- 投稿日:2020-11-12T23:48:21+09:00
AWS SDK for RubyでS3オブジェクトサイズの取得
HLS形式の動画サイズ取得の為に使いました!
※オブジェクトデータ1000件以上を想定しています。
client = AWS::S3::new size = 0 options = { bucket: [バケット名], prefix: [プレフィックス] } loop do object_list = client.list_objects_v2(options) object_list.contents.each do |object| size += object.size end options[:continuation_token] = object_list.next_continuation_token break unless object_list.next_continuation_token end gigabyte = (size / (2 ** 30).to_f).round(2)CLIだとさらに簡単
AWS CLIを使ってS3上にあるファイル数とファイルサイズの合計を取得する$ aws s3 ls s3://[バケット名]/[フォルダ名]/ --recursive --human --sum実装後にLambdaに書けばよかったなーーと反省。
- 投稿日:2020-11-12T23:44:21+09:00
Quarkusを動かしてdocker imageをAmazonECSで動かすまで
別サイト
に書いていたのだけどサ終してしまったので移行した記事その5
2019/03/16のものQuarkus
Javaのフレームワーク。
特徴としてはネイティブ用のバイナリを生成して起動がめっちゃ早いとかそんな前提条件
- Java 8以上
- Maven 3.5.3以上
らしい
GraalVM
GraalVMをインストール
.bash_profile等に設定export GRAALVM_HOME=[インストールフォルダ]/Contents/Home新規プロジェクト
Quarkusの公式に従いプロジェクト作成コマンド実行
mvn io.quarkus:quarkus-maven-plugin:0.11.0:create \ -DprojectGroupId=org.acme \ -DprojectArtifactId=getting-started \ -DclassName="org.acme.quickstart.GreetingResource" \ -Dpath="/hello"実装
公式スタートガイドに従って作成
ソースはデフォルトでも入っているのでそのままでも動きます
公式ではAPIの追加とかこうやるんだぞみたいなのが書いてあるのでそのままやる
動かすときのコマンドを理解するのが大事ぽさローカル起動
mvn compile quarkus:devjar作成
mvn packagejar起動
java -jar target/getting-started-1.0-SNAPSHOT-runner.jarネイティブバイナリ作成
mvn package -Pnativeネイティブバイナリ起動
./target/quarkus-quickstart-runnerコンテナ作成
mvn package -Pnative -Dnative-image.docker-build=truedockerビルド
docker build -f src/main/docker/Dockerfile -t quarkus .run
docker run -i --rm -p 8080:8080 quarkusローカルでもjarでもバイナリでもdockerでも同じように動きました
$ curl http://localhost:8080/hello/greeting/quarkus hello quarkusAWS側へのデプロイ
dockerイメージを作成できたのでAWS ECSへのデプロイまでをやる
ECR作成
新規リポジトリの作成で「quarkus」という名前で作ってみる
イメージのpush
作成したリポジトリの「プッシュコマンドの表示」に従ってコマンド実行
aws ecr get-login --no-include-email --region ap-northeast-1 ## ログインコマンドが出るのでそのまま実行 ## 作成したイメージをタグ付け docker tag quarkus:latest xxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/quarkus:latest ## push docker push xxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/quarkus:latestECR上でpushされていれば成功
タスク作成
ECSからタスク定義作成
イメージのところにECRで定義されているものを入力して作成
DockerfileのEXPOSEをいじればいいのかもしれないがデフォルトが8080で受けるようなので
ポートマッピングは80 8080で設定する
クラスター作成
クラスターの作成を選択
EC2付きにしてインスタンスタイプやインスタンス数等を自由に選んで作成
EC2がアクティブになるまでまつ
タスク実行
タスクのタブからタスクの実行を選択して実行
少し待つとRUNNINGになる
sshでインスタンスに入って確認
80で受けて8080にマッピングされるようになってる$ docker container ls CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 29c1fb97dc07 xxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/quarkus "./application -Dqua…" 9 seconds ago Up 8 seconds 0.0.0.0:80->8080/tcp ecs-quarkus-5-quarkus-e491bef2eefec1fcfc01 0187c98c619b amazon/amazon-ecs-agent:latest "/agent" About an hour ago Up About an hour ecs-agent接続確認
ブラウザから見ると
http://[EC2のパブリックDNS]/hello/greeting/quarkus
表示された!
感想
Quarkusの起動は、あれ、もう起動してるのかという感覚になるぐらい早かった
普段Javaを使うことが多いのだけど起動が長いのはお約束だったのでかなり新鮮
ECSは作成に最初何度か手間取ったけどなんとかできてよかった
クラスターとかタスクというのがなんなのかいまいちとっつきづらかった。。。
あとはポートマッピングのところで最初は動的マッピングとかにしてたらポートがずれてて動かないってのではまったり。。。
更新するときは
- Javaを書く
- dockerイメージ作成
- ECRにpush
- ECSにタスク定義(リビジョン作成)
- サービス更新でリビジョンを更新
という感じなのかな






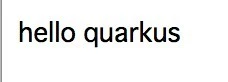
- 投稿日:2020-11-12T23:25:53+09:00
[AWS][docker] docker build 時にインターネット接続に失敗
AWS EC2 上で docker イメージをビルドしようとして、ハマったので覚え書き。
現象
docker イメージのビルドで以下のエラーになった。
内容は fluentd のイメージにプラグインの gem を追加するというもの。$ docker build . --no-cache Sending build context to Docker daemon 2.048kB Step 1/4 : FROM fluent/fluentd:v1.11.4-2.0 v1.11.4-2.0: Pulling from fluent/fluentd df20fa9351a1: Pull complete 5bbb4150a5a0: Pull complete 0a2f393cb307: Pull complete b1dea35b5d99: Pull complete 65de893ed157: Pull complete Digest: sha256:0c6ae6c72902cbc3a4f60bc15069cb89fd72b57391bff150960a6f911361d6c9 Status: Downloaded newer image for fluent/fluentd:v1.11.4-2.0 ---> 7bcbcb847e0d Step 2/4 : USER root ---> Running in 79fb5c74b17f Removing intermediate container 79fb5c74b17f ---> 03af9cdb324e Step 3/4 : RUN gem install fluent-plugin-cloudwatch-logs ---> Running in 1bcf43a8efb2 ERROR: Could not find a valid gem 'fluent-plugin-cloudwatch-logs' (>= 0), here is why: Unable to download data from https://rubygems.org/ - no such name (https://rubygems.org/specs.4.8.gz) ERROR: Service 'fluentd' failed to build : The command '/bin/sh -c gem install fluent-plugin-cloudwatch-logs' returned a non-zero code: 2rubygems.org に接続できないというもので、調べてみるとプロキシの設定が必要などの情報が出てくる。
が、ホスト上では接続できているので関係はなさそう。サイトへの直接アクセスもできず、名前解決もできていない。
で、分かったのはネットワークインターフェースの eth0 がないこと。$ docker build . --no-cache Sending build context to Docker daemon 2.048kB Step 1/3 : FROM fluent/fluentd:v1.11.4-2.0 ---> 7bcbcb847e0d Step 2/3 : USER root ---> Running in c80c0a20cd21 Removing intermediate container c80c0a20cd21 ---> 16f2ba30695a Step 3/3 : RUN ifconfig ---> Running in 1d9cb7d5e2ec lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ::1/128 Scope:Host UP LOOPBACK RUNNING MTU:65536 Metric:1 RX packets:0 errors:0 dropped:0 overruns:0 frame:0 TX packets:0 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:0 (0.0 B) TX bytes:0 (0.0 B) Removing intermediate container 1d9cb7d5e2ec ---> de98e34f64e7 Successfully built de98e34f64e7ホスト側で見てみると docker0 がなく、docker network でデフォルトの bridge がいないことが分かった。
$ docker network ls NETWORK ID NAME DRIVER SCOPE 2d9ce67d06f5 host host local 9a455bcae53c none null local確認
ホストの OS は Amazon Linux 2 (EKS-Optimized) ですが、別のサーバでは問題なくビルドできていたので、比べてみるとバージョンが違っている。
- amazon-eks-node-1.11-v20190220 → ビルドできている環境
- amazon-eks-node-1.17-v20201002 → ビルド失敗する環境
それぞれの docker のバージョンを見てみると、以下の違いがあった。
# ビルドできている環境 $ docker version Client: Version: 18.06.1-ce API version: 1.38 Go version: go1.10.3 Git commit: e68fc7a215d7133c34aa18e3b72b4a21fd0c6136 Built: Mon Jan 28 21:03:38 2019 OS/Arch: linux/amd64 Experimental: false : # ビルド失敗する環境 $ docker version Client: Version: 19.03.6-ce API version: 1.40 Go version: go1.13.4 Git commit: 369ce74 Built: Fri May 29 04:01:26 2020 OS/Arch: linux/amd64 Experimental: false :なお、ビルドできている方ではデフォルトの bridge ネットワークが存在している。
$ docker network ls NETWORK ID NAME DRIVER SCOPE 2f3fd9d451c6 bridge bridge local cd2fe4f72dff host host local f56d76b46acb none null localこの bridge の有無が docker build のエラー原因かは情報を見つけられなかったのですが、デフォルト bridge の有無の方向で調べてみると /etc/docker/daemon.json という設定ファイルが出てきたので上記のサーバで比較してみた。
ビルドできている環境
/etc/docker/daemon.json{ "log-driver": "json-file", "log-opts": { "max-size": "10m", "max-file": "10" }, "live-restore": true, "max-concurrent-downloads": 10, "default-ulimits": { "nofile": { "Name": "nofile", "Soft": 2048, "Hard": 8192 } } }ビルド失敗する環境
/etc/docker/daemon.json{ "bridge": "none", "log-driver": "json-file", "log-opts": { "max-size": "10m", "max-file": "10" }, "live-restore": true, "max-concurrent-downloads": 10 }bridge: none という設定が関係しそう。
対処
/etc/docker/daemon.json ファイルの bridge: none の設定を削除して docker サービスを再起動してみる。
$ sudo service docker restart上記のコマンドでサービス再起動をしてもすぐ解決しなかった。
その後、stop、start と別にしたり、systemctl コマンドで操作したりしてるうちにデフォルト bridge ができた。どうも、稼働中のコンテナがいたり、docker-compose で作られるネットワークがいるとダメなようで、すべてのコンテナを停止して、後から作られたネットワークも削除してから docker サービスを再起動したら設定が反映された。
$ docker network ls NETWORK ID NAME DRIVER SCOPE c4433dcfbe9b bridge bridge local 2d9ce67d06f5 host host local 9a455bcae53c none null local先ほどの docker build を試してみると、eth0 もできてる。
$ docker build . --no-cached Sending build context to Docker daemon 2.048kB Step 1/3 : FROM fluent/fluentd:v1.11.4-2.0 ---> 7bcbcb847e0d Step 2/3 : USER root ---> Using cache ---> 15b06f798b72 Step 3/3 : RUN ifconfig ---> Running in 713f15663040 eth0 Link encap:Ethernet HWaddr 02:42:AC:12:00:02 inet addr:172.18.0.2 Bcast:172.18.255.255 Mask:255.255.0.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:2 errors:0 dropped:0 overruns:0 frame:0 TX packets:0 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:180 (180.0 B) TX bytes:0 (0.0 B) lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 UP LOOPBACK RUNNING MTU:65536 Metric:1 RX packets:0 errors:0 dropped:0 overruns:0 frame:0 TX packets:0 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:0 (0.0 B) TX bytes:0 (0.0 B) Removing intermediate container 713f15663040 ---> 6d99f256433b Successfully built 6d99f256433b元の fluentd のビルドを試してみると、gem のダウンロードもできて、問題なくビルドができるようになった。
$ docker build . --no-cached Sending build context to Docker daemon 2.048kB Step 1/4 : FROM fluent/fluentd:v1.11.4-2.0 ---> 7bcbcb847e0d Step 2/4 : USER root ---> Using cache ---> a733f7c02648 Step 3/4 : RUN gem install fluent-plugin-cloudwatch-logs ---> Running in 1d43a2226fb4 Successfully installed jmespath-1.4.0 Successfully installed aws-partitions-1.391.0 Successfully installed aws-eventstream-1.1.0 Successfully installed aws-sigv4-1.2.2 Successfully installed aws-sdk-core-3.109.2 Successfully installed aws-sdk-cloudwatchlogs-1.38.0 Successfully installed fluent-plugin-cloudwatch-logs-0.11.1 7 gems installed Removing intermediate container 1d43a2226fb4 ---> f7242c21bd02 Step 4/4 : USER fluent ---> Running in 7baaad7e3b2d Removing intermediate container 7baaad7e3b2d ---> c39b2ddf48d9 Successfully built c39b2ddf48d9ビルドエラーは解消できたのでひとまずは完了ですが、なぜ新しいバージョンの docker、OS 環境で bridge が無効化されているのかが分からない。
デフォルトの bridge は作るべきではないという情報も見かけたのだけど、なぜダメで、bridge を作らないのであればどうすべきかというはっきりとした情報が見つけられなかった。
あるいは EKS-Optimized なイメージなので、通常はランタイムのみの利用で docker build の実行を想定していないのかもしれない。
- 投稿日:2020-11-12T23:18:05+09:00
SAM が自動生成するリソースの調べ方
tl;dr
AWS でサーバレス開発するときによく使う SAM (Serverless Application Model)、いろいろリソースを自動的に作ってくれて便利なんですが、ときどき自動で作成されるリソースの論理 ID がドキュメントされてなくて、自動作成されたリソースが参照できなくて困るときがあります。
そんなときは、
sam deployの出力にある LogicalResourceId を見れば論理 ID がわかります。ここに出てるの LogicalResourceId を指定することで、template.yamlからそのリソースを参照することができます。
この例の場合
AWS::ApiGateway::RestApiが自動で作られたリソースなんですが、その ID が "ServerlessRestApi" というのがわかる、という寸法です。LogicalResourceId は、
sam deployの出力に加えて、 AWS マネジメントコンソールからも見ることができます。細かい説明
AWS SAM?
AWS が提供している Serverless Application Model (SAM) は、サーバレス開発で使うリソースのデプロイを宣言的に書くための仕組みです。 AWS で Infrastruture as Code を実現する仕組みである CloudFormation の拡張として実装されています。SAM を使うと、簡単な定義で Lambda や APIGateway など、必要なリソースをいろいろと立ち上げてくれて、けっこう便利です。
自動生成リソースと、まれにある困ったこと
この自動で作られるリソースをテンプレート内で参照したい場合、基本的にはドキュメントにかかれているので、その値を使えばよいのですが、たまーにリソース名がドキュメントに書かれていないものがあります。
たとえば下記のような
template.yamlを用意して、sam-cliを実行することで、Lambda 関数に加えて、API Gateway の RestApi や、実行に必要なロールなど諸々のリソースが一発で作ってくれ、https://......./api_endpointという Web API が立ち上がります。template.yamlAWSTemplateFormatVersion: "2010-09-09" Transform: AWS::Serverless-2016-10-31 Description: CloufFormation Template for project_name Resources: EndPointFunction: Type: AWS::Serverless::Function Properties: Runtime: python3.8 CodeUri: src Handler: lambda_handler.lambda_handler Events: API: Type: Api Properties: Path: /api_endpoint Method: postこのとき、実際に生成された API のフルパスを出力しようとすると、API Gateway の RestApi リソースを参照する必要があるのですが、SAM のドキュメント には
a default AWS::Serverless::Api resource is createdとあるのみで、テンプレート内から参照するための論理 ID は書かれていません(2020/11 現在)これまで、どうやって自動で作られるリソースを参照したいときにどうすればいいのか途方に暮れてしまい、手動でリソースを作るようにしていたのですが、、、
解決策
ある日、LogicalResourceId をみればよいことに気づきました。
ここの値を使うことで、例えば
template.yamlOutputs: ApiEndpointURL: Description: API Endpoint URL Value: !Sub "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/${ServerlessRestApi.Stage}/api_endpoint"といったように、
ServerlessRestApiを参照して、必要な情報を出すことができます!余録
まあ、こういうドキュメントをみても論理 ID がわからないものがあれば、ドキュメントに PR を投げる、というのが本筋ではありますが、どう直せばよいかを知るのと、当座の作業を進めるための方法として、残しておきます。
StackOverflow でも困ってる人がいたので、回答しておきました。

- 投稿日:2020-11-12T21:21:08+09:00
Amazon Redshift でcliから複数のクエリを投げてみた
Amazon Redshiftで複数クエリを投げる時にめちゃくちゃ苦労したので、まとめてみる。
利用環境はMacです。
前回の記事に引き続いて検証しました〜!【背景】
- Athenaで複数のクエリを投げてみました(こちらご参照ください)が、Redshiftも同じ感じで出来そう?
- 出来るなら検証しちゃった方がいいしやってみよう!!
こんな課題感で手を動かし始めました。
【実際にやったこと/考えていたこと】
- cliからクエリ投げられる方法を探す
- 全然見つからない?
- rubyのgemを使ってみる
- 何使ったらいけるのかわかりにくい!!
- 英語のドキュメントでわかりにくい!!
結局二つ目のgemで複数クエリ投げることができましたので、詰まった一つ目と一緒にまとめていきたいと思います〜!
(会社の先輩にとても助けていただきました?♂️)cliからクエリを投げられる方法を探す
公式ドキュメントを参考にcliからawsに接続する方法を色々と探していました。
クラスターの削除や、追加については書いてあるものの、DBを立てて、クエリを投げるとこまで書いてありませんでした。JSONでスクリプト書いてcurlで送れるだろ〜。どっかにサンプルコード書いてるだろ〜と思っていたので、なかなか調べても出てこなく、どんどん沼にはまっていった気がします。。。
ここで、先輩に一度相談して、"Gemでいいのあると思うから調べてみて〜"とのこと。
全く、考えになかったですが、"Gem redshift"と検索すると何件がヒットしました。そこで"aws-sdk-redshift"というのを見つけました。rubyのgemを使ってみる
こちらの記事を参考にやってみてました〜!
まずaws-sdkをインストールする
日本語の参考ドキュメントの通り進めていくと(少し違いますが)、まず以下のスクリプトでレスポンスが返ってきました。
ここまででエラーが出たら、クラスターが作成できているか、必要なIAMがアタッチされているかどうかなどこちらの記事を参考にデバックしてみてください。Redshiftとの接続require 'aws-sdk' cluster_identifier = "クラスター識別子" aws_client = AWS::Redshift.client.new( :redshift_endpoint => "エンドポイント", :access_key_id => 'xxxxxxxxxxxx', :secret_access_key => 'xxxxxxxxxxxxxxx' ) cluster = aws_client.describe_clusters( :cluster_identifier => cluster_identifier ).clusters[0] dbuser=cluster.master_username dburl="DBI:Pg:dbname=#{cluster.db_name};host=#{cluster.endpoint.address};port=#{cluster.endpoint.port}" puts dbuser puts dburlよし!じゃあこのまま、クエリを投げよう!!!!(......どうやって???)
となりました。あまり意味もわからないまま、認証はできた。
あまり意味もわからないが、DBも接続できた??
あまり意味もわからないから、クエリを投げるメソッドがあるのかわからない。。。となっていました。
aws_client.methodsで、しらみつぶしにメソッド名を見て行ってもそれらしきメソッドもなく、(api_requestsがそれか!!と思いましたが、うまくできませんでした。)
ここでもう一度先輩に聞きに行くことに、、、、
すると"RedshiftDataAPIServiceってのあるけどこれは??"とのこと、、、
なんで気がつかなかったんだ!!RedshiftDataAPIService見たら、execute_statementとかget_statement_resultある
そこからは早かったです。
先ほどのスクリプトを以下のように書き換えました。クラスターのdbに対してクエリを投げるrequire 'aws-sdk' aws_client = Aws::RedshiftDataAPIService::Client.new( access_key_id: '********************', secret_access_key: '************************', ) 10.times do |i| aws_client.execute_statement({ cluster_identifier: 'クラスター識別子', database: 'DB名', db_user: 'マスターユーザー名', sql: 'select * from db.table名' }) endすると、、、何の音沙汰もない、、、、
そりゃそうです。これはクエリを投げるためのメソッド。
management consoleに見に行ったら、クエリが実行されてました。ちなみに、レスポンスも返ってきてます。↓公式ドキュメント参照
ここで返ってきてるidを取得して、get_statement_resultでクエリの結果も確認することができます〜!!
※レスポンスをparseして、表示するところまで一つのスクリプトで書きたかったのですが、ここはまだ出来ていません。。。
今後やっていきたいと思います!!まとめ
- athenaでやった通り進めたらいけると思っていたら、全然方向性が違ったので、大変だった
- 詰まったときに何で詰まっているのか、何のためにしているのかを明確にすると、方向転換ができる
英語のドキュメントが多く、日本語が少なくて大変だったので、まとめます
引き続き学びがあれば更新していきたいと思います〜:)

- 投稿日:2020-11-12T19:16:09+09:00
[AWS SAM] テンプレートの階層化(スタックのネスト)
AWS::Serverless::Applicationを使用したテンプレートの階層化サービスごとにテンプレートファイルを分けて以下のような構成を作る
src/ ├─ api-gateway/ │ ├─ template.yaml # API Gateway定義、API GatewayからコールされるLambda等の定義 │ ├─ swagger.yaml │ ├─ aaa/function.py # Lambda関数 │ └─ bbb/function.py # Lambda関数 │ ├─ iot-core/ │ ├─ template.yaml # IoT Coreの定義、デバイス間通信時にコールされるLambda定義等 │ └─ ccc/function.py # Lambda関数 │ ├─ cognito/ │ ├─ template.yaml # Cognitoのユーザプール定義、認証時にコールされるLambda等の定義 │ └─ ddd/function.py # Lambda関数 │ │ ├─ s3/ │ ├─ template.yaml # S3のバケット定義、バケット操作時にコールされるLambda等の定義 │ └─ eee/function.py # Lambda関数 │ └─ template.yaml # 各サービスのtemplate.yamlをまとめるためのtemplate.yaml各サービスフォルダ以下の
template.yaml(api-gateway/template.yaml等)は、通常通りCloudFormationまたはSAMの書式に従って記述する
src/template.yamlで、各サービスフォルダ以下のtemplate.yamlで定義されたリソースをアプリケーション(AWS::Serverless::Application)として定義する
AWS::Serverless::Applicationの構文については公式ドキュメント参照
src/template.yamlは以下のようになるsrc/template.yamlAWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Resources: CognitoStack: Type: AWS::Serverless::Application Properties: Location: cognito/template.yaml # template.yamlのパス Parameters: StackName: !Ref AWS::StackName ApiGatewayStack: Type: AWS::Serverless::Application Properties: Location: api-gateway/template.yaml Parameters: StackName: !Ref AWS::StackName S3BucketName: !GetAtt S3Stack.Outputs.S3BucketName IoTCoreStack: Type: AWS::Serverless::Application Properties: Location: iot-core/template.yaml Parameters: StackName: !Ref AWS::StackName S3Stack: Type: AWS::Serverless::Application Properties: Location: s3/template.yaml Parameters: StackName: !Ref AWS::StackName
Locationに各template.yamlのパスを指定、
Parametersに各template.yamlに渡すパラメータを指定している
Parametersで渡された値は以下のように参照するParameters: StackName: Type: String Resources: testFunction: Type: AWS::Serverless::Function Properties: FunctionName: !Sub '${StackName}_testFunction' ...テンプレート間のパラメータ受け渡し
例えば
s3/template.yamlで生成したバケット名をapi-gateway/template.yamlで参照したい場合、
s3/template.yamlは以下のようにOutputsを使用してバケット名を出力するs3/template.yamlAWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Parameters: StackName: Type: String Resources: InfoS3Bucket: Type: AWS::S3::Bucket Properties: BucketName: !Sub '${StackName}-test-bucket' AccessControl: Private PublicAccessBlockConfiguration: BlockPublicAcls: True BlockPublicPolicy: True IgnorePublicAcls: True RestrictPublicBuckets: True Outputs: S3BucketName: # バケット名を出力 Value: !Ref InfoS3Bucket # 上記InfoS3Bucketで定義したバケットの名前を出力する出力された値は、
src/template.yamlで他のtemplate.yamlにParametersで渡すsrc/template.yamlAWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Resources: ... ApiGatewayStack: Type: AWS::Serverless::Application Properties: Location: api-gateway/template.yaml Parameters: StackName: !Ref AWS::StackName S3BucketName: !GetAtt S3Stack.Outputs.S3BucketName # s3/template.yamlで出力した値を渡す ... S3Stack: Type: AWS::Serverless::Application Properties: Location: s3/template.yaml Parameters: StackName: !Ref AWS::StackName生成されるスタック
スタックをネストして定義すると、出力結果は以下のように、
各template.yamlごとに「ネストされた」とついたスタックが生成される
親になっているスタックを削除すると、ネストされている全スタックの全リソースが削除される

- 投稿日:2020-11-12T19:07:59+09:00
コンテンツ配信を日本国内に限定する方法
こんにちは!
暦の上ではもう冬になってしまいましたが、みなさんはいかがお過ごしでしょうか?
私はまだまだ秋を楽しみたいので、埼玉県にあるムーミンバレーパークで秋をたくさん感じてきました!
やっぱり、自然の中を歩くのは気持ちがいいですね。大自然とムーミンに癒されたstreampackのrisakoです今回は、
Amazon CloudFront(以下、CloudFront)を使用したコンテンツの配信制限についてです。
「CloudFrontで制限がかけられるとは!」と感動した機能でしたのでご紹介します!構成
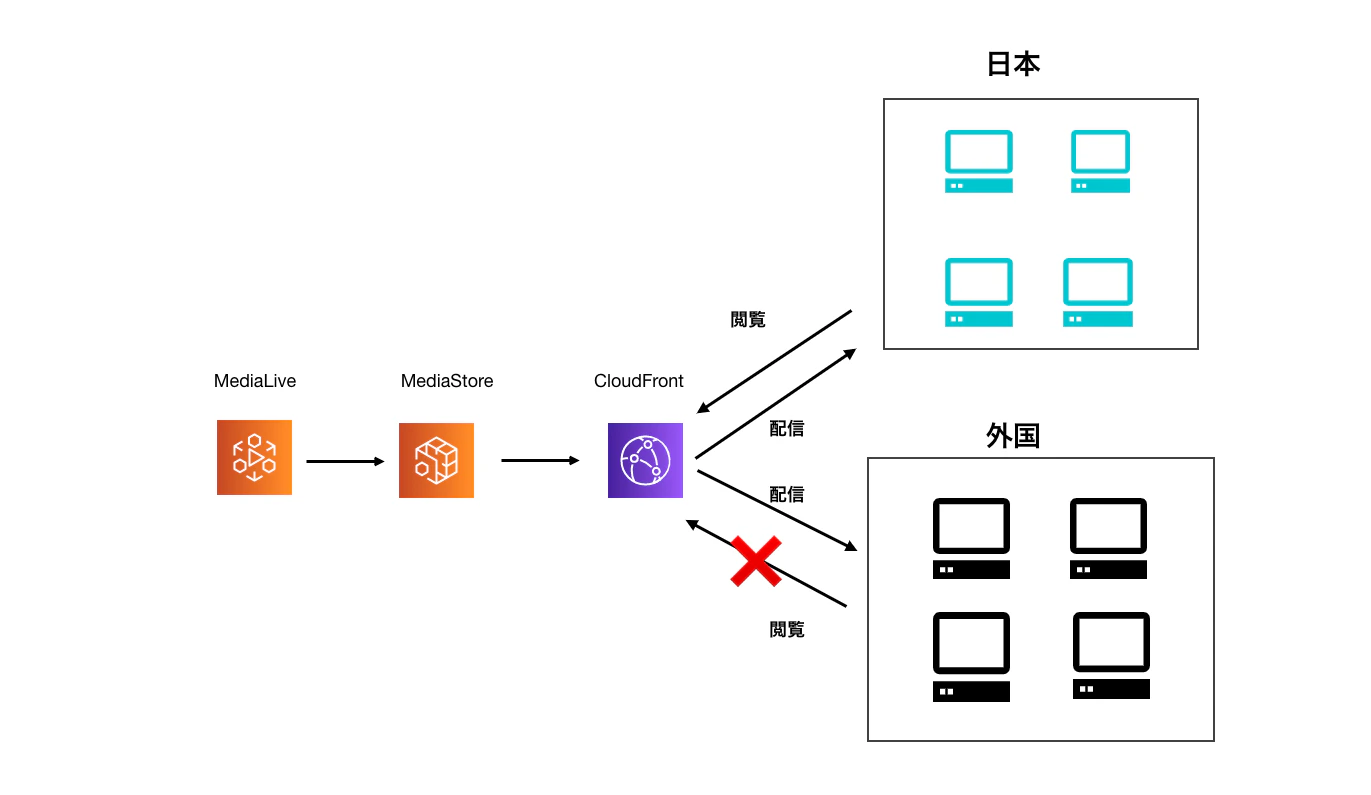
今回は、
AWS MediaLive(以下、MediaLive)とAWS MediaStore(以下、MediaStore)を使った動画配信の構成です。もちろん、動画配信ではなくWebサイトでもCloudFrontで同様に制限をかけることができます!
今回の構成と実現したいことを図で表すとこのようになります。
- CloudFront Distributionはすでに作成されていることを想定していますので、作成方法は省略します。
- 動画配信構成の作成・設定方法は省略します。
CloudFront設定方法
- 使用するCloudFront Distributionを選択
- 上部に表示されている項目から、
Restrictionsを選択- 配信制限をかける前は以下のような画面になっています。今回のメインはGeo Restrictionの設定変更です!左上の
Editから設定します。
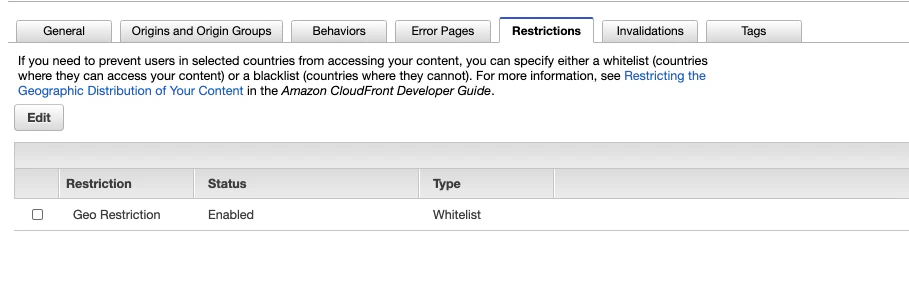
- 設定は以下のように変更します。
項目 値 備考 Enable Geo-Restriction Yes Restriction Type Whitelist Blacklist は特定の国のアクセスを拒否する場合に使用します。 Countries JP -- JAPAN 複数選択可能です。 5.以上で変更は完了です!動作確認をしてみましょう。
変更後のRestrictionsの画面はこのようになっています。
動作確認
日本からのアクセス
まずはじめに通常通り日本からCloudFrontにアクセスし、映像が視聴できるか確認します。
ちゃんと視聴できていますね。
念の為、curlコマンドでも確認....
ちゃんと200が返って来ています!$ curl -I https://xxxxxx.cloudfront.net/test/live.m3u8 HTTP/2 200海外からのアクセス
次に、外国からのアクセスを想定してCloudFrontにアクセスしてみましょう。
今回は、バージニア北部に作成したEC2からアクセスしてみます。curlコマンドで確認
403でアクセスできていないことがわかります。$ curl I https://xxxxxx.cloudfront.net/test/live.m3u8 curl: (6) Could not resolve host: I <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <HTML><HEAD><META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=iso-8859-1"> <TITLE>ERROR: The request could not be satisfied</TITLE> </HEAD><BODY> <H1>403 ERROR</H1> <H2>The request could not be satisfied.</H2> <HR noshade size="1px"> The Amazon CloudFront distribution is configured to block access from your country. We can't connect to the server for this app or website at this time. There might be too much traffic or a configuration error. Try again later, or contact the app or website owner. <BR clear="all"> If you provide content to customers through CloudFront, you can find steps to troubleshoot and help prevent this error by reviewing the CloudFront documentation. <BR clear="all"> <HR noshade size="1px"> <PRE> Generated by cloudfront (CloudFront) Request ID: jGIOUWRCtRzkEAA3VNpUJt6Hlyulk-lrcOs4OXbFMOcYe-DiS13tNg== </PRE> <ADDRESS> </ADDRESS>curlコマンドで確認する以外にも、webpagetestというwebサイトを使用すると、簡単に海外からのアクセスを想定して検証できます!
ちなみに、今回の場合はec2と同じバージニアからアクセスすると、このような画面が表示されるようです。
curlコマンドで表示されたものと同じですね。
しっかり、海外からのアクセスをブロックできていることがわかります!
まとめ
簡単にポチポチするだけでアクセス制限がかけられるので、とても簡単でした。
一番間違えてはいけないのはwhitelistとBlacklistの箇所ですね笑
意味が真逆になってしまうので、そこだけは注意が必要だと感じました。最後まで読んでいただきありがとうございました
参考&フリー動画素材
https://docs.aws.amazon.com/ja_jp/AmazonCloudFront/latest/DeveloperGuide/georestrictions.html
https://aws.amazon.com/jp/premiumsupport/knowledge-center/cloudfront-geo-restriction/
BigBuckBunny

- 投稿日:2020-11-12T17:56:16+09:00
パスワード認証を用いたAWS CloudWatchダッシュボード共有についての情報
1.やりたいこと
1) 共有対象者はID,パスワード認証を行ってダッシュボードを閲覧する。 2) 特定のダッシュボードを共有する設定を行う。2.共有手段
CloudWatchダッシュボード共有設定には以下3通りの方法がある。
1) 特定のダッシュボードに対してユーザーに閲覧権限を与え、ID,パスワード認証を行ってもらう方法。 2) 1 つのダッシュボードを公開して共有し、リンクを持っている全員がダッシュボードを表示できるようにする方法。 3) アカウントのすべての CloudWatch ダッシュボードを共有し、 ダッシュボードアクセス用のサードパーティーのシングルサインオン (SSO) プロバイダーを指定する方法。やりたいことは1)なのでパスワード認証について考えてみる。
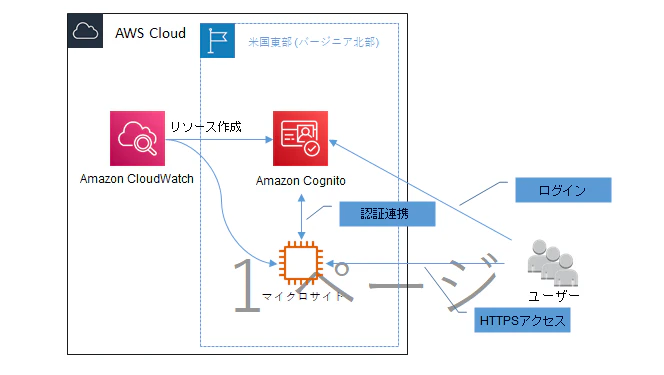
3.CloudWatchダッシュボード共有概要図
おそらく以下のような感じ
図1, 1)の手段を用いたCloudWatchダッシュボード共有概要図4.作成されるリソース
CloudWatch ダッシュボード共有設定において、下記項目分のリソースが追加される。
1) Cognitoユーザープール 2) Cognitoユーザー 3) Cognitoアプリクライアント 4) Cognito IDプール 5) IAMロール 6) マイクロサイト ※Amazon Cognito リソースに関しては米国東部(バージニア北部)にて作成される。 ※マイクロサイトはダッシュボード共有に際してホスト用として自動的に作られる。 マイクロサイトに関しては自分のAWSアカウントに対して作られるものではないそうで、こちらでは管理できない。5.アカウント関連
ユーザーの追加、削除、グループの設定はAmazon Cognitoで行う。
以下、共有に際しての役割について概要を示す。1, ユーザー ここでは共有対象者を指す。ユーザー作成はダッシュボード共有設定初期段階か、 Cognitoユーザープールより追加できる。後者の場合、共有するには共有用グループに追加することによって共有できる。 2, グループ CloudWatch ダッシュボード共有設定の過程で作成されたCognitoユーザープール内のグループは、IAMロールが割り当てられている。 このグループにCognito内のユーザーを追加することによってダッシュボードを閲覧することができるようになる。 3, IAMロール IAMロールにはCloudWatchの特定のダッシュボードへのアクセス権限が割り当てられている。
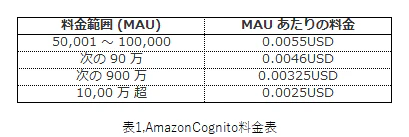
6.料金
CloudWatchダッシュボードにより参照される際の通常の API コール料金に加えて、Cognitoの料金がかかる。
CloudWatchダッシュボード ユーザーが欲しい情報によってバリエーションが多いため省略。 Amazon Cognito Cognitoは月間アクティブユーザー(MAU)にのみ基づいて計算される。 その月にサインアップ、サインイン、トークンの更新またはパスワードの変更など、当該ユーザーに関わる ID 操作が発生した場合、 そのユーザーは MAU としてカウントされる。その月に非アクティブなユーザー分は課金されない。 マイクロサイト マイクロサイトに関しては課金はなし。

- 投稿日:2020-11-12T17:42:45+09:00
AWSのsecurity groupがどのリソースと紐づけられているかを見つける方法。
背景
気づいたら増えまくってるsecurity group。
整理する際に、どれがどのリソースに使われてるのかを調べる方法。参考 : https://aws.amazon.com/jp/premiumsupport/knowledge-center/ec2-find-security-group-resources/
正確な調べ方
- 'セキュリティグループ'から該当sgのidを調べる。
- 'ネットワークインターフェース'を開き、該当idを貼り付ける。
- sgが紐づけられたeni一覧が出るので、そこからどのリソースについてるかを調べる。
雑な調べ方
- 'セキュリティグループ'から該当sgをチェックし削除を選択。
- 何かと紐づけられてる場合は、「消せません」とアラートが出てくるので、リンクに飛ぶ。
- 紐づけられてるものがない場合は、「消してもいいですが?」とアラートが出てくるので、消しても良さそうなら消す。
- 投稿日:2020-11-12T17:24:41+09:00
EC2インスタンスにデプロイしたwebアプリケーションを、Route 53 で独自ドメインと紐づける
EC2インスタンスにデプロイしたNuxt.js アプリケーションに、 Route 53 で独自ドメインを紐づけたい。
こちらの記事を見ながら、
VPC + EC2でNuxt.js アプリケーションをデプロイしました。しかし、EC2インスタンスに割り当てられているパブリックIPv4アドレス(例:
x.xx.xxx.xx)は定期的に変更されてしまうので、せっかくなら自身で取得した独自ドメインと紐づけたいと考えました。作業の流れ
- こちらの記事を参考に、アプリケーションをデプロイした。
- Elastic IP アドレスを、EC2インスタンスに割り当てる。
- Route53 で独自ドメインを取得する。 ※ 独自ドメインをお持ちの方はホストゾーンを作成する。
- レコードを作成し、独自ドメインを紐づける
2〜4の流れを解説します。
1. 前提条件
・2020/11/11 時点のAWSコンソール画面です。AWSコンソール画面は頻繁に変更されるので、ご注意ください。
・EC2でwebアプリをデプロイし、IPアドレスでアクセスできている。
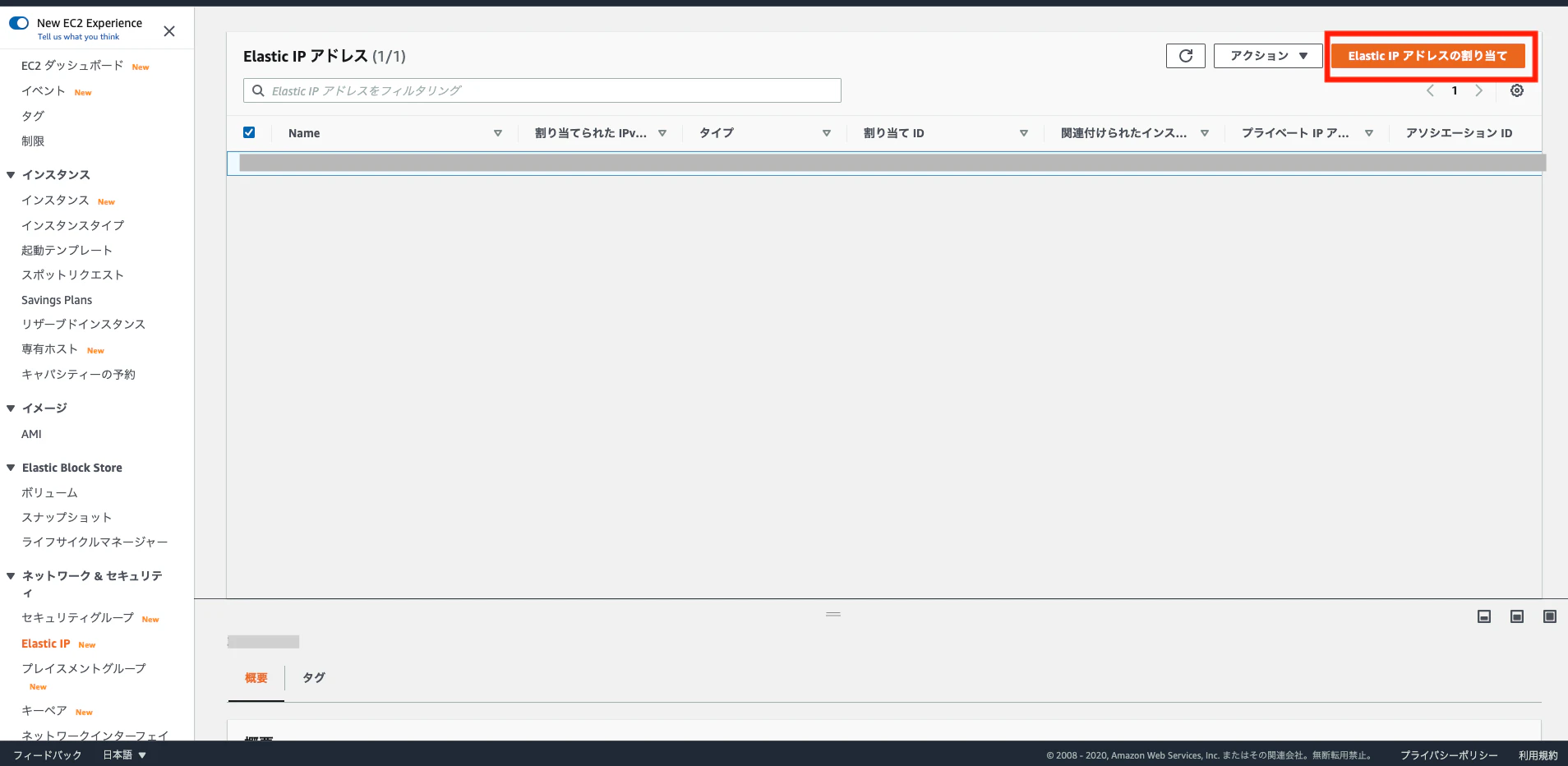
・外部サイトで独自ドメイン を取得している。(今回は、すでに取得済みのドメインを紐付けます。)2. Elastic IP アドレスを、EC2インスタンスに割り当てる。
・AWSコンソールで
サービス→EC2を選択
・EC2ダッシュボードで、「Elastic IP」を選択
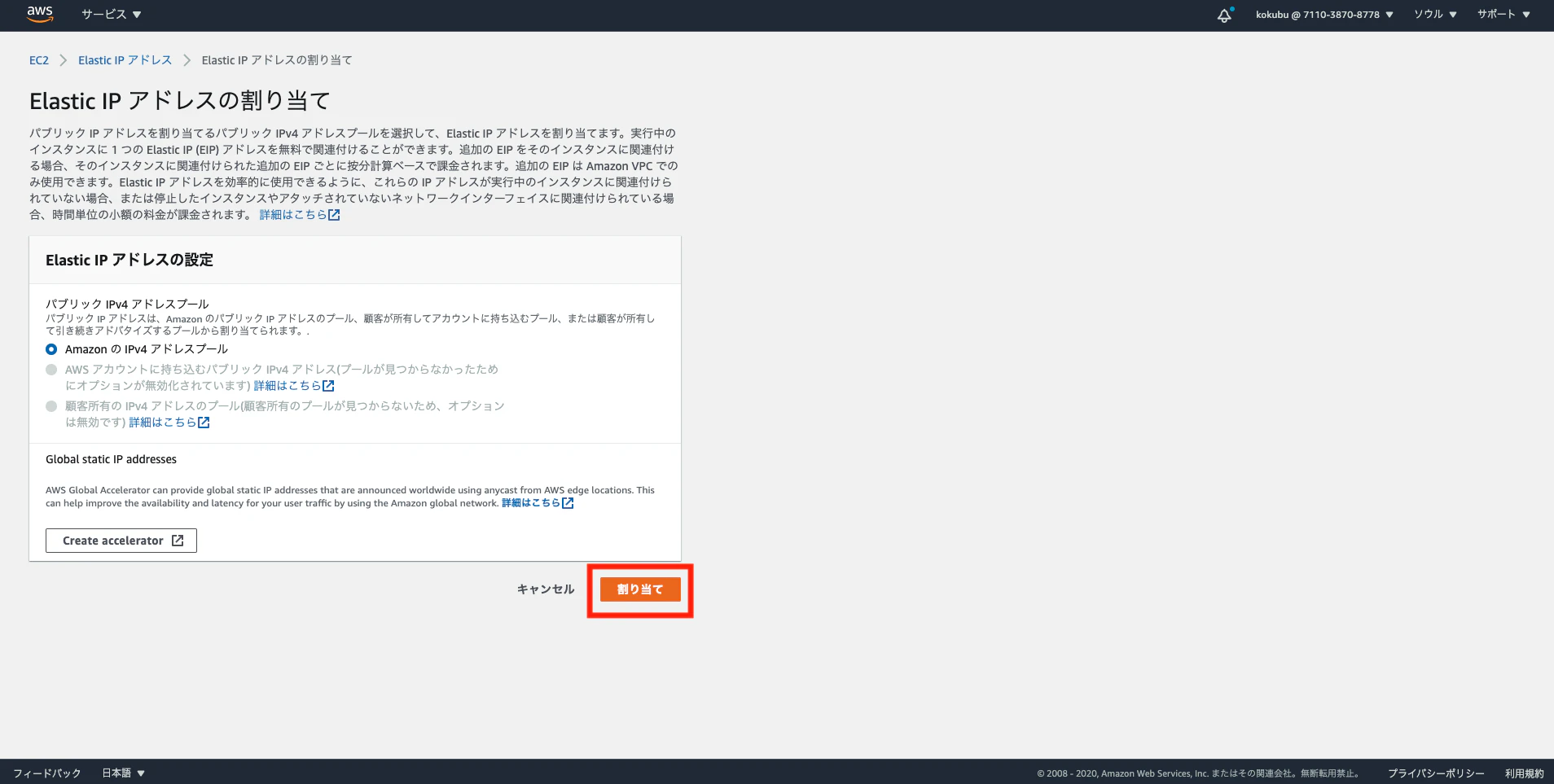
・「Elastic IPアドレスの割り当て」をクリック
・特に設定を変更することなく、「割り当て」をクリック
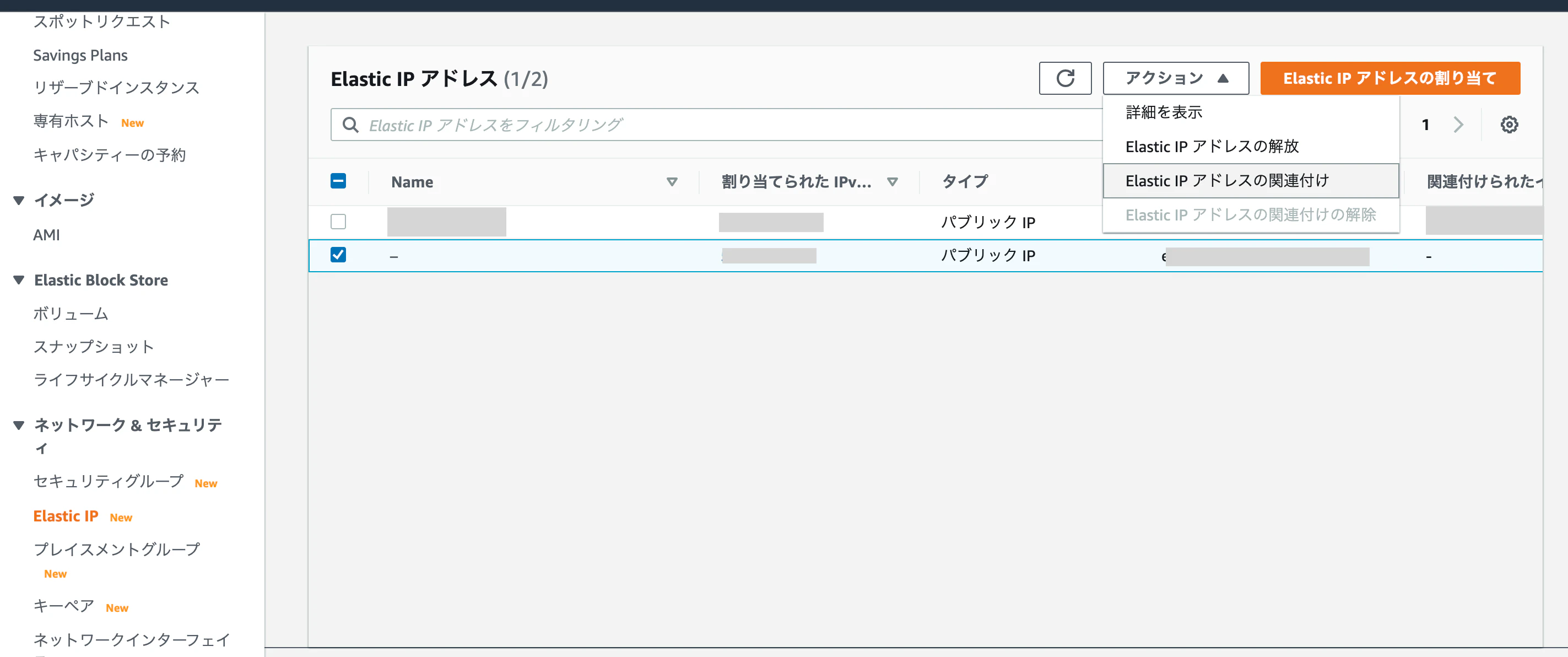
・Elastic IPアドレスが発行されたことを確認し、「アクション」タブから「Elastic IP アドレスの関連付け」をクリック
・作成したインスタンスとそのプライベートIPアドレスを選択して、「関連づける」をクリック
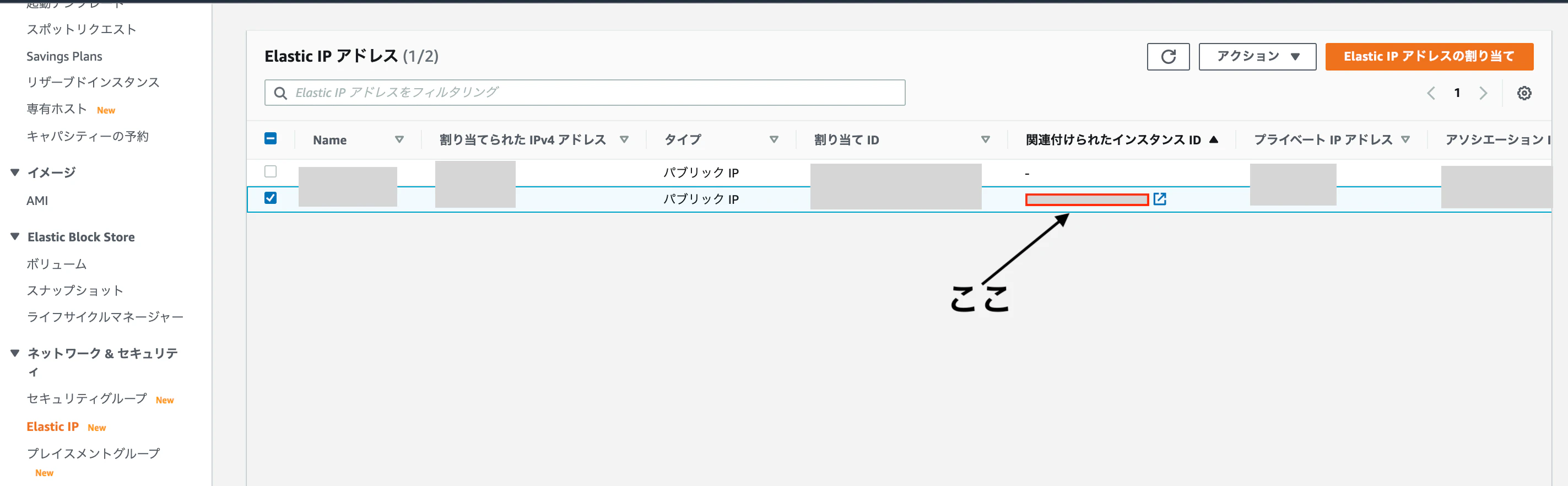
以上で、EC2インスタンスにElastic IPアドレスの割り当てが完了しました。割り当てが成功されていると「
関連付けられたインスタンスID」にインスタンスIDが表示されます。
この段階で、
http://[Elastic IPアドレス]にアクセスすると、デプロイしたアプリケーションを確認できると思います。
(Nuxt.jsアプリケーションの場合は、http://[Elastic IPアドレス]:[PORT番号]にアクセスする。
例:http://xx.x.xxx.xx:3000)3. Route53 でホストゾーンを作成する。
今回は「ムームードメイン」で取得したドメインを利用します。
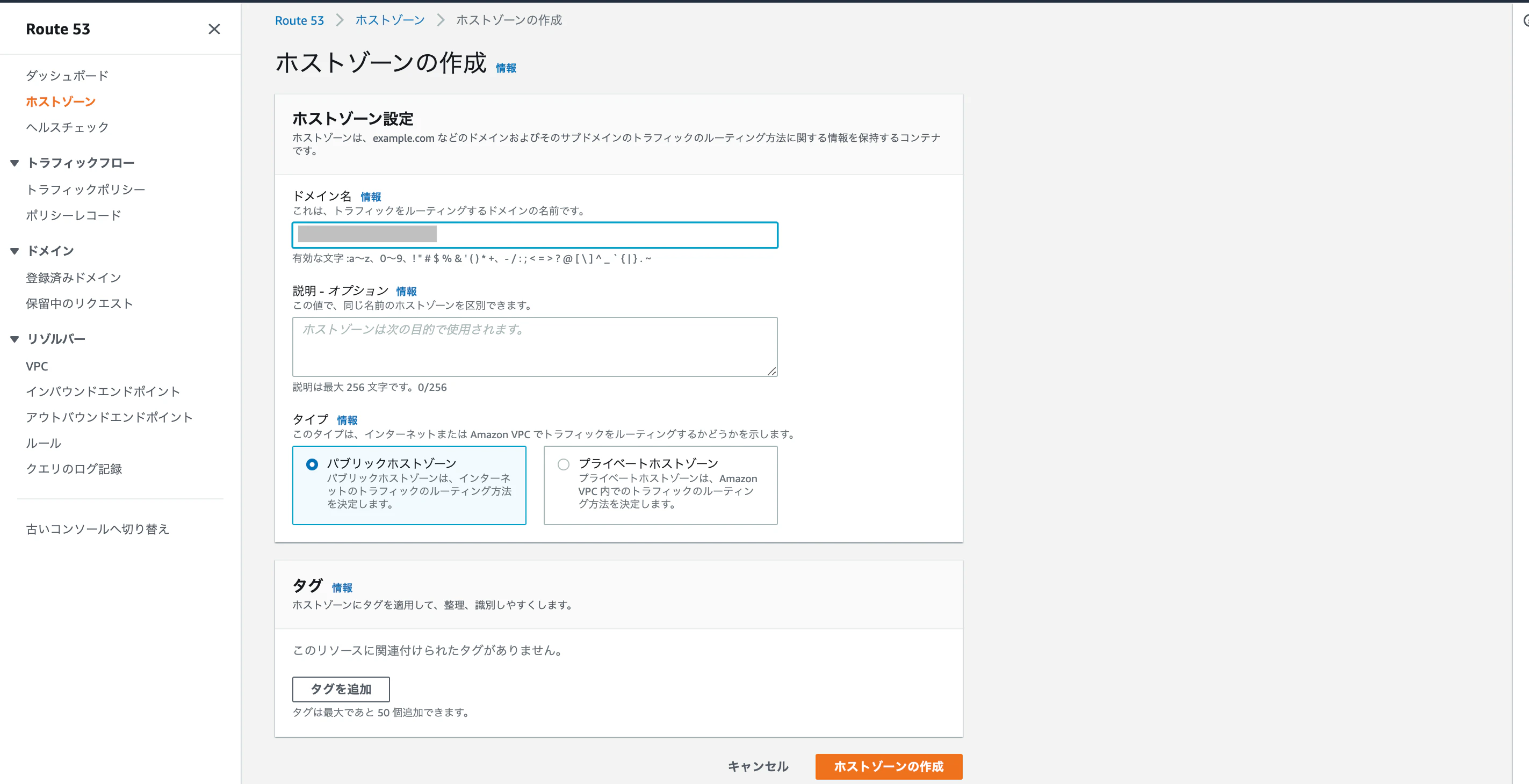
・AWSコンソールでサービス→Route53を選択し、「ホストゾーンの作成」をクリック
・自分が取得したドメイン を入力し、「ホストゾーンの作成」をクリック
ホストゾーンが作成されたら、登録したドメイン名をクリックしホストゾーンのレコードを確認します。
NS,SOAタイプの2種類のレコードが自動的に作成されていることを確認してください。
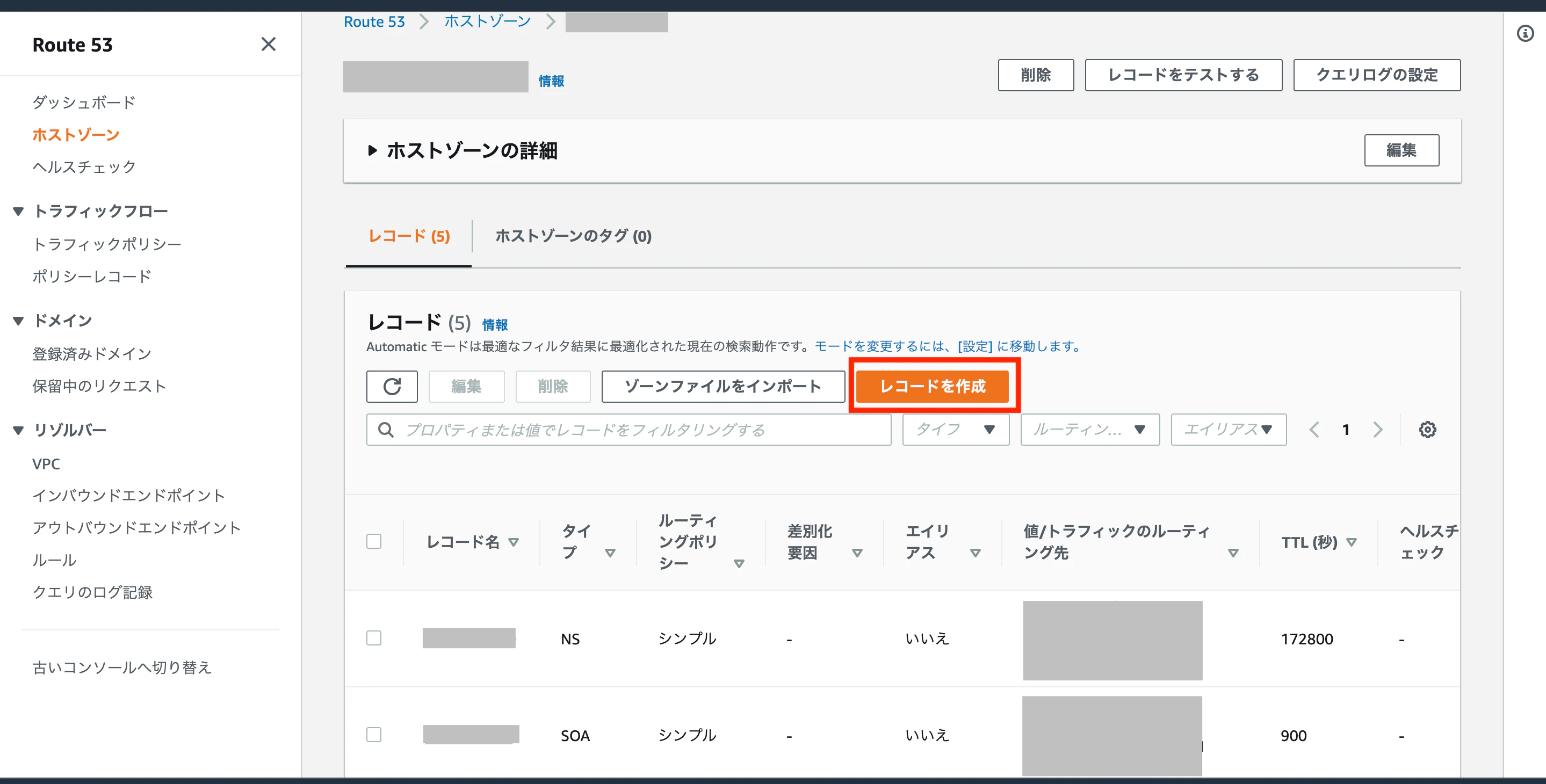
・レコードを作成する。
「シンプルルーティング」を選択して、「次へ」をクリック→「シンプルなレコードを定義」をクリック
- レコード名:サブドメインにルーティングする場合は入力する。空白のままにすると、ドメイン名でルーティングする。
- 値/トラフィックのルーティング先:一番上の「
レコードタイプに応じたIPアドレスまたは別の値」を選択し、割り当てたElastic IPアドレスを入力する。- 「
シンプルなレコードを定義」をクリック
以上で、
http://[Elastic IPアドレス]もしくは、http://[ドメイン名]にアクセスできると思います。
(Nuxt.jsアプリケーションの場合は、http://[ドメイン名]:[PORT番号]にアクセスする。)お疲れ様でした!



- 投稿日:2020-11-12T15:36:57+09:00
AWS CLIでEKSクラスタのEC2インスタンスを起動・停止するシェル
はじめに
ローカルPCからAWS CLIを利用して、EKSクラスタのワーカーノードであるEC2インスタンスを起動・停止します。
検証環境など、コスト削減のため、利用しない時はEC2インスタンスを停止にすると思いますが、AWS CLIで変更します。予めjqをインストールして奥必要があります。
スクリプト
1. EKSクラスタのワーカーノードであるEC2インスタンスを起動する
start_cluster_nodes.sh#!/bin/sh cd `dirname $0` CLUSTER_NAME=[クラスタ名] AUTO_SCALING_GROUP_NAME=$(aws autoscaling describe-auto-scaling-groups --query 'AutoScalingGroups[?contains(Tags[?Key==`eks:cluster-name`].Value, `'${CLUSTER_NAME}'`)].AutoScalingGroupName' | jq -r '. | tostring' | sed -e 's/\[//' -e 's/\]//' -e 's/\"//g' ) EC2_INSTANCE_IDS=($(aws ec2 describe-instances --filter "Name=tag:eks:cluster-name,Values=${CLUSTER_NAME}" --query "Reservations[].Instances[].InstanceId" | jq -r '. | tostring' | sed -e 's/\[//' -e 's/\]//' -e 's/\"//g' -e 's/,/ /g')) for instance_id in ${EC2_INSTANCE_IDS[@]}; do aws ec2 start-instances --instance-ids ${instance_id} aws autoscaling attach-instances --instance-ids ${instance_id} \ --auto-scaling-group-name ${AUTO_SCALING_GROUP_NAME} done2. EKSクラスタのワーカーノードであるEC2インスタンスを停止する
stop_cluster_nodes.sh#!/bin/sh cd `dirname $0` CLUSTER_NAME=[クラスタ名] AUTO_SCALING_GROUP_NAME=$(aws autoscaling describe-auto-scaling-groups --query 'AutoScalingGroups[?contains(Tags[?Key==`eks:cluster-name`].Value, `'${CLUSTER_NAME}'`)].AutoScalingGroupName' | jq -r '. | tostring' | sed -e 's/\[//' -e 's/\]//' -e 's/\"//g' ) EC2_INSTANCE_IDS=($(aws ec2 describe-instances --filter "Name=tag:eks:cluster-name,Values=${CLUSTER_NAME}" --query "Reservations[].Instances[].InstanceId" | jq -r '. | tostring' | sed -e 's/\[//' -e 's/\]//' -e 's/\"//g' -e 's/,/ /g')) for instance_id in ${EC2_INSTANCE_IDS[@]}; do aws autoscaling detach-instances --instance-ids ${instance_id} \ --auto-scaling-group-name ${AUTO_SCALING_GROUP_NAME} --should-decrement-desired-capacity aws ec2 stop-instances --instance-ids ${instance_id} done
- 投稿日:2020-11-12T15:35:43+09:00
AWSの有料サポートプランについてまとめ
AWSのサポートについて、問い合わせした内容をまとめておきます。
いくつかのサポートの中で得た知識をまとめただけの備忘録です。1つの契約で全ての質問に対応してもらえるか
他のアカウントの件についてはサポートを受けることはできない。(当たり前ですね笑)
サポートに加入しているアカウントについてのサポートのみのため、
複数のアカウントを契約しており、それぞれに対してサポートが必要な場合は、
それぞれのアカウントでサポート契約を結ぶ必要があります。サポートのケース作成数に上限があるか
ケースの作成数には上限はなく、無制限のケースをオープン可能。
ケースをクローズしたのち、新たに不明点が見つかった場合には、
同じケースを再度オープンにする、または、新たなケースを作ることができます。サードパーティ製ソフトウェアサポートについて
ビジネス以上のプランにて、サードパーティ製ソフトウェアサポートをベストエフォートで対応してもらえる。
今回は、Nginx まわりの原因調査をお願いした場合に、このように回答されました。
なお、今回は、原因が Nginx ではない(サーバの設定で解決できる)場合の可能性があったため、
その点については回答をもらうことができました。実際に環境にアクセスして原因究明に当たってもらえるか
SSHなどでサーバにログインし、確認しながらのサポートはしてもらえない。
環境にアクセスするようなサポートが必要な場合には、
AWSサポートではなく、AWSパートナーの利用をオススメされました。
※ AWSパートナーを探したい場合には、こちらからも相談可能なようです最低利用期間はあるか
30日間です。
最低30日契約すれば、40日目でも50日目でも、好きなタイミングでのサポートの解約が可能です。
月をまたいで30日契約した場合に料金はどのように計算されるか
料金を決定するためのAWSの月額料金は、月ごとに計算されるようです。
例)仮に、10月21日〜11月19日(30日)のみ契約していた場合
- 10月21日〜10月31日の利用料金をもとに計算され、10月ご利用分として課金
- 11月1日〜11月19日の利用料金をもとに計算され、11月ご利用分として課金
一度解約したあと、再度契約することは可能か
可能です。
問題が起こったときだけサポートプランを契約するような利用方法も可能とのことです。
※ ただし、毎回30日間の最低利用期間が発生します
- 投稿日:2020-11-12T15:22:47+09:00
AWSWAFでブロックログのアラートをフィルタリングしつつSlackへ飛ばす
構成
- WAFで攻撃を検知したらSlackへ飛ばす
WAF → KinesisFirehose → Lambda → Slack
↓
→ S3バケットWAF
ルール設定
- ルールは汎用的なものを設定
- AWSManagedRulesCommonRuleSet
- AWS-AWSManagedRulesLinuxRuleSet
- DefaultActionはAllow
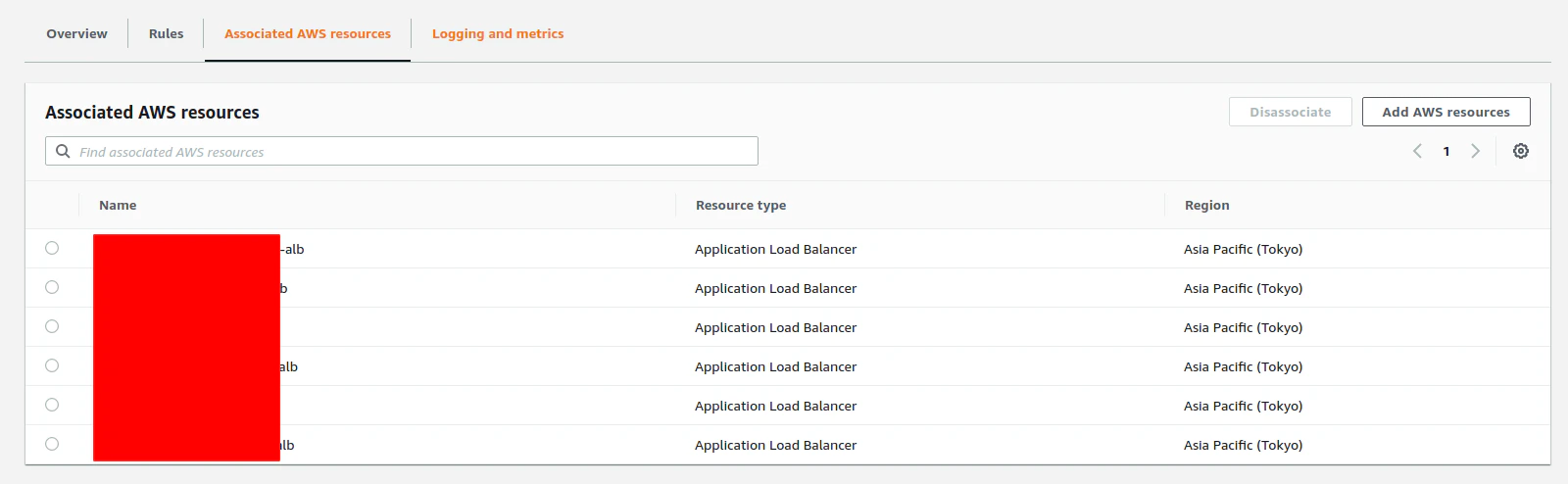
接続リソース設定
- 紐づけたいALBを指定
Logging and metrics設定
- KinesisiFirehoseにログ出力するようにする

KinesisFirehose
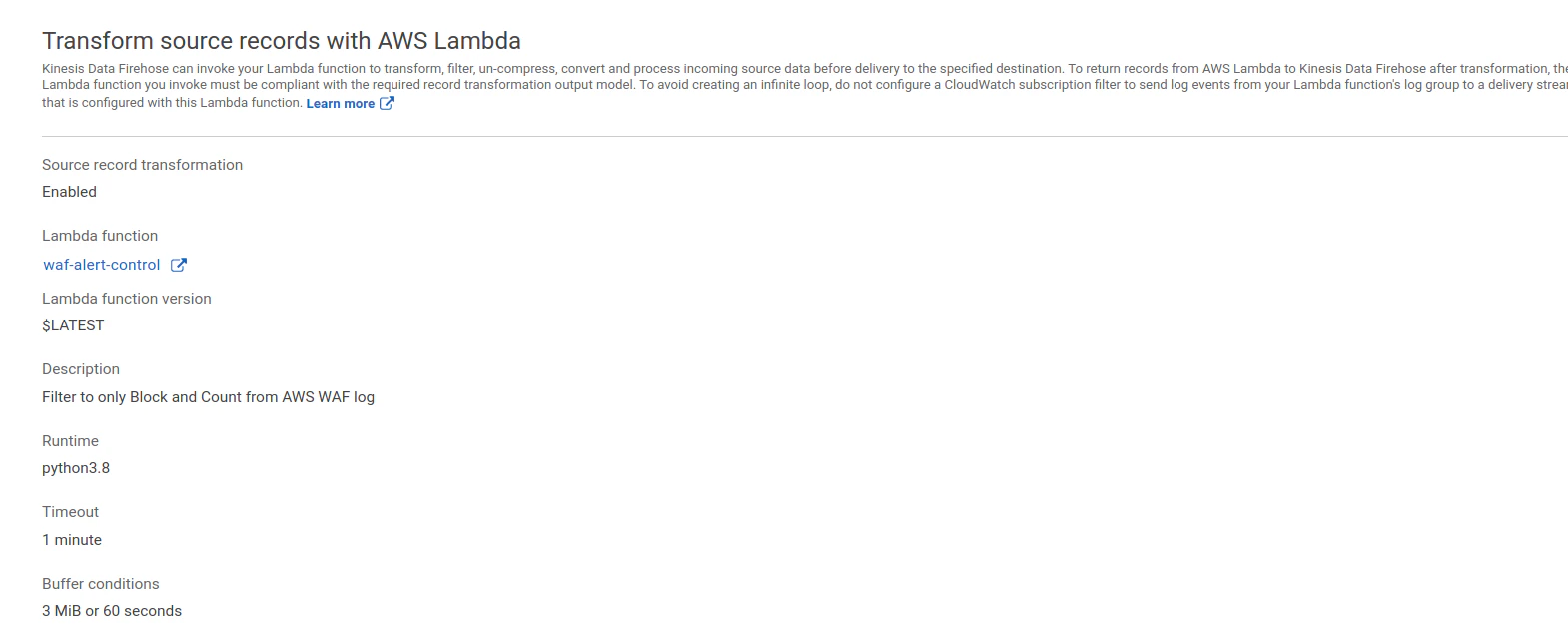
Transform設定
- kinesisFirehoseのJson出力をLambdaへ渡す
- Lambda側でのトリガーでKinesisFirehoseを指定することはできない
Lambda設定
- トリガー、送信先は指定なし
ソースコード
- ランタイムはpython3.8
- AWSManagedRulesCommonRuleSetの中で
NoUserAgent_HEADERとUserAgent_BadBots_HEADERがやたらでるので、Slackへは飛ばしたくない- それ以外のルールはSlackへ飛ばす
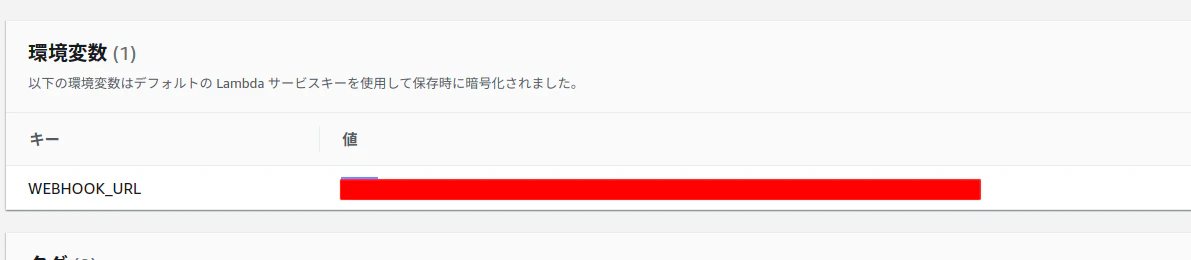
import base64 import json import os import urllib.request def lambda_handler(event, context): output = [] for record in event['records']: output_record = { 'recordId': record['recordId'], 'result': 'Ok', 'data': record['data'] } output.append(output_record) a = base64.b64decode(record['data']) b = json.loads(a) # if b['action'] != 'ALLOW': # print("action not ALLOW") if b["ruleGroupList"][0]["terminatingRule"]["ruleId"] != 'NoUserAgent_HEADER' and b["ruleGroupList"][0]["terminatingRule"]["ruleId"] != 'UserAgent_BadBots_HEADER': print("terminatingRule is not NoUserAgent_HEADER") response = post_slack(b) print(output_record) return {'records': output} def post_slack(msg): send_data = { "username": "notify_slack", "icon_emoji": ":vampire:", "color":"#D00000", "text": "WAF攻撃検知", "attachments":[ { "fallback":"fallback Test", "color":"#D00000", "fields":[ { "title":"詳細内容", "value":str(msg) } ] } ] } send_text = "payload=" + json.dumps(send_data) # send_text = "payload=" + json.dumps(jsondata) method = 'POST' headers = {'Content-Type': 'application/json'} WEB_HOOK_URL = os.environ['WEBHOOK_URL'] request = urllib.request.Request( WEB_HOOK_URL, data=send_text.encode('utf-8'), method=method ) with urllib.request.urlopen(request) as response: response_body = response.read().decode('utf-8') print("send ok")環境変数
- SlackのWebhookURLを指定する
動作確認用のテストデータ
- kinesisFirehoseから送られるであろうデータ形式
- dataはkinesisFirehoseからs3バケットに出力されているWAFのログをbase64エンコードしたもの
- lambda関数では、data部分をデコードし、terminatingRuleを判定するようにしている
{ "invocationId": "invocationIdExample", "deliverySteamArn": "arn:aws:kinesis:EXAMPLE", "region": "ap-northeast-1", "records": [ { "recordId": "49546986683135544286507457936321625675700192471156785154", "approximateArrivalTimestamp": 1495072949453, "kinesisRecordMetadata": { "sequenceNumber": "49545115243490985018280067714973144582180062593244200961", "subsequenceNumber": "123456", "partitionKey": "partitionKey-03", "shardId": "shardId-000000000000", "approximateArrivalTimestamp": 1495072949453 }, "data": "ew0KCSJ0aW1lc3RhbXAiOiAxNjA0Nzc0MzM1MTEyLA0KCSJmb3JtYXRWZXJzaW9uIjogMSwNCgkid2ViYWNsSWQiOiAiYXJuOmF3czp3YWZ2MjphcC1ub3J0aGVhc3QtMToxMTExMTExMTExMTpyZWdpb25hbC93ZWJhY2wvdmFtZGVtaWMtd2FmdjIveHh4eHh4eHgtY2UwYi00ZWYwLTkxZGUtYjQ0OTg1NmFmNDUxIiwNCgkidGVybWluYXRpbmdSdWxlSWQiOiAiQVdTTWFuYWdlZFJ1bGVzQ29tbW9uUnVsZVNldCIsDQoJInRlcm1pbmF0aW5nUnVsZVR5cGUiOiAiTUFOQUdFRF9SVUxFX0dST1VQIiwNCgkiYWN0aW9uIjogIkJMT0NLIiwNCgkidGVybWluYXRpbmdSdWxlTWF0Y2hEZXRhaWxzIjogW10sDQoJImh0dHBTb3VyY2VOYW1lIjogIkFMQiIsDQoJImh0dHBTb3VyY2VJZCI6ICIxMTExMTExMTExMS1hcHAvdmFtZGVtaWMtZGV2LWJ1c2luZXNzLWRldjItYWxiLzI4YWU3NjcyYzExMTExMWRjIiwNCgkicnVsZUdyb3VwTGlzdCI6IFsNCgkJew0KCQkJInJ1bGVHcm91cElkIjogIkFXUyNBV1NNYW5hZ2VkUnVsZXNDb21tb25SdWxlU2V0IiwNCgkJCSJ0ZXJtaW5hdGluZ1J1bGUiOiB7DQoJCQkJInJ1bGVJZCI6ICJOb1VzZXJBZ2VudF9IRUFERVIiLA0KCQkJCSJhY3Rpb24iOiAiQkxPQ0siLA0KCQkJCSJydWxlTWF0Y2hEZXRhaWxzIjogbnVsbA0KCQkJfSwNCgkJCSJub25UZXJtaW5hdGluZ01hdGNoaW5nUnVsZXMiOiBbXSwNCgkJCSJleGNsdWRlZFJ1bGVzIjogbnVsbA0KCQl9DQoJXSwNCgkicmF0ZUJhc2VkUnVsZUxpc3QiOiBbXSwNCgkibm9uVGVybWluYXRpbmdNYXRjaGluZ1J1bGVzIjogW10sDQoJImh0dHBSZXF1ZXN0Ijogew0KCQkiY2xpZW50SXAiOiAiMTI2LjIwOS4yMjEuNCIsDQoJCSJjb3VudHJ5IjogIkpQIiwNCgkJImhlYWRlcnMiOiBbDQoJCQl7DQoJCQkJIm5hbWUiOiAiSG9zdCIsDQoJCQkJInZhbHVlIjogImRldjIudmFtZGVtaWMuanAiDQoJCQl9LA0KCQkJew0KCQkJCSJuYW1lIjogIkFjY2VwdCIsDQoJCQkJInZhbHVlIjogIiovKiINCgkJCX0NCgkJXSwNCgkJInVyaSI6ICIvIiwNCgkJImFyZ3MiOiAiIiwNCgkJImh0dHBWZXJzaW9uIjogIkhUVFAvMS4xIiwNCgkJImh0dHBNZXRob2QiOiAiR0VUIiwNCgkJInJlcXVlc3RJZCI6ICIxLTVmYTZlOWJmLTIyMmU3NmNkNWJkNDQyYTEyYjg5YmM5YSINCgl9DQp9" } ] }テスト
- こちらの2パターンのテストを行い、挙動を見る
参考
https://dev.classmethod.jp/articles/aws-waf-block-log-pipeline/



- 投稿日:2020-11-12T14:11:07+09:00
【MacOS】aws-sam-cliをインストールする。
- 投稿日:2020-11-12T14:08:23+09:00
[AWS CloudFormation][AWS SAM] Cognito ユーザプール、アプリクライアント定義
ユーザプール定義
構文については公式ドキュメント参照
設定したい項目以外はデフォルトで定義したものが以下
UserPool: Type: AWS::Cognito::UserPool Properties: UserPoolName: !Sub '${StackName}_UserPool' UsernameConfiguration: CaseSensitive: false AdminCreateUserConfig: AllowAdminCreateUserOnly: true AccountRecoverySetting: RecoveryMechanisms: - Name: admin_only Priority: 1 LambdaConfig: PreAuthentication: !GetAtt PreAuthenticationHook.Arnマネージメントコンソールで内容確認
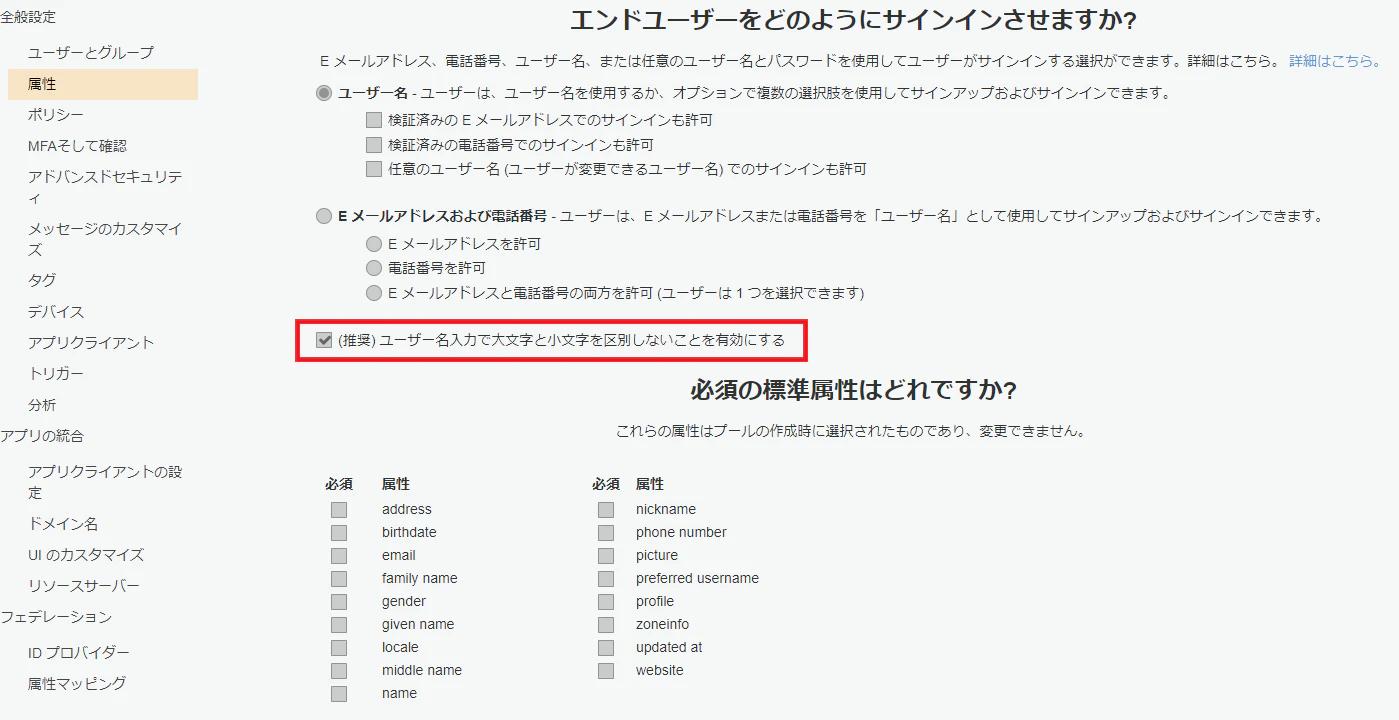
属性
- サインインに使用する属性は
ユーザ名Emailや、電話番号を使用する場合は、
AutoVerifiedAttributesで指定する
- 追加属性はなし
追加したい場合は、
AliasAttributesで指定する
- ユーザ名入力で大文字、小文字を区別しない
テンプレートの以下部分で設定
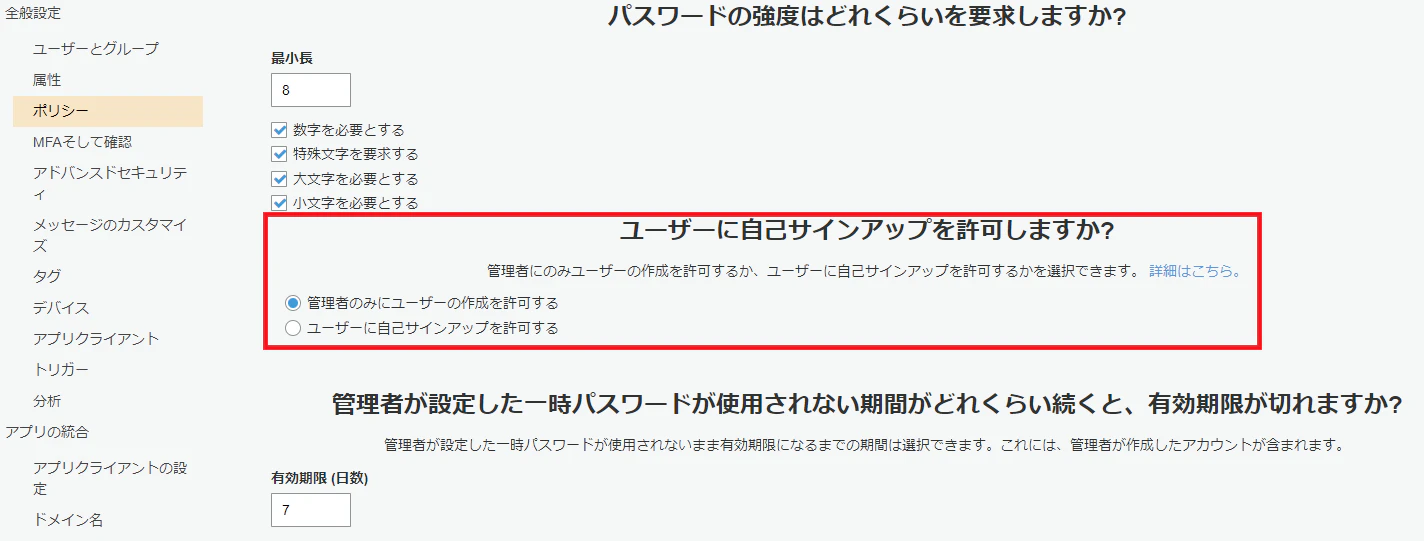
UsernameConfiguration: CaseSensitive: falseポリシー
- 管理者のみサインアップ可能とする
テンプレートの以下部分で設定
AdminCreateUserConfig: AllowAdminCreateUserOnly: trueMFAそして確認
- アカウント回復方法をなしとする
テンプレートの以下部分で設定
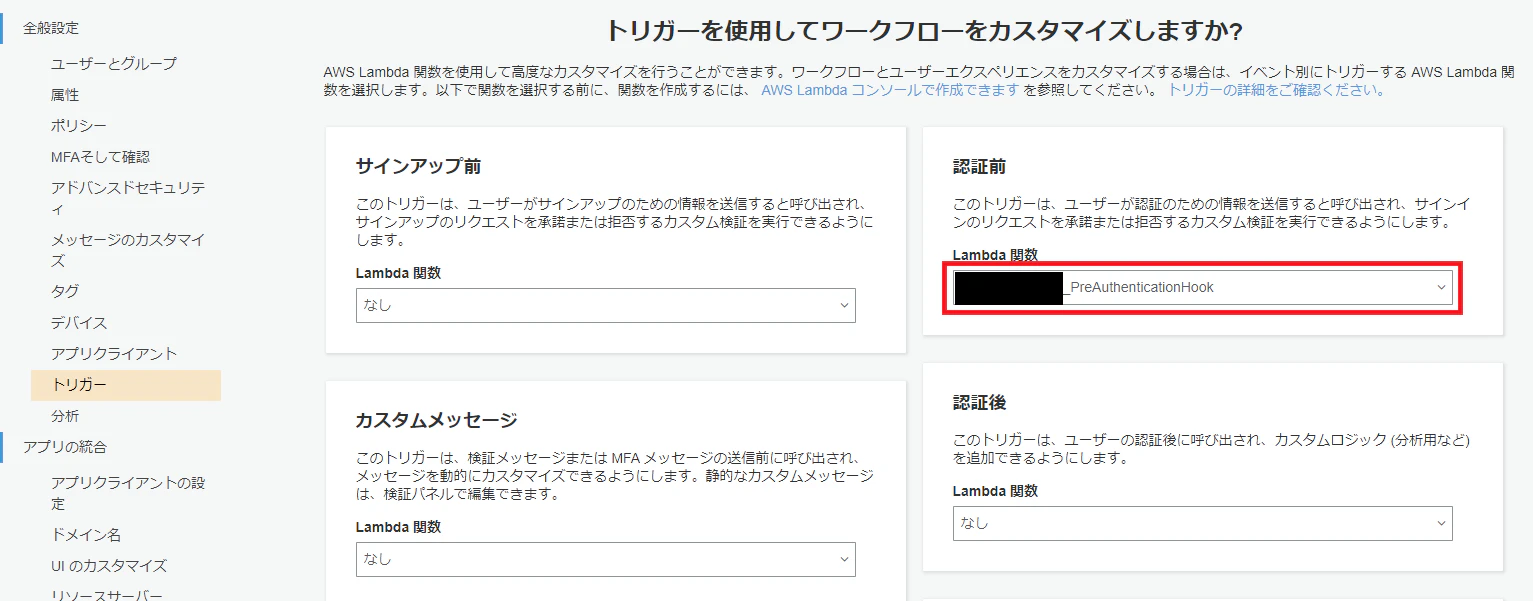
AccountRecoverySetting: RecoveryMechanisms: - Name: admin_only Priority: 1トリガ
- 認証前にフックするLambdaを指定
テンプレートの以下部分で設定
LambdaConfig: PreAuthentication: !GetAtt PreAuthenticationHook.Arn上記以外のタイミングでフックするLambda設定に関しては公式ドキュメント参照
以下、Lambdaの定義例
関数本体と、Cognitoに与えるLambda実行権限を定義PreAuthenticationHook: Type: AWS::Serverless::Function Properties: FunctionName: !Sub '${StackName}_PreAuthenticationHook' CodeUri: pre-Authentication-hook/ Handler: function.lambda_handler Runtime: python3.8 LambdaAddPermission: Type: AWS::Lambda::Permission Properties: Action: lambda:InvokeFunction FunctionName: !GetAtt PreAuthenticationHook.Arn Principal: cognito-idp.amazonaws.comアプリクライアント定義
構文については公式ドキュメント参照
設定したい項目以外はデフォルトで定義したものが以下
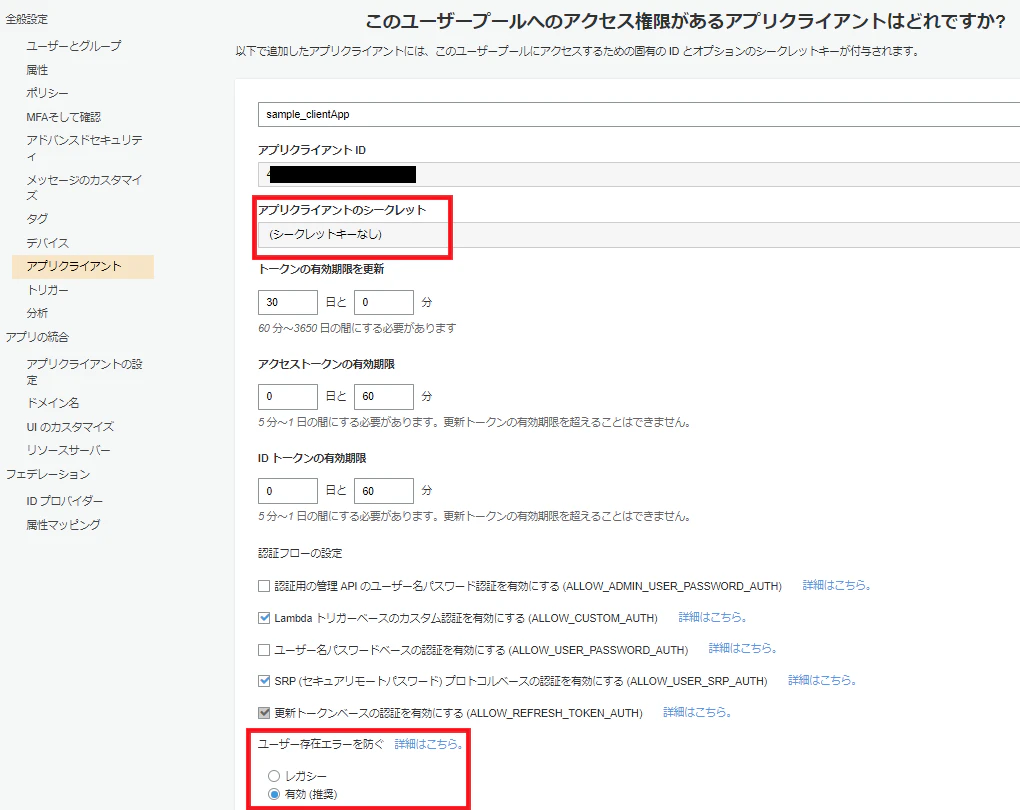
UserPoolClient: Type: AWS::Cognito::UserPoolClient Properties: UserPoolId: !Ref UserPool # 定義したユーザプールを参照 ClientName: !Sub '${StackName}_clientApp' GenerateSecret: false PreventUserExistenceErrors: ENABLEDマネージメントコンソールで内容確認
アプリクライアント
- アプリクライアントのシークレットなし
テンプレートの以下部分で設定
GenerateSecret: false
- ユーザの存在エラーを防ぐを有効設定
テンプレートの以下部分で設定
PreventUserExistenceErrors: ENABLEDトークンの有効期限設定
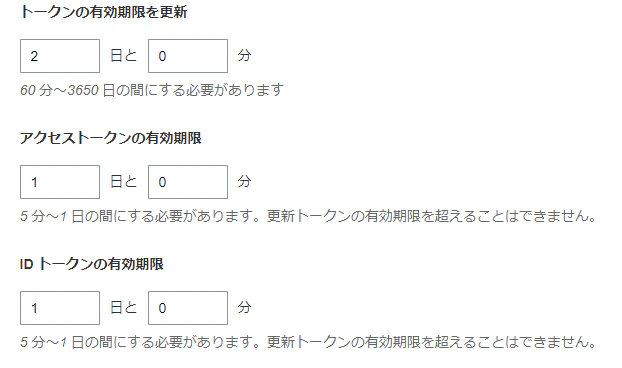
UserPoolClient: Type: AWS::Cognito::UserPoolClient Properties: UserPoolId: !Ref UserPool ClientName: !Sub '${StackName}_clientApp' GenerateSecret: false RefreshTokenValidity: 2 AccessTokenValidity: 1 IdTokenValidity: 1 PreventUserExistenceErrors: ENABLED上記のように
- 更新トークンの有効期限:2
- アクセストークンの有効期限:1
- IDトークンの有効期限:1
と設定してみたところ、以下のように日に値が設定された
分単位の設定ができない。。
以下、各設定値の最大値から単位は秒と考えられるが、マネジメントコンソールで秒は設定できないのでそれもおかしい
とりあえずAWSに不具合があるようなので、有効期限は全てデフォルトで運用


- 投稿日:2020-11-12T14:07:30+09:00
MacOSでAWS CLIをupgradeする。
- MacOS
- AWS CLI 2
curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target /公式:https://docs.aws.amazon.com/cli/latest/userguide/install-cliv2-mac.html#cliv2-mac-install-cmd
- 投稿日:2020-11-12T12:25:35+09:00
AWSの資格を取得してからオンプレ環境の運用保守をやった感想
こんにちは、初投稿です。
まずは自己紹介をしようと思います。
※正直どうでもいいので、すっ飛ばしてください。新卒一年目で、IT企業に勤めてます。(インフラ整備)
大学は文系の大学でFランだったので、ほとんど大学ではゲーム(LOL、FPS)かぼーっとして生きていたため、勉強は一切してないです。現在持っている資格は
・AWSクラウドプラクティショナー 9/24に取得
・教員免許(社会科)
ぐらいです。
本題です
さて、最近ふとした理由でAWSクラウドプラクティショナーの資格を取得しました。
理由としましては、クラウド最強!!っておもってたので、知識が少しほしかったからです。ですが、現在就いている案件がなんとオンプレ環境の運用保守です。
いやもう、ツールの名前や製品がわからず正直泣きそうな毎日です、なんといいますか、お経聞いてるかなぁ…ただ、ひとつ分かったことがあります。
それは…AWS最強じゃん!!! 再認識
今仕事でやってる、運用、保守のアカウント管理だったり、ログの確認やスイッチの設定や冗長性についてもAWSマネージドサービスにお任せしちゃえば仕事楽やん!
って思いました。※AWSマネージドサービスとは…??
https://aws.amazon.com/jp/managed-services/今回、オンプレの環境に就いて、まぁ良くも悪くもAWSの素晴らしさを改めて認識しました。
※この記事は、AWSのがいかにぶっ壊れ性能なのかを言いたかっただけです。
またなんかあれば投稿します。
追記
1年目で取得した方がいい資格や、NWの知識についての補い方など、アドバイス欲しいです。
ちなみに、現在はLpic1とCCNA目指してます?
- 投稿日:2020-11-12T11:34:16+09:00
AWSを勉強する - EC2
Amazon Elastic Compute Cloud(EC2)
従量課金で利用可能な仮想サーバー。
起動、ノード追加、削除、マシンスペック変更
任意のAZにインスタンスを立ち上げてサーバーとして利用する。EC2のセッティング
- 利用するAMIイメージ(OSセッティング)を選択
- インスタンスタイプを選択
- ストレージを選択
- セキュリティグループを選択
- SSHキーペアを設定
AMIイメージ
インスタンス起動用のOSイメージのこと(WindowsとかLinuxとか)。
下記の中から用途に合わせたAMIイメージを選択する
- AWSが用意して提供しているAMI(Windowsとか)
- 誰かが作成した有料のAMI
- AMIを自作する
インスタンスタイプ
CPU・メモリ、ストレージ、ネットワークキャパシティなどのスペックを選択。
個々の設定でより低コストで最適なパフォーマンスを出せるセッティングが必要。
通常は、オンデマンドでインスタンスを購入する。名前の構成↓
(ファミリー)(世代).(インスタンスの容量)
例)t2.nanoインスタンスファミリー
- M5:汎用
- T2:汎用
- C5:コンピューティング最適化
- H1:ストレージ最適化
- D2:ストレージ最適化
- R4:メモリ最適化
- X1:メモリ最適化
- F1:FPGA
- G2:GPU
その他、詳細:https://aws.amazon.com/jp/ec2/instance-types/
リザーブドインスタンス
利用期間を長期指定して利用する形式。
スタンダード コンバーティブル 利用期間 1年(40%割引)
3年(60%割引)1年(31%割引)
3年(54%割引)AZ/インスタンスサイズ/
ネットワークタイプ変更可否有 有 インスタンスファイリー/OS/
テナンシー/支払いオプションの変更可否なし 有 リザーブドインスタンス
マーケットプレイスでの販売可否可能 今後可能となる予定 ユースケース
- 一定した状態または使用量が予測可能なワークロード
- 災害対策などキャパシティ予約が可能なアプリケーション
スポットインスタンス
予備のコンピューティング容量をオンデマンドインスタンスに比べて割引で利用できるEC2インスタンス
- 予備用を入札式で利用するため安い
- 起動に通常より少し時間がかかる
- 予備用のため途中で削除される可能性がある(一時的な拡張などの用途で利用)
Saving Plan
1~3年の期間に一定の使用量を守ることによりAmazon EC2コストを削減する。
ストレージ
基本的にはEBSを選択する。
- インスタンスストア
- ホストコンピュータに内蔵されたディスクでEC2と不可分のブロックレベルの物理ストレージ
- EC2の一時的なデータが保持され、EC2の停止・終了をともにクリアされる
- 無料
- Elastic Block Store(EBS)
- ネットワークで接続されたブロックレベルのストレージでEC2とは独立して管理される
- EC2をTerminate(接続を遮断)してもEBSは保持可能で、SnapshotをS3に保持可能
- 別途EBS料金が必要
セキュリティグループ
インスタンスへのトラフィックのアクセス可否を設定するファイアーウォール機能を提供
アクセスする範囲を設定することで安全性を高める。キーペア
キーペアを利用して自身がダウンロードした秘密鍵とマッチした公開鍵を有するインスタンスにアクセスする。
EC2のバックアップ
EC2インスタンスは定期的にバックアップすることが重要。
- 定期的にバックアップを取る
- 定期的にリカバリプロセスを確認する
- 複数のAZに重要なアプリケーションをデプロイすること
- フェイルオーバー対応を準備すること
- イベントをモニタリングして対応できるようにすること
- インスタンス起動時に動的IPアドレス処理の設定を行うこと
参考
- 投稿日:2020-11-12T10:59:20+09:00
Python (Boto3) @ Lambda で CloudWatch Logs の特定のログストリームにログを出力する
■ はじめに
Python (Boto3) @ Lambda から CloudWatch Logs の特定のログストリームにログを出力したかったので、やってみました。
■ コード
コードは、以下。
def put_logs(client, group_name, stream_name_prefix, message): try: exist_log_stream = True log_event = { 'timestamp': int(time.time()) * 1000, 'message': message } sequence_token = None for i in range(2): try: if exist_log_stream == False: create_log_stream_response = client.create_log_stream( logGroupName = group_name, logStreamName = stream_name_prefix) exist_log_stream = True if sequence_token is None: put_log_events_response = client.put_log_events( logGroupName = group_name, logStreamName = stream_name_prefix, logEvents = [log_event]) else: put_log_events_response = client.put_log_events( logGroupName = group_name, logStreamName = stream_name_prefix, logEvents = [log_event], sequenceToken = sequence_token) except client.exceptions.ResourceNotFoundException as e: exist_log_stream = False except client.exceptions.DataAlreadyAcceptedException as e: sequence_token = e.response.get('expectedSequenceToken') except client.exceptions.InvalidSequenceTokenException as e: sequence_token = e.response.get('expectedSequenceToken') except Exception as e: print(e) break except Exception as e: print(e)■
sequenceTokenの取得の仕方こちらの記事 ( Lambda (Python) から特定のログストリームにログを書こうとして苦戦した2つのポイント - Qiita ) にもありますが、
put_log_eventsでログをPUTする際、例外はありますが、基本的にはsequenceTokenを設定する必要があります。
- put_log_events - CloudWatchLogs — Boto3 Docs 1.16.15 documentation
- 新しく作成されたログストリームでのアップロードには、シーケンストークンは不要。
describe_log_streamsによるsequenceTokenの取得記事の中では
describe_log_streamsによって、ログストリームの存在判定とsequenceTokenの取得を行っており、describe_log_streamsのレスポンスからnextTokenとして取得しています。ですが、実は CloudWatch Logs のクォータ - Amazon CloudWatch Logs にも書かれていますが、
describe_log_streamsにはクォータによる制限があります。
DescribeLogStreams
- 1 リージョン、1 アカウントあたり 5 件のトランザクション/秒 (TPS)。
- クォータの引き上げをリクエスト可。
その為、使い方にもよりますが、出力頻度が高い場合は、クォータの制限に引っ掛かり遅延が発生することがあり、実際、Lambda から結構な頻度でログを出力したところ、
describe_log_streamsでの遅延が発生してしまいました。
put_log_eventsによるsequenceTokenの取得そこで、AWS サポート に相談したところ、
put_log_eventsによるsequenceTokenの取得を提案されました。put_log_events - CloudWatchLogs — Boto3 Docs 1.16.15 documentation にも記載されていますが、
InvalidSequenceTokenExceptionからexpectedSequenceTokenとして取得出来るみたいです。もちろん
put_log_eventsにもクォータの制限はありますが、describe_log_streamsより緩めです。
PutLogEvents
- 1 秒、1 ログストリームあたり 5 リクエスト。
- 追加のリクエストは調整され、クォータは変更不可。
- 1 リージョン、1 アカウントあたり 800 件のトランザクション/秒 (TPS)。
- クォータの引き上げをリクエスト可。
今回のやり方にしたところ遅延が解消されましたので、使い方にもよりますが、出力する頻度が多い場合は
put_log_eventsを使ったほうが良い様に思います。逆に、今回のやり方でも遅延が発生が解消されない場合は、別のやり方を検討する必要があるかもしれません。
■ 出力先のログストリームの存在確認
上述した記事 ( Lambda (Python) から特定のログストリームにログを書こうとして苦戦した2つのポイント - Qiita ) では、
describe_log_streamsで、sequenceTokenの取得だけではなく、ログストリームの存在確認も行っていましたが、クォータの制限によりdescribe_log_streamsは使えませんので、別のやり方で確認する必要があります。ただ、これも
put_log_eventsのExceptionsで確認出来るみたいです。ResourceNotFoundExceptionに入ってきたらログストリームが存在しないということで、create_log_streamを実行します。■ ハマりポイント
上述しましたが…、最初は問題無かったのにリクエスト頻度が増えるに連れて Lambda の実行時間が伸びて非常に困りました。当然、コストにも跳ね返ってきますしね…。
とりあえず、AWS サポート さんに相談して良かったです。Boto3 documentation — Boto3 Docs 1.16.16 documentation に記載されているものの、相談しなかったら、見つけられなかった気がします…。どうもありがとうございました。?♂️?♂️?♂️
■ まとめ
参考になれば♪
???
- 投稿日:2020-11-12T09:46:13+09:00
【簡単に変更履歴を管理】AWS Config導入事例5選【導入事例から学ぶ】
以前お伝えした運用改善系のサービスの一つAWS configで何ができるのかを調べてみました。
AWS運用改善サービスランキング【AWS Management Governance】はじめに
AWSを運用していると
「この設定、いつ誰が何のために入れたんだろう」
という悩みを持ったことはないでしょうか?
私はインフラエンジニアを10年近く経験していますが、結構ありますね。
※細かい権限を設定されているが、謎にAdministrator権限が追加されているIAMなど。。AWS Configはこの悩みを解決してくれる機能を持っていて、導入も簡単に行えます。
(「何のために」は推測するしかないですが、、)
それだけでなく、色々な活用方法があったのでそれを紹介していきます。AWS Config 導入
導入手順
下記のサーバーワークスの動画を見ると分かりやすいと思います。
ハンズオン形式で設定項目をみることができます。
導入は簡単ですね。【はじめてのAWS #09】 AWS Config を設定してみよう
AWS Configの設定
下記4つの設定項目があります。
必須の設定はリソースタイプ指定とS3です。
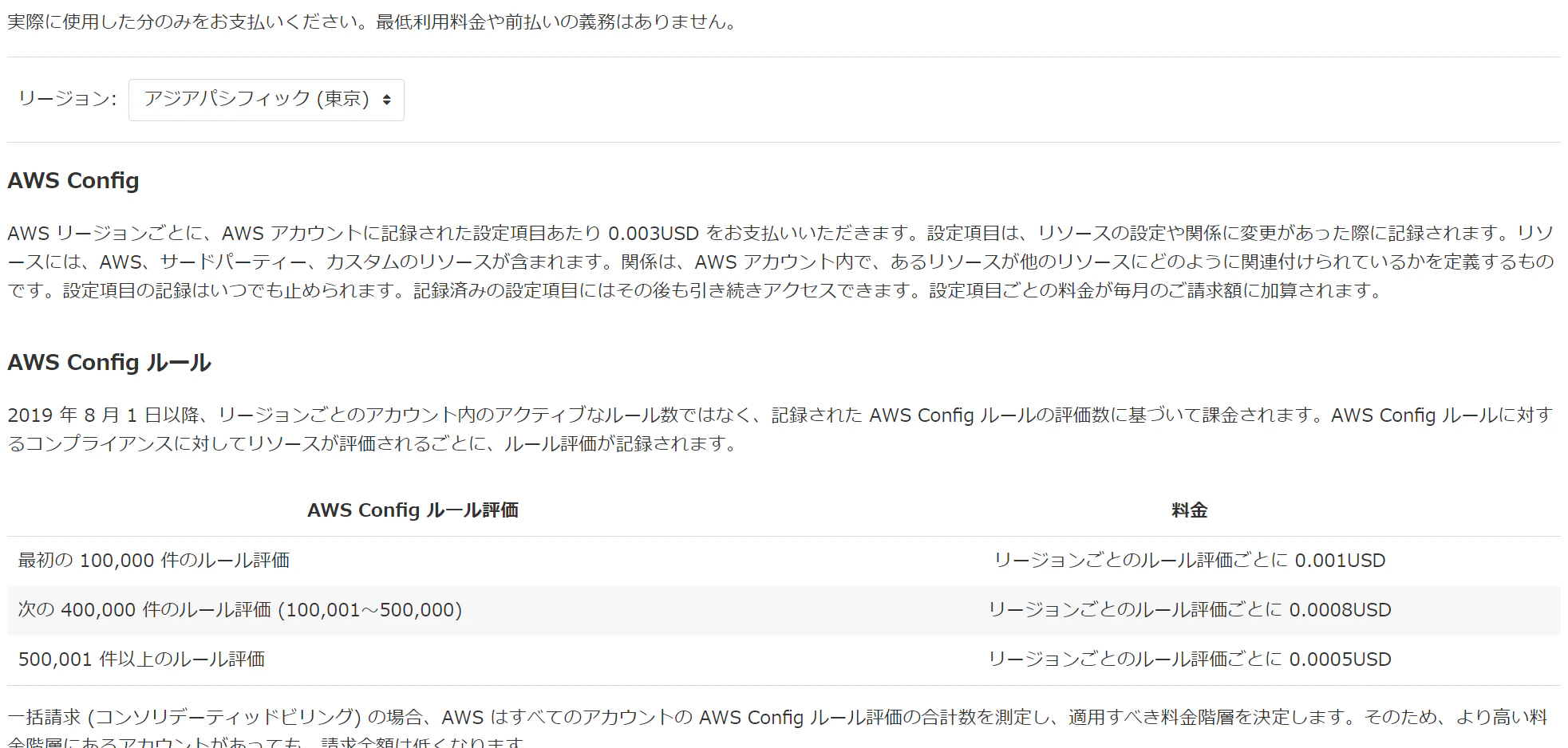
AWS Configの料金
従量課金のため、使ってみないとどの程度の料金になるか分かりません。
Config Ruleの課金体系の理解は下記の記事を見ると分かりやすいかと思います。
[Config Rulesが激安になるのでみんな使ったほうが良いRuleを紹介します!](https://dev.classmethod.jp/articles/recommend-config-rules-for-all-user/)AWS Config導入事例
Preziのケーススタディ(2016年)
https://aws.amazon.com/jp/solutions/case-studies/prezi/
リソース構成の変更追跡と変更管理のルールに使用した事例です。
FanDuelケーススタディ(2014年)
https://aws.amazon.com/jp/solutions/case-studies/fanduel/
AWSのマネージドサービスにAWS Configを利用した事例です。
マネージドサービスでも使えるんですね。
調べてみたらマネージドサービスでもかなり使えるようになっています。
参考:サポートされているリソースタイプ100を超えるAWSアカウント運用におけるガードレール構築事例
https://engineering.visional.inc/blog/171/awssummit_securityguardrail/
これまでのセキュリティはゲート(チェックリストなどで厳しく管理)という考え方でした。
アジリティを維持してガバナンスコントロールを実現するために新しくガードレールという考え方が生まれています。
AWS Configを利用することでルール外の動作を自動検知する運用がガードレールになります。
隠れて守らないこともできるゲートより、ガードレールの方が理想に見えます。
セキュリティで加速するクラウドジャーニー
https://pages.awscloud.com/rs/112-TZM-766/images/C1-04.pdf
事例ではないですが、一般的なCloudConfigを使う例となります。
AWS Configは発見的コントロールに分類されたセキュリティ対策製品になります。
AWSセキュリティ導入パック(CloudShift)
https://cloudshift.stylez.co.jp/aws-security-pack/
こちらも事例ではないですが、AWSのセキュリティ対策をパッケージ化したサービスなので、
参考になると思います。
AWS Configは設定変更履歴管理とルール準拠状況確認の役割をはたしています。
さいごに
事例をみても変更履歴管理と想定外設定の発見(Config Rule)という2つの役割を果たすサービスであることが分かりました。
ルールをどうするかの検討はありますが、導入が簡単なため、まずは有効化してみるのはありかなと思います。
最終的にはガードレールの考え方を適用していきたいと思います。





- 投稿日:2020-11-12T09:31:23+09:00
AWS EC2にdockerをインストールする
はじめに
AWS EC2にdockerをインストールする手順です。
インストール手順
- Amazon Linux 2
ターミナル# yumのアップデート sudo yum update -y # dockerのインストール sudo amazon-linux-extras install docker -y # dockerの起動 sudo service docker start # ec2-userのセカンダリグループにdockerを追加する # ※これによりsudoを利用せずとも、dockerコマンドが利用できるようになる sudo usermod -a -G docker ec2-user # 一度、ターミナルを再接続する # インストールの確認 docker info
- 投稿日:2020-11-12T08:54:43+09:00
projen ではじめる快適 AWS CDK Construct Library 開発生活
はじめに
AWS CDK では 独自の Construct Library を作成し、npm や PyPI に公開することができます。
私も先日 cdk-ecr-image-scan-notify という Construct Library を公開したのですが
projen を使用することで Construct Library の作成~リリースがとても捗ったのでご紹介します。本記事の内容は 以下のバージョンで動作を確認しています。
- projen: v0.3.162
- AWS CDK: v1.73.0
What is projen?
projen は近年複雑化しているプロジェクト構成をコードで定義し、管理するためのツールです。
AWS CDK チームのコアメンバーである Elad Ben-Israel 氏を中心に開発されています。https://github.com/projen/projen
projen では
package.json、.gitignore等、通常は自分で管理する必要のある
多くのプロジェクトファイルを自動で管理します。
ジェネレーターとしてプロジェクト作成時に各種ファイルを生成するだけでなく、
projen が継続してこれらの構成を更新し、維持します。あらかじめ定義されているプロジェクトタイプを使用して新規プロジェクトを簡単に開始できます。
2020/11 時点で以下のプロジェクトタイプをサポートしています。Commands: projen new awscdk-app-ts AWS CDK app in TypeScript. projen new awscdk-construct AWS CDK construct library project. projen new cdk8s-construct CDK8s construct library project. projen new jsii Multi-language jsii library project. projen new nextjs Next.js project without TypeScript. projen new nextjs-ts Next.js project with TypeScript. projen new node Node.js project. projen new project Base project. projen new react React project without TypeScript. projen new react-ts React project with TypeScript. projen new typescript TypeScript project. projen new typescript-app TypeScript app.awscdk-construct は jsii を使用した Contruct をビルドするための環境を作成します。
jsii により TypeScript のコードから Python, Java, .NET で動作するライブラリを生成できます。Create project
新規プロジェクトの作成
projen new awscdk-constructで Construct Library プロジェクトを作成します。$ mkdir cdk-sample-lib && cd cdk-sample-lib $ npx projen new awscdk-construct npx: installed 63 in 8.37s ? Created .projenrc.js for AwsCdkConstructLibrary ? Synthesizing project... $GIT_USER_NAME is not definedこの時点でプロジェクトディレクトリ配下に、
.projenrcが作成されます。const { AwsCdkConstructLibrary } = require('projen'); const project = new AwsCdkConstructLibrary({ authorAddress: "user@domain.com", authorName: $GIT_USER_NAME, cdkVersion: "1.60.0", name: "cdk-sample-lib", repository: "https://github.com/user/cdk-sample-lib.git", }); project.synth();.projenrc の修正
使用する AWS CDK やその他のモジュールの依存関係を追加できます。
cdkDependencies: [ '@aws-cdk/aws-lambda', '@aws-cdk/core' ], deps: [ 'super-useful-lib' ]jsii で TypeScript 以外の言語にクロスコンパイルを行う場合はターゲット言語を追加します。
python: { distName: 'cdk-sample-lib', module: 'cdk_sample_lib', },その他に指定可能なオプションについては API.md をご確認ください。
参考例として、修正後のファイルは以下のようになります。const { AwsCdkConstructLibrary } = require('projen'); const PROJECT_NAME = "cdk-sample-lib" const project = new AwsCdkConstructLibrary({ authorAddress: "hayaok333@gmail.com", authorName: "hayao-k", cdkVersion: "1.73.0", name: PROJECT_NAME, repository: "https://github.com/hayao-k/cdk-sample-lib.git", defaultReleaseBranch: 'main', cdkDependencies: [ '@aws-cdk/core', '@aws-cdk/aws-lambda' ], python: { distName: PROJECT_NAME, module: 'cdk_sample_lib', }, }); project.synth();projen コマンドの実行
.projenrcを編集したら、projen コマンドを実行し、変更を反映します。 (yarn が必要です)$ npx projen npx: installed 63 in 5.491s ? Synthesizing project... ? yarn install --check-files yarn install v1.22.5 info No lockfile found. [1/5] Validating package.json... [2/5] Resolving packages... [3/5] Fetching packages... info fsevents@2.2.1: The platform "linux" is incompatible with this module. info "fsevents@2.2.1" is an optional dependency and failed compatibility check. Excluding it from installation. [4/5] Linking dependencies... [5/5] Building fresh packages... success Saved lockfile. Done in 20.34s. ? jest: * => ^26.6.3 ? @types/jest: * => ^26.0.15 ? ts-jest: * => ^26.4.4 ? eslint: * => ^7.13.0 ? eslint-import-resolver-node: * => ^0.3.4 ? eslint-import-resolver-typescript: * => ^2.3.0 ? eslint-plugin-import: * => ^2.22.1 ? json-schema: * => ^0.2.5 ? Synthesis complete ---------------------------------------------------------------------------------------------------- Commands: BUILD compile Only compile watch Watch & compile in the background build Full release build (test+compile) TEST test Run tests test:watch Run jest in watch mode eslint Runs eslint against the codebase RELEASE compat Perform API compatibility check against latest version release Bumps version & push to master docgen Generate API.md from .jsii manifest bump Commits a bump to the package version based on conventional commits package Create an npm tarball MAINTAIN projen Synthesize project configuration from .projenrc.js projen:upgrade upgrades projen to the latest version MISC start Shows this menu Tips: ? The VSCode jest extension watches in the background and shows inline test results ? Install Mergify in your GitHub repository to enable automatic merges of approved PRs ? Set `autoUpgradeSecret` to enable automatic projen upgrade pull requests ? `API.md` includes the API reference for your library ? Set "compat" to "true" to enable automatic API breaking-change validation
package.jsonの作成とインストールをはじめ、.gitignoreや.npmignore、eslint、jsii の構成
ライセンスファイル等が projen により自動で生成されていることがわかります。
新規プロジェクトを作成するたびに、既存のプロジェクトからコピーしてくるといった作業が不要になります。
これらのファイルを編集する場合、必ず.projenrcを修正し、projen コマンドを再実行する必要があります。
手動で編集した場合、ビルドが失敗します。$ tree -L 1 -a . ├── .eslintrc.json ├── .github ├── .gitignore ├── LICENSE ├── .mergify.yml ├── node_modules ├── .npmignore ├── package.json ├── .projenrc.js ├── README.md ├── src ├── test ├── tsconfig.jest.json ├── version.json ├── .versionrc.json └── yarn.lockDevelopmet
ここでは シンプルに Hello World の Lambda を作成する例を考えてみます。
projen により以下のディレクトリがすでに作成されています。. ├── lib/ ├── src/ ├── test/
libディレクトリにはコンパイルされたファイルが配置されます。
Lambda 関数のコードは CDK のコードにインラインでも挿入できますが、
今回は 別途functionsディレクトリを作成し、配置、参照させます。fucntions/index.jsexports.handler = async (event) => { const response = { statusCode: 200, body: JSON.stringify('Hello from Lambda!'), }; return response; };
srcディレクトリには以下の2ファイルを作成します。src/index.tsimport { Code, Function, Runtime } from '@aws-cdk/aws-lambda'; import * as cdk from '@aws-cdk/core'; export class CdkSampleLib extends cdk.Construct { constructor(scope: cdk.Construct, id: string) { super(scope, id); new Function(this, 'HelloWorld', { handler: 'index.handler', code: Code.fromAsset('functions'), runtime: Runtime.NODEJS_12_X, }); } }src/integ.default.tsimport * as cdk from '@aws-cdk/core'; import { CdkSampleLib } from './index'; const app = new cdk.App(); const stack = new cdk.Stack(app, 'MyStack'); new CdkSampleLib(stack, 'Cdk-Sample-Lib');
testディレクトリには以下のファイルを作成しました。test/hello.test.tsimport * as cdk from '@aws-cdk/core'; import { CdkSampleLib } from '../src/index'; import '@aws-cdk/assert/jest'; test('create app', () => { const app = new cdk.App(); const stack = new cdk.Stack(app); new CdkSampleLib(stack, 'TestStack'); expect(stack).toHaveResource('AWS::Lambda::Function'); });Unit Test, Build, Release
projen から生成された package.json により、各種 scripts が定義済みです。
Unit Test
yarn testでテストを実行します。
yarn build時も実行されるため、ここでは実行例は割愛します。Build
yarn buildでテストを実行し、TypeScript を jsii モジュールにコンパイルします。
また jsii-docgen によりコード内のコメントから API ドキュメント (API.md) を生成します。
さらに jsii-pacmak によりdistディレクトリに各言語固有の公開パッケージを作成します。$ yarn build yarn run v1.22.5 $ yarn run test && yarn run compile && yarn run package $ rm -fr lib/ && jest --passWithNoTests --updateSnapshot && yarn run eslint PASS test/hello.test.ts ✓ create app (197 ms) ----------|---------|----------|---------|---------|------------------- File | % Stmts | % Branch | % Funcs | % Lines | Uncovered Line #s ----------|---------|----------|---------|---------|------------------- All files | 100 | 100 | 100 | 100 | index.ts | 100 | 100 | 100 | 100 | ----------|---------|----------|---------|---------|------------------- Test Suites: 1 passed, 1 total Tests: 1 passed, 1 total Snapshots: 0 total Time: 4.713 s, estimated 7 s Ran all test suites. $ eslint --ext .ts,.tsx --fix --no-error-on-unmatched-pattern src test $ jsii --silence-warnings=reserved-word --no-fix-peer-dependencies && jsii-docgen $ jsii-pacmak Done in 51.38s.ビルドが成功したら、以下のようにローカルでデプロイを試すことができます。
$ cdk deploy --app='./lib/integ.default.js' This deployment will make potentially sensitive changes according to your current security approval level (--require-approval broadening). Please confirm you intend to make the following modifications: IAM Statement Changes ┌───┬───────────────────────────────────────────────┬────────┬────────────────┬──────────────────────────────┬───────────┐ │ │ Resource │ Effect │ Action │ Principal │ Condition │ ├───┼───────────────────────────────────────────────┼────────┼────────────────┼──────────────────────────────┼───────────┤ │ + │ ${Cdk-Sample-Lib/HelloWorld/ServiceRole.Arn} │ Allow │ sts:AssumeRole │ Service:lambda.amazonaws.com │ │ └───┴───────────────────────────────────────────────┴────────┴────────────────┴──────────────────────────────┴───────────┘ IAM Policy Changes ┌───┬───────────────────────────────────────────────────────────┬────────────────────────────────────────────────────────────┐ │ │ Resource │ Managed Policy ARN │ ├───┼───────────────────────────────────────────────────────────┼────────────────────────────────────────────────────────────┤ │ + │ ${Cdk-Sample-Lib/HelloWorld/ServiceRole} │ arn:${AWS::Partition}:iam::aws:policy/service-role/AWSLamb │ │ │ │ daBasicExecutionRole │ └───┴───────────────────────────────────────────────────────────┴────────────────────────────────────────────────────────────┘ (NOTE: There may be security-related changes not in this list. See https://github.com/aws/aws-cdk/issues/1299) Do you wish to deploy these changes (y/n)? y MyStack: deploying... [0%] start: Publishing 20472c64d312cc547a9359d36b04cfc75633027c0b13c3c07b96dfdf1b1c428f:current [100%] success: Published 20472c64d312cc547a9359d36b04cfc75633027c0b13c3c07b96dfdf1b1c428f:current MyStack: creating CloudFormation changeset... [██████████████████████████████████████████████████████████] (4/4) ✅ MyStack Stack ARN: arn:aws:cloudformation:ap-northeast-1:123456789012:stack/MyStack/b7e03de0-2442-11eb-b897-06ee62aadd34削除も同様です。
$ cdk destroy --app='./lib/integ.default.js' Are you sure you want to delete: MyStack (y/n)? y MyStack: destroying... 5:27:29 PM | DELETE_IN_PROGRESS | AWS::CloudFormation::Stack | MyStack 5:27:34 PM | DELETE_IN_PROGRESS | AWS::IAM::Role | Cdk-Sample-Lib/HelloWorld/ServiceRole ✅ MyStack: destroyedRelease
まずは変更をコミットします。
$ git add . $ git commit -m "feat: release 0.0.1"
yarn releaseでバージョンをバンプし、CANGELOG.md が自動で更新されます
その後、GitHub のリリースブランチへ push します。$ yarn release yarn run v1.22.5 $ yarn run --silent no-changes || (yarn run bump && git push --follow-tags origin main) $ yarn run --silent no-changes || standard-version ✔ bumping version in version.json from 0.0.0 to 0.0.1 ✔ Running lifecycle script "postbump" ℹ - execute command: "yarn run projen && git add ." ? yarn install --check-files ? Synthesis complete ---------------------------------------------------------------------------------------------------- Commands: BUILD compile Only compile watch Watch & compile in the background build Full release build (test+compile) TEST test Run tests test:watch Run jest in watch mode eslint Runs eslint against the codebase RELEASE compat Perform API compatibility check against latest version release Bumps version & push to main docgen Generate API.md from .jsii manifest bump Commits a bump to the package version based on conventional commits package Create an npm tarball MAINTAIN projen Synthesize project configuration from .projenrc.js projen:upgrade upgrades projen to the latest version MISC start Shows this menu Tips: ? The VSCode jest extension watches in the background and shows inline test results ? Install Mergify in your GitHub repository to enable automatic merges of approved PRs ? Set `autoUpgradeSecret` to enable automatic projen upgrade pull requests ? `API.md` includes the API reference for your library ? Set "compat" to "true" to enable automatic API breaking-change validation ✔ created CHANGELOG.md ✔ outputting changes to CHANGELOG.md ✔ committing version.json and CHANGELOG.md and all staged files ✔ tagging release v0.0.1 ℹ Run `git push --follow-tags origin master` to publishもしくは
yarn bumpを実行することで任意のバージョンにバンプすることが可能です。$ yarn bump --release-as 1.0.0 && git push --follow-tags origin main
projenコマンド実行時に Github Actions のワークフロー定義も生成されており、
パッケージリポジトリへのリリースも簡単に自動化することができます。
Build workflow (.github/workflows/build.yaml):
pull request 作成時に起動
ライブラリのビルドおよび、改ざん (手動修正されていないか) のチェックRelease workflow (.github/workflows/release.yaml):
リリースブランチへの push 時に起動
リリースブランチでのビルドジョブ後、npm や PyPI などの各言語のリポジトリへの公開が自動で行われます。
リポジトリへのリリースには jsii-release が使用されています。
Release ジョブを正常に動作させるには、公開する言語に応じた Secrets を
GitHub リポジトリに登録する必要があります。
- npm:
NPM_TOKEN- .NET:
NUGET_API_KEY- Java:
MAVEN_GPG_PRIVATE_KEY,MAVEN_GPG_PRIVATE_KEY_PASSPHRASE,MAVEN_PASSWORD,MAVEN_USERNAME,MAVEN_STAGING_PROFILE_ID- Python:
TWINE_USERNAME,TWINE_PASSWORDさいごに
projen を使用することで、Construct Library の実装に集中することができます。
(もちろん通常の CDK App についても)
参考の GitHub リポジトリとしては冒頭でご紹介した cdk-ecr-image-scan-notify を
ご確認いただければと思います。Construct Library 自体もぜひ使ってみていただけると嬉しいです。ECR のイメージスキャン結果を Slack 通知する Lambda 関数 と EventBrigde のイベントルールを AWS CDK で Construct Library として公開してみました!
— hayao_k (@hayaok3) November 3, 2020
TypeScript と Python で利用できます。https://t.co/AseGERM45u pic.twitter.com/kPSMHBal91projen を使用した Construct Library の作成については台北の AWS Community Builder である
Neil Kuan (@guan840912) からの紹介と多くの協力により学ぶことができました。
彼の GitHub アカウントで複数の Construct Library が公開されているので、こちらもチェックしてみてください!以上です。
参考になれば幸いです。
- 投稿日:2020-11-12T07:29:53+09:00
CloudFormationをゼロから勉強する。(その8:スタックのネスト)
はじめに
本記事でも何度か紹介している
AWS Black Belt Online Seminarですが、また新しいセミナーが公開されたようです。3か月くらい前にもCloudFormationのセミナーが公開されていましたが、それだけ
CloudFormationの需要があるということなんでしょうね。
その6では
Transformを使用した他テンプレートのインクルードを試しましたが、今回はスタックをネスト構成にしてテンプレートを分割してみようと思います。ネストとは
イメージとしてはその6の
Transformでのテンプレート分割と同じような方法となりますが、Transformのインクルードはベーステンプレートの一部を別ファイルにして呼び出すイメージなので、実行単位であるスタックとしては1スタックであるのに対して、ネストは他のスタックを呼び出すイメージとなるので、実行時の見え方は複数スタックとなります。共通コンポーネント用スタックを作成して、個々のスタックから呼び出すようにするのがAWSのベストプラクティスとのことです。
・・・とはいえ
Transformのインクルードでも書き方次第でネストした場合と同じことができそうなのでいまいち区別がし辛いですが、ネストの場合はその6で書いたようなyamlの書き方の制約は無いので、Transformのインクルードはリソースの一部パラメータ(例えばタグ)を分割したりするのに使い、ネストはリソース自体を分割したりするのに使うといった区別が良いかと思います。ネストの書式
ResourcesセクションにAWS::CloudFormation::Stackタイプのリソースを作成することでネストしたスタックを指定できます。ネストしたファイル名を指定する必要があるため、
PropertiesでTemplateURLの指定が必須となります。また、
S3バケットへのアップロードが必要となるため、Transformでのインクルードと同様、実行する前にpackageコマンドでURLの変換、S3バケットへのアップロードを行う必要があります。ネストしたスタックの指定方法(抜粋)Resources: NestStack1: Type: AWS::CloudFormation::Stack Properties: TemplateURL: ./vpc.yamlネストしたスタックへの入出力
ネストのスタックは親子関係となるため、
親スタックから子スタックを呼び出す構成になります。入出力の関係は
子スタックをプログラミング言語の関数として考えるとイメージが湧きやすいと思いますが、親スタックで子スタックからの入出力を受ける場合、子スタック(という関数)に引数を渡すのが入力で、子スタック(という関数)からの戻り値が出力となります。子スタック側での入出力書式
これはネストしていない場合と同じく
Parametersセクションで上位からの入力を受けて、Outputsで結果を上位へ渡します。親スタック側での入力書式
親スタックから子スタックへ値を入力するためにはネストするスタックのPropertiesにParametersを記載して子スタックに渡す値を記載する必要があります。上述の例で言うと、
親スタックから子スタック(という関数)へ引数を渡す方法が、PropertiesのParametersとなります。子スタックへの入力値指定例Resources: NestStack1: ★子スタック名 Type: AWS::CloudFormation::Stack Properties: TemplateURL: ./vpc.yaml Parameters: NestVPCRange: !Ref VPCRange NestSubnetRange1: !Ref SubnetRange1親スタック側での出力書式
子スタック(という関数)からの戻り値は!GetAtt組み込み関数で以下の書式で記載することで取得できます。出力値(戻り値)の取得!GetAtt [子スタック名].Outputs.[子スタック側のOutputリソース名]例えば
親スタックで前項目の子スタックへの入力値指定例の設定、子スタックで以下のような出力設定を行ったとします。子スタック側でのOutput(抜粋)Outputs: NestSubnet1Id: ★Outputリソース名 Value: !Ref EC2Subnet1その場合、
子スタックの出力値(戻り値)を取得するためには以下の指定を行うことで取得できます。親スタック側でのNestStack1出力値の取得例!GetAtt NestStack1.Outputs.NestSubnet1Idネストスタック間の入出力まとめ
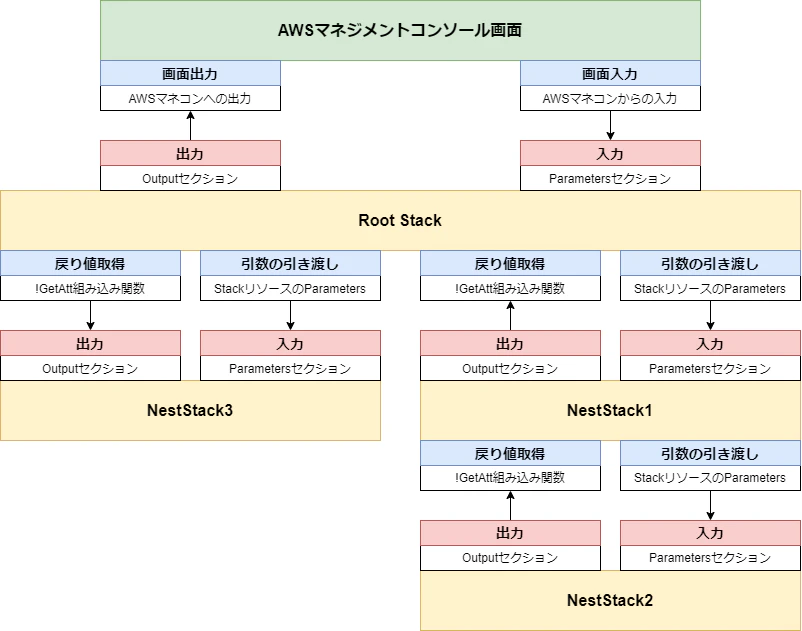
ネストスタック間の入出力について、AWSマネジメントコンソール画面からの入出力も含めたイメージ図を描いてみました。
青が
子スタックとのやり取り、赤が自スタックでのやり取りとなります。
基本のイメージが分かれば、図のような複雑なスタック構成でも悩むことはないかと思いますが、注意点として、各スタック間の値の入出力は単純なネストの記述ではスタックを飛び越してやり取りできません。
そのため、例えば図中の
NestStack2の出力値をNestStack3で使用したい場合は、まずNestStack1のOutputでNestStack2の戻り値をRoot Stackに渡し、次にRoot StackからNestStack3のParametersでNestStack3に値を引き渡す必要があります。もしスタックを飛び越してやり取りしたい場合は、
Outputセクションで値をExportすればやり取りすることが可能なようです。
※Exportする方法(Cross Stack Reference)は次回試そうと思います。今回作成する構成
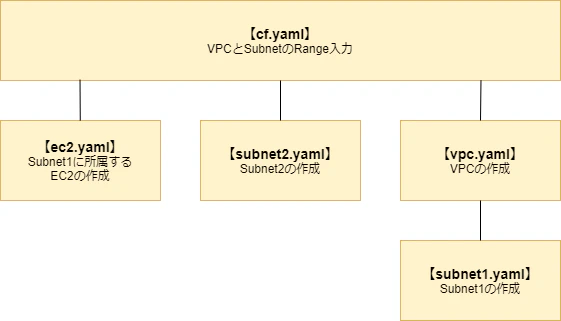
今回は以下のような構成を作ってみようと思います。
ルートスタック用テンプレートの作成
各
子スタックで使用するVPCRange、SubnetRange1、SubnetRange2を読み込み、各スタックの入力に引き渡します。また、
vpc.yamlで作成するVPC IDとsubnet1.yamlで作成するSubnet1のIDはsubnet2.yamlとec2.yamlで使用するため、vpc.yamlの出力値をsubnet2.yamlとec2.yamlの入力値として!GetAttで指定するようにします。ルートスタック用テンプレート(cf.yaml)AWSTemplateFormatVersion: 2010-09-09 Resources: NestStack1: Type: AWS::CloudFormation::Stack Properties: TemplateURL: ./vpc.yaml Parameters: NestVPCRange: !Ref VPCRange NestSubnetRange1: !Ref SubnetRange1 NestStack3: Type: AWS::CloudFormation::Stack Properties: TemplateURL: ./subnet2.yaml Parameters: NestVpcId: !GetAtt NestStack1.Outputs.NestVpcId NestSubnetRange2: !Ref SubnetRange2 NestStack4: Type: AWS::CloudFormation::Stack Properties: TemplateURL: ./ec2.yaml Parameters: NestSubnetId: !GetAtt NestStack1.Outputs.NestSubnet1Id Parameters: VPCRange: Type: String Description: "VPC Subnet Range" SubnetRange1: Type: String Description: "Subnet Range1" SubnetRange2: Type: String Description: "Subnet Range2"VPCスタック用テンプレートの作成
VPC Rangeと、子スタックとなるsubnet1.yamlのSubnet1 Rangeの情報をParametersセクションで受け取り、subnet1.yamlにSubnet1 Rangeの値を渡します。また、
Subnet1のIDは、ec2.yamlでも使用するため、subnet1.yamlの出力値をvpc.yamlの出力値としてルートスタックとなるcf.yamlに渡すようにします。VPCスタック用テンプレート(vpc.yaml)AWSTemplateFormatVersion: 2010-09-09 Parameters: NestVPCRange: Type: String NestSubnetRange1: Type: String Resources: EC2VPC1: Type: 'AWS::EC2::VPC' Properties: CidrBlock: !Ref NestVPCRange Tags: - Key: "Name" Value: "cf_VPC1" NestStack2: Type: AWS::CloudFormation::Stack Properties: TemplateURL: ./subnet1.yaml Parameters: NestVpcId: !Ref EC2VPC1 NestSubnetRange1: !Ref NestSubnetRange1 Outputs: NestVpcId: Value: !Ref EC2VPC1 NestSubnet1Id: Value: !GetAtt NestStack2.Outputs.NestSubnet1IdSubnet1スタック用テンプレートの作成
親スタックとなるvpc.yamlからの値をParametersで受け、Subnet1のIDをOutputsで出力するようにします。Subnet1スタック用テンプレート(subnet1.yaml)AWSTemplateFormatVersion: 2010-09-09 Parameters: NestVpcId: Type: 'AWS::EC2::VPC::Id' NestSubnetRange1: Type: String Resources: EC2Subnet1: Type: 'AWS::EC2::Subnet' Properties: VpcId: !Ref NestVpcId CidrBlock: !Ref NestSubnetRange1 Tags: - Key: "Name" Value: "cf_Subnet1" Outputs: NestSubnet1Id: Value: !Ref EC2Subnet1Subnet2スタック用テンプレートの作成
subnet2.yamlは他スタックで使用する値は無いので、親スタックとなるcf.yamlからの値をParametersで受けるだけになります。Subnet2スタック用テンプレート(subnet2.yaml)AWSTemplateFormatVersion: 2010-09-09 Parameters: NestVpcId: Type: 'AWS::EC2::VPC::Id' NestSubnetRange2: Type: String Resources: EC2Subnet2: Type: 'AWS::EC2::Subnet' Properties: VpcId: !Ref NestVpcId CidrBlock: !Ref NestSubnetRange2 Tags: - Key: "Name" Value: "cf_Subnet2"EC2スタック用テンプレートの作成
subnet1.yamlで出力したSubnet1のIDをParametersで読み込み、EC2インスタンスを作成します。EC2スタック用テンプレート(ec2.yaml)AWSTemplateFormatVersion: 2010-09-09 Parameters: NestSubnetId: Type: 'AWS::EC2::Subnet::Id' Resources: EC2Instance: Type: 'AWS::EC2::Instance' Properties: ImageId: ami-0cc75a8978fbbc969 InstanceType: t2.micro KeyName: staging_key NetworkInterfaces: - AssociatePublicIpAddress: "true" SubnetId: !Ref NestSubnetId DeviceIndex: 0テンプレートの実行
ネスト化により、テンプレートが複数に分かれるため、その6と同様、packageとdeployコマンドでテンプレートの変換と実行を行います。URLなどのテンプレートの変換は、
ルートスタックで行えば、子スタックも自動的に変換とS3への転送が行われるため、ルートスタック用テンプレートのみ実行します。テンプレートの変換とS3バケットへの転送aws cloudformation package --template-file cf.yaml --s3-bucket [S3バケット名] --output-template-file output.yaml
packageコマンド実行後、deployコマンドでS3バケットに転送したテンプレートを実行します。テンプレートの実行aws cloudformation deploy --template-file output.yaml --stack-name stack-test --parameter-overrides VPCRange=172.24.0.0/16 SubnetRange1=172.24.0.0/24 SubnetRange2=172.24.1.0/24
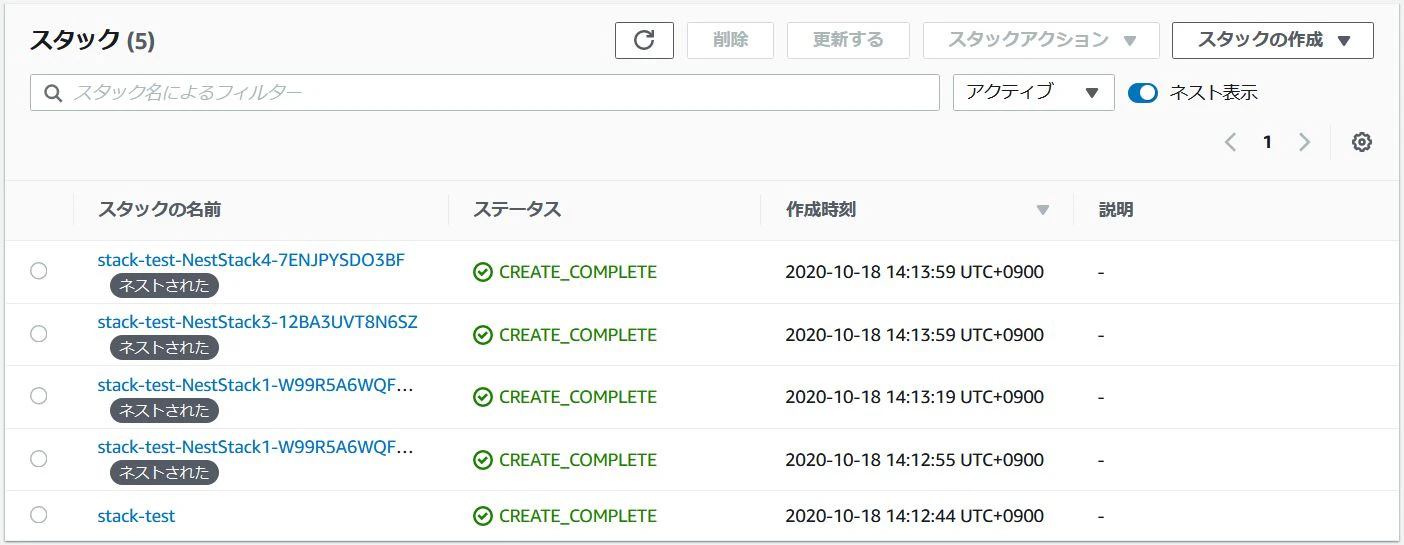
CloudFormationのスタック画面で以下の様になれば成功です。
おわりに
スタックのネストは親子関係となるため、構造が分かりやすく、書き方とイメージを覚えてしまえば分かりやすいと感じました。次も同じようなテンプレート分割方法となる
クロススタック参照(Cross Stack Reference)を勉強してみようと思います。
- 投稿日:2020-11-12T00:56:52+09:00