- 投稿日:2019-11-27T23:02:06+09:00
機械学習で画像認識モデルを自作してAndroidアプリを実装する最短経路について
この記事の目的
- 画像認識モデルを簡単に作って,簡単にアプリとして動かす方法を共有する
実行環境
- google colaboratory(ランタイム:GPU)(tensorflow 2.0)(Google Chrome)
- win 10
- Android Studio(3.5.2)
- android 9.0(Huawei mate 10 pro)
この記事で書くこと
画像認識モデルのためのデータセット作成方法
以下のステップを踏む
1. 認識したいクラスを複数作る.(ここではクラスA,B,Cとする)
2. クラスA,B,Cの画像を集める
3. クラスA,B,Cの画像をトレーニング用,テスト用に分けるクラスA,B,Cの画像を集める
すでに画像を集めている場合はスキップ
まだ集めていない場合はgoogle_image_download(参考URL)が便利.
キーワードや拡張子,サイズ,枚数などを指定して画像をダウンロードしてくれる.
※ちゃんと学習させたいなら,ダウンロードしてきた画像を認識したい部分だけ切り出す作業を行う.(かなり時間がかかりますが,必要な場合が多いと思います.いい方法あれば教えてください...)クラスA,B,Cの画像をトレーニング用,テスト用に分ける
トレーニング用,テスト用に画像をいい感じに分ける(トレーニング8割:テスト2割ぐらい?)
具体的には以下のような構成のフォルダを作る
images
├train
│└A
│ └a01.jpg
│ └aslfdjk.png
│ ...
│└B
│ └ba.jpg
│ └dskrup.png
│ ...
│└C
│ └ba.jpg
│ └sdddrrd.png
│ ...
│
├validation
│└A
│ └fwwqd.jpg
│ └qiita.png
│ ...
│└B
│ └sddd.jpg
│ └reag.png
│ ...
│└C
│ └vtet.jpg
│ └fhyr.png
│ ...画像認識モデルの作成方法
モデルは以下のステップで作成する
1. tensorflowのtutorialを使用
2. 1.でモデルをトレーニングするデータを自作のものに置き換える
3. Android Studioでの実装を考慮してモデルの形を微修正し,モデルをトレーニング
4. トレーニングしたモデルの保存方法tensorflowのtransfer learningのtutorialを使用
簡単さを重視し,tensorflowが提供しているtutorialを流用したコードを(参考URL)※URLを押すといきなりgoogle colaboratoryが開きます
google colaboratory の使い方については公式HPを参考.モデルをトレーニングするデータを自作のものに置き換える
ソースコードのこの部分
from google.colab import drive drive.mount('/content/drive') PATH = '/content/drive/'+'google drive上の自分のデータセットのある場所までのパス'これを入力すると,google driveに対してのアクセスを許可するか?という旨の認証を求められる.個人的には気にならないので特に考えず認証したが,気になる人はgoogle colaboraotryで自分のデータセットを読み込ませるのはやめたほうが良い.
Android Studioでの実装を考慮してモデルの形を微修正してモデルをトレーニング
ソースコードのこの部分
このあと以下のコードセルまでを順次実行するとモデルのトレーニングができる
history = model.fit_generator( train_data_gen, steps_per_epoch=total_train // batch_size, epochs=epochs, validation_data=val_data_gen, validation_steps=total_val // batch_size )トレーニングしたモデルの保存方法
これだけ
saved_model_dir = base_dir+'保存したい場所' tf.saved_model.save(model, saved_model_dir)作成した画像認識モデルをAndroid Studioで読み込み動かす方法
以下のステップを踏む
1. 保存したモデルをTensorFlow Liteモデルに変換し,保存する
2. Android studioのプロジェクトを作る
3. Android studioで保存したモデルを読み込み,アプリを動かす保存したモデルをTensorFlow Liteモデルに変換し,保存する
これだけ
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) tflite_model = converter.convert() with open(base_dir+'モデルの名前.tflite', 'wb') as f: f.write(tflite_model)保存したモデルをダウンロードしてローカルに保存しておく.
Android studioのプロジェクトを作る
まずAndroid studioをインストールし(参考URL),
例によってtensorflowが提供するquick startを流用する.参考URL
に従っていくと,ローカル環境にexampleという名前のフォルダが作成されるので,以下のパスにあるandroidプロジェクトを開く
\examples\lite\examples\image_classification\androidAndroid studioで保存したモデルを読み込み,アプリを動かす
以下のステップで行う
1. ローカルに保存した.tfliteファイルをassetフォルダに置く
2. クラスを記載した.txtファイルをassetフォルダに置く
3. .jaファイルを一部書き換えるローカルに保存した.tfliteファイルをassetフォルダに置く
以下のフォルダに置く.
\examples\lite\examples\image_classification\android\app\src\main\assets
同じところに.tfliteがいくつか入っている.クラスを記載した.txtファイルをassetフォルダに置く
今回の場合,クラスA,B,Cを以下のように書き,.tfliteファイルと同じ場所に保存する.
mylabel.textA B C.javaファイルを一部書き換える
まず,
\examples\lite\examples\image_classification\android\app\src\main\java\org\tensorflow\lite\examples\classification\tflite\ClassifierFloatMobileNet.java
の56行目return "mobilenet_v1_1.0_224.tflite";を以下のように書き換える
return "モデルの名前.tflite";次に,
\examples\lite\examples\image_classification\android\app\src\main\java\org\tensorflow\lite\examples\classification\tflite\Classifier.java
の110行目public static Classifier create(Activity activity, Model model, Device device, int numThreads) throws IOException { if (model == Model.QUANTIZED) { return new ClassifierQuantizedMobileNet(activity, device, numThreads); } else { return new ClassifierFloatMobileNet(activity, device, numThreads); } }を以下のように書き換える
public static Classifier create(Activity activity, Model model, Device device, int numThreads) throws IOException { //if (model == Model.QUANTIZED) { //return new ClassifierQuantizedMobileNet(activity, device, numThreads); //} else { return new ClassifierFloatMobileNet(activity, device, numThreads); //} }最後にAndroid Studioでmake projectを行う.
その後スマホをPCにつなぎ,Run'app'を実行.するとスマホにTFL Classifyという名前のアプリがインストールされ,実行される.
画面の下のほうにA,B,Cのconfidence(どのくらいそのクラスらしいかを%で示したもの)が表示される.筆者の失敗談
筆者が躓いた失敗(?)談のうち,参考になるかもしれないものを共有しておく.
失敗(?)1
pytorchモデルをtensorflowLITEモデルに変換することにトライし,結局挫折した.
主にこの2つのHPを参考にしたが,URL1,URL2
どちらもよくわからないエラーが出てやめてしまった.今思うとkerasとtf.kerasがどちらも存在したことが原因だったかもしれない.今度検証してみようかな?今回はとにかく早く自作モデルをandroidアプリで動かしたかったため,結局tensorflow tutorialを利用してモデルを作成し,上記のようにkerasモデルをtensorflowLITEモデルに変換した.
上のURL1にも記載されているように
そんな中、TensorFlowが明らかにPyTorchに対して優位な点として、以下のようなものが挙げられます。
TPUを使って学習できる
TFLite や TensorFlow.js など、フロントエンドでのデプロイを容易にするAPIが充実しているアプリへの転用を容易にするサポートが現在tensorflowのほうが手厚いようです.
失敗(?)2
色んなコードを集めているうちにkerasとtf.kerasが混ざってしまっていた.途中からkeras絶対消すマンとしてtf.kerasに書き換えまくった.
失敗(?)3
モデルの出力がデフォルトのtutorialコードでは1つになっていることに気づかず,android studioで出力が足りないよ!というエラーを吐かせまくった.
エラーの原因がkerasからTFLiteConverterを使って.tfliteファイルを作るところにあると考え,そこで時間を使いまくった...
結局このURLで,自作モデルの評価をやってみるうちに「なんか出力のshapeおかしくね?」となり,モデルの形がおかしいことに気づいた失敗(?)4
モデルを量子化してみたが,android studioで読み込めず断念.結局floatモデルを使用した.
量子化した方がモデルのサイズが小さくなるし処理が早くなりそうだったのでトライしたが,できなかった.
これはまだ原因がわかっていない.失敗(?)5
そもそも当初は物体認識に何を使うか決めておらず,darknetでyoloを使おうと思っていたが,自作モデルを流用する方法がわからず,どうやればいいかわからず断念.知り合いからpytorchが簡単でいいよ!と教えられ,失敗1につながった.こう考えるとすぐ諦めてるな...
失敗(?)6
クラスA,B,Cの画像を集めるで簡単に画像をgoogle_image_downloadを使って集めればいいよ!と書いているが,結構これがしんどい.もちろん不適切な画像もダウンロードしてくるので,そこから捨てたりトリミングしたりがまず大変で,その後クラス分けの作業が待っている.
世の中でアノテーションが仕事になる理由が分かったが,リアルMPが減りそうなのであまりやりたくない...
関連ワードとしてactive learningなるものがあり,認識率が上がる画像を自動で選んでくれるという方法のようだ.できたら便利.かなぁ?失敗(?)7
この記事を書き始めたのち,tensorflowのtutorialの内容が変わっていたことに気づく.
実は筆者はtransfer learningのtutorialを使っていたのだが,自分のコードを公開するのが面倒だったため,仕方なくimage classificationのtutorialを説明に使用.
自分でモデル作るより,少ないデータ数で精度が上がると言われているtransfer learningが便利だと思っています.
現在のtransfer learningのtutorialはデータの読み込みがtfのものから読み込むようになっており,そこを変更して書くのが煩雑なため,説明に使用することを断念.
自分のデータをtransfer learningで使用したい!という要望があれば頑張る気になるかもしれません...
- 投稿日:2019-11-27T00:21:21+09:00
TensorFlowで使えるデータセット機能が強かった話
TFで使えるデータセット機能
TFでは
tf.data.Datasetと言う非常に強力なデータセット機能があります。
具体的に何ができるのかというと、データの塊を入れるとパイプラインを構築してデータを吐き出すジェネレータを作成する機能が使えます。データパイプラインを使用する強み
tf.data.Datasetデータパイプラインを用いると以下のことができます。
- Batchごとにデータを排出
- データをShuffleしながら排出
- データを指定回数Repeatしながら排出
- チェインメソッドにより複雑に変形可能
- データを途中で変換掛けながら排出
- GPU演算中にCPUでデータセットを用意
特に、データ変換機能は、DataAugmentationが応用でき、Generatorとして非常に強力です。
さらにいえば、keras.preprocessing.image.ImageDataGeneratorで結構苦労された方もいらっしゃったのでは?と思いますが、
データのAugmentationがボトルネックになって一向に学習が進まない、遅い。とかって経験ありませんか?
tf.data.Datasetではそういったボトルネックを解消してくれる事でしょう。使ってみたくなってきましたか? 今回はそういった部分でのハンズオンを記事を用意しました。
是非お役に立てればと思います。注意?
基本的にEager modeで動くので、TF2.0でなければ動きません。
Dataset作成
基本
まずは基本からおさらいしましょう。Dataset化はこのように行います。
Dataset化import tensorflow as tf import tensorflow.keras as keras dataset = tf.data.Dataset.from_tensor_slices(tf.range(10))Generatorなので、for文で値が次々に排出されていきます。
Data排出for item in dataset: print(item)結果tf.Tensor(0, shape=(), dtype=int32) tf.Tensor(1, shape=(), dtype=int32) tf.Tensor(2, shape=(), dtype=int32) tf.Tensor(3, shape=(), dtype=int32) tf.Tensor(4, shape=(), dtype=int32) tf.Tensor(5, shape=(), dtype=int32) tf.Tensor(6, shape=(), dtype=int32) tf.Tensor(7, shape=(), dtype=int32) tf.Tensor(8, shape=(), dtype=int32) tf.Tensor(9, shape=(), dtype=int32)このようにしてDataset化することができます。
別のデータ媒体でも大丈夫
listなども当然入れられます。
listの場合dataset = tf.data.Dataset.from_tensor_slices([0,1,2,3,4]) for item in dataset: print(item)結果tf.Tensor(0, shape=(), dtype=int32) tf.Tensor(1, shape=(), dtype=int32) tf.Tensor(2, shape=(), dtype=int32) tf.Tensor(3, shape=(), dtype=int32) tf.Tensor(4, shape=(), dtype=int32)ですが、以下のようなListはDatasetには入れられません。
Raggedなlistdataset = tf.data.Dataset.from_tensor_slices([[1,2],[3],[4,5,6]])結果--------------------------------------------------------------------------- TypeError Traceback (most recent call last) /usr/local/lib/python3.6/dist-packages/tensorflow_core/python/data/util/structure.py in normalize_element(element) 90 try: ---> 91 spec = type_spec_from_value(t, use_fallback=False) 92 except TypeError: 11 frames TypeError: Could not build a TypeSpec for [[1, 2], [3], [4, 5, 6]] with type list During handling of the above exception, another exception occurred: ValueError Traceback (most recent call last) /usr/local/lib/python3.6/dist-packages/tensorflow_core/python/framework/constant_op.py in convert_to_eager_tensor(value, ctx, dtype) 94 dtype = dtypes.as_dtype(dtype).as_datatype_enum 95 ctx.ensure_initialized() ---> 96 return ops.EagerTensor(value, ctx.device_name, dtype) 97 98 ValueError: Can't convert non-rectangular Python sequence to Tensor.advanced:Ragged Tensor
しかし、TensorFlowにはRagged Tensorと呼ばれる機能があります。
それは横道に話がそれてしまうので、詳しくはGuideの方を参考にしてください。
最新版TFでは以下のようなことができます。RaggedTensor#tf-nightly(最新版TF)バージョンのみ実行可能 data = tf.ragged.constant([[1,2],[3],[4,5,6]]) ds = tf.data.Dataset.from_tensor_slices(data) for x in data: print(x)結果tf.Tensor([1 2], shape=(2,), dtype=int32) tf.Tensor([3], shape=(1,), dtype=int32) tf.Tensor([4 5 6], shape=(3,), dtype=int32)これで、文章系タスクもPaddingせずにKerasなどに流し込むことができるっぽいです(要検証)。
複数Input
推論元の(いわゆる説明変数)データXと、推論の答え(いわゆる目的変数)データYは
Batchで流す時には一緒に流してFor文を回した方がいいですよね。
そう言う時は、複数のInput処理を行います。複数のInput処理dataset = tf.data.Dataset.from_tensor_slices((tf.range(10),tf.range(10,20))) for item1,item2 in dataset: print(item1,item2)結果tf.Tensor(0, shape=(), dtype=int32) tf.Tensor(10, shape=(), dtype=int32) tf.Tensor(1, shape=(), dtype=int32) tf.Tensor(11, shape=(), dtype=int32) tf.Tensor(2, shape=(), dtype=int32) tf.Tensor(12, shape=(), dtype=int32) tf.Tensor(3, shape=(), dtype=int32) tf.Tensor(13, shape=(), dtype=int32) tf.Tensor(4, shape=(), dtype=int32) tf.Tensor(14, shape=(), dtype=int32) tf.Tensor(5, shape=(), dtype=int32) tf.Tensor(15, shape=(), dtype=int32) tf.Tensor(6, shape=(), dtype=int32) tf.Tensor(16, shape=(), dtype=int32) tf.Tensor(7, shape=(), dtype=int32) tf.Tensor(17, shape=(), dtype=int32) tf.Tensor(8, shape=(), dtype=int32) tf.Tensor(18, shape=(), dtype=int32) tf.Tensor(9, shape=(), dtype=int32) tf.Tensor(19, shape=(), dtype=int32)複数DatasetをPythonのZip的に流したい
複数のInput,複数のOutputを構成するマルチタスクラーニング手法を用いたい時は、
以下のようにdatasetをpythonのzipのように流すこともできます。zipdatasetX = tf.data.Dataset.from_tensor_slices(tf.range(-10,0)) datasetY = tf.data.Dataset.from_tensor_slices((tf.range(10),tf.range(10,20))) dataset = tf.data.Dataset.zip((datasetX,datasetY)) for itemX,(itemY1,itemY2) in dataset: print(itemX,itemY1,itemY2)結果tf.Tensor(-10, shape=(), dtype=int32) tf.Tensor(0, shape=(), dtype=int32) tf.Tensor(10, shape=(), dtype=int32) tf.Tensor(-9, shape=(), dtype=int32) tf.Tensor(1, shape=(), dtype=int32) tf.Tensor(11, shape=(), dtype=int32) tf.Tensor(-8, shape=(), dtype=int32) tf.Tensor(2, shape=(), dtype=int32) tf.Tensor(12, shape=(), dtype=int32) tf.Tensor(-7, shape=(), dtype=int32) tf.Tensor(3, shape=(), dtype=int32) tf.Tensor(13, shape=(), dtype=int32) tf.Tensor(-6, shape=(), dtype=int32) tf.Tensor(4, shape=(), dtype=int32) tf.Tensor(14, shape=(), dtype=int32) tf.Tensor(-5, shape=(), dtype=int32) tf.Tensor(5, shape=(), dtype=int32) tf.Tensor(15, shape=(), dtype=int32) tf.Tensor(-4, shape=(), dtype=int32) tf.Tensor(6, shape=(), dtype=int32) tf.Tensor(16, shape=(), dtype=int32) tf.Tensor(-3, shape=(), dtype=int32) tf.Tensor(7, shape=(), dtype=int32) tf.Tensor(17, shape=(), dtype=int32) tf.Tensor(-2, shape=(), dtype=int32) tf.Tensor(8, shape=(), dtype=int32) tf.Tensor(18, shape=(), dtype=int32) tf.Tensor(-1, shape=(), dtype=int32) tf.Tensor(9, shape=(), dtype=int32) tf.Tensor(19, shape=(), dtype=int32)batch化
要素ごとではなく、Batchごとに出力したい時は、チェインメソッドみたく
tf.data.Datasetの先に.batch(batch_size)をつけますBatchdataset = tf.data.Dataset.from_tensor_slices(tf.range(10)).batch(5) for item in dataset: print(item)結果tf.Tensor([0 1 2 3 4], shape=(5,), dtype=int32) tf.Tensor([5 6 7 8 9], shape=(5,), dtype=int32)repeat
.repeat(repeat_num)は単純にデータセットを繰り返したい時に使います。
.repeat()の場合は無限にリピートするので注意です。repeatdataset = tf.data.Dataset.from_tensor_slices(tf.range(3)).repeat(3) for item in dataset: print(item)結果tf.Tensor(0, shape=(), dtype=int32) tf.Tensor(1, shape=(), dtype=int32) tf.Tensor(2, shape=(), dtype=int32) tf.Tensor(0, shape=(), dtype=int32) tf.Tensor(1, shape=(), dtype=int32) tf.Tensor(2, shape=(), dtype=int32) tf.Tensor(0, shape=(), dtype=int32) tf.Tensor(1, shape=(), dtype=int32) tf.Tensor(2, shape=(), dtype=int32)もちろん、チェインメソッドなので、
.Batchメソッドと併用もできます。repeat_batchdataset = tf.data.Dataset.from_tensor_slices(tf.range(10)).repeat(3).batch(7) for item in dataset: print(item)結果tf.Tensor([0 1 2 3 4 5 6], shape=(7,), dtype=int32) tf.Tensor([7 8 9 0 1 2 3], shape=(7,), dtype=int32) tf.Tensor([4 5 6 7 8 9 0], shape=(7,), dtype=int32) tf.Tensor([1 2 3 4 5 6 7], shape=(7,), dtype=int32) tf.Tensor([8 9], shape=(2,), dtype=int32)逆も可
batch_repeatdataset = tf.data.Dataset.from_tensor_slices(tf.range(10)).batch(7).repeat(3) for item in dataset: print(item)結果tf.Tensor([0 1 2 3 4 5 6], shape=(7,), dtype=int32) tf.Tensor([7 8 9], shape=(3,), dtype=int32) tf.Tensor([0 1 2 3 4 5 6], shape=(7,), dtype=int32) tf.Tensor([7 8 9], shape=(3,), dtype=int32) tf.Tensor([0 1 2 3 4 5 6], shape=(7,), dtype=int32) tf.Tensor([7 8 9], shape=(3,), dtype=int32)shuffle
基本
概念が少々複雑なので、少し詳しく説明します。
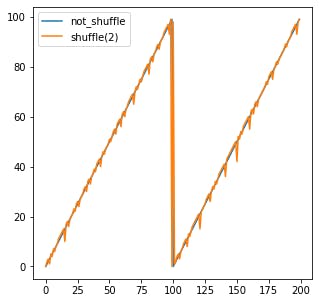
.shuffle(buffer_size)はbuffer_sizeの幅でシャッフルしていくイメージです。
つまり、.shuffle(1)は全く変わりませんし、.shuffle(2)は隣同士で入れ替わるかどうかを端から端までやります。shuffle1dataset = tf.data.Dataset.from_tensor_slices(tf.range(10)).shuffle(1) for item in dataset: print(item)結果tf.Tensor(0, shape=(), dtype=int32) tf.Tensor(1, shape=(), dtype=int32) tf.Tensor(2, shape=(), dtype=int32) tf.Tensor(3, shape=(), dtype=int32) tf.Tensor(4, shape=(), dtype=int32) tf.Tensor(5, shape=(), dtype=int32) tf.Tensor(6, shape=(), dtype=int32) tf.Tensor(7, shape=(), dtype=int32) tf.Tensor(8, shape=(), dtype=int32) tf.Tensor(9, shape=(), dtype=int32)shuffle2dataset = tf.data.Dataset.from_tensor_slices(tf.range(10)).shuffle(2) for item in dataset: print(item)結果tf.Tensor(1, shape=(), dtype=int32) tf.Tensor(2, shape=(), dtype=int32) tf.Tensor(0, shape=(), dtype=int32) tf.Tensor(3, shape=(), dtype=int32) tf.Tensor(4, shape=(), dtype=int32) tf.Tensor(5, shape=(), dtype=int32) tf.Tensor(6, shape=(), dtype=int32) tf.Tensor(7, shape=(), dtype=int32) tf.Tensor(9, shape=(), dtype=int32) tf.Tensor(8, shape=(), dtype=int32)2は微妙にshuffleされているのがわかる。
グラフ化
graph-shuffle1import matplotlib.pyplot as plt dataset1 = tf.data.Dataset.from_tensor_slices(tf.range(100)).repeat(2) dataset2 = tf.data.Dataset.from_tensor_slices(tf.range(100)).repeat(2).shuffle(1) X=[] Y=[] for item in dataset1: X.append(item.numpy()) for item in dataset2: Y.append(item.numpy()) plt.figure(figsize=(5,5),facecolor="white") plt.plot(X) plt.plot(Y) plt.legend(['not_shuffle', 'shuffle(1)'], loc='upper left') plt.show()
2の場合
10の場合
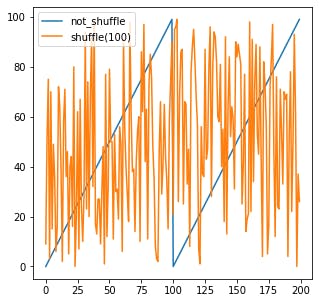
100(全体Shuffle)の場合
つまり、全体Shuffleしたい場合は、データサイズそのままを記入すれば全体でランダムにすることができます。
チェインメソッド化
これも
.repeat,.batch同様にチェインメソッドで複雑に構成できます。shuffle-chain1dataset = tf.data.Dataset.from_tensor_slices(tf.range(10)).repeat(3).batch(7) for item in dataset: print(item) print("----------") dataset = tf.data.Dataset.from_tensor_slices(tf.range(10)).repeat(3).batch(7).shuffle(5) for item in dataset: print(item)結果tf.Tensor([0 1 2 3 4 5 6], shape=(7,), dtype=int32) tf.Tensor([7 8 9 0 1 2 3], shape=(7,), dtype=int32) tf.Tensor([4 5 6 7 8 9 0], shape=(7,), dtype=int32) tf.Tensor([1 2 3 4 5 6 7], shape=(7,), dtype=int32) tf.Tensor([8 9], shape=(2,), dtype=int32) ---------- tf.Tensor([4 5 6 7 8 9 0], shape=(7,), dtype=int32) tf.Tensor([0 1 2 3 4 5 6], shape=(7,), dtype=int32) tf.Tensor([8 9], shape=(2,), dtype=int32) tf.Tensor([1 2 3 4 5 6 7], shape=(7,), dtype=int32) tf.Tensor([7 8 9 0 1 2 3], shape=(7,), dtype=int32)お分かりいただけただろうか。要はこの場合BatchをShuffleしています。
非直感的な例
shuffle-chain2dataset = tf.data.Dataset.from_tensor_slices(tf.range(10)).shuffle(10).batch(7) for item in dataset: print(item)結果tf.Tensor([0 4 7 8 1 3 2], shape=(7,), dtype=int32) tf.Tensor([5 9 6], shape=(3,), dtype=int32)これはまぁいいとして、次がちょっと不思議に思う人もいるかもしれないです。
shuffle-chain3dataset = tf.data.Dataset.from_tensor_slices(tf.range(10)).shuffle(10).batch(7).repeat(3) for item in dataset: print(item)tf.Tensor([8 5 7 3 4 6 9], shape=(7,), dtype=int32) tf.Tensor([2 1 0], shape=(3,), dtype=int32) tf.Tensor([2 7 8 3 9 5 4], shape=(7,), dtype=int32) tf.Tensor([0 1 6], shape=(3,), dtype=int32) tf.Tensor([4 2 8 1 5 6 3], shape=(7,), dtype=int32) tf.Tensor([7 9 0], shape=(3,), dtype=int32)この結果を見ると、shuffle→batch→repeatと言う順番でそれぞれ塊ごとに処理しているという訳ではないことがわかります。
つまり何が言いたいのかというと、これはあくまでパイプラインであって、チェインメソッドごとに一気に処理している訳ではない。ということなのです。map
ここからが本題です。
.map(op)では値を直接変えるパイプラインを組むことができます。mapdataset = tf.data.Dataset.from_tensor_slices(tf.range(10)).map(lambda x: x**4) for item in dataset: print(item)結果tf.Tensor(0, shape=(), dtype=int32) tf.Tensor(1, shape=(), dtype=int32) tf.Tensor(16, shape=(), dtype=int32) tf.Tensor(81, shape=(), dtype=int32) tf.Tensor(256, shape=(), dtype=int32) tf.Tensor(625, shape=(), dtype=int32) tf.Tensor(1296, shape=(), dtype=int32) tf.Tensor(2401, shape=(), dtype=int32) tf.Tensor(4096, shape=(), dtype=int32) tf.Tensor(6561, shape=(), dtype=int32)分岐も可能
分岐dataset = tf.data.Dataset.from_tensor_slices(tf.range(10)).map(lambda x: (x,x**2)) for item1,item2 in dataset: print(item1,item2)結果tf.Tensor(0, shape=(), dtype=int32) tf.Tensor(0, shape=(), dtype=int32) tf.Tensor(1, shape=(), dtype=int32) tf.Tensor(1, shape=(), dtype=int32) tf.Tensor(2, shape=(), dtype=int32) tf.Tensor(4, shape=(), dtype=int32) tf.Tensor(3, shape=(), dtype=int32) tf.Tensor(9, shape=(), dtype=int32) tf.Tensor(4, shape=(), dtype=int32) tf.Tensor(16, shape=(), dtype=int32) tf.Tensor(5, shape=(), dtype=int32) tf.Tensor(25, shape=(), dtype=int32) tf.Tensor(6, shape=(), dtype=int32) tf.Tensor(36, shape=(), dtype=int32) tf.Tensor(7, shape=(), dtype=int32) tf.Tensor(49, shape=(), dtype=int32) tf.Tensor(8, shape=(), dtype=int32) tf.Tensor(64, shape=(), dtype=int32) tf.Tensor(9, shape=(), dtype=int32) tf.Tensor(81, shape=(), dtype=int32)画像におけるMap
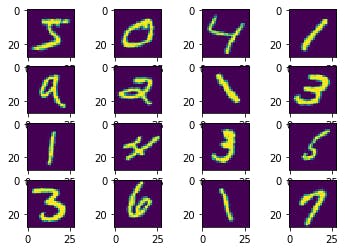
例えば、MNISTにおける回転のDataAugmentationを行いたいと考えたときに、具体的にどういうコードになるのかというと、以下のコードになります。
rotate_mnistimport matplotlib.pyplot as plt import numpy as np from scipy import ndimage def rotate(image): return ndimage.rotate(image, np.random.uniform(-30, 30), reshape=False) @tf.function def rotate_tf(image): rotated = tf.py_function(rotate,[image],[tf.int32]) return rotated[0] (train_x, train_y), (test_x, test_y) = keras.datasets.mnist.load_data() train_x = train_x.reshape(-1,28,28,1) train_ds = tf.data.Dataset.from_tensor_slices(train_x) batched_train_ds = train_ds.map(rotate_tf).batch(16) #ここが肝心のMap # pick images in first batch first_batch = next(iter(batched_train_ds)) sample_images = first_batch.numpy().reshape((-1,28,28)) plt.figure(facecolor="white") for i, sample_image in enumerate(sample_images): plt.subplot(4,4,i+1) plt.imshow(sample_image) plt.grid(False) plt.show()
py_functionと@tf.functionというものが出てきましたね、
これついては、かなり闇の技術というか、謎な部分が多いので詳細な説明は避けますが、
三行で説明すると、
- 本来tf系オペレーションで構成すると処理は早くなる。
- けどそれだけだとカバーしきれない処理は多いので、
py_functionと@tf.functionを使うと、コード解釈してtfオペレーションで実行してくれるという感じです。解釈してくれるので再代入とか、解釈の難しいコードを突っ込むと謎のエラーで死にます(3敗)
もちろん、@tf.functionも高速ですが、できる限り自分のコードでtfオペレーションを組んで、
Augmentaionなどをすると速度的にも、保守運用的にも非常にいいです。
(preprocessという名前で@tf.functionを作ると死ぬので注意です:2敗)TFオペレーションに書き換えた例を紹介しましょう。
tf_addon_rotateimport tensorflow_addons as tfa import numpy as np @tf.function def rotate_tf(image): if image.shape.__len__() ==4: random_angles = tf.random.uniform(shape = (tf.shape(image)[0], ), minval = -30*np .pi / 180, maxval = 30*np.pi / 180) if image.shape.__len__() ==3: random_angles = tf.random.uniform(shape = (), minval = -30*np .pi / 180, maxval = 30*np.pi / 180) return tfa.image.rotate(image,random_angles) (train_x,train_y),(test_x,test_y) = keras.datasets.mnist.load_data() train_x=train_x.reshape(-1,28,28,1) train_ds=tf.data.Dataset.from_tensor_slices(train_x) train_ds=train_ds.map(rotate_tf).batch(512) for x in train_ds: X = x.numpy().reshape((-1,28,28)) plt.figure(facecolor="white") for i in range(16): plt.subplot(4,4,i+1) plt.imshow(X[i,:]) plt.grid(False) plt.show()Map高速化
例えば、先ほどのMNISTの画像加工にかかる時間、
これが遅いと全体のトレーニング時間にも影響してくるはずです。
そこで、高速化テクニックをここでご紹介しましょう。scipy VS TF_addons
先ほど、オペレーションはTF系に任せた方が早いと述べましたが本当でしょうか?
検証してみましょう。speed_scipy%%time import matplotlib.pyplot as plt import numpy as np from scipy import ndimage def rotate(image): return ndimage.rotate(image, np.random.uniform(-30, 30), reshape=False) @tf.function def rotate_tf(image): rotated = tf.py_function(rotate,[image],[tf.int32]) return rotated[0] (train_x, train_y), (test_x, test_y) = keras.datasets.mnist.load_data() train_x = train_x.reshape(-1,28,28,1) train_ds = tf.data.Dataset.from_tensor_slices(train_x) batched_train_ds = train_ds.map(rotate_tf).batch(512) for imgs in batched_train_ds: imgs結果CPU times: user 47.5 s, sys: 2.81 s, total: 50.3 s Wall time: 36.7 s一方、tf_addonsでは
speed_tfa%%time import tensorflow_addons as tfa import numpy as np @tf.function def rotate_tf(image): if image.shape.__len__() ==4: random_angles = tf.random.uniform(shape = (tf.shape(image)[0], ), minval = -30*np .pi / 180, maxval = 30*np.pi / 180) if image.shape.__len__() ==3: random_angles = tf.random.uniform(shape = (), minval = -30*np .pi / 180, maxval = 30*np.pi / 180) return tfa.image.rotate(image,random_angles) (train_x, train_y), (test_x, test_y) = keras.datasets.mnist.load_data() train_x = train_x.reshape(-1,28,28,1) train_ds = tf.data.Dataset.from_tensor_slices(train_x) batched_train_ds = train_ds.map(rotate_tf).batch(512) for imgs in batched_train_ds: imgs結果CPU times: user 4.81 s, sys: 372 ms, total: 5.18 s Wall time: 3.32 s圧倒的にTFAの方が早いですね。
Batch化を先にした場合との比較
他にどうすれば高速化するかというと、Batchファーストでやると早くなります。
speed_test_batch_first%%time import tensorflow_addons as tfa import numpy as np @tf.function def rotate_tf(image): if image.shape.__len__() ==4: random_angles = tf.random.uniform(shape = (tf.shape(image)[0], ), minval = -30*np .pi / 180, maxval = 30*np.pi / 180) if image.shape.__len__() ==3: random_angles = tf.random.uniform(shape = (), minval = -30*np .pi / 180, maxval = 30*np.pi / 180) return tfa.image.rotate(image,random_angles) (train_x, train_y), (test_x, test_y) = keras.datasets.mnist.load_data() train_x = train_x.reshape(-1,28,28,1) train_ds = tf.data.Dataset.from_tensor_slices(train_x) batched_train_ds = train_ds.batch(512).map(rotate_tf) for imgs in batched_train_ds: imgs結果CPU times: user 1.36 s, sys: 19.1 ms, total: 1.38 s Wall time: 440 msこれには理由があって、Batchを最後に持ってくるとmapではbatch_size=1で処理するので遅いです。
どうせBatch化するなら最初にやっておくとお得ということですね。prefetch機能
詳しくは公式ガイドがもっともわかりやすいのですが、解説すると、
GPUが計算している間にBatchデータをCPU側で用意しておくという機能です。
not prefetch
prefetch
(公式ガイドより引用)
これを使うとI/OやDataAugmentationでボトルネックになっていた学習も早く終わります。
こちら、実験したかったのですが、どうもKeras.fit_generatorとtf.data.datasetがうまくかみ合わず、
うまくいくサンプルも発見できなかったため、後日の内容とさせていただきます。まとめ
- tf.dataset.Datasetを使うとデータパイプラインを構築できる。
.mapはやり方によって速度が大きく変わる。- DataAugmentationのパフォーマンスを大きくあげられる
明日はこれを用いて、自作TrainingLoopを作成していきます!