- 投稿日:2020-09-16T23:42:23+09:00
データベースの種類について
データベースサービスの相違点について自分なりにまとめてみました。
まだまだAWSサービスについての知識については未熟ですが、備忘録として記事にします。
もし、データベースの相違点で思い出したいときに参考までに読んでください。データベースの種類
データベースの種類には大きく分けて二つあります。
データ間の関係性を定義して利用するリレーショナルデータベース。
データ間の関係性のないデータベース、データはKey,value型によるKVSデータを利用するNoSQL型のデータベース(非リレーショナルデータベース)です。NoSQLのタイプ
NoSQLには下記の4つのタイプがあります。
タイプ 特徴 キーバリューストア キーに対してバリューを入れる単純な構造。データ読み込みが高速。高速なパフォーマンスと分散型拡張に優れている。 ワイドカラムストア 列指向とも呼ばれ、キーを利用するがデータはカラムに格納する。非機能データを大規模に格納するのが目的 ドキュメントデータベース JSONやXMLなどのデータを格納。複雑なデータ構造を扱うアプリで生産性高く柔軟に開発する グラフデータベース データ同士の関係をグラフで相互に結びついた要素で構成される。RDBと比較して高速横断検索が可能。 データベース各種類について
RDB
- 概要
業務向けのDB。基本はリレーショナルデータベース。
SQLでのデータ操作が可能。
- アーキテクチャ
テーブル間のリレーショナルが定義されたデータモデル
- 利用ケース
会計データなどの業務系構造化データ
オンプレ AWSサービス MySQL、Oracleなど RDS データウェアハウス(DWH)
- 概要
構造化データを利用した経営分析向けデータベース。
データの読み込み、集約に特化したBIデータ分析用のデータベース。
読み込むデータ構造を予め設計して、加工してから利用文のデータを蓄積
レスポンス重視でデータ抽出・集計が早いが、更新、トランザクションは遅い。* アーキテクチャ
データをパーティショニングして、複数ディスクから読み込む
- 利用データ
会計データなどの業務系の構造化データの分析用に加工し、BIで利用
KPI測定・競合分析・アクセス分析など
オンプレ AWSサービス Oracle Exadata, VERTICA,TERADATAなど Redshift 分散型DB・データレイク
- 概要
ビッグデータやIOTデータを蓄積して高速処理を可能にするDBとストレージの組み合わせ。
データの抽出に特化。
分散してデータを保存しており、ビッグデータの高速処理向け。
- アーキテクチャ
SQLライクなクエリ操作可能
INSERT・UPDATE・DELETEはない
トランザクションはない
データの書き込みは一括ロードまたは全件削除のみ
- 利用データ
ビッグデータ
オンプレ AWSサービス Impala,HDFSなど S3 KVS:キーバリュー型
- 概要
シンプルなデータ構造にすることで高速処理を可能にしたDB
- アーキテクチャ
強い整合性を犠牲にして、結果的な整合性を採用
分散むけデータモデル・クエリの採用
トランザクション・集計・JOINなどの不可
- 利用データ
大規模WEBサイトのバックエンドデータ(ユーザーセッション、ユーザー属性、事前計算データのキャッシュ)
メッセージングシステムのデータ
大規模書き込みが必要なIOTセンサーデータ
オンプレ AWSサービス radis,riak ElastiCache,DynamoDB ワイドカラム型
- 概要
キーに対してカラムを大規模に登録できるのがワイドカラム型
分散してシンプルなオペレーションを高速に実行できるDB
データ取得する際にデータ結合しなくても済むように、可能な限り多くのデータを同じ行に保持
アーキテクチャ
結果結合性を採用
キースペース、カラムファミリ、ロウ、カラムの入れ子構造
SQLライクなデータ操作が可能
データの更新は挿入による上書き利用データ
Facebook/Twitterなどのソーシャルデータの位置情報データストレージ
リアルタイム分析
データマイニング処理
オンプレ AWSサービス HBASE,cassandra DynamoDB ドキュメントDB
- 概要
ドキュメント指向データベースで様々なデータ構造のドキュメントを混在して保存することができる。
- アーキテクチャ
JSON/CMLをデータモデルに利用
小規模データの同期集計処理が可能だが、バッチは不向き
SQLライクなデータ操作が可能でKVSよりもクエリが豊富なため操作しやすい
Shardingによるデータベースの分散化
- 利用データ
半構造化データ(XML/JSON)
大規模WEBのログ補完など
オンラインゲームデータ
カタログ管理
オンプレ AWSサービス mongoDB,MarkLogic,CouchDB,Couchbase Amazon DocumentDB, mongoDB インメモリデータグリッド
- 概要
大量のデータを多数のサーバのメモリ上で分散して管理する
ミリ秒単位の高速応答処理が可能
- アーキテクチャ
データをメモリ上に置くことで、高速なデータアクセスが実現
データを多数のサーバで分散して管理
- 利用データ
金融の取引処理データでミリ秒以下の応答時間を実現
オンプレ AWSサービス GEODE,ORACLE,hazelcast,Ignite,Infinispon Redis ElastiCache, Memcached ElastiChache 全検索型エンジン×分散型DB
- 概要
全検索型のデータ検索エンジンで、分散データベースと連携して検索データベースを構築
検索条件との関係性・関連性が高いデータを抽出して返す
- アーキテクチャ
Elasticsearchは前文検索用のライブラリ。Apach Luceneを利用したデータストア
分析の柔軟性や速度が高く、分析、蓄積・可視化環境を容易に構築可能
- 利用データ
半構造化データ(XML/JSON)
高可用な全検索エンジン
サイト内でデータの検索
デバイス登録状況・配信状況のリアルタイム可視化などリアルタイム検索要件/検索行動の可視化
オンプレ AWSサービス elasticsearch,kibana Elasticsearch Service グラフDB
- 概要
グラフ演算に特化したDBでデータ間の繋がり方を検索・可視化に利用
- アーキテクチャ
グラフデータ構造を取るため、RDB以上にスケールアウトができない
レコード数が増えると、検索にかかる時間と難易度が増大
ACID特性が担保されていおり、オブジェクト間の関連付けを簡単に表現できる
- 利用データ
最短経路探索
金融取引の詐欺検出
ソーシャルネットワークによるリレーション計算
オンプレ AWSサービス neo4j Amazon Neptune 分散OLTP
- 概要
グローバルに分散され、強制合成を揃えたデータベース
- アーキテクチャ
リレーショナルデータベースの構造と非リレーショナルデータベーるの分散スケーラビリティを兼ね揃える
高い可用性、高性能のトランザクションと強制合成が実現
- 利用データ
大規模な業務データ処理
オンプレ AWSサービス Amazon aurora まとめ
データ構造がシンプルで利用しやすい場合はNoSQLのKVS、ワイドカラム、ドキュメントDBを利用し、
複雑なDB処理が必要な場合はRDBやグラフDBを利用する。
検索に特化したい場合はElasticSearch
DWHとして利用したい場合はRedshift
データレイクとして利用する場合はS3
- 投稿日:2020-09-16T22:36:57+09:00
“Beyond the Twelve-Factor App” & “The Twelve-Factor App”から学びAWSで実践する (1)1つのコードベース、1つのアプリケーション / コードベース - バージョン管理されている1つのコードベースと複数のデプロイ
解説
本ファクターでは、アプリケーションのソースコードの管理方法、デプロイの考え方を述べています。
アプリケーションはバージョン管理されたリポジトリに単一のコードとして管理されていること
ようするにGitでソースコードを管理しましょうということです。ソースコードの変更がきちんと管理されているというのがアプリケーション開発の出発点になります。企業やチームで開発する場合はもちろんですが、個人で開発する場合も必ずバージョン管理ツールを使いましょう。ソースの修正は意図をもって行い、その意図が記録されているという状況が健全です。アプリケーションは単一のコードから複数の環境にデプロイされること
アプリケーションをデプロイする場合には、管理されているコードから実施しましょう。デプロイは開発用、テスト用、ステージング用、プロダクション用といったように様々な用途で複数の環境に展開することができるようにしておく必要があります。なお、単一のコードといっても、同じバージョンのコードがデプロイされている必要はありません。バージョン管理されているコードのどの部分からでも、好きな環境にデプロイできるようになっているべきです。例えば、プロダクション環境はテストがすべて完了したコードのバージョンでデプロイするべきだし、開発やテスト用の環境には新規に追加した機能を含んだコードからデプロイすることになるでしょう。一つのコードから複数のアプリケーションを生みださないこと
一つのコード管理の中に複数のアプリケーションを入れるのはやめましょう。具体的には、複数の起動スクリプトやmain関数などが単一のコードに入っていることを禁じています。この状態は複数の開発チームが単一のコードに対してメンテしている状態になっていることを示しているという指摘です。この状態では他にも、異なるライフサイクルのアプリケーションが一つのコードに入っているということになります。あるタイミングのソースコードはアプリ1はプロダクションレベル、アプリ2が開発中というような状況になると適切なバージョン管理ができません。このようになっている場合には、アプリケーション毎にそれぞれリポジトリを用意し別々に管理することを始めましょう。ソースの分割に当たって、共通ライブラリ的な部分があれば、これも別のリポジトリで管理し分けて管理していきます。
Beyondの中では、さらにコンウェイの法則(組織やチームの構成はソフトウェアアーキテクチャに反映される)に関してもここで触れています。アプリケーションを適切な単位に分解しマイクロサービス化することを提唱しています。モノリシックで大きなシステムが一つのコードとして管理されている場合、この時も一つのリポジトリで多くの開発チームが同時に作業をしていることでしょう。たとえ複数のアプリケーションを生みだしていなくても結局は同じ状況になります。それを解消するための方法論としてマイクロサービスとなります。これは先ほどの分割よりは大変でしょうが、継続して開発を続けていく上では必要なリファクタリングです。実践
Gitを使ったソースコードの管理手法
世の中には多くのGit互換のリポジトリが存在します。最も有名なのがGitHubです。他にも、Bitbucket、GitLabといったパブリックサービスが存在します。使い勝手はそれぞれでしょうが各チームの事情に合ったものを選択してよいと思います。個人で利用する場合でも必ずこういったリポジトリを利用しコードの管理をしましょう。なお、古い体質の日本企業だと「パブリックサービスにソースを預けるなんて」となり簡単には使わせてもらえないこともあるでしょう。その時はGitLabを独自で運用するという選択が現実的かもしれません。また、AWSを使ったサービスの開発を行っているのであれば、CodeCommitを使ってしまうのもありかもしれません(グレーゾーンですが・・・)。
Gitの運用ワークフロー
Gitを運用する上で、ワークフローを決める必要があります。有名どころは、Git Flow、GitHub Flow、GitLab Flowといったところです。開発の現場に合わせたフローを導入すれば良いですが、筆者としてはGitHub Flowをおすすめします。この中では最もシンプルでわかりやすく、普段の開発をスピード感を持って進められます。あまり複雑な手順を開発チーム全員に理解してもらうのは導入コストがかさみますし、複雑なフローは日常の開発でストレスがたまります。GitHub Flowだと開発者にとっての手順は非常に簡単です。デプイに関しては少し工夫が必要かと思いますが、開発のコミットの方がデプロイの回数よりも圧倒的に多いですし、開発作業に携わる人よりもデプロイを担当する人のが少ないのが一般的なので複雑なことをやる人が全体では少なくなります。普段の開発しやすさを重視するのがチーム全体としてはプラスになるのではないかと思います。
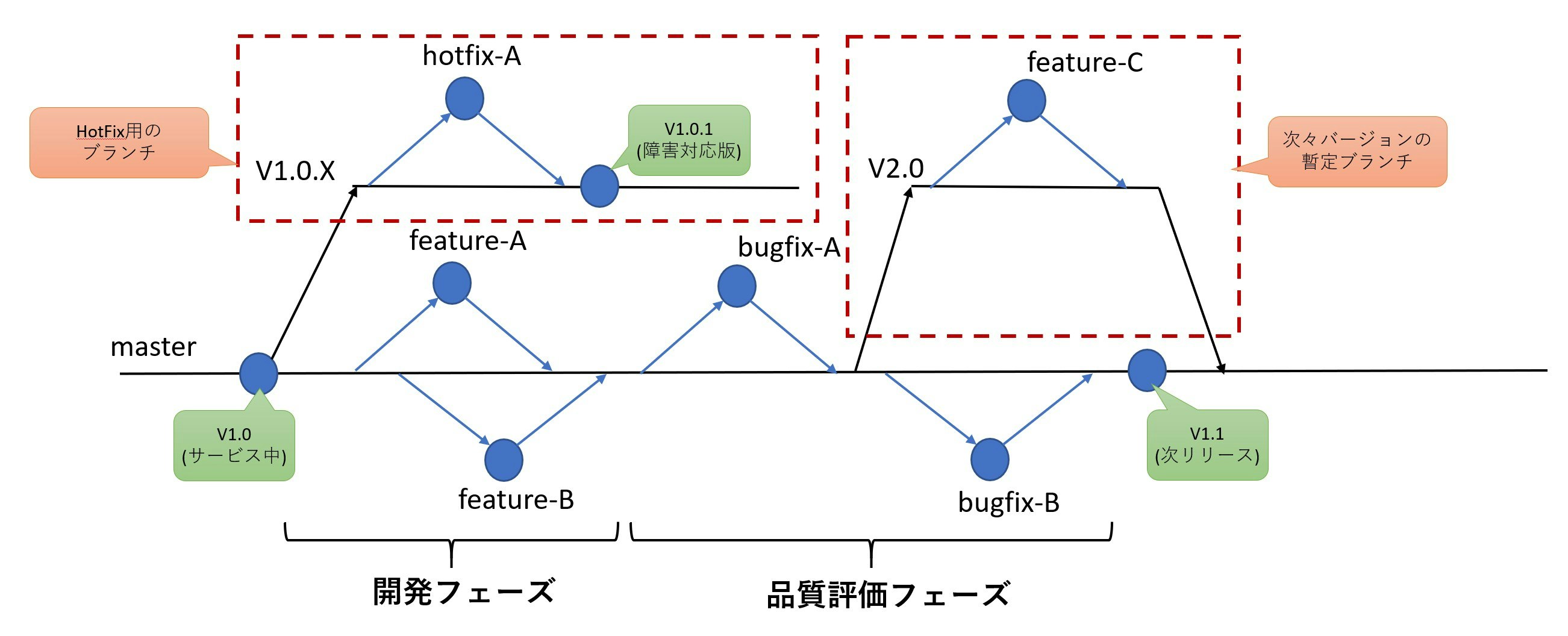
上がGitHub Flowの簡単な模式図です。GitHub Flowのポイントをまとめると以下になります。
masterブランチ を常にデプロイ可能な状態に保ちます- 新しい何かを始めるときには、
masterブランチから説明的なブランチ(feature-X、bugfix-Yといった、何を目的にどんなことをやっているのかがわかるブランチ)を作成して作業を行います- 作業ブランチへのコミットに対して意見をもらいたい場合や、
masterブランチにマージしてもらいたいときにはプルリクエストを作成しレビュアーに送ります- レビュアーはプルリクエストに対応して、コードをレビューし
masterブランチにマージします変更するたびにブランチを作り、変更をすぐに''master''ブランチに反映してしまうモデルです。開発者は''master''ブランチからブランチを作って開発し、''master''ブランチにマージするという作業をひたすら繰り返すとこになります。
この時最も重要なのは''master''ブランチを常にデプロイ可能な状態に保つというところです。masterブランチに変更をマージするときには、ソースコードのレビューだけでなく、きちんとテストを通してから行うことが必須になります。マージリクエスト実施時やマージ時などにCIでテストが自動で動くようにしておく必要があるでしょう、これができていないとmasterブランチがビルドできなくなったり、まったく動かなくなったりすることになるのでこのGitHub Flowの大原則が破綻してしまいます。デプロイスクリプトの管理
デプロイは当然自動化のためのスクリプトを用意することになると思いますが、ソースコードの
masterブランチが常にデプロイ可能ということは、どのタイミングのmasterブランチでもデプロイできるようになっている必要があります。デプロイのためのコードもソースコードと一緒に管理することが理想だと思います。なお、デプロイをJenkinsを使って実施するといつ構成はよくあるのですが、Jenkinsジョブ自体をこのソース管理と一緒にバージョン管理をするのは結構難しいです。デプロイスクリプトに与えるパラメータに非互換の変更を入れてしまったりすると、XXバージョンまでのデプロイ用ジョブと、XXバージョン以降のデプロイ用のジョブといった形になってしまうことがあります。これは広義の意味で単一のリポジトリでバージョン管理されることを破ってしまっているので。Jenkinsのジョブに修正が必要になるような変更があったとしても過去のデプロイスクリプトが動作するのかといったことはケアするとよいでしょう。様々なバージョンのデプロイ
GitHub Flowであれば、デプロイは常に
masterブランチの成果物から実施されることになります。日本メーカのように品質保証部門でテストをし品質を担保してから市場へリリースするといった製品ライフサイクルを持つ場合、いくつかの例外ケースでGitHub Flowがはまらないところが出てきます。ここでの話は、組み込みやパッケージといったソフトウェア製品を前提とした製品ライフサイクルがクラウドサービスの開発にも適応されているような現場での話になりますので、いつでも当てはまるわけではなく限られた条件下での話なのでご了承ください。前提条件
- 市場へのリリースには、品質保証部門がテストを行い問題ないことを確認したのち行われる(裏を返すと品質保証部門のテストが実施されていないアプリケーションはリリースしてはいけない)
- 第三者(品質保証部門)によるテストが実施されているので品質は高く市場での障害発生頻度は低い
- 製品のリリースサイクルは長く、典型的なウォーターフォール開発である
次々バージョンの開発開始
次バージョンの実装は完了し、品質保証部門での評価が行われている途中から次々バージョンの実装が始まることはよく発生します。この場合
masterブランチの状態は品質保証部門へ投入したもの、もしくは品質保証部門で発見された障害に対して修正を行ったバージョンとなります。次々バージョン向けの修正が次バージョン向けの製品に混入することはプロセス上許されないので、masterブランチへの次々バージョン向け実装のマージは許されません。ずっとブランチのまま実装をマージせずに放置するのも開発効率という点で良いことがありません。この場合。GitHub Flowの原則を少し破り、一時的に次々バージョンの開発のためにブランチを増やして対応します。下の図で示したV2.0ブランチがそれにあたります。このブランチのライフサイクルは短く、次バージョンであるV1.1のコードがFixするまでの間の短期的なものになります。この期間だけは複数バージョンの平行稼働が行われます。なお、masterブランチのモジュールは品質保証環境に、V2.0ブランチのコードは、開発環境へデプロイするといったこともできるようにしておく必要があります。
なお、逆パターンとしてV2.0を始めざるを得ないタイミングで_V_1.1__側をブランチしてmasterブランチを次々バージョンの開発とする手もありますがGitHub Flowの原則を考えると前者の方法の方が良いと思います。(master`ブランチが最も安定しているバージョンで、次々バージョン用の説明的なブランチがある状態)障害発生時の対応
次バージョンの開発中にすでにデプロイ済みの現行製品で市場障害が発生した場合の対応です。障害が致命的な場合、直ちに現行バージョンを修正して修正版をリリースする必要があります。評価が完了していない次バージョンがコミットされている''master''ブランチからリリースすることは当然許されません。この場合、一時的なブランチを追加します。下の図に示した
V1.0.Xブランチがそれにあたります。このブランチのライフサイクルは現行バージョンに障害が出てから、次のバージョンのリリースが完了するまでです。障害が発生し、急ぎで修正が必要な場合のみなので、障害の少ないプロダクトでは、このブランチは多くの場合存在しないことになります。なお、一度このブランチを作成したらそれは破棄するのではなく、V1.0の障害対応版であるV1.0.1を市場投入した後もV1.1リリースまではブランチを維持しておきます、万が一次の障害が発生したら、このブランチをもとに開発を行いリリースします。
まとめ
最初のファクターとして、アプリケーションのソースコードの管理方法、デプロイの考え方をGitHub Flowを前提において話を進めてきました。AWS色がほぼない記事になってしましたが、このファクターの内容では無理にAWSを利用しなくても良いと思います。

- 投稿日:2020-09-16T21:32:18+09:00
“Beyond the Twelve-Factor App” & “The Twelve-Factor App”から学びAWSで実践する (0)はじめに
はじめに
実践! ソフトウェア開発というテーマで色々記事を書いていきます。今回は、Beyond the Twelve-Factor AppとThe Twelve-Factor Appを学び、それを踏まえて、クラウド開発を行うために何を実践していくのが良いかという記事をシリーズで書いていきたいと思います。
The Twelve-Factor Appとは
wikiから引用すると、2011年、サービスプラットフォーム企業であるHerokuの開発者により提案されたソフトウェア開発の方法論です。内容に関してはWebで公開されており日本語訳が存在します。原文より、方法論のコンセプト部分をそのまま引用します。
現代では、ソフトウェアは一般にサービスとして提供され、Webアプリケーション や Software as a Service と呼ばれる。
Twelve-Factor Appは、次のようなSoftware as a Serviceを作り上げるための方法論である。・セットアップ自動化のために 宣言的な フォーマットを使い、プロジェクトに新しく加わった開発者が要する時間とコストを最小化する。
・下層のOSへの 依存関係を明確化 し、実行環境間での 移植性を最大化 する。/
・モダンな クラウドプラットフォーム 上への デプロイ に適しており、サーバー管理やシステム管理を不要なものにする。
・開発環境と本番環境の 差異を最小限 にし、アジリティを最大化する 継続的デプロイ を可能にする。
・ツール、アーキテクチャ、開発プラクティスを大幅に変更することなく スケールアップ できる。Twelve-Factorの方法論は、どのようなプログラミング言語で書かれたアプリケーションにでも適用できる。
また、どのようなバックエンドサービス(データベース、メッセージキュー、メモリキャッシュなど)の組み合わせを使っていても適用できる。そして、以下が12のファクターになります。
The Twelve Factors
I. コードベース - バージョン管理されている1つのコードベースと複数のデプロイ
II. 依存関係 - 依存関係を明示的に宣言し分離する
III. 設定 - 設定を環境変数に格納する
IV. バックエンドサービス - バックエンドサービスをアタッチされたリソースとして扱う
V. ビルド、リリース、実行 - ビルド、リリース、実行の3つのステージを厳密に分離する
VI. プロセス - アプリケーションを1つもしくは複数のステートレスなプロセスとして実行する
VII. ポートバインディング - ポートバインディングを通してサービスを公開する
VIII. 並行性 - プロセスモデルによってスケールアウトする
IX. 廃棄容易性 - 高速な起動とグレースフルシャットダウンで堅牢性を最大化する
X. 開発/本番一致 - 開発、ステージング、本番環境をできるだけ一致させた状態を保つ
XI. ログ - ログをイベントストリームとして扱う
XII. 管理プロセス - 管理タスクを1回限りのプロセスとして実行する抽象的なのでわかりにくいと思いますが、非常に重要なことが書かれています。文章量も大したことないですし、日本語訳されているのでまずは目を通してみてください。また、解説記事も色々ありますのでそちらを見ていただくとよいかと思います。
Beyond the Twelve-Factor Appとは
Pivotal社のKevin Hoffman氏がThe Twelve Factors Appをベースにクラウド開発の最近のトレンドを取り込んで3つの定義を追加してアップデートしたソフトウェア開発論です。ここから原文がダウンロードして入手できます。こちらは残念ながら日本語訳がありませんし、ほどほどのボリュームがあります。
そして、以下が12+3のファクターになります。2,14,15の3ファクターが新規に増えたものになり、残りはオリジナルの12ファクターと同等のものになります。
- One codebase, one application
- API first
- Dependency management
- Design, build, release, and run
- Configuration, credentials, and code
- Logs
- Disposability
- Backing services
- Environment parity
- Administrative processes
- Port binding
- Stateless processes
- Concurrency
- Telemetry
- Authentication and authorization
目次
Beyondの15ファクターを15回に分けて連載風に進めていきたいと思います。タイトルの前者がBeyond、後者がオリジナルの定義になります。それぞれのファクターに関しての解説と実践するにはどういったことをするべきなのかをまとめていきます。
(1)1つのコードベース、1つのアプリケーション / コードベース - バージョン管理されている1つのコードベースと複数のデプロイ
(2)APIファースト
(3)依存関係管理 / 依存関係 - 依存関係を明示的に宣言し分離する
(4)設計、ビルド、リリース、実行 / ビルド、リリース、実行 - ビルド、リリース、実行の3つのステージを厳密に分離する
(5)構成、クレデンシャル、およびコード / 設定 - 設定を環境変数に格納する
(6)ログ / ログ - ログをイベントストリームとして扱う
(7)廃棄容易性 / 廃棄容易性 - 高速な起動とグレースフルシャットダウンで堅牢性を最大化する
(8)バックエンドサービス / バックエンドサービス - バックエンドサービスをアタッチされたリソースとして扱う
(9)環境パーティー / 開発/本番一致 - 開発、ステージング、本番環境をできるだけ一致させた状態を保つ
(10)管理プロセス/ 管理プロセス - 管理タスクを1回限りのプロセスとして実行する
(11)ポートバインディング / ポートバインディング - ポートバインディングを通してサービスを公開する
(12)ステートレスプロセス / プロセス - アプリケーションを1つもしくは複数のステートレスなプロセスとして実行する
(13)並行性/ 並行性 - プロセスモデルによってスケールアウトする
(14)テレメトリー
(15)認証と認可
- 投稿日:2020-09-16T19:57:45+09:00
【AWS SOA】RDSバックアップとスナップショットの違いの備忘録
RDSバックアップ
・DBインスタンスの自動バックアップ・保存を行う。自動バックアップでは、DBインスタンスのストレージボリュームのスナップショットが作成される
・事前に設定したバックアップ保持期間に従って、DBインタンスの自動バックアップが作成・保存される
・DBインスタンスを削除すると自動バックアップで作成したスナップショットは削除されるRDSスナップショット
・ユーザーが手動でバックアップを取りたい場合、DBのスナップショットを取得する
・手動バックアップで作成したスナップショットは、DBインスタンスを削除しても自動で削除されないバックアップとスナップショットを取得する方法
RDS>データベース>該当のDB識別子>メンテナンスとバックアップで状況を確認可能。
バックアップの変更
該当のDB識別子の上の方に変更があるので選択する。
バックアップの保存期間を適宜変更する。
バックアップのスナップショット
該当のDB識別子>メンテナンスとバックアップ>スナップショットでスナップショットの取得を選択する。
スナップショット名を入力し、スナップショットの取得を選択する。
参考
Ultimate AWS Certified SysOps Administrator Associate 2020
この1冊で合格! AWS認定ソリューションアーキテクト - アソシエイト テキスト&問題集
https://stay-ko.be/aws/solutionarchitect-pro-aws-rds-db-snapshot-backup-restore


- 投稿日:2020-09-16T19:56:36+09:00
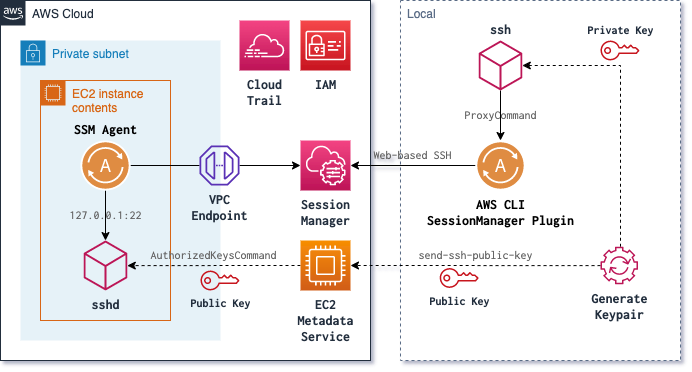
[AWS]踏み台不要、キーペア登録不要、ポート開放不要のSSH接続環境を作る
概要
EC2インスタンスにSSHでログインする。
接続先のインスタンスはプライベートサブネット上に立っている前提。インスタンスからSessionManagerへの接続はVPCエンドポイントを経由する。
クライアントは、SessionManagerのシェルアクセスではなく、普通のSSHコマンドを使う。インスタンスにキーペアは登録しない。
接続時にEC2 Instance Connectを使って一時的に登録する。
キーペアは接続ごとに生成/破棄する。構成を図にするとこんな感じになると思う。
メリット
キーペアの管理が不要
秘密鍵を管理する必要がなくなる。
公開鍵の登録も不要になるため、仮に秘密鍵が漏れてもログインできない。22番ポートの開放が不要
インバウンドの接続がなくなるので、22番ポートを開ける必要がなくなる。バッションサーバーが不要
インターネットに不要な口を開ける必要がなくなる。IAMで接続制御ができる
EC2 Instance ConnectのAPIはIAMで制御できる。CloudTrailで接続の監査ができる
試してないがEC2 Instance Connectのリクエストなどの監査ができる。シェルアクセスより軽快(な気がする)
SSM Agentは通信に専念しているので負荷が低そう。
シェルアクセスより動作が軽いんじゃないかと思う。デメリット
アクセスキーの管理
IAMで制御するのでアクセスキーの管理は相変わらず重要。
とはいえ、秘密鍵を~/.sshに置きっぱなしにしているよりは安全じゃないかと思う。
今はAWS CLIで自動的にAssumeRoleするような設定も簡単にできるので。準備が面倒
AWS上の設定や、ローカルPCでも色々と設定しないといけないので面倒。
うまくやればCloudFormationで構築できるかもしれない。VPCエンドポイントが高い
正直高すぎるんじゃないかと思う。
たぶん、できて当然と思っている機能に金を払わされてるからなんだろう。結構すぐ切れる
ちょっと放っておくとすぐ切れる。使ってる時に切断されることはない。
何かいい方法があるかもしれないけど、まだ見つけられていない・・・準備
面倒な準備をしていく。
AWS
VPCエンドポイント
プライベートサブネット内のインスタンスにSessionManagerで接続するには、NATやVPCエンドポイントの設定が必要。
VPCエンドポイントは各サブネットごとに設定する必要がある。ここ に書いてある中で
com.amazonaws.ap-northeast-1.ec2以外が必要。
ログを出力するならS3のVPCエンドポイントも必要かもしれない。セキュリティグループ
SessionManagerで接続するので22番ポートの開放が不要になる。
もし開いている場合は閉じる。マネージドインスタンス
マネージドインスタンスとして認識されていないとSessionManagerで接続できない。
EC2インスタンス用のIAMロールにAmazonSSMManagedInstanceCoreポリシーをつけること。
AmazonEC2RoleForSSMは古い。認識されているかどうかは、AWSコンソールのSystemsManager>マネージドインスタンスで確認できる。
SSM Agent
SessionManagerを使って接続するインスタンスには、SSM Agentがインストールされている必要がある。
StateManagerを使うことでSSM Agentを常に最新の状態に保つことができる。
マネージドインスタンスのページでAgent auto updateボタンをクリックするだけ。この時点でAWSコンソールからシェルアクセスはできるんじゃないかと思う。
EC2 Instance Connect
キーペア登録不要でログインするために必要。
最新のAmazon Linuxではインストール済み。
/opt/aws/bin/以下にeic-*で始まるコマンドがあるはず。
ない場合は ここ を参考にしてインストールする。IAMロール
SessionManager関連の設定はこちら。
クイックスタートデフォルト IAM のポリシー Session Manager | AWS Systems Manager ユーザーガイドEC2 Instance Connect関連の設定はこちら。
タスク 4: EC2 Instance Connect の IAM アクセス許可を設定する | Amazon EC2
Linuxインスタンス用ユーザーガイド
Amazon EC2 Instance Connect のアクション、リソース、および条件キー | AWS IAMユーザーガイドローカルPC
Session Manager Plugin
ここ に書いてある方法に従ってインストールする。
一応 Homebrewでインストールできるようにしている人 も見かけた。使ってないけど。ssh
~/.ssh/configにProxyCommandの設定を追記する。Host i-* mi-*↲ ProxyCommand sh -c "aws ssm start-session --target %h --document-name AWS-StartSSHSession --parameters 'portNumber=%p'"↲EC2 Instance Connect CLI
msshコマンドを使うとキーペアの自動生成などしてくれるらしい。
今は自作のコマンドで同じようなことをやってしまってるのでインストールしてない。
5年たったらAWS CLIの薄いラッパーコマンドが出来ていた | Qiita接続
公開鍵の登録
一時的なキーペアを作成し、公開鍵を接続先インスタンスに登録する。
キーペアの生成
ssh-keygenで適当に作成。
たしかRSAじゃないと接続できなかったと思う。$ ssh-keygen -t rsa -b 4096公開鍵の登録
$ aws ec2-instance-connect send-ssh-public-key \ --instance-id i-1234567890abcdef0 \ --instance-os-user ec2-user \ --availability-zone ap-northeast-1a \ --ssh-public-key file://path/my-rsa-key.pub { "RequestId": "f31e23d4-1786-4761-8583-bb03de0795c9", "Success": true }SSH接続
一時的な秘密鍵を使って接続してみる(公開鍵の有効期限は60秒)。
$ ssh -vvv -i ~/.ssh/tmp.pem -l ec2-user i-1234567890abcdef0普通のSSH接続なのでポートフォワーディングなどもそのまま出来る。
- 投稿日:2020-09-16T19:39:24+09:00
AWS CodeBuildのテストレポート機能は、やはり build か post_build でしか使えない
TL; DR
CodeBuild のテストレポート生成コマンドは、
buildまたはpost_buildシーケンスのcommandsセクションで指定しましょう。
そうしないと、テスト失敗時にテストレポートを表示してくれません。はじめに
CodeBuild に、テストレポート機能がリリースされて久しいですね。
僕も、既にいくつか記事を書いていますが、テストカバレッジが表示できるようになり、使いやすさに拍車がかかりました。
- CodeBuildのテストレポート機能が一般公開されたから使ってケチつけてみた - Qiita
- CodeBuildのテストレポート機能でコードカバレッジレポートがサポートされたから、また使ってケチつけてみた - Qiita
そんな便利なテストレポート機能ですが、何度か使っていくうちに、とある現象に気付いたので、記述していきます。
テストレポート生成コマンドを指定できるのは
buildまたはpost_buildだけ?ドキュメントに記載されている、次の文言を見つけました。
buildまたはpost_buildシーケンスのcommandsセクションで、レポートグループに対して指定したテストケースを実行するコマンドを指定します。これが何を意味するのかというと、 buildspec.yml ファイルにおいて、次のように記述する必要があることを意味します。
つまり、 CodeBuild では、テストレポート生成コマンドであるnpm run testを、buildまたはpost_buildシーケンスのcommandsセクションで指定するように要求しているわけです。buildspec.ymlversion: 0.2 phases: install: commands: - npm install pre_build: commands: # この pre_build シーケンスではテストレポート生成コマンドを指定しない - npm run test build: commands: # この build シーケンスか、 - npm run test post_build: commands: # この post_build シーケンスでテストレポート生成コマンドを指定する - npm run testしかし、テストレポート生成コマンドを
pre_buildシーケンスで指定しても、テスト成功時には CodeBuild のテストレポートに表示されます。
この現象は、単純にドキュメントの不備なのかと軽く思っていたのですが、別の問題で明らかになりました。テストレポート生成コマンドを
pre_buildで指定するとテストレポートが表示されないしばらくして、テストが失敗してしまうと、なぜか CodeBuild のテストレポートに表示されない問題にぶつかりました。
いろいろ試行錯誤した結果、どうやらpre_buildでは、テスト失敗時のテストレポートファイルを、 CodeBuild のテストレポート機能が読取ってくれないようです。buildspec.ymlversion: 0.2 phases: install: commands: - npm install pre_build: commands: # pre_build でテストが失敗すると、失敗結果がテストレポートとして読取ってくれない - npm run test build: commands: # build か post_build でテストが失敗すると、失敗結果がテストレポートとして読取ってくれる - npm run testテストレポートは、成功時であっても失敗時であっても表示してほしいため、テスト失敗時にテストレポートを表示しない事象に遭遇してしまった際は、非常に焦りました。
最初はnpm run test失敗結果(利用している Jest コマンドの失敗結果)である Error Code 1 に未対応なのかなーと、的外れなところを調べていました。
- node.js - npm error ELIFECYCLE while running the test - Stack Overflow
- npm ERR! code ELIFECYCLE if 1 test fails · Issue #7803 · facebook/jest
おわりに
少しは仕様書を信じようと思いました。
- 投稿日:2020-09-16T19:26:12+09:00
AWS Cognito
- 投稿日:2020-09-16T16:58:49+09:00
AWS初心者がgithubとAWSを使用する際に気を付けたいこと
記事を書いた動機
誤ってawsのアクセスキーとシークレットキーをgithubに挙げてしまった際、とても肝を冷やしたため。
自分はおそらく運が良かった&awsの対応が手厚かったために被害自体はなかったのですが、他の事例を見ると何百万という請求が発生し得る、とんでもないミスなので多くの人が知って一人でもこういうミスをしないことと、自分のミスの戒めのためです。なぜ高額請求が発生するか
①awsのアクセスキーとシークレットキーをgithubに挙げてしまう
②クローラー等で、githubに挙げられているawsのキーが検知されてしまう
③勝手にキーを使われてマイニング等のためにEC2を限度いっぱいまで使われるといった流れです。今回助かった原因
僕が何かをした、ということではなくaws側が手厚く対策をしてくれていたからです。
githubにawsのアクセスキーとシークレットキーを挙げると、悪意のある人だけでなくawsも検知をしているみたいで、
事故が発生してから僕の場合は一時間前後でメールが届きました。事前にこういった事故を防ぐためにしておきたいこと
①そもそもawsのアクセスキーとシークレットキーをどこかに書くといったことをしない
その代わりにIAMRoleを使いましょう。
localで使う時は.envに書いて、終わったら消せばいいです。②githubのcommit時にアクセスキーやシークレットキーを検知するようにする
git-secretsというものを使います。
詳しい使い方は
クラウド破産しないように git-secrets を使う
Windowsにgit-secretsをインストール
を参考にすればよいでしょう。
これで①で.envやほかの場所に書きっぱなしでも検知してくれます。③DBのパスワードとかIAMRoleでなんとかならない場合は?
awsのParameterStoreやSecretManagerを使いましょう。
①、②、③で共通することは、公開する場所にはapiKey等の大事な情報は書かないようにしようということです。
当たり前のことかもしれませんが、僕は全くといっていいほど気にも留めずgithubに挙げてしまっていました。
というのも、ローカル環境で実験しているネットの記事を元にそのままアクセスキーとシークレットキーを書いたまま、何も考えずにgithubに挙げるという考えなしの行為が原因でした。もしやってしまった場合は
①rootUserのパスワードを変更する
②流出してしまったIAMUSERを削除
③全リージョンのEC2、EBS、セキュリティグループに不審な制作物が確認
をしましょう。
実際対応されていた体験談としてはこちらが参考になります。
初心者がAWSでミスって不正利用されて$6,000請求、泣きそうになったお話。
AWSが不正利用され300万円の請求が届いてから免除までの一部始終
AWSで不正利用され80000ドルの請求が来た話おわりに
今回の事故の原因はそもそもアクセスキーとシークレットキーを何の疑問も持たずgithubに挙げてしまったことに起因するので、
IAMRoleを使うことを念頭に置いて、予防策としてgit-secretsを使えば自分から流出させてしまうような事故は防げるのではないかなと思います。
少しでも同じようなミスをして悲しいことになってしまう人が減ってくれることを祈ります...
- 投稿日:2020-09-16T16:35:37+09:00
Pandas DataFrame を .csv.gz として Amazon S3 に保存する
Pandas DataFrame を gzip 圧縮しつつ CSV ファイルとして Amazon S3 バケットに保存しようとしたときに少しハマったので備忘録。
import gzip from io import BytesIO import pandas as pd import boto3 def save_to_s3(df: pd.DataFrame, bucket: str, key: str): """Pandas DataFrame を .csv.gz として Amazon S3 に保存する""" buf = BytesIO() with gzip.open(buf, mode="wt") as f: df.to_csv(f) s3 = boto3.client("s3") s3.put_object(Bucket=bucket, Key=key, Body=buf.getvalue())ポイントとしては以下。
gzip.openの第一引数は gzip フォーマットを表す file-like オブジェクトなのでBytesIO()を入力するpandas.DataFrame.to_csvの出力は文字列なので、gzip.openのmodeは「テキスト書き込み (wt)」を指定する最初
pandas.DataFrame.to_csvにcompression="gzip"を指定すれば明示的に圧縮しなくてもいけるかと思って試したが、to_csvに file-like オブジェクトを入力した場合はcompressionオプションは無視されるらしく、使えなかった。
- 投稿日:2020-09-16T14:15:25+09:00
AWS Pinpoint メール配信までの使い方ざっくりメモ
AWS Pinpointはカスタマーエンゲージメントを目的としたシステムの統合プラットフォームです。
メッセージ配信と分析でそれぞれ別のシステムを開発、連携することなく、全てをAmazon Pinpointに統合して管理、運用することができます。
開発者だけではなくマーケティング担当者の利用も想定しているため、分析結果をグラフィカルに表示する機能もついているのがすごいところですね。とりあえずどんなもんなのかなーというのが気になったので、ちょろっと触ってみたという個人的なメモです。
簡単に実施できそうかなという理由でメール配信を行う場合を試してみます。
設定の大まかな流れはメール配信設定のチュートリアルに従って実施しますが、リソース作成はAWS CLIを利用して実施していきます。AWS CLIは以下のバージョンを利用しています。
$ aws --version aws-cli/2.0.48 Python/3.7.4 Darwin/19.6.0 exe/x86_64プロジェクトの設定
まずは管理のベースとなるプロジェクトの設定を行います。
1. プロジェクトの作成
まずはプロジェクトを作ります。プロジェクト作成にはcreate-appを実行します。
$ json=$(cat << EOS { "CreateApplicationRequest": { "Name":"<project_name>" } } EOS ) $ aws pinpoint create-app --cli-input-json "$json"Nameがプロジェクト名です。以降の操作で
ApplicationIdを求められることがありますが、この場合はここで指定した名前ではなく自動的に割り当てられたIDの方を指定する形になります。create-appに限らず、PinpointのCLIは
--cli-input-jsonオプションをつけることでJSON形式で設定値を渡すことができます。
--generate-cli-skeletonオプションをつけることでリソースを作成せずに設定用JSONのスケルトンだけを出力することも可能です。2. Emailチャネルの有効化
続いてメール配信が出来るようにEmailチャネルを有効化します。
有効化にはupdate-email-channelを実行します。$ json=$(cat << EOS { "ApplicationId": "<project_id>", "EmailChannelRequest": { "Enabled": true, "FromAddress": "<default_sender_address>", "Identity": "arn:aws:ses:<region>:<account_id>:identity/<email_address_or_domain>" } } EOS ) $ aws pinpoint update-email-channel --cli-input-json "$json"
項目 型 用途 Enabled true / false trueを設定するとEmailチャネルを有効化します。 FromAddress string メール送信時のデフォルト送信元アドレスを設定します。 Identity string メール送信時に利用するAmazon Simple Email ServiceのAmazon Resource Nameを設定します。identity/の後ろにドメインを指定した場合はそのドメインの任意のメールアドレスから送信可能です。 今回はお試しなので
Identityにはメールアドレスを設定しました。
FromAddressに設定したメールアドレスには利用確認メールを送る必要があります。
裏側ではメール送信にAmazon Simple Email Service (SES)を使っているようで、SESの操作であるcreate-email-identityを実行して確認メールを送信できます。$ aws sesv2 create-email-identity --email-identity <default_sender_address>このメールに記載されているURLへアクセスすることで送信元アドレスとして利用可能になるようです。
また、Emailチャネルの場合、作成直後は不正使用から保護するためにサンドボックス環境としてセットアップされるようです。
https://docs.aws.amazon.com/pinpoint/latest/userguide/tutorials-send-an-email-upload-contacts.htmlIf this is your first time using Amazon Pinpoint, your account is in the sandbox. When your account is in the sandbox, you can only send email to verified identities.
この状態では検証済みメールアドレスのみ送受信が可能です。(テストメール送信機能を行う場合は任意のアドレスでも受信のみ可)
このサンドボックス環境もSESが持っている機能のようです。必要な手続きを行うことで本番運用環境へ移行できます。Email送信の設定
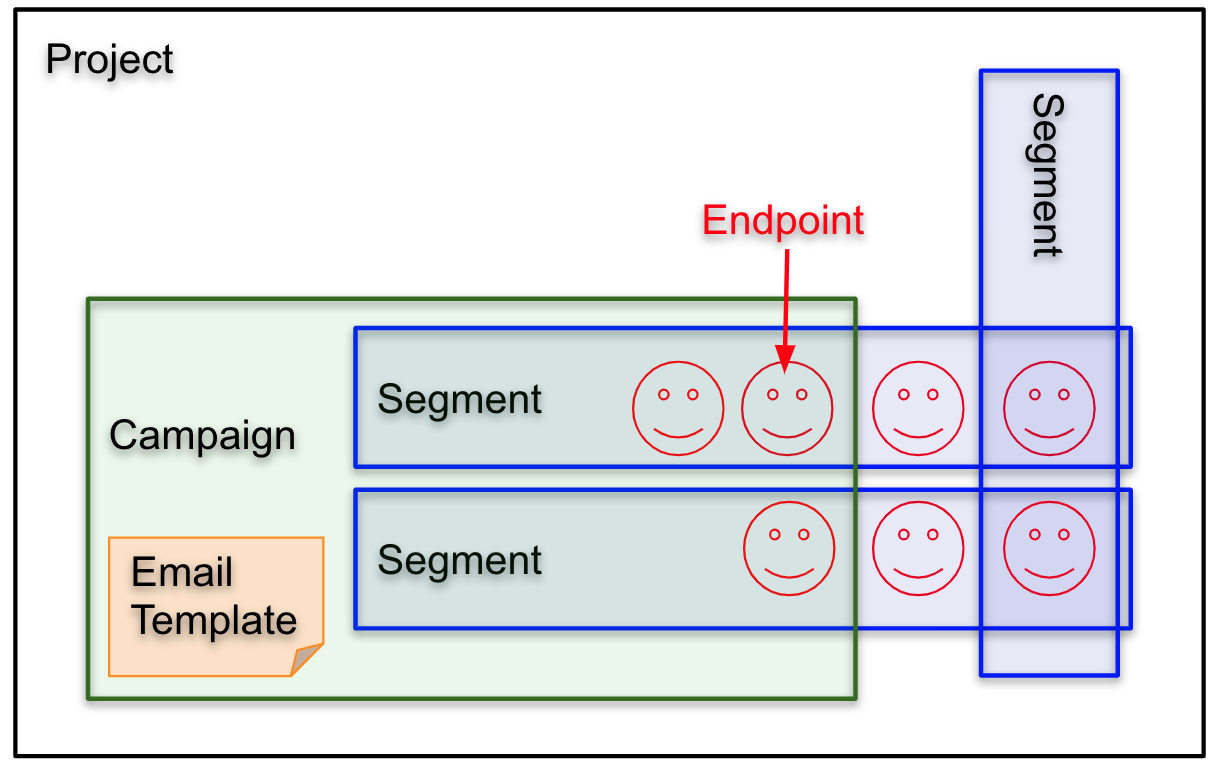
メール送信を行うには以下を作成する必要があります。
1. エンドポイント: 実際の送信先
2. セグメント: まとめて通知する集団(複数のエンドポイントの集まり)
3. メールテンプレート: 送信するメール内容のテンプレート
4. キャンペーン: メール送信を行う単位全体像としては以下のような感じです。
1. エンドポイントの作成
エンドポイントの作成にはupdate-endpointを実行します。
$ json=$(cat << EOS { "ApplicationId": "<project_id>", "EndpointId": "<endpoint_name>", "EndpointRequest": { "Address": <recipient_address>, "ChannelType": "EMAIL" } } EOS ) $ aws pinpoint update-endpoint --cli-input-json "$json"ChannelTypeにEMAILを指定することで、このエンドポイントを利用した時はメールが使われるようになります。
たくさん作成するときはupdate-endpoints-batchを利用したり、S3にアップロードした設定ファイルを読み込んで作成する方法を選択した方が良さそうです。2. セグメントの作成
セグメントの作成にはcreate-segmentを実行します。
$ json=$(cat << EOS { "ApplicationId": "<project_id>", "WriteSegmentRequest": { "Dimensions": { "Demographic": { "Channel": { "DimensionType": "INCLUSIVE", "Values": ["EMAIL"] } } }, "Name": "<segment_name>" } } EOS ) $ aws pinpoint create-segment --cli-input-json "$json"例としてChannelTypeがEMAILのエンドポイントを対象とするセグメントを作成します。
対象とするエンドポイントの条件を細かく設定したりセグメントのグルーピング設定を行うことでメール送信後により細かい分析ができるようになりそうですが、とりあえずシンプルなルールで作ってみます。3. メールテンプレートの作成
メールテンプレートのの作成にはcreate-email-templateを実行します。
$ json=$(cat << EOS { "EmailTemplateRequest": { "HtmlPart": "<!DOCTYPE html>\n<html lang=\"en\">\n<head>\n<meta http-equiv=\"Content-Type\" content=\"text/html; charset=utf-8\" />\n</head>\n<body>\n<p>Hi!</p>\n<p style=\"color:red;\">This is sent from my first Amazon Pinpoint!</p>\n</body>\n</html>", "Subject": "Hello, Amazon Pinpoint!", "TemplateDescription": "My first template.", "TextPart": "Hi! \nThis is sent in plain text from my first Amazon Pinpoint!" }, "TemplateName": "<template_name>" } EOS ) $ aws pinpoint create-email-template --cli-input-json "$json"
項目 型 用途 HtmlPart string HTMLメールの本文を設定します。 Subject string メールのタイトルを設定します。 TemplateDescription string (任意)テンプレートの説明を設定します。 TextPart string (任意)テキストメールのみを受け付けている場合の本文を設定します。 TemplateName string テンプレート名を設定します。 以下のようなメールが送られる想定のテンプレートを作成してみました。
4. キャンペーンの作成
キャンペーンの作成にはcreate-campaignを実行します。
以下の例ではキャンペーンを作成したらすぐにメールを送信します。$ json=$(cat << EOS { "ApplicationId": "<project_id>", "WriteCampaignRequest": { "Name": "<campaign-name>", "Schedule": { "IsLocalTime": false, "StartTime": "IMMEDIATE", "Timezone": "UTC" }, "SegmentId": "<segment_id>", "SegmentVersion": <segment_version>, "TemplateConfiguration": { "EmailTemplate": { "Name": "<email_template_name>" } } } } EOS ) $ aws pinpoint create-campaign --cli-input-json "$json"主な設定は以下です。
項目 型 用途 Schedule.StartTime string キャンペーンの開始タイミングを設定します。IMMEDIATEを指定すると即時で実行されます。 SegmentId string 送信対象セグメントのIDを設定します。セグメントのIDはコンソール上から確認できる他、get-segmentsで一覧を取得することでも確認できます。 SegmentVersion string 送信対象セグメントのバージョンを設定します。 EmailTemplate.Name string 利用するメールテンプレート名を設定します。 設定するとセグメントに含まれるエンドポイント全てに対してメールが送信されます。
送信結果の確認
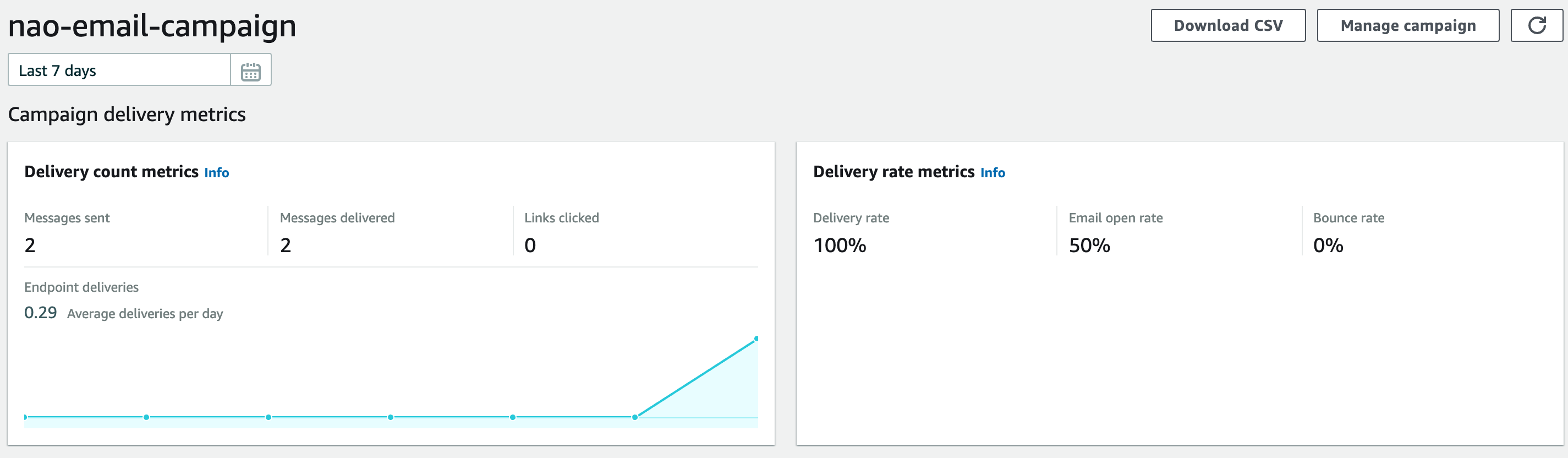
Amazon Pinpoint Console上からキャンペーンのメール送信結果を確認できます。
試しに2件送って1件だけ開封した結果が以下です。
送られてきたメールをみてみると、開封は本文に1×1pxのdisplay:noneなimageタグを埋め込むことで検知しているようです。
imageタグのsrcのURLにはメールヘッダのMessage-IDを含んでいたので、それを元によしなに突合して……いるのかどうかまではわかりませんが、このURLへのアクセスでカウントしてくれているっぽいです。
開封確認の方法としてはよくある形式ですね。メール開封率などの指標はget-campaign-date-range-kpiを実行して取得することも出来ます。
$ json=$(cat << EOS { "ApplicationId": "<project_id>", "CampaignId": "<campaign_id>", "KpiName": "email-open-rate", "StartTime": "1970-01-01T00:00:00", "EndTime": "1970-01-01T00:00:00" } EOS ) $ aws pinpoint get-campaign-date-range-kpi --cli-input-json "$json"
KpiNameに取得したい指標を指定して取得する形です。設定可能な値は公式ドキュメントにまとまっています。
今回はエンドポイント等に細かい情報をまったく設定しなかったため単純なメール送信と結果確認だけでした。
ただ、適切に設定することでより柔軟にターゲットを指定してメールを送信したり、詳細な分析ができるものと思います。
また、設定次第でメールに記載されたリンクへ遷移した後のファネル分析も行えるようです。
自前で分析システムを構築しなくても分析が出来るのは1つのメリットかなと思いました。

- 投稿日:2020-09-16T10:59:43+09:00
AWS subnet IP reservation
Small tip
特定SubnetのIPレンジにおいて静的IPを割り振ったEC2などを立てたいことが有ると思う。こういったときレンジの最初と最後以外にも避けておくべき(すでに予約されている)IPアドレスがあるのでご注意ください。私はハマった。
例) Sbunet CIDR 10.0.0.0/24の場合
- 10.0.0.0: ネットワークアドレスなので使えない
- 10.0.0.1: ネットワークアドレス+1はVPCルーター用にAWSにより予約されている
- 10.0.0.2: ネットワークアドレス+2はDNSサーバアドレスとしてAWSにより予約されている
- 10.0.0.3: ネットワークアドレス+3は将来の用途のためにAWSにより予約されている
- 10.0.0.255: Networkブロードキャストアドレス