- 投稿日:2019-11-27T23:23:21+09:00
docker-compose upでPythonのログが出力されない
結論
-uオプションで解決したdocker-compose.ymlcommand: python -u main.py経緯
以下のようなファイルをdocker-compose.ymlの
commandに指定したらログに何も出力されなかった。1import time print('hoge') while True: print('fuga') time.sleep(1)原因調査のために部分的に切り分けていきます。
docker-compose runだと動作するdocker-compose run python bashで入ったbash内で立ち上げたpythonインタプリタ内でも動作する最終的にpythonスクリプトを何行かづつコメントアウトしたりして、ついに
while True:以下が問題らしい事がわかりました。2標準出力とバッファリング
Pythonの
print()などによる標準出力はすぐには出力されずバッファリングされ、タイミングを見て出力されます。つまり、
while True:によって実行がいつまで経っても終了せず、またバッファが一杯になることもないため、出力を受け取るdocker-composeに結果が渡されなかったということでした。
pythonにはバッファリングを無効化するためのオプション-uがあり、これを指定することで解決できました。参考:
Python 3 で標準出力のブロックバッファリングを止める方法 - Qiita
head コマンドの不思議な挙動と標準入出力のバッファリング - CUBE SUGAR CONTAINER
- 投稿日:2019-11-27T23:02:06+09:00
機械学習で画像認識モデルを自作してAndroidアプリを実装する最短経路について
この記事の目的
- 画像認識モデルを簡単に作って,簡単にアプリとして動かす方法を共有する
実行環境
- google colaboratory(ランタイム:GPU)(tensorflow 2.0)(Google Chrome)
- win 10
- Android Studio(3.5.2)
- android 9.0(Huawei mate 10 pro)
この記事で書くこと
画像認識モデルのためのデータセット作成方法
以下のステップを踏む
1. 認識したいクラスを複数作る.(ここではクラスA,Bとする)
2. クラスA,Bの画像を集める
3. クラスA,Bの画像をトレーニング用,テスト用に分けるクラスA,B,Cの画像を集める
すでに画像を集めている場合はスキップ
まだ集めていない場合はgoogle_image_download(参考URL)が便利.
キーワードや拡張子,サイズ,枚数などを指定して画像をダウンロードしてくれる.
※ちゃんと学習させたいなら,ダウンロードしてきた画像を認識したい部分だけ切り出す作業を行う.(かなり時間がかかりますが,必要な場合が多いと思います.いい方法あれば教えてください...)クラスA,B,Cの画像をトレーニング用,テスト用に分ける
トレーニング用,テスト用に画像をいい感じに分ける(トレーニング8割:テスト2割ぐらい?)
具体的には以下のような構成のフォルダを作る
images
├train
│└A
│ └a01.jpg
│ └aslfdjk.png
│ ...
│└B
│ └ba.jpg
│ └dskrup.png
│ ...
│└C
│ └ba.jpg
│ └sdddrrd.png
│ ...
│
├validation
│└A
│ └fwwqd.jpg
│ └qiita.png
│ ...
│└B
│ └sddd.jpg
│ └reag.png
│ ...
│└C
│ └vtet.jpg
│ └fhyr.png
│ ...画像認識モデルの作成方法
モデルは以下のステップで作成する
1. tensorflowのtutorialを使用
2. 1.でモデルをトレーニングするデータを自作のものに置き換える
3. Android Studioでの実装を考慮してモデルの形を微修正し,モデルをトレーニング
4. トレーニングしたモデルの保存方法tensorflowのtransfer learningのtutorialを使用
簡単さを重視するために,tensorflowが提供しているtutorialを使用する(参考URL)※URLを押すといきなりgoogle colaboratoryが開きます
モデルをトレーニングするデータを自作のものに置き換える
tutorialのソースコードのこの部分
PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')を以下のように変える
from google.colab import drive drive.mount('/content/drive') PATH = '/content/drive/'+'google drive上の自分のデータセットのある場所までのパス'これを入力すると,google driveに対してのアクセスを許可するか?という旨の認証を求められる.個人的には気にならないので特に考えず認証したが,気になる人はgoogle colaboraotryで自分のデータセットを読み込ませるのはやめたほうが良い.
Android Studioでの実装を考慮してモデルの形を微修正してモデルをトレーニング
ソースコードのこの部分
model = Sequential([ Conv2D(16, 3, padding='same', activation='relu', input_shape=(IMG_HEIGHT, IMG_WIDTH ,3)), MaxPooling2D(), Conv2D(32, 3, padding='same', activation='relu'), MaxPooling2D(), Conv2D(64, 3, padding='same', activation='relu'), MaxPooling2D(), Flatten(), Dense(512, activation='relu'), Dense(1, activation='sigmoid') ])を以下のように変更
model = Sequential([ Conv2D(16, 3, padding='same', activation='relu', input_shape=(IMG_HEIGHT, IMG_WIDTH ,3)), MaxPooling2D(), Conv2D(32, 3, padding='same', activation='relu'), MaxPooling2D(), Conv2D(64, 3, padding='same', activation='relu'), MaxPooling2D(), Flatten(), Dense(512, activation='relu'), Dense(3, activation='sigmoid') ])このあと以下のコードセルまでを順次実行するとモデルのトレーニングができる
history = model.fit_generator( train_data_gen, steps_per_epoch=total_train // batch_size, epochs=epochs, validation_data=val_data_gen, validation_steps=total_val // batch_size )トレーニングしたモデルの保存方法
これだけ
saved_model_dir = base_dir+'保存したい場所' tf.saved_model.save(model, saved_model_dir)作成した画像認識モデルをAndroid Studioで読み込み動かす方法
以下のステップを踏む
1. 保存したモデルをTensorFlow Liteモデルに変換し,保存する
2. Android studioのプロジェクトを作る
3. Android studioで保存したモデルを読み込み,アプリを動かす保存したモデルをTensorFlow Liteモデルに変換し,保存する
これだけ
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) tflite_model = converter.convert() with open(base_dir+'モデルの名前.tflite', 'wb') as f: f.write(tflite_model)保存したモデルをダウンロードしてローカルに保存しておく.
Android studioのプロジェクトを作る
まずAndroid studioをインストールし(参考URL),
例によってtensorflowが提供するquick startを流用する.参考URL
に従っていくと,ローカル環境にexampleという名前のフォルダが作成されるので,以下のパスにあるandroidプロジェクトを開く
\examples\lite\examples\image_classification\androidAndroid studioで保存したモデルを読み込み,アプリを動かす
以下のステップで行う
1. ローカルに保存した.tfliteファイルをassetフォルダに置く
2. クラスを記載した.txtファイルをassetフォルダに置く
3. .jaファイルを一部書き換えるローカルに保存した.tfliteファイルをassetフォルダに置く
以下のフォルダに置く.
\examples\lite\examples\image_classification\android\app\src\main\assets
同じところに.tfliteがいくつか入っている.クラスを記載した.txtファイルをassetフォルダに置く
今回の場合,クラスA,B,Cを以下のように書き,.tfliteファイルと同じ場所に保存する.
mylabel.textA B C.javaファイルを一部書き換える
まず,
\examples\lite\examples\image_classification\android\app\src\main\java\org\tensorflow\lite\examples\classification\tflite\ClassifierFloatMobileNet.java
の56行目return "mobilenet_v1_1.0_224.tflite";を以下のように書き換える
return "モデルの名前.tflite";次に,
\examples\lite\examples\image_classification\android\app\src\main\java\org\tensorflow\lite\examples\classification\tflite\Classifier.java
の110行目public static Classifier create(Activity activity, Model model, Device device, int numThreads) throws IOException { if (model == Model.QUANTIZED) { return new ClassifierQuantizedMobileNet(activity, device, numThreads); } else { return new ClassifierFloatMobileNet(activity, device, numThreads); } }を以下のように書き換える
public static Classifier create(Activity activity, Model model, Device device, int numThreads) throws IOException { //if (model == Model.QUANTIZED) { //return new ClassifierQuantizedMobileNet(activity, device, numThreads); //} else { return new ClassifierFloatMobileNet(activity, device, numThreads); //} }最後にAndroid Studioでmake projectを行う.
その後スマホをPCにつなぎ,Run'app'を実行.するとスマホにTFL Classifyという名前のアプリがインストールされ,実行される.
画面の下のほうにA,B,Cのconfidence(どのくらいそのクラスらしいかを%で示したもの)が表示される.筆者の失敗談
筆者が躓いた失敗(?)談のうち,参考になるかもしれないものを共有しておく.
失敗(?)1
pytorchモデルをtensorflowLITEモデルに変換することにトライし,結局挫折した.
主にこの2つのHPを参考にしたが,URL1,URL2
どちらもよくわからないエラーが出てやめてしまった.今思うとkerasとtf.kerasがどちらも存在したことが原因だったかもしれない.今度検証してみようかな?今回はとにかく早く自作モデルをandroidアプリで動かしたかったため,結局tensorflow tutorialを利用してモデルを作成し,上記のようにkerasモデルをtensorflowLITEモデルに変換した.
上のURL1にも記載されているように
そんな中、TensorFlowが明らかにPyTorchに対して優位な点として、以下のようなものが挙げられます。
TPUを使って学習できる
TFLite や TensorFlow.js など、フロントエンドでのデプロイを容易にするAPIが充実しているアプリへの転用を容易にするサポートが現在tensorflowのほうが手厚いようです.
失敗(?)2
色んなコードを集めているうちにkerasとtf.kerasが混ざってしまっていた.途中からkeras絶対消すマンとしてtf.kerasに書き換えまくった.
失敗(?)3
モデルの出力がデフォルトのtutorialコードでは1つになっていることに気づかず,android studioで出力が足りないよ!というエラーを吐かせまくった.
エラーの原因がkerasからTFLiteConverterを使って.tfliteファイルを作るところにあると考え,そこで時間を使いまくった...
結局このURLで,自作モデルの評価をやってみるうちに「なんか出力のshapeおかしくね?」となり,モデルの形がおかしいことに気づいた失敗(?)4
モデルを量子化してみたが,android studioで読み込めず断念.結局floatモデルを使用した.
量子化した方がモデルのサイズが小さくなるし処理が早くなりそうだったのでトライしたが,できなかった.
これはまだ原因がわかっていない.失敗(?)5
そもそも当初は物体認識に何を使うか決めておらず,darknetでyoloを使おうと思っていたが,自作モデルを流用する方法がわからず,どうやればいいかわからず断念.知り合いからpytorchが簡単でいいよ!と教えられ,失敗1につながった.こう考えるとすぐ諦めてるな...
失敗(?)6
クラスA,B,Cの画像を集めるで簡単に画像をgoogle_image_downloadを使って集めればいいよ!と書いているが,結構これがしんどい.もちろん不適切な画像もダウンロードしてくるので,そこから捨てたりトリミングしたりがまず大変で,その後クラス分けの作業が待っている.
世の中でアノテーションが仕事になる理由が分かったが,リアルMPが減りそうなのであまりやりたくない...
関連ワードとしてactive learningなるものがあり,認識率が上がる画像を自動で選んでくれるという方法のようだ.できたら便利.かなぁ?失敗(?)7
この記事を書き始めたのち,tensorflowのtutorialの内容が変わっていたことに気づく.
実は筆者はtransfer learningのtutorialを使っていたのだが,自分のコードを公開するのが面倒だったため,仕方なくimage classificationのtutorialを説明に使用.
自分でモデル作るより,少ないデータ数で精度が上がると言われているtransfer learningが便利だと思っています.
現在のtransfer learningのtutorialはデータの読み込みがtfのものから読み込むようになっており,そこを変更して書くのが煩雑なため,説明に使用することを断念.
自分のデータをtransfer learningで使用したい!という要望があれば頑張る気になるかもしれません...
- 投稿日:2019-11-27T22:17:35+09:00
Python 三次元の直交座標と極座標の変換
直交座標(x, y, z) to 極座標(r, θ, φ)
\left\{ \begin{array}{l} r =\sqrt{x^2+y^2+z^2} \\ \theta =\arccos(z/\sqrt{x^2+y^2+z^2}) \\ \phi = \arctan (y, x) \\ \end{array} \right.import math radius = math.sqrt(x ** 2 + y ** 2 + z ** 2) theta = math.acos(z / radius) phi = math.atan2(y, x)極座標(r, θ, φ) to 直交座標(x, y, z)
\left\{ \begin{array}{l} x=r\sin\theta\cos\phi \\ y=r\sin\theta\sin\phi \\ z=r\cos\theta \end{array} \right.import math x = radius * math.sin(theta) * math.cos(phi) y = radius * math.sin(theta) * math.sin(phi) z = radius * math.cos(theta)最近良く使うのでメモった。
- 投稿日:2019-11-27T21:38:32+09:00
プログラミング問題集(問31〜問35)
問31: 1変数の確率的勾配降下法 (stochastic gradient descent, SGD)
以下に示す関数の最小値を、確率的勾配降下法で求めなさい。また、そのアルゴリズムを説明し、パラメータを変化させた時の挙動の変化も説明しなさい。
- $f(x) = x ^ 2 + 2 x + 1$
- $g(x) = x^4 − 4 x^3 − 36 x^2$
問32: 2変数の確率的勾配降下法 (stochastic gradient descent, SGD)
以下に示す関数の最小値を、確率的勾配降下法で求めなさい。また、そのアルゴリズムを説明し、パラメータを変化させた時の挙動の変化も説明しなさい。
- $f(x, y) = (x - 1) ^ 2 + 2 (y + 1)^2$
- $g(x, y) = (x^4 + 2 x^2 + 1) (y^2 + 2y + 1)$
問33:回転
二次元ユークリッド座標上の点 $P = (x, y)$ と角度 $t$ (degree) を入力したとき、原点 $O = (0, 0)$ から反時計回りに $t$ だけ回転させた座標を出力する関数を作りなさい。
例33-1
P = [1, 0] t = 45[0.70710678, 0.70710678]例33-2
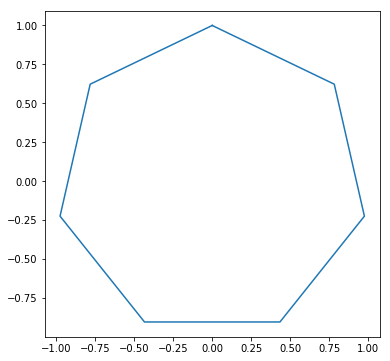
P = [0, 1] t = 30[-0.5 , 0.8660254]問34:正多角形
二次元座標上の点 $P = (x, y)$ と整数 $n$ を入力したとき、点 $P$ をひとつの頂点とし原点 $O = (0, 0)$ を重心とする正 $n$ 角形の頂点を出力する関数を作り、その正 $n$ 角形を描画しなさい。
例34-1
P = [0, 1] n = 5
例34-2
P = [0, 1] n = 7
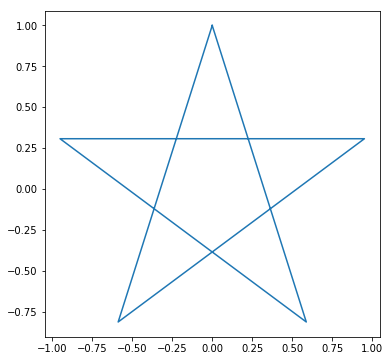
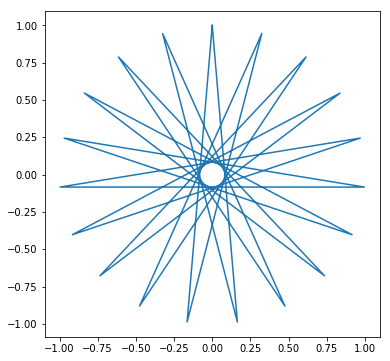
問35:芒星図形
正 $n$ 角形の頂点の集合 $P_i (i = 1 ... n)$ に対して、点 $P_n$ と点 $P_1$, 点 $P_i$ と $P_{i+1}$ を線で結んでいくと正 $n$ 角形が描画できるが、線を結ぶ順序を工夫すると芒星図形が描ける。以下の図形を描画しなさい。
例35-1
例35-2
例35-3


- 投稿日:2019-11-27T20:32:51+09:00
matplotlibグラフ関係忘備録
日本語化
import matplotlib.pyplot as plt import japanize_matplotlib保存(解像度も設定)
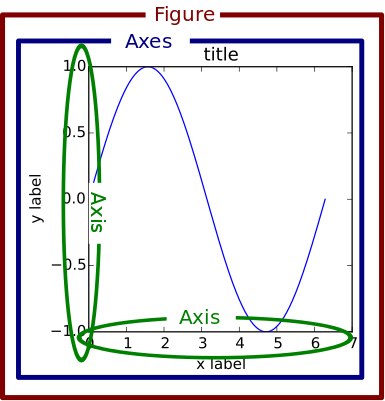
plt.savefig("name.png",format = 'png', dpi=300)figureとaxesを同時作成
下記の例では、axは行×列数個の要素を持つ。
#figureという大きな領域を用意し、rows_graph×columns_graph個のグラフ描画領域を作成するイメージ fig, ax = plt.subplots(rows_graph,columns_graph,figsize=(10,42)) #各ax要素にアクセスし、プロット。 ax[i_row,j_col].plot(x,y) #複数描きたい場合は、for文(ネスト)で複数のグラフ描画 for j,day in enumerate(date_list): for i,item in enumerate(cal_items): ax[i,j].plot(x,y)タイトル、軸、凡例関係
axisではなく、axesのメソッドであることに注意
ax1.set_title('タイトル') ax.set_xlabel('x軸名') ax.set_ylabel('y軸名') ax1.set_xlim(min,max) ax1.set_ylim(min,max) ax.legend(['A','B'])#系列が2つある時https://matplotlib.org/1.5.1/faq/usage_faq.html#parts-of-a-figure
- 投稿日:2019-11-27T20:32:51+09:00
matplotlibグラフ関係忘備録(最小限)
日本語化
import matplotlib.pyplot as plt import japanize_matplotlib保存(解像度も設定)
plt.savefig("name.png",format = 'png', dpi=300)figureとaxesを同時作成
下記の例では、axは行×列数個の要素を持つ。
#figureという大きな領域を用意し、rows_graph×columns_graph個のグラフ描画領域を作成するイメージ fig, ax = plt.subplots(rows_graph,columns_graph,figsize=(10,42)) #各ax要素にアクセスし、プロット。 ax[i,j].plot(x,y) #複数描きたい場合は、for文(ネスト)で複数のグラフ描画 for j,day in enumerate(date_list): for i,item in enumerate(cal_items): ax[i,j].plot(x,y)タイトル、軸、凡例関係
axisではなく、axesのメソッドであることに注意
ax.set_title('タイトル') ax.set_xlabel('x軸名') ax.set_ylabel('y軸名') ax.set_xlim(min,max) ax.set_ylim(min,max) ax.legend(['A','B'])#系列が2つある時https://matplotlib.org/1.5.1/faq/usage_faq.html#parts-of-a-figure
- 投稿日:2019-11-27T20:10:00+09:00
PoertyをWindowsで使ってみる
元記事はこちらです
Pythonのパッケージ管理とか仮想環境を管理するツールのお話です。
Pipenvは普通に使っているのですが、poetryはまだまともに使ったことがないので、ちょっと試してみました。
環境
- OS: Windows 10 Pro
- Python: 3.7.5と2.7.17がインストール済み、Py Launcherは有効
今回の目標
poetryで3.7用と2.7用のプロジェクトフォルダを作り、それぞれのフォルダで
poetry run python --versionを実行して表示されるPythonのバージョンが違ったら成功、といったところです。poetryインストール
poetry公式のインストール方法でおすすめされている
curl -sSL https://raw.githubusercontent.com/sdispater/poetry/master/get-poetry.py | pythonの方法だと、Windowsにおいては下記の問題があります。
- 最後の
pythonがPython2.7でも3.7でもない、謎のpython.exeに当たってしまう。- (問題という程ではありませんが)poetryの0.12系がインストールされる。1.0.0bxxをインストールするには
--previewオプションをつけたいが、この方法ではオプションをつける方法がないっぽい。まず1点目の謎の
python.exe問題についてですが、これはWindows 10に割と最近導入されたらしいアプリ実行エイリアスの影響です。Windowsの設定→アプリと機能→アプリ実行エイリアスを開くとアプリ インストーラー(python.exe)とアプリ インストーラー(python3.exe)があるので、両方オフにします。(パスの優先順を変更するでもいいですけど)
2点目については別のインストール方法に変えるしかありません。ドキュメントで非推奨扱いされていますが、Pipenvと同じようにpipコマンドでユーザグローバルにインストールしちゃいます。おすすめの方法でもいい感じにインストールできるようになることを待ちましょう。なお、この方法だとpoetry、poetry.batの2ファイルがあるフォルダ(今回はPython3.7にインストールしたので
%APPDATA%\Python\Python37\Scripts)に手動でパスを設定する必要があります。
- Powershellなどのシェルで
py -3 -m pip install --user --pre poetryを実行- (今回はユーザ)環境変数PATHに
%APPDATA%\Python\Python37\Scriptsを追加- シェルを再起動
- シェル上で
poetry --versionを実行、今回はPoetry version 1.0.0b8が返ってくるこれでpoetryのインストールは終了です。
poetry設定変更
poetryは仮想環境(virtualenv)も管理してくれるのですが、標準設定だと仮想環境の設置先が
%USERDIR%\Local\pypoetry\Cache\virtualenvsとなっています。Visual Studio Codeなどで使う分にはプロジェクトフォルダの中に仮想環境が作られる方が何かとやりやすかったりするので、poetryの設定を一部変更します。> poetry config --list cache-dir = "C:\\Users\\xxxxxxxx\\AppData\\Local\\pypoetry\\Cache" virtualenvs.create = true virtualenvs.in-project = false (←これをtrueにしたい) virtualenvs.path = "{cache-dir}\\virtualenvs" > poetry config virtualenvs.in-project true > poetry config --list cache-dir = "C:\\Users\\xxxxxxxx\\AppData\\Local\\pypoetry\\Cache" virtualenvs.create = true virtualenvs.in-project = true virtualenvs.path = "{cache-dir}\\virtualenvs"この状態でpoetryに仮想環境を作らせると、
[プロジェクトフォルダ]\.venvに作られます。プロジェクト切り替えテスト
ではpoetryを使ってPython3.7と2.7のプロジェクトを1つずつ作ってみます。今回はpoetryをPython3.7にインストールしているので、特に指定をしないとPython3.7用のプロジェクトが作られます。
> poetry new py3test Created package py3test in py3test > cd py3test > poetry install Creating virtualenv py3test in C:\Work\py3test\.venv Updating dependenciesResolving dependencies... (0.4s) (pytestや依存パッケージがインストールされます) > poetry run python --version Python 3.7.5次にPython2.7用のプロジェクトを作ります。ポイントは下記の2点です。
- 依存するPythonのバージョンを2.7に変更する
- pytestはPython2.7に対応しているのは4.6系まで
> cd .. > poetry new py2test Created package py2test in py2test > cd py2test 【重要】ここでpyproject.tomlを編集します。 python = "^3.7" → python = "^2.7" pytest = "^5.2" → pytest = "^4.6" > poetry env use C:\Python27\python.exe Creating virtualenv py2test in C:\Work\py2test\.venv Using virtualenv: C:\Work\py2test\.venv > poetry install Updating dependencies Resolving dependencies... (1.1s) (pytestや依存パッケージがインストールされます) > poetry run python --version Python 2.7.17確認のため、Python3.7用プロジェクトに移動してみます。
> cd ..\py3test > poetry run python --version Python 3.7.5カレントフォルダによってPythonの仮想環境を使い分けていることがわかります。これで実験は終了です。
まとめ
WindowsでpyenvではなくPy Launcherを使い、poetryで仮想環境を操作することができました。おそらくこのやり方で使えるだろうとは思いますが、今のところWindows上ではPipenvの方がまだ楽な状況かなと思います。

- 投稿日:2019-11-27T20:08:06+09:00
Python loggingでsyslog出力するサンプルプログラム
#!/usr/bin/python # -*- coding: utf-8 -*- import logging import logging.handlers logging.basicConfig(filename='/tmp/logger.log', level=logging.DEBUG) log = logging.getLogger("test_logge_name") syslog_handler = logging.handlers.SysLogHandler(address="/dev/log", facility=logging.handlers.SysLogHandler.LOG_LOCAL1) #syslog_handler.setLevel(logging.WARNING) log.addHandler(syslog_handler) log.debug('Test Debug message') log.info('Test Info message') log.warning('Test Warning message') log.error('Test Error message') log.critical('Test Critical message')
- 投稿日:2019-11-27T18:30:07+09:00
【Django】Modelを作成後makemigrationsを実行してもNo changes detectedになる
現象
新規にmodelを作成後、makemigrationsを実行しても下記のような出力となり、マイグレーションファイルが作成されない現象に遭遇したので、その対応策をメモ。
# modelを新規作成後下記コマンドを実行 $ python manage.py makemigrations No changes detectedフォルダの構造
※詳細は割愛
app ├─migrations ├─models │ ├─__init__.py │ ├─accounts.py │ └─users.py # 今回新しく追加したmodel └─views ├─__init__.py └─account.py原因
どうやらmodelsフォルダに分割してmodelを作成している場合は_init_.pyに新規で作成したmodelをインポートしないと認識してくれないらしい。
もともとの_init_.pyの中身
app/models/__init__.pyfrom accounts.py import AccountsModelここに新しく追加したusers.pyを追加する。
app/models/__init__.pyfrom accounts.py import AccountsModel from users.py import UsersModel # 新規に追加再度実行
$ python manage.py makemigrations Migrations for 'app': app\migrations\0002_users.py - Create model UsersModel無事に作成できました!
- 投稿日:2019-11-27T18:07:48+09:00
「実践! Chainrとロボットで学ぶディープラーニング」をシミュレーション環境で動かしてみた
概要
「実践! Chainerとロボットで学ぶディープラーニング」には、実はシミュレーション環境が用意[1]されており、実機を購入しなくても教材の内容を楽しむことができます! 今回は、そのシミュレーション環境でどんな事ができるか試してみました。
「実践! Chainerとロボットで学ぶディープラーニング」とは
「実践! Chainerとロボットで学ぶディープラーニング」[2]は、Preferred Networks、株式会社アフレル、山梨大学が共同で開発した教材で、教育版レゴマインドストームEV3を使って、Pythonによるプログラミングから、オープンソースの深層学習フレームワークChainerまで学習することができる教材です。
【発表】プログラミング教材 「実践!Chainerとロボットで学ぶディープラーニング」をアフレルさんと共同開発しました。
— Preferred Networks JP (@PreferredNetJP) October 7, 2019
深層学習の正しい知識の学習機会をより広く提供し、実務領域への活用を促進するため無料公開しています。高校・大学の授業や自主学習にご利用ください! https://t.co/5OTEXWNRsuこの教材自体は無料なのですが、動かすための実機を購入するとなると結構なお値段になります(税込 ¥78,980)。気軽に試すにはちょっとお高いお値段で私も購入するのをためらっていました。
しかし!!!実は以下のようなシミュレーション環境も教材には用意されています。
これを使えばサンプルを動かして、購入するか検討できますね。
環境設定
シミュレーション環境はpfnet-research/chainer-ev3/document/simulator_setup.mdに用意されております。リンク先の手順に従って設定してみましょう。
サンプル実行
実行
環境が設定できたら早速サンプルコードを動かしてみましょう。
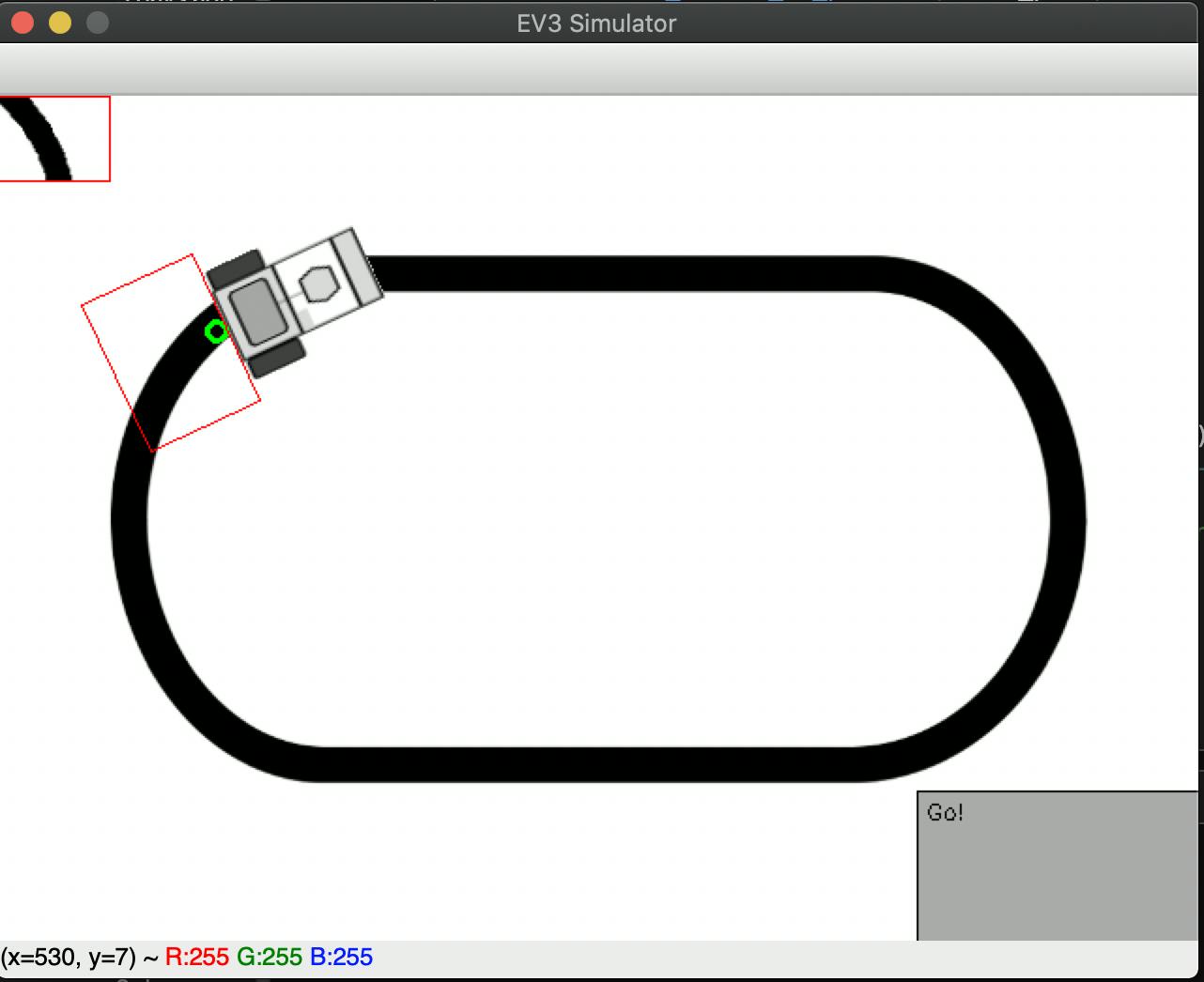
linetrace_controller1.ipynbにルールベースでライントレースするnotebookが用意されています。ドキュメント[1]に書いてあるとおり、以下の手順でサンプルコードを実行してみましょう。
Jupyter Labの左側のリストから
linetrace_controller1.ipynbを開く。Jupyter Lab上で
linetrace_controller1.ipynbを実行。シミュレーターのウインドウ上で、
tキーを押し、シミュレーションを開始。すると以下のようにルールベースのライントレースのシミュレーションが動くはずです。
シミュレーションを停止したいときは再度、
tキーを押しましょう。コードの説明
# タッチセンサーを押して離すとスタート. ev3.lcd_draw_string('Push to start.', 0) while not ev3.touch_sensor_is_pressed(touch_port): pass while ev3.touch_sensor_is_pressed(touch_port): pass ev3.lcd_draw_string('Go!', 0)
- ここを見ると、タッチセンサーが押されるまで後続の処理に進まないことがわかります。
- シミュレーターでは、
tキーがタッチセンサーに相当するので、tキーを押すことで動き出すことがわかります。# 制御ループ while True: # タッチセンサーが押されたら終了. if ev3.touch_sensor_is_pressed(touch_port): break # P制御でステアリング値を計算. white = 70 # 白面上の反射値. black = 5 # 黒面上の反射値. midpoint = (white + black) / 2 # 平均値を計算. color = ev3.color_sensor_get_reflect(color_port) steer = 1.5 * (color - midpoint) # p * (測定値 - 平均値) # EV3へ制御値を送信. ev3.motor_steer(lmotor_port, rmotor_port, 10, int(steer))
- ここは、実際のライントレースの処理部分になります。
- ここで、
ev3.color_sensor_get_reflect(ポート番号)]はカラーセンサーから反射光の値を取得する関数です。
- 引数: 右表のポート番号を指定(今回は変数内に指定)
- 戻り値: 反射光の値(0~100)
- ここの値が大きいほど白いものがカラーセンサーに写っていることがわかります。
- なので、カラーセンサーに写っている色が黒いほど正の方向(左)、白いほど負の方向(右)に舵を切ることがわかります。
Chainerを使った学習と推論
テキスト自体もこちらpfnet-research/chainer-robotcar-textで公開されています。現在の最新版はchainer-robotcar-text-v1.1.0.pdfのようです。ここの手順にしたがって、Chainerをつかったライントレースをしてみます。
上記テキストのp.133から課題の説明がありますが、以下の順序で機械学習ベースのライントレースを行います。
- 訓練データセットの作成
- ルールベースのライントレースプログラムを動かすことで、カメラ画像(特徴量)と制御角度(ラベル)の組を作成する
- モデルの訓練
- 作成したデータセットを使用して、モデルを訓練します。
- モデルによるライントレースの実行
- 訓練したモデルを使用して、カメラ画像から制御角度を予測し、ev3を動かします。
訓練データセットの作成
機械学習を行うには入力に使う特徴量とそれの出力に対応するラベルが必要になります。ルールベースのライントレースプログラムを動かし、その時のカメラ画像(特徴量)と制御角度(ラベル)をロギングすることで訓練に使用するデータセットを作成します。
実行
プログラムは
ml_linetrace_logger.ipynbに用意されています。中身を見てみると、上記で説明したlinetrace_controller1.ipynbとほとんど変わらないことがわかりますね。違いは以下です。
- 白と黒の反射光の値をカラーセンサーから取得して定義していること
- カメラ画像と制御角度を保存していること
大体3000サンプルのデータが必要なので5周くらいさせてみましょう。データセットは
ml_linetrace_data/(日付)-(時刻)ディレクトリ以下に保存されます。モデルの訓練
プログラムは
ml_linetrace_trainer.ipynbに用意されています。実行する前に、input_dirを先程作成したデータセットの場所にしましょう。
だいたい、30epochほど訓練すると十分なようです。作成したモデルはml_linetrace_model/mychain.modelに保存されます。import os import numpy as np from PIL import Image import chainer from chainer.datasets import LabeledImageDataset from chainer.datasets import TransformDataset import chainer.links as L import chainer.functions as F from chainer import serializers from chainer import training from chainer.training import extensions # Network definition class MLP(chainer.Chain): def __init__(self): super(MLP, self).__init__() with self.init_scope(): self.l1 = L.Linear(300, 256) # 300(20*15) -> 256 units self.l2 = L.Linear(256, 256) # 256 units -> 256 units self.l3 = L.Linear(256, 1) # 256 units -> 1 def forward(self, x): h1 = F.relu(self.l1(x)) h2 = F.relu(self.l2(h1)) return self.l3(h2) # Preprocess data def preprocess(in_data): img, label = in_data img = img / 256. # normalization img = img.reshape(300) # 2-dim (20,15) -> 1-dim (300) label = label.reshape(1) # scalar -> 1-dim return img, label input_dir = 'ml_linetrace_data/20191129-173344' out_dir = 'ml_linetrace_model' batchsize = 100 epoch = 30 # Set up a neural network to train model = L.Classifier(MLP(), lossfun=F.mean_squared_error, accfun=F.mean_absolute_error) # Setup an optimizer optimizer = chainer.optimizers.Adam() optimizer.setup(model) # Load the dataset dataset = LabeledImageDataset(os.path.join(input_dir, 'list.txt'), os.path.join(input_dir, 'images'), label_dtype=np.float32) # Divide dataset into training and validation threshold = np.int32(len(dataset) * 0.8) train = TransformDataset(dataset[0:threshold], preprocess) val = TransformDataset(dataset[threshold:], preprocess) # Set iterators train_iter = chainer.iterators.SerialIterator(train, batchsize) val_iter = chainer.iterators.SerialIterator(val, batchsize, repeat=False, shuffle=False) # Setup an Updater updater = training.updaters.StandardUpdater(train_iter, optimizer) # Setup a Trainer trainer = training.Trainer(updater, (epoch, 'epoch'), out='result') trainer.extend(extensions.LogReport()) trainer.extend(extensions.Evaluator(val_iter, model)) trainer.extend(extensions.PrintReport(['epoch', 'main/loss', 'main/accuracy', 'validation/main/loss', 'validation/main/accuracy', 'elapsed_time'])) # Run the Trainer trainer.run() # Save the model, the optimizer and config. if not os.path.exists(out_dir): os.makedirs(out_dir) print('save the model') serializers.save_npz('{}/mlp.model'.format(out_dir), model.predictor) print('save the optimizer') serializers.save_npz('{}/mlp.state'.format(out_dir), optimizer)モデルによるライントレースの実行
プログラムは
ml_linetrace_controller.ipynbに用意されています。ml_linetrace_model/mychain.modelに保存されたモデルを使って実行します。
すると、こんな感じでちゃんと学習できているような様子が見られます。
import time import numpy as np from PIL import Image import chainer from chainer import configuration import chainer.links as L import chainer.functions as F from chainer import serializers from lib.ev3 import EV3 from lib.vstream import VideoStream touch_port = EV3.PORT_2 lmotor_port = EV3.PORT_B rmotor_port = EV3.PORT_C # Network definition class MLP(chainer.Chain): def __init__(self): super(MLP, self).__init__() with self.init_scope(): self.l1 = L.Linear(300, 256) # 300(20*15) -> 256 units self.l2 = L.Linear(256, 256) # 256 units -> 256 units self.l3 = L.Linear(256, 1) # 256 units -> 1 def forward(self, x): h1 = F.relu(self.l1(x)) h2 = F.relu(self.l2(h1)) return self.l3(h2) # Set up a neural network of trained model predictor = MLP() # Load the model serializers.load_npz('ml_linetrace_model/mlp.model', predictor) # Run VideoStream by setting image_size and fps vs = VideoStream(resolution=(20, 15), framerate=10, colormode='binary').start() ev3 = EV3() ev3.enable_watchdog_task() ev3.motor_config(lmotor_port, EV3.LARGE_MOTOR) ev3.motor_config(rmotor_port, EV3.LARGE_MOTOR) ev3.sensor_config(touch_port, EV3.TOUCH_SENSOR) print("Push the touch sensor to start the linetracer") while not ev3.touch_sensor_is_pressed(touch_port): pass # Confirm the touch sensor is released. while ev3.touch_sensor_is_pressed(touch_port): pass # Enable evaluation mode for faster inference. with configuration.using_config('train', False), chainer.using_config('enable_backprop', False): while True: # Break this loop when the touch sensor was pressed. if ev3.touch_sensor_is_pressed(touch_port): break im = vs.read() # Get a current image in PIL format. im = np.asarray(im, dtype=np.float32) # Convert to numpy array. x = im / 255. # Normalization x = x.reshape(1, 300) # (20, 15) -> (1, 300) y = predictor(x) # Predict steer value from x. steer = y.data[0, 0] print("predicted steer = {}".format(steer)) ev3.motor_steer(lmotor_port, rmotor_port, 10, int(steer)) vs.stop() ev3.motor_steer(lmotor_port, rmotor_port, 0, 0) ev3.close()おまけ
シミュレータで作ったモデルを実機で動かしたところ、無事動きました!
Chainerとシミュレーターを使ってモデルを作り、それを実機で動かしたバージョン pic.twitter.com/hoCpQAeYZ4
— くめざわ (Chainer Evangelist) (@kumezawa_) November 30, 2019Reference


- 投稿日:2019-11-27T17:44:51+09:00
【Python】数字が入ったListを文字列結合して出力ファイルへ書き出す
pickleとかありましたが、数字が入っているとバグるようなので原始的にやります。data = [[1,2,3,4,5,6], [1,2,3,4,5,6]] def c(data): outputfile = open("./output.txt", "w") for d in data: if(len(d) == 6): str_list = map(str, d) write_data = ",".join(str_list)+"\n" outputfile.write(write_data) outputfile.close() c(data)結果
output.txt1,2,3,4,5,6 1,2,3,4,5,6Point
- 一度使用したファイルのcloseを忘れずに
- mapで要素全てをStringに変換
- 投稿日:2019-11-27T17:43:35+09:00
python csvデータ 要素の頻度
pythonのpandasを用いてcsvの要素の頻度について求めたいのですが、列と行を指定してその中から要素の頻度を調べることは可能なのでしょうか?
参考としてこちらを読みました。
https://note.nkmk.me/python-pandas-value-counts/ご教授お願いいたします。
- 投稿日:2019-11-27T17:38:19+09:00
言語処理100本ノック-71(StanfordNLP使用):ストップワード
言語処理100本ノック 2015の71本目の記録です。
今回はストップワード除外のためにnltkパッケージとstanfordNLPパッケージを使っています。単純なストップワードの辞書をnltkパッケージから取得し、品詞によって記号なども判定しています。
今までは基本的に「素人の言語処理100本ノック」とほぼ同じ内容にしていたのでブロクに投稿していなかったのですが、「第8章: 機械学習」については、真剣に時間をかけて取り組んでいてある程度変えているので投稿します。まだ、途中までしか出来ていない状態ですがStanfordNLPをメインに使用していく予定です。参考リンク
リンク 備考 071.ストップワード.ipynb 回答プログラムのGitHubリンク 素人の言語処理100本ノック:71 言語処理100本ノックで常にお世話になっています PythonによるStanfordNLP入門 Stanford Core NLPとの違いがわかりやすかったです 環境
種類 バージョン 内容 OS Ubuntu18.04.01 LTS 仮想で動かしています pyenv 1.2.15 複数Python環境を使うことがあるのでpyenv使っています Python 3.6.9 pyenv上でpython3.6.9を使っています
3.7や3.8系を使っていないことに深い理由はありません
パッケージはvenvを使って管理しています上記環境で、以下のPython追加パッケージを使っています。通常のpipでインストールするだけです。
種類 バージョン nltk 3.4.5 stanfordnlp 0.2.0 課題
第8章: 機械学習
本章では,Bo Pang氏とLillian Lee氏が公開しているMovie Review Dataのsentence polarity dataset v1.0を用い,文を肯定的(ポジティブ)もしくは否定的(ネガティブ)に分類するタスク(極性分析)に取り組む.
71. ストップワード
英語のストップワードのリスト(ストップリスト)を適当に作成せよ.さらに,引数に与えられた単語(文字列)がストップリストに含まれている場合は真,それ以外は偽を返す関数を実装せよ.さらに,その関数に対するテストを記述せよ.
「適当に」ですか・・・
回答
回答前提
課題の「適当に」をどうしようかと思案しました。その結果、
nltkパッケージで定義しているストップワードと、形態素解析した結果の品詞情報を使い真偽判定することに決めました。回答プログラム(準備編) 071_1.ストップワード(準備).ipynb
まずは準備があります。これは回答の実行と別でパッケージインストール後に1回だけ実行する必要があります。
ntlkパッケージのストップワード一覧をダウンロードします。これはpip installと別に最初に実行します。import nltk # ストップワードのダウンロード nltk.download('stopwords') # ストップワード確認 print(nltk.corpus.stopwords.words('english'))またstanfordNLPパッケージの英語モデルをダウンロードします。約250MBあるので注意してください。これも
pip installと別に最初に実行します。import stanfordnlp stanfordnlp.download('en') stanfordnlp.Pipeline()回答プログラム(実行編) 071_2.ストップワード(実行).ipynb
from nltk.corpus import stopwords import stanfordnlp # 速くするためにタプルとして定義 STOP_WORDS = set(stopwords.words('english')) # Universal POS tags に準拠していそう # https://universaldependencies.org/u/pos/ EXC_POS = {'PUNCT', # 句読点 'X', # その他 'SYM', # 記号 'PART', # 助詞('sなど) 'NUM'} # 番号 # プロセッサをデフォルトの全指定にすると遅かったので最低限に絞る # https://stanfordnlp.github.io/stanfordnlp/processors.html nlp = stanfordnlp.Pipeline(processors='tokenize,pos,lemma') # ストップワード真偽判定 def is_stopword(word): return True if word.lemma in STOP_WORDS \ or word.upos in EXC_POS \ else False # 試しに3文を判定 with open('./sentiment.txt') as file: for i, line in enumerate(file): # 最初の3文字はネガポジを示すだけなのでnlp処理しない(少しでも速くする) doc = nlp(line[3:]) print(i, line) for sentence in doc.sentences: for word in sentence.words: print(word.text, word.upos, word.lemma, is_stopword(word)) if i == 2: break回答解説
今回は単純なストップワード除外だけでなく、形態素解析して助詞なども除外しています。
まず、ストップワードをタプル形式で取得しています。# 速くするためにタプルとして定義 STOP_WORDS = set(stopwords.words('english'))また、使わない品詞として以下の定義をしています。
ここの種類はUniversal POS tabsとして定義されているものと同様っぽいです。EXC_POS = {'PUNCT', # 句読点 'X', # その他 'SYM', # 記号 'PART', # 助詞('sなど) 'NUM'} # 番号肝心の関数は以下の定義です。
lemmaはLemmatisationにあるようにレンマと言って辞書に定義されている形式に変換します(例:better -> good)。# ストップワード真偽判定 def is_stopword(word): return True if word.lemma in STOP_WORDS \ or word.upos in EXC_POS \ else Falseあとはファイルを読み込んでストップワード判定させています。stanfordnlpの処理は遅いので、少しでも早くするためにネガポジを示す最初の3文字を除外しています。
今回は試しに最初の3文だけを実行しています。with open('./sentiment.txt') as file: for i, line in enumerate(file): # 最初の3文字はネガポジを示すだけなのでnlp処理しない(少しでも速くする) doc = nlp(line[3:]) print(i, line) for sentence in doc.sentences: for word in sentence.words: print(word.text, word.upos, word.lemma, is_stopword(word)) if i == 2: break実行結果はこんな感じです。
0 +1 a chick flick for guys . a DET a True chick NOUN chick False flick NOUN flick False for ADP for True guys NOUN guy False . PUNCT . True 1 +1 an impressive if flawed effort that indicates real talent . an DET a True impressive ADJ impressive False if SCONJ if True flawed VERB flaw False effort NOUN effort False that PRON that True indicates VERB indicate False real ADJ real False talent NOUN talent False . PUNCT . True 2 +1 displaying about equal amounts of naiveté , passion and talent , beneath clouds establishes sen as a filmmaker of considerable potential . displaying VERB displaying False about ADP about True equal ADJ equal False amounts NOUN amount False of ADP of True naiveté NOUN naiveté False , PUNCT , True passion NOUN passion False and CCONJ and True talent NOUN talent False , PUNCT , True beneath ADP beneath False clouds NOUN cloud False establishes VERB establish False sen NOUN sen False as ADP as True a DET a True filmmaker NOUN filmmaker False of ADP of True considerable ADJ considerable False potential NOUN potential False . PUNCT . True
- 投稿日:2019-11-27T17:33:36+09:00
【開発環境】本番DBに近いデータセットの作り方
概要
Webサービスを作っていると、手元の開発環境でも本番環境のデータベースに近いデータが欲しくなりませんか?なりますよね。
本番DBで実行したデータの整合性を保つためのパッチを自分のローカルの環境では当て忘れていた…等で手元のデータが期待していない形になっていることもあるでしょう。
また、シードデータを用意するのも一つの手ですが、シードデータのメンテナンスに意外とコストがかかったり、データの特性が本番データと違うことが影響してリリースしてみたらパフォーマンスに問題が…ということも起きます。ということで、本番DBから部分的にデータを取り出してローカルで使うということをしてみたので、そのスクリプトと共にやったことの要約を書いていきます。
スクリプトはPythonで書いているので、Python読めない方はごめんなさい…超大前提として、本番データを何も加工せずにローカルにもってくると法律的にヤバいサービスはたくさんあると思うので、適切なマスキング処理を必ず入れてください。
マスキングの方法はデータの特性にも依るのでこの記事では詳細に触れません。全体の流れ
- 本番DBのテーブルの部分集合となるテーブルを作成する
- 部分集合のテーブルのdumpを作成する
- ローカルでそのdumpをimportする
注意)
本番DBと書いていますが、当然本番稼働しているDBサーバーには影響のない場所で行ってください。
スナップショットから復元した別のサーバー上で作業することを想定しています。
もし本番環境でやらかしてしまった場合には来年の 本番環境でやらかしちゃった人 Advent Calendar にぜひエントリーしてください!1. 本番DBのテーブルの部分集合となるテーブルを作成する
ここが一番考えることが多い部分です。
分かりやすいように例を出して説明します。本に関する管理サービスを考えた時に books, users, favs の3テーブルがあり、favsからbooksとusersにForeign Keyを張っているとします。
部分集合となるテーブルの作成と言っているのは、本番DBにbooks: 100万, users: 100万, favs: 500万 のレコードあった時にローカルで使いたいデータ books: 1万, users: 1万, favs: 5万 を持つテーブルを作成することを指しています。
部分集合のテーブルを便宜的にそれぞれ books_small, users_small, favs_small と呼ぶことにします。CREATE TABLE books_small SELECT * FROM books LIMIT 10000; CREATE TABLE users_small SELECT * FROM users LIMIT 10000; CREATE TABLE favs_small SELECT * FROM favs LIMIT 50000;とやりたくなりますが、favs_small には books_small と users_small に対する Foreign Key の制約があるためこれだけでは成功しません。(favs_small には users_small に含まれないが users には含まれるユーザが入っている可能性があるため)
さらに今回の例ではテーブルの依存関係が単純なので book, users の後に favs を実行すれば依存先がすでに作られていて問題とならないことが明らかですが、テーブル間の依存関係の解決を100以上のテーブルに対して人間が行うのは現実的ではありません。
つまり課題としては下の2つがあり、これを満たすようにして部分集合のテーブルを作成していきます。
i. 部分集合のテーブル作成時に Foreign Key の依存先から作りたい
ii. 部分集合のテーブルにデータを入れる時に Foreign Key の制約を守りたいi. 部分集合のテーブル作成時に Foreign Key の依存先から作りたい
これを達成するためには依存されている側からテーブルを作っていく必要があります。
どの順にテーブルを作っていけばよいのかを返してくれるget_table_list()の関数を定義してみます。from typing import List import MySQLdb.cursors global db db = MySQLdb.connect() def get_table_list() -> List[str]: """ データの依存関係も意識しながらcreate tableやinsertしていく順番にテーブル名を返す """ global db def _get_list_of_referring_tables(table_name) -> List[str]: """ `show create table` をして Foreign Key を張っているテーブル名の一覧を取得 依存先のテーブルの依存先も見に行くために再帰的に処理する """ tables = [table_name] cur.execute(f'show create table {table_name}') statement = cur.fetchone()['Create Table'] references = re.findall(r'REFERENCES `(\w+)`', statement) if references: for referring_table in references: tables = _get_list_of_referring_tables(referring_table) + tables # 依存しているのが前 return tables # `show tables` して取得したテーブル一覧を table_list に入れる。(依存関係は気にしない) cur = db.cursor() cur.execute("show tables") rows = cur.fetchall() table_list = [] for row in rows: table_list.append(row['Tables_in_[database]']) # 依存されているテーブルが必ず前に来るように、順番に意味をもたせたテーブル一覧 (テーブル名の重複許可) table_list_order_by_referred = [] for table_name in table_list: table_list_order_by_referred += _get_list_of_referring_tables(table_name) # table_list_order_by_referred には重複してテーブル名が入っているので重複を取り除く # 前から順番に重複を消していくことで依存されているものが先に来る unique_table_list_order_by_referred = [] for table_name in table_list_order_by_referred: if table_name not in unique_table_list_order_by_referred: unique_table_list_order_by_referred.append(table_name) return unique_table_list_order_by_referredこれで
get_table_list()で得られるテーブル順にCREATE TABLE books_small SELECT * FROM books LIMIT 10000;的なことをしていけばテーブル間の依存関係は解決です。
ii. 部分集合のテーブルにデータを入れる時に Foreign Key の制約を守りたい
続いて、データを入れる時の依存関係の解決方法です。
先程も書きましたが何も考えずにCREATE TABLE books_small SELECT * FROM books LIMIT 10000; CREATE TABLE users_small SELECT * FROM users LIMIT 10000; CREATE TABLE favs_small SELECT * FROM favs LIMIT 50000;をすると
Cannot add or update a child row: a foreign key constraint failsなエラーで怒られます。
favs_small には books_small と users_small に入っている book と user だけのレコードが入ってほしい訳ですね。選択肢としては以下の2つかと思います。
- create table するときの insert 部分で制限する
CREATE TABLE favs_small SELECT * FROM favs WHERE book_id IN (SELECT id FROM books_small) AND user_id IN (SELECT id FROM users_small) LIMIT 50000;
- Foreign Key のチェックを外して入れてから、不要なデータを削除してチェックを復活させる
SET FOREIGN_KEY_CHECKS = 0 CREATE TABLE favs_small SELECT * FROM favs LIMIT 50000; DELETE FROM favs_small WHERE book_id NOT IN (SELECT id FROM books_small); DELETE FROM favs_small WHERE user_id NOT IN (SELECT id FROM users_small); SET FOREIGN_KEY_CHECKS = 1どちらでも良いのですがSQL文を組み立てるコストが後者の方が低く感じたので今回はそちらのアプローチにしました。
ちなみに
DELETE FROM favs_small WHERE book_id NOT IN (SELECT id FROM books_small);は少なくともMySQLで実行する場合、
DELETE ... NOT IN ...の実行計画の組み立てが下手なのかものすごく時間がかかるのでSELECT id FROM favs_small WHERE book_id NOT IN (SELECT id FROM books_small); DELETE FROM favs_small WHERE id IN ([上で取得したidのリスト]);の2つのクエリに分解して実行すると早くて嬉しいです。
ということでそれをPythonで実現するとこんな感じのコードになります。
# 各テーブルのレコード数上限をこんな感じで定義しておく TABLE_RECORD_LIMIT = { 'users': 10000, 'books': 10000, 'favs': 50000, } def create_small_table(): """ [table_name]_small というテーブルを作って、そこにdumpする対象のデータを入れていく。 """ global db table_list = get_table_list() cur = db.cursor() for table_name in table_list: small_table_name = get_small_table_name(table_name) cur.execute(f'SHOW CREATE TABLE {table_name}') table_meta_data = cur.fetchone()['Create Table'] # `table_name` が依存しているテーブルの名前の一覧を取得 references = re.findall(r'REFERENCES `(\w+)`', table_meta_data) limit_statement = '' if table_name in TABLE_RECORD_LIMIT: limit_statement = f'LIMIT {TABLE_RECORD_LIMIT[table_name]}' cur.execute('SET FOREIGN_KEY_CHECKS = 0') cur.execute(f'CREATE TABLE {small_table_name} SELECT * FROM {table_name} {limit_statement}') for parent_table in references: small_parent_table = get_small_table_name(parent_table) reference_column_name = get_reference_column_name(table_meta_data, parent_table) cur.execute(f""" SELECT id FROM {small_table_name} WHERE {reference_column_name} NOT IN (SELECT id FROM {small_parent_table}) """) delete_id_list = ','.join([str(row['id']) for row in cur.fetchall()]) if delete_id_list: cur.execute(f'DELETE FROM {small_table_name} WHERE id IN ({delete_id_list})') cur.execute('SET FOREIGN_KEY_CHECKS = 1') def get_small_table_name(original_table_name): """ 好きなように実装してもらって良いですが 元のテーブル名よりも長いものを返すとテーブル名の最大長に違反する可能性があるので注意です """ return original_table_name + '_small' # return original_table_name[:-2] + '_s' # 私はこちらで実装しました def get_reference_column_name(table_meta_data, referring_table_name): """ `SHOW CREATE TABLE` で取得したテーブルのメタデータ(table_meta_data)から、 参照先のテーブル(referring_table_name)を指しているカラム名を取得する """ return re.findall(r'\(`(\w+)`\) REFERENCES `' + referring_table_name, table_meta_data)[0]注意点としては、favs の取得件数上限を50000と一番最初に定義していますが、50000個取ってきた後に制約違反のレコードをdeleteしているので実際に残るのは50000件以下になります。
厳密に50000件取りたい場合には、先ほど説明した2つある選択肢のうち1つめの手法をとると実現できます。2.部分集合のテーブルのdumpを作成する
ここまででForeign Keyの整合性が取れた部分集合なテーブルができたので、あとは何も考えずにそのテーブルのダンプを取るだけです。
mysqldumpを使いたい人はshow tablesした結果に対して部分集合なテーブルのpost-fixである_smallとかでgrepして$ mysqldump -u user -p [database] books_small users_small favs_small hoge_small .... > hoge.dumpなコマンドを組み立てればよいです。
dumpするところも自分で書きたい人は頑張りましょう、こんな感じで書けます。
マスキングする処理はココで入れると便利かと思います。from functools import lru_cache def create_small_db_dump(): global db cur = db.cursor() table_list = get_table_list() BATCH_SIZE = 30000 for table_name in table_list: small_table_name = get_small_table_name(table_name) offset = 0 while True: cur.execute(f'SELECT * FROM {small_table_name} LIMIT {BATCH_SIZE} OFFSET {offset}') rows = cur.fetchall() if not rows: break create_insert_statement(table_name, rows) offset += batch_size def create_insert_statement(table_name, rows): """ :param table_name: insert する先のテーブル名 :param rows: テーブルを select * した結果の配列 :return: """ global output_file statement = f'INSERT INTO {table_name} VALUES ' for i, row in enumerate(rows): value_list = row.values() tmp = '(' for value in value_list: tmp += convert_to_str(table_name, i, value) tmp += ',' tmp = tmp[:-1] + '),' statement += tmp statement = statement[:-1] + ';' output_file.write(f'{statement}\n\n') # どのテーブルのN個目のカラムをどうマスキングするか # ちょっと複雑なことしたかったら Lambda 関数とか使うとよさそう MASKING_TARGET = { 'users': {2: '***'}, } def convert_to_str(table_name, i, value): """ インポートできる形にエスケープする マスキング処理もここでやる """ if table_name in MASKING_TARGET: if i in MASKING_TARGET[table_name]: return MASKING_TARGET[table_name][i] elif isinstance(value, str): escaped = value.replace("\\", "\\\\").replace("'", "\\'") return f"'{escaped}'" elif isinstance(value, int): return str(value) elif isinstance(value, float): return str(value) elif isinstance(value, datetime.datetime): return f"'{str(value)}'" elif isinstance(value, datetime.date): return f"'{str(value)}'" elif value is None: return 'null' # 必要に応じてパターン追記してね else: raise Exception(f'Value Error. data: {value}, data class: {value._class_}') # create_small_db_dump() を呼ぶ段階では元のテーブルと _small なテーブルが混在していますが、 # 欲しいのは元のテーブルの情報だけなので、 # _small なテーブルを作る前に get_table_list() が呼ばれる前提で cache をもっておくと良いです # (それが暗黙的過ぎて怖い場合には get_table_list() の中に _small なテーブルを弾く処理を書いてください) @lru_cache(maxsize=1) def get_table_list() -> List[str]: # 上で書いた処理あとは既存のDBをdropする処理とか、create table する処理が必要になるのでササッと書きましょう。
ここまでついて来れていればすぐに書けるはず。def build_drop_and_create_database_statement(database_name): global output_file output_file.write(f'DROP DATABASE IF EXISTS {database_name};\n') output_file.write(f'CREATE DATABASE IF NOT EXISTS {database_name};\n') output_file.write(f'USE {database_name};\n\n') def build_create_table_statement(): global db table_list = get_table_list() cur = db.cursor() for table_name in table_list: cur.execute(f'show create table {table_name}') statement = cur.fetchone()['Create Table'] output_file.write(f'{statement};\n\n')3. ローカルでそのdumpをimportする
ココまでくればdumpファイルをローカルにもってきてimportするだけです。
$ mysql -u user -p database < hoge.dumpお疲れさまでした。
感想
最初は部分集合なテーブルを作る方針ではなくて、元のテーブルから直接INSERT文生成しながらデータの整合性を取っていく方針だったのですが、dump(長時間) -> insert(長時間) の途中で「Foreign Keyの整合性とれませーん!」とか「このデータエスケープされてませーん!」ってエラーがでて考慮漏れ発覚。みたいな感じでPDCAのサイクルが長すぎて効率悪すぎたので、先に整合性の取れたデータ量の小さい部分集合のテーブルを作ってそれを愚直にdumpする作戦に切り替えました。
本番データを扱うので気をつけないといけないことは多いですが、開発環境でより現実に近いデータで動作確認できることで開発効率が上がると良いなーと思っています。
- 投稿日:2019-11-27T17:15:05+09:00
python sqlalchemyでoracleに接続しようとするとUnicodeDecodeErrorが出る
Python3.7 sqlalchemyでoracleに接続しようとしたら下記エラーが出てしまった。
cx_Oracle単体ではoracleに接続できているようなので何が原因がよくわからなかった。なかなか情報にたどり着けず、
encodingとかcharsetとかずいぶん遠回りしたので記載しておきます。参考)
http://blog.kzfmix.com/entry/1361525164UnicodeDecodeError: 'utf-8' codec can't decode byte 0x98 in position 11: invalid start byte下記をpyのソースに埋め込んでエラーが解決した。
import os os.environ["NLS_LANG"] = "JAPANESE_JAPAN.AL32UTF8"
- 投稿日:2019-11-27T17:10:41+09:00
Pythonで数字to漢数字の変換
きっかけ
テストケースで1郎2郎3郎...みたいなのを作ってたんですが、
名前にアラビア数字というのもいかがなものかと思いまして、変換してやるようにしました。int2kanint
python3.7.5で動いてますint2kanint# -*- coding: utf-8 -*- import csv def int2kanint(num) : suji = ["","一","二","三","四","五","六","七","八","九"] kugiri = ["","十","百","千"] tani = ["","万","億","兆","京","垓","?","穣","溝","澗","正","載","極","恒河沙","阿僧祇","那由他","不可思議","無量大数"] num = list(map(int,list(str(num)))) kansuji = [] for k, v in zip(range(len(num)), reversed(num)) : keta = [] keta.append(suji[v if v>2 else 0 if k%4 else v]) keta.append(kugiri[k%4 if v>0 else 0]) keta.append((tani[0 if k%4 else int(k/4) if any(list(reversed(num))[k:(k+4 if len(num)>=(k+4) else len(num))]) else 0])) kansuji.append("".join(keta)) kansuji = "".join(reversed(kansuji)) return kansuji if kansuji else "零"以下に説明を連ねていきます。
変数
説明が怪しい日本語になってますが、何となく察していただけると幸いです。
変数名 意味 型 suji 一から九までの漢数字です string[] kugiri 十,百,千といった区切りです string[] tani 四桁区切りの単位です string[] num 変換前のアラビア数字です int → int[] keta 四桁区切り毎の漢数字です string[] kansuji 変換後の漢数字です string[] → string 変換方法
suji,kugiri,taniでそれぞれ分けて、最後に結合する形をとっています。
私が習った漢数字のルールを基に、それぞれ変換を行っていきます。
地域差、業界差あるとは思いますがそこは一旦置いておきましょう。suji
それぞれの桁の値を表す一から九の漢数字には以下のルールがあります。
- 値が0でない限り、
零は省略する
- 例:4203 → 四千二百三
〇とする場合がありますが今回は含めません十,百,千の前にくる一は省略する
- 例:11111 → 一万千百十一
よって
値が2以下かつ一の位ではないのであれば省略、それ以外は出力
と考えれば良いでしょう。
そのため、sujiを出す為の処理は以下のようになります。sujisuji[0 if v<2 and k%4 else v]
sujiはインデックスと漢数字が連動してるリストです。
上記の条件を満たしていれば空文字を、それ以外の場合は漢数字を返す形になります。
(関数でもないのに返すというのも変ですが)kugiri
漢数字では四桁毎に数を区切りますが、その中で十,百,千とさらに桁を区切ります。
その際には以下のようなルールがあります。
- 桁に該当する値がなければ、省略する
- 例:2035070 → 二百三万五千七十
これだけですね。
kugirikugiri[k%4 if v>0 else 0]内容もシンプルです。
tani
漢数字では四桁毎に数を区切りる際には以下のルールがあります。
- 四桁の中身がなければ、単位を表す漢数字は省略する
- 例:123400005678 → 千二百三十四億五千六百七十八
ここだけ見ればシンプルなんですが、私のアルゴリズムではかなりややこしくなってしまいました。
というのも、与えられた値を漢数字に変換する際に、以下のようなfor文で各桁を参照しています。for文for k, v in zip(range(len(num)), reversed(num)) :
kにはインデックス、vには各桁の値が入るわけですが、reversed(num)としてるように一桁目から見てるわけです。
処理としては 四桁毎に単位を出力する と考えるのですが、四桁の中身がない場合、単位を省略しなければなりません。
そうすると必然的に四桁先を見ればいいだけなんですが、値が四桁もない場合を考慮しなければならないわけです。解決策としては以下のとおりです。
tanitani[0 if k%4 or not any(list(reversed(num))[k:(k+4 if len(num)>=(k+4) else len(num))]) else int(k/4)]値が
十,百,千の桁であるまたは四桁の中身が1つもないのであれば省略、それ以外は出力という形に落ち着きました。
anyで四桁分の値を参照しに行くのですが、四桁先がリストの末尾を超えた場合、末尾まで参照する、といった感じです。終わりに
競技プログラミングとも言えなくもない、アルゴリズムを考える課題は大好きなので、ついつい熱中して作ってしまいました。
数字to漢数字はいくらでもやりようがあると思うのですが、リストを使ったやり方は今回初めて思いついたので、とても楽しかったです。
高速化・簡易化できる書き方がありましたら、ぜひともご教授ください!
- 投稿日:2019-11-27T17:09:34+09:00
PySpark で when をチェーンしたときの処理順序
PySpark で
whenをチェーンするコードを書いていたときに「これって SQL と同じように先に書いた
whenが優先される?」
「メソッドチェーンだから後ろに書いたwhenで上書きされる?」と不安になったので、実際に検証コードを書いて調べた。
ダミーデータ
df = spark.createDataFrame([(1,),(2,),(3,)], schema=('val',)) display(df)
val 1 2 3 Spark SQL の場合
# Spark SQL から触れるように一時テーブルとして登録 df.registerTempTable('tmp')SELECT val, CASE WHEN val <= 1 THEN 'label_1' WHEN val <= 2 THEN 'label_2' ELSE 'label_3' END AS label FROM tmp
val label 1 label_1 2 label_2 3 label_3 SQL の場合は当然、先に書いた
WHENの条件が優先される。PySpark の場合
from pyspark.sql import functions as F df_label = df.withColumn('label', F.when(F.col('val') <= 1, 'label_1') .when(F.col('val') <= 2, 'label_2') .otherwise('label_3') ) display(df_label)
val label 1 label_1 2 label_2 3 label_3 PySpark で
whenをチェーンした場合でも、Spark SQL と同様に先に書いたwhenの条件が優先されるらしい。
- 投稿日:2019-11-27T16:24:42+09:00
1/30 days hackerrank で学んだこと。
この記事は、
pythonを用いてHackerRank1/30に取り組んだ時に、
調べた内容をまとめたものです。データ型~数値の扱い~
int:整数を扱う
double:有効桁数15桁
float:有効桁数6,7桁
string:文字列型の扱い
round:四捨五入データ型の変換をキャストという。
printで数値を出力するときにstrをよく忘れるので注意です。listで文字列を1文字ずつ認識できる
例)
str="Hacker" char_list=list(str) print(char_list)で、
["H", "a", "c", "k", "e", "r"]と出力されます。リストを文字列に変換する
つまり今度は、
["H", "a", "c", "k", "e", "r"]
と表示されるものを、
Hackerに
直したいということです。①forをつかう
str_list = ['python', 'list', 'exchange'] mojiretu = ' ' for x in str_list: mojiretu += x print(mojiretu)実行結果:pythonlistexchange
②joinを使う
join関数の使い方
文字列 = ‘区切り文字’.join(リスト)str_list = ['python', 'list', 'exchange'] mojiretu = ','.join(str_list) print(mojiretu)実行結果:python,list,exchange
スライス
列の要素を部分的に取り出すのに有用な方法です。
基本の例)
@ycctw1443さんのものを引用しています。
```
a = [1, 2, 3, 4, 5]
print(a[0: 4])
print(a[: 4])
print(a[-3:])
print(a[2: -1])すると、 [1, 2, 3, 4] [1, 2, 3, 4] [3, 4, 5] [3, 4] と出力されます。 これを発展させ、 「n番目ごとに要素を得る」こともできます。 `a[始まりの位置: 終わりの位置: スライスの増分]`です。a = [1, 2, 3, 4, 5]
print(a[:: 2])
print(a[1:: 2])
print(a[::-1])
print(a[1::-1])
```
結果)
[1, 3, 5]
[2, 4]
[5, 4, 3, 2, 1]
[2, 1]複数の文字列を入力する
input().split()printと%
%を使えば、変数が組み込まれた文字列を
簡潔に出力することができます。print("好きな果物は、%sです。" %'リンゴ') print("好きな果物は、%sと%sです。" %('リンゴ','ミカン')) x = 'サッカー' y = 'スノーボード' print("好きなスポーツは、%sと%sです。"%(x,y))%sはstr()をあらわし、
値を文字列として整数も少数も表示できますが、
%dとすると整数になります。%rはrepr()で、
渡された値をそのまま表示します。Star演算子
配列を展開することができます。
参考
https://programming-study.com/technology/python-list-join/
https://code-graffiti.com/print-format-with-string-in-python/
- 投稿日:2019-11-27T16:20:56+09:00
ゆっくりprint
はい。TSUMUGIです。
今回はちょっとゆっくりprintさせたいなぁって思ったんでやります。とりあえずググってやろうかなって思ってこれ見てpython2系だったからprintをちょっと直して実行したらゆっくりプリントされたんですよ。(ここで終わりじゃないよ)
import time def print_slow(str): for letter in str: print(letter) time.sleep(0.3) print_slow("junk") #j #u #n #kはい。改行されちゃうんですよ!
まぁend指定すればいいんですけどね(まだ終わりじゃない)import time def print_slow(str): for letter in str: print(letter,end='') time.sleep(0.3) print_slow("junk") #junkこれみただけじゃわかんないんですけど実行すればわかります。1.2秒待ってから一気にプリントしやがるんですよこいつ。ひどい。泣いちゃう。
んでこれ見てやったらできた。
↓↓↓結論のコード↓↓↓import time def print_slow(str): for letter in str: print(letter,end='',flush=True) time.sleep(0.3) print_slow("junk") #junk完璧。ゆっくりぷりんと。スリープの秒数帰ればもっと早くしたり遅くしたりできる。すごい。
ってことで見てくださりありがと?!
コメントや編集リクエストばんばん下さると幸いです!
- 投稿日:2019-11-27T16:00:00+09:00
01. 「パタトクカシーー」
01. 「パタトクカシーー」
「パタトクカシーー」という文字列の1,3,5,7文字目を取り出して連結した文字列を得よ.
Go
package main import "fmt" func main() { var src string = "パタトクカシーー"; var des string = ""; // rune 型へ変換 msrc := []rune(src); // 1.ループで処理 for i := 0; i <= 7; i++ { // 問題では 1,3,5,7 指定だが奇数判定で対応 if (i % 2) != 0 { des += string(msrc[i]); } } fmt.Println(des); }python
# -*- coding: utf-8 -*- src = u"パタトクカシーー" des = "" # 1.ループで処理(range) reverse = "" for i in range(len(src)): # 問題では 1, 3, 5, 7 指定だが奇数判定で対応 if i % 2 != 0 : des += src[i] print(des) # -*- coding: utf-8 -*- src = u"パタトクカシーー" des = "" # 1.ループで処理(range) reverse = "" for i in range(len(src)): # 1, 3, 5, 7 指定だが奇数判定で対応 if i % 2 != 0 : des += src[i] print(des) # 2.スライスで処理(ステップを指定) print(src[1::2])Javascript
var src = "パタトクカシーー"; var dsc = "" // 1.ループで処理 for (var i = 0; i < src.length; i++) { // 問題では 1, 3, 5, 7 指定だが奇数判定で対応 if (i % 2 != 0) { dsc += src[i]; } } console.log(dsc);まとめ
単純なループ処理しか思いつかない。
他のロジックって有るのかな?。100本ノックの記事探してみる。
1,3,5,7 を渡すと、切り出してくれる標準関数とか有るのかな?。
- 投稿日:2019-11-27T15:47:54+09:00
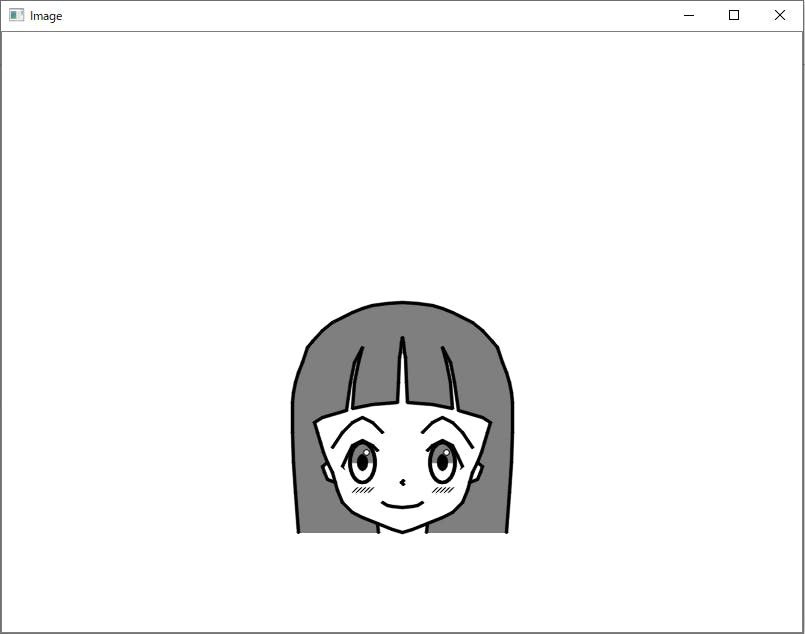
Python+OpenCVでイラストを描く
Python+OpenCVでイラストを書いてみました。
絵心がなく絵が描けない→プログラムは書ける→プログラムで絵を描けばいいじゃない という無謀な発想です。
線の位置を全部ベタで座標指定していて難しいことは全くしていません。
girl1.pyimport numpy as np import cv2 # 白で塗りつぶす img = np.full((600, 800, 3), 255, dtype=np.uint8) # 補助線 #cv2.rectangle(img, (300, 300), (500, 500), (127, 127, 127), 1, cv2.LINE_AA) #cv2.line( img, (300, 400), (500, 400), (127, 127, 127), 1, cv2.LINE_AA) #cv2.line( img, (400, 300), (400, 500), (127, 127, 127), 1, cv2.LINE_AA) #cv2.line( img, (300, 450), (500, 450), (127, 127, 127), 1, cv2.LINE_AA) #cv2.line( img, (300, 435), (500, 435), (127, 127, 127), 1, cv2.LINE_AA) #cv2.circle( img, (400, 400), 100, (127, 127, 127), 1, cv2.LINE_AA) #cv2.ellipse( img, ((400, 400), (170, 200), 0), (127, 127, 127), 1, cv2.LINE_AA) # 髪塗りつぶし 全部繋げるとうまく塗りつぶせないので4つに分けている pts1_1 = np.array([ # 髪(右外側) (400, 270), (415, 271), (430, 273), (440, 276), (450, 280), (460, 285), (470, 290), (480, 298), (490, 309), (495, 315), (500, 330), (504, 340), (507, 350), (509, 360), (510, 370), (510, 400), (509, 430), (507, 460), (504, 500), # 首(右) (424, 500), (425, 491), # 輪郭右(耳除く) (430, 489), (440, 485), (450, 480), (460, 470), (465, 458), (467, 450), (475, 447), (478, 440), (480, 434), (475, 430), (479, 420), (482, 410), (485, 400), (488, 390), # 髪(右内側)途中まで (488, 390), (480, 385), (456, 378), (452, 350), (448, 330), ], dtype=np.int32) cv2.fillConvexPoly(img, pts1_1, (127, 127, 127)) # 髪塗りつぶし pts1_2 = np.array([ # 頭頂 (400, 270), # 髪(右内側)途中から (440, 315), (444, 330), (448, 350), (450, 376), (430, 372), (405, 370), (404, 350), (403, 325), (402, 320), (401, 310), (400, 305), ], dtype=np.int32) cv2.fillConvexPoly(img, pts1_2, (127, 127, 127)) # 髪塗りつぶし pts1_3 = np.array([ # 頭頂 (400, 270), # 髪(左内側)途中まで # (400, 305), (399, 310), (398, 320), (397, 325), (396, 350), (395, 370), (370, 372), (350, 376), (352, 350), (356, 330), (360, 315), ], dtype=np.int32) cv2.fillConvexPoly(img, pts1_3, (127, 127, 127)) # 髪塗りつぶし pts1_4 = np.array([ # 髪(左内側)途中から (352, 330), (348, 350), (344, 378), (320, 385), (312, 390), # 輪郭左(耳除く) (312, 390), (315, 400), (318, 410), (321, 420), (325, 430), (320, 434), (322, 440), (325, 447), (333, 450), (335, 458), (340, 470), (350, 480), (360, 485), (370, 489), # 首(左) (375, 491), (376, 500), # 髪(左外側) (296, 500), (293, 460), (291, 430), (290, 400), (290, 370), (291, 360), (293, 350), (296, 340), (300, 330), (305, 315), (310, 309), (320, 298), (330, 290), (340, 285), (350, 280), (360, 276), (370, 273), (385, 271), (400, 270), ], dtype=np.int32) cv2.fillConvexPoly(img, pts1_4, (127, 127, 127)) # 輪郭 pts2 = np.array([ # (400, 300), # (410, 301), # (420, 303), # (430, 306), # (440, 310), # (450, 315), # (460, 320), # (470, 328), # (480, 339), # (485, 345), # (491, 360), # (491, 370), # (490, 380), (488, 390), (485, 400), (482, 410), (479, 420), (475, 430), (470, 440), (465, 458), (460, 470), (450, 480), (440, 485), (430, 489), (420, 493), (410, 497), (400, 500), (390, 497), (380, 493), (370, 489), (360, 485), (350, 480), (340, 470), (335, 458), (330, 440), (325, 430), (321, 420), (318, 410), (315, 400), (312, 390), # (310, 380), # (309, 370), # (309, 360), # (315, 345), # (320, 339), # (330, 328), # (340, 320), # (350, 315), # (360, 310), # (370, 306), # (380, 303), # (390, 301), # (400, 300), ], dtype=np.int32) cv2.polylines(img, [pts2], False, ( 0, 0, 0), 2, cv2.LINE_AA) # 右目 cv2.ellipse( img, (440, 430), ( 12, 20), 180, 0, 180, (127, 127, 127), -1, cv2.LINE_AA) cv2.ellipse( img, ((440, 430), ( 25, 40), 0), ( 0, 0, 0), 2, cv2.LINE_AA) cv2.ellipse( img, ((440, 430), ( 10, 16), 0), ( 0, 0, 0), -1, cv2.LINE_AA) cv2.ellipse( img, ((444, 420), ( 6, 6), 0), (255, 255, 255), -1, cv2.LINE_AA) cv2.ellipse( img, ((444, 420), ( 6, 6), 0), ( 0, 0, 0), 1, cv2.LINE_AA) # 左目 cv2.ellipse( img, (360, 430), ( 12, 20), 180, 0, 180, (127, 127, 127), -1, cv2.LINE_AA) cv2.ellipse( img, ((360, 430), ( 25, 40), 0), ( 0, 0, 0), 2, cv2.LINE_AA) cv2.ellipse( img, ((360, 430), ( 10, 16), 0), ( 0, 0, 0), -1, cv2.LINE_AA) cv2.ellipse( img, ((364, 420), ( 6, 6), 0), (255, 255, 255), -1, cv2.LINE_AA) cv2.ellipse( img, ((364, 420), ( 6, 6), 0), ( 0, 0, 0), 1, cv2.LINE_AA) # 右眉毛 pts3 = np.array([ (420, 400), (430, 390), (440, 385), (450, 390), (460, 400), (470, 415), ], dtype=np.int32) cv2.polylines(img, [pts3], False, ( 0, 0, 0), 2, cv2.LINE_AA) #左眉毛 pts4 = np.array([ (380, 400), (370, 390), (360, 385), (350, 390), (340, 400), (330, 415), ], dtype=np.int32) cv2.polylines(img, [pts4], False, ( 0, 0, 0), 2, cv2.LINE_AA) # 右まつ毛 pts5 = np.array([ (425, 418), (430, 413), (440, 408), (450, 413), (455, 423), (460, 434), ], dtype=np.int32) cv2.polylines(img, [pts5], False, ( 0, 0, 0), 2, cv2.LINE_AA) pts5_5 = np.array([ (460, 434), (458, 437), ], dtype=np.int32) cv2.polylines(img, [pts5_5], False, ( 0, 0, 0), 1, cv2.LINE_AA) # 左まつ毛 pts6 = np.array([ (375, 418), (370, 413), (360, 408), (350, 413), (345, 423), (340, 434), ], dtype=np.int32) cv2.polylines(img, [pts6], False, ( 0, 0, 0), 2, cv2.LINE_AA) pts6_5 = np.array([ (340, 434), (342, 437), ], dtype=np.int32) cv2.polylines(img, [pts6_5], False, ( 0, 0, 0), 1, cv2.LINE_AA) # 鼻 pts7 = np.array([ (401, 448), (399, 450), (401, 452), ], dtype=np.int32) cv2.polylines(img, [pts7], False, ( 0, 0, 0), 2, cv2.LINE_AA) # 口 pts8 = np.array([ (380, 470), (385, 473), (390, 474), (400, 475), (410, 474), (415, 473), (420, 470), ], dtype=np.int32) cv2.polylines(img, [pts8], False, ( 0, 0, 0), 2, cv2.LINE_AA) # 首(右) pts9 = np.array([ (425, 491), (424, 500), ], dtype=np.int32) cv2.polylines(img, [pts9], False, ( 0, 0, 0), 2, cv2.LINE_AA) # 首(左) pts10 = np.array([ (375, 491), (376, 500), ], dtype=np.int32) cv2.polylines(img, [pts10], False, ( 0, 0, 0), 2, cv2.LINE_AA) # 右耳 pts11 = np.array([ (475, 430), (480, 434), (478, 440), (475, 447), (467, 450), ], dtype=np.int32) cv2.polylines(img, [pts11], False, ( 0, 0, 0), 2, cv2.LINE_AA) # 左耳 pts11 = np.array([ (325, 430), (320, 434), (322, 440), (325, 447), (333, 450), ], dtype=np.int32) cv2.polylines(img, [pts11], False, ( 0, 0, 0), 2, cv2.LINE_AA) # 髪(右外側) pts12 = np.array([ (400, 270), (415, 271), (430, 273), (440, 276), (450, 280), (460, 285), (470, 290), (480, 298), (490, 309), (495, 315), (500, 330), (504, 340), (507, 350), (509, 360), (510, 370), (510, 400), (509, 430), (507, 460), (504, 500), ], dtype=np.int32) cv2.polylines(img, [pts12], False, ( 0, 0, 0), 2, cv2.LINE_AA) # 髪(左外側) pts13 = np.array([ (400, 270), (385, 271), (370, 273), (360, 276), (350, 280), (340, 285), (330, 290), (320, 298), (310, 309), (305, 315), (300, 330), (296, 340), (293, 350), (291, 360), (290, 370), (290, 400), (291, 430), (293, 460), (296, 500), ], dtype=np.int32) cv2.polylines(img, [pts13], False, ( 0, 0, 0), 2, cv2.LINE_AA) # 髪(右内側) pts16 = np.array([ (400, 305), (401, 310), (402, 320), (403, 325), (404, 350), (405, 370), (430, 372), (450, 376), (448, 350), (444, 330), (440, 315), (448, 330), (452, 350), (456, 378), (480, 385), (488, 390), ], dtype=np.int32) cv2.polylines(img, [pts16], False, ( 0, 0, 0), 2, cv2.LINE_AA) # 髪(左内側) pts17 = np.array([ (400, 305), (399, 310), (398, 320), (397, 325), (396, 350), (395, 370), (370, 372), (350, 376), (352, 350), (356, 330), (360, 315), (352, 330), (348, 350), (344, 378), (320, 385), (312, 390), ], dtype=np.int32) cv2.polylines(img, [pts17], False, ( 0, 0, 0), 2, cv2.LINE_AA) # 右頬 cv2.line(img, (430, 460), (435, 455), ( 0, 0, 0), 1, cv2.LINE_AA) cv2.line(img, (434, 460), (439, 455), ( 0, 0, 0), 1, cv2.LINE_AA) cv2.line(img, (438, 460), (443, 455), ( 0, 0, 0), 1, cv2.LINE_AA) cv2.line(img, (442, 460), (447, 455), ( 0, 0, 0), 1, cv2.LINE_AA) cv2.line(img, (446, 460), (451, 455), ( 0, 0, 0), 1, cv2.LINE_AA) # 左頬 cv2.line(img, (350, 460), (355, 455), ( 0, 0, 0), 1, cv2.LINE_AA) cv2.line(img, (354, 460), (359, 455), ( 0, 0, 0), 1, cv2.LINE_AA) cv2.line(img, (358, 460), (363, 455), ( 0, 0, 0), 1, cv2.LINE_AA) cv2.line(img, (362, 460), (367, 455), ( 0, 0, 0), 1, cv2.LINE_AA) cv2.line(img, (366, 460), (371, 455), ( 0, 0, 0), 1, cv2.LINE_AA) cv2.imshow('Image', img) cv2.waitKey(0) cv2.destroyAllWindows()■参考
Python, OpenCVで図形描画(線、長方形、円、矢印、文字など) | note.nkmk.me
Amazon.co.jp: 萌えキャラクターの描き方 顔・からだ編 (マンガの技法書) eBook: 伊原達矢, 角丸つぶら: Kindleストア
- 投稿日:2019-11-27T15:31:41+09:00
[Python]ポケモンで学ぶオブジェクト指向プログラミング
最近ポケモンソードシールドが発売され、大人気でございます。
というわけで、このポケモン人気に便乗してポケモンを使ってオブジェクト指向プログラミングを説明します。
オブジェクト指向プログラミングとは?
オブジェクトを直訳すると「もの」。すなわち、物を作るようにプログラミングをしようというわけです。
ものには、特徴だったりパーツだったり動作があるはずです。ものの種類を「クラス」、ものそれぞれを「インスタンス」、ものの動作を「メソッド」と呼びます。
例えば、ポケモンのリザードンを考えてみましょう。リザードンには名前・レベル・HP・攻撃などのステータスがあります。
リザードンという種族(クラス)には、「りざすけ」「りざまる」などいろんな名前のリザードン(インスタンス)がいます。
また、リザードンが覚える技の1つとして火炎放射があります。これがメソッドとなります。
これらをコード化すると以下のようになります。
#リザードンクラス class Charizard(object): #インスタンスを作ったときに動く部分(いわゆる初期設定) def __init__(self,name,level,hp,attack,defence,sp_attack,sp_defence,speed): self.name = name #値の定義以外もできる print('いけ!{}!'.format(self.name)) self.level = level self.type1 = 'ほのお' self.type2 = 'ひこう' self.hp = hp self.attack = attack self.defence = defence self.sp_attack = sp_attack self.sp_defence = sp_defence self.speed = speed #火炎放射(メソッド) def flame_radiation(self,enemy): #相性補正 compatibility_coefficient = 1 for Type in [enemy.type1,enemy.type2]: if Type == 'くさ'or'むし'or'こおり'or'はがね': compatibility_coefficient *= 2 #ダメージ計算(メソッド使用時はこの式がわからなくても良い(カプセル化)) damage = ((self.level*2/5+2)*(90*self.sp_attack/enemy.sp_defence)/50+2)*compatibility_coefficient print('{}の火炎放射!'.format(self.name)) print('{}は{}に{}のダメージを与えた!'.format(self.name,enemy.name,np.round(damage))) if compatibility_coefficient >= 2: print('こうかはばつぐんだ!!') #これはインスタンス rizasuke = Charizard('りざすけ',100,297,183,192,317,206,328) #これもインスタンス rizamaru = Charizard('りざまる',50,200,100,100,150,100,150)一度クラスを読み込めば、数行のコードで簡単に実行することができます。
ちなみにメソッドに関しては、面白いことに別のクラスを対象にしても実行できます。
試しにフシギバナクラスを作り、フシギバナクラスに対して火炎放射メソッドを実行してみましょう。
class Fushigibana(object): def __init__(self,name,level,hp,attack,defence,sp_attack,sp_defence,speed): self.name = name print('いけ!{}!'.format(self.name)) self.level = level self.type1 = 'くさ' self.type2 = 'どく' self.hp = hp self.attack = attack self.defence = defence self.sp_attack = sp_attack self.sp_defence = sp_defence self.speed = speed rizasuke = Charizard('りざすけ',100,297,183,192,317,206,328) fussi = Fushigibana('ふっしー',100,364,180,202,328,236,196) rizasuke.flame_radiation(fussi) ##実行結果 #いけ!りざすけ! #いけ!ふっしー! #りざすけの火炎放射! #りざすけはふっしーに414.0のダメージを与えた! #こうかはばつぐんだ!!オブジェクト指向プログラミングの大きな特徴として、以下の3つがあります。
・カプセル化
・継承
・ポリモーフィズムカプセル化(情報隠蔽)
先程の火炎放射メソッドの中に、ダメージ計算式がありました。見た目からして複雑そうな式です。
しかし、実際にメソッドを実行するときは、
rizasuke.flame_radiation(fussi)と書くだけで容易に実行できます。ダメージ計算式を知る必要はありません。一般的な例でいうと、print()関数も同じです。簡単に出力できる関数ではありますが、その処理内容がどうなっているか知っている人はごく小数でしょう。
このように、クラス内部の情報や処理が隠せることを、カプセル化と呼びます。カプセル化によって内部情報を書き換えられないようにできたり、クラスやメソッドの理解が簡単になります。
また、ステータスなどの情報を1つのクラス内にまとめて書くので、管理が楽になります。
継承
先程のコードのように特徴や動作がまとめられるだけでもオブジェクト指向プログラミングは非常に便利なものですが、ポケモンは今や890種類(wikipediaより)と言われています。ポケモンそれぞれのメソッドを1から書くのは面倒です。
そこで便利なのが「継承」(オーバーライド)です。やり方は、小クラスの引数に親クラスを入れた上で、
super().継承したいメソッドを入れるだけです。ここでは、HPや攻撃などのステータス・火炎放射などの技を共有するためにポケモンクラスを設定しています。
以下のコードのように新たなポケモンクラス(親クラス)を実装し、リザードンやカイリューなどの子クラスへ継承することで、ステータスや技のコードを二重に書く必要がなくなります。これなら、890種のポケモンも難なく実装できそうです。
#親クラス class Pokemon(object): def __init__(self,name,level,hp,attack,defence,sp_attack,sp_defence,speed): self.name = name print('いけ!{}!'.format(self.name)) self.level = level self.type1 = None self.type2 = None self.hp = hp self.attack = attack self.defence = defence self.sp_attack = sp_attack self.sp_defence = sp_defence self.speed = speed #火炎放射 def flame_radiation(self,enemy): #相性補正 compatibility_coefficient = 1 for Type in [enemy.type1,enemy.type2]: if Type == 'くさ'or'むし'or'こおり'or'はがね': compatibility_coefficient *= 2 damage = ((self.level*2/5+2)*(90*self.sp_attack/enemy.sp_defence)/50+2)*compatibility_coefficient print('{}の火炎放射!'.format(self.name)) print('{}は{}に{}のダメージを与えた!'.format(self.name,enemy.name,np.round(damage))) if compatibility_coefficient >= 2: print('こうかはばつぐんだ!!') #リザードン(子クラス) class Charizard(Pokemon): def __init__(self,name,level,hp,attack,defence,sp_attack,sp_defence,speed): super().__init__(name,level,hp,attack,defence,sp_attack,sp_defence,speed) self.type1 = 'ほのお' self.type2 = 'ひこう' def flame_radiation(self,enemy): super().flame_radiation(enemy) #カイリュー(子クラス) class Cairyu(Pokemon): def __init__(self,name,level,hp,attack,defence,sp_attack,sp_defence,speed): super().__init__(name,level,hp,attack,defence,sp_attack,sp_defence,speed) self.type1 = 'ドラゴン' self.type2 = 'ひこう' def flame_radiation(self,enemy): super().flame_radiation(enemy) #カイリューの火炎放射にだけつく特性(ポリモーフィズム説明のための仮特性) print('相手はやけどになった!') rizasuke = Charizard('りざすけ',100,297,183,192,317,206,328) ryu_kun = Cairyu('りゅーくん',100,323,403,226,212,299,196) rizasuke.flame_radiation(ryu_kun) ryu_kun.flame_radiation(rizasuke) ##実行結果 #いけ!りざすけ! #いけ!りゅーくん! #りざすけの火炎放射! #りざすけはりゅーくんに329.0のダメージを与えた! #りゅーくんの火炎放射! #りゅーくんはりざすけに319.0のダメージを与えた! #相手はやけどになった!ポリモーフィズム
ポリモーフィズムとは、直訳すると多態性・多相性・多様性と呼ばれるものです。多様性が最も馴染み深いかと思います。
継承と併用することで、同じ命令を出しても違う結果(多様な結果)を出せることが大きな特徴です。
継承の例で出したコードをもう一度見てください。カイリューの火炎放射メソッドの中に、
super().flame_radiation(enemy)に加えてprint('相手はやけどになった!')が入っています。リザードンの火炎放射メソッドの中には入っていません。このようにすると、リザードンの火炎放射はやけどせず、カイリューの火炎放射は必ずやけどする仕様にできます(実際のポケモンはこんな仕様ではありません)。
まとめ
「ポケモンで学ぶオブジェクト指向プログラミング」自体は二番煎じのネタですが、カプセル化や継承などオブジェクト指向プログラミングの3大要素について説明したものはありません。そこらへんがうまく伝わればと思います。
ただ、習うより慣れろで、実際に書いて見たほうが理解は絶対深まりますし、オブジェクト指向プログラミングのメリットも少しずつ体感で分かってきます。
初心者の方は、オブジェクト指向プログラミングなんて難しそうと敬遠せず、ぜひ一度自分でいろいろと書いてみてください。
参考文献
オブジェクト指向がわからない! そんなあなたの脳味噌をオブジェクト脳にする準備体操
【Python】オブジェクト指向プログラミングの概念と書き方
- 投稿日:2019-11-27T15:21:29+09:00
Time Series Decomposition
月次リターンのカレンダー効果を検証
statsmodelsのdecomposeを用いて、ハロウィーン効果、Sell in Mayなど巷で言われるカレンダー効果が見られるか実験
import numpy as np import pandas as pd import statsmodels.api as sm import pandas_datareader.data as web import warnings warnings.filterwarnings('ignore') import matplotlib.pyplot as plt plt.style.use('seaborn-darkgrid') plt.rcParams['axes.xmargin'] = 0.01 plt.rcParams['axes.ymargin'] = 0.01 window = 250*3 '''S&P500データ取得 ''' data1 = web.DataReader("^GSPC", "yahoo", "1980/1/1").dropna() # Treasury Yield 10 Yearsデータ取得 data2 = web.DataReader("^TNX", "yahoo", "1980/1/1").dropna() # 日々年率Volatility = 10%にレバレッジ調整した設定 ret = pd.DataFrame(data1['Adj Close'] / data1['Adj Close'].shift(1) - 1) ret = 0.1 * ret / (ret.rolling(252).std()*np.sqrt(252)).shift(1) data1 = 100*((1 + ret).cumprod()).dropna(axis=0) data1_freq = data1.resample('M').last().fillna(method='ffill') data1_freq['ret1'] = data1_freq['Adj Close']/data1_freq['Adj Close'].shift(1) - 1 # 月次ターンを再作成 data1_freq_equity_curve = 100*((1 + data1_freq['ret1']).cumprod()).dropna(axis=0) data1_freq_equity_curve.index = pd.to_datetime(data1_freq_equity_curve.index) # 通期、10年(120ヵ月)、5年(60ヵ月) res_all = sm.tsa.seasonal_decompose(data1_freq_equity_curve, freq=12) res_10Y = sm.tsa.seasonal_decompose(data1_freq_equity_curve[-120:], freq=12) res_5Y = sm.tsa.seasonal_decompose(data1_freq_equity_curve[-60:], freq=12) seasonality = pd.concat([res_all.seasonal, res_10Y.seasonal, res_5Y.seasonal], axis=1) seasonality.columns = ['1981-', '10Y', '5Y'] m_seasonality = seasonality.groupby(seasonality.index.month).mean() # Creat Figure month = m_seasonality.index height = m_seasonality * 100 bar_width = 0.3 plt.figure(figsize=(10, 4), dpi=80) plt.bar(month, height['1981-'], tick_label=month, width=0.3, label='1981-') plt.bar(month + bar_width, height['10Y'], tick_label=month, width=0.3, label='10Y') plt.bar(month + 2*bar_width, height['5Y'], tick_label=month, width=0.3, label='5Y') plt.xticks(month + bar_width, month) plt.legend() plt.title("Average Return by Month") plt.xlabel("Month") plt.ylabel("Ave.Ret(%)") plt.show()seasonalにリターンを見ると
- Sell in Mayは近年言えてそう
- 年末売り/年初買い?
Decomposition(Trend, Seasonality, Residual)
res_10Y.plot() plt.show()
- 短期的な平均回帰や、マーケット動向を把握するのに使用
- 過去のマーケット環境(Volatility水準の差etc.)の調整が工夫入りそう


- 投稿日:2019-11-27T14:35:09+09:00
言語処理100本ノック-70(StanfordNLP使用):データの入手・整形
言語処理100本ノック 2015の70本目の記録です。
基本的に「素人の言語処理100本ノック」とほぼ同じ内容にしていたので、ブロクに投稿していなかったのですが、「第8章: 機械学習」については、真剣に時間をかけて取り組んでいてある程度変えているので投稿します。まだ、途中までしか出来ていない状態ですがStanfordNLPをメインに使用していく予定です。参考リンク
リンク 備考 070.データの入手・整形.ipynb 回答プログラムのGitHubリンク 素人の言語処理100本ノック:70 言語処理100本ノックで常にお世話になっています PythonによるStanfordNLP入門 Stanford Core NLPとの違いがわかりやすかったです 環境
種類 バージョン 内容 OS Ubuntu18.04.01 LTS 仮想で動かしています pyenv 1.2.15 複数Python環境を使うことがあるのでpyenv使っています Python 3.6.9 pyenv上でpython3.6.9を使っています
3.7や3.8系を使っていないことに深い理由はありません
パッケージはvenvを使って管理しています問題
第8章: 機械学習
本章では,Bo Pang氏とLillian Lee氏が公開しているMovie Review Dataのsentence polarity dataset v1.0を用い,文を肯定的(ポジティブ)もしくは否定的(ネガティブ)に分類するタスク(極性分析)に取り組む.
70. データの入手・整形
文に関する極性分析の正解データを用い,以下の要領で正解データ(sentiment.txt)を作成せよ.
- rt-polarity.posの各行の先頭に"+1 "という文字列を追加する(極性ラベル"+1"とスペースに続けて肯定的な文の内容が続く)
- rt-polarity.negの各行の先頭に"-1 "という文字列を追加する(極性ラベル"-1"とスペースに続けて否定的な文の内容が続く)
- 上述1と2の内容を結合(concatenate)し,行をランダムに並び替える
sentiment.txtを作成したら,正例(肯定的な文)の数と負例(否定的な文)の数を確認せよ.
読み込むファイルの注意点
- 文字コードがUTF-8ではなくWINDOWS-1252らしい(しっかりと確認していませんが「素人の言語処理100本ノック:70」と同じふぁいる読み込みをしています)
- 英語だけでなくウムラウトを含むテキストがある(「Ü」みたいな文字)
- 基本的に全文字が小文字化されています
回答
回答前提
Jupyter Notebookのディレクトリの下にこんなフォルダ構成にしています。元データを解凍して置いています。
└── rt-polaritydata ├── rt-polarity.neg └── rt-polarity.pos回答プログラム 070.データの入手・整形.ipynb
import codecs import random FNAME_SMT = 'sentiment.txt' pos_prefix = '+1' neg_prefix = '-1' result = [] def read_file(fname, prefix): # codecsを使わずにopen関数で読み込めるか未確認() with codecs.open(fname, encoding='cp1252') as file: # Encodingは Windows-1252 return ['{0} {1}'.format(prefix, line.strip()) for line in file] # ポジティブ読込 result.extend(read_file('./rt-polaritydata/rt-polarity.pos', pos_prefix)) # ネガティブ読込 result.extend(read_file('./rt-polaritydata/rt-polarity.neg', neg_prefix)) random.shuffle(result) with open(FNAME_SMT, 'w') as file_out: file_out.write('\n'.join(result)) # 数の確認 cnt_pos = 0 cnt_neg = 0 with open(FNAME_SMT) as file: for line in file: if line.startswith(pos_prefix): cnt_pos += 1 elif line.startswith(neg_prefix): cnt_neg += 1 print('pos:{}, neg:{}'.format(cnt_pos, cnt_neg))回答解説
基本的にファイル読込と書込なのであまり特筆することをしていないです。
ファイルオープンのためにcodecsライブラリを使っていますが、これは素人の言語処理100本ノック:70の該当箇所をコピペしただけなので、通常のopen関数でも可能かは検証していません。
ただ、後続のプログラムでまたcodecsライブラリを使いたくなかったので保存はUTF-8にしています。それでもウムラウトを含んだ文字も正しく保存できています。実行すると最後の
pos:5331, neg:5331
- 投稿日:2019-11-27T13:52:22+09:00
AtCoderのコンテスト情報を毎週通知するSlackBotを作ってみた
AtCoderのコンテスト情報を通知するためのSlackbotを作成しました。
(1)BotのAPIトークンの取得とslackbotのインストール
Slackbotを作成する前にAPIトークンの取得およびslackbotのインストールが必要です。
この二つについてはPythonでSlackBot開発①「APIキーの取得と簡単な返答」に書かれていることをそのまま実行しました。
書かれている通りに実行を行い、Botとの会話で適当な文字列を送ると以下のようにDEFALUT_REPLYで設定した文言が返ってきます。
(2)Webスクレイピング
Slackbotが動くことを確認したのでスクレイピングをしてAtCoderのコンテスト情報を集めていきます。以下がそのコードになります。
scrape.pyfrom urllib import request from bs4 import BeautifulSoup import re import datetime #時刻とURLの組を返す def scrape_active(): ''' 今開催しているコンテストの情報を返す関数 ''' re_contests=[] #そのURLの情報を受け取る url="https://atcoder.jp" html=request.urlopen(url) #パーサでページの情報を解析する soup=BeautifulSoup(html, "html.parser") #contest-table-activeのidをもつdivタグの中に今開催しているコンテストの情報が入っている contests1=soup.find("div",id="contest-table-active") #コンテストがなかった場合(soupにNoneが入ってしまうので) if contests1 is None: return re_contests contests2=contests1.find("tbody") contests3=contests2.find_all("tr") #re_contestsにコンテストのurlと終了の日時を格納する for c in contests3: re_contests_sub=[] #コンテストページのurlをurl2に格納 d=c.find("a",href=re.compile("contests")) url2=url+d.get("href") html2=request.urlopen(url2) soup2=BeautifulSoup(html2, "html.parser") #classはPythonでは予約語なのでclass_ sftime=soup2.find_all("time",class_="fixtime-full") #終了の時間のみをre_contests_subに格納 re_contests_sub.append(sftime[1]+" 終了") #コンテストページのurlもre_contests_subに格納 re_contests_sub.append(url2) re_contests.append(re_contests_sub) return re_contests def scrape_upcoming(): ''' 一週間以内に開催されるコンテストの情報を返す関数 ''' re_contests=[] url="https://atcoder.jp" html = request.urlopen(url) soup = BeautifulSoup(html, "html.parser") #contest-table-upcomingのidをもつdivタグの中に一週間以内に開催されるコンテストの情報が入っている contests1=soup.find("div",id="contest-table-upcoming") #コンテストがなかった場合(soupにNoneが入ってしまうので) if contests1 is None: return re_contests contests2=contests1.find("tbody") contests3=contests2.find_all("tr") #今日の日時を取得(月曜日) w=datetime.datetime.today() #コンテストのurlと開始の日時をre_contestsに格納 for c in contests3: re_contests_sub=[] d1=c.find("time") #分まで入ってるところだけをスライスして渡す #strtotime関数によりstringからdatetimeオブジェクトに帰る t=strtotime(d1.text[:16]) #その週の日曜までにないコンテストは格納しなくて良い if (t-w).days>=7: break #formatを統一するためにtimetostr関数を使う コンテストの開始の日時を格納する re_contests_sub.append(timetostr(t)+" 開始") d2=c.find("a",href=re.compile("contests")) #コンテストページのurlもre_contests_subに格納 re_contests_sub.append(url+d2.get("href")) re_contests.append(re_contests_sub) return re_contests def strtotime(date_sub): ''' datetimeオブジェクトにして返す ''' return datetime.datetime.strptime(date_sub,'%Y-%m-%d %H:%M') def timetostr(date_sub): ''' datetimeオブジェクトをstrオブジェクトにして返す ''' W=["月","火","水","木","金","土","日"] return ('%d-%d-%d(%s) %d:%s'%( date_sub.year,date_sub.month,date_sub.day,W[date_sub.weekday()],date_sub.hour,str(date_sub.minute).ljust(2,"0") ))コメントアウトで何をやっているのかは書いていますが、関数の使い方などでわからないことがあれば、参考にしたページを見るようにしてください。
参考にしたページ
Beautiful Soup での スクレイピング基礎まとめ [初学者向け]
BeautifulSoup+Requestsの基本
Python日付型
datetime(3)Slackへの投稿
集めたコンテスト情報をSlackへ投稿していきます。
run.pyfrom slackbot.bot import Bot from slacker import Slacker import slackbot_settings import scrape import datetime def make_message(channel,slack,s,message): ''' slack.chat.post_messagを用いてメッセージを送る。 ''' for i in s: message=message+"\n"+i[0]+"\n"+i[1]+"\n" #pos_messageでslackに投稿ができる #channelには投稿したいチャンネル #messageには投稿したいメッセージ #as_userはTrueにしておくことでurlが展開されて投稿される slack.chat.post_message(channel, message, as_user=True) def info(channel,slack): #先にスクレイピングをしてコンテスト情報を格納しておく s1=scrape.scrape_active() s2=scrape.scrape_upcoming() #コンテスト情報がない(長さが0)の場合はコンテストが存在しないというメッセージを送る if len(s1)!=0: make_message(channel,slack,s1,"*[開催中のコンテスト一覧]*") else: slack.chat.post_message(channel,"*開催中のコンテストはありません*",as_user=True) if len(s2)!=0: make_message(channel,slack,s2,"*[今週のコンテスト一覧]*") else: slack.chat.post_message(channel,"*今週のコンテストはありません*",as_user=True) def main(): #Botを動かす前にそのチャンネルにBotアプリケーションを追加することを忘れずに channel="競プロ" #API tokenはslackbot_settings.pyに保存しておく slack = Slacker(slackbot_settings.API_TOKEN) #月曜であることの確認 if datetime.datetime.today().weekday()==0: info(channel,slack) bot = Bot() bot.run() if __name__ == "__main__": main()(2)と同様、コメントアウトを参照してください。(詳しく説明すると長くなって読みにくいので)
参考にしたページ
chat.postMessage
SlackのIncoming Webhooksで投稿したURLが展開されなくて困った話
Slack APIでbotを作る2: メッセージ投稿編(4)Herokuへのデプロイ
(3)まででローカルでは
python run.pyを打つことで動かすことができるはずです。次はHerokuへデプロイします。(Herokuは無料で使えるサーバーみたいなもの)
Heroku自体はGitのリモートリポジトリと考えれば扱いは難しくないので、Gitを勉強しておけば使い方はわかるはずです。(ProgateのGitの章がまとまってておすすめです。)
また、Gitを使ってHerokuにファイルをPushしていくのですが、参考の記事に書かれている通り、Procfile、requirements.txt、runtime.txt、の三つのファイルを作成してからPushしましょう。(作成しないと色々エラー吐かれまくって虚無になります。)参考にしたページ
SlackbotをPythonで作成する
pythonで作ったSlackBotを常駐化するまでの備忘録(5)環境変数の設定
(1)で参考にしている記事の通りにやっていればslackbot_settignsというファイルができていてAPI_TOKENとDEFAULT_REPLYの二つの変数が定義されているはずです。
しかし、このままだと、ソースコードが流出した時にトークンの値が得られてしまい、Botが乗っ取られてしまうので、ソースコード内にはトークンの値を書かずに環境変数とする必要があります。
ローカルではexport 環境変数名=値というコマンドを打てば良いですが、herokuの環境変数を設定をする場合は、heroku config:set 環境変数名=値とすることで環境変数を設定できます。また、Herokuの該当のアプリケーションのSettingsのConfig Varsにおいて環境変数の設定をすることができます。
これにより環境変数は設定でき、以下のようにslackbot_settignsを書き換えれば環境変数の設定は完了です。slackbot_settings.pyimport os #環境変数の取得 API_TOKEN=os.environ["API_TOKEN"] DEFAULT_REPLY=os.environ["DEFAULT_REPLY"]os.environの使い方についてはPythonで環境変数を取得・追加・上書き・削除(os.environ)を参考にしてください。
参考にしたページ
【Python】PythonプログラムをHerokuにデプロイする方法
→Herokuの使い方も載ってます。(6)スケジューラの登録
最後にスケジューラを登録したら自動化が全て完了です。
まず、スケジューラをアドオンとして追加するのですが、クレジットカードの登録が必要です。アカウントのページから登録を済ますようにしましょう。
登録したら$ heroku addons:create scheduler:standardでスケジューラをアドオンに追加でき、heroku addons:open schedulerでスケジューラへの登録のページを開くことができます。
開いたページにある"Add job"を押すと、動かす時間の間隔と実行して欲しいコマンドを登録することで定期的に実行することができます。(ちなみに、スケジューラに登録せずに動かすと、約六時間おきに実行されます。)
また、自分の場合は週に一回実行させたかったので、毎日実行させてプログラムの方で週一日のみ目的の処理をするように変えました。(また、時間がUTC表記なので日本時間に直すにはUTC時間に九時間足す必要があることにも注意してください。)参考にしたページ
- 投稿日:2019-11-27T13:47:04+09:00
それぞれが任意の分布に従う,相関を持つ2確率変数の(近似的)作り方メモ
要点
- 標準正規分布に従う確率変数X,χ2分布に従う確率変数Yを,任意の相関係数ρで作成する方法を探していました.
- X, Yともに標準正規分布に従うならば,以下の方法で作成することができます.
- numpy.random.multivariate_normal関数を使用する.
- 多次元標準正規分布ならば,分散共分散行列が相関行列と等しくなるので, covmtx=[[1,ρ],[ρ,1]]
- 標準正規分布でなくても,平均がゼロで分散が等しい分布ならば,horiemさん解説のこの方法で生成できます.
- X~標準正規分布とY~χ2分布はこの方法の条件を満たさないので、別の方法で生成する必要があります.
- 一時しのぎの荒業として,多次元標準正規分布で相関を持たせて2確率変数を生成し,その片方を別の確率分布に従うように変換する方法をメモしておきます.
- Y -> 標準正規分布の累積分布cdf(Y) -> 任意の分布のパーセント点関数ppf(cdf(Y)) -> Z
- なんのこっちゃ、というときはこちらを参照のこと.
- 変換後の相関係数の値を厳密に指定できないという欠点があるので、要注意.
コード
sample.py# import numpy as np # import scipy.stats as spstats # generate X,Y ~ multinormal(mu = [0,0], cov = [[1,ρ],[ρ,1]]) rho_norm = 0.8 # correlation coeff for multinorm mu = [0, 0] # mean of X, Y cov = [ [1, rho_norm], [rho_norm, 1] ] # cov matrix vals_norm = np.random.multivariate_normal(mu, cov, 100000) x_norm = vals_norm[:,0] y_norm = vals_norm[:,1] # np.corrcoef(x_norm, y_norm) gives a rho value around rho_norm # convert Y to Z ~ chi2(k) k = 3 # parameter of chi2 dist z_chi2 = spstats.chi2.ppf(spstats.norm.cdf(y_norm, loc = 0, scale = 1), df = k) # x_norm ~ norm(mu = 0, var = 1) and z_chi2 ~ chi2(k = 3) # np.corrcoef(x_norm, z_chi2) gives a rho value a bit smaller than rho_norm結果
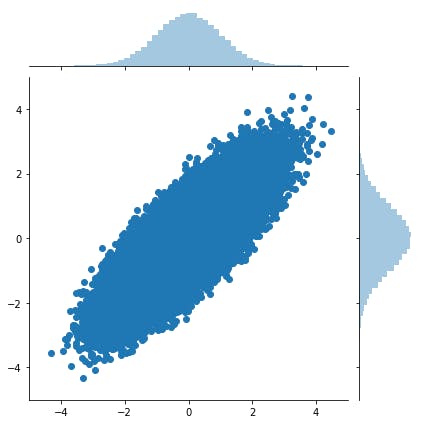
相関係数0.8で生成したX, Yの散布図と周辺分布はこんな感じになります.
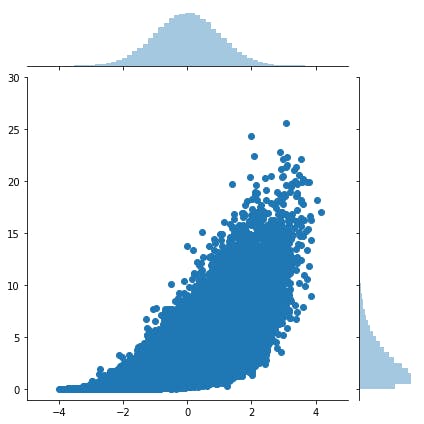
で,上記の変換を噛ませたZについて,Xとの散布図と周辺分布はこんな感じになります.
Z(縦軸)について,周辺分布がk=3のχ2分布に変換されていることがわかります.
このときの相関係数(相関行列が求まるので,[0,1]成分)は
正の相関は保たれていますが,多次元標準正規分布でX-Y間に指定した相関係数(0.8)より小さくなっちゃってますね.今回はYをχ2分布へ変換しましたが,任意の分布へ変換することが可能です.また,Xも同様に変換可能です.
注意点
この方法では変換後の相関係数を厳密に指定することができません.
もっと正攻法は方法があるように思いますが,ちょっと見つけることができなかったので,ここにメモしておきます.
誰かもっとやりやすい方法教えてください.11/26追記:matlabの本家解説にこんなのありました.ほぼ同じアプローチですが,より詳細に記述されています.FMI(For My Info)

- 投稿日:2019-11-27T13:47:00+09:00
PyInstallerがPython3.8でエラーになる場合の対応(TypeError: an integer is required (got type bytes))
事象
記事投稿時点(2019/11/27)だとPyInstallerをPython3.8で実行すると、以下のエラーが発生する
TypeError: an integer is required (got type bytes)
エラーの理由
現在(2019/11/27)の安定板であるPyInstaller3.5が、Python3.8に対応していないため。
対応策
Development版をダウンロードする。
pipでインストールするなら以下の通り。pip install https://github.com/pyinstaller/pyinstaller/archive/develop.tar.gz
- 投稿日:2019-11-27T13:47:00+09:00
PyInstaller3.5がPython3.8でエラーになる場合の対応(TypeError: an integer is required (got type bytes))
事象
記事投稿時点(2019/11/27)だとPyInstallerをPython3.8で実行すると、以下のエラーが発生する
TypeError: an integer is required (got type bytes)
エラーの理由
現在(2019/11/27)の安定板であるPyInstaller3.5が、Python3.8に対応していないため。
対応策
Development版をダウンロードする。
pipでインストールするなら以下の通り。pip install https://github.com/pyinstaller/pyinstaller/archive/develop.tar.gz
- 投稿日:2019-11-27T13:45:29+09:00
django-import-exportで管理画面にCSVエクスポート機能を追加する
Djangoのadminサイト、調べてみるといろいろプラグインがあるらしい。
管理画面のデータをCSVなどの形式でインポート/エクスポートしたくなったので、
調べてみたらdjango-import-exportで簡単にできた。その時の備忘録。インストール
まずはpipでインストール
$ pip install django-import-export設定
import_exportをINSTALLED_APPSに追加# settings.py INSTALLED_APPS = ( ... 'import_export', )admin.pyに追加
対象のデータに対する設定を追加していく。
サンプルのモデルはこんな感じ。
# models.py class Book(models.Model): name = models.CharField('Book name', max_length=100) author = models.CharField('Book name', max_length=100)django-import-exportの設定。
対象とするモデルに対して
ModelResourceを継承したクラスを追加する。
設定関連はココに書いていくらしい。# admin.py from django.contrib import admin from import_export import resources from import_export.admin import ImportExportModelAdmin from .models import Book class BookResource(resources.ModelResource): # Modelに対するdjango-import-exportの設定 class Meta: model = Book @admin.register(Book) class BookAdmin(ImportExportModelAdmin): # ImportExportModelAdminを利用するようにする ordering = ['id'] list_display = ('id', 'title', 'author') # django-import-exportsの設定 resource_class = BookResource最後に、ImportExportModelAdminを継承したAdminクラスを用意して、
resource_classにModelResourceを継承したクラスを設定すればOK!すると、こんな感じにボタンが表示される。簡単(´ω`)
小ネタ
Exportだけにする: Importを無効化
インポートは別にいらないなと思ったので、無効化してみた。
ExportMixinだけにするといいらしい。# ... 略 from import_export.admin import ExportMixin @admin.register(Book) class BookAdmin(ExportMixin, admin.ModelAdmin): # ExportMixinをadmin.ModelAdminに追加すればOK ordering = ['id'] list_display = ('id', 'title', 'author') # django-import-exportsの設定 resource_class = BookResourceExportできるフォーマットを指定する
デフォルトだとJSONとかYMLとかいろいろ選べるけどCSVだけでいいので、
選択できる部分を絞ってみた。formatsを指定すればOK# ... 略 from import_export.formats import base_formats @admin.register(Book) class BookAdmin(ImportExportModelAdmin): ordering = ['id'] list_display = ('id', 'title', 'author') # django-import-exportsの設定 resource_class = BookResource formats = [base_formats.CSV] # formatsで指定できる以上!!
こんなのつくってます!!
積読用の読書管理アプリ 『積読ハウマッチ』をリリースしました!
積読ハウマッチは、Nuxt.js+Firebaseで開発してます!
もしよかったら、遊んでみてくださいヽ(=´▽`=)ノ
要望・感想・アドバイスなどあれば、
公式アカウント(@MemoryLoverz)や開発者(@kira_puka)まで♪参考にしたサイト様

- 投稿日:2019-11-27T13:10:08+09:00
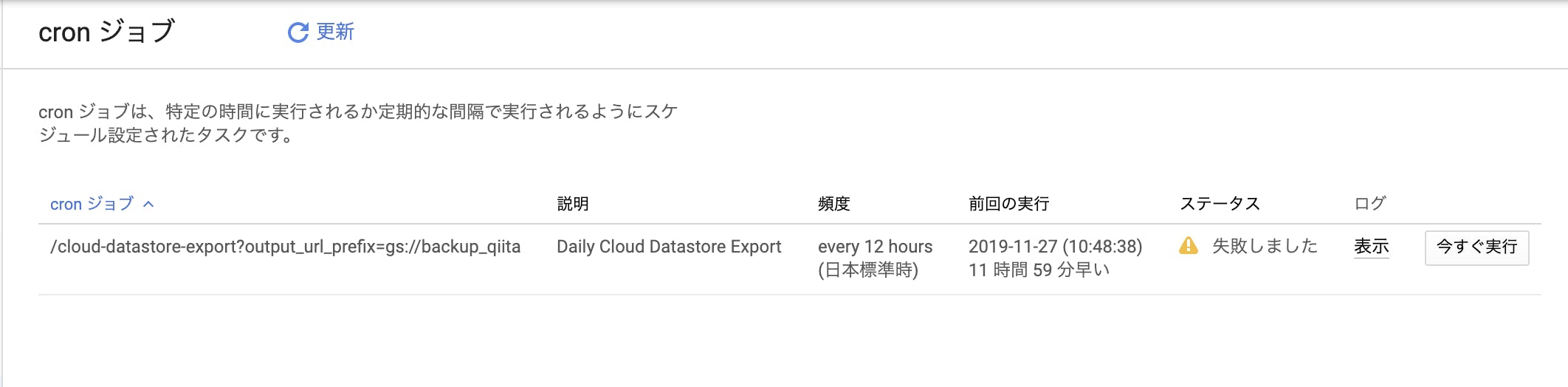
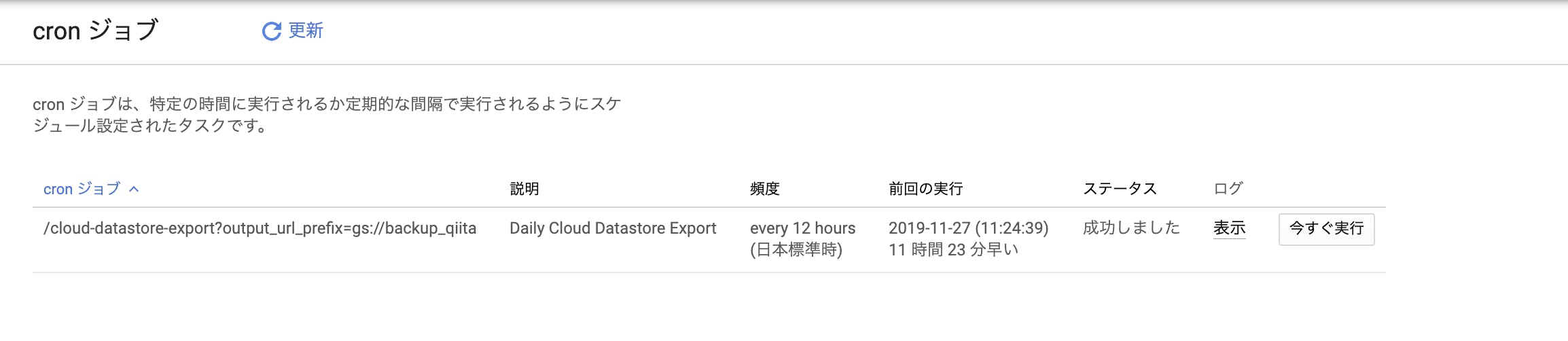
GCP DatastoreのExport機能を自動的に実行する方法
今回はGoogleCloudPlatformのDatastoreの自動バックアップの取り方を紹介します
前提
- Datastoreにエンティティが存在する
手順
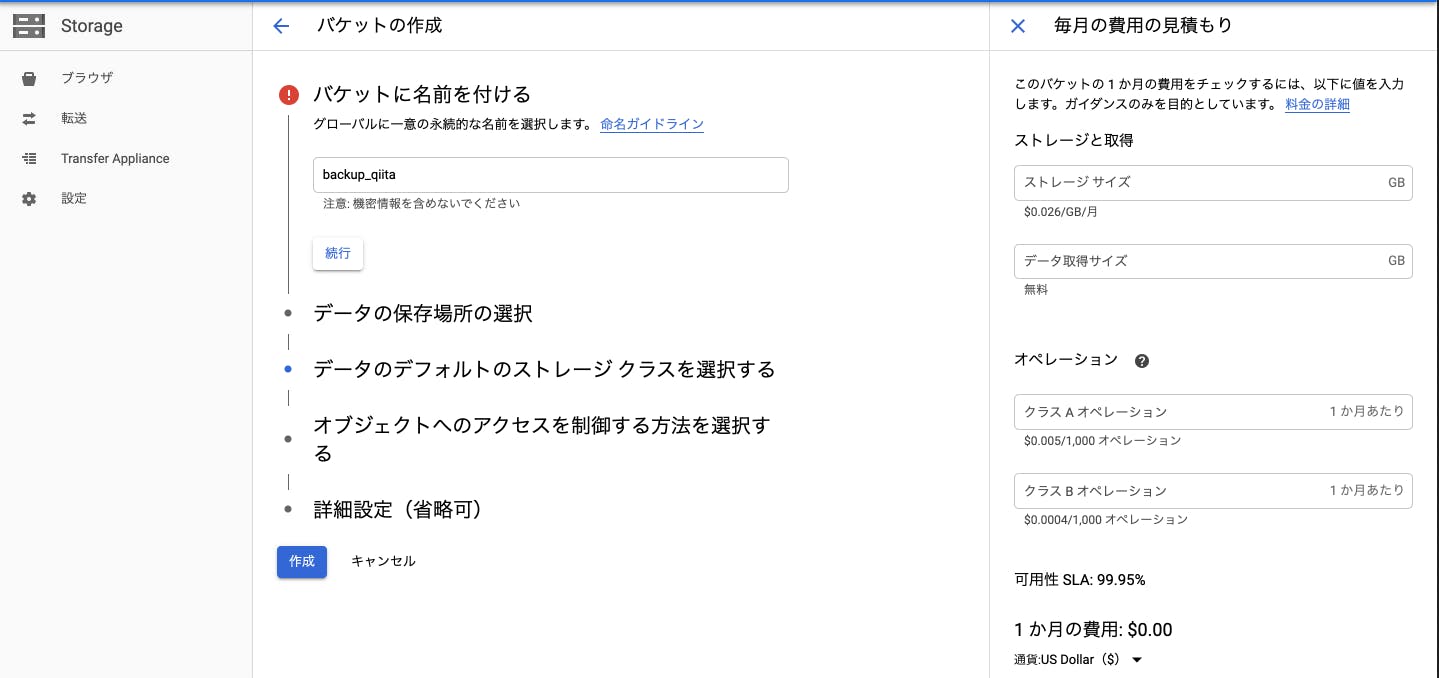
1,Storageでバックアップするためのバケットを作ります
GoogleCloudPlatformStorageへアクセスし、プロジェクトを選択します
[バケット作成]をクリックし、バケットを作成します
- バケットに名前を入れる
- 英数小文字で名前を入れましょう(今回はbackup_qiitaでやります)
- データの保存場所の選択
- Region:特定の地理的な場所
- Multi-region:米国などの2つ以上の地理的な場所を含む広い地理的な場所
- Dual-region:フィンランドやオランダなどペアを示すの特定の地理的な場所
- データのデフォルトのストレージ クラスを選択する
- Standard:短期間のストレージや頻繁にアクセスされるデータに最適
- Nearline:アクセス頻度が月1回以下のデータやバックアップに最適
- Coldline:アクセス頻度が年1回以下のデータやバックアップに最適
- オブジェクトへのアクセスを制御する方法を選択する
- きめ細かい管理
- 均一
- 詳細設定(省略可)
設定ができたら[作成]を押します
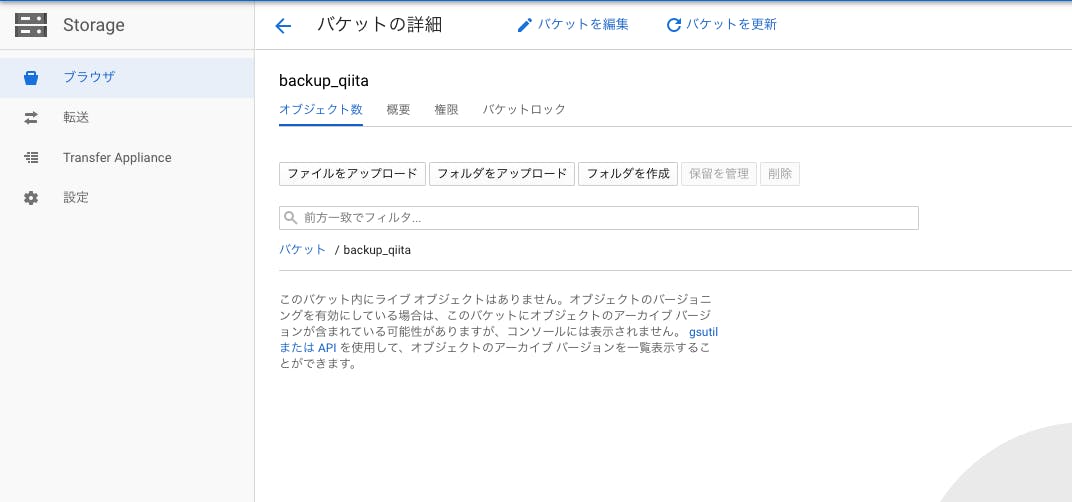
こんな感じでバックアップを入れるバケットができました。
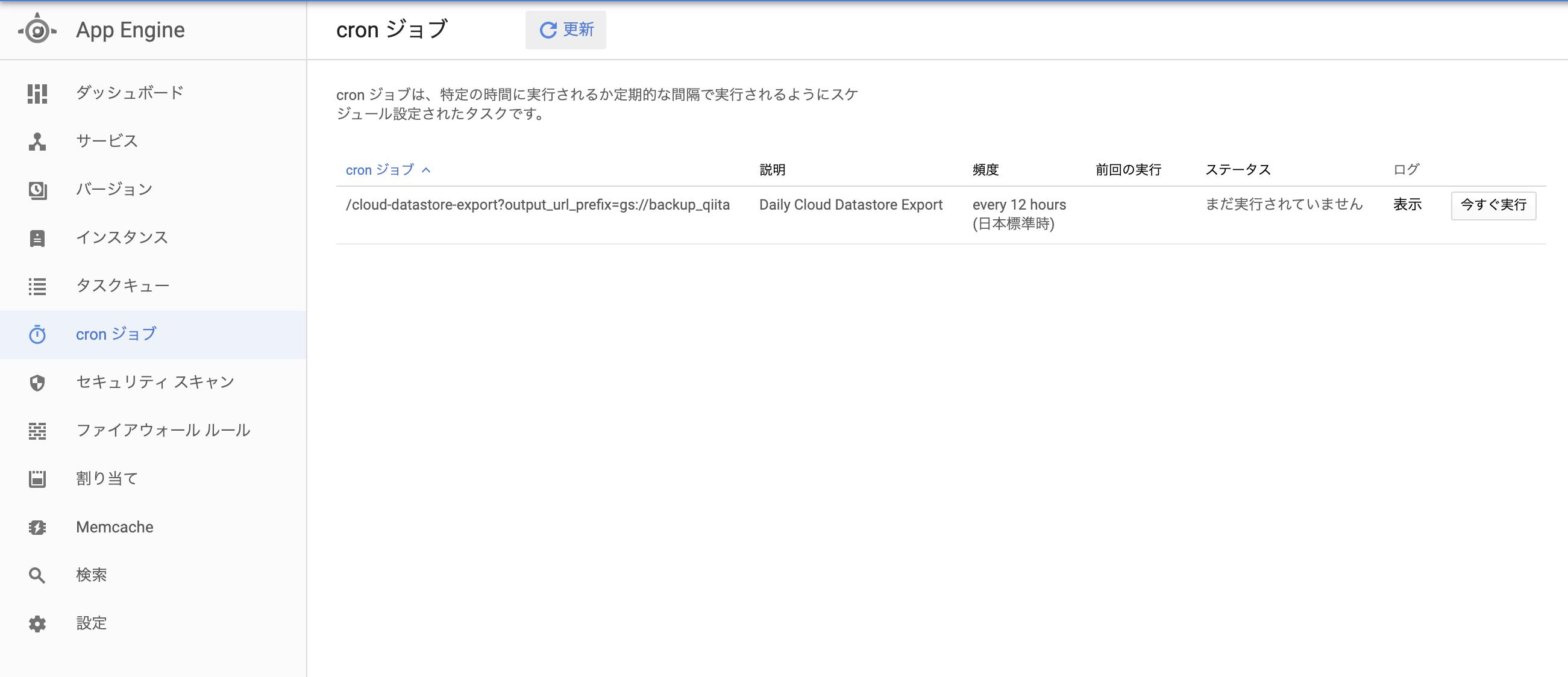
では次にバケットにバックアップを入れるための設定を行います2,Datastoreのエンティティを受け取り、バックアップを取るソースコードを作成する
ここではhttps://cloud.google.com/datastore/docs/schedule-export?hl=jaを
参考にしながらYaml、Pythonで追加していきます。
まずはYamlで[app.yaml]を作成します。(既にある場合はフォルダを作成しその中に作成しましょう)
←こんな感じに私はbackupフォルダで置いてます
ここのapp.yamlはPythonの設定をするために用意します。
app.yamlruntime: python27 api_version: 1 threadsafe: true service: cloud-datastore-admin libraries: - name: webapp2 version: "latest" handlers: - url: /cloud-datastore-export script: cloud_datastore_admin.app login: adminでは次にPythonで[cloud_datastore_admin.py]も用意しましょう
cloud_datastore_admin.pyimport datetime import httplib import json import logging import webapp2 from google.appengine.api import app_identity from google.appengine.api import urlfetch class Export(webapp2.RequestHandler): def get(self): access_token, _ = app_identity.get_access_token( 'https://www.googleapis.com/auth/datastore') app_id = app_identity.get_application_id() timestamp = datetime.datetime.now().strftime('%Y%m%d-%H%M%S') output_url_prefix = self.request.get('output_url_prefix') assert output_url_prefix and output_url_prefix.startswith('gs://') if '/' not in output_url_prefix[5:]: # Only a bucket name has been provided - no prefix or trailing slash output_url_prefix += '/' + timestamp else: output_url_prefix += timestamp entity_filter = { 'kinds': self.request.get_all('kind'), 'namespace_ids': self.request.get_all('namespace_id') } request = { 'project_id': app_id, 'output_url_prefix': output_url_prefix, 'entity_filter': entity_filter } headers = { 'Content-Type': 'application/json', 'Authorization': 'Bearer ' + access_token } url = 'https://datastore.googleapis.com/v1/projects/%s:export' % app_id try: result = urlfetch.fetch( url=url, payload=json.dumps(request), method=urlfetch.POST, deadline=60, headers=headers) if result.status_code == httplib.OK: logging.info(result.content) elif result.status_code >= 500: logging.error(result.content) else: logging.warning(result.content) self.response.status_int = result.status_code except urlfetch.Error: logging.exception('Failed to initiate export.') self.response.status_int = httplib.INTERNAL_SERVER_ERROR app = webapp2.WSGIApplication( [ ('/cloud-datastore-export', Export), ], debug=True)このように入力ができたならデプロイを行いましょう
1.gcloudが適正なプロジェクトに対して構成されるように[config set]を使います
gcloud config set project [プロジェクト名]2.[app.yaml]をプロジェクトにデプロイ ※[app.yaml]が置かれているディレクトリを間違えないように!!
gcloud app deploy上手くデプロイできたら自動バックアップの下準備が完了です。
次で自動化させていきます。3,cronジョブで自動的に実行するように設定する
ここもhttps://cloud.google.com/datastore/docs/schedule-export?hl=jaを参考に進めていきます
まずGCPのschedule-datastore-exportsを呼び出すcronジョブを設定するために
[cron.yaml]を作成します。cron.yamlcron: - description: "説明文" url: /cloud-datastore-export?output_url_prefix=gs://[バケット名] target: cloud-datastore-admin timezone: Asia/Tokyo schedule: every 12 hoursこれで問題なければデプロイを行いましょう
gcloud app deploy cron.yaml詳しく設定する場合 ~選択範囲~
バックアップする際、特定の種類のエンティティのみをエクスポートする場合はkindを使いましょう
url: /cloud-datastore-export?output_url_prefix=gs://[バケット名]&kind=[エンティティの種類の名前]特定のものを複数指定することも可能です
url: /cloud-datastore-export?output_url_prefix=gs://[バケット名]&kind=[エンティティの種類の名前]&kind=[エンティティの種類の名前]特定のエンティティに名前空間が存在する場合にエクスポートする場合は
url: /cloud-datastore-export?output_url_prefix=gs://[バケット名]&kind=[エンティティの種類の名前]&kind=[エンティティの種類の名前]と入力してあげると細かく設定をしてあげることもできます
詳しく設定する場合 ~時間設定~
バックアップが実行する時間は[schedule]に時間を指定してあげましょう
現在は12時間毎に1回バックアップを実行する設定にしてありますが、1日に1回ならschedule: every 24 hours毎日00:00にバックアップを実行する場合は
schedule: every day 00:00など幅広く設定することができます
詳しくはhttps://cloud.google.com/appengine/docs/flexible/java/scheduling-jobs-with-cron-yaml?hl=ja#defining_the_cron_job_scheduleに詳細が載っております
ちなみにバックアップを実行する基準時間を日本時間に設定する場合はtimezone: Asia/Tokyoとすれば日本時間で行われます。
4,cronジョブの実装
実際に動くかテストしてみよう
AppEngineのcronジョブがこのように表示していればcronが上手くできています
さてさて[今すぐ実行]で動かしてみましょう
いざ!ワーオ、エラッター(´゚д゚`)
そんなときはログの[表示]でエラーを見ましょうログでエラーを見る
ログを表示してみたところ、403と出ていますね
開くと"The caller does not have permission"と書かれてますね…
つまりは「インポート、エクスポートにおける権限持ってねーです」ってことですね
じゃあ権限を与えにいきましょう
権限を与える
IANと管理でIAMを開きます
その中で[プロジェクトID]@appspot.gserviceaccount.comを編集しましょう
[別の役割を追加]を押して
Datastoreの[CloudDatastoreインポート/エクスポート管理者]を選択して保存!
ということでもう一度実行しに戻りましょう
もう一度[今すぐ実行]を押すと…
できました!!これで12時間毎にデータを取ってくれるようになりました!
最後に
皆様いかがでしたでしょうか、上手くいきましたか?
私はこの解説が上手くいったかがヒヤヒヤしてます(´゚д゚`)でもこのようにDatastoreのデータをバックアップしておくと
人為的なミスで消したり、何かしらのトラブルにも対応できますので
やってて損はないと思いますでは長くなりましたがありがとうございました!!
参考URL
https://cloud.google.com/storage/docs/locations?_ga=2.5981299.-176719181.1568084299
https://cloud.google.com/datastore/docs/schedule-export?hl=ja