- 投稿日:2021-03-22T23:59:31+09:00
Python実践データ分析100本ノック作業記録【第一章~第二章】
はじめに
第一章の残りだけで終わらせようと思ったら、大半が写経になったから第二章までやることにしました。
最近、チーム内でデータ解析を行うことが増えたのでこの経験を活かせるのがちょっと嬉しい。
第一章続き(抜粋)
ノック8
試しに年齢で振り分けて消費金額の年代別の差を見たい場合、
次のようにすれば良い。
numpy由来ののブロードキャストのおかげで楽にかけて良いね。joined_dataframe["age_div10"] = joined_dataframe["age"] // 10 print(joined_dataframe.groupby("age_div10")["price"].mean())ノック10
matplotlibもまともに扱ったことがなかったので、試しにコンソールにユーザーガイドのを書き込んでみたら、import後にこんな表記が出た。
Backend TkAgg is interactive backend. Turning interactive mode on.
下記ソースをコンソールに流し込んだら勝手にグラフが出てきたけど、同じ内容のpyファイルを作ってそれを実行させたらグラフが出てこず、axes.show()をしなければグラフが出てこなかった。
インタラクティブモードってそういうことか。import matplotlib.pyplot as plt import numpy as np fig, ax = plt.subplots() # Create a figure containing a single axes. ax.plot([1, 2, 3, 4], [1, 4, 2, 3]) # Plot some data on the axes.ある程度は写経をしていたが、python自体はそれなりに触っているため、
最後のplotの部分は体が受け付けず、下記のような作りに書き換えた。month_axis = list(graph_data.index) item_type_list = list(graph_data.columns) for data_name in item_type_list: plt.plot(month_axis, graph_data[data_name], label=data_name) plt.legend() plt.show()第二章
ノック11
第一章のときのライブラリ構造に追加し、openpyxlとxlrdを追加。
例外のメッセージにに従って順番にインストールしていたので、xlrdはいらなかったかも。
xls形式のデータを読むときは必須だったはずだけど。ノック15
複雑そうな処理だけど、まずは自分の頭で考えてみたかったから考えてみた。
第一章のような商品マスタを作ることを意識して結合すればいけると思う。まずは各商品ごとに値段候補を書き出してみる。
import pandas as pd customer_data = pd.read_excel("kokyaku_daicho.xlsx") sell_report = pd.read_csv("uriage.csv") sell_report["purchase_dt"] = pd.to_datetime(sell_report["purchase_date"]) sell_report["purchase_month"] = sell_report["purchase_dt"].dt.strftime("%Y%m") sell_report["item_name"] = sell_report["item_name"].str.upper() sell_report["item_name"] = sell_report["item_name"].str.replace(" ", "") sell_report["item_name"] = sell_report["item_name"].str.replace(" ", "") item_price_table = sell_report[["item_name", "item_price"]] for name in sell_report["item_name"].unique(): price_list = item_price_table[item_price_table["item_name"] == name]["item_price"].unique() print(name, price_list, end=" / ")下のような出力を意図通りに得られた。NaNではない方を抽出して商品名と価格のDataFrameを作って結合すれば良さそうだ。
商品A [100. nan] / 商品S [ nan 1900.] / 商品Z [2600.] / 商品V [2200. nan]
つまり、for文以下はこうなる。
for name in sell_report["item_name"].unique(): price_list = all_sell_item_price_table[all_sell_item_price_table["item_name"] == name]["item_price"].unique() item_price_table = item_price_table.append({"item_name": name, "item_price": [price for price in price_list if not math.isnan(price)][0]}, ignore_index=True) sell_report = pd.merge(sell_report.drop(columns="item_price"), item_price_table, on="item_name")本の方ではlocプロパティが使われていた。そっちのほうが上のソースに相当する処理が1.5倍早かった。
第二章の残りは本とコードと変わらないので省略。
次回、第三章から。
もうそろそろ毎回printするのが面倒になってきたからJupyter Notebookを使うかな。
- 投稿日:2021-03-22T23:30:39+09:00
自分自身のフィールド値を利用したannotate処理
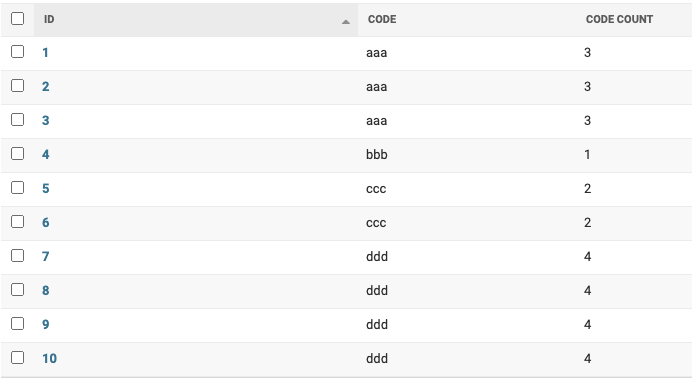
やりたいこと
class MyModel(models.Model): code = models.CharField(max_length=10)こんな感じのモデルで、
こんな感じで同じコードが設定されている数をカウントしたい。
ナイーブな解法と問題点
class MyModelAdmin(admin.ModelAdmin): list_display = ( 'id', 'code', 'code_count', ) def code_count(self, obj): return MyModel.objects.filter(code=obj.code).count()adminやmodelにメソッド追加すればできはするが
こんな感じでレコードの数だけsqlが発行される。
(n+1問題が発生する)SubqueryとOuterRefを使用したannotate
SubqueryとOuterRefを使って自分自身のcodeを使ったsubqueryを発行すればできる。
from django.contrib import admin from django.db.models import Count, OuterRef, Subquery from .models import MyModel @admin.register(MyModel) class MyModelAdmin(admin.ModelAdmin): list_display = ( 'id', 'code', 'code_count', ) def get_queryset(self, request): sub_query = MyModel.objects.filter( code=OuterRef('code') ).values('code').annotate(count=Count('code')).values('count') return MyModel.objects.annotate(code_count=Subquery(sub_query)) def code_count(self, obj): return obj.code_count
code=OuterRef('code')で外側にある自分自身のcodeで絞る。
codeの数でカウントを取りたいので.values('code')とannotate(Count('code'))でGroup化する。sub_queryの結果は1つじゃないといけないので、 最後に
.values('count')でcodeのカウント数だけ返す。あとは
code_countという名前で先程作ったsub_queryをannotateしてあげる。これで objectに
code_countというcode件数のattributeがつくので、methodでその値を返してあげると完成。
行数分発行されていたqueryが1つにまとまった。
発行されるsql文はこんな感じ。
外側のcodeを使って、内側で
code_countを作っているのがわかる。
調べてもわからなかったのにコード書いたあとで下記のキーワードでググったら同じようなコードが見つかった。
django count outerref



- 投稿日:2021-03-22T23:29:02+09:00
julia v1.5.4から始めるJupyter Notebook
前回、juliaをインストールしたあと思うところあって、環境をきれいにしたところ、juliaがちょっとバージョンアップしていた。特に困ったことはないけど再々々々度書いてみる。
やってみた環境
- Windows 10 Home (64bit) Ver 20H2 (OSビルド19042.868)
- julia v1.5.4 (64bit)
やり方
- juliaがインストール済みの前提(インストーラー版)
- juliaのコンソールを起動(緑字のプロンプト)
]キーを押してパッケージモードへ(青字のプロンプトになる)add IJuliaを実行(Installing known registries into ~となり、しばらく時間がかかる)- Building IJulia → ~と出て完了
- バックスペースでパッケージモードを抜ける(緑字のプロンプト)
using IJuliaを実行(Precompilingされる)notebook(detached=true)を実行- 「install Jupyter via Conda, y/n? [y]:」と聞かれるので
yを入力- 関連パッケージがダウンロードとインストールされる。(結構時間がかかるので気長に待つ)
- Jupyterが起動する!「New」のプルダウンにはJulia 1.3.1、Julia 1.4.2、Julia 1.5.4とpython 3が出てくる
juliaからインストールしたcondaはjulia専用(?!)なのでDisk容量がもったいないといえばもったいないけど、面倒なことを考えないでJupyterが使えるようになるのでまずやりたいことをやる!という場合にはいいんではないでしょうか?
ちなみにjuliaからインストールしたcondaでインストールしたパッケージの確認などは次のようにします。
julia> using Conda Julia> Conda.list() # Condaでインストールしたパッケージ一覧 Julia> Conda.update() # Condaでインストールしたパッケージのアップデート Julia> Conda.install("package_Name") # Condaで"package_Name"をインストール⇒「conda install -y package_Name」を実行 Julia> Conda.clean() # Condaでインストールされた不要なパッケージの削除上記の
using Condaでエラーが出る場合は一回だけ次のようにパッケージを追加する必要があります。
]キーを押してパッケージモードへ(青字のプロンプトになる)(@v1.5) pkg> add Conda普段のjupyter起動
念のためですがインストールが終われば次からは下記だけでjupyter Notebookが起動します。
julia> using IJulia julia> notebook(detached=true)
- 投稿日:2021-03-22T23:21:35+09:00
pymooを使って多目的最適化のNSGA-Ⅱを実装してみた
- 製造業出身のデータサイエンティストがお送りする記事
- 今回はpymooを使って多目的最適化手法の中で、NSGA-Ⅱを実装しました。
はじめに
過去に多目的最適化(NSGA-Ⅱ)ををご紹介しておりますので、概要的な部分はこちらの記事を参考にしてください。
また、deapを使ってNSGA-Ⅱも記事として書いておりますので、参考にしてください。使用するライブラリー(pymoo)
今回は最適化ライブラリpymooを使って実装したいと思います。
NSGA-Ⅱの実装
NSGA-Ⅱの実装コードは下記の通りです。
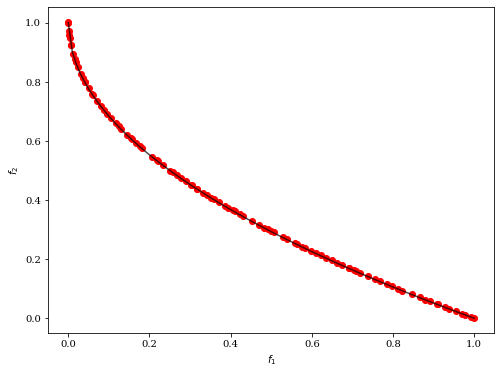
今回は多目的最適化問題における一般的な問題の一つとして、ZDT4を使用しました。# 必要なライブラリーのインポート from pymoo.algorithms.nsga2 import NSGA2 from pymoo.factory import get_problem from pymoo.optimize import minimize from pymoo.visualization.scatter import Scatter problem = get_problem("zdt4") algorithm = NSGA2(pop_size=100) res = minimize(problem, algorithm, ('n_gen', 250), seed=1, verbose=False) plot = Scatter() plot.add(problem.pareto_front(), plot_type="line", color="black", alpha=0.7) plot.add(res.F, color="red") plot.show()
deapと違って凄い簡単ですね。
簡単に何を行っているかを説明しますと、
- problem:問題を定義しております(今回はzdt4を使用)
- algorithm:アルゴリズムを定義しております(今回はNSGA2)
- minimize:目的関数の最適化方向を定義しております(今回は最小化)
- n_gen:世代数
- pop_size:集団内の個体数
あとは可視化を行っているだけです。
さいごに
最後まで読んで頂き、ありがとうございました。
今回は、pymooを使って多目的最適化のNSGA-Ⅱを実装しました。
凄い簡単にできました。ただ、実際の業務で使用する際は、細かい制約条件をどこまで落とし込めるライブラリーなのかを調査する必要がありそうです。
時間があるい時に確認しようと思います。訂正要望がありましたら、ご連絡頂けますと幸いです。
- 投稿日:2021-03-22T21:22:02+09:00
チートシート ~ 入力 ~
目次
1-入力が1つのみの場合
N = int(input())
2-入力が1行で複数の場合
2.1-入力が1行で数個の場合X,Y = map(int,input().split())
2.2-入力が1行で多数の場合mat = list(map(int, input().split()))
3-入力が複数行で各行に1つずつの場合mat = [int(input()) for _ in range(N)]
4-入力が複数行で複数の場合1-入力が1つのみの場合
input_1.pyN = int(input())入力の型に応じて
intの部分を str とか float とかに変更2-入力が1行で複数の場合
2.1-入力が1行で数個の場合
input_2.1.pyX,Y = map(int,input().split())
X,Yの部分を、入力と同じ数の任意の変数に変更2.2-入力が1行で多数の場合
input_2.2.pymat = list(map(int, input().split()))入力数に関わらず自動で1次元配列が作成され、入力が要素として順に格納される
3-入力が複数行で各行に1つずつの場合
input_3_A.py#N = int(input()) mat = [int(input()) for _ in range(N)]下のやつよりもこっちのほうが楽ですね
そもそもこういうタイプの入力はあまりAtcoderでは見ないけど.....input_3_B.pyN = int(input()) mat = [0]*N for i in range(N): mat[i] = int(input()) #print(mat)for文で入力が1つのみの場合を回して、用意した配列に順に格納していくだけ
4-入力が複数行で複数の場合
input_4_A.pyN,M = map(int,input().split()) mat = [[0] * M for i in range(N)] # [[0] * 横 for i in range(縦)] for i in range(N): tmp = list(map(int, input().split())) for j in range(M): mat[i][j] = tmp[j] #print(mat)入力が複数行で各行に1つずつの場合と同じことを2次元配列でやる
2次元配列を使うと行と列を混合しやすいので注意input_4_B.pyN = int(input()) X = [0]*N Y = [0]*N for i in range(N): x,y = map(int,input().split()) X[i] = x Y[i] = y #print(X) #print(Y)2次元配列を使うと混乱しやすいので、入力が数種類ならそれぞれ別に配列を作成して格納する方が楽
input_4_C.pyH,W = map(int,input().split()) mat = [[0] * W for i in range(H)] # [[0] * 横 for i in range(縦)] for i in range(H): tmp = str(input()) for j in range(W): mat[i][j] = tmp[j] #print(mat)Atcoderでよくある
#と.で地図とかを表すような入力用(入力が数字か文字列かの違い)
出力でこの形式を使わないなら、最初に扱いやすいよう0/1とかに変換しといた方がいいかも
- 投稿日:2021-03-22T21:07:25+09:00
【衛星画像解析】夜間光データから機械学習を使ってGDPを推定してみた
こんにちは、しゅれぬこ(@syurenuko)です。
この記事を書いている2021年3月現在、データ分析コンペプラットフォーム「Solafune」にて、「夜間光データから土地価格を予測」という非常にChallengingな内容のコンペが開催されています。
ざっくりどういうコンペか説明しますと、PlaceID(匿名化された地域ID)、Year(年)、MeanLight(その地域の平均光量)、SumLight(合計光量)の4つが与えられて、未知のテストデータのAverageLandPrice(土地価格)を予測せよといった内容です。
土地価格が決まる要因として、都市部に近い、開発が進んでいて将来性が見込めるなどの様々なものがありますが、このコンペでは夜間光からいかに正確に土地価格を予測できるのかを競います。夜間光はその土地の経済活動と密接な関係にあるため(都市部では光は強く、地方や自然が多い地域では光は弱くなる)、経済指標として活用したり、経済動向を分析・予測するといった活用事例があるとのこと。
え、じゃあ夜間光データを使って土地価格以外にも何か予測してみよう!
と思い付いてしまったので、各国の経済状況の指標であるGDP(国内総生産)の推定ができないか試してみました。
もちろん使えるデータは「夜間光データから得られる情報のみ」です。
果たしてどれくらいの精度が得られるのか検証です!実行環境
Google Colabratory
今回の記事で使ったコードは全て私のGitHub上で公開しています。参考記事&データ出典
記事作成にあたり、以下の記事を参考にさせていただきました。
【入門】Pythonによる人工衛星データ解析(Google Colab環境)
Python&R: 総合データサイトDatahubの使用法, R使用したデータサイト
Version 4 DMSP-OLS Nighttime Lights Time Series
【DataHub】Country, Regional and World GDP (Gross Domestic Product)
国土数値情報(国土交通省)機械学習で使用したデータセットはDMSP-OLS衛星の夜間光画像(2009
年)、DataHub.ioのGDPデータ(2009年)から独自に作成しました。1. 夜間光データを観察してみる
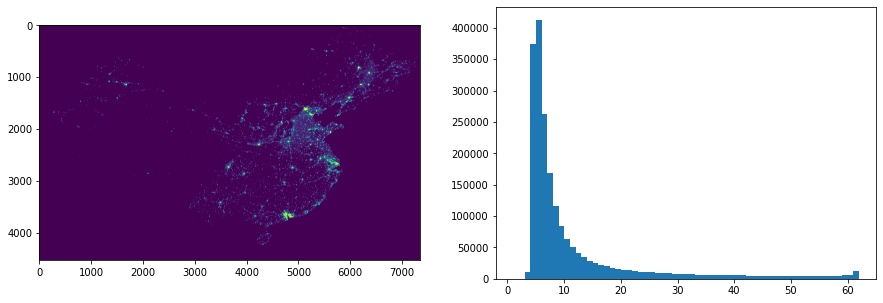
まずは衛星画像から夜間光データがどのようなものなのか観察してみます。
夜間光コンペの出典が”DMSP-OLS”ということで、ここのデータセットの衛星データを使いました。各国の夜間光、光量の分布を可視化してみます。
・日本
・ドイツ
・中国
・イギリス
綺麗ですね(小並感)
都市部に光が集中していることがよくわかると思います。DMSP-OLS衛星には以下の特徴があります
- 解像度が1kmメッシュ
- 1kmメッシュごとに光量0~63の離散値を取る
- 63段階の光の明るさは必ずしも比例していない(63以上は飽和していて正確に反映できていない)
- 雲の影響で光を上手く検知できていない可能性がある
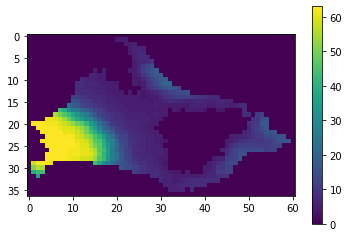
夜景で有名な函館市の夜間光を可視化してみました。
1k㎡のピクセルで光量が可視化されていることがよくわかると思います2. 特徴量生成
GDPを推定するにあたり、有効であると思われる特徴量を作成していきます。
夜間光データ縛りということで特徴量を捻り出すのが大変そうです...ということで以下の特徴量を作成しました。
GDPとの相関も確認していきます。(図の圧倒的にGDPが高い国はアメリカです)
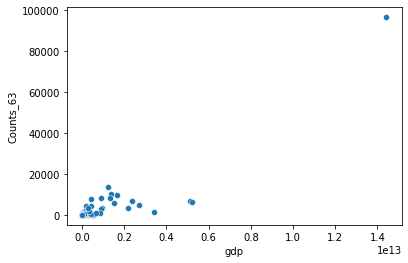
SumLight(合計光量)
光量の合計値です。合計光量が多いとその分経済活動が活発であると考えられるため、推定に寄与する特徴量になりそうです。実際にGDPとの関係を可視化すると合計光量が増えるに従ってGDPが増加する相関が確認できます。
MeanLight(平均光量)
その国の面積の1㎢のピクセルあたり、平均してどれだけの光量をとっているのかの数値です。必ずしも平均光量の数値が高いからといってGDPも高いとは限らないことがわかります。経済活動が活発なGDPが高い国でも、光量も上から下までバラつきがあり国土面積がある程度あると平均光量はそこまで高くならない、ということでしょうか。
Area(面積)
その国の面積です。面積が大きい分それに比例して経済活動の総量も増えるのでは、という仮説を立てて特徴量作成しました。(今回は1~63の光が検出された部分の合計を面積としたので実際の国土面積とは異なります。)確認してみると面積とGDPにはある程度の相関がありそうです。
Counts_63(最大光量である光量63の個数)
先ほどDMSP-OLS衛星の特徴で述べましたが、63段階の光は完全に比例していないため、飽和状態の可能性がある光量63に関しては別に考える必要があります。(例えば光量100相当の光であっても上限の光量63になっている)そこで光量63を取るエリアに関しては「特に経済活動が活発である」とみなし、この1k㎡のエリアがいくつあるのかカウントします。
Percentage_63(光量63の割合)
「Counts_63」からの流れで、全体のうちの光量63の割合です。光量63の割合が高いからといってGDPが高いことにはならないようです。
Variation(光量のばらつき(変動係数))
光が検出された1k㎡のエリアは1~63の値を取りますが、国によってこの63段階の光量のばらつきがどの程度なのか調べてみます(標準偏差だと面積のスケールによって値が左右されてしまうので、変動係数を用いてばらつきを調べます)
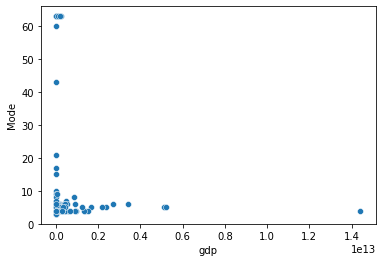
Mode(その国の最頻値の光量)
国によって1~63の光量のうち、どの光量が最も頻繁に現れるのかを調べました。
光量max付近の数値を出してる国があったので、Modeで降順ソートして調べたらこの国々でした。
マカオ、香港、シンガポールなど国土面積が狭く、経済活動が活発な国が目立ちますね。
シンガポールに至っては全体の86%が光量63...・【参考】シンガポールの夜間光画像(真っ黄色でした)
推定に効くのか微妙なのもありましたが、パッと思いついた特徴量はこれくらいですね...
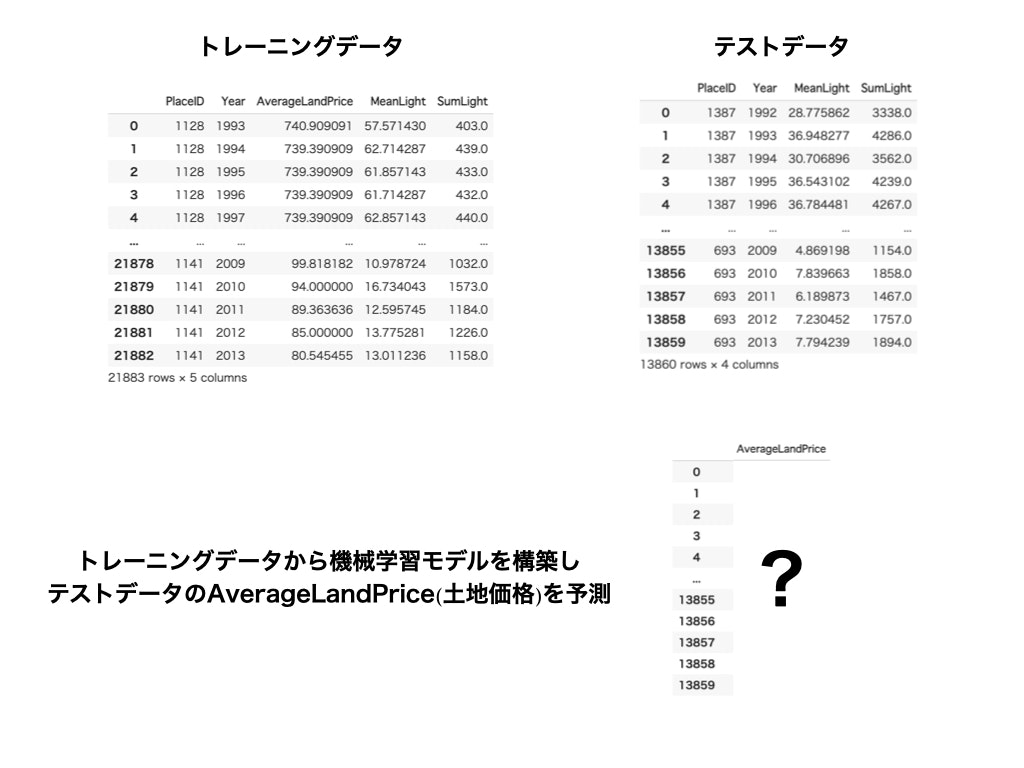
とりあえずこれで学習を回してみましょう!3. トレーニングデータとテストデータに分割する
トレーニングデータ(機械学習で学習するデータ)とテストデータ(GDPの推定に使うデータ)に分割していきたいと思います。
GDPですがばらつきがかなり大きかったため、GDPの外れ値(第一四分位数ー1.5×四分位範囲以下 or 第三四分位数+1.5×四分位範囲以上)を取る国は今回の検証では対象外としました。外れ値除去の結果残った171の国のデータを使っていきますということでtrain_test_split(test_size=0.25)でトレーニングデータ128個、テストデータ43個に分割しました。
機械学習モデルから推定されたGDPと実際のテストデータのGDPの値を比べて、夜間光データからどれくらい正確に推定できているのかを調べます。
4. LightGBMで学習してみる
予測に当たって使用する機械学習モデルに、線形回帰やランダムフォレスト、NNなどがありますが、今回はKaggleなどの機械学習コンペの上位解法でもよく使われるGBDT系の機械学習アルゴリズム、”LihghtGBM”を使ってGDPを推定してみたいと思います。
k分割交差検証(n_split=5)で学習させます。
(データ数が少ないので学習に1秒ほどしかかかりませんでした笑)一応下図がfeature importanceです。
SumLight(合計光量)が最も推定に寄与しているという結果になりました。
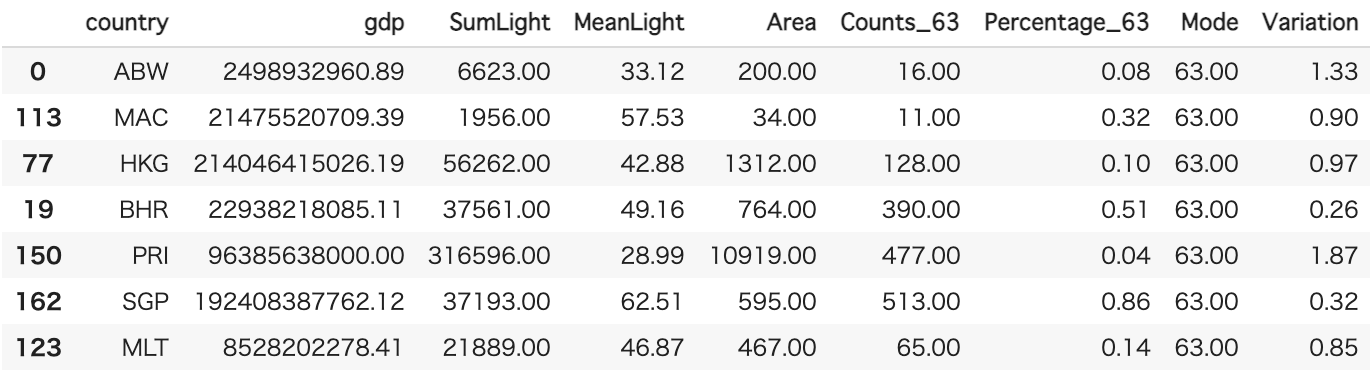
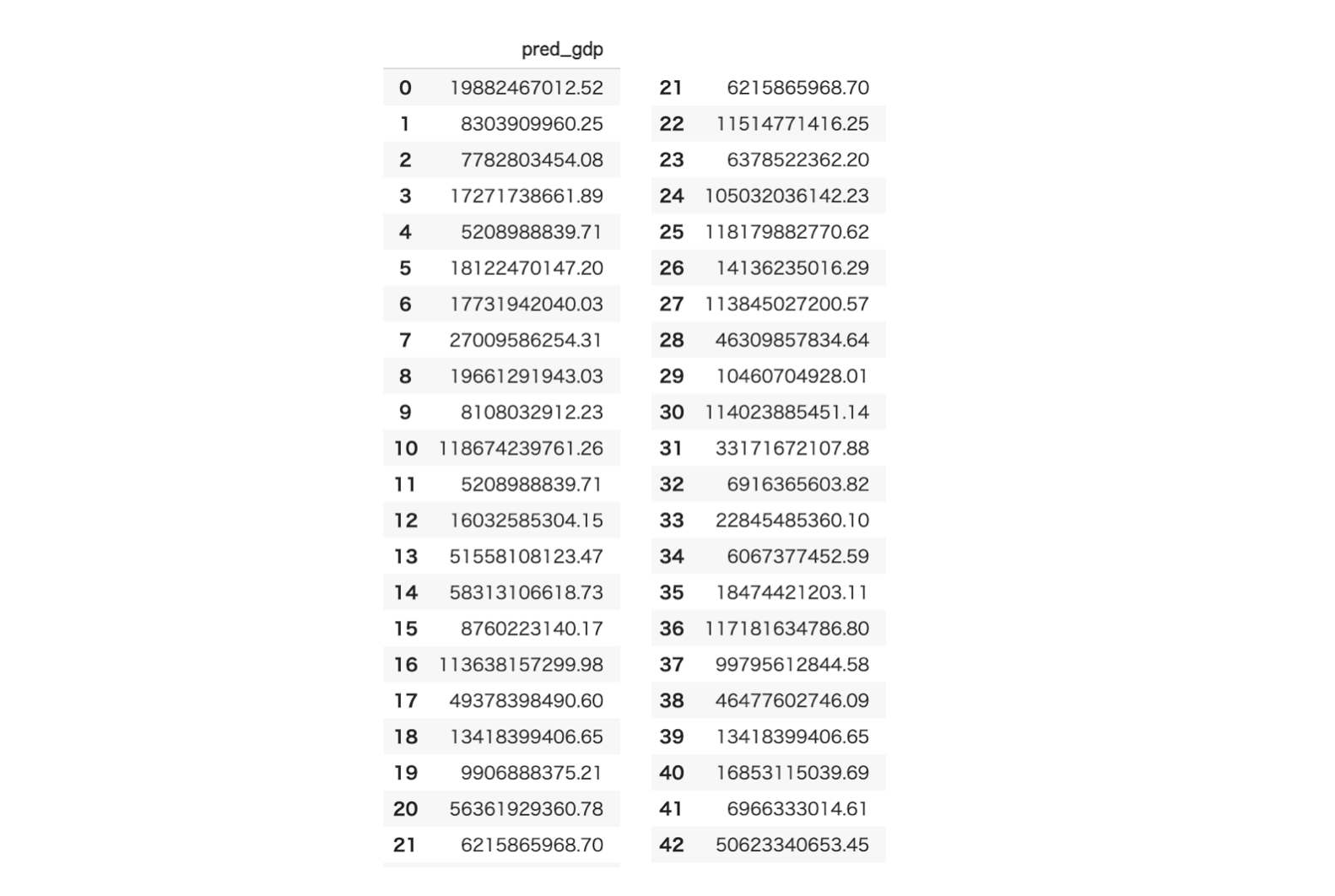
推定されたテストデータのGDP一覧が以下になります。
5.推定されたGDPと実際のGDPの値を比べてみる
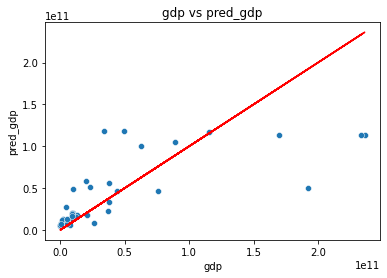
では推定されたGDPと実際のGDPを比べてみましょう。散布図を作成し、両者の値が一致している赤い直線上からどれくらい外れているのか見てみます。決定係数(1に近いほど正確に推定できている)も確認してみます。
~結果~
・決定係数0.53417
ほぼ正確に推定できている国もありますが、GDPが高めの国は結構ブレが大きいですね...
特徴量取捨選択するなどし、改めて学習させて一番良い結果が出たのが下図です。・決定係数0.61066
散布図がさっきとほとんど変わっていないように見えますが、GDP低めの国が赤線上付近に若干のまとまりを見せたのでわずかに改善しました。
決定係数0.61...決して悪い数字ではないとは思いますが微妙です。結論ですが、
「夜間光データはGDPの推定に全く寄与しないわけではないけれども、精度を求めようとするとそれだけでは物足りない部分あるなぁ...」って感じですね。しかし、「夜間光データのみ」から作ったモデルにしてはそれなりの精度を出すことができたのではないでしょうか?
今回は夜間光データのみでしたが、他の情報(人口など)を入れてみたり、対数変換を適用したり、他の機械学習モデルを用いることで更なる精度向上を見込めると思います。ただここまでやっておいて今更なんだという話ですが、GDPの場合だとデータ数が少なすぎるので、推定精度向上のために機械学習であれこれ試してみるデータとしては不向きな気がします。市町村レベルとかの細かいデータにしてデータ数を確保し、市町村の財政力指数を夜間光データから推定するなどにしてもよかったかもしれません。(気になった方はやってみてください)
6. 終わりに ~衛星データの可能性~
非常に簡単なモデルでしたが、各国のGDPを大まかに推定することができるモデルを作成することができました。他にも夜間光の増減から翌年のGDPを推定するなどという時系列的な扱いをしてみても面白いかもしれません。まだまだ使い道はたくさんあると思います。
最後に衛星データの可能性について。
衛星データを用いることで夜間光に限らず包括的に地球上を観察することができます。分解能もかなり向上しており、目的用途に合うセンサも様々なものがあるため、衛星という超マクロな視点により大きなブレイクスルーが起きるかもしれません。衛星は周回して地球を回っているので、ある地域の時系列変化なども簡単に比べることができますし、何より地理的制限がないため地球上どこでも観察可能なのが最大の魅力です。
国内でも民間ロケット打ち上げの試みがあるなど、今世界中で宇宙ビジネスが盛り上がりを見せています。将来的に衛星を宇宙に飛ばす金銭的技術的ハードルが下がったら、細かいニーズに合わせた衛星を飛ばし、得られたデータを提供するビジネスが展開される...かも?
非常に将来が楽しみな分野だと個人的に感じています。
この記事が夜間光データを始めとする衛星データの可能性を少しでも伝えられたら嬉しいです。












- 投稿日:2021-03-22T19:56:37+09:00
N-n. タイトル(コンテンツ名、例えば自動化など) テンプレ
- 投稿日:2021-03-22T19:55:29+09:00
4-1. 音声認識
- 投稿日:2021-03-22T19:47:33+09:00
ドラクエウォークのモンスターをk-meansでクラスタリングしてみた
YouTubeのゲーム実況などを見てると「このモンスターはあのモンスターと似てますね」という発言を聞くことがあるが、そのたびに、よく頭に入ってるなぁと感心する。ドラクエウォークはモンスターを倒すと稀に「こころ」を入手でき、身につけるとHPが高くなるなど効果があるが、この8つのパラメータをk-meansでクラスタリングすると、似たようなことができるんじゃないだろうか。
まず、こんなCSVファイルを用意する。(別に作ったやつの流用なので、ちょっと古い)
name,cost,color,hp,mp,power,defense,attack,recover,speed,skill フレイザードA,99,紫,90,85,15,26,64,25,47,69 暴嵐天バリゲーンA,99,黄,110,44,51,79,29,29,28,44 アカイライS,99,青,79,47,55,52,25,23,72,72 ホロコーストS,99,紫,74,87,14,46,72,29,54,63 ガーゴイルA,98,赤,73,31,68,41,11,11,60,53これをpandasで読み込みscikit-learnのKMeansでクラスタリングする。とりあえず10個に分類してみた。
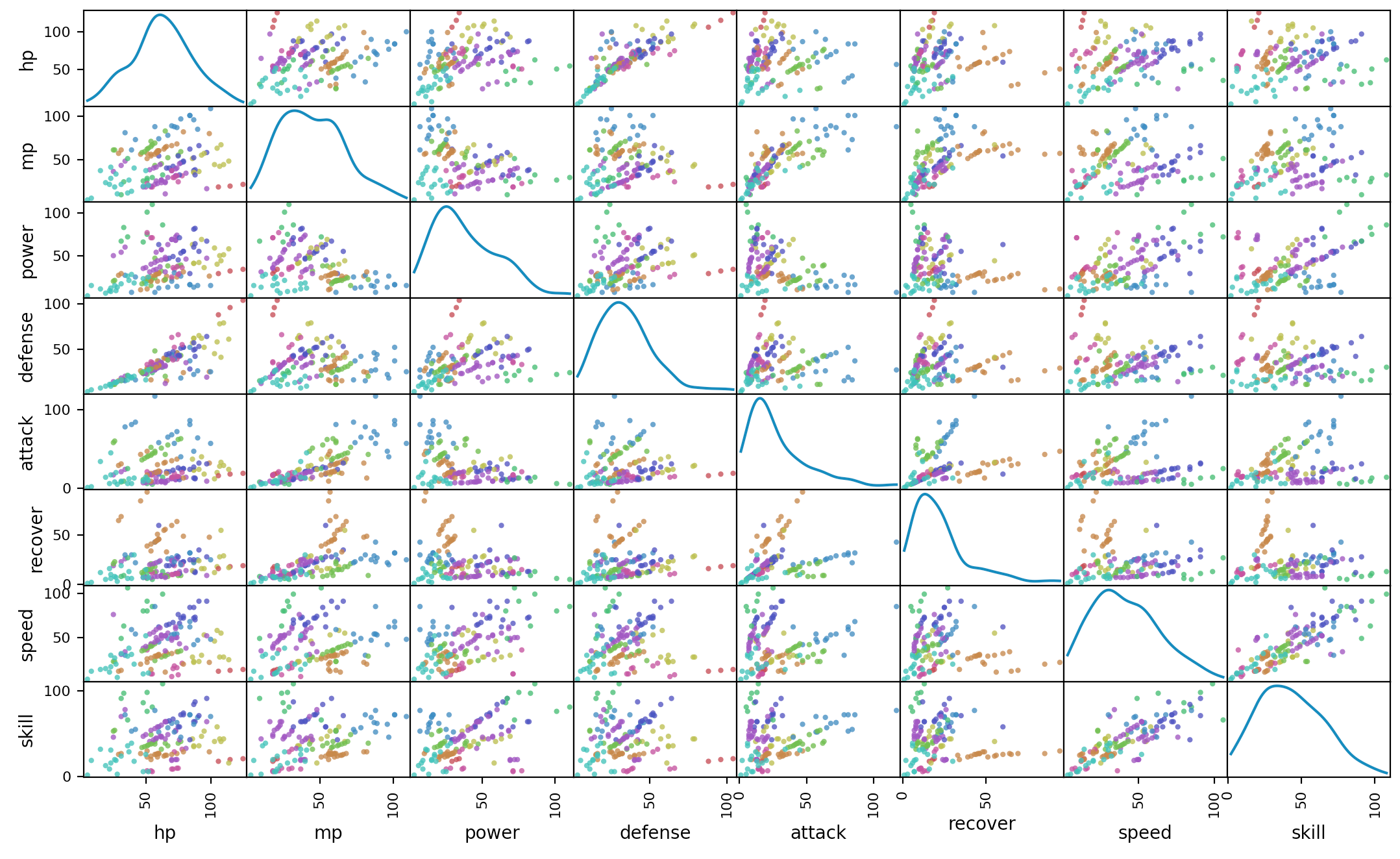
import pandas as pd import pprint from sklearn.cluster import KMeans n_cluster = 10 monsters = pd.read_csv("monster.txt", sep=',', na_values=".") df = monsters.drop('name',axis=1).drop('color',axis=1) kmeans_model = KMeans(n_clusters=n_cluster).fit(df.iloc[:, 1:]) labels = kmeans_model.labels_ monster_type = [] for i in range(n_cluster): monster_type.append([]) n = 0 for i in labels.tolist(): name = names.iloc[n]['name'] monster_type[i].append(name) n = n + 1 pprint.pprint(monster_type)これを見やすく整形してみたのがこちら。ちょっとクラスタ数が10だと大雑把すぎるかもしれない。
参考にした記事で色分けして表示していたので、同じように表示してみた。
https://qiita.com/maskot1977/items/34158d044711231c4292# https://www.color-site.com/separate_hues color_codes = { 0:'#BA7836', 1:'#ADBA36', 2:'#5EBA36', 3:'#36BA5E', 4:'#36BAAD', 5:'#3678BA', 6:'#4336BA', 7:'#9236BA', 8:'#BA3692', 9:'#BA3643', } colors = [color_codes[x] for x in labels] import matplotlib.pyplot as plt from pandas import plotting plotting.scatter_matrix( df[df.columns[1:]], figsize=(6,6), color=colors, alpha=0.8, diagonal='kde' ) plt.show()
データ一式は下記に置いているので試したかったらgit cloneしていただければ。

- 投稿日:2021-03-22T19:31:06+09:00
Python + Seleniumでブラウザ操作の自動化をしてみた
Python + Seleniumでブラウザ操作の自動化をしてみた
Webブラウザで同じような作業を繰り返す必要がある時に、手動で操作するのが面倒、と感じることがあると思います。
例えばニュースサイトを1日1回見て記事タイトルを10件保存したいという場合に、毎回手動で1つずつタイトルをコピペして、という作業をするのはとても面倒です。他にも、同じような内容をフォームに繰り返し入力するなど、手作業だと時間がかかる場面は多いでしょう。このような場合に役立つのがブラウザ自動化です。どうやったら自動操作できるのでしょうか。
ブラウザ自動化には様々な方法がありますが、その1つにSeleniumというツールを使う方法があります。Pythonで簡単なコードを書くことでブラウザを思いのままに操作できます。他にもRuby、JavaScriptなど多くの言語に対応しているという特徴があります。
今回はPython、Google Chromeを使って実際に試してみたのでやり方を紹介します。Seleniumのインストール
Macの方はこちらを見て下さい。
https://scraping-for-beginner.readthedocs.io/ja/latest/src/0.htmlWindowsの方はこちらのサイトの「Python環境(Windows)」を見て下さい。
https://www.seleniumqref.com/introduction/webdriver_intro.htmlWindowsの方は、ブラウザに対応するドライバを入手する際にこちらからダウンロードします。ダウンロードしたら、自分のPCのどこか分かりやすい場所に展開します。
https://sites.google.com/a/chromium.org/chromedriver/downloadsChromeのバージョンとドライバのバージョンが違うとエラーとなる場合があります。その際はChromeのバージョンと同じバージョンのドライバをダウンロードして使う必要があるようです。
これで準備完了です。
コードを書いて動作確認してみましょう。
3行目のexecutable_path="..."の箇所には、先程保存したドライバの場所を指定します。
Windowsの場合もMacと同様に、ディレクトリの区切りを / にするとうまく動作します。
ファイル selenium_test.pyfrom selenium import webdriver
from time import sleep
driver = webdriver.Chrome(executable_path="C:/Users/Aiueo/chromedriver.exe")driver.get("https://www.google.co.jp")
sleep(3)
elem = driver.find_element_by_class_name("gLFyf")
elem.send_keys("PHP エンジニア")
sleep(3)
elem = driver.find_element_by_class_name("gNO89b")
elem.click()
sleep(5)driver.quit()
コードを書いたら、次のように実行します。
$ python selenium_test.py
もしくは
$ python3 selenium_test.pyChromeが起動し、「PHP エンジニア」の検索結果が表示されました。
(PHP_input.png)
(PHP_result.png)Windowsで画像のようなファイアウォールの警告が出てきた場合は、「アクセスを許可する」をクリックします。
(python_firewall.png)
また、次のようなエラーが出ているかもしれませんが、一応動作はするので気にしなくてよいです。
(usb_device_error.png)
driver.get("URL")と書くと、指定したページにアクセスできます。
動作が速くならないように所々にsleepを入れて、目で見て動作がわかるようにしています。
find_element_by_class_name("クラス名")で、クラス名をもとに要素を取得することができます。Google検索のページではgLFyf、gNO89bなどのクラス名が出てきますが、別のWebサイトでは違うクラス名になりますので、コードを書く時はクラス名を確かめる必要があります。クラス名を知りたい部分(検索boxなど)の上で右クリックし、「検証」をクリックすると確認できます。ちなみに、Windowsの場合にディレクトリの区切りを \ にするとエラーが出て動かない場合があるので、気をつけましょう。
(path_backslash_error.png)
では次に、「PHP エンジニア」の検索を行った後で「Ruby エンジニア」で検索し、その検索結果のタイトルを5件取得するようにしてみます。結果はprintメソッドでターミナルに表示します。
ファイル selenium_test.py
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome(executable_path="C:\Users\Aiueo\chromedriver.exe")driver.get("https://www.google.co.jp")
sleep(3)
elem = driver.find_element_by_class_name("gLFyf")
elem.send_keys("PHP エンジニア")
sleep(3)
elem = driver.find_element_by_class_name("gNO89b")
elem.click()
sleep(5)driver.get("https://www.google.co.jp")
sleep(3)
elem = driver.find_element_by_class_name("gLFyf")
elem.send_keys("Ruby エンジニア")
sleep(3)
elem = driver.find_element_by_class_name("gNO89b")
elem.click()sleep(3)
elems = driver.find_elements_by_class_name("g")
for i in range(5):
title = elems[i].find_element_by_class_name("LC20lb").find_element_by_tag_name
("span")
print(title.text)
sleep(5)driver.quit()
先ほどと同様に実行します。
$ python selenium_test.py
もしくは
$ python3 selenium_test.pyターミナルの表示(一例)
Rubyエンジニアになるには|未経験から就職・転職する方法 ...
Rubyエンジニアの仕事内容 - レバテックフリーランス
求人ボックス|Ruby エンジニアの仕事・求人情報
Ruby エンジニアの求人 | Indeed (インディード)
Rubyエンジニアとは?未経験からRubyエンジニアになる方法 ...(Ruby_input.png)
(Ruby_result.png)検索結果のタイトルを一覧表示できました。
find_elements_by_class_name("クラス名")は、elementsと複数形になっています。同じクラス名の要素が複数あった場合に全て取得します。要素を1つ取り出す際には elems[0] のように番号を指定します。1つ注意点があります。driver.getを用いると指定したURLへ移動できますが、for、while文の中で用いると繰り返しアクセスすることになります。コードの書き方を間違えると同じWebサイトに短時間に何度もアクセスしてしまい、不正アクセスとみなされてしまう可能性があるので、sleepなどを使って充分に時間を空けるようにして下さい。
(参考 https://ja.wikipedia.org/wiki/岡崎市立中央図書館事件)
また、WebサイトによってはSeleniumでアクセスできないように対策されている場合があります。その場合は仕方がないので諦めましょう。ブラウザ自動化ツール「Selenium」の紹介でした。様々な場面で応用が効くと思うので、ぜひ使ってみて下さい。
- 投稿日:2021-03-22T19:29:05+09:00
【5分でSaaSアプリ作成】スマレジアプリ・スターターパックを公開しました
はじめに
スマレジという非常に多機能なPOS・勤怠管理システム・オーダーシステムを低価格で提供しているタブレットPOSサービスがあるのですが、2020年8月1より、アプリマーケット上の『アプリ』という形で開発者が独自に機能を追加し、スマレジユーザーに売ることが出来るサービスが開始しました。
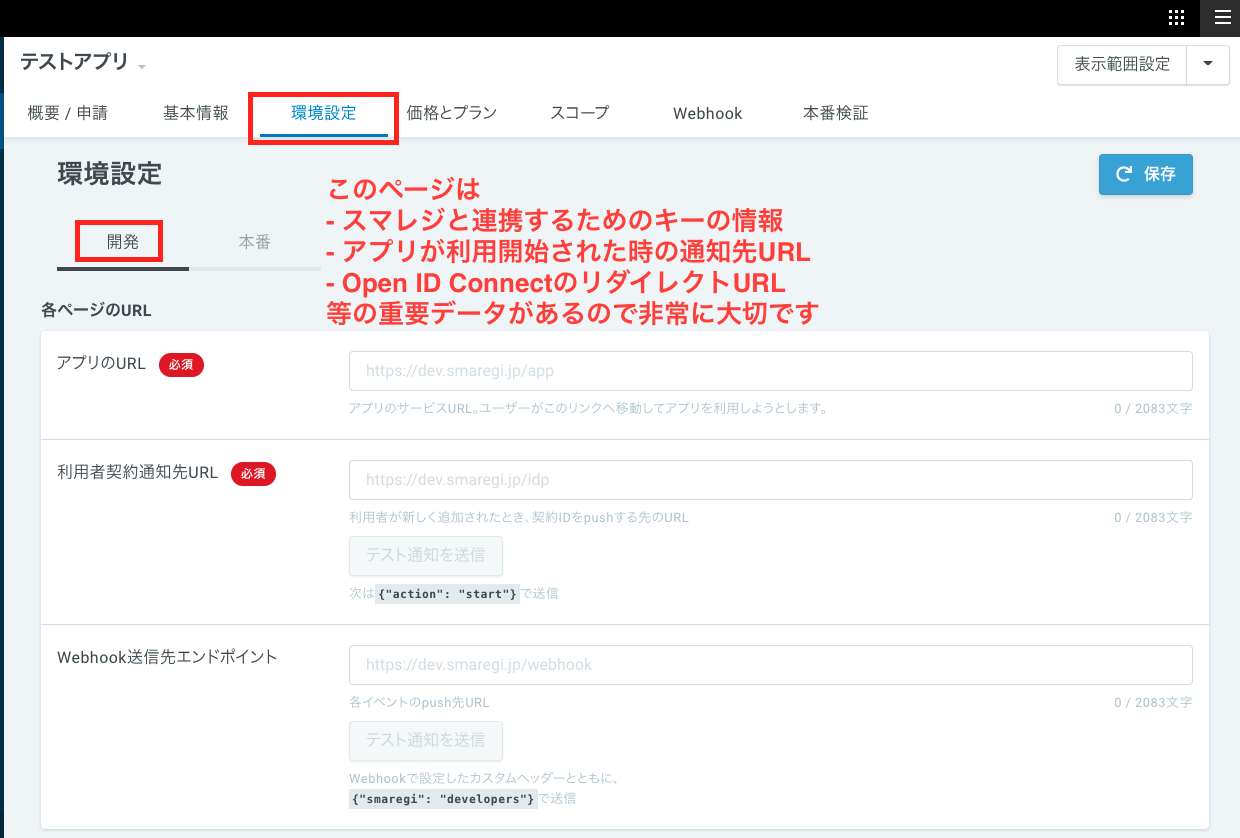
スマレジ本体のデータのほぼ全てがAPIで公開されているため、店舗の売上や勤怠のリアルタイムのデータを取得できるなど、非常に面白いサービスなのですが、アプリマーケットが賑わわないと、そもそもアプリが使われません(MacのApp Storeがいい例ですね)。アプリ開発にはSaaSサービスとの連携アプリともあって、OpenID Connectなど最低限の実装が少し高いハードルになっています。
そのため、これらの最初に躓く部分を出来る限り取り払い、簡単にアプリを作れるテンプレートとして「スマレジアプリ・スターターパック」を作りました。このパックを使うと、アカウント取得などの事前準備が終わっていれば、約5分でアプリを作成し、スマレジのプラットフォームとつなぐことができます。
OpenID Connectでのログイン機能もスターターパックで提供されるので、アプリの機能に集中することができます。スターターパックという名前の通り、実装したい機能を簡単に追加できるようにしているため、このパックを元に本番アプリの作成・公開も可能です。
本記事では、スターターパックの概要と使用方法を書いています。スターターパックの詳細なしくみやアーキテクチャについては後日別の記事で書きますが、仕組みを理解していなくても問題なくアプリを動かせるようになっています。
特徴
こちらのスターターパックを使うだけで、スマレジのOpenIDでログイン機能を持ち、契約期間内の契約者にはHello Worldを表示するアプリをGoogle Cloud上でデプロイすることができます。アプリの部分を最低限にしていますので、まずHello Worldアプリを実装できたら、簡単にアプリで実装したい機能を追加していくことができます。
以下のような特徴を持っています。
- ユーザー数が100人程度で、月あたりのログイン数が1000アクセス程度の想定で、月額約3円のクラウドコストで収まる設計
- ユーザー数が10万人となっても落ちないスケールアウト設計
- IaCに沿ったパッケージのため、インスタンスの設定やデプロイもすべてコード化されています。ローカルで起動して簡単にテストができ、デプロイもスクリプトを走らせるだけです
- 障害時・エラー時にすぐにアラートが来るようにデフォルトで設定済みです(解除も可能)
構成
全体がサーバーレス構成となっております。Google CloudのFaaSであるCloud Functionを使う構成です。サーバー等のミドルウェアはGoogle Cloudで管理されるため、開発者はそのミドルウェア上で動くコードだけを開発・デプロイすればよい形です。
データベースにはFirestoreというNoSQLを使っておりますが、アプリからの使い勝手もよく、データの確認もGUIで簡単にできます。
- Python3.8ベース
- メインコンポーネント:Cloud Function+Firestore
- サブコンポーネント:Cloud Storage(実行バイナリの保存先)、Error Reporting(アラート用)
必要要件
- MacOSでの開発を想定(スクリプト構成のため)
- Google Cloud環境
- Docker環境
パッケージのダウンロード
GitHubでホストしていますので、こちらから
git cloneしていただくか、ZIPでダウンロードして下さい。
スマレジ・スターターパックのGitHubレポはこちら使い方
事前準備
必要な事前準備は以下の通りです。すでにインストール済みであれば、各項目はスキップしていただいて構いません。
1. スマレジの開発アカウントの取得
2. Google Cloudのアカウント取得、CLIツールのインストール
3. Dockerのインストールスマレジとの連携の関係で、ローカルサーバーだけではアプリを動かせません。パブリックにアクセス可能なサーバーが必要な関係上、Google Cloudでのアカウントを必須にしています。今後、AWSやAzure等で提供できるように機能追加予定です。(もしくは有志の方、ぜひPRお待ちしています!)
1. スマレジ開発アカウントの取得
アカウント申請
スマレジから公式のチュートリアルがあるので、こちらの通りにセットアップして下さい。
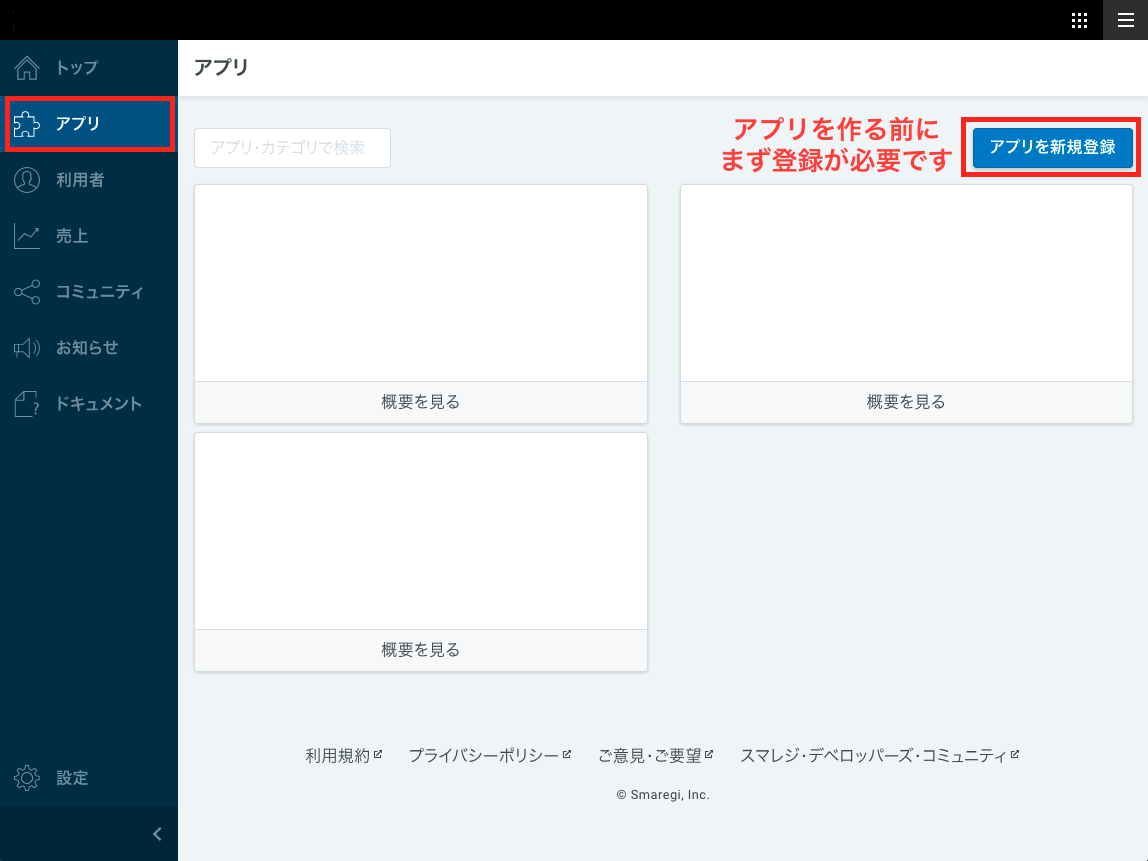
https://help.smaregi.jp/hc/ja/articles/360051440053-%E9%96%8B%E7%99%BA%E8%80%85%E3%82%A2%E3%82%AB%E3%82%A6%E3%83%B3%E3%83%88%E3%82%92%E4%BD%9C%E6%88%90%E3%81%99%E3%82%8Bスマレジアプリの準備
アプリのキーが必要なため、最初にアプリを登録する必要があります。以下のステップの通り勧めていけば大丈夫です。
2. Google Cloudの準備
Google Cloudは約3万円ほどの無料枠があるので、スターターパックを走らせても課金されることはありません。また、1ヶ月スタータパックを走らせても、100ユーザー程度では月10円もかからず運用できますので、ご安心下さい。必要無くなれば、プロジェクトをまるごと消すことで、全てのリソースを削除できるため、追加で課金されることもありません。
アカウントの作成
こちらの公式ページからスタートして下さい。Googleアカウントが必須となります。
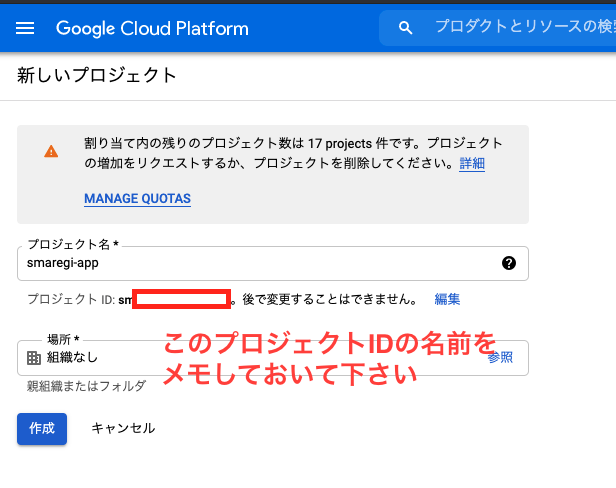
初期セットアップ
Google Cloudのアカウントを作成したら、まずは新しいプロジェクトを作って下さい。今後はこのプロジェクト配下に全てのリソースが配置されます。また、削除も用意になるので、他のプロジェクトがあっても、別で作られることをおすすめします。
次に、FirestoreというデータベースをGUIで作成します。残念ながら、現在(2021-03)ではCLIが提供されていないため、GUI上でセットアップをする必要があります。
CLIツール(Google Cloud SDK)のインストール
こちらの公式ガイドにしたがってGoogle Cloud SDKをインストールして下さい。
3. Dockerの準備
こちらの公式ガイドにしたがってDocker Desktop for Macをインストールして下さい。インストール後、以下を実行してみて動けば問題ありません。
docker run --rm helloworldこれですべての事前準備が完了です!
スターターキットの初期セットアップ
ソースのダウンロードと初期セットアップ
gitからソースコードをcloneして、初期セットアップ用のシェルスクリプトを実行しましょう。このときに作成したGoogle CloudのプロジェクトIDが聞かれるので、入力して下さい。また、Google Cloudへログインするようリクエストされるので、立ち上がったブラウザからログインして下さい。
git clone https://github.com/senbishi21/smaregi-app-starter.git (もしくはzipダウンロードでも可能) smaregi-app-starter/_init/init.sh
Google CloudのFirestoreのページで以下のように表示されたら成功です。
設定情報の入力
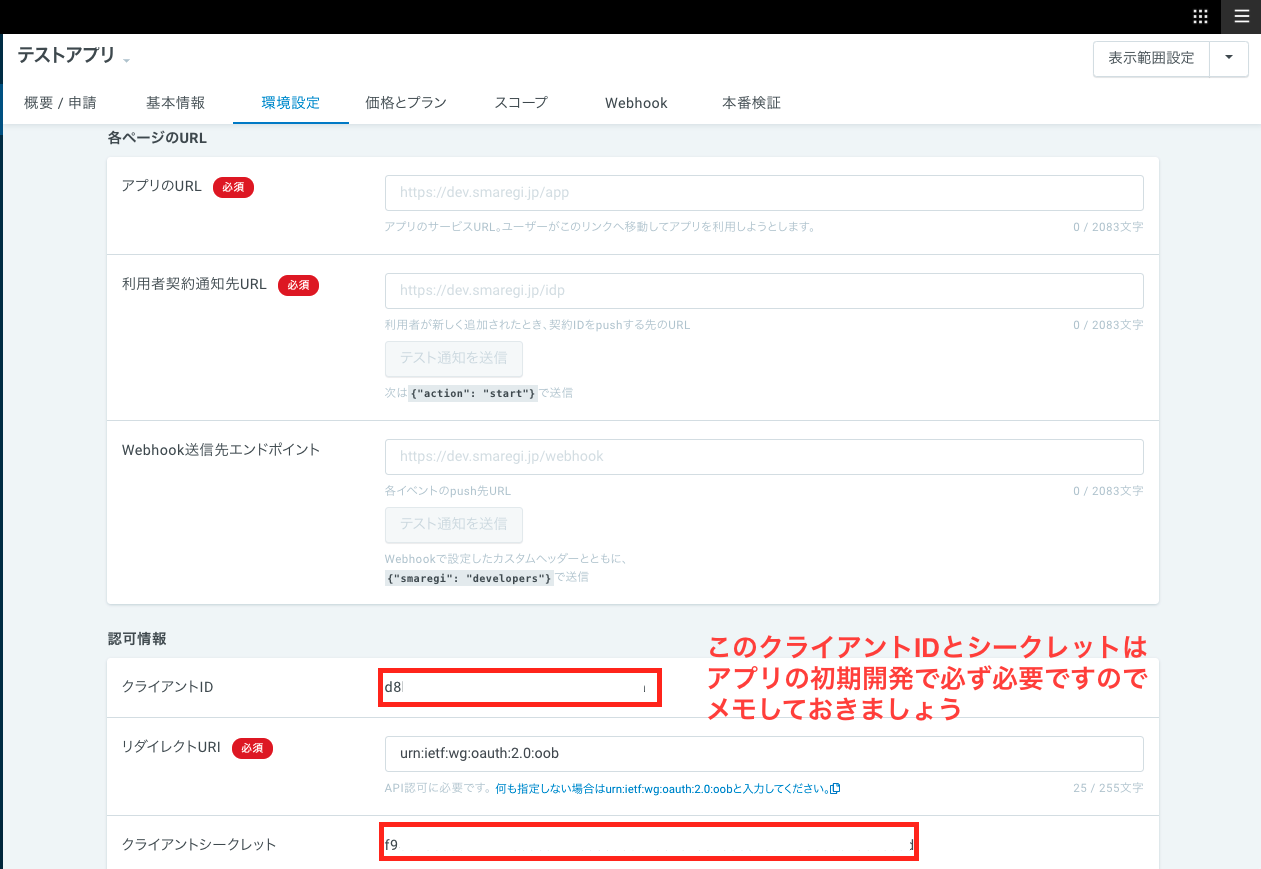
_init/credentials/secrets.txtに、スマレジアプリの設定でメモした内容を入力して下さい。ダブルクオート等は不要です。QA_MAIN_URL以外を埋めて下さい。例:
QA_APP_CLIENT_ID=xxxx QA_APP_CLIENT_SECRET=xxxxx PROD_APP_CLIENT_ID=xxxxx PROD_APP_CLIENT_SECRET=xxxxx LOCAL_CONTRACT_ID=xxxx QA_MAIN_URL=変更して下さい PROJECT_ID=xxxアプリの実行とデプロイ -メインページ
cf-main/のフォルダで./run.shを実行すると、ローカルでスタンドアローンで起動するウェブサーバーが動きます。自動でブラウザも開くので、こちらで以下のような画面がでたら成功です。
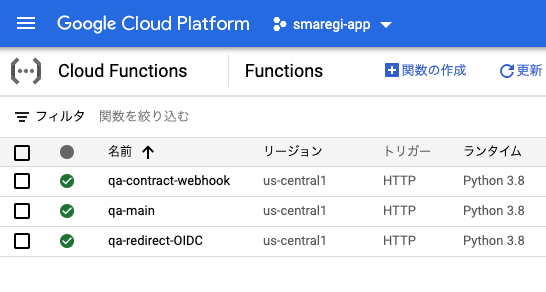
問題なければ、./deploy.shを実行して下さい。こちらでGoogle CloudのCloud FunctionというFaaSサービスにコードをデプロイします。デプロイには約2分ほどかかります。終了したら、Google CloudでCloud Functionのページを見てみて下さい。以下のように、緑のアイコンとなっていれば成功です。
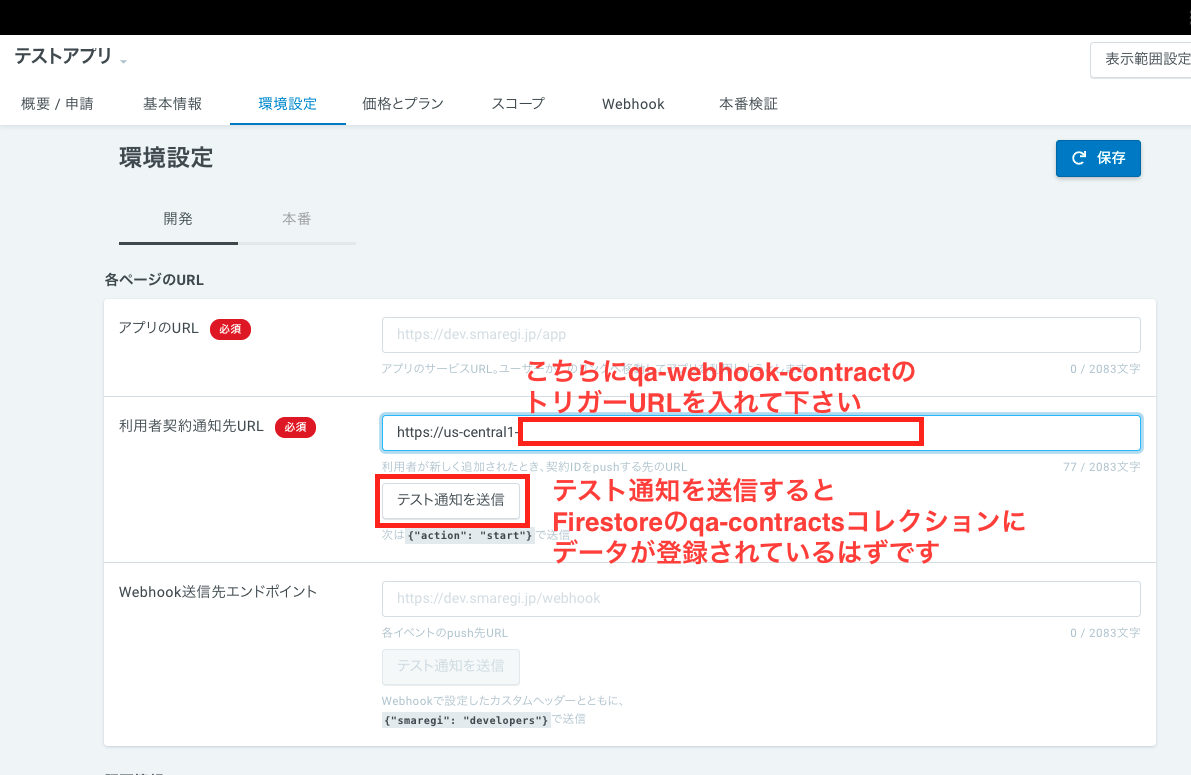
qa-mainをクリックすると、トリガーURLという項目があるので、それを_init/credentials/secrets.txtのQA_MAIN_URLにコピーして下さい。アプリの実行とデプロイ -OIDCリダイレクトとアプリ利用通知
その後、cf-redirect-OIDC, cf-contract-webhookで./deploy.shを実行して下さい。同じように約2分ほどかかりますので、終了したら、Cloud Functionのページで緑のアイコンとなっていることを確認して下さい。
cf-contract-webhookはアプリの使用を始める時・終了する際に、スマレジ側から呼ばれるWebhook型のサーバー(コンテナ)です。スマレジのアプリ画面で、以下のように設定して下さい。設定のあと、「テスト通知を送信」というボタンを押すと・・・
以下のように契約者情報がFirestoreデータベースに入ったことを確認出来ると思います。これで、アプリの契約が開始・終了した時にデータベースに保存されるようになりました。
完了!
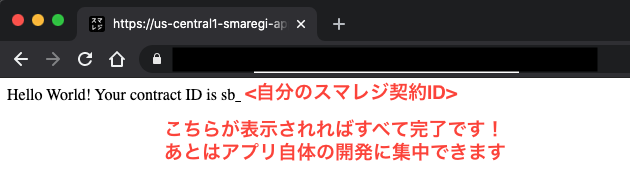
これですべて完了です!cf-mainのURLにアクセスしてみて下さい。以下のようにスマレジのOpenIDのページにリダイレクトされ、ログイン(認証)してアプリを認可すると、以下のように自分のアプリが表示され、契約者IDも反映されるはずです。QA環境では10分でクッキーの有効期限が切れるようになっているので、手早くリダイレクトの動作をテストできます。
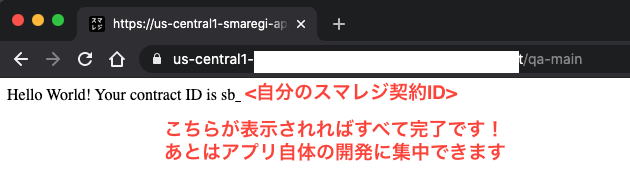
あとは、実装したい機能やウェブページをcf-mainにて実装すればOKです!PythonのFlaskをベースにしているので、かなり簡単に機能やロジックの実装ができると思います。
補足
OSSについて
当コードはGitHub上にホストしていますので、PR大歓迎です。ただし、以下のルールを守って頂けると幸いです。
- セキュリティ情報(CloudのTokenやCredential情報等)はDockerfileに入れ込まず、_init/credentialsのフォルダでのみ保持する。こちらのフォルダは.gitignoreで無視されるため、空のテンプレートファイルを_init/credentials-templateに入れ込んで下さい。
- ディレクトリ内でrun.shでローカルに走らせる、deploy.shでクラウド環境にデプロイする、という構成をお願いします。ローカルで走らせることがない場合、run.shをなくすか、echoでその旨を伝えるだけのスクリプトにして下さい。
料金について
料金のシミュレーションはGoogle Cloud price estimateで。
- 100人のユーザーが1000アクセス/月で、5分ごとにスマレジのデータを同期する場合の料金シミュレーションでは月のコストが2.44円です:料金詳細参考ページ
- 10万人のユーザーが全員毎日5アクセスする大規模システムで、5分ごとにスマレジのデータを同期する場合の料金シミュレーションでは月のコストが19万円/月となります:料金詳細参考ページ
スマレジアプリマーケットについて
スマレジアプリマーケットに登録された開発者には、スマレジの担当者からアプリの作り方等について、かなり手厚いサポートが受けられますので、ぜひ活用してみて下さい!私自身もかなりお世話になっています。
また、テクニカルサポートはスマレジ Developers Communityで受け付けているそうで、レスポンスが早い上、機能改善のケースでも実装が早いです。
どちらも、Appl○のiOSアプリや○ndroidアプリストアの対応より相当に早く、サポートも手厚いですので、どんどん使っていくのが早道です。
その他参考資料
- 【スマレジアプリを作ってみた#3】認証機能の実装:こちらの方がOpenIDでのログインの仕組みなど紹介してくださっています。
- 【スマレジアプリを作ってみた#5】Sandboxでの動作確認(テスト):同じ作者の方で、本番環境でのテスト手法を共有してくださってます。
注釈





- 投稿日:2021-03-22T17:31:03+09:00
楽天ユーザー 楽天のくじを全て自動で引く
楽天くじとは
楽天には毎日引けるくじがあります。
くじに当選すると、1〜1000ポイントがもらえるものもあります。
(大体が1か10ポイント)楽天の公式にはくじ一覧が載っているサイトがあります。
しかし、楽天のくじはここに載ってるだけではなく、もっとたくさんあります。
(全て自力で探すのはキツい笑)
それが一覧で掲載されているサイトが以下のサイトになります。
今回はこれらたくさんのくじを、seleniumを使うことで全て自動で引きたいと思います。
楽天くじのURLリスト
url_list = [{'url':'https://kuji.rakuten.co.jp/9d91da42ab','name':'infoseeek'}, {'url':'https://kuji.rakuten.co.jp/889373540e','name':'infoseeekNews'}, {'url':'https://kuji.rakuten.co.jp/842378b442','name':'LINE'}, {'url':'https://kuji.rakuten.co.jp/46211bf9dd','name':'TV'}, {'url':'https://kuji.rakuten.co.jp/bc23814a75','name':'楽天toto'}, {'url':'https://kuji.rakuten.co.jp/8c538152dd','name':'楽天宝くじ'}, {'url':'https://kuji.rakuten.co.jp/4ad36145c2','name':'楽天くじ広場'}, {'url':'https://kuji.rakuten.co.jp/d2b37c7d6a','name':'楽天e-NAVI'}, {'url':'https://kuji.rakuten.co.jp/fae37d0d91','name':'楽天e-NAVI さかな'}, {'url':'https://kuji.rakuten.co.jp/8212abcffe','name':'楽天e-NAVI じゃんけん'}, {'url':'https://kuji.rakuten.co.jp/42136c5d7d','name':'楽天ブックスfacebook'}, {'url':'https://kuji.rakuten.co.jp/6e2381eb02','name':'pointmall部活'}, {'url':'https://kuji.rakuten.co.jp/26d37b04b2','name':'楽天レシピ'}, {'url':'https://kuji.rakuten.co.jp/4e9371dd92','name':'楽天car'}, {'url':'https://kuji.rakuten.co.jp/10a37ad0e0','name':'楽天×ぐるなび'}, {'url':'https://kuji.rakuten.co.jp/9ea32a8dfa','name':'楽天カレンダー1'}, {'url':'https://kuji.rakuten.co.jp/34e2cb79fa','name':'楽天カレンダー2'}, {'url':'https://kuji.rakuten.co.jp/256356cd1a','name':'楽天カードラッキーくじ'}, {'url':'https://kuji.rakuten.co.jp/4351057845','name':'楽天ツールバーラッキーくじ'}, {'url':'https://kuji.rakuten.co.jp/9a0381a85d','name':'楽天デリバリー'}, {'url':'https://kuji.rakuten.co.jp/7a1321943c','name':'スマホアプリ限定ラッキーくじ'}, {'url':'https://kuji.rakuten.co.jp/a29321bc36','name':'スマホスマホ限定ラッキーくじ'}, {'url':'https://kuji.rakuten.co.jp/fc437af2c7','name':'スマホリワード特集'}, {'url':'https://kuji.rakuten.co.jp/95737c358e','name':'楽天edyくじ'}, {'url':'https://kuji.rakuten.co.jp/1473379bb1','name':'スマホ楽天pointclub'}, {'url':'https://kuji.rakuten.co.jp/a24364f880','name':'スマホ楽天pointclub'}, {'url':'https://kuji.rakuten.co.jp/4592a41e4c','name':'スマホ楽天カードスマホ'}, {'url':'https://kuji.rakuten.co.jp/e7a37ae390','name':'スマホ楽天リワード'}, {'url':'https://kuji.rakuten.co.jp/2d1381326a','name':'マネ活ラッキーくじ'}, {'url':'https://kuji.rakuten.co.jp/27436a510a','name':'スマホ毎日ラッキーくじ'}, #その他、特殊なくじ {'url':'https://point.rakuten.co.jp/doc/lottery/lucky/','name':'スマホ楽天pointclub'}, {'url':'https://pointmall.rakuten.co.jp/','name':'スマホDAILY CHANCEくじ'},]3月初旬時点での、楽天くじのURLリストになります。
実行コード
for page in tqdm(url_list): try: if page['url'] == 'https://pointmall.rakuten.co.jp/': driver.get(page['url']) time.sleep(1) driver.find_element_by_xpath('//*[@id="side"]/div[1]/ul/li/div[1]/a/img').click() driver.find_element_by_xpath('//*[@id="side"]/div[1]/ul/li/div[2]/div/div[1]/div[6]').click() time.sleep(14) elif page['url'] == 'https://point.rakuten.co.jp/doc/lottery/lucky/': driver.get(page['url']) time.sleep(2) driver.find_element_by_xpath('//*[@id="cp_btn_start"]/a/img').click() time.sleep(14) else: driver.get(page['url']) time.sleep(1) driver.find_element_by_xpath('//*[@id="entry"]').click() time.sleep(14) except NoSuchElementException: print('###エラー 次のくじに進みます。' + page['name'] + '###') time.sleep(1)くじリストの最後の
「楽天PointClubアプリラッキーくじ」
「楽天ポイントモール DAILY CHANCEくじ」
に関してはくじの引き方が他のくじと異なるので、if文で分岐させています。改善点
実際に使ってみて思ったこと
・URLが頻繁に変わるくじ
・キャンペーンのたびに新たに追加されるくじ
これらの問題を解決しなければならないと思いました。
ぶっちゃけURLリストを作っている時にアホくさいなと感じていました。次回
くじサイトから直接リンクをクリックするプログラムにすることで解決する。
- 投稿日:2021-03-22T17:07:24+09:00
【やさしく】Python基礎文法、まとめてみました
はじめに
はじめまして、千々松のいるです。
Python。人気ですよね。
統計学や機械学習の人気が上昇すればするほど人気になっている感じがします。私もこれから機械学習を勉強していこうかなという人間なので、今回は私と同じようにこれからPythonを学んでいく人向けに基礎文法についてまとめてみました。馴染みやすさを重視しているので厳密な解説は公式ドキュメント等で確認いただけたらと思います。
対象読者
- これからPythonを学ぼうとしている方
- 学生の方
目次
概観
まず1章では、プログラミングの要となるデータの型について見ていきます。コンテナと呼ばれるlistのような型から徐々に複雑になっていきますが、できるだけ体系立てて学んでいけたらと思います。
2章では、プログラミングの流れとなる制御フローについて見ていきます。制御フローに関しては、ピアノの楽譜によく似ていると思います。ピアノでもトゥ・コーダでコーダの位置までジャンプしたり、ダル・セーニョでセーニョの位置まで戻ったりしますよね。これをプログラミングではgotoやreturnで表現します。なにも難しいことじゃなくて、楽譜やソースコードの中で分岐や繰り返しがよく行われるというだけの話だと思います。
3章では、関数について見ていきます。
関数はよく利用する処理をまとめて再利用可能にするために使われます。引数の使い方などを確認していきます。4章では、クラスについて見ていきます。関数と同じくコードの再利用という意味合いが強いですね。
ここでは実際にポケモンのクラスからポケモンを生成して、クラスを利用する意義と、あと継承について学んでいきたいと思います。環境
Python 3.7.0
1. データ型
さて、プログラミングといえばまずはデータですよね。データは料理で言えば食材みたいなもので、データがないとプログラミングははじまりません。
プログラミング言語で扱うデータには型というものが存在しています。型っていうのを簡単に言うと分類だと思います。
料理でも、和食・洋食・中華があるようにプログラミングのデータにもいろいろな型があります。
和食だったら白だし、洋食だったらコンソメ、中華だったら鶏がらというように、データも型によって使える関数が違ってきたりするので、型とその型がどういう処理に対応しているかを学ぶことは重要ですね。ちなみに、PythonはJavaやGoなんかの静的型付け言語とは違って動的型付け言語なので、型を指定する必要はないんですよね。
でも、Pythonにもデータ型は存在するので以下の表を使って説明していきます。
※型付けに関しては、ここでは深く触れません。表1. Pythonのデータ型
項番 大分類 小分類 具体例 1-1 真理値型 bool型 True, False 1-2 文字列型 str型 'あいう', 'abc' 1-3 数値型 int型 1, 0, -3 1-4 数値型 float型 3.14, 0.3, -2.7 1-5 数値型 complex型 2j, 3+5j 1-6 配列型 list型 ['a','あ', 2.5] 1-7 配列型 tuple型 (-3j, True) 1-8 辞書型 dict型 {'key': 'value'} 1-9 集合型 set型 {'a', -3.14} 1-1. bool型
真理値として用いる組み込み定数は2つしかないです。TrueとFalseだけですね。ランプのON/OFFみたいなイメージなのかなと思ってます。
真理値? 何それ?? って感じだと思うんですけど
数学用語で言うと、真と偽ってやつですね。論理と集合の単元で出てきたやつです。
全てのオブジェクトは組み込み関数bool()によって、TrueかFalseに分類されます。零や空のオブジェクトはFalseを返して、それ以外はTrueを返しますね。>>> bool(2) True >>> bool(0) False >>> bool('') False真理値に対して適用される演算子は論理演算子(ブール演算子)と呼ばれていて、and, or, notの3種類が存在します。and, orに関してはビット演算子を用いても同じ結果になりますね。
>>> t = True >>> f = False >>> >>> t and f False >>> t or f True >>> not t False >>> t & f # andと同じ False >>> t | f # orと同じ True1-2. str型
''や""みたいなアポストロフィかクォーテーションでデータを囲んで扱う文字列型です。逆に言えば、引用符で囲まれたデータは真理値や数値だって全部str型になるということです。
ちなみに、データが何の型かは組み込み関数type()で判別できます。>>> s1 = '文字列' >>> s2 = 'True' >>> s3 = '3' >>> >>> type(s1) <class 'str'> >>> type(s2) <class 'str'> >>> type(s3) <class 'str'>演算子としては、算術演算子の+と*が使えます。あと、str型はイテラブル(繰り返し可能)なオブジェクトなので、for文みたいなループ処理も使えます。
私はstr型にfor文が使えるの、最初は意外でした。
皆さんはそうでもなかったですか?>>> s1 = 'フシギダネ' >>> s2 = 'つるのムチ' >>> >>> s1 + s2 'フシギダネつるのムチ' >>> s2 * 3 'つるのムチつるのムチつるのムチ' >>> >>> for s in s1: ... print(s) ... フ シ ギ ダ ネ1-3. int型
数値型には整数を扱うint型、浮動小数点数を扱うfloat型、複素数を扱うcomplex型の3種類が存在します。
まずは整数を扱うint型から。
算術演算子としては、+, -, *, /, %, //, **の7演算子全てが使えます。四則演算では、除算以外がint型に閉じていると言えますね。>>> 3 + 4 7 >>> 3 - 4 -1 >>> 3 * 4 12 >>> 3 / 4 # float型になる 0.75 >>> 3 % 4 # 剰余 3 >>> 3 // 4 # 切り捨て除算 0 >>> 3 ** 4 # べき乗 811-4. float型
浮動小数点数を扱う数値型ですね。int型と同じく全ての算術演算子をサポートしていて、float型の四則演算はfloat型に閉じます(強制的にfloat型で表記されます)。
あと、無限大(infinity)やNaN(Not a Number)もfloat型として扱われるから注意です。
そして、無限大やNaNを含む数値同士の演算結果は無限大やNaNをそのまま返します。>>> 0.25 + 4 4.25 >>> 0.25 - 4 -3.75 >>> 0.25 * 4 # float型は維持される 1.0 >>> 0.25 / 4 0.0625 >>> 0.25 % 4 0.25 >>> 0.25 // 4 0.0 >>> 0.25 ** 4 0.00390625 >>> infinity = float('inf') >>> infinity * 100 # infを含む演算 inf >>> nan = float('nan') >>> nan - 3.14 # NaNを含む演算 nan1-5. complex型
複素数を扱う数値型ですね。複素数平面すら理解していない私が説明するのもなんですが、とりあえず数値にjかJを付けると虚数として認識されます、それだけです。
ちなみに虚数については数学ではiを、工学ではjを用いるらしいですね。
実部は.real、虚部は.imagを付けることでfloat型として取得することも可能です。>>> c = 2 + 3j >>> type(c) <class 'complex'> >>> c.real # float型として取得 2.0 >>> c.imag 3.0 >>> type(c.real) <class 'float'>1-6. list型
要素を1列に並べて各要素ごとに参照できるデータ構造をコンテナオブジェクトと言って、内部の要素が可変なものをlist型、不変なものをtuple型として扱っています。
各要素が異なるデータ型であっても問題はなくて、コンテナの中にコンテナの要素を格納することだって可能です。
コンテナの中にコンテナを入れたりするのを入れ子構造(ネスト)とか言ったりします。
各要素にアクセスする際には、list[番号]のように記述すれば大丈夫です。ちなみに、listの番号(インデックス)は1からじゃなくて、0からだから注意が必要です。>>> li1 = ['切り干し大根', 7j, False] >>> li2 = [1, ['利根川', '最上川'], True] >>> >>> li1[2] False >>> li2[1] ['利根川', '最上川']list型もstr型みたいに+と*の算術演算子が使用可能です。
>>> li1 + li2 ['切り干し大根', 7j, False, 1, ['利根川', '最上川'], True] >>> li2 * 3 [1, ['利根川', '最上川'], True, 1, ['利根川', '最上川'], True, 1, ['利根川', '最上川'], True]コンテナは格納するだけじゃなくて、要素を増やしたり、減らしたりする組み込みのメソッドも用意されています。
要素を増やすときは、list.append(要素)。減らしたいときは、list.pop(インデックス)を使います。
でも、popは厳密には要素を削除してるというよりは、非復元抽出をしているイメージですね。
なので、popで抽出してきた要素は別の変数にすることも可能です。>>> li1 = ['フ', 'シ', 'ギ'] >>> li1.append('ソウ') >>> li1 ['フ', 'シ', 'ギ', 'ソウ'] >>> li1.pop(1) 'シ' >>> li1 ['フ', 'ギ', 'ソウ'] >>> li1 = ['フ', 'シ', 'ギ', 'ソウ'] >>> >>> var = li1.pop(3) >>> var # 要素が抽出されている 'ソウ'最後にスライスについて説明します。スライスっていうのは言葉通り、list型の要素を部分的に抽出するものですね。
イメージでいうと、カステラを包丁で切っているような感じでしょうか。list[始点:終点]のようにして要素を抽出します。
インデックスに負数を入力すると、末尾の要素から起算して要素を抽出することになります。
あと、スライスしても元の配列は維持されます。>>> li = ['フシギダネ', 'フシギソウ', 'フシギバナ', 'ヒトカゲ', 'リザード', 'リザードン'] >>> li_slice = li[1:3] >>> li_slice ['フシギソウ', 'フシギバナ'] >>> li_reverce = li[-3:-1] >>> li_reverce ['ヒトカゲ', 'リザード'] >>> li_reverce = li[-3:] >>> li_reverce ['ヒトカゲ', 'リザード', 'リザードン'] >>> li ['フシギダネ', 'フシギソウ', 'フシギバナ', 'ヒトカゲ', 'リザード', 'リザードン']1-7. tuple型
tuple型は、list型の要素を不変にしたものです。
不変なので、要素を増やしたり引いたりすることはできません。でも、tupleをスライスして別のtupleを作成したりすることは可能です。>>> tu = ('アチャモ', 'キモリ', 'ミズゴロウ') >>> tu.append('エネコ') # 要素は変えられない Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'tuple' object has no attribute 'append' >>> tu_slice = tu[1:3] >>> tu_slice ('キモリ', 'ミズゴロウ') >>> tu # 元のtupleに影響はない ('アチャモ', 'キモリ', 'ミズゴロウ')1-8. dict型
ここまでの配列はなんとなく分かるかと思いますが辞書型がちょっととっつきにくいですよね。
dict型は{'key': 'value'}のように記述されて、keyとvalueの組み合わせを格納します。これまでのものは要素をインデックスで取得していましたが、dict型はkeyを指定して要素を取得する点で違いがあります。
あと、for文の使い方も少し工夫が必要です。>>> dic_eva = {'序': 'YOU ARE (NOT) ALONE.', '破': 'YOU CAN (NOT) ADVANCE.', 'Q': 'YOU CAN (NOT) REDO.', 'シン': 'シ ン・エヴァンゲリオン劇場版'} >>> dic_eva['序'] # keyでvalueを取得できる 'YOU ARE (NOT) ALONE.' >>> dic_eva[0] # インデックスでは値を参照できない Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 0 >>> for key in dic_eva: ... print(key) ... 序 破 Q シン普通にfor文を回すとkeyの値が取得されます。valueの方を取得したい場合は以下のようにする必要があります。また、keyとvalueを両方を取得することも可能です。
>>> for value in dic_eva.values(): # valueを取得 ... print(value) ... YOU ARE (NOT) ALONE. YOU CAN (NOT) ADVANCE. YOU CAN (NOT) REDO. シン・エヴァンゲリオン劇場版 >>> for key, value in dic_eva.items(): # keyとvalueを取得 ... print(key, value) ... 序 YOU ARE (NOT) ALONE. 破 YOU CAN (NOT) ADVANCE. Q YOU CAN (NOT) REDO. シン シン・エヴァンゲリオン劇場版1-9. set型
私はあんまり使ったことがありませんが集合を表すデータ型です。数学記号と同じく{要素1, 要素2, ... , 要素n}というように書きます。
listと同じように見えますが大きな違いは、setには順序性がないことです。
というのも、setでは要素の取得をすることができません。setでできるのは要素の追加と削除くらいになります。>>> se = {'サンダー', 'ファイアー', 'フリーザー'} >>> se.add('ホウオウ') >>> se.add('ルギア') >>> se {'ルギア', 'ファイアー', 'サンダー', 'フリーザー', 'ホウオウ'} # 順序性がない >>> se.remove('ホウオウ') # 要素を指定して削除 >>> se {'ルギア', 'ファイアー', 'サンダー', 'フリーザー'} >>> se.pop() # なにが削除されるかは不定 'ルギア' >>> se {'ファイアー', 'サンダー', 'フリーザー'} >>> se.pop() 'ファイアー' >>> se {'サンダー', 'フリーザー'}あと、不変の集合型でfrozenset型もあります。これはlistなりsetなりのコンテナに組み込み関数frozenset()を適用してあげると実装できます。
>>> li = [1,2,3] >>> frozen_li = frozenset(li) >>> type(frozen_li) <class 'frozenset'>コンテナオブジェクトの特性
また、コンテナにはそれぞれイテラブル、シーケンス、ミュータブルなどの特性が存在します。
まず、イテラブルというのは、日本語では反復可能体みたいに言われていて、簡単に言うとfor文のようなループ処理が可能なデータ型を指します。
解説したデータ型の中では、(str, list, tuple, dict, set, frozenset)がイテラブルにあたります。これらはfor文のinの先に指定できるということですね。>>> st = 'オーダイル' >>> for s in st: ... print(s) ... オ ー ダ イ ル >>> li = [1,2,3] >>> for i in li: ... print(i) ... 1 2 3 >>> tu = ('a', 'b', 'c') >>> for f in tu: ... print(f) ... a b c >>> dic = {1: 'フシギダネ', 2: 'フシギソウ', 3:'フシギバナ'} >>> for key in dic: ... print(key) ... 1 2 3 >>> se = {1,2,3} >>> for f in se: ... print(f) ... 1 2 3 >>> frozen_se = frozenset(se) >>> for f in frozen_se: ... print(f) ... 1 2 3次に、シーケンスですが、これは順序性のあるコンテナになります。簡単に言うと、[インデックス]のような形で要素を取得できるデータ型のことを言います。
具体的には、(str, list, tuple)などがシーケンスですね。
最初の頃はstr型がシーケンスな感じがしないですが、慣れてくるとだんだんコンテナっぽく見えてくるはずです。>>> st[0] # str型 'オ' >>> li[1] # list型 2 >>> tu[2] # tuple型 'c'最後に、ミュータブルです。日本語で言うと変更可能体とか言うそうです。これは要素の変更、追加や削除ができるものを指します。逆にできないものはイミュータブルと言います。
ミュータブルなコンテナオブジェクトは、(list, dict, set)で、それ以外はイミュータブルなものになりますね。>>> li # list型 [1, 2, 3] >>> li[1] = 7 >>> li [1, 7, 3] >>> dic # dict型 {1: 'フシギダネ', 2: 'フシギソウ', 3: 'フシギバナ'} >>> dic[1] = 'チコリータ' >>> dic {1: 'チコリータ', 2: 'フシギソウ', 3: 'フシギバナ'} >>> se # set型 {1, 2, 3} >>> se.add(4) # 要素の変更はできないですが、追加・削除が可能 >>> se {1, 2, 3, 4}また、これらの特性については、用語集やこちらのブログに詳しくまとまっていたので適宜ご参照ください。
2. 制御フロー
次はプログラムの流れについて見ていきましょう。
概観のところでも触れましたが、ソースコードは楽譜のように、順序や流れのある命令文となっています。
具体的には、条件分岐や繰り返し、例外処理などがそれにあたりますね。制御フローの文は複合文と言って、文のブロックの中に節を含みます。表にすると下表のようになりますね。
表2. Pythonの制御フローにおける文・節
項番 分類 文 節 2-1 条件分岐 if文 elif節, else節 2-2 繰り返し while文 else節 2-3 繰り返し for文 else節 2-4 例外処理 try文 except節, else節, finally節 2-1. if文
まず初めに、ご存知if文ですね。これは条件分岐の時に使われる制御文です。
イメージは下図みたいな感じで、条件を満たした時、満たさなかった時で、違う経路を通ります。
条件によって違う経路を通って、最終的に合流するイメージですね。
図2-1. if文のイメージ図
出典簡単なif文の例はこんな感じです。
>>> your_age = 18 >>> if your_age < 20: ... print('お酒は禁止です') ... else: ... print('お酒OKです') ... お酒は禁止ですyour_ageが20未満だったのでif文中の命令が実行されましたね。ここで出てくるelse節というのは、それ以外という意味で、数学的には補集合のような立ち位置だと思います。if文以外の条件すべてといった感じですね。
注目して欲しいのは条件分岐なので、if文の命令文とelse節の命令文が同時には起こらないということです。
お酒は禁止な世界線とお酒OKな世界線しか選べないということですね。最後にelif節を説明します。
これはifとelseの二元論では収まらない時に使用します。>>> partner = input('ホウエン御三家で好きなポケモンは? :') ホウエン御三家で好きなポケモンは? :アチャモ >>> if partner == 'アチャモ': ... print('アチャモを てにいれました') ... elif partner == 'ミズゴロウ': ... print('ミズゴロウを てにいれました') ... else: ... print('キモリを てにいれました') ... アチャモを てにいれましたこんな感じですね。
繰り返しになりますが、if文、elif節、else節は排他的なので同時には起こりえません。ちょうどアチャモとミズゴロウを同時にオダマキ博士からもらうのは無理なのと同じですね。
(ちなみに、私はアチャモをワカシャモにしたくなさすぎて四天王までアチャモのままで行ったことがあります ※主戦力はサーナイト)2-2. while文
繰り返し処理ですね。
ピアノの反復記号と同じでひとかたまりの処理を繰り返します。
図2-2. while文のイメージ図
>>> age = 0 >>> while i < 20: ... print('お酒は禁止です') ... age += 1 ... お酒は禁止です お酒は禁止です お酒は禁止です お酒は禁止です お酒は禁止です お酒は禁止です お酒は禁止です お酒は禁止です お酒は禁止です お酒は禁止です お酒は禁止です お酒は禁止です お酒は禁止です お酒は禁止です お酒は禁止です お酒は禁止です お酒は禁止です お酒は禁止です お酒は禁止です お酒は禁止ですちなみに、繰り返し(ループ)をさせていると最後だけ別の処理をしたいことってありますよね。γ世界線に移動する時とか。
そういうときはelse節を使用します。if文での補集合的な考え方とは少し違いますが、ループを抜けるときに一度だけ実行することが可能です。>>> i = 0 >>> while i < 20: ... print('失敗した') ... i += 1 ... else: ... print('ようそこ、γ世界線へ') ... 失敗した 失敗した 失敗した 失敗した 失敗した 失敗した 失敗した 失敗した 失敗した 失敗した 失敗した 失敗した 失敗した 失敗した 失敗した 失敗した 失敗した 失敗した 失敗した 失敗した ようそこ、γ世界線へあと、途中でループを抜けたい時ってありますよね。ちょうど死に戻りしてばっかりでもう嫌になった時とか?
そういう時にはbreak文を使います。break文は単純文と言ってその後に節をとらずにそれだけで完結します。
break文はif文中で使われて、一度実行されると強制的にループから抜けることができます。>>> i = 0 >>> while i < 20: ... print('死に戻り') ... i += 1 ... if i == 15: ... print('諦めます') ... break ... else: ... print('ハッピーエンド') ... 死に戻り 死に戻り 死に戻り 死に戻り 死に戻り 死に戻り 死に戻り 死に戻り 死に戻り 死に戻り 死に戻り 死に戻り 死に戻り 死に戻り 死に戻り 諦めます諦めちゃいましたね。ハッピーエンドを見ることができませんでした。
諦めるのは嫌ですよね。そういう時はループ中にある条件の時だけ処理をスキップさせて次のループに入るということもできます。そういう時に使うのがcontinue文ですね。これも単純文なのでcontinueという単語だけで完結します。>>> i = 0 >>> while i < 25: ... i += 1 ... if i == 18: ... print('諦めるのは簡単です') ... print('でも、あなたには、似合わない') ... continue ... print(i, '死に戻り') ... else: ... print('ハッピーエンド') ... 1 死に戻り 2 死に戻り 3 死に戻り 4 死に戻り 5 死に戻り 6 死に戻り 7 死に戻り 8 死に戻り 9 死に戻り 10 死に戻り 11 死に戻り 12 死に戻り 13 死に戻り 14 死に戻り 15 死に戻り 16 死に戻り 17 死に戻り 諦めるのは簡単です でも、あなたには、似合わない 19 死に戻り 20 死に戻り 21 死に戻り 22 死に戻り 23 死に戻り 24 死に戻り 25 死に戻り ハッピーエンドこんな感じでcontinue文は以降の処理をスキップして次のループに入ります。
(18 死に戻りの処理を行わず次のループからはじめています)2-3. for文
さて、ようやくお馴染みのfor文ですね。プログラミング黎明期の繰り返しと言えばwhile文だったんですが、while文って繰り返しの回数を指定して実行できないじゃないですか。
でも、現実的には繰り返しの回数を指定して繰り返し処理したい時って非常に多いです。
そこで生まれたのがfor文ですね。
while文でもiみたいに回数を数えるカウンターを置いて、ループを抜ける回数を設定していたと思います。
イメージでいうとfor文はwhile文 + カウンターといった感じですかね。>>> for i in range(10): ... print('ねむたい') ... ねむたい ねむたい ねむたい ねむたい ねむたい ねむたい ねむたい ねむたい ねむたい ねむたいfor文でもwhile文と同じようにelse節でループを抜ける時の処理を記述することが可能です。
>>> for i in range(10): ... print('ねむたい') ... else: ... print('もうねよう') ... ねむたい ねむたい ねむたい ねむたい ねむたい ねむたい ねむたい ねむたい ねむたい ねむたい もうねよう内包表記
for文は回数付きのwhile文を簡略化するものでしたね。簡略化ということで、ここではコンテナを簡潔に作るテクニックにも触れておきます。
例えば、0-9の数値型を入れたリストを作りたい時とかってありますよね。
普通だったらこう書きます。>>> li = [0,1,2,3,4,5,6,7,8,9] >>> li [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]手作業ですね。
まぁ、10個くらいならいいんですが、100個とかになるとちょっと面倒ですし、1000個とか言われたらお手上げですよね?そういう時に役立つのが内包表記です。
list型の場合は["output" for "input" in range("n")]
みたいな感じで書きます。(""で囲まれた文字は任意の変数を表しています。文字列型というわけではないのでご注意ください)
>>> li = [x for x in range(10)] >>> li [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> li = [x**2 for x in range(10)] >>> li [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]数学的に言うと、"output"のところが出力値であるf(x)、"input"のところが入力値であるx、"n"が繰り返し回数を意味しています。
ちなみに、内包表記は後にif文を加えることも可能です。これは偶数だけ欲しい時とかに使えますね。
>>> li = [x for x in range(10) if x % 2 == 0] >>> li [0, 2, 4, 6, 8]あと、dict型でも使用可能です。
{"output_key": "output_value" for "input" in range("n")}みたいな書き方になりますね。>>> dic = {x*2: x**2 for x in range(10)} >>> dic {0: 0, 2: 1, 4: 4, 6: 9, 8: 16, 10: 25, 12: 36, 14: 49, 16: 64, 18: 81}2-4. try文
これは例外が発生するif文のようなイメージです。例外というのはErrorのことですね。例えば、list型で要素が存在しないインデックスを指定するとErrorがでます。
>>> li = [0,1,2] >>> li[3] Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: list index out of rangeこういう例外が発生しそうな処理をする時に使うのがtry文です。例外が発生しそうな処理をtry文に、例外が発生した時の処理をexcept節に記述していきます。
>>> try: # 例外が発生しそうな処理を記述 ... li[3] ... except: # 例外が発生した時の処理を記述 ... print('例外が発生したよ') ... 例外が発生したよさて、これだけではあんまり喜びを感じないかもしれませんね。
そんなtry文が本領を発揮するのはループ中だと思っています。
以下の処理を見てください。>>> li = [2,4,'はち',16] >>> for i in li: ... i / 2 ... 1.0 2.0 Traceback (most recent call last): File "<stdin>", line 2, in <module> TypeError: unsupported operand type(s) for /: 'str' and 'int'list中の要素を2で割る処理を記述していますが、途中文字列をはさんでいるのでErrorが発生して処理が中断されてしまいました。
でも、Errorが発生してもとりあえず最後までやって欲しいなーって時ありますよね?
例えば、Webでスクレイピングとかする時にリンク切れしているページでいちいち止まられるとたまりません。そういう時に使うのがtry文です。>>> li = [2,4,'はち',16] >>> for i in li: ... try: ... i / 2 ... except TypeError as e: ... print(e) ... 1.0 2.0 unsupported operand type(s) for /: 'str' and 'int' 8.0 # とりあえず最後まで実行できたこのようにexcept節を記述しておくととりあえず最後まで処理をしてくれます。
なので、Errorが発生しそうなループを実行する際はtry文がよく実行されます。3. 関数
関数っていうのはコードを再利用するためのセットみたいなものです。短いコードなら関数や後述のクラスを使う必要はないんですが、コードが複数のモジュールに渡ったり、複数のパッケージを使ったりする時には必ず必要になってくるんです。
まずは簡単に下の数式を書いてみましょう。
$f(x) = x ^ 2$
def "function_name"("arguments"):
みたいな感じで書けます。
function_nameというのは関数名で、argumentsというのは引数と呼ばれていて、要は入力値ですね。複数書くことも可能です。>>> def f(x): ... return x**2 ... >>> f(3) 9こんな感じで簡単な二次関数を記述することができました。
引数について
関数の入力値である引数ですが、いろいろ種類がありますので確認していきましょう。
3-1. 位置引数
普通に引数を設定すると位置引数になります。
要は順番通りに反映されている値ですね。>>> def f(a,b,c): ... print(a) ... print(b) ... print(c) ... >>> f(1,2,3) # 順番通りに反映されます 1 2 3ところで、*argsとか見たことありませんか?
私は学びたての頃にこの文字列を見て「?」となった経験があります。
これは可変長位置引数と言って、要は引数がいくつ続くかわからない時に仮引数に設定されるものです。
ここで仮引数というのは関数定義時に設定される引数のことで
def f("仮引数")←ここのことですね。
それに対して、実際に実行される時に代入される引数を実引数と言います。
f("実引数")みたいな感じですね。話を戻しますが*argsというのは、仮引数をいくつ設定していいか分からない時に用いるものです。
>>> def f(*args): # 仮引数 ... print(args) ... >>> f(1,2) # 実引数 (1, 2) # tupleで取得される >>> def f(*args): ... for arg in args: # 各要素を取得する場合 ... print(arg) ... >>> f(1,2,3) 1 2 3このように実引数がいくつになっても(可変長であっても)対応可能で便利になりましたね。
3-2. キーワード引数
実引数にキーワードを指定して代入する方法です。
dict型の考え方と通ずるところがあって、位置(インデックス)による参照ではなくて、keyによる参照というイメージですね。実引数の順序に関わらず入力したキーワードに代入されます。
また、キーワード引数の後に位置引数は続けられないので注意です。>>> def f(a,b,c): ... print(a) ... print(b) ... print(c) ... >>> f(c=3, a=1, b=2) 1 2 3 >>> f(c=3, a=1, 2) # キーワード引数の後に位置引数は取れない File "<stdin>", line 1 SyntaxError: positional argument follows keyword argumentまた、位置引数と同じく可変長なキーワード引数も存在します。こちらは**kwargsと書きます。
kwargsはdict型として代入されます。>>> def f(**kwargs): ... for key, value in kwargs.items(): ... print(key, value) ... >>> f(a=1,b=2,c=3) a 1 b 2 c 33-3. デフォルト引数
仮引数にはデフォルト値を設定することができます。デフォルト値を設定してデフォルト引数とした場合は、実引数に何も代入しなかった時にデフォルト引数が暗黙的に呼び出されます。
>>> def g(a=0): ... print(a) ... >>> g() # a=0がそのまま呼び出される 0 >>> g(3) # a=3となり、3が出力される 3無名関数lambda
lambdaと書いてラムダと読みます。
波長かな?と思った人は物理屋さんですね。
でも、波長じゃありません。
使い捨て関数みたいな感じですね。冒頭で関数が再利用するための道具です、みたいなこと言いましたがラムダは再利用しない1回こっきりの関数です。
関数の引数に関数を取るような時に使われますね。例えば、map()という組み込み関数があります。
これはmap("function", "iterable")のようにして、引数に関数とイテラブルなコンテナを取って、コンテナの要素ごとに関数を実行するものになります。
使用例として、数値型を要素に持つlistの各要素に対して演算を行いたいケースを想定します。
普通にmap()を使う場合、いちいち関数を定義してあげる必要があります。>>> li = [1,2,3,4,5] >>> def f(x): ... return x*2 ... >>> list(map(f, li)) [2, 4, 6, 8, 10]こんな時に使えるのがlambdaです。
関数を定義することなく1行でスマートに書くことができます。
構文はlambda "input": "output"
のようになります。
>>> li = [1,2,3,4,5] >>> list(map(lambda x: x*2, li)) [2, 4, 6, 8, 10]こんな感じで、わざわざ関数を定義することなく演算することができましたね。
4. クラス
オブジェクト指向の要素の一つですね。オブジェクト指向については、いろんな流派があるようなのでここでの説明は割愛します。
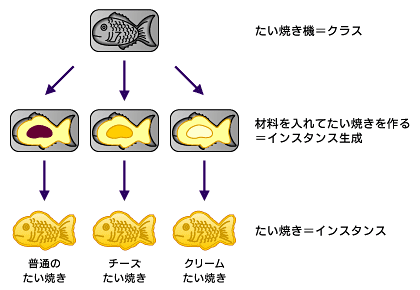
クラスに関しては、よくたい焼き機だ!とか言われてますよね。
聞けば、たい焼き機が元になる設計図のようなものでクラスと呼ばれていて、たい焼きが実際に生み出されるものでインスタンスとか呼ばれています。
初心者の人には意味不明かもしれませんがとりあえずイメージを下に貼っておきますね。
図4-1. クラスとインスタンスのイメージ要は量産する時に役立つテンプレートみたいなものと思ってもらったらいいのかなと思います。
今回はたい焼きの代わりにポケモンを作る場合のことを考えていきたいと思います。
まず、dict型でポケモンを作っていきましょう。便宜的に順番は公式なものではないです。
まずは名前とポケモンの説明、タイプだけを定義していきます。
こちらはインタプリタ(黒い画面の即レスしてくるやつ)ではなくて、IDEのエディタ(VisualStudioCode)を使って記述していきます。zenigame = {'name': 'ゼニガメ', 'doc': 'かめのこポケモン', 'type': 'みず'} kameiru = {'name': 'カメール', 'doc': 'かめポケモン', 'type': 'みず'} kamex = {'name': 'カメックス', 'doc': 'こうらポケモン', 'type': 'みず'} hitokage = {'name': 'ヒトカゲ', 'doc': 'とかげポケモン', 'type': 'ほのお'} rizard = {'name': 'リザード', 'doc': 'かえんポケモン', 'type': 'ほのお'}さて、次はリザードンを作りたいのですが、困りましたね。
リザードンはご存知の通り、ほのお・ひこうタイプなのでタイプが2つあります。
なのでkeyをtypeからtype1とtype2に変更させたいです。
でも、ちょっと全部変更し直すのはちょっと面倒ですよね。まあ、今回は6体目なんで大丈夫ですけど、71体目とかではじめてタイプが2つあるポケモンがでてきたりしたらさすがに嫌ですよね。
そういう面倒な仕様変更にお応えするのがクラスです。
今度は先のdictをクラスを使って記述していきます。クラスは
class "class_name":
で実装できます。
ちなみに、クラス内の関数のことをメソッドと呼び、メソッドは第一引数としてselfが必要です(便宜的に"self"という文字列を使ってますが規定はないです、言語によって違いがあってjavaなら"this"です)
そして、インスタンスを作る際に__init__という特殊メソッドを定義する必要があります。__init__みたいに__で囲まれたメソッドはすべて特殊メソッドとして扱われて、クラスに特性を持たせるために必要です。
class Pokemon: """ポケモンの型""" def __init__(self, name, doc, type): # インスタンスを作成 self.name = name self.doc = doc self.type = type zenigame = Pokemon('ゼニガメ', 'かめのこポケモン', 'みず') kameiru = Pokemon('カメール', 'かめポケモン', 'みず') kamex = Pokemon('カメックス', 'こうらポケモン', 'みず') hitokage = Pokemon('ヒトカゲ', 'とかげポケモン', 'ほのお') rizard = Pokemon('リザード', 'かえんポケモン', 'ほのお') print(zenigame.__dict__) # 結果はdict型の時と同じになります。 # {'name': 'ゼニガメ', 'doc': 'かめのこポケモン', 'type': 'みず'}ここにリザードンを追加する場合はtypeをtype1にしてtype2を追加する必要がありますが、クラスを使うとクラスの定義部分を変更するだけで済みます。
class Pokemon: """ポケモンの型""" def __init__(self, name, doc, type1, type2=None): self.name = name self.doc = doc self.type1 = type1 self.type2 = type2 zenigame = Pokemon('ゼニガメ', 'かめのこポケモン', 'みず') # 変更なし rizardon = Pokemon('リザードン', 'かえんポケモン', 'ほのお', 'ひこう') print(zenigame.__dict__) # {'name': 'ゼニガメ', 'doc': 'かめのこポケモン', 'type1': 'みず', 'type2': None} print(rizardon.__dict__) # {'name': 'リザードン', 'doc': 'かえんポケモン', 'type1': 'ほのお', 'type2': 'ひこう'}また、せっかくポケモンを作ったので今度は技を覚えさせたいとしましょう。そんな要望も、クラスなら実現可能なんです。
class Pokemon: """ポケモンの型""" def __init__(self, name, doc, type1, type2=None): self.name = name self.doc = doc self.type1 = type1 self.type2 = type2 def attack(self, attack_name): """技""" print(f"{self.name}は {attack_name}を くりだした!") zenigame = Pokemon('ゼニガメ', 'かめのこポケモン', 'みず') zenigame.attack('みずでっぽう') # ゼニガメは みずでっぽうを くりだした!こんな感じですね。
これは私の解釈ですがクラスを使うことによって、構文を英文法のようにSVO(主語・述語・目的語)でまとめることが可能なんですよね。
以下の文に注目してください。zenigame.attack('みずでっぽう')
この文を無理やり日本語訳すると「ゼニガメが 技をくりだした みずでっぽうを」みたいに解釈できませんか?
これはzenigameがPokemonクラスのインスタンスとなりこの文の主語になっていて、その後にattack()というメソッドが述語になっていて、最後に'みずでっぽう'という引数が目的語になっています。
なんだか今まで出てきた変数や関数がまとまった感じがしますよね。これがオブジェクト指向が整理術だと言われる所以だと思っていて醍醐味なんじゃないかなぁと思います。継承
最後にクラスの継承を説明しておきますね。
これは親クラスの属性を利用した子クラスを利用する時に使われます。数学的に言うと、ある集合の部分集合を作るイメージです。例えば、先のPokemonクラスを親クラスとして、ひでん要員(SecretMember)クラスを子クラスとして作成してみましょう。
そうすると、SecretMemberクラスはばっこしPokemonクラスのメソッドも利用することができます。class Pokemon: """ポケモンの型""" def __init__(self, name, doc, type1, type2=None): self.name = name self.doc = doc self.type1 = type1 self.type2 = type2 def attack(self, attack_name): """技""" print(f"{self.name}は {attack_name}を くりだした!") # PokemonクラスをSecretMemberクラスに継承させる class SecretMember(Pokemon): # 親クラスを引数に取るだけです """ひでん要員""" def secret_attack(self, attack_name): """ひでん技""" print(f"{self.name}は {attack_name}を わすれられない!") rizardon = SecretMember('リザードン', 'かえんポケモン', 'ほのお', 'ひこう') rizardon.secret_attack('そらをとぶ') # リザードンは そらをとぶを わすれられない! rizardon.attack('かえんほうしゃ') # ちゃんと親クラスのメソッドも利用できる # リザードンは かえんほうしゃを くりだした!こんな感じであるクラスの属性を利用した似たようなクラスを作るときは継承を使います。
※余談ですが、昔のポケモン(7世代サン・ムーンより前)はひでん技とかいうものがあって、ひでん技は通常時では忘れされることができなかったんですよね。
7世代以降のポケモンでは、ポケモンライドとかそらとぶタクシーとかでひでん技は廃止されました。
ポケモンもいろいろ仕様変更を繰り返しているんです。おわりに
以上で終わりです。
ここまで読んでくださった方は長々とありがとうございました。
厳密さや詳細な解説を省略して雰囲気でまとめた感が満載ですね。
読者の皆様はそろそろ厳密な解説を読みたくなってきたんじゃないかなぁということで以下参考から公式ドキュメントを見て頂ければと思います。この記事がPythonを学ぶなにかのとっかかりになれば嬉しいです。
参考
[3]Python実践入門


- 投稿日:2021-03-22T16:36:15+09:00
LEGO SPIKEプライムをターミナルから制御する
なぜSPIKEプライム?
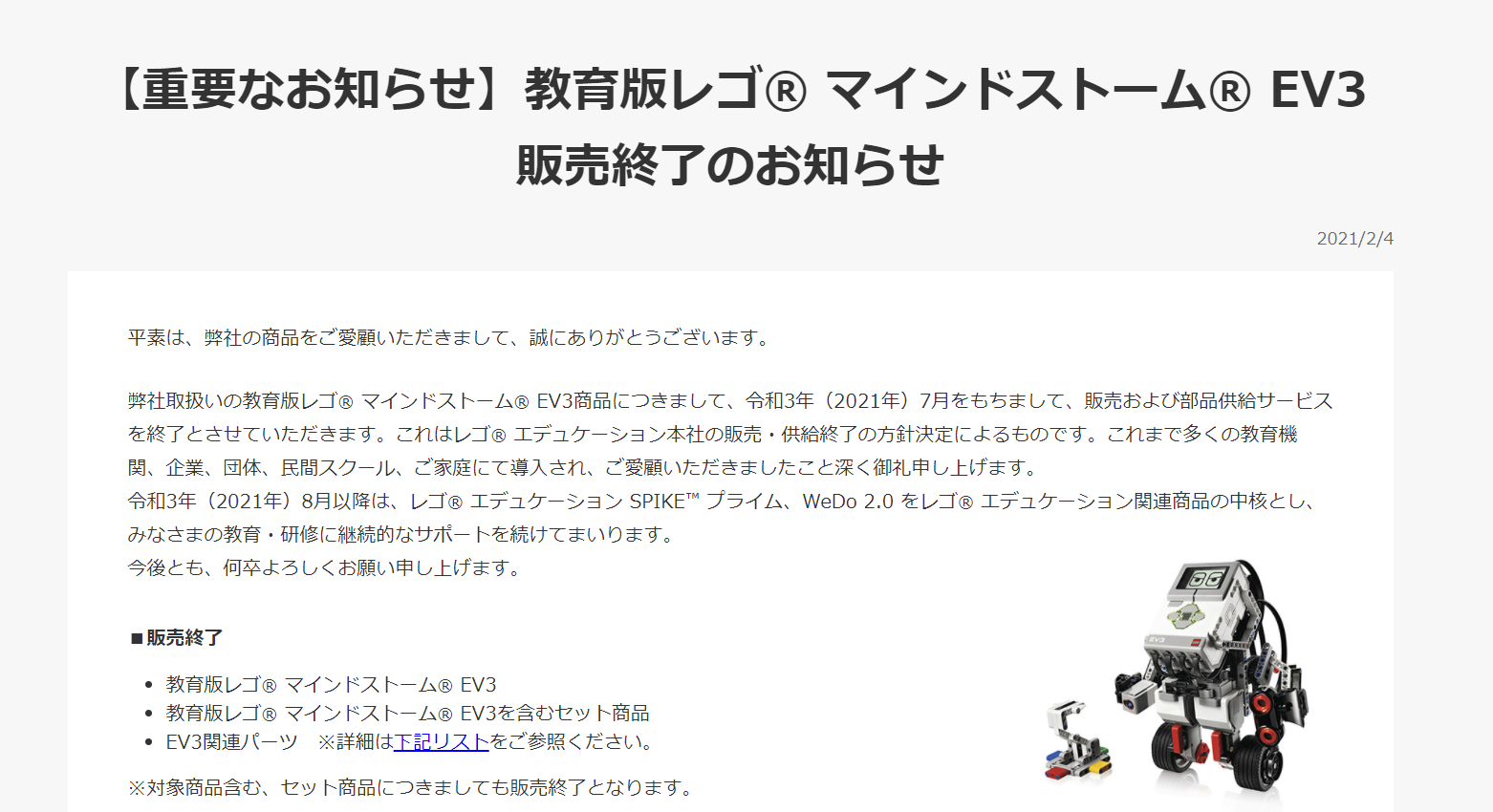
久しぶりの更新になるが、先月LEGOから衝撃の発表があった。
【重要なお知らせ】教育版レゴ® マインドストーム® EV3 販売終了のお知らせあの教育版レゴ® マインドストーム® EV3が終売に向かっていくことが発表された。
そのため後継品であるSPIKEプライムについての投稿や情報発信が増えていくだろう。SPIKEプライムについて
SPIKEプライムについて詳しくはこちらを参照
ハードウェア
EV3と比較すると、センサーなどの構成はそのままに組み立てや見た目などがとっつきやすいようにデザインされている。
入力出力ポートが一体化されているが全体数としては8→6ポートと減っているなど違う点も散見される。
しかしこれでセンサーやモーターをどこに挿したらいいかはわかりやすくなっており入門としては優しくなっている。内包されているLEGOパーツもかなり便利なパーツが含まれており、ロボットモデルの組み立てはかなりやりやすい印象。
ソフトウェア
プログラミング環境としては、EV3の時と同様に専用のソフトウェアが用意されている。
ソフトウェア内ではScratchベースでのアイコンプログラミングと、MicroPythonを使ったテキストプログラミングが最初からサポートされている。
Scratchベースのアイコンプログラミング
MicroPythonでのテキストプログラミングターミナルエミュレーターから直接MicroPythonを実行してみる
上記でSPIKEプライムのプログラミング環境を紹介したが今回はどちらも利用しない。
今回はSPIKEプライムのハブにはMicroPythonがインストールされているので、シリアル通信でPCからハブに直接アクセスしてインタプリタ形式でPythonプログラムを実行してみようと思う。今回のPCの環境は以下である。
- Windows 10
- ターミナルエミュレーターとしてPuttyを利用する
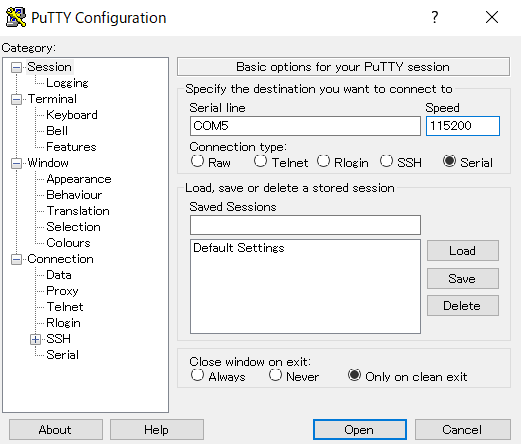
まずはPuttyをダウンロードしインストールする。
こちらより環境にあわせてmsiファイルをダウンロードし実行・インストールする。PCとSPIKEプライムのハブをUSBケーブルで接続し、SPIKEプライムの電源をONにする。
デバイスマネージャーを開きハブが何番のポートに接続されているか確認する。
画像ではCOM5にハブが接続されている。
Puttyを開き
Connection typeのSerialにチェックを入れる。(初期ではSSHに入っている。)
チェックを入れたらSerial Line欄に調べたCOMポートを入力する。(画像ではCOM5を入力している。)
隣のSpeedに115200と入力する。(初期では9600が入っている。)
Speedの115200はシリアルコンソールの速度として一般的にサポートされている速度らしい。9600もサポートされているので動作は問題なくできるがここは変更を推奨する。
前述の手順を入力できたら
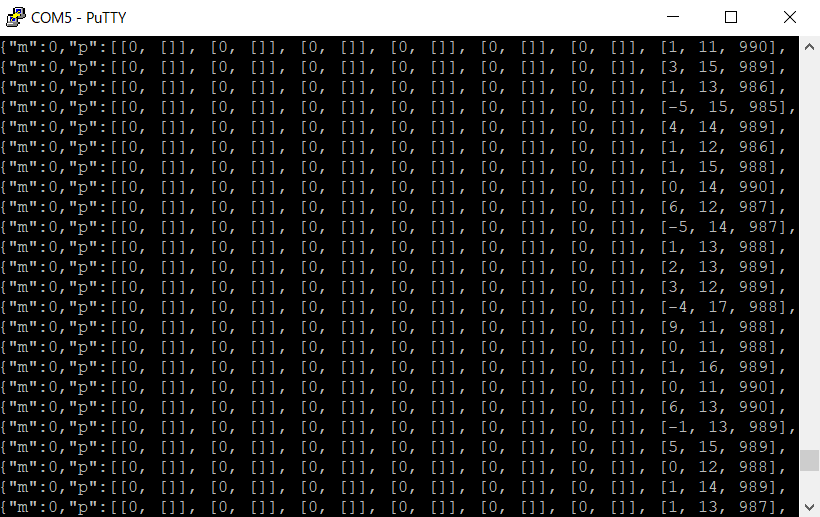
Openをクリックする。
するとハブにアクセスしたターミナルウィンドウが起動しハブに内蔵されているセンサーの値を返し始める。
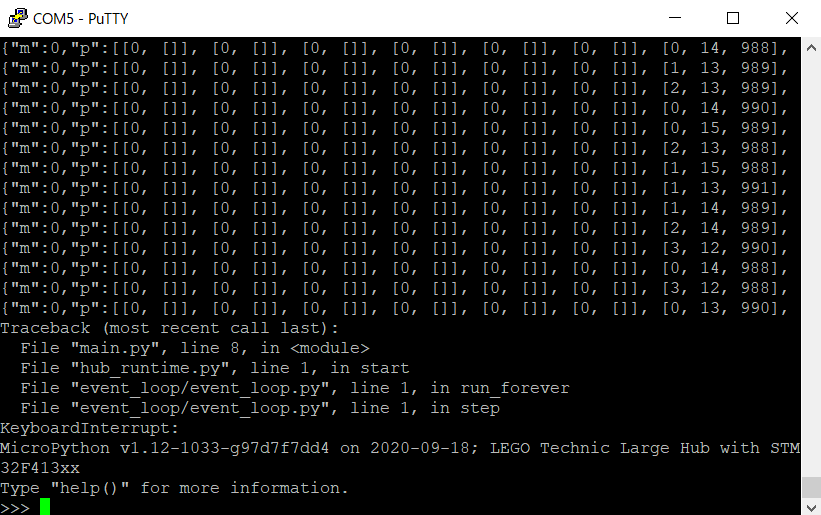
この状態でCtrl+Cキーを押すことでインタプリタのMicroPythonを入力することができるようになる。
簡単なプログラムの実行
MicroPythonを実行できるようになったので以下のような簡単なプログラムを実行してみる。
import hub
hub.display.show(‘Test’)
インタプリタなので一行ずつ入力するごとにEnterキーを入力する必要がある。
2行目を入力しEnterキーを押すと実行される。
以下が実行結果になる。
一定間隔で
Testの文字がハブに表示される。他にどのようなメソッドがあるか調べるには
hub.と入力しEnterを押すことでそれ以降に入力することができるメソッド一覧が表示されるので
必要に応じて調べながらプログラムを作成することができる。Appendix
ハブ内にインストールされているMicroPythonのバージョンを調べてみた。
以下のコードで調べることができる。
import sys
sys.version_info
バージョンの情報がタプル形式で返される。
インストールされているMicroPythonのバージョンは3.4.0であることがわかった。










- 投稿日:2021-03-22T16:15:12+09:00
【Python】for文でインデックスを自動採番する(自分でn += 1 とかしない)方法(備忘録)
自分用メモ
enumerate(iterable, start=0)を使う。enumerate
そもそも
enumerate(iterable, start=0)とはカウント(デフォルトは0)と、iterable上のイテレーションによって得られた値を含むタプルを返す組み込み関数。seasons = ['Spring', 'Summer', 'Fall', 'Winter'] seasons_index_0 = list(enumerate(seasons)) seasons_index_1 = list(enumerate(seasons, 1)) seasons_index_5 = list(enumerate(seasons, 5)) print(seasons_index_0) print(seasons_index_1) print(seasons_index_5)出力結果
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')] [(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')] [(5, 'Spring'), (6, 'Summer'), (7, 'Fall'), (8, 'Winter')]for文と比較すると下記1、2は等価
#1.enumerate enumerate(seasons) #2.for文とn += 1 def enumerate(sequence, start=0): n = start for elem in sequence: yield n, elem n += 1enumerateを使ったインデックス付きループ
enumerateを応用してインデックス付きのループを実装する。
seasons = ['Spring', 'Summer', 'Fall', 'Winter'] for i, season in enumerate(seasons): print(i, "," ,season)出力
0 , Spring 1 , Summer 2 , Fall 3 , Winterインデックスの開始を変えるなら
seasons = ['Spring', 'Summer', 'Fall', 'Winter'] for i, season in enumerate(seasons, 5): print(i, "," ,season)出力
5 , Spring 6 , Summer 7 , Fall 8 , Winterこれは便利。
応用
JSON形式の辞書リストデータに対しても実行してみる
member_list = [ {'No': 1, 'Name': 'Yamada Taro', 'LastLoginTime': '2021-03-16 15:44:16'}, {'No': 2, 'Name': 'Yamada Jiro', 'LastLoginTime': '2021-03-10 00:12:17'}, {'No': 3, 'Name': 'Yamada Saburo', 'LastLoginTime': '2021-03-20 12:01:02'}, {'No': 4, 'Name': 'Yamada Shiro', 'LastLoginTime': '2020-12-24 00:00:13'}, {'No': 5, 'Name': 'Yamada Goro', 'LastLoginTime': '2021-03-17 11:01:55'}, ] for i, member in enumerate(member_list): print(i, "," ,member)出力
0 , {'No': 1, 'Name': 'Yamada Taro', 'LastLoginTime': '2021-03-16 15:44:16'} 1 , {'No': 2, 'Name': 'Yamada Jiro', 'LastLoginTime': '2021-03-10 00:12:17'} 2 , {'No': 3, 'Name': 'Yamada Saburo', 'LastLoginTime': '2021-03-20 12:01:02'} 3 , {'No': 4, 'Name': 'Yamada Shiro', 'LastLoginTime': '2020-12-24 00:00:13'} 4 , {'No': 5, 'Name': 'Yamada Goro', 'LastLoginTime': '2021-03-17 11:01:55'}問題なくインデックスを取得出来る。
参考リンク
Python docs #enumerate以上
- 投稿日:2021-03-22T15:02:16+09:00
[IPython embed] 良いかわからないけど,使ってたデバッグ方法
プログラムを書くとき
この時に,途中でこのコードが正しいのか確認したい・一応かけたけど途中のとこの数値とかがあっているかの確認したいという場合があります.そんな時,私は以下の手法で確認していました.linux上で動かせるのでかっこいい.
ただし,もっと良い方法とかあるかもしれないのでより良い方法を教えてくださると嬉しいです.!!!!!EMBEDDING!!!!!!
この題のようにembedというのを間に打ち込めば,linuxのようなターミナル上で確認することができます.vscodeのデバッグ昨日よりかっこいいと思っているので,私は多用しています.
まずは黙ってインストール
pip install IPython
Defaulting to user installation because normal site-packages is not writeable
Collecting IPython
Downloading ipython-7.16.1-py3-none-any.whl (785 kB)
|████████████████████████████████| 785 kB 3.3 MB/s
Collecting backcall
・・・・・・・・こんな感じでインストール完了したらいざ!
まずはサンプルコードembed1.pyがあったとします.embed1.pyfrom IPython import embed cnt = 0 for i in range(10): cnt+=i print(cnt)これはまあ単純にカウントするだけのコード.答えは45.
しかし途中でドンくらいの数字になっているのか確認したい場合,embedが使えます.↓
↓ これにembedを加えます.
↓embed2.pyfrom IPython import embed cnt = 0 for i in range(10): ####### embed() ###### cnt+=i print(cnt)↓
↓ そしてターミナルで実行.
↓python .\embed2.py Python 3.6.4 (v3.6.4:d48eceb, Dec 19 2017, 06:04:45) [MSC v.1900 32 bit (Intel)] Type 'copyright', 'credits' or 'license' for more information IPython 7.16.1 -- An enhanced Interactive Python. Type '?' for help. In [1]:そうすると,
In [1]:
に入力できるようになります.
そこで,cntを入力します.In [1]: cnt Out[1]: 0 In [2]: exit() Python 3.6.4 (v3.6.4:d48eceb, Dec 19 2017, 06:04:45) [MSC v.1900 32 bit (Intel)] Type 'copyright', 'credits' or 'license' for more information IPython 7.16.1 -- An enhanced Interactive Python. Type '?' for help. In [1]: cnt Out[1]: 0 In [2]: exit() Python 3.6.4 (v3.6.4:d48eceb, Dec 19 2017, 06:04:45) [MSC v.1900 32 bit (Intel)] Type 'copyright', 'credits' or 'license' for more information IPython 7.16.1 -- An enhanced Interactive Python. Type '?' for help. In [1]: cnt Out[1]: 1 In [2]: i Out[2]: 2このようになります.
また現在のデバッグを抜けたい場合は
exit()
といれれば出られます.他にもこのembedでコードが止まった状態でimportしたり,ファイル情報を読み込みして検算したり,と様々なやり方があるので,是非使ってみて下さい.
- 投稿日:2021-03-22T15:02:16+09:00
[IPython embed] ちょっと便利なデバッグ方法
プログラムを書くとき
この時に,途中でこのコードが正しいのか確認したい・一応かけたけど途中のとこの数値とかがあっているかの確認したいという場合があります.そんな時,私は以下の手法で確認していました.linux上で動かせるのでかっこいい.
ただし,もっと良い方法とかあるかもしれないのでより良い方法を教えてくださると嬉しいです.!!!!!EMBEDDING!!!!!!
この題のようにembedというのを間に打ち込めば,linuxのようなターミナル上で確認することができます.vscodeのデバッグ昨日よりかっこいいと思っているので,私は多用しています.
まずは黙ってインストール
pip install IPython
Defaulting to user installation because normal site-packages is not writeable
Collecting IPython
Downloading ipython-7.16.1-py3-none-any.whl (785 kB)
|████████████████████████████████| 785 kB 3.3 MB/s
Collecting backcall
・・・・・・・・こんな感じでインストール完了したらいざ!
まずはサンプルコードembed1.pyがあったとします.embed1.pyfrom IPython import embed cnt = 0 for i in range(10): cnt+=i print(cnt)これはまあ単純にカウントするだけのコード.答えは45.
しかし途中でドンくらいの数字になっているのか確認したい場合,embedが使えます.↓
↓ これにembedを加えます.
↓embed2.pyfrom IPython import embed cnt = 0 for i in range(10): ####### embed() ###### cnt+=i print(cnt)↓
↓ そしてターミナルで実行.
↓python .\embed2.py Python 3.6.4 (v3.6.4:d48eceb, Dec 19 2017, 06:04:45) [MSC v.1900 32 bit (Intel)] Type 'copyright', 'credits' or 'license' for more information IPython 7.16.1 -- An enhanced Interactive Python. Type '?' for help. In [1]:そうすると,
In [1]:
に入力できるようになります.
そこで,cntを入力します.In [1]: cnt Out[1]: 0 In [2]: exit() Python 3.6.4 (v3.6.4:d48eceb, Dec 19 2017, 06:04:45) [MSC v.1900 32 bit (Intel)] Type 'copyright', 'credits' or 'license' for more information IPython 7.16.1 -- An enhanced Interactive Python. Type '?' for help. In [1]: cnt Out[1]: 0 In [2]: exit() Python 3.6.4 (v3.6.4:d48eceb, Dec 19 2017, 06:04:45) [MSC v.1900 32 bit (Intel)] Type 'copyright', 'credits' or 'license' for more information IPython 7.16.1 -- An enhanced Interactive Python. Type '?' for help. In [1]: cnt Out[1]: 1 In [2]: i Out[2]: 2このようになります.
また現在のデバッグを抜けたい場合は
exit()
といれれば出られます.他にもこのembedでコードが止まった状態でimportしたり,ファイル情報を読み込みして検算したり,と様々なやり方があるので,是非使ってみて下さい.
- 投稿日:2021-03-22T14:59:14+09:00
Django quote_from_bytes() expected bytes
問題
class Create(generic.CreateView): template_name = ... form_class = ... def get_success_url(self): return redirect(reverse_lazy("blog:detail", kwargs={...}))とかの
Viewを書いてたら、
quote_from_bytes() expected bytesってエラーが出た。解決
def get_success_url(self): return reverse_lazy("blog:detail", kwargs={...})
get_success_urlはURLを返す。
考えてみたらその通りだった。
- 投稿日:2021-03-22T14:37:02+09:00
私の好きな複数のファイル読み込みの方法
python globとは
pythonにはさまざまなモジュールがあり,その中で私はglobというのが結構好きで使っていました.
簡単に説明すると,
glob=掴む
的な意味なので,複数のファイルを探るといったときに使えます.使い方
まず,複数のファイルを用意します.
a000.txt
a001.txt
a002.txt
a003.txt
a004.txt
があったとします.a.pyimport glob a = glob.glob('./a*.txt') print(a)> python .\a.py['.\a000.txt', '.\a001.txt', '.\a002.txt', '.\a003.txt', '.\a004.txt']
こんな感じで結果が表示されます.
このようにa***.txtのファイルを探すことに成功しました.もしディレクトリ内にb***.txtといったファイルがある場合,それは読み込みされずa始まりのファイルのみが選択されます.そして使った後に数値ファイルであれあnumpy.loadtxt,ファイル形式であればfileを使ったおなじみの手法でファイル内のデータを読み込めます.
例えば,file形式でファイル読み込みの場合,
b.pyimport glob a = glob.glob('./a*.txt') print(a) for i in a: print(i) with open(i) as f: b = f.read() print(b)['.\a000.txt', '.\a001.txt', '.\a002.txt', '.\a003.txt', '.\a004.txt']
.\a000.txt
this is 1
.\a001.txt
this is 2
.\a002.txt
this is 3
.\a003.txt
this is 4
.\a004.txt
this is 5こんな感じで表示されます.
- 投稿日:2021-03-22T14:37:02+09:00
[python glob] 私の好きな複数のファイル読み込みの方法
python globとは
pythonにはさまざまなモジュールがあり,その中で私はglobというのが結構好きで使っていました.
簡単に説明すると,
glob=掴む
的な意味なので,複数のファイルを探るといったときに使えます.使い方
まず,複数のファイルを用意します.
a000.txt
a001.txt
a002.txt
a003.txt
a004.txt
があったとします.a.pyimport glob a = glob.glob('./a*.txt') print(a)> python .\a.py['.\a000.txt', '.\a001.txt', '.\a002.txt', '.\a003.txt', '.\a004.txt']
こんな感じで結果が表示されます.
このようにa***.txtのファイルを探すことに成功しました.もしディレクトリ内にb***.txtといったファイルがある場合,それは読み込みされずa始まりのファイルのみが選択されます.そして使った後に数値ファイルであれあnumpy.loadtxt,ファイル形式であればfileを使ったおなじみの手法でファイル内のデータを読み込めます.
例えば,file形式でファイル読み込みの場合,
b.pyimport glob a = glob.glob('./a*.txt') print(a) for i in a: print(i) with open(i) as f: b = f.read() print(b)['.\a000.txt', '.\a001.txt', '.\a002.txt', '.\a003.txt', '.\a004.txt']
.\a000.txt
this is 1
.\a001.txt
this is 2
.\a002.txt
this is 3
.\a003.txt
this is 4
.\a004.txt
this is 5こんな感じで表示されます.
- 投稿日:2021-03-22T11:55:53+09:00
[Python][Pandas] Dataframeの列の処理いろいろ
個人的な備忘録です。
pandasの文字列の列にスライスを適用
https://note.nkmk.me/python-pandas-str-slice/
df['a'].str[:2]pandasで文字の長さによる抽出
https://ja.stackoverflow.com/questions/63216/pandas%E3%81%A7%E6%96%87%E5%AD%97%E3%81%AE%E9%95%B7%E3%81%95%E3%81%AB%E3%82%88%E3%82%8B%E6%8A%BD%E5%87%BA
mask = df['moji'].str.len() >= 3
df[mask]pandas.DataFrame, Seriesの要素の値を置換するreplace 正規表現
()で囲んだ部分をグループとして、置換後の値の中で\1, \2のように順番に使用可能。
https://note.nkmk.me/python-pandas-replace/
df.replace('(.)li(.)', r'\1LI\2', regex=True)
※rを入れるのを忘れないこと!DataFrameに合計の列(行)を追加
https://www.kite.com/python/answers/how-to-sum-rows-of-a-pandas-dataframe-in-python
df['sum'] = df.sum(axis=1)カラム名変更
print(df.rename(columns={'A': 'a', 'C': 'c'}))
※意外に面倒・・Change to datetime format
https://stackoverflow.com/questions/25146121/extracting-just-month-and-year-separately-from-pandas-datetime-column
df['date_column'] = pd.to_datetime(df['date_column'])全部のシートへアクセス
for sheetN in pd.ExcelFile(fname).sheet_names:
https://stackoverflow.com/questions/26521266/using-pandas-to-pd-read-excel-for-multiple-worksheets-of-the-same-workbook
- 投稿日:2021-03-22T11:28:28+09:00
signate:日本取引所グループ ニュース分析チャレンジ①
初めに
この記事は、現在signateで開催されているニュース分析チャレンジのコンペティションの自分の学習過程を発信するために記述しています。
おそらく、チュートリアルに関しては自分なりに噛み砕いた形でコンペティション期間中に記載し、実際の提出モデルに関しては、コンペティション終了後に提出すると思います。
本記事のシリーズについて
本記事は、signateで公開されているチュートリアルを自分なりに噛み砕いて、
再掲載することを目的に記述しています。そのため、誤り等あるかもしれませんが、その際にはご指摘いただくとありがたいです。
本コンペティション参加動機
僕は、資産運用を実際に行っており、できれば機械学習を活用してポートフォリオを作成できないか考えていました。今回は、その足掛かりとなりうるコンペティションとなっているため、かなり意欲的に参加・開発ができるかなと思っています。
このコンペを通して次のことを身につけたいと思っています。
・基礎的な金融知識
・機械学習を活用した、資産運用AIの開発次回予告
次回は、チュートリアル第二章について自分なりに咀嚼して書いていきたいと思います。
- 投稿日:2021-03-22T10:12:10+09:00
反復的量子位相推定(IQPE)で水素分子の基底エネルギーを計算する
論文[1]をもとに反復的量子位相推定(IQPE)で水素分子の基底エネルギーを計算することを目標とします。
Quantum Native Dojoの7-1を参考にコードを実装し、実際の挙動を確かめてみました。
あくまで自分の勉強用のメモとして書いたので間違っている箇所などがあれば教えていただけると幸いです。反復的量子位相推定について
反復的量子位相推定では補助ビット1つで任意の桁数までの位相推定を行うことができます。 1回の計算過程で固有値の位相$0.j_1...j_t$の1つの桁($j_k$)を求めることができます。詳しくはQuantum Native Dojoの7-1を参考にしてください。
求める手順
0.ハミルトニアンのサイズを対照性などを利用して削減する。
1. ハミルトニアンの時間発展演算子$U=e^{-iH\tau}$を精度よく近似する。
2. 制御時間発展演算子を量子コンピュータで計算できるサイズに分解し実装する。
3. 基底状態と十分重なりのある初期状態を準備する。
4. IQPEでエネルギー固有値を求める。以下ではこの手順に沿って説明していきます。
0. ハミルトニアンのサイズを対照性などを利用して削減する。
水素分子のハミルトニアンを第2量子化し、STO-6G基底関数のもとでBravyi-Kitaev変換を行うと、ハミルトニアンは4量子ビットを用いて表されます。ただ、この量子ビット数は電子数一定という条件を使って2個まで削減することができ、ハミルトニアンは以下の形で表現できます。 $$H=g_0\boldsymbol{1}+g_1Z_0+g_2Z_1+g_3Z_0Z_1+g_4X_0X_1+g_5Y_0Y_1$$
1. ハミルトニアンの時間発展演算子を精度よく近似する。
IQPEで用いる制御ユニタリ演算$\Lambda(U^{2^{k}})$を実装するため、まずは時間発展演算子$U=e^{-iH\tau}$を量子回路に実装します。まず$g_0\boldsymbol{1}$と$g_3Z_0Z_1$についてはハミルトニアンのほかの項と可換であるので
$$U=\exp \left[-i\tau\sum_{i}g_iH_i \right]=\exp \left[-i\tau g_0\textbf{1} \right] \exp[-i\tau g_3Z_0Z_1]{\rm{exp}}[-i\tau H_{\rm{eff}}]$$
となります。(可換な演算子AとBについてはexp(A+B)=exp(A)exp(B)となることを用いました。)
ここで
$$H_{\rm{eff}}=g_1Z_0+g_2Z_1+g_4X_0X_1+g_5Y_0Y_1$$
です。$g_0\boldsymbol{1}$と$g_3Z_0Z_1$の寄与は後から足し合わせればよいので以下では$H_{\rm{eff}}$の固有値を$U_{\rm{eff}}:={\rm{exp}}[-i\tau H_{\rm{eff}}]$のIQPEを用いて求めることを考えます。$U_{\rm{eff}}$をトロッター分解すると
$$U_{\text{eff}} = \exp \left[−i \tau \sum_{i=1,2,4,5} g_i H_i \right] \approx U_{\text{Trot}}^{(N)} (\tau) := \left( \prod_{i=1,2,4,5} \exp[-i g_i H_i \tau/N] \right)^N$$
となります。ここで$ U_{\text{Trot}}^{(N)} (\tau)$に表れる積の各項はパウリ行列の積の指数関数の形$\rm{exp}( i\theta P)$の形をしているので量子ゲートによって容易に実装できます。今回は扱う行列が4×4と小さいので、実際に$H_{\textrm{eff}}$を対角化してみてその最小固有値$E_{\textrm{min}}$を求め、$ U_{\text{Trot}}^{(N)} (\tau)$の固有値の$e^{i \lambda_{\textrm{Trot}}\tau}$の$\lambda_{\textrm{Trot}}$と比較してみます。
まずは$H_{\textrm{eff}}$の対角化を行います。
以下では量子回路シミュレータであるQulacsを用いて計算を行っていきます。
ここでエネルギーの単位はハートリー(Hartree)が使われています。pip install qulacs pyscf openfermion openfermionpyscf from functools import reduce import numpy as np from numpy.linalg import matrix_power, eig from scipy.sparse.linalg import eigsh from openfermion.ops import QubitOperator from openfermion.linalg import get_sparse_operator from qulacs import QuantumState, Observable, QuantumCircuit import matplotlib.pyplot as plt def hamiltonian_eff(): """ distance = 0.70 A removed I and 'Z0 Z1' terms, which add up to -1.31916027 """ n_qubits = 2 g_list = [0.3593, 0.0896, -0.4826, 0.0896]## taken from table 1 of paper [1] pauli_strings = ['Z0','Y0 Y1','Z1','X0 X1'] hamiltonian = QubitOperator() for g,h in zip(g_list,pauli_strings): hamiltonian += g *QubitOperator(h) sparse_matrix = get_sparse_operator(hamiltonian, n_qubits=n_qubits)#get_sparse_operatorは演算子から疎行列を得る vals, vecs = eigsh(sparse_matrix, k=1, which="SA") ## 最も小さい固有値と対応する固有ベクトルが得られる return sparse_matrix, vals gomi,eigs = hamiltonian_eff() exact_eigenvalue = eigs[0] print('exact_eigenvalue:{} Ha'.format(exact_eigenvalue))次に$ U_{\text{Trot}}^{(N)} (\tau)$を対角化します。後のステップでは$ U_{\text{Trot}}^{(N)} (\tau)$を量子回路として具体的に実装しますが、ここでは$H_i^2=I$のとき
$$
\left( \prod_{i=1,2,4,5} \exp[-i g_i H_i \tau/N] \right)^N = \left( \prod_{i=1,2,4,5} \left( \cos(g_i\tau/N) I -i \sin(g_i\tau/N) H_i \right) \right)^N
$$
となる性質を用いて計算します。そして$N=1,3,...,9$において$ U_{\text{Trot}}^{(N)} (\tau)$の固有値$e^{i \lambda_{\textrm{Trot}}\;\tau}$の$\lambda_{\textrm{Trot}}$と$E_{\textrm{min}}$を比較します。def order_n_trotter_approx(t,n_trotter_steps): """ ordering: 'Z0', 'Y0 Y1', 'Z1', 'X0 X1' Returns: sparse_matrix: trotterized [exp(iHt/n)]^n args: list of phases of each eigenvalue, exp(i*phase) """ n_qubits = 2 g_list = [0.3593, 0.0896, -0.4826, 0.0896] pauli_strings = ['Z0','Y0 Y1','Z1','X0 X1'] terms = [] for g,h in zip(g_list,pauli_strings): arg = g * t / n_trotter_steps qop = complex(np.cos(arg),0)* QubitOperator("") - complex(0,np.sin(arg))*QubitOperator(h) terms += [get_sparse_operator(qop, n_qubits=n_qubits)] sparse_matrix = terms[0] for i in range(3): sparse_matrix = np.dot(sparse_matrix,terms[i+1]) """ sparse_matrix = reduce(np.dot, terms)でも同じ """ matrix = matrix_power(sparse_matrix.toarray(),n_trotter_steps)##U_{trot}^{(N)} vals, vecs = eig(matrix)## e^{i lambda_{trot} } args = np.angle(vals)## [-pi, pi] の範囲で固有値(今回はλ×τに当たる)が得られる->今回、求める固有値が-0.86付近と分かっているので修正不要。 return sparse_matrix, sorted(args) tau = 0.640 ## taken from table 1 of paper [1] print('N, E_trot, |exact_eig - E_trot|') for n in range(1,10,2): gomi,phases = order_n_trotter_approx(tau,n) e_trotter = phases[0]/tau ##上で得られたargsはλ×τなのでλを求めるためにτで割る。 print( f"{n}, {e_trotter:.10f}, {abs(exact_eigenvalue - e_trotter):.3e}" )実行結果は以下のようになります。
N, E_trot, |exact_eig - E_trot|
1, -0.8602760326, 4.842e-04
3, -0.8607068561, 5.342e-05
5, -0.8607410548, 1.922e-05
7, -0.8607504700, 9.804e-06
9, -0.8607543437, 5.931e-06このように次数が大きくなるほど近似精度が上がっており、真のエネルギー固有値を化学的精度( 1.6×10−3 Ha)と呼ばれる、化学計算において必要とされる精度で近似するには今回はN=1で十分であることが分かります。
2. 制御時間発展演算子を量子コンピュータで計算できるサイズに分解し実装する。
量子コンピュータ上で制御時間発展演算子 $\Lambda \left( \left( U_{\textrm{Trot}}^{(N)} \right)^{2^k} \right)$ を実装するためには、これを簡単な量子ゲートに分解する必要があります。
今回の例では$ U_{\text{Trot}}^{(N)} $に含まれる、
- $\Lambda(R_Z(\theta))$
- $\Lambda(R_{XX}(\theta))$
- $\Lambda(R_{YY}(\theta))$
という制御回転ゲートを実装できれば良いです。
以下のコードでは、 Qulacs で制御時間発展演算子 $\Lambda \left( \left( U_{\textrm{Trot}}^{(N)} \right)^{2^k} \right)$ の量子回路を実装し、IQPEで実行すべき回路を作っています。
def IQPE_circuit(g_list, tau, kickback_phase, k, n_trotter_step = 1): n_qubits = 3 ## 2 for system, and 1 for ancillary a_ind = 2 ##index of ancillary phi = -(tau/n_trotter_step) * g_list ##パウリ演算子の係数 circuit = QuantumCircuit(n_qubits) ##ここから回路を構成する。まずancilaにアダマールをかける circuit.add_H_gate(a_ind) ##ancilaにkickback位相回転ゲートをかける circuit.add_RZ_gate(a_ind,kickback_phase) ##制御時間発展演算子を2^{k-1}回かける for _ in range(2**(k-1)): for _ in range(n_trotter_step): # CU(Z0) つまり controlled exp(i phi[0]*Z_0) circuit.add_RZ_gate(0,phi[0]) circuit.add_CNOT_gate(a_ind,0) circuit.add_RZ_gate(0,-phi[0]) circuit.add_CNOT_gate(a_ind,0) # CU(Y0 Y1) circuit.add_Sdag_gate(0) circuit.add_Sdag_gate(1) circuit.add_H_gate(0) circuit.add_H_gate(1) circuit.add_CNOT_gate(0,1) circuit.add_RZ_gate(1,phi[1]) circuit.add_CNOT_gate(a_ind,1) circuit.add_RZ_gate(1,-phi[1]) circuit.add_CNOT_gate(a_ind,1) circuit.add_CNOT_gate(0,1) circuit.add_H_gate(0) circuit.add_H_gate(1) circuit.add_S_gate(0) circuit.add_S_gate(1) # CU(Z1) circuit.add_RZ_gate(1, phi[2]) circuit.add_CNOT_gate(a_ind, 1) circuit.add_RZ_gate(1, -phi[2]) circuit.add_CNOT_gate(a_ind, 1) # CU(X0 X1) circuit.add_H_gate(0) circuit.add_H_gate(1) circuit.add_CNOT_gate(0, 1) circuit.add_RZ_gate(1, phi[3]) circuit.add_CNOT_gate(a_ind, 1) circuit.add_RZ_gate(1, -phi[3]) circuit.add_CNOT_gate(a_ind, 1) circuit.add_CNOT_gate(0, 1) circuit.add_H_gate(0) circuit.add_H_gate(1) ## Apply Hadamard to ancilla circuit.add_H_gate(a_ind) return circuit3. 基底状態と十分重なりのある初期状態を準備する。
これまでは簡単のために ? に作用する状態は固有状態と仮定してきました。しかし、入力波動関数が固有状態と十分近い場合、高い精度でその固有値を求めることができます。
今回の水素分子の基底エネルギーを求める問題の場合、Hatree-Fock状態 |?⟩=|01⟩ が十分基底状態に近いので、これを用いて基底エネルギーを求めます。
4. IQPEでエネルギー固有値を求める。
from qulacs.circuit import QuantumCircuitOptimizer def iterative_phase_estimation(g_list, tau, n_itter, init_state, n_trotter_step=1, kickback_phase = 0.0): for k in reversed(range(1, n_itter+1)): psi = init_state.copy() circuit = IQPE_circuit(np.array(g_list), tau, kickback_phase, k, n_trotter_step = n_trotter_step) ##実行時間短縮のために回路の最適化を行う opt = QuantumCircuitOptimizer() max_block_size = 4 opt.optimize(circuit,max_block_size) ##回路の実行 circuit.update_quantum_state(psi) ##部分トレース p0 = psi.get_marginal_probability([2,2,0]) p1 = psi.get_marginal_probability([2,2,1]) ##位相キックバックの更新 print(f"k={k:2d}, p0={p0:.3f}, p1={p1:.3f}") kth_digit = 1 if (p0 < p1) else 0 kickback_phase = 0.5*kickback_phase + np.pi*0.5*kth_digit return 2 * kickback_phase ```python n_qubits = 3 #2つは電子配置、1つは補助 g_list = [0.3593, 0.0896, -0.4826, 0.0896] # pauli_strings = ['Z 0', 'Y 0 Y 1', 'Z 1', 'X 0 X 1'] hf_state = QuantumState(n_qubits) hf_state.set_computational_basis(0b001) #|0>|01> tau = 0.640 e_trotter = -0.8602760325707504 ##U_{Trot}^{(N)}の理論値 print(f"e_trotter={e_trotter:.10f}") result_list = [] for n_itter in range(1, 13): iqpe_phase = iterative_phase_estimation(g_list, tau, n_itter, hf_state, n_trotter_step=5 , kickback_phase = 0.0) e_iqpe = -iqpe_phase/tau## U=exp(-iH*tau)なのでIQPEでは-H*tauの固有値を求めたことになる。なのでHの固有値に変換する。 print(f"n_itter={n_itter:2d}, e_iqpe={e_iqpe:10f}, error={np.abs(e_iqpe-e_trotter):.5e}") result_list.append([n_itter,e_iqpe]) #結果のプロット result_array = np.array(result_list) plt.xlabel("# of digit", fontsize = 15) plt.ylabel("Error", fontsize = 15) plt.semilogy(result_array[:,0], np.abs(result_array[:,1]-e_trotter), "bo-") plt.xlim(0,13) plt.fill_between([0,13], 1.6e-3, color = "lightgrey") ## chemical accuracy領域を着色
上の実行結果から12桁以上求めれば化学的精度が達成されることがわかります。
色々試して気付いたこと
トロッター分解の次数を増やしても精度は変わらなかった。これはQPEで固有値の位相の各桁を求める際に多数決を利用しているので、1次のままでもほぼ正確に位相の値が求められているからだと考えられる。
n_itter(求める位相の桁数)は13くらいまでは1分程度で求められた。逆にこれ以上の桁数は求めるのにもっと時間がかかってしまう(指数的な増加)。
なぜかn_trotter_stepを増加させると一番下の桁の精度が落ちる。
次に試したいこと
- トロッター分解以外で時間発展演算子を実装する手法を試す。
- juliaなどほかの言語で実装して計算時間を比較する。
参考文献
[1]P. J. J. O’Malley et al. , “Scalable Quantum Simulation of Molecular Energies“, PHYSICAL REVIEW X 6, 031007 (2016)

- 投稿日:2021-03-22T09:14:23+09:00
[Python]Unionで不便なケースと、それを解決するジェネリックのTypeVarについて
ここ数か月、Pythonで型付きの状態でお仕事やプライベートでのコーディングをしてみて、UnionやTypeVarなどのジェネリックのものなどの使い分けに少し慣れてきたので備忘録として軽く備忘録としてアウトプットしておきます。ジェネリックについてもある程度深堀りします。
使う環境
- Python 3.8.5
- Pylance(型チェック用)
複数の型の引数と返却値を受け付ける関数でAnyを使う時の問題点
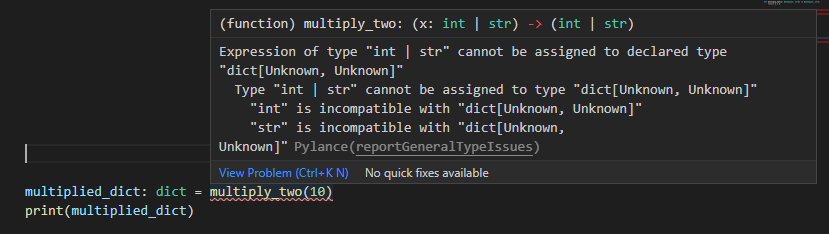
複数の型を受け付ける関数を作る場合、Any型を使うという選択肢があります。例えば以下のように引数の値を2倍するという関数を考えてみます。整数などを指定した場合には2倍された値、文字列などが指定されればその文字列を2回分繰り返した値が返却されます。
from typing import Any def multiply_two(x: Any) -> Any: return x * 2返却値部分で以下のように整数として型アノテーションしようが、文字列として型アノテーションしようがこれならエラーにはなりませんし、プログラムは正常に結果を返してくれます。
>>> multiplied_int: int = multiply_two(10) >>> print(multiplied_int) 20>>> multiplied_str: str = multiply_two('Hello!') >>> print(multiplied_str) Hello!Hello!しかし、値によっては2倍できない型のものも存在します。例えば辞書などを指定してしまうと以下のようにランタイムエラーになってしまいます。
>>> multiplied_dict: dict = multiply_two({'x': 100}) >>> print(multiplied_dict) TypeError: unsupported operand type(s) for *: 'dict' and 'int'単体テストなどをきっちり書いておけばもちろん多くは防げる問題ではありますが、デプロイ前などに型チェックなどが走ってチェックがされているとより一層安心できます。Anyだとこの辺のチェックがうまくいきません。
複数の型を受け付けるUnion型がうまく使えるケースと不便に感じるケース
先ほどの関数で、引数の値をintもしくはstrのみに制限する形にしようと思います。まずは利用頻度の高いUnionを使っていってみます。
from typing import Any, Union def multiply_two(x: Union[int, str]) -> Any: return x * 2こうすると引数に整数や文字列を指定した場合は型チェックは通過しますが、辞書などを指定した際にはエラーにすることができます。
multiplied_dict: dict = multiply_two({'x': 100}) print(multiplied_dict)
しかし返却値に関してはAnyのままなので、例えば引数だけ整数などにして返却値は辞書として型アノテーションがしてあってもそのままチェックを通過してしまいます。
multiplied_dict: dict = multiply_two(10)そのため返却値もUnionでintもしくはstrを返却するように調整してみます。
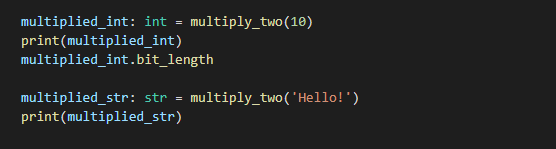
def multiply_two(x: Union[int, str]) -> Union[int, str]: return x * 2これであれば返却値が辞書になっていたらエラーで弾いてくれます。
しかしながら、これではintやstr単体で返却値に対して型アノテーションをしている場合もエラーになります。
multiplied_int: int = multiply_two(10) print(multiplied_int)
整数の値が返ってくる・・・と分かっている場合でも、関数の型アノテーション内容に準じて
Union[int, str]といったように返却値に型アノテーションをする必要があります。以下のように返却値に型アノテーションを書いた場合にはエラーにはなりません。
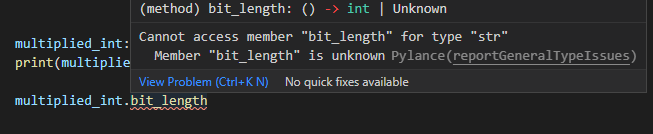
multiplied_int: Union[int, str] = multiply_two(10) print(multiplied_int)一見良さそうに見えますし、実際これで特に問題にならないケースも多くあります。ただし、以下のように整数用のメソッドや属性値などにアクセスした際にエラーになってしまうという不便な点があります。
Union[int, str]の指定なので、もし文字列が返却された場合にエラーになってしまうという型の判定なのでチェックとしては安全で正しい挙動になります。multiplied_int.bit_length
isinstanceなどで型チェックしつつ分岐させてあげればエラー自体は出なくなります。
if isinstance(multiplied_int, int): multiplied_int.bit_lengthただし毎回分岐などさせるのは手間です。返却値のUnionのの型アノテーションもそうですが、記述が煩雑且つ複雑になってしまいます。
TypeVarによるジェネリック型で解決する
こういったケースではジェネリックという型を使うことで解決できます。ジェネリクス・テンプレートなどと色々な呼ばれ方をしますが、他のプログラミング言語だと一般的な機能ですね。
例えばRustのThe Rust Programming Languageとかでも入門本の時点で出てきます。
ただしPython界隈では型を使うケースが多くなってきたのがここ数年の話なので、私が読んだPython入門本にはもちろん出てきませんでしたしお恥ずかしながらここ数か月前まではPythonにもジェネリック型があることを把握していませんでした(Classic Computer Science Problems in Pythonの本を読んでいて知りました)。
また、利用に関してもPylance(Pyright)でのチェックが予期したジェネリックの挙動になってくれなかった?感じがあり(勘違いだったかもしれませんが、今は想定通りに動いています)、最近まで利用せずにいました。実際に使ってみると前述のUnionで不便だった点などが解決して快適です。
ジェネリック型を使うことで複数の型を受け付けつつ、引数と返却値で型を一致させたり・・・といった制御が可能になります。
使い方としては、まずはimportでTypeVarというクラスを読み込みます。
from typing import TypeVar続いてそのクラスをインスタンス化します。慣習的にTypeのTとかそういった短い名前が使われることが多いです。第一引数には型の名前を指定します。特に理由がなければ変数名と同じ値を指定します。
T = TypeVar('T')後は関数の引数や返却値に定義した変数(T)を指定していきます。引数と返却値が同じTの型なので、例えば引数に整数を指定すれば返却値も整数、文字列を指定すれば返却値も文字列という制約が付与されます。
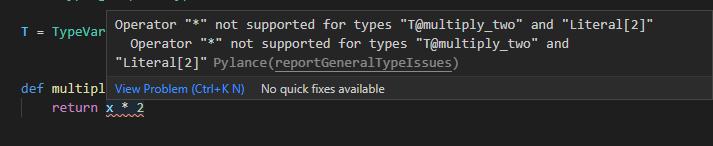
def multiply_two(x: T) -> T: return x * 2しかしこのままでは、TはAnyと同様に何の型でも受け付けるようになってしまいます。
型によっては乗算(*)の処理ができない型もあるため、この記述だと上記の関数はエラーになってしまいます。
そこで、乗算のインターフェイスがある型のみに制限する(今回はintとstr)ためには、TypeVarの第二引数以降に引数に型を指定していきます。複数の型を受け付ける場合には順番に各引数に指定してきます。
T = TypeVar('T', int, str)これで返却値の型の指定がintやstr単体の指定でもエラーにならなくなりました。属性やメソッドへのアクセス時もisinstanceなどの分岐も不要になります。
引数に文字列、返却値に整数・・・といった記述を誤ってしてしまった場合でもエラーを検知してくれます。
multiplied_int: int = multiply_two('Hello!')
また、返却値側の型アノテーションを省略した場合も正しく値は整数だと認識してくれます。
multiplied_int = multiply_two(10)
関数側で返却値がAnyなどになっていると、返却値側の型アノテーションを省略しているとAnyとしか認識してくれません(入力補完などの面でAnyになっていると不便ですしチェックも甘くなります)。この辺りの面でもAnyを指定するよりも開発体験が良くなります。
def multiply_two(x: Any) -> Any: return x * 2 multiplied_int = multiply_two(10)
クラス内でもジェネリックを利用する
ジェネリックはクラスでも使うことができます。そのクラス内で特定の値の型を固定して使うことができます(各メソッドや属性をまたぐ形で指定することができます)。
使い方としてはまずはGenericクラスをimportします。
from typing import Generic続いてGenericを継承する形でそのクラスを作ります。
[]の括弧内に利用したいジェネリックの変数(今回はT)を指定します。その後は各メソッドなどでジェネリックで指定しておきます。class Value(Generic[T]): def __init__(self, value: T) -> None: self.value = value def multiply_two(self) -> T: return self.value * 2インスタンス化などの際の型アノテーション時には
[]の括弧と共にTに設定したい型を指定します。以下の例では[int]とすることで、このインスタンスではTの値はintで固定するといった定義になります。int_value: Value[int] = Value(100)試しにコンストラクタの引数に文字列を指定してみるとエラーになることが確認できます。
int_value: Value[int] = Value('Hello!')
これで、例えば整数と文字列で同じインターフェイスを持つクラスでそれぞれ個別にクラスを定義したりといった煩雑なことをせずに記述を統一することができます。






- 投稿日:2021-03-22T09:11:43+09:00
【Pandas】簡単な英語のように使えるメソッドの紹介 no.17
こんにちは、まゆみです。Pandasについての記事をシリーズで書いています
今回は17回目になります
『Pythonは簡単な英文のようにコードを書ける』
とよく言われますが、Pandasの英語そのもののようなメソッドを見つけたので、今日はそのメソッドを集めて記事を書いてみます。
色んなところで活用できるようなメソッドなので、是非最後まで読んで見てくださいね。
ではさっそく始めていきます
.isin() メソッド
このメソッドで使う上で注意点は、例え文字列1つだけを引数として使いたい時も、『リスト型』にしなければいけないということです。
引用元:Pandasドキュメント前回の記事で使ったのと同じデータを使って実際の使い方を示していきます
read_csv()メソッドで読み込むと上のスクショのような感じになりますコラムGroup1の中に、『Toy』があるかどうかを.isin()メソッドで調べてみます。
isin()メソッドの引数として入れるコラム名は1つだけですが、リスト型にしました。Group1がToyになっているところがTrueとして返されます。
では、isin()の引数に2つのコラム名を取ってみます
Group1コラムの値が
Toy もしくは Sporting
のrow がTrue として返されました。
.isin()メソッドと ORは同じ
(※2つ以上の条件があってORを使ってデータをはじき出す方法は前回の記事に書いています)
.isin()メソッドは条件を2つ以上使う時のORと同じ結果になりますが、コードを書く量はより少なくて済みます。
.isnull() .notnull() メソッド
.isnull()は欠損値をFalseで返し、.notnull()は欠損値をTrueで返します
Intelligence のコラムにいくつか欠損値がありますので、(NaNとなっているところです。)Intelligence のコラムに.isnull() .notnull()を使って実験します
.isnull() と.notnull()では逆の結果を返してくれます。
.between() メソッド
.between()メソッドでの注意点は、2つの引数の値を含めた範囲が指定されるということです。
例えば.between(2,5)とすると、2~5までの範囲を指定し、2も5も範囲に含みます。
コラムAvgPopPrice(子犬の価格)で500ドルから1000ドルのものの真偽を確かめてみましょう
1000ドルちょうどの、AffenpinscherもTrue として返されました。
引用元:Pandasドキュメントまた、このメソッドは整数だけではなく、小数点(floating number)でも、時間(.to_datetime()でdatetime オブジェクトにしたもの)の範囲でも指定する事ができます
試しに、アメフト選手のデータのなかに、選手の誕生日のデータがあるので
1985年から1990年生まれの選手
のデータをピックアップします
※年月日の比較をPandasで行うには、datetimeオブジェクトに作り替える必要がありますので、分からない方はこちらの記事を参考にどうぞ
この範囲に生まれた選手のデータを表示させますね。
まとめ
今回は、簡単な英作文を作るように使えるPandas のメソッドを紹介しました。
お役に立てれば幸いです。





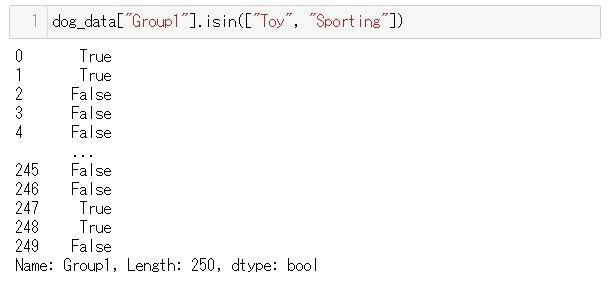



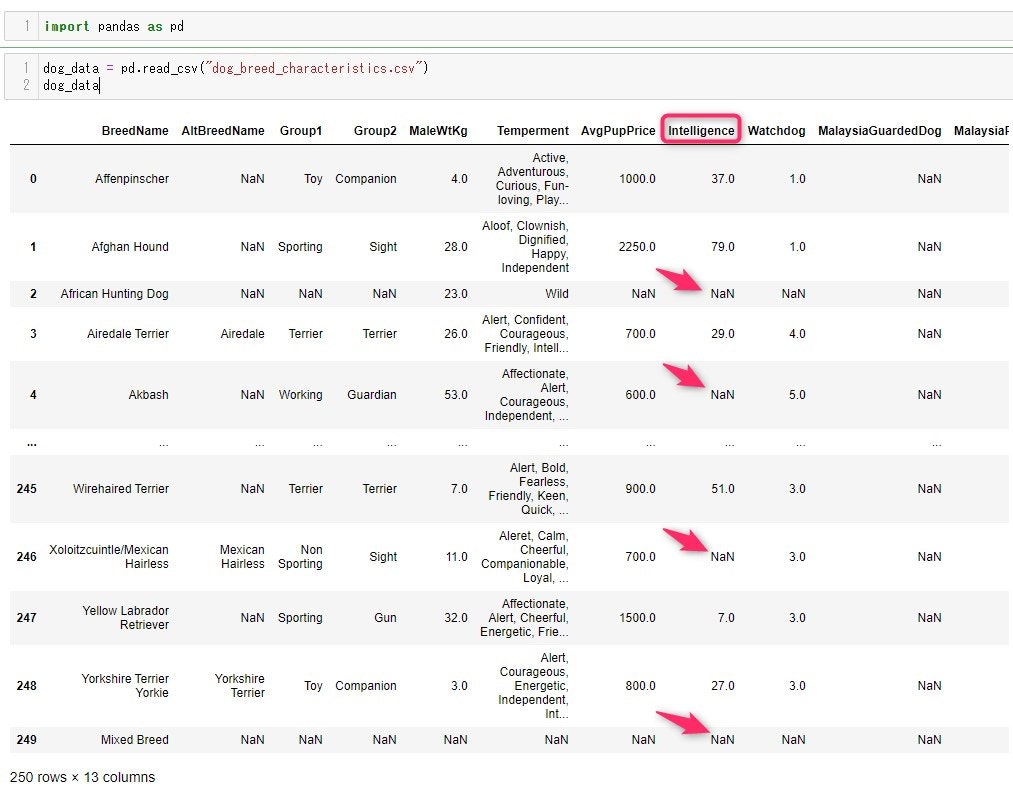
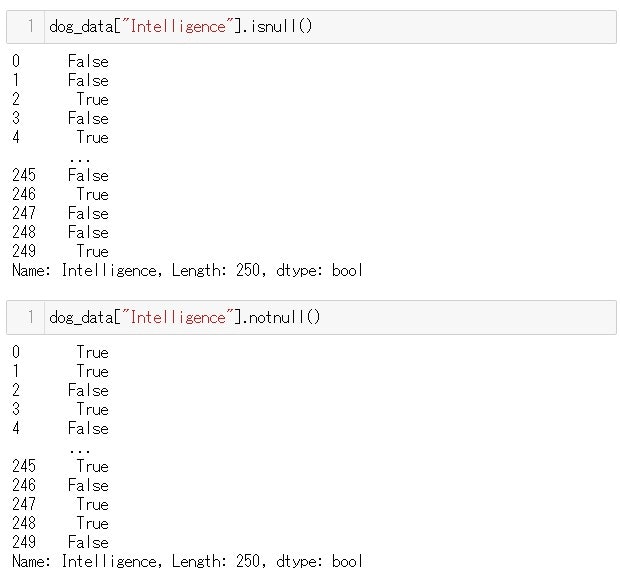

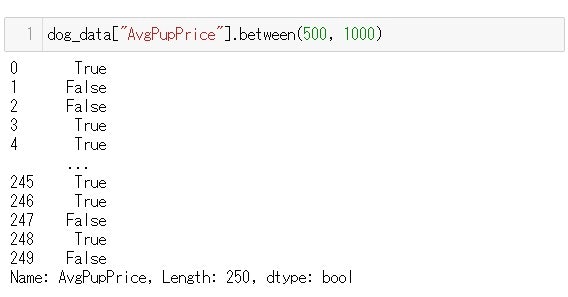

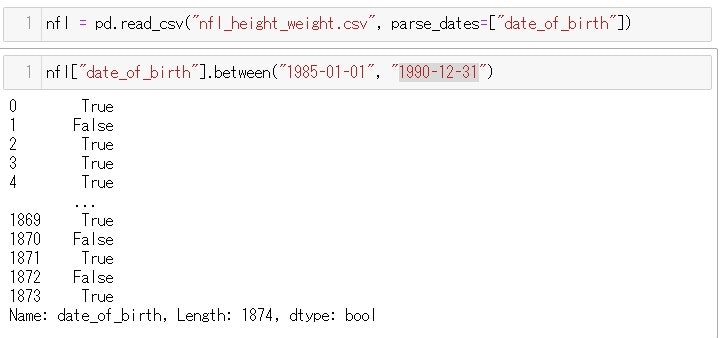

- 投稿日:2021-03-22T05:13:21+09:00
pythonのprintいろいろ
この記事の目的
Pythonの出力
文字色
エスケープシーケンスを直前に出力することで、それ以降の文字色を変更することができるようです。そのため毎回最後にリセットするための
"\033[0m"も出力しています。color_dic = {"black":"\033[30m", "red":"\033[31m", "green":"\033[32m", "yellow":"\033[33m", "blue":"\033[34m", "end":"\033[0m"} def print_color(text, color="red"): print(color_dic[color] + text + color_dic["end"])text = "青い文字で出力" print_color(text, "blue")
上書き
普通に
print(i)を回していると1,2,3...が縦長になってしまうので結果が見づらくなりますが、これならスペースを取らないので見やすそうです。import sys for i in range(1000): sys.stdout.write("\r{}".format(i)) sys.stdout.flush()
上の
\rを除くと改行せず出力を続けていくことができます。import sys for i in range(10): sys.stdout.write("{}".format(i)) sys.stdout.flush()
ただし、これは
endを指定することによっても実現できます。for i in range(10): print(i, end="")外部書き出し
パッケージを使っていると様々な結果がprintで書き出されることがあると思います。これらをテキスト形式で外部に出力するための設定です。自分で書いたコードであれば
fileを指定すれば良いですが、それが出来ない場合の力技です。# printをテキストに書き出す設定 temp_sysout = sys.stdout sys.stdout = open("test.txt","w") # メインのプリントする関数など print("hello world") # もとに戻す sys.stdout = temp_sysout
参考
Qiita:コンソールに色付きの出力をする方法
Qiita:コンソールへの出力を上書きしてゆく方法
Hatena:pythonで標準出力されたデータを取得する


- 投稿日:2021-03-22T05:13:21+09:00
Pythonのprintいろいろ
この記事の目的
Pythonの出力
文字色
エスケープシーケンスを直前に出力することで、それ以降の文字色を変更することができるようです。そのため毎回最後にリセットするための
"\033[0m"も出力しています。color_dic = {"black":"\033[30m", "red":"\033[31m", "green":"\033[32m", "yellow":"\033[33m", "blue":"\033[34m", "end":"\033[0m"} def print_color(text, color="red"): print(color_dic[color] + text + color_dic["end"])text = "青い文字で出力" print_color(text, "blue")
上書き
普通に
print(i)を回していると1,2,3...が縦長になってしまうので結果が見づらくなりますが、これならスペースを取らないので見やすそうです。import sys for i in range(1000): sys.stdout.write("\r{}".format(i)) sys.stdout.flush()
上の
\rを除くと改行せず出力を続けていくことができます。import sys for i in range(10): sys.stdout.write("{}".format(i)) sys.stdout.flush()
ただし、これは
endを指定することによっても実現できます。for i in range(10): print(i, end="")外部書き出し
パッケージを使っていると様々な結果がprintで書き出されることがあると思います。これらをテキスト形式で外部に出力するための設定です。自分で書いたコードであれば
fileを指定すれば良いですが、それが出来ない場合の力技です。# printをテキストに書き出す設定 temp_sysout = sys.stdout sys.stdout = open("test.txt","w") # メインのプリントする関数など print("hello world") # もとに戻す sys.stdout = temp_sysout
参考
Qiita:コンソールに色付きの出力をする方法
Qiita:コンソールへの出力を上書きしてゆく方法
Hatena:pythonで標準出力されたデータを取得する
- 投稿日:2021-03-22T00:43:37+09:00
転移学習で「呪術廻戦」のキャラの分類やってみた!
今回は、今流行りの呪術廻戦で機械学習やってみました!
画像検索で拾った画像を約90%の精度で見分けることができました!
VGG16を転移学習させたモデルで予測した画像の一覧
ちなみにキャラクターは、
itadori(虎杖悠仁)
呪術廻戦の主人公
hushiguro(伏黒恵)
呪術高専の1年生、十種影法術を使う
nobara(釘崎野薔薇)
呪術高専の1年生、芻霊呪法を使う
gojo(五条悟)
呪術高専に所属する教師で、特級の名を冠する現代最強の呪術師
todo(東堂葵)
呪術高専京都校に所属する3年生、手を叩いて術式範囲内にある物の位置を入れ替えるKerasで実装(データセット準備)
今回は、Google Colaboratoryを使って誰でも簡単に実装できるようにしています。
スクリプトを実装する前にデータセットを用意します。
GitHubからデータセットはダウンロードできます。GitHub
今回は、jyujyutu_VGGというフォルダの中にdisplay , test , train , validationを作っています。
画像は train = 250枚、validation = 50枚、test = 50枚
の内訳で入っています。displayは冒頭のような画像を表示させるときに使う用で、
中身はtestと同じです!displayは用意しなくても大丈夫です。
このデータセットは、Googleの画像検索で自作しました。
ライブラリのインポートとモデル構築
jyujyutu_VGG.zipをダウンロードしたら、
Google Driveにアップロードしておきましょう。# Googleドライブをマウント from google.colab import drive drive.mount('/content/drive').zipのままGoogle Driveにアップロードしてください!
# Google ColaboratoryでZipファイルを解凍 from zipfile import ZipFile file_name = '/content/drive/My Drive/jyujyutu_VGG.zip' with ZipFile(file_name, 'r') as zip: zip.extractall()zipファイルのままアップロードして、ここで解凍した方が時間短縮になります。
from keras.models import Model from keras.layers import Dense, GlobalAveragePooling2D,Input from keras.applications.vgg16 import VGG16 from keras.preprocessing.image import ImageDataGenerator from keras.optimizers import SGD from keras.callbacks import CSVLogger必要なライブラリをimportします。
n_categories=5 batch_size=32 train_dir='/content/jyujyutu_VGG/train' validation_dir='/content/jyujyutu_VGG/validation' file_name='vgg16_jyujyutu_file' base_model=VGG16(weights='imagenet',include_top=False, input_tensor=Input(shape=(224,224,3)))今回は、5人のキャラクターを分類するので、n_categories = 5とします。
x=base_model.output x=GlobalAveragePooling2D()(x) x=Dense(1024,activation='relu')(x) prediction=Dense(n_categories,activation='softmax')(x) model=Model(inputs=base_model.input,outputs=prediction)#fix weights before VGG16 14layers for layer in base_model.layers[:15]: layer.trainable=False model.compile(optimizer=SGD(lr=0.0001,momentum=0.9), loss='categorical_crossentropy', metrics=['accuracy']) model.summary()今回の実装では、15層以降のみを学習させています。
最終的な出力は1次元(COVID-19かどうか確率)なので、新たな全結合層を追加しています。
転移学習、VGG16について詳しくは
VGG16を転移学習させて「まどか☆マギカ」のキャラを見分ける
を見てください。#save model json_string=model.to_json() open(file_name+'.json','w').write(json_string)画像の前処理をして学習
train_datagen=ImageDataGenerator( rescale=1.0/255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True) validation_datagen=ImageDataGenerator(rescale=1.0/255) train_generator=train_datagen.flow_from_directory( train_dir, target_size=(224,224), batch_size=batch_size, class_mode='categorical', shuffle=True ) validation_generator=validation_datagen.flow_from_directory( validation_dir, target_size=(224,224), batch_size=batch_size, class_mode='categorical', shuffle=True ) hist=model.fit_generator(train_generator, epochs=100, verbose=1, validation_data=validation_generator, callbacks=[CSVLogger(file_name+'.csv')]) #save weights model.save(file_name+'.h5')ImageDataGeneratorは画像を整形したり、水増しするのに便利です。
読み込むフォルダを与えれば、自動的にそのフォルダの名前をラベルにしてくれます。ImageDataGeneratorは、デフォルトの機能だけでなく、
関数として定義してあげれば他のData Augmentationも出来るのでめっちゃ便利です!結果
test画像でモデルを評価します
from keras.models import model_from_json import matplotlib.pyplot as plt import numpy as np import os,random from keras.preprocessing.image import img_to_array, load_img from keras.preprocessing.image import ImageDataGenerator from keras.optimizers import SGD batch_size=32 file_name='vgg16_jyujyutu_file' test_dir='jyujyutu_VGG/test' display_dir='jyujyutu_VGG/display' label=['gojo','hushiguro','itadori','nobara','todo'] #load model and weights json_string=open(file_name+'.json').read() model=model_from_json(json_string) model.load_weights(file_name+'.h5') model.compile(optimizer=SGD(lr=0.0001,momentum=0.9), loss='categorical_crossentropy', metrics=['accuracy']) #data generate test_datagen=ImageDataGenerator(rescale=1.0/255) test_generator=test_datagen.flow_from_directory( test_dir, target_size=(224,224), batch_size=batch_size, class_mode='categorical', shuffle=True ) #evaluate model score=model.evaluate_generator(test_generator) print('\n test loss:',score[0]) print('\n test_acc:',score[1])
validation_accuracyは最終的に約90%になりました。
test accuracyが約96%になりました。訓練画像250枚(各キャラ50枚ずつ)で、Google ColaboratoryのGPUを使えば
かなり短時間で学習できました。今後の検討
今回は、VGG16を転移学習させて「まどか☆マギカ」のキャラを見分けるの記事を参考に、
簡単に好きなデータセットで実装できることを試し、さらに今の流行りにも乗ってみました。
今後、Mixup や Random Erasing , Cutmixなども試して、精度が向上するかどうか
やってみたいですね!
参考文献










- 投稿日:2021-03-22T00:27:16+09:00
無料で作るWebサービス Codelet 作成日記 #1 環境構築
Herokuを使う
英語っぽくない名前で覚えにくい! Hero + Haiku(俳句)なんだって。知らんけど。
http://computerbecamecloud.blogspot.com/2013/12/engine-yardheroku-paas.htmlこの記事通りにやったらできるよ!
思った以上に簡単にできるよ!
https://qiita.com/sho7650/items/ebd87c5dc2c4c7abb8f0
開発環境(Windows10)にPythonをインストールする
とりあえず開発環境で実行できないことには始まらない。
このサイトを参考に、雑にVSCodeにPython開発環境をインストールしてみる。
https://docs.microsoft.com/ja-jp/learn/modules/python-install-vscode/
何となくできた。試しにHellow Worldする。
https://dianxnao.com/visual-studio-code%E3%81%A7python%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%9F%E3%83%B3%E3%82%B0%E3%82%92%E5%A7%8B%E3%82%81%E3%82%8B%EF%BC%88windows%E7%B7%A8%EF%BC%89/#toc7
できた。WebフレームワークFlaskをインストールする
これを試してみるが、PowerShellの設定で阻まれたっぽい。
https://www.atmarkit.co.jp/ait/articles/1807/24/news024.html
PowerShellの設定で、ローカルのスクリプトはすべて実行可能にした。
https://qiita.com/Targityen/items/3d2e0b5b0b7b04963750とりあえずflaskのインストールはできたっぽい。
動いた。
ところで、Terminalの上の方で失敗したログが出てるけど、環境変数FLASK_APPに設定できるプログラムの入り口が「wsgi.py」または「app.py」のどちらかに限定されるって、仕様としてどうなの?
それならそもそも環境変数FLASK_APPって不要なんじゃないの?
まぁいいや。


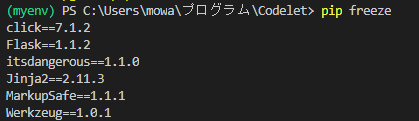

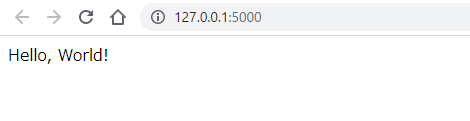
- 投稿日:2021-03-22T00:27:16+09:00
無料で作るWebサービス Codelet 作成日記 #1 環境構築①
Herokuを使う
英語っぽくない名前で覚えにくい! Hero + Haiku(俳句)なんだって。知らんけど。
http://computerbecamecloud.blogspot.com/2013/12/engine-yardheroku-paas.htmlこの記事通りにやったらできるよ!
思った以上に簡単にできるよ!
https://qiita.com/sho7650/items/ebd87c5dc2c4c7abb8f0
開発環境(Windows10)にPythonをインストールする
とりあえず開発環境で実行できないことには始まらない。
このサイトを参考に、雑にVSCodeにPython開発環境をインストールしてみる。
https://docs.microsoft.com/ja-jp/learn/modules/python-install-vscode/
何となくできた。試しにHellow Worldする。
https://dianxnao.com/visual-studio-code%E3%81%A7python%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%9F%E3%83%B3%E3%82%B0%E3%82%92%E5%A7%8B%E3%82%81%E3%82%8B%EF%BC%88windows%E7%B7%A8%EF%BC%89/#toc7
できた。WebフレームワークFlaskをインストールする
これを試してみるが、PowerShellの設定で阻まれたっぽい。
https://www.atmarkit.co.jp/ait/articles/1807/24/news024.html
PowerShellの設定で、ローカルのスクリプトはすべて実行可能にした。
https://qiita.com/Targityen/items/3d2e0b5b0b7b04963750とりあえずflaskのインストールはできたっぽい。
動いた。
ところで、Terminalの上の方で失敗したログが出てるけど、環境変数FLASK_APPに設定できるプログラムの入り口が「wsgi.py」または「app.py」のどちらかに限定されるって、仕様としてどうなの?
それならそもそも環境変数FLASK_APPって不要なんじゃないの?
まぁいいや。