- 投稿日:2020-08-23T23:48:37+09:00
Amazon ECS Workshop #2 ~コンテナのデプロイ~
環境構成図
本投稿では下図の構成図のコンポーネントを構築していきます。
タイトルにあるコンテナのデプロイに進む前の環境準備部分がかなり多くなりますが、ご了承ください。
※IAM周りの権限は適宜付与している前提で進めていきます。コンテナ&ECSに関する各コンポーネントの簡単な説明は下記をご参照ください。
introduction編環境準備
CloudFormation実行環境
本投稿内で作成するリソースは基本的にCloudFormation(以下CFn)を利用して構築していきます。
CFnのテンプレートのコーディング環境として、クライアント端末に下記を準備します。
※テンプレートはコンソール操作からアップロードし、スタック作成しません。エディタにこだわりありません。
- エディタ:Visual Studio Code
拡張パッケージ:CloudFormation(コード補完), CloudFormation Linter(エラーチェック)VPC/Subnet作成
とりあえずのSubnetを作成します。本来であればLB-コンテナの構成を意識して、LB用のPublicなSubnetとコンテナ配置用のPrivateなSubnetを作るところですが、まずはコンテナ配置できたことをコンソール上から確認できることを目標に1Subnetの構成にしています。
構築用のCFnテンプレートは下記に貼っておきます。
VPC&Subnet構築テンプレート
vpc-create-cfn-template.ymlAWSTemplateFormatVersion: "2010-09-09" Description: VPC and Subnet Create Metadata: "AWS::CloudFormation::Interface": ParameterGroups: - Label: default: "Project Name Prefix" Parameters: - PJPrefix - Label: default: "Network Configuration" Parameters: - VPCCIDR - PublicSubnetACIDR ParameterLabels: VPCCIDR: default: "VPC CIDR" PublicSubnetACIDR: default: "PublicSubnetA CIDR" # ------------------------------------------------------------# # Input Parameters # ------------------------------------------------------------# Parameters: PJPrefix: Type: String VPCCIDR: Type: String Default: "10.65.0.0/16" PublicSubnetACIDR: Type: String Default: "10.65.1.0/24" Resources: # ------------------------------------------------------------# # VPC # ------------------------------------------------------------# # VPC Create VPC: Type: "AWS::EC2::VPC" Properties: CidrBlock: !Ref VPCCIDR EnableDnsSupport: "true" EnableDnsHostnames: "true" InstanceTenancy: default Tags: - Key: Name Value: !Sub "${PJPrefix}-vpc" # InternetGateway Create InternetGateway: Type: "AWS::EC2::InternetGateway" Properties: Tags: - Key: Name Value: !Sub "${PJPrefix}-igw" # IGW Attach InternetGatewayAttachment: Type: "AWS::EC2::VPCGatewayAttachment" Properties: InternetGatewayId: !Ref InternetGateway VpcId: !Ref VPC # ------------------------------------------------------------# # Subnet # ------------------------------------------------------------# # Public SubnetA Create PublicSubnetA: Type: "AWS::EC2::Subnet" Properties: AvailabilityZone: "ap-northeast-1a" CidrBlock: !Ref PublicSubnetACIDR VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "${PJPrefix}-public-subnet-a" # ------------------------------------------------------------# # RouteTable # ------------------------------------------------------------# # Public RouteTableA Create PublicRouteTableA: Type: "AWS::EC2::RouteTable" Properties: VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "${PJPrefix}-public-route-a" # ------------------------------------------------------------# # Routing # ------------------------------------------------------------# # PublicRouteA Create PublicRouteA: Type: "AWS::EC2::Route" Properties: RouteTableId: !Ref PublicRouteTableA DestinationCidrBlock: "0.0.0.0/0" GatewayId: !Ref InternetGateway # ------------------------------------------------------------# # RouteTable Associate # ------------------------------------------------------------# # PublicRouteTable Associate SubnetA PublicSubnetARouteTableAssociation: Type: "AWS::EC2::SubnetRouteTableAssociation" Properties: SubnetId: !Ref PublicSubnetA RouteTableId: !Ref PublicRouteTableA # ------------------------------------------------------------# # Output Parameters # ------------------------------------------------------------# Outputs: # VPC VPC: Value: !Ref VPC Export: Name: !Sub "${PJPrefix}-vpc" VPCCIDR: Value: !Ref VPCCIDR Export: Name: !Sub "${PJPrefix}-vpc-cidr" # Subnet PublicSubnetA: Value: !Ref PublicSubnetA Export: Name: !Sub "${PJPrefix}-public-subnet-a" PublicSubnetACIDR: Value: !Ref PublicSubnetACIDR Export: Name: !Sub "${PJPrefix}-public-subnet-a-cidr" # Route PublicRouteTableA: Value: !Ref PublicRouteTableA Export: Name: !Sub "${PJPrefix}-public-route-a"ECR作成
こちらもとりあえずのイメージ格納用のレポジトリを作成します。
ライフサイクルポリシーなどは設定していないレポジトリです。
ECR構築テンプレート
ecr-create-cfn-template.ymlAWSTemplateFormatVersion: "2010-09-09" Description: Create ECR Resources: # ------------------------------------------------------------# # ECR # ------------------------------------------------------------# # ECR Create MyRepository: Type: AWS::ECR::Repository Properties: RepositoryName: "myrepository" # ------------------------------------------------------------# # Output Parameters # ------------------------------------------------------------# Outputs: # ECR MyRepository: Value: !Ref MyRepository Export: Name: !Sub "myrepository"踏み台EC2作成
ECRにイメージをpushするための踏み台Serverを構築します。
Userdataを利用してDockerのインストールまで済ませておきます。
構築用のテンプレートは下記の通りです。
踏み台EC2構築テンプレート
bastionec2-cfn-template.ymlAWSTemplateFormatVersion: "2010-09-09" Description: Create Bastion-EC2 Metadata: "AWS::CloudFormation::Interface": ParameterGroups: - Label: default: "Project Name Prefix" Parameters: - PJPrefix - Label: default: "EC2 Configuration" Parameters: - ImageId - InstanceTypeParameter - DiskSize - SSHLocation - KeyName - IAMRoleParameter ParameterLabels: ImageId: default: "AMI ID" InstanceTypeParameter: default: "Instance Type" DiskSize: default: "Disk Size(GiB)" SSHLocation: default: "Permit SSH Src IP Address" KeyName: default: "SSH Key Name" IAMRoleParameter: default: "IAM Role" # ------------------------------------------------------------# # Input Parameters # ------------------------------------------------------------# Parameters: PJPrefix: Type: String ImageId: Type: AWS::EC2::Image::Id Default: ami-0f310fced6141e627 InstanceTypeParameter: Default: t2.small Type: String DiskSize: Default: 8 Type: String SSHLocation: Default: 127.0.0.0/32 Type: String MinLength: 9 MaxLength: 18 AllowedPattern: (\d{1,3})\.(\d{1,3})\.(\d{1,3})\.(\d{1,3})/(\d{1,2}) KeyName: Type: AWS::EC2::KeyPair::KeyName IAMRoleParameter: Type: String # ------------------------------------------------------------# # EC2 Create # ------------------------------------------------------------# Resources: EC2: Type: AWS::EC2::Instance Properties: DisableApiTermination: "true" InstanceInitiatedShutdownBehavior: stop ImageId: !Ref ImageId KeyName: !Ref KeyName InstanceType: !Ref InstanceTypeParameter BlockDeviceMappings: - DeviceName: "/dev/xvda" Ebs: DeleteOnTermination: "false" VolumeSize: !Ref DiskSize VolumeType: "gp2" NetworkInterfaces: - AssociatePublicIpAddress: "true" DeleteOnTermination: "true" DeviceIndex: "0" SubnetId: { "Fn::ImportValue": !Sub "${PJPrefix}-public-subnet-a" } GroupSet: - !Ref EC2SG IamInstanceProfile: !Ref IAMRoleParameter UserData: Fn::Base64: | #!/bin/sh #TimeZone Setting JST sudo timedatectl set-timezone Asia/Tokyo #Docker Install and Boot sudo yum update -y sudo yum -y install docker sudo systemctl start docker sudo systemctl enable docker Tags: - Key: Name Value: !Sub ${PJPrefix}-BastionEC2 ## EIP Create ElasticIp: Type: AWS::EC2::EIP Properties: InstanceId: !Ref EC2 Domain: vpc ## EC2 SecurityGroup Create EC2SG: Type: AWS::EC2::SecurityGroup Properties: GroupName: ec2-ssh-permit GroupDescription: Allow SSH and HTTP access only MyIP VpcId: { "Fn::ImportValue": !Sub "${PJPrefix}-vpc" } SecurityGroupIngress: # ssh - IpProtocol: tcp FromPort: 22 ToPort: 22 CidrIp: !Ref SSHLocation # ------------------------------------------------------------# # EC2 Output # ------------------------------------------------------------# Outputs: ElasticIp: Value: !GetAtt EC2.PublicIp Description: Public IP of EC2 instanceイメージのプッシュ
1. ECRログイン
aws ecr get-login --region ap-northeast-1 --no-include-email※上記コマンドのレスポンスコードを入力することでログインが完了する
docker login -u AWS -p XXXXXXXXX2. イメージ用のDockerfile生成
Dockerfileの内容は下記の通り。
FROM ubuntu:18.04 # Install dependencies RUN apt-get update && \ apt-get -y install apache2 # Install apache and write hello world message RUN echo 'Test Ver1' > /var/www/html/index.html # Configure apache RUN echo '. /etc/apache2/envvars' > /root/run_apache.sh && \ echo 'mkdir -p /var/run/apache2' >> /root/run_apache.sh && \ echo 'mkdir -p /var/lock/apache2' >> /root/run_apache.sh && \ echo '/usr/sbin/apache2 -D FOREGROUND' >> /root/run_apache.sh && \ chmod 755 /root/run_apache.sh EXPOSE 80 CMD /root/run_apache.sh3. ビルド~プッシュ
docker build -t test-ver1 . docker tag test-ver1 XXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/myrepository docker push XXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/myrepository:latestやっとイメージのプッシュが完了しました。ここまでが長かったです…w
ECSに対するデプロイ
ようやくになりましたが、ECRにプッシュされたイメージをECS on Fargateでデプロイします。
下記Cfnテンプレートを利用して、ECSCluster/タスク定義/Serviceといった各コンポーネントを構築します。
ecs-cfn-template.ymlAWSTemplateFormatVersion: "2010-09-09" Description: Create Container with ECS on Fargate Metadata: "AWS::CloudFormation::Interface": ParameterGroups: - Label: default: "Project Name Prefix" Parameters: - PJPrefix - Label: default: "ECS Configuration" Parameters: - ECSTaskCPUUnit - ECSTaskMemory - HTTPLocation - IAMRoleParameter ParameterLabels: ECSTaskCPUUnit: default: "ECSTaskCPUUnit" ECSTaskMemory: default: "ECSTaskMemory" HTTPLocation: default: "Permit HTTP Src IP Address" IAMRoleParameter: default: "IAM Role" # ------------------------------------------------------------# # Input Parameters # ------------------------------------------------------------# Parameters: PJPrefix: Type: String ECSTaskCPUUnit: AllowedValues: [ 256, 512, 1024, 2048, 4096 ] Type: String Default: "256" ECSTaskMemory: AllowedValues: [ 512, 1024, 2048, 4096 ] Type: String Default: "512" HTTPLocation: Default: 127.0.0.0/32 Type: String MinLength: 9 MaxLength: 18 AllowedPattern: (\d{1,3})\.(\d{1,3})\.(\d{1,3})\.(\d{1,3})/(\d{1,2}) IAMRoleParameter: Type: String # ------------------------------------------------------------# # ECS Create # ------------------------------------------------------------# Resources: ## ECS Cluster ECSCluster: Type: AWS::ECS::Cluster Properties: ClusterName: !Sub ${PJPrefix}-Cluster ## ECS LogGroup ECSLogGroup: Type: AWS::Logs::LogGroup Properties: LogGroupName: !Sub /ecs/logs/${PJPrefix} ## ECS TaskDefinition ECSTaskDefinition: Type: AWS::ECS::TaskDefinition Properties: Cpu: !Ref ECSTaskCPUUnit ExecutionRoleArn: !Ref IAMRoleParameter Family: !Sub ${PJPrefix}-task Memory: !Ref ECSTaskMemory NetworkMode: awsvpc RequiresCompatibilities: - FARGATE ContainerDefinitions: - Name: !Sub ${PJPrefix}-ecscontainer Image: !Sub ${AWS::AccountId}.dkr.ecr.ap-northeast-1.amazonaws.com/myrepository LogConfiguration: LogDriver: awslogs Options: awslogs-group: !Ref ECSLogGroup awslogs-region: !Ref "AWS::Region" awslogs-stream-prefix: !Ref PJPrefix MemoryReservation: 128 PortMappings: - HostPort: 80 Protocol: tcp ContainerPort: 80 ## ECS Service ECSService: Type: AWS::ECS::Service Properties: Cluster: !Ref ECSCluster DesiredCount: 1 LaunchType: FARGATE NetworkConfiguration: AwsvpcConfiguration: AssignPublicIp: ENABLED SecurityGroups: - !Ref ECSSG Subnets: - { "Fn::ImportValue": !Sub "${PJPrefix}-public-subnet-a" } ServiceName: !Sub ${PJPrefix}-ecsservice TaskDefinition: !Ref ECSTaskDefinition ## ECS SecurityGroup Create ECSSG: Type: AWS::EC2::SecurityGroup Properties: GroupName: ecs-http-permit GroupDescription: Allow HTTP access only MyIP VpcId: { "Fn::ImportValue": !Sub "${PJPrefix}-vpc" } SecurityGroupIngress: # - IpProtocol: tcp FromPort: 80 ToPort: 80 CidrIp: !Ref HTTPLocationコンソール画面からデプロイされていることを確認します。
定義したクラスタ名やタスク定義に従ってタスク(今回は1コンテナ)が起動していることが分かります。
最後にデプロイしたコンテナに踏み台EC2よりアクセスしてみます。(一時的にSGのインバウンドを開けています)
コンソールで確認したPublic IPに対して、curlでリクエストを投げたところ「Test Ver1」でレスポンスが返却されており、
ECRにpushしたイメージ(Dockerfile内でindex.htmlを書き換えています。)がデプロイされていることが分かります。まとめ
今回はコンテナをECS on Fargateにデプロイできるところまで実施しました。
CFnのテンプレートを参考にしていただければ、アカウントしかない状況からかなり簡単に構築まで進むかと思います。次回はコンテナのリソース状況のモニタリングをCloudwatchを利用してやってみようと思います!










- 投稿日:2020-08-23T23:08:33+09:00
【AWS】AWS Ground Stationなるサービスについてちょっと調べてみた
AWS Ground Stationを調べてみる経緯
AWSマネジメントコンソールを触っている際、サービス一覧に「衛星」のカテゴリが気になったのでちょっと調べてみることにしました。
AWS Ground Stationってなにもの
ざっくり説明
・人工衛星が取得したデータをAWSに送ることが出来るサービスのようです。
・地上に自前でアンテナを用意する必要は無くAWSが設置したGround Station(地上にあるアンテナ)で人工衛星からデータを受信することが出来るようです。
・人工衛星との通信時間をスケジューリングして使用するようです。
・人工衛星から送られてきたデータはEBS、EFS、S3に保存することが出来るようです。
・現在使用できるアンテナは、「米国東部 (オハイオ)」「米国西部 (オレゴン)」「中東 (バーレーン)」「欧州 (ストックホルム)」「アジアパシフィック (シドニー)」「欧州 (アイルランド)」の6つ
AWS公式サイトの概要説明どんなことに使用するの?
・自然災害
自然災害発生中、ダウンリンクされた映像データを迅速に分析して、生存者の割り出し、構造画像の査定、およびこのデータを迅速に第一に応答した人および救助隊にストリーミングできます。分析およびマシンラーニングをこのデータに適用して、最も安全な避難路および一時的避難のための最良の場所、および非常薬施設を割り出すことができます。
・正確な天気予報
AWS クラウドを使用することにより、世界中からダウンリンクされた天気データを分析して、より正確に天気パターンを予測できます。これは船舶、飛行機、トラックおよび人が所在する地区の荒れ模様の天気に対する認識を高め、効率的に危険な状況を避けるのに役立ちます。
・ビジネストレンド査定
駐車場、物流センター、小売店などの様々な商業施設のレーダー衛星映像を使用して、たとえ暗闇や曇りの天気でも、自動的に車両、交通および利用客の流れのパターンを計測します。これを他の分析や機械学習などの AWS のサービスと、日時および天気の条件とともに組み合わせて、ビジネスおよび経営のトレンドをリアルタイムで査定することができます。これらの識見は、世界中至るところにいる関連ビジネス分析者および意思決定者にすばやく流れます。
感想
AWSのサービスに人工衛星と通信するサービスがあったのは驚きですね。
AWS Ground Stationはアンテナは用意してくれますが人工衛星は自分で飛ばさないといけないので個人使用は難しそう...
(人工衛星との通信は男心くすぐられるロマンあふれるサービス)
いつか仕事で関わってみたいと思いました。
- 投稿日:2020-08-23T22:51:45+09:00
AWS愛用者がまよぶGCP:GoogleAppEngineの特長
務めている会社や家でもAWSしか利用したことがあったのですが、転職先にGCPを使う可能性が出てきたので、GCPを勉強しようと思います。
WEBエンジニアとして使う可能性が高い、GoogleAppEngineについて調べました。
GoogleAppEngineの特長
複数バージョン管理
GAEでは、1つのWebアプリケーションに他してい複数のバージョンを配置可能。
バージョンの切り替えなどができるため、デプロイの動作確認で問題なければ、すぐに新しいバージョンに切り替えたりすることができるトラフィック分割
サービスの各バージョンに対してユーザからのトラフィックを分割可能。
アプリケーションの新機能のリリースだけを切り分けてのトラフィックの確認も可能。自動スケーリング
サービスへ負荷が増大した際に自動的にアプリケーションを動作させるインスタンスを増やし、負荷が低下しあ場合は自動的にインスタンスを減らしてくれる。
参考
- 投稿日:2020-08-23T22:33:31+09:00
AWS認定ソリューションアーキテクトに合格しました
AWS認定ソリューションアーキテクト(SAA)に合格したので、忘れないうちに記録を残しておきます。
1. 受験した動機
業務で担当しているプロダクトのインフラがAWSで構築されていて、EC2やRDS、S3をなんとなく触っていた程度でした。
ちなみにエンジニア歴は8ヶ月です。業務で実際に触るAWSのサービスは限られるのですが、
- もっとAWSの全体像を理解して知識を深めたい
- インフラの基礎を勉強したい
といった理由でSAAの勉強をはじめました。
2. 取得してみて
まず「SAAを取得すること」と「AWSでインフラが構築できるようになること」は別物です。
合格してみて強く感じますが、ただ資格の勉強をしても実際にAWSを使えるようにはなりません。業務や個人サービスで実際に手を動かして初めて使えるスキルとなるので、SAAはその準備程度として捉えたほうが良さそうです。
SAAを取得するメリットとしては、
- AWSでインフラを構築する際の現時点でのベストプラクティスを理解できる
- AWSの様々なサービスの特徴を理解し、組み合わせることで最適な設計のイメージができるようになる
- 新しい技術を導入する際の比較として、AWSのサービス知識が使える (メール配信にはSESかSendGridか、サーバー監視にはCloudWatchかMackerelか、などなど)
等が挙げられます。
基本的に「広く浅く」勉強することがSAA取得では求められます。
3. 学習期間と教材
学習期間は1ヶ月半くらい、勉強時間にすると約100時間でしょうか。
たまに業務で気になったことの調査や、興味のある記事のハンズオンに浮気はしましたが、SAAの勉強は平日で〜2時間、休日は2〜5時間程度を毎日続けました。教材は下記を使用しました。(書籍は先に合格していた社内の先人に借りました、感謝?)
【Udemy】
- これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)
- 【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)
【書籍】
4. 学習手順
勉強開始〜2週目
まずはUdemyの「これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)」でハンズオン中心の学習をしました。
EC2やRDS等の基本サービス中心ですが、手を動かしながら学習することでイメージしやすくなります。
資格を取ることが目的ではなく、実際にAWSを使えるようになることが目的なので、ハンズオンはしっかりやることをおすすめします。
AWSの無料枠だけでは収まらないですが、僕の場合は500円程度の料金ですみました。この講座は説明がわかりやすく導入には大変良いですが、試験範囲は広いので他の教材も併用したほうが良さそうです。
最後の模擬試験はネットにある無料の問題よりも質はいいと思います。Udemyと並行して書籍2冊を読みました。
「AWS認定資格試験テキスト AWS認定 ソリューションアーキテクト-アソシエイト」はサービス毎に詳しく解説されていました。
「徹底攻略 AWS認定 ソリューションアーキテクト – アソシエイト教科書」はAWSのWell-Architectedフレームワークに沿って、観点別にまとめられています。この2冊は異なるまとめ方がされているので、違う視点からポイントを押さえられるので併用にはいい組み合わせでした。
3〜5週目
一通り、ハンズオンでの学習が終了したら、ひたすら模擬試験を繰り返しました。
上記講座についてる模擬試験3回分に加えて、「【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)」の6回分です。スコアはこんな感じです。
答えを覚えるだけでなく、全選択肢の説明ができるようになるくらいまで、毎回見直しに時間をかけました。
1回目 2回目 3回目 4回目 5回目 付属模擬1 63 75 93 95 100 付属模擬2 55 76 78 95 模擬試験1 87 95 96 模擬試験2 64 87 95 100 模擬試験3 52 90 98 95 模擬試験4 52 80 95 92 模擬試験5 53 81 92 95 模擬試験6 56 80 93 92 6週目〜
ここまでくると自分の苦手な分野も分かってくるので、苦手分野を中心にUdemyの講座を見直したり、上記2冊の書籍を読み直したりしました。
5. 感想
ソリューションアーキテクトを受験して、繰り返しですが「SAAを取得すること」と「AWSでインフラが構築できるようになること」は別物だと感じました。
今後は業務や個人学習で実際にAWSを動かしながら、クラウドインフラを深めていきたいです。試験内容に関してですが、マイクロサービスの連携や疎結合化に関するSQSの問題が多かったように思います。
反復学習が大事なので、何回も同じ問題集・書籍に取り組むことが試験対策としては良さそうでした。
- 投稿日:2020-08-23T22:15:03+09:00
AWSサービスのみでサーバーを監視してみる
この記事
インフラエンジニアをやっています。
AWSを業務で使い始めて始めにやったことを思い出すと、EC2とCloudWatchでした。
監視ソフトウェアを使わずとも、それこそ最低限の監視であればスッと始められるし料金も知れてるので、今回はその内容を少し書きます。
設計ではなく手法の話になります。
対象読者はAWSを使って監視というものを試したことがない方、あるいはSAA試験対策の一貫になったりするかと思います。
監視の種類
あくまでサーバーの監視ってどんなのだっけ?というお話。
死活監視
サーバー息してる?といういわゆるping応答の監視
リソース監視
リソースという言葉は広い意味で取れるが、例えばCPUやストレージ容量といった基本的なもの
ずっとCPUが90%以上だったら、サーバーが超人気なのか、サーバー内の処理でなにか問題が起きているのか。
ログ監視
Webサーバーに誰かが侵入しようとしていないか?secureログに、大量のSSHアタックの形跡があるかもしれない。
または、アプリケーションのログで実はエラーが流れていて、気づけないかもしれない。特定のログを通知する場合はログの監視が必要サービス/URL監視
いわゆる外形監視。
Webサーバーのような、Webページを表示するものであれば、そのページが外から開けるのか定期的に確認
サーバーが息していても、サービスは落ちてて503レスポンスで見れていない、なんてケースもあるクラウドならではの監視
コスト監視
AWS料金をサービスごと、リージョンごとに監視し、予算を超えそうならば通知させることで未然に対策を気づいて対策を打つこともできる。AWS API監視、リソース監視
AWSサービスへのアクセスがいつ、どのユーザによってされたのかをログ証跡として保存、また特定の変更などを監視できる
マネジメントコンソールへのログインも同様AWS側の障害
AWS側で起きている障害状況は公開されているので、そちらもチェック(監視)する必要があります。AWSで監視に活用できる身近なサービス
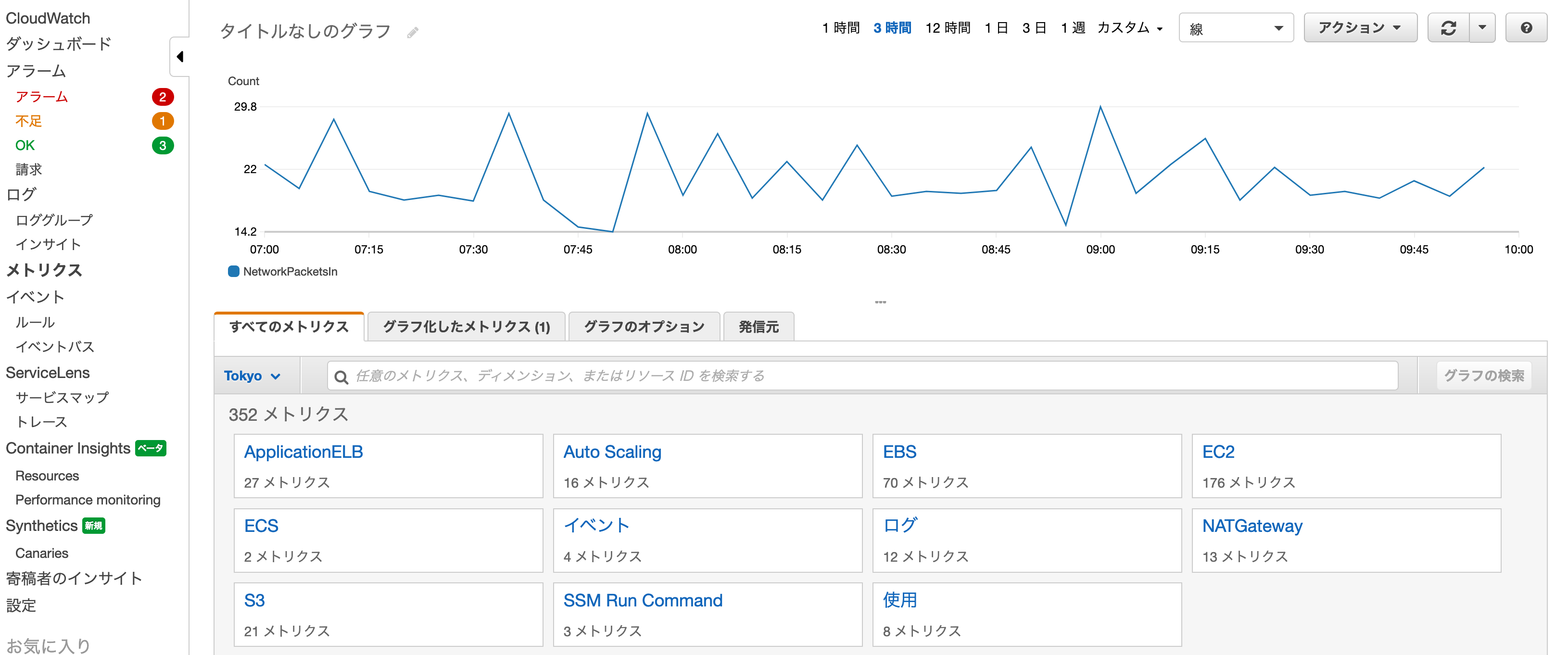
CloudWatch
AWSでサーバーを立てたり、データベースを立てたりするとデフォルトで「メトリクス」が取得できる。
CloudWatch「メトリクス」コンソール画面↑メトリクスとは、事前にAWS上のリソースがCloudWatchに発行する各リソース状況の時系列データポイントのこと。
基本間隔は1分または5分で、詳細メトリクスに変更すると秒単位にまで変えられる。
つまり、このメトリクスに対して閾値さえ設定してしまえば最低限アラートを設定することはできる。また、サーバー内に設定を追加すれば、ログ監視(CloudWatch Logs)をしたり、
標準メトリクスにはない項目をカスタムメトリクスとして作成することもできる。Config
指定したAWSリソースの設定変更などを監視できる。
例えば、ALBやEC2の開けてはいけないポートを誰かが間違って開けてしまった際に、SNSを使って通知させることや、Lambdaで修正することも可能。SNS
各アラートを通知するために使用。
アラート用のトピックを作成して、EmailやSlackなど、通知させるエンドポイントをサブスクライブさせる。CloudTrail
AWSユーザーの使用したAPI履歴を証跡として残してくれる。
例えば、インスタンスを終了したユーザのイベント記録や発信元IPアドレス等を記録している。
認証エラーが起きたら通知することなども可能。GuardDuty
AWSリソース全体の脅威検知を行う。
各AWSリソースのログを収集して、機械学習を用いて検知してくれるサービスで、有効化するだけで使用可能。
全体といっているのは、我々が使用するクレデンシャル情報等も対象となるため。※AWS Macieも機械学習を使用したセキュリティサービスだが、主な違いとして
MacieはS3の保護に特化しており、マルチアカウントでの運用でも役立てられるサービス。やってみる
定番のEC2の監視設定をやってみます。
SSHアクセス検知のために、CloudWatch Logsも使って入れ込んでみます。・CPU使用率が80%を超えたら通知
→リソース監視
・SSHアクセス不可だった場合の通知
→ログ監視EC2のメトリクスを見てみると
EC2の標準メトリクスはどんな物があるのか見てみる。
AWSコンソールでCloudWatchの画面へ
メトリクス > 検索で、該当のインスタンスidを入れる
おそらくデフォルトだと、14種類くらいのEC2メトリクスが表示される
例えばこんなメトリクスが存在します
・CPU使用率;CPUUtilization ・ディスクパフォーマンス;DiskWriteBytes ・インスタンスで受信したネットワークトラフィックバイト数;NetworkInAmazon EC2 のモニタリング
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/monitoring_ec2.htmlEC2に対するアラームの設定
今回はCPU使用率である CPUUtilizationに対して一定のしきい値を超えたらアラームを設定したいので
アラーム > アラームの作成 > メトリクスの選択で、該当のインスタンスidを入れてCPUUtilizationを選択デフォルトで5分間平均の値を対象とするのでそのまま。
条件を、「80%よりも大きい」に設定して次へ
通知に設定するSNSトピックをこの画面から作成できるため、今回用のトピックを作成する
最後にアラーム名をわかりやすい名前に決めて、作成完了。
尚、トピックをサブスクライブしたEmail等で設定確認をする必要があるので、届いたmailを確認しておく
これでCPU監視設定は終わり
SSHの監視
SSHのログは、EC2内の
/var/log/secure
にログが残る。(今回はAmazonLinux2を使用)CloudWatch Logsに対してこのファイルを配信するように設定して、特定ワードで引っ掛ければ実現できる。
もちろん他の使い方も可能まず、EC2に対してCloudWatch Logsへの権限を与える必要がある。
AWSのドキュメントでRoleが記載されているためそちらを拝借する
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/logs/QuickStartEC2Instance.htmlAWSコンソールでIAM > ポリシーの作成 > JSON
にてJSONを貼り付けて、ポリシーの確認。
名前をつけ、ポリシー作成完了
次に、このポリシーのみを使用したRoleを作成する。
IAM > ロール > ロールの作成でEC2を選択
次のステップで、先ほど作成したポリシーを選択
Role名を決めて、作成完了あとはEC2にRoleを適用
コンソールのEC2インスタンス一覧にて、該当のEC2に対してアクションからRole適用を選択
これでEC2からCloudWatchにログを送る権限はOK適用したら、実際にEC2にCloudWatchLogsへの仕掛けをいれていく
EC2に入り、awslogs パッケージをインストール
[ec2-user@ip-192-168-2-173 ~]$ sudo yum update -y [ec2-user@ip-192-168-2-173 ~]$ sudo yum install -y awslogs設定ファイル/etc/awslogs/awscli.confにて対象のリージョンを指定
/etc/awslogs/awscli.conf[plugins] cwlogs = cwlogs [default] region = ap-northeast-1/etc/awslogs/awslogs.confにて対象ファイル情報等を設定(追記)
/etc/awslogs/awslogs.conf# SSH logs [/var/log/secure] file = /var/log/secure log_group_name = ssh_logs log_stream_name = {instance_id}/var/log/secure datetime_format = %b %d %H:%M:%Sファイルを保存したら、いよいよawslogsを起動して、配信開始!
[ec2-user@ip-10-0-0-229 ~]$ sudo systemctl start awslogsd.service [ec2-user@ip-10-0-0-229 ~]$ sudo systemctl enable awslogsd.service Created symlink from /etc/systemd/system/multi-user.target.wants/awslogsd.service to /usr/lib/systemd/system/awslogsd.service.その後、時間が立つとログが確認できるので
CloudWatch > ロググループ > log_group_nameで設定した名前(↑だとssh_logs)
にて、ログが確認
SSH失敗すると、/secureログに
sshd[xxxxx]: Connection closed by xxx.xxx.xx.xx port xxxxx [preauth]
のようなログが出力されますが、今回はそのログに対して
"[preauth]"というワードでフィルタする先程のロググループの画面にメトリクスフィルタがあるので「メトリクスフィルターを作成」
今回の引っ掛けたい文字列 preauth を設定
その後フィルタ名などを設定して、完了
最後に「アラームを作成」から先程と同じSNSトピックに対してのアラームを作成してOK!
SSHでキーペアなしでテストしたら、
ALARM: "SSH Failed" in Asia Pacific (Tokyo)
みたいなアラートがメール等で届けば確認完了。まとめ
設定自体はシンプルで、予め用意されているものが多いので、その範疇だと設定はかんたんです。
ただ前提として、監視はこんなもので終わりではなく
・障害となる前に、問題になる傾向を事前検出できるパラメータはどれか
・アラートの閾値は、サーバーの傾向からどの値にするべきか
・企業/プロジェクトの予算に合わせた最大限の監視手法はどの組み合わせか
…
など様々な目線で設計する必要があります。監視すべきシステム全体を見ると、EC2やECS以外にも、LoadBalancer, RDSなど見るべきリソースはたくさんあります。
前提として
CloudWatchメトリクスは監視する項目すべてを既存のメトリクスでカバーしているわけではなく、
メモリ使用率やプロセスの監視など、より詳細なOSのパラメータを検出する必要がある場合は
カスタムメトリクスを入れ込む必要があります。
今回の例のようなシンプルな監視だったらいいですが、場合によってはコストを考え
MackerelやZabbixといったソフトウェアを導入するほうがコスパが高い場合も大いにあり得ますね。以上、今回はAWSサービスのみを使って行う監視の、ごく一例でした。
最後に、この記事は後々追記・変更していくと思います。
読んでいただきありがとうございました。















- 投稿日:2020-08-23T22:12:17+09:00
LaravelをRDSと繋ぐ
TL;DR
- RDSを構築して、RDS情報をenvs/配下の値を適切に埋める
- envファイルに設定したい文字列に#がある時はダブルクオーテーションで括る
RDS構築
一連の流れを説明とともに記述します。詳しいことは載っていないので注意です。
また、今回はRDSをパブリックサブネットに配置します。
(外部から繋ぎたいため)本来はVPC内のプライベートサブネットに置き、
EC2などからしか接続させないようにするのがオーソドックスかと思います。
- VPC作成
- VPC > インターネットゲートウェイからインターネットゲートウェイを作成し、VPCにアタッチ
- VPC > ルートテーブルから、VPCのルートテーブルにサブネットの関連づけをする
- VPC > サブネットからパブリックサブネットを2つ作る (※1)
- EC2 > セキュリティグループからRDS用のセキュリティグループ作成。
今回はパブリックサブネットに置くので、外部(XServer)のIPをインバウンドとして設定- RDS > サブネットグループを先に作成
- 先ほどつくった2つのサブネットを選択
- RDS > パラメータグループを先に作成
- デフォルトであるものを適用させないくらいの文脈で作成
- RDS > オプショングループを先に作成
- デフォルトであるものを適用させないくらいの文脈で作成
- RDSからデータベースの作成 (かいつまんで状況↓)
- DBインスタンスサイズ
- テスト環境なのでバースト可能クラスのt2.micro選択
- ストレージ
- ストレージタイプ:汎用
- ストレージの自動スケーリングは無効に(テスト環境なので)
- 可用性と耐久性
- スタンバイインスタンスを作成しないでください
- テスト環境なので。2つ作ったサブネットの1つだけ使う感じ
- 接続
- 先ほどつくったVPC
- サブネットグループ
- 先ほど作ったもの
- パブリックアクセス可能
- あり。
- 今回、外部から接続させるため。プライベートサブネット上であれば「なし」
- セキュリティグループ
- 先ほど作ったもの
- アベイラビリティゾーン
- 2つのサブネットのどちらか好きな方
- データベース認証
- パスワード認証
- 追加設定
- DBパラメータグループ
- 先ほど作ったもの
- オプショングループ
- 先ほど作ったもの
- 自動バックアップの有効化。30日くらい
- モニタリングは無効化
- 削除保護の有効化
- データベースの作成! (※2)
※1. RDSのサブネットを複数持たせる件について
RDSはマルチAZ、冗長化が簡単にできるように、デフォルトで複数のサブネットを用意したグループを作らせる
※2. Cannot create a publicly accessible DBInstance. The specified VPC does not support DNS resolution
↓ありがとうございます???
Lalavelへの記述
envs/配下に適切に情報を記述する。
- DB_HOST
- 接続とセキュリティ > エンドポイントを記述
- XXXX.YYYYYYY.ZZZZZZ.rds.amazonaws.com なやつ
- DB_DATABASE
- データベース名
- Sequel ProからRDSに接続してデータベース作成してそれを書いた
- DB_USERNAME
- とりえあずさっき作成したユーザを記述
- DB_PASSWORD
- さっき作成したユーザのパスワードを記述
↑の設定後、以下を実行
php artisan config:clear php artisan cache:clear設定したenvがうまく反映されない
SQLSTATE[HY000] [1045] Access denied for user 'XXX'@'YYYYY' (using password: YES) (SQL: delete from `cache`)がでまくった。usernameは合ってそうだが、host名(DB_HOSTに設定したRDSのエンドポイント)が正しくなさそうな感じになる。
結論としては passwordにシャープが入っていた ため。
コメント化されてしまい、うまくenvファイルがパースできなかったみたい。
(host名が間違っているのかと思ってかなりの時間を割いて調べてしまった?)envのパスワード部分を以下のようにダブルクオーテーションで括ることで解決。
DB_PASSWORD="XXXXXX"
できた???
- 投稿日:2020-08-23T21:46:07+09:00
DynamoDBはどんなCRUD操作が可能か確認する
はじめに
以前の記事で書いたように、DynamoDBはちゃんとキャパシティ管理さえしてあげれば、サーバレスで高性能でかなり良い感じなデータベースだ。
ただし、データベースと言ってもRDBとは違うので、そちらに慣れている人にはハマりどころが多々ある。
DynamoDBではどんなCRUD操作が可能かを確認しておこう。
前提条件
前提条件はあまりないが、以下の記事くらいを読んでおくと入りが良いとおもう。
- 【Qiita】AWS DynamoDBと仲良くなれるかもしれないまとめ
特に、LSI、GSIはちゃんと理解しておかないと混乱することになるのでしっかり覚えておこう。
事前準備
今回は、以下のような仕様のデータベースを管理する前提とする。
- 社員ID(項目名:id)をキーとする社員管理テーブルを想定
- 社員は複数の部署(項目名:department)に所属可能である
- 社員の年齢をデータベースに持っておく上記から、ハッシュキーは
idとする。
と同時に、2つ目の要件を満たすために、departmentをレンジキーに指定する。
さらに、どんな検索要件に対応できるか確認するために、GSIとLSIにdepartmentを設定したテーブルをそれぞれ用意する。
※これ、書いてから気付いたが、別にテーブル分けなくてもそれぞれのインデックスを設定すれば1つのテーブルでも実験できたな……。上記のテーブルを用意するTerraformは以下のような感じで準備。
################################################################################ # DynamoDB Table # ################################################################################ resource "aws_dynamodb_table" "test" { name = "test-table" billing_mode = "PROVISIONED" read_capacity = 1 write_capacity = 1 hash_key = "id" range_key = "department" attribute { name = "id" type = "S" } attribute { name = "department" type = "S" } local_secondary_index { name = "department_lsi" range_key = "department" projection_type = "ALL" } global_secondary_index { name = "department_gsi" hash_key = "department" write_capacity = 1 read_capacity = 1 projection_type = "ALL" } }さらに、スクリプトで以下のような感じでベースとなるアイテムをロードしておく。
def prepare_001(): try: with table.batch_writer() as batch: batch.put_item(Item={ 'id': '00001', 'department': '11111', 'age': 35 }) batch.put_item(Item={ 'id': '00001', 'department': '22222', 'age': 35 }) batch.put_item(Item={ 'id': '00002', 'department': '11111', 'age': 28 }) batch.put_item(Item={ 'id': '00003', 'department': '11111', 'age': 34 }) batch.put_item(Item={ 'id': '00004', 'department': '22222', 'age': 39 }) return "OK" except Exception as error: return error実験開始
重複したキーの項目をPUTする
def test_001_01(): try: table.put_item(Item={ 'id': '00001', 'department': '11111', 'age': 36 }) return "OK" except Exception as error: return error結果:重複したキーの項目が更新された。
単一項目の非キー項目のアップデート
def test_001_02(): try: option = { 'Key': {'id': '00001', 'department': '11111'}, 'UpdateExpression': 'set #age = :age', 'ExpressionAttributeNames': { '#age': 'age' }, 'ExpressionAttributeValues': { ':age': 37 } } table.update_item(**option) return "OK" except Exception as error: return error結果:問題なく実行可能。
単一項目のキー項目のアップデート
def test_001_03(): try: option = { 'Key': {'id': '00001', 'department': '11111'}, 'UpdateExpression': 'set #department = :department, #age = :age', 'ExpressionAttributeNames': { '#department': 'department', '#age': 'age' }, 'ExpressionAttributeValues': { ':department': "33333", ':age': 37 } } table.update_item(**option) return "OK" except Exception as error: return error結果:エラーになる。キー項目の更新は
delete→putするしかないようだ(詳細は後述)。'An error occurred (ValidationException) when calling the UpdateItem operation: One or more parameter values were invalid: Cannot update attribute department. This attribute is part of the key'ハッシュキーのみでqueryする
def test_001_04(): try: response = table.query( KeyConditionExpression=Key('id').eq('00001') ) return response['Items'] except Exception as error: return error 結果:同一ハッシュキーのアイテムが複数返却される。 ## ハッシュキー+レンジキーでqueryする def test_001_05(): try: response = table.query( KeyConditionExpression=Key('id').eq('00001') & Key('department').eq('22222') ) return response['Items'] except Exception as error: return error結果:単一アイテムに絞り込まれて返却される
ハッシュキー+レンジキー以外の項目でqueryする
def test_001_06(): try: response = table.query( KeyConditionExpression=Key('id').eq('00001'), FilterExpression=Attr('age').eq(35) ) return response['Items'] except Exception as error: return error結果: queryで指定した条件で絞ることができる
LSIでレンジキーのみ指定してqueryする
def test_001_07(): try: response = table.query( IndexName="department_lsi", KeyConditionExpression=Key('department').eq('11111') ) return response['Items'] except Exception as error: return error結果: 不可能。LSIの場合、ハッシュキーが必要になるためエラーになる。
'An error occurred (ValidationException) when calling the Query operation: Query condition missed key schema element: id'GSIでレンジキーのみ指定してqueryする
def test_001_08(): try: response = table.query( IndexName="department_gsi", KeyConditionExpression=Key('department').eq('11111') ) return response['Items'] except Exception as error: return error結果: GSIの場合はハッシュキー不要なので、セカンダリインデックスで指定したアイテムが複数返却される
GSIでレンジキーのみ指定してqueryしてさらに件数を2件までに絞る
def test_001_09(): try: response = table.query( IndexName="department_gsi", KeyConditionExpression=Key('department').eq('11111'), Limit=2 ) return response['Items'] except Exception as error: return error結果: 想定通りの件数で絞られる
キー項目を更新できない代わりに、delete → put する
def test_001_10(): try: table.delete_item(Key={ 'id': '00001', 'department': '22222' }) table.put_item(Item={ 'id': '00001', 'department': '33333', 'age': 36 }) return "OK" except Exception as error: return error結果: 問題なく動作。ただし、DynamoDBは結果整合でしかないため、delete前にput結果が取得されることを考慮しておく。
- 投稿日:2020-08-23T21:41:36+09:00
[AWS] Lambda関数のユニットテストをローカル環境で実行してみよう
前提
今回は、以下のような前提で検証してみたいと思います。
- SAM
- Lambda
- Python3.8
- pytest
- moto(モック)
- DynamoDB
なお、SAMを使用すると、Dockerん環境を使って擬似的にローカル環境にDynamoDBなどを構築することができますが、今回は、ユニットテスト(将来的な自動テスト)を見据えてのテストについて検証してみたいと思います。
プロジェクト作成
では、まず最初にプロジェクトを作成します。
もし、SAMでのプロジェクト作成がよくわからない方は、事前に
- [AWS] Serverless Application Model (SAM) の基本まとめ
- [AWS] Serverless Application Model (SAM) でAPI Gateway + Lambda + DynamoDBなサンプルを作成してみる
に目を通されることをおすすめします。
$ sam init --runtime=python3.8 Which template source would you like to use? 1 - AWS Quick Start Templates 2 - Custom Template Location Choice: 1 Project name [sam-app]: Cloning app templates from https://github.com/awslabs/aws-sam-cli-app-templates.git AWS quick start application templates: 1 - Hello World Example 2 - EventBridge Hello World 3 - EventBridge App from scratch (100+ Event Schemas) 4 - Step Functions Sample App (Stock Trader) 5 - Elastic File System Sample App Template selection: 1 ----------------------- Generating application: ----------------------- Name: sam-app Runtime: python3.8 Dependency Manager: pip Application Template: hello-world Output Directory: . Next steps can be found in the README file at ./sam-app/README.md必要なパッケージのインストール
ユニットテストを実行するために必要なPythonのパッケージをインストールします。
$ pipenv install pytest pytest-mock mocker moto --devユニットテスト
以下のコマンドで、Lamnda関数を呼び出して、各Lambda関数のユニットテストを実行できます。
まずは、デフォルトで作成されているHelloWorldのLambda関数のテスト(こちらのテストコードもデフォルトで作成済み)を実行してみましょう。$ python -m pytest tests ============================= test session starts ============================== platform darwin -- Python 3.8.5, pytest-6.0.1, py-1.9.0, pluggy-0.13.1 rootdir: /Users/******/aws/github/sam-app plugins: mock-3.3.0 collected 1 item tests/unit/test_handler.py . [100%] ============================== 1 passed in 0.02s ===============================1件のテストが成功したことがわかります。
DynamoDBアクセスコードの追加
今回は、ユニットテストすることだけを目的とするため、特にSAMの設定変更等は行わずに、テストに必要な変更のみを行うようにします。
では、DynamoDBにアクセス(レコード追加)する処理の追加を行ってみます。hello_world/app.pyimport json import boto3 import os from datetime import datetime def lambda_handler(event, context): try: event_body = json.loads(event["body"]) dynamodb = boto3.resource("dynamodb") table = dynamodb.Table("Demo") table.put_item( Item={ "Key": event_body["test"], "CreateDate": datetime.utcnow().isoformat() } ) return { "statusCode": 200, "body": json.dumps({ "message": "hello world", }), } except Exception as e: return { "statusCode": 500, "body": json.dumps({ "message": e.args }), }テストコードに、DynamoDBのモックアップを追加
tests/unit/test_handler.pyimport boto3 import json import pytest from hello_world import app from moto import mock_dynamodb2 @pytest.fixture() def apigw_event(): """ Generates API GW Event""" return { "body": '{ "test": "body"}', "resource": "/{proxy+}", "requestContext": { "resourceId": "123456", "apiId": "1234567890", "resourcePath": "/{proxy+}", "httpMethod": "POST", "requestId": "c6af9ac6-7b61-11e6-9a41-93e8deadbeef", "accountId": "123456789012", "identity": { "apiKey": "", "userArn": "", "cognitoAuthenticationType": "", "caller": "", "userAgent": "Custom User Agent String", "user": "", "cognitoIdentityPoolId": "", "cognitoIdentityId": "", "cognitoAuthenticationProvider": "", "sourceIp": "127.0.0.1", "accountId": "", }, "stage": "prod", }, "queryStringParameters": {"foo": "bar"}, "headers": { "Via": "1.1 08f323deadbeefa7af34d5feb414ce27.cloudfront.net (CloudFront)", "Accept-Language": "en-US,en;q=0.8", "CloudFront-Is-Desktop-Viewer": "true", "CloudFront-Is-SmartTV-Viewer": "false", "CloudFront-Is-Mobile-Viewer": "false", "X-Forwarded-For": "127.0.0.1, 127.0.0.2", "CloudFront-Viewer-Country": "US", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8", "Upgrade-Insecure-Requests": "1", "X-Forwarded-Port": "443", "Host": "1234567890.execute-api.us-east-1.amazonaws.com", "X-Forwarded-Proto": "https", "X-Amz-Cf-Id": "aaaaaaaaaae3VYQb9jd-nvCd-de396Uhbp027Y2JvkCPNLmGJHqlaA==", "CloudFront-Is-Tablet-Viewer": "false", "Cache-Control": "max-age=0", "User-Agent": "Custom User Agent String", "CloudFront-Forwarded-Proto": "https", "Accept-Encoding": "gzip, deflate, sdch", }, "pathParameters": {"proxy": "/examplepath"}, "httpMethod": "POST", "stageVariables": {"baz": "qux"}, "path": "/examplepath", } @mock_dynamodb2 def test_lambda_handler(apigw_event, mocker): dynamodb = boto3.resource('dynamodb') dynamodb.create_table( TableName='Demo', KeySchema=[ { 'AttributeName': 'Key', 'KeyType': 'HASH' }, { 'AttributeName': 'CreateDate', 'KeyType': 'RANGE' } ], AttributeDefinitions=[ { 'AttributeName': 'Key', 'AttributeType': 'S' }, { 'AttributeName': 'CreateDate', 'AttributeType': 'S' } ], ProvisionedThroughput={ 'ReadCapacityUnits': 10, 'WriteCapacityUnits': 10 } ) ret = app.lambda_handler(apigw_event, "") data = json.loads(ret["body"]) assert ret["statusCode"] == 200 assert "message" in ret["body"] assert data["message"] == "hello world" # assert "location" in data.dict_keys()主な修正点は、
- importに必要な定義追加
test_lambda_handler前に@mock_dynamodb2追加test_lambda_handlerで、Lambda関数呼び出し前に擬似的にDynamoDBのテーブル作成です。
ユニットテスト実行
では、早速ユニットテストを実行してみます。
$ python -m pytest tests ============================= test session starts ============================== platform darwin -- Python 3.8.5, pytest-6.0.1, py-1.9.0, pluggy-0.13.1 rootdir: /Users/******/aws/github/sam-app plugins: mock-3.3.0 collected 1 item tests/unit/test_handler.py . [100%] =============================== warnings summary =============================== [pytest] /Users/******/.local/share/virtualenvs/sam-app-3Tr4jFKA/lib/python3.8/site-packages/boto/plugin.py:40 /Users/******/.local/share/virtualenvs/sam-app-3Tr4jFKA/lib/python3.8/site-packages/boto/plugin.py:40: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses import imp /Users/******/.local/share/virtualenvs/sam-app-3Tr4jFKA/lib/python3.8/site-packages/moto/cloudformation/parsing.py:407 /Users/******/.local/share/virtualenvs/sam-app-3Tr4jFKA/lib/python3.8/site-packages/moto/cloudformation/parsing.py:407: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3, and in 3.9 it will stop working class ResourceMap(collections.Mapping): -- Docs: https://docs.pytest.org/en/stable/warnings.html一応、成功していますが、警告が出ています。
これは、現在のPythonのバージョンでは、motoなどで使用している一部機能が使用停止されていることを表しています。
今回のユニットテストには影響のない警告なので、プロジェクトのホームにpytest.iniという名称でファイルを作成し、以下を記述して保存してみましょう。pytest.ini[pytest] filterwarnings = ignore::DeprecationWarningでは、再度実行してみましょう。
$ python -m pytest tests ============================= test session starts ============================== platform darwin -- Python 3.8.5, pytest-6.0.1, py-1.9.0, pluggy-0.13.1 rootdir: /Users/******/aws/github/sam-app, configfile: pytest.ini plugins: mock-3.3.0 collected 1 item tests/unit/test_handler.py . [100%] ============================== 1 passed in 2.10s ===============================今度は警告なく終了しました。
まとめ
ユニットテストは、ソースコード変更時に自動実行されることが望ましいです。
今回は、ユニットテストの実行をローカルで行っているため、ソースコード部分のみの修正に留めていますが、CI/CDのパイプラインの延長で行う場合は、requirements.txtや各定義ファイルにも修正が必要です。
次回は、その辺のパイプラインとの結合も含めた検証を、どこかのタイミングでやってみたいと思います。サンプルコードリポジトリ
- 投稿日:2020-08-23T21:30:09+09:00
別アカウントのS3にレプリ_ただのメモ書き
GudardDutyのログは仕様上暗号化されてS3に出力される。そのログをS3レプリケーションで別のAWSアカウントにレプリケーションしたい
アカウントA ==> アカウントB
環境
アカウントA
- GuardDutyログを暗号化するKMSキー:gd-test-src
- GuardDutyログを保存するS3バケット:gd-src
- GuardDuty有効化
アカウントB
- KMSキー:gd-test-dst
- アカウントAのGuardDutyログのレプリ先S3バケット:gd-test-dst
S3バケット作成
アカウントBで操作
S3バケットgd-dstを作成
バージョニング有効化KMSの作成
アカウントAで操作
CMKを"gd-test-src"で作成
キーポリシーに以下を追加
{ "Sid": "Allow GuardDuty to use the key", "Effect": "Allow", "Principal": { "Service": "guardduty.amazonaws.com" }, "Action": "kms:GenerateDataKey", "Resource": "*" }アカウントBで操作
CMKを"gd-test-dst"で作成
このCMKのARNをコピーしておくarn:aws:kms:ap-northeast-1:xxxxxxxxxxxx:key/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxGuardDuty設定
アカウントAで操作
GuardDutyを有効化
S3バケット設定:「今すぐ設定する」をクリックし"gd-src"のバケットを新規作成
S3のバケットポリシーが勝手に入る
このバケットのバージョニングを有効化しておくKMS:"gd-test-src"を選択
GuardDutyでサンプル実行してS3ログ出力を確認しといてもよい(S3出力されるまでに多少ディレイ有り)
S3レプリケーション設定
アカウントAで操作
S3バケットで、レプリケーション->ルールの追加
"gd-src"の全てのコンテンツ
"KMSで暗号化されたオブジェクトを複製する"にチェック
キーに"gd-test-src"
バケット名(アカウントIDとバケット名)
アカウントBのKMS CMKのARNを入れ、"オブジェクト所有者を送信先バケット所有者に変更"にチェックを入れる
"新しいロールを作成"を選びS3ロールを自動作成
"s3crr_role_for_gd-src_to_gd-test-dst"と言うロールが作成される
https://aws.amazon.com/jp/blogs/news/replicating-existing-objects-between-s3-buckets/自動作成されたIAMロールのARNはコピーしておく
arn:aws:iam::xxxxxxxxxxxx:role/service-role/s3crr_role_for_gd-src_to_gd-test-dst送信先用のバケットポリシーは後でコピーできるので無視し
KMSキーポリシーは手元にコピーしておき、KMS CMKの"gd-test-src"のキーポリシーに追加しておく
[次へ]->[完了]をクリックする。次の画面になる。
S3バケットレプリケーション設定
アカウントBで操作
レプリ先S3バケットの、レプリケーション->アクション->"オブジェクトの受信"をクリックする
この操作を行うことで、簡単に送信先用のS3バケットポリシーの設定などを行える
送信元のAWSアカウントIDを入れる。するとその送信元AWSアカウントIDを踏まえたバケットポリシーが作成される。[設定の適用]をクリックすると自動作成されたバケットポリシーが適用される。[設定の適用]をクリックする
KMSのキーポリシーは手元にコピーし、KMS CMKの"gd-test-dst"に追記しておく
ただ、rootが付いたprincipalになっているので、より操作を制限したいのであれば、送信元で作成したレプリケーション用のIAMロールで絞る。
※"arn:aws:iam::accountid:root"のrootが付いたプリンシパルは、"arn:aws:iam::accountid"と意味は同じです。
これはアカウント自体を示すもので、ARNで示してるアカウントから見て当該バケットを所有しているのと同じアクセス権限設定が可能。
このアカウントのユーザーでちゃんとこのS3バケットに権限があれば(またはadministrator権限があるなど)、アクセスできる。
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/reference_identifiers.html#identifiers-arns※ドキュメントのロール名の書き方サンプルが少し分かりづらいので注意
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/replication-walkthrough-2.htmlドキュメントには以下のように書かれているが
arn:aws:iam::source-bucket-acct-ID:source-acct-IAM-role実際の自動作成されるIAMロールのARNは以下のように"service-role"という箇所が入っているので注意
arn:aws:iam::xxxxxxxxxxxx:role/service-role/s3crr_role_for_gd-src_to_gd-test-dst動作確認
アカウントAで操作
GDのサンプル生成
S3に出力されてる確認アカウントBで操作
S3にレプリされてる確認参考
手動でレプリケーション用のIAMロール作成
S3がレプリする際に使うIAMロールの作成(サービスロール)
手動作成の公式ドキュメント
ロールとポリシーと信頼関係を作ってる
これらの権限を付与してます↓アクセスポリシーは、以下のアクションに対するアクセス許可を付与します。
s3:GetReplicationConfiguration および s3:ListBucket — レプリケート元バケットでのこれらのアクションのアクセス許可により、Amazon S3 はレプリケーション設定とリストバケットのコンテンツを取得できます (現在のアクセス許可モデルでは、削除マーカーにアクセスするには s3:ListBucket アクセス許可が必要です)。
s3:GetObjectVersion および s3:GetObjectVersionAcl — すべてのオブジェクトに付与されているこれらのアクションのアクセス許可により、Amazon S3 はオブジェクトに関連付けられた特定のオブジェクトバージョンおよびアクセスコントロールリスト (ACL) を取得することができます。
s3:ReplicateObject および s3:ReplicateDelete — レプリケート先バケットのオブジェクトに対するこれらのアクションのアクセス許可により、Amazon S3 はレプリケート先バケットにオブジェクトまたは削除マーカーをレプリケートできます。削除マーカーの詳細については、「削除オペレーションがレプリケーションに与える影響」を参照してください。







- 投稿日:2020-08-23T19:02:21+09:00
AWS勉強 振り返りまとめ (2)
AWS ソリューションアーキテクト アソシエイト受験に向けて取り組んできた勉強において、
振り返っておくと良さそうな部分をまとめてみました (その2)
同じように AWS の勉強をしている方の参考になれば嬉しいです
前はこれ
AWS勉強 振り返りまとめ (1)
Load Balancing 系
- 静的/動的なスケーリング
- 静的 : desired-capacity が固定
- 動的 : desired-capacity が可変 = Auto Scaling (それはそう)
- ステップスケーリングポリシー
- CloudWatch から取得できるメトリクスの値に応じて増やす台数を調整できる。
- e.g. cpu 使用率 60% => 1台, ~ 70% => 2, ~ 80% => 3
- ELBのターゲットグループを設定すれば、ELB構成を利用してELBのヘルスチェックによりAutoScalingを実行することができる。
- ELB の実態がなくても、Auto Scaling の機能は使える。
- ASG の Termination Policy のデフォルト設定は、OldestLaunchConfiguration からClosestToNextInstanceHour の順番に適用される。
- OldestLaunchConfiguration : 使用されている Launch Template の古い順
- ClosestToNextInstanceHour : 追加課金が発生するタイミングが早い順
- RDS はインスタンスタイプの縮小はできるが、ストレージサイズの縮小はできない (拡張のみ)。
ElactiCache
タイプ別特徴
タイプ スレッド スナップショット機能 データの永続化 ユースケース Redis シングルスレッド あり 可能 複雑なデータの処理や分析処理、機械学習など Memcached マルチスレッド なし 不可能 シンプルなデータのオーケストレーション(管理の自動化) Cloudfront
- リクエストヘッダーに Accept-Encoding:gzip が指定されており、オリジンサーバ (S3 など) が gzip に対応していない場合、Cloudfront のエッジロケーションにて gzip 圧縮を行い配信が可能。
SQS
- Pull / P2P なメッセージングサービス。
- ユースケース
- 大量リクエストのバッファリング
- ワークキューとしてアプリケーション間の依存関係を弱める。
- プロデューサー(メッセージを送る側)とコンシューマ(受け取る側)が双方の稼働状況(メンテナスなど)の影響を受けにくい。
- リクエストのオフロード
- 軽い処理をプロデューサーが応答し、重い処理はキューに積んでコンシューマーに対応させる。
- ターゲットのファンアウト(一括送信)
- SNS と組み合わせることで、1つのメッセージ送信で並列化が可能になる。
- SNS を使用しない場合は、プロデューサー側で並列化の制御をする必要がある。
- 単発のメッセージではなく、関連する複数のメッセージを処理する場合は Kinesis を使う。
- e.g. 映像データ, 1台のデバイスから発生するログの解析
SNS
- Push / Pub-Sub なメッセージングサービス
- Pub-Sub : Publisher(発行者) と Subscriber(購読者) との間に Topic (所有者) がある。
- ロール
- Topic Owner : Topic を作成
- Subscriber : 購読する Topic を選択
- Publisher : Topic へ向けて Message を送信
- SNS のエンドポイントとして Lambda を指定することで、他のAWSリソースを Subscriber のように扱うことができる。
- 配信の順序
- 基本的には Topic に対して発行された順序で、Publisher からの Message を配信するようになっているが、ネットワーク上の問題により、結果的に Subscriber 側に Message の順番が入れ替わって届く可能性もある。
- 対して SQS はキューのタイプを FIFO キューにすることで、発行と配信の順序付けを行うことができる。
Lambda
- Lambda の課金は 100 ミリ秒単位の実行時間から換算される。
- 実行に関わるパーミッション
- Execution : LambdaがS3やDynamoDBなどのAWSリソースから実行できる許可設定を行う。
- Invocation : Lamdba を外部リソースから実行できる許可設定を行う。
- ポーリングベースのイベントソース
- ストリームベース : DynamoDB, Kinesis Data Stream
- 非ストリームベース : S3
- ユースケース
- モバイル・API関連
- Webアプリのモバイルバックエンド
- データ配信APIとしてリアルタイムに情報を配信
- データ加工・連携処理
- S3へのデータアップロードをトリガーにデータ処理
- イベント駆動の業務処理連携 w/SQS
- 短時間処理の並列実行
- アプリケーションのフロー管理
- データイベント処理
- ストリームデータの連続処理
- チャットボット
- IoTバックエンド
- データ変更トリガー
- DynamoDB (DyamoDBストリーム有効) => Lambda => RDS
- バックエンドデータ処理
- ログデータ収集処理
- 機械学習などデータパイプライン
- データレイクからのデータ加工
- スケジュール・ジョブ
- API Gateway は最大数十万個のAPI同時呼び出し/受付が可能である。
CloudFormation
- テキストファイルのテンプレートを用いることで、ほぼ全ての AWS リソースをスタックと呼ばれる単位でプロビジョニングできるサービス。
- 他プロビジョニングサービスとの比較 (導入コストの昇順, CloudFormation が最も難しい)
- Beanstalk
- とりあえずデプロイだけサクッとしたい人向け (自動で運用サポート)
- WEBアプリケーションやワーカー環境などの構築によく用いられる。
- OpsWorks
- アプリケーション志向のAWSリソース(EC2, Elastic IP, ...)に限定される。
セキュリティ/運用
- CodePipeline は他の Code シリーズのサービス以外にも、ECSなどにも利用可能である。
KMS で使われるキー
- CMK (カスタマーマスターキー) : 暗号化の実行の際に最初に作成されるキーで、暗号化キーを暗号化する。
- 暗号化キー (カスタマーデータキー) : 実際のデータを暗号化する。
検出制御系サービスとその対象
サービス 対象 CloudTrail AWSユーザーの行動ログ CloudWatch AWSリソースのメトリクス AWS Guard Duty AWS 上で悪意のある操作や不正な動作 AWS Shield DDoS に対する保護 IAM Access Analyzer 外部と共有されているリソース/データへの意図しないアクセス Amazon Inspector セキュリティ評価の実施 運用系サービスとその管理対象
サービス 対象 AWS Config リソースの変更/構成(Stream, History, Snapshot から成る) AWS Service Catalog AWSでの使用が承認された IT サービスのカタログ AWS Artifact コンプライアンス関連(Artifact Reports, Artifact Agreements から成る) AWS System Manager 運用タスクの自動化 その他
- Snowball
- セキュリティに考慮して設計されたデバイスを使用するペタバイト規模のデータ転送ソリューション(デバイス)で、AWS クラウド内外に大容量データを転送することが可能になる。
- 1台当たり 50 or 80 TB のストレージがあり、42 or 72 TB が使用可能である。
- ストレージ/スペックの最適化が行われた Snowball Edge Storage / Compute Optimzied も存在する。 ストレージ容量は 100 TB (83 TB が使用可能)。
- 投稿日:2020-08-23T18:48:36+09:00
AWS勉強 振り返りまとめ (1)
AWS ソリューションアーキテクト アソシエイト受験に向けて取り組んできた勉強において、
振り返っておくと良さそうな部分をまとめてみました (その1)
メモ程度の内容ですが、同じように AWS の勉強をしている方の参考になれば嬉しいですIAM
- 1アカウントあたりのIAMの制限(数)
- IAMユーザー : 5000
- IAM ユーザーは10個のIAMグループに所属可能
- IAMグループ : 300
- IAMロール : 1000
- AWS Organizations は IAM のアクセス管理を容易にするサービス。
- アクセス権限自体の編集を行うものではない。
EC2
EBS のボリュームタイプ
タイプ ユースケース 最大スループット[MiB/sec] 料金 [USD/GB] 汎用SSD バランス良い 250 0.1 プロビジョンドIOPS SSD 大規模なDBワークフロー等IOPS重視 1000 0.125 + 0.065 (IOPS向上分の費用) スループット最適化HDD ビッグデータ処理やログ解析 500 0.045 Cold HDD アクセス頻度の低いデータ(ログデータ等)用 250 0.025 ゴールデンイメージ : ソフトウェアがインストールされた最新の状態のAMI
Reserved Instance (RI) による価格メリット適用範囲
- RIを購入した AZ or リージョン内のインスタンスに対して、価格メリットが適用される。
- 上記のルールは RI を購入したアカウントだけでなく、そのアカウントの一括請求グループに所属するアカウントにも適用される。
VPC
- セキュリティグループとACLの違い
- セキュリティグループ : インスタンスに対するトラフィック制御
- ACL : サブネットのトラフィック制御
- どちらの設定内容も即時反映される
- Direct Connect
- オンプレ環境と AWS リソース間を、高い信頼性&ネットワーク帯域幅の専用線を用いて接続するサービス。
- より短時間で接続設定を完了したい場合は、サイト間VPN (Site2Site VPN) 接続によって VPN トンネルを作成することも可能。
- オンプレ=>クラウド移行に使用されるサービスではない。
- Transit Gateway
- 1,000 以上のVPCとオンプレ間の相互接続を可能にするマネージドサービス。 (巨大なルーター)
- ネットワークの共用がスコープ。
- アプリケーションの共用が目的であれば、PrivateLink w/NLB を使用する。
- S3, Dynamo DB にアクセスする場合は VPC エンドポイントを用いる。
- 他のリージョンサービスにおいては NAT ゲートウェイを経由する。
DB系
- なんとなく用途別サービス紹介
- データレイクとしてデータ蓄積, アクセス頻度の少ないデータ保存には S3
- ビッグデータ解析などの高速処理や、一度にアクセスが集中アプリケーションには DynamoDB
- DynameDBでもいけそうなケースだが、より複雑なクエリ処理(JOIN, TRANSACTION, COMMIT, ROLLBACK など)が必要な場合は RDS
- 検索効率重視ときたら ElasticSearch
- リアルタイム処理ときたら ElasticCache
- マッピング表示ときたらグラフDBを提供する Neptune
- DAX (Data Accelerator) クラスター
- DynamoDB のインメモリキャッシュ。
- マルチAZで構成することで 1秒間に数百万件のリクエスト処理を可能にする。
- Aurora Serverless
- DBインスタンスクラスを指定せずにデータベースエンドポイントを作成することができるサービス。
- データベースの容量範囲を指定することで、自動的にリソースがスケーリングされる。
- その処理負荷が一定ではないが、高性能なパフォーマンスが必要なケースに適している。
- Storage Gateway
- オンプレから実質無制限のクラウドストレージ (RDS, S3, ...) へのアクセスを提供するハイブリッドクラウドストレージサービス。
- 用途ごとにボリュームタイプの設定が必要。
- 保管型ボリューム : オンプレ側をプライマリとして使用したい場合
- キャッシュ型ボリュームクラウドストレージサービスをプライマリとして使用したい場合
S3
- ストレージクラス
クラス 特徴 耐久性[%] 可用性[%] STANDARD ベーシック 99.999999999 99.99 STANDARD-IA(Insufficient Access) ↑ より安価 低頻度だが高速な取得が要求されるケース 99.999999999 99.9 One Zone-IA ↑と同ケース+低コスト (1 AZのみの運用) 99.999999999 99.5 Intelligent-Tiering アクセス頻度に応じてデータを自動で分類してコスト削減 99.99 99.9 RRS 低冗長化(現在非推奨) 99.99 99.99 Amazon Glacier 最安 アーカイブ用 99.999999999 N/A
- アクセス制御の手段
- バケットポリシー : アクセスを行うインスタンスが不特定多数の場合
- IAMロール : アクセスを行うインスタンスが特定できる場合
Glacier の選択余地
- Glacier は最も安価な S3 のボリュームタイプ。
- 低頻度アクセスときたら Standerd-IA を選びがちだが、コスト最適化重視かつ数分でのデータ取得で良い場合は Glacier が最適である。
- データ取り出しのオプションを "迅速取り出し" すれば、1~5分で取得可能になる。
- 必要とされるデータ取得時間が 12 時間以上でも問題ない場合は、Glacier Deep Archive が最適である。
バケットとオブジェクトの所有者が異なるケース
- AWS アカウント A が作成したバケットに AWS アカウント B がアップロードしたオブジェクトの所有者はアカウント B であり、デフォルトではアカウント A はそのオブジェクトにアクセスできない。
- アカウント A にアクセス権を付与するためには、アップロードされたオブジェクトの ACL を更新する必要がある。or クロスアカウント設定?
5xx エラーが発生する場合のトラブルシューティング
- エラー発生の時点で、S3 がリクエストを処理しきれていない状態にある。特に 503 Slow Down では S3 バケットが許容できるリクエスト率を超えて、非常に高いことを示している。
- 処理できていないリクエストを再試行すため、以下の手順に従って耐障害メカニズムを持たせる必要がある。
- リクエストするアプリケーションの再試行メカニズムを有効にする。
- リクエスト率を徐々に増やすようにアプリケーションを設定する。
- 複数のプレフィックスにオブジェクトを分散する。
- 投稿日:2020-08-23T17:29:20+09:00
AWS クイックスタートで Pivotal Cloud Foundry (VMware Tanzu Application Service) をサクッとたててみた
はじめに
3 年ほど前に Cloud Foundry ネタで社外イベントに登壇したのですが、ひょんなことから社内勉強会でリバイバル発表することになりました。さすがに 3 年前とは成熟度の面で差があると思い、最新情報をキャッチアップするために Cloud Foundry 環境構築に踏み切りました。
Ubuntu on WSL へのローカルデプロイを試みましたが、絶対的なメモリ不足により断念せざるを得ませんでした。続いて、mac へのローカルデプロイは試行錯誤の上、なんとかうまくいきましたが、リソース的にはギリギリです(何か別の重いアプリを起動するとスワップが発生してしまう)。
Cloud Foundry のように複数の役割を持ったノードが協調し合って成立する仕組みをローカルデプロイすること自体に無理があるのかも知れません。ありがたいことに AWS クイックスタートに「AWS での Pivotal Cloud Foundry」が用意されていますので、今回はその手順をまとめておきたいと思います。
前提条件
- AWS アカウントを持っていること
- VMware Tanzu Network (Pivotal Network) アカウントを持っていること
VMware Tanzu Network (Pivotal Network) アカウントをお持ちでない方は、「Ubuntu on WSL でローカル Cloud Foundry (PCF Dev) を動かそうとしてみた」の「Cloud Foundry (PCF Dev) の入手」手順 をご参考にサインアップしてください。
AWS クイックスタートにアクセスする
以下の URL にアクセスします。
https://aws.amazon.com/jp/quickstart/architecture/pivotal-cloud-foundry/ちなみに、日本語では
Pivotal Cloud Foundryのままですが、英語ではVMware Tanzu Application Service on AWSに変更されています。
- 日本語タイトル:AWS での Pivotal Cloud Foundry
- 英語タイトル:VMware Tanzu Application Service on AWS
スクロールダウンし、「デプロイ方法」 を選択します。5 ステップの手順が記載されていますので、順番にやっていきます(ステップ 1 は、スキップします)。
- AWS アカウントをお持ちでない場合は、https://aws.amazon.com でサインアップしてください。
- Amazon Route 53 で、PCF ドメイン用のホストゾーンを作成します。
- ドメインの SSL 証明書を AWS Certificate Manager にインポートします。
- クイックスタートを起動し、必要なパラメータを指定します。デプロイには 2.5~3 時間かかります。
- AWS アカウントにプロビジョニングされた PCF リソースにアクセスして、デプロイをテストします。
さらに詳細な手順については、デプロイメントガイド(PDF)もご確認ください。
Route 53 で PCF ドメイン用のホストゾーンを作成する(ステップ 2)
既存のホストゾーンを利用しました。説明上、便宜的に
hoge.comとしておきます。ドメインの SSL 証明書を AWS Certificate Manager にインポートする(ステップ 3)
SSL 証明書を生成する
デプロイメントガイド(PDF)の 8 ページ目に記載されている通り、以下の URL にアクセスし、
scriptsフォルダのgen_ssl_certs.shファイルをダウンロードするかコピペしておきます。
https://github.com/aws-quickstart/quickstart-pivotal-cloudfoundry入手した
gen_ssl_certs.shを実行します。パラメータとして PCF 用のドメイン名を指定します。素直にpcfサブドメインとしました。SSL 証明書を生成するgen_ssl_certs.sh pcf.hoge.com実行すると、以下の 2 ファイルが出力されます。
- pcf.hoge.com.crt
- pcf.hoge.com.key
SSL 証明書をインポートする
AWS Certificte Manager にアクセスし、「証明書のインポート」を選択します。「証明書本文」に crt ファイルの内容を、「証明書のプライベートキー」に key ファイルの内容をそれぞれコピーし、「次へ」を選択します。
AWS Certificte Manager に以下のエントリーが追加されていることを確認しました。
- ドメイン名:*.pcf.hoge.com
- 追加の名前:*.sys.pcf.hoge.com, *.apps.pcf.hoge.com, *.login.sys.pcf.hoge.com, *.uaa.sys.pcf.hoge.com
後続の手順で必要になるので、追加した証明書の詳細を表示して ARN を控えておきましょう。
クイックスタートを実行する前に
DeploymentSize を決めておく
後続の手順で DeploymentSize パラメータ(SmallFootPrint/Starter/Multi-AZ)を指定する必要があるため、どの規模感にするか検討しておきましょう。以下は、EC2 インスタンスの数ですが、その他のリソースについても デプロイメントガイド(PDF)の 9 ページ目にまとまっています。
- 10 instances (SmallFootPrint)
- 22 instances (Starter)
- 40 instances (Multi-AZ)
わたしは「サクッとお試し」が目的ですので、
SmallFootPrintを選択しました。ちなみにSmallFootPrintは 10 インスタンスと記載されていますが、実際に起動されているのは 15 インスタンスでした。少し余裕を見ておいた方がよさそうです。サービスクォータの上限緩和をしておく
わたしは、ほぼまっさらなアカウントで
SmallFootPrintを選択したため、特に必要ありませんでしたが、Multi-AZ などを選択した場合、サービスクォータの上限に抵触し、デプロイが失敗するケースがあります。デプロイ環境に応じて、適切に上限緩和しておく必要があります。公式のサポートフォーラムでも、デプロイ失敗の原因として挙げられていました。
Tanzu Network の API トークンを控えておく
Tanzu Network にサインインし、
Edit Profileメニューを選択します。
User Profile でスクロールダウンし、
LEGACY API TOKEN [DEPRECATED]の値を控えておきます。
クイックスタートを起動する(ステップ 4)
テンプレートの指定(スタックの作成:ステップ 1)
クイックスタートを起動 リンクを選択します。CloudFormation の「スタック作成」にリダイレクトされますが、デフォルトでオレゴンリージョン(us-west-2)に設定されていますので、東京リージョン(ap-northeast-1)に切り替えてから、「次へ」を選択します。
スタックの詳細を指定(スタックの作成:ステップ 2)
以下の値を指定し、「次へ」を選択します。
- スタックの名前
- スタックの名前:Pivotal-Cloud-Foundry(変更なし)
- Amazon EC2 Configuraiton
- Environment ID:pcf(変更なし)
- Keypair:[キーペア](選択 ※既存のキーペアを選択しました)
- SSL Certificate ARN:[証明書の ARN ※先ほど控えておいたもの](入力)
- Forward Log Output:true(変更)
- Network and DNS Configuration
- Ops Manager & Bootstrap Ingress:0.0.0.0/0(入力 ※一旦、ガバガバにしておきます)
- Route 53 Hosted Zone ID:
hoge.com(選択)- Domain:
pcf.hoge.com(入力)- Pivotal Cloud Foundry Configuration
- Size of the Deployment:SmallFootPrint(変更)
- Skip SSL Validation:true(変更 ※true に変更しないとデプロイエラーになります)
- Pivotal Network Token:[トークン ※先ほど控えておいたもの](入力)
- Admin Email:[メールアドレス](入力)
- Ops Manager Admin Password:[パスワード](入力 ※英数字とダッシュとアンダースコアのみ許容されます。その他の記号を使わないようご注意ください)
- Custom Branding Company Name:[自社の名前](変更)
- AWS Quick Start Configuration
- Quick Start S3 Bucket Name:aws-quickstart(変更なし)
- Quick Start S3 Bucket Prefix:quickstart-pivotal-cloudfoundry/(変更なし)
- Pivotal's End User License Agreement
- Accept EULA:Yes(変更)
スタックオプションの指定(スタックの作成:ステップ 3)
「次へ」を選択します。
レビュー(スタックの作成:ステップ 4)
以下のチェックボックスを
ONにして、「スタックの作成」を選択します。
- AWS CloudFormation によって IAM リソースがカスタム名で作成される場合があることを承認します。
- AWS CloudFormation によって、次の機能が要求される場合があることを承認します: CAPABILITY_AUTO_EXPAND
あとは、ひたすら待ちます。AWS クイックスタートの「デプロイ方法」には、“デプロイには 2.5~3 時間かかります。” と記載されていますが、わたしの場合は、SmallFootPrintだったためか、1 時間 50 分ほどでデプロイ完了しました。
PCF リソースにアクセスして、デプロイをテストする(ステップ 5)
Ops Manager にアクセスする
https://opsman.pcf.hoge.com/ にアクセスします。以下を入力して
SIGIN INを選択します。
- ユーザ:admin
- パスワード:スタック作成時に
Ops Manager Admin Passwordに指定したパスワード
サインインに成功すると、Ops Manager ページが表示されます。
Apps Manager のパスワードを確認しておく
デプロイメントガイド(PDF)の 16 ページ目に以下のように記載されています。
Password: You can find the password in the Pivotal Application Service tile in Ops
Manager. For instructions, see the Pivotal documentation.Pivotal から VMware Tanzu に名称されていますので、Ops Manager の
Small Footprint VMware Tanzu Application Serviceタイルを選択します。Small Footprint VMware Tanzu Application Service が表示されたらCredentialsタブを選択します。
スクロールダウンし、
UAAセクションのAdmin CredentialsアイテムのLink to Credentialリンクを選択します。
JSON 形式で Credential が返されますので、
passwordの値を控えておきましょう。.uaa.admin_credentials{ credential: { type: "simple_credentials", value: { identity: "admin", password: "ここにパスワードが記載されています" } } }Apps Manager にアクセスする
https://apps.sys.pcf.hoge.com/ にアクセスします。以下を入力して
SIGIN INを選択します。
- ユーザ:admin
- パスワード:先ほど控えておいた UAA admin のパスワード
サインインに成功したら、
Apps Managerタイルを選択します。
Apps Manager が表示されました。
CF CLI からログインする
以下のコマンドを実行してログインしてみます。CF CLI が未インストールの方は、「Ubuntu on WSL でローカル Cloud Foundry (PCF Dev) を動かそうとしてみた」の「Cloud Foundry CLI のインストール」手順 を参考にしてください。
cf login --skip-ssl-validation認証情報が求められますので、以下の値を入力します。
- Email:admin
- パスワード:先ほど控えておいた UAA admin のパスワード
% cf login --skip-ssl-validation API エンドポイント: https://api.sys.pcf.hoge.com Warning: Your targeted API's version (3.80.0) is less than the minimum supported API version (3.85.0). Some commands may not function correctly. Email: admin パスワード: 認証中です... OK Select an org: 1. aws-service-broker-org 2. system 組織 (enter to skip): 1 Targeted org aws-service-broker-org. Targeted space aws-service-broker-space. API エンドポイント: https://api.sys.pcf.hoge.com API version: 3.80.0 ユーザー: admin 組織: aws-service-broker-org スペース: aws-service-broker-spaceさいごに
AWS クイックスタートに「AWS での Pivotal Cloud Foundry」が用意されていますので、サクッといくだろうと思ってはじめたのですが、自身の無知ゆえにそれなりにハマりました。
pcf.hoge.comというホストゾーンを作成してスタック作成を試み、名前解決ができずロールバックされました。Skip SSL Validationがデフォルトのまま(false)でロールバックされました。何度もロールバックされたので、S3 バケット数の上限に達してしまったこともありました。公式のサポートフォーラムでも同様の事象が数件ヒットするものの、未解決だったり、解決策がアンマッチだったりして(クォータ緩和で解決されているパターンが多い)、とくかく情報が少ないという印象です。そうした状況を少しでも改善するために、当記事がお役に立てれば幸いです。
参考リンク
https://aws.amazon.com/jp/quickstart/architecture/pivotal-cloud-foundry/
https://aws-quickstart.s3.amazonaws.com/quickstart-pivotal-cloudfoundry/doc/pivotal-cloud-foundry-on-the-aws-cloud.pdf
https://github.com/aws-quickstart/quickstart-pivotal-cloudfoundry
https://qiita.com/syamamotorhead/items/0e69836e579078a0a2ac
https://qiita.com/syamamotorhead/items/c9871a62ffe88071897c













- 投稿日:2020-08-23T17:25:26+09:00
AWS IoT + Cognito + IAM + Amplifyでユーザ認証・IoTデバイスと通信するAndroidアプリ
目的
IoTデバイス(例えばLEDや各種センサ、それらを接続したRaspberry Piなど)をモバイルアプリから操作したい時、あるユーザが所有しているデバイス以外は操作できないようにデバイスとユーザは一意に紐付けられている必要があります。
上記を実現するためにAWS IoT・Cognito・IAM・Amplifyを使用してユーザ認証機能を実装し、ユーザに紐付けられたデバイスとMQTTメッセージを双方向にやり取りできるAndroidアプリを作成します。ソースコード→GitHub
使用環境
- Windows 10
- Android Studio 4.0.1
- Kotlin 1.4.0
- Amplify CLI 4.27.3
- Pixel 3a(Android 10)
前提条件
- AWSアカウント作成済み
- AWS IAMユーザ作成済み
- Amplify導入済み
AWS IoT
モノを作成する
ここで作成したモノの名前は、ユーザ名やMQTTクライアントIDとして使用します。
開発者ガイドの下記ページを参考に、AWS IoTコンソールを操作してモノを作成します。例として「testuser」というモノを作成しました。
タイプやグループは設定しなくてもOKです。
なお、本来はここで証明書を作成してモノに割り当て、証明書と秘密鍵をダウンロード、デバイスに保存して使用します。
今回はデバイスの代わりにコンソール内のテストクライアントを使用して動作確認するので説明を省略します。ポリシーを作成する
AWS IoT Coreポリシーをモノに割り当てると、デバイスに対してAWS IoTで実行できる操作を許可・拒否することができます。
例としてポリシー名を「testpolicy」とし、「ステートメントを追加」欄でアドバンストモードにして下記を入力します。
下記のポリシーは認証情報が割り当てられたデバイスだけが「デバイス名/*」トピックにアクセスすることを許可します。
*はワイルドカードなので、例えばモノの名前が「testuser」の場合「testuser/to」にも「testuser/from」にもアクセスできます。
ポリシーの書き方は下記ページを参照してください。<your-region>、<your-aws-account>は自分の環境に合わせて変更してください。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "iot:Connect" ], "Resource": [ "*" ], "Condition": { "Bool": { "iot:Connection.Thing.IsAttached": [ "true" ] } } }, { "Effect": "Allow", "Action": "iot:Subscribe", "Resource": [ "arn:aws:iot:<your-region>:<your-aws-account>:topicfilter/${iot:Connection.Thing.ThingName}/*" ] }, { "Effect": "Allow", "Action": [ "iot:Publish", "iot:Receive" ], "Resource": [ "arn:aws:iot:<your-region>:<your-aws-account>:topic/${iot:Connection.Thing.ThingName}/*" ] } ] }AWS IoT エンドポイント
AWS IoTコンソールの左メニューから「設定」を開き、エンドポイントをメモしておきます。
プロジェクトの作成
Android Studioでプロジェクトを作成します。
例としてプロジェクト名は「SignedInPubSub」、パッケージ名は「com.example.signedinpubsub」とします。
テンプレートは「Empty Activity」にしました(あとで適宜Viewを追加します)。
プロジェクトの設定はAmplifyを設定した後で行いますので、一旦ここまでで保存しておきます。
AWS Amplify
コマンドプロンプトなどで先ほど作成したプロジェクトのルートディレクトリまで移動し、下記コマンドを実行します。
>amplify initいくつか質問されますので答えていくとルートディレクトリに開発環境が追加されます。
続いて、下記コマンドを実行します。>amplify add auth同様に質問に答えます。
domain name prefixはデフォルト値でOKです。
下記コマンドを実行して設定した環境をアップロードします。>amplify pushブラウザからAWS Amplifyコンソールを開き、作成したアプリ(SignedInPubSub)を選択し、
「Backend environments」->「Authentication」をクリックします。
「View in Cognito」をクリックしてCognitoユーザープールへ移動します。
AWS Cognito
ユーザープール
ユーザープールIDをメモしておきます。
左メニューから「全般設定」->「ポリシー」をクリックし、下図の通り設定して変更を保存します。
左メニューから「全般設定」->「ユーザーとグループ」->「ユーザーの作成」をクリックします。
ユーザ名はAWS IoTで作成したモノの名前(ここではtestuser)と一致させます。
左メニューから「全般設定」->「アプリクライアント」をクリックし、末尾に「_app_client」が付いているものを削除します。
また、末尾に「_app_clientWeb」が付いているアプリクライアントIDをメモしておきます。
「詳細を表示」をクリックし、下記項目を有効にして変更を保存します。
左メニューから「アプリの統合」->「アプリクライアントの設定」をクリックし、下図の通り設定します。
Amplifyで入力した仮のサインイン/サインアウトURIが入っていますのでそれぞれ「https」を「com.example.signedinpubsub」へ書き換えます。
URLの先頭部分(URLスキーム)はWebブラウザを使ってサインインした後でアプリに戻ってくるために必要になるので、アプリ固有のものを指定します。
ちなみに今回はURLスキームとしてAndroidアプリのパッケージ名を指定しましたが、一般的なもの以外であれば何でもOKです。
左メニューから「アプリの統合」->「ドメイン名」をクリックし、ドメインのプレフィックスをメモしておきます。
IDプール
上メニューから「フェデレーティッドアイデンティティ」をクリックします。
Amplifyが自動的にIDプールを作成していますのでクリックします。
このページの通りに作っている場合は、「signedinpubsubccd*****_identitypool_ccd*****__dev」のような名前になっているはずです。
次に右上にある「IDプールの編集」をクリックします。
IDプールのIDをメモしておきます。
「認証フローの設定」を開き、メッセージをクリックします。
また、先ほどユーザープールで削除したアプリクライアントと同じIDが設定されている認証プロバイダを削除します。
AWS IAM
AWS IAMコンソールに移動します。
左メニューから「アクセス管理」->「ロール」をクリックします。
Amplifyが作成したロールが表示されているので、authRole、unauthRoleそれぞれにIAMポリシーを割り当てます。
まずはunauthRoleをクリックし、「アクセス制限」->「ポリシーをアタッチします」をクリックします。
検索欄に「deny」と入れ、「AWSDenyAll」にチェックを入れて「ポリシーのアタッチ」をクリックします。
続いてauthRoleも同様に、検索欄に「IoTFull」と入れて「AWSIoTFullAccess」にチェックを入れて「ポリシーのアタッチ」をクリックします。
これで認証済みのユーザはAWS IoTでのあらゆる操作が可能になります。
今回はすでに用意されているポリシーを割り当てましたが、実際の運用では必要な操作のみ許可するべきです。
詳しくは下記ページを参照してください。IAM ロール - AWS Identity and Access Management
Androidアプリの作成
再びAndroid Studioでの作業です。
下記ページを参考にAndroidアプリの設定を行います。Project Setup - Create your application - Amplify Docs
build.gradle
build.gradle(Project:SignedInPubSub)を開き、repositioriesにmavenCentral()を追記します。
build.gradle(Project:SignedInPubSub)buildscript { repositories { ... mavenCentral() } } allprojects { ... repositories { ... mavenCentral() } ... }続いてbuild.gradle(Module:app)を開き、compileOptionsとdependenciesを追記します。
build.gradle(Module:app)android { ... compileOptions { // Support for Java 8 features coreLibraryDesugaringEnabled true sourceCompatibility JavaVersion.VERSION_1_8 targetCompatibility JavaVersion.VERSION_1_8 } } dependencies { ... implementation 'com.amazonaws:aws-android-sdk-iot:2.17.1' implementation 'com.amplifyframework:core:1.1.2' implementation 'com.amplifyframework:aws-auth-cognito:1.1.2' implementation 'com.auth0.android:jwtdecode:2.0.0' coreLibraryDesugaring 'com.android.tools:desugar_jdk_libs:1.0.10' ... }エディタ上側に下図の表示が出ます。右にある「Sync Now」をクリックします。
amplifyconfiguration.json
Amplifyが自動的に作成しています。デフォルトだと「プロジェクトのルートディレクトリ\app\src\main\res\raw」にあります。
下記のように修正します。
<>で囲まれた部分は上記でメモしておいたIDなどに変更します。amplifyconfiguration.json{ "UserAgent": "aws-amplify-cli/2.0", "Version": "1.0", "auth": { "plugins": { "awsCognitoAuthPlugin": { "UserAgent": "aws-amplify-cli/0.1.0", "Version": "0.1.0", "IdentityManager": { "Default": {} }, "CredentialsProvider": { "CognitoIdentity": { "Default": { "PoolId": "<your-identify-pool-id>", "Region": "<your-region>" } } }, "CognitoUserPool": { "Default": { "PoolId": "<your-user-pool-id>", "AppClientId": "<your-app-client-id>", "Region": "<your-region>" } }, "Auth": { "Default": { "OAuth": { "WebDomain": "<your-domain-prefix>.auth.<your-region>.amazoncognito.com", "AppClientId": "<your-app-client-id>", "SignInRedirectURI": "com.example.signedinpubsub://signin/", "SignOutRedirectURI": "com.example.signedinpubsub://signout/", "Scopes": [ "openid", ] }, "authenticationFlowType": "USER_SRP_AUTH" } } } } } }awsconfiguration.json
amplifyconfiguration.jsonと同様に修正します。
awsconfiguration.json{ "UserAgent": "aws-amplify-cli/0.1.0", "Version": "0.1.0", "IdentityManager": { "Default": {} }, "CredentialsProvider": { "CognitoIdentity": { "Default": { "PoolId": "<your-identify-pool-id>", "Region": "<your-region>" } } }, "CognitoUserPool": { "Default": { "PoolId": "<your-user-pool-id>", "AppClientId": "<your-app-client-id>", "Region": "<your-region>" } }, "Auth": { "Default": { "OAuth": { "WebDomain": "<your-domain-prefix>.auth.<your-region>.amazoncognito.com", "AppClientId": "<your-app-client-id>", "SignInRedirectURI": "com.example.signedinpubsub://signin/", "SignOutRedirectURI": "com.example.signedinpubsub://signout/", "Scopes": [ "openid", ] }, "authenticationFlowType": "USER_SRP_AUTH" } } }strings.xml
TextView等に表示する文字を定義します。
strings.xml<resources> <string name="app_name">SignedInPubSub</string> <string name="text_connecting">Connecting…</string> <string name="text_reconnecting">Reconnecting…</string> <string name="text_connected">Connected.</string> <string name="text_disconnected">Disconnected.</string> <string name="text_connect">Connect</string> <string name="text_publish">Publish</string> <string name="text_subscribe">Subscribe</string> <string name="text_disconnect">Disconnect</string> </resources>activity_main.xml
画面のレイアウトを定義します。
activity_main.xml<?xml version="1.0" encoding="utf-8"?> <androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:app="http://schemas.android.com/apk/res-auto" xmlns:tools="http://schemas.android.com/tools" android:layout_width="match_parent" android:layout_height="match_parent" tools:context=".MainActivity"> <Button android:id="@+id/buttonConnect" android:layout_width="wrap_content" android:layout_height="wrap_content" android:layout_marginStart="16dp" android:layout_marginTop="28dp" android:enabled="false" android:text="@string/text_connect" app:layout_constraintEnd_toStartOf="@+id/buttonDisconnect" app:layout_constraintStart_toStartOf="parent" app:layout_constraintTop_toTopOf="parent" /> <Button android:id="@+id/buttonDisconnect" android:layout_width="wrap_content" android:layout_height="wrap_content" android:layout_marginTop="28dp" android:enabled="false" android:text="@string/text_disconnect" app:layout_constraintEnd_toStartOf="@+id/buttonPublish" app:layout_constraintStart_toEndOf="@+id/buttonConnect" app:layout_constraintTop_toTopOf="parent" /> <Button android:id="@+id/buttonPublish" android:layout_width="wrap_content" android:layout_height="wrap_content" android:layout_marginTop="28dp" android:enabled="false" android:text="@string/text_publish" app:layout_constraintEnd_toStartOf="@+id/buttonSubscribe" app:layout_constraintStart_toEndOf="@+id/buttonDisconnect" app:layout_constraintTop_toTopOf="parent" /> <Button android:id="@+id/buttonSubscribe" android:layout_width="wrap_content" android:layout_height="wrap_content" android:layout_marginTop="28dp" android:layout_marginEnd="16dp" android:enabled="false" android:text="@string/text_subscribe" app:layout_constraintEnd_toEndOf="parent" app:layout_constraintStart_toEndOf="@+id/buttonPublish" app:layout_constraintTop_toTopOf="parent" /> <TextView android:id="@+id/textViewStatus" android:layout_width="345dp" android:layout_height="40dp" android:layout_marginStart="32dp" android:layout_marginTop="16dp" android:layout_marginEnd="32dp" app:layout_constraintEnd_toEndOf="parent" app:layout_constraintHorizontal_bias="1.0" app:layout_constraintStart_toStartOf="parent" app:layout_constraintTop_toBottomOf="@+id/buttonConnect" /> <TextView android:id="@+id/textViewMessage" android:layout_width="345dp" android:layout_height="540dp" android:layout_marginStart="32dp" android:layout_marginTop="32dp" android:layout_marginEnd="32dp" app:layout_constraintEnd_toEndOf="parent" app:layout_constraintHorizontal_bias="1.0" app:layout_constraintStart_toStartOf="parent" app:layout_constraintTop_toBottomOf="@+id/textViewStatus" /> </androidx.constraintlayout.widget.ConstraintLayout>AndroidManifest.xml
AndroidManifest.xml<?xml version="1.0" encoding="utf-8"?> <manifest xmlns:android="http://schemas.android.com/apk/res/android" package="com.example.signedinpubsub"> <uses-permission android:name="android.permission.INTERNET"/> <application android:name=".Initialization" android:allowBackup="true" android:icon="@mipmap/ic_launcher" android:label="@string/app_name" android:roundIcon="@mipmap/ic_launcher_round" android:supportsRtl="true" android:theme="@style/AppTheme"> <activity android:name=".MainActivity" android:launchMode="singleInstance"> <intent-filter> <action android:name="android.intent.action.MAIN" /> <category android:name="android.intent.category.LAUNCHER" /> </intent-filter> <intent-filter> <action android:name="android.intent.action.VIEW" /> <category android:name="android.intent.category.DEFAULT" /> <category android:name="android.intent.category.BROWSABLE"/> <data android:scheme="com.example.signedinpubsub" /> </intent-filter> </activity> </application> </manifest>Constants.kt
プログラム内で使用する定数を記述するクラス「Constants」を作成します。
<>で囲まれた部分は、上記でメモしておいたIDなどに変更します。Constants.ktpackage com.example.signedinpubsub class Constants { companion object{ const val LOG_TAG = "SignedInPubSub" const val AUTH_LOG_TAG = "AuthQuickStart" const val CALLBACK_SCHEME = "com.example.signedinpubsub" const val AWS_IOT_ENDPOINT = "<your-iot-endpoint>" const val AWS_IOT_POLICY = "testpolicy" const val AWS_COGNITO_USER_POOL_ID = "cognito-idp.<your-region>.amazonaws.com/<your-user-pool-id>" const val AWS_COGNITO_POOL_ID = "<your-identify-pool-id>" val REGION = Regions.AP_NORTHEAST_1 // Change to your region } }Initialization.kt
アプリ起動時にAmplifyプラグインを初期化するクラス「Initialization」を作成します。
Initialization.ktpackage com.example.signedinpubsub import android.app.Application import android.util.Log import com.amplifyframework.AmplifyException import com.amplifyframework.auth.cognito.AWSCognitoAuthPlugin import com.amplifyframework.core.Amplify class Initialization: Application() { override fun onCreate() { super.onCreate() // Amplifyの初期化(アプリ起動時に1回だけ実施) try { Amplify.addPlugin(AWSCognitoAuthPlugin()) Amplify.configure(applicationContext) Log.i(Constants.LOG_TAG, "Initialized Amplify") } catch (error: AmplifyException) { Log.e(Constants.LOG_TAG, "Could not initialize Amplify", error) } } }MainActivity.kt
メイン画面での処理です。
MainActivity.ktpackage com.example.signedinpubsub import android.content.Intent import android.os.Bundle import android.util.Log import android.widget.Button import android.widget.TextView import androidx.appcompat.app.AppCompatActivity import com.amazonaws.auth.CognitoCachingCredentialsProvider import com.amazonaws.mobileconnectors.iot.AWSIotMqttClientStatusCallback import com.amazonaws.mobileconnectors.iot.AWSIotMqttManager import com.amazonaws.mobileconnectors.iot.AWSIotMqttQos import com.amazonaws.regions.Region import com.amazonaws.services.cognitoidentity.AmazonCognitoIdentityClient import com.amazonaws.services.cognitoidentity.model.GetIdRequest import com.amazonaws.services.iot.AWSIotClient import com.amazonaws.services.iot.model.* import com.amplifyframework.auth.AuthSession import com.amplifyframework.auth.cognito.AWSCognitoAuthSession import com.amplifyframework.auth.result.AuthSessionResult import com.amplifyframework.core.Amplify import com.auth0.android.jwt.DecodeException import com.auth0.android.jwt.JWT import java.io.UnsupportedEncodingException import kotlin.collections.HashMap class MainActivity : AppCompatActivity() { override fun onCreate(savedInstanceState: Bundle?) { super.onCreate(savedInstanceState) setContentView(R.layout.activity_main) // ユーザ認証の有効期限切れまたは未認証の場合はWebブラウザを開いて認証 Amplify.Auth.signInWithWebUI( this, { result -> // サインイン成功 Log.i(Constants.AUTH_LOG_TAG, result.toString()) fetchSession() }, { error -> // サインイン失敗 Log.i(Constants.AUTH_LOG_TAG, error.toString()) } ) } // Webブラウザで認証した後戻ってきた時の処理 override fun onNewIntent(intent: Intent?) { super.onNewIntent(intent) if(intent?.scheme != null && Constants.CALLBACK_SCHEME == intent.scheme) { Amplify.Auth.handleWebUISignInResponse(intent) } } // セッションを取得 private fun fetchSession() { Amplify.Auth.fetchAuthSession( { session -> // ユーザ名とユーザIDトークンのペアを取得 val pair = getUserNameAndIdToken(session) if(pair != null){ val thingName = pair.first val idToken = pair.second // 認証情報プロバイダの初期化 val credentialsProvider = CognitoCachingCredentialsProvider( applicationContext, Constants.AWS_COGNITO_POOL_ID, Constants.REGION ) // 認証情報プロバイダにユーザプールIDと認証済みユーザをマッピング val logins: MutableMap<String, String> = HashMap() logins[Constants.AWS_COGNITO_USER_POOL_ID] = idToken credentialsProvider.logins = logins Thread { // AWS IoTクライアントの作成 val client = AWSIotClient(credentialsProvider) client.setRegion(Region.getRegion(Constants.REGION)) // モノが作成されているか確認 val listThingsReq = ListThingsRequest() val listThings = client.listThings(listThingsReq) var hasAdded = false for (i in listThings.things) { if (i.thingName == thingName) { hasAdded = true } } // モノが作成されていない場合はユーザ名で作成する if (!hasAdded) { try{ val thingReq = CreateThingRequest() thingReq.thingName = thingName client.createThing(thingReq) }catch(error: Exception){ Log.e(Constants.LOG_TAG, "Could not create the thing.", error) } } // Cognito IDの取得 val getIdReq = GetIdRequest() getIdReq.logins = credentialsProvider.logins getIdReq.identityPoolId = Constants.AWS_COGNITO_POOL_ID val cognitoIdentity = AmazonCognitoIdentityClient(credentialsProvider) cognitoIdentity.setRegion(Region.getRegion(Constants.REGION)) val getIdRes = cognitoIdentity.getId(getIdReq) // プリンシパルがモノに割り当てられているか確認 val listPrincipalThingsReq = ListPrincipalThingsRequest() listPrincipalThingsReq.principal = getIdRes.identityId val listPrincipalThings = client.listPrincipalThings(listPrincipalThingsReq) var hasAttached = false for (i in listPrincipalThings.things) { if (i == thingName) { hasAttached = true } } // プリンシパルが割り当てられていない場合はモノにプリンシパルを割り当てる if (!hasAttached){ try{ val policyReq = AttachPolicyRequest() policyReq.policyName = Constants.AWS_IOT_POLICY // AWS IoTにアクセスするためのポリシー policyReq.target = getIdRes.identityId // Cognito ID client.attachPolicy(policyReq) // ポリシーをCognito IDに割り当てる val principalReq = AttachThingPrincipalRequest() principalReq.principal = getIdRes.identityId // プリンシパル(Cognito ID) principalReq.thingName = thingName // モノの名前 client.attachThingPrincipal(principalReq) // プリンシパルをモノに割り当てる }catch(error: Exception){ Log.e(Constants.LOG_TAG, "Could not attach the principal to the thing.", error) } } // MQTTクライアントを作成 val mqttManager = AWSIotMqttManager(thingName, Constants.AWS_IOT_ENDPOINT) mqttManager.keepAlive = 10 val buttonConnect: Button = findViewById(R.id.buttonConnect) val buttonDisconnect: Button = findViewById(R.id.buttonDisconnect) val buttonSubscribe: Button = findViewById(R.id.buttonSubscribe) val buttonPublish: Button = findViewById(R.id.buttonPublish) val textViewStatus: TextView = findViewById(R.id.textViewStatus) val textViewMessage: TextView = findViewById(R.id.textViewMessage) runOnUiThread { buttonConnect.isEnabled = true // 接続可能になった時、Connectボタンを有効にする // Connectボタンがクリックされた時の処理 buttonConnect.setOnClickListener { buttonConnect.isEnabled = false try { mqttManager.connect(credentialsProvider) { status, throwable -> Log.d(Constants.LOG_TAG, "Status = $status") runOnUiThread { when (status) { AWSIotMqttClientStatusCallback.AWSIotMqttClientStatus.Connecting -> { textViewStatus.text = getString(R.string.text_connecting) } AWSIotMqttClientStatusCallback.AWSIotMqttClientStatus.Connected -> { textViewStatus.text = getString(R.string.text_connected) buttonDisconnect.isEnabled = true buttonPublish.isEnabled = true buttonSubscribe.isEnabled = true } AWSIotMqttClientStatusCallback.AWSIotMqttClientStatus.Reconnecting -> { if (throwable != null) { Log.e(Constants.LOG_TAG, "Connection error.", throwable) } textViewStatus.text = getString(R.string.text_reconnecting) } AWSIotMqttClientStatusCallback.AWSIotMqttClientStatus.ConnectionLost -> { if (throwable != null) { Log.e(Constants.LOG_TAG, "Connection error.", throwable) } textViewStatus.text = getString(R.string.text_disconnected) buttonConnect.isEnabled = true } else -> { textViewStatus.text = getString(R.string.text_disconnected) buttonConnect.isEnabled = true } } } } } catch (error: Exception) { Log.e(Constants.LOG_TAG, "Subscription error.", error) } } // Disconnectボタンがクリックされた時の処理 buttonDisconnect.setOnClickListener { buttonDisconnect.isEnabled = false buttonPublish.isEnabled = false buttonSubscribe.isEnabled = false buttonConnect.isEnabled = true try { mqttManager.disconnect() } catch (error: Exception) { Log.e(Constants.LOG_TAG, "Disconnect error.", error) } } // Publishボタンがクリックされた時の処理 buttonPublish.setOnClickListener { try { mqttManager.publishString("{\"message\":\"Test.\"}", "$thingName/to", AWSIotMqttQos.QOS1) } catch (error: Exception) { Log.e(Constants.LOG_TAG, "Publish error.", error) } } // Subscribeボタンがクリックされた時の処理 buttonSubscribe.setOnClickListener { buttonSubscribe.isEnabled = false try { mqttManager.subscribeToTopic( "$thingName/from", AWSIotMqttQos.QOS1 ) { topic, data -> runOnUiThread { // トピックにメッセージが発行された時のみ実行 try { val message = String(data) textViewMessage.text = message } catch (error: UnsupportedEncodingException) { Log.e(Constants.LOG_TAG, "Message encoding error.", error) } } } } catch (error: Exception) { Log.e(Constants.LOG_TAG, "Subscription error.", error) } } } }.start() } }, { error -> Log.e(Constants.AUTH_LOG_TAG, error.toString()) } ) } // ユーザ名とユーザIDトークンの取得 private fun getUserNameAndIdToken(session: AuthSession): Pair<String, String>? { val cognitoAuthSession = session as AWSCognitoAuthSession // セッション取得 when (cognitoAuthSession.identityId.type) { // セッション取得が成功した場合はユーザ名とユーザIDトークンのペアを返す AuthSessionResult.Type.SUCCESS -> { val tokens = cognitoAuthSession.userPoolTokens.value if(tokens != null){ val idToken = tokens.idToken // ユーザIDトークン try{ val jwt = JWT(idToken) val token = jwt.toString() val name = jwt.getClaim("cognito:username").asString() if(name != null) return Pair(name, token) }catch(error: DecodeException){ Log.e(Constants.LOG_TAG, "Could not decode tokens.", error) } } } // セッション取得に失敗した場合はnullを返す AuthSessionResult.Type.FAILURE -> { Log.i(Constants.AUTH_LOG_TAG, "IdentityId not present because: " + cognitoAuthSession.identityId.error.toString()) } } return null } }動作確認
AWS IoTコンソールの左メニューから「テスト」をクリックします。
トピックのサブスクリプション欄に「testuser/to」と入力し、「トピックへのサブスクライブ」をクリックします。
アプリを起動するとWebブラウザが開きサインインを要求されるので、あらかじめ作成しておいたユーザ名「testuser」でサインインします。
ユーザ認証に成功するとConnectボタンが押せるようになります(少し時間がかかります)。
Connectボタンを押すとMQTTクライアントへ接続します。
MQTTクライアントへの接続が成功すると、Disconnectボタン、Publishボタン、Subscribeボタンが有効になります。
Publishボタンを押すとトピック「testuser/to」へメッセージが送られ、AWS IoTコンソール上にメッセージが表示されます。
Subscribeボタンを押すとトピック「testuser/from」からのメッセージ待ち状態になります。
トピックを「testuser/from」に書き換えて、「トピックに発行」をクリックします。
アプリにメッセージが表示されます。
Amplifyが内部で大部分の処理をやってくれているので、ほとんどドキュメント通りに進めていくことでサインイン機能を実装できました。
参考にしたWebサイト




























- 投稿日:2020-08-23T16:26:38+09:00
AWS上にサーバーを作る(序章)
序章について
この記事を書くに至った経緯を掲載しておきます。
こういう人向け
僕は今までパブリッククラウドと呼ばれるクラウドサーバーの類は使ったことがない。
なぜなら料金が「使った分だけ」という青天井の料金体系なので、
- 会社では・・・不明瞭な料金のせいで「・・・で、結局月々いくらかかんの?」に回答できなく予算を通せず
- 個人では・・・操作ミスで巨額の支払いが来るのが怖くて申し込みすらできず
たぶんこういう人って多いはず。
そして、外部公開用のサーバーは星の数ほどあるけれど、社内向けあるいは外から見られては困るサーバー(開発用途、テスト用途、勉強用なので自己資金)を作ってみたい人いきたいと思いますので、用途にマッチしている人。
そんな人に読んでもらえるとありがたいです。スキルについて
僕はこんなレベルの人間です。
- オンプレでサーバーを作ったことがある
- VirtualBox、KVM、vmware ESXiで仮想マシンを作ったことがある
- レンタルサーバー会社で借りた共用レンタルサーバーを使ったことがある
- レンタルサーバー会社で申し込んだVPSをベースにサーバーを作ったことがある
- 業務で扱うサーバーOSはWindows ServerとCentOS
- Raspberry Piを使ってWebサーバーを立ててみたことがある
- 自宅にRaspberry Piを使ってドメインコントローラーを立てて運用したことがある
- HTML、PHP、MySQLあたりならかろうじて触ったことがあるけど難しいのはNG
- 家のルーターはコンシューマー向けのものから勉強も兼ねて中古のYAMAHAのRTXで運用を始めた
- 自宅にリモートアクセスVPNで接続できる仕組みを勉強用に構築してみた
- 「エンタープライズ向けのPCはやっぱりWindowsだろ」って思ってる
- 「流行りのAWS使いたいなー/触ってみたいなー」って思ってる
要するに、AWSやAzureという名前は知ってるけど、EC2とかVPCはよく知らないレベルからのスタートです。
あ、嘘です。AWSが提供するDNSサービス、「Route 53」は、月々の運用料金が缶ジュース1本分という記事を見たので、勉強用にお名前ドットコムで取得したドメインと同じく勉強用にさくらインターネットで立てたVPSの紐づけ用に2ホスト利用させていただいていました。
ちなみに本当に毎月缶ジュース1本分(2ホストで利用料1.00USD+税金0.10USD=1.10USD)です。(公開サーバーだけど誰もアクセスしに来ないし。。。)目標とするゴール地点
何を作るか
一応目標が必要ですね。
今回、僕は勉強用に自費でサーバーを立ててみるので、なるべく性能よりもコスト優先で設計していきたいところ。もちろん無料枠をなるべく使っていきたい。OSのチョイス
Windows Serverはライセンス料金がおそらく上乗せされるのと、GUIがあるので、必然的にスペックを上げなければならないので、ここはLinux択一です。
公開?非公開?
今回は勉強用、かついろんな人がアクセスしてしまうと料金があがってしまうので、非公開択一です。公開用サーバーを立てたい人は、たぶん探せばいっぱい情報あると思います。
非公開であるが故??
どうせ非公開にするならば、拠点間VPN(自宅とAWS間をVPNでつなげる)もできるかな??
作る物の宣言
「僕は勉強のため、
- 初めてAWSのサービスを使い
- 自宅からVPNでのみアクセスできる
- ランニングコストのかからない
サーバーをインターネット上に立てます!!」
次回の内容
実際にAWSのサービスを見てみましょうかねー
To be continued...
- 投稿日:2020-08-23T15:02:29+09:00
AWS FireLens 用 fluentd コンテナの開発時のみ <source> を追加する
問題
FireLens でユーザー独自の fluentd を使う場合、設定ファイルに以下のような <source> セクションが自動で追加される。
fluent.conf<source> @type unix path /var/run/fluent.sock </source> <source> @type forward bind 127.0.0.1 port 24224 </source>設定ファイルに上記のような記述が既にされていた場合、重複が生じてしまい以下のようなエラーが発生してしまう。
[error]: unexpected error error_class=Errno::EADDRINUSE error=#<Errno::EADDRINUSE: Address in use - bind(2) for "0.0.0.0" port 24224>fluentd コンテナをローカル環境などで開発する段階においては、何らかの <source> がないと入力が得られずテストができないため、ECS で動かすタイミングで上記エラーに遭遇することがある。
対応策
- 開発時だけ設定ファイルに <source> を入れて、開発が終わったら消す
- 愚直なパターン。
- Dockerfile の ARG などを活用して、開発ビルド時のみ <source> を入れるようにする
- 開発以外のときは <source> が入らないように RUN をうまいこと書く。
@type fileなど重複しない type で代用する
- ファイルなど別の type 経由でデバッグする方法。
- 別のコンテナから起動して、コンテナ上で設定ファイルに <source> を追加する
- 後述。
1 に関しては手間がかかってしまうほか、設定の消し忘れで FireLens のエラーを誘発してしまう恐れが常につきまとう。
2./3. は、開発用のロジックがプロダクション環境にも含まれてしまう問題がある。これをどう捉えるかは人次第だが、個人的には若干の気持ち悪さが残る。主題: 別のコンテナから起動させる
4 の方法について: 基本的には 1. と似たアプローチだが、これをコンテナという仮想環境上で行う点が違いとなる。
DockerfileFROM <開発中のコンテナ> # localhost を listen する設定を追加 RUN sed -e '1i<source>' \ -e '1i @type forward' \ -e '1i port 24224' \ -e '1i bind 0.0.0.0' \ -e '1i</source>' \ -i <設定ファイルへのパス>上記をビルドして実行すれば、fluentd 本体の設定ファイルには手を加えることなく、ローカル開発時のみ <source> を追加することができる。これにより fluent-cat で自由にデバッグ入力が可能となる。
また、上記例では forward type を指定したが、sample (dummy) type を指定することで fluent-cat が不要になる。
https://docs.fluentd.org/input/sampleリポジトリにしたのでよければどうぞ。
https://github.com/tsubasaogawa/aws-firelens-fluentd-dev-kitむすび
本手法の欠点として、FROM で fluentd コンテナを指定している都合上、 fluentd コンテナにビルドが生じるたびに本コンテナのビルドも必要になる。頻繁に fluentd コンテナをビルドするような開発スタイルだと、多少の手間がどうしても発生してしまう。
願わくば FireLens 側でエラーの発生を避ける方法があればこんなことをせずに済むのだけど、なにかご存知な方教えてください。
- 投稿日:2020-08-23T14:44:33+09:00
ECRのイメージをプルするCodebuildをTerraformで作る
はじめに
ECRに保存しているイメージをCodebuildで使用したかったので、その設定をTerraformでやってみました。
Terraformを使用したからといって特別なことをやっているわけではありませんが、備忘録として。環境
- Terraform : 0.12.29
- Terraform aws provider : 3.3.0
ECRリポジトリ
以下のようなECRリポジトリを作成します。
このリポジトリにCodebuildで動かすイメージを保存していきます。resource "aws_ecr_repository" "example" { name = "example" image_tag_mutability = "MUTABLE" image_scanning_configuration { scan_on_push = true } }公式のガイドを参考に、CodebuildからイメージをプルできるECRのポリシーを設定します。
[アクション] で、プル専用アクションとして [ecr:GetDownloadUrlForLayer]、[ecr:BatchGetImage]、および [ecr:BatchCheckLayerAvailability] を選択します。
また、今回はCodebuildとECRリポジトリでクロスアカウントを行わないので
プロジェクトで CodeBuild の認証情報を使用して Amazon ECR のイメージをプルする場合は、[サービスプリンシパル] に「codebuild.amazonaws.com」と入力します。
以上を参考にTerraformでポリシーを書くとこうなります。
resource "aws_ecr_repository_policy" "example" { repository = aws_ecr_repository.example.name policy = data.aws_iam_policy_document.example.json } data "aws_iam_policy_document" "example" { statement { actions = [ "ecr:BatchCheckLayerAvailability", "ecr:BatchGetImage", "ecr:GetDownloadUrlForLayer" ] principals { type = "Service" identifiers = ["codebuild.amazonaws.com"] } } }ECRリポジトリの設定は以上です。
Codebuildプロジェクト
今回は、ECRからのプルを検証することが目的なのでシンプルなプロジェクトを作成します。
ECRの方でCodebuildの認証情報を用いてプルするようにしたので
image_pull_credentials_type = "CODEBUILD"を設定する必要があります。
特に指定しない場合、デフォルトでCODEBUILDが設定されるようですがここでは明示的に
設定しています。Terraform codebuild_project image_pull_credentials_type
resource "aws_codebuild_project" "example" { name = "example-project" description = "example-project" service_role = aws_iam_role.this.arn artifacts { type = "NO_ARTIFACTS" } environment { compute_type = "BUILD_GENERAL1_SMALL" image = "{ECRリポジトリー内のイメージURI}" type = "LINUX_CONTAINER" image_pull_credentials_type = "CODEBUILD" } source { type = "GITHUB" location = "{ビルドに使用するGitリポジトリのURL}" git_clone_depth = 1 } }ECR側でプルを許可しているため、Codebuildのにアタッチするポリシーは
ログの作成に関わるものだけでいいみたいです。resource "aws_iam_role_policy" "example" { name = "example" role = aws_iam_role.this.id policy = data.aws_iam_policy_document.example.json } data "aws_iam_policy_document" "example" { statement { actions = [ "logs:CreateLogStream", "logs:PutLogEvents" ] resources = [ "*", ] } }これらの設定でECRのイメージを使用してビルドができます。
Codebuild側にもプルするために権限が必要だと思っていたのですが、
不要だったみたいです。
- 投稿日:2020-08-23T13:23:23+09:00
AWSのDynamoDBのテーブルをCSVファイルでエクスポートするPythonスクリプトを作成しました
目的
AWSのDynamoDBのテーブルをCSVファイルでエクスポートをするPythonスクリプトを作成しました。
※下記の記事を参考にさせていただきました。
DynamoDBのテーブルをscanするPythonコード前提条件
- Python3がインストール済みであること
- AWS CLI バージョン2がインストール済みであること
- aws configure コマンドで認証情報、リージョン、出力形式を設定済みであること
- AWSのDynamoDBにテーブルが存在すること
※今回は、DynamoDBに以下のテーブルが存在している前提です。
※テーブル名:GPSLog(GPSログデータ)
実行
- 出力CSVファイルを指定してください。
- Pythonスクリプトを実行してください。
DynamoDBtoCSV.pyimport os import csv import json import datetime import boto3 from boto3.session import Session # 出力CSVファイル指定 output_csvfile = "出力CSVファイルを指定してください" # 出力CSVファイルの存在チェック(ヘッダー有無の判断) if(os.path.exists(output_csvfile)): header_flg = 0 else: header_flg = 1 # boto3でDynamoDBに接続 dynamodb = boto3.resource('dynamodb') # テーブルをフルスキャン def get_records(table, **kwargs): while True: response = table.scan(**kwargs) for item in response['Items']: yield item if 'LastEvaluatedKey' not in response: break kwargs.update(ExclusiveStartKey=response['LastEvaluatedKey']) records = get_records(dynamodb.Table('GPSLog')) # 出力CSVファイルに書き込む with open(output_csvfile, 'a', encoding='shift_jis') as output_csvfile_fp: fieldnames = ['datetime', 'lat', 'lon', 'status', 'mode', 'speed', 'epx', 'epy'] csvfile_writer = csv.DictWriter(output_csvfile_fp, fieldnames=fieldnames, lineterminator='\n') # 出力CSVファイル新規作成時、ヘッダー出力 if header_flg == 1: csvfile_writer.writeheader() header_flg == 0 for record in records: # print(record) # 出力CSVファイルに書き込む csvfile_writer.writerow({ 'datetime': record['datetime'] + '+09:00', 'lat': record['lat'], 'lon': record['lon'], 'status': record['status'], 'mode': record['mode'], 'speed': record['speed'], 'epx': record['epx'], 'epy': record['epy'] }) print(u'処理終了')

- 投稿日:2020-08-23T13:10:31+09:00
boto3-stubs を使って、boto3 でコード補完を有効にしよう
Python で AWS 系のプログラムを組んでると、必ずといっていいほど、boto3 という AWS SDK のお世話になるはずです。
この boto3、AWS のサービスをすべて叩けるたくさんの機能持ちなのに、型がないためコード補完が聞きません。
boto3.client("s3")などと、サービス名を文字列で受け取るので、型定義としてはBaseClient型になっていて、各サービス用のクライアントの型になってないんですね。普段、補完がガンガン聞く環境で開発しているので、これがなかなかにつらい。なんとかならないものかと思って探してみたところ boto3-stubs というパッケージを見つけました。このなかで、s3 や ec2 などの各サービス用のクライアント・リソースの型が定義されているので、この型をつけてあげると、、、
こんなかんじで補完をしてくれるようになります! これはいい!!
インストール
pip install boto3-stubs[essential]バージョンは boto3 と合わせてつくようになっているので、特定の boto3 を使っている場合も、同じバージョン番号を指定してあげれば、問題なく利用できます。パッケージは自動で更新されていて、boto3 が更新された日に boto3-stubs もリリースされているようです。
上記の
[essential]指定では、 "ec2, s3, rds, lambda, sqs, dynamo, cloudformation" のクラスが入ります。これだけで 7MB ぐらい必要ということで、いきなり全部入るようにはなってないようです。他に必要なのがあれば、[essential,ecs]といった形で適宜、指定してあげれば OK です。使い方
import boto3 from mypy_boto3_s3 import S3Client, S3ServiceResource # from boto3-stubs s3: S3Client = boto3.client("s3") s3_r: S3ServiceResource = boto3.resource("s3")これで、
s3,s3_r変数にコード補完が聞くようになります。型を指定してあげるので、VSCode など型に基づく補完がきくエディタなら、なんでも同じやり方で OK です。余談
- boto3-stubs を mypy で使うと、型指定を手で書かなくても型チェックできる仕組みがあるようです。
- boto3 プロジェクトでも、stub を用意する動きはあるっぽいです。将来的には、このあたりも動きがある、かもしれません。


- 投稿日:2020-08-23T12:54:45+09:00
AWS LambdaにてPython3でS3でファイルが追加されたイベントを取得し、実行する。
概要
調べたので備忘録
手順
Lambda上部のデザイナーから「トリガーを追加」をクリック
S3を選択
- 対象バケットを選択、「全てのオブジェクト作成イベント」を選びます。

※必要あればプレフィックスなどは自由に設定してください。
変更後、「保存」をクリックしてください。
- コードはこんな感じで取得できます。
def lambda_handler(event, context): for record in event['Records']: bucket = record['s3']['bucket']['name'] key = record['s3']['object']['key'] exec(bucket,key)※アクセス権限の設定がない場合は失敗する可能性があります。
参考
サンプル Amazon S3 関数コード
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/with-s3-example-deployment-pkg.html#with-s3-example-deployment-pkg-python


- 投稿日:2020-08-23T12:07:29+09:00
S3をLAN経由で利用する

- 投稿日:2020-08-23T03:46:06+09:00
Hands-on Apache Superset, Amazon S3, and Amazon Athena
What is Apache Superset?
"Apache Superset (incubating) is a modern, enterprise-ready business intelligence web application". (Apache Software Foundation)
Some other equivalents you might've heard of would be Tableau or PowerBI, but they're all business licensed software.
What about Amazon S3 and Athena?
S3 : "Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance. " (Amazon Web Service)
Athena : "Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run." (Amazon Web Service)
What You'll Need Beforehand
- An AWS account (and cash duh).
- AWS credentials set.
- An Ubuntu 18.04+ environment.
- Mapbox account.
pipinstalled.Installation
PyAthena
- Apache Superset needs an API interface to interact with AWS Athena.
pip install "PyAthena>1.2.0"Apache Superset
- Install superset
pip install apache-superset
- Initialize the database
superset db upgrade
- Create an admin user (you will be prompted to set a username, first and last name before setting a password)
export FLASK_APP=supersetsuperset fab create-admin
- Load some data to play with
superset load_examples
- Create default roles and permissions
superset initWorkflow
- To start a development web server on port 8088, use -p to bind to another port
superset run -p 8088 --with-threads --reload --debugger
- Switch to your browser and go to http://127.0.0.1:8088/, you should now see something resembling the following
- Login with the admin account you have just created. You'll see some examples have been loaded if you followed the tutorial. Play with them if you want to, but we'll be using some other data for demonstrative purposes.
- Throw some data into an AWS S3 bucket to process with. This airbnb data from kaggle is what I'll be using.
aws s3 cp ~PATH/TO/AB_NYC_2019.csv s3://YOUR-BUCKET
- Now, come back to your Apache Superset's UI and add the click on
Databases, then the+button on the top right hand corner.
Modify and add the following text to
SQL Alchemy URI.awsathena+rest://{aws_access_key_id}:{aws_secret_access_key}@athena.{region_name}.amazonaws.com/{schema_name}?s3_staging_dir={s3_staging_dir}
- Log into AWS Athena's interface and define the columns you need for your database. I won't be using all the columns for simplicity.(Make sure that the region of your AWS Athena and the S3 bucket you made is the same) If you're familiar enough with AWS Athena, you can execute the exact query on Apache Superset's UI.
- Going back to your Apache Superset UI, you should see the following
- Run a query of your preference and click on
Explore.
- Running a
deck.glvisualization gives us ...
- Oops, seems like we need a map token from MapBox. Register an account and export your token as an environment variable to
MAPBOX_API_KEY. See the official documentationexport MAPBOX_API_KEY=your-token
- Restart your server and you should now see ...
Darker grids are where the average Airbnb price are higher.
Here's a place where some of the more expensive Airbnb's rooms are clustered, and the reasons might be apparent.
Conclusions
There are a lot left to talk about with Apache Superset, AWS S3, and AWS Athena, but the general idea here is to demonstrate a data analysis workflow combining various tools. Indeed, one can achieve this without using any of the above, for instance, with the combination of Tableau and Google Bigquery.
Reference
- Apache Software Foundation, "Apache Superset (incubating)", Apache Software Foundation. https://superset.incubator.apache.org/#apache-superset-incubating. 22 August 2020.
- Amazon Web Service, "Amazon S3", Amazon Web Service. https://aws.amazon.com/s3/. 22 August 2020.
- Amazon Web Service, "Amazon Athena", Amazon Web Service. https://aws.amazon.com/athena/. 22 August 2020.











- 投稿日:2020-08-23T02:00:16+09:00
AWS Transit Gateway経由でオンプレミスとOracle Cloudを接続してみてみた
■ 目的
Transit Gateway(TGW)を使用すれば、複数の VPC および Direct Connect(DX) や VPNを使用してオンプレミスネットワークを相互接続できます。
既存AWSとオンプレミスを専用線やVPNで接続している環境に、TGWから足を一本出して、他Network,他Cloudへ接続できます。ということで、前回AWSとオンプレミスにVPN接続している環境のTGWから専用線でOracle Cloud Infrastructure(OCI)へ接続して、オンプレミスと通信できるようにしてみてみます
この手順では、Network の Route経路は BGPで伝搬しあうので、オンプレミス側のCPEには手を加える必要はありません。
ちょこっと従量課金で数時間、追加接続してみてみます。■ 構成
AWSとオンプレミスの構成は前回の手順で構成しておきます。
・参考:YAMAHA NVR700W から AWS Transit Gateway経由で IPSec VPN接続してみてみた今回は、既存TGW と Megaport Cloud Router(MCR)を使用して、AWS Direct Connect と OCI FastConnectをマルチ・クラウド接続してみてみます。
■ OCI:FastConnect作成
(1) OCI Webコンソール
上部にある Regionを、'Japan Central(Osaka)'へ設定し、
左ペインにある [ネットワーキング] > [FastConnect]をクリック
(2) FastConnt接続画面
[FastConnectの作成]をクリック
(3) 接続の作成:接続タイプ画面
以下のように設定し、[次]をクリック- 接続タイプ: FastConnectパートナー - パートナー: Megaport: Service
(4) 接続の作成:構成画面
以下のように設定し、[作成]をクリック- 名前: 任意の名前を設定 - コンパートメント: 作成する コンパートメントを設定 - 仮想回線タイプ:[プライベート仮想回線]を選択 - 動的ルーティング・ゲートウェイ:接続するDRGを選択 - プロビジョニングされた帯域幅:設定したい帯域を選択 - 顧客BGP IPアドレス: /30 または/31の MCR側BGP用ピアIPアドレスを設定 - Oracle BGP IPアドレス:'顧客BGP IPアドレス'と対になるOCI側のIPアドレスを設定 - 顧客BGP ASN:Megaport MCRのASN'133937'を設定
(5) 接続が作成されました画面
「OCID」をコピーします。
この「OCID」を使用してMCRと接続します
VCのアイコンは、プロバイダ保留中のためオレンジ色になります
MCR側で設定し開通するとグリーン色になります■ Megaport: MCR作成
以下URLで事前に作成したユーザーアカウントでログインしMCRを作成していきます
(1) Megaport Webコンソール
Megaport:https://www.megaport.com/ へLogin
(2) Megaport Service 画面
[Service]タブ > 右上にある[Create MCR]をクリック
(3) New MCR:Select Location画面
Select MCR LocationからMCRを配置するRegionとData Centerを選択し、[Next]をクリック- Region: AWSとOCI近郊のRegionを選択 - Location: AWSとOCI近郊のLocationを選択
(4) New MCR:Configure画面
以下のように設定し、[Next]をクリック- Rate Limit: MCRの帯域を選択(この帯域範囲内から、各Cloud接続へ帯域を割り当てていきます) - MCR Name: MCRの名前を設定 - MCR ASN: MCRのデフォルトASN 133937を設定※ 今回Rate Limitは、AWSとOCIそれぞれ1GBづつ帯域設定するので、2GB以上のRate Limitを設定しておきます
(5) Summary画面
設定内容を確認し、問題なければ[Add MCR]をクリック
■ Megaport: VXC作成
OCI,AWSをMCRに接続するためのVirtual Cross Connect(VXC)を作成します。
● MCRとOCI接続VXC作成
Megaport Webコンソールから MCRとOCIで作成したFastCOnnectを接続するVXCを作成します
(1) Service画面
Add Connection欄にある[Oracle Cloud]をクリック
(2) New Connection:Select Port画面
以下のように設定し、[Next]をクリック- Select Provider: [Oracle Cloud]を選択 - Oracle Virtual Circuit ID: OCIの「FastConnect」作成で発行された[OCID]を記入 - Choose from available Oracle Ports: 1本目は[Primary]を選択、冗長用途の2本目は[Secondary]を選択
(3) New Connection:Connection Details画面
以下項目を設定し、[Next]をクリック・Name your Connection: 接続名を設定 ・Rate Limit: 作成したRate Limitの帯域を設定 ※ここでの帯域は、Azureと揃えるため50Mbpsを設定
(5) New Connection:MCR A End画面
以下を設定し、その横にある[Add]をクリック- IP address including subnet mask: OCI FastConnectで設定した'顧客BGP IPアドレス'を設定
(6) New Connection:MCR A End +Add画面
BGP Connections項にある[+Add GBP Connection]をクリック
(7) BGP Connection画面
以下項目を設定し、[Add]をクリック- Local IP: 前画面で設定したIPを選択 - Peer IP: OCI FastConnectで設定した 'OCI側のBGPピアIPアドレス'を設定 - Peer ASN: OCIのASN '31898'を設定
(8) New Connection:BGP Connections画面
設定したBGP設定内容を確認し、問題なければ、[Next]をクリック
(9) New Connection:Summary画面
設定項目を確認し、問題なければ、[Add VXC]をクリック
● MCRとAWS接続VXC作成
(1) Services画面
作成したMCRの欄にある[+Connection]をクリック
(2) New Connection:Select Port画面
Select Providerから、[Amazon Web Sercvises]を選択
AWS Connection Type項目は以下のように設定し、[Next]をクリック- AWS Connection Type: [Hosted Connection]を選択 - Select Destination Port: AWSとOCIに近い場所を選択、ここでは[Equinix DA1]を選択
(3) Conection Details画面
以下内容を設定し、[Next]をクリック- Name your connection: 任意の名前を設定 - Rate Limit : DirectConnectの帯域を設定
(4) MCR A End
[Next]をクリック
(5) Cloud Derails画面
- AWS Connection Name: 任意の名前を設定 - AWS Account ID: AWSの契約しているAccountIDを設定
(6) Summary画面
内容を確認し、[Add VXC]をクリック
● Megaport Order
(1) Sercvice画面
左ペインにある [Order]をクリック
(2) Order Service画面
内容を確認し、[Order Now]をクリック
(3) Order完了
Orderが完了し、アイコンが緑色になればActivate完了
■ OCI FastConnect Status確認
FastConnect画面へ遷移し、以下状態が緑色であることを確認
- ライフサイクル状態: プロビジョニング済 - BGP状態: 稼働中
■ AWS Direct Connect設定
● Direct Connect Gateway作成
(1) Direct Connectゲートウェイ画面
[Direct Connect] > [Direct Connectゲートウェイ]をクリックし、[Direct Connectゲートウェイを作成する]をクリック
(2) Direct Connectゲートウェイを作成する画面
以下内容を設定し、[Direct Connectゲートウェイを作成する]をクリック- 名前: 任意の名前を設定 - Amazon側のASN: 他と重複しないPrivate ASNを設定
(3) Direct Connectゲートウェイを作成完了
● Transit GatewayとDirect Connect Gatewayの関連付け
(1) トランジットゲートウェイの関連付け
[Direct Connect] > [トランジットゲートウェイ]をクリックし、[Direct Connectゲートウェイを関連付ける]をクリック
(2) Direct Connectゲーウェイの関連付ける画面
以下内容を設定し、[Direct Connectゲートウェイを関連付ける]をクリック- アカウント所有者: ここでは[マイアカウント]を選択 - Direct Connectゲートウェイ: 作成したDirect Connectゲートウェイを選択 - 許可されたプレフィックス: Direct Connect通して対抗へBGP伝搬する静的プレフィックスを設定※ ここでのBGP伝搬するプレフィックスは、以下を設定して、AWS VPCとオンプレミスのNetworkをOCIと通信できるように設定
(3) Direct Connectゲーウェイの関連付け完了
● 接続設定
[Direct Connect] > [接続]をクリックし、接続画面を表示
(1) Direct Connect 接続画面
MegaportでAWSのVXCを作成すると、AWS側に接続が作成されます
作成された接続のIDをクリック
(2) 接続 承認
承認して Direct ConnectをActivateします
[承認する]をクリック
(8) ホスト接続を承認する
承認する場合、[承認する]をクリック
(9)
状態が"available"になればActivate完了
● 仮想インターフェース Transit VIF作成
承認してActicateされた接続に仮想インターフェースを作成します
ここでは、Transit Gatewayへ接続するTransit VIFとして作成します(1) 接続画面
[仮想インターフェースを作成する]をクリック
(2) 仮想インターフェースを作成する画面
以下内容を設定し、[仮想インターフェースを作成する]をクリック- タイプ: トランジット - 仮想インターフェース名: 任意の名前を設定 - 接続: 前項で承認した接続を選択 - VLAN: 自動で採番された番号をそのまま使用 - BGP ASN: MegaportのBGP ASN "133937"を設定
(3) ピアリング確認
仮想インターフェースを作成すると、以下画面のようにピアリング項目に仮想インターフェースが作成されます
次に、MegaportとBGP接続する設定をするために、以下ピアリング情報をメモして、MegaportのVXCへ設定しBGP疎通できるようにします・メモ情報 - BGP認証キー: Megaport VXCへ設定する認証するキー - ルーターのピアIP: Megaport側に設定するBGP Peer IP - AmazonルーターのピアIP: AWS側のBGP Peer IP
■ Megaport VXCへ AWS BGP設定
(1) Megaport画面
Megaport画面へ遷移し、作成したAWS 接続(VXC)の [歯車アイコン]をクリック
(2) Config A End画面
Config A End画面まで[次へ]をクリックし、以下内容を設定し、右横の[+Add]をクリック- IP address including subnet mask: メモした「AWS側のBGP Peer IP」を設定
(3) Config A End: MCR Connection Detail画面
[+ Add BGP Connections]をクリック
(4) BGP Connection画面
メモしておいたAWS側のピアリング情報を使用して以下内容を設定し、[Add]をクリック- Local IP: AWS側のBGP Peer IPを設定 - Peer IP: Megaport側に設定するBGP Peer IP - Peer ASN: AWS側 Direct ConnectのASNを設定 - BGP Auth: BGP認証キーを設定
(5) Config A End画面
設定した内容を確認し、[Save]をクリックして保存
[Save]をクリックすると数分で内容が反映されます。
[Save]をクリックして保存したら、[Next]をクリック
(6) Connection Detail画面
以下ステータス項目を確認し、グリーン色になっていることを確認し。[Close]をクリック・確認ステータス - Provisionig Status - Service Status - BGP IP Address
■ 仮想インターフェース Transit VIFステータス確認
(1) ピアリング画面
以下ステータス項目を確認し、グリーン色になっていることを確認・確認ステータス - 状態 - BGPステータス
■ オンプレミスBGP ルーター確認
Transit VIFが作成されステータスがUPしたので、AWS VPCとOCIのNertworkがBGPにより、Transit Gatewayからオンプレミスへ伝搬されます。
ということで、オンプレミスBGP ルーターで ruteを確認Route確認
以下Routemが追加されていることを確認
・AWS側 172.31.0.0/16 172.32.0.0/16 ・OCI側 10.10.0.0/24# show ip route Destination Gateway Interface Kind Additional Info. default 100.100.100.100 WAN1(PDP) static 10.10.0.0/24 169.254.141.153 TUNNEL[2] BGP path=64512 65534 23456 31898 169.254.141.152/30 - TUNNEL[2] implicit 169.254.154.136/30 - TUNNEL[1] implicit 172.31.0.0/16 169.254.141.153 TUNNEL[2] BGP path=64512 172.32.0.0/16 169.254.141.153 TUNNEL[2] BGP path=64512 192.168.0.0/24 192.168.0.1 LAN1 implicit 100.0.0.0/8 100.100.100.101 WAN1 implicit● OCI Service GatewayでのOSN Route追加
OCIのTransit Routingの機能により、Oracle Services Network内にあるObject Storge,Autonomous DatabaseなどのPublic ServiceのアドレスをOn-Premises NetworkへBGPで伝搬できます。
ということで、この設定をした時の show ip routeものせておきます・参考: Transit Routing + IPSec VPN / FastConnectで Object Storage, Autonomous Databaseへ接続してみてみた
# show ip route Destination Gateway Interface Kind Additional Info. default 100.100.100.100 WAN1(PDP) static 10.10.0.0/24 169.254.141.153 TUNNEL[2] BGP path=64512 65534 23456 31898 118.238.201.33/32 100.100.100.100 WAN1 temporary 129.213.0.128/25 169.254.141.153 TUNNEL[2] BGP path=64512 65534 23456 31898 129.213.2.128/25 169.254.141.153 TUNNEL[2] BGP path=64512 65534 23456 31898 129.213.4.128/25 169.254.141.153 TUNNEL[2] BGP path=64512 65534 23456 31898 130.35.16.0/22 169.254.141.153 TUNNEL[2] BGP path=64512 65534 23456 31898 130.35.96.0/21 169.254.141.153 TUNNEL[2] BGP path=64512 65534 23456 31898 130.35.144.0/22 169.254.141.153 TUNNEL[2] BGP path=64512 65534 23456 31898 130.35.200.0/22 169.254.141.153 TUNNEL[2] BGP path=64512 65534 23456 31898 134.70.24.0/21 169.254.141.153 TUNNEL[2] BGP path=64512 65534 23456 31898 134.70.32.0/22 169.254.141.153 TUNNEL[2] BGP path=64512 65534 23456 31898 138.1.48.0/21 169.254.141.153 TUNNEL[2] BGP path=64512 65534 23456 31898 140.91.10.0/23 169.254.141.153 TUNNEL[2] BGP path=64512 65534 23456 31898 140.91.12.0/22 169.254.141.153 TUNNEL[2] BGP path=64512 65534 23456 31898 147.154.0.0/19 169.254.141.153 TUNNEL[2] BGP path=64512 65534 23456 31898 147.154.32.0/25 169.254.141.153 TUNNEL[2] BGP path=64512 65534 23456 31898 169.254.141.152/30 - TUNNEL[2] implicit 169.254.154.136/30 - TUNNEL[1] implicit 172.31.0.0/16 169.254.141.153 TUNNEL[2] BGP path=64512 172.32.0.0/16 169.254.141.153 TUNNEL[2] BGP path=64512 192.168.0.0/24 192.168.0.1 LAN1 implicit 192.168.254.8/30 169.254.141.153 TUNNEL[2] BGP path=64512 65534 23456 192.168.255.4/30 169.254.141.153 TUNNEL[2] BGP path=64512 65534 23456 100.0.0.0/8 100.100.100.101 WAN1 implicit■ 接続確認
● OCI --> AWS TransitGW --> On-Premises 接続確認
(1) ssh接続確認
[opc@ashburn-inst01 ~]$ ssh -i id_rsa onp@192.168.100.250 hostname MacBook(2) traceroute経路確認
[opc@ashburn-inst01 ~]$ sudo traceroute -I 192.168.100.250 traceroute to 192.168.100.250 (192.168.100.250), 30 hops max, 60 byte packets 1 140.91.196.117 (140.91.196.117) 0.163 ms 0.145 ms 0.143 ms 2 192.168.254.9 (192.168.254.9) 0.423 ms 0.431 ms 0.429 ms 3 169.254.255.21 (169.254.255.21) 30.951 ms 30.968 ms 31.000 ms 4 * * * 5 169.254.3.2 (169.254.3.2) 1269.335 ms 1275.945 ms 1282.945 ms 6 169.254.141.154 (169.254.141.154) 1288.168 ms * * 7 * 192.168.100.250 (192.168.100.250) 1277.702 ms 1304.450 ms● OCI --> AWS VPC-172.31.0.0/16 接続確認
(1) ssh接続確認
[opc@ashburn-inst01 ~]$ ssh -i AWS_EC2.pem ec2-user@172.31.0.11 hostname ip-172-31-0-11.ec2.internal(2) traceroute経路確認
[opc@ashburn-inst01 ~]$ sudo traceroute -I 172.31.0.11 traceroute to 172.31.0.11 (172.31.0.11), 30 hops max, 60 byte packets 1 140.91.196.83 (140.91.196.83) 0.164 ms 2.992 ms 3.011 ms 2 192.168.254.9 (192.168.254.9) 0.457 ms 0.469 ms 0.471 ms 3 169.254.255.21 (169.254.255.21) 31.842 ms 31.918 ms 31.922 ms 4 * * * 5 172.31.0.11 (172.31.0.11) 64.219 ms 64.240 ms 64.283 ms● OCI --> AWS VPC-172.32.0.0/16 接続確認
(1) ssh接続確認
[opc@ashburn-inst01 ~]$ ssh -i AWS_EC2.pem ec2-user@172.32.0.22 hostname ip-172-32-0-22.ec2.internal(2) traceroute経路確認
[opc@ashburn-inst01 ~]$ sudo traceroute -I 172.32.0.22 traceroute to 172.32.0.22 (172.32.0.22), 30 hops max, 60 byte packets 1 140.91.196.154 (140.91.196.154) 0.177 ms 0.151 ms 0.139 ms 2 192.168.254.9 (192.168.254.9) 0.491 ms 0.498 ms 0.497 ms 3 169.254.255.21 (169.254.255.21) 30.977 ms 30.988 ms 31.020 ms 4 * * * 5 172.32.0.22 (172.32.0.22) 63.744 ms 63.757 ms 63.754 ms● On-Premises --> AWS TrangitGW --> OCI 接続確認
(1) ssh接続確認
[onp@MacBook:~]$ ssh -i id_rsa opc@10.10.0.2 hostname ashburn-inst01(2) traceroute経路確認
[onp@MacBook:~]$ sudo traceroute -I 10.10.0.2 traceroute to 10.10.0.2 (10.10.0.2), 30 hops max, 60 byte packets 1 setup.netvolante.jp (192.168.100.1) 0.291 ms 0.236 ms 0.247 ms 2 * * * 3 169.254.255.1 (169.254.255.1) 272.054 ms 276.146 ms 276.092 ms 4 169.254.255.21 (169.254.255.21) 316.146 ms 319.963 ms 327.776 ms 5 169.254.255.22 (169.254.255.22) 361.839 ms 373.655 ms 377.585 ms 6 140.91.196.51 (140.91.196.51) 377.529 ms 409.678 ms 413.609 ms 7 10.10.0.2 (10.10.0.2) 427.790 ms 292.284 ms 288.214 ms■ 参考
● Megaport
・ Megaport
・ Megaport Enabled Locations
・ Simple, Scalable Pricing
・ Network Latency: Data for Megaport’s Network Latency Times
・ Connecting to AWS Direct Connect
・ Connecting to Oracle Cloud Infrastructure FastConnect● OCI
・ FastConnectの接続モデル
・ FastConnect - Oracle Cloud Portal● AWS
・ “共有型”AWS DirectConnectでも使えるAWS Transit Gateway
・ AWS Transit Gateway - Awsstatic


















































- 投稿日:2020-08-23T01:15:52+09:00
AWS CloudFormationではじめるIaC入門
この記事について
Infrastructure as Code(IaC)は、アプリのインフラ部分をコード化・ファイル化して管理する手法のことで、現代のイケてる開発では積極的に導入されています。
この記事では、IaCを導入することでどのようなメリットが得られるのか、またAWS CloudFormationを使って実際にIaCをするにはどうしたらいいのか、ということについて説明します。前提条件
適切なIAMユーザーと紐付いたAWS CLIが既に用意・設定されているものとします。
なぜIaCをやるのか
IaCを導入することによって得られるメリットは主に以下の通りです。
再現性の担保・複製を簡単にする
「本番環境と同じ構成の検証用・開発用環境を用意したい」という状況はよくあることと思います。
そのときに、「1年前に作ったこの環境を複製したいけど、Webコンソールでどうやって設定したんだっけ???」となってしまったら、目的を達成することは(当時の記憶・ドキュメントが残っていない場合)ほぼ不可能でしょう。このときに、「このコードからインフラ構築をしました」という設定ファイルが残っていれば、もう一度そのファイルからインフラ生成をすれば簡単に同じ環境を構築することができるのです。
品質の担保
IaCを導入することのメリットとしてもう一つ、「失敗したらそれを一旦全部捨てて最初からやり直せる」ということが挙げられます。
インフラでよくありがちなのが、「一旦作って、後に不具合が出たから少しだけ直して……の繰り返しのうちに、何がどうなっているのか誰もわからなくなっている」というパターンです。
その場しのぎの修正を繰り返した結果、システム構成が非効率的なものになってしまうということも考えられます。そうなったときに、今動いているシステムに影響が出ないようにインフラ構成を再構築するというのは、もはや新規開発とコスト・労力は変わりません。
また、修正を繰り返した結果生まれた"うなぎのタレ"のようなインフラ構成は、もはや誰も同じものを作れないような代物になっていることでしょう。「失敗したらもう元には戻せない」以上、その場しのぎの修正をするのも大変にストレスの大きい作業です。「失敗したらもう一度やり直せる」というのは、それはつまり「インフラ上に乗っているアプリケーションコードと同様のCI/CDパイプラインを組める」ということです。したがって、アプリと同じだけの品質をインフラでも簡単に保つことができるのです。
CloudFormationでのIaC実践
ここからは、IaCを行うための実際の手順を紹介します。
IaCのためのツールはTerraformやOpsWorksなど様々なものが存在しますが、ここではAWSのCloudFormationを利用します。0. CloudFormationの用語
CloudFormationで登場する概念・用語についてまず説明します。
- テンプレート: CloudFormationで使う、インフラをコードで表現した設定ファイルのこと。
- スタック: 1つのテンプレートから生成される複数のリソースのことをまとめてこう呼ぶ。インフラリソースの生成・更新・削除は基本的にスタック単位で行うことになる。
1. テンプレートファイルの作成
IaCというからには、インフラ構成をコード、つまりファイルの形で書く必要があります。
CloudFormationでは、jsonかyaml形式の2種類のフォーマットに対応しています。ここではyaml形式のものを紹介します。config.ymlAWSTemplateFormatVersion: 2010-09-09 Description: Main template for VPC Resources: CFnVPC: Type: AWS::EC2::VPC Properties: CidrBlock: 10.0.0.0/16 Tags: - Key: Name Value: CFnVPC Outputs: VPCID: Description: VPC ID Value: !Ref CFnVPC Export: Name: !Sub ${AWS::StackName}-VPCID各項目の意味は以下の通りです。
- AWSTemplateFormatVersion: テンプレート記法のバージョン。現状利用できるのは"2010-09-09"のみ。
- Description: 何のテンプレートなのかの説明を書く
- Resources: EC2やVPCなど、AWSのどんなリソース(Type)をどんな設定(Properties)で作るかをここに列挙する
- Outputs: CloudFormationで作られたリソースの情報のうち、どれを出力するかを設定
Resources, Outputsの詳細については次の章で後述します。
2. テンプレートファイルのバリデーション
正しいフォーマットでテンプレートを書けているのかコマンドで確認してみましょう。
config.ymlというテンプレートファイルをチェックするには、ファイルがあるディレクトリに移動して以下のコマンドを打ちます。$ aws cloudformation validate-template --template-body file://config.yml3. テンプレートからAWSリソースの作成
1つのテンプレートファイルに記載された内容は、1つのスタックとしてまとめられます。
テンプレートファイルから「stack-example」という名前をつけたスタックを作成するには、以下のコマンドを実行します。$ aws cloudformation create-stack --stack-name stack-example --template-body file://config.yml4. AWSリソースの変更・更新
config.ymlの内容を修正して、その変更をAWSに反映したいという場合は、以下のようにスタック名とテンプレートファイルを指定してupdate-stackコマンドを実行します。$ aws cloudformation update-stack --stack-name stack-example --template-body file://config.yml5. CloudFormationスタックの削除
CloudFormationのスタックで作成したAWSリソースを丸ごと削除したい場合は、スタック名を指定した
delete-stackコマンドで可能です。$ aws cloudformation delete-stack --stack-name stack-exampleテンプレートファイルの書き方
Resourcesの部分
テンプレートファイルには、「このスタックでどのようなインフラリソースを生成するのか」というのを指定するResourcesという項目があります。
config.ymlResources: CFnVPC: Type: AWS::EC2::VPC Properties: CidrBlock: 10.0.0.0/16 Tags: - Key: Name Value: CFnVPC上記の例の場合、VPCに、「CFnVPC」という変数名・論理名をつけたという状態です。
これがVPCであることは「Type」という項目に、VPCに行う設定は「Properties」という項目に記されています。
Type、Propertiesにどんな項目があるのかは、必要に応じて以下の公式ドキュメントを参照すれば良いでしょう。
参考:AWS公式ドキュメント AWS リソースおよびプロパティタイプのリファレンスOutputsの部分
Outputsは、1つのスタックから生成されたリソースのIDやDBエンドポイントなどの情報を出力するための仕組みです。
例えば、上記の例ではOutputs項目は以下のようになっていました。config.ymlOutputs: VPCID: Description: VPC ID Value: !Ref CFnVPC Export: Name: !Sub ${AWS::StackName}-VPCIDここでは、「ResourcesでCFnVPCという変数名をつけたVPCのID」を、「(スタック名)-VPCID」という名前で出力する、という意味です。
このテンプレートからスタックを生成した結果、CloudFormationのwebコンソールからは、このようにOutputsで指定した通りのリソース情報を確認することができます。
IaCをやるときの心構え
ここまでの紹介でCloudFormationを導入する準備は整っていますが、CloudFormationでIaCをやるときには、「Webコンソールで決してインフラを触らないという鉄の意志」が必要です。
これは、自動で用意したインフラをCloudFormationの管轄範囲外でいじるとうまくいかなくなる、というのもそうですが、上で紹介した「再現性・品質の担保」といったIaCのメリットが享受できなくなってしまうからです。IaCのメリットは、インフラをコードで全て完結させるからこそ生まれるものであって、手動での構築を少しでも含む中途半端なIaCはむしろやらない方がマシともいえるでしょう。
それでも「やる」と決めた方は、ぜひCloudFormationで始めてみませんか?
参考文献

- 投稿日:2020-08-23T00:02:31+09:00
SSHクライアントは必要か?
はじめに
AWSの学習をしていて、際疑問に思ったことを書きます。
SSHでの接続
サーバーにインストールしたソフトウェアの操作には、SSHという仕組みを使ってリモート接続し、操作するのが通例だそうです。
参考書では、サーバー側でSSHを使用するためのプログラムであるデーモン※を動かし、クライアント側には、操作するためのソフトウェアをインストールする必要がある(PuttyやTera Termなど)と述べていましたが、
実際のところAWSを利用してアプリのデプロイ作業をしていて、ソフトウェアをインストールした覚えがありません。そこでSSHクライアントについて調べてみたら、結論としてMacもWindowsもそれぞれソフトウェアをインストールする必要性は必須ではないことがわかりました。
その理由については以下の通りです。
●Macの場合
Mac OSでは初期状態としてターミナルがインストールされていて、ターミナルからSSHコマンドの利用ができるので、ソフトウェアを入れる必要がありません。●Windowsの場合
Windows10 バージョン1803からは、SSHクライアントが組み込まれているので、特にシステム上で設定をする必要もなくSSHコマンドが使えるようになっています。
[Windowsの設定]-[アプリ]-[オプション機能]で入ると、OpenSSH クライアントがインストールされていることが確認できます。現時点では、ここまでの理解ですが、ソフトウェアを入れることでプラスとなる点が何かしらあるはずなので、追々調べてみようと思います。
※デーモンとは
「デーモン(Daemon)」は、設定しておくと、アプリケーションを起動するときに、バックグラウンドでアプリケーションサーバを常時起動させておくことができます。
例として、railsでの開発環境でrails s -b 0.0.0.0で起動する場合、Ctrl+Cなどを行わないとターミナル上で別の作業ができません。
そのため、アプリケーション起動のコマンドが入力されたときに、アプリケーションサーバ(pumaなど)がデーモンとしてバックグラウンドで常時起動するように設定します。