- 投稿日:2019-11-24T23:37:42+09:00
【Python】NumPyを使った行列の乗算処理時間
NumPyとは
皆様も御存知の通り、Pythonは機械学習やAI分野に強いプログラミング言語です。
その理由は数学系の学術ライブラリの潤沢さにあります。
NumPyはその代表格とも言えるPythonのライブラリです。NumPyを使って行列計算(乗算)
行列の乗算をNumPyを使って処理してみようと思います。
人間の手計算では正方行列3*3でも苦労すると思います。
ここでは100*100を処理した時間を計測したいと思います。# NumPyをインポート import numpy as np import time from numpy.random import rand # 行列 100*100を指定 N = 100 # 行列を初期化、乱数を発生させる matA = np.array(rand(N, N)) matB = np.array(rand(N, N)) matC = np.array([[0] * N for _ in range(N)]) # 開始時間を取得 start = time.time() # 行列乗算を実行 matC = np.dot(matA, matB) # 小数第2位で打ち切って出力 print("NumPyを使った計算結果:%.2f[sec]" % float(time.time() - start))処理結果
NumPyを使った計算結果:0.03[sec]
NumPyを使わず、Pythonのfor文をネストして計算
# NumPyをインポート import numpy as np import time from numpy.random import rand # 行列 100*100を指定 N = 100 # 行列を初期化、乱数を発生させる matA = np.array(rand(N, N)) matB = np.array(rand(N, N)) matC = np.array([[0] * N for _ in range(N)]) # 開始時間を取得 start = time.time() # for文をネスト for i in range(N): for j in range(N): for k in range(N): matC[i][j] = matA[i][k] * matB[k][j] print("Pythonのfor文での計算結果:%.2f[sec]" % float(time.time() - start))処理結果
Pythonのfor文での計算結果:0.92[sec]
100*100の行列計算ではNumPyとfor文のネストでは約9倍もの処理時間の差
ライブラリを使うと単にコードが平易に扱いやすくなるだけでなく、
処理時間も大幅に削減でき、またシステムの負荷も大幅に下げられることが伺えます。勉強あるのみですね。
■ 参考文献
Pythonで動かして学ぶ! あたらしい深層学習の教科書 機械学習の基本から深層学習まで (AI & TECHNOLOGY) 株式会社アイデミー石川聡彦 著
https://www.shoeisha.co.jp/book/detail/9784798158570
- 投稿日:2019-11-24T23:36:53+09:00
pypyodbcを使って手っ取り早くAS/400からデータを取得してみた 仕込編1
前回の記事、pypyodbcを使って手っ取り早くAS/400からデータを取得してみたでIBMi へのODBC接続ができるようになってので、いろいろやりたいことが出てきたのですが、考えてみたら仕込みが必要なので、今回その辺を作成してみました。
「その1」となっているのは、まだ道半ばで、入力部分の処理だけしか出来てないからです。
出力の方は実機がないと検証が難しいので、今回はパスしています。実験環境
- Windows7 (今回は実際の接続は行わない部分なので、自宅PCで検証)
- Python 3.8
- ipyhon 7.9.0 (いろいろ検証するために使用)
ヘルパーモジュール
後で使い倒したろうと考え、"sql_helper.py"というファイル(モジュール)にいろいろなものを詰め込んでいきます。パッケージを探せば見つかりそうな基本的な機能ですが、Pythonの復習をかねて車輪を再発明してみました。
今のところはこんな感じ。
sql_helper.pydef _load_lines(filename, encoding='utf-8'): return [ l for l in open(filename, 'r', -1, encoding) ] def load_raw_string(filename, encoding='utf-8', rstrip=True, lstrip=False): def _echo(x): return x if ( rstrip and lstrip): func = str.strip elif (not rstrip and lstrip): func = str.lstrip elif ( rstrip and not lstrip): func = str.rstrip # default else: func = _echo # dummy if rstrip: term = "\n" # cause rstrip(None) is remove "\n"! else: term = "" s = _load_lines(filename, encoding) return term.join( list(map(lambda x: func(x), s)) ) def load_sql(filename, encoding='utf-8', lstrip=False): sts = [] for st in strip_comment( load_raw_string(filename, encoding, True, lstrip) ).split(";\n"): if (st.isspace() or st == "" ): continue sts.append(st.strip("; \t\n") ) return sts def load_config(filename, encoding='utf-8'): cf = {} for line in strip_comment(load_raw_string(filename, encoding)).split("\n"): if ( line == "" or line.isspace() ): continue key_, val_ = line.split("=") cf[ key_.strip() ] = val_.strip() return cf # ...もう少しだけ続きます...簡単に説明します。
_load_lines()
指定されたファイルを読み込んで。単純に1行1要素のリストを作ってお終い。毎回
open(xxx,...).readline()を書きたくないだけです。load_raw_string()
上の
_load_line()を使って取得したリストを読み込んで、行ごとにlstrip()、rstrip()を掛けた後、単独の文字列に再構成して返しています。
行頭の空白削除と、行末の空白削除の要否を選択できた方が良いかな?という安易な決断をした挙句、コードが大きくなりました。_load_lines()の前は、そのために追加することになった機能です。(リターン文を一行で終わらせたい為、とも言います)
funcはパラメータによって、str.lstrip、str.rstrip、str.strip、_echo(入力値を返すだけ)を入れ替えています。
str.rstrip、str.strip を引数なしで呼ぶと行末にある改行も消えてしまうので、行末削除を指定したときは、termに改行記号を、そうでなければ、空白文字を入れて return文で再構成しています。load_sql()
filename から、SQLを取得します。この中に";"(+改行)が含まれていれば、そこで分割してSQL文のlistにして戻せばお終い。
と考えたまではよかったのですが、これを実現するために、延々ヘルパーのヘルパーを作る羽目に...。
例えば、コメントの中の";\n"でブった切られるとまずいだろ?とか、引用符の中にある";\n"でぶった切られるとまずいでしょ? とかです。
複合ケースとして、...; /*ブロックコメント*/となっていると、コメント除去した後に、もう一度行末の空白を除去しなきゃ";\n"にマッチしない! 等々...。最終的にやっていることは、こんな感じです
1. 先ほどの load_row_string() を使って行末空白を除去
2. strip_comment() (後述)でコメントを除去、ついでにコメント除去した結果、行末になってしまった空白を除去
3. ここでやっと";\n" でSQL単独文に分割
4. 各文末の";"そのものを除去
5. 4.をリストに詰め直して返す普通にSQLの簡易字句解析器を作った方が早かったかもしれません。
load_config()
以下の形式のファイルを読み込むと...
sample_connection.txt/* supports sql style comments */ driver = {iSeries Access ODBC Driver} system = 127.0.0.1 uid = USER01 pwd = USER01 DefaultLibraries = MYLIB,TESTLIB1,TESTLIB2libraryこんな感じの辞書に変換します。
{'DefaultLibraries': 'MYLIB,TESTLIB1,TESTLIB2', 'driver': '{iSeries Access ODBC Driver}', 'pwd': 'USER01', 'system': '127.0.0.1', 'uid': 'USER01'}この辞書を pypyodbc.connect() 関数に渡してやれば、ずらずらとパラメータを書き連ねる必要もありません。
odbctest.pyfrom pypyodbc import connect import sql_helper as helper config = helper.load_config( "sample_connection.txt" ) with connect( **config ) as connection: # データベースにアクセス処理...strip_comment()
ソースが長くなるので、はしょっていたコメント除去機能になります。
sql_helper.pyfrom enum import Enum, auto class States(Enum): Statement = auto() Quoted = auto() Comment = auto() End = auto() _LimitLen = 999999999 def _singlequote_begin(s, b): p = s.find("'", b) return p if (p >= 0) else _LimitLen def _singlequote_end(s, b): p = s.find("'", b) if (p >= 0 and p == s.find("''", b)): p = _singlequote_end(s, p + 2) # find recursive return (_next, p, 0, States.Statement) if (p >= 0) else (None. _LimitLen, 0, States.End) def _doublequote_begin(s, b): p = s.find('"', b) return p if (p >= 0) else _LimitLen def _doublequote_end(s, b): p = s.find('"', b) return (_next, p, 0, States.Statement) if (p >= 0) else (None, _LimitLen, 0, States.End) def _block_comment_begin(s, b): p = s.find("/*", b) return p + 1 if (p >= 0) else _LimitLen def _block_comment_end (s, b): p = s.find("*/", b) return (_next, p + len("*/") - 1, len("*/") -1, States.Statement) if (p >= 0) else (None, _LimitLen, 0, States.End) def _line_comment_begin(s, b): p = s.find("--", b) return p + 1 if (p >= 0) else _LimitLen def _line_comment_end(s, b): p = s.find("\n", b) return (_next, p + len("\n") - 1, len("\n") - 1, States.Statement) if (p >= 0) else (None, _LimitLen, 0, States.End) def _quote_begin(s, b): next_state = States.Quoted sq, dq = _singlequote_begin(s, b), _doublequote_begin(s, b) if (min(sq, dq) == _LimitLen): next_state = States.End return (_singlequote_end, sq, 0, next_state) if (sq < dq) else (_doublequote_end, dq, 0, next_state) def _comment_begin(s, b): bc, lc = _block_comment_begin(s, b), _line_comment_begin(s, b) if (min(bc, lc) == _LimitLen): next_ = States.End return (_line_comment_end, lc, 0, States.Comment) if (lc < bc) else (_block_comment_end, bc, 0, States.Comment) def _next(s, b): q_func, q_pos, q_ad, q_st = _quote_begin(s, b) c_func, c_pos, c_ad, c_st = _comment_begin(s, b) return (q_func, q_pos, 0, q_st) if (q_pos < c_pos) else (c_func, c_pos, 0, c_st) def strip_comment( st ): # 短縮評価 if st == None or len( st.strip() ) == 0: return "" if ("/*" not in st) and ("--" not in st): return "\n".join( list ( map(lambda x: x.rstrip(), st.split("\n")))) chars = list( st ) comments = _find_comment_pos( st ) comments.reverse() for c in comments: del chars[ c[0]: c[1]] return "\n".join( list( map(lambda x: x.rstrip() , "".join( chars ).split("\n")) ) ) def _find_comment_pos( st ): cur = -1 begin = 0 comments = [] state = States.Statement pstate = None func = _next while (True): func, pos, adv, state = func(st, cur + 1) # 検索終了 if ( state == States.End): if (pstate == States.Comment): comments.append((begin, len(st))) break cur = pos # コメント開始 -> 後続処理をスキップ if (state == States.Quoted): pstate = state continue # end comment if (pstate == States.Comment): comments.append((begin, pos + adv)) pstate = state continue # begin comment if (state == States.Comment): begin = pos - 1 # previous a length of single/double quotation pstate = state return commentsもう、自分で何を書いたか覚えてないので、間単に説明します。
概要
strip_comment() と、コメント位置を検索して(開始位置,終了位置)のリストを返す関数 _find_comment_pos() 関数が主要な関数で、その前にズラズラ並んだ関数、オブジェクトは。_find_comment_pos()が利用しているヘルパです。
雑多な関数群は、もともと _find_comment() の内部関数として定義していましたが、こうすると、
func, pos, adv, state = func(st, cur + 1)を実行したときに、先頭の func (次の検索すべき関数が返される)が、通常の関数オブジェクトではなく、3項目のタプルになっているようです。
この対処法を調べるのが大変そうなので、素直に通常の関数に変更しています。(そのせいで余計な関数をモジュール内に撒き散らすことに...)_find_comment_pos()
ローカル変数 '''func``` は、次に検索に使用する関数を保持しています。現在のステータスと、ヒットした文字("/*"とか"'"とか改行とか) で場合分けしても実現できますが、条件分岐が酷いことになりそうなので、ヒットした文字に応じて適切な検索関数を返すようにしています。
例) "/"が見つかったら、次に探すのは"*/"と決まるので、それを探す関数 _block_comment_end() が決まるこのとき一緒に、ヒットした位置を返せばコト足りるかな? と思いましたが、やっぱりこの情報がほしい、これも必要となって、各関数からは4つ値を返す羽目に...。
その後は、コメント位置をスライスで指定きるように数値を調整して、listに詰め込んでいます。
(もう詳細は忘れた..)strip_comment()
コメント位置が定まったので、後はスライスを使ってコメントを除去するだけ!!
string クラスには、スライス位置の文字を除去するメソッドがない!!
仕方がないので、
chars = list( st )で文字のリストに直し、そのリストに対しdel chars[begin:end]することでやっと念願のアイスソーd、じゃなくてコメントの除去に成功しました。最後のリターン文ですが、コメント除去の後の行末空白("本文; /* コメント */\n" パターン)を更に消し去る為に、また回りくどい処理を書くことになりました。
最後に
テストに使用したファイルと、テストコードです。(sample_connection.txt)は掲載済みのため省略)
sample_multi_statement.sqlselect * from SYSLIBL where TYPE not like = "';%" ;/* comment */ select * from SYSTABLES ; /* "" ' '' ; ; " */ ; -- empty statement select * from SYSCOLUMNS ; select * from SYSIBM.SYSDUMMY1;strip_commentの短絡評価確認用
sample_multi_statement.sqlselect * from SYSLIBL where TYPE not like = "';%" ; select * from SYSTABLES ; ; select * from SYSCOLUMNS ; select * from SYSIBM.SYSDUMMY1;sql_helper.pydef test_loading(): from pprint import pprint file = "sample_multi_statement.sql" print( f'\ntest load_sql("{file}") ----------------------------') sts = load_sql( file ) pprint( sts ) file = "sample_multi_statement2.sql" print( f'\ntest load_sql("{file}") ----------------------------') sts = load_sql( file ) pprint( sts ) file = "sample_config.txt" print( f'\ntest load_config("{file}") ----------------------------') config = load_config( file ) pprint( config )読み込み処理だけで予想以上のコード量になりました。
IBM i での使用を前提に作成を始めましたが、ここまでの内容でしたら、他のDBMSの前処理として流用できると思います。次回があれば、出力側に取り掛かります。
- 投稿日:2019-11-24T23:16:33+09:00
Pythonのsocketとsslでサーバを作りブラウザからアクセスさせてみた
HTTPSクライアントの動作確認を行う時などで、ダメなHTTPヘッダとか文法的にNGなHTMLあるいは文法的にNGなJavaScriptを相手に送り返したいというのが目的で作りました。
- sslのwrap_socketを使っています
- Web系のフレームワークとかではないので、ヘッダとかボディはまぁ好き勝手にやれます。
環境としては以下の感じです。
- 確認はオレオレ認証でやりました
- Ubuntu 18-04、Python 3.7.3 で動作を確認しました。
- Windows10のFireFoxとChromeで動作確認しています。あとSafari系も多分動くとは思います。
証明書関係
opensslを使ってやります。
オレオレでとにかくSSLしてくれさえすりゃいいってんでしたら、以下にやり方が書いてあります(参考にさせて頂きました。ありがとうございます)
https://qiita.com/masakielastic/items/05cd6a36bb6fb10fccf6
https://stackoverflow.com/a/41366949/531320
例えば鍵を mock.key 、証明書を mock.crt というファイル名にしたいなら以下です。ドメインは超適当(使わないので…)
openssl req -x509 -newkey rsa:4096 -sha256 -nodes -keyout mock.key -out mock.crt -subj "/CN=test.com" -days 3650これで後Python書けばSSL出来ます。
Pythonコード
以下の記事のコードをベースに書かせて頂きました(参考にさせて頂きました。ありがとうございます)
https://qiita.com/butada/items/9450e39d8d4aac6ac1fe
公式のドキュメントは以下。
https://docs.python.org/3/library/ssl.html
で、書いたコードがこれっす。
#!/usr/bin/env python # coding: utf-8 import socket import ssl import sys ''' ここらは環境とかに応じてよしなにお願いします ''' TEST_IP = '10.0.0.12' TEST_PORT = 443 TEST_KEY = "mock.key" TEST_CERT = "mock.crt" class TestSSLServer: ''' SSLサーバの基本動作系を雑にまとめてみた ''' def init_soccket(self, key, cert, ip, port): self.ssl_context = ssl.create_default_context(ssl.Purpose.CLIENT_AUTH) self.ssl_context.load_cert_chain(certfile=cert, keyfile=key) self.bind_socket = socket.socket() self.bind_socket.setsockopt( socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) self.bind_socket.setsockopt( socket.SOL_SOCKET, socket.SO_REUSEPORT, 1) self.bind_socket.bind((ip, port)) self.bind_socket.listen(5) # 適当っす def finsih_socket(self): self.connection_stream.shutdown(socket.SHUT_RDWR) self.connection_stream.close() def accept_socket(self): while True: try: self.accept_socket, _fromaddr = self.bind_socket.accept() self.connection_stream = self.ssl_context.wrap_socket( self.accept_socket, server_side=True) return except ssl.SSLError: ''' Chrome, Firefoxはこっちのエラーが出る オレオレでもいいから接続に備えてacceptに戻る ''' print("wrap: SSL error:", sys.exc_info()[0]) continue except OSError: ''' Safari系はこっちのエラーが出る オレオレでもいいから接続に備えてacceptに戻る ''' print("wrap: OS error:", sys.exc_info()[0]) continue except BaseException: ''' 他は知らないので、プロセス終了して無かった事にしますw(CTRL-Cとかがここに来るはず) ''' print( "wrap: Unexpected error:", sys.exc_info()[0]) sys.exit(1) def read_stream(self): bin_data = self.connection_stream.read() return bin_data def write_stream(self, bin_data): self.connection_stream.sendall(bin_data) if __name__ == '__main__': ''' 初期化 ''' server = TestSSLServer() server.init_soccket(TEST_KEY, TEST_CERT, TEST_IP, TEST_PORT) ''' 接続待ち ''' server.accept_socket() ''' リクエスト、レスポンス一回ずつ ''' bin_data = server.read_stream() if bin_data: print (bin_data) content = "<html>test</html>" text = "HTTP/1.1 200 OK\r\n" text += "Content-Length: " + str(len(content)) + "\r\n\r\n" text += content server.write_stream(text.encode()) ''' 切断、リソース解除 ''' server.finsih_socket()元のコードはPython2でしたが3で動くようにしています。また途中で止めた時とかの事も考慮して、SO_REUSEADDRの設定もしています。
後、ブラウザからアクセスしてもOKなようにエラー時の挙動を変更しています。具体的にはオレオレに起因して認証に失敗しますと、ssl.SSLErrorとかOSErrorが出ますので、その際にはacceptからやりなおすだけっすw
- TEST_IP, TEST_PORT, TEST_KEY, TEST_CERTはそれぞれ自分の環境に合わせて変更下さい。
- 何がしかのリクエストが来たら、レスポンスを返して終わりにするだけの簡単なコードとなっています。受けたレスポンスは確認用にprintしています。
- 想定しない問題が起きたらsys.exitでプロセス事無かった事にする適当なプログラムですのでそこはご容赦。
- なので接続前にCTRL-Cとかでも抜ける事が出来るはず。
コードを見ると分かりますがヘッダとかボディも自分で全部書かないとダメです。つまり、文法とかも気にせず好きなデータを突き返す事が出来ます。
実行方法
実行方法ですがポート443使うとなるとUbuntuではsudoする必要がありました。こんな感じですね。
sudo python3.7 sample_server.py後はブラウザから
https://xxx.xxxx.xxxx.xxx:nnnnって感じでアクセスすればいいです。TEST_PORTを443にしてあれば:nnnnは不要です。オレオレなんで、証明書に関してお叱りを受けるかと思いますが、承知の上で接続という流れでやると test と出てくる筈です。
- 投稿日:2019-11-24T23:12:07+09:00
Colab使って、画像の真偽をDNNに学習させてみるまで
はじめに
Colaboratoryで、画像の真偽を学習してみようと思ったが、いろんなところに情報があって集めるのが大変だった。そこで、もう完成したものをそのまま貼り付けようと思った。
Pythonなんとなくわかる人向けです。ドンッ
https://colab.research.google.com/drive/1ETjxVKCA3zv391tEAY5RHM_cyipIA9D-?hl=jaそのまま使える人はいないと思いますが、誰かの参考になれば。
Jupyter-notebookとかPythonとか詳しくない状態で作ったので、なんか指摘も来るといいな。やりたかったこと
私がやりたかったことはこれ。
- Colaboratoryを使う
- 画像の真偽を学習させたい
- ディープラーニング
- 訓練データ(画像)はGoogleDriveにある
- 画像は横100px縦150pxのPNGファイル
- 画像はZIPで圧縮してあって、フォルダ構成は下記の通り
- 学習の履歴をグラフで見たいし、そのグラフやモデル情報をGoogleDriveに保存したい
ZIPファイルフォルダ構成
- images.zip
- 0(フォルダ)
- 偽判定の画像
- 1(フォルダ)
- 真判定の画像
やっていること
簡単にやっていることの説明を書く。Colaboratoryにアクセスして、コードを参照のこと。
1つ目のセル(GoogleDriveのマウント)
GoogleDriveをマウントする。見ての通り。
世の中的には、GitHub使うのが多そうですね。GoogleDriveだと、毎回認証がめんどくさい。2つ目のセル(訓練データの展開)
GoogleDriveにある訓練データのZIPファイルを、ディスクに展開する。
訓練データの画像1枚1枚をGoogleDriveから読み込むこともできるが、遅い。ZIPファイルにしておいて、全部ディスクに展開した後、ディスクから読み込んだ方がはるかに速いのでこうしている。3つ目のセル(訓練データの読み込み)
訓練データとテストデータ、真偽同数にしたかったので、シャッフルしつつ真偽交互に画像パスを返すジェネレータ
generate_pathsを作った。
すなわち、
偽として 0-1, 0-2, 0-3, 0-4, 0-5
真として 1-1, 1-2, 1-3, 1-4, 1-5
の10枚の画像があったとして、
0-3, 1-5, 0-1, 1-1, 0-2, 1-3, 0-4, 1-4, 0-5, 1-2
のように返す。ジェネレータなんか使わず、普通にリストをシャッフルした方がわかりやすかったかも?
load_dataメソッドでは、実際に画像を読み込んで配列にしている。今回扱った画像は、背景が白のものが多いので、1 - X / 255として、白黒反転させて0~1の浮動小数点にしている。大体が0で、時々1がある状態となる。
カラーの画像もあるので、inputのチャネル数は3で。4つ目のセル(学習)
頑張って学習する。
いつ学習が終わったかわかるように、終わった時間を保存するのも忘れない。import datetime tz_jst = datetime.timezone(datetime.timedelta(hours=9), name="JST") now = datetime.datetime.now(tz_jst) str_now = now.strftime("%Y/%m/%d %H:%M:%S") print(f"訓練が終了 {str_now}")モデル全体と、そのアーキテクチャを保存しておく。
5つ目のセル(グラフを描画)
%matplotlib inlineを付けて画面上に表示するとともに、GoogleDriveにも保存する。結論
Colaboratory、GPUとか無料で使えてとても便利。どこでも、iPhoneからでもアクセスできていいですね。ただ、昼間とかに、GPUとTPU使えなくなることがあって悲しい。
学習結果に関しては、accuracy、0.7強…ですって。いろいろ試行錯誤してみたけど、ちょっと微妙…
訓練データがなんなのかはちょっと言えないのだけど、この結果に関しては訓練データが悪い(というか問題が悪い)と信じている。
- 投稿日:2019-11-24T23:06:40+09:00
AtCoder Beginner Contest 146 参戦記
AtCoder Beginner Contest 146 参戦記
A - Can't Wait for Holiday
2分半で突破. 書くだけ.
S = input() if S == 'SUN': print(7) elif S == 'MON': print(6) elif S == 'TUE': print(5) elif S == 'WED': print(4) elif S == 'THU': print(3) elif S == 'FRI': print(2) elif S == 'SAT': print(1)B - ROT N
4分半で突破. 書くだけ.
N = int(input()) S = input() print(''.join(chr((ord(c) - ord('A') + N) % 26 + ord('A')) for c in S))C - Buy an Integer
16分で突破. 一目にぶたんで、最近やったなーと ABC144E のソースコードをコピってきて、is_ok を書き直して、調整してポイ. 調整に手間取ったのでまだめぐる式が手についてないなあという感想.
A, B, X = map(int, input().split()) def is_ok(N): return A * N + B * len(str(N)) <= X ok = 0 ng = 10 ** 9 + 1 while ng - ok > 1: m = (ok + ng) // 2 if is_ok(m): ok = m else: ng = m print(ok)D - Coloring Edges on Tree
敗退. 幅優先探索というアルゴリズム方針はあっていたようなのだが……. 最初に書いたのは TLE を食らい、書き直したのはデータ構造が駄目で MLE を食らったので…….
- 投稿日:2019-11-24T22:50:48+09:00
PythonでPillowを使ってファイルを作る
コンター図をパラパラ漫画みたいにしたGIF動画を作ったので備忘録。
環境はPython 3.6.8matplotlib.animation
matplotlib.animationで動くグラフは作れるみたい。
GIFファイルとして保存するにはwriterにimagemagickを使うのが普通の様子。
imagemagick
windowsにインストールする場合、ちょっと面倒な様子。
インストールしようとして参考にさせていただいたページ。
https://higuma.github.io/2016/08/31/imagemagick-1/PythonのライブラリPillow
Pillowについて参考にさせていただいたサイト。
インストールとか
https://note.nkmk.me/python-pillow-basic/GIFの作り方
https://note.nkmk.me/python-pillow-gif/作ってみる
import_lib.pyimport pandas as pd import numpy as np import matplotlib.pyplot as plt import os from PIL import Image, ImageDrawこんな感じのデータを用意する。
座標はこんな感じを想定
test_data.pytest_data = pd.DataFrame({'key':range(10), 't1': [10] * 10, 't2': [i * 10 + 10 for i in range(10)], 't3': [i * 10 + 20 for i in range(10)], 't4': [5] * 10, 't5': [i * 10 + 5 for i in range(10)], 't6': [i * 10 + 15 for i in range(10)], 't7': [3] * 10, 't8': [i * 10 + 2 for i in range(10)], 't9': [i * 10 + 10 for i in range(10)]}) t = ['t' + str(int(i)) for i in range(1, 10)] x = [i * 10 for i in range(1, 4)] * 3 y = [10] * 3 + [20] * 3 + [30] * 3コンター図を作る用のデータ抽出関数を作っておく
create_function.pydef f_contour_data(df, timing): # コンター図を描きたいタイミングの行のデータを抽出 df0 = df[df['key'] == timing].copy() # 抽出したデータを使いやすいようにindexを0にしておく df0.reset_index(drop = True, inplace = True) x = [10, 20, 30] # コンター図のx軸 y = [10, 20, 30] # コンター図のy軸 # 番号のリストを作る # [[t1, t2, t3], [t4, t5, t6], [t7, t8, t9]] # これをつくる l_T = [] for i in range(len(y)): T = ['t' + str(int(j + i * 3)) for j in range(1, 4)] l_T.append(T) # x軸の2darrayをつくる x0 = np.empty((0, len(y))) # 空のndarrayをつくる for i in range(len(y)): x0 = np.append(x0, np.array([x]), axis = 0) # xをndarrayに換えてx0に追加 # y軸の2darrayをつくる y0 = np.empty((0, len(y))) for i in range(len(y)): y0 = np.append(y0, np.array([[y[i]] * 3]), axis = 0) # z軸の2darrayをつくる z0 = np.empty((0, len(y))) for i in range(len(y)): temp = [] T = l_T[i] for s in T: temp.append(df0[s][0]) z0 = np.append(z0, np.array([temp]), axis = 0) return x0, y0, z0, l_T # l_Tは確認用 削除してもOKこれを使ってコンター図をテキトーに描くとこんな感じになる。
create_contour.pyx0, y0, z0, l_t = f_contour_data(df = test_data, timing = 0) plt.figure() p = plt.contourf(x0, y0, z0, cmap = 'jet') cbar = plt.colorbar(p)
あとはこれをループでどんどん作って保存していく。
loop.pyl_img = [] # コンター図の.pngのpathをいれるようのリスト os.makedirs('Contour_gif/', exist_ok = True) # グラフ保存用のフォルダ―を作る lv = [i * 10 for i in range(14)] for i in range(10): x0, y0, z0, l_tc = f_contour_data(df = test_data, timing = i) plt.figure() p = plt.contourf(x0, y0, z0, lv, 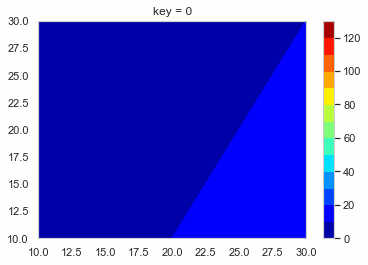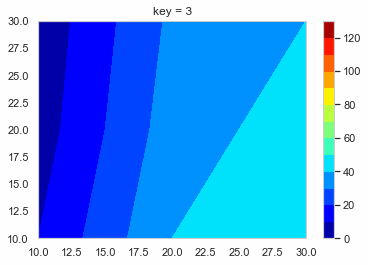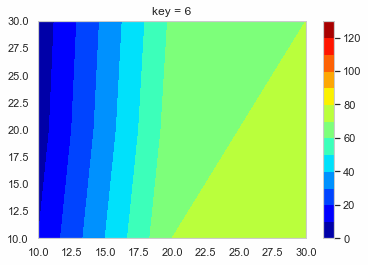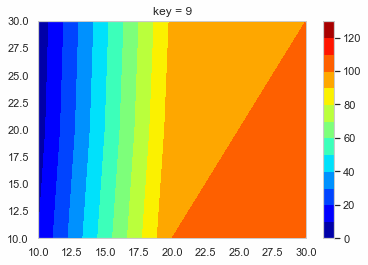 cmap = 'jet') cbar = plt.colorbar(p) plt.title('key = ' + str(int(i))) save_path = 'Contour_gif/key_' + str(int(i)) + '.png' plt.savefig(save_path, bbox_inches="tight") # 作ったグラフを保存 l_img.append(save_path) # コンター図の順番を確実に維持したいのでココでリストに追加しておく images = [] # 開いたpngを入れておくよう。 # 別にl_imgの範囲は指定しなくてもOK 画像の容量によっては怒られるけど。。。 for s in l_img[0:151]: im = Image.open(s) images.append(im) # images[0]を起点に残りをつなげる durationで切り替わりの時間(msec) loop = 0 で無限ループ images[0].save('test.gif', save_all = True, append_images = images[1: len(images)], duration = 500, loop = 0, optimaize = False)こんな感じのGIFファイルができる。

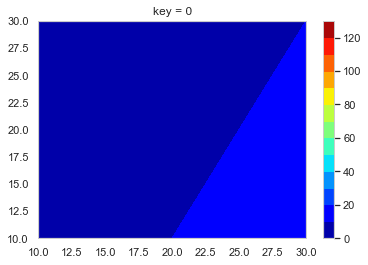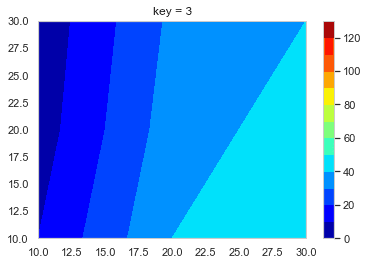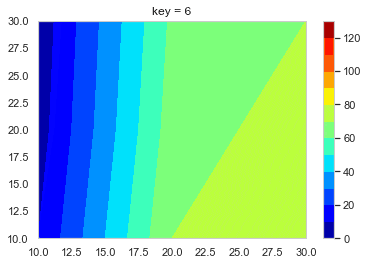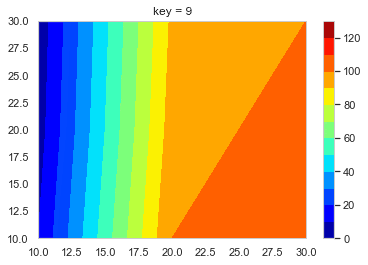
- 投稿日:2019-11-24T22:50:48+09:00
PythonでPillowを使ってGIFファイルを作る
コンター図をパラパラ漫画みたいにしたGIF動画を作ったので備忘録。
環境はPython 3.6.8matplotlib.animation
matplotlib.animationで動くグラフは作れるみたい。
GIFファイルとして保存するにはwriterにimagemagickを使うのが普通の様子。
imagemagick
windowsにインストールする場合、ちょっと面倒な様子。
インストールしようとして参考にさせていただいたページ。
https://higuma.github.io/2016/08/31/imagemagick-1/PythonのライブラリPillow
Pillowについて参考にさせていただいたサイト。
インストールとか
https://note.nkmk.me/python-pillow-basic/GIFの作り方
https://note.nkmk.me/python-pillow-gif/作ってみる
import_lib.pyimport pandas as pd import numpy as np import matplotlib.pyplot as plt import os from PIL import Image, ImageDrawこんな感じのデータを用意する。
座標はこんな感じを想定
test_data.pytest_data = pd.DataFrame({'key':range(10), 't1': [10] * 10, 't2': [i * 10 + 10 for i in range(10)], 't3': [i * 10 + 20 for i in range(10)], 't4': [5] * 10, 't5': [i * 10 + 5 for i in range(10)], 't6': [i * 10 + 15 for i in range(10)], 't7': [3] * 10, 't8': [i * 10 + 2 for i in range(10)], 't9': [i * 10 + 10 for i in range(10)]}) t = ['t' + str(int(i)) for i in range(1, 10)] x = [i * 10 for i in range(1, 4)] * 3 y = [10] * 3 + [20] * 3 + [30] * 3コンター図を作る用のデータ抽出関数を作っておく
create_function.pydef f_contour_data(df, timing): # コンター図を描きたいタイミングの行のデータを抽出 df0 = df[df['key'] == timing].copy() # 抽出したデータを使いやすいようにindexを0にしておく df0.reset_index(drop = True, inplace = True) x = [10, 20, 30] # コンター図のx軸 y = [10, 20, 30] # コンター図のy軸 # 番号のリストを作る # [[t1, t2, t3], [t4, t5, t6], [t7, t8, t9]] # これをつくる l_T = [] for i in range(len(y)): T = ['t' + str(int(j + i * 3)) for j in range(1, 4)] l_T.append(T) # x軸の2darrayをつくる x0 = np.empty((0, len(y))) # 空のndarrayをつくる for i in range(len(y)): x0 = np.append(x0, np.array([x]), axis = 0) # xをndarrayに換えてx0に追加 # y軸の2darrayをつくる y0 = np.empty((0, len(y))) for i in range(len(y)): y0 = np.append(y0, np.array([[y[i]] * 3]), axis = 0) # z軸の2darrayをつくる z0 = np.empty((0, len(y))) for i in range(len(y)): temp = [] T = l_T[i] for s in T: temp.append(df0[s][0]) z0 = np.append(z0, np.array([temp]), axis = 0) return x0, y0, z0, l_T # l_Tは確認用 削除してもOKこれを使ってコンター図をテキトーに描くとこんな感じになる。
create_contour.pyx0, y0, z0, l_t = f_contour_data(df = test_data, timing = 0) plt.figure() p = plt.contourf(x0, y0, z0, cmap = 'jet') cbar = plt.colorbar(p)
あとはこれをループでどんどん作って保存していく。
loop.pyl_img = [] # コンター図の.pngのpathをいれるようのリスト os.makedirs('Contour_gif/', exist_ok = True) # グラフ保存用のフォルダ―を作る lv = [i * 10 for i in range(14)] for i in range(10): x0, y0, z0, l_tc = f_contour_data(df = test_data, timing = i) plt.figure() p = plt.contourf(x0, y0, z0, lv,  cmap = 'jet') cbar = plt.colorbar(p) plt.title('key = ' + str(int(i))) save_path = 'Contour_gif/key_' + str(int(i)) + '.png' plt.savefig(save_path, bbox_inches="tight") # 作ったグラフを保存 l_img.append(save_path) # コンター図の順番を確実に維持したいのでココでリストに追加しておく images = [] # 開いたpngを入れておくよう。 # 別にl_imgの範囲は指定しなくてもOK 画像の容量によっては怒られるけど。。。 for s in l_img[0:151]: im = Image.open(s) images.append(im) # images[0]を起点に残りをつなげる durationで切り替わりの時間(msec) loop = 0 で無限ループ images[0].save('test.gif', save_all = True, append_images = images[1: len(images)], duration = 500, loop = 0, optimaize = False)こんな感じのGIFファイルができる。
- 投稿日:2019-11-24T21:28:31+09:00
PHPがメインの経験者が、Pythonを始めて5日目の話(selenium)PHP vs Python
はじめに
今回はseleniumを使用してChromeブラウザをコントロールしてWEBのサービスに保存されているファイルをダウンロードするのが目的です。もう一点の重要な目的はPHPとPythonで同じダウンロードを行い、結果の比較をしたいと思います。ダウンロードはWEBメールの添付ファイルが最初の目的でしたが、Slack や Facebook Cybozu 等、現在はPHPのコードで大体可能です。この話を聞いた某編集者がハッキングだと言われましたが、普通に自分でログインしてダウンロードするのと基本的に変わりませんので、堂々とやって良い処理です。以下、PHPだと selenium-webdriverを利用する事になる訳で、今になりPythonの場合と比較して複雑に感じます。PHPで動かす場合には次の記事を参考にさせていただきました。この記事にあるように準備が色々とあります。「seleniumを使ってPHPでChromeの自動操作をする」その準備を終えて、seleniumを起動します。
1.PHP編(seleniumの起動)
java -jar selenium-server-standalone.jar &2.PHP編(実際にログインしダウンロードまで行きます)
このコード、一部意図的では無い部分があります。結果的に試行錯誤して上手くログインしてダウンロード出来たので採用したコードで、例えばスクリーンショットも不要ですが、撮るとダウンロード出来たのでそのまま残したものです。PHPでseleniumは以外に大変なのかもしれません。これからPythonで同じ事をやるとどうなるか楽しみですが、Pythonの場合もseleniumのインストールを別途やらなくてはならないので、同じ環境でやって良いものか気になります。
download.phprequire_once './vendor/autoload.php'; use Facebook\WebDriver\Remote\RemoteWebDriver; use Facebook\WebDriver\Remote\DesiredCapabilities; use Facebook\WebDriver\WebDriverExpectedCondition; use Facebook\WebDriver\WebDriverBy; // ダウンロードしたchromedriverのパスを指定 $screenPath = $relative.'/g_screenshot.png'; $driverPath = '/usr/local/bin/chromedriver'; putenv("webdriver.chrome.driver=" . $driverPath); // Chromeを起動するときのオプション指定用 $options = new ChromeOptions(); // ヘッドレスで起動するように指定 $options->addArguments([ '--no-sandbox', '--headless', // ヘッドレスで起動するように指定。ダウンロードフォルダ指定が無効になる。 '--disable-gpu', // ヘッドレスで暫定的に必要なフラグ '--ignore-certificate-errors', // SSLセキュリティ証明書のエラーページ(「このサイトのセキュリティ証明書は信頼できません」のページ)を表示しません。 ]); $caps = DesiredCapabilities::chrome(); $caps->setCapability(ChromeOptions::CAPABILITY, $options); $driver = ChromeDriver::start($caps, null, 1000*60*5, 1000*60*10); $path = dirname(__FILE__).'/data'; # ダウンロードされるWEBサーバーのパス(このプログラムからのパス) $this->setDownloadDir($driver, $path); $driver->manage()->window()->maximize(); // 仮想ログイン、$atarget はダウンロードするファイルのリンク $driver->get($wtarget); # このリンク先のファイルがダウンロードされます。 $element = $driver->findElement(WebDriverBy::name('username')); $element->sendKeys($wuser); $element = $driver->findElement(WebDriverBy::name('password')); $element->sendKeys($wpass); $element->submit(); $driver->manage()->timeouts()->implicitlyWait(5); $driver->takeScreenshot($screenPath); //$driver->manage()->getCookies(); // 仮想ログイン完了3.PHPで構築した環境で from selenium import webdriver が動作しない
この問題ですが、
Python 3.7.5 (default, Nov 1 2019, 19:15:52) では未だにエラーになっているのですが、もう一つの
Python 2.7.17 (default, Oct 25 2019, 10:08:31) ではすんなり動きます。二つの環境がそれぞれ呼び出すモジュールの関係なのでしょう。webdriver.py# 限りなく自分用のメモです。 from selenium import webdriver # from <module> import <driver> # ImportError: cannot import name 'webdriver' from 'selenium' (unknown location)ほぼパスの問題だと思いますが、Python 3.7.5 はエラーのままになっています。
- 投稿日:2019-11-24T21:17:16+09:00
python で gif の読み込みと表示
完全にメモです。。
職業柄よく使う気がして(?)読み込み
scikit-video バージョン
- 安全策ならこう
from skvideo.io import vread gif = vread("sample.gif") # print(gif.shape) # => (例): (21, 600, 600, 3)
- でも↑は遅いので↓のほうがいいと思う
OpenCV バージョン
- 速い
import cv2 import numpy as np # faster than `vread` in `skvideo.io` def vread(path, T=30): cap = cv2.VideoCapture(path) gif = [cap.read()[1][:,:,::-1] for i in range(T)] gif = np.array(gif) cap.release() return gif gif = vread("sample.gif", T=21) # print(gif.shape) # => (例): (21, 600, 600, 3)
- フレーム数は与えてあげないといけないのだけが難点。
表示
ウィンドウ表示
import cv2 cv2.namedWindow("frame", cv2.WINDOW_NORMAL) for t in range(len(gif)): cv2.imshow("frame", gif[t]) cv2.waitKey(50) # 少しだけ待たないと表示されない cv2.destroyAllWindows()
jupyter上での表示
import matplotlib.pyplot as plt %matplotlib inline plt.figure(figsize=(21,9)) for t in range(21): plt.subplot(3,7,t+1) plt.imshow(gif[t]) plt.show()
実行時間の比較
- OpenCVの勝ち!
以上!
(gifはここから拝借しました https://miro.medium.com/max/1200/1*LnQ5sRu-tJmlvRWmDsdSvw.gif)


- 投稿日:2019-11-24T21:17:16+09:00
pythonでgifの読み込み・表示と高速化【OpenCV】
完全にメモです。。
職業柄よく使う気がして(?)読み込み
scikit-video バージョン
- 安全策ならこう
from skvideo.io import vread gif = vread("sample.gif") # print(gif.shape) # => (例): (21, 600, 600, 3)
- でもこれは遅いので↓のほうがいいと思う
OpenCV バージョン
- 速い
import cv2 import numpy as np # faster than `vread` in `skvideo.io` def vread(path, T=30): cap = cv2.VideoCapture(path) gif = [cap.read()[1][:,:,::-1] for i in range(T)] gif = np.array(gif) cap.release() return gif gif = vread("sample.gif", T=21) # print(gif.shape) # => (例): (21, 600, 600, 3)
- フレーム数は与えてあげないといけないのだけが難点。
表示
ウィンドウ表示
import cv2 cv2.namedWindow("frame", cv2.WINDOW_NORMAL) for t in range(len(gif)): cv2.imshow("frame", gif[t]) cv2.waitKey(50) # 少しだけ待たないと表示されない cv2.destroyAllWindows()
jupyter上での表示
import matplotlib.pyplot as plt %matplotlib inline plt.figure(figsize=(21,9)) for t in range(21): plt.subplot(3,7,t+1) plt.imshow(gif[t]) plt.show()
実行時間の比較
- OpenCVの勝ち!
以上!
(gifはここから拝借しました https://miro.medium.com/max/1200/1*LnQ5sRu-tJmlvRWmDsdSvw.gif)
- 投稿日:2019-11-24T20:39:51+09:00
Twitterスクレイピング&データフレーム化
なぜこの記事を書いたか
twitter感情分析に必要なデータの準備、すなわち
「(1)PythonでTwitterスクレイピング⇨(2)スクレイピング結果をデータフレームとして出力」をシームレスに解説している記事がなかったからです。「Twiiterスクレイピング」や「Pythonで感情分析(ネガポジ分析)」、「データフレーム」はそれぞれポピュラーなテーマなので単体ではよく解説記事を見かけます。しかしどれも部分的で、当時初心者レベルの自分には痒いところに手が届かず、中々苦労しました。
本記事の内容
本記事のコードをコピペすればそのまま任意のキーワードやユーザーからツイートを取得、データフレームとして出力が出来ます。ただし、TwiiterAPIを取得していることが前提です。
注意点
・スクレイピングはTwiiter社の規約に則って行いましょう(このコードだと多分問題ないと思うのですが・・・。問題あれば是非ご指摘ください)
・twitterAPIの制限で1週間前までのツイートしか取得できません
・本記事ではTwitterAPI登録方法とコードの解説は省略します(いつか追記するかも)
・本記事ではテキストデータの整形は扱いません(いつか追記するかも)
・本記事ではデータフレームとして出力したデータを感情分析するコードは扱いません(別の記事で書くかも)環境
・Google Colaboratory
・Python3コード
[1/3]準備
まず、各種ライブラリのインポートと、TwitterAPIのセットを行います。
個人で取得した4つのTwitterAPIキーをCK,CS,AT,ASの''内に入れてください。# -*- coding: utf-8 -*- import pandas as pd from requests_oauthlib import OAuth1Session import json import datetime, time, sys from abc import ABCMeta, abstractmethod CK = '??????????' # Consumer Key CS = '??????????' # Consumer Secret AT = '??????????' # Access Token AS = '??????????' # Accesss Token Secert[2/3]ツイートを取得
ツイートを取得します。
(1)ある単語を含むツイートを取得 or (2)あるユーザーIDのツイートを取得 が可能です。お好みで。
一番下のtotal=内に任意の数値を入れれば、その数までのツイートを取得できます。class TweetsGetter(object): __metaclass__ = ABCMeta def __init__(self): self.session = OAuth1Session(CK, CS, AT, AS) @abstractmethod def specifyUrlAndParams(self, keyword): ''' 呼出し先 URL、パラメータを返す ''' @abstractmethod def pickupTweet(self, res_text, includeRetweet): ''' res_text からツイートを取り出し、配列にセットして返却 ''' @abstractmethod def getLimitContext(self, res_text): ''' 回数制限の情報を取得 (起動時) ''' def collect(self, total = -1, onlyText = False, includeRetweet = False): ''' ツイート取得を開始する ''' #---------------- # 回数制限を確認 #---------------- self.checkLimit() #---------------- # URL、パラメータ #---------------- url, params = self.specifyUrlAndParams() params['include_rts'] = str(includeRetweet).lower() # include_rts は statuses/user_timeline のパラメータ。search/tweets には無効 #---------------- # ツイート取得 #---------------- cnt = 0 unavailableCnt = 0 while True: res = self.session.get(url, params = params) if res.status_code == 503: # 503 : Service Unavailable if unavailableCnt > 10: raise Exception('Twitter API error %d' % res.status_code) unavailableCnt += 1 print ('Service Unavailable 503') self.waitUntilReset(time.mktime(datetime.datetime.now().timetuple()) + 30) continue unavailableCnt = 0 if res.status_code != 200: raise Exception('Twitter API error %d' % res.status_code) tweets = self.pickupTweet(json.loads(res.text)) if len(tweets) == 0: # len(tweets) != params['count'] としたいが # count は最大値らしいので判定に使えない。 # ⇒ "== 0" にする # https://dev.twitter.com/discussions/7513 break for tweet in tweets: if (('retweeted_status' in tweet) and (includeRetweet is False)): pass else: if onlyText is True: yield tweet['text'] else: yield tweet cnt += 1 if cnt % 100 == 0: print ('%d件 ' % cnt) if total > 0 and cnt >= total: return params['max_id'] = tweet['id'] - 1 # ヘッダ確認 (回数制限) # X-Rate-Limit-Remaining が入ってないことが稀にあるのでチェック if ('X-Rate-Limit-Remaining' in res.headers and 'X-Rate-Limit-Reset' in res.headers): if (int(res.headers['X-Rate-Limit-Remaining']) == 0): self.waitUntilReset(int(res.headers['X-Rate-Limit-Reset'])) self.checkLimit() else: print ('not found - X-Rate-Limit-Remaining or X-Rate-Limit-Reset') self.checkLimit() def checkLimit(self): ''' 回数制限を問合せ、アクセス可能になるまで wait する ''' unavailableCnt = 0 while True: url = "https://api.twitter.com/1.1/application/rate_limit_status.json" res = self.session.get(url) if res.status_code == 503: # 503 : Service Unavailable if unavailableCnt > 10: raise Exception('Twitter API error %d' % res.status_code) unavailableCnt += 1 print ('Service Unavailable 503') self.waitUntilReset(time.mktime(datetime.datetime.now().timetuple()) + 30) continue unavailableCnt = 0 if res.status_code != 200: raise Exception('Twitter API error %d' % res.status_code) remaining, reset = self.getLimitContext(json.loads(res.text)) if (remaining == 0): self.waitUntilReset(reset) else: break def waitUntilReset(self, reset): ''' reset 時刻まで sleep ''' seconds = reset - time.mktime(datetime.datetime.now().timetuple()) seconds = max(seconds, 0) print ('\n =====================') print (' == waiting %d sec ==' % seconds) print (' =====================') sys.stdout.flush() time.sleep(seconds + 10) # 念のため + 10 秒 @staticmethod def bySearch(keyword): return TweetsGetterBySearch(keyword) @staticmethod def byUser(screen_name): return TweetsGetterByUser(screen_name) class TweetsGetterBySearch(TweetsGetter): ''' キーワードでツイートを検索 ''' def __init__(self, keyword): super(TweetsGetterBySearch, self).__init__() self.keyword = keyword def specifyUrlAndParams(self): ''' 呼出し先 URL、パラメータを返す ''' url = 'https://api.twitter.com/1.1/search/tweets.json' params = {'q':self.keyword, 'count':100} return url, params def pickupTweet(self, res_text): ''' res_text からツイートを取り出し、配列にセットして返却 ''' results = [] for tweet in res_text['statuses']: results.append(tweet) return results def getLimitContext(self, res_text): ''' 回数制限の情報を取得 (起動時) ''' remaining = res_text['resources']['search']['/search/tweets']['remaining'] reset = res_text['resources']['search']['/search/tweets']['reset'] return int(remaining), int(reset) class TweetsGetterByUser(TweetsGetter): ''' ユーザーを指定してツイートを取得 ''' def __init__(self, screen_name): super(TweetsGetterByUser, self).__init__() self.screen_name = screen_name def specifyUrlAndParams(self): ''' 呼出し先 URL、パラメータを返す ''' url = 'https://api.twitter.com/1.1/statuses/user_timeline.json' params = {'screen_name':self.screen_name, 'count':200} return url, params def pickupTweet(self, res_text): ''' res_text からツイートを取り出し、配列にセットして返却 ''' results = [] for tweet in res_text: results.append(tweet) return results def getLimitContext(self, res_text): ''' 回数制限の情報を取得 (起動時) ''' remaining = res_text['resources']['statuses']['/statuses/user_timeline']['remaining'] reset = res_text['resources']['statuses']['/statuses/user_timeline']['reset'] return int(remaining), int(reset) if __name__ == '__main__': # キーワードで取得 getter = TweetsGetter.bySearch(u'Python') # ユーザーを指定して取得 (screen_name) #getter = TweetsGetter.byUser('@realDonaldTrump') list_text = [] list_id = [] list_user_screenname = [] list_created_at = [] for tweet in getter.collect(total = 3000): list_text.append(tweet['text']) list_id.append(tweet['id']) list_user_screenname.append(tweet['user']['screen_name']) list_created_at.append(tweet['created_at'])[3/3] スクレイピング結果をデータフレームとして出力
Columns: [text, id, user, created_at]
Row: ツイートの数分(例えば3000個ツイートを取得したなら3000)
のデータフレームが出来ます。df = pd.DataFrame(columns=['text', 'id', 'user', 'created_at']) df_new = df.assign(text=list_text, id=list_id, user=list_user_screenname, created_at=list_created_at) print(df_new)[2/3]最後のfor文でリストにスクレピング結果を格納して、リストからデータフレームを作っています。
が、本来[2/3]の最後のfor文の部分で直接データフレームを作ることも可能です。
とりあえず動くものの、そもそももっとスマートに書ける部分はいくらでもありますね。時間あるときに校正します。
スクレイピングの実行部分とデータフレーム作る部分を分けたかったため、このような書き方をしています。参考文献
TwitterAPI でツイートを大量に取得。サーバー側エラーも考慮(pythonで)
Twitterスクレピング箇所はほぼこちらの記事の通り引用しています。
解説も丁寧で分かりやすく、素晴らしい記事です。
- 投稿日:2019-11-24T19:52:58+09:00
Pythonで自由群を作ってみる
群とは
なにか「2項演算」ができる、空集合でない集合$G$であって、
(つまり、$g, h \in G$とすると、2項演算$g\cdot h$があり、演算結果もGの元、つまり$g\cdot h\in G$となるものであって)
次の条件を満たすもののことを群といいます。
- (単位元) 単位元と呼ばれる元$e\in G$があり、任意の元$a \in G$に対し、$e\cdot a = a \cdot e = a$が成り立つ
- (逆元) 任意の元$a\in G$に対し、ある元$b \in G$が存在し、$a\cdot b = b \cdot a = e$が成り立つ。$b$は$a$の逆元と呼ばれ、$a^{-1}$と書く
- (結合法則) 任意の元$a, b, c \in G$に対し、$(a\cdot b)\cdot c = a \cdot (b \cdot c)$が成り立つ
群の例
- 足し算ができる整数は、群です(単位元→$0$, $a$の逆元→$-a$, 結合法則→足し算は結合法則が成り立つことが知られている)
- 足し算ができる有理数も群です(同上)。また、掛け算ができる、有理数から0を除いたもの、も群です。(0も含む有理数だと、0の逆元が定義できないので群ではありません)
自由群
群の定義以外、何も制約がないのが自由群です。
ここでは、自由群の中でも2つの元から生成される$F_2$について考えます。つまり、単位元と、2つの元$a, b \in F_2$と、その逆元$a^{-1}, b^{-1}$から、好きなのを選んで演算して、を好きなだけ繰り返してできるものを考えます。
$F_2 = \{e, a, b, a^{-1}, b^{-1}, aa, ab, ab^{-1}, ba, ba^{-1}, bb, a^{-1}b, a^{-1}a^{-1}, a^{-1}b^{-1}, \dots\}$
逆元は?
$a$の逆元が$a^{-1}$なのは分かりましたが、では、$ab^{-1}aab$など、組み合わさったものの逆元はどうなるでしょう?
実はこれは、それぞれの元の逆元を取って、さらに、順番を逆転させたもの、つまりこの場合は$b^{-1}a^{-1}a^{-1}ba^{-1}$が逆元になります。
実際、これらを演算してみると\begin{eqnarray} ab^{-1}aab\cdot b^{-1}a^{-1}a^{-1}ba^{-1} & = & ab^{-1}aa \cdot a^{-1}a^{-1}ba^{-1}\\ & = & ab^{-1}a \cdot a^{-1}ba^{-1}\\ & = & ab^{-1} \cdot ba^{-1}\\ & = & a \cdot a^{-1}\\ &=&e\\ \\ b^{-1}a^{-1}a^{-1}ba^{-1}\cdot ab^{-1}aab & = & b^{-1}a^{-1}a^{-1}b\cdot b^{-1}aab\\ & = & b^{-1}a^{-1}a^{-1}\cdot aab\\ & = & b^{-1}a^{-1}\cdot ab\\ & = & b^{-1}\cdot b\\ & = & e \end{eqnarray}確かに、逆元になっていることが分かります。
Pythonでやってみよう
Pythonは演算子オーバーロードが簡単なのでやりやすいですね。
早速やってみます。実装方針として、$a$とか$ab$とかを、文字列で持つことにします。
また、逆元は大文字のA, Bで持つことにします。逆元計算のためには、
str.swapcaseメソッドを使い、文字列をひっくり返します。
長年Pythonを使っていましたが、swapcaseを使ったのは人生で初めてです。
なんと、このメソッドは、大文字は小文字に、小文字は大文字にする、というメソッドです。'heLLo woRLd, ゎぃゎ ヵッォ ゃ ωπ'.swapcase() # => 結果は次行 'HEllO WOrlD, ゎぃゎ ヵッォ ゃ ΩΠ'残念ながら(?)、小さいひらがなは大きくなりませんが、ASCII文字じゃなくてもギリシャ文字は変換されるらしいです。まぁ、そんなことはどうでもいいので実装しましょう。
大事なことは大体考えたので、コードをガーッと書きましょう。
from collections import namedtuple FreeGroupBase = namedtuple('FreeGroupBase', 's') class FreeGroup(FreeGroupBase): def __init__(self, s: str): if s.lower().replace('a', '').replace('b', ''): # a, bのみから生成されているか確認 raise ValueError('Unexpected element is contained') # 逆元を ~a のように取ることにします def __invert__(self) -> 'FreeGroup': return FreeGroup(self.s.swapcase()[::-1]) # 演算を * で行うことにします def __mul__(self, other: 'FreeGroup') -> 'FreeGroup': return FreeGroup(self._mul_impl(self.s, other.s)) @classmethod def _mul_impl(cls, lhs: str, rhs: str) -> str: '演算の実装' if not lhs: # lhsが単位元 return rhs if not rhs: # rhsが単位元 return lhs if lhs[-1].swapcase() == rhs[0]: # ...a * ~a... の形だと、a * ~aを打ち消せる return cls._mul_impl(lhs[:-1], rhs[1:]) return lhs + rhs # そうでなければ、文字列を単にくっつけたもの def __repr__(self) -> 'str': if not self.s: return 'e' return ' * '.join(e if e.lower() else '~' + e.tolower() for e in self.s) a = FreeGroup('a') b = FreeGroup('b') e = FreeGroup('') g = a * b * b * a * ~b * ~b * ~a * a * b * (a * a * b) print(g) print(g * ~g) print(~g * g)うん、なんかいい感じにできてますね。
- 投稿日:2019-11-24T19:21:06+09:00
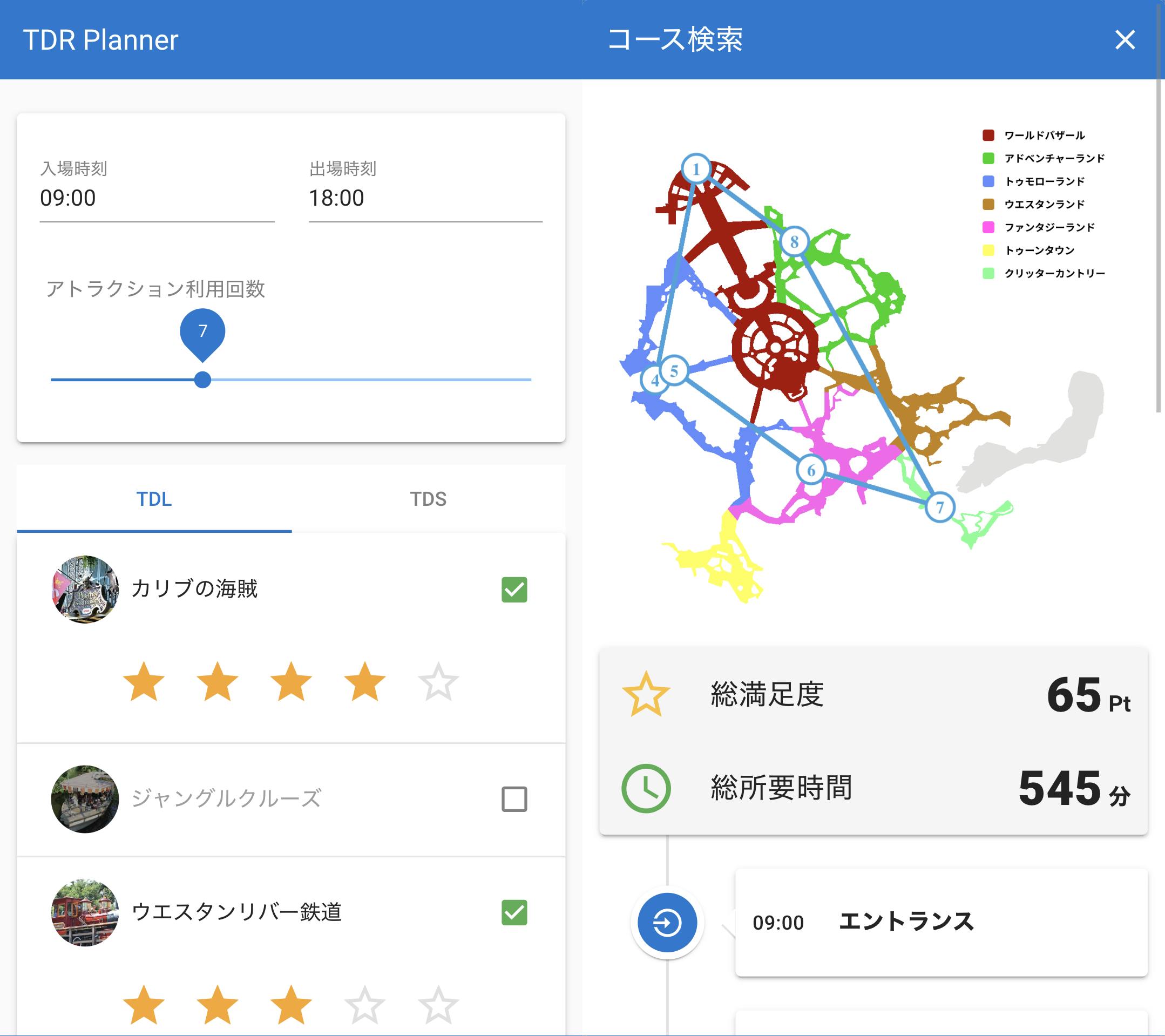
夢の国の最適経路を(量子)アニーリングで求めてみた
はじめに
夢の国...そう、それは夢と魔法の王国として知られる東京ディズニーランド。
みなさんも一度は訪れたことがあると思いますが、休日だとかなりの混雑ですよね。
そんな時に夢の国での負担となるのが待ち時間と移動距離です。待ち時間と移動距離が短くなるようなコースがあったら理想的ですね。
しかし、いざ自分で考えるとなると膨大なアトラクションの位置と待ち時間を正確に把握する必要があります。それはめんどくさいので、夢をぶち壊すようですが夢の国の経路を最適化してくれるWebアプリを作ってみました。
最適化手法はいろいろありますが、今ちょうど大学の卒論で扱っている量子アニーリングで挑戦してみました。先に試したい方はこちらからどうぞ!
https://tdr-planner.web.app/
最適化処理は30秒くらいかかってしまうのでしばらくお待ち下さいm(_ _)m用語解説
専門用語がたくさん登場するので予めざっくりと解説しておきます。
量子コンピュータ
量子コンピュータは大きく以下の2種類に分類されます。
方式 特徴 ゲート方式 汎用的であらゆる量子計算を実現可能(汎用機) イジングモデル方式 組合せ最適化問題に特化している(専用機) ぱっと見では汎用的なゲート方式の方が優れている気がしますが、高速であることが保証されている計算はまだ限定的です。
今回はディズニーのコース最適化問題を組合せ最適化問題として捉え、イジングモデル方式で解いてみます。
組合せ最適化問題
イジングモデル方式の量子コンピュータで扱える組合せ最適化問題とは以下のような問題です。
組合せ最適化問題とは、様々な制約の下で多くの選択肢の中から、ある指標(価値)を最も良くする変数の値(組合せ)を求めることです。
上記引用元に具体例があるのでそちらを参考にするとわかりやすいと思います。
今回扱う問題では、アトラクションをどのような順番で回るかという膨大な組合せの中から、最も満足度が高くなるような組合せを見つけるということになります。
イジングモデル
急に専門性が高くなりましたが、避けては通れないので解説しておきます。
イジングモデル方式の量子コンピュータは組合せ最適化問題に特化した専用機ということで、入力が特定の形に限定されています。その入力形式がイジングモデルと呼ばれる統計力学で用いられるモデルです。
量子コンピュータ(イジングモデル方式)にイジングモデルの形で入力すると、そのモデルのエネルギーが最小となるような変数の組合せを探索してくれるといった感じです。
具体的なエネルギーの式は以下のように表現されます。
$$
H = \sum_{i \neq j}J_{ij}\sigma_{i}\sigma_{j} + \sum_{i}h_{i}\sigma_{i}\quad(\sigma = \pm 1)
$$いきなり複雑な数式が出てきて、は?って感じですよね。筆者も理論的な解説には自信がないのでここでは割愛します。
ただ一つ、$H$ は $\sigma$ の最大2次の多項式で表現されるということだけ認識しておいてください。解く際には、$\sigma$ の係数を行列形式で入力すると、$H$ が最小となるような $\sigma$ の組合せを探索してくれます。
とりあえず量子コンピュータで解くには、$\sigma$ の最大2次の多項式で表現することが最初の目標となります。QUBO
QUBOはイジングモデルと似た別のモデルで、エネルギーは以下の式で表されます。
$$
H = \sum_{i \neq j}J_{ij}x_{i}x_{j} + \sum_{i}h_{i}x_{i}\quad(x \in 0,1)
$$イジングモデルとの違いは、変数が $\pm 1$をとる $\sigma$ から $0,1$ をとる $x$ に置き換わっただけです。
今回のディズニーのコース最適化ではQUBOを使用します。
大まかな流れ
- ディズニーのコース最適化を組合せ最適化問題としてQUBOで定式化する
- 実際に(量子)コンピュータで解いてみる
- Webアプリ化してみる
問題の定式化
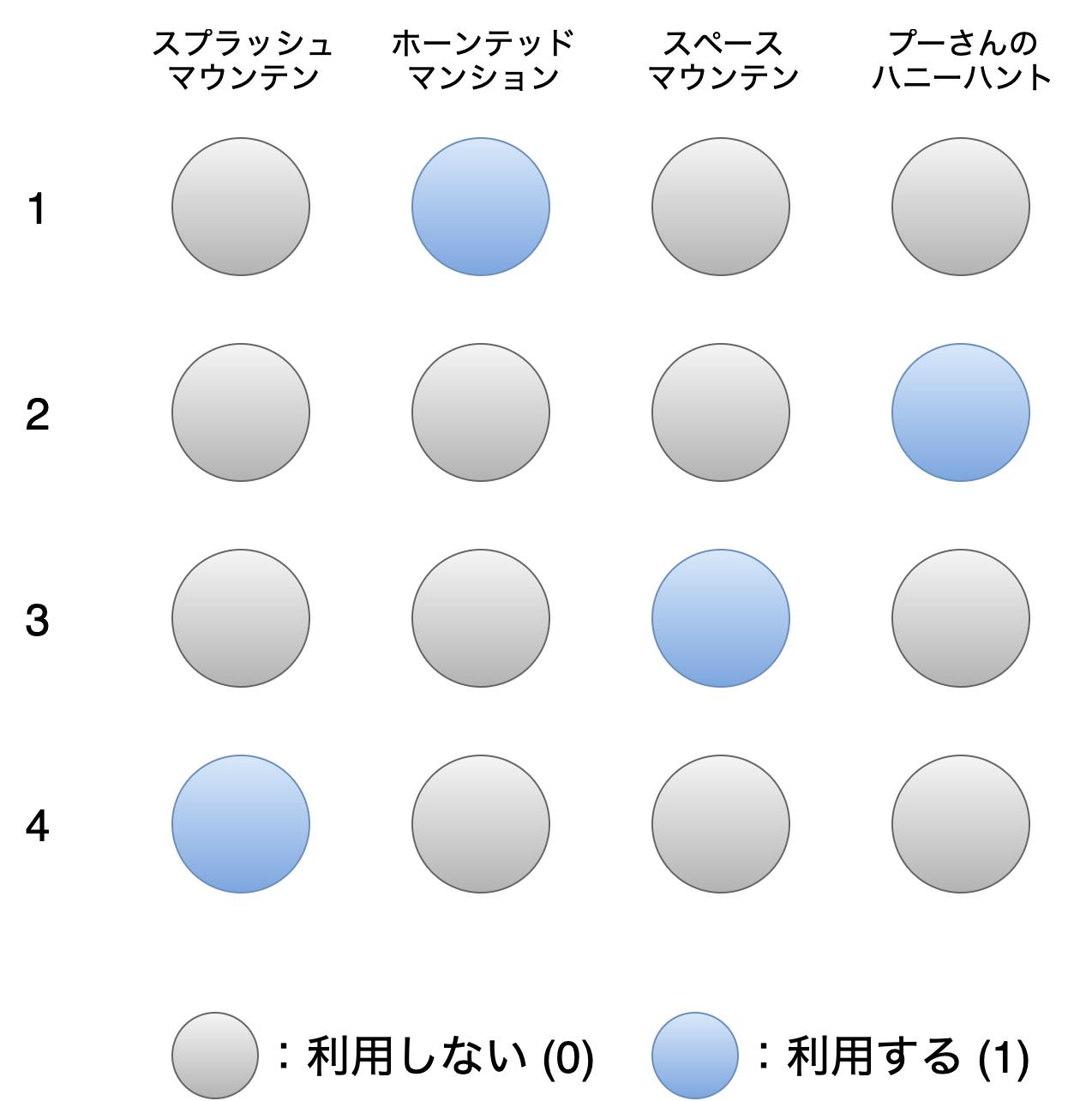
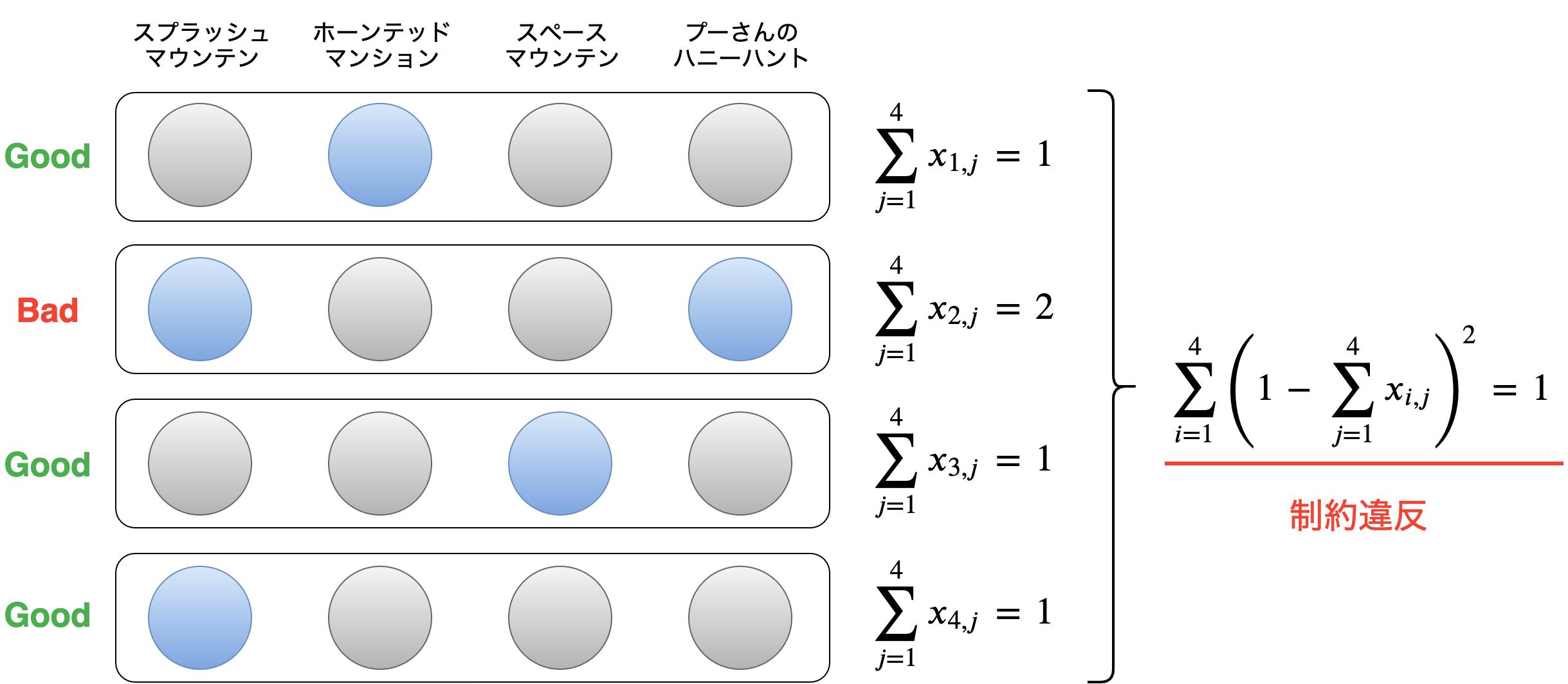
問題の定式化では、以下の図を用いて考えていきます。
上の図の丸はQUBOにおけるバイナリ変数 $x_{i,j}\ (1 \leq i,j \leq 4)$ に相当します。
「何番目に利用するか」が行、「どのアトラクションを利用するか」が列に対応していて、
$i$ 番目にアトラクション $j$ を利用するかを行列で表現します。上の図の場合、ホーンテッドマンション → プーさんのハニーハント → スペースマウンテン → スプラッシュマウンテンの順で利用するコースを表現しています。
たった4つのアトラクションだけで考えていますが、4×4=16個の $x$ の組合せは、2の16乗で65536通りにもなります。
量子コンピュータはこの65536通りの組合せの中から、QUBOで示したエネルギー $H$ が最小となる $x$ の組合せを見つけて上の図のような行列形式で返してくれます。つまり、理想的なコースのときに $H$ が最小となるような式を $x$ (2次以下)を用いて表現できれば量子コンピュータで最適化することができます。一般的に、$H$ を考える際には $H$ を構成する項として目的項と制約項を考えます。
項 役割 目的項 最大化 or 最小化したい目的となる項。良い結果ほど値が小さくなるように設定する。 制約項 制約を満たす場合に最小となる項。制約に違反する場合はペナルティとして値が大きくなるように設定する。 以降は↑を踏まえて $H$ を考えていきます。
ただし、アトラクションの利用数(行数)とアトラクション数(列数)は一般化してそれぞれ $n, m$ とします。
(図では便宜上、$n=m=4$ とします)目的
冒頭で待ち時間や移動距離を短くしたい述べたのでそれが目的のように思えますが、実際にディズニーランドに行くとき「待ち時間は合計で3時間以内にしたい!」とかいう人はいないと思います。
現実的には「アトラクションにたくさん乗りたい!」が目的だと思います。ただし、量だけじゃなく質も考慮する必要があります。待ち時間が短いからってミニーの家に10回も行っても嫌ですよね。
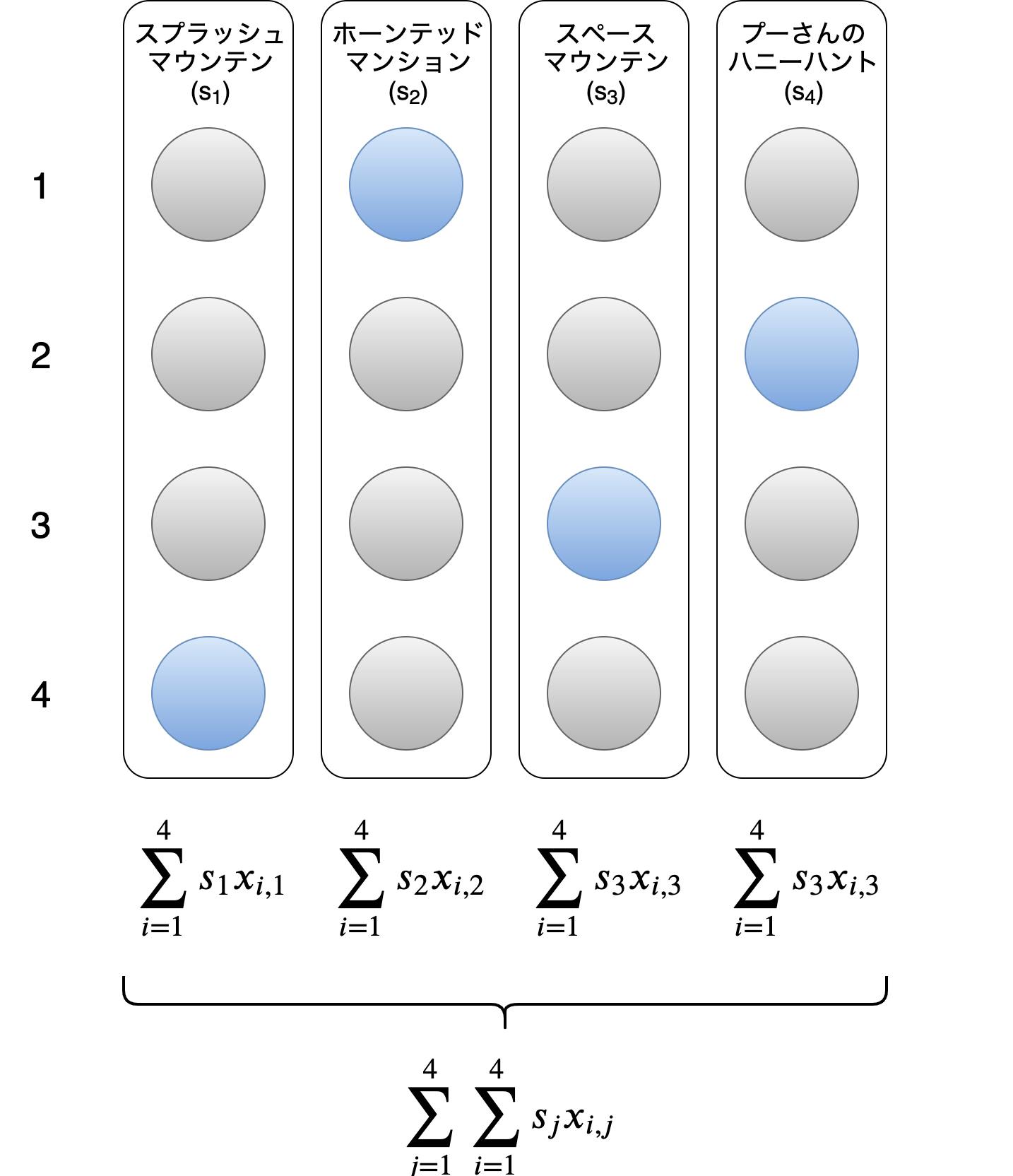
そこで、各アトラクションに10段階の満足度を設定し、総満足度の最大化を目的とします。アトラクション $j$ の満足度を $s_j\ \ (1 \leq j \leq n, 1 \leq s_j \leq 10)$ とすると、総満足度 $S$ は以下のようになります。
$$
S = \sum_{j=1}^{m}\sum_{i=1}^{n}s_{j}x_{i,j}
$$図で表すとこんな感じです。
今回は総満足度の最大化が目的ですが、目的項は良い結果ほど値が小さくなるように設定する必要があるため、符号を反転したものを目的項 $H_{aim}$ として設定します。
$$
H_{aim} = -\sum_{j=1}^{m}\sum_{i=1}^{n}s_{j}x_{i,j}
$$制約A
目的項が決まったので、とりあえずそれだけで最適化するとどうなるでしょうか。
高確率でこのような解が得られます。
そりゃそうです。全部利用すれば満足度は最大になります。
でもこれでは同時に4つのアトラクションを利用することになり、コースとして成立していません。そこで、同時に複数のアトラクションの利用は禁止という制約を設定します。
各行に青丸は必ず1個のみということに相当します。この制約はQUBOで頻繁に登場するone-hotという制約で、以下の式で表現されます。$$
H_{a} = \sum_{i=1}^{n}\left(1-\sum_{j=1}^{m}x_{i,j}\right)^2
$$図で表すとこんな感じです。
上の図では、2行目に青丸が2つあり制約違反のため $H_{a}=1$ となります。
制約を満たしていれば $H_{a}$ は最小値0をとります。制約B
目的項と制約項Aで最適化するとどうなるでしょうか。
おそらくこのような解が得られます。(※カッコ内の数字は満足度)
制約項Aによってコースとしては成立していますが、スプラッシュマウンテン4連続という大胆なコースになっています。
スプラッシュマウンテンの満足度を最も高く設定しているので当然といえば当然です。
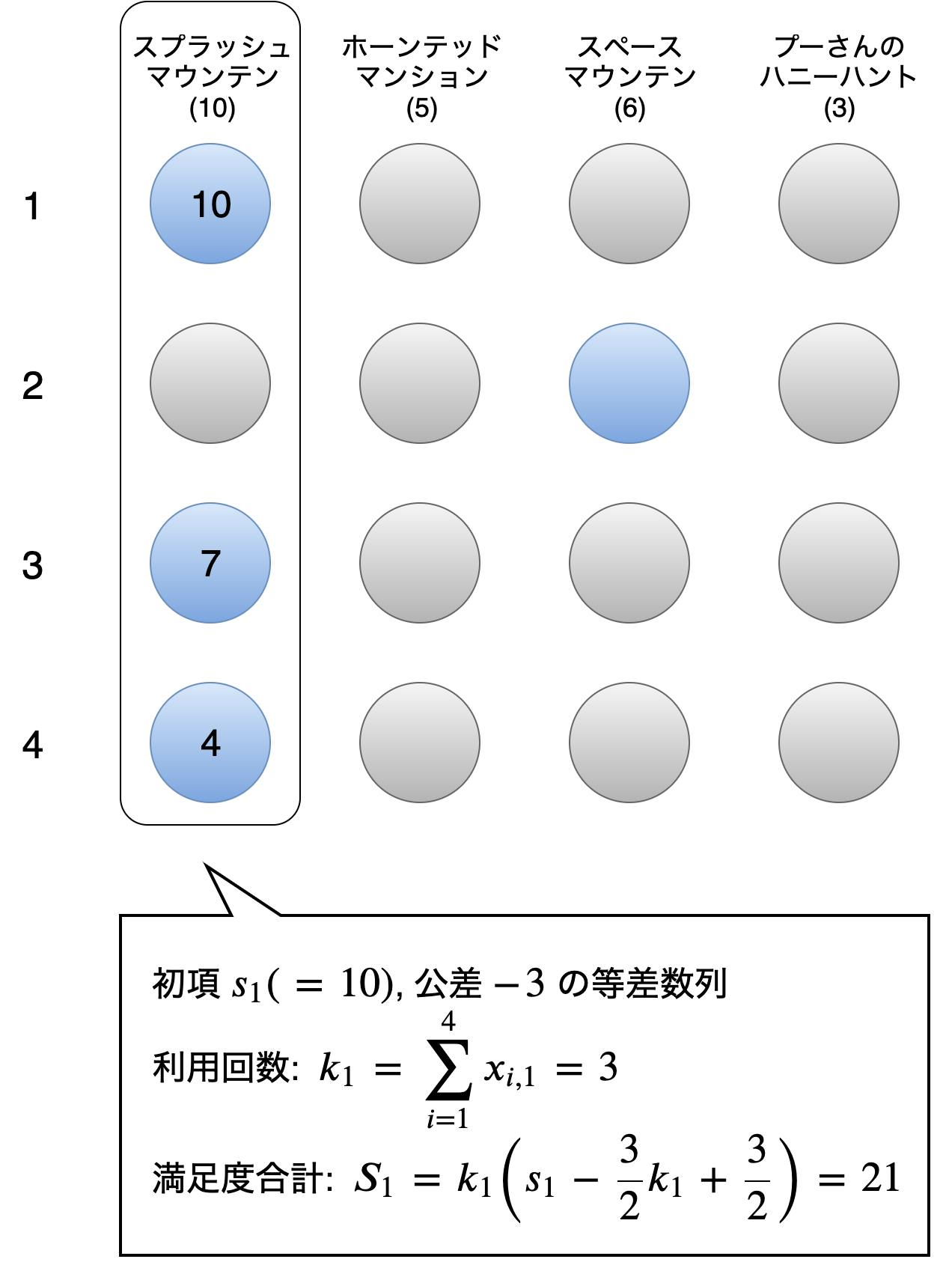
しかし、いくら人気なアトラクションといえど4回も乗るのは良いコースとは言えませんね。そこで、アトラクションを複数回利用する場合は利用するたびに満足度が3減少するという制約を設定します。
例えばスプラッシュマウンテンを3回利用する場合、1回目は10、2回目は7、3回目は4といったように満足度が下がっていきます。こうすれば、3回目の満足度は4なので、スペースマウンテン(6)やホーンテッドマンション(5)が選ばれるようになります。制約としていますが、総満足度の計算に関わることなので目的項 $H_{aim}$ を改変します。
あるアトラクションの満足度合計を計算して、すべてのアトラクションについて総和をとる方針とします。
あるアトラクション $a$ の利用回数 $k_{a}$ は、$$
k_{a}=\sum_{i=1}^{n}x_{i,a}
$$となります。アトラクション $a$ の満足度は利用するたびに3減少するため、初項 $s_a$ 公差-3の等差数列とみなすことができ、その合計 $S_{a}$ は以下の式で表されます。(等差数列の和)
$$
S_{a}=\frac{1}{2}k_{a}(2s_{a}+(k_{a}-1)\times(-3))= k_{a}(s_{a} - \frac{3}{2}k_{a} + \frac{3}{2})
$$スプラッシュマウンテンを3回利用する場合を図で表すとこんな感じです。
すべてのアトラクションについてこの総和をとったものが総満足度なので、
$$
S = \sum_{j=1}^{m}S_{j}
= \sum_{j=1}^{m}
\left(
\sum_{i=1}^{n}x_{i,j}
\left(
s_j-\frac{3}{2}\sum_{i=1}^{n}x_{i,j}+\frac{3}{2}
\right)
\right)
$$となります。最初に設定した目的項と同様に符号を反転したものを目的項として設定します。
$$
H_{aim}= -\sum_{j=1}^{m}
\left(
\sum_{i=1}^{n}x_{i,j}
\left(
s_j-\frac{3}{2}\sum_{i=1}^{n}x_{i,j}+\frac{3}{2}
\right)
\right)
$$制約C
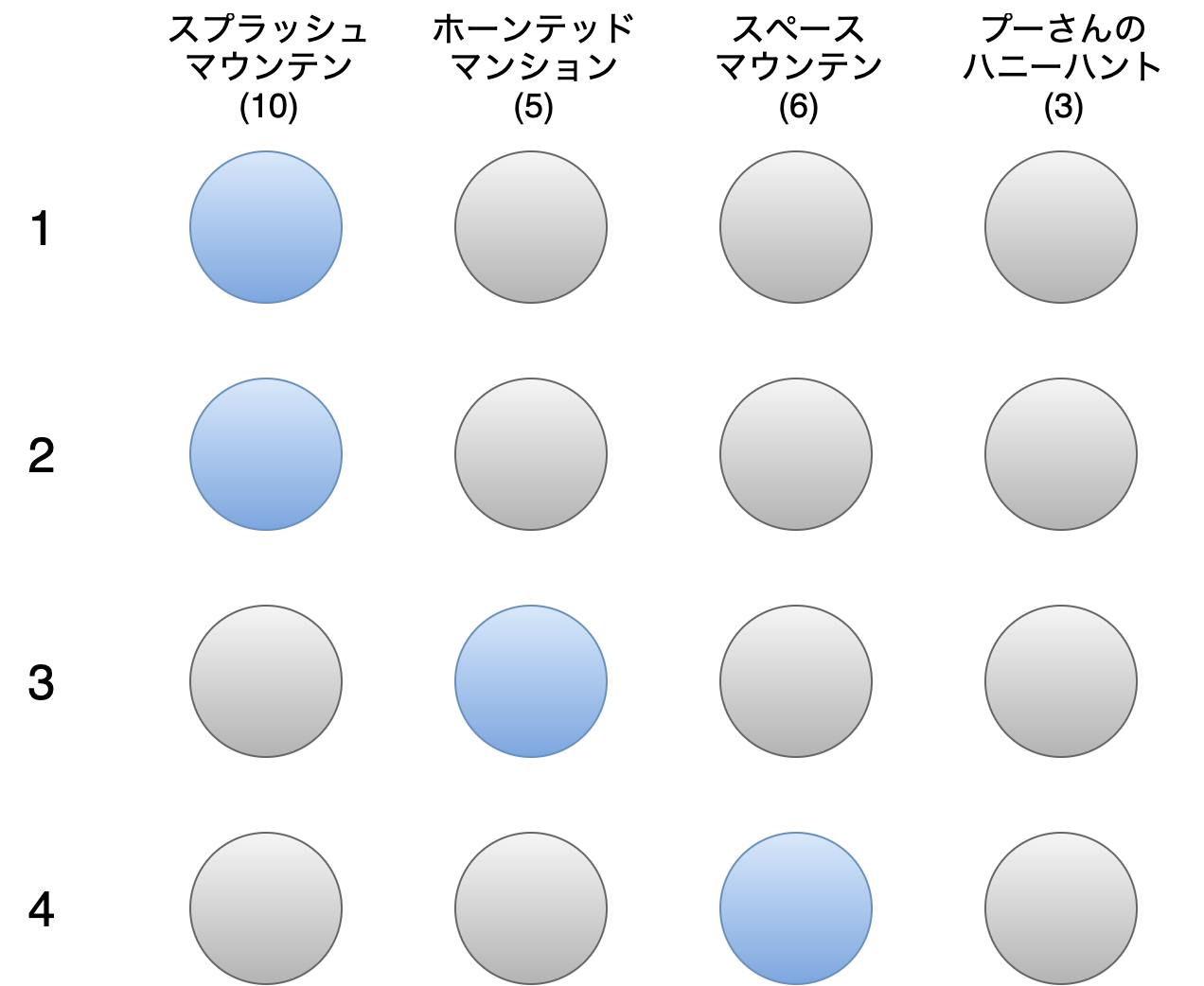
新たに設定した目的項を使って最適化するとどうなるでしょうか。
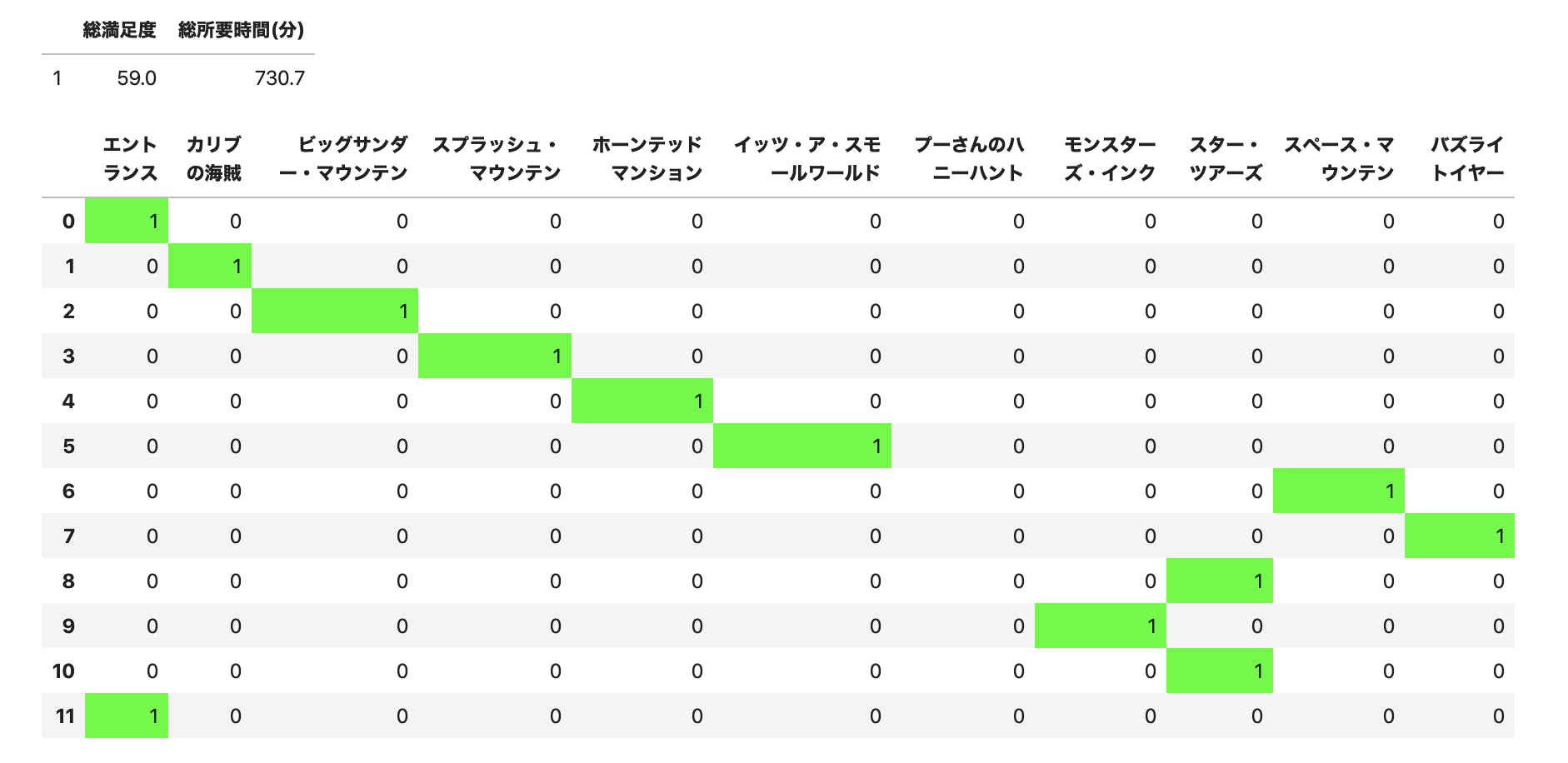
以下のようなものが最適解の一例として得られます。
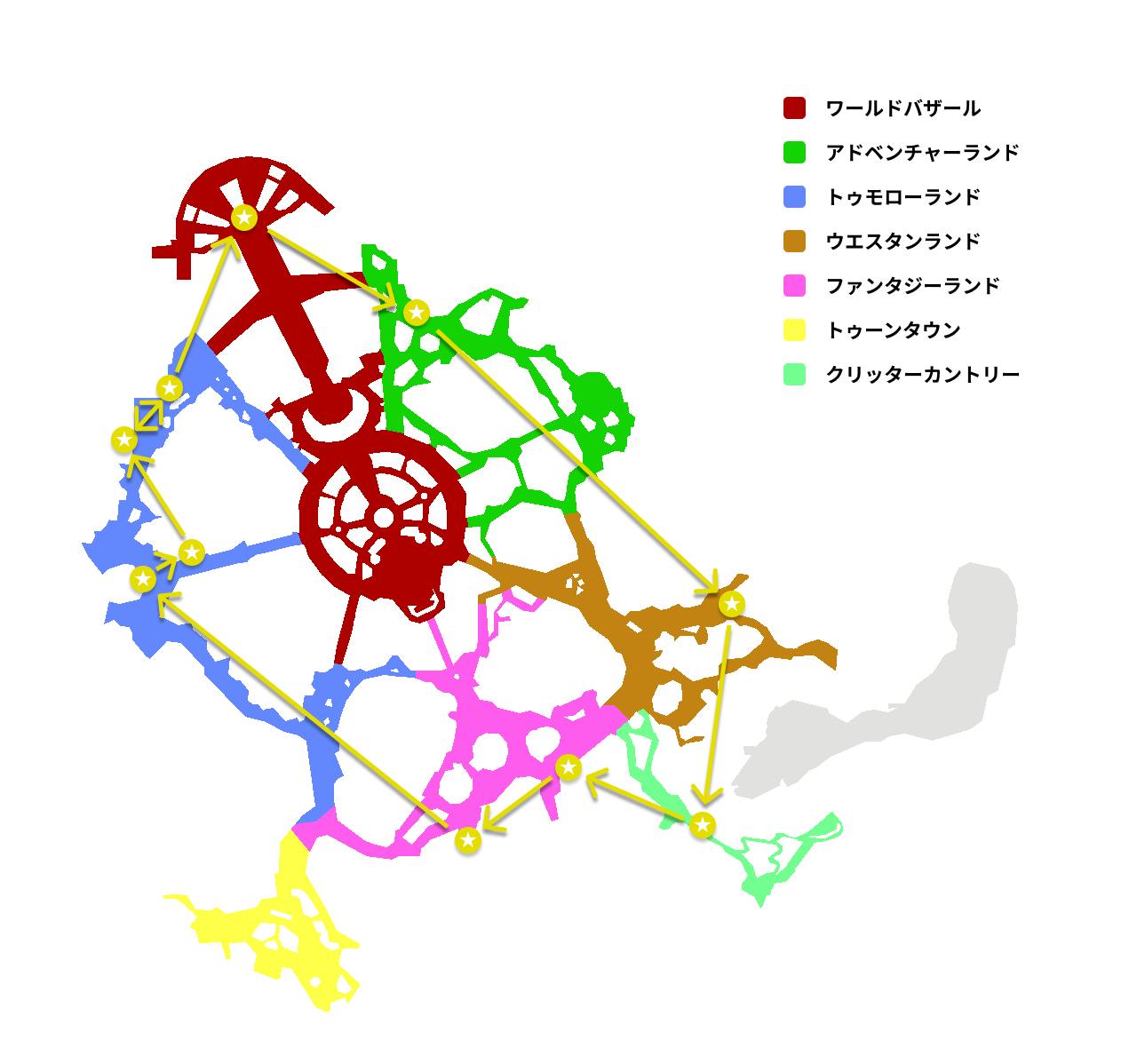
だいぶまともなコースになってきたので、次に移動距離ついて考えてみます。
各アトラクションの位置関係と上の図のコースは以下のようになります。
概略図なので実際の位置関係とは異なりますが、移動距離の大小関係は正しく表現されています。
スペースマウンテンとホーンテッドマンションの順番は逆の方が移動距離は短くなりますね。前述したように、移動距離を短くするのが理想ですが、具体的に総移動距離を〇〇m以内にしたいというのは現実的ではありません。
そこで、総所要時間が○○時間以内という制約を設定します。
移動時間と待ち時間を計算してこの制約を表現すれば、限られた時間内で総満足度を最大化してくれるので、自ずと移動時間と待ち時間が短くなってくれるはずです。この制約を表現するにあたり、以下の3つを定義しておきます。
- 滞在予定時間(分): $t_{max}$
- アトラクション $j$ のコスト(=待ち時間+所要時間)(分): $c_{j}\ (1 \leq j \leq n)$
- 2つのアトラクション $i, j$ 間の移動時間(分): $d_{i,j}\ (1 \leq i,j \leq n)$
総所要時間を 「利用するアトラクションの総コスト」 + 「総移動時間」に分けて考えます。
まず、利用するアトラクションの総コスト $C$ は最初に設定した目的項と同様の考え方で以下のように表せます。満足度 $s$ をコスト $c$ に置き換えただけです。
$$
C = \sum_{j=1}^{m}\sum_{i=1}^{n}c_{j}x_{i,j}
$$次に、総移動時間 $D$ は巡回セールスマン問題と同様の考え方で以下のように表せます。
(図で表現するのが難しくて断念しました...理解したい方は巡回セールスマン問題を調べてみてください)$$
D = \sum_{t=1}^{n-1}\sum_{i=1}^{m}\sum_{j=1}^{m}d_{i,j}x_{t,i}x_{t+1,j}
$$総所要時間 $(C+D)$ と、滞在予定時間 $t_{max}$ との差を制約項 $H_{b}$ として設定します。
$$
H_{b}=\sum_{j=1}^{m}\sum_{i=1}^{n}c_{j}x_{i,j}+\sum_{t=1}^{m-1}\sum_{i=1}^{n}\sum_{j=1}^{n}d_{i,j}x_{t,i}x_{t+1,j} -t_{max}
$$$H_{b}$ は総所要時間が滞在予定時間を超える場合、ペナルティとして値が大きくなるので制約項としての役割を果たしています。
ただし、総所要時間が短いほど $H_{b}$ は小さくなってしまうので総所要時間が短いコースが選ばれやすくなってしまいます。これについては後述するハイパーパラメータで調整します。制約D
制約項 $H_{b}$ を加えて最適化するとこのようになりました。
ちゃんと距離を考慮してホーンテッドマンションを先に行くようになりましたね。
ただ、スプラッシュマウンテンが連続するのが気になります。コンピュータ的には連続で乗ればその間の移動時間が0になるので、複数回利用する場合は連続にしてしまいます。
2回乗るのはOKだとしてもできれば連続は避けたいですよね。そこで、同一アトラクションを連続で利用してはいけないという制約を設定します。
これは列方向には青丸が隣接しないことに相当し、以下の式で表されます。$$
H_{c} = \sum_{j=1}^{m}\sum_{i=1}^{n-1}x_{i,j}x_{i+1,j}
$$図で表すとこんな感じです。
上の図では、1列目に青丸が隣接する部分があり制約違反のため $H_{c}=1$となります。
制約を満たしていれば $H_{c}$ は最小値0をとります。制約E
ここまで4つのアトラクションで考えてきたため、いきなりスプラッシュマウンテンといったようなコースになっています。
でも現実のコースでは、エントランスから入ってエントランスに帰ってくる必要がありますね。そこで、コースの最初と最後はエントランスを利用するという制約を設定します。
エントランスも一つのアトラクションとみなし、列として加えます。コースの途中で利用する必要はないので満足度は0にします。
エントランスが一列目とすると、この制約は以下の式で表されます。H_{d} = 2 - x_{1,1} - x_{n,1}図で表すとこんな感じです。1列目の先頭 $(x_{1,1})$ と末尾 $(x_{5,1})$ が青丸であれば制約を満たします。
制約を満たしていれば $H_{d}$ は最小値0をとります。
定式化まとめ
長くなりましたが以上でかなり妥当なコースが求まるようになりました。
ディズニーのコース最適化についての定式化を以下にまとめます。入力データ
変数 内容 $n$ 1つのコースにおけるアトラクション利用数(何個乗りたいか) $m$ アトラクション数(東京ディズニーランド: 34) $t_{max}$ 滞在予定時間(分) $s_{j}$ アトラクション $j$ の満足度 $(1 \leq j \leq n, 1 \leq s_{j} \leq 10)$ $c_{j}$ アトラクション $j$ のコスト(分) $(1 \leq j \leq n)$ $d_{i,j}$ アトラクション $i,j$ 間の移動時間(分) $(1 \leq i,j \leq n)$ 目的
- 総満足度の最大化
制約
- 同時に複数のアトラクションの利用は禁止
- アトラクションを複数回利用する場合は利用するたびに満足度が3ずつ減少
- 総所要時間が滞在予定時間以内
- 同一アトラクションの連続利用は禁止
- コースの最初と最後はエントランスを利用
エネルギー関数
\begin{align} H_{aim}&=-\sum_{j=1}^{m}\left(\sum_{i=1}^{n}x_{i,j}\left(s_j-\frac{3}{2}\sum_{i=1}^{n}x_{i,j}+\frac{3}{2}\right)\right) \\ H_{a}&=\sum_{i=1}^{n}\left(1-\sum_{j=1}^{m}x_{i,j}\right)^2 \\ H_{b}&=\sum_{j=1}^{m}\sum_{i=1}^{n}c_{j}x_{i,j}+\sum_{t=1}^{n-1}\sum_{i=1}^{m}\sum_{j=1}^{m}d_{i,j}x_{t,i}x_{t+1,j} -t_{max} \\ H_{c}&=\sum_{j=1}^{m}\sum_{i=1}^{n-1}x_{i,j}x_{i+1,j} \\ H_{d}&=2- x_{1,1}-x_{n,1} \end{align}最終的なエネルギー関数 $H$ は以下のようになります。
$\alpha,\beta,\gamma,\delta$ は制約の重みを表す正のハイパーパラメータです。H = H_{aim} + \alpha H_{a} + \beta H_{b} + \gamma H_{c} + \delta H_{d}(量子)コンピュータで解いてみる
定式化したエネルギー関数を用いて実際に解いてみます。
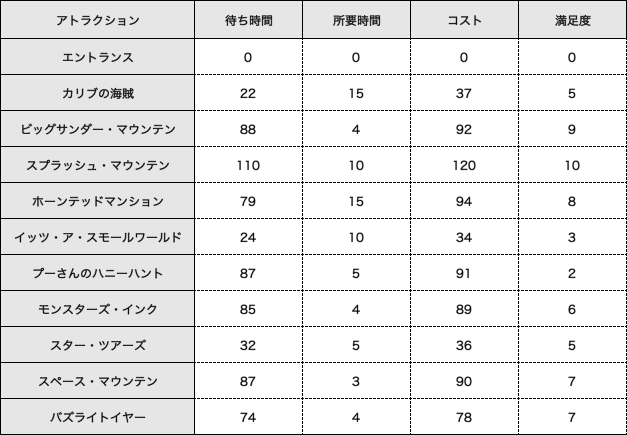
今回は独断と偏見で選んだ人気がありそうな10種類のアトラクションを対象とします。まず以下のような入力データを用意します。
待ち時間はこちらのサイトを参考にしました。混雑度が普通の土日レベルの日の各アトラクションの一日の平均待ち時間を使用します。
(待ち時間は刻々と変化する時系列データですが、計算簡略のためどの時間に行っても一定の待ち時間であるものと仮定します。)
所要時間はディズニーの公式サイトに掲載されているものを使用します。
コストは待ち時間+所要時間で、満足度は僕の好みです。アトラクション間の移動時間はデータが見つからず困っていたところ、ディズニー好きの友人が協力してくれてアトラクション間の距離を算出してくれました。
どうやって算出したのか聞いたら、Googleマップに各アトラクションと通路の分岐点をノードとして設定し、ダイクストラ法で最短距離を求めてくれたとのこと。
しかも、Googleマップだけだとキャストしか通れない通路もあるため、Googleマップをベースにしてゲストが通れる通路だけの地図を作ってから求めるという徹底ぶりです。理系のディズニー好きって恐ろしいですね...
↑ダイクストラでアトラクション間の最短距離を求めるために友人が作成してくれたマップ。
これを見てディズニーランドだとわかる人がいるのだろうか…入力データが用意できたので量子コンピュータに入力する形式に変換します。
本来は $H$ をどうにかして展開し、 $x$ の一次の項と二次の項の係数行列(QUBO行列)を作成するのですが、今回は可読性の高いコードでQUBO行列を生成してくれるpythonのライブラリpyquboを利用しました。import numpy as np import pandas as pd from pyqubo import Array, Sum, Num, Constraint, Placeholder cost_data = pd.read_csv('tdl_cost.csv') distance_data = pd.read_csv('tdl_distance.csv', header=None) s = cost_data['value'].to_numpy() c = cost_data['cost'].to_numpy() d = (distance_data / 80).to_numpy() # 歩行速度を分速80mと仮定して移動時間(分)に変換する n = 12 m = len(c) t_max = 60 * 12 x = Array.create('x', (n, m), 'BINARY') # 目的項 H_aim = -Sum(0, m, lambda j: Sum(0, n, lambda i: x[i,j]) * (s[j] - 1.5 * Sum(0, n, lambda i: x[i,j]) + 1.5)) # 同時に複数のアトラクションの利用は禁止 H_a = Constraint(Sum(0, n, lambda i: (1 - Sum(0, m, lambda j: x[i,j])) ** 2), 'alpha') # 総所要時間が滞在予定時間以内 C = Sum(0, m, lambda j: Sum(0, n, lambda i: (c[j] * x[i,j]))) D = Sum(0, n-1, lambda t: Sum(0, m, lambda i: Sum(0, m, lambda j: (d[i,j] * x[t,i] * x[t+1,j])))) H_b = Constraint(C + D - t_max, 'beta') # 同一アトラクションの連続利用は禁止 H_c = Constraint(Sum(0, m, lambda j: Sum(0, n-1, lambda i: x[i,j] * x[i+1,j])), 'gamma') # コースの最初と最後はエントランスを利用 H_d = Constraint(2 - x[0,0] - x[n-1,0], 'delta') # エネルギー関数(目的項にも重みを付けました) H = 30 * H_aim + Placeholder('alpha') * H_a + Placeholder('beta') * H_b + Placeholder('gamma') * H_c + Placeholder('delta') * H_d # 制約項の重み付けハイパーパラメータ params = { 'alpha': 60, 'beta': 2, 'gamma': 60, 'delta': 100 } # QUBO行列を生成 model = H.compile() qubo, offset = model.to_qubo(feed_dict=params)最後の行で生成したquboを量子コンピュータに投げれば最適化した結果が得られます。
一般利用可能な量子コンピュータとしてはD-Waveというマシンがありますが、D-Waveは解けるQUBOモデルに制限があって今回の問題は適していません。今回は大学の研究で使用している富士通デジタルアニーラを使用しました。
デジタルアニーラは量子現象に着想を得たデジタル回路で構成されたもので、正確には量子コンピュータではありません。
なので、「夢の国の最適経路を量子アニーリングで求めてみた」と謳っていますが、すみませんタイトル詐欺ですm(_ _)m
量子アニーリングのシミュレーション的なものという認識でお願いしますm(_ _)mデジタルアニーラを使用するコードは非公開のライブラリを用いているので掲載できませんが、結果は以下のようになりました。
総所要時間は10分オーバーしてしまっていますが許容できる範囲です。
ハイパーパラメータをチューニングすれば改善されるはずです。
プーさんのハニーハントだけ利用していませんが、コストが4番目に高いのに満足度を最低にしているので妥当な結果です。ディズニーのマップにコースを描画すると以下のような感じです。
矢印は直線ルートなので正確ではありませんが、パークを一周するような無駄のないコースになってくれました。
Webアプリ化
協力してくれたディズニー好きの友人にコースの妥当性を確認してもらってたのですが、その都度ローカルのPCで入力を変更して計算し直し、結果を送るのがめんどくさかったのでWebアプリ化してみました。
ディズニーシーのデータもあるのでランドとシー両方試せます!
バックエンド
最適化処理をしてコースを返すだけのシンプルなAPIが一つあればいいのでGoogle Cloud Functionsを利用しました。
基本的にはここのpythonの実装と同じで、満足度 $(s)$、アトラクションの利用個数 $(m)$、 滞在予定時間 $(t_{max})$ をHTTPリクエストからの入力にしました。
肝心のアニーリング処理ですが、公開する私的なアプリケーションで研究用のマシンを使うわけにはいかないので代替案を考える必要がありました。ありがたいことにpyquboにはSA(Simulated Annealing)が実装されているので、Cloud Functions上ではこちらを利用しました。
生成したQUBO行列に対して以下のコードで簡単にシミュレーションできます。
※もちろんこれも量子アニーリングではありませんm(_ _)mfrom pyqubo import solve_qubo raw_solution = solve_qubo(qubo) decoded_solution, broken, energy = model.decode_solution(raw_solution, vartype='BINARY', feed_dict=params)↑で求めた結果をいい感じに整形して以下のようなjsonを返すAPIにしました。
{ "totalScore": 72.0, "totalAttractionTime": 699, "totalTravelTime": 26, "totalTime": 725 "course": [ { "attraction": "エントランス", "attractionId": 0, "waitingTime": 0, "requiredTime": 0.0, "startTime": "09:00", "endTime": "09:00", "x": 655, "y": 830 }, { "attraction": "モンスターズ・インク", "attractionId": 31, "waitingTime": 85, "requiredTime": 4.0, "startTime": "09:02", "endTime": "10:31", "x": 815, "y": 740 }, { "attraction": "スペース・マウンテン", "attractionId": 33, "waitingTime": 87, "requiredTime": 3.0, "startTime": "10:35", "endTime": "12:05", "x": 1005, "y": 600 }, ... { "attraction": "エントランス", "attractionId": 0, "waitingTime": 0, "requiredTime": 0.0, "startTime": "21:13", "endTime": "21:13", "x": 655, "y": 830 } ] }フロントエンド
時間や満足度の入力フォームとAPIを叩いて結果を表示する機能だけでよかったので、最近よく見るNuxt + Vuetifyでさくっと作り、SPAとしてfirebaseでホスティングしています。(faviconがNuxtだしVuetify感が全面的に出ててちょっと恥ずかしい...)
理想としてはディズニーの公式マップに経路を描画してみたかったです。
一応ダメ元で東京ディズニーリゾートに問い合わせたところ、普通にNGでした。
でもさすがディズニーと言うべきか、公式のマップ画像使わせてくれというふざけた大学生にも丁寧な対応をしてくれました。東京ディズニーランド・シーのマップの画像を個人の方のWEBサイトに掲載する事はご遠慮頂いております。
せっかく、ご連絡をいただきましたにもかかわらず、このような回答をさしあげますことを、私どもも心苦しく存じますが、何とぞご理解ください。おわりに
卒論で量子アニーリングをやるので、いろいろな組合せ最適化問題を解いて慣れようというのが元々のきっかけでした。
でもどうせ解くなら現実的でおもしろい問題がいいなと思ってこんな問題を設定しました。当初は卒論の息抜き程度に軽くやるつもりでしたが、友人が驚異的なくらい協力してくれたし(距離を算出してくれた人)、想像以上にまともな結果になったのでせっかくだからアウトプットしておこうと思ってまとめました。
実際のディズニーはもっと複雑な要素が絡んでくるのでアプリケーションとしては以下のような課題が山積みです。
- 待ち時間を時系列データとして扱っていない(どの時間に行っても同じ待ち時間としている)
- ファストパスを考慮していない
- ランチやディナー、ショーなどアトラクション以外のものを考慮していない
要するにまだまだクソアプリなので今後暇なときに進化させていこうかなと思ってます。
他にも量子アニーリングで解く問題募集してるので、おもしろいアイデアあればコメントに書いていただけると嬉しいです!






- 投稿日:2019-11-24T19:02:39+09:00
【unix】ゾンビプロセス・孤児プロセスって何。
自分の記録用
環境
さくらレンタルサーバー
Flask 1.1.1
Werkzeug 0.16.0やりたいこと
クライアントからリクエストがあった際に、
- 親プロセス
- forkで子プロセスを生成
- クライアントに、responseを返す
- 子の終了を待たずに、消滅
- 子プロセス
- クライアントから渡された処理を行う
- 処理終了後、消滅
疑問点
親が先死ぬとゾンビだ孤児だが出ちゃって邪魔らしい?
double fork?みたいなことしなきゃいけないらしい?
といった記述があったので、実際に調べてみた。結果
ゾンビプロセスとは
処理の終了した子プロセスで、親プロセスのwaitを待っている状態のプロセス。
子プロセスがforkされた段階でプロセステーブルに子プロセスが追加され、親プロセスのwaitをもって子プロセスはプロセステーブルから削除される。
つまり、処理は終了しているが親にwaitで引き取られていないプロセスのこと。孤児プロセスとは
親プロセスが先に終了してしまい、親のwaitにより引き取られなくなった子プロセスのこと。親プロセスが先に死んでしまった子プロセスは、initプロセスにre-parentingされ、以後initプロセスが親プロセスとなる。
initプロセスは積極的にwaitを実施し、孤児プロセスを終了させる。まとめ
つまり、親プロセスが常駐プロセスで、いろんなタイミングで子を作り、どのタイミングでwaitを呼べばわからないような場合に、ゾンビプロセスが大量にできてしまいシステムを圧迫する、ということっぽい。
今回実現したい機能では、先に親プロセスがさっさと死ぬため、子プロセスはinitにきちんと引き取られrて終了するだろうから、double forkとかしないでよさげ。
参考ページ
用語のイメージが掴みやすい
まとめとしてわかりやすい
double forkが必要な場合やその理由について
HATENA Blog : Double forkによるプロセスのデーモン化と、ファイル変更時の自動サーバーリロードの実装 (Python)
- 投稿日:2019-11-24T19:00:46+09:00
リングフィットアドベンチャーを買いたかった話
背景
みなさん運動してますか?
引きこもりにはもってこいのリングフィットアドベンチャーが最近任天堂から発売されました!!
私も買いたかったのですが、どこも品切れらしくて辛いです。かと言って、メルカリとかヤフオクで転売ヤーから高値で買うのも腹立つので、なんとか正規ルートで買おうと頑張ってみました。やったこと
色々ググってるとどうも時々通販で、商品が入荷され在庫が復活するということを聞きました。ただ、ずっと通販サイトの前で張り付いているわけには行かないので、在庫が復活したら通知してくれないかなーと考えていました。
そこで、こういう便利なサイトをつかって、ここで在庫が復活していたらLineで通知するアプリを作りました。成果物はこちら!
https://github.com/aitaro/inventory-notificationちなみにitemcodeを変えたら他の商品でも使えます。
環境構築
正直言語はなんでもいいです。個人的にRubyが好きなのですが、なんとなくPythonにしました。
開発はローカルでやりますが、在庫通知という特性上、どこかにデプロイすることを念頭において開発しましょう。フォルダ構造
. ├── README.md ├── main.py └── requirements.txtrequirements.txtline-bot-sdk selenium chromedriver-binary実装
基本的には2ステップです。
- net-zaiko.comからスクレイピング
- lineへ送信
これを適当なサーバにデプロイします。(今回はheroku)
スクレイピングはseleniumを使う方法とbeautifulsoup4を使う方法がありますが、このサイトではアクセスしてから他のサイトの在庫情報を取りに行くので、ブラウザの挙動をそのまま再現するseleniumを使います。また、lineはここからbotを作成し、アクセストークンを発行します。コード中の
GOOGLE_CHROME_SHIMはchromeの実行ファイルの場所です。main.pyfrom linebot import LineBotApi from linebot.models import TextSendMessage from selenium import webdriver from selenium.webdriver.chrome.options import Options import chromedriver_binary import re import time import os # 在庫情報取得 # リングフィットアドベンチャー item_id = '4902370543278' # item_id = '4988013097025' # ブラウザーを起動 options = Options() options.binary_location = os.getenv('GOOGLE_CHROME_SHIM') options.add_argument('--headless') driver = webdriver.Chrome(options=options) # net-zaikoにアクセス url = 'https://www.net-zaiko.com/item/' + item_id driver.get(url) time.sleep(10) targetElements = driver.find_elements_by_css_selector("#sl0 .siSa,.siSb,.siSc,.siSd,.siSe") title = driver.find_element_by_id("itmH0").text # それぞれのネットショップで在庫があるか確認 flag = False for el in targetElements: # amazonはマケプレでぼったくってくるから除外 pattern = r'Amazon\.co\.jp' result = re.search(pattern, el.text) if not result: flag = True print('在庫あり') print(el.text) print(title) # ブラウザーを終了 driver.quit() # Lineに通知 line_bot_api = LineBotApi(os.getenv('LINE_CHANNEL_ACCESS_TOKEN')) if flag: messages = TextSendMessage(text=f"{title}の商品在庫があります!\nこちらよりアクセスして下さい{url}") line_bot_api.broadcast(messages=messages)工夫した点
- サイトによって在庫ありの表記に揺れがあったので、緑枠(siSa 〜 siSe)で在庫ありを判定
- Amazonはマケプレボッタクリ詐欺がひどいので除外
デプロイ
chromeが入って、定期実行できる必要があったので、その条件で色々検討したのですが、herokuが無料で行けそうだったのでherokuにしました。
herokuでのアプリに作り方は割愛しますが、add-onでheroku schedulerを入れるのと、buildpackでchromeとchromedriveを入れるといけます。ここらへん参照。感想
2時間ぐらいかけてつくりました。まだ買えてません。早くほしいです。
スクレイピングは迷惑にならない範囲でやりましょう。
- 投稿日:2019-11-24T18:37:27+09:00
VScode+Pyrightで新しめのPython言語機能の混入を防ぐ
Pyrightって何?
PyrightはMicrosoft謹製のPython向け静的解析ツールです。
もともと型チェックが得意な同ツールですが、型チェックの他にもコード内に意図せず未サポートの文法(Python 3.8のセイウチ演算子など)が使われていないかチェックする機能も備えています。
このチェック機能があれば、Python 3.8の新機能盛り沢山のコードを配布したら配布先で動かなかった!(Python 3.4 (2014年) のままだった)、といったトラブルを未然に防ぐことができます。
このようにPyrightは型チェックだけでなくコード側でPythonの対象バージョンを絞ることもでき非常に強力な静的解析ツールと言えるでしょう。PyrightはVScodeの拡張機能として利用可能です。
余談: 名称の「Pyright」はパイライト鉱石(Pyrite; 黄鉄鉱)とかけているようです。ロゴのデザインを見ても素敵ですね。
やり方
さて本題です。設定の手順は以下の通りです。
- VScodeの拡張機能Pyrightをインストールする。
- 自身のプロジェクトのルートディレクトリに
pyrightconfig.json(下記参照)を用意する。- VScodeを再起動する(設定を反映させるため)。
pyrightconfig.json{ "pythonVersion": "3.4" }コメント: 上記の設定では、自身のプロジェクトの中でPython 3.4でサポートされていない文法(ex. セイウチ演算子、f記法)がProblemとして検出されます。
サンプル
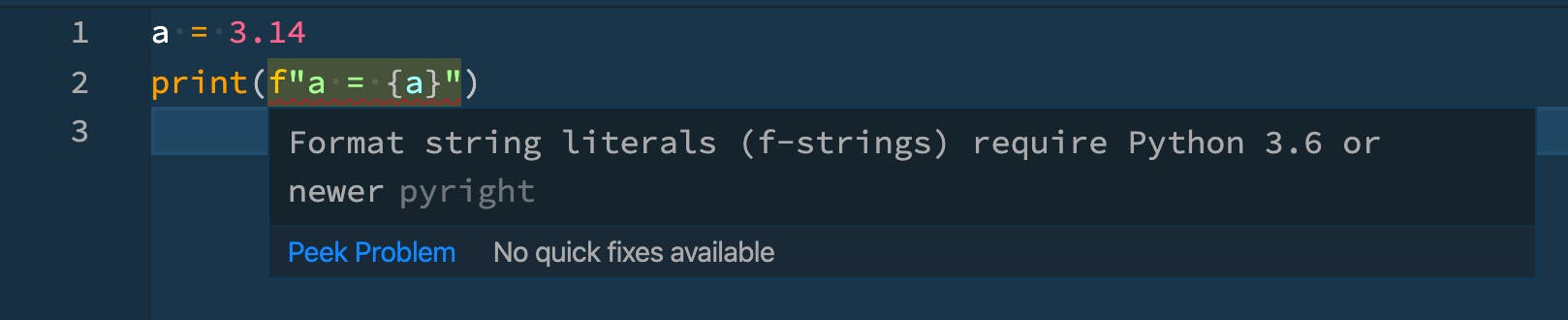
実際に未サポートの文法(f記法)を使用した場合の結果を見てみます。下記のサンプルコードをご覧ください。
test_pyright.pya = 3.14 print(f"a = {a}")見ての通りPython 3.4では未サポートのf記法が使用されています。
このときVScode上では、下のスクリーンショットのとおり、該当箇所に赤い下線が引かれてProblemとして強調されていることがわかります。またパネル部分にもProblemとして表示されます。▼ VScodeの画面(上:エディタ部分、下:パネル部分)
コメント: 赤い下線の箇所にカーソルを乗せることで「 f記法はPython 3.6以上が必要です 」と書かれたツールチップが表示されます。
このチェック機能があれば、「○○○はPython 3.8からだっけな? △△△は〜」と呟きながらその都度リファレンスを確認せずに済みますのでとっても快適です。
Pyright、すごい。
参考リンク
- microsoft/pyright: Static type checker for Python(GitHubのページ)
- pyright/configuration.md at master · microsoft/pyright(pyrightconfig.jsonの書き方について)
- Pyrightで型チェックしたいのにimportで怒られるときの対処法 - Qiita(pyrightconfig.jsonの存在を知るきっかけになった記事です。感謝?)


- 投稿日:2019-11-24T18:37:27+09:00
VScode+Pyrightで新しめのPython文法の混入を防ぐ
Pyrightって何?
PyrightはMicrosoft謹製のPython向け静的解析ツールです。
もともと型チェックが得意な同ツールですが、型チェックの他にもコード内に意図せず未サポートの文法(Python 3.8のセイウチ演算子など)が使われていないかチェックする機能も備えています。
このチェック機能があれば、Python 3.8の新機能盛り沢山のコードを配布したら配布先で動かなかった!(Python 3.4 (2014年) のままだった)、といったトラブルを未然に防ぐことができます。
このようにPyrightは型チェックだけでなくコード側でPythonの対象バージョンを絞ることもでき非常に強力な静的解析ツールと言えるでしょう。PyrightはVScodeの拡張機能として利用可能です。
余談: 名称の「Pyright」はパイライト鉱石(Pyrite; 黄鉄鉱)とかけているようです。ロゴのデザインも素敵ですね。
やり方
さて本題です。設定の手順は以下の通りです。
- VScodeの拡張機能Pyrightをインストールする。
- 自身のプロジェクトのルートディレクトリに
pyrightconfig.json(下記参照)を用意する。- VScodeを再起動する(設定を反映させるため)。
pyrightconfig.json{ "pythonVersion": "3.4" }コメント: 上記の設定では、自身のプロジェクトの中でPython 3.4でサポートされていない文法(ex. セイウチ演算子、f記法)がProblemとして検出されます。
サンプル
実際に未サポートの文法(f記法)を使用した場合の結果を見てみます。下記のサンプルコードをご覧ください。
test_pyright.pya = 3.14 print(f"a = {a}")見ての通りPython 3.4では未サポートのf記法が使用されています。
このときVScode上では、下のスクリーンショットのとおり、該当箇所に赤い下線が引かれてProblemとして強調されていることがわかります。またパネル部分にもProblemとして表示されます。▼ VScodeの画面(上:エディタ部分、下:パネル部分)
コメント: 赤い下線の箇所にカーソルを乗せることで「 f記法はPython 3.6以上が必要です 」と書かれたツールチップが表示されます。
このチェック機能があれば、「○○○はPython 3.8からだっけな? △△△は〜」と呟きながらその都度リファレンスを確認せずに済みますのでとっても快適です。
Pyright、すごい。
参考リンク
- microsoft/pyright: Static type checker for Python(GitHubのページ)
- pyright/configuration.md at master · microsoft/pyright(pyrightconfig.jsonの書き方について)
- Pyrightで型チェックしたいのにimportで怒られるときの対処法 - Qiita(pyrightconfig.jsonの存在を知るきっかけになった記事です。感謝?)
- 投稿日:2019-11-24T18:25:23+09:00
Atcoderで累積和が出てきたのでこれを機にちょっと勉強する
累積和とは
サイズNの配列があって、ある区間iからjまでの和$(0<=i<j<=N)$を爆速で取り出すことができるアルゴリズム。
すでに先人達が多くの解説記事を上げているので、詳細な解説はここでは書かない。
(個人的にはけんちょんさんの記事がわかりやすかった)
累積和を何も考えずに書けるようにする!Pythonで累積和を実装する
脳筋実装すればこうなる。
# 1~10のリスト a = [1,2,3,4,5,6,7,8,9,10] # 累積和用リスト s = [0] * 10 s[0] = a[0] for i in range(1, 10): s[i] = s[i-1] + a[i] print(s) # [1, 3, 6, 10, 15, 21, 28, 36, 45, 55]例えば、インデックスが3〜7の区間の和を取りたければ
7までの和ー2までの和で求めることができる。print(s[6] - s[1]) #25こういった配列sを作る方法は上に上げた脳筋forループの他にもいくつかあるが、pythonを使う上で一番早いのはおそらく
Numpy.cumsumである。速度については下記記事で検証されているので、気になる方はどうぞ。
リストから和のリストを得る(累積和)
cumsumの使い方は↓import numpy as np # 1~10のリスト a = [1,2,3,4,5,6,7,8,9,10] # 累積和用リスト s = np.cumsum(a) print(s) # [ 1 3 6 10 15 21 28 36 45 55]Pythonは便利なライブラリが多くていいですね。
おまけ
累積和を勉強しようと思ったきっかけ
昨日参加したDDCC2019( https://atcoder.jp/contests/ddcc2020-qual )のB問題にて、累積和を使えば簡単に解けるという話を聞いた。
(脳筋実装で 1WA 1TLE 58分でACしたのは内緒)
Bに58分かかったんですが、累積和とやらを知ってたらもっと早く解けるんですか?
— サーロイン (@sirloin2299) November 23, 2019Twitterでフォローしてる競プロerの方々もよく累積和ガーとよく言っているし、有名なアルゴリズムっぽいのでこれを機に勉強してみるか!となった。
- 投稿日:2019-11-24T18:15:03+09:00
Ubuntu18.04にPython3.8 + Pipenv環境を構築
はじめに
Ubuntu18.04に環境構築したので、作業メモとして残します。
Python3.8のインストールにはpyenvを使用します。環境
Ubuntu 18.04.3 LTS
手順
1.Git インストール
$ sudo apt install git2.pyenv インストール
githubからpyenvをクローンする。
$ git clone https://github.com/pyenv/pyenv.git ~/.pyenvパスを環境変数に設定。
Ubuntuだと.bash_profileでなく.bashrcに記載する。
[参考]
https://github.com/pyenv/pyenv#basic-github-checkout$ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrcシェル起動時にpyenvが起動されるように設定。
$ echo -e 'if command -v pyenv 1>/dev/null 2>&1; then\n eval "$(pyenv init -)"\nfi' >> ~/.bashrcシェル再読込 & インストール確認。
$ exec "$SHELL" $ pyenv --version pyenv 1.2.15-2-g22c020223.Python3.8 インストール
Pythonのビルドに必要なパッケージをインストールする。
[参考]
https://github.com/pyenv/pyenv/wiki#suggested-build-environment$ sudo apt-get update; sudo apt-get install --no-install-recommends make build-essential libssl-dev zlib1g-dev libbz2-dev libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev xz-utils tk-dev libxml2-dev libxmlsec1-dev libffi-dev liblzma-devPython 3.8.0 をインストール(時間がかかるので気長に待ちます)
$ pyenv install 3.8.0インストール確認
$ pyenv versions * system 3.8.04.ローカルで使用するPythonを指定する
pyenvでインストールしただけではPython3.8は有効にならないので、明示的にバージョンを指定する。
$ mkdir -p ~/sample/py38 $ cd ~/sample/py38 $ pyenv local 3.8.0ローカル以下(上の例だとpy38ディレクトリ以下)でpython3.8が有効になる。(pipコマンドも同様)
$ python --version Python 3.8.0 $ pip --versoin pip 19.2.35.Pipenv インストール
$ pip install pipenv $ pipenv --version pipenv, version 2018.11.266.Pipenv プロジェクト作成
環境変数に
PIPENV_VENV_IN_PROJECT=trueを指定すると、プロジェクト直下にvenvディレクトリが作成される。vscodeとの連携がしやすいため、ここではtrueに設定する。$ mkdir pipenvdemo $ cd pipenvdemo $ export PIPENV_VENV_IN_PROJECT=true $ pipenv --python 3
- 投稿日:2019-11-24T18:14:31+09:00
一定間隔処理でつまずいたので共有
※Python歴3ヶ月の新米です。
Windows10
python3.6.8を利用しています背景
一定間隔でネットから情報を取ってくる必要がありました。
初めにseleniumとchromedriverで情報採集する関数を作り、テストした結果正常に動きました。
次にこちらの記事を見て、まさにこれだ!となったので関数を置き換えて実行しました。
ところがChromeが2つ開いて全ての動作が2回実行されてしまっていました。
いやあ困った!注意書き
さて以下本題ですが、自分はこうしたら直ったよと言うただの報告です。詳しい人がいらっしゃいましたらコメント欄に解説お願いいたします。その際強い言葉を使わないようにお願いします。怖いので。
方法
t.start()
↓
↓
t.run()に変更するだけです。
結果
結果、2度実行されると言うことは防がれ上手いこと情報を引っ張ってこれています。めでたしめでたし。
たったこれだけの作業なのにまさかstartを変えたら上手く行くとは思わず時間が溶けたので似たような初心者を減らすために書きました。
解決のためにネットサーフィンしまくってる時に、この問題に直面している海外の人を見かけたので日本人にもいるはず...!という訳で考察はすごい人お願い致しますm(._.)m
考察
- 投稿日:2019-11-24T18:11:28+09:00
Pytestで標準出力をテストする
業務でPythonを使うことになり、標準出力をテストしたかったのでメモとして
準備
- Python 3系
- pytest
pip install pytestテスト対象コード
下記プログラムをテストしたいと思います。
sayメソッドで標準出力へ出すだけです。hogehoge.pyclass HogeHoge: def __init__(self, name): self.name = name def say(self): print("Hello ! My name is " + self.name + ".")テストコード
pytestにある fixture、capfdを使うtest_hogehoge.pyfrom hogehoge import HogeHoge def test_say(capfd): instance = HogeHoge("Taro") instance.say() out, err = capfd.readouterr() assert out == "Hello ! My name is Taro.\n" assert err is ''[Sun Nov 24 17:58:49 2019] Running: c:\python\python.exe -m pytest ============================== test session starts =============================== platform win32 -- Python 3.7.2, pytest-5.3.0, py-1.8.0, pluggy-0.13.1 rootdir: D:\Document\repository\study_pytest collected 1 item test\test_hogehoge.py . [100%] =============================== 1 passed in 0.08s ================================まとめ
標準出力のテストには、
capfdを使おう。標準エラーも取得できます。
- 投稿日:2019-11-24T18:01:22+09:00
BoxCox変換と木系アルゴリズム
機械学習の勉強仲間の友人がKaggleのハウスプライスの課題で、
>Box-cox変換をしたという話をしていました!
それで精度が上がったとのこと!https://sonaeru-blog.com/kaggle-4/
上記の記事を参考にしたそうです。そもそもBox-cox変換ってなんや!!と思いましたので、
自分なりに調べたことをメモにします。その友人曰く、
>正規分布に近づけるという意味では対数化と同じようなものなのかなととのこと。
Box-cox変換ってなに??
こちらの記事が、大変参考になりました。
https://gakushukun1.hatenablog.com/entry/2019/04/29/112424式
変換前後
対数変換をより一般化したものと考えると良いように思います。
実際λ=0のときには、対数変換になります。対数変換は、どちらかというと、上の図に近いような0でピークがあって、
裾野が正規分布よりずっと長い分布なら、理論的に完璧に正規分布に置き換えることができる。実際上の方のグラフは下に比べて、λが0に近い値なので、
これくらいの分布なら、多分、対数変換でも線形回帰でほぼ問題ないような気がします。
(なんとなくこれまで拙い自分の経験則。と言いつつ、Box-cox変換したらもっと精度上がる?)しかし、そもそもこれって、線形回帰アルゴリズムを前提としてますよね!
決定木系のアルゴリズムはBox-coxが必要か?
Kagglerとしての順位を少しでも上げたい自分として、
個人的に一番きになるのは、LGBMのような、いわゆる「木系」は、
説明変数の特徴量エンジニアリングとして、
box_coxが不要と考えて問題ないのか?それとも使った方が良いのか??https://toukei-lab.com/box-cox%E5%A4%89%E6%8F%9B%E3%82%92%E7%94%A8%E3%81%84%E3%81%A6%E6%AD%A3%E8%A6%8F%E5%88%86%E5%B8%83%E3%81%AB%E5%BE%93%E3%82%8F%E3%81%AA%E3%81%84%E3%83%87%E3%83%BC%E3%82%BF%E3%82%92%E8%A7%A3%E6%9E%90
>最近流行りの機械学習手法はノンパラメトリックモデルと呼ばれ、
>背後に分布を想定していないものが多いです。こちらの記事によると不要とのこと!!
「numericなパラメータも、結局大小関係でしか判定され得ないから」
が理由だと思ってます。ただ、目的変数に関しては、必ずしもそうでないように思う。
(実際、目的変数を対数にとることも多いので)
その理由は数少ない大きな外れ値への、モデルのペナルティを下げるため
と理解しています。じゃあ、
目的変数をBoxCock変換する場合はあり得るのか?
https://books.google.co.jp/books?id=t1a_DwAAQBAJ&pg=PA222&lpg=PA222&dq=%E7%9B%AE%E7%9A%84%E5%A4%89%E6%95%B0+boxcox&source=bl&ots=L7yjHQ6y6G&sig=ACfU3U3U1ugf0XhDVN_4fKAVnYe9xcFBSQ&hl=ja&sa=X&ved=2ahUKEwi2p_-itoLmAhXZA4gKHUutDmcQ6AEwBXoECAoQAQ#v=onepage&q=%E7%9B%AE%E7%9A%84%E5%A4%89%E6%95%B0%20boxcox&f=false
どうやらあるようです。
ただそれはすなわち、コスト関数にRMSEを使わないことと、
多分同義なので、そちらの選択の方が直観的な気がします。
https://www.sciencedirect.com/science/article/abs/pii/S0031320396000775?via%3Dihub
そして、見事に目的変数をboxcox変換するようなコスト関数を実装しましたというabstractの論文を発見しました。中身は見れねぇ!し、ちょっと飽きたので、この辺にしておきます。
勉強は積み重ね
今回、知らない言葉を調べ初めて、自分なりに納得感のある答えに辿り着いた上で、
新たな疑問の仮説を立て、それについての知見を得られたのは、非常に気持ち良い体験でした。でも、一つ一つは最近知ったばかりのことの積み重ねだなと感じました。
・指数関数についてそこそこ知ってる(これは昔のおかげ)
・β関数について知ってる(これは統計勉強会です)
・木系は変換が不要(これは昨日、渡辺さんが言ってました)
・目的変数は変換することがある(これは最近よく出くわす)
・RMSEは残差の分布を正規分布と仮定してる(これは授業でやりましたね)
・コスト関数は個別に実装できる(これは最近のKaggleです)引き続き頑張ろうと思います。
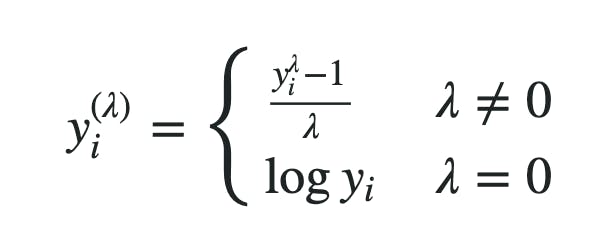
- 投稿日:2019-11-24T17:59:59+09:00
Remotte(リモッテ)で時系列データの詳細を見る
前回は利用者としてログインし、アプリの利用ページを表示してみた。
今回はその画面から「詳細画面」を表示してみる。準備
リモッテでは、利用者ログインし、画面左上のメニューボタンを押し、ステーションの承認をした後、表示したい「利用ページ」を選択することでアプリの画面を表示する。まずは「ステーションの管理」アプリの利用ページを表示するところまでの操作をしておこう。
詳細画面を表示
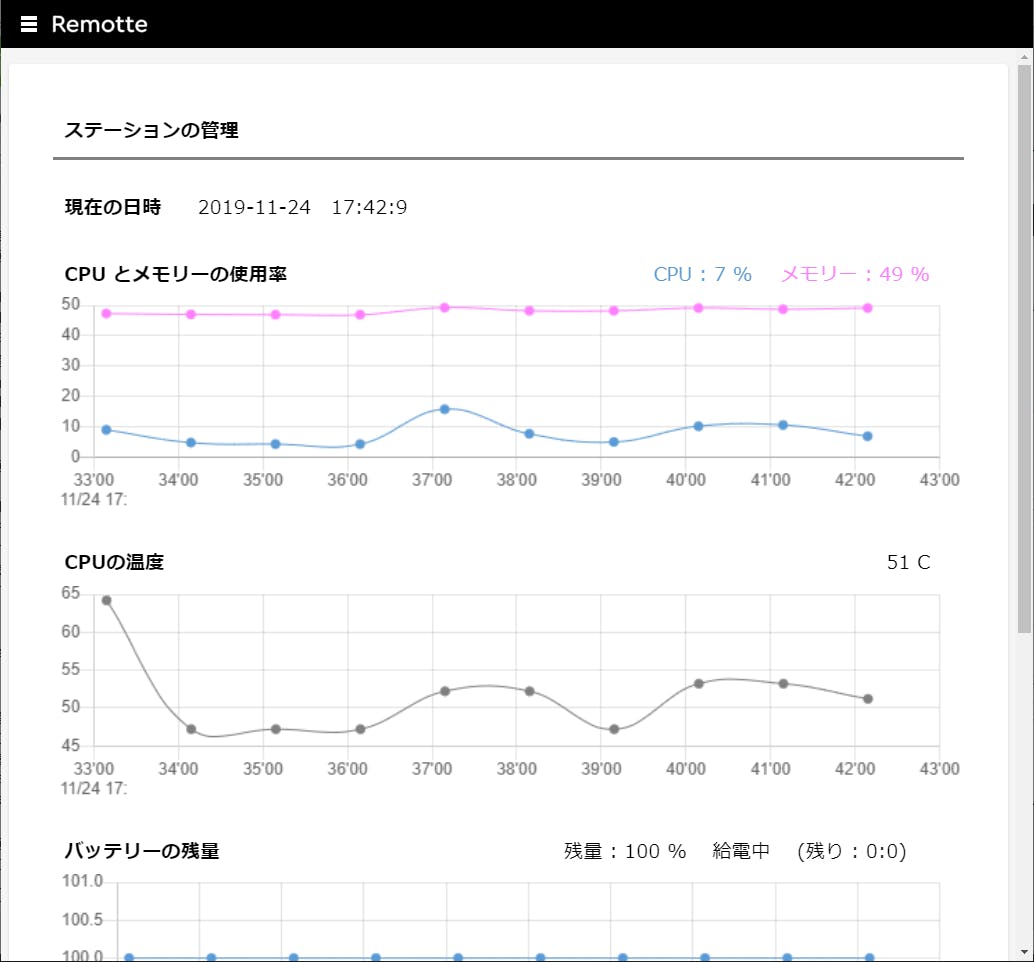
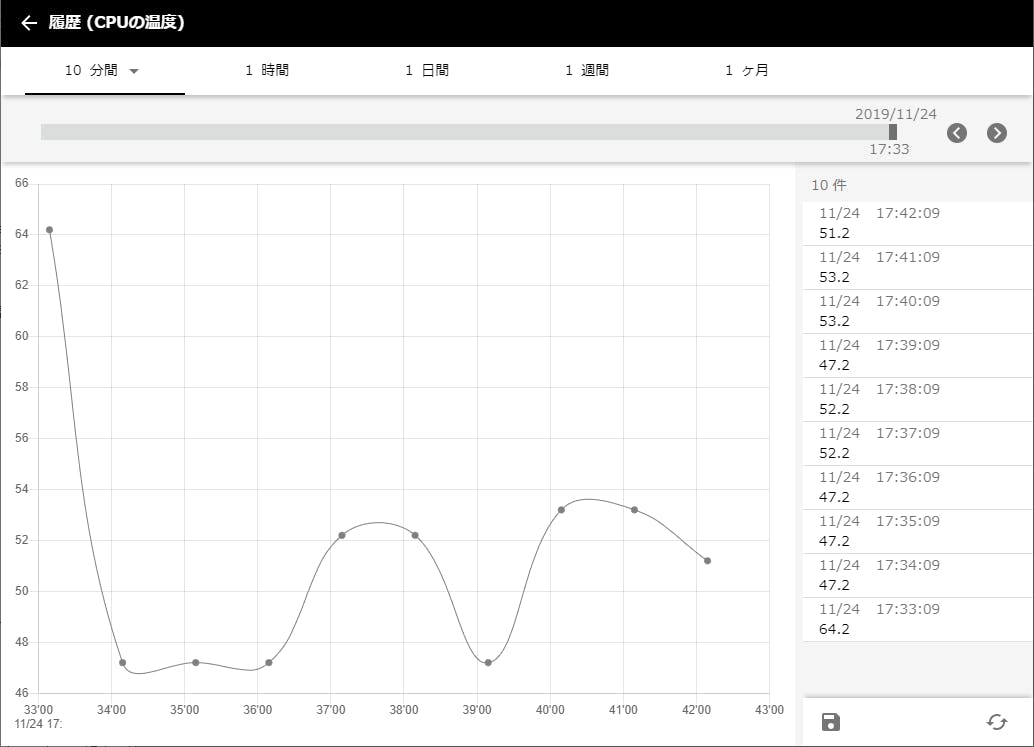
上記の様に、「ステーションの管理」アプリの利用ページ「現在の状態」にて、グレー色の折れ線グラフとして表示されている「CPU の温度」には過去10分間の履歴が表示されている。このグラフをダブルクリックして履歴の詳細画面を表示してみよう。
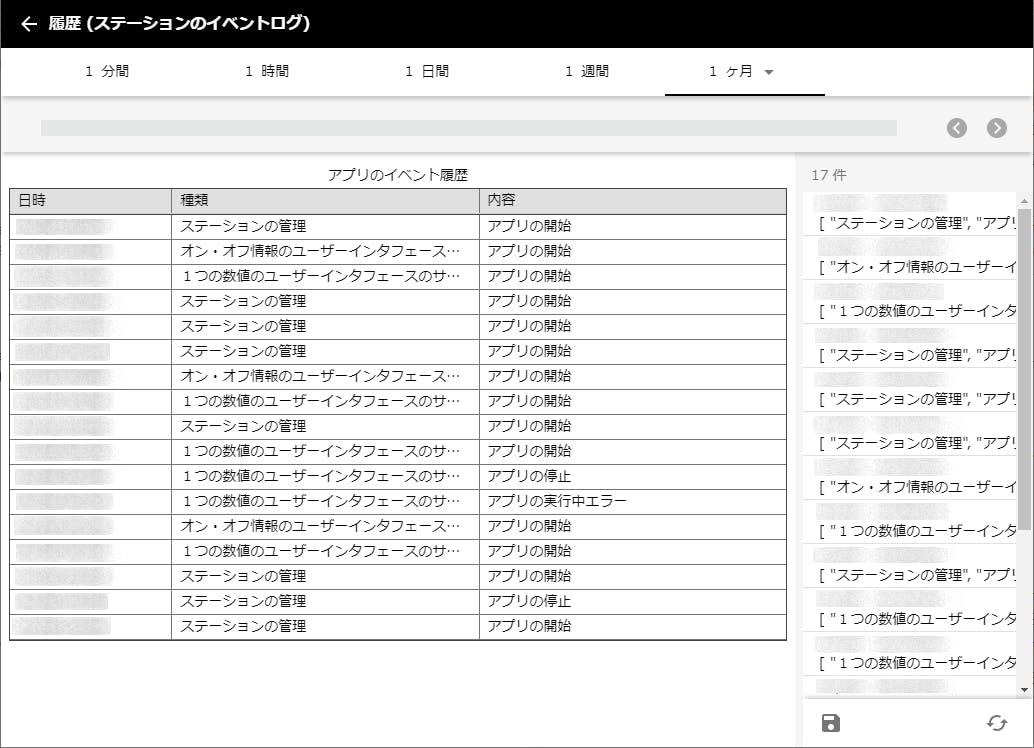
履歴の詳細画面ではまず、その上部にて、画面に表示する情報の時間幅を選択できる。上記では、「10分間」が選択されているので、折れ線グラフの左端から右端までは10分間という訳だ。上から2段目では「日時」を選択する。スライダを左右に動かしたり、左右の矢印ボタンをクリック、ないしはグラフ表示部分を左右にフリックすることで、表示したい過去の日時を移動できる。画面の右側には、選択された日時から時間幅分の生のデータが表示されている。また、その下の保存ボタンをクリックすれば、表示中のデータを CSV 形式で保存できる。詳細画面から元の利用ページに戻るには、画面左上の左矢印を押せばよい。同様にして、「ステーションの管理」アプリの利用ページ「ログ」で表示されている3つのテーブル表示の履歴の詳細画面も見てみよう。時間幅を「1ヶ月」にすると、より多くの情報が表示されるはずだ。
詳細画面に遷移する表示要素
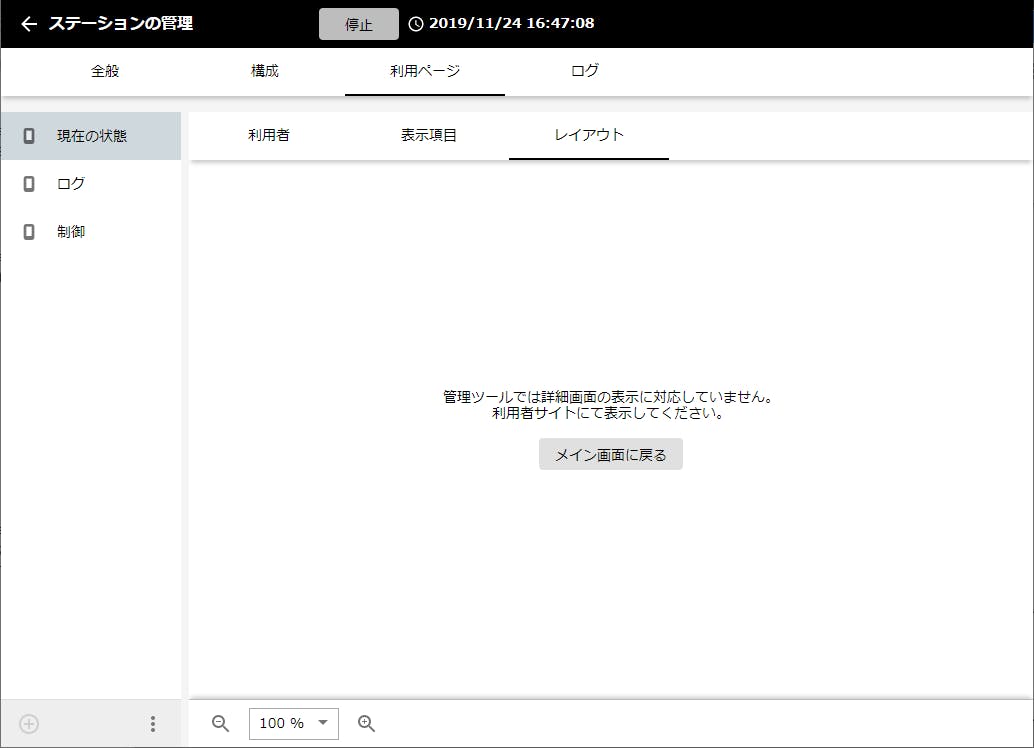
何でもかんでもダブルクリックすれば詳細画面が表示されるかと言えばそうではない。詳細画面が存在する表示要素は、履歴のグラフや表といった過去のデータを表示する要素と、次回の投稿で操作してみる予定のビデオ、音声といった表示要素だ。注意点としては、これらの詳細画面は利用者ログインした場合にのみ表示可能で、管理ツールからは表示できないこと。管理ツールでダブルクリックすると以下の画面が表示される。
まとめ
履歴の詳細画面を表示することで、過去の情報を簡単にきれいに表示できた。次回はリモッテの大きな特徴の1つであるビデオと音声を扱ってみる。リモッテ・ストアから一番簡単なアプリ「ビデオと音声の配信」をダウンロード、実行し、同時にその詳細画面からスナップショットを撮ったり、ビデオ録画、再生およびファイル保存する操作をしてみよう。
- 投稿日:2019-11-24T17:47:20+09:00
Python 画像の読み込みを高速化する
画像処理や画像系ディープラーニングでは,画像を読み込む処理が頻繁に発生します.
数百枚ならまだしも,数万枚規模になると読み込むだけで数分かかってしまいますし,1回だけならまだしも,実験のために何度も読み込むならなおさら高速化したいところです.
ここでは,いくつかのライブラリを比較して,読み込み時間を減らす方法を紹介します.
結論
pickleかnp.saveで画像を保存しておく(データサイズは肥大化する)pickleのプロトコルは新しいのを使うnp.uint8で保存する実行環境
- macOS Mojave 10.14.6
- Python 3.6
読み込み速度の比較
使用したライブラリと,画像1枚の読み込み(numpy.arrayとしてデータを取得)にかかった時間は以下の通りです.
ライブラリ 読み込み時間 OpenCV 4.23 ms matplotlib 4.37 ms keras.preprocessing 3.49 ms skimage 2.56 ms PIL 2.63 ms numpy 333 µs pickle(protocol=1) 597 µs pickle(protocol=2) 599 µs pickle(protocol=3) 112 µs pickle(protocol=4) 118 µs _pickle(protocol=4) 117 µs 読み込んだ画像は512×512のpngファイルです.
numpyとpickleについては,あらかじめ画像を
.npy,.pickleとして保存しておいたものを読み込みましたので,公平な比較ではありません.
前もって画像を変換しておけば,これくらいの速度が出るという表であり,numpyやpickleが一概に速いと結論できるものではありません.pickleは
pickle.dumpする際にprotocolを指定することができ,新しいプロトコルほど,読み込みの速度が上がるそうですので,プロトコルごとに画像データを保存しています.accimageのような高速なライブラリもありますが,macOSに対応していなかったので使用していません.
hdf5という選択肢もありますが,未検討です.
使用したコードは以下のとおりです.(jupyter notebook使用)
import cv2 import matplotlib.pyplot as plt import pickle import numpy as np from keras.preprocessing import image from PIL import Image from skimage import io import _pickle def imread1(path): return cv2.imread(path) def imread2(path): return plt.imread(path) def imread3(path): img = image.load_img(path) return image.img_to_array(img) def imread4(path): return io.imread(path) def imread5(path): img = Image.open(path) return np.asarray(img) def numpy_load(path): return np.load(path) def pickle_load(path): with open(path, mode='rb') as f: return pickle.load(f) def _pickle_load(path): with open(path, mode='rb') as f: return _pickle.load(f) %timeit img = imread1(img_path) %timeit img = imread2(img_path) %timeit img = imread3(img_path) %timeit img = imread4(img_path) %timeit img = imread5(img_path) %timeit img = numpy_load(npy_path) %timeit img = pickle_load(pickle_path_1) %timeit img = pickle_load(pickle_path_2) %timeit img = pickle_load(pickle_path_3) %timeit img = pickle_load(pickle_path_4) %timeit img = _pickle_load(pickle_path_4)データサイズの比較
512×512の.png画像を,numpyとpickleで保存した際のサイズは以下の通りです.
ライブラリ データ型 サイズ 元データ - 236 KB numpy np.uint8 820 KB pickle(protocol=1) np.uint8 820 KB pickle(protocol=2) np.uint8 820 KB pickle(protocol=3) np.uint8 787 KB pickle(protocol=4) np.uint8 787 KB numpy np.float32 3.1 MB pickle(protocol=1) np.float32 4.9 MB pickle(protocol=2) np.float32 4.8 MB pickle(protocol=3) np.float32 3.1 MB pickle(protocol=4) np.float32 3.1 MB np.uint8でも,元データの3倍以上の容量を占めてしまうことがわかりました.
ストレージに余裕があって,読み込み速度をできるだけ上げたい場合には,いったんnpyやpickleなどで読み込みやすいように変換しておくのがよいようです.
- 投稿日:2019-11-24T16:47:15+09:00
強化学習19 Colaboratory+Mountain_car+ChainerRL
強化学習18まで終了していることが前提です。
途中で切れてしまうことが続いていました。
強制的に終了されている感じ。
そこで、2000エポック毎に終了して、前のデータがあればそれを継続するようにしました。
GPUなしランタイムモードでやるとプリエンプティブルのように、Google都合で切られるのかもしれません。GPUランタイムモードだと大丈夫でした。そうなのでしょうか?
4000回の学習で到達しています。Google Driveのマウント
import google.colab.drive google.colab.drive.mount('gdrive') !ln -s gdrive/My\ Drive mydriveインストール
!apt-get install -y xvfb python-opengl ffmpeg > /dev/null 2>&1 !pip install pyvirtualdisplay > /dev/null 2>&1 !pip -q install JSAnimation !pip -q install chainerrlパラメータ初期化
gamename='MountainCar-v0' # Set the discount factor that discounts future rewards. gamma = 0.99 # Use epsilon-greedy for exploration myepsilon=0.003 myDir='mydrive/OpenAI/MountainCar/' mySteps=400000 # Train the agent for 2000 steps my_eval_n_episodes=1 # 10 episodes are sampled for each evaluation my_eval_max_episode_len=200 # Maximum length of each episodes my_eval_interval=200 # Evaluate the agent after every 1000 steps myOutDir=myDir+'result' # Save everything to 'result' directory myAgentDir=myDir+'agent' # Save Agent to 'agent' directory myAnimName=myDir+'movie_montaincar.mp4' myScoreName=myDir+"result/scores.txt"Program
import
import chainer import chainer.functions as F import chainer.links as L import chainerrl import gym import numpy as npenv initialize
env = gym.make(gamename) print('observation space:', env.observation_space) print('action space:', env.action_space) obs = env.reset() print('initial observation:', obs) action = env.action_space.sample() obs, r, done, info = env.step(action) print('next observation:', obs) print('reward:', r) print('done:', done) print('info:', info)Deep Q Network setting
obs_size = env.observation_space.shape[0] n_actions = env.action_space.n q_func = chainerrl.q_functions.FCStateQFunctionWithDiscreteAction( obs_size, n_actions, n_hidden_layers=2, n_hidden_channels=50)Use Adam to optimize q_func. eps=1e-2 is for stability.
optimizer = chainer.optimizers.Adam(eps=1e-2) optimizer.setup(q_func)Agent Setting
DQN uses Experience Replay.
Specify a replay buffer and its capacity.
Since observations from CartPole-v0 is numpy.float64 while
Chainer only accepts numpy.float32 by default, specify a converter as a feature extractor function phi.
explorer = chainerrl.explorers.ConstantEpsilonGreedy( epsilon=myepsilon, random_action_func=env.action_space.sample) replay_buffer = chainerrl.replay_buffer.ReplayBuffer(capacity=10 ** 6) phi = lambda x: x.astype(np.float32, copy=False) agent = chainerrl.agents.DoubleDQN( q_func, optimizer, replay_buffer, gamma, explorer, replay_start_size=500, update_interval=1, target_update_interval=100, phi=phi)Train
Set up the logger to print info messages for understandability.
import os if (os.path.exists(myAgentDir)): agent.load(myAgentDir) import logging import sys logging.basicConfig(level=logging.INFO, stream=sys.stdout, format='') chainerrl.experiments.train_agent_with_evaluation( agent, env,steps=mySteps,eval_n_steps=None,eval_n_episodes=my_eval_n_episodes,eval_max_episode_len=my_eval_max_episode_len, eval_interval=my_eval_interval,outdir=myOutDir) agent.save(myAgentDir)Data Table
import pandas as pd import glob import os score_files = glob.glob(myScoreName) score_files.sort(key=os.path.getmtime) score_file = score_files[-1] df = pd.read_csv(score_file, delimiter='\t' ) dffigure Average_Q
df.plot(x='steps',y='average_q')Test
import2
from pyvirtualdisplay import Display display = Display(visible=0, size=(1024, 768)) display.start() from JSAnimation.IPython_display import display_animation from matplotlib import animation import matplotlib.pyplot as plt %matplotlib inlineTest Program
frames = [] env = gym.make(gamename) envw = gym.wrappers.Monitor(env, myOutDir, force=True) for i in range(3): obs = envw.reset() done = False R = 0 t = 0 while not done and t < 200: frames.append(envw.render(mode = 'rgb_array')) action = agent.act(obs) obs, r, done, _ = envw.step(action) R += r t += 1 print('test episode:', i, 'R:', R) agent.stop_episode() #envw.render() envw.close() from IPython.display import HTML plt.figure(figsize=(frames[0].shape[1]/72.0, frames[0].shape[0]/72.0),dpi=72) patch = plt.imshow(frames[0]) plt.axis('off') def animate(i): patch.set_data(frames[i]) anim = animation.FuncAnimation(plt.gcf(), animate, frames=len(frames),interval=50) anim.save(myAnimName) HTML(anim.to_jshtml())
- 投稿日:2019-11-24T15:47:38+09:00
二部グラフの判定
問題:CODE FESTIVAL 2017 qual B 3steps
https://atcoder.jp/contests/code-festival-2017-qualb/tasks/code_festival_2017_qualb_cfrom collections import defaultdict, deque, Counter import sys def LI(): return list(map(int, sys.stdin.buffer.readline().split())) def bipartite_or_not(G, s=0): n = len(G) global color color = [0] * n color[s] = 1 dq = deque([s]) while dq: u = dq.popleft() for v in G[u]: if color[v] == 0: color[v] = -color[u] dq += [v] else: if color[u] == color[v]: return False return True n, m = LI() G = [[] for _ in range(n)] for a, b in LIR(m): G[a - 1] += [b - 1] G[b - 1] += [a - 1] if bipartite_or_not(G): print(color.count(1) * color.count(-1) - m) else: print(n * (n - 1) // 2 - m)
- 投稿日:2019-11-24T14:23:30+09:00
頑張って最適化関数を作ってみたけど上手くいかなかった話
参考
https://qiita.com/tokkuman/items/1944c00415d129ca0ee9
実行ソース
https://github.com/akidukin/optimize_test/blob/master/benchmark_optimizer.py
対象
- 自己満
何したの??
参考にさせていただいたURLを元に
- SGD
- MomentumSGD
- AdaGrad
- RMSprop
をpythonで書いてみてこの記事にある (https://qiita.com/Akidukin14/items/4cf3fd1a065726450e4d)
- sphere関数
- losenbrock関数
- styblinskitang関数
に適用させてみてどのような動きをするのか見てみたかったそれぞれの偏微分式は自分で解いたのでそこも悪いのかも
結果
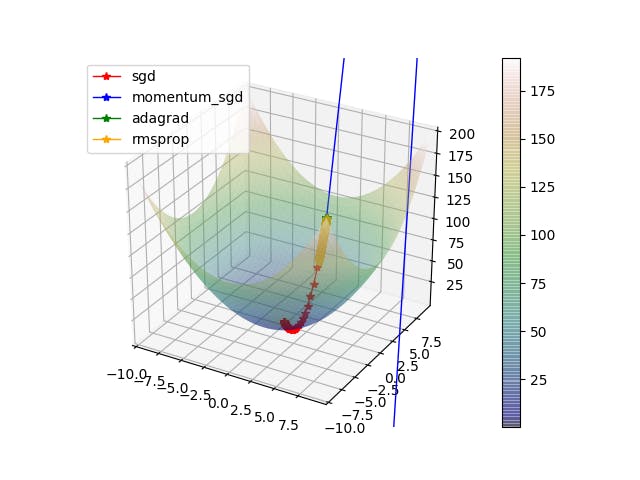
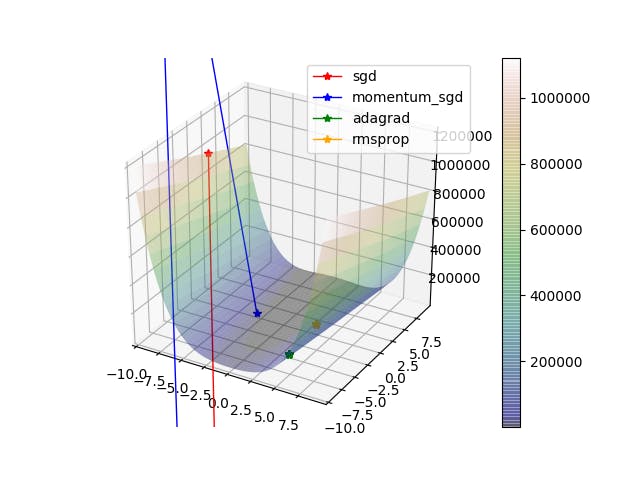
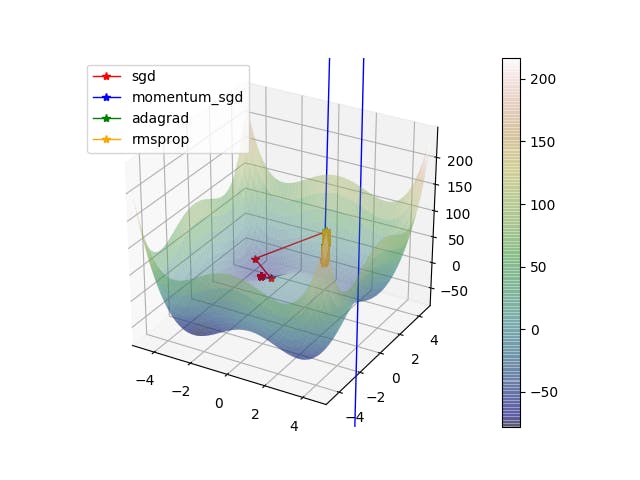
まとめ
MomentumSGDが特にひどい、全部どこいくねーんと
疲れたのでもういいやと思いました まる
- 投稿日:2019-11-24T12:48:50+09:00
LambdaからBigQueryを実行する
はじめに
LambdaからBigQueryのクエリを発行します。その調査記録です。
基本はAWSを使用していますが、定期的にGCPのBigQueryを参照する機会がありました。
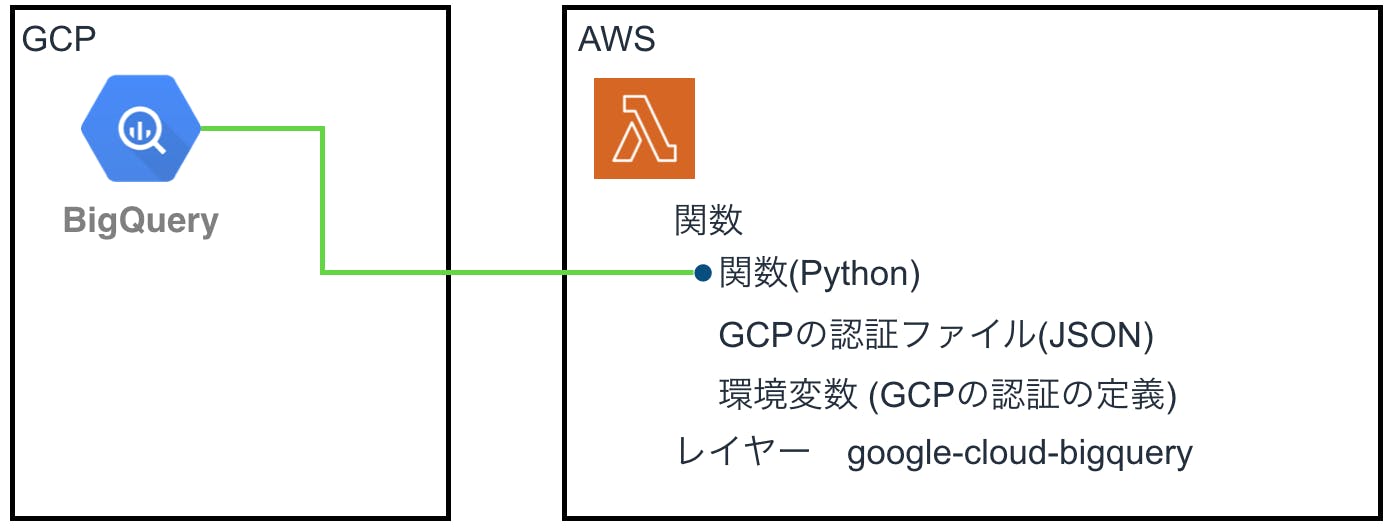
簡単にLambdaで実行すると便利かと思いました。環境の概要
LambdaのPythonから、GCPのSDKを使用します。
GCPのSDKはレイヤーに保持します。
AWS側に、GCPの認証を設定する必要があります。
SDKと言っているのは、Pythonのクライアントライブラリーのことです。
https://googleapis.dev/python/bigquery/latest/generated/google.cloud.bigquery.client.Client.html手順
前提条件
AWSアカウントを所有している。
GCPアカウントを所有している。APIからBigQueryを使える。
BigQueryテーブルは作成済み。
AWSのアクセスキーを所有しているLambda関数を作成する。
BigQueryを実行するのみのPythonコードです。まずは、これを動かします。
- Lambda関数の設定は以下です。
- 新規作成
- Python3.7
- アクセス権限は自動生成のCloudWatch Logsのみ。
- タイムアウトは30秒にしました。
- レイヤーと環境変数は後ほど。
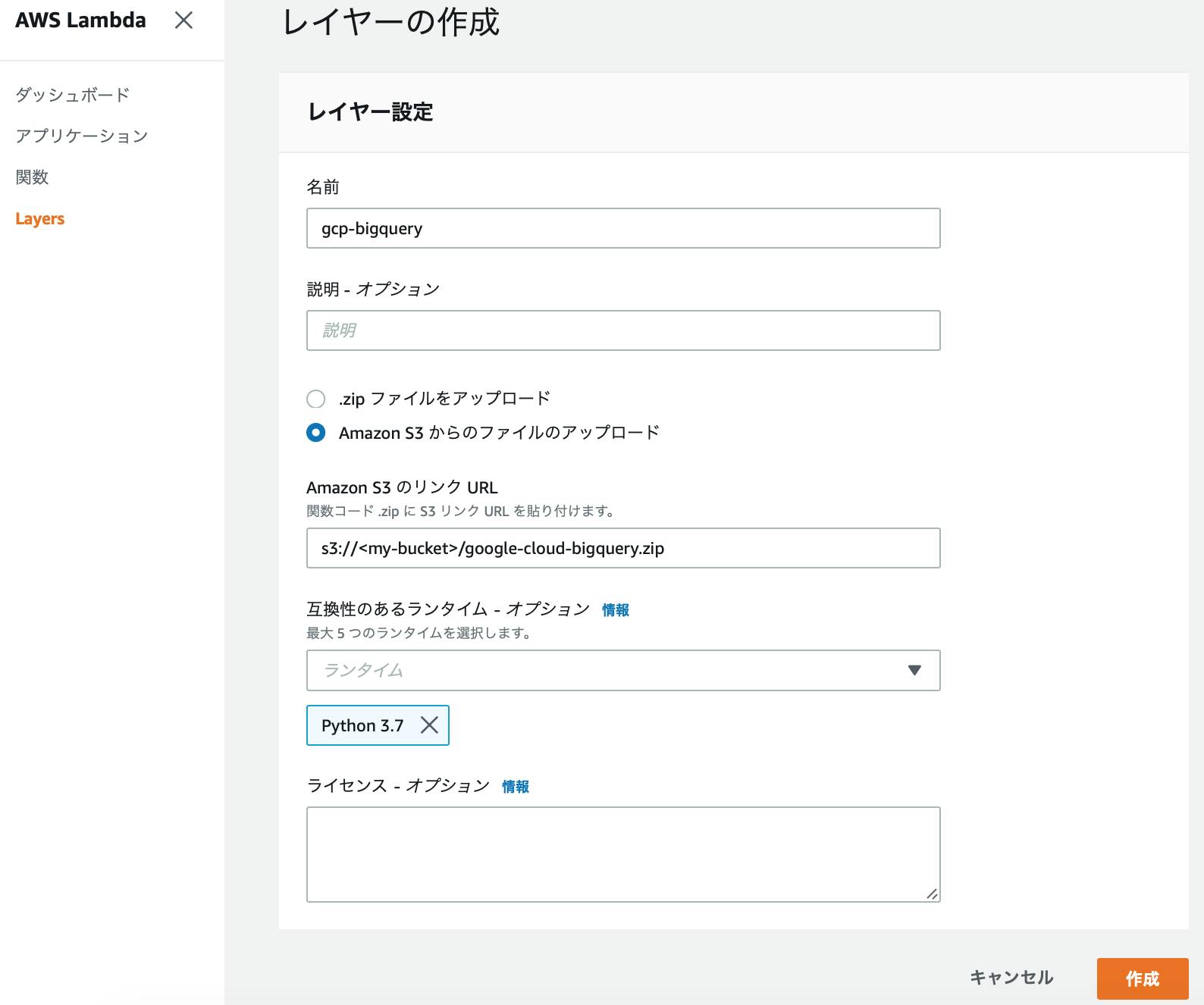
import json from google.cloud import bigquery def lambda_handler(event, context): client = bigquery.Client() sql = """ SELECT * FROM `<my-project>.<my-dataset>.<my-table>` LIMIT 10 """ # Run a Standard SQL query using the environment's default project results = client.query(sql).result() for row in results: print(row) return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') }Lambdaのレイヤーに登録するための、GCPのSDKを作成する。
LambdaのPythonで
import bigqueryを使用するために、SDKをレイヤーに追加します。
pipで取得してzipで固めます。
EC2でLinuxをスポットインスタンスで起動して、S3に置く手順です。さくっと。
Amazon Linux2をEC2のスポットインスタンスで作成します。
- スペックは小さめで十分です。
- IAMロールは、
AmazonEC2RoleforSSMだけ追加したものを付与します。Systems Managerのセッションマネージャーで接続するため。- セキュリティグループはインウンドなしのもの。
- キーペアもなし。
インスタンスが起動したら、Systems Managerのセションマネージャーから接続します。
実行手順を記載します。<>の箇所は、自分の値を設定します。
# ec2-userになる sudo su - ec2-user# pipのインストール sudo yum install python3 -y curl -O https://bootstrap.pypa.io/get-pip.py sudo python3 get-pip.py export PATH=$PATH:/usr/local/bin# sdkのインストール&zip化 pip install google-cloud-bigquery -t ./python/lib/python3.7/site-packages/ zip -r google-cloud-bigquery.zip python # protobufが必要なため追加 pip install protobuf --upgrade -t ./python/lib/python3.7/site-packages/ zip -r google-cloud-bigquery.zip ./python/lib/python3.7/site-packages/google/protobuf# aws cliの設定 aws configure # 以下を設定します。 AWS Access Key ID [None]: <my-access-key> AWS Secret Access Key [None]: <my-secret-key> Default region name [None]: ap-northeast-1 Default output format [None]: json# s3に保存 aws s3 mb s3://<my-bucket> aws s3 cp google-cloud-bigquery.zip s3://<my-bucket>SDKをs3に保存したら、スポットインスタンスは削除してしまってよいです。
作成したライブラリをLambdaのレイヤーに登録する。
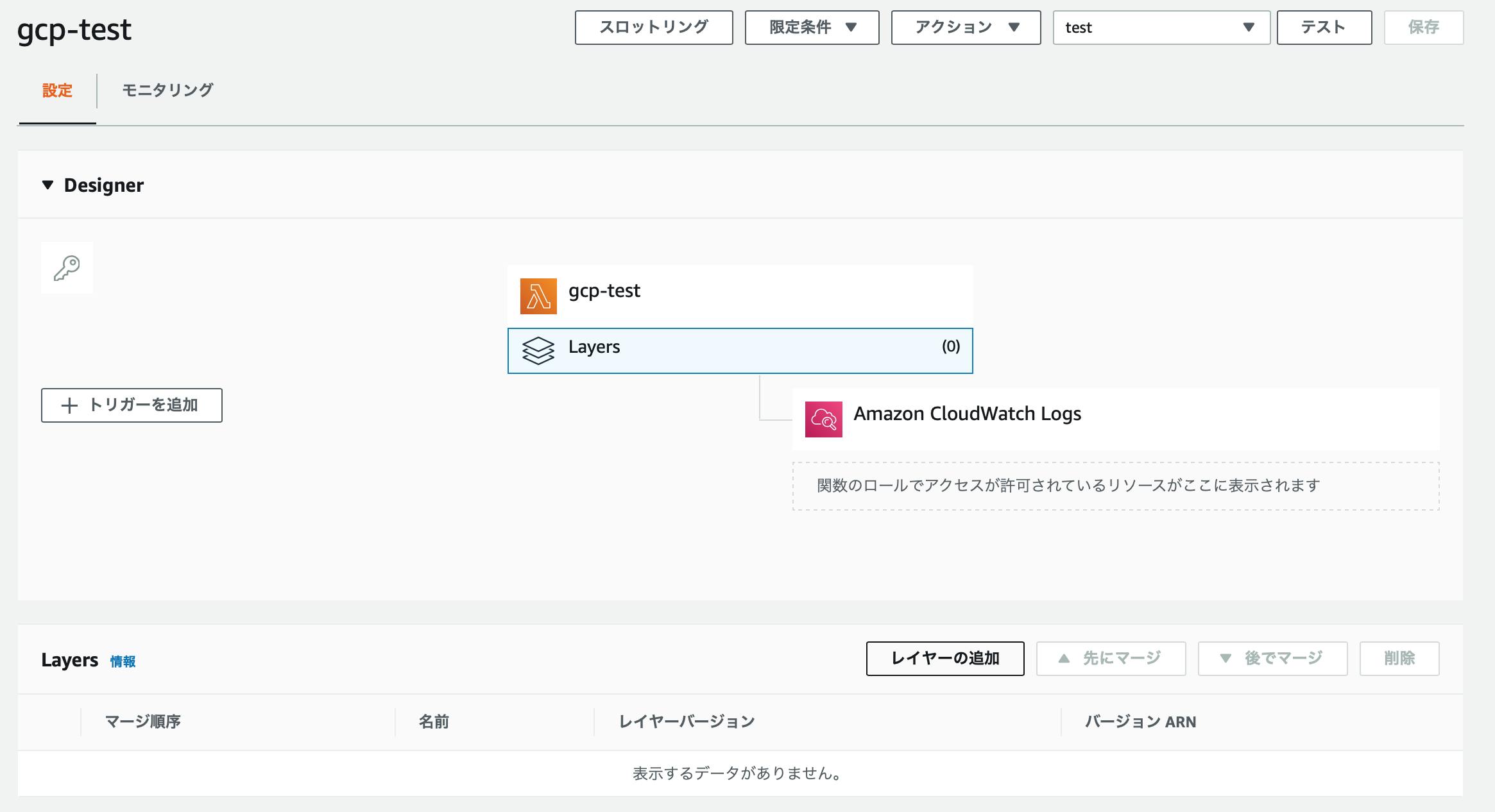
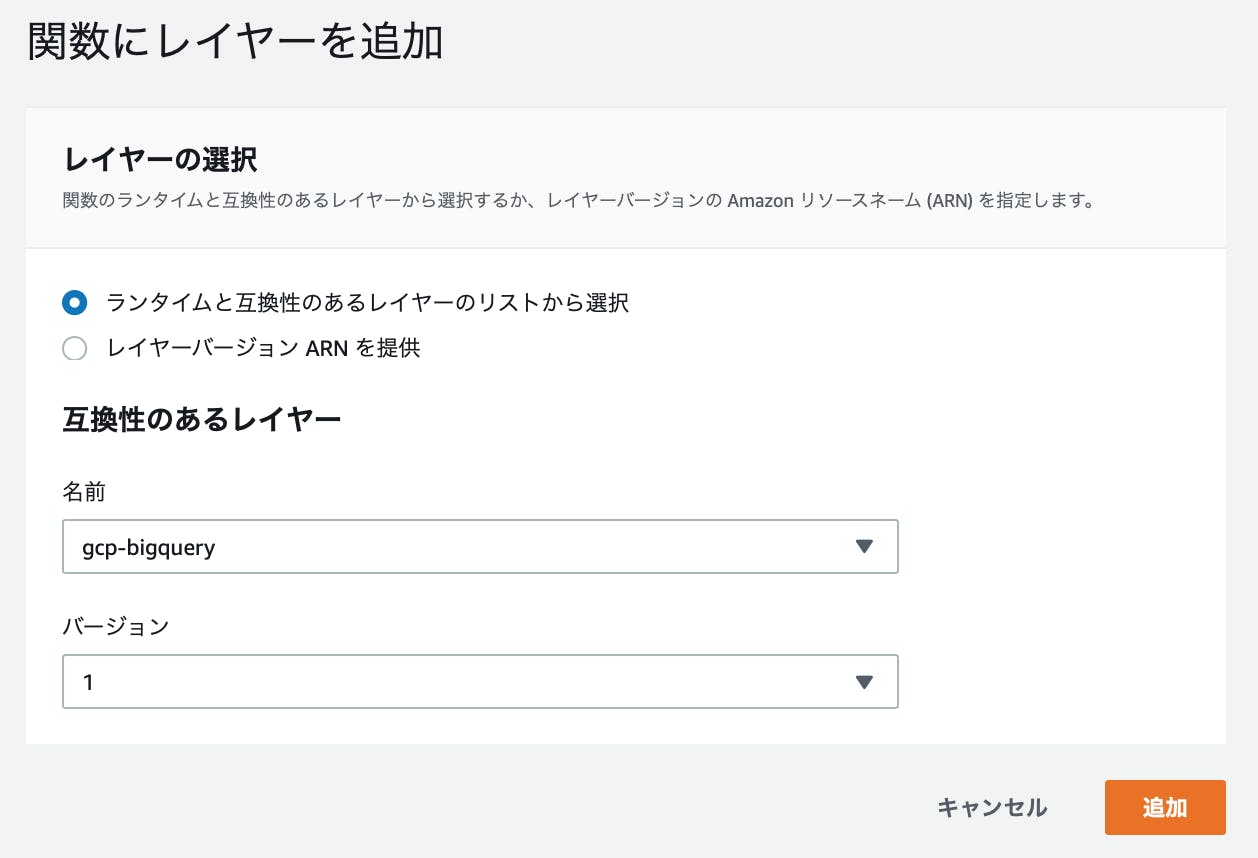
Lambdaに戻ります。
レイヤーを作成します。
関数にレイヤーを追加します。
- レイヤーを選択して、
レイヤーの追加を押します名前は、「お客様のレイヤー」から選択。バージョンは作成したものを選択。
- レイヤーが追加されました。
レイヤーを追加すれば、S3のファイルは削除してしまって大丈夫です。
GCPの認証ファイルを取得する。
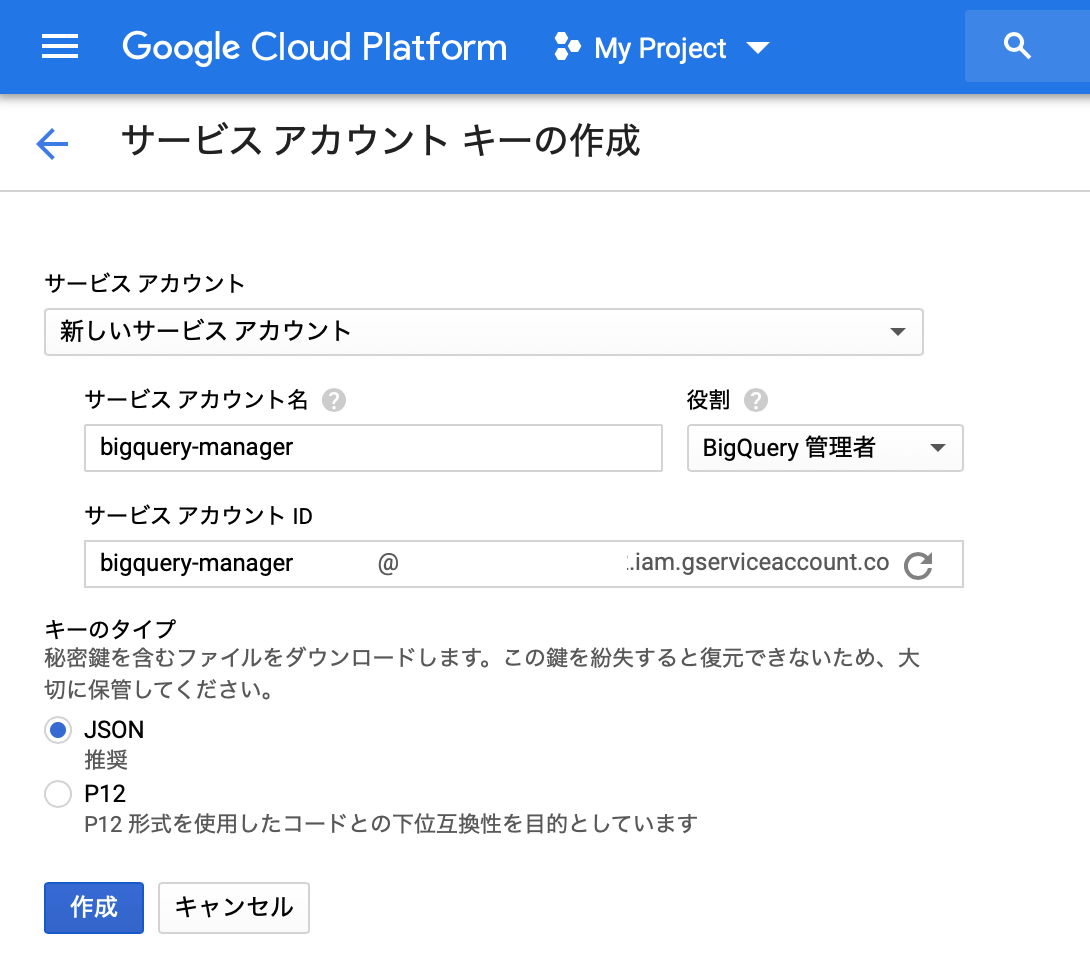
- 認証を追加する必要があります。
https://cloud.google.com/docs/authentication/production
jsonのサービスアカウントキーを作成します。
上記リンク中の
[サービス アカウントキーの作成] ページに移動から。
役割は「BigQuery管理者」を選択しました。
GCPの認証ファイルを、Lambdaに登録する。
jsonは
New Fileから、テキストをコピー&ペーストで追加しました。
環境変数GOOGLE_APPLICATION_CREDENTIALSを追加します。
テスト実行
Lambdaコンソールからテスト実行できました!
つまった点
protobufが無いとエラーが出て困りました・・・
StackOverflowで事例を検索して解決しました。おわりに
いろいろこれでいいのかと思うところはありますが、実行出来たので掲載しました!
SDKはpython直下に置くべきか、site-packagesに置くべきか。
LambdaのPythonも、3.8が最新になってますね・・・SDKの作り方はこれでよいのか。
zipに追加するところGCPの認証ファイルはもっと隠せないのか。
環境変数、KMS、パラメータストアなどで。

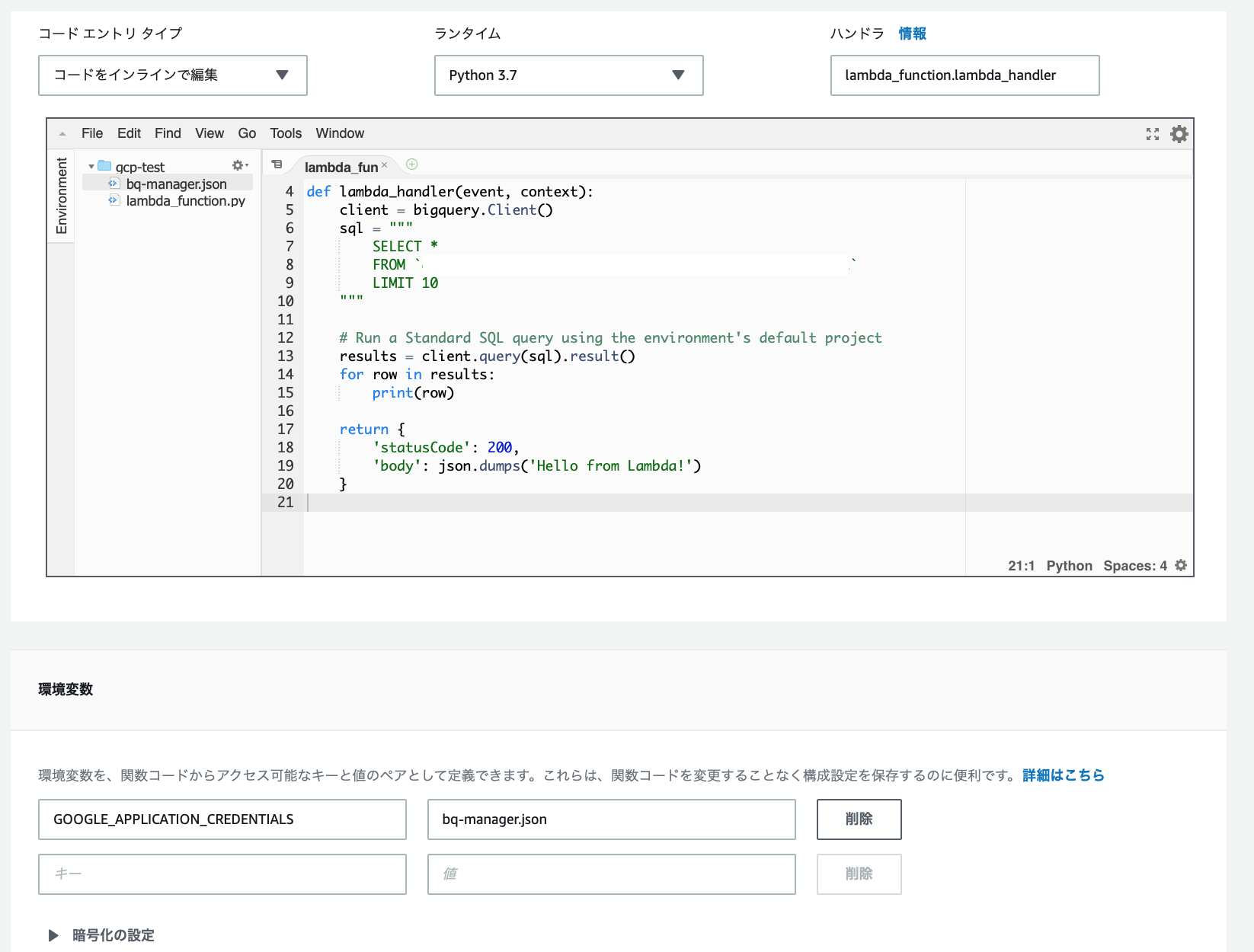
- 投稿日:2019-11-24T12:21:58+09:00
Jetson Nanoで簡単顔認識トライ
はじめに
Jetson NanoでWebカメラを使用してリアルタイム顔認識を試しました。
- Jetson Nano
- Python3.6.8
- OpenCV3.3.1 (4.1.0を入れたつもりだったが...)
- Webカメラ(ロジクールのやつ)
参考にしたページ
画像取得トライ
まずはWebカメラでどうすれば画像を取得できるのかを確認します。
めっちゃ簡単でした。camTest.pyimport cv2 # カメラを起動 capture = cv2.VideoCapture(0) while(True): # 1フレームの画像を取得 ret, frame = capture.read() # 画像をウィンドウに表示 cv2.imshow("frame", frame) # qを押されたら停止 if cv2.waitKey(1) & 0xFF == ord('q'): break # 解放 capture.release() cv2.destroyAllWindows()
qを押せば止まるのですが、ターミナルではなくウィンドウにフォーカスがある状態で押さないと正常に機能しません。顔認識
OpenCVをインストールした時にカスケード分類器のファイルが一緒に入っているのでそれを使います。
(https://github.com/opencv/opencv/tree/master/data/haarcascades)顔認識の手順は以下のようです
1. 画像を取得
2. グレースケールに変換
3. 顔認識処理
4. 認識位置に枠を書くfind_face.py# -*- coding: utf-8 -*- import time import cv2 # フレームサイズ(大きいと処理が重たくなります) FRAME_W = 320 FRAME_H = 240 # 顔検出用のカスケード分類器(特徴量をまとめたファイルらしい) # 他のフォルダにあったものを読み込もうとしたらエラーになったので同じフォルダにコピーした cascadeFilePath = './haarcascade_frontalface_default.xml' cascade = cv2.CascadeClassifier(cascadeFilePath) # カメラ設定 cam = cv2.VideoCapture(0) time.sleep(1) # 起動待ち(とりあえず) cam.set(cv2.CAP_PROP_FPS, 60) # 60もでたか不明 cam.set(cv2.CAP_PROP_FRAME_WIDTH, FRAME_W) cam.set(cv2.CAP_PROP_FRAME_HEIGHT, FRAME_H) while(True): # qで終了 if cv2.waitKey(1) & 0xFF == ord('q'): break # 画像取得 ret, frame = cam.read() # グレースケールに変換 gray_image = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY) # 顔認識 facerect = cascade.detectMultiScale(gray_image, scaleFactor=1.1, minNeighbors=2, minSize=(30, 30)) # 顔が検出されたか if len(facerect) > 0: # 枠線用の色 line_color = (255, 102, 51) # テキストの色 font_color = (255, 102, 51) # 検出した顔に枠とFACEの文字を書く for (x, y, width, height) in facerect: cv2.rectangle(frame, (x, y), (x + width, y + height), line_color, 2) cv2.putText(frame, 'FACE', (x, y), cv2.FONT_HERSHEY_SIMPLEX, 0.7, font_color, 1, cv2.LINE_AA) # ウィンドウに表示 cv2.imshow('frame', frame) # 終了処理 cam.release() cv2.destroyAllWindows()リアルタイムに認識されました!
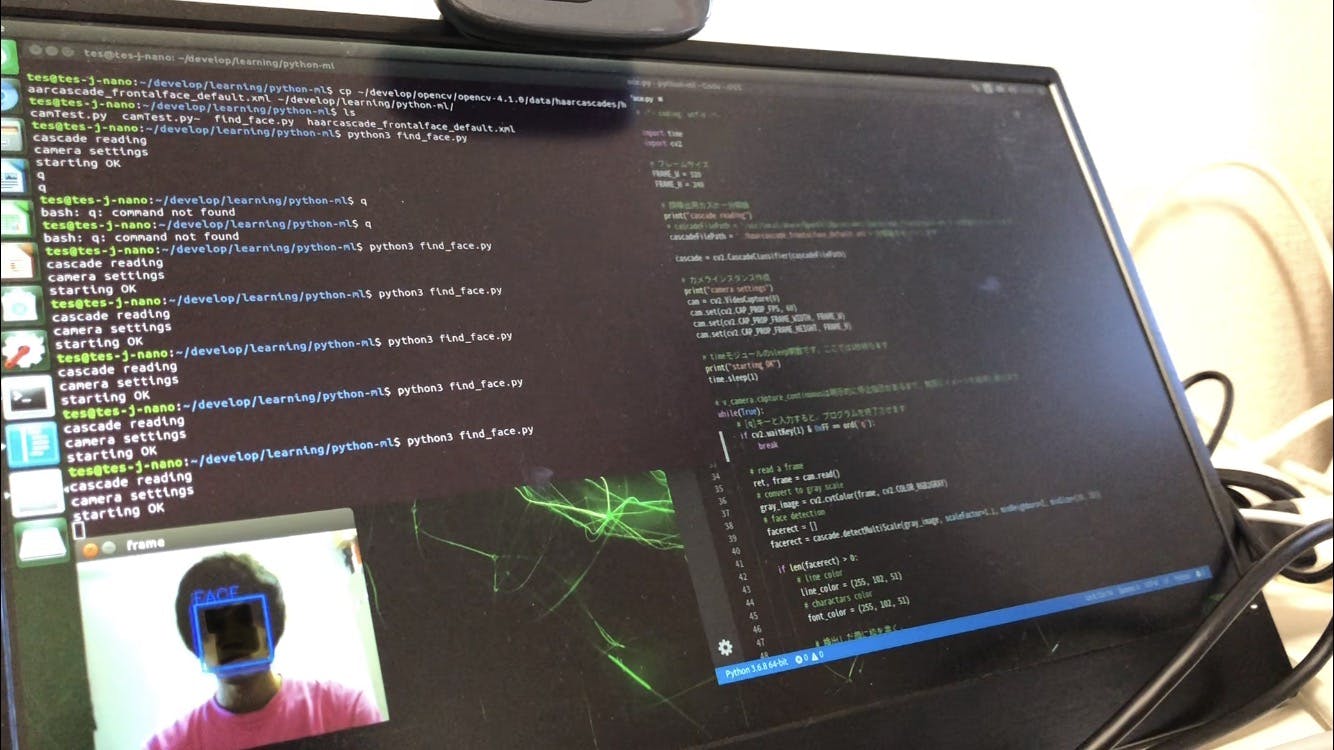
- 投稿日:2019-11-24T12:21:58+09:00
Jetson NanoとWebカメラで簡単顔認識トライ
はじめに
Jetson NanoでWebカメラを使用してリアルタイム顔認識を試しました。
- Jetson Nano
- Python3.6.8
- OpenCV3.3.1 (4.1.0を入れたつもりだったが...)
- Webカメラ(ロジクールのやつ)
参考にしたページ
画像取得トライ
まずはWebカメラでどうすれば画像を取得できるのかを確認します。
めっちゃ簡単でした。camTest.pyimport cv2 # カメラを起動 capture = cv2.VideoCapture(0) while(True): # 1フレームの画像を取得 ret, frame = capture.read() # 画像をウィンドウに表示 cv2.imshow("frame", frame) # qを押されたら停止 if cv2.waitKey(1) & 0xFF == ord('q'): break # 解放 capture.release() cv2.destroyAllWindows()
qを押せば止まるのですが、ターミナルではなくウィンドウにフォーカスがある状態で押さないと正常に機能しません。顔認識
OpenCVをインストールした時にカスケード分類器のファイルが一緒に入っているのでそれを使います。
(https://github.com/opencv/opencv/tree/master/data/haarcascades)顔認識の手順は以下のようです
1. 画像を取得
2. グレースケールに変換
3. 顔認識処理
4. 認識位置に枠を書くfind_face.py# -*- coding: utf-8 -*- import time import cv2 # フレームサイズ(大きいと処理が重たくなります) FRAME_W = 320 FRAME_H = 240 # 顔検出用のカスケード分類器(特徴量をまとめたファイルらしい) # 他のフォルダにあったものを読み込もうとしたらエラーになったので同じフォルダにコピーした cascadeFilePath = './haarcascade_frontalface_default.xml' cascade = cv2.CascadeClassifier(cascadeFilePath) # カメラ設定 cam = cv2.VideoCapture(0) time.sleep(1) # 起動待ち(とりあえず) cam.set(cv2.CAP_PROP_FPS, 60) # 60もでたか不明 cam.set(cv2.CAP_PROP_FRAME_WIDTH, FRAME_W) cam.set(cv2.CAP_PROP_FRAME_HEIGHT, FRAME_H) while(True): # qで終了 if cv2.waitKey(1) & 0xFF == ord('q'): break # 画像取得 ret, frame = cam.read() # グレースケールに変換 gray_image = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY) # 顔認識 facerect = cascade.detectMultiScale(gray_image, scaleFactor=1.1, minNeighbors=2, minSize=(30, 30)) # 顔が検出されたか if len(facerect) > 0: # 枠線用の色 line_color = (255, 102, 51) # テキストの色 font_color = (255, 102, 51) # 検出した顔に枠とFACEの文字を書く for (x, y, width, height) in facerect: cv2.rectangle(frame, (x, y), (x + width, y + height), line_color, 2) cv2.putText(frame, 'FACE', (x, y), cv2.FONT_HERSHEY_SIMPLEX, 0.7, font_color, 1, cv2.LINE_AA) # ウィンドウに表示 cv2.imshow('frame', frame) # 終了処理 cam.release() cv2.destroyAllWindows()リアルタイムに認識されました!