- 投稿日:2020-03-05T23:48:44+09:00
バリデーションについてのメモランダム
モデルのバリデーションについてあまりに忘れるので、最低限覚えておきたいことをまとめる。
この記事では、hold-out法やクロスバリデーションなど主なバリデーション手法と、時系列データの扱いにも少し触れる。
参考文献: Kaggle本1. 準備
1-1. 環境
記事中のコードは、Windows-10, Python 3.7.3で動作を確認した。
import platform print(platform.platform()) print(platform.python_version())1-2. データセット
回帰、二値分類用データセットを、sklearn.datasetsから読み込む。
from sklearn import datasets import numpy as np import pandas as pd # 回帰用データセット boston = datasets.load_boston() boston_X = pd.DataFrame(boston.data, columns=boston.feature_names) boston_y = pd.Series(boston.target) # 二値分類用データセット cancer = datasets.load_breast_cancer() cancer_X = pd.DataFrame(cancer.data, columns=cancer.feature_names) cancer_y = pd.Series(cancer.target)2. hold-out法
最も単純で分かりやすい方法である。一部をバリデーション用にとっておいて、残りでモデルを学習する。
よく「7 : 3に分けましょう」などと聞くけれど、考えてみればそんなのデータ量に依存するので決まった比率はない。
バリデーションデータは学習に使えないので、データ量が少ない場合は後述のクロスバリデーション等を検討すべきだし、逆に膨大ならhold-out法で対処すべきだろう。
基本的にはシャッフルしてデータを分割する。ただし、時系列データのときはシャッフルしない。過去の情報から未来を予測しようとしているのに、シャッフルしてしまうとその未来の情報を学習してしまう(リークする)リスクがあるからだ。一度それでエラい目に遭った。
以下は、データを3 : 1に分け、決定係数で評価するコードである。ちなみに、決定係数などの評価指標については以前こちらにまとめた。from sklearn.linear_model import LinearRegression from sklearn.metrics import r2_score from sklearn.model_selection import train_test_split tr_x, va_x, tr_y, va_y = train_test_split(boston_X, boston_y, test_size=0.25, random_state=2020, shuffle=True) slr = LinearRegression() slr.fit(tr_x, tr_y) va_pred = slr.predict(va_x) score = r2_score(va_y, va_pred) print(score)0.732147337324218
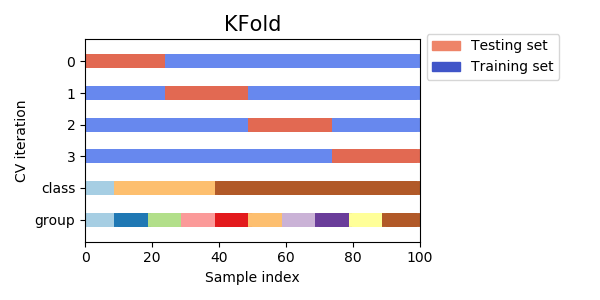
3. クロスバリデーション
先程のhold-out法を複数回繰り返す方法。イメージはロケットえんぴつ。あるブロックでモデルを評価したら、次はそのブロックを学習データに足し込み別のブロックで評価して……をブロックの数だけ繰り返す。
hold-out法ではバリデーションデータを学習に使えないので、データ量が少ない場合はクロスバリデーションを選ぶことが多い。
ブロックの数 = fold数は、増やすほど学習データが増える半面、計算時間も増す。これもデータ量次第だが、4, 5ぐらいが一般的だろう。
モデルの精度(汎化性能)を評価する際は、各foldのスコア平均を見るか、全foldの予測値であらためてスコアを計算すればいい。
以下がクロスバリデーションのコード。hold-out法ほどシンプルじゃないのでいっつも忘れる。from sklearn.metrics import mean_absolute_error from sklearn.model_selection import KFold i = 0 scores = [] kf = KFold(n_splits=4, shuffle=True, random_state=2020) for tr_idx, va_idx in kf.split(boston_X): i += 1 tr_x, va_x = boston_X.iloc[tr_idx], boston_X.iloc[va_idx] tr_y, va_y = boston_y.iloc[tr_idx], boston_y.iloc[va_idx] slr = LinearRegression() slr.fit(tr_x, tr_y) va_pred = slr.predict(va_x) score = mean_absolute_error(va_y, va_pred) print('fold{}: {:.2f}'.format(i, score)) scores.append(score) print(np.mean(scores))fold1: 3.34
fold2: 3.39
fold3: 3.89
fold4: 3.02
3.4098095699116184これでバリデーションは完了だが、fold数だけモデルができてしまった。どうにか一つにまとめる必要がある。
- 各foldのモデルの平均をとる。
- あらためてデータ全体でモデルを学習する。
どちらでも構わないだろうが、実務なら後者で作ったモデルを保存・運用すればいいのではないだろうか。
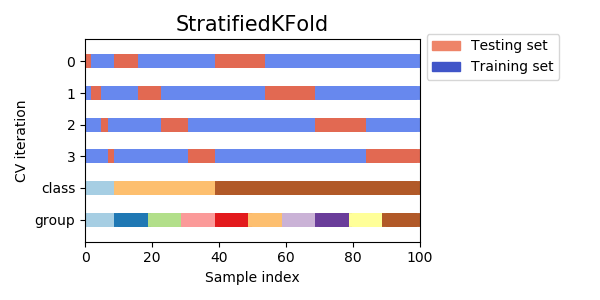
4. stratified k-fold
こちらは分類タスクの際に用いる方法。
例えば、陰性か陽性かに分類するタスクで、陽性が極端に少ないような場合、ランダムにデータ分割したらバリデーションデータに1件も陽性がない、なんてことが起こるかもしれない。
そこで、foldごとに含まれるクラスの割合が等しくなるよう層化抽出 (stratified sampling) したいというモチベーションが生まれる。
逆に、割合が均衡ならあまり気にすることはない。
from sklearn.linear_model import LogisticRegression from sklearn.metrics import log_loss from sklearn.model_selection import StratifiedKFold # hold-out法でも可能 # tr_x, va_x, tr_y, va_y = train_test_split(cancer_X, cancer_y, test_size=0.25, random_state=2020, shuffle=True, stratify=cancer_y) i = 0 scores = [] kf = StratifiedKFold(n_splits=4, shuffle=True, random_state=2020) for tr_idx, va_idx in kf.split(cancer_X, cancer_y): i += 1 tr_x, va_x = cancer_X.iloc[tr_idx], cancer_X.iloc[va_idx] tr_y, va_y = cancer_y.iloc[tr_idx], cancer_y.iloc[va_idx] lr = LogisticRegression(solver='liblinear') lr.fit(tr_x, tr_y) va_pred = lr.predict_proba(va_x)[:, 1] score = log_loss(va_y, va_pred) print('fold{}: {:.2f}'.format(i, score)) scores.append(score) print(np.mean(scores))fold1: 0.11
fold2: 0.17
fold3: 0.09
fold4: 0.07
0.110300743720015445. その他のバリデーション
その他、使ったことないけどこんなのあるんだ、ということで手法だけメモしておく。
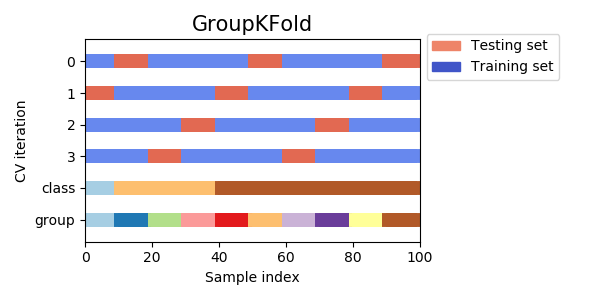
5-1. group k-fold
グループを表す変数でデータを分割する手法。例えば、顧客単位の購買履歴を学習し、新規顧客をスコアリングするといったタスクの場合、学習データとバリデーションデータに同一顧客が混在してほしくない。答えが一部学習データに混ざってしまう (リーク) と考えられるからである。
そこで、顧客IDを使ってデータを分割したい、といったときにgroup k-foldを行う。
GroupKFoldというクラスが使える。ただしシャッフルと乱数シードの機能がない。
5-2. leave-one-out (LOO)
これも使ったことがない。極端にデータが少なく、N数を目一杯増やしたい → レコード数だけfold数を増やしてしまえ、という過激な手法らしい。
KFoldでn_splitsにレコード数を指定すればいいだけだが、LeaveOneOutという専用のクラスもある。6. 時系列データのバリデーション
ここまで扱ってきた手法を、そのまま時系列データに用いてはならない、ということがこの記事で最も重要なことかもしれない。
古い / 新しいということはそれだけで情報なので、学習や評価の際も必ず時系列は意識しなければならない。6-1. データセット
sklearn.datasetsにはちょうどいい時系列データがないので、ここではSIGNATEの【練習問題】お弁当の需要予測データを使う。
※規約的に使っていいか分からなかったので問い合わせたところ「非営利目的の場合に限り分析結果やソースコードの公開は可能」との回答を頂いた。優しい。
チュートリアルに沿って以下加工を行う。
- 傾向が異なる古い (5月以前の) データは除外
- 特徴量として、日数、お楽しみメニューフラグ、カレーフラグを作成
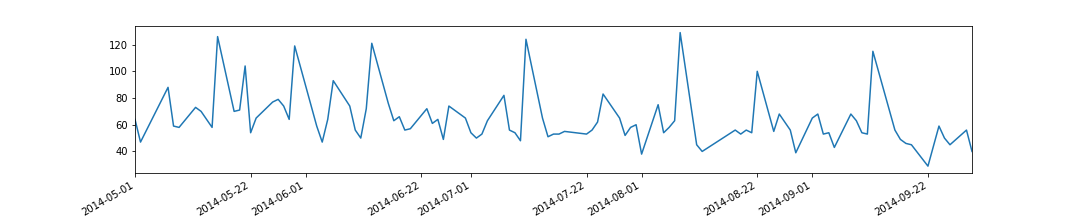
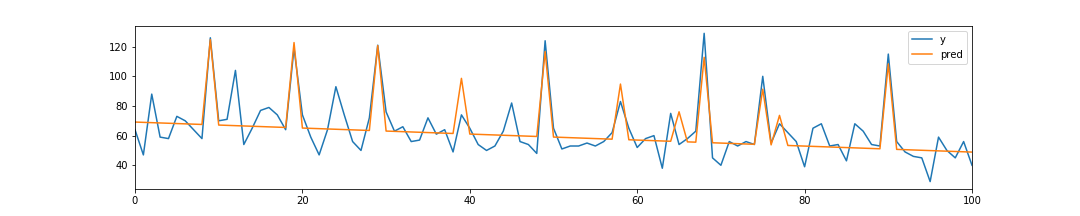
import matplotlib.pyplot as plt %matplotlib inline # データ読み込み train = pd.read_csv('./train.csv') # 傾向が異なる古いデータを除外 train.index = pd.to_datetime(train['datetime']) train = train['2014-05-01':].copy() # プロット train['y'].plot(figsize=(15, 3)) plt.show() # 特徴量作成 train = train.reset_index(drop=True) train['days'] = train.index train['fun'] = train['remarks'].apply(lambda x: 1 if x == 'お楽しみメニュー' else 0) train['curry'] = train['name'].apply(lambda x: 1 if x.find('カレー') >= 0 else 0) train_X = train[['days', 'fun', 'curry']].copy() train_y = train['y'].copy()
基本的には右肩下がりの販売数 (日数と負の相関) だが、人気メニュー (お楽しみメニュー、カレー) 時にスパイクしている。
単純な線形回帰でどこまで予測できるだろうか。from sklearn.metrics import mean_squared_error slr = LinearRegression() slr.fit(train_X, train_y) train['pred'] = slr.predict(train_X) rmse = np.sqrt(mean_squared_error(train['y'], train['pred'])) print(rmse) train.plot(y=['y', 'pred'], figsize=(15, 3)) plt.show()10.548692191381326
だいぶ外れているが、大まかな傾向は掴めている。
残差と他の特徴量との関係を見たい気持ちをぐっとこらえ、バリデーションの話題に戻る。6-2. 時系列データのクロスバリデーション
最もシンプルなのは、シャッフルしないhold-out法だろう。train_test_split関数の引数shuffleにFalseを指定すればいい。古いデータで学習し、新しいデータで評価することで、時系列データでも問題なくバリデーションすることができる。
ただし、直近の、つまり最近の傾向を最もよく反映しているであろうデータを学習に使わないのはやはりもったいない。
そのため、汎化性能を確かめられたらあらためて全データで再学習する場合が多いだろう。
それでも、他の期間に対しても精度が出るのかとか、単純にデータ量が足りないとか、つまりもっと効率的にデータを使いたいという不満が残るはずだ。
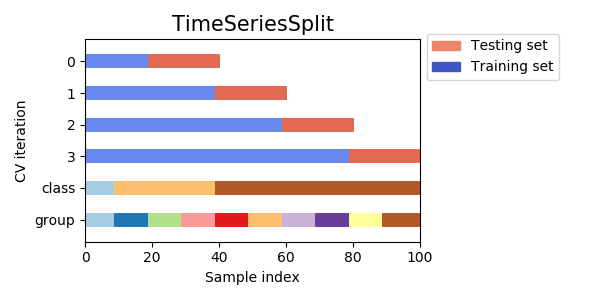
そこで、TimeSeriesSplitという手法が登場する。発想自体は単純で、要するに時系列的順序を守ってクロスバリデーションする方法だ。
しかしこれにしたって、やっぱり直近のデータは使えないじゃないかとか、foldごとに学習データの長さが違うとか、不満は残る。だが使えるに越したことはない。from sklearn.model_selection import TimeSeriesSplit i = 0 scores = [] tss = TimeSeriesSplit(n_splits=4) for tr_idx, va_idx in tss.split(train_X): i += 1 tr_x, va_x = train_X.iloc[tr_idx], train_X.iloc[va_idx] tr_y, va_y = train_y.iloc[tr_idx], train_y.iloc[va_idx] slr = LinearRegression() slr.fit(tr_x, tr_y) va_pred = slr.predict(va_x) score = np.sqrt(mean_squared_error(va_y, va_pred)) print('fold{}: {:.2f}'.format(i, score)) scores.append(score) print(np.mean(scores))fold1: 20.29
fold2: 9.21
fold3: 15.05
fold4: 9.68
13.557202833084698なかなか判断に困る結果だ。学習データを増やすほど精度が良くなっている、というわけでもないのが面白い。色々と試す余地は残っているが、この記事のスコープを超えるためここで終える。
このように、どうにも時系列データのバリデーションははっきりとした結論を下すのが難しい。とくに、事実直近にトレンドの変化が起こっているような場合、学習データでバリデーションデータを説明できない方が正しいのであって、むしろバリデーションデータでモデルを学習すべき状況と言える。
制御系なんかでは、RMSEか何かで精度を監視しておいて、閾値を下回ったら既存制御に戻し、必要数データが溜まったら再学習して制御を再開する、なんて運用がありえるだろう。あるいは、オンライン学習でモデルを更新し続けるという考えもあるかもしれない。
需要予測系はどうなのだろうか。必ずしもコンペみたいに一定期間を予測しなければならないわけでもないだろうから、短期の自己相関を考慮したARIMAモデルなども有力だろう。今度需要予測チームに聞いてみたい。
- 投稿日:2020-03-05T23:37:40+09:00
【備忘録】python+vscode+pipenvありがちだけどwarningとかめんどかったので備忘録
初投稿です。
今まではnotepad++を使ってコードを書いていたのですが色々便利ということでVScodeを使おうと思い立ちました。
pythonの勉強用なのですが、せっかくならpipenvとか使って管理しやすいようにしたいなーと思って環境を作ってました。
しかしwarningが消えなかったり色々苦戦したので、備忘録的にここに残しておこうと思います。今回構築する環境は以下になります。
-OS:windows10
-Python:3.8
-使用ライブラリ:pipenv、Django1.VScodeのインストール
以下ページから自分の環境にあったものをインストールしてください。
https://code.visualstudio.com/download2.pythonのインストール
以下ページから環境に沿った欲しいバージョンのものをダウンロードしてインストールしてください。
https://www.python.org/downloads/windows/
また、windowsの場合途中に環境変数を追加するチェックボックスがあるはずなので、忘れずにチェックをいれてください。
("Add pythonX.X to PATH"みたいな文言のチェックボックスがあります。)
インストールしたら一応以下コマンドでインストールが完了していることを確認しましょう。python --versionバージョン情報が表示されたら正常にインストールされたということです。
(PATHが通ってなかったらここでコマンドを認識できないと思います。)3.Pipenvをインストールする。
2からそのままインストールしちゃいましょう。
以下のコマンドを実行してください。pip install pipenvpipenvのインストールが完了したら環境変数の追加を行います。
以下の環境変数を追加し、値を"true"に設定してください。PIPENV_VENV_IN_PROJECTこれを実施することでpipenvで仮想環境を作った際にワークディレクトリに".venv"フォルダ作られるようになります。
この環境変数を追加しなかった場合、ユーザフォルダ配下に作成されてしまいます。
それでも問題ないのですが、後々VScode上で環境及びフォルダを管理するときに地味に面倒くさいので設定しておくことをお勧めします。4.VScodeを設定していく。
1.サイドバーのExtentionsから以下を検索してインストールしてください。
(Pythonの便利ツールパッケージ。Lint機能とか、自動インデントとかやってくれる。)python extension for visual studio code2."ファイル"→"基本設定"で設定を開き、"拡張機能"→"python"の中の"Python: Venv Path"に以下を設定する。
.venv,これを設定するとワークスペースを開いた際に直下にある.venvフォルダを読み込んでくれるようです。
3.一旦VScodeを再起動。ここまでの設定を読み込ませます。
4.ここから本格的に環境を作っていきます。
"ファイル"→"フォルダーを開く"から自分が作業するフォルダを開きます。
5."ターミナル"→"新しいターミナル"と選択しターミナルを開きます。
6.pipenvで仮想環境を作っていきます。ターミナルで以下コマンドを実行してください。pipenv installこの時右下に「仮想環境作られたみたいやけど、使うん?」みたいなことを英語で聞かれるので"YES"を選びましょう。
すると以下のようなフォルダ構成になると思います。. ├─.venv ←pipenvで作られる ├─.vscode ←Yesをクリックしたら作られる ├─Pipfile ←pipenvで作られる └─Pipfile.lock ←pipenvで作られる.vscodeが作られなかった(もしくはNoをクリックしてしまった場合)ワークスペース直下に適当な名前の.pyのファイルを作りましょう。そしたら作られるはずです。
7.ワークスペース直下に".env"という名前のフォルダを作って以下を記述します。PYTHONPATH=.venv/src8."./.vscode/setting.json"に以下を追加します。
"python.envFile": "${workspaceFolder}\\.env"
バックスラッシュはエスケープキーとして認識されるので二重にするのを忘れないでください。
7、8の手順を踏むことによって仮想環境でライブラリを読み込めずワーニングが出るということがなくなります。あとは
pipienv install xxxでお好みのライブラリをインストールして
pipenv shellを実行すればお好みの仮想環境で開発することができます!
以上です!お疲れさまでした!最後に
今まではとりあえずコードが打てれば良いの精神であまり気にしてなかったのですが、現場によってはvscodeが標準だったりgitとの連携が便利だったりということで使い始めた次第です。
この記事を書いてる先から今日も頭の中の消しゴムは頑張って仕事をしていて
消えゆく記憶と格闘しながら作成した次第です。お前こんなんも知らんのかい?
ここ違うで等ありましたら是非ご指摘いただけると嬉しいです。
先達の皆様よろしくお願いします。
- 投稿日:2020-03-05T22:59:17+09:00
OpenJtalkを使って日本語をRaspberry Piに喋らせる
この記事でできること
・OpenJtalkのRaspberry Piにインストール
・実際に"こんにちは"を音声出力動作環境
・Raspberry P i3 model B
・OS: Raspbian前提
・ラズパイのssh接続で操作できる or ディスプレイで操作可能
・日本語入力が可能OpenJtalkのインストール
自分は、この記事を参考にしてインストールしました。
まずは、以下を実行します
sudo apt-get update #アップデートする sudo apt-get install open-jtalk #インストール次に推奨されているパッケージもインストールします。
sudo apt-get install open-jtalk-mecab-naist-jdic hts-voice-nitech-jp-atr503-m00テスト
これでもう音声出力はできます!
OpenJtalkは日本語の音声ファイルを作ってからそれを再生するという順序になっています。
まず、以下で音声ファイルを作ります。echo "こんにちは" | open_jtalk -x /var/lib/mecab/dic/open-jtalk/naist-jdic -m /usr/share/hts-voice/nitech-jp-atr503-m001/nitech_jp_atr503_m001.htsvoice -ow ~/ojtalk.wavこれで同じディレクトリにojtalk.wavという音声ファイルができたと思います。
それでは次に再生します。aplay ~/ojtalk.wav"こんにちは"
と出力されましたか?オプションの意味
-x 使う辞書
-m どの声を使うか(男声or女声など)
-ow 出力ファイルを指定ノイズが多い時
ちなみにですが、3.5mmのアナログ出力だとノイズが乗ってしまって綺麗に聞こえないことがあります。(自分はそうでした、、、)
その時は、HDMIでディスプレイに接続してディスプレイから出力してみてください。
おそらく回路が原因のノイズは消えます。音声ファイル保存せずに出力
今回は、音声ファイルを作ってから出力しましたが、発話させる度に音声ファイルが保存されていくのは少し気持ち悪いという方は、以下で音声ファイルを作らずにできます。
echo "こんにちは" | open_jtalk -x /var/lib/mecab/dic/open-jtalk/naist-jdic -m /usr/share/hts-voice/nitech-jp-atr503-m001/nitech_jp_atr503_m001.htsvoice -ow /dev/stdout | aplay --quiet女性の音声をダウンロード
MMDAgentのパッケージを使用します。
まずは以下を実行してダウンロード
wget https://sourceforge.net/projects/mmdagent/files/MMDAgent_Example/MMDAgent_Example-1.7/MMDAgent_Example-1.7.zip次にそのzipを解凍します
unzip ./MMDAgent_Example-1.7.zipそしてフォルダーの中にあるmeiちゃんの音声フォルダーを
/usr/share/hts-voice/のディレクトリー下にコピーします。sudo cp -r ./MMDAgent_Example-1.7/Voice/mei/ /usr/share/hts-voice/これで音響モデルをこれに変えれば女性音声になります。
オプションの -m 音響モデル
に相当する部分ですね。echo "こんにちは” |open_jtalk -x /var/lib/mecab/dic/open-jtalk/naist-jdic -m /usr/share/hts-voice/mei/mei_normal.htsvoice -ow ~/ojtalk.wav aplay ~/ojtalk.wavこれで女性の音声になったと思います。
まとめ
今回はOpenJtalkのインストールとそのテストをお届けしました。
次は、APIで取得した情報やweb scrapingしたものを話すプログラムを作っていきたいと思います!
では!
- 投稿日:2020-03-05T22:46:05+09:00
オレオレデザインパターン:Glocal Variable
概要
Pythonのライブラリでたまに見る、「withの中でのみアクセスできるグローバル変数」という設計パターンに、オレオレの名前をつけてまとめてみた。
すでに名前がついてたらすいません。
例題
ある設定に基づき実験(関数
experiment)を行うプログラムを書く。実験は複数の関数(
firstsecond)に分割して記述されており、どちらも設定を参照してある実験操作を行う。
config0とconfig1に基づき二回実験を行いたい。ストレートに書くとこう。
# 本当はもっといろいろ設定がある config0 = { "id": 0 } config1 = { "id": 1 } def first(conf): # なんかする print(f"{conf['id']}: first") def second(conf): # なんかする print(f"{conf['id']}: second") def experiment(conf): first(conf) second(conf) def main(): experiment(config0) experiment(config1) main()ただこの書き方だと、プログラムが複雑になったとき、設定をバケツリレーしていくのがやや面倒。なしですませられないか?
一つの解法はグローバル変数を使うことだが……。
conf = config0 def first(): print(f"{conf['id']}: first") def second(): print(f"{conf['id']}: second") def experiment(): first() second() def main(): global conf experiment() conf = config1 experiment() main()あきらかにこれはやばやば。
- グローバル変数を使ったことで、変数に処理がどう依存するか追跡が難しくなる。
- 上に加え、グローバル変数を途中で変化させていることで、状態の変化過程が追跡しきれずバグになりがち
- 例えば今回の場合、
mainを呼び出した後confがconfig1になってることを忘れて、config0のつもりで再度mainを実行したりするとやばいパターンの導入
バケツリレーを避け、グローバル変数の導入も避けたいということで、その中間的な書き方としてGlocal Variableパターンを紹介する。
config.pyfrom contextlib import contextmanager _config = None _initialized = False @contextmanager def configure(data): global _config global _initialized before = _config before_initialized = _initialized _config = data _initialized = True try: yield finally: _config = before _initialized = before_initialized def get_config(): if _initialized: return _config else: # 本当はもうちょっと真面目に例外投げるべき raise RuntimeErrorfrom config import get_config, configure def first(): print(f"{get_config()['id']}: first") def second(): print(f"{get_config()['id']}: second") def experiment(): first() second() def main(): with configure(config0): experiment() with configure(config1): experiment() main()
- バケツリレーは避けることができた
- グローバル変数に比べると安全
configureのコンテキストの中でしか変数が使えないので、自由度に制限がある- configを直接変化させる術がなく、withを通してしか設定できない
- withの前後で必ずconfigが初期化・解放されるので、わけのわからない値が残っていてバグを起こす心配がない
- ただし、「スコープ」(withの中)以外で
get_configを呼び出しても、静的解析でエラーは拾えないこのように、
- withの前後でグローバル変数を設定・初期化し
- そのグローバル変数を読み出す関数を用意する
パターンをGlocal Variableと呼ぶことにする。
どういう時に使うか?
- 多くの関数で共有したいデータが存在する
- 面倒くさくないならバケツリレーを使えばいい
- そのデータを動的に決める・変える需要がある
- なければグローバル変数にしたほうがシンプル
実例
Pythonのライブラリではいくつか使われている。
- 深層学習パッケージのmxnetでは、行列を計算するコンテキスト(CPU, GPU)をGlocal Variableで設定できる
- Webフレームワークのflaskでは、リクエストパラメータをグローバル変数のように参照できるが、コード上で設定する場合はGlocal Variableパターンを使う
Racketだと、
parametrizeというシンタクスが存在し、これが汎用のGlocal Variable機能を提供する。バリエーション
デフォルト値
初期値をあらかじめ決めることもできる。先ほど言及したmxnetでは、CPUでの計算がデフォルト値になっている。
変更
セッターも用意すれば、with内でGlocal Variableを変更することもできる。
param.py_param = None _initialized = False @contextmanager def parametrize(data): global _param global _initialized before = _param before_initialized = _initialized _param = data _initialized = True try: yield finally: _param = before _initialized = before_initialized def set_param(data): if _initialized: global _param _param = data else: raise RuntimeError def get_param(): if _initialized: return _param else: raise RuntimeErrorfrom param import parametrize, set_param, get_param with parametrize(3): with parametrize(4): print(get_param()) set_param(2) print(get_param()) print(get_param()) get_param() # 4 # 2 # 3 # RuntimeError読み取りしかできない場合に比べると、状態を追う努力が必要な分危険度は高まる。
だが状態変化の影響はwith内に限定できるので、グローバル変数に比べれば安全。
パーサなどを書く場合は、「まだ読んでいない文章」をGlocal Variableにして、少しずつ先頭から消費していくような書き方をすると、バケツリレーなしで書けて便利かも。
注意
Glocal Variableの値は、getterが記述された場所ではなく、実行されたタイミングで決まることに注意しよう。
def get_print_config(): # この2ではなく with configure(2): def print_config(): print(get_config()) return print_config print_config = get_print_config() # この3が参照される with configure(3): print_config() # 3備考
元々はPythonでも状態モナドのdo記法みたいな感じで書けないかなーと思って、flaskやmxnetのことを思い出し、こういうパターンあるなと気づいたのだった。
- 投稿日:2020-03-05T22:23:33+09:00
PythonとRubyのインスタントメソッド文法(勉強中)
今回はPythonとRubyの勉強として、
インスタンスメソッドの文法を比較してみたいと思います。
インスタンスメソッドはオブジェクト指向の基本的な内容で、
様々な言語で比較してみたいと考えております。今回の用いるPythonとRubyは下記バージョンで実施しております。
Python: 3.7.4
Ruby: 2.6.3Pythonでの例
test.pyclass Test: def __init__(self): print('勉強中')Rubyでの例
test.rbclass Test def initialize puts('勉強中') end end比較のすると「:」や「end」の有無などが違うかなという印象です。
随時更新させていただきます。
- 投稿日:2020-03-05T22:21:00+09:00
dockerでpythonを使う
docker pull python docker run --name python -i -t python /bin/bash参考
https://dev.classmethod.jp/cloud/aws/win10_docker_python_ecs_cfn/
https://qiita.com/chroju/items/ce9cae248cc016745c66
- 投稿日:2020-03-05T22:12:29+09:00
学習記録#1
やったこと
Udemy「PythonによるWebスクレイピング〜入門編〜【業務効率化への第一歩】」の12-14
- ランキングサイトを模したページを使って、特定の要素(titleクラスのh1タグの中身など)をまとめて拾う方法
- はじめに要素を拾う際
browser.find_elemtent_by_class_name〜とするときのbrowser.を忘れてしまう- リストの最初が0ってのにいまいち慣れない
読んだもの
https://qiita.com/katz_PG/items/a95a0f91705f80ffc47c
「Twitter漁るの面白そう」と思ったけど、スクレイピング禁止されてるのか。知らなかった。その他
-Jupyter notebookを終わる時はブラウザ側で終了→コンソールでCtrl+C
- 投稿日:2020-03-05T21:57:08+09:00
機械学習のアルゴリズム(ロジスティック回帰)
はじめに
以前、「機械学習の分類」で取り上げたアルゴリズムについて、その理論とpythonでの実装、scikit-learnを使った分析についてステップバイステップで学習していく。個人の学習用として書いてるので間違いなんかは大目に見て欲しいと思います。
今回はロジスティック回帰について。ロジスティック回帰も、回帰と書いてはいるものの、パーセプトロンのように二値分類を扱うアルゴリズムです。
今回参考にしたのは以下のサイト。ありがとうございます。
理論
ロジスティック回帰の理論について、まずは活性化関数であるシグモイド関数を導出してみます。
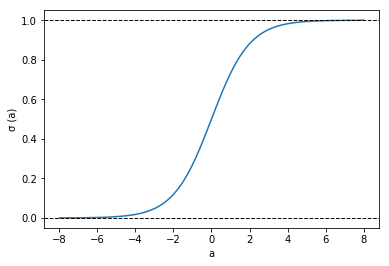
シグモイド関数
ロジスティック回帰は二値分類なので、クラス$C_1$と$C_2$について考える。$C_1$の確率$P(C_1)$と$C_2$の確率$P(C_2)$の合計は1です。
データ列$\boldsymbol{x}$を与えた時に$C_1$になる確率は、ベイズの定理より
\begin{align} P(C_1|\boldsymbol{x})&=\frac{P(\boldsymbol{x}|C_1)P(C_1)}{P(\boldsymbol{x})} \\ &= \frac{P(\boldsymbol{x}|C_1)P(C_1)}{P(\boldsymbol{x}|C_1)P(C_1)+P(\boldsymbol{x}|C_2)P(C_2)} \\ &= \frac{1}{1+\frac{P(\boldsymbol{x}|C_2)P(C_2)}{P(\boldsymbol{x}|C_1)P(C_1)}} \\ &= \frac{1}{1+\exp(-\ln\frac{P(\boldsymbol{x}|C_1)P(C_1)}{P(\boldsymbol{x}|C_2)P(C_2)})} \\ &= \frac{1}{1+\exp(-a)} = \sigma(a) \end{align}この$\sigma(a)$のことをシグモイド関数と呼びます。シグモイド関数は以下のように、0から1の値をとるので、確率を表すに都合の良い関数です。
ロジスティック回帰のモデル
与えられたデータ列$\boldsymbol{x}=(x_0,x_1,\cdots,x_n)$と教師のクラス分類$\boldsymbol{t}=(t_0,t_1,\cdots,t_n)$を用い、
L(\boldsymbol{x})=\frac{1}{1+\exp(-\boldsymbol{w}^T\boldsymbol{x})}のパラメータ$\boldsymbol{w}=(w_0,w_1,\cdots,w_n)$を最適化していきます。
クロスエントロピー誤差
ある$x_i$が与えられたときにクラスが$C_1$になる確率$P(C_1|x_i)$を$p_i$とすると、クラスが$C_2$になる確率$P(C_2|x_i)$は$(1-p_i)$となる。つまり、クラスが$t_i$になる確率$P(t_i|x_i)$は、$$P(t_i|x_i)=p_i^{t_i}(1-p_i)^{1-t_i}$$となる。
これを全データに適用すると、
\begin{align} P(\boldsymbol{t}|\boldsymbol{x})&=P(t_0|x_0)P(t_1|X_1)\cdots P(t_{n-1}|x_{n-1}) \\ &=\prod_{i=0}^{n-1}P(t_i|x_i) \\ &=\prod_{i=1}^{n-1}p_i^{t_i}(1-p_i)^{1-t_i} \end{align}となります。この両辺の対数をとると、
\log P(\boldsymbol{t}|\boldsymbol{x}) = \sum_{i=0}^{n-1}\{t_i\log p_i+(1-t_i)\log (1-p_i)\}これは対数尤度と呼ばれ、対数尤度を最大にするために、符号を反転して、
E(\boldsymbol{x}) = -\frac{1}{n}\log P(\boldsymbol{t}|\boldsymbol{x}) = \frac{1}{n}\sum_{i=0}^{n-1}\{-t_i\log p_i-(1-t_i)\log (1-p_i)\}この$E$をクロスエントロピー誤差関数と言います。
あとで使うので、$E$の微分は、\frac{\partial{E}}{\partial{w_i}}=\frac{1}{n}\sum_{i=0}^{n-1}(p_i-t_i)x_iとなります(説明省略)
共役勾配法
さて、クロスエントロピー誤差関数を最小化するためには、以前も出てきた勾配法を使います。ここでも、最急降下法や確率的勾配降下法が使えるんですが、共役勾配法(Conjugate Gradient Method)を使います。詳しい話はWikipedia:共役勾配法に譲りますが、最急勾配法と比べると高速かつ学習率を設定しなくても収束するというアルゴリズムです。
これもpythonで実装したいところですが、面倒なので(!)pythonのscipy.optimize.fmin_cgというライブラリを使います。pythonによる実装
ここまでの理論を使ってLogisticRegressionクラスを実装していきます。fmin_cgは勾配関数を与えると良好な結果が出ると言うことで、先ほどの勾配関数を使います。
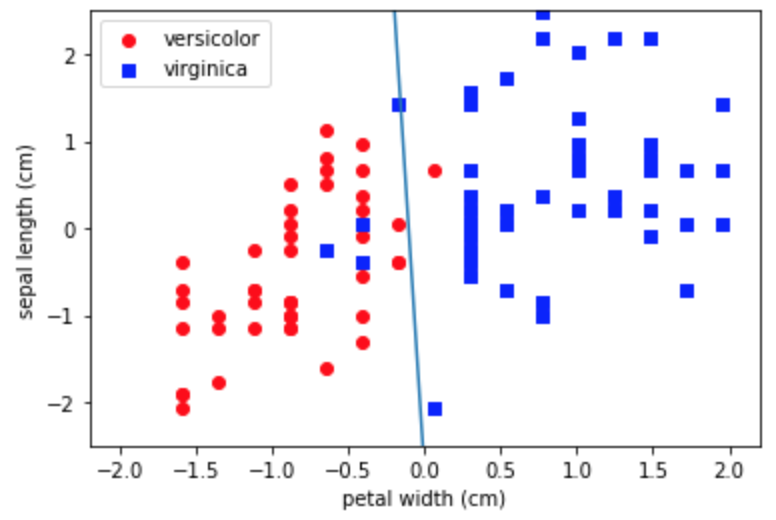
from scipy import optimize class LogisticRegression: def __init__(self): self.w = np.array([]) def sigmoid(self, a): return 1.0 / (1 + np.exp(-a)) def cross_entropy_loss(self, w, *args): def safe_log(x, minval=0.0000000001): return np.log(x.clip(min=minval)) t, x = args loss = 0 for i in range(len(t)): ti = (t[i]+1)/2 h = self.sigmoid(w.T @ x[i]) loss += -ti*safe_log(h) - (1-ti)*safe_log(1-h) return loss/len(t) def grad_cross_entropy_loss(self, w, *args): t, x = args grad = np.zeros_like(w) for i in range(len(t)): ti = (t[i]+1)/2 h = self.sigmoid(w.T @ x[i]) grad += (h - ti) * x[i] return grad/len(t) def fit(self, x, y): w0 = np.ones(len(x[0])+1) x = np.hstack([np.ones((len(x),1)), x]) self.w = optimize.fmin_cg(self.cross_entropy_loss, w0, fprime=self.grad_cross_entropy_loss, args=(y, x)) @property def w_(self): return self.wこのクラスを使ってirisのデータを分類してみます。境界もあわせて描画します。境界は$\boldsymbol{w}^T\boldsymbol{x}=0$の線です。2クラスを1と-1にしたのでそれに合うようなコードにしています。
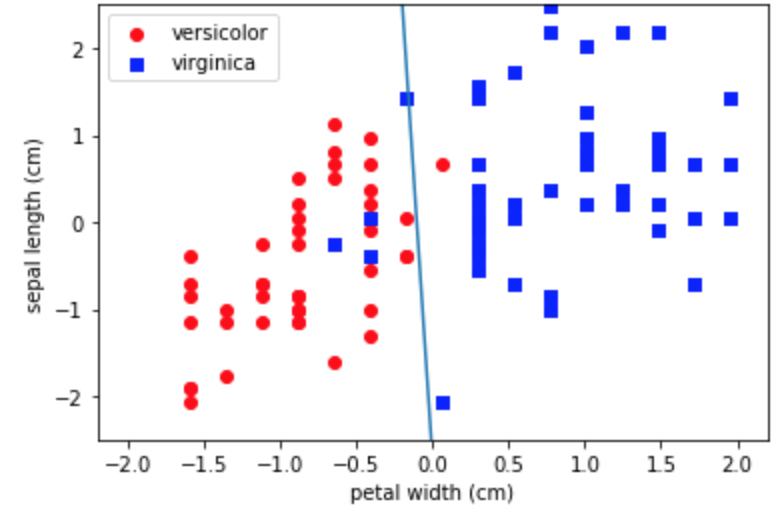
df = df_iris[df_iris['target']!='setosa'] df = df.drop(df.columns[[1,2]], axis=1) df['target'] = df['target'].map({'versicolor':1, 'virginica':-1}) # グラフの描画 fig, ax = plt.subplots() df_versicolor = df_iris[df_iris['target']=='versicolor'] x1 = df_iris[df_iris['target']=='versicolor'].iloc[:,3].values y1 = df_iris[df_iris['target']=='versicolor'].iloc[:,0].values x2 = df_iris[df_iris['target']=='virginica'].iloc[:,3].values y2 = df_iris[df_iris['target']=='virginica'].iloc[:,0].values xs = StandardScaler() ys = StandardScaler() xs.fit(np.append(x1,x2).reshape(-1, 1)) ys.fit(np.append(y1,y2).reshape(-1, 1)) x1s = xs.transform(x1.reshape(-1, 1)) x2s = xs.transform(x2.reshape(-1, 1)) y1s = ys.transform(y1.reshape(-1, 1)) y2s = ys.transform(y2.reshape(-1, 1)) x = np.concatenate([np.concatenate([x1s, y1s], axis=1), np.concatenate([x2s, y2s], axis=1)]) y = df['target'].values model = LogisticRegression() model.fit(x, y) ax.scatter(x1s, y1s, color='red', marker='o', label='versicolor') ax.scatter(x2s, y2s, color='blue', marker='s', label='virginica') ax.set_xlabel("petal width (cm)") ax.set_ylabel("sepal length (cm)") # 分類境界を描画する w = model.w_ x_fig = np.linspace(-2.,2.,100) y_fig = [-w[1]/w[2]*xi-w[0]/w[2] for xi in x_fig] ax.plot(x_fig, y_fig) ax.set_ylim(-2.5,2.5) ax.legend() print(w) plt.show() Optimization terminated successfully. Current function value: 0.166434 Iterations: 12 Function evaluations: 41 Gradient evaluations: 41 [-0.57247091 -5.42865492 -0.20202263]
結構綺麗に分類できているようです。
scikit-learnの実装
scikit-learnもLogisticRegressionクラスがあるので、上のコードとほとんど同じです。
from sklearn.linear_model import LogisticRegression df = df_iris[df_iris['target']!='setosa'] df = df.drop(df.columns[[1,2]], axis=1) df['target'] = df['target'].map({'versicolor':1, 'virginica':-1}) # グラフの描画 fig, ax = plt.subplots() df_versicolor = df_iris[df_iris['target']=='versicolor'] x1 = df_iris[df_iris['target']=='versicolor'].iloc[:,3].values y1 = df_iris[df_iris['target']=='versicolor'].iloc[:,0].values x2 = df_iris[df_iris['target']=='virginica'].iloc[:,3].values y2 = df_iris[df_iris['target']=='virginica'].iloc[:,0].values xs = StandardScaler() ys = StandardScaler() xs.fit(np.append(x1,x2).reshape(-1, 1)) ys.fit(np.append(y1,y2).reshape(-1, 1)) x1s = xs.transform(x1.reshape(-1, 1)) x2s = xs.transform(x2.reshape(-1, 1)) y1s = ys.transform(y1.reshape(-1, 1)) y2s = ys.transform(y2.reshape(-1, 1)) x = np.concatenate([np.concatenate([x1s, y1s], axis=1), np.concatenate([x2s, y2s], axis=1)]) y = df['target'].values model = LogisticRegression(C=100) model.fit(x, y) ax.scatter(x1s, y1s, color='red', marker='o', label='versicolor') ax.scatter(x2s, y2s, color='blue', marker='s', label='virginica') ax.set_xlabel("petal width (cm)") ax.set_ylabel("sepal length (cm)") # 分類境界を描画する w = model.coef_[0] x_fig = np.linspace(-2.,2.,100) y_fig = [-w[0]/w[1]*xi-model.intercept_/w[1] for xi in x_fig] ax.plot(x_fig, y_fig) ax.set_ylim(-2.5,2.5) ax.legend() plt.show()
こちらもうまい具合に分類できています。
まとめ
機械学習の世界でも割と重要(と思われる)なロジスティック回帰についてまとめました。だんだんこの辺りから理論が難しくなってきましたね。
- 投稿日:2020-03-05T21:24:30+09:00
再帰表現メモ
- 投稿日:2020-03-05T18:47:25+09:00
BigQueryのメタ情報を見てみた&使ってみた
はじめに
BigQueryとても便利ですよね。
ひとまずテーブルを入れておくのも、入れたテーブルを高速で集計するのも、更にBigQueryMLとかを使って機械学習も、BigQueryだけでできてしまいます。と便利に使っていて、気がついたら色々なDatasetやTableができてしまっているもの。
そのメタ情報がINFORMATION_SCHEMAを使うと見られるらしいです。今回は、そのINFORMATION_SCHEMAの使い方と、それ以外のメタ情報も合わせて整理していきます。
メタ情報の見方
特定プロジェクトのデータセット一覧の取得
まずは、プロジェクトを指定して中のデータセット一覧を取得する方法です。
SELECT * FROM `myproject.INFORMATION_SCHEMA.SCHEMATA`次の項目が出力されます。
- catalog_name :プロジェクト名
- schema_name :データセット名
- schema_owner :オーナー名?(全てNullだった)
- creation_time :作成日時
- last_modified_time :更新日時
- location :保存ロケーション
オーナー名がNullなのが残念でした。
これで誰が作成したデータセットなのかが分かれば、とても管理が簡単になるのですが。。。
なんとか、入れる方法はないだろうか。特定プロジェクト・データセットのテーブル一覧の取得1
続いて、プロジェクト:データセットを指定して中のテーブル一覧を取得する方法です。
SELECT * FROM `myproject.mydataset.INFORMATION_SCHEMA.TABLES`次の項目が出力されます。
- table_catalog :プロジェクト名
- table_schema :データセット名
- table_name :テーブル名
- table_type :テーブル or VIEW or 外部参照テーブル
- is_insertable_into :INSERTできるか
- is_typed : 不明(No以外ない?)
- creation_time : 作成日時
is_insertable_intoの意味合いがちょっと分かってません。
テーブルはYes, VIEWはNo以外の要素はなさそうですが。それだと、table_typeで十分だし。。。特定プロジェクト・データセットのテーブル一覧の取得2
同じく、プロジェクト:データセットを指定して中のテーブル一覧を取得する方法です。
少し出力される項目が違いますSELECT * FROM `myproject.mydataset.__TABLES__`
- project_id:プロジェクト名
- dataset_id:データセット名
- table_id:テーブル名
- creation_time:作成日時
- last_modified_time:更新日時
- row_count:行数
- size_bytes:データサイズ
- type:1ならTable, 2ならVIEW
見るメタ情報によって、微妙に名称が異なるのが気持ち悪いですね。
同じプロジェクト名を指すのに、catalog_nameだったりtable_catalogだっったり、project_idだったり。
何かBigQuery内で使い分けとかされているのでしょうか。特定プロジェクト・データセットのテーブル一覧の取得3
INFORMATION_SCHEMAでテーブルの付加情報も見られます。
SELECT * FROM `myproject.mydataset.INFORMATION_SCHEMA.TABLE_OPTIONS`次の項目が出力されます。
- table_catalog :プロジェクト名
- table_schema :データセット名
- table_name :テーブル名
- table_type :テーブル or VIEW or 外部参照テーブル
- option_name
- option_type
- option_value
オプションは一瞬何を言っているのか分かりづらいのですが、option_nameに「expiration_timestamp」、option_typeに「TIMESTAMP」、option_valueに日時が入って、この3つでセットになっています。
他にも、descriptionやlabelsとかがありました。
特定プロジェクト・データセットのテーブル一覧+列一覧の取得
テーブルが多くなると、大量にアウトプットされます。
SELECT * FROM `myproject.mydataset.INFORMATION_SCHEMA.COLUMNS`
- table_catalog :プロジェクト名
- table_schema :データセット名
- table_name :テーブル名
- column_name :列名
- ordinal_position : 列番号
- is_nullable :NullがOKか
- data_type :データ型
- is_generated
- generation_expression
- is_stored
- is_hidden
- is_updatable
- is_system_defined
- is_partitioning_column : テーブル分割に用いているか
- clustering_ordinal_position:テーブルクラスタリングに用いているか
解説を書いていないのは、NEVERとかNullしか入っていない列です。
列の意味が分かりませんでした。メタ情報を組み合わせて使ってみる
メタ情報の組み合わせで、あるプロジェクト内のデータセット別の課金額を計算したいと思います。
import pandas as pd query="SELECT schema_name FROM `myproject.INFORMATION_SCHEMA.SCHEMATA`" df = pd.read_gbq(query, project_id='myproject', dialect="standard") df_output = pd.DataFrame() query=""" SELECT "{dataset}" AS dataset, SUM(size_bytes) / 1000000000 AS DataSize, 0.020 * SUM(size_bytes) / 1000000000 AS Cost FROM `myproject.{dataset}.__TABLES__` GROUP BY dataset""" for i, dataset in df.iterrows(): d = pd.read_gbq(query.format(dataset=dataset[0]), project_id='myproject',dialect="standard") df_output=df_output.append(d)BQの保管費用は、「BigQueryの料金」から、1GBあたり$0.02で出しています。
長期保存だと、$0.01になるので、実際の請求額は出てきた結果よりも、もう少し安いかもしれません。おわりに
BigQueryのメタ情報についてまとめてみました。
色々なメタ情報があるので、他のものもありそうですが、ひとまずよく使うものを出してます。
ただ、結構謎な項目があるので、もう少し勉強が必要ですね。
- 投稿日:2020-03-05T17:18:49+09:00
Python学習1週間の初学者が書く基礎的なデータフレーム操作
コードを書いていてつまづいた部分の自分用メモです。
データフレームに関して単純に読み出す、書き出す以外に
「列Aに○があったら1、なかったら2が入っている新規列Bを作りたい」という場合の処理例です。コード例
このコード内で「dfCsv」としているのは一般的に「df」と書かれているものです。
dfex.pyimport csv import codecs import os, os.path import datetime import pandas as pd import warnings CSVFILE="ンナンナ.csv" def main(): #実行時警告がうるさいので非表示 #warnings.simplefilter('ignore') print(str(datetime.datetime.now())+"\t"+"対象データ読み込み開始。") #CSVファイルからデータフレームdfCsvに変換。 dfCsv= pd.read_csv(CSVFILE,encoding='cp932', header=0) print(str(datetime.datetime.now())+"\t"+CSVFILE+": 読み込み完了。") #↓こんな感じでフィルタかけたりもできる。 #dfCsv=dfCsv.query('screen_name.str.startswith("@h") | screen_name.str.startswith("@s")', engine='python') #新しい列を追加するときにはこんな風にしてやればいい。 dfCsv=textSearch(dfCsv) #実行結果をresult.csvに書き出す with open("result.csv",mode='w') as f: s = "" f.write(s) dfCsv.to_csv("result.csv",mode="a") #SS名称データフレームを既存データフレームに追加。 def textSearch(dfTmp): #空のリストを宣言しておいて、 #データフレームから一行読み出しながらappendしていけばデータフレームと同じ行数のリストになる。 profList=[] for profTxt in dfTmp['プロフィール']: profList.append(profTxt) retList=[] for prof in profList: if ("日本" in str(prof)) : ret="日本人" else: ret="日本人じゃない" retList.append(ret) #渡されたデータフレームにこのサブルーチンで作ったリストを結合。 dfTmp['日本人?'] = retList return(dfTmp) if __name__ == "__main__": main()解説
今回の肝はこの部分です。
#新しい列を追加するときにはこんな風にしてやればいい。 dfCsv=textSearch(dfCsv)「textSearchという関数をコールすればいいんだ!」という意味ではありません。
textSearch自体はこのプログラムコード内に定義されています。
データフレームをサブルーチンに渡し、このような形で処理を行なえば
データフレームに処理結果を格納した新規の列を追加することができます。
- 投稿日:2020-03-05T16:51:32+09:00
Julia で PyTorch を呼び出す方法
概要
Conda で仮想環境を作り、その仮想環境の Python で PyTorch を利用可能にし、その Python を PyCall に認識させ、Julia で呼び出す。
- Conda https://conda.io/en/latest/
- Python https://docs.python.org/3/
- PyTorch https://pytorch.org/docs/stable/index.html
- PyCall https://github.com/JuliaPy/PyCall.jl
- Julia https://docs.julialang.org/en/v1/
手順は次の通りである。
- Conda をシェルにインストールする。
- Conda で仮想環境を作る。
- 仮想環境で PyTorch を利用できる状態にする。
- Julia をインストールする。
- PyCall を 仮想環境の Python を参照するようにインストールする。
詳細
Conda のインストール方法は省略する。
conda create -n my_env python=3.8 conda activate my_env conda install -c pytorch pytorch実行するとこんなログになる。
paalon at paalon-mac in ~ ↪ conda create -n my_env python=3.8 (base) Collecting package metadata (current_repodata.json): done Solving environment: done ## Package Plan ## environment location: /Users/paalon/conda/envs/my_env added / updated specs: - python=3.8 The following NEW packages will be INSTALLED: ca-certificates pkgs/main/osx-64::ca-certificates-2020.1.1-0 certifi pkgs/main/osx-64::certifi-2019.11.28-py38_0 libcxx pkgs/main/osx-64::libcxx-4.0.1-hcfea43d_1 libcxxabi pkgs/main/osx-64::libcxxabi-4.0.1-hcfea43d_1 libedit pkgs/main/osx-64::libedit-3.1.20181209-hb402a30_0 libffi pkgs/main/osx-64::libffi-3.2.1-h475c297_4 ncurses pkgs/main/osx-64::ncurses-6.2-h0a44026_0 openssl pkgs/main/osx-64::openssl-1.1.1d-h1de35cc_4 pip pkgs/main/osx-64::pip-20.0.2-py38_1 python pkgs/main/osx-64::python-3.8.1-h359304d_1 readline pkgs/main/osx-64::readline-7.0-h1de35cc_5 setuptools pkgs/main/osx-64::setuptools-45.2.0-py38_0 sqlite pkgs/main/osx-64::sqlite-3.31.1-ha441bb4_0 tk pkgs/main/osx-64::tk-8.6.8-ha441bb4_0 wheel pkgs/main/osx-64::wheel-0.34.2-py38_0 xz pkgs/main/osx-64::xz-5.2.4-h1de35cc_4 zlib pkgs/main/osx-64::zlib-1.2.11-h1de35cc_3 Proceed ([y]/n)? y Preparing transaction: done Verifying transaction: done Executing transaction: done # # To activate this environment, use # # $ conda activate my_env # # To deactivate an active environment, use # # $ conda deactivate paalon at paalon-mac in ~ ↪ conda activate my_env (base) paalon at paalon-mac in ~ ↪ conda install -c pytorch pytorch (my_env) Collecting package metadata (current_repodata.json): done Solving environment: done ## Package Plan ## environment location: /Users/paalon/conda/envs/my_env added / updated specs: - pytorch The following NEW packages will be INSTALLED: blas pkgs/main/osx-64::blas-1.0-mkl intel-openmp pkgs/main/osx-64::intel-openmp-2019.4-233 libgfortran pkgs/main/osx-64::libgfortran-3.0.1-h93005f0_2 mkl pkgs/main/osx-64::mkl-2019.4-233 mkl-service pkgs/main/osx-64::mkl-service-2.3.0-py38hfbe908c_0 mkl_fft pkgs/main/osx-64::mkl_fft-1.0.15-py38h5e564d8_0 mkl_random pkgs/main/osx-64::mkl_random-1.1.0-py38h6440ff4_0 ninja pkgs/main/osx-64::ninja-1.9.0-py38h04f5b5a_0 numpy pkgs/main/osx-64::numpy-1.18.1-py38h7241aed_0 numpy-base pkgs/main/osx-64::numpy-base-1.18.1-py38h6575580_1 pytorch pytorch/osx-64::pytorch-1.4.0-py3.8_0 six pkgs/main/osx-64::six-1.14.0-py38_0 Proceed ([y]/n)? y Preparing transaction: done Verifying transaction: done Executing transaction: doneJulia を起動する。
paalon at paalon-mac in ~ ↪ julia (my_env) _ _ _ _(_)_ | Documentation: https://docs.julialang.org (_) | (_) (_) | _ _ _| |_ __ _ | Type "?" for help, "]?" for Pkg help. | | | | | | |/ _` | | | | |_| | | | (_| | | Version 1.3.1 (2019-12-30) _/ |\__'_|_|_|\__'_| | Official https://julialang.org/ release |__/ |PyCall を追加し、
ENV["PYCALL_JL_RUNTIME_PYTHON"]とENV["PYTHON"]をSys.which("python")に設定し、ビルドすると利用可能になる。(v1.3) pkg> add PyCall Updating registry at `~/.julia/registries/General` Updating git-repo `https://github.com/JuliaRegistries/General.git` Resolving package versions... Updating `~/.julia/environments/v1.3/Project.toml` [438e738f] + PyCall v1.91.4 Updating `~/.julia/environments/v1.3/Manifest.toml` [8f4d0f93] + Conda v1.4.1 [438e738f] + PyCall v1.91.4 [81def892] + VersionParsing v1.2.0 julia> ENV["PYCALL_JL_RUNTIME_PYTHON"] = Sys.which("python") "/Users/paalon/conda/envs/my_env/bin/python3.8" julia> ENV["PYTHON"] = Sys.which("python") "/Users/paalon/conda/envs/my_env/bin/python3.8" (v1.3) pkg> build PyCall Building Conda ─→ `~/.julia/packages/Conda/3rPhK/deps/build.log` Building PyCall → `~/.julia/packages/PyCall/zqDXB/deps/build.log` julia> using PyCall [ Info: Precompiling PyCall [438e738f-606a-5dbb-bf0a-cddfbfd45ab0] julia> torch = pyimport("torch") PyObject <module 'torch' from '/Users/paalon/conda/envs/my_env/lib/python3.8/site-packages/torch/__init__.py'> julia> x = torch.tensor([1, 2, 3]) PyObject tensor([1, 2, 3])例
import torch dtype = torch.float device = torch.device("cpu") # device = torch.device("cuda:0") # Uncomment this to run on GPU # N is batch size; D_in is input dimension; # H is hidden dimension; D_out is output dimension. N, D_in, H, D_out = 64, 1000, 100, 10 # Create random Tensors to hold input and outputs. # Setting requires_grad=False indicates that we do not need to compute gradients # with respect to these Tensors during the backward pass. x = torch.randn(N, D_in, device=device, dtype=dtype) y = torch.randn(N, D_out, device=device, dtype=dtype) # Create random Tensors for weights. # Setting requires_grad=True indicates that we want to compute gradients with # respect to these Tensors during the backward pass. w1 = torch.randn(D_in, H, device=device, dtype=dtype, requires_grad=True) w2 = torch.randn(H, D_out, device=device, dtype=dtype, requires_grad=True) learning_rate = 1e-6 for t in range(500): # Forward pass: compute predicted y using operations on Tensors; these # are exactly the same operations we used to compute the forward pass using # Tensors, but we do not need to keep references to intermediate values since # we are not implementing the backward pass by hand. y_pred = x.mm(w1).clamp(min=0).mm(w2) # Compute and print loss using operations on Tensors. # Now loss is a Tensor of shape (1,) # loss.item() gets the scalar value held in the loss. loss = (y_pred - y).pow(2).sum() if t % 100 == 99: print(t, loss.item()) # Use autograd to compute the backward pass. This call will compute the # gradient of loss with respect to all Tensors with requires_grad=True. # After this call w1.grad and w2.grad will be Tensors holding the gradient # of the loss with respect to w1 and w2 respectively. loss.backward() # Manually update weights using gradient descent. Wrap in torch.no_grad() # because weights have requires_grad=True, but we don't need to track this # in autograd. # An alternative way is to operate on weight.data and weight.grad.data. # Recall that tensor.data gives a tensor that shares the storage with # tensor, but doesn't track history. # You can also use torch.optim.SGD to achieve this. with torch.no_grad(): w1 -= learning_rate * w1.grad w2 -= learning_rate * w2.grad # Manually zero the gradients after updating weights w1.grad.zero_() w2.grad.zero_()をほとんどそのまま Julia に移植すると
ENV["PYCALL_JL_RUNTIME_PYTHON"] = Sys.which("python") ENV["PYTHON"] = Sys.which("python") # python の構成を変えたときは次の行を実行してビルドする。 # using Pkg; Pkg.build("PyCall") using PyCall torch = pyimport("torch") dtype = torch.float device = torch.device("cpu") # device = torch.device("cuda:0") # Uncomment this to run on GPU # N is batch size; D_in is input dimension; # H is hidden dimension; D_out is output dimension. N, D_in, H, D_out = 64, 1000, 100, 10 # Create random Tensors to hold input and outputs. # Setting requires_grad=False indicates that we do not need to compute gradients # with respect to these Tensors during the backward pass. x = torch.randn(N, D_in, device=device, dtype=dtype) y = torch.randn(N, D_out, device=device, dtype=dtype) # Create random Tensors for weights. # Setting requires_grad=True indicates that we want to compute gradients with # respect to these Tensors during the backward pass. w1 = torch.randn(D_in, H, device=device, dtype=dtype, requires_grad=true) w2 = torch.randn(H, D_out, device=device, dtype=dtype, requires_grad=true) learning_rate = 1e-6 for t in 1:500 # Forward pass: compute predicted y using operations on Tensors; these # are exactly the same operations we used to compute the forward pass using # Tensors, but we do not need to keep references to intermediate values since # we are not implementing the backward pass by hand. y_pred = x.mm(w1).clamp(min=0).mm(w2) # Compute and print loss using operations on Tensors. # Now loss is a Tensor of shape (1,) # loss.item() gets the scalar value held in the loss. loss = (y_pred - y).pow(2).sum() if t % 100 == 0 println("$(t) $(loss.item())") end # Use autograd to compute the backward pass. This call will compute the # gradient of loss with respect to all Tensors with requires_grad=True. # After this call w1.grad and w2.grad will be Tensors holding the gradient # of the loss with respect to w1 and w2 respectively. loss.backward() # Manually update weights using gradient descent. Wrap in torch.no_grad() # because weights have requires_grad=True, but we don't need to track this # in autograd. # An alternative way is to operate on weight.data and weight.grad.data. # Recall that tensor.data gives a tensor that shares the storage with # tensor, but doesn't track history. # You can also use torch.optim.SGD to achieve this. @pywith torch.no_grad() begin # 代入してしまうと、置き換えてしまうので使わないこと。 # w1 -= learning_rate * w1.grad # w2 -= learning_rate * w2.grad w1.sub_(learning_rate * w1.grad) w2.sub_(learning_rate * w2.grad) # Manually zero the gradients after updating weights w1.grad.zero_() w2.grad.zero_() end endとなる。
- 投稿日:2020-03-05T15:19:39+09:00
AI Academyのオンライン講座でAIエンジニアになれるのか?
Quoraで面白い質問があったので共有したいと思います。
https://qr.ae/ppjph1色々な回答があったので私なりにまとめてみました。詳しく知りたい人はリンクから見てください。
結論から言うと、AIエンジニアになれます。
しかし、オンライン講座だけでなく、その講座を修了したら、自分なりに本を読んだり、調べたりして独学する必要があるそうです。
やっぱり、プログラミングは独学が一番の近道なんですね。。。
- 投稿日:2020-03-05T14:39:39+09:00
Could not find encoder for codec id 27: Encoder not found | python opencv
要旨
pythonのopencv-pythonでmp4形式の動画を書き出そうとした際のエラーです.
エラー内容
Could not find encoder for codec id 27: Encoder not foundエラー原因 (コード抜粋)
video_FourCC = int(vid.get(cv2.CAP_PROP_FOURCC)) output_path = "test.mp4" out = cv2.VideoWriter(output_path, video_FourCC, video_fps, video_sizevideo_FourCCの形式が良くなかったのが原因.
なおoutput_pathをmp4形式の際のエラーと思われます.エラー修正後 (コード抜粋)
video_FourCC = cv2.VideoWriter_fourcc(*"mp4v") output_path = "test.mp4" out = cv2.VideoWriter(output_path, video_FourCC, video_fps, video_sizevideo_FourCCを上記のように書き換えると正しく動きます.
- 投稿日:2020-03-05T13:55:07+09:00
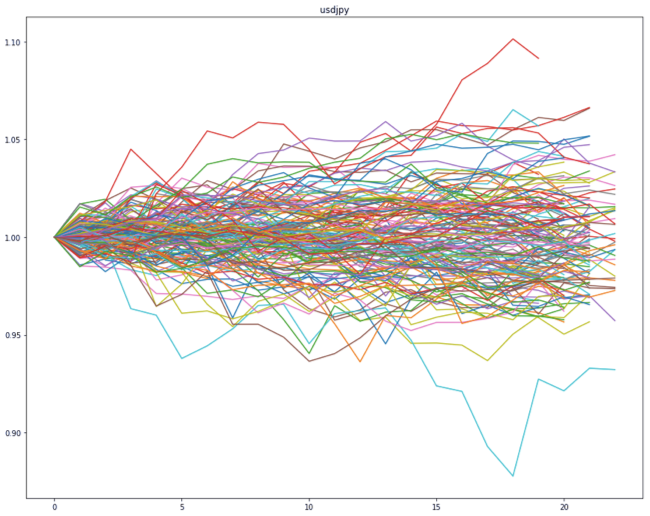
k-medoidsでドル円をクラスタリング, 正答率を求めてみた.(Part1/3 ロジック編)
はじめに
「株価や為替の予測って面白そうだな〜」「いくつか論文を読んでみようかな〜」から始まり, いくつか興味のありそうな論文や学会資料を適当にダウンロードして読んでたら, 個人的にものすごく面白そうな資料を見つけて感動しました.
そこで終わったらdame.
読むだけじゃなくて自分なりに実装してみようということで, 今まで株価や為替のデータに触れたこともなかったけど, データを取得して, 一応形にしてみました.対象:
プログラミングの四則演算やif文, for文といった基本的なことはわかり, 株価や為替の分析に興味がある人向け.(既に高度な知識を持ち,様々な予測や解析を行える人向けではないです.(まず僕が書けない...笑))概要:
k-medoids法を用いて過去のドル円をクラスタリングし, 正答率を求める, そして少し改良してみる, までの流れが記述してあります. 全編で3つのPartに分けました. Part1(この記事)はロジックのみを記述しています.Part2では結果の考察をして, Part3で詳しいコードの解説をしています.1 データの取得
今回はドル円の日足データを過去15年, 時間足データを過去5年分ぐらい取得しました.
データを取得できることすら知らなかったので, ここで結構手間取りましたが, 偶然「oanda api」なる存在を発見し, 使い方をまとめてあるQiitaを参考に, なんとか取得することができました.
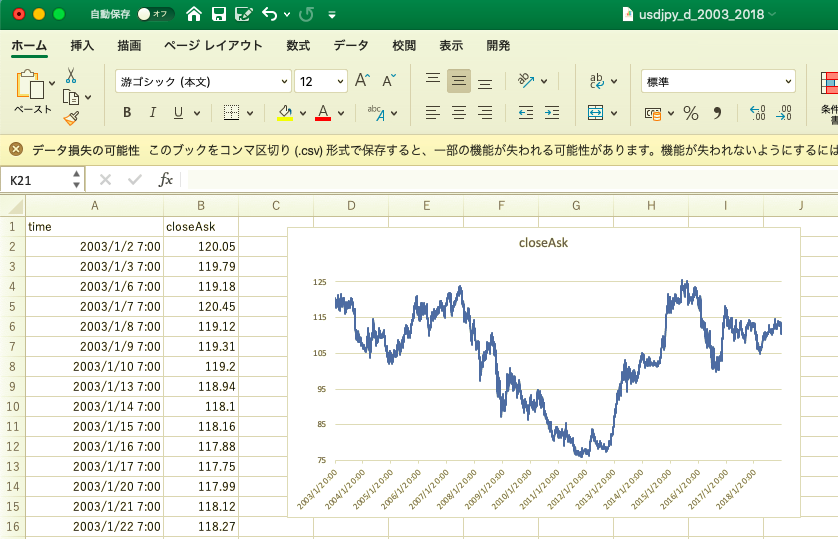
取得した日足データはこんな感じ(下図).
excelの方がなんとなく親近感が湧きます.OANDA APIからデータを取得
僕は大量の為替過去データをFX APIから取得する方法(機械学習用)を参考にデータを取得しました.
APIを使えるようになるまでの手順で手間取ったので, 以下に手順を載せました.
まずoanda apiとはFX業者oandaが提供しているapiです
使うためにはidとkeyが必要で, oandaのデモ口座を開設しなければなりません.
「oandaのホームページ」https://www.oanda.jp
ホームページから「新規口座開設」→「デモ口座 新規開設」を選択します.
無料デモ口座開設フォームで各種情報を入力し, デモ口座IDの発行. その後IDとパスワードが添付されたメールが送られてくるので, デモ口座にログインします.
下図真ん中部分の口座情報の中に「AccountID」があります.
右下の「APIアクセスの管理」から入りPersonalAccessTokenを取得をしましょう.
AccountIDとAccessKey(PersonalAccessTokenが取得できればこれでAPIを使用することができます.oandapyというパッケージをインストールして
pip install git+https://github.com/oanda/oandapy.git為替の情報を取得します.
必要なライブラリを読み込み, 試しに現時点のドル円レートを取得してみます.import pandas as pd import oandapy import configparser import datetime from datetime import datetime, timedelta import pytz account_id = "xxxxx" access_key = "xxxxx" #oandaAPIの呼び出し oanda = oanda.API(access_token = access_key, environment = "practice") #今の時間のドル円レートを取得 res = oanda.get_prices(instruments = "USD_JPY")出力結果↓↓↓
{'prices': [{'ask': 107.321,
'bid': 107.317,
'instrument': 'USD_JPY',
'time': '2020-03-05T06:12:23.365940Z'}]}
コロナウイルスの影響で112円台から107円台に暴落してますね.
ここから先は大量の為替過去データをFX APIから取得する方法(機械学習用)にものすごくわかりやすく書いてあるので, この記事を参考に希望する期間のデータを取得してください.2 分析方法
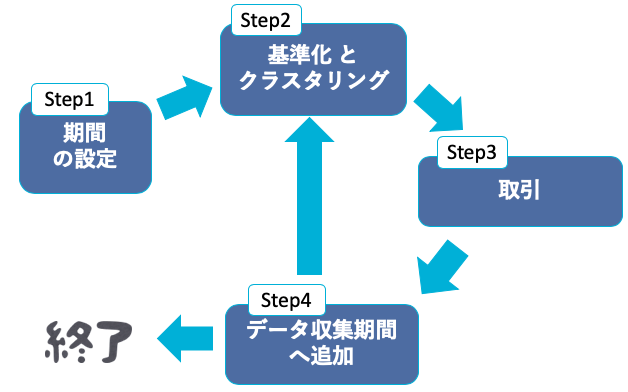
以下のStepに沿って分析を行います.
Step1:予測期間, データ収集期間, 検証期間を決める
Step2:データ収集期間のクラスタリングを行う
Step3:検証期間のうち, 予測期間の取引を行う
Step4:行った取引期間のデータを, データ収集期間へ追加
Step5:検証期間が終わっていない時Step2に戻り, 検証期間が終わっている時終了する.
それぞれの期間は次の意味を持っています.
データ収集期間:過去の値動きを参照する期間.(一般的に訓練データ)
検証期間:正答率を評価する為の期間.(一般的にテストデータ)
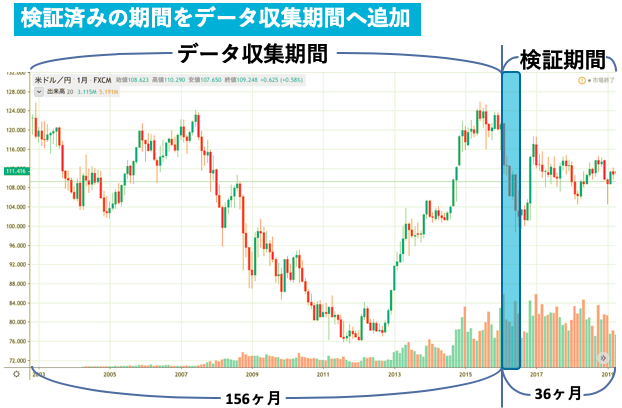
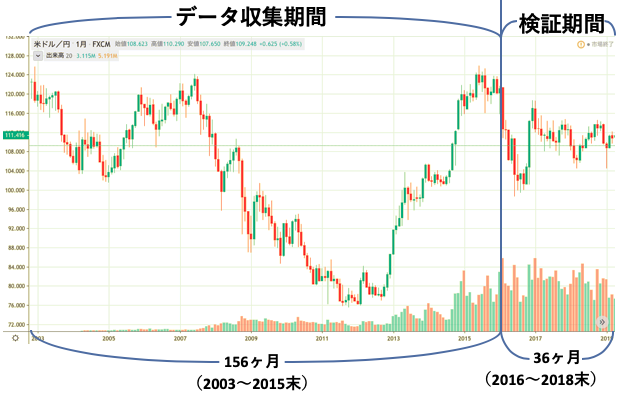
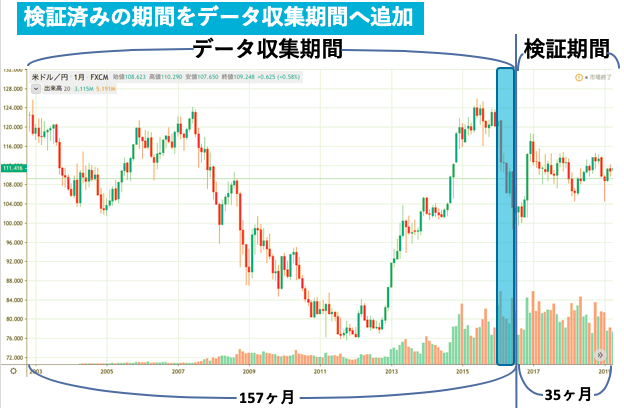
予測期間:来月,来週,明日どうなるのか?という予測をする期間(月毎, 週毎, 日毎の3つを用意した)例として予測期間を月毎, データ収集期間を2003~2015年末までの156ヶ月, 検証期間を2016~2018年末までの36ヶ月とする.(一度理解すればあとは期間を変えるだけ)
図にするとこんな感じ.(下図)
Step2でk-medoid法をデータ収集期間に適用します.
イメージとしては「データ収集期間をいくつかのパターンに分けた際, これから予測する期間はどのパターンになるだろうか」です.
なのでまずデータ収集期間をいくつかのパターンに分類します.
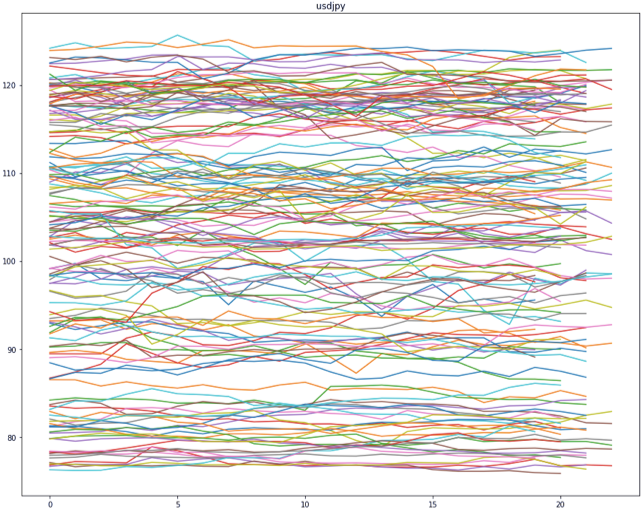
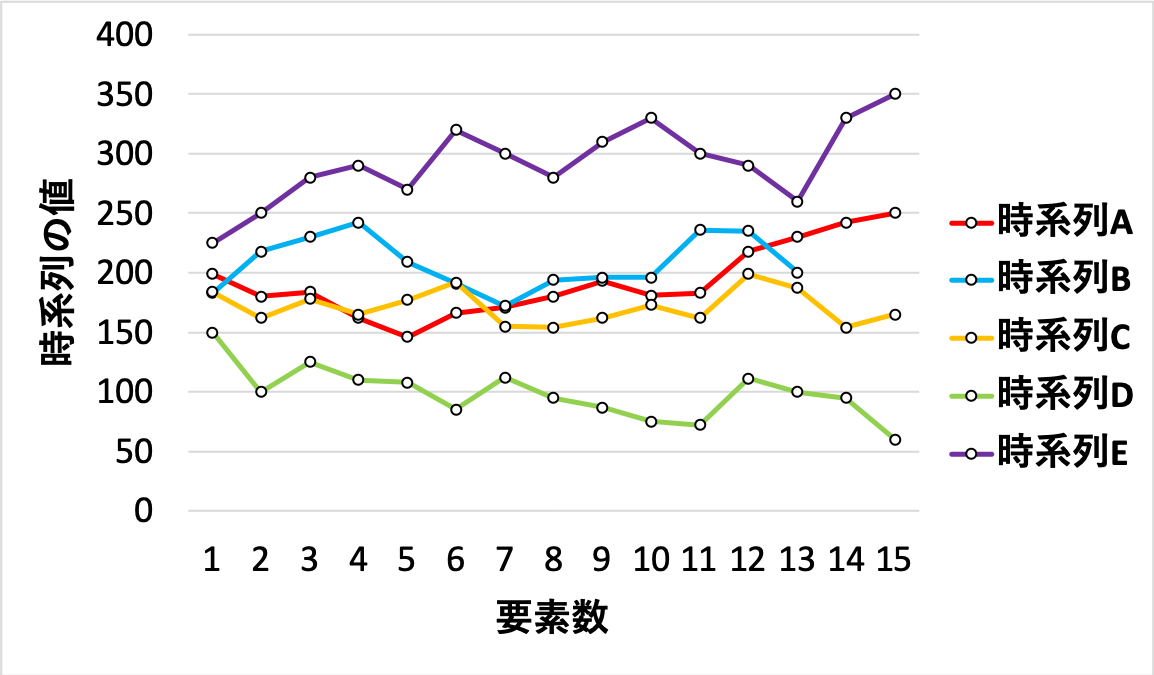
チャートの値動きは基本的に上昇, 横ばい, 下落の3パターンに分類されるので, ここでは3つのクラスに分類します.156ヶ月の値動きをまとめてみるとこんな感じになります.(下図)
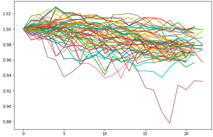
系列数は156本で, 要素数にばらつきがある理由は, 30日で終わる月や31日で終わる月,2月といった違いがあるからです.
また外国為替は休日や元旦は取引されないので, 各系列の要素数は18~22ぐらいになります.各系列の特徴を把握する為, それぞれ期初の値(要素[0])で各要素を割ってあげます. するとこんな感じになります.(下図)
DTW距離
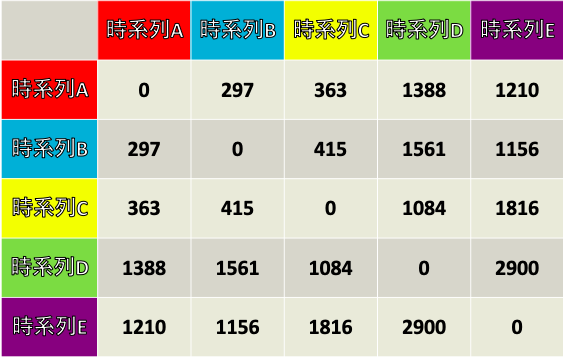
それでは次にこのこんがらがってる系列たちを3つに分類してあげます.
しかしここで問題になるのが,どうやって分類するのか?です. 時系列の形状をそれぞれ定量的に評価できるのか?と思っていましたが, DTW距離という測定方法を使えば解決することができます.
これはDTW関数の中に比較したい2つの時系列を入れると値が返ってくるもので, これを利用して各時系列間を定量的に評価することができます.例として以下のようなA~Eまでの時系列があった場合
AとBの時系列をDTW関数の中にいれると297となります.
A~Eまでの全ての組み合わせでDTW関数を求めると下の表のようになり,
一番近い時系列AとBのDTW距離は297, 一番遠い時系列DとEのDTW距離は2900と, グラフを見たときに近い, 離れてると認識した情報を定量的に評価できます.k-medoids法
次にいよいよk-medoids法を用いてクラスタリングを行います.
k-medoids法とはk-means法と類似した分割最適化クラスタリングの手法で, k-means法では基点を重心(centroid)にしますが, k-medoids法では割り当てられたクラスの中で, 他全ての点との距離の合計が最小となる点を基点(medoids)とします. その為, k-means法では重心の計算方法から, 外れ値の影響を受けやすいという欠点がありますが, k-medoids法では基点(medoids)にクラスないのデータの1つが割り当てられるので, 外れ値の影響が少なくなるという利点があります.DTW距離によって時系列間の距離を数値化し, k-medoids法を使って数値化されたdtw行列を分類します. プログラムなど実際の挙動はコード編に記述しました.
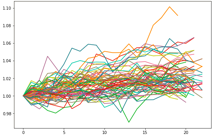
3つのクラスに分類するとこんな感じ.(下図)
なんとなく横ばいクラス(53系列), 上昇クラス(37系列), 下落クラス(66系列)に分かれています.次に取引を行います.
予測する系列の1つ前の系列に注目して, その系列がどのクラスに所属するのかを確認します.
そのクラスの半分以上の系列が上昇(下落)していた場合, 将来上昇(下降)すると予測し, 買い(売り)の判断をします.
実際に少しでも上昇していたら成功とカウントし, 予測した期間をデータ収集期間の中に格納して再度クラスタリングを行います.
先ほどの例でいうと, 検証期間(2016~2018末)の1つ目である2016年1月を予測する場合は, 1つ前の系列である2015年12月の系列の分類されたクラスを確認. そのクラスに従って取引, 終了後2016年1月の系列をデータ収集期間の中に格納し再度クラスタリング, 次に2016年2月の系列を予想する, という流れです.
このようにデータ収集期間と検証期間を色々工夫したり, 予測期間を変えたりして正答率を求めました.
次のPart2で結果の考察とモデルの改良を行っていきます.参考文献
・大量の為替過去データをFX APIから取得する方法(機械学習用)
・株価変動パターンの類似性を用いた株価予測
・価格変動パターンを用いた市場予測k-Medoids Clustering with Indexing Dynamic Time Warpingの株式市場への適用
・価格変動パターンによる証券/為替/仮想通貨市場の分析


- 投稿日:2020-03-05T13:27:31+09:00
いまさらだけど、Chainerで顔認識をしてみよう(予測フェーズ編)
概要
いまさらだけど、Chainerで顔認識をしてみよう(学習フェーズ編)の続きで、今回は予測フェーズです。
USB接続式ウェブカメラを用いて顔の認識を行ってみます。
環境
-Software-
Windows 10 Home
Anaconda3 64-bit(Python3.7)
Spyder
-Library-
Chainer 7.0.0
opencv-python 4.1.2.30
-Hardware-
CPU: Intel core i9 9900K
GPU: NVIDIA GeForce RTX2080ti
RAM: 16GB 3200MHz
(PCでもウェブカメラがあれば実行可能)参考
書籍
Pythonで始めるOpenCV4プログラミング 北山 直洋 (著)
(Amazonページ)
サイト
Chainer APIリファレンスプログラム
一応、Githubに上げておきます。
https://github.com/himazin331/Face-Recognition-Chainer-
リポジトリには学習フェーズ、予測フェーズ、データ加工プログラム、Haar-Cascadeが含まれています。前提
本プログラムの動作にはHaar-Like特徴量のCascadeファイルが必須です。
今回はOpenCVのHaar-Cascadeを使用します。
なお、Cascadeはリポジトリに含まれるので別途用意する必要はありません。ソースコード
コードが汚いのはご了承ください...
face_recog_CH.pyfrom PIL import Image import numpy as np import cv2 import sys import os import argparse as arg import chainer import chainer.links as L import chainer.functions as F import chainer.serializers as S # ==================================== face_recog_train_CH.pyと同じネットワーク構成 ==================================== class CNN(chainer.Chain): def __init__(self, n_out): super(CNN, self).__init__( conv1=L.Convolution2D(1, 16, 5, 1, 0), conv2=L.Convolution2D(16, 32, 5, 1, 0), conv3=L.Convolution2D(32, 64, 5, 1, 0), link=L.Linear(None, 1024), link_class=L.Linear(None, n_out), ) def __call__(self, x): h1 = F.max_pooling_2d(F.relu(self.conv1(x)), ksize=2) h2 = F.max_pooling_2d(F.relu(self.conv2(h1)), ksize=2) h3 = F.relu(self.conv3(h2)) h4 = F.relu(self.link(h3)) return self.link_class(h4) # ================================================================================================================ def main(): # コマンドラインオプション引数 parser = arg.ArgumentParser(description='Face Recognition Program(Chainer)') parser.add_argument('--param', '-p', type=str, default=None, help='学習済みパラメータの指定(未指定ならエラー)') parser.add_argument('--cascade', '-c', type=str, default=os.path.dirname(os.path.abspath(__file__))+'/haar_cascade.xml'.replace('/', os.sep), help='Haar-cascadeの指定(デフォルト値=./haar_cascade.xml)') parser.add_argument('--device', '-d', type=int, default=0, help='カメラデバイスIDの指定(デフォルト値=0)') args = parser.parse_args() # パラメータファイル未指定時->例外 if args.param == None: print("\nException: Trained Parameter-File not specified.\n") sys.exit() # 存在しないパラメータファイル指定時->例外 if os.path.exists(args.param) != True: print("\nException: Trained Parameter-File {} is not found.\n".format(args.param)) sys.exit() # 存在しないHaar-cascade指定時->例外 if os.path.exists(args.cascade) != True: print("\nException: Haar-cascade {} is not found.\n".format(args.cascade)) sys.exit() # 設定情報出力 print("=== Setting information ===") print("# Trained Prameter-File: {}".format(os.path.abspath(args.param))) print("# Haar-cascade: {}".format(args.cascade)) print("# Camera device: {}".format(args.device)) print("===========================") # カメラインスタンス生成 cap = cv2.VideoCapture(args.device) # FPS値の設定 cap.set(cv2.CAP_PROP_FPS, 60) # 顔検出器のセット detector = cv2.CascadeClassifier(args.cascade) # 学習済みパラメータの読み込み model = L.Classifier(CNN(2)) S.load_npz(args.param, model) red = (0, 0, 255) green = (0, 255, 0) p = (10, 30) while True: # フレーム取得 _, frame = cap.read() # カメラ認識不可->例外 if _ == False: print("\nException: Camera read failure.\n".format(args.param)) sys.exit() # 顔検出 gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = detector.detectMultiScale(gray) # 顔未検出->continue if len(faces) == 0: cv2.putText(frame, "face is not found", p, cv2.FONT_HERSHEY_SIMPLEX, 1.0, red, thickness=2) cv2.imshow("frame", frame) if cv2.waitKey(1) & 0xFF == ord('q'): break continue # 顔検出時 for (x, y, h, w) in faces: # 顔領域表示 cv2.rectangle(frame, (x, y), (x+w, y+h), red, thickness=2) # 顔が小さすぎればスルー if h < 50 and w < 50: cv2.putText(frame, "detected face is too small", p, cv2.FONT_HERSHEY_SIMPLEX, 1.0, red, thickness=2) cv2.imshow("frame", frame) break # 検出した顔を表示 cv2.imshow("gray", cv2.resize(gray[y:y + h, x:x + w], (250, 250))) # 画像処理 face = gray[y:y + h, x:x + w] face = Image.fromarray(face) face = np.asarray(face.resize((32, 32)), dtype=np.float32) recog_img = face[np.newaxis, :, :] # 顔識別 y = model.predictor(chainer.Variable(np.array([recog_img]))) c = F.softmax(y).data.argmax() if c == 0: cv2.putText(frame, "Unknown", p, cv2.FONT_HERSHEY_SIMPLEX, 1.0, green, thickness=2) elif c == 1: cv2.putText(frame, "Kohayakawa", p, cv2.FONT_HERSHEY_SIMPLEX, 1.0, green, thickness=2) cv2.imshow("frame", frame) if cv2.waitKey(1) & 0xFF == ord('q'): break # リソース解放 cap.release() cv2.destroyAllWindows() if __name__ == "__main__": main()実行結果
今回は、安倍晋三さんと麻生太郎さんを識別してみました。
学習データ件数はどちらも100枚です。
コマンド
python face_recog_CH.py -p <パラメータファイル> -c <cascade> (-d <カメラデバイスID>)説明
予測フェーズということで、カメラを用いて顔の識別をするプログラムになります。
ネットワークモデル
CNNクラスですが、学習フェーズ(face_recog_train_CH.py)のネットワークモデルと全く同じものを
そのまま記述してください。構造がちょっとでも違うと動きません。
ハイパーパラメータや層が違ければ、重みなどのパラメータの個数も異なるため、学習により最適化されたパラメータを
適用することができません。CNNクラス# ==================================== face_recog_train_CH.pyと同じネットワーク構成 ==================================== class CNN(chainer.Chain): def __init__(self, n_out): super(CNN, self).__init__( conv1=L.Convolution2D(1, 16, 5, 1, 0), conv2=L.Convolution2D(16, 32, 5, 1, 0), conv3=L.Convolution2D(32, 64, 5, 1, 0), link=L.Linear(None, 1024), link_class=L.Linear(None, n_out), ) def __call__(self, x): h1 = F.max_pooling_2d(F.relu(self.conv1(x)), ksize=2) h2 = F.max_pooling_2d(F.relu(self.conv2(h1)), ksize=2) h3 = F.relu(self.conv3(h2)) h4 = F.relu(self.link(h3)) return self.link_class(h4) # ================================================================================================================
セットアップ
カメラインスタンスの生成やcascadeの読み込み、パラメータの取り込みを行います。
# カメラインスタンス生成 cap = cv2.VideoCapture(args.device) # FPS値の設定 cap.set(cv2.CAP_PROP_FPS, 60) # 顔検出器のセット detector = cv2.CascadeClassifier(args.cascade)
chainer.serializers.load_npz()でネットワークモデルにパラメータを適用します。
注意として、学習フェーズでL.Classifier()でモデルをラップしてインスタンスを生成しましたが、
予測フェーズでも同じようにモデルをL.Classifier()でラップする必要があります。# 学習済みパラメータの読み込み model = L.Classifier(CNN(2)) S.load_npz(args.param, model)
顔認識
まず、カメラで撮影を行います。
cap.read()で撮影を行えます。
1回cap.read()を実行させたら1枚の静画像が得られます。
while文やfor文を使って逐次cap.read()を実行させ、得られる静画像を連続して出力することで動いてるように見せます。
cap.read()は2つの値を返します。
1つめは撮影ができているか否かのフラグ(コード上では_)。
2つめに実際に撮影した静画像(コード上ではframe)。以下、静画像をフレームと表記します。
while True: # フレーム取得 _, frame = cap.read() # カメラ認識不可->例外 if _ == False: print("\nException: Camera read failure.\n".format(args.param)) sys.exit() # 顔検出 gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = detector.detectMultiScale(gray) # 顔未検出->continue if len(faces) == 0: cv2.putText(frame, "face is not found", p, cv2.FONT_HERSHEY_SIMPLEX, 1.0, red, thickness=2) cv2.imshow("frame", frame) if cv2.waitKey(1) & 0xFF == ord('q'): break continueフレーム取得後、フレームをグレースケール化し、Haar-Like特徴量のCascadeを用いて顔検出を行います。
detector.detectMultiScale()は顔を検出した場合、検出位置の情報(座標と幅高さ)を返し、検出できなかった場合は、
なにも返しません。顔を検出できなかった時、ウィンドウ上に「face is not found」と出力し、continueします。
顔を検出した時の処理を説明します。
返却される検出箇所のx座標とy座標、幅と高さを用いて、画像処理を施します。
# 顔検出時 for (x, y, h, w) in faces: # 顔領域表示 cv2.rectangle(frame, (x, y), (x+w, y+h), red, thickness=2) # 顔が小さすぎればスルー if h < 50 and w < 50: cv2.putText(frame, "detected face is too small", p, cv2.FONT_HERSHEY_SIMPLEX, 1.0, red, thickness=2) cv2.imshow("frame", frame) break # 検出した顔を表示 cv2.imshow("gray", cv2.resize(gray[y:y + h, x:x + w], (250, 250))) # 画像処理 face = gray[y:y + h, x:x + w] face = Image.fromarray(face) face = np.asarray(face.resize((32, 32)), dtype=np.float32) recog_img = face[np.newaxis, :, :] # 顔識別 y = model.predictor(chainer.Variable(np.array([recog_img]))) c = F.softmax(y).data.argmax() if c == 0: cv2.putText(frame, "Abe Sinzo", p, cv2.FONT_HERSHEY_SIMPLEX, 1.0, green, thickness=2) elif c == 1: cv2.putText(frame, "Aso Taro", p, cv2.FONT_HERSHEY_SIMPLEX, 1.0, green, thickness=2) cv2.imshow("frame", frame) if cv2.waitKey(1) & 0xFF == ord('q'): break画像処理は具体的に、
①フレームから顔領域の切り出し
②顔領域をリサイズするために、一度配列(array)から画像に変換
③32px×32pxにリサイズ
④配列の次元を追加(チャンネル数の追加, [チャンネル数, 高さ, 幅])
を行ってます。さて、識別できる形にデータを加工できたら、いよいよ顔の認識です。
y = model.predictor(chainer.Variable(np.array([recog_img])))
で予測を開始します。chainer.Variable()はデータを連鎖律に対応付けさせる関数です。
次に、c = F.softmax(y).data.argmax()で予測結果をソフトマックス関数に通した後、argmaxで
もっとも大きい要素(インデックス)を返却します。そして最後にif文を使って、要素(インデックス)に対応したクラス名を出力してやります。
今回は安倍晋三と麻生太郎の2クラス分類ですが、どちらでもない顔を学習させて、
安倍晋三でも麻生太郎でもない顔を入力させたとき、「どちらでもない」なんていう出力をすることも可能です。おわりに
もともと、これらのプログラムは高校の課題研究(卒業研究)で開発したものなのでコードとか適当です。
分類するクラス数を変えるのは学習データさえあれば容易にできますので、好きなようにしていただければなと思います。


- 投稿日:2020-03-05T13:09:26+09:00
時差出勤始まったので退勤時刻を教えてくれるBotを作った
昨今の感染症の影響で時差出勤が始まったので
出勤時間を投稿すると退勤時間を教えてくれるBotを作ってみました。環境
- python 3.6.6
- Heroku
参考
SlackBotプロジェクトのディレクトリ構成、Herokuとの連携については以下サイトを参考にさせていただきました。
https://qiita.com/akabei/items/ec5179794f9e4e1df203ソースコード
上記、参考にさせていただいたサイトを元にSlackBotの動作が確認できた(おみくじ引けた)ので、退勤時間を計算するコードを作成していきます
・投稿時刻を出社時刻として退勤時間を計算する
from datetime import datetime, timedelta, timezone from slackbot.bot import listen_to @listen_to(r'^出勤$') def work_time(message): JST = timezone(timedelta(hours=+9), 'JST') start_now = datetime.now(JST) end_time = start_now + timedelta(hours=8, minutes=45) message.reply(end_time.strftime("%H:%M"))実行結果 ↓↓
これだと出社してすぐにメッセージを送らないといけないので、時間指定できるパターンも作ります
・出勤時刻を指定して退勤時刻を計算する
import re from datetime import datetime, timedelta, timezone from slackbot.bot import respond_to, listen_to @listen_to(r'^出勤\s[0-9]+:[0-9]+$') def work_time(message): JST = timezone(timedelta(hours=+9), 'JST') current = datetime.now(JST) text = message.body['text'] result = re.match(".*\s([0-9]+):([0-9]+)", text) hour = result.group(1) minute = result.group(2) start_now = datetime( year=current.year, month=current.month, day=current.day, hour=int(hour), minute=int(minute)) end_time = start_now + timedelta(hours=8, minutes=45) message.reply(end_time.strftime("%H:%M"))実行結果 ↓↓
こでれ何時に出社しても、定時は何時だ?と悩まなくてもよくなりました
まとめ
・(わかりやすくまとめていただけていた記事があったので)SlackBotをデプロイしてやりとりできるようになるまでが簡単だった
・多くの人が時差出勤になったことで、遅い時間の電車が混んできたので結局元の時間に戻って、Botの活躍の場はなくなってしまった
- 投稿日:2020-03-05T12:35:46+09:00
Pandas DataFrame を CSV ファイルとしてダウンロードさせる
Web サーバを Python で作っていて、Pandas DataFrame を CSV ファイルとしてダウンロードさせたいときのメモ。
body = df.to_csv(index=False).encode('utf_8_sig') headers = { 'Content-Type': 'text/csv', 'Content-Disposition': 'attachment; filename="data.csv"', } return web.Response(body=body, headers=headers)これは aiohttp Server の例だが、他のフレームワークでも同様だと思う。
pandas.DataFrame.to_csvは出力先を指定しなければそのまま CSV 文字列を返してくれる- CSV ファイルが Excel で開かれることが想定される場合は
utf_8_sig(BOM 付き UTF-8) でエンコードしておくと文字化けしなくて良いContent-Dispositionヘッダを付加することでダウンロード時のファイル名を指定することができる
- 日本語ファイル名を使う時はエンコードが必要
このあたりがポイント。
- 投稿日:2020-03-05T12:13:56+09:00
言語処理100本ノック-45:動詞の格パターンの抽出
言語処理100本ノック 2015「第5章: 係り受け解析」の45本目「動詞の格パターンの抽出」記録です。
ifの条件分岐も増え、少しずつ複雑になっています。アルゴリズム考えるのがやや面倒です。参考リンク
リンク 備考 045.動詞の格パターンの抽出.ipynb 回答プログラムのGitHubリンク 素人の言語処理100本ノック:45 多くのソース部分のコピペ元 CaboCha公式 最初に見ておくCaboChaのページ 環境
CRF++とCaboChaはインストールしたのが昔すぎてインストール方法忘れました。全然更新されていないパッケージなので、環境再構築もしていません。CaboChaをWindowsで使おうと思い、挫折した記憶だけはあります。確か64bitのWindowsで使えなかった気がします(記憶が曖昧だし私の技術力の問題も多分にあるかも)。
種類 バージョン 内容 OS Ubuntu18.04.01 LTS 仮想で動かしています pyenv 1.2.16 複数Python環境を使うことがあるのでpyenv使っています Python 3.8.1 pyenv上でpython3.8.1を使っています
パッケージはvenvを使って管理していますMecab 0.996-5 apt-getでインストール CRF++ 0.58 昔すぎてインストール方法忘れました(多分 make install)CaboCha 0.69 昔すぎてインストール方法忘れました(多分 make install)第5章: 係り受け解析
学習内容
『吾輩は猫である』に係り受け解析器CaboChaを適用し,係り受け木の操作と統語的な分析を体験します.
ノック内容
夏目漱石の小説『吾輩は猫である』の文章(neko.txt)をCaboChaを使って係り受け解析し,その結果をneko.txt.cabochaというファイルに保存せよ.このファイルを用いて,以下の問に対応するプログラムを実装せよ.
45. 動詞の格パターンの抽出
今回用いている文章をコーパスと見なし,日本語の述語が取りうる格を調査したい.動詞を述語,動詞に係っている文節の助詞を格と考え,述語と格をタブ区切り形式で出力せよ.ただし,出力は以下の仕様を満たすようにせよ.
- 動詞を含む文節において,最左の動詞の基本形を述語とする
- 述語に係る助詞を格とする
- 述語に係る助詞(文節)が複数あるときは,すべての助詞をスペース区切りで辞書順に並べる
「吾輩はここで始めて人間というものを見た」という例文(neko.txt.cabochaの8文目)を考える.この文は「始める」と「見る」の2つの動詞を含み,「始める」に係る文節は「ここで」,「見る」に係る文節は「吾輩は」と「ものを」と解析された場合は,次のような出力になるはずである.
始める で 見る は をこのプログラムの出力をファイルに保存し,以下の事項をUNIXコマンドを用いて確認せよ.
- コーパス中で頻出する述語と格パターンの組み合わせ
- 「する」「見る」「与える」という動詞の格パターン(コーパス中で出現頻度の高い順に並べよ)
課題補足(「格」について)
プログラムを完成させる目的では特に意識をしませんが、日本語の「格」というのは奥が深そうです。興味が出たらWikipedit「格」を見てみましょう。私はチラ見程度です。
昔、オーストラリアでランゲージ・エクスチェンジをしていたときに「は」と「が」の何が違うのかを聞かれたことを思い出しました。回答
回答プログラム 045.動詞の格パターンの抽出.ipynb
import re # 区切り文字 separator = re.compile('\t|,') # 係り受け dependancy = re.compile(r'''(?:\*\s\d+\s) # キャプチャ対象外 (-?\d+) # 数字(係り先) ''', re.VERBOSE) def __init__(self, line): #タブとカンマで分割 cols = separator.split(line) self.surface = cols[0] # 表層形(surface) self.base = cols[7] # 基本形(base) self.pos = cols[1] # 品詞(pos) self.pos1 = cols[2] # 品詞細分類1(pos1) class Chunk: def __init__(self, morphs, dst): self.morphs = morphs self.srcs = [] # 係り元文節インデックス番号のリスト self.dst = dst # 係り先文節インデックス番号 self.verb = '' self.joshi = '' for morph in morphs: if morph.pos != '記号': self.joshi = '' # 記号を除いた最終行の助詞を取得するため、記号以外の場合はブランク if morph.pos == '動詞': self.verb = morph.base if morph.pos == '助詞': self.joshi = morph.base # 係り元を代入し、Chunkリストを文のリストを追加 def append_sentence(chunks, sentences): # 係り元を代入 for i, chunk in enumerate(chunks): if chunk.dst != -1: chunks[chunk.dst].srcs.append(i) sentences.append(chunks) return sentences, [] morphs = [] chunks = [] sentences = [] with open('./neko.txt.cabocha') as f: for line in f: dependancies = dependancy.match(line) # EOSまたは係り受け解析結果でない場合 if not (line == 'EOS\n' or dependancies): morphs.append(Morph(line)) # EOSまたは係り受け解析結果で、形態素解析結果がある場合 elif len(morphs) > 0: chunks.append(Chunk(morphs, dst)) morphs = [] # 係り受け結果の場合 if dependancies: dst = int(dependancies.group(1)) # EOSで係り受け結果がある場合 if line == 'EOS\n' and len(chunks) > 0: sentences, chunks = append_sentence(chunks, sentences) with open('./045.result_python.txt', 'w') as out_file: for sentence in sentences: for chunk in sentence: if chunk.verb != '' and len(chunk.srcs) > 0: # 係り元助詞のリストを作成 sources = [sentence[source].joshi for source in chunk.srcs if sentence[source].joshi != ''] if len(sources) > 0: sources.sort() out_file.write(('{}\t{}\n'.format(chunk.verb, ' '.join(sources))))以下はUNIXコマンド部分です。
grepコマンドを初めて使いましたが便利なのですね。UNIXコマンド部# ソート、重複除去とカウント、降順ソート sort 045.result_python.txt | uniq --count | sort --numeric-sort --reverse > "045.result_1_すべて.txt" # 「(行頭)する(空白)」を抽出、ソート、重複除去とカウント、降順ソート grep "^する\s" 045.result_python.txt | sort | uniq --count | sort --numeric-sort --reverse > "045.result_2_する.txt" # 「(行頭)見る(空白)」を抽出、ソート、重複除去とカウント、降順ソート grep "^見る\s" 045.result_python.txt | sort | uniq --count | sort --numeric-sort --reverse > "045.result_3_見る.txt" # 「(行頭)与える(空白)」を抽出、ソート、重複除去とカウント、降順ソート grep "^与える\s" 045.result_python.txt | sort | uniq --count | sort --numeric-sort --reverse > "045.result_4_与える.txt"回答解説
Chunkクラス
Chunkクラスで動詞と助詞の原型を格納しています。1文節に複数の動詞があった場合は、後勝ちにしています。格となる助詞は文節の最後に出てくるはずなのですが、記号を考慮した条件分岐を入れています。
class Chunk: def __init__(self, morphs, dst): self.morphs = morphs self.srcs = [] # 係り元文節インデックス番号のリスト self.dst = dst # 係り先文節インデックス番号 self.verb = '' self.joshi = '' for morph in morphs: if morph.pos != '記号': self.joshi = '' # 記号を除いた最終行の助詞を取得するため、記号以外の場合はブランク if morph.pos == '動詞': self.verb = morph.base if morph.pos == '助詞': self.joshi = morph.base出力部分
係り元の助詞はリスト内包表記でリスト化して、「辞書順に並べる」を満たすためにソートしています。そして、最後に
join関数を使ってスペース区切りで出力しています。ネストが深くて、書いていて気持ち悪いです。with open('./045.result_python.txt', 'w') as out_file: for sentence in sentences: for chunk in sentence: if chunk.verb != '' and len(chunk.srcs) > 0: # 係り元助詞のリストを作成 sources = [sentence[source].joshi for source in chunk.srcs if sentence[source].joshi != ''] if len(sources) > 0: sources.sort() out_file.write(('{}\t{}\n'.format(chunk.verb, ' '.join(sources))))出力結果(実行結果)
プログラム実行すると以下の結果が出力されます。多いので10行だけここに表示します。
Pythonの出力結果
045.result_python.txt(冒頭10行)生れる で つく が と 泣く で いる て は 始める で 見る は を 聞く で 捕える を 煮る て 食う てUNIXコマンドの出力結果
多いので10行だけここに表示します。
045.result_1_すべて.txt(冒頭10行)3176 ある が 1997 つく が と 800 云う は 721 ある が と に 464 られる に 330 られる て と 309 思う と 305 見る の 301 かく たり を 262 ある まで045.result_2_する.txt(冒頭10行)1099 する が 651 する が と 221 する で に は 109 する でも に 86 する まで 59 する と は は は 41 する たり は へ 27 する たり と は を 24 する て まで 18 する として045.result_3_見る.txt(冒頭10行)305 見る の 99 見る は を 31 見る て て は 24 見る から て 19 見る から 11 見る から て て 7 見る が ので 5 見る て て て は 2 見る ながら に を 2 見る で ばかり も「与える」は出現頻度少なかく、これで全部です。
045.result_4_与える.txt7 与える に を 4 与える で に を 3 与える て と は を 1 与える けれども は を 1 与える か として 1 与える が て と に は を
- 投稿日:2020-03-05T10:52:35+09:00
Herokuを使ってMySQLへ接続する手順まとめ
概要
現在制作しているラインボットにデータベースを使った機能を追加しようと思い、Herokuを用いてMySQLへの接続を試みたがかなり躓いた所があったので今回まとめていこうと思います。
環境
- macOS
- python3.7.1
- MySQL5.6.47
- mysqlclient1.4.6
この記事で書かないこと
- MySQLの詳細なクエリの使い方
手順
1.MySQLのインストール
MySQLそのものを
pip install mysqlでインストールします。2.コネクタのインストール
コネクタのインストールを行います。
正直役割がよく理解できていませんが、名前の通りMySQLのサーバーとの接続の為に必要だと思われます。
コネクタには目的や使用言語等でいくつもの種類がありますが、自分はmysqlclientを使用しています。
こちらもpip install mysqlclientでインストールします。3.Herokuでの準備
自分の場合は後述のMySQLの準備などを全て終えた後に、いざ動作確認をしようとHerokuへコードをプッシュし動かしてみたのですが、MySQLのインポートエラーが出てしまいました。
原因は二つあったのですが、まず一つ目がプッシュしたファイルの内、requirementsの記載です。
こちらにMySQLのコネクターを記載していなかった為、エラーが発生しました(因みに、最初はよくわからずMySQL自体のバージョンを記載していたのですが、これだとプッシュした時点でエラーが発生します)。二つ目は、HerokuでMySQLを使う際はClearDBというものを使うらしく、そこから作ったアカウントが必要になります。
詳しい登録方法は割愛しますが、注意点として殆どのClearDBについての記事で、登録した後環境変数のCLEARDB_DATABASE_URLをコピーして先頭をmysql2に変更してDATABASE_URLに設定すると書いてありますが、こちらの操作はRubyの場合にのみ必要みたいです。その為、今回は
heroku addons:create cleardb:igniteでClearDBを追加した際のCLEARDB_DATABASE_URLのアカウントをそのまま使用しMySQLに入ることにしました。
CLEARDB_DATABASE_URLにmysql://[username]:[password]@[hostname]/[db_name]?reconnect=trueの形で記載されているので、ターミナル上でmysql --host=[hostname] --user=[username] --password=[password] [db_name]と入力すれば入ることができます。4.MySQLでの準備
無事MySQLに入ることができたら必要なテーブルなどを作成していくのですが、ここで問題が発生。
普通にテーブルを作ろうとモニタでクエリを打ち込んだのですが、ERROR 2013というエラーがでました。
エラーメッセージで調べてみると、connect_timeoutなどの数値を大きくすれば解決するようでしたが、根本的な解決策ではないというのとrootユーザーで入れば問題なく処理ができることから、ClearDB特有の問題があるのではないかと考えました。
そこで、ClearDBのサイトをよく見てみると、データベースの編集等を行う際は、MySQL Workbench,Sequel Pro for Mac OS X,Navicatなどの使用を推奨します。
という旨の記載を発見。
これらは、直接クエリを入力せずにMySQLの操作を行うことができるGUIツールらしく、以前どなたかの記事でMySQL Workbenchを使っているのを見たのでこちらを試すことに。
詳しい操作方法などはこちらの記事を参考に、無事必要なテーブルを作成することができました。余談ですがMySQLの練習がてら初めてrootユーザーでMySQLに入ろうとした際、パスワードがいくら探しても分かりませんでした。
MySQLをインストールしたときの所定のファイルに初期パスワードが記載してあるということまでは分かったのですが、いくら手順通りにやってもこのファイルを見つけることができませんでした。
結果としてこちらの記事を参考に何とかMySQLに入ることができました。まとめ
長々と書きましたが要約すると
- MySQLのインストール
- コネクタのインストール
- HerokuでClearDBの登録(requirementsにコネクタのバージョンを記載)
- MySQL WorkbenchでClearDB内の編集
となります。
今回、データベースという新しい分野に挑戦してみて、今までやってきたコードを正確に書くということとは別の視点が必要になりとても勉強になりました。
ベータベースはほぼ全てのサービスで必須らしいので、今回を機にしっかりと知識を身に着け自分のスキルの幅を広げたいと思います。参考
- 投稿日:2020-03-05T09:57:55+09:00
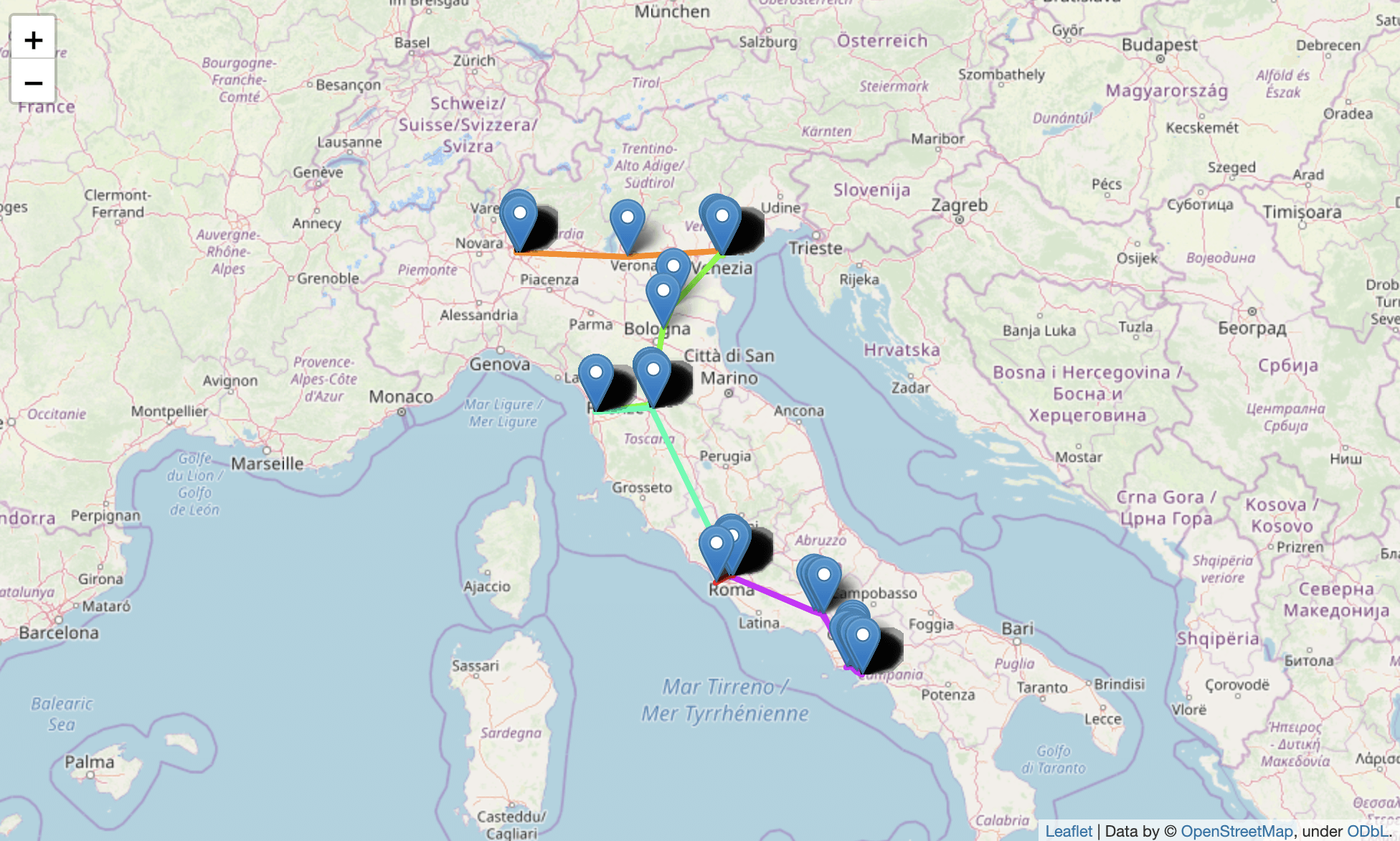
イタリア新婚旅行の地図アルバムをPythonで作って共有してみた結果
しばらく前にイタリアへ新婚旅行に行きました。ミラノ・ヴェネツィア・フィレンツェ・ピサ・ローマ・ポンペイを1週間で回るツアーで、気づいたら1000枚くらい写真を撮っていました〜。
そこそこ自由時間もあって毎日1万歩くらいは散策したのでルート込みで記録に残しておきたい、ということで地図アルバムを作ってみました……!可視化
全体像はこんな感じ。OpenStreetMapの地図を使ってます。
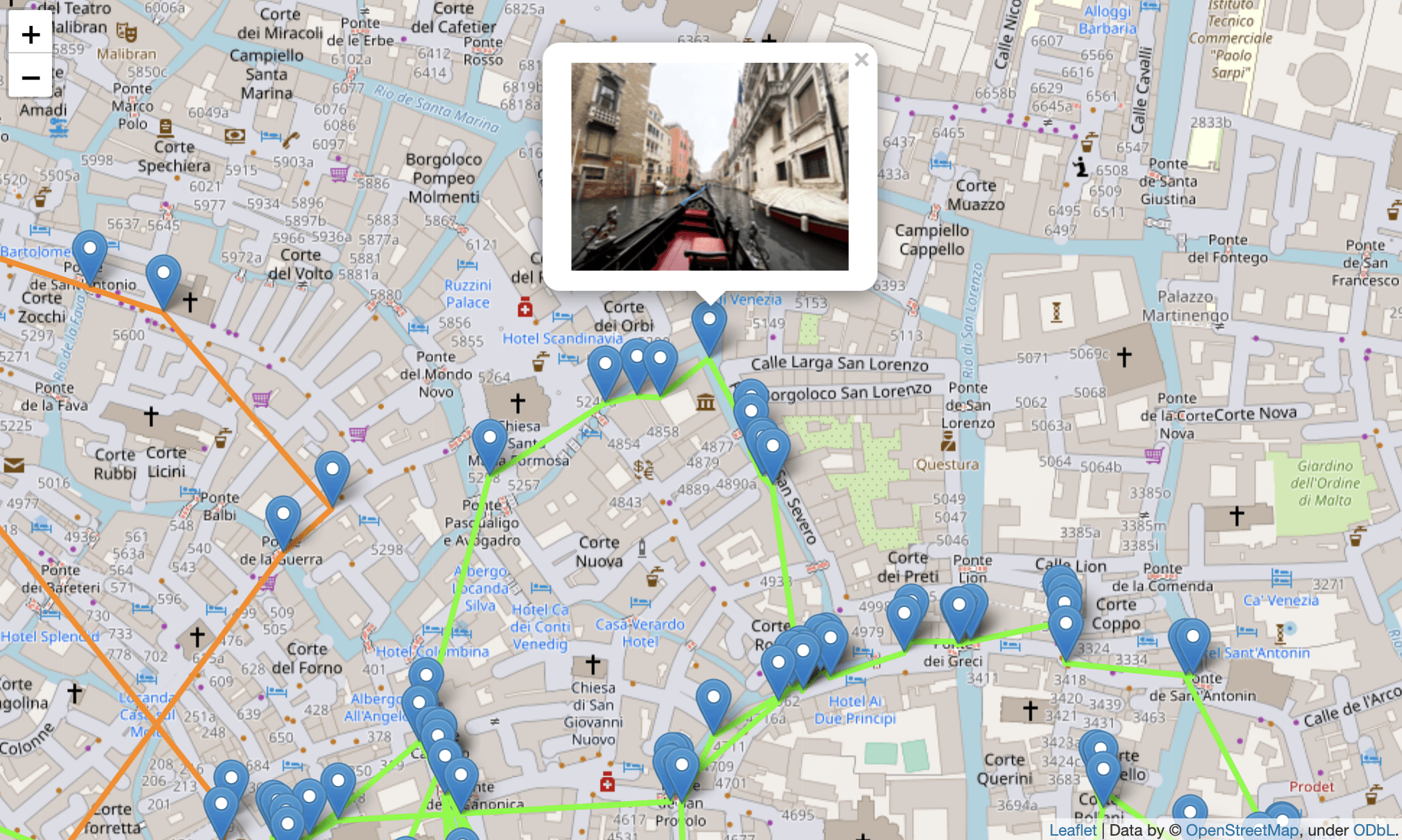
ここから、たとえばヴェネツィアをズームアップすると、こんな風に散策ルートが見れます。日にちによって色分けをしていて、ヴェネツィアは一泊したので二色ルートがありますね。
そしてマーカーが写真を撮ったポイントで、クリックすると写真がポップアップします。
こちらが元写真です。ゴンドラ遊覧中に撮ったので、マーカーも水路上にあります。
ヴェネツィアは『ARIA』の聖地ということで楽しみにしていたのですが、期待より遥かに幻想的な水の都でした。全力でオススメします。
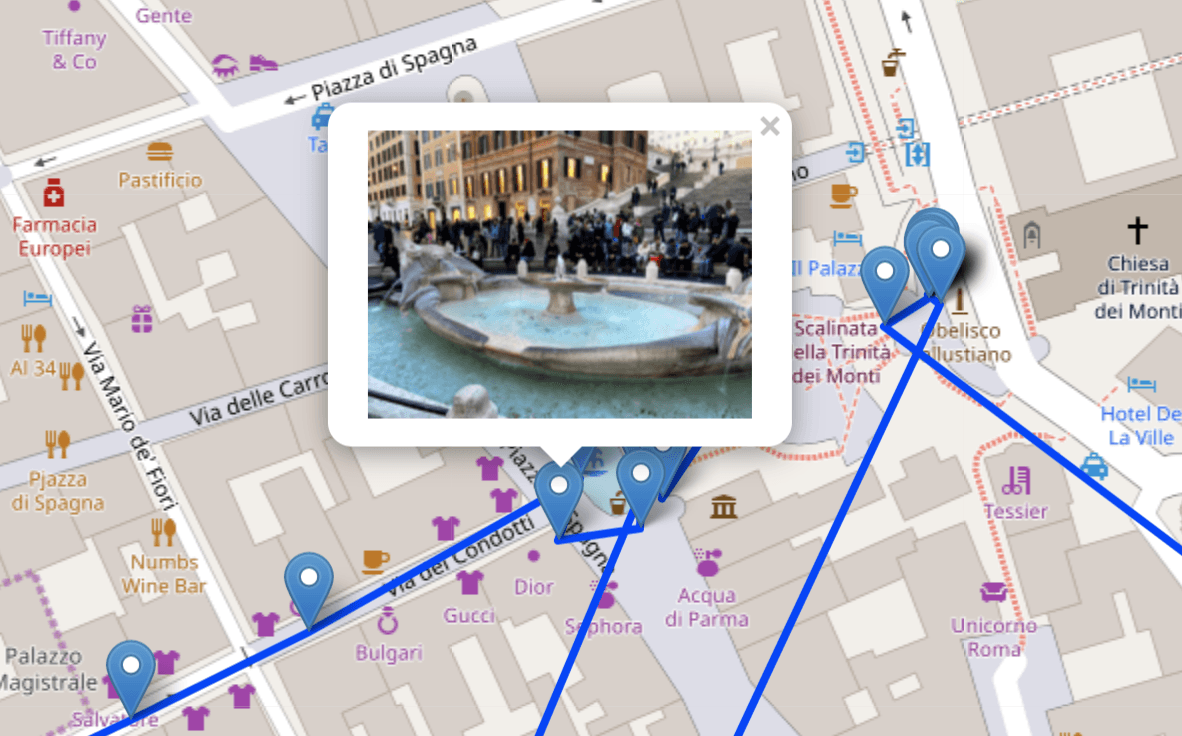
こちらは不朽の名作『ローマの休日』の聖地であるところのスペイン広場です。行きの飛行機で観ました(ぉぃ
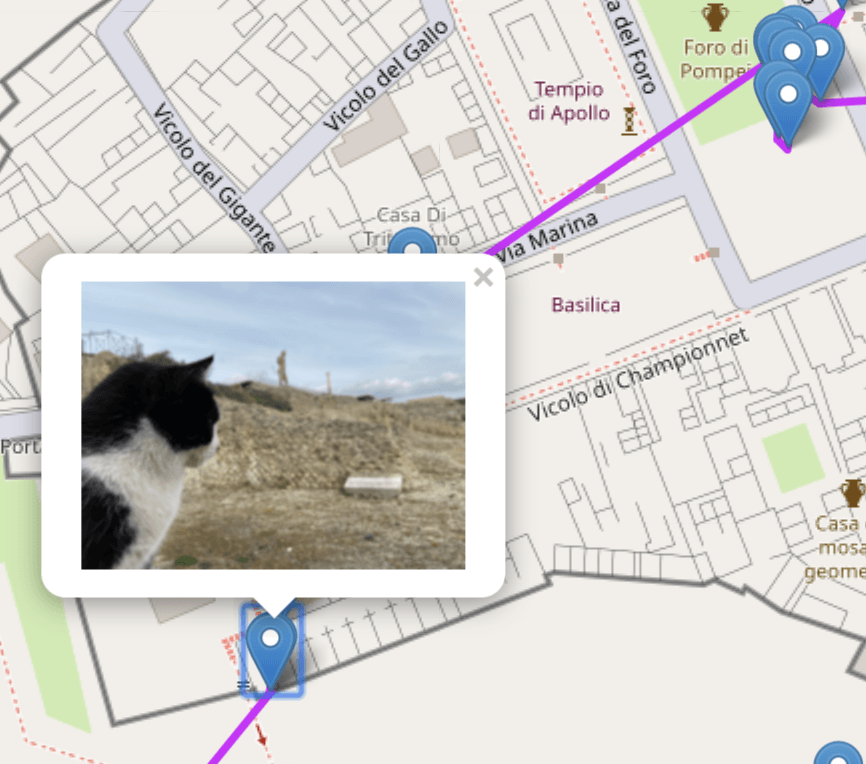
こちらは噴火で滅んだポンペイを見守る猫です。ここにねこが出没します。ねこでした。よろしくおねがいします
反応
家族や友人たちに共有してみたのですが、旅路を追いながら写真を見せつつ思い出を話せたので、だいぶウケ良かったです。この屋台通りを抜けて、このお店でふらっと夕食取って、この道走って集合時間ギリギリだったんだよー、みたいな。
ただJupyterLabのノートブックをエクスポートしたHTMLファイルをそのまま共有したので、エンジニア系の人たちはPythonのコードを読みはじめてしまい、こちらの話をなかなか聞いてくれないという難点はありましたw手順
JupyterLab上で50行程度のPythonコードを書いて、次のような処理を行いました。
Foliumは業務でも使いはじめているのですが、とてもお手軽ですね。
- Pillowで画像ファイルを読みこむ。
- 画像のExifから緯度・経度の情報を抜く。
- 画像のExifから回転・反転の情報を抜いて適用する。
- Foliumに緯度・経度の列を食わせてルートを描く。
- Foliumに緯度・経度とBase64にエンコードした画像を食わせてマーカーを打つ。
- JupterLabでHTML出力する。
Foliumのマーカーにはimageタグを渡せるのですが、どうもローカルファイルは参照できないようなので、Base64にエンコードするという荒技を使っています。
おかげで独立した単一のHTMLファイルを出力できるので共有するのは楽なのですが、縮小しているとはいえ1000枚ほどの画像をぶち込んでいるので、100MBほどのHTMLファイルになりました……wコード
import base64 import folium import glob import pandas as pd from io import BytesIO from matplotlib import pyplot as plt from PIL import ExifTags, Image, ImageOpsdef to_deg(v, ref, pos): d = float(v[0][0]) / float(v[0][1]) m = float(v[1][0]) / float(v[1][1]) s = float(v[2][0]) / float(v[2][1]) return (d + (m / 60.0) + (s / 3600.0)) * (1 if ref == pos else -1)to_trans_methods = { 1: [], 2: [Image.FLIP_LEFT_RIGHT], 3: [Image.ROTATE_180], 4: [Image.FLIP_TOP_BOTTOM], 5: [Image.FLIP_LEFT_RIGHT, Image.ROTATE_90], 6: [Image.ROTATE_270], 7: [Image.FLIP_LEFT_RIGHT, Image.ROTATE_270], 8: [Image.ROTATE_90] }files = glob.glob('/path/to/*.jpg')rows = [] for file in files: with Image.open(file) as im: exif = {ExifTags.TAGS[k]: v for k, v in im.getexif().items() if k in ExifTags.TAGS} if 'GPSInfo' in exif: gps = {ExifTags.GPSTAGS[k]: v for k, v in exif['GPSInfo'].items() if k in ExifTags.GPSTAGS} lat = to_deg(gps['GPSLatitude'], gps['GPSLatitudeRef'], 'N') lon = to_deg(gps['GPSLongitude'], gps['GPSLongitudeRef'], 'E') im.thumbnail((192, 192)) for method in to_trans_methods[exif.get('Orientation', 1)]: im = im.transpose(method) buf = BytesIO() im.save(buf, format="png") rows.append([lat, lon, exif['DateTimeOriginal'], base64.b64encode(buf.getvalue()).decode()]) df = pd.DataFrame(rows, columns=['lat', 'lon', 'dt', 'base64']) df['dt'] = pd.to_datetime(df['dt'], format='%Y:%m:%d %H:%M:%S') df = df.sort_values('dt')fmap = folium.Map(location=[df['lat'].mean(), df['lon'].mean()], zoom_start=6) hsv=[plt.get_cmap('hsv', 12)(i) for i in range(12)] fmap.add_child(folium.ColorLine(zip(df['lat'], df['lon']), colors=df['dt'].dt.day, colormap=hsv, weight=4)) for _, row in df.iterrows(): fmap.add_child(folium.Marker([row['lat'], row['lon']], popup=f'<img src="data:image/png;base64,{row["base64"]}">')) fmap実行環境
$ python --version Python 3.7.4 $ pip list | grep -e folium -e jupyter -e matplotlib -e pandas -e Pillow folium 0.10.1 jupyter-client 5.3.3 jupyter-core 4.5.0 jupyterlab 1.1.4 jupyterlab-server 1.0.6 matplotlib 3.1.2 pandas 1.0.1 Pillow 7.0.0参考リンク
Pythonで写真に埋め込まれているGPS情報から撮影場所を調べよう | マイナビニュース
PILでEXIF Orientationタグを考慮して処理 | Qiita
View image on popup | python-visualization/folium

- 投稿日:2020-03-05T09:10:34+09:00
PythonでWeb APIを叩く
PythonでHTTPにアクセスする方法
- urllibライブラリを使う
- 標準で搭載
- Requestsライブラリを使う
- 要インストール。こちらの方がシンプルにコードを書ける。
今回は、Requestsライブラリを使ってREST形式のWeb APIを扱います。
HTTPメソッド
使う前に HTTPメソッド/REST API について簡単に触れておきます。
クライアントからサーバーに対して行うリクエストの種類をメソッドと呼び、基本的には以下の8種類があります。
メソッド 説明 GET リソースの取得 HEAD リソースのHTTPヘッダーのみを取得 POST クライアントからサーバにデータを送る PUT リソースを保存 DELETE リソースの削除 CONNECT サーバとの間にトンネルを確立 OPTIONS サーバが許可しているメソッドを調べる TRACE サーバまでのネットワーク経路を調べる REST API は、4つのHTTPメソッド「GET」「POST」「PUT」「DELETE」を使用したAPI実装のこと。
HTTPメソッド RESTにおける動作 GET リソース取得(READ) POST リソース作成(CREATE) PUT リソース更新(UPDATE) DELETE リソース削除(DELETE) Requestsライブラリ インストール
インストールはpipで行います。
pip install requests使い方
基本的には以下のようにURLを指定してやればOK(パラメータは任意)
import requests url = "http://xxxxx" pyaload = {"key1":"value1", "key2":"value2"} r = requests.get(url, params=payload)GET以外も使い方は同じ。
r = requests.post(url) r = requests.put(url) r = requests.delete(url)レスポンス
サーバからのレスポンスは、レスポンスの形式に応じて以下のように確認できます。
# テキスト r.text # バイナリ r.content # JSON r.json() # 生レスポンス r.raw # レスポンスのHTTPステータスコード r.status_code実際に使ってみる
こちらの 郵便番号検索API をPythonから叩いてみます。
import requests url = "http://zip.cgis.biz/xml/zip.php" payload = {"zn": "1310045"} r = requests.get(url, params=payload) r.text実行結果
'<?xml version="1.0" encoding="utf-8" ?>\n<ZIP_result>\n<result name="ZipSearchXML" />\n<result version="1.01" />\n<result request_url="http%3A%2F%2Fzip.cgis.biz%2Fxml%2Fzip.php%3Fzn%3D1310045" />\n<result request_zip_num="1310045" />\n<result request_zip_version="none" />\n<result result_code="1" />\n<result result_zip_num="1310045" />\n<result result_zip_version="0" />\n<result result_values_count="1" />\n<ADDRESS_value>\n<value state_kana="トウキョウト" />\n<value city_kana="スミダク" />\n<value address_kana="オシアゲ" />\n<value company_kana="none" />\n<value state="東京都" />\n<value city="墨田区" />\n<value address="押上" />\n<value company="none" />\n</ADDRESS_value>\n</ZIP_result>\n'参考にしたサイト
- 投稿日:2020-03-05T08:57:29+09:00
COVID-19のデータでネットワーク図を作成しました。
はじめに
厚生労働省のCOVID-19の感染状況のデータを基に、グラフやネットワーク図、データテーブルを作成し、Webアプリケーション化しました。作成したアプリは下のリンクのものとなります。
アプリリンク: https://chomoku.herokuapp.com/covid-19
下はネットワーク図の画面です。
利用しているデータは厚生労働省のサイトから取得しています。スクレイピングといっても、pandasのread_html関数を使っているだけです。下のgithubからも取得できますが、後述するようにアプリからも取得できます。
https://github.com/mazarimono/chomoku/blob/master/src/kosei.csv
今回アプリを作成したきっかけは、東洋経済さんの可視化を見て、自分ではこういうところを見てみたいなと思うところがあったのがきっかけでした。
アプリはタブでページが切り替えられ、次の3つの部分に分かれます。
1つ目は普通のグラフを表示するページ。
2つ目がネットワーク図を表示するページ。
3つ目が用いているCSVファイルをテーブルとして表示し、またそのデータをダウンロードできるページ。アプリはWebフレームワークのDashを用いて作成しました。環境は以下のようになります。
Python 3.7.4
dash 1.9.0
dash-core-components 1.8.0
dash-html-components 1.0.2
dash-cytoscape 0.1.1
dash-table 4.6.0
plotly 4.5.0濃厚接触者数と患者数
今回様々なニュースを見ていて気になったのが、近くに長い時間いると感染するのか?ということでした。そこで、厚生省のウェブサイトの数値を見ていると、濃厚接触者数と周囲の患者の発生というデータがありました(ちなみに周囲の患者の発生はあまり更新されないので、データが正確に状況を表しているかどうかという点は不明瞭です)。
そこで、まずはそのデータを可視化してみることにしました。
患者数グラフのページの左下にそのグラフがあります。これはx軸が濃厚接触者数、y軸が患者数です。
ちなみにこの可視化にはPlotly Expressを使っています。DashではGraphコンポーネントにfigureを渡してグラフを表示させます。コードは次のような感じです。
import dash_core_components as dcc import plotly.express as px dcc.Graph( id="ratio_scatter", figure=px.scatter( df_covid, x="contact_num", y="infection_num", title="接触者数(x軸)と周囲の患者発生(y軸)", hover_data=["新No."], ), className="six columns", )ネットワーク図
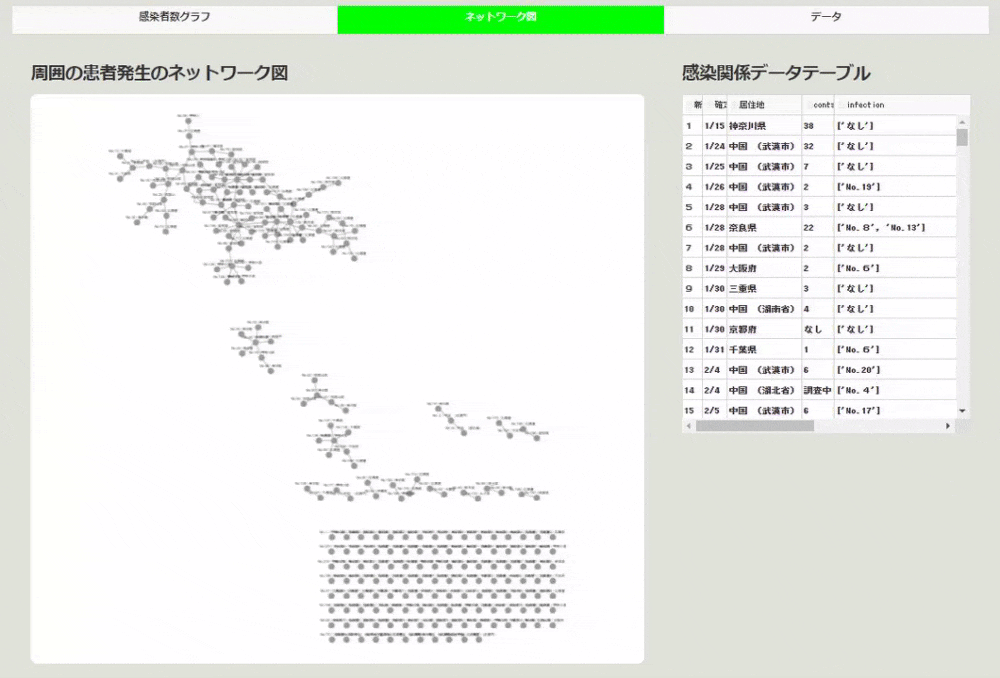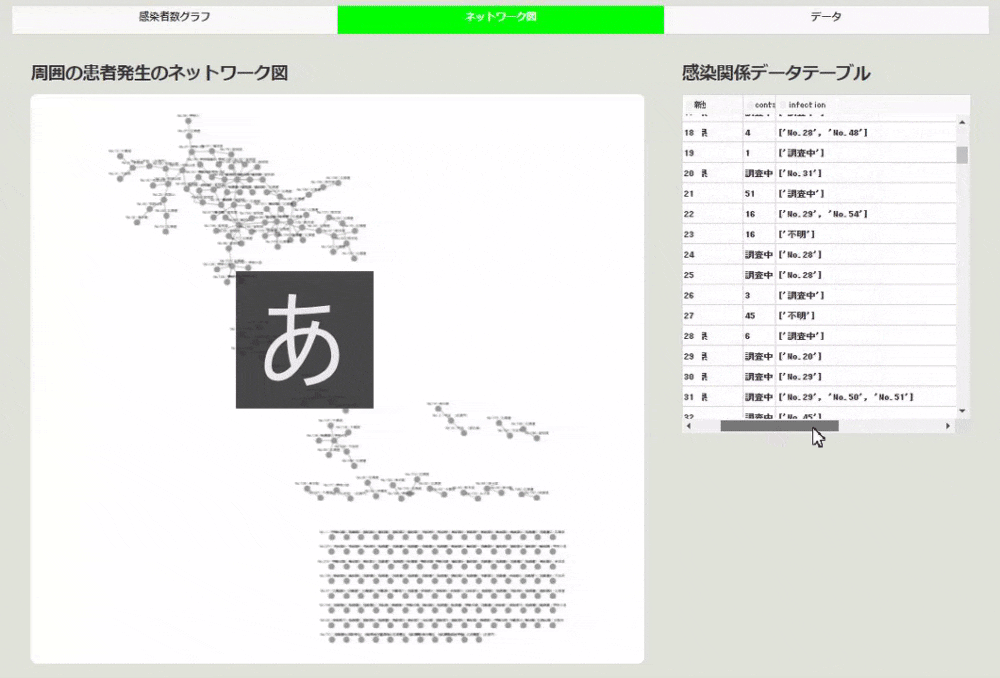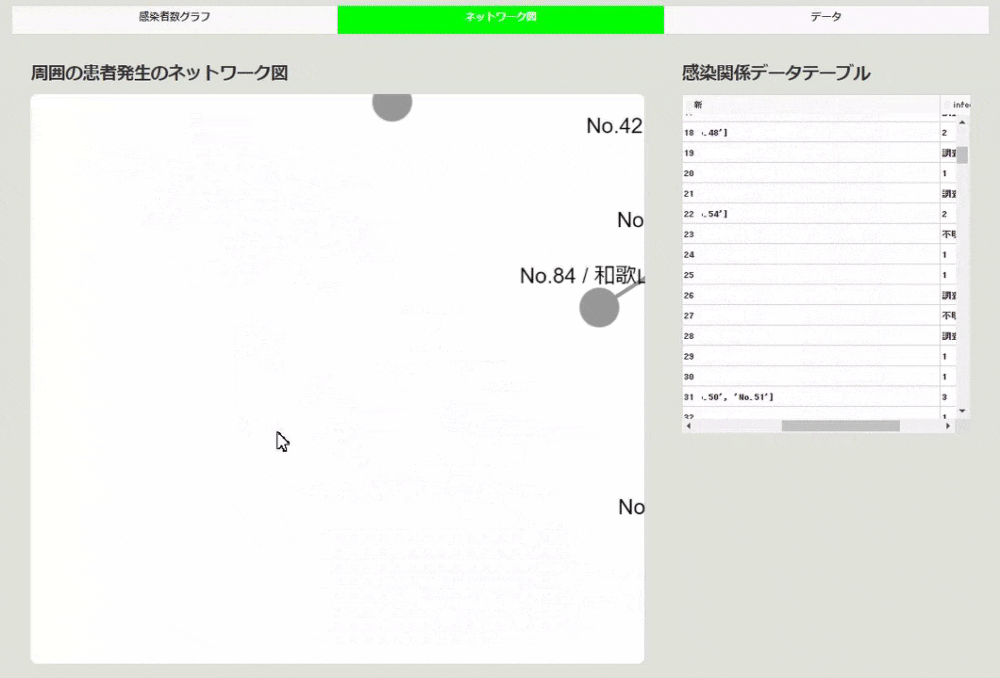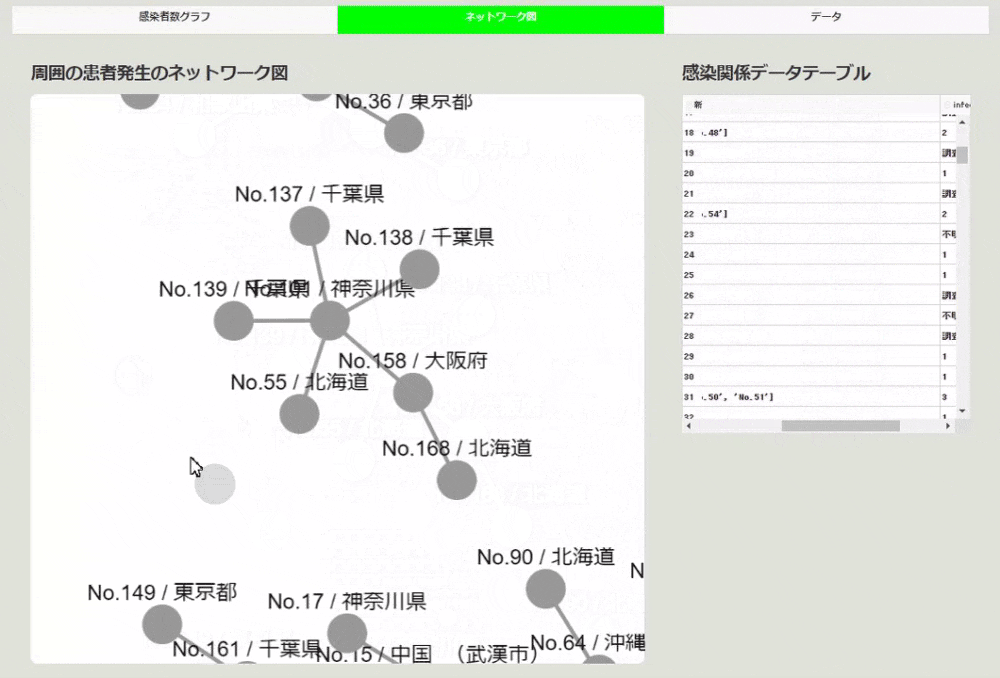
次に、データの「周囲の患者の発生」というところに、患者のナンバーが書かれています。元のデータに「新No.」と「旧No.」があり、どちらを指すのか微妙なところですが、「新No.」を指すと仮定して、ネットワーク図を作成します。
今回ネットワーク図の作成に用いたdash-cytoscapeは、cytoscapeを利用したコンポーネントで、ノードは新No.と居住地を使って作成し、エッジを周囲の患者の発生の番号とつなぎます。そうして、ノードの並びの種類はcoseを選択しています。すると下のようにつながりがあるものを良い感じに並べて表示してくれます。
周囲の患者の発生のデータが「旧No.」で作られていると、このネットワーク図は間違っています。「新No.」で作られているとすると、横につけたデータと比較すると、間違いはなさそうな感じでした。
こうしてみると、かなり患者同士のつながりがありそうにも見えました。ちなみにこの部分の作成はcsvのデータを使って、ノードデータとエッジのデータを作って、cytoscapeで可視化するという感じになっております。コードは次のような感じです。
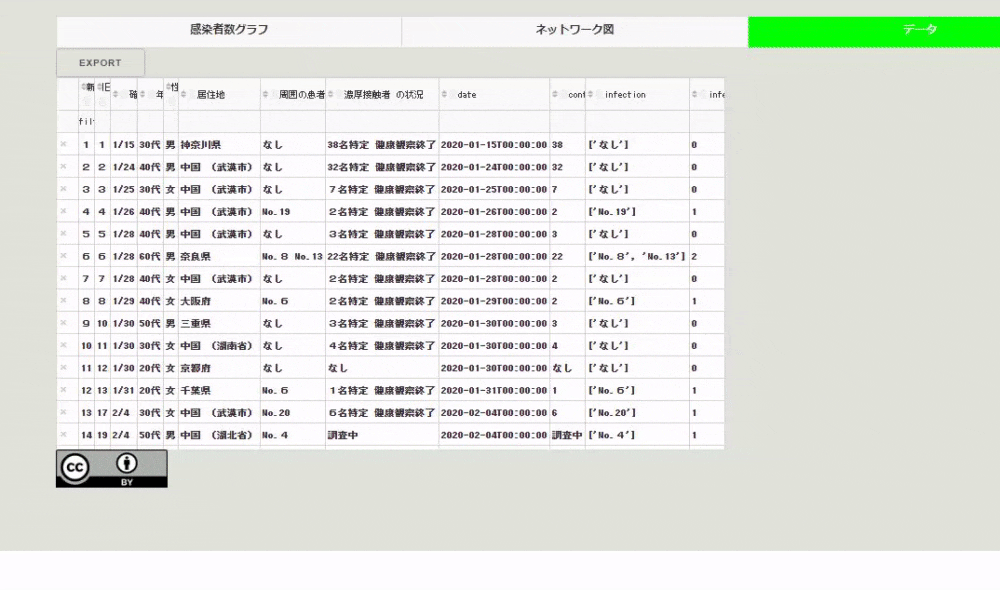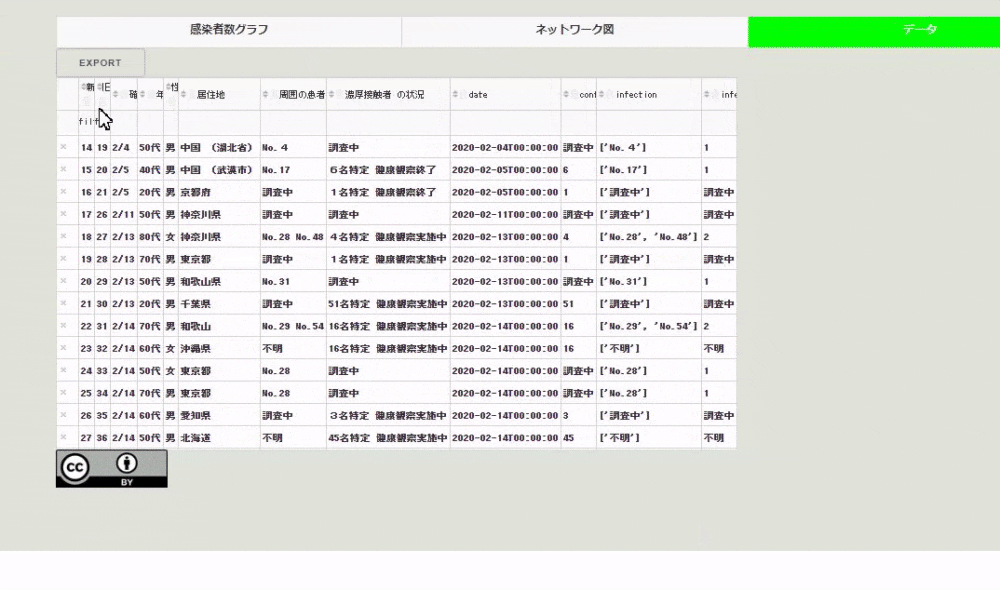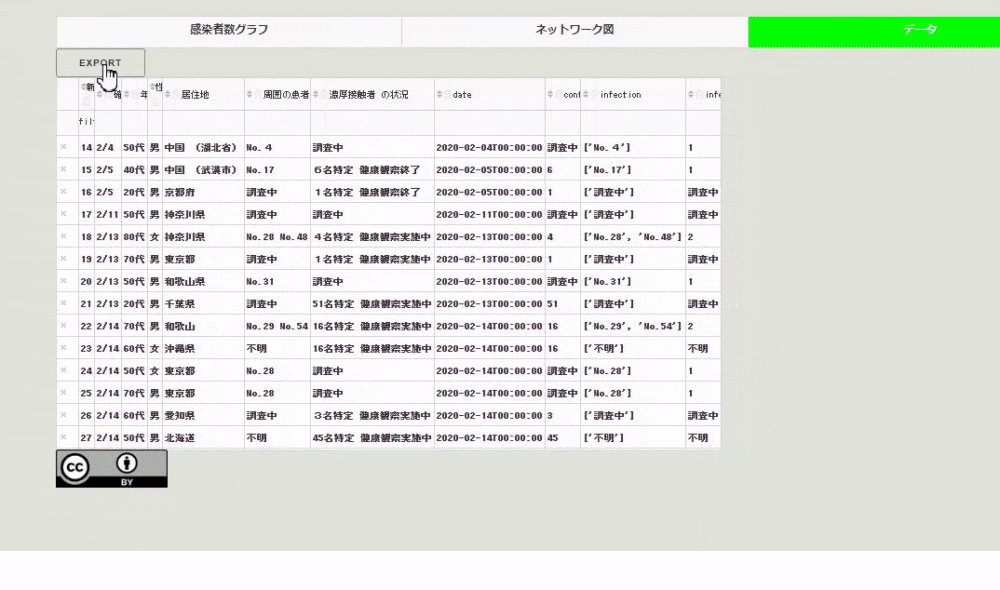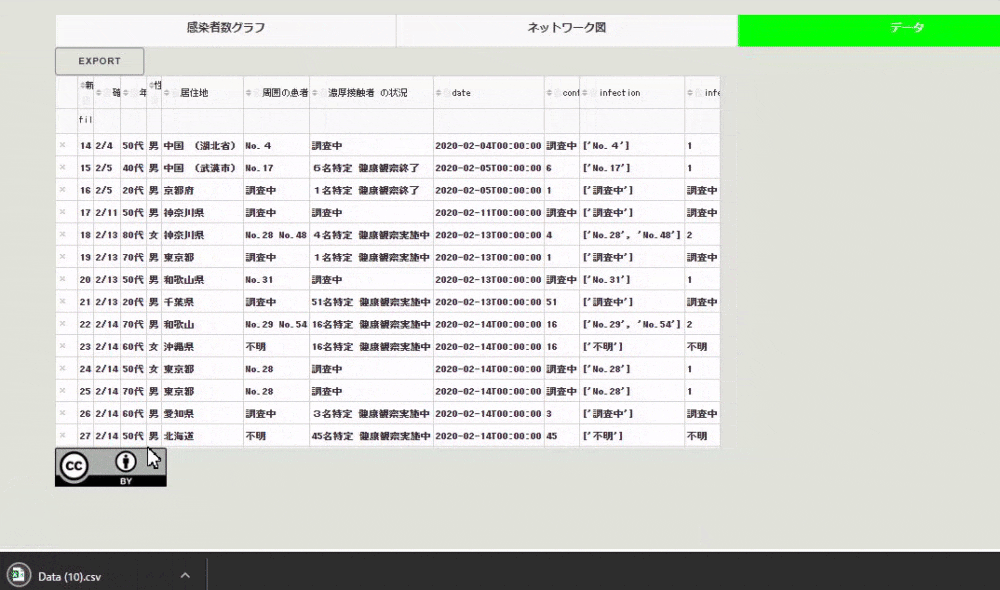
import dash_cytoscape as cyto import pandas as pd import ast # CSVファイルの読み込み df_covid = pd.read_csv("./src/kosei.csv", index_col=0, parse_dates=["date"]) # cytoscapeのelementsに渡すデータの作成 covid_el = [] for i in range(len(df_covid)): covid_el.append( { # ノードのデータの作成 "data": { "id": f"No.{df_covid.iloc[i, 0]}", "label": f"No.{df_covid.iloc[i, 0]} / {df_covid.iloc[i, 5]}", } } ) # エッジのデータの作成 contact_list = [] for i2 in ast.literal_eval(df_covid.iloc[i, -2]): if i2.startswith("No."): covid_el.append( {"data": {"source": f"No.{df_covid.iloc[i, 0]}", "target": f"{i2}"}} ) network = html.Div( [ html.Div( [ html.H4("周囲の患者発生のネットワーク図"), cyto.Cytoscape( id="covid_cyto", layout={"name": "cose"}, # layout coseの選択 elements=covid_el, # ネットワーク図で可視化するデータ style={ "width": "100%", "height": "80vh", "backgroundColor": "white", "borderRadius": "10px", }, ), ], className="eight columns", ),])CSVファイルをテーブルで表示
Dashではテーブルの作成方法は色々とあるのですが、ここではdash-tableを用いてテーブルを作成しています。このテーブルの良いところは、いろいろと編集できる点と、その編集したテーブルのデータを可視化に再利用したり、CSVファイルとしてユーザがダウンロードできる点です。ちなみにデータはCCなのでご自由にお使いください。
例えば「旧No.」以外のデータが欲しいと思った場合、下のようにテーブルのヘッダにあるゴミ箱をクリックしたあと、exportボタンを押すとCSVファイルがダウンロードされます。
テーブルへのcsvファイルのダウンロード機能の付け方ですが、dash-tableパッケージのDataTableインスタンスのexport_formatに"csv"を渡すだけです。ここで作成しているテーブルのコードは次のようになります。
import dash_table table = html.Div( [ dash_table.DataTable( id="covid_table", columns=[{"name": i, "id": i, "deletable": True} for i in df_covid.columns], data=df_covid.to_dict("records"), fixed_rows={"headers": True, "data": 0}, editable=True, filter_action="native", row_deletable=True, sort_action="native", export_format="csv", fill_width=False, virtualization=True, style_cell={"textAlign": "left"}, ), html.Img(src="assets/cc.png"), ] )まとめ
以上、厚生労働省のデータから気になった部分を抜き出して可視化したものをアプリ化してみました。
昨年、EthereumのイベントDevconに参加した時に、台湾のオードリー・タンさんが講演されていたんですね。その時に質問で「日本ではあんま何もわかってないおじいさんがIT担当大臣になったけど、どう思うか」ってのがあって、おいおいそんな答えにくい質問やめとけよと思ったけど、まぁその時質問した人の懸念が現在実現化してしまったみたいなところがあります。
でも、昨日はちょうど東京都が凄いサイトも発表しましたし、どんどん使えるデータが増えて、それを使って役立つものがまた作られてみたいなサイクルができると良いですね。
ちなみにアプリケーションのコードはgithubにあります。アプリケーションは少しずつアップデートしていこうと思います。
https://github.com/mazarimono/chomoku/blob/master/app.py#L837


- 投稿日:2020-03-05T08:57:29+09:00
COVID-19のデータでWebアプリを作成しました。
はじめに
厚生労働省のCOVID-19の感染状況のデータを基に、グラフやネットワーク図、データテーブルを作成し、Webアプリケーション化しました。作成したアプリは下のリンクのものとなります。
アプリリンク: https://chomoku.herokuapp.com/covid-19
下はネットワーク図の画面です。
利用しているデータは厚生労働省のサイトから取得しています。スクレイピングといっても、pandasのread_html関数を使っているだけです。下のgithubからも取得できますが、後述するようにアプリからも取得できます。
https://github.com/mazarimono/chomoku/blob/master/src/kosei.csv
今回アプリを作成したきっかけは、東洋経済さんの可視化を見て、自分ではこういうところを見てみたいなと思うところがあったのがきっかけでした。
アプリはタブでページが切り替えられ、次の3つの部分に分かれます。
1つ目は普通のグラフを表示するページ。
2つ目がネットワーク図を表示するページ。
3つ目が用いているCSVファイルをテーブルとして表示し、またそのデータをダウンロードできるページ。アプリはWebフレームワークのDashを用いて作成しました。環境は以下のようになります。
Python 3.7.4
dash 1.9.0
dash-core-components 1.8.0
dash-html-components 1.0.2
dash-cytoscape 0.1.1
dash-table 4.6.0
plotly 4.5.0濃厚接触者数と患者数
今回様々なニュースを見ていて気になったのが、近くに長い時間いると感染するのか?ということでした。そこで、厚生省のウェブサイトの数値を見ていると、濃厚接触者数と周囲の患者の発生というデータがありました(ちなみに周囲の患者の発生はあまり更新されないので、データが正確に状況を表しているかどうかという点は不明瞭です)。
そこで、まずはそのデータを可視化してみることにしました。
患者数グラフのページの左下にそのグラフがあります。これはx軸が濃厚接触者数、y軸が患者数です。
ちなみにこの可視化にはPlotly Expressを使っています。DashではGraphコンポーネントにfigureを渡してグラフを表示させます。コードは次のような感じです。
import dash_core_components as dcc import plotly.express as px dcc.Graph( id="ratio_scatter", figure=px.scatter( df_covid, x="contact_num", y="infection_num", title="接触者数(x軸)と周囲の患者発生(y軸)", hover_data=["新No."], ), className="six columns", )ネットワーク図
次に、データの「周囲の患者の発生」というところに、患者のナンバーが書かれています。元のデータに「新No.」と「旧No.」があり、どちらを指すのか微妙なところですが、「新No.」を指すと仮定して、ネットワーク図を作成します。
今回ネットワーク図の作成に用いたdash-cytoscapeは、cytoscapeを利用したコンポーネントで、ノードは新No.と居住地を使って作成し、エッジを周囲の患者の発生の番号とつなぎます。そうして、ノードの並びの種類はcoseを選択しています。すると下のようにつながりがあるものを良い感じに並べて表示してくれます。
周囲の患者の発生のデータが「旧No.」で作られていると、このネットワーク図は間違っています。「新No.」で作られているとすると、横につけたデータと比較すると、間違いはなさそうな感じでした。
こうしてみると、かなり患者同士のつながりがありそうにも見えました。ちなみにこの部分の作成はcsvのデータを使って、ノードデータとエッジのデータを作って、cytoscapeで可視化するという感じになっております。コードは次のような感じです。
import dash_cytoscape as cyto import pandas as pd import ast # CSVファイルの読み込み df_covid = pd.read_csv("./src/kosei.csv", index_col=0, parse_dates=["date"]) # cytoscapeのelementsに渡すデータの作成 covid_el = [] for i in range(len(df_covid)): covid_el.append( { # ノードのデータの作成 "data": { "id": f"No.{df_covid.iloc[i, 0]}", "label": f"No.{df_covid.iloc[i, 0]} / {df_covid.iloc[i, 5]}", } } ) # エッジのデータの作成 contact_list = [] for i2 in ast.literal_eval(df_covid.iloc[i, -2]): if i2.startswith("No."): covid_el.append( {"data": {"source": f"No.{df_covid.iloc[i, 0]}", "target": f"{i2}"}} ) network = html.Div( [ html.Div( [ html.H4("周囲の患者発生のネットワーク図"), cyto.Cytoscape( id="covid_cyto", layout={"name": "cose"}, # layout coseの選択 elements=covid_el, # ネットワーク図で可視化するデータ style={ "width": "100%", "height": "80vh", "backgroundColor": "white", "borderRadius": "10px", }, ), ], className="eight columns", ),])CSVファイルをテーブルで表示
Dashではテーブルの作成方法は色々とあるのですが、ここではdash-tableを用いてテーブルを作成しています。このテーブルの良いところは、いろいろと編集できる点と、その編集したテーブルのデータを可視化に再利用したり、CSVファイルとしてユーザがダウンロードできる点です。ちなみにデータはCCなのでご自由にお使いください。
例えば「旧No.」以外のデータが欲しいと思った場合、下のようにテーブルのヘッダにあるゴミ箱をクリックしたあと、exportボタンを押すとCSVファイルがダウンロードされます。
テーブルへのcsvファイルのダウンロード機能の付け方ですが、dash-tableパッケージのDataTableインスタンスのexport_formatに"csv"を渡すだけです。ここで作成しているテーブルのコードは次のようになります。
import dash_table table = html.Div( [ dash_table.DataTable( id="covid_table", columns=[{"name": i, "id": i, "deletable": True} for i in df_covid.columns], data=df_covid.to_dict("records"), fixed_rows={"headers": True, "data": 0}, editable=True, filter_action="native", row_deletable=True, sort_action="native", export_format="csv", fill_width=False, virtualization=True, style_cell={"textAlign": "left"}, ), html.Img(src="assets/cc.png"), ] )まとめ
以上、厚生労働省のデータから気になった部分を抜き出して可視化したものをアプリ化してみました。
昨年、EthereumのイベントDevconに参加した時に、台湾のオードリー・タンさんが講演されていたんですね。その時に質問で「日本ではあんま何もわかってないおじいさんがIT担当大臣になったけど、どう思うか」ってのがあって、おいおいそんな答えにくい質問やめとけよと思ったけど、まぁその時質問した人の懸念が現在実現化してしまったみたいなところがあります。
でも、昨日はちょうど東京都が凄いサイトも発表しましたし、どんどん使えるデータが増えて、それを使って役立つものがまた作られてみたいなサイクルができると良いですね。
ちなみにアプリケーションのコードはgithubにあります。アプリケーションは少しずつアップデートしていこうと思います。
https://github.com/mazarimono/chomoku/blob/master/app.py#L837
- 投稿日:2020-03-05T08:57:29+09:00
COVID-19のデータでネットワーク図を作成した。
はじめに
厚生労働省のCOVID-19の感染状況のデータを基に、グラフやネットワーク図、データテーブルを作成し、Webアプリケーション化しました。作成したアプリは下のリンクのものとなります。
アプリリンク: https://chomoku.herokuapp.com/covid-19
下はネットワーク図の画面です。
利用しているデータは厚生労働省のサイトから取得しています。スクレイピングといっても、pandasのread_html関数を使っているだけです。下のgithubからも取得できますが、後述するようにアプリからも取得できます。
https://github.com/mazarimono/chomoku/blob/master/src/kosei.csv
今回アプリを作成したきっかけは、東洋経済さんの可視化を見て、自分ではこういうところを見てみたいなと思うところがあったのがきっかけでした。
アプリはタブでページが切り替えられ、次の3つの部分に分かれます。
1つ目は普通のグラフを表示するページ。
2つ目がネットワーク図を表示するページ。
3つ目が用いているCSVファイルをテーブルとして表示し、またそのデータをダウンロードできるページ。アプリはWebフレームワークのDashを用いて作成しました。環境は以下のようになります。
Python 3.7.4
dash 1.9.0
dash-core-components 1.8.0
dash-html-components 1.0.2
dash-cytoscape 0.1.1
dash-table 4.6.0
plotly 4.5.0濃厚接触者数と患者数
今回様々なニュースを見ていて気になったのが、近くに長い時間いると感染するのか?ということでした。そこで、厚生省のウェブサイトの数値を見ていると、濃厚接触者数と周囲の患者の発生というデータがありました(ちなみに周囲の患者の発生はあまり更新されないので、データが正確に状況を表しているかどうかという点は不明瞭です)。
そこで、まずはそのデータを可視化してみることにしました。
患者数グラフのページの左下にそのグラフがあります。これはx軸が濃厚接触者数、y軸が患者数です。
ちなみにこの可視化にはPlotly Expressを使っています。DashではGraphコンポーネントにfigureを渡してグラフを表示させます。コードは次のような感じです。
import dash_core_components as dcc import plotly.express as px dcc.Graph( id="ratio_scatter", figure=px.scatter( df_covid, x="contact_num", y="infection_num", title="接触者数(x軸)と周囲の患者発生(y軸)", hover_data=["新No."], ), className="six columns", )ネットワーク図
次に、データの「周囲の患者の発生」というところに、患者のナンバーが書かれています。元のデータに「新No.」と「旧No.」があり、どちらを指すのか微妙なところですが、「新No.」を指すと仮定して、ネットワーク図を作成します。
今回ネットワーク図の作成に用いたdash-cytoscapeは、cytoscapeを利用したコンポーネントで、ノードは新No.と居住地を使って作成し、エッジを周囲の患者の発生の番号とつなぎます。そうして、ノードの並びの種類はcoseを選択しています。すると下のようにつながりがあるものを良い感じに並べて表示してくれます。
周囲の患者の発生のデータが「旧No.」で作られていると、このネットワーク図は間違っています。「新No.」で作られているとすると、横につけたデータと比較すると、間違いはなさそうな感じでした。
こうしてみると、かなり患者同士のつながりがありそうにも見えました。ちなみにこの部分の作成はcsvのデータを使って、ノードデータとエッジのデータを作って、cytoscapeで可視化するという感じになっております。コードは次のような感じです。
import dash_cytoscape as cyto import pandas as pd import ast # CSVファイルの読み込み df_covid = pd.read_csv("./src/kosei.csv", index_col=0, parse_dates=["date"]) # cytoscapeのelementsに渡すデータの作成 covid_el = [] for i in range(len(df_covid)): covid_el.append( { # ノードのデータの作成 "data": { "id": f"No.{df_covid.iloc[i, 0]}", "label": f"No.{df_covid.iloc[i, 0]} / {df_covid.iloc[i, 5]}", } } ) # エッジのデータの作成 contact_list = [] for i2 in ast.literal_eval(df_covid.iloc[i, -2]): if i2.startswith("No."): covid_el.append( {"data": {"source": f"No.{df_covid.iloc[i, 0]}", "target": f"{i2}"}} ) network = html.Div( [ html.Div( [ html.H4("周囲の患者発生のネットワーク図"), cyto.Cytoscape( id="covid_cyto", layout={"name": "cose"}, # layout coseの選択 elements=covid_el, # ネットワーク図で可視化するデータ style={ "width": "100%", "height": "80vh", "backgroundColor": "white", "borderRadius": "10px", }, ), ], className="eight columns", ),])CSVファイルをテーブルで表示
Dashではテーブルの作成方法は色々とあるのですが、ここではdash-tableを用いてテーブルを作成しています。このテーブルの良いところは、いろいろと編集できる点と、その編集したテーブルのデータを可視化に再利用したり、CSVファイルとしてユーザがダウンロードできる点です。ちなみにデータはCCなのでご自由にお使いください。
例えば「旧No.」以外のデータが欲しいと思った場合、下のようにテーブルのヘッダにあるゴミ箱をクリックしたあと、exportボタンを押すとCSVファイルがダウンロードされます。
テーブルへのcsvファイルのダウンロード機能の付け方ですが、dash-tableパッケージのDataTableインスタンスのexport_formatに"csv"を渡すだけです。ここで作成しているテーブルのコードは次のようになります。
import dash_table table = html.Div( [ dash_table.DataTable( id="covid_table", columns=[{"name": i, "id": i, "deletable": True} for i in df_covid.columns], data=df_covid.to_dict("records"), fixed_rows={"headers": True, "data": 0}, editable=True, filter_action="native", row_deletable=True, sort_action="native", export_format="csv", fill_width=False, virtualization=True, style_cell={"textAlign": "left"}, ), html.Img(src="assets/cc.png"), ] )まとめ
以上、厚生労働省のデータから気になった部分を抜き出して可視化したものをアプリ化してみました。
昨年、EthereumのイベントDevconに参加した時に、台湾のオードリー・タンさんが講演されていたんですね。その時に質問で「日本ではあんま何もわかってないおじいさんがIT担当大臣になったけど、どう思うか」ってのがあって、おいおいそんな答えにくい質問やめとけよと思ったけど、まぁその時質問した人の懸念が現在実現化してしまったみたいなところがあります。
でも、昨日はちょうど東京都が凄いサイトも発表しましたし、どんどん使えるデータが増えて、それを使って役立つものがまた作られてみたいなサイクルができると良いですね。
ちなみにアプリケーションのコードはgithubにあります。アプリケーションは少しずつアップデートしていこうと思います。
https://github.com/mazarimono/chomoku/blob/master/app.py#L837
- 投稿日:2020-03-05T07:59:21+09:00
DockerでNGINX + NGINX Unit + MySQLの環境を構築
Dockerの導入
以前、NGINX + NGINX Unit + Flaskの環境を構築しました。
NGINX + NGINX Unit + Flask で PythonのWeb アプリを動かす
前回はVagrantとVirtualBoxで構築しましたが、今回はDockerで構築していこうと思います。
前回と同様に、WebサーバーにNGINXを、APサーバーにNGINX Unitを、フレームワークにFlaskを使用します。
更に今回はデータベースとしてMySQLを追加し、WEB <-> AP <-> DBの環境を構築をしていきます。以下の図のようなイメージです。(本来コンテナはホスト内で起動しますが、わかりやすように分けています)
順を追って構築していくため、できたものをみたい方はGitHubに上げてありますのでそちらをどうぞ。
https://github.com/txkxyx/docker-web
環境
以下の環境で構築していきます。
- ホスト
- OS : macOS Catalina 10.15.3
- Docker : 19.03.5
- コンテナ
- Python : 3.7.3
- Flask : 1.1.1
- NGINX : 1.17.7
- NGINX Unit : 1.14.0
- MySQL : 8.0.18
- Flask SQLAclchemy : 2.4.1
ディレクトリ構成は以下のようにします。
./web |- db // DB用 |- nginx // NGINX用 |- python // NGINX Unit・ソースファイル用 | |- src |- docker-compose.ymlでは始めていきます。
Dockerfiletとdocker-composeの設定値
Dokerfileとdocker-composeで使用する設定値を簡単にまとめておきます。
Dockerfileの設定値
詳しくは公式のDockerfileリファレンスを参照してください。
https://docs.docker.com/engine/reference/builder/
設定値 概要 FROM 使用するイメージを指定する。 WORKDIR 作業ディレクトリを指定する。この宣言以降はコンテナ内の指定したパスで作業を行う。 COPY ホストからコンテナに、指定したディレクトリやファイルをコピーする。 ホスト コンテナの順で指定する。.dockerignoreで指定したファイルは対象外となる。RUN 指定したコマンドを現時点のコンテナ内で実行する。(ビルド時に実行するコマンド) CMD コンテナ起動時に実行するコマンドを指定する。(起動時に実行するコマンド) docker-composeの設定値
詳しくは公式のリファレンスを参照してください。
https://docs.docker.com/compose/compose-file/
設定値 概要 version Docker Engineが対応するファイルフォーマットのバージョン services アプリケーションを構成する各要素 build 起動するコンテナの Dockerfileがあるディレクトリを指定。子要素で、context(DockerfileのあるディレクトリまたはGithubURL)args(Dockerfileに渡す引数)などを指定できる 。image 起動するコンテナが使用するイメージを指定する。 command docker-compose up を実行した際に実行されるコマンド ports コンテナが公開するポートを指定します。 ホスト:コンテナもしくはコンテナのポートのみ指定します。expose リンクするコンテナのみに公開するコンテナのポートを指定します。ホストには公開されません。 environment 起動するコンテナの環境変数を指定します。 volumes コンテナにマウントするホストのディレクトリを指定します。 ホスト:コンテナの形式でパスを指定します。container_name 起動するコンテナのコンテナ名を指定します。 depends_on サービス間の依存関係を指定します。指定したサービス名が先に起動します。 DBコンテナの構築
まずはMySQLのコンテナを構築していきます。
イメージはこんな感じです。
docker-compose.ymlを作成します。web/docker-compose.ymlversion: "3" services: db: image: mysql command: mysqld --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci ports: - "33306:3306" expose: - "3306" environment: MYSQL_ROOT_PASSWORD: root MYSQL_USER: test MYSQL_PASSWORD: test volumes: - ./db/init:/docker-entrypoint-initdb.d container_name: app_dbコンテナの初期起動時にデータベースを作成するように、
dbディレクトリ内にinitディレクトリを作成し、createdatabase.sqlを作成します。web/db/init/createdatabase.sqlCREATE DATABASE app; USE app; CREATE TABLE users( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(255), email VARCHAR(255) ); INSERT INTO users(name,email) VALUES('sample','sample@sample.com'); INSERT INTO users(name,email) VALUES('test','test@test.com'); INSERT INTO users(name,email) VALUES('app','app@app.com'); GRANT ALL ON app.* TO test;以上の設定でdocker-composeでMySQLのコンテナを起動します。
$ docker-compose up $ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES bef9a864276c mysql "docker-entrypoint.s…" 4 minutes ago Up 4 minutes 33060/tcp, 0.0.0.0:33306->3306/tcp app_db
docker psの結果にapp_dbが表示されればコンテナを起動できています。
一度コンテナ内に入って、データベースが作成されているかを確認します。$ docker exec -it app_db bash root@00000000000:/# mysql -u test -p mysql> show databases; +--------------------+ | Database | +--------------------+ | app | | information_schema | +--------------------+ 2 rows in set (0.00 sec) mysql> use app; mysql> select * from users; +----+--------+-------------------+ | id | name | email | +----+--------+-------------------+ | 1 | sample | sample@sample.com | | 2 | test | test@test.com | | 3 | app | app@app.com | +----+--------+-------------------+ 3 rows in set (0.01 sec)
appというデータベースが作成されていることが確認できます。更に、createdatabase.sqlのテーブルとデータが作成されていることが確認できます。
MySQLの構築は以上です。APコンテナの構築
APサーバーとして
NGINX Unitを、実行環境にPython3を、フレームワークとしてFlaskを使用したコンテナを構築します。
NGINX Unitの公式ドキュメントを参考に構築していきます。
イメージはこんな感じです。
NGINX Unitのコンテナの起動
まずは、NGINX UnitのイメージからPython3とFlaskの環境を構築します。開発環境の最小単位はこれでいいかもしれません。
web/pythonディレクトリにDockerfileを追加します。web/python/DorckerfileFROM nginx/unit:1.14.0-python3.7 WORKDIR /usr/src/app COPY src . RUN apt update && apt install -y python3-pip \ && pip3 install --no-cache-dir -r ./requirements.txt \ && rm -rf /var/lib/apt/lists/* CMD ["sleep","infinity"]Docker Hubのnginx/unitのサイトから、NGINX UnitのPython3.7用のイメージを使用します。
次に、
pipでライブラリを一括でインストールできるように、web/python/srcディレクトリにrequirements.txtを作成します。web/python/src/requirements.txtFlask == 1.1.1 flask-sqlalchemy == 2.4.1 PyMySQL == 0.9.3
docker-compose.ymlにNGINX Unitのコンテナの設定を追記します。docker-compose.ymlversion: "3" services: db: image: mysql ports: - "33306:3306" expose: - "3306" environment: MYSQL_ROOT_PASSWORD: root MYSQL_USER: test MYSQL_PASSWORD: test volumes: - ./db/init:/docker-entrypoint-initdb.d container_name: app_db # ↓↓追記 ap: build: ./python ports: - "8080:8080" environment: TZ: "Asia/Tokyo" container_name: app_ap depends_on: - db作成した'Dockerfile'は
web/pythonのディレクトリに存在するので、buildでその場所を指定します。
サーバーのポートは8080をホストに公開するようにします。
起動しているDockerコンテナを停止してから、docker-compose buildでビルドしてからコンテナを起動します。$ docker-compose down $ docker-compose build --no-cache $ docker-compose up $ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES daf4ddc7c11a web_ap "sleep infinity" 41 seconds ago Up 40 seconds 0.0.0.0:8080->8080/tcp app_ap 565eb32e6a39 mysql "docker-entrypoint.s…" 43 seconds ago Up 41 seconds 33060/tcp, 0.0.0.0:33306->3306/tcp app_dbMySQLのコンテナの
app_dbと、NGINX Unitのコンテナのapp_apが起動していることが確認できます。
NGINX Unitのコンテナに入り、requirements.txtのライブラリがインストールされているかを確認します。$ docker exec -it app_ap bash root@00000000000:/# python3 -V Python 3.7.3 root@00000000000:/# pip3 freeze Flask==1.1.1 Flask-SQLAlchemy==2.4.1 PyMySQL==0.9.3上記のライブラリ以外にも、
SQLAlchemyやJinja2などがインストールされています。
ここまでNGINX Unitのコンテナの起動は完了です。続いて、Flaskの実装を行います。Flaskアプリケーションの実装
Flaskアプリケーションの実装をします。作成するファイルとディレクトリは以下のようになります。
./web |- db | |- init | |- createdatabase.sql |- nginx |- python | |- src | | |- app.py ← 追加 | | |- config.json ← 追加 | | |- config.py ← 追加 | | |- run.py ← 追加 | | |- users.py ← 追加 | | |- requirements.txt | | |- templates ← 追加 | | |- list.html ← 追加 | |- Dockerfile ← 更新 |- docker-compose.yml各ファイルは以下のように実装します。
config.py
まずは、DBの接続先などの設定クラスを実装する
config.pyです。
ホスト先は、DBコンテナのコンテナ名app_dbで指定します。web/python/src/config.pyclass Config(object): ''' Config Class ''' # DB URL SQLALCHEMY_DATABASE_URI = 'mysql+pymysql://test:test@app_db:3306/app?charset=utf8'app.py
次にFlaskアプリケーションを起動する
app.pyです。
config.from_object()でアプリケーションの設定クラスを呼び込み、SQLAlchemy()でFlaskアプリケーションでSQLAchemyが使えるように初期化を行います。web/python/src/app.pyfrom config import Config from flask import Flask from flask_sqlalchemy import SQLAlchemy # Create Flask Application application = Flask(__name__) # Set Config Class application.config.from_object(Config) # Set DB db = SQLAlchemy(application)users.py
次にusersテーブルのModelクラスを作成します。
db.Modelクラスを継承したUsersクラスを作成します。web/python/src/users.pyfrom app import db class Users(db.Model): ''' Users Table Model ''' __tablename__ = 'users' id = db.Column(db.Integer, primary_key=True) name = db.Column(db.String(255)) email = db.Column(db.String(255)) def __init__(self,name,email): self.name = name self.email = emailrun.py
次に、Flaskアプリケーションの起動とルーティングのモジュール
run.pyです。
レスポンスにテンプレートファイルを使用するので、render_template()でテンプレートファイルとオブジェクトを指定します。web/python/src/run.pyfrom app import application from users import Users from flask import render_template @application.route('/list') def index(): users = Users.query.order_by(Users.id).all() return render_template('list.html', users=users) if __name__ == '__main__': application.run(host='0.0.0.0', port='8080')list.html
次にテンプレートファイルとなる
list.htmlを作成します。
render_template()でusersオブジェクトが渡されるので、テンプレートエンジンであるJinja2を使用して実装します。web/python/src/templates/list.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Flask Sample</title> </head> <body> <h1>Flask Sample</h1> <table border="1" style="border-collapse: collapse"> <thead> <tr> <th >Id</th> <th >Name</th> <th >EMail</th> </tr> </thead> <tbody> {% for user in users %} <tr> <td>{{user.id}}</td> <td>{{user.name}}</td> <td>{{user.email}}</td> </tr> {% endfor %} </tbody> </table> </body> </html>Dockerfile
Dockerfileを更新します。web/python/DorckerfileFROM nginx/unit:1.14.0-python3.7 WORKDIR /usr/src/app COPY src . RUN apt update && apt install -y python3-pip \ && pip3 install --no-cache-dir -r ./requirements.txt \ && rm -rf /var/lib/apt/lists/* # ↓↓削除config.json
最後にNGINX Unitの設定ファイル
config.jsonを追加します。web/python/src/config.json{ "listeners": { "*:8080": { "pass": "applications/app" } }, "applications": { "app": { "type": "python", "processes": 2, "path": "/usr/src/app/", "module": "run" } } }実装は以上です。
ビルドしてからコンテナを起動してみましょう。
$ docker-compose down $ docker-compose build --no-cache $ docker-compose up $ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES daf4ddc7c11a web_ap "sleep infinity" 41 seconds ago Up 40 seconds 0.0.0.0:8080->8080/tcp app_ap 565eb32e6a39 mysql "docker-entrypoint.s…" 43 seconds ago Up 41 seconds 33060/tcp, 0.0.0.0:33306->3306/tcp app_db
app_apのコンテナの起動後に、コンテナにアクセスしてNGINX Unitの設定ファイルを設定します。$ docker exec -it app_ap bash root@00000000000:/# curl -X PUT --data-binary @config.json --unix-socket /var/run/control.unit.sock http://localhost/config { "success": "Reconfiguration done." }ブラウザで、
http://localhost:8080/listにアクセスして画面が表示されます。
これでAPコンテナの構築は終了です。
Webコンテナの構築
最後にWEBサーバーのNGINXのコンテナを構築していきます。
これでNGINX <-> NGINX Unit <-> Flask <-> MySQLの構成になります。
追加、更新するファイルは以下のようになります。
./web |- db | |- init | |- createdatabase.sql |- nginx | |- Dockerfile ← 追加 | |- index.html ← 追加 | |- nginx.conf ← 追加 |- python | |- src | | |- __init__.py | | |- app.py | | |- config.json | | |- config.py | | |- run.py | | |- users.py | | |- requirements.txt | | |- templates | | |- index.html | |- Dockerfile |- docker-compose.yml ← 更新まずはトップページとなる
index.htmlを作成します。web/nginx/index.html<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Index</title> </head> <body> <h1>Index</h1> <a href="/list">List</a> </body> </html>次に
NGINXのDockerfileを作成します。FROM nginx WORKDIR /var/www/html COPY ./index.html ./ CMD ["nginx", "-g", "daemon off;","-c","/etc/nginx/nginx.conf"]次に、NGINXの設定ファイルを作成します。前回の記事で紹介した設定ファイルから、APサーバーのホストをDocker用に変更します。
nginx.confuser nginx; worker_processes 1; error_log /var/log/nginx/error.log warn; pid /var/run/nginx.pid; events { worker_connections 1024; } http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; #tcp_nopush on; server_tokens off; keepalive_timeout 65; #gzip on; upstream unit-python { server app_ap:8080; # container_nameで指定 } server { listen 80; server_name localhost; # トップページを表示 location / { root /var/www/html; } # /listはAPコンテナにルーティング location /list { proxy_pass http://unit-python; proxy_set_header Host $host; } } }最後にdocker-composeを更新します。
docker-compose.ymlversion: "3" services: db: image: mysql ports: - "33306:3306" expose: - "3306" environment: MYSQL_ROOT_PASSWORD: root MYSQL_USER: test MYSQL_PASSWORD: test volumes: - ./db/init:/docker-entrypoint-initdb.d container_name: app_db ap: build: context: ./python args: project_directory: "/src/" # ↓↓更新 expose: - "8080" volumes: - "./python/src:/projects" environment: TZ: "Asia/Tokyo" container_name: app_ap depends_on: - db # ↓↓追加 web: build: ./nginx volumes: - ./nginx/nginx.conf:/etc/nginx/nginx.conf ports: - "80:80" environment: TZ: "Asia/Tokyo" container_name: "app_web" depends_on: - apビルドしてからコンテナを起動してみましょう。
$ docker-compose down $ docker-compose build --no-cache $ docker-compose up $ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 5b0f06b89db4 web_web "nginx -g 'daemon of…" 2 minutes ago Up 23 seconds 0.0.0.0:80->80/tcp app_web 625f3c025a82 web_ap "/usr/local/bin/dock…" 2 minutes ago Up 2 minutes 8080/tcp app_ap fe5bf54411a2 mysql "docker-entrypoint.s…" 2 minutes ago Up 2 minutes 33060/tcp, 0.0.0.0:33306->3306/tcp app_dbapp_apのコンテナの起動後に、コンテナにアクセスしてNGINX Unitの設定ファイルを設定します。
$ docker exec -it app_ap bash root@00000000000:/# curl -X PUT --data-binary @config.json --unix-socket /var/run/control.unit.sock http://localhost/config { "success": "Reconfiguration done." }ブラウザで、
http://localhost:80にアクセスするとトップページのindex.htmlが表示されます。(8080ポートではアクセスできません)
リンクとなっている
Listを押下すると、Flaskアプリケーションのlist.htmlが表示されます。
以上でNGINXの構築は終了です。
まとめ
DockerでNGINX + NGINX Unit + MySQLの環境を構築することができました。
あとはアプリケーションを作り込むだけです。
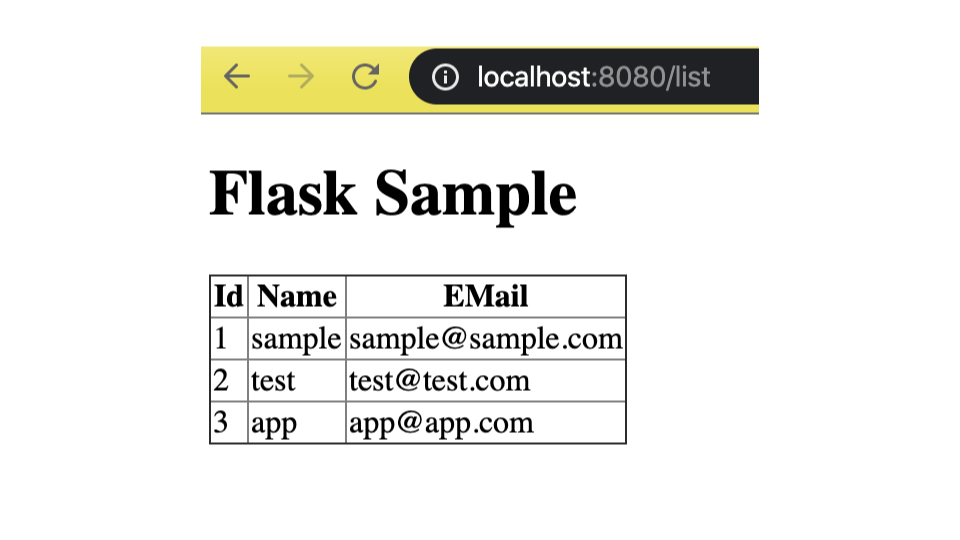
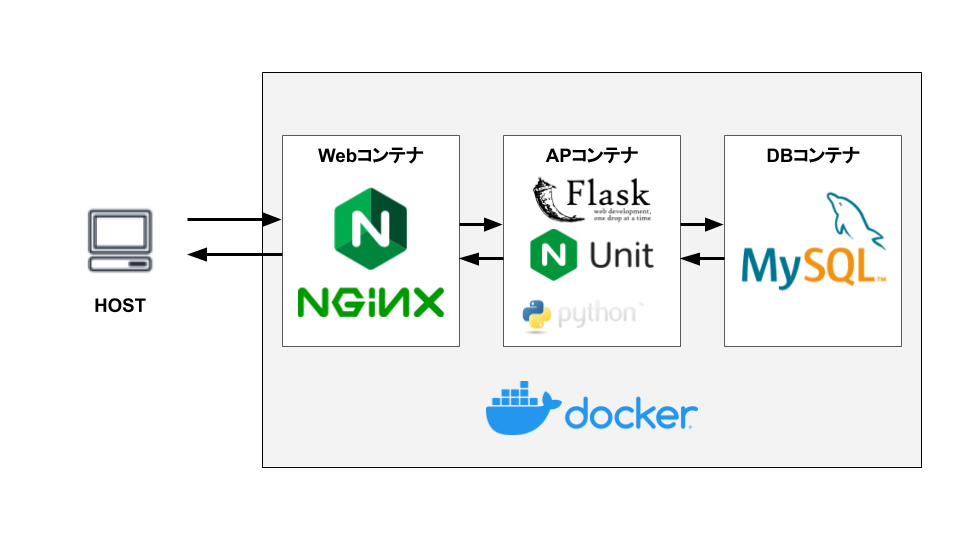

- 投稿日:2020-03-05T07:56:00+09:00
【Django】静的ファイル関連の設定について(css,js,img)
Djangoにてcssファイルや画像ファイルの設定方法をまとめてみた
静的ファイルとは
- cssファイル
- 画像ファイル
- jsファイル
などのクライアントからのリクエストによって、内容が変化しないファイルのことを静的ファイルと言います。
Setting.pyでの設定
設定が必要なパラメータは主に3つです。
- STATIC_URL
- STATICFILES_DIRS
- STATIC_ROOTSTATIC_URL
静的ファイル配信用のURLを指定する。
デフォルトで'/static/'となっている。
http(s)://ホスト名/static/...
でアクセスできるようになる。settings.pySTATIC_URL = '/static/'STATICFILES_DIRS
プロジェクト内で静的ファイルを保存する場所を指定します。
デフォルトでの保存先は
プロジェクト名/アプリ名/static/アプリ名/...
となっているが、複数のアプリケーション内でcssファイルを用いたい時などにいちいちstatic/アプリ名/...と配置するのは面倒なので、
manage.pyやアプリケーションフォルダがあるプロジェクトディレクトリ直下に置くのが好ましい。settings.pySTATICFILES_DIRS = [os.path.join(BASE_DIR, 'static') ]ちなみにBASE_DIRはプロジェクト直下を指すパスで、以下のように同じくsettings.pyにて定義した変数。
settings.pyBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))STATIC_ROOT
setting.pyにてDEBUG=Falseの時に参照される静的ファイルの保存先。つまり本番用。
セキュリティの観点からプロジェクト内での静的ファイルの保存先と本番での保存先は違ったほうが良いという理由から、保存先を変更する。settings.pySTATIC_ROOT = '/var/www/プロジェクト名/static'urls.pyでの設定
urls.pyfrom django.contrib import admin from django.urls import path, include from django.conf import settings from django.conf.urls.static import static urlpatterns = [ path('admin/', admin.site.urls), path('', include('app1.urls')), ] + static(settings.STATIC_URL, document_root=settings.STATIC_ROOT)まず、settingsとstaticをインポートします。
そしてurlpatterns変数に上記のように付け足します。
第一引数には静的ファイルの配信URL、document_root引数には静的ファイルの保存先を指定します。
これにより、URLにアクセスしたとき、静的ファイルの保存先につながるようになります。
ここでSTATICFILES_DIRSは使わないのか?と思ったのですが、恐らくsettings.py内でDEBUG=Trueとなっていればこのdocument_rootは参照されず自動的にSTATICFILES_DIRSが参照されるのだと思います。htmlテンプレートでの呼び出し方
{% load static %} <link rel="stylesheet" type="text/css" href="{% static 'style.css' %}"> <img src="{% static 'images/logo.png' %}">まず{% load static %}でstaticが使えるようにします。
そして、各タグ内のurl指定にて
{% static 'ファイル名' %}
と指定します。これはSTATICFILES_DIRSまたはSTATIC_ROOT以下からのパスを記載します。上の例だと
project -static - images - logo.png L style.css Lmanage.pyといった構造になります。
- 投稿日:2020-03-05T07:56:00+09:00
【Django】静的ファイル関連の設定について(css,js)
Djangoにてcssファイルなどの設定方法をまとめてみた
静的ファイルとは
- cssファイル
- jsファイル
などのクライアントからのリクエストによって、内容が変化しないファイルのことを静的ファイルと言います。
Setting.pyでの設定
設定が必要なパラメータは主に3つです。
- STATIC_URL
- STATICFILES_DIRS
- STATIC_ROOTSTATIC_URL
静的ファイル配信用のURLを指定する。
デフォルトで'/static/'となっている。
http(s)://ホスト名/static/...
でアクセスできるようになる。settings.pySTATIC_URL = '/static/'STATICFILES_DIRS
プロジェクト内で静的ファイルを保存する場所を指定します。
デフォルトでの保存先は
プロジェクト名/アプリ名/static/アプリ名/...
となっているが、複数のアプリケーション内でcssファイルを用いたい時などにいちいちstatic/アプリ名/...と配置するのは面倒なので、
manage.pyやアプリケーションフォルダがあるプロジェクトディレクトリ直下に置くのが好ましい。settings.pySTATICFILES_DIRS = [os.path.join(BASE_DIR, 'static') ]ちなみにBASE_DIRはプロジェクト直下を指すパスで、以下のように同じくsettings.pyにて定義した変数。
settings.pyBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))STATIC_ROOT
setting.pyにてDEBUG=Falseの時に参照される静的ファイルの保存先。つまり本番用。
セキュリティの観点からプロジェクト内での静的ファイルの保存先と本番での保存先は違ったほうが良いという理由から、保存先を変更する。settings.pySTATIC_ROOT = '/var/www/プロジェクト名/static'urls.pyでの設定
urls.pyfrom django.contrib import admin from django.urls import path, include from django.conf import settings from django.conf.urls.static import static urlpatterns = [ path('admin/', admin.site.urls), path('', include('app1.urls')), ] + static(settings.STATIC_URL, document_root=settings.STATIC_ROOT)まず、settingsとstaticをインポートします。
そしてurlpatterns変数に上記のように付け足します。
第一引数には静的ファイルの配信URL、document_root引数には静的ファイルの保存先を指定します。
これにより、URLにアクセスしたとき、静的ファイルの保存先につながるようになります。
ここでSTATICFILES_DIRSは使わないのか?と思われたと思うのですが、これはSTATIC_ROOTが設定されていなかったときSTATICFILES_DIRSが参照される。htmlテンプレートでの呼び出し方
{% load static %} <link rel="stylesheet" type="text/css" href="{% static 'style.css' %}"> <img src="{% static 'images/logo.png' %}">まず{% load static %}でstaticが使えるようにします。
そして、各タグ内のurl指定にて
{% static 'ファイル名' %}
と指定します。これはSTATICFILES_DIRSまたはSTATIC_ROOT以下からのパスを記載します。上の例だと
project -static - images - logo.png L style.css Lmanage.pyといった構造になります。
- 投稿日:2020-03-05T07:27:51+09:00
【Python】ふと、お問い合わせフォームを作りたくなったら
はじめまして、普段はWebサービスの開発をしてます。
はじめに
先日、ふと、お問合わせフォームを用意したくなり、
さらに、その内容を自身のメールアドレス宛に送信したくなったので、
Pythonで実装しました。全体像
本記事では、Djangoを使用します。
Djangoとても便利です。
フォーム定義
フォーム定義は
forms.pyで行います。基本的には、Django標準機能をインポートして作ります。
加えて、フォームの項目を定義します。
「名前」、「連絡先」、「お問い合わせ内容」みたいなやつですね。
各項目の必須設定や文字制限も定義できます。
サンプルコード
# Django標準機能を import from django import forms from django.core.mail import BadHeaderError, send_mail from django.http import HttpResponse # Django設定をimport from django.conf import settings class ContactForm(forms.Form): # フォーム項目として"お名前"を定義 name = forms.CharField( label='', max_length=100, widget=forms.TextInput(attrs={ 'class': 'form-control', 'placeholder': "お名前", }), ) # フォーム項目として"メールアドレス"を定義 email = forms.EmailField( label='', widget=forms.EmailInput(attrs={ 'class': 'form-control', 'placeholder': "メールアドレス", }), ) # フォーム項目として"お問い合わせ内容"を定義 message = forms.CharField( label='', widget=forms.Textarea(attrs={ 'class': 'form-control', 'placeholder': "お問い合わせ内容", }), ) # メールを送信する def send_email(self): subject = "お問い合わせ" message = self.cleaned_data['message'] name = self.cleaned_data['name'] email = self.cleaned_data['email'] from_email = '{name} <{email}>'.format(name=name, email=email) # 受信者リストを指定 recipient_list = [settings.EMAIL_HOST_USER] try: send_mail(subject, message, from_email, recipient_list) except BadHeaderError: return HttpResponse("無効なヘッダが検出されました。")処理定義
処理の定義は
views.pyで行います。こちらも、Django標準機能をインポートして作ります。
加えて、上記のフォーム定義もインポートします。
また、表示させる HTMLや遷移する URLなどを指定します。
サンプルコード
# Django標準機能をimport from django.urls import reverse_lazy from django.views.generic import TemplateView from django.views.generic.edit import FormView # forms.py からフォーム定義をimport from .forms import ContactForm # submitイベントの挙動を定義 class ContactFormView(FormView): # 表示させる html を指定 template_name = 'contact_form.html' # form.py で定義したクラス名を指定 form_class = ContactForm # 遷移後のurlを引数で指定 success_url = reverse_lazy('contact_result') # メールを送信 def form_valid(self, form): form.send_email() return super().form_valid(form) # フォーム送信後の挙動を定義 class ContactResultView(TemplateView): # 表示させる html を指定 template_name = 'contact_result.html' def get_context_data(self, **kwargs): context = super().get_context_data(**kwargs) context['success'] = "お問い合わせは正常に送信されました。" return context画面定義
お問い合わせ画面 と お問い合わせ送信後の画面 を用意します。
お問い合わせ画面では
{{ form.as_p }}を使って、
フォーム定義で定義した項目を<p>タグでレンダリングします。
お問い合わせ画面
contact_form.html<h4>お問い合わせ</h4> <div> <p><br>必要事項を入力して下さい。</p> <form method="POST">{% csrf_token %} {{ form.as_p }} <button type="submit" class="btn">送信</button> <a href="{% url 'top' %}">トップに戻る</a> </form> </div> </div>
お問い合わせ送信後の画面
contact_result.html<div> <p> お問い合わせ 送信完了 </p> <div> <p> お問い合わせありがとうございました。<br> 内容を確認のうえ、回答させて頂きます。 </p> <a href="{% url 'top' %}">トップに戻る</a> </div> </div>URL定義
urls.pyで URL と処理の紐付けを定義します。
サンプルコード
# 処理クラスをimport # <PROJECT_NAME>は自身のプロジェクト名 from <PROJECT_NAME>.views import ContactFormView, ContactResultView urlpatterns = [ # ... path('contact/', ContactFormView.as_view(), name='contact_form'), path('result/', ContactResultView.as_view(), name='contact_result'), ]メール情報定義
最後に、
settings.pyでプログラムで使用するメール情報を定義します。
SMTPサーバーやポート番号、ユーザー情報を指定します。
サンプルコード
EMAIL_HOST = 'smtp.XXX.com' EMAIL_PORT = XXX EMAIL_HOST_USER = 'XXX@XXX.com' EMAIL_HOST_PASSWORD = 'XXX' EMAIL_USE_TLS = Trueまとめ
Django標準機能を使用することで、簡単にお問い合わせフォームが作成できました。
ふと、お問い合わせフォームを作りたくなった時の参考になれば幸いです。
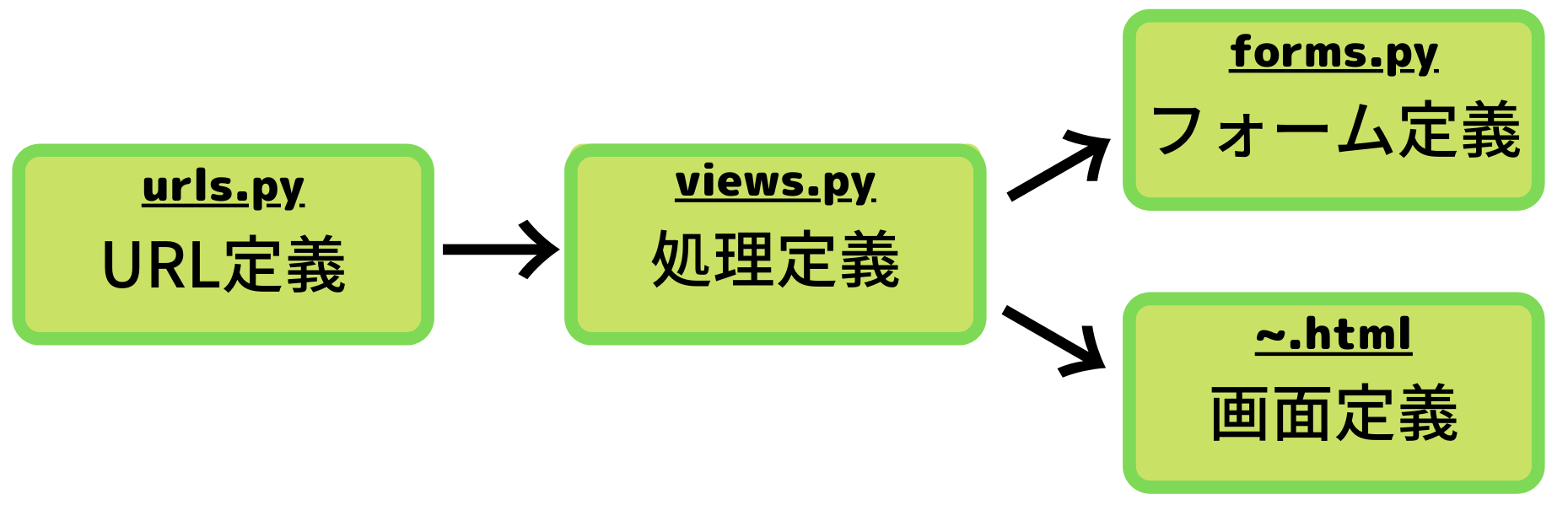
- 投稿日:2020-03-05T06:50:57+09:00
mysqlに接続
mysql-connector-pythonを使う
import mysql.connector conn = mysql.connector.connect(host='127.0.0.1', user='root', password='') cursor = conn.cursor() cursor.execute('CREATE DATABASE test_mysql_database') cursor.close() conn.close() conn = mysql.connector.connect(host='127.0.0.1', database='test_mysql_database') cursor = conn.cursor() cursor.execute('CREATE TABLE persons(' 'id int NOT NULL AUTO_INCREMENT,' 'name VARCHAR(14) NOT NULL,' 'PRIMARY KEY(id))') cursor.execute('INSERT INTO persons(name) values("Mike")') conn.commit() cursor.execute('SELECT * FROM persons') for row in cursor: print(row) cursor.close() conn.close()出力:
(1, 'Mike')