- 投稿日:2019-11-12T23:13:37+09:00
Docker-composeでMySQLの環境構築
なぜDocker-composeなのか?
他のコンテナと合わせて使用することを考えdocker-composeにしました。
構成
├── docker-compose.yml ├──.env └── mysql └── initdb ├── 1_create_tables.sql └── 2_insert_seed.sqldocker-compose.yml
今回はブラウザからもアクセスできるようにしてMySQLをGUIでも操作できるようにしました。
docker-compose.ymlversion: '3' services: mysql: image: mysql:8.0 command: --default-authentication-plugin=mysql_native_password restart: always env_file: .env environment: TZ: "Asia/Tokyo" ports: - 3306:3306 volumes: - mysql:/var/lib/mysql - ./mysql/initdb:/docker-entrypoint-initdb.d phpmyadmin: image: phpmyadmin/phpmyadmin restart: always ports: - 8080:80 environment: PMA_ARBITRARY: 1 env_file: .env depends_on: - mysql volumes: mysql:.env
docker-compose.ymlファイルに書くこともできますが分けた方がいいと思います!
MYSQL_ROOT_PASSWORD: root MYSQL_DATABASE: test_db MYSQL_USER: test MYSQL_PASSWORD: test PMA_HOST: mysql PMA_USER: root PMA_PASSWORD: root初期化用sqlファイル
以下のファイルはあくまで一例です。
自由に書き換えて使用してください。1_create_tables.sql
1_create_tables.sqlcreate table users ( id serial primary key, username varchar(50) unique not null, password varchar(50) not null, email varchar(255) unique not null );2_insert_seed.sql
2_insert_seed.sqlinsert into users (username, password, email) values ('keid', 'keidpass', 'keid@developer.com'); insert into users (username, password, email) values ('jobs', 'jobspass', 'jobs@developer.com'); insert into users (username, password, email) values ('mask', 'maskpass', 'mask@developer.com');起動
docker-compose.ymlファイルのあるディレクトリに移動してください
docker-compose up -dコンテナに入ってMySQLを起動
docker-compose exec mysql bin/bash root@30bffee726ff:/# mysql -u test -p Enter password: test # 入力しても表示されません Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 8 Server version: 8.0.18 MySQL Community Server - GPL Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>phpMyAdminからアクセス
ブラウザなどから
localhost:8080でphpMyAdminにアクセスできます。まとめ
今回はDockerをやって欲しいというリクエストがありましたのでdocker-composeを使用してMySQL環境を構築してみました。
一人でも多くのクジラ信者が増えるようにdockerの良さが伝わればいいなと思います!!
- 投稿日:2019-11-12T19:41:59+09:00
なぜ開発環境をVM+Dockerで構築するのか
業務で仮想マシン(VM:VirtualBOX)上でdocker-composeを動かして開発を行っているので、そのメリット/デメリットについて書いてみようと思います。
メリット①:インフラが可視化できる
VMおよびシステムの構成が以下に集約されるため、どんなソフトを使っているか、どんなアーキテクチャ構成になっているかが分かりやすいです。
また、バージョンを指定してインストールしておけば、バージョン違いによる動作不良なんかも防げます。
- VMの構成:
Vagrantfile- システム構成:
docker-compose.ymlメリット②:バージョン管理できる
Vagrantfileもdocker-compose.ymlもテキストファイルのため、Git等のバージョン管理ツールで管理することができます。メリット③:環境の複製が容易
VirtualBOXとVagrantをインストールしておけば開発環境を簡単に複製することができます。
1時間もあれば環境が作れてしまいます。メンバーが増える場合などに、環境構築に1日以上かけるなんてことがなくなります。
構築手順(例)
- VT-xの有効化(BIOSの設定が必要です)
- VirtualBOXとvagrant、Gitのインストール
- Vagrantfileをクローン
vagrant upを実行この時点で開発環境の構築は完了
vagrant sshでVMにssh接続git clone xxxxxxでプロジェクトをクローン
- docker-compose.ymlが入っているものとする
cd xxx && docker-compose upでプロジェクト起動これだけで環境構築&プロジェクトの起動が完了します。
メリット④:本番環境に近い環境で開発ができる
Windows上で開発する場合、本番や検証環境へデプロイした後にOS依存の不具合が発生することがあります。
開発時から本番と同じOSを使うことでOS依存の不具合を早い段階で回避することができます。その他のメリット
- プロジェクトが終わったらVMを破棄するだけで、ホストOSはクリーンな状態を保てる
- 動かなくなったらVMを破棄して作り直せば良い
デメリット
最初に作る人が大変
最初に環境を作る人は結構大変です。
慣れてる人であればスラスラかけるかもしれませんが、ナレッジのないチームで1から作る場合は結構時間がかかると思います。最初は単純なVMを立ち上げて、VM内でプロジェクトに必要なツールを
yum installして、それらのコマンドをVagrantfileに書いていけばよいと思います。なんかよくわかんないけど、動いてる状態になる
Vagrantfileを作った人以外は、なんかよくわかんないけど環境出来たという状況になりがち。
有識者がいなくなるとメンテできなくなる可能性が高い。。最後に
Vagrantfileができあがるまでは大変ですが、一度できてしまえば楽なのでおススメです。
今後メンバーが増えることが確定している場合などは特に良いですね!時間があればVagrantfileのプラクティスなんかも書いてみたいと思います。
- 投稿日:2019-11-12T18:47:45+09:00
Docker Content Trust 101
はじめに
NIST800-190 (Application Container Security Guide) をベースにコンテナセキュリティについてまとめている中で、Docker Content Trustについて簡単に検証しました。
知識の整理も兼ねて、検証結果と調べた内容を簡単にまとめています。Docker Content Trust(DCT)とは?
Docker version 1.8から提供されている、イメージに対する署名を用いた検証機能です。
DCTにより、ユーザーは「イメージの完全性の検証」と「イメージ提供者の検証」が可能になりました。なぜDCTが必要?
DCTの必要性を理解するには、イメージにおけるセキュリティリスクを理解する必要があります。
NIST800-190 (Application Container Security Guide)の「3.1.5 Use of Untrusted Images」 には、下記のように記載されています。The portability and ease of reuse of containers increase the temptation for teams to run images from external sources that may not be well validated or trustworthy.
(コンテナの可搬性と再利用性によって、チーム内では検証もしくは信頼されていない外部ソースから提供されているイメージを実行する誘惑が強くなります。)記載されている通り、Docker環境はDockerHubなどを用いて第三者提供のイメージを利用できるため、可搬性と再利用性の面で非常に優れています。
一方で、DCTの機能提供以前はイメージは改ざんに弱く、ユーザーはイメージを扱う際に中間者攻撃(MITM)のリスクに晒されていました。
これらのリスクに対応する機能として、DCTが提供されるようになりました。
(イメージダイジェストの生成機能はDocker1.6から提供されていたようですが、ダイジェストを利用したイメージの検証機能は提供されていないようです。)
- イメージの完全性の検証
- 署名を用いてイメージを検証し、改ざんされていないイメージのみを取得できるようにする。
( = docker pullにより取得できるイメージの完全性を担保する)- イメージ提供者の検証
- イメージへの署名と検証をユーザーに強制することで、不正なユーザーによるイメージのpushなどを判別する。(もしくは、処理自体を拒否する)
DCTの仕組み
Docker success centerの記事では、DCTの一連のフローについて下記のように紹介しています。
https://success.docker.com/article/introduction-to-docker-content-trustWhen a publisher using Docker Content Trust pushes an image to a remote registry, Docker Engine signs the image locally with the publisher’s private key.
(Publisherがイメージをレジストリにpushする際に、Publisherの秘密鍵でイメージに署名する)When a user later pulls this image, Docker Engine uses the publisher’s public key to verify that the image is exactly what the publisher created, has not been tampered with, and is up to date.
(ユーザーがイメージをpullする際には、Publisherの公開鍵を利用して、「そのイメージがPublisherが作成したものか」「イメージが改ざんされていないか」「最新のイメージかどうか」を検証する)下記のリンクでも記載されている通り、DCTはデジタル署名と同じ仕組みでイメージの完全性の担保を行なっていると考えられます。
http://pocketstudio.jp/log3/2015/08/14/content-trust-docker-1-8-ja/とりわけ初回の信頼に関して HTTPS を使う公開 PKI に対応することで、セキュリティに対する利便性をもたらします
上記の和訳記事に掲載されていた画像がDCTの仕組みを端的に表しています。
(図中では、署名用の鍵がoffline key、検証用の鍵がtagging keyとして記載されています)
検証
下記の内容について、DCTに対応しているレジストリサービスを利用しながら検証を行います。
- DCTの一連のフロー - レジストリでのDCTの有効化 - レジストリへのイメージのpush - イメージのpull - DCTを有効化していないクライアント利用時の挙動 - 公式イメージのpull今回は、下記のような環境で検証を行います。
- レジストリサービス:IBM Cloud Registry(ICR)
(ライトユーザーのオプションとしてDocker Content Trustの有効化が可能です。)- Docker Engine:19.03
DCTのフロー検証
レジストリ側の設定
レジストリ内で検証用のNamespaceを用意し、クライアント側ではDCTを有効化しておきます。
# レジストリのセットアップ $ ibmcloud cr region-set us-south 地域は「us-south」に設定されました。地域は「us.icr.io」です。 OK $ ibmcloud cr login 「registry.ng.bluemix.net」にログインしています... 「registry.ng.bluemix.net」にログインしました。 「us.icr.io」にログインしています... 「us.icr.io」にログインしました。 # DCTの有効化 $ export DOCKER_CONTENT_TRUST=1 $ export DOCKER_CONTENT_TRUST_SERVER=https://us.icr.io:4443 $ ibmcloud cr namespace-add sign_test $ ibmcloud cr namespace-list レジストリー「us.icr.io」のアカウント「xxx's Account」用の名前空間をリストしています... 名前空間 sign_test OKイメージのpush
事前にイメージに対して、下記の形式でタグを付与しておきます。
us.icr.io/ Namespace名(sign_test)/ レポジトリ名(myhello_repo):バージョン(1.0)タグを付与した後にDCTを有効化して、イメージのpushを行います。
ICRでは、offline keyはroot key、tagging keyはrepository keyとして記載されます。# イメージへのタグ付け $ docker tag myhello:latest us.icr.io/sign_test/myhello_repo:1.0 # タグにイメージが付与されていることを確認 $ docker image ls us.icr.io/sign_test/myhello_repo 1.0 73d3bebec135 7 months ago 6.5MB # タグ付けしたイメージのpush $ docker push us.icr.io/sign_test/myhello_repo:1.0 The push refers to repository [us.icr.io/sign_test/myhello_repo] 8c7811fbf293: Pushed 1.0: digest: sha256:9ae3c4a73834ea96f86808b3d95780d7727f8005f1bf4429f852d3a5258c6558 size: 528 Signing and pushing trust metadata You are about to create a new root signing key passphrase. This passphrasewill be used to protect the most sensitive key in your signing system. Please choose a long, complex passphrase and be careful to keep the password and thekey file itself secure and backed up. It is highly recommended that you use a password manager to generate the passphrase and keep it safe. There will be no way to recover this key. You can find the key in your config directory. # 初回のpush時にoffline key、tagging keyを作成するためにパスフレーズを入力する Enter passphrase for new root key with ID b924e5e: Repeat passphrase for new root key with ID b924e5e: Enter passphrase for new repository key with ID 2b960ef: Repeat passphrase for new repository key with ID 2b960ef: Finished initializing "us.icr.io/sign_test/myhello_repo" Successfully signed us.icr.io/sign_test/myhello_repo:1.0イメージのpush(2回目)
バージョンを上げた同じイメージをpushする際には、tagging key(repository key)のパスフレーズのみが求められます。
# タグ付けしたイメージのpush $ docker push us.icr.io/sign_test/myhello_repo:1.1 The push refers to repository [us.icr.io/sign_test/myhello_repo] 8c7811fbf293: Layer already exists 1.1: digest: sha256:9ae3c4a73834ea96f86808b3d95780d7727f8005f1bf4429f852d3a5258c6558 size: 528 Signing and pushing trust metadata # tagging keyのパスフレーズを入力する Enter passphrase for repository key with ID 2b960ef: Successfully signed us.icr.io/sign_test/myhello_repo:1.1イメージのpull
push後に手元のイメージを削除して、同じイメージをリモートからpullできる状態にします。
その上でイメージをpullすると、付与されているイメージの署名が検証されます。# イメージのpull $ docker pull us.icr.io/sign_test/myhello_repo:1.1 # イメージのダイジェストを突き合わせて、完全性の検証を行う Pull (1 of 1): us.icr.io/sign_test/myhello_repo:1.1@sha256:9ae3c4a73834ea96f86808b3d95780d7727f8005f1bf4429f852d3a5258c6558 sha256:9ae3c4a73834ea96f86808b3d95780d7727f8005f1bf4429f852d3a5258c6558: Pulling from sign_test/myhello_repo Digest: sha256:9ae3c4a73834ea96f86808b3d95780d7727f8005f1bf4429f852d3a5258c6558 # イメージがレポジトリ内で最新かどうかを確認 Status: Image is up to date for us.icr.io/sign_test/myhello_repo@sha256:9ae3c4a73834ea96f86808b3d95780d7727f8005f1bf4429f852d3a5258c6558 Tagging us.icr.io/sign_test/myhello_repo@sha256:9ae3c4a73834ea96f86808b3d95780d7727f8005f1bf4429f852d3a5258c6558 as us.icr.io/sign_test/myhello_repo:1.1 us.icr.io/sign_test/myhello_repo:1.1DCTを有効化していないクライアント利用時の挙動
別の端末で同じユーザーの認証情報を入力してregistryに接続できる状態にしておき、DCTを有効化していない状態でイメージをpushすると処理が拒否されます。
$ ibmcloud cr login 「registry.ng.bluemix.net」にログインしています... 「registry.ng.bluemix.net」にログインしました。 OK $ docker push us.icr.io/sign_test/alpine_repo:1.0 The push refers to repository [us.icr.io/sign_test/alpine_repo] 77cae8ab23bf: Preparing # イメージをpushすると、「Unauthorized」としてpushの実行が拒否される unauthorized: authentication required公式イメージのpull
クライアント側でDCTを有効化した状態で、Docker Hubにある公式イメージ(
alpine)を取得します。
注意点としてはDCTを有効化した状態だと、公式のイメージには自身の署名が付与されていないため、公式のイメージであってもpullができなくなります。今回は、一時的にDCTをクライアント側で無効化することで、署名の検証を回避して公式のイメージを取得しています。
# 署名が付与されていないので、イメージのpullに失敗する $ docker pull alpine Using default tag: latest Error: remote trust data does not exist for docker.io/library/alpine: us.icr.io:4443 does not have trust data for docker.io/library/alpine # DCTを無効化する $ export DOCKER_CONTENT_TRUST=0 $ export DOCKER_CONTENT_TRUST_SERVER=https://registry.ng.bluemix.net:4443 #同じイメージをpullすると、取得できるようになる $ docker pull alpine Using default tag: latest latest: Pulling from library/alpine Digest: sha256:c19173c5ada610a5989151111163d28a67368362762534d8a8121ce95cf2bd5a Status: Image is up to date for alpine:latest docker.io/library/alpine:latest各クラウドベンダーの対応状況(2018/10月末時点)
AWS
AWSのレジストリサービスであるECRは、DCT未対応です。
AWSのContainer-roadmapでは、「Content Trust / Notary support for ECS/ECR」がissueとして挙がっており、9/28の段階で「We're Working On It」のステータスになっています。
https://github.com/aws/containers-roadmap/issues/43GCP
GCPのレジストリサービスであるContainer Registry(GCR)は、DCT未対応です。
実装予定なども不明で、Stack overflowに投稿されたDCTの対応状況に関する質問にも未対応という回答がついていました。
https://stackoverflow.com/questions/53380782/pushing-signed-docker-images-to-gcrAzure
Azure Container Registryでは、DCTの有効化がオプションとして提供されています。
ユーザーにAcrImageSignerのロールを付与することで、IBM Cloud Registry同様にイメージを署名してpushすることが可能になります。
https://docs.microsoft.com/ja-jp/azure/container-registry/container-registry-content-trustIBM Cloud
IBM Cloud Registryでは、DCTの有効化がオプションとして提供されています。
ユーザーへのRoleの付与は必要なく、クライアント側でDCTを有効化することでイメージへの署名が可能になります。
https://cloud.ibm.com/docs/services/Registry?topic=registry-registry_trustedcontent&locale=ja終わりに
Docker Content Trustについて、検証結果と調査した内容をまとめていきました。
自分の勉強した内容の整理のためにも、NIST800-190 (Application Container Security Guide) をベースにしたコンテナセキュリティ周りの記事はこれからも書いていこうと思います。

- 投稿日:2019-11-12T18:02:35+09:00
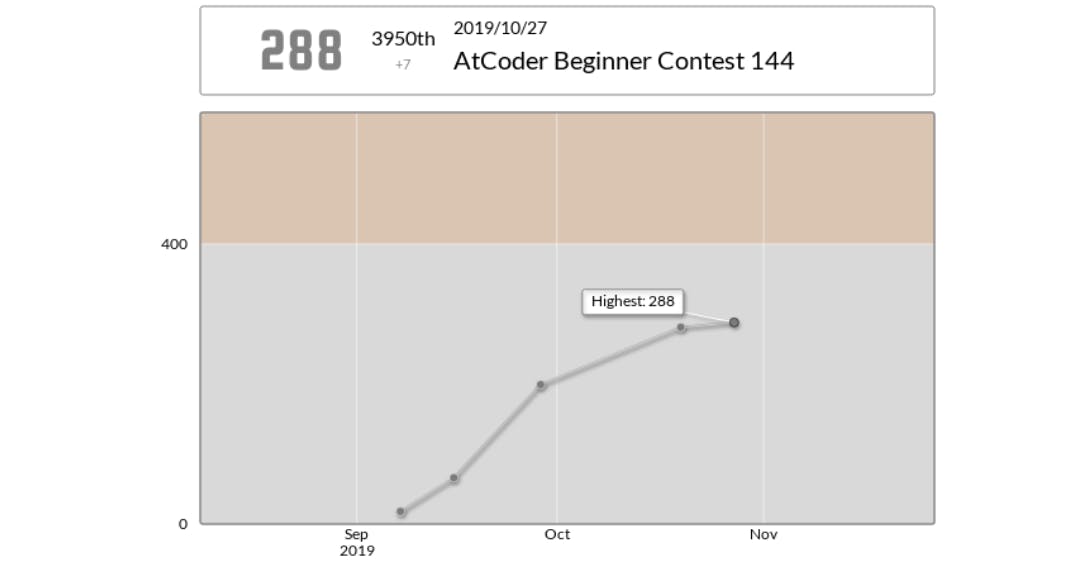
GitHub Actionsで一定間隔ごとにAtCoderのレーティングのグラフを撮ってみた
はじめに
先日AtCoderを始めた@wawawatataruと申します。
レートはまだ茶色にすら到達していませんが楽しく参加しています。
と、AtCoder参加者の方には上図のようなレーティングの画像をTwitterなどで投稿している方も多いと思います。今回はこの作業を今後やらなくてもいいように自動化したいと考え以下の対応をおこないました。
- GitHub Actionsを利用し、一定間隔ごとにAtCoderのレーティング画像を取得
- GitHub Pagesで上記の画像をOGPに設定したページを作成
- OGPを設定したページのURLをTwitterに投稿し固定ツイートにする
上記対応を行うと、下のツイートのようにOGPが自動で更新される(はず)ツイートを行うことができるので、
固定ツイートに設定するだけで、何度もツイートせずに自分のレートを表示することができます。実際のツイート
https://twitter.com/wawawatataru/status/1194150708099964928
できていないこと
OGPの更新方法を完全に理解できていません。
Card validatorでOGPのキャッシュが削除されるという記載を見たのですが、画像更新後、OGPがすぐに更新されることもあれば、Card validatorを使用しても更新されないこともありました……。
詳しい方、教えてください。実際のコード
レーティング画像の取得
レーティング画像はPythonでSeleniumを用いて行っています。
capture_rate.pydef capture_atcoder_rating(): … driver.get("https://atcoder.jp/users/wawawatataru") driver.set_window_size(1920, 1080) driver.find_element_by_id("rating-graph-expand").click() png = driver.find_element_by_class_name("mt-2").screenshot_as_png …AtCoderでは
https://atcoder.jp/users/user_nameでuser_nameのプロフィールページなので、そのページのCSSクラスが.mt-2の部分のスクリーンショットを保存しています。
そうするとページ上部のレーティングの画像が保存できます。TwitterのOGPは1.91:1の割合の画像のため、コード内では
resize_image()で1.91:1になるように白で塗りつぶしています。OGPの設定
GitHub Pagesに設定している
index.html内で行っています。<head> … <meta property="og:title" content="AtCoderRating"> <meta property="og:type" content="website"> <meta property="og:url" content="https://wawawatataru.github.io/atcoder_ogp"> <meta property="og:image" content="https://wawawatataru.github.io/atcoder_ogp/image/screenshot.png"> <meta property="og:site_name" content=""> <meta property="og:description" content="AtCoderのレーティングです。"> <meta name="twitter:card" content="summary_large_image"> … </head>GitHub Actionsの設定
基本的には参考記事の通りに行いました。
一定時間ごとにActionsを実行したかったため、.github/workflows/capture.ymlで実行間隔を設定しています。on: schedule: - cron: "0 1 1-31 * *"ワークフローをトリガーするイベントに関しては公式のヘルプにも記載があるため、そちらをもとに、毎日実行されるように設定しています。
参考にさせていただいた記事
【GitHub Actions】自作Actionsのリリースを自動化する
Github Actionsで遊んでみた
Dockerを使ってHeadless Chromeを動かしてみる
Dockerでheadless-chromeを使ったスクレイピング環境を整える

- 投稿日:2019-11-12T15:39:27+09:00
[AWS SAM]VSCodeでLambda関数をローカルで開発する
目的
AWS Lambdaはコンソール画面からエディタを利用して編集ができます。ローカルファイルをアップロードするにはzip形式でファイルをアップロードする必要がある他、そもそもブラウザが使いづらいという問題点があります。今回は
AWS Toolkit for VSCodeを利用してAWS SAMによるLambda開発を行ってみることを目的とします。自らも初学者であり、他の記事で分からなかった点を補完しながら書いているため初学者向けだと思います。
AWS SAM
AWS(Serverless Application Model)はCloudFormationをサーバーレスアプリケーション用に変形したものらしく、裏ではCloudFormationが動きます。
基本的には公式ドキュメントに従えばHello Worldまでは可能です。
https://docs.aws.amazon.com/ja_jp/serverless-application-model/latest/developerguide/serverless-sam-cli-install-mac.html流れ
awscliのインストール
awscliをインストールすることでawsコマンドが使えるようになります。
pip若しくはbrewでインストールしましょう。筆者はmacユーザかつpythonの管理が面倒だったのでbrewで入れました。サイトには「pipが最も簡単な方法」 と書いてありました。aws-sam-cliのインストール
aws-sam-cliをインストールすることでsamコマンドが使えるようになります。
pip若しくはbrewでインストールしましょう。筆者はmacユーザかつpythonの管理が面倒だったのでbrewで入れました。brew tapは非公式のパッケージをbrew対象に追加するために利用します。brew tap aws/tap brew install aws-sam-clidockerのインストール
最初にbrewでdockerをインストールしたのですが、うまく動かず結局公式サイトからdmgをDLしてインストールしました。Lambdaの動作環境を用意するために使われます。AWS Toolkitを入れてVSCodeからLambda関数を実行するときに自動でdocker環境が立ち上がります。
Install Docker Desktop for MacVSCodeからAWSへの接続
EXTENSION追加
VSCodeの左側のタブからAWS Toolkit for Visual Studio Codeを追加します。これで左側のタブにAWSのアイコンが表示されます。
認証情報の設定
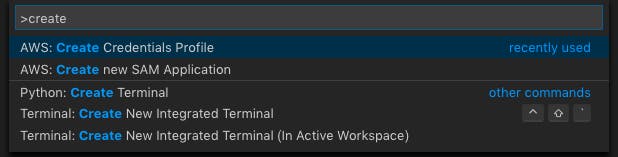
インストール後、
cmd+shift+Pでawsコマンドウィンドウを表示し、Create Credentials Profileを実行します。エディタ若しくはコマンドウィンドウの指示に従い、AWSアカウントのACCESS KEYとSECRET ACCESS KEYを入力します。このawsコマンドにより新たにAWSユーザを作成できます。これは
.aws/配下にvimでcredentialsというファイルを作成または編集する操作と同じです。.aws/configファイルが存在する場合はそれと合わせて読み込まれます。
AWSへ接続
AWSのアイコン→
Connect to AWSをクリックします。.aws/credentialsまたは.aws/configに定義されたユーザが自動で表示されるためその中から選択します。アプリケーションの作成
Create new SAM Applicationを選択します。
次に、Runtimeに使用する言語を選択します。筆者はPython3.7を選択しました。
ワークスペースとなるフォルダを選択し、アプリケーションの名前をつけます。すると自動的にtemplate.yamlが立ち上がります。template.yamlAWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: > test2 Sample SAM Template for test2 # More info about Globals: https://github.com/awslabs/serverless-application-model/blob/master/docs/globals.rst Globals: Function: Timeout: 3 Resources: HelloWorldFunction: Type: AWS::Serverless::Function # More info about Function Resource: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#awsserverlessfunction Properties: CodeUri: hello_world/ Handler: app.lambda_handler Runtime: python3.7 Events: HelloWorld: Type: Api # More info about API Event Source: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#api Properties: Path: /hello Method: get Outputs: # ServerlessRestApi is an implicit API created out of Events key under Serverless::Function # Find out more about other implicit resources you can reference within SAM # https://github.com/awslabs/serverless-application-model/blob/master/docs/internals/generated_resources.rst#api HelloWorldApi: Description: "API Gateway endpoint URL for Prod stage for Hello World function" Value: !Sub "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/hello/" HelloWorldFunction: Description: "Hello World Lambda Function ARN" Value: !GetAtt HelloWorldFunction.Arn HelloWorldFunctionIamRole: Description: "Implicit IAM Role created for Hello World function" Value: !GetAtt HelloWorldFunctionRole.Arn以下のようなファイル群が生成されています。
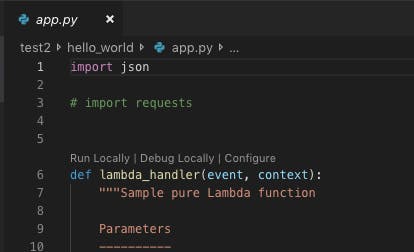
$ tree myapp myapp ├── README.md ├── events │ └── event.json ├── hello_world │ ├── __init__.py │ ├── app.py │ └── requirements.txt ├── template.yaml └── tests └── unit ├── __init__.py └── test_handler.pyこの中でhandlerは
app.pyに記載されています。requirements.txtに必要なパッケージを記載しておけばデプロイ時に自動で追加されます。VSCodeでLambdaをローカルテスト
app.pyのハンドラ上部にRun Locally | Debug Locally | Configureの選択肢が表示されます。Run Locallyを選択すると必要なdocker環境が立ち上がり、ローカルで関数が走ります。何かの不具合があればここでエラーが表示されるため、落ち着いて対応しましょう。
Preparing to run app.lambda_handler locally... Building SAM Application... Build complete. Starting the SAM Application locally (see Terminal for output) Running command: sam local invoke awsToolkitSamLocalResource --template /tmp/aws-toolkit-vscode/vsctkvGlUHf/output/template.yaml --event /tmp/aws-toolkit-vscode/vsctkvGlUHf/event.json --env-vars /tmp/aws-toolkit-vscode/vsctkvGlUHf/env-vars.json Invoking app.lambda_handler (python3.7) 2019-11-08 17:19:07 Found credentials in shared credentials file: ~/.aws/credentials Fetching lambci/lambda:python3.7 Docker container image...... Mounting /tmp/aws-toolkit-vscode/vsctkvGlUHf/output/awsToolkitSamLocalResource as /var/task:ro,delegated inside runtime container START RequestId: df0da3ce-bd4d-1e44-3c27-8ac942c1a17e Version: $LATEST END RequestId: df0da3ce-bd4d-1e44-3c27-8ac942c1a17e REPORT RequestId: df0da3ce-bd4d-1e44-3c27-8ac942c1a17e Duration: 5.88 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 23 MB {"statusCode":200,"body":"{\"message\": \"hello world\"}"} Local invoke of SAM Application has ended.このように出力されればOKです。なお、テストイベントにbodyを追加したい場合は、CodeLensの
Configureをクリックすると一向上の階層の.aws/templates.jsonが開き、eventが空なので要素を追加すれば渡されます。templates.json{ "templates": { "test1/template.yaml": { "handlers": { "app.lambda_handler": { "event": { "bodyとか":"ここに要素を追加" }, "environmentVariables": {} } } } } }VSCodeからのデプロイ
デプロイするにはS3バケットが必要になります。これは、パッケージ化した一連のコード群を配置するためです(多分)。デプロイ後にS3を覗いてもらえば何かのオブジェクトが保存されていることを確認できます。
今まで同様
cmd+shift+Pでウィンドウを開き、Deploy SAM Applicationを選択します。
template.yamlとリージョン、S3バケット名、Stack名を聞かれるので入力します。Stack名とは、CloudFormationにおけるリソースグループ名のようなものです。Stack名は新規の名前を入力すれ新規Stackが作成され、既存の名前を入力するとアップデートされます。CloudFormationがリソースの作成を含むため、Create権限を持ったRoleで実行する必要があります。変更が必要な場合は、
.aws/configで定義します。Starting SAM Application deployment... Building SAM Application... Packaging SAM Application to S3 Bucket: {バケット名} with profile: {プロファイル名} Deploying SAM Application to CloudFormation Stack: localDeployTest2 with profile: {プロファイル名} Successfully deployed SAM Application to CloudFormation Stack: localDeployTest2 with profile: {プロファイル名}このように出力されれば完了です。CloudFormation,Lambda関数,API gatewayが作成されます。ブラウザを開いてコンソールから確認してみましょう。
CloudFormationのStackを消去すると関連するリソースを全て削除することができます。便利ですね。
あとは、実際にコードを変更したらデプロイする、を繰り返せば良さそうですね。ここまでできればHello Worldできたと言ってもいいでしょう。



- 投稿日:2019-11-12T13:04:40+09:00
agora.io RTC カンファレンス 2019 レポート #3
はじめに
2019年10月24日、25日に中国の北京で開催されたRTC Conference 2019というビデオ通話やライブ配信に関わる開発者向けのカンファレンスに参加してきました。カンファレンスの概要については、agora.io RTC カンファレンス 2019 レポート #1に記載しています。
最終回の今回は、私が参加したセッションとセッション会場外の展示についてのレポートです。なお、agora.io RTC カンファレンス 2019 レポート #2でもセッションのレポートを記載しています。#2は、業界トレンドの変遷やAI × RTC をテーマとしたセッションが中心となっています。セッションレポート
まずは私が参加したセッションのレポートを3つ記載します。今回は、システム構成・開発をテーマとしたセッションです。
WebRTCにおけるよくある間違いとその回避方法 [Big Front-end Application]
このセッションでは、BlogGeek.meというWebRTCに関するメディアの運営者であり、W3C WebRTCテクノロジーエバンジェリストでもあるTsahi Levent-Levi氏がはじめにWebRTCの概要について話した後、WebRTCにおけるよくある間違い7つとその回避方法について話しました。
WebRTCの概要については、WebRTCはWebブラウザをベースにした技術で、Java ScriptのAPIを利用したメディアエンジンであるという話をしました。また、WebRTCを構成する要素として、クライアント側はブラウザ、端末、サーバ側はアプリケーションサーバ、Signalingサーバ、メディアサーバ、STUN/TURNサーバを挙げました。
その後、WebRTCにおけるよくある間違い7つとその回避方法について話しました。まず1つ目の間違いは、NAT越えに関する間違いです。Levent-Levi氏は、公開されている (パブリックな) 無償のSTUN/TURNサーバを使うべきではないと主張しました。常に正常に利用できる保証がなく、世界中で広く利用されており、セキュリティリスクも高いからとのことです。
2つ目は、誤ったSignalingのフレームワークを選択することです。おそらくこの指摘は、GitHub等で公開されているコードをコピー&ペーストして利用することに対して、注意を促しているのだと思います。peerjsやEasyRTCなど無償で利用することのできるWebRTCのサンプルコードは数多くあります。ただ、これらのコードは必ずしも管理が行き届いているとは限りません。そのため、自身のサービスの要件を確認したうえで、自分自身でコードのメンテナンスをすることが大切になります。
3つ目は、ローカル環境のみでテストをすることです。多くのサービスでは、実際にそのサービス利用する際は、FWの外に出て、インターネット経由で利用することになります。インターネット経由となると、ローカル環境では発生しなかった問題が発生する可能性もあります。
4つ目は、セキュリティ設定を無視、または忘れることです。ただ、Levent-Levi氏は、WebRTCという技術自体は安全であると言っていました。動画の送信では、SRTP (Secure Real-time Transport Protocol) というプロトコルを利用して、メッセージの暗号化や認証を実施しています。暗号鍵の交換はDTLS (Datagram Transport Layer Security) を通して実施されます。また、Signalingの送信では、HTTPS、もしくはWSS (Web Socket Secure) が利用されます。
Levent-Levi氏が指摘するWebRTCを利用したサービスを提供するうえで重要なセキュリティにおける点とは、アプリケーションロジックやTURNサーバへのアクセス設定、メディアサーバのリソース調整、WebRTCのリリース (アップデート) を注視し続けることです。
5つ目は、統計情報やログを収集しないことです。WebRTCはその技術の特性上、常に全てを自分自身でコントロールできるとは限りません。例えば、各ユーザのネットワーク状態、利用デバイス、ブラウザの自動アップデートなどに起因する問題はサービス提供者自身でコントロールすることが難しいです。しかしながら、サービスユーザから見ると、これらが原因で発生した問題もサービス提供者に原因があると思われてしまうことも多々あります。そのため、問題を分析し、解決に導くためにも必要なデータは収集するべきです。
6つ目は、短期的視点しか持たないことです。一般的にブラウザは6から8週間のサイクルでアップデートが発生します。アップデート内容によっては、セキュリティパッチが含まれていたり、ブラウザの仕様が変更することもあります。サービスを開発する際は、サービスを完成させることだけではなく、その後のメンテナンスについても考慮することも重要です。
そして最後の7つ目は、WebRTCについて理解が足りていないことです。Levent-Levi氏は、その解決策として自身の運営するBlogGeek.meで、WebRTCについて学習することを勧めていました。ちなみにLevent-Levi氏が紹介したサービスでは、1回20分程度のレッスンが40以上あるようです。
このセッションを通して、WebRTCという技術は便利ですが、自分自身でコントロールできない要素も多い技術で、注意するべき点が多い技術であると改めて感じました。また、自分自身でコードのメンテナンスを実施することやセキュリティに対して注意を払うことなどの指摘は、WebRTCに限らず、システム開発全般において重要だと思いました。写真1. 自身のWebRTC学習サービスを紹介するLevent-Levi氏
Kubernetesを利用したビデオストリーミングサーバの構築 [QoE and Architecture]
このセッションでは、データ保護に関するSaaSベンダーであるWishlifeのCTOであるLei Wang氏がKubernetesの概要を説明した後、それを利用したビデオストリーミングサーバの構築方法について話しました。
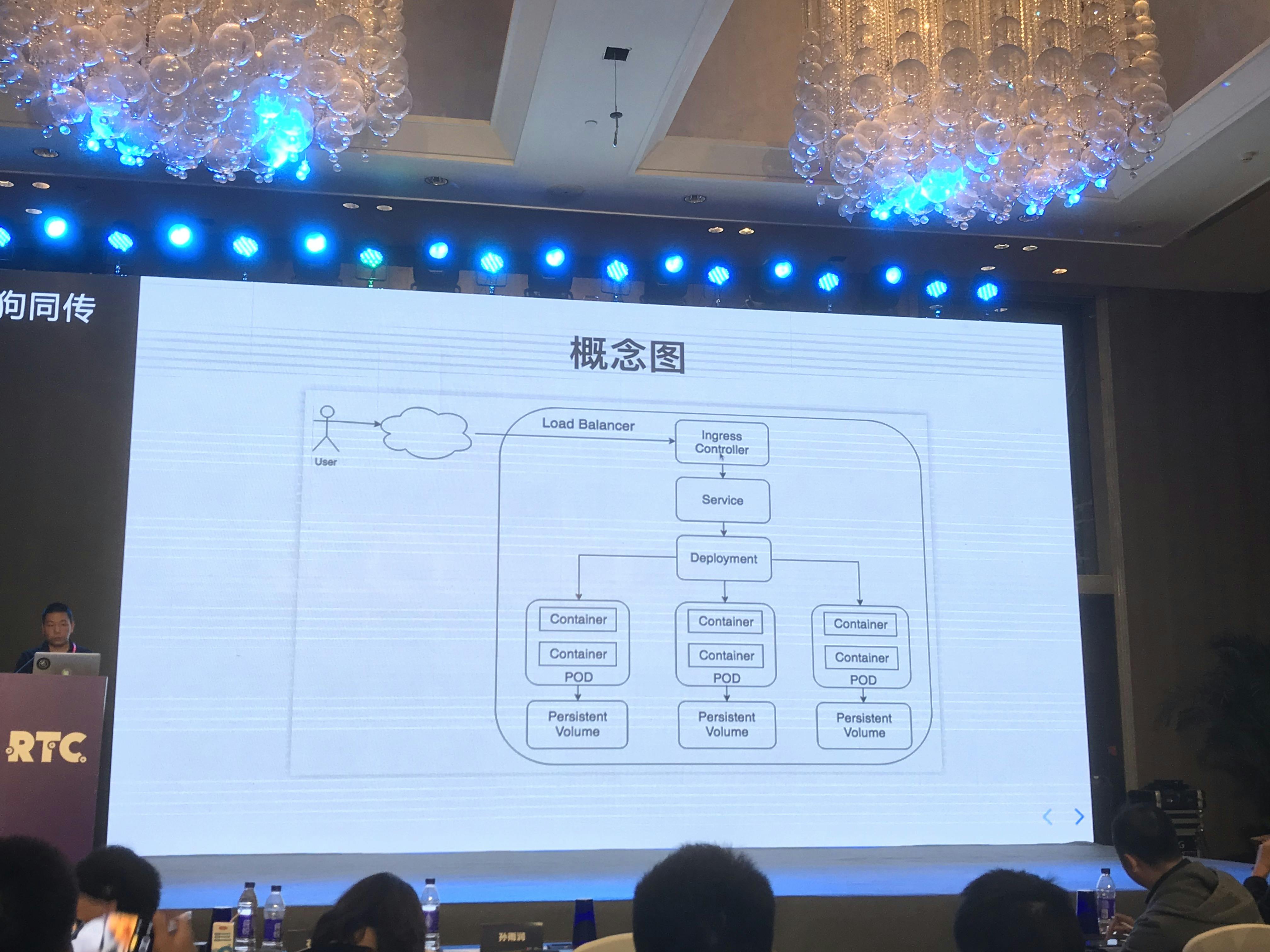
Kubernetesとは、Googleによって開発されたコンテナ化したアプリケーションのデプロイやスケーリング、管理を自動的におこなうためのオープンソースのシステムです。オーケストレーション基盤 (オーケストレーションツール) とも呼ばれているようです。本番環境では、複数のコンテナを動かすことが一般的です。言い換えると、コンテナ単体では、本格的なシステムを運用することは難しいです。しかしながら、各コンテナは独立をしていて、お互いを認識しません。そのため、そうした複数のコンテナを管理するためのツールがKubernetesです。
その後、Wang氏は、Kubernetesを理解するためには、Cluster、Node、Pod、Service、Ingress Controller、Persistent Volume、Persistent Volume Claimという7つの基本概念について理解する必要があると話しました。これらの基本概念については、Kuberbetesのドキュメントで解説されています。そして、これらの概念を用いてKubernetesを利用したビデオストリーミングサーバの構築方法について説明しました。また、それに加えて、複雑なKubernetesを利用したアプリケーションを定義、インストール、アップグレードする際には、Helmというパッケージマネージャ (パッケージ管理システム) が役に立つと話しました。
つまり、複数のコンテナのインフラ管理するための基盤 (ツール) がKubernetesであり、その基盤の上で、Kubernetesをアプリケーションのように扱うことができるシステムがHelmということになると思います。多くの概念が登場したため、それらの関係性の理解に苦労しましたが、コンテナ技術の普及に伴い、それに付随する新しい技術が生まれ、活用されているのだと思いました。Qiitaでも、KubernetesやHelmについて書かれた記事がたくさんあったので、日本でも利用されている技術なのだと思います。写真2. Kubernetesの概念を利用してサーバの構成図について説明するWang氏
Dockerを利用したグローバルマルチクラウドRTCフレームワークの作成 [QoE and Architecture]
このセッションでは、SignalWireのCTOであるEven McGee氏がDockerとその管理ツールであるDocker Swarmの概要を説明し、タイトルにあるグローバルマルチクラウドRTCフレームワークの作成において重要な点について話しました。その後、自社サービスであるSignalWireについて紹介しました。
Dockerとは、コンテナ型の仮想環境を作成、共有、実行するためのプラットフォームです。 McGee氏もコンテナの説明でよくされるようにコンテナの利点として、軽量で高速に起動、停止できることを挙げていました。
また、先ほどのセッションで登場したKubernetesと同じようなコンテナ管理ツールとして、Docker Swarmについて紹介しました。こちらは、Docker社によって開発されたコンテナ管理ツールです。なお、こちらの記事では、KubernetesとDocker Swamについて比較しています。こちらの記事によると、Kubernetesはより複雑な管理が可能であり、Docker Swamはシンプルで構築が容易という点が特徴のようです。
そして、グローバルマルチクラウドRTCフレームワークの作成において重要な点を3つ挙げました。1つ目は、マスターとなるノード (管理コンポーネント) は、近くに配置するが、それぞれのリージョンやプロバイダは別にすることです。なお、McGee氏は、複数のクラウドプロバイダを利用することの利点として、サービスが世界中で利用できることも挙げました。つまり、1つのプロバイダでは、サービス提供できる範囲が限られるが、複数利用すれば、世界中をカバーすることができるということです。次に2つ目は、クラスタ (Docker Swarmの管理対象全体) のログを注視することです。そして3つ目は、クラウド間、サーバ間の通信を暗号化することです。
上記の点の多くは、聞き馴染みのあることでしたが、複数のクラウドプロバイダを利用することで、世界中にサービスを提供するという指摘は、自分にとってはスケールの大きい話で新鮮でした。
その後は、自社サービスであるSignalWireの紹介しました。 McGee氏の話やサービスサイトを一読したところ、SignalWireもagora.ioと同じように映像音声やチャットを利用したアプリケーション用のAPIを提供するサービスのようです。また、SignalWireのアカウントを利用すれば、agora.ioなど他のRTCサービスも利用できることも最後に説明していました。写真3. コンテナ化とDockerについて説明するMcGee氏
展示レポート
セッション会場の外では、agora.ioをはじめ、RTCに関するサービスを提供する各社が様々な展示をしていました。ここではその中から3つ紹介します。
全世界のagora.io利用状況 (Realtime)
Realtimeと呼ばれるagora.ioが提供する分析ツールのひとつです。全世界でのagora.ioのリアルタイムの利用状況を表示しています。こちらの写真は中国時間の10月25日16時53分に撮影しましたが、その時点の利用ユーザ数は、4万2千人ほどでした。Realtimeは2019年11月現在Beta版ですが、agora.ioユーザであれば、利用することができます。
なお、写真の上部に書いてあるAgora Analyticsは、agora.ioが提供する分析ツールの総称で、agora.ioは、このRealtimeをはじめ、様々な分析ツールを提供しています。写真4. Realtime
顔認識技術のデモ
FaceUnityの技術を利用した顔認識技術のデモです。(agora.ioはFaceUnityの顔認識技術もサービスの一部として提供しています) 。水色の枠内に立ち、カメラの前を向いて3秒ほどすると、自動でその人の特徴を捉えたアイコンを生成します。
写真5. 顔認識技術のデモ
遠隔授業のデモ
中国では、遠隔教育も急速に成長している分野の一つのようです。こちらのサービスでは、資料共有やホワイトボード機能などを利用することができます。
なお、その後ろに見えるのは、ゲームセンターなどに置いてあるパンチングマシンです。初日にそれを使って遊んでいる人がたくさんいたせいか、2日目には撤去されていました。写真6. 遠隔授業のデモ
まとめ
カンファレンスは大部分のセッションが中国語でおこなわれ、かつ私の前提知識が不足しているセッションも多かったので、内容を理解することに苦労しました。正直なところ内容をほとんど理解できなかったセッションもありました。ただ、英語でおこなわれたセッションやRTCの市場動向、WebRTC、Dockerなど比較的馴染みのあるセッションは聞いていて楽しかったです。
また、セッション中はほとんど理解ができなかったセッションもこうしてレポートを作成するにあたり、記録することのできた単語から色々と調べていくと、近年様々な研究がおこなわれている技術であることがわかりました。RTC業界といっても数多くの技術要素があり、他種多少な研究がされているのだと思いました。特に今話題のAIを映像・音声技術に取り入れられているという点は自分にとって新鮮でした。ただ、今回のセッションを聞いたうえでよく考えてみると、AIと映像・音声技術は相性のよい分野だと思いました。このように日々の業務に追われていると疎かになりがちなRTC業界のトレンドを知ることができたので、参加することができてよかったです。
今後もこのようなカンファレンスに積極的に参加して、知識を深め、日々の業務に活かしていきたいと思います。最後まで読んでいただきありがとうございました!参照
Enroll to Advanced WebRTC Architecture Course
Concepts - Kubernetes
Kubernetes vs. Docker Swarm: What's the Difference? - The New Stack最後に






- 投稿日:2019-11-12T08:21:42+09:00
GitHub Actions + Trivy でDevSecOpsを実現する
本番環境で稼働中のDockerイメージの脆弱性チェックを定期的に行なっていますか?
デプロイ時に脆弱性チェックをする方法はこちらの記事に書いていますが、運用フェーズに入ってからのセキュリティ対策について書いていませんでした。むしろ長い運用フェーズの方が脆弱性が多く発見されるので定期的なチェックは必須です。しかし、定期的なチェックは面倒だしコストがかかります。
そこで、GitHub ActionsとTrivyを使って手軽に定期的に脆弱性スキャンが行える方法をご紹介します。ただスキャンするだけでは運用時には辛いので、脆弱性が発見されたらGitHubのIssueが作成されるようにします。そうすれば何に対処すればいいか各リポジトリごとに管理できますし、プルリクとIssueを関連づけてプルリクがマージされたらIssueもクローズみたいな運用をすれば対応済みかどうか分かりやすくなります。GitHub Actions
Schedule
定期的にスキャンをするのでGitHub Actionsのschedule機能を使用します。schedule機能と言っても自体は
cronです。例えば毎週月曜日の9:00(JST)にCIを回したいのであれば以下のようになります。
GitHub ActionsはUTCで動くので注意
on: schedule: - cron: '0 0 * * 1'必要なコマンドのインストール
Trivyはもちろんですが、Issueを作成する上で以下のコマンドのインストールをします。
コマンド 説明 Trivy 脆弱性スキャンコマンド hub Issue作成する pandoc Trivyのスキャン結果をHTMLにする - name: Install commands run: | sudo apt install apt-transport-https gnupg wget -qO - https://aquasecurity.github.io/trivy-repo/deb/public.key | sudo apt-key add - echo deb https://aquasecurity.github.io/trivy-repo/deb $(lsb_release -cs) main | sudo tee -a /etc/apt/sources.list.d/trivy.list sudo apt update sudo apt install --no-install-recommends trivy sudo snap install hub --classic VERSION=$(curl --silent "https://api.github.com/repos/jgm/pandoc/releases/latest" | \ grep '"tag_name":' | \ sed -E 's/.*"([^"]+)".*/\1/') curl -L -o pandoc.deb https://github.com/jgm/pandoc/releases/download/${VERSION}/pandoc-${VERSION}-1-amd64.deb sudo dpkg -i pandoc.debDockerイメージのスキャン
Trivyでスキャンする時のオプションはこちらを参考にしてください。ここではseverity(重大度)をHIGH・CRITICALにして、脆弱性を発見したらexit codeを1にします。
- name: Scan Image run: trivy -q --severity HIGH,CRITICAL --exit-code 1 ${IMAGE_NAME} > tmp.txtIssueの作成
脆弱性がなければ終了し、あればIssueをあげます。その前にIssueが見やすくなるようにTextベースのファイルをHTMLに変換します。
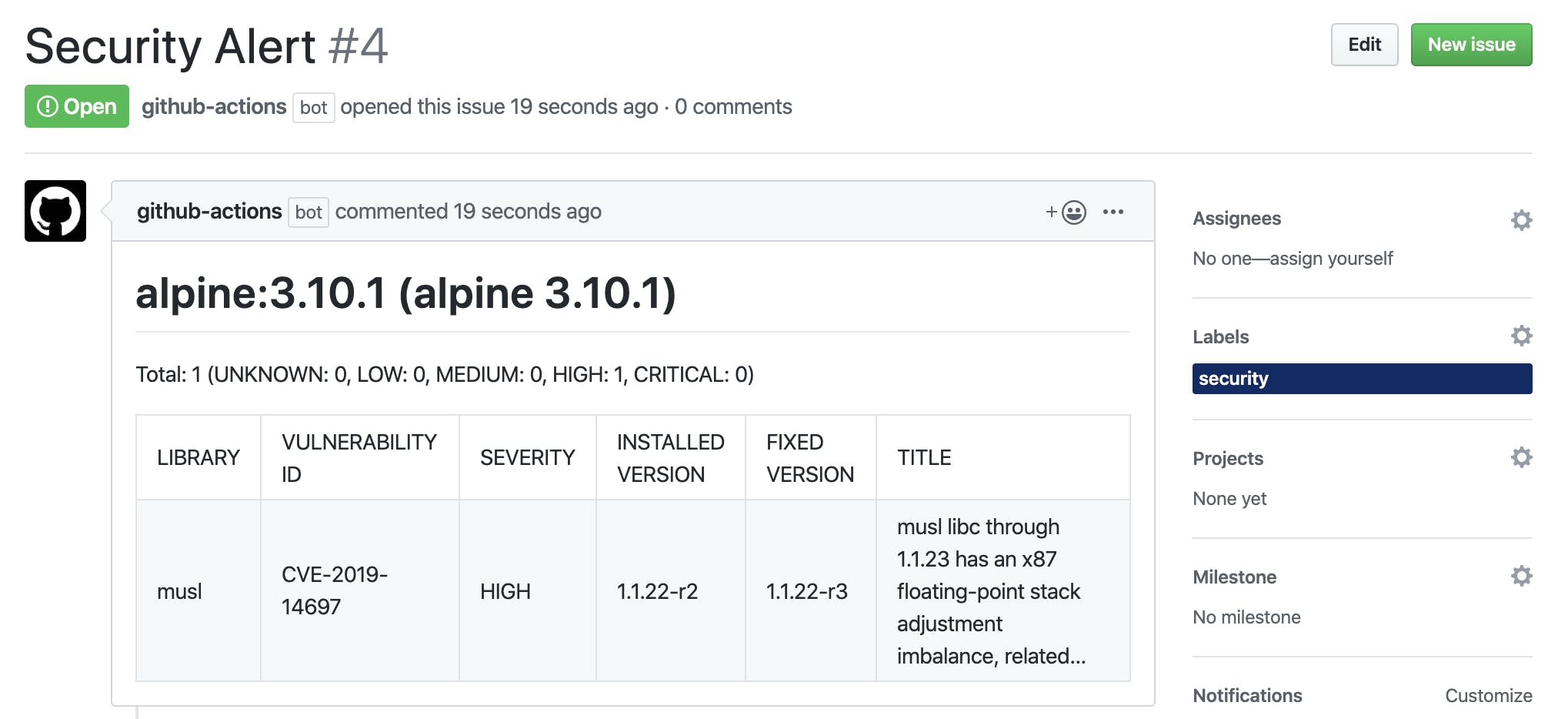
echo -e "Security Alert\n" > result.htmlのSecurity AlertがIssueのタイトル、trivyのスキャン結果は説明欄に記載、hubコマンドの-lオプションでsecurityラベルがつくようになっています。
GITHUB_TOKENとGITHUB_PASSWORDに関してですが、トークンだけあればパスワードは不要とドキュメントに書いてあったのですが認証エラーになったので両方書いてあります。中身の値はどちらも同じですが...- name: Create Issue if: failure() env: GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} GITHUB_PASSWORD: ${{ secrets.GITHUB_TOKEN }} run: | pandoc tmp.txt -o tmp.html sed -i -e "s/<pre><code>//g" tmp.html sed -i -e "s/<\/code><\/pre>//g" tmp.html echo -e "Security Alert\n" > result.html cat tmp.html >> result.html sudo chown root:root / hub issue create -F result.html -l security以下はテスト用にCIを走らせてみた結果です。
いい感じですね
完成形
完成形のWorkflowを書いておきます。
IMAGE_NAMEとGITHUB_USERを自身の環境に合わせて変更すれば動作するはずです。name: Vulnerability scan on: schedule: - cron: '0 0 * * 1' env: IMAGE_NAME: alpine:3.10.1 GITHUB_USER: homoluctus jobs: scan: name: Scan images runs-on: ubuntu-18.04 steps: - uses: actions/checkout@master with: ref: master - name: Install commands run: | sudo apt install apt-transport-https gnupg wget -qO - https://aquasecurity.github.io/trivy-repo/deb/public.key | sudo apt-key add - echo deb https://aquasecurity.github.io/trivy-repo/deb $(lsb_release -cs) main | sudo tee -a /etc/apt/sources.list.d/trivy.list sudo apt update sudo apt install --no-install-recommends trivy sudo snap install hub --classic VERSION=$(curl --silent "https://api.github.com/repos/jgm/pandoc/releases/latest" | \ grep '"tag_name":' | \ sed -E 's/.*"([^"]+)".*/\1/') curl -L -o pandoc.deb https://github.com/jgm/pandoc/releases/download/${VERSION}/pandoc-${VERSION}-1-amd64.deb sudo dpkg -i pandoc.deb - name: Pull images run: docker pull ${IMAGE_NAME} - name: Scan Image run: trivy -q --severity HIGH,CRITICAL --exit-code 1 ${IMAGE_NAME} > tmp.txt - name: Create Issue if: failure() env: GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} GITHUB_PASSWORD: ${{ secrets.GITHUB_TOKEN }} run: | pandoc tmp.txt -o tmp.html sed -i -e "s/<pre><code>//g" tmp.html sed -i -e "s/<\/code><\/pre>//g" tmp.html echo -e "Security Alert\n" > result.html cat tmp.html >> result.html sudo chown root:root / hub issue create -F result.html -l security - name: Notify Result to Slack uses: homoluctus/slatify@master if: always() with: type: ${{ job.status }} channel: '#general' job_name: ':sniper: *Vulnerability Scan*' url: ${{ secrets.SLACK_WEBHOOK }}これで定期的な脆弱性スキャンができるようになりました。
GitHub Actionsと様々なツールを組み合わせればDevOps/DevSecOpsが簡単に実現できますので、試してみる価値はあると思います。
余裕のある方はGitHubのdependabot、Dockerfileのリンター・スキャナであるdockleや有料ツールが豊富ですので、多角的に脆弱性チェックをするのもありでしょう。
- 投稿日:2019-11-12T03:23:16+09:00
Rails 6.0 × MySQL8でDocker環境構築(Alpineベース)
はじめに
Dockerについての知識を深めるため、表記の環境構築をしました。
※当環境は開発環境を想定して構築しています。また、不具合等で後日記事を修正する可能性がありますので、予めご了承下さい。
概要
構成のベースは、主に下記の記事を参考にしました。
・DockerでRails+Webpackerの開発環境を構築するテンプレート
Rails6ではwebpackerが標準で備わっているため、webpacker導入の記事を参考にしました。
当環境の特徴は、
・DockerイメージをAlpine Linuxベースを使用し、軽量化。
・マルチステージビルド機能を使用し、Nodeイメージから実行ファイルをコピーしてくることで、ビルド時間短縮、軽量化。
・Entrykitのコマンド「prehook」を使用し、コンテナ起動時にbundle installすることで、作業効率向上。
です。各項目の参考URLを下記に記載します。・Alpine Linux で Docker イメージを劇的に小さくする
・Multi-stage build でNode.jsのインストールをちょっぴり効率化する
・RailsのDocker環境にEntrykitを導入し、bundle installを自動実行させる方法開発環境
・MacOS Mojave 10.14.6
・Ruby 2.6.5
・Rails 6.0.0
・Docker 19.03.1
・Docker compose ver.1.24.3各種ファイル
Dockerfile.dev
# nodeイメージをビルド FROM node:13.1.0-alpine as node # 軽量のAlpine Linuxベースのイメージ FROM ruby:2.6.5-alpine3.10 # rails consoleの中で日本語入力を設定 ENV LANG C.UTF-8 # 環境構築に必要なパッケージをインストール RUN apk add --no-cache alpine-sdk \ mysql-client \ mysql-dev \ build-base \ bash \ tzdata # Dockerコンテナ起動時の実行タスクを処理するためのツール ENV ENTRYKIT_VERSION 0.4.0 # entrykitインストール RUN wget https://github.com/progrium/entrykit/releases/download/v${ENTRYKIT_VERSION}/entrykit_${ENTRYKIT_VERSION}_Linux_x86_64.tgz \ && tar -xvzf entrykit_${ENTRYKIT_VERSION}_Linux_x86_64.tgz \ && rm entrykit_${ENTRYKIT_VERSION}_Linux_x86_64.tgz \ && mv entrykit /bin/entrykit \ && chmod +x /bin/entrykit \ && entrykit --symlink # javascriptパッケージマネージャ ENV YARN_VERSION 1.19.1 # MSBで、ビルドしたnodeイメージからyarnとnodeをコピー COPY --from=node /opt/yarn-v$YARN_VERSION /opt/yarn COPY --from=node /usr/local/bin/node /usr/local/bin/ # dockerイメージから参照できる様シンボリックリンク作成 RUN ln -s /opt/yarn/bin/yarn /usr/local/bin/yarn \ && ln -s /opt/yarn/bin/yarnpkg /usr/local/bin/yarnpkg # ディレクトリ作成 RUN mkdir /app # 作業フォルダとして設定 WORKDIR /app # entrykitのコマンド設定 ENTRYPOINT [ \ "prehook", "ruby -v", "--", \ "prehook", "bundle install -j3 --quiet", "--"]docker-compose.yml
# docker-compose最新(2019.11.12現)Ver. version: "3.7" # アプリケーションを動かすための各要素 services: app: &app_base # rails server用コンテナ build: # Dockerfileを実行し、ビルドされる時のパス指定 context: . dockerfile: Dockerfile.dev volumes: # マウントする設定ファイルのパス指定 - .:/app - bundle-data:/usr/local/bundle ports: # port番号(docker:host) - "3000:3000" depends_on: # Service同士の依存関係 - db command: bash -c "rm -f tmp/pids/server.pid && bundle exec rails s -p 3000 -b '0.0.0.0'" tty: true # railsのデバッグを使用するための設定 stdin_open: true # 同上 webpack: # webpack-dev-server用コンテナ <<: *app_base command: "bin/webpack-dev-server" ports: - "3035:3035" depends_on: - app tty: false stdin_open: false db: # データベース用コンテナ image: mysql:8.0.18 command: --default-authentication-plugin=mysql_native_password # ユーザーの認証方式変更 environment: MYSQL_ROOT_PASSWORD: password ports: - "4306:3306" volumes: - "mysql-data:/var/lib/mysql" volumes: mysql-data: driver: local bundle-data: driver: local説明についてはコメントアウトの通りです。
また、Mysql8ではユーザーの認証方式がcaching_sha2_passwordに変わっているみたいで、現環境だと対応するのが厳しいため、一時的に5.7までの認証方式であるmysql_native_passwordに変更しています。
他、基本的には参考サイトと構成は同じです。注意すべき点はrails newの後、
database.ymlとwebpacker.ymlの変更を忘れないことです。database.yml
default: &default adapter: mysql2 encoding: utf8mb4 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root password: password host: dbwebpacker.yml
dev_server: https: false host: webpack port: 3035 public: localhost:3035 hmr: falseデータベースのパスワードは
docker-compose.ymlに記載したパスを、両ファイルのhostにはそれぞれのコンテナ名を記載してください。
- 投稿日:2019-11-12T00:57:45+09:00
jupyter でNotebook changedが出まくるバグ?
jupyterでcodingしてると、定期的に5分に一回くらい、
Notebook changed
という表示が出て[×] を押しに行かなきゃいけなくなるという不具合が発生。
この、すごく辛い修行によって、マウスパッドの操作力を鍛えていたのですが、
流石にこれからのAI時代に不要なスキルなのではないかと考えなおしまして調べました。少々マニアックな症状だったためか、日本語で検索しても引っかからず、
いよいよエンジニア英語力が試される!https://github.com/jupyter/notebook/issues/484
結論を言いますと、
https://github.com/jupyter/notebook/pull/3273上記のようにバグフィックスされていて、
~/.jupyter/nbconfig/notebook.json{ "Notebook": { "Header": false, "Toolbar": true }, "Cell": { "cm_config": { "lineNumbers": false } }, "last_modified_check_margin": 10000 }とすると良いらしい。
last_modified_buffer
より良い名前はないかい?→last_modified_check_margin
はどうだ?みたいな、おしゃれな会話がなされているのですが、
私のようなヒヨッコエンジニアからすると、答えをもう少し丁寧に書いて欲しい涙ー*ー*ー
ちなみに自分の環境は、以下です。docker使ってる結構出るっぽいですね。
仮想環境とサーバーの時間のズレが発生しやすい?gcp
dockerのnotebook/datascience-notebook
mac catalina