- 投稿日:2019-11-12T23:15:57+09:00
Android フォアグラウンドからバックグラウンド、その逆のイベントとる
ハマりすぎたのでメモ2
参照とかnugetからパッケージ落としてくるとこは前記事を参照仕組みはarch.lifecycle extentionsって言うのでなんでもライフサイクルが管理できる様になる
何も入れないとActivityはonPauseとonResumeとかあるのでこれはいらないが、
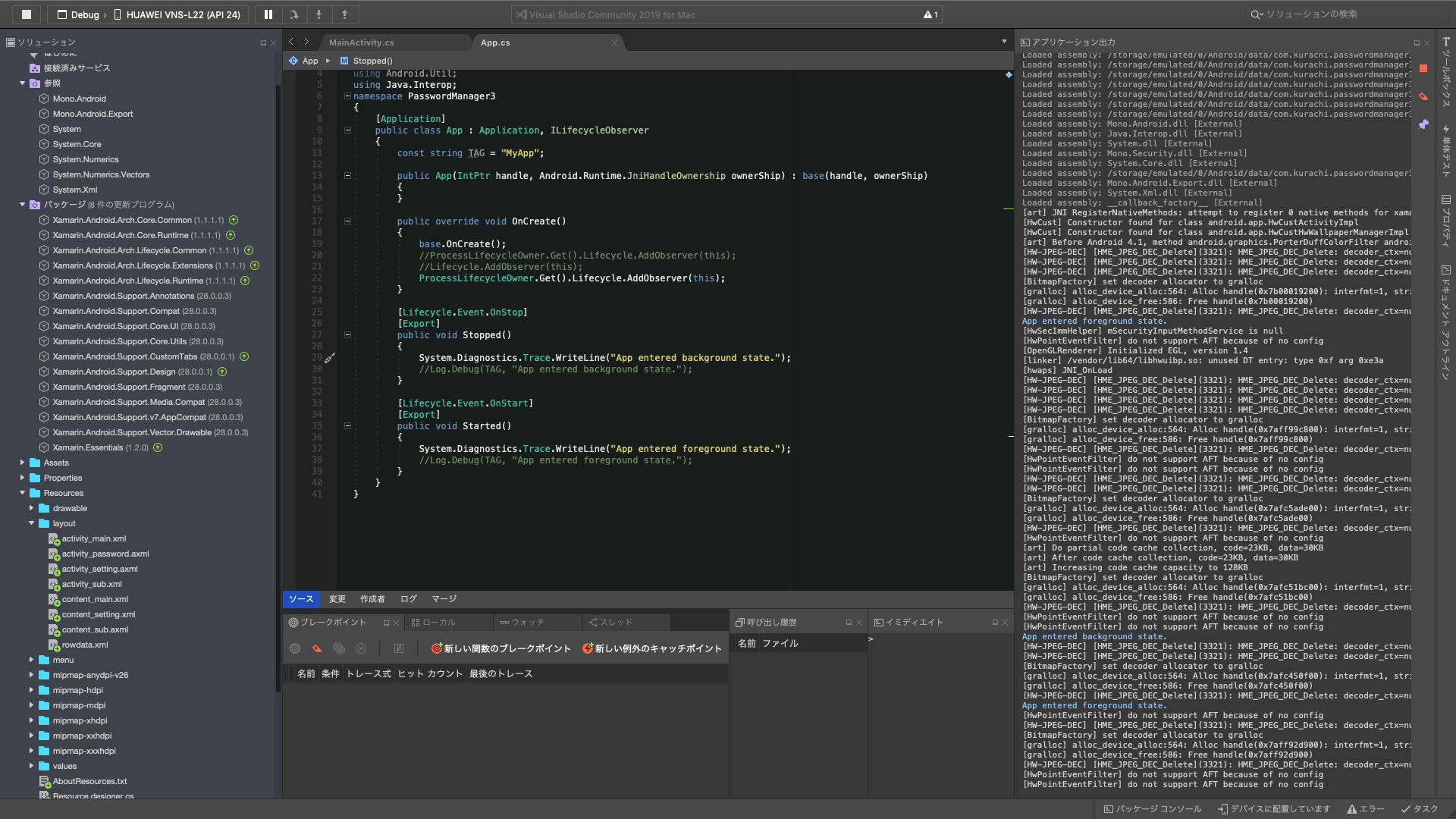
これをアプリケーション自体に適用するとアプリケーションがフォアグラウンドになった時とかバックグラウンドになった時のイベントをハンドリングできる様になる画像を見れば以下のことが分かる
・アプリケーション自体のクラスの実装の仕方
・アプリがバックグラウンド、フォアグラウンドに行った時のイベントハンドリングのメソッド
・nugetから落とすパッケージ
・参照に入れるもの(参照を追加で検索>Extentionでヒットするやつを一つ追加)ちなみにアプリのバージョンは8.1
arch.lifecycle extentionsとかはlatestじゃなくて1.1.1(これは前の記事参照このProcessLifeCycleObserverを使うサンプルはJavaのやつとかはインターネットにたくさん落ちてるがC#のやつはまじで落ちてない。
のでここに書いておく追記
ProcessLifecycleObserver.Get()..
のくだりはクリーンと言うかプロジェクトを別のPCに移してvs立ち上げ直したらエラーが取れた
- 投稿日:2019-11-12T20:20:09+09:00
追記型ストレージFasterLogについて
始めに
Microsoftは、ローカルで使えるストレージライブラリのFASTERというものを開発している。
このFASTER、最初はキーバリューストアであるFasterKVのみ提供していた。しかし、バージョン2019.10.31.1より、FasterLogという、データの追記に特化した機能が追加された。
少し触ってみると、今自分が実現したい機能を丁度良くカバーしてそうなので、使い方や注意点を書いておく。FasterKVは論文も発表されているので、特徴や理論的な裏付け等が知りたければそちらも参照のこと。
今回紹介するFasterLogは、FasterKVで使用しているストレージ機能のベース部分を利用した、追記と範囲検索に特化したものとなる。
なお、FasterLogは今もなおインターフェイスの更新が行われており、この記事で書かれていることと微妙に差異があるかもしれないので注意が必要。
この記事では2019.11.18.1をベースに解説を行う。特徴
- データはディスクに保存される
- ドライバを書けばローカルディスク以外にも対応可能
- 扱えるデータ型はバイト配列のみ
- 以下の操作が可能
- 追記
- データの範囲検索
- 過去のある時点までのレコード削除
- 特定レコードの削除は不可
- 途中にデータを挿入することは不可
使い方
プロジェクトへの導入
普通にnugetパッケージとして公開されているので、PackageReference等で追加すればOK。
ストレージデバイスインスタンスを作成する
まず、以下のコードでログを格納するディスク領域を作成する。
// using FASTER.core; // 独自ストレージを使用する場合、FASTER.core.IDeviceを実装したインスタンスを代わりに生成する // ファイルパスのみ必須。 IDevice logDevice = Devices.CreateLogDevice("[格納するファイルのパス]");なお、
deleteOnCloseというオプション引数が使用可能だが、これを使用すると、後でデータを開こうとした時に挙動がおかしくなるので設定しないこと。
ここで生成したIDeviceは、必ずプログラム終了時にlogDevice.Close()すること。
IDisposeは実装してないので、try-finallyで囲むと良い。FasterLogインスタンスを生成する
ストレージデバイスインスタンスを生成したら、以下のようにして、FasterLogインスタンスを生成する。
// using FASTER.core; // LogDeviceのみ必須 var fls = new FasterLogSettings() { LogDevice = logDevice }; using(var fl = new FasterLog(fls)) { // 処理 // flインスタンスはプロセス内で使い回すこと }FasterLogSettingsのその他項目について
FasterLogSettingsのその他項目は以下のようになる。
- PageSizeBits
- 格納データページの基本単位
- 各レコードは、メタデータと実データが必ず同じページに収まるように格納される
- つまり、一レコード当たりの最大サイズがこの値に依存して決定される
- ファイルの空間効率にも影響するので、サイズ設定は慎重に
- 単位は何ビット使用するかなので、例えば8を指定したら
2^8 = 256(bytes)となる- 初期値は22(
2^22 ≒ 4MB)- MemorySizeBits
- オンメモリに乗せる最大データ容量
- 単位はPageSizeBitsと同じ
- 初期値は23(
2^23 ≒ 8MB)- 最低でもPageSizeBits+1必要で、下回るとFasterLogインスタンス生成時にエラーが出る
- SegmentSizeBits
- オンメモリに乗らないデータを格納するファイルのサイズ
- 初期値は30(=1GB)
- LogCommitManager
- トランザクションを管理する
- リカバリ等も担当
- LogCommitFile
- デフォルトのLogCommitManagerを使う場合に使用するトランザクションファイルのベースパス
- GetMemory
- データ読出しの時に呼ばれるコールバック関数
- LogChecksum
- ログ整合性のためのチェックサムをどのように追加するか
- ファイルが壊れた場合に検知ができるため、データの重要度に応じてオンにしておく
- 本体データ+メタデータのXORを集計しているため、オーバーヘッドはそれなりに大きいと思われる
- None=チェックサム追加をしない、PerEntry=レコードごとにチェックサムを取得する
- デフォルト=None
生成されるファイル
FasterLogをnewした時点で、以下のファイルが生成される
- ログセグメントデータ:
[CreateLogDeviceで指定したファイル].[0始まり数字]
- データ本体が格納される
- 初期状態の場合、
2^[SegmentSizeBits]bytesのサイズをアロケートしようとするので注意(デフォルト1GB)- ログデータが
2^[SegmentSizeBits]を超えるたびに、新しくセグメントファイルを作成する- トランザクションファイル:
[CreateLogDeviceで指定したファイル].commit
- 論理的なアドレスの開始点、終点が書き込まれる
- サイズは常に36bytes
FasterLogSettings.LogCommitFileで生成パスを変更可能データを追加する
データの追加は以下のように行う
// FasterLog fl; // byte[] data; // ReadOnlySpan<byte>でも可 // Enqueueの時点ではまだ永続化はされない long recordAddress = fl.Enqueue(data); // コミットデータの永続化 fl.Commit(true);
Commitした時点でディスクに書き出される。
戻り値として、追加したデータの論理アドレスが取得できる。データを読み出す
データの読み出しは、C#8.0とそれより前でやり方が異なる。
共通事項
下記のように、
FasterLog.Scan([開始アドレス], [終端アドレス])を使用する。// FasterLog fl; // fl.Scan([論理開始アドレス], [論理終端アドレス])という風にして指定する using(FastLogScanIterator iter = fl.Scan(fl.CommittedBeginAddress, fl.CommittedUntilAddress)) { // enumeratorで走査 }ここでいう開始アドレスと終端は、全てのログを見るなら
FasterLog.CommittedBeginAddressとFasterLog.CommittedUntilAddressをそれぞれ指定すると良い。
全てのログを見たくない場合は、終端アドレスに、[開始アドレス] + [適当なバイト数]を指定する。走査中に、現在見ているログの論理アドレスを知りたい場合は、
FastLogScanIterator.CurrentAddress、次のエントリのアドレスを知る場合は、FastLogScanIterator.NextAddressを使用する。非同期(C#8.0)
IAsyncEnumerableを使用する。// FasterLog fl; // fl.Scan([論理開始アドレス], [論理終端アドレス])という風にして指定する using(FastLogScanIterator iter = fl.Scan(fl.CommittedBeginAddress, fl.CommittedUntilAddress)) { // dataの型はbyte[] // lenはデータ長(bytes) // 2019.11.18では二つだけだが、最新ソースでは更に long currentAddress も追加になる模様 // https://github.com/microsoft/FASTER/commit/bf657635374873958d96b31db1299b58ef9a17b1 await foreach(var (data, len) in iter.GetAsyncEnumerable()) { // データの参照 } }
FastLogScanIterator.GetAsyncEnumerable(CancellationToken ct = default)では、foreachの要素に単純にnewされたbyte[]を受け取るが、代わりにSystem.Buffers.MemoryPool<byte>のインスタンスを渡すと、メモリプール経由でバッファの確保を行うため、アロケーションが減らせる。
ただし、IMemoryOwner<byte>自体のアロケーションは避けられないため、ゼロではない。
また、使い終わったIMemoryOwner<byte>はDisposeを行わないと、メモリリークの原因になる。非同期(C#7.x以前)
FastLogScanIterator.[GetNext,NextAddress,WaitAsync]等を駆使する// FasterLog fl; using(FastLogScanIterator iter = fl.Scan(fl.CommittedBeginAddress, fl.CommittedUntilAddress)) { while(iter.NextAddress >= [終端アドレス]) { // データを取り出すまでループと待機を行う // 引数は、データ本体、データ長、現在のアドレスの三つ while(!iter.GetNext(out var entry, out var length, out var currentAddress)) { if(iter.NextAddress >= [終端アドレス]) { break; } await iter.WaitAsync(); } // データの参照 } }データの削除
データの削除には、
FasterLog.TruncateUntil(long untilAddress)またはFasterLog.TruncateUntilPageStart(long untilAddress)を使用する。TruncateUntil
TruncateUntilはデータの開始アドレス(BeginAddress)から、指定されたアドレス直前までのデータを削除するという挙動である。
注意点として、レコード境界ではない中途半端なアドレスを指定すると、次回のScan時にエラーが出るという仕様がある。回避するには、末尾アドレス(FasterLog.TailAddress)を指定するか、下記のようにScanの途中で得たNextAddressで、正確なレコード境界を取得して指定するというやり方がある
// FasterLog fl; long untilAddress = 0; using(var iter = fl.Scan(fl.BeginAddress, [終端])) { await foreach(var x in iter.GetAsyncEnumerable()) { // 処理 untilAddress = iter.NextAddress; } } fl.TruncateUntil(untilAddress); // 最後にCommitすると変更が反映される fl.Commit(true);より安全に、かつ大雑把に消したい場合は、後述の
TruncateUntilPageStartを使用するTruncateUntilPageStart
TruncateUntilPageStartはデータの開始アドレスから、指定されたアドレスに紐づくページの直前までを消去するという挙動である。
レコードはページをまたぐことは仕様上ないため、TruncateUntilで起こったような問題は起きない。
ただし、正確な消去はできないため、大雑把にログローテーション等をしたい場合に使うと良いだろうパフォーマンス上の注意点
追記、削除する時は、操作後にコミットを行い永続化する必要があるが、コミットはFasterLogの中で最もコストのかかる処理だという事を念頭に置いた方が良い。しかし、コミットしないとデータが永続化されないので、信頼性が下がる。悩ましいところである。
つまり、より高速にデータを処理したい場合は、信頼性を下げずにいかにコミット回数を減らすかということを考える。ではどうすればいいか。以下のようなやり方を一例として示そうと思う。
Commitタスクを独立させる
箇条書きにすると以下のような動作になる
- 追記タスクを並列化する
- 追記タスクは、自分の書き込みが完了するまでWaitForCommitAsyncで待機する
- 追加で、一つだけひたすらコミットだけするタスクを作成する
- 追記タスクは、コミットタスクに自分が追記したレコードのアドレスを渡す
- コミットタスクは、現在のコミット済み終端アドレスと受け取ったレコードアドレスを比較して、未コミットと判断したら、コミットを行う
タスク間のデータ受け渡しは、
System.Threading.Channelsが使えると思う。追加されたデータが永続化されるまで待機する
さて、このやり方では、追記とコミットが別タスクで行われる状態になる。しかし、要件によっては、データ消失を可能な限り避けるため、自分で追加したデータが、確実に永続化されたかどうか確認する必要が出てくる。
そこで、FasterLog.WaitForCommitAsync(long address, CancellationToken ct)を使用する。
引数にはFasterLog.Enqueueで得たアドレスを指定する。
これを使うと、指定されたアドレスがコミットされたと判断されるまで(address <= CommittedUntilAddressになるまで)待機が発生する。コード例
具体的には、少々長くなるが以下のようなコードになる。
using System; using System.Threading; using System.Threading.Tasks; using System.Threading.Channels; using FASTER.core; using System.IO; using System.Linq; namespace fasterlabs { static class FasterLogCommitTest { static long EnqueueData(long value, FasterLog fl) { Span<long> data = stackalloc long[1]; if (fl.TryEnqueue(System.Runtime.InteropServices.MemoryMarshal.AsBytes(data), out var logicalAddress)) { return logicalAddress; } else { return -1; } } public static async ValueTask DoTest(int TaskNum) { const long TotalCount = 100000; // ensure using cleared data if (File.Exists("logcommittest.log.0")) { File.Delete("logcommittest.log.0"); } if (File.Exists("logcommittest.log.commit")) { File.Delete("logcommittest.log.commit"); } var log = Devices.CreateLogDevice("logcommittest.log"); var channel = Channel.CreateUnbounded<long>(); using (var fl = new FasterLog(new FasterLogSettings() { LogDevice = log })) { var sw = new System.Diagnostics.Stopwatch(); sw.Start(); using (var csrc = new CancellationTokenSource(1000 * 240)) { await Task.WhenAll( Task.WhenAll(Enumerable.Range(0, TaskNum).Select(async idx => { long logicalAddress = 0; try { for (int i = 0; i < TotalCount / TaskNum; i++) { logicalAddress = EnqueueData(i + idx * TotalCount, fl); await channel.Writer.WriteAsync(logicalAddress, csrc.Token).ConfigureAwait(false); await fl.WaitForCommitAsync(logicalAddress, csrc.Token).ConfigureAwait(false); // Console.WriteLine($"{idx}, {i}, {logicalAddress}"); } } catch (Exception e) { Console.WriteLine($"producer error({idx}, {logicalAddress}, {fl.CommittedUntilAddress}, {fl.TailAddress}): {e}"); } // Console.WriteLine($"exit producer({idx}, {sw.Elapsed})"); })).ContinueWith(t => channel.Writer.Complete()), Task.Run(async () => { int commitCount = 0; try { while (true) { if (!await channel.Reader.WaitToReadAsync(csrc.Token).ConfigureAwait(false)) { break; } while (channel.Reader.TryRead(out var untiladdr)) { if (fl.CommittedUntilAddress <= untiladdr && fl.CommittedUntilAddress != fl.TailAddress) { fl.Commit(true); // await fl.CommitAsync(csrc.Token).ConfigureAwait(false); commitCount++; } } } } catch (Exception e) { Console.WriteLine($"consumer error:{e}"); } Console.WriteLine($"exit consumer({commitCount})"); }).ContinueWith(t => { if(fl.CommittedUntilAddress != fl.TailAddress) { Console.WriteLine($"last commit"); fl.Commit(true); } }) ).ConfigureAwait(false); sw.Stop(); Console.WriteLine($"Multi({TotalCount}, {TaskNum}): {sw.Elapsed}, iops = {(TotalCount * 1000) / sw.Elapsed.TotalMilliseconds}"); } } log.Close(); } } }バージョン2019.11.18.1より前のバージョンでは、
CommitAsyncするとWaitForCommitAsyncとスレッドプールの消費が競合して、デッドロック状態になる場合があるので注意すること。(該当github issue)終りに
今回はログ向けストレージ機能を持つFasterLogを紹介した。実際制約もあるので、あらゆる場面で使用できるわけではないが、それでも他には無い特徴を持っているため、役に立つ場面では役に立つと思われる。
機会があれば、コミット回数や並列数を変えて性能テスト等を行ってみたい。また、近く大幅なPRが来る予定なので、その辺りが来たらまたこの記事を更新したい。
参考リンク
- 投稿日:2019-11-12T17:02:10+09:00
ASP.NET Core MVC 階層化アーキテクチャ Chap4 (データアクセスオブジェクトを抜き出しModel層を作成する)
前回のコンテンツASP.NET Core MVC 階層化アーキテクチャ Chap3 (個別Repositoryで独自処理を実装する)までの内容は、Repositoryパターンを用いて、Controllerからデータアクセスのオブジェクトを分離することまで出来ました。
今回は新しくプロジェクト(Model層)を作成して、その中にデータアクセスのオブジェクトをまとめる作業を行います。
そうすることで、Web層とModel層の責務がハッキリ分離することができます。
- Web層 : リクエスト処理とデータ表示
- Model層 : データアクセス
前提
このコンテンツで扱うこと
- dotnet cli で新規プロジェクトの作成&参照の設定
開発環境
環境/ソフトウェア 内容 オペレーティングシステム Windows 10 1903 .NET Core SDK 3.0.100 IDE Visual Studio Code 1.39.1 Browser Google Chrome 78.0.3904.70 dotnet cli で新規プロジェクトの作成
ソリューションフォルダ配下にて以下のdotnetコマンドを実行してください。
# 新規プロジェクト作成(クラスライブラリ) dotnet new classlib -f netstandard2.1 -n ds.NorthwindApp.Modelds.NorthwindApp.Modelのフォルダ配下に移動して、以下のコマンドを実行します。
## Ef Coreのモジュール追加 dotnet add package Microsoft.EntityFrameworkCore.Design dotnet add package Microsoft.EntityFrameworkCore.SqlServerdotnet cli で参照の追加
再度ソリューションフォルダ配下に移動して、以下のコマンドを実行します。
## ソリューションにプロジェクトを追加 dotnet sln add ds.NorthwindApp.Model ## WebプロジェクトがModelプロジェクトを参照するように追加 dotnet add ds.NorthwindApp.Web/ds.NorthwindApp.Web.csproj reference ds.NorthwindApp.Model/ds.NorthwindApp.Model.csprojデータアクセスのオブジェクトの移動
WebプロジェクトのModels配下のクラスをすべてをModelプロジェクトに移動します。
名前空間の置き換え
名前空間を書きどおりに置き換えを行います。
置き換え前 置き換え後 ds.NorthwindApp.Web.Models ds.NorthwindApp.Model 最後にプロジェクトをビルドして、動作確認を行います。
まとめ
通常、開発案件の初期段階でアーキテクチャ設計がすでに決まっています。
このように途中でプロジェクトを作成して、レイヤー分けをすることはあんまりしません。また、プロジェクトは必ずしも分ける必要はありません。
システム規模が小さければ、フォルダをきちんと分ければそれだけでも十分です。しかし、規模が少しでも大きくなるとオブジェクトの責務ごとに別々のプロジェクトに分けるようが構造がわかりやすいし、
メンテナンスもしやすいです。備考
今回作成したソースコードです。
では!!( `ー´)ノ

- 投稿日:2019-11-12T12:40:05+09:00
[Unity] [SkinnedMeshRenderer] Humanoidで使われるMesh
Humanoidで使われるMeshに関する情報をまとめておきます。
Humanoidで使うということでboneへウェイトが塗られていたり, blendShapeが設定されていたりするものを想定しています。
(このようなMeshは毎フレーム、ボーンの変化に対する頂点位置の計算などをする必要があるのでMeshRendererではなく必ずSkinnedMeshRendererに設定されている必要があります)Mesh
Mesh 公式リファレンス
SkinnedMeshRenderer.meshとSkinnedMeshRenderer.sharedMeshから取得できるが
前者はそのオブジェクト特有のメッシュで、変更しても他に影響がない
後者は変更によって同じメッシュを共有するオブジェクトに影響を与えるこれを変更しただけではUnity再起動時に初期化されてしまうので
新しいMeshアセットとして書き出しておく必要があります。vertices
verticesに頂点の位置(Vector3)が入っている
vertices.Lengthが頂点数メッシュ内のローカル座標なのでワールド座標として扱いたい場合はTransform.TransformPoint(Vector3 localPosition)で変換する
normals(法線), uvs(uv情報), boneWeights(ウェイト情報)はindexでverticesと対応させている
normals.Length == uvs.Length == boneWeights.Length == vertices.Lengthtriangles
trianglesはverticesのindex情報を持っている
(3つの頂点で1つのポリゴンとしているため, triangles.Lengthは3の倍数)
([0, 1, 2]や[3, 4, 5]が一つのポリゴン)
Unityでは時計回りがポリゴンの表であるSubMesh
小さなメッシュの単位。1つのSubMeshには必ず1つのマテリアルが適応されている
Meshのマテリアル数==submeshの個数==Mesh.subMeshCountMesh.GetIndices(int submesh)で特定のSubMeshに所属する頂点のindex配列を取得できる
(頂点そのものの情報ではない。あくまでMesh.verticesと対応付けられたindex)
SkinnedMeshRenderer.sharedMaterialsで得られるMaterials配列のindexを引数に入れるとそのMaterialsに対応したSubMeshの情報を取得できる
頂点以外にもポリゴン(Mesh.GetTriangles(int submesh))なども取得できるboneWeights
SkinnedMeshRendererしか持ちえない
boneIndex0~3はSkinnedMeshRenderer.bonesのindex情報を持っている
weight0~3はウェイト情報(0~1)
Mesh.boneWeightsで得た配列を変更した場合元データも変わってしまうため,
元は変更させたくない場合はMesh.GetBoneWeights(List boneWeights)を使うblendShape
SkinnedMeshRendererしか持ちえない
SkinnedMeshRenderer.blendShapesで取得可能存在するblendShapeの名前や変化量の変更はできないので
Mesh.ClearBlendShapesで一度削除して
新しい名前や変化量を設定してMesh.AddBlendShapeFrameで作成する必要がある関連リンク・参考
http://edom18.hateblo.jp/entry/2017/06/09/080802
https://qiita.com/keito_takaishi/items/8e56d5117ee90502e864
- 投稿日:2019-11-12T11:18:55+09:00
[C#] mp3ファイルを再生する
もくじ
→https://qiita.com/tera1707/items/4fda73d86eded283ec4fやりたいこと
WPF(.net Framework4.7)のアプリで、mp3のサウンドファイルを鳴らしたい。
やりかた
Windows Media Playerを使用する。
具体的には、C:\Windows\System32\wmp.dllを使用する。手順
下記のようにする。
- プロジェクトの参照に、
C:\Windows\System32\wmp.dllを追加する。- 使用するcsの先頭に
using WMPLib;を追記する。- 下記のサンプルのように、WindowsMediaPlayerクラスを使用し音声再生を実装する。
サンプル
using System.Windows; using WMPLib; namespace WpfApp38 { public partial class MainWindow : Window { // メディアプレーヤークラスのインスタンスを作成する WindowsMediaPlayer _mediaPlayer = new WindowsMediaPlayer(); public MainWindow() => InitializeComponent(); private void Button_Click(object sender, RoutedEventArgs e) { _mediaPlayer.URL = @"sound.wav";// mp3も使用可能 _mediaPlayer.controls.play(); } } }※今回試した時は、音声ファイルはプロジェクトの直下に「追加」して、「出力ディレクトリにコピー」の設定を「常にコピー」にして使用した。
そうすれば、ビルドするとexeと同じところにコピーされて、ファイル名だけ指定する形で使用できた。他のやり方
音を鳴らす方法は、他のやり方もある様子。こちらのページがとても分かりやすい。
https://qiita.com/Oichan/items/b93e8e8ba8211b925d0aできれば、
.NETの標準で用意されたものでやりたいので、上記記事にある「System.Media.SoundPlayer」でやりたい。いずれ試す。(mp3が使えないようだが...)参照
第01回 プロジェクト作成と曲再生
https://www.usefullcode.net/2016/03/01_createproject.htmlC#でサウンドを鳴らす
いくつかの方法が説明されている。
https://qiita.com/Oichan/items/b93e8e8ba8211b925d0a
- 投稿日:2019-11-12T10:52:19+09:00
[C#] デストラクタとDisposeについて
もくじ
→https://qiita.com/tera1707/items/4fda73d86eded283ec4fDispose関連
- 【C#】Disposeとは?
- [C#] デストラクタとDisposeについてやりたいこと
Disposeできるクラスを書くためにIDisposableのインターフェースを実装しようと思い、IDisposableでAlt+Enterを押し、「Disposeパターンを使ってインターフェースを実装します」を選択して、出てきたコードの中に「上の Dispose(bool disposing) にアンマネージ リソースを解放するコードが含まれる場合にのみ、ファイナライザーをオーバーライドします。」という文言が、自分が「デストラクタ」だと思っているもの(~MyClass()のところ)に書かれているのを発見。
デストラクタ?ファイナライザ?これって何が違うのか?
あとDispose()の中でDispose(bool)を読んだりしているが、なんでそんなもの分けて作ってるのか?
ファイナライザ?の中で呼んでいるDispose(false)は何なのか?となったので、それぞれどういうものなのかはっきりしたい。しらべたこと
はっきり言って、100%は理解できてない。主に
- 「デストラクタ」と「ファイナライザ」の違いはなにか?
- C#でDisupose()をちゃんと実装するには?
ということを調べたので、現状の理解をまとめておく。
中途半端な内容で恐縮ですが、間違いなどあれば、ご指摘頂ければ幸いです。用語としてのファイナライザー
多くの場合、下記のようなものを指す。
- GCに回収された時点で呼ばれるメソッド。
- 自分で呼ばれるタイミングを制御できない。
用語としてのデストラクタ
多くの場合、下記のようなものを指す。
- newしたものをdeleteしたときに呼ばれるメソッド。
- そのため、自分で呼ばれるタイミングを制御できる。
C#のファイナライザー
- C#にはファイナライザーを書く書き方(文法)「は存在しない。なので存在する(書ける)のはデストラクタのみ。
- C#では、MyClassクラスであれば「~MyClass()」と書いてデストラクタとなる。これが、GCに回収されるときに呼ばれるメソッドとなる。(ファイナライザ的な動作をする)
- ++C++のサイトでは、これのことを「デストラクター」と呼んでいる。こちら参照。
- C++/CLIには、デストラクタとファイナライザの両方を書く文法があるが、C#はデストラクタのみ。
- VisualStudioでIDisposableインターフェースを実装するときに「Disposeパターンを使ってインターフェースを実装します」を選択してでてくるコードのコメントの中ではこれのことを「ファイナライザ」と呼んでいるので、混乱してしまう。
- C++のデストラクタとC#のファイナライザー(の役割をするデストラクタ)の書き方が同じなので、また混乱してしまう。
- javaに、finalizeメソッドというのがあり、それが「GCに回収された時点で呼ばれる」メソッドである。C#の
ファイナライザーデストラクタはそれと同じような動きをする。C#での実装方法
- Disposeについて
- Disposeできるクラスを作成するには、IDisposableインターフェースを実装する。
- 基本的には、Disposeは、例えばFileStreamクラスを使用して開いたファイルを使い終わったら閉じる、のように、ユーザーが自分のタイミングで使ったリソースの占有を止めるときに呼ぶものである。
- これを便利に書く書き方が、
using()である。(usingが終わったら、書かなくてもDisposeしてくれる)IDisposableの実装について
- 自分でDisposeできるクラスを実装するときに、ALT+ENTを押して「Disposeパターンを使ってインターフェースを実装します」を選ぶと、Disposeパターンを自動で書いてくれる。
- その中のDispose(bool)について、
- Dispose(true)が、Disposeで呼ばれるメソッドになる。(なる、というか、そのようにする)
- Dispose(false)が、デストラクタ(やってることとしてはファイナライザ)で呼ばれるものになる。(する)
- こちらが詳しい。
- やっている内容としては、マネージ/アンマネージのリソースの後処理。下記の通り。
マネージ/アンマネージの解放について
- デストラクタ(~MyClass()と書くやつ)には、
- マネージリソースの解放処理を書かない。
- アンマネージリソースの解放処理を書く。
- ※デストラクタでDispose(false)を呼んだ時に、これをするように作る。
- Disposeの実装には、
- マネージリソースの解放処理を書く。
- アンマネージリソースの解放処理も書く。
- ※Dispose(引数なし)でDispose(true)を呼んだ時に、これをするように作る。
アンマネージのリソースをデストラクタにも書くのは、(もしDisposeでの開放が行われなかった場合でも)確実に開放を行うため。
アンマネージドのリソースが無い場合は、デストラクタを書かなくてもよい。(Disposeパターンで出てくるひな形の通り、コメントアウトでOK)
備考
知りたいことは、下の「参考」のところに書かせて頂いたページにすべて書いてあるのだが、自分の現状の理解をまとめたかった次第。
参考
MsDocs デストラクタについて
https://docs.microsoft.com/ja-jp/dotnet/csharp/programming-guide/classes-and-structs/destructorsMsDoscs ファイナライザーについて
https://docs.microsoft.com/ja-jp/dotnet/csharp/programming-guide/classes-and-structs/destructors
→「ファイナライザー」の別名が「デストラクタ」だと言ってる。デストラクター(++C++)
https://ufcpp.net/study/csharp/resource/rm_destructor/IDisposable インターフェイスの実装
https://ufcpp.net/study/csharp/rm_disposable.html?sec=idisposable#idisposable
>「IDisposable インターフェイスの実装」の項目。C# のファイナライザ、Dispose() メソッド、IDisposable インターフェースについて
https://qiita.com/Zuishin/items/9efc9c8cbb98300bbc64デストラクタ
Wikipedia。ここでファイナライザについても言及されている。
https://ja.wikipedia.org/wiki/%E3%83%87%E3%82%B9%E3%83%88%E3%83%A9%E3%82%AF%E3%82%BF
>「ファイナライザ」の項を参照。短い文章だが、なんかしっくりきた。

- 投稿日:2019-11-12T09:16:12+09:00
.NET CORE でXunitで単体テストをする
関わっている案件が半年ほど前に変わり、単体テストを作りながら実装するようになって思ったことをまとめます。
そもそも単体テストとは
Googleで「単体テスト」で検索するとトップに出てきた記事の引用です。
単体テスト(ユニットテストと呼ばれることもあります)は、プログラムを構成する比較的小さな単位(ユニット)が個々の機能を正しく果たしているかどうかを検証するテストです。
通常、関数やメソッドが単体テストの単位(ユニット)となります。 プログラムが全体として正しく動作しているかを検証する結合テストは、開発の比較的後の段階でQAチームなどによって行なわれることが多いのとは対照的に、単体テストは、コード作成時などの早い段階で開発者によって実施されることが多いのが特徴です。
https://www.techmatrix.co.jp/t/quality/unittest.html書いてみる
環境
- Visual Studio Code 1.40.0
- dotnet core 2.2
- Moq 4.13.1
- 拡張機能 .NET Core Test Explorer
テスト
public class TargetClassTest { [Fact(DisplayName = "名前が生成される")] public void Test1() { var mockservice = new Mock<IService>(); mockservice.Setup(x => x.Exist(It.IsAny<string>())).Returns(false); var target = new TargetClass(mockservice.Object); var response = target.CreateName("hogehoge"); Assert.True(response == "Test.hogehoge"); } [Fact(DisplayName = "登録済みのためエラー")] public void Test2() { var mockservice = new Mock<IService>(); mockservice.Setup(x => x.Exist(It.IsAny<string>())).Returns(true); var target = new TargetClass(mockservice.Object); var ex = Assert.Throws<Exception>(() => { return target.CreateName("hogehoge"); }); Assert.True(ex.Message == "already exist."); } }テスト対象
/// <summary> /// テストするクラス /// </summary> public class TargetClass { private readonly IService service; public TargetClass(IService service) { this.service = service; } public string CreateName(string name) { if (service.Exist(name) == true) throw new Exception("already exist."); var result = $"Test.{name}"; return result; } } /// <summary> /// Injectionされるサービス /// </summary> public interface IService { bool Exist(string name); }要点
- アトリビュートでテストの内容がファイルを開かなくてもわかるように記述
- DIされるサービスはMockを使用してテスト項目は対象クラスのみに限定する
- Assertでレスポンスが期待値か確認する
- Exceptionを発生させる場合は、Throwsで何のExceptionか指定して受け取り、Message等を確認する
最後にテストの必要性
「対価」の有無で決まると思います。
クライアントがいて納品が発生するならテストは必要でしょうし、自身の業務の効率化・自動化のためのツール程度であれば不要。
(後者はテストしたいならしてもいいと思います)テストは引用の中にもあるように「機能を正しく果たしているかどうか検証する」ことを目的としているので、
「テスト」≒「設計」 であることを忘れないようにしたいです。
- 投稿日:2019-11-12T05:02:18+09:00
C#大統一理論
C#大統一理論とは
CySharpのneueccさんが提唱している理論で、ザックリ言えば
サーバーサイドもクライアントサイドもC#で完結できるとよくね?
という理論です。
そして現状サーバーサイドとクライアントサイドの両方で使える言語はC#を除くとJavaScriptくらいだと思います(なんかあったら教えてください)
C#でクライアントサイドを作るにはXamarinやゲームエンジンのUnityが筆頭になります。
C#のよさ
いろいろありますが、個人的に上げるなら
- 比較的言語が若く(C++と比較して)、LINQなどモダンな文法仕様が遂次追加されている(というかLINQは単独で良い)。
- 単純に.NET Coreがクラスプラットフォームで安定して動作する。マイクロソフトが本気を出してるからサーバーサイド、クライアントサイドから機械学習まで使える範囲がめちゃくちゃ広い。
- decimalみたいな型までサポートしていて、業務利用での実用性を重視している。
静的型付けは義務であり利点ではありません。
C#に統一することのメリット
単純に言語を統一したほうが楽
一時期はやったMEAN(すべてJavaScriptに統一する奴)みたいなやつです。MEANと違って.NET Coreで環境を統一できればクライアントサイドエンジニアがサーバーサイドエンジニアのプログラムに携わることも比較的容易です(学習コストが0というわけではありません)サーバーサイドとクライアントサイドでデータを受け渡す方法に悩まない
これは完全にMagicOnionの受け売りです。jsonで渡す?postに載せる?REST?gRPCってめっちゃだるくね?みたいな問題をある程度マシにしてくれます。
なぜ広まらないのか
- .NET Core以前の.NET環境がWindows依存
LAMP環境が流行ったころにMicrosoftはWISP(Windows, Internet Information Services, SQL Server, なんかの言語)を提唱していたり、完全にWindows依存な環境の時代が長かったのが原因の一つとして挙げられると思います。
C#に入門するなら
プログラミング経験者は「実戦で役立つ C#プログラミングのイディオム/定石&パターン」https://gihyo.jp/book/2017/978-4-7741-8758-7 を買いましょう。とても良き
- 投稿日:2019-11-12T02:23:39+09:00
Clean Architectureの実践から多くを学んだ記録
はじめに
素晴らしい記事を読む
⇒ カッコイイ!
⇒ 採り入れる
⇒ 実際にやってみたらナゾだらけだぞ?
⇒ 理解した
の過程を共有します。
原本読んでないので、実践ベースです。間違ってたら指摘ください。
実際のソースコードも作ってみた(現在作成中)ので、参考にしてください。
採り入れた範囲
Webアプリケーションのバックエンドに取り入れました。
図だとこんな感じです。
HTTP 呼び出し 呼び出し フロント <----> コントローラー --> ユースケース --> リポジトリ | | 呼び出し | └> プレゼンター
- コントローラー -> WebAPIのルーター
- ユースケース -> ドメインロジック
- リポジトリ -> 外部へのアクセス
- プレゼンター -> PDF出したり
という感じで、ノリで作成しましたが
深まるナゾ
- プレゼンターって「表示」に使うなら、ここでの「フロント」ってどういう立ち位置なんだ?
- まあPDF作成はそれっぽいからいいとして、、
- と、とりあえずコントローラーから帰ってきたデータを、Reactでパリッと表示しておけば、、
- リポジトリからDBアクセスしてデータ返す時点で、どこまで絞リ込みしていいんだ?
- データ絞り込むしかないか。。。
- ドメインロジック入っちゃうやん。。。
- でも全件取得はパフォーマンスが。。。
- 最後に残った「ドメインロジック」とは一体なんだったのか?ただの残りかすなのか。。。?
⇒ 深まるナゾ。。。となり、
ここで自分のやってきたことに不安を覚え始める。。。そして
DDDの記事に出会う
皆さんはソフトウェア設計をする際に、なにをしますか?
僕にとっての正解は、ドメインモデリングです。
というのは、この素晴らしい記事を読んで、そう思ったからです。
https://little-hands.hatenablog.com/entry/2018/10/08/goal-of-ddd
この時点で、モデリングした結果できたものは、Clean Architectureにおける「エンティティ + ユースケース」にほぼ同義なんじゃないか?とか考えだす。
そして、モデリングしたドメインを継続的に、ソフトウェアに反映し続ける。。。
この響き。。。ムム!?アジャイル!?お前アジャイルじゃないか!?
アジャイルと絡めて、考えだす
アジャイルな開発をやっているとよく出てくるのが、ユーザーストーリーとかペルソナとかのツールが出てきます。(実際はWFとかでも使えます)
ここで詳しく書くつもりはないんですが、あれらは要求分析ツールのようなもので、
ユーザー自身・顧客の中で、まとまっていない抽象的な要求、というか「想い」みたいな、ざっくりしたものを具体的にしていくときに使ったりします。
こうしてできたものが、ドメインにおいてソフトウェア化によって解決すべき問題になります。
要求からブレークダウンしよう
今まで、さっき述べたような「問題」が発生するたびに、僕はこう考えてきたわけです。
- ええと、その項目ってDBにあったっけっか
- どうやって取得しよう
- パフォーマンスは…
いわばリポジトリから作ってきたようなものです。
でもそうすると、リポジトリに
GetAllData()とかいう良くわからんメソッドを作ってしまうわけです。ユーザーの「僕は、期限内のTODOをみたいんだけどなぁ」という要求を考えてみましょう。
もうちょっと突き詰めておきましょう。
僕「TODOの何を見たいですか?」
ユーザー「名前と発行日とあとそれから~~~」
僕「とりあえず最低限でお願いします」
ユーザー「名前と発行日は必須です!」
僕「名前だけじゃだめですよね?」
ユーザー「発行日がないと、さすがに使い物にならんわ。。。」
僕「そうっすね。。。今後さらに項目が必要なら、ユーザーストーリー考えましょう。」
ユーザー「はい。」
以上のやりとりは、ユーザーストーリーを分割したかったりするときにします。
分割すると、範囲が狭まる分、目的が明確になります。
目的が明確 = 「ドメインロジックの特化」
なので、ユーザーストーリーの分割とは実はドメインロジックの特化そのものなのです。
この部分が特化されていない=目的があいまいだと、ドメインロジックが複雑になってしまうので気を付けましょう。
コントローラーをつくる
ええと、僕=tanakaだとしたら、
/tanaka/todoとかで、tanakaの期限内のTODOが取れて、画面にリストで出るところまで考えたとしましょう。コントローラーでは、HTTP通信のエンドポイントの定義と、パラメータのフォーマットチェックとかをして、問題なさそうならユースケースを呼び出します。
この時、複数のユースケースを使っていいかというと、たぶんいいんだと思います。ファサードっていうんですかね。
あと、ユースケースとかリポジトリでエラーを
throwして、コントローラーでcatchして、HTTPステータス400番代とかで返したりします。これで、
Input/Output/Errorというインターフェース3大要素をケアできました。ユースケースをつくる
「期限内のTODOを取得する」ので、それをそのままメソッドにします。
IntimeTodo GetIntimeTodo(string userId)を作ります。この時、Todo GetTodo(string userId, bool intime)とか作ると失敗します。
intime=falseとかで「期限外」が取れるケースなんて考えるのはやめましょう。たぶん欲しくなるのは「期限外」じゃなくて「完了済み」とか「期限切れ(完了は含めない)」とかですよね?
そのたびに、
CompletedTodo GetCompletedTodo(string userId)とかExpiredTodo GetExpiredTodo(string userId)とか作りましょう。
IntimeTodoとCompletedTodoって、Todoじゃだめなの?って思うかもしれませんが、恐らくIntimeTodoには「完了日」が存在しないので、別々にしといてあげた方が余計な属性値の容量でネットワークを圧迫するリスクを回避できるかもしれません。「Todo名・発行日」が必要なので、UseCase Output Portはこんな感じ。
namespace TodoApp.UseCase.Todo { internal class IntimeTodo { internal string Name { get; set; } internal DateTime IssuedDate { get; set; } } }YAGNI然り、「必要そうだから」という理由でドメインロジックのバリエーションを増やすと失敗します。
要らなかったものを作る=コード・テストパターンが増える=コストになってしまいます。
オーバーロードを活用したい人は、
IntimeTodo GetTodo(Intime input)とかにして、namespace TodoApp.UseCases.Todo { internal class Intime { string userId { get; set; } } }としてあげましょう。
言い過ぎかもしれませんが、ドメインロジックの汎用性のことは考えるのをやめてもいいくらいです。目的に特化しましょう。
目的が同じで使いまわせたら「ラッキ~!」くらいで十分です。たぶん。
リポジトリをつくる
TodoクラスとList<Todo> GetTodo()1を作る。以上。Todo.csnamespace TodoApp.Gateways.Todo { internal class Todo { internal string Name { get; set; } internal DateTime IssuedDate { get; set; } } }でもそうすると、リポジトリに
GetAllData()とかいう良くわからんメソッドを作ってしまうわけです。とか言ってたくせに、全件取得して満足してみます。
だって今のところ、tanakaのTODOリスト全件取得するだけなんですから。
tanakaのTODOリストが全部で、1万件あるでしょうか?
もしそうなら、tanakaさんのペルソナに「俺は、多忙すぎてTODOが日に1000個追加される」と書き忘れたのは誰だ!とキレるところです。
あ、でもtanakaの分取りたいのに、suzukiのリストはさすがにいらないですね ⇒
GetTodo(string userId)これなら、今後
GetCompletedとかGetExpiredとかユースケースが増えても、Todoクラスを拡張して自動テスト流せば、GetIntimeTodoは動作が保証されますね。このようにリポジトリは、ユースケースとは逆に「汎化」を意識すべきだと僕は思います。
ですが、画面には1000件分のデータの統計情報しか要らないのに、全件取得だと10万件取ってくるような場合、パフォーマンスがままならないときはあります。
たとえば、全ユーザーの登録しているデータの中から、「指定した日付で発行されたTodoの情報を見たい」場合です。
「日付での絞り込み」は当然ユースケースの責務なのですが、もしかしたら1万人 × 平均50件=50万件のデータを全部とってきて、メモリ上で日付の絞り込みをかけるのは、パフォーマンス的によろしくないかもしれません。
そういった場合は、
List<Todo> GetTodo(string userId)とは別に、List<Todo> GetTodo(string userId, DateTime issuedDate)という風に、引数で取れるデータをフィルターできるようなメソッドを追加してあげましょう。ただ「完了日で絞り込み」メソッドを追加するとき、
List<Todo> GetTodo(string userId, DateTime completedDate)になり、オーバロードができないので、
List<Todo> GetTodo(string userId, IssuedDateFilter filter)としてあげればよいかと思います。namespace TodoApp.Gateways.Todo { internal class IssuedDateFilter { DateTime issuedDate { get; set; } } }また、上のような例の場合は、テーブルの「発行日」列にインデックスを張るのを忘れずにしましょう。
どうでしょうか。これで後から、
「なんで発行日の絞り込みのリポジトリ作ってあるの?」 → パフォーマンス劣化を防ぐためですよ~というリポジトリの責務が果たすべきDBへのアプローチを表現できています。
「発行日で絞り込みたいな~」→ これ使いな!つ
List<Todo> GetTodo(string userId, IssuedDateFilter filter)という風にできます。
え?間違えて全件取得の方を使ってパフォーマンスが劣化したらどうするかですか?
パフォーマンステストしろよコメントや、Warningを出す属性とかつけて、リントを工夫するといいかもしれませんね。
結局フロントとはなんなのか
(作成中)
ドメインの変化に強いアプリにするのだから、ドメインの変化を大事にしよう
実はここまでで書いたコードは(たぶん)SOLIDに違反していません。
顧客の要求を細分化し、反復的・継続的にソフトウェアに反映していき、その際に必要な階層化をClean Architectureにより実践することで、自然と変化に強いアプリケーションができるのです。
近頃は、DevOpsとかDesignOpsなど騒がれていますが、本来ソフトウェア開発とは始めから終わりまでシームレスで、お互いに依存し、切っても切り離せないものだと思っています。
そこを認め、関係する当事者が協調して開発していくことが必要なのだと強く感じます。
そして少なくとも、顧客は変化への対応を求める生き物だと僕は思っています。
顧客と協調し、良いアプリケーションで利益を得ていくためにも、変化に強いアプリケーションを作れるようになることは、エンジニアとしての必須スキルと言えるでしょう。
さいごに
最初に言った通り「Clean Architecture」の本は、読んでないのだけれども調べてみたら著者がすごい人でした。
Robert C. Martinさん
「セカンドボブ」という、某スポンジのようなあだ名を付けられた神です。
アジャイル宣言まで宣言しているうえにあの「SOLID原則」のネタ元となる原則をぶちかましまくった超人らしいです。2
僕なんて、この5つのうちDを理解するだけでも結構かかったのに。。。
きっと僕みたいな奴に対して、SOLIDの概念が伝わらなくて伝わらなくて悔しくてClean Architecture書いたのでしょう。ごめんなさい。最初疑っちゃいました。そしてありがとうございます。
よくよく考えると、SOLIDのDとかってきっと、リポジトリから作ってた今までの制御を逆転させて、上位モジュールから作っても、下位に依存せずにテストできるようにするテクニックですよね。
そう考えると、要求をブレークダウンするClean Architectureに対するアプローチは正しいんじゃないかなと思ってます。
こうしてClean Architectureを実践することで、SOLIDを理解させてくるあたり、さすがはボブおじさんです。
IEunmerableとか.NETユーザー以外にはわかりづらそうなので、Listになってます。 ↩