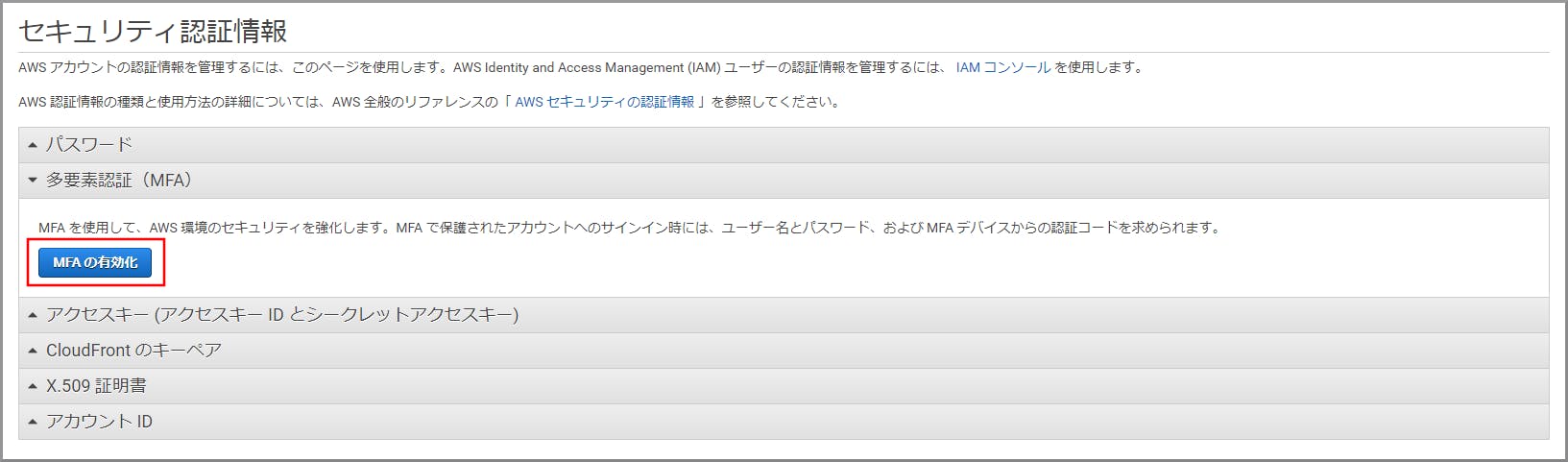
$ pip install aws-sam-cli
$ sam --version
SAM CLI, version 0.31.0
これだけです。
サンプルAWS SAMアプリケーションをダウンロードする
AWS SAM CLIのバージョンによって、ダウンロード時のコマンドが変わります。
SAM CLI version 0.30.0 より新しい場合は、下記のコマンドになります。
$ sam init --runtime python3.7 --dependency-manager pip --app-template hello-world --name sam-app
Quick start templates may have been updated. Do you want to re-download the latest [Y/n]: y
特に何も表示されずに、完了しました。
sam-app ディレクトリが出来ています。
$ cd sam-app/
$ ls
README.md events hello_world template.yaml tests
$ ls hello_world/
__init__.py app.py requirements.txt
$ ls tests/
unit
$ ls tests/unit/
__init__.py test_handler.py
template.yaml のあるディレクトリで下記コマンドを実行します。
$ sam build
Building resource 'HelloWorldFunction'
Running PythonPipBuilder:ResolveDependencies
Running PythonPipBuilder:CopySource
Build Succeeded
Built Artifacts : .aws-sam/build
Built Template : .aws-sam/build/template.yaml
Commands you can use next
=========================
[*] Invoke Function: sam local invoke
[*] Package: sam package --s3-bucket <yourbucket>
ビルドされたファイルを確認します。
$ ls .aws-sam/build/
HelloWorldFunction template.yaml
$ sam local start-api
Mounting HelloWorldFunction at http://127.0.0.1:3000/hello [GET]
You can now browse to the above endpoints to invoke your functions. You do not need to restart/reload SAM CLI while working on your functions, changes will be reflected instantly/automatically. You only need to restart SAM CLI if you update your AWS SAM template
2019-11-12 00:10:20 * Running on http://127.0.0.1:3000/ (Press CTRL+C to quit)
※ここで別ターミナルを起動してcurlを実行(詳細、後述)
Invoking app.lambda_handler (python3.7)
Fetching lambci/lambda:python3.7 Docker container image......
Mounting /home/user01/python375/sam-app/.aws-sam/build/HelloWorldFunction as /var/task:ro,delegated inside runtime container
START RequestId: ebf27a72-6c64-15f8-7ace-996a84d48b4f Version: $LATEST
END RequestId: ebf27a72-6c64-15f8-7ace-996a84d48b4f
REPORT RequestId: ebf27a72-6c64-15f8-7ace-996a84d48b4f Duration: 6.58 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 18 MB
No Content-Type given. Defaulting to 'application/json'.
2019-11-12 00:11:32 127.0.0.1 - - [12/Nov/2019 00:11:32] "GET /hello HTTP/1.1" 200 -
crtl + c で停止します。
$ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
005c0e19f8b4 lambci/lambda:python3.7 "/var/rapid/init --b…" 1 second ago Up Less than a second quirky_merkle
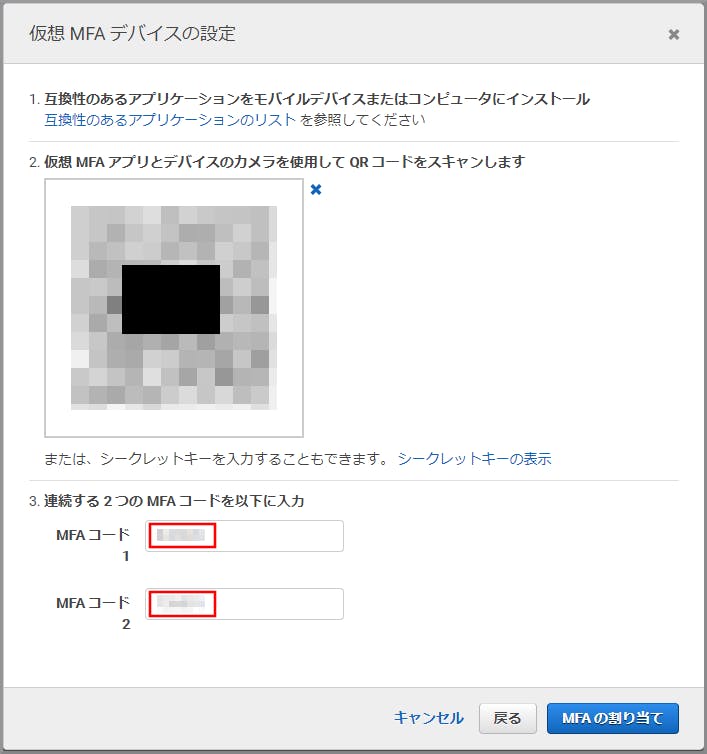
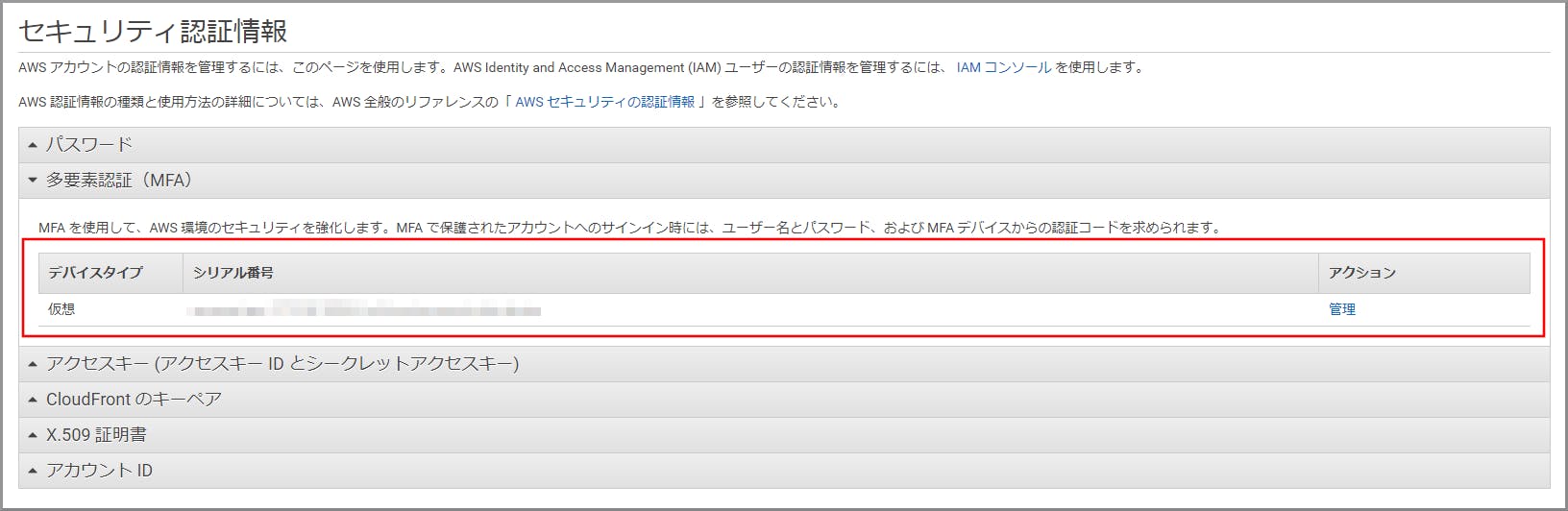
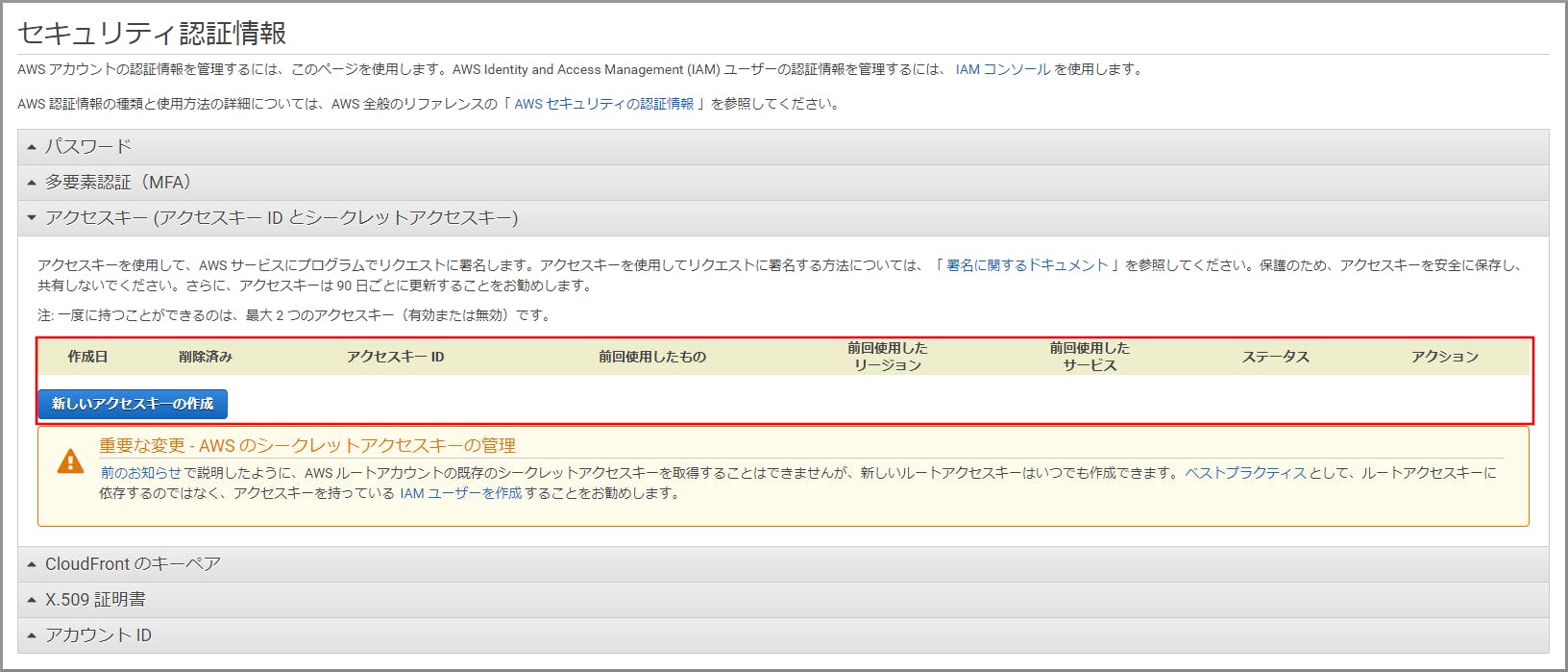
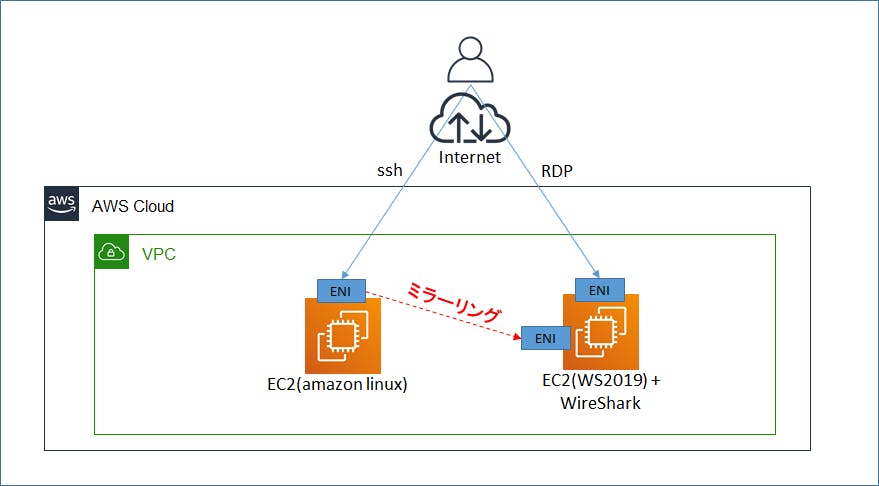
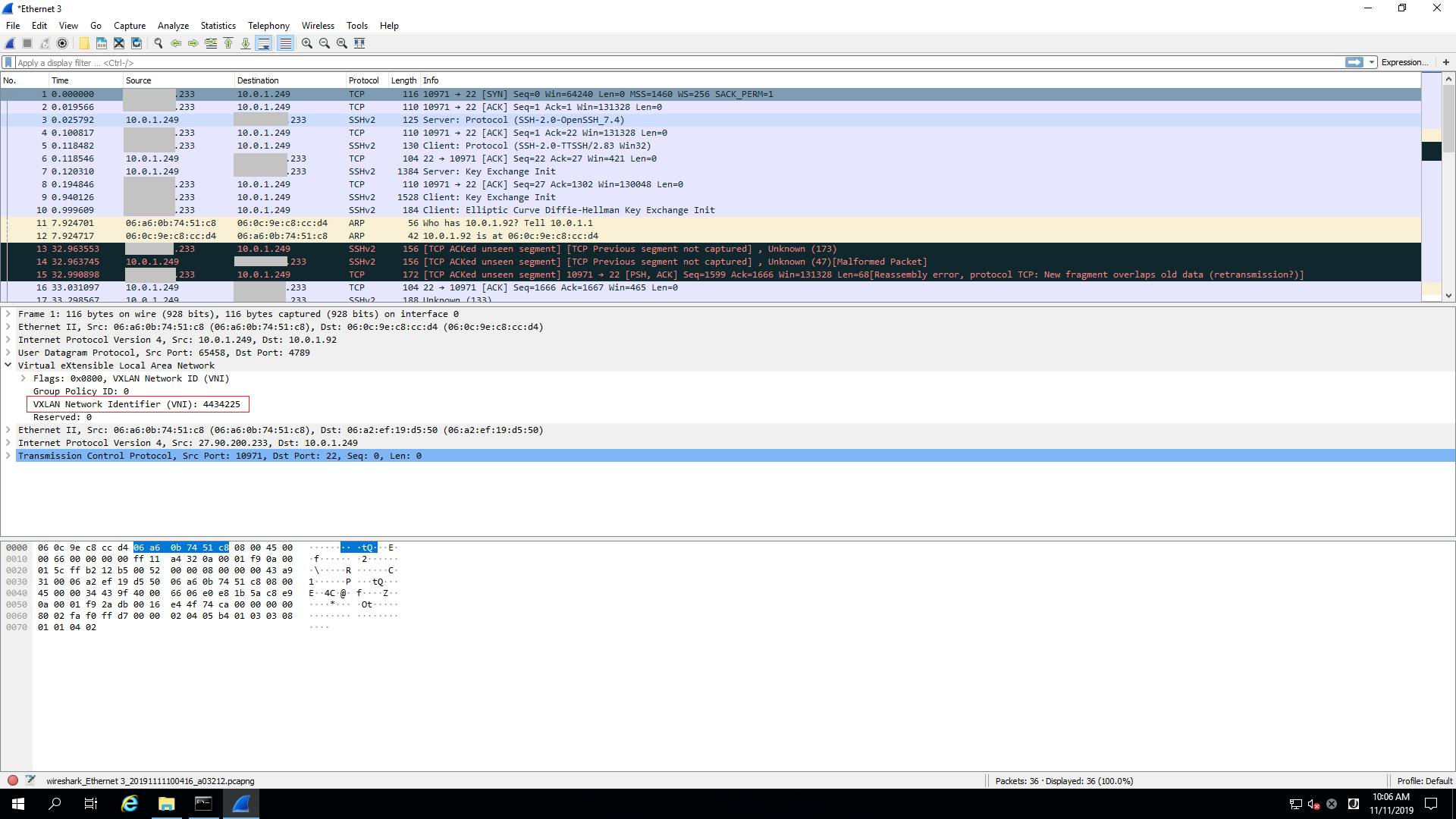
最初にbrewでdockerをインストールしたのですが、うまく動かず結局公式サイトからdmgをDLしてインストールしました。Lambdaの動作環境を用意するために使われます。AWS Toolkitを入れてVSCodeからLambda関数を実行するときに自動でdocker環境が立ち上がります。 Install Docker Desktop for Mac
VSCodeからAWSへの接続
EXTENSION追加
VSCodeの左側のタブからAWS Toolkit for Visual Studio Codeを追加します。これで左側のタブにAWSのアイコンが表示されます。
AWSのアイコン→Connect to AWSをクリックします。.aws/credentialsまたは.aws/configに定義されたユーザが自動で表示されるためその中から選択します。
アプリケーションの作成
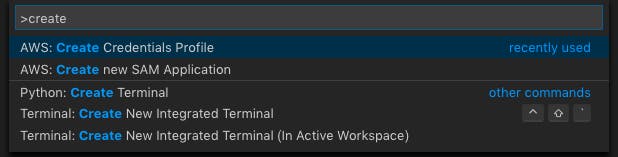
Create new SAM Applicationを選択します。
次に、Runtimeに使用する言語を選択します。筆者はPython3.7を選択しました。
ワークスペースとなるフォルダを選択し、アプリケーションの名前をつけます。すると自動的にtemplate.yamlが立ち上がります。
template.yaml
AWSTemplateFormatVersion:'2010-09-09'Transform:AWS::Serverless-2016-10-31Description:>test2Sample SAM Template for test2# More info about Globals: https://github.com/awslabs/serverless-application-model/blob/master/docs/globals.rstGlobals:Function:Timeout:3Resources:HelloWorldFunction:Type:AWS::Serverless::Function# More info about Function Resource: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#awsserverlessfunctionProperties:CodeUri:hello_world/Handler:app.lambda_handlerRuntime:python3.7Events:HelloWorld:Type:Api# More info about API Event Source: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#apiProperties:Path:/helloMethod:getOutputs:# ServerlessRestApi is an implicit API created out of Events key under Serverless::Function# Find out more about other implicit resources you can reference within SAM# https://github.com/awslabs/serverless-application-model/blob/master/docs/internals/generated_resources.rst#apiHelloWorldApi:Description:"APIGatewayendpointURLforProdstageforHelloWorldfunction"Value:!Sub"https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/hello/"HelloWorldFunction:Description:"HelloWorldLambdaFunctionARN"Value:!GetAttHelloWorldFunction.ArnHelloWorldFunctionIamRole:Description:"ImplicitIAMRolecreatedforHelloWorldfunction"Value:!GetAttHelloWorldFunctionRole.Arn
Preparing to run app.lambda_handler locally...
Building SAM Application...
Build complete.
Starting the SAM Application locally (see Terminal for output)
Running command: sam local invoke awsToolkitSamLocalResource --template /tmp/aws-toolkit-vscode/vsctkvGlUHf/output/template.yaml --event /tmp/aws-toolkit-vscode/vsctkvGlUHf/event.json --env-vars /tmp/aws-toolkit-vscode/vsctkvGlUHf/env-vars.json
Invoking app.lambda_handler (python3.7)
2019-11-08 17:19:07 Found credentials in shared credentials file: ~/.aws/credentials
Fetching lambci/lambda:python3.7 Docker container image......
Mounting /tmp/aws-toolkit-vscode/vsctkvGlUHf/output/awsToolkitSamLocalResource as /var/task:ro,delegated inside runtime container
START RequestId: df0da3ce-bd4d-1e44-3c27-8ac942c1a17e Version: $LATEST
END RequestId: df0da3ce-bd4d-1e44-3c27-8ac942c1a17e
REPORT RequestId: df0da3ce-bd4d-1e44-3c27-8ac942c1a17e Duration: 5.88 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 23 MB
{"statusCode":200,"body":"{\"message\": \"hello world\"}"}
Local invoke of SAM Application has ended.
Starting SAM Application deployment...
Building SAM Application...
Packaging SAM Application to S3 Bucket: {バケット名} with profile: {プロファイル名}
Deploying SAM Application to CloudFormation Stack: localDeployTest2 with profile: {プロファイル名}
Successfully deployed SAM Application to CloudFormation Stack: localDeployTest2 with profile: {プロファイル名}
#!/usr/local/bin/python3.6
# AWS
from boto3 import Session
from botocore.exceptions import BotoCoreError, ClientError
from contextlib import closing
import os,sys,subprocess
session = Session(region_name="us-west-2")
polly = session.client("polly")
ttsdt=[
('Ivy' ,"Thank you for calling. I'm sorry but I can't answer your call right now. Please leave a message at the tone . I'll get back to you as soon as possible."),
('Joey' ,"Thank you for calling. I'm sorry but I can't answer your call right now. Please leave a message at the tone . I'll get back to you as soon as possible."),
('Mizuki',"お電話ありがとうございます。ただいま、電話に出ることができません。ピーッという音が鳴りましたら[発信音の後に]、メッセージをお願いします。こちらからすぐにお電話いたします。"),
('Takumi',"お電話ありがとうございます。ただいま、電話に出ることができません。ピーッという音が鳴りましたら[発信音の後に]、メッセージをお願いします。こちらからすぐにお電話いたします。")
]
for id,tx in ttsdt:
print(tx)
try:
response = polly.synthesize_speech(Text=tx, OutputFormat="mp3", VoiceId=id)
except (BotoCoreError, ClientError) as error:
print(error)
sys.exit(-1)
if "AudioStream" in response:
with closing(response["AudioStream"]) as stream:
output = id+".mp3"
try:
with open(output, "wb") as file:
file.write(stream.read())
except IOError as error:
print(error)
sys.exit(-1)
print("synthesize_speech OK ->>" + output)
subprocess.Popen(['mpg123', '-q',output ]).wait()
else:
print("Could not stream audio")
sys.exit(-1)
sotosugi:~/environment $ eksctl create cluster -f sample-clusterconfig.yaml
[ℹ] eksctl version 0.7.0
[ℹ] using region ap-northeast-1
[ℹ] setting availability zones to [ap-northeast-1c ap-northeast-1a ap-northeast-1d]
[ℹ] subnets for ap-northeast-1c - public:192.168.0.0/19 private:192.168.96.0/19
[ℹ] subnets for ap-northeast-1a - public:192.168.32.0/19 private:192.168.128.0/19
[ℹ] subnets for ap-northeast-1d - public:192.168.64.0/19 private:192.168.160.0/19
[ℹ] nodegroup "ng" will use "ami-02e124a380df41614" [AmazonLinux2/1.14]
[ℹ] using Kubernetes version 1.14
[ℹ] creating EKS cluster "sample" in "ap-northeast-1" region
[ℹ] 1 nodegroup (ng) was included (based on the include/exclude rules)
[ℹ] will create a CloudFormation stack for cluster itself and 1 nodegroup stack(s)
[ℹ] if you encounter any issues, check CloudFormation console or try 'eksctl utils describe-stacks --region=ap-northeast-1 --name=sample'
[ℹ] CloudWatch logging will not be enabled for cluster "sample" in "ap-northeast-1"
[ℹ] you can enable it with 'eksctl utils update-cluster-logging --region=ap-northeast-1 --name=sample'
[ℹ] 2 sequential tasks: { create cluster control plane "sample", create nodegroup "ng" }
[ℹ] building cluster stack "eksctl-sample-cluster"
[ℹ] deploying stack "eksctl-sample-cluster"
[ℹ] building nodegroup stack "eksctl-sample-nodegroup-ng"
[ℹ] --nodes-min=3 was set automatically for nodegroup ng
[ℹ] --nodes-max=3 was set automatically for nodegroup ng
[ℹ] deploying stack "eksctl-sample-nodegroup-ng"
[✔] all EKS cluster resources for "sample" have been created
[✔] saved kubeconfig as "/home/ubuntu/.kube/config"
[ℹ] adding identity "arn:aws:iam::221193251029:role/eksctl-sample-nodegroup-ng-NodeInstanceRole-QFBSLXDG07HK" to auth ConfigMap
[ℹ] nodegroup "ng" has 0 node(s)
[ℹ] waiting for at least 3 node(s) to become ready in "ng"
[ℹ] nodegroup "ng" has 3 node(s)
[ℹ] node "ip-192-168-22-44.ap-northeast-1.compute.internal" is ready
[ℹ] node "ip-192-168-60-210.ap-northeast-1.compute.internal" is ready
[ℹ] node "ip-192-168-67-211.ap-northeast-1.compute.internal" is ready
[ℹ] kubectl command should work with "/home/ubuntu/.kube/config", try 'kubectl get nodes'
[✔] EKS cluster "sample" in "ap-northeast-1" region is ready
sotosugi:~/environment $
クラスターを確認。
sotosugi:~/environment $ eksctl get cluster
NAME REGION
sample ap-northeast-1
sotosugi:~/environment $ aws eks list-clusters
{
"clusters": [
"sample"
]
}
sotosugi:~/environment $ kubectl get node
NAME STATUS ROLES AGE VERSION
ip-192-168-22-44.ap-northeast-1.compute.internal Ready <none> 5m42s v1.14.7-eks-1861c5
ip-192-168-60-210.ap-northeast-1.compute.internal Ready <none> 5m45s v1.14.7-eks-1861c5
ip-192-168-67-211.ap-northeast-1.compute.internal Ready <none> 5m47s v1.14.7-eks-1861c5
sotosugi:~/environment $
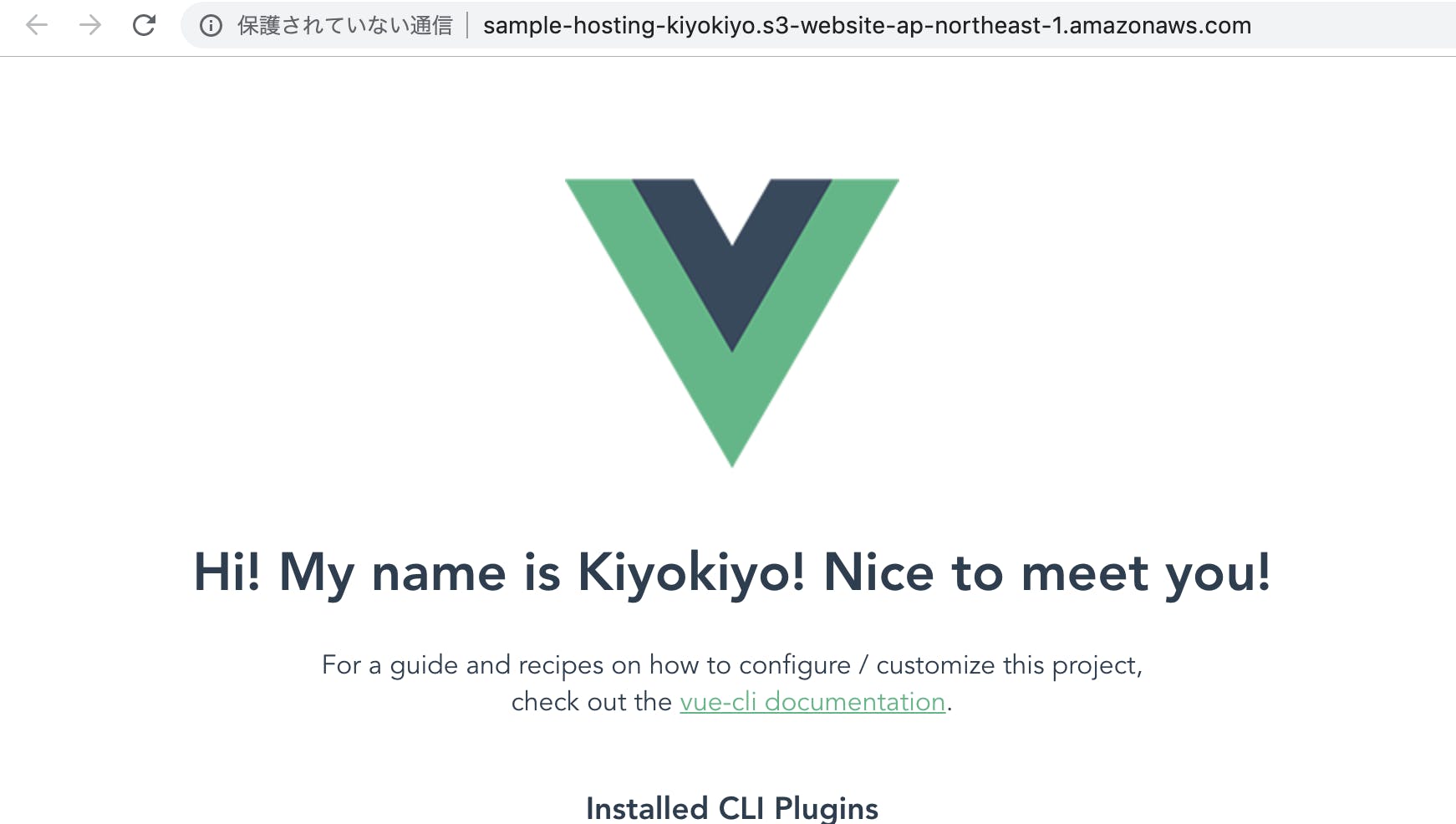
上記の手順でWebページの公開はできるようになりましたが、Webページを更新するたびにIAMユーザでログインし、S3バケットに格納してあるファイルを削除して、ローカルにある新しいファイルをアップロードし直す、というのはかなり面倒です。Vue.jsでは npm run serveでローカルサーバーを起動し、 npm run buildでビルドを行うことができます。
それと同じノリで、 npm run deployで、S3へのデプロイができるよう設定を組みましょう。
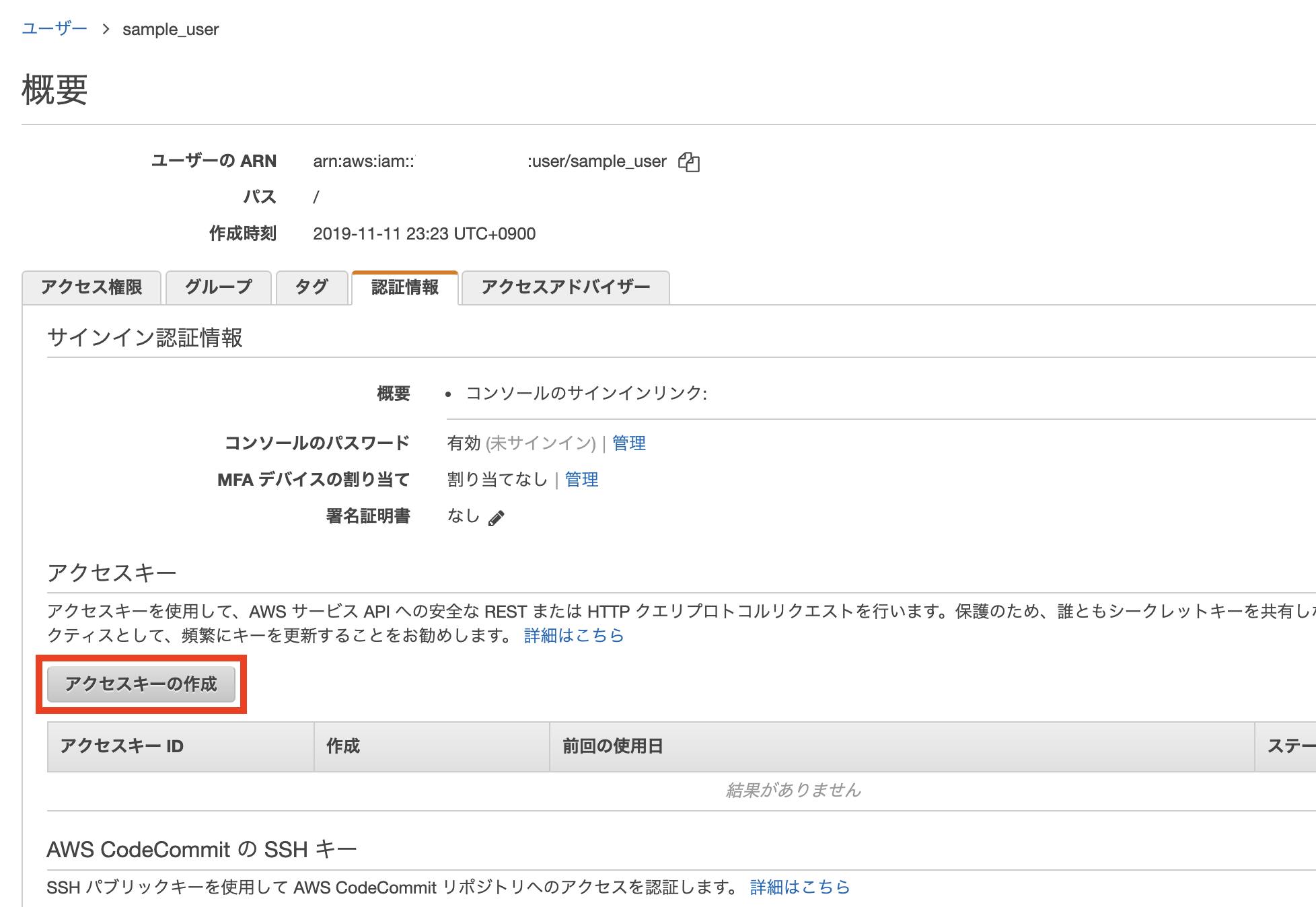
$ aws configure
AWS Access Key ID [None]: XXXX
AWS Secret Access Key [None]: XXXXXXXX
Default region name [None]: ap-northeast-1
Default output format [None]: text