- 投稿日:2021-03-22T21:54:20+09:00
AWS IoT Coreってなんだろ?
AWS IoT Coreってなんだろ?
SAAの試験の練習問題で何回か見たことはあるAWS IoT Coreというサービスですが、何となく「IoTの開発に使うんだろうなあ」ぐらいにしか思っておらず、実際にどんなサービスなのかは全く知りません。
なので、今回は新たなインプットとして、AWS IoT Coreについて調べて、サービスの概要をつかんでいきたいと思います!ドキュメントを読もう!
まずはざっくりとドキュメントを読んでみます。
AWS IoT Core(デバイスをクラウドに接続)| AWSよりAWS IoT Core とは何ですか?
AWS IoT Core を使用すれば、IoT デバイスを AWS クラウドに接続できます。サーバーをプロビジョニングまたは管理する必要はありません。AWS IoT Core では数十億個のデバイスと数兆件のメッセージをサポートしており、それらのメッセージを AWS エンドポイントや他のデバイスに確実かつセキュアに処理してルーティングします。AWS IoT Core を使用すれば、アプリケーションがインターネットに接続されていない場合でも、すべてのデバイスを常に追跡して通信できます。
IoT機器とAWSをつないで、データをやり取りするためのサービスっぽいですね。
サーバーの管理不要なので、AWSお得意のフルマネージドサービスですね!
気になったのは、オフラインでも使えるようなことが書かれている点です。どういうことなのか、もう少し読み進めてみましょう!AWS IoT Core を使用すると、AWS と AWS Lambda、Amazon Kinesis、Amazon S3、Amazon SageMaker、Amazon DynamoDB、Amazon CloudWatch、AWS CloudTrail、Amazon QuickSight、および Alexa Voice Service といった Amazon のサービスを簡単に使用して、インフラストラクチャの管理をせずに、接続されたデバイスで生成されたデータを収集、処理、分析し、そのデータに基づいてアクションを起こす IoT アプリケーションを構築できます。
色々なAWSサービスと連携できるんですね!
インフラ管理が不要ということで、サーバレスなサービスとの連携というイメージでしょうか。
集めたデータや分析結果からアクションを起こすこともできると書かれています。利点
サーバーを管理せずにデバイスを接続および管理する
AWS IoT Core を使用すると、任意の数のデバイスをクラウドや他のデバイスに接続できます。サーバーをプロビジョニングまたは管理する必要はありません。AWS IoT Core を使用すれば、デバイスフリートを簡単かつ確実にスケーリングできます。
前述の通り、サーバー不要というメリットが大きいようです。
セキュアなデバイスの接続とデータ
AWS IoT Core では、デバイスを初めて AWS IoT Core に接続するときの自動化された構成と認証を行うのみならず、接続するすべてのポイントで認証とエンドツーエンドの暗号化を提供しているため、デバイスと AWS IoT Core との間でアイデンティティが証明されたデータのみが交換されます。さらに、詳細なアクセス許可のポリシーを適用することによって、デバイスとアプリケーションにセキュアにアクセスできます。
全てのポイントで暗号化しているというところがポイントでしょうか。
ご希望の接続プロトコルを選択してください
AWS IoT Core を使用すると、IoT デバイスを接続および管理するためのユースケースに最も適した通信プロトコルを選択できます。AWS IoT Core は、MQTT (メッセージキューとテレメトリトランスポート)、HTTPS (ハイパーテキスト転送プロトコル - セキュア)、MQTT over WSS (WebSockets セキュア)、および LoRaWAN (低電力長距離広域ネットワーク) をサポートします。
IoTのことは正直まだよく分からないけど、データのやり取りには色んなプロトコルを使うんですね。そのプロトコルを選べますよってことが書かれています。
デバイスデータの処理と実行
AWS IoT Core を使用すると、定義したビジネスルールに基づいて、デバイスデータを迅速にフィルタリング、変換、実行できます。いつでもルールを更新して、新しいデバイスやアプリケーションの機能を実装できます。
処理のルールを作成できて、ルールはいつでも更新できるみたいです。
ミラーデバイスの状態
冒頭で気になったオフラインでも使用できるという内容がこのミラーデバイスの状態に記載されていました。
AWS IoT Core では Device Shadow を使用して、いつでも読み取りや設定を行えるよう、接続されたデバイスの最新の状態が保存され、アプリケーションにはデバイスが常にオンラインであるかのように表示されます。つまり、接続が切断された場合でもアプリケーションでデバイスの状態を読み取ることができ、デバイスが再接続された時にデバイスの状態を設定して実装することができます。
オンライン時にデバイスの最新状態をIoT Coreに保存し、オフライン時はデバイスを読み取って、またオンラインになったら最新の状態にするってことかな?
そういえば先日勉強したAWS AppSyncでも同じようなこと言ってました。よくある質問
上記はトップページの内容ですが、以下のよくある質問ページでも概要や詳細が記載されていますので、併せてご覧下さい!
よくある質問 - AWS IoT Core | AWSドキュメント以外も読んでみよう!
ここまではドキュメントをサラッと読んできましたが、もう少し理解を深めるためにクラスメソッドさんのお力をお借りします。
【入門】AWS IoT Coreを理解するために必要な6つのポイント | DevelopersIO以下の6つがポイントのようです。
・メッセージブローカー(プロトコル)
・メッセージブローカー(トピック)
・セキュリティ&アイデンティティ
・ルールエンジン
・アクション
・デバイスシャドウまた、以下の図を用いて紹介されています。
メッセージブローカー(プロトコル)
AWS IoT Core側でデバイスからのメッセージを受け取る際に複数のプロトコルがあります。
具体的なプロトコルとしてはHTTPS、MQTT、MQTT over WebSocketがサポートされています。ドキュメントにもありましたが、IoT Coreがメッセージを受け取るときの4つのプロトコルですね。
メッセージブローカー(トピック)
WebAPIでいうエンドポイントに当たる部分です。トピックを設定することで受信対象を識別することができます。
トピックに設定したURIに向けてデバイス側が送信を行うことでデータの受信ができます。このへんはSNSとかと同じ感覚ですね。トピックごとに通信先を変えて使うイメージでしょうか。
セキュリティ&アイデンティティ
AWS IoT Coreでは、デバイスの認証情報とポリシーを管理できます。
証明書の管理自体はAWS IoTで生成することも可能ですし、独自の証明書を登録して使用することもできます。ポリシーはIAM ポリシーと同じルールで管理されます。
AWS IoT Coreに接続した際に証明書で認証して、認可はポリシーで管理できます。なんかACMみたいだなって思いました。ACMでも証明書発行か独自の証明書を使うか選べるので、そういうイメージかな?
ポリシーはIAMと同じルールみたいです。
最後の一文が分かりやすいです!(神)ルールエンジン
SQLベースの文法でトピックにきた値を整形・追記、フィルタリングしてデータの受け渡しができます。ここで取得したデータをアクションに流すことで、AWS内部の別のサービスにデータを送ることができます。
中身はSQLベースのクエリでFROM句の部分に取得するトピックを指定して、アクションに渡したい内容をSELECT句で指定できます。またトピックから取得するデータをWHERE句でフィルタリングすることなどもできます。これがドキュメントに書かれていたルールか。
SQLベースなんですね。面白い!
AWS Black Belt Tech シリーズ 2015 - AWS IoTよりアクション
AWS IoT Core からAWS内部の別のサービスに繋ぐアクションを設定できます。
現在は、AWS Lambda、Amazon Kinesis、Amazon S3、Amazon SageMaker、Amazon DynamoDB、Amazon SNS、Amazon SQS、Amazon CloudWatch、AWS CloudTrail、Amazon QuickSight、Alexa Voice ServiceなどAWSサービスへの接続や外部のWebサービスにメッセージ送信ができます。それぞれのサービスを動かすためには処理に必要となるロールをアクションに対してアタッチする必要があります。AWSサービスだけじゃなくて、外部のWebサービスともやり取りできるんですね。
デバイスシャドウ
デバイスシャドウは、IoT Coreに接続するデバイスの現在の状態を保存したり取得する際に使います。
データの実態はJSON形式で保存されています。名前通りデバイスに対する影のようなもので、デバイスの状態(電灯のIoTであれば電気のOn・Offなど)をJSONで管理します。デバイス側とAWS側で状態を相互に伝える際にはシャドウを介してやりとりすることで、デバイスのネットワーク接続が途切れていてもデバイスの状態をAWS側で保持してネットワーク接続時にデバイスへ反映することができます。オフラインの特徴でも出てきましたね。
JSON形式なんですね。こいつのおかげでデバイスがオフライン時にもAWS側ではデータが失われずに済むといういいやつですね。一連の流れのまとめ
- デバイスがトピックに向けてMQTTでパブリッシュ
- 証明書やポリシーで認証・認可をチェック
- シャドウにデータが流れてシャドウを更新
- デフォルトの設定でシャドウ更新時に特定のトピックへ向けてパブリッシュ
- トピックを対象にいれているルールクエリが起動
- ルールクエリに基づいてデータを抽出
- DynamoDBにルールクエリで抽出したデータを反映するアクションを実行

まとめ
今回は名前だけしか知らなかったAWS IoT Coreについて調べてみました。
まだざっくりとしか分かっていませんが、プロトコルが複数あったり、SQLベースでフィルタリングできたり、面白そうです!
今は仕事でIoTに関わることがなかなかありませんが、機会があれば使ってみたいサービスですね!
今回は用語の勉強みたいになってしまいましたが、これはこれで良い勉強になりました!ご覧頂きありがとうございました!
参考資料
AWS IoT Core(デバイスをクラウドに接続)| AWS
よくある質問 - AWS IoT Core | AWS
【入門】AWS IoT Coreを理解するために必要な6つのポイント | DevelopersIO



- 投稿日:2021-03-22T21:05:47+09:00
docker/docker-composeをAWS AmazonLinux 2にインストール
概要
タイトル通りですが、普段使用しているLinuxと少し違っていたので備忘録として記載します
前提条件
AWS EC2(t2-micro/Amazon Linux2)
Dockerのインストール
yum install でdockerを指定すれば使えるようになります。
$ sudo yum -y update $ sudo yum -y upgrade $ sudo yum -y install dockerdocker-composeのインストール
こっちが少しだけ手こずりました。
$ sudo curl -L "https://github.com/docker/compose/releases/download/1.26.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose $ sudo chmod +x /usr/local/bin/docker-compose $ sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
- 投稿日:2021-03-22T21:04:09+09:00
AWS インフラ構築 学習まとめ
はじめに
本記事を書いた理由は、
AWSのデプロイができたことに満足しただけで現状の知識は0であった。
そのため、せっかくAWSでインフラ構築できたのだから説明できるくらいの理解度は持っておきたいので復習という目的で書いた。構成図
サーバー環境
【Web サーバー】 Nginx
【アプリケーションサーバー】 Puma使用したAWSのサービス
VPC(Amazon Virtual Private Cloud)
RDS(Amazon Relational Database Service)
EC2(Amazon Elastic Compute Cloud)
Route 53
ACM(Certificate Manager)
ALB(Application Load Balancer)
S3(Amazon Simple Storage Service)
IAM(AWS Identity and Access Management)月額料金
AWSを使用し始めた月が約1000円
翌月から100円
理由は分かりませんが、アクセスが少ないからだと思っています。簡単にAWSサービス説明
VPC(Amazon Virtual Private Cloud)
ユーザー専用のプライベートなネットワーク環境を提供するサービス。
VPCの中に、EC2とRDSを構築する。EC2(Amazon Elastic Compute Cloud)
インスタンス(仮想マシーン)
EC2ではLinuxやWindowsなど、OSの仮想サーバーを実行できる環境を用意することができる。RDS(Amazon Relational Database Service)
データベースサービス
Region(リージョン)
データセンター。いろんな地域にリージョンは存在する。
AWSで仮想サーバーを構築するには、どのリージョンに作成するか決める。
日本で運用するなら基本東京リージョン。サブネット
VPCの中に、小さいネットワークの集まりを作ることができる。
パブリックとプライベートがあり
パブリックはEC2など
プライベートは、外部からのアクセスを遮断したいデータベースなどで使われるElastic IP
固定されたIPを割り当てる。
EC2作成時のIPアドレスは、EC2を再起動したりすると固定化されてないため変更される。
なのでElastic IPを紐付ける。
サイトを公開するなら必要。独自ドメイン取得する時も必要。インターネットゲートウェイ
VPCをインターネット接続できるようにする「出入り口」
ルートテーブル
ネットワークの経路を設定する。
インターネットゲートウェイを使って、サブネットにアクセス可能にしても接続できない。
そこで、ルートテーブルで指定先を明確にする。セキュリティグループ
インスタンスごとに許可する通信を設定する
Route 53
DNSサービス
DNS(Domain Name System)とは→IPアドレスとドメインを結びつける
IPアドレス=111.111.11
ドメイン=qiita.comみたいなのACM(Certificate Manager)
HTTPS化に必要
SSL/TLS サーバー証明書を取得できるALB(Application Load Balancer)
HTTPS化に必要
負荷を分散させる役割。IAM(AWS Identity and Access Management)
AWSアカウント(ルートユーザー)は、AWS全ての操作、クレジットの登録・変更ができる。
ルートユーザのみでは、情報漏洩すれば不正利用される恐れがある。
そこでIAMユーザーを使う。
IAMは、操作が制限されていて必要な操作のみできる。最悪不正アクセスされても最小限で抑えられる。インフラ構築理由
なぜAWS
初学者は「Heroku」を使用したデプロイが多いため、差別化したかった
インフラ設計・構築がどうやるのか気になった
業務で使用されることが多いからRoute 53
独自ドメイン取得のために、「お名前.com」を利用
Route 53では、取得したドメインをIPアドレスに変換できる
つまり、取得したドメインをALBに結びつけるためにRoute 53を使用
↓ドメインを取得した私のポートフォリオです
https://re-life.work/ALB、ACM(HTTPS化)
ACMでSSL/TLS サーバー証明書を取得
SSL/TLS サーバー証明書をALBに結びつけることで、HTTPS化できる。
Route53の設定も色々あります。SSLサーバー証明書とは、「安心できるサイトです」という証明書
SSL化(HTTPS化)するメリット
・サイトのデータが暗号化される。
・GoogleがSSL化を推奨している。
https://qiita.com/nakanishi03/items/3a514026acc7abe25977EC2サブネット2つ用意
ALBでサブネット2つ以上選択する必要があった。
ロードバランサーの可用性を高めるために必要らしく、おそらく負荷を均等にするために必要なのかと思ってます。RDSサブネット2つ用意
マルチAZ構成時に必要のため、作成。
AZ(アベイラビリティゾーン)とはひとつ以上のデータセンターのことで
マルチAZは、複数のデータセンターを利用するということとほぼ同じなので、高い可用性を維持できる。
今回は、低コストに抑えたいため冗長化はしてないです。
RDSのバックアップのために、スナップショットは作成済。
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/USER_CreateSnapshot.htmlS3
S3は高い耐久性、安価、データ量無制限という特徴があるみたいです。
使用理由は、ポートフォリオの画像アップロード機能とバックアップ保存のため
RailsでActiveStorageという機能を使ってパソコン上に画像を保存していたが、本番環境ではクラウドにデータ保存するように設定するため終わり
インフラの知識を復習したら、忘れてること・新たに知ったことがあった。
今回は、インフラ構築から2ヶ月ほど経っていたが、アウトプット後は直ぐに復習する方が思い出しやすく効率が良さそう。
また、学習の定着はインプットではなく、思い出そうとした際に定着するらしい。
インプットしながらのアウトプットで学習してきたが、アウトプットの復習は今回が初めてで、復習することで以前より理解度が深まったことから復習の重要性を再確認できた。以上。

- 投稿日:2021-03-22T19:56:15+09:00
ServiceNowのデータをAppFlow経由でS3に保管してみる
ServiceNow内のデータをどこかに保管しておきたいのですが、楽にできそうなAmazon AppFlowを触ってみることにしました。今回はサーバーの構成情報をS3に保管するという体です。Amazon AppFlowとは
Amazon AppFlowはSaaSのアプリケーションとAWSサービスのデータ転送を可能にする「フルマネージド(ここ重要)」なサービスです。SlackやDatadogなど20のサービス(2021/3現在)と接続が可能になっています。
App Flowのセットアップ方法はドキュメントに書いていますが、GUIどおりに進めていけば問題なかったです。
https://docs.aws.amazon.com/ja_jp/appflow/latest/userguide/requirements.htmlAWS Management Consoleへログインし、AppFlowを選択する
マネジメントコンソールから検索画面で入力します使用するサービスを選択する
データ送信元のサービスをここで選択します。
新規作成でも大丈夫ですが、ここで選択をしておくと送信元を選択するときに自動で選択されるのでちょっと楽になります。フローの詳細を指定
フロー名を入力する以外はデフォルトのままにしますフローを設定
送信元と送信先を設定します。送信元は自動で選択されているのでそのままです(新規作成から作成した人はここで送信元のサービスを選択します)。接続のボタンがあるので詳細情報を入力します。送信元の詳細
接続するを押すとインスタンスの情報を入力します。
- ユーザー:管理者権限をもつユーザーを入力する必要があるので、使用するユーザーにロールが付与されているかは確認をしておきます。
- パスワード:特に説明なし
- インスタンス名:ServiceNowの個人インスタンスはdevXXXXXX(数字)で表記されているので、そこをコピペしてきます。
- 接続名;どこと接続するのかわからなくなるので、自分が後々わかれば大丈夫です(今回は- ServiceNowからAWSへの接続テストなので名前も適当にしています)
上記を入力後に接続を押すと、問題なければServiceNowオブジェクトを選択が表示されます。
今回は構成管理のサーバー名を保存したいので、cmdb_si_serverを選択します。どの情報を送信させたいのかはここで検索することも出来ますが、予めServiceNow上でのテーブル名をメモって置くほうがスムーズに行きます送信先の詳細
送信先は送信元と違って数が限られています(オレゴンはHoneyCodeが追加されています)。
今回単純にServiceNow上のデータを保管したいだけなので、S3を選択します。フロートリガー
いつどのタイミングで転送するのかを選択します。1分おきにデータを取りに行く設定もできますが、課金されるのも嫌なので今回はオンデマンドで実行を選択します
画面はスケジュールで実行を選択した場合、どのぐらい細かく見れるのかを表示させたかっただけです。データフィールドをマッピング
送信元の情報を送信先のどこにマッピングするのかをここで設定します。そのまま全てを保存したいだけなので、今回は「全てのフィールドを直接マッピングする」を選択します。
問題がなければ次へ。フィルターを追加する
必要なものだけを送信したい場合はここで指定ができます。
お試しで入力しますが、全部取り込みたい場合はそのまま次へいきます。
確認して全てOKなら、フローを作成を押します。フローを実行する
無事に作成されたのでフローを実行します。割とすぐに完了しましたって出ました。
S3のバケットを見てみるときちんと出力されていました。
ファイルをダウンロードして中身を見るとサーバー41台がしっかり「全部」送信されたのが確認できました。
(devXXXXXXは変換しました。ちなみにこれらは全部デモデータです)ServiceNowでデータを追加して再度フローを実行する
せっかくなのでサーバーの情報を追加してもう一度実行してみます。
ServiceNowにログインし、フィルターナビゲーターと呼ばれる検索窓に「cmdb_ci_server.list」と入力し、サーバー一覧を表示させます。
新規作成画面から情報を入力して送信します。サーバー名等情報は思いついたものを適当に入力しました。
これで42台に増えましたので、AWSのAppFlowの画面から同じようにフローを実行します。
結果がこちら。S3のバケットには新規でファイルが作成され、中身を見るとちゃんと先程のデータがきちんと追加されていますね。構築も管理もめっちゃ楽
ServiceNowのデータ連携をするのに書いたコードは「ゼロ」です。わかりやすくマッピングしたり、データの精査にはCSVファイルを出力したりフィルターの設定をする必要がありますが、どちらにしてもコードを一切書かなくても良いのがメリットです。
ServiceNowは外部の連携ツールにMIDサーバーを経由させるのですが、構築するのが地味にめんどくさいです。
そのためだけに作るのが面倒だったなんて言えない
AppFlowを使ってやると1時間もかからずに自動バックアップの仕組みを作れるので、便利だなーって感じました(小並感)


















- 投稿日:2021-03-22T19:02:34+09:00
SSMって便利。でも管理が大変。なのでToolを作った話
はじめに
各EC2のユーザー管理がしんどいしんどい。
だってインスタンスが20~30種類あって、インスタンス毎にユーザーが独立されて管理されているんですぜ。
そもそも、EC2にユーザーいる?sshする必要ってある?しなくても済むように設計するべきだよね。
接続する時はSSMでいいよね。と言う訳でそんな構成に。
したはよいが、今度はSSMする時に「え〜っと。どうやるんだっけ?」
と言う経年劣化による記憶容量がScaleIn、コマンドが思い出せない事案が発生。
ならToolを作りましょう。
構築
コマンドを実装
$ vim ssm.shssm.sh#!/bin/sh AWS_CONFIG='~/.aws/config' profile='' function showProfile() { echo '# Input profile.' echo '## profile list.' cat ~/.aws/config | grep profile echo '##' read input if [ -z $input ] ; then echo 'Done.' exit 1 else profile=$input fi } function ssmInstance() { echo '# Input ResourceId.' echo '## ResourceId list.' aws ec2 describe-tags --profile $profile --output table --filters "Name=resource-type,Values=instance" echo '## ResourceId list.' read input if [ -z $input ] ; then echo 'Done.' exit 1 else aws ssm start-session --target $input --profile $profile fi } showProfile ssmInstanceコマンドを移動
$ chmod 744 ssm.sh $ mv ssm.sh /usr/local/bin/ssm以上。
実際に使ってみる。
$ ssm # Input profile. ## profile list. [profile profile-dev] [profile profile-prod] [profile teck] [profile pricate-dev] ## -- 接続対象のprofileを入力 # Input ResourceId. ## ResourceId list. ------------------------------------------------------------------------------------------ | DescribeTags | +----------------------------------------------------------------------------------------+ || Tags || |+----------------------------+-----------------------+---------------+-----------------+| || Key | ResourceId | ResourceType | Value || |+----------------------------+-----------------------+---------------+-----------------+| || Name | i-xxx | instance | webapp_1 || || Name | i-xxx | instance | webapp_2 || || Name | i-xxx | instance | batch || || Name | i-xxx | instance | nat || |+----------------------------+-----------------------+---------------+-----------------+| ## ResourceId list. -- 接続対象のResourceIdを入力 Starting session with SessionId: xxxxxxxx sh-4.2$ -- 接続!!!終わりに
EC2のユーザーを脳死で追加してしまうと、いざと言うときに管理や棚卸しがとても大変。
なのでそもそも「EC2に接続しないように・させないように」する設計が大事。※ ECS / Fargateを使えば万事解決
- 投稿日:2021-03-22T17:50:46+09:00
【AWS】【AppSync】Did not receive a successful HTTP code. になったとき
開発途中のiOSアプリを1週間ぶりに動かしてみたところ,下記のエラーが出て絶望しかけたので対処法を残しておく.(しょうもないことだった〜)
Did not receive a successful HTTP code.iOSアプリ上のボタンを押すことで,AppSyncを使ってGraphQLでDynamoDBにデータを格納しているのだが,データの格納・取得いずれのボタンを押しても上記のエラーが発生した.
原因としては,AppSyncの認証方法をAPIキーにしているのだが,そのAPIキーの有効期限が過ぎていたことだった.(AppSyncの初期設定時に下記の質問でデフォルトの7日にしていた)
? After how many days from now the API key should expire (1-365)変更方法は簡単!
AWSマネジメントコンソールで「AppSync」を選択
↓
AppSyncのダッシュボードで利用しているAPIを選択
↓
左のメニューから「設定」を選択
↓
APIキーの項目で利用しているはずのキーが「期限切れ」になっていると思うので,そのキーを選択・編集
また期限が切れた頃に慌てふためいてそう・・?

- 投稿日:2021-03-22T17:21:38+09:00
【AWS】AWS Managed Microsoft ADのパスワードポリシーに要注意
はじめに
結論から申し上げますと、AWS Managed Microsoft ADのデフォルトのドメインポリシーパスワード有効期間が42日間となっております(※2021/03/22時点)。
つまり、デフォルトのドメインポリシーで42日間以内に一回もパスワードを変更しない場合は、AWS Managed Microsoft ADのパスワードが失効になってしまいます。
もしAWS Managed Microsoft ADをほかのAWSサービス(例えばFSx)と繋いて構成を組んでいる場合は、デフォルトのドメインポリシーで42日間に一回もAWS Managed Microsoft ADのパスワードを変更しない場合は、そのサービスが42日後に接続できなくなりますので、要注意です。AWS Managed Microsoft ADパスワードポリシー
下記AWS公式サイト上で記載されているパスワードポリシーを引用します。
AWS Managed Microsoft AD では、AWS Managed Microsoft AD ドメインで管理するユーザーのグループ別に異なるきめ細かいパスワードおよびアカウントロックアウトのポリシー (「きめ細かいパスワードポリシー」とも呼ばれる) を定義して割り当てることができます。AWS Microsoft AD ディレクトリを作成すると、デフォルトのドメインポリシーが作成され、ディレクトリに適用されます。このポリシーには、以下の設定が含まれます。
ポリシー 設定 パスワードの履歴を記録する 24 個のパスワードを記憶 最大のパスワード有効期間 42 日間 * 最小のパスワード有効期間 1 日 パスワードの最小長 7 文字 パスワードは複雑さの要件を満たす必要がある 有効 元に戻せる暗号化を使用してパスワードを保存 Disabled
- 注意: 42 日間の最大パスワード有効期間は管理者パスワードにも適用されます。
出典URL:https://docs.aws.amazon.com/ja_jp/directoryservice/latest/admin-guide/ms_ad_password_policies.html
実際に遭ったこと
Amazon FSx for Windowsを使用するために、AWS Managed Microsoft ADが構成要件となっています。私はAWS Managed Microsoft ADとAmazon FSx for Windowsを合わせて利用しています。
当初はAWS Managed Microsoft ADのパスワード有効期間があることを知らずに、構築後にそのままFSxとの接続をしていましたが、42日間経った後に、EC2からFSxへの接続が出来なくなっている事象が発生しました。
上記は当初EC2からFSxへ接続する際に、AD認証側で「パスワード有効期間が切れています」というエラーメッセージが表示されています。対応策
MicrosoftのActive Directoryページを見てみると、GPOでは0日指定で無効化も可能です。
You can set passwords to expire after a number of days between 1 and 999, or you can specify that passwords never expire by setting the number of days to 0
ただしベストプラクティスには30~90日の変更がお勧められています。
Set Maximum password age to a value between 30 and 90 days, depending on your environment. This way, an attacker has a limited amount of time in which to compromise a user's password and have access to your network resources.
運用面とセキュリティリスク対応の観点から、基本的にはAWS Managed Microsoft AD有効期間を設け日数に設定するのが一番良いです。
ただし、運用面の効率化の観点のアイデアとしては、パスワード更新のPowerShellもしくはAWS CLIによるスクリプトの自動化が挙げられます。
個人はスクリプトによるパスワード自動更新を選択しました。パスワード自動更新スクリプト
当時書いたスクリプトは下記となります。
@echo off cls& color 0a & title パスワード設定 Made By HYJ 2020/08/28 rem ------AD password change script------- powershell -NoProfile -ExecutionPolicy Unrestricted -Command "& { Reset-DSUserPassword -UserName <AWS Managed Microsoft ADで設定されたユーザー> -DirectoryId <AWS Managed Microsoft ADのディレクトリ ID> -NewPassword <ここにパスワードを入力> }"書いたスクリプトをEC2(Windows)に格納し、CloudWatch Events + AWS Systems Managerで一ヶ月に一回定期実行するように設定しました。(後日当方法を公開します)
またWindowsのタスクスケジューラに登録しても実行ができますので、どちらかを選択していただければと思います。ちなみに公式サイト上に載せている参考URLをシェアします:https://docs.aws.amazon.com/ja_jp/directoryservice/latest/admin-guide/ms_ad_manage_users_groups_reset_password.html
感想
Microsoft ADまわりと関わってくると、必要とされる考慮事項をしっかりと事前に調査しておく必要があります。今回はいい勉強になりました。

- 投稿日:2021-03-22T15:20:09+09:00
AWS Cloud9 のディスク容量を増やす
AWSのcloud9サービスでmysqlを導入しようとしたところ空き容量が足りなかった。
なので以下の方法を試した。
まずは
$dfコマンドで空き容量を確認。Filesystem 1K-blocks Used Available Use% Mounted on devtmpfs 485132 0 485132 0% /dev tmpfs 503448 0 503448 0% /dev/shm tmpfs 503448 456 502992 1% /run tmpfs 503448 0 503448 0% /sys/fs/cgroup /dev/xvda1 10473452 10145328 328124 97% / tmpfs 100692 0 100692 0% /run/user/1000/dev/xvda1が97%埋まっています。
これを次のシェルスクリプト
#!/bin/bash # Specify the desired volume size in GiB as a command-line argument. If not specified, default to 20 GiB. SIZE=${1:-20} # Get the ID of the environment host Amazon EC2 instance. INSTANCEID=$(curl http://169.254.169.254/latest/meta-data/instance-id) # Get the ID of the Amazon EBS volume associated with the instance. VOLUMEID=$(aws ec2 describe-instances \ --instance-id $INSTANCEID \ --query "Reservations[0].Instances[0].BlockDeviceMappings[0].Ebs.VolumeId" \ --output text) # Resize the EBS volume. aws ec2 modify-volume --volume-id $VOLUMEID --size $SIZE # Wait for the resize to finish. while [ \ "$(aws ec2 describe-volumes-modifications \ --volume-id $VOLUMEID \ --filters Name=modification-state,Values="optimizing","completed" \ --query "length(VolumesModifications)"\ --output text)" != "1" ]; do sleep 1 done #Check if we're on an NVMe filesystem if [ $(readlink -f /dev/xvda) = "/dev/xvda" ] then # Rewrite the partition table so that the partition takes up all the space that it can. sudo growpart /dev/xvda 1 # Expand the size of the file system. # Check if we are on AL2 STR=$(cat /etc/os-release) SUB="VERSION_ID=\"2\"" if [[ "$STR" == *"$SUB"* ]] then sudo xfs_growfs -d / else sudo resize2fs /dev/xvda1 fi else # Rewrite the partition table so that the partition takes up all the space that it can. sudo growpart /dev/nvme0n1 1 # Expand the size of the file system. # Check if we're on AL2 STR=$(cat /etc/os-release) SUB="VERSION_ID=\"2\"" if [[ "$STR" == *"$SUB"* ]] then sudo xfs_growfs -d / else sudo resize2fs /dev/nvme0n1p1 fi firesize.shとしてどこでもいいのでファイルを作成。
その後
$ sh resize.sh 30
をターミナルに打ってあげて完了。Filesystem Inodes IUsed IFree IUse% Mounted on devtmpfs 121283 284 120999 1% /dev tmpfs 125862 2 125860 1% /dev/shm tmpfs 125862 388 125474 1% /run tmpfs 125862 16 125846 1% /sys/fs/cgroup /dev/xvda1 1015248 358584 656664 36% / tmpfs 125862 2 125860 1% /run/user/100036%の余裕ができました。☻
- 投稿日:2021-03-22T14:37:48+09:00
【図解】初心者が最低限知っておきたいサーバ周りの仕組み
サーバ周りの仕組みについて、初心者でも最低限知っておくべきだと感じた内容を整理しています。
ここでいう「最低限」とは、プログラミング言語を勉強し、何かしらアプリケーションを作成して、ユーザが利用可能な状態にし(デプロイ)、公開するうえで必要になる知識のことです。
「サーバ」とは何か
ユーザーの要求(リクエスト)に応じて、サービスを提供(レスポンス)するコンピュータやプログラムのことを「サーバ」と言います。
例えば、ユーザーが「このWebページを閲覧したい」とリクエストしたら、サーバはそのWebページの表示に必要な処理を実行し、ユーザに返します。これによってユーザーが使用しているブラウザに、Webページが表示されます。
ここまでは、プログラミングを勉強していない人でも、知っている人は多いと思います。
サーバには「OS」と「ミドルウェア」が必要
このように、サーバはとても重要な役割を担っているわけですが、
サーバは一体どうやって、ユーザの要求に対しレスポンスを返しているのでしょうか?
これを理解するには、まずサーバがどのように構成されているか知っておく必要があります。
物理サーバ(物理的に存在するサーバ)の構成要素を簡略的に図示してみました。
一番下の「ハードウェア」はサーバそのもの、一番上の「アプリケーション」は作成しているWebサービスと考えればOKです。では、間にある2つの要素は何でしょうか?
- OS: サーバやPCなどのコンピュータを動かすために不可欠なソフトウェア
- ミドルウェア: OS上で動作し、アプリケーションとOSの中間に入り仲介役を担うソフトウェア
定義を見てもいまいちピンとこないかもしれません。
ただ、ここで重要なのはそれぞれの定義というより、"サーバには「OS」と「ミドルウェア」がセットで必要"だということです。というのも、サーバを用意したとしても、それ自体は、OSやミドルウェアがインストールされていない限り、ただの「箱」にすぎません。
この「箱」は、当然まだサーバとしての機能を持っていないので、「サービスを提供する」というサーバとしての役割を「箱」に与えるには、ソフトウェア(OSとミドルウェア)をインストールする必要があります。つまり、サーバに「サーバ」として機能してもらうのに、OSとミドルウェアが必要になります。このうち、「どの」役割をサーバに担ってもらうかを司っているのが、ミドルウェアです。
サーバは役割ごとに分業している
サーバに機能(役割)を付帯するミドルウェアは、付帯したい機能・役割に応じて様々存在します。
言い換えれば、「どの」役割をサーバに持ってもらいたいかに応じて、適切なミドルウェアを選択し、インストールする必要があります。例えば、Webアプリケーションの場合、①Webサーバ ②APサーバ ③DBサーバが必要(これらのサーバについては後述)になりますが、DBサーバを構築したいならDBサーバ用のサーバソフトウェア(=ミドルウェア)をインストールする、といった運びです。
また、1台のサーバにいくつも機能・役割を詰め込んでしまうと、サーバの負荷やリスクが高まるため、サーバ1台につき一つの役割(≒1つのミドルウェア)を付与するのが基本です。つまり、Webサーバ/APサーバ/DBサーバが必要な場合、それぞれ別々にサーバを構築します。
サーバからレスポンスが返ってくる仕組み
冒頭で「サーバは一体どうやって、ユーザの要求に対しレスポンスを返しているのか」と問いました。
これに対し、ここまでは前提となるサーバの構成要素について整理してきました。では、サーバにOSやミドルウェアを搭載して、Webサーバ/APサーバ/DBサーバを構築できたとしましょう。これらの3つのサーバは、それぞれどんな役割を持っていて、どのように処理が実行されることで、最終的にユーザにレスポンスを返しているのでしょうか?
この答えは、「Web三層構造」をもとに説明できます。下図のように整理されます。
ポイントとしては、
- Webサーバ:HTMLやCSSなどの静的コンテンツをクライアントに返す。リクエストされたページが動的コンテンツを含む場合、APサーバに処理をリクエストし、APサーバから返ってきた処理結果をWebブラウザに返す。
- APサーバ:Webサーバからのリクエストを、Ruby/JAVA/PHPなどの言語を実行して処理する。例えば、Ruby on Railsでアプリケーション作成した場合、APサーバがRailsを実行し、MVCに基づいて処理を行う。加えて、必要に応じDBサーバにデータを要求する。
- DBサーバ:データの保存・更新・引き出し(抽出)・を行い、要求されたデータをAPサーバに返す。
これらの処理を経て、ユーザのリクエストがWebブラウザに返ります。
仮想サーバは物理サーバと何が違うのか
クラウドコンピューティングを利用する人は多いと思います。この場合、実際に操作するのは物理サーバではなく、仮想サーバになります。
例えば私はAWSを使用しているので、EC2と呼ばれるAWSの仮想サーバに、先ほどのWebサーバやAPサーバ、DBサーバを構築していきます。
「仮想サーバ」と言ってもイメージがつきにくいので、図式化してみましょう。
物理サーバの構成要素と比較してみると、わかりやすいと思います。
物理サーバの場合、ハードウェア1台に対し一つのサーバが原則です。
これに対し、仮想サーバはハードウェア1台に対し、複数構築できます。Webサーバ/APサーバ/DBサーバを立てるとして、物理サーバなら3つのハードウェアが必要なところ、仮想サーバを利用するなら1つの物理ハードウェアの上にそれらを構築することができる、ということです。
なお、仮想サーバの場合も、やはりサーバを立ち上げた段階では、「箱」にすぎません。
例えば、AWSならEC2(仮想サーバ)を簡単に作成できますが、その上にミドルウェアをインストールして初めて、WebサーバやAPサーバとしての機能をそれぞれ持つことができます。おわりに
プログラミングの教材には、「Nginxをインストールするには…」といった具体的な手順は事細かに記載されています。一方で、前提となる仕組みの部分については、割愛されている部分も多いように思います。
実際私も、ただ書かれているがまま手順に則って、まずはサーバ構築を進めてみましたが、今回整理したような、仕組みの部分が前提として頭になかったため、「いま自分がこれを実行することで、何にどう働きかけたのか」まったく想像ができませんでした。
そもそも自分が、「Nginxをインストールすることで、Webサーバを構築している」ことすら理解できていませんでした。前提として、「サーバはそれ単体では"箱"にすぎず、ミドルウェアを入れないと〇〇サーバとして機能しない」ということすら、わかっていなかったからです。
自分なりに調べてみると、インフラ関連は「(初心者には)詳細すぎる」説明か、「部分的すぎて全体像が見えない」説明が多く、「デプロイするまでに必要不可欠な要点だけを押さえた」整理が必要だと感じて、この投稿を作ってみました。まだまだ初心者の域ですので、理解が誤っている点などあれば、ぜひご指摘ください。




- 投稿日:2021-03-22T14:37:48+09:00
【図解】初心者が知っておきたいサーバ周りの仕組みの話
サーバ周りの仕組みについて、初心者でも最低限知っておくべきだと感じた内容を整理しています。
ここでいう「最低限」とは、プログラミング言語を勉強し、何かしらアプリケーションを作成して、ユーザが利用可能な状態にし(デプロイ)、公開するうえで必要になる知識のことです。
「サーバ」とは何か
ユーザーの要求(リクエスト)に応じて、サービスを提供(レスポンス)するコンピュータやプログラムのことを「サーバ」と言います。
例えば、ユーザーが「このWebページを閲覧したい」とリクエストしたら、サーバはそのWebページの表示に必要な処理を実行し、ユーザに返します。これによってユーザーが使用しているブラウザに、Webページが表示されます。
ここまでは、プログラミングを勉強していない人でも、知っている人は多いと思います。
サーバには「OS」と「ミドルウェア」が必要
このように、サーバはとても重要な役割を担っているわけですが、
サーバは一体どうやって、ユーザの要求に対しレスポンスを返しているのでしょうか?
これを理解するには、まずサーバがどのように構成されているか知っておく必要があります。
物理サーバ(物理的に存在するサーバ)の構成要素を簡略的に図示してみました。
一番下の「ハードウェア」はサーバそのもの、一番上の「アプリケーション」は作成しているWebサービスと考えればOKです。では、間にある2つの要素は何でしょうか?
- OS: サーバやPCなどのコンピュータを動かすために不可欠なソフトウェア
- ミドルウェア: OS上で動作し、アプリケーションとOSの中間に入り仲介役を担うソフトウェア
定義を見てもいまいちピンとこないかもしれません。
ただ、ここで重要なのはそれぞれの定義というより、"サーバには「OS」と「ミドルウェア」がセットで必要"だということです。というのも、サーバを用意したとしても、それ自体は、OSやミドルウェアがインストールされていない限り、ただの「箱」にすぎません。
この「箱」は、当然まだサーバとしての機能を持っていないので、「サービスを提供する」というサーバとしての役割を「箱」に与えるには、ソフトウェア(OSとミドルウェア)をインストールする必要があります。つまり、サーバに「サーバ」として機能してもらうのに、OSとミドルウェアが必要になります。このうち、「どの」役割をサーバに担ってもらうかを司っているのが、ミドルウェアです。
サーバは役割ごとに分業している
サーバに機能(役割)を付帯するミドルウェアは、付帯したい機能・役割に応じて様々存在します。
言い換えれば、「どの」役割をサーバに持ってもらいたいかに応じて、適切なミドルウェアを選択し、インストールする必要があります。例えば、Webアプリケーションの場合、①Webサーバ ②APサーバ ③DBサーバが必要(これらのサーバについては後述)になりますが、DBサーバを構築したいならDBサーバ用のサーバソフトウェア(=ミドルウェア)をインストールする、といった運びです。
また、1台のサーバにいくつも機能・役割を詰め込んでしまうと、サーバの負荷やリスクが高まるため、サーバ1台につき一つの役割(≒1つのミドルウェア)を付与するのが基本です。つまり、Webサーバ/APサーバ/DBサーバが必要な場合、それぞれ別々にサーバを構築します。
サーバからレスポンスが返ってくる仕組み
冒頭で「サーバは一体どうやって、ユーザの要求に対しレスポンスを返しているのか」と問いました。
これに対し、ここまでは前提となるサーバの構成要素について整理してきました。では、サーバにOSやミドルウェアを搭載して、Webサーバ/APサーバ/DBサーバを構築できたとしましょう。これらの3つのサーバは、それぞれどんな役割を持っていて、どのように処理が実行されることで、最終的にユーザにレスポンスを返しているのでしょうか?
この答えは、「Web三層構造」をもとに説明できます。下図のように整理されます。
ポイントとしては、
- Webサーバ:HTMLやCSSなどの静的コンテンツをクライアントに返す。リクエストされたページが動的コンテンツを含む場合、APサーバに処理をリクエストし、APサーバから返ってきた処理結果をWebブラウザに返す。
- APサーバ:Webサーバからのリクエストを、Ruby/JAVA/PHPなどの言語を実行して処理する。例えば、Ruby on Railsでアプリケーション作成した場合、APサーバがRailsを実行し、MVCに基づいて処理を行う。加えて、必要に応じDBサーバにデータを要求する。
- DBサーバ:データの保存・更新・引き出し(抽出)・を行い、要求されたデータをAPサーバに返す。
これらの処理を経て、ユーザのリクエストがWebブラウザに返ります。
仮想サーバは物理サーバと何が違うのか
クラウドコンピューティングを利用する人は多いと思います。この場合、実際に操作するのは物理サーバではなく、仮想サーバになります。
例えば私はAWSを使用しているので、EC2と呼ばれるAWSの仮想サーバに、先ほどのWebサーバやAPサーバ、DBサーバを構築していきます。
「仮想サーバ」と言ってもイメージがつきにくいので、図式化してみましょう。
物理サーバの構成要素と比較してみると、わかりやすいと思います。
物理サーバの場合、ハードウェア1台に対し一つのサーバが原則です。
これに対し、仮想サーバはハードウェア1台に対し、複数構築できます。Webサーバ/APサーバ/DBサーバを立てるとして、物理サーバなら3つのハードウェアが必要なところ、仮想サーバを利用するなら1つの物理ハードウェアの上にそれらを構築することができる、ということです。
なお、仮想サーバの場合も、やはりサーバを立ち上げた段階では、「箱」にすぎません。
例えば、AWSならEC2(仮想サーバ)を簡単に作成できますが、その上にミドルウェアをインストールして初めて、WebサーバやAPサーバとしての機能をそれぞれ持つことができます。おわりに
プログラミングの教材には、「Nginxをインストールするには…」といった具体的な手順は事細かに記載されています。一方で、前提となる仕組みの部分については、割愛されている部分も多いように思います。
実際私も、ただ書かれているがまま手順に則って、まずはサーバ構築を進めてみましたが、今回整理したような、仕組みの部分が前提として頭になかったため、「いま自分がこれを実行することで、何にどう働きかけたのか」まったく想像ができませんでした。
そもそも自分が、「Nginxをインストールすることで、Webサーバを構築している」ことすら理解できていませんでした。前提として、「サーバはそれ単体では"箱"にすぎず、ミドルウェアを入れないと〇〇サーバとして機能しない」ということすら、わかっていなかったからです。
自分なりに調べてみると、インフラ関連は「(初心者には)詳細すぎる」説明か、「部分的すぎて全体像が見えない」説明が多く、「デプロイするまでに必要不可欠な要点だけを押さえた」整理が必要だと感じて、この投稿を作ってみました。まだまだ初心者の域ですので、理解が誤っている点などあれば、ぜひご指摘ください。
- 投稿日:2021-03-22T14:00:19+09:00
AWS CDK を用いた Linux 仮想サーバーの構築
概要
前回は EC2 ダッシュボードの GUI に従って インスタンス(Linux 仮想サーバー)を起動した。今回は東京大学計数工学科で2020年度S1/S2タームに開講された"システム情報工学特論" を参考に、クラウド開発キット(Cloud Development Kit : CDK) というソフトウェア開発プラットホームを用いてインスタンスを起動する手順を紹介する。講義資料の手順に従うために必要な環境設定を中心に解説する。
環境
- MacBook Air (Retina, 13-inch, 2018)
- macOS Big Sur (Version 11.2.3)
- メモリ 16 GB
CDK とは
CDK は CloudFormation を構築するソフトウェア開発プラットホームであり、現在は TypeScript(JavaScript)、Python、Java、C#(.NET)の 4 言語でサポートされている。本項では AWS 無料アカウントを用いて Python プラットホームによる開発に取り組む。CDK の使い方は、こちらのワークショップに従ってアプリを作成することで効率的に習得することもできる。
CDK を用いた Linux 仮想サーバーの構築
STEP1: AWS CLI のインストール
前回のように AWS の各種設定・操作はマネージメントコンソールから視覚的に行うこともできる。一方で AWS 専用の CLI(コマンドラインインターフェース)を用いることで各種設定・操作を管理・自動化することもできる。
AWS CLI はawsから始まる一連のコマンドであり、様々なサービスを迅速に利用することができる。AWS CLI をローカルにインストールする方法はこちらに記載されているが、前回構築した Linux 仮想サーバーに AWS CLI は標準搭載されているため今回はこちらを利用する。前回の要領で Linux 仮想サーバーに SSH 接続してみよう。STEP2: VScode と SSH 接続
テキストエディタの中でも VSCode は拡張機能で SSH 接続が可能になるため、AWS の開発に利用されることが多い。公式でも AWS のコードエディタとして VSCode が推奨されている。日本語ではこちらに詳しくまとめられている。VSCode で SSH 接続拡張機能をインストールし、前回作成したキーペアを用いて SSH 接続しよう。
これにより仮想サーバーのコード編集がリモートで可能になる。STEP3: AWS CDK のインストール
AWS CDK は
npmを用いてインストールする。まずはこちらを参考にnpmをインストールし、続けてこちらに従って CDK をインストールする。
npmインストールのためにnvmをインストールする。ターミナル$ curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.34.0/install.sh | bash
nvmを有効にする。ターミナル$ . ~/.nvm/nvm.sh
nvmでnpmをインストールする。ターミナル$ nvm install node
npmで CDK をインストールする。ターミナル$ npm install -g aws-cdkCDK のバージョンが正しく確認できれば正常にインストールされている。
ターミナル$ cdk --version 1.94.1 (build 60d8f91)STEP4: AWS シークレットキーの取得・登録
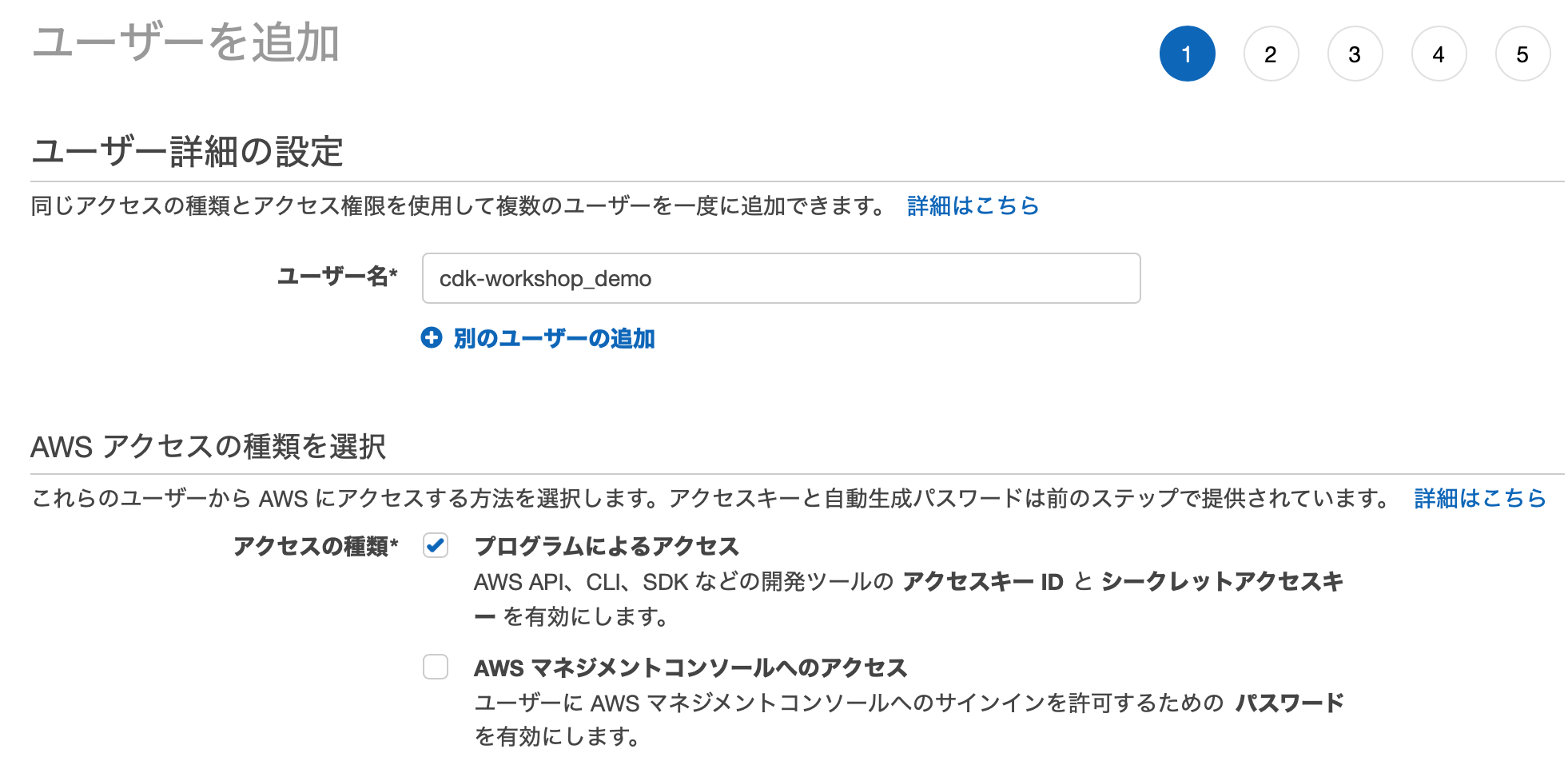
AWS CLI や AWS CDK を用いてアプリ開発に取り組む場合、ユーザー認証にシークレットキーが必要である。こちらに従ってシークレットキーを取得しよう。
まずユーザー名を指定し、「アクセスの種類」で「プログラムによるアクセス」にチェックを入れる。
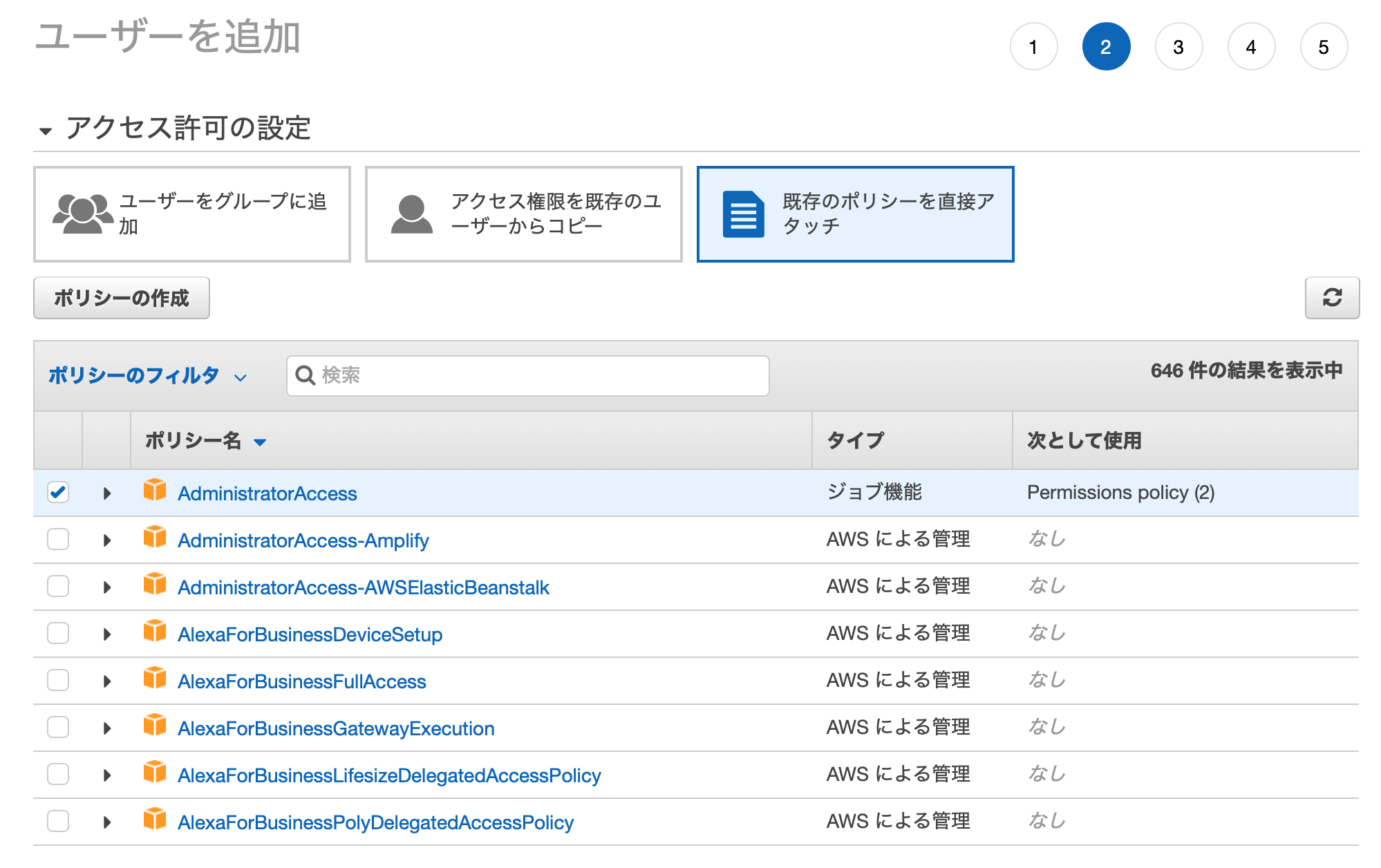
次に「アクセス許可の設定」で「既存のポリシーを直接アタッチ」を選択し、「ポリシー名」で「AdministratorAccess」にチェックを入れる。
その他の設定は行わず「確認」ボタンを押すとアクセスキー ID および「シークレットアクセスキー」が得られる。このページから移動するとアクセスキーは二度と得られなくなるため .csv でダウンロードして保存しておこう。
AWS CLI を用いてシークレットキーを登録しよう。
aws configureというコマンドで登録できる。ターミナル$ aws configure AWS Access Key ID [None]: アクセスキーID AWS Secret Access Key [None]: シークレットアクセスキー Default region name [None]: ap-northeast-1 Default output format [None]: jsonここで登録した内容は
.aws/configおよび.aws/credentialsに書き込まれる。先ほど SSH 接続した VSCode で確認してみるとよい。
configure の内容は環境変数にも代入しておく。以下の内容は
~/.bash_profileに書きこおくと毎回代入しなくても済むようになる。同様に VSCode で編集してもよいだろう。ターミナル$ export AWS_ACCESS_KEY_ID=アクセスキーID $ export AWS_SECRET_ACCESS_KEY=シークレットアクセスキー $ export AWS_DEFAULT_REGION=ap-northeast-1シークレットキーの取得・登録を行わずに AWS CDK を利用しようとすると以下のエラーが表示されるため注意。
ターミナルUnable to resolve AWS account to use. It must be either configured when you define your CDK or through the environmentSTEP5: ソースコードのダウンロード
AWS CDK を用いて Linux 仮想サーバーを構築する際に必要なソースコードをダウンロードする。今回は東京大学計数工学科で2020年度S1/S2タームに開講された"システム情報工学特論" の Hands-on を参考に取り組む。
gitをインストールし、続けてソースコードをダウンロードしよう。ターミナル$ sudo yum install git $ git clone https://gitlab.com/tomomano/intro-aws.gitこれを実行するとソースコードや講義資料を含む
intro-aws/が得られる。フォルダの中身を VSCode で確認しておこう。今回はintro-aws/handson/01-ec2で作業を行う。
STEP6: EC2 インスタンスの起動
こちらを参考に EC2 インスタンスを起動する。
まずは Python3 をインストールし、venvで仮想環境を構築する。ターミナル$ cd intro-aws/handson/01-ec2 $ sudo yum install python3 -y $ python3 -m venv .env $ source .env/bin/activate $ pip install -r requirements.txt次に AWS CLI を用いてキーペアを作成する。前回は EC2 ダッシュボードの GUI で作成したが、このようにコマンドでも実行できる。
KEY_NAMEは自由に設定してよい。ターミナル$ export KEY_NAME="HirakeGoma" $ aws ec2 create-key-pair --key-name ${KEY_NAME} --query 'KeyMaterial' --output text > ${KEY_NAME}.pem $ mv HirakeGoma.pem ~/.ssh/ $ chmod 400 ~/.ssh/HirakeGoma.pemCDK で仮想サーバーをデブロイし、SSH 接続する。
以下のように表示されればインスタンス起動が成功している。ターミナル$ cdk deploy -c key_name="HirakeGoma" $ ssh -i ~/.ssh/HirakeGoma.pem ec2-user@3.113.6.36 __| __|_ ) _| ( / Amazon Linux AMI ___|\___|___| https://aws.amazon.com/amazon-linux-ami/2018.03-release-notes/今回開発したアプリの概要は講義資料を参考にしてください。
参考

- 投稿日:2021-03-22T13:49:30+09:00
Amplify×Lambda×SESでメール配信
概要
開発中のアプリにレポートを投稿した際にメール通知が必要ということでAWSのSESを利用した検証を行いました。
メール通知やメール配信を考えている方の少しでも参考になればと思います。事前に
アプリケーション
Amplify SNS Wrokshopの「FOLLOW/TIMELINE機能の実装」までを実装済みの方を前提としています。
しかし、SESの実装自体は簡単ですので、Amplify SNS Wrokshopをやっていない方でも実装できると思います。Email認証
SESの送信元は検証済みのEメールアドレスが必要となります。
検証済みのEメールアドレスがない方はこちらを参考に準備してください。実装
権限設定
LambdaにSESの権限を与えるには
amplify/backend/function/createPostAndTimeline/createPostAndTimeline-cloudformation-template.jsonを編集します。
lambdaexecutionpolicy>PolicyDocument>Statement>Actionにses:SendEmailとses:SendRawEmailを追加します。"lambdaexecutionpolicy": { "DependsOn": [ "LambdaExecutionRole" ], "Type": "AWS::IAM::Policy", "Properties": { "PolicyName": "lambda-execution-policy", "Roles": [ { "Ref": "LambdaExecutionRole" } ], "PolicyDocument": { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "ses:SendEmail", // Here! "ses:SendRawEmail" // Here! ], "Resource": { "Fn::Sub": [ "arn:aws:logs:${region}:${account}:log-group:/aws/lambda/${lambda}:log-stream:*", { "region": { "Ref": "AWS::Region" }, "account": { "Ref": "AWS::AccountId" }, "lambda": { "Ref": "LambdaFunction" } } ] } } ] } } },AWS SDKのインストール
AWS SDKを
amplify/backend/function/createPostAndTimeline/srcにインストールします。cd amplify/backend/function/createPostAndTimeline npm install aws-sdk送信処理
ここから
amplify/backend/function/createPostAndTimeline/src/index.jsに送信処理を加えていきます。まずは、AWS SDKを読み込みます。
const AWS = require("aws-sdk")さらに、フォロー処理の下あたりに処理を加えます。
1.送信するEmailのparamsを設定
2.リージョンを設定
3.送信処理exports.handler = async (event, context, callback) => { ・ ・ ・ const listFollowRelationshipsResultWithOwner = await graphqlClient.query({ query: gql(listFollowRelationships), fetchPolicy: 'network-only', variables: queryInput, }); // 1.送信するEmailのparamsを設定 const params = { Destination: {// 必須 CcAddresses: [ 'EMAIL_ADDRESS', ], ToAddresses: [ 'EMAIL_ADDRESS', ] }, Message: { // 必須 Body: { // 必須 Text: { Charset: 'UTF-8', Data: `投稿内容:${res.data.createPost.content}\n投稿日時:${new Date(res.data.createPost.timestamp)}`, }, }, Subject: { Charset: 'UTF-8', Data: '投稿しました' }, }, Source: 'SENDER_EMAIL_ADDRESS', // From・必須 } // 2.リージョンを設定 AWS.config.update({ region: "ap-northeast-1" }) // 3.送信処理 const ses = new AWS.SES() try { await ses.sendEmail(params).promise() console.log("Success to Send an Email") return } catch (e) { console.log(`Failed to Send an Email: ${e}`) return } return post; };送信結果
アプリを起動して、投稿をするとメールが届きました!
まとめ
今回はSESでメールの送信を実装しましたが、Lambdaに権限を追加すれば他のAWSのサービスも利用できそうです。
SESには、今回使っていない設定やテンプレートなどがあるようなので、カスタマイズしたい方はこちらを参考にしてみてください。参考
使用した E メールの送信Amazon SES
Lambda と Amazon SES を使用して E メールを送信するにはどうすればよいですか?
- Miyata Koki -
O:inc.でAmplify×React×React Nativeを使用して開発しています。大学のゼミでは統計学をPythonで行っています。
インターンやゼミで学んだ情報を発信していくので、フォロバするのでぜひこちらのアカウントのフォローお願いします!

- 投稿日:2021-03-22T13:05:43+09:00
Fargateプラットフォーム1.4.0の変更点
Fargateプラットフォームバージョン をLATESTにすると1.4.0を指すようになった。
1.3.0から1.4.0の主な変更点は下記の通り。
- EFSエンドポイントのサポート
- ボリュームサイズが単一ボリュームで20GBに
- ネットワーク経路の変更
- CloudWatch Container Insightsにネットワーク関連のメトリクス追加
- CAP_SYS_PTRACEのサポート
- メタデータサービスv4の提供
- メタデータサービスにネットワーク関連の情報とAZ情報の追加
- 共通ECSエージェントからFargate専用エージェントへの変更
ネットワーク関連の変更点
いまいちネットワーク関連の変更点がよく分からなかったので調べた。
FargateのENI
Fargateは、コンテナを実行する仮想サーバーをAWSユーザーから隠蔽することで、管理コストを減らしてくれる。
仮想サーバーは、AWS管轄のVPCで動作しており、そのVPC内のENIがアサインされる。
これを Fargate ENI と呼ぶ。仮想サーバー上で動作する個々のFargateタスクには、AWSユーザー側のVPCのENIがアサインされる。
これを Task ENI と呼ぶ。通信処理ごとのネットワーク経路
1.3.0までは、一部の通信をFargate ENI経由で行っていた。
Fargate ENIなのでAWSユーザーからは見えないVPC上を経由していたはず。
一部の通信はこちら。
- ECRへのログイン
- Secrets Managerへのアクセス
- Parameter Storeへのアクセス
1.4.0からは、Fargate ENIが使われなくなり、全てTask ENIを経由するようになった。
Task ENIはAWSユーザーのVPCを経由し、ユーザーの管理下にあることになる。注意点
ネットワーク経路の変更に伴って、VPCエンドポイント経由でアクセスしているリソースの追加設定が必要になる。
ECRに対する処理は、ログインとイメージのダウンロードがあり、それぞれにエンドポイントがあるため1.4.0以降は両方の設定が必要になる。ECR関連のVPCエンドポイントについては、こちらにまとめた。
- 投稿日:2021-03-22T12:58:44+09:00
Refileの保存先をS3に変更する(Rails, AWS)
環境
- Ruby 2.6.3
- Rails 5.2.4
[IAM]ユーザー作成
IAMのダッシュボードでユーザーを選択し、ユーザーの追加をクリックします。
ユーザー名を入力AWSアクセスの種類を選択プログラムによるアクセスを選択肢、次へ
既存のポリシーを直接アタッチを選択後S3で検索
AmazonS3FullAccessを選択し、次へ
ユーザー登録は完了させ、.csvダウンロードする。
access_keysecret_access_keyが書いてあるので忘れないように保管する。
[S3]バケットポリシーの編集
S3に入ってバケットの選択し、アクセス許可のタブをクリック
バケットポリシーを編集するをクリックし、下のコード追加します。
AWSアカウントのidは右上の自分の名前をクリックし、マイアカウントの数字です。{ "Version": "2012-10-17", "Statement": [ { "Sid": "PublicReadGetObject", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::awsアカウントのid:user/IAMで作成したユーザー名"" }, "Action": "s3:GetObject", "Resource": "arn:aws:s3:::バケット名/*" } ] }refile.rbを作成
$ touch config/initializers/refile.rbconfig/initializers/refile.rbrequire 'refile/s3' #if !Rails.env.production? # 開発環境でS3へアップロードできているか確認する方法 if Rails.env.production? # 本番環境の場合 aws = { access_key_id: ENV['S3_ACCESS_KEY_ID'], # アクセスキーID secret_access_key: ENV['S3_SECRET_ACCESS_KEY'], # シークレットアクセスキー region: 'ap-northeast-1', # リージョン bucket: 'S3バケット名', } Refile.cache = Refile::S3.new(prefix: 'cache', **aws) Refile.store = Refile::S3.new(prefix: 'store', **aws) end
Refile.cacheRefile.store残っていると本番環境で反映されなかったので
エラーになる方は消した方がいいです。.envAWS_ACCESS_KEY_ID="アクセスキー" AWS_SECRET_ACCESS_KEY="シークレットキー"Gemfilegem "refile-s3"
bundle installでgemを入れます。
本番環境にも同じように反映させたら完成です。参考になった記事です
https://qiita.com/matsubishi5/items/c2abdd7375a4c683392a
https://qiita.com/piyor/items/36d2c3c9b8fd638a71a0


- 投稿日:2021-03-22T12:19:08+09:00
【AWS】CloudWatch Event Bus(イベントバス) 機能でクロスアカウント間イベント転送
はじめに
業務上に、異なるAWSアカウント間でのアラーム統一管理ニーズがありました。
調べたところ、CloudWatchのEvent Bus機能が使えそうなので、それを使ってクロスアカウント間でCloudWatchイベント転送を実現してみました。構成図
今回の構成図は下記となります。
今回はアカウントAのEC2が停止したら、CloudWatchのEvent Bus機能を経由し、アカウントBのSNSでメールを送信させるという仕組みになります。
なお、今回はアカウントAでEC2をCloudWatchのターゲットにしていましたが、それとほかに、Lambda、API Gatewayのサービスも使えます。いろいろと用途が幅広く、AWSクロスアカウント間でCloudWatchを経由して何かの機能を実現したときに、ぜひご参考ください。1.アカウントBで、アカウントAとのイベントバス追加
アカウントBのAWSマネジメントコンソール画面に、「CloudWatch」を入力し、クリックします。
左側メニューに「イベントバス」をクリックし、次に「アクセス許可の追加」をクリックします。
アカウントID欄に、アカウントAのIDを入力し、「追加」をクリックします。
2.アカウントBでSNSトピックを作成
アカウントBのAWSコンソール画面からSNSを検索し、下記のようにSNS機能画面にアクセスします。
左側メニューから「トピック」をクリックし、「トピックの作成」をクリックします。
名前欄に命名規則に従って名称を入力し、ほかの設定はそのままデフォルトにして作成します。今回はテストのため、テスト名を入れました。
上記作成したトピックに入り、「サブスクリプションの作成」をクリックします。
トピックARNを上記作成したトピックのARNを選びます。
プロトコル欄に「Eメール」をクリックします。
エンドポイントに受信したいメールアドレスを入力します。
これでサブスクリプションが作成しました。
上記ご入力したメールに、AWSからのメッセージが届きます。
「Confirm subscription」をクリックします。
下記のように「Subscription confirmed!」というメッセージが表示されれば成功です。
3.アカウントAでCloudWatchのルール作成
アカウントAでCloudWatch画面に入り、左側メニュー「ルール」をクリックし、「ルールの作成」をクリックします。
「イベントパターン」をクリックします。
サービス名に「EC2」を選択します。
イベントタイプに「EC2 Instance State-change Notification」を選択します。
→「特定の状態」をクリックし、「Stopped」を選択します。
→「特定のインスタンスID」をクリックし、通知したいインスタンスのIDを入力します。
ターゲットに「別のAWSアカウントのイベントバス」を選択し、アカウントBのIDを入力します。
下記「この特定のリソースに対して新しいロールを作成する」をクリックします。
次に「設定の詳細」をクリックし、名称を入れます。(※ここで省きます)
下記のように、ルールの作成が完了しました。
4.アカウントBでCloudWatchのルール作成
アカウントBでCloudWatch画面に入り、左側メニュー「ルール」をクリックし、「ルールの作成」をクリックします。
イベントパターンをクリックし、下記のJSONコードを入力します。
{ "source": [ "aws.ec2" ], "account": [ "アカウントAのID" ], "detail-type": [ "EC2 Instance State-change Notification" ], "detail": { "state": [ "stopped" ] } }ターゲット欄に「SNSトピック」を選択します。
トピックは上記手順2で作成したトピックをお選びください。
[Input Path] に以下を入力します。{"instance-id":"$.detail.instance-id", "state":"$.detail.state", "time":"$.time", "region":"$.region", "account":"$.account"}[Input Template] に以下を入力します。
"At <time>, the status of your EC2 instance <instance-id> on account <account> in the AWS Region <region> has changed to <state>."※カスタマイズした内容を入力することもできます。
「詳細の設定」をクリックします。
名前欄に命名規則に従って名称を入れます。
「ルールの作成」をクリックします。
5.テスト
上記3で指定したインスタンスを停止してみます。
該当インスタンスを右クリックし、「インスタンスの状態」→「停止」をクリックします。
下記のように、インスタンス停止のお知らせがメールに届いております。
これでクロスアカウント間CloudWatchによるEC2ステータス変化メール通知機能が実現できました。
最後
CloudWatchのEvent Bus機能はいろいろとクロスアカウント間で幅広く使えるので、今回はEC2停止だけを試しました。AWSクロスアカウント間でCloudWatchを経由して何かの機能を実現したときに、ぜひご参考ください。
参考資料
1.https://dev.classmethod.jp/articles/cloudwatch-events-event-bus/
2.https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/events/CloudWatchEvents-CrossAccountEventDelivery.html
3.https://docs.aws.amazon.com/AmazonCloudWatch/latest/events/CloudWatchEvents-CrossAccountEventDelivery.html



















- 投稿日:2021-03-22T11:57:08+09:00
IAMユーザーに AWS Cost Explorer へのアクセスを許可する
概要
IAMユーザーで Cost Explorer にアクセスするための設定方法を備忘として残しています。
設定前は画像の通り権限エラーとなります。
手順
画面右上のアカウント名から「マイアカウント」をクリック
※ルートユーザーでログインしている状態で操作してください。
IAM ユーザー/ロールによる請求へのアクセス を有効化
ポリシーを作成
JSONで下記の通りに記述
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "aws-portal:ViewBilling", "Resource": "*" }, { "Effect": "Allow", "Action": "ce:GetCostAndUsage", "Resource": "*" } ] }ポリシー名を入力して作成
IAMユーザーにポリシーをアタッチ
以上で設定が完了です。








- 投稿日:2021-03-22T08:48:06+09:00
EC2にJavaWebアプリ環境を構築 #4
EC2にJavaWebアプリ環境を構築 #1
EC2にJavaWebアプリ環境を構築 #2
EC2にJavaWebアプリ環境を構築 #3
EC2にJavaWebアプリ環境を構築 #4目次
1.はじめに
2.プログラム作成
3.データベース作成
4.動作確認
5.アップロードはじめに
- 前回
- インストール作業終了
プログラム作成
簡単なプログラムを動してみる
eclipse起動
新規→動的Webプロジェクト
今回はプロジェクト名を"sample"にするTomcatは10を使用する
ファイルはindex.jsp
RegisterServlet.javaのみ追加
Tomcat10は9に比べてファイルが扱いやすい印象
mysql-connecterはver.8.0.22を使用
記事を書いている時点での最新は8.0.23だが、
なぜか動かなかった…MySQLに直接あーだこーだすればできるみたいな記事も見つけたが、
今回の方針とは異なるため8.0.22で行うダウンロードリンク
Operating System:Platform Independent
ZIPをダウンロード、解凍、mysql~22.jarを
libに配置
Tomcat10はimportの記述を書き換える必要がある改行して保存するだけで勝手に全て書き換えてくれる
選択
改行
保存
プログラム全体はこんな感じ
入力した文字をデータベースに保存するだけの超簡単なプログラム
余談ですが、フォントは白源1という日本人の方が作成したものを使用してますプログラミングで有名なフォントは大体全部使いましたが、これが一番いい
Shellでも使えるので、本当におすすめ
index.jsp
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%> <!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <title>サンプル</title> </head> <body> <%= request.getAttribute("word") %> <form action="register" method="post"> <dl> <dt>ワード</dt> <dd><input type="text" name="word"></dd> </dl> <button type="submit">登録</button> </form> </body> </html>RegisterServlet.java
Postの処理のみ記載request.setCharacterEncoding("UTF-8"); // パラメーター取得 String word = request.getParameter("word"); // JDBCドライバ try { Class.forName("com.mysql.cj.jdbc.Driver"); } catch (ClassNotFoundException e) { e.printStackTrace(); } try { Connection con = DriverManager.getConnection( "jdbc:mysql://localhost/sample?characterEncoding=utf8&serverTimezone=JST", "root", ""); String sql = "INSERT INTO words (word)" + " VALUES (?)"; PreparedStatement smt = con.prepareStatement(sql); smt.setString(1, word); smt.executeUpdate(); smt.close(); con.close(); } catch(Exception e) { e.printStackTrace(); } request.setAttribute("word", word); request.getRequestDispatcher("index.jsp").forward(request, response);データベース作成
CREATE DATABASE IF NOT EXISTS `sample` DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci; USE `sample`; DROP TABLE IF EXISTS `words`; CREATE TABLE IF NOT EXISTS `words` ( `id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT, `created_at` timestamp NOT NULL DEFAULT current_timestamp(), `updated_at` timestamp NOT NULL DEFAULT current_timestamp() ON UPDATE current_timestamp(), `word` varchar(256) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
必要最低限!!
動作確認
localhost:8080/sample
から追加できた
動作確認完了
コンソールでエラーもなしアップロード
EC2にアップロードしていく
sample.warにエクスポート
sample.warは、「C:\users\ユーザー名」に置いた想定で説明
sample.pem、sample.war、パブリックIPv4
は各自のものにscp -i sample.pem sample.war ec2-user@パブリックIPv4:/home/ec2-user100%になれば完了
ssh -i sample.pem ec2-user@パブリックIPv4で接続
下記コマンド実行
sudo cp sample.war /opt/tomcat/webappsこれでアプリケーションの配置が終了
EC2でMySQLに接続し、
先程のデータベースを作成すればOK作成したアプリにアクセスする
http://パブリックIPv4 DNS/sample最後駆け気味だが、動作確認も問題なく無事終了









- 投稿日:2021-03-22T00:39:50+09:00
AWS Fault Injection Simulatorを使ってみる
1 AWS Fault Injection Simulatorってなに?
- AWS FIS
- フォルトインジェクションテストを実行することのできるフルマネージドサービス
- AWSにて構築した環境にて障害を意図的に発生させることができ、その時のシステムの挙動を確認することができる
- 結果より、システムの弱い点を洗い出し、機能やサービスのパフォーマンス向上につなげることができる
2 早速使っていく (チュートリアル編)
AWSのドキュメントを見ながらチュートリアルを進めていく
https://docs.aws.amazon.com/fis/latest/userguide/what-is.html2.1 事前準備
2.1.1 テスト内容の決定
- どのようなテストを実行するか決定する
- 1つのテストに複数アクション、複数ターゲットを設定することができるが、組み合わせる必要のないものは分けて実験テンプレートを作成する方が良い
2.1.2 IAMポリシー、ロールの設定
- デフォルトではAWS FISから各サービスを実行する権限がないため、設定していく
ロール
IAMロールを作成する
- ユースケースにはFISがまだ並んでいないので、
- AWSサービス
- EC2
- を選択

- ポリシーは一旦skip
- 後で作成した物をアタッチする
- タグは必要あればつける
- ここではskip
- ロール名等は好きな物を入れる

- 作成を実行
そうすると、AWS サービス:ec2でロールが作成される
fisへ変更するため、選択して編集する
- 信頼関係タブを選択
- 信頼関係の編集

- 以下に置き換える
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "fis.amazonaws.com" }, "Action": "sts:AssumeRole", "Condition": {} } ] }ここでロールARNをコピーしておく
ポリシーの作成1
- JSONタブを選択
- 以下をコピーして貼り付け
{ "Version": "2012-10-17", "Statement": [ { "Sid": "FISPermissions", "Effect": "Allow", "Action": [ "fis:*" ], "Resource": "*" }, { "Sid": "ReadOnlyActions", "Effect": "Allow", "Action": [ "ssm:Describe*", "ssm:Get*", "ssm:List*", "ec2:DescribeInstances", "rds:DescribeDBClusters", "ecs:DescribeClusters", "ecs:ListContainerInstances", "eks:DescribeNodegroup", "cloudwatch:DescribeAlarms", "iam:ListRoles" ], "Resource": "*" }, { "Sid": "IAMPassRolePermissions", "Effect": "Allow", "Action": [ "iam:PassRole" ], "Resource": "arn:aws:iam::111122223333:role/roleName" }, { "Sid": "PermissionsToCreateServiceLinkedRole", "Effect": "Allow", "Action": "iam:CreateServiceLinkedRole", "Resource": "*", "Condition": { "StringEquals": { "iam:AWSServiceName": "fis.amazonaws.com" } } } ] }以下の行は、先ほどコピーしたARNに置換する
"Resource": "arn:aws:iam::111122223333:role/roleName"
- タグは必要あればつける
- 今回はskip
- 名前と説明をつけ、作成
- 今回はこちら : AwsFisFullAccessPolicy #### ポリシーの作成2
- 以下の設定でポリシーを作成
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowFISExperimentRoleReadOnly", "Effect": "Allow", "Action": [ "ec2:DescribeInstances", "ecs:DescribeClusters", "ecs:ListContainerInstances", "eks:DescribeNodegroup", "iam:ListRoles", "rds:DescribeDBInstances", "rds:DescribeDbClusters", "ssm:ListCommands" ], "Resource": "*" }, { "Sid": "AllowFISExperimentRoleEC2Actions", "Effect": "Allow", "Action": [ "ec2:RebootInstances", "ec2:StopInstances", "ec2:StartInstances", "ec2:TerminateInstances" ], "Resource": "arn:aws:ec2:*:*:instance/*" }, { "Sid": "AllowFISExperimentRoleECSActions", "Effect": "Allow", "Action": [ "ecs:UpdateContainerInstancesState", "ecs:ListContainerInstances" ], "Resource": "arn:aws:ecs:*:*:cluster/*" }, { "Sid": "AllowFISExperimentRoleEKSActions", "Effect": "Allow", "Action": [ "ec2:TerminateInstances" ], "Resource": "arn:aws:ec2:*:*:instance/*" }, { "Sid": "AllowFISExperimentRoleFISActions", "Effect": "Allow", "Action": [ "fis:InjectApiInternalError", "fis:InjectApiThrottleError", "fis:InjectApiUnavailableError" ], "Resource": "arn:*:fis:*:*:experiment/*" }, { "Sid": "AllowFISExperimentRoleRDSReboot", "Effect": "Allow", "Action": [ "rds:RebootDBInstance" ], "Resource": "arn:aws:rds:*:*:db:*" }, { "Sid": "AllowFISExperimentRoleRDSFailOver", "Effect": "Allow", "Action": [ "rds:FailoverDBCluster" ], "Resource": "arn:aws:rds:*:*:cluster:*" }, { "Sid": "AllowFISExperimentRoleSSMSendCommand", "Effect": "Allow", "Action": [ "ssm:SendCommand" ], "Resource": [ "arn:aws:ec2:*:*:instance/*", "arn:aws:ssm:*:*:document/*" ] }, { "Sid": "AllowFISExperimentRoleSSMCancelCommand", "Effect": "Allow", "Action": [ "ssm:CancelCommand" ], "Resource": "*" } ] }
- 今回はこちらで名前を決定 : AwsFisAllowService
ロールにポリシーをアタッチ
- 作成したロールに上記2つのポリシーをアタッチする
- AwsFisFullAccessPolicy
- AwsFisAllowService

これで権限の準備は完了
2.1.3 EC2インスタンスの作成
- テスト用にEC2インスタンスを2つ立ち上げる
- 特に何か指定があるわけではないので以下で作成する
- インスタンスタイプ : t2.micro
- AMI : Amazon Linux 2
- タグ :
- (1台目) Name / FIStest01
- (2台目) Name / FIStest02

これで検証用環境の準備は完了
2.1.4 CloudWatchの設定(任意)
後々CPU負荷テストを設定するため、CloudWatchにてアラームの設定をしておく (stopさせる)
作成したインスタンスに対して、とりあえずCPUUtilization(CPU使用率)で設定する(通知は設定するか、削除するかは好きな方でok)
アクションはEC2インスタンスの停止
これでやっとFIS以外の事前準備は完了
2.2 実験テンプレート作成
今回、シンプルな実験を定義する
内容としては
1. EC2インスタンス1台停止
2. 1.の後にEC2インスタンス全停止
というフォルトインジェクション
- 説明は適当な物を入力
- IAM ロールは先ほど作成した物を設定

- アクションを作成
- ターゲットは後ほど変えるので、デフォルトのまま
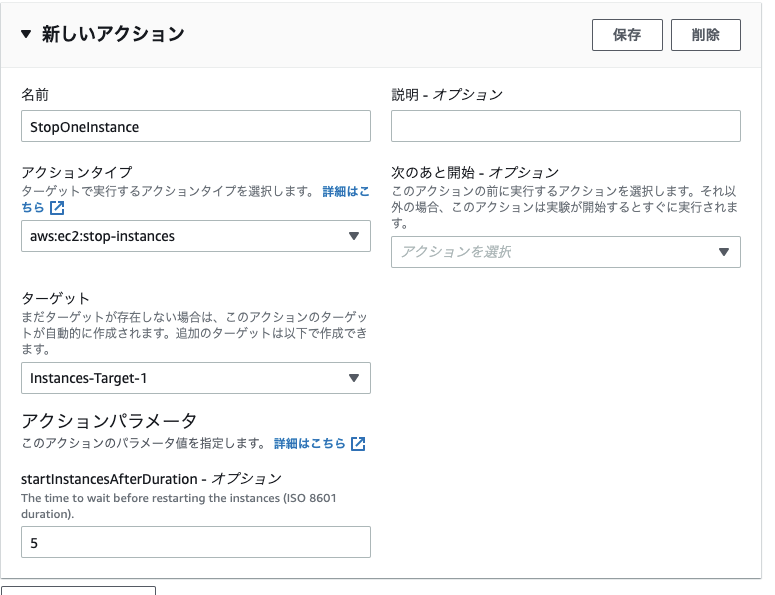
- デフォルトに設定されていたターゲットの編集
- リソースIDは事前準備で作成したEC2インスタンスIDを設定する


- 新たなターゲットの追加
- リソースIDは事前準備で作成したEC2インスタンスIDを設定する

- 再度アクションの追加を行う

- 停止条件に先ほどCloudWatchで設定したアラームを設定する (任意)
- これを設定しておくことで、アラームがなった時に実験を停止してくれる
- 実験は実行時間で費用が発生するので思わぬ費用の発生を防ぐことができる

2.3 実験の開始
実験のテンプレートを選択し、実験の開始を行う
2.4 実験の確認
完了後、completedにステータスが変化する
今回EC2インスタンスをstopする実験だったが、実験完了後に自動的に起動するため、EC2を確認すると起動している
メトリクスを確認すると途中にstopしていたことがわかる
(わかりづらいが、途中stopしていた)
2.5 実験の後片付け
実験が完了完了したら不要なものは削除する
- EC2インスタンス
- IAMロール、ポリシー
- 実験テンプレート
- CloudWatchアラーム
3 Next
- 今回、AWS FISにいついてチュートリアルを実行
- Nextとしてはより実用的に使うためのアクションの設定方法を詳しくみていく
- EC2インスタンスのstopだけでは実験としては十分な設計はできないため







- 投稿日:2021-03-22T00:20:42+09:00
AWS OpsWorks とは
勉強前イメージ
自動でインフラ作るイメージ
調査
AWS OpsWorks とは
ChefやPuppet を使って運用を自動化する構成管理のサービスで
システムの構成などを一元的に設定することができます
EC2インスタンスやオンプレの環境でのサーバ設定やデプロイ、管理を自動化できます。
OpsWorks には3つの種類が存在します。ChefやPuppet とは?
- Chef
シェフ と読み、
ファイルに記述した設定内容に応じて自動的にユーザーの作成やパッケージのインストールを行う
サーバ管理ツールになります。
- Puppet
パペット と読み、
Chefと同様にサーバーの環境設定やインストールなどを自動化する設定管理ツールになります。どちらも古くからあるansibleみたいなやつだなぁと思いました。
AWS OpsWorks の3つの種類
- AWS OpsWorks スタック
サーバの管理サービスとAWSのアプリケーションの管理サービスで、
データベースやアプリケーションなどスタックとして作成し、EC2などを設定したり
他のAWSサービスに接続させることが出来ます。
- AWS OpsWorks for Chef Automate
Chef Automateのフルマネージド設定管理サービスで
すでにChefを利用している場合はこちらを選択します。
サーバー設定やバックアップが自動化され、サーバなど管理する必要がなくなります。
- AWS OpsWorks for Puppet Enterprise
Puppet Enterpriseのフルマネージド設定管理サービスで
すでにPuppetを利用している場合はこちらを選択します。
こちらもフルマネージドなのでサーバなど管理する必要がなくなります。AWS OpsWorks スタックの用語
- スタック
- 全インスタンスの構成を管理します
- リージョン間でもコピーが可能なので、リージョンごとにスタックを立てて同様のサーバを構築できます
- レイヤー
- どんなパッケージをインストールするかのレシピを指定します
- App
- アプリケーションサーバにデプロイされるもの
勉強後イメージ
イメージとしては、
RDSのAuroraとmysqlとpostgresqlって感じ?
AWS独自と元々あるやつに適応したやつみたいな参考



- 投稿日:2021-03-22T00:20:14+09:00
Amazon FSx とは
勉強前イメージ
ファイルシステムな感じがする・・・ただのイメージだけど
調査
Amazon FSx とは
フルマネージド型のファイルストレージサービスになります。
FSxにはファイルシステムのタイプが以下の2種類あります。
- Amazon FSx for Windows File Server
- ビジネス向けで、Active Directoryとの連携が可能
- SMBプロトコルを介してアクセス
- Amazon FSx for Lustre
- 機械学習や動画処理など速度が必要な高性能ファイルシステム
- ミリ秒未満のレイテンシーや最大1秒あたり数百ギガバイトのスループットで処理が可能
Amazon FSx の特徴
- フルマネージド型
マネジメントコンソールからすぐに作成でき、
ストレージサービスの構築については考える必要がありません。
- 可用性・耐久性
FSx for Windows File Server ではシングルAZ,マルチAZの選択が可能で、
FSx for Lustre では、データに合わせてデプロイタイプとストレージタイプを選択することが出来ます。Amazon FSx for Windows File Server について
- Windows Serverに構築
Windows Server上に構築されたストレージで、下記の機能が提供されています。
- エンドユーザーファイルの復元
- ユーザークォータ
- アクセスコントロールリスト(ACL)
- 高速なパフォーマンス
ストレージオプションが存在し、SSD,HDDのどちらも選べるようになっています。
また、ファイルシステムのスループットレベルを選択していつでも変更できます。
- ユースケース
- ホームディレクトリ
- ウェブ配信、コンテンツ管理
Amazon FSx for Lustre について
- 高性能
データ処理用に最適化されており、高いパフォーマンスが提供されている
- s3のデータとのリンク
バケットをリンクさせることで
Lustreからs3のデータにアクセスすることが出来ます。
- ユースケース
- 機械学習
- ビデオレンダリングなどメディア処理
勉強後イメージ
またストレージサービスきた・・・
いっぱいあるけど、イメージとしてはファイルサーバ的な立ち位置なのかな
またまとめないと。
windows file serverの記事いっぱいあるのに、Lustreは少ない気がする参考
