- 投稿日:2020-08-30T22:57:46+09:00
[Java] 条件分岐
if文
if文は数値や文字列などの評価(比較)結果を判定します。評価結果が「true(真)」の場合、ifブロック内の処理が実行されます。評価結果が「偽 (false)」 の場合はelse文を組み合わせます。
if( 条件文 ) { // 条件文が真 (true) のときにここが実行される } else { // 条件文 が偽 (false) のときにここが実行される }if文など、処理分岐するためには条件を判定する必要があります。判定のことを「評価」と呼びます。
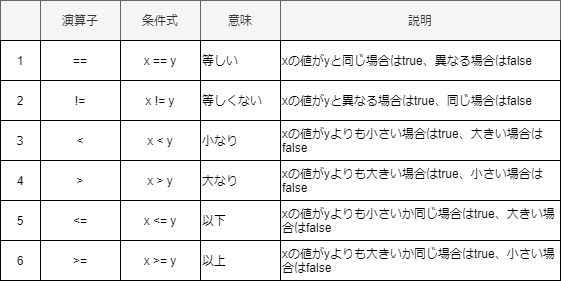
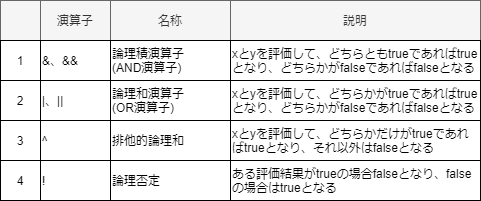
関係演算子
論理演算子
switch文
switch 文は指定した変数が特定の値をとる場合に、実行するコードを指定できます。 変数は switch で指定して、条件となる値は case に指定します。case 値: に続けて、 実行するコードを指定できます。コードブロックは break まで実行されます。
switch( 変数 ) { case 値1: case 値2: // 値1 か値 2 のときここが実行される break; case 値3: // 値3 のときにここが実行される break; default: // 値1, 2, 3 のいずれでもない時にここが実行される break; }
- 投稿日:2020-08-30T22:53:37+09:00
KotlinとC#からみたJava言語
はじめに
「KotlinとC#からみたJava言語」というタイトルからは、KotlinやC#に詳しい人間が、Javaを体験してみた結果の報告というようなものを期待する人もいると思うのだが、これはそうした文章ではない。JavaもC#も遊び程度に触ったことがある人間が『Kotlin In Action』という本に刺激を受けて(また、業務都合でC#の本も一冊読んで)書いたものだ。この本は大変面白い本で、Kotlinの知識だけでなく、Java言語についての見識も深めることができた。
本稿はその知見を、プログラミング言語について考える材料になるのではないかと思い、残すものだ。
Javaの弱点
なぜKotlinやC#を勉強するとJavaの知見が得られるのか。それは両言語ともにJavaを大いに参考にし、それをもっと使いやすくするために設計された言語だからだ。そのため両言語が補った部分を見ると、逆にJavaの何を弱点として認識したのかが分かる。
では一体Javaの弱点とは何なのか。沢山あるのだが、ここでは、①値型定義機能の欠如、②仮想関数の継承、③NULL安全の欠如の3つに絞ることにする。この3つは互いに密接に関連している。
値型定義機能の欠如
値型とは、その実際の値によって表される型のことであり、値型の変数は直接その値を保持する。値型はJavaではbooleanやintやdoubleなどの基本データ型にしか存在しない。その逆は参照型であり、その型の変数は直接値を保持せず、その参照を値として持つ。Javaでは基本データ型以外の全ての型が参照型だ。
Javaでは基本データ型以外の型は、あらかじめ用意されている型もユーザが定義する型も、全て参照型となる。つまりユーザは値型を定義できない。
対照的にJavaを参考にして作られたC#には、初期バージョンの時から構造体というユーザが値型を定義するための言語機能が用意されていた。
値型は2つの値が同じであること(等価性という)の確認とそのコピーを作ることが容易である。例えば、Javaの基本型は等価演算子(==)で2つの値が等しいことを確認できるし、代入演算子(=)で値のコピーを作ることができる。
参照型の場合は、等価演算子ではその参照値が等しいこと、すなわち同一性(この場合は同じものを参照していること)の確認を行うことになるし、代入演算子ではその参照値のコピーを行い、実際の値のコピーは作らない。
Javaの参照型で等価性を確認するためは、equalsメソッドを(同時にhashCodeも)オーバーライドする必要があるし、オブジェクトのコピーが必要な場合は、cloneメソッドをオーバライドするか、コピーコンストラクタを用意する必要がある。
値型がないことが弱点となるのは、アプリケーションではこの2つの機能を使う機会がとても多いからだ。このため、Javaでアプリケーションを作る場合には、そのソースコード中には、大量のボイラープレート(言語仕様上必要となる、お決まりのコードのこと)が埋め込めれることとなる(実際には、Javaのソースコードにボイラープレートが大量に埋め込まれることになるのは、KotlinやC#でプロパティと呼ばれる言語機能がないことがより大きな要因だが、話が煩雑になるのでここでは省略する)。
ではなぜJavaは基本データ型以外の全ての型を参照型としたのか? 理由はJavaの作者のジェームス・ゴスリンに聞いてみるしかないのだが、想像してみることはできる。
Javaはオブジェクト指向言語として大いに喧伝された言語だ。Javaが生まれた当時、オブジェクト指向言語が備えているべき機能として、次の3つが挙げられていた。
- 情報隠蔽
- 継承
- 多態性
Javaはこのうち多態性を仮想関数の継承とオーバーライドにより実現するのだが、これはJavaでは参照型でしか実現できない機能だ。このため、オブジェクト指向言語を志向したJavaは、値型をできる限り排除しようとしたのではないだろうか。むしろ基本データ型を値型としたのはパフォーマンスなどを考慮しての止むを得ない選択だったと言えるだろう。
また、Javaは「演算子のオーバーロードができない」という特徴を持つが、これもユーザ定義の値型を作成できないという特徴と関連していると思われる。
演算子の多重定義についてJavaの作者のジェームス・ゴスリンは以下のようなを言っているそうだ。
おそらく、20~30%の人が演算子のオーバーロードを諸悪の根源と考えていることでしょう。どこかの誰かが演算子のオーバーロードを使って、たとえばリストの挿入に「+」なんかを割り当てたりして、人生をものすごくめちゃくちゃに混乱させてしまったものだから、これに大きなバツ印が付けられてしまったのでしょう。問題の多くは、分別のあるやり方でオーバーロードできる演算子はせいぜい半ダースくらいしかないというのに、定義したくなるような演算子は数千、数百万個もあり、その中からどれかを選ばなければならなくなるのですが、その選択自体が自分の直感に反してしまうというところからきています。
すなわち、ジェームス・ゴスリンは演算子のオーバーロードを嫌っている。
だが、もしJavaが言語機能としてユーザ定義の値型を採用していた場合、演算子のオーバーロードを採用しないという選択は出来なかったのではないだろうか。少なくとも言語の欠陥として目立ったはずだ。
例えば代表的な値型の一つに複素数型がある。これがもし定義できた場合、この型に対するプラス演算子やマイナス演算子が定義できないというのは言語的欠陥だろう。だがもし参照型としてしか定義できなければ、演算子のオーバーロードができなかったとしても、言語的欠陥として目立つことはなくなる。
値型を定義する機能をなくすことで大嫌いな演算子のオーバーロード機能を省くことが可能になる。これはJavaにとって、とても都合が良かったのではないだろうか。
仮想関数の継承
先述した通り、Javaはオブジェクト指向言語として大いに喧伝された言語であり、仮想関数の継承とオーバーライドによる多態性を積極的に支援するような言語設計が行われている。すなわち、特に何も指定しなければ、クラスは継承可能なクラスとなり、クラスで定義した関数は、オーバライド可能な仮想関数となる。
では、この言語仕様の何が問題なのだろうか。
実は、大いに問題がある。仮想関数は、「脆弱な基底クラス(fragile base class)」と呼ばれる、今ではよく知られている問題を引き起こす。このため、現在では使用を控えることが推奨されているのだ。
「脆弱な基底クラス問題」とは、基底クラスのコードが変更されたときに、その変更がサブクラスが期待するものではなくなってしまったために、サブクラスでの不正な挙動を引き起こすという問題だ。(詳しくは、https://en.wikipedia.org/wiki/Fragile_base_class などを参照していただきたい)
この問題を回避するために、Javaの名著として知られている『Effective Java』では、「継承のために設計および文書化する、でなければ継承を禁止する」方法を勧めている。すなわち、継承による多態性を使用する場合は、基底クラスの実装内容を文書として公開する(そうでなければそもそも継承は使わない)ように勧めている。これはオブジェクト指向の重要な要素と言われている「情報隠蔽」を放棄することを意味する。
NULL安全の欠如
基本型以外の型を全て参照型としたために目立ってしまった言語の欠陥がある。それがNULL安全の欠如だ。
Javaの参照型は値を参照する型ではあるが、何も参照していない値(NUL)を持つことができる。この時、通常の値を参照している前提で、その型のメンバ(メソッドやフィールド)を参照するとNullPointerException(いわゆるヌルポ)という例外が発生する。NULL安全とは簡単にいうとこのNullPointerExceptionを発生させない仕組みのことだ。
JavaがNULL安全ではないことが、言語的欠陥と言えるのは、一方でJavaが型安全をうたった言語であるからだ(例えば、C言語は型安全な言語とはいわれないし、NULL参照も問題とされない)。
型安全とは、型に対する不正な操作をコンパイルエラーの検出などで未然に防ぐ仕組みのことだ。例えば、ある変数の型がString型である場合は、その変数にはString型に許された操作以外の操作を行おうとすると、Javaではコンパイルエラーが発生する。NULL参照は、Javaの型安全における唯一の例外となっている。
JavaにおいてNULL安全の欠如が問題となったのは、Javaが大変広く普及した言語であり多くのプログラマがこの問題に悩まされたことが大きいが、基本データ型以外は全て参照型というJavaの特徴もこれを後押ししている。
Javaの名誉のために一言付け加えておくと、Javaが生まれた当時、NULL安全という言葉は無かったように思う。少なくとも一般的に知られた機能ではなかった。このためJavaがNULL安全ではないというのは仕方がないことと言える。
弱点への対策
では、これらの弱点をJavaはどのように克服しようとしているか。また、KotlinとC#はこれらに対する対策をどのように行っているかをみていこう。
値型定義機能の欠如への対策
Javaの場合
Javaではユーザ定義型は全て参照型となるため、厳密には値型を定義することはできないが、値のように振舞う型を定義することはできる。すなわち、equalsメソッドで同値比較が可能で、コピーを作るのが容易な型というだ。但し、この場合は多くのボイラープレートをソースに追加しなければならなくなることは、先に述べた通りとなる。
この問題に対する解決策として、まず世に出てきたのがIDEによるボイラープレートの自動生成という方法だ。しかし、これはソースを作成する時の負担軽減にはなっても、あとで見直す時の負担の軽減にはならない。
そこで出てきたのがLombokというライブラリだ。このライブラリを導入するとクラスにDataアノテーションをつけるだけで、ソースコードからは見えないところで、equalsなどのボイラープレートを自動生成してくれる。
さらに、Java14からはRecordという新しい仕組みが導入され、値型がないというJavaの弱点がさらに補完されることになった。
Kotlinの場合
KotlinはJavaと同様、JVM上で動くように設計された言語だ。このため、基本データ型以外の型は全て参照型であるという性質を持ち、値型は定義できない。但し、Javaと同じで値型のように振舞うクラスを定義することはできる。
クラスにdataという修飾子をつけるだけで、equals、hashCode、toString、copyなどのメソッド自動生成される仕組みが最初から用意されている(これらのメソッドはソースからは見えない)。
C#の場合
先に述べた通り、C#には構造体という値型を定義するための仕組みを持っている。
さらに、匿名型というリテラルのように使える型も、同値比較のためのEquals関数が自動で付与されるため、値型のように使用することができる。
C#7.0からはタプルという型が使えるようになった。これも値型のように同値比較やコピーが容易な型だ。
仮想関数の継承への対策
Javaの場合
final修飾子をつけたクラスを継承しようとしたり、同修飾子をつけたメソッドをオーバライドしようとするとコンパイルエラーとなる。これはJavaに最初からついていた機能だ。基本的にクラスやメソッドには全てfinalをつけるようにすることで、「脆弱な基底クラス」問題を回避することができる。
Java5.0で導入されたアノテーションにより、メソッドをオーバライドする際にはOverrideアノテーションをつけることが推奨されるようになった。これはオーバライド行わない新規メソッドを意図せず作成してしまうというミスを回避するために追加された機能だが、オーバライドを行うことを少しだけ面倒にするという効果がある。
先に紹介した『Effective Java』では「継承よりコンポジションを選ぶ」という方法を勧めている。これは、既存のクラスを継承する代わりに、既存のクラスのインスタンスを参照するprivateフィールドを新たなクラスに持たせ、新たなクラスの各メソッドは、保持している既存クラスの対応するメソッドを呼び出してその結果を返す(これを委譲と呼ぶ)という方法だ。これにより「脆弱な基底クラス」問題を回避することができる。また、大抵のIDEはこの方法を支援する機能を持っている。但し、この方法は大量のボイラープレートを生み出す。
Kotlinの場合
Kotlinでは、デフォルトでクラスをfinalとして扱う。つまり、何も修飾子をつけないクラスは派生クラスを作ることができない。継承を行えるようにするためにはopen修飾子をつけなければならない。
同じようデフォルトでメソッドをfinalとして扱う。つまり、何も修飾子を付けないメソッドはオーバーライド不可となる。オーバライド可能とするためにはopen修飾子を付けなければならない。また、派生クラスでそのメソッドをオーバライドする際にはoverride修飾子を付けなければならない(Javaで対応する機能のOverrideアノテーションは任意)。
Kotlinは「継承よりコンポジションを選ぶ」という方法を積極的に支援するを持っている。byキーワードによってインターフェースから継承されるメソッドを他のクラスに委譲することが簡単にできるようになっている。
Kotlinには、継承によらないクラスの機能拡張の方法として、拡張関数という仕組みが用意された。これは継承の代わりとはならないし、普通のメソッド定義よりも制限が多いが、既存のクラスにメソッドを後から追加する強力な手段となっている。
C#の場合
C#では、クラスにsealed修飾子をつけることでそのクラスの継承を禁止することができる。但し、Kotlinとは違ってこれはデフォルトではない。
Kotlinと同じようにメソッドはデフォルトでオーバライド可能とはならない。オーバーライド可能とするためには、virtual修飾子を付けねばならず、派生クラスでそのメソッドをオーバライドする際には、override修飾子を付けなければならない。
Kotlinのようにクラス委譲の仕組みは用意されていない。クラス委譲を行う際には、Javaと同じようにボイラープレートを書かなければならない。
Kotlinと同じように、既存クラスにメソッドを追加する方法として拡張メソッドという仕組みがある。もっともこの機能は、C#3.0で追加されたものなので、Kotlinがそれを参考に拡張関数という仕組みを言語の仕様に取り込んだということだ。
NULL安全の欠如への対策
Javaの場合
JSR305や先に紹介したLombokなどのライブラリを導入すると、NullableアノテーションやNonNullアノテーションが使えるようになる。これらはNullPointerExceptionの検出を助けてくれる(その仕様はライブラリごとに異なる)。
Java8からは、Nullの可能性がある参照型のラッパークラスとしてOptionalクラスが使えるようになった。このクラスのメソッドはNullとそれ以外の場合とを区別するため、NullPointerExceptionの発生を減らすことができる。
Kotlinの場合
Kotlinの型システムではnull許容型(nullの可能性がある型)とnull非許容型(nullを許容しない型)が区別されているため、NullPointerExceitionの回避が容易になっている。Kotlinで普通に型名をそのまま使って型を(例えばStringのように)宣言した場合、それはnull非許容型となる。null許容型とするためには型名の後に疑問符を(例えばString?のように)付ける必要がある。
null非許容型は、nullを持たないため、NullPointerExceitionを発生させることはない。さらにKotlinは、null許容型に対して次のような構文を用意しNullPointerExceitionを発生しにくくしている。
- 安全呼び出し演算子(?.)
- nullチェックとメソッド呼び出しを結合する演算子
- エルビス演算子(?:)
- nullの代わりにデフォルト値を返す演算子
- 安全キャスト(as)
- 指定された型に値をキャストしようとし、型が違う場合はnullを返す
- 非null表明(!!)
- 任意の型をnull非許容型に変換するための構文。値がnullの場合は例外をスローする
- let関数
- nullチェックとラムダ呼び出しを結合するための構文
C#の場合
2019年9月にリリースされたC# 8.0からはnull許容参照型が使えるようになった。これはKotlinと同じように、型名の後ろに疑問符を付けたときのみ、その変数や関数の戻り値にnullを許可するという機能だ。Kotlinとの違いは、過去のバージョンとの互換性を保つために、null 許容注釈コンテキストを有効にしたときのみ、null許容参照型が使えることだ。
C#にはそれぞれ導入時期は異なるが、NULLに配慮した次のような演算子がある。
- null合体演算子(??)
- 左側のオペランドがnullではない場合、そのオペランドの値を、それ以外の場合は、右側のオペランドの評価結果を返す演算子
- null合体割り当て演算子(=??)
- 左側のオペランドがnullに評価された場合にのみ、右側のオペランドの値を左側のオペランドに割り当てる演算子
- null免除演算子(!)
- オペランドをnull非許容型として解釈するよう指示を与える演算子。コンパイラの静的フロー分析にのみ影響を与え、実行時には影響を与えない
- null条件演算子(?.、?[])
- 左側のオペランドがnull参照ののときにはnullを、それ以外の場合は左側のオペランドのメンバ(フィールドやプロパティやメソッドなどのこと)である右側のオペランドを評価し、その結果を返す。インデクサーを呼び出すときのみ?[]を使用する
最後に
C++言語の設計者であるストラウストラップはその著書『C++の設計と進化』で次のように述べている。
「私が予言したように、Javaは年月を経て新しい機能を身につけていき、その結果単純さという"もともとの長所"を打ち消してしまったが、だからといって性能をあげることもなかった。新しい言語というものはいつだって「単純さ」を売りにし、その後、実世界のアプリケーション向けにサイズも複雑さも増して、生き延びていく」と述べている。
全くその通りだなと思う。JavaやC#は今ではもう十分複雑な言語だし、まだ生まれて間もないKotlinもやがて複雑な言語に育っていくのだろう。生きている言語とはそういうものなのだ。
- 投稿日:2020-08-30T22:23:59+09:00
担当したPJの単体テストが地獄絵図だったので独自に作成したガイド(?)を公開する
はじめに
こんにちは, ねげろんです。
2020年上期にとあるJavaの開発案件にアサインされたのですが, 自分含めメンバが作成したUTコードが カオスここに極まれり でした。
例えば,
・JUnit4とJUnit5のコードが混在しているテスト
・何もassertせずにただメソッドを呼んでいるだけのテスト
・成功するときと失敗するときがある再現性がないテスト
・ステータスコードが200だろうが404だろうが500だろうが成功してしまうモックを使った正常系テスト
などなど・・・。本PJは追加機能実装のため下期も開発を継続するのですがこのままではまずいと思い,
先輩社員の方に相談のもと単体テストのガイド(?)を作ることにしました。本記事ではそのガイドを公開します。
ただし, 上述したような 混沌とした現場 のためのガイドであるということをご承知おきください。
また筆者自身も単体テストに精通しているわけではありません。
もし「もっとこうしたほうがいいよ!」や「それは間違っている!」みたいな意見がございましたら是非コメントに書いていただければと思います!本記事が「単体テストってどう進めればいいの?」と悩んでいる方の助けになれば幸いです!
以下, JUnit5を想定しての記述です。
基本
テストケース
- 一つのテストケースにあまり多くのテストを含めず簡潔にする
- NGになった際の解析が面倒になってしまう
- テストケース内は4フェーズでテストする
- 【事前準備】 → 【実行】 → 【検証】 → 【後処理】の4フェーズでテストを記載する
Add.java// テスト対象クラス public class Calc { public int add(int a, int b) { return a + b; } }CalcTest.javaimport static org.junit.jupiter.api.Assertions.*; import org.junit.jupiter.api.Test; // テストクラス class CalcTest { @Test void addメソッドに2と3を渡すと5を返す() { // 【事前準備】 Calc sut = new Calc(); int expected = 5; // 【実行】 int actual = sut.add(2, 3); // 【検証】 assertEquals(expected, actual); // 【後処理】 /* * インスタンスの破棄やファイルのcloseなど * 必要があれば処理を書く */ } }
- 【実行】フェーズでは 評価対象のメソッドもしくはコンストラクタを1つだけ呼ぶ
- 横断的な評価をする場合は別だが, 単体テストではそもそも横断的なテストはあまり行わない
- 【検証】フェーズでは
assertEquals(期待値, 検査対象)という構文で評価を行う
- 他のassertionに
assertTrue/False,assertNull/NotNull,assertSame/NotSameなどがあるので必要に応じて使い分ける- JUnit4では
assertThat(検査対象, matcher関数(期待値))という構文で評価をしていたが, asserThatとMatcher関数はJUnit5では廃止された- 該当ライブラリを読み込めば使用することは可能
- 例外がthrowされていることのテストには
assertThrowsを用いるBookshelf.java// テスト対象クラス public class Bookshelf { String[] books = new String[3]; public String addBook(int i, String title) { books[i] = title; return title; } public List<String> readBook(String str) throws IOException { Path path = Paths.get(str); List<String> lines = Files.readAllLines(path, StandardCharsets.UTF_8); return lines; } }BookshelfTest.javaimport static org.junit.jupiter.api.Assertions.*; import org.junit.jupiter.api.Test; import java.io.IOException; // テストクラス class BookshelfTest { @Test void インデックスに3以上を指定してaddBookメソッドを呼ぶとArrayIndexOutOfBoundsExceptionをthrowする() { // 【事前準備】 Bookshelf sut = new Bookshelf(); // 【実行】 assertThrows(ArrayIndexOutOfBoundsException.class, () -> sut.addBook(3, "JavaTextBook")); } @Test void 存在しないファイルを指定してreadBookメソッドを呼ぶとIOExceptionをthrowする() { // 【事前準備】 Bookshelf sut = new Bookshelf(); // 【実行】 assertThrows(IOException.class, () -> sut.readBook("hoge.txt")); } }命名規則について
- テストクラス名はテスト対象クラス名の末尾に「Test」をつけて命名する
- 例えばConfigクラスのテストクラス名は「ConfigTest」とする
- テストメソッド(=テストケース)は 日本語でテストの内容を簡潔に書く
- 例) addメソッドに2と3を渡したら5を返す ( )
- 足し算( ), 足し算ケース1 ( ), 足し算ケース2( ), …のような何を評価しているか分からないようなテスト名は避けること
- JUnit5では
@DisplayNameアノテーションでテストの表示名を設定できる- メソッド名には「数値から始めることはできない」等の制約があるのでこのアノテーションを付与したほうが便利なこともある
- 評価対象クラスのオブジェクトの変数名は sut (System Under Test) とする
- 実行結果の変数名は actual や actualXXX , 期待値の変数名は expected や expectedXXX など, それぞれ実行結果と期待値であることがわかるようにする
- 必ずしも変数に入れる必要はない
assertEquals(0, actual);のような即値のほうが分かり易いものは即値でよいJUnit5の推奨機能
テストの構造化
- テストの構造化を行えば, 各テストケースを前処理や目的によってグループ化することができる
- 内部クラスに
@Nestedアノテーションを付与することで階層化を実現する@BeforeEachや@AfterEachアノテーションを付与すれば各テストを実行する前の事前処理や後処理を書くこともできる- 階層ごとに選択してテストを実行することも可能
BookshelfTest.javaimport static org.junit.jupiter.api.Assertions.*; import java.io.IOException; import org.junit.jupiter.api.BeforeEach; import org.junit.jupiter.api.Nested; import org.junit.jupiter.api.Test; class BookshelfTest { @Nested class 本を本棚に3冊まで格納できる { private Bookshelf sut; private String expected1 = "JavaText"; private String expected2 = "PythonText"; private String expected3 = "RubyText"; @BeforeEach void setUp() { sut = new Bookshelf(); } @Test void addBookメソッドに本を1冊追加できる () { // 【事前準備】 // 【実行】 String actual = sut.addBook(0, expected1); // 【検証】 assertEquals(expected1, actual); } @Test void addBookメソッドに本を2冊追加できる () { // 【事前準備】 // 【実行】 String actual1 = sut.addBook(0, expected1); String actual2 = sut.addBook(1, expected2); // 【検証】 assertEquals(expected1, actual1); assertEquals(expected2, actual2); } @Test void addBookメソッドに本を3冊追加できる () { // 【事前準備】 // 【実行】 String actual1 = sut.addBook(0, expected1); String actual2 = sut.addBook(1, expected2); String actual3 = sut.addBook(1, expected3); // 【検証】 assertEquals(expected1, actual1); assertEquals(expected2, actual2); assertEquals(expected3, actual3); } } @Nested class 異常系のテスト { private Bookshelf sut; @BeforeEach void setUp() { sut = new Bookshelf(); } @Test void インデックスに3以上を指定してaddBookメソッドを呼ぶとArrayIndexOutOfBoundsExceptionをthrowする() { // 【事前準備】 Bookshelf sut = new Bookshelf(); // 【実行】 assertThrows(ArrayIndexOutOfBoundsException.class, () -> sut.addBook(3, "JavaTextBook")); } @Test void 存在しないファイルを指定してreadBookメソッドを呼ぶとIOExceptionをthrowする() { // 【事前準備】 Bookshelf sut = new Bookshelf(); // 【実行】 assertThrows(IOException.class, () -> sut.readBook("hoge.txt")); } } }パラメータ化テスト
- パラメータ化テストを用いれば, 異なる引数で複数回実行できるようになる
- パラメータ化テストでは
@Testではなく@ParameterizedTestアノテーションを付与する- 引数のsourceもアノテーションを付与することで指定する
- いくつかの種類があるがここでは
@CsvSourceアノテーションを例示する
- 他の種類については JUnit5 ユーザガイド を参照せよ
- 外部のcsvファイルを読み込んで引数のsourceにすることも可能 (
@CsvFileSource)BookshelfTest.javaimport static org.junit.jupiter.api.Assertions.*; import org.junit.jupiter.params.ParameterizedTest; import org.junit.jupiter.params.provider.CsvSource; class BookshelfTest { @ParameterizedTest @CsvSource({ "0, JavaText", "1, PythonText", "2, RubyText" }) void Bookshelfに3冊の本棚が格納できる(int index, String title) { Bookshelf sut = new Bookshelf(); assertEquals(title, sut.addBook(index, title)); } }タグ付け
- 各テストコードに
@tagアノテーションを付与することでタグ付けすることが可能
- 指定したタグに紐づくテストのみを実行したり、実行から除外したりできる
BookshelfTest.javaimport static org.junit.jupiter.api.Assertions.*; import org.junit.jupiter.api.Tag; import org.junit.jupiter.api.Test; class BookshelfTest { @Test void addBookメソッドに本を1冊追加できる() { // 【事前準備】 Bookshelf sut = new Bookshelf(); String expected1 = "JavaText"; // 【実行】 String actual = sut.addBook(0, expected1); // 【検証】 assertEquals(expected1, actual); } @Tag("異常系") @Test void インデックスに3以上を指定してaddBookメソッドを呼ぶとArrayIndexOutOfBoundsExceptionをthrowする() { // 【事前準備】 Bookshelf sut = new Bookshelf(); // 【実行】 assertThrows(ArrayIndexOutOfBoundsException.class, () -> sut.addBook(3, "JavaTextBook")); } }2020年上期の開発の中を通して
- privateメソッドのテストを行うかどうかは賛否が分かれるところである
- プライベートメソッドのテストは書かないもの? を参照せよ
- 開発前にチームとして指針を決めておく方が好ましい
- privateメソッドのテストへの対応には例えば以下のようなものが挙げられる:
- publicメソッド経由でテストする
- 別クラスに切り出してpublicメソッドとする
- テスト対象の可視性を (やや) 上げる
- リフレクションでアクセスしてテストを書く
- Lombokを用いて自動生成したメソッド (主にsetterやgetterなど) のテストも書いておく方が好ましい
- もしLombok以外のOSSに切り替えた際に, 互換性を維持できているかの検証の最小単位はそのテストになる
- ただし本PJではカバレッジ集計には含めない
- カバレッジを上げるためだけにテストを書かないようにすること
- カバレッジを上げること と 機能を評価すること の両方を意識してテストコードを書くこと
- 例えばほぼ全てのテストがカバレッジを上げるためにメソッドを呼び出しているだけであれば, それはそのクラスの機能をテストしているとは言えない
- テストコードにおける評価は正しく行うこと
- 例えば, コレクションに何か要素を追加するメソッドをテストする際には, コレクションの要素数が追加した要素数と一致することだけではなく, コレクションの各要素が追加した要素と一致している事まで調べて初めて正しくテストしたといえる
- ドキュメントとしてのテストコードを意識して書くこと
- メソッドの使い方を解説する一番の説明書はテストコードである
- 各自の環境でいつでも成功するテスト ( 再現性のあるテスト ) を作ること
参考文献
- 投稿日:2020-08-30T21:18:44+09:00
bootstrap-selectで作ったセレクトボックスを活性化できないときの対応方法
- 環境
- CentOS Linux release 7.8.2003 (Core)
- openjdk version "11.0.7" 2020-04-14 LTS
- JSF 2.3.9
- jquery 3.2.1
- bootstrap 4.3.1
- bootstrap-select 1.13.14
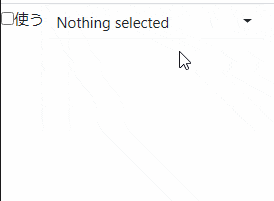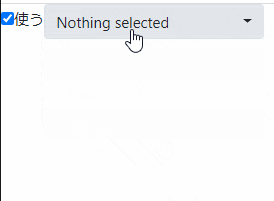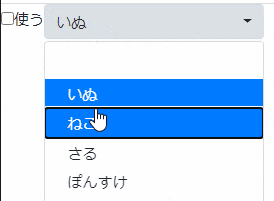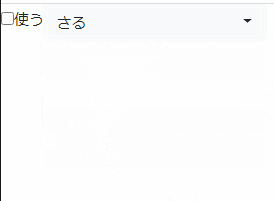
事象 : bootstrap-selectで作ったセレクトボックスを活性化できない
- 初期表示時にセレクトボックスを非活性にする
- チェックボックスを変更すると
onchangeイベントでセレクトボックスの活性非活性を切り替えるはずが活性化しない・・・・
XHTML<!--省略--> <h:form id="formId"> <h:panelGroup> <ui:remove>[使う]チェックボックス</ui:remove> <h:selectBooleanCheckbox id="chekBox" value="#{sampleBean.chekBoxValue}" onchange="changeDisabled();" /> <h:outputLabel value="使う" for="chekBox" /> </h:panelGroup> <h:panelGroup> <ui:remove>セレクトボックス</ui:remove> <h:selectOneMenu id="select" styleClass="selectpicker" value="#{sampleBean.selected}"> <f:selectItems value="#{sampleBean.selectItems}" /> </h:selectOneMenu> </h:panelGroup> </h:form> <!--省略-->JavaScript$(document).ready(function(){ changeDisabled(); }); /** セレクトボックスの活性非活性を切り替える. */ function changeDisabled() { /** @type {boolean} チェックボックスの選択状態. */ var checked = $("#formId\\:chekBox").prop("checked"); if (checked) { // 活性化する $("#formId\\:select").removeAttr('disabled'); $("#formId\\:select").next().children().removeClass('disabled'); } else { // 非活性にする $("#formId\\:select").attr('disabled', 'disabled'); $("#formId\\:select").next().children().addClass('disabled'); } }SampleBean// 省略 public class SampleBean implements Serializable { /** serialVersionUID. */ private static final long serialVersionUID = -6782548672735889274L; /** セレクトボックスの選択肢. */ @Getter private List<SelectItem> selectItems; /** セレクトボックスで選択した値. */ @Getter @Setter private Integer selected; @Getter @Setter private Boolean chekBoxValue = false; /** Beanの初期化処理. */ @PostConstruct public void init() { setSelectItems(); } /** 選択肢を設定する. */ private void setSelectItems() { selectItems = new ArrayList<SelectItem>(); selectItems.add(new SelectItem(0, " ")); selectItems.add(new SelectItem(1, "いぬ")); selectItems.add(new SelectItem(2, "ねこ")); selectItems.add(new SelectItem(3, "さる")); selectItems.add(new SelectItem(4, "ぽんすけ")); } }原因 : 初期表示時に非活性にする処理を実行するタイミングが
readyだからJavaScriptをデバックしながらHTMLの出力を見ているとbootstrap-selectのHTMLが構築されるのは
onloadっぽかったのでいろいろ試してみた。
試してみると初期表示の非活性処理は同じでも、タイミングがreadyとonloadでdisabledが付く場所に違いがあった。
また、バージョンが異なると出力されるHTMLが変わるからかdisabledが付く場所も変わった。非活性処理// selectタグにdisabled属性をつける $("#formId\\:select").attr('disabled', 'disabled'); // selectの隣のタグの子供タグにclass属性のdisabbledをつける $("#formId\\:select").next().children().addClass('disabled');凡例) ★ : 出力されたHTMLで「selectの隣のタグの子供タグ」になるタグ
bootstrap-select 1.13.14 1.13.14 1.6.3 1.6.3 disableするタイミング ready onload ready onload disabled属性が付く select select select select class属性にdisabbledがつく 一番上のdiv,
buttonbutton直下のdiv★ button★,
libutton★,
buttonの隣のdivaria-disabled属性が付く button なし なし なし 今回JavaScriptで活性非活性を切り替える際に行っている処理の場合、
onloadでdisabledが付く場所にしか対応していなかった活性化処理$("#formId\\:select").removeAttr('disabled'); $("#formId\\:select").next().children().removeClass('disabled');bootstrap-select 1.13.14
- bootstrap 4.3.1
- bootstrap-select 1.13.14
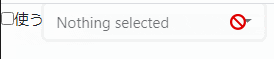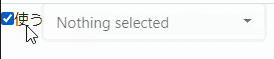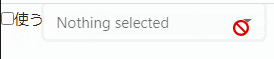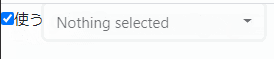
非活性化しない場合に出力されるHTML
<div class="dropdown bootstrap-select"> <select id="formId:select" name="formId:select" class="selectpicker" size="1" tabindex="-98"> <option value="0"> </option> <option value="1">いぬ</option> <option value="2">ねこ</option> <option value="3">さる</option> <option value="4">ぽんすけ</option> </select> <button type="button" class="btn dropdown-toggle btn-light" data-toggle="dropdown" role="combobox" aria-owns="bs-select-1" aria-haspopup="listbox" aria-expanded="false" data-id="formId:select" title="Nothing selected"> <div class="filter-option"><div class="filter-option-inner"><div class="filter-option-inner-inner">Nothing selected</div></div></div> </button> <div class="dropdown-menu "> <div class="inner show" role="listbox" id="bs-select-1" tabindex="-1"> <ul class="dropdown-menu inner show" role="presentation"></ul> </div> </div> </div>readyで非活性化した場合に出力されるHTML
<div class="dropdown bootstrap-select disabled"> <select id="formId:select" name="formId:select" class="selectpicker" size="1" disabled="disabled" tabindex="-98"> <!-- 非活性化しない場合と同じなので省略 --> <button type="button" class="btn dropdown-toggle disabled btn-light" data-toggle="dropdown" role="combobox" aria-owns="bs-select-1" aria-haspopup="listbox" aria-expanded="false" data-id="formId:select" tabindex="-1" aria-disabled="true" title="Nothing selected"> <!-- 非活性化しない場合と同じなので省略 -->onloadで非活性化した場合に出力されるHTML
<!-- 非活性化しない場合と同じなので省略 --> <select id="formId:select" name="formId:select" class="selectpicker" size="1" tabindex="-98" disabled="disabled"> <!-- 非活性化しない場合と同じなので省略 --> <div class="filter-option disabled"><div class="filter-option-inner"><div class="filter-option-inner-inner">Nothing selected</div></div></div> <!-- 非活性化しない場合と同じなので省略 -->bootstrap-select 1.6.3
- bootstrap 3.3.0
- bootstrap-select 1.6.3
非活性化しない場合に出力されるHTML
<select id="formId:select" name="formId:select" class="selectpicker" size="1" style="display: none;"> <option value="0"> </option> <option value="1">いぬ</option> <option value="2">ねこ</option> <option value="3">さる</option> <option value="4">ぽんすけ</option> </select> <div class="btn-group bootstrap-select"> <button type="button" class="btn dropdown-toggle selectpicker btn-default" data-toggle="dropdown" data-id="formId:select" title=" "> <span class="filter-option pull-left"> </span> <span class="caret"></span> </button> <div class="dropdown-menu open"> <ul class="dropdown-menu inner selectpicker" role="menu"> <li data-original-index="0" class="selected"><a tabindex="0" class="" data-normalized-text="<span class="text"> </span>"><span class="text"> </span><span class="glyphicon glyphicon-ok check-mark"></span></a></li> <li data-original-index="1"><a tabindex="0" class="" data-normalized-text="<span class="text">いぬ</span>"><span class="text">いぬ</span><span class="glyphicon glyphicon-ok check-mark"></span></a></li> <li data-original-index="2"><a tabindex="0" class="" data-normalized-text="<span class="text">ねこ</span>"><span class="text">ねこ</span><span class="glyphicon glyphicon-ok check-mark"></span></a></li> <li data-original-index="3"><a tabindex="0" class="" data-normalized-text="<span class="text">さる</span>"><span class="text">さる</span><span class="glyphicon glyphicon-ok check-mark"></span></a></li> <li data-original-index="4"><a tabindex="0" class="" data-normalized-text="<span class="text">ぽんすけ</span>"><span class="text">ぽんすけ</span><span class="glyphicon glyphicon-ok check-mark"></span></a></li> </ul> </div> </div>readyで非活性化した場合に出力されるHTML
<select id="formId:select" name="formId:select" class="selectpicker" size="1" disabled="disabled" style="display: none;"> <!-- 非活性化しない場合と同じなので省略 --> <button type="button" class="btn dropdown-toggle selectpicker disabled btn-default" data-toggle="dropdown" data-id="formId:select" tabindex="-1" title=" "> <!-- 非活性化しない場合と同じなので省略 --> <li data-original-index="0" class="disabled selected"><a tabindex="-1" class="" data-normalized-text="<span class="text"> </span>" href="#"><span class="text"> </span><span class="glyphicon glyphicon-ok check-mark"></span></a></li> <li data-original-index="1" class="disabled"><a tabindex="-1" class="" data-normalized-text="<span class="text">いぬ</span>" href="#"><span class="text">いぬ</span><span class="glyphicon glyphicon-ok check-mark"></span></a></li> <li data-original-index="2" class="disabled"><a tabindex="-1" class="" data-normalized-text="<span class="text">ねこ</span>" href="#"><span class="text">ねこ</span><span class="glyphicon glyphicon-ok check-mark"></span></a></li> <li data-original-index="3" class="disabled"><a tabindex="-1" class="" data-normalized-text="<span class="text">さる</span>" href="#"><span class="text">さる</span><span class="glyphicon glyphicon-ok check-mark"></span></a></li> <li data-original-index="4" class="disabled"><a tabindex="-1" class="" data-normalized-text="<span class="text">ぽんすけ</span>" href="#"><span class="text">ぽんすけ</span><span class="glyphicon glyphicon-ok check-mark"></span></a></li> <!-- 非活性化しない場合と同じなので省略 -->onloadで非活性化した場合に出力されるHTML
<select id="formId:select" name="formId:select" class="selectpicker" size="1" disabled="disabled" style="display: none;"> <!-- 非活性化しない場合と同じなので省略 --> <button type="button" class="btn dropdown-toggle selectpicker btn-default disabled" data-toggle="dropdown" data-id="formId:select" title=" "> <!-- 非活性化しない場合と同じなので省略 --> <div class="dropdown-menu open disabled"> <!-- 非活性化しない場合と同じなので省略 -->対応方法 : 初期表示時に非活性にする処理を
onloadでやる
$(window).on('load', function(){ changeDisabled(); }); // 省略
- 投稿日:2020-08-30T20:01:39+09:00
逆コンパイルして理解する、Java視点からのScala入門(基本編)
この記事は富士通システムズウェブテクノロジーの社内技術コミュニティで、「イノベーション推進コミュニティ」
略して「いのべこ」が企画する、いのべこ夏休みアドベントカレンダー 2020の14日目の記事です。
本記事の掲載内容は私自身の見解であり、所属する組織を代表するものではありません。
ここまでお約束はじめに
この記事は、Scalaを始めたJavaプログラマが、Scalaをコンパイルして生成されたclassファイルを逆コンパイルし、
Java的な観点からScalaを理解したいなと思いついて始めたものです。基本的な流れは以下の通りで進めていきたいと思います。
- docs.scala-lang.org/jaの「TOUR OF SCALA」を見ながら、scalaコードを写経する
- jd-guiというJava Decompilerを使用してclassファイルを逆コンパイルする
- 逆コンパイルしたソースコードを眺めて、あーでもないこーでもないとコメントをつける
以上になります。
それでは、Scalaの世界に少しだけ触れてみましょう。
今回は、TOUR OF SCALAの中から「基本」編を用いてScalaの世界に触れてみたいと思います。(一部発展課題があります)クラス
scalaにおけるクラスは、Javaとほとんど同じに見えますが、コンストラクタのパラメータに違いがあります。
また、オーバーロードについてはどのように実装するのか、サンプルをもとに確認してみましょう。サンプルコード
class Greeter(prefix: String, suffix: String) { def greet(name: String): Unit = println(prefix + name + suffix) }デコンパイル後
package com.github.fishibashi.scaladecompile; import scala.Predef$; import scala.reflect.ScalaSignature; @ScalaSignature(bytes = "\006\005A2A!\002\004\001\037!Aa\003\001B\001B\003%q\003\003\005#\001\t\005\t\025!\003\030\021\025\031\003\001\"\001%\021\025I\003\001\"\001+\005\0359%/Z3uKJT!a\002\005\002\035M\034\027\r\\1eK\016|W\016]5mK*\021\021BC\001\013M&\034\b.\0332bg\"L'BA\006\r\003\0319\027\016\0365vE*\tQ\"A\002d_6\034\001a\005\002\001!A\021\021\003F\007\002%)\t1#A\003tG\006d\027-\003\002\026%\t1\021I\\=SK\032\fa\001\035:fM&D\bC\001\r \035\tIR\004\005\002\033%5\t1D\003\002\035\035\0051AH]8pizJ!A\b\n\002\rA\023X\rZ3g\023\t\001\023E\001\004TiJLgn\032\006\003=I\taa];gM&D\030A\002\037j]&$h\bF\002&O!\002\"A\n\001\016\003\031AQAF\002A\002]AQAI\002A\002]\tQa\032:fKR$\"a\013\030\021\005Ea\023BA\027\023\005\021)f.\033;\t\013=\"\001\031A\f\002\t9\fW.\032") public class Greeter { private final String prefix; private final String suffix; public Greeter(String prefix, String suffix) {} public void greet(String name) { Predef$.MODULE$.println((new StringBuilder(0)).append(this.prefix).append(name).append(this.suffix).toString()); } }ScalaSignature
コンパイルされた時のメタ情報を格納しているらしい。
sealedについての実装方法を確認した記事がqiitaにありました。
https://qiita.com/ocadaruma/items/93818bd1a5318e71f0d8知りたいことかどうかはわかりませんが、なるほどそのためにあるんですね。。。
コンストラクタの引数
引数の
prefix: String, suffix: Stringが、private finalなフィールドとして定義されました。
※finalになるのは、コンストラクタの引数がデフォルトでval(変更不可)だからでしょう。試しに、
varなパラメータとしてコンストラクタパラメータを書いてみると以下のようになります。class Greeter(var prefix: String, var suffix: String) { def greet(name: String): Unit = println(prefix + name + suffix) }public class Greeter { private String prefix; private String suffix; public String prefix() { return this.prefix; } public void prefix_$eq(String x$1) { this.prefix = x$1; } public String suffix() { return this.suffix; } public void suffix_$eq(String x$1) { this.suffix = x$1; } public Greeter(String prefix, String suffix) {} public void greet(String name) { Predef$.MODULE$.println((new StringBuilder(0)).append(prefix()).append(name).append(suffix()).toString()); } }
finalがなくなり、getterメソッド(prefix(), suffix())と、setterメソッド($eq)が生成されていることがわかります。
scalaのコードから呼ぶときは、普通にprefixでgetもsetもできそうですが、Javaコードから呼ぶ場合はフィールド名_$eqになりそうです。
ややこしいですね・・・greetメソッド
greetメソッドでは、
+メソッド(scalaでは、+もメソッドとして扱われる!)で文字列を連結していました。ですが、逆コンパイルした結果を見ると、StringBuilderを使用し、文字列を連結しています。なんと!かしこい!
Javaのコードで文字列を結合して処理をして居ようものなら、「StringBuilderを使ってください」とレビュー表に書かれること間違いなしですが、Scalaの場合はその心配がありません。
試しにJavaで書き直してデコンパイルした結果が以下の通りです。
JavaGreeeter.java// コンパイル前コード //public class JavaGreeter { // private final String prefix; // // private final String suffix; // // public JavaGreeter(String prefix, String suffix) { // this.prefix = prefix; // this.suffix = suffix; // } // // public String greet(String name) { // return prefix + name + suffix; // } //} import scala.Predef$; public class JavaGreeter { private final String prefix; private final String suffix; public JavaGreeter(String prefix, String suffix) { this.prefix = prefix; this.suffix = suffix; } public void greet(String name) { Predef$.MODULE$.println(this.prefix + this.prefix + name); } }単純に文字列を結合するようになっているようです。
おそらく、Scalaでは演算子もすべて関数として扱われます。Stringの+メソッド自体がおそらくStringBuilderを使う動きになっているのではないかと想像しています(もしかしたら、scalacがStringBuilderで解釈するようになっているのかもしれませんが・・・)なお、リテラルを使用した場合でも、同じようにStringBuilderを使ってくれるみたいです。
def greet(name: String): Unit = println(s"${prefix} ${name} ${suffix}") /** public void greet(String name) { Predef$.MODULE$.println((new StringBuilder(2)).append(prefix()).append(" ").append(name).append(" ").append(suffix()).toString()); } */オブジェクト
次は
objectです。Javaのjava.lang.Objectではないです。
Scalaのobjectは、JavaでいうところのSingletonパターンに該当するでしょうか。
以下のような構文になります。サンプルコード
object IdFactory { private var counter = 0 def create(): Int = { counter += 1 counter } }デコンパイル後
IdFactory.class@ScalaSignature(bytes = "\006\0051:Qa\002\005\t\002E1Qa\005\005\t\002QAQaG\001\005\002qAq!H\001A\002\023%a\004C\004#\003\001\007I\021B\022\t\r%\n\001\025)\003 \021\025Q\023\001\"\001,\003%IEMR1di>\024\030P\003\002\n\025\005q1oY1mC\022,7m\\7qS2,'BA\006\r\003)1\027n\0355jE\006\034\b.\033\006\003\0339\taaZ5uQV\024'\"A\b\002\007\r|Wn\001\001\021\005I\tQ\"\001\005\003\023%#g)Y2u_JL8CA\001\026!\t1\022$D\001\030\025\005A\022!B:dC2\f\027B\001\016\030\005\031\te.\037*fM\0061A(\0338jiz\"\022!E\001\bG>,h\016^3s+\005y\002C\001\f!\023\t\tsCA\002J]R\f1bY8v]R,'o\030\023fcR\021Ae\n\t\003-\025J!AJ\f\003\tUs\027\016\036\005\bQ\021\t\t\0211\001 \003\rAH%M\001\tG>,h\016^3sA\00511M]3bi\026$\022a\b") public final class IdFactory { public static int create() { return IdFactory$.MODULE$.create(); } }IdFactory$.classpublic final class IdFactory$ { public static final IdFactory$ MODULE$ = new IdFactory$(); private static int counter = 0; private int counter() { return counter; } private void counter_$eq(int x$1) { counter = x$1; } public int create() { counter_$eq(counter() + 1); return counter(); } }なんと!匿名クラスが出来上がりました。
おそらくですが、Singletonオブジェクトである
IdFactory$と、それを呼び出すIdFactoryクラスという構成です。分離されてしまう理由があるのでしょうか。勉強を進めていくうえで何かあると思って今回はこれで終わりです。
公式ドキュメントにも、後で詳しく取り扱いますとあるので、期待ですtrait
traitとは何ぞや。
interfaceのようなものなんですが、フィールドも持ててデフォルト実装もできて、はたまた複数のトレイトを継承(mixin)することができるらしいです。ここでは、traitの作成と、継承したクラスを作成しどのようなクラスが作成されるのかを見てみましょう。
サンプルコード
trait Greeter { def greet(name: String): Unit = println("Hello, " + name + "!") } class DefaultGreeter extends Greeter class CustomizableGreeter(prefix: String, postfix: String) extends Greeter { override def greet(name: String): Unit = { println(prefix + name + postfix) } }デコンパイル後
今回は全部で3つのクラスファイルが出来上がりました。
Javaの場合は、1つのjavaソースコードに複数のpublicクラスを作ることができませんので、複数に分割されました。Greeter.java@ScalaSignature(bytes = "\006\005!2qa\001\003\021\002\007\005Q\002C\003\025\001\021\005Q\003C\003\032\001\021\005!DA\004He\026,G/\032:\013\005\0251\021AD:dC2\fG-Z2p[BLG.\032\006\003\017!\t!BZ5tQ&\024\027m\0355j\025\tI!\"\001\004hSRDWO\031\006\002\027\005\0311m\\7\004\001M\021\001A\004\t\003\037Ii\021\001\005\006\002#\005)1oY1mC&\0211\003\005\002\007\003:L(+\0324\002\r\021Jg.\033;%)\0051\002CA\b\030\023\tA\002C\001\003V]&$\030!B4sK\026$HC\001\f\034\021\025a\"\0011\001\036\003\021q\027-\\3\021\005y)cBA\020$!\t\001\003#D\001\"\025\t\021C\"\001\004=e>|GOP\005\003IA\ta\001\025:fI\0264\027B\001\024(\005\031\031FO]5oO*\021A\005\005") public interface Greeter { static void $init$(Greeter $this) {} default void greet(String name) { Predef$.MODULE$.println((new StringBuilder(8)).append("Hello, ").append(name).append("!").toString()); } }traitはinterfaceになりました
DefaultGreeter.java@ScalaSignature(bytes = "\006\005i1AAA\002\001\031!)q\003\001C\0011\tqA)\0324bk2$xI]3fi\026\024(B\001\003\006\0039\0318-\0317bI\026\034w.\0349jY\026T!AB\004\002\025\031L7\017[5cCND\027N\003\002\t\023\0051q-\033;ik\nT\021AC\001\004G>l7\001A\n\004\0015\031\002C\001\b\022\033\005y!\"\001\t\002\013M\034\027\r\\1\n\005Iy!AB!osJ+g\r\005\002\025+5\t1!\003\002\027\007\t9qI]3fi\026\024\030A\002\037j]&$h\bF\001\032!\t!\002\001") public class DefaultGreeter implements Greeter { public void greet(String name) { Greeter.greet$(this, name); } public DefaultGreeter() { Greeter.$init$(this); } }インタフェースのデフォルト実装を呼び出す形になっています。
@ScalaSignature(bytes = "\006\005M2A!\002\004\001\037!A!\004\001B\001B\003%1\004\003\005'\001\t\005\t\025!\003\034\021\0259\003\001\"\001)\021\025a\003\001\"\021.\005M\031Uo\035;p[&T\030M\0317f\017J,W\r^3s\025\t9\001\"\001\btG\006d\027\rZ3d_6\004\030\016\\3\013\005%Q\021A\0034jg\"L'-Y:iS*\0211\002D\001\007O&$\b.\0362\013\0035\t1aY8n\007\001\0312\001\001\t\027!\t\tB#D\001\023\025\005\031\022!B:dC2\f\027BA\013\023\005\031\te.\037*fMB\021q\003G\007\002\r%\021\021D\002\002\b\017J,W\r^3s\003\031\001(/\0324jqB\021Ad\t\b\003;\005\002\"A\b\n\016\003}Q!\001\t\b\002\rq\022xn\034;?\023\t\021##\001\004Qe\026$WMZ\005\003I\025\022aa\025;sS:<'B\001\022\023\003\035\001xn\035;gSb\fa\001P5oSRtDcA\025+WA\021q\003\001\005\0065\r\001\ra\007\005\006M\r\001\raG\001\006OJ,W\r\036\013\003]E\002\"!E\030\n\005A\022\"\001B+oSRDQA\r\003A\002m\tAA\\1nK\002") public class CustomizableGreeter implements Greeter { private final String prefix; private final String postfix; public CustomizableGreeter(String prefix, String postfix) { Greeter.$init$(this); } public void greet(String name) { Predef$.MODULE$.println((new StringBuilder(0)).append(this.prefix).append(name).append(this.postfix).toString()); } }implementsした実装をoverrideしてるだけのようです。まぁまぁ想定内ですね。
mixin
Scalaではmixinを用いて複数のクラスを合成することができます。
Javaでは複数のクラスやInterfaceを継承することはできず、単一の親クラスを継承することができます。mixinを用いたサンプルコード
Mixin.scalaabstract class BaseMixinSample(val prefix: String, val suffix: String) { def greet(name: String): Unit = println(prefix + name + suffix) } trait TraitA { val a: String def A(): Unit = println("A") } trait TraitB { val b: String def B(): Unit = println("B") } class DefaultMixinSample() extends BaseMixinSample("Hello", "!") with TraitA with TraitB { override def greet(name: String): Unit = super.greet(name) override val a: String = "Value is A" override val b: String = "Value is B" }デコンパイル後
import scala.Predef$; import scala.reflect.ScalaSignature; @ScalaSignature(bytes = "\006\005U2Qa\002\005\002\002EA\001\002\007\001\003\006\004%\t!\007\005\tK\001\021\t\021)A\0055!Aa\005\001BC\002\023\005\021\004\003\005(\001\t\005\t\025!\003\033\021\025A\003\001\"\001*\021\025q\003\001\"\0010\005=\021\025m]3NSbLgnU1na2,'BA\005\013\0039\0318-\0317bI\026\034w.\0349jY\026T!a\003\007\002\025\031L7\017[5cCND\027N\003\002\016\035\0051q-\033;ik\nT\021aD\001\004G>l7\001A\n\003\001I\001\"a\005\f\016\003QQ\021!F\001\006g\016\fG.Y\005\003/Q\021a!\0218z%\0264\027A\0029sK\032L\0070F\001\033!\tY\"E\004\002\035AA\021Q\004F\007\002=)\021q\004E\001\007yI|w\016\036 \n\005\005\"\022A\002)sK\022,g-\003\002$I\t11\013\036:j]\036T!!\t\013\002\017A\024XMZ5yA\00511/\0364gSb\fqa];gM&D\b%\001\004=S:LGO\020\013\004U1j\003CA\026\001\033\005A\001\"\002\r\006\001\004Q\002\"\002\024\006\001\004Q\022!B4sK\026$HC\001\0314!\t\031\022'\003\0023)\t!QK\\5u\021\025!d\0011\001\033\003\021q\027-\\3") public abstract class BaseMixinSample { private final String prefix; private final String suffix; public String prefix() { return this.prefix; } public String suffix() { return this.suffix; } public BaseMixinSample(String prefix, String suffix) {} public void greet(String name) { Predef$.MODULE$.println((new StringBuilder(0)).append(prefix()).append(name).append(suffix()).toString()); } } public class DefaultMixinSample extends BaseMixinSample implements TraitA, TraitB { public void B() { TraitB.B$(this); } public void A() { TraitA.A$(this); } public DefaultMixinSample() { super("Hello", "!"); TraitA.$init$(this); TraitB.$init$(this); } public void greet(String name) { super.greet(name); } public static void test() { DefaultMixinSample$.MODULE$.test(); } } public interface TraitA { static void $init$(TraitA $this) {} default void A() { Predef$.MODULE$.println("A"); } String a(); } public interface TraitB { static void $init$(TraitB $this) {} default void B() { Predef$.MODULE$.println("B"); } String b(); }どうやら、traitにフィールドを定義すると、暗黙的にフィールド名と同等のメソッドがインタフェースに生まれるようです。
で、そのフィールドを取得するメソッドの実態を合成先のクラスで定義してあげることにより、traitを実現しているようです。最後に
記事の執筆にあたり、Scalaの仕組みについて理解をすることが目的でしたが、JavaプログラマがScalaってちょっといいかも!と思ってもらえるきっかけになったらなーと思うようになりました。
結構歴史のある言語ですが、Javaプログラマからすると目新しい機能や見ていてほしくなる機能がたくさんあって非常に魅力的な言語だと思います。今後も学習を進めていくうえで同じようにまたJava視点からScalaを見つめなおす機会が作れたらいいなと思っています。
- 投稿日:2020-08-30T17:27:45+09:00
新卒SESの備忘録 【Java オブジェクト指向編】
【Java オブジェクト指向編】
新人研修時のJava オブジェクト指向のメモです。
オブジェクト指向(プロパティ、メソッド)
部品化の考え方であり、「人間が把握しきれない複雑さ」を克服するために考えられた。
//① public class Car{ String maker int displacement String color void start(){ System.out.println("発進") } void turn(){ System.out.println("曲がる") } void stop(){ System.out.println("停止") } }//② public class TestCar{ public static void main(String[] args) { Car car = new Car(); } }オブジェクト指向でやっていること。(上記の例)
①車の設計書を作成
↓
②車の設計書を元に、インスタンス(new)車を製造。コンストラクタは、インスタンス化後にすぐに実行される。最初のみ。
//コンストラクタの基本書式 public class クラス名 クラス名() { //ここに自動実行処理を記述する。 } }コンストラクタは、メソッド名とクラス名が同じ。メソッド宣言に戻り値なし(voidもなし)
クラスブロックの中に宣告された変数を、フィールドという。【オブジェクト指向の3大機能】
①カプセル化(アクセス制御)
private 同一クラスからしかアクセスできない
クラスは、private
メソッドは、public
フィールドは、private で修飾する。フィールドは、privateで隠して、getter,setter メソッド経由でアクセスする。
メソッドでフィールドを保護している。getterとsetter
//getterメソッドの定石 public 値を取り出すフィールドの型 getフィールド名() { return this.フィールド名; }自分のクラスのフィールドを他クラスから呼び出せるようにするために、
フィールドの中身を返すだけのメソッド//setterメソッドの定石 public void setフィールド名(フィールドの型 任意の変数名) { this.フィールド名 = 任意の変数名; }ある特定のフィールドに、指定された値を代入するだけのメソッド
②継承( 【extends】 類似したものを作成)
オーバーライドとは、親クラスを継承した子クラスを宣言する時に、親クラスのメンバを子クラス側で上書きすることをいう。
継承は、ある2つのクラスに特化・汎化の関係があることを示す。
継承元を、スーパークラス
継承先を、サブクラス※宣言時にfinalと記述すれば、クラスは継承できない。
③多様性(だいたい同じように。その結果が効率よい開発に)
インスタンスを曖昧に捉えて考える。
is-aの関係 子クラスis-a親クラス(子クラスは親クラスの一種)
①②③ これらを利用して、コンピューター内の仮想世界を再現
Javaの仮想世界は、コンピュータのメモリ領域
雑談
Java研修で学習したオブジェクト指向が現在の業務で活かされています。
この記事は、プログラミング初心者の私がまとめたものなので、何か助言がありましたら、コメントを頂けるととても嬉しいです!業務外は、Ruby,Ruby on Railsを使用して、ポートフォリオ作成をしています。
今後も引き続き頑張っていきます。

- 投稿日:2020-08-30T16:01:26+09:00
Effective Java 回復可能な状態にはチェックされる例外を、プログラミングエラーには実行時例外を使う
Effective Javaの独自解釈です。
第3版の項目70について、自分なりにコード書いたりして解釈してみました。ざっくり
「回復可能」とは、例外が発生してもカレントスレッドを停止させず、別の制御に状態を戻せること。例外が発生する可能性をメソッド実装者が認識しているので、チェック例外を出力し、メソッドの呼び出し元にハンドリングを強制させる。
「プログラミングエラー」とは、メソッドが実装者の禁止している使われ方で使われ、カレントスレッドを停止させる必要があるもの。(一般にキャッチすべきではない)実行時例外を出力させる。チェック例外が必要な例
以下のようなサービス層のメソッドを考える。
- 指定したIDの本を購入
- 参照テーブルは「本」「銀行口座」「購入済み本」テーブル
- 「銀行口座」に本を購入できる金額があれば、「購入済み本」に本を追加し、「銀行口座」の残高を減らす
- 「銀行口座」に本を購入できる金額がなければ、残高不足例外を出力
※ テーブル定義などは省略しています。
本購入メソッド
/** * 指定したIDの本を購入 * 購入した本は購入済み本テーブルに追加し、残高を減らす * 残高不足の場合は例外を出力 * * @param bookId 購入対象の本ID * @param userId ユーザーID * @throws InsufficientFundsException 残高不足例外 */ public void buyBook(String bookId, int userId) throws InsufficientFundsException { // 購入する本の値段を取得 Book selectedBook = bookDao.selectByBookId(bookId); int bookPrice = selectedBook.getPrice(); // 残高を取得 BankAccount myBankAccount = bankAccountDao.selectByUserId(userId); int myBalance = myBankAccount.getBalance(); // 残高不足の場合に例外を出力 if (bookPrice > myBalance) { int shortage = bookPrice - myBalance; throw new InsufficientFundsException("残高不足です。", shortage); } // 購入した本を購入済み本テーブルに追加 BoughtBook myBoughtBook = new BoughtBook(); myBoughtBook.setUserId(userId); myBoughtBook.setBookId(bookId); boughtBookDao.insert(myBoughtBook); // 残高を減らし更新 int afterMyBalance = myBalance - bookPrice; myBankAccount.setBalance(afterMyBalance); bankAccountDao.update(myBankAccount); }残高不足例外クラス
/** * 残高不足例外 */ public class InsufficientFundsException extends Exception { private int shortage; /** * 例外メッセージと不足金額 * * @param message 例外メッセージ * @param shortage 不足金額 */ public InsufficientFundsException(String message, int shortage) { super(message); this.shortage = shortage; } public int getShortage() { return this.shortage; } }チェック例外を出力する理由
本を購入できるかできないかは現在の銀行口座の残高に依存する。要するに、本が購入できないという例外的状況が発生する可能性があるので、チェック例外を出力して、呼び出し元に他の処理へ変更させるなり、エラーメッセージを出させるなりしてハンドリングを強制させる。
もし非チェック例外を出力した場合、呼び出し側がハンドリングの実装が必要なことに気づかず、回復処理に入らないままカレントスレッドが停止してしまう恐れがある。ハンドリングに追加情報を含める
出力する例外には追加情報を含めると、ハンドリング側で役立つことがある。
例えば上記コードでは、不足残高情報を例外に含めることで、ハンドリング側でユーザーにエラーメッセージを出したい時に、残高がいくら不足しているのかを明示することができる。実行時例外が必要な例
以下のようなサービス層のメソッドを考える。
- 指定した額を指定した相手に送金
- 参照するのは送金相手の「銀行口座」テーブル
- 「銀行口座」の残高を、指定した送金額だけ追加
- 指定した送金額が正数でなければ引数不正例外を出力
※自分の残高を減らす処理は省略しています。
送金メソッド
/** * 指定した相手に、指定した額を送金する * 送金額は正数を指定すること * * @param transferPrice 送金額 * @param targetUserId 送金相手のID */ public void transferMoney(int transferPrice, int targetUserId) { if (transferPrice <= 0) { throw new IllegalArgumentException("送金額は正数で指定する必要があります。"); } BankAccount targetBankAccount = bankAccountDao.selectByUserId(targetUserId); int nowBalance = targetBankAccount.getBalance(); int afterBalance = nowBalance + transferPrice; targetBankAccount.setBalance(afterBalance); bankAccountDao.update(targetBankAccount); }実行時例外を出力する理由
このメソッドは正数以外の送金額指定を禁止している。負数が指定された場合は相手の残高を減らしてしまうからだ。
メソッド呼び出し側の実装で正数以外の指定を100%防げるので、もし正数以外が指定された場合はプログラムのバグと判断し、実行時例外を出力し、カレントスレッドを停止させる。処理を続けた場合、意図せぬ処理が走ることがあり危険だからである。(補足) 実行時例外全てがキャッチすべきでないという訳ではない
実行時例外は全てキャッチしてはいけないという訳ではなく、Springのデータアクセス例外は実行時例外として実装されており、キャッチして別の検査例外を再スローすることがある。
- 投稿日:2020-08-30T12:44:54+09:00
SXSSFWorkbookを利用する際の個人的な注意点 (行単位のアクセス単位は避けたほうが無難 / 既存のxlsxファイルで書き込み済みの行にはアクセスできない)
概要
Apache POIでXSSFWorkbookを利用する場合、頭をもたげてくるのはメモリ問題。XSSFWorkbookは読み込んだデータや書き込んだデータをすべてメモリ上に展開します。そのため、大きなサイズのExcelを作ったり読んだりするときはよくよく注意しないと、OutOfMemoryErrorを起こしがちです。
Apache POIではこのXSSFWorkbookのメモリ食いすぎ問題に対応するため、SXSSFWorkbookという、全データをメモリには展開せず、一時ファイルに書き出すことで、メモリ消費量を節約するAPIが用意されています。XSSFWorkbookと同じWorkbookインターフェースを実装しているので、
Workbook book = new XSSFWorkbook(); // ↓ Workbook book = new SXSSFWorkbook();というように、実装クラスだけ差し替えて、メモリ消費量節約を実現した気になることが多いのですが、SXXFWorkbookには利用上の注意点があります。
1. 行単位のアクセス単位は避けたほうが無難
SXSSFWorkbookのメモリ節約ロジック、つまり一時ファイルへの書き出しロジックは「
windowSize行だけをメモリ上に保持し、それを超える行を作ろうとした瞬間に、それより前の行はすべて一時ファイルに書き出す」というものです。そして、一時ファイルに書き出された前の行については、アクセスすることはできません。これは以下のようなソースコードで確認することができます。
try (Workbook book = new SXSSFWorkbook()) { Sheet sheet = book.createSheet(); // 2行目から1000行目まで書き込み。 for (int i = 1; i < 1000; i++) { sheet.createRow(i).createCell(0).setCellValue(String.valueOf(i)); } // 2行目に書き込み忘れがあったので、2行目のRowを取ろうとしても // 戻り値がnullになるため、書き込めない sheet.getRow(1); // => null // 1行目に書き込み忘れがあったので、1行目のRowを作ろうとしても // 例外(*)が発生して、書き込めないどころか、アプリケーションが終了してしまう。 sheet.createRow(0); } catch (IOException e) { e.printStackTrace(); }上記の(*)で発生する例外は次の通りです。
Exception in thread "main" java.lang.IllegalArgumentException: Attempting to write a row[0] in the range [0,899] that is already written to disk. at org.apache.poi.xssf.streaming.SXSSFSheet.createRow(SXSSFSheet.java:131) at org.apache.poi.xssf.streaming.SXSSFSheet.createRow(SXSSFSheet.java:65) at poi.Main.main(Main.java:25)一応、メモリ上に保持されている行については、ランダムアクセスは可能です。メモリに保持する行を決める
windowSizeについても、コンストラクタやセッターで変更可能ですが、制御がややこしくなりがちで、それに伴うバグも生み出しかねないと考えています。個人的にはSXSSFWorkbookを利用する場合は、行単位のランダムアクセスは避けて、上の行から下の行にかけて順次アクセスするほうがよいと思います。2. 既存のxlsxファイルで書き込み済みの行にはアクセスできない
既存のxlsxファイルにSXSSFWorkbookを使って、データを書き込みたいということもあると思います。このとき注意したいのは「既存のxlsxファイルで書き込み済みの行は一時ファイルに書き込まれてしまい、SXSSFWorkbookではアクセスができない」ということです。
たとえば、2行目から1000行目まで書き込み済みのエクセルファイル
2-1000.xlsxがあったとします。これを読み込んで、書き込み済みの行にアクセスしてみます。try (Workbook book = new SXSSFWorkbook(new XSSFWorkbook("2-1000.xlsx"))) { Sheet sheet = book.getSheetAt(0); // 2行目に書き込み忘れがあったので、2行目のRowを取ろうとしても // 戻り値がnullになるため、書き込めない sheet.getRow(1); // => null // 1行目に書き込み忘れがあったので、1行目のRowを作ろうとしても // 例外(*)が発生して、書き込めないどころか、アプリケーションが終了してしまう。 sheet.createRow(0); } catch (IOException e) { e.printStackTrace(); }上記の(*)で発生する例外は次の通りです。
Exception in thread "main" java.lang.IllegalArgumentException: Attempting to write a row[0] in the range [0,999] that is already written to disk. at org.apache.poi.xssf.streaming.SXSSFSheet.createRow(SXSSFSheet.java:138) at org.apache.poi.xssf.streaming.SXSSFSheet.createRow(SXSSFSheet.java:65) at poi.Main.main(Main.java:21)「テンプレートファイルみたいなものをシステム内に持っていて、バッチ処理やオンライン処理において、テンプレートファイルにデータを書き込み、結果ファイルをユーザが利用する」というユースケースがありがちですが、こういうユースケースではきちんと設計しないと、SXSSFWorkbookが利用できないということです。
環境情報 (pom.xml抜粋)
<dependencies> <!-- https://mvnrepository.com/artifact/org.apache.poi/poi --> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</artifactId> <version>4.1.2</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.poi/poi-ooxml --> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi-ooxml</artifactId> <version>4.1.2</version> </dependency> </dependencies> <properties> <maven.compiler.source>11</maven.compiler.source> <maven.compiler.target>11</maven.compiler.target> </properties>参考
- 投稿日:2020-08-30T11:49:59+09:00
JavaFX + IntelliJ + Scene BuilderでGUIアプリケーションを作るサンプル
はじめに
GUIアプリケーションを作りたいと思いました。GUIアプリを作るためのライブラリやフレームワークは色々ありますが、個人的には一番得意なJavaで作れたらいいなと思い、JavaFXを使って開発するための環境構築をしてみました。
サンプルを作っただけで満足しちゃったけど!肝心なところは他の記事に丸投げするクソ記事ですのでご注意ください。
でも、他の記事に書かれているのと同じことをそのまま書くのは色々とアレだと思うので仕方ないのではないかと(言い訳)ソースはこちらです。
https://github.com/dhirabayashi/javafx_sample超適当な用語説明
JavaFX
- Javaでいい感じのGUIアプリを作れるライブラリ
- もともとはRIAのライブラリだったが、
RIAがオワコンになったため今は普通のGUIライブラリになっている- 今はJDKに同梱されなくなったので、OpenJFXを別途導入する必要がある(Gradleがいい感じにやってくれるけど)
IntelliJ(IntelliJ IDEA)
- Javaに対応したIDE
- 今はEclipseよりも人気が高い気がする
- 有料のUltimateと無料のCommunity版がある
- 今回のサンプルではCommunity版を使用する
SceneBuilder
- JavaFXでの開発を楽にしてくれるツール
- ドラッグ&ドロップでコンポーネントを配置するなど、GUIベースで開発ができる
環境
- macOS Catalina 10.15.6
- AdoptOpenJDK 14.0.1
環境構築手順
JDKとIntelliJはインストール済みとします。
IntelliJでJavaFXプロジェクトを作成する
下記の記事を参考になさるといいでしょう。プロジェクトの作成からサンプルコードの作成、実行まで一通り網羅されていてわかりやすいです。
IntelliJ IDEAとGradleでのJavaFXアプリケーション開発 〜環境構築からサンプルコードまで〜しかし、私の環境ではなぜかうまく動かなかったため、少しソースを変更しました。
Class#getResource() → ClassLoader#getResource()MainApp.javapackage com.github.dhirabayashi.javafx; import javafx.application.Application; import javafx.fxml.FXMLLoader; import javafx.scene.Parent; import javafx.scene.Scene; import javafx.stage.Stage; import java.util.Objects; public class MainApp extends Application { @Override public void start(Stage stage) throws Exception { var cl = getClass().getClassLoader(); Parent root = FXMLLoader.load(Objects.requireNonNull(cl.getResource("scene.fxml"))); Scene scene = new Scene(root); scene.getStylesheets().add(Objects.requireNonNull(cl.getResource("styles.css")).toExternalForm()); stage.setTitle("JavaFXサンプル"); stage.setScene(scene); stage.show(); } }Scene BuilderとIntelliJの連携
上記の手順だけでも開発は可能になりますが、全部コードベースで開発するよりも、Scene Builderを導入してGUIベースで開発したほうが楽だと思いますので、その手順を示します。(やはり丸投げですが)
これについてはIntelliJの公式ヘルプがありますので、それをご覧になるといいです。
JavaFX Scene Builderを構成するやっていることとしては、Scene Builderを別途インストールして、そのパスをIntelliJで設定するだけです。
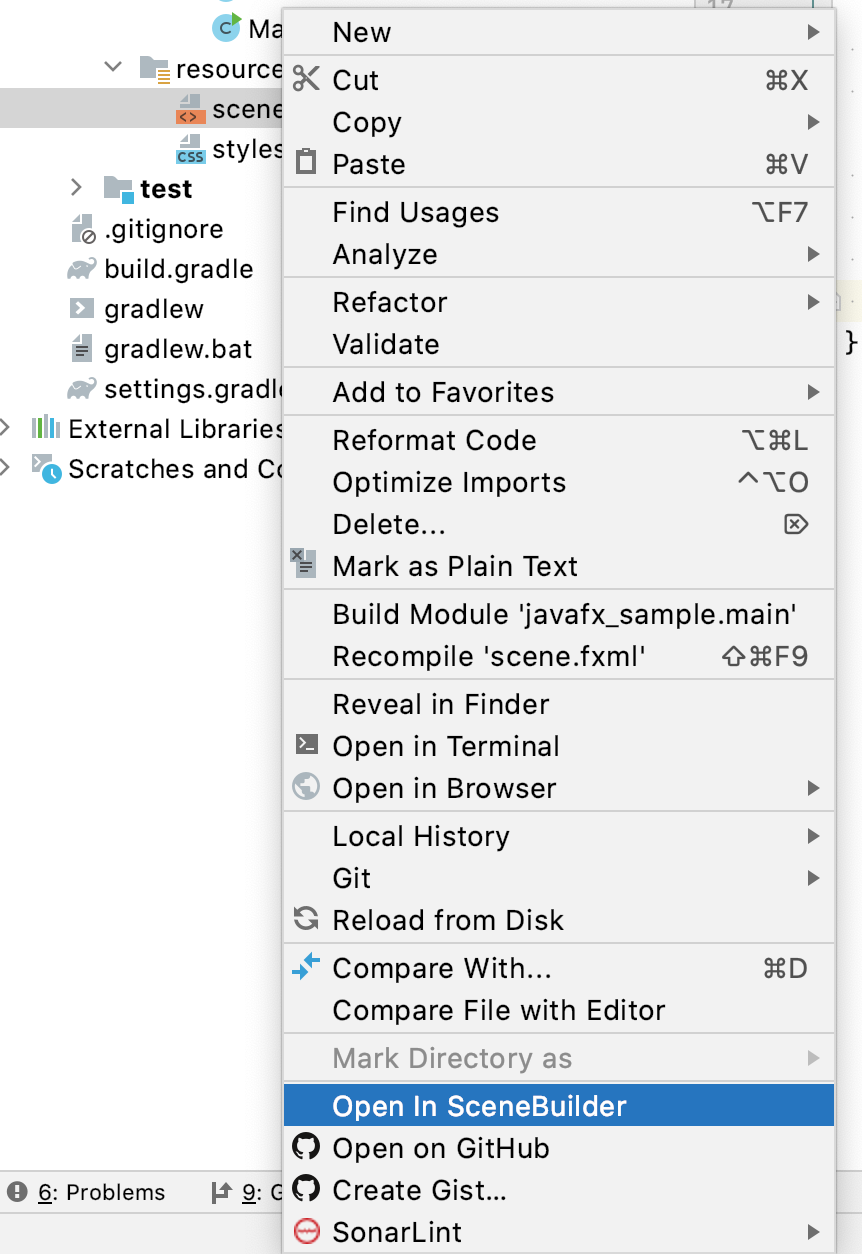
日本語化していない場合はメニュー名が違っていると思いますが、Preferencesを開いて「JavaFX」で検索すれば出てきます。JavaFXではfxmlファイルを編集することでGUIの開発を行いますが、Scene Builderを使うとそのfxmlの内容をいい感じに書き換えてくれるというイメージです。
Scene Builderを開くには、fxmlファイルを選択して右クリックメニューから「Open in SceneBuilder」を選択します。1
Scene Builderの使い方はこちらの記事がわかりやすかったです。Eclipseの例となっていますが、Scene Builderを開いた後の操作は変わりません。
Scene Biulder の基本的な使い方おわりに
予告通りのクソ記事でしたが、とりあえずJavaFXの開発環境ができてよかったです。
ダブルクリックでfxmlファイルを開き、左下のタブで「Scene Builder」を選択するという方法もありますが、その手順だと後述のプレビューやコントローラのスケルトンコード生成機能が使えないっぽいので、右クリックからの起動がおすすめです。 ↩
- 投稿日:2020-08-30T11:30:38+09:00
AtCoder Beginner Contest 177 C問題「Sum of product of pairs」解説(Python3,C++,Java)
注意)解答例はPython3のみ出来ております。C++,Javaの方は「全ての提出」からコードを見て実装することをおすすめします。
皆さんこんにちは(コンテスト後の方はこんばんは!)Ruteです!
AtCoder Beginner Contest 177 C問題の解説をこれから始めます!
A問題,C問題の解説は以下のリンクより見ることが出来ますのでご確認下さい!!各問題の解説
A問題 B問題 C問題 準備中 準備中 この記事です 問題概要
$N$個の整数$A_1,...A_N$で構成された数列が与えられる。
$1 \leq i < j \leq N$を満たす全ての組$(i,j)$についての$A_i×A_j$の和を$mod(10^9+7)$で求めよ。問題URL :https://atcoder.jp/contests/abc177/tasks/abc177_c
制約
・$2 \leq N \leq 2×10^5$
・$0 \leq A_i \leq 10^9$
・入力は全て整数解説
$A_1,...A_N$のうち、$(i,j)$の組は$(N-1)+(N-2)+....1$組あり、$\frac{N(N-1)}{2}$組あることが分かります。これらを$1$個ずつ考え計算していくと$O(N^2)$の計算量が必要になります。
一般的に、コンピューターで1秒間に処理できる計算回数はおよそ$10^8$回(1億回)なので制約上、この計算量では実行時間制限を超過してしまいます。ここで、問題を別の視点で考えてみましょう。
入力例1・出力例1では、答えは$11$ですが、
答えについて、
\sum_{i = 1}^{N-1} \sum_{j = i+1}^{N} A_i A_jになることが分かっています。
そこで、まずは $\sum_{j = i+1}^{N} A_j$について求めることを考えます。
ここで用いるテクニックは 累積和と呼ばれるものです。
累積和とは、あらかじめ初項からある項までの和を求め、それについての数列を作るというものです。
累積和で作成する数列の例としては、
数列$B$ : ($B_1,B_2, ... B_N$)が与えられた時、
$[0 , \sum_{i = 1}^{1} B_i , \sum_{i = 1}^{2} B_i , ... \sum_{i = 1}^{N} B_i ]$
というものがあります。詳しくは、けんちょんさんの累積和の記事をご覧下さい。
今回、考える累積和としては、長さ$N-1$の数列
$[\sum_{j = 2}^{N} A_j , \sum_{j = 3}^{N} A_j , ... \sum_{j = N}^{N} A_j]$
です。
これは、数列Aの総和から$A_{j-1}$を引き続けて、その都度数列に値を挿入し続ければ作成することが出来ます。これで、$\sum_{j = i+1}^{N} A_j$ の数列が出来ました。この数列を$C$とおくことにします。
次に、
\sum_{i = 1}^{N-1} \sum_{j = i+1}^{N} A_i A_jを求めるために、各$i(1 \leq i \leq N-1)$について$A_i × C_i$を計算します。
その値を、求める答えの値に加算していきます。最後に、答えの値を$(10^9+7)$で割ったあまりを出力すれば良いです。
ここで、Pythonの場合は多倍長整数に対応しているのでその都度答えを$(10^9+7)$で割らなくても良いですが、C++やJavaの場合は、計算の途中で64bit整数型の範囲よりも答えが大きくなる可能性があります。(
longやlong long intなど)(いわゆるオーバーフローと呼ばれるものです)なぜなら、 $2^{63}-1 \simeq 9.22×10^{18}$となりますが、$A_i$の制約より、$10^{18}$を$10$回以上足すケースがあることも考えられるからです。
結局、求める値は足したあとその都度$10^9+7$で割った余りにし続けても最終的には同じになるので、$10^9+7$で割った余りにし続ければオーバーフローを気にしなくてもよくなります。
計算量は累積和の処理で$O(N)$, 各$i(1 \leq i \leq N-1)$について$A_i × C_i$を計算するときに$O(1)$かかるので、$O(N)$となります。
以下、Pyhton3,C++,Javaでの解答例を示します.
(8/30 11:29時点 Python3の解答例のみ示しています。C++,Javaは準備ができ次第作成しますので、更新をお待ち頂きたいと思います)
Python3での解答例
ABC177C.pyN = int(input()) #入力する整数 A = list(map(int,input().split())) #入力する数列A SUMA = sum(A) #数列の和 MOD = 10**9 + 7 # mod C = [0] * (N-1) #累積和数列 for i in range(N-1): #\sum_{j = i+1}^{N}を求めて数列に代入する SUMA -= A[i] C[i] = SUMA ans = 0 #求める答え for i in range(N-1): ans += A[i]*C[i] ans %= MOD #その都度modで割った余りにする print(ans) #答えを出力する #計算量はO(N)です。
C++での解答例
準備中です
Javaでの解答例
準備中です
- 投稿日:2020-08-30T09:42:41+09:00
【Android 9.0 Pie Java】RecyclerView 長押しで要素毎に内容の変わるコンテキストメニューを表示する
RecyclerViewで要素を長押しして、要素毎に内容の変わるコンテキストメニューを表示する方法の記事が見当たらなかったのでメモしてみます!
↓完成イメージ↓
実装方法
コンテキストメニューの表示
Activity or Fragmentに
View.OnCreateContextMenuListenerをimplementsします。
SampleFragment.javapublic class SampleFragment extends Fragment implements View.OnCreateContextMenuListener {他にもViewHolderにimplementsするパターンもありますが、
コンテキストメニューを要素毎に内容を出し分けしたくて、都合のよかったFragmentにimplementsしました。次に、RecyclerViewを生成をしているonCreatedViewメソッドで
SampleFragment.javaRecyclerView rv = view.findViewById(R.id.recyclerView); // Adapter等のアタッチは省略します registerForContextMenu(rv); // 追記を追記します。
registerForContextMenuはView.OnCreateContextMenuListenerをimplementsすることで呼び出せるようになります。
この記述でコンテキストメニューを認識させることができます。続いて、Fragmentに
onCreateContextMenuを実装します。SampleFragment.java@Override public void onCreateContextMenu(ContextMenu menu, View v, ContextMenu.ContextMenuInfo menuInfo) { // 長押しされたメッセージ位置を取得し、 // RecyclerViewで表示させているListのindexとして扱い、 // ユーザーIDを取得してメニューの出し分けを実現 if (list.get(adapter.getPosition()).getUserId() == loginUserId) { menu.add(Menu.NONE, 1, Menu.NONE, "コピー"); menu.add(Menu.NONE, 2, Menu.NONE, "編集"); menu.add(Menu.NONE, 3, Menu.NONE, "削除"); } else { menu.add(Menu.NONE, 1, Menu.NONE, "コピー"); } }ContextMenuオブジェクトに追加したい内容をaddする形で簡単に項目を追加できます。
addメソッドの第二引数に数値をセットしていますが、これは押された際のリスナーのハンドリングで使用します。
参考程度ですが、Adapterに以下の要領でgetPosition()メソッドを用意して、長押しされた要素の位置を取得できるようにしています。Adapter.java@Override public void onBindViewHolder(final ChatViewHolder holder, int position) { // 省略 holder.itemView.setOnLongClickListener(new View.OnLongClickListener() { @Override public boolean onLongClick(View v) { setPosition(holder.getPosition()); return false; } }); } // 長押しされた要素の位置を取得する public int getPosition() { return position; } // 長押しされた要素の位置をセットする public void setPosition(int position) { this.position = position; }ここまでの実装でコンテキストメニューは表示できます。
コンテキストメニューのイベントリスナー
以下のように、
onContextItemSelectedを実装し、中でswitch文を用いてハンドリングします。
MenuItem.getItemId()で先ほど登録した各要素の判別用の数値が取得できますので、
switch文で振り分ける感じですね。SampleFragment.java@Override public boolean onContextItemSelected(MenuItem item) { switch (item.getItemId()) { case 1: // TODO メッセージをクリップボードにコピー return true; case 2: // TODO メッセージを編集 return true; case 3: // TODO メッセージを削除 return true; default: return false; } }以上です。
どなたかの参考になりましたら幸いです!!
