- 投稿日:2020-11-12T23:26:00+09:00
PyTorch 1.7でtorch-scatterをインストール
環境
- Windows 10
- python 3.6.11
- Pytorch 1.7.0
- torch-scatter 2.0.5
取り急ぎ成功したので急いでメモ。
$ pip install torch-scatter -f https://pytorch-geometric.com/whl/torch-1.7.0.html Looking in links: https://pytorch-geometric.com/whl/torch-1.7.0.html Collecting torch-scatter Downloading https://pytorch-geometric.com/whl/torch-1.7.0/torch_scatter-2.0.5%2Bcu110-cp36-cp36m-win_amd64.whl (2.4 MB) |████████████████████████████████| 2.4 MB 544 kB/s Installing collected packages: torch-scatter Successfully installed torch-scatter-2.0.5しかし動かそうとすると失敗
$ python natura/bin/pytorch_sample.py Traceback (most recent call last): File "natura/bin/pytorch_sample.py", line 9, in <module> from torch_scatter import scatter_max File "C:\Users\dff40\.conda\envs\pytorch04gpu\lib\site-packages\torch_scatter\__init__.py", line 12, in <module> library, [osp.dirname(__file__)]).origin) File "C:\Users\dff40\.conda\envs\pytorch04gpu\lib\site-packages\torch\_ops.py", line 105, in load_library ctypes.CDLL(path) File "C:\Users\dff40\.conda\envs\pytorch04gpu\lib\ctypes\__init__.py", line 348, in __init__ self._handle = _dlopen(self._name, mode) OSError: [WinError 126] 指定されたモジュールが見つかりません。 (pytorch04gpu)あきらめず
エラー内容はGPU関連っぽい。CPU版をインストールすればよいかも。そこでアンインストールして以下を実行
$ pip install torch-scatter==latest+cpu -f https://pytorch-geometric.com/whl/torch-1.7.0.html Looking in links: https://pytorch-geometric.com/whl/torch-1.7.0.html Collecting torch-scatter==latest+cpu Downloading https://pytorch-geometric.com/whl/torch-1.7.0/torch_scatter-latest%2Bcpu-cp36-cp36m-win_amd64.whl (289 k B) |████████████████████████████████| 289 kB 364 kB/s Installing collected packages: torch-scatter Successfully installed torch-scatter-2.0.5これでさっきのコマンドを動かすと無事動いた!
- 投稿日:2020-11-12T23:26:00+09:00
PyTorch 1.7でtorch-scatterをインストール(失敗)
環境
- Windows 10
- python 3.6.11
- Pytorch 1.7.0
- torch-scatter 2.0.5
取り急ぎ成功したので急いでメモ。
$ pip install torch-scatter -f https://pytorch-geometric.com/whl/torch-1.7.0.html Looking in links: https://pytorch-geometric.com/whl/torch-1.7.0.html Collecting torch-scatter Downloading https://pytorch-geometric.com/whl/torch-1.7.0/torch_scatter-2.0.5%2Bcu110-cp36-cp36m-win_amd64.whl (2.4 MB) |████████████████████████████████| 2.4 MB 544 kB/s Installing collected packages: torch-scatter Successfully installed torch-scatter-2.0.5しかし動かそうとすると失敗
$ python natura/bin/pytorch_sample.py Traceback (most recent call last): File "natura/bin/pytorch_sample.py", line 9, in <module> from torch_scatter import scatter_max File "C:\Users\dff40\.conda\envs\pytorch04gpu\lib\site-packages\torch_scatter\__init__.py", line 12, in <module> library, [osp.dirname(__file__)]).origin) File "C:\Users\dff40\.conda\envs\pytorch04gpu\lib\site-packages\torch\_ops.py", line 105, in load_library ctypes.CDLL(path) File "C:\Users\dff40\.conda\envs\pytorch04gpu\lib\ctypes\__init__.py", line 348, in __init__ self._handle = _dlopen(self._name, mode) OSError: [WinError 126] 指定されたモジュールが見つかりません。 (pytorch04gpu)
- 投稿日:2020-11-12T22:35:25+09:00
主成分分析を初歩からの理解
はじめに
今回は主成分分析を勉強し直したのでまとめていきます。
主成分分析自体は前にも勉強したことあったのですが、分散共分散行列から固有値ベクトル算出して次元圧縮するであったり、scikit-learnを使って実装くらいの知識しかありませんでした。
しかしなぜ分散共分散行列の固有値から軸を求められるのか等、知らなかったので私なりに初歩的なところから理論をまとめてみることにしました。(私は忘れやすいので)
そして最後は理論をもとにpythonで実装して見ました。
よければ最後までお付き合いください。主成分分析とは(概要)
まず主成分分析についてと流れを簡単に説明します。
主成分分析とはデータの次元が大きいときに次元を圧縮して見やすくするために使用される手法です。
下図のようにある方向に軸を取りその軸に垂直に点を落としてみると効率よく2次元データを1次元で表すことができます。
もちろん軸と実際の点との距離(各点から伸びる線)の分が持つ情報は落ちてしまいます。
そのため最も情報が落ちないように分散が最大になるように軸を決めます。(詳しくは後ほど)
今回は2次元データを1次元にしていますが、高次元のデータをこのように圧縮することで私たちにも解釈しやすくなったり、分類の精度をあげたりすることができます。具体例
具体的な例を考えます。
ある5人の5教科の成績が
名前 国語 社会 英語 算数 理科 A 60 70 70 40 30 B 70 60 80 30 30 C 40 20 30 70 80 D 30 20 40 80 80 E 30 30 30 80 70 だったとします。
明らかに偏ってますが...
この人たちの傾向はどのようなものか考えたとき一つの手段としてグラフ化があります。
しかし5次元のデータに対してプロットをするときは図示や理解共になかなか難しいです。
ちなみにこれを3次元空間+色(赤具合と青具合)で表すと次のようになりました。
やはり、このグラフでは何を言っているのかわかりにくいかと思います。(今回は5教科であるためわからないこともないのですが、これがもしよくわからないデータの集まりだとあたりをつけるのが難しいです)
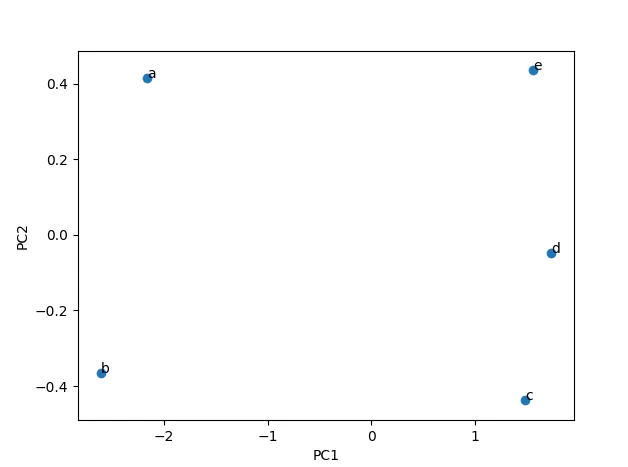
今度はこれを主成分分析で次元圧縮して2次元で図にしてみると次のようになりました。
(PCとは主成分:principal componentの事です)
主成分分析の結果のそれぞれの軸が何を表しているかの解釈は私たちが行わなければなりません。
今回の例の場合はPC1は理系科目が高い人は高い値、理系科目が不得意な人が低い値を取っているように感じられます。そのためPC1は理系の得意度を示しているのではないかと解釈します。
PC2ですが、こちらは正直何を示しているのか私には解釈できません(これからもうちょっと解釈の仕方は勉強していきます)。しかしここで寄与率をみてみます。
寄与率とは各軸がどの程度元のデータを説明できているか、の値です。
詳しくは先で説明しますが、今回の寄与率は
PC 寄与率 PC1 9.518791e-01 PC2 3.441020e-02 PC3 1.275504e-02 PC4 9.556157e-04 PC5 8.271560e-35 となり、PC1の成分で95%説明できていて、PC2で3.4%説明できている事がわかります。
そのためPC1だけでほとんどこのデータが説明できているのかもしれません。
今回はイメージしやすいように文系科目理系科目で点数を偏らせて示しましたが、このように主成分分析は次元が多いデータをイメージしやすいようにする分析方法の一つです。
今回はこの主成分分析を私のような人でも理解できるように説明していきたいと考えています。主成分分析とは(理論)
主成分分析の理論を細かく見ていきます。上の図は前述したように2次元のデータを新しい1次元のデータに変換しています。軸とデータ点の距離が大きいほどデータの損失があると考えられるため分散が最も大きい方向を求める必要があります。(一番分散が大きい方向が第一主成分)
この方向はどのように見つけるかと言うと分散共分散行列の一番大きい固有値に対応する固有ベクトルを求めれば良いのですが、なぜそれで考えられるのか見ていきたいと思います。まず1点だけを考えてみます。
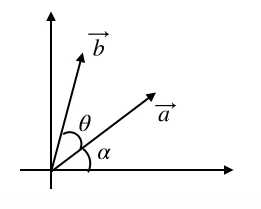
あるデータ点と軸となるベクトルを次のように定義します。
\vec{x}= \left[ \begin{array}{r} x_1 \\\ x_2 \end{array} \right] \\\ \vec{v}= \left[ \begin{array}{r} v_1 \\\ v_2 \end{array} \right] \\\ ただし\|\vec{v}\|=1 \\\するとベクトル$\vec{x}を$ベクトル$\vec{v}$軸に垂直に落とした時の長さは
\vec{v}^\mathrm{T}\vec{x}=\left[ \begin{array}{r} v_1 & v_2 \end{array} \right]\left[ \begin{array}{r} x_1 \\\ x_2 \end{array} \right]=v_1 x_1+v_2 x_2で示されます。
ここで余談となるのですが、長さが$\vec{v}^\mathrm{T}\vec{x}$で示される証明を行います。
気になる人だけみていただければと思います。
まずベクトル$\vec{a}$とベクトル$\vec{a}$を$\theta$回転させたベクトル$\vec{b}$を次のように定義します。
$\vec{a}= \left[ \begin{array}{r} a_1 \\ a_2 \end{array} \right]$
$\vec{b}= \left[ \begin{array}{r} b_1 \\ b_2 \end{array} \right]=\left[ \begin{array}{r} cos\theta&-sin\theta \\ sin\theta & cos\theta \end{array} \right]\left[ \begin{array}{r} a_1 \\ a_2 \end{array} \right]$基本的なことですがベクトル$\vec{a}$にかけられている
$\left[ \begin{array}{r} cos\theta&-sin\theta \\ sin\theta & cos\theta \end{array} \right]$
はベクトル$\vec{a}$を$\theta$回転させる行列です。
ばぜこの行列で回転する変換ができる理由は加法定理によって証明することができます。加法定理による証明
ベクトルの長さをrとするとベクトル$\vec{a}$とベクトル$\vec{b}$は次のように表される。$\vec{a}= \left[ \begin{array}{r} rcos\alpha \\ rsin\alpha \end{array} \right]$
$\vec{b}= \left[ \begin{array}{r} rcos(\alpha + \theta) \\ rsin(\alpha + \theta) \end{array} \right]=\left[ \begin{array}{r} rcos(\alpha)cos(\theta) - rsin(\alpha)sin(\theta) \\ rsin(\alpha)cos(\theta)+rcos(\alpha)sin(\theta) \end{array} \right]=\left[ \begin{array}{r} cos\theta&-sin\theta \\ sin\theta & cos\theta \end{array} \right]\left[ \begin{array}{r} rcos(\alpha) \\ rsin(\alpha) \end{array} \right]=\left[ \begin{array}{r} cos\theta&-sin\theta \\ sin\theta & cos\theta \end{array} \right]\vec{a}$よって証明される。
証明するのはベクトル$\vec{b}$をベクトル$\vec{a}$軸状に垂直に落とした時の長さが等しくなれば良いため
$|\vec{b}|cos\theta=\vec{v}^\mathrm{T}\vec{b}$
が示されれば良いということになります。
ベクトル$\vec{v}$はベクトル$\vec{a}$と同じ方向で大きさが1であるため$\vec{v}=\frac{1}{\sqrt{a_1^2+a_2^2}}\vec{a}$
である。
そのため$\vec{v}^\mathrm{T}\vec{b}=\frac{1}{\sqrt{a_1^2+a_2^2}}\left[ \begin{array}{r} a_1 & a_2 \end{array} \right]\left[ \begin{array}{r} b_1 \\ b_2 \end{array} \right]$
$\quad\ =\frac{1}{\sqrt{a_1^2+a_2^2}}\left[ \begin{array}{r} a_1 & a_2 \end{array} \right]\left[ \begin{array}{r} cos\theta&-sin\theta \\ sin\theta & cos\theta \end{array} \right]\left[ \begin{array}{r} a_1 \\ a_2 \end{array} \right]$
$\quad\ =\frac{1}{\sqrt{a_1^2+a_2^2}}\left[ \begin{array}{r} a_1 & a_2 \end{array} \right]\left[ \begin{array}{r} a_1cos\theta-a_2sin\theta \\ a_1sin\theta+a_2cos\theta \end{array} \right]$
$\quad\ =\frac{1}{\sqrt{a_1^2+a_2^2}}(a_1^2cos\theta-a_1a_2sin\theta+a_1a_2sin\theta+a_2^2cos\theta)$
$\quad\ =\frac{1}{\sqrt{a_1^2+a_2^2}}(a_1^2+a_2^2)cos\theta$
$\quad\ =\sqrt{a_1^2+a_2^2}cos\theta$
$\quad\ =|\vec{b}|cos\theta$よって$\vec{v}^\mathrm{T}\vec{x}$によってベクトル$\vec{x}$をベクトル$\vec{v}上に垂直に落とした時の長さを求めることができる。$
つまり求める$\vec{v}$はデータ点がn個ある時のこの長さ$\vec{v}^\mathrm{T}\vec{x}$の分散が大きくなるベクトルとなります。
$\vec{v}^\mathrm{T}\vec{x}$の分散は$$\frac{1}{n-1}\sum_{i=1}^{n}\left[\vec{v}^\mathrm{T}(\vec{x_i}-\hat{\mu})\right]^2\ \;=\; \vec{v}^{\mathrm{T}}\frac{1}{n-1}\sum_{i=1}^n(\vec{x_i}-\hat{\mu})(\vec{x_i}-\hat{\mu})^\mathrm{T}\vec{v}$$
$(\vec{a}\vec{b})^\mathrm{T}=\vec{a}^{\mathrm{T}} \vec{b}^{\mathrm{T}}$である。
ここでベクトル$\vec{v}$で囲まれ他部分は分散共分散行列の形であるため
$$\Sigma=\frac{1}{n-1}\sum_{i=1}^n(\vec{x_i}-\hat{\mu})(\vec{x_i}-\hat{\mu})^\mathrm{T}\ $$
と置くと
分散は$$\vec{v}^\mathrm{T}\Sigma\vec{v}$$
と置く事ができる。
つまりこの分散が最大となる方向のベクトル$\vec{v}$を求めるために$$\max_{v:|v|=1}(\vec{v}^\mathrm{T}\Sigma\vec{v})$$
を考えます。
ここで$\Sigma$は半正定値行列であるため直行行列で対角化する事ができます。全ての零ベクトルでない $x∈ℝ^n$ について $x^TAx≥0$ が成り立つとき半正定値(positive semidefinite)という
--Horn and Johnson(2013) Definition 4.1.11--つまり
$$\Sigma\vec{v_i}=\lambda_i\vec{v_i}$$
となる固有ベクトルと固有値を考え
V=[v_1,v_2,...,v_d] \\\ \Lambda=diag(\lambda_1,\lambda_2,...,\lambda_d)と置いた時
$\Sigma V$とはVベクトルをそれぞれ対応する固有値倍に変換しているため$$\Sigma V=V\Lambda$$
であり
$V$は直交行列であるので$$\Sigma = V\Lambda V^\mathrm{T} \quad V^\mathrm{T}\Sigma V=\Lambda$$
これをもとに分散が最大化されるベクトルを求めていきます。
私が参考にした物では以下のように最大化解が一番大きい固有値であると証明されていました。(参考文献[1])
しかし私はこれがいまいち理解できなかったため私なりに考えて見ました。(間違っていればご指摘ください)
計算の簡略化のため2次元の場合を考えます、
まず\begin{align} V&=\left[\begin{array}{cc} v_1 & v_2\end{array} \right]=\left[\begin{array}{cc} v_{1x} & v_{2x} \\\ v_{1y} & v_{2y}\end{array} \right] \\\ \vec{v}&=\left[\begin{array}{c} v_x \\\ v_y \end{array}\right] \\\ \Lambda&=\left[\begin{array}{cc} \lambda_1 &0 \\\ 0 & \lambda_2 \end{array}\right] \end{align}と置きます。
そしてかっこの中身を式変形していきます。\begin{align} \vec{v}^\mathrm{T}\Sigma\vec{v} &= \vec{v}^\mathrm{T}V\Lambda V^\mathrm{T}\vec{v} \\\\ &= \vec{v}^\mathrm{T}\left[\begin{array}{cc} v_{1x} & v_{2x} \\\ v_{1y} & v_{2y}\end{array} \right]\left[\begin{array}{cc} \lambda_1 &0 \\\ 0 & \lambda_2 \end{array}\right] \left[\begin{array}{cc} v_{1x} & v_{1y} \\\ v_{2x} & v_{2y}\end{array} \right]\vec{v} \\\\ &=\vec{v}^\mathrm{T}\left[ \begin{array}{cc} v_{1x}^2\lambda_1+v_{2x}^2 \lambda_2 & v_{1x} v_{1y} \lambda_1 +v_{2x} v_{2y} \lambda_2 \\\ v_{1x} v_{1y} \lambda_1 +v_{2x} v_{2y} \lambda_2 & v_{1y}^2\lambda_1+V_{2y}^2 \lambda_2 \end{array} \right] \vec{v} \\\\ &=\vec{v}^\mathrm{T}\left( \left[ \begin{array}{cc} v_{1x}^2 & v_{1x} v_{1y} \\\ v_{1x} v_{1y} & v_{1y}^2 \end{array} \right]\lambda_1+\left[ \begin{array}{cc} v_{2x}^2& v_{2x} v_{2y} \\\ v_{2x} v_{2y} &V_{2y}^2 \end{array} \right]\lambda_2\right) \vec{v} \\\\ &=\vec{v}^\mathrm{T} \left[ \begin{array}{cc} v_{1x}^2 & v_{1x} v_{1y} \\\ v_{1x} v_{1y} & v_{1y}^2 \end{array} \right]\vec{v}\lambda_1+\vec{v}^\mathrm{T}\left[ \begin{array}{cc} v_{2x}^2& v_{2x} v_{2y} \\\ v_{2x} v_{2y} &V_{2y}^2 \end{array} \right]\vec{v}\lambda_2 \\\ \end{align}$\lambda_1$の項のみを取り出して考えて見ると
\begin{align} \vec{v}^\mathrm{T} \left[ \begin{array}{cc} v_{1x}^2 & v_{1x} v_{1y} \\\ v_{1x} v_{1y} & v_{1y}^2 \end{array} \right]\vec{v}\lambda_1&=\left[\begin{array}{c} v_x & v_y \end{array}\right] \left[ \begin{array}{cc} v_{1x}^2 & v_{1x} v_{1y} \\\ v_{1x} v_{1y} & v_{1y}^2 \end{array} \right]\left[\begin{array}{c} v_x \\\ v_y \end{array}\right]\lambda_1 \\\\ &=(v_{1x}^2 v_x^2+2v_{1x}v_{1y}v_xv_y+v_{1y}^2 v_y^2)\lambda_1 \\\\ &=(v_{1x}v_x+v_{1y}v_y)^2\lambda_1 \\\\ &=\left(\left[\begin{array}{c}v_{1x} & v_{1y} \end{array}\right]\left[\begin{array}{c} v_x \\\ v_y \end{array}\right]\right)^2\lambda_1 \\\\ &=\left(\vec{v_1}^\mathrm{T} \vec{v}\right)^2\lambda_1 \end{align}となる。
つまり\begin{align} \max_{v:|v|=1}\left(\vec{v}^\mathrm{T}\Sigma\vec{v}\right) &=\max_{v:|v|=1}\left(\left(\vec{v_1}^\mathrm{T}\vec{v}\right)^2\lambda_1+\left(\vec{v_2}^\mathrm{T}\vec{v}\right)^2\lambda_2\right) \\\ &=\max_{v:|v|=1}\left(\sum_{i=1}^2\left(\vec{v_i}^\mathrm{T}\vec{v}\right)^2\lambda_i\right) \\\ 一般化すると \\\ &=\max_{v:|v|=1}\left(\sum_{i=1}^d\left(\vec{v_i}^\mathrm{T}\vec{v}\right)^2\lambda_i\right) \end{align}となる。
この時$\vec{v},\vec{v_i}$は単位ベクトルで$\vec{v_1},\vec{v_2},...,\vec{v_d}$は互いに直行している。
そのため、$\vec{v}=\vec{v_i}$の時$$\max_{v:|v|=1}\left(\vec{v_i}^\mathrm{T}\vec{v}\right)=1$$
となる。(同じ方向の単位ベクトルの内積は1をとる)
同じように$i\neq j$の時$$\max_{v:|v|=1}\left(\vec{v_j}^\mathrm{T}\vec{v}\right)=0$$
である。(直行するベクトルの内積は0)
つまり最大値をとるときはベクトルvが最大の固有値と対応する固有ベクトルと等しくなるときであるため
$$\max_{v:|v|=1}\left(\sum_{i=1}^d\left(\vec{v_i}^\mathrm{T}\vec{v}\right)^2\lambda_i\right)=\lambda_1$$
となる。
また、同じように2番目に分散の大きい軸を取りたいときは$\vec{v}$を2番目に大きい固有値に対応する固有ベクトルと同じ方向に合わせれば良いという事になります。
分散共分散行列と相関行列
主成分分析を行う時、分散共分散行列の固有ベクトルをとる時と相関行列の固有ベクトルをとる方法があると聞いた事がある方がいるかと思います。
そもそも相関行列とはデータをそのデータの標準偏差で割ったものの分散共分散行列です。
先に平均も引いてしまって問題ないため、標準化されたデータの分散共分散行列でもあります。
つまりデータを先に標準化してしまえば先ほどの理論とやることは同じとなるため、標準偏差の固有ベクトルでも主成分分析できる事がわかると思います。
そのため実際どちらの方法をとっても主成分分析を行う事ができまが、相関行列の固有ベクトルをとった方が良いと言われています。
なぜならデータそのままの分散共分散行列だとデータの単位がバラバラでそこを考慮しなくてはいけないからです。
そのため単位をない状態にして主成分分析を行なった方が良いと言われています。(具体的にどのように影響が出るのかは例で説明できなかったので何か遭遇したら追記したいと思います)寄与率
最後に寄与率についてです。
寄与率とはそのデータがどのくらいデータを示しているかを差します。
そしてその値は理論でもお話したように分散の大きさで示す事ができ、分散の大きさはある方向ベクトルを取った時の固有値となりました。
その固有値の割合を求めれば良いため、寄与率PVは
$$PV_i=\frac{\lambda_i}{\sum_{j=1}^{d}\lambda_j}$$によって求められます。
実装
それではこの理論を用いて実装して見たいと思います。
ここで使用するデータは最初の概要でも使った5人の成績データを用います。
名前 国語 社会 英語 算数 理科 A 60 70 70 40 30 B 70 60 80 30 30 C 40 20 30 70 80 D 30 20 40 80 80 E 30 30 30 80 70 まず正解としてscikit-learnのPCAの実装を見て見ます。
実装したところこのようになりました。pandasを使用しているのは私が使い慣れていないための勉強を兼ねているだけですscikit_pca.pyimport matplotlib.pyplot as plt import numpy as np from sklearn.decomposition import PCA import pandas as pd #データの作成 name = ['a','b','c','d','e'] a = np.array([60,70,70,40,30]) b = np.array([70,60,80,30,30]) c = np.array([40,20,30,70,80]) d = np.array([30,20,40,80,80]) e = np.array([30,30,30,80,70]) #フレームワークに格納 df = pd.DataFrame([a,b,c,d,e],columns=['language','society','english','math','science'],index=name) dfs = df.iloc[:,:].apply(lambda x:(x-x.mean())/x.std(),axis=0) #データの標準化 #scikit-learnでのPCAインスタンス化と学習 pca = PCA() pca.fit(dfs) feature=pca.transform(dfs) #結果の出力 print(pd.DataFrame(feature,columns=["PC{}".format(x+1) for x in range(len(dfs.columns))]).head()) plt.figure() for i in range(len(name)): plt.annotate(name[i],xy=(feature[i,0],feature[i,1])) plt.scatter(feature[:,0],feature[:,1],marker='o') plt.xlabel('PC1') plt.ylabel('PC2') plt.show() print(pd.DataFrame(pca.explained_variance_ratio_,index=["PC{}".format(x+1) for x in range(len(dfs.columns))]))結果は以下のようになりました。
$python scikit_pca.py PC1 PC2 PC3 PC4 PC5 0 -2.161412 0.414977 -0.075496 -0.073419 4.163336e-17 1 -2.601987 -0.364980 0.088599 0.064849 4.163336e-17 2 1.479995 -0.437661 -0.290635 -0.037986 4.163336e-17 3 1.727683 -0.047103 0.382252 -0.035840 -1.387779e-17 4 1.555721 0.434767 -0.104720 0.082396 -1.457168e-16 0 PC1 9.518791e-01 PC2 3.441020e-02 PC3 1.275504e-02 PC4 9.556157e-04 PC5 8.271560e-35
続いて理論に基づいて実装して見ました。
クラスとしてMyPCAを定義し、scikit-learnと同様に使えるようにfit()メソッドで学習、transform()メソッドで新しい空間に射影する処理をしています。
クラスの定義以外は前のプログラムのpca=PCA()を
pca=MyPCA()に変更するだけなので省略して、クラスの定義のみ載せていますが、次のようになりました。
my_pca.py#myPCA program class MyPCA: e_values = None #固有値の保存 e_covs = None #固有ベクトルの保存 explained_variance_ratio_ = None def fit(self,dfs): #pandasデータでもnumpyデータでも使えるようにするための処理 if(type(dfs)==type(pd.DataFrame())): all_data = dfs.values else: all_data=dfs data_cov=np.cov(all_data,rowvar=0,bias=0) #分散共分散行列処理 self.e_values,self.e_vecs=np.linalg.eig(data_cov) #固有値と固有ベクトルの算出 self.explained_variance_ratio_= self.e_values/self.e_values.sum() #寄与率の計算 def transform(self,dfs): #pandasデータでもnumpyデータでも使えるようにするための処理 if(type(dfs)==type(pd.DataFrame())): all_data = dfs.values else: all_data=dfs feature = [] for e_vec in self.e_vecs.T: temp_feature=[] for data in all_data: temp_feature.append(np.dot(e_vec,data)) #内積計算 feature.append(temp_feature) return np.array(feature).Tそして結果です。
PC1 PC2 PC3 PC4 PC5 0 2.161412 -0.414977 -0.075496 -7.771561e-16 0.073419 1 2.601987 0.364980 0.088599 1.665335e-15 -0.064849 2 -1.479995 0.437661 -0.290635 -4.996004e-16 0.037986 3 -1.727683 0.047103 0.382252 -5.551115e-16 0.035840 4 -1.555721 -0.434767 -0.104720 0.000000e+00 -0.082396 Attribute Qt::AA_EnableHighDpiScaling must be set before QCoreApplication is created. 0 PC1 9.518791e-01 PC2 3.441020e-02 PC3 1.275504e-02 PC4 2.659136e-17 PC5 9.556157e-04
このようになりました。
おそらく固有ベクトルが反転してしまったため正負逆転してしまっているところもありますが、同じような解析結果が出せたかと思います。終わりに
今回は主成分分析の理論について個人的備忘録も兼ねて書いて見ました。
証明をところどころ挟んだので読みにくい記事になってしまった感が否めないのですが、私のような人は細かいところが気になって進めないこともあるかと考えできるだけ証明しました。今回取り上げた主成分分析はscikit-learnで簡単に使えてしまうので中身をあまり理解せず使うのが気持ち悪く感じていたので今回一応理解ができた気がするのでスッキリしました。
ただ、scikit-learnでの実装をのぞいて見たところ特異値分解によって実装しているようです。
ただ対称行列の場合は固有値分解と特異値分解の結果は同じになるようなので、今回のような分散共分散行列や相関行列に適用するときはどちらでもいいのかと感じました。
もし機会があれば一般化以外で特異値分解を使う利点も調べて見たいと思います。参考文献
[1]http://ibis.t.u-tokyo.ac.jp/suzuki/lecture/2015/dataanalysis/L7.pdf データ解析 第七回「主成分分析」
[2]https://seetheworld1992.hatenablog.com/entry/2017/03/17/104807 分散共分散行列(と相関行列)は半正定値であることを証明する




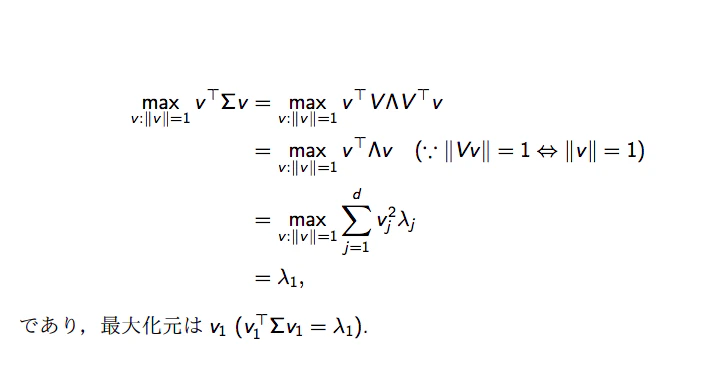


- 投稿日:2020-11-12T22:35:25+09:00
主成分分析を初歩から数学的な理解
はじめに
今回は主成分分析を勉強し直したのでまとめていきます。
主成分分析自体は前にも勉強したことあったのですが、分散共分散行列から固有値ベクトル算出して次元圧縮するであったり、scikit-learnを使って実装くらいの知識しかありませんでした。
しかしなぜ分散共分散行列の固有値から軸を求められるのか等、知らなかったので私なりに初歩的なところから計算上での理論をまとめてみることにしました。(私は忘れやすいので)
そして最後は理論をもとにpythonで実装して見ました。
よければ最後までお付き合いください。主成分分析とは(概要)
まず主成分分析についてと流れを簡単に説明します。
主成分分析とはデータの次元が大きいときに次元を圧縮して見やすくするために使用される手法です。
下図のようにある方向に軸を取りその軸に垂直に点を落としてみると効率よく2次元データを1次元で表すことができます。
もちろん軸と実際の点との距離(各点から伸びる線)の分が持つ情報は落ちてしまいます。
そのため最も情報が落ちないように分散が最大になるように軸を決めます。(詳しくは後ほど)
今回は2次元データを1次元にしていますが、高次元のデータをこのように圧縮することで私たちにも解釈しやすくなったり、分類の精度をあげたりすることができます。具体例
具体的な例を考えます。
ある5人の5教科の成績が
名前 国語 社会 英語 算数 理科 A 60 70 70 40 30 B 70 60 80 30 30 C 40 20 30 70 80 D 30 20 40 80 80 E 30 30 30 80 70 だったとします。
明らかに偏ってますが...
この人たちの傾向はどのようなものか考えたとき一つの手段としてグラフ化があります。
しかし5次元のデータに対してプロットをするときは図示や理解共になかなか難しいです。
ちなみにこれを3次元空間+色(赤具合と青具合)で表すと次のようになりました。
やはり、このグラフでは何を言っているのかわかりにくいかと思います。(今回は5教科であるためわからないこともないのですが、これがもしよくわからないデータの集まりだとあたりをつけるのが難しいです)
今度はこれを主成分分析で次元圧縮して2次元で図にしてみると次のようになりました。
(PCとは主成分:principal componentの事です)
主成分分析の結果のそれぞれの軸が何を表しているかの解釈は私たちが行わなければなりません。
今回の例の場合はPC1は理系科目が高い人は高い値、理系科目が不得意な人が低い値を取っているように感じられます。そのためPC1は理系の得意度を示しているのではないかと解釈します。
PC2ですが、こちらは正直何を示しているのか私には解釈できません(これからもうちょっと解釈の仕方は勉強していきます)。しかしここで寄与率をみてみます。
寄与率とは各軸がどの程度元のデータを説明できているか、の値です。
詳しくは先で説明しますが、今回の寄与率は
PC 寄与率 PC1 9.518791e-01 PC2 3.441020e-02 PC3 1.275504e-02 PC4 9.556157e-04 PC5 8.271560e-35 となり、PC1の成分で95%説明できていて、PC2で3.4%説明できている事がわかります。
そのためPC1だけでほとんどこのデータが説明できているのかもしれません。
今回はイメージしやすいように文系科目理系科目で点数を偏らせて示しましたが、このように主成分分析は次元が多いデータをイメージしやすいようにする分析方法の一つです。
今回はこの主成分分析を私のような人でも理解できるように説明していきたいと考えています。主成分分析とは(理論)
主成分分析の理論を細かく見ていきます。上の図は前述したように2次元のデータを新しい1次元のデータに変換しています。軸とデータ点の距離が大きいほどデータの損失があると考えられるため分散が最も大きい方向を求める必要があります。(一番分散が大きい方向が第一主成分)
この方向はどのように見つけるかと言うと分散共分散行列の一番大きい固有値に対応する固有ベクトルを求めれば良いのですが、なぜそれで考えられるのか見ていきたいと思います。まず1点だけを考えてみます。
あるデータ点と軸となるベクトルを次のように定義します。
\vec{x}= \left[ \begin{array}{r} x_1 \\\ x_2 \end{array} \right] \\\ \vec{v}= \left[ \begin{array}{r} v_1 \\\ v_2 \end{array} \right] \\\ ただし\|\vec{v}\|=1 \\\するとベクトル$\vec{x}を$ベクトル$\vec{v}$軸に垂直に落とした時の長さは
\vec{v}^\mathrm{T}\vec{x}=\left[ \begin{array}{r} v_1 & v_2 \end{array} \right]\left[ \begin{array}{r} x_1 \\\ x_2 \end{array} \right]=v_1 x_1+v_2 x_2で示されます。
ここで余談となるのですが、長さが$\vec{v}^\mathrm{T}\vec{x}$で示される証明を行います。
気になる人だけみていただければと思います。
まずベクトル$\vec{a}$とベクトル$\vec{a}$を$\theta$回転させたベクトル$\vec{b}$を次のように定義します。
$\vec{a}= \left[ \begin{array}{r} a_1 \\ a_2 \end{array} \right]$
$\vec{b}= \left[ \begin{array}{r} b_1 \\ b_2 \end{array} \right]=\left[ \begin{array}{r} cos\theta&-sin\theta \\ sin\theta & cos\theta \end{array} \right]\left[ \begin{array}{r} a_1 \\ a_2 \end{array} \right]$基本的なことですがベクトル$\vec{a}$にかけられている
$\left[ \begin{array}{r} cos\theta&-sin\theta \\ sin\theta & cos\theta \end{array} \right]$
はベクトル$\vec{a}$を$\theta$回転させる行列です。
ばぜこの行列で回転する変換ができる理由は加法定理によって証明することができます。加法定理による証明
ベクトルの長さをrとするとベクトル$\vec{a}$とベクトル$\vec{b}$は次のように表される。$\vec{a}= \left[ \begin{array}{r} rcos\alpha \\ rsin\alpha \end{array} \right]$
$\vec{b}= \left[ \begin{array}{r} rcos(\alpha + \theta) \\ rsin(\alpha + \theta) \end{array} \right]=\left[ \begin{array}{r} rcos(\alpha)cos(\theta) - rsin(\alpha)sin(\theta) \\ rsin(\alpha)cos(\theta)+rcos(\alpha)sin(\theta) \end{array} \right]=\left[ \begin{array}{r} cos\theta&-sin\theta \\ sin\theta & cos\theta \end{array} \right]\left[ \begin{array}{r} rcos(\alpha) \\ rsin(\alpha) \end{array} \right]=\left[ \begin{array}{r} cos\theta&-sin\theta \\ sin\theta & cos\theta \end{array} \right]\vec{a}$よって証明される。
証明するのはベクトル$\vec{b}$をベクトル$\vec{a}$軸状に垂直に落とした時の長さが等しくなれば良いため
$|\vec{b}|cos\theta=\vec{v}^\mathrm{T}\vec{b}$
が示されれば良いということになります。
ベクトル$\vec{v}$はベクトル$\vec{a}$と同じ方向で大きさが1であるため$\vec{v}=\frac{1}{\sqrt{a_1^2+a_2^2}}\vec{a}$
である。
そのため$\vec{v}^\mathrm{T}\vec{b}=\frac{1}{\sqrt{a_1^2+a_2^2}}\left[ \begin{array}{r} a_1 & a_2 \end{array} \right]\left[ \begin{array}{r} b_1 \\ b_2 \end{array} \right]$
$\quad\ =\frac{1}{\sqrt{a_1^2+a_2^2}}\left[ \begin{array}{r} a_1 & a_2 \end{array} \right]\left[ \begin{array}{r} cos\theta&-sin\theta \\ sin\theta & cos\theta \end{array} \right]\left[ \begin{array}{r} a_1 \\ a_2 \end{array} \right]$
$\quad\ =\frac{1}{\sqrt{a_1^2+a_2^2}}\left[ \begin{array}{r} a_1 & a_2 \end{array} \right]\left[ \begin{array}{r} a_1cos\theta-a_2sin\theta \\ a_1sin\theta+a_2cos\theta \end{array} \right]$
$\quad\ =\frac{1}{\sqrt{a_1^2+a_2^2}}(a_1^2cos\theta-a_1a_2sin\theta+a_1a_2sin\theta+a_2^2cos\theta)$
$\quad\ =\frac{1}{\sqrt{a_1^2+a_2^2}}(a_1^2+a_2^2)cos\theta$
$\quad\ =\sqrt{a_1^2+a_2^2}cos\theta$
$\quad\ =|\vec{b}|cos\theta$よって$\vec{v}^\mathrm{T}\vec{x}$によってベクトル$\vec{x}$をベクトル$\vec{v}上に垂直に落とした時の長さを求めることができる。$
つまり求める$\vec{v}$はデータ点がn個ある時のこの長さ$\vec{v}^\mathrm{T}\vec{x}$の分散が大きくなるベクトルとなります。
$\vec{v}^\mathrm{T}\vec{x}$の分散は$$\frac{1}{n-1}\sum_{i=1}^{n}\left[\vec{v}^\mathrm{T}(\vec{x_i}-\hat{\mu})\right]^2\ \;=\; \vec{v}^{\mathrm{T}}\frac{1}{n-1}\sum_{i=1}^n(\vec{x_i}-\hat{\mu})(\vec{x_i}-\hat{\mu})^\mathrm{T}\vec{v}$$
$(\vec{a}\vec{b})^\mathrm{T}=\vec{a}^{\mathrm{T}} \vec{b}^{\mathrm{T}}$である。
ここでベクトル$\vec{v}$で囲まれ他部分は分散共分散行列の形であるため
$$\Sigma=\frac{1}{n-1}\sum_{i=1}^n(\vec{x_i}-\hat{\mu})(\vec{x_i}-\hat{\mu})^\mathrm{T}\ $$
と置くと
分散は$$\vec{v}^\mathrm{T}\Sigma\vec{v}$$
と置く事ができる。
つまりこの分散が最大となる方向のベクトル$\vec{v}$を求めるために$$\max_{v:|v|=1}(\vec{v}^\mathrm{T}\Sigma\vec{v})$$
を考えます。
ここで$\Sigma$は半正定値行列であるため直行行列で対角化する事ができます。全ての零ベクトルでない $x∈ℝ^n$ について $x^TAx≥0$ が成り立つとき半正定値(positive semidefinite)という
--Horn and Johnson(2013) Definition 4.1.11--つまり
$$\Sigma\vec{v_i}=\lambda_i\vec{v_i}$$
となる固有ベクトルと固有値を考え
V=[v_1,v_2,...,v_d] \\\ \Lambda=diag(\lambda_1,\lambda_2,...,\lambda_d)と置いた時
$\Sigma V$とはVベクトルをそれぞれ対応する固有値倍に変換しているため$$\Sigma V=V\Lambda$$
であり
$V$は直交行列であるので$$\Sigma = V\Lambda V^\mathrm{T} \quad V^\mathrm{T}\Sigma V=\Lambda$$
これをもとに分散が最大化されるベクトルを求めていきます。
私が参考にした物では以下のように最大化解が一番大きい固有値であると証明されていました。(参考文献[1])
しかし私はこれがいまいち理解できなかったため私なりに考えて見ました。(間違っていればご指摘ください)
計算の簡略化のため2次元の場合を考えます、
まず\begin{align} V&=\left[\begin{array}{cc} v_1 & v_2\end{array} \right]=\left[\begin{array}{cc} v_{1x} & v_{2x} \\\ v_{1y} & v_{2y}\end{array} \right] \\\ \vec{v}&=\left[\begin{array}{c} v_x \\\ v_y \end{array}\right] \\\ \Lambda&=\left[\begin{array}{cc} \lambda_1 &0 \\\ 0 & \lambda_2 \end{array}\right] \end{align}と置きます。
そしてかっこの中身を式変形していきます。\begin{align} \vec{v}^\mathrm{T}\Sigma\vec{v} &= \vec{v}^\mathrm{T}V\Lambda V^\mathrm{T}\vec{v} \\\\ &= \vec{v}^\mathrm{T}\left[\begin{array}{cc} v_{1x} & v_{2x} \\\ v_{1y} & v_{2y}\end{array} \right]\left[\begin{array}{cc} \lambda_1 &0 \\\ 0 & \lambda_2 \end{array}\right] \left[\begin{array}{cc} v_{1x} & v_{1y} \\\ v_{2x} & v_{2y}\end{array} \right]\vec{v} \\\\ &=\vec{v}^\mathrm{T}\left[ \begin{array}{cc} v_{1x}^2\lambda_1+v_{2x}^2 \lambda_2 & v_{1x} v_{1y} \lambda_1 +v_{2x} v_{2y} \lambda_2 \\\ v_{1x} v_{1y} \lambda_1 +v_{2x} v_{2y} \lambda_2 & v_{1y}^2\lambda_1+V_{2y}^2 \lambda_2 \end{array} \right] \vec{v} \\\\ &=\vec{v}^\mathrm{T}\left( \left[ \begin{array}{cc} v_{1x}^2 & v_{1x} v_{1y} \\\ v_{1x} v_{1y} & v_{1y}^2 \end{array} \right]\lambda_1+\left[ \begin{array}{cc} v_{2x}^2& v_{2x} v_{2y} \\\ v_{2x} v_{2y} &V_{2y}^2 \end{array} \right]\lambda_2\right) \vec{v} \\\\ &=\vec{v}^\mathrm{T} \left[ \begin{array}{cc} v_{1x}^2 & v_{1x} v_{1y} \\\ v_{1x} v_{1y} & v_{1y}^2 \end{array} \right]\vec{v}\lambda_1+\vec{v}^\mathrm{T}\left[ \begin{array}{cc} v_{2x}^2& v_{2x} v_{2y} \\\ v_{2x} v_{2y} &V_{2y}^2 \end{array} \right]\vec{v}\lambda_2 \\\ \end{align}$\lambda_1$の項のみを取り出して考えて見ると
\begin{align} \vec{v}^\mathrm{T} \left[ \begin{array}{cc} v_{1x}^2 & v_{1x} v_{1y} \\\ v_{1x} v_{1y} & v_{1y}^2 \end{array} \right]\vec{v}\lambda_1&=\left[\begin{array}{c} v_x & v_y \end{array}\right] \left[ \begin{array}{cc} v_{1x}^2 & v_{1x} v_{1y} \\\ v_{1x} v_{1y} & v_{1y}^2 \end{array} \right]\left[\begin{array}{c} v_x \\\ v_y \end{array}\right]\lambda_1 \\\\ &=(v_{1x}^2 v_x^2+2v_{1x}v_{1y}v_xv_y+v_{1y}^2 v_y^2)\lambda_1 \\\\ &=(v_{1x}v_x+v_{1y}v_y)^2\lambda_1 \\\\ &=\left(\left[\begin{array}{c}v_{1x} & v_{1y} \end{array}\right]\left[\begin{array}{c} v_x \\\ v_y \end{array}\right]\right)^2\lambda_1 \\\\ &=\left(\vec{v_1}^\mathrm{T} \vec{v}\right)^2\lambda_1 \end{align}となる。
つまり\begin{align} \max_{v:|v|=1}\left(\vec{v}^\mathrm{T}\Sigma\vec{v}\right) &=\max_{v:|v|=1}\left(\left(\vec{v_1}^\mathrm{T}\vec{v}\right)^2\lambda_1+\left(\vec{v_2}^\mathrm{T}\vec{v}\right)^2\lambda_2\right) \\\ &=\max_{v:|v|=1}\left(\sum_{i=1}^2\left(\vec{v_i}^\mathrm{T}\vec{v}\right)^2\lambda_i\right) \\\ 一般化すると \\\ &=\max_{v:|v|=1}\left(\sum_{i=1}^d\left(\vec{v_i}^\mathrm{T}\vec{v}\right)^2\lambda_i\right) \end{align}となる。
この時$\vec{v},\vec{v_i}$は単位ベクトルで$\vec{v_1},\vec{v_2},...,\vec{v_d}$は互いに直行している。
そのため、$\vec{v}=\vec{v_i}$の時$$\max_{v:|v|=1}\left(\vec{v_i}^\mathrm{T}\vec{v}\right)=1$$
となる。(同じ方向の単位ベクトルの内積は1をとる)
同じように$i\neq j$の時$$\max_{v:|v|=1}\left(\vec{v_j}^\mathrm{T}\vec{v}\right)=0$$
である。(直行するベクトルの内積は0)
つまり最大値をとるときはベクトルvが最大の固有値と対応する固有ベクトルと等しくなるときであるため
$$\max_{v:|v|=1}\left(\sum_{i=1}^d\left(\vec{v_i}^\mathrm{T}\vec{v}\right)^2\lambda_i\right)=\lambda_1$$
となる。
また、同じように2番目に分散の大きい軸を取りたいときは$\vec{v}$を2番目に大きい固有値に対応する固有ベクトルと同じ方向に合わせれば良いという事になります。
分散共分散行列と相関行列
主成分分析を行う時、分散共分散行列の固有ベクトルをとる時と相関行列の固有ベクトルをとる方法があると聞いた事がある方がいるかと思います。
そもそも相関行列とはデータをそのデータの標準偏差で割ったものの分散共分散行列です。
先に平均も引いてしまって問題ないため、標準化されたデータの分散共分散行列でもあります。
つまりデータを先に標準化してしまえば先ほどの理論とやることは同じとなるため、標準偏差の固有ベクトルでも主成分分析できる事がわかると思います。
そのため実際どちらの方法をとっても主成分分析を行う事ができまが、相関行列の固有ベクトルをとった方が良いと言われています。
なぜならデータそのままの分散共分散行列だとデータの単位がバラバラでそこを考慮しなくてはいけないからです。
そのため単位をない状態にして主成分分析を行なった方が良いと言われています。(具体的にどのように影響が出るのかは例で説明できなかったので何か遭遇したら追記したいと思います)寄与率
最後に寄与率についてです。
寄与率とはそのデータがどのくらいデータを示しているかを差します。
そしてその値は理論でもお話したように分散の大きさで示す事ができ、分散の大きさはある方向ベクトルを取った時の固有値となりました。
その固有値の割合を求めれば良いため、寄与率PVは
$$PV_i=\frac{\lambda_i}{\sum_{j=1}^{d}\lambda_j}$$によって求められます。
実装
それではこの理論を用いて実装して見たいと思います。
ここで使用するデータは最初の概要でも使った5人の成績データを用います。
名前 国語 社会 英語 算数 理科 A 60 70 70 40 30 B 70 60 80 30 30 C 40 20 30 70 80 D 30 20 40 80 80 E 30 30 30 80 70 まず正解としてscikit-learnのPCAの実装を見て見ます。
実装したところこのようになりました。pandasを使用しているのは私が使い慣れていないための勉強を兼ねているだけですscikit_pca.pyimport matplotlib.pyplot as plt import numpy as np from sklearn.decomposition import PCA import pandas as pd #データの作成 name = ['a','b','c','d','e'] a = np.array([60,70,70,40,30]) b = np.array([70,60,80,30,30]) c = np.array([40,20,30,70,80]) d = np.array([30,20,40,80,80]) e = np.array([30,30,30,80,70]) #フレームワークに格納 df = pd.DataFrame([a,b,c,d,e],columns=['language','society','english','math','science'],index=name) dfs = df.iloc[:,:].apply(lambda x:(x-x.mean())/x.std(),axis=0) #データの標準化 #scikit-learnでのPCAインスタンス化と学習 pca = PCA() pca.fit(dfs) feature=pca.transform(dfs) #結果の出力 print(pd.DataFrame(feature,columns=["PC{}".format(x+1) for x in range(len(dfs.columns))]).head()) plt.figure() for i in range(len(name)): plt.annotate(name[i],xy=(feature[i,0],feature[i,1])) plt.scatter(feature[:,0],feature[:,1],marker='o') plt.xlabel('PC1') plt.ylabel('PC2') plt.show() print(pd.DataFrame(pca.explained_variance_ratio_,index=["PC{}".format(x+1) for x in range(len(dfs.columns))]))結果は以下のようになりました。
$python scikit_pca.py PC1 PC2 PC3 PC4 PC5 0 -2.161412 0.414977 -0.075496 -0.073419 4.163336e-17 1 -2.601987 -0.364980 0.088599 0.064849 4.163336e-17 2 1.479995 -0.437661 -0.290635 -0.037986 4.163336e-17 3 1.727683 -0.047103 0.382252 -0.035840 -1.387779e-17 4 1.555721 0.434767 -0.104720 0.082396 -1.457168e-16 0 PC1 9.518791e-01 PC2 3.441020e-02 PC3 1.275504e-02 PC4 9.556157e-04 PC5 8.271560e-35
続いて理論に基づいて実装して見ました。
クラスとしてMyPCAを定義し、scikit-learnと同様に使えるようにfit()メソッドで学習、transform()メソッドで新しい空間に射影する処理をしています。
クラスの定義以外は前のプログラムのpca=PCA()を
pca=MyPCA()に変更するだけなので省略して、クラスの定義のみ載せていますが、次のようになりました。
my_pca.py#myPCA program class MyPCA: e_values = None #固有値の保存 e_covs = None #固有ベクトルの保存 explained_variance_ratio_ = None def fit(self,dfs): #pandasデータでもnumpyデータでも使えるようにするための処理 if(type(dfs)==type(pd.DataFrame())): all_data = dfs.values else: all_data=dfs data_cov=np.cov(all_data,rowvar=0,bias=0) #分散共分散行列処理 self.e_values,self.e_vecs=np.linalg.eig(data_cov) #固有値と固有ベクトルの算出 self.explained_variance_ratio_= self.e_values/self.e_values.sum() #寄与率の計算 def transform(self,dfs): #pandasデータでもnumpyデータでも使えるようにするための処理 if(type(dfs)==type(pd.DataFrame())): all_data = dfs.values else: all_data=dfs feature = [] for e_vec in self.e_vecs.T: temp_feature=[] for data in all_data: temp_feature.append(np.dot(e_vec,data)) #内積計算 feature.append(temp_feature) return np.array(feature).Tそして結果です。
PC1 PC2 PC3 PC4 PC5 0 2.161412 -0.414977 -0.075496 -7.771561e-16 0.073419 1 2.601987 0.364980 0.088599 1.665335e-15 -0.064849 2 -1.479995 0.437661 -0.290635 -4.996004e-16 0.037986 3 -1.727683 0.047103 0.382252 -5.551115e-16 0.035840 4 -1.555721 -0.434767 -0.104720 0.000000e+00 -0.082396 Attribute Qt::AA_EnableHighDpiScaling must be set before QCoreApplication is created. 0 PC1 9.518791e-01 PC2 3.441020e-02 PC3 1.275504e-02 PC4 2.659136e-17 PC5 9.556157e-04
このようになりました。
おそらく固有ベクトルが反転してしまったため正負逆転してしまっているところもありますが、同じような解析結果が出せたかと思います。終わりに
今回は主成分分析の理論について個人的備忘録も兼ねて書いて見ました。
証明をところどころ挟んだので読みにくい記事になってしまった感が否めないのですが、私のような人は細かいところが気になって進めないこともあるかと考えできるだけ証明しました。今回取り上げた主成分分析はscikit-learnで簡単に使えてしまうので中身をあまり理解せず使うのが気持ち悪く感じていたので今回一応理解ができた気がするのでスッキリしました。
ただ、scikit-learnでの実装をのぞいて見たところ特異値分解によって実装しているようです。
ただ対称行列の場合は固有値分解と特異値分解の結果は同じになるようなので、今回のような分散共分散行列や相関行列に適用するときはどちらでもいいのかと感じました。
もし機会があれば一般化以外で特異値分解を使う利点も調べて見たいと思います。参考文献
[1]http://ibis.t.u-tokyo.ac.jp/suzuki/lecture/2015/dataanalysis/L7.pdf データ解析 第七回「主成分分析」
[2]https://seetheworld1992.hatenablog.com/entry/2017/03/17/104807 分散共分散行列(と相関行列)は半正定値であることを証明する
- 投稿日:2020-11-12T22:24:53+09:00
ベルマーク教育助成財団の週別ベルマーク受付状況のPDFから都道府県別・市区町村別に集計する
はじめに
ベルマーク教育助成財団の週別ベルマーク受付状況のPDFから都道府県別・市区町村別に集計しました
現在はウェブベルマークというのも始まっていてウェブベルマークサイトからお好きなショップにアクセスお買い物に応じてベルマークポイントがたまります
じゃらんや楽天トラベルなども利用可能なのでGo To トラベルを申し込む前にご利用するだけで、自己負担なく支援できます。
※要事前登録
説明
こちらの処理はX座標、Y座標のlimitの範囲にあるのもを多い座標の位置に集約しています
文字数が多く2段になっているものや、多少ずれているところを調整していますdef snap_adjustment(s, limit=5): count = s.value_counts().sort_index() index = 0 value = 0 for i, v in count.items(): if (i - index) < limit: if v > value: s = s.replace(index, i) index = i value = v else: s = s.replace(i, index) else: index = i value = v return sプログラム
import pathlib import time import pandas as pd import pdfplumber import requests from bs4 import BeautifulSoup def fetch_file(url, dir="."): r = requests.get(url) r.raise_for_status() p = pathlib.Path(dir, pathlib.PurePath(url).name) p.parent.mkdir(parents=True, exist_ok=True) with p.open(mode="wb") as fw: fw.write(r.content) return p def snap_adjustment(s, limit=5): count = s.value_counts().sort_index() index = 0 value = 0 for i, v in count.items(): if (i - index) < limit: if v > value: s = s.replace(index, i) index = i value = v else: s = s.replace(i, index) else: index = i value = v return s url = "https://www.bellmark.or.jp/collect/accept.htm" headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko" } r = requests.get(url, headers=headers) r.raise_for_status() soup = BeautifulSoup(r.content, "html.parser") links = { href.get("href") for href in soup.select("div.cal-process > div.cal-row-date > div > a") } dfs = [] for link in links: p = fetch_file(link) with pdfplumber.open(p) as pdf: for page in pdf.pages: crop = page.within_bbox((0, 65, page.width, page.height - 40)) df_tmp = ( pd.DataFrame(crop.extract_words(keep_blank_chars=True)) .astype({"x0": float, "x1": float, "top": float, "bottom": float}) .sort_values(["top", "x0"]) ) df_tmp["top"] = snap_adjustment(df_tmp["top"], 6) df_tmp["x0"] = snap_adjustment(df_tmp["x0"]) table = ( df_tmp.pivot_table( index=["top"], columns="x0", values="text", aggfunc=lambda x: "".join(str(v) for v in x), ) ).values df = pd.DataFrame(table, columns=["都道府県", "市", "区町村", "参加団体", "受付日"]) dfs.append(df) time.sleep(3) df = pd.concat(dfs) df df["市区町村"] = df["市"].fillna("") + df["区町村"].fillna("") df1 = df.reindex(columns=["都道府県", "市区町村", "参加団体", "受付日"]) df1.to_csv("data.csv") df1都道府県別
import japanize_matplotlib import matplotlib as mpl import matplotlib.pyplot as plt mpl.rcParams["figure.dpi"] = 200 df1["都道府県"].value_counts(ascending=True).plot.barh(figsize=(5, 10)) # グラフを保存 plt.savefig("01.png", dpi=200, bbox_inches="tight") plt.show()
市区町村別
s = df1.groupby(["都道府県", "市区町村"])["市区町村"].count().sort_values(ascending=True) s.tail(50).plot.barh(figsize=(5, 10)) # グラフを保存 plt.savefig("02.png", dpi=200, bbox_inches="tight") plt.show()



- 投稿日:2020-11-12T22:23:39+09:00
gdal_mergeで巨大ファイルが生成されるときの対処法
gdal_mergeで巨大なファイルが生成されてしまう...
tifデータなどを扱うgdalモジュール.
gdal_merge.pyはそのモジュール内にある、tifデータを位置情報に基づいて結合するスクリプト.ドキュメント内のスクリプト(以下)を実行したところ...
python gdal_merge.py -init 255 -o out.tif in1.tif in2.tif150MB程度のファイルを2つ結合しただけなのに、30GBを超える超巨大ファイルが生成された
(GとMをFinderが間違えているのではと何回も見返しました)解消法
tifファイルは基本的に圧縮されているものらしく、先ほどのスクリプトに圧縮方法を表すタグをつけると圧縮してくれるらしい.
値がない部分などを圧縮するため、離れた地点の画像を合成すると大きなファイルになるらしい.python gdal_merge.py -init 255 -o out.tif in1.tif in2.tif -co COMPRESS=DEFLATEこれで150MB程度の合成されたファイルが生成されました.
ちなみに圧縮率は多少少なくなるもののファイル互換性が高い圧縮方法などもあるそう
python gdal_merge.py -init 255 -o out.tif in1.tif in2.tif -co -co COMPRESS=LZW
- 投稿日:2020-11-12T20:55:26+09:00
keyhac で画面3分割
Windows には、 Win キーと矢印キーの同時押しで画面を左右2分割(上下も含めると4分割)できる「スナップ機能」があります。今回は keyhac でこの機能を拡張し、1:2 の比率でもスナップできるようにしてみます。
ウィンドウを並べて閲覧したいけれど半分だと小さすぎるし、かといって手で都度リサイズするのも煩わしい……などとお悩みの方にオススメです。
(完成イメージ↓)
コード
config.pyの関数configureの中身を書いていきます。
※今回は最低限の部分のみ記述しています。基本的な設定等は 以前の記事 参照。def configure(keymap): keymap.replaceKey("(28)", 236) # 変換キーに仮想コード236を割り当て keymap.defineModifier(236, "User1") # 変換キーを仮想修飾キー "U1" として使う def triple_snap(position = "center", Narrow = False): main_monitor_info = (pyauto.Window.getMonitorInfo())[0] non_taskbar_area = main_monitor_info[1] [monitor_left, monitor_top, monitor_right,monitor_bottom] = non_taskbar_area monitor_width = monitor_right - monitor_left ratio = 3 if Narrow: wnd_width = int(monitor_width / ratio) wnd_pos_table = { "center": { "left": wnd_width, "right": wnd_width * 2, }, "left": { "left": monitor_left, "right": wnd_width, }, "right": { "left": wnd_width * 2, "right": monitor_right, }, } else: wnd_width = int(monitor_width / ratio) * 2 wnd_pos_table = { "center": { "left": int(monitor_width / ratio / 2), "right": int(monitor_width / ratio / 2) + wnd_width, }, "left": { "left": monitor_left, "right": wnd_width, }, "right": { "left": int(monitor_width / ratio), "right": monitor_right, }, } wnd_area = wnd_pos_table[position] rect = [wnd_area["left"], monitor_top, wnd_area["right"], monitor_bottom] wnd = keymap.getTopLevelWindow() if list(wnd.getRect()) == rect: wnd.maximize() else: if wnd.isMaximized(): wnd.restore() wnd.setRect(rect) for k in [ ("U1-M" , lambda: triple_snap("center", False)), ("S-U1-H", lambda: triple_snap("left" , False)), ("S-U1-L", lambda: triple_snap("right" , False)), ("C-U1-H", lambda: triple_snap("left" , True)), ("C-U1-L", lambda: triple_snap("right" , True)), ("C-U1-M", lambda: triple_snap("center", True)), ("U1-H" , "Win-Left"), ("U1-L" , "Win-Right"), ]: keymap_global[k[0]] = k[1]実行イメージ
変換キーと M で画面中央部にモニタ幅の 2/3 でウィンドウを持ってきます。もう一度同じキーを押すと最大化します。
同時に Ctrl を押していると幅が 1/3 に。
変換キーと H・L には通常の左右スナップを割り当てて、 Shift を押していると 2/3 、 Ctrl を押していると 1/3 幅でスナップします。
(そもそもマルチモニタにできれば万事解決なんですけどね)



- 投稿日:2020-11-12T20:23:08+09:00
PythonのSeleniumでよく使うであろう備忘録
参考URL
タイトル URL Selenium for Python Elementにフォーカスを当てる https://qiita.com/BlueSilverCat/items/e1dc9ec65f235a7fff01 【Python】SeleniumでHeadless Chromeを使おう https://qiita.com/derodero24/items/9e9567790bde9e4b9d0c
- 投稿日:2020-11-12T19:12:44+09:00
[Blender×Python] 回転をマスターしよう!!
目次
0.立方体を回転させよう
1.トーラスを回転させよう
2.サンプルコード
3.英単語まとめ0.立方体を回転させよう
0-0.1つの立方体を回転させよう
◯1番シンプルな回転の方法です。
import bpy #計算に必要なものがいろいろ入ってる import math #立方体を追加する関数 bpy.ops.mesh.primitive_cube_add( scale=(1, 1, 1), #引数の追加 #math.piは180度のことなので math.pi * 1/6 = 30(度) #X軸を中心に30度回転させる rotation = (math.pi*1/6,0,0) )
0-1.立方体を回転させて並べよう
◯少しずつずらして配置していきます。
import bpy import math #100回反復処理をする for i in range(0,100): bpy.ops.mesh.primitive_cube_add( #少しずつ上にずらす location=(0, 0, i/50), scale=(1, 1, 0.05), #180 * i * 36(度)ずつずらしていく rotation = (0, 0, math.pi*i*10/360) )
0-2.色をつけてみよう
◯上記のコードの応用です。
import bpy import math #materialという変数を自分でつくる(materialは素材という意味) material = bpy.data.materials.new('Red') #色を定義する(R,G,B,A) material.diffuse_color = (1.0, 0.0, 0.0, 1.0) #100回繰り返す for i in range(0,100): bpy.ops.mesh.primitive_cube_add( #すこしずつ上にずらす location=(0, 0, i/50), scale=(1, 1, 0.05), #少しずつ回転させる rotation = (0, 0, math.pi*i*10/360) ) #オブジェクトに自分で定義した色を追加する(appendは追加という意味) bpy.context.object.data.materials.append(material)
1.トーラスを回転させよう
1-0.トーラスを変形させよう
import bpy #トーラスを追加する関数 bpy.ops.mesh.primitive_torus_add( location=(0, 0, 0), major_radius=1.0, minor_radius=0.01, rotation=(0, 0, 0) ) #Y軸方向に縮める bpy.ops.transform.resize(value=(1, 0.3, 1))
1-0.トーラスを回転させて並べよう
◯形を作った後に回転させる方法です。
import bpy import math for i in range(0,36): bpy.ops.mesh.primitive_torus_add( location=(0, 0, 0), major_radius=1.0, minor_radius=0.01, ) #Y軸方向に縮める bpy.ops.transform.resize(value=(1, 0.3, 1)) #Z軸を中心に回転する bpy.ops.transform.rotate(value=math.pi*i*10/360,orient_axis='Z')
1-2.トーラスに色をつけよう
◯1つの軸を中心に回転させた後に、別の軸を中心に回転させています。
import bpy import math #材質の定義 material = bpy.data.materials.new('Red') material.diffuse_color = (1.0, 0.0, 0.0, 1.0) for i in range(0,36): for j in range(0,36): bpy.ops.mesh.primitive_torus_add( location=(0, 0, 0), major_radius=1.0, minor_radius=0.01, ) #Y軸方向に縮める bpy.ops.transform.resize(value=(1, 0.3, 1)) #Z軸を中心に回転させる bpy.ops.transform.rotate(value=math.pi*j*10/360,orient_axis='Z') #Y軸を中心に回転させる bpy.ops.transform.rotate(value=math.pi*i*10/360,orient_axis='Y') #自分で定義した赤色を使う bpy.context.object.data.materials.append(material)
2.サンプルコード
立方体を回転させるコード
import bpy #計算に必要なものがいろいろ入ってる import math #立方体を追加する関数 bpy.ops.mesh.primitive_cube_add( scale=(1, 1, 1), #引数の追加 #math.piは180度のことなので math.pi * 1/6 = 30(度) #X軸を中心に30度回転させる rotation = (math.pi*1/6,0,0) )立方体を回転させて並べていくコード
import bpy import math #100回反復処理をする for i in range(0,100): bpy.ops.mesh.primitive_cube_add( #少しずつ上にずらす location=(0, 0, i/50), scale=(1, 1, 0.05), #180 * i * 36(度)ずつずらしていく rotation = (0, 0, math.pi*i*10/360) )並べた立方体に色をつけるコード
import bpy import math #materialという変数を自分でつくる(materialは素材という意味) material = bpy.data.materials.new('Red') #色を定義する(R,G,B,A) material.diffuse_color = (1.0, 0.0, 0.0, 1.0) #100回繰り返す for i in range(0,100): bpy.ops.mesh.primitive_cube_add( #すこしずつ上にずらす location=(0, 0, i/50), scale=(1, 1, 0.05), #少しずつ回転させる rotation = (0, 0, math.pi*i*10/360) ) #オブジェクトに自分で定義した色を追加する(appendは追加という意味) bpy.context.object.data.materials.append(material)トーラスを変形させるコード
import bpy #トーラスを追加する関数 bpy.ops.mesh.primitive_torus_add( location=(0, 0, 0), major_radius=1.0, minor_radius=0.01, rotation=(0, 0, 0) ) #Y軸方向に縮める bpy.ops.transform.resize(value=(1, 0.3, 1))トーラスを回転させて並べるコード
import bpy import math for i in range(0,36): bpy.ops.mesh.primitive_torus_add( location=(0, 0, 0), major_radius=1.0, minor_radius=0.01, ) #Y軸方向に縮める bpy.ops.transform.resize(value=(1, 0.3, 1)) #Z軸を中心に回転する bpy.ops.transform.rotate(value=math.pi*i*10/360,orient_axis='Z')トーラスに色をつけて、2つの軸を中心に回転させるコード
import bpy import math #材質の定義 material = bpy.data.materials.new('Red') material.diffuse_color = (1.0, 0.0, 0.0, 1.0) for i in range(0,36): for j in range(0,36): bpy.ops.mesh.primitive_torus_add( location=(0, 0, 0), major_radius=1.0, minor_radius=0.01, ) #Y軸方向に縮める bpy.ops.transform.resize(value=(1, 0.3, 1)) #Z軸を中心に回転させる bpy.ops.transform.rotate(value=math.pi*j*10/360,orient_axis='Z') #Y軸を中心に回転させる bpy.ops.transform.rotate(value=math.pi*i*10/360,orient_axis='Y') #自分で定義した赤色を使う bpy.context.object.data.materials.append(material)3.英単語まとめ
英単語 日本語訳 import 輸入する/手に入れる math 数学 mesh 頂点、辺、面の集合 scale 大きさ primitive 原始的な add 追加する rotation 回転 pi π( = 180度) range 幅 cube 立方体 material 素材 diffuse 拡散、散乱 context 文脈、環境 object もの、物体 data 情報 append 加える、追加する major 大きな minor 小さな radius 半径 transform 変換 resize 大きさの変更 axis 軸 orient 方向 rotate 回転する rotation 回転 value 値 location 位置、座標 operation 運用、操作






- 投稿日:2020-11-12T18:59:03+09:00
seabornでheatmap描いてみた�【Python】
実験データを使ってヒートマップを描く練習してみました。
matplotlib,seaborn,pandasのインポート
%matplotlib inline
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
上記コードで準備完了。データの読み込み
ec_am = pd.read_csv('./ec_am.csv')
データは6行10列
ヒートマップの作成
まずは何も条件指定しないでやってみる。
heatmap1 = sns.heatmap(ec_am)
plt.savefig("heatmap1.png")
plt.savefig("heatmap1.png")で図をheatmap1という名前のpng形式で保存。 保存先は開いてるjupyter notebookと同じファイル。次にいろんな条件を試してみる。
heatmap2 = sns.heatmap(ec_am, yticklabels=False, cbar=False)
plt.savefig("heatmap2.png")
yticklabelsでY軸ラベルの指定。cbarでカラーバーを指定。Falseだと無くなる。
heatmap3 = sns.heatmap(ec_am, cmap="Wistia", annot=True, fmt="1.2f")
plt.savefig("heatmap3.png")
cmapで色を指定。annotでデータの数値を表示。fmt="1.xf"(xには正の整数)で小数点第x位まで表示。
色の種類はbeizのノートを参照。
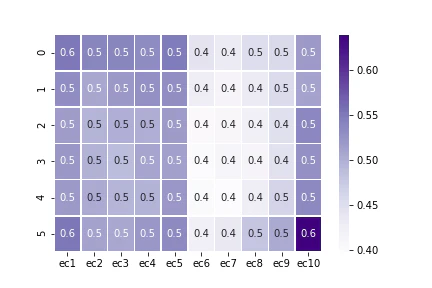
heatmap4 = sns.heatmap(ec_am, cmap="Purples", annot=True, fmt="1.1f", linewidths=.5)
plt.savefig("heatmap4.png")
linewidthsでセルの間に線を描く(この場合太さ0.5)。




- 投稿日:2020-11-12T18:19:47+09:00
「伸び悩んでいる3年目Webエンジニアのための、Python Webアプリケーション自作入門」を更新しました
本を更新しました
チャプター「複数回のHTTPリクエストに繰り返し応答できるようにする」 を更新しました。
続きを読みたい方は、ぜひBookの「いいね」か「筆者フォロー」をお願いします ;-)
以下、書籍の内容の抜粋です。
Webサーバーがリクエストを1回だけしか処理できない問題
そろそろこの問題に対処しましょう。
皆さんにこれまで作ってもらったWebサーバーは、一回のHTTPリクエストを処理するとすぐに終了してしまいます。
そのため、繰り返しリクエストに応答しようと思うと毎回サーバーを起動しなおさなければいけません。
開発中に動作確認のたびにサーバーを起動するのがめんどくさいというのもありますが、一般的なWebページを正常に表示する上でも問題があります。
HTMLから外部ファイルの参照ができない
例えば、前章で作ってもらった
index.htmlを下記のように変更してみてください。
study/static/index.html<!doctype html> <html lang="ja"> <head> <meta charset="UTF-8"> <title>HenaServer</title> <link rel="stylesheet" href="index.css"> </head> <body> <img alt="logo" src="logo.png"> <h1>Welcome to HenaServer!</h1> </body> </html>6行目:
<link rel="stylesheet" href="index.css">
10行目:<img alt="logo" src="logo.png">を追加しました。
よくある外部CSSファイルの読み込みと、画像ファイルの読み込みです。
次に、読み込もうとしているファイルを、同じディレクトリ内に新しく用意します。
CSSファイルの内容は下記のようにしています。
study/static/index.cssh1 { color: red; }画像ファイルはこちらです。
study/static/logo.png
https://github.com/bigen1925/introduction-to-web-application-with-python/blob/main/codes/chapter12/static/logo.png画像ファイルは何でも良いのですが、本書では「いらすとや」^[https://www.irasutoya.com/] から拝借しています。お好きな画像を使っていただいて構いません。
見ていただければ分かるように、通常のWebページであればChromeにはロゴ画像が表示され、文字にはCSSが適用されて赤色に表示されるはずです。
では、サーバーを起動してChromeで
http://localhost:8080/index.htmlへアクセスしてみましょう。
これはよくないですね。
画像もCSSも読み込まれていません。
ブラウザはWebサーバーからレスポンスを受け取った際、レスポンスボディのHTML内に外部ファイル参照(
<img src="">、<script src="">、<link href="">など)が記載されていると、再度リクエストを送信しなおしてファイル内容を取得しようとします。しかし、私たちのWebサーバーは最初のリクエストを処理したあと、すぐにプログラムを終了させてしまうため、追加のリクエスト(今回でいうとCSSと画像のリクエスト)を処理できていないのです。
その様子を、もう少し具体的に見てみましょう。
ChromeにはHTTPリクエストの通信結果を詳細に見れる「開発者ツール」という機能が備わっています。
そちらを使って、実際に行われたリクエストの様子を確認していきます。さきほどChromeで
http://localhost:8080/index.htmlにアクセスした画面で、ctrl+shift+jを押してみましょう。
(または、画面を右クリックして検証を選択し、Consoleタブを開きます)
図のように、既に
index.cssとlogo.pngを取得する際に、Webサーバーとのコネクションに失敗したことを示すエラーログが表示されています。(Chromeは他にも、特に指示がなくても勝手にファビコンの画像を取得しにくような仕様になっており、そちらのエラーも表示されていますが、本書では特に気にする必要はありません。)
次に、開発者ツールの
Networkタブを開き、サーバーを起動してからリロードしてみましょう。
(ネットワークタブは、開発者ツールを開いて以降の通信のみ情報を表示するため、リロードする必要があります)
Chromeはこのページを表示するために、全部で4件の通信を行っていることが分かります。
(バージョンや環境によって内容は異なるかもしれません、)内訳を見てみると、
index.htmlを取得する通信は成功(statusが200)しており、index.cssとlogo.pngは通信に失敗(statusがfailed)していることが分かります。繰り返しリクエストを処理できるようにする
このままでは「ただ面倒くさい」だけではなく、CSSや画像、JSなどを使った普通のWebページ1つすら表示できないということが分かりました。
では、Webサーバーを改良して、これらの問題を解決していきましょう。
ソースコード
まずは、コネクションを確立してレスポンスを返す処理を無限ループに中に入れることで、繰り返しリクエストに対応できるようにします。
ソースコードがこちらです。
study/WebServer.py
https://github.com/bigen1925/introduction-to-web-application-with-python/blob/main/codes/chapter12/WebServer.py解説
30行目
while True:まず一番大きな変更点として、「クライアントからのコネクションを待つ」〜「コネクションを終了する」までの処理(31行目-97行目)をまるごと無限ループの中にいれたところです。
(無限ループの記法が分からない方は、「python while true」で調べてみてください。)たった1行ですが、これにより、1つのリクエストの処理が完了し、コネクションを終了させた後、ループの先頭にもどり再度リクエストを待機することになります。
次のリクエストの処理が完了すると、またループの先頭に戻り、次のリクエストを待ちます。つまり、プログラムを起動した人が明示的にプログラムを中断させるまで、無限にリクエストをさばき続けるプログラムになります。
89-97行目
except Exception: # リクエストの処理中に例外が発生した場合はコンソールにエラーログを出力し、 # 処理を続行する print("リクエストの処理中にエラーが発生しました。") traceback.print_exc() finally: # 例外が発生した場合も、発生しなかった場合も、TCP通信のcloseは行う client_socket.close()ついでに、例外処理を追加しておきました。
例外処理をしておかないとループの途中で例外が発生した場合にプログラム全体が停止してしまいますが、上記のようにハンドリングすることでその時扱っているリクエストの処理だけ中断させますが、プログラム全体は停止せずに次のループへ進むことになります。
また、
cient_socketのclose()はtry句の末尾でやるのではなく、finally句で行います。
try句の末尾でやってしまうと、途中で例外が発生した場合にコネクションの切断がスキップされてしまうためです。動かしてみる
では実際に動かしてみましょう。
いつもどおりコンソールからサーバーを起動します。
続きはBookで!




- 投稿日:2020-11-12T17:10:44+09:00
操作ログ整形ツールを作る 3日目
3日目
RuntimeError: The current Numpy installation (中略) fails to pass a sanity check due to a bug in the windows runtime. See this issue for more information: https://tinyurl.com/y3dm3h86の原因を探る。
for more information を見ると以下。
https://developercommunity.visualstudio.com/content/problem/1207405/fmod-after-an-update-to-windows-2004-is-causing-a.html
use numpy==1.19.3 works?https://qiita.com/bear_montblanc/items/b4b75dfd77da98076da5
ググったらまんまこれ
あまり根拠がわからず信じるのは何だがそのままやってみる
→エラーが消えた。えー。CSVのソートをしたい
https://note.nkmk.me/python-pandas-sort-values-sort-index/
に戻る。チュートリアル通りfirstpandas.pyimport pandas as pd df = pd.read_csv('sample_pandas_normal.csv', index_col=0) print(df)で、実行。
C:\workspaces\playground>firstpandas.py age state point name Alice 24 NY 64 Bob 42 CA 92 Charlie 18 CA 70 Dave 68 TX 70 Ellen 24 CA 88 Frank 30 NY 57おー、でた。これにソートを掛けてみる。こんなんでよいの?
firstpandas.pyimport pandas as pd df = pd.read_csv('sample_pandas_normal.csv', index_col=0) df.sort_values('age') print(df)結果、変わらない。いや感覚でやっちゃ良くない。。
まず公式ドキュメントはこの辺
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.sort_values.htmlもう一度。
結論から書くと、これでイメージが付いた。firstpandas.pyimport pandas as pd df = pd.read_csv('sample_pandas_normal.csv') print(df) df_s = df.sort_values('age') print(df_s)C:\workspaces\playground>firstpandas.py name age state point 0 Alice 24 NY 64 1 Bob 42 CA 92 2 Charlie 18 CA 70 3 Dave 68 TX 70 4 Ellen 24 CA 88 5 Frank 30 NY 57 name age state point 2 Charlie 18 CA 70 0 Alice 24 NY 64 4 Ellen 24 CA 88 5 Frank 30 NY 57 1 Bob 42 CA 92 3 Dave 68 TX 70Pythonの文法からもっかいおさらいしたほうが良いね
Python3チートシート(基本編)
Pythonチートシート 基本要素編(@IT)
Pandas 公式チートシートを翻訳しました一旦ここまで。
日付でソートしてみる
さて用いるCSVをちょっと変えて、日付カラムを足した。
sample_pandas_date.csvname,age,state,point,birthday Alice,24,NY,64,1996/1/2 Bob,42,CA,92,1978/2/2 Charlie,18,CA,70,2002/3/4 Dave,68,TX,70,1952/1/1 Ellen,24,CA,88,1996/1/5 Frank,30,NY,57,1990/5/15firstpandas.pyimport pandas as pd df = pd.read_csv('sample_pandas_date.csv') print(df) df_s = df.sort_values('birthday') print(df_s)これでどうなるのかというと結果以下。
C:\workspaces\playground>firstpandas.py name age state point birthday 0 Alice 24 NY 64 1996/1/2 1 Bob 42 CA 92 1978/2/2 2 Charlie 18 CA 70 2002/3/4 3 Dave 68 TX 70 1952/1/1 4 Ellen 24 CA 88 1996/1/5 5 Frank 30 NY 57 1990/5/15 name age state point birthday 3 Dave 68 TX 70 1952/1/1 1 Bob 42 CA 92 1978/2/2 5 Frank 30 NY 57 1990/5/15 0 Alice 24 NY 64 1996/1/2 4 Ellen 24 CA 88 1996/1/5 2 Charlie 18 CA 70 2002/3/4それっぽくなってきた。
そろそろ本当の操作ログを用いてみよう。
と、実際のCSVを置いてみたらやっぱりエラーが出た。盛り上がってきたところで一旦ここまで。C:\workspaces\playground>firstpandas.py Traceback (most recent call last): File "C:\workspaces\playground\firstpandas.py", line 3, in <module> df = pd.read_csv('oplog20201112.csv') File "C:\Users\works\AppData\Local\Programs\Python\Python39\lib\site-packages\pandas\io\parsers.py", line 688, in read_csv return _read(filepath_or_buffer, kwds) File "C:\Users\works\AppData\Local\Programs\Python\Python39\lib\site-packages\pandas\io\parsers.py", line 454, in _read parser = TextFileReader(fp_or_buf, **kwds) File "C:\Users\works\AppData\Local\Programs\Python\Python39\lib\site-packages\pandas\io\parsers.py", line 948, in __init__ self._make_engine(self.engine) File "C:\Users\works\AppData\Local\Programs\Python\Python39\lib\site-packages\pandas\io\parsers.py", line 1180, in _make_engine self._engine = CParserWrapper(self.f, **self.options) File "C:\Users\works\AppData\Local\Programs\Python\Python39\lib\site-packages\pandas\io\parsers.py", line 2010, in __init__ self._reader = parsers.TextReader(src, **kwds) File "pandas\_libs\parsers.pyx", line 537, in pandas._libs.parsers.TextReader.__cinit__ File "pandas\_libs\parsers.pyx", line 740, in pandas._libs.parsers.TextReader._get_header UnicodeDecodeError: 'utf-8' codec can't decode byte 0x83 in position 0: invalid start byte
- 投稿日:2020-11-12T16:34:38+09:00
DTMの標高値をグラフで表示してみた
DTMとは
Digital Terrain Mapの略。今回は火星探査機MROに搭載されたHiRISEというカメラが取得したDEMデータを使う。
HiRISEとは
MROの搭載カメラの一つ。めちゃくちゃ高解像度。
上の画像もその一つらしい。(これは擬似カラー画像)手順
ダウンロード:HiRISE アーカイブサイト
ESPとかPSPとかはカメラが画像を取得した時のmodeになっている。(どれでもいい)今回はPythonで読んでいきます。
適当にgdalとか使って読み込んでください。(飛ばします。)dtm.pyxx=int(len(data_array))+1 yy=int(len(data_array[0]))+1 data_array = np.where(data_array<=-8000, data_array*(-0.0), data_array) x = np.arange(0, xx-1, 1) y = np.arange(0, yy-1, 1) Z = data_array Y, X = np.meshgrid(y, x) fig = plt.figure() ax = Axes3D(fig) ax.plot_wireframe(X, Y, Z) plt.show()雑な直貼り。
配列の長さ出して。-8000以下の標高はありえないから...それを使う。無効値をとりあえず0。max, minを特定。メッシュでプロット。
ちなみに、値とかみていくのにコメントアウト含めると270行もあった。中身こんなに薄いのに...とりあえず、こんな感じでやると
こんなのができる。見にくい!
まとめ
表示はできたから綺麗にしようかな...
これ何に使うのかはわかりませんw
何かしらには使えるかな...綺麗にすれば!以上!雑多なまとめでした!
以降も何かしら面白いことや研究の延長戦でやったことなどをまとめてみます。
研究も就活もやらなくては...ゲームもしたいんだけどなぁ...


- 投稿日:2020-11-12T16:29:52+09:00
PythonでNetCDF形式のデータを扱う
環境
Ubuntu18.04LTS
Python3環境構築
Python3でNetCDF形式のファイルを使用するためにはNetCDF4モジュールが必要。
このモジュールはpip3で簡単にインストールできた。PythonでNetCDFファイルのI/O
以下は緯度、経度、時間の三次元変数T2が格納されたNetCDFファイルを開いて、新たにtest_ncout.ncというファイルを作成するプログラム。
#coding: utf-8 # This is a sample program to read and write s netCDF file with Python3 from netCDF4 import Dataset import numpy as np #*~*~*~*~*~*~*~*~*~*~*~*~*~*~* #read netCDF file #*~*~*~*~*~*~*~*~*~*~*~*~*~*~* #open a netCDF file to read ifile = "test.nc" ncin = Dataset(ifile, 'r') #check #print(ncin.file_format) #get variables #print(ncin.variables.keys()) #get axis data tin = ncin.variables['time'] latin = ncin.variables['lat'] lonin = ncin.variables['lon'] #get length of axis data ntime = len(tin) nlat = len(latin) nlon = len(lonin) #check axis #print(tim[:]) #print(latin[:]) #print(lonin[:]) #read data vin = ncin.variables['T2'] #check data #print(vin[:,:,:,:]) #*~*~*~*~*~*~*~*~*~*~*~*~*~*~* #write netCDF file #*~*~*~*~*~*~*~*~*~*~*~*~*~*~* #open a netCDF file to write ncout = Dataset('test_ncout.nc', 'w', format="NETCDF4") #check file format #print(ncout.file_format) #define axix size ncout.createDimension('time',ntime) ncout.createDimension('lat', nlat) ncout.createDimension('lon', nlon) #create time axis time = ncout.createVariable('time', np.dtype('f4').char, ('time')) time.long_name = 'time' time.units = 'months since 1850-1-1' time.axis = 'T' #create lat axis lat = ncout.createVariable('lat', np.dtype('f4').char, ('lat')) lat.long_name = 'latitude' lat.units ='degrees_north' lat.axis = 'Y' #create lon axis lon = ncout.createVariable('lon', np.dtype('f8').char, ('lon')) lon.long_name = 'longitude' lon.units = 'degrees_east' lon.axis = 'X' #create variable arry vout = ncout.createVariable('T2', np.dtype('f4').char, ('time', 'lat', 'lon')) vout.long_name = '2m temperature' vout.units = 'K' #copy axis from original data time[:] = tin[:] lon[:] = lonin[:] lat[:] = latin[:] vout[:] = vin[:] ncin.close() ncout.close()リファレンス
http://unidata.github.io/netcdf4-python/
https://github.com/Unidata/netcdf4-python
- 投稿日:2020-11-12T15:47:09+09:00
PySpark チートシート【Python】
はじめに
この記事は、PySpark 3.0.1 documentation の内容をベースとしています。
簡単に呼び出すことが可能な関数の動きを知っておくことで、より迅速に実装の方針を立てることができるかと思います。
Introduction
JupyterLab PySpark Kernel
先ずは GCP の Dataproc を利用して PySpark を動かす環境を作ります。
gcloud dataproc clusters create <cluster name> --enable-component-gateway --region <region> --zone <zone> \ --master-machine-type n1-standard-2 --master-boot-disk-size 500 --num-workers 2 \ --worker-machine-type n1-standard-2 --worker-boot-disk-size 500 --image-version 1.4-debian10 --optional-components ANACONDA,JUPYTER \ --scopes https://www.googleapis.com/auth/cloud-platform,https://www.googleapis.com/auth/devstorage.full_control --project <project id>--enable-component-gateway を設定しているのでクラスタの UI から JupyterLab を選択できるようになっています。
データは kaggle の Titanic Data を用います。import library
import pandas as pd import numpy as np import sys import time from google.cloud import storage as gcs from io import BytesIO from fs_gcsfs import GCSFS from fs import open_fs import gcsfs import pyspark from pyspark.sql import SparkSession from pyspark.sql.types import * from pyspark.sql import Row ,functions as F from pyspark.sql import SQLContext from pyspark.sql.functions import UserDefinedFunction from pyspark.sql.functions import * from pyspark.sql.window import Windowsys.path >> ['/opt/conda/anaconda/lib/python36.zip', '/opt/conda/anaconda/lib/python3.6', '/opt/conda/anaconda/lib/python3.6/lib-dynload', '', '/opt/conda/anaconda/lib/python3.6/site-packages', '/usr/lib/spark/python', '/opt/conda/anaconda/lib/python3.6/site-packages/IPython/extensions', '/root/.ipython']gcsfs = GCSFS(bucket_name = <bucket_name>) gcsfs.tree() >> |-- .ipynb_checkpoints | -- error (resource '/.ipynb_checkpoints' not found) |-- google-cloud-dataproc-metainfo | -- error (resource '/google-cloud-dataproc-metainfo' not found) |-- notebooks | -- jupyter | -- Untitled.ipynb -- titanic_data.csvload CSV data (as Pandas DataFrame) from Cloud Storage
bucket_name = "<bucket_name>" file_name = "titanic_data.csv" project_id = "<project_id>"# with Pandas titanic_data = pd.read_csv("<Cloud Storage Path>")# with gcsfs fs = gcsfs.GCSFileSystem(project = project_id) with fs.open('{}/titanic_data.csv'.format(bucket_name)) as file: titanic_data = pd.read_csv(file)# with gcs client = gcs.Client() bucket = client.get_bucket(bucket_name) blob = gcs.Blob(file_name, bucket) content = blob.download_as_string() titanic_data = pd.read_csv(BytesIO(content))write PySPark DataFrame (as Pandas DataFrame) to Cloud Storage
titanic_data.toPandas().to_csv('gs://pyspark_output/output.csv', header = True)Spark DataFrame
# spark = SparkSession.builder.appName("titanic_data_").getOrCreate() schema = StructType([ StructField("PassengerId", IntegerType(), True), StructField("Survived", IntegerType(), True), StructField("Pclass", IntegerType(), True), StructField("Name", StringType(), True), StructField("Sex", StringType(), True), StructField("Age", DoubleType(), True), StructField("SibSp", IntegerType(), True), StructField("Parch", IntegerType(), True), StructField("Ticket", StringType(), True), StructField("Fare", DoubleType(), True), StructField("Cabin", StringType(), True), StructField("Embarked", StringType(), True), ]) titanic_data = spark.read.format("com.databricks.spark.csv").options(header = "true").load("gs://{}/titanic_data.csv".format(bucket_name), schema = schema) # titanic_data = spark.read.format("com.databricks.spark.csv").option("header", "true").load("gs://{}/titanic_data.csv".format(bucket_name), schema = schema) titanic_data.show(5) >> +-----------+--------+------+--------------------+------+---+-----+-----+----------------+-------+-----+--------+ |PassengerId|Survived|Pclass| Name| Sex|Age|SibSp|Parch| Ticket| Fare|Cabin|Embarked| +-----------+--------+------+--------------------+------+---+-----+-----+----------------+-------+-----+--------+ | 1| 0| 3|Braund, Mr. Owen ...| male| 22| 1| 0| A/5 21171| 7.25| null| S| | 2| 1| 1|Cumings, Mrs. Joh...|female| 38| 1| 0| PC 17599|71.2833| C85| C| | 3| 1| 3|Heikkinen, Miss. ...|female| 26| 0| 0|STON/O2. 3101282| 7.925| null| S| | 4| 1| 1|Futrelle, Mrs. Ja...|female| 35| 1| 0| 113803| 53.1| C123| S| | 5| 0| 3|Allen, Mr. Willia...| male| 35| 0| 0| 373450| 8.05| null| S| +-----------+--------+------+--------------------+------+---+-----+-----+----------------+-------+-----+--------+ only showing top 5 rowsEmbarked の欠損値を削除しておきます。
titanic_data = titanic_data.filter(F.col('Embarked').isNotNull()) titanic_data.filter(F.col('Embarked').isNull()).count() >> 0titanic_data >> DataFrame[PassengerId: int, Survived: int, Pclass: int, Name: string, Sex: string, Age: double, SibSp: int, Parch: int, Ticket: string, Fare: double, Cabin: string, Embarked: string, Embarked_labeled: string, Age_cat: string]titanic_data.count() >> 889titanic_data.printSchema() >> root |-- PassengerId: integer (nullable = true) |-- Survived: integer (nullable = true) |-- Pclass: integer (nullable = true) |-- Name: string (nullable = true) |-- Sex: string (nullable = true) |-- Age: double (nullable = true) |-- SibSp: integer (nullable = true) |-- Parch: integer (nullable = true) |-- Ticket: string (nullable = true) |-- Fare: double (nullable = true) |-- Cabin: string (nullable = true) |-- Embarked: string (nullable = true) |-- Embarked_labeled: string (nullable = true) |-- Age_cat: string (nullable = true)titanic_data.dtypes >> [('PassengerId', 'int'), ('Survived', 'int'), ('Pclass', 'int'), ('Name', 'string'), ('Sex', 'string'), ('Age', 'double'), ('SibSp', 'int'), ('Parch', 'int'), ('Ticket', 'string'), ('Fare', 'double'), ('Cabin', 'string'), ('Embarked', 'string'), ('Embarked_labeled', 'string'), ('Age_cat', 'string')]DataFrame ⇔ RDD
# DataFrame -> RDD titanic_data.rdd # DataFrame <- RDD spark.createDataFrame(titanic_data.rdd)SparkSQL
titanic_data.registerTempTable('titanic_data_table') spark.sql("select PassengerID, Embarked from titanic_data_table where Embarked = 'S' ").toPandas().iloc[0:5] >> PassengerID Embarked 0 1 S 1 3 S 2 4 S 3 5 S 4 7 S spark.sql("select age, \ case when age <= 12 then 'C' \ when age between 13 and 19 then 'T' \ when age between 20 and 25 then '1' \ when age between 26 and 34 then '2' \ when age between 35 and 49 then '3' \ when age >= 50 then '4' end as age_cat \ from titanic_data_table").toPandas().iloc[0:5] >> age age_cat 0 22 1 1 38 3 2 26 2 3 35 3 4 35 3Functions
Max / Min / Avg (or Mean) / Std / Sum / Count
titanic_data.agg({'Fare': 'max'}).collect() >> [Row(max(Fare)=512.3292)]Join
join(other, on=None, how=None)[source]
Joins with another DataFrame, using the given join expression.<Parameters>
other – Right side of the joinon – a string for the join column name, a list of column names, a join expression (Column), or a list of Columns. If on is a string or a list of strings indicating the name of the join column(s), the column(s) must exist on both sides, and this performs an equi-join.
how – str, default inner. Must be one of: inner, cross, outer, full, fullouter, full_outer, left, leftouter, left_outer, right, rightouter, right_outer, semi, leftsemi, left_semi, anti, leftanti and left_anti.
random_number_pddf = pd.DataFrame(np.random.randint(100, size = 889)[:, np.newaxis], columns = {'random_number'}) data_for_join_ = pd.concat([titanic_data_.PassengerId, random_number_pddf], axis = 1) data_for_join = spark.createDataFrame(data_for_join_) # how = 'inner' data_join = titanic_data.join(data_for_join, titanic_data.PassengerId == data_for_join.PassengerId, how = 'inner').drop(data_for_join.PassengerId) data_join.printSchema() >> root |-- PassengerId: integer (nullable = true) |-- Survived: integer (nullable = true) |-- Pclass: integer (nullable = true) |-- Name: string (nullable = true) |-- Sex: string (nullable = true) |-- Age: double (nullable = true) |-- SibSp: integer (nullable = true) |-- Parch: integer (nullable = true) |-- Ticket: string (nullable = true) |-- Fare: double (nullable = true) |-- Cabin: string (nullable = true) |-- Embarked: string (nullable = true) |-- Embarked_labeled: string (nullable = true) |-- Age_cat: string (nullable = true) |-- random_number: double (nullable = true)groupBy
time_ = time.time() titanic_data.groupby('Embarked', 'Survived').count().sort('count', ascending = False).show(5) time_ = time.time() - time_ >> +--------+--------+-----+ |Embarked|Survived|count| +--------+--------+-----+ | S| 0| 427| | S| 1| 217| | C| 1| 93| | C| 0| 75| | Q| 0| 47| +--------+--------+-----+ only showing top 5 rows np.round(time_, 3) >> 2.426time_ = time.time() spark.sql("select Embarked, Survived, \ count(*) as per_Embarked_cat \ from titanic_data_table \ group by Embarked, Survived order by per_Embarked_cat desc").show(5) time_ = time.time() - time_ >> +--------+--------+----------------+ |Embarked|Survived|per_Embarked_cat| +--------+--------+----------------+ | S| 0| 427| | S| 1| 217| | C| 1| 93| | C| 0| 75| | Q| 0| 47| +--------+--------+----------------+ only showing top 5 rows np.round(time_, 3) >> 1.794Drop
titanic_data.select('Pclass', 'Age', 'Name').drop('Name').show(5) >> +------+----+ |Pclass| Age| +------+----+ | 3|22.0| | 1|38.0| | 3|26.0| | 1|35.0| | 3|35.0| +------+----+ only showing top 5 rowsDuplicate
titanic_data.select('Pclass', 'Age', 'Name').show(10) >> +------+----+--------------------+ |Pclass| Age| Name| +------+----+--------------------+ | 3|22.0|Braund, Mr. Owen ...| | 1|38.0|Cumings, Mrs. Joh...| | 3|26.0|Heikkinen, Miss. ...| | 1|35.0|Futrelle, Mrs. Ja...| | 3|35.0|Allen, Mr. Willia...| | 3|null| Moran, Mr. James| | 1|54.0|McCarthy, Mr. Tim...| | 3| 2.0|Palsson, Master. ...| | 3|27.0|Johnson, Mrs. Osc...| | 2|14.0|Nasser, Mrs. Nich...| +------+----+--------------------+ only showing top 10 rows titanic_data.select('Name').distinct().count() >> 889 titanic_data.select('Name').count() >> 889 titanic_data.dropDuplicates(['Name']).select('Pclass', 'Age', 'Name').show(10) >> +------+----+--------------------+ |Pclass| Age| Name| +------+----+--------------------+ | 2|40.0|Watt, Mrs. James...| | 1|36.0|Young, Miss. Mari...| | 1|null|Parr, Mr. William...| | 3|19.0|Soholt, Mr. Peter...| | 3|31.0|Goldsmith, Mrs. F...| | 3|42.0| Dimic, Mr. Jovan| | 1|48.0|Harper, Mr. Henry...| | 1|38.0|Reuchlin, Jonkhee...| | 2|18.0|Fahlstrom, Mr. Ar...| | 2|42.0|Hosono, Mr. Masabumi| +------+----+--------------------+ only showing top 10 rows titanic_data.dropDuplicates(['Name']).select('Pclass', 'Age', 'Name').count() >> 889Explode / Split / Regexp Replace
explode: Returns a new row for each element in the given array or map. Uses the default column name col for elements in the array and key and value for elements in the map unless specified otherwise.
split: Splits str around matches of the given pattern.
regexp_replace: Replace all substrings of the specified string value that match regexp with rep.
titanic_data.select('name').show(5) >> +--------------------+ | name| +--------------------+ |Braund, Mr. Owen ...| |Cumings, Mrs. Joh...| |Heikkinen, Miss. ...| |Futrelle, Mrs. Ja...| |Allen, Mr. Willia...| +--------------------+ only showing top 5 rows titanic_data.withColumn('Name', explode(split(regexp_replace(F.col('name'), "(^\[)|(\]$)", ""), ", "))).select('name').show(5) >> +--------------------+ | name| +--------------------+ | Braund| | Mr. Owen Harris| | Cumings| |Mrs. John Bradley...| | Heikkinen| +--------------------+ only showing top 5 rowsWindow-function
以下では Window 関数を扱います。
from pyspark.sql.window import Window from pyspark.sql.functions import *Rank
window_ = Window.partitionBy('Embarked').orderBy('Fare') titanic_data.withColumn('rank', rank().over(window_)).select('Embarked', 'Fare', 'rank').show(5) >> +--------+------+----+ |Embarked| Fare|rank| +--------+------+----+ | Q| 6.75| 1| | Q| 6.75| 1| | Q|6.8583| 3| | Q| 6.95| 4| | Q|7.6292| 5| +--------+------+----+ only showing top 5 rowsPercent Rank
window_ = Window.partitionBy('Embarked').orderBy('Fare') titanic_data.withColumn('percent_rank', percent_rank().over(window_)).select('Embarked', 'Fare', F.round('percent_rank', 2).alias('percent_rank')).show(5) >> +--------+------+------------+ |Embarked| Fare|percent_rank| +--------+------+------------+ | Q| 6.75| 0.0| | Q| 6.75| 0.0| | Q|6.8583| 0.03| | Q| 6.95| 0.04| | Q|7.6292| 0.05| +--------+------+------------+ only showing top 5 rowsDense Rank
window_ = Window.partitionBy('Embarked').orderBy('Fare') titanic_data.withColumn('dense_rank', dense_rank().over(window_)).select('Embarked', 'Fare', 'dense_rank').show(5) >> +--------+------+----------+ |Embarked| Fare|dense_rank| +--------+------+----------+ | Q| 6.75| 1| | Q| 6.75| 1| | Q|6.8583| 2| | Q| 6.95| 3| | Q|7.6292| 4| +--------+------+----------+ only showing top 5 rowsRow Number
window_ = Window.partitionBy('Embarked').orderBy('Fare') titanic_data.withColumn('row_number', row_number().over(window_)).select('Embarked', 'Fare', 'row_number').show(5) >> +--------+------+----------+ |Embarked| Fare|row_number| +--------+------+----------+ | Q| 6.75| 1| | Q| 6.75| 2| | Q|6.8583| 3| | Q| 6.95| 4| | Q|7.6292| 5| +--------+------+----------+ only showing top 5 rowsCume Dist
window_ = Window.partitionBy('Embarked').orderBy('Fare') titanic_data.withColumn('cumulative_dist', cume_dist().over(window_)).select('Embarked', 'Fare', F.round('cumulative_dist', 2).alias('cumulative_dist')).show(10) >> +--------+------+---------------+ |Embarked| Fare|cumulative_dist| +--------+------+---------------+ | Q| 6.75| 0.03| | Q| 6.75| 0.03| | Q|6.8583| 0.04| | Q| 6.95| 0.05| | Q|7.6292| 0.06| | Q| 7.725| 0.08| | Q|7.7292| 0.09| | Q|7.7333| 0.14| | Q|7.7333| 0.14| | Q|7.7333| 0.14| +--------+------+---------------+ only showing top 10 rowsLead
window_ = Window.partitionBy('Embarked').orderBy('Fare') titanic_data.withColumn('lead', lead('Fare', 2).over(window_)).select('Embarked', 'Fare', 'lead').show(5) >> +--------+------+------+ |Embarked| Fare| lead| +--------+------+------+ | Q| 6.75|6.8583| | Q| 6.75| 6.95| | Q|6.8583|7.6292| | Q| 6.95| 7.725| | Q|7.6292|7.7292| +--------+------+------+ only showing top 5 rowsLag
window_ = Window.partitionBy('Embarked').orderBy('Fare') titanic_data.withColumn('lag', lag('Fare', 2).over(window_)).select('Embarked', 'Fare', 'lag').show(5) >> +--------+------+------+ |Embarked| Fare| lag| +--------+------+------+ | Q| 6.75| null| | Q| 6.75| null| | Q|6.8583| 6.75| | Q| 6.95| 6.75| | Q|7.6292|6.8583| +--------+------+------+ only showing top 5 rowsAggregate
window_ = Window.partitionBy('Embarked').orderBy('Fare') window_agg = Window.partitionBy('Embarked') titanic_data.withColumn('row', row_number().over(window_))\ .withColumn('avg', avg(F.col('Fare')).over(window_agg))\ .withColumn('max', max(F.col('Fare')).over(window_agg))\ .select('Embarked', 'row', 'avg', 'max').show(5) >> +--------+---+------------------+----+ |Embarked|row| avg| max| +--------+---+------------------+----+ | Q| 1|13.276029870129872|90.0| | Q| 2|13.276029870129872|90.0| | Q| 3|13.276029870129872|90.0| | Q| 4|13.276029870129872|90.0| | Q| 5|13.276029870129872|90.0| +--------+---+------------------+----+ only showing top 5 rowstitanic_data.withColumn('row', row_number().over(window_))\ .withColumn('avg', avg(F.col('Fare')).over(window_agg).alias('avg'))\ .withColumn('max', max(F.col('Fare')).over(window_agg)).where(F.col('row') == 1)\ .select('Embarked', F.round(F.col('avg'), 2).alias('Fare_avg'), F.round(F.col('max'), 2).alias('Fare_max'))\ .sort('Fare_avg', ascending = False).show() >> +--------+--------+--------+ |Embarked|Fare_avg|Fare_max| +--------+--------+--------+ | C| 59.95| 512.33| | S| 27.08| 263.0| | Q| 13.28| 90.0| +--------+--------+--------+UserDefinedFunction
UserDefinedFunction【PySpark】
# from pyspark.sql.functions import UserDefinedFunction # from pyspark.sql import SQLContext, Row # from pyspark.sql.types import * def LabelEncoder(x): if x == 'S': x_ = 0 elif x == 'C': x_ = 1 elif x == 'Q': x_ = 2 return x_ udf_label_Encoder = UserDefinedFunction(LabelEncoder) titanic_data.filter('Age > 12').withColumn('Embarked_labeld', udf_label_Encoder(F.col('Embarked'))).select('PassengerId', 'Embarked_labeld').show(5) # titanic_data.filter('Age > 12').withColumn('Embarked_labeld', udf_label_Encoder('Embarked')).select('PassengerId', 'Embarked_labeld').show(5) >> +-----------+--------------+ |PassengerId|Embarked_label| +-----------+--------------+ | 1| 0| | 2| 1| | 3| 0| | 4| 0| | 5| 0| +-----------+--------------+ only showing top 5 rowstitanic_data.select('PassengerId', udf_label_Encoder('Embarked').alias('Embarked_label')).filter('PassengerId >= 2').show(5) >> +-----------+--------------+ |PassengerId|Embarked_label| +-----------+--------------+ | 2| 1| | 3| 0| | 4| 0| | 5| 0| | 6| 2| +-----------+--------------+ only showing top 5 rows# from pyspark.sql.functions import when titanic_data.withColumn('Embarked', when(F.col('Embarked') == 'S', '0').when(F.col('Embarked') == 'C', '1').otherwise('3'))\ .withColumnRenamed('Embarked', 'Embarked_label').select('PassengerId', 'Embarked_label').filter('PassengerId >= 2').show(5) >> +-----------+--------------+ |PassengerId|Embarked_label| +-----------+--------------+ | 2| 1| | 3| 0| | 4| 0| | 5| 0| | 6| 2| +-----------+--------------+ only showing top 5 rowsUserDefinedFunction【SparkSQL】
タイムゾーンを変更しておくことで SaprkSQL により新しく作られた DataFrame に対して PySpark 関数を実行できるようになります。
spark.conf.set("spark.sql.session.timeZone", "Asia/Tokyo") titanic_data.registerTempTable('titanic_data_table') spark.udf.register('LabelEncoder_', LabelEncoder) spark.sql('''select PassengerId, LabelEncoder_(Embarked) as Embarked_labeled from titanic_data_table''').show(5) >> +-----------+--------------+ |PassengerId|Embarked_label| +-----------+--------------+ | 1| 0| | 2| 1| | 3| 0| | 4| 0| | 5| 0| +-----------+--------------+ only showing top 5 rowsまとめ
PySpark では豊富な関数が提供されています。
そのうちの幾つかをまとめてみました。参考 URL

- 投稿日:2020-11-12T14:22:20+09:00
Flask-sqlalchemyでマルチデータベースの使用
テーマ
Flask-sqlalchemyのSQLクエリで、マルチデータベースを呼び出すとエラーになる。
SQLクエリは、ClassifyMaster.query.all()を実施し、SQLALCHEMY_TRACK_MODIFICATIONS = Falseでログで出したものをコピペfrom flask import Flask from flask_sqlalchemy import SQLAlchemy app = Flask(__name__) db = SQLAlchemy(app) class Master(db.Model): id = db.Column(db.Integer, primary_key=True) title = db.Column(db.String) sql = db.Column(db.String(500)) class ClassifyMaster(db.Model): __tablename__ = "classify_master" __bind_key__ = "db_classify" #db.Column情報の設定 id = db.Column(db.Integer, primary_key=True) DB_MAIN = 'sqlite:///data.db' DB_CLASSIFY = 'sqlite:///classify/data.db' SQLALCHEMY_DATABASE_URI = DB_MAIN SQLALCHEMY_BINDS = { "db_classify" : DB_CLASSIFY} db.session.add(Master(title = '品種分類表', sql = """SELECT ClassifyMaster.id FROM ClassifyMaster""" ))エラー内容
バインド先のデータベースが見つからない
(Pdb) db.session.execute(text) INFO:sqlalchemy.engine.base.Engine:SELECT ClassifyMaster.id FROM ClassifyMaster INFO:sqlalchemy.engine.base.Engine:() *** sqlalchemy.exc.OperationalError: (sqlite3.OperationalError) no such table: ClassifyMaster [SQL: SELECT ClassifyMaster.id FROM ClassifyMaster] (Background on this error at: http://sqlalche.me/e/e3q8)どうやって調べていくのか?
丸一日かけてマルチデータベースについて調べるが、有力回答が得られず。
結局はSQLITEの使い方を調べまくり、ハンドで
ATTACH DATABASEをつけたら、クエリが動くことを確認した。
https://sqlite-r.com/attach_database(Pdb) db.session.execute(r"""ATTACH DATABASE 'classify\data.db' as x;""") (Pdb) db.session.execute('SELECT * FROM x.classify_master') INFO:sqlalchemy.engine.base.Engine:SELECT * FROM x.classify_master INFO:sqlalchemy.engine.base.Engine:() <sqlalchemy.engine.result.ResultProxy object at 0x000001F679DDA730>一応解決策は見出せたが、もっとスマートにできないかと調査しはじめる。
Flask-Sqlalchemyの分かったこと
ソース解析 → さすがスクリプト言語。
分かりやすい → 万歳!def get_tables_for_bind(self, bind=None): """Returns a list of all tables relevant for a bind.""" result = [] for table in itervalues(self.Model.metadata.tables): if table.info.get('bind_key') == bind: result.append(table) return result def get_binds(self, app=None): """Returns a dictionary with a table->engine mapping. This is suitable for use of sessionmaker(binds=db.get_binds(app)). """ app = self.get_app(app) binds = [None] + list(app.config.get('SQLALCHEMY_BINDS') or ()) retval = {} for bind in binds: engine = self.get_engine(app, bind) tables = self.get_tables_for_bind(bind) retval.update(dict((table, engine) for table in tables)) return retval def _execute_for_all_tables(self, app, bind, operation, skip_tables=False): app = self.get_app(app) if bind == '__all__': binds = [None] + list(app.config.get('SQLALCHEMY_BINDS') or ()) elif isinstance(bind, string_types) or bind is None: binds = [bind] else: binds = bind for bind in binds: extra = {} if not skip_tables: tables = self.get_tables_for_bind(bind) extra['tables'] = tables op = getattr(self.Model.metadata, operation) op(bind=self.get_engine(app, bind), **extra)テーブルの取り出し
そもそもbindって、Flask側で宣言してたやん
(sqlarchemy関係あらへん・・・)これが第一の勘違い
binds = [None] + list(app.config.get('SQLALCHEMY_BINDS') or ()) (Pdb) binds [None, 'db_classify']エンジンの取得
- 取得したbindsを引数に渡す
get_engine(app=None, bind=None) #Returns a specific engine.(Pdb) db.get_engine(app, binds[0]) Engine(sqlite:///C: .... data.db) (Pdb) db.get_engine(app, binds[1]) Engine(sqlite:///C: .... classify\data.db)おー、取れた取れた!
ついでにテーブルも
(Pdb) db.get_tables_for_bind(bind=binds[1]) [Table('classify_master', MetaData(bind=None), Column('id', Integer(), table=<classify_master>, primary_key=True, nullable=False))]ここの
<classify_master>になっている奴が、たぶんSqlAlchemyでバインドされるんやろ
ATTACH DATABASEで、適当なネームスペースにデータソースをくっ付けたら、ええんやな!
ということで、方針決まりさあ、コーディング開始!
まとめ
結局は、Flask-SqlalchemyはTEXT()をカバーしていなかったのか?
→ この件、ISSUEを挙げるべきなのか?いや、そもそも生クエリ嫌だからORMにしたんじゃねぇ?
って返されるかもしれないしかしながら、クエリを動的にデータベースに突っ込みたいというニーズもあり、
やはり生クエリでの処理は必須だと思われる。つづく
- 投稿日:2020-11-12T13:52:35+09:00
VSCodeで手軽にpythonを勉強したい人のための環境構築(for Mac)
はじめに
「さぁ、Pythonの勉強をしよう」
と、思い立って環境を作るところから始めようと調べ始めると、
「Homebrewが…」「Pathを確認して…」「デフォルトのバージョンが…」などと
初心者の心を折ろうとする分岐がいくつも存在すると感じるのは私だけでしょうか?色々やり方はあるかと思いますが、
私はシンプルにDockerとVisual Studio Code(以下、VSCode)の拡張機能を使って環境を作るのが
面倒なく楽なのではないかと感じましたので、それを記録として残しておきます。もっとオススメがあるよ、という方はコメントいただければ幸いです。
インストール
それぞれ公式サイトよりダウンロード、インストールします。
Dockerは仮想マシンを作ることが出来るサービスです。
こちらは初めて使用する際はアカウントを作る必要があります。VSCodeのインストールはこちらの記事がとてもわかり易いです。
MacOSでVisual Studio Codeをインストールする手順VSCodeに拡張機能を入れる
- VSCodeを開く。
- 拡張機能から
Remote - Containersをインストールする。
ディレクトリとファイルを準備する
- 新しくフォルダを作成する
- .devcontainerという名前のフォルダを作る
- その中にdevcontainer.jsonというファイルを作る
1.のフォルダにはDockerfileとdocker-compose.yamlという2つのファイルを作成する各種設定ファイルを書く
1. Dockerfile
pythonのバージョンを3.9に指定しています。
VSCode内でソースコードを自動整形するためのautopep8と、
コード解析ツールのpylintも一緒に入れておきます。DockerfileFROM python:3.9 USER root RUN apt-get update && apt-get -y install locales git wget unzip vim && \ localedef -f UTF-8 -i ja_JP ja_JP.UTF-8 ENV LANG ja_JP.UTF-8 ENV LANGUAGE ja_JP:ja ENV LC_ALL ja_JP.UTF-8 ENV TZ JST-9 ENV TERM xterm ARG DEBIAN_FRONTEND=noninteractive RUN pip install -U pip && \ pip install -U autopep8 && \ pip install -U pylint VOLUME /root/2. docker-compose.yaml
後でVSCodeがこのファイルを見て
buildとup -dをしてくれます。docker-compose.yamlversion: "3.8" services: python3.9: build: context: . dockerfile: Dockerfile volumes: - .:/root/ working_dir: /root/ tty: true3. devcontainer.json
このファイルが無くても上記で出来る環境を使用できますが、
VSCodeから簡単に環境の中に入るにはこのファイルが必要です。(※このファイルは
.devcontainerフォルダの中に置いて下さい)
(Finderから隠しファイル表示を切り替えるにはcommand + shift + .(ピリオド)で可能)devcontainer.json{ "name": "Python3.9", "dockerComposeFile": [ "../docker-compose.yml" ], "service": "python3.9", "workspaceFolder": "/root/", "settings": { "terminal.integrated.shell.linux": null }, "extensions": [ "ms-ceintl.vscode-language-pack-ja", "ms-python.python", "oderwat.indent-rainbow", "almenon.arepl" ] }
extensionsには、以下の内容の拡張機能を自動でインストールするようにしています。
* VSCodeを日本語化する「Japanese Language Pack」
* Pythonのための「Python」
* インデントを見やすくする「indent-rainbow」
* リアルタイムでデバッグしてくれる「AREPL for python」
VSCodeから仮想環境を作成する
1. Remoteを開く
左下にある下記画像のようなアイコンを選択する
2. 「Open folder in Container」を選択する
3. 上記に自分で作成したフォルダを選択する
4. 仮想マシンの準備がはじまる
「show log」をクリックすると、実際にdocker-compose up -dなどコマンドが実行されている様子がみられるので、裏で何が行われているか確認したい方は見ると良いでしょう。うまく環境が構築されると、下記のような画面になります。
(私はテーマやアイコンの拡張なども入れているため、見た目は一部違うことがあります)
Pythonが無事動くか確認する
せっかく導入した拡張機能の
AREPLを併用して確認します。1.
.pyファイルを作ってAREPLを起動するここでは
test.pyという名前のファイルを作りました。
作ったら、画像のように猫みたいなアイコンをクリックします。
2. ソースコードを書いてみる
何でも良いので、ソースコードを書いてみましょう。
書いている間にリアルタイムで変数やprint文が表示されているのが確認できます。画像内ではわざと定義していない変数をprintしようとしています。
一応エディタで下線を引いて教えてくれている状態ですが、
AREPLの画面ですでにnot definedと教えてくれています。
注意点としては、あまり重たい処理にはAREPLは向かないです。
例えば上記for文のrangeが10000を超えてくると、当然ですがかなり反映が遅くなります。
その状態でrangeの数を減らしても、前の実行が終わらないと反映されません。本当に簡単な軽いプログラムで処理内容をできるだけすぐ見たい方におすすめですが、
そうではないなら、AREPLは使用しない方が良いかもしれませんね。3. 自動整形を使ってみる
option + shift + Fできれいに整えてくれます。4. プログラムを実行してみる
F5でプログラムが実行できます。
が、下記のように毎回デバッグの種類を聞かれて「Python File」を選択するのも面倒です。
そこで、.vscodeという隠しフォルダに、
launch.jsonというデバッグの設定ファイルを作成します。
下記の表示から「launch.jsonファイルを作成します」を選択し、「Python File」を選択すれば、自動でそのファイルを作成してくれます。
今度こそ
F5を押すだけで、
下部のコンソール画面に実行結果が表示されます。
おわりに
VSCodeには他にも紹介しきれないくらいデバッグに便利な機能があります。
仮想環境には何をインストールしようが壊そうが、
実環境に影響なく、簡単に同じ環境を再生できるのが魅力的ですね。
初めてPython環境を作る方でこれを読んでいる方がいらっしゃいましたら、ぜひ試してみてくださいね。





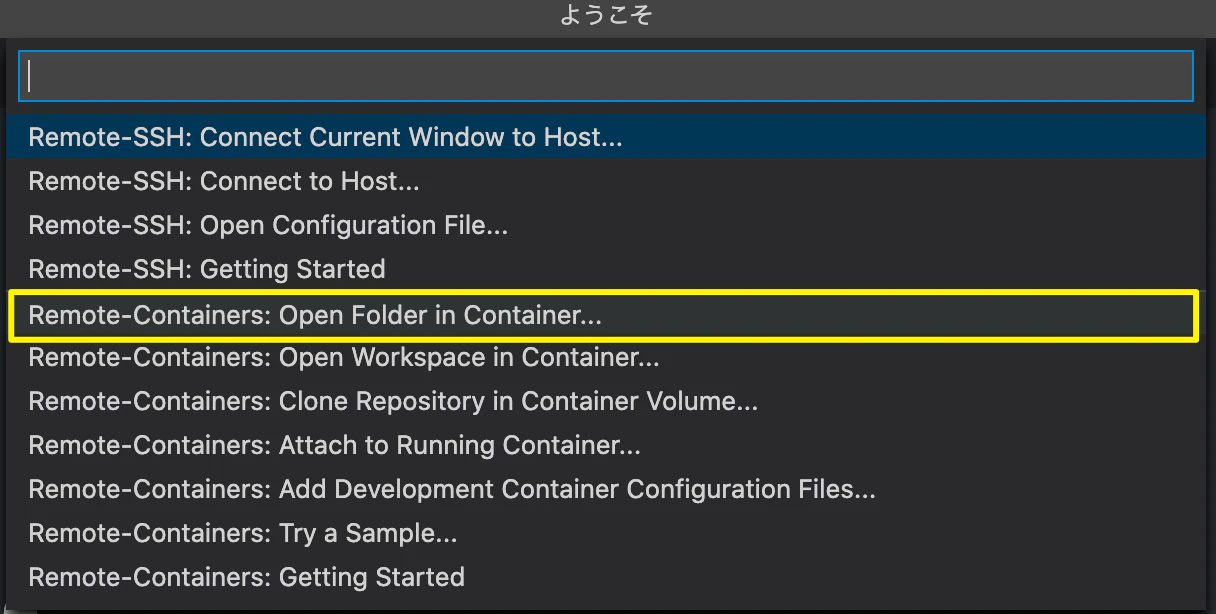



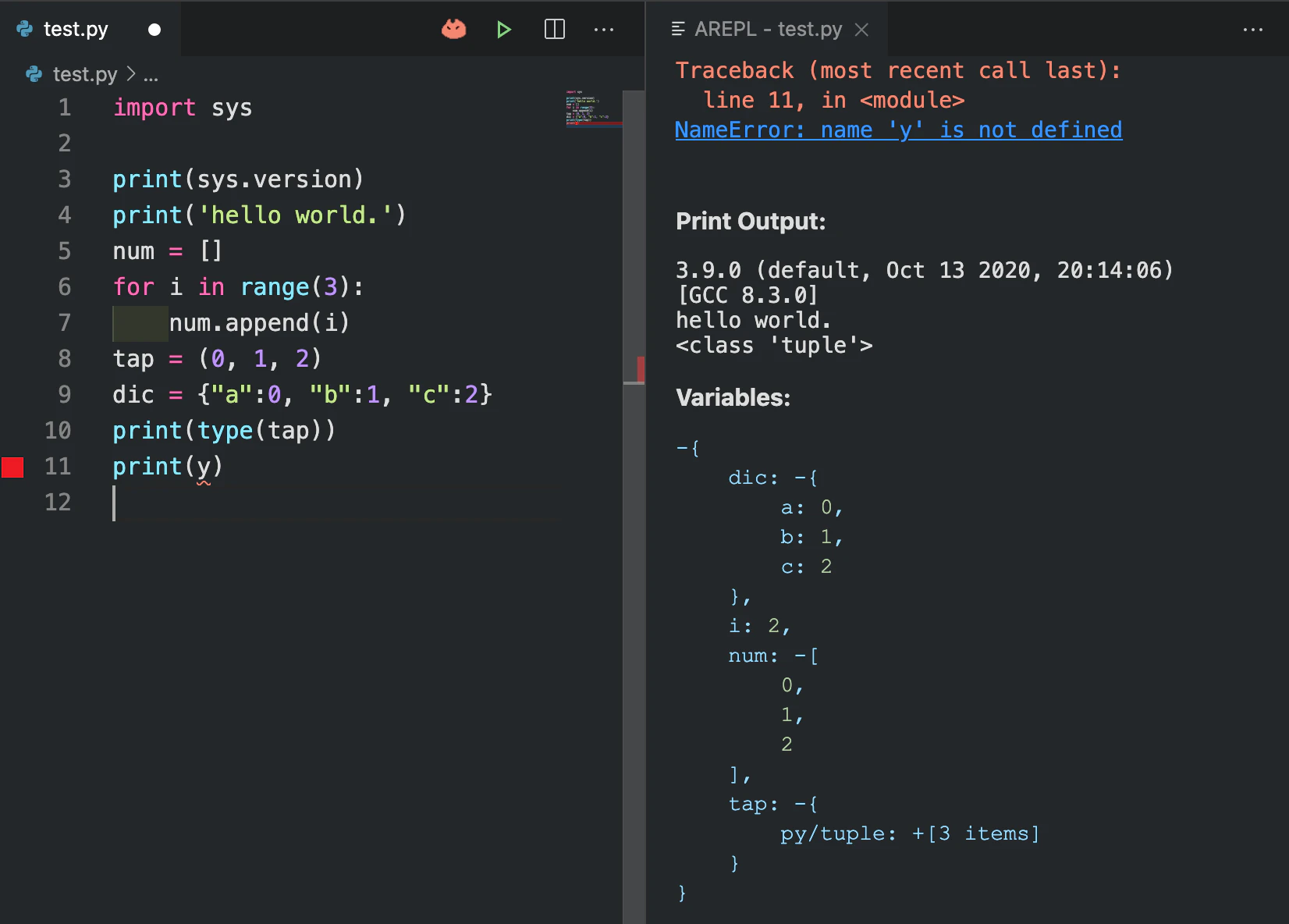



- 投稿日:2020-11-12T13:02:43+09:00
ピタゴラスの定理 Python
ピタゴラスの数について
あの有名な三平方の定理の元となっているピタゴラスの定理は直角三角形において
$a^2 + b^2 = c^2$
が成立することをしまします。この(a.b,c)が自然数であるような組み合わせの数をピタゴラス数といいます。
紀元前の古代に活躍していた天才ピタゴラスは、この組み合わせを以下の公式$(a,b,c) = \frac{n^2 - 1}{2}, n, \frac{n^2 + 1}{2}$
と表現できることに気づいていました。
しかし、この公式は、ピタゴラス数が無限に存在することを示すことは出来ていますが、網羅しているわけではないのです。
では、網羅する公式は存在するのでしょうか?
その最初の答えは7世紀のインドの文献に残っていると言われています。
m > nとして
$a = k(m^2 - n^2), b = 2kmn, c = k(m^2 + n~2)$やはりインドの数学力は進んでいる!!
Pythonでピタゴラス数を出力
def Pythagoras(n :int) -> list: answer = [] answer.append((n**2-1)/2) answer.append(n) answer.append((n**2+1)/2) return answer for i in range(1,100,2): answer = Pythagoras(i) for i in range(0,3): answer[i] = int(answer[i]) print(answer)
a b c 4 3 5 12 5 13 24 7 25 40 9 41 60 11 61 84 13 85 112 15 113 144 17 145 180 19 181 220 21 221 264 23 265 312 25 313 小さい組み合わせなら(6,8,10)を飛ばしてしまっていることがわかります
# m > n def Pythagoras_2(k :int, m :int, n: int) -> list: answer = [] answer.append(k*(m**2 - n**2)) answer.append(2*k*m*n) answer.append(k*(m**2 + n**2)) return answer for k in range(1,5): for m in range(1,5): for n in range(1,10): if m <= n : break print(Pythagoras_2(k,m,n))
a b c 3 4 5 8 6 10 5 12 13 15 8 17 12 16 20 7 24 25 6 8 10 16 12 20 10 24 26 30 16 34 24 32 40 14 48 50 9 12 15 24 18 30 15 36 39 45 24 51 36 48 60 21 72 75 12 16 20 32 24 40 20 48 52 60 32 68 48 64 80 28 96 100 ピタゴラス数の組み合わせを網羅的に表現出来ています
※$a^2 + b^2 = c^2$とpythonで出力した表の(a,b,c)を一致させることが出来ませんでした。 良いループ処理が思いつく方は教えていただけると幸いです。
- 投稿日:2020-11-12T13:02:43+09:00
ピタゴラス数 Python
ピタゴラス数について
あの有名な三平方の定理の元となっているピタゴラスの定理は直角三角形において
$a^2 + b^2 = c^2$
が成立することをしまします。この(a.b,c)が自然数であるような組み合わせの数をピタゴラス数といいます。
紀元前の古代に活躍していた天才ピタゴラスは、この組み合わせを以下の公式$(a,b,c) = \frac{n^2 - 1}{2}, n, \frac{n^2 + 1}{2}$
と表現できることに気づいていました。
しかし、この公式は、ピタゴラス数が無限に存在することを示すことは出来ていますが、網羅しているわけではないのです。
では、網羅する公式は存在するのでしょうか?
その最初の答えは7世紀のインドの文献に残っていると言われています。
m > nとして
$a = k(m^2 - n^2), b = 2kmn, c = k(m^2 + n~2)$やはりインドの数学力は進んでいる!!
Pythonでピタゴラス数を出力
def Pythagoras(n :int) -> list: answer = [] answer.append((n**2-1)/2) answer.append(n) answer.append((n**2+1)/2) return answer for i in range(1,100,2): answer = Pythagoras(i) for i in range(0,3): answer[i] = int(answer[i]) print(answer)
a b c 4 3 5 12 5 13 24 7 25 40 9 41 60 11 61 84 13 85 112 15 113 144 17 145 180 19 181 220 21 221 264 23 265 312 25 313 小さい組み合わせなら(6,8,10)を飛ばしてしまっていることがわかります
# m > n def Pythagoras_2(k :int, m :int, n: int) -> list: answer = [] answer.append(k*(m**2 - n**2)) answer.append(2*k*m*n) answer.append(k*(m**2 + n**2)) return answer for k in range(1,5): for m in range(1,5): for n in range(1,10): if m <= n : break print(Pythagoras_2(k,m,n))
a b c 3 4 5 8 6 10 5 12 13 15 8 17 12 16 20 7 24 25 6 8 10 16 12 20 10 24 26 30 16 34 24 32 40 14 48 50 9 12 15 24 18 30 15 36 39 45 24 51 36 48 60 21 72 75 12 16 20 32 24 40 20 48 52 60 32 68 48 64 80 28 96 100 ピタゴラス数の組み合わせを網羅的に表現出来ています
※$a^2 + b^2 = c^2$とpythonで出力した表の(a,b,c)を一致させることが出来ませんでした。 良いループ処理が思いつく方は教えていただけると幸いです。
- 投稿日:2020-11-12T12:32:16+09:00
日本全国の郵便番号⇔住所変換を行うPythonライブラリ『Jusho』
使用方法
$ pip install jusho
でインストール。 githubfrom jusho import Jusho postman = Jusho() """ 郵便番号から取得""" print(postman.from_postal_code('160-0021')) # '1600021', '〒1600021' なども有効 # 〒160-0021, 東京都 新宿区 歌舞伎町(TOKYO TO SHINJUKU KU KABUKICHO) kabukicho = postman.from_postal_code('160-0021') print(kabukicho.hyphen_postal, kabukicho.prefecture_kanji, kabukicho.city_kanji, kabukicho.town_area_kanji) # 160-0021 東京都 新宿区 歌舞伎町 """ 漢字表記のほかに、カタカナ表記、ヘボン式表記もあります """ print(kabukicho.prefecture_kana, kabukicho.prefecture_eng) # トウキョウト TOKYO TO """ 住所データから郵便番号を取得することもできます """ print(self.postman.address_from_town('東京都', '新宿区', '歌舞伎町', 'kanji')) # 〒160-0021, 東京都 新宿区 歌舞伎町(TOKYO TO SHINJUKU KU KABUKICHO) """ 表記の手伝いのために、それぞれの市区町村や都道府県からそれ以下の地域の一覧などを取得することもできます """ print(self.postman.prefectures) # [('アイチケン', '愛知県', 'AICHI KEN'), ('アオモリケン', '青森県', 'AOMORI KEN'), ('アキタケン... print(self.postman.cities_from_prefecture('東京都', 'kanji')) # [('チヨダク', '千代田区', 'CHIYODA KU'), ('チュウオウク', '中央区', 'CHUO KU'), ('ミナトク', '... print(self.postman.towns_from_city('東京都', '新宿区', 'kanji')) # [<Address: 〒160-0000, 東京都 新宿区 以下に掲載がない場合(TOKYO TO SHINJUKU KU IKANIKEISAIGANAIBAAI)>, <Address: 〒160-0005, 東京都 新宿区 愛住町(TOKYO TO SHINJUKU KU AIZUMICHO)>, <Address: 〒162-0803, 東京都 新宿区 赤城下町(TOKYO TO SHINJUKU KU AKAGI SHITAMACHI)>, <Address: 〒162-0817, 東京都 新宿区 赤城元町(TOKYO TO SHINJUKU KU AKAGI MOTOMACHI...郵便番号⇔住所変換ライブラリの『Jusho』
を紹介します(ステマ)
従来でもposutoというライブラリがあり、こちらもほぼ同等の情報を提供しています。
しかし、内部でjsonデータをdictとして保持しているためメモリを多く使い、かつ郵便番号→住所の一方向の検索しかできないという欠点があり、自分が使うには少々勝手が悪かったので新たにデータベースにデータを格納するタイプのライブラリにしました。そのおかげで住所→郵便番号の検索もできるようになり、使い勝手がよくなったと思います。
データは日本郵便が公式で公開しているものを用い、一部データ抜けがある分に関しては自分で補いました。
使用方法は
使用方法の通りです。以下のように動作するdemoも用意しています。
何かバグやリクエストなどあればgithubのほうによろしくお願いします。
ぜひ便利にお使いください!

- 投稿日:2020-11-12T12:27:21+09:00
画像を検索して貼れるDiscord Botを作る
画像検索できるbotを作ったのでその時の知見を書こうと思います。
作った物
このような感じで、与えられたキーワードから画像を検索し、貼り付けてくれます。
導入はこちらからできるので、よかったらよろしくお願いします!使用方法
ソースコード(github)環境
- python 3.7.9
- discord.py 1.5.1
- bs4 0.0.1
- psycopg2 2.8.6
- urllib3 1.25.11
Discord.pyの使い方
こちらの記事を参考に作成しました。Discord.pyを触ったことない方は、先にこちらを読むことをおすすめします。
画像を検索してurlを取得
画像検索結果の取得
urllibを使用して画像を検索し、htmlを取得します。
この際、htmlの内容が変わってしまうので、User-Agentを必ず指定してください。find_image.pyfrom urllib import request as req from urllib import parse def find_image(keyword): urlKeyword = parse.quote(keyword) url = 'https://www.google.com/search?hl=jp&q=' + urlKeyword + '&btnG=Google+Search&tbs=0&safe=off&tbm=isch' headers = {"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0",} request = req.Request(url=url, headers=headers) page = req.urlopen(request) html = page.read() page.close() return html画像urlの取得
通常、スクレイピングで画像を取得する場合、imgタグから取得できますが、Google画像検索の場合それだと圧縮された画像しか取得できないです。
なので、オリジナルの画像を取得するためには、Seleniumなどでこちらの記事のように、クリックして取得しなければいけないのですが、負荷や速度を考慮して今回は別の方法を取っています。
宣伝ですが、BeautifulSoupを高速化するコツについて記事を書いたので、よかったらこちらを参考にしてくださいUser-Agentをブラウザで指定した場合、下のようにsctiptタグにメソッド呼び出しが実装されているのでそれを使用します。
<script nonce> AF_initDataCallback({ key: 'ds:1', isError: false, hash: '2', data: [null, [ [ ["g_1", [ ["生 クリーム", ["https://encrypted-tbn0.gstatic.com/images?q\u003dtbn%3AANd9GcR_QK2ghJ5WWcj-Tcf9znnP6_rZwe7f2MCwWUERoVqVLNRFsj4D\u0026usqp\u003dCAU", null, null, true, [null, 0], false, false], "/search?q\u003d%E3%83%97%E3%83%AA%E3%83%B3\u0026tbm\u003disch\u0026chips\u003dq:%E3%83%97%E3%83%AA%E3%83%B3,g_1:%E7%94%9F+%E3%82%AF%E3%83%AA%E3%83%BC%E3%83%A0:FuBfrMHhliU%3D", null, null, [null, null, null, null, "q:プリン,g_1:生 クリーム:FuBfrMHhliU\u003d"], 0], ["コンビニ", ["https://encrypted-tbn0.gstatic.com/images?q\u003dtbn%3AANd9GcThveHaG9uvSFj6QwXIVDoJPs9P3KjNdnl-I35Wf0WzAKNffK_m\u0026usqp\u003dCAU", null, null, true, [null, 0], false, false], "/search?q\u003d%E3%83%97%E3%83%AA%E3%83%B3\u0026tbm\u003disch\u0026chips\u003dq:%E3%83%97%E3%83%AA%E3%83%B3,g_1:%E3%82%B3%E3%83%B3%E3%83%93%E3%83%8B:tHwRIJyFAco%3D", null, null, [null, null, null, null, "q:プリン,g_1:コンビニ:tHwRIJyFAco\u003d"], 1], .......ただ、これが曲者で、検索した時の場所がキーワードごとによって違うため、xpathやcssセレクターでの取得ができず、属性の指定のもないので絞り込みもできず、しかも、変数を展開した上でのjson形式になっているため、簡単にjsonデータに変換することができないです。
なので、ゴリ押ししました。
まず、scriptタグを全て取得し、AF_initDataCallbackから始まる内容を探してそれを無理やり整形してjsonが読み込める形にします。ただ、構造が辞書型ではなく配列のため、indexを決め打ちして取得しています。
正直、スレクイピングのやり方としては下の下ですが、今回のbotのように速度が求められているため、この実装で妥協しました。find_image.pyimport bs4 def scrap_image_urls(html, start = 0, stop = 1)): soup = bs4.BeautifulSoup(html, 'html.parser', from_encoding='utf8') soup = soup.find_all('script') data = [c for s in soup for c in s.contents if c.startswith('AF_initDataCallback')][1] data = data[data.find('data:') + 5:data.find('sideChannel') - 2] data = json.loads(data) data = data[31][0][12][2] image_urls= [x[1][3][0] for x in data if x[1]] image_urls= [url for url in image_urls if not is_exception_url(url)][start:stop] return image_urlsただ、インスタなどのスクレイピング対策を行っているサイトは、urlを取得できないため弾いています。
find_image.pyexception_urls = [ '.cdninstagram.com', 'www.instagram.com' ] def is_exception_url(str): return any([x in str for x in exception_urls])Prefixを動的に変化させる
prefix(コマンドの最初につける接頭語)を変換させる機能を実装しました。
いろいろ方法はありますが、今回はHeroku Postgresを使用しています。
最初、jsonファイルで管理していましたが、herokuは毎日リセットが入るのでデータが吹っ飛びました。。。
herokuへのデプロイの流れは最初に紹介した記事に詳しく載っているので、そちらを参照してください。
psqlコマンドの導入が必要になります。Heroku Postgresアドオンの追加
無料プランのhobby-devでアドオンを追加します。最大レコード行数は10Kです。
$ heroku addons:create heroku-postgresql:hobby-dev -a [APP_NAME]データベースへのアクセス
まず作成したデータベース名を確認します。
Add-onの行を参照してくださいheroku pg:info -a discordbot-findimage次に、データベースにアクセスします。
先ほど取得したデータベース名を使用してくださいheroku pg:psql [DATABASE_NAME] -a [APP_NAME]これでSQLを実行できますので、テーブルを作成してください。
create table guilds ( id varchar(255) not null, prefix varchar(255) not null, PRIMARY KEY (id) );PythonからPostgreSQLにアクセスする
今回は、psycopg2を使用しています。
データベースのurlは作成した段階で環境変数に定義されているので、それを使用します。find_image.pyimport psycopg2 db_url = os.environ['DATABASE_URL'] conn = psycopg2.connect(db_url)Discordサーバーごとに動的にprefixを適用する
discord.Clientはコンストラクタでメッソドを渡すことができるので、インスタンス生成の際に渡します。
例では、discord.Clientの子クラスであるdiscord.ext.commands.Botを使用しています。find_image.pyfrom discord.ext import commands import psycopg2 defalut_prefix = '!' table_name = 'guilds' async def get_prefix(bot, message): return get_prefix_sql(str(message.guild.id)) def get_prefix_sql(key): with conn.cursor() as cur: cur.execute(f'SELECT * FROM {table_name} WHERE id=%s', (key, )) d = cur.fetchone() return d[1] if d else defalut_prefix bot = commands.Bot(command_prefix=get_prefix)DiscordサーバーごとにPrefixを設定する
今回の場合set_prefixコマンドを実行すると、UPSERTクエリが走るようにしています。
find_image.pyfrom discord.ext import commands import psycopg2 table_name = 'guilds' def set_prefix_sql(key, prefix): with conn.cursor() as cur: cur.execute(f'INSERT INTO {table_name} VALUES (%s,%s) ON CONFLICT ON CONSTRAINT guilds_pkey DO UPDATE SET prefix=%s', (key, prefix, prefix)) conn.commit() @bot.command() async def set_prefix(ctx, prefix): set_prefix_sql(str(ctx.guild.id), prefix) await ctx.send(f'The prefix has been changed from {ctx.prefix} to {prefix}')最後に
ここまで読んでいただきありがとうございました!
Discord Botの作成やスクレイピングの際に参考になれば幸いです!

- 投稿日:2020-11-12T11:55:17+09:00
文字列に変数を混ぜる方法を言語ごとにまとめてみた
ゆるっと Advent Calender 2020 の初日に参加させていただきましたー。
よろしくお願いします。初日にふさわしいかわかりませんが、ゆるゆる仕事してたら恥をかいた件を書きますね。
先日先輩にレビューしてもらったとき、文字列の中に変数を足しこむやり方を、+演算子を使ってやっていたら先輩に『ダサい』と一蹴されました。(*'▽')ガフッ
string.jsconst word = "hogehoge"; const text = "彼はおもむろにこう言った。\n『 " + word + " 』、と。"; console.log(text);彼はおもむろにこう言った。 『 hogehoge 』、と。勉強不足でごめんなさい。( ;∀;)
あと、ユニク〇ばかり着ててごめんなさい。反省したので自分の学んだことのある言語での書き方や名称をまとめたい思います。
Javascript, Node.js
Javascript および Node.js ではテンプレートリテラルという名称になっています。
文字列をグレイヴ・アクセント(`)で囲み、変数を入れるときはドル記号と波括弧でくくります。
templateLiterals.jsconst word = "hogehoge"; const text = `彼はおもむろにこう言った。\n『 ${word} 』、と。`; console.log(text);彼はおもむろにこう言った。 『 hogehoge 』、と。Python
Python ではフォーマット済み文字列リテラルという名称になっています。
fまたはFを先頭に書いてから文字列を書いていきます。
変数を入れるときは波括弧で区切ります。formattedStringLiteral.pyword = "hogehoge"; text = f"彼はおもむろにこう言った。\n『 {word} 』、と。"; print(text);彼はおもむろにこう言った。 『 hogehoge 』、と。Java
ない。
強いて言うなら
String.format()を使うとできる。stringFormat.javaString word = "hogehoge"; String text = "彼はおもむろにこう言った。\n『 %s 』、と。"; String output = String.format(text, word); System.out.println(output);彼はおもむろにこう言った。 『 hogehoge 』、と。C♯
C# では文字列補間という名称になっています。
$を先頭に書いてから文字列を書いていきます。
変数を入れるときは波括弧で区切ります。stringInterpolation.csstring word = "hogehoge"; string text = $"彼はおもむろにこう言った。\n『 {word} 』、と。"; System.Console.WriteLine(text);彼はおもむろにこう言った。 『 hogehoge 』、と。おわりに
Java にはなかったもんなー( ゚Д゚)
知らなかったの私だけかもしれませんが、実践に勝る経験はありませんね。
この記事が誰かの助けになれば幸いです。|д゚)
自身のメモ用でもあるので、新しい言語を使うときには更新していきますー。
ではまた!(^^)/
参考にさせていただきましたm(_ _)m
MDN - テンプレートリテラル
Python documentation - フォーマット済み文字列リテラル
.NET documentation - 文字列補間
- 投稿日:2020-11-12T11:36:00+09:00
Jw_cadでPythonを活用するには(その1 外部変形とは)
Jw_cadでPythonを活用するには(その1)
建築設備(電気)の設計をしているのだが、
Jw_cadというフリーソフトウェアを使用して設計図を作図している。
基本的に"楽に仕事したい"と考えているので、
Jw_cadとPythonを連携させて、業務負担を減らしたい。仕事休みたい足がかりとして、Jw_cadの【外部変形】という機能を使ってPythonを活用してみる。
【外部変形】とは
Jw_cadで行えない事を他アプリケーションで処理、Jw_cad上に反映するという機能である。
動作的には
1. 「Jw_cad上から外部変形ファイル(.bat)選択」
2. 「.batファイル内記載の通りに処理」
3. 「Jw_cad上に反映」ここでPythonをどう挟むかというと、
1. 「Jw_cad上から外部変形ファイル(.bat)選択」
2. 「.batファイル内で"Python"を呼び出し処理」
3. 「Jw_cad上に反映」
という流れ。このページでは、
外部変形ファイルの作成~実行までを解説。【外部変形】の.batファイルを作成
まず、.batファイルを簡単に説明すると、
.batファイル内に記載している内容を実行するファイル。メモ帳で下記の内容を打ち込み、名前をつけて保存で
hogehoge.batで保存。@echo off ← おまじない。 REM 外部変形起動(hello world!!) ← Jw_cad上で外部変形を選択する画面での表示名称 REM #jww ← 「この外部変形はjww形式ですよ」の意味 echo hello world!! ← コマンドプロンプト上でhello world!!と表示。 pause >nul ← コマンドプロンプトが一瞬だけ表示され消える為、pauseを記入して`一時停止`。通常の.batファイルでは
REM ~~~と記載すると、
記載しても実行されない文字列になるのだが、
Jw_cadではREM #~~~という記載はJw_cad内のみで動作するコマンド【外部変形】hogehoge.batを実行
上記の文字列はJw_cadで
hogehoge.batを選択すると
コマンドプロンプト上にhello world!!と表示される外部変形ファイル。Jw_cadでの外部変形ファイルの開き方は、[その他] → 外部変形(G) → hogehoge.batを選択
hogehoge.batを選択するとコマンドプロンプトでhello world!!と表示される。まとめ
このページではPythonの動作する下地として
外部変形の.batファイルの作成、Jw_cad上からの実行までを解説した。
(その2)では、外部変形.batファイルで記述するREM #~~~の解説などを行いたい。参考文献・ソフトウェア
Jw_cadのページ ← Jw_cadの公式ページです。
Markdown記法 チートシート ← Qittaの書き方で参考にさせてもらいました。
- 投稿日:2020-11-12T11:22:33+09:00
fastTextでYahoo!ニュースをクラスタリング
前回こちらの記事にて青空文庫の書籍をDoc2Vecでクラスタリングしようとしました。
少しうまくいったかなという程度だったのですが、正直微妙な結果となってしまいました。
そこで今回はDoc2Vecに代わり、fastTextというライブラリを用いて、Yahooニュース記事のクラスタリングを行おうと思います。fastTextとは
fastTextとはFacebookによって開発が行われたオープンソースの自然言語処理ライブラリです。
高機能で予測精度も良く、更に高速に予測をします。
メイン機能は教師あり学習による分類と教師なし学習による単語のベクトル生成です。今回は教師あり学習による分類機能を用いて、記事のカテゴリを予測してみようと思います。
詳しくはfastText公式リファレンスへ!
Pythonについての機能はGitHubが詳しかったです!開発環境
- Docker → こちらで記事にしています
- JupyterLab
実装スタート
import pandas as pd, numpy as np import re import MeCab import fasttext import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn import preprocessing from sklearn.decomposition import PCA import japanize_matplotlibニュースデータ取得
Yahooニュースをスクレイピングでご紹介したコードを利用して取得したデータを読み込みます。
アメリカ大統領選挙の直後ということもあり、国際ニュースが多いですね。df = pd.read_csv('./YahooNews.csv') df
title category text 0 損? あざとかわいい吉岡里帆 エンタメ 女優吉岡里帆27の2年ぶり2冊目の写真集里帆採取 by Asami Kiyokawa集英社... 1 鬼滅の「聖地」潤う観光地 経済 コロナ禍にもかかわらず異例の大ヒットを記録している劇場版鬼滅の刃 無限列車編映画にとどまらず... 2 電通G コロナで営業利益半減 経済 電通グループが10日発表した2020年19月期連結決算国際会計基準は売上高に当たる収益が9... 3 香港民主派議員、全員辞職 国際 12 北京共同新華社電によると中国の全人代常務委員会会議は11日香港立法会定数70の議員資格... 4 専門家組織 全国的に感染増加 国内 新型コロナウイルス対策を助言する厚生労働省の専門家組織アドバイザリーボードの会合が11日開... ... ... ... ... 512 ホワイトハウス周辺で4人刺傷 国際 米NBCテレビなどによると米大統領選でトランプ大統領とバイデン前副大統領の双方の支持者が集... 513 一方的な勝利宣言 米の反応は 国際 FNNプライムオンラインアメリカ大統領選挙の投票日から一夜明けた4日午前10時前のワシントン... 514 NY株続伸、一時600ドル超高 国際 ニューヨーク時事開票作業が進む米大統領選でトランプバイデン両候補の大接戦が続く中4日午前の... 515 セガサミー ゲーセン運営撤退 経済 セガサミーホールディングスは4日娯楽施設を運営する連結子会社セガエンタテインメント東京の株... 516 中国、海上警備に武器使用へ 国際 北京共同中国全国人民代表大会全人代国会は4日海上警備を担う中国海警局の権限を定める海警法草... 517 rows × 3 columns
辞書&関数定義
# MeCabの辞書にNEologdを指定。 # mecabは携帯素解析用、wakatiは分かち書き用 mecab = MeCab.Tagger('-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd/') wakati = MeCab.Tagger("-Owakati -d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd/") # 形態素解析を行う関数を定義 # ファイルを入力するとファイルを出力し、文字列を渡すと文字列を返します。引数fileで変更します。 # 単に分かち書きしたいだけの場合は引数にmecab=wakatiとすると実現できます。 def MecabMorphologicalAnalysis(path='./text.txt', output_file='wakati.txt', mecab=mecab, file=False): mecab_text = '' if file: with open(path) as f: for line in f: mecab_text += mecab.parse(line) with open(output_file, 'w') as f: print(mecab_text, file=f) else: for path in path.split('\n'): mecab_text += mecab.parse(path) return mecab_text # v1とv2のコサイン類似度を出力します。 def cos_sim(v1, v2): return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))データ前処理
fastTextで利用するための形に変形します。
fastTextは下記のような形にデータを整形してあげることで、簡単に教師あり学習を行うことができます。
詳しくは公式チュートリアルをご参照ください。__label__sauce __label__cheese how much does potato starch affect a cheese sauce recipe ? __label__food-safety __label__acidity dangerous pathogens capable of growing in acidic environments __label__cast-iron __label__stove how do i cover up the white spots on my cast iron stove ? __label__restaurant michelin three star restaurant; but if the chef is not there上記の形に整形するために以下の処理を行います。
①ニュースのカテゴリの前に__label__を挿入 → リストに格納
②本文は上記で定義したMecabMorphologicalAnalysis関数を利用して分かち書き → リストに格納
③train_test_splitを用いてtrainデータとvalidデータに分割
④trainとvalidでそれぞれカテゴリと本文を結合してファイルに保存# ① cat_lst = ['__label__' + cat for cat in df.category] print("cat_lst[:5]:", cat_lst[:5]) # 内容を確認 print("len(cat_lst):", len(cat_lst)) # ラベル数を確認cat_lst[:5]: ['__label__エンタメ', '__label__経済', '__label__経済', '__label__国際', '__label__国内'] len(cat_lst): 517# ② text_lst = [MecabMorphologicalAnalysis(text, mecab=wakati) for text in df.text] print("text_lst[0][:50]:", text_lst[0][:50]) # 1行目を確認 print("text_lst[1][:50]:", text_lst[1][:50]) # 2行目を確認 print("len(text_lst):", len(text_lst)) # 記事の数を確認text_lst[0][:50]: 女優 吉岡里帆 27 の 2年ぶり 2 冊 目 の 写真集 里帆 採取 by Asami Kiyok text_lst[1][:50]: コロナ禍 に も かかわら ず 異例 の 大 ヒット を 記録 し て いる 劇場版 鬼滅の刃 無限 len(text_lst): 517# ③ text_train, text_valid, cat_train, cat_valid = train_test_split( text_lst, cat_lst, test_size=0.2, random_state=0, stratify=cat_lst ) # ④ with open('./news.train', mode='w') as f: for i in range(len(text_train)): f.write(cat_train[i] + ' '+ text_train[i]) with open('./news.valid', mode='w') as f: for i in range(len(text_valid)): f.write(cat_valid[i] + ' ' + text_valid[i])モデルの学習と評価
fastTextは
train_supervisedで簡単に学習を行うことができます。
wordNgramsに引数を渡すことでn-gram処理を行ったり、lossにhsを入れてhierarchical softmaxを使って高速に処理を行ったり、とにかく高機能です!!学習も素晴らしいのですが、
model.testとするとすぐに精度の評価ができることもfastTextの特徴だと思います。
下記に示す通りvalidデータに対してもなかなか良い精度が出るということがわかります。model = fasttext.train_supervised(input='./news.train', lr=0.5, epoch=500, wordNgrams=3, loss='ova', dim=300, bucket=200000) print("TrainData:", model.test('news.train')) print("Valid", model.test('news.valid'))TrainData: (413, 1.0, 1.0) Valid (104, 0.75, 0.75)validデータを用いた精度確認
学習に用いていないvalidデータを用いて、モデルの精度を確認してみましょう。
①validデータの内容をl_stripに格納
②label,text,sizeをそれぞれリストに格納。labelはニュースのカテゴリ、textは本文、sizeはモデルの予測に対する確率です。正規表現を用いて必要な部分を抽出しています。
③ニュースを一つづつ取り出して、カテゴリ予測をしてみます。predictの引数kの数だけ候補を表示します。その下のarrayにはモデルが行った予測に対する確率が順番に表示されます。# ① with open("news.valid") as f: l_strip = [s.strip() for s in f.readlines()] # strip()を利用することにより改行文字除去 # ② labels = [] texts = [] sizes = [] for t in l_strip: labels.append(re.findall('__label__(.*?) ', t)[0]) texts.append(re.findall(' (.*)', t)[0]) sizes.append(model.predict(re.findall(' (.*)', t))[1][0][0])# ③ print("<{}>".format(labels[0])) print(texts[0])<経済> 電通グループ が 10日 発表 し た 2020年 19 月 期 連結決算 国際会計基準 は 売上高 に 当たる 収益 が 94 減 の 6763 億 円 本業 の もうけ を 示す 営業利益 は 185 億 円 に 半減 し た 新型コロナウイルス感染症 の 影響 を 受け 国内外 で テレビ や インターネット 向け など の 広告 需要 が 落ち込ん だ 営業利益 の 半減 は 年末 から 来年3月 にかけて 実施 する 早期退職 プログラム の ほか 退職者 向け に 業務委託 を 手掛ける 新 会社設立 など の 構造改革 費用 251 億 円 を 計上 し た ため 一方 コロナ禍 で 一連 の MA 合併 買収 費用 が 想定 を 下回る 結果 純利益 は 22倍 の 102 億 円 を 確保 し た 2月 に 子会社化 を 決め た 米メディア ストーム 社 を はじめ 多く の 企業価値 が 下落 し 株式 の 追加 取得 に かかる 見積 費 が 約 300億円 減少 し たmodel.predict(texts[0], k=3)(('__label__経済', '__label__国内', '__label__ライフ'), array([9.88678277e-01, 1.48057193e-01, 3.89984576e-04]))print("<{}>".format(labels[1])) print(texts[1])<経済> 任天堂 は 5日 家庭 用 ゲーム機 ニンテンドースイッチ の 世界 で の 累計 販売台数 が 9月 末 時点 で 6830 万 台 に なっ た と 発表 し た ファミリーコンピュータ ファミコン の 6191 万 台 を 上回っ た 新型コロナウイルス の 感染拡大 に 伴う 巣ごもり消費 が 追い風 と なり 2017年 3月 の 発売 から 約 3年 半 で 達成 し た スイッチ は 据え置い て も 持ち運ん で も ゲーム が でき 幅広い 世代 から 支持 さ れ た 今年3月 に 発売 し た ソフト あつまれ どうぶつの森 が ヒット し て スイッチ の 販売 を 押し上げ た スイッチ は 20年 49 月 だけ で 1253 万 台 が 売れ たmodel.predict(texts[1], k=3)(('__label__経済', '__label__スポーツ', '__label__国内'), array([0.00338661, 0.00206074, 0.00081409]))print("<{}>".format(labels[2])) print(texts[2])<スポーツ> JERA セリーグ 巨人 6 ― 2 ヤクルト 7日 東京ドーム 今季限り で 現役 引退 する 巨人 の 岩隈久志 投手 39 の 引退セレモニー が 7日 の ヤクルト 23回 戦 東京ドーム の 試合後 に 行わ れ た 今季 最多 と なる 2 万 6649 人 の ファン の 前 で 岩隈 は 本日 をもちまして 21年間 の プロ野球 生活 に 幕 を 閉じ ます 21年間 すばらしい チームメート に 恵まれ 最高 の 野球 人生 を 送る こと が でき 感謝 の 思い で いっぱい です と 語っ た そして この 2年間 ジャイアンツ で 1軍 復帰 する こと は でき ませ ん でし た が 現役 最後 に ジャイアンツ の ユニホーム を 着 て この 日 を 迎え られ た こと に 幸せ を 感じ て い ます これから も 野球 を通じて 誰か を 幸せ に できる 存在 で い たい と 思い ます 21年間 本当にありがとうございました と スピーチ し た その後 は 現在 ヤクルト で マリナーズ 時代 の チームメート 青木 楽天 で 一緒 に プレー し た 嶋 から 花束 を 受け取っ た さら に 菅野 から も 花束 を 受け取る と 続け て 原監督 が 自ら 岩隈 の 元 へ 駆け寄り ナイン と 一緒に 記念撮影 を 行っ た そして 最後 は 3人 の 子どもたち から も 花束 を 受け取り 再び 記念撮影 を し て ファン に 別れ を 告げ て い た 報知新聞社model.predict(texts[2], k=3)(('__label__スポーツ', '__label__エンタメ', '__label__ライフ'), array([8.55861187e-01, 1.00888625e-01, 7.65405654e-04]))ベクトル表現についての分析
ここまでで分析を終わりにしても良いのですが、fastTextの
get_sentence_vectorという機能を使って記事ごとのベクトルを取得して、さらに分析を行ってみましょう。
①記事一つ一つに対してベクトルを取得し、リストに格納していきます。
②ベクトル、ラベル、サイズをnumpy配列に変更します。(ラベル、サイズについては取得済)
③StandardScalerを用いてベクトルを標準化
④主成分分析器PCAを用いて次元削減
⑤上記で定義したcos_sim関数を用いて記事ごとの類似度を算出。同じカテゴリの記事の類似度が最も高くなりました。
⑥ベクトルを2次元プロット。sizesの数値によって点の大きさが変化します。# ① vectors = [] for t in texts: vectors.append(model.get_sentence_vector(t)) # ② vectors = np.array(vectors) labels = np.array(labels) sizes = np.array(sizes) # ③ ss = preprocessing.StandardScaler() vectors_std = ss.fit_transform(vectors) # ④ pca = PCA() pca.fit(vectors_std) feature = pca.transform(vectors_std) feature = feature[:, :2]# ⑤ print("<{}><{}>".format(labels[0], labels[1])) cos_sim(vectors[0], vectors[1])<経済><経済> 0.9514279print("<{}><{}>".format(labels[1], labels[2])) cos_sim(vectors[1], vectors[2])<経済><スポーツ> 0.9299138print("<{}><{}>".format(labels[0], labels[2])) cos_sim(vectors[0], vectors[2])<経済><スポーツ> 0.79527444# ⑥ x0, y0, z0 = feature[labels=='エンタメ', 0], feature[labels=='エンタメ', 1], sizes[labels=='エンタメ']**2*200 x1, y1, z1 = feature[labels=='スポーツ', 0], feature[labels=='スポーツ', 1], sizes[labels=='スポーツ']**2*200 x2, y2, z2 = feature[labels=='ライフ', 0], feature[labels=='ライフ', 1], sizes[labels=='ライフ']**2*220 x3, y3, z3 = feature[labels=='国内', 0], feature[labels=='国内', 1], sizes[labels=='国内']**2*220 x4, y4, z4 = feature[labels=='国際', 0], feature[labels=='国際', 1], sizes[labels=='国際']**2*220 x5, y5, z5 = feature[labels=='地域', 0], feature[labels=='地域', 1], sizes[labels=='地域']**2*220 x6, y6, z6 = feature[labels=='経済', 0], feature[labels=='経済', 1], sizes[labels=='経済']**2*220 plt.title("Yahooニュース") plt.scatter(x0, y0, label="エンタメ", s=z0) plt.scatter(x1, y1, label="スポーツ", s=z1) plt.scatter(x2, y2, label="ライフ", s=z2) plt.scatter(x3, y3, label="国内", s=z3) plt.scatter(x4, y4, label="国際", s=z4) plt.scatter(x5, y5, label="地域", s=z5) plt.scatter(x6, y6, label="経済", s=z6) plt.legend(title="category") plt.show()
考察
今回はfastTextの教師あり学習を実施しました。ですのでこのように綺麗に分類されたプロットが得られるのも当然かもしれません。
ですので次回はfastTextの教師なし学習を実施してプロットしてみて、教師あり学習の時と比較してみると面白いかもしれません。参考文献
青空文庫の書籍をDoc2Vecでクラスタリング fastText
GitHub (fastText/python)
mecab(NEologd辞書)環境をDocker(ubuntu)で構築
Yahooニュースをスクレイピング
fastText tutorial(Text classification)
【Python NumPy】コサイン類似度の求め方 主成分分析を Python で理解する
matplotlib Scatter plots with a legend
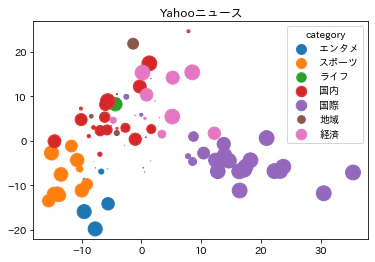
- 投稿日:2020-11-12T11:22:33+09:00
fastTextで「Yahoo!ニュース」をクラスタリング
前回こちらの記事にて青空文庫の書籍をDoc2Vecでクラスタリングしようとしました。
少しうまくいったかなという程度だったのですが、正直微妙な結果となってしまいました。
そこで今回はDoc2Vecに代わり、fastTextというライブラリを用いて、Yahooニュース記事のクラスタリングを行おうと思います。fastTextとは
fastTextとはFacebookによって開発が行われたオープンソースの自然言語処理ライブラリです。
高機能で予測精度も良く、更に高速に予測をします。
メイン機能は教師あり学習による分類と教師なし学習による単語のベクトル生成です。今回は教師あり学習による分類機能を用いて、記事のカテゴリを予測してみようと思います。
詳しくはfastText公式リファレンスへ!
Pythonについての機能はGitHubが詳しかったです!開発環境
- Docker → こちらで記事にしています
- JupyterLab
実装スタート
import pandas as pd, numpy as np import re import MeCab import fasttext import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn import preprocessing from sklearn.decomposition import PCA import japanize_matplotlibニュースデータ取得
Yahooニュースをスクレイピングでご紹介したコードを利用して取得したデータを読み込みます。
アメリカ大統領選挙の直後ということもあり、国際ニュースが多いですね。df = pd.read_csv('./YahooNews.csv') df
title category text 0 損? あざとかわいい吉岡里帆 エンタメ 女優吉岡里帆27の2年ぶり2冊目の写真集里帆採取 by Asami Kiyokawa集英社... 1 鬼滅の「聖地」潤う観光地 経済 コロナ禍にもかかわらず異例の大ヒットを記録している劇場版鬼滅の刃 無限列車編映画にとどまらず... 2 電通G コロナで営業利益半減 経済 電通グループが10日発表した2020年19月期連結決算国際会計基準は売上高に当たる収益が9... 3 香港民主派議員、全員辞職 国際 12 北京共同新華社電によると中国の全人代常務委員会会議は11日香港立法会定数70の議員資格... 4 専門家組織 全国的に感染増加 国内 新型コロナウイルス対策を助言する厚生労働省の専門家組織アドバイザリーボードの会合が11日開... ... ... ... ... 512 ホワイトハウス周辺で4人刺傷 国際 米NBCテレビなどによると米大統領選でトランプ大統領とバイデン前副大統領の双方の支持者が集... 513 一方的な勝利宣言 米の反応は 国際 FNNプライムオンラインアメリカ大統領選挙の投票日から一夜明けた4日午前10時前のワシントン... 514 NY株続伸、一時600ドル超高 国際 ニューヨーク時事開票作業が進む米大統領選でトランプバイデン両候補の大接戦が続く中4日午前の... 515 セガサミー ゲーセン運営撤退 経済 セガサミーホールディングスは4日娯楽施設を運営する連結子会社セガエンタテインメント東京の株... 516 中国、海上警備に武器使用へ 国際 北京共同中国全国人民代表大会全人代国会は4日海上警備を担う中国海警局の権限を定める海警法草... 517 rows × 3 columns
辞書&関数定義
# MeCabの辞書にNEologdを指定。 # mecabは携帯素解析用、wakatiは分かち書き用 mecab = MeCab.Tagger('-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd/') wakati = MeCab.Tagger("-Owakati -d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd/") # 形態素解析を行う関数を定義 # ファイルを入力するとファイルを出力し、文字列を渡すと文字列を返します。引数fileで変更します。 # 単に分かち書きしたいだけの場合は引数にmecab=wakatiとすると実現できます。 def MecabMorphologicalAnalysis(path='./text.txt', output_file='wakati.txt', mecab=mecab, file=False): mecab_text = '' if file: with open(path) as f: for line in f: mecab_text += mecab.parse(line) with open(output_file, 'w') as f: print(mecab_text, file=f) else: for path in path.split('\n'): mecab_text += mecab.parse(path) return mecab_text # v1とv2のコサイン類似度を出力します。 def cos_sim(v1, v2): return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))データ前処理
fastTextで利用するための形に変形します。
fastTextは下記のような形にデータを整形してあげることで、簡単に教師あり学習を行うことができます。
詳しくは公式チュートリアルをご参照ください。__label__sauce __label__cheese how much does potato starch affect a cheese sauce recipe ? __label__food-safety __label__acidity dangerous pathogens capable of growing in acidic environments __label__cast-iron __label__stove how do i cover up the white spots on my cast iron stove ? __label__restaurant michelin three star restaurant; but if the chef is not there上記の形に整形するために以下の処理を行います。
①ニュースのカテゴリの前に__label__を挿入 → リストに格納
②本文は上記で定義したMecabMorphologicalAnalysis関数を利用して分かち書き → リストに格納
③train_test_splitを用いてtrainデータとvalidデータに分割
④trainとvalidでそれぞれカテゴリと本文を結合してファイルに保存# ① cat_lst = ['__label__' + cat for cat in df.category] print("cat_lst[:5]:", cat_lst[:5]) # 内容を確認 print("len(cat_lst):", len(cat_lst)) # ラベル数を確認cat_lst[:5]: ['__label__エンタメ', '__label__経済', '__label__経済', '__label__国際', '__label__国内'] len(cat_lst): 517# ② text_lst = [MecabMorphologicalAnalysis(text, mecab=wakati) for text in df.text] print("text_lst[0][:50]:", text_lst[0][:50]) # 1行目を確認 print("text_lst[1][:50]:", text_lst[1][:50]) # 2行目を確認 print("len(text_lst):", len(text_lst)) # 記事の数を確認text_lst[0][:50]: 女優 吉岡里帆 27 の 2年ぶり 2 冊 目 の 写真集 里帆 採取 by Asami Kiyok text_lst[1][:50]: コロナ禍 に も かかわら ず 異例 の 大 ヒット を 記録 し て いる 劇場版 鬼滅の刃 無限 len(text_lst): 517# ③ text_train, text_valid, cat_train, cat_valid = train_test_split( text_lst, cat_lst, test_size=0.2, random_state=0, stratify=cat_lst ) # ④ with open('./news.train', mode='w') as f: for i in range(len(text_train)): f.write(cat_train[i] + ' '+ text_train[i]) with open('./news.valid', mode='w') as f: for i in range(len(text_valid)): f.write(cat_valid[i] + ' ' + text_valid[i])モデルの学習と評価
fastTextは
train_supervisedで簡単に学習を行うことができます。
wordNgramsに引数を渡すことでn-gram処理を行ったり、lossにhsを入れてhierarchical softmaxを使って高速に処理を行ったり、とにかく高機能です!!学習も素晴らしいのですが、
model.testとするとすぐに精度の評価ができることもfastTextの特徴だと思います。
下記に示す通りvalidデータに対してもなかなか良い精度が出るということがわかります。model = fasttext.train_supervised(input='./news.train', lr=0.5, epoch=500, wordNgrams=3, loss='ova', dim=300, bucket=200000) print("TrainData:", model.test('news.train')) print("Valid", model.test('news.valid'))TrainData: (413, 1.0, 1.0) Valid (104, 0.75, 0.75)validデータを用いた精度確認
学習に用いていないvalidデータを用いて、モデルの精度を確認してみましょう。
①validデータの内容をl_stripに格納
②label,text,sizeをそれぞれリストに格納。labelはニュースのカテゴリ、textは本文、sizeはモデルの予測に対する確率です。正規表現を用いて必要な部分を抽出しています。
③ニュースを一つづつ取り出して、カテゴリ予測をしてみます。predictの引数kの数だけ、確率の高い順に予測を表示します。その次のarrayには対応する確率が表示されます。全問正解なので良好です。# ① with open("news.valid") as f: l_strip = [s.strip() for s in f.readlines()] # strip()を利用することにより改行文字除去 # ② labels = [] texts = [] sizes = [] for t in l_strip: labels.append(re.findall('__label__(.*?) ', t)[0]) texts.append(re.findall(' (.*)', t)[0]) sizes.append(model.predict(re.findall(' (.*)', t))[1][0][0])# ③-1 print("<{}>".format(labels[0])) print(texts[0]) print(model.predict(texts[0], k=3))<経済> 電通グループ が 10日 発表 し た 2020年 19 月 期 連結決算 国際会計基準 は 売上高 に 当たる 収益 が 94 減 の 6763 億 円 本業 の もうけ を 示す 営業利益 は 185 億 円 に 半減 し た 新型コロナウイルス感染症 の 影響 を 受け 国内外 で テレビ や インターネット 向け など の 広告 需要 が 落ち込ん だ 営業利益 の 半減 は 年末 から 来年3月 にかけて 実施 する 早期退職 プログラム の ほか 退職者 向け に 業務委託 を 手掛ける 新 会社設立 など の 構造改革 費用 251 億 円 を 計上 し た ため 一方 コロナ禍 で 一連 の MA 合併 買収 費用 が 想定 を 下回る 結果 純利益 は 22倍 の 102 億 円 を 確保 し た 2月 に 子会社化 を 決め た 米メディア ストーム 社 を はじめ 多く の 企業価値 が 下落 し 株式 の 追加 取得 に かかる 見積 費 が 約 300億円 減少 し た (('__label__経済', '__label__国内', '__label__ライフ'), array([9.88678277e-01, 1.48057193e-01, 3.89984576e-04]))# ③-2 print("<{}>".format(labels[1])) print(texts[1]) print(model.predict(texts[1], k=3))<経済> 任天堂 は 5日 家庭 用 ゲーム機 ニンテンドースイッチ の 世界 で の 累計 販売台数 が 9月 末 時点 で 6830 万 台 に なっ た と 発表 し た ファミリーコンピュータ ファミコン の 6191 万 台 を 上回っ た 新型コロナウイルス の 感染拡大 に 伴う 巣ごもり消費 が 追い風 と なり 2017年 3月 の 発売 から 約 3年 半 で 達成 し た スイッチ は 据え置い て も 持ち運ん で も ゲーム が でき 幅広い 世代 から 支持 さ れ た 今年3月 に 発売 し た ソフト あつまれ どうぶつの森 が ヒット し て スイッチ の 販売 を 押し上げ た スイッチ は 20年 49 月 だけ で 1253 万 台 が 売れ た (('__label__経済', '__label__スポーツ', '__label__国内'), array([0.00338661, 0.00206074, 0.00081409]))# ③-3 print("<{}>".format(labels[2])) print(texts[2]) print(model.predict(texts[2], k=3))<スポーツ> JERA セリーグ 巨人 6 ― 2 ヤクルト 7日 東京ドーム 今季限り で 現役 引退 する 巨人 の 岩隈久志 投手 39 の 引退セレモニー が 7日 の ヤクルト 23回 戦 東京ドーム の 試合後 に 行わ れ た 今季 最多 と なる 2 万 6649 人 の ファン の 前 で 岩隈 は 本日 をもちまして 21年間 の プロ野球 生活 に 幕 を 閉じ ます 21年間 すばらしい チームメート に 恵まれ 最高 の 野球 人生 を 送る こと が でき 感謝 の 思い で いっぱい です と 語っ た そして この 2年間 ジャイアンツ で 1軍 復帰 する こと は でき ませ ん でし た が 現役 最後 に ジャイアンツ の ユニホーム を 着 て この 日 を 迎え られ た こと に 幸せ を 感じ て い ます これから も 野球 を通じて 誰か を 幸せ に できる 存在 で い たい と 思い ます 21年間 本当にありがとうございました と スピーチ し た その後 は 現在 ヤクルト で マリナーズ 時代 の チームメート 青木 楽天 で 一緒 に プレー し た 嶋 から 花束 を 受け取っ た さら に 菅野 から も 花束 を 受け取る と 続け て 原監督 が 自ら 岩隈 の 元 へ 駆け寄り ナイン と 一緒に 記念撮影 を 行っ た そして 最後 は 3人 の 子どもたち から も 花束 を 受け取り 再び 記念撮影 を し て ファン に 別れ を 告げ て い た 報知新聞社 (('__label__スポーツ', '__label__エンタメ', '__label__ライフ'), array([8.55861187e-01, 1.00888625e-01, 7.65405654e-04]))ベクトル表現についての分析
ここまでで分析を終わりにしても良いのですが、fastTextの
get_sentence_vectorという機能を使って記事ごとのベクトルを取得して、さらに分析を行ってみましょう。
①記事一つ一つに対してベクトルを取得し、リストに格納していきます。
②ベクトル、ラベル、サイズをnumpy配列に変更します。(ラベル、サイズについては取得済)
③StandardScalerを用いてベクトルを標準化
④主成分分析器PCAを用いて次元削減
⑤上記で定義したcos_sim関数を用いて記事ごとの類似度を算出。同じカテゴリの記事の類似度が最も高くなりました。
⑥ベクトルを2次元プロット。sizesの数値によって点の大きさが変化します。(sizesは予測の可能性が格納されています。)# ① vectors = [] for t in texts: vectors.append(model.get_sentence_vector(t)) # ② vectors = np.array(vectors) labels = np.array(labels) sizes = np.array(sizes) # ③ ss = preprocessing.StandardScaler() vectors_std = ss.fit_transform(vectors) # ④ pca = PCA() pca.fit(vectors_std) feature = pca.transform(vectors_std) feature = feature[:, :2]# ⑤-1 print("<{}><{}>".format(labels[0], labels[1])) cos_sim(vectors[0], vectors[1])<経済><経済> 0.9514279# ⑤-2 print("<{}><{}>".format(labels[1], labels[2])) cos_sim(vectors[1], vectors[2])<経済><スポーツ> 0.9299138# ⑤-3 print("<{}><{}>".format(labels[0], labels[2])) cos_sim(vectors[0], vectors[2])<経済><スポーツ> 0.79527444# ⑥ x0, y0, z0 = feature[labels=='エンタメ', 0], feature[labels=='エンタメ', 1], sizes[labels=='エンタメ']**2*500 x1, y1, z1 = feature[labels=='スポーツ', 0], feature[labels=='スポーツ', 1], sizes[labels=='スポーツ']**2*500 x2, y2, z2 = feature[labels=='ライフ', 0], feature[labels=='ライフ', 1], sizes[labels=='ライフ']**2*500 x3, y3, z3 = feature[labels=='国内', 0], feature[labels=='国内', 1], sizes[labels=='国内']**2*500 x4, y4, z4 = feature[labels=='国際', 0], feature[labels=='国際', 1], sizes[labels=='国際']**2*500 x5, y5, z5 = feature[labels=='地域', 0], feature[labels=='地域', 1], sizes[labels=='地域']**2*500 x6, y6, z6 = feature[labels=='経済', 0], feature[labels=='経済', 1], sizes[labels=='経済']**2*500 plt.figure(figsize=(14, 10)) plt.rcParams["font.size"]=20 plt.scatter(x0, y0, label="エンタメ", s=z0) plt.scatter(x1, y1, label="スポーツ", s=z1) plt.scatter(x2, y2, label="ライフ", s=z2) plt.scatter(x3, y3, label="国内", s=z3) plt.scatter(x4, y4, label="国際", s=z4) plt.scatter(x5, y5, label="地域", s=z5) plt.scatter(x6, y6, label="経済", s=z6) plt.title("Yahooニュース") plt.xlabel('1st dimension') plt.ylabel('2nd dimension') plt.legend(title="category") plt.show()
考察
- 「エンタメ」と「スポーツ」がかなり近い位置にいます。1次元目では重なっている部分が多いですが、2次元目でしっかり分かれています。これは納得できます。
- 「国際」と「国内」はしっかり分かれていて、経済はその間くらいにあります。これも納得ができます。
- 「スポーツ」と「国内」が近いですが、Yahooニュースは海外よりも国内のスポーツ記事を取り上げることが多いからでしょうか。
- 「地域」は「国内」の近くにいくつかプロットされていますが小さくプロットされているので確率が低いです。確かに「地域」の記事を読んで「国内」か「地域」か判断するのは難しいかもしれないです。
全体的にはうまくクラスタリングできているのではないでしょうか。
今回はfastTextの教師あり学習を実施しました。ですのでこのように綺麗に分類されたプロットが得られるのも当然かもしれません。
ですので次回はfastTextの教師なし学習を実施してプロットしてみて、教師あり学習の時と比較してみると面白いかもしれません。参考文献
Yahoo!ニュース
青空文庫の書籍をDoc2Vecでクラスタリング
fastText
GitHub (fastText/python)
mecab(NEologd辞書)環境をDocker(ubuntu)で構築
Yahooニュースをスクレイピング
fastText tutorial(Text classification)
【Python NumPy】コサイン類似度の求め方 主成分分析を Python で理解する
matplotlib Scatter plots with a legend

- 投稿日:2020-11-12T11:22:33+09:00
fastTextがすごい!「Yahoo!ニュース」をクラスタリング
前回こちらの記事にて青空文庫の書籍をDoc2Vecでクラスタリングしようとしました。
少しうまくいったかなという程度だったのですが、正直微妙な結果となってしまいました。
そこで今回はDoc2Vecに代わり、fastTextというライブラリを用いて、Yahooニュース記事のクラスタリングを行おうと思います。fastTextとは
fastTextとはFacebookによって開発が行われたオープンソースの自然言語処理ライブラリです。
高機能で予測精度も良く、更に高速に予測をします。
メイン機能は教師あり学習による分類と教師なし学習による単語のベクトル生成です。今回は教師あり学習による分類機能を用いて、記事のカテゴリを予測してみようと思います。
詳しくはfastText公式リファレンスへ!
Pythonについての機能はGitHubが詳しかったです!開発環境
- Docker → こちらで記事にしています
- JupyterLab
実装スタート
import pandas as pd, numpy as np import re import MeCab import fasttext import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn import preprocessing from sklearn.decomposition import PCA import japanize_matplotlibニュースデータ取得
Yahooニュースをスクレイピングでご紹介したコードを利用して取得したデータを読み込みます。
アメリカ大統領選挙の直後ということもあり、国際ニュースが多いですね。df = pd.read_csv('./YahooNews.csv') df
title category text 0 損? あざとかわいい吉岡里帆 エンタメ 女優吉岡里帆27の2年ぶり2冊目の写真集里帆採取 by Asami Kiyokawa集英社... 1 鬼滅の「聖地」潤う観光地 経済 コロナ禍にもかかわらず異例の大ヒットを記録している劇場版鬼滅の刃 無限列車編映画にとどまらず... 2 電通G コロナで営業利益半減 経済 電通グループが10日発表した2020年19月期連結決算国際会計基準は売上高に当たる収益が9... 3 香港民主派議員、全員辞職 国際 12 北京共同新華社電によると中国の全人代常務委員会会議は11日香港立法会定数70の議員資格... 4 専門家組織 全国的に感染増加 国内 新型コロナウイルス対策を助言する厚生労働省の専門家組織アドバイザリーボードの会合が11日開... ... ... ... ... 512 ホワイトハウス周辺で4人刺傷 国際 米NBCテレビなどによると米大統領選でトランプ大統領とバイデン前副大統領の双方の支持者が集... 513 一方的な勝利宣言 米の反応は 国際 FNNプライムオンラインアメリカ大統領選挙の投票日から一夜明けた4日午前10時前のワシントン... 514 NY株続伸、一時600ドル超高 国際 ニューヨーク時事開票作業が進む米大統領選でトランプバイデン両候補の大接戦が続く中4日午前の... 515 セガサミー ゲーセン運営撤退 経済 セガサミーホールディングスは4日娯楽施設を運営する連結子会社セガエンタテインメント東京の株... 516 中国、海上警備に武器使用へ 国際 北京共同中国全国人民代表大会全人代国会は4日海上警備を担う中国海警局の権限を定める海警法草... 517 rows × 3 columns
辞書&関数定義
# MeCabの辞書にNEologdを指定。 # mecabは携帯素解析用、wakatiは分かち書き用 mecab = MeCab.Tagger('-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd/') wakati = MeCab.Tagger("-Owakati -d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd/") # 形態素解析を行う関数を定義 # ファイルを入力するとファイルを出力し、文字列を渡すと文字列を返します。引数fileで変更します。 # 単に分かち書きしたいだけの場合は引数にmecab=wakatiとすると実現できます。 def MecabMorphologicalAnalysis(path='./text.txt', output_file='wakati.txt', mecab=mecab, file=False): mecab_text = '' if file: with open(path) as f: for line in f: mecab_text += mecab.parse(line) with open(output_file, 'w') as f: print(mecab_text, file=f) else: for path in path.split('\n'): mecab_text += mecab.parse(path) return mecab_text # v1とv2のコサイン類似度を出力します。 def cos_sim(v1, v2): return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))データ前処理
fastTextで利用するための形に変形します。
fastTextは下記のような形にデータを整形してあげることで、簡単に教師あり学習を行うことができます。
詳しくは公式チュートリアルをご参照ください。__label__sauce __label__cheese how much does potato starch affect a cheese sauce recipe ? __label__food-safety __label__acidity dangerous pathogens capable of growing in acidic environments __label__cast-iron __label__stove how do i cover up the white spots on my cast iron stove ? __label__restaurant michelin three star restaurant; but if the chef is not there上記の形に整形するために以下の処理を行います。
①ニュースのカテゴリの前に__label__を挿入 → リストに格納
②本文は上記で定義したMecabMorphologicalAnalysis関数を利用して分かち書き → リストに格納
③train_test_splitを用いてtrainデータとvalidデータに分割
④trainとvalidでそれぞれカテゴリと本文を結合してファイルに保存# ① cat_lst = ['__label__' + cat for cat in df.category] print("cat_lst[:5]:", cat_lst[:5]) # 内容を確認 print("len(cat_lst):", len(cat_lst)) # ラベル数を確認cat_lst[:5]: ['__label__エンタメ', '__label__経済', '__label__経済', '__label__国際', '__label__国内'] len(cat_lst): 517# ② text_lst = [MecabMorphologicalAnalysis(text, mecab=wakati) for text in df.text] print("text_lst[0][:50]:", text_lst[0][:50]) # 1行目を確認 print("text_lst[1][:50]:", text_lst[1][:50]) # 2行目を確認 print("len(text_lst):", len(text_lst)) # 記事の数を確認text_lst[0][:50]: 女優 吉岡里帆 27 の 2年ぶり 2 冊 目 の 写真集 里帆 採取 by Asami Kiyok text_lst[1][:50]: コロナ禍 に も かかわら ず 異例 の 大 ヒット を 記録 し て いる 劇場版 鬼滅の刃 無限 len(text_lst): 517# ③ text_train, text_valid, cat_train, cat_valid = train_test_split( text_lst, cat_lst, test_size=0.2, random_state=0, stratify=cat_lst ) # ④ with open('./news.train', mode='w') as f: for i in range(len(text_train)): f.write(cat_train[i] + ' '+ text_train[i]) with open('./news.valid', mode='w') as f: for i in range(len(text_valid)): f.write(cat_valid[i] + ' ' + text_valid[i])モデルの学習と評価
fastTextは
train_supervisedで簡単に学習を行うことができます。
wordNgramsに引数を渡すことでn-gram処理を行ったり、lossにhsを入れてhierarchical softmaxを使って高速に処理を行ったり、とにかく高機能です!!学習も素晴らしいのですが、
model.testとするとすぐに精度の評価ができることもfastTextの特徴だと思います。
下記に示す通りvalidデータに対してもなかなか良い精度が出るということがわかります。model = fasttext.train_supervised(input='./news.train', lr=0.5, epoch=500, wordNgrams=3, loss='ova', dim=300, bucket=200000) print("TrainData:", model.test('news.train')) print("Valid", model.test('news.valid'))TrainData: (413, 1.0, 1.0) Valid (104, 0.75, 0.75)validデータを用いた精度確認
学習に用いていないvalidデータを用いて、モデルの精度を確認してみましょう。
①validデータの内容をl_stripに格納
②label,text,sizeをそれぞれリストに格納。labelはニュースのカテゴリ、textは本文、sizeはモデルの予測に対する確率です。正規表現を用いて必要な部分を抽出しています。
③ニュースを一つづつ取り出して、カテゴリ予測をしてみます。predictの引数kの数だけ、確率の高い順に予測を表示します。その次のarrayには対応する確率が表示されます。全問正解なので良好です。# ① with open("news.valid") as f: l_strip = [s.strip() for s in f.readlines()] # strip()を利用することにより改行文字除去 # ② labels = [] texts = [] sizes = [] for t in l_strip: labels.append(re.findall('__label__(.*?) ', t)[0]) texts.append(re.findall(' (.*)', t)[0]) sizes.append(model.predict(re.findall(' (.*)', t))[1][0][0])# ③-1 print("<{}>".format(labels[0])) print(texts[0]) print(model.predict(texts[0], k=3))<経済> 電通グループ が 10日 発表 し た 2020年 19 月 期 連結決算 国際会計基準 は 売上高 に 当たる 収益 が 94 減 の 6763 億 円 本業 の もうけ を 示す 営業利益 は 185 億 円 に 半減 し た 新型コロナウイルス感染症 の 影響 を 受け 国内外 で テレビ や インターネット 向け など の 広告 需要 が 落ち込ん だ 営業利益 の 半減 は 年末 から 来年3月 にかけて 実施 する 早期退職 プログラム の ほか 退職者 向け に 業務委託 を 手掛ける 新 会社設立 など の 構造改革 費用 251 億 円 を 計上 し た ため 一方 コロナ禍 で 一連 の MA 合併 買収 費用 が 想定 を 下回る 結果 純利益 は 22倍 の 102 億 円 を 確保 し た 2月 に 子会社化 を 決め た 米メディア ストーム 社 を はじめ 多く の 企業価値 が 下落 し 株式 の 追加 取得 に かかる 見積 費 が 約 300億円 減少 し た (('__label__経済', '__label__国内', '__label__ライフ'), array([9.88678277e-01, 1.48057193e-01, 3.89984576e-04]))# ③-2 print("<{}>".format(labels[1])) print(texts[1]) print(model.predict(texts[1], k=3))<経済> 任天堂 は 5日 家庭 用 ゲーム機 ニンテンドースイッチ の 世界 で の 累計 販売台数 が 9月 末 時点 で 6830 万 台 に なっ た と 発表 し た ファミリーコンピュータ ファミコン の 6191 万 台 を 上回っ た 新型コロナウイルス の 感染拡大 に 伴う 巣ごもり消費 が 追い風 と なり 2017年 3月 の 発売 から 約 3年 半 で 達成 し た スイッチ は 据え置い て も 持ち運ん で も ゲーム が でき 幅広い 世代 から 支持 さ れ た 今年3月 に 発売 し た ソフト あつまれ どうぶつの森 が ヒット し て スイッチ の 販売 を 押し上げ た スイッチ は 20年 49 月 だけ で 1253 万 台 が 売れ た (('__label__経済', '__label__スポーツ', '__label__国内'), array([0.00338661, 0.00206074, 0.00081409]))# ③-3 print("<{}>".format(labels[2])) print(texts[2]) print(model.predict(texts[2], k=3))<スポーツ> JERA セリーグ 巨人 6 ― 2 ヤクルト 7日 東京ドーム 今季限り で 現役 引退 する 巨人 の 岩隈久志 投手 39 の 引退セレモニー が 7日 の ヤクルト 23回 戦 東京ドーム の 試合後 に 行わ れ た 今季 最多 と なる 2 万 6649 人 の ファン の 前 で 岩隈 は 本日 をもちまして 21年間 の プロ野球 生活 に 幕 を 閉じ ます 21年間 すばらしい チームメート に 恵まれ 最高 の 野球 人生 を 送る こと が でき 感謝 の 思い で いっぱい です と 語っ た そして この 2年間 ジャイアンツ で 1軍 復帰 する こと は でき ませ ん でし た が 現役 最後 に ジャイアンツ の ユニホーム を 着 て この 日 を 迎え られ た こと に 幸せ を 感じ て い ます これから も 野球 を通じて 誰か を 幸せ に できる 存在 で い たい と 思い ます 21年間 本当にありがとうございました と スピーチ し た その後 は 現在 ヤクルト で マリナーズ 時代 の チームメート 青木 楽天 で 一緒 に プレー し た 嶋 から 花束 を 受け取っ た さら に 菅野 から も 花束 を 受け取る と 続け て 原監督 が 自ら 岩隈 の 元 へ 駆け寄り ナイン と 一緒に 記念撮影 を 行っ た そして 最後 は 3人 の 子どもたち から も 花束 を 受け取り 再び 記念撮影 を し て ファン に 別れ を 告げ て い た 報知新聞社 (('__label__スポーツ', '__label__エンタメ', '__label__ライフ'), array([8.55861187e-01, 1.00888625e-01, 7.65405654e-04]))ベクトル表現についての分析
ここまでで分析を終わりにしても良いのですが、fastTextの
get_sentence_vectorという機能を使って記事ごとのベクトルを取得して、さらに分析を行ってみましょう。
①記事一つ一つに対してベクトルを取得し、リストに格納していきます。
②ベクトル、ラベル、サイズをnumpy配列に変更します。(ラベル、サイズについては取得済)
③StandardScalerを用いてベクトルを標準化
④主成分分析器PCAを用いて次元削減
⑤上記で定義したcos_sim関数を用いて記事ごとの類似度を算出。同じカテゴリの記事の類似度が最も高くなりました。
⑥ベクトルを2次元プロット。sizesの数値によって点の大きさが変化します。(sizesは予測の可能性が格納されています。)# ① vectors = [] for t in texts: vectors.append(model.get_sentence_vector(t)) # ② vectors = np.array(vectors) labels = np.array(labels) sizes = np.array(sizes) # ③ ss = preprocessing.StandardScaler() vectors_std = ss.fit_transform(vectors) # ④ pca = PCA() pca.fit(vectors_std) feature = pca.transform(vectors_std) feature = feature[:, :2]# ⑤-1 print("<{}><{}>".format(labels[0], labels[1])) cos_sim(vectors[0], vectors[1])<経済><経済> 0.9514279# ⑤-2 print("<{}><{}>".format(labels[1], labels[2])) cos_sim(vectors[1], vectors[2])<経済><スポーツ> 0.9299138# ⑤-3 print("<{}><{}>".format(labels[0], labels[2])) cos_sim(vectors[0], vectors[2])<経済><スポーツ> 0.79527444# ⑥ x0, y0, z0 = feature[labels=='エンタメ', 0], feature[labels=='エンタメ', 1], sizes[labels=='エンタメ']*1000 x1, y1, z1 = feature[labels=='スポーツ', 0], feature[labels=='スポーツ', 1], sizes[labels=='スポーツ']*1000 x2, y2, z2 = feature[labels=='ライフ', 0], feature[labels=='ライフ', 1], sizes[labels=='ライフ']*1000 x3, y3, z3 = feature[labels=='国内', 0], feature[labels=='国内', 1], sizes[labels=='国内']*1000 x4, y4, z4 = feature[labels=='国際', 0], feature[labels=='国際', 1], sizes[labels=='国際']*1000 x5, y5, z5 = feature[labels=='地域', 0], feature[labels=='地域', 1], sizes[labels=='地域']*1000 x6, y6, z6 = feature[labels=='経済', 0], feature[labels=='経済', 1], sizes[labels=='経済']*1000 plt.figure(figsize=(14, 10)) plt.rcParams["font.size"]=20 plt.scatter(x0, y0, label="エンタメ", s=z0) plt.scatter(x1, y1, label="スポーツ", s=z1) plt.scatter(x2, y2, label="ライフ", s=z2) plt.scatter(x3, y3, label="国内", s=z3) plt.scatter(x4, y4, label="国際", s=z4) plt.scatter(x5, y5, label="地域", s=z5) plt.scatter(x6, y6, label="経済", s=z6) plt.title("Yahooニュース") plt.xlabel('1st dimension') plt.ylabel('2nd dimension') plt.legend(title="category") plt.show()
考察
- 「エンタメ」と「スポーツ」がかなり近い位置にいます。1次元目では重なっている部分が多いですが、2次元目でしっかり分かれています。これは納得できます。
- 「国際」と「国内」はしっかり分かれていて、経済はその間くらいにあります。これも納得ができます。
- 「スポーツ」と「国内」が近いですが、Yahooニュースは海外よりも国内のスポーツ記事を取り上げることが多いからでしょうか。
- 「地域」は「国内」の近くにいくつかプロットされていますが小さくプロットされているので確率が低いです。確かに「地域」の記事を読んで「国内」か「地域」か判断するのは難しいかもしれないです。
全体的にはうまくクラスタリングできているのではないでしょうか。
今回はfastTextの教師あり学習を実施しました。ですのでこのように綺麗に分類されたプロットが得られるのも当然かもしれません。
ですので次回はfastTextの教師なし学習を実施してプロットしてみて、教師あり学習の時と比較してみると面白いかもしれません。参考文献
Yahoo!ニュース
青空文庫の書籍をDoc2Vecでクラスタリング
fastText
GitHub (fastText/python)
mecab(NEologd辞書)環境をDocker(ubuntu)で構築
Yahooニュースをスクレイピング
fastText tutorial(Text classification)
【Python NumPy】コサイン類似度の求め方 主成分分析を Python で理解する
matplotlib Scatter plots with a legend
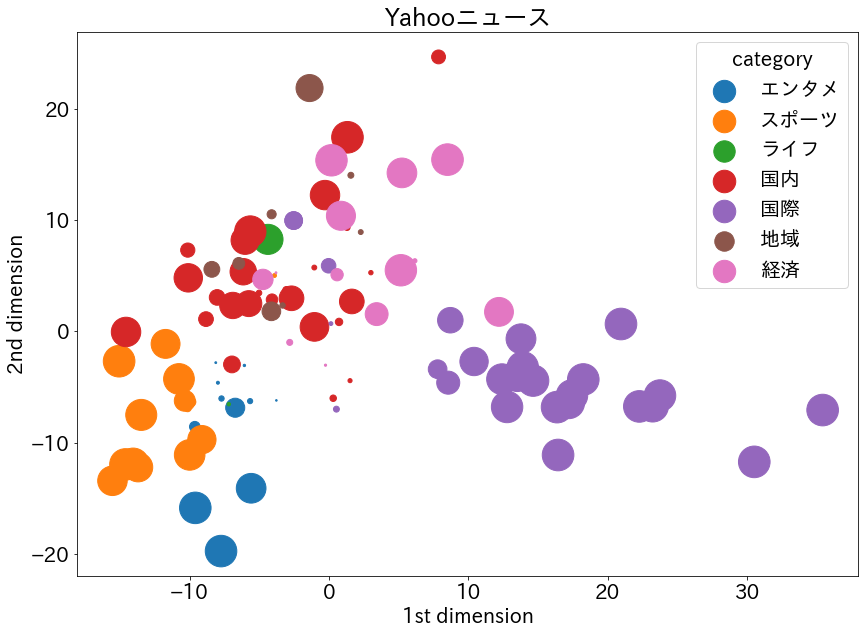
- 投稿日:2020-11-12T10:59:20+09:00
Python (Boto3) @ Lambda で CloudWatch Logs の特定のログストリームにログを出力する
■ はじめに
Python (Boto3) @ Lambda から CloudWatch Logs の特定のログストリームにログを出力したかったので、やってみました。
■ コード
コードは、以下。
def put_logs(client, group_name, stream_name_prefix, message): try: exist_log_stream = True log_event = { 'timestamp': int(time.time()) * 1000, 'message': message } sequence_token = None for i in range(2): try: if exist_log_stream == False: create_log_stream_response = client.create_log_stream( logGroupName = group_name, logStreamName = stream_name_prefix) exist_log_stream = True if sequence_token is None: put_log_events_response = client.put_log_events( logGroupName = group_name, logStreamName = stream_name_prefix, logEvents = [log_event]) else: put_log_events_response = client.put_log_events( logGroupName = group_name, logStreamName = stream_name_prefix, logEvents = [log_event], sequenceToken = sequence_token) except client.exceptions.ResourceNotFoundException as e: exist_log_stream = False except client.exceptions.DataAlreadyAcceptedException as e: sequence_token = e.response.get('expectedSequenceToken') except client.exceptions.InvalidSequenceTokenException as e: sequence_token = e.response.get('expectedSequenceToken') except Exception as e: print(e) break except Exception as e: print(e)■
sequenceTokenの取得の仕方こちらの記事 ( Lambda (Python) から特定のログストリームにログを書こうとして苦戦した2つのポイント - Qiita ) にもありますが、
put_log_eventsでログをPUTする際、例外はありますが、基本的にはsequenceTokenを設定する必要があります。
- put_log_events - CloudWatchLogs — Boto3 Docs 1.16.15 documentation
- 新しく作成されたログストリームでのアップロードには、シーケンストークンは不要。
describe_log_streamsによるsequenceTokenの取得記事の中では
describe_log_streamsによって、ログストリームの存在判定とsequenceTokenの取得を行っており、describe_log_streamsのレスポンスからnextTokenとして取得しています。ですが、実は CloudWatch Logs のクォータ - Amazon CloudWatch Logs にも書かれていますが、
describe_log_streamsにはクォータによる制限があります。
DescribeLogStreams
- 1 リージョン、1 アカウントあたり 5 件のトランザクション/秒 (TPS)。
- クォータの引き上げをリクエスト可。
その為、使い方にもよりますが、出力頻度が高い場合は、クォータの制限に引っ掛かり遅延が発生することがあり、実際、Lambda から結構な頻度でログを出力したところ、
describe_log_streamsでの遅延が発生してしまいました。
put_log_eventsによるsequenceTokenの取得そこで、AWS サポート に相談したところ、
put_log_eventsによるsequenceTokenの取得を提案されました。put_log_events - CloudWatchLogs — Boto3 Docs 1.16.15 documentation にも記載されていますが、
InvalidSequenceTokenExceptionからexpectedSequenceTokenとして取得出来るみたいです。もちろん
put_log_eventsにもクォータの制限はありますが、describe_log_streamsより緩めです。
PutLogEvents
- 1 秒、1 ログストリームあたり 5 リクエスト。
- 追加のリクエストは調整され、クォータは変更不可。
- 1 リージョン、1 アカウントあたり 800 件のトランザクション/秒 (TPS)。
- クォータの引き上げをリクエスト可。
今回のやり方にしたところ遅延が解消されましたので、使い方にもよりますが、出力する頻度が多い場合は
put_log_eventsを使ったほうが良い様に思います。逆に、今回のやり方でも遅延が発生が解消されない場合は、別のやり方を検討する必要があるかもしれません。
■ 出力先のログストリームの存在確認
上述した記事 ( Lambda (Python) から特定のログストリームにログを書こうとして苦戦した2つのポイント - Qiita ) では、
describe_log_streamsで、sequenceTokenの取得だけではなく、ログストリームの存在確認も行っていましたが、クォータの制限によりdescribe_log_streamsは使えませんので、別のやり方で確認する必要があります。ただ、これも
put_log_eventsのExceptionsで確認出来るみたいです。ResourceNotFoundExceptionに入ってきたらログストリームが存在しないということで、create_log_streamを実行します。■ ハマりポイント
上述しましたが…、最初は問題無かったのにリクエスト頻度が増えるに連れて Lambda の実行時間が伸びて非常に困りました。当然、コストにも跳ね返ってきますしね…。
とりあえず、AWS サポート さんに相談して良かったです。Boto3 documentation — Boto3 Docs 1.16.16 documentation に記載されているものの、相談しなかったら、見つけられなかった気がします…。どうもありがとうございました。?♂️?♂️?♂️
■ まとめ
参考になれば♪
???
- 投稿日:2020-11-12T10:25:36+09:00
初心者でも無料でSplatoon2の戦績をstat.inkに定期投稿できるdisocrd bot
はじめに
PC初心者でも、スマホしかない人でも、stat.inkにSplatoonの戦績を自動アップロードするdiscord botを作れるようにしたいなというのが、基本的な考えです。
とりあえず無料でstat.inkに戦績を投稿するDiscord Botを作りたい・使いたいという人は、準備方法や使い方についてはGitHub RepositoryのREADMEに詳しく書いたので、そちらをご確認ください。
この記事ではHerokuで稼働するDiscord Botについて工夫した点をお話します。
作成するdiscord botの機能
splatnet2stat.pyを利用してstat.inkに複数アカウントの戦績を自動アップロードする。- discord botを起動後にbotの機能だけでiksm_sessionの取得(自動アップロードの準備)ができる
- bot起動準備を含めてスマホだけですべての作業が完結できる (PCを使える方が便利とはいえ)
問題点と解決策
Herokuではファイル作成・書き込みに制限があります。
- 一時ファイル作成用の
/tmpにしかファイルを作成できない。(※もともとのファイルは/app以下に入っている。)
- さらに
/tmpの中も一定時間(最大24時間)ごとにリセットされる。- つまりBot起動後に生成されるファイルを継続的に保存できる場所はない。
これに付随する問題は2点あります。
iksm_sessionの保存場所
discord botを起動後にbotの機能だけでiksm_sessionの取得(自動アップロードの準備)ができる
上の機能の仕様上、iksm_session(厳密にはconfig.txtの中身)はbotをherokuで実行した後に取得されます。
それらのデータを永遠に保存しておくために、今回はHerokuの環境変数を利用しました。Herokuの環境変数はHeroku管理画面から設定できますが、HerokuのREST APIからも更新できます。つまりHerokuで実行されているBot内から環境変数に出力し、データを継続的に保存することが可能です。
-> 詳しくはPlatform API Reference #config-vars-updateapp_name=os.getenv("HEROKU_APP_NAME", "app-splat") #HEROKU_APP_NAME if app_name=="": print("環境変数のHEROKU_APP_NAMEが定義されていません。") return patch_url = f"https://api.heroku.com/apps/{app_name}/config-vars" headers= {"Authorization": f"Bearer {os.getenv('HEROKU_APIKEY')}", "Content-Type":"application/json", "Accept":"application/vnd.heroku+json; version=3"} res=requests.patch(patch_url, headers=headers, json=new_envs)環境変数更新後にdynoは一度再起動されます。
また、注意点としてHerokuの環境変数は合計で32KBまでしか利用できません。戦績アップロード実行時のconfig.txtの位置
splatnet2statink.pyはiksm_sessionなどが記されたconfig.txtが同じディレクトリに置かれていることを想定されています。
そのままですが、config_pathを書き換えます。なお、localでの実験も想定して、環境変数はHerokuでデフォルトで設定される
os.getenv("DYNO")の有無で使い分けます。splatnet2statink## splatnet2statink/iksm.py config_path="/tmp/config.txt" if os.getenv("DYNO", False) else f"{os.path.dirname(__file__)}/../tmp/config.txt" ## splatnet2statink/splatnet2statink.py config_path=iksm.config_path他の問題点として以下があります。
なぜかjson.loads()がstringになる
これは別記事に書きました。-> HerokuでPythonのjson.loads()がstrを返す問題
stringにならない場合もあるので、今はtypeの判別を挟んでいます。Herokuloaded_tmp=json.loads(dumped_string) loaded_dict=eval(loaded_tmp) if (loaded_tmp)==str else loaded_tmpGitHub Repository
- GitHub Repository: DiscordBot_Heroku_Stat.ink
- 投稿日:2020-11-12T10:25:34+09:00
Flaskのログ処理でルートロガー以外のロガーを出力する
はじめに
pythonでロギングを実装しようとするときは基本的に公式のチュートリアルを参考に構築すると思います。
https://docs.python.org/ja/3/howto/logging.html
logging_test.pyimport logging def main(): logging.info("it is logging.")しかし、この記事でも指摘されているように上段部分に書かれている方法はあまり適切な方法ではなく、以下の記法が推奨されています。
logger_test.pyfrom logging import getLogger logger = getLogger(__name__) def main(): logger.info("it is logger.")そのため、基本的にはこの方法でロギングの実装をおこなうべきで、実際に配布されているパッケージのログ出力はロガー名が定義されているものが主流です。
Flaskでのロギング
一方、Flaskでロギングを実施する際は以下のサイトを参考に実装される方が多いのではないかと思います。
https://msiz07-flask-docs-ja.readthedocs.io/ja/latest/logging.html
その際、dictConfigを参考に実装すると、
app.pyfrom flask import Flask from logging.config import dictConfig from src.logging import logging_test, logger_test dictConfig({ 'version': 1, 'formatters': {'default': { 'format': '[%(asctime)s] %(levelname)s in %(module)s: %(message)s', }}, 'handlers': {'wsgi': { 'class': 'logging.StreamHandler', 'stream': 'ext://flask.logging.wsgi_errors_stream', 'formatter': 'default' }}, 'root': { 'level': 'INFO', 'handlers': ['wsgi'] } }) app = Flask(__name__) @app.route('/') def hello_world(): logging_test.main() logger_test.main() return 'Hello, World!' if __name__ == "__main__": app.run(debug=True)loggerのログが出力されなくなります。
[2020-11-12 09:47:05,506] INFO in logging_test: it is logging. [2020-11-12 09:47:05,506] INFO in _internal: 127.0.0.1 - - [12/Nov/2020 09:47:05] "GET / HTTP/1.1" 200 -これはgetLoggerによってロガー名を定義したことでルートロガーでなくなるためです。
そのため、Flaskのログとして出力するためには出力したいロガーをdictConfigにloggersを追加する必要があります。'loggers': {'src': { 'level': 'INFO' }},こうすることでsrc配下のロガーを出力できるようになります。
[2020-11-12 10:02:17,987] INFO in logging_test: it is logging. [2020-11-12 10:02:17,987] INFO in logger_test: it is logger. [2020-11-12 10:02:17,988] INFO in _internal: 127.0.0.1 - - [12/Nov/2020 10:02:17] "GET / HTTP/1.1" 200 -ログを出力するハンドラを個別に指定することもできます。
その場合、ログが二重に出力されるので、propagateをFalseに設定しておくとそれを防止することができます。'loggers': {'src': { 'level': 'INFO', 'handlers': ['wsgi'], 'propagate': False }},importしたパッケージのロガーを出力
またこれを応用することで、importしたパッケージのロガーを出力することもできます。
例えば、Flask-OAuthlibのロガーを出力したい場合は、以下の設定をloggersに追加します。'flask_oauthlib': { 'level': 'DEBUG' }こうすることで、先ほどと同様にパッケージのログ出力を確認することができるようになります。
最後に
と言うことを調べるのに微妙に時間を使ってしまいましたので備忘録として残しておきます。