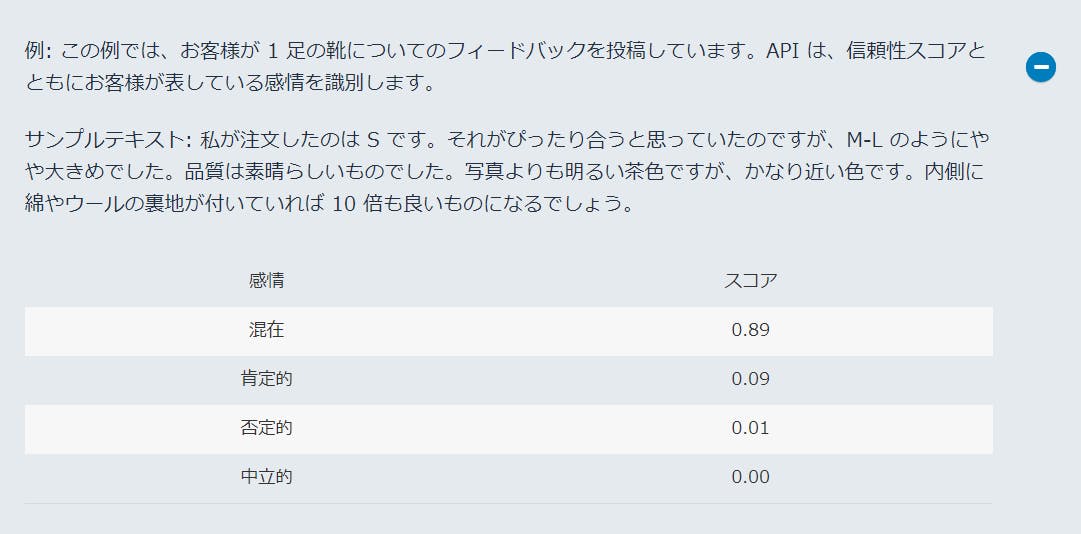
Sentiment(感情分析)
4種類で表した感情の分析ができます。肯定的、否定的、中立的(感情の振れ幅が一定)、または混在。
たとえば、センチメント分析を使用して、ブログ投稿に対するコメントのセンチメントを判断し、
読者が投稿を気に入ったかどうかを判断できます。
実際に触ってみました
小説「そして、バトンは渡された/瀬尾まいこ」さんのAmazonのレビューを分析してみました。
Amazon Comprehendのページに行ったらReal-time analysisを左メニューから選択。
Input textにテキストを貼り付けてAnalyzeのボタンを押すだけ。(本当に何も難しいことがない、、、!)
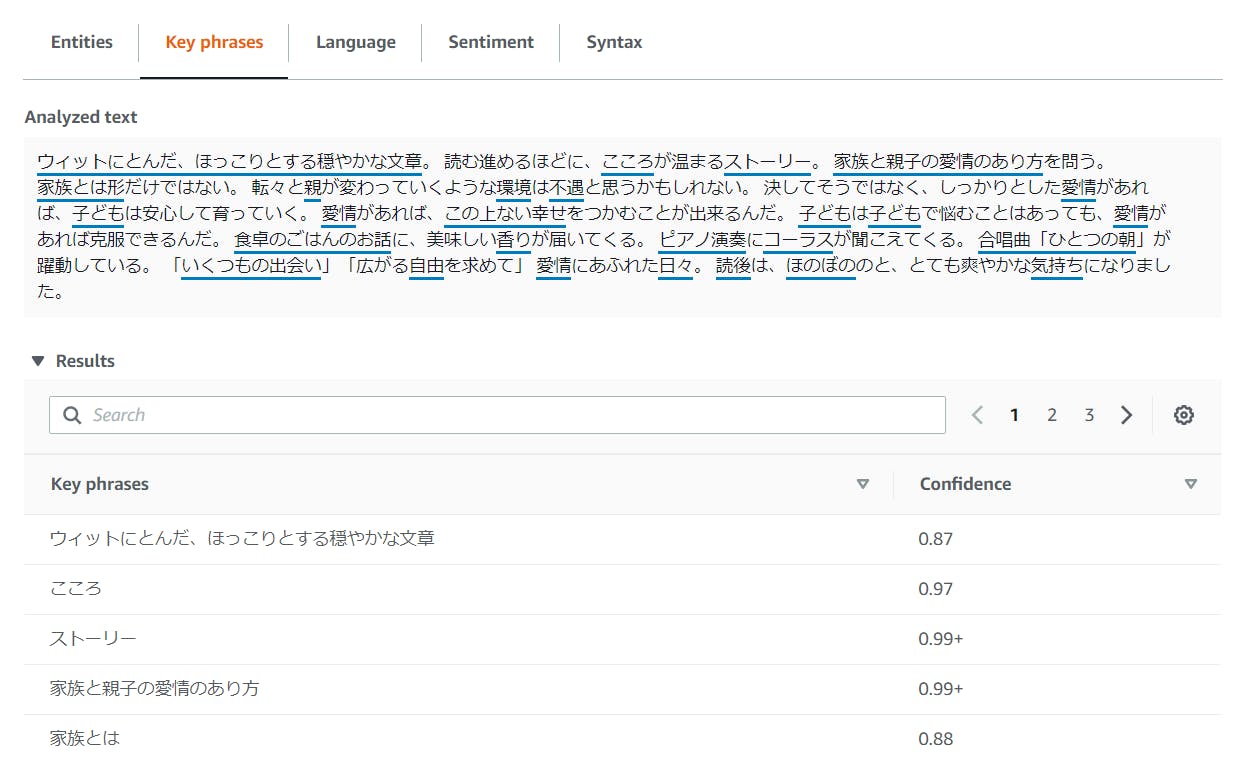
Entities
赤線が引かれ、数値というよりはタイトルになりそうな言葉が抽出されています。
Key phrases
こちらでは青線が引かれ、感情や叙情的フレーズ、特徴的な動詞が抽出されています。
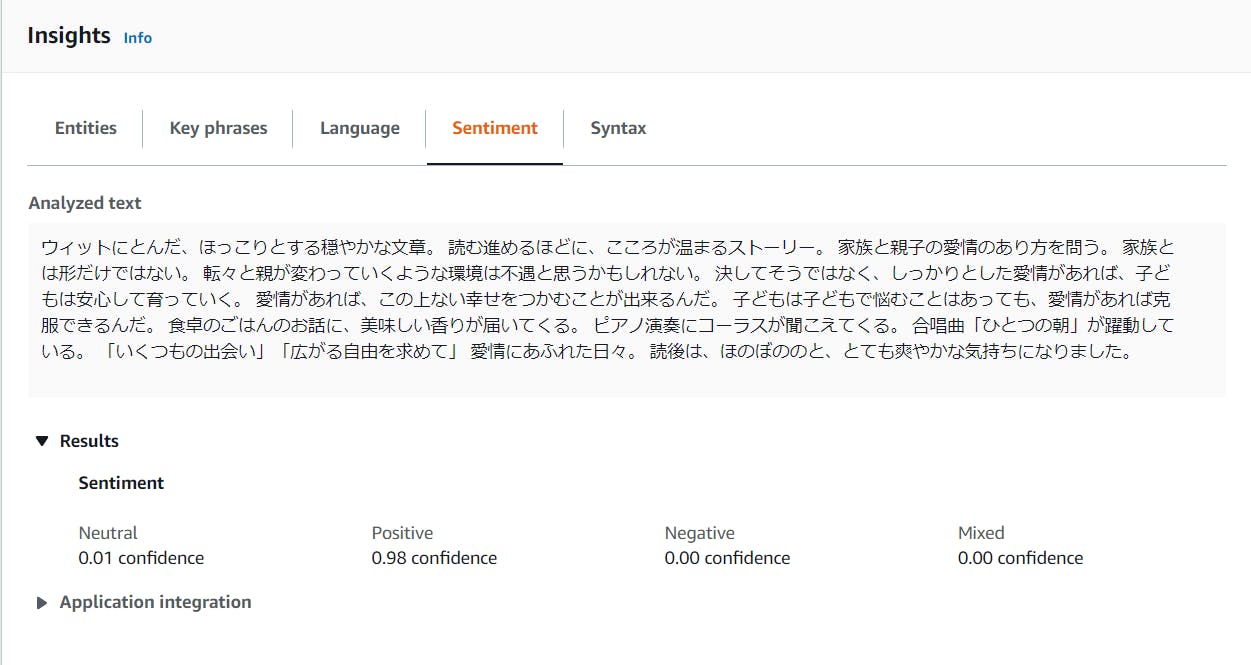
エンティティよりキーフレーズの方が抽出量も多いです。Sentiment
個人的に一番気になっていたセンチメントも98%肯定的でポジティブなレビューであるという分析結果!
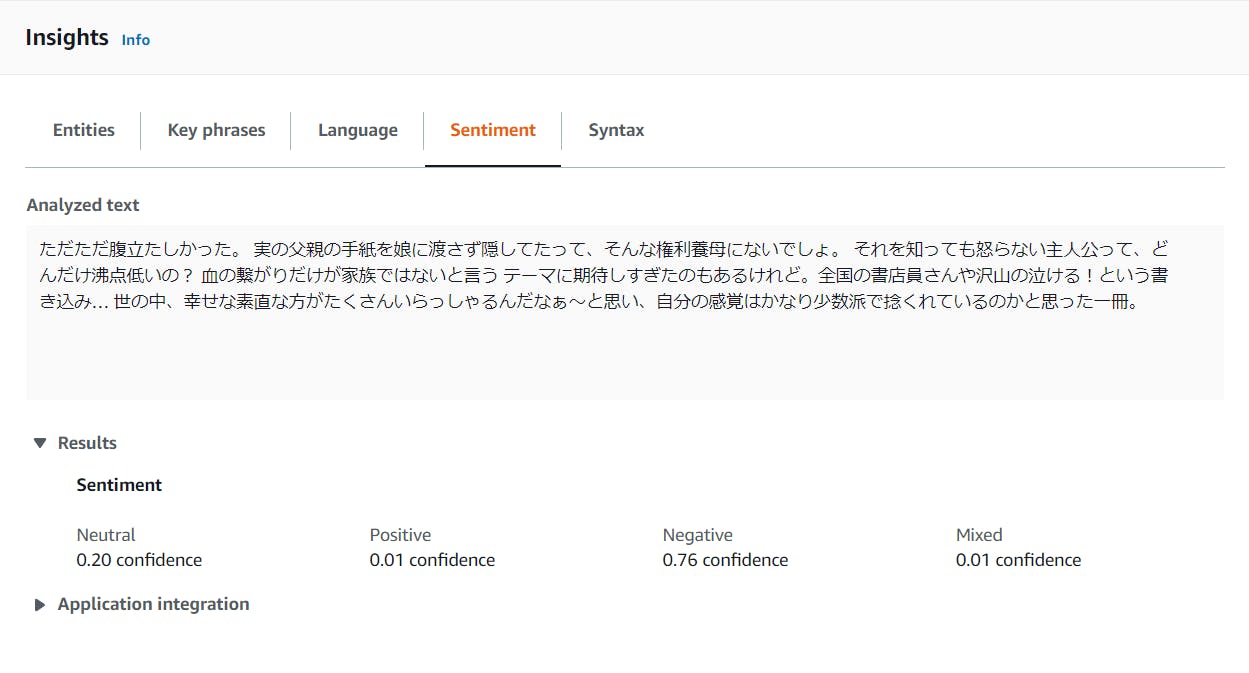
マイナスな文章はどうなる?
しっかり辛口なレビューであることがわかりますね。「幸せな」あたりから微量なポジティブを抽出しているのでしょうか。
「期待しすぎた」「捻くれている」
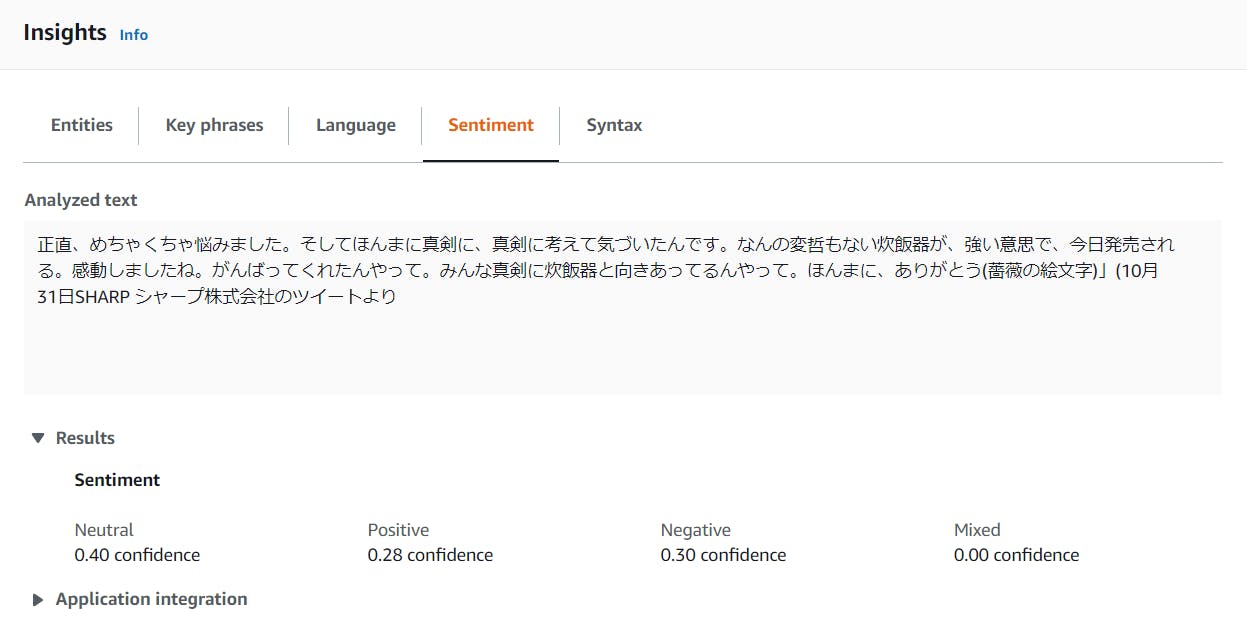
こんな細かな混在した気持ちも分析してくれています。想像以上です。企業公式アカウントのTwitterでSHARP株式会社「シャープさん(@SHARP_JP)」が「炊飯器発売のお知らせ」で呟いた友永構文のシュールなツイートも分析してもらいました。(個人的な興味で)
正直、めちゃくちゃ悩みました。そしてほんまに真剣に、真剣に考えて気づいたんです。なんの変哲もない炊飯器が、強い意思で、きょう発売される。感動しましたね。がんばってくれたんやって。みんな真剣に炊飯器と向きあってるんやって。ほんまに、ありがとう? pic.twitter.com/1PAYIakvhL
— SHARP シャープ株式会社 (@SHARP_JP) October 31, 2019
感情が深すぎます。
価格
Amazonお馴染みの従量課金制です。初回一年は無料枠が使えます。
エンティティ認識、感情分析、構文解析、キーフレーズ抽出、言語検出のリクエストは
100 文字で 1 ユニットとして計算され、各リクエストにつき 3 ユニット (300 文字) が
最低料金となります。こちらもAmazonの料金説明から抜粋しています。
最後に
ここまで抽出や分析ができると、テキストから最善の回答を得る、トピック別にドキュメントを整理する
独自のデータでのモデルのトレーニング、業界に特化したテキストのサポートが簡単に実現できそうですね!
例えば、顧客が満足か不満足かに関して頻繁にコメントのある製品について
その特徴を特定することができます。製品レビュー、ソーシャルメディアフィード、ニュース記事、ドキュメント、その他のソースからテキスト内の意味や関連性も検出できるのでこれから沢山活用できそうです!
公式サイトリンク




- 投稿日:2019-12-03T16:08:31+09:00
【AWS】RustでLambdaを書く
この記事は Rustその2 Advent Calendar 2019 12/3 の記事です。
以前ブログでも書いたのですが、今回はServerlessFramework用のプロジェクトを作るための最小限のことだけ書いていきます。
環境構築
Rust
バージョン rustc 1.41.0-nightly rustup 1.20.2 cargo 1.41.0-nightly ServerlessFramework
バージョン yarn 1.19.2 serverless 1.58.0 serverless-rust 0.3.7 Rustインストール
consolecurl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
.profileにPATHが更新されるので確認して、読み込みます。console$ cat ~/.profile export PATH="$HOME/.cargo/bin:$PATH" $ source ~/.profile
cargoコマンドが使えれば完了です。console$ cargo version cargo 1.41.0-nightly (8280633db 2019-11-11)ServerlessFrameworkのインストール
今回は
yarnを使って準備していきます。
まずはyarn initでpackage.jsonを作ります。
ひとまずすべてデフォルトで作ります。console$ yarn init yarn init v1.19.2 question name (rust_serverless): question version (1.0.0): question description: question entry point (index.js): question repository url: question author: question license (MIT): question private: success Saved package.json出来上がるとこんな感じになります。
package.json{ "name": "rust_serverless", "version": "1.0.0", "main": "index.js", "license": "MIT" }ここから、
ServerlessFrameworkとserverless-rustを追加$ yarn add serverless@1.58.0$ yarn add serverless-rust@0.3.7追加後のpackage.jsonはこうなります。
{ "name": "rust_serverless", "version": "1.0.0", "main": "index.js", "license": "MIT", "dependencies": { "serverless": "^1.58.0", "serverless-rust": "^0.3.7" } }プロジェクト作成
rustのtemplateは現在ないみたいなので、
sls createコマンドは使いません。
まずは、serverless.ymlを手書きします。serverless.ymlservice: rust-sample provider: name: aws runtime: rust memorySize: 128 region: ap-northeast-1 plugins: - serverless-rust package: individually: true functions: rust-sample: handler: rust-sample events: - http: path: / method: GET次にrustの初期化をします。
serverless.yml、package.jsonと同じ位置で以下のコマンドを叩きます。$ cargo initここまでやると、以下のディレクトリ構成になってると思います。
コーディング
まず、main.rs用のサンプルのコードになります。
もとのコード消して、こちらに差し替えます。main.rsuse lambda_http::{lambda, IntoResponse, Request}; use lambda_runtime::{error::HandlerError, Context}; use serde_json::json; fn main() { lambda!(handler) } fn handler( _: Request, _: Context, ) -> Result<impl IntoResponse, HandlerError> { Ok(json!({ "message": "AWS Lambda on Rust" })) } #[cfg(test)] mod tests { use super::*; #[test] fn handler_handles() { let request: Request<> = Request::default(); let expected = json!({ "message": "AWS Lambda on Rust" }) .into_response(); let response = handler(request, Context::default()) .expect("expected Ok(_) value") .into_response(); assert_eq!(response.body(), expected.body()) } }次に、上記のソースに必要なPackageを
Cargo.tomlに追加します。Cargo.toml[package] name = "rust-sample" version = "0.1.0" authors = ["hisayuki <*****@***>"] edition = "2018" # See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html [dependencies] lambda_runtime = "0.2.1" lambda_http = "0.1.1" log = "0.4" serde_json = "^1" serde_derive = "^1"このときに、
[package]のnameをserverless.ymlのhandler名と一緒にします。serverless.ymlfunctions: example-function: handler: rust-sample events: - http: path: / method: GETこの段階で、
main.rsの単体テストは出来るので実際にやってみます。
コマンドはcargo testになります。console$ cargo test Finished test [unoptimized + debuginfo] target(s) in 0.20s Running target/debug/deps/rust_sample-eb5e576424cf1ee7 running 1 test test tests::handler_handles ... ok test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
Cargo.tomlにpackageを設定してからcargoコマンドを実行していない場合は、ここでpackageのインストールが始まります。テスト
Lambdaのローカル単体テスト
Lambdaとしてテストスル場合、ローカルであってもリクエストを渡す必要があります。
Requestを渡さないとエラーが返ってきます。console{"errorType":"JsonError","errorMessage":"JsonError: invalid type: string \"\", expected struct LambdaRequest at line 1 column 2"}そのため、本来API Gatewayから送られてくるRequestの簡易版を用意します。
example_request.json{ "path": "/", "httpMethod": "GET", "headers": { "Host": "amazonaws.com" }, "requestContext": { "accountId": "", "resourceId": "", "stage": "dev", "requestId": "", "identity": { "sourceIp": "" }, "resourcePath": "", "httpMethod": "", "apiId": "" }, "queryStringParameters": {} }ディレクトリ構成はこんな感じ。
プロジェクトのrootで以下のコマンドを打つと実行結果が帰ってきます。
console$ yarn sls invoke local -f example-function --path test/resources/example_request.json yarn run v1.19.2 $ /Users/hisayuki/docker_dev/rust_serverless/node_modules/.bin/sls invoke local -f rust-sample --path test/resources/example_request.json Serverless: Building native Rust rust-sample func... Finished release [optimized] target(s) in 3.04s adding: bootstrap (deflated 61%) Serverless: Packaging service... Serverless: Building Docker image... START RequestId: 7cdd45ff-65e6-1b2f-f341-832c8239935c Version: $LATEST END RequestId: 7cdd45ff-65e6-1b2f-f341-832c8239935c REPORT RequestId: 7cdd45ff-65e6-1b2f-f341-832c8239935c Init Duration: 161.04 ms Duration: 5.20 ms Billed Duration: 100 ms Memory Size: 1536 MB Max Memory Used: 10 MB {"statusCode":200,"headers":{"content-type":"application/json"},"multiValueHeaders":{"content-type":["application/json"]},"body":"{\"message\":\"AWS Lambda on Rust\"}","isBase64Encoded":false} ✨ Done in 54.26s.API Gateway経由のローカル結合テスト
他言語で使われている
serverless-offlineのPackageを追加しようとおもったのですが・・・
Rustはserverless-offline対応していないので、ローカルでは出来ないです。
API GatewayからのテストはAWS上にデプロイして行います。AWS上でのLambda単体テスト
まず、AWS上に
sls deployでデプロイします。console$ yarn sls deploy --aws-profile [プロファイル名] yarn run v1.19.2 $ /Users/hisayuki/docker_dev/rust_serverless/node_modules/.bin/sls deploy --aws-profile [プロファイル名] Serverless: Building native Rust rust-sample func... Finished release [optimized] target(s) in 2.05s objcopy: stlfi43N: debuglink section already exists adding: bootstrap (deflated 60%) Serverless: Packaging service... Serverless: Uploading CloudFormation file to S3... Serverless: Uploading artifacts... Serverless: Uploading service rust-sample.zip file to S3 (1.06 MB)... Serverless: Validating template... Serverless: Updating Stack... Serverless: Checking Stack update progress... ........................... Serverless: Stack update finished... Service Information service: rust-sample stage: dev region: ap-northeast-1 stack: rust-sample-dev resources: 10 api keys: None endpoints: GET - https://a5uhcphfsj.execute-api.ap-northeast-1.amazonaws.com/dev/ functions: example-function: rust-sample-dev-example-function layers: None Serverless: Run the "serverless" command to setup monitoring, troubleshooting and testing. ✨ Done in 59.47s.deploy完了すると、マネジメントコンソールでも確認できます。
deploy後に
localをつけずに実行します。console$ yarn sls invoke -f example-function --aws-profile [プロファイル名] yarn run v1.19.2 $ /Users/hisayuki/docker_dev/rust_serverless/node_modules/.bin/sls invoke -f example-function --path test/resources/example_request.json --aws-profile [プロファイル名] { "statusCode": 200, "headers": { "content-type": "application/json" }, "multiValueHeaders": { "content-type": [ "application/json" ] }, "body": "{\"message\":\"AWS Lambda on Rust\"}", "isBase64Encoded": false } ✨ Done in 2.79s.このように、Responseが返ってきます。
AWS上でのAPI Gateway経由結合テスト
こちらは、先程のLambdaのdeploy時にAPI Gatewayの作成とEndpointが作成されています。
deploy時のResponseendpoints: GET - https://a5uhcphfsj.execute-api.ap-northeast-1.amazonaws.com/dev/マネジメントコンソールでも確認できます。
テストの方法は
curlで実行をします。$ curl -X GET https://a5uhcphfsj.execute-api.ap-northeast-1.amazonaws.com/dev/ {"message":"AWS Lambda on Rust"}これでAPI Gatewayからの実行テストも完了
まとめ
serverless-offlineが使えないのは残念ですが、RustでのLambda作成もだいぶ整ってきてます。
今回は書きませんでしたが、DynamoDBへの問い合わせ、複数Fanctionの作成方法もあります。
デフォルトで型とテストを備えているRustで、ぜひAPIの作成をしてみてください。




- 投稿日:2019-12-03T16:08:31+09:00
【AWS】RustでServerlessFrameworkを使ってみる
この記事は Rustその2 Advent Calendar 2019 12/3 の記事です。
以前ブログでも書いたのですが、今回はRustを使ってServerlessFramework用のプロジェクトを作るための最小限のことだけ書いていきます。
環境構築
Rust
バージョン rustc 1.41.0-nightly rustup 1.20.2 cargo 1.41.0-nightly ServerlessFramework
バージョン yarn 1.19.2 serverless 1.58.0 serverless-rust 0.3.7 Rustインストール
consolecurl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
.profileにPATHが更新されるので確認して、読み込みます。console$ cat ~/.profile export PATH="$HOME/.cargo/bin:$PATH" $ source ~/.profile
cargoコマンドが使えれば完了です。console$ cargo version cargo 1.41.0-nightly (8280633db 2019-11-11)ServerlessFrameworkのインストール
今回は
yarnを使って準備していきます。
まずはyarn initでpackage.jsonを作ります。
ひとまずすべてデフォルトで作ります。console$ yarn init yarn init v1.19.2 question name (rust_serverless): question version (1.0.0): question description: question entry point (index.js): question repository url: question author: question license (MIT): question private: success Saved package.json出来上がるとこんな感じになります。
package.json{ "name": "rust_serverless", "version": "1.0.0", "main": "index.js", "license": "MIT" }ここから、
ServerlessFrameworkとserverless-rustを追加$ yarn add serverless@1.58.0$ yarn add serverless-rust@0.3.7追加後のpackage.jsonはこうなります。
{ "name": "rust_serverless", "version": "1.0.0", "main": "index.js", "license": "MIT", "dependencies": { "serverless": "^1.58.0", "serverless-rust": "^0.3.7" } }プロジェクト作成
rustのtemplateは現在ないみたいなので、
sls createコマンドは使いません。
まずは、serverless.ymlを手書きします。serverless.ymlservice: rust-sample provider: name: aws runtime: rust memorySize: 128 region: ap-northeast-1 plugins: - serverless-rust package: individually: true functions: example-function: handler: rust-sample events: - http: path: / method: GET次にrustの初期化をします。
serverless.yml、package.jsonと同じ位置で以下のコマンドを叩きます。$ cargo initここまでやると、以下のディレクトリ構成になってると思います。
コーディング
まず、main.rs用のサンプルのコードになります。
もとのコード消して、こちらに差し替えます。main.rsuse lambda_http::{lambda, IntoResponse, Request}; use lambda_runtime::{error::HandlerError, Context}; use serde_json::json; fn main() { lambda!(handler) } fn handler( _: Request, _: Context, ) -> Result<impl IntoResponse, HandlerError> { Ok(json!({ "message": "AWS Lambda on Rust" })) } #[cfg(test)] mod tests { use super::*; #[test] fn handler_handles() { let request: Request<> = Request::default(); let expected = json!({ "message": "AWS Lambda on Rust" }) .into_response(); let response = handler(request, Context::default()) .expect("expected Ok(_) value") .into_response(); assert_eq!(response.body(), expected.body()) } }次に、上記のソースに必要なPackageを
Cargo.tomlに追加します。Cargo.toml[package] name = "rust-sample" version = "0.1.0" authors = ["hisayuki <*****@***>"] edition = "2018" # See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html [dependencies] lambda_runtime = "0.2.1" lambda_http = "0.1.1" log = "0.4" serde_json = "^1" serde_derive = "^1"このときに、
[package]のnameをserverless.ymlのhandler名と一緒にします。serverless.ymlfunctions: example-function: handler: rust-sample events: - http: path: / method: GETこの段階で、
main.rsの単体テストは出来るので実際にやってみます。
コマンドはcargo testになります。console$ cargo test Finished test [unoptimized + debuginfo] target(s) in 0.20s Running target/debug/deps/rust_sample-eb5e576424cf1ee7 running 1 test test tests::handler_handles ... ok test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
Cargo.tomlにpackageを設定してからcargoコマンドを実行していない場合は、ここでpackageのインストールが始まります。テスト
Lambdaのローカル単体テスト
Lambdaとしてテストスル場合、ローカルであってもリクエストを渡す必要があります。
Requestを渡さないとエラーが返ってきます。console{"errorType":"JsonError","errorMessage":"JsonError: invalid type: string \"\", expected struct LambdaRequest at line 1 column 2"}そのため、本来API Gatewayから送られてくるRequestの簡易版を用意します。
example_request.json{ "path": "/", "httpMethod": "GET", "headers": { "Host": "amazonaws.com" }, "requestContext": { "accountId": "", "resourceId": "", "stage": "dev", "requestId": "", "identity": { "sourceIp": "" }, "resourcePath": "", "httpMethod": "", "apiId": "" }, "queryStringParameters": {} }ディレクトリ構成はこんな感じ。
プロジェクトのrootで以下のコマンドを打つと実行結果が帰ってきます。
console$ yarn sls invoke local -f example-function --path test/resources/example_request.json yarn run v1.19.2 $ /Users/hisayuki/docker_dev/rust_serverless/node_modules/.bin/sls invoke local -f rust-sample --path test/resources/example_request.json Serverless: Building native Rust rust-sample func... Finished release [optimized] target(s) in 3.04s adding: bootstrap (deflated 61%) Serverless: Packaging service... Serverless: Building Docker image... START RequestId: 7cdd45ff-65e6-1b2f-f341-832c8239935c Version: $LATEST END RequestId: 7cdd45ff-65e6-1b2f-f341-832c8239935c REPORT RequestId: 7cdd45ff-65e6-1b2f-f341-832c8239935c Init Duration: 161.04 ms Duration: 5.20 ms Billed Duration: 100 ms Memory Size: 1536 MB Max Memory Used: 10 MB {"statusCode":200,"headers":{"content-type":"application/json"},"multiValueHeaders":{"content-type":["application/json"]},"body":"{\"message\":\"AWS Lambda on Rust\"}","isBase64Encoded":false} ✨ Done in 54.26s.API Gateway経由のローカル結合テスト
他言語で使われている
serverless-offlineのPackageを追加しようとおもったのですが・・・
Rustはserverless-offline対応していないので、ローカルでは出来ないです。
API GatewayからのテストはAWS上にデプロイして行います。デプロイ
AWS上に
sls deployでデプロイします。console$ yarn sls deploy --aws-profile [プロファイル名] yarn run v1.19.2 $ /Users/hisayuki/docker_dev/rust_serverless/node_modules/.bin/sls deploy --aws-profile [プロファイル名] Serverless: Building native Rust rust-sample func... Finished release [optimized] target(s) in 2.05s objcopy: stlfi43N: debuglink section already exists adding: bootstrap (deflated 60%) Serverless: Packaging service... Serverless: Uploading CloudFormation file to S3... Serverless: Uploading artifacts... Serverless: Uploading service rust-sample.zip file to S3 (1.06 MB)... Serverless: Validating template... Serverless: Updating Stack... Serverless: Checking Stack update progress... ........................... Serverless: Stack update finished... Service Information service: rust-sample stage: dev region: ap-northeast-1 stack: rust-sample-dev resources: 10 api keys: None endpoints: GET - https://a5uhcphfsj.execute-api.ap-northeast-1.amazonaws.com/dev/ functions: example-function: rust-sample-dev-example-function layers: None Serverless: Run the "serverless" command to setup monitoring, troubleshooting and testing. ✨ Done in 59.47s.deploy完了すると、マネジメントコンソールでも確認できます。
AWS上でのLambda単体テスト
deploy後に
localをつけずにinvokeで実行します。console$ yarn sls invoke -f example-function --aws-profile [プロファイル名] yarn run v1.19.2 $ /Users/hisayuki/docker_dev/rust_serverless/node_modules/.bin/sls invoke -f example-function --path test/resources/example_request.json --aws-profile [プロファイル名] { "statusCode": 200, "headers": { "content-type": "application/json" }, "multiValueHeaders": { "content-type": [ "application/json" ] }, "body": "{\"message\":\"AWS Lambda on Rust\"}", "isBase64Encoded": false } ✨ Done in 2.79s.このように、Responseが返ってきます。
AWS上でのAPI Gateway経由結合テスト
こちらは、先程のLambdaのdeploy時にAPI Gatewayの作成とEndpointが作成されています。
deploy時のResponseendpoints: GET - https://a5uhcphfsj.execute-api.ap-northeast-1.amazonaws.com/dev/マネジメントコンソールでも確認できます。
テストの方法は
curlで実行をします。$ curl -X GET https://a5uhcphfsj.execute-api.ap-northeast-1.amazonaws.com/dev/ {"message":"AWS Lambda on Rust"}これでAPI Gatewayからの実行テストも完了
まとめ
serverless-offlineが使えないのは残念ですが、RustでのLambda作成もだいぶ整ってきてます。
今回は書きませんでしたが、DynamoDBへの問い合わせ、複数Fanctionの作成方法もあります。
デフォルトで型とテストを備えているRustで、ぜひAPIの作成をしてみてください。参照Github
- 投稿日:2019-12-03T15:50:48+09:00
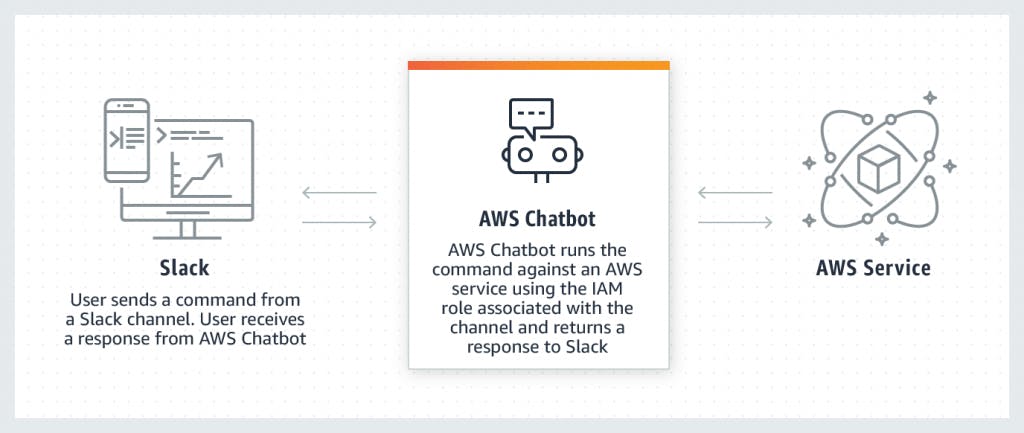
Terraformで構築するAmazon SNSからAWS Lambdaを呼び出すためのトリガ
はじめに
こんにちは、SREエンジニアやっています、@hayaosatoです。
今回はAmazon SNS(以下、SNS)からAWSLambda(以下、Lambda)を呼び出すためのトリガをTerraformで構築してみようと思います。
コードはこちら前回、似たようなことをSQSからのトリガ設定をTerraformで実装したのですが、
その際に利用したlambda_event_source_mappingでは、一部のリソースでしかLambdaのトリガを設定することができませんでした。
そこで、今回はLambdaにおけるそのほかのリソースへをトリガにするlambda_permissionを利用してSNSからのトリガを構築してみようと思います。Lambda
アプリケーションはSQSの時と同様、Slack通知を行うアプリケーションにしています。
arvhive_fileでLambda関数用のzipファイルを作成して、生成したzipファイルをLambda関数としてアップします。data archive_file "default" { type = "zip" source_dir = "src" output_path = var.output_path } resource "aws_lambda_function" "default" { filename = var.output_path function_name = var.service_name role = aws_iam_role.default.arn handler = "lambda_function.lambda_handler" source_code_hash = data.archive_file.default.output_base64sha256 runtime = "python3.6" environment { variables = { SLACK_API_KEY = var.SLACK_API_KEY } } }また、SlackのAPIトークンは環境変数から利用しているので、Lambdaにも環境変数を定義します。
IAM
Lambdaを実行するためのIAM Roleも定義する必要があるので、このリソースも合わせて作っておきます。
resource "aws_iam_policy" "default" { name = var.service_name description = "IAM Policy for ${var.service_name}" policy = file("${var.service_name}-policy.json") } resource "aws_iam_role_policy_attachment" "default" { role = aws_iam_role.default.name policy_arn = aws_iam_policy.default.arn }SNS
SNSに関しては、サブスクリプションでLambda関数を指定してリソースを作成してあげる必要があります。
resource "aws_sns_topic" "default" { name = var.service_name delivery_policy = file("sns_delivery_policy.json") } resource "aws_sns_topic_subscription" "default" { topic_arn = aws_sns_topic.default.arn protocol = "lambda" endpoint = aws_lambda_function.default.arn }連携
ここからが本題で、Lambda関数に対してSNSからのトリガを設定してあげます。
resource "aws_lambda_permission" "default" { statement_id = "AllowExecutionFromSNS" action = "lambda:InvokeFunction" function_name = aws_lambda_function.default.function_name principal = "sns.amazonaws.com" source_arn = aws_sns_topic.default.arn }もし、S3からのトリガを設定したい場合は
resource "aws_lambda_permission" "s3_trigger" { statement_id = "AllowExecutionFromS3Bucket" action = "lambda:InvokeFunction" function_name = aws_lambda_function.default.arn principal = "s3.amazonaws.com" source_arn = aws_s3_bucket.default.arn }のようになります。
結果
sample.tfvarsにSlackのAPIトークンを記入して、
$ terraform apply -var-file sample.tfvarsすると
できました。最後に
Lambdaへのトリガ設定もTerraformで設定できるようになりました。
サーバレスが捗りますね参考
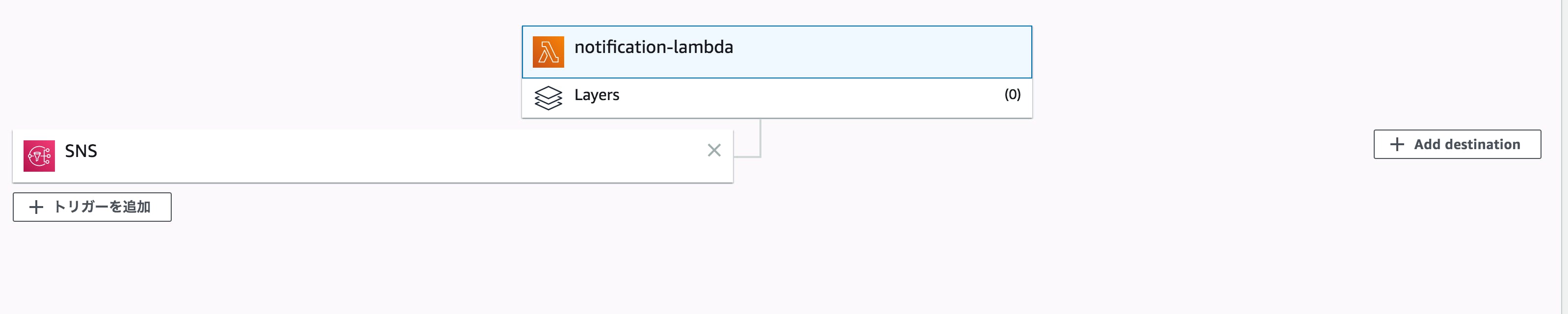
- 投稿日:2019-12-03T15:43:52+09:00
【サーバレス機械学習入門】AWS Lambda レイヤーの使い方
はじめに
これは機械学習ツールを掘り下げる by 日経 xTECH ビジネスAI③ Advent Calendar 2019の1日目の記事です。
12/20に記事を書こうと思っていたのですが1日目が埋まっていなかったので突貫工事で記事を書きました。
私はAWS Lambdaが大好きなので、Lambdaで機械学習するノウハウを書いていこうと思います。
本記事ではLambda関数でPandasなどの外部ライブラリを使う方法をまとめておきます。1
これまでのAWS Lambda
これまでのAWS Lambdaでは、外部ライブラリを用いる場合2
- Lambda関数のソースコード
- ライブラリのソースコード
これらをZipファイル(デプロイパッケージ)にまとめてアップロードする必要がありました。
その結果、関数の呼び出しは出来るがコンソール上で編集が出来ないという何とも不便な状況でした。
これを解決するのがAWS Lambda レイヤーです。
AWS Lambda Layersとは
追加のコードとコンテンツをレイヤーの形式で取り込むように Lambda 関数を設定することができます。レイヤーは、ライブラリ、カスタムランタイム、またはその他の依存関係を含む ZIP アーカイブです。レイヤーを使用することで、関数のライブラリを使用することができます。デプロイパッケージに含める必要はありません。
直訳日本語が難しいので端的にまとめると。”外部ライブラリや自作モジュールなどをレイヤー形式で取り込むことが出来る機能”のことです。
ライブラリの使い回しやコンソール上での編集が可能になります。
Getting Started
- Cloud9の設定
- Python環境構築
- ZIPアーカイブの作成
- Layerの作成
Cloud9のセッティング
ここではLambdaLayersの開発環境としてCloud9を使います。
コードを記述、実行、デバッグできるクラウドベースの統合開発環境 (IDE)
AWS Cloud9(Cloud IDE でコードを記述、実行、デバッグ)| AWS
環境構築はデフォルト設定のままで大丈夫です。
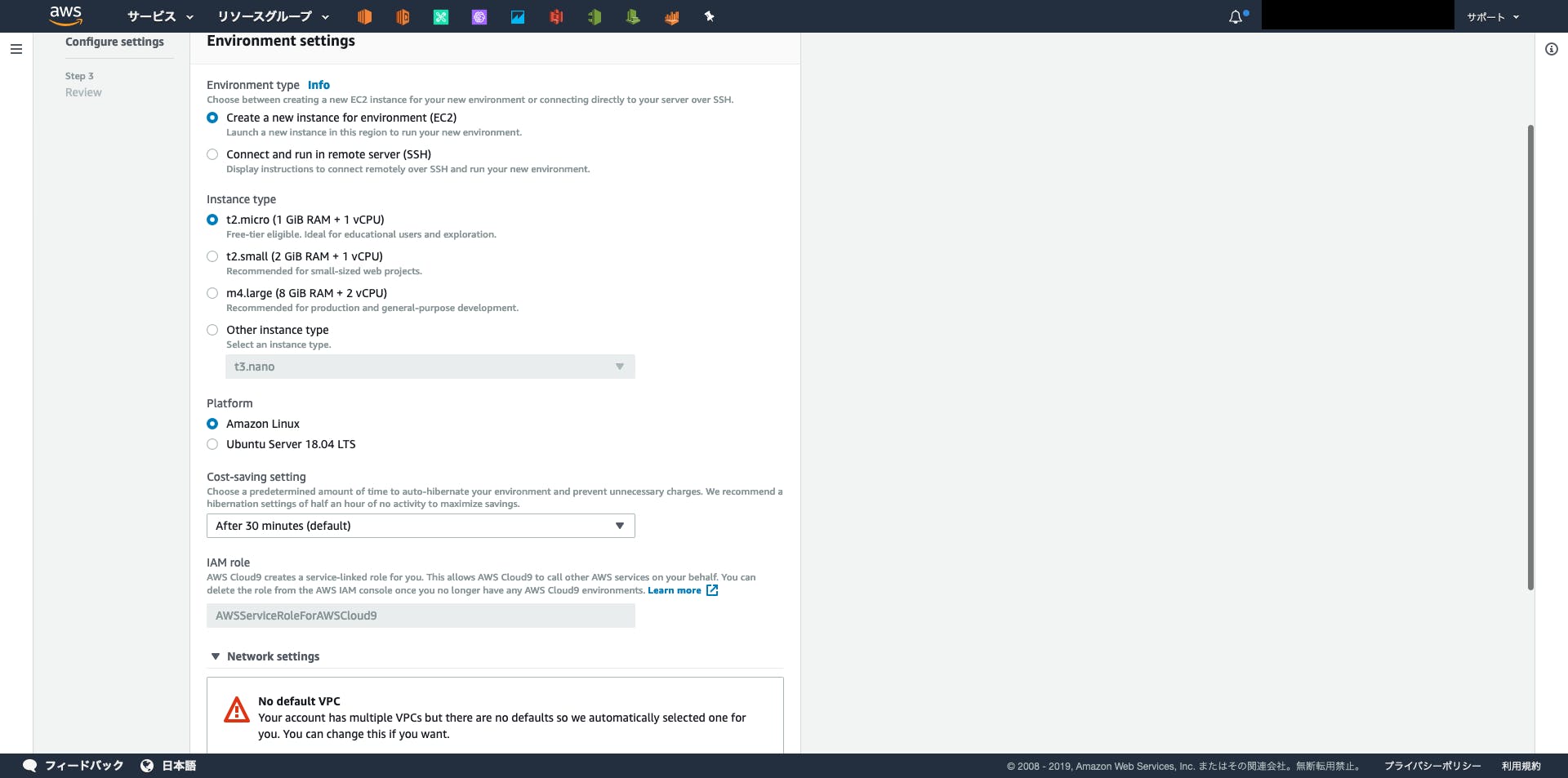
①環境名と説明書きを入力
②インスタンスタイプやOSなどの設定
③あとは作成するだけ
うまくいけば下記のようなIDEが使えるようになります。
Python環境構築
ここでは複数バージョンのPythonを扱えるようにしたいのでpyenvのインストールとPython3.8のインストールを行います。
[Python] pyenvを使ってPythonの複数のバージョンを使い分ける - YoheiM .NET
# pyenvのインストール curl -L https://raw.githubusercontent.com/yyuu/pyenv-installer/master/bin/pyenv-installer | bash # 環境変数の設定 vi ~/.bashrc
.bashrcのファイルの末尾に下記を追記するexport PATH="/home/ec2-user/.pyenv/bin:$PATH" eval "$(pyenv init -)" eval "$(pyenv virtualenv-init -)"
.bashrcを再読み込みsource ~/.bash_profilepythonのバージョン変更
ここでは3.8.0に変更してみます。
# python3.8をインストール pyenv install 3.8.0 # python3.8を設定 pyenv global 3.8.0インストールされているか確認します。
# pyenvでインストール済みのバージョン確認 pyenv versions # 現在のpythonバージョン python3 -V
python -Vで確認すると3.6.8になっているので注意。Zipアーカイブ作成
mkdir layer_pandas && cd $_ mkdir python && cd $_ pip3 install -t ./ pandas cd ../ zip -r layer_pandas.zip python/
pip installではなくpip3 installを使うこと!
完成したlayer_pandas.zipをダウンロードもしくはS3にアップロードしておきます。
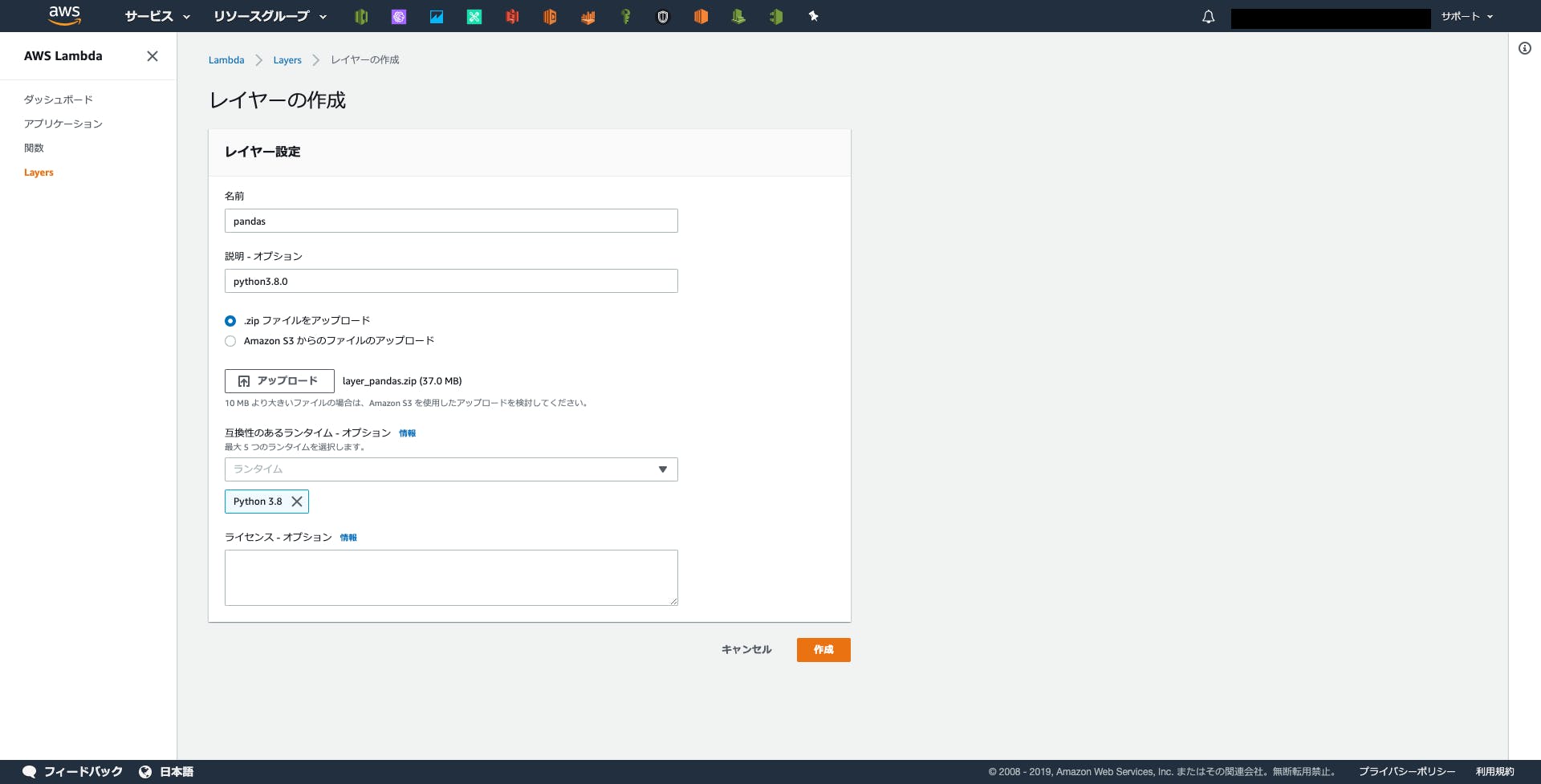
Layerの作成
Lambdaのコンソール画面の左のカラムの最下部にLayerという項目があるので、下記のように設定&アップロード。
しばらく待つとレイヤーが作成されます。
実験
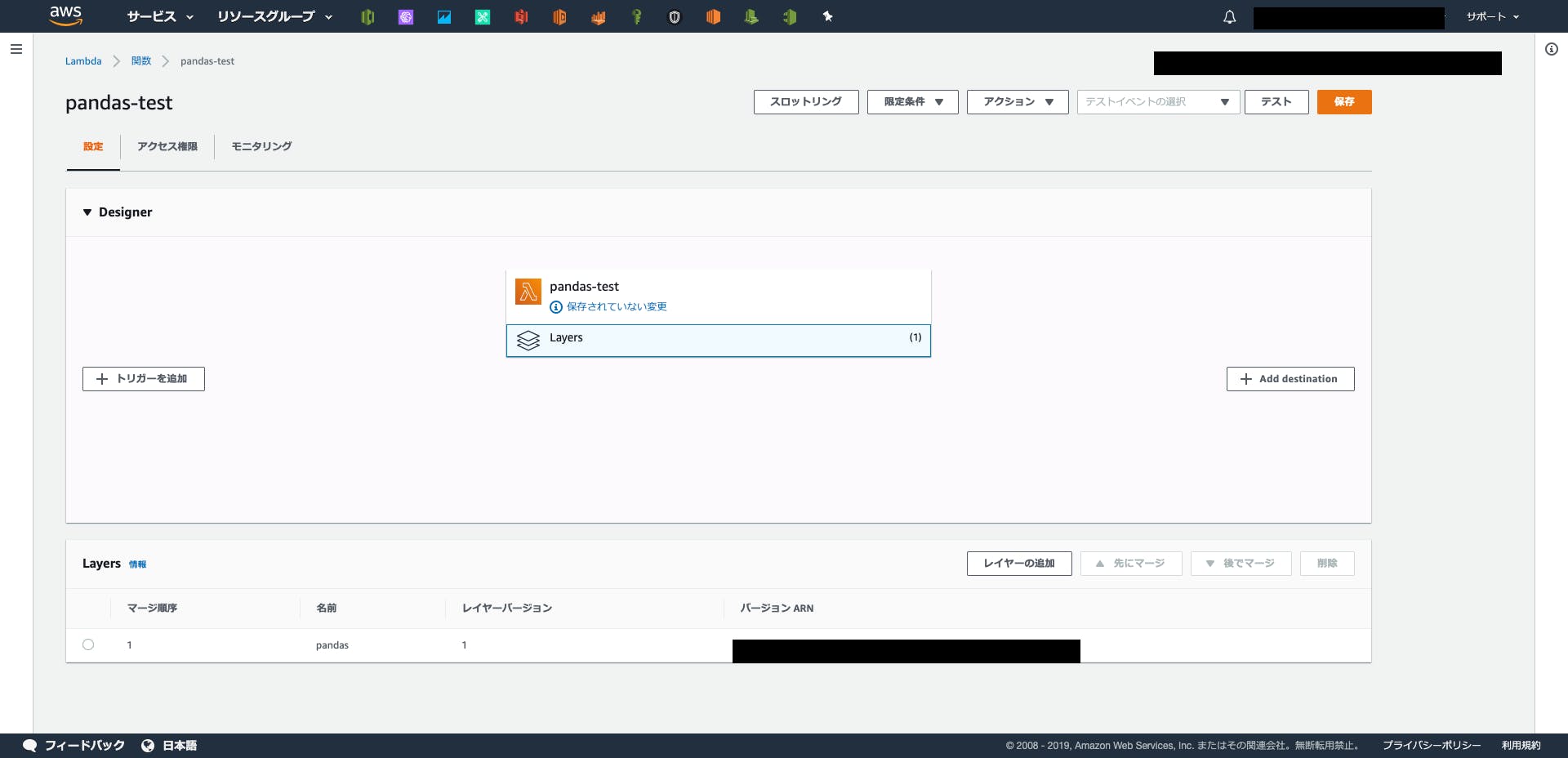
少しわかりにくいですが、画面中央のLayersの部分をクリックすると設定可能です。
PandasはNumpy同梱なので
np.xxxxxも使えるようになります。
まとめ
LambdaLayersを使えばLambda開発がぐっとラクになります。
特にwebデータの収集用のレイヤーを用意すると使い回しが効くのでオススメです。
mkdir layer_scraping && cd $_ mkdir python && cd $_ pip3 install -t ./ beautifulsoup4 pip3 install -t ./ requests pip3 install -t ./ pandas cd ../ zip -r layer_scraping.zip python/おわりに
とりあえず、Getting Startedな内容ですがLambdaで機械学習する準備が整いました。次はLightGBMやTensorflowなどの機械学習フレームワークが動かせるか検証したいと思います。
現場からは以上です。


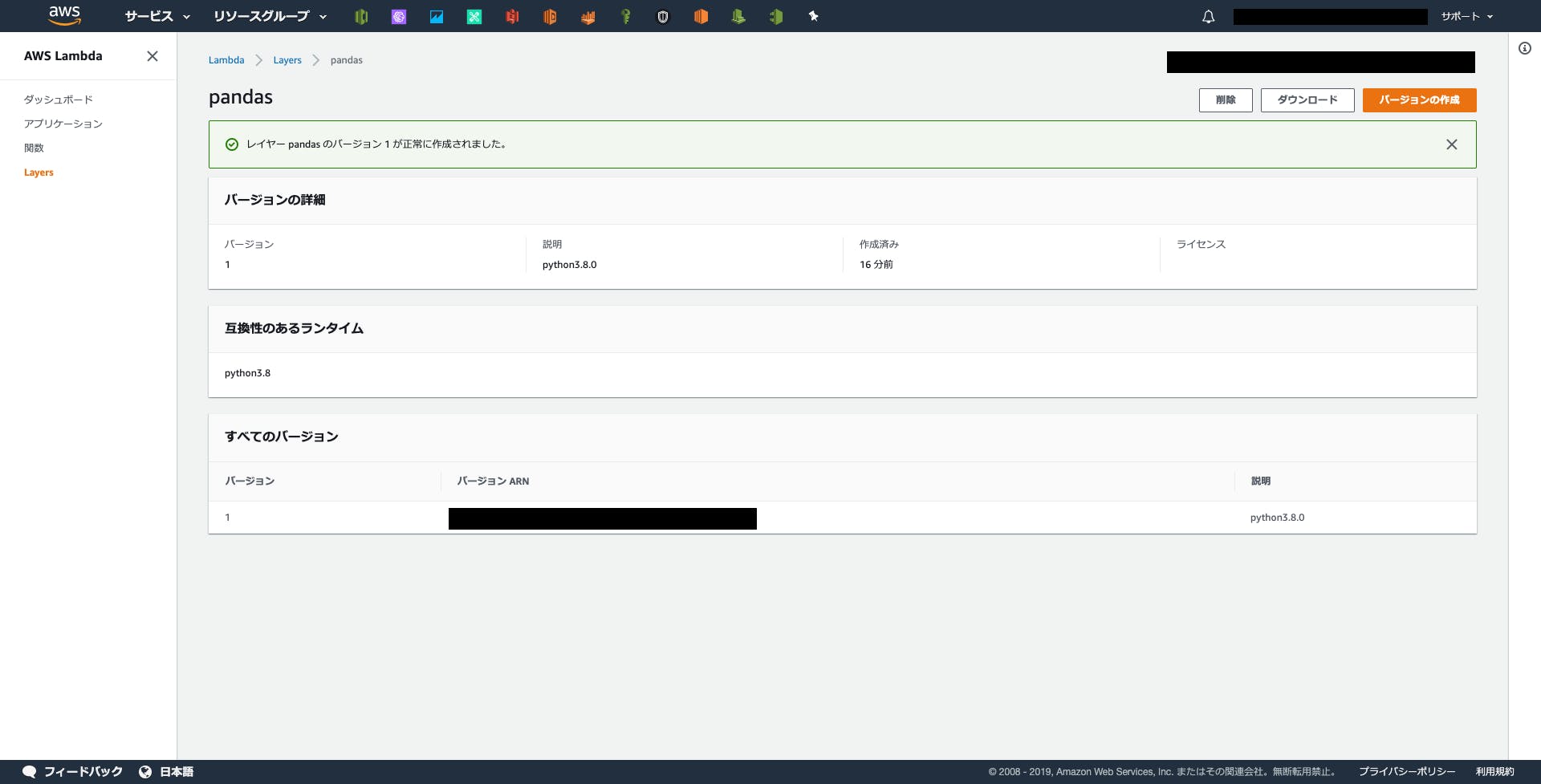

- 投稿日:2019-12-03T15:37:09+09:00
【爆速Terraform入門】AWS環境をコードで管理してみよう
まえがき
東南アジア発のスタートアップスタジオ、GAOGAOでエンジニアをしているMass-minと申します。
先日は、GAOGAOにて開発をサポートさせていただいている株式会社Ancar様のアドベントカレンダーで、記事を書かせていただきました!まだ読んでない方は是非!【ザンギョーウはヤメロ】スクラム開発で、チームが絶対に残業してはいけない理由
そんなこんなで、今日はAncar様にてサービス開発を行った際に得た技術的知見をアウトプットしていこうかと思います。
インフラ構築どうしてる?
みなさま、インフラ構築ってどうしてますか?
よほど大きな規模のプロダクトやレスポンスにシビアな要求があるプロダクトでない限りは、お手軽さという面でオンプレよりクラウドに軍配が上がるかと思います。
AWSやGCP、Azureなどを使っているサービスは、今や世の中の大半を占めると言っても過言ではないかと思われます。そんな今の世の中ですが、一度クラウドサービスのコンソール上でポチポチボタンを押して環境を構築した後、その環境をドキュメントなり何なりで適切に管理、保守出来ているチームは意外に少ないのでは、と思いました。
ドキュメントに落とし込んでいれば、同じような環境をもう一度作成する場合のスピードは段違いになりますよね。特にスタートアップにおいて、仮説検証の段階で環境を作っては壊しを繰り返す場合は顕著です。
また変更した箇所をちゃんとドキュメントにも反映していれば、わざわざコンソール画面の中で設定の項目を見なくてよくなります。
したがって、何かしらのカタチで環境をまるごと管理したいという欲求が出てきます。ここで登場するのがTerraformです。Terraformはクラウド環境を独自の言語でコード化して管理し、コマンド1発で環境のセットアップ、及び削除を行えるツールです。
TerraformはHashiCorp社が運営するサービスで、AWSが提供しているわけではありません。AWSに縛られず、GCPやAzureなどの環境もTerraformでコード管理することが出来ます。つまり一度Terraformの書き方を覚えてしまえば、どんな環境でもおおよそコード化して管理できてしまう、というわけです。ステキじゃないですか!というわけで今回は、Terraformの入門編。EC2インスタンスの設定をコード化して、環境構築を行ってみましょう。
おしながき
- 前提
- Terraformのインストール
- EC2インスタンスの設定
- 初級編 - TerraformでEC2インスタンスを作成してみる
- 中級編 - コードの内容を追ってみる
- 実践編 - Nginxをインストールしてトップページを表示
前提
- OS: macOS 10.15.1
- AWS CLIはインストール済み(credentials設定済み)
- まだ入ってない人は以下の手順でインストールしてください
Terraformのインストール
Macの場合はHomebrewでTerraformがインストールできます。
HomebrewでTerraformをインストール$ brew update $ brew install terraform2019/12/03時点では、Ver0.12.16が入りました。
Terraformのバージョン確認$ terraform -v Terraform v0.12.16EC2インスタンスの設定
初級編
さて、ではお待ちかねのEC2インスタンス作成です。
まずTerraformのコードを置くディレクトリを作成しましょう。ディレクトリを作成し移動$ mkdir terraform $ cd terraform/Terraformコードを書くファイルの作成と初期設定
Terraformのコードは
.tfという拡張子のファイルに書きます。今回はEC2インスタンスに関する記述をするので、ファイル名はec2.tfとしましょう。ec2.tfprovider "aws" { profile = "default" region = "ap-northeast-1" } resource "aws_instance" "terraform-web" { ami = "ami-0ab3e16f9c414dee7" instance_type = "t2.micro" tags = { Name = "ec2-terraform" } }とりあえずこれだけ。この状態で、terraformプロジェクトの初期設定を行います。
初期化$ terraform init
Terraform has been successfully initialized!と出れば完了です。何かしらエラーが出た人は、前提の欄に書いたAWS CLIのcredentials設定が終わっていないかもしれませんね。AWS CLIの設定を見てキーの設定を行ってください。作成計画を確認し、実際にコードを実行する
さて、では次に作成される予定のEC2について、作成計画を見てみましょう。
作成計画を見る$ terraform planなんかワーって出てきたかと思います。とりあえず次のステップ、実際にインスタンスを作成するところまでいってみましょう。
Terraformコードの実行$ terraform apply
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.のようになれば作成完了です。では、AWSのコンソールにいってEC2インスタンスのタブを見てみましょう。
おおっ!ちゃんとインスタンスが作成されていますね!このように、コード化した設定からEC2インスタンスを起動することができました!

中級編
作成できたのはいいものの、やっていることがよく分かりませんね。もうちょっと深堀りしてみましょう。
ちなみにTerraformのAWS関連公式ドキュメントはこちらです。公式をあたるのが一番早いです。コマンド
まず、terraformのコマンドについて。今出てきた3種類は、それぞれ以下のようになっています。
コマンド 内容 備考 init Terraformプロジェクトの初期設定を行う AWS CLIのcredentialsが設定済みである事が前提 plan Terraformコードの実行計画を見る いわゆるdry run apply Terraformコードの実行 したがって、コードを書いたらplanで環境がどうなるかを確認し、OKそうならapplyで実行、という流れになります。
コード
次に、
ec2.tfの中を見てみましょう。1行1行にコメントを書いてみました。ec2.tfprovider "aws" { # AWS以外にも、GCPやAzure、Herokuなどがここに入る profile = "default" # キーを指定せず、AWS CLIに設定したdefaultのcredentials情報を用いる region = "ap-northeast-1" # Terraformのコードで環境を作成する対象のリージョン } resource "aws_instance" "terraform-web" { # EC2インスタンスに関する記述。コード内ではterraform-webという名前でアクセスできる ami = "ami-0ab3e16f9c414dee7" # どのAMIをベースにインスタンスを作成するか、ID指定 instance_type = "t2.micro" # インスタンスタイプ指定 tags = { Name = "ec2-terraform" # タグに Name: ec2-terraform をセット } }もうお分かりですね。
providerで対象とするサービスを指定し、認証情報やリージョンを設定する。
そして、構築したい個々の内容をresourcenに書いていく、という感じです。
今はEC2のみ設定していますが、RDSやS3、VPCだって同じように書けます。書いていくとだんだん分かるのですが、コード管理できるのはめちゃめちゃ楽ですよ!実践編
それではみなさんよいクリスマスを!...とはならず。EC2がポッと1つたっただけでは面白くないですよね。最後に、EC2インスタンスにNginxをインストールしトップページを表示するところまでやって終わりにしましょう。
セキュリティグループの設定
プラウザからアクセスしてNginxのトップページを表示するには、80番ポートへのアクセスを受け付ける必要があります。
また、そもそもNginxをインストールするためにssh接続してインスタンスにアクセスしなければなりませんね。したがって、22番ポートも開けなければいけません。これらを設定していきましょう。ec2.tfprovider "aws" { profile = "default" region = "ap-northeast-1" } # セキュリティグループ resource "aws_security_group" "terraform-web-sg" { egress { from_port = 80 to_port = 80 protocol = "tcp" cidr_blocks = [ "0.0.0.0/0" ] } tags = { Name = "sg-terraform" } } # インバウンドのルール resource "aws_security_group_rule" "inbound_http" { security_group_id = aws_security_group.terraform-web-sg.id type = "ingress" from_port = 80 to_port = 80 protocol = "tcp" cidr_blocks = [ "0.0.0.0/0" ] } resource "aws_security_group_rule" "inbound_ssh" { security_group_id = aws_security_group.terraform-web-sg.id type = "ingress" from_port = 22 to_port = 22 protocol = "tcp" cidr_blocks = [ "0.0.0.0/0" ] } # EC2 resource "aws_instance" "terraform-web" { ami = "ami-0ab3e16f9c414dee7" instance_type = "t2.micro" vpc_security_group_ids = [aws_security_group.terraform-web-sg.id] # <= 追加 tags = { Name = "ec2-terraform" } }まず、セキュリティグループの
egressはアウトバウンド、igressはインバウンドのルールに関する記述です。セキュリティグループにルールを複数追加したい場合は、aws_security_group_ruleで記述します。そしてEC2の記述には、セキュリティグループのidについての記述を追加します。では
terraform applyを叩いてコンソールを見てみましょう。
ちゃんと複数ルールが設定されたセキュリティグループが作成されています!
EC2インスタンスにも作成されたセキュリティグループが正しく割り当てられていますね!
Nginxのインストール
さぁ、ここまできたならあとはもう少し。Nginxのインストールを行いましょう。
ここで、ssh接続するために鍵の設定が必要になりますので、先にキーペア作成を行っておきます。本筋とずれるので詳細は省きます。やり方はAWS公式ドキュメントをみてくださいね。さて、鍵ファイルが出来ました。自分は作成したファイルを
~/.ssh/test_terraform.pemに置いていますので、それをコードに記述していきます。長くなるので、以下はEC2に関する記述の部分だけを記しています。ec2.tf# EC2 resource "aws_instance" "terraform-web" { ami = "ami-0ab3e16f9c414dee7" instance_type = "t2.micro" vpc_security_group_ids = [aws_security_group.terraform-web-sg.id] key_name = "test_terraform" # <= 追加 tags = { Name = "ec2-terraform" } provisioner "remote-exec" { # <= 追加 connection { host = self.public_dns type = "ssh" user = "ec2-user" private_key = file("~/.ssh/test_terraform.pem") } inline = [ "sudo yum -y update && sudo yum install -y nginx && sudo service nginx start" ] } }例のごとく、
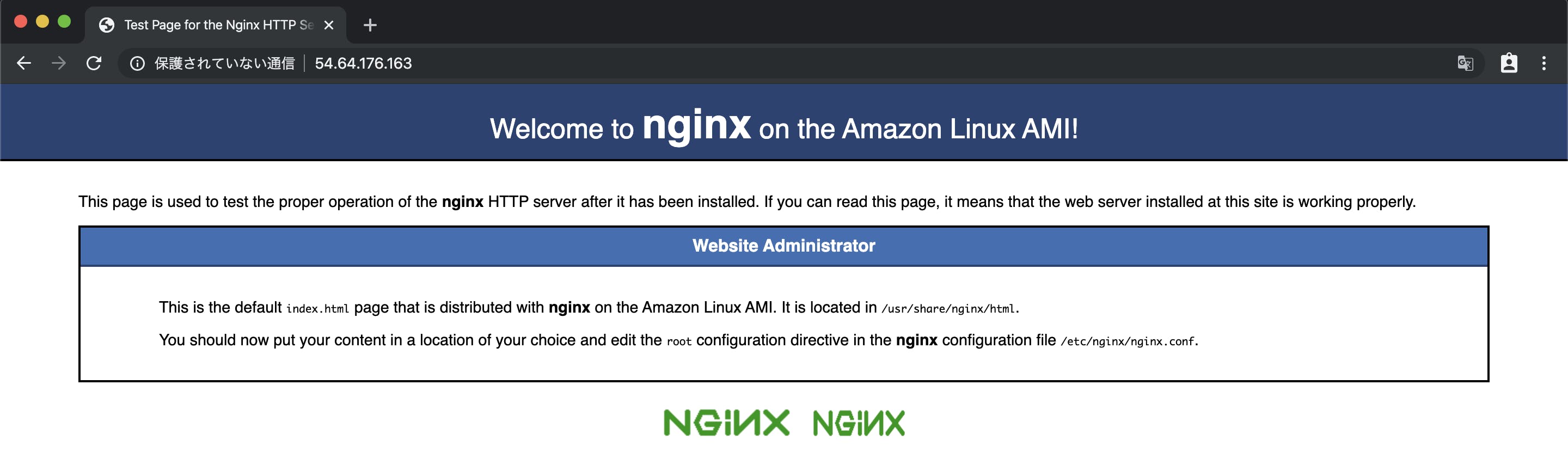
Apply complete! Resources: 1 added, 0 changed, 1 destroyed.と出たら完了です。ではちゃんとNginxが動いているか確認しましょう!
まずはTerraformで作成した環境の内容を表示するコマンドを打ってみます。内容表示$ terraform showズラズラと出てきたかと思いますが、これが構築された環境の内容です。
EC2の記述の中に、public_ipというのがあると思います。これが、作成したEC2インスタンスに振られたパブリックIPです!
では、ブラウザでこのIPにアクセスしてみましょう!
おおお!!無事にNginxのトップページが表示されました!このようにして、コードで環境の設定からプロビジョニングまで行うことができちゃうんですね!ビバTerraform!!
まとめ
Terraformを使うことによって、今までクラウドコンソール上でポチポチやってた環境をコード化して管理することが出来るようになりました!
いずれにせよコード化が出来たことにより、環境の変更差分等は全てGitで管理できるようになります。いつ誰が何をどのように変更したか見えるかできるので、今まで以上に安心して環境構築 & 保守ができるようになるのではないでしょうか!
また、一度よくあるインフラ形態をコード化しておけば、それを他のアプリケーションでも使い回すことが可能になります。まさに爆速インフラ構築!
ということで、インフラをコードに落として安心、安全な開発体制を整えていきましょう!*なお今回のサンプルコードはGitHubにあげていますので、勉強用に是非お使いください!



- 投稿日:2019-12-03T15:18:09+09:00
家の環境(温度・湿度)をAWSに蓄積して分析してみるの巻 その1
ゴール
- センサーデバイスからAWSにデータを送り、集めたデータをもとに家の環境を可視化すること。
目的
- 来年からAWSを使ったDB周りの開発をやる予定なのですが、これまで実務で経験なかったので、勉強のためにやってみようと思いました。
- とは言え何作ろう?と思ったときに、来年第一子が生まれるので、家の環境のデータを集めて分析して、改善できるようにしたいなと思ったので。
環境
- 開発PC(mac)
- ESP-IR+TPH Monitor 完成品
- USB変換チップとケーブル(DSD TECH USB to TLL Serial)
- ACアダプタ
- AWS IoT
セットアップ
開発PCのセットアップ
AWS IoTのセットアップ
バージョンによって操作手順が変わったりするので、参考程度に読んでください。
- AWSコンソールで
IoT Coreのサービスを選択します。ポリシーの作成
安全性 > ポリシーを選択します。- こんな画面が表示されるので
ポリシーの作成を選択します。
- ポリシーの名前とアクションの認可を設定します。とりあえず今回はずぶずぶの設定にします。

- 作成を選択します。問題なかったら正常に作成されたよのメッセージが出ます。
Thingsと証明書の作成
管理 > モノを選択します。まだデバイス登録がない場合はこんな画面が出るので、モノの登録を選択します。

単一のモノを作成するを選択します。
- デバイスの名前や属性(≒タグ)などの設定をおこないます。今回は家の環境を測定をするということで、名前に
house_environment_sensorと名付けました。 また、検索可能なモノの属性の設定 (オプション)というところでタグ登録ができるので製品名と機能(何が測定できるか)を設定しました。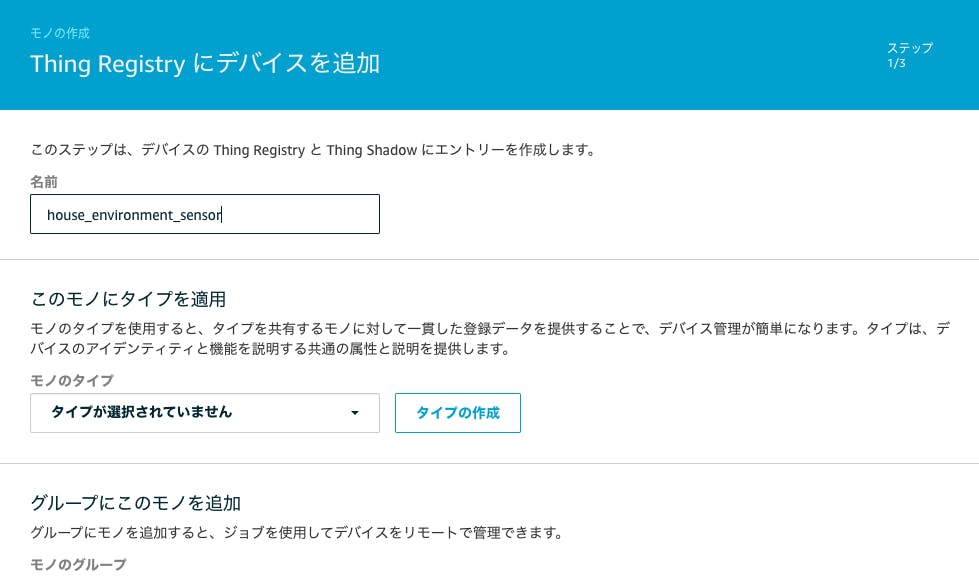

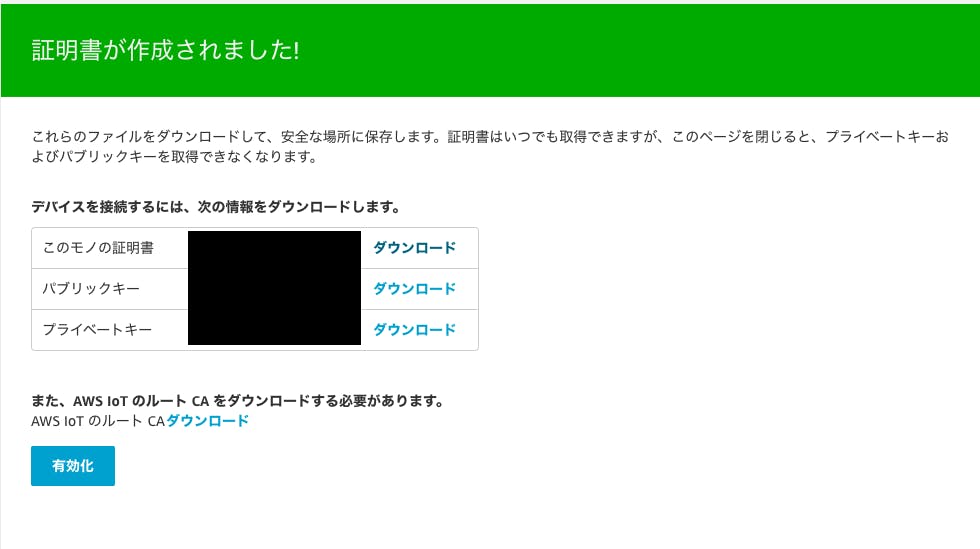
- 証明書の設定画面に移ります。
今回は1-Click 証明書作成 (推奨)で証明書作成をおこないます。
- 証明書が作成されるので作成されたキー等のファイルをダウンロードします(ページ閉じるとダウンロードできなくなるので注意。ただしルートCA証明書はここでもダウンロードできます)。
- 同じ画面下にある、
ポリシーをアタッチを選択します。- 作成したポリシーが選択されていることを確認して、
モノの登録を選択します。これでデバイスの設定が作成されました。
- 最後に、証明書を有効化します。
安全性 > 証明書で、作成した証明証のアクションで有効化を選択します。AWS IoTへの接続確認
PCからAWS IoTへmqtt接続の確認をします。Mosquittoを使ってテストしてみようと思います。
- Mosquittoをインストールします(参考)。
- こちらを参考に接続テストをおこないます。注意としては、ルートCAのファイルは
Amazon Trust Services エンドポイントのルートCAじゃないと接続できません(新しく作成した場合はこれじゃないとダメっぽい)。その2へつづく
- 投稿日:2019-12-03T15:09:38+09:00
FargateのコンテナでOSコマンドやsshで入りたい!! それssm-agentで解決できます
Fargate便利ですよね。煩わしいインスタンス管理から開放させて素早く環境が用意できます。
ですがECSと違って一点大きな問題があります。docker exec や SSH が実行できない!!
EC2に慣れている人にはSSHで調べられないのはちょっとうっ。。。。って思います。(少なからず自分はそうでした)
ではできないのか?というとそうでもないらしくいくつか方法はあるようです。
- SSHの環境を設定してそこからコンテナに入る
- ssm-agent経由でコンテナに入る
SSHの環境を整えても良いのですが、それだとせっかくのセキュアな環境が勿体ないので今回はssm-agentを経由したコンテナの入り方を構築したのでメモ代わりに残しておきます。
環境
- AWS Fargate
参考にした記事
- [AWS ECS]Fargateのcontainerにシェルで入りたい(sshd無しで!)
- これしかまともな情報がなかったので助かりました!!
やること
- DockerImageにssm-agentをインストールする
- Systems managerのハイブリッドアクティベーションの機能を使ってコンテナをmanagedする
- ssm-agentの起動コマンドを使ってマネージド化する
- Systems Managerのセッションスタート及びRun Commandができるか確認する
Dockerfileにssm-agentをインストールする処理を追加する
今回のコンテナはnodeJSのコンテナでPythonがなかったのでPythonのインストールも含めています(ssm-agentがPythonを使用するため)
DockerfileFROM node:10.16.3-stretch-slim RUN apt-get update && apt-get install -y \ curl \ && apt-get clean \ # Python Install RUN apt-get update && apt install -y \ zlib1g-dev \ libssl-dev \ libreadline-dev \ libsqlite3-dev \ libbz2-dev \ libncurses5-dev \ libgdbm-dev \ liblzma-dev \ tk-dev zlibc \ libffi-dev \ zip \ unzip \ && apt-get clean \ && curl https://www.python.org/ftp/python/3.7.5/Python-3.7.5.tgz | tar zx -C /usr/local/src/ \ && cd /usr/local/src/Python-3.7.5 \ && ./configure \ && make && make install \ && ln -s /usr/local/bin/python3 /usr/local/bin/python RUN curl https://s3.ap-northeast-1.amazonaws.com/amazon-ssm-ap-northeast-1/latest/debian_amd64/amazon-ssm-agent.deb -o /tmp/amazon-ssm-agent.deb \ && dpkg -i /tmp/amazon-ssm-agent.deb \ && cp /etc/amazon/ssm/seelog.xml.template /etc/amazon/ssm/seelog.xmlAWS Systems Managerのアクティベーションを使用してコンテナインスタンスをマネージドインスタンスにする
このアクティベーションという機能がよくできているやつで物理のオンプレミスインスタンスやラズパイ、ローカルのdocker等ssm-agentがあればssm-agent経由でSystems Managerの機能が使用できます。
ただし注意事項でEC2等はAWSの管理化に置かれているインスタンスなので料金はかかりませんが
それ以外のサーバーを登録すると時間当たりの料金が発生します。Systems Manager#オンプレミスインスタンス管理
試算するとssm-agent経由でマネージドインスタンスに登録した時点で
【計算式】料金 = (マネージドインスタンス管理時間単価 x 24(時間)× 日数 【コスト】5.004 USD = (0.00695 x 24) x 30となって1コンテナタスクあたり月額約5 USD程かかるのでご注意してください。
起動スクリプトを記載する
こんな感じの起動スクリプトを記載します
start.sh#! /usr/bin/env bash set -e if [ "$SSM_ACTIVATE" = "true" ]; then ACTIVATE_PARAMETERS=$(aws ssm create-activation \ --default-instance-name "$RESOURCE_STAGE-$SERVICE_NAME-$RESOURCE_VERSION" \ --description "$RESOURCE_STAGE-$SERVICE_NAME-$RESOURCE_VERSION" \ --iam-role "service-role/AmazonEC2RunCommandRoleForManagedInstances" \ --registration-limit 5) export ACTIVATE_CODE=$(echo $ACTIVATE_PARAMETERS | jq -r .ActivationCode) export ACTIVATE_ID=$(echo $ACTIVATE_PARAMETERS | jq -r .ActivationId) amazon-ssm-agent -register -code "${ACTIVATE_CODE}" -id "${ACTIVATE_ID}" -region "ap-northeast-1" -y nohup amazon-ssm-agent > /dev/null & fi . . ## この後にコンテナで実行したい処理を記載するインストールしたssm-agentのコマンドでマネージド化しますとこんな形で登録済みインスタンスとして登録されます
ECS Task Definitionsの修正
TaskRoleには
- AmazonSSMManagedInstanceCore
- AmazonSSMAutomationRole
- AmazonSSMDirectoryServiceAccess
が最低限必要になります
CloudFormationで記載していますがお好きな形で適宜修正してください
template.ymlParameters: TaskDefinitionEnvSSMActivate: Type: String Description: true is ssma-agent start mode task definitions Default: true Resources: ECSTaskRole: Type: AWS::IAM::Role Properties: RoleName: "{your role name}" Path: / AssumeRolePolicyDocument: Statement: - Effect: Allow Principal: Service: [ "ecs-tasks.amazonaws.com" ] Action: sts:AssumeRole - Effect: Allow Principal: Service: [ "ssm.amazonaws.com" ] Action: sts:AssumeRole ManagedPolicyArns: - arn:aws:iam::aws:policy/service-role/AmazonSSMAutomationRole - arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore - arn:aws:iam::aws:policy/AmazonSSMDirectoryServiceAccess ECSTaskDefinition: Type: "AWS::ECS::TaskDefinition" Properties: Cpu: {your vCPU} Memory: {your Memory} ExecutionRoleArn: {yourExecutionRoleArn} TaskRoleArn: !GetAtt ECSTaskRole.Arn Family: {Your family name} NetworkMode: awsvpc RequiresCompatibilities: - FARGATE ContainerDefinitions: - Name: {your container name} Image: !Sub - "${AWS::AccountId}.dkr.ecr.ap-northeast-1.amazonaws.com/${ECRRepository}" Environment: - Name: SSM_ACTIVATE Value: !Ref TaskDefinitionEnvSSMActivate - Name: SERVICE_NAME Value: !Ref ServiceName - Name: RESOURCE_STAGE Value: !Ref Prefix - Name: RESOURCE_VERSION Value: !Ref CFVersion - Name: SERVICE_STAGE Value: !Ref ServiceStage Command: [ "sh", "start.sh" ] LogConfiguration: LogDriver: awslogs Options: awslogs-group: !Ref ECSTaskLogGroup awslogs-region: !Ref AWSLogRegion awslogs-stream-prefix: "ecs" MemoryReservation: 128 PortMappings: - HostPort: 80 Protocol: tcp ContainerPort: 80 - HostPort: 10443 Protocol: tcp ContainerPort: 10443抜粋していますが
* Environment SSM_ACTIVATEのフラグで起動コンテナのssm-agentモードでの起動か否かをハンドリングしています。デフォルトはfalseで運用してトラブルシューティングをしたい場合はtrueにフラグを立てて実行する戦略です。
繋いで見る
ではこの状態で
- セッションマネージャー
- コマンドの実行
をやってみましょう
登録したインスタンスはハイブリッドアクティベーションからアクティベーションIDをコピーして
検索をかけるとわかります。
これで接続ができます。
補足: テストが終わった後のマネージドインスタンスの掃除
aws-cliでいけます
aws ssm delete-activation --activation-id {ActivateId} aws ssm deregister-managed-instance --instance-id "mi-12345abcd"最後に
最後の手段で使う処理なので常時。というよりかはどうしても困ったら実行する手段として覚えて置くとよいですね。

- 投稿日:2019-12-03T14:27:34+09:00
NoSQL×PaaSで運用するナレッジベース+WebAPI
これはなに
NoSQLとPaaSでナレッジベース+WebAPIを構築した際のノウハウのまとめです。
文字列タグ指向無向グラフ型ナレッジベースというアーキテクチャを実装する場合に、
Heroku + Redis + FastAPI で構築した例と、
AWS(DynamoDB + Lambda + API Gateway) で構築した例を紹介します。コード部分は全て
Python3.8.0を使用しています。※ 現在AWS編が未完成です。ごめんなさい。
ナレッジベースとは?
ナレッジベースには様々な定義がありますが、この記事では
「知識をコンピュータが読み取り可能な形式で格納したデータベース」を指します。
知識ベースナレッジデータベースKBなどの呼ばれ方もあります。
文字列タグ指向無向グラフ型ナレッジベース
今回例として構築するナレッジベースです。
名前だけでは分かりにくいと思うので、イメージ図を用意しました。
(可視化は未実装のためマインドマップツール coggle で作成)
なお、このアーキテクチャは流通しているものではなく、
GraphQLから着想を得て独自に設計したものです。
(サーベイはしていないのでもしかしたら既存かもしれません)「文字列タグ指向」について
このナレッジベースでは文字列(とその集合)データのみを扱い、
全ての文字列をタグとして扱います。上の図の例では、
Webサービス名アカウントIDURL記事タイトル概念プログラミング言語
などの各文字列を1つのタグとして扱っています。仕様上、文字列には空白や改行文字などは含まないものとします。
「無向グラフ型」について
このナレッジベースでは、関係のあるタグを結び付けるようにします。
例えば
フレームワークというタグには
RailsLaravelDjangoFlask
というタグが紐付いているというデータが取得可能で、
例えば
QiitaとPythonのどちらのタグも紐付いているのは
https://qiita.com/1ntegrale9/items/94ec4437f763aa623965
というタグ(QiitaのPythonに関する記事URL)、のようにデータを取得できます。
上の図では頂点(文字列)がタグ、辺が関係を表しています。
そして無向なので双方参照が可能です。
また包含関係などは考慮しないので、重み付けはありません。参考記事:グラフ理論の基礎 - Qiita
このナレッジベースの役割
「2つの文字列を格納する」という単純な操作の繰り返しだけで、
辞書的な知識体系(集合知)を形成することです。そして爆速で育て上げるためにWebAPIが必要になります。
構築例:Redis + FastAPI + Heroku
手軽に無料で運用したい場合はこちらを採用します。
Heroku の初期設定や Redis の基本操作はこちらで解説しています。
Heroku×Redis×Python で始める NoSQL DB 入門 - QiitaRedis
オンメモリで読み書きが高速なKVSです。永続化にも対応しています。
1つのタグに複数のタグを紐付けたいので、集合型のみを使います。ライブラリのインストール
Python で扱うため、redis-py を利用します。
python3 -m pip install redis hiredishiredis-py は C 実装の高速なパーサのラッパーです。
redis-py 側が hiredis を検知してパーサを切り替えてくれるので入れておきます。Redisに接続
以下のコードで接続の初期化を行います。
Heroku Redis が自動で設定してくれる環境変数REDIS_URLを使います。import redis, os conn = redis.from_url(os.environ['REDIS_URL'], decode_responses=True)デフォルトだと日本語の表示に不具合があるので、
decode_responses=Trueは必須です。全てのタグを取得
keys()を使って取得します。def get_all_tags(): return sorted(conn.keys())タグが一覧で見れると便利なので用意しておきます。
ただ規模が大きくなると負荷が高くなるので注意が必要です。紐付くタグを取得する
smembers(key)使って取得します。def get_related_tags(tag): r.smembers(tag) if r.exists(tag) else []念のため、存在しないタグを指定された場合は空配列を返すようにします。
存在確認にはexists(key)を使います。2つのタグを紐付けて格納する
sadd(key, value)を使って集合型データを格納します。
双方向に紐付けたいので、key-value を入れ替えて2回実行します。def set_relation_tags(tag1, tag2): return conn.pipeline().sadd(t1, t2).sadd(t2, t1).execute()Redis はトランザクションをサポートしており、redis-py の場合は
pipeline()からexecute()までのチェーンにすることで、
トランザクション内での一括実行ができます。また、pipeline メソッドによるアトミックな実行は、個別実行よりも高速のようです。
PythonでRedisを効率的に使う(redis-pyのパフォーマンスをあげるには) - [Dd]enzow(ill)? with DB and PythonFastAPI
FastAPI は Python の Web フレームワークの1つで、
シンプルな WebAPI を少ないコードで実装できるのと、
API ドキュメントを設定なしで自動生成してくれるのが特徴です。
Flask Responder Starlette DRF などはオーバースペックで、
Bottle は逆に機能が足りず、FastAPIがちょうどよくハマりました。ライブラリのインストール
python3 -m pip install fastapi uvicorn email-validatorUvicorn は高速なASGIサーバーです。FastAPIの起動に使います。
Gunicorn の typo ではないです。email-validator は入れておかないと起動時に怒られます。何故か。
アプリケーションの初期化
非常にシンプルです。
main.pyfrom fastapi import FastAPI app = FastAPI()引数の
titleとdiscriptionを設定すると、
上記画像のような自動生成される API Doc にタイトルと説明部が反映されます。main.pyapp = FastAPI( title='collective-intelligence', description='文字列タグ指向無向グラフ型ナレッジベース', )また、
docs_urlを指定すると、API Doc のURLを変更できます。
デフォルトでは/docsですが、ルートにしておくのも良いでしょう。main.pyapp = FastAPI(docs_url='/')全てのタグを取得
シンプルに HTTPメソッド(GET) と URL と返り値を書くだけです。
リストか辞書を返り値にすることで JSON レスポンスになります。main.py@app.get('/api') def read_all_tags(): return get_all_tags()この定義が API Doc に自動で反映されます。
更に右上のTry it outからリクエストを実行できます。
指定のタグに紐付くタグを取得
タグには記号も含む任意の文字列を想定しており、
クエリストリングでは対応できないため、POST にしておきます。main.py@app.post('/api/pull') def read_related_tags(tag: str): return get_related_tags(tag)引数に指定した
tag: strをリクエストボディから受け付けます。
型アノテーションを付けていますが、これを利用してリクエストのバリデーションを行います。
適合しない場合、422 Validation Errorがレスポンスになります。
2つのタグを紐付けて格納する
FastAPI は pydantic という、
型アノテーションを活用するためのライブラリを内包しています。
これを利用して独自の型を定義し、バリデーションに利用します。main.pyfrom pydantic import BaseModel class Tags(BaseModel): tag1: str tag2: str @app.post('/api/push') def create_tags_relationship(tags: Tags): set_tags_relationship(tags.tag1, tags.tag2) return {tag: get_related_tags(tag) for _, tag in tags}
定義した型は Schema として API Doc に反映されます。
FastAPI の起動
先ほど紹介した Uvicorn で起動します。
main.py内のappで初期化した場合はmain:appと指定します。
--reloadオプションにより、ファイル変更時にリロードして反映してくれます。$ uvicorn main:app --reload INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit) INFO: Started reloader process [57749] INFO: Started server process [57752] INFO: Waiting for application startup. INFO: Application startup complete.
http://127.0.0.1:8000またはhttp://127.0.0.1:8000/docsにアクセスすると、
API Doc が表示されることが確認できると思います。Heroku
Webアプリケーションを手軽にデプロイできるPaaSです。
多くの言語・フレームワークに対応しており、
PostgreSQL や Redis も一定枠まで無料でホスティングしてくれます。最初に以下の手順が必要です。
- アカウント登録 Heroku | Sign up
- カード登録 Account · Billing | Heroku
- アプリ作成 Create New App | Heroku
- Redisアドオン追加 Heroku Redis - Add-ons - Heroku Elements
必要なファイルの用意
以下のファイルが必要になります。
これを GitHub リポジトリに用意します。$ tree . ├── main.py # アプリケーション ├── Procfile # プロセス実行コマンド定義ファイル ├── requirements.txt # 依存ライブラリ定義ファイル └── runtime.txt # Pythonバージョン定義ファイルProcfileweb: uvicorn main:app --host 0.0.0.0 --port $PORTrequirements.txtfastapi email-validator uvicorn redis hiredisruntime.txtpython-3.8.0実際のディレクトリ も参考にしてください。
アプリケーションのデプロイ
Dashboard の Deploy タブからデプロイ作業を行います。
GitHub と連携してリポジトリを紐付け、Manual Deployを実行します。
Automatic deploysも設定しておくと、master への push 時に自動でデプロイしてくれます。
build が無事に完了したら、
登録されたプロセスをConfigure Dynosから ON にしておきます。
Dashboard 右上の
Open appからデプロイされたアプリケーションを確認できます。構築例:AWS(DynamoDB + Lambda + API Gateway)
執筆中のため公開をお待ちください
スケーラビリティを意識するならこちらを採用します。
柔軟にデータ構造を変えることも可能です。初めての、LambdaとDynamoDBを使ったAPI開発 - Qiita
API Gateway + Lambda + DynamoDB - QiitaAmazon DynamoDB
RDBと同様に1テーブル1プライマリキーが基本です。
ソートキーを追加することによってプライマリキーのユニーク制限を緩和できます。開始方法 - Amazon DynamoDB | AWS
初めてのサーバーレスアプリケーション開発 ~DynamoDBにテーブルを作成する~ | Developers.IO
無料枠で頑張るためにDynamoDBのキャパシティを理解する - ITと筋トレの二刀流テーブルの設計
プライマリキー:タグ
ソートキー:timestampテーブルの作成
AWS Lambda
初めてのサーバーレスアプリケーション開発 ~LambdaでDynamoDBの値を取得する~ | Developers.IO
GitHub Actionsを使ってAWS Lambdaへ自動デプロイ (詳説+デモ手順付きver) - Qiita2つのタグを紐付けて格納する
Lambda が呼び出されると lambda_handler 関数が実行される
import boto3, time from decimal import Decimal def lambda_handler(event, context): timestamp = Decimal(time.time()) table = boto3.resource('dynamodb').Table('collective-intelligence') with table.batch_writer() as batch: # 複数putする場合はbatch_writerを使うと良い batch.put_item(Item={ 'tag': event['tag1'], 'related_tag': event['tag2'], 'timestamp': timestamp }) batch.put_item(Item={ 'tag': event['tag2'], 'related_tag': event['tag1'], 'timestamp': timestamp }) return {'statusCode': 201}指定のタグに紐付くタグを取得
import boto3 from boto3.dynamodb.conditions import Key def lambda_handler(event, context): table = boto3.resource('dynamodb').Table('collective-intelligence') response = table.query(KeyConditionExpression=Key('tag').eq(event['tag'])) # tag指定で検索 tags = set(item['related_tag'] for item in response['Items']) # set型に格納して重複を削る return {'statusCode': 200, 'body': list(tags)} # JSONレスポンスのためlist型にキャストAmazon API Gateway
WebAPIの作成と管理をしてくれる
初めてのサーバーレスアプリケーション開発 ~API GatewayからLambdaを呼び出す~ | Developers.IO
ゼロから作りながら覚えるAPI Gateway環境構築 | Developers.IO
Amazon API Gateway チュートリアル - Amazon API Gatewayリソースとメソッドの作成
/push と /pull で POST を作成
リクエストの検証を設定
Lambdaを実行する前に弾けるとコストが下がってよい
- モデル(JSON Schema)の定義
- 設定->リクエストの検証に「本文の検証」を設定
- リクエスト本文にモデルを設定
JSON Schema Tool
リクエストおよびレスポンスマッピングのモデルおよびマッピングテンプレートを作成する - Amazon API Gateway
APIGatewayの新機能Request Validationを試してみた - エムティーアイ エンジニアブログメソッドの作成
メソッドの選択
メソッド管理画面
PULLモデルの作成
PUSHモデルの作成
リクエストの検証を設定
PULL API のテスト
PUSH API のテスト
利用料金に関して
Billing 画面の請求書から確認します。
まだ本稼働しているわけではないですが、
テストで数百件のリクエスト/レスポンスの送受信を行った結果0円だったので、
お試しで使う分には恐れることはなさそうです。
GCP vs AWS
GCP(Firestore)とAWS(DynamoDB)で悩みましたがDynamoDBを採用しました。
GCP側で選択する場合、4つのデータストアサービスから悩むことになると思いますが、
趣味で使うならFirestore一択だと思います。
データベースを選択: Cloud Firestore または Realtime Database | Firebase終わりに
これらはほぼ独学で得た内容ですが、
新しい技術を習得するスキルは会社のモダンな環境で得られたものだと思います。
強いエンジニアが新技術をガンガン使っていく現場で働けるというのは最高の体験です。また、Heroku側の構成のものを公開しています。
公開時点でデータは空ですが、自由に触ってみてください。
https://collective-intelligence.herokuapp.com/
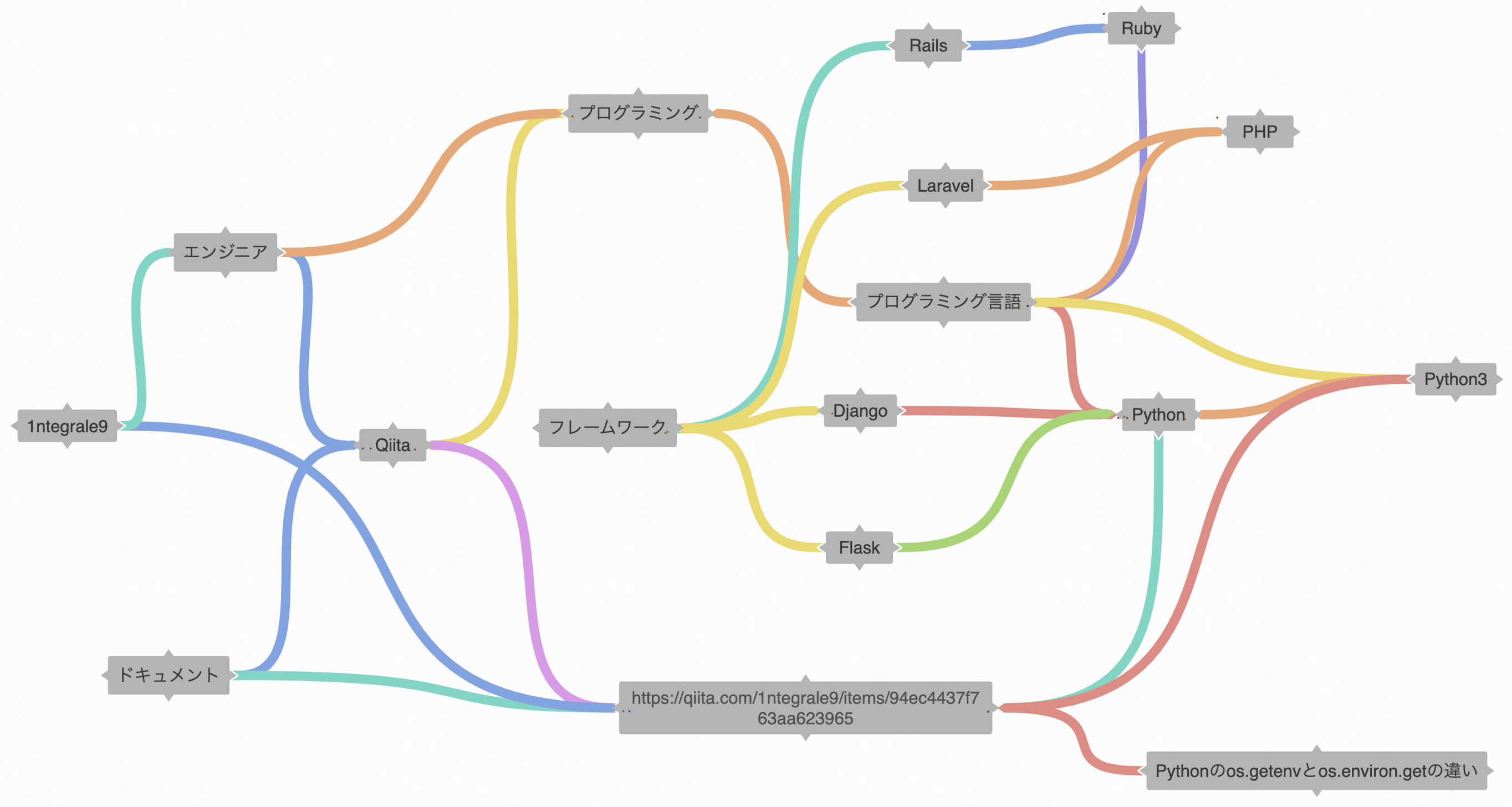
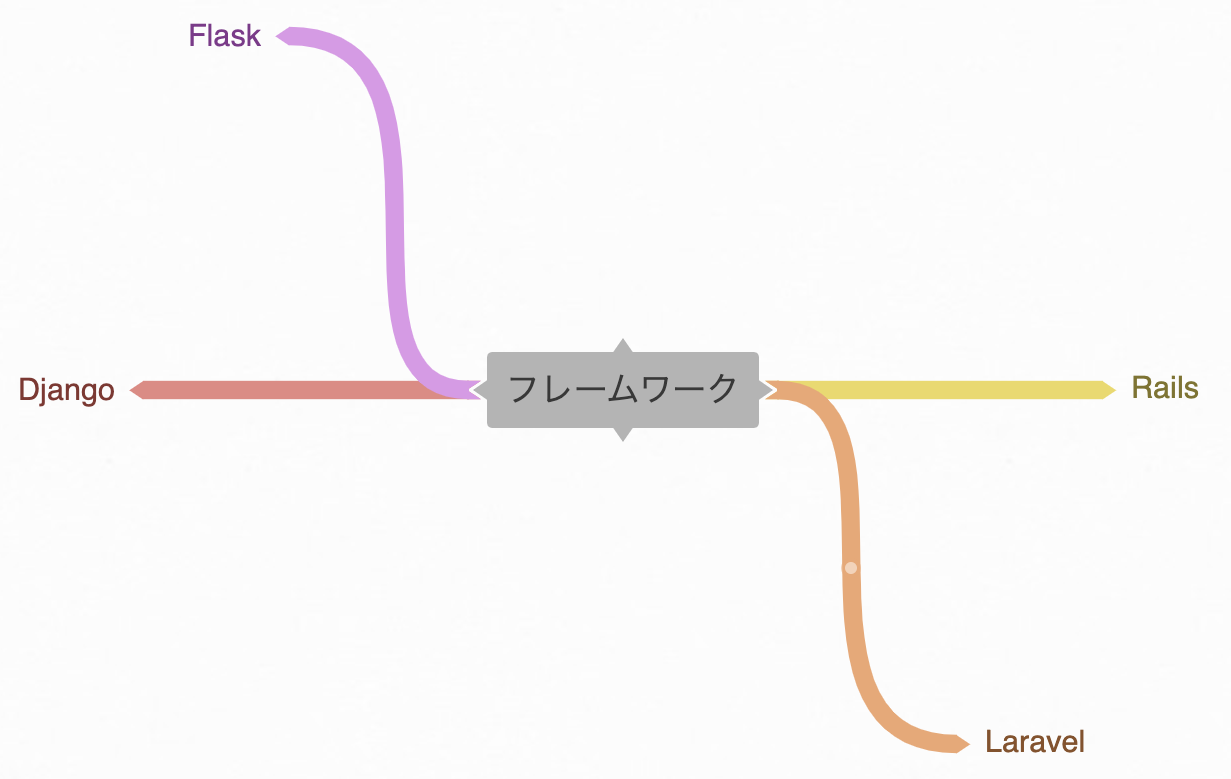


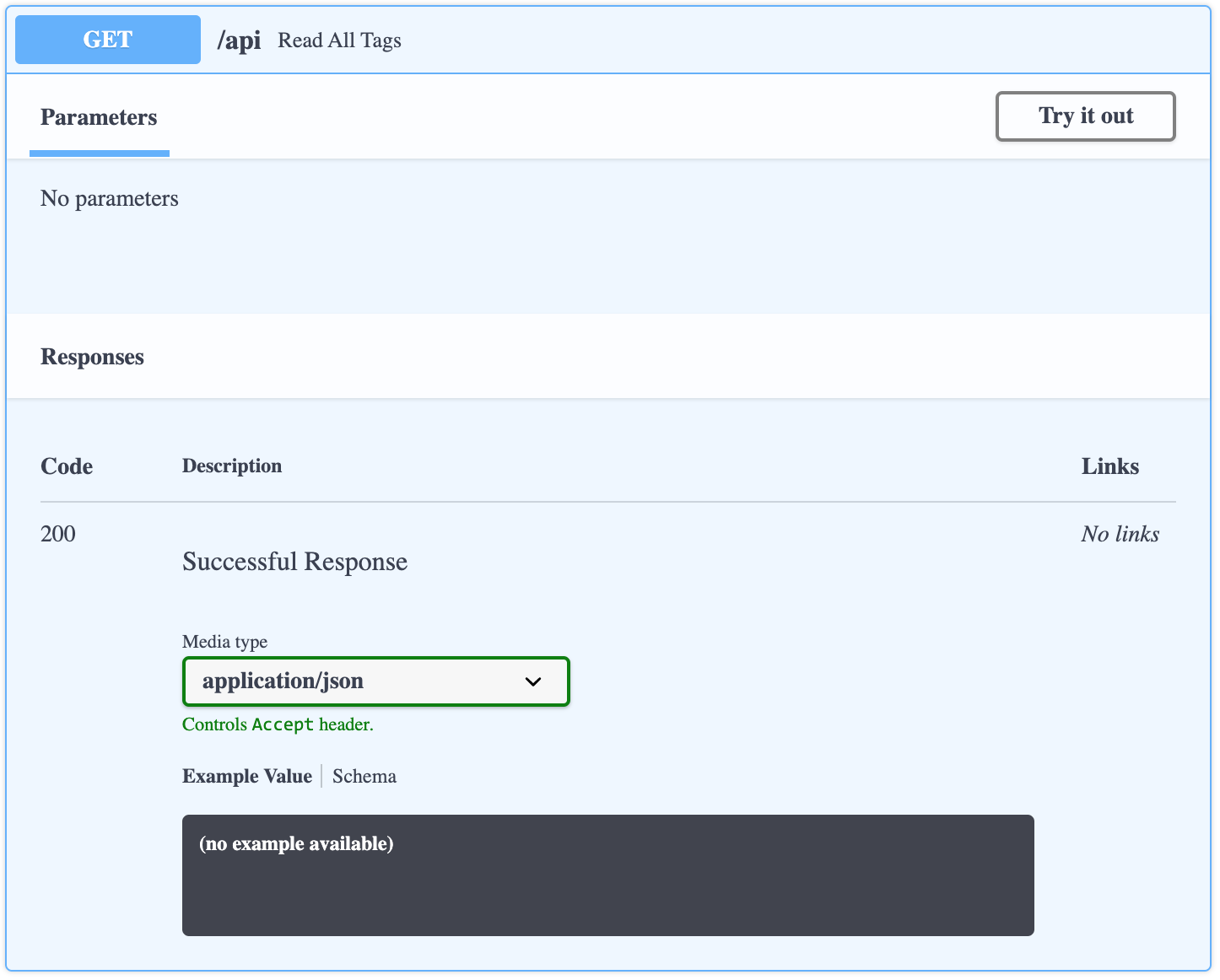
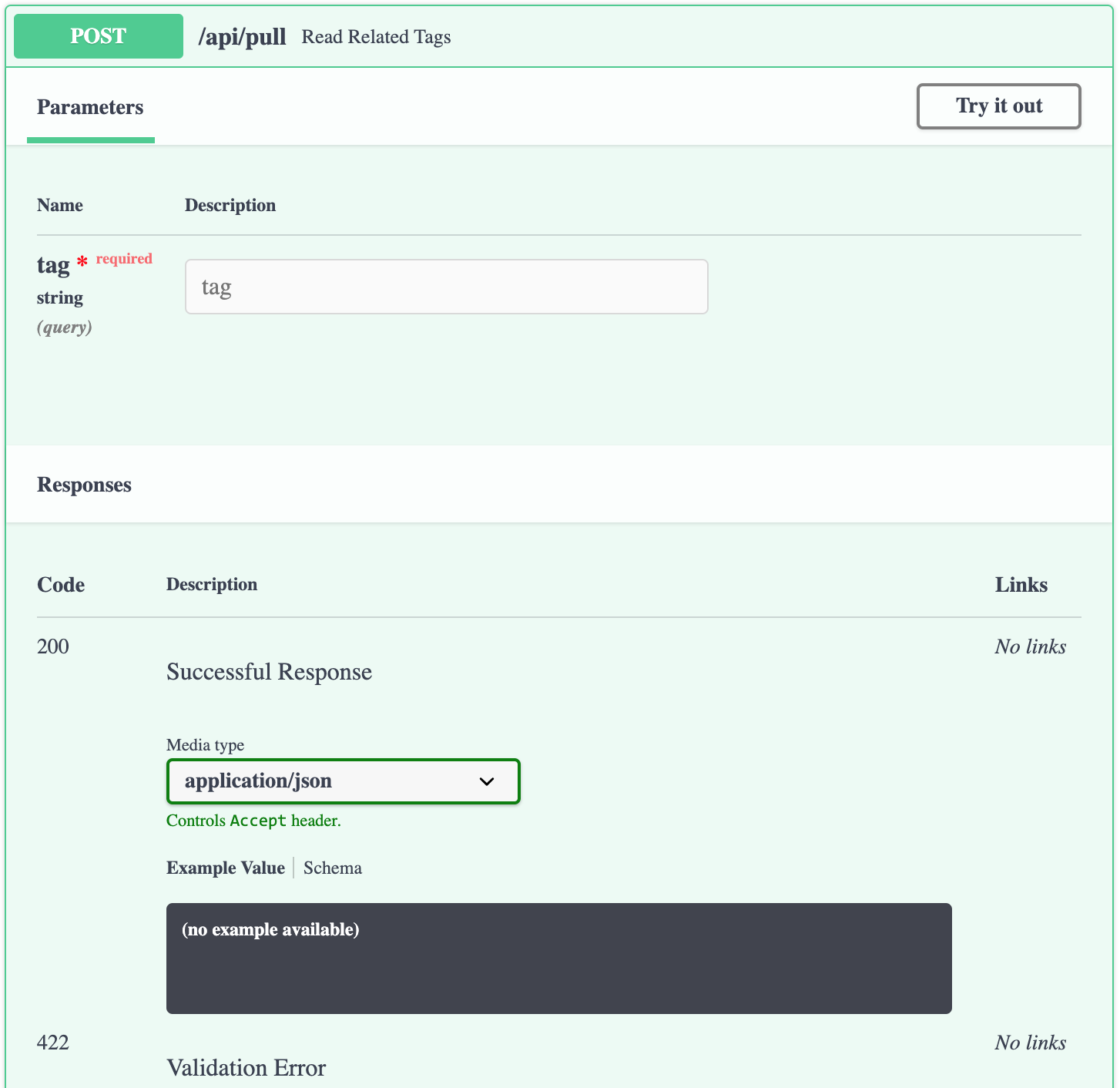
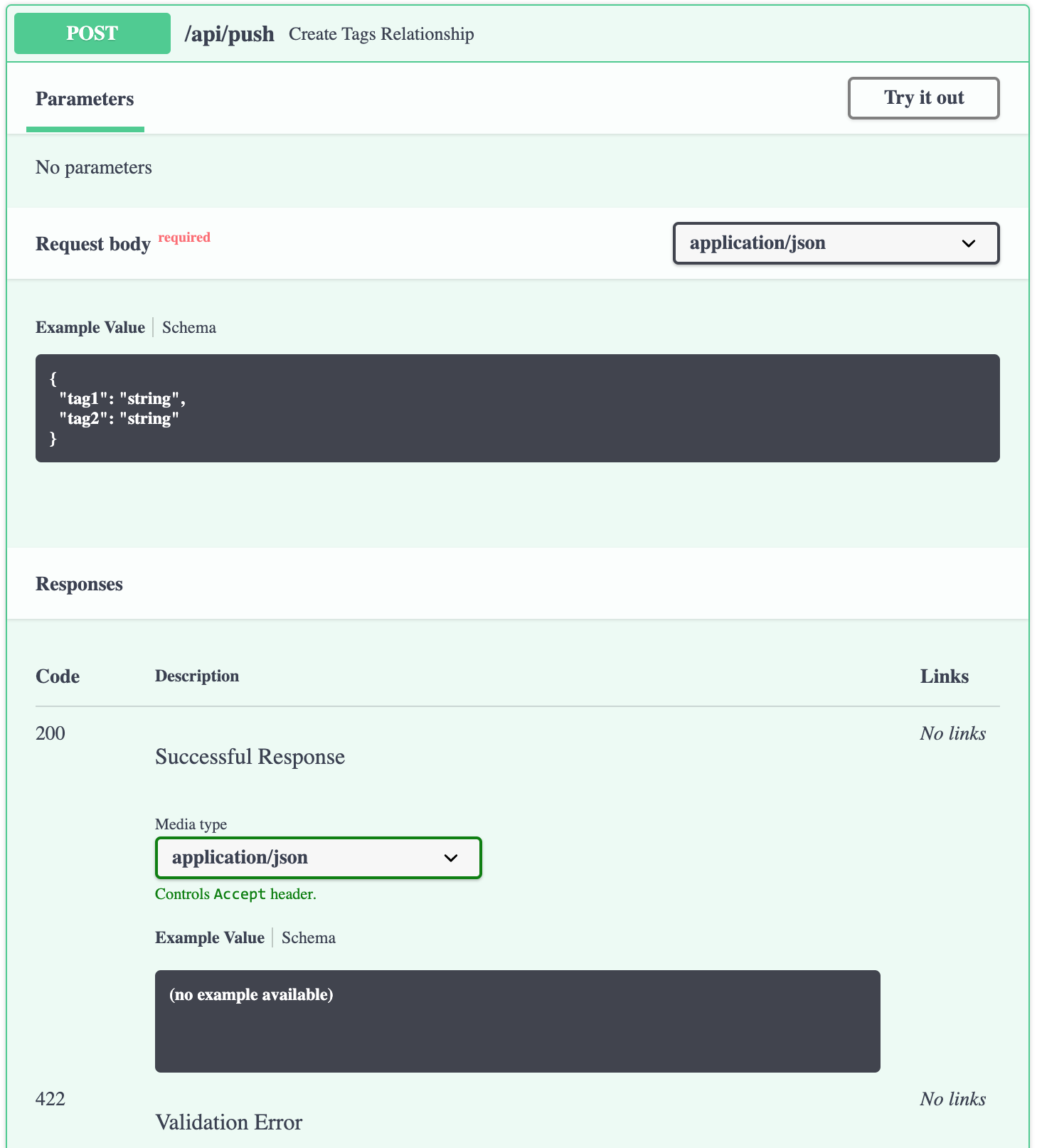

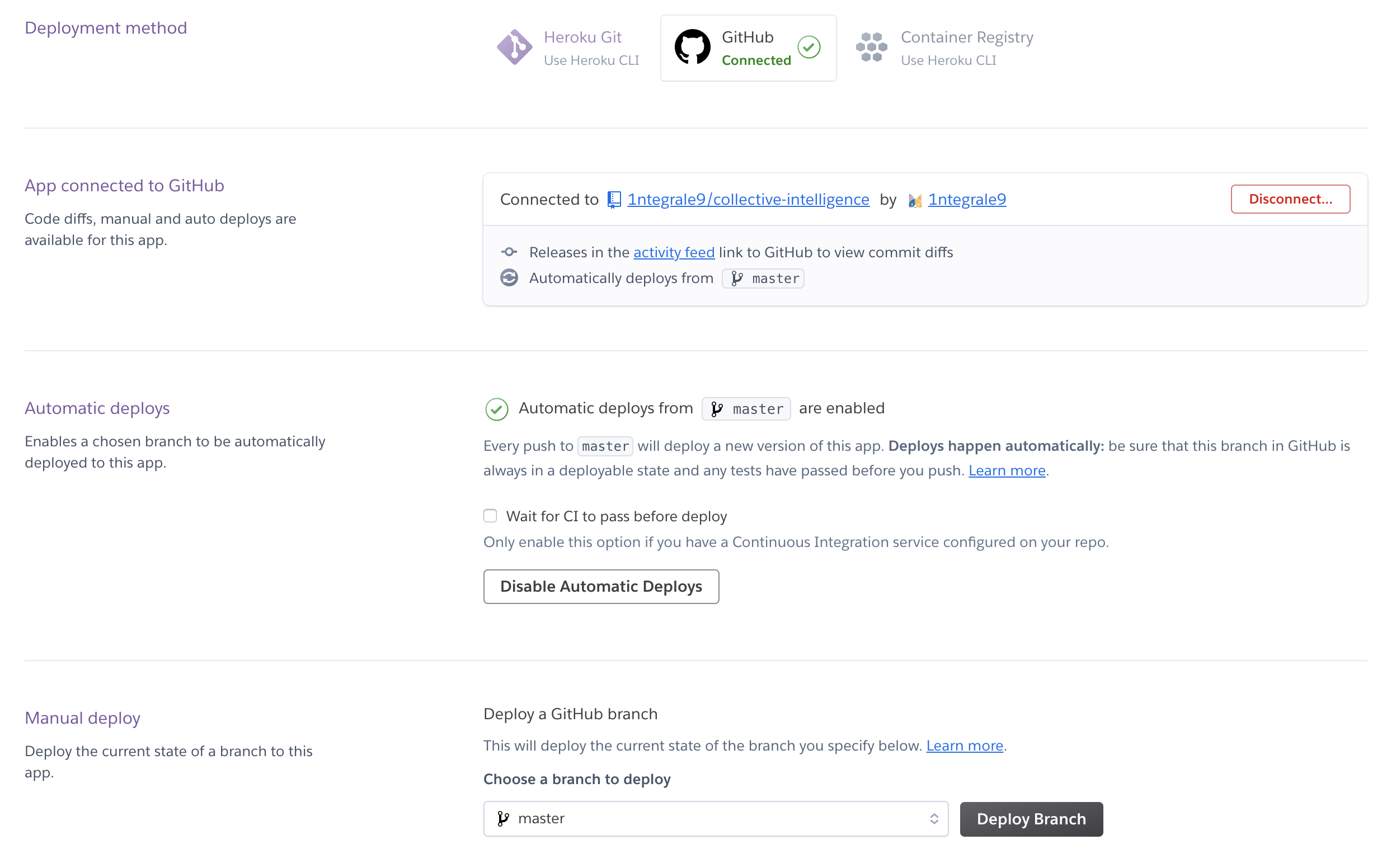
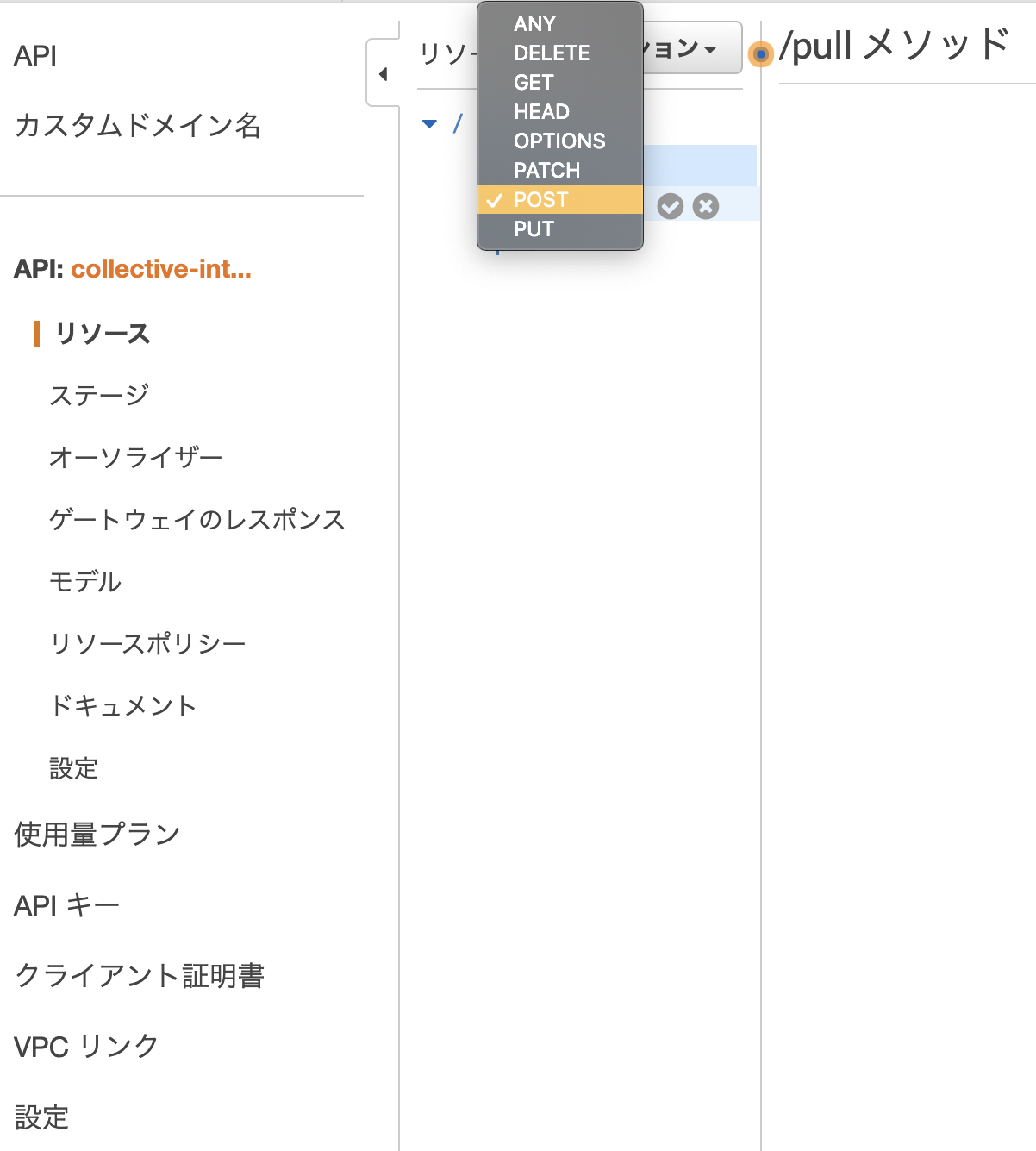


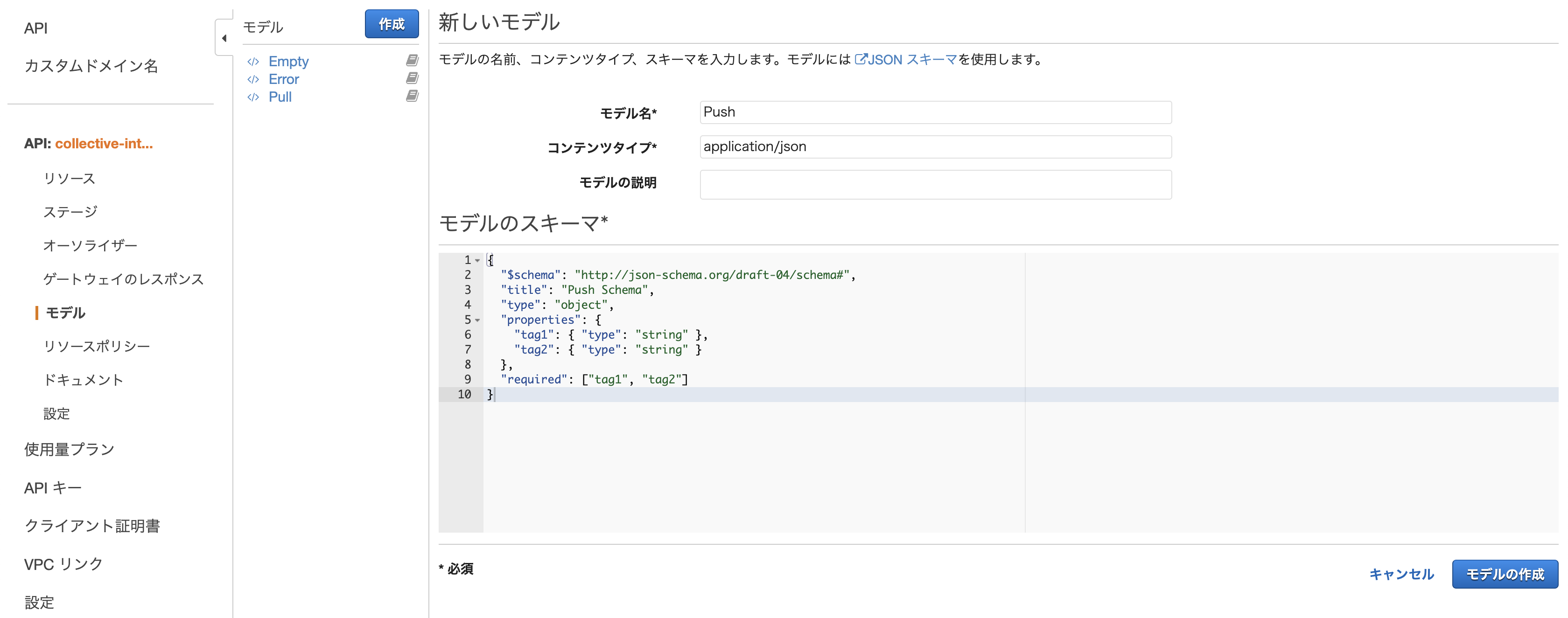
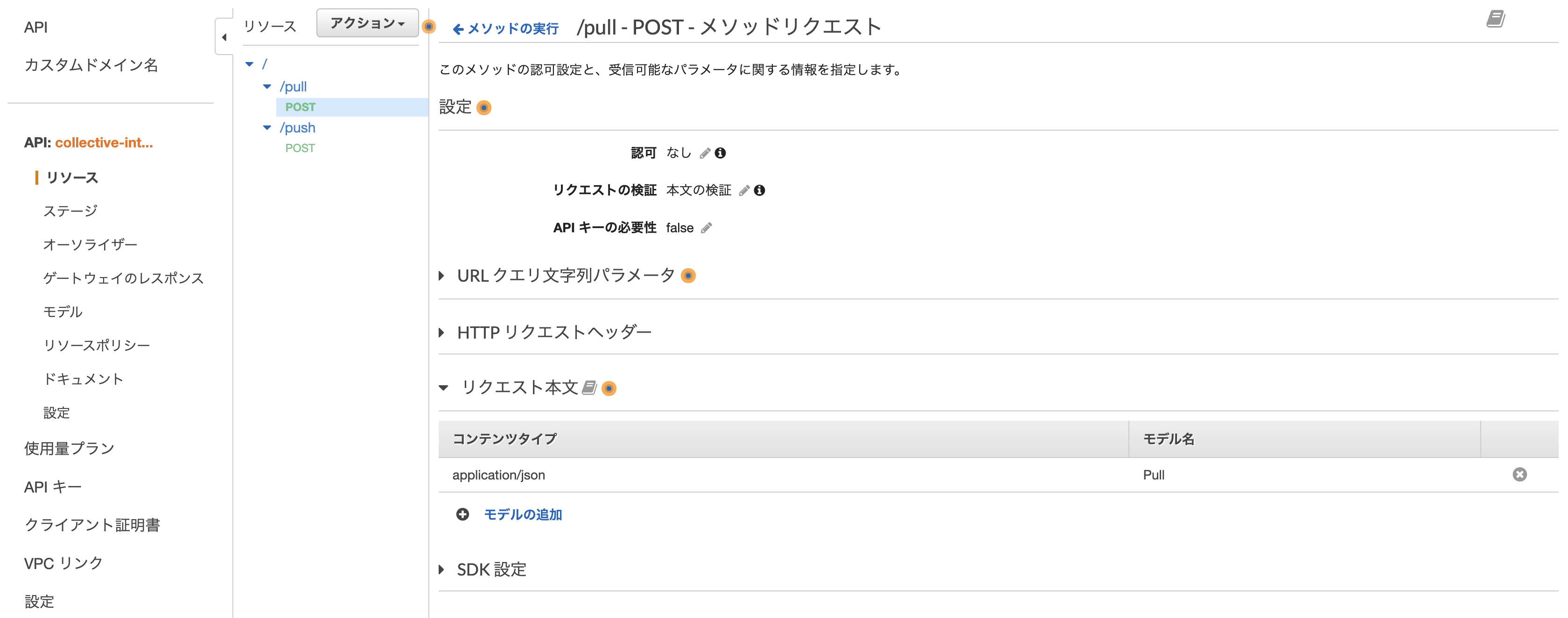

- 投稿日:2019-12-03T12:57:00+09:00
忙しい人のための AWS re:Invent 2019 直前アップデートまとめ
こんにちは、あやたこです。
AWS re:Invent 2019が遂に始まりましたね。
後日そちらについてもまとめたいとは思いますが、まずは例年通り直前にとてつもない量のアップデートが発表されているので、主要サービスの気になるアップデートについて独断と偏見でピックアップしてまとめておきたいと思います。
IAM関連
IAM Roleの最終利用時間がAPIで取得できるようになりました
- 使用していないRoleを特定しやすくなりました
Identify unused IAM roles easily and remove them confidently by using the last used timestamp
IAMからOrganizationsのOUを参照してリソースの共有ができるようになりました
Use IAM to share your AWS resources with groups of AWS accounts in AWS Organizations
EC2関連
EC2 AutoScalingでMaximum Instance Lifetimeがサポートされました
- 確実にインスタンスをリサイクルすることで、セキュリティやパフォーマンス要件を最新に保ちます
Amazon EC2 Auto Scaling Now Supports Maximum Instance Lifetime
EC2 AutoScalingで重み付け対応が可能になりました
Amazon EC2 Auto Scaling Now Supports Instance Weighting
T系インスタンスの無制限モードをサポートしました
Amazon EC2 T instances now support Unlimited Mode at AWS account level
EBS Fast Snapshot Restoreにより、スナップショットから作成されたボリュームのPre-Warmが不要になりました
ELB関連
ALBが重み付けルーティングを実行できるようになりました
- 異なるコンピューティングタイプ間でもダウンタイム0で移行させられます
Application Load Balancer simplifies deployments with support for weighted target groups
共有VPCがNLBをサポートしました
- NLBを利用してPrivateLinkを作成することも可能
Shared VPC now supports Network Load Balancer
RDS関連
RDS for SQL ServerからCloudWatchへログをPublishできるようになりました
Amazon RDS for SQL Server からのログファイルを Amazon CloudWatch へ発行可能に
ストレージ関連
Storage GatewayがVMware HAをサポートしました
AWS Storage Gateway adds HA on VMware and new performance monitoring metrics
DataSyncが大幅に安くなりました
AWS DataSync announces a 68% price reduction
DataSyncにスケジュール機能がサポートされました
AWS DataSync adds the ability to schedule data transfers
FSx for Windows File ServerがMultiAZ対応しました
Amazon FSx for Windows File Server now supports file systems that span multiple Availability Zones
その他
Kinesis Data AnalyticsがVPC内リソースにアクセスできるようになりました
Access resources within your Amazon Virtual Private Cloud using Amazon Kinesis Data Analytics
GuardDutyからS3へ調査結果のエクスポートが可能になりました
Amazon GuardDuty が Amazon S3 バケットへの調査結果のエクスポートをサポート
CloudTrailのInsights機能がリリースされました
- ユーザーアクティビティとAPIコールの異常なパターンを検知してくれます(GuardDuty的な)
AWS CloudTrail announces CloudTrail Insights
ChatbotがSlackからのコマンド実行をサポートしました
AWS Chatbot now supports running commands from Slack (beta)
時間に余裕のある方は
上記はアップデートのごくごく一部なので、その他のアップデートや詳細につきましてはAWS本家まとめよりご確認くださいませ
re:Invent 2019に向けて 2019年11月後半アップデートのまとめ 第一弾
re:Invent 2019に向けて 2019年11月後半アップデートのまとめ 第二弾
re:Invent 2019に向けて 2019年11月後半アップデートのまとめ 第三弾
re:Invent 2019に向けて 2019年11月後半アップデートのまとめ 第四弾
re:Invent 2019に向けて 2019年11月後半アップデートのまとめ 第五弾
- 投稿日:2019-12-03T12:49:21+09:00
AWS AmplifyとIonicを組み合わせてモバイルアプリまで爆速で開発する
はじめまして。Advent Calendar初参加になります!AWS Amplifyは一年前くらいから触り始めてその便利さから愛用しているので、今回はその知見をアウトプットできたらと思います。
目黒にあるAWS Loft TokyoでAWS Amplifyに出会った
1年ほど前、東京都の目黒駅徒歩1分の場所に「AWS Loft Tokyo」なる施設がオープンしました。
スタートアップとデベロッパーのための「挑戦をカタチにする場所」というコンセプトです。https://aws.amazon.com/jp/start-ups/loft/tokyo/
今回のAWS Amplify Advent Calendarを作ったのもスタートアップソリューションアーキテクトの塚田さん( @akitsukada )ですね。
Loftにはオープンから足を運んでおり、コワーキング利用終了後に毎週のように開催される技術系イベントに参加していました。
参加したイベントの一つが「AWS Amplify Blackbelt公開収録 & AppSync入門」です。Ionic(アイオニック)とは
Ionicとは、HTML / CSS / JSの技術でモバイルアプリを作るためのUIフレームワークと言ったところでしょうか。iOS / AndroidのUIに極限まで近づけたUIコンポーネントが提供されており、美しいUIのアプリを素早く構築することができます。
CordovaやCapacitorを使うことで、Ionicで作ったアプリをiOS / Android用アプリとしてビルドしてApp Store / Google Playに並べることができます。
僕は3年ほどスタートアップで一人エンジニアをやっていたので、iOS / Androidアプリを一気に構築できるIonicがとても気に入っていました。
そこにAWS Amplifyが加わることで、フロントエンドからバックエンドまで一人で作ることができるくらいスピードを上げることができます。
今回はそんなIonicで作ったアプリにAWS Amplifyを組み込んで使うための手順をまとめようと思います。
動作確認環境
- macOS Catalina 10.15
- VS Code
- node.js v12.7.0
- @angular/core 8.1.2
- @ionic/angular 4.7.1
- aws-amplify 1.2.4
- aws-amplify-angular 4.7.1
- @amplify/cli 3.17.0
Ionicプロジェクトを新しく作成する
まずはIonic CLIを利用してプロジェクトを生成します。
npxを使うことでIonic CLIをグローバルインストールしていなくてもコマンドを利用できます。# CLIでプロジェクトを作成開始 $ npx ionic start # プロジェクト名を指定 ? Project name: AmplifyIonicChat # JSフレームワークを選択:今回はAngularを利用 ? Framework: Angular # テンプレートを選択 ? Starter template: blank # ディレクトリに移動 $ cd AmplifyIonicChatこの時点でのディレクトリ構造は次のようになります。
基本的にはAngular CLIで生成されるディレクトリと同じです。$ tree -I node_modules . ├── angular.json ├── browserslist ├── e2e │ ├── protractor.conf.js │ ├── src │ │ ├── app.e2e-spec.ts │ │ └── app.po.ts │ └── tsconfig.json ├── ionic.config.json ├── karma.conf.js ├── package-lock.json ├── package.json ├── src │ ├── app │ │ ├── app-routing.module.ts │ │ ├── app.component.html │ │ ├── app.component.scss │ │ ├── app.component.spec.ts │ │ ├── app.component.ts │ │ ├── app.module.ts │ │ └── home │ │ ├── home.module.ts │ │ ├── home.page.html │ │ ├── home.page.scss │ │ ├── home.page.spec.ts │ │ └── home.page.ts │ ├── assets │ │ ├── icon │ │ │ └── favicon.png │ │ └── shapes.svg │ ├── environments │ │ ├── environment.prod.ts │ │ └── environment.ts │ ├── global.scss │ ├── index.html │ ├── main.ts │ ├── polyfills.ts │ ├── test.ts │ ├── theme │ │ └── variables.scss │ └── zone-flags.ts ├── tsconfig.app.json ├── tsconfig.json ├── tsconfig.spec.json └── tslint.jsonこれだけでもう動作確認ができるので、AWS Amplify JavaScript Frameworkを入れる前に一旦動かしてみます。
# 開発サーバーを起動 $ npx ionic serve自動でデフォルトのブラウザが開き、アプリケーションが表示されます。
これだけでiOS端末ではiOSのスタイルが、Android端末ではマテリアルデザインのスタイルが適用されたアプリケーションの雛形が出来上がります。
AWS Amplify JavaScript Frameworkをインストール
Ionicアプリケーションの準備が整ったので、ここから本題のAWS Amplifyを導入します。
公式ドキュメントがAngular / Ionicでの導入方法を出してくれているので、それに従います。https://aws-amplify.github.io/docs/js/angular
AWS Amplify関連パッケージのインストール
まずAWS Amplify関連のパッケージをインストールします。
aws-amplify-angularというパッケージがあるのでそれを使います。$ npm install aws-amplify aws-amplify-angularAngular 6以上で必要となる設定を書く
window.globalとwindow.processがセットされている必要があるとのことです。指示に従って以下の設定をsrc/polyfills.tsに追記します。src/polyfills.tsに追加する内容(window as any).global = window; (window as any).process = { env: { DEBUG: undefined }, };
src/polyfills.tsは最終的には以下のようになりました。Ionic CLI(Angular CLI)が説明のためのコメントを大量に書いてくれていますが、見やすくするために全て削除しています。編集後のsrc/polyfills.tsimport './zone-flags.ts'; import 'zone.js/dist/zone'; (window as any).global = window; (window as any).process = { env: { DEBUG: undefined }, };余談ですが、公式ドキュメントに、
Please also note that the AWS Amplify Angular components do not yet support Ivy.
と書いてありました。Ivyのサポートはまだ無いようですね...
TypeScriptのコンパイルオプションを調整する
src/tsconfig.app.json内のcompilerOptionsセクションのtypesにnodeを追加します。ちなみに、src/tsconfig.jsonというファイルもあるので混同しないよう注意が必要です。編集後のsrc/tsconfig.app.json{ "extends": "./tsconfig.json", "compilerOptions": { "outDir": "./out-tsc/app", "types": ["node"] }, "include": [ "src/**/*.ts" ], "exclude": [ "src/test.ts", "src/**/*.spec.ts" ] }これでIonicアプリへのAWS Amplify JavaScript Frameworkのインストールは完了です。
AWS Amplifyの初期設定を行う
AWS Amplify CLIを使って初期設定を行います。初期設定はプロジェクトごとに行う必要がある操作になります。
# Amplify CLIの初期設定を開始 $ npx amplify init # プロジェクト名を指定 ? Enter a name for the project AmplifyIonicChat # 環境名を指定 ? Enter a name for the environment dev # エディタを指定 ? Choose your default editor: Visual Studio Code # 開発に使う言語を指定 ? Choose the type of app that you re building javascript # 開発に使うフレームワークを指定 ? What javascript framework are you using ionic # ソースコードのディレクトリを指定 ? Source Directory Path: src # ビルド後の成果物の格納先ディレクトリを指定 ? Distribution Directory Path: www # ビルドコマンドを指定 ? Build Command: npm run-script build # 開発サーバー起動コマンドを指定 ? Start Command: ionic serve # Amplify CLIが使うAWSプロファイルを使う ? Do you want to use an AWS profile? Yes # プロファイルを指定:今回は個人用のAWSに繋がるプロファイルとして用意してある「private」を指定 ? Please choose the profile you want to use privateここまで指定するとCloudFormationが起動して、バックエンドに必要なリソースを生成します。
ここでは以下のリソースが作成されます。「この時点で作るリソースあるの?」という感じですが、何か意図があるのでしょうか。。。
- S3バケット
- Cognitoフェデレーテッドアイデンティティでの認証済みクライアントが引き受けるロール(AuthRole)
- Cognitoフェデレーテッドアイデンティティでの未認証クライアントが引き受けるロール(UnauthRole)
AWS AmplifyのAuthenticationカテゴリを使ってユーザー認証を実装する
ここからはAWS Amplify CLIを使ってAWSクラウド上にバックエンドを構築していきます。
Authenticationカテゴリの設定をAmplify CLIで構築する
まずはアプリケーションにサインアップ・サインイン機能を作るために、AWS AmplifyのAuthenticationカテゴリをセットアップします。
こちらは公式ドキュメントの以下の箇所に沿って進めます。
https://aws-amplify.github.io/docs/js/authentication#automated-setup
# Amplify CLIを使ってAuthenticationカテゴリを追加 $ npx amplify add auth # 認証の設定をどのように行うか指定:今回はデフォルトの設定を利用 Do you want to use the default authentication and security configuration? Default configuration # サインインに使える属性を指定 How do you want users to be able to sign in? Username # 追加の設定をするかどうかを指定 Do you want to configure advanced settings? No, I am done.これで設定は完了です。この時点ではまだバックエンドに設定は適用されていません。
設定をバックエンドに適用する
では、実際に設定をバックエンドに適用します。
# 変更をバックエンドに適用 $ npx amplify push # 変更内容が出るので、確認して先へ進む Current Environment: dev | Category | Resource name | Operation | Provider plugin | | -------- | ------------------------ | --------- | ----------------- | | Auth | amplifyionicchatd1aa1b6e | Create | awscloudformation | ? Are you sure you want to continue? (Y/n)マネジメントコンソールで確認すると、Amazon Congitoのユーザープールが作成されていることがわかります。
Ionicアプリにバックエンドへの接続情報を適用する
先ほどの
$ npx amplify pushコマンド実行のタイミングで、バックエンドの接続情報(CognitoのユーザープールIDやアイデンティティプールID等)がsrc/aws-export.jsというファイルに出力されました。
aws-export.jsは以下のようなシンプルなJSファイルです。// WARNING: DO NOT EDIT. This file is automatically generated by AWS Amplify. It will be overwritten. const awsmobile = { "aws_project_region": "ap-northeast-1", "aws_cognito_identity_pool_id": "<アイデンティティプールID>", "aws_cognito_region": "ap-northeast-1", "aws_user_pools_id": "<ユーザープールID>", "aws_user_pools_web_client_id": "<ユーザープールクライアントID>", "oauth": {} }; export default awsmobile;1行目にコメントで書いてある通り、このファイルは今後の
$ npx amplify pushコマンド実行時に上書きされるので、手作業で変更してはいけません。Amplify Frameworkを初期化する
Amplify Frameworkに
aws-exports.jsに書かれた設定情報を読み込ませるため、src/main.tsに以下のようにAmplifyの初期化処理を書きます。src/main.tsimport { enableProdMode } from '@angular/core'; import { platformBrowserDynamic } from '@angular/platform-browser-dynamic'; import { AppModule } from './app/app.module'; import { environment } from './environments/environment'; // 以下3行を追加 import Amplify from 'aws-amplify'; import awsconfig from './aws-exports'; Amplify.configure(awsconfig); if (environment.production) { enableProdMode(); } platformBrowserDynamic().bootstrapModule(AppModule) .catch(err => console.log(err));ちなみに、公式ドキュメントでは、
Amplifyのインポート元は@aws-amplify/coreとなっていますが、そのまま書いてもうまくいかず以下のようなエラーが出てしまいます。
これを解消するために、
Amplifyはaws-amplifyから読み込むようにしています。これでフロントエンドとバックエンドの接続が完了です。
Angularのモジュールの整理をしておく
ここで一旦今後のためにAngularプロジェクトとしての準備を行います。
- 未ログイン状態のときにアクセスできるページ群を管理する
PublicModuleを作成- ログイン状態のときにアクセスできるページ群を管理する
ClosedModuleを作成- アプリケーション全体から利用するモジュールをまとめた
SharedModuleを作成Angularの「モジュール」
Angularでは、アプリケーションを「モジュール」という単位に分割できます。ページコンポーネントを一つのモジュールとして作成しておくことで、そのページが必要となったタイミングでモジュールごと読み込む遅延読み込み(Lazy Loading)ができます。
モジュールの定義には
@NgModuleデコレータを使います。あるモジュールAであるモジュールBを使いたい場合、モジュールBの定義箇所の
@NgModuleの宣言内のimportsにモジュールAを指定します。Angularには最上位のモジュールである
AppModuleが存在します。
そして、$ ionic startコマンドでBlankテンプレートを選択して作成した雛形には、Homeページ用のHomeModuleも生成されています。未ログイン状態でアクセスできるページ群を管理するPublicModuleを作成する
Ionic CLIを使ってモジュールを作成します。
$ npx ionic g module pages/publicこれで、
src/app/pages/public/public.module.tsが作成されます。中身は以下のようにしました。ルーティングは後ほど追加していくので、まだ何も作成していません。src/app/pages/public/public.module.tsimport { NgModule } from '@angular/core'; import { Routes, RouterModule } from '@angular/router'; // ここにルーティングの定義を書いていく const routes: Routes = []; @NgModule({ imports: [RouterModule.forChild(routes)] }) export class PublicModule { }ログイン状態でアクセスできるページ群を管理するClosedModuleを作成する
PublicModuleと同様にモジュールを作成します。$ npx ionic g module pages/closedsrc/app/pages/closed/closed.module.tsimport { NgModule } from '@angular/core'; import { Routes, RouterModule } from '@angular/router'; // ここにルーティングの定義を書いていく const routes: Routes = []; @NgModule({ imports: [RouterModule.forChild(routes)] }) export class ClosedModule { }AppRoutingModuleにPublicModuleとClosedModuleを追加する
最後に、アプリケーションのルートのルーティング定義である
AppRoutingModuleにPublicModuleとClosedModuleを登録します。
これでPublicModuleやClosedModuleに書いたルーティングが有効になります。src/app/app-routing.module.tsimport { NgModule } from '@angular/core'; import { PreloadAllModules, RouterModule, Routes } from '@angular/router'; const routes: Routes = [ // 直下へのアクセスは /auth へリダイレクト { path: '', redirectTo: 'auth', pathMatch: 'full' }, // 未ログイン状態でアクセスできる画面群のルーティング { path: '', loadChildren: () => import('./pages/public/public.module').then(m => m.PublicModule) }, // ログイン状態でアクセスできる画面群のルーティング { path: '', loadChildren: () => import('./pages/closed/closed.module').then(m => m.ClosedModule) }, ]; @NgModule({ imports: [ RouterModule.forRoot(routes, { preloadingStrategy: PreloadAllModules }) ], exports: [RouterModule] }) export class AppRoutingModule { }Angularでは、URLでの画面遷移を許可するかどうかを制御する「ガード」という仕組みがあります。このガードを
PublicModuleとClosedModuleにかけることで、ログイン状態のときはサインアップフォームへのアクセスはリダイレクト、未ログイン状態のときはサインアップフォームへリダイレクトといった制御をきれいに書くことができます。アプリケーション全体で使うモジュールをまとめたSharedModuleを作る
前述の通り各ページはそれぞれ独立したモジュールになっているので、それらのモジュールで共通したい処理はまとめておくと楽です。
全ページで使うIonicModuleやFormsModule等は全てSharedModuleに含めてしまい、各ページのモジュールからはこのSharedModuleのみインポートするようにします。$ npx ionic g module sharedこれで、
src/app/shared/shared.module.tsが生成されました。内容は以下のようにします。
src/app/shared/shared.module.tsimport { NgModule } from '@angular/core'; import { IonicModule } from '@ionic/angular'; import { FormsModule } from '@angular/forms'; import { CommonModule } from '@angular/common'; import { AmplifyIonicModule, AmplifyService } from 'aws-amplify-angular'; const modules = [ FormsModule, IonicModule, CommonModule, AmplifyIonicModule, ]; @NgModule({ imports: [...modules], exports: [...modules], providers: [AmplifyService], }) export class SharedModule { }importを絶対パスで書けるようにする
ソースコードをディレクトリで整理していくと、
import文が以下のようになったりします。import { MyService } from '../../../../../services/myservice/myservice.service';これだと辛いので、プロジェクトのルートディレクトリから絶対パスで指定できるようにしておきます。
tsconfig.jsonのcompilerOptionsにpathsを指定します。tsconfig.json{ "compilerOptions": { (...略) "paths": { "@/*": ["src/*"] }, (...略) } }この設定を書くことによって、先ほどの
import文は以下のように書くことができます。import { MyService } from '@/services/myservice/myservice.service`;雛形で生成されていたAppModuleを調整する
後ほど
AppComponentでAWS Amplifyが提供するAmplifyServiceを使うので、AppModuleでもSharedModuleをインポートするようにしておきます。同時に雛形で生成されていた不要なモジュールのインポートも削除します。
src/app/app.module.tsimport { NgModule } from '@angular/core'; import { RouteReuseStrategy } from '@angular/router'; import { BrowserModule } from '@angular/platform-browser'; import { IonicModule, IonicRouteStrategy } from '@ionic/angular'; import { AppComponent } from './app.component'; import { AppRoutingModule } from './app-routing.module'; import { SharedModule } from './shared/shared.module'; @NgModule({ declarations: [AppComponent], imports: [ BrowserModule, SharedModule, IonicModule.forRoot(), AppRoutingModule, ], providers: [ { provide: RouteReuseStrategy, useClass: IonicRouteStrategy } ], bootstrap: [AppComponent] }) export class AppModule {}雛形で生成されていたHomePageを調整する
最後に、整理したモジュールの構造の中に自動生成された
HomePageを入れます。
生成されたときはsrc/app/home/にあったHomePageの一式をsrc/app/pages/closed/に移します。そして、
src/app/pages/closed/home/home.module.tsを以下のように調整します。
(FormsModule/IonicModule/CommonModuleのインポートをSharedModuleのインポートに置き換えました)src/app/pages/closed/home/home.module.tsimport { NgModule } from '@angular/core'; import { RouterModule } from '@angular/router'; import { HomePage } from './home.page'; import { SharedModule } from '@/app/shared/shared.module'; @NgModule({ imports: [ SharedModule, RouterModule.forChild([{ path: '', component: HomePage }]) ], declarations: [HomePage] }) export class HomePageModule {}最後に、
ClosedModuleにHomePageのルーティングを定義します。src/pages/closed/closed.module.tsimport { NgModule } from '@angular/core'; import { Routes, RouterModule } from '@angular/router'; const routes: Routes = [ { path: 'home', loadChildren: () => import('./home/home.module').then(m => m.HomePageModule), }, ]; @NgModule({ imports: [ RouterModule.forChild(routes), ] }) export class ClosedModule { }結構調整作業が多くなってしまいました。本稿の主役はAWS Amplifyですが、せっかくなのである程度アプリケーションとしてスケールさせられる体制を整える方法まで書きたいと思っています。
認証を扱うページを生成する
先ほどバックエンドにAWSの認証基盤であるAmazon Cognitoを構築できたので、先ほど作ったIonicアプリでサインアップ・サインインできるようにします。
AWS Amplifyのすごいところは、サインイン周りを一発で実装できるコンポーネントを各フレームワークで用意してくれているところです(!)
具体的には、
<amplify-authenticator>というコンポーネントが提供されていて、これをアプリケーション内に配置するとサインインフォームが出現します。認証をWebアプリケーションに組み込む場合、
- サインアップ画面は
/sign-up- サインイン画面は
/sign-in- パスワードリマインダーは
/passwordのようにそれぞれURLを分けることが一般的かと思います。
しかし、今回は認証周りを
<amplify-authenticator>コンポーネントを利用して行うため、認証を扱う画面は1つあれば十分です。認証機能を配置するページを作成する
Ionic CLIを使って認証用の画面を用意します。CLIを使ってページを生成する場合、自動的にモジュールが作成され、遅延読み込みが有効になります。
認証を扱う画面は未ログイン状態でのみ閲覧可能としたいので、先ほど作成した
PublicModule以下にページのモジュールを作成します。$ npx ionic g page pages/public/authこれで以下のファイルが出来上がりました。
src/app/pages/public/auth/auth.page.ts src/app/pages/public/auth/auth.page.spec.ts src/app/pages/public/auth/auth.page.html src/app/pages/public/auth/auth.page.scss src/app/pages/public/auth/auth.module.ts src/app/pages/public/auth/auth-routing.module.ts今回はルーターの設定も
auth.module.tsに書いていくことにするので、auth-routing.module.tsは削除します。
認証用のページのモジュールであるauth.module.tsは以下のように記述します。src/app/pages/public/auth/auth.module.tsimport { RouterModule } from '@angular/router'; import { NgModule } from '@angular/core'; import { SharedModule } from '@/app/shared/shared.module'; import { AuthPage } from './auth.page'; @NgModule({ imports: [ SharedModule, RouterModule.forChild([{ path: '', component: AuthPage }]), ], declarations: [AuthPage] }) export class AuthPageModule {}最後に、
/authでこのページにアクセスできるよう、PublicModuleにルーティング定義を追加します。src/pages/public/public.module.tsimport { NgModule } from '@angular/core'; import { Routes, RouterModule } from '@angular/router'; const routes: Routes = [ { path: 'auth', loadChildren: () => import('./auth/auth.module').then(m => m.AuthPageModule), }, ]; @NgModule({ imports: [ RouterModule.forChild(routes), ] }) export class PublicModule { }これで
/authページの準備は完了です。http://localhost:8100/authにブラウザでアクセスすると以下のような画面が表示されます。
AWS Amplifyが提供してくれている認証コンポーネントを配置する
では、作成した
AuthPageにAWS Amplifyが提供してくれている<amplify-authenticator-ionic>コンポーネントを配置してみます。src/pages/public/auth/auth.page.html<ion-header> <ion-toolbar> <ion-title>auth</ion-title> </ion-toolbar> </ion-header> <ion-content> <div class="ion-padding"> <amplify-authenticator-ionic></amplify-authenticator-ionic> </div> </ion-content>Ionicを使わない素のAngularの場合、
<amplify-authenticator>コンポーネントを利用しますが、Ionicを使う場合は専用の<amplify-authenticator-ionic>コンポーネントを使うことができます。なんとこれだけで認証周りの画面の実装が完了します。
試しにサインアップしてみる
表示されているサインイン画面の下の方の「Create account」をクリックします。
すると、サインアップ画面に遷移します。
遷移する、といっても<amplify-authenticator-ionic>コンポーネントがサインアップフォームのUIに変わるだけでルーティングは変わりません。サインアップフォームで情報を入力します。
デフォルトの設定では、以下の項目を入力する必要があります。
- ユーザー名
- メールアドレス
- パスワード(英数字 + 記号 / 8文字以上)
- 電話番号(
090の先頭のゼロは取る)
これで「Create Account」をクリックするとCognitoユーザープールにアカウントが作成されます。
メールアドレスの開通確認もデフォルトで用意されているので、入力したメールアドレスの受信トレイを確認します。シンプルなメールが届いていました。
サインアップすると
<amplify-authenticator-ionic>コンポーネントは自動的に以下のようなメールアドレス開通確認コード入力画面に切り替わるので、メールで届いた6桁の確認コードを入力します。
「Confirm Code」をクリックするとサインアップが完了します。サインアップ後は改めてログインする必要があります。
登録したアカウント情報でサインインすると、
<amplify-authenticator-ionic>コンポーネントは以下のようなUIに切り替わりました。
(ちなみにちょいちょいconsoleに出ているエラーはアカウント情報を何度か入力し間違えたためです?)
これでIonicアプリにAWS Amplifyを使って認証システムを組み込むことができました。
認証周りは実は結構複雑で、以下のような画面をユーザーの状態に応じて出し分ける必要があります。
- サインアップ
- メールアドレスの開通確認
- サインイン
- パスワードリマインダー
- パスワード再設定
AWS Amplify JavaScript Frameworkを使うことでこの辺りをコンポーネント一発で構築できるのは非常に強力です。
Amplifyの認証状態をIonicアプリに同期する
さて、準備の段階で頑張って
PublicModuleとClosedModuleを作って、未認証状態と認証状態の画面群を分けました。サインインは
<amplify-authenticator-ionic>コンポーネントで行えばよいですが、Amplifyが内部的に持っているログイン状態に応じてルーティングを変えたいです。AppComponentにAmplifyの認証状態を監視するコードを追加する
Ionicアプリのルートコンポーネントとして、
AppComponentというコンポーネントがあるので、そこでAmplifyの認証状態を監視してルーティングに反映させようと思います。Ionic CLIでプロジェクトを作ると、
AppComponentにはネイティブアプリ向けのスプラッシュスクリーンやステータスバーの操作処理が書かれていますが、今回は必要ないのでガンガン削除します。完成形のみ書きます。
src/app/app.component.ts(一通り実装済み)import { Component, OnInit } from '@angular/core'; import { NavController } from '@ionic/angular'; import { AmplifyService } from 'aws-amplify-angular'; @Component({ selector: 'app-root', templateUrl: 'app.component.html', styleUrls: ['app.component.scss'] }) export class AppComponent implements OnInit { constructor( private navCtrl: NavController, private amplifyService: AmplifyService, ) {} ngOnInit() { this.amplifyService.authStateChange$.subscribe(authState => { switch (authState.state) { case 'signedIn': this.navCtrl.navigateForward(['/home']); break; case 'signedOut': this.navCtrl.navigateForward(['/auth']); break; } }); } }
Observableをsubscribeするときは、必要なくなったときに必ずunsubscribeしないとメモリリークにつながりますが、ことAppComponentに関してはアプリケーションが生きている間はずっと存在している間はずっと存在するので、特にunsubscribeする処理は書いていません。AmplifyをAngularから使うためには、
aws-amplifyパッケージから個別にAuthやAPIをインポートしてもよいのですが、AngularにはDI(Dependency Injection)という強力な仕組みがあります。
aws-amplify-angularパッケージでは、そのDI経由でAmplifyを操作できるようにAmplifyServiceというサービスクラスを提供してくれています。また、AngularはRxJSと密結合です。
AmplifyServiceでは、Amplifyが内部的に持っているログイン状態の変化をRxJSのObservableとして提供してくれています。(this.amplifyService.authState()の部分)この状態でサインインすると、自動的に
HomePageに遷移します。とりあえずHomePageにサインアウトボタンを設置する
サインアウトも試したいので、
HomePageにサインアウトボタンを設置します。Ionicを使っているので、ヘッダーにアイコンを使ったボタンを設置するのは一瞬でできてしまいます。src/app/pages/closed/home/home.page.html<ion-header> <ion-toolbar> <ion-title> Ionic Blank </ion-title> <!-- ここから追加 --> <ion-buttons slot="end"> <ion-button slot="icon-only" (click)="onSignOutButtonClicked()"> <ion-icon name="log-out"></ion-icon> </ion-button> </ion-buttons> <!-- ここまで追加 --> </ion-toolbar> </ion-header> <ion-content> <div class="ion-padding"> The world is your oyster. <p>If you get lost, the <a target="_blank" rel="noopener" href="https://ionicframework.com/docs/">docs</a> will be your guide.</p> </div> </ion-content>続いて
src/app/pages/closed/home/home.page.tsにサインアウト処理を書いていきます。こちらもAmplifyServiceをDIして、用意されているメソッドを使えば簡単にできます。src/app/pages/closed/home/home.page.tsimport { Component } from '@angular/core'; import { AmplifyService } from 'aws-amplify-angular'; @Component({ selector: 'app-home', templateUrl: 'home.page.html', styleUrls: ['home.page.scss'], }) export class HomePage { constructor( private amplifyService: AmplifyService, ) {} onSignOutButtonClicked() { this.amplifyService.auth().signOut(); } }こんな感じで動作します。いい感じですね!
ここまででIonicアプリにAmplify Frameworkを組み込むことができました。
続きは続編にて:AWS AppSyncのセットアップとリクエスト
ここまでの作業をまとめると、
- Ionic CLIを使ってIonicプロジェクトを作成
- Amplify CLIを使ってバックエンドにAmazon Cognitoを構築
- Amplify Frameworkをセットアップ
- Amplify提供の
<amplify-authenticator-ionic>コンポーネントを使って認証周りをサクッと構築- Amplifyが持つ認証状態をAngular側で監視してルーティングを切り替える
になります。
一番書きたかったのはAWS AppSyncでGraphQL APIを作成してAWS Amplify JavaScript Frameworkから叩く部分でしたが、予想以上に準備の手順が多かったのでこのあたりで一旦切りたいと思います。
今回がQiitaのアドベントカレンダー発挑戦なのでこんな感じで良いのか若干不安ですが、勢いで2日間書くことにしているので、続編は12/17の記事でお送りできたらと思います。
ざっくりですが、この後はAWS AppSyncを使ってAPIを立てて、リアルタイムで同期されるチャットアプリを作ろうと思っています。
チャットアプリはAppSyncの練習としてよく題材にされているイメージです。
awslabsにもChatQLというAngular+AppSyncのサンプルがあったり。この後の実装はチャットアプリに寄せたものになっていく予定ですが、本記事の内容は割と汎用性のあるものに仕上げたつもりです。
AWS Amplifyでバックエンドを爆速開発できるのに加えて、Ionicでフロントエンドも爆速開発できたらより夢が広がりませんか!?
AWS Amplify Advent Calendar、明日は @moaible4qiita さんです!


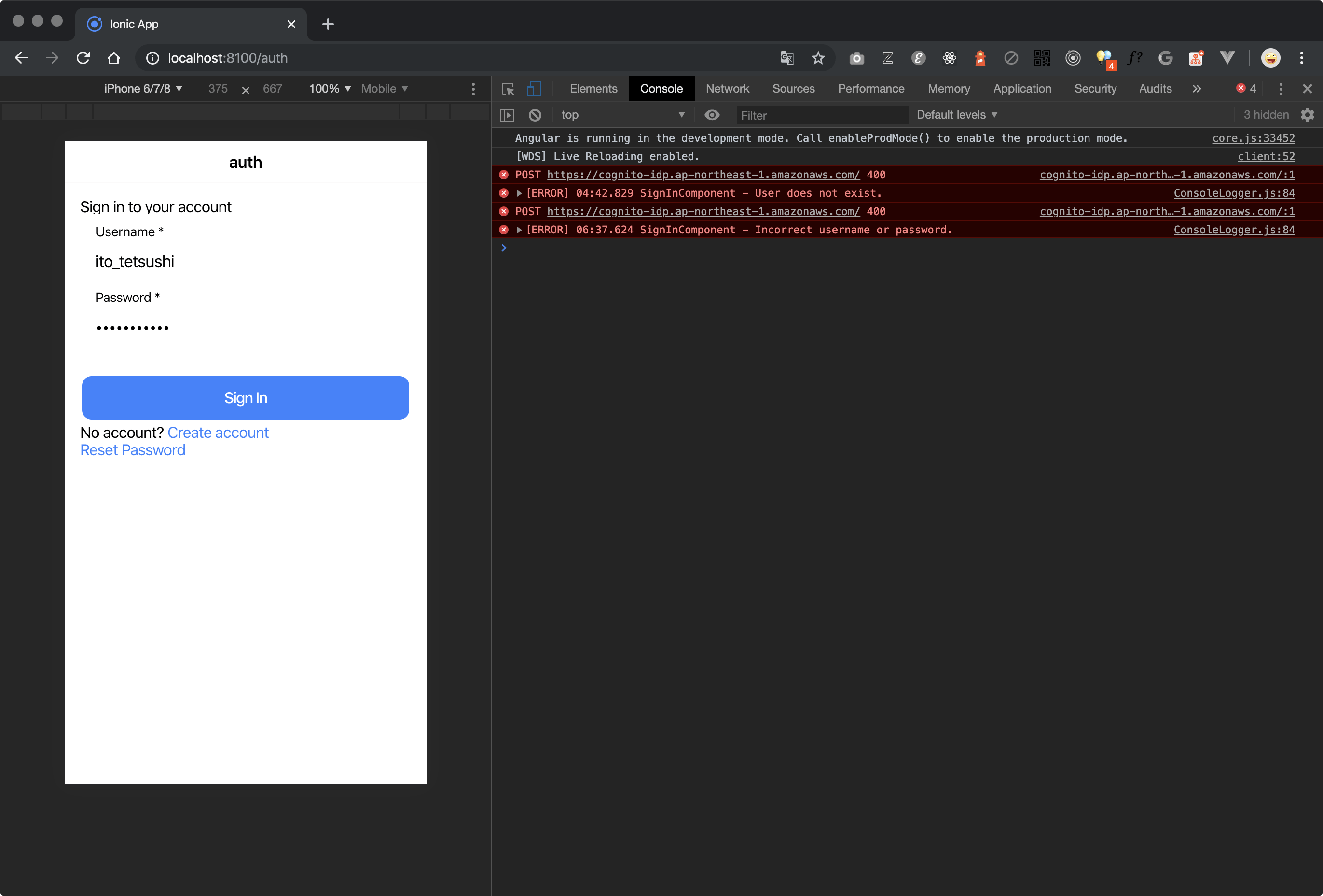
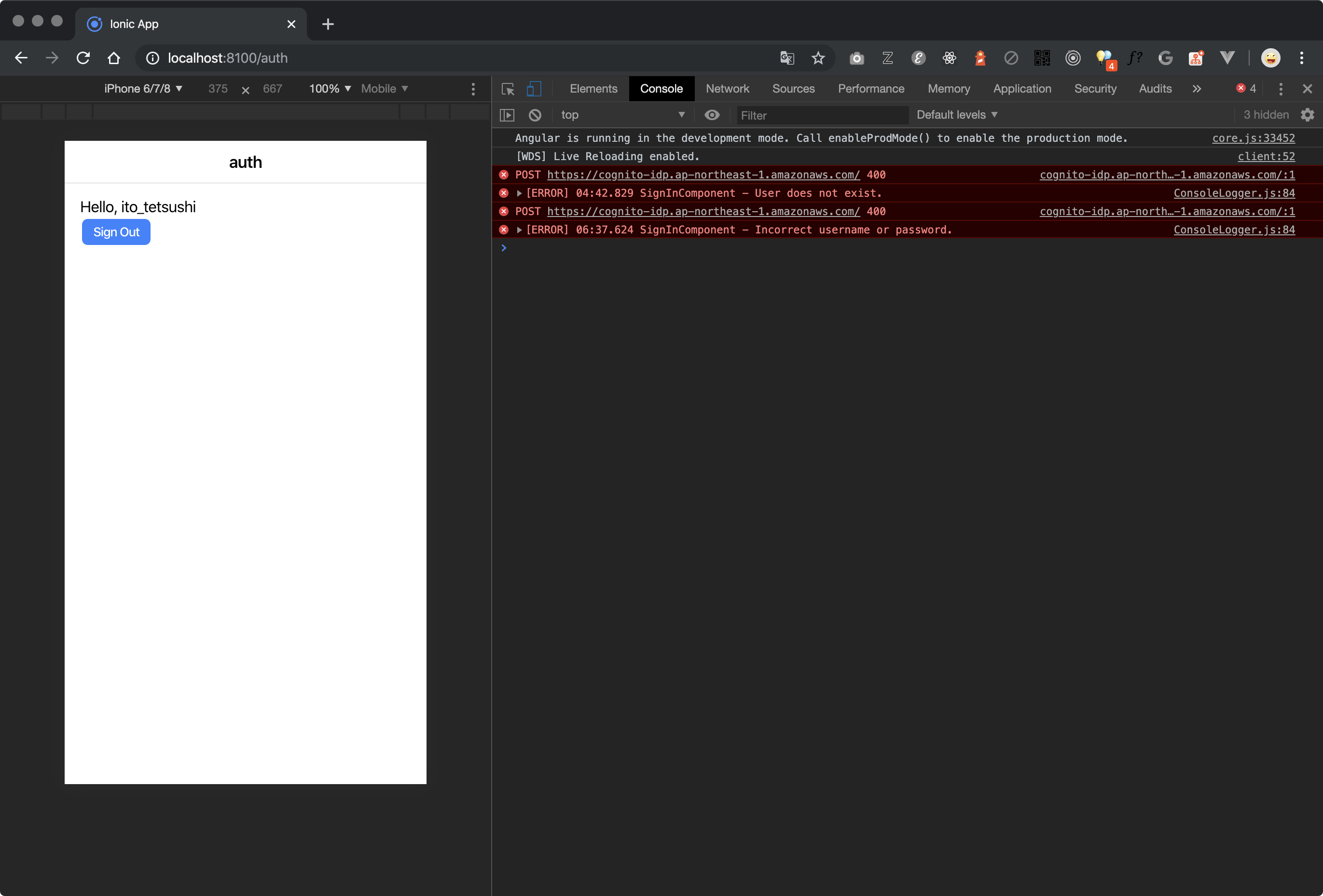

- 投稿日:2019-12-03T12:43:40+09:00
[AWS SSO] SAML認証で追加したアカウントへのsts一時認証キーの取得方法
[AWS SSO] SAML認証で追加したアカウントへのsts一時認証キーの取得方法
AWS SSO SAML認証で追加したアカウントへのsts一時キーの取得方法
AWS SSOってとにかく便利! そう思っている今日このごろです今回はAWS SSOを使って2種類のアカウントへのアクセスkeyの取得を試しました
- AWS organizations配下のアカウントをSSO配下に参加させるパターン
- 別組織のアカウントをSAML認証によりSSO配下に参加させるパターン
AWS organizations配下のアクセスkeyの取得
まず、こちらはすごく便利ですね。
コンソールからボタンポチポチで追加できますし、一時keyの発行もブラウザベースで簡単に可能です。対象のアカウントを選択して
command line or programmatic accessをポチると
これだけで一時アクセスkeyが取得できます。
ひじょーに簡単ですね。
AWS CLI v2 がつい先日リリースされましたがSSOに対応しているのでもっと楽にできるかもしれませんね。SAML認証により追加したアカウントのkeyの取得
今回の主題はこっちです。
SAML認証で別アカウントを追加した場合 この画面がありません。
その場合のアクセスkeyの取得方法です。
(※前提としてすでにSSO配下にアカウントが追加されいてるとします。追加方法はこちら)そして今回解説する元記事はこちら (AWS CLI を使用して SAML 認証情報を呼び出し、保存する方法を教えてください。)
簡単に書くと、以下の3つを準備します。
- IAM のプロバイダの ARN [※一度取得したら変わらない]
- ロール ARN [※一度取得したら変わらない]
- assume-role-with-samlを使用しますが、そこで使うSAML認証の情報の取得 [※都度取得必要]
1. IAM のプロバイダの ARN
keyを取得したいアカウントのIAMから↓を取得
2. ロール ARN
keyを取得したいアカウントのIAMから↓を取得
(注: 最大セッション期間は任意に設定してください)
3. SAMLの認証情報の取得
問題はこれです。
SAMLの認証情報ってどうやって取るんや。。。って話ですね。google chromeなら↓で取れます。 NetworkのPreseverlogをOnにした状態で、
SSOからアカウントを選択し、その瞬間に検証を有効にするとsamlという 名前の行があります。
ただこれを表示させるには、スピードとタイミングが命です! 遅いとでてきませんw
↑を選択して下の方に、SAMLResponse:があります。超長いですが全部コピります。
手順的にかなり大変なので、google 拡張の SAML-Trancer というのを使わせていただくと割と
簡単に取得できます。
1〜3の情報を元にcliを使い一時認証keyを発行します。
aws cliがインストールされている環境で以下bashを実行します
(多分awkの中のRSが参考にしたサイトは間違っている? ので自分で実装しました)
注:SAML取得後 5分以内に取得しないと、タイムオーバでkeyの取得に失敗します#!/bin/bash prvider_arn="arn:aws:iam::xxxxxxx:saml-provider/xxxx" # 1.の値 role_arn="arn:aws:iam::xxxx:role/xxxxx" # 2.の値 saml_response=$(cat ./saml_data) # 3.の値をsaml_dataというファイルに貼り付けています seconds="43200" # 認証keyの有効時間です。 ロールの最大時間をオーバするとエラーになります aws sts assume-role-with-saml --role-arn ${role_arn} --principal-arn ${prvider_arn} --saml-assertion ${saml_response} --duration-seconds ${seconds} | awk -F':' ' BEGIN { print "[account]"} /:/{ gsub(/"/, "", $2) } { gsub(/,/, "", $2) } /AccessKeyId/{ print "aws_access_key_id = " $2 } /SecretAccessKey/{ print "aws_secret_access_key = " $2 } /SessionToken/{ print "aws_session_token = " $2 } ' exit実行結果
$ ./sample.sh [account] aws_access_key_id = ASIAXXXXXXXXXXXXXXXX aws_secret_access_key = NjXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX aws_session_token = FwoGZXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX= $これを~/.aws/credentialsにはりcliを発行すると接続ができるようになります!
試しにs3をlsしてみます。 問題なくバケットの一覧が返ってきました ! $ aws --profile account s3 ls 2019-08-09 13:42:23 xxxxxxxx 2019-09-24 17:00:25 xxxxxxxx (略) ]$以上がkeyの発行手順になります。
SAML認証で追加したアカウントのkeyの発行は結構めんどくさいですね。
慣れると結構時間をかけずにできるようになりますw (いいのか...?)できれば、AWS organizations配下にアカウントを作るほうがメンテが楽なのでおすすめします。
やむを得ずの方はこの方法をお試しください。今回はAWS SSOに関する記事が少なかったので記載しました
よかったら いいね お願いします。では、よいAWSライフを!

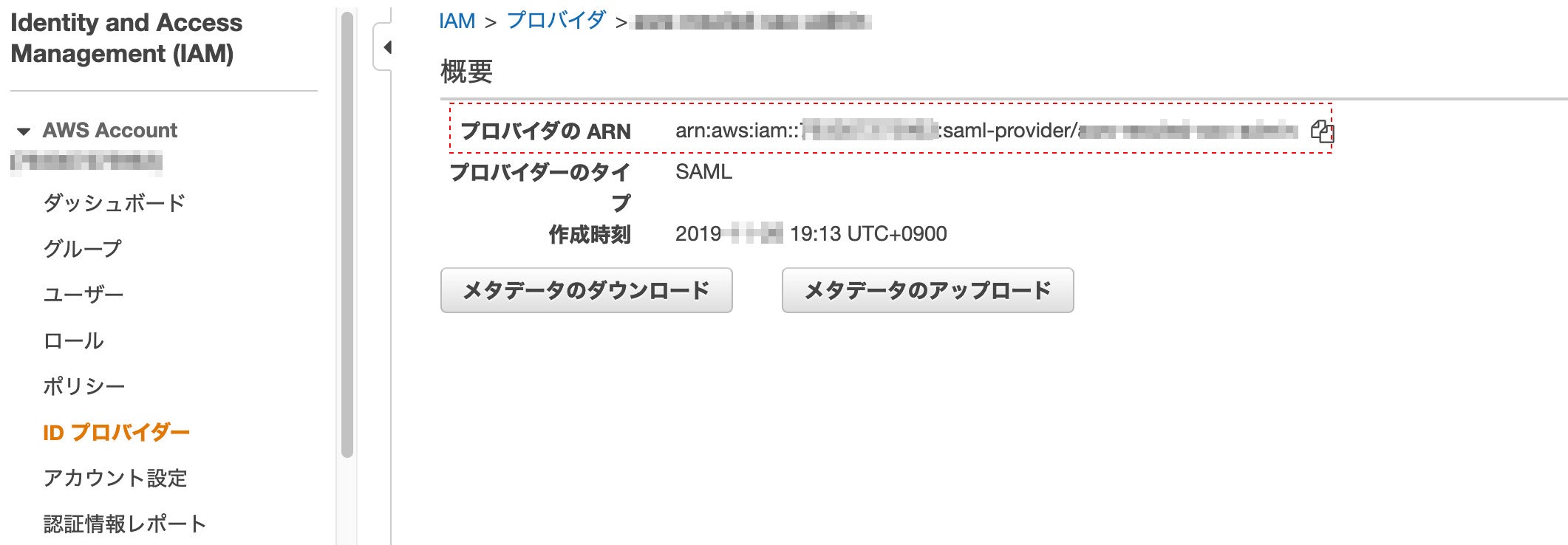


- 投稿日:2019-12-03T12:21:35+09:00
EKSで困ったことを振り返る
はじめに
これは、Amazon EKS Advent Calendar 2019 5日目の記事です。
今回は、Amazon EKSをサクッと使おうと思ったら思いの外ハマったことを振り返りつつシェアしようと思います。
ハマったこと
1. 構成管理に使うべきツールの正解がわからない
EKSを構築、運用する上で構成管理のコストは無視できない概念です。何より、日々の運用が大変なものは選びたくありません。
今年の10月にこちらのアナウンスで公式ツールに採用された今、特に大きな理由がない限りはeksctlを使っておけば安牌のように思います。
EKSの技術選定をしていたのは今年の夏頃なのですが、当時はeksctlは公式のツールではなくサードパーティのツールとして提供されていました。この時点でEKSの構成管理を行うには大きく分けて3種類の方法がありました。
方法 メリット デメリット 備考 Terraform 既存の技術スタックを使い回せる(チームでGCPメインでやってる) OSSベースなのでコントリビューターの頑張りに左右される
初期の構築コストが高いCloudFormation AWS公式の構成管理ツール、SecretsManagerなどが使いやすい、eksctlで吐き出したYAMLを使い回すことも可能 Terraformよりも記述量が少し多かった
AWS専用の技術スタックeksctl とにかく初期構築コストが低い(体感、GKE + Terraformくらい楽) いろいろ抽象化される分自分でいじるのが難しい
(当時は)公式ツールではなかったのでOSSコントリビューターの頑張りに左右される
EKSでしか使わない概念、CLIベースなので宣言的に扱えない部分があるeksctlは内部的にCloudFormationとkubectlを呼び出している eksctlは当時から非常に魅力的な選択肢だったのですが、やはり抽象化されすぎている印象が拭えず踏み切れないまま、このときは一旦Terraformで動かし始めることにしました。
2. Kubernetes以外に知らないといけないことが多すぎる
さて、eksctlを使わないので、EKSを構築する上で知らないといけない多くのことをノウハウとして蓄積する必要があります。
i. IAMポリシーが大変
甘えといえば甘えですが、AWSの柔軟かつ自由度の高いIAMは、裏を返すと検証コストの高い存在でもあります。
逃げ道はなく、基本的にはがんばるしかありませんでした。しかしeksctlのプリセットを読み込むことで自分たちの実現したいポリシーに必要なものを理解することができたのは良かったかなと思います(本来そういう使い方をすべきではないのはそうなんですが)。
ii. VPCやサブネットへのタグ付けなど、とにかく制約条件が多い
AWS的にそういう実装をするほうが黒魔術にならないんだろうなというのは理解しつつも、タグつけるのかぁ。。。みたいな感じで初期構築のトラシューが結構たいへんだった記憶があります。
このへんをやっていると、AWSが難しいのかEKSが難しいのかKubernetesが難しいのかよくわからなくなってきます。
Ref: 公式ドキュメント
iii. クラスター作成時にRBACのAdminの指定ができない(CloudFormationを作成したロールが管理者になる)
https://github.com/aws/containers-roadmap/issues/554
Issueも作ったんですが、クラスター作成時に「このロールの人にkubectl叩ける権限をあげてください」という指定ができるようになってほしいです。
CloudFormationのスタックを作成する権限を使ってしまうと多くの場合Adminレベルの強い権限を渡さないといけないため、スコープとしてKubernetesクラスターの管理をするには強すぎる権限を一時的にでも与えることになってしまいます。
正直いい状態とは言えないので、改善されると良いなあと思っています。
3. ワーカーノード追加するためには実質EC2ノードを自分たちで管理しないといけなかった(過去形)
マネージドノードグループが追加されたので今はこの必要はありません。端的に言ってこの追加は神だったと思います!!!!
Before: https://gist.github.com/inductor/83b2b14fdf0893cfd417ab66b951f199
After: https://gist.github.com/inductor/2959e397a59be756ba8b6afab0db0a81多少ポリシーは色々違いますが記述量が全く違いますよね・・・。
EKS on Fargate
Containers Roadmapが立ち上がってから比較的昔からずっと要望があったこちらのIssueがついにCloseされました。神。
eksctlも既にFargate対応済みのRC版が出ており、とてもいい感じ!
Ref: https://github.com/weaveworks/eksctl/releases/tag/0.11.0-rc.0執筆時点でリリースは「明日」と書かれているので、この記事が公開される頃にはbrew tapにも公開されているかも。
https://github.com/weaveworks/eksctl/pull/1623#issuecomment-561378258EKS on Fargateについてはたくさん書きたいことがありましたが@amsy810氏のブログに詳しく書かれているのでまあいいか、という感じです。
現状だとまだCLB/NLBに対応していないのと、eksctlにattachPolicyARNsがほしいなと個人的には思いました。
https://github.com/weaveworks/eksctl/issues/1631Feature request、Issueなどは積極的に作っていきましょう!!!
4. eksctl(CloudFormation+Kubernetes YAML)を使ったとしても初期構築のいずれかの部分は命令的にやらないといけない部分がある
先日のアナウンスを踏まえてeksctlを見直しているのですが、まだいくつかクラスター管理において課題に感じていることがあります。
課題: どうせなら全部宣言的に構成管理をしたい
クラスター作成からアプリケーションの最も基本的なYAMLを流すまでの流れを全部Declarativeにやりたい(クラスター構築して引き渡すまでを全部自動化したい)のですが、現状権限周りや初期の部分で一部命令的に実行する必要のある箇所があってGitOpsなどを使ったクラスター自体の管理とアプリケーション自体の管理を始めるまでに少し手数があります。
具体的な方法: https://www.weave.works/blog/automate-eks-cluster-configuration-with-gitops-and-eksctl
解決策は?
ノードグループの管理まで全部含めて宣言的に管理したいなあ、具体的にはeksctlにもapply句が増えてくれればCRUDの忖度がいらないので便利になるだろうな、と思っています。
KubeConのときにWeaveworksの人にそういう話をしたら、わかるけどEKS側でAPI増やしてくれないと厳しい、と言われました。AWSさんお願いします
- 投稿日:2019-12-03T09:00:04+09:00
Amazon SNS -> AWS Lambda -> Slack -> AWS ChatbotでAWSコマンドを実行する
AWSからSlack上でAWSコマンドが実行できる、という発表があったので、直接入力ではなく他のサービスからの書き込みでも対応しているのか確認してみた。
https://aws.amazon.com/jp/blogs/devops/running-aws-commands-from-slack-using-aws-chatbot/
事前準備はスキップ
SlackとAWS Chatbotの紐付け設定などは本家サイトにあるのでスキップ。
Lambdaの実装
こんな感じのシンプルなもの
import json import os import logging import urllib.request logger = logging.getLogger(__name__) SLACK_URL = os.environ['SLACK_URL'] def lambda_handler(event, context): logger.info('Start Slack message sending.') message = event['Records'][0]['Sns']['Message'] params = { "text": message, "icon_emoji": ":heavy_exclamation_mark:" } text = "payload=" + json.dumps(params) request = urllib.request.Request( SLACK_URL, data = text.encode("utf-8"), method="POST" ) with urllib.request.urlopen(request) as response: response = response.read().decode("utf-8") return response
message変数にはSNSから送られてきたメッセージが入っているので、それを抽出しています。eventに格納されるSNSからのデータは以下の通り。{ "Records": [ { "EventSource": "aws:sns", "EventVersion": "1.0", "EventSubscriptionArn": "ARN内容", "Sns": { "Type": "Notification", "MessageId": "メッセージID", "TopicArn": "SNSのトピックARN", "Subject": "タイトル", "Message": "メッセージ内容", "Timestamp": "送付時刻", "SignatureVersion": "1", "Signature": "XXX", "SigningCertUrl": "https://XXX", "MessageAttributes": {} } } ] }SNS側の設定
以下のようなSNSの設定をしてLambdaに情報を流すようにする。(とてもシンプルで、特に特殊な設定はしていないです)
メッセージをSNSから送付してみる
以下のようなメッセージをSNSからPublishしてみます。
<@aws> help※はSlackでメンションを送る際の記法。
しばらくするとSlack側にメッセージが投稿され、AWSコマンドの発行結果が返ってきました。
まとめ
簡単にですが、AWS Chatbotを通じてAWSコマンドを発行することは、Slackへの他サービスからの書き込みでもできることが確認できました。Slack -> AWS Chatbot -> AWSコマンド発行の可能性がまた広がりました。