- 投稿日:2021-03-15T22:24:57+09:00
【Elasticsearch】Amazon Elasticsearch Serviceに分散表現のベクトルを格納するフィールドタイプ「dense_vector」が存在せず困った話
はじめに
少し長くなりそうなので結論から言いますと、分散表現のベクトルを格納するフィールドタイプ「dense_vector」の代わりにAmazon Elasticsearch Serviceに用意されているフィールドタイプ「knn_vector」を使用することにして困りごとを解消いたしました。
困ったこと
Elasticsearch 7.3のリリースで追加された高次元ベクトルのドキュメントスコアリング機能を用いてとある文章の機械学習を行い、「テキスト類似性検索」を実装しました。
始めにElastic社のElasticsearch(以下、Elasticsearch)を使用してローカル環境で機械学習を行っており、その後しばらくして学習済データをAmazon Elasticsearch Service(以下、Amazon ES)に移行する必要が出てきました。その際にエラーが発生し、後続作業が中断する事態となってしまいました。※テキスト類似性検索(または類似文書検索)とは「文章を数値化し、その数値の類似度をもって検索対象の文章群の中から検索条件に近い文章を選択する自然言語処理の技術」です。
原因
エラーの原因は単純なことでした。存在しないフィールドタイプを使用しようとしてエラーとなってしまっていたのです。
Elasticsearch上で分散表現のベクトルを格納する際にフィールドタイプ「dense_vector」を使用していたのですが、Amazon ESに該当のフィールドタイプが存在しなかったのです。対処法
何か手はないかとAmazon ESのドキュメントを読み漁ったところ、「KNN」というアルゴリズムがフィールドタイプ「knn_vector」として用意されていることがわかりました。
Amazon ESの開発者ガイドを見てみると関連する k-近隣住民 アルゴリズム、KNN Amazon Elasticsearch Service では、ベクトル空間内の点を検索し、ユークリッド距離またはコサインの類似性によって、それらの点の「最も近くの隣人」を見つけることができます。ユースケースには、推奨 (音楽アプリケーションの「あなたにおすすめの曲」機能など)、画像認識、不正行為の検出などがあります。
と書いてあります(日本語ページの原文ママ)。何やら「dense_vector」と同様に高次元ベクトルを格納できるフィールドタイプのようです。
試しにAmazon ES上にフィールドタイプ「knn_vector」のフィールドを定義し、「dense_vector」に格納していたベクトルデータをインポートしてみたところエラーなく登録できました。
検索クエリの違い
フィールドタイプが異なるので検索クエリも変わってきます。
1.Elasticsearchの「dense_vector」
"query": { "script_score": { "query": {"match_all": {}}, "script": { "source": "cosineSimilarity(params.query_vector, doc['text_vector']) + 1.0", "params": {"query_vector": target_vector} } } }2.Amazon ESの「knn_vector」
"query": { "knn": { "text_vector": { "vector": target_vector, "k": 100 } } }検索結果の差分
アルゴリズムが異なるため、当然検索結果も違ってくると思います。
今回は「それらしい結果が取得できている」で検証を終えています。
いつかちゃんと検索結果の違いについて調査しようと思います。参考サイト
Amazon Elasticsearch Service>開発者ガイド>KNN
Amazon ElasticsearchServiceのK-NNを触ってみる
ベクトルフィールドを使ったテキスト類似性検索
Elasticsearchで分散表現を使った類似文書検索
- 投稿日:2021-03-15T22:15:49+09:00
Lambda で返ってくる文字列でハマった
問題
Lambda、API Gateway を使って Web ブラウザからの入力結果を処理していた。Lambda 関数の戻り値に不要なダブルクォーテーションがついていた。
以下のような Lambda 関数を作成した。
lambda_function.pyif bool: return 'Exist' else: return 'NotExist'lambda_function.pyの戻り値がresponse.text()に格納されるのだが、bool が True であるにも関わらず、result === 'Exist' の結果が false になっていた。
main.jsfetch(url, requestOptions) .then(response => response.text()) .then(result => { if (result === 'Exist') { alert('存在します。'); } else { alert('存在しません。'); } })ログを見ると、result の値が
""Exist""となっていた。そこで replace メソッドを使った。main.jsfetch(url, requestOptions) .then(response => response.text()) .then(result => { if (result.replace(/"/g, '') === 'Exist') { alert('存在します。'); } else { alert('存在しません。'); } })replace
'Hello, WORLD!'.replace(/o/ig, '') // 結果:"Hell, WRLD!"
- i フラグ:大文字と小文字の違いを無視して置換
- g フラグ:指定した正規表現にマッチするすべての文字列を置換(グローバルマッチ)
参考記事
- 投稿日:2021-03-15T22:00:33+09:00
DynamoDBストリームについて調べてみた!
DynamoDBストリームについて調べてみた!
AWS SAAの練習問題でもよく出てきたDynamoDBストリームという機能があります。DynamoDBのテーブルの更新とか削除とかのイベント発生時に別のサービスのトリガーに使うぐらいしか知らないので、今回はもう一歩踏み込んでみようと思います!
DynamoDBストリームって何?
まずはDynamoDBストリームとは?からいきましょう!
DynamoDB ストリーム は、DynamoDB テーブル内の項目レベルの変更の時系列シーケンスをキャプチャし、この情報を最大 24 時間ログに保存します。
保管時の暗号化では、DynamoDB ストリームのデータが暗号化されます。
DynamoDBテーブルでストリームを有効にすると、DynamoDB はテーブル内のデータ項目に加えられた各変更に関する情報をキャプチャします。
ストリームの変更データキャプチャDynamoDB - Amazon DynamoDBより難しく書いてありますが、DynamoDBのテーブルのデータに変更があった時に、その変更情報を暗号化してログに保存しとくよ、というかんじです。
以下がメリットと書かれています。
DynamoDB ストリーム は以下のことを確認するのに役立ちます。
・各ストリームレコードは、ストリームに 1 回だけ出現します。
・DynamoDB テーブルで変更された各項目について、ストリームレコードは項目に対する実際の変更と同じ順序で出現します。
DynamoDB ストリーム は、ストリームレコードをほぼリアルタイムで書き込むため、これらのストリームを使用し、内容に基づいてアクションを実行するアプリケーションを構築できます。変更があったらリアルタイムで何か処理をしたいときに使えるんですね。
さて、もう少し踏み込むとしますか!
エンドポイントが別々
AWS では、DynamoDB と DynamoDB ストリーム. に別個のエンドポイントが維持されます。
データベースのテーブルとインデックスを使用するには、アプリケーションが DynamoDB エンドポイントにアクセスする必要があります。DynamoDB ストリーム レコードを読み込んで処理するには、アプリケーションが同じリージョンの DynamoDB ストリーム エンドポイントにアクセスする必要があります。へぇ~!って実はDynamoDBは10分ぐらいしか触ったことないので全然知らないんですけど、テーブルへのアクセスとストリームへのアクセスのエンドポイントは別々なんですね。
どうやって設定するの?
そもそも設定方法を知らないです・・・。
新しいテーブルでは、そのテーブルの作成時にストリームを有効にできます。既存のテーブルでストリームを有効または無効にすることや、ストリームの設定を変更することができます。DynamoDB ストリーム は非同期的に動作するため、ストリームを有効にしてもテーブルのパフォーマンスに影響はありません。
ストリームはいつでも有効または無効にできます。あ、そうなんですね。テーブル作成時でもいいし後からでも影響なく設定できると。マネジメントコンソールでやるのが手っ取り早いらしいです。
ストリームレコードとシャード
よう分からん横文字があらわれた!
ストリームは、ストリームレコードで構成されています。各ストリームレコードは、ストリームが属する DynamoDB テーブル内の 1 件のデータ変更を表しています。
ストリームレコードは、グループ (つまり、シャード) に整理されます。
図を見るとわかりやすいかな。
ストリームレコードは1つの変更に関するデータ、それが集まるとシャードってグループで、この全体がストリームってことかな。データの保持について
DynamoDB ストリーム 内のすべてのデータは、24 時間保持されます。特定のテーブルの直近 24 時間のアクティビティを取得して分析できます。ただし、24 時間を超えたデータはすぐにトリミング (削除) される可能性があります。
テーブルのストリームを無効にした場合、ストリーム内のデータは 24 時間読み込み可能な状態になります。この時間が経過すると、データは期限切れになり、ストリームレコードは自動的に削除されます。既存のストリームを手動で削除するためのメカニズムはありません。保持期限 (24 時間) が切れ、すべてのストリームレコードが削除されるまで待つ必要があります。ふむふむ。まず24時間保持されると。
ただし24時間を超えると削除される可能性があって、無効にすると24時間は読み込めるけどタイムオーバーすると期限切れで自動削除されちゃうのか。しかも手動では削除できないとは。ユースケース
- ある AWS リージョンのアプリケーションが、DynamoDB テーブルのデータを変更します。別の AWS リージョンの 2 番目のアプリケーションがそのデータ変更を読み込み、データを別のテーブルに書き込みます。このとき、元のテーブルと同期されたレプリカを作成します。
- 人気のモバイルアプリは、1 秒あたり数千件の更新速度で、DynamoDB テーブルのデータを変更します。別のアプリケーションは、これらの更新に関するデータをキャプチャして保存し、モバイルアプリの使用状況メトリクスをほぼリアルタイムで提供します。
- グローバルなマルチプレーヤーゲームには、データを複数の AWS リージョンに保存するマルチマスタートポロジがあります。各マスターは、リモートリージョンで発生した変更を使用および再現することにより同期されます。
- アプリケーションは、友人の 1 人が新しい画像をアップロードするとすぐに、グループ内のすべての友人のモバイルデバイスに通知を自動送信します。
- 新しいお客様がデータを DynamoDB テーブルに追加します。このイベントにより、新しいお客様にようこそメールを送信する別のアプリケーションが起動されます。
ざっくりまとめると大規模なシステムでのリアルタイム処理といったところでしょうか。この規模の話になるともはや「すげぇなあ」と見上げるかんじです。でも知らぬ間にお世話になってそうなのでちょっと親近感もわくかも?
まとめ
今回はなんとなく知ってたDynamoDBストリームについて、もう一歩踏み込んで調べてみました。
多分これでもまだ浅いとは思うんですが、個人的には今回の内容でも知らなかったことだらけだったのでよい勉強になりました。
エンドポイントが別、有効・無効の切り替え可能、ストリームレコードとシャード、保持期限などなど新しいことを吸収できました。あとは実施使ってみるのがいいんでしょうけど、なかなか手が出せない領域なので、使うときにはこの記事を読み返そうと思います!
それでは今日はこのへんで!

- 投稿日:2021-03-15T21:51:34+09:00
DynamoDBの古いデータを自動削除する機能の紹介
90日以上経った古いデータを削除したい
DynamoDBはデータを保存する容量によっても課金されますので、古いデータ量が大きい場合は削除するだけでコストダウンになります。そんな時、Lambdaを定期実行して削除していっても構わないのですが、DynamoDBにはぴったしな機能があります。
Time to live(生存時間)
この機能はNumber typeのカラムを指定し、生存時間を決めます。例えば90日とか。そうすると、AWSが自動で指定したカラムの値をチェックして古ければ削除してくれます。
コード書かなくてよいので便利です。しかし、重要な条件があります。
指定したカラムの値が秒単位のUnix Timestampである必要があります。
- 投稿日:2021-03-15T21:15:16+09:00
【未経験者】PHPとLaravelそれぞれで類似ポートフォリオ作ってみた
はじめに
こんにちは、おーもとと申します。エンジニアに転職をするため学習している初学者です。
私は車が好きで、「近年の若者の車離れ」という問題にフォーカスしたアプリを制作しようと思いました。
色々あって、生のPHPとLaravelの二通りの類似ポートフォリオを制作したので、記事にしてみました。制作背景
若者が車を持たない理由には様々な理由があると思いますが、
「欲しいと思えるほど魅力を感じる車に出会っていないからなのでは?」
と思い、
・かわいいやかっこいいというスタイル
・大きさ
・国産か外車か
・アウトドアや街乗りという用途
これらの項目に当てはまる車を、結果として表示するアプリを制作することにしました。
(これらの特徴は全て私が定めているため、投票などにより特徴を決める機能をつけたいです)11月 PHPでアプリ開発
10月からPHPの学習を始めていたので、そのアプリはPHPで制作しました。
カーセンサーAPIを使用して、車の情報を取得します。
解説動画:https://www.youtube.com/watch?v=ZXbgUtjxKM8
機能
ユーザー登録関連
⚪︎ ログイン
⚪︎ ログアウト
⚪︎ 新規登録
⚪︎ ユーザー件数を表示車の検索機能
⚪︎ 車の見た目→「かわいい」「かっこいい」「シンプル」「おしゃれ」「レトロ」
⚪︎ 車のサイズ→「ふつう」「すごくおおきい」「おおきい」「ちいさい」
⚪︎ 車の製造国→「国産車」「外車」
⚪︎ 車の用途 →「街乗り」「アウトドア」「スポーツ」カーセンサーAPI連携
⚪︎ DBにある車情報と合致した車情報を取得
⚪︎ cronでキャッシュファイル自動生成苦労した点
検索結果の画像表示高速化
検索の度にAPIからデータを取得していたので、電波の悪い場所では結果の表示に1分以上かかっていました。
そのため、毎日APIからデータを取得するバッチ処理をcronで自動化し、キャッシュ化することで、ユーザーにストレスのない速度で結果を表示させることができました。EC2へデプロイ
公式ドキュメントを参考にしデプロイしました。
その際、インフラの知識が不足していたため、デプロイに一週間以上かかりました。APIのサービス終了!!
転職活動を始めようとした際、一週間後にカーセンサーAPIサービスが終了すると知りました。
急いで提供元へ問い合わせたところ、
「完全に提供が終了すること」「24時間以上のキャッシュデータの保有も禁止」、ということを告げられました。
その後、他の車データAPIの提供元を調べましたが他にありませんでした。
画像だけでもどうにかならないかと思い、ト◯タや◯産などの画像利用規約を確認しましたが、
営利目的ではない&提供元のURLなどの情報を記載する
としても、利用は禁止でした。
そのためLaravelの勉強も兼ねて、画像問題を解決できるアプリの制作に取り掛かりました。1月 Laravelでアプリ開発
12月末からLaravelの学習を始め、1月からアプリの制作に取り掛かりました。
前回のPHPで制作したポートフォリオとの違い
画像の取得にAPIを用いていましたが、ユーザーから愛車の画像を提供してもらう方針に変更し、機能の追加などを行いました。
完成
アプリのURL:https://pf-kurushira.com
(スマホサイズにも対応しています)
使用技術
使用言語
⚪︎ HTML
⚪︎ CSS
⚪︎ SCSS
⚪︎ PHP 7.4.14
⚪︎ Laravel 6.20.11インフラ
⚪︎ Github Actions 自動デプロイ
⚪︎ Docker 20.10.2 / docker-compose 1.27.4
⚪︎ nginx 1.18
⚪︎ mysql 5.7.31 / PHPMyAdmin
⚪︎ AWS ( EC2, ALB, ACM, S3, RDS, Route53, VPC, EIP, IAM)インフラ構成図
機能一覧
機能 概要 ユーザー管理機能 新規登録・ログイン・ログアウトができます 簡単ログイン機能 ログイン画面のゲストログインをクリックすることで、ゲストユーザーとしてログインできます おすすめ車種検索機能 条件を選択すると、それにあった車種一覧を表示します 検索履歴機能 直近の検索履歴・結果を表示します 画像提供機能 ユーザーの所有している車の画像を提供できます 提供した画像の削除機能 提供した画像を削除できます 提供画像一覧表示機能 自身が提供した画像一覧を表示します。 ユーザー情報編集機能 ご登録いただいたユーザー名・メールアドレスを変更できます Twitterシェア機能 車の検索結果をツイートすることができます レスポンシブ機能 スマホサイズ(320~540px)にも対応しています DB設計
各テーブルについて
テーブル名 説明 users 登録ユーザー情報 cars 登録車情報 histories 直近の検索結果の情報 car_images 提供画像の情報 苦労した点
ユーザー情報編集ページのバリデーション
LaravelのAuth機能のバリデーションを使いまわそうとしましたが、ブラックボックスになっていて苦労しました。
→新しくバリデーションを作成。S3からオブジェクト削除
画像の削除機能でDBからだけでなく、S3からもオブジェクトを削除する必要があり苦労しました。
→解決方法を記事にしました
laravel6でS3に画像アップロード&削除今後の課題
機能
機能 概要 英訳機能 Google Cloud Translation APIを利用して翻訳 通報機能 ユーザーの投票で不適切な画像を削除 技術
⚪︎ テスト
⚪︎ Dockerを用いた本番環境の構築
⚪︎ ECSへデプロイ参考にした学習教材など
PHP/Laravel
・【Udemy】PHP+MySQL(MariaDB) Webサーバーサイドプログラミング入門
・【書籍】詳細!PHP 7+MySQL 入門ノート
・【書籍】PHPフレームワークLaravel入門 第2版
・【書籍】PHPフレームワーク Laravel実践開発
・Laravel6.0(PHP7.3)+MySQL+Laradockで簡易的なECサイトを作るAWS
・【Udemy】AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得
Docker
・【超入門】20分でLaravel開発環境を爆速構築するDockerハンズオン
さいごに
生のPHPでひとつPFを制作したのは、基礎力が身についたので良かったと思います。
今回ポートフォリオ完成を優先したため、ECSではなくEC2へデプロイしました。
まだ課題も多いですが、ブラッシュアップしていきたく思っています。
長くなりましたが、ここまで読んでくださりありがとうございました!!




- 投稿日:2021-03-15T20:33:02+09:00
【AWS】Direct Connect フェイルオーバーテスト機能使ってみた
はじめに
だいぶ時間経ってしまっているのですが、、
1年位前アップデート(2020/6/3))があった、AWS DirectConnectでフェイルオーバーテスト機能についてのメモです。アップデート直後に、たまたまAWS 専用線アクセス体験ラボトレーニングに参加し、AWS DirectConnect環境構築しており、その際にフェイルオーバーテスト機能も試していました。
せっかくなので実際にやってみた記録(とやり方)をまとめておこうと思い、アップデートからだいぶ時間経ってますが一応残しておきます。なお、実際にやってみたのは2020年06月頃になるので、マネジメントコンソールの画面キャプチャなどはその当時(2020年06月頃)のものになりますので、その点ご承知おきください。
嬉しいこと
これまで、物理的に回復性がある接続を介して BGP セッションを確立できましたが、AWS では設定の回復性をテストするために障害を誘発するツールが提供されていませんでした。
お客様は今後、フェイルオーバーテスト機能を使用することで、自身で指定した時間 BGP セッションをシャットダウンできます。
また、テスト中、テスト前の設定に戻すために、いつでもフェイルオーバーテストをキャンセルすることもできます。
今までは、AWS Direct Connect環境の回線冗長化を確認したい場合、
CGW(BGPルータ)側で障害を発生させることでしか確認ができませんでしたが
フェイルオーバーテスト機能によって、AWS側の障害起因での切り替え試験を再現できるようになりました。
これによって、本当に耐障害性のあるネットワークとして構成できているかを、
実環境でテストにて確認することが可能になりました。やってみた
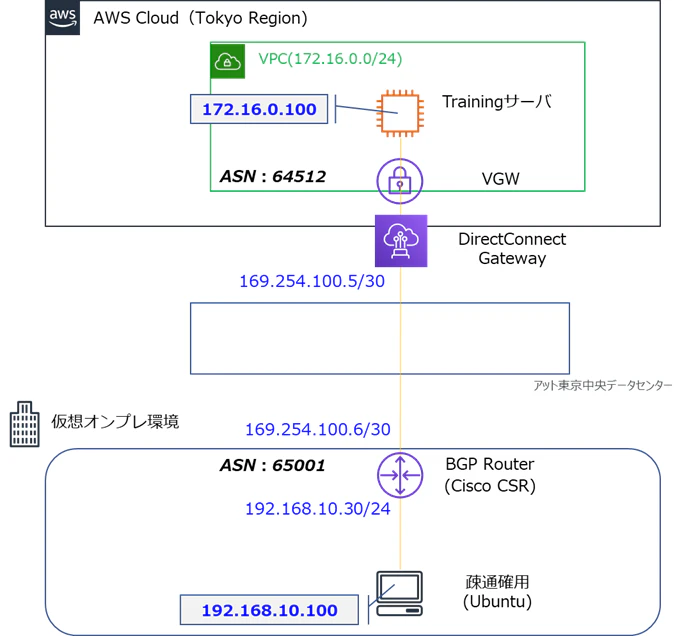
全体環境イメージ
今回の検証環境イメージは以下の通りです。(後述しますが、冗長構成も試しています。)
この状態でフェイルオーバーテストを実施してみました。
仮想オンプレ環境はハンズオン用ラボ環境としてAWSから貸し出されたものを使用してます。
実施方法
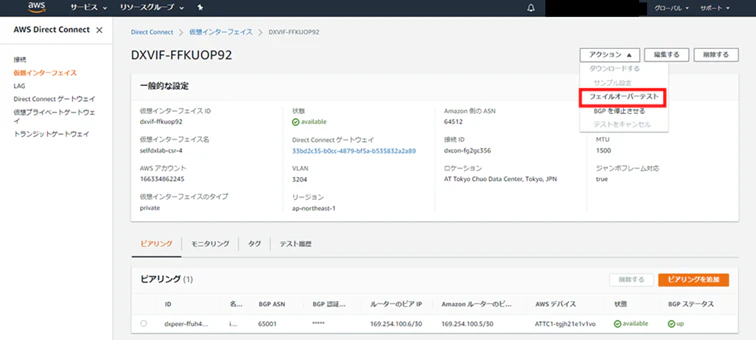
[Services]-[Networking & Content Delivery]-[Direct Connect]をクリックします。
[仮想 Interfaces]を開き、対象の仮想 Interfacesを選択します。
今回は「selfdxlab-csr-4」を選択します。
[アクション] -[フェイルオーバーテスト]を選択します。
障害テストの開始画面にて、必要項目を入力してテストを開始します。(設定可能な時間は1~180分)
今回は[テストの最大時間]を1分に設定します。
正常にテストが開始されると、「BGP 障害テストが正常に開始されました」と表示されます。
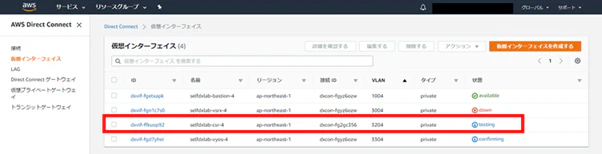
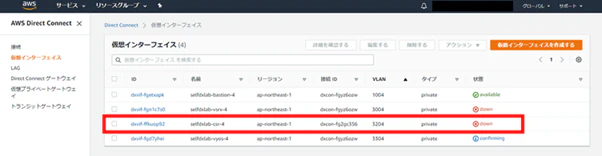
テスト開始後疎通可能になるまで、以下のように遷移します。
[testing]→[down]→[avalilable]
BGP停止時に設定した[テストの最大時間](今回は1分)が経過すると、BGPセッションが回復します。
テストを実行した仮想インターフェイスの画面からテスト履歴を確認できます。
履歴画面では[テスト開始時刻]、[テスト終了時刻]、[テストステータス]が確認できます。
※先程テストを実行した履歴のステータスはcompleteになっていることが確認できます。
実検証結果
実際にフェイルオーバーテストをやって、どの程度通信断となるのか(設定したテスト時間通りか?)シングル構成で確認してみました。
また冗長構成でもテストを実施してみて、通信断にならないかどうか確認してみました。全体構成(シングル構成)
- [テスト最大時間:1分] シングル構成
- pingダウン時間:約100秒 ※設定時間(1分)よりちょっと長い。。
ubuntu→Trainingサーバping結果aws@ubuntu:~$ ping 172.16.0.100 PING 172.16.0.100 (172.16.0.100) 56(84) bytes of data. 64 bytes from 172.16.0.100: icmp_seq=1 ttl=243 time=5.08 ms ~省略~ 64 bytes from 172.16.0.100: icmp_seq=9 ttl=243 time=3.63 ms From 172.16.0.100 icmp_seq=10 Destination Host Unreachable ~省略~ From 172.16.0.100 icmp_seq=106 Destination Host Unreachable 64 bytes from 172.16.0.100: icmp_seq=107 ttl=243 time=3.67 ms 64 bytes from 172.16.0.100: icmp_seq=108 ttl=243 time=3.49 msBGPセッション停止~回復【CSR出力ログ】$ show log *Jun 17 15:33:54.294: %BGP-5-ADJCHANGE: neighbor 169.254.100.5 Down BGP Notification received ~省略~ *Jun 17 15:35:31.088: %BGP-5-ADJCHANGE: neighbor 169.254.100.5 UpBGPセッション停止~回復【CSRルーティング情報】★正常時 $ show ip bgp Network Next Hop Metric LocPrf Weight Path *> 172.16.0.0 169.254.100.5 100 0 64512 i ★フェイルオーバーテスト実施時 $ show ip bgp Network Next Hop Metric LocPrf Weight Path (何も出力されない)全体構成(冗長構成)
- Juniper(VSR)と、Cisco(CSR)で冗長化しています。
- 経路冗長の仕組みは、WAN側:eBGPのLocalPreferenceとAS PATHで行き戻りの経路制御、LAN側:iBGPです。
- [テスト最大時間:1分] 冗長構成
- pingダウン時間:断なし
ubuntu→Trainingサーバping結果aws@ubuntu:~$ ping 18 72.16.0.100 PING 172.16.0.100 (172.16.0.100) 56(84) bytes of data. 64 bytes from 172.16.0.100: icmp_seq=1 ttl=243 time=5.91 ms 64 bytes from 172.16.0.100: icmp_seq=2 ttl=243 time=9.59 ms ~省略~ 64 bytes from 172.16.0.100: icmp_seq=91 ttl=243 time=7.98 ms 64 bytes from 172.16.0.100: icmp_seq=92 ttl=243 time=7.41 ms From 172.16.0.100: icmp_seq=93 Redirect Host(New nexthop: 172.16.0.100) 64 bytes from 172.16.0.100: icmp_seq=93 ttl=243 time=9.05 ms 64 bytes from 172.16.0.100: icmp_seq=94 ttl=243 time=4.86 msBGPセッション停止~状態遷移【VSR出力ログ】*Jun 17 15:33:54.294: %BGP-5-ADJCHANGE: neighbor 169.254.100.5 Down BGP Notification received ~省略~ *Jun 17 15:35:31.088: %BGP-5-ADJCHANGE: neighbor 169.254.100.5 UpBGPセッション停止~状態遷移【VSRルーティング情報】★正常時 aws@vsrx> show route 172.16.0.0 inet.0: 11 destinations, 12 routes (11 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 172.16.0.0/16 *[BGP/170] 00:00:01, localpref 200 AS path: 64512 I > to 169.254.100.1 via ge-0/0/0.0 ★フェイルオーバーテスト実施時(NextHopがCSRに向く) aws@vsrx> show route 172.16.0.0 inet.0: 11 destinations, 12 routes (11 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 172.16.0.0/16 *[BGP/170] 08:16:00, MED 0, localpref 100, from 10.0.0.254 AS path: 64512 I > to 192.168.10.30 via ge-0/0/1.0最後に
NW環境としての冗長性をよりきちんと確認出来るので、
オンプレとクラウドのハイブリッド環境を構築する上では、とても有益な機能だと思いました。断時間が想定より長かった理由は分かりませんでしたが。。
実際にやってみてどう動くかまで、CGW(BGPルータ)側の挙動含めて確認できたのはよかったです。参考にさせていただいた記事:







- 投稿日:2021-03-15T20:05:06+09:00
AWS Batch とは
勉強前イメージ
バッチスケジューラー的なもの?
調査
AWS Batch とは
フルマネージド型のバッチ処理実行サービスです。
フルマネージド型なのでインフラを構成する必要がなく、設定後すぐ使えるようになります。AWS Batch の特徴
- フルマネージド型
上記でも記載しましたが、
フルマネージド型なので、インフラ面での設定等はほぼなく
webから設定するだけで稼働させることが出来ます。
また、実行するインフラを Fargate やEC2インスタンスなど選ぶことが出来ます。
- 依存関係があるジョブを実行することが出来る
よくジョブには前後の依存関係がある場合が多く、
依存関係がある場合でも配列ジョブというジョブ定義を行うことにより処理制御を行うことが出来ます。
- ジョブに優先度を持たせることによって、リソースの最適化を行う
ジョブに優先度を持たえることができ、それによってリソースを最適な形で割り当ててコストを抑えることが出来ます。
- モニタリングやログ記録
ジョブの主要なメトリクスについてはマネジメントコンソール上で確認が出来、
その他の詳細なログ等に関してはCloudWatch Logsでも確認することが出来ます。用語
AWS Batchでは様々用語があるので、今回は主要な下記の4つを確認いたします。
- ジョブ
- ジョブ定義
- ジョブキュー
- コンピューティング環境
ジョブ
AWS Batchで実行される作業の単位です
後ほど記載するジョブ定義を参照する必要があります。ジョブ定義
実行方法を定義する、ジョブの雛形となるテンプレートのようなものでジョブの実行方法を定義します。
ジョブキュー
ジョブキューは投入されたジョブの行列で
ジョブが投入されるとジョブキューに送信され、コンピューティングリソースにスケジューリング出来るまで待機します。コンピューティング環境
ジョブが実行するコンピューティング環境になります。
様々種類を選ぶことが出来ます。
勉強後イメージ
バッチスケジューラーというより、「ジョブを実行するもの」のイメージ。
定期実行は他のサービスと連携したらいけると思う
cronって感じではない参考


- 投稿日:2021-03-15T19:02:55+09:00
AWS Backup のモニタリングを設定する
はじめに
2021/2/3 に AWS Backup のイベントとメトリクスが Amazon EventBridge と Amazon CloudWatch で利用可能になりました。
これまでも AWS Backup Notification API により Amazon SNS を使用したイベント通知を行うことも可能でしたが、このアップデートによって、より多くのバックアッププロセスをモニタリングできるようになりました。
上記を使用して AWS Backup のモニタリングを設定する流れについて記載します。
以下には触れません。
- AWS Backup 自体の詳細や設定手順
- AWS Backup Notification API による通知の設定手順
- AWS CloudTrail による API Call のモニタリング
Amazon CloudWatch
概要
CloudWatch のメトリクスでは大きく分けるとバックアップジョブおよび復旧ポイントに関するメトリクスを取得することができます。
2021年3月時点で取得可能なメトリクスは以下のとおりです。 (AWS ドキュメントより引用)バックアップジョブに関するメトリクス
メトリクス 概要 NumberOfBackupJobsCreated 作成されたバックアップジョブの数 NumberOfBackupJobsPending 実行しようとしているバックアップジョブの数 NumberOfBackupJobsRunning 現在実行されているバックアップジョブの数 NumberOfBackupJobsAborted スケジュールされたが、開始されなかったバックアップジョブの数 NumberOfBackupJobsCompleted 完了したバックアップジョブの数 NumberOfBackupJobsFailed 失敗したバックアップジョブの数 NumberOfBackupJobsExpired ライフサイクル設定に基づいて削除を試行したが削除できなかったバックアップジョブの数 NumberOfCopyJobsCreated クロスアカウントおよびクロスリージョンコピージョブの数 NumberOfCopyJobsRunning 現在実行されているクロスアカウントおよびクロスリージョンコピージョブの数 NumberOfCopyJobsCompleted 完了したクロスアカウントおよびクロスリージョンコピージョブの数 NumberOfCopyJobsFailed 失敗したクロスアカウントおよびクロスリージョンコピージョブの数 NumberOfRestoreJobsPending 実行しようとしている復元ジョブの数 NumberOfRestoreJobsRunning 現在実行されている復元ジョブの数 NumberOfRestoreJobsCompleted 完了した復元ジョブの数 NumberOfRestoreJobsFailed 失敗した復元ジョブの数 復旧ポイントに関するメトリクス
メトリクス 概要 NumberOfRecoveryPointsCompleted 作成された復旧ポイントの数 NumberOfRecoveryPointsPartial 作成を完了できなかったリカバリポイントの数 NumberOfRecoveryPointsExpired ライフサイクル設定に基づいて削除を試行したが削除できなかった復旧ポイントの数 NumberOfRecoveryPointsDeleting 削除を実行している復旧ポイントの数 NumberOfRecoveryPointsCold ライフサイクル設定に基づいてコールドストレージに移行された復旧ポイントの数 またディメンションには AWS Backup で取得するリソースタイプとバックアップボールト名を利用できますので、EC2 などの特定のリソースタイプや任意のバックアップボールトの単位、またはその組み合わせでアラームを設定することができます。
アラームの設定
どのメトリクスを監視すべきかについてはシステム要件によって異なるかと思いますが、
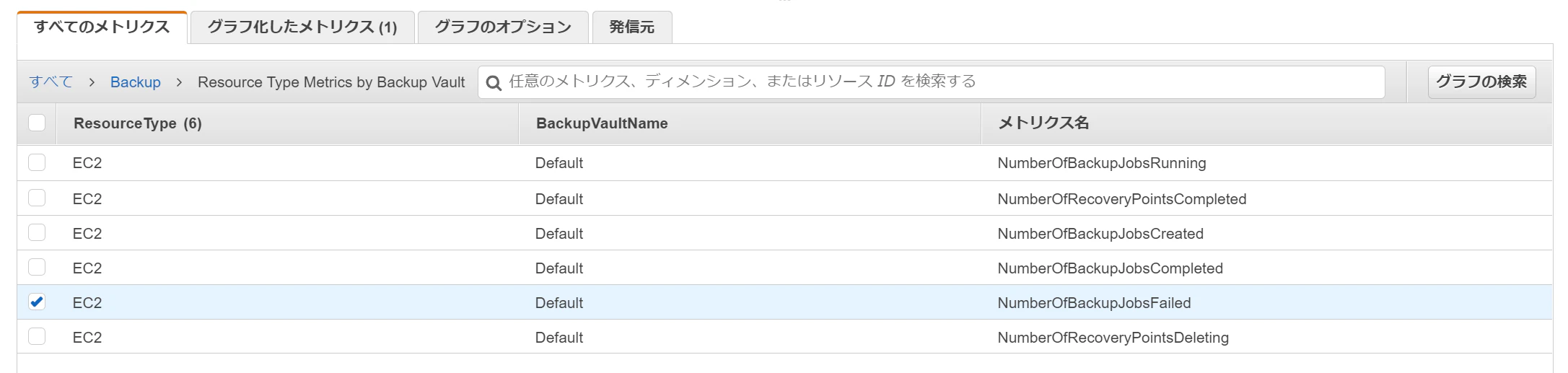
NumberOfBackupJobsFailedのアラームをコンソール上から定義してみます。CloudWatch コンソールのアラームからアラームの作成を選択します。
メトリクスの選択では AWS の名前空間 から AWS Backup を選択します。
ここでは Default のバックアップボールトかつ、EC2 のバックアップに対するアラートを設定したいと思いますので、Resource Type Metrics by Backup Vaultからメトリクスを選択します。
以下のように、
ResourceType: EC2,BackupVault: Default,メトリクス名: NumberOfBackupJobsFailedにチェックし、メトリクスの選択を完了します。
選択時に出力されるメトリクスの数は実際の AWS アカウント内の設定、運用状況により異なります。これまでバックアップに失敗していない場合は
NumberOfBackupJobsFailed自体が表示されない可能性があります。その場合、異なるメトリクスを選択後に手動でメトリクスを書き換えることもできます。メトリクス選択後に条件を指定します。
ここでは統計を合計に、静的なしきい値の条件を 1 以上として次に進みます。
アクションの設定で通知先の SNS Topic を選択するか新規作成します。ここでは AWS Chatbot 用に定義済みの SNS Topic を選択し、Slack に通知してみたいと思います。
AWS Chatbot の設定例については以前書いた記事で紹介しておりますので、詳細を確認したい方は参照いただければと思います。
最後にアラーム名と説明 (オプション) を指定してアラームの作成を完了します。
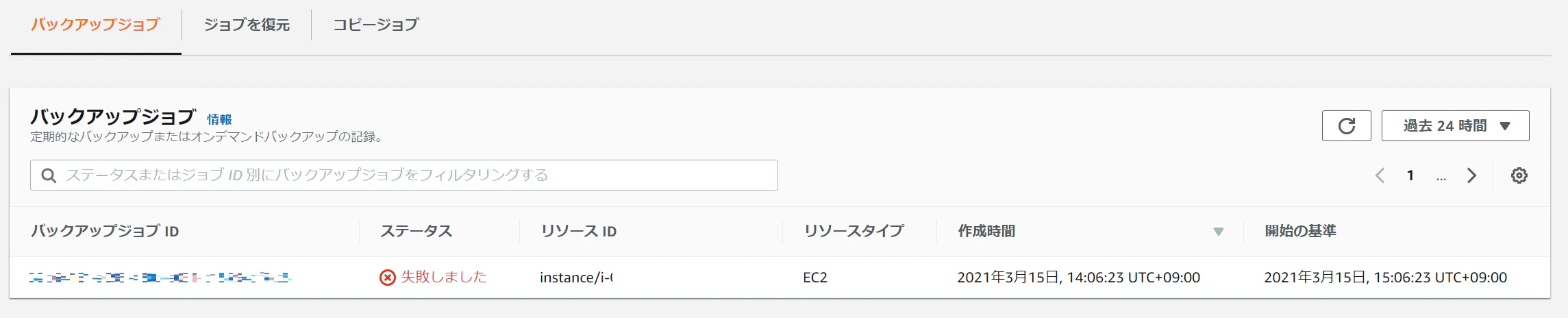
今回は BackupJobFailed というアラーム名を設定しました。
以下は実際にバックアップを失敗させたときの Slack へのアラーム通知例です。CloudWatch メトリクスの通知では対象のリソース ID までは確認できないことに注意してください。
参考まですが、意図的にバックアップジョブを失敗させる方法としては、テスト用の EC2 インスタンスを起動&終了させ、終了したインスタンスを指定してオンデマンドバックアップを実行する手順が簡単かと思います。
Amazon EventBridge
概要
EventBridge ではバックアッププロセスに関するより多くのステータス変化をイベントとして検知することができます。
2021年3月現在で検知可能なイベントは以下のとおりです。 (AWS ドキュメントより引用)
Event type States Backup Vault State Change CREATED, DELETED, MODIFIED Backup Plan State Change CREATED, DELETED, MODIFIED Backup Job State Change CREATED, ABORTED, COMPLETED, FAILED, EXPIRED, PENDING, RUNNING Copy Job State Change CREATED, COMPLETED, FAILED, RUNNING Restore Job State Change CREATED, COMPLETED, FAILED, PENDING, RUNNING Recovery Point State Change MODIFIED, COMPLETED, PARTIAL, EXPIRED, DELETED Region Setting State Change MODIFIED バックアップジョブや復旧ポイントに関する情報だけでなく、バックアップボールトやバックアッププランなどの設定に対する状態変化を追うことができます。
AWS Backupは、5分ごとにベストエフォートでイベントを EventBridge に送信するため、リアルタイムの検知ではないことにご注意ください。
また残念ながら 2021/3/15 時点で EventBridge のスキーマレジストリにスキーマ情報の登録がありません。参考までに Backup Job State Change では以下のようなイベントが発行されます。{ "version": "0", "id": "12345abc-defg-6789-hijk-012345lmnopq", "detail-type": "Backup Job State Change", "source": "aws.backup", "account": "123456789012", "time": "2021-03-15T07:11:40Z", "region": "ap-northeast-1", "resources": [], "detail": { "backupJobId": "abcde012-3456-efgh-7890-ijklmn123456", "backupVaultArn": "arn:aws:backup:ap-northeast-1:123456789012:backup-vault:Default", "backupVaultName": "Default", "bytesTransferred": "0", "creationDate": "2021-03-15T07:11:37.928Z", "iamRoleArn": "arn:aws:iam::123456789012:role/service-role/AWSBackupDefaultServiceRole", "resourceArn": "arn:aws:ec2:ap-northeast-1:123456789012:instance/i-xxxxxxxxxxxxxxxxx", "resourceType": "EC2", "state": "FAILED", "statusMessage": "Invalid value 'i-xxxxxxxxxxxxxxxxx' for instanceId. Instance is not in state 'running' or 'stopping' or 'stopped'", "startBy": "2021-03-15T08:11:37.928Z", "percentDone": 0.0 } }バックアップ対象のリソース ID やバックアップ失敗時のステータスメッセージなど CloudWatch メトリクスよりも詳細な情報を確認できます。
設定例
イベントルール作成時のイベントパターン定義でサービス毎の事前定義パターンとして
サービス名: Backupと前述のイベントタイプを選択できます。
上記で設定されるデフォルトのイベントパターンではバックアップジョブに対するすべての状態変化を検知してしまいます。FAILED と ABORTED だけなど特定のステータスのみを検知したい場合は、前述のイベント例を参考に以下のようにイベントパターンを編集します。
{ "source": ["aws.backup"], "detail-type": ["Backup Job State Change"], "detail": { "state": [ "ABORTED", "FAILED" ] } }イベントパターンの定義後、任意のターゲットアクションを設定してイベントルールの作成を完了します。
動作確認例は割愛しますが、バックアップジョブ失敗時ターゲットに指定した Lambda 関数が起動されることを確認しています。結局どれを使えばいいのか
CloudWatch メトリクスと EventBridge の AWS サービスイベントに加えて AWS Backup Notification API を含めると 3 通りの設定方法があることになります。
CloudWatch メトリクスのメリットはダッシュボードによる可視化、既存アラーム運用への統合がしやすいという点があります。
一方で EventBridge ではリソース ID やステータスメッセージなどの詳細情報を取得しつつ、Lambda 関数などの任意のアクションを設定することが可能であるため、より柔軟な対応が可能です。また意図しない構成変更等も検知できるため、基本的には CloudWatch メトリクスと併用できるものです。AWS Backup Notification API を使用する場合でも以下のような設定を行うことでバックアップジョブ失敗のモニタリングを行うこともできますが、若干手順がわかりにくいです。
また EventBridge や CloudWatch メトリクスはバックアップボールトや、コピージョブ、リージョン設定など Notification API よりも多くの状態変化を検知できますので、新規で設定するのであれば基本的には AWS Backup Notification API は対象外として問題ないのではと考えます。
参考
公式ドキュメント
以前書いた記事
以上です。
参考になれば幸いです。







- 投稿日:2021-03-15T18:45:41+09:00
Greengrass(V1)のOTAアップデートを実施する
はじめに
今回はGreengrassのOTAアップデートを実施しました。
手順は以下を参考にしています。
参考:AWS IoT Greengrass Core ソフトウェアの OTA 更新なお、デバイスは以前GreengrassをインストールしたJetson nanoを利用しています。
参考:Greengrass(V1)をクイックスタートでインストールしてみる1 IAMの設定
OTAアップデートを実施するロールを作成します。
このロールには、アップデート用のソフトウェアをS3から取得するためのポリシーもアタッチします。1-1 IAMロールの作成
1.IAMのマネジメントコンソールで左のメニューから ロール をクリック
2.「ロールの作成」をクリック
3.「AWSサービス」内のIoT > IoT を選択して「次のステップ:アクセス権限」をクリック
4.次の画面はそのままで「次のステップ:タグ」をクリック
5.次の画面もそのままで「次のステップ:確認」をクリック
6.ロール名に任意の名前を入力して「ロールの作成」をクリック
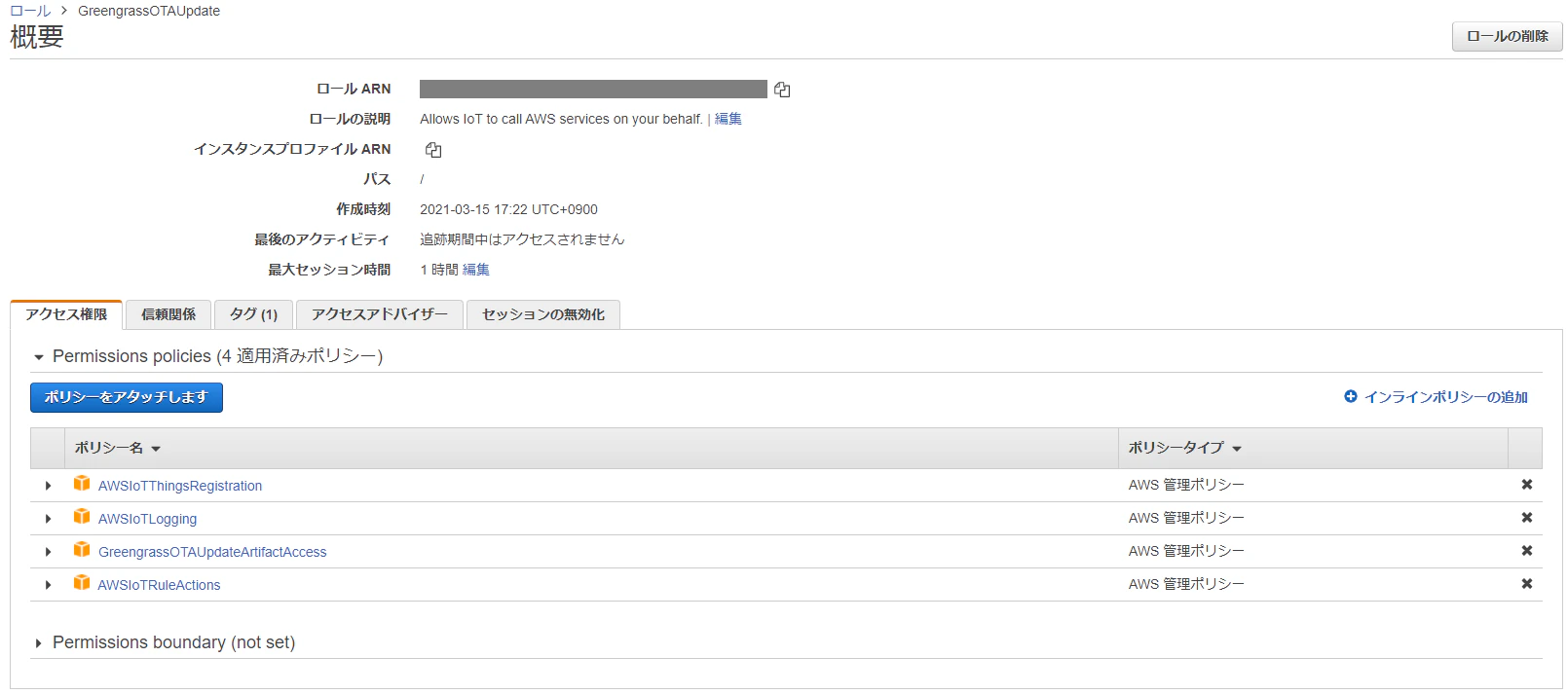
1-2 IAMポリシーのアタッチ
1.IAMのマネジメントコンソールで左のメニューから ロール をクリック
2.先ほど作成したロールをクリック
3.「ポリシーをアタッチします」をクリック
4.「GreengrassOTAUpdateArtifactAccess」をチェックして「ポリシーのアタッチ」をクリック
5.ポリシーがアタッチされていることを確認する
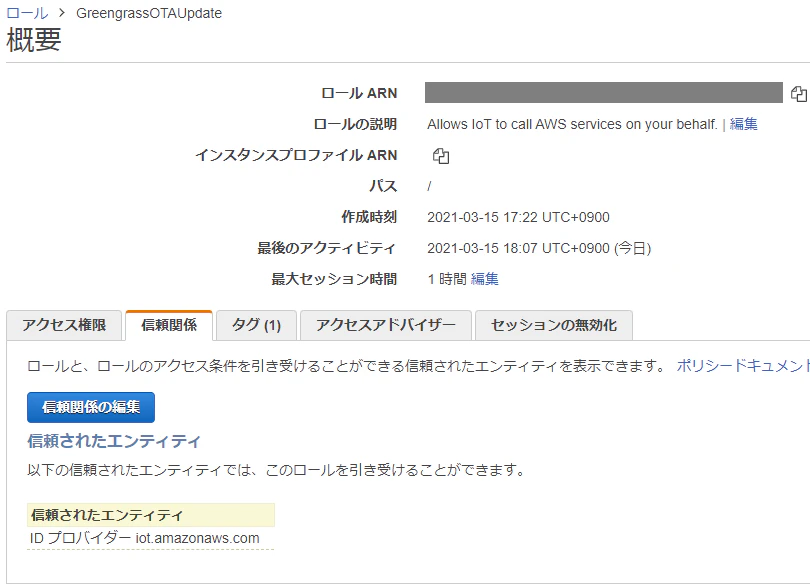
1-3 備考:信頼ポリシーについて
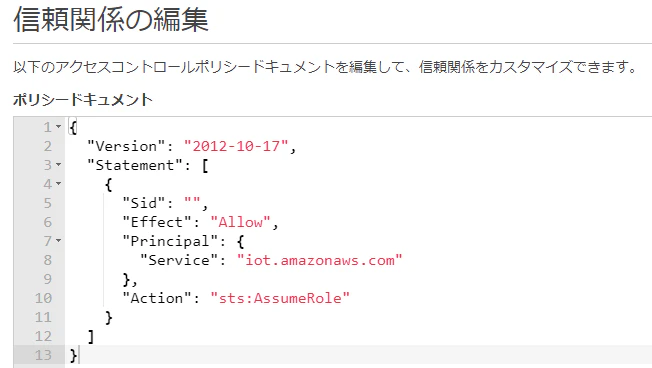
AWSの公式ドキュメントには以下の記載があります。
ロールにアタッチされた信頼ポリシーは、sts:AssumeRole アクションを許可し、iot.amazonaws.com をプリンシパルとして定義する必要があります。
出典:Requirements > OTA更新のIAMアクセス許可今回作成したポリシーについては、作成した段階で公式ドキュメントに記載のポリシーが存在したため、追加の作業はしていません。
作成したIAMロールの 信頼関係タブ > 「信頼関係の編集」をクリック で確認できます。
クリックすると以下の通り信頼ポリシーの編集画面に遷移する
※なお、信頼ポリシーの確認については以下の記事が参考になりました。
ポリシーを追加しようとしてエラーが出てしまい、同じくハマりかけました…
参考:lambda@edgeを使おうとしたらroleにハマった1-4 備考:実行ユーザのポリシーについて
AWSの公式ドキュメントには以下の記載があります。
さらに、OTA 更新を開始するユーザーには、greengrass:CreateSoftwareUpdateJob および iot:CreateJob を使用するアクセス許可と、iam:PassRole を使用して署名者ロールのアクセス許可を渡すアクセス許可が必要です。
出典:Requirements > OTA更新のIAMアクセス許可今回の以降の手順を実施するにあたっては上記操作は実施せずに完遂しています。
私が利用していたIAMユーザが「AdministratorAccess」ポリシーをアタッチされたグループに所属していることに起因するかと思いますので、そうでない場合は公式ドキュメントの通りの権限付与が必要になるかと思います。2 OTAアップデートを実施する
GreengrassのOTAアップデートは以下2種類があるので、どちらも実施しました。
- Greengrass Core ソフトウェア
- Greengrass Core OTA エージェントを更新する
2-1 OTAエージェントの起動
更新対象のエッジデバイスでOTAエージェントを先に実行します。
なお、OTAエージェントが複数起動していると競合してエラーになることがあるようです。競合の原因となる可能性があるため、コア上で OTA 更新エージェント の複数のインスタンスを起動しないでください。
出典:OTA 更新の作成1.更新対象のデバイス(今回はJetson nano)で以下のコマンドを実施
cd /greengrass/ota/ota_agent sudo ./ggc-ota2.エージェントが1つのみ起動していることを確認する
ps aux | grep -E "greengrass.*ota" root 1647 0.0 0.1 79080 4476 ? Ssl 17:52 0:00 /greengrass/ota/ota_agent_v1.0.0_0/ggc-ota -p 2534 root 14225 0.0 0.0 6696 2280 pts/2 S+ 18:00 0:00 grep --color=auto -E greengrass.ota2-2 OTAエージェントのアップデート
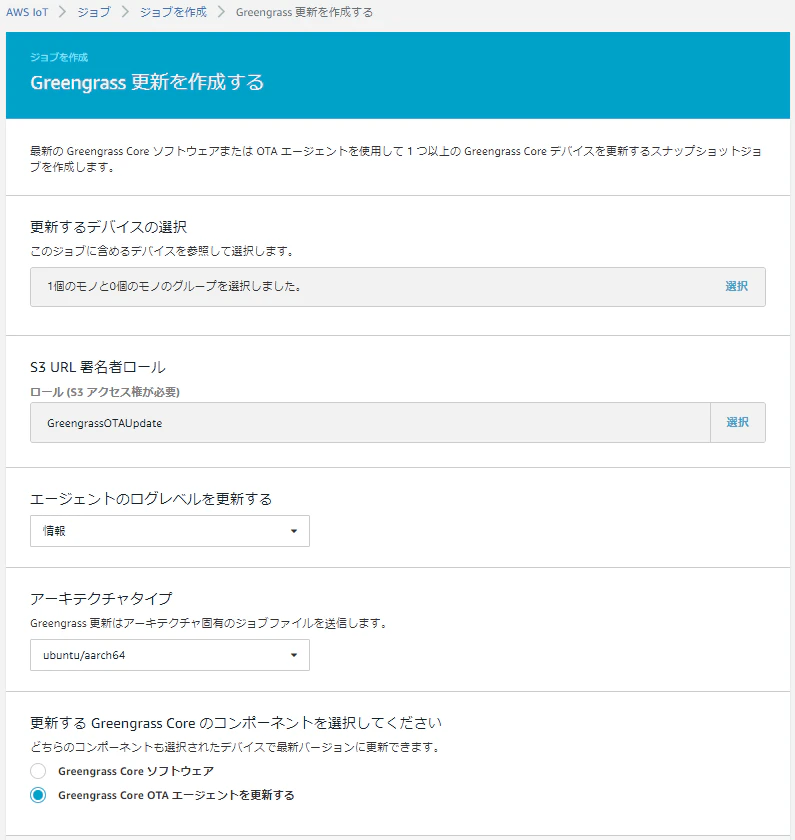
1.IoT Coreのマネジメントコンソールで左のメニューから 管理 > ジョブ の順にクリック
2.「ジョブを作成する」をクリック
3.「Core更新ジョブの作成」をクリック
4.以下の通り設定して「作成」をクリック
※クリックと同時にジョブが実行されるので注意
- 更新するデバイスの選択:※任意のモノ・モノのグループ(複数選択可)
- S3URL署名者ロール:※作成したIAMロール
- エージェントのログレベルを更新する:※任意のログレベル
- アーキテクチャタイプ:ubuntu/aarch64 ※対象のデバイスのアーキテクチャにあわせる
- 更新するコンポーネント:Greengrass Core OTAエージェントを更新する
5.一覧に作成したジョブが表示されるのでクリック
6.進行状況と成否を確認する
2-3 Greengrass Coreのアップデート
先ほどの「2-2 OTAエージェントのアップデート」と同様の手順です。
1.IoT Coreのマネジメントコンソールで左のメニューから 管理 > ジョブ の順にクリック
2.「作成」をクリック
3.「Core更新ジョブの作成」をクリック
4.以下の通り設定して「作成」をクリック
※クリックと同時にジョブが実行されるので注意
- 更新するデバイスの選択:※任意のモノ・モノのグループ(複数選択可)
- S3URL署名者ロール:※作成したIAMロール
- エージェントのログレベルを更新する:※任意のログレベル
- アーキテクチャタイプ:ubuntu/aarch64 ※対象のデバイスのアーキテクチャにあわせる
- 更新するコンポーネント:Greengrass Coreソフトウェア
5.一覧に作成したジョブが表示されるのでクリック
6.進行状況と成否を確認する
※詳細 をクリックすることで実行内容の詳細を確認することができる
3 備忘録
3-1 アップデートされたことの確認
更新対象のデバイスでプロセスを確認するとバージョン箇所の数字が+1されていることが分かります。
#Greengrass Coreの確認(***/packages/1.11.0_x となっている) ps aux | grep -E "greengrass.*daemon" root 28748 0.1 0.5 1083884 22420 ? Sl 18:08 0:00 /greengrass/ggc/packages/1.11.0_1/bin/daemon -core-dir /greengrass/ggc/packages/1.11.0_2 -greengrassdPid 28743 root 29048 0.0 0.0 6696 620 pts/2 S+ 18:13 0:00 grep --color=auto -E greengrass.*daemon #OTAエージェントの確認(***/ota_agent_1.0.0_x となっている) ps aux | grep -E "greengrass.*ota" root 1647 0.0 0.1 79080 4476 ? Ssl 17:52 0:00 /greengrass/ota/ota_agent_v1.0.0_1/ggc-ota -p 2534 root 14225 0.0 0.0 6696 2280 pts/2 S+ 18:00 0:00 grep --color=auto -E greengrass.ota3-2 アップデート中のLambdaの挙動
OTAアップデートに際してはGreengrass Coreはシャットダウンされ、Core上で実行されているLambdaも終了されます。
その他、アップデートに際しての注意事項は公式ドキュメントを確認した方がいいでしょう。
参考:Considerations3-3 アップデート後の不具合と解消
今回、「Greengrass Coreソフトウェア」アップデート後にLambdaが実行できなくなりました。
また、デプロイも以下の通り失敗しました。
なお、以下の通りGreengrass Coreを再起動することでLambda、デプロイともに正常に実行できるようになりました。#greengrassの終了 sudo /greengrass/ggc/core/greengrassd stop #greengrassの起動 sudo /greengrass/ggc/core/greengrassd start4 おわりに
マネジメントコンソールから簡単にOTAアップデートを実施することが出来ました。
グループ化してまとめて実行できるのは便利だと思います。ただ、「3-3 アップデート後の不具合と解消」のようにGreengrassの再起動が必要になるのは手間でした。
解消法があれば教えていただけるとありがたいです。







- 投稿日:2021-03-15T17:21:32+09:00
AWS CLIでECRの棚卸しをし、Lifecycle Policyの設定の有無やストレージ使用量を出力します。
背景
特定のAWSアカウントだけECRの値段が跳ね上がっていたので調査しました。
ECRの料金はストレージ量とデータ転送量の2点ですが、ストレージ使用量を調べてみました。ECRの料金についてはこちら!
※以下は20210315時点の東京リージョンの値段です
ストレージ数 料金 すべてのGB/月あたり 0.10USD
データ受信 料金 すべてのデータ受信 0.00USD/GB
データ送信 料金 1 GB/月まで 0.00USD/GB 次の 9.999 TB/月 0.114USD/GB 次の 40 TB/月 0.089USD/GB 次の 100 TB/月 0.086USD/GB 150 TB/月以上 0.084USD/GB 各種バージョン
$ aws --version aws-cli/2.1.30 Python/3.8.8 Darwin/20.3.0 exe/x86_64 prompt/off $ jq --version jq-1.6スクリプト
#!/bin/bash PROFILE="profile-12341234" REPOSITORYS=$(aws ecr describe-repositories \ --profile ${PROFILE} \ --query 'repositories[*].repositoryName' \ --output text) for REPOSITORY in ${REPOSITORYS} do RES=$(aws ecr describe-images \ --repository-name ${REPOSITORY} \ --profile ${PROFILE}) # ポリシーがなければNotFoundExceptionに入るのでエラーは捨てる POLICY=$(aws ecr get-lifecycle-policy \ --repository-name ${REPOSITORY} \ --profile ${PROFILE} 2> /dev/null) if [ $? -gt 0 ]; then IS_ENABLE_POLICY=0 else IS_ENABLE_POLICY=1 fi echo "${REPOSITORY},$(echo ${RES} | jq '[.imageDetails[].imageSizeInBytes] | add'),$(echo ${RES} | jq '[.imageDetails[]] | length'),${IS_ENABLE_POLICY}" done出力結果
以下のようにCSV形式で出力されます。
リポジトリ名, サイズ(byte), イメージ数, Lifecycle Policyが有効かどうかrepository1,15209655632,72,0 repository2,null,0,1 repository3,null,0,0この結果をもとにLifecycle Policyで特定数以上のイメージは削除するなどの設定を加えるといいかもしれません。
- 投稿日:2021-03-15T17:21:32+09:00
AWS CLIでECRの棚卸しをしつつ、Lifecycle Policyの設定の有無やストレージ使用量を出力します。
背景
特定のAWSアカウントだけECRの値段が跳ね上がっていたので調査しました。
ECRの料金はストレージ量とデータ転送量の2点ですが、ストレージ使用量を調べてみました。ECRの料金についてはこちら!
※以下は20210315時点の東京リージョンの値段です
ストレージ数 料金 すべてのGB/月あたり 0.10USD
データ受信 料金 すべてのデータ受信 0.00USD/GB
データ送信 料金 1 GB/月まで 0.00USD/GB 次の 9.999 TB/月 0.114USD/GB 次の 40 TB/月 0.089USD/GB 次の 100 TB/月 0.086USD/GB 150 TB/月以上 0.084USD/GB 各種バージョン
$ aws --version aws-cli/2.1.30 Python/3.8.8 Darwin/20.3.0 exe/x86_64 prompt/off $ jq --version jq-1.6スクリプト
#!/bin/bash PROFILE="profile-12341234" REPOSITORYS=$(aws ecr describe-repositories \ --profile ${PROFILE} \ --query 'repositories[*].repositoryName' \ --output text) for REPOSITORY in ${REPOSITORYS} do RES=$(aws ecr describe-images \ --repository-name ${REPOSITORY} \ --profile ${PROFILE}) # ポリシーがなければNotFoundExceptionに入るのでエラーは捨てる POLICY=$(aws ecr get-lifecycle-policy \ --repository-name ${REPOSITORY} \ --profile ${PROFILE} 2> /dev/null) if [ $? -gt 0 ]; then IS_ENABLE_POLICY=0 else IS_ENABLE_POLICY=1 fi echo "${REPOSITORY},$(echo ${RES} | jq '[.imageDetails[].imageSizeInBytes] | add'),$(echo ${RES} | jq '[.imageDetails[]] | length'),${IS_ENABLE_POLICY}" done出力結果
以下のようにCSV形式で出力されます。
リポジトリ名, サイズ(byte), イメージ数, Lifecycle Policyが有効かどうかrepository1,15209655632,72,0 repository2,null,0,1 repository3,null,0,0この結果をもとにLifecycle Policyで特定数以上のイメージは削除するなどの設定を加えるといいかもしれません。
- 投稿日:2021-03-15T17:21:32+09:00
AWS CLIでECRの棚卸しをして、Lifecycle Policyが無いものやストレージ使用量を出力します。
背景
特定のAWSをアカウントだけECRの値段が跳ね上がっていたので調査しました。
ECRの料金はストレージ量とデータ転送量の2点ですが、ストレージ使用量を調べてみました。ECRの料金についてはこちら!
※以下は20210315時点の東京リージョンの値段です
ストレージ数 料金 すべてのGB/月あたり 0.10USD
データ受信 料金 すべてのデータ受信 0.00USD/GB
データ送信 料金 1 GB/月まで 0.00USD/GB 次の 9.999 TB/月 0.114USD/GB 次の 40 TB/月 0.089USD/GB 次の 100 TB/月 0.086USD/GB 150 TB/月以上 0.084USD/GB 各種バージョン
$ aws --version aws-cli/2.1.30 Python/3.8.8 Darwin/20.3.0 exe/x86_64 prompt/off $ jq --version jq-1.6スクリプト
#!/bin/bash PROFILE="profile-12341234" REPOSITORYS=$(aws ecr describe-repositories \ --profile ${PROFILE} \ --query 'repositories[*].repositoryName' \ --output text) for REPOSITORY in ${REPOSITORYS} do RES=$(aws ecr describe-images \ --repository-name ${REPOSITORY} \ --profile ${PROFILE}) # ポリシーがなければNotFoundExceptionに入るのでエラーは捨てる POLICY=$(aws ecr get-lifecycle-policy \ --repository-name ${REPOSITORY} \ --profile ${PROFILE} 2> /dev/null) if [ $? -gt 0 ]; then IS_ENABLE_POLICY=0 else IS_ENABLE_POLICY=1 fi echo "${REPOSITORY},$(echo ${RES} | jq '[.imageDetails[].imageSizeInBytes] | add'),$(echo ${RES} | jq '[.imageDetails[]] | length'),${IS_ENABLE_POLICY}" done出力結果
以下のようにCSV形式で出力されます。
リポジトリ名, サイズ(byte), イメージ数, Lifecycle Policyが有効かどうかrepository1,15209655632,72,0 repository2,null,0,1 repository3,null,0,0この結果をもとにLifecycle Policyで特定数以上のイメージは削除するなどの設定を加えるといいかもしれません。
- 投稿日:2021-03-15T16:31:42+09:00
Amazon Redshift ML で機械学習モデル構築 #2 MLモデル構築
はじめに
サンプルデータを AWS Redshift にインポートし、Amazon Redshift ML で機械学習モデルを構築するまでの流れです。作成したばかりの AWS アカウントを想定しているので、周辺環境の設定内容で引っかかった方はご参照ください。
第1回では AWS環境の構築手順、第2回の本記事は機械学習モデルを作成するまでの手順をまとめました。
ローデータテーブル作成
以下 SQL クライアントでクエリをたたいています。
モデル作成の権限をユーザーに付与します。1GRANT CREATE MODEL TO awsuser;作成するデータベースやモデルを保持するスキーマを作成します。
2CREATE SCHEMA redshiftml_test;ローデータ用のテーブルを作成します。
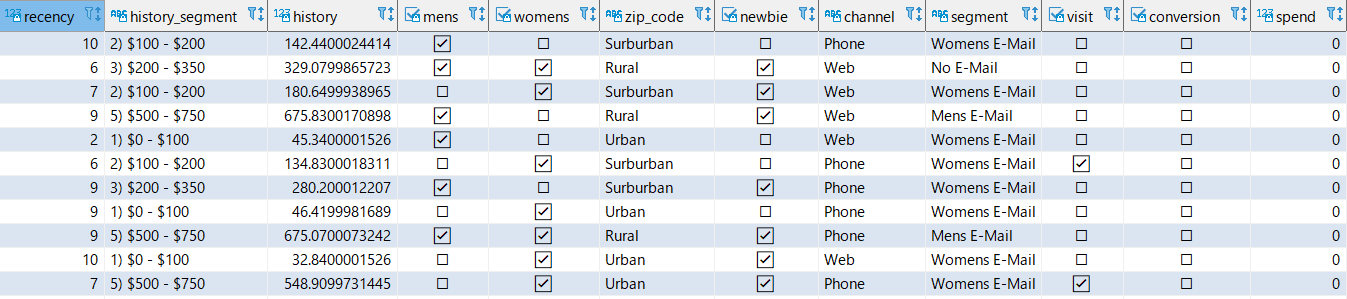
3create table redshiftml_test.minethatdata_orig( recency int4, history_segment varchar(256), history float (8), mens boolean, womens boolean, zip_code varchar(256), newbie boolean, channel varchar(256), segment varchar(256), visit boolean, conversion boolean, spend float (8) );S3 から CSV データをインポートします。
CSV data S3 URIとiam-role-arnはリソース作成時に拾ったパラメータです。4copy redshiftml_test.minethatdata_orig from '{CSV data S3 URI}' iam_role '{iam-role-arn}' csv IGNOREHEADER 1 ;ローデータテーブルのプレビュー
5select * from redshiftml_test.minethatdata_orig limit 10;out
学習用テーブル作成
以降のクエリを別のユーザーが行う場合は、スキーマの変更権限を付与します。
6GRANT CREATE, USAGE ON SCHEMA redshiftml_test TO awsuser;モデル学習しやすいようにテーブルを作成します。
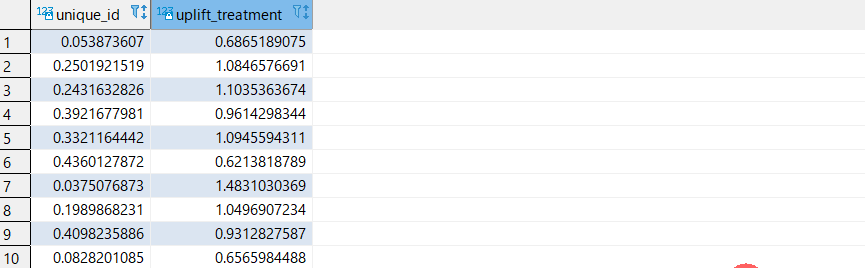
- segment (受け取ったキャンペーンメールの種類。Mens E-mail, Womens E-mail, No E-mail) を 1/0 で表現 (w 列)
- Spend (過去2週間の購入金額) を目的変数として利用 (y 列)
- 通し番号を unique_id として付与
- unique_id ベースで TRAIN データと TEST データに分割 (assigm 列)
7CREATE TABLE redshiftml_test.MineThatData AS SELECT *, CASE WHEN unique_id >= 0.50 THEN 'TRAIN' ELSE 'TEST' END AS assign FROM ( SELECT *, RANDOM() AS unique_id, CASE segment WHEN 'Mens E-Mail' THEN 1 WHEN 'No E-Mail' THEN 0 END AS w, spend AS y FROM redshiftml_test.minethatdata_orig WHERE segment IN ('Mens E-Mail', 'No E-Mail') )学習用テーブルのプレビュー
8select * from redshiftml_test.MineThatData limit 10;out
モデル構築
TRAIN データに割り振ったユーザーから (assign = 'TRAIN')、男性向けメールを送るを送ったユーザーを抽出し (w = 1) 、指標値を MSE とした回帰モデルを作成します。
- MSE (平均二乗誤差)
- 成果位地と予測値の差を事情し、平均値をとったもの
- 実際と予測値の誤差が大きいほどモデルの精度が悪いと判断
- 外れ値にも過剰適合(=過学習)してしまう可能性も
今回のケースだとこのようになります。
9CREATE MODEL redshiftml_test.uplist_treatment FROM ( SELECT recency, history, mens, womens, zip_code, newbie, channel, y FROM redshiftml_test.MineThatData WHERE w = 1 AND assign = 'TRAIN' ) TARGET y FUNCTION uplift_treatment IAM_ROLE '{iam-role-arn}' AUTO ON PROBLEM_TYPE REGRESSION OBJECTIVE 'MSE' SETTINGS ( S3_BUCKET '{s3 bucket name}' );以下クエリでモデルの概要を取得できます。
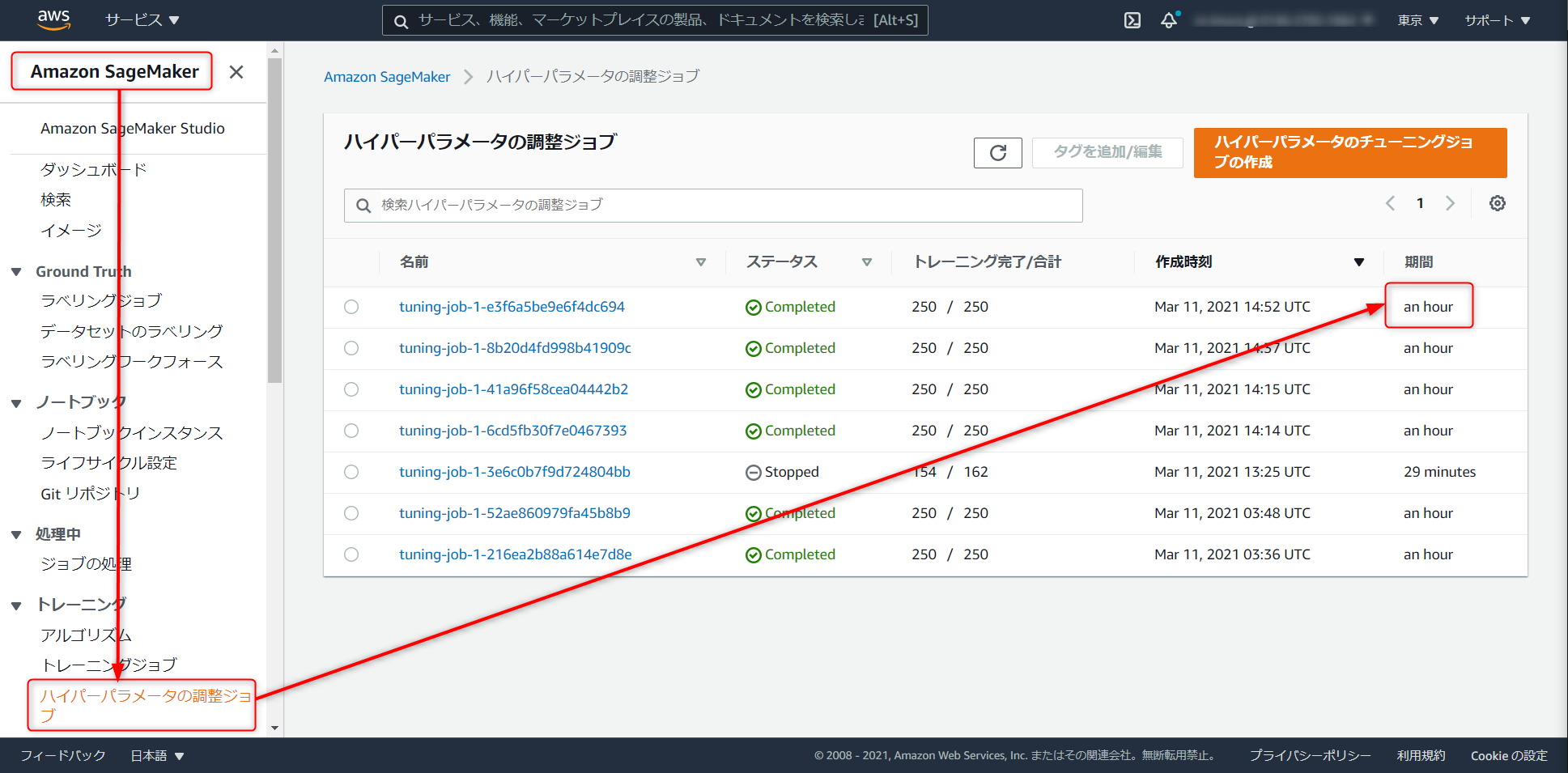
10SHOW MODEL redshiftml_test.uplist_treatment今回のデータセットではモデル構築の完了に一時間ほど要しました。
完了次第、SageMaker > ハイパーパラメータの調整ジョブ からジョブの実行にかかった時間などを見ることができます。未完了の状態で推論するクエリを投げてもモデルの準備ができていないと怒られます。のんびり待ちましょう。
推論実行
推論結果の参照を Redshift の別ユーザーが行う場合は、権限を付与します
11GRANT EXECUTE ON MODEL redshiftml_test.uplist_treatment TO awsuser;以下で Redshift 経由で推論結果を取得できます。uplift_treatment の数値が高いユーザーに対して優先的に販促キャンペーンを打てそうです。
12SELECT unique_id, redshiftml_test.uplift_treatment(RECENCY, HISTORY, MENS, WOMENS, ZIP_CODE, NEWBIE, CHANNEL) FROM ( SELECT * FROM redshiftml_test.MineThatData WHERE w = 1 AND assign = 'TEST' )out
CREATE MODEL 構文
AUTO_ML を利用する場合
上記では AUTOML 機能を用いました。 (
AUTO ON)
もっともシンプルに実装する場合の基本構文は以下の通りです。AUTO_ONの場合CREATE MODEL model_name FROM { table_name | ( select_query ) } TARGET column_name FUNCTION prediction_function_name IAM_ROLE 'iam_role_arn' SETTINGS ( S3_BUCKET 'bucket' )AUTO_ML を利用しない場合
トレーニングする際のモデルタイプやハイパーパラメータにあたりが付く場合は、AUTOML 昨日を利用せずに実行できます (
AUTO OFF)2021年3月15日現在、XGBoost のみサポート されています。CREATE MODEL 構文は以下の通り。
AUTO_OFFの場合CREATE MODEL model_name FROM { table_name | (select_statement ) } TARGET column_name FUNCTION function_name IAM_ROLE 'iam_role_arn' AUTO OFF MODEL_TYPE XGBOOST OBJECTIVE { 'reg:squarederror' | 'reg:squaredlogerror' | 'reg:logistic' | 'reg:pseudohubererror' | 'reg:tweedie' | 'binary:logistic' | 'binary:hinge' | 'multi:softmax' | 'rank:pairwise' | 'rank:ndcg' } HYPERPARAMETERS DEFAULT EXCEPT ( NUM_ROUND '10', ETA '0.2', NUM_CLASS '10', (, ...) )完全な CREATE MODEL 構文
完全な構文は以下のとおりです。
CREATE MODEL model_name FROM { table_name | ( select_statement ) } TARGET column_name FUNCTION function_name IAM_ROLE 'iam_role_arn' [ AUTO ON / OFF ] -- default is AUTO ON [ MODEL_TYPE { XGBOOST } ] -- not required for non AUTO OFF case, default is the list of all supported type -- required for AUTO OFF [ PROBLEM_TYPE ( REGRESSION | BINARY_CLASSIFICATION | MULTICLASS_CLASSIFICATION ) ] -- not supported when AUTO OFF [ OBJECTIVE ( 'MSE' | 'Accuracy' | 'F1' | 'F1_Macro' | 'AUC' | 'reg:squarederror' | 'reg:squaredlogerror'| 'reg:logistic'| 'reg:pseudohubererror' | 'reg:tweedie' | 'binary:logistic' | 'binary:hinge', 'multi:softmax' ) ] -- for AUTO ON: first 5 are valid -- for AUTO OFF: 6-13 are valid [ PREPROCESSORS 'string' ] -- required for AUTO OFF, when it has to be 'none' -- optional for AUTO ON [ HYPERPARAMETERS { DEFAULT | DEFAULT EXCEPT ( Key 'value' (,...) ) } ] -- support XGBoost hyperparameters, except OBJECTIVE -- required and only allowed for AUTO OFF -- default NUM_ROUND is 100 -- NUM_CLASS is required if objective is multi:softmax (only possible for AUTO OFF) SETTINGS ( S3_BUCKET 'bucket', | -- required KMS_KEY_ID 'kms_string', | -- optional S3_GARBAGE_COLLECT on / off, | -- optional, defualt is on. MAX_CELLS integer, | -- optional, default is 1,000,000 MAX_RUNTIME integer (, ...) -- optional, default is 5400 (1.5 hours) )詳細はこちらをどうぞ
備考
メトリクス
機械学習モデルの品質を測定するための指標として5種から選択できます。
データセットや予測対象の属性、予測結果の用途に応じてどのメトリクスが適当かどうか変わってきます。
- Accuracy
- 他項分類のデフォルトメトリクス
- MSE
- 回帰のデフォルトメトリクス
- 利用されるデータに外れ値が多い場合精度が低くなりやすいので注意
- F1
- 二項分類のデフォルト
- 適合率と再現率を等しく重視する
- 回帰でMSEだと精度が上がりにくい場合にも
- F1macro
- 他項分類で利用
- F1 スコアの他項分類版
- AUC
- 確率を返すロジスティクス回帰などの二項分類で利用
ハイパーパラメータ調整ジョブの実行時間
モデル学習がいつ終わるか把握したいものですが、SQL クライアントからはこの情報をパッシブに取得できません。以下迂回策です。
CloudWatch を利用
先述の通り、RedshiftML の学習データは指定の S3 バケットに保存され、学習完了時に削除されます。これをトリガーにして CloudWatch で通知を受け取るように設定します。
なお、S3_GARBAGE_COLLECT オプションを明示する際は ON にする必要があります (デフォルトはON)
MAX_RUNTIME を設定
トレーニングの最大時間を指定するオプションです。
デフォルト値は 90分 (5,400秒) で、データセットが小さい場合は指定値よりも早く完了します。
ジョブ完了通知ではありませんが、短時間でトライアンドエラーして進めたい時に使えそうです。参考クエリ
ちらほら使うクエリを乗せておきます。
0-- アクセス可能なモデル一覧取得 SHOW MODEL ALL; -- Redshift データベースからのモデルの削除 drop model redshiftml_test.uplist_treatment; -- テーブル名一覧取得 SELECT DISTINCT pg_table_def.tablename FROM pg_table_def WHERE schemaname = 'public' AND tablename NOT LIKE'%_pkey' ORDER BY tablename; -- インポートでエラーが出る場合にはこちらからログを参照 select query, substring(filename,22,25) as filename,line_number as line, substring(colname,0,12) as column, type, position as pos, substring(raw_line,0,30) as line_text, substring(raw_field_value,0,15) as field_text, substring(err_reason,0,45) as reason from stl_load_errors order by query desc limit 10;まとめ
SQL だけで機械学習モデルのデプロイ、Redshift 経由で推論結果の取得までできるのは便利ですね。
バックエンドでは SageMaker Autopilot が動作しているので、SageMaker のコンソールからモデルをデプロイすればエンドポイント経由での推論も可能です。
そうなればドリフト値を SageMaker Model Monitor でトラッキング出来るので MLOPS 環境の構築のハードルも下がるのではないでしょうか?
Redshift ユーザーは是非触ってみてください。参考リンク
モデリング部分のSQLスクリプトはこちらの記事からお借りしたものをベースにしています
Amazon Redshift ML の紹介記事です。
公式ドキュメント

- 投稿日:2021-03-15T14:52:25+09:00
Greengrass(V1)でストリームマネージャーを利用してみる
はじめに
今回、以下の公式ドキュメントの手順通り、Greengrass(V1)でストリームマネージャーを利用してみました。
参考:クラウドへのデータストリームのエクスポート (コンソール)AWSなお、デバイスは以前GreengrassをインストールしたJetson nanoを利用しています。
参考:Greengrass(V1)をクイックスタートでインストールしてみる1 事前準備
ストリームマネージャーの使用に必要な環境の設定と、今回のデータ送信先とするKinesis Data Streamsを準備します。
1-1 Javaのインストール
以下のコマンドでJetson nanoにJavaをインストールする
sudo apt install openjdk-8-jdk1-2 Python3.7のインストール
StreamManagerClient で AWS IoT Greengrass Core SDK for Python を使用するにはPython3.7以降が必要になります。
インストールされていない場合は事前にインストールします。sudo apt install python3.71-3 データの送信先(Kinesis Data Streams)の作成
1.Kinesisのマネジメントコンソールに移動し、「Kinesis Data Streams」にチェックして「データストリームを作成」をクリック
2.以下の通り作成する
- データストリーム名:MyKinesisStream
- 開いているシャードの数:1
3.正常に作成されたことを確認する
4.ARNを控えておく1-4 IAMロールの設定
GreengrassがKinesisにデータを書き込めるよう権限を追加します。
1.IoT Coreのマネジメントコンソールで左のメニューから Greengrass > クラシック(V1) > グループ > 対象のグループ の順にクリック
2.設定 で現在のグループのロールを確認する
3.IAMのマネージメントコンソールに移動し、左のメニューからポリシーをクリック
4.「ポリシーの作成」をクリックする
5.JSONタブをクリックし、以下の通りポリシーを作成する
※Resource箇所はKinesis作成時に控えておいたARNに置きかえる
※ポリシーの名前は任意の名前とする{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "kinesis:PutRecords" ], "Resource": [ "arn:aws:kinesis:リージョン:account-id:stream/MyKinesisStream" ] } ] }6.IAMのマネージメントコンソールで左のメニューから ロール をクリック
7.Greengrassグループに現在アタッチされているロールに先ほど作成たポリシーをアタッチする
8.IoT CoreのマネージメントコンソールでGreengrassグループの設定画面に追加したポリシーが表示されていることを確認する2 Lambda関数の作成(ローカル)
ローカルでストリームマネージャー実行用のLambda関数を作成します。
2-1 greengrasssdkの準備
ストリームマネージャーをLambda関数で利用するためにgreengrasssdk for Pythonを利用します。
利用にあたっては、公式ドキュメントの記載通り、デプロイするLambda関数のパッケージに含めるSDKの用意が必要です。Greengrass Lambda 関数で SDK を使用するには、AWS Lambda にアップロードする Lambda 関数デプロイパッケージに SDK を含めます。
出典:SDKs 関数のGreengrass Lambda1.「AWS IoT Greengrass Core SDK for Python」のGitHubレポジトリにアクセスし、Code > Download ZIP の順にクリック
Github:AWS IoT Greengrass Core SDK for Python
2.ダウンロードした「aws-greengrass-core-sdk-python-master.zip」を解凍する
3.SDKの依存関係をインストールする#requirements.txtがあるディレクトリに移動 cd ***/aws-greengrass-core-sdk-python-master #依存関係のインストール pip install --target . -r requirements.txt※解凍してできたフォルダに「cbor2」、「cbor2-4.12.dist-info」が追加された
2-2 関数の作成(ローカル)
1.以下の通り「transfer_stream.py」を作成する
※今回は公式ドキュメント通りに作成transfer_stream.pyimport asyncio import logging import random import time from greengrasssdk.stream_manager import ( ExportDefinition, KinesisConfig, MessageStreamDefinition, ReadMessagesOptions, ResourceNotFoundException, StrategyOnFull, StreamManagerClient, ) # This example creates a local stream named "SomeStream". # It starts writing data into that stream and then stream manager automatically exports # the data to a customer-created Kinesis data stream named "MyKinesisStream". # This example runs forever until the program is stopped. # The size of the local stream on disk will not exceed the default (which is 256 MB). # Any data appended after the stream reaches the size limit continues to be appended, and # stream manager deletes the oldest data until the total stream size is back under 256 MB. # The Kinesis data stream in the cloud has no such bound, so all the data from this script is # uploaded to Kinesis and you will be charged for that usage. def main(logger): try: stream_name = "SomeStream" kinesis_stream_name = "MyKinesisStream" # Create a client for the StreamManager client = StreamManagerClient() # Try deleting the stream (if it exists) so that we have a fresh start try: client.delete_message_stream(stream_name=stream_name) except ResourceNotFoundException: pass exports = ExportDefinition( kinesis=[KinesisConfig(identifier="KinesisExport" + stream_name, kinesis_stream_name=kinesis_stream_name)] ) client.create_message_stream( MessageStreamDefinition( name=stream_name, strategy_on_full=StrategyOnFull.OverwriteOldestData, export_definition=exports ) ) # Append two messages and print their sequence numbers logger.info( "Successfully appended message to stream with sequence number %d", client.append_message(stream_name, "ABCDEFGHIJKLMNO".encode("utf-8")), ) logger.info( "Successfully appended message to stream with sequence number %d", client.append_message(stream_name, "PQRSTUVWXYZ".encode("utf-8")), ) # Try reading the two messages we just appended and print them out logger.info( "Successfully read 2 messages: %s", client.read_messages(stream_name, ReadMessagesOptions(min_message_count=2, read_timeout_millis=1000)), ) logger.info("Now going to start writing random integers between 0 and 1000 to the stream") # Now start putting in random data between 0 and 1000 to emulate device sensor input while True: logger.debug("Appending new random integer to stream") client.append_message(stream_name, random.randint(0, 1000).to_bytes(length=4, signed=True, byteorder="big")) time.sleep(1) except asyncio.TimeoutError: logger.exception("Timed out while executing") except Exception: logger.exception("Exception while running") def function_handler(event, context): return logging.basicConfig(level=logging.INFO) # Start up this sample code main(logger=logging.getLogger())2.以下4点を選択して圧縮する
※公式ドキュメントに則って圧縮してできたzipファイルは「transfer_stream_python.zip」とする
- transfer_stream.py
- greengrasssdk
- cbor2
- cbor2-4.12.dist-info
2-3 Lambda関数の作成(クラウド)
1.Lambdaのマネジメントコンソールで以下の通り関数を作成する
- 一から作成
- 関数名:TransferStream ※公式ドキュメントにあわせた
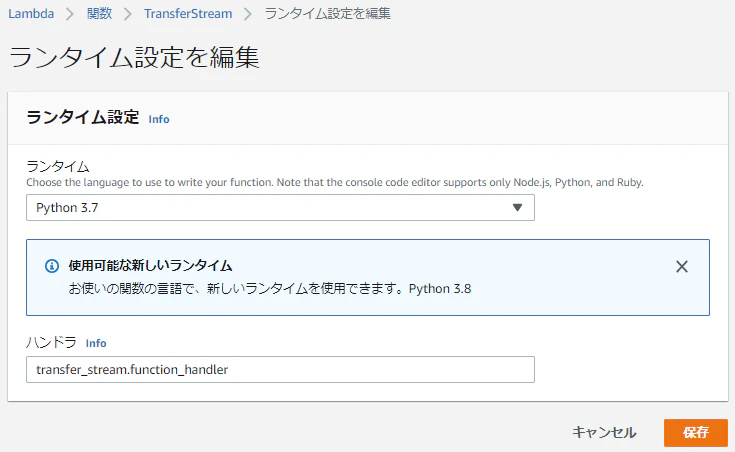
- ランタイム:Python 3.7
2.関数が作成されたら、コードタブで アップロード元 > zipファイル の順にクリック
3.ファイル選択ウィンドウで先ほど作成したzipファイル「transfer_stream_python.zip」を選択して「保存」をクリック
4.コードタブでランタイム設定の「編集」をクリック
5.ハンドラを「transfer_stream.function_handler」に修正して「保存」をクリック
※独自でファイル名、関数名をつけている際は「[プログラムファイル名].[関数名]」とする
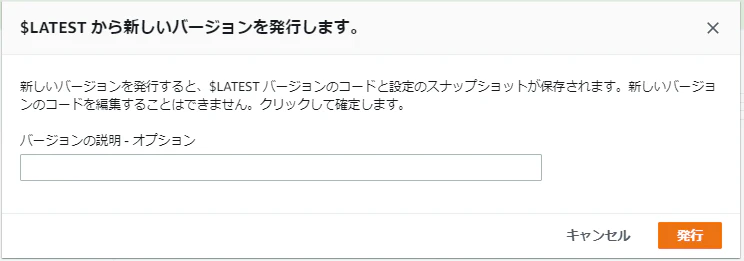
6.関数画面で アクション > 新しいバージョンを発行 をクリックし、「発行」をクリックする
7.アクション > エイリアスを作成 をクリック
8.以下の通りエイリアス設定を入力し、「保存」をクリックする
- 名前:GG_TransferStream ※公式ドキュメントにあわせた
- バージョン:1
3 Greengrassグループのデプロイ
作成したLambda関数をGreengrassグループに紐づけJetson nanoにデプロイします。
3-1 Lambda関数をグループに追加する
1.IoT Coreのマネジメントコンソールで左のメニューから Greengrass > クラシック(V1) > グループ > 対象のグループ の順にクリック
2.Lambda をクリック > 「Lambdaの追加」をクリック
3.GreengrassグループへのLambdaの追加画面で「既存のLambdaの使用」をクリック
4.作成したLambda関数「transfer_stream」を選択して「次へ」をクリック
5.作成したエイリアス「GG_TransferStream」を選択して「完了」をクリック
6.グループのLambda画面の「TransferStream」上で ... > 設定の編集 の順にクリック
7.以下の通り設定を変更して「更新」をクリック
- メモリ制限:32MB
- Lambdaのライフサイクル:存続期間が長く無制限に稼働する関数にする
3-2 ストリームマネージャーの有効化
ストリームマネージャーを利用するため、コンソール画面でストリームマネージャーを有効化します。
1.IoT Coreのマネジメントコンソールで左のメニューから Greengrass > クラシック(V1) > グループ > 対象のグループ の順にクリック
2.設定 をクリックし「ストリームマネージャー」が有効になっているか確認する
※以降は「無効」だった場合の手順
3.編集 をクリックし、設定画面で「有効化」を選択して「保存」をクリック
4.グループの設定画面で「ストリームマネージャー」が有効になっていることを確認する3-3 グループのデプロイ
1.Jetson nano上でGreengrassが起動していることを確認する
※起動していないとデプロイできない#Greengrassが起動しているか確認 ps aux | grep -E "greengrass.*daemon" #起動していない場合は以下のコマンドで起動 sudo /greengrass/ggc/core/greengrassd start2.IoT Coreのマネジメントコンソールで 左のメニューから Greengrass > クラシック(V1) > グループ の順にクリック
3.一覧で作成したグループ名をクリックして詳細画面に遷移し、アクション > デプロイの順にクリック
4.「正常に完了しました」と表示されることを確認する4 動作検証
Kinesis Data StreamsにJetson nanoからデータが送られることを確認します。
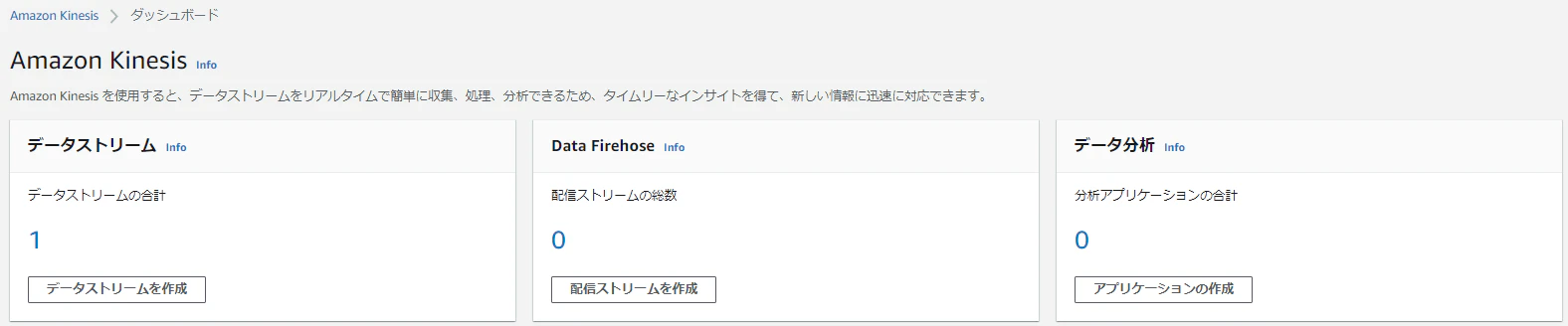
1.Kinesisのマネジメントコンソール > データストリームの数字 の順にクリック
※以下画像の場合は「1」がリンクになっている
2.作成したストリーム「MyKinesisStream」をクリック
3.成功するとモニタリングタブの「Put レコード」などに値が表示される
※デプロイ後、表示されるまでに数分ほどかかった
5 後片付け
以下を削除します。
- デプロイした関数「TransferStream」
- Kinesis Data Streamsで作成したデータストリーム「MyKinesisStream」
5-1 Lambda関数「TransferStream」の削除
1.IoT Coreのマネジメントコンソールで 左のメニューから Greengrass > クラシック(V1) > グループ の順にクリック
2.一覧で作成したグループ名をクリックして詳細画面に遷移し、Lambda をクリック
3.「TransferStream」上で ... > 関数の削除 の順にクリック
4.グループをデプロイする
※Lambdaには関数が残っているので、不要な場合はそちらも削除する5-2 データストリーム「MyKinesisStream」の削除
1.Kinesisのマネジメントコンソール > データストリームの数字 の順にクリック
2.作成した「MyKinesisStream」を選択して、アクション > 削除 の順にクリック6 おわりに
今回は公式ドキュメント通りに実施し、ストリームマネージャーを使えるところまでざっくりと確認できました。
以降、これをベースとしてデータのフィルタリングや集約、他のAWSサービスへのエクスポートなどを行おうと思います。7 参考文献(文中で登場していないもの)












- 投稿日:2021-03-15T14:44:00+09:00
【AWS】 Amazon CloudFront簡単まとめ(CDNの説明付き)
Amazon CloudFront
AWSのサービスの一つで、静的、動的なウェブコンテンツ(データ、動画、アプリケーションなど)の配信を高速化する、安全性の高さが魅力のサービスです。
有名なサービスですと、Amazon primeやHuluにも使用されています。
メリット
● 安全性が高い
HTTPS接続などフィールドレベルの暗号化ができ、機密データのセキュリティ強化ができます。
● コストの削減
無料枠が設けられているほか、利用した分の料金のみが課せられるため余分な費用はかからない。
つまり、最低料金や一定額の料金のお支払いがありません。
● 可用性の向上
DDoS対策やトラフィックの分散という点からサービスの可用性を向上させています。
※
DDoS(Distributed Denial of Service)
特定のネットワークやWebサービスを、意図的に利用できないようにする攻撃行為です。※
トラフィック
通信回線やネットワーク上で送受信される信号、データ、その量や密度のことを指します。※
可用性
一定時間のうち、システムを稼働可能な割合(%)を意味する「稼働率」で表現されます。
● 高速な配信(低レイテンシー) / サーバの負荷軽減
CDNが組み込まれているため、ウェブコンテンツの高速な配信やサーバーの負荷軽減に繋がります。
エッジサーバを活用することで、HTTPリクエスト時に毎回サイトの作成元まで辿る必要が無くなるため、低レイテンシーでの素早いレスポンスができます。
この詳細については、次の題目で取り上げます。※
レイテンシー
要求を出してから実際にデータが送られてくるまでに生じる、通信の遅延時間
CDN(Content Delivery Network)
ファイルをダウンロード配信するための技術です。
アクセス元から距離的に一番近い場所にあるサーバーを自動で選択し、コンテンツをダウンロードさせるということです。(用語)
オリジン(オリジンサーバ)
元のデータが入っているサーバを指します。
エッジ(エッジサーバ)
データを代わりに配信してくれるサーバを指します。
※ キャッシュサーバと呼ぶこともあるそうです。
キャッシュ
(下図のストレージ部分に)Webサイトのコンテンツを保存することを指します。
それでは、このCDNがどうしてメリットに繋がるのか考えてみます。
例えば、あるサイトを全世界に向けて公開していたとき、作成元(オリジン)が日本であるとします。この時同じ日本国内から閲覧されるのと、海外から閲覧されるのでは物理的な距離の違いから、通信によるレイテンシーが異なります。つまり、同じ日本国内から閲覧をするよりも、距離の離れた海外から閲覧をする方がレイテンシーが高く(遅延時間が長く)なります。
これを解決するのが、CDNの仕組みです。
1つ目のメリットは、
レイテンシーの軽減です。
閲覧者(デバイス)とサイト(ネットワーク)の間にエッジサーバというものを設けます。
エッジには、初回は何もデータが入っていない状態です。しかし、初回にオリジンからデータを取得した際に、そのデータがエッジに保存されるようになっており、2回目以降は毎回オリジンからデータを取得する必要がなくなります。ただし、エッジ(ストレージ)にデータがあれば、その中から取得しますが、2回目以降の通信でも保存されていないデータであれば、オリジンから取得します。つまり、遠く離れたオリジンからデータを取得するよりも、世界各地にある距離の近いエッジ(ストレージ)からデータを取得するので、レイテンシーの軽減に繋がるという訳です。
2つ目のメリットは、負荷分散です。
上記での説明内容と重複しますが、サイトの閲覧者全員がオリジンからデータを取得していた場合、アクセスが集中してしまいます。しかし、それぞれの閲覧者が一番近いエッジを活用することにより、オリジンへのアクセス集中を防ぐことができるため、システムの負荷分散へと繋がります。
結果的に、安定したサービスを供給することが可能となります。
終わり
CloudFrontについてのまとめを書くつもりが、CDNについての説明が長くなってしまいました...
普段利用しているネットの裏側が少し理解できて、個人的には興味が深まりました!
今回の記事は以上となります。
最後までご覧いただきまして、ありがとうございます。
また、もし内容に誤りなどがございましたら、ご指摘いただけますと幸いです。
![[CDN.png]](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F942338%2Fe1298c9f-87cc-0b07-ea57-36e031d2fa50.png?ixlib=rb-1.2.2&auto=format&gif-q=60&q=75&s=21dc736857866953fd4458ec4879796d)
- 投稿日:2021-03-15T13:04:51+09:00
【AWS】GPUインスタンスを利用するためには
背景
AWS EC2インスタンスを起動するのは、チュートリアルや当サイトの記事、ブログ等々で簡単に行なえます。
しかし、GPUインスタンスクラスはデフォルトでは起動できないようになっており、そのために躓きました。
その際の対処について、ここに記しておきます。先人たちの知恵をお借りするなどして解決できたことを、この場をお借りして感謝するとともに、大変恐縮ですが自分のメモとして、こちらへまとめておきます。
環境
(本番)
- AWS EC2 (Amazon Linux 2)
- Putty 0.74- AWS EC2 (Amazon Linux 2)1.現象
GPUインスタンス(g4dn.xlarge など)が起動できない。
G4dn インスタンスは、機械学習推論やグラフィックを大量に使用するワークロードを高速化するために設計されています。
2.原因
マネジメントコンソールの EC2 において、画面左のサイドメニュー[制限]で確認できる「All G instances のオンデマンドを実行中」の "現在の制限" 欄が 0 vCPU となっているため。
3.対処
この "現在の制限" を 0→n へ変更する申請を行ないます。
画面左のサイドメニューより、[制限]をクリックします。
画面上部の検索窓に「G」と入力し検索すると、以下のように対象がある程度絞られます。
このうち、「All G instances のオンデマンドを実行中」を見付けて、ラジオボタンをONします。
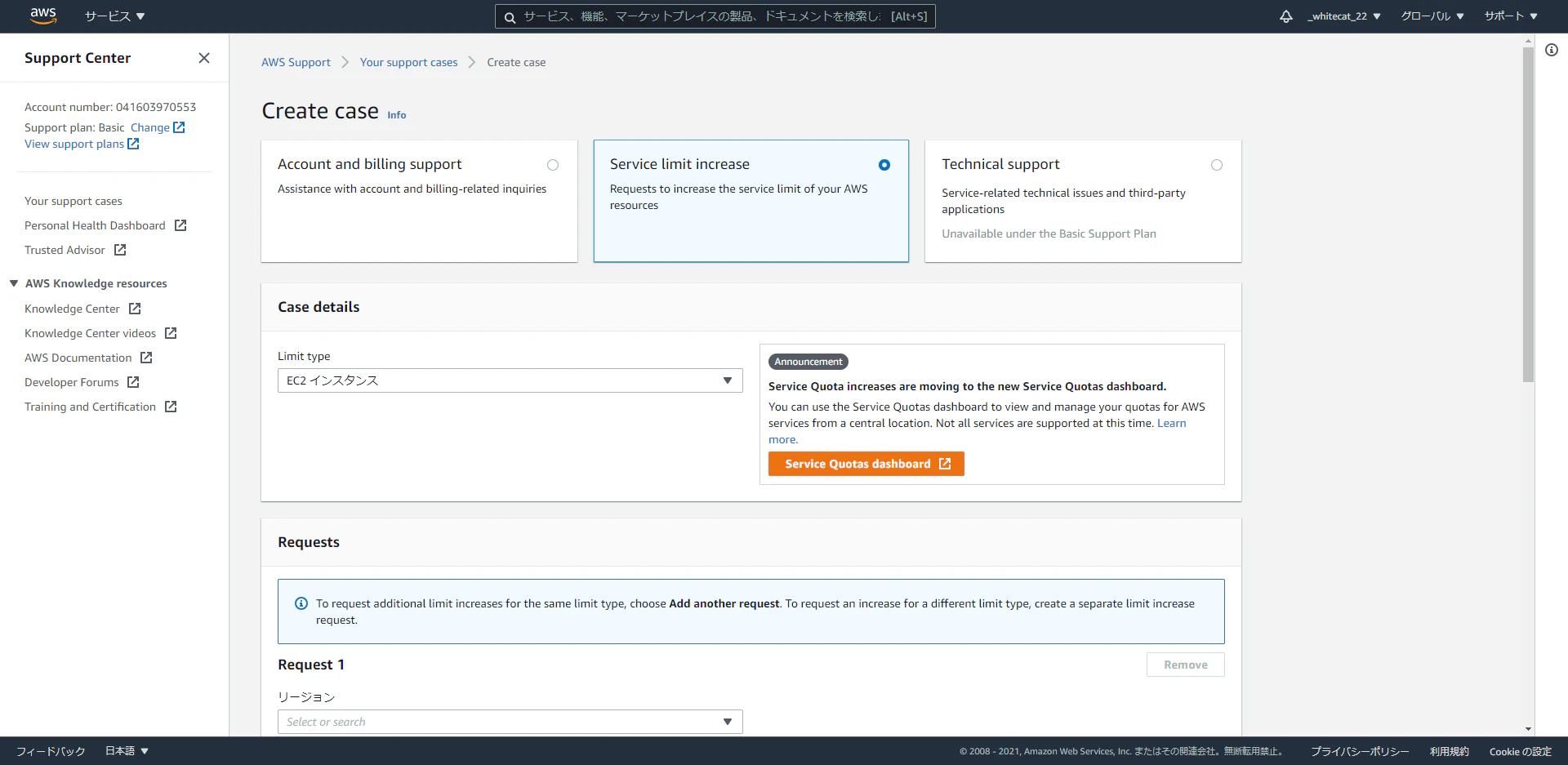
画面右上の[制限緩和のリクエスト]ボタンをクリックします。画面が遷移し、英語の画面が表示されます。
画面上部、中央の「Service limit inclease」のラジオボタンがONとなっていること、Case Detail欄で「EC2インスタンス」が選択されていることを確認し、画面下部の「Requests」欄へスクロールします。
※このとき、画面右上のリージョン名は「グローバル」となっていますが、間違いではありません。(「グローバル」から変更できません。)
requests欄は、以下の設定とします。
リージョン名: プルダウンから「アジアパシフィック(東京)」を選択
プライマリインスタンスタイプ: プルダウンから「All G instances」(GPUを利用できるインスタンスタイプ)を選択します。
New limit value: 任意 ※当記事での説明では「8」とします。
画面最下部までスクロールし、[Submit]ボタンをクリックします。
※「Case description」欄は未記入で問題ありません。
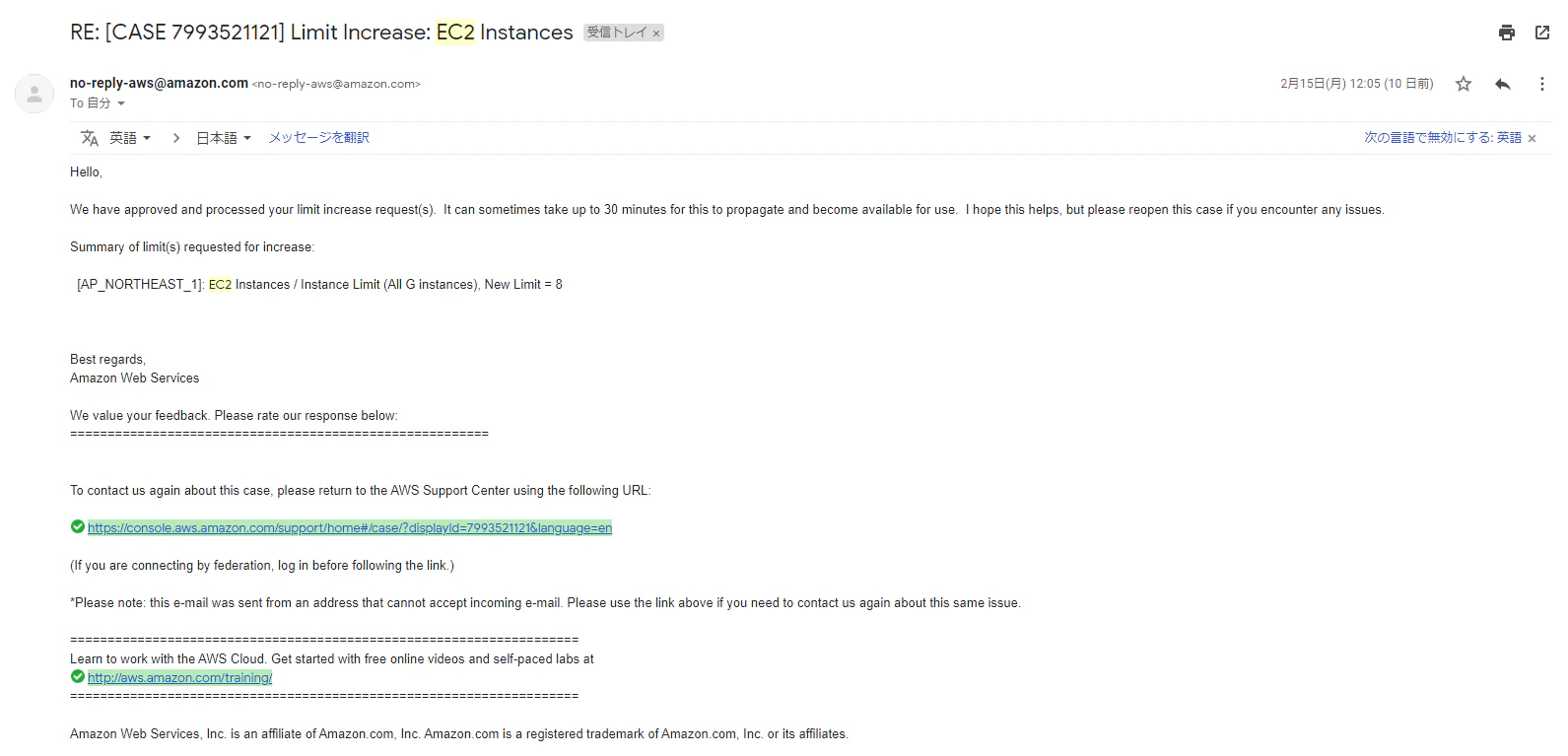
AWS側で受け付けたことを示すメールが届きます。
・1通目:
『内部レビューして承認するまで待ってて~』
というような内容。
・2通目:
『内部レビューして承認されたから、制限解除したよ~』
『30分ほどで使えるようになるからねぇ~』
というような内容。私のケースでは、この2通のメールの間は約10分でした!
そして、使えるようになるまで30分とありますため、おやつ?&飲み物☕で、しばし休憩しましょう。
あとは、いつも通りの手順で、[インスタンスの起動]からインスタンスを起動するだけです。途中で、"Gクラス" を選択することをお忘れなく。
(編集後記)
どのクラスのインスタンスも即座に起動できるものと思っていましたが、制限がかかっているとは露知らず。
この制限に気付くまでに思わぬ時間を費やしてしまいました。制限緩和の申請から実際に利用可能(インスタンス起動可能)となるまでは、申請のタイミングや申請の混み具体で多少変動するかと思います。
利用したいときにすぐに利用可能とならない場合が考えられますので、利用が想定された場合はお早めに申請しておくことをオススメいたします。皆様のご参考になれば幸いです。



- 投稿日:2021-03-15T10:17:51+09:00
ecsクラスタにあるコンテナたちのヘルスチェックを AWS Lambda(boto3)で実装してみた
概要
ECSクラスタ内でバッチ処理を行うコンテナが常駐しているのですが、
ここ最近Fargateのメモリを食い潰してて、よろしくない挙動をしていました。問題はつくりにあったのですが、それより問題だったのはヘルスチェックが実装されていなかったこと。
そこで既存のコンテナたちを変更することなく、
boto3を利用したヘルスチェックを実装することにしました。図にしてみると
元々内部でログ検知の仕組みがLambdaで動いているので、アラート自体はそちらに任せることにしました。
ヘルスチェックのログを別関数でチェックしてもらうイメージ。やったこと
とりあえずLambdaだけで構築なので、Serverless Frameworkでやりました。
ただ一点厄介事がありました・・(詳細は後述lambda実装
# coding: UTF-8 import datetime import time import boto3 import os from src.log import get_logger logger = get_logger() def lambda_handler(event, context): logger.info("START") client = boto3.client('ecs') clusterName = "hoge-cluster" # ECSサービス一覧を取得 serviceList = client.list_services( cluster=clusterName, ) # ECSサービス詳細取得 describeService = client.describe_services( cluster=clusterName, services=serviceList["serviceArns"], ) # ログ取得 logGroupName = "/ecs/hoge-service" queryId = get_log_queryId(logGroupName) logResults = get_log_insights(queryId) for service in describeService['services']: # タスク定義取得 task = client.describe_task_definition( taskDefinition=service["taskDefinition"] ) containerDefinition = task['taskDefinition']['containerDefinitions'][0] taskName = containerDefinition['name'] # 対象タスクのログが取得できない場合エラー if (logResults is not None): if (taskName in logResults["results"]): logger.error(f"{taskName}タスクとまってます") else: logger.info(f"{taskName}タスク動いてます") logger.info("END") def get_log_queryId(logGroupName): """ cwl insightsで取得するログのQueryIdを返す 直近5分間のログを検索範囲とする """ # logstream 取得 five_minutes_ago = datetime.datetime.now() - datetime.timedelta(minutes=5) startTime = five_minutes_ago.replace(second=0, microsecond=0) endTime = startTime + \ datetime.timedelta(minutes=5) - datetime.timedelta(milliseconds=1) # cwl insights client = boto3.client('logs') start_query_res = client.start_query( logGroupName=logGroupName, startTime=int(startTime.timestamp()), endTime=int(endTime.timestamp()), queryString=""" fields @ logStream | parse @ logStream '*/*/*' as a, task, b | stats count() as logcount by task """, limit=20 ) # cwl insightsでQueryId発行 queryId = start_query_res['queryId'] logger.info(f"queryIdは{queryId}") return queryId def get_log_insights(queryId): """ QueryIdを利用してcwl insightsを取得 """ client = boto3.client('logs') response = None count = 1 while response is None or response['status'] == 'Running': # 10回試して取得出来ない場合は処理終了 if (count > 10): break print('Waiting for query to complete ...') time.sleep(1) response = client.get_query_results( queryId=queryId ) count += 1 return responseserverlessのプラグインが使えない・・
slsで速攻で実装だ〜と思ったのですが、つまづきました・・・
サブスクリプションフィルタの設定はpluginがあったのでいけると思ったんですが、うまくいかず。
見た所メンテがされておらず、色々試したが断念・・・
LambdaだけでCfn用意するのは微妙だったので今回は見送り。サブスクリプションフィルタの設定は手動で実行としました。。
デプロイ
GitHub Actions上で
sls deploy実行させています
最近はghでリリースする事を覚えて楽しんでます?gh release create 202103xx.1 -t "healthcheck release" -n "gogo"
所感:CDK書こうと思った
TypeScript書いてみたいだけです。
こんな感じでサブスクリプションフィルタの設定出来るので↓//subscripition filter設定 fn.logGroup.addSubscriptionFilter("hogeSubscriptionFilter",{ destination: new logs_destinations.LambdaDestination(destFn), filterPattern: logs.FilterPattern.allTerms("?WARNING", "?ERROR"), })以下参照↓
https://docs.aws.amazon.com/cdk/api/latest/docs/aws-logs-readme.html#subscriptions-and-destinations便利〜〜〜
参考ドキュメント
https://qiita.com/chii-08/items/e20651e7912596e9a556
https://docs.aws.amazon.com/cdk/api/latest/docs/aws-logs-readme.html#subscriptions-and-destinations
https://cli.github.com/

- 投稿日:2021-03-15T09:04:25+09:00
terraformを使ってみる
terraformを使ってみる
自社でterraformの簡単な使用方法について説明する機会があるので準備するにあたってのメモ
AWSアカウントの取得
無料枠でやる。普通にアカウントを作成する
初回ログインの注意点
ログインは
ルートユーザーの E メールを使用したサインインから入る予算の設定
AWS Billing→Budgetsを選んで予算を設定しておくといいかも?
やらかしてEC2作りっぱなしにして延々使用料を払いたくないなら10ドルくらいの設定を入れておくといいかも。regionの設定
東京(ap-northeast-1)に変更しておく。画面右上のuser名の右から変更可能。
忘れてるとオハイオとかにリソース作ることになる。別にそれ自体に問題は無いが別のregionのリソースは見えないのでどこに作るにしても自分がどこのregionにリソースを作ったのか忘れないようにする。その一環として東京regionに変更してリソースを作成する。リソースを作成する
下準備
terraformを叩くためのEC2を立てる。
VPCはdefaultで作成済みの所にたてる
subnetも同様
INGも同様EC2の作成
Amazon Linux 2
t2.microセキュリティグループはとりあえず自宅の回線IPから入れるようにしておけばおっけー
EIPの割り当て
EIPをamazonからもらって、作成したEC2に割り当てます。
割り当てないで借りっぱなしにするとコストがかかるので注意ec2の初期設定
ユーザーを作る
PW設定する
sudo権限持たせるやりたい人は/etc/ssh/sshd_configのPasswordAuthenticationをyesにしておくとPW認証で入れる
俺はやらない
IAMユーザーの作成
ここまでは管理アカウントでやってたが、terraformで何かするならIAMで権限を付けたユーザーが必要になる。
IAMで自分のアカウントを作成し、初回ログインまで行う事。
権限はAdministratorAccessがついていれば困ることは無い。ユーザーを作成したら、認証情報タブからアクセスキーを生成する。
ここで生成するアクセスキーとシークレットアクセスキーがterraformに必要。シークレットアクセスキーは生成時しか確認できないためメモすること。terraformの導入
wget unzipも必要だがこれは標準で入っている。無ければyumで入れる。
terraform本体はzipで取得する
$ wget https://releases.hashicorp.com/terraform/0.13.0/terraform_0.13.0_linux_amd64.zip
0.13.0/terraform_0.13.0_linux_amd64.zipの部分は適宜変更
$ sudo unzip ./terraform_0.13.0_linux_amd64.zip -d /usr/local/bin/
$ terraform -vで動作確認[yamanashi@ip-172-31-46-224 ~]$ terraform -v Your version of Terraform is out of date! The latest version is 0.13.5. You can update by downloading from https://www.terraform.io/downloads.html Terraform v0.13.0おっけー
terraform
作業ディレクトリを作成する
[yamanashi@ip-172-31-46-224 test01]$ pwd /home/yamanashi/terraform/test01provider.tf
AWSのregionとか使うアカウント等の情報を書き込む。
[yamanashi@ip-172-31-46-224 test01]$ cat provider.tf provider "aws" { version = "~> 2.0" region = "ap-northeast-1" access_key = "AKIXXXXXXXXXXXXXXXX" secret_key = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" }access_key/secret_keyは作成したIAMユーザーで生成したものを書き込む
init
terraform initは初回に実行するコマンド。必要なコンポーネントを自動で取得してくれる
provider.tfがしっかりかかれていればaws関連モジュールを取得してくれる。[yamanashi@ip-172-31-46-224 test01]$ terraform init Initializing the backend... Initializing provider plugins... - Finding hashicorp/aws versions matching "~> 2.0"... - Installing hashicorp/aws v2.70.0... - Installed hashicorp/aws v2.70.0 (signed by HashiCorp) Terraform has been successfully initialized! You may now begin working with Terraform. Try running "terraform plan" to see any changes that are required for your infrastructure. All Terraform commands should now work. If you ever set or change modules or backend configuration for Terraform, rerun this command to reinitialize your working directory. If you forget, other commands will detect it and remind you to do so if necessary.vpc.tf
[yamanashi@ip-172-31-46-224 test01]$ cat vpc.tf resource "aws_vpc" "test-vpc" { cidr_block = "10.40.0.0/16" instance_tenancy = "default" enable_dns_support = true enable_dns_hostnames = true tags = { Name = "test-main" } } resource "aws_subnet" "test-subnet" { vpc_id = aws_vpc.test-vpc.id cidr_block = "10.40.0.0/24" availability_zone = "ap-northeast-1a" #map_public_ip_on_launch = true tags = { Name = "test-subnet" } }ec2.tf
[yamanashi@ip-172-31-46-224 test01]$ cat ec2.tf resource "aws_instance" "terraform-ec2-01" { ami = "ami-034968955444c1fd9" availability_zone = "ap-northeast-1a" instance_type = "t2.micro" key_name = "test-key" subnet_id = aws_subnet.test-subnet.id #vpc_security_group_ids = ["sg-62486b04"] associate_public_ip_address = false private_ip = "10.40.0.74" root_block_device { volume_type = "gp2" volume_size = 8 delete_on_termination = true } tags = { "Name" = "terraform-ec2-01" } } resource "aws_instance" "terraform-ec2-02" { ami = "ami-034968955444c1fd9" availability_zone = "ap-northeast-1a" instance_type = "t2.micro" key_name = "test-key" subnet_id = "subnet-953190dd" associate_public_ip_address = false private_ip = "172.31.46.10" root_block_device { volume_type = "gp2" volume_size = 8 delete_on_termination = true } tags = { "Name" = "terraform-ec2-02" } }terraform-ec2-01はterraformコードで作ったvpcに建てる
terraform-ec2-02はデフォルトvpcに立てて、sshで入れるようにした。
ssh -i ./test-key.pem ec2-user@172.31.46.10
VPCの作成
名前なんでも良し
CIDRブロックは10.*.0.0/16subnetの作成
VPCにさっき作成したVPCを指定する
CIDRブロックは10.*.0.0/24IGWの作成
ssh接続するために作成する。
作成後、アクションから作成したVPCにアタッチする
- 投稿日:2021-03-15T02:52:19+09:00
既存のALBを削除せずにALB Ingress ControllerからALB LoadBalancer Controllerに移行する
はじめに
ALB LoadBalancer ControllerはKubernetesからELBを操作するためのものです。
元々はALB Ingress Controllerという名称で、複数NamespaceのIngressリソースを1つのALBで対応することができませんでした。これは以前記事に書いた通り、NGINX Ingress ControllerをALBとアプリケーションの間に挟むことで解決することができました。
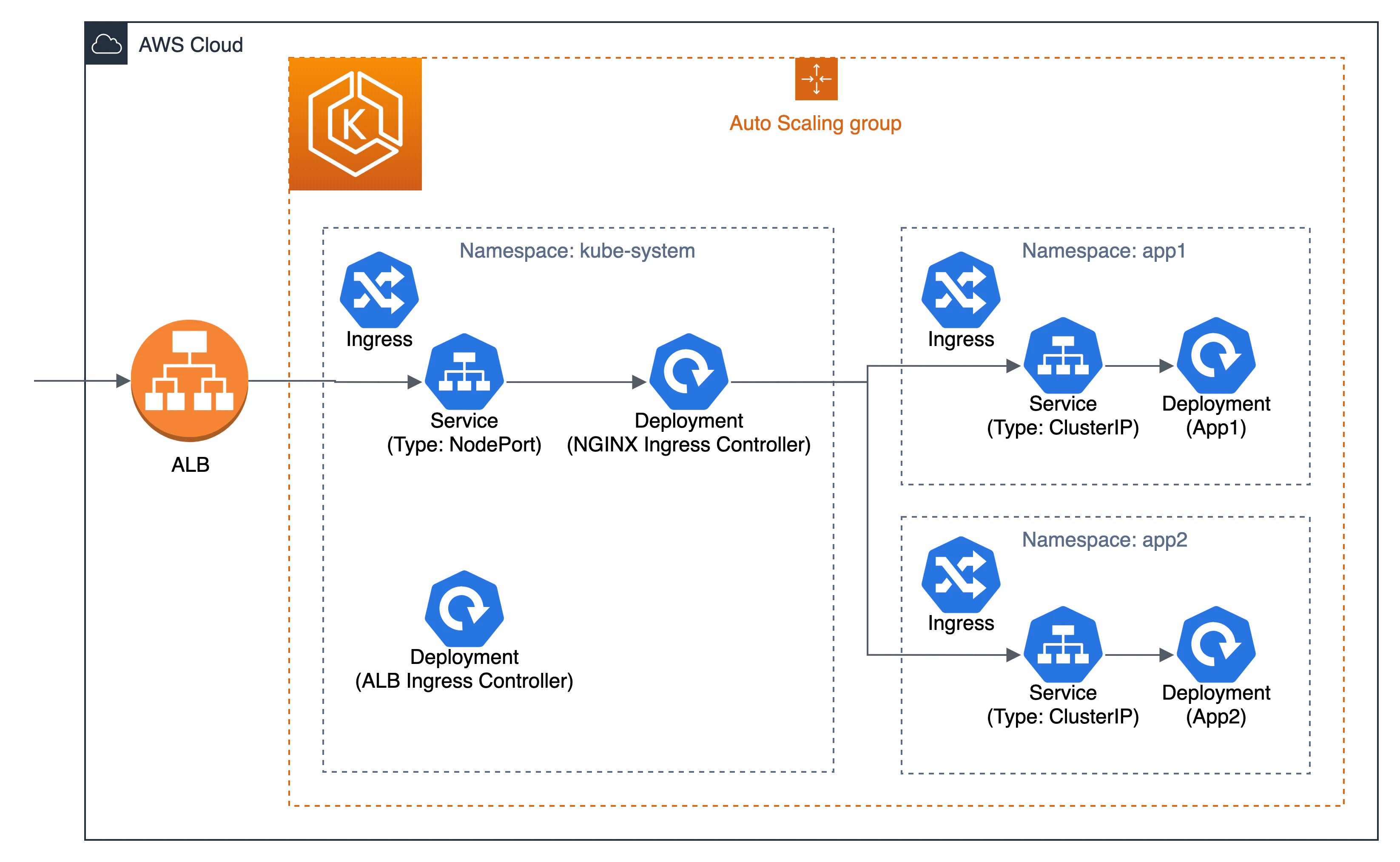
ALB Ingress ControllerとNGINX Ingress Controllerを使用するときの構成は下図になります。
一方、ALB LoadBalancer Controllerでは下図のようにIngressリソースなしで1つのALBで複数Namespace上のアプリケーションにルーティングさせることができます。
今回は既存のALBを削除せずにALB Ingress Controller + NGINX Ingress Controllerの構成からALB LoadBalancer Controllerの構成に移行する手順を説明します。
事前準備
ALB Ingress ControllerとNGINX Ingress ControllerをHelmでデプロイします。IAM Role for ServiceAccountを使用しています。
aws-alb-ingress-controller-values.yamlclusterName: <CLUSTER_NAME> awsRegion: ap-northeast-1 awsVpcID: <VPC_ID> rbac: serviceAccountAnnotations: eks.amazonaws.com/role-arn: <IAM_ROLE_ARN>nginx-ingress-values.yamlcontroller: service: type: NodePort$ helm install aws-alb-ingress-controller \ incubator/aws-alb-ingress-controller \ -f aws-alb-ingress-controller-values.yaml \ --version 0.1.11 \ -n kube-system $ helm install nginx-ingress \ stable/nginx-ingress \ -f nginx-ingress-values.yaml \ --version 1.39.0 \ -n kube-systemALB Ingress Controllerで使用するIAM RoleにアタッチするIAM Policyは以下になります。
後述するALB LoadBalancer Controllerでも同じIAM Roleを使用します。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "acm:DescribeCertificate", "acm:ListCertificates", "acm:GetCertificate" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "ec2:AuthorizeSecurityGroupIngress", "ec2:CreateSecurityGroup", "ec2:CreateTags", "ec2:DeleteTags", "ec2:DeleteSecurityGroup", "ec2:DescribeAccountAttributes", "ec2:DescribeAddresses", "ec2:DescribeInstances", "ec2:DescribeInstanceStatus", "ec2:DescribeInternetGateways", "ec2:DescribeNetworkInterfaces", "ec2:DescribeSecurityGroups", "ec2:DescribeSubnets", "ec2:DescribeTags", "ec2:DescribeVpcs", "ec2:ModifyInstanceAttribute", "ec2:ModifyNetworkInterfaceAttribute", "ec2:RevokeSecurityGroupIngress" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "elasticloadbalancing:AddListenerCertificates", "elasticloadbalancing:AddTags", "elasticloadbalancing:CreateListener", "elasticloadbalancing:CreateLoadBalancer", "elasticloadbalancing:CreateRule", "elasticloadbalancing:CreateTargetGroup", "elasticloadbalancing:DeleteListener", "elasticloadbalancing:DeleteLoadBalancer", "elasticloadbalancing:DeleteRule", "elasticloadbalancing:DeleteTargetGroup", "elasticloadbalancing:DeregisterTargets", "elasticloadbalancing:DescribeListenerCertificates", "elasticloadbalancing:DescribeListeners", "elasticloadbalancing:DescribeLoadBalancers", "elasticloadbalancing:DescribeLoadBalancerAttributes", "elasticloadbalancing:DescribeRules", "elasticloadbalancing:DescribeSSLPolicies", "elasticloadbalancing:DescribeTags", "elasticloadbalancing:DescribeTargetGroups", "elasticloadbalancing:DescribeTargetGroupAttributes", "elasticloadbalancing:DescribeTargetHealth", "elasticloadbalancing:ModifyListener", "elasticloadbalancing:ModifyLoadBalancerAttributes", "elasticloadbalancing:ModifyRule", "elasticloadbalancing:ModifyTargetGroup", "elasticloadbalancing:ModifyTargetGroupAttributes", "elasticloadbalancing:RegisterTargets", "elasticloadbalancing:RemoveListenerCertificates", "elasticloadbalancing:RemoveTags", "elasticloadbalancing:SetIpAddressType", "elasticloadbalancing:SetSecurityGroups", "elasticloadbalancing:SetSubnets", "elasticloadbalancing:SetWebACL" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "iam:CreateServiceLinkedRole", "iam:GetServerCertificate", "iam:ListServerCertificates" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "cognito-idp:DescribeUserPoolClient" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "waf-regional:GetWebACLForResource", "waf-regional:GetWebACL", "waf-regional:AssociateWebACL", "waf-regional:DisassociateWebACL" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "tag:GetResources", "tag:TagResources" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "waf:GetWebACL", "wafv2:GetWebACLForResource" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "ec2:CreateTags", "ec2:DeleteTags" ], "Resource": "arn:aws:ec2:*:*:security-group/*", "Condition": { "Null": { "aws:ResourceTag/ingress.k8s.aws/cluster": "false" } } }, { "Effect": "Allow", "Action": [ "elasticloadbalancing:AddTags", "elasticloadbalancing:RemoveTags", "elasticloadbalancing:DeleteTargetGroup" ], "Resource": [ "arn:aws:elasticloadbalancing:*:*:targetgroup/*/*", "arn:aws:elasticloadbalancing:*:*:loadbalancer/net/*/*", "arn:aws:elasticloadbalancing:*:*:loadbalancer/app/*/*" ], "Condition": { "Null": { "aws:ResourceTag/ingress.k8s.aws/cluster": "false" } } } ] }次に、ALBに設定するためのIngressリソースをデプロイします。
annotationsにalb.ingress.kubernetes.io/load-balancer-attributesで削除保護を設定しています。これによりIngressリソースを削除してもALBが削除されることはなくなります。alb-ingress.yamlapiVersion: extensions/v1beta1 kind: Ingress metadata: annotations: alb.ingress.kubernetes.io/scheme: internet-facing kubernetes.io/ingress.class: alb alb.ingress.kubernetes.io/load-balancer-attributes: deletion_protection.enabled=true name: alb-ingress namespace: kube-system spec: rules: - http: paths: - backend: serviceName: nginx-ingress-controller servicePort: 80$ kubectl apply -f alb-ingress.yaml次に、2つのNamespaceにアプリケーションをデプロイします。今回はNGINXを使用しています。
FQDNは例としてそれぞれapp1.sample.com、app2.sample.comと記述しています。app.yamlkind: Namespace apiVersion: v1 metadata: name: app1 --- apiVersion: extensions/v1beta1 kind: Ingress metadata: name: app1-ing namespace: app1 annotations: kubernetes.io/ingress.class: nginx spec: rules: - host: app1.sample.com http: paths: - backend: serviceName: app1-svc servicePort: 80 --- apiVersion: v1 kind: Service metadata: name: app1-svc namespace: app1 spec: type: ClusterIP ports: - name: http-port protocol: TCP port: 80 targetPort: 80 selector: app: app1 --- apiVersion: apps/v1 kind: Deployment metadata: name: app1-deploy namespace: app1 spec: replicas: 1 selector: matchLabels: app: app1 template: metadata: labels: app: app1 spec: containers: - name: app1 image: nginx:1.13 ports: - containerPort: 80 --- kind: Namespace apiVersion: v1 metadata: name: app2 --- apiVersion: extensions/v1beta1 kind: Ingress metadata: name: app2-ing namespace: app2 annotations: kubernetes.io/ingress.class: nginx spec: rules: - host: app2.sample.com http: paths: - backend: serviceName: app2-svc servicePort: 80 --- apiVersion: v1 kind: Service metadata: name: app2-svc namespace: app2 spec: type: ClusterIP ports: - name: http-port protocol: TCP port: 80 targetPort: 80 selector: app: app2 --- apiVersion: apps/v1 kind: Deployment metadata: name: app2-deploy namespace: app2 spec: replicas: 1 selector: matchLabels: app: app2 template: metadata: labels: app: app2 spec: containers: - name: app2 image: nginx:1.13 ports: - containerPort: 80$ kubectl apply -f app.yamlALB LoadBalancer Controllerへの移行
ここでは、移行する手順を説明します。
1. ALB Ingress Controllerの削除
既存のALB Ingress Controllerを削除します。Ingressリソースは削除しないことに注意します。
$ helm uninstall aws-alb-ingress-controller -n kube-system2. ALB LoadBalancer Controllerのデプロイ
TargetGroupBindingのCRDをデプロイします。
$ kubectl apply -k "github.com/aws/eks-charts/stable/aws-load-balancer-controller//crds?ref=master"ALB LoadBalancer ControllerをHelmでデプロイします。バージョンに気をつけます。
aws-load-balancer-controller-values.yamlclusterName: <CLUSTER_NAME> region: ap-northeast-1 vpcId: <VPC_ID> serviceAccount: annotations: "eks.amazonaws.com/role-arn": <IAM_ROLE_ARN>$ helm install aws-load-balancer-controller \ eks/aws-load-balancer-controller \ -f aws-load-balancer-controller-values.yaml \ --version 1.0.8 \ -n kube-system3. Ingressリソースの削除
ALBの設定をKubernetesリソースから操作することはやめます。Ingressリソースは不要になるため削除します。
$ kubectl delete -f alb-ingress.yaml4. TargetGroupの作成
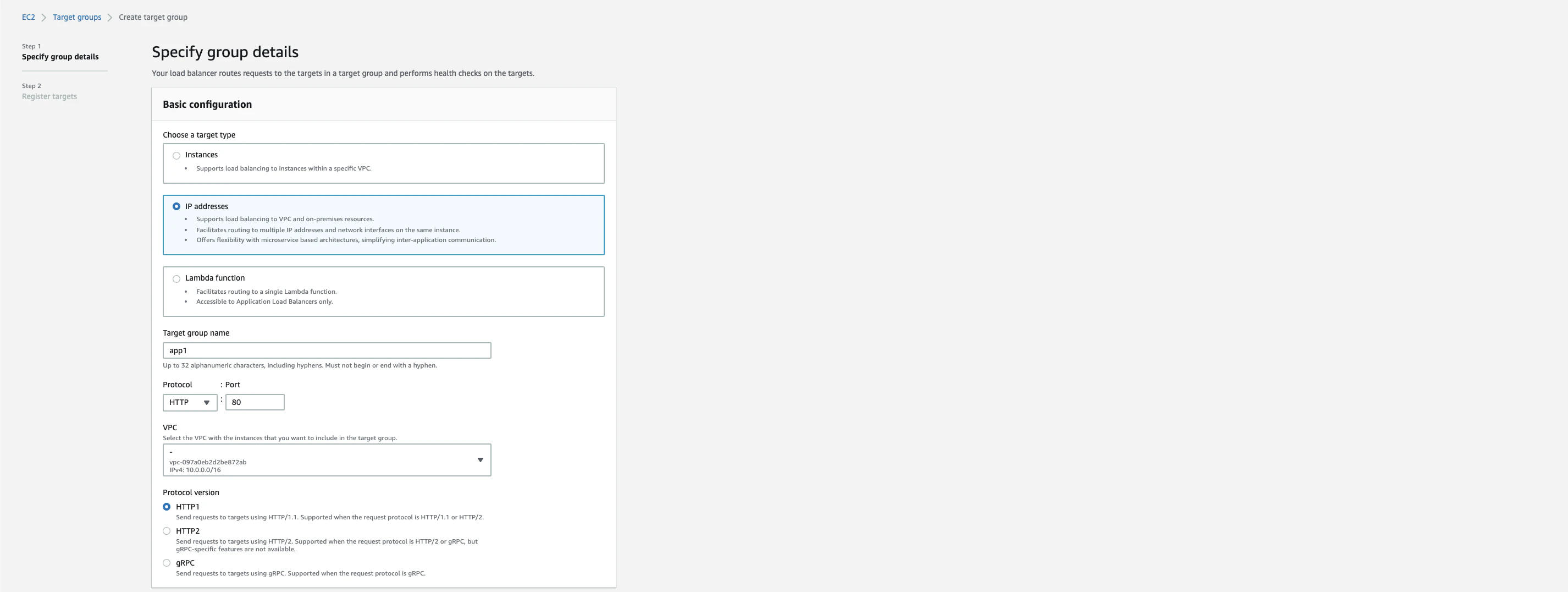
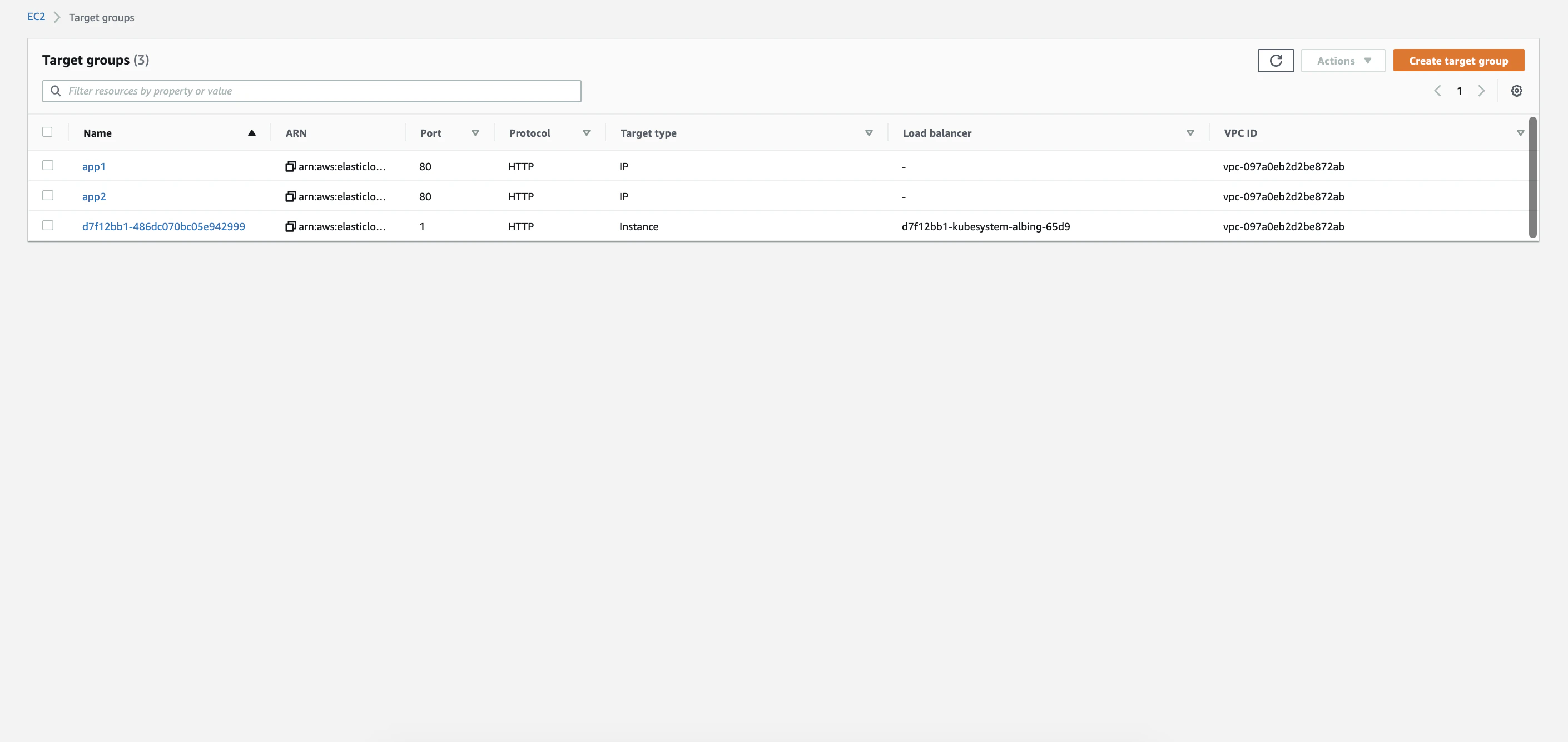
Serviceへのルーティングを設定するためにTargetGroupをAWSコンソールから作成していきます。下画像ではALB Ingress Controllerが作成したものが残っていますが、まだ削除しません。
target typeはIP addressにします。
Register targetsには何も記入せず作成します。
今回は2つのアプリケーションをデプロイするので2つ分TargetGroupを追加しました。
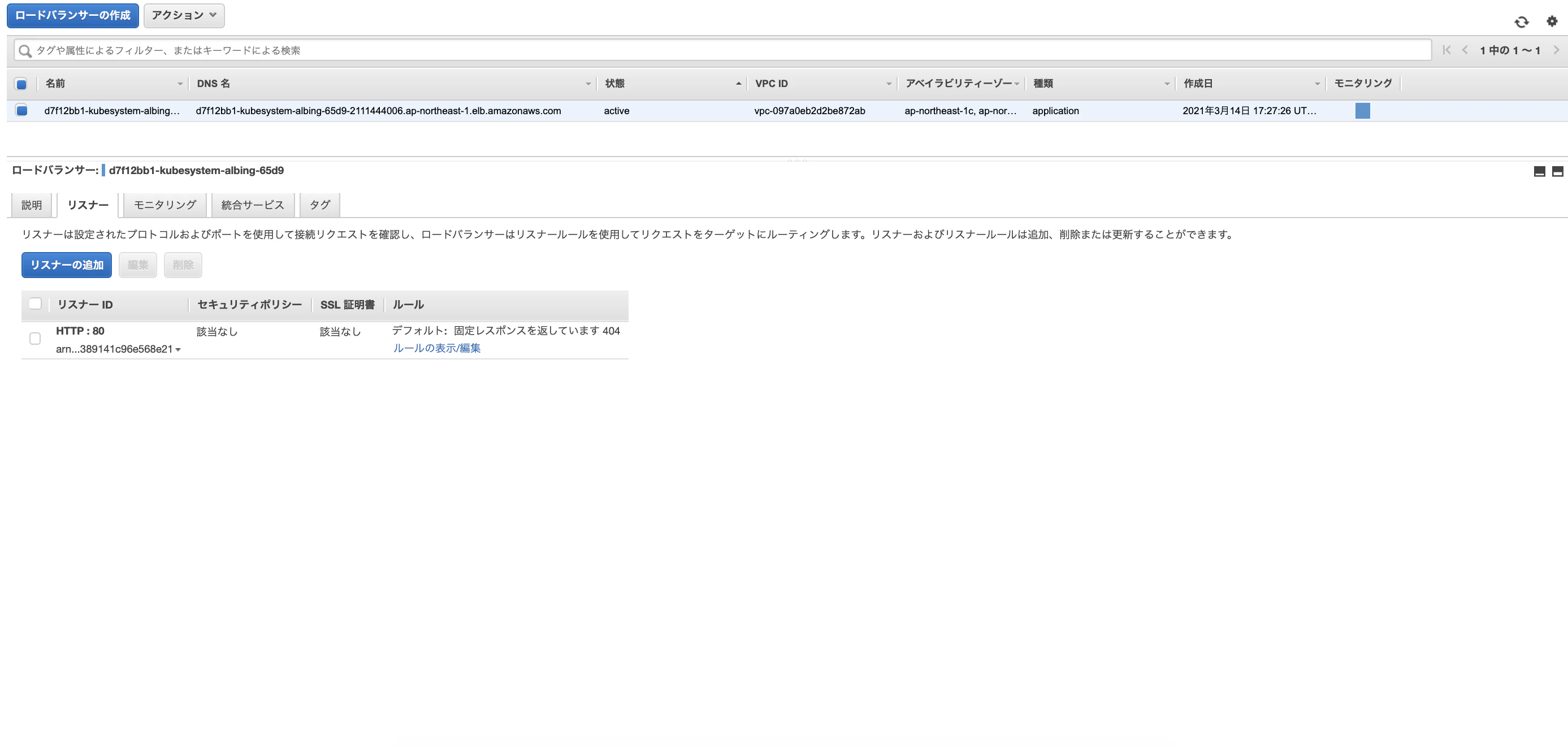
5. リスナールールの変更
ALB Ingress Controllerが作成したALBのリスナールールを変更していきます。
全てのリクエストがNGINX Ingress Controllerに向かうようになっています。これにルールを追加します。
ホスト名に合わせて宛先を先ほど作成したTargetGroupになるようにしています。
6. TargetGroupBindingリソースの作成
TargetGroupとServiceを紐づけるための設定を加えます。SecurityGroupはALBに設定されているものを使用します。
targetgroupbinding.yamlapiVersion: elbv2.k8s.aws/v1beta1 kind: TargetGroupBinding metadata: name: app1-tgb namespace: app1 spec: serviceRef: name: app1-svc port: 80 targetGroupARN: <TARGET_GROUP_ARN> targetType: ip networking: ingress: - from: - securityGroup: groupID: <SECURITY_GROUP_ID> ports: - protocol: TCP --- apiVersion: elbv2.k8s.aws/v1beta1 kind: TargetGroupBinding metadata: name: app2-tgb namespace: app2 spec: serviceRef: name: app2-svc port: 80 targetGroupARN: <TARGET_GROUP_ARN> targetType: ip networking: ingress: - from: - securityGroup: groupID: <SECURITY_GROUP_ID> ports: - protocol: TCP$ kubectl apply -f targetgroupbinding.yaml7. ゴミ掃除
ALBリスナールールからNGINX Ingress Controller向けの設定を削除します。
IngressリソースとNGINX Ingress Controllerは不要なので削除します。
$ kubectl delete ing app1-ing -n app1 $ kubectl delete ing app2-ing -n app2 $ helm uninstall nginx-ingress -n kube-system確認
移行前のURLでアプリケーションにアクセスできることを確認します。
まとめ
既存のALBを削除せずにALB Ingress Controller + NGINX Ingress ControllerからALB LoadBalancer Controllerに移行する手順を説明しました。
これによりALBをKubernetes側で管理する必要がなくなり、且つ複数Namespace上のアプリケーションにアクセスする時も1つのALBで事足りるので移行するメリットは大きいです。参考







- 投稿日:2021-03-15T02:30:52+09:00
AWSのEBSスナップショットの説明に「from」記述がなくなった件について
何が起こった?
全くの偶然で、AWSのEBSスナップショットに関する一つの仕様変更に気づきました。
EC2インスタンスからAMIを作成する際に、AMIにアタッチされるスナップショットも同時に生成されます。そして下記スクリーンショットが示しているように、当該スナップショットの説明については、今まで
from vol-xxxxxxxxの文言が記載されていたところ、いつの間にかこの文言が消えてしまいました。
ちなみに、2021/3/15現在、私が持っている2つのAWSアカウントにて検証したところ、両方ともこの事象が発生していることを確認できました。
何がいけないの?
一見どうでもいい仕様変更になりますが、場合によって結構大きな問題を引き起こす可能性があります。
実は、私が管理しているAWSアカウントで、下記の記事を参考し、AMIを登録解除するときに、そのAMIにアタッチしているスナップショットも自動的に削除する機構を用意しております。
AMI登録解除時の、スナップショット自動削除を設定してみたこの機構におけるLambda関数の一部として、以下のコードが実装されています。
sample.py# 削除対象のスナップショットを取得 response = client.describe_snapshots( Filters=[ { 'Name': 'description', 'Values': [ 'Created by CreateImage(*) for ' + image_id + ' from *', ] } ] )つまり、
from *がdescriptionの値として含まれていることがフィルター条件になっていますが、今回の仕様変更によって、 本来抽出できるはずのスナップショットが抽出できなくなります 。その結果、気づいていない間に不要なスナップショットがどんどん溜まってしまって、無駄な料金が発生してしまいます。じゃあどうすれば良いの?
フィルター条件を下記のように修正し、
fromの記述を除外します。sample.py'Created by CreateImage(*) for ' + imageID + '*'最後に
こちらのAWSアカウントにおけるスナップショットの蓄積状況から見ると、この事象はおおよそ2021年2月中旬頃から発生した模様です。
正直この事象はAWS側が意図した仕様変更なのか単純な不具合なのか分からず、ググっても関連する記事が全く見つかりませんでした。
ただ、ものすごく軽微な変更であっても、今回みたいに余剰コストの発生に直結する可能性もあるので、似たような方法でスナップショットの抽出を行っている方は、今一度動作確認をしてみましょう。

- 投稿日:2021-03-15T01:35:55+09:00
【AWS】CloudFront+S3でコンテンツを即時反映する方法
はじめに
静的および動的なウェブコンテンツ (.html、.css、.js、イメージファイルなど) をAmazon S3に低コストかつ安全に格納し、Amazon CloudFrontを用いて効率よくコンテンツを配信するという設計は割と良くあるのではないでしょうか。
しかし、効率よくコンテンツを配信してくれる反面、即時差し替えたいファイルがあっても「キャッシュのせいでなかなか反映されない」ということが起こります。
AWSの公式にも下記のように記載されています。デフォルトでは、CloudFront は Amazon S3 からのレスポンスを 24 時間 (86,400 秒間のデフォルト TTL) キャッシュしています。リクエストが エッジロケーションに到着してから24 時間以内に Amazon S3 を提供した場合、Amazon S3 のコンテンツを更新したとしても、CloudFront はキャッシュされたレスポンスを使います。
この記事では、そんなキャッシュ問題を簡単に解消する方法を紹介します。
対処方法
即時差し替えたいファイルがあっても「キャッシュのせいでなかなか反映されない」・・・それならば「CloudFrontのキャッシュを削除してしまえばいいじゃん」という方法の紹介です。
早速キャッシュの削除方法を説明します。
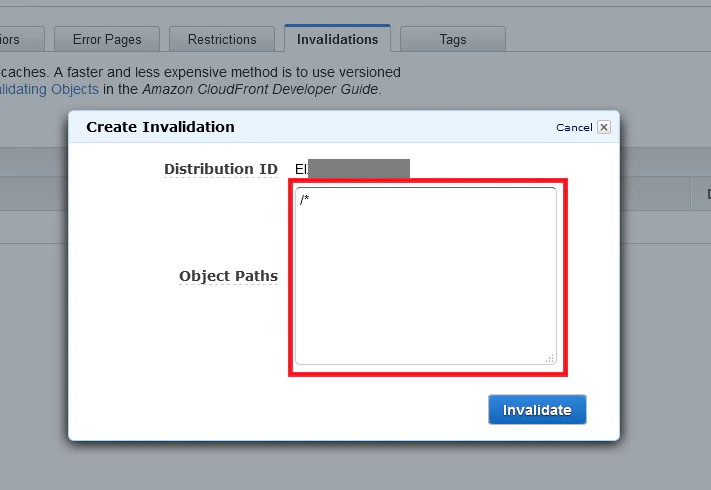
手順1
マネージメントコンソールで 「CloudFront Distributes」を開き、キャッシュを削除したいサイトの「ID」をクリックします(ディストリビューションの選択)。
手順2
「Invalidations」タブを選択し、「Create Invalidation」ボタンをクリックします。
手順3
モーダルが表示されるので、「Object Paths」のテキストボックスにキャッシュを削除したいファイルのパスを入力します。
私はまとめてキャッシュを削除したいので常に「/*」(すべてのキャッシュを削除)と指定していますが、全削除はリスクがありそうなので「/css/*」のように部分削除することをオススメします。
「Invalidate」 ボタンをクリックするとキャッシュの再作成が開始されます。
手順4
数分待ちます。
Statusが「Completed」となればキャッシュの再作成が完了しています。
以上です。
AWSの公式ドキュメントに別の対策が載っていたのでそちらもリンクを置いておきます。
(今回紹介したキャッシュの削除の方が簡単だとは思います。)
CloudFront が、Amazon S3 から古いコンテンツを提供し続けるのはなぜですか?



- 投稿日:2021-03-15T00:06:53+09:00
AWS CodePipelineでGitHubのソースをS3へデプロイする
はじめに
CodePipeline 設定手順の備忘録。
やりたいこと
- GitHubへのpushをトリガーにして、S3に自動デプロイしたい
- 環境を分けたい(開発、ステージング、本番)
- デプロイ結果をslack通知したい
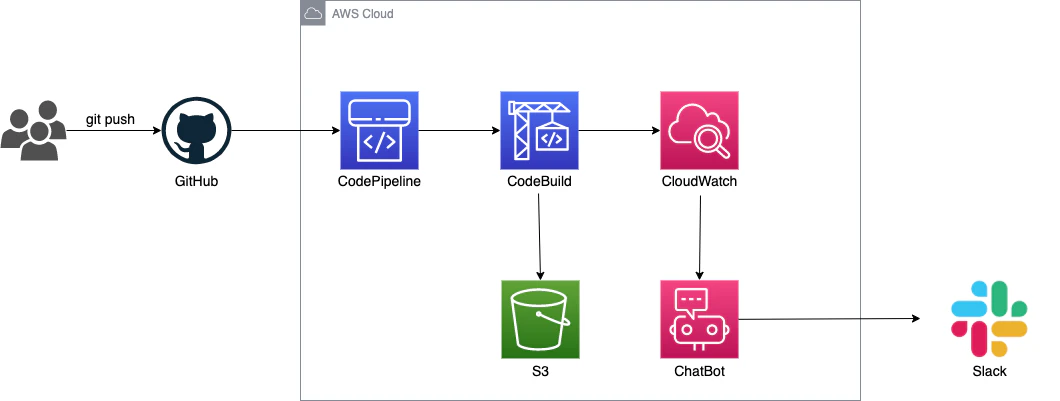
構成図
※ ng new コマンドで作成した Angular のサンプルコードをデプロイします。
設定手順
1. CodePipeline の設定
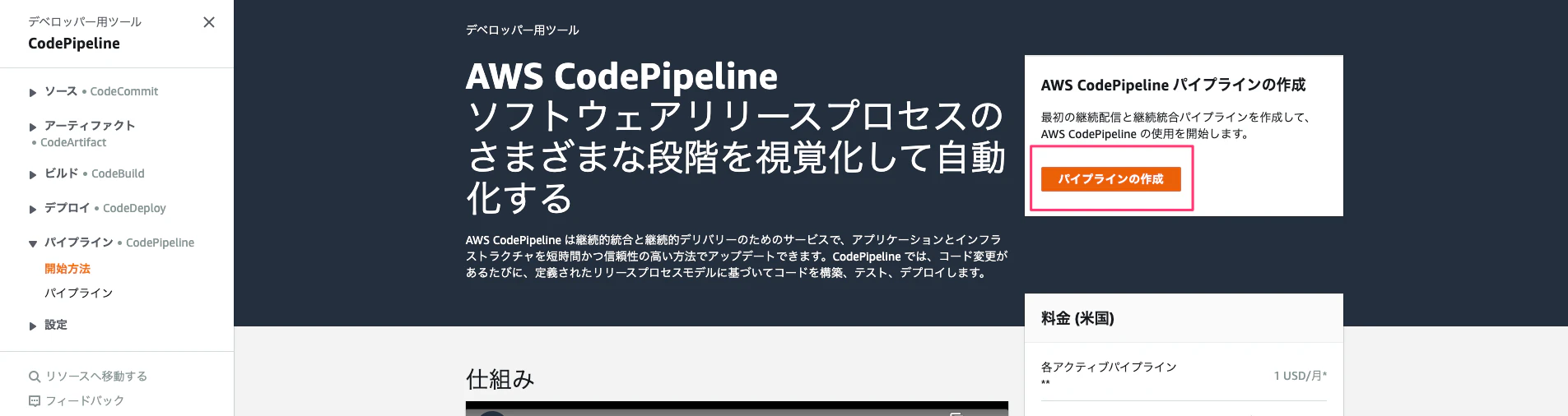
「パイプラインの作成」から作成を開始します。
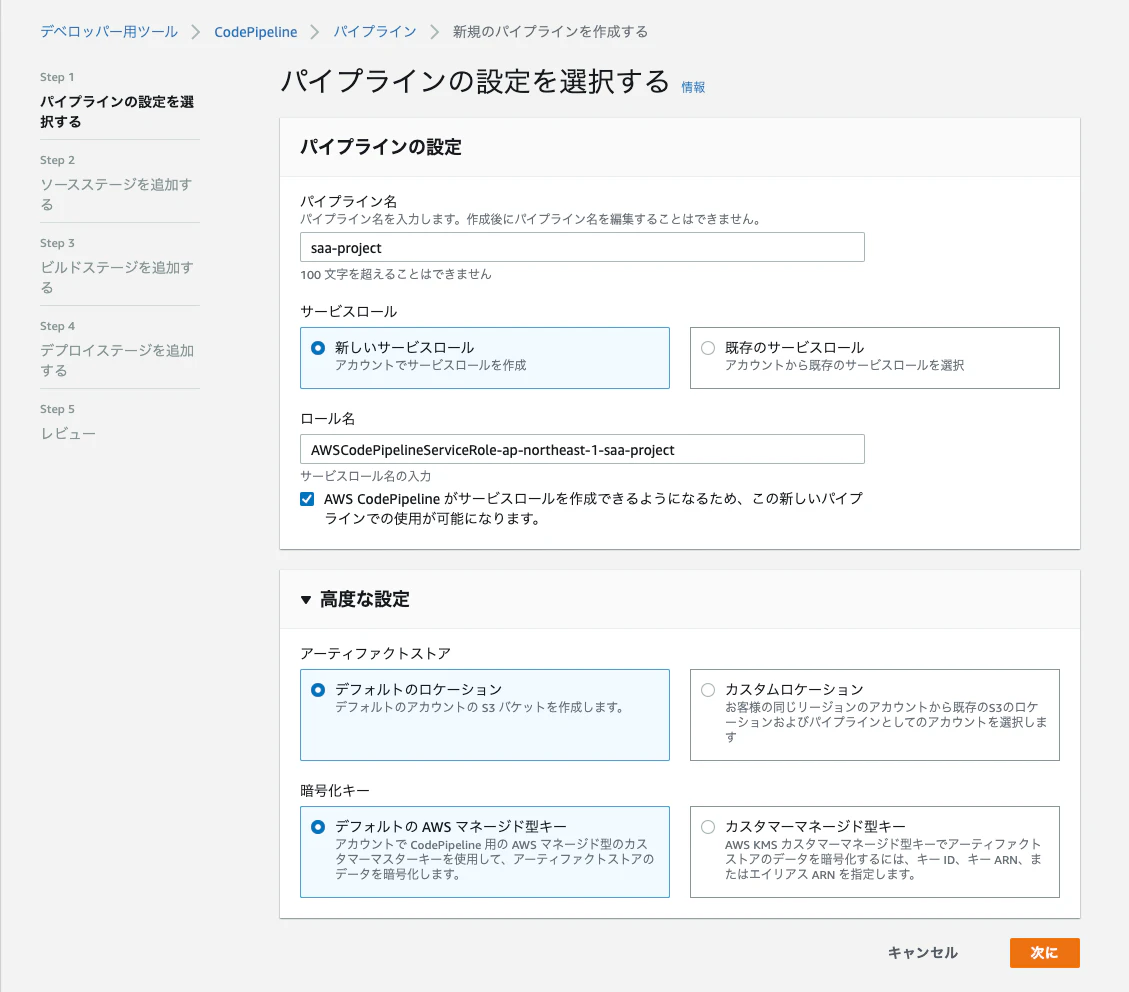
パイプライン名を入力して、初回はロールを新規で作成します。
ソースプロバイダーはGitHubを選択。(バージョン1は非推奨となっているため、バージョン2を選択。)
参考:
「新しいアプリをインストールする」を選択。
リポジトリを選択し、「Install」を押下します。
CodePipelineの設定画面に戻るので、リポジトリとブランチを選択します。
(開発やステージング、本番で環境を分けて使う場合は、環境ごとにブランチとパイプラインを作成するのがいいのでしょうか?)→ 環境ごとにブランチを分ける、というのは本来のgitの使い方ではないためNG
次にビルドステージを設定します。
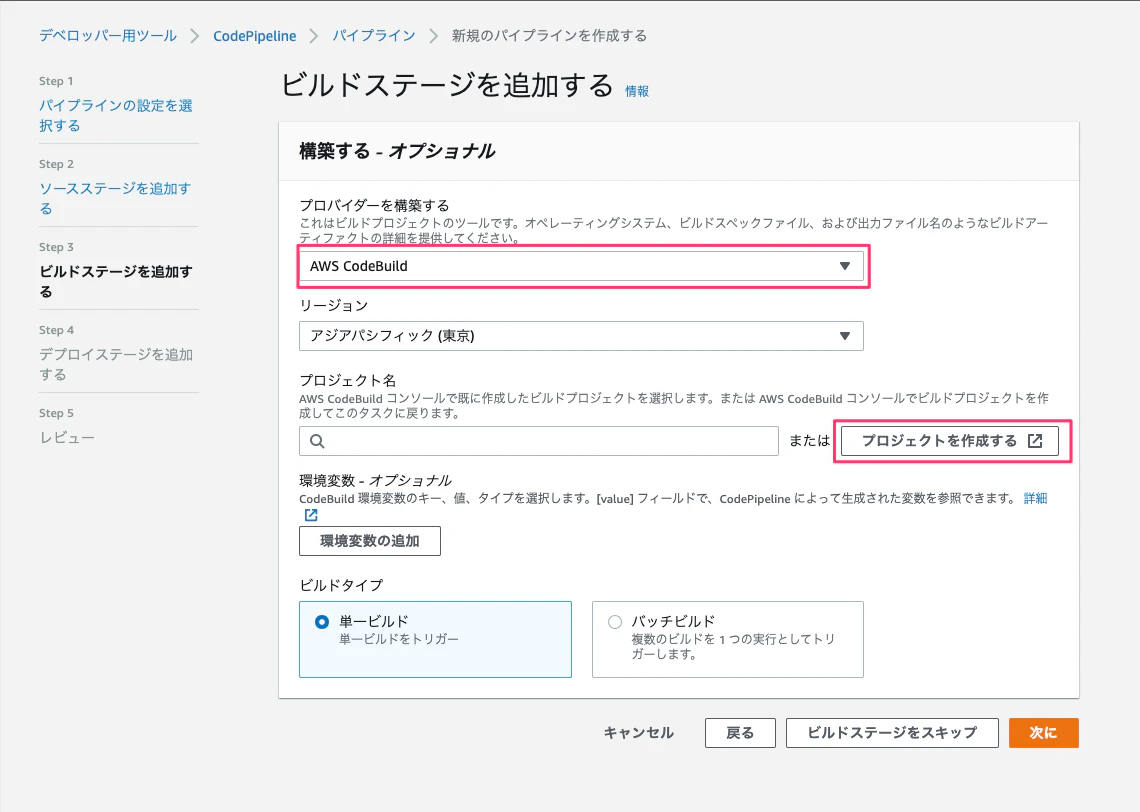
AWS CodeBuild と Jenkins が選択可能ですが、ここでは AWS CodeBuild を選択。
「プロジェクト名」項目では、「プロジェクトを作成する」を選択する。
プロジェクトを作成します。
(ここで設定した環境変数は、buildspec.ymlで呼べるらしい。)
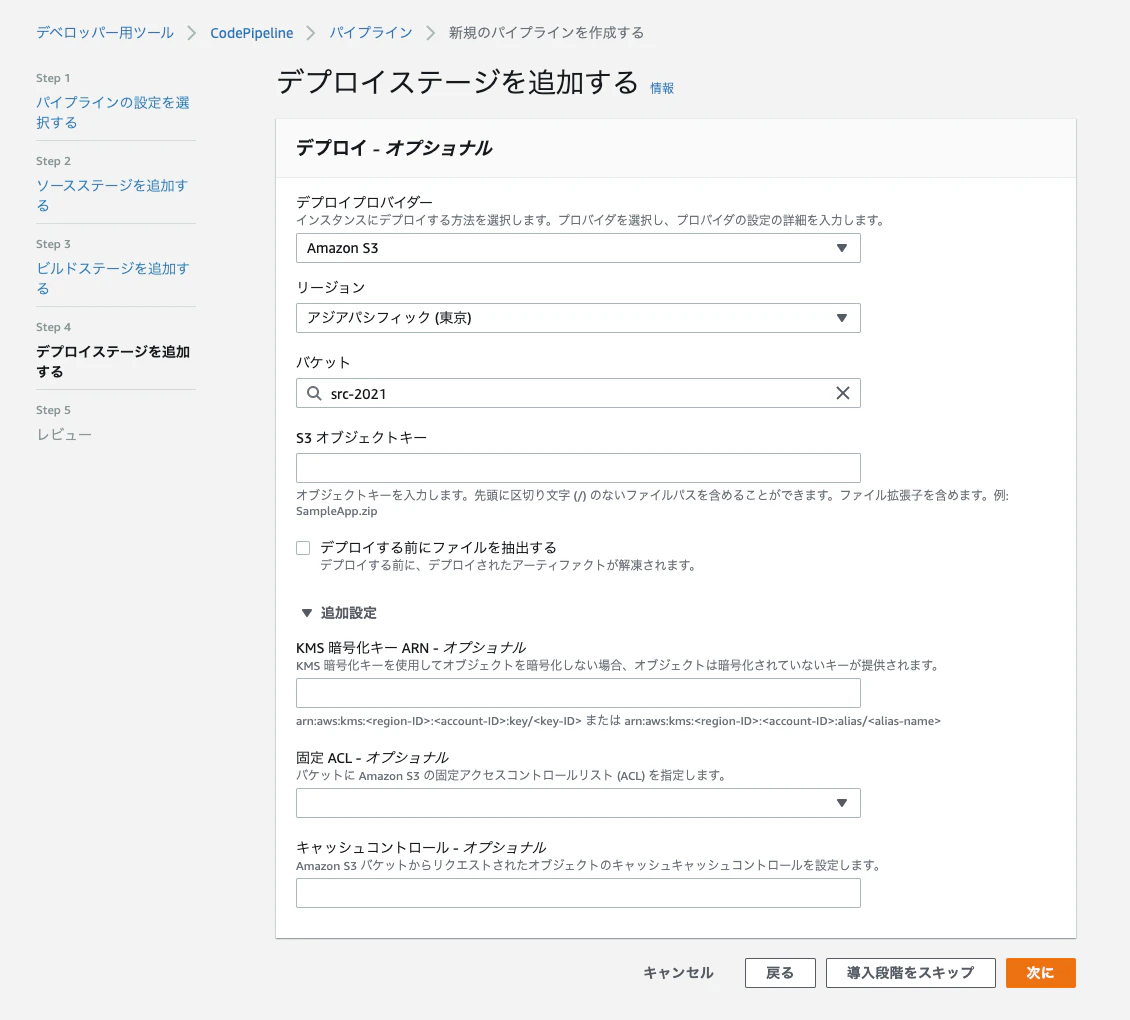
最後にデプロイステージの設定。S3を選択します。(バケットは事前に作成しておきます)
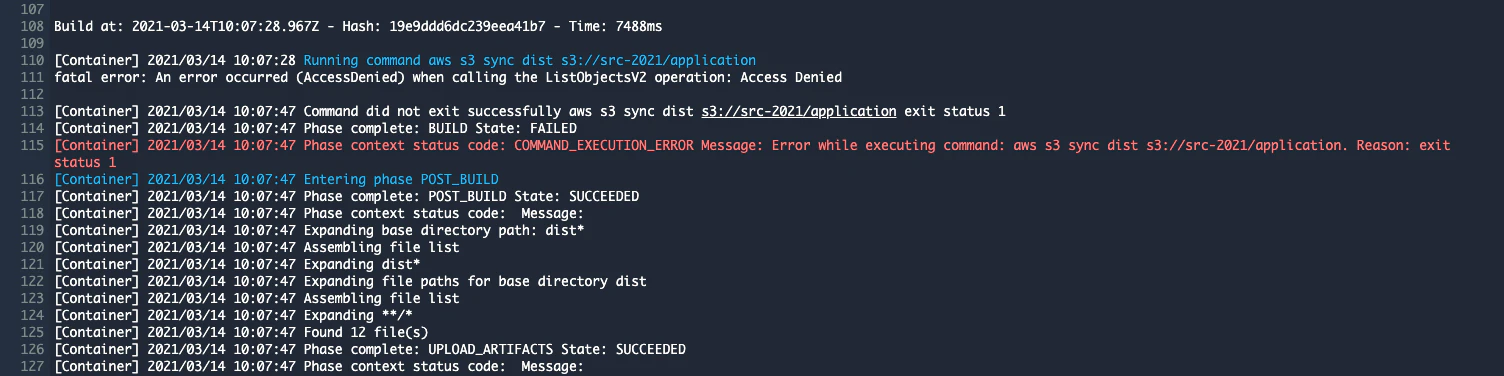
設定が完了すると、設定したパイプラインが実行されますが、CodeBuild の実行で失敗します。
CodeBuild を実行するには、buildspec.yml というyamlファイルにビルド時に実行するシェルコマンドを記述し、デプロイするソースコードのルートディレクトリに配置する必要があります。
ルートディレクトリに以下のような buildspec.yml を作ります。
ng build で出力された dist ディレクトリ配下のファイルを S3 にアップロードしています。version: 0.2 phases: install: runtime-versions: nodejs: 12 commands: - npm install -g - npm install --save-dev @angular-devkit/build-angular - npm install -g @angular/cli build: commands: - ng build - aws s3 sync dist s3://src-2021/application artifacts: files: - '**/*' base-directory: 'dist*'参考:
(runtime-versions で指定する node.js のバージョンは、10と12のみのようです。)
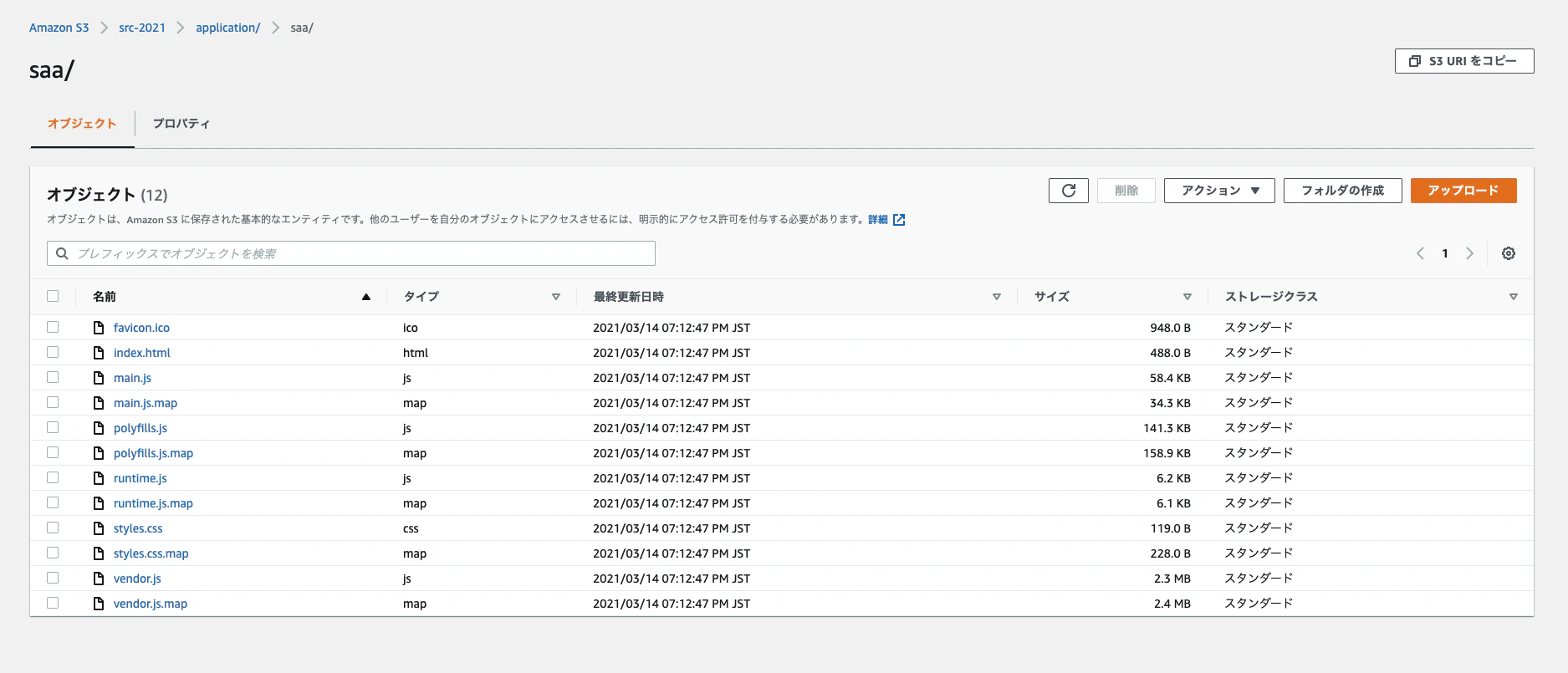
buildspec.yml を git push すると、パイプラインが実行され、今度は成功です。
S3 にデプロイされました。
備考:
CodeBuild のロールに S3 へのアクセス許可ポリシーをアタッチしておく必要あり。
2. slack への通知設定
CodePipeline, CodeCommit, CodeBuild は、SNS もしくは ChatBot と連携ができるので、
ChatBot と連携させて slack 通知します。
成功や失敗時以外にも、トリガーとなるイベントがいろいろ選択可能です。
設定後、再度パイプラインを実行して、slack通知を確認できました。
以上で設定完了です。
追記
・GitHubへのpushをトリガーするというのは、手軽にデプロイができすぎてしまうので、本番環境の場合は考える必要がある。