- 投稿日:2020-03-05T21:37:54+09:00
TypeScriptでスクレイピングしてみよう
初めに
TypeScriptによるスクレピングの簡単な手法を紹介したいと思います。
記事のポイントはあくまでもTypeScriptの使用、高度なスクレピング技法の紹介ではありません。前提条件
- ある程度Typescriptの文法が分かってること
- Node.jsの環境が整って、npmコマンド使えること
- グローバル環境にTypeScriptに入ってること
- 法に触れること、人に迷惑かけることをしないこと
プロジェクト初期化
mkdir [好きなディレクトリ] && cd [好きなディレクトリ]package.jsonとtsconfig.jsonの初期化
npm init -y && tsc --initプロジェクトのフォルダ内にsrcフォルダを作ります。
mkdir srctscofig.jsonのrootDirをsrcフォルダに指定します。
tscofig.json... "rootDir": "./src", /* Specify the root directory of input files. Use to control the output directory structure with --outDir. */ ...srcフォルダ内にcrowllwe.tsファイルを作って、中身
console.log('test')を追加します。crowllwe.tsconsole.log('test');現時点使用するライブラリをインストール
- npm install typescript -D
- npm install ts-node -D
package.jsonを修正します。
package.json... "scripts": { "dev": "ts-node ./src/crowller.ts" }, ...コマンドラインで
npm run devを実行します。testがもし正常に表示出来たらオーケーです。$ npm run dev > [好きなディレクトリ名]@1.0.0 dev [好きなディレクトリ名] > ts-node ./src/crowller.ts testここまで初期化は完了です。
ディレクトリ構成は以下の通りです。好きなディレクトリ |-node_modules |-src |- |- crowller.ts |- package-lock.json |- package.json |- tsconfig.jsonHTMLレスポンス取得
ターゲットサイトからHtmlレスポンスもらう必要がある為、リクエスト送れるライブラリ
superagentを使用します。npm install superagent --saveインストール終わったら、crowller.tsにimportします。
crowller.tsimport superagent from 'superagent'この場合、恐らくIDEに怒られます。vscode使用してコーティングする場合、以下のメッセージが表示されます。
'superagent' が宣言されていますが、その値が読み取られることはありません。ts(6133) モジュール 'superagent' の宣言ファイルが見つかりませんでした。'/qiita-spider-ts/node_modules/superagent/lib/node/index.js' は暗黙的に 'any' 型になります。 Try `npm install @types/superagent` if it exists or add a new declaration (.d.ts) file containing `declare module 'superagent';`ts(なぜなら、
superagentはjavascriptで書かれているライブラリ、Typescriptが直接認識することができません。
その場合、ライブラリの翻訳ファイルが必要になります。翻訳ファイルは.d.tsの拡張子を持ってます。翻訳ファイルをインストールします。
npm install @types/superagent -Dこれでエラーが解決できるはずです、それでも消えない場合、一回IDEを再起動することお勧めします。
実際リクエスト送信して、HTMLリスポンス受けとってみましょう。
ターゲットサイトは任意で構いません。crowller.tsimport superagent from 'superagent' class Crowller { private url = "url" constructor(){ this.getRawHtml(); } async getRawHtml(){ const result = await superagent.get(this.url); console.log(result.text) } } const crowller = new Crowller()
npm run devで実行すると、レスポンスもらえたらオーケーです。サンプル... <span class='c-job_offer-detail__term-text'>給与</span> </div> </th> <td class='c-job_offer-detail__description'> <strong class='c-job_offer-detail__salary'>550万 〜 800万円</strong> </td> </tr> <tr> <th> ...レスポンスから必要なデータを抜き取る
正規表現で抜き取ることもできますが、今回は多少便利になる
cheerioというライブラリを使用します。
ドキュメントnpm install cheerio --save npm install @types/cheerio -Dcheerioを使用すれば、jQueryのような文法でHTMLをから内容を抜き取れます。
実際使ってみます、下記のDOM構造からテキスト内容を抜き取るためにcrowller.tsを修正します。
crowller.tsimport superagent from 'superagent'; import cheerio from 'cheerio'; class Crowller { private url = "url" constructor(){ this.getRawHtml(); } async getRawHtml(){ const result = await superagent.get(this.url); this.getJobInfo(result.text); } getJobInfo(html:string){ const $ = cheerio.load(html) const jobItems = $('.c-job_offer-recruiter__name'); jobItems.map((index, element)=>{ const companyName = $(element).find('a').text(); console.log(companyName) }) } } const crowller = new Crowller()実行してみます。
$ npm run dev > qiita-spider-ts@1.0.0 dev 好きなディレクトリ名\qiita-spider-ts > ts-node ./src/crowller.ts xxx株式会社 株式会社xxx xxx株式会社 ...データの保存
srcフォルダと同じ階層でデータ保存用のdataフォルダを新規追加します。|- node_modules |- src |- data |- |- crowller.ts |- package-lock.json |- package.json |- tsconfig.json取得したデータをjson形式でdataフォルダに保存します。
その前にデータに含む要素を決めるためのインターフェースを定義します。
転職サイトをターゲットにしてるため、会社名とポジションと提示年収の三つをインターフェースの要素として追加します。crowller.ts... interface jobInfo { companyName: string, jobName: string, salary: string } ...そして配列に継承させて、データを入れていきます。
crowller.ts... getJobInfo(html:string){ const $ = cheerio.load(html) const jobItems = $('.c-job_offer-box__body'); const jobInfos:jobInfo[] = [] //インターフェース継承 jobItems.map((index, element) => { const companyName = $(element).find('.c-job_offer-recruiter__name a').text(); const jobName = $(element).find('.c-job_offer-detail__occupation').text(); const salary= $(element).find('.c-job_offer-detail__salary').text(); jobInfos.push({ companyName, jobName, salary }) }); const result = { time: (new Date()).getTime(), data: jobInfos }; console.log(result); } ...再度実行してみます。データが綺麗になってることが分かります。
$ npm run dev > qiita-spider-ts@1.0.0 dev 好きなディレクトリ名\qiita-spider-ts > ts-node ./src/crowller.ts { time: 1583160397866, data: [ { companyName: 'xx株式会社', jobName: 'フロントエンドエンジニア', salary: 'xxx万 〜 xxx万円' }, { companyName: '株式会社xxxx', ...保存用の関数を定義
generateJsonContentというデータ保存用の関数を定義します。crowller.ts... async getRawHtml(){ const result = await superagent.get(this.url); const jobResult = this.getJobInfo(result.text); //整形後のデータを受け取ります。 this.generateJsonContent(jobResult); //保存用の関数に渡します。 } // 保存用の関数 generateJsonContent(){ } ... getJobInfo(html:string){ ... const result = { time: (new Date()).getTime(), data: jobInfos }; return result }でも、そのままデータを受け取れないので保存用の
interfaceを定義します。crowller.tsinterface JobResult { time: number, data: JobInfo[] }それを保存用の関数の引数型として渡します。
crowller.ts... generateJsonContent(jobResult:JobResult){ } ...データをファイルに保存するために、node.jsのファイル操作関連のライブラリをimport
crowller.tsimport fs from 'fs'; import path from 'path'generateJsonContent関数の中身書いていきます。
scowller.ts... generateJsonContent(jobResult:JobResult){ const filePath = path.resolve(__dirname, '../data/job.json') let fileContent = {} if(fs.existsSync(filePath)){ fileContent = JSON.parse(fs.readFileSync(filePath, 'utf-8')); } fileContent[jobResult.time] = jobResult.data; fs.writeFileSync(filePath, JSON.stringify(fileContent)); } ...今の内容ですと、恐らく
fileContent[jobResult.time]がエラーになると思います。
エラーの内容は以下の通り。(property) JobResult.time: number Element implicitly has an 'any' type because expression of type 'number' can't be used to index type '{}'. No index signature with a parameter of type 'number' was found on type '{}'.ts(7053)これを解決するには
fileContentに型を振る必要があります。
そのままlet fileContent:any = {}にしてもいいですが、
ちゃんとしたインターフェース定義した方がtypescriptらしいです。crowller.ts... interface Content { [propName: number]: JobInfo[]; } ... generateJsonContent(jobResult:JobResult){ ... let fileContent:Content = {} ... }最後に実行してみましょう。
npm run dev
dataフォルダの下にjob.jsonファイルが作られて、データも保存されてるはずです。
終わりに
最初計画として、Typescriptを使ってExpressでスクレピングコントロールできるAPIを作るまでやりたかったのですが、
流石に長すぎて良くないと思いましたので、また今度時間ある時に。crowller.tsimport fs from 'fs'; import path from 'path' import superagent from 'superagent'; import cheerio from 'cheerio'; interface JobInfo { companyName: string, jobName: string, salary: string } interface JobResult { time: number, data: JobInfo[] } interface Content { [propName: number]: JobInfo[]; } class Crowller { private url = "url" constructor(){ this.getRawHtml(); } async getRawHtml(){ const result = await superagent.get(this.url); const jobResult = this.getJobInfo(result.text); this.generateJsonContent(jobResult) } generateJsonContent(jobResult:JobResult){ const filePath = path.resolve(__dirname, '../data/job.json') let fileContent:Content = {} if(fs.existsSync(filePath)){ fileContent = JSON.parse(fs.readFileSync(filePath, 'utf-8')); } fileContent[jobResult.time] = jobResult.data; fs.writeFileSync(filePath, JSON.stringify(fileContent)); } getJobInfo(html:string){ const $ = cheerio.load(html) const jobItems = $('.c-job_offer-box__body'); const jobInfos:JobInfo[] = [] jobItems.map((index, element)=>{ const companyName = $(element).find('.c-job_offer-recruiter__name a').text(); const jobName = $(element).find('.c-job_offer-detail__occupation').text(); const salary = $(element).find('.c-job_offer-detail__salary').text(); jobInfos.push({ companyName, jobName, salary }) }); const result = { time: (new Date()).getTime(), data: jobInfos }; return result } } const crowller = new Crowller()


- 投稿日:2020-03-05T20:48:45+09:00
Node.js Expressフレームワークを使用する(雛形生成)
はじめに
前回の投稿でExpressフレームワークを前準備しましたので、次にexpressコマンドで雛形を生成します。
環境
OS:Windows 10 Pro 64bit
node.js:v12.16.1
npm:v6.13.4
Express:v4.16.1雛形の生成
expressコマンドで生成します。
あらかじめコマンドプロンプトで作業フォルダに移動します。
今回は「D:\Node\ExpressTest01」を作業フォルダにします。D: CD Node\ExpressTest01移動しましたら、次のコマンドで雛形を生成します。
express --view=ejs「--view=ejs」オプションはテンプレートエンジンにEJSを使用すると言う意味になります。
D:\Node\ExpressTest01>express --view=ejs create : public\ create : public\javascripts\ create : public\images\ create : public\stylesheets\ create : public\stylesheets\style.css create : routes\ create : routes\index.js create : routes\users.js create : views\ create : views\error.ejs create : views\index.ejs create : app.js create : package.json create : bin\ create : bin\www install dependencies: > npm install run the app: > SET DEBUG=expresstest01:* & npm startこれで雛形は生成されました。
Visual Studio Codeで開きますとこのようになります。
使用するライブラリの一括インストール
次のコマンドを実行して、ライブラリの一括インストールを行います。
npm installnpmはpackage.jsonの「dependencies」に指定されているライブラリを一括インストールする機能があります。
雛形を生成した際に、必要なライブラリ情報が全て記載されるので便利です。D:\Node\ExpressTest01>npm install npm notice created a lockfile as package-lock.json. You should commit this file. added 53 packages from 38 contributors and audited 141 packages in 5.167s found 0 vulnerabilities動作確認
コマンドプロンプトで次のコマンドを実行します。
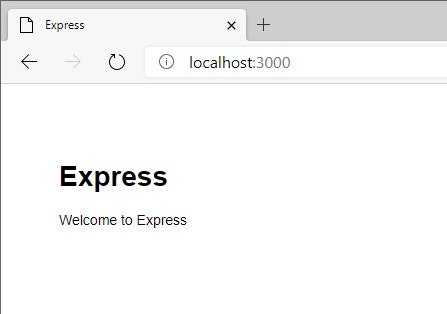
npm startD:\Node\ExpressTest01>npm start > expresstest01@0.0.0 start D:\Node\ExpressTest01 > node ./bin/wwwブラウザで「http://localhost:3000」にアクセスします。
次のキャプチャが表示されればOKです。
コマンドプロンプトには次のように表示されます。
GET / 304 14.612 ms - - GET /stylesheets/style.css 304 1.752 ms - -停止したい時は「Ctrl + C」です。
「バッチ ジョブを終了しますか (Y/N)?」と聞かれますので、「Y」を入力します。バッチ ジョブを終了しますか (Y/N)? Yまとめ
このような流れで雛形を生成します。

- 投稿日:2020-03-05T14:21:30+09:00
Nuxt.jsでprocess.env.NODE_ENVを参照する際の挙動についてまとめてみた
Nuxtで
process.env.NODE_ENVを参照する際にハマりがちだったので挙動をまとめました。なお、環境は以下のとおりです。
package.json"dependencies": { "cross-env": "7.0.0", "nuxt": "2.11.0" },※この記事で記載しているファイルは内容を一部抜粋したものです。
デフォルトの挙動
まず、何の設定もせずに
yarn devしたときとyarn build && yarn startしたときの値を確認します。package.json"scripts": { "dev": "nuxt", "build": "nuxt build", "start": "nuxt start" },pages/index.vue<template> <div /> </template> <script> export default { mounted() { console.log(process.env.NODE_ENV); } }; </script>
実行方法 process.env.NODE_ENV yarn dev "development" yarn build && yarn start "production" このようにデフォルトで値が入っていることがわかりました。次に、環境変数を指定した際の挙動を見ていきます。
環境変数を指定したとき
package.json"scripts": { "dev": "cross-env NODE_ENV=dev nuxt", "build": "cross-env NODE_ENV=build nuxt build", "start": "cross-env NODE_ENV=start nuxt start" },
実行方法 process.env.NODE_ENV yarn dev "development" yarn build && yarn start "production" 環境変数に指定した値が入ると思いきや、デフォルトの値が優先されてしまいました。これでは困るので、次に
NODE_ENVをnuxt.config.jsに指定したときの挙動を見てみます。env を指定したとき
nuxt.config.jsenv: { NODE_ENV: process.env.NODE_ENV }package.json"scripts": { "dev": "cross-env NODE_ENV=dev nuxt", "build": "cross-env NODE_ENV=build nuxt build", "start": "cross-env NODE_ENV=start nuxt start" },
実行方法 process.env.NODE_ENV yarn dev "dev" yarn build && yarn start "build" 今回はこのようにビルド時に埋め込んだ値が取得できることがわかりました。
まとめ
というわけで、
process.env.NODE_ENVの値を Nuxt で定義したコンポーネントから取得する際は、nuxt.config.jsのenvプロパティにNODE_ENVを指定したほうが間違いは起こりにくいかもしれません。しかし、今回の記事では触れていませんが、例えば Nuxt を express で動かす際などは、
process.env.NODE_ENVの値をserver.jsなどのファイルから参照する関係で、予想と違う形でprocess.env.NODE_ENVの値が返ってくることがあるかもしれません。あまりないケースかとは思いますが、そのようなことを考えると build 時とサーバー起動時に設定する
NODE_ENVの値は同じにしておいたほうが無難っぽいです。
- 投稿日:2020-03-05T14:20:41+09:00
Lambda から DynamoDB にアクセス (Node.js)
テーブルの一覧
list_tables.jsvar AWS = require("aws-sdk"); var dynamodb = new AWS.DynamoDB({region: 'us-east-1'}) var params = { Limit: 100} exports.handler = async (event) => { console.log("*** start ***") try { var data = await dynamodb.listTables(params).promise() console.log(data) } catch (ee) { console.log(ee) } const response = { statusCode: 200, body: JSON.stringify('Hello from Lambda!'), } return response; }テーブルの説明
describe_table.jsvar AWS = require("aws-sdk"); var dynamodb = new AWS.DynamoDB({region: 'us-east-1'}) var table = "Movies" var params = {TableName: table} exports.handler = async (event) => { console.log("*** start ***") try { var data = await dynamodb.describeTable(params).promise() console.log(data) } catch (ee) { console.log(ee) } const response = { statusCode: 200, body: JSON.stringify('Hello from Lambda!'), } return response }
- 投稿日:2020-03-05T12:59:42+09:00
local host に接続したいのですがfirebase に繋がってしまいます。
こんにちは、 node初心者です。
個人プロジェクトでセットアップをしているのですがnodeを起動してlocalhost にアクセスしようとしたところで以前installしたfirebaseに繋がってしまいます。
何か策はないでしょうか?よろしくお願いします。!
- 投稿日:2020-03-05T10:55:39+09:00
【Node.js】定義したクラスを別のファイルで使用する
定義したクラスを別のファイルで使用するには、module.exportsを使います。
まず元となるクラスを作成
smartPhone.jsclass iphone { constructor() { } call(){ console.log('call'); } mail(){ console.log('mail'); } } class android { constructor() { } call(){ console.log('call'); } mail(){ console.log('mail'); } }module.exportsで外部に公開します。
smartPhone.jsmodule.exports = iphoneこれだけで、外部へ公開することができます。
しかし、今回クラスは2つあります。
クラスが複数ある場合はどうするかというと、objectにしてしまいます。smartPhone.jsmodule.exports = { IPHONE: iphone, ANDROID: android }Keyは適当な名前、valueはクラス名を設定します。
これで指定したクラスが外部から読み込めるようになりました。早速別ファイルから読み込んでみます。
requireで呼び出します。usePhone.jsconst iphone = require('./smartphone').IPHONE const android = require('./smartphone').ANDROIDrequireの引数にファイル名を指定します。".js"は省略可能です。
上記ではクラスごとで定数に代入していますが、わざわざこんなことはしません。usePhone.jsconst {IPHONE,ANDROID} = require('./smartphone')分割代入をします。
あとはクラスをnewすればOKです。
usePhoneconst a = new IPHONE() a.call() const b = new ANDROID() b.call()
- 投稿日:2020-03-05T02:08:12+09:00
AWS Lambda入門②(Node編)〜DynamoDBにアクセスする〜
概要
- AWS Lambda入門①(Node編)〜関数をデプロイして動かす〜の続編です
- 今回はLambdaからDynamoDBにアクセスしてデータを保存したり取得したりしてみます
- テーブルから全件取得、1件取得、1件登録の3つの関数を作成します
DynamoDBとは
- AWSが提供するマネージドなデータベースサービスです
- RDBとは異なりkey-value形式なドキュメントデータベースです
LambdaからDynamoDBにアクセスしてみる
DynamoDBの設定
- まずはDynamoDBを使うためにServerlesFrameworkの設定をします
DynamoDBのテーブル定義の設定
- DynamoDBはデータベースなのでテーブルの作成からはじめます
- これまでと同じようにこれもServerlessFrameworkの機能で行うことができます
- 今回はHelloテーブルを作ってみます
serverless.ymlを修正します
- 見づらいのでデフォルトで記載されていたコメントアウトは全て削除しています
serverless.ymlservice: sls-sample # AWS周りの設定 provider: name: aws runtime: nodejs12.x region: ap-northeast-1 stage: dev environment: DYNAMODB_TABLE: ${self:service}-${self:provider.stage} iamRoleStatements: - Effect: Allow Action: - dynamodb:Query - dynamodb:Scan - dynamodb:GetItem - dynamodb:PutItem - dynamodb:UpdateItem - dynamodb:DeleteItem Resource: 'arn:aws:dynamodb:${self:provider.region}:*:table/${self:provider.environment.DYNAMODB_TABLE}*' # Lambdaの設定 functions: hello: handler: handler.hello # DynamoDBの設定 resources: Resources: Hello: Type: AWS::DynamoDB::Table Properties: TableName: ${self:provider.environment.DYNAMODB_TABLE}-hello AttributeDefinitions: - AttributeName: id AttributeType: S KeySchema: - AttributeName: id KeyType: HASH ProvisionedThroughput: ReadCapacityUnits: 1 WriteCapacityUnits: 1
- 大きく分けて前段と後段の2つの定義を追加しています
serverless.ymlenvironment: DYNAMODB_TABLE: ${self:service}-${self:provider.stage} iamRoleStatements: - Effect: Allow Action: - dynamodb:Query - dynamodb:Scan - dynamodb:GetItem - dynamodb:PutItem - dynamodb:UpdateItem - dynamodb:DeleteItem Resource: 'arn:aws:dynamodb:${self:provider.region}:*:table/${self:provider.environment.DYNAMODB_TABLE}*'
- environmentはファイル内で扱える変数のような感じです
- テーブル名につけるprefixが何度か登場することになるのでenvironmentに定義しています
self:serviceは一行目のserviceの値でself:provider.stageは7行目あたりのstageの値- iamRoleStatementsはLambdaを実行するユーザの権限にDynamoDBへのアクセス許可を追加しています
serverless.ymlresources: Resources: Hello: Type: AWS::DynamoDB::Table Properties: TableName: ${self:provider.environment.DYNAMODB_TABLE}-hello AttributeDefinitions: - AttributeName: id AttributeType: S KeySchema: - AttributeName: id KeyType: HASH ProvisionedThroughput: ReadCapacityUnits: 1 WriteCapacityUnits: 1
- テーブルの定義をしています
- テーブル名は上で定義したprefixにつなげてhelloという名前にしています
テーブルを作成する
serverless.ymlに設定を追加した状態でデプロイすると自動でテーブルが作成されますsls deploy
- Webコンソールにアクセスしてテーブルができていることを確認してみましょう
DynamoDBへのアクセス処理の実装
ライブラリの追加
- DynamoDBにアクセスするために必要なライブラリを追加します
npm i aws-sdk # or yarn add aws-sdkDynamoDBへの接続処理
- 今回は以下の3つの処理を実装しようと思います
- 全量取得
- IDで検索して1件取得
- 1件登録
- 全部一気にやると量が多いのでまずは全量取得からいきます
handler.jsを修正しますhandler.js'use strict'; // AWS SDKをimport const AWS = require('aws-sdk'); // DynamoDBにアクセスするためのクライアントの初期化 const dynamo = new AWS.DynamoDB.DocumentClient(); // 環境変数からテーブル名を取得(あとでserverless.ymlに設定します) const tableName = process.env.tableName; // 全量取得 module.exports.getAll = async () => { const params = { TableName: tableName, }; try { // DynamoDBにscanでアクセス const result = await dynamo.scan(params).promise(); // 正常に取得できたらその値を返す return { statusCode: 200, body: JSON.stringify(result.Items), }; } catch (error) { // エラーが発生したらエラー情報を返す return { statusCode: error.statusCode, body: error.message, }; } }; module.exports.hello = async event => { return { statusCode: 200, body: JSON.stringify({ message: event }), }; };
- 説明はだいたいコードのコメントに書いておきました
- 今回はテーブルの内容を全量取得するので
.scan()を使いましたがDynamoDB Clientは以下のようなAPIを提供します
- 複数件取得
- scan: 全件取得
- query: 条件に該当した項目を全件取得
- 単項目操作
- get: 1件取得
- put: 1件置換
- update: 1件部分更新
- delete: 1件削除
- 新しく
module.exportを追加したのでserverless.ymlも修正します
- functionの項目を修正します
serverless.yml# ...省略 functions: hello: handler: handler.hello getAll: handler: handler.getAll environment: tableName: ${self:provider.environment.DYNAMODB_TABLE}-hello # ...省略
handler.jsでmodule.export.getAllとしたのでhandler: handler.getAllを追加しましたenvironmentはhandler.jsに対して環境変数としてテーブル名を渡していますローカルで動作確認
- Lambdaのコードができたので動かしてみます
- デプロイする前にローカルで動作確認しましょう
DynamoDBをローカルで動かすための設定
serverless-dynamodb-localというDynamoDBをローカルで動かすライブラリがあるのでインストールしますyarn add -D serverless-dynamodb-local
- DynamoDBをローカルで動かすための設定も追加します
serverless.ymlの一番下に追加してくださいserverless.yml# ...省略 plugins: - serverless-dynamodb-local custom: dynamodb: stages: dev start: port: 8082 inMemory: true migrate: true seed: true seed: hello: sources: - table: ${self:provider.environment.DYNAMODB_TABLE}-hello sources: [./seeds/hello.json]
pluginsは先程インストールしたserverless-dynamodb-localを使うことを宣言していますcustom.dynamodbでローカルでDBを起動する時に使う設定をしています
portは何でも大丈夫です(デフォルトは8000)seedは事前に登録しておくテストデータの設定です
- 登録するデータは
./seeds/hello.jsonに定義しておきます- テストデータとして
seeds/hello.jsonを作成しますseeds/hello.json[ { "id": "1", "message": "Hello" }, { "id": "2", "message": "Hello!!!" }, { "id": "3", "message": "Hello World" } ]
- ServerlessFrameworkを使ってDBをインストールしセットアップを完了させます
sls install dynamodbLambda関数にローカルDB用の処理を追加
- ローカルのDBを使うために
handler.jsに少し手を加えますhandler.js'use strict'; const AWS = require('aws-sdk'); // 環境変数にLOCALが設定されていたらローカルDB用の設定を使う(portはymlで定義したものを設定) const options = process.env.LOCAL ? { region: 'localhost', endpoint: 'http://localhost:8082' } : {}; const dynamo = new AWS.DynamoDB.DocumentClient(options); // ...省略ローカルでDBにアクセスする
- 準備が長くなりましたがいよいよアクセスしてみます
- まずはDBを起動します
sls dynamodb start
- 以下のようなログが出ればOKです
$ sls dynamodb start Dynamodb Local Started, Visit: http://localhost:8082/shell Serverless: DynamoDB - created table sls-sample-dev-hello Seed running complete for table: sls-sample-dev-hello
- LambdaのgetAll関数を叩きます
LOCAL=trueは環境変数としてLOCALにtrueを設定しています(handler.jsでローカルのDBを見に行く判定で使っていたやつ)LOCAL=true sls invoke local --function getAll
- 以下のようなログがでればOKです!
{ "statusCode": 200, "body": "[{\"message\":\"Hello\",\"id\":\"1\"},{\"message\":\"Hello!\",\"id\":\"2\"},{\"message\":\"Hello World\",\"id\":\"3\"}]" }AWSにデプロイして動作確認
- ローカルで確認できたらAWSにデプロイしましょう
sls deploy
- コマンド一発でデプロイできて便利ですね
- serverlessコマンドでアクセスしてみましょう
sls invoke --function getAll
- 現状データがないのでデータは0件ですが200が返ってきていれば成功です
{ "statusCode": 200, "body": "[]" }
- この時点でデータがとれることを確認したい人はWebコンソール上でデータを追加した上で叩いてみてください
- あとでもいい人は次でデータ登録処理も追加するのでそのあとに取得できることは確認できます
残りの関数を追加する
- 同じ要領で1件取得と1件登録の処理を追加してみましょう
関数と設定の追加
handler.jsの一番下に関数を追加するhandler.js// ...省略 // 1件取得 module.exports.get = async event => { // パラメータで渡されたidを取得 const { id } = event; // 検索条件のidを指定 const params = { TableName: tableName, Key: { id }, }; try { const result = await dynamo.get(params).promise(); return { statusCode: 200, body: JSON.stringify(result.Item), }; } catch (error) { return { statusCode: error.statusCode, body: error.message, }; } }; // 1件登録 module.exports.put = async event => { // 一意な値を作るためにタイムスタンプを取得 const id = String(Date.now()); const { message } = event; const params = { TableName: tableName, Item: { id, message }, }; try { const result = await dynamo.put(params).promise(); return { statusCode: 200, body: JSON.stringify(result), }; } catch (error) { return { statusCode: error.statusCode, body: error.message, }; } };
- 全件取得の時は
.scan()を使いましたが1件取得は.get()1件登録はput()を使っていますserverless.ymlのfunctionの項目に設定を追加しますservreless.yml# ...省略 functions: hello: handler: handler.hello getAll: handler: handler.getAll environment: tableName: ${self:provider.environment.DYNAMODB_TABLE}-hello get: handler: handler.get environment: tableName: ${self:provider.environment.DYNAMODB_TABLE}-hello put: handler: handler.put environment: tableName: ${self:provider.environment.DYNAMODB_TABLE}-helloローカルで動作確認
- 1件登録
LOCAL=true sls invoke local --function put --data '{"message": "Hello!!!!!"}'
- 以下のようなログが出ればOK
{ "statusCode": 200, "body": "{\"id\":\"1583340674414\",\"message\":\"Hello!!!!!\"}" }
- 1件取得
LOCAL=true sls invoke local --function get --data '{"id": "1"}'
- 以下のようなログが出ればOK
{ "statusCode": 200, "body": "{\"message\":\"Hello\",\"id\":\"1\"}" }AWSで動作確認
- ServerlessFrameworkのコマンドでデプロイします
sls deploy
- 1件登録
sls invoke --function put --data '{"message": "Hello!!!!!"}'
- 以下のようなログが出ればOK
{ "statusCode": 200, "body": "{\"id\":\"1583340839287\",\"message\":\"Hello!!!!!\"}" }
- 1件取得
- 直前の1件登録で追加したデータのIDを指定してみましょう
sls invoke --function get --data '{"id": "1583340839287"}'
- 以下のようなログが出ればOK
{ "statusCode": 200, "body": "{\"id\":\"1583340839287\",\"message\":\"Hello!!!!!\"}" }おまけ
- 今回はscanとgetとputを作成しましたがquery(検索条件を指定して複数件取得)の場合は以下のような感じになります
- パラメータで指定したIDに合致するレコードが複数ある場合に全部取得できるような感じです
module.exports.query = async event => { const { id } = event; const params = { TableName: tableName, KeyConditionExpression: 'id = :id', ExpressionAttributeValues: { ':id': id }, }; try { const result = await dynamo.query(params).promise(); return { statusCode: 200, body: JSON.stringify(result.Items), }; } catch (error) { return { statusCode: error.statusCode, body: error.message, }; } };感想
- LambdaからDynamoDBへのアクセスはDynamoDB Clientを使うと扱いやすいですね
- ServerlessFrameworkや周辺ライブラリを使うとローカルでも動作確認できるので環境周りもとても充実しています
- けっこう長くなってしまいましたがここまで読んでいただきありがとうございました


- 投稿日:2020-03-05T00:03:41+09:00
Node.js製Lambdaの速度劣化箇所をX-RAYを使って特定する
はじめに
「お気に入りのテレビ番組の有無を答えてくれるAlexaスキルを作ってみた」でNode.js製のLambdaを作ったのですが、
ただ、スキルを呼び出した後、返答が返ってくるまで少しタイムラグがあるのが気になりますね
…
いずれにしてもX-RAYを仕掛けて、番組表取得で遅くなっているのか、その後の処理で遅くなっているのかなどを見極めたいと思っています。ということで、X-RAYを使って、速度が遅くなっている箇所を特定したいと思います。
コンソールからの設定
まず最初にコードには手を入れず、LambdaのコンソールからX-RAYの設定をしてみます。
Lambdaのコンソールにて、対象関数の「AWS X-RAY」の箇所のチェックボックスをONにします。
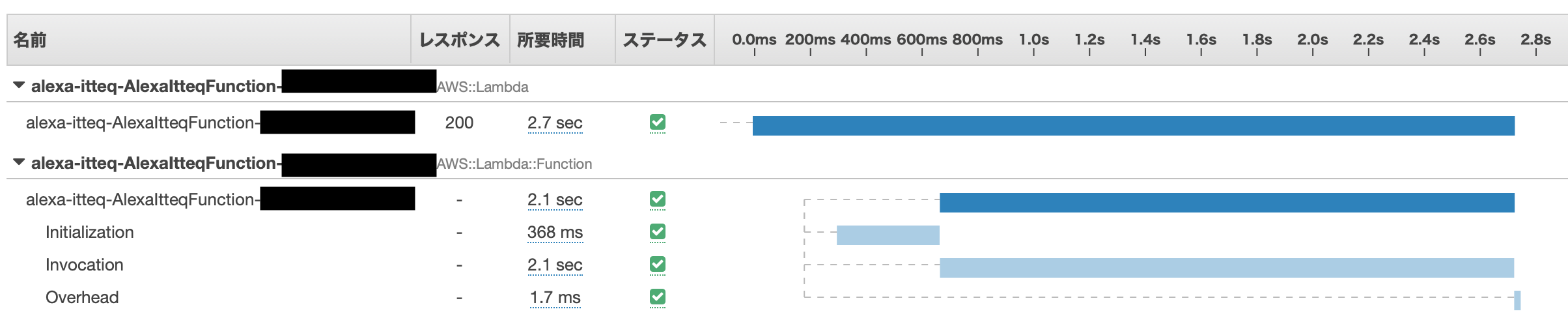
この状態でLambdaを動かした後、X-RAYのコンソールの「Service Map」を開くとこんな感じで表示されます。
「Traces」から詳細を見ることができます。
この時点だとLambdaの実処理としては2.1秒かかっている、というのがわかる程度ですね。
コード修正1:外部とのhttp通信時間を調べる
処理の内訳を調べるため、まず外部とのhttp通信の時間がどれくらいを占めているのかを調べてみます。
今回のコードはaxiosを使ってyahooのテレビ表をhttpsで取りに言っているのですが、その所要時間を調べるために以下のコードを冒頭に入れてみます。
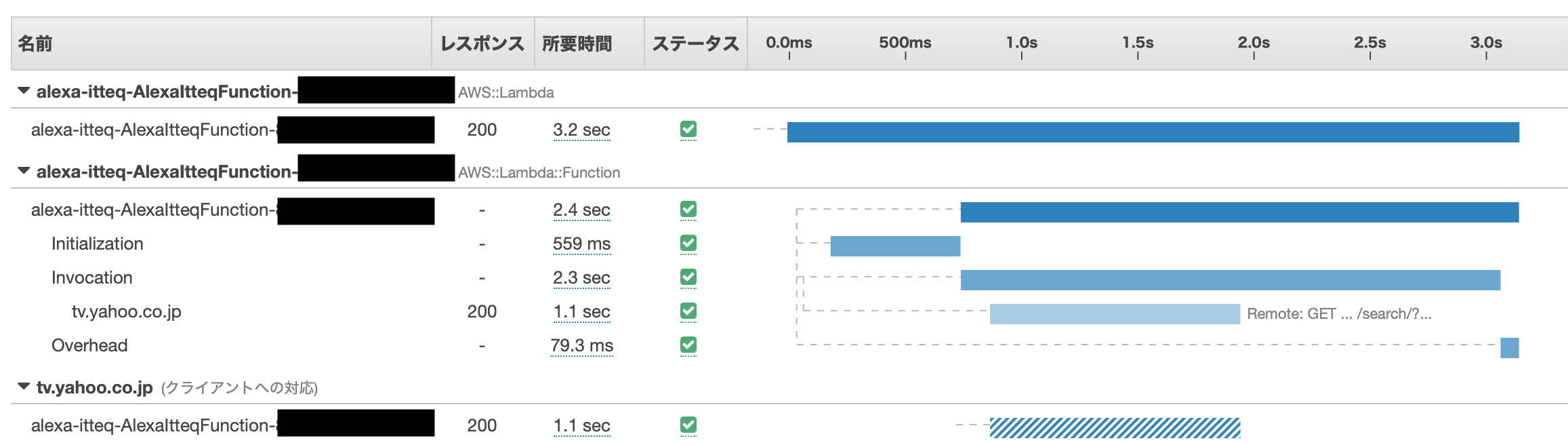
※xray-sdkは事前にnpmなりyarnなりで用意しておいてください。const awsXRay = require('aws-xray-sdk') awsXRay.captureHTTPsGlobal(require('https')) awsXRay.capturePromise()このコードを追加した状態で、再度ビルド、デプロイした後、実際に動作、X-RAYコンソールを開く、という操作をしてみます。
Service Map
Traces
ざっくりですが、2秒ちょっとの処理時間のうち前半約1秒がhttpsを使った番組表取得に費やされていることがわかります。
コード修正2:任意の区間を計測する
今度はコードに手を入れていきます。
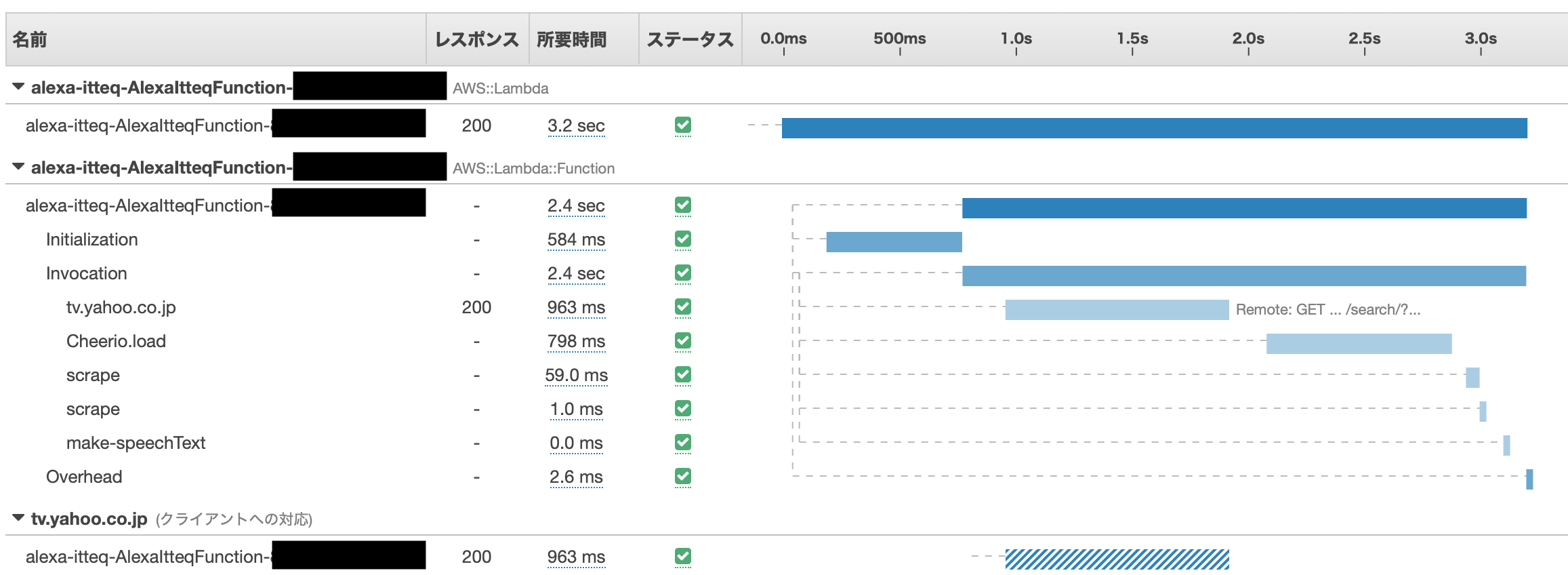
経過時間を測りたい区間にcaptureFuncやcaptureAsyncFuncを埋め込んでいきます。awsXRay.captureFunc('Cheerio.load', () => { $ = Cheerio.load(response.data) })awsXRay.captureFunc('scrape', () => { const left = $('div.leftarea', elm) const right = $('div.rightarea', elm) dateString = $('p:first-of-type > em', left).text() timeString = $('p:nth-of-type(2) > em', left).text() titleString = $('p:first-of-type > a', right).text() })awsXRay.captureFunc('make-speechText', () => { if (filtered.length > 0) { // 今日ある場合は、番組詳細まで返す const subStr = filtered.map(x => { const timeString = x.time.replace('~', 'から') const result = timeString + 'に' + x.title + 'が' return result }).join('、') speechText = '今日は' + subStr + 'あります。' } else if (programInfos.length > 0) { // 今日はないけど、明日以降見つかったら、日付と時刻を返す。 const subStr = programInfos.map(x => { const result = x.date.replace('/', '月') + '日' + x.time.replace('~', 'から') return result }).join('と、') speechText = '今日はイッテQはありませんが、' + subStr + 'にあるようです。' } else { // ない speechText = '今日はイッテQはありません。' } })今までと同じく実行後にX-RAYコンソール…
Service Mapは特に変わらないので、Tracesのみ。
これで、先に見たテレビ欄の取得とCheerioでのhtmlロードで処理時間の大半を使っていることがわかりました。
終わりに
今回のX-RAYでの調査により、遅いと感じていたAlexaスキルの処理時間の大半はHTTPS通信(1回)とCheerio.loadによるHTMLの読み込み処理(1回)で占められていることがわかりました。
となると、対応方法としては、以下のどちらかかな、と考えています。
- 番組表取得(HTTPS通信)とCheerioによるHTML解析処理は定期処理で事前に終わらせておく。Alexaスキルから呼び出されたときは解析済みの結果を使って文言整形する
- Cheerio以外のHTMLパーサを使用する(libxmljsとか???)
X-RAYは万能薬ではないですが、使ってみるとなかなか便利な機能だと思いますので、まだ使ったことない方は、ぜひともお試しあれ。



- 投稿日:2020-03-05T00:01:42+09:00
Serverless Framework で AWS Lambda と API Gateway をデプロイする
Serverless Meetup Tokyo #16 (オンライン開催) を拝見していて、ちょうど今、AWS への各種リソースのデプロイの自動化が課題だったので、よい機会と思い Serverless Framework を使ってみた。
尚、Serlverless Framwork については知っていたが、offline-start しか使ったことがなかった程度の人間です。やったこと
弊社では Webシステムを、
- フロントエンド: SPA(Angular)
- バックエンド:
- REST っぽいAPI: Lambda + API Gateway
- DB: PostgreSQL 他
で組むことが増えてきていて、プロジェクトの取っ掛かり時の環境構築を手動でやっているのがダルくなってきた。
今回は、「REST っぽいAPI: Lambda + API Gateway」のところを Serverless Framework で自動化してみた。手順
1. 環境構築用 IAM の作成
IAM コンソールで「serverless_deployment」という名前で作成。以下のポリシーをアタッチした。
- AWSLambdaFullAccess
- AmazonS3FullAccess
- AmazonAPIGatewayAdministrator
- AWSCloudFormationFullAccess
さらに、以下のようなインラインポリシーを追加した。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "iam:DeleteRolePolicy", "iam:CreateRole", "iam:DeleteRole", "iam:PutRolePolicy" ], "Resource": "*" } ] }IAMFullAccess はさすがにヤバいかなと思い必要な権限だけ抽出したものだが、たぶん他の xxxFullAccess も必要なものだけにした方がよいだろう。
作成した IAM のアクセスキーなどを自PCの
~/.aws/credentialsに追加した。ちなみに環境は Windows 10 内の WSL(Ubuntu)。.aws/credentials
[serverless-deployment] aws_access_key_id = AKIAxxxxx aws_secret_access_key = 49s9xxxxxxxxxxxxxxxxxxxxxxxxxxxx2. ツールのインストール
awscli は現在最新の v2 をインストール
node は 12.14.1
そして Serverless Framework をインストールする。
npm install serverless -g source ~/.bash_profile serverless --version > Framework Core: 1.65.0 > Plugin: 3.4.1 > SDK: 2.3.0 > Components: 2.22.3global じゃなくてもいいけど、パス通すのが面倒なので。
3. テンプレートからプロジェクトの作成
serverless create --template aws-nodejsで、nodejs のテンプレートから Serverless Framework のプロジェクトを作成。
また、
npm initで適当にpackage.jsonを作って、npm install --save-dev serverless-plugin-custom-binaryを実行しておく。これは後に必要になるプラグイン。
lsすると以下のようなファイルとディレクトリがある。handler.js node_modules package-lock.json package.json serverless.yml4. serverless.yml を編集する
serverless.ymlを開いて次のように編集する(これだと最早テンプレートの意味ないが)。service: my-awesome-service plugins: - serverless-plugin-custom-binary custom: apiGateway: binaryMediaTypes: - image/jpeg provider: name: aws runtime: nodejs12.x stage: ${opt:stage, 'dev'} region: ap-northeast-1 apiName: ${self:service}-${self:provider.stage} functions: api: handler: handler.hello name: ${self:service}-api-${self:provider.stage} events: - http: path: /{proxy+} method: get integration: lambdaまず
service: my-awesome-service、これが AWS に作成されるリソース名の元になるのでちゃんと考えて命名しよう。重複したらどうなちゃうのかは不明。 kebab-case を採用しておくと良いと思われる。例えばサービス名で S3 Bucket を作りたいとき、Bucket 名は CamelCase(大文字) を許可してないため。次に Plugins と binaryMediaTypes。これを行うために先に serverless-plugin-custom-binary をインストールしておいた。
provider-apiName。これは API Gateway の名前なんだけど、これをしない場合
<stage名>-<service名>になる。Lambda とかは<service名>-<stage名>となり逆で気持ち悪いので、他の同じになるように直している。stage: ${opt:stage, 'dev'}。単純に
stage: devとするだけだと、--stage prodを引数で指定された値が${self:provider.stage}に代入されないので注意。functions-api。Labmda に
<service名>-<stage名>-apiという名前の関数が作成される。"api" は任意の名称で ok。functions-api-name。既定だと
<service名>-<stage名>-apiになるが、<service名>-api-<stage名>にしたい(stage名は最後尾に統一したい) のでname: ${self:service}-api-${self:provider.stage}とした。handler: handler.hello。
handles.jsの hello 関数を呼び出すの意。path: /{proxy+}。呼び出し URL のパス部分を全てスルーする。
https://hoge.net/dev/fuga/piyo/gegeとか。integration: lambda。既定で ON ぽいので要らないかも。
5. AWS にデプロイする
serverless deploy --aws-profile serverless-deploymentを実行する。
--aws-profile serverless-deploymentで AWSプロファイルを指定している事に注意。Serverless: Packaging service... Serverless: Excluding development dependencies... Serverless: Creating Stack... Serverless: Checking Stack create progress... ........ Serverless: Stack create finished... Serverless: Uploading CloudFormation file to S3... Serverless: Uploading artifacts... Serverless: Uploading service MyAwesomeService.zip file to S3 (1.13 KB)... Serverless: Validating template... Serverless: Updating Stack... Serverless: Checking Stack update progress... ............................... Serverless: Stack update finished... Service Information service: MyAwesomeService stage: dev region: ap-northeast-1 stack: MyAwesomeService-dev resources: 11 api keys: None endpoints: GET - https://xxxx.execute-api.ap-northeast-1.amazonaws.com/dev/{proxy+} functions: api: MyAwesomeService-dev-api layers: None Serverless: Run the "serverless" command to setup monitoring, troubleshooting and testing.なんやかんや実行されてデプロイされたみたい。
6. デプロイされたか確認
API Gateway
Lambda
cURL で呼び出してみる。
curl https://xxxx.execute-api.ap-northeast-1.amazonaws.com/dev/aaa/bbb/ccc{"statusCode":200,"body":"{\n \"message\": \"Go Serverless v1.0! Your function executed successfully!\"...うまくいったみたい。
7. 後片付け(削除)
serverless remove --aws-profile serverless-deploymentですべてのリソースがキレイさっぱり消えます。これはこれで怖いので IAM の権限で制限したほうが良さそう。
トラブルシューティング
Q: デプロイが全然終わらない
A: Console から CloudFormation の該当スタックを削除してリトライ
Q: sls deploy や remove が「S3 のバケットが無い」とかでエラーになる
A: 該当バケット(
my-awesome-service-veri-serverlessdeploymentbucke-rzr9e2jjdrlvのようなごちゃごちゃしたやつ) を手動作成するか、Console から CloudFormation の該当スタックを削除してリトライ今後やりたいこと
- Lambda へ VPC の設定
- Lambda タイムアウト値の設定
- スクリプトでビルドとか Webpack した結果を Serverless でデプロイ
- S3 Bucket の作成
- S3 に SPA をデプロイ
- リソース権限周りをもっと深堀り
参考
- Serverless Framework - AWS Lambda Guide - Introduction
- Serverless Variables
- Serverless FlameworkでAPI Gatewayのバイナリメディアタイプを設定する方法 - Qiita
- Serverless Framework で API Gateway & Lambda を構築する - Qiita
- Serverlessで任意のディレクトリ配下に、関数毎にディレクトリを切ってソースを配置する with webpack building - Qiita
- 一時的にPATHを追加する(Linux) - Qiita
- ServerlessFrameworkでS3の静的サイトのホスティングをする - マコーの日記



