- 投稿日:2019-11-12T23:54:22+09:00
PandasのDataFrameに対する基本操作をJupyter Notebook上で試す
いままでPythonでPandasでのデータ操作は、必要になったらググって使い方を調べればいいという程度のスタンスでしたが、データ分析や機械学習のあたりを勉強するにあたって、Jupyter Notebookでデータをスラスラと操作できないと話にならないと感じてきて、Pandasの使い方を基本から改めて整理して勉強し始めています。この記事はその勉強ノートです。
DataFrameの概要
PandasのDataFrameは、行と列のある表形式のデータのイメージです。行には0から始まる行番号を付けることもありますが、文字列でもいいようです。列には列の名前がついています。
DataFrameは表形式であるのに対して、Seriesという列だけのオブジェクトもあります。
DataFrameとSeriesの内容は以下の記事がとても参考になりました。
僕のpandas.SeriesとDataFrameのイメージは間違っていた - Qiitaこの記事の内容は、以下のリンク先に従って準備したJupyter Notebookの環境で試しています。
Jupyter NotebookをDockerを使って簡単にインストールし起動(nbextensions、Scalaにも対応) - Qiitaこの環境でブラウザで8888番ポートにアクセスして、Jupyter Notebookを使うことができます。右上のボタンのNew > Python3をたどると新しいノートを開けます。
Pythonパッケージインポート
import pandas as pdCSVファイルから読み込む
# ヘッダーがある場合 df = pd.read_csv("data.csv") # ヘッダー行が列名になる # ヘッダーがない場合 df = pd.read_csv("data.csv", header=None) # 0から始まる番号が列名になる # ヘッダーがなく列名を指定したい場合 df = pd.read_csv("data.csv", names=["id", "target", "data1", "data2", "data3"])この記事のこれ以降は、適当な乱数で作成したCSVファイル
https://github.com/suzuki-navi/sample-data/blob/master/sample-data-1.csv
を使っています。(GitHubってCSVファイルも整形して表示してくれるんですね)
データの内容を確認
DataFrameのオブジェクトはJupyter Notebook上で内容を簡単に確認できます。
データの一部だけを見たい場合
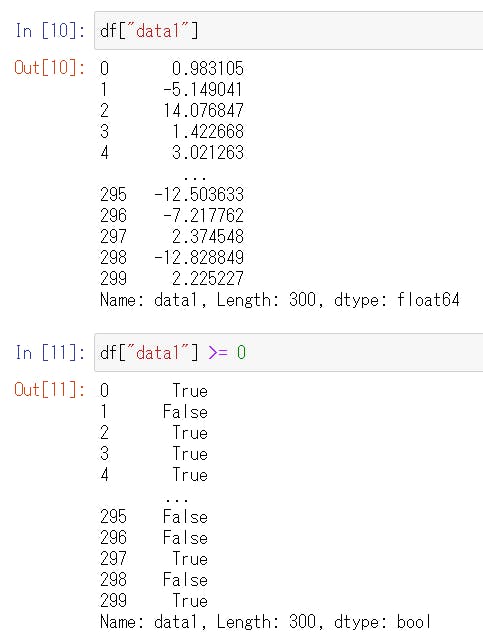
# 先頭の5行 df.head() # 先頭の3行 df.head(3) # or df[:3] # 最後の5行 df.tail() # 最後の3行 df.tail(3) # 11行目から20行目だけを抜き出す # (0から始まるインデックスでいうと10から19) df[10:20] # 11行目から最後までを抜き出す # (0から始まるインデックスでいうと10から後ろ) df[10:] # 11行目のみを確認 # (0から始まるインデックスでいうと10) df.loc[10] # 特定の列のみを抜き出す df[["target", "data1"]] # 特定の列のみを抜き出す # DataFrameでなくSeriesになる df["data1"] # df[["data1"]]とは異なる # 特定の行範囲の特定の列のみを抜き出す df[["target", "data1"]][10:20] # or df[10:20][["target", "data1"]]一部の行のみを抜き出しても、行についているインデックスは維持されます。
データの形式を確認
df.shape # => (300, 5) df.columns # => Index(['id', 'target', 'data1', 'data2', 'data3'], dtype='object') df.dtypes # => id int64 # target int64 # data1 float64 # data2 float64 # data3 float64 # dtype: object列に対して演算
列に対して演算ができます。
df["data1"]はSeriesですが、df["data1"] / 100のように書くとSeriesの各要素に対して/ 100という演算をして、結果をSeriesで取得できます。
列同士の演算もできます。
df["data1"] + df["data2"]行を条件で抽出
# df["data1"] >= 0 がTrueとなる行のみからなるDataFrameを生成 # 行のインデックスは維持されるので、とびとびの番号になる df[df["data1"] >= 0] # SQLみたいにクエリすることもできる df.query('data1 >= 30 and target == 1') # クエリの中に文字列を入れたい場合は "" で囲む df.query('target == "1"')重複を削除した値の一覧を取得
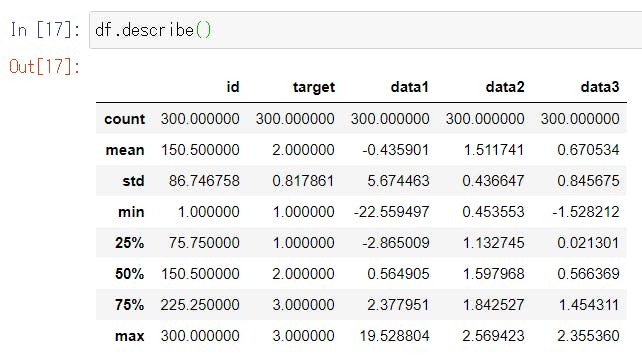
df["target"].unique() # => array([3, 2, 1])数値の列についての統計量を取得
df.describe()
ソート
以下は、
data1列で行を並び替えたDataFrameを返します。# data1列の昇順 df.sort_values("data1") # data1列の降順 df.sort_values("data1", ascending=False) # 複数の列で並び替え df.sort_values(["target", "data1"], ascending=False)第1ソートを
target降順、第2ソートをdata1昇順とするにはどうしたらいいんだろう?列を追加
以下の例では、既存の列に演算を施した新しい値の列を右端に追加する。
df["data_sum"] = df["data1"] + df["data2"] + df["data3"]
以上。



- 投稿日:2019-11-12T23:44:38+09:00
動画からキャプチャ画像を撮る方法(OpenCV)
きっかけ
OpenCVを使って長い動画を一部だけ保存する方法で取得した1分動画から画像処理のサンプル画像用に好きなところでキャプチャを撮るスクリプトを作ってみたっす
開発
Viewを表示して キーボードの s[save] ボタンを押すとキャプチャが保存されます。
import cv2 if __name__ == '__main__': cap = cv2.VideoCapture('one_minutes.mp4') window_name = "Drop Out NHK" save_press_count = 1 while True: presskey = cv2.waitKey(1) if not cap.isOpened(): break ret, frame = cap.read() if presskey == ord('q'): break elif presskey == ord('s'): cv2.imwrite("capture_{}.png".format(save_press_count), frame) # capture ボタンを押しただけ 画像を保存 save_press_count += 1 cv2.imshow(window_name,frame) cap.release() cv2.destroyWindow(window_name)結果
おわりに
OpenCV 2 プログラミングブック にあったコードを思い出して C++ -> Python に書き換えただけです。
処理用に複数枚の画像が欲しかっただけです。参考にしたリンク




- 投稿日:2019-11-12T22:42:28+09:00
PyTorchのBidirectional LSTMのoutputの仕様を確認してみた
はじめに
LSTMのリファレンスにあるように、PyTorchでBidirectional LSTMを扱うときはLSTMを宣言する際に
bidrectional=Trueを指定するだけでOKと、(KerasならBidrectionalでLSTMを囲むだけでOK)とても簡単に扱うことができます。
が、リファレンスを見てもLSTMをBidirectionalにしたきの出力についてはあまり触れられていないように思います。
ぱっとググってみてもPyTorchにおけるBidirectional LSTMの出力の仕様がいまいちよくわからなかったので、ここに簡単にまとめておきます。参考
- Bidirectional recurrent neural networks
- Understanding Bidirectional RNN in PyTorch
- Bidirectional LSTM output question in PyTorch
- わかるLSTM ~ 最近の動向と共に
仕様確認
参考1.や2.を見るとわかるように双方向のRNNやLSTMは前方向と後ろ方向のRNNやLSTMが重なっただけと至ってシンプルであることがわかるかと思います。
とりあえず実際に使ってみます。
import torch import torch.nn as nn # 各系列の埋め込み次元数を5 # LSTM層の隠れ層のサイズは6 # batch_first=Trueでインプットの形式を(batch_size, vocab_size, embedding_dim)にしてる # bidrectional=Trueで双方向LSTMを宣言 bilstm = nn.LSTM(5, 6, batch_first=True, bidrectional=True) # バッチサイズを1 # 系列の長さは4 # 各系列の埋め込み次元数は5 # であるようなtensorを生成する a = torch.rand(1, 4, 5) print(a) #tensor([[[0.1360, 0.4574, 0.4842, 0.6409, 0.1980], # [0.0364, 0.4133, 0.0836, 0.2871, 0.3542], # [0.7796, 0.7209, 0.1754, 0.0147, 0.6572], # [0.1504, 0.1003, 0.6787, 0.1602, 0.6571]]]) # 通常のLSTMと同様に出力は2つあるので両方受け取る out, hc = bilstm(a) print(out) #tensor([[[-0.0611, 0.0054, -0.0828, 0.0416, -0.0570, -0.1117, 0.0902, -0.0747, -0.0215, -0.1434, -0.2318, 0.0783], # [-0.1194, -0.0127, -0.2058, 0.1152, -0.1627, -0.2206, 0.0747, -0.0210, 0.0307, -0.0708, -0.2458, 0.1627], # [-0.0163, -0.0568, -0.0266, 0.0878, -0.1461, -0.1745, 0.1097, 0.0230, 0.0353, -0.0739, -0.2186, 0.0818], # [-0.1145, -0.0460, -0.0732, 0.0950, -0.1765, -0.2599, 0.0063, 0.0143, 0.0124, 0.0089, -0.1188, 0.0996]]], # grad_fn=<TransposeBackward0>) print(hc) #(tensor([[[-0.1145, -0.0460, -0.0732, 0.0950, -0.1765, -0.2599]], # [[ 0.0902, -0.0747, -0.0215, -0.1434, -0.2318, 0.0783]]], # grad_fn=<StackBackward>), #tensor([[[-0.2424, -0.1340, -0.1559, 0.3499, -0.3792, -0.5514]], # [[ 0.1876, -0.1413, -0.0384, -0.2345, -0.4982, 0.1573]]], # grad_fn=<StackBackward>))通常のLSTMと同様に出力は
outとhcと2つあって、hcのほうは通常のLSTMと同様にhc=(h,c)とタプル形式で返ってきます。通常のLSTMの出力と違う点は以下の2つかと思います。
outの各要素の次元がLSTMの隠れ層の次元のサイズ(今回は6)ではなく、その倍の値(今回であれば12)になっているhcの各要素hやcが2つ返ってきているこれらがどういうことかについて、ずばり図で説明すると以下の通りです。
(
cは省略してます。Embedding層も書いちゃったけど、Embedding層はLSTMでやってないです。)
上の図からわかるように
outの各要素は前方向と後ろ方向の各隠れ層ベクトルを結合しています。(なので各要素の次元が通常の2倍になってる。)
また、hc=(h,c)のhは前方向と後ろ方向のそれぞれの最後の隠れ層ベクトルを返しています。つまり、
outの最後の要素の前半分はhc=(h,c)としたときのh[0]と一致outの最初の要素の後ろ半分はhc=(h,c)としたときのh[1]と一致することになります。上のサンプルのソースコードの出力からそれが読み取れますが、つまりはこういうこと。
print(out[:,-1][:,:6]) # outの最後の要素の前半分 print(hc[0][0]) # 前方向LSTMの最後の隠れ層の値 #tensor([[-0.1145, -0.0460, -0.0732, 0.0950, -0.1765, -0.2599]], grad_fn=<SliceBackward>) #tensor([[-0.1145, -0.0460, -0.0732, 0.0950, -0.1765, -0.2599]], grad_fn=<SelectBackward>) print(out[:,0][:,6:]) # outの最初の要素の後ろ半分 print(hc[0][1]) # 後ろ方向LSTMの最後の隠れ層の値 #tensor([[ 0.0902, -0.0747, -0.0215, -0.1434, -0.2318, 0.0783]], grad_fn=<SliceBackward>) #tensor([[ 0.0902, -0.0747, -0.0215, -0.1434, -0.2318, 0.0783]], grad_fn=<SelectBackward>)出力の仕様がわかったらあとはお好きなように料理すればよいですが、
文章分類のようなMany to OneのモデルをBidirectional LSTMにする際はLSTMの第2戻り値を結合したり、平均とったり、要素積をとったりといろいろ方法があるようです。
Kerasの場合なんかは(デフォルトでは)Keras側で結合してくれるようですが、PyTorchの場合はこれらの処理は自前で実装する必要があると思われます。
例えば私が過去に投稿したLSTMによる文章分類をBidirectional LSTMにする場合は以下のような感じになります。class LSTMClassifier(nn.Module): def __init__(self, embedding_dim, hidden_dim, vocab_size, tagset_size, batch_size=100): super(LSTMClassifier, self).__init__() self.batch_size = batch_size self.hidden_dim = hidden_dim self.word_embeddings = nn.Embedding(vocab_size, embedding_dim, padding_idx=0) self.bilstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True, bidirectional=True) # 前方向と後ろ方向の最後の隠れ層ベクトルを結合したものを受け取るので、hidden_dimを2倍している self.hidden2tag = nn.Linear(hidden_dim * 2, tagset_size) self.softmax = nn.LogSoftmax() def forward(self, sentence): embeds = self.word_embeddings(sentence) _, bilstm_hc = self.bilstm(embeds) # bilstm_out[0][0]->前方向LSTMの最後の隠れ層ベクトル # bilstm_out[0][1]->後ろ方向LSTMの最後の隠れ層ベクトル bilstm_out = torch.cat([bilstm_hc[0][0], bilstm_hc[0][1]], dim=1) tag_space = self.hidden2tag(bilstm_out) tag_scores = self.softmax(tag_space.squeeze()) return tag_scoresおわりに
- 世間的にはこんなことすぐにわかりそうな話なのかもしれませんが、自分みたいにPyTorchでBidirectional LSTMを扱うときに一瞬でもあれ?って思った人にこの記事が届いてお調べになるお時間をお助けできれば幸いです。
- ちなみにGRUもLSTMと同様に
bidirectional=TrueでBidirectional GRUになります。出力の形式は上のLSTMの仕様がわかっていれば何の問題もないかと思います。おわり


- 投稿日:2019-11-12T22:38:59+09:00
【株価分析】日経平均でpandas学習(005:年/年月ごとのグルーピング~統計情報の確認)
前回(ローソク足チャート(仮名)まで)の続きから
前回はローソク足チャートを色々変更加えて編集しようと思ったけど、それより先にgroupbyの機能についてまとめておきたかったので、先に本稿を記載します。
前回までのプログラム(再掲)
Study_Code.pyimport pandas as pd import logging # 【株価分析】架空データでpandas学習(003)より追加 from pandas import Series, DataFrame import numpy as np import matplotlib.pyplot as plt import matplotlib.dates as mdates from mpl_finance import candlestick_ohlc # ログフォーマットの指定 # %(asctime)s : LogRecord が生成された時刻を人間が読める書式で表したもの。 # %(funcName)s : ロギングの呼び出しを含む関数の名前 # %(levelname)s : メッセージのための文字のロギングレベル # %(lineno)d : ロギングの呼び出しが発せられたソース行番号 # %(message)s : msg % args として求められた、ログメッセージ fomatter = logging.Formatter('%(asctime)s:%(funcName)s:%(levelname)s:%(lineno)d:\n%(message)s') # ロガーの設定(ログレベルをINFO) logger = logging.getLogger(__name__) logger.setLevel(logging.INFO) # ハンドラーの設定(出力ファイルの変更/ログレベルの設定/ログフォーマットの設定) handler = logging.FileHandler('info_log.log') handler.setLevel(logging.INFO) handler.setFormatter(fomatter) logger.addHandler(handler) # CSVファイル(SampleStock01.csv)の文字コードを指定 dframe = pd.read_csv('NikkeiAverage.csv', encoding='SJIS', \ header=1, sep='\t') # 日付型に変換 dframe['日付'] = pd.to_datetime(dframe['日付']) # 日付の列をインデックスに指定する dframe = dframe.set_index('日付') # 始値~終値を数値に変換 dframe = dframe.apply(lambda x: x.str.replace(',','')).astype(np.float32) # ロガー利用に変更 logger.info(dframe) # インデックスを出力 logger.info(dframe.columns) # 始値と終値だけを出力 logger.info(dframe[['始値','終値']]) # インデックスの確認 logger.info(dframe.index) # 型の確認 logger.info(dframe.dtypes) #プロット用データの作成 ohlc = zip(mdates.date2num(dframe.index), dframe['始値'], dframe['終値'], dframe['高値'], dframe['終値']) logger.info(ohlc) # キャンパスの作成 fig = plt.figure() # X軸のフォーマットを整形する ax = plt.subplot() ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y/%m/%d')) # ローソク足チャートを描画する candlestick_ohlc(ax, ohlc, width=0.7, colorup='g', colordown='r') # 画像を保存する plt.savefig('Candle_Chart.png')年/年月ごとにグルーピングする
前回までのプログラムは2016年から2019年までの4年分のデータを一気に扱っていましたが、せっかくインデックスを日付型にしたので、今回は
1. 2016年のデータ
2. 2017年のデータ
3. 2018年のデータ
4. 2019年のデータ
と年ごとにまた
- 2016年1月のデータ
- 2016年2月のデータ
- 2016年3月のデータ ︙
- 2019年10月のデータ
- 2019年11月のデータ
と年月ごとにグルーピングしてみようと思います。
なお、少々記事がくどいので本稿からはポイントのみを記載し、最後の章に全体のプログラムを記載する形にしたいと思います。
確認インデックスの年/年月情報を抽出
まずは、下記ソースコードにて、インデックスの年情報を確認してみます。
Conf_Code.pylogger.info(dframe.index.year)実行結果
info_log2019-11-12 21:40:26,133:<module>:INFO:42: Int64Index([2016, 2016, 2016, 2016, 2016, 2016, 2016, 2016, 2016, 2016, ... 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019], dtype='int64', name='日付', length=942)続いてインデックスの年月情報を確認してみます。
Conf_Code.pylogger.info([dframe.index.year, dframe.index.month])実行結果
info_log2019-11-12 22:12:26,052:<module>:INFO:42: [Int64Index([2016, 2016, 2016, 2016, 2016, 2016, 2016, 2016, 2016, 2016, ... 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019], dtype='int64', name='日付', length=942), Int64Index([ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... 10, 10, 10, 10, 10, 11, 11, 11, 11, 11], dtype='int64', name='日付', length=942)]※年月情報でグルーピングする場合は、[dframe.index.year, dframe.index.month]のようにリストの形で渡して上げる必要があるようです。
(他にいい方法があったら随時訂正します)年ごとにグルーピング
Conf_Code.pyfor Conf_DF in dframe.groupby([dframe.index.year]) : logger.info(Conf_DF)実行結果
info_log2019-11-12 21:49:34,031:<module>:INFO:44: (2016, 始値 高値 安値 終値 日付 2016-01-04 18818.580078 18951.119141 18394.429688 18450.980469 2016-01-05 18398.759766 18547.380859 18327.519531 18374.000000 2016-01-06 18410.570312 18469.380859 18064.300781 18191.320312 2016-01-07 18139.769531 18172.039062 17767.339844 17767.339844 2016-01-08 17562.230469 17975.310547 17509.640625 17697.960938 ... ... ... ... ... 2016-12-26 19394.410156 19432.480469 19385.939453 19396.640625 2016-12-27 19353.429688 19478.580078 19352.060547 19403.060547 2016-12-28 19392.109375 19442.130859 19364.730469 19401.720703 2016-12-29 19301.039062 19301.039062 19092.220703 19145.140625 2016-12-30 18997.679688 19176.810547 18991.589844 19114.369141 [245 rows x 4 columns]) 2019-11-12 21:49:34,051:<module>:INFO:44: (2017, 始値 高値 安値 終値 日付 2017-01-04 19298.679688 19594.160156 19277.929688 19594.160156 2017-01-05 19602.099609 19615.400391 19473.279297 19520.689453 2017-01-06 19393.550781 19472.369141 19354.439453 19454.330078 2017-01-10 19414.830078 19484.900391 19255.349609 19301.439453 2017-01-11 19358.640625 19402.169922 19325.460938 19364.669922 ... ... ... ... ... 2017-12-25 22909.410156 22948.830078 22870.189453 22939.179688 2017-12-26 22922.949219 22950.150391 22877.630859 22892.689453 2017-12-27 22854.390625 22936.160156 22854.390625 22911.210938 2017-12-28 22912.050781 22954.449219 22736.429688 22783.980469 2017-12-29 22831.490234 22881.210938 22753.199219 22764.939453 [247 rows x 4 columns]) 2019-11-12 21:49:34,069:<module>:INFO:44: (2018, 始値 高値 安値 終値 日付 2018-01-04 23073.730469 23506.330078 23065.199219 23506.330078 2018-01-05 23643.000000 23730.470703 23520.519531 23714.529297 2018-01-09 23948.970703 23952.609375 23789.029297 23849.990234 2018-01-10 23832.810547 23864.759766 23755.449219 23788.199219 2018-01-11 23656.390625 23734.970703 23601.839844 23710.429688 ... ... ... ... ... 2018-12-21 20310.500000 20334.730469 20006.669922 20166.189453 2018-12-25 19785.429688 19785.429688 19117.960938 19155.740234 2018-12-26 19302.589844 19530.349609 18948.580078 19327.060547 2018-12-27 19706.189453 20211.570312 19701.759766 20077.619141 2018-12-28 19957.880859 20084.380859 19900.039062 20014.769531 [245 rows x 4 columns]) 2019-11-12 21:49:34,088:<module>:INFO:44: (2019, 始値 高値 安値 終値 日付 2019-01-04 19655.130859 19692.580078 19241.369141 19561.960938 2019-01-07 19944.609375 20266.220703 19920.800781 20038.970703 2019-01-08 20224.669922 20347.919922 20106.359375 20204.039062 2019-01-09 20366.300781 20494.349609 20331.199219 20427.060547 2019-01-10 20270.880859 20345.919922 20101.929688 20163.800781 ... ... ... ... ... 2019-11-01 22730.490234 22852.720703 22705.599609 22850.769531 2019-11-05 23118.789062 23328.519531 23090.939453 23251.990234 2019-11-06 23343.509766 23352.560547 23246.570312 23303.820312 2019-11-07 23283.140625 23336.000000 23253.320312 23330.320312 2019-11-08 23550.039062 23591.089844 23313.410156 23391.869141 [205 rows x 4 columns])dframe.groupby([dframe.index.year])にて、グルーピングすれば
1. 2016年は[245 rows x 4 columns]
2. 2017年は[247 rows x 4 columns]
3. 2018年は[245 rows x 4 columns]
4. 2019年は[205 rows x 4 columns]と正常にデータを抽出出来ました。
グルーピングする前が[942 rows x 4 columns]だったので、変更された点が分かります。
ただ少し気になるのは
読み込み元のデータが
2019/11/8 23,550.04 23,591.09 23,313.41 23,391.87
に対してデータフレームに格納される値は
2019-11-08 23550.039062 23591.089844 23313.410156 23391.869141
だった(他の日も全て)ので、おそらくdframe = dframe.apply(lambda x: x.str.replace(',','')).astype(np.float32)で変換した時に小数点以下第2位以下が正しく変換出来ていないようです。
正直2019年11月12日時点では株価分析において小数点以下の数字を気にする必要性を感じないので無視しますが、科学計算をする場合は丸め誤差問題に苦しみそうな気がします・・・
年月ごとにグルーピング
Conf_Code.pyfor Conf_DF in dframe.groupby([dframe.index.year, dframe.index.month]) : logger.info(Conf_DF)実行結果
info_log(前略) 2019-11-12 22:05:00,120:<module>:INFO:45: ((2019, 11), 始値 高値 安値 終値 日付 2019-11-01 22730.490234 22852.720703 22705.599609 22850.769531 2019-11-05 23118.789062 23328.519531 23090.939453 23251.990234 2019-11-06 23343.509766 23352.560547 23246.570312 23303.820312 2019-11-07 23283.140625 23336.000000 23253.320312 23330.320312 2019-11-08 23550.039062 23591.089844 23313.410156 23391.869141)小数点以下第2位以下にゴミが入っているのは相変わらずですが、、、
月ごとの統計情報を確認
前章にて月ごとに分割出来たので、各月の統計情報を確認してみます。
Conf_Code.pydef Output_Describe(temp_DF) : logger.info(temp_DF.index) logger.info(temp_DF.describe()) dframe.groupby([dframe.index.year, dframe.index.month]).apply(Output_Describe)実行結果
info_log(前略) 2019-11-12 22:25:51,012:Output_Describe:INFO:43: DatetimeIndex(['2019-10-01', '2019-10-02', '2019-10-03', '2019-10-04', '2019-10-07', '2019-10-08', '2019-10-09', '2019-10-10', '2019-10-11', '2019-10-15', '2019-10-16', '2019-10-17', '2019-10-18', '2019-10-21', '2019-10-23', '2019-10-24', '2019-10-25', '2019-10-28', '2019-10-29', '2019-10-30', '2019-10-31'], dtype='datetime64[ns]', name='日付', freq=None) 2019-11-12 22:25:51,043:Output_Describe:INFO:44: 始値 高値 安値 終値 count 21.000000 21.000000 21.000000 21.000000 mean 22173.896484 22250.916016 22117.458984 22197.476562 std 610.297974 598.321411 619.635559 591.679626 min 21316.179688 21410.199219 21276.009766 21341.740234 25% 21494.480469 21629.240234 21483.179688 21587.779297 50% 22451.150391 22522.390625 22424.919922 22451.859375 75% 22725.439453 22780.990234 22704.330078 22750.599609 max 22953.169922 23008.429688 22935.349609 22974.130859 (後略)2019年10月のデータを元に終値カラムで確認すると、
- データ数が21日分
- 2019年10月の日経平均の平均価格(ややこしいな)が、終値で22197.476562円
- 分散が591.679626
- 一番安かった価格(0%点)が21341.740234円
- 2019年10月の価格帯で25%点の価格が21587.779297円
- 2019年10月の価格帯で25%点の価格が22451.859375円
- 2019年10月の価格帯で25%点の価格が22750.599609円
- 一番高かった価格(100%点)が22974.130859円
と確認できます。
執筆中(中途半端な記事が並んでごめんなさい。最後までまとめますが、覚書は覚えている時に書いておかないとすぐ忘れてしまうので、、、)
分散ってどういう意味なのか?
これをグラフで可視化するとどうなるか?
一番安かったのは2019年10月の何日だったのか?等以降の章に記載したいと思います。
- 投稿日:2019-11-12T22:32:21+09:00
スケーリング
3σ法の適用
3σ法を用いて、外れ値除去することで決定係数が落ちてしまった。
このことを過学習というスケーリング方法
スケーリングすることで重みの確認
重要なパラメータがわかりやすくなった





- 投稿日:2019-11-12T22:05:15+09:00
強化学習6 初めてのChainerRL
ChainerRLクイックリファレンス
https://chainer-colab-notebook.readthedocs.io/ja/latest/notebook/hands_on/chainerrl/quickstart.html強化学習5まで終了しているのが前提です。
クイックリファレンスを参照しながら、以下のファイルを作ります。train.pyimport chainer import chainer.functions as F import chainer.links as L import chainerrl import gym import numpy as np env = gym.make('CartPole-v0') print('observation space:', env.observation_space) print('action space:', env.action_space) obs = env.reset() env.render() print('initial observation:', obs) action = env.action_space.sample() obs, r, done, info = env.step(action) print('next observation:', obs) print('reward:', r) print('done:', done) print('info:', info) class QFunction(chainer.Chain): def __init__(self, obs_size, n_actions, n_hidden_channels=50): super().__init__() with self.init_scope(): self.l0 = L.Linear(obs_size, n_hidden_channels) self.l1 = L.Linear(n_hidden_channels, n_hidden_channels) self.l2 = L.Linear(n_hidden_channels, n_actions) def __call__(self, x, test=False): """ Args: x (ndarray or chainer.Variable): An observation test (bool): a flag indicating whether it is in test mode """ h = F.tanh(self.l0(x)) h = F.tanh(self.l1(h)) return chainerrl.action_value.DiscreteActionValue(self.l2(h)) obs_size = env.observation_space.shape[0] n_actions = env.action_space.n q_func = QFunction(obs_size, n_actions) optimizer = chainer.optimizers.Adam(eps=1e-2) optimizer.setup(q_func) # Set the discount factor that discounts future rewards. gamma = 0.95 # Use epsilon-greedy for exploration explorer = chainerrl.explorers.ConstantEpsilonGreedy( epsilon=0.3, random_action_func=env.action_space.sample) # DQN uses Experience Replay. # Specify a replay buffer and its capacity. replay_buffer = chainerrl.replay_buffer.ReplayBuffer(capacity=10 ** 6) # Since observations from CartPole-v0 is numpy.float64 while # Chainer only accepts numpy.float32 by default, specify # a converter as a feature extractor function phi. phi = lambda x: x.astype(np.float32, copy=False) # Now create an agent that will interact with the environment. agent = chainerrl.agents.DoubleDQN( q_func, optimizer, replay_buffer, gamma, explorer, replay_start_size=500, update_interval=1, target_update_interval=100, phi=phi) n_episodes = 200 max_episode_len = 200 for i in range(1, n_episodes + 1): obs = env.reset() reward = 0 done = False R = 0 # return (sum of rewards) t = 0 # time step while not done and t < max_episode_len: # Uncomment to watch the behaviour # env.render() action = agent.act_and_train(obs, reward) obs, reward, done, _ = env.step(action) R += reward t += 1 if i % 10 == 0: print('episode:', i, 'R:', R, 'statistics:', agent.get_statistics()) agent.stop_episode_and_train(obs, reward, done) print('Finished.') agent.save('agent') env.close()※env.close()を入れないとエラー表示が出ます。
ちゃんと動けば、以下のように出力されます。
observation space: Box(4,) action space: Discrete(2) initial observation: [-0.04736688 -0.01970095 -0.00356997 0.01937746] next observation: [-0.0477609 0.17547202 -0.00318242 -0.27442969] reward: 1.0 done: False info: {} episode: 10 R: 54.0 statistics: [('average_q', 0.02431227437087797), ('average_loss', 0), ('n_updates', 0)] episode: 20 R: 38.0 statistics: [('average_q', 0.6243046798922441), ('average_loss', 0.08867046155807262), ('n_updates', 378)] episode: 30 R: 46.0 statistics: [('average_q', 2.2610338271644586), ('average_loss', 0.09550022600040467), ('n_updates', 784)] episode: 40 R: 84.0 statistics: [('average_q', 5.323362298387771), ('average_loss', 0.16771472656243475), ('n_updates', 1399)] episode: 50 R: 91.0 statistics: [('average_q', 9.851513830734694), ('average_loss', 0.19145745620246343), ('n_updates', 2351)] episode: 60 R: 99.0 statistics: [('average_q', 14.207080180752635), ('average_loss', 0.22097823899753388), ('n_updates', 3584)] episode: 70 R: 200.0 statistics: [('average_q', 17.49337381852232), ('average_loss', 0.18525375351216344), ('n_updates', 5285)] episode: 80 R: 124.0 statistics: [('average_q', 18.933387631649587), ('average_loss', 0.1511605453710412), ('n_updates', 7063)] episode: 90 R: 200.0 statistics: [('average_q', 19.55727598346719), ('average_loss', 0.167370220872378), ('n_updates', 8496)] episode: 100 R: 200.0 statistics: [('average_q', 19.92113421424675), ('average_loss', 0.15092426599174535), ('n_updates', 10351)] episode: 110 R: 161.0 statistics: [('average_q', 19.870179660112395), ('average_loss', 0.1369066775700466), ('n_updates', 12169)] episode: 120 R: 200.0 statistics: [('average_q', 19.985680296882315), ('average_loss', 0.13667809001004586), ('n_updates', 13991)] episode: 130 R: 200.0 statistics: [('average_q', 20.016279858512945), ('average_loss', 0.14053696154447365), ('n_updates', 15938)] episode: 140 R: 180.0 statistics: [('average_q', 19.870299413261478), ('average_loss', 0.1270716956269478), ('n_updates', 17593)] episode: 150 R: 200.0 statistics: [('average_q', 19.990808581945565), ('average_loss', 0.1228807602095278), ('n_updates', 19442)] episode: 160 R: 130.0 statistics: [('average_q', 19.954955203815164), ('average_loss', 0.14701205384726732), ('n_updates', 21169)] episode: 170 R: 133.0 statistics: [('average_q', 19.994069560095422), ('average_loss', 0.12502104946859763), ('n_updates', 22709)] episode: 180 R: 200.0 statistics: [('average_q', 19.973195015705674), ('average_loss', 0.1227321977377075), ('n_updates', 24522)] episode: 190 R: 200.0 statistics: [('average_q', 20.050942533128573), ('average_loss', 0.09264820379188309), ('n_updates', 26335)] episode: 200 R: 191.0 statistics: [('average_q', 19.81062306392066), ('average_loss', 0.11778217212419012), ('n_updates', 28248)] Finished.
- 投稿日:2019-11-12T21:44:27+09:00
asyncio を使って非同期処理をしてみた
きっかけ
asyncioの良さげなサンプルコードがなかったのですが、Python でのオンデマンド・データ, 第 3 回 コルーチンと asyncioがレストランにいるウェイターが複数のオーダーに対応するといったより具体的なストーリーを交えて説明していたので一番分かりやすくて参考になります。
よく見かけるpython3 の async/awaitを理解するやPythonにおける非同期処理: asyncio逆引きリファレンスよりも良いです。開発
import asyncio import time async def start_time(src): await asyncio.sleep(src) print("START!!!") async def main_process(span): idx = 1 while True: await asyncio.sleep(span) num_active_tasks = len([ task for task in asyncio.Task.all_tasks(loop) if not task.done()]) if num_active_tasks == 1: break print("[run:{}]{}秒経過".format(num_active_tasks, idx * span)) idx += 1 async def end_time(src): await asyncio.sleep(src) print("END!!!") if __name__ == "__main__": loop = asyncio.get_event_loop() try: loop.run_until_complete( asyncio.gather( start_time(10), main_process(1), end_time(20) ) ) finally: loop.close()注目点は
len([ task for task in asyncio.Task.all_tasks(loop) if not task.done()])
でasyncio.Task.all_tasks(loop) if not task.done()とすることで現在常駐しているタスクを取得することができます。結果
出力結果は下記の通りです。
メイン処理のみ起動している場合はloopから抜けています。[run:3]1秒経過 [run:3]2秒経過 [run:3]3秒経過 [run:3]4秒経過 [run:3]5秒経過 [run:3]6秒経過 [run:3]7秒経過 [run:3]8秒経過 [run:3]9秒経過 START!!! [run:2]10秒経過 [run:2]11秒経過 [run:2]12秒経過 [run:2]13秒経過 [run:2]14秒経過 [run:2]15秒経過 [run:2]16秒経過 [run:2]17秒経過 [run:2]18秒経過 [run:2]19秒経過 END!!!おわりに
asyncio.Task.all_tasks()ですが Python3.7 以降では非推奨で3.9では削除されるとのことです。特にasyncioの部分でversionが上がるごとに書き方がかなり様変わりしそうです。
(Python3.8 doc Task オブジェクト を参照)参考したリンク
- 投稿日:2019-11-12T21:35:09+09:00
Scikit-learn のさわり
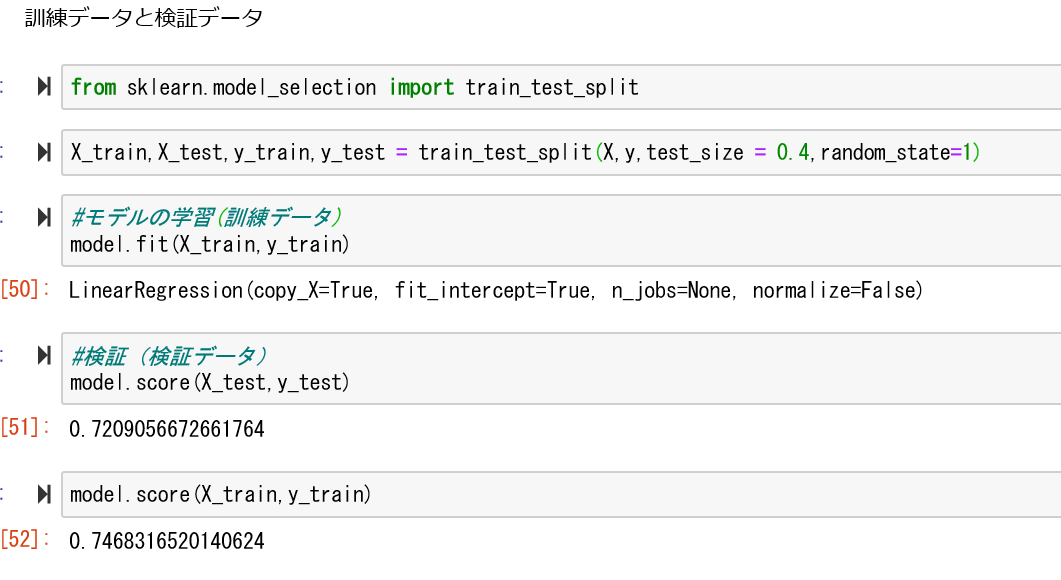
model.coef_ = 偏回帰係数
model.intercept_ = 切片
test_size = 0.4 訓練データ、検証データの比率
random_state = 1 再現性を高めるため乱数固定
訓練データでfit パラメータ調整して
検証データで決定係数出力




- 投稿日:2019-11-12T21:24:17+09:00
初心者がUE4でルービックキューブ風なものを作って強化学習用のライブラリにしたい #4
前回に引き続き初心者がUE4を絡めたPythonライブラリを作れないか色々進めていく記事です(ほぼ自分のための備忘録としての面が強い・・)。
Pythonスクリプトでのimportなどはできるのか試してみる
PyActorのブループリントにていずれかのPythonモジュールを指定するわけですが、その際に他のScriptフォルダー以下のPythonモジュールをimportできるのか試してみました。
ue.logなどでコンソール出力してみた感じ、どうやらPyActorのブループリントで指定したもののみ実行されるようです。
他のモジュールのimport自体はエラーが発生しないようなのですが、そのモジュールで追加してある関数などを呼び出すとエラーになってしまいます。
pipでインストールしてあるものは問題なく使えるものの、基本的に1つのPyActorに対して1つのモジュールと考えておいたほうが良さそうですね。ただ、それだと共通の処理などで困ってしまいます。そこで、pipでライブラリが追加されるフォルダにcommonといったフォルダを追加してimportできないか試してみます。
Plugins\UnrealEnginePython\Binaries\Win64のpipでライブラリフォルダが追加されるプラグインディレクトリにcommonというフォルダを追加し、SQLite関係のものの共通処理を書く想定でsqlite_utils.pyというファイルを追加しました。そのファイルに以下のような記述を試しにしておきます。sqlite_utils.pydef print_test(ue): ue.log('sqlite_utils test')続いてPyActorで指定したモジュールで以下ように記述を追加します。
import unreal_engine as ue from common import sqlite_utils sqlite_utils.print_test(ue=ue)pipで扱われるディレクトリはパスが通っているはずなので、きっとimportできるはず・・・という想定で試しています。
UE4でプレビュー(というよりPlayの方が単語が正しいか・・・)してみます。
無事importしたモジュールが呼び出されているようです。
複数のモジュールをまたぐPythonの記述が必要な時にはライブラリフォルダにモジュール追加する形で良さそうですね。また、common.sqlite_utilsモジュールでunreal_engineを直接importせずに、PyActorで指定したモジュールから、関数の引数で渡していますが、これはPyActorで指定したモジュールじゃないとue.logとしても動作してくれませんでした。おそらくPyActorで指定したモジュール以外で、unreal_engineモジュールのimportは使えないのでしょう。
そのため、共通モジュール側でunreal_engineモジュールが必要な場合は今回みたく引数で渡すようにして対応します。Pythonスクリプトのテストをどうしようか考える
開発上、Pythonスクリプトでテストを書きたいところです。
しかし、前述の通りPyActorのクラス1つにつき1モジュールという制約があり、且つunreal_engineモジュールが絡むものなどはUE4でPlayしないとテストができないので、pytestなんかのテストランナーが使えません。そこで、イレギュラーな感じですが以下のように進めてみます。
- 各PyActorで指定したモジュール自体にtest_というプリフィクスでテストの関数を書いていく。
- 共通モジュールに簡単な自前のテストランナー(凝ったものは作らない)用のコードを用意する。
- PyActor指定モジュールのトップレベルの箇所に、自前のテストランナーに自身のモジュールを引数で渡すようにし、渡されたテストランナー側でtest_というプリフィクスの関数を一通り実行するようにする。
とりあえず自前のテストランナーから対応していきます。
common.python_test_runner.py"""各Pythonスクリプトのテストの実行を扱うモジュール。 Notes ----- - unreal_engine モジュールを絡ませる都合、テスト用のモジュールを分けずに 運用を行う。 """ from datetime import datetime import inspect def run_tests(ue, target_module): """ 対象のモジュールに対して定義されているテストを実行する。 Parameters ---------- ue : unreal_engine 各PyActorで指定されたPythonモジュール内でimportされた、 UnrealEnginePythonライブラリのモジュール。 target_module : module テスト対象のモジュール。モジュール内でtest_というプリフィクスの 関数が実行される。 """ ue.log( '%s %sモジュールのテストを開始...' % (datetime.now(), target_module.__name__)) members = inspect.getmembers(target_module) for obj_name, obj_val in members: if not inspect.isfunction(obj_val): continue if not obj_name.startswith('test_'): continue ue.log( '%s 対象の関数 : %s' % (datetime.now(), obj_name)) pre_dt = datetime.now() obj_val() timedelta = datetime.now() - pre_dt ue.log('%s ok. %s秒' % (datetime.now(), timedelta.total_seconds()))細かいところは後で調整するとして、一旦はシンプルな実装でいいでしょう。
ビルトインのinspectモジュールのgetmembers関数で、引数に指定したモジュールのメンバー要素を取れるのでそれをループで回し、isfunction関数で関数かチェック、且つ関数名がtest_というプリフィクスを持つ場合にのみ処理を流すようにしています。
後はテスト時間や対象のモジュール名・関数名などをコンソール出力する記述のみです。別途、PyActorで指定するモジュールで、UE4→Pythonライブラリという流れでデータを渡すためのSQLite書き込み用のモジュールを用意します。
そちらに、後で消しますがテストランナーの動作確認用としてaddという加算の関数を用意しました。to_python_sqlite_writer.py"""UE4からPythonライブラリ用のSQLiteへのデータの書き込みを扱う ためのモジュール。 """ import sys import importlib import time import unittest import unreal_engine as ue from common import python_test_runner importlib.reload(python_test_runner) def add(a, b): time.sleep(1) return a + b def test_add(): added_val = add(a=1, b=3) assert added_val == 4 python_test_runner.run_tests( ue=ue, target_module=sys.modules[__name__])テスト時間の表示確認のため、わざと関数内で1秒スリープさせています。
前述の通り、テストも同一のモジュール内に書くようにしています。
最後にトップレベルの箇所にテストランナーの処理を呼び出しています。自身のモジュールはsys.moduels[__name__]とすることで取れます。なお、PyActorで指定したモジュールはコード更新後UE4側で自動でリロードされるようにしました(設定のポップアップが出たため)が、共通モジュールのものなどは自動でリロードされないようです。そのため、コード変更が即時で反映されなかったりするため、即時反映のためにimportlibでreloadさせています(最終的には消すかも・・)。
UE4でPlayしてみます。
テストが流れました。細かい点は必要に応じて後で調整するとして、とりあえずは大丈夫そうですね・・・
テストライブラリでnoseを入れておく
最近プライベートでコードを書くときはテストランナーとかの優秀さでpytestを使うことが多いのですが、今回はassertの関数だけ使えればいい(assert_equalとかassert_raisesとか)ので、楽をするためnoseのテストライブラリを入れておきます。
$ ./python.exe -m pip install --target . noseSuccessfully installed nose-1.3.7UE4上で使えることを確認するため、少し前にテストの検証で書いたコードを調整します。
to_python_sqlite_writer.pyfrom nose.tools import assert_equal ... def test_add(): added_val = add(a=1, b=3) assert_equal(added_val, 4)
問題なく動いているようです。
SQLiteでの読み書きの部分を進めてみる
前回SQLite用にSQLAlchemyを入れて最低限importなどができるところまで対応しましたが、もう少し検証で問題ないことを確認するのと、暫定ファイルの整理などをしていきます。
まずはh5pyなどの検証で使っていたpython_and_h5py_test.pyとそれに紐づくブループリントクラスを削除しておきます。まずは共通モジュールでの、SQLiteのSQLAlchemyのパスを指定するための文字列を取得する処理を追加します。
common\sqlite_utils.py"""SQLite関係の共通処理を記述したモジュール。 """ import os import sys DESKTOP_FOLDER_NAME = 'cubicePuzzle3x3' def get_sqlite_engine_file_path(file_name): """ SQLiteのSQLAlchemy用のエンジン指定用のファイルパスを取得する。 Parameters ---------- file_name : str 拡張しを含んだ対象のSQLファイル名。 Returns ------- sqlite_file_path : str SQLite用のエンジン指定用のパスの文字列。 sqlite:/// から始まり、デスクトップにSQLite用のフォルダが作られる 形で設定される。 Notes ----- 保存先のフォルダが存在しない場合には生成される。 """ dir_path = os.path.join( os.environ['HOMEPATH'], 'Desktop', DESKTOP_FOLDER_NAME) os.makedirs(dir_path, exist_ok=True) sqlite_file_path = 'sqlite:///{dir_path}/{file_name}'.format( dir_path=dir_path, file_name=file_name, ) return sqlite_file_path書いていて気づきましたが、これだと共通モジュールに対するテストが書けません(このモジュール自体でueモジュールをimportてきない)。
そのため、共通モジュールのテストを実行するためのモジュールとPyActorのブループリントクラスを追加しておいて、そちら経由で各共通モジュールのテストを実行する形で対応します。
Content\Scripts\run_common_module_tests.py"""Pythonプラグインのcommonディレクトリ以下のモジュールに対して テストを実行する。 """ import sys import inspect import unreal_engine as ue from common import python_test_runner from common.tests import test_sqlite_utils NOT_TEST_TARGET_MODULES = [ sys, inspect, ue, python_test_runner, ] members = inspect.getmembers(sys.modules[__name__]) for obj_name, obj_val in members: if not inspect.ismodule(obj_val): continue is_in = obj_val in NOT_TEST_TARGET_MODULES if is_in: continue python_test_runner.run_tests(ue=ue, target_module=obj_val)BP側はBP_RunCommonModuleTestsという名前にしました。
テストを書いていきます。共通モジュールの方は、ueモジュールのimportとかは前述のコードによって不要なのと、モジュールが分かれていても問題が無いため、普通のテストと同じようにテストモジュール用のディレクトリを挟んでtest_<モジュール名>.pyという形で進めていきます。
common\tests\test_sqlite_utils.py"""sqlite_utils モジュールのテスト用のモジュール。 """ from nose.tools import assert_equal, assert_true from common import sqlite_utils def test_get_sqlite_engine_file_path(): sqlite_file_path = sqlite_utils.get_sqlite_engine_file_path( file_name='test_dbfile.sqlite') assert_true( sqlite_file_path.startswith('sqlite:///') ) is_in = sqlite_utils.DESKTOP_FOLDER_NAME in sqlite_file_path assert_true(is_in) assert_true( sqlite_file_path.endswith('/test_dbfile.sqlite') )UE4をPlayしてみます。
大丈夫そうですね。これで共通モジュール側もテストが書けるようになりました。
問題点として、pytestなどで用意されている、特定のモジュールや特定の関数のみのテストが現状できない・・・といったところでしょうか。
この点は、テストが増えてきて結構しんどい感じになってきたら考えます(特定のモジュールだけさくっとテストできるようにしたりなど)。
実装が終わるまで、テスト時間が気にならないレベルのままな可能性も高いですしね・・・SQLiteのテスト用の挙動の確認と、初期化の処理とPyActorのスクリプトでクラスを挟んだ場合のテストを考える
UE4で作業していて、SQLiteを使ったテストをした際に、Playをもう一度実行してもSQLiteのファイルに対してロックがかかったままというケースが発生しました(途中でエラーになった場合など)。
実際にパッケージングされたときなどは一度アプリを落としてとなったりしそうな気もしますが、開発中はロックを解除するために毎回UE4を再起動したり・・・というのは手間なため、Playのたびに別のSQLiteのファイルになるようにPlayを押したタイミングでの日時情報をファイル名に差し込むようにしておきます。
initializer.pyという名前とPyActorのブループリントを追加します。Content\Scripts\initializer.py"""ゲーム開始時などに最初に実行される処理を記述したモジュール。 """ import json from datetime import datetime import os import sys import time import importlib from nose.tools import assert_equal, assert_true import unreal_engine as ue from common import const, file_helper from common.python_test_runner import run_tests importlib.reload(const) importlib.reload(file_helper) def save_session_data_json(): """ 1回のゲームセッションにおけるスタート時の情報を保持するための JSONファイルの保存を行う。 """ session_data_dict = { const.SESSION_DATA_KEY_START_DATETIME: str(datetime.now()), } file_path = file_helper.get_session_json_file_path() with open(file_path, mode='w') as f: json.dump(session_data_dict, f) ue.log('initialized.') save_session_data_json() def test_save_session_data_json(): pre_session_json_file_name = const.SESSION_JSON_FILE_NAME const.SESSION_JSON_FILE_NAME = 'test_game_session.json' expected_file_path = file_helper.get_session_json_file_path() save_session_data_json() assert_true(os.path.exists(expected_file_path)) with open(expected_file_path, 'r') as f: json_str = f.read() data_dict = json.loads(json_str) expected_key_list = [ const.SESSION_DATA_KEY_START_DATETIME, ] for key in expected_key_list: has_key = key in data_dict assert_true(has_key) os.remove(expected_file_path) const.SESSION_JSON_FILE_NAME = pre_session_json_file_name run_tests( ue=ue, target_module=sys.modules[__name__])ファイル操作用の共通モジュールとそのテストも追加します。
Win64\common\file_helper.py"""ファイル操作関係の共通処理を記述したモジュール。 """ import os import time import json from datetime import datetime from common.const import DESKTOP_FOLDER_NAME from common import const def get_desktop_data_dir_path(): """ デスクトップのデータ保存用のディレクトリを取得する。 Returns ------- dir_path : str 取得されたデスクトップのデータ保存用のディレクトリパス。 Notes ----- 保存先のフォルダが存在しない場合には生成される。 """ dir_path = os.path.join( os.environ['HOMEPATH'], 'Desktop', DESKTOP_FOLDER_NAME) os.makedirs(dir_path, exist_ok=True) return dir_path def get_session_json_file_path(): """ 1回のゲームセッションにおけるスタート時の情報を保持するための JSONファイルのパスを取得する。 Returns ------- file_path : str 対象のファイルパス。 """ file_path = os.path.join( get_desktop_data_dir_path(), const.SESSION_JSON_FILE_NAME ) return file_path def get_session_start_time_str(remove_symbols=True): """ 1回のゲームセッション開始時の日時の文字列をJSONファイルから取得する。 SQLiteのファイル名などに利用される。 Parameters ---------- remove_symbols : bool, default True 返却値の文字列から記号を取り除き、半角整数のみの値に 変換するかどうか。 Returns ------- session_start_time_str : str 1回のゲームセッション開始時の日時の文字列。 """ time.sleep(0.1) file_path = get_session_json_file_path() with open(file_path, mode='r') as f: data_dict = json.load(f) session_start_time_str = str( data_dict[const.SESSION_DATA_KEY_START_DATETIME]) if remove_symbols: session_start_time_str = session_start_time_str.replace('-', '') session_start_time_str = session_start_time_str.replace('.', '') session_start_time_str = session_start_time_str.replace(':', '') session_start_time_str = session_start_time_str.replace(' ', '') return session_start_time_strSQLite共通処理用のモジュールも追加しておきます。
Win64\common\sqlite_utils.py"""SQLite関係の共通処理を記述したモジュール。 """ import os import sys import sqlalchemy from sqlalchemy.orm import sessionmaker from common import file_helper def get_sqlite_engine_file_path(file_name): """ SQLiteのSQLAlchemy用のエンジン指定用のファイルパスを取得する。 Parameters ---------- file_name : str 拡張しを含んだ対象のSQLファイル名。 Returns ------- sqlite_file_path : str SQLite用のエンジン指定用のパスの文字列。 sqlite:/// から始まり、デスクトップにSQLite用のフォルダが作られる 形で設定される。 Notes ----- 保存先のフォルダが存在しない場合には生成される。 """ dir_path = file_helper.get_desktop_data_dir_path() sqlite_file_path = 'sqlite:///{dir_path}/{file_name}'.format( dir_path=dir_path, file_name=file_name, ) return sqlite_file_path def create_session(sqlite_file_name, declarative_meta): """ SQLiteのセッションを生成する。 Parameters ---------- sqlite_file_name : str 対象のSQLiteファイルの名称。 declarative_meta : DeclarativeMeta 対象のSQLiteの各テーブルのメタデータを格納したオブジェクト。 Returns ------- session : Session 生成されたSQLiteのセッション。 """ sqlite_file_path = get_sqlite_engine_file_path( file_name=sqlite_file_name) engine = sqlalchemy.create_engine(sqlite_file_path, echo=True) declarative_meta.metadata.create_all(bind=engine) Session = sessionmaker(bind=engine) session = Session() return sessionWin64\common\tests\test_sqlite_utils.py"""sqlite_utils モジュールのテスト用のモジュール。 """ import os from nose.tools import assert_equal, assert_true from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer from common import sqlite_utils, file_helper def test_get_sqlite_engine_file_path(): sqlite_file_path = sqlite_utils.get_sqlite_engine_file_path( file_name='test_dbfile.sqlite') assert_true( sqlite_file_path.startswith('sqlite:///') ) is_in = file_helper.DESKTOP_FOLDER_NAME in sqlite_file_path assert_true(is_in) assert_true( sqlite_file_path.endswith('/test_dbfile.sqlite') ) def test_create_session(): if not os.path.exists(file_helper.get_session_json_file_path()): return session_start_time_str = file_helper.get_session_start_time_str() sqlite_file_name = 'test_%s.sqlite' % session_start_time_str expected_file_path = sqlite_utils.get_sqlite_engine_file_path( file_name=sqlite_file_name) if os.path.exists(expected_file_path): os.remove(expected_file_path) declarative_meta = declarative_base() class TestTable(declarative_meta): id = Column(Integer, primary_key=True) __tablename__ = 'test_table' session = sqlite_utils.create_session( sqlite_file_name=sqlite_file_name, declarative_meta=declarative_meta) test_data = TestTable() session.add(instance=test_data) session.commit() query_result = session.query(TestTable) for test_data in query_result: assert_true(isinstance(test_data.id, int)) expected_file_path = expected_file_path.replace('sqlite:///', '') assert_true( os.path.exists(expected_file_path)) session.close() os.remove(expected_file_path)initializer.pyを挟んだはいいものの、実際に使うときにはinitializerよりも後にSQLiteに繋ぐモジュールの処理は実行してもらう必要があります。一方で、PyActorでどのモジュールが先に実行されるかは不明です(場合によってはinitializerよりも先に他のモジュールのトップレベルのスクリプトが実行される)。
そこで、initializerの後じゃないと困るものに関してはPyActorでクラスを指定する形で、begin_playメソッド経由でスタートさせるようにします(begin_play経由だと、各モジュールのトップレベルの処理よりも確実に後に実行されるようです。少なくとも現状試した限りでは)。
※以下で1つ暫定のテーブルのモデルを追加してありますが、動作確認後とかに削除します。テストもとりあえずは最低限エラーにならないといった程度のライトなものです。
Content\Scripts\to_python_sqlite_writer.py"""UE4からPythonライブラリ用のSQLiteへのデータの書き込みを扱う ためのモジュール。 """ import sys import importlib import time import unittest import time import unreal_engine as ue from nose.tools import assert_equal, assert_true import sqlalchemy from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String from common import python_test_runner, sqlite_utils, file_helper importlib.reload(python_test_runner) importlib.reload(sqlite_utils) declarative_meta = declarative_base() class ToPythonSqliteWriter: class TestTable(declarative_meta): id = Column(Integer, primary_key=True) name = Column(String(length=256)) __tablename__ = 'test_table' def begin_play(self): """ ゲームPlay開始時に実行される関数。 Notes ----- 各モジュールのトップレベルの処理よりは後に実行される。 """ self.session_start_time_str = \ file_helper.get_session_start_time_str() self.SQLITE_FILE_NAME = 'to_python_from_ue4_%s.sqlite'\ % self.session_start_time_str self.session = sqlite_utils.create_session( sqlite_file_name=self.SQLITE_FILE_NAME, declarative_meta=declarative_meta, ) python_test_runner.run_begin_play_test( begin_play_test_func=self.test_begin_play ) def test_begin_play(self): assert_equal( self.session_start_time_str, file_helper.get_session_start_time_str(), ) is_in = 'to_python_from_ue4_' in self.SQLITE_FILE_NAME assert_true(is_in) is_in = '.sqlite' in self.SQLITE_FILE_NAME assert_true(is_in) query_result = self.session.query(self.TestTable) python_test_runner.run_tests( ue=ue, target_module=sys.modules[__name__])また、現在追加したテストランナーが、トップレベルのものしか対応していないので、別途begin_playの特殊なUE4のイベントに絡んだメソッドに対するテストを実行するための
run_begin_play_testという関数を挟んでおきます。Win64\common\python_test_runner.pydef run_begin_play_test(begin_play_test_func): """ PyActorで指定したクラスのbegin_playメソッドに対するテストを 実行する。 Parameters ---------- begin_play_test_func : function 対象のbegin_playメソッドのテスト。 """ begin_play_test_func()現状ほぼ内容は無いですが、後で開発中のみ実行するように処理を挟みます(まだそこまでUE4側と連携できていないので)。
生成されたSQLiteファイルを確認してみる
テストが通ることを確認し、デスクトップを確認してみるととりあえずはファイルが生成されていることが分かります。
内容も少し確認しておきます。
DB Browser for SQLiteをインストールして、内容を確認してみます。
とりあえずUE4経由でのSQLiteは問題なく動いてくれているようです。
パッケージングされた環境かどうかの値をPython側で取れるようにする
Python側でも、Is Packaged for Distributionのノードの値を取れるようにし、テストなどが開発中のみ実行されるようにしておきます。
ただ、関数呼び出しがuobject経由でしかできない都合、クラスを経由する必要があり、どうしてもinitializerのトップレベルの部分で処理ができません。
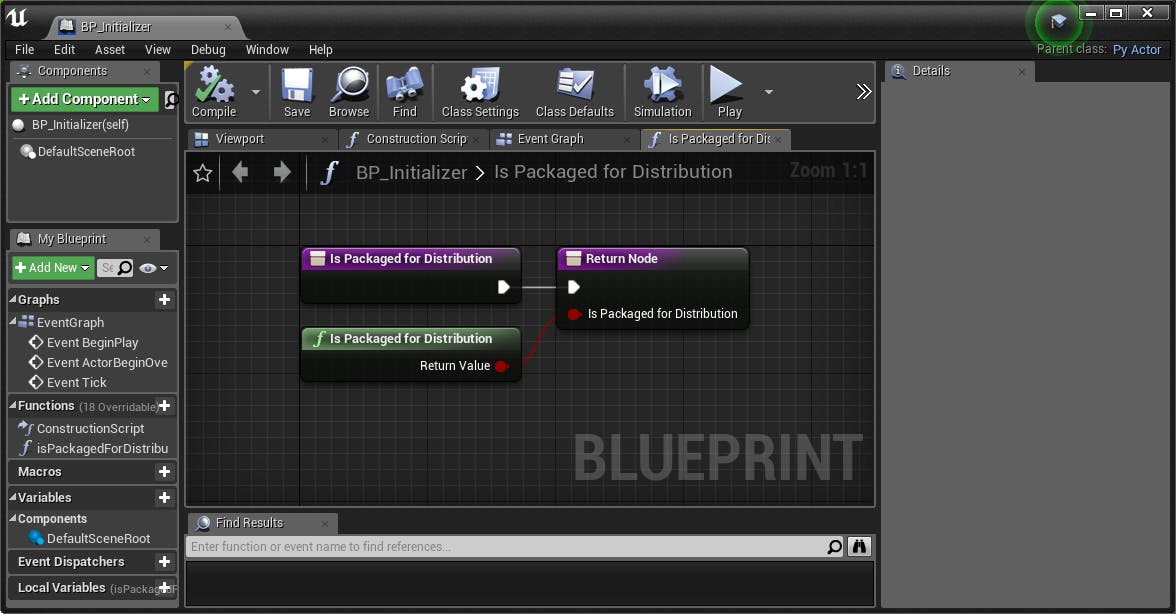
まあ無駄な処理を減らす程度のものなのと、どうこうてきるものでもないので、細かいことは気にせずに進めましょうか・・・PythonからUE4のブループリント上の関数を呼びだす必要があるので、まずはブループリントに対象の関数を追加します。
シンプルに用意されている関数の値を返却するだけの関数です。
この関数無く、直接用意されている関数(紫ではなく緑のもの)をPythonから呼び出せるのかな?と試しましたが、そんなことはなく弾かれたので普通に用意します。また、ブループリント上でクラスの指定をしておきます。
Python側の対応を進めます。
クラスのuobjectを経由する必要があるので、クラスを用意します。Content\Scripts\initializer.pyclass Initializer: def begin_play(self): """ ゲームPlay開始時に実行される関数。 """ self.is_packaged_for_distribution = \ self.uobject.isPackagedForDistribution()[0] _update_packaged_for_distribution_value( is_packaged_for_distribution=self.is_packaged_for_distribution) def _update_packaged_for_distribution_value(is_packaged_for_distribution): """ 配布用にパッケージングされた環境(本番用)かどうかの 真偽値の値を更新する。 Parameters ---------- is_packaged_for_distribution : bool 設定する真偽値。 """ file_path = file_helper.get_session_json_file_path() if os.path.exists(file_path): with open(file_path, mode='r') as f: session_data_dict = json.load(f) else: session_data_dict = {} if is_packaged_for_distribution: is_packaged_for_distribution_int = 1 else: is_packaged_for_distribution_int = 0 with open(file_path, mode='w') as f: session_data_dict[ const.SESSION_DATA_KEY_IS_PACKAGED_FOR_DISTRIBUTION] = \ is_packaged_for_distribution_int json.dump(session_data_dict, f) def test__update_packaged_for_distribution_value(): pre_session_json_file_name = const.SESSION_JSON_FILE_NAME const.SESSION_JSON_FILE_NAME = 'test_game_session.json' expected_file_path = file_helper.get_session_json_file_path() _update_packaged_for_distribution_value( is_packaged_for_distribution=True) with open(expected_file_path, mode='r') as f: session_data_dict = json.load(f) assert_equal( session_data_dict[ const.SESSION_DATA_KEY_IS_PACKAGED_FOR_DISTRIBUTION], 1 ) _update_packaged_for_distribution_value( is_packaged_for_distribution=False) with open(expected_file_path, mode='r') as f: session_data_dict = json.load(f) assert_equal( session_data_dict[ const.SESSION_DATA_KEY_IS_PACKAGED_FOR_DISTRIBUTION], 0 ) os.remove(expected_file_path) const.SESSION_JSON_FILE_NAME = pre_session_json_file_nameなお、
self.uobject.isPackagedForDistribution()[0]という値の取り方をしていますが、ブループリントの関数の返却値が1件だけでもPython側ではタプルで渡されるためにこのようにしています。
UE4上でコンソール出力してもFalseとなっているのに、なんだか分岐がうまくいかない・・と悩むこと数分。
どうやら(False,)みたいなタプル表示ではなくダイレクトにFalseやTrueといった感じでコンソール出力されるようです。これは紛らわしい・・・(せめてコンマを・・・)
型を表示したらtupleになっていて気づきました。値の取得処理に関しても追加しておきます。
Win64\common\file_helper.pydef get_packaged_for_distribution_bool(): """ 配布用にパッケージングされた状態かどうかの真偽値を取得する。 Notes ----- 初回起動時の最初のみ、値の保存前で正常に値が取れないタイミングが 存在する。その場合はFalseが返却される。 Returns ------- is_packaged_for_distribution : bool Trueで配布用にパッケージングされた状態(本番用)、Falseで 開発用。 """ file_path = get_session_json_file_path() if not os.path.exists(file_path): return False with open(file_path, mode='r') as f: json_str = f.read() if json_str == '': session_data_dict = {} else: session_data_dict = json.loads(json_str) has_key = const.SESSION_DATA_KEY_IS_PACKAGED_FOR_DISTRIBUTION \ in session_data_dict if not has_key: return False is_packaged_for_distribution = session_data_dict[ const.SESSION_DATA_KEY_IS_PACKAGED_FOR_DISTRIBUTION] if is_packaged_for_distribution == 1: return True return FalseWin64\common\tests\test_file_helper.pydef test_get_packaged_for_distribution_bool(): pre_session_json_file_name = file_helper.const.SESSION_JSON_FILE_NAME file_helper.const.SESSION_JSON_FILE_NAME = 'test_game_session.json' file_path = file_helper.get_session_json_file_path() if os.path.exists(file_path): os.remove(file_path) # ファイルが存在しない場合の返却値を確認する。 is_packaged_for_distribution = \ file_helper.get_packaged_for_distribution_bool() assert_false(is_packaged_for_distribution) # ファイルは存在するものの、空文字が設定されている場合の # 返却値を確認する。 with open(file_path, 'w') as f: f.write('') is_packaged_for_distribution = \ file_helper.get_packaged_for_distribution_bool() assert_false(is_packaged_for_distribution) # 値に1が設定されている場合の返却値を確認する。 with open(file_path, 'w') as f: session_data_dict = { const.SESSION_DATA_KEY_IS_PACKAGED_FOR_DISTRIBUTION: 1, } json.dump(session_data_dict, f) is_packaged_for_distribution = \ file_helper.get_packaged_for_distribution_bool() assert_true( is_packaged_for_distribution ) # 値に0が設定されている場合の返却値を確認する。 with open(file_path, 'w') as f: session_data_dict = { const.SESSION_DATA_KEY_IS_PACKAGED_FOR_DISTRIBUTION: 0, } json.dump(session_data_dict, f) is_packaged_for_distribution = \ file_helper.get_packaged_for_distribution_bool() assert_false(is_packaged_for_distribution) os.remove(file_path) file_helper.const.SESSION_JSON_FILE_NAME = pre_session_json_file_name以下のようにテストランナーの各所に分岐を挟んでおきます。
Win64\common\python_test_runner.pydef run_tests(ue, target_module): ... is_packaged_for_distribution = \ file_helper.get_packaged_for_distribution_bool() if is_packaged_for_distribution: return ...初期表示のランダムな状態の反映を行う
現状、色が揃った状態でスタートするので、これを普通のルービックキューブ的な感じにランダムに回転させておきます。
アニメーションしない即時の回転処理を用意してあるので、そちらを使ってブループリントに関数を追加していきます。
また、環境のリセット処理がOpenAIのGymライブラリでは関数名がresetとなっているので、そちらにならってresetとしておきます(最初だけでなく再度動かす際にも利用します)。まずは何度回すのかの値を取得します。
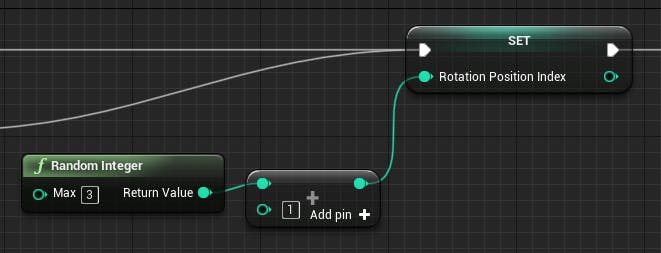
NumPyのrandintみたいなものがRandom Integerノードで用意されているようなのでそちらを使います。最小値は0、最大値はMax - 1で設定されるようです。
また、そのままだと0が出たときに最初から面が揃っている・・・みたいなことが発生してしまうので、MAXノードを挟んで最低200回は回転するというようにしておきます。
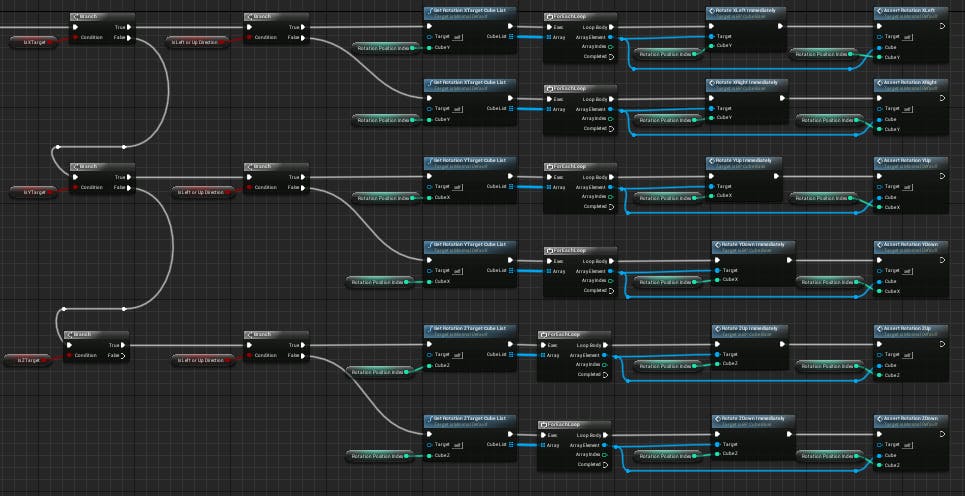
ループ中でどの方向に回転させるのかの判定用に真偽値をローカル変数で用意しておきます。
また、ループの先頭で一通りFalseにしておきます。
まずはXYZどの方向に回転させるのかの真偽値でTrueにするものをランダムに決定します。
Switchノードをはじめて使ってみます。プログラミングに慣れていれば特に悩むことなく使える形でいいですね。
続いて回転方向。左に回転させるのか右に回転させるのか、もしくは上に回転させるのか下に回転させるのかの対象をランダムに決定します。
最後に、どの列を回転させるのかといった値を算出します。1~3の値を算出する必要があるため、0~2までの値をRandom Integerノードで出してから1インクリメントしています。
後は、決定された値に応じてBranchで分岐させて必要な回転を実行させて完了です。
動かしてみます。
いい感じに色がばらけました。どんな感じに回転させれば色が全面揃うのかいまいち分かりませんね・・・。
もう一度実行してみます。
ちゃんとさっきとは異なる感じになっています。大丈夫そうですね。
ループがかなり多い処理ではありますが、私のデスクトップ環境では一瞬で終わるのと、特にFPS維持しないといけないとかでもないですし、そもそも学習で強化学習動かす方はデスクトップでしょうしそれなりに良いスペックのPCの方が大半でしょうから問題ないと判断します。回転中かどうかの真偽値の取得処理を用意する
アニメーション中に別の回転の回転が実行されると困ります。
最終的にはPython側でエラー制御などしようと思いますが、とりあえずブループリント上での実装を追加し、そちらと連携する形でPythonのコードを書いていきます。名前はGymライブラリの用語に準じてBP_Actionという名前のPyActorを継承したブループリントで作っていきます。
※Gymライブラリ回りの単語に関しては強化学習入門#1 基本的な用語とGym、PyTorch入門とかをご確認ください。ブループリントを追加したはいいものの、そういえばレベルに配置されているアクターってどう取得するんだ・・?と思ったところ、公式のドキュメントで書かれていました。
Get All Actors Of Classノードでいけそうですので試してみます。
シンプルにループで回して名前を画面にprintするだけのノードです。
ちゃんと表示されています。お手軽。
これを使えば、BP_Actionのブループリント内で、回転中のキューブのアクターが存在するかどうかの値を取るための関数が用意できそうです。
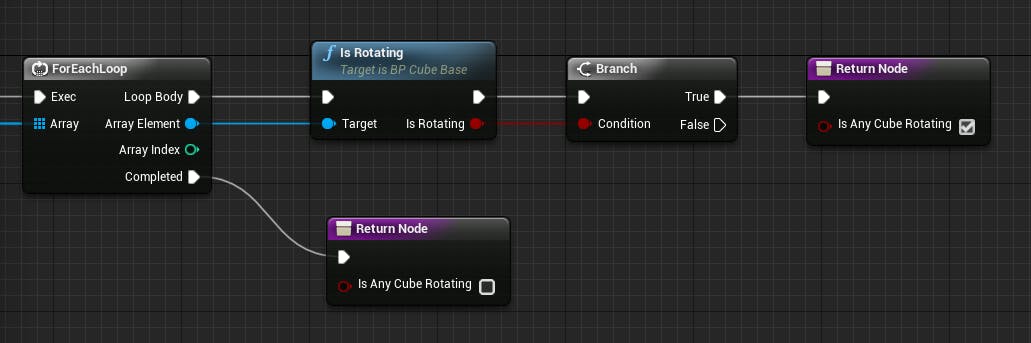
BP_CubeBaseの基底クラスのブループリントに、isRotatingという関数を追加します。
各回転方向で対象の回転の真偽値を取得する関数は以前用意していたので、そちらを呼び出しつつ、ローカル変数で真偽値の配列を用意して配列を統合いていきます。
配列に対する配列の追加はAPPENDノードでできるようです(Pythonでいうところのextend的な挙動)。
一通りの真偽値が配列に追加し終わったら、配列を渡してその配列でいずれかの真偽値がTrueならTrueが返ってくる関数を以前別の箇所で用意して使っていた(そちらは配列が3件とかで指定していましたが・・・)ので、そちらを利用します。
BP_ActionのブループリントにisAnyCubeRotatingという名前の関数で作っていきます。
少し前に触れたGet All Actors Of Classを使って配列を取得し、ループで回します。
ループ中で回転しているキューブがあればTrueのReturn Nodeへ、もし1つも回転しているものが見つからないままループが終わったらFalseのReturn Nodeへ流すようにします。
また、BP_Actionのブループリントで、Pythonのモジュールとクラスの指定をしておきます。
Python側でaction.pyというモジュールを追加して、処理を書いていきます。
まだPython側から回転の処理などを書いていないので、テストなどは一旦スキップします(機能テスト関係が整備してあればもう書くのですが、整備してないのとUE4関係のものはよく分かっていないので)。また、tickでコンソール出力を試してみます(今のところは必ずFalseが返るはず)。Content\Scripts\action.py"""Agentにおける何らかの行動制御に関連した処理を記述したモジュール。 """ import unreal_engine as ue class Action: def tick(self, delta_time): """ ゲームPlay中、約1フレームごとに実行される関数。 Parameters ---------- delta_time : float 前回のtick呼び出し後からの経過秒。 """ ue.log(is_any_cube_rotating(action_instance=self)) def is_any_cube_rotating(action_instance): """ いずれかのキューブが回転中かどうかの真偽値を取得する。 Parameters ---------- action_instance : Action uobjectを持ったActionクラスのインスタンス。 Returns ---------- is_rotating : bool いずれかのキューブが回転中であればTrueが設定される。 """ is_rotating = action_instance.uobject.isAnyCubeRotating()[0] return is_rotatingログを見るとFalseが出力されていることが分かります。
... LogPython: False LogPython: False LogPython: False LogPython: False ...とりあえずは大丈夫そうですね。コンソール出力を消しておいて、どんどん次にいきます。
NumPyを入れておく
hdf5関係をアンインストールした際に、dependenciesとしてインストールされたNumPyも一緒にアンインストールしてしまいましたが、やっぱり使いたいところが出てきたためNumPyのみ入れておきます。
$ ./python.exe -m pip install --target . numpySuccessfully installed numpy-1.17.3Action関係の制御の実装を進める。
まずはとりあえずActionの番号の割り振りを定義しました。
重複やリストにちゃんと含まれているかなどはチェックされるようにしておきます。Content\Scripts\action.pyimport numpy as np ... ACTION_ROTATE_X_LEFT_1 = 1 ACTION_ROTATE_X_LEFT_2 = 2 ACTION_ROTATE_X_LEFT_3 = 3 ACTION_ROTATE_X_RIGHT_1 = 4 ACTION_ROTATE_X_RIGHT_2 = 5 ACTION_ROTATE_X_RIGHT_3 = 6 ACTION_ROTATE_Y_UP_1 = 7 ACTION_ROTATE_Y_UP_2 = 8 ACTION_ROTATE_Y_UP_3 = 9 ACTION_ROTATE_Y_DOWN_1 = 10 ACTION_ROTATE_Y_DOWN_2 = 11 ACTION_ROTATE_Y_DOWN_3 = 12 ACTION_ROTATE_Z_UP_1 = 13 ACTION_ROTATE_Z_UP_2 = 14 ACTION_ROTATE_Z_UP_3 = 15 ACTION_ROTATE_Z_DOWN_1 = 16 ACTION_ROTATE_Z_DOWN_2 = 17 ACTION_ROTATE_Z_DOWN_3 = 18 ACTION_LIST = [ ACTION_ROTATE_X_LEFT_1, ACTION_ROTATE_X_LEFT_2, ACTION_ROTATE_X_LEFT_3, ACTION_ROTATE_X_RIGHT_1, ACTION_ROTATE_X_RIGHT_2, ACTION_ROTATE_X_RIGHT_3, ACTION_ROTATE_Y_UP_1, ACTION_ROTATE_Y_UP_2, ACTION_ROTATE_Y_UP_3, ACTION_ROTATE_Y_DOWN_1, ACTION_ROTATE_Y_DOWN_2, ACTION_ROTATE_Y_DOWN_3, ACTION_ROTATE_Z_UP_1, ACTION_ROTATE_Z_UP_2, ACTION_ROTATE_Z_UP_3, ACTION_ROTATE_Z_DOWN_1, ACTION_ROTATE_Z_DOWN_2, ACTION_ROTATE_Z_DOWN_3, ] ... def test_ACTION_LIST(): assert_equal( len(ACTION_LIST), len(np.unique(ACTION_LIST)) ) members = inspect.getmembers(sys.modules[__name__]) for obj_name, obj_val in members: if not obj_name.startswith('ACTION_ROTATE_'): continue assert_true(isinstance(obj_val, int)) is_in = obj_val in ACTION_LIST assert_true(is_in) python_test_runner.run_tests( ue=ue, target_module=sys.modules[__name__])定義した定数名に準じて、BP_Actionに各アクションの関数を追加していきます。
と思ったものの、回転で対象となるキューブのリストを算出する関数がレベルのブループリントに書いてしまっていました。
BP_Actionからその関数を呼び出すのが大分面倒そうな印象があります・・やらかした感が・・・(慣れるまでこの参照ができないという点でついやらかしてしまう・・・)
参考 : レベルブループリントを参照する方法を考える嘆いていてもしょうがないので、キューブの基底クラスのブループリントに、各回転で対象となるキューブかどうかの真偽値を取得する関数を先に追加していきます(そうすればレベル内のキューブはGet All Actors Of Classノードで取れるので・・)。
関数ライブラリを試してみる
続きを進める前に、assertのヘルパー的なものなどをレベルのブループリントに書いていましたが、それだとBPクラスで使えなかったりで不便に感じる時があるので、調整を考えます。
調べてみると、どうやら関数ライブラリというものがあるようです。
関数ライブラリとは
どこからでもアクセスできる色んな関数を一か所にまとめて持つことができるブループリントです。
通常のブループリントと違い、変数を保持することができず、イベントグラフも存在しません。マクロも作れず、関数のみ作成可能です。
この中に書いた関数は、どのブループリント、それこそアクターやレベル問わず使えるようになります。
[UE4] 関数ライブラリとマクロライブラリの上手な活用作り方は以下の記事で書かれていました
UE4 汎用関数の作成(Blueprint Function Library)
慣習として、関数ライブラリのフォルダはどんな名前がいいのでしょう・・・?
動画や書籍で、ブループリントはBluePrints、ファイル名は先頭にBP_と付けましょうとか、マテリアルはMaterialsにしましょうとかそういった慣習が紹介されていましたが、関数ライブラリはどうだったか・・・そもそも関数ライブラリが紹介されていただろうか・・・(アウトプットしていないとすぐ忘れて良くないですね・・・)とりあえず、仕事ではないので気軽にLibrariesというフォルダ名にしておきましょうか。
ファイル名はLIB_とプリフィクス付けるようにしてみます。
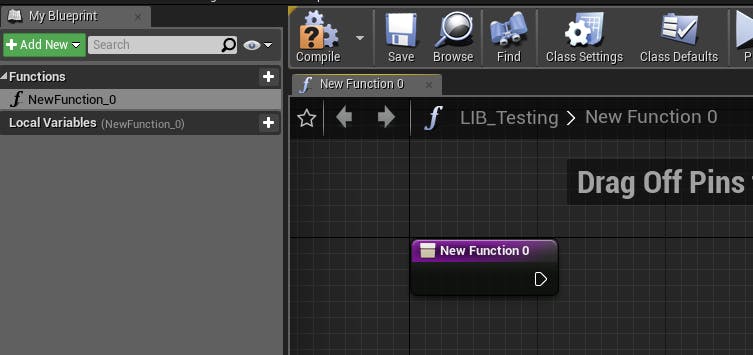
コンテンツブラウザで新規ファイルを追加し、Blueprints → Blueprint Function Libraryと選択すると作れるようです。
テスト関係を追加していきたいのでLIB_Testingという名前にしました。
開いてみたらこんな感じのようです。関数とローカル変数のみのごくシンプルな構成のブループリントみたいですね。
移しておきたい関数をこちらに移して、既存のレベルBP上の関数をそちらに差し替えておきます。ライブラリに追加した関数は、特に何もしないでもそのままレベルのBPやほかのBPクラスから呼び出せるようです。
これでBPクラス内でのライトな値のチェックなどもやりやすくなりました。
キューブの基底クラスに回転の対象かどうかの真偽値取得の処理を追加していく
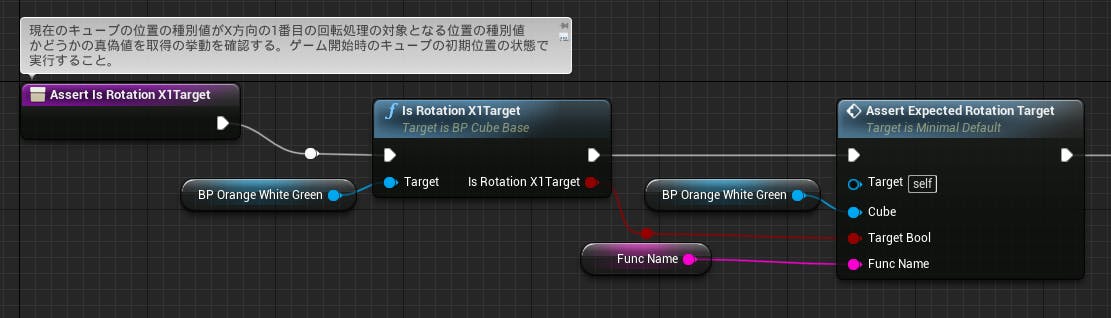
前述のように、BP_CubeBaseの基底クラスから回転の対象かどうかの真偽値を取得できるようにし、BP_Actionから呼び出せるようにします。
以下のような真偽値を返す形の関数をXYZで1~3の範囲で作るので、関数を9個追加していきます。
共通部分は別の関数に切り分けてあります。また、対象の回転で対象となるキューブの位置の種別の配列は定数ですでに以前用意していたのでそちらを使っていきます。
共通処理の内部では、配列分ループを回して、
現在のキューブの位置の種別値が、現在のループでのインデックスの配列の値と一致する場合はTrue、ループ終わっても該当するものが無ければFalseを返すようにしています。
細かいところは省きますが、ある程度処理の挙動を確認するためのテストを書いておきます。
回転の9個分用意ができて、テストも引っかからない形になったので次へ進みます。
試しに1つ、BP_Actionに回転の関数を一つ追加してみます。まずはシンプルなアニメーションしないタイプの回転の方から進めていきます。まずはキューブのアクターを取得し、ループを回します。
後は先ほど用意した回転対象かどうかの真偽値での分岐を設けて、Trueなら回転するようにします。
Python側でも雑に試してみます。
Content\Scripts\action.pyclass Action: total_delta_time = 0 is_rotated = False def tick(self, delta_time): """ ゲームPlay中、約1フレームごとに実行される関数。 Parameters ---------- delta_time : float 前回のtick呼び出し後からの経過秒。 """ self.total_delta_time += delta_time if self.total_delta_time > 5 and not self.is_rotated: self.uobject.rotateXLeftImmediately1() self.is_rotated = Trueこれでとりあえず5秒後くらいに1回即時で回転します。
プレビューしてみましたが大丈夫そうです。
他の回転の処理も同様に組んでいきますが、その前に回転結果のテスト用の関数を、BP_Action側からも参照できるように関数ライブラリ側に移動させておき、レベル側の関数は置換して切り落としておきます。移動後、対象の回転後の値のチェック用の関数を今回BP_Actionに追加した関数の末尾に追加しておき、プレビューしてチェックに引っかからないことを確認しておきます。
とりあえず大丈夫そうなので、他の方向の回転なども一通り追加して、Python側から呼び出してみて動作確認しておきます。
Pythonを経由する即時の回転の処理は大丈夫そうです。
次回は、アニメーション付きの回転の処理をPythonに繋いでいく形で作業を進めていきます(記事が長くなってきたので、今回の記事はこの辺りにしておこうと思います)。気になった点
- たまに、Pythonスクリプトの更新が反映されないことがありました(UE4再起動すると直る)。Pythonプロセスが起動したままになるので、長時間そのままだと色々不整合的にうまく処理が通らない・・・みたいなケースに悩まされました。importlibとか使っても直らないケースが・・・。起動にそこまで時間がかかるというものでもないですか、少々気になりますね・・・。いい感じの方法無いだろうか・・・(後でUnrealEnginePythonのプラグインのgithubのissueとか漁ってみてもいいかもと考えています・・)
参考ページまとめ


























- 投稿日:2019-11-12T21:01:00+09:00
ちょっとブログ感覚でじぶんが触れたことあるものまとめ
python
flask
pythonのwebアプリケーション用ライブラリ。
プロトコル通信での送受信を結構簡単に行える。受信した数値に対してpython側で計算をしたり、表にまとめるなどできる。インスタグラムなどの大規模なシステム構築には向かないらしい。しかし、簡単なウェブアプリケーションを作るうえでは問題ない。
正確な情報や不正確な情報が蔓延しているので、実際に実装して確かめる必要がある。ポート開放の知識が必要。http://python.zombie-hunting-club.com/entry/2017/11/03/223503
flaskの使い方の初歩はここから学んだ。https://qiita.com/keimoriyama/items/7c935c91e95d857714fb
https://qiita.com/5zm/items/ac8c9d1d74d012e682b4
【クラインアント→サーバー】クライアントからファイルを貰う方法の参考に。https://qiita.com/5zm/items/760000cf63b176be544c
【サーバー→クラインアント】プロトコル通信使って、クライアントにファイルを投げる方法の参考に。matplotlib,sympy
ふと思い立って、グラフ描画をしたくなったときのやつ。
matplotlibは描画用ライブラリ、sympyはシミュレーション用ライブラリ。なんかよくはわからんけど、二つとも使う。https://qiita.com/HigashinoSola/items/2ab8894b543e0c55cfa7
このページはうまくまとめられているので初心者向けによい。https://qiita.com/orange_u/items/8a1e285a45093857aef7
3D描画する際に参考にした。https://matplotlib.org/3.1.0/gallery/mplot3d/text3d.html
3D描画にテキストを記述する方法。上のページ内にも書いてあるが、import matplotlib.pyplot as plt fig=plt.figure() ax=Axes3D(fig) ax.text(x,y,z,Text,dir) #x,y,zは座標、Textはstr型の文字、dirは(x,y,z)でカメラに対してのアングル
- 投稿日:2019-11-12T20:53:47+09:00
Django + Google Cloud Strageで、ImageFieldの画像をサーバでも正常に表示させる
HerokuやGAE(Google App Engine)などのサーバで、ImageFieldを使用しても画像が正常に表示されません。
これは、SQLが画像のアップロードに対応していないためで、これの解決にはGoogle Cloud StrageやAmazon S3などのクラウドストレージに画像をアップロードしなければなりません。
今回は、Google Cloud Storageに画像をアップロードする方法をご紹介します。
Django Strage (Google Cloud Storage) 公式ドキュメント
https://django-storages.readthedocs.io/en/latest/backends/gcloud.htmlDjango Strage のインストール
Django で Google Cloud Strage を扱うための Django ライブラリ、
Django Strage (Google Cloud Storage)をpipでインストールします。bash$ pip install django-storages[google]Google Cloud Platform で認証情報の取得
Google Cloud Platform から、 Cloud Strageの認証情報の登録と、認証情報の記載された JSON ファイルを取得します。
サービスアカウントの取得
Googleスタートガイド (https://cloud.google.com/docs/authentication/getting-started) から取得できます。
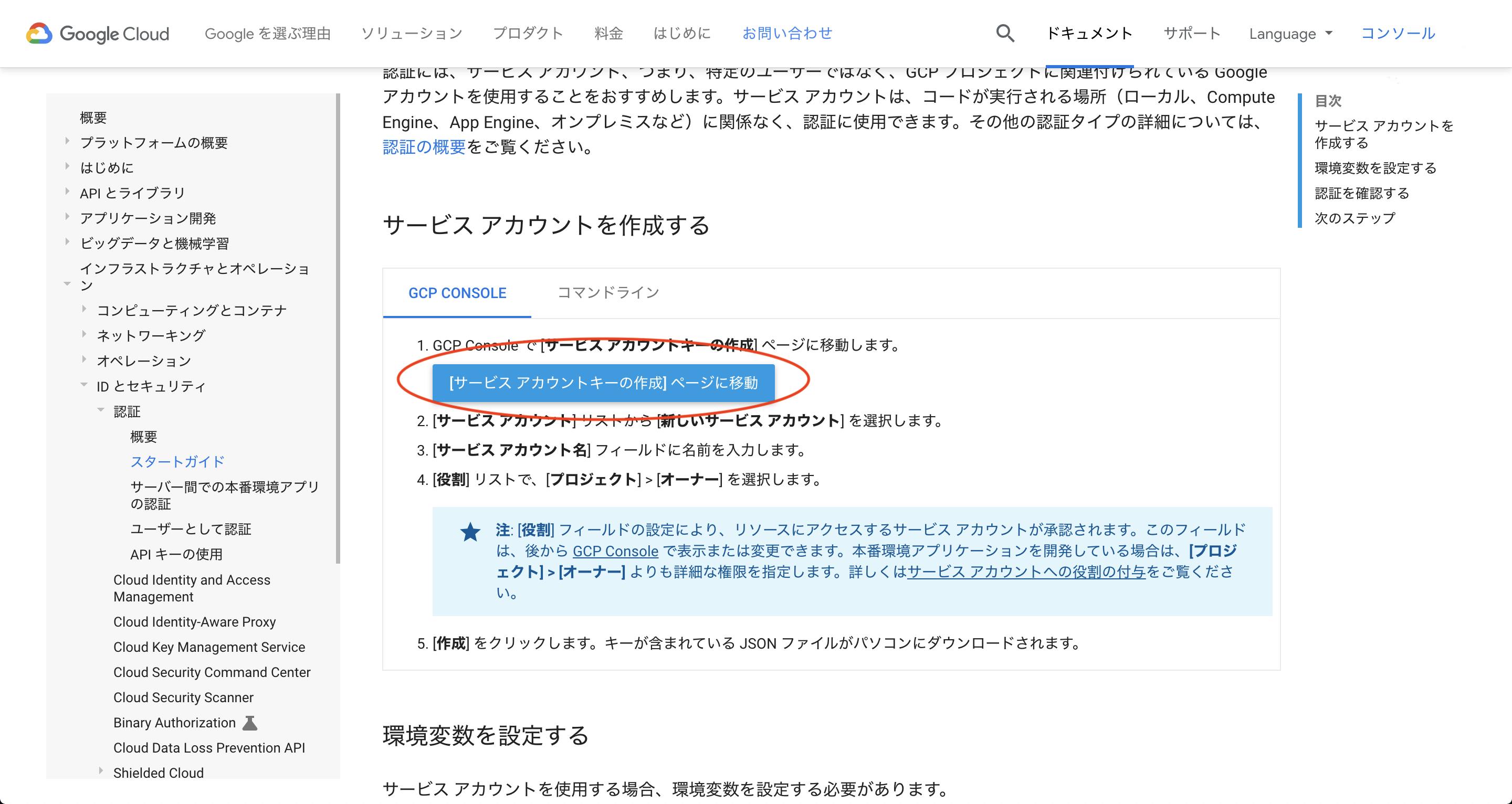
手順1
Googleスタートガイド (https://cloud.google.com/docs/authentication/getting-started) のリンクから、「[サービスアカウントキーの作成]ページに移動」を選択
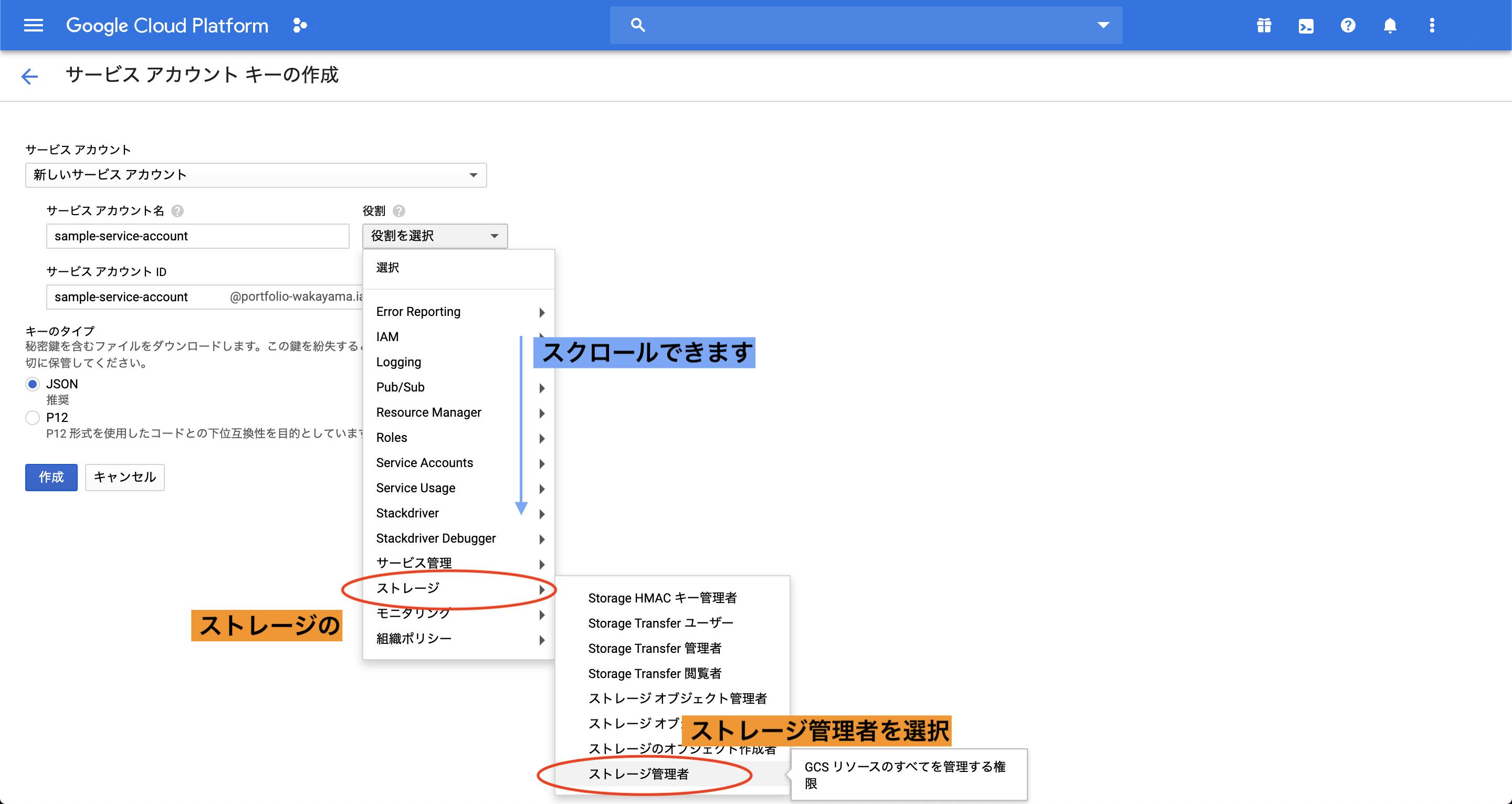
手順2
新しいサービスアカウントを作成で、サービスアカウント名を入力。
その後、役割から「ストレージ」 -> 「ストレージ管理者」を選択。
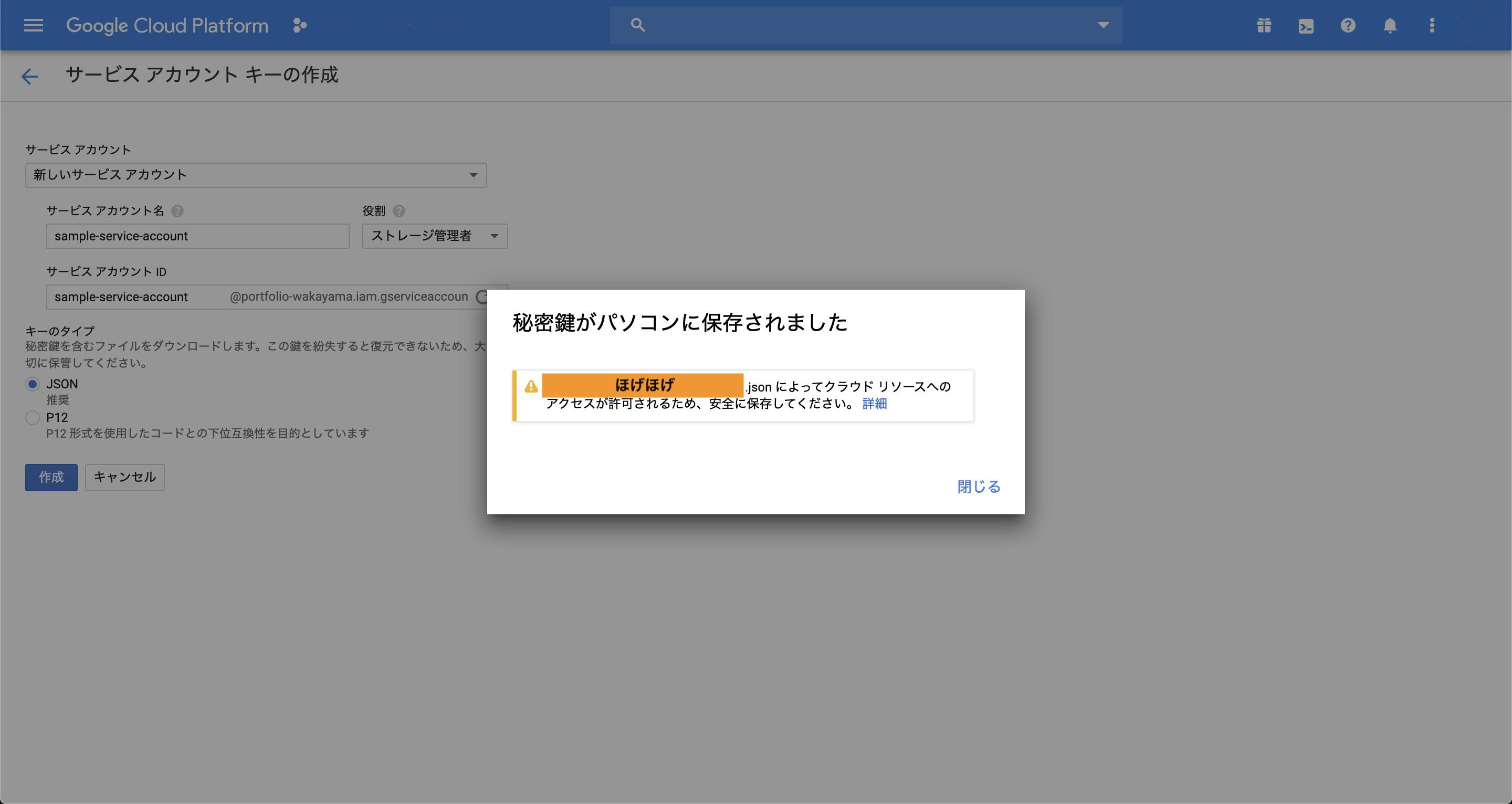
キーのタイプがJSONになっていることを確認して、「作成」ボタンを押下してください。
そうすると、JSONファイルがダウンロードされます。
ダウンロードしたJSONファイルは、Djangoプロジェクトのルートディレクトリに配置してください。
Google Cloud Strageのバケットの作成
Cloud Strageの単位をバケットといいます(データを入れるバケツみたいな意味)
これを作成して、データを収納します。Google Cloud Console (Cloud Strage)
https://console.cloud.google.com/storage/browser上記URLからアクセスすると、以下のような作成画面に遷移すると思うので、新規バケットを作成します。
完了すると以下のような画面になります。
これで、Google Cloud Platform console での設定は完了です。
Djangoでの設定
settings.pyに設定の追加
settings.pyファイルでデフォルトのストレージとバケット名を設定します。
settings.pySTATIC_URL = '/static/' STATIC_ROOT = os.path.join(BASE_DIR, 'staticfiles') STATICFILES_STORAGE = 'storages.backends.gcloud.GoogleCloudStorage' MEDIA_URL = '/media/' MEDIA_ROOT = os.path.join(BASE_DIR, 'media') DEFAULT_FILE_STORAGE = 'storages.backends.gcloud.GoogleCloudStorage' GS_BUCKET_NAME = '[YOUR_BUCKET_NAME_GOES_HERE]' from google.oauth2 import service_account GS_CREDENTIALS = service_account.Credentials.from_service_account_file( os.path.join(BASE_DIR, '[YOUR_AUTHENTICATON_KEY_FILE_NAME].json'), )以上で設定は完了です。
あとは以下のコマンドを実行しましょう。
bash$ python manage.py collectstaticそして設定の変更をサーバにデプロイすると正常に機能するはずです。
お疲れ様でした。



- 投稿日:2019-11-12T20:48:04+09:00
OpenCVを使って長い動画を一部だけ保存する方法
きっかけ
グフ/増殖系YouTuber の 「NHK」で増えて「ぶっ壊す」で倍になる立花孝志 にsyncしました
ちょうど良い動画素材で、領域分割・顔認識・テロップを消すには・・・などなど何かしらでopencvで出来そうです。
この動画は18分あるのですが候補者が登場する冒頭の1分だけを使いたいと思っています。
で、一部分だけ時間によって抽出する方法をpythonとOpenCVのみでやってみます。元素材
方法
- 元動画からfps(1秒あたりのフレーム数)を抽出する
開始時間 * fpsor終了時間 * fpsでフレーム数を計算する
time.time()で計測しようとしたのですがフレーム数ベースで制御した方が成功しました。また、
候補者が登場する冒頭の1分なので
- 開始時間 = 30秒
- 終了時間 = 90秒
としました。
開発
import cv2 if __name__ == '__main__': cap = cv2.VideoCapture('drop_out_nhk.mp4') cap_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) cap_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) fps = cap.get(cv2.CAP_PROP_FPS) fourcc = cv2.VideoWriter_fourcc('m','p','4','v') writer = cv2.VideoWriter('one_minutes.mp4',fourcc, fps, (cap_width, cap_height)) # 抽出したい開始or終了時間 begin = 30 end = 90 for i in range(end * fps): ret, frame = cap.read() if ret: if begin * fps < i: writer.write(frame) writer.release() cap.release()結果
多分これでちょうど1分になったと思います。
おわりに
asyncioとか使おうと思ったのですが、割とすんなり実装できました。 画像サイズを変えるとなぜかコーデックでミスります。参考にしたリンク


- 投稿日:2019-11-12T20:26:33+09:00
Python + ImageMagick > BMP形式の文字一覧から文字を切り出す (東雲フォントのBMP変換に対して)
動作環境Ubuntu 16.04 LTS Python 3.5.2 ImageMagick 6.8.9-9 Q16 x86_64 2018-09-28概要
- 東雲フォント(BDF形式)をBMP形式に変換した
- BMP形式から各文字を切り出す
- 16x16のフォント
実装 v0.1
枠線は2ピクセル。
divide_191112.pyimport subprocess as sb import sys # on Python 3.5.2 # Ubuntu 16.04 LTS # cut out 16x16 bitmap fonts BORDER_WIDTH = 2 INFILE = "shnmk16.bmp" idx = 0 for lin in range(10): for col in range(32): idx = idx + 1 xpos = BORDER_WIDTH + (BORDER_WIDTH + 16) * col ypos = BORDER_WIDTH + (BORDER_WIDTH + 16) * lin aform = "convert %s -crop 16x16+%d+%d wrk-%03d.bmp" acmd = aform % (INFILE, xpos, ypos, idx) print(acmd) sb.getoutput(acmd)wrk-000.bmpのように文字ごとにファイルになる。
これを使ってanimated gifを作成できる。切り出したファイル
- wrk-148: 数値の始まり
- wrk-158: upper case英字の始まり
- wrk-184: lower case英字の始まり
- wrk-210: ひらがなの始まり
- wrk-293: カタカナの始まり
実装 v0.2
- 16x16を32x32へ
- imagemagickで画像のリサイズ by @tukiyo3 さん
- 情報感謝です。
- 白黒反転する
- カメラ写りが悪かったので
- Invert colors with ImageMagick
divide_191112.pyimport subprocess as sb import sys # on Python 3.5.2 # Ubuntu 16.04 LTS # cut out 16x16 bitmap fonts BORDER_WIDTH = 2 INFILE = "shnmk16.bmp" idx = 0 for lin in range(10): for col in range(32): idx = idx + 1 xpos = BORDER_WIDTH + (BORDER_WIDTH + 16) * col ypos = BORDER_WIDTH + (BORDER_WIDTH + 16) * lin # aform = "convert %s -crop 16x16+%d+%d wrk-%03d.bmp" # x 1 aform = "convert %s -crop 16x16+%d+%d -resize 32x32 -channel RGB -negate wrk-%03d.bmp" # x2 invert acmd = aform % (INFILE, xpos, ypos, idx) print(acmd) sb.getoutput(acmd)
- 投稿日:2019-11-12T19:40:00+09:00
Pythonで蟻本"Lake Counting"を解いてみた
ゆっくりだけど蟻本解いていきます。
今日はLake Counting。lake_counting.pydef lake_counting(lake): # 水たまりWの数を数える # 8近傍で隣接しているWは一つの水たまりとみなす # 文字列のlakeを配列に格納 def lake_to_list(lake): lake_list = [] lake = lake.split() for i in range(len(lake)): lake_list.append([]) for j in range(len(lake[0])): lake_list[i].append(lake[i][j]) return lake_list def dfs(lake_list, x, y): lake_list[y][x] = "." # Wの箇所を見つけたらその周り8か所を探索 # Wを見つけたら.に置き換える # これにより隣接しているWも含めた水たまりの数1カウントとできる for dx in range(-1, 2): for dy in range(-1, 2): nx = x + dx ny = y + dy if nx >= 0 and nx < len(lake_list[0]) and ny >= 0 and ny < len(lake_list): #隣接しているWがあればそのまた隣接も探索 if lake_list[ny][nx] == "W": dfs(lake_list, nx, ny) def main(): lake_cnt = 0 lake_list = lake_to_list(lake) # lake配列を順に探していってWを見つけたら # dfs関数が働く for y in range(len(lake_list)): for x in range(len(lake_list[0])): if lake_list[y][x] == "W": dfs(lake_list, x, y) lake_cnt += 1 print (lake_cnt) main()テストケース lake = """ W........WW. .WWW.....WWW ....WW...WW. .........WW. .........W.. ..W......W.. .W.W.....WW. W.W.W.....W. .W.W......W. ..W.......W. """ lake_counting(lake) #出力:3
- 投稿日:2019-11-12T19:22:23+09:00
CNNを用いた画像認識 馬と鹿
はじめに
初めての機械学習を行う際に、画像認識に興味があり、やってみようと思ったのですが、どういったアプローチにしようか迷っていました。
そこで、Aidemyの「CNNを用いた画像認識」というコースがあったので、それを受講し、CNNをやることにしました。最初に考えたのが、競馬が好きなので競走馬の分類。
【競走馬 = 騎手が乗っている馬】として考えて、競争馬でも裸馬でも、【馬】として認識できるものを作ろうと考えました。分類は馬と鹿にしました。
理由は、馬の画像収集の過程でCIFAR-10のデータセットも使わさせて頂いたのですが、CIFAR-10の中にdeer(鹿)があったからです。
動物として似ているものに挑戦してみたかったので、ちょうど良かったです。TODO
- 画像収集
- 収集画像の処理
- 画像の水増し
- 画像を学習/検証データにする
- モデル構築と保存
- 結果のグラフ化
- 別の画像でテスト
画像収集
画像収集には、以下を利用しました。
- Google Images Download
- bing_image_downloader API
検索ワード「競走馬」「Race horse」「Cheval de course」 約1400枚
検索ワード「鹿」約800枚
- データセット
- CIFAR-10のhorse 1001枚
- CIFAR-10のdeer 999枚
収集画像の処理
データセットは完璧に処理済みなので、Webから拾ってきた画像を処理します。
1.重複画像の削除
image hash(phash)を利用して、重複画像を抽出します。
ImageHashで同じ画像を持つフォルダを検出する
こちらのコードを引用、編集したものを使いました。from PIL import Image, ImageFile import imagehash import os # サイズの大きな画像をスキップしない ImageFile.LOAD_TRUNCATED_IMAGES = True # phash 2つの画像のハッシュ値の差分を出力 def image_hash(img, otherimg): # phashを指定 hash = imagehash.phash ( Image.open ( img ) ) other_hash = imagehash.phash ( Image.open ( otherimg ) ) return hash - other_hash # 画像サイズの小さい方を検出する def minhash(img, otherimg): # (幅, 高さ)のタプル hash_size = Image.open ( img ).size otherhash_size = Image.open ( otherimg ).size if hash_size == otherhash_size: return 0 if hash_size < otherhash_size: return 1 # 以下のパスに調べてほしい画像の入ったディレクトリを保存 default_dir = '画像の入ったディレクトリを保存したパス' # 調べてほしい画像の入ったディレクトリを取得 img_dir = os.listdir ( default_dir ) # 調べてほしい画像の入ったパスを取得 img_dir_path = os.path.join ( default_dir, img_dir[0] ) # 画像のリストを取得 img_list = os.listdir ( img_dir_path ) # 画像が2枚以上あれば、画像のパスを取得してリスト化 img_path = [os.path.join ( img_dir_path, i ) for i in img_list if len ( os.path.join ( img_dir_path, i ) ) > 2] # フォルダ内の画像の数の取得 img_list_count = len ( img_list ) i = 0 delete_list = [] # image_hash(),minhash()でフォルダごとの画像を比較 while i < img_list_count: # 進捗状況 print ( '実行中 : ', str ( i + 1 ) + '/' + str ( img_list_count ) ) # i + 1 で2回目の比較のものと、同じ画像の比較をしない for j in range ( i + 1, img_list_count ): # ハッシュ値の差分が10以下なら同一の画像として認識 if image_hash ( img_path[i], img_path[j] ) < 10: print ( img_path[i] + ' | vs | ' + img_path[j] ) # 画像サイズが同じだった場合片方のパスをdelete_listに格納 if minhash ( img_path[i], img_path[j] ) == 0: if not img_path[j] in delete_list: delete_list.append ( img_path[i] ) # 画像サイズの小さい方のパスをdelete_listに格納 if minhash ( img_path[i], img_path[j] ) == 1: delete_list.append ( img_path[i] ) j += 1 i += 1 # 削除したい画像パスの表示 print ( delete_list ) # 削除したい画像を開く場合 # def open_folder(path): # subprocess.run ( 'explorer {}'.format ( path ) ) # # for i in range ( len ( delete_list ) ): # open_folder ( delete_list[i] ) # 続けて削除したい場合 # for i in delete_list: # try: # os.remove( i ) # except OSError : # pass参考文献
pythonを使ってORBとPerceptual Hashで画像の類似度を比べてみる
Perceptual Hashを使って画像の類似度を計算してみる
2.関係ない画像の削除、そして画像をRGB形式に変換
学習に使用できないと思われる画像を、手動で削除しました。
RGB形式への変換はこちらを参考にさせて頂きました。
機械学習用に画像を前処理するこうして処理済みの画像を用意できました。
- horseフォルダ 約1400枚 → 計438枚
- deerフォルダ 約800枚 → 計139枚
上記の画像にプラスCIFAR-10の画像を使います。
画像の水増し
horseフォルダ APIで拾った459枚、
deerフォルダ API + CIFAR-10
1138枚
をImageDataGeneratorで水増しします。fit_generator()、flow()を使用してそのままモデルを訓練できますが、今回は単純な水増しが目的です。
ですので、生成した画像を自身のドライブに保存します。
from keras.preprocessing.image import ImageDataGenerator import os datagen = ImageDataGenerator(rotation_range=20, # ランダムに回転する回転範囲(単位degree) width_shift_range=0.2, # ランダムに水平方向に平行移動する、画像の横幅に対する割合 height_shift_range=0.2, # ランダムに垂直方向に平行移動する、画像の縦幅に対する割合 shear_range=0.2, # せん断の度合い。大きくするとより斜め方向に押しつぶされたり伸びたりしたような画像になる(単位degree) zoom_range=0.2, # ランダムに画像を圧縮、拡大させる割合。最小で 1-zoomrange まで圧縮され、最大で 1+zoom_rangeまで拡大される horizontal_flip=True) # ランダムに水平方向に反転 root_dir = './data/padding' # 水増ししたい画像フォルダのあるパス targetsize = (128, 128) # 加工サイズ save_dir = os.listdir(root_dir) # 水増しした画像を保存するフォルダ名 save_path = os.path.join('./data/save', save_dir[0]) # 水増しした画像の保存先 increase = len(os.listdir(os.path.join(root_dir, save_dir[0]))) # 水増ししたい画像フォルダに入っている画像の数 increase_count = 1 # 1枚につき、このパターン数だけ水増し(increase✕increase_countの数だけ画像が増える) # 保存先ディレクトリが存在しない場合、作成 if not os.path.exists(save_path): os.makedirs(save_path) # flow_from_directory()で水増ししたい画像(フォルダ)の取得と、水増しした画像の加工と保存を同時におこなう ffd = datagen.flow_from_directory( directory=root_dir, target_size=targetsize, color_mode='rgb', batch_size=increase, save_to_dir=save_path) [next(ffd) for i in range(increase_count)]
horseフォルダ 2000枚
deerフォルダ 2000枚
が用意できました。参考文献
Keras - Keras の ImageDataGenerator を使って学習画像を増やす
Keras CNN を改造してImageDataGenerator(画像水増し機能)を理解する
classifier_from_little_data_script_1.py
KerasのImageDataGeneratorで学習用画像を水増しする方法
Image Preprocessingインポート
「結果のグラフ化」までのインポートは以下の通り
# plaidMLをKarasで動かすためのコード import plaidml.keras plaidml.keras.install_backend() from sklearn.model_selection import train_test_split from keras.callbacks import ModelCheckpoint from keras.layers import Conv2D, MaxPooling2D, Dense, Dropout, Flatten from keras.models import Sequential from keras.utils import np_utils from keras import optimizers from keras.preprocessing.image import img_to_array, load_img import keras import glob import numpy as np import matplotlib.pyplot as plt画像を学習/検証データにする
- 画像サイズを全て統一
- 配列化
- 学習データ8割、検証データ2割の割合で分ける
# 画像ディレクトリのパス root_dir = './data/' # 画像ディレクトリ名 baka = ['horse', 'deer'] X = [] # 画像の2次元データを格納するlist y = [] # ラベル(正解)の情報を格納するlist for label, img_title in enumerate(baka): file_dir = root_dir + img_title img_file = glob.glob(file_dir + '/*') for i in img_file: img = img_to_array(load_img(i, target_size=(128, 128))) X.append(img) y.append(label) # Numpy配列を4次元リスト化(*, 244, 224, 3) X = np.asarray(X) y = np.asarray(y) # 画素値を0から1の範囲に変換 X = X.astype('float32') / 255.0 # ラベルをOne-hotにしたラベルに変換 y = np_utils.to_categorical(y, 2) # データを分ける X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=0) xy = (X_train, X_test, y_train, y_test) # .npyで保存 np.save('./npy/train.npy', xy) # 学習用の画像データ(行(高さ), 列(幅), 色(3))の確認(入力層input_shapeと同じ) print('3次元 :', X_train.shape[1:])モデル構築と保存
ここの部分は試行錯誤
model.fit()のcallbacksでModelCheckpointを使用して、エポック毎にmodelを保存します。
最終的に、val_lossが最小値の時のmodel全体が、hdf5形式で残ります。
モデル、グラフは最終的なテストで一番正解率が高かったものを載せます。# 入力層,隠れ層(活性化関数:relu) model.add ( Conv2D ( 32, (3, 3), activation='relu', padding='same', input_shape=X_train.shape[1:] ) ) model.add ( MaxPooling2D ( pool_size=(2, 2) ) ) model.add ( Conv2D ( 32, (3, 3), activation='relu', padding='same' ) ) model.add ( MaxPooling2D ( pool_size=(2, 2) ) ) model.add ( Conv2D ( 64, (3, 3), activation='relu' ) ) model.add ( MaxPooling2D ( pool_size=(2, 2) ) ) model.add ( Conv2D ( 128, (3, 3), activation='relu' ) ) model.add ( MaxPooling2D ( pool_size=(2, 2) ) ) model.add ( Flatten () ) model.add ( Dense ( 512, activation='relu' ) ) model.add ( Dropout ( 0.5 ) ) # 出力層(2クラス分類)(活性化関数:softmax) model.add ( Dense ( 2, activation='softmax' ) ) # コンパイル(学習率:1e-3、損失関数:categorical_crossentropy、最適化アルゴリズム:RMSprop、評価関数:accuracy(正解率)) rms = optimizers.RMSprop ( lr=1e-3 ) model.compile ( loss='categorical_crossentropy', optimizer=rms, metrics=['accuracy'] ) # 学習モデルのエポック epoch = 50 # モデルを保存するパス fpath = f'./model/model.{epoch:02d}-.h5' # エポックごとにモデルを保存するかチェック mc = ModelCheckpoint ( filepath=fpath, monitor='val_loss', # 評価をチェックする対象 verbose=1, save_best_only=True, # val_lossの最新の最適なモデルは上書きされない save_weights_only=False, # Falseの場合モデル全体が保存 mode='min', # チェックの対象がval_lossなので最小を指定 period=1 ) # チェックするエポックの間隔 # 構築したモデルで学習 history = model.fit ( X_train, y_train, batch_size=64, epochs=epoch, callbacks=[mc], validation_data=(X_test, y_test) )結果のグラフ化
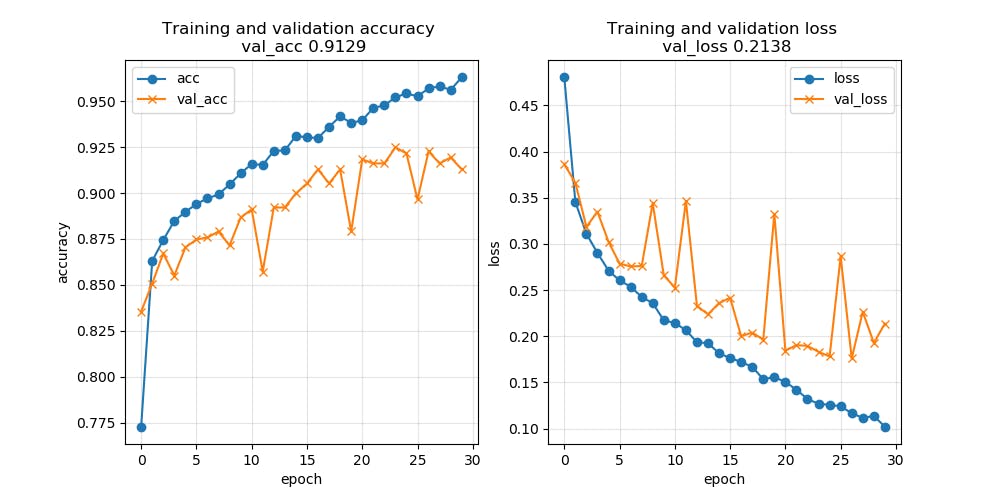
グラフに表示される数値はmodel.h5の数値ではなく、最後のエポックの数値になります。
# 可視化 fig = plt.figure(figsize=(18, 6)) # ウィンドウ作成 # 正解率グラフ plt.subplot(1, 2, 1) # 2つ横に並べて右側に表示 plt.plot(history.history['acc'], label='acc', ls='-', marker='o') # 学習用データのaccuracy plt.plot(history.history['val_acc'], label='val_acc', ls='-', marker='x') # 訓練用データのaccuracy plt.title(f'Training and validation accuracy \n val_acc {score[1]:.4f}') # タイトル plt.xlabel('epoch') # 横軸 plt.ylabel('accuracy') # 縦軸 plt.legend(['acc', 'val_acc']) # 凡例 plt.grid(color='gray', alpha=0.2) # グリッド表示 # 損失グラフ plt.subplot(1, 2, 2) # 2つ横に並べて左側に表示 plt.plot( history.history['loss'], label='loss', ls='-', marker='o') # 学習用データのloss plt.plot(history.history['val_loss'], label='val_loss', ls='-', marker='x') # 訓練用データのloss plt.title(f'Training and validation loss \n val_loss {score[0]:.4f}') plt.xlabel('epoch') plt.ylabel('loss') plt.legend(['loss', 'val_loss']) plt.grid(color='gray', alpha=0.2) # 保存 plt.savefig('1.png') plt.show()
保存されたモデル
Epoch 15/50
・・・・・・
3200/3200 [==============================] - 122s 38ms/step - loss: 0.1067 - acc: 0.9625 - val_loss: 0.1872 - val_acc: 0.9363グラフに安定感がないため、
Epoch15がval_loss最小値になりました。
val_loss: 0.1872 - val_acc: 0.9363学習率が高いことや、データ数が少ないことが考えられ、
また後半は過学習を起こしています。これをもとに改善したことを、この記事の終わりの方の「試してみたこと」に記載しました。結果的にダメでしたが……
別の画像でテスト
全く別の画像を用意し、保存したモデルで判別します。
# plaidMLをKarasで動かすためのコード import plaidml.keras plaidml.keras.install_backend() from keras.preprocessing.image import img_to_array, load_img from keras.models import load_model import numpy as np import glob # モデルデータのパス hdf_path = './model/model.20-val_loss 0.2648 - val_acc 0.8793.h5' # モデル読み込み model = load_model(hdf_path) # テストする画像が入っているディレクトリ img_path = './baka/' # 14枚の画像取得 img_list = glob.glob(img_path + '*') size = (128, 128, 3) for index, i in enumerate(img_list): # 画像をサイズを変えて読み込み、配列化 test_img = img_to_array(load_img(i, target_size=size)) # 0~1の範囲にする test_img = test_img / 255 # 4次元配列に test_img = test_img[np.newaxis, ...] # 予測 pre = model.predict(test_img) if np.max(pre[0]) == pre[0, 0]: print(f'{img_list[index]} -> {pre} は 馬') if np.max(pre[0]) == pre[0, 1]: print(f'{img_list[index]} -> {pre} は 鹿')配列の左側の数字が高いと馬、右側の数字が高いと鹿です。
deer1.jpg -> [[0.08649362 0.9135064 ]] は 鹿
deer2.jpg -> [[5.096481e-06 9.999949e-01]] は 鹿
deer3.jpg -> [[0.01137464 0.9886254 ]] は 鹿
deer4.jpg -> [[0.04577665 0.9542234 ]] は 鹿
deer5.jpg -> [[1.0562457e-07 9.9999988e-01]] は 鹿
deer6.jpg -> [[0.10744881 0.89255124]] は 鹿
deer7.jpg -> [[0.5856648 0.41433516]] は 馬
horse1.jpg -> [[0.00249346 0.99750656]] は 鹿
horse10.jpg -> [[0.6968936 0.30310643]] は 馬
horse2.jpg -> [[0.90138936 0.09861059]] は 馬
horse3.jpg -> [[9.9987268e-01 1.2731158e-04]] は 馬
horse4.jpg -> [[9.9999964e-01 4.1403896e-07]] は 馬
horse5.jpg -> [[9.999294e-01 7.052123e-05]] は 馬
horse6.jpg -> [[9.9999738e-01 2.6105645e-06]] は 馬
horse7.jpg -> [[0.93193245 0.06806755]] は 馬
horse8.jpg -> [[0.01251398 0.987486 ]] は 鹿
horse9.jpg -> [[0.00848716 0.99151284]] は 鹿正解率は76.47%でした。
一番の目的であった、競走馬の判定としてはhorse10.jpgは【馬】判定でしたが、horse8.jpg、horse9.jpgは【鹿】判定でした。
原因はデータセットにあるのか、データサイズにあるのか、それとも全然別にあるのか、勉強がまだまだ足りないことを思い知りました。
試したことの一部を載せます。
試したことその1
データセットを変更
- horseフォルダの変更
- 競走馬の正面からの写真を21枚増やす
- 計459枚を水増したものだけをhorseフォルダに入れる (CIFAR-10のhorse 1001枚を使わない)
- horseフォルダに合わせてdeerフォルダを水増し (こちらはCIFAR-10のdeer 999枚を使っている)
horseフォルダ → 2295枚
deerフォルダ → 2295枚
そして、層などは変えませんでしたが、学習率を1e-4に下げました。
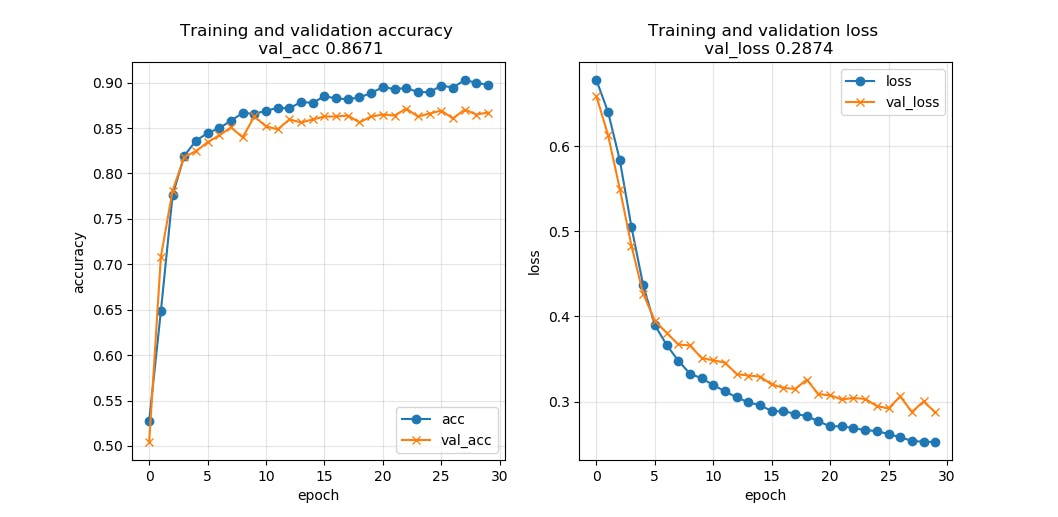
Epoch 27/30
・・・・・・
3672/3672 [==============================] - 139s 38ms/step - loss: 0.1167 - acc: 0.9570 - val_loss: 0.1760 - val_acc: 0.9227グラフが安定していません
テスト結果不正解
deer1.jpg -> [[0.5788138 0.42118627]] は 馬
deer5.jpg -> [[0.5183205 0.48167947]] は 馬
horse8.jpg -> [[0.0699899 0.93001 ]] は 鹿
正解
horse9.jpg -> [[0.612066 0.38793397]] は 馬
horse10.jpg -> [[0.7463752 0.2536248]] は 馬正解率70.59%、下がってしまいました。
試したことその2
今度は学習率を1e-5まで更に下げ、バッチサイズを32にしました。層などは変えていません。
グラフは安定傾向になりました。
しかし、テストの正解率は47.06%、かなり下がってしまいました。試したことその3
上記のデータセットで他にもいろいろ試しましたが、期待する結果が得られなかったため、再度データセットを変更しました。
- horseフォルダの変更
- 使用していなかったCIFAR-10のhorse 1001枚を使う ただし、水増しはWebから拾った方だけ(459枚→1275枚)
- deerフォルダは特に変更なし、数を合わせただけ
horseフォルダ → 2276枚
deerフォルダ → 2276枚また、層を減らしました
# 入力層,隠れ層(活性化関数:relu) model.add ( Conv2D ( 32, (3, 3), activation='relu', padding='same', input_shape=X_train.shape[1:] ) ) model.add ( MaxPooling2D ( pool_size=(2, 2) ) ) model.add ( Conv2D ( 32, (3, 3), activation='relu', padding='same' ) ) model.add ( MaxPooling2D ( pool_size=(2, 2) ) ) model.add ( Conv2D ( 64, (3, 3), activation='relu' ) ) model.add ( MaxPooling2D ( pool_size=(2, 2) ) ) model.add ( Flatten () ) model.add ( Dense ( 64, activation='relu' ) ) model.add ( Dropout ( 0.5 ) ) # 出力層(2クラス分類)(活性化関数:softmax) model.add ( Dense ( 2, activation='softmax' ) )コンパイル(学習率:1e-4、損失関数:categorical_crossentropy、最適化アルゴリズム:RMSprop、評価関数:accuracy(正解率))
エポック epochs=20、バッチサイズ batch_size=32
Epoch 18/20
3641/3641 [==============================] - 131s 36msstep - loss 0.2647 - acc 0.8846 - val_loss 0.2948 - val_acc 0.8716グラフは若干安定傾向ですが、テストの正解率は64.71%でした。
テスト画像からみる考察
シグモイド関数なども含め、いろいろ試しましたが、
deer1.jpgは馬と判定される確率高いです。
それ以上にhorse8.jpg、horse9.jpgの競走馬正面画像が鹿と判定されやすいです。
データが足りないかもしれません。おわりに
正解率を上げるためには、まだまだいろいろな技術がありますが、一度ここで終えて、またチャレンジしたいと思います。学習率減衰、アンサンブル学習、転移学習、EfficientNetなどなど。
自分の理想とする結果は得られませんでしたが、CNNを用いた画像認識を行ってみることはできました。
参考文献
Kerasで2種類(クラス)への分類
CNNの学習に最高の性能を示す最適化手法はどれか
バレンタインデーにもらったチョコが本命かどうか判定するAIを実際に作って公開した(2019)
画像等の配列を扱うときの操作方法
TensorFlow + Kerasでフレンズ識別する - その2: 簡単なCNNを使った学習編
ディープラーニング 脱超初心者向け基礎知識
KerasでCNNを簡単に構築
美女を見分けられない機械はただの機械だ:Pythonによる機械学習用データセット生成
画像認識で坂道グループの判別AIの作成
画像認識で「綾鷹を選ばせる」AIを作る
MNISTでハイパーパラメータをいじってloss/accuracyグラフを見てみる
CNNをKerasで
最良のモデルを保存する(ModelCheckpointの使い方)
ディープラーニングを使用して「あなたにそっくりな女優判別プログラム」を作ったおはなし
KerasでDNN実装
KERASで学習済みのモデルをロードして画像1枚を判別




- 投稿日:2019-11-12T18:56:30+09:00
「Azure ML Studioで機械学習」の要点
「Azure ML Studioで機械学習」の要点
この本 →クラウドではじめる機械学習 改訂版
が簡素だけども難しすぎずに小綺麗にまとまっているので要点をまとめておく。
回帰による数値予測(サンプル:新車販売価格予測)
例:リテールでの販売予測(前年の販売数、曜日、天気、広告打った・打たない、などの相関項目をもとに解析し未来の販売数を予測。
線形回帰 (linear regression)
【数式】
y : 予測日の販売数
x1~xm : 馬力、燃料タイプ、燃費、ホイールベース、ブランド価値、などの変数
w1~wm : 偏回帰係数(重みのこと. feature weight)
c : 定数項(Bias)
※ 変数が多すぎると過学習になる精度評価
・MAE(Mean Absolute Error: 平均絶対誤差)・・・0に近いほどいい
予測値と正解値の差を平均したもの。
・RMSE(Root Mean Squared Error: 二乗平均平方根誤差):
・法定係数(Coerfficient of Determination)
予測値と正解値の相関係数の二乗。1に近くなるほどいいデータ分割
・ホールドアウト法
学習用データを学習用と評価用にランダムに分割
・交差検証(cross validation)
学習用データをk個分に分割。そしてk回評価精度向上
・正規化(regularization)
変数が多すぎて重みパラメーターが大きくなりすぎ過学習するのをふせぐために重みパラメーターに比例するペナルティ値を加算する。
【数式】
予測値と正解値の誤差の二乗の和、に重みパラメーターの二乗の和をパラメーターとして加える。
ベイズ線形回帰 (bayesian linear regression)
計算式は線形回帰と同じ。ただ重みパラメーターが一定ではなく確率分布であるとするモデル。
最尤推定(MLE: Maximum Likelihood Estimation.誤差が0になるように重みパラメーターを定める方法)だけだと学習用データの数を考慮しない場合不正確になるところを、事象の起こった回数を考慮してくれる。(事前分布と事後分布)
クラス分類(サンプル:乳癌データから陽性陰性のクラス分類)
例:銀行での与信審査を職業、年収、預金額、延滞遅延などの相関項目を解析し支払い能力を予測。
ロジスティック回帰
ある特定の事象が起きる確率を予測する。
【数式】
x1~xm : 年齢、腫瘍の大きさ、腫瘍の悪性度、閉経したしない、などの変数
w1~wm : 偏回帰係数(重みのこと. feature weight)
c : 定数項(Bias)
P : 確率
確率の閾値をたとえば0.5にすることによって陽性陰性の推定をする1対多分類器(one-vs.-rest classifier)
A~Eまでクラスを作ったとしたら、それぞれに対する判別式(上記数式)を用意し最も高い確率を示したクラスに該当データを割り当てる。
1対1分類器(one-vs.-one classifier)
A~Eまでクラスを作ったとしたら、A-B,A-C,A-D...とすべての1対1の組み合わせを試す。組み合わせ数
k×(k-1)÷2回。A~Eだったら10回。その10回のうち多数決で多かったクラスに該当データを割り当て。精度評価
・正解率(Accuracy)・・・100%に近いほどいい
陽が9割あった場合、アホみたくぜんぶ正解にしてしまっても正解率90%になってしまう。・真陽性率(TPR: True Positive Rate)・・・100%に近いほどいい
陽データだけを対象にどのくらい合っていたか・偽陽性率(FPR: False Positive Rate)・・・0%に近いほどいい
陰データだけを対象にどのくらい誤って陽としてしまったか・AUC(Area Under the Curve)・・・1.0に近いほどいい
偽陽性率と真陽性率とはトレードオフになる。そこで偽陽性率と真陽性率をROC曲線のグラフにしその曲線の下側の面積がAUC。・適合率(Precision)・・・100%に近いほどいい
推測が陽としたデータを対象にどのくらい正解データも陽であるか・再現率(Recall)・・・100%に近いほどいい
正解データの陽を対象にどのくらい推測データが正しくよう陽と判定できたか。・F値(F1 score)・・・1.0に近いほどいい
再現率と適合率もトレードオフ。これを総合的に判断する指標
精度向上
ロジスティック回帰以外の手法を試す。サポートベクトルマシン(SVM)やDecision Forest、Boosted Decision Treeなど
クラスタリング(サンプル:アヤメの分類)
例:旅行代理店の顧客の志向を、近場志向、海外志向、温泉志向などのグループに分類しそれぞれの志向にもとづいた販促資料を配布。
k-means法
任意のクラスタ数k個の中心点データを選び、ユークリッド距離またはコサイン類似度を用いて他のデータを各クラスタに分類する
ユークリッド距離
簡単。グラフ上の点aと点bの距離。
変数がm個の場合は【数式】
コサイン類似度
ベクトルの向きの近さ。同じ方向向いてれば+1, 垂直なら0, 逆向きなら-1
【数式】
k-means++法
k-means法を改良。これが主流。
クラスタの中心点をできるだけ離れるように選ぶ。また少数の集団はかけ離れたデータは無視する。精度評価
教師なし学習なので分析者が適当に見てみるしかない。
精度向上
・正規化
値のスケールが大きい変数xを平均値:0,標準偏差:1になるようにスケール変換する。z得点(z-score)とか呼ぶ。
異常検知(サンプル:クレジットカード使用データから異常支払い検知)
例:河川の上流、中流、下流の各水位センサーから鉄砲水のような災害前兆を検知する。
One-Class SVM
密度推定アルゴリズム。データの正常域を円で表しその円に入らないデータを異常と検知。以下の数式で求められる値を最小化するように学習する。
【数式】
R: 円の半径
n: データ件数
ζ: データが円をはみ出した長さ
ν: 分析者があたえるペナルティの重み(小さくすればより多くの学習データを正常域に含めようとする。νが0だと学習用データのすべてを円内に収めてしまう)カーネルトリック
データの密集域が離れているときに、正常域を歪んだ曲線で囲ってくれる。
精度評価
・適合率(Precision)・・・大きいほど検知漏れが少ない
異常検知推測が「異常」としたデータを対象にどのくらい正解データも「異常」であるか・再現率(Recall)・・・大きいほど検知漏れが少ない
正解データの「異常」を対象にどのくらい推測データが正しく「異常」と判定できたか。・F値(F1 score)・・・1.0に近いほどいい
再現率と適合率もトレードオフ。これを総合的に判断する指標
精度向上
適合率と再現率はトレードオフ。異常事象の検知漏れを減らしたいか誤検知を減らしたいか。
νを大きくすると(0.5など)正常域は狭まる。逆に0.02などにするとだいぶ正常域に入ってしまう。ML Studioではηで設定する。カーネル関数を変えてみる
カーネルトリックで使われるカーネル関数。
・RBFカーネル(ML Studioのデフォルト)
・多項式カーネル
・シグモイドカーネル異常検知の手法を変えてみる
・主成分分析による異常検知(PCA-Based Anomaly Detection)
・Times Series Anomaly Detection(気温の変遷や株価推移など時系列データの場合)
レコメンデーション(サンプル:レストラン評価データよりユーザーにおすすめレストランを提示)
例:Amazonの「この商品を買った人は以下の商品も買ってます」みたいな
強調フィルタリング
自分が与えた評点(rating, preference)と他者が与えた評点を併用しておすすめ商品を推測。アイテムベースとユーザーベースがある。
アイテムベースレコメンド
ユーザーが高い評点を与えた商品と類似性の高い商品をレコメンド。
ユーザーベースレコメンド
ユーザーと類似度の高いユーザーを複数選び、それぞれが高い評点をつけた商品をレコメンド
MatchBox
強調フィルタリングでは初見ユーザーや新商品が蚊帳の外になる(コールドスタート問題(cold-start problem)。商品やユーザーの属性情報からレコメンドするようにしたマイクロソフト独自のアルゴリズム。さらに徐々に蓄積されていく評点も併用して使う。
【式】
κは属性の数従って学習用データは評点データ、ユーザー属性データ、商品属性データの3種類用意する。
精度評価
・NDCG(Normarized Discounted Cumulative Gain)・・・1.0に近いほどいい
デフォルト
・MAE(Mean Absolute Error: 平均絶対誤差)・・・0に近いほどいい
予測値と正解値の差を平均したもの。
・RMSE(Root Mean Squared Error: 二乗平均平方根誤差):精度向上
特徴ベクトルの長さ(κ)を調整する。MS Studioでは「Train Matchbox Recommender」の[Number of traits]
実用化
実戦モードに切り替え
1.Score Matchbox Recommenderの[Recommended item selection]を[From All Items]に変更する。→ 実戦モードに。
2. 入力ポートは利用者IDのみしか受け付けなくなるので、Manipulationから「Select Columns in Dataset」を追加してuserIDだけを出力するように設定。
3. RUN
Webサービスの発行
実戦モードにて
1. [SET UP WEB SERVICE]から[Predictive Web Service]をクリック
2. [Web service input],[Web service output]モジュールが追加される
- [Select Columns in Dataset]を外して[Web service input]を[Score Matchbox Recommender]の入力ポートに。
[Deploy web servce]をクリック。以下の画面に遷移。APIキーが発行された。
REQUEST/RESPONSEをクリックすると別のウインドウが開き画面下の方にサンプルコードがある。
6.コードの
api_key = "abc123"のabc123を自分用のに変更。以下のコードのvaluesを例えばUserID"U1048"に変更。#変更前 data = { "Inputs": { "input1": { "ColumnNames": ["userID"], "Values": [ [ "value" ], [ "value" ], ] }, },#変更後 data = { "Inputs": { "input1": { "ColumnNames": ["userID"], "Values": [ [ "U1048" ] ] }, },PythonApplication.pyとかで保存。
- コマンドで
$ python PythonApplication.pyと打てば結果が返ってくる。$ python PythonApplication.py {"Results":{"output1":{"type":"table","value":{"ColumnNames":["User","Item 1","Item 2","Item 3","Item 4","Item 5"],"ColumnTypes":["String","String","String","String","String","String"],"Values":[["U1048","134986","135030","135052","135045","135025"]]}}}}
- 2019年11月現在Python2系のサンプルコードになっている。Python3系の場合は以下の通り。
import urllib.request # If you are using Python 3+, import urllib instead of urllib2 import json data = { "Inputs": { "input1": { "ColumnNames": ["userID"], "Values": [ [ "U1048" ] ] }, }, "GlobalParameters": { } } body = str.encode(json.dumps(data)) url = 'https://japaneast.services.azureml.net/workspaces/0e3c5988af4b43d7ac14fa55244b9f9d/services/53da3266168a4c8a8814e3adac2a6821/execute?api-version=2.0&details=true' api_key = '<APIキー>' # Replace this with the API key for the web service headers = {'Content-Type':'application/json', 'Authorization':('Bearer '+ api_key)} req = urllib.Request(url, body, headers) try: response = urllib.urlopen(req) # If you are using Python 3+, replace urllib2 with urllib.request in the above code: # req = urllib.request.Request(url, body, headers) # response = urllib.request.urlopen(req) result = response.read() print(result) except urllib.request.HTTPError, error: print("The request failed with status code: " + str(error.code)) # Print the headers - they include the requert ID and the timestamp, which are useful for debugging the failure print(error.info()) print(json.loads(error.read()))
urllib2をurllib.requestに変えるだけ。
以上。









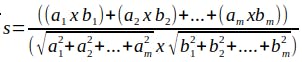









- 投稿日:2019-11-12T17:42:59+09:00
巨大地震のきっかけは月なのか?
0. Abstract
- 巨大地震(M>8のもの)は多くの場合、月による潮汐応力による地球の変形が、発生のトリガとなっているらしい(例えば[1])
- 過去に発生した地震を、統計的に扱った論文もいくつかあった
- しかし、当然といえば当然なのだが、Tidal Phase Angleについて議論していても、Lunar AgeやLunar Phaseを明確に示したものは見つからなかった
- Tidal Phase Angleは、Lunar Ageとほぼ同じような振るまいとなるので、当然といえば当然か
- 一般人が自分でTidal Phase Angleを計算できるとは到底思えない
- しかし、月と太陽の位置なら自分で見ればわかる
- なので、Lunar AgeとEarathquakeの発生状況を可視化した
1. Introduction
このレポートは、過去の地震が統計的にどのような
月の位置とその位相の時に発生したのかを可視化するものである。月からの潮汐の影響を初めて議論したのは、いまから100年以上も前のSchuster (1987)[1]である。
その後、地球潮汐と地震の関係については、特定の震源(群)を対象とした研究としてTanaka (2012)[4]や Ide et al. (2016)[5]といった研究がある。またTsuruoka and Ohtake (1995)[2]は、世界で発生した地震を対象にして地球潮汐との関係を議論したが、非学術領域の一般の人々からみて難解である。
そのため、結局のところ月と地震の関係については、世の多くの人から見ると、いまいち要領を得ない。そこで月や太陽を見れば、その地震が発生する確率を想起できるようにすることが、このレポートの目的である。
2. Data
2.1 Data Source
可視化対象とする地震カタログは、米国地質研究所(USGS: United States Geological Survey)が提供した(と思われる)、Significant Earthquakes, 1965-2016を利用する。
このデータは、マグニチュードMが5.5以上のものだけがカタログされている。USGSだけではなく、日本の気象庁や防災研でも過去の地震カタログを公開している。しかしシンプルな一覧になっておらず、非常に使いにくい。そのため、上述のデータを利用する。
本来、地震はそれぞれ各地点でのプレートテクトニクスによるものなので、地域特性というものが必ず存在する。今回、全地球という広域の地震活動を対象としたため、地域特性を一切考慮していない。そのために、本職の研究者から見たときに何かしら違和感を覚える内容かもしれないことにご留意いただきたい。
2.2 Data Overview
まずはデータを読みこんで、最初の数行を確認する。
分析と可視化は、pythonを利用する。import math import datetime import os, sys import numpy as np import pandas as pd DATA_DIR = "/kaggle/input/earthquake-database/" + os.sep # read data file earthquake = pd.read_csv( DATA_DIR+"database.csv", sep=",", parse_dates={'datetime':['Date', 'Time']}, encoding="utf-8", error_bad_lines=False, ) # treating irregular data for idx in [3378,7512,20650]: earthquake.at[idx, "datetime"] = earthquake.at[idx, "datetime"].split(" ")[0] earthquake["datetime"] = pd.to_datetime(earthquake["datetime"], utc=True) earthquake.set_index(["datetime"], inplace=True) earthquake.head() """ Output Latitude Longitude Type Depth Depth Error Depth Seismic Stations Magnitude Magnitude Type Magnitude Error Magnitude Seismic Stations ... Horizontal Error Root Mean Square ID Source Location Source Magnitude Source Status inner moon_dist sun_dist datetime 1965-01-02 13:44:18 19.246 145.616 Earthquake 131.6 NaN NaN 6.0 MW NaN NaN ... NaN NaN ISCGEM860706 ISCGEM ISCGEM ISCGEM Automatic 0.364867 4.128686e+08 1.471089e+11 1965-01-04 11:29:49 1.863 127.352 Earthquake 80.0 NaN NaN 5.8 MW NaN NaN ... NaN NaN ISCGEM860737 ISCGEM ISCGEM ISCGEM Automatic -0.996429 4.065270e+08 1.471063e+11 1965-01-05 18:05:58 -20.579 -173.972 Earthquake 20.0 NaN NaN 6.2 MW NaN NaN ... NaN NaN ISCGEM860762 ISCGEM ISCGEM ISCGEM Automatic 0.947831 4.052391e+08 1.471037e+11 1965-01-08 18:49:43 -59.076 -23.557 Earthquake 15.0 NaN NaN 5.8 MW NaN NaN ... NaN NaN ISCGEM860856 ISCGEM ISCGEM ISCGEM Automatic 0.248578 3.896846e+08 1.471106e+11 1965-01-09 13:32:50 11.938 126.427 Earthquake 15.0 NaN NaN 5.8 MW NaN NaN ... NaN NaN ISCGEM860890 ISCGEM ISCGEM ISCGEM Automatic -0.988605 3.882323e+08 1.471218e+11 """こんな感じのデータとなっていた。
2.3 World Map
地震の震源分布を確認する。
import matplotlib.pyplot as plt from mpl_toolkits.basemap import Basemap %matplotlib inline ti = "Map of Earthquake's epicenter duaring 1965-2016" fig = plt.figure(figsize=(18, 18), dpi=96) plt.rcParams["font.size"] = 24 m = Basemap(projection='robin', lat_0=0, lon_0=-170, resolution='c') m.drawcoastlines() m.fillcontinents(color='#606060', zorder = 1) for i in range(5,10,1): #print(i) tmp = earthquake[(earthquake["Magnitude"]>=i)&(earthquake["Magnitude"]<i+1)&(earthquake["Type"]=="Earthquake")] x, y = m(list(tmp.Longitude), list(tmp.Latitude)) points = m.plot(x, y, "o", label=f"Mag.: {i}.x", markersize=0.02*float(i)**3.2, alpha=0.55+0.1*float(i-5)) plt.title(f"{ti}", fontsize=22) plt.legend(bbox_to_anchor=(1.01, 1), loc='upper left', borderaxespad=0, fontsize=18) plt.savefig(OUTPUT_DIR+f'{ti}.png', bbox_inches='tight')
環太平洋造山帯に、地震が集中していることが明瞭である。
っていうか日本ヤバイ。2.4 Distribution of the Depth
震源の深さ分布を確認する。
ti = "Distribution of Earthquake's Depth" plt.figure(figsize=(20, 12), dpi=96) plt.rcParams["font.size"] = 24 for i in range(5,9,1): #print(i) tmp = earthquake[(earthquake["Magnitude"]>=i)&(earthquake["Magnitude"]<i+1)&(earthquake["Type"]=="Earthquake")] plt.hist(tmp["Depth"], bins=50, density=True, histtype='step', linewidth=2.5, label=f"Mag.: {i}.x") plt.legend(bbox_to_anchor=(1.02, 1), loc='upper left', borderaxespad=0, fontsize=18) plt.xlabel("Depth, km") plt.ylabel("Count of Earthquake (Normarized at Total surface=1)") plt.title(f"{ti}") plt.savefig(OUTPUT_DIR+f'{ti}.png', bbox_inches='tight')
大半の地震は、
- 深さ100㎞以下の表層部分に集中している
- 深さ550-650kmの領域にも、わずかながら発生している
ことがわかる。
このグラフだけからはわからないが、深さ550kmを超えるような地震はおそらくプレート境界型ではなく、大陸中央部の大陸地殻内部で発生した地震なのだろう。潮汐応力や海洋潮汐を起因とする地震の発生震度は、そのメカニズムからしておよそ最大70-80kmまでとなる。
以降、可視化の対象とするデータは、80km以浅のものを対象とすることにする。earthquake = earthquake[earthquake["Depth"]<80] earthquake = earthquake[earthquake["Type"]=="Earthquake"]3. Orbit calculation of the Moon and the Sun from the Earth
地球表層部における月からの潮汐応力は、以下の時に大きくなる
- 月―地球間の距離が近い時
- 起潮力は、距離の 3乗に反比例 するため
- 距離の影響が強いため、太陽の影響は月のおよそ45%
- 新月か満月の時
- 太陽と月からの万有引力が同じ方向となり、万有引力のベクトルが揃うため
- 満潮か干潮の前後
- 海面の高さ変化がが、地殻への荷重の変化となるため
そこで、取得した地震リストの各時刻に対して
- 月―地球間の距離
- 太陽―地球間の距離
- 震源地から見た太陽と月の位相角
- 震源地から見た月の方位と高度
を求めることにする。
3.1 Library
天体の位置計算に便利なライブラリであるAstoropyを使用する。
3.2 Eephemeris for Astronomical position calculation
天体の位置計算を行う際の天文暦として、JPL (Jet Propulsion Laboratory:米国ジェット推進研究所)が公開している天文暦のうち、最新のDE432sを使用する。DE432sは、DE432より短期間(1950-2050)である代わりに、ファイルサイズが小さく(~10MB)、扱いやすい。
3.3 Obtaining of Phase Angle between the Sun and the Moon
4. Data Visualization
5. Summay
地震の発生時刻における月と太陽の位置関係を調べた。
その結果、地球全体で見たときの大きな地震(M>5.5)で以下のようなことがわかった。
- 統計的な観点で、地震の発生トリガとして月(厳密には月軌道の特徴)は地震に強い関連がありそう
- 地球が月と太陽から受ける潮汐応力の変動に対応して、地震の発生件数が増減している
- 年周期(季節変動)は確認できなかった
さらに、以下のような傾向があることも分かった。
- 地震は、月の公転軌道上の近地点ないし遠地点の周辺で発生する
- 地震の発生日は、 満月ないし新月の日の周辺が多い
- 地震の発生時刻は、 月の出ないし月の入り周辺の時刻で多い
本来ならば、個々の地震の震源の特徴をもとに、本当に月潮汐に起因した地震かどうかの精査を行う必要がある。例えば、特定の震源を対象とした研究としてTanaka (2012)[4]や Ide et al. (2016)[5]といった研究がある。が、そこは本職の研究者に託し、ここでは世界の地震に対する統計的な傾向の話にとどめる。
5. Future Prospects
言われるまでもなく、日本は地震大国である。そのため、過去に地震を起因とする津波や火事などを含めて、大きな災害がたびたび発生した。そのため、地震予知に大きな関心を持ち、地震予知連絡会なる組織が政府主導で運営されている。
しかし、地震はその多くがプレート破壊型の地震で、間接的に同じプレートテクトニクスを起因とする断層型地震を含めると、全地震の大半を占める(出典元は失念)。
いずれにしても、両者はともに地球プレートの破壊活動で起こるもので、また一般的に破壊活動の将来予測は、そもそも物理学的に不可能である
(よほど特殊な条件下なら不可能ではないが、そうした特殊な条件が自然にそろうことはまずない)。したがって 「地震予知は原理的に不可能である」 が、最近は行政も防災ではなく減災に力点をシフトさせつつある。減災という観点ならば、天気予報のような感覚で発生確率を扱うことができれば、QOLの向上に寄与できる可能性もある(例えば、今週は大地震の確率が高いから、遠出は再来週にしよう、など)。
Future Work
ある程度の範囲の特定地域を対象に、同じような可視化をしてみたいと思う。
地域によっては、強く月の影響が表れるところもあるかもしれない。Reference
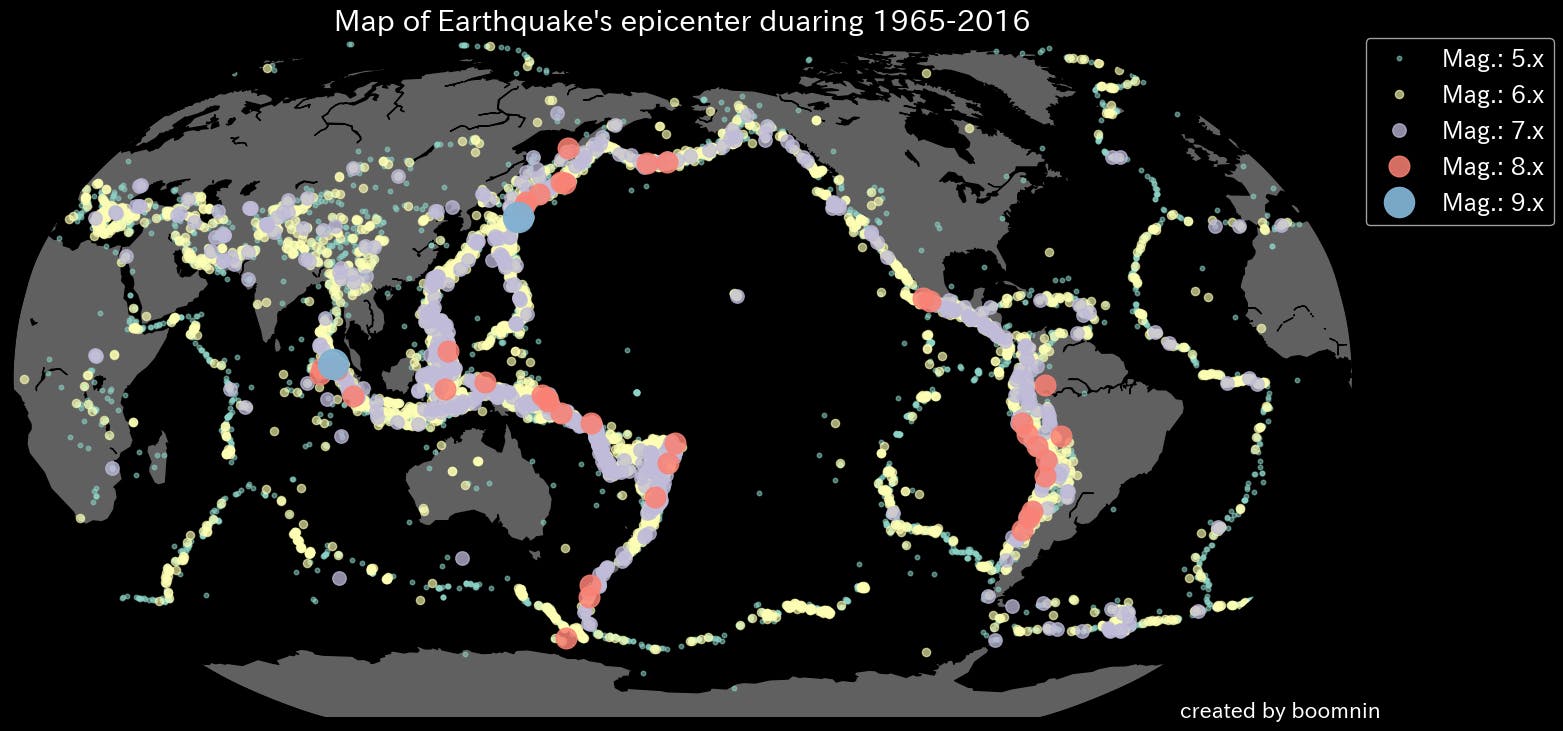
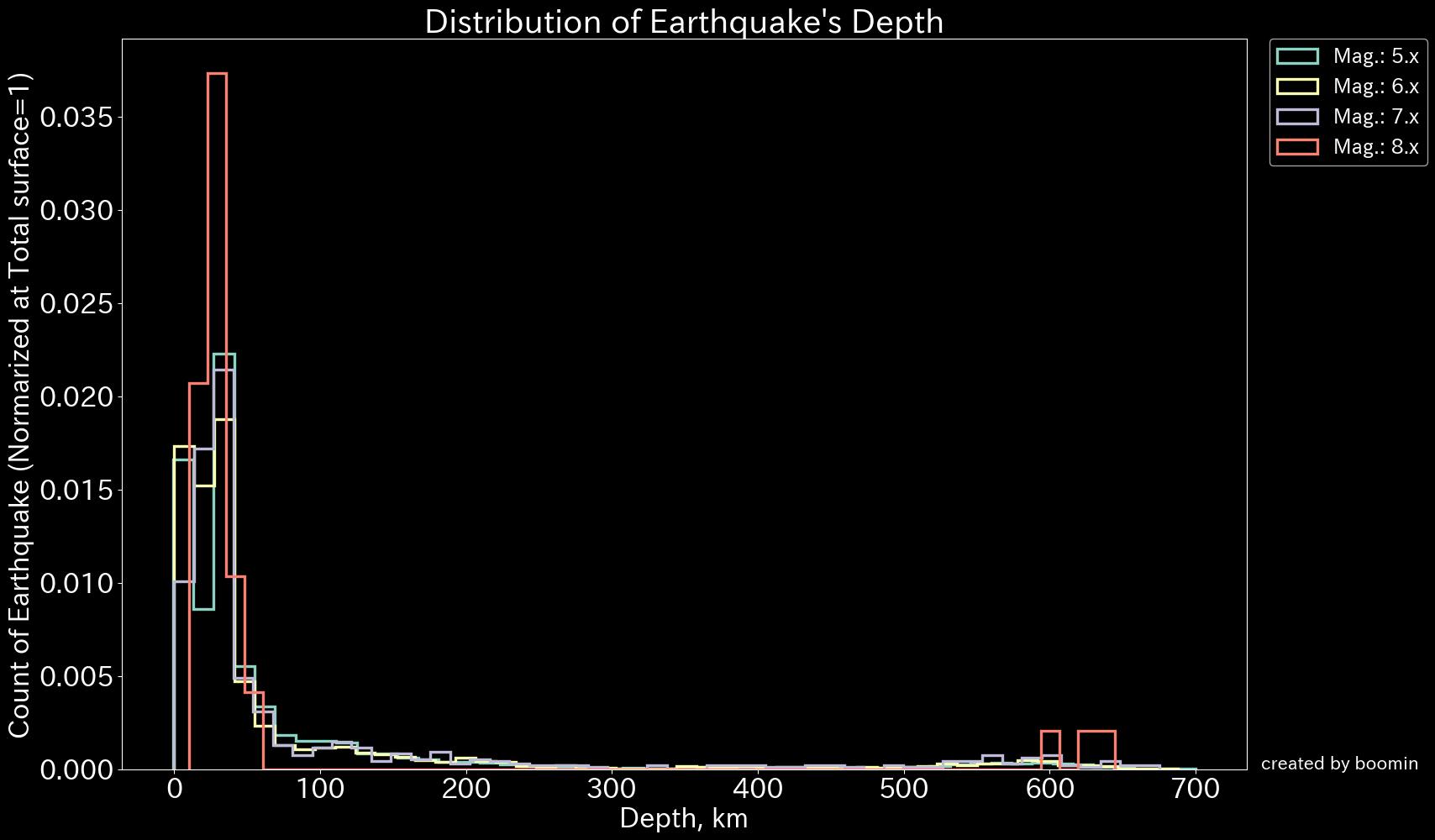
- 投稿日:2019-11-12T17:31:12+09:00
Pythonでテキストマイニング ~スクレイピング編~
仕事柄機械学習とかそのあたりを扱っていて、何となくテキストマイニングの方に興味がわいたので、取り組んでみた内容の備忘録として投稿します。
今回はスクレイピング編なんですが、最終的にはスクレイピングしたテキスト情報を解析していくなんてことを考えているので、そのあたりもまとまったら随時投稿していきます。実行環境
Python でスクレイピングを行おうと思ったら真っ先に思いついたのがrequests とBeautifulSoup だったので、今回はこの組み合わせでいこうと思います。
ちなみに私は普段はJSerなので、スクレイピング関係はよくpuppeteerを利用します。
まぁそれはいいとして、実際にスクレイピングを始めてみましょう。まずは動くか確認
pythonでコードを書くとき、もちろん直接「~.py」ファイルに書いて構いませんが、Jupyter Notebookを利用すると出力された結果が見やすいなど色々と便利な部分があるのでテスト程度ならJupyter Notebookを利用することをお勧めします。
特に今回は、Googleが提供しているGoogle Colaboratoryを使ってテストしてみます。ライブラリのインストールも不要で、Googleのアカウントだけあれば動かせます。Colaboratoryを開いて新規ノートブック作成
ウェブブラウザでColaboratoryを開いて、
「ファイル」>「Python3の新しいノートブック」から新しいノートブックを作成します。
もはや説明はいらないかと思いますが、中央のエリアにあるセルにコードを記述していきます。
ライブラリのインポート
importimport requests from bs4 import BeautifulSoupURLの指定
今回は私の職業柄、建築xコンピューテーションのポータルサイトであるArchiFuture Web のヘッドラインニュース 最新10行ニュースをスクレイピングしてみようと思います。
(ArchiFuture)urlを指定url = "http://www.archifuture-web.jp/headline/457.html"requestsを使ってページにアクセス
実際にページにアクセスできるか見てみましょう。ページにアクセスres = requests.get(url) resこれを実行すると、おそらく
レスポンス<Response [200]>が返ってくると思います。
HTTPレスポンスコードについて知りたい方はこちらをご参照ください。ページの中身を見たい場合は、
res.textレスポンス'<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">\n<html xmlns="http://www.w3.org/1999/xhtml" lang="ja" xml:lang="ja" dir="ltr" xmlns:og="http://ogp.me/ns#" xmlns:fb="http://www.facebook.com/2008/fbml">\n<head>\n<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />\n<meta http-equiv="Content-Style-Type" content="text/css" />\n<meta http-equiv="Content-Script-Type" content="text/javascript" />\n<!-- [if lt IE]><meta http-equiv="imagetoolbar" content="no" /><![endif] -->\n<title>「Archi Future 2019」が史上最高の来場者数を集めて盛況に開催|Headline(ヘッドライン)|建築 × コンピュテーションのポータルサイト\u3000Archi Future Web</title>\n<meta name="Description" content="建築 × コンピュテーションのポータルサイト「Archi Future Web」です。" />\n<meta name="keywords" content="建築,コンピュテーション,Archi Future">\n<meta property="og:site_name" content="建築 × コンピュテーションのポータルサイト\u3000Archi Future Web">\n<meta property="og:title" content="「Archi Future 2019」が史上最高の来場者数を集めて盛況に開催">\n<meta property="og:type" content="article">\n<meta property="og:description" content="第12回目となる「Archi Future 2019」が、先週の10月25日(金)に開催された。開催当日は、強烈な雨と風のあいにくの天候にも関わらず、来場者数は...">\n<meta property="og:url" content="http://www.archifuture-web.jp/headline/457.html" />\n<meta property="og:image" content="http://www.archifuture-web.jp/headline/img/4/c/4c57dc333a5c9d674ef327289a500800.jpg" />\n<meta property="og:image:width" content="700" />\n<meta property="og:image:height" content="467" />\n<meta property="og:locale" content="ja_JP">\n<link rel="stylesheet" type="text/css" href="../common/css/import.css" />\n<!-- [if lt IE 9]><link rel="stylesheet" type="text/css" href="../common/css/ie.css" /><![endif] -->\n<script type="text/javascript" src="../common/js/jquery.js"></script>\n<script type="text/javascript" src="../common/js/init.js"></script>\n<script type="text/javascript" src="../common/js/Nav.js"></script>\n</head>\n\n<body id="headline">\n<div id="container">\n<script type="text/javascript">header(\'../\');</script>\n<hr class="hide" />\n\n<h2><img src="img/title.jpg" width="960" height="60" alt="Headline(ヘッドライン)"/></h2>\n\n<div id="content">\n<div class="section">\n<div id="mainContent">\n\n<!--========\u3000SNS\u3000========-->\n<div id="sns" class="clearfix">\n<div class="facebook"><div id="fb-root"></div>\n<script>(function(d, s, id) {\n var js, fjs = d.getElementsByTagName(s)[0];\n if (d.getElementById(id)) return;\n js = d.createElement(s); js.id = id;\n js.src = "//connect.facebook.net/ja_JP/sdk.js#xfbml=1&appId=152808698121811&version=v2.0";\n fjs.parentNode.insertBefore(js, fjs);\n}(document, \'script\', \'facebook-jssdk\'));</script><div class="fb-share-button" data-href="http://www.archifuture-web.jp/headline/457.html" data-layout="button"></div></div>\n<div class="twitter"><a href="https://twitter.com/share" class="twitter-share-button" data-lang="ja" data-count="none">ツイート</a> <script>!function(d,s,id){var js,fjs=d.getElementsByTagName(s)[0],p=/^http:/.test(d.location)?\'http\':\'https\';if(!d.getElementById(id)){js=d.createElement(s);js.id=id;js.src=p+\'://platform.twitter.com/widgets.js\';fjs.parentNode.insertBefore(js,fjs);}}(document, \'script\', \'twitter-wjs\');</script></div>\n<!-- /#sns --></div>\n\n<!--========\u3000本文\u3000========-->\n\n<div class="page-title">\n<p><img src="img/icon_new.gif" width="112" height="20" alt="最新10行ニュース"/></p>\n<h2>「Archi Future 2019」が史上最高の来場者数を<br />\r\n集めて盛況に開催</h2>\n</div>\n<p class="page-data">2019.10.28</p>\n\n<p>第12回目となる「Archi Future 2019」が、先週の10月25日(金)に開催された。<br />\r\n開催当日は、強烈な雨と風のあいにくの天候にも関わらず<span style="font-size:12px;">、</span>来場者数は前回比で5.4%の増加の<br />\r\n5,509人となり、史上最高となる来場者数を集める盛況な開催となった。<br />\r\n米国の著名な設計事務所のDiller Scofidio + Renfroによる基調講演や、大手ゼネコンの現場所<br />\r\n長クラス5人によるパネルデ<span style="font-size:12px;">ィ</span>スカ<span style="font-size:12px;">ッ</span>シ<span style="font-size:12px;">ョ</span>ンは<span style="font-size:12px;">、</span>600席に拡大した会場が満席となり<span style="font-size:12px;">、</span>パネルデ<span style="font-size:12px;">ィ</span><br />\r\nスカッションは席をさらに100席増設するほどの盛況ぶりだ<span style="font-size:12px;">っ</span>た。講演会・セミナーはどの講座<br />\r\nもほぼ満席となり<span style="font-size:12px;">、</span>展示会場も大変多くの来場者が訪れ<span style="font-size:12px;">、</span>会場全体が大変活気に満ちた、大盛況<br />\r\nな開催となった。岡田氏と山梨氏の特別対談1、豊田氏と松島氏の特別対談2をはじめ、どの<br />\r\nセッシ<span style="font-size:12px;">ョ</span>ンも建築の新しい方向性と明るい未来を感じさせてくれる、充実した内容であった。<br />\r\nArchi Future 2019のレポートについては、今後、当サイトで紹介する予定だ。<br />\r\n<br />\r\n<a href="http://www.archifuture.jp/2019/" target="_blank"><p class="image al_center"><img src="./img/4/c/4c57dc333a5c9d674ef327289a500800.jpg" alt="\u3000「Archi Future 2019」オフィシャルサイトのトップページ" width="600" height="400" /></p><p class="caption">\u3000「Archi Future 2019」オフィシャルサイトのトップページ</p></a></p>\n\n<!--========\u3000ナビゲーション\u3000========-->\n<div id="page-navi" class="clearfix clr">\n<ul>\n<li class="go-top"><a href="../index.html"><span>></span> トップページに戻る</a></li>\n<li class="go-list"><a href="index.html"><span>></span> 記事一覧に戻る</a></li>\n</ul>\n</div>\n\n<!--========\u3000最新の記事\u3000========-->\n<div id="page-new" class="clr">\n<h2>最新の記事</h2>\n<ul class="list01">\n<li><a href="457.html" target="">「Archi Future 2019」が史上最高の来場者数を集めて盛況に開催<br />\n2019.10.28\u3000<img src="img/icon_new.gif" width="112" height="20" alt="最新10行ニュース"/></a></li>\n<li><a href="456.html" target="">過去最大のスケールでいよいよ明日25日にArchi Future 2019が開催<br />\n2019.10.24\u3000<img src="img/icon_new.gif" width="112" height="20" alt="最新10行ニュース"/></a></li>\n<li><a href="455.html" target="">今週の10月25日(金)に「Archi Future 2019」が開催<br />\n2019.10.21\u3000<img src="img/icon_new.gif" width="112" height="20" alt="最新10行ニュース"/></a></li>\n</ul>\n</div>\n\n<!--========\u3000プレミアムバナー\u3000========-->\n\r\n<div id="premiumbanner" class="al_center clr">\r\n<a href="http://www.archifuture.jp/2019/" class="premiumbanner-left banner" target="_blank" id="premium-24"><img src="../img_banner/premium/img/8/2/8280d8bb17d4c09e872441a1ba21eae0.png" width="270" height="180" alt="Archi Future 2019"/></a>\r\n<a href="http://www.archifuture.jp/2019/" class="premiumbanner-right banner" target="_blank" id="premium-25"><img src="../img_banner/premium/img/6/a/6ad8af52988f0560acbb6c08377d79f3.png" width="270" height="180" alt="Archi Future 2019"/></a>\r\n</div>\r\n\n\n<!--========\u3000レクタングルスーパーバナー\u3000========-->\n\r\n<p id="superbanner" class="al_center"><a href="http://www.archifuture.jp/2019/" class="banner" id="super-14"><img src="../img_banner/super/img/9/9/99ae81e84701bf687561a0ca026bdef0.png" width="600" height="90" alt="Archi Future 2019"/></a></p>\r\n\n\n<!-- /#mainContent --></div>\n\n<div id="sidebar">\n<!--========\u3000広告バナー\u3000========-->\n\r\n<ul id="banner" class="clr">\r\n<li><a href="https://www.cradle.co.jp/" target="_blank" class="banner" id="default-5"><img src="../img_banner/default/img/2/f/2f1b60f601b0f99e6094e32d7fd0b26d.gif" width="270" height="80" alt="ソフトウェアクレイドル"/></a></li>\r\n<li><a href="https://product.metamoji.com/gemba/eyacho/" target="_blank" class="banner" id="default-24"><img src="../img_banner/default/img/2/8/280e8426c1fb78ee0e67b2d009d7c9d2.gif" width="270" height="80" alt="MetaMoJi様"/></a></li>\r\n<li><a href="https://www.izumi-soft.jp/product-category/bim-%E7%A9%BA%E8%AA%BF%E8%A8%AD%E5%82%99%E8%A8%AD%E8%A8%88/" target="_blank" class="banner" id="default-16"><img src="../img_banner/default/img/1/8/18ef602ddf1e9f1e3c5f00a7674725a2.gif" width="270" height="80" alt="イズミシステム設計様"/></a></li>\r\n<li><a href="http://www.nyk-systems.co.jp/" target="_blank" class="banner" id="default-6"><img src="../img_banner/default/img/3/b/3b747d65472ce7be37b8235fc703432d.gif" width="270" height="80" alt="NYKシステムズ様"/></a></li>\r\n<li><a href="http://www.pivot.co.jp/" target="_blank" class="banner" id="default-12"><img src="../img_banner/default/img/6/d/6d10409aeb0b2d23bd73b9ccc70cc08d.gif" width="270" height="80" alt="建築ピボット様"/></a></li>\r\n<li><a href="http://www.applicraft.com/" target="_blank" class="banner" id="default-20"><img src="../img_banner/default/img/9/0/90cc824aac1eda2ba2c37046e55dd79c.gif" width="270" height="80" alt="アプリクラフト様"/></a></li>\r\n<li><a href="http://bit.ly/2Bw8tEc" target="_blank" class="banner" id="default-3"><img src="../img_banner/default/img/7/d/7dbe65f17a1bf153277ba5b466580556.jpg" width="270" height="80" alt="グラフィソフトジャパン様"/></a></li>\r\n<li><a href="https://autode.sk/2TXDSqE" target="_blank" class="banner" id="default-11"><img src="../img_banner/default/img/e/c/ecb06a6b95c9e79935b6a7df88384ab3.jpg" width="270" height="80" alt="オートデスク様"/></a></li>\r\n<li><a href="https://licensecounter.jp/aec-collection-bim/" target="_blank" class="banner" id="default-22"><img src="../img_banner/default/img/1/0/10bcd30f085e6ce4dab4b824c64817a6.gif" width="270" height="80" alt="SB C&S様"/></a></li>\r\n<li><a href="https://www.nvidia.com/ja-jp/design-visualization/industries/architecture-engineering-construction/?nvid=nv-int-pcjp12rrdsfrqr-44523" target="_blank" class="banner" id="default-21"><img src="../img_banner/default/img/d/5/d53b3fe7fec2bc10858a26f88556c8fb.jpg" width="270" height="80" alt="エヌビディア様"/></a></li>\r\n<li><a href=" https://www.aanda.co.jp/Vectorworks2019/index.html?utm_source=af&utm_medium=banner&utm_campaign=bnr_20190921" target="_blank" class="banner" id="default-9"><img src="../img_banner/default/img/7/2/72745a704c3abe2513357559102be116.jpg" width="270" height="80" alt="エーアンドエー様"/></a></li>\r\n<li><a href="http://j-bim.gloobe.jp/" target="_blank" class="banner" id="default-4"><img src="../img_banner/default/img/a/9/a9f022f44cac2878ac5936fcf4b26175.gif" width="270" height="80" alt="福井コンピュータアーキテクト様"/></a></li>\r\n<li><a href="http://www.env-simulation.com" target="_blank" class="banner" id="default-18"><img src="../img_banner/default/img/e/3/e3d7f1694a53705271dc5e751519d0d8.gif" width="270" height="80" alt="環境シミュレーション様"/></a></li>\r\n<li><a href="http://www.f-cadewa.com/" target="_blank" class="banner" id="default-8"><img src="../img_banner/default/img/f/0/f0a5e6fe83e322a2d62a2461855a6c2a.gif" width="270" height="80" alt="富士通四国インフォテック様"/></a></li>\r\n<li><a href="https://www.photoruction.com/?utm_source=afw&utm_medium=banner&utm_campaign=201903" target="_blank" class="banner" id="default-23"><img src="../img_banner/default/img/2/8/28dba36bb5e98ff9a4514ae00e93844b.png" width="270" height="80" alt="フォトラクション様"/></a></li>\r\n</ul>\r\n<script type="text/javascript">\r\n<!--\r\nvar top_url = \'/\';\r\n//-->\r\n</script>\r\n<script type="text/javascript" src="../common/js/banner_track.js"></script>\r\n\n\n<!-- /#sidebar --></div>\n<!-- /#section --></div>\n<!-- /#content --></div>\n\n<script type="text/javascript">footer(\'../\');</script>\n\n<!-- /#container --></div>\n</body>\n</html>'ただしこれだと、テキストデータとしてぎっしり詰まったHTMLが返ってきて、何が何やらいまいちわかりません。
そこでBeautifulSoupを利用して、HTMLをパースしてあげましょう。BeautifulSoupを使う
htmlのパースsoup = BeautifulSoup(res.text, 'html.parser') soupこちらの結果を見てみましょう
レスポンス<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html dir="ltr" lang="ja" xml:lang="ja" xmlns="http://www.w3.org/1999/xhtml" xmlns:fb="http://www.facebook.com/2008/fbml" xmlns:og="http://ogp.me/ns#"> ---(省略)--- <!--======== 本文 ========--> <div class="page-title"> <p><img alt="最新10行ニュース" height="20" src="img/icon_new.gif" width="112"/></p> <h2>「Archi Future 2019」が史上最高の来場者数を<br/> 集めて盛況に開催</h2> </div> <p class="page-data">2019.10.28</p> <p>第12回目となる「Archi Future 2019」が、先週の10月25日(金)に開催された。<br/> 開催当日は、強烈な雨と風のあいにくの天候にも関わらず<span style="font-size:12px;">、</span>来場者数は前回比で5.4%の増加の<br/> 5,509人となり、史上最高となる来場者数を集める盛況な開催となった。<br/> 米国の著名な設計事務所のDiller Scofidio + Renfroによる基調講演や、大手ゼネコンの現場所<br/> 長クラス5人によるパネルデ<span style="font-size:12px;">ィ</span>スカ<span style="font-size:12px;">ッ</span>シ<span style="font-size:12px;">ョ</span>ンは<span style="font-size:12px;">、</span>600席に拡大した会場が満席となり<span style="font-size:12px;">、</span>パネルデ<span style="font-size:12px;">ィ</span><br/> スカッションは席をさらに100席増設するほどの盛況ぶりだ<span style="font-size:12px;">っ</span>た。講演会・セミナーはどの講座<br/> もほぼ満席となり<span style="font-size:12px;">、</span>展示会場も大変多くの来場者が訪れ<span style="font-size:12px;">、</span>会場全体が大変活気に満ちた、大盛況<br/> な開催となった。岡田氏と山梨氏の特別対談1、豊田氏と松島氏の特別対談2をはじめ、どの<br/> セッシ<span style="font-size:12px;">ョ</span>ンも建築の新しい方向性と明るい未来を感じさせてくれる、充実した内容であった。<br/> Archi Future 2019のレポートについては、今後、当サイトで紹介する予定だ。<br/> <br/> <a href="http://www.archifuture.jp/2019/" target="_blank"><p class="image al_center"><img alt=" 「Archi Future 2019」オフィシャルサイトのトップページ" height="400" src="./img/4/c/4c57dc333a5c9d674ef327289a500800.jpg" width="600"/></p><p class="caption"> 「Archi Future 2019」オフィシャルサイトのトップページ</p></a></p> ---(省略)--- </html>いい具合にhtmlを解析して表示してくれています。
取りたい情報にありつく
それではいよいよ本題ですね。
今回は10行記事の内容を取得したいので、まずは記事本文がどこにあるかを探しましょう。
書かれている内容と照らし合わせて見つけても構いませんが、Web系ならここはディベロッパーツールを使って探しましょう。
こんな感じですね。
(うむむ……idもクラスも振られていないなぁ……)idやクラスが振られている場合は、cssセレクターを利用して指定すれば簡単に取れるのですが、今回は特にそういったものはないので記事が書かれているpタグをすべて取得することにします。
pタグを取得p_tags = soup.select('p') p_tagspタグの取得結果[<p><img alt="最新10行ニュース" height="20" src="img/icon_new.gif" width="112"/></p>, <p class="page-data">2019.10.28</p>, <p>第12回目となる「Archi Future 2019」が、先週の10月25日(金)に開催された。<br/> 開催当日は、強烈な雨と風のあいにくの天候にも関わらず<span style="font-size:12px;">、</span>来場者数は前回比で5.4%の増加の<br/> 5,509人となり、史上最高となる来場者数を集める盛況な開催となった。<br/> 米国の著名な設計事務所のDiller Scofidio + Renfroによる基調講演や、大手ゼネコンの現場所<br/> 長クラス5人によるパネルデ<span style="font-size:12px;">ィ</span>スカ<span style="font-size:12px;">ッ</span>シ<span style="font-size:12px;">ョ</span>ンは<span style="font-size:12px;">、</span>600席に拡大した会場が満席となり<span style="font-size:12px;">、</span>パネルデ<span style="font-size:12px;">ィ</span><br/> スカッションは席をさらに100席増設するほどの盛況ぶりだ<span style="font-size:12px;">っ</span>た。講演会・セミナーはどの講座<br/> もほぼ満席となり<span style="font-size:12px;">、</span>展示会場も大変多くの来場者が訪れ<span style="font-size:12px;">、</span>会場全体が大変活気に満ちた、大盛況<br/> な開催となった。岡田氏と山梨氏の特別対談1、豊田氏と松島氏の特別対談2をはじめ、どの<br/> セッシ<span style="font-size:12px;">ョ</span>ンも建築の新しい方向性と明るい未来を感じさせてくれる、充実した内容であった。<br/> Archi Future 2019のレポートについては、今後、当サイトで紹介する予定だ。<br/> <br/> <a href="http://www.archifuture.jp/2019/" target="_blank"><p class="image al_center"><img alt=" 「Archi Future 2019」オフィシャルサイトのトップページ" height="400" src="./img/4/c/4c57dc333a5c9d674ef327289a500800.jpg" width="600"/></p><p class="caption"> 「Archi Future 2019」オフィシャルサイトのトップページ</p></a></p>, <p class="image al_center"><img alt=" 「Archi Future 2019」オフィシャルサイトのトップページ" height="400" src="./img/4/c/4c57dc333a5c9d674ef327289a500800.jpg" width="600"/></p>, <p class="caption"> 「Archi Future 2019」オフィシャルサイトのトップページ</p>, <p class="al_center" id="superbanner"><a class="banner" href="http://www.archifuture.jp/2019/" id="super-14"><img alt="Archi Future 2019" height="90" src="../img_banner/super/img/9/9/99ae81e84701bf687561a0ca026bdef0.png" width="600"/></a></p>]どうやらpタグの中では2番目(0から数えて)にあるようですので、この中から2番目の要素のテキストを抽出していきます。
記事の取得article = p_tags[2].get_text() atricle記事取得結果'第12回目となる「Archi Future 2019」が、先週の10月25日(金)に開催された。\r\n開催当日は、強烈な雨と風のあいにくの天候にも関わらず、来場者数は前回比で5.4%の増加の\r\n5,509人となり、史上最高となる来場者数を集める盛況な開催となった。\r\n米国の著名な設計事務所のDiller Scofidio + Renfroによる基調講演や、大手ゼネコンの現場所\r\n長クラス5人によるパネルディスカッションは、600席に拡大した会場が満席となり、パネルディ\r\nスカッションは席をさらに100席増設するほどの盛況ぶりだった。講演会・セミナーはどの講座\r\nもほぼ満席となり、展示会場も大変多くの来場者が訪れ、会場全体が大変活気に満ちた、大盛況\r\nな開催となった。岡田氏と山梨氏の特別対談1、豊田氏と松島氏の特別対談2をはじめ、どの\r\nセッションも建築の新しい方向性と明るい未来を感じさせてくれる、充実した内容であった。\r\nArchi Future 2019のレポートについては、今後、当サイトで紹介する予定だ。\n\n\u3000「Archi Future 2019」オフィシャルサイトのトップページ'近づいてきましたね。
ということで、不要な改行コードたちは消しちゃいましょう。記事のテキストのみ抽出lines = [line.strip() for line in text.splitlines()] # タグを排して文字だけ取得 ten_lines_news = lines[0:10] # 不要部分の削除 ten_lines_news10行ニュースの中身['第12回目となる「Archi Future 2019」が、先週の10月25日(金)に開催された。', '開催当日は、強烈な雨と風のあいにくの天候にも関わらず、来場者数は前回比で5.4%の増加の', '5,509人となり、史上最高となる来場者数を集める盛況な開催となった。', '米国の著名な設計事務所のDiller Scofidio + Renfroによる基調講演や、大手ゼネコンの現場所', '長クラス5人によるパネルディスカッションは、600席に拡大した会場が満席となり、パネルディ', 'スカッションは席をさらに100席増設するほどの盛況ぶりだった。講演会・セミナーはどの講座', 'もほぼ満席となり、展示会場も大変多くの来場者が訪れ、会場全体が大変活気に満ちた、大盛況', 'な開催となった。岡田氏と山梨氏の特別対談1、豊田氏と松島氏の特別対談2をはじめ、どの', 'セッションも建築の新しい方向性と明るい未来を感じさせてくれる、充実した内容であった。', 'Archi Future 2019のレポートについては、今後、当サイトで紹介する予定だ。']うまく取れましたね。
配列の個数が10個ってところが興奮ポイントですね。最後に、1行のテキストにまとめます。
1つのテキストにten_lines_news_text = "" for line in ten_lines_news: ten_lines_news_text += line ten_lines_news_text記事の周辺情報も拾っておく
スクレイピングの醍醐味はたくさんの情報を一気にとってくることですよね。
そうなったとき、現状では取得してきた情報を識別することができません。今回は2段構えとして、記事が投稿された日付と、記事のURLに割り当てられている番号を取得して記事IDとしようと思います。
先ほどpタグを一括取得したときに出てきたデータを見るとわかる通り、日付の部分にはクラスが割り当てられています。
これを利用して今度は日付を取得しておきましょう。投稿日の取得date = soup.select('.page-data')[0].string date取得結果'2019.10.28'あとは記事のidですが、記事ページのURL
"http://www.archifuture-web.jp/headline/457.html"
のhtmlファイルの名前の部分を利用するようにしておきます。
(今回は面倒だから一旦直書きでIDをつけておきましょう)記事のIDid = 457処理の関数化
ここまでで作成した処理を一旦関数にしましょう。
- ページにアクセス
- htmlのパース
- pタグを取得
- 記事の取得
- 記事のテキストのみ抽出
- 1つのテキストに
の4つの処理を一つの関数にまとめ、URLを入れたら10行記事のテキストを返すように作成します。
処理の関数化def get_article(url): res = requests(url) soup = BeautifulSoup(res.text, ‘html.parser’) # 記事の取得 p_tags = soup.select(‘p’) article = p_tags[2].get_text() lines = [line.strip() for line in text.splitlines()] # タグを排して文字だけ取得 ten_lines_news = lines[0:10] # 不要部分の削除 # 一つのテキストデータに格納 ten_lines_news_text = "" for line in ten_lines_news: ten_lines_news_text += line date = soup.select('.page-data')[0].string # 投稿日時 id = 457 # 記事のID return ten_lines_news_textこれがpythonスクリプトファイル(.py)で実行可能かを確認し、実行できたら以降のステップはpythonスクリプトファイル内に記載していきましょう。
CSVファイルに保存してみる
取得した情報を取得しっぱなしではもったいないので、csvファイルに書き込んでみましょう。
pythonでcsvデータを扱うライブラリはいくつかありますが、今回はpandasを使います。
行と列のデータを扱う時に非常に便利なので、個人的に気に入っているライブラリです。先に書き込み先のcsvファイルを準備しておきましょう(今回はtxt_data.csvの名前で作成)。
arricles.csvとかの方がしっくりきたな……txt_data.csvid,date,textpandasを利用してファイルの読み書きを行います。
csvへの書き込みcsv_file = 'csv/txt_data.csv' df = pd.read_csv(csv_file) text = value results = pd.DataFrame([id, date, text], columns=['id', 'date', 'text']) df = pd.concat([df, results]) df.to_csv(csv_file, index=False) print("success writing to %s" % csv_file)書き込み完了後のcsvデータid,date,text 457,2019.10.28,第12回目となる「Archi Future 2019」が、先週の10月25日(金)に開催された。開催当日は、強烈な雨と風のあいにくの天候にも関わらず、来場者数は前回比で5.4%の増加の5,509人となり、史上最高となる来場者数を集める盛況な開催となった。米国の著名な設計事務所のDiller Scofidio + Renfroによる基調講演や、大手ゼネコンの現場所長クラス5人によるパネルディスカッションは、600席に拡大した会場が満席となり、パネルディスカッションは席をさらに100席増設するほどの盛況ぶりだった。講演会・セミナーはどの講座もほぼ満席となり、展示会場も大変多くの来場者が訪れ、会場全体が大変活気に満ちた、大盛況な開催となった。岡田氏と山梨氏の特別対談1、豊田氏と松島氏の特別対談2をはじめ、どのセッションも建築の新しい方向性と明るい未来を感じさせてくれる、充実した内容であった。Archi Future 2019のレポートについては、今後、当サイトで紹介する予定だ。これで取得した情報をcsvデータとして保存することができました。
次回は、これまでに投稿された記事を全て取りに行って、そのテキストデータを保存する仕組みの作成を解説します。参考
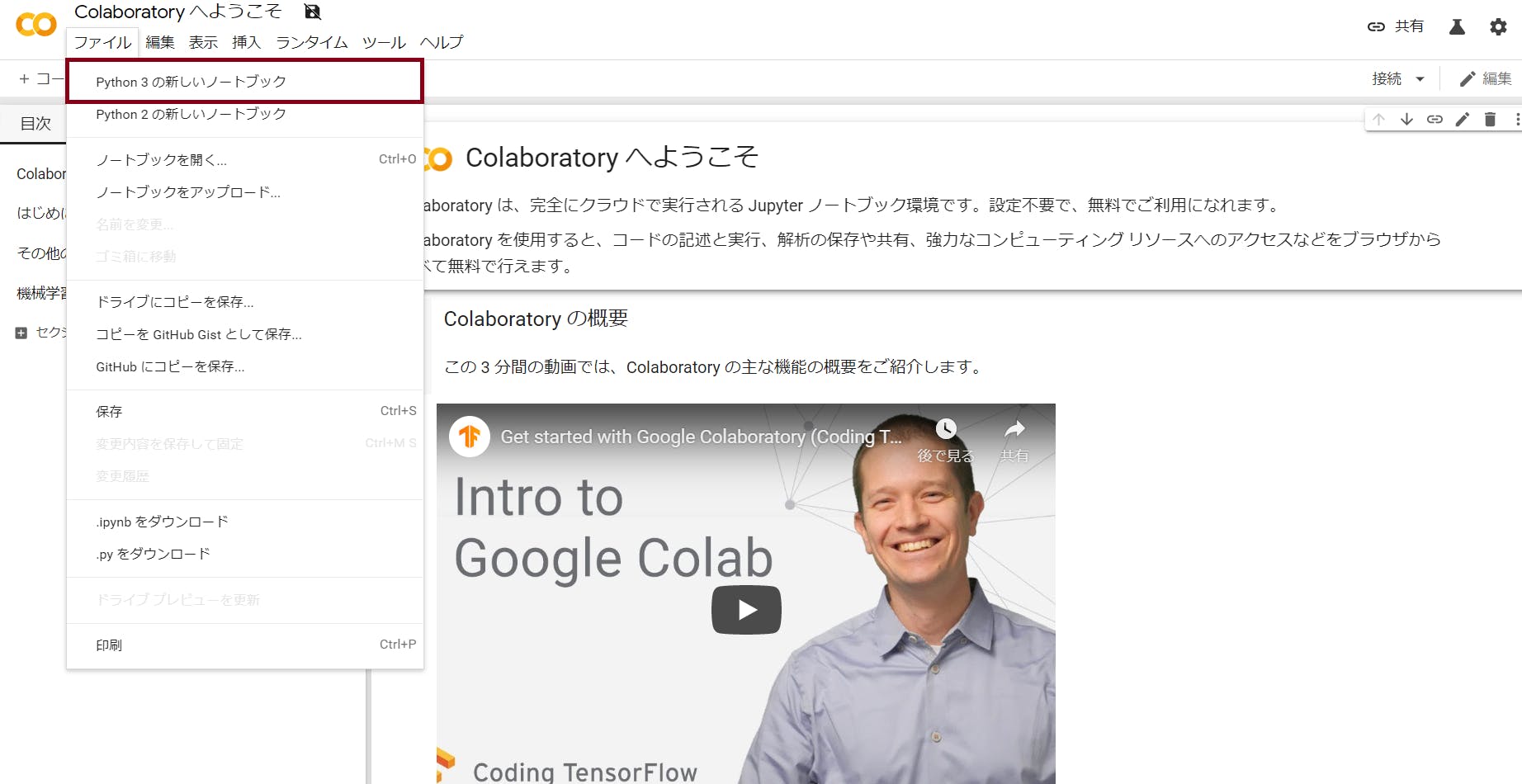

- 投稿日:2019-11-12T17:27:24+09:00
pypyodbcを使って手っ取り早くAS/400からデータを取得してみた
永らく(3か月くらい) IBM client solution の「SQL scriptの実行」を使ってSQLの発行・データ取得を行っていましたが、データ件数が5000件を超えたあたりから、全件取得するために延々スクロールさせるのが面倒になってきたので、PythonとODBCを利用して一括取得の実験をしてみました。
実験コードですので、エラーチェックや出力結果のフォーマットは度外視しています。
実験環境
PC環境
- Windows10
- python 3.8
- pypyodbc 1.3.4
- IBM i Access Client Solutions 1.1.0 (ODBCドライバ)
接続先環境
- AS400 V7R3
準備
Pythonの取得
python.org から最新安定板を取得してインストールします。
インストール後、"python.exe"のあるフォルダにパスを通しておきます。pypyodbcの取得
なぜ、一般的なpyodbcではなく、pypyodbcにしたかといえば、pipでのインストールに失敗したからです。IBM推奨の ibm_db も試してみましたが、両者共にMicrosoft Visual C++14 を要求された為、今回はパスです。
python添付の"pip"を使用してインストールします。
pip install pypyodbcIBM i Access Client Solutions の取得
数か月前に設定しましたので、内容はうろ覚えです。
https://www.ibm.com/support/pages/ibm-i-access-client-solutions にアクセスします。
"Downloads for IBM i Access Client Solutions"と書かれたリンクを辿ります。途中でIBM ID の認証を求められますので、IDのある方は入力、無ければ新規登録(無償)します。
"ACS Windows App Pkg English (64bit)" をクリックしてダウンロードします。インストーラ形式になっていますので、インストーラの手順に従ってインストールします。
テストコード
odbctest.pyimport pypyodbc # 接続情報取得 config = {} with open("connection_config.txt", 'r', encoding="utf-8") as conf: for line in conf.read().splitlines(): key_, val_ = line.replace(" ", "").split("=") config[ key_ ] = val_ # DB接続 connection = pypyodbc.connect( driver='{iSeries Access ODBC Driver}', system = config["system"], uid = config["uid"], pwd = config["pwd"] ) cur = connection.cursor() # SQL実行 statement = open("statement.sql", 'r', encoding="utf-8").read() cur.execute( statement ) for row in cur: print( row )ソースは大きく3パートに分かれています。
「接続情報取得」ではデータベースへの接続情報を外部ファイルから取り込んで、辞書に保管しています。外部ファイル "connection_config.txt"は以下のようになっています。
connection_config.txtsystem = xxx.xxx.xxx.xxx uid = USER pwd = PASWORD「DB接続」では読み込んだ接続情報を使用してデータベースへの接続を試み、カーソルを取得します。
「SQL実行」では、外部ファイルに書き込んだSQLを読み込んで、カーソルの execute()に渡してSQLを発行します。
その下の for ループで1行ごとにprint()関数に投げ込んで標準出力に書き込みます。実行結果
statement.sqlselect * from QSYS2.LIBLISTstatement.sqlに上記のSQLを記述して実行してみましょう。
>python testodbc.py (1, 'QSYS', 'QSYS', 'SYSTEM', 0, '\x0eäýäþämäwäáäÝäbäJäÝäÞäì\x0f') (2, 'QSYS2', 'QSYS2', 'SYSTEM', 0, 'CPI\x0eá¶àªäýäþämäwäáäÝäbäJäÝäÞäì\x0f') (3, 'QHLPSYS', 'QHLPSYS', 'SYSTEM', 0, None) (4, 'QUSRSYS', 'QUSRSYS', 'SYSTEM', 0, 'Sモヘホオテ Lケイネアネモ カナネ Uヘオネヘ') (5, 'QIWS', 'QIWS', 'PRODUCT', 0, None) (6, 'QGPL', 'QGPL', 'USER', 0, 'GENERAL PURPOSE LIBRARY') (7, 'QTEMP', 'QTEMP', 'USER', 0, None)文字化けは仕様です...。
いくつかのIBM提供オブジェクトのラベルはうまく変換してくれないようですが、普通に作ったテーブルでしたら、SQLを使用してようが、AS/400固有の機能を使用していようが、日本語も問題なく読める文字に変換してくれます。ファイルにリダイレクトすれば、何万件の結果があろうと数秒から数十秒で終わるはずです。
サーバの性能にもよりますが、試しに、15カラム × 10000件、計算量やや多めのSQLを実行してみると、5秒程度で書込み完了しました(出力ファイルサイズ 1MB)。これで、全結果セットの取得の為に、延々ページダウンキーを押し続ける苦行から解放されます。
- 投稿日:2019-11-12T16:57:18+09:00
JSONとは何ぞ?。[メモ]
はじめに
pythonを学んでいたところjson.dumps()などでてきたが、まずJSONって何?となり調べてみました。
以下、JSONについて分かったことです。
参考記事
非エンジニアでもわかるjson形式のスクリプトを徹底解剖!【Python】JSONデータの使い方(jsonモジュール)
結論
JSONとは、JavaScriptに使われている
データ記載フォーマットの1つ。JSON(JavaScript Object Notation)
まず、JavaScriptとはプログラミング言語の1つ。
主にウェブブラウザ上で使われ、動作が軽く実行速度が速いことが特徴。
JSONが広く使われる理由
● JavaScript 以外のプログラム言語でも読み取れ、とても扱いやすい形式。
●データ量が少なく通信がスムーズに行うことができる。
●何がどのデータなのかわかりやすく判読性が高い。
どのように使われているのか?
●JavaScriptが使われているところ
●扱う文字や読みやすさを優先しているところ
おわり
pythonでは形式を読み取ったり書き出したり変換すれば問題ないかな
修正
プログラミング→プログラミング言語
- 投稿日:2019-11-12T16:50:18+09:00
自作ロボット(ローバー)のROS対応
はじめに
ROS(Robot Operating System)というものが著者の周りで流行っている。ROSとは簡単に言うとロボット開発を支援するためのミドルウェアみたいなものである。
これを使うことで1から自分でプログラムを書く手間を省くことが出来るため、「専門知識はないけど自動運転の車を作ることが出来ました!」ということが可能となる。
さらにシュミレータ上での動作確認も容易になり、実機を用いずに手軽に動作確認をすることもできるようになる。
問題点
「ROS入門」みたいにPub・Sub通信から丁寧に教えてくれる記事や書籍はたくさんある。
しかし多くの人のゴールは「ROSを学ぶこと」ではなく、「ROSを使って〇〇の機能を実現したい」ではなかろうか?
先行研究を調べることが大事だと2年間大学院に通って理解はしている。
しかし、「理論の大枠を掴むためにとりあえず動かしてみよう」ということも、難しいことを学ぼうとする初学者のモチベーション継続に大事だと考える。
そこで本記事では自作ロボットを動かすために必要な環境構築に重点を置き、ソースの説明を極力省いている。
自作ロボットにはNexus robotが開発した3WD48mmオムニホイールモバイルロボット(以下、ローバー)を使用している。
本記事を読むことのメリット
「ROSを用いてロボットを動かしてみた」と言える
実機を持っていなくてもシュミレーションまでは出来るため、
ROSで何ができるかを体験できるオムニホイール3輪機構をもつロボットなら自分のロボットでも
動かしてみることが可能準備物
Ubuntu 16.04
ローバー(なくても第1章はできる)
各記事へのリンクまとめ
ROSを用いたローバー制御(シュミレーター編)
※作成中Arduinoを用いたローバー制御(実機編)
※作成中ROS + Arduinoでのローバー制御
※作成中おわりに
著者は読書が好きだ。
将来自分の学んだことを文章にする仕事でもしたいと考えているので、
練習がてら大学院生の暇な時間を使ってこの記事を書いている。誰かに読んでもらい、役に立てたら幸いである。

- 投稿日:2019-11-12T16:26:11+09:00
東京大学大学院情報理工学系研究科 創造情報学専攻 2018年度夏 プログラミング試験
2018年度夏の院試の解答例です
※記載の内容は筆者が個人的に解いたものであり、正答を保証するものではなく、また東京大学及び本試験内容の提供に関わる組織とは無関係です。出題テーマ
- 画像圧縮
- byteファイル書き出し
問題文
※ 東京大学側から指摘があった場合は問題文を削除いたします。
配布ファイル
※ 公開されていないので以下は筆者が適当に作ったものです
image1.txt
19 7 0 17 13 1 29 3 27 5 11 23 0 0 0 255 255 255 19 7 0 255 255 255 29 3 27 5 11 23 0 0 0 255 255 255 19 7 0 17 13 1 255 255 255 5 11 23 0 0 0 255 255 255 19 7 0 17 13 1 29 3 27 255 255 255 0 0 0 255 255 255 19 7 0 17 13 1 29 3 27 255 255 255 0 0 0 255 255 255 1 1 1 10 10 10 100 100 100 50 80 46 96 71 1 255 255 255(1)
# (1) file_path = 'image1.txt' def solve(file_path): with open(file_path, mode='r') as f: ret = [] lines = f.readlines() for line in lines: ret.extend(line.rstrip('\n').split(' ')) print(int(len(ret) / 3))(2)
import sys sys.path.append('..') import IsStrNumber as isn from Divisors import divisors file_path = 'image1.txt' def is_white(cell): total = 0 for c in cell: total += c return total == (255 * 3) def solve(file_path): array = [] cells = [] with open(file_path, mode='r') as f: lines = f.readlines() for line in lines: array.extend(line.rstrip('\n').split(' ')) for i in range(0, int(len(array) / 3)): idx = i * 3 cell = [isn.STRtoNumber(array[idx]), isn.STRtoNumber(array[idx+1]), isn.STRtoNumber(array[idx+2])] cells.append(cell) cell_num = len(cells) divs = divisors(cell_num) width = 0 for div in divs: if (width != 0): break col_num = div row_num = int(cell_num / div) for i in range(0, row_num): right_end_cell = cells[i * col_num + col_num - 1] if (not is_white(right_end_cell)): break if (i == row_num - 1): width = col_num print(width)(4)
import sys sys.path.append('..') import IsStrNumber as isn import numpy as np file_path = 'image1.txt' def is_white(cell): total = 0 for c in cell: total += c return total == (255 * 3) def light_degree(cell): ret = 0 for c in cell: ret += c**2 return ret def solve(file_path): array = [] cells = [] with open(file_path, mode='r') as f: lines = f.readlines() for line in lines: array.extend(line.rstrip('\n').split(' ')) for i in range(0, int(len(array) / 3)): idx = i * 3 cell = [isn.STRtoNumber(array[idx]), isn.STRtoNumber(array[idx+1]), isn.STRtoNumber(array[idx+2])] cells.append(cell) cell_num = len(cells) divs = divisors(cell_num) cell_order = np.array(range(0, cell_num)) def cmp(order): cell = cells[order] return light_degree(cell) sorted_cell_order = sorted(cell_order, key=cmp) cell_idx = sorted_cell_order[int(cell_num / 2)] print('index: {0}, {1}'.format(cell_idx, cells[cell_idx]))(4)
import sys sys.path.append('..') import IsStrNumber as isn import numpy as np file_path = 'image1.txt' def is_white(cell): total = 0 for c in cell: total += c return total == (255 * 3) def light_degree(cell): ret = 0 for c in cell: ret += c**2 return ret def solve(file_path, k): array = [] cells = [] with open(file_path, mode='r') as f: lines = f.readlines() for line in lines: array.extend(line.rstrip('\n').split(' ')) for i in range(0, int(len(array) / 3)): idx = i * 3 cell = [isn.STRtoNumber(array[idx]), isn.STRtoNumber(array[idx+1]), isn.STRtoNumber(array[idx+2])] cells.append(cell) cell_num = len(cells) cell_order = np.array(range(0, cell_num)) def cmp(order): cell = cells[order] return light_degree(cell) sorted_cell_order = sorted(cell_order, key=cmp) def pr(index): print('index: {0}, {1}'.format(index, cells[index])) for i in range(0, k): idx = int(cell_num * i / k) cell_idx = sorted_cell_order[idx] pr(cell_idx)(5)
import sys sys.path.append('..') import IsStrNumber as isn import numpy as np file_path = 'image1.txt' def is_white(cell): total = 0 for c in cell: total += c return total == (255 * 3) def light_degree(cell): ret = 0 for c in cell: ret += c**2 return ret def distance(cell1, cell2): return abs(cell1[0] - cell2[0]) + abs(cell1[1] - cell2[1]) + abs(cell1[2] - cell2[2]) def solve(file_path, k): array = [] cells = [] with open(file_path, mode='r') as f: lines = f.readlines() for line in lines: array.extend(line.rstrip('\n').split(' ')) for i in range(0, int(len(array) / 3)): idx = i * 3 cell = [isn.STRtoNumber(array[idx]), isn.STRtoNumber(array[idx+1]), isn.STRtoNumber(array[idx+2])] cells.append(cell) cell_num = len(cells) cell_order = np.array(range(0, cell_num)) def cmp(order): cell = cells[order] return light_degree(cell) sorted_cell_order = sorted(cell_order, key=cmp) def pr(index): print('index: {0}, {1}'.format(index, cells[index])) # 最終的なclassterを代表するcellに対応するindexを入れていく # initialize representative_cells = [] # classterに属する画素indexをそのclasster(array)に格納して管理 # initialize classter_cells_array = [] for i in range(0, 11): classter_cells = [] for j in range(0, k): classter_cells.append([]) classter_cells_array.append(classter_cells) def get_cell(order_idx): return cells[sorted_cell_order[order_idx]] # 並べ替えた後(sorted_cell_order)のindex: t = 0 for i in range(0, k): idx = int(cell_num * i / k) representative_cells.append(get_cell(idx)) # cellを分類する def classify(t, idx): cell = get_cell(idx) classified_idx = 0 min_dis = 30000 for i in range(0, k): representative_cell = representative_cells[i] dis = distance(representative_cell, cell) if (dis <= min_dis): classified_idx = i min_dis = dis classter_cells_array[t][classified_idx].append(idx) # cellをclasster分け : t = 0 for i in range(0, len(sorted_cell_order)): cell = get_cell(i) classify(0, i) def center_cell(classter): r = 0 g = 0 b = 0 for i in classter: cell = get_cell(i) r += cell[0] g += cell[1] b += cell[2] return [int(r / len(classter)), int(g / len(classter)), int(b / len(classter))] for t in range(1, 11): for i in range(0, k): representative_cells[i] = center_cell(classter_cells_array[t-1][i]) for j in range(0, len(sorted_cell_order)): cell = get_cell(j) classify(t, j) print(representative_cells)(6)
import sys sys.path.append('..') from math import sqrt def intsqrt(num): return int(sqrt(num)) import IsStrNumber as isn import numpy as np file_path = 'image1.txt' def is_white(cell): total = 0 for c in cell: total += c return total == (255 * 3) def light_degree(cell): ret = 0 for c in cell: ret += c**2 return ret def distance(cell1, cell2): return abs(cell1[0] - cell2[0]) + abs(cell1[1] - cell2[1]) + abs(cell1[2] - cell2[2]) def solve(file_path, k): array = [] cells = [] with open(file_path, mode='r') as f: lines = f.readlines() for line in lines: array.extend(line.rstrip('\n').split(' ')) for i in range(0, int(len(array) / 3)): idx = i * 3 cell = [isn.STRtoNumber(array[idx]), isn.STRtoNumber(array[idx+1]), isn.STRtoNumber(array[idx+2])] cells.append(cell) cell_num = len(cells) divs = divisors(cell_num) # initialize cell_order = np.array(range(0, cell_num)) def cmp(order): cell = cells[order] return light_degree(cell) sorted_cell_order = sorted(cell_order, key=cmp) def pr(index): print('index: {0}, {1}'.format(index, cells[index])) # 最終的なclassterを代表するcellに対応するindexを入れていく # initialize representative_cells = [] # classterに属する画素indexをそのclasster(array)に格納して管理 # initialize classter_cells_array = [] for i in range(0, 11): classter_cells = [] for j in range(0, k): classter_cells.append([]) classter_cells_array.append(classter_cells) def get_cell(order_idx): return cells[sorted_cell_order[order_idx]] # 並べ替えた後(sorted_cell_order)のindex: t = 0 for i in range(0, k): idx = int(cell_num * i / k) representative_cells.append(get_cell(idx)) # cellを分類する def classify(t, idx): cell = get_cell(idx) classified_idx = 0 min_dis = 3000 for i in range(0, k): representative_cell = representative_cells[i] dis = distance(representative_cell, cell) if (dis <= min_dis): classified_idx = i min_dis = dis classter_cells_array[t][classified_idx].append(idx) # cellをclasster分け : t = 0 for i in range(0, len(sorted_cell_order)): cell = get_cell(i) classify(0, i) def center_cell(classter): r = 0 g = 0 b = 0 for i in classter: cell = get_cell(i) r += cell[0] g += cell[1] b += cell[2] return [int(r / len(classter)), int(g / len(classter)), int(b / len(classter))] for t in range(1, 11): for i in range(0, k): representative_cells[i] = center_cell(classter_cells_array[t-1][i]) for j in range(0, len(sorted_cell_order)): cell = get_cell(j) classify(t, j) compressed_cells = [] # initailize for i in range(0, cell_num): compressed_cells.append([]) for i, classters in enumerate(classter_cells_array[10]): for idx in classters: original_idx = sorted_cell_order[idx] compressed_cells[original_idx] = representative_cells[i] w = intsqrt(len(cells)) h = w s = w * h * 3 w_b = w.to_bytes(4, byteorder='big') h_b = h.to_bytes(4, byteorder='big') s_b = s.to_bytes(4, byteorder='big') attribute = [77, 77, 0, 42, 0, 0, 0, 8, 0, 7, 1, 0, 0, 4, 0, 0, 0, 1, 'w', 1, 1, 0, 4, 0, 0, 0, 1, 'h', 1, 2, 0, 3, 0, 0, 0, 3, 0, 0, 0, 98, 1, 6, 0, 3, 0, 0, 0, 1, 0, 2, 0, 0, 1, 17, 0, 4, 0, 0, 0, 1, 0, 0, 0, 104, 1, 21, 0, 3, 0, 0, 0, 1, 0, 3, 0, 0, 1, 23, 0, 4, 0, 0, 0, 1, 's', 0, 0, 0, 0, 0, 8, 0, 8, 0, 8] with open('image.tif', 'wb') as fout: for i in attribute: if (i == 'w'): fout.write(w_b) elif (i == 'h'): fout.write(h_b) elif (i == 's'): fout.write(s_b) else: fout.write(i.to_bytes(1, byteorder='big')) for cell in compressed_cells: for i in range(0, 3): fout.write(cell[i].to_bytes(1, byteorder='big'))感想
- きつかった...
- やってること自体は複雑ではないはずなのにすごく解くのに時間がかかった...
- cellクラスを作るのをサボるべきでは無い。後ろの問題に行くほど作っておけばよかったと感じた
- (6)はbyteでの書き出しがわからなかったのでググりました...(本番ならアウト)
- python使いなれてないせいで、初めてenumerate()関数という便利なものを知れた
- 画像処理とかやっている人にとっては楽な問題なのかな...??(そういう方にとってこの問題の立ち位置とか教えてもらえると助かります)


- 投稿日:2019-11-12T16:26:11+09:00
東京大学大学院情報理工学系研究科 創造情報学専攻 2019年度夏 プログラミング試験
2019年度夏の院試の解答例です
※記載の内容は筆者が個人的に解いたものであり、正答を保証するものではなく、また東京大学及び本試験内容の提供に関わる組織とは無関係です。出題テーマ
- 画像圧縮
- byteへ変換そしてbinary書き出し
問題文
※ 東京大学側から指摘があった場合は問題文を削除いたします。
配布ファイル
※ 公開されていないので以下は筆者が適当に作ったものです
image1.txt
19 7 0 17 13 1 29 3 27 5 11 23 0 0 0 255 255 255 19 7 0 255 255 255 29 3 27 5 11 23 0 0 0 255 255 255 19 7 0 17 13 1 255 255 255 5 11 23 0 0 0 255 255 255 19 7 0 17 13 1 29 3 27 255 255 255 0 0 0 255 255 255 19 7 0 17 13 1 29 3 27 255 255 255 0 0 0 255 255 255 1 1 1 10 10 10 100 100 100 50 80 46 96 71 1 255 255 255(1)
# (1) file_path = 'image1.txt' def solve(file_path): with open(file_path, mode='r') as f: ret = [] lines = f.readlines() for line in lines: ret.extend(line.rstrip('\n').split(' ')) print(int(len(ret) / 3))(2)
import sys sys.path.append('..') import IsStrNumber as isn from Divisors import divisors file_path = 'image1.txt' def is_white(cell): total = 0 for c in cell: total += c return total == (255 * 3) def solve(file_path): array = [] cells = [] with open(file_path, mode='r') as f: lines = f.readlines() for line in lines: array.extend(line.rstrip('\n').split(' ')) for i in range(0, int(len(array) / 3)): idx = i * 3 cell = [isn.STRtoNumber(array[idx]), isn.STRtoNumber(array[idx+1]), isn.STRtoNumber(array[idx+2])] cells.append(cell) cell_num = len(cells) divs = divisors(cell_num) width = 0 for div in divs: if (width != 0): break col_num = div row_num = int(cell_num / div) for i in range(0, row_num): right_end_cell = cells[i * col_num + col_num - 1] if (not is_white(right_end_cell)): break if (i == row_num - 1): width = col_num print(width)(4)
import sys sys.path.append('..') import IsStrNumber as isn import numpy as np file_path = 'image1.txt' def is_white(cell): total = 0 for c in cell: total += c return total == (255 * 3) def light_degree(cell): ret = 0 for c in cell: ret += c**2 return ret def solve(file_path): array = [] cells = [] with open(file_path, mode='r') as f: lines = f.readlines() for line in lines: array.extend(line.rstrip('\n').split(' ')) for i in range(0, int(len(array) / 3)): idx = i * 3 cell = [isn.STRtoNumber(array[idx]), isn.STRtoNumber(array[idx+1]), isn.STRtoNumber(array[idx+2])] cells.append(cell) cell_num = len(cells) divs = divisors(cell_num) cell_order = np.array(range(0, cell_num)) def cmp(order): cell = cells[order] return light_degree(cell) sorted_cell_order = sorted(cell_order, key=cmp) cell_idx = sorted_cell_order[int(cell_num / 2)] print('index: {0}, {1}'.format(cell_idx, cells[cell_idx]))(4)
import sys sys.path.append('..') import IsStrNumber as isn import numpy as np file_path = 'image1.txt' def is_white(cell): total = 0 for c in cell: total += c return total == (255 * 3) def light_degree(cell): ret = 0 for c in cell: ret += c**2 return ret def solve(file_path, k): array = [] cells = [] with open(file_path, mode='r') as f: lines = f.readlines() for line in lines: array.extend(line.rstrip('\n').split(' ')) for i in range(0, int(len(array) / 3)): idx = i * 3 cell = [isn.STRtoNumber(array[idx]), isn.STRtoNumber(array[idx+1]), isn.STRtoNumber(array[idx+2])] cells.append(cell) cell_num = len(cells) cell_order = np.array(range(0, cell_num)) def cmp(order): cell = cells[order] return light_degree(cell) sorted_cell_order = sorted(cell_order, key=cmp) def pr(index): print('index: {0}, {1}'.format(index, cells[index])) for i in range(0, k): idx = int(cell_num * i / k) cell_idx = sorted_cell_order[idx] pr(cell_idx)(5)
import sys sys.path.append('..') import IsStrNumber as isn import numpy as np file_path = 'image1.txt' def is_white(cell): total = 0 for c in cell: total += c return total == (255 * 3) def light_degree(cell): ret = 0 for c in cell: ret += c**2 return ret def distance(cell1, cell2): return abs(cell1[0] - cell2[0]) + abs(cell1[1] - cell2[1]) + abs(cell1[2] - cell2[2]) def solve(file_path, k): array = [] cells = [] with open(file_path, mode='r') as f: lines = f.readlines() for line in lines: array.extend(line.rstrip('\n').split(' ')) for i in range(0, int(len(array) / 3)): idx = i * 3 cell = [isn.STRtoNumber(array[idx]), isn.STRtoNumber(array[idx+1]), isn.STRtoNumber(array[idx+2])] cells.append(cell) cell_num = len(cells) cell_order = np.array(range(0, cell_num)) def cmp(order): cell = cells[order] return light_degree(cell) sorted_cell_order = sorted(cell_order, key=cmp) def pr(index): print('index: {0}, {1}'.format(index, cells[index])) # 最終的なclassterを代表するcellに対応するindexを入れていく # initialize representative_cells = [] # classterに属する画素indexをそのclasster(array)に格納して管理 # initialize classter_cells_array = [] for i in range(0, 11): classter_cells = [] for j in range(0, k): classter_cells.append([]) classter_cells_array.append(classter_cells) def get_cell(order_idx): return cells[sorted_cell_order[order_idx]] # 並べ替えた後(sorted_cell_order)のindex: t = 0 for i in range(0, k): idx = int(cell_num * i / k) representative_cells.append(get_cell(idx)) # cellを分類する def classify(t, idx): cell = get_cell(idx) classified_idx = 0 min_dis = 30000 for i in range(0, k): representative_cell = representative_cells[i] dis = distance(representative_cell, cell) if (dis <= min_dis): classified_idx = i min_dis = dis classter_cells_array[t][classified_idx].append(idx) # cellをclasster分け : t = 0 for i in range(0, len(sorted_cell_order)): cell = get_cell(i) classify(0, i) def center_cell(classter): r = 0 g = 0 b = 0 for i in classter: cell = get_cell(i) r += cell[0] g += cell[1] b += cell[2] return [int(r / len(classter)), int(g / len(classter)), int(b / len(classter))] for t in range(1, 11): for i in range(0, k): representative_cells[i] = center_cell(classter_cells_array[t-1][i]) for j in range(0, len(sorted_cell_order)): cell = get_cell(j) classify(t, j) print(representative_cells)(6)
import sys sys.path.append('..') from math import sqrt def intsqrt(num): return int(sqrt(num)) import IsStrNumber as isn import numpy as np file_path = 'image1.txt' def is_white(cell): total = 0 for c in cell: total += c return total == (255 * 3) def light_degree(cell): ret = 0 for c in cell: ret += c**2 return ret def distance(cell1, cell2): return abs(cell1[0] - cell2[0]) + abs(cell1[1] - cell2[1]) + abs(cell1[2] - cell2[2]) def solve(file_path, k): array = [] cells = [] with open(file_path, mode='r') as f: lines = f.readlines() for line in lines: array.extend(line.rstrip('\n').split(' ')) for i in range(0, int(len(array) / 3)): idx = i * 3 cell = [isn.STRtoNumber(array[idx]), isn.STRtoNumber(array[idx+1]), isn.STRtoNumber(array[idx+2])] cells.append(cell) cell_num = len(cells) divs = divisors(cell_num) # initialize cell_order = np.array(range(0, cell_num)) def cmp(order): cell = cells[order] return light_degree(cell) sorted_cell_order = sorted(cell_order, key=cmp) def pr(index): print('index: {0}, {1}'.format(index, cells[index])) # 最終的なclassterを代表するcellに対応するindexを入れていく # initialize representative_cells = [] # classterに属する画素indexをそのclasster(array)に格納して管理 # initialize classter_cells_array = [] for i in range(0, 11): classter_cells = [] for j in range(0, k): classter_cells.append([]) classter_cells_array.append(classter_cells) def get_cell(order_idx): return cells[sorted_cell_order[order_idx]] # 並べ替えた後(sorted_cell_order)のindex: t = 0 for i in range(0, k): idx = int(cell_num * i / k) representative_cells.append(get_cell(idx)) # cellを分類する def classify(t, idx): cell = get_cell(idx) classified_idx = 0 min_dis = 3000 for i in range(0, k): representative_cell = representative_cells[i] dis = distance(representative_cell, cell) if (dis <= min_dis): classified_idx = i min_dis = dis classter_cells_array[t][classified_idx].append(idx) # cellをclasster分け : t = 0 for i in range(0, len(sorted_cell_order)): cell = get_cell(i) classify(0, i) def center_cell(classter): r = 0 g = 0 b = 0 for i in classter: cell = get_cell(i) r += cell[0] g += cell[1] b += cell[2] return [int(r / len(classter)), int(g / len(classter)), int(b / len(classter))] for t in range(1, 11): for i in range(0, k): representative_cells[i] = center_cell(classter_cells_array[t-1][i]) for j in range(0, len(sorted_cell_order)): cell = get_cell(j) classify(t, j) compressed_cells = [] # initailize for i in range(0, cell_num): compressed_cells.append([]) for i, classters in enumerate(classter_cells_array[10]): for idx in classters: original_idx = sorted_cell_order[idx] compressed_cells[original_idx] = representative_cells[i] w = intsqrt(len(cells)) h = w s = w * h * 3 w_b = w.to_bytes(4, byteorder='big') h_b = h.to_bytes(4, byteorder='big') s_b = s.to_bytes(4, byteorder='big') attribute = [77, 77, 0, 42, 0, 0, 0, 8, 0, 7, 1, 0, 0, 4, 0, 0, 0, 1, 'w', 1, 1, 0, 4, 0, 0, 0, 1, 'h', 1, 2, 0, 3, 0, 0, 0, 3, 0, 0, 0, 98, 1, 6, 0, 3, 0, 0, 0, 1, 0, 2, 0, 0, 1, 17, 0, 4, 0, 0, 0, 1, 0, 0, 0, 104, 1, 21, 0, 3, 0, 0, 0, 1, 0, 3, 0, 0, 1, 23, 0, 4, 0, 0, 0, 1, 's', 0, 0, 0, 0, 0, 8, 0, 8, 0, 8] with open('image.tif', 'wb') as fout: for i in attribute: if (i == 'w'): fout.write(w_b) elif (i == 'h'): fout.write(h_b) elif (i == 's'): fout.write(s_b) else: fout.write(i.to_bytes(1, byteorder='big')) for cell in compressed_cells: for i in range(0, 3): fout.write(cell[i].to_bytes(1, byteorder='big'))感想
- きつかった...
- やってること自体は複雑ではないはずなのにすごく解くのに時間がかかった...
- cellクラスを作るのをサボるべきでは無い。後ろの問題に行くほど作っておけばよかったと感じた
- (6)はbyteへの変換がわからなかったのでググりました...(本番ならアウト)
- python使いなれてないせいで、初めてenumerate()関数という便利なものを知れた
- 画像処理とかやっている人にとっては楽な問題なのかな...??(そういう方にとってこの問題の立ち位置とか教えてもらえると助かります)
- 投稿日:2019-11-12T16:25:11+09:00
最大値を探そう python (修正ver)
先日上げた「最大値を探そうpython」の修正verです。以前のコードの悪い点と変更点は以下の通りです。
悪い点
・リストの要素がすべて負の時、最大値が0になってしまう
・処理速度が遅い変更点
・最大値候補の初期値をリストの適当な要素に設定
・while文からfor文にする
悪い点の二点を踏まえてリファクタリングをしてみました
num = int(input("何個数値を代入しますか?")) value_list = [] #数値を格納する配列を用意する for i in range(num): value = int(input("数値を代入して下さい")) value_list.append(value) #用意したリストに値を追加していく max_value = value_list[0] #リストの要素で初期化 for i in range(num): if value_list[i] > max_value: max_value = value_list[i] print(max_value) #最大値を出力変更した部分
代入(変更前)while i < num: value = int(input("数値を代入して下さい")) value_list.append(value) #用意したリストに値を追加していく i += 1代入(変更後)for i in range(num): value = int(input("数値を代入して下さい")) value_list.append(value) #用意したリストに値を追加していく比較(変更前)max_value = 0 #最大値を0で初期化 i = 0 while i < num: if value_list[i] >= max_value: #格納した数値を順番に比較していく max_value = value_list[i] i += 1比較(変更後)max_value = value_list[0] #リストの要素で初期化 for i in range(num): if value_list[i] > max_value: max_value = value_list[i]
初期値を入力した要素に設定することで入力された要素がすべて負の時も正常に最大値が出るようになりました。
さらに、while文からfor文にしたことで無駄に初期化や加算処理をすることがなくなりました。max関数を使ってみた
pythonには与えられた要素を持つオブジェクトから最大値を求める関数があるとコメントで指摘してもらったので早速使ってみました。
num = int(input("何個数値を代入しますか?")) value_list = [] #数値を格納する配列を用意する for i in range(num): value = int(input("数値を代入して下さい")) value_list.append(value) #用意したリストに値を追加していく print(max(value_list))出力結果
何個数値を代入しますか? 3 数値を代入して下さい -3 数値を代入して下さい -2 数値を代入して下さい -5 -2
意見、ご指摘して下さったみなさんありがとうございました。
- 投稿日:2019-11-12T16:20:26+09:00
【Python】前にアンダースコア(アンダーバー)2つの関数って何
classの中にある関数の前にアンダースコアが2つある時がある
def __hogehoge(): print('Hello.')なんの意味があるのか知らなかったので備忘録
結論:そのclass内でしか呼び出せなくなる練習してみる
実際にやってみよう〜
下記のようなサンプルを用意
※わかりやすように関数名はpublic、privateとしてますが稼働に際して意味はありません。train.pyclass Hoge: def __init__(self): print('this is init function.') def public(): print('this is public function.') def __private(): print('this is private function.')【ターミナル】でこのファイルがあるディレクトリまで移動してから以下のように実行
Hogeクラスの実行
__init__はclassを実行すると必ず呼び出される$python >>> from train import Hoge >>> Hoge() this is init function.public関数の実行
ターミナルの先ほどの続きに以下のように入力
>>> Hoge.public() this is public function.何も付いていない関数は問題なく呼び出せる
private関数の実行
ターミナルの先ほどの続きに以下のように入力
>>> Hoge.__private() Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: type object 'Hoge' has no attribute '__private'外部からの呼び出し失敗
- 投稿日:2019-11-12T16:17:02+09:00
【Python中級者への道】lambda式を使う
まとめへのリンク
https://qiita.com/ganariya/items/fb3f38c2f4a35d1ee2e8
はじめに
Pythonの勉強をするために、acopyという群知能ライブラリを写経していました。
acopyでは、多くのPythonの面白い文法・イディオムが使われており、その中でも便利だなぁというのをまとめています。
今回は、Pythonのlambda式について学びます。
lambda式とは?
ラムダ式とは、他の多くのプログラミング言語でも利用される概念で、無名関数の意味をさします。
名前をつけるまでもない、利用するスコープが非常に小さい場合に、無名な関数をその場で定義して使い捨てる というのがラムダ式です。C++では
[](){}の表記で利用できます。lambda式の例
lambda式は
lambda 引数: 処理の形で表記します。
処理の結果として、必ず値が返されるという特徴があります。例えば、2つの整数の引数を足し算するadd関数、そしてそれをlambdaで表したlm_add関数を作成してみます。
def add(x, y): return x + y lm_add = lambda x, y: x + y x = 10 y = 40 ''' 50 50 ''' print(add(x, y)) print(lm_add(x, y))add関数と同じ挙動を示すのがlm_add関数です。
引数$x, y$を受け取り$x+y$を計算したあと、強制的にreturnされます。通常の関数と同様に、可変長引数を利用できます。
f = lambda *args, **kwargs: print(args, kwargs) ''' (10, 'a') {'hello': 'world'} ''' f(10, 'a', hello='world')活用例
lambda式は、基本的に使い捨てで名前をつけるまでもない、極小のスコープのみで利用します(するべきと考えています)。
例えば
- ソートの基準として
- 最大値の基準として
など組み込み関数と組み合わせて使用することが多いです。特に競技プログラミングでは多用します。
例えば、以下はタプルの配列を第$1$要素を基準として昇順に並べ、もし同じならば第$0$要素で昇順にさらに並び替えます。
tuples = [(10, -3), (4, 10), (-4, 13), (-20, -50), (-20, 1), (0, 0), (-22, -50)] tuples = sorted(tuples, key=lambda x: (x[1], x[0])) ''' [(-20, -50), (-22, -50), (10, -3), (0, 0), (-20, 1), (4, 10), (-4, 13)] ''' print(tuples)以上のような比較関数はわざわざスコープの外に定義するまでもないため、また、関数の位置が遠くなり、処理を追う負担を減らすため、lambdaで定義すると良さそうです。
最後に
lambdaについて見てみました。
特に競技プログラミングでPythonでやっていると多用します。
他の言語でもラムダ式を活用していきたいです。Pythonだと$2$つの要素で入れ替えるソート(C++のソートなど)
はクラスにeq, ltを定義するしかないんでしょうか...(ラムダでできると楽なのですが)参考文献
- 投稿日:2019-11-12T15:42:47+09:00
TwitterScraperを使ってスクレイピングできるのでは
自前でTwitter APIを用意するのが規約上面倒くさくなっているけど、Twitterをスクレイピングしたいってことあると思います。
OSSでTwitterScraperというPythonライブラリがある(みたいです)。はじめに
Twitter社的には、Twitterの事前の承諾なしにスクレイピングすることは禁止されています。
そのため、当記事はあくまでこんな風に使えるかもしれないという想像の記事です。(という予防線を張っておきます)(iii) Twitterから提供されている当社の現在利用可能な公開インターフェースを経由する (かつ、該当する使用条件に従う) ことなく、その他の何らかの手段 (自動その他を問わず) で本サービスへのアクセスもしくはその検索を行うか、またはアクセスもしくは検索を試みること。ただし、Twitterと別途締結した契約によりこれを行うことが特に認められている場合はこの限りではありません (注: 本サービスのクローリングは、robots.txtファイルの定めによる場合には許されます。ただし、Twitterの事前の承諾なしに本サービスのスクレイピングを行うことは明示的に禁じられています)。
https://twitter.com/ja/tos/previous/version_9これを見て使ってみようという人はあくまで自己責任でお願いします。
やりたいこと
「コンプティーク 2019年10月号」でアイカツオンパレード!の特集記事が掲載されました。
その中で、「アイカツオンパレード緊急読者アンケート」なる企画があり、Twitter上で2019年8月23日18:00~2019年8月25日17:59の短い期間でしたがアンケートが行われました。そのアンケート回答の収集として使えたらいいなというのがやりたかったことになります。
実装
from twitterscraper import query_tweets import datetime as dt import pandas as pd # input begin_date = dt.date(2019,8,23) end_date = dt.date(2019,9,1) pool_size = (end_date - begin_date).days # tweetの収集 tweets = query_tweets("#コンプアイカツアンケート", begindate=begin_date, enddate=end_date, poolsize=pool_size, lang="ja") tuple_tweet=[(tweet.user_id, tweet.text.replace("\n","\t"), tweet.timestamp) for tweet in tweets] # ツイートが重複しているので重複削除する df = pd.DataFrame(set(tuple_tweet), columns=['user_id', 'tweet', 'post']) df.sort_values('post').reset_index(drop=True)欲しい情報はあくまでツイート内容のみなので、不要なユーザ名やリツイート回数などは除去しています。
この後前処理として整形作業が必要なので、改行をタブ区切りに変更して作業しやすくしています。
注意点として、TwitterScraperは単純に処理しようとするとレコードが重複します。
(ぱっと見、begindate、enddateの期間が重複して取れるという感じではないっぽいけど、詳細は分からないです。)
そのため、setで重複削除しています。
poolsizeもよくわからなかったのですが、内部の処理を見る限りsinceとuntilの期間の設定に必要でデフォルト値が20のため、そのままデフォルト値を使うと同日のデータが生まれてしまうので、終了-開始の日付をセットしています。最後に
『アイカツオンパレード!』は
テレビ東京系 毎週土曜日 午前10時30分~
BSテレ東毎週月曜日夕方5時~
から好評放送中です!また、分析結果についてははてなブログ上でやっているので、興味あれば併せてみてもらえればと思います。
- 投稿日:2019-11-12T15:17:28+09:00
S&P500構成銘柄の株価のデータをyahoo financeから取得し、相関の高いペアを見つける。
記事概要
「株Aが上がると、株Bも上がる」「株Aが下がると、株Bも下がる」というような現象を「連れ高」、「連れ安」と言います。天才トレーダーのBNFさんは株式の売買にこれを利用して大儲けしたそうです。
自分も真似をして大儲け!と思ったのですが、連動するペアを見つける方法って調べてもいいものがでてこない。
そこで、Pythonで実装してみたので、コードとその説明を公開します。コード
Githubに置いています。ご自由にどうぞ
https://github.com/toshiikuoo/puclic/blob/master/%E6%A0%AA%E4%BE%A1%E7%9B%B8%E9%96%A2.ipynb動作
動作の流れは次のようになります
wikipediaのS&P500のページから銘柄一覧の情報を取得
↓
取得した銘柄一覧の株価をyahoo financeから取得
↓
全ての銘柄の組み合わせのペアについて株価の相関を算出 ※相関:二つのデータがどれだけ似ているかを数値化したもの
↓
相関が大きい順にペアを並び替えコードの説明
上のコードを抜粋しながら説明します。
- 必要なライブラリのインポート
# 必要なライブラリimport !pip install lxml html5lib beautifulsoup4 import pandas as pd from pandas import Series,DataFrame from pandas_datareader import DataReader import numpy as np from datetime import datetime from scipy.stats.stats import pearsonr import itertools # Install yfinance package. !pip install yfinance # Import yfinance import yfinance as yf
- wikipediaのS&P500のページから銘柄一覧の情報を取得。銘柄のlistを作成。
# S&P全銘柄のリストを作成 url="https://en.wikipedia.org/wiki/List_of_S%26P_500_companies" sp500_list=pd.read_html(url)[0].Symbol.values.tolist() len(sp500_list)
- yahoo financeから銘柄のlistの株価を取得。
# sp500銘柄の終値を1つのDataFrameに格納 close_sp500_list=yf.download(sp500_list_yahoo,'2019-10-04','2019-11-01')["Adj Close"]
- 取得した株価から相関を算出
# 列ごとのペアで相関を算出 # 算出した相関を入れるための辞書型作成 correlations={} # 相関を算出 for cola,colb in itertools.combinations(sp500_list_yahoo,2): nas=np.logical_or(np.isnan(close_sp500_list.loc[:,cola]),np.isnan(close_sp500_list.loc[:,colb])) try: correlations[cola + '__'+ colb]=pearsonr(close_sp500_list.loc[:,cola][~nas],close_sp500_list.loc[:,colb][~nas]) except ValueError: pass # 出力された結果"correlations"はリスト形式なのでDataFrameに変換 result=DataFrame.from_dict(correlations,orient='index') result.columns=['PCC','p-value'] print(result.sort_values('PCC'))結果
最終的な出力は以下。各銘柄ペアの相関がソートされて出力されている。
PCC p-value BKR__SPGI -0.968878 1.437804e-03 BIIB__HAS -0.962712 8.038530e-13 BKR__PGR -0.959178 2.465597e-03 PGR__WCG -0.941347 6.818268e-11 CI__PGR -0.935051 1.840799e-10 ... ... ... CNC__WCG 0.996087 1.493074e-22 BKR__PRGO 0.997290 1.101006e-05 CBS__VIAB 0.998546 7.579099e-27 BBT__STI 0.998835 8.266321e-28 GOOGL__GOOG 0.999502 1.701271e-31 [127260 rows x 2 columns]今後のアクション
出力結果を使って相関の高い銘柄群のグループ化をしたい。
(質問・改善点など気軽に連絡ください。初投稿なのでおかしなとこあると思います。Github難しい。。。)
- 投稿日:2019-11-12T15:17:14+09:00
Raspberry pi 喋らせよう 詐欺撃退電話
我が家にも詐欺グループから電話が来ました。
内容は、「インターネット使っていますよね!」「はい使っています」「こちらは管理サイトです。」なんの管理サイトかわからないので口を合わせて応対。おかしい電話でうざい。
留守電を買おうとアマゾンでポチリそうになったが高いのでやめた。間違ってRasp piをポチリました。そうだPBXを作ろう。留守電もAsteriskに入っているし、我が家は、ひかり電話だから簡単に接続できるはずだ。簡単な設定とIVRのスクリプトにより作れるはずだ。IP-PBXとは、電話機とLANネットワークを構築し、インターネットを活用した通話を可能とする電話交換機です。
IVR(Interactive Voice Response )とは、入電の際、あらかじめ用意された音声による案内や、入電理由に応じた番号入力でコミュニケーターへ対応の振り分けを行うシステムです。
Raspberry pi を使って詐欺撃退電話作成しよう。
Asterisk (PBX)とは、電話回線の交換機のことで、内線電話の接続をコントロールするもの。
内線同士を接続するほか、外線から内線にかかってきたもの、内線から外線へかけるものもコントロールする。
この機能を用い、Raspberry PIに喋らせる。前提条件
- 光電話化(ip電話化)されている。
- 番号通知の契約されている。
- 家庭用インターネット契約がある。
電話の親機は、Raspberry pi、子機は、家族のスマートフォン!
スマートフォンの準備
お好きなsip ip-phoneをインストールください。
ダウンロードして携帯にインストールしてください。
設定は簡単です。
ルータのひかり電話設定
まずテスト用に内線3番にiPhoneをつなぎます。
試しに0120で始まる通販サイトにでんわしてください。
- Raspberry piにpbx(asterisk)インストールします。 ダウンロード等インストールの方法を下記に示します。
$ sudo su # cd /usr/src # wget http://downloads.asterisk.org/pub/telephony/asterisk/asterisk-16-current.tar.gz # tar zxvf asterisk-16-current.tar.gz # cd asterisk-16.3.0 root@raspberrypi:/usr/src/asterisk-16.3.0# sudo apt-get update -y root@raspberrypi:/usr/src/asterisk-16.3.0# sudo apt-get install -y libedit-dev root@raspberrypi:/usr/src/asterisk-16.3.0# apt-get install ncurses-dev libxml2 libxml2-dev sqlite libsqlite3-dev libssl-dev root@raspberrypi:/usr/src/asterisk-16.3.0# apt-get install alsa-utils sox libsox-fmt-all^ root@raspberrypi:/usr/src/asterisk-16.3.0# apt-get install uuid uuid-runtime uuid-dev root@raspberrypi:/usr/src/asterisk-16.3.0# apt-get install libjansson4 libjansson-dev root@raspberrypi:/usr/src/asterisk-16.3.0# apt-get install libpjsip-simple2 libpjsip-ua2 libpjsip2 libpjproject-dev libsrtp-dev srtp-utils root@raspberrypi:/usr/src/asterisk-16.3.0# apt-get install subversion root@raspberrypi:/usr/src/asterisk-16.3.0# apt-get install liburi-escape-xs-perl root@raspberrypi:/usr/src/asterisk-16.3.0# cpan URI::Escape root@raspberrypi:/usr/src/asterisk-16.3.0# cpan URI::Escape root@raspberrypi:/usr/src/asterisk-16.3.0# cpan LWP::UserAgent root@raspberrypi:/usr/src/asterisk-16.3.0# cpan LWP::Protocol::https root@raspberrypi:/usr/src/asterisk-16.3.0# cpan JSON root@raspberrypi:/usr/src/asterisk-16.3.0# apt-get install flac root@raspberrypi:/usr/src/asterisk-16.3.0# ./configure --with-jansson-bundled下記のようなAsterisk イラストマークが出れば成功
.$$$$$$$$$$$$$$$=.. .$7$7.. .7$$7:. .$$:. ,$7.7 .$7. 7$$$$ .$$77 ..$$. $$$$$ .$$$7 ..7$ .?. $$$$$ .?. 7$$$. $.$. .$$$7. $$$$7 .7$$$. .$$$. .777. .$$$$$$77$$$77$$$$$7. $$$, $$$~ .7$$$$$$$$$$$$$7. .$$$. .$$7 .7$$$$$$$7: ?$$$. $$$ ?7$$$$$$$$$$I .$$$7 $$$ .7$$$$$$$$$$$$$$$$ :$$$. $$$ $$$$$$7$$$$$$$$$$$$ .$$$. $$$ $$$ 7$$$7 .$$$ .$$$. $$$$ $$$$7 .$$$. 7$$$7 7$$$$ 7$$$ $$$$$ $$$ $$$$7. $$ (TM) $$$$$$$. .7$$$$$$ $$ $$$$$$$$$$$$7$$$$$$$$$.$$$$$$ $$$$$$$$$$$$$$$$. configure: Package configured for: configure: OS type : linux-gnueabihf configure: Host CPU : armv7l configure: build-cpu:vendor:os: armv7l : unknown : linux-gnueabihf : configure: host-cpu:vendor:os: armv7l : unknown : linux-gnueabihf : root@raspberrypi:/usr/src/asterisk-16.3.0#日本語音声ファイルをインストール
root@raspberrypi:/usr/src/asterisk-16.3.0# make menuselectメニュー画面から Core Sound PackagesでCORE_SOUND-JA-....の必要なフォーマットのファイルを選択する。
下記のように選択する
次にmakeを実行する
root@raspberrypi:/usr/src/asterisk-16.3.0# make成功するとmake install
設定ファイルのバックアップ
root@raspberrypi:/home/pi# cd /etc/asterisk root@raspberrypi:/etc/asterisk# cp sip.conf sip.conf.bak root@raspberrypi:/etc/asterisk# cp extensions.conf extensions.conf.bakaquestalkpiのインストール
Asterisk用ホルダ作成
mkdir /usr/lib/asterisk/atp
cp /home/pi/aquestalkpi/* /usr/lib/asterisk/atp
cp -r /home/pi/aquestalkpi/* /usr/lib/asterisk/atp
```
つづく



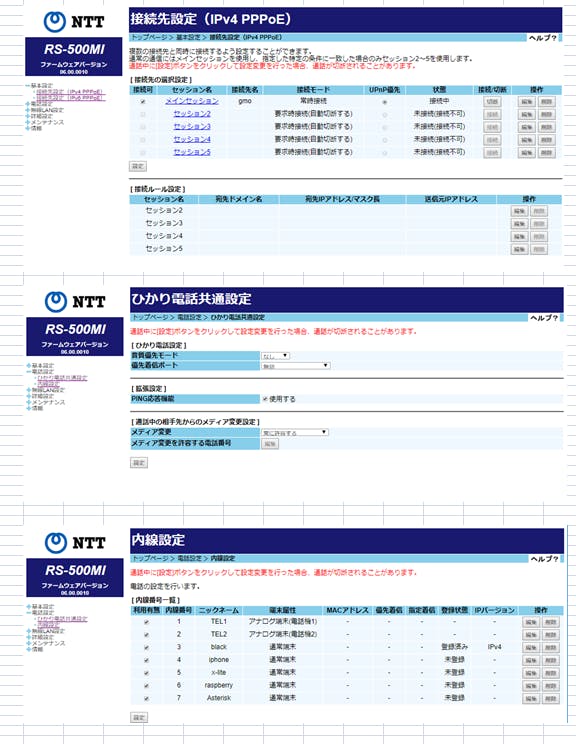
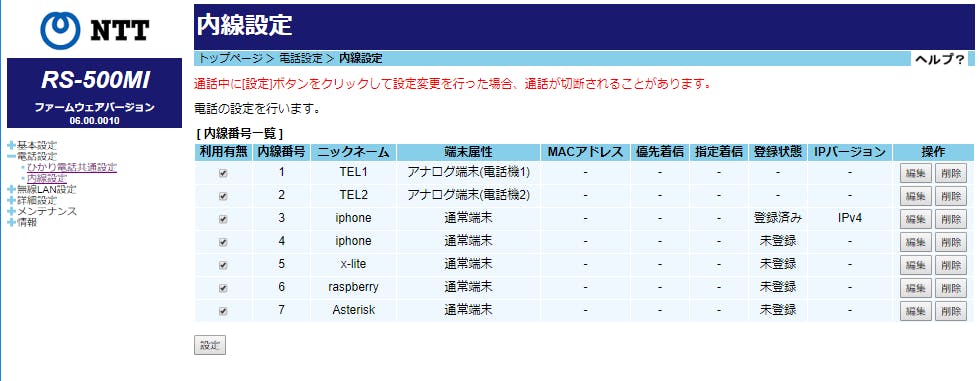



- 投稿日:2019-11-12T15:13:51+09:00
Gaugeをインストールして公式のサンプルを動かすまで
基本的に公式Documentが充実しているので、読んでいけばスムーズに使い始められます。
ただ、一部
- 公式通りにやってもうまくいかない
- 手順が抜けている
- 全体が英語
などあるので、改めて説明する意味も無くはないかな、と思って書きました。
そもそもGaugeとは
Markdownで仕様を書いて自動テストができるツールです。
といってもMarkdownさえ書けばいいわけではなく、コーディングも必要です。たとえば「ネットで何か検索をする」という処理(Gaugeの単位で言うとシナリオ)を実現するために、
- Googleのホームに遷移する
- 「ほげ」と検索する
という操作(Gaugeの単位で言うとステップ)が必要になります。
それぞれのステップを以下のようにコーディングをしておきます。
step("Goto Google's home page", () => { goto("google.com") }); step("Search for <query>", (query) => { write(query); press("Enter"); });実際のテストシナリオを書く時にはこれらを呼び出して、以下のように書きます。
# Search the internet ## Look for cakes * Goto Google's home page * Search for "Cup Cakes" ## Look for movies * Goto Google's home page * Search for "Star wars"Seleniumそのままでテスト手順をコーディングしていったものに比べて、自然言語に近い分テストの内容がぱっと見でわかりやすく、テスター向きだとされています。
このように書くと「BDDか」と思うかもしれませんが、Gaugeの公式では「我々が提供しているのはBDDツールではない」と言っています。
Minding the Gap between BDD and Executable Specifications | Gauge Blog
Although there are instances where our users use Gauge as a BDD Tool, our focus hasn't been BDD but on building features that give teams the confidence to release.
チームにリリースする勇気を与えるための機能に注力したい、と書かれています。
1. インストール
公式のインストール手順に従います。
Gauge Documentation — Gauge 0.9.9 documentation
OSと言語とIDEを選ぶとそれにあったインストール手順が出てきます。初見のとき感動しましたこれ。
今回はWindows/Python/Visual Studio Codeを選択しました。
1-1. Gaugeのインストール
インストーラのリンクがあるので、クリックしてダウンロードし、インストーラを実行。
インストールの過程で、コンポーネントの選択を求められます。
Additional plugins can be install using the command 'gauge install <plugin>'
とあるように、あとから追加もできるので、今時点で必要なPythonのみにチェックを入れます。
1-2. VSCodeの拡張機能をインストール
VSCode上で"Gauge"で拡張機能を検索したらすぐに出てきました。
Install。
2. プロジェクトを作る
成功した手順
Gaufeのプロジェクト用にフォルダを作成し、その中で以下コマンドを実行。
> gauge init python一瞬で成功しました。
C:\>gauge init python Telemetry --------- This installation of Gauge collects usage data in order to help us improve your experience. The data is anonymous and doesn't include command-line arguments. To turn this message off opt in or out by running 'gauge telemetry on' or 'gauge telemetry off'. Read more about Gauge telemetry at https://gauge.org/telemetry Downloading python.zip . Copying Gauge template python to current directory ... Successfully initialized the project. Run specifications with "gauge run specs/". Compatible language plugin python is not installed. Installing plugin... . Successfully installed plugin 'python' version 0.3.6※Gaugeのインストール手順の途中でPythonにチェックを入れたはずなのですが・・・
必要なモジュールをインストールするため、プロジェクト内の
requirements.txtを使って、> pip install -r requirements.txtを実行しましょう。
失敗した手順
一応残しておきます。
Gauge Documentation — Gauge 0.9.9 documentationに沿って行います。
VSCode上で
Ctrl+Shift+pを押してコマンドパレットを出し、Gauge: Create a new Gauge Project
を選択
→Pythonを選択
→フォルダのルートを選ぶように出てくるので、選択
→プロジェクト名を設定このあと、Initializing project... と表示された状態で待ち続け、なぜか処理が終わらず・・・。
3. サンプルの実行
作成したプロジェクトの中にサンプルファイルが入っているので、実行してみます。
コマンドは
> gauge run specsです。
成功すると以下のようなログが表示されます。
C:>gauge run specs Python: 3.7.2 # Specification Heading ## Vowel counts in single word P P ## Vowel counts in multiple word P P Successfully generated html-report to => C:\hoge\reports\html-report\index.html Specifications: 1 executed 1 passed 0 failed 0 skipped Scenarios: 2 executed 2 passed 0 failed 0 skipped Total time taken: 381msそして、プロジェクト内にreportsというフォルダが作成され、その中にHTMLのレポートが出力されます。
エラーが発生した場合
以下のようなエラーがでた場合、おそらくはgetgaugeというモジュールを取得できていません。前項の、requirements.txtを使ったインストールを行ってください。
(ここまで略) subprocess.CalledProcessError: Command '['C:\\hoge\\Python\\Python37\\python.exe -m pip install getgauge==0.3.6 --user']' returned non-zero exit status 1. Traceback (most recent call last): File "start.py", line 8, in <module> import grpc ModuleNotFoundError: No module named 'grpc' Error ---------------------------------- [Gauge] Failed to start gauge API: Runner with pid 27004 quit unexpectedly(exit status 1). Get Support ---------------------------- Docs: https://docs.gauge.org Bugs: https://github.com/getgauge/gauge/issues Chat: https://gitter.im/getgauge/chat Your Environment Information ----------- windows, 1.0.6, 2bc49db html-report (4.0.8), python (0.3.6), screenshot (0.0.1)