- 投稿日:2020-12-08T23:28:26+09:00
【Android】root判定によるチート対策
PONOS Advent Calendar 2020 9日目の記事です。
昨日は@nissy_gpさんのNode.js+Sequelizeで楽観的ロックを使って動作を確認するでした。
はじめに

前回の記事で「Android開発者向けオプションを使ったチート対策」を紹介しました。
今回は、「root判定によるチート対策」を紹介します。この記事の対象者
・アプリ開発者
・Android開発者root化された端末の判定
メモリハックによる値書き換えなどのチート行為は
root化された端末を使用して行われるケースが多いです。今回はアプリ側から
suコマンドを実行して
IOExceptionの有無で判定してみましょう。
・IOException発生の場合はroot権限なし ー> 通常端末
・IOException発生しない場合はroot権限あり ー> root端末java.lang.Runtimeクラスの
exec(String command)メソッドを使用します。boolean isRoot = false; try { Process process = Runtime.getRuntime().exec("su"); process.destroy(); isRoot = true; Log.d(TAG, "Root!!"); } catch (IOException e) { Log.d(TAG, "NotRoot!!"); } catch (Exception e){ e.printStackTrace(); } if(isRoot){ //root権限ありの時の処理 //例:情報をサーバーに送信し、root化解除を促すポップアップ表示 }メリット
アプリのセキュリティーレベルを上げることができる。
実装コストが軽いデメリット
マニアックな海外製端末で初期出荷状態から
root権限が付与されているケースなどがあり、健全ユーザーがチート扱いされてしまう場合もある。
※経験則になってしまいますが、このパターンはかなりレアケースでした。注意点
リバースエンジニアリングによるコード改竄で今回のコードを無効化されてしまう恐れもあります。
root対策と同時にリパッケージされた不正アプリ対策を実装するのがお勧めです。
不正アプリ対策
・メモリシャッフル
・難読化
・SafetyNet導入
などがあり、SafetyNet の Attestation APIを使用してリパッケージされていないか判定することができます。SafetyNetの紹介
SafetyNetでできること
SafetyNet Attestation API:
正規の Android デバイスで、正規のアプリかどうか判定できるSafetyNet Safe Browsing API:
URL が Google によって既知の脅威としてマークされているかどうかを判定できるSafetyNet reCAPTCHA API:
悪意のあるトラフィックを検知することができるSafetyNet Verify Apps API:
有害なアプリから端末を保護することができるSafetyNet Attestation API
実装方法は公式に記載されているので省略しますが
以下の手順で正規アプリかどうか判定することができます。
1.SafetyNet 構成証明をリクエスト2.SafetyNet 構成認証レスポンスを各種検証
3.apkPackageName: 呼び出し元のアプリのパッケージ名のチェック
4.APK証明書のSHA-256ハッシュ:署名に使用したAPK証明書を検証
5.APKのSHA-256ハッシュ:APKがリリースしたものから改ざんされていないことを確認するために、APKのSHA-256ハッシュが同一か検証
6.BasicIntegrityがtrueであることを確認
※検証処理はサーバー側で行うこと
まとめ
今回紹介したroot判定は自前で実装する手法でしたが
SafetyNet Attestation API
を使用してでも判定することができます。
構成認証レスポンスのBasicIntegrityがfalseの場合はroot端末です他にもSafetyNetを使用したチート対策があるので
公式ドキュメントを読んでおくことをお勧めします。明日は@blockの記事です。
お楽しみに!!
- 投稿日:2020-12-08T23:04:28+09:00
MyBatis内のSQL <![CDATA[ 比較演算子 ]]>
Mapper.xmlファイル内のSQLで引っかかったので個人的メモ。
Mapper.xml'select A.cutromer_id ,A.number ,case when B.customer is not null and B.customer <![CDATA[<>]]> '' else '' end AS C from A left join B on A.cutromer_id = B.cutromer_id'MySQLに読み替える際、<![CDATA[ ]]>を除いて書き換える必要がありました。
*比較演算子はちゃんと書く。MySQL.'select A.cutromer_id ,A.number ,case when B.customer is not null and B.customer <> '' else '' end AS C from A left join B on A.cutromer_id = B.cutromer_id'MyBatisはXMLファイルにSQL文を定義して使用する。
XMLなので比較演算子が直接、使えないのがわかっていたつもりでした?
- 投稿日:2020-12-08T22:08:58+09:00
try-with-resources文でリソースにnullを割り当ててもNullPointerExceptionは起きない
ちょっと不思議に思って調べたら普通に仕様に書いてあった。
A resource is closed only if it initialized to a non-null value.Main.javaimport java.io.*; public class Main { class SomeResource implements Closeable{ public void close() throws IOException{ System.out.println("closing"); } } public static void main(String[] args){ try(SomeResource res = null){ System.out.println("try"); }catch (Exception e){ System.out.println(e); } } }実行結果
trytry()内で割り当てた変数がnullの場合close()は呼ばれないのでぬるぽの心配はない。
仕事でこんなコードを見かけて
Hoge.javatry{ SomeResource res = createRes(); res.doSomthing(); }finallry{ if (res != null){ res.close() } }try-with-resourcesで書き直したらres==nullのときどうなるんだろうと思ったので試してみた。
- 投稿日:2020-12-08T21:21:42+09:00
Javaで任意のファイルを画像ファイルに偽装(暗号化)
1. はじめに
みなさんは隠したいファイルとか無いですか?
Dドライブにあるファイルとかここでは簡単に画像ファイルに偽装(暗号化)する方法について説明します。
お遊び的なテーマです。
アプリケーションで一番の処理がデータ(情報)を操作する事がですので、
皆さんが良く目にするデータである画像ファイルを題材としました。ちなみに、暗号化された情報は画像ファイルなんで、
ぱっとみ暗号化されたものなのか解らない。2. 画像ファイルの構成
今回はJPGファイルを対象とします。
JPGのデータ構成の詳細は以下の記事を参考にして下さい。
(全体の構成は本質ではない為)ここで重要なマーカーは
開始マーカーのFFF8
終了マーカーのFFF9
そしてコメントのFFFEです。コメントであれば、何を書き込んでも影響が無いので、
ここに別のファイル情報を書き込んで偽装してみましょうか。3. ファイル情報の埋め込み方
JPEGファイルのデータ構成は以下になっています。
FFF8 ~画像データ~ FFF9これを
FFF8 FFFE<バイト長><埋め込みデータ> ~画像データ~ FFF9のようにします。
コメントマーカーの後にはコメントのバイト長を2byteで指定します。4. 埋め込みデータ形式
4.1. 基本フォーマット
FFFEはjpgフォーマットのコメントマーカーなので、
そのままデータ部として使うと既存のコメントと区別がつかない。
従って、情報を付与して他のコメントと区別を付ける必要がある。従って、
FFFE<バイト長><識別子><埋め込みデータ>のようにコメントマーカー直後に、
識別子を入れて他のコメントと区別を付ける。識別子と既存のコメントについて偶然の一致は発生する可能性があるため、
ある程度アリエナイ識別子にして回避する。徹底的に回避しようとすると、
既存コメントに対して識別子と同一データがあればエスケープする。
全コメントを先に見て識別子を動的に変える。
とかあるのですが、
今回の主題ではないので解りやすくする。
めんどうだからとかじゃないよ4.2. 埋め込みデータのヘッダ部
埋め込むファイルのメタデータとして色々あるのですが、
とりあえずファイル名だけを保存します。FFFE<バイト長>"HDFN"<ファイル名> 例:FFFE000C"HDFNtest.txt" ※文字列は16進数ではなくダブルクォートでくくって表現ます。 ※ファイル名が8文字(test.txt)+識別子(HDFN)でバイト長は16進数で000C4.3. 埋め込みデータのデータ部
バイト長が2バイトでの表現なので65536が最大バイト数になります。
このままだと容量の大きなファイルが埋め込めない。従って、以下のように複数のコメントマーカーで
データを細切れにしてコメントを分ける。FFFE<バイト長>"BDDT"<埋め込みデータ> FFFE<バイト長>"BDDT"<埋め込みデータ> FFFE<バイト長>"BDDT"<埋め込みデータ> FFFE<バイト長>"BDDT"<埋め込みデータ> ...あと、普通に埋め込んでも面白くないので、
以下の利点を考え圧縮して埋め込もうと思う。
- 容量の増加量が減りより偽装が増す。(元が圧縮ファイルなら減らないけど。。。)
- 圧縮することにより、平文にくらべ看破されずらくなる。
なので圧縮してみましょう、
GZIPOutputStreamを挟むだけです。5. Let's コーディング
ここまでくれば後はコーディングするだけ。
大したコードでもないので、1Classファイルで表現します。
ライブラリも標準ライブラリのみを使用です。
Java11で書きました。5.1. 暗号化
メソッド構成は以下
execute:画像ファイルを出力
⇒writeHeader:埋め込み情報のヘッダ部(ファイル名)出力
⇒writeBody:埋め込み情報のデータ部(圧縮バイト配列)出力package test; import java.io.ByteArrayOutputStream; import java.io.File; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import java.io.OutputStream; import java.nio.charset.StandardCharsets; import java.nio.file.Path; import java.util.zip.GZIPOutputStream; /** * 暗号化 */ public class Encord { /** jpgの開始マーカー */ private static byte[] PIC_START = new byte[] { (byte) 0xFF, (byte) 0xD8 }; /** jpegのコメントマーカー */ private static byte[] COM_START = new byte[] { (byte) 0xFF, (byte) 0xFE }; /** 埋め込み情報のヘッダ部として使用するコメント後に付与する文字列 */ private static byte[] HEADER_START = new byte[] { 'H', 'D', 'F', 'N' }; /** 埋め込み情報のデータ部として使用するコメント後に付与する文字列 */ private static byte[] DATA_START = new byte[] { 'B', 'D', 'D', 'T' }; /** 埋め込み時に使用するバッファサイズ */ private static final int BUFFER_SIZE = 0x2000; /** * 実行。 * * 埋め込み後は元ファイルに.jpgを付与して出力する。 * * @param implFilePath 埋め込みファイル * @param picPath 画像ファイル */ public void execute(final Path implFilePath, final Path picFilePath) { var fileName = implFilePath.getFileName().toString(); var outfile = new File(implFilePath.getFileName() + ".jpg"); try (var picIs = new FileInputStream(picFilePath.toFile()); var implIs = new FileInputStream(implFilePath.toFile()); var os = new FileOutputStream(outfile);) { for (var c : PIC_START) { if ((byte) picIs.read() != c) { throw new IllegalArgumentException("画像ファイル不正"); } } os.write(PIC_START); writeHeader(fileName, os); writeBody(implIs, os); var buffer = new byte[BUFFER_SIZE]; int len; while ((len = picIs.read(buffer)) >= 0) { os.write(buffer, 0, len); } } catch (Exception e) { throw new RuntimeException(e); } } /** * ヘッダ部出力。 * * @param fileName * @param os * @throws IOException */ private void writeHeader(final String fileName, final FileOutputStream os) throws IOException { var fileNameBytes = fileName.getBytes(StandardCharsets.UTF_8); var headerSize = getComSize(fileNameBytes.length, HEADER_START); os.write(COM_START); os.write(getComSizeData(headerSize)); os.write(HEADER_START); os.write(fileNameBytes); } /** * データ部出力。 * * @param implIs 埋め込みファイル * @param os 出力ファイルOS * @throws IOException */ private void writeBody(final FileInputStream implIs, final FileOutputStream os) throws IOException { var buffer = new byte[BUFFER_SIZE]; var gaos = new ByteArrayOutputStream(); // 圧縮データ取得用OS var gzipos = new GZIPOutputStream(gaos); // 圧縮OS while (true) { var len = implIs.read(buffer); if (len < 0) { gzipos.close(); writeData(os, gaos.toByteArray()); break; } gzipos.write(buffer, 0, len); writeData(os, gaos.toByteArray()); gaos.reset(); } } /** * データ部出力(分割単位)。 * * @param os 出力ファイルOS * @param compressBytes 圧縮したバイト配列 * @throws IOException */ private void writeData(final OutputStream os, final byte[] compressBytes) throws IOException { if (compressBytes.length > 0) { var size = getComSize(compressBytes.length, DATA_START); var sizeData = getComSizeData(size); os.write(COM_START); os.write(sizeData); os.write(DATA_START); os.write(compressBytes); } } /** * 付与情報を含めたデータサイズを算出する。 * * @param len 対象データの文字列 * @param bytes 付与情報 * @return データサイズ */ private static final int getComSize(final int len, final byte[] bytes) { return len + bytes.length + COM_START.length; } /** * データサイズをバイト配列にする * * @param size データサイズ * @return バイト配列 */ private static final byte[] getComSizeData(final int size) { return new byte[] { (byte) (size / 0x100), (byte) (size % 0x100) }; } }5.2. 複合化
メソッド構成は以下
GSInputStreamというデータが埋め込まれた画像ファイルからデータ部のみを抽出する、
InputStreamを作成する。execute:GSInputStreamで画像情報からデータ部のみを抽出し複合化してファイルに出力する
って単純なんだけど、処理をGSInputStreamに寄せています。
GZIPのバイト配列を取得するISを作ればシンプルになるなと考え、
GSInputStreamというデータ部のみ抽出するISを作成しました。package test; import java.io.BufferedOutputStream; import java.io.File; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.nio.ByteBuffer; import java.nio.charset.StandardCharsets; import java.nio.file.FileAlreadyExistsException; import java.nio.file.Files; import java.nio.file.Path; import java.nio.file.StandardCopyOption; import java.util.ArrayDeque; import java.util.Queue; import java.util.UUID; import java.util.zip.GZIPInputStream; /** * 複合化 * */ public class Decord { /** jpgのコメントマーカー */ private static byte[] COM_START = new byte[] { (byte) 0xFF, (byte) 0xFE }; /** 埋め込み情報のヘッダ部として使用するコメント後に付与する文字列 */ private static byte[] HEADER_START = new byte[] {'H', 'D', 'F', 'N'}; /** 埋め込み情報のデータ部として使用するコメント後に付与する文字列 */ private static byte[] DATA_START = new byte[] {'B', 'D', 'D', 'T'}; /** READバッファサイズ */ private static final int BUFFER_SIZE = 0x2000; /** WRITEバッファサイズ */ private static final int SIZE_8M = 1024 * 1024 * 8; /** * 実行。 * * @param implFilePath 埋め込まれた画像ファイル */ public void execute(final Path implFilePath) { /* 一時的に出力するテンポラリファイル */ var tmpFile = new File("TMP_" + UUID.randomUUID() + ".tmp"); try (var implIs = new FileInputStream(implFilePath.toFile()); var gsis = new GSInputStream(implIs); // 画像ファイルからGZIP圧縮領域のみを取得する自作IS Class var gzipis = new GZIPInputStream(gsis); var os = new BufferedOutputStream( new FileOutputStream(tmpFile), SIZE_8M);) { var buffer = new byte[BUFFER_SIZE]; int len; /* 解答してテンポラリファイルに出力 */ while ((len = gzipis.read(buffer)) >= 0) { os.write(buffer, 0, len); } os.close(); var outFileName = gsis.getFileName(); /* テンポラリファイルを取得したファイル名にMOVE */ copyToDecodeFile(tmpFile, outFileName); } catch (IOException e) { /* 一応お掃除 */ if (tmpFile.exists()) { try { Files.delete(tmpFile.toPath()); } catch (IOException e1) { // NP } } throw new RuntimeException(e); } } /** * テンポラリファイルをコピーして複合ファイルを作成する。 * @param tmpFile テンポラリファイル * @param outFileName 複合ファイル */ private void copyToDecodeFile(final File tmpFile, final String outFileName) { try { if (outFileName != null) { var outFile = new File(outFileName); if (outFile.exists()) { throw new FileAlreadyExistsException(outFileName); } Files.move(tmpFile.toPath(), outFile.toPath(), StandardCopyOption.REPLACE_EXISTING); } else { Files.delete(tmpFile.toPath()); } } catch (IOException ex) { throw new RuntimeException(ex); } } /** * 画像データからGZIP圧縮領域だけ取得するIS。 * * データ領域をバッファリングしてReadで取得できるようにしているだけ。 * */ private class GSInputStream extends InputStream { /** バッファキュー */ private final Queue<Byte> queueBuffer; /** 画像ファイルIS */ private InputStream is; /** 出力ファイル名 */ private String outFileName = null; /** 埋め込みデータのバイト数 */ private int impleDataCnt = 0; /** 埋め込みファイル名のバイト数 */ private int nameCnt = 0; /** バッファサイズ */ private byte[] buffer = new byte[BUFFER_SIZE]; /** 識別子保存領域 */ private Byte[] identifier = new Byte[8]; /** ファイル名格納領域 */ private ByteBuffer bb = ByteBuffer.allocate(255); /** * コンストラクタ * @param is 画像ファイルIS */ public GSInputStream(final InputStream is) { this.queueBuffer = new ArrayDeque<>(); this.is = is; } /** * データロード * * @return ロード結果文字数 * @throws IOException */ private int readData() throws IOException { var len = is.read(buffer); for (int i = 0; i < len; i++) { if (nameCnt > 0) { readFileName(i); } else if (impleDataCnt > 0) { readBody(i); } else { if (outFileName == null) { if (checkIdentifier(buffer[i], HEADER_START)) { nameCnt = (identifier[2] & 0xFF) * 0x100 + (identifier[3] & 0xFF) - HEADER_START.length - COM_START.length; } } else { if (checkIdentifier(buffer[i], DATA_START)) { impleDataCnt = (identifier[2] & 0xFF) * 0x100 + (identifier[3] & 0xFF) - DATA_START.length - COM_START.length; } } } } return len; } /** * データ領域取得 * @param i 埋め込みファイルバイトデータ */ private void readBody(int i) { queueBuffer.add(buffer[i]); if (--impleDataCnt == 0) { clearIdentifier(); } } /** * ヘッダファイル名領域取得 * @param i ヘッダファイル名のバイトデータ */ private void readFileName(int i) { bb.put(buffer[i]); if (--nameCnt == 0) { bb.flip(); outFileName = StandardCharsets.UTF_8.decode(bb).toString(); clearIdentifier(); } } @Override public int read() throws IOException { while (queueBuffer.size() == 0) { var len = readData(); if (len < 0) { return -1; } } return queueBuffer.poll() & 0xFF; } /** * ファイル名取得 * @return ファイル名 */ public String getFileName() { return outFileName; } /** * データ領域マーカー判定 * @param b バイトデータ * @param bytes 識別子チェック用配列 * @return */ private final boolean checkIdentifier(final byte b, final byte[] bytes) { for (int i = 0; i < identifier.length; i++) { if (identifier[i] == null) { final boolean result; switch (i) { case 0: case 1: result = b == COM_START[i]; break; case 2: case 3: result = true; break; case 4: case 5: case 6: case 7: result = (b == bytes[i - 4]); break; default: throw new IllegalArgumentException(); } if (result) { identifier[i] = b; if (i == identifier.length - 1) { return true; } } else { clearIdentifier(); } break; } } return false; } /** * 識別子保存一時領域クリア */ private void clearIdentifier() { for (int j = 0; j < identifier.length; j++) { identifier[j] = null; } } } }6. 実行結果
6.1. 「test.txt」を「適当な画像ファイル.jpg」に埋め込みます。
6.2. 「test.txt」はこんなふうに1~0を大量に並べたテキストファイル。
6.3. 埋め込んだ結果の画像ファイルはちゃんと開けます。
※容量は58KBで圧縮が効いている事を確認。
6.4. 複合もきちんとできました。
6.5. ファイルの中身も変わりありません。
6.6. 次に、さっきのテキストをzip圧縮してから埋め込みます。
6.7. ZIP ⇒ GZIP と二回実施した事で、更に容量が減った。。。。。
※ちなみに圧縮ファイル(XLSXも圧縮ファイル)の場合はほぼ加算されます。
※バイナリも正常に扱える(解答)できることも確認済み。
7. まとめ
今回データを画像ファイルに暗号化する方法をやってみた。
このロジックを知らない人にとっては複合化できない、
秘密鍵暗号の一種だと思います。課題としては、
1. 画像ファイルにあるコメントの構成が一致している場合は複合化できなくなる。
⇒対応例:ファイル内で絶対使われない文字列や構成を使用する(処理前に、画像ファイルの全バイトを検査する)
2. ファイル名は平文で登録されていてテキストとして覗ける。
⇒対応例:ファイル名を暗号化する。(1bit ADDするとか、ボディと同じように圧縮するとか)
3. ロジックを知っていたら複合化できる。
⇒対応例:パスワード機能を実装する。(ZipOutputStream使えば楽)
etc...「etc...」ってのは
手遊びで作ったので他にも絶対あるだろうなぁと。。。データ扱うって本当に面白いですよね。
それでは、
さよなら、さよなら、さよなら







- 投稿日:2020-12-08T21:03:33+09:00
ArchUnit 実践:ドメイン層で発生した例外は UI 層やアプリ層で捕捉しきる(大域例外ハンドラで捕捉しない)
// 実行環境 * AdoptOpenJDK 11.0.9.1+1 * Spring Boot 2.4.0 * JUnit 5.7.0 * ArchUnit 0.14.1アーキテクチャテストのモチベーション
ドメイン固有の例外は、そのユースケースを制御する責務をもつコントローラーやアプリケーションサービスで捕捉し、適切な後処理を行うべき。
Spring Boot でいうと、
@ExceptionHandlerを付与したメソッド(大域例外ハンドラ)が、ドメイン層の例外を捕捉しないことを担保したい。アーキテクチャテストの実装
package com.example; import com.tngtech.archunit.base.DescribedPredicate; import com.tngtech.archunit.core.domain.JavaClass; import com.tngtech.archunit.core.domain.JavaClasses; import com.tngtech.archunit.core.importer.ClassFileImporter; import com.tngtech.archunit.core.importer.ImportOption; import org.junit.jupiter.api.Test; import org.springframework.web.bind.annotation.ExceptionHandler; import java.util.List; import static com.tngtech.archunit.lang.syntax.ArchRuleDefinition.methods; class ArchitectureTest { // 検査対象のクラス private static final JavaClasses CLASSES = new ClassFileImporter() .withImportOption(ImportOption.Predefined.DO_NOT_INCLUDE_TESTS) .importPackages("com.example"); @Test void ドメイン層で発生した例外を大域例外ハンドラで捕捉しない() { methods().that().areAnnotatedWith(ExceptionHandler.class) .should() .notHaveRawParameterTypes(new DescribedPredicate<>("ドメイン層の例外クラス") { /** * @param params `@ExceptionHandler` でアノテートされたメソッドの引数のリスト * @return 引数にドメイン層の例外クラスを含む場合、true */ @Override public boolean apply(final List<JavaClass> params) { JavaClass exceptionClass = params.stream() .filter(clazz -> clazz.isAssignableTo(Exception.class)) .findFirst() .orElseThrow(); return exceptionClass.getPackageName().startsWith("com.example.domain"); } }) .check(CLASSES); } }
- 投稿日:2020-12-08T20:24:11+09:00
【Java】文字列を分割する方法
プログラミング勉強日記
2020年12月8日
3日連続JavaのString型の扱いになるが、今日は文字列を分解するsplitメソッドの使い方をまとめる。splitメソッドとは
文字列を分割して、分割した文字列を配列として格納するメソッド。区切りたい文字には正規表現を設定することができ、分割回数の数値によって空白文字の消去にも使うことができる。String型の配列として返す。(正規表現についてはこちらの記事で詳しく扱っている。)
csvファイルといったカンマ区切りの文字列のファイルを操作するときによく使われる。splitメソッドの書き方文字列.split(区切りたい文字列, 分割回数);サンプルコードpublic class Main { public static void main(String[] args) { String str = "white,green,blue,red"; String[] colors = str.split(","); for (int i = 0; i < colors.length; i++) { System.out.println(colors[i]); } } }実行結果white green blue red文字列の数を指定する場合
splitメソッドの第2引数に1以上の整数を設定することで、文字列の分割回数を制御することができる。
サンプルコードpublic class Main { public static void main(String[] args) { String str = "white,green,blue,red,,"; String[] colors = str.split(",", 3); for (int i = 0; i < colors.length; i++) { System.out.println(colors[i]); } } }実行結果white green blue,red末尾の空白文字の要素を削除する場合
第2引数が0もしくは何も設定しない場合は、末尾の空白文字を削除することができる。削除したくないときは
-1といったマイナスの値を設定する。サンプルコードpublic class Main { public static void main(String[] args) { String str = "white,green,blue,red,,"; String[] colors = str.split(",", 0); System.out.println("第二引数が0の場合"); for (int i = 0; i < colors.length; i++) { System.out.println(i + ":" + colors[i]); } colors = str.split(",", -1); System.out.println("第二引数が-1の場合"); for (int i = 0; i < colors.length; i++) { System.out.println(i + ":" + colors[i]); } } }実行結果第二引数が0の場合 0:white 1:green 2:blue 3:red 第二引数が-1の場合 0:white 1:green 2:blue 3:red 4: 5:間にある空白文字を削除する場合
間の空白文字を削除するときには正規表現を使う。
サンプルコードpublic class Main { public static void main(String[] args) { String str = "white ,green ,blue,red"; String[] colors = str.split("[\\s]*,[\\s]*"); for (int i = 0; i < colors.length; i++) { System.out.println(colors[i]); } } }実行結果white green blue red参考文献
2分で理解!Javaの文字列を分割するsplitメソッド【Stringクラス】
Javaのsplitの使い方を現役エンジニアが解説【初心者向け】
- 投稿日:2020-12-08T17:49:21+09:00
JDBCの実行【基礎】
MySQLとEclipseを使ってデータベースへの接続処理をやってみます。
SQL
データベース用のデータには次のSQLを使います。
艦これが好きなので艦娘の情報にしました。
create database if not exists demo; use demo; drop table if exists kanmusu; CREATE TABLE `kanmusu` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(64) DEFAULT NULL, `ship_classification` varchar(64) DEFAULT NULL, `abbreviations` varchar(64) DEFAULT NULL, `sister` varchar(64) DEFAULT NULL, `level` INT(3) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=latin1; INSERT INTO `kanmusu` (`id`, `name`, `ship_classification`, `abbreviations`, `sister`, `level`) VALUES (1, 'Hamakaze', 'Destroyer', 'DD', 'Urakaze', 153); INSERT INTO `kanmusu` (`id`, `name`, `ship_classification`, `abbreviations`, `sister`, `level`) VALUES (2, 'Kitakami', 'Light Cruiser', 'CL', 'Oi', 133); INSERT INTO `kanmusu` (`id`, `name`, `ship_classification`, `abbreviations`, `sister`, `level`) VALUES (3, 'Abukuma', 'Light Cruiser', 'CL', 'Nagara', 133); INSERT INTO `kanmusu` (`id`, `name`, `ship_classification`, `abbreviations`, `sister`, `level`) VALUES (4, 'Shimakaze', 'Destroyer', 'DD', NULL, 131); INSERT INTO `kanmusu` (`id`, `name`, `ship_classification`, `abbreviations`, `sister`, `level`) VALUES (5, 'Zuikaku', 'Aircraft Carrier', 'CV', 'Shoukaku', 130); INSERT INTO `kanmusu` (`id`, `name`, `ship_classification`, `abbreviations`, `sister`, `level`) VALUES (6, 'Shoukaku', 'Aircraft Carrier', 'CV', 'Zuikaku', 129); INSERT INTO `kanmusu` (`id`, `name`, `ship_classification`, `abbreviations`, `sister`, `level`) VALUES (7, 'Tone', 'Flying-Deck Cruiser', 'CF', 'Chikuma', 127); INSERT INTO `kanmusu` (`id`, `name`, `ship_classification`, `abbreviations`, `sister`, `level`) VALUES (8, 'Maya', 'Heavy Cruise', 'CA', 'Choukai', 125); INSERT INTO `kanmusu` (`id`, `name`, `ship_classification`, `abbreviations`, `sister`, `level`) VALUES (9, 'Husou', 'Battleship', 'BB', 'Yamashiro', 122); INSERT INTO `kanmusu` (`id`, `name`, `ship_classification`, `abbreviations`, `sister`, `level`) VALUES (10, 'Musashi', 'Battleship', 'BB', 'Yamato', 122); INSERT INTO `kanmusu` (`id`, `name`, `ship_classification`, `abbreviations`, `sister`, `level`) VALUES (11, 'Ise', 'Battleship', 'BB', 'Hyuga', 121); INSERT INTO `kanmusu` (`id`, `name`, `ship_classification`, `abbreviations`, `sister`, `level`) VALUES (12, 'Saratoga', 'Aircraft Carrier', 'CV', 'Lexington', 121);MySQL Workbenchで新しいユーザーを作成して↑のSQLを読み込みます。
次に、以下SQLを実行して正しく表示されるかを確認します。
SELECT * FROM demo.kanmusuこんな感じになればOK
Eclipseからデータベースに接続する
EclipseでJDBCを使うためにMySQLコネクタをEclipseに読み込みます。
手順は次の通り
- このページ (https://www.mysql.com/jp/products/connector/)からJDBC Driver for MySQL (Connector/J)のダウンロードを選択
- Select Operating SystemでPlatform Independentを選択
- Platform Independent (Architecture Independent), ZIP Archiveのダウンロードをクリック
- 次のページではログインしなくて良いので下のNo thanks, just start my download.をクリック
ダウンロードが終わったらzipを解凍する
ファイル内のmysql-connector-java-XXXXXをコピーする
コピーしたものをEclipseで作成したプロジェクトにペーストする
Add JARsで先程のJARファイルをプロジェクトに追加する
これで準備完了です。
Javaのコード
import java.sql.*; public class JdbcTest { public static void main(String[] args) throws SQLException { Connection myConn = null; Statement myStmt = null; ResultSet myRs = null; String dbUrl = "jdbc:mysql://localhost:3306/demo"; String user = "student"; String pass = "studentpassword"; try { // 1. データベースに接続する myConn = DriverManager.getConnection(dbUrl, user, pass); // 2. ステートメントを作る myStmt = myConn.createStatement(); // 3. SQLクエリを実行する myRs = myStmt.executeQuery("select * from kanmusu"); // 4. リザルトセットを処理する while (myRs.next()) { System.out.println(myRs.getString("name") + " is Lv. " + myRs.getString("level")); // 行からデータを取得 } } catch (Exception exc) { exc.printStackTrace(); } finally { if (myRs != null) { myRs.close(); // 利用しなくなったデータベースへの接続を切断する } if (myStmt != null) { myStmt.close(); } if (myConn != null) { myConn.close(); } } } }実行するとこんな感じになります。
Hamakaze is Lv. 153 Kitakami is Lv. 133 Abukuma is Lv. 133 Shimakaze is Lv. 131 Zuikaku is Lv. 130 Shoukaku is Lv. 129 Tone is Lv. 127 Maya is Lv. 125 Husou is Lv. 122 Musashi is Lv. 122 Ise is Lv. 121 Saratoga is Lv. 121参考
- next() メソッドについて https://www.atmarkit.co.jp/ait/articles/0107/11/news001.html
- printStackTraceについて https://itsakura.com/java_printstacktrace





- 投稿日:2020-12-08T16:41:48+09:00
【Java】ApachePOIでExcelを出力する
初めに
yuji323です。今回の記事では、JavaのライブラリであるApachePOIを使ってExcelファイルを出力する方法について記事にします。
背景
業務で必要にかられたので。あと調べても古い記事が多くてちょっと不安だったので。
環境
pom.xml<dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</artifactId> <version>4.1.0</version> </dependency> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi-ooxml</artifactId> <version>4.1.0</version> </dependency>作成パターン① -.xlsxファイルを新規作成する
Java上で新規に.xlsxファイルを作成します。コードは以下
class CreateNewFile{ public static void main(String[] args){ // 出力先ファイルパス String output = "C\\users\\user\Desktop\newFileFromOrigin.xlsx" // 各オブジェクト作成 Workbook book = new XSSFWorkbook(); Sheet sheet = book.getSheet(this.sheetName); Row row; Cell cell; // Excelに書き込み row = sheet.getRow(0); cell = row.getCell(0); cell.setCelValue("Hello POI") // 出力 FileOutputStream fos = new FileOutputStream(fullDataExcelPath); book.write(fos); book.close(); fos.close(); } }作成パターン② -既存の.xlsxファイルをもとに作成する。
class CreateNewFile{ public static void main(String[] args){ // 入力ファイルパス String input = "C\\users\\user\Desktop\template.xlsx" // 元ファイル読み込み Workbook book = WorkbookFactory.create(new FileInputStream(input)); Sheet sheet = book.getSheetAt(0); Row row; Cell cell; // Excelに書き込み row = sheet.getRow(0); cell = row.getCell(0); cell.setCelValue("Hello POI") // 出力 book.write(new FileOutputStream(fullDataExcelPath)); book.close(); fos.close(); } }まとめ
・新規作成するとき:Workbook book = new XSSFWorkbook();
・元ファイルから作成するとき:Workbook book = WorkbookFactory.create(new FileInputStream("ファイルパス"));
でファイル作成できる。
- 投稿日:2020-12-08T15:27:04+09:00
エンジニア未経験が1か月でJava Silverに合格した話(勉強方法・受験当日の流れ)
はじめに
2020年7月から独学でJavaを勉強しているのですが、先日Java Silverに合格しました。
この記事では、1 エンジニア未経験者が独学でJava Silverに合格した勉強方法
2 受験当日の流れについてまとめます。
2については、「試験ってどんな感じで実施されるのか?」「メモは取れるのか?」等について意外と情報が少なく、CBT形式の試験になじみのなかった私にとっては当日までかなりの不安材料になっていました。同じような方もいるのではと思ったのでここに記録しておこうと思います。受験前の知識・能力
簡単にまとめますが、こんな感じです。
・ 2020年7月からプログラミングを独学で勉強中
・ 本職はITと全く関わりのない職種で、勉強開始時点でIT関連の知識はほぼゼロ
・ Javaの入門書『スッキリわかるJava入門 入門編』全部と『同書 実践編』第1章まで勉強済
・ サーブレット&JSPでツイートアプリを作成勉強期間
・勉強開始時期 2020年11月初旬
・受験日 2020年12月7日
・勉強時間 週に10~12時間くらい結果、合格ライン63%に対し、正答率79%でした。
勉強方法
教材
メイン教材:『徹底攻略 Java SE11 Silver 問題集』
サブ教材 :『スッキリわかるJava入門 実践編』(1~6章)基本的には黒本1冊でいけます。
サブ教材の方は、ラムダ式等、全く馴染みのない分野に差し掛かった時に参照しました。前提
この勉強方法をやる場合、最低でもJavaの入門書を1冊終わらせておいた方がいいです。急いで黒本に手をつけるより、その方が効率的です。
また、賛否あるかもしれませんが、私のおすすめの入門書は『スッキリわかるJava入門 入門編』です。プログラミング経験ゼロでこの本を手に取りましたが、特に苦を感じることなく1周できました。1 黒本1~11章を章ごとに2,3周やる
この本は、1~11章がテーマ毎の例題集、12,13章が総仕上げ問題になっています。
1周目は問題を解くのに時間をかけすぎず、わからない部分をはっきりさせたらすぐ解説読んでください。入門書で出てこなかった知識がバンバン出てくるので、悩むだけ無駄です。この本は問題構成がしっかり考えられていて、基礎部分から応用部分に向かって進むように解説が練られています。この本の解説を読むと、各章の知識がしっかり身に着きます。
その上で2周目、3周目に取り組みます。2 頻繁に間違える分野をまとめる
2,3周すると、できない問題がはっきりします。その際、やみくもに周回を重ねるのではなく、自分でまとめを作りましょう。(ブログでもいいですし、単なるメモでもいいと思います。)黒本解説ページから重要な部分を抜き出して書き留めるだけで、覚えがぐっとよくなります。
例:【Java】Javaの配列ルールまとめ【Java Silver】
3 総仕上げ問題(12,13章)を解く(2、3周)
1~11章がある程度わかってきたら、総仕上げ問題に取り掛かります。12,13章は一応模試形式になっていますが、「試験前の腕試し」というよりかは「1~11章で解説しきれていない細かい部分の補完」といった意味合いが強いです。試験直前まで取っておかず、早めに手を付けた方がいいです。
問題数が多いので、解答全てを読む必要はなし。時間をかけるのは解けなかった問題のみでいいので、13章まで必ずやりましょう。4 1~13章通して復習
最後に、頻繁に間違える問題をピックアップして繰り返し解きます。
必要に応じてまとめ、メモを作成。受験申込~受験当日
自分が「受験前知りたかったな」と思ったことをメインに列挙します。
受験申込
受験申込については、こちらの記事がものすごく参考になったので、紹介させていただきます。
Oracleの試験は受験用バウチャーを販売している機関と受験申込をする機関が違うこともあり、手続がかなり難解でした・・・
こちらの記事に沿って進めていき、なんとか無事申込できました。本当に助かりました。受験当日
必要なもの
必要なものはただ1つ。本人確認書類のみです。
ただ、最低でも2通必要です。私は運転免許証と保険証の組み合わせで提示しました。
詳細はこちら。受付~試験室入室
・受付では、「氏名」と「試験予定時刻」を申告すればOKです。ピアソンの予約画面等を提示する必要はありませんでした。
・受付で本人確認書類を提示し、写真撮影を行いました。(ものの10秒で終わりました)
・その後受験要領の説明、ロッカーのカギを渡され、身分証明書1通・ロッカーのカギ以外はロッカーにしまうよう指示されます。指示されたものをロッカーにしまったら、試験室の方に案内されます。
試験について
・試験室に案内される際、A4サイズのラミネート加工された白紙と、油性ペンを渡されます。試験中のメモはその紙で行います。(試験はパソコンで行われますが、試験用のアプリケーション以外は使用できないようになっており、パソコンでメモをとったり、計算したりということはできません。)
・試験はすべて選択式ですが、マウスで選択肢のチェックボックスをクリックしていく形で行われます。それ以外の操作(マウスで文字列を選択したり)はできません。
・アプリケーションには、レビュー機能があり、後で確認したい問題にチェックを付けることができます。また、レビュー画面では「未回答の問題」だけに絞って表示させる機能もあり、自分でメモしておく必要がなく便利でした。
試験中の時間管理について
・試験開始時刻は、ディスプレイ上の「試験開始」ボタンをクリックした時です。受付が早く済めば予定時刻より早く開始できますし、もし手続が長引いて、入室が遅れても試験時間が削られるということはないようです。
・残り時間はディスプレイ右上に表示されます。
・回答が早めに終了した場合、試験時間がどれだけ残っていても、試験中に回答の提出、退室ができるようでした。
実際に受けてみて
試験内容
・あくまで体感ですが、黒本で全く触れられてない部分を問う問題は1割もありませんでした。また、問題の1割程度は黒本と全く一緒、選択肢を変えただけな問題でした。
・今回私が受験した問題は、特に13章で出題されたものと似ている問題が多かったです。13章をもっとちゃんとやればよかったと後悔。
その他
・受付時に「ロッカーに荷物を収納するよう」指示されるので、受付後にゆっくり参考書を確認する時間はありませんでした。試験開始前に落ち着いて最後の確認をしたい方は、受付前に済ませておいた方がいいかも。
・私は平日の昼間に新宿のテストセンターで受験したのですが、10数人入れる試験室で自分1人だったので非常に快適でした。土日だと混雑していて物音等が気になるという話もありました。都合のつく方は人の少なそうな時間帯を選ぶといいかもしれません。
さいごに
最初の目的は「資格取得」でしたが、Javaにしっかり向き合う良い機会になりました。
- 投稿日:2020-12-08T15:27:04+09:00
エンジニア未経験が独学でJava Silverに合格した話(勉強方法・受験当日の流れ)
はじめに
2020年7月から独学でJavaを勉強しているのですが、先日Java Silverに合格しました。
この記事では、1 エンジニア未経験者が独学でJava Silverに合格した勉強方法
2 試験当日の流れについてまとめます。
2については、「試験ってどんな感じで実施されるのか?」「メモは取れるのか?」等の情報が意外と少なく、CBT形式の試験になじみのなかった私にとっては当日までかなりの不安材料になっていました。同じような方もいるのではと思ったのでここに記録しておこうと思います。受験前の知識・能力
簡単にまとめますが、こんな感じです。
・ 2020年7月からプログラミングを独学で勉強中
・ 本職はITと全く関わりのない職種で、勉強開始時点でIT関連の知識はほぼゼロ
・ Javaの入門書『スッキリわかるJava入門 入門編』全部と『同書 実践編』第1章まで勉強済
・ サーブレット&JSPでツイートアプリを作成勉強期間
・勉強開始時期 2020年11月初旬
・受験日 2020年12月7日
・勉強時間 週に10~12時間くらい結果、合格ライン63%に対し、正答率79%でした。
勉強方法
教材
メイン教材:『徹底攻略 Java SE11 Silver 問題集』
サブ教材 :『スッキリわかるJava入門 実践編』(1~6章)基本的には黒本1冊でいけます。
サブ教材の方は、ラムダ式等、全く馴染みのない分野に差し掛かった時に参照しました。前提
この勉強方法をやる場合、最低でもJavaの入門書を1冊終わらせておいた方がいいです。急いで黒本に手をつけるより、その方が効率的です。
また、賛否あるかもしれませんが、私のおすすめの入門書は『スッキリわかるJava入門 入門編』です。プログラミング経験ゼロでこの本を手に取りましたが、特に苦を感じることなく1周できました。1 黒本1~11章を章ごとに2,3周やる
この本は、1~11章がテーマ毎の例題集、12,13章が総仕上げ問題になっています。
1周目は問題を解くのに時間をかけすぎず、わからない部分をはっきりさせたらすぐ解説読んでください。入門書で出てこなかった知識がバンバン出てくるので、悩むだけ無駄です。この本は問題構成がしっかり考えられていて、基礎部分から応用部分に向かって進むように解説が練られています。まず解説をしっかり読み、その上で2周目、3周目に取り組みます。
2 頻繁に間違える分野をまとめる
2,3周すると、できない問題がはっきりします。その際、やみくもに周回を重ねるのではなく、自分でまとめを作りましょう。(ブログでもいいですし、単なるメモでもいいと思います。)黒本解説ページから重要な部分を抜き出して書き留めるだけで、覚えがぐっとよくなります。
例:【Java】Javaの配列ルールまとめ【Java Silver】
3 総仕上げ問題(12,13章)を解く(2,3周)
1~11章がある程度わかってきたら、総仕上げ問題に取り掛かります。12,13章は一応模試形式になっていますが、「試験前の腕試し」というよりかは「1~11章で解説しきれていない細かい部分の補完」といった意味合いが強いです。試験直前まで取っておかず、早めに手を付けた方がいいです。
問題数が多いので、解答全てを読む必要はなし。時間をかけるのは解けなかった問題のみでいいので、13章まで必ずやりましょう。4 1~13章通して復習
最後に、頻繁に間違える問題をピックアップして繰り返し解きます。
必要に応じてまとめ、メモを作成。
受験申込~受験当日
自分が「受験前に知りたかったな」と思ったことをメインに列挙します。
受験申込
受験申込については、こちらの記事がものすごく参考になったので、紹介させていただきます。
Oracleの試験は受験用バウチャーを販売している機関と受験申込をする機関が違うこともあり、手続がかなり難解でした・・・
こちらの記事に沿って進めていき、なんとか無事申込できました。本当に助かりました。受験当日
必要なもの
必要なものはただ1つ。本人確認書類のみです。
ただ、最低でも2通必要です。私は運転免許証と保険証の組み合わせで提示しました。
詳細はこちら。受付~試験室入室
・受付では、「氏名」と「試験予定時刻」を申告すればOKです。ピアソンの予約画面等を提示する必要はありませんでした。
・受付で本人確認書類を提示し、写真撮影を行いました。(ものの10秒で終わりました)
・その後受験要領の説明、ロッカーのカギを渡され、身分証明書1通以外はロッカーにしまうよう指示されます。指示されたものをロッカーにしまったら、試験室の方に案内されます。
試験について
・入室前にA4サイズのラミネート加工された白紙と、油性ペンを渡されます。試験中のメモはその紙で行います。(試験はパソコンで行われますが、試験用のアプリケーション以外は使用できないようになっており、パソコンでメモをとったり、計算したりということはできません。)
・試験はすべて選択式で、チェックボックスをクリックしていく形で行われます。それ以外の操作(マウスで文字列を選択したり)はできません。
・試験用アプリにはレビュー機能があり、後で確認したい問題にチェックを付けることができます。また、レビュー画面では「未回答の問題」だけに絞って表示させる機能もあり、自分でメモしておく必要がなく便利でした。
試験中の時間管理について
・試験開始時刻は、ディスプレイ上の「試験開始」ボタンをクリックした時です。受付が早く済めば予定時刻より早く開始できますし、もし手続が長引いて、入室が遅れても試験時間が削られるということはないようです。
・残り時間はディスプレイ右上に表示されます。
・回答が早めに終了した場合、残り時間に関わらず試験中に回答の提出、退室ができます。
実際に受けてみて
試験内容
・あくまで体感ですが、黒本で全く触れられてない部分を問う問題は1割もありませんでした。また、問題の1割程度は黒本と全く一緒、選択肢を変えただけな問題でした。
・今回私が受験した問題は、特に13章で出題されたものと似ている問題が多かったです。13章をもっとちゃんとやればよかったと後悔。
その他
・受付時に「ロッカーに荷物を収納するよう」指示されるので、受付後にゆっくり参考書を確認する時間はありませんでした。試験開始前に落ち着いて最後の確認をしたい方は、受付前に済ませておいた方がいいかも。
・試験時間は3時間ですが、試験途中の入退出は禁止でした。トイレ行きたくても行けません・・・「途中でトイレ行きたくなったらどうしよう」と少しだけ不安になりました。
さいごに
最初の目的は「資格取得」でしたが、勉強してみると自分の理解が全然足りていなかったということを思い知らされ・・・Javaにしっかり向き合う良い機会になりました。この試験は試験終了後の結果通知で、ミスの多かった分野を教えてくれるので、自分の弱点もわかります。
これからも地道に、頑張って勉強していこうと思います!
- 投稿日:2020-12-08T14:43:58+09:00
JDBCの概要と使い方
JDBC (Java DataBase Connectivity)とは
Javaアプリケーションとリレーショナルデータベースをつなげるもの (API)。
特徴
- 様々なデータベースへのポータブルなアクセスを提供する 異なるデータベースごとにコードを書く必要がない
- Call Level Interface ANSI SQL 2003 をサポートしている
- カスタムのSQLステートメントをビルドできる
- select, insert, update, delete
- inner / outer join
- ストアドプロシージャをコールする
サポートしているデータベース
JDBCのアーキテクチャー
- JDBCドライバー
- データベースへの接続を提供する
- JDBCのコールを特定のデータベース用に変換する
- JDBCドライバーの実装
- データベースのベンダーによって供給される
JDBCドライバーマネージャー
- データーベースコネクションストリングに基づいたアプリケーションの接続を助ける
JDBC API
JDBCのAPIは次のパッケージで定義される
java.sql // と javax.sqlキーとなるクラス
- java.sql.DriverManager
- java.sql.Connection
- java.sql.Statement
- java.sql.ResultSet
- javax.sql.DataSource (コネクションプーリングのために)
開発プロセス
- データベースへ接続する
- ステートメントオブジェクトを作成する
- SQLクエリを実行する
- リザルトセットを処理する
1. データベースへ接続する
データベースに接続するために、JDBCのURLのフォームが必要
jdbc:<ドライバーのプロトコル>:<ドライバーコネクションの詳細>import java.sql*; ... String dbUrl = "jdbc:mysql://localhost:3306/demo"; // データベースのURL String user = "student"; // ユーザー名 String pass = "student"; // パスワード Connection myConn = DriverManger.getConnection(dbUrl, user, pass); // データベースへの接続データベースへの接続に失敗したら例外が投げられます。
java.sql.SQLExeption // urlなどの認証情報が間違っている java.lang.ClassNotFoundException // JDBCドライバーがパスに入っていない2. ステートメントオブジェクトを作成する
ステートメントとは、広義で「命令」のこと。
SQLは命令の一種。import java.sql*; ... String dbUrl = "jdbc:mysql://localhost:3306/demo"; // データベースのURL String user = "student"; // ユーザー名 String pass = "student"; // パスワード Connection myConn = DriverManger.getConnection(dbUrl, user, pass); // データベースへの接続 Statement myStmt = myConn.createStatement(); // ステートメントオブジェクトの作成3. SQLクエリを実行する
import java.sql*; ... String dbUrl = "jdbc:mysql://localhost:3306/demo"; // データベースのURL String user = "student"; // ユーザー名 String pass = "student"; // パスワード Connection myConn = DriverManger.getConnection(dbUrl, user, pass); // データベースへの接続 Statement myStmt = myConn.createStatement(); // ステートメントオブジェクトの作成 ResultSet = myTs = myStmt.executeQuery("select * from employees"); // SQLクエリの実行4. Result Setを処理する
- カーソルは最初の行の1つ前に置かれる(カーソルってなに?)
- カーソル(簡単にまとめると、検索結果に対して1件ずつ処理するための仕組み)
- このページも参考になる (https://www.techscore.com/tech/sql/SQL12/12_02.html/)
- ResultSet.next() メソッド
- 一行ずつ進む
- 処理する行があればtrueを返す
- データを読み込むためのメソッド
- getXXX(columnName)
- getXXX(columnIndex) // 1オリジンになる (one-based)
import java.sql*; ... String dbUrl = "jdbc:mysql://localhost:3306/demo"; // データベースのURL String user = "student"; // ユーザー名 String pass = "student"; // パスワード Connection myConn = DriverManger.getConnection(dbUrl, user, pass); // データベースへの接続 Statement myStmt = myConn.createStatement(); // ステートメントオブジェクトの作成 ResultSet = myTs = myStmt.executeQuery("select * from employees"); // SQLクエリの実行 while (myRs.next()) { // 各行のデータを読み込む System.out.println(myRs.getString("last_name")); System.out.println(myRs.getString("first_name")); }まとめ
JDBCでデータベースを操作する流れは以下のとおりです。
- データベースへ接続する
- ステートメントオブジェクトを作成する
- SQLクエリを実行する
- リザルトセットを処理する

- 投稿日:2020-12-08T14:14:41+09:00
commons-lang3のFailableが便利
先にまとめ
Java8で登場したLambda式を使うと、例外処理が煩雑になりがちだけど、Apache Commons Lang3(3.11以降)のFailableを使用すると以下のようにスッキリ書ける。
使用前
private static void deleteFiles(List<Path> paths) throws IOException { for (Path path : paths) { Files.deleteIfExists(path); } }使用後
private static void deleteFiles(List<Path> paths) throws IOException { paths.forEach(Failable.asConsumer(Files::deleteIfExists)); }以下、ここに至る経緯。読み飛ばし可。
Streamを使うと途端に例外処理が面倒になるよね
Java8でLambda式が登場し、コードがなんかカッコよく書けるようになった。早速自分もLambdaしてみよう!モダンなプログラマーっぽくなろう!とやってみると、例外処理でハマる。
private static void deleteFiles(List<Path> paths) throws IOException { for (Path path : paths) { Files.deleteIfExists(path); } }これをLambdaで書いてみる。
private static void deleteFiles(List<Path> paths) throws IOException { paths.forEach(Files::deleteIfExists); }すると、
Files.deleteIfExistsがthrowするIOExceptionが処理されない、とコンパイルエラーになってしまう。よく見るとConsumer.acceptにはthrows定義が無いので当然ではある。
従ってこれを以下のようにtry-catchでIOExceptionをハンドルする必要がある。しかし、これでは発生したIOExceptionをメソッドの呼び出し元にthrowするというインターフェイスを崩してしまうことになる。(またなにより、Lambdaを使ってカッコよく、という当初の目的が達せられず、レガシーなJavaおじさんに戻ってしまうことになる。)private static void deleteFiles(List<Path> paths) throws IOException { paths.forEach(t -> { try { Files.deleteIfExists(t); } catch (IOException e) { // handle e } }); }ちなみに、インターフェイスを崩さないよう発生例外を送出するにはこのような実装が必要になり、レガシーJavaおじさんどころか、退化してしまっているんではないかと思われる。
private static void deleteFiles(List<Path> paths) throws IOException { try { paths.forEach(t -> { try { Files.deleteIfExists(t); } catch (IOException e) { throw new UncheckedIOException(e); } }); } catch (UncheckedIOException e) { throw e.getCause(); } }解決
世の中のみなさんはどうしているのだろう、と調べていたら、こんな事例が。
(ネタ元が見当たらない。海外の人の投稿だったと記憶。ConsumerではなくFunctionの例だったかも。)public class RethrowFunctions { @FunctionalInterface public interface ConsumerWithExceptions<T, E extends Exception> { void accept(T t) throws E; } public static <T, E extends Exception> Consumer<T> rethrowConsumer(ConsumerWithExceptions<T, E> consumer) throws E { return t -> { try { consumer.accept(t); } catch (Exception exception) { // CS:IGNORE Exceptionのcatchは仕方ない throwAsUnchecked(exception); } }; } private static <E extends Throwable> void throwAsUnchecked(Exception exception) throws E { throw (E) exception; }これを使うと、以下のように書ける。これならインターフェイスも崩さず、そしてシンプル!
private static void deleteFiles(List<Path> paths) throws IOException { paths.forEach(RethrowFunctions.rethrowConsumer(Files::deleteIfExists)); }という訳で同様の実装を以下のFunctionalInterfaceに対しても実装し、そのjavaファイルを必要なプロジェクトに配って回ったのである。
(配布方法がイマイチではあるが、いろいろと制約事項があり。)
- java.lang.Runnable
- java.util.function.Function
- java.util.function.Predicate
- java.util.function.Supplier
- java.util.function.BiConsumer
- java.util.function.BiFunction
- java.util.function.BiPredicate
解決、その後
ある日、commons-lang3に
Failableというものを発見。もしや?!と思ってみてみると、まさに前述のRethrowFunctionsと同じことを実現するものであった。commons-lang3であればすでに様々なプロジェクトで使用しているし汎用的なものなので、これからは自作javaファイルを配らずこちらを使うことにしよう。というわけで、commons-lang3の
Failableおすすめ。
- 投稿日:2020-12-08T12:57:58+09:00
循環的複雑度を測定して、生産性をBoostしよう!(Java)
本記事では、
- プロジェクトのリスク患部にすぐ効き
- すばやくテスト実行ができ
- 本当に重要なことに焦点をあてることができ
- アプリケーションコードとテストコードのバランスを保つことができ
- CIに組み込むことができ
- IDEで使えて生産性を爆上げできる
といったツールを紹介します。
それがOpenCloverというツールです。
OpenCloverとは
高機能なJavaカバレッジ計測ツールの1つです。
もともとはAtlassianという会社の製品だったのですが、2017年にOSSになりました。以降も開発は続けられているようですが、現在(2020/12時点)の最新版のリリースは2019年10月のものとなっています。特徴
対応言語
Java,Groovy,AspectJに対応しています。値段
OSSなのでもちろん無料です。
コードカバレッジの種類
3種類のカバレッジを提供しています。
- method coverage
- テスト実行時に使用されたメソッドの計測
- statement coverage
- テスト実行時に通ったコードの計測
- branch coverage
- テスト実行時のコードの分岐(if文とか)の計測
コードメトリクスの種類
20種類以上のメトリクス計測を行うことができます。ここではいくつか主要なものを紹介したいと思います。
- complexity
- 循環的複雑度の計測
- avgMethodComplexity
- 1メソッドあたりの分岐数による複雑度の平均
- complexityDensity
- 1文あたりの循環的複雑度(=循環的複雑度の密度)
- Branches
- 分岐の数
- Statements
- コード実行行
- Total Coverage
- テストによってカバーされた割合
- ncLineCount
- コメント行を除いた行数
- lineCount
- 行数
循環的複雑度については、ググるとわかりやすい説明が出てくるのでそちらを参照してみてください。Qiitaにもいくつか記事が上がっています。
例:
public class Complexity { public String helloWorld() { return "Hello world"; } public String greet(boolean isMorning) { if (isMorning) { return "Good Morning"; } else { return "Hello"; } } }public class ComplexityTest { @Test public void returnHelloWorld() { Complexity target = new Complexity(); String actual = target.helloWorld(); assertEquals("Hello world", actual); } @Test public void returnGoodMorning() { Complexity target = new Complexity(); String actual = target.greet(true); assertEquals("Good Morning", actual); } }以上のようなコードで単体テストを実行すると、
以上のような結果が得られます。
helloWorld()は分岐なしで循環的複雑度が1、greet(boolean isMorning)はif elseで循環的複雑度が2なので、1クラスあたりの循環的複雑度の合計が3、平均が1.5となります。
また、カバレッジ率もファイル、クラス、メソッドごとに割合が表示されます。public String numToString(int num) { if (num == 1) { return "1"; } else if (num == 2) { return "2"; } else if (num == 3) { return "3"; } else if (num == 4) { return "4"; } else if (num == 5) { return "5"; } else { return "not supported"; } }以上のようなコードを追加してテストを実行してみると、
カバレッジ率や循環的複雑度の合計・平均、分岐の数などが再計算されます。対応ツール
ビルドツール
- Ant
- Maven
- Gradle
- Grails
- Griffon
CIツール
- Jenkins
- Hudson
- Bamboo
IDE
- Eclipse
- IntelliJ IDEA
その他
- Sonar
- JIRA
テストツール
- JUnit 3 & 4
- TestNG
- Spock
レポートファイル
以下のファイルに計測結果を出力できます。
- HTML
- XML
- JSON
- TEXT
使用例(Eclipse)
導入手順
http://openclover.org/doc/manual/latest/eclipse--openclover-for-eclipse-in-10-minutes.html
↑に書いてあるとおりにプラグインを導入していきます。
使用しているeclipseのバージョンは2019-03です。
- 上部メニューの
Help → Install new softwareを選択- `
Addボタンをクリック、Name:のテキストボックスには適当に何か名前を入れて、Location:にhttp://openclover.org/update を入れて、AddボタンをクリックClover 4が表示されるのでチェックボックスにチェックするFinishボタンをクリック- ライセンスに同意して、再起動が促されるのでeclipseを再起動
使用方法
https://github.com/ludopradel/refactoring-movie-rental
https://github.com/42skillz/MovieRental
↑のコードを使用しています。
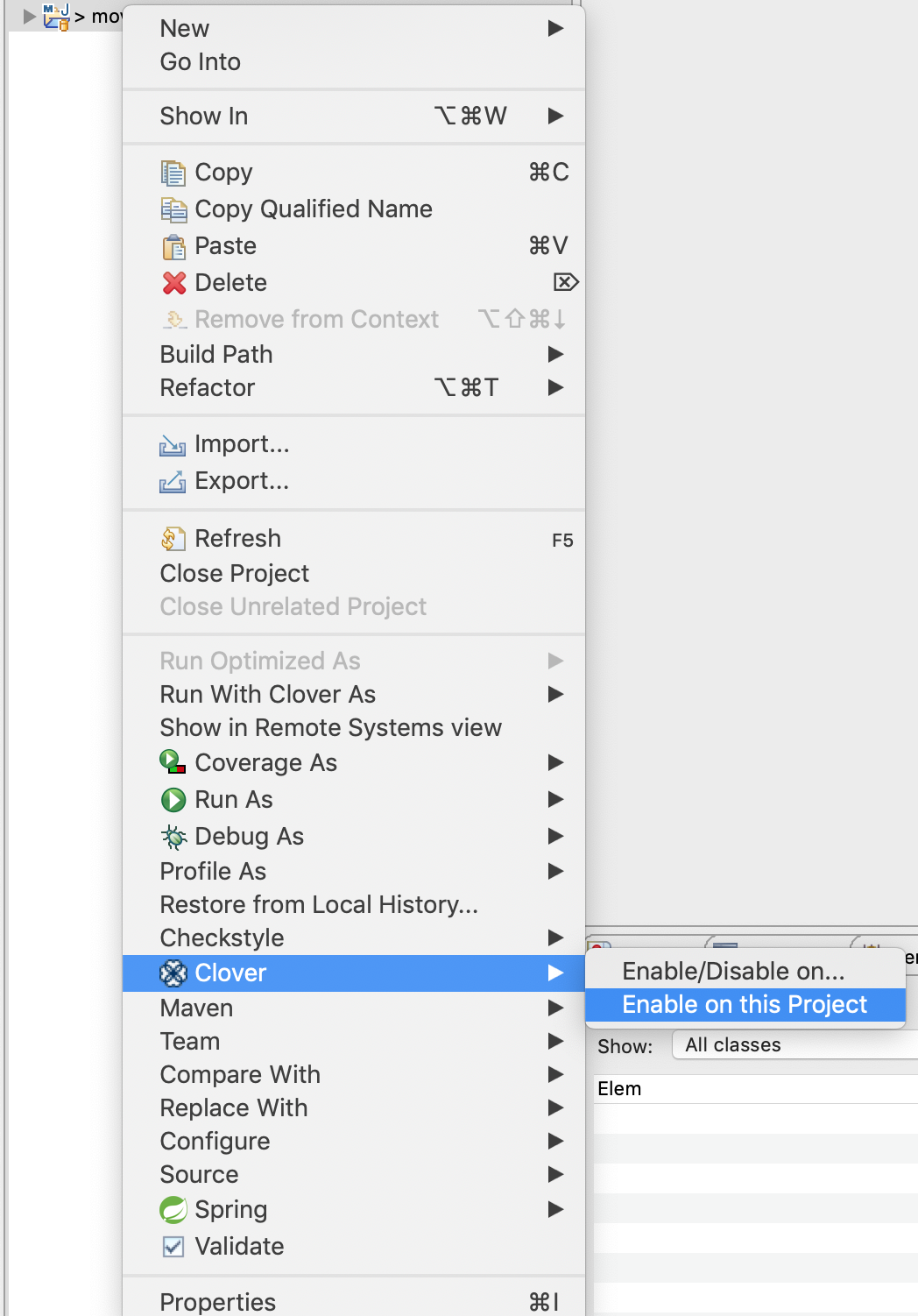
- プロジェクトを選択して右クリック
Clover → Enable on this Projectをクリック (Enable/Disable onを選択すると、複数のプロジェクトでCloverの使用可否を設定できる) (このときメトリクス測定コードを対象のプロジェクトコードに埋め込み、別のファイルとしてビルドするため、プロジェクトが巨大な場合は時間がかかる)- Cloverがenableになったプロジェクトで単体テストを実行すると、カバレッジ、メトリクスの測定がされます
テスト実行後
実行したテストでカバーされたコードの背景色は緑色、カバーされなかったコードは赤色になります。
左側には表示される数字は、実行したテストによってコードが通った回数になります。各タブについて
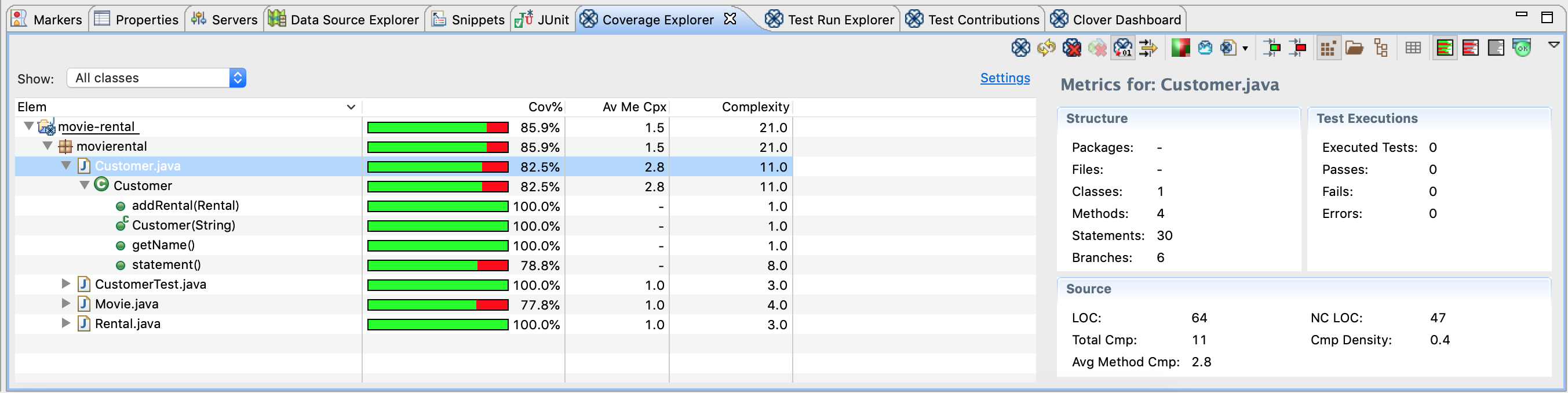
Coverage Explorer
各クラス/メソッドのテストカバレッジ率、メソッドの平均複雑度と複雑度が表示されます。このタブがCloverのHome画面のようなもので、右上のアイコンでいろいろな操作が可能です。
- Cloverのenbale/disabel
- カバレッジの更新、カバレッジ記録の削除
- レポートの出力
- プロジェクトの表示
- カバレッジの背景色の表示
などの操作ができます。
Test Explorer
実行したテストのリスト、いつ実行したか、テスト結果、テスト実行時間、テスト実行時のメッセージが表示されます。
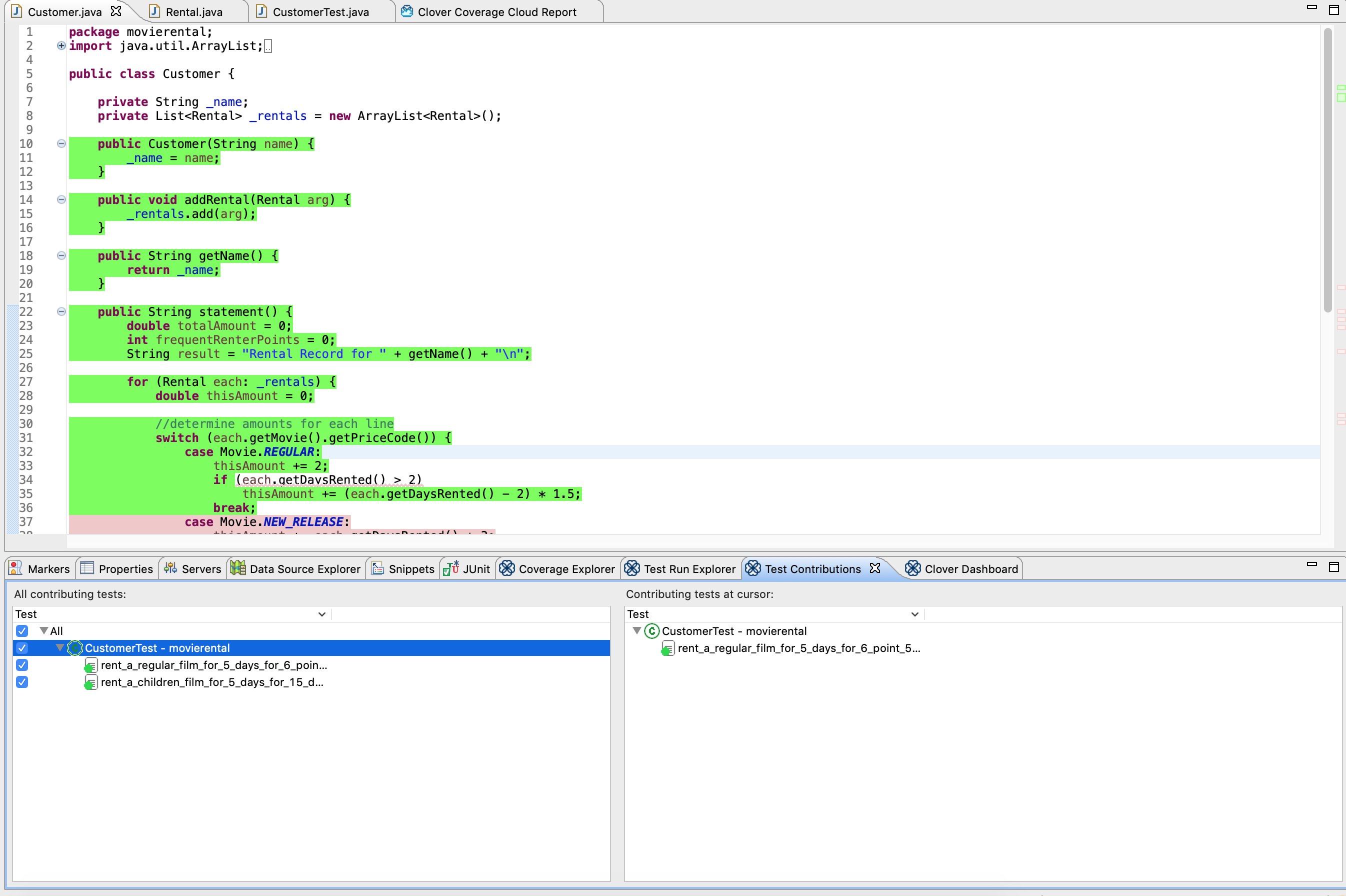
ほとんどJUnitのタブと差はありませんが、こちらのほうが見やすいと思います。Test Contribution
エディターで開いているファイルのコードカバーに貢献(直訳)しているテストが左側に、カーソル位置を通っているテストが右側に表示されますClover Dashboard
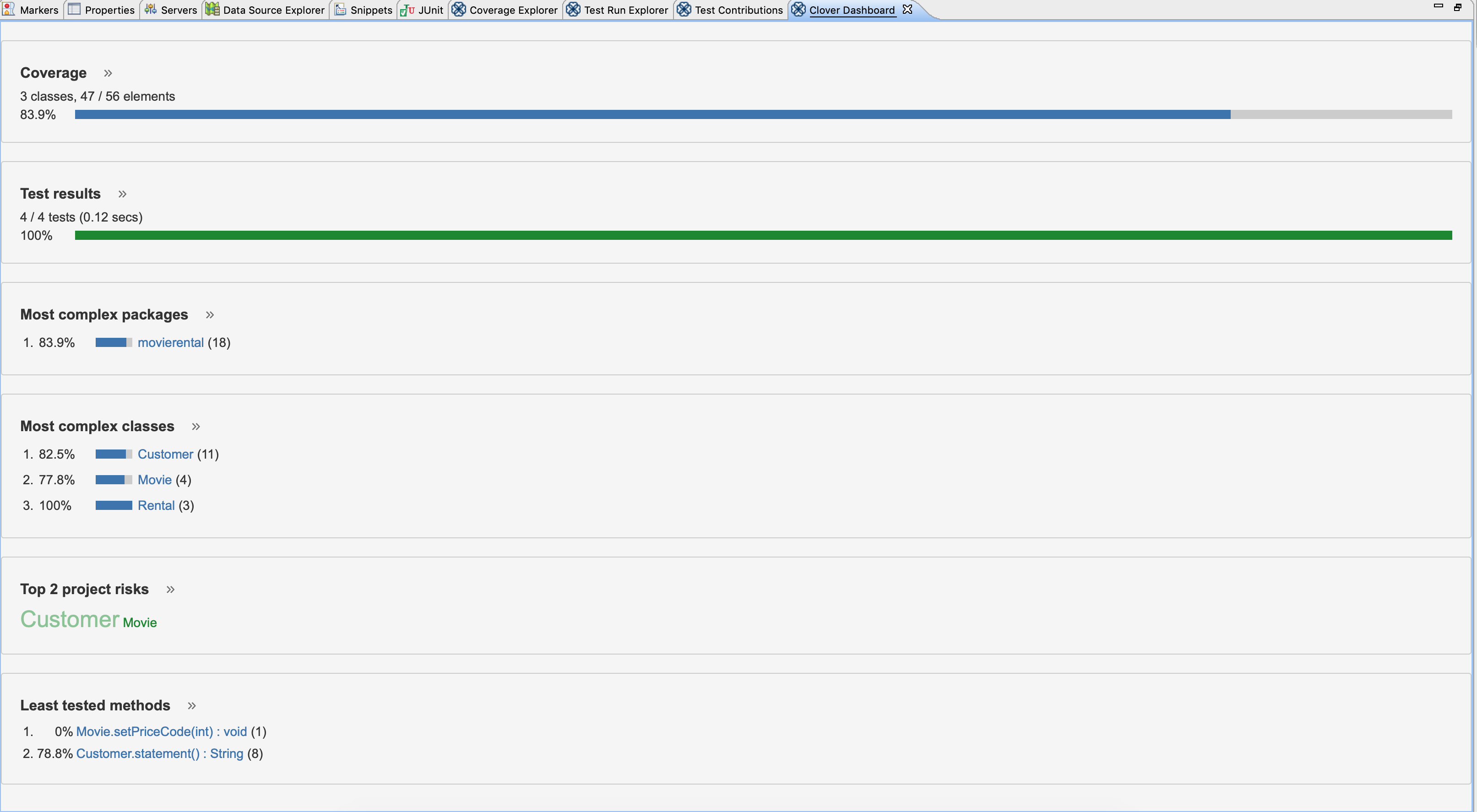
文字通りダッシュボードです。カバレッジ、テスト結果、循環的複雑度の高いパッケージ、クラス、プロジェクト内でリスクの高い(=複雑度が高い)クラス、最新のテストしたメソッドの概要が表示され、その詳細画面へと遷移することができます。レポート内容
http://openclover.org/doc/manual/4.2.0/general--understanding-reports-current.html
Dashboard
コード分析結果の概要やグラフが表示されます。See moreのやパッケージ/クラス/メソッドのリンクをクリックすると、それぞれのタブページに遷移します。Application code
プロジェクト、パッケージレベルのコードメトリクスの概要が表示されます。また、各ソースファイルのメトリクス、カバレッジ結果も閲覧することが可能です。Test code
Application Codeタブの内容と同様です。テストファイルのコードメトリクス、カバレッジ結果を閲覧できます。
Test results
実行されたテストに関する情報が表示されます。テスト結果や期間、テスト対象となったクラスのリストなど。
Top risks
Openclover特有のレポート結果の1つです。
コードのカバレッジ率が低→高になるにつれ、色が赤→緑となっています。
またメソッドの複雑度が高いクラスほど大きい文字で表示されます。
クラス名が赤色に近く大きいフォントサイズであるほど、コードがテストされておらず複雑なクラスになっている(=リスクが高い)ということになります。直感的でわかりやすいですね。Quick wins
これもOpenclover特有のレポート結果の1つです。
Quick winsという名の通り、簡単に勝てる、つまり「これをテストすれば簡単に全体的なカバレッジがあがる」というクラスを示してくれています。
("low hanging coverage fruit" = 低いところに吊るされたカバレッジフルーツ = 楽に手に入れる、達成することができるカバレッジ目標)
テストされていないコードや分岐が多→少になるにつれ、赤→緑となっています。
またコードや分岐の数が多いクラスほど大きい文字で表示されます。
クラス名が赤色に近く大きいフォントサイズであるものからテストを達成することで、全体的なテストの達成率をあげることができるということになります。
Top risksと文字色、大きさの指標が違うところに注意しましょう。Coverage tree map
これも面白い分析結果です。
テストしたプロジェクトのカバレッジ率と複雑度がマップ上に可視化されたものになります。
マップ上の領域が広く赤いほど、複雑度が高くテストによってカバーされていないクラスになるので、その部分をクリックしてどんなコード内容になっているのかを確認するといった使い方ができるかと思います。
規模が大きめのプロジェクトでマップすべてが緑色で埋め尽くされたら、きっと壮観なマップになることでしょう。本ツールの使い所
例えば、テストコートがあまり充実していない、そもそもテストコードがないというようなレガシープロジェクトにおいて、このツールは強力な効果を発揮するでしょう。
そういったレガシープロジェクトでは、テストを追加しよう、リファクタリングをしようという方針が決まっても、どこから手をつけたらいいかわからないといったケースが多々あるかと思います。
そこでこのツールを使ってレポート出力をしてみて、どこのクラスが循環的複雑度が高いのかなどの内容をチーム内で共有し、テストを追加、リファクタしていくクラスを決定するといった計画が立てやすくなると思います。また、そもそも単体テストを追加していくことやリファクタリングをすることに懐疑的な方々に対しての説得材料として、レポートを使うことができるかもしれません。
「現状のプロダクトはこんなにコードが複雑になっていて、これ以上機能追加をしていくとバグの混入率も高くなるし、機能追加にも時間がかかります」といった内容を数値と一緒に提示することができれば、コードの改善に割ける時間をGETしやすくなるでしょう。テストコードが充実しているプロジェクトでも、機能追加した際のテストの抜け漏れを確認しやすいと思います。
あるいは、新人教育のツールとしても一役買うかもしれません。
私は新人のときに課題でデモアプリを作成しました。そのときに先輩社員から「1メソッドあたり多くても10~20行になるように作ってみるといいよ」と目標を提示されました。
処理を分割して可読性の良いコードを書く、といった意図があったと思われますが、たとえ1メソッドあたり10行前後で書かれていてもif文がnestしまくっていたり論理演算子が多かったりしていたら、行数は短くても読みやすいとは言えません。
そこでこのツールを用いてコードの複雑度を計測して、その数値を10以下に抑えるといった目標でコードを書いてもらえば、より可読性の良いコードを書く練習になると思います(循環的複雑度が10以下だと非常に良い構造だと言われています)。
また、自分で書いたコードが客観的に見て良いコードなのかというのを数値で判断することができ、そこからコードの改善意識も高まるかもしれません。豊富な分析結果がレポートとしてきれいに可視化されるので、大規模なプロジェクトになるほど、使い勝手のよいコード共有ツールとして使用できるかと思います。
まとめ
導入も簡単にできるし、使い方も難しくなく、レポートも直感的でわかりやすく読みやすい。そして無料!
とりあえず入れておいて損はないと思います。上手く使えれば謳い文句にもある通り、生産性を大幅にブーストすることも可能でしょう。
Javaで開発をしている方々、ぜひ1度試してみてはいかがでしょうか?













- 投稿日:2020-12-08T07:54:40+09:00
【Java・SpringBoot】明示的トランザクション処理(SpringBootアプリケーション実践編21)
ホーム画面からユーザー一覧画面に遷移し、ユーザーの詳細を表示するアプリケーションを作成して、Spring JDBCの使い方について学びます⭐️
前回は、トランザクションの基本的な処理である宣言的トランザクション実装したので、今回は明示的トランザクションを学びます^^
構成は前回/これまでの記事を参考にしてください⭐️前回の記事
Java・SpringBoot】宣言的トランザクション処理(SpringBootアプリケーション実践編20)明示的トランザクション
- 実践では宣言的トランザクションを使う
- Springが用意するトランザクションでは対応できない場合に、明示的トランザクションを使う
明示的トランザクションの使い方
- PlatformTransactionManagerクラス
- トランザクションを開始、コミットなどをするクラス
PlatformTransactionManager txManager; //トランザクション開始 TransactionStatus status = txManager.getTransaction(def); //コミット txManager.commit(status);
- DefaultTransactionDefinitionクラス
- トランザクションの設定をするクラス
DefaultTransactionDefinition def = new DefaultTransactionDefinition(); //トランザクションの名前を設定 def.setName("UpdateUser"); //読取専用ではない設定 def.setReadOnly(false); //トランザクションの伝播レベルをREQUIREDに設定 def.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRED);明示的トランザクション実践
UserService.java@Service public class UserService { //中略(全文は下記参考) @Autowired PlatformTransactionManager txManager; //中略(全文は下記参考) /** * 1件更新用メソッド. */ public boolean updateOne(User user) throws DataAccessException { //インスタンス生成 DefaultTransactionDefinition def = new DefaultTransactionDefinition(); //設定 def.setName("UpdateUser"); def.setReadOnly(false); def.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRED); //トランザクション開始 TransactionStatus status = txManager.getTransaction(def); // 判定用変数 boolean result = false; try { // 1件更新 int rowNumber = dao.updateOne(user); if (rowNumber > 0) { // update成功 result = true; } }catch (Exception e){ txManager.rollback(status); throw new DataAccessException("ERROR Update",e) {}; } //コミット txManager.commit(status); return result; } //中略(全文は下記参考) }SpringBootを起動してホーム画面確認!
- http://localhost:8080/home
- ユーザ一覧からユーザ詳細画面に移り、ユーザー名更新
- "Update Oyakata Neko"に名前を更新しても、ユーザ名が変わっていない(更新失敗)、トランザクションがロールバックできていることがわかりました〜〜!^^
- 明示的トランザクションは、AOP内でサービスクラスのメソッドを実行する前後で、トランザクションの開始/コミットをすればOK!
(参考)コード全文
UserService.javapackage com.example.demo.login.domain.service; import java.io.IOException; import java.nio.file.FileSystem; import java.nio.file.FileSystems; import java.nio.file.Files; import java.nio.file.Path; import java.util.List; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.beans.factory.annotation.Qualifier; import org.springframework.dao.DataAccessException; import org.springframework.stereotype.Service; import org.springframework.transaction.PlatformTransactionManager; import org.springframework.transaction.TransactionDefinition; import org.springframework.transaction.TransactionStatus; import com.example.demo.login.domain.model.User; import com.example.demo.login.domain.repository.UserDao; import org.springframework.transaction.support.DefaultTransactionDefinition; @Service public class UserService { @Autowired @Qualifier("UserDaoJdbcImpl") UserDao dao; @Autowired PlatformTransactionManager txManager; /** * insert用メソッド. */ public boolean insert(User user) { // insert実行 int rowNumber = dao.insertOne(user); // 判定用変数 boolean result = false; if (rowNumber > 0) { // insert成功 result = true; } return result; } /** * カウント用メソッド. */ public int count() { return dao.count(); } /** * 全件取得用メソッド. */ public List<User> selectMany() { // 全件取得 return dao.selectMany(); } /** * 1件取得用メソッド. */ public User selectOne(String userId) { // selectOne実行 return dao.selectOne(userId); } /** * 1件更新用メソッド. */ public boolean updateOne(User user) throws DataAccessException { //インスタンス生成 DefaultTransactionDefinition def = new DefaultTransactionDefinition(); //設定 def.setName("UpdateUser"); def.setReadOnly(false); def.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRED); //トランザクション開始 TransactionStatus status = txManager.getTransaction(def); // 判定用変数 boolean result = false; try { // 1件更新 int rowNumber = dao.updateOne(user); if (rowNumber > 0) { // update成功 result = true; } }catch (Exception e){ txManager.rollback(status); throw new DataAccessException("ERROR Update",e) {}; } //コミット txManager.commit(status); return result; } /** * 1件削除用メソッド. */ public boolean deleteOne(String userId) { // 1件削除 int rowNumber = dao.deleteOne(userId); // 判定用変数 boolean result = false; if (rowNumber > 0) { // delete成功 result = true; } return result; } // ユーザー一覧をCSV出力する. /** * @throws DataAccessException */ public void userCsvOut() throws DataAccessException { // CSV出力 dao.userCsvOut(); } /** * サーバーに保存されているファイルを取得して、byte配列に変換する. */ public byte[] getFile(String fileName) throws IOException { // ファイルシステム(デフォルト)の取得 FileSystem fs = FileSystems.getDefault(); // ファイル取得 Path p = fs.getPath(fileName); // ファイルをbyte配列に変換 byte[] bytes = Files.readAllBytes(p); return bytes; } }


- 投稿日:2020-12-08T07:03:48+09:00
弊社の新人さんに贈りたい弊社の開発環境セットアップ手順だけ見ていても身につかない知識
アドベントカレンダーではありますまいかAdvent Calendar 2020 8日めの記事ですぞ。
弊社にもいわゆるオンボーディング時に見てもらうための「開発環境セットアップ」手順がある。弊社の最重要機密である技術レベルが漏洩してしまうので詳しくは書けない。しかしそこには、それだけ知って何か意味ある?というものも含まれる(何々エラーが出たらリロードせよの類)いや違う、重要なのはそんな断片的な回避チートではない。「なぜ」それが必要なのか、あるいは「どういう背景があるのか」。知らないと弊社以外で生きられなくなりますよ。私のように。
以上をアンチパターンとしたところを動機に、本稿では知識を一般論化し世界に共有(というかインターネット上に共有)できるレベルに砕いて記しておこうとおもいました。中身はまあまあ真面目。
まず結論
開発環境セットアップ手順だけ見ていても身につかない知識
=「これは何故?」を書かれている手順から1歩だけ踏み込もう。と言いたい。書かれていることをなぞれば開発環境は作れる。が、開発環境を壊して、それを自分で直せるように、あるいは改善できるようになる力を持つことのほうが、弊社以外で通用する知識だと思います。
Eclipse
冒頭のっけから Download eclipse 書かれているが極論Eclipseでないといけないということはない。
もちろん、最も普及しているIDEのひとつ ではある。
Eclipse.zip を Cドライブ直下 で解凍してください。等々指示があるがそれも便宜上ではある。ハマるので一旦私もそうしているが、単に説明する側の都合と言うことを意識しよう。Cが使えないことももちろんあるだろうし、容量の問題もある。何度も書くがEclipseが絶対ということはない。
EclipseのFormatter
以下の起動経路より Formatter を開きます
Window > Preferences > java > Code Style > Formatter
ルールだと思ってそのまま入れるべきだが、Eclipseのフォーマッター設定 にも書かれているとおりこれで我々のコーディング規約(基本的な)に乗れるよ、ということ。Console2
入れなくても問題は無い。
console2をインストールしていない場合は、ラボの先輩にインストール方法を聞きにいきましょう
が、これも手段の一つ。Windowsで使えるターミナルとシェルのまとめ を読む。Installed JREs
Import Project
Importダイアログを開き、「Existing Maven Projects」を選択してNextボタンをクリックします。
とか書いてあるがMavenとは何だとなると思う。【超初心者向け】Maven超入門 を踏まえる。ビルドツールはいろいろある けども我々がここでたまたまMavenだったのです。Tomcat
Eclipseで先述の記事の サーバ の項に出てくる。
Setup Server
弊社プロダクトに特有の暗号化ファイル名がいくつか出てくるんだが、そいつらにデータベースや、アプリケーションサーバのURLが書いてあることに気づくだろうか。そう、大事な接続情報は暗号化して保持しているのだ。コンテキストパスと設定テキストなどの関係をつかむ必要がある。上のTomcatと一緒に調べていくがよし。
JDBC Driver
JDBCドライバでMySQLに接続 とか、どんなデータベースだとしてもこういうものが必要で、と言うことを理解したい。
起動時、jdbcからエラーが出る場合
Pathがおかしかったり、環境変数がおかしかったり。
projectが ! 状態になった場合
.classpathと.projectあたりがズレているといわれる。が、つまり?
Eclipseの.classpath / .projectファイルには何が含まれていますか?java.lang.NoClassDefFoundError
出る出る。
java.lang.NoClassDefFoundError
java.lang.ClassNotFoundException って、どういうことよ?git pullで最新のソースを取得する
全プロジェクトを選択→F5キーで外部からのソースの変更を反映するなどとあるが、Eclipseでもなんでも便利なショートカットを覚えておこう。eclipseでよく使うショートカットJavaScriptのファイルを開く
EclipseでJavaScriptのファイルを開くと、重くて動かせなくなったり、OutOfMemory等のエラーが発生します。EclipseではJavaScriptのページを開かないようにしてください。などと言う怖い忠告があったりする。JavaScript用エディタ
JavaScriptの編集を行えるソフトは、Sublime Textや、Webstormなどがある。とはあるが、AtomユーザもSublimeユーザも、死角が無いエディタ「VS CODE」に乗り換えよう など、色々。ググり力・質問力
色々書きましたが最も必要なのは結論、これです。
エラー解決の正攻法と質問力・ググり力
誰も教えてくれないググり方
調べたいことをGoogleで調べる技術3選
英語なら
foobar not workingだけ覚えておけばよし。
人に聞くときは 良い質問とは何か を参考にどうぞ!
- 投稿日:2020-12-08T01:22:50+09:00
地理院タイルから三次元地形モデルを作ってみる
概要
このエントリは、FOSS4G Advent Calendar 2020 12日目の記事です。
@t_matと申します。
本職は測量設計会社の環境調査部門の人で、いわゆる「非IT系エンジニア」ですが、プログラミングに興味があり、夜な夜な、その時々に思いついたものを作っています。今回は、国土地理院タイルデータから広域の三次元地形モデルを作成するツールを作ってみました。
ブラタモリやたまたま視聴した日本地形連合の公開シンポの影響で地理・地形の面白さを知り、最近ちょこちょこモデルを作って眺めています。
いまどきは様々なツールで三次元地形を閲覧することができるので、需要があるかはハテナ?ですが、モデルをファイルに出力できれば、色々と活用できるかもと思い、投稿することにしました。開発環境
開発環境は以下のとおりです。実行にはJRE1.8以降が必要です。
開発言語:Java1.8
プロジェクト管理:maven
依存ライブラリ:JTS、TINFOUR、GSON
IDE:Eclipse
なお、作成したモデルは、Windows標準のPrint3Dなどでも閲覧できますが、MeshLabを使いました。作ったもの
今回、個人的に作っていたクラスを整理し、以下のツールを作成しました。
- TileImageGetter.jar:GeoJsonで定義した範囲の地理院タイルを取得・結合するツール
- PlyCreator.jar:テクスチャ画像とDEM画像からPLY形式の三次元地形モデルを生成するツール
- DEMInterpoler.jar:DEM画像を任意解像度に補間するツール
- TerrainImageProcesser.jar:DEM画像からCS立体画像等を生成するツール
- ImageMul.jar:複数の画像の乗算画像を生成するツール
ソースコードはGithubにアップしました(12/7)。 https://github.com/termat/geoply
また、実行形式JarファイルとサンプルデータをGoogleDriveにおいておきます。
https://drive.google.com/file/d/1o6Gi9SsyKR958GtIZ2ABjflECJFFDqja/view?usp=sharing
geoply
├── TileImageGetter.jar
├── PlyCreator.jar
├── DEMInterpoler.jar
├── TerrainImageProcesser.jar
├── ImageMul.jar
├── aso (サンプルデータ)
├── izu (サンプルデータ)
└── takao (サンプルデータ)三次元地形モデルの生成手順
三次元地形モデルの生成手順は以下のとおりです。
QGISでモデル領域のGeojsonを作成し、その領域のDEM画像(標高PNG)と航空写真等を地理院タイルから取得してピクセル情報をXYZRGBデータとし、TINで面を構成してサーフェイスモデルの三次元地形モデルを作成します。
各ツールの説明
以下に各ツールの使用方法を説明します。
なお、コマンドラインの引数は、オプション等を付けて指定する形にすべきですが、今回は省略しています。
また、大きなモデルを作る時は-Xmxコマンドなどで、JVMに多めのメモリを割り当てる必要があります。TileImageGetter.jar
TileImageGetterは、地理画像タイルを取得・結合し、画像データを出力するツールです。
以下のコマンドで、設定ファイル(json)に定義した条件の画像が取得できます。java -jar TileImageGetter.jar [設定ファイルのパス]設定ファイルの内容は以下のとおりです。
サンプルをお使いになる場合は環境に合わせてパス等を変更する必要があります。{ "num":2, //平面直角座標系のNoを指定 "geojson":"C:/Data/geoply/aso/aso.geojson", //取得する領域のgeojson "zoom":15, //取得する画像のズームレベル "url":["https://cyberjapandata.gsi.go.jp/xyz/dem5a_png/", //取得するタイルのurlのリスト "https://cyberjapandata.gsi.go.jp/xyz/dem5b_png/", //上位URLのタイル画像が無い場合 "https://cyberjapandata.gsi.go.jp/xyz/dem5c_png/"], //は下位URLを検索する "out":"C:/Data/geoply/aso/", //出力先 "name":"dem", //出力ファイル名のprefix "ext":"png" //取得するタイル画像の拡張子、航空写真の場合はjpg }本ツールで行っている処理は、下図のとおりです。
こうした処理を行うため、Geojsonを読み込むクラス(GeojsonData.java)、緯度経度と平面直角座標系を変換するクラス(LotLatXY.java)、ラスタ用座標ファイルの処理クラス(WorldFile.java)を作成しています。
なお、座標変換は国土地理院の「Gauss-Krüger 投影における経緯度座標及び平面直角座標相互間の座標換算についてのより簡明な計算方法」を、ラスタ用座標ファイル(ワールドファイル)は農研機構の「ラスタデータ用の座標ファイル(ワールドファイル)について」を参考にしました。
PlyCreator.jar
DEM画像とテクスチャとして使用する画像から、PLYファイルを生成するツールです。
モデル化の考え方は以下のとおりで、DEM画像のXYZ座標とテクスチャ画像のRGBをVertexとし、TINにより面情報を作成して、サーフェイスモデルの三次元地形モデルを生成します。
以下のコマンドで、PLY形式のモデルが出力されます。java -jar PlyCreator.jar [テクスチャ画像のパス] [DEM画像のパス] [出力ファイルのパス]
サンプルでは、以下のコマンドで、画像の様な三次元モデルが生成されます。
# DEM画像の取得 C:\Data\geoply> java -jar TileImageGetter.jar ./aso/dem.json # 航空写真の取得 C:\Data\geoply> java -jar TileImageGetter.jar ./aso/photo.json # 三次元モデルの生成 C:\Data\geoply> java -jar PlyCreator.jar ./aso/photo.png ./aso/dem.png ./aso/photo.ply
DEMInterpoler.jar
DEM画像を任意の解像度にリサイズするツールです。
例えば、航空写真はズームレベル16、DEM画像はズームレベル15など、ズームレベルが異なる場合に、補間によりズームレベル16相当のDEM画像を生成するのに使用します。
DEM(標高値)の補間はTIN補間を使用しています。
以下のコマンドで、参照画像と同じ解像度のDEM画像が生成されます。なお、DEM画像はモデル領域周辺のDEMを複数指定することができます。java -jar DEMInterpoler.jar [参照画像のパス] [出力ファイルのパス] [DEM画像のパス]・・・
TerrainImageProcesser.jar
写真画像だけでモデルを作るのも味気ないので、DEM画像からCS立体図等を生成するツールをついでに作りました。net.termat.geo.image配下の画像処理クラス、net.teramt.geo.tool配下のグラジエント処理クラスを使用して作成しています。
以下のコマンドで、傾斜量図、曲率図、CS立体図が生成されます。なお、[コマンド]はcurve、slope、csが指定できます。java -jar TerrainImageProcesser.jar [コマンド] [DEM画像のパス] [出力ファイルのパス]
ImageMul.jar
GIMPを使えば良いのですが、手っ取り早く乗算画像を作りたかったので作成したものです。
以下のコマンドで指定したファイルの乗算画像が生成されます。なお、乗算する画像は2枚以上指定する必要があります。java -jar ImageMul.jar [出力ファイルのパス] [乗算する画像ファイル]・・・
モデルの作成例
伊豆半島(サンプル:izuフォルダ)
サンプルファイルでは、以下のコマンドで、画像の様な三次元モデルが生成されます。
なお、植生図は、エコリスさんが公開されている植生図タイルを使用させて頂きました。# DEM画像の取得 C:\Data\geoply> java -jar TileImageGetter.jar ./izu/dem.json # 植生図画像の取得 C:\Data\geoply> java -jar TileImageGetter.jar ./izu/vega.json # DEM画像の補間(※DEM標高値の欠測地域があっため) C:\Data\geoply> java -jar DEMInterpoler.jar ./izu/std.png ./izu/dem2.png ./izu/dem.png # 植生図三次元モデルの生成 C:\Data\geoply> java -jar PlyCreator.jar ./izu/vega.png ./izu/dem2.png ./izu/vega.ply以下が生成された伊豆半島の三次元地形モデルです。
竹林(黄色)は東向き斜面に多いようですが、何か要因があるのか気になります。
高尾山(サンプル:takaoフォルダ)
以下のコマンドで、画像の様な三次元モデルが生成されます。
なお、高尾山では、DEMはズームレベル15、航空写真と標準地図はズームレベル16で取得しているので、DEMInterpolerでズームレベル16相当のDEM画像を作成しています。# DEM画像取得 C:\Data\geoply> java -jar TileImageGetter.jar ./takao/dem.json # 航空写真取得 C:\Data\geoply> java -jar TileImageGetter.jar ./takao/photo.json # 標準地図取得 C:\Data\geoply> java -jar TileImageGetter.jar ./takao/std.json # ズームレベル16相当のDEM画像生成 C:\Data\geoply> java -jar DEMInterpoler.jar ./takao/std.png ./takao/dem2.png ./takao/dem.png # DEM画像からCS立体図を生成 C:\Data\geoply> java -jar TerrainImageProcesser.jar cs ./takao/dem2.png ./takao/cs2.png # 航空写真とCS立体図の乗算画像を生成 C:\Data\geoply> java -jar ImageMul.jar ./takao/csphoto.png ./takao/cs2.png ./takao/photo.png # 乗算画像の三次元地形モデルを生成 C:\Data\geoply> java -jar PlyCreator.jar ./takao/csphoto.png ./takao/dem2.png ./takao/csphoto.ply # 標準地図の三次元地形モデルを生成 C:\Data\geoply> java -jar PlyCreator.jar ./takao/std.png ./takao/dem2.png ./takao/std.ply
その他、エコリスさんが公開されている植生図タイルなどを活用すれば、立体植生図的なものも作成できます。
最後に
わずか数分で地形モデルが作れるのはオープンソースの文化とオープンデータの取組のおかげです。感謝。
こうしたモデルは、見て楽しむ?だけでなく、二次元不等流計算等の数値解析に使えそうなので、そのうち、試してみたいと思っています。
あと、個人的に気になっているのが、Windows標準のPrind3Dで「見積原価」って表示が出てくるので、ひょっとすると、3Dプリンタで地形モデルを出力できるのかな?ということです。
3Dプリンタを所有していないので、試したことはないのですが、出力できたら面白そうだと思っています。












