- 投稿日:2019-07-14T23:13:44+09:00
OpenCVの勉強③(分類器を作成してみる)
OpenCVの勉強、第3回です。
前回は予め準備されているカスケード分類器を使ってオブジェクト検出をしましたが、
今回はカスケード分類器を自作してみたいと思います。目標
テニスボールを検出できるカスケード分類器を作る。
作業フォルダの準備
分類器を作成する作業フォルダの作成と、必要なファイルの準備をします。
<DIR> cascade <DIR> neg <DIR> pos <DIR> vec opencv_annotation.exe opencv_createsamples.exe opencv_ffmpeg346_64.dll opencv_interactive-calibration.exe opencv_traincascade.exe opencv_version.exe opencv_version_win32.exe opencv_visualisation.exe opencv_world346.dll opencv_world346d.dllフォルダ
まず親フォルダを作成(私の場合はD:\opencvcascadeとしました)。
その中に「cascade」「neg」「pos」「vec」というフォルダを作成します。ファイル
exeファイルとdllファイルは、学習済みの分類器をOpenCVの公式サイトからダウンロードします。
* 上部にある「Releases」から、OpenCV - 3.4.6(※)の「Win Pack」をダウンロード
* ダウンロードしたファイルを解凍
* \opencv346\build\x64\vc15\binの中に必要なファイルが入っていますので、exeファイルとdllファイルを作業フォルダにコピーしてください。※OpenCV – 4.1.0以降は、「opencv_createsamples.exe」と「opencv_traincascade.exe」が入っていないため、OpenCV3以前のものをダウンロードします。
画像ファイルの準備
機械学習をするための画像ファイルを準備します。
精度を高めようとすると、正解データ7000枚、不正解データ3000枚程度が必要らしいですが、この場は分類器作成の手順を優先して、正解データ約70枚、不正解データ約60枚で進めたいと思います。不正解画像
negフォルダの中に、正解を含まない画像を保存します。正解を含まなければ何でもいいです。
私はオンラインプログラミング教室で配布された犬猫画像を保存しました。
正解画像
posフォルダの中に、正解画像を保存します。
(この後の作業で、poslistにファイル名と正解の場所を記入するという作業があります。画像ファイルの大きさが1枚毎に違ったり、画像の中にテニスボール以外のものが入っていると場所の指定が面倒なので、全て200px × 200pxのサイズにトリミングして保存しました)
画像ファイルリストの作成
ネガリスト
コマンドプロンプトでnegディレクトリに移動。
以下コマンドを実行すると、neglist.txtが生成されます。dir *.jpg /b > neglist.txtneglistはフルパスで記載しないとエラーが出るらしいので、全てフルパスを追記します。
neglist.txt
D:\opencvcascade\neg\cat-001.jpg ←(一行ずつフルパスを追記する)
D:\opencvcascade\neg\cat-002.jpg
D:\opencvcascade\neg\cat-003.jpgポジリスト
コマンドプロンプトでposディレクトリに移動。
以下コマンドを実行すると、neglist.txtが生成されます。dir *.jpg /b > poslist.txtposlistはファイル名と正解の対象物の数と位置(x軸、Y軸の範囲)を記入する必要があります。
poslist.txt
01.jpg1 0 0 200 200←(対象物の数、x軸、Y軸の範囲を追記する)
02.jpg1 0 0 200 200
02.jpg1 0 0 200 200今回使った画像ファイルは事前に、テニスボールを中心に置いて200px × 200pxのサイズにトリミングしたため、対象物の位置はx軸-0px-200px、y軸-0px-200pxとしています。
精度をあげようと思ったら、正確に対象物の座標を指定してあげる必要があります。opencv_createsamplesによるベクトルファイルの作成
createsamplesコマンドを使用することで、1枚の画像から角度やサイズを変更した大量のサンプルを自動生成することが出来ます。
コマンドプロンプトで親ディレクトリ(私の場合はD:\opencvcascade)に移動。
以下コマンドを実行すると、vecフォルダ内にpositive.vecファイルが生成されます。opencv_createsamples.exe -info pos/poslist.txt -vec vec/positive.vec -num 1000 -maxidev 40 -maxxangle 0.8 -maxyangle 0.8 -maxzangle 0.5
オプション名 用途 ここでのパラメータ -info 正解画像リストファイル pos/poslist.txt -vec ベクトルファイル保存場所 vec/positive.vec -num 生成する画像数 1000 -maxidev 最大明度差 40 -maxxangle 最大回転角度 0.8 -maxyangle 最大回転角度 0.8 -maxzangle 最大回転角度 0.5 traincascadeによるカスケード分類器の作成
ここまで下準備を終えたら、ようやくcascade分類器の作成です。
以下コマンドを実行すると、cascadeフォルダ内にファイルが生成されます。opencv_traincascade.exe -data cascade -vec vec/positive.vec -bg neg/neglist.txt -numPos 70 -numNeg 60
オプション名 用途 ここでのパラメータ -data 生成した分類器を保存するフォルダ cascade -vec ベクトルファイル保存場所 vec/positive.vec -bg ネガティブ画像のリストが記述されたテキストファイル neg/neglist.txt -numPos 使用するポジティブ画像の数 70 -numNeg 使用するポジティブ画像の数 60 実行すると、計算が始まり、コマンドプロンプトには以下のように表示されます。
PARAMETERS: cascadeDirName: cascade vecFileName: vec/positive.vec bgFileName: neg/neglist.txt numPos: 70 numNeg: 60 numStages: 20 precalcValBufSize[Mb] : 1024 precalcIdxBufSize[Mb] : 1024 acceptanceRatioBreakValue : -1 stageType: BOOST featureType: HAAR sampleWidth: 24 sampleHeight: 24 boostType: GAB minHitRate: 0.995 maxFalseAlarmRate: 0.5 weightTrimRate: 0.95 maxDepth: 1 maxWeakCount: 100 mode: BASIC Number of unique features given windowSize [24,24] : 162336 ===== TRAINING 0-stage ===== <BEGIN POS count : consumed 70 : 70 NEG count : acceptanceRatio 60 : 1 Precalculation time: 0.127 +----+---------+---------+ | N | HR | FA | +----+---------+---------+ | 1| 1| 1| +----+---------+---------+ | 2| 1| 0.366667| +----+---------+---------+ END> Training until now has taken 0 days 0 hours 0 minutes 0 seconds. ===== TRAINING 1-stage ===== <BEGIN POS count : consumed 70 : 70 NEG count : acceptanceRatio 60 : 0.461538 Precalculation time: 0.127 +----+---------+---------+ | N | HR | FA | +----+---------+---------+ | 1| 1| 1| +----+---------+---------+ | 2| 1| 1| +----+---------+---------+ | 3| 1| 0.433333| +----+---------+---------+ END> Training until now has taken 0 days 0 hours 0 minutes 0 seconds.枚数が少ないせいか、20回のTRAININGで26秒で生成が終わりました。
cascadeフォルダの中を見てみると、cascade.xmlというファイルが生成されていますので、これを使ってオブジェクト検出をしていきます。
(他にもStageXXというファイルが生成されていますが、それは使いません)検証
では、自分で作成した分類器でオブジェクト検出をしてみましょう。
pythonプログラムはOpenCVの勉強②で使ったものを一部修正して使います。
tennisball.pyimport cv2 # 入力画像の読み込み(テスト用画像ファイル) img = cv2.imread("tennisball.jpg") # カスケード型識別器(自作した分類器) cascade = cv2.CascadeClassifier("cascade.xml") gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # face→ballに変更(そのままでもいいですけど) ball = cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=3, minSize=(30, 30)) # 顔領域を赤色の矩形で囲む for (x, y, w, h) in ball: cv2.rectangle(img, (x, y), (x + w, y+h), (0,0,200), 3) # 結果画像を保存 cv2.imwrite("result_tennisball.jpg",img) #結果画像を表示 cv2.imshow('image', img) cv2.waitKey(0)
- 上記のpythonファイル(tennisball.py)
- 分類器(cascade.xml)
- テスト用の画像ファイル(tennisball.jpg) 上記のファイルを同じフォルダに保存し、pythonファイルを実行してみましょう。
$ python tennisball.py結果
これは手前の2つのボールは検出できました(少しズレてますが)
これはボールは検出できたようですが、その他多数いろんなものも検出されちゃってます
(これはこれで何かカッコいいのですが)
キウイとテニスボールって似てますもんね(笑)
テニスボールは特徴量が少なく、サンプルの画像数も少なかったせいか、分類器の精度はイマイチでしたが、作成方法はわかりました。
参考文献





- 投稿日:2019-07-14T22:45:33+09:00
【Audio入門】音を発生する♬
これまでなんとなく当然だと思っていたが、まず正しい音を正確に出力するところからやろうと思う。
技術的には、これまでも何度か書いているので、いきなりコードを出してちょっと説明したいと思う。コード解説
import wave import numpy as np from matplotlib import pylab as plt import struct import pyaudio import matplotlib以下に発生する音の属性を示す。
a = 1 #振幅 fs = 44100 #サンプリング周波数 f0 = 400 #基準周波数 f1 = f0+10 #重畳する音の周波数 sec = 5 #秒;発生時間 CHUNK=1024 #一度にサンプリングするframe数 p=pyaudio.PyAudio() stream=p.open( format = pyaudio.paInt16, channels = 1, rate = fs, frames_per_buffer = CHUNK, input = True, output = True) # inputとoutputを同時にTrueにする以下で実際に出力するサイン波を生成する。
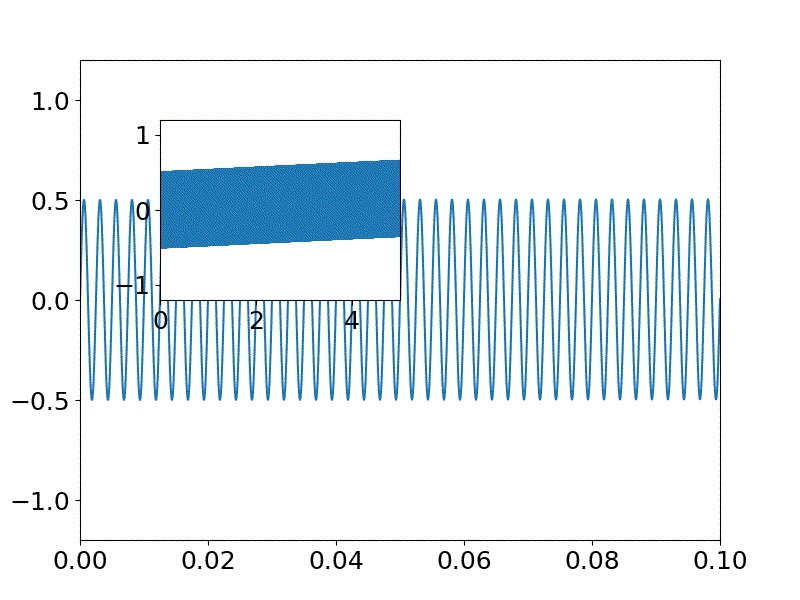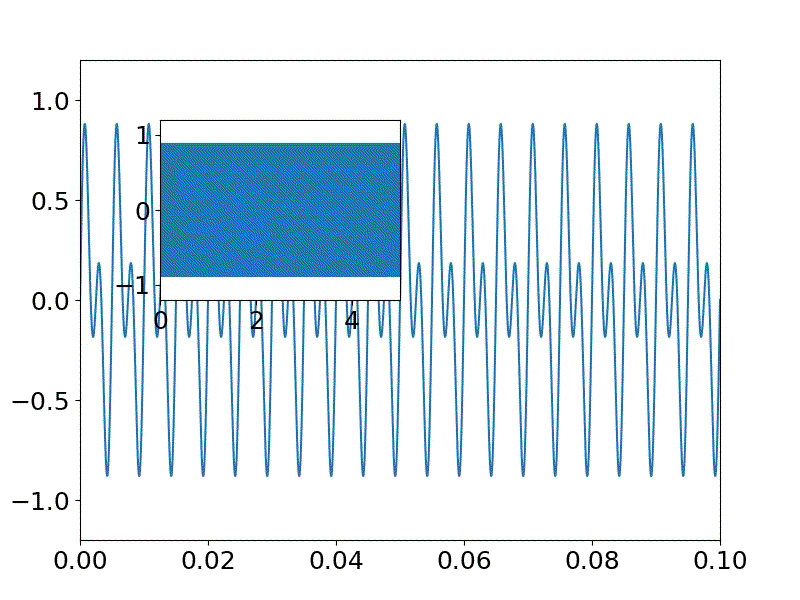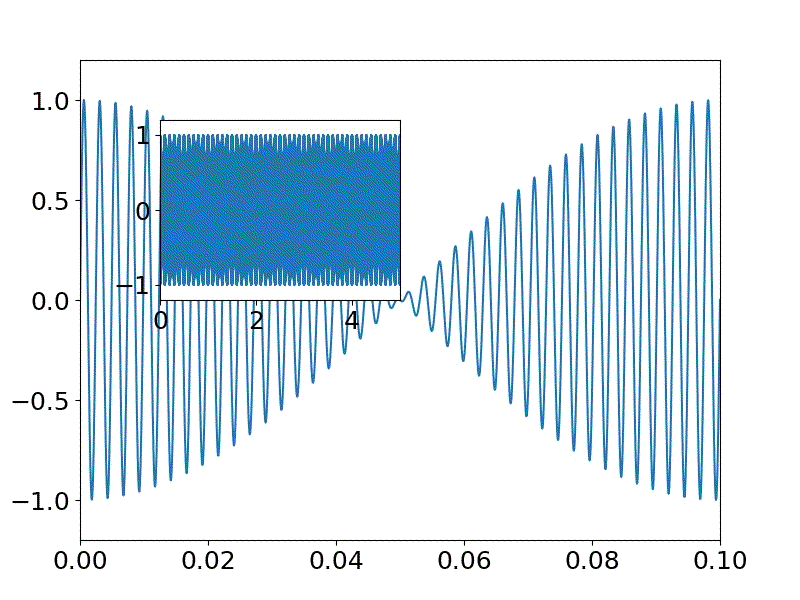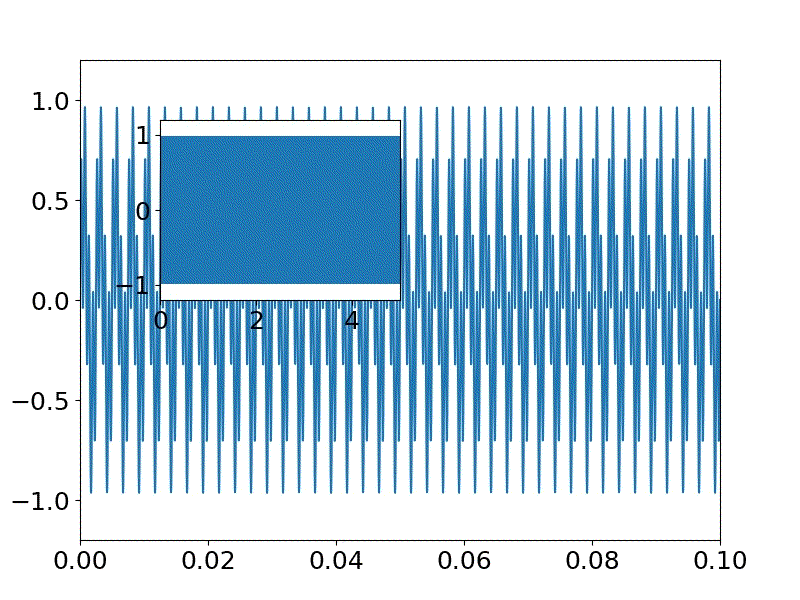
※今回は二つの波を重畳するswav=[] for n in np.arange(fs * sec): #サイン波を生成 s = (a * np.sin(2.0 * np.pi * f0 * n / fs)+ a * np.sin(2.0 * np.pi * f1 * n / fs))/2 swav.append(s)発生するサイン波を描画する。
0-0.1秒までのものとハウリングを見るために全体0-5秒の図を描画するが、
昨夜プロットの配置の仕方を学んだので、それを応用している。
※配置する図のデータは同一で範囲指定など変えて、描画できる#サイン波を表示 matplotlib.rcParams.update({'font.size': 18, 'font.family': 'sans', 'text.usetex': False}) fig = plt.figure(figsize=(8,6)) #(width,height) x_offset=np.round(0.05*4,decimals=2) y_offset=np.round(0.05*10,decimals=2) width=0.3 height=0.3 axes1 = fig.add_axes([0.1, 0.1, 0.8, 0.8]) # main axes axes2 = fig.add_axes([x_offset, y_offset, width, height]) # insert axes x = np.linspace(0, sec, int(fs*sec)) #sec;サンプリング時間、fs*sec;サンプリング数 axes1.set_ylim(-1.2,1.2) axes1.set_xlim(0,0.1) #0-0.1 sec axes1.plot(x,swav) axes2.set_ylim(-1.2,1.2) axes2.set_xlim(0,5) #0-5 sec axes2.plot(x,swav) plt.pause(1) plt.savefig('./fft/sound_'+str(f0)+'_'+str(f1)+'.jpg')swavに格納された音データを以下によりwavファイルとして保存する。
#サイン波を-32768から32767の整数値に変換(signed 16bit pcmへ) swav = [int(x * 32767.0) for x in swav] #バイナリ化 binwave = struct.pack("h" * len(swav), *swav) #サイン波をwavファイルとして書き出し w = wave.Wave_write("./fft/output"+str(f0)+"_"+str(f1)+".wav") params = (1, 2, fs, len(binwave), 'NONE', 'not compressed') w.setparams(params) w.writeframes(binwave) w.close()最後に作成した音をスピーカーから出力する。
※inputに置き換える必要はないが、一応勘違い防止のために一度inputに代入してから出力しているinput = binwave output = stream.write(input)いろいろな音を作成して聞き比べる
今回は、基準振動を400Hzとして、以下の音を重畳して作成して遊んでみた
f_list=[0.01,0.1,0.5,1,2,5,10,50,100,200,300,350,400.1,400.2,400.5,401,402,405,410,420,450,500,600,800,1000,1200,1400,1600]結果は以下のような画像が得られる。
上記のパラメータでGifアニメーションにする。
対応する音は以下に置いた。
AudioAutoencoder/sound_generation/melody.wav音の不思議
作成した音を聞いてみると、
1.400-402の重畳はいわゆるハウリングのようにウワ~ンウワ~ンと聞こえます
2.高周波例えば400-1000の重畳だと、この高調波側が周波数が高くなるにしたがって、大きな音で聞こえます
3.低周波の音との重畳400-1などでは、1Hzは可聴音ではないので関係なさそうです。しかし、音が大きくなったり小さくなったり、ハウリングのように聞こえることもあります
4.一番たぶん音声と関係するのはそれらの間の周波数例えば、400-600のような場合です。これは、まだまだですが音声の’う’と同じような音が出ます。これは先日のフォルマント合成の話と同じような現象です。コードは以下に置きました
・AudioAutoencoder/sin_sound.py
まとめ
・いろいろな音をサイン波で作成して遊んでみた
・発生した音は高々二音だが、「音の不思議」に記載したように多彩な音を発生する・これらをFFT~STFT,そしてwavelet変換して分析する
・さらに男性声、女性声の分析及びそれらの音声合成を実施する

- 投稿日:2019-07-14T22:06:18+09:00
Windows10 で Python をインストール
こんにちは。ドミノ(@dr3mms)です。
Windowsで環境を作るのに毎回検索するのでまとめました。ダウンロード
下のPython 3.7.4のDownloadをクリック
Windows x86-64 executable installerをクリックしてダウンロード
インストール
python-3.7.4-amd64.exeを管理者として実行する
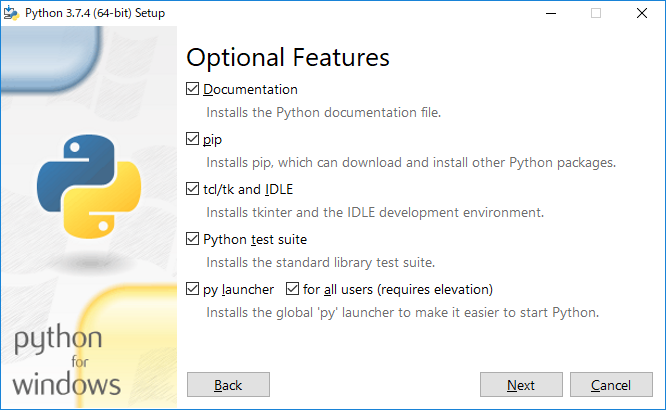
Add Python 3.7 to PATHにチェックを入れる(環境変数に設定する)
Customize installationをクリックする
デフォルトでNext
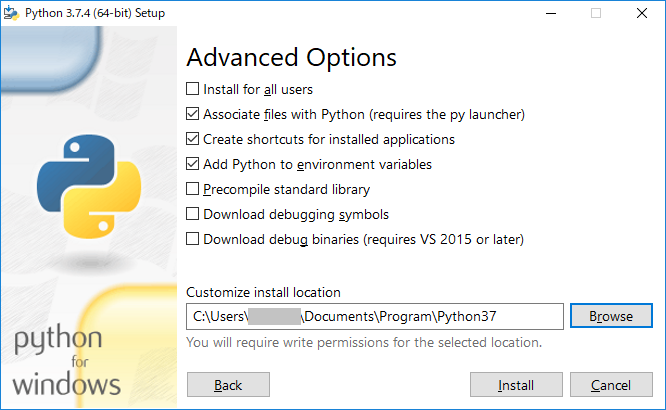
Customize intall locationは任意のパス\Python37にする
Installをクリックしてインストール
pyenv インストール
pip install pyenv-win --target ~/.pyenv環境変数
PATHに以下を設定する
{ホームディレクトリ}\.pyenv\pyenv-win\bin
{ホームディレクトリ}\.pyenv\pyenv-win\shimspipenv インストール
pip install pipenvAWS CLI インストール
pip install awscli


- 投稿日:2019-07-14T21:57:01+09:00
CentOS7にFlask+nginx+uwsgiの環境構築をする
はじめに
pythonでweb開発をしようとしてDjangoを使おうと思ったのですが、
ここはあえて「まいくろふれーむわーく」と言われるFlaskを使ってみることにしました。
おまけにnginxやuwsgiなどのサーバー周りもちょっと勉強してみました。
初投稿です。変なとこがあればコメントください!環境
・CentOS Linux release 7.6.1810 (Core)
・Python 3.7.3
・Flask 1.0.3
・nginx/1.17.1
・uwsgi 2.0.18基本的な準備
必要なパッケージのインストール
パッケージをインストールします。# yum install gcc zlib-devel bzip2 bzip2-devel readline readline-devel sqlite sqlite-devel openssl openssl-devel xz xz-devel libffi-devel findutils git libffi-develpyenvのインストール
今回はpyenvを使っていくので、gitからおとしてきてください。
$ git clone https://github.com/yyuu/pyenv.git ~/.pyenvパスを通す
パスを通して反映させます。
$ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(pyenv init -)"' >> ~/.bash_profile $ source ~/.bash_profile$ pyenv --versionpyenv --versionでバージョンが表示されるのを確認してください。
python3のインストール
$ pyenv install --listと実行して表示された中で、インストールしたいバージョンを選びます。
今回は現在で最新の3.7.3にしました。$ pyenv install 3.7.3 $ pyenv global 3.7.3「python -V」で3.7.3と表示されれば完了です。
仮想環境の構築
Flaskの公式サイトで記述してあるとおり、
virtualenvというツールを使います。pipでvirtualenvをインストールします。
$ pip install --upgrade pip $ pip install virtualenvこれで基本的な準備は完了です。
Flaskのインストール
プロジェクトの作成
まずは、プロジェクトのディレクトリを作成します。今回はホームディレクトリの直下に作成することとします。
$ cd $ mkdir project_name $ cd project_name仮想環境の設定
$ virtualenv envと実行します。
すると、「env」というディレクトリができました。これでパッケージとかを仮想的に管理しているのでしょうね。きっと。
(詳しくは分からないです...ごめんなさい...)$ source env/bin/activateと実行すると、プロンプトが
(env)[user_name@hostname project_name]という感じになっていると思います。
このプロンプトの先頭に(env)がついていると仮想環境に入れているということになります。
ちなみに仮想環境から出るときは、$ deactivateこれでOKです。
Flaskのインストール
$ pip install Flask $ pip install flask_wtf pymysql requests response一応必要そうなパッケージもインストールしておきました。
この時点でHello Worldはできます。
ためしに「app.py」というファイルを作って、
以下のように記述してください。app.pyfrom flask import Flask app = Flask(__name__) @app.route("/") def index(): return "Hello World!" if __name__ == "__main__": app.run(host="0.0.0.0")これで、
$ python app.pyと実行してアクセスすると、「Hello World!」と表示されているはずです。
続きます。
nginxの導入
nginxのインストール
CentOSのリポジトリにはnginxがデフォルトで入っていないということなので、新しく追加します。
# cd /etc/yum.repos.d # touch nginx.repo # vi nginx.repo「nginx.repo」というファイルを作成し、以下のように記述します。
nginx.repo[nginx] name = nginx repo baseurl = http://nginx.org/packages/mainline/centos/7/$basearch/ gpgcheck = 1 enabled = 1 gpgkey = http://nginx.org/keys/nginx_signing.key [nginx-source] name = nginx source baseurl = http://nginx.org/packages/mainline/centos/7/SRPMS/ gpgcheck = 1 enabled = 0 gpgkey = http://nginx.org/keys/nginx_signing.keyyumを使用してnginxをインストールします。
# yum install nginxnginxの設定
後述するuwsgiと連携できるように設定します。
# cd /etc/nginx/conf.d/移動先に、「nginx.conf」というファイルがあります。これが設定ファイルです。中を開くと、
nginx.confhttp { ~ 略 ~ }というようなものが書いてあると思います。
このhttp内にserverの記述をします。nginx.confhttp { ~ 略 ~ server { listen 80; server_name [ホスト名]; root /usr/share/nginx/html; location / { index index.html; include uwsgi_params; uwsgi_pass unix:///tmp/nignx.sock; } } }これでnginxの設定はひとまず終了です。
他に、SSLの設定やhttpステータスエラー時の設定などもこのファイルを使用します。(今回は割愛)nginxの起動
起動 # systemctl start nginx 停止 # systemctl stop nginx 再起動 # systemctl restart nginx 自動起動設定 # systemctl enable nginxuwsgi導入
uwsgiのインストール
$ pip install uwsgiuwsgiの設定
プロジェクトのディレクトリ直下に「uwsgi.ini」「uwsgi.pid」というファイルを作成します。
uwsgi.iniには以下のように記述します。[uwsgi] current_release = /home/user_name/project_name wsgi-file = %(current_release)/app.py callable = app daemonize = %(current_release)/uwsgi.log log-reopen = true log-maxsize = 8000000 logfile-chown = on logfile-chmod = 644 processes = 4 threads = 2 thunder-lock = true max-requests = 3000 max-requests-delta = 300 pidfile = %(current_release)/uwsgi.pid vacuum = true socket = ///tmp/uwsgi.sock chmod-socket = 666それぞれの意味はググればすぐに見つかると思うのでここでは割愛します。
uwsgiの起動
$ uwsgi --ini uwsgi.ini [uWSGI] getting INI configuration from uwsgi.ini止めるときは
$ uwsgi --stop uwsgi.pidとします。
以上です。
つまったところ
すべてうまく設定できてエラーもでてないのにアクセスできないなー詰んだなーと思っていたのですが、
firewallが邪魔だったというオチでした。httpとhttpsのポート開放をします。
# firewall-cmd --zone=public --add-service=http # firewall-cmd --zone=public --add-service=https恒久的にやる場合は、
# firewall-cmd --zone=public --add-service=http --permanent # firewall-cmd --zone=public --add-service=https --permanentと実行します。
- 投稿日:2019-07-14T20:37:31+09:00
【Python】Python初心者がYoutubeから動画をダウンロードするスクリプトを解説
1. はじめに
とある動画素材を探してネットの海を彷徨っていたところ、FireFoxのアドオンであるVideo Download Helperで動画をダウンロードすると、動画の左上にQRコードが烙印されてしまうという噂を発見。ついでにmacではコンパニオンアプリと呼ばれる補助アプリを複数ダウンロードさせられるようです。
そこで方針転換し動画DLできるスクリプトをQiitaで探したところ、@ryuta69さんの素晴らしいスクリプトを発見しました。
そのまま使用させていただくことも考えたのですが、Pythonの入門がてらgithubのコードを一行一行読み解いて解説記事を作ることにしました。完成したスクリプトでは以下のようにコマンドを打つことで、YouTubeから動画をDLできます。
python [スクリプトの名前].py [YouTube動画のURL]2. 対象者
- 超Python初心者
- Pythonを触ったことがないプログラミング経験者
3. 対象じゃない人
- YouTubeの動画をDLしたい人 → ryuta69さんの記事を読んでください。
4. 前提条件
ryuta69さんの記事にある通り、必要なツールをインストールしてください。
5. 今回解説するryuta69さんのコード(一部省略)
今回はYouTubeのダウンロードのみ解説するので、コードの後半は省略させていただきます。
main.pyimport re, sys, os, time, subprocess from bs4 import BeautifulSoup from urllib.request import urlopen, urlretrieve main_links = [ "https://www.youtube.com/", "https://soundcloud.com/", "https://www.nicovideo.jp/" ] ero_links = [ "https://www.xvideos.com/" ] # youtube soundcloud nicovideo if any(s in sys.argv[1] for s in (main_links)): ans = input("type mp3 or mp4: ") if "https://www.youtube.com/" in sys.argv[1] and "list=" in sys.argv[1]: th_list = sys.argv[1].split("list=")[1] else: th_list = sys.argv[1] if ans=="mp3": cmd = 'youtube-dl -o ./%(playlist)s/%(title)s.%(ext)s -ci --extract-audio --audio-format mp3 --add-metadata ' + th_list if ans=="mp4": cmd = 'youtube-dl -o ./%(playlist)s/%(title)s.%(ext)s -i -f mp4 --add-metadata ' + th_list subprocess.check_call(cmd.split()) sys.exit()(後略)
引用元
xvideo-youtube-niconico-soundcloud-download
6. 一行ずつ解説
コード中の各機能ごとに解説したいと思います。
6-1. ライブラリの宣言
Pythonのコードでは、冒頭で使用する標準ライブラリやパッケージを宣言します。
import re, sys, os, time, subprocessこの一行で宣言されている5つは全てPythonの標準ライブラリです。
・re : 正規表現の処理。文字列の抽出や置換、分割など。
・sys : インタプリタや実行環境の情報を扱う。コマンドラインの引数も扱える。
・os : OSに依存する機能を使えるようにする。
・time : 時間に関する広い用途で使われる。時刻取得や時刻フォーマット作成など。
・subprocess : Python以外のアプリを起動したり、実行結果を取得できる。続いては外部パッケージです。
from bs4 import BeautifulSoup from urllib.request import urlopen, urlretrieve・form ~ import ~
from以下のライブラリから、import以下のモジュールのみ取ってくるという記述です。・BeautifulSoup
webサイトのHTML上から要素を取ってくること(スクレイピング)ができるライブラリです。
今回は使用しませんが、他の動画サイトからDLするときは必要になります。・urllib.request
URLを読みこめるモジュールで、その中からurlopenとurlretreiveという関数を用います。
それぞれurlopenはGETリクエストを投げる、urlretreiveはオブジェクトをダウンロードするという働きがあります。
こちらも今回は使用しません。6-2. DL対象サイトを指定する
main_links =[ "https://www.youtube.com/", "https://www.nicovideo.jp/" ]動画をDL対象のサイトのURLを、このリストに格納して指定します。
コマンドライン上で入力したURLがこのリスト内の要素の文字列とマッチする場合、DLすることができます。6-3. URLの動画サイトの判定
ここから、入力されたURLが指定した動画サイトのものかを判定します。
if any(s in sys.argv[1] for s in (main_links)):冒頭の判定文ですが、これは入力されたURLが先ほどのmain_linkで指定したサイトのものかどうかを判定しています。
様々なメソッドが使用されているので、一つ一つ解説します。
解説の都合上順番が前後しますが、ご了承ください。・"for s in (main_links)"
main_linksリストの各要素を"s"と置いて、それぞれに処理を施します。・"s in sys.argv[1]"
sys.argvはコマンドライン上で入力された引数のリストで、[1]はそれの1番目を指しています。
ここでの"in"はfor文中のinとは異なり、検索の演算子の役割を担っています。
直訳すると、s(main_linksで指定したサイトURLの文字列)がsys.argv[1](コマンドライン上で入力されたURL)の中に存在するか。
つまり、入力したURLがYouTubeかニコニコ動画の動画であれば、trueを返します。・any(条件式)
条件式が一つでもtrueであれば、trueを返します。
これと対照なのがall(条件式)メソッドで、こちらは条件式が全てtrueのときのみtrueを返します。結局このif文では、コマンドライン上で入力したURLがYouTubeかニコニコ動画のものであればtrue、そうでなければfalseという判定をしています。
6-4. DLしたいフォーマットの指定
ans = input("type mp3 or mp4: ")ryuta69さんのスクリプトはmp3でもmp4でもDLできるようになっているので、ここでコマンド実行者にどちらかを指定させています。
入力した文字列がans変数に格納されます。6-5. YouTube動画がプレイリストにある場合の対応
YouTubeでプレイリスト内の動画のURLをコピペすると、"https://www.youtube.com/watch?v=hogehoge&list=fugafuga" のようにURLに「list=fugafuga」という余計な部分が付いてしまいます。
th_listという変数に有効なURLを代入するために、余計な部分を除去する必要があります。if "https://www.youtube.com/" in sys.argv[1] and "list=" in sys.argv[1]: th_list = sys.argv[1].split("list=")[1] else: th_list = sys.argv[1]一行目のif文では、入力したURLがYouTubeのもので、さらに"list="の文字列が含まれているかを判定し、プレイリスト経由の動画であるかを判定しています。falseの場合はそのままでいいのですが、trueの場合は特別な処理が必要になります。
そこで二行目では、"https://www.youtube.com/watch?v=hogehoge&list=fugafuga"というURLを、"https://www.youtube.com/watch?v=hogehoge&"と"fugafuga"に分割しています。split(文字列)関数は、長い文字列を指定した文字で分割することができます。
この場合、"list="の前と後の二つを要素に含んだ["https://www.youtube.com/watch?v=hogehoge&", "fugafuga"]というリストを生成します。
そこでsys.argv[1].split("list=")[1]とリストの1番目を指定することで、上手くプレイリスト部分wp除去することができました。6-6. 動画をDLする
いよいよ大詰めです。動画をDLするコマンドを指定していきます。
if ans=="mp3": cmd = 'youtube-dl -o ./%(playlist)s/%(title)s.%(ext)s -ci --extract-audio --audio-format mp3 --add-metadata ' + th_list if ans=="mp4": cmd = 'youtube-dl -o ./%(playlist)s/%(title)s.%(ext)s -i -f mp4 --add-metadata ' + th_listmp3とmp4のどちらの場合でも、cmdという変数にコマンドの文字列を代入します。
"youyube-dl"というのはコマンドライン上でYouTubeから動画をDLできるツールです。
これに様々なオプションを付け加えていきます。・-o [ファイル名]
保存するファイル名を指定できます。"%()s"ものはテンプレートといい、動画ファイルの情報を引っ張ってくることができます。例えば、"%(ext)s"は拡張子を表しています。・-c
ダウンロードが中断されても再開しないようにします。・-i
ダウンロードエラーを無視します。・--extract-audio
動画ファイルから音声のみを抽出します。・--audio-format [フォーマット]
音声ファイルの形式を指定します。ここではmp3に指定しています。・--add-metadata
ファイルにメタデータを書き込みます。・-f [フォーマット]
フォーマットを指定します。そのほかにもこちらのサイトに全てのオプションが紹介されています。
youtube-dl オプション一覧及びそのメモ6-7. コマンドを実行しプログラムを終える
最後に前項で書いたコマンドを実行します。
subprocess.check_call(cmd.split()) sys.exit()冒頭に紹介した通り、外部アプリを実行するときはsubprocessライブラリを使います。
check_call(リスト)関数はプログラムの出力とエラーを逐次出力してくれます。
check_call関数の引数はリストなので、cmd.split()をすることでコマンドをスペースで区切ったリストにしています。
つまり、["youtube-dl", "-o", …]という形に変換しています。二行目のsys.exit()は、プログラムを終了させるコマンドです。
URLがYouTubeまたはニコニコ動画である場合のif文中の処理が終わったので、ここでプログラムを終了させる必要があります。7. 動作確認
コマンドライン上で以下のコマンドを打ってみましょう。
無事DLできたら成功です!python [スクリプトの名前].py [YouTube動画のURL]動かない場合は以下の原因が考えられます。
1. デフォルトのpythonコマンドのバージョンが古いpython -Vを実行してpythonのバージョンを確認しましょう。
python3がすでにインストールされている場合は、ホームディレクトリの.bash_profile(なければ作成)にエイリアスを追加するとpython3のコマンドを実行することができます。alias python="python3"
- pipがインストールされたpythonのバージョンが古い
pip -Vと打つと最後尾にpythonのバージョンが表示されます。
ここがpython3ではなかった場合は、コマンドを実行する際に"pip"の代わりに"pip3"を打つことで、python3にライブラリをインストールすることができます。8. 最後に
解説は以上になります。
コードを引用させていただいたryuta69さん、本当にありがとうございました。9. 参考記事、引用コード
スクリプトの紹介記事(Qiita)
XvideosのMP3/MP4を一括でダウンロードするスクリプト作ってみた(おまけでyoutubeとかニコニコもOK)スクリプトのコード(github)
xvideo-youtube-niconico-soundcloud-download
- 投稿日:2019-07-14T19:40:16+09:00
Bokehが素晴らしすぎてわずか130行で対話的可視化ツールを作ってしまった話
はじめに
前回 matplotlibで4種類の可視化手法(PCA, tSNE, MDS, UMAP)の実行結果を表示するコマンドを作成した。
しかし、グラフの点にフォーカスをあてどのデータかを表示したり(いわいるhoverというやつ)、色設定する項目を動的に変更できないという不満があったので、かねてから注目していたBokehを使って実現した。BokehのAPIが想像以上に素晴らしく、たった一日で、しかもわずか130行のコードにより、当初目的としていた可視化ツールを作ることができたのでその一部始終をここに残しておく。作りたいもののイメージと実現方法
BokehのWidgetを使って以下を実現する。
- 画面上でinputファイル(CSV)、可視化手法を指定して可視化を行うことができる。CSVファイルの書式は前回と同じフォーマット。
- 指定したCSVファイルの項目に応じてグラフ上の点の色が異なるようにする。項目は動的に変更可能とする。
- グラフの点にフォーカスをあてると、IDや特定の値を表示する。
- CSVファイルの内容をグリッドの形式で表示し、グラフの点と選択が連動するとよい。
(グラフで点を選択した場合、グリッドの対応する点も選択状態になる。逆もしかり)要するにグラフをみて、このあたりに固まっているデータ群って、どんな感じのデータだっけ?というのを対話的にやりたいわけで。
できあがったもの
これが起動画面。
右側の「Input CSV」テキストボックスに解析したいCSVファイルを設定し、その下のラジオボタンで実行したい可視化手法を指定し、「Execute」ボタンをクリックすると、可視化処理が走り、終わったら左側にグラフが表示され、右下のデータグリッドにCSVファイルのデータが表示される。
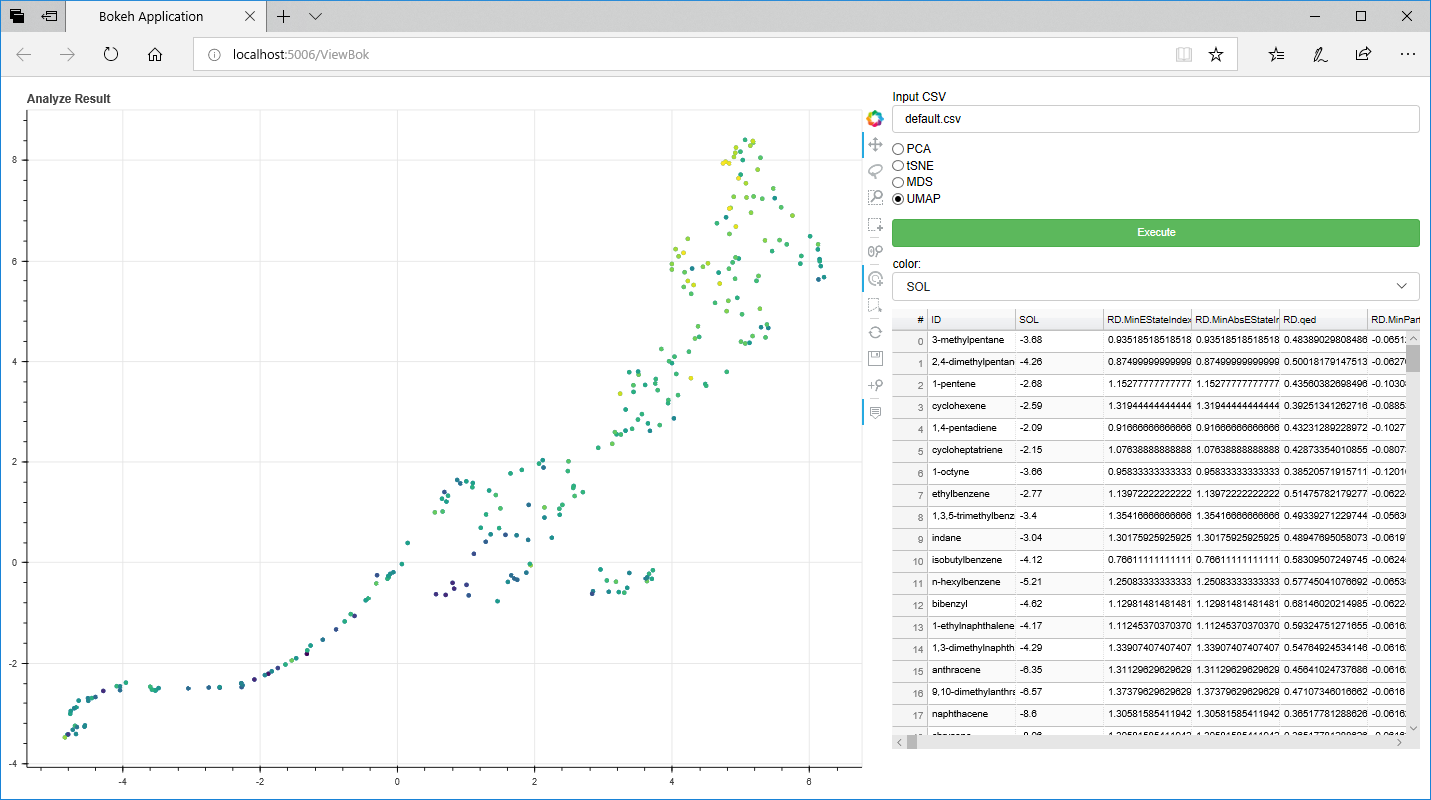
これが実行結果。グラフの操作(拡大、縮小や選択)は、グラフの右側にあるアイコンでできる。
また、「Color」セレクトボックスを変更すると、その項目により色分けする。(デフォルトはCSVの一列目の目的変数)
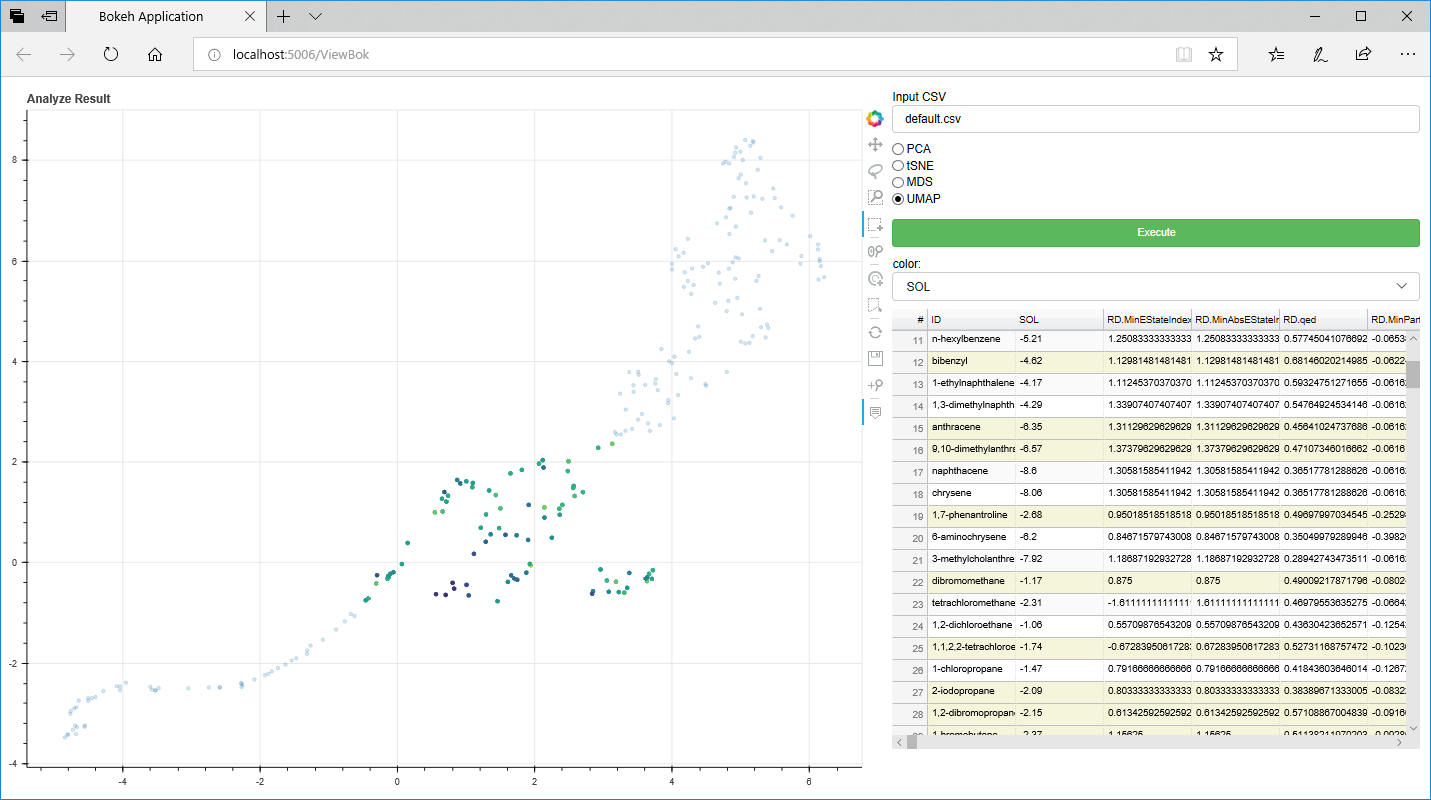
そして、感心した機能がこれ。グラフの点を選択すると(下図の場合、真ん中付近の点をまとめて選択している)、それに連動して右のデータグリッドの対応する行に色がついた状態なる。ちなみにデータグリッド(Bokehではデータテーブルというのか)は、ソート等一通りの機能を備えている。
以下からソースコード等を説明する。
実行環境
- Windows10
- Anaconda
- Python3.7
- Bokeh 1.2
- scikit-learn 0.21.2
- umap-learn 0.3.9
ソースコード
これが130行のコード。解説は後ろに記載。
import pandas as pd from sklearn.manifold import TSNE, MDS from sklearn.decomposition import PCA import umap import bokeh from bokeh.events import ButtonClick from bokeh.models import CustomJS, HoverTool, ColumnDataSource from bokeh.models.widgets import Button, Select, RadioGroup, TextInput, TableColumn, DataTable from bokeh.layouts import Column, Row from bokeh.io import curdoc from bokeh.plotting import figure from bokeh.transform import linear_cmap def main(): # color selectが変更された時の処理 def color_select_callback(attr, old, new): # color_selectで選択された項目の値に対応したmapperを用意 mapper = linear_cmap(field_name=new, palette=bokeh.palettes.Viridis256, low=min(df[new].values), high=max(df[new].values)) # 新たなmapperでグラフを再描画 p.circle(x="0", y="1", source=source, line_color=mapper, color=mapper) # execute button がクリックされた時の処理 def execute_button_callback(event): # テキストエリアに指定された入力ファイル読み込み global df df = pd.read_csv(csv_input.value, index_col=0) # 1列目がTargetと仮定(color_selectのデフォルト) df_target = df.iloc[:, 0] df_data = df.iloc[:, 1:] # 2列目以降のデータで可視化のための解析開始 if method_radio_group.active == 0: pca = PCA(n_components=2) result = pca.fit_transform(df_data) elif method_radio_group.active == 1: tsne_model = TSNE(n_components=2) result = tsne_model.fit_transform(df_data) elif method_radio_group.active == 2: mds = MDS(n_jobs=4) result = mds.fit_transform(df_data) elif method_radio_group.active == 3: result = umap.UMAP().fit_transform(df_data) # Dictionaryに解析結果を格納 dict = {"0": result[:, 0], "1": result[:, 1]} # データフレームのID(index)をDictionaryに格納 dict["ID"] = df.index.values # データテーブルに登録する列情報の設定 columns = list() columns.append(TableColumn(field="ID", title="ID", width=100)) for column in df.columns: dict[column] = df[column].values columns.append(TableColumn(field=column, title=column, width=100)) # Dictionaryをソースと紐づける source.data = dict # データテーブルの列を設定する data_table.columns = columns target_column = df.columns.values[0] # color_selectで選択された項目の値に対応したmapperを用意 mapper = linear_cmap(field_name=target_column, palette=bokeh.palettes.Viridis256, low=min(df[target_column].values), high=max(df[target_column].values)) # 新たなmapperでグラフを再描画 p.circle(x="0", y="1", source=source, line_color=mapper, color=mapper) # hoverの設定(indexとIDを表示) hover = HoverTool(tooltips=[ ("index", "$index"), ("ID", "@ID"), (target_column, "@"+target_column), ]) p.add_tools(hover) color_select.options = list(df.columns) # リセット (https://github.com/bokeh/bokeh/issues/5071 を参考に入れてみたが現状動作しない) CustomJS(args=dict(p=p), code=""" p.reset.emit() """) # データソースの初期設定 source = ColumnDataSource(data=dict(length=[], width=[])) source.data = {"0": [], "1": []} # CSVファイル設定テキストボックス csv_input = TextInput(value="default.csv", title="Input CSV") # 可視化手法選択ラジオボタン method_radio_group = RadioGroup( labels=["PCA", "tSNE", "MDS", "UMAP"], active=3) # 解析実行ボタン execute_button = Button(label="Execute", button_type="success") execute_button.on_event(ButtonClick, execute_button_callback) # グラフ初期設定 p = figure(tools="pan,box_zoom,lasso_select,box_select,poly_select,tap,wheel_zoom,reset,save,zoom_in", title="Analyze Result", plot_width=1000, plot_height=800) p.circle(x="0", y="1", source=source) # 色設定項目用選択セレクトボックス color_select = Select(title="color:", value="0", options=[]) color_select.on_change("value", color_select_callback) # データ表示データテーブル data_table = DataTable(source=source, columns=[], width=600, height=500, fit_columns=False) operation_area = Column(csv_input, method_radio_group, execute_button, color_select, data_table) layout = Row(p, operation_area) curdoc().add_root(layout) main()実行方法
bokehをインストールしていれば、上のコードを書いたファイルを指定して(以下例ではViewBok.py)、以下のようなコマンドを実行するとブラウザが起動し、画面が表示される。
bokeh serve --show ViewBok.pyソース解説
ソースをみて不明なところは参考文献を見てもらった方が早いとおもうが、一応説明。
- 全ての基本となるData Sourceの定義を
source = ColumnDataSource(data=dict(length=[], width=[]))source.data = {"0": [], "1": []}で行う。これをグラフやデータテーブルが参照することで各部品が連動するわけだ。- 画面に並べる部品を定義する。TextInput、RadioGroup、Button、figure、Select、DataTableね。
- 部品にイベントがある場合、イベントに応じた関数を設定。 このアプリの場合、ButtonとSelectの2つしかイベントはない。 Buttonの場合は、on_eventメソッドで、イベントハンドラ(画面上に書いたexecute_button_callback関数)と紐づける。 Selectの場合は、on_changeメソッドで、イベントハンドラ(画面上に書いたcolor_select_callback関数)と紐づける。 注意すべきは、それぞれイベントハンドラが受け取る引数の形がきまっているので、そこはドキュメントを読んだりして試行錯誤する必要がある。
- 各イベントハンドラでやりたい処理を書く。 "Execute" Buttonが押された場合の説明をざっくりすると、
- まずCSVテキストボックスからファイルパスを読み取り、DataFrameで読み取って、ラジオボタンで選択された手法に応じた処理を実行する。
- 結果配列(X、Y)をDictionaryの対応するキーに格納する。このキーはグラフに表示する際の cp.circle(x="0", y="1", source=source)```のxとyで指定している値と合わせておけばOKだ。
- データテーブルに表示させる値も2と同じDictionaryに登録しておく。またデータテーブルの各列をTableColumnTableColumnとして定義し、それをリストにいれてdata_tableと紐づける。
source.data = dictによってDictionaryとデータソースを紐づける。これによってデータとグラフ、データテーブルが紐づくのだ。- hoverやcolor_selectの設定(詳細省略)。
今後の課題
- 解析が終わってグラフの再描画した後、解析手法によってスケールが変わるため、CustomJSを使ってリセットを実行しているが、うまく動いておらず、毎回手動でリセットを実行している。
- 化合物データで解析する場合、hoverに化合物の画像を表示したい。化合物の画像化はRDKitでできるとして、hoverへの画像表示も、参考に示したURLを参照すればできそう。
- X軸、Y軸に項目を指定して、Scatter Plotも表示できるようにしたい。
- データテーブルで選択された項目についてデータをダウンロードしたい。JavaScriptとの連動が必要?
- 複数のグラフをリンクさせることができるようなので、複数のグラフを並べて表示し、同じ点がいろいろなグラフのどこに位置するか、一目でわかるように表示させたい。
- リファレンスガイドをみると、ネットワークグラフも表示できるようなので試したい。
- アニメーション機能を触る(もはや利用シーンがイメージできないが、面白そうという理由だけ)
参考
- 投稿日:2019-07-14T19:25:13+09:00
七転八倒プログラミング!(退屈なことはPythonにやらせよう_第4章演習_4.10.2)
1.はじめに
こんにちは。yutomanです。情シスの仕事を自動化したいという下心からpythonの勉強を始めた初学者です。
『退屈なことはPythonにやらせよう ―ノンプログラマーにもできる自動化処理プログラミング』(著・Al Sweigart,訳・相川 愛三,オライリージャパン,2017)を買ったは良いのですが理解するまでに七転八倒しましたので、せっかくならばこの七転八倒泥まみれの様子をお見せして、同じ空の下にいるどこかの初学者の一助になりたく、この記事を書きます。2.転びながら解いていく
1.問題文を読む。
問題はまずはじめにリスト"grid"を読者に与えます。
"0"で模様を描いているようですが、どうやら横向きのハート型のようです。問題文には
上記のgridの値を受け取り、次のような絵として表示するコードを書きなさい。
とあります。その直後に通常のハート型の絵が描かれていますので
このハート型を90度右に回転させるプログラムを書くことがこの問題の目的だとわかります。2.とりあえず問題文で与えられたリストを書く。
まずは何はともあれ、材料となるリストを記載しておきます。
リスト"grid"grid = [['.', '.', '.', '.', '.', '.', ], ['.', '0', '0', '.', '.', '.', ], ['0', '0', '0', '0', '.', '.', ], ['0', '0', '0', '0', '0', '.', ], ['.', '0', '0', '0', '0', '0', ], ['0', '0', '0', '0', '0', '.', ], ['0', '0', '0', '0', '.', '.', ], ['.', '0', '0', '.', '.', '.', ], ['.', '.', '.', '.', '.', '.', ]]3.90度右に回転させる方法を考える。
さて、この絵を右に回転させると言ったって、一体どうしたら良いのでしょう。
考えてみると、スマホの画面に映った写真を回転させる時、写真は実際に回転しているのでしょうか?
いえ、違いますね。画像を構成する細かい点々が並び直されてあたかも右回転したように見えるだけです。その発想を今回の問題にも適用させると、
プロセスは何でも良いから結果としてハートの形が右回転した形に変わっていれば良いということです。したがって、リスト"grid"に並んでいる値(0と.)を取得して右回転したかのような形に並び直してしまえば良いのです。
4.1列目を取得する。
リスト"grid"はご丁寧にも"列"と"行"がわかりやすいように記載されています。
"列"とは表でいう"縦の並び"、"行"とは表でいう"横の並び"です。これが大きなヒントになっています。つまりハートが右回転したように見えるには、
リスト"grid"の列が、行に並び変わっていれば良いのです。と言う訳で、まずは左から1列目の値をすべて取得して、上から1行目に並べ直します。
リスト"grid"に注目しましょう。リストの中に、さらにリストがある構造をしています。
リストの中にリストがある場合、第1インデックスでどのリストか指定して、第2インデックスでそのリストの中の値を示すのでしたね。例えば"grid[0][0]"は、リスト0個目の0番目の値を指すわけです。これを繰り返して、左から1列目の値を取得し表示します。リスト"gridの1列目を取得し表示する。(コード)"print(grid[0][0]) #リスト0個目の0番目の値を表示 print(grid[1][0]) #リスト1個目の0番目の値を表示 print(grid[2][0]) #リスト2個目の0番目の値を表示 print(grid[3][0]) #リスト3個目の0番目の値を表示 print(grid[4][0]) #リスト4個目の0番目の値を表示 print(grid[5][0]) #リスト5個目の0番目の値を表示 print(grid[6][0]) #リスト6個目の0番目の値を表示 print(grid[7][0]) #リスト7個目の0番目の値を表示 print(grid[8][0]) #リスト8個目の0番目の値を表示これを実行すると…
リスト"gridの1列目を取得し表示する。(結果). . 0 0 . 0 0 . .まぁそりゃそうだ。
これではただ1列目を取得して、また1列目に並び直しただけです。あまり意味がありません。
そこで、関数print()の呼び出し時に自動的に改行をさせないためのおまじない「end = ''」を第2引数に入れましょう。リスト"gridの1列目を取得し表示する。(コード2)print(grid[0][0], end = '')#0個目の0番目の値を標示 print(grid[1][0], end = '')#1個目の0番目の値を標示 print(grid[2][0], end = '')#2個目の0番目の値を標示 print(grid[3][0], end = '')#3個目の0番目の値を標示 print(grid[4][0], end = '')#4個目の0番目の値を標示 print(grid[5][0], end = '')#5個目の0番目の値を標示 print(grid[6][0], end = '')#6個目の0番目の値を標示 print(grid[7][0], end = '')#7個目の0番目の値を標示 print(grid[8][0], end = '')#8個目の0番目の値を標示これを実行すると
リスト"gridの1列目を取得し表示する。(結果2)..00.00..おお!!1行目にきちんと並びました。
これをリスト"grid"の2列目、3列目…と繰り返していけば良いのです。ん…?「繰り返し」…。そう!for文の出番ですね!
5.for文で繰り返し処理を行う。
リスト"grid"は6列ありますから、6回「4.1列目を取得する。」と同じ処理を繰り返す必要があります。
ただし、「4.1列目を取得する。」ではprint()関数を9回も書きました。最高にめんどくさいので、これも繰り返し処理をしましょう。そもそも9回print()関数を書いたのは、リスト"gird"の要素が9つあるからでした。for文を使うとたった2行にまとめることができます。
リスト"gridの1列目を取得し表示する。(コード3)for i in range(9): print(grid[i][0], end = '')ただし、
これは1~9個の要素の中の0番目の値、すなわち1列目の値を取得して1行目に並べているだけです。
そうなっている理由は「print(grid[i][0], end = '')」と2個目のインデックスを[0]と固定している為です。
つまりこの2個目のインデックスも繰り返し処理の中で変化していく必要があります。2個目のインデックスは、「今何列目の値を取得しているか」を示しています。
したがって、繰り返しが始まった時は1で、繰り返しが終わる時は最終列、すなわち6になっている必要があります。リスト"gridの全ての列を取得し表示する。(コード)for j in range(6): for i in range(9): print(grid[i][j], end = '')とします。
6.形を整える。
一見、先程の繰り返し処理で完璧にできたかに思えますが、
実はこのまま実行すると以下のように表示されます。リスト"gridの全ての列を取得し表示する。(結果)..00.00...0000000..0000000...00000.....000.......0....うまく繰り返しはできているのですが
そのまま横一列に並んでしまうのです。これを避けるには
列ごとの処理が終わったタイミングで改行させれば良いのです。具体的には1つ目のfor文の中で、「print('')」と空白文字を記載するすることで、強制的に改行させます。
リスト"gridの全ての列を取得し表示する。(コード2)for j in range(6): for i in range(len(grid)): print(grid[i][j], end = '') print('')7.完成
解答コードgrid = [['.', '.', '.', '.', '.', '.', ], ['.', '0', '0', '.', '.', '.', ], ['0', '0', '0', '0', '.', '.', ], ['0', '0', '0', '0', '0', '.', ], ['.', '0', '0', '0', '0', '0', ], ['0', '0', '0', '0', '0', '.', ], ['0', '0', '0', '0', '.', '.', ], ['.', '0', '0', '.', '.', '.', ], ['.', '.', '.', '.', '.', '.', ]] for j in range(6): for i in range(9): print(grid[i][j], end = '') print('')結果..00.00.. .0000000. .0000000. ..00000.. ...000... ....0....きちんと右回転(したかのように)できました!
今後も他の演習プロジェクトについて七転八倒解説を書いていきたいと思います!!
yutoman3.参考
以下参考にさせていただきました。とても助かりました。
①『退屈なことはPythonにやらせよう』第4章演習プロジェクト 文字絵グリッド
②『退屈なことはPythonにやらせよう』4章 演習プロジェクト
- 投稿日:2019-07-14T19:18:54+09:00
LeetCode / Remove Duplicates from Sorted Array
(ブログ記事からの転載)
[https://leetcode.com/problems/remove-duplicates-from-sorted-array/]
Given a sorted array nums, remove the duplicates in-place such that each element appear only once and return the new length.
Do not allocate extra space for another array, you must do this by modifying the input array in-place with O(1) extra memory.
Example 1:
Given nums = [1,1,2],
Your function should return length = 2, with the first two elements of nums being 1 and 2 respectively.
It doesn't matter what you leave beyond the returned length.Example 2:
Given nums = [0,0,1,1,1,2,2,3,3,4],
Your function should return length = 5, with the first five elements of nums being modified to 0, 1, 2, 3, and 4 respectively.
It doesn't matter what values are set beyond the returned length.Clarification:
Confused why the returned value is an integer but your answer is an array?
Note that the input array is passed in by reference, which means modification to the input array will be known to the caller as well.予め昇順にソートされた数値のリストを、重複を削除するように直接修正したリストを作成するという問題です。
入力のリストを直接修正するというのがポイントで、アウトプットのために別のリストを用意しない解法が求められています。この問題はBad評価が多いのですが、おそらく以下が原因と思います。
入力のリストnumsに対して、関数の返り値はリストの要素数nで、正解を判定する対象はnums[:n]になる
なぜこういうややこしい設定にしたのか・・・問題文を最後まで読む力を試してるんですかね。回答・解説
解法1
公式の解法はこちら。
入力のリストの要素数が0の場合は0を返しておきます。
iとjという2つの変数を作成し、これをポインタとして使います。
jはリストの要素数分ループを回すための通常のポインタで、iはリスト中の値が変わったときだけ+1し、リストの要素を新しい値で置き換えるためのポインタです。
このようにすることで、最後に正解を判定する対象nums[:i+1]が重複のない異なる値から構成されることになります。class Solution: def removeDuplicates(self, nums: List[int]) -> int: if len(nums) == 0: return 0 i = 0 for j in range(1, len(nums)): if nums[j] != nums[i]: i += 1 nums[i] = nums[j] return i + 1解法2
計算量は解法1が優れているのですが、正解を判定する対象はnums[:n]になるのがどうにも気に入らず、numsがそのまま正解判定対象になるように書いたのが以下です。
まあ私の意地みたいなコードなので、ご参考まで。
リストの初期の要素数分だけループを回し、重複する値はdelで削除していくという処理です。class Solution: def removeDuplicates(self, nums): if len(nums) == 0: return 0 i = 1 for _ in range(1,len(nums)): if nums[i] == nums[i-1]: del nums[i] else: i += 1 return len(nums)
- 投稿日:2019-07-14T18:34:00+09:00
TensorFlow,PyTorchの比較
TensorFlow,PyTorchの比較
普段はTensorFlowを用いて機械学習、Deep Learningの勉強をしているのですが、今回は現在流行っているPyTorchを用いてプログラムの作成を行ったのでTensorFlowとPyTorchの比較を行ってみました。
TensorFlowとは?
TensorFlowとはGoogle社が2017年にリリースしたオープンソースの機械学習用ライブラリです。
PyTorchとは?
PyTorchはfacebook社の人工知能研究グループが開発したオープンソースの機械学習用ライブラリです。
今回使用したPCのスペック
今回プログラムを動かす際に使用したPCのスペックは以下の通りです。
・Mac book pro2017
・Mac OS Mojave
・プロセッサ 2.3 GHz Intel Core i5
・メモリ 8GB学習データ
今回は一次元のデータを用いて識別を行うデータで検証を行った。また、今回は2000回学習を行なった。
TensorFlowでの結果
TensorFlowを用いた場合の結果は以下のようになった。
正解率は70%程度であり、学習時間は354秒程度となった。
PyTorchでの結果
PyTorchを用いた場合の結果は以下のようになった。
正解率は70%程度であり、学習時間は3.5秒程度となった。
使用してみた感想
TensorFlow,PyTorch共に結果としては正解率が70%程度であまり精度に違いはなかった。
しかし、学習にかかった時間はTensorFlowに比べPyTorchは100倍も早い結果となった。
使用した感覚としてはPyTorchは初期値に依存する傾向が強いように感じた。
TensorFlowは学習している最中にメモリが溜まるため学習が進むにつれて1回学習するのにかかる時間が長くなる。最後に
今回はあくまでもノートパソコンで計算を回した結果であり、GPUやTPUを用いて計算を行えば結果は変わるかもしれません。
今後TPUを用いて計算を回す予定があるのでその時にもう一度比較を行いたいと考えています。


- 投稿日:2019-07-14T18:30:09+09:00
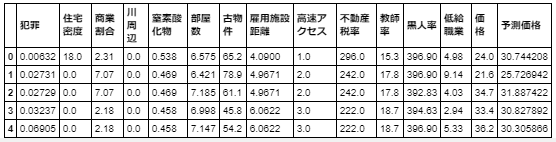
【Pythonデータ分析ケーススタディー】もしボストンの住宅価格のデータ分析を頼まれたら・・・汗汗汗
おつかれさまです、かきうち(@kakistuter)です。
ほんまビビりまくってるんですが、実務を想定して勉強しておこうと思って、ケーススタディーを実施。もちろん仕事中にカンニングできるようにQiitaにアップしておく。
オーダー
おい、垣内!
このデータ(Boston house prices dataset)を使ってボストンの住宅価格のデータ分析をしてくれ。オーダーを理解する
Boston house prices datasetはボストン住宅価格、犯罪率、密集度、小売業比率・・・のデータセットである。
https://scikit-learn.org/stable/datasets/index.html#boston-house-prices-datasetなのでおそらく依頼主は、、、
- ボストンの住宅価格は、犯罪率、密集度、小売業比率・・・のどれと相関が高いのか?
- もし犯罪率がこの値で密集度がこの値で・・・だったらボストンの住宅価格はどれくらいになるのか?
あたりを知りたいのだと想定する。
で、依頼主に「こういうことですよね」と確認して「そうだよ」となったとする。つまり今回のゴールまでのポイントは
- ボストンの住宅価格と相関の高い要素がなにか特定する
- ボストンの住宅価格の計算式を導く
- その計算式の信頼性を計算する
では早速いってみよう!
事前準備
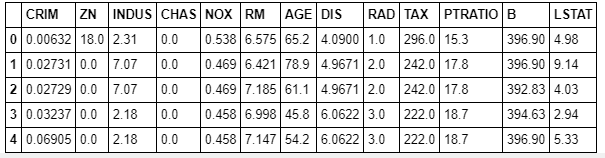
# pandasはデータの取扱系ライブラリ import pandas as pd # とくにDataFrameはよく使うので、個別importしておく from pandas import DataFrame # numpyは行列計算系ライブラリ import numpy as np # matplotlibとseabornはグラフ系ライブラリ import matplotlib.pyplot as plt import seaborn as sns # Jupyter Notebookを使う想定なのでブラウザ上にグラフ表示できるように設定 %matplotlib inline # scikit-learnという機械学習ライブラリから今回のデータ取り込み用のdatasetをインポート from sklearn import datasetsデータの取り込み
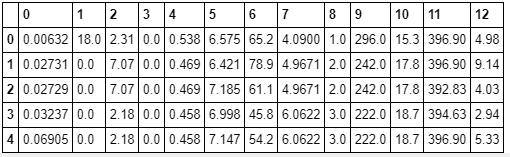
datasets = datasets.load_boston() df = DataFrame(datasets.data) # dataメソッドでデータ部分を取り出せる df.head()するとこんな感じでデータが取れます。
カラム名が数字なのでここに既定のカラム名を入れます。
df.columns = datasets.feature_names # feature_namesメソッドでカラム名の部分を取り出せる df.head()するとこんな感じになります。
なんのこっちゃ分からんのでこれに基づいて日本語にします。
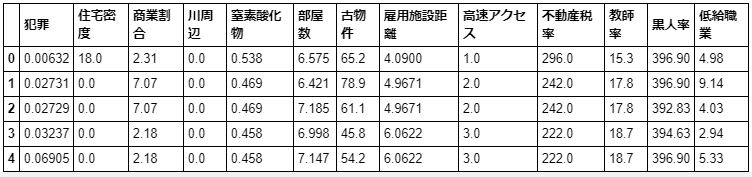
feature_names_japanese = ['犯罪', '住宅密度', '商業割合', '川周辺', '窒素酸化物', '部屋数', '古物件', '雇用施設距離', '高速アクセス', '不動産税率', '教師率', '黒人率', '低給職業'] df.columns = feature_names_japanese # df.columnsにリストを代入することでカラム名を変更できる df.head()こんな感じになります。
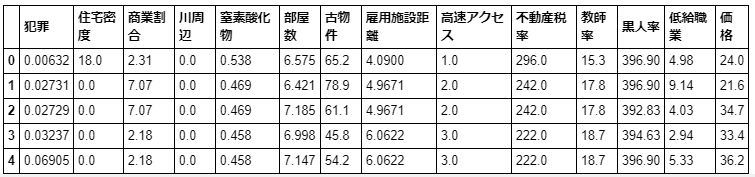
次に肝心の住宅価格データをDataFrameにくっつけます。
df['価格'] = datasets.target # targetメソッドで住宅価格のリストが取り出せます # df['新カラム名']にリストを代入することで、新カラム名の列ができます df.head()こんな感じになります。
欠損値が無いか確認しておきます。
df.info()
奇跡的にも欠損値はなく、データは506行あるとわかりました。
どんな感じのデータかをなんとなくつかむ
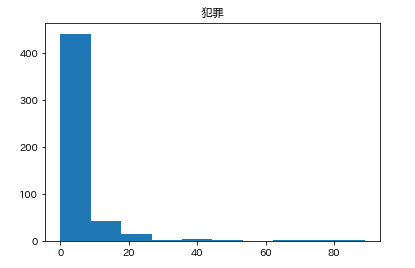
数字みててもわかりづらいので、各カラムがどんな感じになっているか見るために、
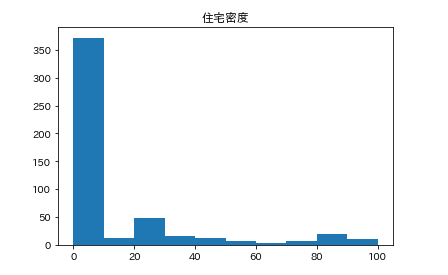
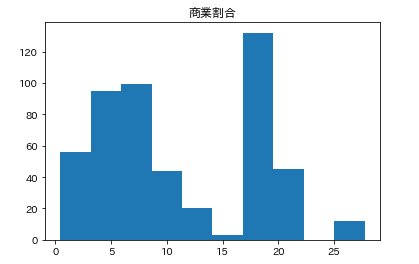
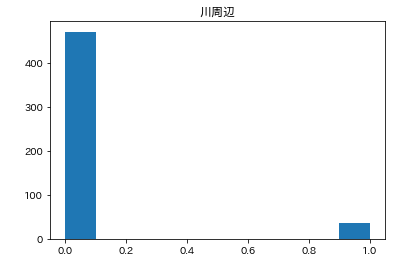
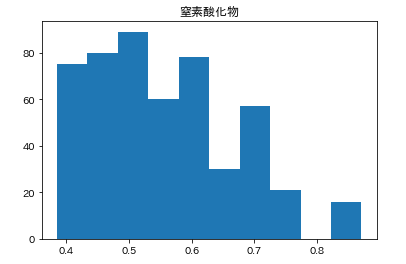
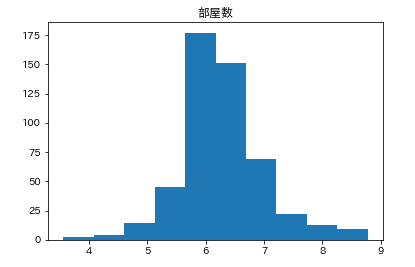
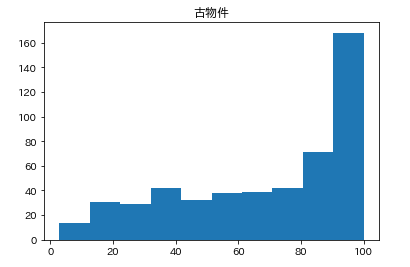
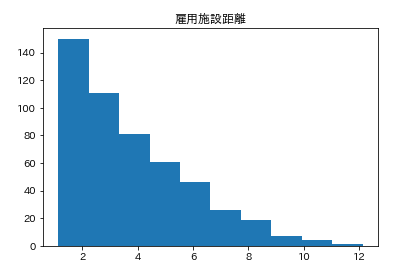
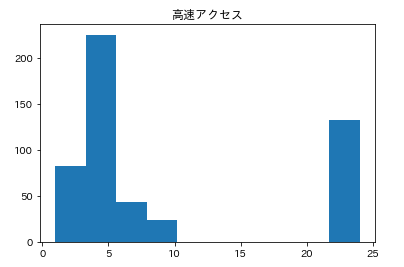
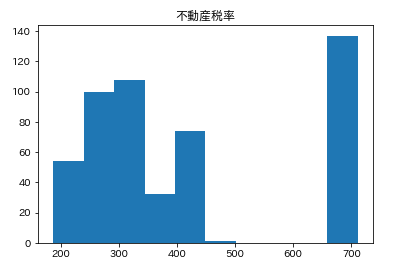
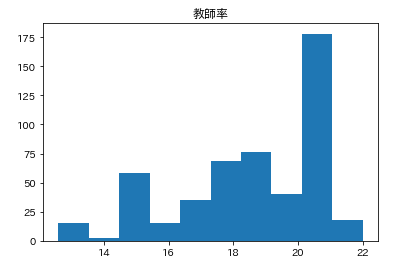
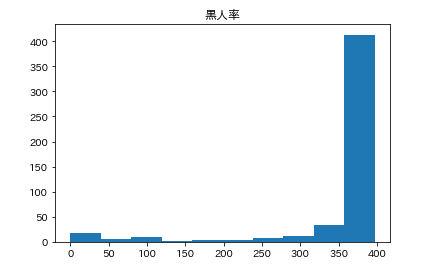
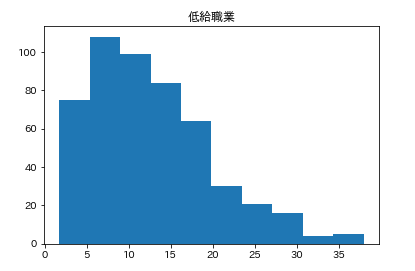
カラムごとのヒストグラムを表示させます。plt.subplot() # subplot()でグラフを並べて表示させます。そうでなければグラフが重なって表示されてしまいます。 for feature_name in feature_names_japanese: plt.hist(df[feature_name]) # hist(データ)でヒストグラムが表示できます。 plt.title(feature_name) plt.show()こんな感じになります。
こんな感じでそれぞれ分布してるんだなーとざっくりつかみます。
つぎにどれくらい相関しているのか調べる
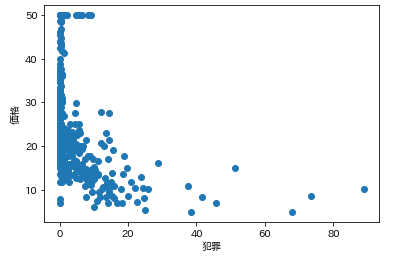
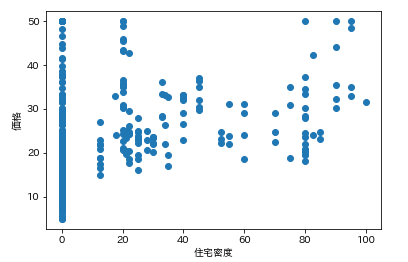
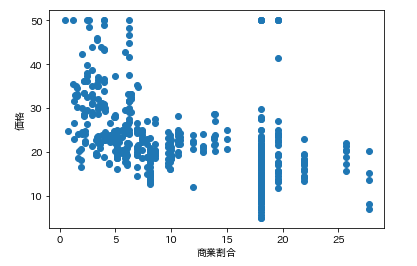
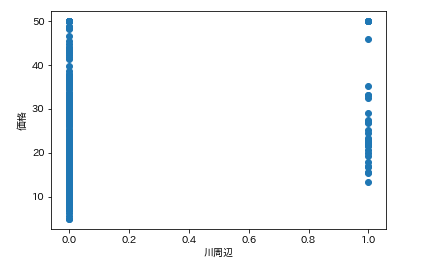
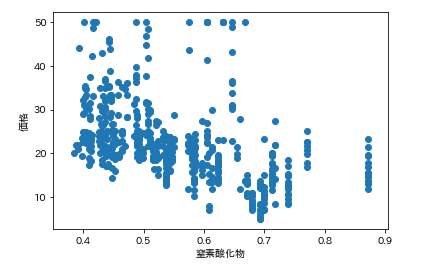
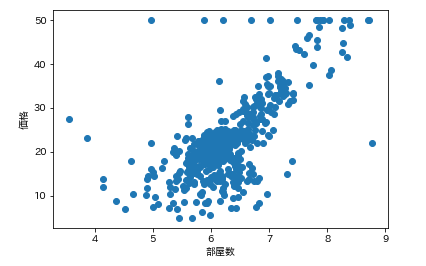
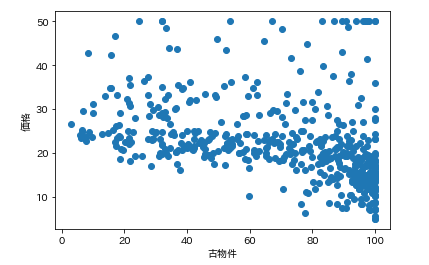
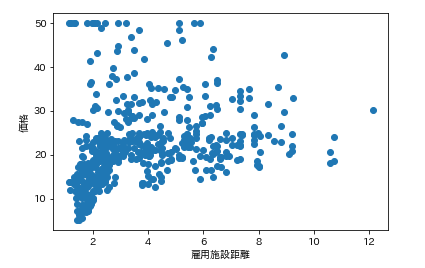
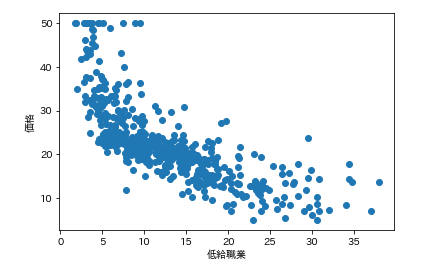
で今回の狙いは価格なので、各カラムの要素がどれくらい価格と連動しているかを調べます。
そんなときは散布図が一番です。
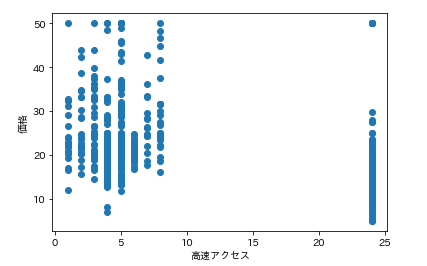
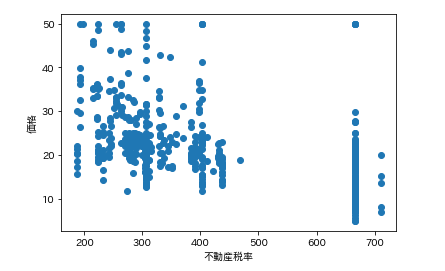
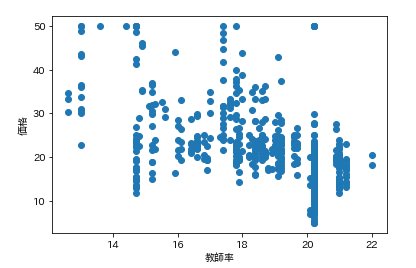
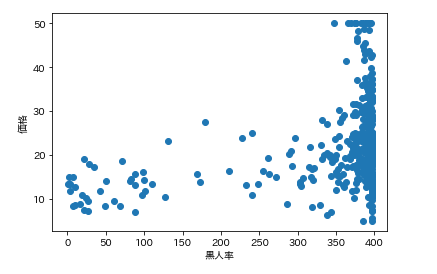
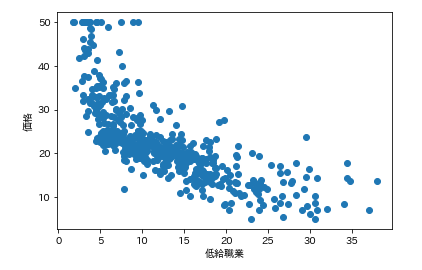
各カラムと価格の散布図を一気に描きます。plt.subplot() for feature_name in feature_names_japanese: plt.scatter(df[feature_name], df['価格']) # scatter(X軸要素, Y軸要素)で散布図が表示できます。 plt.xlabel(feature_name) plt.ylabel('価格') plt.show()こんな感じになります。
ふむふむ。相関してそうなのもあれば、全然してないのもあるし。
分かったような、、分からないような。。こんなときに便利なのが相関係数です。
相関係数はどれくらい相関しているかを数字で表すものです。
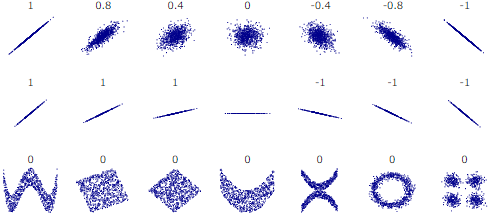
相関係数のイメージはこんな感じです。
※参考:https://upload.wikimedia.org/wikipedia/commons/d/d4/Correlation_examples2.svgつまり、
- 1.0 → 完全一致
- 0.8 → 結構相関している
- 0.4 → 微妙に相関しているけど、微妙
- 0.0 → 相関関係なし
- -0.4 → 微妙に逆相関しているけど、微妙
- -0.8 → 結構逆相関している
- -1.0 → 完全逆相関
という感じです。
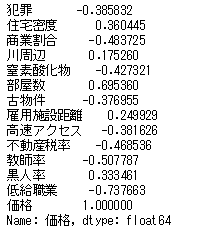
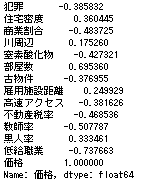
では先ほどの散布図の相関係数を確認します。df.corr()['価格'] # corrメソッドで相関係数を算出できる
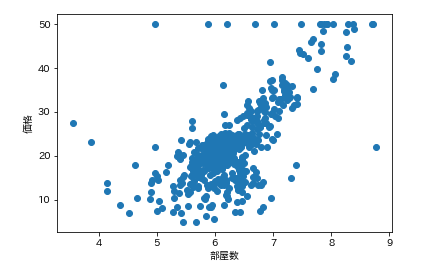
つまり、部屋数と低給職業の2つが価格と結構相関(逆相関)してるなとはっきり確認できます。
確かに散布図を振り返ってみるとそうですね。
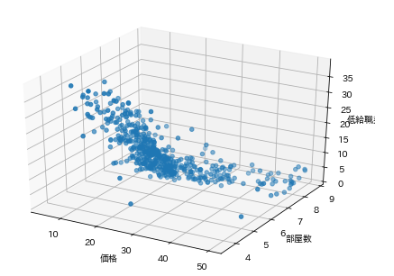
ではこの相関性の高い部屋数と低給職業と価格で3Dグラフを描いてみましょう。
from mpl_toolkits.mplot3d import Axes3D # 3Dグラフ作成のためにAxes3Dをインポート fig=plt.figure() ax=Axes3D(fig) ax.scatter3D(df['価格'], df['部屋数'], df['低給職業']) ax.set_xlabel('価格') ax.set_ylabel('部屋数') ax.set_zlabel('低給職業')こんな感じになります。
けっこういい感じにまとまっていますね。
連動性がいい感じに働いていることがわかります。でもこれだけじゃ住宅価格の予測ができません。
なんとなくこの辺?というのは分かりますが、計算式がないのでザックリすぎます。ボストンの住宅価格の計算式を求める
では計算式(回帰式)を求めていきましょう。
今回は線形回帰という手法で分析をすすめます。
線形回帰とは、価格=部屋数×〇+低給職業×〇+別の要素×〇+別の要素×〇+・・・+定数(切片)といった式を導き出す手法です。
価格を目的変数とよび、部屋数や低給職業や別の要素を説明変数と呼びます。では線形回帰に必要なライブラリをインポートします。
from sklearn import linear_modelつぎに、目的変数と説明変数を何にするか自分で決めます。
今回は目的変数を価格、説明変数を部屋数と低給職業にします。
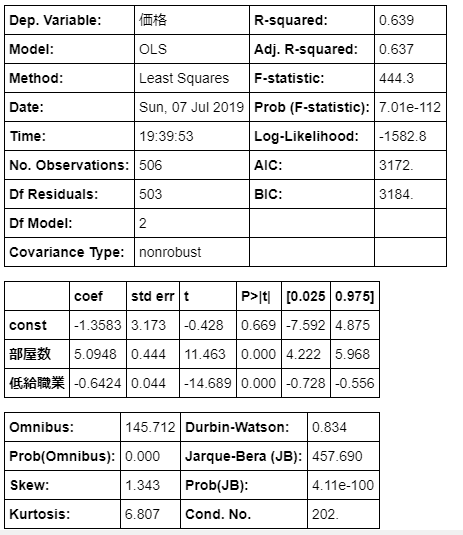
以下のようにコーディングします。# まずは線形回帰をつかうことを指定 clf = linear_model.LinearRegression() # 説明変数をDataFrameとして設定し、arrayに変換 X = df[['部屋数', '低給職業']].as_matrix() # 目的変数をDataFrameとして設定し、arrayに変換 Y = df['価格'].as_matrix() # fitメソッドで第1引数に説明変数arrayを第2引数に目的変数を指定する。 clf.fit(X, Y)問題なく線形回帰が完了されれば
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)と出力されます。
そしてcoef_メソッドで各説明変数の係数を出力します。clf.coef_
array([ 5.09478798, -0.64235833])と出力されました。
次にintercept_メソッドで定数(切片)を出力します。clf.intercept_
-1.3582728118744889と出力されました。
つまり回帰式は価格=部屋数×5.09478798-低給職業×0.64235833-1.3582728118744889だとわかります。
またこの計算式で表される線上から実際の値がどれだけ一致しているかの指標をscoreメソッドで出力できます。clf.score(X, Y)
0.63856160626034031と出力されました。
この値は決定係数とよび、相関係数の2乗のことです。
寄与率とよばれることもあります。
決定係数はおおまかな目安としては0.5以上であれば(相関係数が0.7以上もしくは0.7以下なので)マッチ度が高いと言われています。また別の方法として
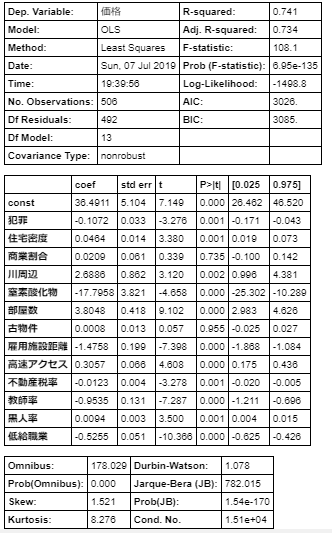
statsmodelsを使って線形分類をすることもできます。
以下のようにコーディングします。# Xに説明変数のDataFrameを代入します。 X = df[['部屋数', '低給職業']] # さらに切片を追加する指定を行います。 X = sm.add_constant(X) # Yに目的変数のDataFrameを代入します。 Y = df['価格'] # 次に線形回帰をOLSという手法で計算するように指定します。(OLSは最小二乗法というメジャーな計算方法です) model = sm.OLS(Y, X) # fitメソッドで計算を開始します。 result = model.fit() # summaryメソッドで計算結果を出力します。 result.summary()するとこんな感じになります。
いろいろ数値がでていますが、重要な指標としては、
- 一番上の表の
R-squared→決定係数(相関係数の2乗)- 一番上の表の
Adj. R-squared→調整済決定係数(のちほど説明)- 真ん中の表の
coef→各説明変数の係数(constは切片の値をしめしている)- 真ん中の表の
t→各説明変数の目的変数に対する影響力- 真ん中の表の
P>|t|→出力される回帰式から大きく外れる危険度といったところです。
つまりこの表からわかることは、
- 価格=部屋数×5.0948-低給職業×0.6424-1.3583
- 決定係数は0.639なのでまずます
- 価格に対する影響度は低給職業>部屋数>定数(切片)
- 切片の
P>|t|の値が大きく、この値は疑わしいということです。
説明変数でどれを選択すべきか?
このあたりで疑問が起こります。
今回は説明変数を部屋数と低級職業としましたが、ほかに適切なものもあるかもしれません。もっと説明変数が多いほうが良いかもしれません。
どのようにして適切な説明変数を選択すればいのでしょうか。今回は変数減少法という手法を使ってみます。
これは、まず全変数をつかって線形回帰を行い、その計算結果を判断基準として不適切な変数を取り除いていく手法です。
※ほかには変数増加法というのもあるようです。では全変数で
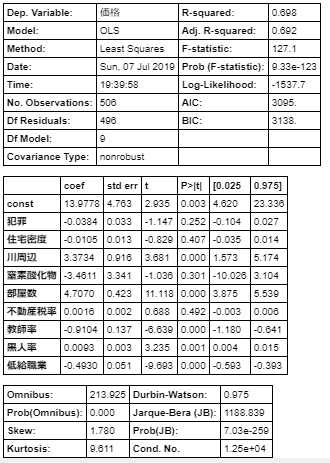
statsmodelsを使って線形分類します。X = df[['犯罪', '住宅密度', '商業割合', '川周辺', '窒素酸化物', '部屋数', '古物件', '雇用施設距離', '高速アクセス', '不動産税率', '教師率', '黒人率', '低給職業']] X = sm.add_constant(X) Y = df['価格'] model = sm.OLS(Y, X) result = model.fit() result.summary()結果はこんな感じです。
変数が多いときに回避すべき現象に多重共線性というものがあります。
多重共線性とは、説明変数間で相関係数が高いときに発生します。
適切でない計算式となたとえば部屋数と住宅敷地の広さという説明変数があったとき、その2つは相関が強いため、適切な線形回帰分析結果を出力できません。具体的な対策の方法としては相関係数の符号と説明変数の符号が異なる変数を排除することです。
(本来であれば、目的変数と正に相関していれば、回帰式の説明変数の係数も正になるはずと考えられるからです。負に相関していれば、回帰式の説明変数の係数も負。)さきほど求めた各要素の相関係数はこれです。
この相関係数と回帰式の係数の符号が一致していないのは、
商業割合、古物件、雇用施設距離、高速アクセスです。
この4つを取り除いてもう一度線形分類します。X = df[['犯罪', '住宅密度', '川周辺', '窒素酸化物', '部屋数', '不動産税率', '教師率', '黒人率', '低給職業']] X = sm.add_constant(X) Y = df['価格'] model = sm.OLS(Y, X) result = model.fit() result.summary()結果はこんな感じです。
相関係数と回帰式の係数の符号が一致していないのは、住宅密度、不動産税率です。
またP>|t|は回帰式から外れる危険度を指します。少なくとも0.05は下回っていることが推奨されています。
この観点から危険性が高い説明変数として、犯罪、窒素酸化物があります。
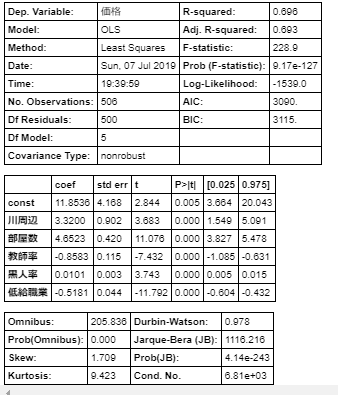
この住宅密度、不動産税率、犯罪、窒素酸化物を取り除いて再度線形回帰を実施します。X = df[['川周辺', '部屋数', '教師率', '黒人率', '低給職業']] X = sm.add_constant(X) Y = df['価格'] model = sm.OLS(Y, X) result = model.fit() result.summary()結果はこんな感じです。
この結果は、符号の不一致もなく、
P>|t|も適性です。
したがって適切な説明変数は、川周辺、部屋数、教師率、黒人率、低給職業の5つのどれかの組み合わせです。
(5個すべて使うべきか、どれか4個なのか、どれか3個なのか、、、)この判断を行う指標が調整済み決定係数です。
決定係数は回帰式とのマッチ度を表しますが、一方で説明変数が増えると増加するという特徴ももっています。
調整済決定係数は説明変数が増えると増加するという特徴をなくしたものになります。つまり、どれか1つ説明変数をけずってみて、調整済決定係数の増減を確認してみます。
どれを削るか?
t値が目的変数への影響度を指しているので、tの絶対値が一番小さい川周辺を削って線形回帰を行ってみます。X = df[['部屋数', '教師率', '黒人率', '低給職業']] X = sm.add_constant(X) Y = df['価格'] model = sm.OLS(Y, X) result = model.fit() # rsquared_adjメソッドで調整済決定係数のみ出力することができます。 result.rsquared_adj結果は0.68525372051445432でした。
これは川周辺を削っていないときの値「0.693」よりも低下しているので、
変数5個のほうが良いと判断できます。
同様にほかの変数を削ってみても「0.693」よりも低下していることが確認できました。つまり適切な説明変数は川周辺、部屋数、教師率、黒人率、低給職業の5つであると判断できます。
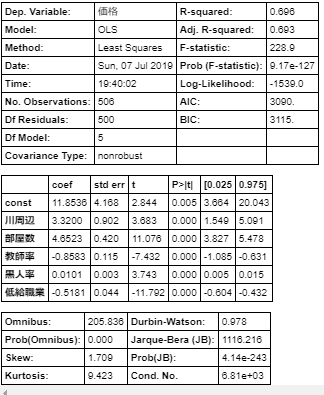
では最後にもう一度説明変数5個で線形回帰を実施します。X = df[['川周辺', '部屋数', '教師率', '黒人率', '低給職業']] X = sm.add_constant(X) Y = df['価格'] model = sm.OLS(Y, X) result = model.fit() result.summary()
これで妥当性の高い回帰式が以下であるとわかりました。
価格=川周辺×3.3200+部屋数×4.6523-教師率×0.8583+黒人率×0.0101-低給職業×0.5181+11.8536どれくらいのズレが発生するかを視覚化する
妥当な回帰式は分かりましたが、人がみて分かるようにするには決定係数だけでは不十分です。
最後に95%でこの区間内に収まっている(予測区間95%)として視覚化しましょう。ではまず、回帰式から予測される数値を予測価格としてDataFrameに追加します。
def formula(elements): chrs, rm, ptratio, b, lstat = elements return result.params['川周辺'] * chrs + result.params['部屋数'] * rm + result.params['教師率'] * ptratio + result.params['黒人率'] * b + result.params['低給職業'] * lstat + result.params['const'] # paramsで説明変数の係数が取得できます df['予測価格'] = df[['川周辺', '部屋数', '教師率', '黒人率', '低給職業']].apply(formula,axis=1) df.head()こんな感じになります。
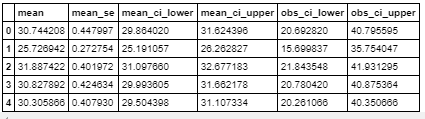
次に予測区間を出力します。
summary = result.get_prediction().summary_frame(alpha=0.05) # get_prediction().summary_frame()メソッドで予測区間を出力できる summary.head()こんな感じです。
obs_ci_lowerは指定した信頼度内でどれくらい下振れするか
obs_ci_upperは指定した信頼度内でどれくらい下振れするか
を示しています。つまり95%の確率で、実際の価格は、
obs_ci_lower以上で、obs_ci_upper以下であるということを意味しています。
ではこれらの結果をDataFrameでまとめて、予測価格で昇順に並べ替えます。df_predict = pd.concat([summary, df['予測価格'], df['価格']], axis =1).sort_values(by = '予測価格') df_predict.head()こんな感じです。
これを視覚化します。
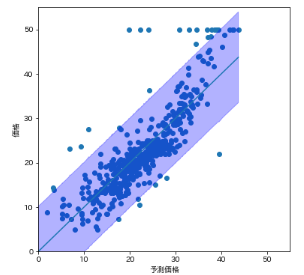
縦軸を価格、横軸を回帰式計算結果として、予測区間を薄青色で、回帰式を青線で、実際の価格データを青点にしてみます。plt.figure(figsize=(6, 6)) plt.scatter(df_predict['予測価格'], df_predict['価格']) plt.plot(df_predict['予測価格'], df_predict['mean']) # fill_betweenメソッド(第1引数はX軸、第2引数はY軸下限、第3引数でY軸上限)で間の範囲に色付けできる plt.fill_between(df_predict['予測価格'], df_predict['obs_ci_lower'], df_predict['obs_ci_upper'], alpha=0.3, color='b') plt.xlim([0, 55]) plt.ylim([0, 55]) plt.xlabel('予測価格') plt.ylabel('価格') plt.show()こんな感じです。
なんとなく薄青色範囲内に95%くらいの青点が入っていることも確認できます。
95%の確率でこの青色の範囲にはいりますよと説明できるようになりました。最後に
もし不適切なロジックがあればどんどんコメントから指摘お願いします!!
参考にさせていただきました、ありがとうございます!
https://openbook4.me/projects/183/sections/1366
https://mathtrain.jp/suitei
https://mathtrain.jp/ketteikeisu
https://qiita.com/yut-nagase/items/6c2bc025e7eaa7493f89
https://bellcurve.jp/statistics/course/8891.html
https://momonoki2017.blogspot.com/2018/01/scikit-learn_28.html
https://karupoimou.hatenablog.com/entry/2019/05/12/175745
https://pythondatascience.plavox.info/scikit-learn/線形回帰
https://qiita.com/gatchaman-20140215/items/86299f4501d9f3576ea2
https://qiita.com/ynakayama/items/36b7c1640e6a02ce2e00
https://tanuhack.com/python/statsmodels-multiple-lra/
https://qiita.com/ground0state/items/529a76ce2a450754cbb0
https://qiita.com/pshiko/items/17454ae238534444b222
http://cranethree.hatenablog.com/entry/2015/07/25/204608

- 投稿日:2019-07-14T18:07:21+09:00
Kerasで作成したモデルを変換してiOSに組み込み
やること
前回記事(【Tensorflow・VGG16】転移学習による画像分類)で作成したモデルを使ってiPhone上で写真を撮影し、それを推定してみる。
手順概要
- Kerasで作成したモデル(.h5)を変換
- Xcodeでプロジェクトを作成
- 画面のパーツ作成 & コードの関連付け
- カメラへのアクセス許可 & カメラを起動するコードを追加
- ボタン(写真撮影)押下時の挙動
- モデルを読み込んで推定
動作環境
- macOS Catalina 10.15 beta
- Python 3.6.8
- keras 2.2.4
- coremltools 2.1.0
- Xcode 10.2.1
1. Kerasで作成したモデル(.h5)を変換
- 前回記事で作成したモデル(vgg16_transfer.h5)を使い、iOSで利用可能なモデルに変換する
モデルの変換import coremltools coreml_model = coremltools.converters.keras.convert( 'vgg16_transfer.h5', input_names='image', image_input_names='image', output_names='Prediction', class_labels=['apple', 'tomato', 'strawberry'], ) coreml_model.save('./vgg16_transfer.mlmodel')2. Xcodeでプロジェクトを作成
- Xcodeを起動し、「Create a new Xcode project」を選択
- 「Single View App」を選択

- 'Product Name'は任意の名称を付ける。Languageは「Swift」、チェックボックス(Use XX, include XX)は全て外し、Nextボタンを押下する
3. 画面のパーツ作成 & コードの関連付け
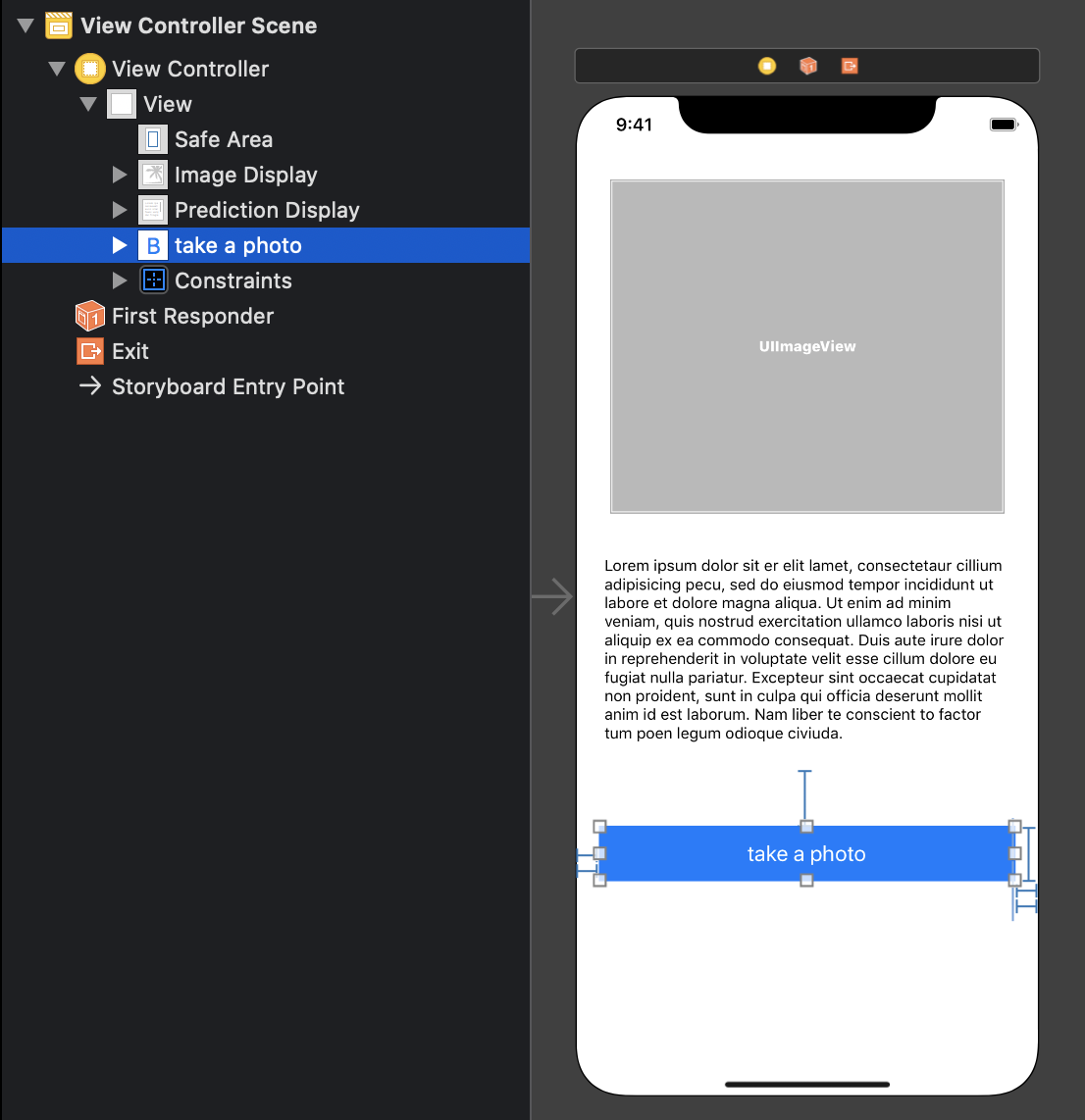
Xcode上で下記3つの画面のパーツを追加する
- Image View(写真を表示する領域)
- Text View(推定結果を表示する領域)
- Button(カメラを起動するボタン)
こんな感じのレイアウトにしておく
各パーツの関連付けを実施する
Image ViewとText Viewは「class ViewController」の下に追加(パーツを選択し、controlキーを押下しながら追加)
Buttonは「override func viewDidLoad()」の下に追加
Name(とConnection)はそれぞれ下記で設定
- Image View : imageDisplay(Connection : Outlet)
- Text View : predictionDisplay(Connection : Outlet)
- Button : takePhoto(Connection : Action)
各パーツの関連付け# Image View @IBOutlet weak var imageDisplay: UIImageView! # Text View @IBOutlet weak var predictionDisplay: UITextView! # Button @IBAction func takePhoto(_ sender: Any) { }4. カメラへのアクセス許可 & カメラを起動するコードを追加
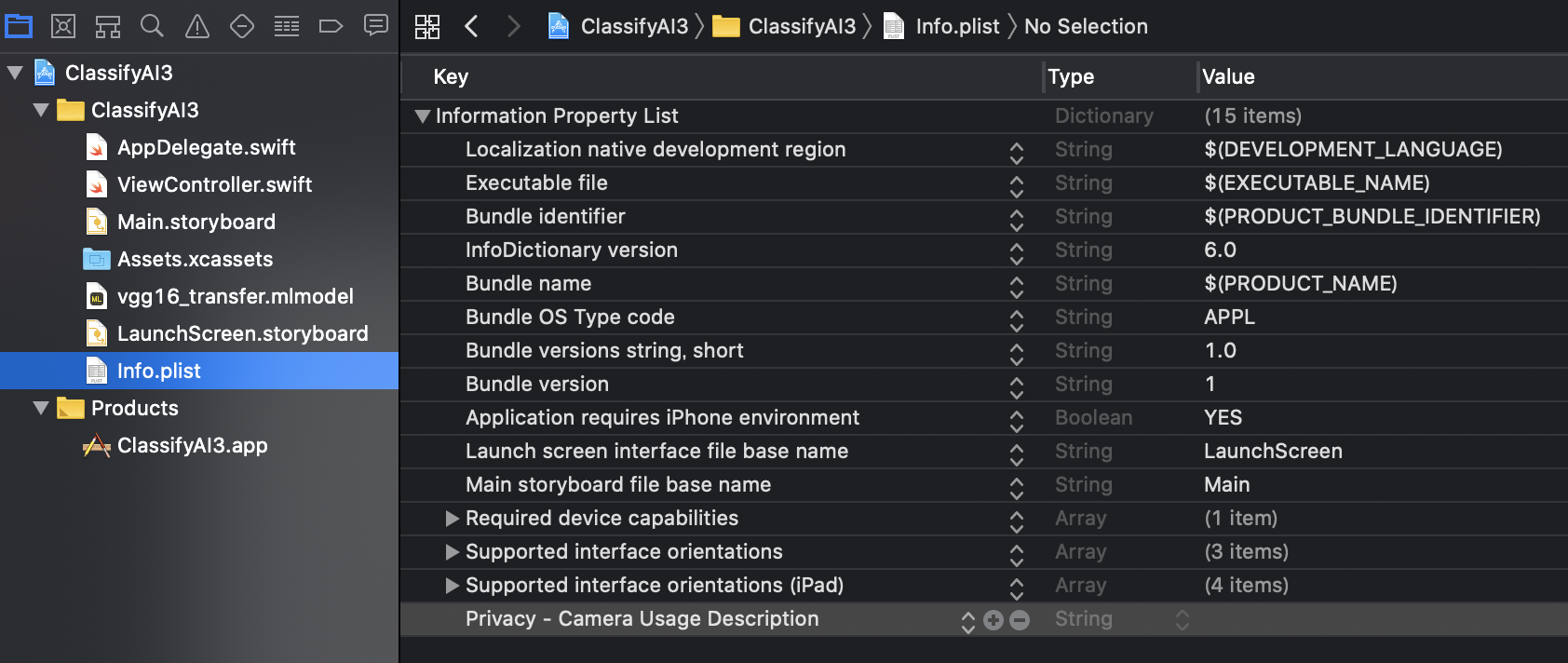
info.plistに「Privacy - Camera Usage Description」を追加し、カメラへのアクセスを許可する
下記2つの「delegate」(イベントを検知・処理)を追加する。(カメラを表示する画面、写真を保存した時に元の画面に戻る操作を行うことが可能)
- UIImagePickerControllerDelegate
- UINavigationControllerDelegate
カメラの撮影画面を表示するために「imagePicker」という変数を追加
アプリが起動した直後に「imagePicker」を初期化するコードを「viewDidLoad()」内に追加
カメラを起動(before)class ViewController: UIViewController { @IBOutlet weak var imageDisplay: UIImageView! @IBOutlet weak var predictionDisplay: UITextView! override func viewDidLoad() { super.viewDidLoad() // Do any additional setup after loading the view. } # ~~~ 省略 ~~~ }カメラを起動(after)class ViewController: UIViewController, UIImagePickerControllerDelegate, UINavigationControllerDelegate { @IBOutlet weak var imageDisplay: UIImageView! @IBOutlet weak var predictionDisplay: UITextView! var imagePicker: UIImagePickerController! override func viewDidLoad() { super.viewDidLoad() // Do any additional setup after loading the view. # 初期化 imagePicker = UIImagePickerController() # delegate:イベントを受け渡しする変数 imagePicker.delegate = self # sourceType : カメラからデータを撮るか、アルバムから読込か -> 今回はカメラ imagePicker.sourceType = .camera } # ~~~ 省略 ~~~ }5. ボタン(写真撮影)押下時の挙動
- 4.で作成しておいたimagePickerを表示するため、present関数を「takePhoto」で呼び出す
before@IBAction func takePhoto(_ sender: Any) { }after@IBAction func takePhoto(_ sender: Any) { present(imagePicker, animated: true, completion: nil) }
- 写真を撮り終わった後の処理を記載(imagePickerController)
- imageDisplayのimage属性を更新する
- infoに撮影した画像が入っているため、それを取り出してimageDisplayのimage属性にセットする
- infoのUIImagePickerController.InfoKeyに各種属性が入っているため、「originalImage」というプロパティを設定する('as? UIImage'でタイプを指定する)
- 画像を設定したら、先程のImagePickerを閉じる(dismiss)
afterfunc imagePickerController(_ picker: UIImagePickerController, didFinishPickingMediaWithInfo info: [UIImagePickerController.InfoKey : Any]) { imageDisplay.image = info[UIImagePickerController.InfoKey.originalImage] as? UIImage imagePicker.dismiss(animated: true, completion: nil) }6. モデルを読み込んで推定
- mlmodelを読み込みして、そのモデルに画像ファイルを渡して推定する
- 1.で変換したモデル(vgg16_transfer.mlmodel)をXcodeのプロジェクトにドラッグ・アンド・ドロップする
- 下記ライブラリを追加する
- CoreML : 機械学習のライブラリ
- Vision : 画像ファイルを扱うライブラリ
ライブラリの追加import CoreML import Vision
- 推定処理を加える
- imagePickerControllerの後ろに推定処理(imagePrediction)を加える
- 引数に画像ファイルを指定(画面上に表示した内容と同じ(imageDisplay.image))
beforefunc imagePickerController(_ picker: UIImagePickerController, didFinishPickingMediaWithInfo info: [UIImagePickerController.InfoKey : Any]) { imageDisplay.image = info[UIImagePickerController.InfoKey.originalImage] as? UIImage imagePicker.dismiss(animated: true, completion: nil) }afterfunc imagePickerController(_ picker: UIImagePickerController, didFinishPickingMediaWithInfo info: [UIImagePickerController.InfoKey : Any]) { imageDisplay.image = info[UIImagePickerController.InfoKey.originalImage] as? UIImage imagePicker.dismiss(animated: true, completion: nil) imagePrediction(image: (info[UIImagePickerController.InfoKey.originalImage] as? UIImage)!) }
- 推定処理(imagePrediction)の関数を作成
- モデルの読み込み
モデルの読み込みfunc imagePrediction(image: UIImage) { guard let model = try? VNCoreMLModel(for: vgg16_transfer().model) else { fatalError("Model not found") }
- VNCoreMLRequestのインスタンスを生成
- 推定結果をresultsに格納する(推定結果は「VNClassificationObservation」という変数に入って返ってくる)
- results.firstにスコアの高いデータが格納されている
- predictionDiaplayに推定結果を表示する
- firstResult.confidence : 確率(少数で入っているので、100倍して%表示)
- firstResult.identifier : ラベル(推定結果)
モデルによる推定処理let request = VNCoreMLRequest(model: model) { [weak self] request, error in guard let results = request.results as? [VNClassificationObservation], let firstResult = results.first else { fatalError("No results found") } DispatchQueue.main.async { self?.predictionDisplay.text = "Accuracy: = \(Int(firstResult.confidence * 100))% \n\nラベル: \((firstResult.identifier))" } }
- requestに対する処理を記載
- ciImageというデータ型に変換できないと推定処理が出来ないため、取得出来ない場合はエラー
- Visionフレームワークで画像を使うためのimageHandlerという変数を宣言し、VNImageRequestHandlerを生成
- imageHandlerにrequestを実行させる
guard let ciImage = CIImage(image: image) else { fatalError("Can't convert image.") } let imageHandler = VNImageRequestHandler(ciImage: ciImage) DispatchQueue.global(qos: .userInteractive).async { do { try imageHandler.perform([request]) } catch { print("Error") } }
- コードの全体は以下の通り
ViewController.swiftimport UIKit import CoreML import Vision class ViewController: UIViewController, UIImagePickerControllerDelegate, UINavigationControllerDelegate { @IBOutlet weak var imageDisplay: UIImageView! @IBOutlet weak var predictionDisplay: UITextView! var imagePicker: UIImagePickerController! override func viewDidLoad() { super.viewDidLoad() // Do any additional setup after loading the view. imagePicker = UIImagePickerController() imagePicker.delegate = self imagePicker.sourceType = .camera } @IBAction func takePhoto(_ sender: Any) { present(imagePicker, animated: true, completion: nil) } func imagePickerController(_ picker: UIImagePickerController, didFinishPickingMediaWithInfo info: [UIImagePickerController.InfoKey : Any]) { imageDisplay.image = info[UIImagePickerController.InfoKey.originalImage] as? UIImage imagePicker.dismiss(animated: true, completion: nil) imagePrediction(image: (info[UIImagePickerController.InfoKey.originalImage] as? UIImage)!) } func imagePrediction(image: UIImage) { guard let model = try? VNCoreMLModel(for: vgg16_transfer().model) else { fatalError("Model not found") } let request = VNCoreMLRequest(model: model) { [weak self] request, error in guard let results = request.results as? [VNClassificationObservation], let firstResult = results.first else { fatalError("No results found") } DispatchQueue.main.async { self?.predictionDisplay.text = "Accuracy: = \(Int(firstResult.confidence * 100))% \n\nラベル: \((firstResult.identifier))" } } guard let ciImage = CIImage(image: image) else { fatalError("Can't convert image.") } let imageHandler = VNImageRequestHandler(ciImage: ciImage) DispatchQueue.global(qos: .userInteractive).async { do { try imageHandler.perform([request]) } catch { print("Error") } } } }ソースコード
https://github.com/hiraku00/ios_camera
('vgg16_transfer.h5'と'vgg16_transfer.mlmodel'は除外)参考文献

- 投稿日:2019-07-14T17:09:43+09:00
Cloud9でAWS CDK (Python3) をインストールする方法
AWS CDKがGA!
2019年7月11日に、AWS Cloud Development Kit (AWS CDK)がGAしました。
Infrastructure as Codeの観点では、CloudFormationを使うよりも開発が楽になるとかなんとか言われていますが、実際に試さねば分からないだろうと思い、早速手を動かしてみることにしました。本記事では、Cloud9を使ってAWS CDKを開始する方法をまとめてみました。
Python3でCDKを書く前提での覚書となります。AWS CDKとは
公式「What Is the AWS CDK?」の解説を紐解いていきます。
- AWS CDKは、クラウドインフラストラクチャをコードで定義するためのソフトウェア開発フレームワークです。
- AWS CDKを使ってコードを書き、実行すると、AWS CloudFormationを通じてインフラストラクチャがプロビジョニングされます。
- CloudFormationとの違いとして、TypeScript、JavaScript、Pythonといった、開発者が慣れ親しんだプログラミング言語でインフラストラクチャを定義できます。
- if分岐やforループを活用できることから、CloudFormationに比べて記述量も減らせそう。
既に、PythonでAWSのインフラストラクチャをプロビジョニングするtroposphereもありますが、AWSが公式でCDKを出してきたことで、サポート面で安心できるCDKの利用が増えていくのかなと思ったりしています。
AWS CDKをCloud9にインストール
AWS CDK (Python3) を利用して、AWS CDK Appsを開発するための準備をします。
必要条件
・Node.js 8.11.x 以降のバージョンが必要です。
・Python3.6 以降のバージョンが必要です。
・AWS CDK CLIを利用するため、CredentialsとAWSリージョンを特定する必要があります。インストール
Cloud9でターミナルを開き
npm install -g aws-cdkを実行します。install$ npm install -g aws-cdk /home/ec2-user/.nvm/versions/node/v8.16.0/bin/cdk -> /home/ec2-user/.nvm/versions/node/v8.16.0/lib/node_modules/aws-cdk/bin/cdk > core-js@2.6.9 postinstall /home/ec2-user/.nvm/versions/node/v8.16.0/lib/node_modules/aws-cdk/node_modules/core-js > node scripts/postinstall || echo "ignore" Thank you for using core-js ( https://github.com/zloirock/core-js ) for polyfilling JavaScript standard library! The project needs your help! Please consider supporting of core-js on Open Collective or Patreon: > https://opencollective.com/core-js > https://www.patreon.com/zloirock Also, the author of core-js ( https://github.com/zloirock ) is looking for a good job -) + aws-cdk@1.0.0 added 267 packages from 249 contributors in 12.069sインストールが成功していれば
cdk --versionでバージョンを確認できます。version$ cdk --version 1.0.0 (build d89592e)ここで、Cloud9で通常使用するPythonが3.6に設定されていることを
python --versionで改めて確認しておきます。(master) $ python --version Python 3.6.8もし2.7.xだった場合は、こちらのリンク先の手順で、Python3を使えるように設定を切り替えましょう。
AWS Cloud9 でPython3を使うための設定
アプリを作る
次に、空のディレクトリを作って、ディレクトリに移動した後
cdk init --language pythonコマンドで、アプリを初期化します。(Gitリポジトリができます)
今回は分かりやすいようにCDKというディレクトリ名にしていますが、名前は何でも良いです。
言語を指定するのは、このcdk initを実行する時です。init$ mkdir CDK $ cd CDK $ cdk init --language python Applying project template app for python Initializing a new git repository... (略) Enjoy!結果を確認してみます。
cdk initの結果、いろいろできています。(master) $ ls -al total 40 drwxr-xr-x 5 ec2-user ec2-user 4096 Jul 13 07:05 . drwxr-xr-x 11 ec2-user ec2-user 4096 Jul 13 05:49 .. -rw-rw-r-- 1 ec2-user ec2-user 138 Jul 13 07:05 app.py drwxrwxr-x 2 ec2-user ec2-user 4096 Jul 13 07:05 cdk -rw-rw-r-- 1 ec2-user ec2-user 32 Jul 13 07:05 cdk.json drwxrwxr-x 5 ec2-user ec2-user 4096 Jul 13 07:05 .env drwxrwxr-x 7 ec2-user ec2-user 4096 Jul 13 07:05 .git -rw-rw-r-- 1 ec2-user ec2-user 1651 Jul 13 07:05 README.md -rw-rw-r-- 1 ec2-user ec2-user 5 Jul 13 07:05 requirements.txt -rw-rw-r-- 1 ec2-user ec2-user 1008 Jul 13 07:05 setup.py次に、CDKが依存するパッケージをインストールします。
(master) $ sudo pip install -r requirements.txt Obtaining file:///home/ec2-user/environment/CDK (from -r requirements.txt (line 1)) Collecting aws-cdk.core (from cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/60/99/6b1bc6e1059d0d97050550cfb7aee7ca154cf69ef4afd85e516340b8fd6d/aws_cdk.core-1.0.0-py3-none-any.whl (508kB) 100% |████████████████████████████████| 512kB 2.4MB/s Collecting jsii~=0.14.0 (from aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/fc/30/0954b455242b6b9a01f614db21d8a1707d62c7d302420a6c72c93faeb80e/jsii-0.14.0-py3-none-any.whl (236kB) 100% |████████████████████████████████| 245kB 4.6MB/s Collecting aws-cdk.cx-api>=1.0.0,~=1.0 (from aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/98/be/53a9bb48df0bd066fe1a227a93df70a957b717ce741d6746085bdb49e1ef/aws_cdk.cx_api-1.0.0-py3-none-any.whl (78kB) 100% |████████████████████████████████| 81kB 6.1MB/s Collecting publication>=0.0.3 (from aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/f8/d3/6308debad7afcdb3ea5f50b4b3d852f41eb566a311fbcb4da23755a28155/publication-0.0.3-py2.py3-none-any.whl Collecting attrs>=18.2 (from jsii~=0.14.0->aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/23/96/d828354fa2dbdf216eaa7b7de0db692f12c234f7ef888cc14980ef40d1d2/attrs-19.1.0-py2.py3-none-any.whl Collecting cattrs (from jsii~=0.14.0->aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/4a/4e/f8bfec0990a2d4f9f79d4417336b761c58c849672cd3b81637a22f02bb20/cattrs-0.9.0-py2.py3-none-any.whl (54kB) 100% |████████████████████████████████| 61kB 8.0MB/s Collecting typing-extensions>=3.6.4 (from jsii~=0.14.0->aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/27/aa/bd1442cfb0224da1b671ab334d3b0a4302e4161ea916e28904ff9618d471/typing_extensions-3.7.4-py3-none-any.whl Collecting python-dateutil (from jsii~=0.14.0->aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Using cached https://files.pythonhosted.org/packages/41/17/c62faccbfbd163c7f57f3844689e3a78bae1f403648a6afb1d0866d87fbb/python_dateutil-2.8.0-py2.py3-none-any.whl Collecting importlib-resources; python_version < "3.7" (from jsii~=0.14.0->aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/2f/f7/b4aa02cdd3ee7ebba375969d77c00826aa15c5db84247d23c89522dccbfa/importlib_resources-1.0.2-py2.py3-none-any.whl Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.6/site-packages (from python-dateutil->jsii~=0.14.0->aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Installing collected packages: attrs, cattrs, typing-extensions, python-dateutil, importlib-resources, jsii, publication, aws-cdk.cx-api, aws-cdk.core, cdk Running setup.py develop for cdk Successfully installed attrs-19.1.0 aws-cdk.core-1.0.0 aws-cdk.cx-api-1.0.0 cattrs-0.9.0 cdk importlib-resources-1.0.2 jsii-0.14.0 publication-0.0.3 python-dateutil-2.8.0 typing-extensions-3.7.4Hallo World!
app.pyを開いて、テストコードを書き換えます。
app.py#!/usr/bin/env python3 from aws_cdk import core from cdk.cdk_stack import CdkStack app = core.App() CdkStack(app, "HelloWorldStack") app.synth()
cdk lsで、スタックの一覧を列挙できます。(master) $ cdk ls HelloWorldStackこの時、内部的にはapp.pyの中の
app.synth()が呼ばれて、cdk.outの下にHelloWorldStack.template.jsonができて、その結果をリストしているようです。
※app.synth()を消して実行したらcdk lsの実行に失敗しました。(master) $ ls cdk.out/ cdk.out HelloWorldStack.template.json manifest.json
XXX.template.jsonはCloudFormationのテンプレートになります。
CDKでコードを書き、内部的にCloudFormationを使ってインフラストラクチャをデプロイしていくという流れが想像できます。ここまでの手順で、Cloud9上でAWS CDKをインストールし、Python3を使って開発を進める準備が整いました。
参考文献
- 投稿日:2019-07-14T17:09:43+09:00
Cloud9にAWS CDK (Python3) をインストールする方法
AWS CDKがGA!
2019年7月11日に、AWS Cloud Development Kit (AWS CDK)がGAしました。
Infrastructure as Codeの観点では、CloudFormationを使うよりも開発が楽になるとかなんとか言われていますが、実際に試さねば分からないだろうと思い、早速手を動かしてみることにしました。本記事では、Cloud9を使ってAWS CDKを開始する方法をまとめてみました。
Python3でCDKを使って開発する前提での覚書となります。AWS CDKとは
公式「What Is the AWS CDK?」の解説を紐解いていきます。
- AWS CDKは、クラウドインフラストラクチャをコードで定義するためのソフトウェア開発フレームワークです。
- AWS CDKを使ってコードを書き、実行すると、AWS CloudFormationを通じてインフラストラクチャがプロビジョニングされます。
- CloudFormationとの違いとして、TypeScript、JavaScript、Pythonといった、開発者が慣れ親しんだプログラミング言語でインフラストラクチャを定義できます。
- if分岐やforループを活用できることから、CloudFormationに比べて記述量も減らせそう。
既に、PythonでAWSのインフラストラクチャをプロビジョニングするtroposphereもありますが、AWSが公式でCDKを出してきたことで、サポート面で安心できるCDKの利用が増えていくのかなと思ったりしています。
AWS CDKをCloud9にインストール
AWS CDK (Python3) を利用して開発するための準備をします。
必要条件
・Node.js 8.11.x 以降のバージョンが必要です。
・Python3.6 以降のバージョンが必要です。
・AWS CDK CLIを利用するため、CredentialsとAWSリージョンを特定する必要があります。インストール
Cloud9でターミナルを開き
npm install -g aws-cdkを実行します。install$ npm install -g aws-cdk /home/ec2-user/.nvm/versions/node/v8.16.0/bin/cdk -> /home/ec2-user/.nvm/versions/node/v8.16.0/lib/node_modules/aws-cdk/bin/cdk > core-js@2.6.9 postinstall /home/ec2-user/.nvm/versions/node/v8.16.0/lib/node_modules/aws-cdk/node_modules/core-js > node scripts/postinstall || echo "ignore" Thank you for using core-js ( https://github.com/zloirock/core-js ) for polyfilling JavaScript standard library! The project needs your help! Please consider supporting of core-js on Open Collective or Patreon: > https://opencollective.com/core-js > https://www.patreon.com/zloirock Also, the author of core-js ( https://github.com/zloirock ) is looking for a good job -) + aws-cdk@1.0.0 added 267 packages from 249 contributors in 12.069sインストールが成功していれば
cdk --versionでバージョンを確認できます。version$ cdk --version 1.0.0 (build d89592e)ここで、Cloud9で通常使用するPythonが3.6に設定されていることを
python --versionで改めて確認しておきます。(master) $ python --version Python 3.6.8もし2.7.xだった場合は、こちらのリンク先の手順で、Python3を使えるように設定を切り替えましょう。
AWS Cloud9 でPython3を使うための設定
アプリを作る
次に、空のディレクトリを作って、ディレクトリに移動した後
cdk init --language pythonコマンドで、アプリを初期化します。(Gitリポジトリができます)
今回は分かりやすいようにCDKというディレクトリ名にしていますが、名前は何でも良いです。
言語を指定するのは、このcdk initを実行する時です。init$ mkdir CDK $ cd CDK $ cdk init --language python Applying project template app for python Initializing a new git repository... (略) Enjoy!結果を確認してみます。
cdk initの結果、いろいろできています。(master) $ ls -al total 40 drwxr-xr-x 5 ec2-user ec2-user 4096 Jul 13 07:05 . drwxr-xr-x 11 ec2-user ec2-user 4096 Jul 13 05:49 .. -rw-rw-r-- 1 ec2-user ec2-user 138 Jul 13 07:05 app.py drwxrwxr-x 2 ec2-user ec2-user 4096 Jul 13 07:05 cdk -rw-rw-r-- 1 ec2-user ec2-user 32 Jul 13 07:05 cdk.json drwxrwxr-x 5 ec2-user ec2-user 4096 Jul 13 07:05 .env drwxrwxr-x 7 ec2-user ec2-user 4096 Jul 13 07:05 .git -rw-rw-r-- 1 ec2-user ec2-user 1651 Jul 13 07:05 README.md -rw-rw-r-- 1 ec2-user ec2-user 5 Jul 13 07:05 requirements.txt -rw-rw-r-- 1 ec2-user ec2-user 1008 Jul 13 07:05 setup.py次に、CDKが依存するパッケージをインストールします。
(master) $ sudo pip install -r requirements.txt Obtaining file:///home/ec2-user/environment/CDK (from -r requirements.txt (line 1)) Collecting aws-cdk.core (from cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/60/99/6b1bc6e1059d0d97050550cfb7aee7ca154cf69ef4afd85e516340b8fd6d/aws_cdk.core-1.0.0-py3-none-any.whl (508kB) 100% |████████████████████████████████| 512kB 2.4MB/s Collecting jsii~=0.14.0 (from aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/fc/30/0954b455242b6b9a01f614db21d8a1707d62c7d302420a6c72c93faeb80e/jsii-0.14.0-py3-none-any.whl (236kB) 100% |████████████████████████████████| 245kB 4.6MB/s Collecting aws-cdk.cx-api>=1.0.0,~=1.0 (from aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/98/be/53a9bb48df0bd066fe1a227a93df70a957b717ce741d6746085bdb49e1ef/aws_cdk.cx_api-1.0.0-py3-none-any.whl (78kB) 100% |████████████████████████████████| 81kB 6.1MB/s Collecting publication>=0.0.3 (from aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/f8/d3/6308debad7afcdb3ea5f50b4b3d852f41eb566a311fbcb4da23755a28155/publication-0.0.3-py2.py3-none-any.whl Collecting attrs>=18.2 (from jsii~=0.14.0->aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/23/96/d828354fa2dbdf216eaa7b7de0db692f12c234f7ef888cc14980ef40d1d2/attrs-19.1.0-py2.py3-none-any.whl Collecting cattrs (from jsii~=0.14.0->aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/4a/4e/f8bfec0990a2d4f9f79d4417336b761c58c849672cd3b81637a22f02bb20/cattrs-0.9.0-py2.py3-none-any.whl (54kB) 100% |████████████████████████████████| 61kB 8.0MB/s Collecting typing-extensions>=3.6.4 (from jsii~=0.14.0->aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/27/aa/bd1442cfb0224da1b671ab334d3b0a4302e4161ea916e28904ff9618d471/typing_extensions-3.7.4-py3-none-any.whl Collecting python-dateutil (from jsii~=0.14.0->aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Using cached https://files.pythonhosted.org/packages/41/17/c62faccbfbd163c7f57f3844689e3a78bae1f403648a6afb1d0866d87fbb/python_dateutil-2.8.0-py2.py3-none-any.whl Collecting importlib-resources; python_version < "3.7" (from jsii~=0.14.0->aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/2f/f7/b4aa02cdd3ee7ebba375969d77c00826aa15c5db84247d23c89522dccbfa/importlib_resources-1.0.2-py2.py3-none-any.whl Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.6/site-packages (from python-dateutil->jsii~=0.14.0->aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Installing collected packages: attrs, cattrs, typing-extensions, python-dateutil, importlib-resources, jsii, publication, aws-cdk.cx-api, aws-cdk.core, cdk Running setup.py develop for cdk Successfully installed attrs-19.1.0 aws-cdk.core-1.0.0 aws-cdk.cx-api-1.0.0 cattrs-0.9.0 cdk importlib-resources-1.0.2 jsii-0.14.0 publication-0.0.3 python-dateutil-2.8.0 typing-extensions-3.7.4Hallo World!
app.pyを開いて、テストコードを書き換えます。
app.py#!/usr/bin/env python3 from aws_cdk import core from cdk.cdk_stack import CdkStack app = core.App() CdkStack(app, "HelloWorldStack") app.synth()
cdk lsで、スタックの一覧を列挙できます。(master) $ cdk ls HelloWorldStackこの時、内部的にはapp.pyの中の
app.synth()が呼ばれて、cdk.outの下にHelloWorldStack.template.jsonができて、その結果をリストしているようです。
※app.synth()を消して実行したらcdk lsの実行に失敗しました。(master) $ ls cdk.out/ cdk.out HelloWorldStack.template.json manifest.json
XXX.template.jsonはCloudFormationのテンプレートになります。
CDKでコードを書き、内部的にCloudFormationを使ってインフラストラクチャをデプロイしていくという流れが想像できます。ここまでの手順で、Cloud9上でAWS CDKをインストールし、Python3を使って開発を進める準備が整いました。
参考文献
- 投稿日:2019-07-14T16:40:02+09:00
ウィナー・ホッフ方程式をPythonで解いてみた,その5
ウィナーフィルタを再帰最小二乗法(RLS1)で解く
数式2は
(\boldsymbol A + \boldsymbol x \boldsymbol x^H )^{-1} = \boldsymbol A^{-1} - \frac{\boldsymbol A^{-1} \boldsymbol x \boldsymbol x^H \boldsymbol A^{-1} }{1 + \boldsymbol x^H \boldsymbol A^{-1} \boldsymbol x} \\の補助定理を使って
\begin{align} \hat{\boldsymbol R}_k &= \hat{\boldsymbol R}_{k-1} + \boldsymbol u_k \boldsymbol u_k^H \\ \hat{\boldsymbol r}_k &= \hat{\boldsymbol r}_{k-1} + \boldsymbol u_k d_k^* \\ \\ \boldsymbol P_k &= \hat{\boldsymbol R}_k^{-1} \\ \boldsymbol P_k &= (\hat{\boldsymbol R}_{k-1} + \boldsymbol u_k \boldsymbol u_k^H )^{-1} \\ &= \boldsymbol P_{k-1} - \frac{\boldsymbol P_{k-1} \boldsymbol u_k \boldsymbol u_k^H \boldsymbol P_{k-1} }{1 + \boldsymbol u_k^H \boldsymbol P_{k-1} \boldsymbol u_k} \\ \\ \boldsymbol g_k &= \frac{\boldsymbol P_{k-1} \boldsymbol u_k }{1 + \boldsymbol u_k^H \boldsymbol P_{k-1} \boldsymbol u_k} \\ \boldsymbol P_k &= \boldsymbol P_{k-1} - \boldsymbol g_k \boldsymbol u_k^H \boldsymbol P_{k-1} \\ \\ \boldsymbol g_k + \boldsymbol g_k \boldsymbol u_k^H \boldsymbol P_{k-1} \boldsymbol u_k &= \boldsymbol P_{k-1} \boldsymbol u_k \\ \boldsymbol g_k &= \boldsymbol P_{k-1} \boldsymbol u_k - \boldsymbol g_k \boldsymbol u_k^H \boldsymbol P_{k-1} \boldsymbol u_k \\ &= \boldsymbol P_k \boldsymbol u_k \\ \\ \boldsymbol w_k &= \boldsymbol P_k \hat{\boldsymbol r}_k \\ &= \boldsymbol P_k (\hat{\boldsymbol r}_{k-1} + \boldsymbol u_k d_k^*) \\ &= (\boldsymbol P_{k-1} - \boldsymbol g_k \boldsymbol u_k^H \boldsymbol P_{k-1}) \hat{\boldsymbol r}_{k-1} + \boldsymbol P_k \boldsymbol u_k d_k^*) \\ &= \boldsymbol w_{k-1} - \boldsymbol g_k \boldsymbol u_k^H \boldsymbol w_{k-1} + \boldsymbol g_k d_k^* \\ &= \boldsymbol w_{k-1} + \boldsymbol g_k ( d_k^* - \boldsymbol u_k^H \boldsymbol w_{k-1}) \\ &= \boldsymbol w_{k-1} + \boldsymbol g_k \xi_k^* \\ \\ \xi_k &= d_k - \boldsymbol w_{k-1}^H \boldsymbol u_k \\ \end{align}をこう。整理すると,初期値を
\boldsymbol P_0 = \alpha^{-1} \boldsymbol I \\ \boldsymbol w_0 = \boldsymbol 0として,
\begin{align} \boldsymbol g_k &= \frac{\boldsymbol P_{k-1} \boldsymbol u_k }{1 + \boldsymbol u_k^H \boldsymbol P_{k-1} \boldsymbol u_k} \\ \xi_k &= d_k - \boldsymbol w_{k-1}^H \boldsymbol u_k \\ \boldsymbol w_k &= \boldsymbol w_{k-1} + \boldsymbol g_k \xi_k^* \\ \boldsymbol P_k &= (\boldsymbol I - \boldsymbol g_k \boldsymbol u_k^H ) \boldsymbol P_{k-1} \\ y_k &= \boldsymbol w_k^H \boldsymbol u_k \end{align}こう。Pythonのコードはこう。ただ,結構遅い。$K$を小さくするか何かしないと微妙?。忘却係数は未適用。
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt import scipy.signal as sg from mpl_toolkits.mplot3d import Axes3D z = np.arange(0, 512) h0 = 1 / (1 + np.exp(0.0001 * (z - 128) ** 2)) #h0=1/(1+np.exp(0.03*z)) Wref = h0 / np.sum(h0) * 2 plt.plot(Wref) plt.title("$w_{ref}$") plt.show() #x = np.linspace(0, 1, 4096) x = np.linspace(0, 2, 8192) #y1 = np.sin(2 * np.pi * x) + 0.2 * np.sin(np.pi * 20 * (x + 0.1)) y1 = np.sin(2 * np.pi * x) + 0.2*np.sin(np.pi * 20 * x + 0.1 * np.pi) y2 = sg.lfilter(Wref, [1], y1) #μ = 1.0 α = 0.00001 #Ls = 128 K = 512 #shift = 32 #N = np.append(np.arange(Ls, len(x), shift), len(x)) N = np.arange(len(x)) yk = np.zeros(len(x)) last_Pk = np.eye(K) / α last_wk = np.zeros(K) wk = np.zeros((len(N), K)) ξk = np.zeros(len(N)) for n in N: dk = y2[n] if n < K: uk = np.zeros(K) uk[:n+1] = y1[n::-1] else: uk = y1[n:n-K:-1] gk = last_Pk @ uk / (1 + uk.T @ last_Pk @ uk) ξk[n] = dk - last_wk.T @ uk wk[n] = last_wk + gk * np.conj(ξk[n]) Pk = (np.eye(K) - np.outer(gk, uk.T)) @ last_Pk yk[n] = np.conj(wk[n].T) @ uk last_wk = wk[n] last_Pk = Pk #print(n, ξk[n]) plt.plot(N, ξk) plt.xlim(0) plt.legend(["$\|ξ_k\|$"]) plt.show() plt.plot(y2) plt.plot(yk) plt.xlim(0) plt.legend(["$y2$", "$yk$"]) plt.show() plt.plot(yk-y2) plt.xlim(0) plt.legend(["$yk-y2$"]) plt.show() err = np.sum(np.abs(wk - np.ones((wk.shape[0],1)) * Wref), axis=1) / np.sum(np.abs(Wref)) plt.plot(N, err) plt.xlim(0) plt.legend(['$\\frac{ \| w_k-w_{ref} \| }{ \| w_{ref} \| }$']) plt.show() XX, YY = np.meshgrid(np.arange(wk.shape[1]), N) plt.figure().add_subplot(111, projection='3d').plot_wireframe(XX, YY, wk) plt.title("$wk$") plt.show()
- 投稿日:2019-07-14T16:21:31+09:00
discord.py のデバッガー ddiscord が便利
discord.py のデバッグは少し難しい
discord.py という、discord BOT を作るためのパッケージがあります。
大変使いやすくて良いのですが、非同期であるがゆえにデバッグが難しく、起動にも時間がかかるため、ちょっとしたモデレーション目的でコードを実行するのも面倒で困っていました。
そこで、デバッグを簡単にするためのツール ddiscord を開発しました。ddiscord はこう使う
コマンド
ddiscordを実行するとトークンを問われるので、自分のBOTのトークンを入力してください。
起動するとdiscord.Clientのインスタンスclientが使用可能な状態で REPL もどきが起動します。$ ddiscord - Debugger for discord.py - Running on Python 3.7.2. Send EOF (Ctrl-D) to exit. Logged in as YourBot#0000 (012345678901234567) You can refer to your Client instance as `client` variable. i.e. client.guilds >>> len(client.guilds) 1 >>> client.user.bot True >>> await client.guilds[0].create_text_channel('test') <TextChannel id=012345678901234567 name='test' position=1> >>>見ての通り discord.py の簡単なデバッグや、またコマンドによるサーバーの管理を行うことができます。
インストール方法
PyPIに登録してありますので、
pip installできます。$ python3 -m pip install ddiscordQ and A
起動時に毎回トークンを入力するのがめんどくさい
カレントディレクトリに
tokenというテキストファイルがあれば、ddiscord はそのファイルの中身をトークンとして認識します。
また、環境変数DISCORD_TOKENがあれば、それをトークンとして認識します。
またトークンをコマンド引数として渡すこともできますので、複数のトークンを別々のエイリアスに登録しておくのも便利かと思います。
その他の起動方法は GitHub に書いてあります。for文とか入力できないの?
今はまだ複数行の入力を受け付けません。方法を見つけたらそのうち対応したいですね……。
もし実現するためのアイデアをお持ちでしたらコメントやPRをいただけると助かります!
早速ですがアドバイスを頂いて、複数行に渡るコードをサポートしました!Ctrl-C で終了しようとしたらなんかエラーめっちゃ出たんだけど
既知のバグです。EOF を送信すればエラーなしに正常終了してくれます。Windows では
Ctrl-Z、Linux ではCtrl-Dです。
原因が掴めず困っているので、こちらもアドバイスありましたらぜひおねがいします。
- 投稿日:2019-07-14T15:40:19+09:00
<初心者>vue.jsでリンクの動的生成とルーティング。おまけでPythonによる頻出語のピックアップ。
やったこと
以前作ったwebサービスに機能追加しました。
サービスの詳細はこちらの記事参照ください。「<初心者>レファレンス協同データベースの記事をランダムに表示するWEBサービスをvue.jsで作りました。」
記事の詳細ページにキーワードの項目を設けて、クリックすると検索画面に飛ぶようにしました。
なぜやるのか
現状の問題点
前回記事(cssのアニメーションで検索ボックス上部にレコメンド事例紹介機能を搭載してみた。[2019/07/13追記※3回])と同様、「レファレンスサービス利用経験者が少ないため、どんな事例があるかわかりにくい。」という欠点があります。
今回採用する改善方法
そこで、一つの記事を読んだあとに関連する記事を見てもらえるようにキーワードのタグを作成。タグによって新たな検索行動を促すことで、サイト内での回遊率アップに繋げます。
キーワードは、レファレンス協同データベースの各記事のおそらく半数近くには設定されているのでこれを利用します。設定されていない記事も多いので、プラスαとしてPythonによる頻出単語のピックアップも行いました。しかし、Pythonについてはまだ実装はしていません。
実装方法
シンプルです。
詳細ページにおける他の項目と同様、xmlからキーワードを取得します。
Detail.vueconst keywords = result.getElementsByTagName("reference")[0].getElementsByTagName("keyword")||ページに反映する際にリンクを設定。
Detail.vue<h3 id="keyword">キーワード</h3> <span v-for="keyword in refqa.keywords" class="tag" v-bind:key=keyword> <a v-bind:href="'https://testreftika.web.app/keyword/' + keyword">{{keyword}}</a> </span>リンクはルーターでトップページに飛ばす
router.js{ path: '/keyword/:keyword', component: Home },トップページでは、リンクを解釈します。/keyword/hogeであれば、hogeを検索ボックスに入力。
Home.vuecreated: function() { 省略 if(this.path.match(/\/keyword\/./) ){this.keyword=this.$route.params.keyword} }上記パス(this.path)はjavascriptで取得している。
Home.vuedata() { return { 省略 path:location.pathname, }検索ボックスに入力語は自動で検索されるように実装している。前回記事「cssのアニメーションで検索ボックス上部にレコメンド事例紹介機能を搭載してみた。[2019/07/13追記※3回]」参照。
Home.vueクリックしたときに、検索ボックスにキーワードを入力するメソッド setInputBox(searchtext){ document.getElementById( "searchbox" ).value = searchtext; this.keyword=searchtext; ←この後、this.keywordを監視しているメソッドが検索を実行する },プラスα:Pythonによる頻出語のピックアップ
大まかな流れ
①xmlでデータ取得
②mecabで名詞・形容詞のみピックアップ&stopwordを除外して単語をリスト化
③Counterでリストの各要素の出現個数をカウント、出力全文です。
import MeCab from collections import Counter import urllib.request import xml.etree.ElementTree as ET #②mecabで名詞・形容詞のみピックアップ&stopwordを除外して単語をリスト化する関数 def get_dokuritsugo_by_mecab(text): tagger = MeCab.Tagger('/usr/local/lib/mecab/dic/mecab-ipadic-neologd/') tagger.parse('') node = tagger.parseToNode(text) word_list = [] while node: pos = node.feature.split(",")[0] if pos in ["名詞", "形容詞"]: word = node.surface if not word in stoplist: word_list.append(word) node = node.next return(word_list) #ストップワードについては下記 with open('stopword.txt', 'r', encoding='utf-8') as file: stoplines = file.readlines() stoplist = [] for l in stoplines: stoplist.extend(l) #①xmlでデータ取得。「。」で区切り一文ずつmecabを呼び出している。 url = 'http://crd.ndl.go.jp/api/refsearch?type=reference&query=sys-id=1000161493' ←apiの呼び出し req = urllib.request.Request(url) with urllib.request.urlopen(req) as response: XmlData = response.read() root = ET.fromstring(XmlData) QAtext = root[4][0][0].text + root[4][0][2].text #※レスポンスのxmlの仕様です。 #※root[4][0][0]に質問、root[4][0][2]に回答が入っています。 print(QAtext) texts = QAtext.split('。') list = [] sentences = [] for text in texts: list.extend(get_dokuritsugo_by_mecab(text)) c = Counter(list) #③Counterでリストの各要素の出現個数をカウント、出力 print(list) print(c.most_common()[0]) print(c.most_common()[1]) print(c.most_common()[2])ストップワードは、
英語は、sklearn.feature_extraction、日本語はslothlibを使用させていただきました。2つをローカルでtxtファイルにがっちゃんこした上で、記号を付け加えて利用しています。出力結果
◆くしゃみの回数で意味が違うという迷信を友人と話していると解釈が違いました。何種類かあるのでしょうか。(北九州市立中央図書館)では、
('くしゃみ', 23) ('噂', 5) ('風邪', 5)◆インドの教育事情と教育に関わる社会問題について分かる資料(日本貿易振興機構アジア経済研究所図書館)
('教育', 8) ('インド', 7) ('請求', 5)※「請求」は図書の「請求記号」という文言が多数使われているため多くなっている。
◆「この道をいけばどうなるものか」から始まる言葉の全文が知りたい。良寛の言葉らしい。(福井県立図書館)
('言葉', 7) ('詩', 5) ('一休宗純', 5)記事との偶然の出会いをつくるサービスとしては、そこそこ十分な結果かと思われます。
「請求記号」「国立国会図書館」など、図書館で頻繁に使用される語は除くように調整すれば使えるかもしれません。応答速度などを見ながら、今後試していきます。
参考:
◆mecabのインストール(Windows)
PythonとMeCabで形態素解析(on Windows)
◆mecabの使い方
B'zの歌詞をPythonと機械学習で分析してみた 〜LDA編〜
◆NEologd辞書のインストール
WindowsでNEologd辞書を比較的簡単に入れる方法◆PythonのCounter
PythonのCounterでリストの各要素の出現個数をカウント
◆PythonとXML
PythonでXMLをパースする今回は単純な頻出語で行ったが、調べるうちにTF-IDFによる重みづけやJaccard係数を使用した共起ネットワークも気になった。
検索機能に用いられている、特徴語とそのさまざまな抽出方法
世界のラーメンスタイルをNetworkXで可視化する
Pythonを使って文章から共起ネットワークを作るreftikaもぜひのぞいてみてください。
- 投稿日:2019-07-14T15:26:32+09:00
プログラミングマスコットのドット絵を書いた
プログラム言語のマスコット、ロゴ
あなたはPCにステッカー貼ってますか?
利用言語を愛していますか?
言語のOSSにプルリクエストを送るためなら睡眠時間を削れますか?そんなあなたに送るプログラムマスコット`sです。
きっかけはUTme!で自作Tシャツを作りたいと思っていた時に、プログラマーが目にするマスコットアニマル`sという記事を見たこと。
あと、三連休なのに予定がないからだZE
(2019/07/14)
Gopher (Go)
マスコットといえばgopherくん。
ドット絵と寸胴ボディの親和性がGood。
"gopher" by Renée French CC-BY-3.0Duke (java)
Go言語のライバル?でもあるjavaのDukeさん。
マザー2のザコキャラ感がすんごい。
"Duke" by Sun Microsystems BSDrustacean (rust)
rustのrustaceanさん。
前者2人を圧倒的速度で凌駕する高速カニさん。(強い)
Moby Dock (Docker)
DockerのMoby Dock親方。
みんなを支える縁の下の力持ち。
みんなを載せてるのでこんなイメージ。
android robot (android)
その名の通りアンドロイドのロボットでandroid robotさん。
ドット絵にしても変わった感が無い・・・
"android robot" by google.com CC BY 3.0jenkins logo (jenkins)
怒り顔など、何かと改変されがちなジェンキンスのロゴ。
あなた、名が無きおじさんだったのね・・・
"jenkins logo" by jenkins.io CC BY-SA 3.0Tux (linux)
linuxのTaxさん。
可愛く見えて実は二段腹のおじさんペンギン。
"Tux" by Larry Ewing、Simon Budig、Anja GerwinskiGitLab logo (GitLab)
昔は怖かったGitLabのロゴ。
狐じゃないよ!たぬきだよ!
"GitLab logo" by gitlab.com CC BY-NC-SA 4.0Python logo (Python)
もはやマスコットではなくなってきた、Pythonのロゴマーク。
"python logo" by Python Software Foundation PSF licensepostgreSQL logo (postgreSQL)
一番難しかった。ポスグレのぞうさん。
"PostgreSQL" by postgresql.org PostgreSQL licenseMySQL logo (MySQL)
ポスグレ書くならこっちもね!MySQLのイルカさん。
笑顔がかわいい。
Slack logo (Slack)
みんなの雑談部屋。slackのロゴ。
新デザインにだんだん慣れてきた。
※著作件に関する記載が見つからなかったので、問題あればコメントなどで指摘してください。HTML5 logo (HTML5)
HTML5のロゴ。
筆者は20代半ばなので、5とそれ以前の違いがわかっていない。
"HTML5" by World Wide Web Consortium CC BY 3.0Javascript logo (JavaScript)
HTMLやったならこっちもね。
JavaScriptさん。
※こちらも著作権に関する記載が見当たらなかったです。UBUNTU logo (UBUNTU)
Macが買えず使っていたUBUNTUさん。
WSL2に期待中。
ReactJS logo (ReactJS)
個人的な思い入れ(業務で利用)だけで書いたReactJS。
複雑な構造をドット絵で書くのは無理あるよね。。。
"ReactJS logo" by facebook.com CC BY 4.0最後に
こんな感じのTシャツを着ている人がいたら声をかけてください。きっと私です。
著作件について
この記事に記載している画像はすべてSlackスタンプ、アイコンに流用していただいてかまいません。
ただし、全てのマスコット、ロゴは原案者がいらっしゃいます。
必ず著作件の確認、表示の上ご利用ください。
(octcat-githubは著作件縛りきつくて書いたけど載せれなかった。)


















- 投稿日:2019-07-14T15:18:19+09:00
conda updateで「Solving environment: failed」となった時の解決法
- 投稿日:2019-07-14T15:09:36+09:00
ユークリッド距離さえあればコサイン類似度が計算できる。
概要
scikit-learnでk-meansを用いてクラスタリングしているときに思いました。
「距離関数をコサイン類似度にしたい」
scikit-learnのk-meansでは距離関数としてユークリッド距離しか使えません。
scikit-learnのコードを書き換えて、独自の距離関数を使えるようにした記事もあります。
しかし、結構面倒くさそうだし処理速度の低下が気になります。
そこでこんな投稿を見つけました。
本投稿はこの投稿を要約・加筆します。
結論を言うと
「正規化してからユークリッド距離をとるとコサイン類似度を測れる」
です。距離関数の定義
まずユークリッド距離とコサイン類似度の定義を確認しておきます。
2点 $P(x_1, ..., x_n), Q(y_1, ..., y_n)$ に対して、$\vec{x}=(x_1, ..., x_n), \vec{y}=(y_1, ..., y_n)$ とします。ユークリッド距離は
$$d(P, Q) = |\vec{x} - \vec{y}| = \sqrt{\sum_{k=1}^{n} (x_k-y_k)^2}$$
コサイン類似度は
$$cos(\vec{x}, \vec{y}) = \frac{\vec{x}\cdot\vec{y}}{|\vec{x}||\vec{y}|} = \frac{\sum_{k=1}^{n}x_k y_k}{\sqrt{\sum_{k=1}^{n}x_k^2} \sqrt{\sum_{k=1}^{n}y_k^2} }$$
です。コサイン類似度をユークリッド距離で測る
$\vec{x}, \vec{y}$ を正規化したものを改めて $\vec{x}, \vec{y}$ とします。
すると、$|\vec{x}| = 1, |\vec{y}| = 1, cos(\vec{x}, \vec{y}) = \vec{x}\cdot\vec{y}$となります。
ここでユークリッド距離を計算すると(ルートを書くのが面倒なので2乗してます。)\begin{align} d(P, Q)^2 &= |\vec{x} - \vec{y}|^2 \\ &= |\vec{x}|^2 - 2 \vec{x} \cdot \vec{y} + |\vec{y}|^2 \\ &= 2(1 - cos(\vec{x}, \vec{y})) \end{align}つまり、「ユークリッド距離が 0 に近い」と「コサイン類似度が 1 に近い」が同値になります。
また、コサイン類似度はベクトルのなす角によって決まり、正規化はベクトルの長さのみを変更するものなので、正規化前と後でコサイン類似度は変化しません。
よって、
「正規化後のユークリッド距離が近い」⇔「コサイン類似度が高い」
となります。直感的な理解
2次元で考えるとわかりやすいです。
正規化後はP, Qは単位円上にあるので、下図のような状況になります。
$d(P, Q)$ と $\vec{x}, \vec{y}$ のなす角 $\theta$ が連動していることがわかります。
$\vec{x}, \vec{y}$ のコサイン類似度が高いということは、なす角 $\theta$ が小さいということなので、
正規化後では「ユークリッド距離が近い」⇔「コサイン類似度が高い」となります。
コード例
scikit-learnで書く場合は以下のようになります。
from sklearn import preprocessing, cluster normalized_vec_list = preprocessing.normalize(vec_list) result = cluster.KMeans(n_clusters=5).fit(normalized_vec_list)おわり
いちいち距離関数を独自に設定せずとも、ちょっとした工夫(正規化)をするだけでOKというのがお手軽で良いですね。
ただし、コサイン類似度にしか対応できません。
その他の距離関数を使うための工夫があれば是非教えてください。
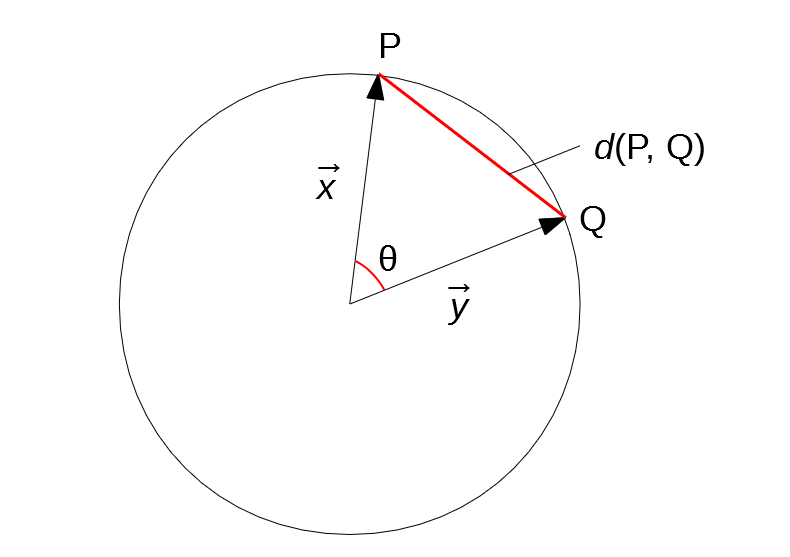
- 投稿日:2019-07-14T14:02:49+09:00
halocode使ってみた!
使用キット
・Makeblock HaloCode スタンダードキット
ワニ口クリップとかAndoroidとかでよく使うmicro USB Type-Bケーブルとか入ってます
環境
OS : Windows10
言語 : python(+ブロック図)セットアップ
スタートアップガイドに従ってやってきます
ソフトウェアダウンロード
・mBlock Software Download をクリック
・ダウンロードサイトでWindowsをクリック
・V5.1.0.exe がダウンロードされるので、「管理者として実行」をします
・日本語を選択してOKをクリック
・保存場所もこだわりがなければそのままOKをクリック
・ショートカットの名前変更もできるみたいですが、今回はそのままで「次へ」
・デスクトップへのショートカット追加もしたいのでそのまま「次へ」
・インストールします
・1~2分でインストールが終わるので「完了」
・mblockの画面が出てきたらソフトウェアのセットアップは完了です
途中でパンダが手を振ってくれてめちゃくちゃかわいい
画面的にはscrachっぽいですね
パンダがかわいいので圧倒的mblock派になりそうですHaloCodeの動作確認
・HaloCodeとPCを接続します
キットの中にあるUSBコードでHaloCodeとPCを繋ぎます
繋がるとHaloCodeのLEDがビカビカ光るのでわかりやすいです
・次にソフトウェアとHalocodeの接続を設定します
・mblockの画面で、デバイスにある追加をクリック
・デバイスライブラリのHaloCodeを選択し「OK」をクリック
・デバイス欄にHaloCodeが追加されました
・ここで、セットアップで外したHaloCodeをPCと繋ぎなおしましょう
・繋いだらデバイス欄のアップロードモードを「ON」にして「接続」をクリックします
・接続ウィンドウが出てくるので「接続」をクリック
・デバイス欄がこんな感じになったらHaloCodeとPCがちゃんとつながっています
・このままプログラムを作ってるとまぶしいので、「切断」をクリックしてUSBケーブルをPCから抜きましょう
プログラムをHaloCodeに書き込むときは上記の手順をもう一回やるとアップロードできるようになりますセットアップは以上で終わりです
次は、HaloCodeを使って遊んでみますプログラムの実行
LEDを赤く光らせる
・http://docs.makeblock.com/halocode/en/tutorials/use-python.html から
pythonのサンプルコードをコピーして、python用のエディターページに書き込みます
↓
LED.pyimport halo import event @event.start def on_start(): halo.led.show_all(200, 0, 0) # すべてのLEDを赤色に点灯させる time.sleep(5) # 5秒間、現在の状態をキープする halo.led.off_all() # すべてのLEDを消灯させる・デバイス欄からアップロードをクリックして書き込み
ボタンを押したらLEDが3秒間赤く光る
・今度はブロック図からpythonコードに変換してから書き込んでみます
・下図のようにブロック図を作成します
・右端にある</>を押してpythonに変換する
PCにHaloCodeを繋いだ状態じゃないと</>が出てこないようなので注意
・変換したプログラムをpythonエディターページにコピーする
・HaloCodeにアップロードして実行すると、ボタンを押したときLEDが赤色に光ります
あとがき
今回はセットアップとLチカサンプルだけで終了
HaloCodeには他にも音声認識や動作認識(ジャイロセンサ)も積んであるようでまだまだ遊べることが多そうです
ブロック図でのプログラミングも充実してるので子供の自由研究とかにも良さそう

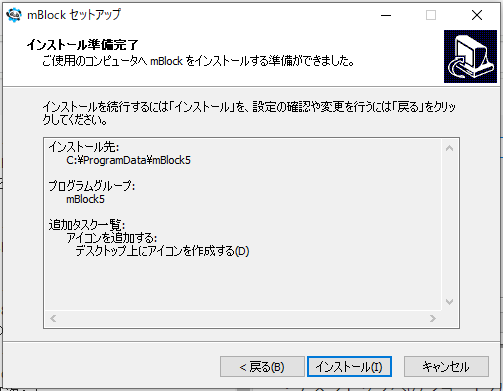

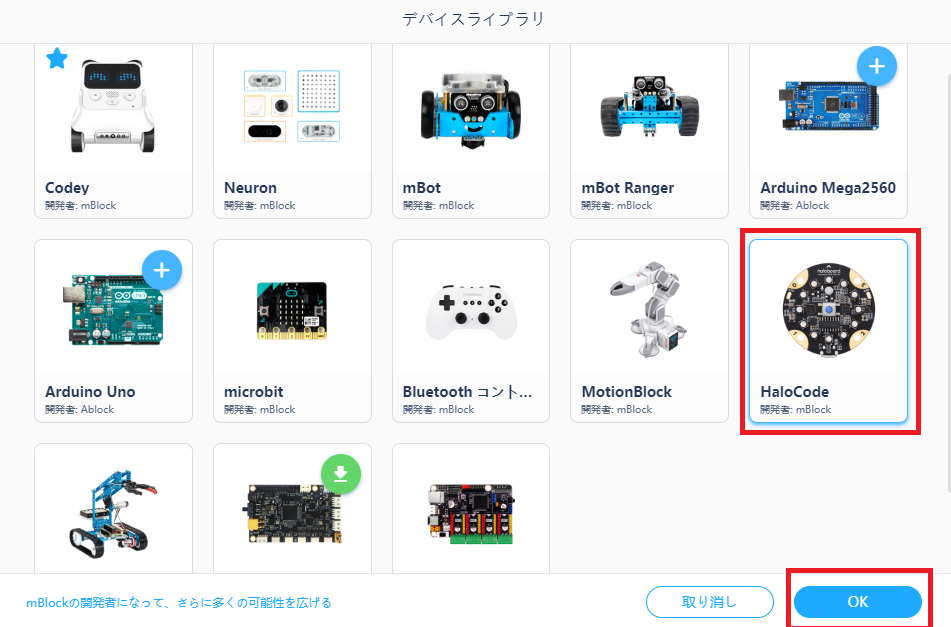
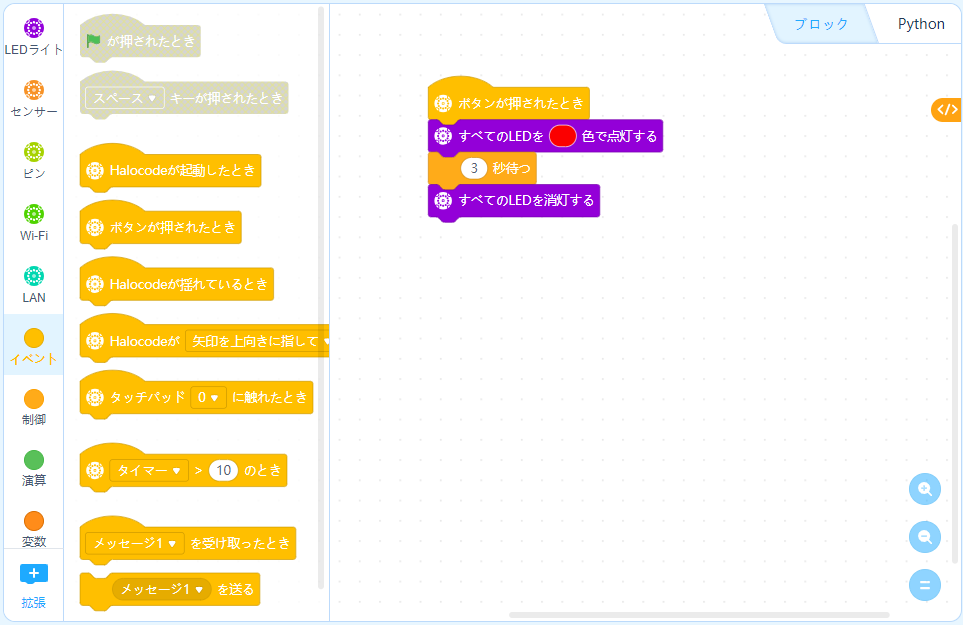
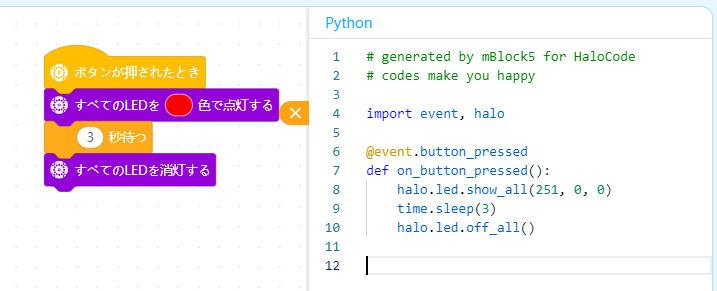
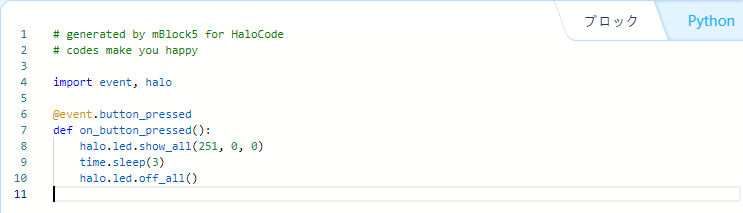
- 投稿日:2019-07-14T13:58:28+09:00
素人がガウス過程回帰を勉強する(2)途中
素人がガウス過程回帰を勉強する(2)
このページのスクリプトの2つ目をやってみました。
http://statmodeling.hatenablog.com/entry/how-to-use-GPyimport GPy import pandas as pd import numpy as np import matplotlib.pyplot as plt kernel = GPy.kern.RBF(1) # kernel = GPy.kern.RBF(1) + GPy.kern.Bias(1) + GPy.kern.Linear(1) x = [-6.836951,-5.927641,-5.907641,-5.476121,-4.387844,-3.739508,-3.40779,-2.537614,-1.89467,-0.683068,0.688162,0.897893,1.129219,2.512134,2.581766,4.268952,4.427094,4.944368,5.819585,6.15919] y = [-1.826294,0.054874,0.024874,0.336462,-0.818773,-1.251986,-1.194328,0.528471,1.592675,1.896029,-0.056895,-0.74296,-1.053691,-2.835724,-2.327798,-1.328631,-1.066197,-1.634321,-1.088327,-0.867389] D = pd.DataFrame(data = [x,y],index = ['X','Y'] ) d =D.T model = GPy.models.GPRegression(d.X[:, None], d.Y[:, None], kernel=kernel) print(model.optimize()) model.plot() plt.savefig('fig2.png') ## prediction x_pred = np.linspace(-10, 10, 100) x_pred = x_pred[:, None] y_qua_pred = model.predict_quantiles(x_pred, quantiles=(2.5, 50, 97.5))[0] print(y_qua_pred)
- 投稿日:2019-07-14T13:34:55+09:00
tensorflowをAzure App Service上で動かしてみる
いよいよtensorflowの画像認識をAzure App Serviceで動かす事にトライしました。
demo
手順
もはや定型処理になりつつありますが、python拡張モジュールを入れて、ライブラリを追加します。
1.Google Colaboratoryだとtensorflowはライブラリとして用意されているので、今回はそちらを利用しました。こちらの記事を参考にcifar10。h5の画像識別モデルを作成しました。これを一旦ローカルにダウンロードしてからAzure App Serviceにftpでアップロードして利用します。
2.AzureのWebappsはPythonサーバを作成。
3.webappsダッシュボードの「開発ツール」→「拡張機能」→「追加」でPython 3.6.4 x64を追加。
4.webappsダッシュボードの「高度なツール」→「移動」→「Debugconsole」→「CMD」→「フォルダ選択ができるのでPython364x64」を選んで、コンソール画面でライブラリを追加。
python -m pip install --upgrade pip pip install Flask pip install tensorflow pip install Pillow5.ファイル転送とjpegファイルをtensorflowが処理できる形式に変更する処理を加えてWebAppsアプリを作成します。
ソース
tensorUpload.html{% extends "base.html" %} {% block body %} <form action="/upload" method="post" enctype="multipart/form-data"> <h2>アップロード</h2> <table> <tr> <td><input type="file" name="uploadFile"/></td> </tr> <tr> <td><img src="{{ url_for('static', filename=file_url) }}"></td> <td>result = {{ result }}</td> <td><input type="submit" value="submit"/></td> </tr> </table> </form> {% endblock %}main.py# -*- coding: utf-8 -*- from common import * import tensorflow as tf application = Flask(__name__) application.config.from_object(__name__) ################################################################## # 初期メニュー ################################################################## @application.route('/') def index(): return render_template('index.html') #各画面からの戻りの時はこちら(/でうまく戻れないので) ※indexとIndexをわざと変えている @application.route('/Index',methods=['POST']) def Index(): return render_template('index.html') #************************************** # アップロード #************************************** #アップロード @application.route('/tensorUpload',methods=['POST']) def tensorUpload(): return render_template('Upload.html') #*********************************************************************************** # アップロードデータ作成 https://qiita.com/5zm/items/ac8c9d1d74d012e682b4 #*********************************************************************************** UPLOAD_DIR = "./static/result/" label_names = ["airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"] @application.route('/upload', methods=['POST']) def upload_multipart(): if 'uploadFile' not in request.files: make_response(jsonify({'result':'uploadFile is required.'})) file = request.files['uploadFile'] fileName = file.filename if '' == fileName: return render_template('Upload.html', file_url='', status='') try: #saveFileName = datetime.datetime.now().strftime("%Y%m%d_%H%M%S_") + fileName saveFileName = fileName os_saveFileName = os.path.join(UPLOAD_DIR, saveFileName) file.save(os_saveFileName) file_url = "result/" + saveFileName except: return render_template('Upload.html', file_url='', result = 'error1') try: #モデルの読込 model_loaded=tf.keras.models.load_model("./static/cifar10.h5") #画像の読込とtensorflowが処理できるように変換 img_path = os_saveFileName img = tf.keras.preprocessing.image.load_img(img_path, target_size=(32, 32)) x = tf.keras.preprocessing.image.array_to_img(img) x = np.expand_dims(x, axis=0) except: return render_template('Upload.html', file_url=file_url, result = 'error2') #テストデータの予測 try: pred = model_loaded.predict_classes(x) result = label_names[pred[0]] except: return render_template('Upload.html', file_url='', result = 'error3') return render_template('Upload.html', file_url=file_url, status='ok',result = result) #リクエストエンティティが大きすぎます @application.errorhandler(werkzeug.exceptions.RequestEntityTooLarge) def handle_over_max_file_size(error): print("werkzeug.exceptions.RequestEntityTooLarge") return 'result : file size is overed.' #************************************** # サーバ起動 マルチスレッド指定 デフォルトはTrueの動きをするようだが。 https://qiita.com/5zm/items/251be97d2800bf67b1c6 #************************************** if __name__ == '__main__': application.debug = True # デバッグ application.run(host='0.0.0.0', port=8000, threaded=True)その他【index.html】 {% extends "base.html" %} {% block body %} <div class="container"> <table class="table table-striped table-condensed"> <thead> <tr> <th>NO</th> <th>プログラム名</th> <th>リンク</th> <th>備考</th> </tr> </thead> <tbody> <tr> <th scope="row">1</th> <td>tensorflow画像識別</td> <td> <form action="{{ url_for('tensorUpload') }}" style="display: inline" method="post"> <button type="submit" class="btn btn-default" style="width: 120px; padding: 5px;">Upload</button> </form> </td> <td></td> </tr> </tbody> </table> </div> {% endblock %}web.config、base.html、common.pyは前記事と同じです。
入力は適当なjpegファイルを選んでアップするとそれなりに判別してくれます。
だいぶ機械学習らしいアプリになってきました。
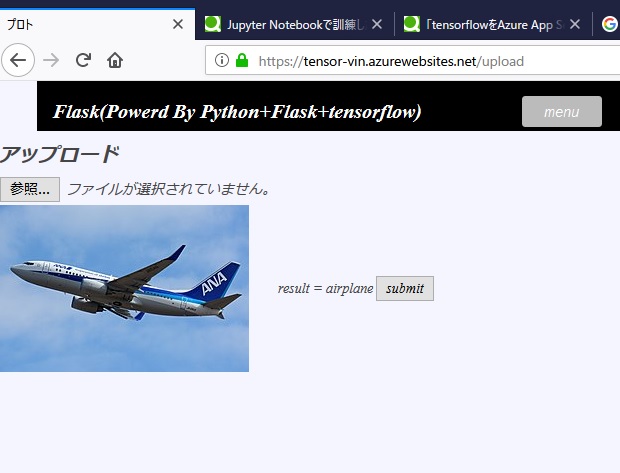
- 投稿日:2019-07-14T13:31:45+09:00
スクレイピング:htmlのテーブルから情報を抜きcsvにする方法
この記事では.
旅行などで検索サイトを使わない場合などにwikiやお国のサイトを使うが、
プレーンなhtmlに情報が張り付いているので検索が面倒。こういうやつ。
https://www.env.go.jp/water/yusui/result/sub4-2/PRE13-4-2.htmlということで、スクレイピングして自分で検索可能なものを作る際にデータを抜き出すときのメモ。
htmlのテーブルならヘッダも含めてループしてcsvにしておく。(今回特殊なヘッダなので手で作ったけど、、)
あと、コードはurl固定だけど、PRE{都道府県コード}の引数を与えれば全都道府県を一回でcsvにすることが可能。
都道府県コードは別ページにあった。スクレイピングのコード
import requests from bs4 import BeautifulSoup import csv # アクセスするURL url = 'https://www.env.go.jp/water/yusui/result/sub4-2/PRE13-4-2.html' # reqest and parse response = requests.get(url) response = BeautifulSoup(response.content, 'html.parser') # テーブル情報を取得 table = response.findAll('table') rows = response.findAll('tr') # csvデータ作成 csvFile = open("ebooks2.csv", 'wt', newline = '', encoding = 'utf-8') writer = csv.writer(csvFile) # ヘッダーが二重になっていて取り出すのが面倒なのでここは記載してしまう csvItem = ['回答市区町村名','名称','ふりがな','所在地','概要等','アクセス制限','湧水保全活動','湧水写真・位置図'] writer.writerow(csvItem) # ここからが1行ごとの処理 for row in rows : # 項目ずつlist.append csvItem = [] for cell in row.findAll('td'): csvItem.append(cell.text) # ヘッダもこのループ内なので項目がない場合は無視 if len(csvItem) > 0: writer.writerow(csvItem) csvFile.close()参考
ほぼほぼ以下をコピペで使ってます.
https://qiita.com/hujuu/items/b0339404b8b0460087f9
誰かが作ったapiサービス
https://springwaterapi.docs.apiary.io/#
- 投稿日:2019-07-14T13:31:45+09:00
スクレイピングでhtmlのテーブルから情報を抜きcsvにする方法
この記事では.
旅行などで検索サイトを使わない場合などにwikiやお国のサイトを使うが、
プレーンなhtmlに情報が張り付いているので検索が面倒。こういうやつ。
https://www.env.go.jp/water/yusui/result/sub4-2/PRE13-4-2.htmlということで、スクレイピングして自分で検索可能なものを作る際にデータを抜き出すときのメモ。
htmlのテーブルならヘッダも含めてループしてcsvにしておく。(今回特殊なヘッダなので手で作ったけど、、)
あと、コードはurl固定だけど、PRE{都道府県コード}の引数を与えれば全都道府県を一回でcsvにすることが可能。
都道府県コードは別ページにあった。スクレイピングのコード
import requests from bs4 import BeautifulSoup import csv # アクセスするURL url = 'https://www.env.go.jp/water/yusui/result/sub4-2/PRE13-4-2.html' # reqest and parse response = requests.get(url) response = BeautifulSoup(response.content, 'html.parser') # テーブル情報を取得 table = response.findAll('table') rows = response.findAll('tr') # csvデータ作成 csvFile = open("ebooks2.csv", 'wt', newline = '', encoding = 'utf-8') writer = csv.writer(csvFile) # ヘッダーが二重になっていて取り出すのが面倒なのでここは記載してしまう csvItem = ['回答市区町村名','名称','ふりがな','所在地','概要等','アクセス制限','湧水保全活動','湧水写真・位置図'] writer.writerow(csvItem) # ここからが1行ごとの処理 for row in rows : # 項目ずつlist.append csvItem = [] for cell in row.findAll('td'): csvItem.append(cell.text) # ヘッダもこのループ内なので項目がない場合は無視 if len(csvItem) > 0: writer.writerow(csvItem) csvFile.close()参考
ほぼほぼ以下をコピペで使ってます.
https://qiita.com/hujuu/items/b0339404b8b0460087f9
誰かが作ったapiサービス
https://springwaterapi.docs.apiary.io/#
- 投稿日:2019-07-14T13:12:15+09:00
pandasで文字列からなる列を操作する
下書きに眠っていたので供養
スタックオーバーフローの下記記事をまとめました。
Convert categorical data in pandas dataframe - Stack Overflow
カテゴリカルにせず、文字列の列を整数列に変換する場合
In [1]: pd.factorize( ['B', 'C', 'D', 'B'] )[0] Out[1]: array([0, 1, 2, 0])カテゴリカル変数として扱う場合
In [1]: df = pd.DataFrame( {'col1':[1,2,3,4,5], 'col2':list('abcab'), # str 'col3':list('ababb') # str }) In [2]: df.columns Out[2]: Index(['col1', 'col2', 'col3'], dtype='object')この時点で全ての列はobjectになっているので、categoryにcastする
In [3]: df['col2'] = df['col2'].astype('category') In [4]: df['col3'] = df['col3'].astype('category')
select_dtypes(['category'])でカテゴリカル変数になっている列を取得できるので、In [5]: cat_columns = train.select_dtypes(['category']).columns In [6]: cat_columns Out[6]: Index(['col2', 'col3'], dtype='object')となる。
- 投稿日:2019-07-14T13:11:37+09:00
Pythonで、パッケージやモジュールの構造を視覚化する
下書きに眠っていたので供養
何がしたかったか
タイトルの通り。
Pythonで提供されているモジュールの全体像を知りたいときが度々あるけれど、日本語で調べてもなかなかヒットしないので、メモしておく。Snakefood
Snakefoodというモジュールを使うとできるらしい。僕らのStack Overflow(本家)を調べると簡単に見つかった。
visualize structure python module - Stack Overflowインストール
このSnakefood, PyPIに登録されているsetup.pyが古いからか、エラーを吐く。
C:\ pip install snakefood Collecting snakefood Using cached snakefood-1.4.tar.gz complete output from command python setup.py egg_info: Traceback (most recent call last): File "<string>", line 1, in <module> File "C:\Users\Owner\AppData\Local\Temp\pip-build-umj3pjm5\snakefood\setup.py", line 19 except IOError, e: SyntaxError: invalid syntax ---------------------------------------- Command "python setup.py egg_info" failed with error code 1 in C:\Users\Owner\AppData\Local\Temp\pip-build-umj3pjm5\snakefood\setup.pyどう見ても", e"がおかしいが、自分で直すのも不安なので、本家から持ってくることに。
snakefood: Python Dependency GraphsBitbucketへのリンクがあるので、そこから落とせる。
僕は pip の仕組みなんて知らずに使っている新人類なので、インストーラの指定とかやったことない。以下を参考にした。
【Python】pipの使い方 - TASK NOTESpipで -e オプションをつけて、レポジトリを指定すればインストールできる。
分散バージョン管理システム周りのことはよくわからないので、いったんローカルに落としたフォルダを指定した。C:\ pip install -e {path} Obtaining file:///{path} Installing collected packages: snakefood Running setup.py develop for snakefood Successfully installed snakefoodとなって完了。
補足
他に、少なくとも2つツールがあった。
Python dependencies inside a package - Stack Overflow
- 投稿日:2019-07-14T13:05:40+09:00
Enviro pHATを使って室内環境モニタリング
下書きに残っていたので供養
「いわゆるIoT」を感じられる一品に
Raspberry Piを色々なセンサやアクチュエータと組み合わせて、色々なことができます。
中には電気回路設計をしなくても良い(オールインワンの)ものもあります。
例えばHATは、GPIOにそのまま差し込んで色々なことができるシロモノです。ここでは、周りの環境測定に特化したEnviro pHATを使ってみます。
PIMORONI: Getting started with Enviro pHATよりEnviro pHATの使い方
基本的に下記サイトに書いてあることが全てです。
PIMORONI: Getting started with Enviro pHATpythonライブラリを用意してくれているので、非常に簡単に使えます。
curlして、python上でimportすればおk
curl https://get.pimoroni.com/envirophat | bashimport envirophat as ev測定上の精度や単位に注意が必要です。
精度は、型番から調べることができます。
単位はドキュメントを読むと書いてあります。
Enviro pHATで出来ること
1. 光・色測定
TCS3472 による光・色測定が可能。
ev.light.light() #光強度 [lux] r, g, b = ev.light.rgb() #色強度 [-] (0-255)2. 気圧・温度測定
BMP280 による気圧・温度測定が可能。湿度センサはなし。
ev.weather.pressure() #気圧 [hPa] ev.weather.temperature() #温度 [degC]3. モーションセンサと磁気測定
LSM303D による3軸加速度・磁気測定が可能。
x, y, z = ev.motion.accelerometer() #加速度 [G (= 9.806 65 m/s2)] ev.motion.heading() # 向き [deg]4. LEDの点灯
ev.leds.on() #点灯 ev.leds.off() #消灯5. アナログ入力
ADS1015 によるAD変換が可能。
詳細はデータシートを参照。室内環境モニタリング
ここでは、室内の気圧・温度を測定して、1時間後のそれぞれの値を簡単に予測したいと思います。
いくつかのパッケージがインストールされていることを前提とします。
普通にpipでインストールできます。sudo pip install --no-cache-dir ipython matplotlib pandas(cacheの問題がmatplotlib導入時に良く起こるみたいです。)
a. 気圧・温度測定
測定は先に述べたように簡単に行えます。
b. 測定値のプロット
測定しながらインタラクティブにプロットするための方法として、ここではJupyter Notebook上
c. 天気の予測

- 投稿日:2019-07-14T12:43:02+09:00
天使が舞い降りる ・・・IBMとクラウドと 2019/07 中盤
最近の話題
AzureがAWSを追い越したってことです。
Azureの話を認識したのは去年のはじめくらいでした。
駅の画像で大企業がAzure使ってるのをみて・・・おおって思ったね。
AWSの凋落がここから始まるという人もいるけれど・・・そうでもないことを祈ります。
JavaとかPythonとかやるんだったらAWSの方が使いやすいような気がしてるんで・・・クラウドに期待すること
プログラマー目線で見れば一人の人間がやれる範囲が増えるんじゃないかと思います。
自由度が上がるんじゃないかと思うね。IBM Developer Dojo
IBMさんが意欲的な取り組みをしているらしいです。以下 connpassでの説明
IBM Developer Dojo は毎週水曜日をベースに開発者向けイベントを開催しています。 人気のコンテンツを集め、約8週間でクラウドの基礎から応用まで学べるコースになっています。
イベント情報を順次追加していきますので、皆様のご参加をお待ちしております。
https://ibm-developer.connpass.com/すごい人がアメリカ?から来るらしい。
https://ibm-developer.connpass.com/event/139025/
Linuxカーネル開発者やLinux Foundation COOが来るらしいし
https://ibm-developer.connpass.com/event/138242/
DockerとKubernetesのメンテナーかつKnativeのオファリングマネージャーが解説 !
だそうです。
どちらも7月19日と7月23日で知らせも急に来たので本当に驚いたし、もうちょっと前に知らせてくれたら
休みをそちらに振り分けることもできたのにすごい残念。
英語に触れる貴重な機会だしね。
なんか事情があって大物たちが来ているのかと思うのも楽しいかも・・・・
- 投稿日:2019-07-14T11:23:07+09:00
Mac内蔵カメラの動画をpythonでキャプチャ
目的
Mac内蔵カメラの動画をpythonでキャプチャした際の備忘録です。
準備
環境:mac os x 10.13 High Sierra
python3
opencv2ライブラリコード
カメラから動画を撮影するのコードそのまま実行して動きました。
グレイスケール画像表示は下記
sample-grey.pyimport numpy as np import cv2 cap = cv2.VideoCapture(0) while(True): # Capture frame-by-frame ret, frame = cap.read() # Our operations on the frame come here gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # Display the resulting frame cv2.imshow('frame',gray) if cv2.waitKey(1) & 0xFF == ord('q'): break # When everything done, release the capture cap.release() cv2.destroyAllWindows()カラー画像表示は下記
sample-color.pyimport numpy as np import cv2 cap = cv2.VideoCapture(0) while(True): # Capture frame-by-frame ret, frame = cap.read() # Display the resulting frame cv2.imshow('frame',frame) if cv2.waitKey(1) & 0xFF == ord('q'): break # When everything done, release the capture cap.release() cv2.destroyAllWindows()テスト
$ python sample-grey.py
--
$ python sample-color.py
備考
Videoデバイス番号はどこから参照すれば良いかわからず決め打ちしています。
(Videoデバイス番号はffmpegを下記の通りコマンド実行した際の、FaceTime HD Cameraが該当?確かではありません。)$ ffmpeg -list_devices true -f avfoundation -i dummy ffmpeg version 4.1.2 Copyright (c) 2000-2019 the FFmpeg developers [AVFoundation input device @ 0x7feac1504980] AVFoundation video devices: [AVFoundation input device @ 0x7feac1504980] [0] FaceTime HD Camera [AVFoundation input device @ 0x7feac1504980] [1] Capture screen 0 [AVFoundation input device @ 0x7feac1504980] AVFoundation audio devices: [AVFoundation input device @ 0x7feac1504980] [0] Soundflower (2ch) [AVFoundation input device @ 0x7feac1504980] [1] Soundflower (64ch) [AVFoundation input device @ 0x7feac1504980] [2] Built-in Microphone参考


- 投稿日:2019-07-14T11:08:45+09:00
pandasの基本的な操作を身体に染み込ませるための問題集を作る
前書き
最近Kaggleのタイタニックコンペでデータ分析の学習に取り組み始めましたが、
pandasの使い方がどうしてもおぼつかない状態でした。
そのため、諸先輩方のKernelを参考によく使いそうな操作を繰り返して身体に染み込ませることにしました。まずはタイタニックコンペのチュートリアル的なKernelを一つこなすなどして、
ある程度pandasを動かしてからご利用いただければと思います。また、本記事はPythonインタープリタで実施することを想定しています。
記事中の解答例とは違う方法でも全く問題ございません。
より楽な方法、より一般的な方法がございましたら教えていただけますととてもありがたいです。0.はじめに
pandasをimportしておく
import pandas as pd以下のファイルを使用するのでダウンロードしておく。
pandas_train.csv (Googleドライブ)
※KaggleのタイタニックコンペのCSVファイルを適当に架空の情報に書き換えました。
Titanic: Machine Learning from Disaster | Kaggle
実行環境
$ python3 --version Python 3.6.5 $ sw_vers ProductName: Mac OS X ProductVersion: 10.14.5 $ pip3 show pandas Name: pandas Version: 0.24.21.新しいDataFrameを作る
1-1.以下のdf_sampleという名前のDataFrameを作成する
A B C D 0 a aa aaa aaaa 1 b bb bbb bbbb 2 c cc ccc cccc 3 d dd ddd dddd 4 e ee eee eeee
回答1-1
1-1.pydf_sample = pd.DataFrame({ "A" : ["a","b","c","d","e"], "B" : ["aa","bb","cc","dd","ee"], "C" : ["aaa","bbb","ccc","ddd","eee"], "D" : ["aaaa","bbbb","cccc","dddd","eeee"]}) #>>> df_sample # A B C D #0 a aa aaa aaaa #1 b bb bbb bbbb #2 c cc ccc cccc #3 d dd ddd dddd #4 e ee eee eeee2.あるCSVファイルを操作する
以下のファイルを使用する。
pandas_train.csv (Googleドライブ)2-1. pandas_train.csvを読み込んで変数dfに格納する
回答2-1
2-1.pydf = pd.read_csv("{ファイルパス}/pandas_train.csv")2-2. 2-1でdfに格納したデータをpandas_train2.csvというファイル名で出力する
回答2-2
2-2.pydf.to_csv("{ファイルパス}/pandas_train2.csv")2-3. pandas_train.csv内のSatisfied列を全て0に変更する
回答2-3
2-3.pydf["Satisfied"] = 0 #>>> df["Satisfied"] #0 0 #1 0 #2 0 #3 0 #4 0 #5 0 #6 0 #7 0 #8 0 #9 0 #10 0 #11 0 #12 0 #13 0 #14 0 #15 0 #16 0 #17 0 #18 0 #19 0 #Name: Satisfied, dtype: int642-4. Age列を数値で4等分にビン分割してAgeBinという列を作成する
回答2-4
2-4.pydf["AgeBin"] = pd.cut(df["Age"], 4) #4等分にした年齢層ごとのSatisfiedの数は以下のように表示される #>>> pd.crosstab(df["AgeBin"],df["Satisfied"]) #Satisfied 0 1 #AgeBin #(0.944, 15.0] 3 2 #(15.0, 29.0] 2 2 #(29.0, 43.0] 3 2 #(43.0, 57.0] 1 22-5. Fare列を人数で4等分にビン分割してFareBinという列を作成する
回答2-5
2-5.pydf["FareBin"] = pd.qcut(df["Fare"], 4)2-6. Age列の欠損値をAge列の中央値で埋める
回答2-6
2-6.pydf["Age"].fillna(df["Age"].median(), inplace = True) #>>> df["Age"].isnull().sum() #02-7. Embarked列の欠損値をEmbarked列の最頻値で埋める
回答2-7
2-7.pydf["Embarked"].fillna(["Embarked"].mode()[0], inplace = True) #>>> df["Embarked"].isnull().sum() #02-8. PassengerId, Ticketという列を削除する
回答2-8
2-8.pydf.drop(["PassengerId", "Ticket"], axis=1, inplace=True) #>>> df.columns #Index(['Satisfied', 'Pclass', 'Sex', 'Name', 'Age', 'SibSp', 'Parch', 'Fare', # 'Cabin', 'Embarked', 'AgeBin', 'FareBin'], # dtype='object')2-9. SibSp列の値とParch列の値の和に1を足した値を持つFamirySize列を作成する
回答2-9
2-9.pydf["FamilySize"] = df["SibSp"] + df["Parch"] + 1 #>>> df.loc[:,["FamilySize","SibSp","Parch"]] # FamilySize SibSp Parch #0 2 1 0 #1 2 1 0 #2 1 0 0 #3 2 1 0 #4 1 0 0 #5 1 0 0 #6 1 0 0 #7 5 3 1 #8 3 0 2 #9 2 1 0 #10 3 1 1 #11 1 0 0 #12 1 0 0 #13 7 1 5 #14 1 0 0 #15 1 0 0 #16 6 4 1 #17 1 0 0 #18 2 1 0 #19 1 0 02-10. 全て値が1のIsAlone列を作成し、2-9のFamilySize列が1より大きい行のみ0に変更する
回答2-10
2-10.pydf["IsAlone"] = 1 df["IsAlone"].loc[dataset["FamilySize"] > 1] = 0 #>>> df.loc[:,["IsAlone","FamilySize"]] # IsAlone FamilySize #0 0 2 #1 0 2 #2 1 1 #3 0 2 #4 1 1 #5 1 1 #6 1 1 #7 0 5 #8 0 3 #9 0 2 #10 0 3 #11 1 1 #12 1 1 #13 0 7 #14 1 1 #15 1 1 #16 0 6 #17 1 1 #18 0 2 #19 1 12-11. df内のSex列, Embarked列をone-hotエンコーディングに変更する
回答2-11
2-11.pydf = pd.get_dummies(df, columns=["Sex","Embarked"]) #>>> df.head(5) # Satisfied Pclass Name Age SibSp Parch Fare Cabin FareBin FamilySize IsAlone Sex_female Sex_male Embarked_Nagoya Embarked_Osaka Embarked_Tokyo #0 0 3 Sato, Mr. Ren 21.0 1 0 870.000 NaN (866.999, 966.0] 2 0 0 1 0 0 1 #1 1 1 Suzuki, Mrs. Himari 37.0 1 0 8553.996 C85 (3523.374, 8553.996] 2 0 1 0 0 1 0 #2 1 3 Tanaka, Miss. Mei 25.0 0 0 951.000 NaN (866.999, 966.0] 1 1 1 0 0 0 1 #3 1 1 Ito, Mrs. Riko 34.0 1 0 6372.000 C123 (3523.374, 8553.996] 2 0 1 0 0 0 1 #4 0 3 Takahashi, Mr. Haruto 34.0 0 0 966.000 NaN (866.999, 966.0] 1 1 0 1 0 0 12-12. df内のSatisfied列以外を取り出してdf_1, Satisfied列とName列だけを取り出してdf_2という新しいDataframeを作成する
回答2-12
2-12.pydf_1 = df.drop(["Satisfied"], axis = 1) #>>> df_1.head(5) # Pclass Name Age SibSp Parch Fare Cabin AgeBin FareBin FamilySize IsAlone Sex_female Sex_male Embarked_Nagoya Embarked_Osaka Embarked_Tokyo #0 3 Sato, Mr. Ren 21.0 1 0 870.000 NaN (15.0, 29.0] (866.999, 966.0] 2 0 0 1 0 0 1 #1 1 Suzuki, Mrs. Himari 37.0 1 0 8553.996 C85 (29.0, 43.0] (3523.374, 8553.996] 2 0 1 0 0 1 0 #2 3 Tanaka, Miss. Mei 25.0 0 0 951.000 NaN (15.0, 29.0] (866.999, 966.0] 1 1 1 0 0 0 1 #3 1 Ito, Mrs. Riko 34.0 1 0 6372.000 C123 (29.0, 43.0] (3523.374, 8553.996] 2 0 1 0 0 0 1 #4 3 Takahashi, Mr. Haruto 34.0 0 0 966.000 NaN (29.0, 43.0] (866.999, 966.0] 1 1 0 1 0 0 1 df_2 = df[["Satisfied","Name"]] #>>> df_2.head(5) # Satisfied Name #0 0 Sato, Mr. Ren #1 0 Suzuki, Mrs. Himari #2 0 Tanaka, Miss. Mei #3 0 Ito, Mrs. Riko #4 0 Takahashi, Mr. Haruto3.CSVファイルの情報を確認する
pandas_train.csvをdfに格納しなおしてから実施します。
df = pd.read_csv("{ファイルパス}/pandas_train.csv")3-1. dfの行数と列数を表示する
回答3-1
3-1.pydf.shape #(20, 12)3-2. dfの列の名前の一覧を表示する
回答3-2
3-2.pydf.columns #Index(['PassengerId', 'Satisfied', 'Pclass', 'Sex', 'Name', 'Age', 'SibSp', # 'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'], # dtype='object')3-3. dfの各列の欠損値でないデータの数とデータの型を表示する
回答3-3
3-3.pydf.info() #<class 'pandas.core.frame.DataFrame'> #RangeIndex: 20 entries, 0 to 19 #Data columns (total 12 columns): #PassengerId 20 non-null int64 #Satisfied 20 non-null int64 #Pclass 20 non-null int64 #Sex 20 non-null object #Name 20 non-null object #Age 17 non-null float64 #SibSp 20 non-null int64 #Parch 20 non-null int64 #Ticket 20 non-null object #Fare 20 non-null float64 #Cabin 5 non-null object #Embarked 16 non-null object #dtypes: float64(2), int64(5), object(5)3-4. dfの各列の欠損値の数を表示する
回答3-4
3-4.pydf.isnull().sum() #PassengerId 0 #Satisfied 0 #Pclass 0 #Sex 0 #Name 0 #Age 3 #SibSp 0 #Parch 0 #Ticket 0 #Fare 0 #Cabin 15 #Embarked 4 #dtype: int643-5. dfの各数値データの要約統計量を表示する
回答3-5
3-5.pydf.describe() # PassengerId Satisfied Pclass Age SibSp Parch Fare #count 20.00000 20.000000 20.000000 17.000000 20.000000 20.000000 20.000000 #mean 10.50000 0.500000 2.450000 27.000000 0.700000 0.500000 2663.924400 #std 5.91608 0.512989 0.825578 17.779904 1.080935 1.192079 2167.066511 #min 1.00000 0.000000 1.000000 1.000000 0.000000 0.000000 867.000000 #25% 5.75000 0.000000 2.000000 13.000000 0.000000 0.000000 966.000000 #50% 10.50000 0.500000 3.000000 26.000000 0.000000 0.000000 1962.000000 #75% 15.25000 1.000000 3.000000 37.000000 1.000000 0.250000 3523.374000 #max 20.00000 1.000000 3.000000 57.000000 4.000000 5.000000 8553.9960003-6. dfの各数値データの要約統計量を10%刻みで表示する
回答3-6
3-6.pydf.describe(percentiles=[.1,.2,.3,.4,.5,.6,.7,.8,.9]) # PassengerId Satisfied Pclass Age SibSp Parch Fare #count 20.00000 20.000000 20.000000 17.000000 20.000000 20.000000 20.000000 #mean 10.50000 0.500000 2.450000 27.000000 0.700000 0.500000 2663.924400 #std 5.91608 0.512989 0.825578 17.779904 1.080935 1.192079 2167.066511 #min 1.00000 0.000000 1.000000 1.000000 0.000000 0.000000 867.000000 #10% 2.90000 0.000000 1.000000 2.200000 0.000000 0.000000 935.253600 #20% 4.80000 0.000000 1.800000 13.000000 0.000000 0.000000 963.000000 #30% 6.70000 0.000000 2.000000 17.800000 0.000000 0.000000 1000.297200 #40% 8.60000 0.000000 3.000000 22.600000 0.000000 0.000000 1470.398400 #50% 10.50000 0.500000 3.000000 26.000000 0.000000 0.000000 1962.000000 #60% 12.40000 1.000000 3.000000 32.400000 1.000000 0.000000 2307.600000 #70% 14.30000 1.000000 3.000000 34.600000 1.000000 0.000000 3278.700000 #80% 16.20000 1.000000 3.000000 37.800000 1.000000 1.000000 3637.396800 #90% 18.10000 1.000000 3.000000 53.400000 1.200000 1.100000 6238.350000 #max 20.00000 1.000000 3.000000 57.000000 4.000000 5.000000 8553.9960003-7. dfの各オブジェクト型データの要素数、ユニーク数、最頻値、最頻値の出現回数を表示
回答3-7
3-7.pydf.describe(include="O") # Sex Name Ticket Cabin Embarked #count 20 20 20 5 16 #unique 2 20 20 5 3 #top female Shimizu, Mrs. Tsumugi PP 95491 G6 Tokyo #freq 11 1 1 1 113-8. dfのSatisfied列で0の数と1の数を表示した後、0の割合と1の割合を表示
回答3-8
3-8.pydf["Satisfied"].value_counts() #1 10 #0 10 #Name: Satisfied, dtype: int64 df["Satisfied"].value_counts()/len(df["Satisfied"]) #1 0.5 #0 0.5 #Name: Satisfied, dtype: float643-9. 男女別のSatisfiedの0と1の数と割合をクロス集計で表示
回答3-9
3-9.pypd.crosstab(df["Sex"], df["Satisfied"]) #Sex female male #Satisfied #0 2 8 #1 9 1 pd.crosstab(df["Sex"], df["Satisfied"], normalize="index") #Sex female male #Satisfied #0 0.2 0.8 #1 0.9 0.13-10. 各行について、Satisfiedが0であるかどうかの真偽値を表示する
回答3-10
3-10.pydf["Satisfied"] == 0 #0 True #1 False #2 False #3 False #4 True #5 True #6 True #7 True #8 False #9 False #10 False #11 False #12 True #13 True #14 True #15 False #16 True #17 False #18 True #19 False3-11. 各行について、Satisfiedが0の行を全て表示する
回答3-11
3-11.pydf[df["Satisfied"] == 0] # PassengerId Satisfied Pclass Sex Name Age SibSp Parch Ticket Fare Cabin Embarked #0 1 0 3 male Sato, Mr. Ren 21.0 1 0 A/5 211711 870.000 NaN Tokyo #4 5 0 3 male Takahashi, Mr. Haruto 34.0 0 0 746900 966.000 NaN Tokyo #5 6 0 3 male Watanabe, Mr. Hinata NaN 0 0 661754 1014.996 NaN Nagoya #6 7 0 1 male Yamamoto, Mr. Itsuki 53.0 0 0 34926 6223.500 E46 Tokyo #7 8 0 3 male Nakamura, Master. Yuto 1.0 3 1 699818 2529.000 NaN NaN #12 13 0 3 male Sasaki, Mr. Minato 19.0 0 0 A/5. 21511 966.000 NaN Tokyo #13 14 0 3 male Yamaguchi, Mr. Hiroto 38.0 1 5 694164 3753.000 NaN Tokyo #14 15 0 3 female Matsumoto, Miss. Yuna 13.0 0 0 700812 942.504 NaN NaN #16 17 0 3 male Kimura, Master. Hiroto 1.0 4 1 765304 3495.000 NaN Nagoya #18 19 0 3 female Saito, Mrs.Hina 30.0 1 0 691526 2160.000 NaN Tokyo3-12. Satisfiedが1の行でAge列だけを表示する。ただしAgeが欠損値の行は省く
回答3-12
3-12.pydf[df["Satisfied"] == 1].Age.dropna() #1 37.0 #2 25.0 #3 34.0 #8 26.0 #9 13.0 #10 3.0 #11 57.0 #15 54.0 #Name: Age, dtype: float643-13. dfの上から5行目までを表示する
回答3-13
3-13.pydf.head(5) # PassengerId Satisfied Pclass Sex Name Age SibSp Parch Ticket Fare Cabin Embarked #0 1 0 3 male Sato, Mr. Ren 21.0 1 0 A/5 211711 870.000 NaN Tokyo #1 2 1 1 female Suzuki, Mrs. Himari 37.0 1 0 PC 175991 8553.996 C85 Osaka #2 3 1 3 female Tanaka, Miss. Mei 25.0 0 0 STON/O2. 31012821 951.000 NaN NaN #3 4 1 1 female Ito, Mrs. Riko 34.0 1 0 227606 6372.000 C123 Tokyo #4 5 0 3 male Takahashi, Mr. Haruto 34.0 0 0 746900 966.000 NaN Tokyo3-14. df内のデータの中から無作為に選んだ5行を表示する
回答3-14
3-14.pydf.sample(5) # PassengerId Satisfied Pclass Sex Name Age SibSp Parch Ticket Fare Cabin Embarked #6 7 0 1 male Yamamoto, Mr. Itsuki 53.0 0 0 34926 6223.5 E46 Tokyo #15 16 1 2 female Inoue, Mrs. Kotone 54.0 0 0 497412 1920.0 NaN Tokyo #10 11 1 3 female Yoshida, Miss. Yuina 3.0 1 1 PP 95491 2004.0 G6 Tokyo #17 18 1 2 male Hayashi, Mr. Aoi NaN 0 0 488746 1560.0 NaN Tokyo #3 4 1 1 female Ito, Mrs. Riko 34.0 1 0 227606 6372.0 C123 Tokyo3-15. df内のAge列だけを表示する
回答3-15
3-15.pydf["Age"] #または #df.Age #0 21.0 #1 37.0 #2 25.0 #3 34.0 #4 34.0 #5 NaN #6 53.0 #7 1.0 #8 26.0 #9 13.0 #10 3.0 #11 57.0 #12 19.0 #13 38.0 #14 13.0 #15 54.0 #16 1.0 #17 NaN #18 30.0 #19 NaN #Name: Age, dtype: float643-16. df内のAge列とName列だけを表示する
回答3-16
3-16.pydf.loc[:,["Age","Name"]] # Age Name #0 21.0 Sato, Mr. Ren #1 37.0 Suzuki, Mrs. Himari #2 25.0 Tanaka, Miss. Mei #3 34.0 Ito, Mrs. Riko #4 34.0 Takahashi, Mr. Haruto #5 NaN Watanabe, Mr. Hinata #6 53.0 Yamamoto, Mr. Itsuki #7 1.0 Nakamura, Master. Yuto #8 26.0 Kobayashi, Mrs. Aoi #9 13.0 Kato, Mrs. Mio #10 3.0 Yoshida, Miss. Yuina #11 57.0 Yamada, Miss. Rin #12 19.0 Sasaki, Mr. Minato #13 38.0 Yamaguchi, Mr. Hiroto #14 13.0 Matsumoto, Miss. Yuna #15 54.0 Inoue, Mrs. Kotone #16 1.0 Kimura, Master. Hiroto #17 NaN Hayashi, Mr. Aoi #18 30.0 Saito, Mrs.Hina #19 NaN Shimizu, Mrs. Tsumugi3-17. df内の奇数の行だけを表示する
回答3-17
3-17.pydf.iloc[lambda x: x.index % 2 == 1] # PassengerId Satisfied Pclass Sex Name Age SibSp Parch Ticket Fare Cabin Embarked #1 2 1 1 female Suzuki, Mrs. Himari 37.0 1 0 PC 175991 8553.996 C85 Osaka #3 4 1 1 female Ito, Mrs. Riko 34.0 1 0 227606 6372.000 C123 Tokyo #5 6 0 3 male Watanabe, Mr. Hinata NaN 0 0 661754 1014.996 NaN Nagoya #7 8 0 3 male Nakamura, Master. Yuto 1.0 3 1 699818 2529.000 NaN NaN #9 10 1 2 female Kato, Mrs. Mio 13.0 1 0 475472 3608.496 NaN Osaka #11 12 1 1 female Yamada, Miss. Rin 57.0 0 0 227566 3186.000 C103 NaN #13 14 0 3 male Yamaguchi, Mr. Hiroto 38.0 1 5 694164 3753.000 NaN Tokyo #15 16 1 2 female Inoue, Mrs. Kotone 54.0 0 0 497412 1920.000 NaN Tokyo #17 18 1 2 male Hayashi, Mr. Aoi NaN 0 0 488746 1560.000 NaN Tokyo #19 20 1 3 female Shimizu, Mrs. Tsumugi NaN 0 0 5298 867.000 NaN Osaka参考にさせていただきました
カレーちゃん - YouTube
A Data Science Framework: To Achieve 99% Accuracy | Kaggle