- 投稿日:2019-07-14T22:58:29+09:00
SageMakerでKerasの独自モデルをトレーニングしてデプロイするまで(Python3対応)
SageMakerでKerasの独自モデルをトレーニングしてデプロイするまで(Python3対応)
TL;DR
AWS SageMakerにおいて、Kerasによる独自モデルをトレーニングし、SageMakerのエンドポイントとしてデプロイします。
また、形態素解析やベクトル化のような前処理を、個別にDockerコンテナを作成することなしにエンドポイント内で行うようにします。このために、SageMaker TensorFlow Serving Containerを利用します。
SageMaker TensorFlow Serving Containerを利用するメリットは以下のとおりです。
- 学習時はスクリプトモードでOK。
- 前処理用に別に専用インスタンスが不要。エンドポイントで完結。
- 形態素解析やベクトル化のような前処理を行う独自の推論用スクリプトを利用できる。
- 個別にDockerコンテナを作成する必要が無い。
- TensorFlowModelと違ってPython3が利用できる。
KerasとTensorFlow付属のKerasの違いに注意
Kerasは独立したモジュールとTensorFlow付属のモジュールの2種類があります。
SageMakerのエンドポイント用のモデルは、Kerasのモデルではなく、TensorFlowのモデルとして保存する必要があり、Estimator内で実行する学習用コードの中でTensorFlowのモデルとしてKerasモデルを保存する必要があります。
しかしながら、SageMakerのEstimatorがTensorFlowのセッションを初期化するため、独立したモジュールのKerasを利用するとセッション初期化のタイミングの問題により、Estimator内で実行する学習用コードの中でTensorFlowのモデルとして保存する場合に、未初期化の変数が発生して失敗します。
このため、以下の様にTensorFlow付属のKerasモジュールのみを利用してKerasモデルを作成します。
# 以下のように`keras`を利用することはできません。 # from keras import Input, Model # from keras.layers.wrappers import Bidirectional # from keras.layers import Dense, Dropout, LSTM, Embedding # 以下のように`tensorflow.python.keras`を使用します。 from tensorflow.python.keras import Input, Model from tensorflow.python.keras.layers.wrappers import Bidirectional from tensorflow.python.keras.layers import Dense, Dropout, LSTM, Embeddingラベルデータの準備
ラベルデータはAWS S3上に配置されていることが前提となっています。
ベンチマーク用データ
京都大学情報学研究科--NTTコミュニケーション科学基礎研究所 共同研究ユニットが提供するブログの記事に関するデータセットを利用しました。 このデータセットでは、ブログの記事に対して以下の4つの分類がされています。
- グルメ
- 携帯電話
- 京都
- スポーツ
全体の流れ
- 事前準備
- 学習用スクリプトとモジュールの準備
- トレーニングの実行
- 学習したモデルのダウンロード
- 推論用スクリプトを含めてパッケージング
- エンドポイントの作成
- エンドポイントの削除
事前準備
学習用スクリプトの準備
train/train_v1.pyとして用意します。前述のようにTensorFlow付属のKerasモジュールのみを利用してモデルを作成する必要があります。
また、モデルの保存はTensorFlowのモデルとして保存するためにtf.saved_model.simple_saveを使用します。その他、Kerasに依存したサードパーティーモジュールを利用する場合、それらのサードパーティーモジュールもTensorFlow付属のKerasを利用する必要があります。
今回はkeras-self-attentionを利用するため、環境変数としてTF_KERASに1を設定してからimportすることで、keras-self-attentionがTensorFlow付属のKerasを利用するようになります(これはkeras-self-attention独自の実装です)。推論用スクリプトの準備
predict/code/inference.pyとして用意します。この際、code/inference.pyは固定である点に注意してください。
SageMaker TensorFlow Serving Containerは、以下のように推論するための学習済みモデルと推論用スクリプトが並んで存在することを前提としています。model.tar.gz ├── [Model Version] │ ├── variables │ └── saved_model.pb └── code ├── inference.py └── requirements.txt学習時と違い、
code配下にrequirements.txtを配置することで、デプロイ時に依存したモジュールを自動的にインストールしてくれます。ディレクトリ構成
├── predict │ ├── [Model Version] <- ダウンロードした学習済みモデル。 │ └── code │ ├── inference.py │ └── requirements.txt └── train ├── train_v1.py └── [Moduels] <- 学習用スクリプトが依存するモジュール。
train/[Modules]は学習用スクリプトと同じディレクトリに配置することで、学習用スクリプトの方でパスの違いを意識せずにimportすることができます。学習用スクリプトとモジュールの準備
学習用スクリプトと依存するモジュールを準備します。
依存するモジュールはpip install [Module] --target trainで対象のディレクトリに配置します。Estimatorでは、この
train配下をsrcに指定することで、学習で使用するコンテナにまるごと配置します。!pip install text-vectorian --target train !pip install keras-self-attention --target train!cat train/train_v1.pyimport os # SeqSelfAttentionをTensorFlow付属のKerasモジュールを利用するために必要な設定です。 # 以下の設定が無効な場合は、Kerasのバージョンが合わずに_create_modelが失敗します。 os.environ['TF_KERAS'] = '1' import sys import numpy as np import pandas as pd from keras_self_attention import SeqSelfAttention import pickle import logging from tensorflow.python.keras import utils from tensorflow.python.keras.callbacks import LambdaCallback, EarlyStopping, ModelCheckpoint from tensorflow.python.keras.preprocessing.sequence import pad_sequences from tensorflow.python.keras import Input, Model from tensorflow.python.keras.layers.wrappers import Bidirectional from tensorflow.python.keras.layers import Dense, Dropout, LSTM, Embedding from tensorflow.python.keras.models import Sequential, load_model from tensorflow.python.keras import backend as K import tensorflow as tf import argparse from text_vectorian import SentencePieceVectorian input_len = 64 logger = logging.getLogger(__name__) vectorian = SentencePieceVectorian() def _save_model(checkpoint_filename, history, model_dir, output_dir): ''' モデルや実行履歴を保存します。 ''' # Checkpointからモデルをロードし直し(ベストなモデルのロード) model = load_model(checkpoint_filename, custom_objects=SeqSelfAttention.get_custom_objects()) # Historyの保存 history_df = pd.DataFrame(history.history) history_df.to_csv(output_dir + f'/history.csv') # Endpoint用のモデル保存 with tf.keras.backend.get_session() as sess: tf.saved_model.simple_save( sess, args.model_dir + '/1', inputs={'inputs': model.input}, outputs={t.name: t for t in model.outputs}) def _save_labels(data, output_dir): ''' 推論で利用するためのラベルデータの情報を保存します。 ''' del data['labels'] del data['features'] data_filename = output_dir + f'/labels.pickle' with open(data_filename, mode='wb')as f: pickle.dump(data, f) def _load_labeldata(train_dir): ''' ラベルデータをロードします。 ''' features_df = pd.read_csv( f'{train_dir}/features.csv', dtype=str) labels_df = pd.read_csv(f'{train_dir}/labels.csv', dtype=str) label2index = {k: i for i, k in enumerate(labels_df['label'].unique())} index2label = {i: k for i, k in enumerate(labels_df['label'].unique())} class_count = len(label2index) labels = utils.np_utils.to_categorical( [label2index[label] for label in labels_df['label']], num_classes=class_count) features = [] for feature in features_df['feature']: features.append(vectorian.fit(feature).indices) features = pad_sequences(features, maxlen=input_len, dtype='float32') logger.info( f'データ数: {len(features_df)}, ラベル数: {class_count}, Labels Shape: {labels.shape}, Features Shape: {features.shape}') return { 'class_count': class_count, 'label2index': label2index, 'index2label': index2label, 'labels': labels, 'features': features, 'input_len': input_len } def _create_model(input_shape, hidden, class_count): ''' モデルの構造を定義します。 ''' wv = vectorian._vectorizer.model.wv input_tensor = Input(input_shape) # TensorFlow付属のKerasモジュールを使用する必要があるため、 # gensimのget_keras_embeddingを利用せずに、kerasのEmbeddingレイヤーを # 直接使用します。 x1 = Embedding(input_dim=wv.vectors.shape[0], output_dim=wv.vectors.shape[1], weights=[wv.vectors], trainable=False)(input_tensor) x1 = SeqSelfAttention( attention_type=SeqSelfAttention.ATTENTION_TYPE_MUL)(x1) x1 = Bidirectional(LSTM(hidden))(x1) x1 = Dense(hidden * 2)(x1) x1 = Dropout(0.1)(x1) output_tensor = Dense(class_count, activation='softmax')(x1) model = Model(input_tensor, output_tensor) model.compile(loss='categorical_crossentropy', optimizer='nadam', metrics=[ 'acc', 'mse', 'mae', 'top_k_categorical_accuracy']) model.summary() return model if __name__ == '__main__': # Estimatorのパラメータは本スクリプトの引数として指定されるため、argparseで解析します。 # Pythonの文法上Estimatorのパラメータはスネークケースですが、引数として渡される場合は`--`をプレフィクスにしたチェーンケースになっています。 # なおhyperparameterとして渡すdictオブジェクトは、名前の変換は行われないのでそのまま引数名として受け取ります。 parser = argparse.ArgumentParser() # Estimatorのパラメータとして渡されるパラメータ parser.add_argument('--epochs', type=int, default=10) parser.add_argument('--batch-size', type=int, default=100) parser.add_argument('--hidden', type=int) parser.add_argument('--container-log-level', type=int, default=logging.INFO) parser.add_argument('--validation-split', type=float, default=0.1) # 環境変数として渡されるパラメータ parser.add_argument('--model-dir', type=str, default=os.environ['SM_MODEL_DIR']) parser.add_argument('--train-dir', type=str, default=os.environ['SM_CHANNEL_TRAIN']) parser.add_argument('--test-dir', type=str, default=os.environ['SM_CHANNEL_TEST']) parser.add_argument('--output-dir', type=str, default=os.environ['SM_OUTPUT_DATA_DIR']) parser.add_argument('--model-version', type=str, default='') args, _ = parser.parse_known_args() # ログレベルを引数で渡されたコンテナのログレベルと合わせます。 logging.basicConfig(level=args.container_log_level) # ラベルデータをロードします。 data = _load_labeldata(args.train_dir) # モデルの定義を行います。 model = _create_model(data['features'][0].shape, args.hidden, data['class_count']) # 学習用のデータを準備します。 train_features = data['features'] train_labels = data['labels'] # 学習を実行します。 # verboseを2に指定するのはポイントです。デフォルトは1ですが、そのままではプログレッシブバーの出力毎にログが記録されるため冗長です。 # 2にすることで、epochごとの結果だけ出力されるようになります。 if args.validation_split > 0: monitor_target = 'val_acc' else: monitor_target = 'acc' checkpoint_filename = f'model_{args.model_version}.h5' history = model.fit(train_features, train_labels, batch_size=args.batch_size, validation_split=args.validation_split, epochs=args.epochs, verbose=2, callbacks=[ EarlyStopping( patience=3, monitor=monitor_target, mode='max'), ModelCheckpoint(filepath=checkpoint_filename, save_best_only=True, monitor=monitor_target, mode='max') ]) # Checkpointからロードし直すため、一度モデルを削除します。 del model # 学習したモデルを保存します。 _save_model(checkpoint_filename, history, args.model_dir, args.output_dir) # 推論時に利用するラベルデータの情報を保存します。 _save_labels(data, args.output_dir)トレーニングの実行
Estimatorを利用してトレーニングを実行します。
なお、ハイパーパラメータのチューニングについてはSageMakerでTensorFlow+Kerasによる独自モデルをトレーニングする方法を参照してください。
PROJECT_NAME = 'sagemaker-with-keras-traing2deploy' TAGS = [{ 'Key': 'example.ProjectName', 'Value': PROJECT_NAME }] VERSION = 'v1' BUCKET_NAME = f'sagemaker-us-east-1.example.com' DATA_ROOT = f's3://{BUCKET_NAME}/{PROJECT_NAME}' TRAINS_DIR = f'{DATA_ROOT}/data/trains' TESTS_DIR = f'{DATA_ROOT}/data/tests' OUTPUTS_DIR = f'{DATA_ROOT}/outputs' ROLE = 'arn:aws:iam::012345678901:role/service-role/AmazonSageMaker-ExecutionRole-20181129T043923'from sagemaker.tensorflow import TensorFlow import logging params = { 'batch-size': 256, 'epochs': 10, 'hidden': 32, 'validation-split': 0.1, 'model_version': VERSION } metric_definitions = [ {'Name': 'train:acc', 'Regex': 'acc: (\S+)'}, {'Name': 'train:mse', 'Regex': 'mean_squared_error: (\S+)'}, {'Name': 'train:mae', 'Regex': 'mean_absolute_error: (\S+)'}, {'Name': 'train:top-k', 'Regex': 'top_k_categorical_accuracy: (\S+)'}, {'Name': 'valid:acc', 'Regex': 'val_acc: (\S+)'}, {'Name': 'valid:mse', 'Regex': 'val_mean_squared_error: (\S+)'}, {'Name': 'valid:mae', 'Regex': 'val_mean_absolute_error: (\S+)'}, {'Name': 'valid:top-k', 'Regex': 'val_top_k_categorical_accuracy: (\S+)'}, ] estimator = TensorFlow( role=ROLE, source_dir='train', entry_point=f'train_{VERSION}.py', train_instance_count=1, train_instance_type='ml.p2.xlarge', framework_version='1.12.0', py_version='py3', script_mode=True, hyperparameters=params, output_path=OUTPUTS_DIR, container_log_level=logging.INFO, metric_definitions=metric_definitions, tags=TAGS ) inputs = {'train': TRAINS_DIR, 'test': TESTS_DIR}import shortuuid uuid = shortuuid.ShortUUID().random(length=8) estimator.fit(job_name=f'{PROJECT_NAME}-{VERSION}-s-{uuid}', inputs=inputs)学習したモデルのダウンロード
SageMaker TensorFlow Serving Containerでは、推論用スクリプトと学習したモデルを一緒に含めてmodel.tar.gzとして再パッケージする必要があります。
このため、まずは学習済みモデルをダウンロードします。また、推論時に人が読んで理解できるラベルとして推論結果を出力するために、学習時に保存しておいた
labels.pickleを含むoutput.tar.gzもダウンロードします。import boto3 import urllib s3 = boto3.resource('s3') bucket = s3.Bucket(BUCKET_NAME) model_url = urllib.parse.urlparse(estimator.model_data) output_url = urllib.parse.urlparse(f'{estimator.output_path}/{estimator.latest_training_job.job_name}/output/output.tar.gz') bucket.download_file(model_url.path[1:], 'predict/model.tar.gz') bucket.download_file(output_url.path[1:], 'predict/output.tar.gz')!cd predict; tar zxvf model.tar.gz !cd predict; tar zxvf output.tar.gz1/ 1/variables/ 1/variables/variables.data-00000-of-00001 1/variables/variables.index 1/saved_model.pb history.csv labels.pickleダウンロードしたモデルの動作確認
ダウンロードしたモデルをTensorflowで直接推論して動作を確認します。
この手順は実施しなくても問題ありません。import tensorflow as tf from tensorflow.python.saved_model import tag_constants # TensorFlowによるモデルのロード session = tf.keras.backend.get_session() tf_model = tf.saved_model.loader.load(session, [tag_constants.SERVING], 'predict/1'); # input/outputのシグネチャ名確認 model_signature = tf_model.signature_def['serving_default'] input_signature = model_signature.inputs output_signature = model_signature.outputs for k in input_signature.keys(): print(k) for k in output_signature.keys(): print(k)# input/output Tensorの取得 input_tensor_name = input_signature['inputs'].name label_tensor_name = output_signature['dense_1_1/Softmax:0'].name input_name = session.graph.get_tensor_by_name(input_tensor_name) label_name = session.graph.get_tensor_by_name(label_tensor_name)# 推論の実行 import numpy as np from text_vectorian import SentencePieceVectorian vectorian = SentencePieceVectorian() max_len = 64 features = np.zeros((1, max_len)) inputs = vectorian.fit('これはグルメです。').indices for i, index in enumerate(inputs): pos = max_len - len(inputs) + i features[0, pos] = index label_pred = session.run([label_name], feed_dict={input_name: features}) label_pred推論用スクリプトを含めてパッケージング
推論用スクリプトと学習したモデルを一緒に
model.tar.gzとしてパッケージングします。
また、推論結果を人が読んで理解できるラベルにマッピングするためdictであるlabels.pickleもcodeディレクトリに含めるようにすることで、推論用スクリプトから参照できるようにします。!cat predict/code/inference.pyimport os import io import json import requests import logging import numpy as np import pickle import pandas as pd from text_vectorian import SentencePieceVectorian logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) vectorian = SentencePieceVectorian() input_len = 64 dim = 100 def handler(data, context): """Handle request. Args: data (obj): the request data context (Context): an object containing request and configuration details Returns: (bytes, string): data to return to client, (optional) response content type """ processed_input = _process_input(data, context) response = requests.post(context.rest_uri, data=processed_input) return _process_output(response, context) def _process_input(data, context): if context.request_content_type == 'application/json': body = data.read().decode('utf-8') param = json.loads(body) query = param['q'] features = np.zeros((1, input_len)) inputs = vectorian.fit(query).indices for i, index in enumerate(inputs): if i >= input_len: break pos = input_len - len(inputs) + i features[0, pos] = index return json.dumps({ 'inputs': features.tolist() }) raise ValueError('{"error": "unsupported content type {}"}'.format( context.request_content_type or "unknown")) def _process_output(data, context): if data.status_code != 200: raise ValueError(data.content.decode('utf-8')) response_content_type = 'application/json' body = json.loads(data.content.decode('utf-8')) predicts = body['outputs'][0] labels_path = '/opt/ml/model/code/labels.pickle' with open(labels_path, mode='rb') as f: labels = pickle.load(f) rets = _create_response(predicts, labels) logger.warn(rets) return json.dumps(rets), response_content_type def _create_response(predicts, labels): rets = [] for index in np.argsort(predicts)[::-1]: label = labels['index2label'][index] prob = predicts[index] rets.append({ 'label': label, 'prob': prob }) return rets!cd predict; mv labels.pickle code !cd predict; tar zcvf model.tar.gz 1 code1/ 1/variables/ 1/variables/variables.index 1/variables/variables.data-00000-of-00001 1/saved_model.pb code/ code/inference.py code/.ipynb_checkpoints/ code/.ipynb_checkpoints/requirements-checkpoint.txt code/.ipynb_checkpoints/inference-checkpoint.py code/labels.pickle code/requirements.txtimport urllib predict_model_url = urllib.parse.urlparse(f'{estimator.output_path}/{estimator.latest_training_job.job_name}/predict/model.tar.gz') bucket.upload_file('predict/model.tar.gz', predict_model_url.path[1:])エンドポイントの作成
sagemaker.tensorflow.serving.Modelを利用してdeployを行います。
この際、以下の注意事項があります。frame_versionのバージョンによってはPythonの
f-stringが使えない
framework_versionに1.13を指定します。1.12だとPythonのバージョンが3.5でありf-stringが使えないため要注意です。インスタンスタイプの指定
ml.t2.mideumではメモリ不足で起動しなかったため、ml.t2.largeにしています。
なお、2019/07時点ではデプロイ時にt3系インスタンスを指定することができません。from sagemaker.tensorflow.serving import Model tensorflow_serving_model = Model(model_data=f'{predict_model_url.scheme}://{predict_model_url.hostname}{predict_model_url.path}', role=ROLE, framework_version='1.13')predictor = tensorflow_serving_model.deploy(initial_instance_count=1, instance_type='ml.t2.large', tags=TAGS)エンドポイントによる推論結果確認
boto3を使用してエンドポイントに文字列を入力することで、意図した推論結果が得られることを確認します。
import json client = boto3.client('sagemaker-runtime') query = { 'q': '電波が悪い' } res = client.invoke_endpoint( EndpointName=predictor.endpoint, Body=json.dumps(query), ContentType='application/json', Accept='application/json' ) body = res['Body'] ret = json.load(body) print(ret)[{'label': '携帯電話', 'prob': 0.96622}, {'label': '京都', 'prob': 0.0231401}, {'label': 'グルメ', 'prob': 0.00758497}, {'label': 'スポーツ', 'prob': 0.00305547}]エンドポイントの削除
最後に不要になったエンドポイントを削除します。
エンドポイントの利用を継続する場合は、実施不要です。predictor.delete_endpoint()参考文献
- 投稿日:2019-07-14T22:05:37+09:00
AWSでゼロからサーバを立ち上げるまで
Amazon EC2 の初期導入を代行した。
2019年7月時点のAWS画面を用いて、クラウド初級者向けに実例を示して手順を説明する。AWSアカウントの作成
何はともあれアカウントを作成しなければ始まらない。公式チュートリアルの AWSアカウント作成の流れ に沿って進めよう。
アカウント作成後は、下表チェックリストに従って速やかにセキュリティ対策を行うこと。
確認事項 チェック ルートアカウント(特権ユーザ)のMFA(多要素認証、2段階認証)を有効にしたか? 日常の操作にルートアカウントを使うことがないように、管理用のIAMユーザを作成したか? アクセス許可の管理を容易にするため、IAMグループを作成したか? 強力なIAMパスワードポリシーを設定したか? 未使用のアクセスキーは削除されているか? 具体的な手順は@tmknomさんの記事、AWSアカウントを取得したら速攻でやっておくべき初期設定まとめに書かれているので参照して欲しい。
AWSマネジメントコンソールにログイン
ルートアカウントからログアウトし、先ほど作成した管理用のIAMユーザでコンソールにログインしなおす。
経理部門用IAMユーザの作成
経理部門が請求情報を確認するためのアカウントを作成しよう。
AWSに直接携わっていない経理担当者にこのアカウントを持たせることで、サービスを誤って停止してしまうといった事故を防止できる。ポリシーの作成
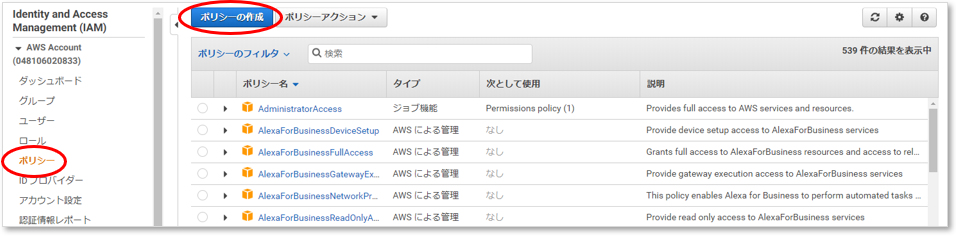
IAMのメニュー [ポリシー]
[ポリシーの作成] をクリックする。
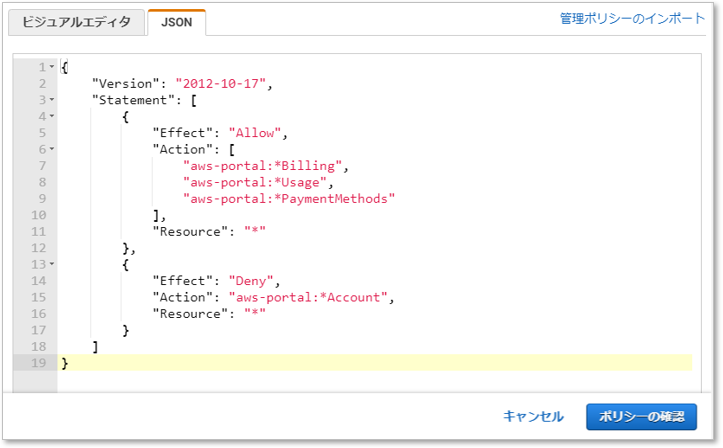
AWSユーザーガイド【例8:アカウント設定へのアクセスは拒否し、その他の請求および使用状況の情報へのフルアクセスは許可する】のJSONテキストをコピペする。
JSON{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "aws-portal:*Billing", "aws-portal:*Usage", "aws-portal:*PaymentMethods" ], "Resource": "*" }, { "Effect": "Deny", "Action": "aws-portal:*Account", "Resource": "*" } ] }グループの作成
IAMのメニュー [グループ]
ユーザーの作成
IAMのメニュー [ユーザー]
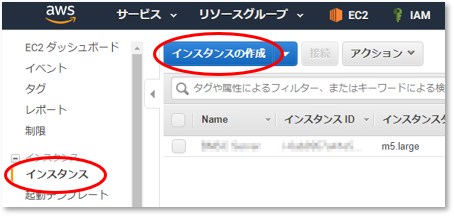
インスタンスの作成
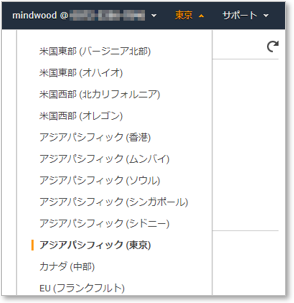
メニュー [EC2] を選択する。作成前に今のリージョンを確認しておこう。(今回は東京を選択する)
EC2のメニュー [インスタンス]
Amazonマシンイメージ(AMI)の選択
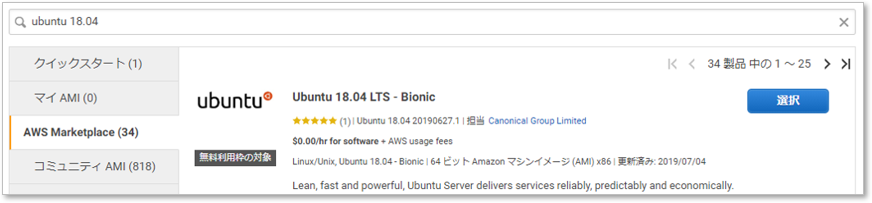
AMIには、AWSが提供するもの、ユーザーコミュニティが提供するもの、ソフトウェアベンダーが提供するもの(Marketplace)がある。
今回は、MarketplaceからUbuntu 18.04を選択する。
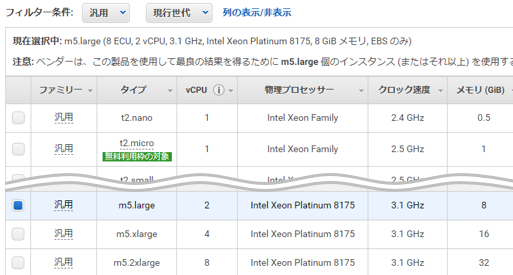
インスタンスタイプの選択
ここでは
m5.largeを選択(1時間当たり約13円)。今あえて前世代のm4.largeを選択する理由も無いだろう。
Amazon EC2 インスタンスタイプ
インスタンスの詳細の設定
インスタンスを誤って削除しないように、削除保護の有効化をチェックしておくと安全だ。
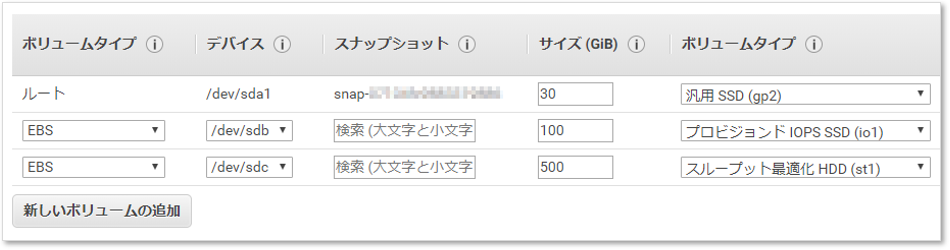
ストレージの追加
今回は、IoT機器からセンサーのデータを受け取るWeb/DBサーバを構築するので、パーティションを下表のように分割した。
デバイス 容量 マウント先 備考 /dev/sda1 30GB / /dev/sdb 100GB /data MongoDB(スキーマレスのNoSQL型データベース)で使うため、IOPS重視とする。 /dev/sdc 500GB /archive ログやビッグデータなど大量データを保存するのに使うため、スループット重視とする。 [新しいボリュームの追加] をクリックし、次のように入力。
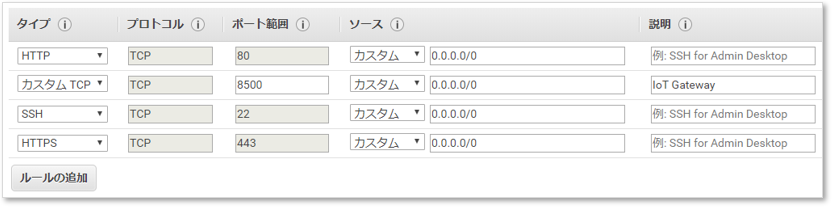
セキュリティグループの設定
要はファイアウォールのことだ。特に解説は不要だろう。
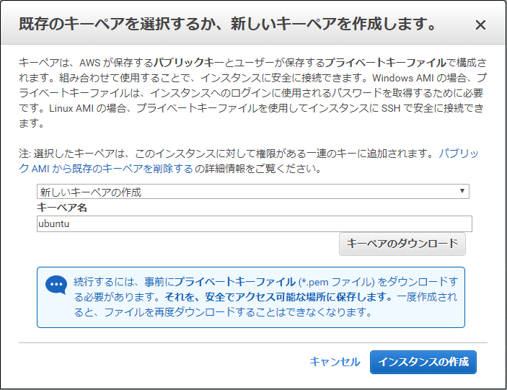
新しいキーペアの作成
インスタンス作成の最終工程である。
[キーペアのダウンロード]、[インスタンスの作成] の順にクリックすれば完了する。
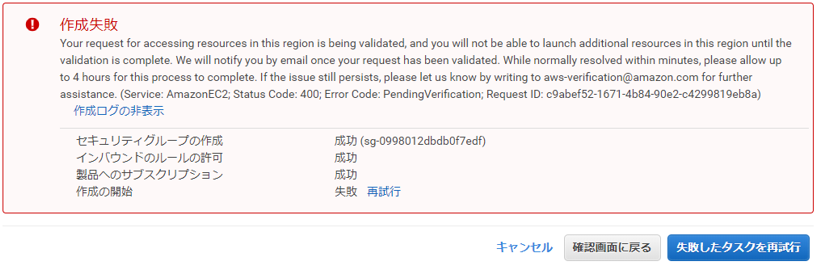
もし、下のようなメッセージが出ても、暫くして再試行すれば問題ないので慌てずに。
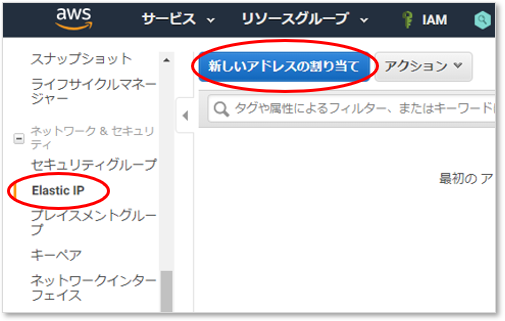
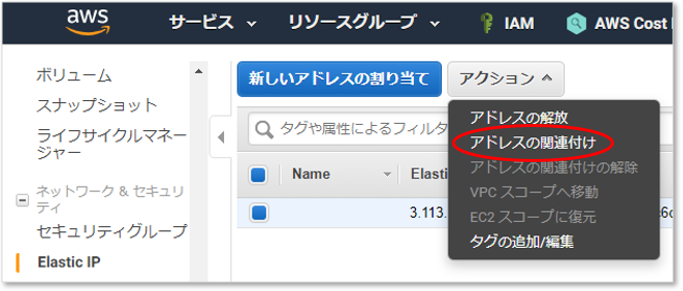
IPアドレスを割り当てる
インスタンス作成時に自動付与されたパブリックIPアドレス(グローバルIPアドレス)は変化する場合があるので、固定化する。
EC2のメニュー [Elastic IP]
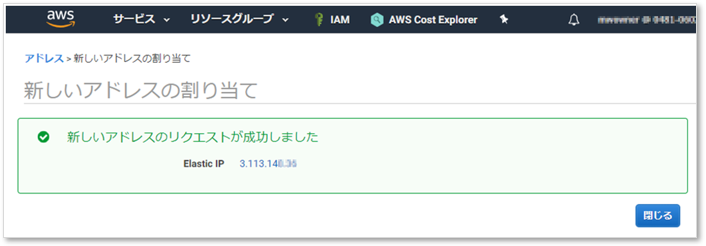
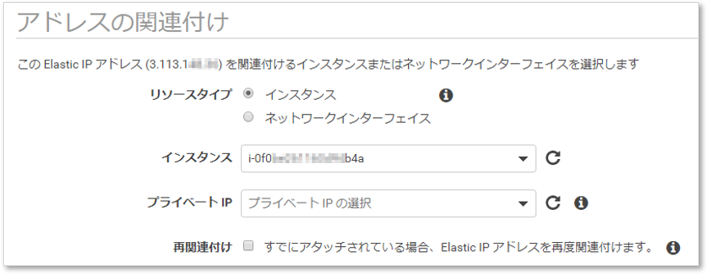
IPアドレスをインスタンスに関連付ける
割り当てされたIPアドレスを選択し、アクションメニューからインスタンスに関連付けよう。
リソースタイプにインスタンス、インスタンスにはインスタンスIDを指定する。
以上でコンソール側の操作は終わりだ。
Linuxの初期設定
インスタンス作成時にダウンロードしたキーペア(秘密鍵)を使い、サーバにログインする。
Ubuntuの場合、初期ユーザー名はec2-userではなくubuntuになる。パッケージ更新
sudo su - apt -y update apt -y upgradeパーティション作成
lsblkコマンドで、SSDやHDDなどのブロックデバイスを一覧で表示できる。
フォーマットしたいデバイス名を確認しよう。$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT loop0 7:0 0 88.4M 1 loop /snap/core/7169 loop1 7:1 0 18M 1 loop /snap/amazon-ssm-agent/1335 nvme0n1 259:0 0 100G 0 disk nvme2n1 259:1 0 500G 0 disk nvme1n1 259:2 0 30G 0 disk └─nvme1n1p1 259:3 0 30G 0 part /なお、Nitro世代(ニトロではなくナイトロと読むらしい)のインスタンスでは、NVMeデバイス名に名前が変わる。
例えば/dev/sda1が/dev/nvme1n1p1という具合だ。mkfs -t ext4 /dev/nvme0n1 mkdir /data mount /dev/nvme0n1 /dataマウントに成功したら
fstabに登録しよう。
デバイス名は変わる可能性があるので、起動時のマウントはUUIDにすべきだ。
UUIDはmkfsしたときに表示される他、blkidコマンドでも確認できる。/etc/fstabUUID=xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx /data ext4 defaults,nofail 0 2日本語化
これはお好みで。
apt -y install language-pack-ja-base language-pack-ja ibus-mozc localectl set-locale LANG=ja_JP.UTF-8 LANGUAGE="ja_JP:ja" source /etc/default/locale apt -y install manpages-ja manpages-ja-dev timedatectl set-timezone Asia/Tokyo開発者用アカウント作成
sudo権限付のアカウントとキーペアを作成する。
adduser user gpasswd -a user sudo su - user ssh-keygen -t rsa mv ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys chmod 600 ~/.ssh/authorized_keysキーペアのうち、秘密鍵となる
~/.ssh/id_rsaを安全なルートで開発者に渡そう。
なお、パスワード無しで sudo させたい場合は、--disabled-passwordを付けてadduserし、/etc/sudoers.d/90-cloud-init-usersuser ALL = NOPASSWD:ALLのように追加する。
ホスト名の変更
EC2では、ホスト名の初期値がプライベートIPアドレス(例:
ip-12-34-56-78)になっている。
これがシェルプロンプトの一部に表示されるのだが、いくつも端末を立ち上げていると今どこにいるか分かり難く、危険なので変更する。hostnamectl set-hostname newhostnameバックアップの取得
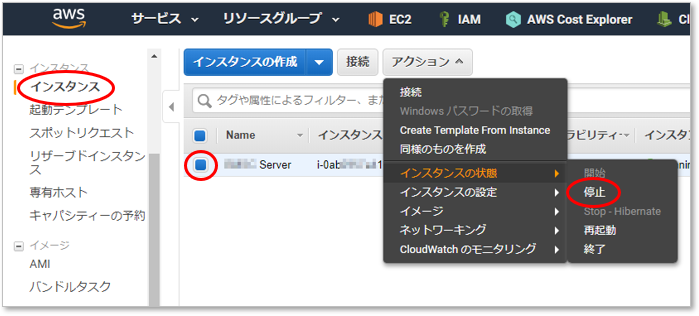
開発者にサーバを引き渡す前にバックアップ(スナップショット)を取得するため、再びコンソールにログインする。
インスタンスの停止
必須ではないが推奨されている。
アクションメニューの [インスタンスの状態] から [停止] をクリックする。
EC2では [停止] と [終了] は意味がまったく違うので気を付けよう。
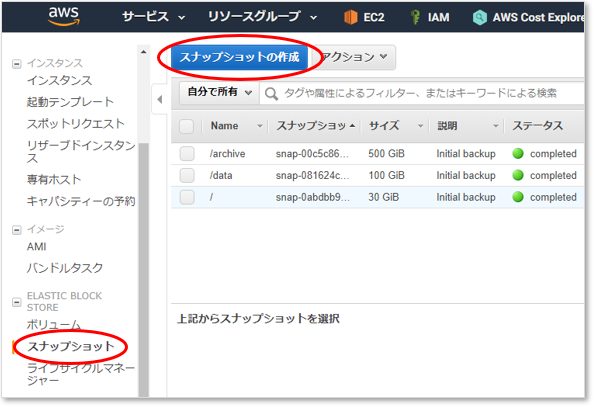
スナップショットの作成
リソースタイプにインスタンスを選択し、対象インスタンスを選ぶだけでOKだ。
これでスナップショットからいつでも復元できる。
復元のやり方は何パターンかあり、Qiitaにも記事は沢山あるので色々試してみて欲しい。DNS登録
ネームサーバを自前で管理しているので、今回は Route 53 を使わない。
ゾーンファイルにAレコードを追加する。/usr/local/etc/namedb/master/example.com.zone$TTL 3600 $ORIGIN example.com. @ IN SOA foo.example.com. ( 2019071401 ; Serial 43200 ; Refresh after 12 hours 3600 ; Retry after one hour 2419200 ; Expire after 4 weeks 1200 ) ; Negative cache TTL of 20 minutes ; ; Authoritative name servers ; IN NS ns01.example.com. ; ; Host ; bar 300 IN A 12.34.56.78サーバの引き渡し
例えば下のような設定ワークシートをたくさん書かなければならないときでも、AWS SDKを使えば労力を抑えられる。
仕様書をExcelで自動生成している例を見つけたので、最後にリンクを載せておく。
https://dev.classmethod.jp/cloud/excel_aws_spec_autogeneration/

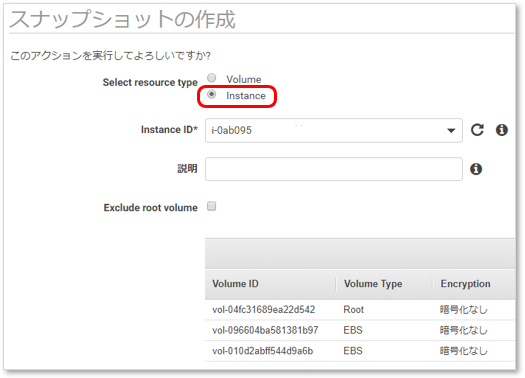
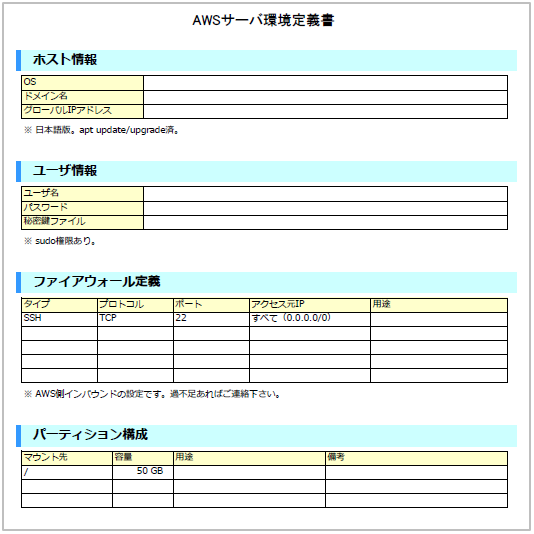
- 投稿日:2019-07-14T21:11:55+09:00
AWS サーバ構築(ファイルサーバ)その3 DFS 名前空間
前回の続きで FSx レプリケーション後のフェールオーバーについてです。
DFS でフェールオーバー
レプリケートした FSx をフェールオーバーさせるには Windows Server の DFS 名前空間を利用します。AWS のサービスでは今の所自動でフェールオーバーさせる方法がありません。
CloudWatch や Route53 でそのうち対応してくれるのを期待します。名前空間の作成と共有と公開
名前空間の作成
- 名前空間サーバー用に EC2 (Windows Server) を作成します。冗長構成にする場合、2台作成します。
- Active Directory に参加します。
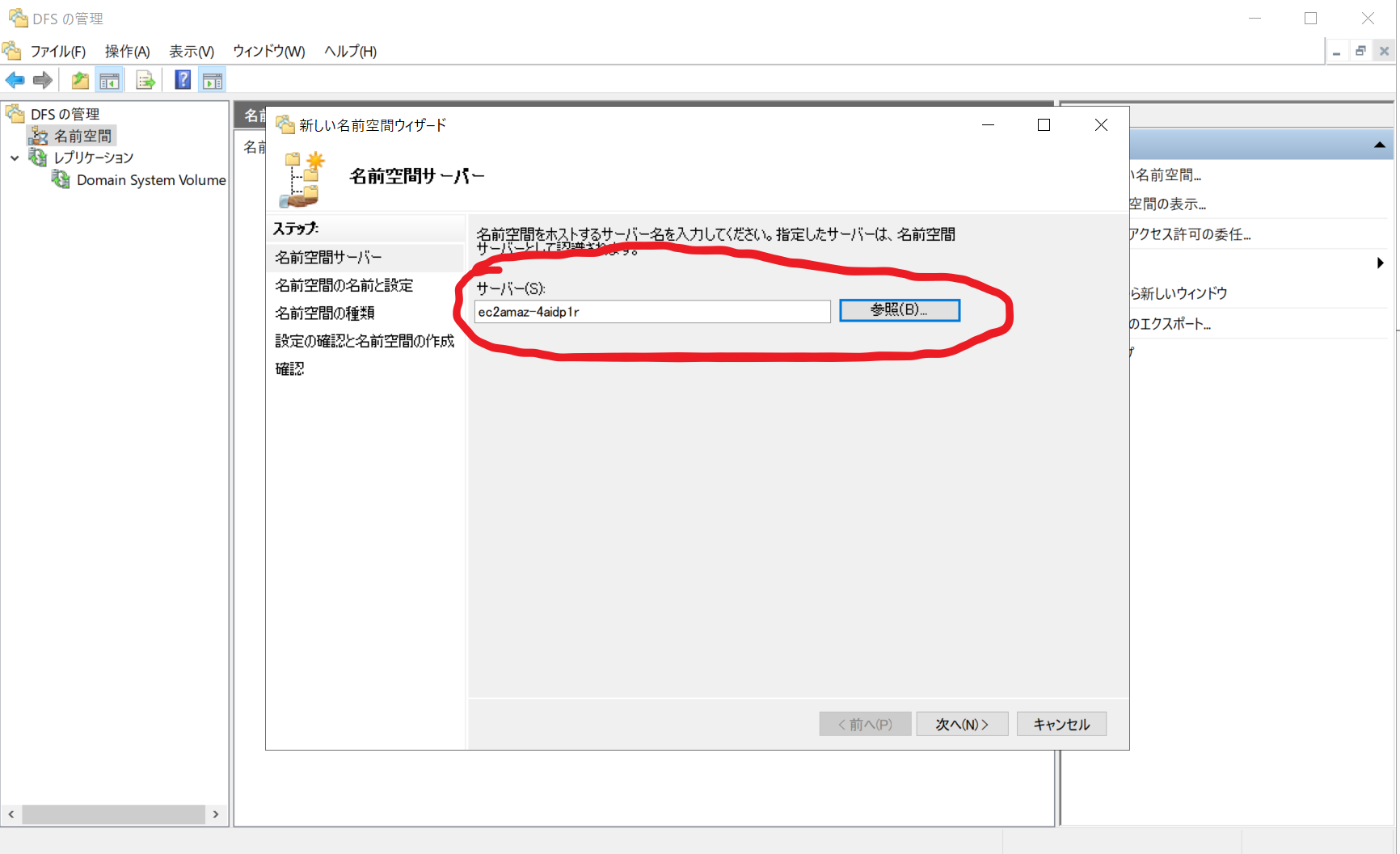
- DFS 管理ツールを起動し、名前空間を右クリック > 新しい名前空間(N)...
- サーバーを選択します。作業中のサーバーのコンピューター名をセットします。
- 名前空間名を入力します。説明文にあるように、名前空間公開後はファイルサーバーには「\domain名\入力した名前\」でアクセスします。 Public と入力したら、 \example.local\Public\ になります。
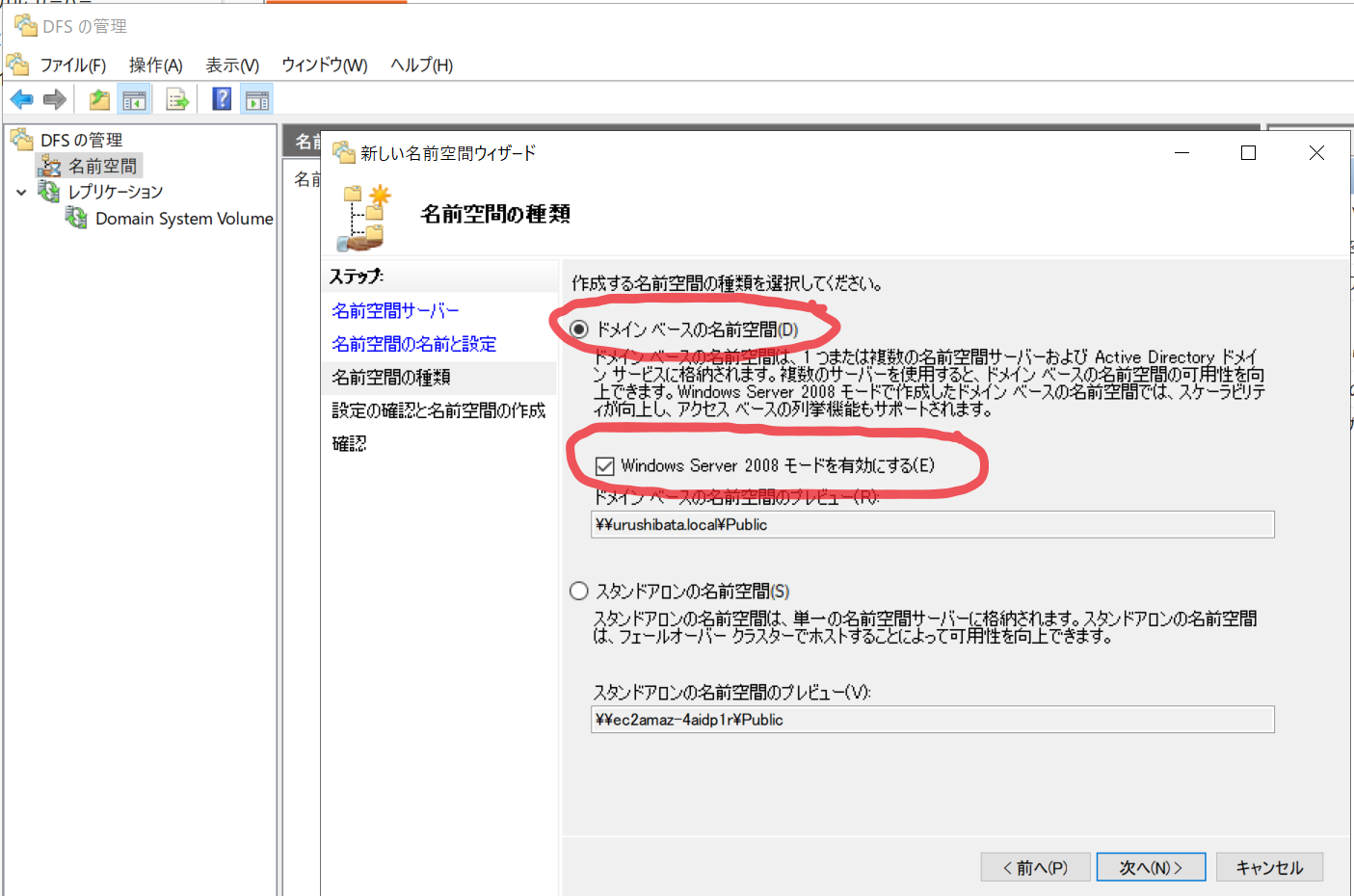
- ドメインベースの名前空間(D) を選択し、「Windows Server 2008 モードを有効にする(E)」にチェックを付けます。
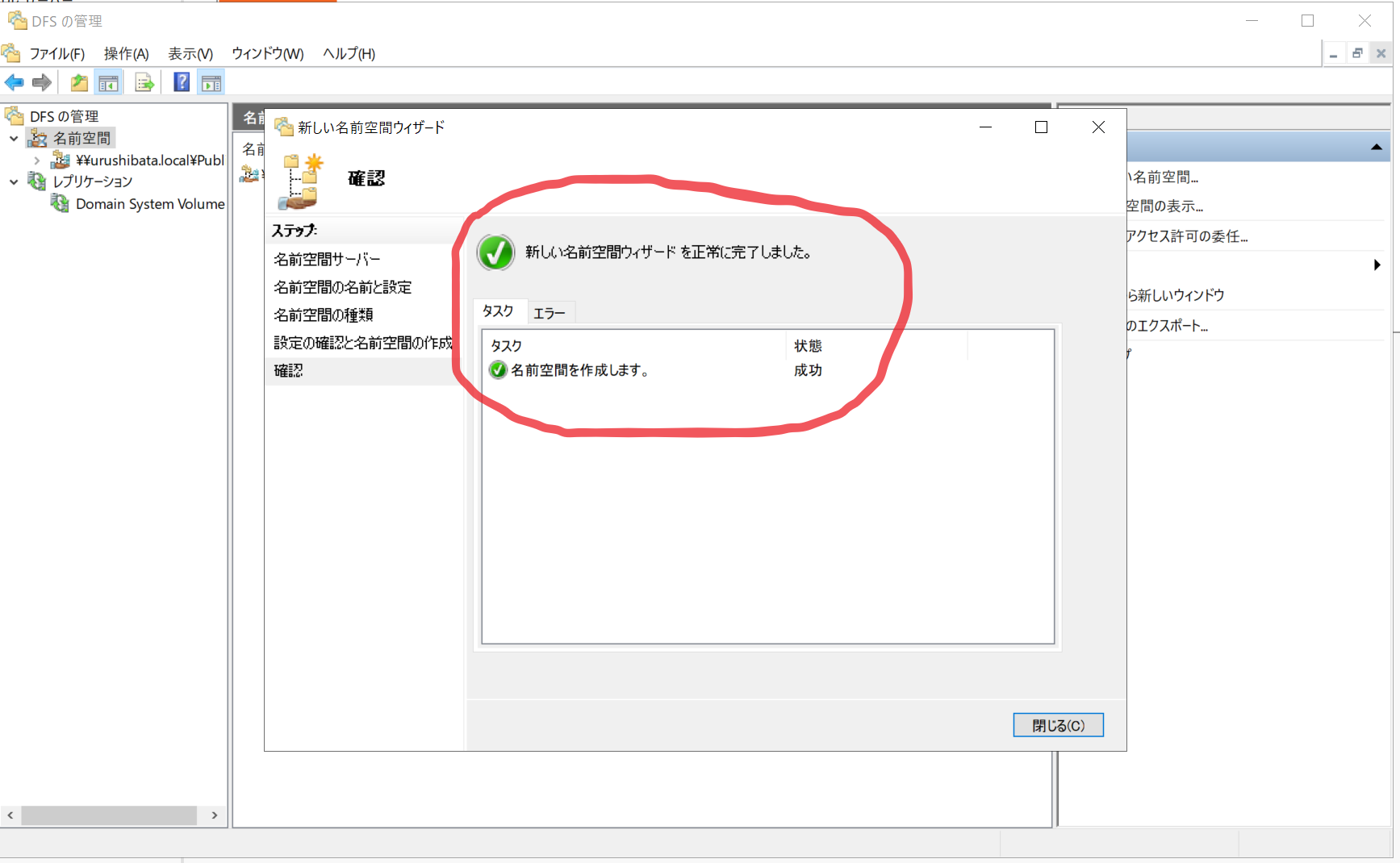
- 確認画面が出るので、作成(E) をクリックします。
- 作成完了です。
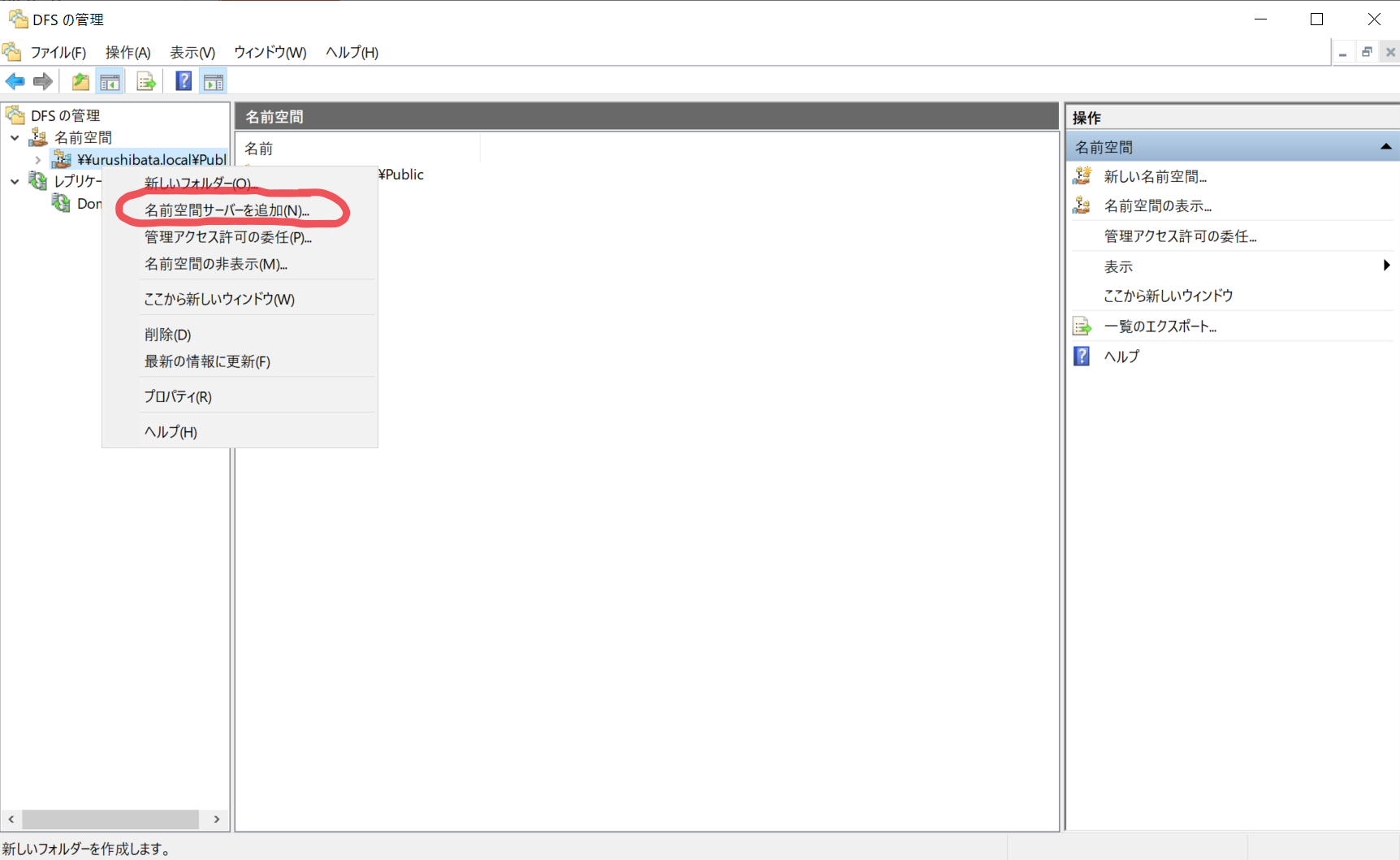
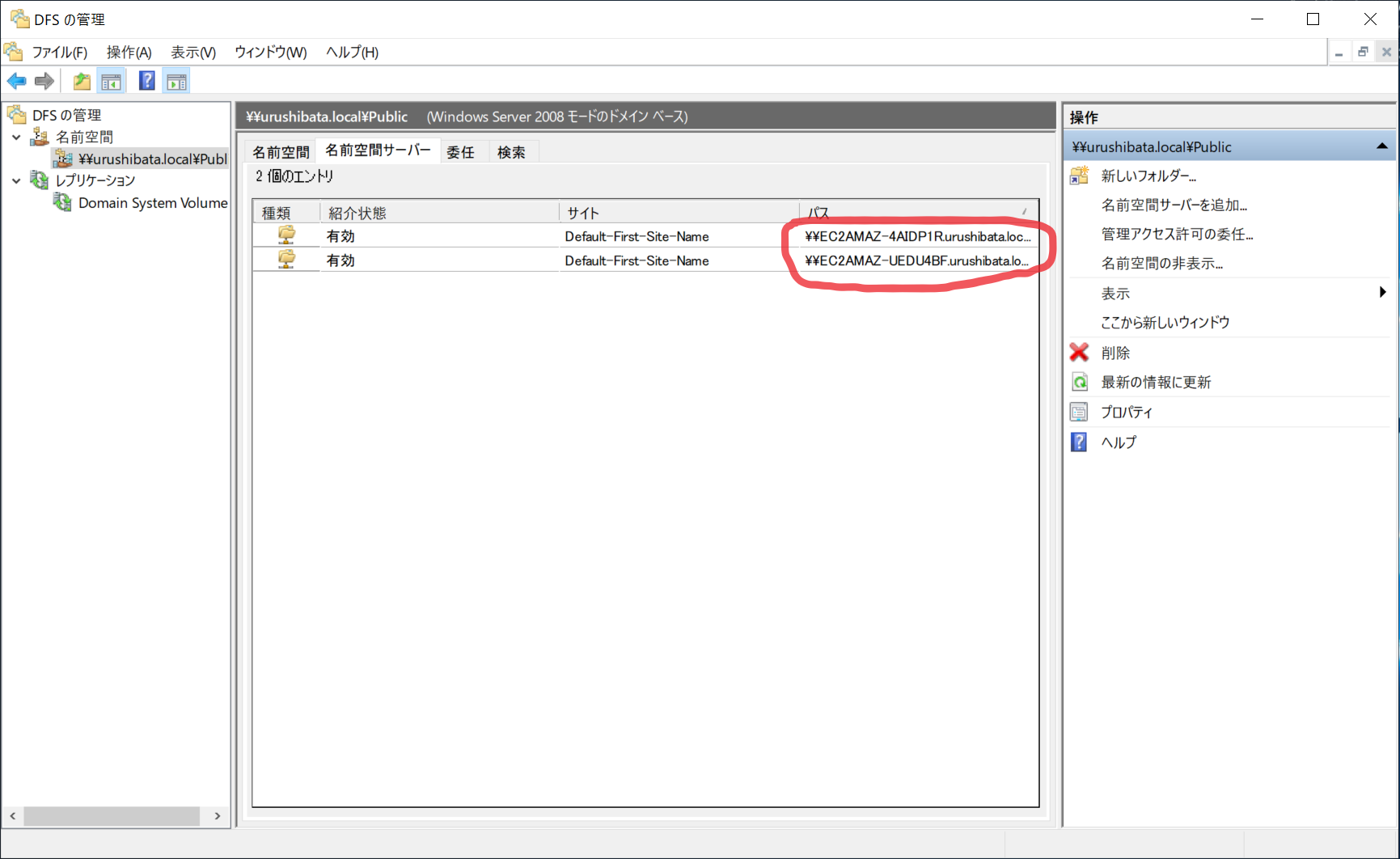
名前空間管理サーバーの冗長化
- 引き続き DFS 管理ツールで、先程作成した名前空間を右クリック > 名前空間サーバーを追加(N)...
- もう一台の Windows Server を選択します。
- OK 押すとサーバーが追加されます。
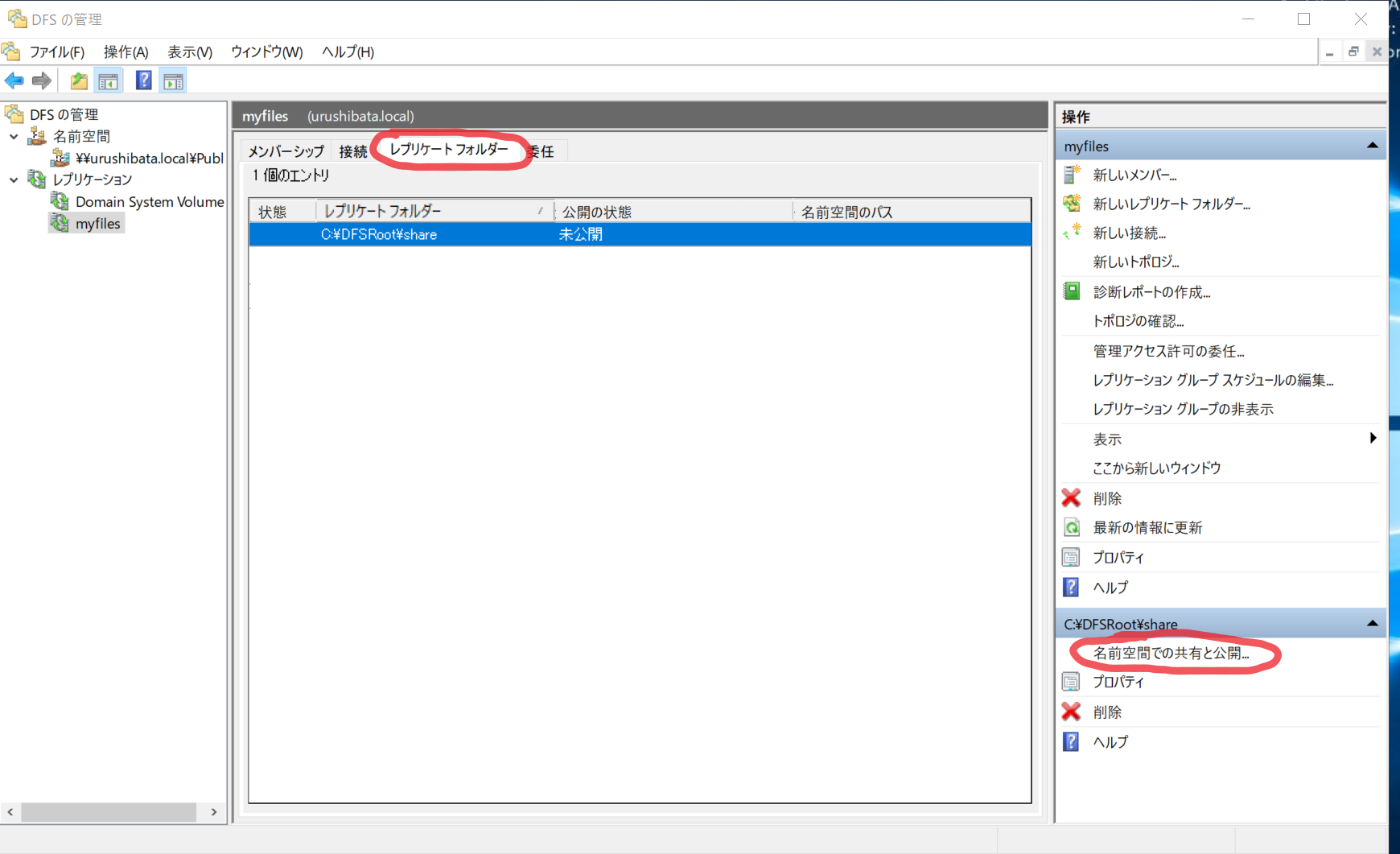
名前空間の公開
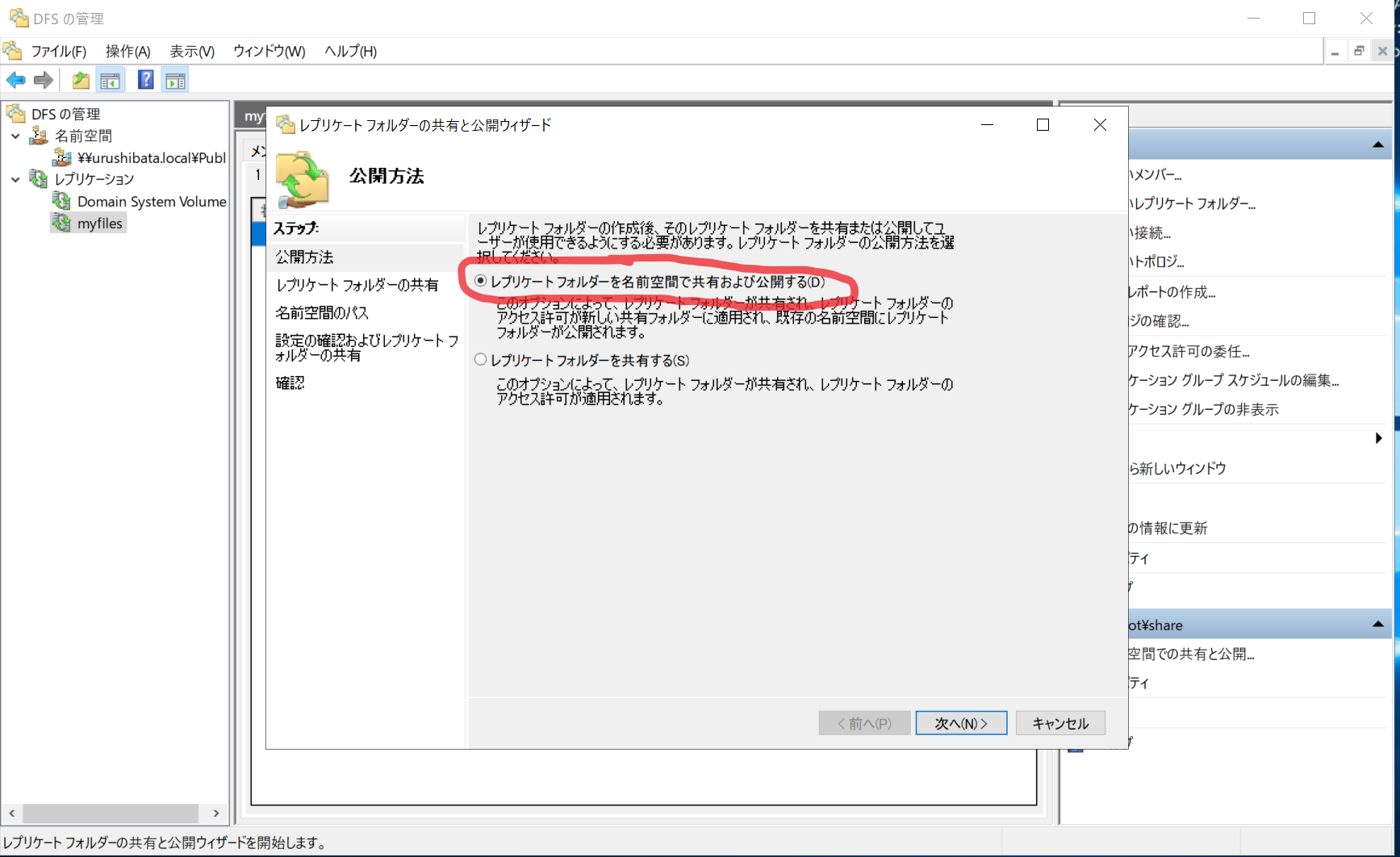
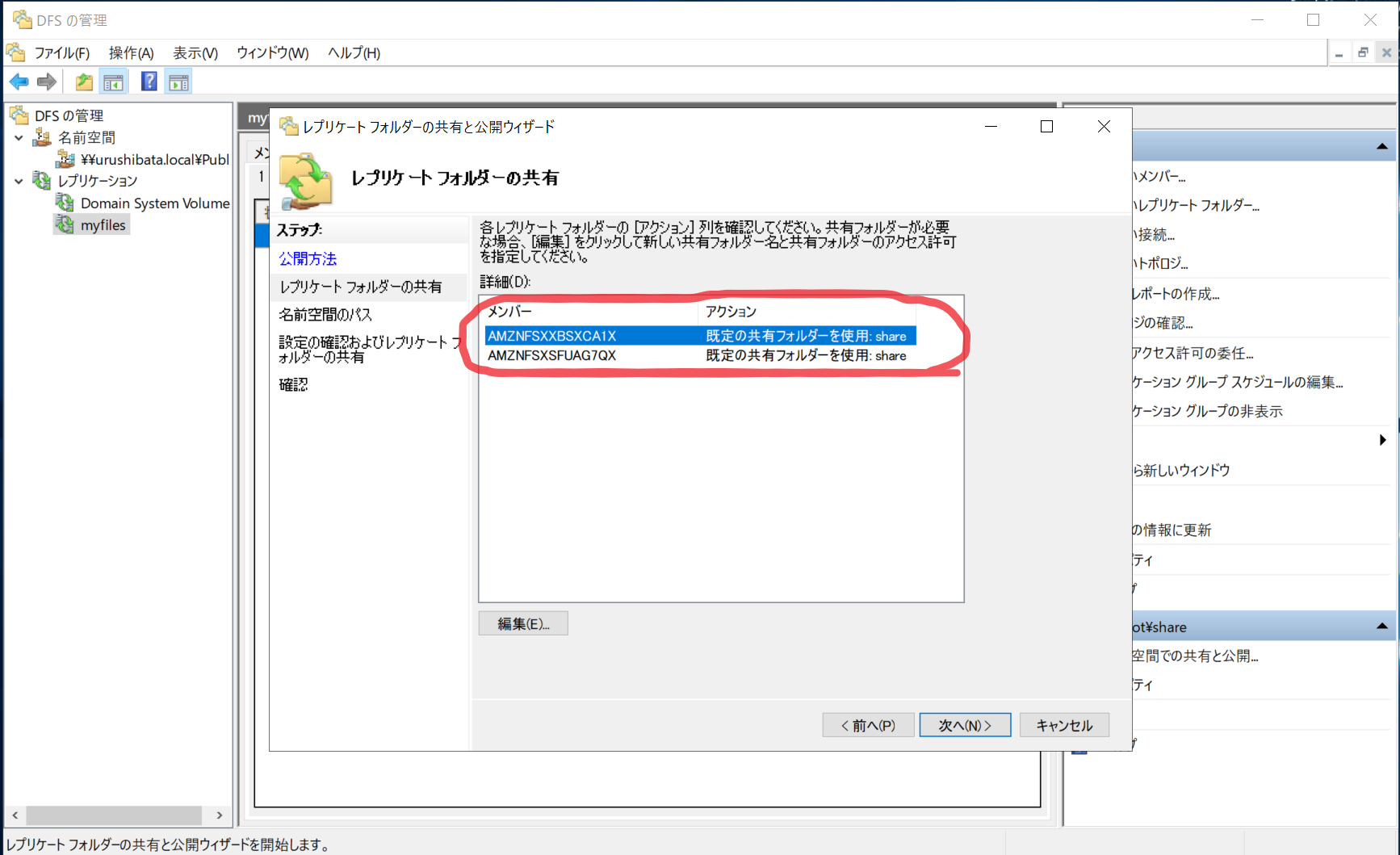
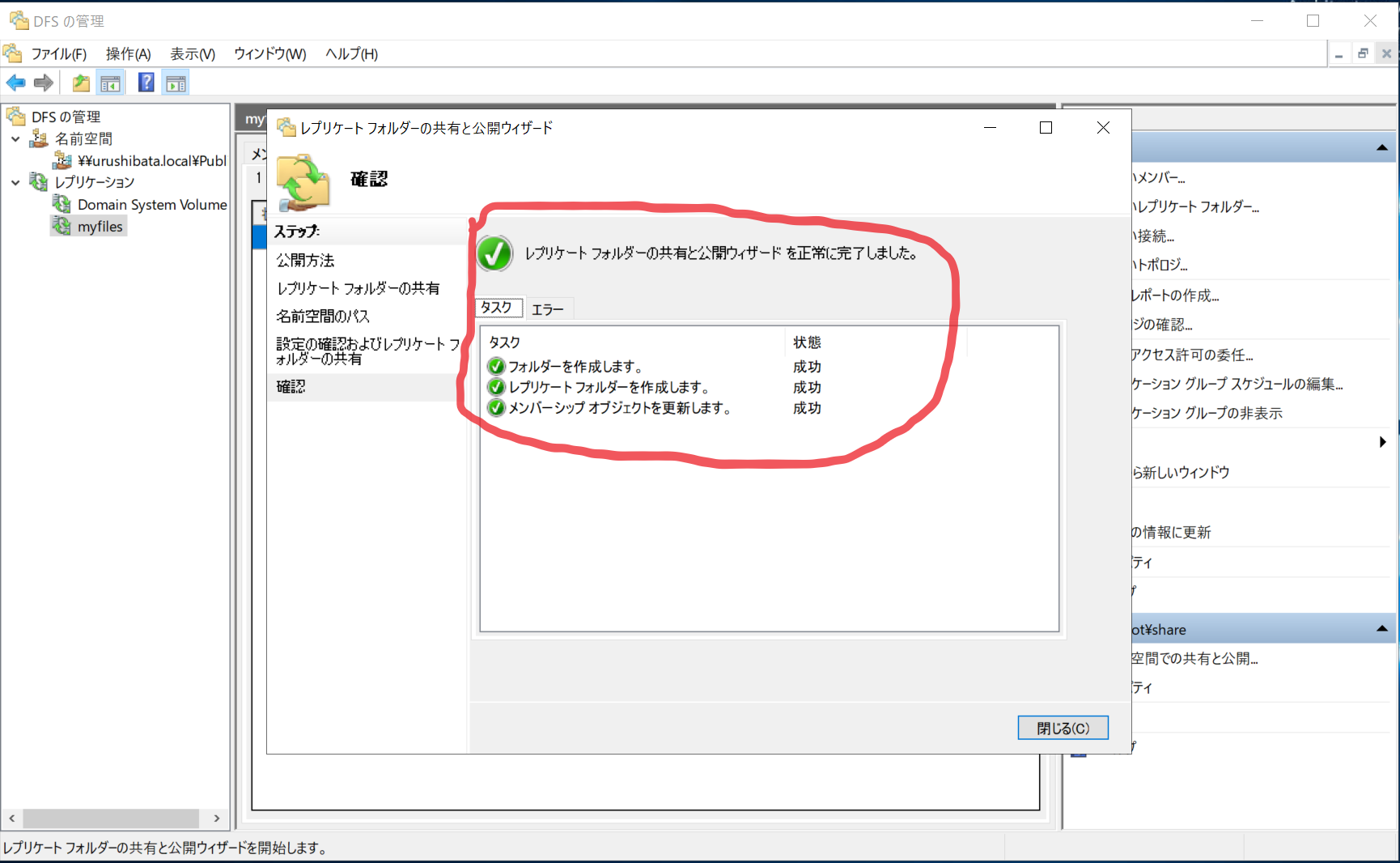
- 公開したいレプリケーションを選択 > レプリケーションフォルダータブ > 名前空間の共有と公開…
- 「レプリケーションフォルダーを名前空間で共有および公開する(D)」を選択 > 次へ(N)
- 次へ(N)
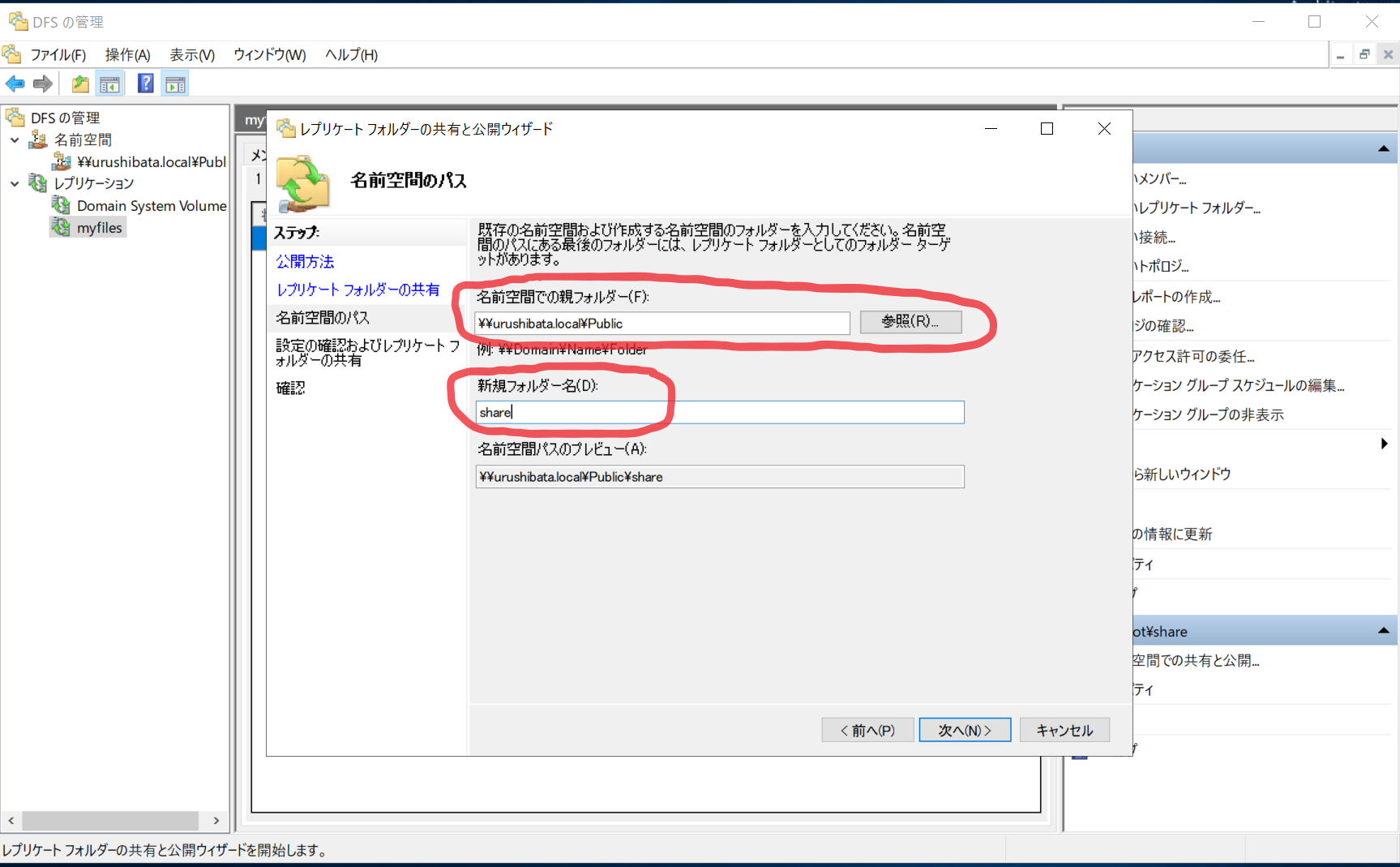
- 「参照(R)」から作成した名前空間を選択します。「新規フォルダー名(D):」には任意の名前を入力します。
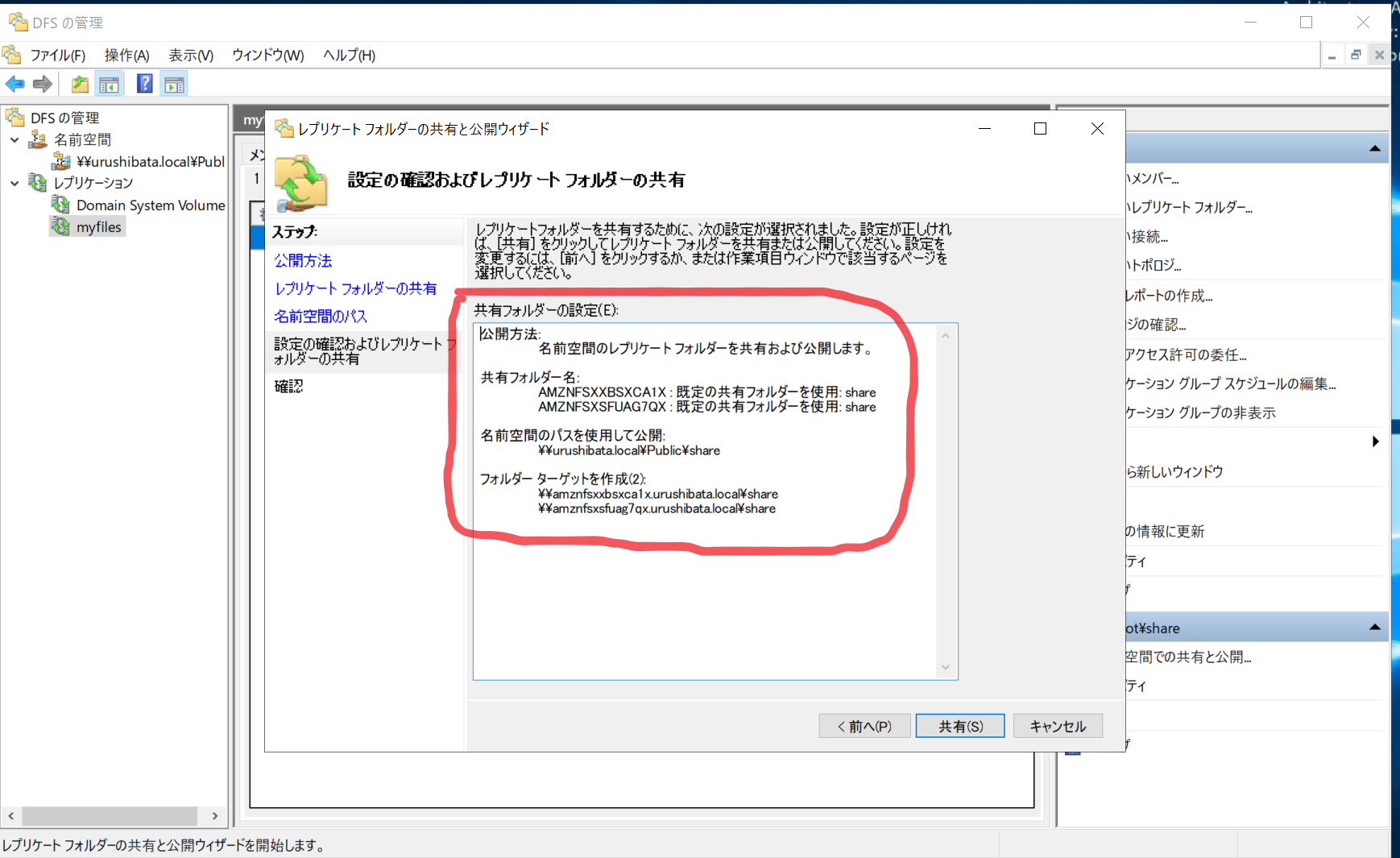
- 確認画面で「共有(S)」をクリックします。
- 作成完了
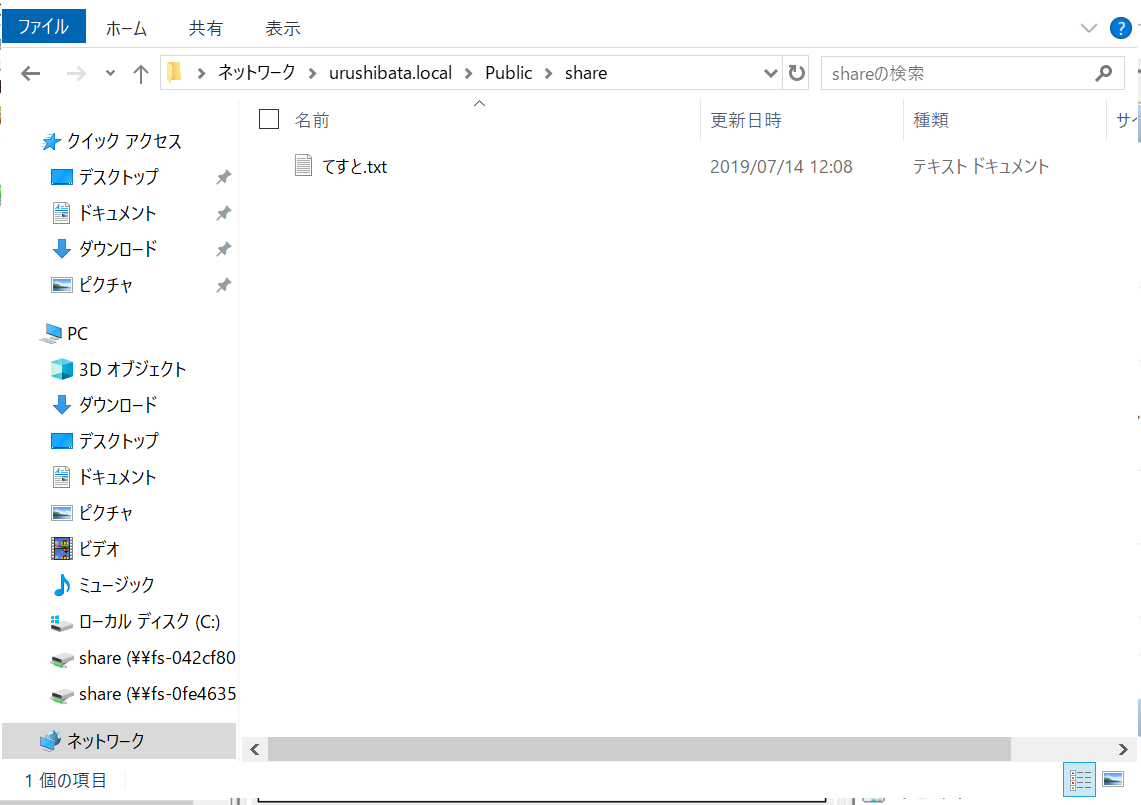
- アクセスしてみます。このパスにアクセスすると、1台がエラーになっても名前空間サーバーがフェールオーバーして、セカンダリーの FSx に向けてくれます。
トラブルシューティング
- サーバーの追加でエラーになる
- 名前解決できない
DFS でコンピューター名を名前解決する時、RPC プロトコルを使用します。セキュリティーグループ、ネットワーク ACL でポート135を許可しているか確認してください。その他開放しないといけないポートがあるので確認してください1。セキュリティーグループだけでなく、ネットワークACLでブロックしている場合もあります。- 追加サーバーに DFS 機能が追加されていない
追加するサーバーにも DFS 機能をインストールします。
インバウンドでTCP/UDP 445 (SMB)、TCP 135 (RPC)、TCP/UDP 1024-65535 (Ephemeral ports for RPC) を許可する。Getting Started with Amazon FSx: Step8 ↩




- 投稿日:2019-07-14T20:20:41+09:00
ACMでSSL証明書を別リージョンで発行する際、同一サブドメインなら別途CNAMEレコード登録は不要な件
このページについて
・同一サブドメインのSSL証明書のDNS認証は、AWSの別リージョンごとにCNAMEレコード登録する必要がないことの検証になります。
経緯
・先日、お客様の環境でファイルアップロードすると「504 Gateway Timeout Error」が発生し、原因がCloudFrontの「Origin Request Timeout」値が30秒だったためでした。
当値の上限は60秒(AWS上限緩和申請で60秒以上に上限をあげることは可能だが何秒まで上限緩和できるのかはわかりません。。)だったため、以下構成に変更しようということになりました。
(CLBの「Idle Timeout」値を600秒に設定すれば、504エラーを解決できると考えたため。)・変更前
・変更後
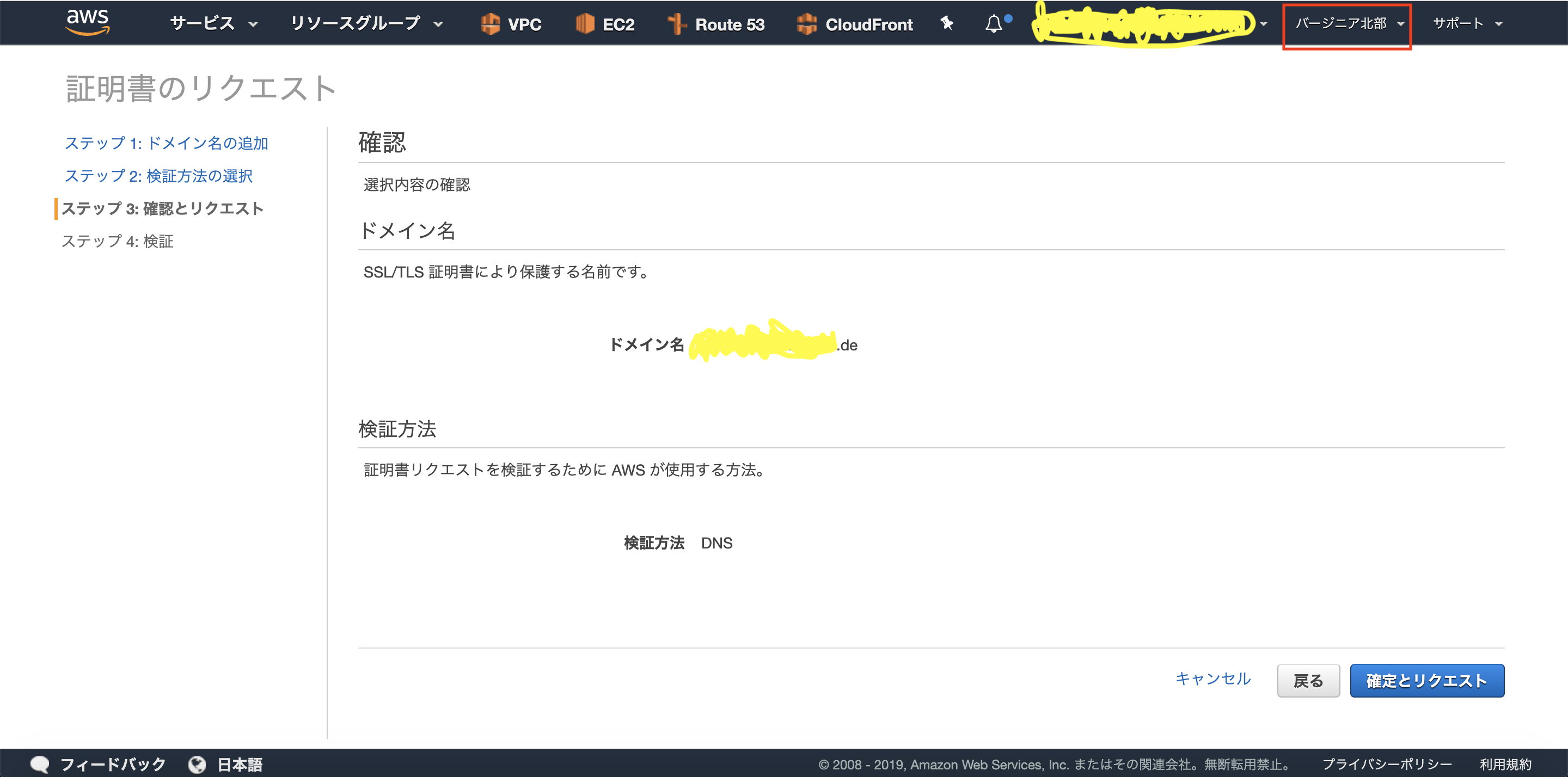
CloudFront用のSSL証明書発行は、バージニア北部リージョンで発行しており、CLBを配置するリージョンが東京リージョンだったため、東京リージョンで別途証明書発行する必要がありました。
その際、証明書の検証をDNSにて実施しようと考えていましたが、バージニア北部と同一のCNAMEレコードが発行されたため、Route53にDNS検証用CNAMEレコードの登録は実施する必要がないことを初めて知り、記事にすることにしました。検証
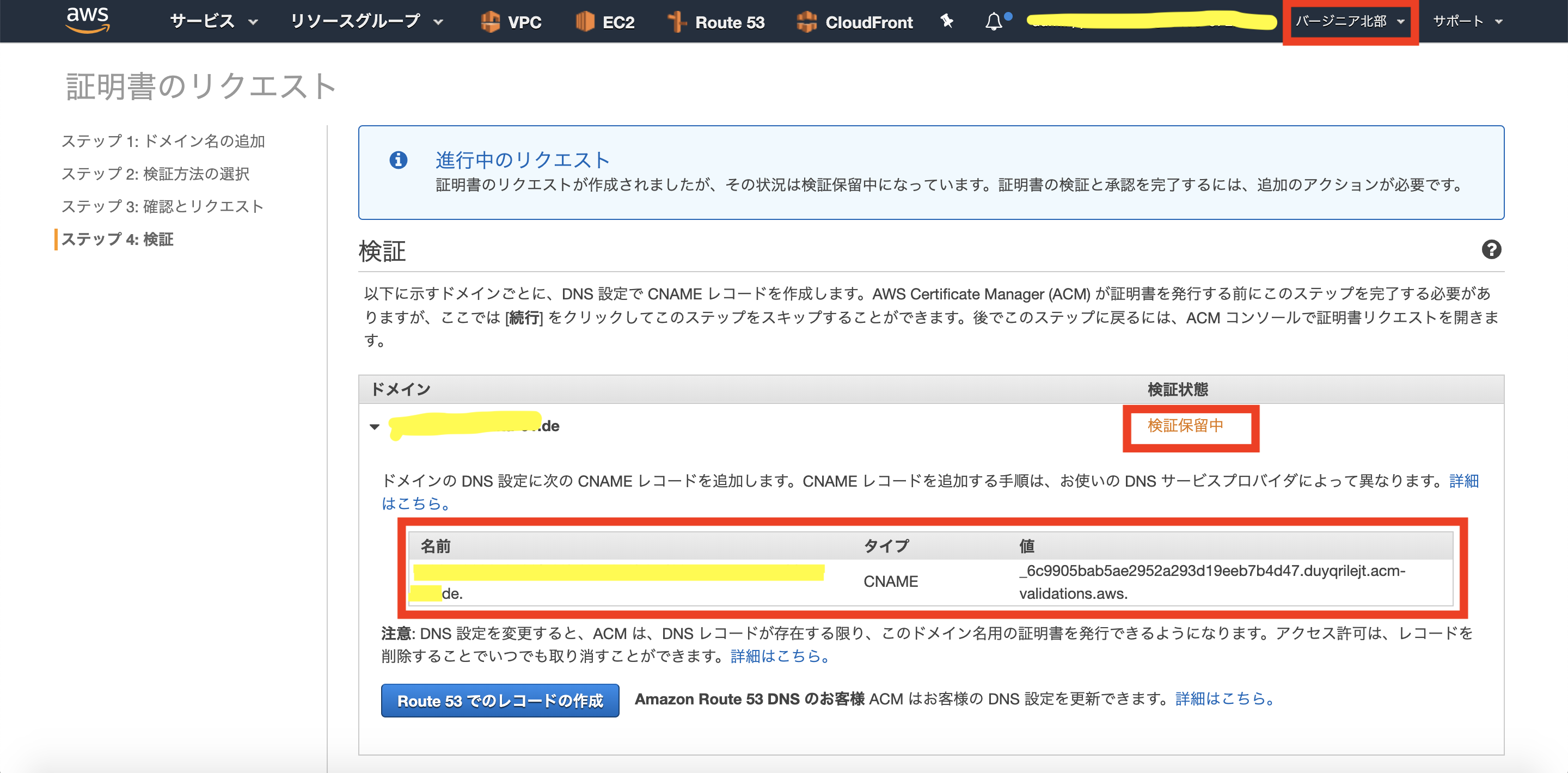
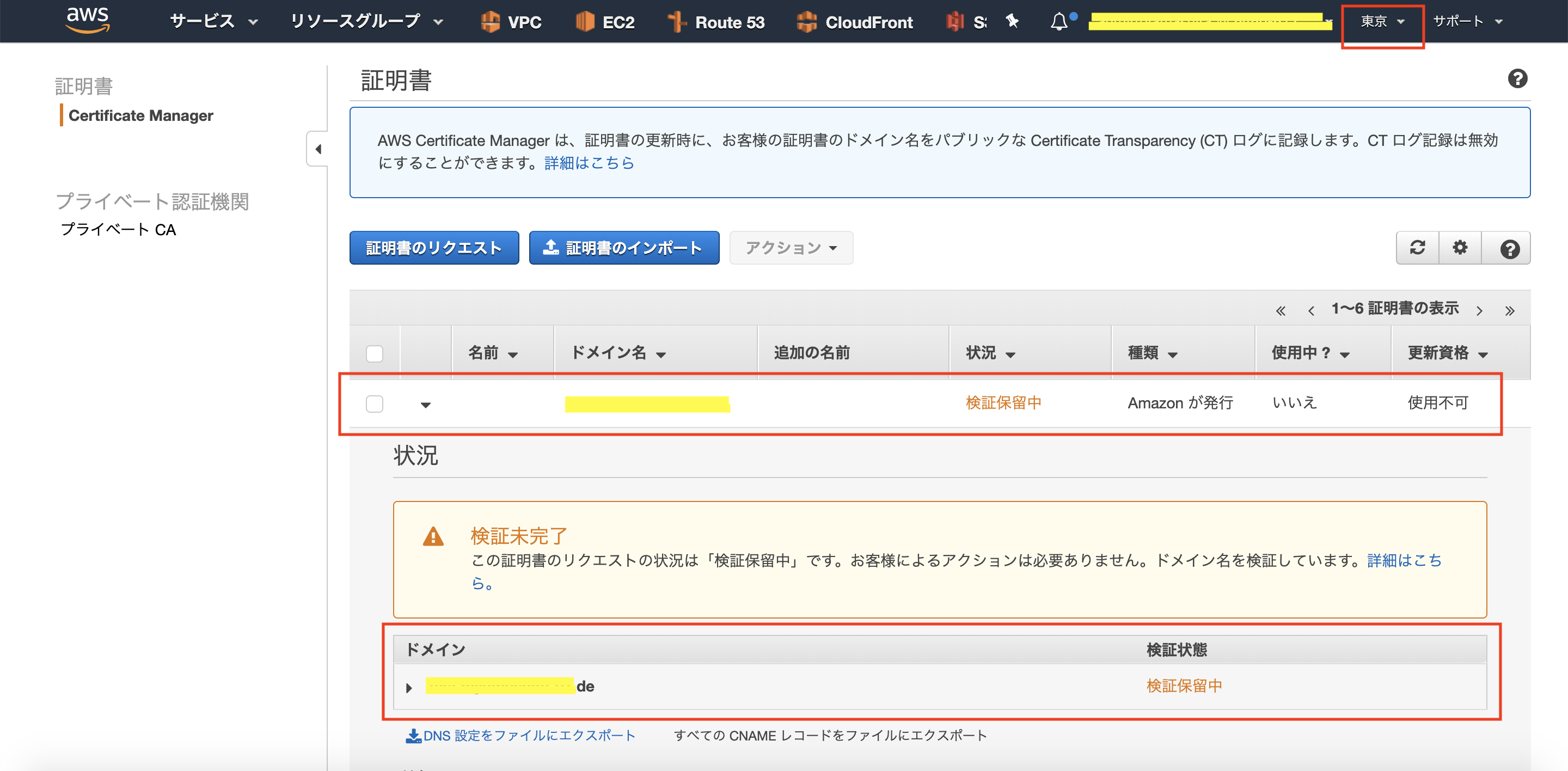
1.リージョン「バージニア北部」でサブドメイン用のSSL証明書を発行します。
2.「1」により、CNAMEレコードが発行されます(DNSサーバへレコード登録していないため、検証状態が「検証保留中」になっています)。
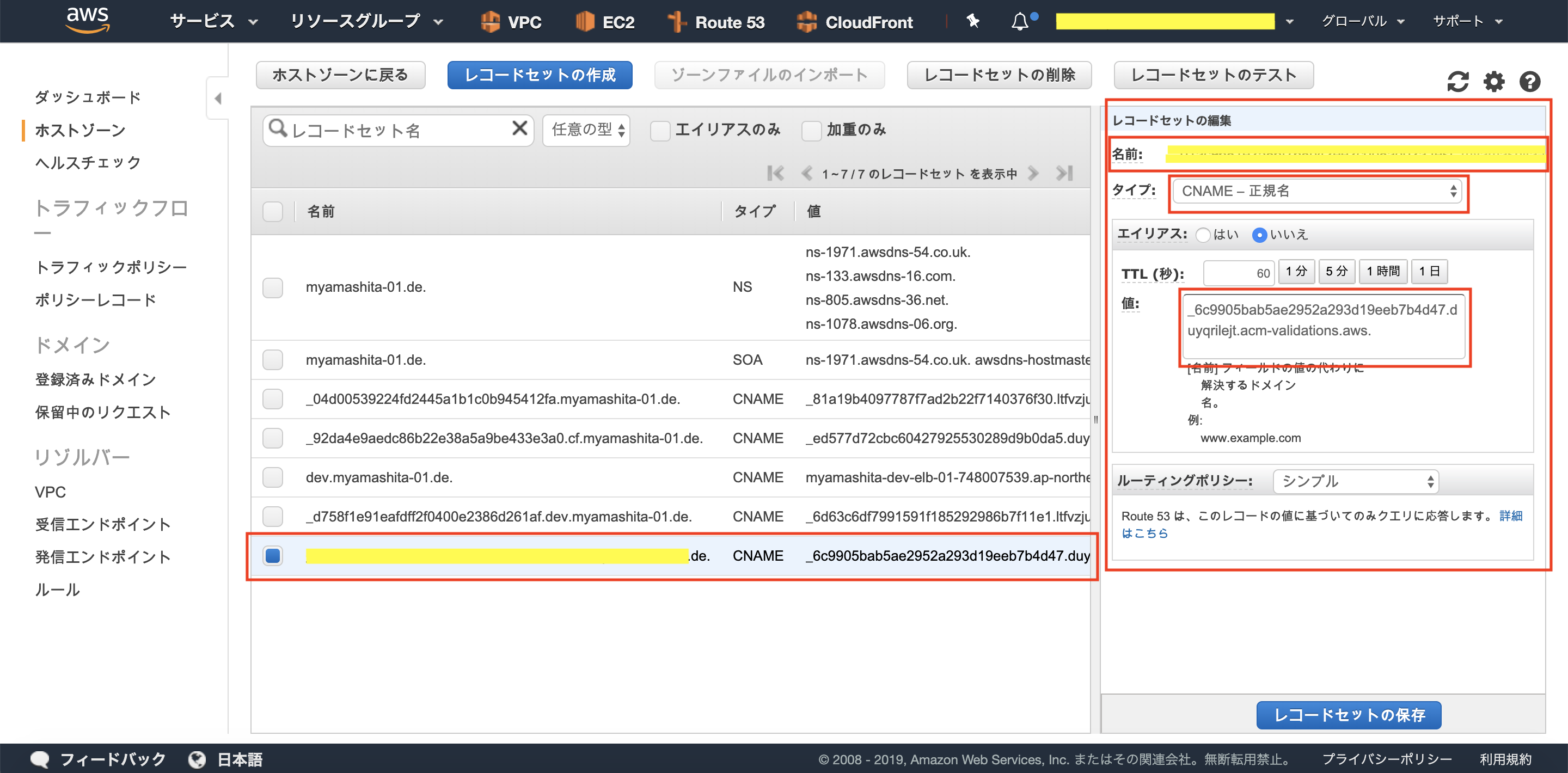
3.検証用CNAMEレコードを、Route53に登録します。
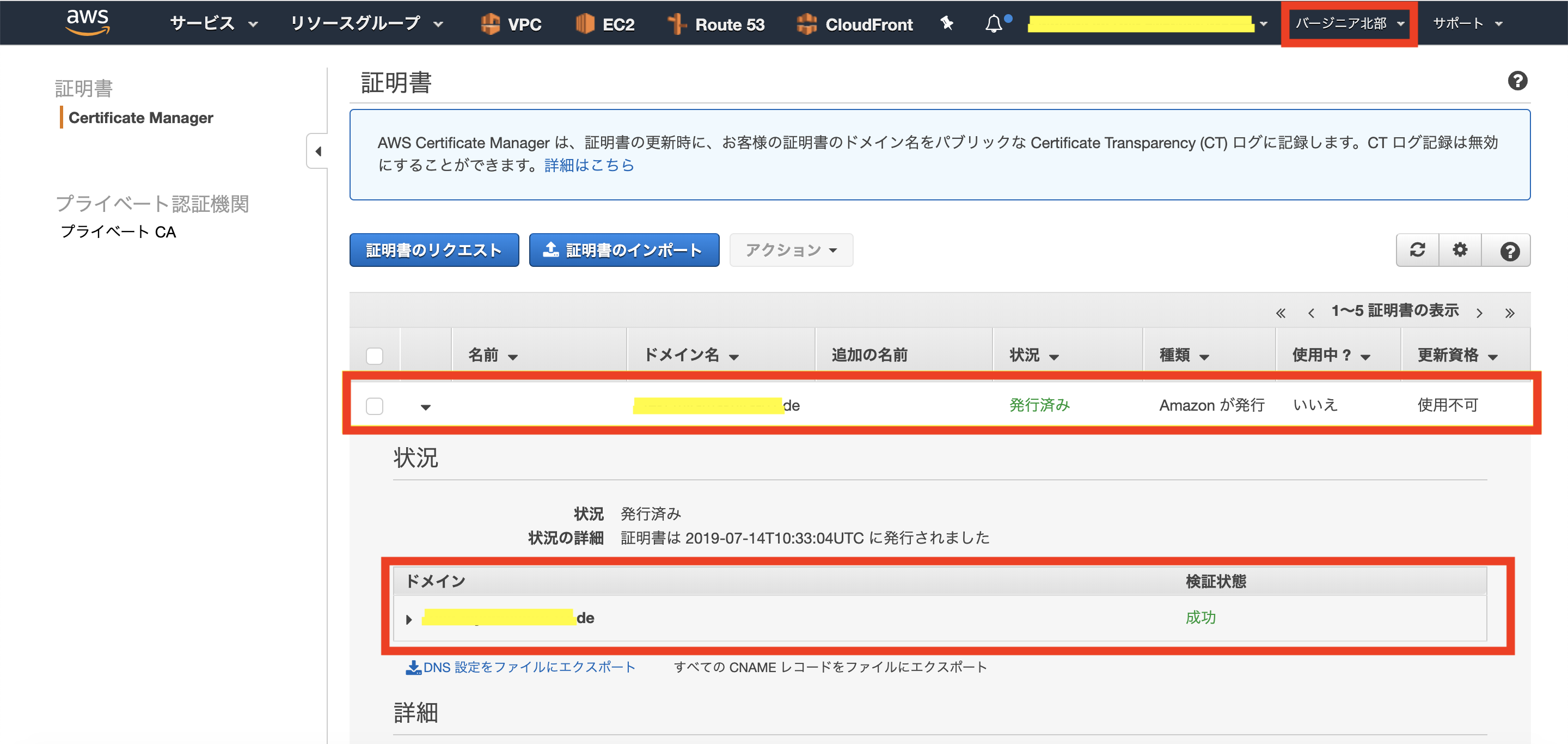
4.しばらくすると、Route53にCNAMEレコードを登録したため、検証状態が「成功」になりました。
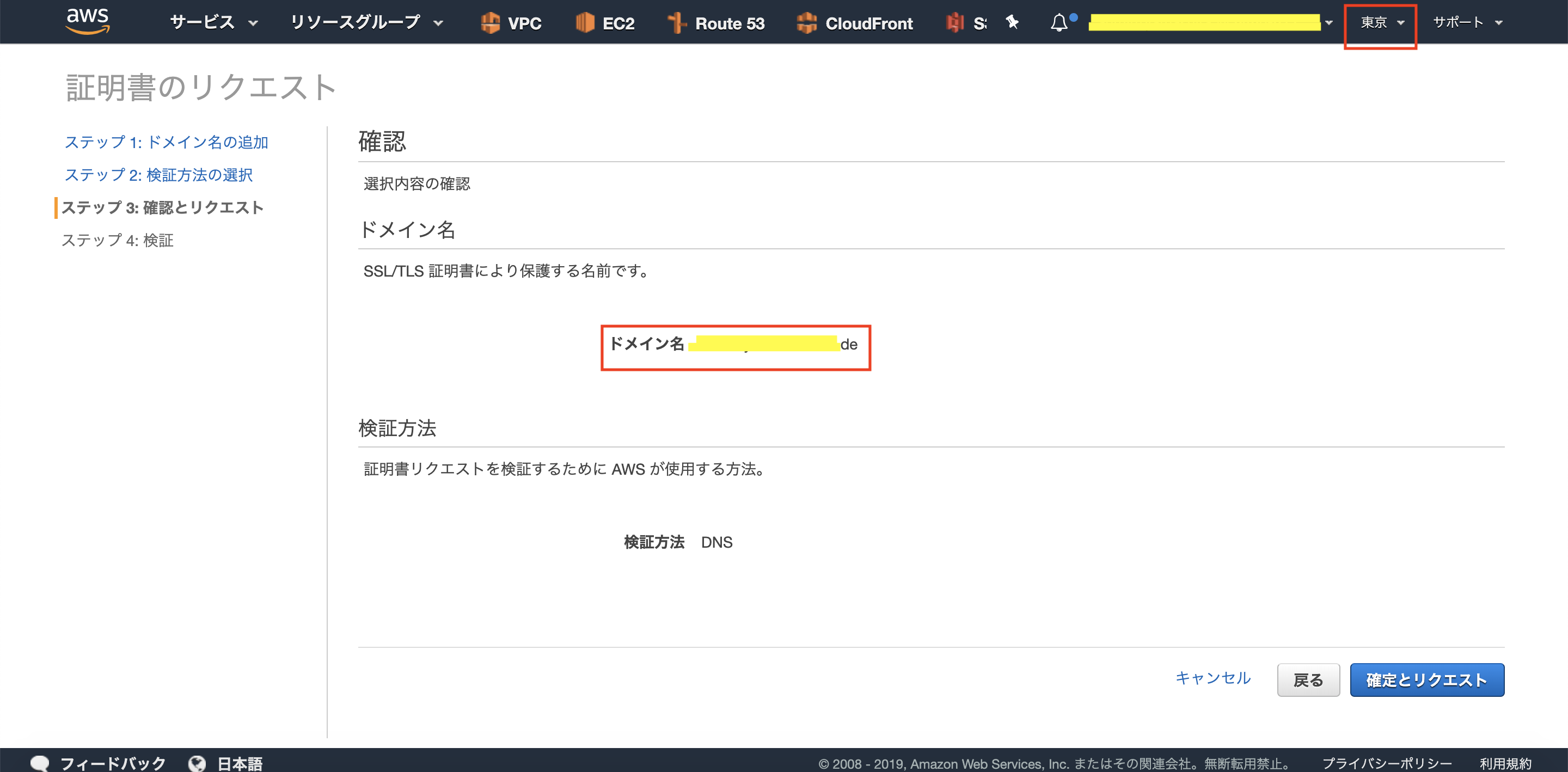
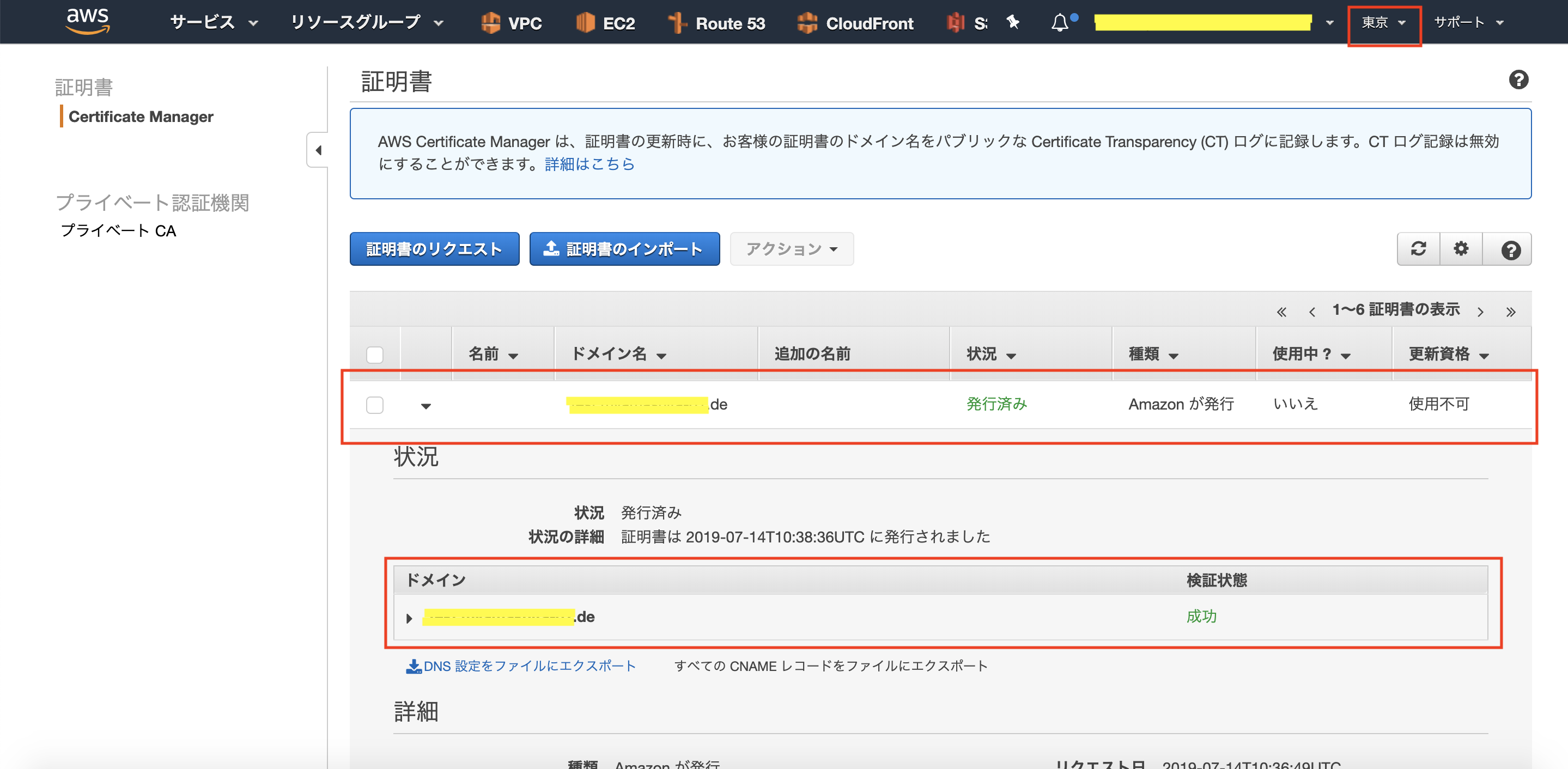
5.次は、リージョン「東京」で、同じサブドメインのSSL証明書を発行します。
6.リージョン「バージニア北部」のときと同様に、検証状態が「検証保留中」になっています。
7.しばらくすると(Route53へのCNAMEレコード登録未実施の状態で)、検証状態が「成功」になりました。
あとがき
DNSサーバへのレコード登録は、別会社が管理している場合、都度レコードの登録を依頼しなければならないので手間です。
今回の知見により、無駄なレコード登録依頼をせずに済みそうです(今回、レコード登録依頼をして、後からきづいたんですけどね。。)。
ただ、なぜリージョンごとに別のCNAMEレコードが吐き出されないのかが理解できていないので勉強するひつようがあるというのが現状です(1サブドメインにつき1CNAMEレコードなのかな。。??)。

- 投稿日:2019-07-14T20:10:23+09:00
AWS認定ソリューションアーキテクト-アソシエイトに合格した話
概要
AWSのベンダー資格である、ソリューションアーキテクトアソシエイトを受験し合格したので、勉強方法を共有します。
動機
個人的な今年度の目標でAWS認定資格のプロフェッショナルを2種取得することを設定していました。
しかし、はや第一四半期が終わり、進捗はありませんでした。
このままでは年度末の詰め込みが辛くなると感じたので、せめてアソシエイトぐらい取っておかないとなーとといった危機感から受験しました。受験前のAWSの経験・知識
- 新卒2年目
- LPIC level1、IPAの応用情報・DBスペシャリストを保有している
- 業務・趣味を合わせたAWS経験は半年ほど
- Gitlabサーバの構築・運用
- 開発環境・CICDパイプライン構築
- AWSで使用したことのあるサービス
- EC2,VPC,Route53,Cognito,Lamda,S3,RDS,DynamoDB,CodeBuild,CodeCommit,CodeDeploy,CodePipeline,IAM
勉強方法
やったことは模試受験、WEB問題集1周、AWSInnovate資料流し読み、模擬の問題を再確認です。
模試受験
最初に2000円払って公式の模擬試験を受けて自分のレベルを確認しました。
というのも、バックグラウンド的に実は何もしなくても合格できるのではないかと淡い期待があったからです。
また、後の復習用に出題画面のスクリーンショットを取っておきました。
※控えた問題を公開することは規約違反になるのでやめましょう。結果は6割程度の正解率でした。
各サービスの基礎は抑えているものの、例えばボリュームの種類などの細かいことは知らないといった感触でした。確実に合格するために8割程度の正解率は欲しい思うものの、
AWSの各種ドキュメントやホワイトペーパーを網羅的に読むといった、結局何を覚えれば良いか分からない勉強はしたくない思いが有りました。WEB問題集
過去のAWS以外の試験経験から、私はWEB上から過去問ベースで勉強する方法が向いているという実感がありました。
無料のWEB問題集が無かったため、以下のサイトのダイヤモンドプランに登録しました。
AWS WEB問題集で学習しよう
※6000円ほどかかりますが、圧倒的問題量と次回受験予定のソリューションアーキテクトプロフェッショナルの問題も用意されていたので、市販の本をそれぞれ買うより割安と判断しました。受験日を自由に決められる試験はダラダラと勉強を続けても辛いだけであることをLPICで経験していたので、
短期集中で2日で1周850問を解き切りました。
正解率は全体を平均して6~7割程度だったと思います。2週目は8~9割程度いくだろうという感触を得れたため、最低限の知識の確認だけ済まして試験を申し込むことにしました。
もし参考にされる場合、周回数は知識の定着具合にあわせてください。ただ、だらだら周回するのは経験上とても辛いです。
AWSInnovate資料流し読み
一応試験申し込み前に知識の抜け漏れをざっと確認する意味で、
今年の5月に開催されたAWSInnovateのソリューションアーキテクトアソシエイト向けの試験対策講座の資料を全て流し読みしました。
AWSInnovateで資料だけは一通りダウンロードしていたので流用しました。この確認作業は正直不要でした。WEB問題集で8~9割程度取れるようになっていれば、自然と身についているはずです。
AWS未経験の方はWEB問題集に取り組む前に読んでおくと、全体が把握できて効果的だと思います。
※今は、どこから資料をダウンロードできるのか分かりませんが。。模擬の問題を再確認
最初に模試を受けた時に控えておいた問題を確認します。
問題はしっかり忘れていたものの、9割方確信をもって答えれるようになっていました。おおよそ合格する安心が持てたので、記憶が忘却する前に急いで翌日の受験申込みをしました。
結果
881点で無事合格しました。
WEB問題集をマスターすることが最強の勉強法だと感じました。
試験中、WEB問題集に収録されていた問題と完全に一致・類似しているといった問題が半分以上あったように感じました。今後受験される方へ
学生向け
時間が許されるのであれば、AWSをまずは最初触りましょう。
学生がAWSのコンソールを触ったことが無い状態で、資格ありきで勉強をスタートする意味は特に無いと思います。Route53,VPC,EC2を駆使してベーシックな構成で開発したのち、APIGateway、LamdaやS3を組み合わせてサーバレスなアーキテクチャで開発できるようになれば、就活でもアピールポイントになりうる非常に良い経験になると思います。
その後は、私の勉強法を踏襲するなりして、試験にフォーカスして知識を吸収してくと良いと思います。
社会人向け
学生向けにはなるべくAWSのサービスに実際に触れた方が良いと書いたものの、AWSコンソールに一切触ったことが無くても合格できる試験内容です。
AWSを多少知っている(サービス名を聞けば、それが何のサービスか分かるぐらい)方であれば、WEB問題集に課金して8割程度の正解率になるまで周回する勉強方法がオススメです。
AWSを何も知らないのであれば、問題集形式でない各サービスを説明した試験対策本を1冊読んでから、問題集に入ると理解しやすいと思います。
ざっと調べた感じ、古いことが気になりますが以下の本が簡単で良さそうです。
合格対策 AWS認定ソリューションアーキテクト -アソシエイ今後
AWS WEB問題集で学習しようにはソリューションアーキテクトプロフェッショナル向けの問題も用意されているので、記憶が定着しているうちにプロフェッショナル向けの勉強を進めます。
- 投稿日:2019-07-14T19:21:00+09:00
AWS cloud9を使ってRuby on Railsを起動させる際に躓いたところ


- 投稿日:2019-07-14T17:09:43+09:00
Cloud9でAWS CDK (Python3) をインストールする方法
AWS CDKがGA!
2019年7月11日に、AWS Cloud Development Kit (AWS CDK)がGAしました。
Infrastructure as Codeの観点では、CloudFormationを使うよりも開発が楽になるとかなんとか言われていますが、実際に試さねば分からないだろうと思い、早速手を動かしてみることにしました。本記事では、Cloud9を使ってAWS CDKを開始する方法をまとめてみました。
Python3でCDKを書く前提での覚書となります。AWS CDKとは
公式「What Is the AWS CDK?」の解説を紐解いていきます。
- AWS CDKは、クラウドインフラストラクチャをコードで定義するためのソフトウェア開発フレームワークです。
- AWS CDKを使ってコードを書き、実行すると、AWS CloudFormationを通じてインフラストラクチャがプロビジョニングされます。
- CloudFormationとの違いとして、TypeScript、JavaScript、Pythonといった、開発者が慣れ親しんだプログラミング言語でインフラストラクチャを定義できます。
- if分岐やforループを活用できることから、CloudFormationに比べて記述量も減らせそう。
既に、PythonでAWSのインフラストラクチャをプロビジョニングするtroposphereもありますが、AWSが公式でCDKを出してきたことで、サポート面で安心できるCDKの利用が増えていくのかなと思ったりしています。
AWS CDKをCloud9にインストール
AWS CDK (Python3) を利用して、AWS CDK Appsを開発するための準備をします。
必要条件
・Node.js 8.11.x 以降のバージョンが必要です。
・Python3.6 以降のバージョンが必要です。
・AWS CDK CLIを利用するため、CredentialsとAWSリージョンを特定する必要があります。インストール
Cloud9でターミナルを開き
npm install -g aws-cdkを実行します。install$ npm install -g aws-cdk /home/ec2-user/.nvm/versions/node/v8.16.0/bin/cdk -> /home/ec2-user/.nvm/versions/node/v8.16.0/lib/node_modules/aws-cdk/bin/cdk > core-js@2.6.9 postinstall /home/ec2-user/.nvm/versions/node/v8.16.0/lib/node_modules/aws-cdk/node_modules/core-js > node scripts/postinstall || echo "ignore" Thank you for using core-js ( https://github.com/zloirock/core-js ) for polyfilling JavaScript standard library! The project needs your help! Please consider supporting of core-js on Open Collective or Patreon: > https://opencollective.com/core-js > https://www.patreon.com/zloirock Also, the author of core-js ( https://github.com/zloirock ) is looking for a good job -) + aws-cdk@1.0.0 added 267 packages from 249 contributors in 12.069sインストールが成功していれば
cdk --versionでバージョンを確認できます。version$ cdk --version 1.0.0 (build d89592e)ここで、Cloud9で通常使用するPythonが3.6に設定されていることを
python --versionで改めて確認しておきます。(master) $ python --version Python 3.6.8もし2.7.xだった場合は、こちらのリンク先の手順で、Python3を使えるように設定を切り替えましょう。
AWS Cloud9 でPython3を使うための設定
アプリを作る
次に、空のディレクトリを作って、ディレクトリに移動した後
cdk init --language pythonコマンドで、アプリを初期化します。(Gitリポジトリができます)
今回は分かりやすいようにCDKというディレクトリ名にしていますが、名前は何でも良いです。
言語を指定するのは、このcdk initを実行する時です。init$ mkdir CDK $ cd CDK $ cdk init --language python Applying project template app for python Initializing a new git repository... (略) Enjoy!結果を確認してみます。
cdk initの結果、いろいろできています。(master) $ ls -al total 40 drwxr-xr-x 5 ec2-user ec2-user 4096 Jul 13 07:05 . drwxr-xr-x 11 ec2-user ec2-user 4096 Jul 13 05:49 .. -rw-rw-r-- 1 ec2-user ec2-user 138 Jul 13 07:05 app.py drwxrwxr-x 2 ec2-user ec2-user 4096 Jul 13 07:05 cdk -rw-rw-r-- 1 ec2-user ec2-user 32 Jul 13 07:05 cdk.json drwxrwxr-x 5 ec2-user ec2-user 4096 Jul 13 07:05 .env drwxrwxr-x 7 ec2-user ec2-user 4096 Jul 13 07:05 .git -rw-rw-r-- 1 ec2-user ec2-user 1651 Jul 13 07:05 README.md -rw-rw-r-- 1 ec2-user ec2-user 5 Jul 13 07:05 requirements.txt -rw-rw-r-- 1 ec2-user ec2-user 1008 Jul 13 07:05 setup.py次に、CDKが依存するパッケージをインストールします。
(master) $ sudo pip install -r requirements.txt Obtaining file:///home/ec2-user/environment/CDK (from -r requirements.txt (line 1)) Collecting aws-cdk.core (from cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/60/99/6b1bc6e1059d0d97050550cfb7aee7ca154cf69ef4afd85e516340b8fd6d/aws_cdk.core-1.0.0-py3-none-any.whl (508kB) 100% |████████████████████████████████| 512kB 2.4MB/s Collecting jsii~=0.14.0 (from aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/fc/30/0954b455242b6b9a01f614db21d8a1707d62c7d302420a6c72c93faeb80e/jsii-0.14.0-py3-none-any.whl (236kB) 100% |████████████████████████████████| 245kB 4.6MB/s Collecting aws-cdk.cx-api>=1.0.0,~=1.0 (from aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/98/be/53a9bb48df0bd066fe1a227a93df70a957b717ce741d6746085bdb49e1ef/aws_cdk.cx_api-1.0.0-py3-none-any.whl (78kB) 100% |████████████████████████████████| 81kB 6.1MB/s Collecting publication>=0.0.3 (from aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/f8/d3/6308debad7afcdb3ea5f50b4b3d852f41eb566a311fbcb4da23755a28155/publication-0.0.3-py2.py3-none-any.whl Collecting attrs>=18.2 (from jsii~=0.14.0->aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/23/96/d828354fa2dbdf216eaa7b7de0db692f12c234f7ef888cc14980ef40d1d2/attrs-19.1.0-py2.py3-none-any.whl Collecting cattrs (from jsii~=0.14.0->aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/4a/4e/f8bfec0990a2d4f9f79d4417336b761c58c849672cd3b81637a22f02bb20/cattrs-0.9.0-py2.py3-none-any.whl (54kB) 100% |████████████████████████████████| 61kB 8.0MB/s Collecting typing-extensions>=3.6.4 (from jsii~=0.14.0->aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/27/aa/bd1442cfb0224da1b671ab334d3b0a4302e4161ea916e28904ff9618d471/typing_extensions-3.7.4-py3-none-any.whl Collecting python-dateutil (from jsii~=0.14.0->aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Using cached https://files.pythonhosted.org/packages/41/17/c62faccbfbd163c7f57f3844689e3a78bae1f403648a6afb1d0866d87fbb/python_dateutil-2.8.0-py2.py3-none-any.whl Collecting importlib-resources; python_version < "3.7" (from jsii~=0.14.0->aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/2f/f7/b4aa02cdd3ee7ebba375969d77c00826aa15c5db84247d23c89522dccbfa/importlib_resources-1.0.2-py2.py3-none-any.whl Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.6/site-packages (from python-dateutil->jsii~=0.14.0->aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Installing collected packages: attrs, cattrs, typing-extensions, python-dateutil, importlib-resources, jsii, publication, aws-cdk.cx-api, aws-cdk.core, cdk Running setup.py develop for cdk Successfully installed attrs-19.1.0 aws-cdk.core-1.0.0 aws-cdk.cx-api-1.0.0 cattrs-0.9.0 cdk importlib-resources-1.0.2 jsii-0.14.0 publication-0.0.3 python-dateutil-2.8.0 typing-extensions-3.7.4Hallo World!
app.pyを開いて、テストコードを書き換えます。
app.py#!/usr/bin/env python3 from aws_cdk import core from cdk.cdk_stack import CdkStack app = core.App() CdkStack(app, "HelloWorldStack") app.synth()
cdk lsで、スタックの一覧を列挙できます。(master) $ cdk ls HelloWorldStackこの時、内部的にはapp.pyの中の
app.synth()が呼ばれて、cdk.outの下にHelloWorldStack.template.jsonができて、その結果をリストしているようです。
※app.synth()を消して実行したらcdk lsの実行に失敗しました。(master) $ ls cdk.out/ cdk.out HelloWorldStack.template.json manifest.json
XXX.template.jsonはCloudFormationのテンプレートになります。
CDKでコードを書き、内部的にCloudFormationを使ってインフラストラクチャをデプロイしていくという流れが想像できます。ここまでの手順で、Cloud9上でAWS CDKをインストールし、Python3を使って開発を進める準備が整いました。
参考文献
- 投稿日:2019-07-14T17:09:43+09:00
Cloud9にAWS CDK (Python3) をインストールする方法
AWS CDKがGA!
2019年7月11日に、AWS Cloud Development Kit (AWS CDK)がGAしました。
Infrastructure as Codeの観点では、CloudFormationを使うよりも開発が楽になるとかなんとか言われていますが、実際に試さねば分からないだろうと思い、早速手を動かしてみることにしました。本記事では、Cloud9を使ってAWS CDKを開始する方法をまとめてみました。
Python3でCDKを使って開発する前提での覚書となります。AWS CDKとは
公式「What Is the AWS CDK?」の解説を紐解いていきます。
- AWS CDKは、クラウドインフラストラクチャをコードで定義するためのソフトウェア開発フレームワークです。
- AWS CDKを使ってコードを書き、実行すると、AWS CloudFormationを通じてインフラストラクチャがプロビジョニングされます。
- CloudFormationとの違いとして、TypeScript、JavaScript、Pythonといった、開発者が慣れ親しんだプログラミング言語でインフラストラクチャを定義できます。
- if分岐やforループを活用できることから、CloudFormationに比べて記述量も減らせそう。
既に、PythonでAWSのインフラストラクチャをプロビジョニングするtroposphereもありますが、AWSが公式でCDKを出してきたことで、サポート面で安心できるCDKの利用が増えていくのかなと思ったりしています。
AWS CDKをCloud9にインストール
AWS CDK (Python3) を利用して開発するための準備をします。
必要条件
・Node.js 8.11.x 以降のバージョンが必要です。
・Python3.6 以降のバージョンが必要です。
・AWS CDK CLIを利用するため、CredentialsとAWSリージョンを特定する必要があります。インストール
Cloud9でターミナルを開き
npm install -g aws-cdkを実行します。install$ npm install -g aws-cdk /home/ec2-user/.nvm/versions/node/v8.16.0/bin/cdk -> /home/ec2-user/.nvm/versions/node/v8.16.0/lib/node_modules/aws-cdk/bin/cdk > core-js@2.6.9 postinstall /home/ec2-user/.nvm/versions/node/v8.16.0/lib/node_modules/aws-cdk/node_modules/core-js > node scripts/postinstall || echo "ignore" Thank you for using core-js ( https://github.com/zloirock/core-js ) for polyfilling JavaScript standard library! The project needs your help! Please consider supporting of core-js on Open Collective or Patreon: > https://opencollective.com/core-js > https://www.patreon.com/zloirock Also, the author of core-js ( https://github.com/zloirock ) is looking for a good job -) + aws-cdk@1.0.0 added 267 packages from 249 contributors in 12.069sインストールが成功していれば
cdk --versionでバージョンを確認できます。version$ cdk --version 1.0.0 (build d89592e)ここで、Cloud9で通常使用するPythonが3.6に設定されていることを
python --versionで改めて確認しておきます。(master) $ python --version Python 3.6.8もし2.7.xだった場合は、こちらのリンク先の手順で、Python3を使えるように設定を切り替えましょう。
AWS Cloud9 でPython3を使うための設定
アプリを作る
次に、空のディレクトリを作って、ディレクトリに移動した後
cdk init --language pythonコマンドで、アプリを初期化します。(Gitリポジトリができます)
今回は分かりやすいようにCDKというディレクトリ名にしていますが、名前は何でも良いです。
言語を指定するのは、このcdk initを実行する時です。init$ mkdir CDK $ cd CDK $ cdk init --language python Applying project template app for python Initializing a new git repository... (略) Enjoy!結果を確認してみます。
cdk initの結果、いろいろできています。(master) $ ls -al total 40 drwxr-xr-x 5 ec2-user ec2-user 4096 Jul 13 07:05 . drwxr-xr-x 11 ec2-user ec2-user 4096 Jul 13 05:49 .. -rw-rw-r-- 1 ec2-user ec2-user 138 Jul 13 07:05 app.py drwxrwxr-x 2 ec2-user ec2-user 4096 Jul 13 07:05 cdk -rw-rw-r-- 1 ec2-user ec2-user 32 Jul 13 07:05 cdk.json drwxrwxr-x 5 ec2-user ec2-user 4096 Jul 13 07:05 .env drwxrwxr-x 7 ec2-user ec2-user 4096 Jul 13 07:05 .git -rw-rw-r-- 1 ec2-user ec2-user 1651 Jul 13 07:05 README.md -rw-rw-r-- 1 ec2-user ec2-user 5 Jul 13 07:05 requirements.txt -rw-rw-r-- 1 ec2-user ec2-user 1008 Jul 13 07:05 setup.py次に、CDKが依存するパッケージをインストールします。
(master) $ sudo pip install -r requirements.txt Obtaining file:///home/ec2-user/environment/CDK (from -r requirements.txt (line 1)) Collecting aws-cdk.core (from cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/60/99/6b1bc6e1059d0d97050550cfb7aee7ca154cf69ef4afd85e516340b8fd6d/aws_cdk.core-1.0.0-py3-none-any.whl (508kB) 100% |████████████████████████████████| 512kB 2.4MB/s Collecting jsii~=0.14.0 (from aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/fc/30/0954b455242b6b9a01f614db21d8a1707d62c7d302420a6c72c93faeb80e/jsii-0.14.0-py3-none-any.whl (236kB) 100% |████████████████████████████████| 245kB 4.6MB/s Collecting aws-cdk.cx-api>=1.0.0,~=1.0 (from aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/98/be/53a9bb48df0bd066fe1a227a93df70a957b717ce741d6746085bdb49e1ef/aws_cdk.cx_api-1.0.0-py3-none-any.whl (78kB) 100% |████████████████████████████████| 81kB 6.1MB/s Collecting publication>=0.0.3 (from aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/f8/d3/6308debad7afcdb3ea5f50b4b3d852f41eb566a311fbcb4da23755a28155/publication-0.0.3-py2.py3-none-any.whl Collecting attrs>=18.2 (from jsii~=0.14.0->aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/23/96/d828354fa2dbdf216eaa7b7de0db692f12c234f7ef888cc14980ef40d1d2/attrs-19.1.0-py2.py3-none-any.whl Collecting cattrs (from jsii~=0.14.0->aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/4a/4e/f8bfec0990a2d4f9f79d4417336b761c58c849672cd3b81637a22f02bb20/cattrs-0.9.0-py2.py3-none-any.whl (54kB) 100% |████████████████████████████████| 61kB 8.0MB/s Collecting typing-extensions>=3.6.4 (from jsii~=0.14.0->aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/27/aa/bd1442cfb0224da1b671ab334d3b0a4302e4161ea916e28904ff9618d471/typing_extensions-3.7.4-py3-none-any.whl Collecting python-dateutil (from jsii~=0.14.0->aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Using cached https://files.pythonhosted.org/packages/41/17/c62faccbfbd163c7f57f3844689e3a78bae1f403648a6afb1d0866d87fbb/python_dateutil-2.8.0-py2.py3-none-any.whl Collecting importlib-resources; python_version < "3.7" (from jsii~=0.14.0->aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/2f/f7/b4aa02cdd3ee7ebba375969d77c00826aa15c5db84247d23c89522dccbfa/importlib_resources-1.0.2-py2.py3-none-any.whl Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.6/site-packages (from python-dateutil->jsii~=0.14.0->aws-cdk.core->cdk==0.0.1->-r requirements.txt (line 1)) Installing collected packages: attrs, cattrs, typing-extensions, python-dateutil, importlib-resources, jsii, publication, aws-cdk.cx-api, aws-cdk.core, cdk Running setup.py develop for cdk Successfully installed attrs-19.1.0 aws-cdk.core-1.0.0 aws-cdk.cx-api-1.0.0 cattrs-0.9.0 cdk importlib-resources-1.0.2 jsii-0.14.0 publication-0.0.3 python-dateutil-2.8.0 typing-extensions-3.7.4Hello World!
app.pyを開いて、テストコードを書き換えます。
app.py#!/usr/bin/env python3 from aws_cdk import core from cdk.cdk_stack import CdkStack app = core.App() CdkStack(app, "HelloWorldStack") app.synth()
cdk lsで、スタックの一覧を列挙できます。(master) $ cdk ls HelloWorldStackこの時、内部的にはapp.pyの中の
app.synth()が呼ばれて、cdk.outの下にHelloWorldStack.template.jsonができて、その結果をリストしているようです。
※app.synth()を消して実行したらcdk lsの実行に失敗しました。(master) $ ls cdk.out/ cdk.out HelloWorldStack.template.json manifest.json
XXX.template.jsonはCloudFormationのテンプレートになります。
CDKでコードを書き、内部的にCloudFormationを使ってインフラストラクチャをデプロイしていくという流れが想像できます。ここまでの手順で、Cloud9上でAWS CDKをインストールし、Python3を使って開発を進める準備が整いました。
参考文献
- 投稿日:2019-07-14T16:50:41+09:00
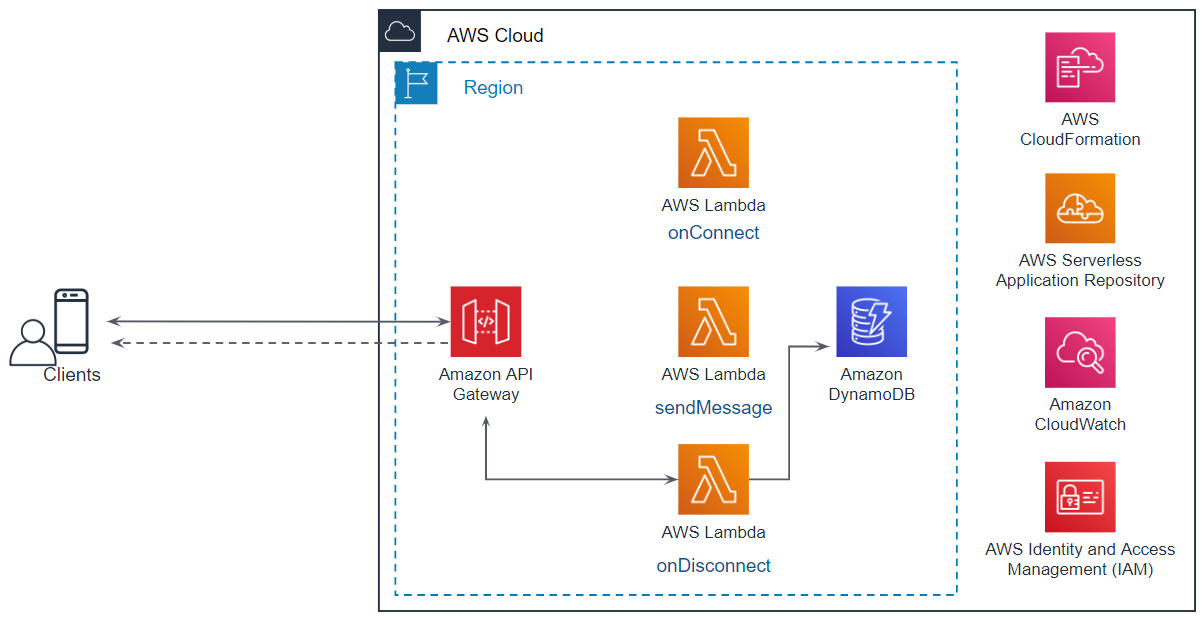
WebSocket - AWS の API Gateway と Lambda でルーム機能付きのchatを作る時の仕様を考える
はじめに
「[発表]Amazon API GatewayでWebsocketが利用可能 - AWS」で紹介されている機能を使って、ルーム機能付きのchatを作ろうとしたときのメモです。
なお、ルーム機能なしであれば、AWSが「aws-samples/simple-websockets-chat-app - GitHub」としてコードを公開しています。
事前準備
AWSのアカウント取得や AWS CLI の設定については完了していることが前提です。
必要なコマンド
作業するにあたっては、次のようなコマンドが必要です。
- git
- aws cli : CloudFormation の操作に使用
- sam : AWS Serverless Application Model (SAM) の操作に使用
- awslogs : CloudWatch のログをローカルPCで確認するために使用
- wscat : WebSocket 通信のクライアントとして使用
動作仕様
全体的な仕様をまとめます。
基本機能
次の3つの機能の実装によって実現します。
- コネクション接続とルームへの参加
- メッセージの送信
- コネクション切断とルームからの退室
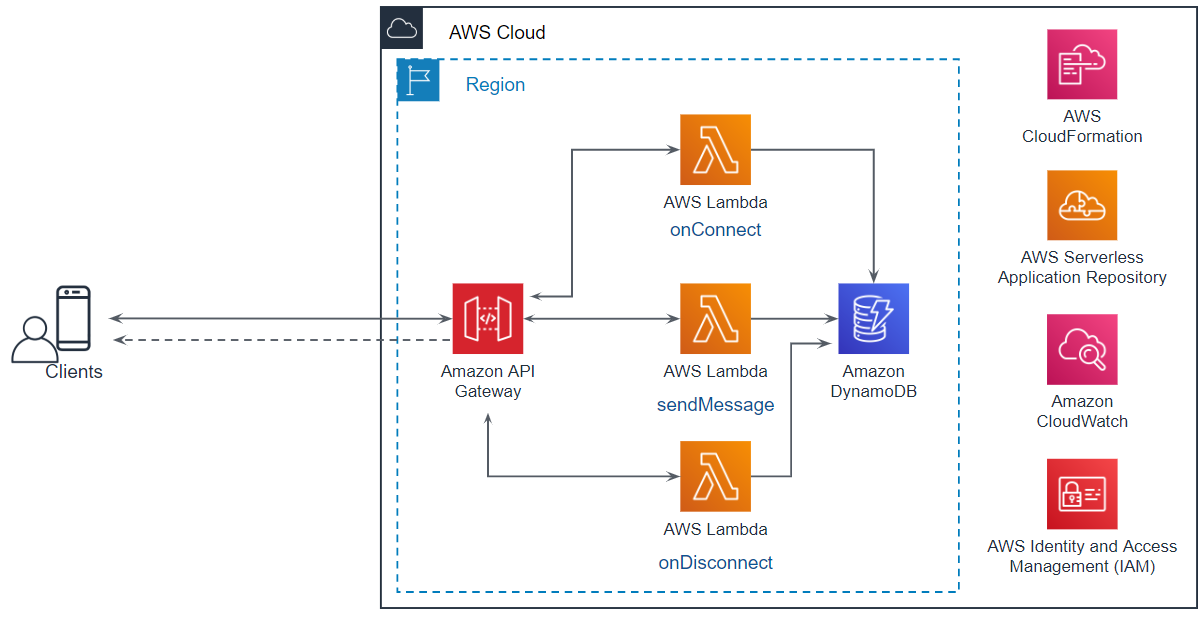
全体構成
システムの全体像は次の通りです。
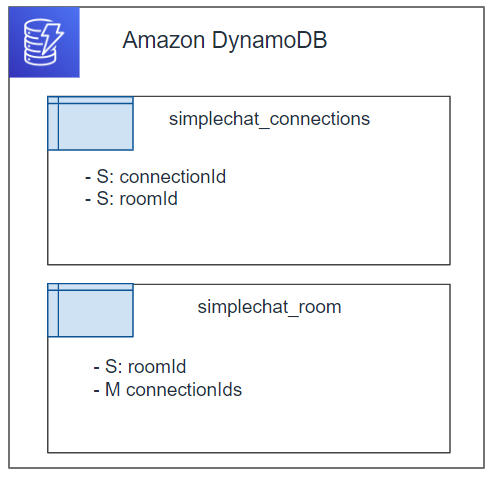
テーブル
コネクション情報とルームの情報を保持するために、DynamoDBに次の2つのテーブルを作成します。
処理
各機能を実現する基本的な処理仕様を記載します。
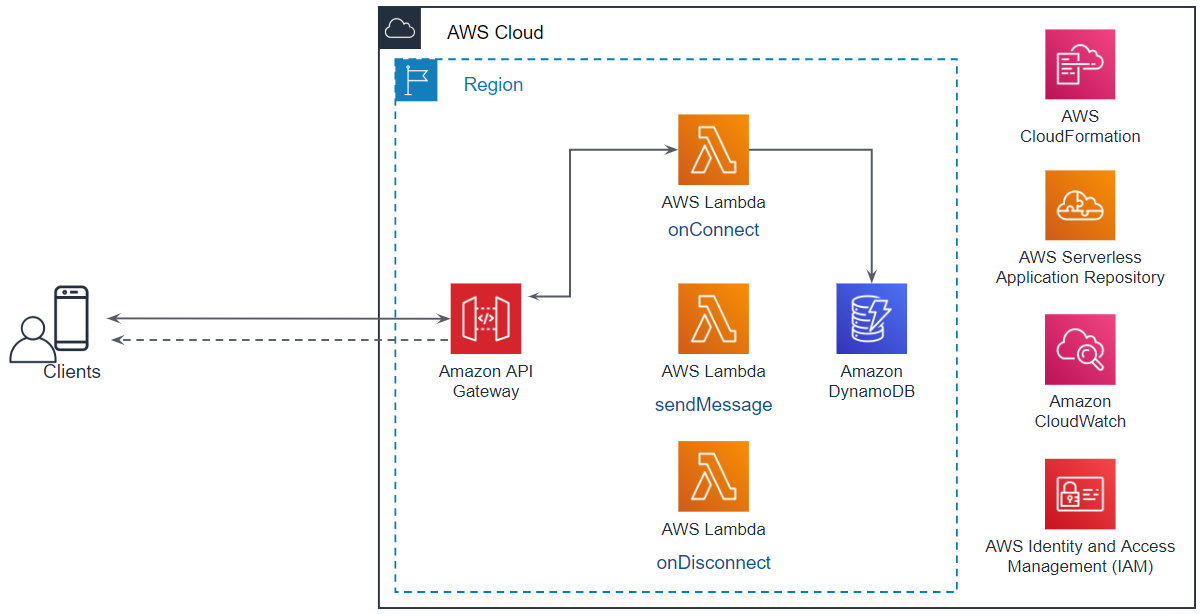
コネクション接続とルームへの参加
本機能の実現にあたっては、次のような処理を実装します。
- コネクションを接続する。
- ルームへの参加する。
- ルーム参加者へメンバーの入室を通知する。
AWSのサンプルと違うところは、以下の2つです。
- ルームへの参加
- 入室済みメンバーへの通知
メッセージの送信
本機能の実現にあたっては、次のような処理を実装します。
- メッセージの送信する。
- ルームメンバーの確認する。
- ルーム参加者へメンバーへメッセージを送信する。
AWSのサンプルと違うところは、以下の2つです。
- ルームメンバーの取得
- ルームメンバーへの通知
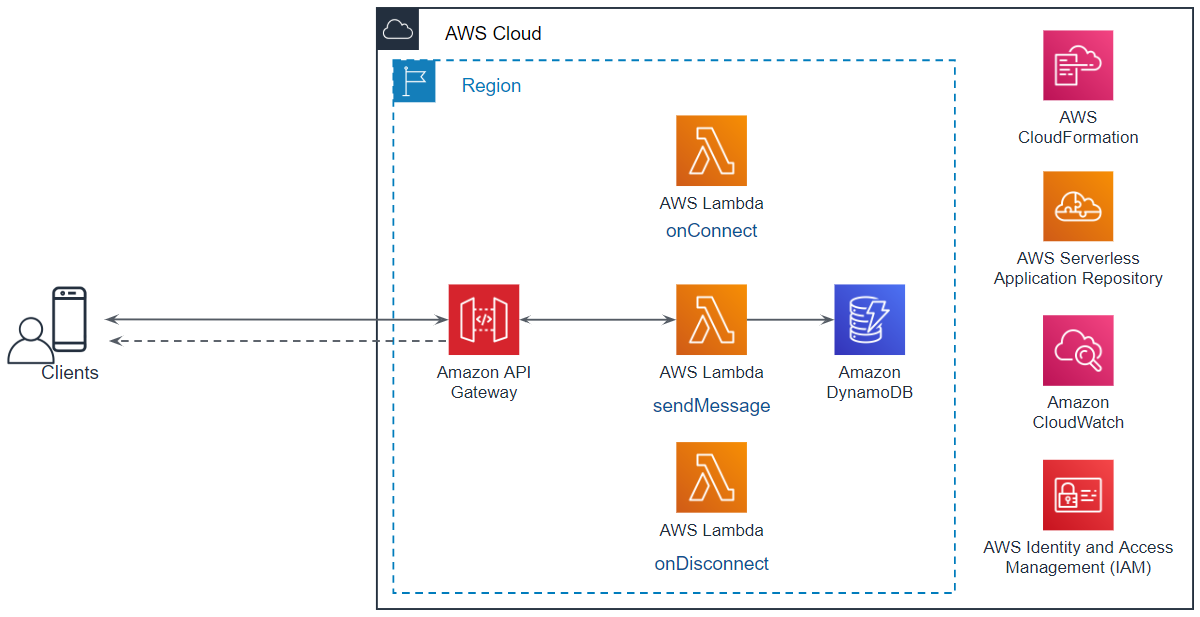
コネクション切断とルームからの退室
本機能の実現にあたっては、次のような処理を実装します。
- ルームから退室する。
- ルームメンバーへメンバーの退室を通知する。
- コネクションを切断する
AWSのサンプルと違うところは、以下の2つです。
- ルームからの退室
- ルームメンバーへの退室の通知
実装
AWS上に実装するための情報を記載します。
全体像
基本的には、記事「【新機能】APIGatewayでWebSocketが利用可能になったのでチャットAPIを構築してみた - Qiita」で紹介されている通り、AWSのテンプレートを使用してまずは構築します。
この記事のままで動かない場合は、記事「WebSocket - AWSのサンプルで API Gateway を使ったchatアプリを作ろうとしたらハマった件」を参照してください。
IAM Role
IAMロールを作成し、次の Policy をアタッチします。
ポリシー名 ポリシータイプ AWSLambdaBasicExecutionRole AWS 管理ポリシー chatFunctionRolePolicy0 インラインポリシー chatFunctionRolePolicy1 インラインポリシー chatFunctionRolePolicy0{ "Statement": [ { "Action": [ "dynamodb:GetItem", "dynamodb:DeleteItem", "dynamodb:PutItem", "dynamodb:Scan", "dynamodb:Query", "dynamodb:UpdateItem", "dynamodb:BatchWriteItem", "dynamodb:BatchGetItem", "dynamodb:DescribeTable" ], "Resource": [ "arn:aws:dynamodb:ap-northeast-1:xxxxxxxxxxxx:table/simplechat_connections", "arn:aws:dynamodb:ap-northeast-1:xxxxxxxxxxxx:table/simplechat_connections/index/*", "arn:aws:dynamodb:ap-northeast-1:xxxxxxxxxxxx:table/simplechat_room", "arn:aws:dynamodb:ap-northeast-1:xxxxxxxxxxxx:table/simplechat_room/index/*" ], "Effect": "Allow" } ] }chatFunctionRolePolicy1{ "Statement": [ { "Action": [ "execute-api:*" ], "Resource": [ "arn:aws:execute-api:ap-northeast-1:xxxxxxxxxxxx:yyyyyyyy/*" ], "Effect": "Allow" } ] }API Gateway
API Gateway は次のように設定します。
ルート 用途 統合タイプ Lambda Region Lambda関数 $connect WebSocket の開始時に使用する。 Lambda関数 ap-northeast-1 onConnect関数 $disconnect WebSocket の終了時に使用する。 Lambda関数 ap-northeast-1 onDisconnect関数 senndmessage WebSocket でメッセージを送信する時に使用する。 Lambda関数 ap-northeast-1 sendMessage関数 AWS Lambda
AWS Lambda では、AWSのサンプルと同様に「Node.js 10.x」を使用します。
各関数では、次のモジュールを使用します。
module名 解説 AWS.DynamoDB.DocumentClient DynamoDBへ接続する際に使用します。 AWS.ApiGatewayManagementApi API Gateway を介してメッセージを送信する際に使用します。
onconnect/app.js
onconnect/app.jsconst AWS = require("aws-sdk"); AWS.config.update({ region: process.env.AWS_REGION }); var docClient = new AWS.DynamoDB.DocumentClient({ apiVersion: "2012-10-08" }); const table_room = "simplechat_room"; exports.handler = async function (event, context, callback) { console.info("START"); console.log("event: ", JSON.stringify(event)); console.log("context: ", JSON.stringify(context)); let connectionId = event.requestContext.connectionId; // Join or New ? // __________________________________________________ let roomId; if (event.queryStringParameters) { if (event.queryStringParameters.roomId) { roomId = event.queryStringParameters.roomId; } } console.log("roomId: ", roomId); if (roomId === void 0) { roomId = "test"; } // Register WebSocket Connection ID // __________________________________________________ var params = { TableName: process.env.TABLE_NAME, Item: { connectionId: connectionId, roomId: roomId } }; docClient.put(params, callback); // Exist Room? // __________________________________________________ var params = { TableName: table_room, Key: { roomId: roomId } }; var room = await getRoom(params); var users; if (room.Item === void 0) { // ルームが未作成の場合、新規で作成する。 console.log("room is not exist"); users = [{ connectionId: connectionId, username: "taro", icon: "avatar" }]; var params = { TableName: table_room, Item: { roomId: roomId, connectionIds: users } }; docClient.put(params, callback); } else { // ルームが存在する場合、既存のルームに入室する。 console.log("room: ", JSON.stringify(room.Item)); console.log("connectionIds: ", JSON.stringify(room.Item.connectionIds)); room.Item.connectionIds.push({ connectionId: connectionId, username: "taro", icon: "avatar" }); users = room.Item.connectionIds; console.log("room is exist"); var params = { TableName: table_room, Item: { roomId: roomId, connectionIds: users } }; docClient.put(params, callback); } // Push Message // __________________________________________________ const apigwManagementApi = new AWS.ApiGatewayManagementApi({ apiVersion: '2018-11-29', endpoint: event.requestContext.domainName + '/' + event.requestContext.stage }); console.log("users: ", JSON.stringify(users)); users.map(async ({ connectionId, username, icon }) => { console.log("connectionId: ", JSON.stringify(connectionId)); var message = { type: "join", member: { connectionId: connectionId, username: username, icon: icon }, room: { users: users } } try { await apigwManagementApi.postToConnection({ ConnectionId: connectionId, Data: JSON.stringify(message) }).promise(); } catch (e) { if (e.statusCode === 410) { console.log(`Found stale connection, deleting ${connectionId}`); await docClient.delete({ TableName: "simplechat_connections", Key: { connectionId } }).promise(); } else { console.error("e: ", JSON.stringify(e)); throw e; } } }); console.info("END"); return { statusCode: 200, body: 'Connection Success.' }; }; /** * */ function getRoom(params) { return new Promise((resolve, reject) => { docClient.get(params, function (err, data) { if (err) { console.log("getRoom(params) ERROR"); reject(err); } else { console.log("getRoom(params) SUCCESS"); resolve(data); } }); }); }
disconnect/app.js
disconnect/app.jsconst AWS = require("aws-sdk"); AWS.config.update({ region: process.env.AWS_REGION }); //var DDB = new AWS.DynamoDB({ apiVersion: "2012-10-08" }); var docClient = new AWS.DynamoDB.DocumentClient({ apiVersion: "2012-10-08" }); const table_room = "simplechat_room"; exports.handler = async function (event, context, callback) { console.info("START"); console.log("event: ", JSON.stringify(event)); console.log("context: ", JSON.stringify(context)); // // __________________________________________________ var params = { TableName: process.env.TABLE_NAME, Key: { connectionId: event.requestContext.connectionId } }; var connection = await getRoom(params); console.log("connection: ", JSON.stringify(connection)); var params = { TableName: table_room, Key: { roomId: connection.Item.roomId, } }; var room = await getRoom(params); console.log("room: ", JSON.stringify(room)); // 自分以外のメンバーを取得する。 const roomMembers = room.Item.connectionIds.filter((member) => { return (member.connectionId != event.requestContext.connectionId); }); console.log("I am : ", JSON.stringify(event.requestContext.connectionId)); console.log("roomMembers: ", JSON.stringify(roomMembers)); // 自分以外のメンバーで登録し直す var params = { TableName: table_room, Item: { roomId: connection.Item.roomId, connectionIds: roomMembers } }; await docClient.put(params, callback).promise(); // connectionId を削除する。 var deleteParams = { TableName: process.env.TABLE_NAME, Key: { connectionId: event.requestContext.connectionId } }; await docClient.delete(deleteParams, callback).promise(); // Push Message // __________________________________________________ const apigwManagementApi = new AWS.ApiGatewayManagementApi({ apiVersion: '2018-11-29', endpoint: event.requestContext.domainName + '/' + event.requestContext.stage }); roomMembers.map(async ({ connectionId, username, icon }) => { console.log("connectionId: ", JSON.stringify(connectionId)); var message = { type: "unjoin", member: { connectionId: connectionId, username: username, icon: icon }, room: { users: roomMembers } } try { await apigwManagementApi.postToConnection({ ConnectionId: connectionId, Data: JSON.stringify(message) }).promise(); } catch (e) { if (e.statusCode === 410) { console.log(`Found stale connection, deleting ${connectionId}`); await docClient.delete({ TableName: "simplechat_connections", Key: { connectionId } }).promise(); } else { console.error("e: ", JSON.stringify(e)); throw e; } } }); console.info("END"); }; /** * */ function getRoom(params) { return new Promise((resolve, reject) => { docClient.get(params, function (err, data) { if (err) { console.log("getRoom(params) ERROR"); reject(err); } else { console.log("getRoom(params) SUCCESS"); resolve(data); } }); }); }
sendmessage/app.js
sendmessage/app.jsconst AWS = require('aws-sdk'); const docClient = new AWS.DynamoDB.DocumentClient({ apiVersion: '2012-08-10' }); const { TABLE_NAME } = process.env; const table_room = "simplechat_room"; exports.handler = async (event, context) => { console.info("START"); console.log("event: ", JSON.stringify(event)); console.log("context: ", JSON.stringify(context)); // // __________________________________________________ var params = { TableName: process.env.TABLE_NAME, Key: { connectionId: event.requestContext.connectionId } }; var connection = await getRoom(params); console.log("connection: ", JSON.stringify(connection)); var params = { TableName: table_room, Key: { roomId: connection.Item.roomId, } }; var room = await getRoom(params); console.log("room: ", JSON.stringify(room)); const apigwManagementApi = new AWS.ApiGatewayManagementApi({ apiVersion: '2018-11-29', endpoint: event.requestContext.domainName + '/' + event.requestContext.stage }); const postData = JSON.parse(event.body).data; console.log("postData: ", JSON.stringify(postData)); const postCalls = room.Item.connectionIds.map(async ({ connectionId }) => { try { await apigwManagementApi.postToConnection({ ConnectionId: connectionId, Data: postData }).promise(); } catch (e) { if (e.statusCode === 410) { console.log(`Found stale connection, deleting ${connectionId}`); await docClient.delete({ TableName: TABLE_NAME, Key: { connectionId } }).promise(); } else { throw e; } } }); try { await Promise.all(postCalls); } catch (e) { return { statusCode: 500, body: e.stack }; } console.info("END"); return { statusCode: 200, body: 'Data sent.' }; }; /** * */ function getRoom(params) { return new Promise((resolve, reject) => { docClient.get(params, function (err, data) { if (err) { console.log("getRoom(params) ERROR"); reject(err); } else { console.log("getRoom(params) SUCCESS"); resolve(data); } }); }); }DynamoDB
DynamoDBには次の2つのテーブルを作成します。
テーブル名 ID 用途 simplechat_connections connectionId コネクション情報の登録 simplechat_room roomId ルーム所属メンバの登録 デバッグ
ローカルPCのコードをコマンドで Lambda へデプロイする
command_powershell// zip 圧縮する compress-archive * ../function.zip // デプロイする aws lambda update-function-code ` --function-name [function name] ` --zip-file fileb://../function.zip ` --profile [profile name]CloudWatch のログをローカルで確認する
command_powershellawslogs get [Log Group Name] ` -w ` -s 10m ` -G ` -S ` --timestamp ` --profile [Profile Name]動作検証
gif などの動作が分かる情報ではないので分かりづらいですが、次のように動作します。
// 接続とルームへの入室 > wscat -c wss://xxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/Prod?roomId=dklfajsd3938daf83dfa connected (press CTRL+C to quit) < {"type":"join","member":{"connectionId":"czeJQeqpNjMAc3g=","username":"taro","icon":"avatar"},"room":{"users":[{"icon":"avatar","connectionId":"czKiJe_BNjMCJew=","username":"taro"},{"icon":"avatar","connectionId":"czKxffiNNjMCF-w=","username":"taro"},]}} // メッセージの送信 > {"message":"sendmessage", "data":"hello world"} < hello world // メンバーの退室通知 < {"type":"unjoin","member":{"connectionId":"czeJ0d6mNjMCFCw=","username":"taro","icon":"avatar"},"room":{"users":[{"icon":"avatar","connectionId":"czKiJe_BNjMCJew=","username":"taro"}]}}おわりに
コードが整理できたらそれも掲載したい。。
参考
CloudWatch
- ECSからcloudwatchにながしたログをtailでみたい - Qiita
- ターミナルから直感的にCloudWatch Logsを検索できるawslogsコマンドの紹介 - Developers.IO
DynamoDB
- 【詳解】JavascriptでDynamoDBを操作する - Qiita
- AWS lambdaからdynamodbに接続: "AccessDeniedException"で怒られたのでポリシーを設定した - Qiita
- Class: AWS.DynamoDB.DocumentClient - AWS DynamoDB DocumentClient
- DynamoDBのテーブルに複雑な構造のドキュメントをputItem()/put()する - Qiita
async/awain
- 投稿日:2019-07-14T16:40:47+09:00
AWSの仮想マシンでJETSON nanoのDockerコンテナを作りたい
JETSONでコンテナ使うのが大変
参考にさせていただくのはこちらの記事。
nanoでも同じでいけるのではないか?
https://tech-blog.abeja.asia/entry/environment-of-building-docker-image-for-jetsonおそらく誰でもやっていると思いますが、勉強がてら自分でも調べながらやってみます。
なにせ、AWSもAZUREも全然使っていないので練習練習。
- 投稿日:2019-07-14T16:07:31+09:00
AWS Cloud9の環境をコピーする
普段からAWS Cloud9の環境で開発していると、環境をコピーしたいと思うことが多々あります。
ググってもピンポイントな記事が無かったので、今回も備忘録的にやり方を残しておきます。前提
そもそも、AWS Cloud9は(多くの場合)EC2インスタンス上で動いているので、
環境をコピーする場合はEC2インスタンスを複製し、
そのEC2インスタンスに繋ぐ環境を新規に作ってあげればよいことになります。EC2インスタンスの複製
このへんのやり方は詳しく説明してくれている記事がいくつもあるので、
それを見ながらやればいいと思います。
Amazon Web Services(AWS) のEC2でインスタンスをコピーする方法AWS Cloud9から接続
次に、AWS Cloud9から上記で複製したEC2インスタンスに接続します。
やり方は以下が参考になります。
AWS Cloud9を東京リージョンのEC2で使う方法ちなみに、接続を行う過程でEC2インスタンスのCUIを操作する必要があるので、
TeratermなどでSSH接続する必要があります。
【初心者向け】Amazon EC2にSSH接続する【Windows、Macintosh】完成
これで完了です。
途中エラーになる場合、EC2インスタンスのセキュリティグループの設定などが上手くいっていない可能性があります。
AWS Cloud9のダッシュボードからボタン一つでできるようになればいいのに・・・注意:このやり方では、AWS Cloud9上でSSH接続の扱いになるため、インスタンスの自動シャットダウンの対象にならないようです。EC2の管理画面から操作すれば問題ないですが、若干めんどくさいですね。。。
- 投稿日:2019-07-14T15:34:35+09:00
WebSocket - AWSのサンプルで API Gateway を使ったchatアプリを作ろうとしたらハマった件
はじめに
「[発表]Amazon API GatewayでWebsocketが利用可能 - AWS」と「【新機能】APIGatewayでWebSocketが利用可能になったのでチャットAPIを構築してみた - Qiita」を参考にして、API Gateway を使用したチャットを作成しようとしたら思わぬところでハマったので、解決したときのメモです。
APIGateway で実現する WebSocket
「[発表]Amazon API GatewayでWebsocketが利用可能 - AWS」にある通り、2018年12月19日に Amazon API Gateway で WebSocket 通信を実現出来るようになりました。
AWS ではこの機能を使用した簡単なチャットアプリを「simple-websockets-chat-app - Serverless」や「aws-samples/simple-websockets-chat-app - GitHub」で公開しています。
このサンプルアプリは以下のような構成で実装されています。
このコードの解説は、「【新機能】APIGatewayでWebSocketが利用可能になったのでチャットAPIを構築してみた - Qiita」という記事で詳細に解説されています。
メッセージが正しく送れない問題
記事を見ると、AWSが公開しているコードをそのままデプロイすれば問題なく動作しているようでしたが、自分がやってみると正しく送ることが出来ませんでした。
Lambda のデバッグログを確認しながら見てみると、
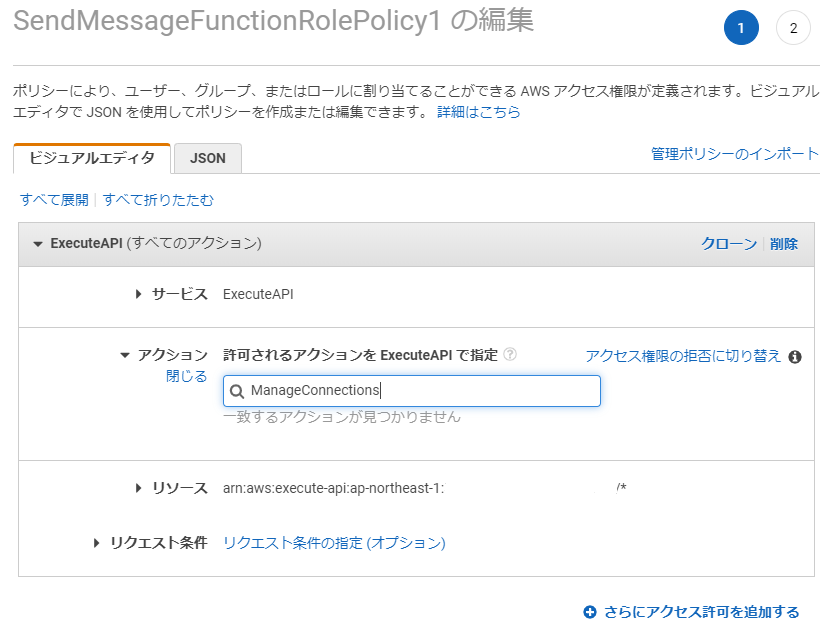
sendMessageの処理をしている箇所でエラーを吐いているようでした。ここで、
sendMessageの Lambda 関数に設定された IAM Role の設定状況を見てみると、以下のように、execute-api:ManageConnectionsが正しく設定されていません。
AWSの記事を見ると、確かに設定が必要と記載がありますが、マネジメントコンソール上では「一致するアクションが見つかりません」となってしまいます。
接続されたクライアントに呼び出しを行うには、アプリケーションに新しいアクセス権 “execute-api:ManageConnections”が必要です。 これは、AWS SAMテンプレートで処理されます。
cf. [発表]Amazon API GatewayでWebsocketが利用可能 - AWSここで、
execute-apiにアクションとして設定出来る選択肢の一覧を探したのですが、以下の記事ではInvalidateCacheとInvokeの2つしか記載がありませんした。
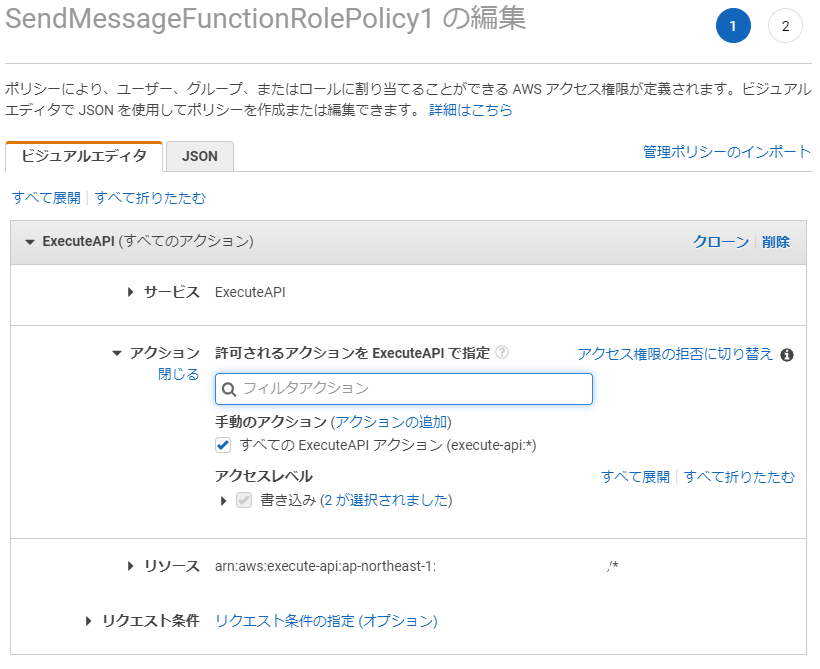
cf. Actions, Resources, and Condition Keys for Amazon API Gateway - AWS Identity and Access Management対策
現状では、以下の図のように「すべての ExecuteAPI アクション」を指定することで、期待する動きを確認することが出来ました。
ドキュメントのアップデートが遅れることはあると思うので、
execute-api:ManageConnectionsが設定出来ないのは日本のリージョンだけなのかもしれませんが、思わぬところでハマってしまいました。参考
APIGatway
IAM
execute-api
- API 実行アクセス権限の IAM ポリシーの例 - Amazon API Gateway
- API を呼び出すためのアクセスの制御 - Amazon API Gateway
- IAM アクセス権限により API へのアクセスを制御する - Amazon API Gateway
- IAM ユーザー認証の使用 - Amazon API Gateway
- Actions, Resources, and Condition Keys for Amazon API Gateway - AWS Identity and Access Management
- AWS Lambda Websockets - Medium
- API Gateway での REST API へのアクセスの制御と管理 - Amazon API Gateway


- 投稿日:2019-07-14T13:50:27+09:00
Laravel + Nuxt + Fargate + ALBでドメインを設定しhttps通信を実現する
下準備
下記の手順でドメインの名前解決は完了させる
【AWS】お名前.com で取得した独自ドメインを Amazon Route 53 で名前解決して EC2 インスタンスの Web サーバーにアクセスさせる手順証明書の発行
お名前で購入したドメインをAWSのALBにhttpsの設定して使う方法。
ALBに対してhttps通信の設定
ALBで今はリダイレクトもやってくれてNginxでリダイレクトの設定を行わなくてもいいらしい
ALBを使ってる時はNginxでhttp->httpsへリダイレクトの設定しなくて良くなった
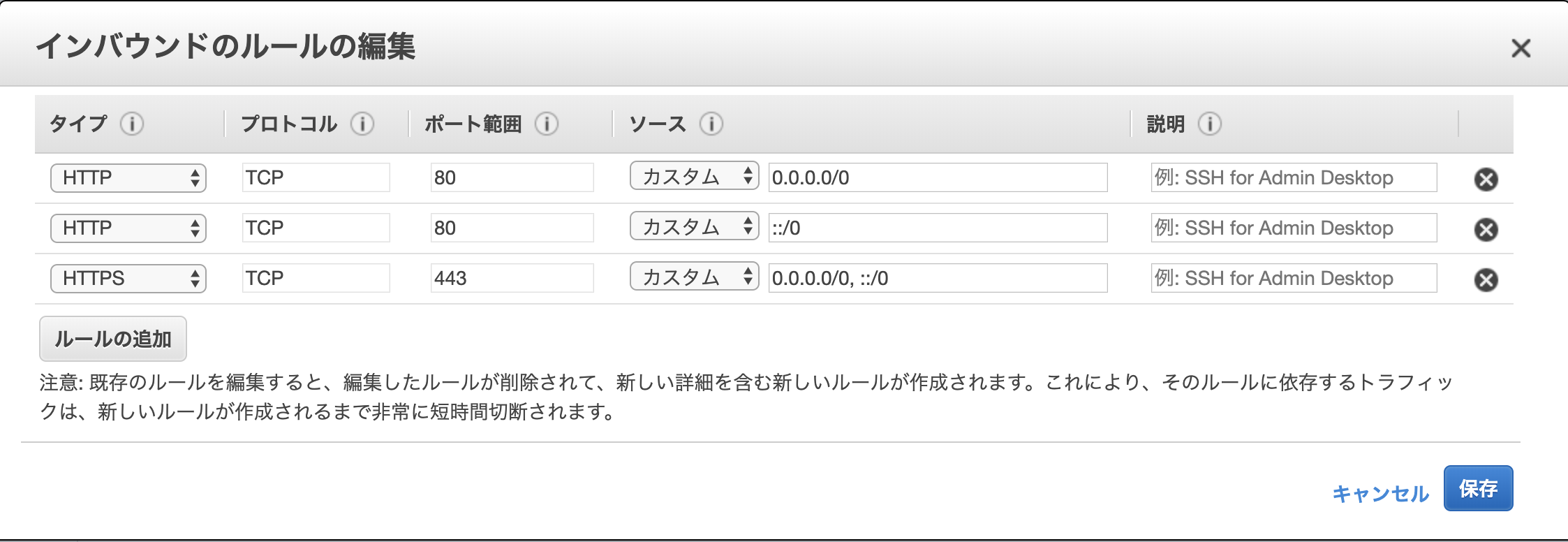
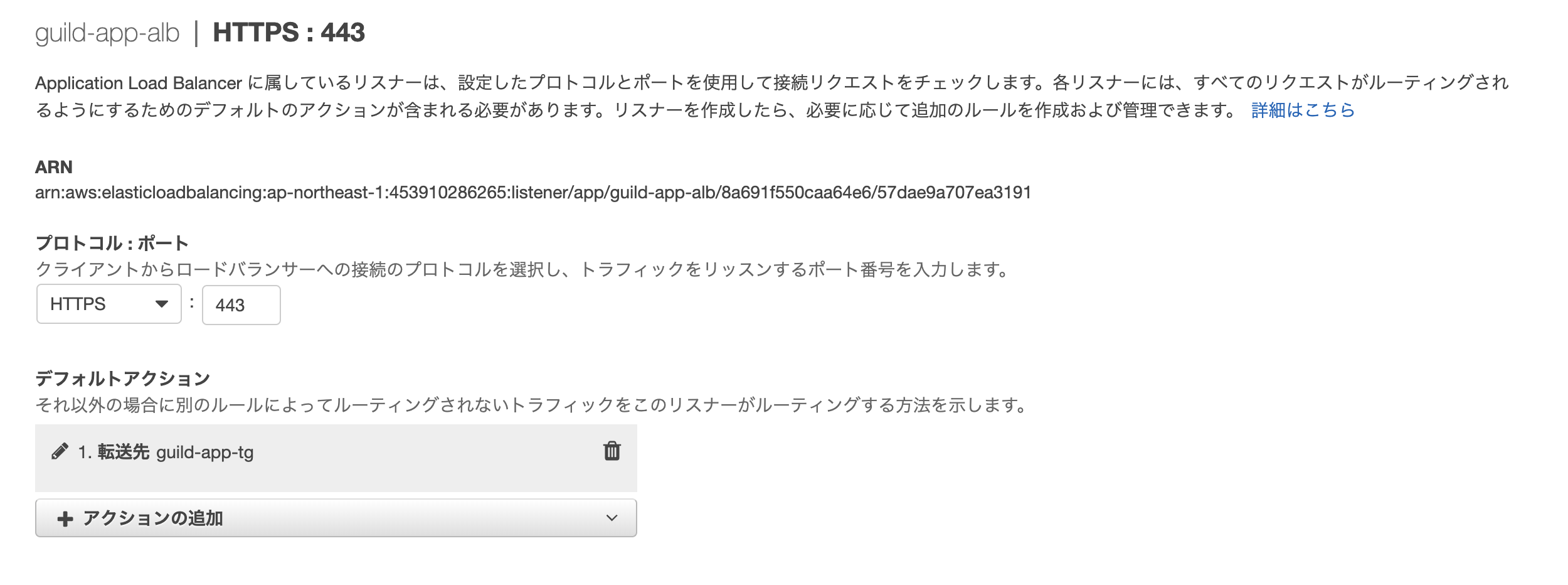
http(80ポート)をhttps(443)にリダイレクトを行う
ALBのセキュリティグループの設定にHTTPSを追加する
ALBのリスナーにHTTPSを追加する
- 投稿日:2019-07-14T12:52:01+09:00
S3からRedshiftにcsvデータを読み込む方法
はじめに
データ分析の独学をするときに環境としてAWSのRedshiftを使おうとしたが、
そもそも初心者なので、色々と手こずった。久しぶりメモとして投稿。ロール作成
Identity and Access Management (IAM)にルールを決めることができるので、
AmazonS3ReadOnlyAccessのみを利用できるルールを作る。クラスタ作成
Redshiftは無料枠があるので、それを利用する。
クイック起動して、ロールを設定してあげる。Query editor
データベースの接続をする(初回のみ)クラスタの設定見れば問題ない。
あとは普通のデータベースと同じ。テーブル作る。S3にアップロード
特記ない。
S3から読み込む
コピーコマンドCOPY 'テーブル名' FROM 's3のパス' IAM_ROLE 'ロール名' IGNOREHEADER 1 CSV;これでエディタで確認できればOK。
無理ならエラーコマンド一つずつ潰すのみ。参考
- 投稿日:2019-07-14T06:08:40+09:00
AWSの勉強
Alexaを買ってアプリを作っているうちにAWSについても勉強しようと思ったので、そのメモ。
1.IAM(あいあむ)ユーザーの設定
2.CloudWatch機能を使って料金アラートを設定する
3.見積方法
http://calculator.s3.amazonaws.com/index.html?lng=ja_JPネットワーク
基本
東京リージョンの中に、リージョンが3つある。
サブネットはリージョンに紐付く。
ルートテーブルはサブネット単位に設定する。使用できるIPアドレス
0,1,2,3,最後の5個はAWSが予約しているため使用できない
Elastic IPアドレス
IPアドレスを固定。
基本は無料だが、サーバが止まっている場合は料金がかかるので注意S3(Simple Storage Service)
サービス一覧
No サービス名 説明 重要度 1 VPC 〇 2 EC2 Elastic Compute Cloud。クラウド内の仮想サーバ 〇 3 RDS 〇 4 ELB 5 S3 〇 6 Route 53 7 IAM 8 1.VPV
2.EC2
サーバを利用できる
2-1.ポイント
- OS / Imageの選択
- インスタンスタイプの選択
- ストレージの選択
- セキュリティグループの設定
- SSHキーペアの設定
2-2.SSHでの接続
IPアドレス:"IPv4 パブリック IP"の値
ユーザー名:ec2-user
パスワード:ダウンロードしたSSHキーファイルを指定99.おまけ
99-1.Teraterm
Beep音を止める
INIファイルに「Beep=on」となっている個所があるので、offにする。
SSH接続のユーザ名を自動入力
「SSH認証」画面で設定する。
99-2.Linuxの設定
ホスト名の変更
以下を参照
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/set-hostname.html
https://www.opensourcetech.tokyo/entry/2018/05/08/CentOS7_%E3%81%AE%E3%83%9B%E3%82%B9%E3%83%88%E5%90%8D%E8%A8%AD%E5%AE%9A%E3%81%AB%E3%81%A4%E3%81%84%E3%81%A6%EF%BC%88hostname_/_nmcli_/_nmtui_/_hostnamectl_/_uname%EF%BC%89OS の言語設定
sudo vi /etc/sysconfig/i18n
====
前)LANG=en_US.UTF-8
後)LANG=ja_JP.UTF-8
====
OS の時刻設定
sudo cp /usr/share/zoneinfo/Japan /etc/localtime
sudo vim /etc/sysconfig/clock
====
ZONE="Asia/Tokyo”
====
ミドルウェアのインストール
- 投稿日:2019-07-14T01:02:20+09:00
AWS Windowsサーバでファイル共有接続できなかった問題
Windows サーバーを利用したファイルサーバーの構築方法
「フェーズ3-2 ファイルサーバーの設定と接続」で詰まった件についてメモ結論としては、セキュリティグループで445ポートを解放すれば解決した。
EC2作成までは順調
フェーズ 1-1:コンソールへのサインインと VPC の作成 ≫
問題なし
フェーズ 1-2:サブネットを追加作成 ≫
問題なし
フェーズ 2-1:Amazon EC2 インスタンスの作成 ≫
以下のエラーが出たが、時間を置いたら解決したので問題なし
Your request for accessing resources in this region is being validated, and you will not be able to launch additional resources in this region until the validation is complete. We will notify you by email once your request has been validated. While normally resolved within minutes, please allow up to 4 hours for this process to complete. If the issue still persists, please let us know by writing to aws-verification@amazon.com for further assistance.
フェーズ 2-2:Elastic IP(固定 IP)の割り当て ≫
問題なし
フェーズ 3-1:Windows サーバーへのリモートデスクトップ接続 ≫
問題なし
問題のフェーズ3-2
フェーズ 3-2:ファイルサーバーの設定と接続 ≫
c直下に/Shareを作成し、右クリックから共有設定
準備が完了したので、クライアントPCからファイル共有接続を試みると、ネットワークエラー(エラーコード:0x80070035)になった。
セキュリティソフトのせいかな?と別PCから試みるも同様のエラー。他にもコントロールパネルから共有設定(サーバー、クライアント)を変更したが、これでも効果なし。
なんでだろう?と思いつつ、サーバーに対してping飛ばしてみると、これも反応なし。
→GUI接続できていて、pingが届かないのはおかしいので、調べてみると以下の記事がヒット。
罠】AWSのEC2インスタンスにPingが通らない原因と解決方法【瞬殺】ありがてえ。pingは通った!
この辺りでなんかAWS側の設定が怪しそうだなーと思いつつも、Windows共有について調査・・・
そういえば、ネットワークエラーのトラブルシューティングの詳細見てなかったな~と思い、詳細を覗いてみると良さげなヒントが書いてあった。ファイルとプリンターの共有リソース(192.168.1.2)はオンラインですが、接続試行に応答しません。
リモートコンピュータはポート445での接続に応答していません。ファイアウォールなたはセキュリティポリシーの設定、あるいはリモートコンピュータが一時的に利用できないことが原因である可能性があります。コンピュータ上のファイアウォールには何の問題も見つかりませんでした。
リモートコンピュータはポート445での接続に応答していません。これっぽい?と思い、セキュリティグループでポート445を許可すると...ようやく繋がった。
反省点
ここのファイル共有接続の部分で2時間近く躓いていた。
主な原因としては、以下の2点だと思う。
1. ハンズオン資料(ステップ 1: ファイル共有の設定(Windowsサーバー))に「※Windows の操作になりますので、詳細設定ついては記載しておりません。」とあったので、自分のWindows共有設定の知識不足が原因だと思い込んでいた。
2. Windowsのトラブルシューティング機能を重要視していなかった。感想・まとめ
とりあえずできてよかった。
ちなみに445ポート(SMB)はファイル共有やプリンタ共有辺りの設定になるらしい。開けないとだめよね。
なかなかハンズオン資料通りには行かないなあ。
(資料ではセキュリティグループ設定デフォルトだったし、ポートを開ける必要があるとか書いてなかったじゃん!(言い訳))