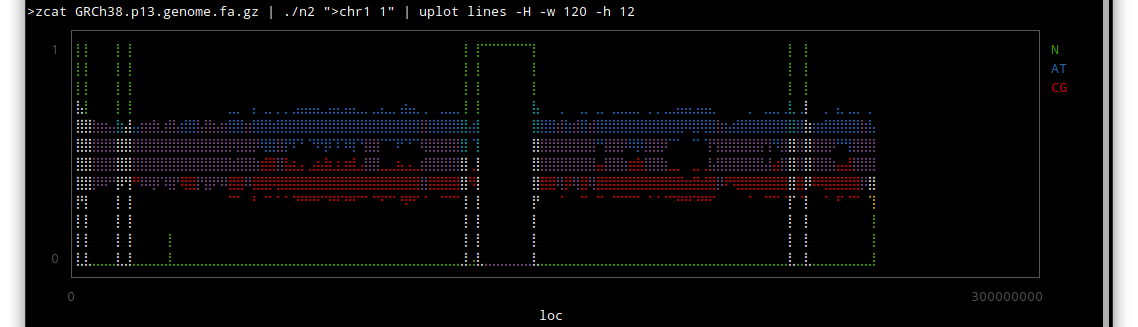
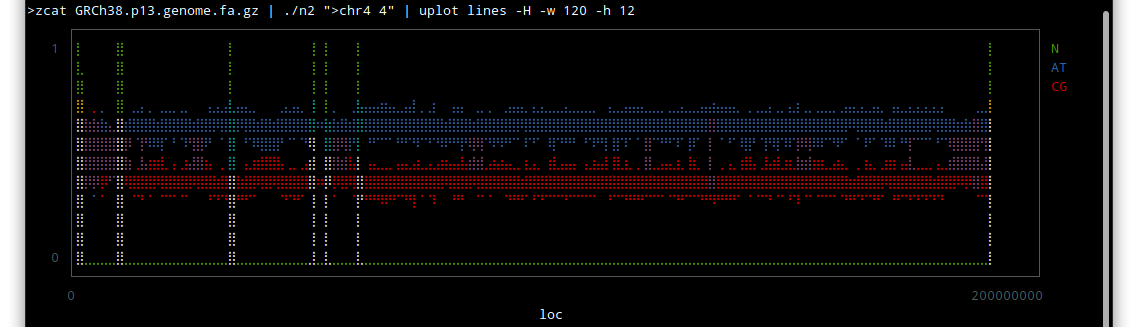
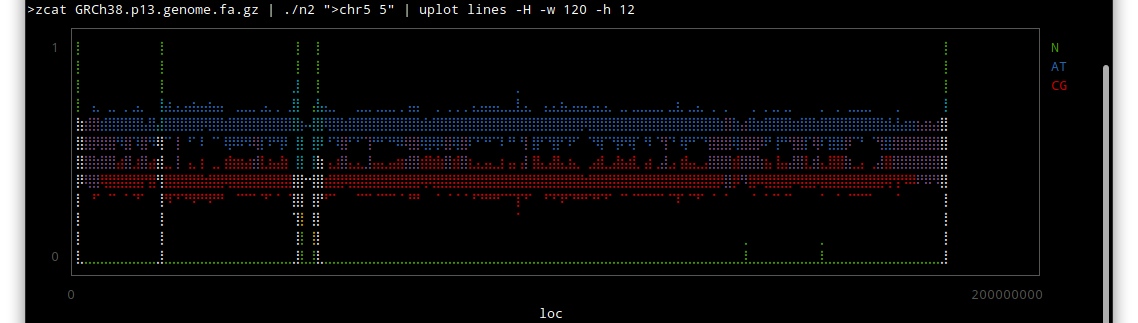
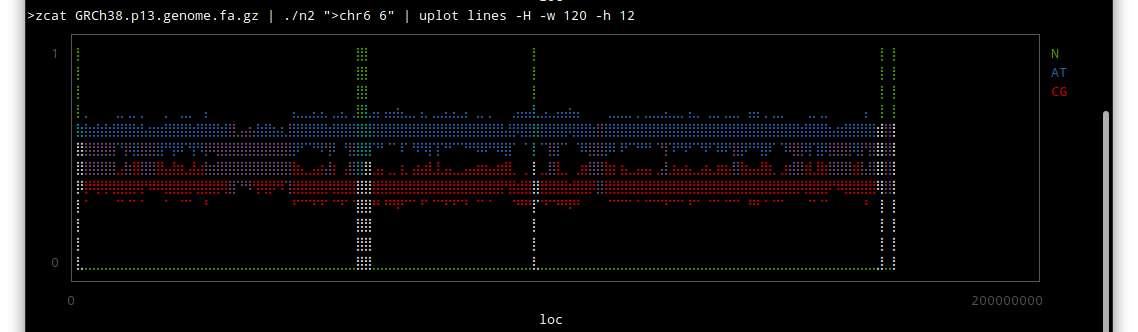
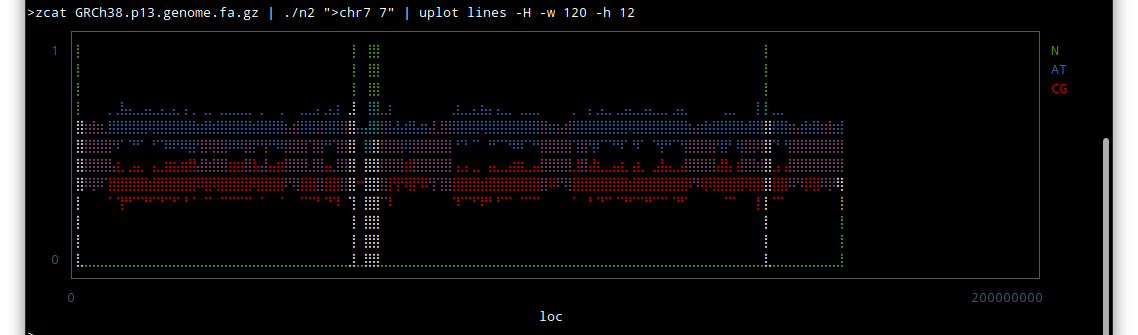
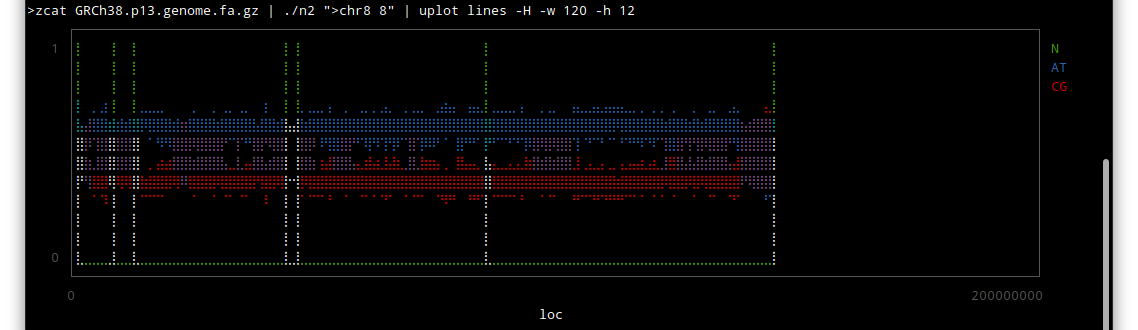
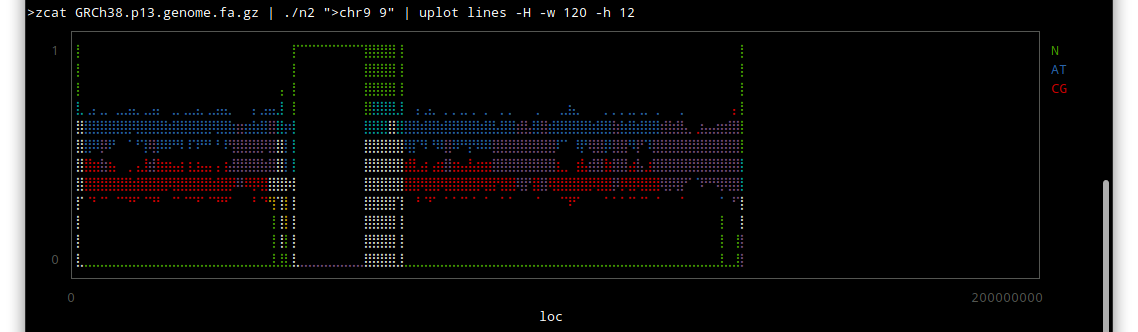
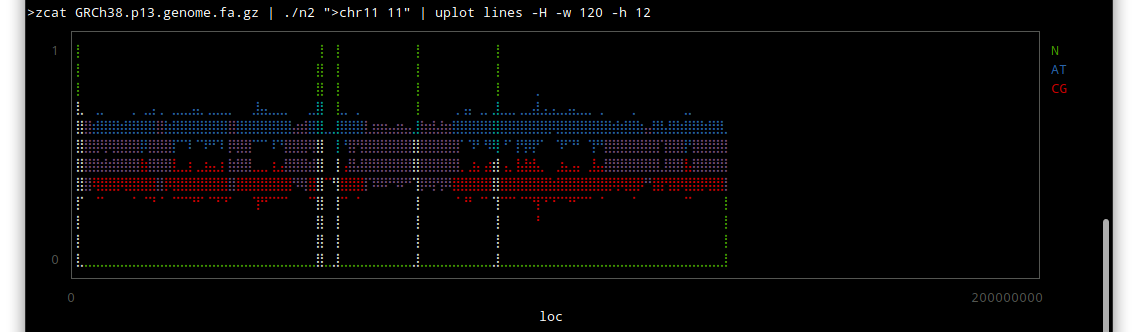
Thor allows you to specify options for its tasks, using method_options to supply a hash of options, or method_option to provide more detail about an individual option.
GitHub/wiki記載のサンプル
method_option:value,:default=>"some value"#=> Creates a string option with a default value of "some value"
You can specify an option that should exist for the entire class by using class_option. Class options take exactly the same parameters as options for individual commands, but apply across all commands for a class.
公式webサイト記載のclass_optionサンプル
classMyCLI<Thorclass_option:verbose,:type=>:booleandesc"hello NAME","say hello to NAME"options:from=>:required,:yell=>:booleandefhello(name)puts"> saying hello"ifoptions[:verbose]output=[]output<<"from: #{options[:from]}"ifoptions[:from]output<<"Hello #{name}"output=output.join("\n")putsoptions[:yell]?output.upcase:outputputs"> done saying hello"ifoptions[:verbose]enddesc"goodbye","say goodbye to the world"defgoodbyeputs"> saying goodbye"ifoptions[:verbose]puts"Goodbye World"puts"> done saying goodbye"ifoptions[:verbose]endend
デプロイする前にローカルで
cap production unicorn:stop
この後に、
bundle exec cap production deploy
をターミナルでうちましょう。unicornがストップします。自動デプロイでも同じようにunicornはストップ
させているはずですが、すぐに反映されないことも多いです。私の環境ではこれですぐにデプロイが反映されています
【参照】 http://w2.cleardb.net/faqs/#general_16
When I use auto_increment keys (or sequences) in my database, they increment by 10 with varying offsets. Why?
ClearDB uses circular replication to provide master-master MySQL support. As such, certain things such as auto_increment keys (or sequences) must be configured in order for one master not to use the same key as the other, in all cases. We do this by configuring MySQL to skip certain keys, and by enforcing MySQL to use a specific offset for each key used. The reason why we use a value of 10 instead of 2 is for future development.
# 配列化 # 返り値"foo bar baz".split["foo","bar","baz"]# ○"foo bar baz".split('')["f","o","o"," ","b","a","r"," ","b","a","z"]"foo bar baz".split(',')["foo bar baz"]"foobarbaz".split["foobarbaz"]"foobarbaz".split('')["f","o","o","b","a","r","b","a","z"]"foobarbaz".split(',')["foobarbaz"]"fooxbarxbaz".split('x')["foo","bar","baz"]# ○"foo, bar, baz".split["foo,","bar,","baz"]"foo, bar, baz".split('')["f","o","o",","," ","b","a","r",","," ","b","a","z"]"foo, bar, baz".split(',')["foo"," bar"," baz"]"foo,bar,baz".split["foo,bar,baz"]"foo,bar,baz".split('')["f","o","o",",","b","a","r",",","b","a","z"]"foo,bar,baz".split(',')["foo","bar","baz"]# ○%w[foo bar baz]["foo","bar","baz"]# ○
#### Cons cells are created by using tuple.
#### All of atoms are string and the null value is None.
defcons(x,y):return(x,y)defcar(s):returns[0]defcdr(s):returns[1]defatom(s):returnisinstance(s,str)ors==Nonedeflist(ts):ifnotts:returnNoneelse:returncons(ts[0],list(ts[1:]))
#include <stdio.h>
#include <stdlib.h>
/* Cons cells are created by using typedef struct. *//* All of atoms are char* and the null value is NULL. */typedefunsignedintvalue_t;enumNODE_TAG{NODE_STRG,NODE_CONS};typedefstruct_node_t_{value_tvalue;enumNODE_TAGtag;}_node_t,*node_t;node_tnode(value_tvalue,enumNODE_TAGtag){node_tn=(node_t)malloc(sizeof(_node_t));n->value=value;n->tag=tag;return(n);}typedefstruct_cons_t_{node_tx;node_ty;}_cons_t,*cons_t;node_tcons(node_tx,node_ty){cons_tc=(cons_t)malloc(sizeof(_cons_t));c->x=x;c->y=y;node_tn=node((value_t)c,NODE_CONS);return(n);}#define str_to_node(s) (node((value_t)(s), NODE_STRG))
#define node_to_str(s) ((char *)(s->value))
#define car(s) (((cons_t)(s->value))->x)
#define cdr(s) (((cons_t)(s->value))->y)
#define atom(s) (s->tag == NODE_STRG)
#define MAXSTR 64
node_tlist(constchars[][MAXSTR],constintn){node_tr=str_to_node(NULL);for(inti=n-1;i>=0;i--){r=cons(str_to_node(s[i]),r);}return(r);}
;;;; Cons cells are created by using lambda closure.;;;; All of atoms are string and the null value is NIL.(defuns_cons(xy)(lambda(f)(funcallfxy)))(defuns_car(c)(funcallc(lambda(xy)x)))(defuns_cdr(c)(funcallc(lambda(xy)y)))(defuns_atom(s)(and(not(functionps))(not(equalsNIL))))(defuns_list(s)(if(nulls)NIL(s_cons(cars)(s_list(cdrs)))))
#### Cons cells are created by using Array.#### All of atoms are string and the null value is nil.defcons(x,y)[x,y].freezeenddefcar(s)s[0]enddefcdr(s)s[1]enddefatom(s)s.is_a?(String)||s==nilenddeflist(s)s.size==0?nil:cons(s[0],list(s[1..-1]))end
//// Cons cells are created by using Array.//// All of atoms are string and the null value is null.functioncons(x,y){returnObject.freeze([x,y]);}functioncar(s){returns[0];}functioncdr(s){returns[1];}functionatom(s){returntypeofs=='string'||s==null;}functionlist(s){returns.length==0?null:cons(s[0],list(s.slice(1)));}
# times = N/25 (40,000件)
# Result
# user system total real
# MyDivsor 0.875262 0.032392 0.907654 ( 0.926605)
# PrimeDiv 0.849263 0.012468 0.861731 ( 0.879886)
# times = N/2 (500,000件)
# Result
# user system total real
# MyDivsor 1.659268 0.058786 1.718054 ( 1.758668)
# PrimeDiv 10.787444 0.118755 10.906199 ( 11.071594)