- 投稿日:2019-10-20T23:59:19+09:00
年末まで毎日webサイトを作り続ける大学生 〜2日目 空白削除システムを作る〜
はじめに
初めまして。
年末まで毎日webサイトを作っている者です。
今日はテキストから空白を削除してくれるシステムを作りました。
扱う技術レベルは低いですが、同じように悩んでる初心者の方の参考になれば幸いです。
今日は2日目。(2019/10/20)
よろしくお願いします。サイトURL
https://sin2cos21.github.io/day2.html
やったこと
テキスト文から空白を除いてくれるシステムをJavaScriptで作りました↓
こだわったところ
入力欄をtextareaにすることで文章をそのままコピペすれば、改行・空白を取り除けるようにしました。
replaceメソッドを使って空白を取り除いています↓<script> function deleteBlank() { target = document.getElementById("output"); text = document.forms.form1.input_text.value; text2 = text.replace(/\s+/g, ""); target.innerText = text2; } </script>htmlの方ではformとtextareaを使っています。クリックすると関数呼び出しします↓
<form action="" name="form1"> <textarea id="input_text" name="form1_text1" class="input_form"></textarea> <br> <br> </form> <div id="output" class="text_output"> </div> </div> <input type="button" value="変換" onclick="deleteBlank();"> <br>感想
一括で空白が削除できるのはいいですね。
今度ぜひ削除パターンにバリエーションを作ってみたいです。(特定の文字の前後だけは削除しないとか)
と、そういえばgithubの方がうまくいっていなくて今僕のgitpages見れないかと思います。
早急に見れるようにしますので今しばらくお待ちください。追記 2019/10/21
サイトは見れるようになりました。
リポジトリを削除したり何やらして、githubに直接ファイルをアップロードしました。
ソースツリー or コマンドを使って送ろうとすると “You must verify your email address.”とerror が出ます。
根本的には解決してないので今後も原因追求に努めたいと思います。

- 投稿日:2019-10-20T22:48:56+09:00
インクリメンタルサーチについての復習
インクリメンタルサーチの復習
Ajaxの非同期通信を学習中で、前回はコメントの投稿をページの再読み込みなしで表示させました。
今回は文字を入力して検索する際、検索ボタンを押して再読み込みをさせずに非同期で検索結果を表示させるようにします。インクリメンタルサーチとは
そもそもインクリメンタルサーチとは、
Incremental Search
Incremental : 増加、増大する、追加する
Search : 検索
と単語の意味で考えると正直分かりませんが、IT用語で「文字入力するたびに自動的に検索が行われる検索方法」を指します。インクリメンタルサーチの実装
インクリメンタルサーチ実装の流れを復習していきます。
あくまでAjax、JavaScriptの流れを把握することが目的なので、HTMLなどの表記はある程度省略していきます。search.js$(function() { $(".search__form").on("keyup", function(){ var input = $(".search__form").val(); $.ajax({ type: 'GET', url: '/products/search', data: { keyword: input }, dataType: 'json' }) .done(function(products) { $(".検索結果表示クラス").empty(); if (products.length !==0) { $(".検索結果表示クラス").append("インクリメンタルサーチの結果を表示させる記述"); } else { $(".検索結果表示クラス").append("検索結果がない旨を表示させる記述"); } }) .fail(function(){ alert('映画検索に失敗しました'); })全体的な記述は上記のようになると思います。
細かい内容をおさらいしていきます。$(".search__form").on("keyup", function(){keyupイベントはキーボードのキーが上がった時に発火します。文字入力でキーを離したタイミングですね。
イベントの発火を検知する場所は、ここでは"search__form"クラスを持つ検索フォームが指定されています。var input = $(".search__form").val();検索フォームに入力されている値をinputに代入します。
$.ajax({ type: 'GET', url: '/products/search', data: { keyword: input }, dataType: 'json' })Ajaxで非同期通信を行う際に指定する内容を記述します。
URL、data内のkey名(keyword)はルーティングやインスタンス変数の定義により変わるので一例です。
今回の記述では、{ keyword: input }データを/products/searchパスにGETメソッドで送り、結果をJSON形式で返してもらいます。.done(function(products) { $(".検索結果表示クラス").empty(); if (products.length !==0) { $(".検索結果表示クラス").append("インクリメンタルサーチの結果を表示させる記述"); } else { "検索結果がない旨を表示させる記述"; } }) .fail(function(){ alert('映画検索に失敗しました'); })
.doneメソッドと.failメソッドは対で記述しておきましょう。そして.failメソッドはalertで「エラーが発生しました」と表示される程度でいいかと思います。今回の
.doneメソッドでは、まず検索結果をproductsに代入します。
現在表示されている検索結果をemptyメソッドで消去します。
emptyメソッドは、その要素そのものではなく子要素を削除します。これで検索結果を表示させる箱は残しながら、中身を全て消してリセットしてしまいます。その後検索結果をリセットされた中身に追加して表示させるようにします。ifを使って場合分けを行います。検索結果の個数が0でなければその結果を表示させ、検索結果の個数が0の場合は検索結果がない旨の記述が適用されます。
結果
検索フォームに文字入力をすると、キーから指を離すたびにフォーム内の文字列が拾われて都度その文字列で検索をかけられます。
文字を入力する度に検索が実行されているわけですから、PC本体やネット回線のスペックがそれなりにないと負荷がすごいことになりそうですね。
ブロードバンドが普及する前にインクリメンタルサーチが使われていたら、どうなっていたのでしょうか?JavaScript(jQuery)の書き方にはまだ慣れませんが、書いている中身はなんとなく分かってきた気がします。一気に書くとさっぱり分かりませんが、一つ一つ読み解きながら進めていくとどうにか分かるようになってきました。
- 投稿日:2019-10-20T21:35:39+09:00
Javascript で diff (内部仕様についての補足)
前回 10/14 に投稿した「Javascript で diff (通信なし、ローカルで完結)」の内部仕様についての補足です。
基本アルゴリズム
基本アルゴリズムは、ほぼMyersのアルゴリズムのままです。
- ファイル1とファイル2から、内容が合致する行を探してペアを生成する。
- ペアが作れない行があったら、それは差分である。
diff_orzでは、各行に対してハッシュ値を生成しておき、ハッシュ値を比較するようにしています。
文字列からハッシュ値を生成する方法として、Murmur Hash が有名ですが、ここでは全体行数の短縮を優先で実装しています。
(ハッシュ値の生成のためだけに600行以上増えるのはうれしくないので)
- 半角空白、半角タブは除外してハッシュ値を生成する。
- ハッシュ値が異なる文字列は、異なる文字列である。
- ハッシュ値が同じ文字列どうしを発見した場合は、文字列の比較を行って本当に同じ文字列か確かめる。
const hash = (s_org, bIgnoreCase) => { let s = s_org.trim().replace(this.BLANK_PATTERN, ""), len = s.length; if (len == 0) { return 0; } if (bIgnoreCase) { s = s.toLowerCase(); } return [...s].reduce((v, c) => { return (c.codePointAt(0) ^ (v << 2)); }, len); }類似行の判別
変更行どうしで差分をとるにあたって、似ている行であれば差分を表示したいが、「どうみても別物の行」は行の削除+行の追加として扱いたいわけです。
よく見かける実装では、
- 内容が一致する行どうしを検出する
- 内容が一致していない行のかたまり(hunk)どうしでword単位の差分を生成する
という手順ですが、これだと似ている行と似ていない行の処理が振り分けられません。
そこで、不一致な行どうしで文字列の類似度をはかっておき、似ていれば差分を表示、似ていなければ削除+追加とします。
類似度の指標はいろいろな人がいろいろなものを考案されていますが、今回はレーベンシュタイン距離を文字列の長さ(2つの文字列のうち、長いほうの長さ)で割ったものを採用します。
半角スペースと半角タブを除いた状態で50%以上合致していれば、類似していると判定することにします。
DiffEngine.CalcScore() 関数のあたりが該当部分です。高速化してみる
実際に実装してみて、表示結果は希望通りになったのですが、レーベンシュタイン距離の計算がとにかく遅い!!
10000行程度のファイルどうしを比較すると数分以上待たされてしまったので、何とか高速化することにします。
類似度は、文字列どうしが似ているかどうかだけ分かればよいので、似ていないと分かった時点でスコア計算を打ち切るようにしました。
また、ファイル内でユニークな内容を持つ行(=同じ内容の行は他に存在しない)について、比較対象のファイルにも同じ内容でユニークな行が存在すれば、そこでペアが確定するため、レーベンシュタイン距離の計算対象から外します。行のハッシュ値を生成した直後の処理で、ユニークな行どうしでペアが作れるかを調べて記録しています。Javascript で関数を入れ子にするとものすごく遅かったので、インライン展開できるところはなるべくインライン展開するようにしています。内側の関数から外側の変数を参照すると遅いようです。
なんとか、10000行くらいのファイルを数秒から10秒くらいで比較できるようになったのですが、基本アルゴリズムがO(N^2)なので、リアルタイムで表示を更新するのはあきらめました。(このへんがdiff_orzの名前の由来だったり………)
- 投稿日:2019-10-20T20:53:18+09:00
Payjpを使って、商品購入機能を実装する【Rails】
概要
「payjp」というgemを使うことで、簡単にクレジットカード(以下CC)購入フォームと機能を作成することができます。
本記事では、某フリマアプリのクローンアプリを開発した際に、購入機能を実装する上で登録画面のマークアップからpayjp利用したサーバーサイドの実装までを紹介していきます。実装する機能
- Checkoutを利用した購入機能(この段階でのみCheckout利用)
- payjp.jsを利用した実装
- CC登録機能
- 登録したCCをユーザー情報と紐づけて表示させる
- CC削除機能
- 購入機能(再実装)
- ユーザー新規登録登録画面でもCC登録ができるようにする(+α)
バージョン情報や前提条件
- ruby 2.5.1
- payjp 5.2.3
- 前提条件
- hamlで記述
- sassで記述
- deviseを導入しており、ログイン機能が実装されている
実装
DB設計やルーティングの違いにより、実装する上で記述内容に差異が生じるかと思います。
適宜考えて実装していただけると幸いです。payjp gemをインストール
Gemfileに以下を記述して、bundle installします。
gem 'payjp'payjpのサイトにアカウント登録
payjpのサイトでアカウントを登録します。
https://pay.jp/APIキーを確認
登録が完了したら、payjpの管理画面でAPIキーを確認します。
今回確認するのは、テスト用の公開鍵(pk~)と秘密鍵(sk~)です。
こちらは後ほど使用するので、画面を残しておきましょう。
購入機能の実装(checkout利用)
続いて購入機能の実装です。
購入機能自体はpayjpで用意されているライブラリ 「Checkout」 を利用すれば、簡単に実装できます。1.ビューファイル編集
購入確認画面のビューファイル内の 「購入する」 の記述を、以下の記述と置き換えます。
app/views/transacts/buy.html.haml= form_with "パスを指定" do :plain %script{type: "text/javascript", src: "https://checkout.pay.jp", class:"payjp-button", "data-text": "購入する", "data-key": "公開鍵(pk_~)"}これだけで購入に関するフォームの記述は終了です。
置き換えた後に表示された「購入する」をクリックすると、CC登録フォームがモーダルで表示されます。
使用するカード情報
カード: 4242424242424242(Visaのテストカード)
有効期限: 現在より未来の期日
CVC番号: 3~4桁の任意の数字
名前: 任意の名前使用するカードはpayjpよりテストカードが用意されているので、そちらを使用しましょう。
https://pay.jp/docs/testcard2.コントローラ編集
app/controllers/transacts_controller.rbrequire 'payjp' def pay Payjp.api_key = "秘密鍵(sk_~)" Payjp::Charge.create( amount: 1100, # 決済する値段 card: params['payjp-token'], # フォームを送信すると生成されるトークン currency: 'jpy' ) end後は、ルーティングを設定すれば、購入できるようになります。
実際に購入できているのが確認できます。
再実装【payjp.jsを利用】
checkoutを利用することで、簡単に購入機能が実装できました。
しかし、現在の実装では実際の運用は難しいので、実際の運用を想定して実装し直します。実装条件
- ログインしているユーザーに紐づけてカード情報を登録する、削除もできる
- ユーザーは登録したCCを使用して、商品を購入できる
- 独自でCC登録フォームを作成する
1.テーブルの作成
マイグレーションファイルを作成し、テーブルの作成とカラムの紐付けを行います。
userは外部キーなので、references型で外部キー制約を指定しています。db/migrate/2019**********_create_cards.rbclass CreateCards < ActiveRecord::Migration[5.2] def change create_table :cards do |t| t.references :user, null: false, foreign_key: true t.string :customer_id, null: false t.string :card_id, null: false end end end記述したら、rake db:migrate を行います。
なお、DBに顧客情報やカード情報そのものを保存することは禁止されているのでご注意ください。http://payjp-announce.hatenablog.com/entry/2017/11/10/182738モデルの紐付け
モデルファイルを作成し、編集します。
以下、カードに関する紐付けの記述のみ載せています。app/models/card.rbclass Card < ApplicationRecord belongs_to :user endapp/models/user.rbclass User < ApplicationRecord devise :database_authenticatable, :registerable, :recoverable, :rememberable, :validatable has_many :cards # 追記する end2.クレジットカード登録フォームのマークアップ
続いて登録フォームを作成します。
今回は、某フリマアプリに寄せてています。
一つのファイルに以下の内容も記述すると、記述量が膨大になるため、部分テンプレートを採用しています。/_card_registration.html.haml.credit-update .credit-update__label クレジットカード情報入力 .card-form .card-form__box = form_tag(cards_path, method: :post, id: 'charge-form', name: "inputForm") do |f| .card-form__box__number %label{class:'box-group--label', for: 'card_number'} カード番号 %span.input-require 必須 = text_field_tag "number", "", class: 'card-number--input', type: "text", id: 'card_number', maxlength: "16", placeholder: "半角数字のみ" .registration-error{type: "hidden", value: "必須項目です"} %ul.card-list -# assets/imagesにimageを設置しており、それをimage_tagで呼び出しています。 %li.card-list--item{ style: "margin-left: 0;"} = image_tag "visa.svg", width:"49", height:"20" %li.card-list--item = image_tag "master-card.svg", width:"34", height:"20" %li.card-list--item = image_tag "saison-card.svg", width:"30", height:"20" %li.card-list--item = image_tag "jcb.svg", width:"32", height:"20" %li.card-list--item = image_tag "american_express.svg", width:"21", height:"20" %li.card-list--item = image_tag "dinersclub.svg", width:"32", height:"20" %li.card-list--item = image_tag "discover.svg", width:"32", height:"20" .card-form__box__expire %label.box-group--label 有効期限 %span.input-require 必須 .card-expire .card-expire__select-month %select#exp_month{name: "exp_month", type: "text"} %option{value: "1"}01 %option{value: "2"}02 %option{value: "3"}03 %option{value: "4"}04 %option{value: "5"}05 %option{value: "6"}06 %option{value: "7"}07 %option{value: "8"}08 %option{value: "9"}09 %option{value: "10"}10 %option{value: "11"}11 %option{value: "12"}12 %i.card-form-expire-icon = image_tag "arrow-bottom.png", size:"16x10",class:"arrow-bottom-icon5" %span{class: "month"} 月 .card-expire__select-year %select#exp_year{name: "exp_year", type: "text"} %option{value: "2019"}19 %option{value: "2020"}20 %option{value: "2021"}21 %option{value: "2022"}22 %option{value: "2023"}23 %option{value: "2024"}24 %option{value: "2025"}25 %option{value: "2026"}26 %option{value: "2027"}27 %option{value: "2028"}28 %option{value: "2029"}29 %i.card-form-expire-icon = image_tag "arrow-bottom.png", size: "16x10",class:"arrow-bottom-icon6" %span{class:"year"} 年 .card-form__box__security-code %label.box-group--label{for: "cvc"} セキュリティーコード %span.input-require 必須 = text_field_tag "cvc", "", class: 'payment__security-code', type: "text", id: "cvc", maxlength: "4" ,placeholder: "カード背面4桁もしくは3桁の番号" .question-form %span.question-form__mark ? %span.question-form__text カード裏面の番号とは? #card_token = submit_tag "追加する", class: "card-form__box__add", id: "token_submit", type: 'button'こちらにcssを当ててあげると以下のようになります。
3.payjp.jsを編集
payjp.jsファイルを作成し、編集します。
checkoutを利用した場合、checkoutが簡単にトークンを作成してくれていましたが、それを利用しないのでpayjp.jsでトークンを生成する処理を記述する必要があります。app/assets/javascripts/payjp.js$(function(){ var submit = document.getElementById("token_submit"); submit.addEventListener('click', function(e){ // 追加するボタンが押されたらイベント発火 e.preventDefault(); // ボタンを一旦無効化 Payjp.setPublicKey("秘密鍵(pk_~)"); var card = { // 入力されたカード情報を取得 number: document.getElementById("card_number").value, exp_month: document.getElementById("exp_month").value, exp_year: document.getElementById("exp_year").value, cvc: document.getElementById("cvc").value }; if (card.number == "", card.exp_month == "1", card.exp_year == "2019", card.cvc == "") { alert("カード情報が入力されていません。"); // 送られた値がデフォルト値だった場合 } else { // デフォルト値以外の値が送られてきた場合 Payjp.createToken(card, function(status, response) { // トークンを生成 if (status === 200) { $("#card_number").removeAttr("name"); $("#exp_month").removeAttr("name"); $("#exp_year").removeAttr("name"); $("#cvc").removeAttr("name"); $("#card_token").append( $('<input type="hidden" name="payjp-token">').val(response.id) ); document.inputForm.submit(); // 生成したトークンを送信する準備を整える alert("登録が完了しました"); } else { alert("正しいカード情報を入力してください。"); } }); } false }); });4.payjp.jsを読み込めるようにする
application.haml.hamlに以下の内容を追記します。
%script{src: "https://js.pay.jp/", type: "text/javascript"}
%script{type: "text/javascript"} Payjp.setPublicKey('公開鍵(pk_~)');app/views/layouts/application.html.haml%html %head %meta{content: "text/html; charset=UTF-8", http: { equiv: "Content-Type" }} %title FreemarketSample59a = csrf_meta_tags = csp_meta_tag = stylesheet_link_tag 'application', media: 'all', 'data-turbolinks-track': 'reload' = javascript_include_tag 'application', 'data-turbolinks-track': 'reload' %script{src: "https://js.pay.jp/", type: "text/javascript"} %script{type: "text/javascript"} Payjp.setPublicKey('公開鍵(pk_~)'); %body = yield5.コントローラを編集
続いてコントローラを編集します。
先ほどはtransacts_controller(商品取引に関する)を編集しましたが、今回は新たにcards_controller(カードに関する)を作成し、それを編集します。app/controllers/cards_controller.rbclass CardsController < ApplicationController require 'payjp' before_action :set_card # 後ほど登録したクレジットの表示画面を作成します。 def index end # クレジットカード情報入力画面 def new if @card redirect_to card_path unless @card else render 'mypages/create_card' end end # 登録画面で入力した情報をDBに保存 def create Payjp.api_key = "秘密鍵(sk_~)" if params['payjp-token'].blank? render 'mypages/create_card' else customer = Payjp::Customer.create( # ここで先ほど生成したトークンを顧客情報と紐付け、PAY.JP管理サイトに送信 email: current_user.email, card: params['payjp-token'], metadata: {user_id: current_user.id} # 記述しなくても大丈夫です ) @card = Card.new(user_id: current_user.id, customer_id: customer.id, card_id: customer.default_card) if @card.save redirect_to cards_path else render 'mypages/create_card' end end end # 後ほど削除機能を実装します。 def destroy end private def set_card @card = Card.where(user_id: current_user.id).first if Card.where(user_id: current_user.id).present? end end秘密鍵を必ず設置するようにしましょう。
6.ルーティングを設定
ルーティングには今後実装するindex、destroyのアクションも記述します。
config/routes.rbresources :cards , only: [:new, :index, :create, :destroy]これでユーザーがクレジットカードを登録できるようになりました。
最後に
本記事の紹介は、一旦ここまでの実装で終わります。
また後日続きの実装を載せたいと考えているので、本記事を通して少しでも読者様の参考になれば幸いです。
また、学習期間3ヶ月の若輩者ですので、記事に多々不備があるかと思います。
ご意見やご質問がありましたらお気軽にご連絡ください。




- 投稿日:2019-10-20T20:08:17+09:00
【HTML、CSS、JSの書式】これを読めばコードが読める!書ける!まとめ!
Webサイトを作ってみたいが、作り方がわからない!そんな方向けに
- HTML、CSS、JSの位置付けを理解する
- 人が書いたコードが読めるようになる
- CodePenで自分でも書いてみる
というステップでWebサイト作りができるようになる記事を書きました。下記にまとめます。
Webの基礎知識
まず、HTML、CSS、JSの位置付けを理解する。
- HTML:文書構造
- CSS:見た目
- JS:動作、変更
※参考:【Webの基礎知識】書ける前に読む!HTML、CSS、JSの書式-1
HTMLの基本
タグと閉じタグで囲う「要素」の解説。
<!--DOM要素--> <タグ名 属性="値">テキスト</タグ名>※参考:【HTMLの基本】書ける前に読む!HTML、CSS、JSの書式-2
CSSの基本
「セレクタ」「プロパティ」「値」などの解説。
/*セレクタ*/ セレクタ { プロパティ: 値; }※参考:【CSSの基本】書ける前に読む!HTML、CSS、JSの書式-3
JSの基本-前編(オブジェクト、関数、変数)
オブジェクト指向「オブジェクト(何が)」「プロパティ(どうなる)」「メソッド(どうする)」や「DOM」「変数」「関数」などを解説。
//プロパティ オブジェクト.プロパティ = 値; //メソッド オブジェクト.メソッド(引数); //変数 const 変数名 = 値; //関数 function 関数名(引数){ //処理 }※参考:【JSの基本-前編】書ける前に読む!HTML、CSS、JSの書式-4
JSの基本-後編(イベント、制御構造)
イベントと制御構造の解説。イベントは「いつ」にあたる部分。制御構造は「分岐」と「反復」。
//イベントリスナ オブジェクト.addEventListener("イベント名", //処理 , false); //if文(分岐) if (条件式) { //処理 } //for文(反復) for (初期化式; 条件式; 増減式) { //処理 }※参考:【JSの基本-後編】書ける前に読む!HTML、CSS、JSの書式-5
HTML、CSS、JSの基本(動画版)
上記の内容を抜粋した動画版。CodePen使ってYoutube上でライブコーディングしてみた。
CodePenでHTML、CSS、JSを体験しよう【クモコツ一人もくもく会-1】
YoutubeのURLはこちら!
- 投稿日:2019-10-20T19:22:10+09:00
リッチテキストエディタライブラリSlateJSの状態・DOM管理方法
リッチテキストエディタライブラリSlateJSを使っていて、
このライブラリがどのようにデータを管理し、DOMに反映し、まだDOMの変更をデータに反映しているのか
また、Controlled Componentとはどう違うのか
が気になったので、中身を読んでみたメモ。Slateの状態管理・React連携
- slate, slate-reactという2つのパッケージがメイン
slate: エディタの内部状態を管理する。Editorクラス(slate/src/controllers/editor.js)がメインのインタフェース。slate-react[React]バインディング。slateのEditorクラスに格納された内部表現を使って[VirutalDOM]を構築する(src/components/*.js)。また、イベントをハンドリングしてEditorクラスのコマンドを叩く。総じて、通常のReactのControlled Componentを作るときにやる処理を巻き取ってくれる(VDOMの宣言+イベントハンドリング→state更新)。Controlled Componentにおけるstate更新が、slateではEditorのコマンド実行になる。slateパッケージ
Editorクラス(controllers/editor.js): Valueを保持したり、プラグイン機構を提供したりと、slateエディタの基盤となる汎用的なフレームワークを提供する。具体的な処理のほとんどはプラグインに抜き出されている。plugins: プラグイン機構はユーザに解放されているが、コア機能の多くもプラグインを利用してslateに組み込まれている。models: データモデルの定義もslateパッケージにある。commands: 組み込みコマンドslate-reactパッケージ
src/components/editor.jsのEditorクラスが、Reactでslateを使うときのエントリポイント。<Editor>として使うときのクラス。
- 内部で
slateのEditorクラスのインスタンスを保持している(this.controller)。- renderでは、
RenderEditorで外側を修飾した後は、Contentクラスに移譲。src/components/content.js
- renderで
Nodeコンポーネントにdocumentを渡して描画する。Nodeは再帰的にValueツリーをrenderする。
- ユーザが適宜カスタマイズできるよう、
renderBlock,renderInline,renderTextがNodeで呼ばれる。- 子Nodeに起きたイベントは全て、
Content(ルートノード)で拾う。Contentクラスに全てのイベントハンドラが定義されている(this.handlers)。this.handlersは結局イベントの種類情報(onInputBeforeなど)を付与して、this.props.onEventを呼ぶsrc/components/editor.jsのEditor.onEvent: 上記Contentからコールバックされる。onEventはさらにthis.controller.runを呼ぶ。this.controller.runはslateのEditor.run。登録されたプラグインからイベントハンドラを呼び出す。slate-reactのpluginsでDOMイベントのハンドラを定義してある。これらのプラグインが上記this.controllerに登録されているため、エディタを構成するDOMで起きたDOMイベントは全てこのハンドラに送られる。
- 流れを整理すると、
NodeでDOMイベント発生- Reactのイベントバブリングにより、
Content(のContainerコンポーネント)にDOMイベントが送られるContent.handlersで捕捉Contentの親であるEditorのonEventにコールバックEditor.onEventからthis.controller.run=slate.Editor.runをコールslate.Editor.runがプラグインのイベントハンドラをコール- さて、
slate-reactのプラグインのうち、AfterPlugin(src/plugins/dom/after.js)を見てみる。これは上記のControlled ComponentでのアナロジーにおけるsetState相当のことを担当している。
AfterPluginのonBeforeInputが、各種のイベントに応じてeditorのコマンドをコールしている。
- 例えば、
'insertText'イベントの時はeditor.insertTextAtRange- このイベントはネイティブDOMイベントである。ネイティブのbeforeInputイベントの
event.eventTypeは https://triple-underscore.github.io/input-events-ja.html#dom-inputevent-inputtype を参照。多種多様なイベントが定義されており、HTML5のレイヤでcontenteditableを利用したリッチテキスト編集サポートが意識されている気がする。単純なinput, textareaのControlled Componentとの違い
- Controlled Componentは、以下の3要素からなる
- 1. データを何らかのstoreに保持(component state, useState hook, redux storeなど)
- 2. データ→VDOMのマッピングの宣言(render関数)
- 3. VDOMのイベントハンドラからデータを更新(this.setState、hookのsetXX、dispatch(action)など)
- slateのモデルでは、この1, 2, 3が以下に対応する
- 1. データを
slateパッケージのEditorに保持。その際のデータモデルもslateに定義される- 2. データ→VDOMのマッピングの宣言(render)は
slate-reactパッケージのEditorcomponentとその子たちで行われる。ユーザは適宜render*でrenderに介入できる- 3. 2. で定義したVDOMのイベントハンドラから、プラグイン機構を介して、
slate-reactのプラグインに定義されたイベントハンドラに処理が移譲される。これらのイベントハンドラからslateのEditorの各種コマンドが呼ばれる。コマンドはデータを書き換える操作を行う。
- コマンドのデータ書き換えは、さらにOperationという操作を通して行われるが、ここでは触れない
- 以上のように、Controlled Componentではユーザが自分で全てを書ける部分を、slateが引き取ってくれている。contenteditableを使う場合、この部分の処理は圧倒的に煩雑になるのであろう。
- Controlled Componentでもredux-formのようなラッパーがある。slateはこれらのラッパーと同じレイヤにいると考えられる。
- inputやtextareaであれば、ユーザが自分でControlled Componentを書けるし、楽をしたければライブラリを使える。一方、contenteditableは自分で書くという選択肢はほとんど候補に挙がらないほど複雑でライブラリ利用一択なのであろう。
- contenteditableの苦しみ: https://www.bokukoko.info/entry/2017/10/08/154950
- とは言っても、自分で頑張る選択肢ももちろんある。[LINEBlog]や[note]は頑張ったようだ。https://engineering.linecorp.com/ja/blog/contentable-development-of-line-blog-apps/ https://note.mu/ct8ker/n/n037f6ba3c318
- この設計の帰結として、自由度がControlled Componentより低くなってしまっている。
- データ管理・変更
- Controlled Componentであれば、stateの持ち主はルートに近いノード。また、そこからstateを直接変更してもVDOMはそれを正しく反映する
- slate-reactの場合、(Controlled Component風にvalue, onChangeが公開されているとはいえ)、勝手にvalueを変更するとエディタが壊れる。valueの変更はcommandで行うしかない。valueの持ち主は親Componentのように見えるが、持ち主にvalueを直接変更する自由はない。
- slate-reactのvalue, onChangeはあくまでイベントハンドリングや保存用データを取得するためのハッチであって、Controlled Componentのようにvalueの直接的な変更権まで親に移譲されるものではないように思われる。 VDOMのrender
- Controlled Componentであれば、データをどのようにViewにマッピングするか(renderの設計)は完全に自由
- slateでは
render*フックを使えるのみSlateJSの"command"という設計について
- HTML5に
execCommandが定義されている。contenteditableと同時に使うといい感じらしい- slateの、「commandを通して対象を操作する」デザインはこの辺りから来ているのかもしれない。
Block,Inline,Textといったデータ構造もDOMを真似ている。全体として、DOMのアナロジーで書けるようにデザインされている?- コマンドクエリ責務分離 も関係? https://docs.microsoft.com/ja-jp/dotnet/architecture/microservices/microservice-ddd-cqrs-patterns/apply-simplified-microservice-cqrs-ddd-patterns
- SlateJSのcommand/query: https://docs.slatejs.org/guides/commands-and-queries
- 投稿日:2019-10-20T19:05:33+09:00
【JavaScript入門】基本的な「単語」と「文法」の理解のための忘備録
ざっくり言うと、「ブラウザを操作するためのプログラミング言語」
HTMLやCSSだけではできないことをするために使う
HTML/CSSで作られた静的なページに対して、JavaScriptで動きをつけていく
- ブラウザを操作する
- HTMLやCSSにはできないことをするために使う
- HTMLやCSSをリアルタイムに書き換える
コンソールに書いてみる
console.log('hogehoge'); //□□は○○を△△せよ //consoleはhogehogeをlogせよ
□□オブジェクト
指示を出す相手○○をメソッド
オブジェクトに対して具体的な実行内容を指示する部分△△をパラメータ
指示に必要な詳細情報、何を出力するのか?JavaScriptを書く場所
- HTML
</body>の直前- javascriptファイルをHTMLに読み込ませる
外部ファイルに書いて読み込ませるのが一般的
<script> console.log('hogehoge'); </script> </body>新しいJavaScriptとして実行する
ブラウザには、ストリクトモード(strict mode)というものがある
古いJavaScriptを実行するモードと、新しいJavaScriptを実行するモードがあり、この新しいJavaScriptを実行するモードがストリクトモードと呼ばれる。
新しいES6のコードは、ストリクトモードでなくとも動作するが、ミスを防ぐための検出機能などがうまく動かない場合もあるらしい。
JavaScriptの先頭には、ストリクトモードの記述をする必要がある
'use strict';<script> 'use strict'; </script>コメントの書き方
CSSと一緒
//単一行コメント /* 複数行 にまたがる コメント */アラート ダイアログボックスを表示させる
alertメソッド
'use strict'; window.alert('アラート文');
確認ダイアログボックス
同じダイアログボックスでも、ユーザーに確認を促すもの
confirmメソッドは、alertメソッドとは違って戻り値を返す。confirmはOKかキャンセルをユーザーにクリックさせ、どちらかのボタンをクリックした時に、trueかfalseの値を返してくる。
クリックされたボタンで次の動きを変えることが可能
'use strict'; if(window.confirm('ダイアログボックス')){ //true[ok]の場合 } else { //false[キャンセル]の場合 }HTMLを書き換える
HTMLを書き換えるには、
HTMLの要素を取得
getElementById
要素のコンテンツを書き換えるtextContentこれらを使ってHTML要素のテキストを書き換えていく。
<h1 id="change">JavaScript入門</h1>'use strict'; document.getElementById('change').textContent = 'Ruby入門';これで、HTMLのテキストが書き換えらる。
変数と定数
変数とは
戻り値を後の処理でも使いたい場合、変数に定義しておけば便利。
JavaScriptの処理の高速化にもなる。
- 変数を定義
- 変数にデータを代入
- 変数からデータを読み取る
- 変数のデータを書き換える
変数を定義する
まず、変数を定義する。
変数の定義方法については、色々ある。
予約語 説明 なし 意図しない結果になることがある。あまり推奨されない var ES5で主流の書き方。現在でも使われている let ES2015で追加された。varより少し制限あるが、副作用が少ない const ES2015で追加された。一度しか代入できない定数で使う。値を書き替えてはいけないことを明示したい時に使う let answeranswerという名前の変数を定義
変数の名前はわかりやすいものを使う変数にデータを代入
変数に保存しておきたいデータを入れる
代入演算子(=)を使う。「=」は、
右側のデータを左側に代入すると言う意味let answer = window.confirm('ダイアログボックス');confirmメソッドは、戻り値があるので、
ユーザーの操作によって、変数に格納される値が変わります。例えば、
let answer = window.confirm('ダイアログボックス'); //ユーザーがOKを選択した場合 let answer = 'true'; //trueが変数に代入される変数からデータを読み取る
console.log(answer);変数のデータを書き換える
answer = 'no';ただし、変数がそのデータを保持していられるのは、そのページが表示されている間だけ。
変数名の付け方
無条件に好きな名前をつけられるわけではないので注意
変数名の命名条件
- アンダースコア(_)、ダラー($)、数字が利用可能。(-)などは使えない
- 半角スペースは使えない
- 1文字目に数字は使えない
- 予約語は使えない条件ではないが、気をつけるポイント
- 1文字の変数名にしない
- 変数名は英単語でつける
定数とは
定義した時に代入したデータを後から書き換えることができない変数のこと。
定数の場合は、letではなくconstを使う条件分岐(if)
if(条件A){ //Aがtrueだった場合の処理 } else if (条件B) { //Bがtrueだった場合の処理 } else { //どちらともfalseだった場合の処理 }比較演算子
演算子 意味 a === b aとbが同じ a !== b aとbが同じでない a < b aがbより小さい a <= b aがb以下 a > b aがbより大きい a >= b aがb以上 参考リンク


- 投稿日:2019-10-20T18:24:53+09:00
Vue + TypeScript のプロジェクトを SonarQube で品質管理する
例
説明に使ったリポジトリ
https://github.com/sterashima78/vue-ts-sonarqube-exampleはじめに
コードの品質を評価するために多くに静的解析手法が提案されている。
これらの解析によって得られる指標を常に観察することで、コードの品質悪化をいち早く検知することが期待できる。
JavaScriptではPlato でいくつかの指標を算出することができると知っていたが、
メンテナンスが滞っていることに加えて、現在私がよく利用しているVueやTypescriptには対応していなかった。そんななかで、SonarQube それに代わるということを知ったので、 Vue + Typescript のプロジェクトに導入した。
本文書は、その導入方法を示したものになる。サンプルプロジェクトの準備
$ vue create vue-ts-sonerqube-example Vue CLI v4.0.4 ? Please pick a preset: Manually select features ? Check the features needed for your project: Babel, TS, Vuex, CSS Pre-processors, Linter, Unit ? Use class-style component syntax? No ? Use Babel alongside TypeScript (required for modern mode, auto-detected polyfills, transpiling JSX)? Yes ? Pick a CSS pre-processor (PostCSS, Autoprefixer and CSS Modules are supported by default): Sass/SCSS (with node-sass) ? Pick a linter / formatter config: Prettier ? Pick additional lint features: Lint on save, Lint and fix on commit ? Pick a unit testing solution: Jest ? Where do you prefer placing config for Babel, PostCSS, ESLint, etc.? In dedicated config filesSonarQube serverの準備
SonarQube は Java製のソフトウェアでJava11以上を要求する。
Docker imageもあるのだが、今回は以下のページでコミュニティーバージョン(ver 8.0)をダウンロードして実行することにした。
https://www.sonarqube.org/downloads/ダウンロードしてきた zip を解凍したら、bin以下に各OSごとの実行用ファイルがあるのでそれを実行する
windowsの場合はsonarqube-8.0\bin\windows-x86-64\StartSonar.batを実行すればいい。http://localhost:9000 を listenするのでブラウザからアクセスできる。
SonarQube のための設定
SonerQubeはソフトウェアのスキャン機能をもっており、そのスキャン結果をサーバに送信することで結果の閲覧ができる。
この時別のツールの結果を読み取らせることができるので、単体テスト結果とlint結果を読み取らせる。以下でそのための設定を行う。依存パッケージインストール
$ npm i -D jest-sonar-reporter sonarqube-scanner npm-run-alllint の設定
以下のタスクを追加する
package.json{ "scripts": { "lint:sonar": "eslint -f json -o report.json ." } }unit testの設定
以下を追加する
jest.config.jsmodule.exports = { testResultsProcessor: "jest-sonar-reporter", collectCoverageFrom: [ "src/**/*.{js,jsx,ts,tsx,vue}", "!<rootDir>/node_modules/" ] };以下のタスクを追加する
package.json{ "scripts": { "test:unit:sonar": "npm run test:unit -- --coverage" } }sonar-scannerの設定
SonerQubeの静的解析とデータ送信を行うsonar-scannerの設定をする。
以下のタスクを追加する
package.json{ "scripts": { "sonar:scan": "sonar-scanner", "sonar": "run-s test:unit:sonar lint:sonar sonar:scan" } }以下の設定ファイルを追加する
sonar-project.propertiessonar.projectKey=vue-ts-sonerqube-example sonar.projectName=vue-ts-sonerqube-example sonar.sources=src sonar.tests=tests sonar.test.inclusions=**/*tests*/** sonar.exclusions=**/*tests*/** sonar.testExecutionReportPaths=test-report.xml sonar.javascript.file.suffixes=.js,.jsx sonar.typescript.file.suffixes=.ts,.tsx,.vue sonar.typescript.lcov.reportPaths=coverage/lcov.info sonar.javascript.lcov.reportPaths=coverage/lcov.info sonar.eslint.reportPaths=report.jsonそのほかの設定は以下を参照する
https://docs.sonarqube.org/latest/analysis/scan/sonarscanner/
Scanの実行
$ npm run sonar以下にアクセスすると結果を閲覧できる。
http://localhost:9000/dashboard?id=vue-ts-sonerqube-example結果閲覧と対応
16件のセキュリティ警告があるので見てみる。
See Ruleを見ると警告についての詳細が出る。
target="_blank"で開かれたサイトに悪意があれば、元ページを操作される恐れがあるという。指摘通りに修正をして再度確認する。
指摘が消えた。
また、新たに生じた誤りなどはないことも示されている。終わりに
上記のような設定をCIに組み込むことで例えばレビュー前に誤りが作りこまれていないかを確認することができる。
これによってレビュー負荷も減ることが期待できる。




- 投稿日:2019-10-20T18:24:53+09:00
Vue + TypeScript のプロジェクトを SonarQubeで静的解析して 品質管理する
例
説明に使ったリポジトリ
https://github.com/sterashima78/vue-ts-sonarqube-exampleはじめに
コードの品質を評価するために多くに静的解析手法が提案されている。
これらの解析によって得られる指標を常に観察することで、コードの品質悪化をいち早く検知することが期待できる。
JavaScriptではPlato でいくつかの指標を算出することができると知っていたが、
メンテナンスが滞っていることに加えて、現在私がよく利用しているVueやTypescriptには対応していなかった。そんななかで、SonarQube それに代わるということを知ったので、 Vue + Typescript のプロジェクトに導入した。
本文書は、その導入方法を示したものになる。サンプルプロジェクトの準備
$ vue create vue-ts-sonerqube-example Vue CLI v4.0.4 ? Please pick a preset: Manually select features ? Check the features needed for your project: Babel, TS, Vuex, CSS Pre-processors, Linter, Unit ? Use class-style component syntax? No ? Use Babel alongside TypeScript (required for modern mode, auto-detected polyfills, transpiling JSX)? Yes ? Pick a CSS pre-processor (PostCSS, Autoprefixer and CSS Modules are supported by default): Sass/SCSS (with node-sass) ? Pick a linter / formatter config: Prettier ? Pick additional lint features: Lint on save, Lint and fix on commit ? Pick a unit testing solution: Jest ? Where do you prefer placing config for Babel, PostCSS, ESLint, etc.? In dedicated config filesSonarQube serverの準備
SonarQube は Java製のソフトウェアでJava11以上を要求する。
Docker imageもあるのだが、今回は以下のページでコミュニティーバージョン(ver 8.0)をダウンロードして実行することにした。
https://www.sonarqube.org/downloads/ダウンロードしてきた zip を解凍したら、bin以下に各OSごとの実行用ファイルがあるのでそれを実行する
windowsの場合はsonarqube-8.0\bin\windows-x86-64\StartSonar.batを実行すればいい。http://localhost:9000 を listenするのでブラウザからアクセスできる。
SonarQube のための設定
SonerQubeはソフトウェアのスキャン機能をもっており、そのスキャン結果をサーバに送信することで結果の閲覧ができる。
この時別のツールの結果を読み取らせることができるので、単体テスト結果とlint結果を読み取らせる。以下でそのための設定を行う。依存パッケージインストール
$ npm i -D jest-sonar-reporter sonarqube-scanner npm-run-alllint の設定
以下のタスクを追加する
package.json{ "scripts": { "lint:sonar": "eslint -f json -o report.json ." } }unit testの設定
以下を追加する
jest.config.jsmodule.exports = { testResultsProcessor: "jest-sonar-reporter", collectCoverageFrom: [ "src/**/*.{js,jsx,ts,tsx,vue}", "!<rootDir>/node_modules/" ] };以下のタスクを追加する
package.json{ "scripts": { "test:unit:sonar": "npm run test:unit -- --coverage" } }sonar-scannerの設定
SonerQubeの静的解析とデータ送信を行うsonar-scannerの設定をする。
以下のタスクを追加する
package.json{ "scripts": { "sonar:scan": "sonar-scanner", "sonar": "run-s test:unit:sonar lint:sonar sonar:scan" } }以下の設定ファイルを追加する
sonar-project.propertiessonar.projectKey=vue-ts-sonerqube-example sonar.projectName=vue-ts-sonerqube-example sonar.sources=src sonar.tests=tests sonar.test.inclusions=**/*tests*/** sonar.exclusions=**/*tests*/** sonar.testExecutionReportPaths=test-report.xml sonar.javascript.file.suffixes=.js,.jsx sonar.typescript.file.suffixes=.ts,.tsx,.vue sonar.typescript.lcov.reportPaths=coverage/lcov.info sonar.javascript.lcov.reportPaths=coverage/lcov.info sonar.eslint.reportPaths=report.jsonそのほかの設定は以下を参照する
https://docs.sonarqube.org/latest/analysis/scan/sonarscanner/
Scanの実行
$ npm run sonar以下にアクセスすると結果を閲覧できる。
http://localhost:9000/dashboard?id=vue-ts-sonerqube-example結果閲覧と対応
16件のセキュリティ警告があるので見てみる。
See Ruleを見ると警告についての詳細が出る。
遷移先から元ページにアクセスさせなくするためらしい。
指摘通りに修正をして再度確認する。
指摘が消えた。
また、新たに生じた誤りなどはないことも示されている。終わりに
上記のような設定をCIに組み込むことで例えばレビュー前に誤りが作りこまれていないかを確認することができる。
これによってレビュー負荷も減ることが期待できる。
- 投稿日:2019-10-20T18:24:53+09:00
Vue + TypeScript のプロジェクトを SonarQubeで品質管理する
例
説明に使ったリポジトリ
https://github.com/sterashima78/vue-ts-sonarqube-exampleはじめに
コードの品質を評価するために多くに静的解析手法が提案されている。
これらの解析によって得られる指標を常に観察することで、コードの品質悪化をいち早く検知することが期待できる。
JavaScriptではPlato でいくつかの指標を算出することができると知っていたが、
メンテナンスが滞っていることに加えて、現在私がよく利用しているVueやTypescriptには対応していなかった。そんななかで、SonarQube それに代わるということを知ったので、 Vue + Typescript のプロジェクトに導入した。
本文書は、その導入方法を示したものになる。サンプルプロジェクトの準備
$ vue create vue-ts-sonerqube-example Vue CLI v4.0.4 ? Please pick a preset: Manually select features ? Check the features needed for your project: Babel, TS, Vuex, CSS Pre-processors, Linter, Unit ? Use class-style component syntax? No ? Use Babel alongside TypeScript (required for modern mode, auto-detected polyfills, transpiling JSX)? Yes ? Pick a CSS pre-processor (PostCSS, Autoprefixer and CSS Modules are supported by default): Sass/SCSS (with node-sass) ? Pick a linter / formatter config: Prettier ? Pick additional lint features: Lint on save, Lint and fix on commit ? Pick a unit testing solution: Jest ? Where do you prefer placing config for Babel, PostCSS, ESLint, etc.? In dedicated config filesSonarQube serverの準備
SonarQube は Java製のソフトウェアでJava11以上を要求する。
Docker imageもあるのだが、今回は以下のページでコミュニティーバージョン(ver 8.0)をダウンロードして実行することにした。
https://www.sonarqube.org/downloads/ダウンロードしてきた zip を解凍したら、bin以下に各OSごとの実行用ファイルがあるのでそれを実行する
windowsの場合はsonarqube-8.0\bin\windows-x86-64\StartSonar.batを実行すればいい。http://localhost:9000 を listenするのでブラウザからアクセスできる。
SonarQube のための設定
SonerQubeはソフトウェアのスキャン機能をもっており、そのスキャン結果をサーバに送信することで結果の閲覧ができる。
この時別のツールの結果を読み取らせることができるので、単体テスト結果とlint結果を読み取らせる。以下でそのための設定を行う。依存パッケージインストール
$ npm i -D jest-sonar-reporter sonarqube-scanner npm-run-alllint の設定
以下のタスクを追加する
package.json{ "scripts": { "lint:sonar": "eslint -f json -o report.json ." } }unit testの設定
以下を追加する
jest.config.jsmodule.exports = { testResultsProcessor: "jest-sonar-reporter", collectCoverageFrom: [ "src/**/*.{js,jsx,ts,tsx,vue}", "!<rootDir>/node_modules/" ] };以下のタスクを追加する
package.json{ "scripts": { "test:unit:sonar": "npm run test:unit -- --coverage" } }sonar-scannerの設定
SonerQubeの静的解析とデータ送信を行うsonar-scannerの設定をする。
以下のタスクを追加する
package.json{ "scripts": { "sonar:scan": "sonar-scanner", "sonar": "run-s test:unit:sonar lint:sonar sonar:scan" } }以下の設定ファイルを追加する
sonar-project.propertiessonar.projectKey=vue-ts-sonerqube-example sonar.projectName=vue-ts-sonerqube-example sonar.sources=src sonar.tests=tests sonar.test.inclusions=**/*tests*/** sonar.exclusions=**/*tests*/** sonar.testExecutionReportPaths=test-report.xml sonar.javascript.file.suffixes=.js,.jsx sonar.typescript.file.suffixes=.ts,.tsx,.vue sonar.typescript.lcov.reportPaths=coverage/lcov.info sonar.javascript.lcov.reportPaths=coverage/lcov.info sonar.eslint.reportPaths=report.jsonそのほかの設定は以下を参照する
https://docs.sonarqube.org/latest/analysis/scan/sonarscanner/
Scanの実行
$ npm run sonar以下にアクセスすると結果を閲覧できる。
http://localhost:9000/dashboard?id=vue-ts-sonerqube-example結果閲覧と対応
16件のセキュリティ警告があるので見てみる。
See Ruleを見ると警告についての詳細が出る。
遷移先から元ページにアクセスさせなくするためらしい。
指摘通りに修正をして再度確認する。
指摘が消えた。
また、新たに生じた誤りなどはないことも示されている。終わりに
上記のような設定をCIに組み込むことで例えばレビュー前に誤りが作りこまれていないかを確認することができる。
これによってレビュー負荷も減ることが期待できる。
- 投稿日:2019-10-20T17:57:47+09:00
Vue.jsでコメント投稿機能を作ってみた。
1.はじめに
今回はjavascriptのフレームワーク、Vue.jsを使って投稿機能を作ってみました。vue.jsを学ぶ際によく題材として使われるToDo管理リストに少し手を加えたもので、映画の感想と評価点を投稿するサイトをイメージして作りました。
2.環境
今回も前回に引き続き、VSCodeを使用して書いていきます。
またVue.jsはVue.js公式ページのCDNのリンクを直接HTML内のbodyタグの一番下に埋め込んで使います。3.完成体
テキストボックスの中にコメントを打ち込み、隣の選択ボタンで星の数に応じた評価点を選択します。
送信ボタンを押すと投稿が完了しました。ちなみに、テキストボックスの中身が未入力の状態で送信ボタンを押しても投稿はされません。
二つ目の投稿をします。するとこの二つの投稿の評価数の平均を計算して評価点が3.50になりました。
三つ目の投稿をしても同じように評価点の平均点を計算します。しかし割り切れない数などある為、toFixedメソッドを使って小数点第二位までしか表示されません。そして今回は各投稿の下にあるdeleteボタンを押すと、
コメントが一つ消されました。
次に送信ボタンの横に⬇︎⬆︎のボタンがありますが押すと、各投稿の評価点をフックに投稿を並び替えてくれます。⬇︎ボタンで評価の高い順、
⬆︎ボタンで評価の低い順です。
4.完成コード
index.html<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>投稿</title> </head> <body> <div class="container" id="app" v-cloak> <h1>評価</h1> <div v-if="length"> <h2>評価点 : {{averageScore}}</h2> </div> <form v-on:submit.prevent> <input type="textarea" v-model="comment"> <select v-model="rate"> <option value="0">☆☆☆☆☆</option> <option value="1">★☆☆☆☆</option> <option value="2">★★☆☆☆</option> <option value="3">★★★☆☆</option> <option value="4">★★★★☆</option> <option value="5">★★★★★</option> </select> <button v-on:click="submit">送信</button> <button v-on:click="sort">⬇︎</button> <button v-on:click="sortUp">⬆︎</button> </form> <div v-for="(comment , index) in comments"> <ul> <li>満足度 : <span>{{'★'.repeat(comment.rate)}}</span></li> <p>コメント : <span>{{comment.comment}}</span></p> <button v-on:click="deleteItem(index)">delete</button> </ul> </div> </div> <script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script> <script src="main.js"></script> </body> </html>main.jslet app = new Vue({ //vueインスタンス生成 el: '#app', //id="app"が属性として使用されているタグ内で使える。(マウント) data: { comment: "", rate: 0, comments: [], sun: 0, length: false, //使いたい変数達 }, methods: { //各メソッドを格納。htmlを見てもらえると「v-on:click="メソッド名"」と記述されているところが複数箇所ありますが要素をクリックした際に下記のメソッドを実行するという意味です。 submit: function () { if (this.comment == "") return; if (this.comment.length > 100) return; let commentItem = { comment: this.comment, rate: this.rate } this.comments.unshift(commentItem); this.sun = this.sun + Number(commentItem.rate) this.comment = "" this.rate = 0 if (this.comments.length > 0) { this.length = true } }, deleteItem: function (index) { this.sun = this.sun - Number(this.comments[index].rate); this.comments.splice(index, 1); if (this.comments.length < 1) { this.length = false } }, sortUp:function(){ let arr = this.comments; arr.sort(function(a,b){ if (a.rate > b.rate) return 1; if (a.rate < b.rate) return -1; return 0; }) this.comments = arr; }, sort:function(){ let arr = this.comments; arr.sort(function(a,b){ if (a.rate > b.rate) return -1; if (a.rate < b.rate) return 1; return 0; }) this.comments = arr; }, }, computed:{ //算出プロパティと言います。変数averageScoreをhtml側で呼び出すと //自動的に関数内の処理を実行してくれます。他にも監視プロパティというものもありますが監視プロパティに比べて //処理結果をキャッシュしてくれるというのが大きな特徴です。 averageScore:function(){ return (this.sun/this.comments.length).toFixed(2) } } })終わりに
以上です。今回は前回に比べてスッキリした解説でしたが実際に手を動かして興味のある方はコピぺしながら勉強をしていただけると幸いです。




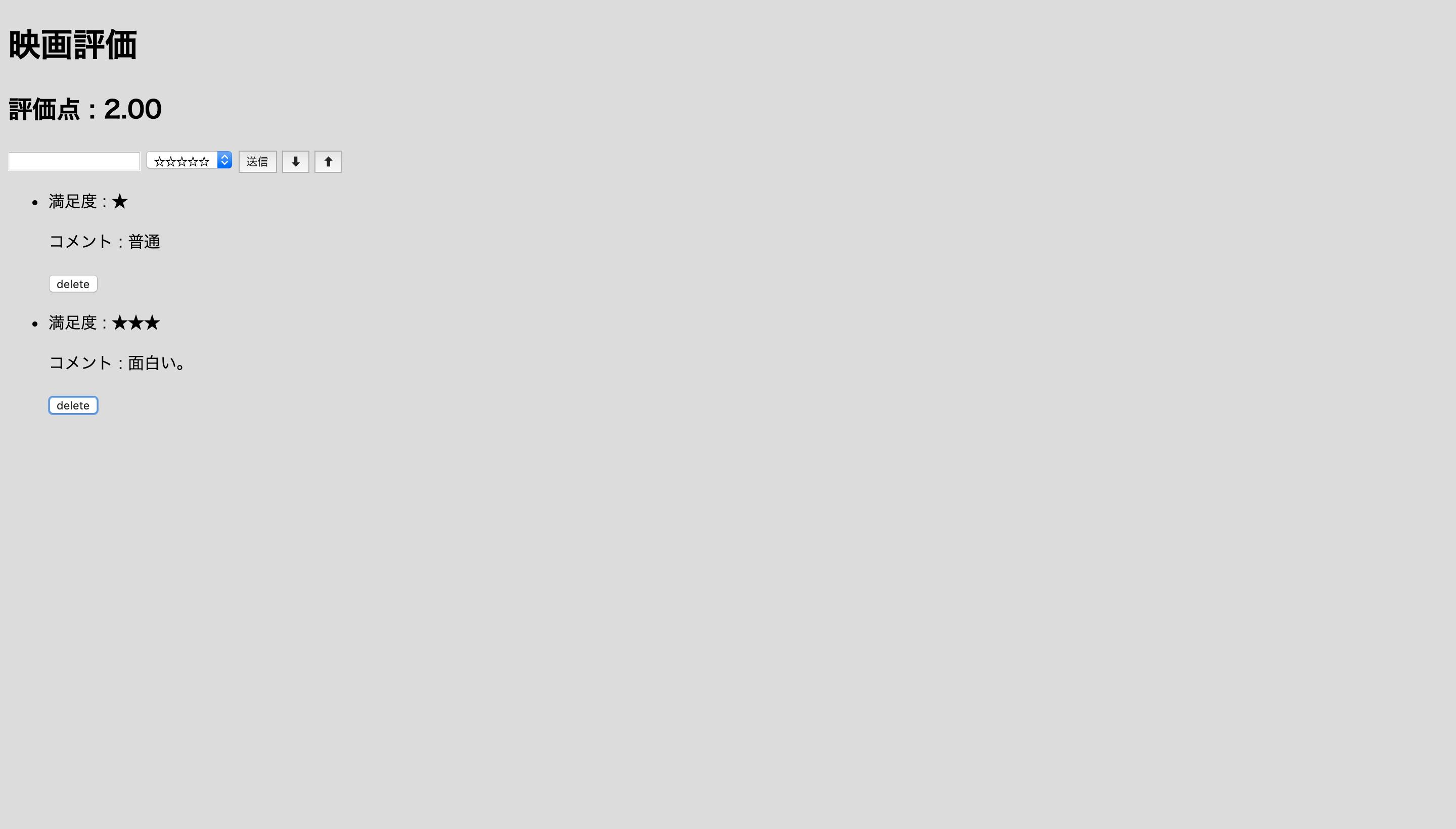
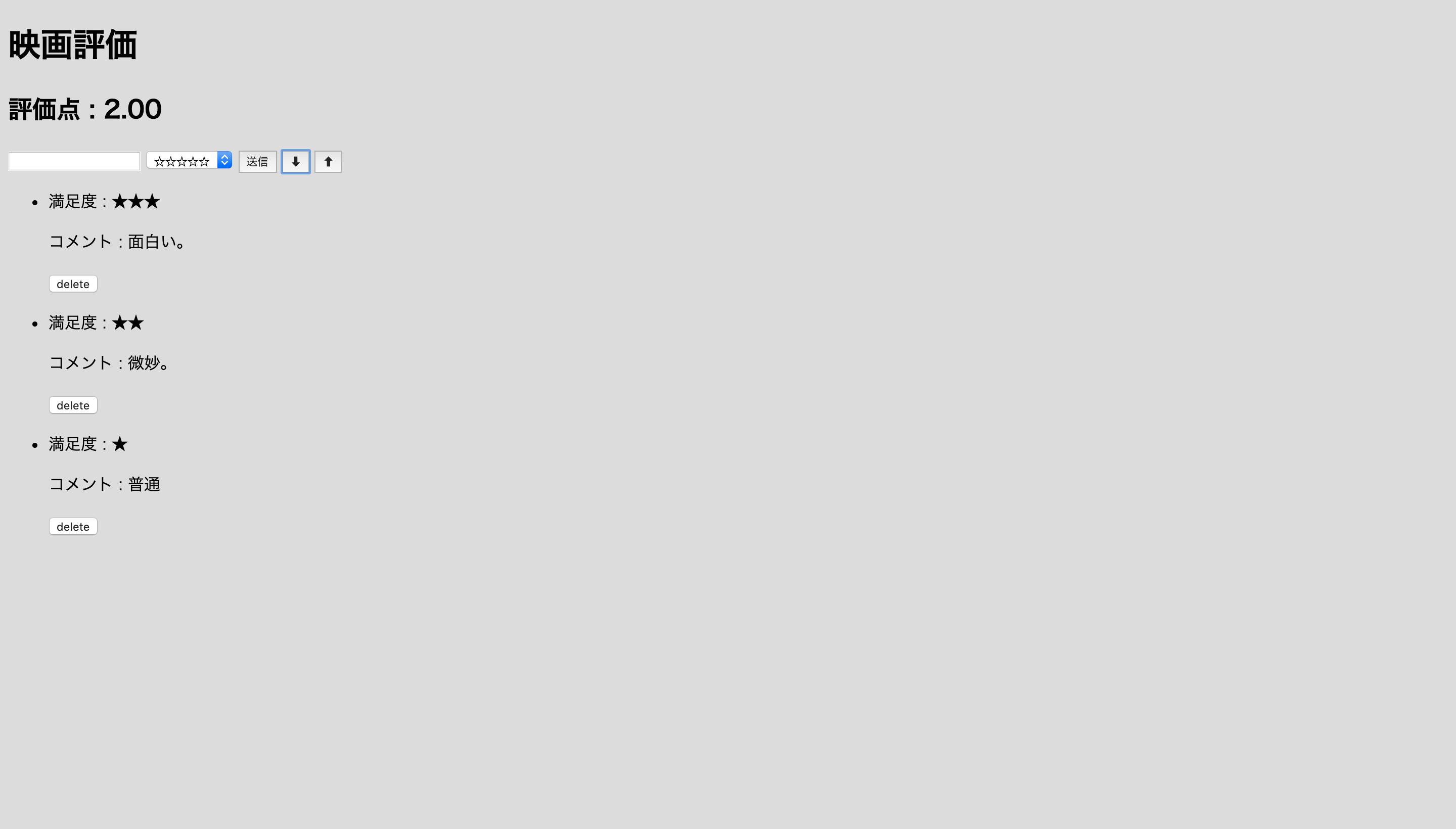

- 投稿日:2019-10-20T17:55:28+09:00
プログレスバーを実装してみた
久しぶりの投稿です。
今回はプログレスバーを実装してみました。
ソース
では、いつもどおりソースを載せておきますね。
progress_practice.html<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>プログレスバー 練習</title> <script src="./js/progressbar.js"></script> </head> <body> <div> <!-- 進捗(%)を表示 --> <input type="text" id="bar" value="0%" style="border-style: none" disabled="true"> <br> <!-- プログレスバー --> <progress id="myProgress" value="0" max="100" width="200px">0%</progress> </div> <!-- ボタンを押すと、プログレスバーが実行される --> <input type="button" id="myButton" onclick="updateProgress()" value="start"> </body> </html>progress.jsvar interval; var val; function updateProgress() { val = 0; document.getElementById("myButton").disabled = true; // 50ミリ秒ごとに更新 interval = setInterval("updateVal()", 50); } function updateVal() { // 進捗(%)を表示する var bar = document.getElementById("bar"); bar.value = val + "%"; // 100%になるまで、バーを更新 if (val < 100) { val += 1; document.getElementById("myProgress").value = val; document.getElementById("myProgress").innerText = val + "%"; // 100%になったら、バーが止まる } else if (val == 100) { clearInterval(interval); document.getElementById("myButton").disabled = false; } }解説
まず、htmlからですね。
プログレスバーのタグはprogress要素となります。次に、jsですね。
ポイントは2つです。
1つ目が、setInterval関数です。
この関数は一定間隔で、処理を実行します。
第一引数に、関数を入れます。
この関数に、処理を実装すれば、いいわけです。
第二引数には、時間を入れます。
指定した時間が経過すると、もう一度第一引数で指定した関数が実行されます。2つ目に、
clearInterval関数です
setIntervalを止めたいときに使うものです。参考
【JavaScript入門】setIntervalの使い方まとめ
<progress要素> - タスクの進捗度 | HTMLのタグリファレンス
- 投稿日:2019-10-20T17:46:25+09:00
Azure Maps を使ってみる Part.2
昨日の続きで Azure Maps の対象範囲をもう少し詳しく見てみようと思います。今回は、Azure Maps を使って目的地までのルートを検索する機能を実装してみました。
目的地までのルートを検索する
Microsoft の公開しているサンプルコードがあります。
https://github.com/Azure-Samples/AzureMapsCodeSamples/blob/master/AzureMapsCodeSamples/Tutorials/route.html
ルートを検索できるライブラリを使用して、地図上でルートを描くようにします。以下の部分で地点間のルートを地図に描きます。サンプルではシアトルとレドモンド間のルートを表示しています。var startPoint = new atlas.data.Feature(new atlas.data.Point([-122.130137, 47.644702]), { title: "Redmond", icon: "pin-blue" }); var endPoint = new atlas.data.Feature(new atlas.data.Point([-122.3352, 47.61397]), { title: "Seattle", icon: "pin-round-blue" }); //Add the data to the data source. datasource.add([startPoint, endPoint]); map.setCamera({ bounds: atlas.data.BoundingBox.fromData([startPoint, endPoint]), padding: 80 }); // Use SubscriptionKeyCredential with a subscription key var subscriptionKeyCredential = new atlas.service.SubscriptionKeyCredential(atlas.getSubscriptionKey()); // Use subscriptionKeyCredential to create a pipeline var pipeline = atlas.service.MapsURL.newPipeline(subscriptionKeyCredential); // Construct the RouteURL object var routeURL = new atlas.service.RouteURL(pipeline); //Start and end point input to the routeURL var coordinates = [[startPoint.geometry.coordinates[0], startPoint.geometry.coordinates[1]], [endPoint.geometry.coordinates[0], endPoint.geometry.coordinates[1]]]; //Make a search route request routeURL.calculateRouteDirections(atlas.service.Aborter.timeout(10000), coordinates).then((directions) => { //Get data features from response var data = directions.geojson.getFeatures(); datasource.add(data); });前の記事の手順でサブスクリプションを入力し、Azure WebApp でデプロイすると以下のように表示されます。
日本の地理情報で実装してみる
では上記のコードを、大井町駅-東京駅間に置き換えてみましょう。
var startPoint = new atlas.data.Feature(new atlas.data.Point([139.735889, 35.606223]), { title: "Oimachi", icon: "pin-blue" }); var endPoint = new atlas.data.Feature(new atlas.data.Point([139.767125, 35.681236]), { title: "Tokyo", icon: "pin-round-blue" }); //Add the data to the data source. datasource.add([startPoint, endPoint]); map.setCamera({ bounds: atlas.data.BoundingBox.fromData([startPoint, endPoint]), padding: 80 }); // Use SubscriptionKeyCredential with a subscription key var subscriptionKeyCredential = new atlas.service.SubscriptionKeyCredential(atlas.getSubscriptionKey()); // Use subscriptionKeyCredential to create a pipeline var pipeline = atlas.service.MapsURL.newPipeline(subscriptionKeyCredential); // Construct the RouteURL object var routeURL = new atlas.service.RouteURL(pipeline); //Start and end point input to the routeURL var coordinates = [[startPoint.geometry.coordinates[0], startPoint.geometry.coordinates[1]], [endPoint.geometry.coordinates[0], endPoint.geometry.coordinates[1]]]; //Make a search route request routeURL.calculateRouteDirections(atlas.service.Aborter.timeout(10000), coordinates).then((directions) => { //Get data features from response var data = directions.geojson.getFeatures(); datasource.add(data); });このようにして同じ手順でデプロイすると結果は以下になりました。
あれっ!?ルートが表示されない、、、。エラーコードを分析して調べてみるとやはり Maps API の方で日本のサポート範囲が問題あるみたいです。
Azure Maps のサポート範囲
上記の実験結果を踏まえ、Azure Maps のサポート範囲を調べてみました。
Azure Maps のルーティングの対象範囲
https://docs.microsoft.com/ja-jp/azure/azure-maps/routing-coverageなななんと、日本がルーティングの範囲から外れていました!これは正直びっくりです。まぁそのうち追加されるだろうと期待しつつちょっとがっかりですね。早く追加されて遊んでみたいです。


- 投稿日:2019-10-20T17:02:06+09:00
そろそろJavaScriptに採用されそうなOptional Chainingを今さら徹底解説
みなさん、Optional Chaining使ってますか? 私は先日出たTypeScript 3.7 Betaを小さいプロジェクトに導入して使ってみました。これはとても快適ですね。
例によって、Optional ChaningもECMAScriptに対するプロポーザルの一つです。つまり、もうすぐ入りそうなJavaScriptの新機能です。プロポーザルはたくさんの種類がありますが、その中でもOptional Chainingはその高い有用性からこれまで多くの注目を集めてきました。Optional Chainingは2019年6月のTC39ミーティングでStage 3に上昇し、いよいよ正式採用が近く期待も高まってきたところです。TypeScript 3.7にも導入されたため、TypeScriptユーザーの方々は11月上旬に正式リリースが予定されているTypeScript 3.7を今か今かと待ち構えていることでしょう(筆者のようにフライングしてBetaで使い始めている人もいるかもしれません)。また、Babelのプラグインも前々から存在したため熱心な方々はもう使っているかもしれません。
となると、巷に、あるいはこのQiitaにもOptional Chaningに関する記事がいくつもあります。そこで自分もOptional Chainingの解説がしたくなってできたのがこの記事です。
この記事を読めばOptional Chaningの全てがわかります。(強気)
なお、Optional Chainingに関する一次的な情報源は(ECMAScriptに正式採用されるまでは)以下のプロポーザルです。一次情報にあたるのが好きな方はぜひ目を通してみましょう。
Optional Chainingの基本
Optional Chainingとは、
?.という新しい構文です。もっとも基本的な用法はプロパティアクセスの
.の代わりに?.を使うものです。obj?.fooとした場合、objがnullishな値(nullまたはundefined)の場合は結果がundefinedとなり、そうでない場合はobj.fooが結果となります。つまり、
obj?.fooというのはおおよそobj != null ? obj.foo : undefinedと同じです1。たとえ
objがnullだったとしてもobj?.fooはnullではなくundefinedになります。間違えやすいので注意しましょう2。背景
この機能の背景には、
undefinedまたはnullに対してプロパティアクセスを行うとエラーになるという言語仕様があります。すなわち、objがnullとかの時にobj.fooを実行するとエラーとなります。ちなみに、プロパティアクセスがエラーとなるのはこの場合のみで、それ以外の場合(
fooというプロパティを持たないオブジェクトや、あるいは数値や文字列といった他のプリミティブ)はエラーにはなりません3。fooというプロパティがない場合、エラーにはならずobj.fooがundefinedとなります。このことから、nullishかもしれない値
objに対してはobj.fooのようなプロパティアクセスをいきなり行うのは危険であり、前述のようにobj != nullというようなチェックが不可欠でした。逆に言えば、nullishな値さえ排除すればとりあえずプロパティの値を取得するところまでは漕ぎ着けることができます(取得できた値がundefinedかもしれませんが)。ということで、nullishな値に対するチェックをより簡単に行えるようにするのが
?.構文ということになります。obj?.fooならば、objがnullishな値であってもエラーが発生せず、代わりにundefinedが結果となります。これにより、残りの場合と一緒に扱うことができるようになるケースは結構多いと思われます。特に、Nullish Coalescing(??演算子)と組み合わせることで、明示的に条件分岐を書かずにnullishな値を適切に処理することができるケースが増えるでしょう。これはとてもうれしい点です。プロポーザルによれば、
?.に類似の構文は以前からC#, Swift, CoffeeScriptなどに存在していました。この中ではCoffeeScriptが最も古く、AltJSであるということもあり今回のプロポーザルに直接的な影響を与えているといえるでしょう。3種類の構文
厳密には、今回のプロポーザルで
?.に関連する構文が3種類追加されます。
obj?.fooobj?.[expr]obj?.(arg1, arg2)一番上はこれまで説明していたやつです。二番目は、お分かりの通り
obj[expr]用の構文で、これをobj?.[expr]に変えることでobjがnullishの場合はエラーではなくundefinedが返るようになります。三番目はオプショナル関数呼び出し構文です。この例は引数2つですがもちろん何個でも構いません。
obj(arg1, arg2)はobjがnullishのときはやはりエラーとなりますが、obj?.(arg1, arg2)はobjがnullishのときは何も行わずにundefinedとなります。なお、objがnullishではないが関数でもない場合は依然としてエラーになりますので注意しましょう。3種類が一貫して
?.というトークンを持っているので分かりやすくていいですね。ただ、?.の直後に[ ]とか( )のような括弧が来る構文が気持ち悪いという人もいるようです(詳しくはすこし後で解説します)。ちなみに、代入には対応していません。つまり、
obj?.foo = 123(objが存在するときのみfooプロパティに123を代入する)のようなことはできません。また、ES2015では
obj.foo`123`のようにタグ付きテンプレートリテラルの記法で関数を呼び出すことが可能になりましたが、これはOptional Chainingのサポート外です。つまり、obj?.foo`123`のようなことはできません。func?.`123`もだめです。短絡評価
Optional Chainingを語る上で外せないのが短絡評価です。実はここがOptional Chainingを理解する上で肝となる部分です。将来足元を掬われないように今のうちにしっかりと理解しておきましょう。
短絡評価とは
短絡評価という単語は、
&&や||に絡んで聞いたことがある方が多いでしょう。これらの演算子は、左側を評価した時点で結果が確定したのであれば右側が評価されません。これを短絡評価と呼びます。const foo = 123; // fooが真なので func() は呼び出されない const v1 = foo || func();上の例では、
||の結果は左側のfooを評価した時点で確定します。よって、右側は意味がないのでそもそも評価されないことになります。
?.の短絡評価
?.の短絡評価についても基本は変わりません。左側を評価した時点で結果が確定するならば、右側は評価されないというのが原則です。
?.の場合は、左側がnullishな値だと判明した時点で結果がundefinedに確定します。よって、その場合は右側は評価されません。このことは例えば次のような場合に影響があります。const foo = obj?.[getKey()];この例では、
objがnullishならばfooにはundefinedが入り、そうでなければfooにはobj[getKey()]が入ります。キーの名前([ ]の中身)を得るにはgetKey()という関数呼び出しを評価する必要があります。ポイントは、短絡評価により
objがnullishな値ならばgetKey()は呼び出されないという点です。まあ、これは次と同じと考えれば自然な動作ですね。この場合も、getKey()が呼び出されるのはobjがnullishでないときだけです。const foo = obj != null ? obj[getKey()] : undefined;関数呼び出しの構文でも同じです。次の例では、
funcがnullishな値のときはfoo(),bar(),baz()は計算されません。func?.(foo(), bar(), baz())オプショナルチェーンの短絡評価
短絡評価の応用例として、次のような場合を考えてみてください。
obj?.foo.bar.baz次の3種類の場合にこれの評価結果はどうなるでしょうか。
objが{ foo: { bar: { baz: 123 } } }の場合。objが{ foo: { bar: null } }の場合。objがundefinedの場合。正解はこうです。
123になる。obj?.foo.barがnullになり、nullのbazプロパティを読もうとしてエラーが発生する。undefinedになる。特に3がポイントです。
objがnullishな値だったことにより、そのあとの部分全部(?.foo.bar.baz)が無視されます。これに関しては、次のような誤解が発生しやすいので注意が必要です。
123になる。- エラーになる。
- エラーになる。(誤解)
3の誤解は次のような考え方をすると発生しがちです。
obj?.foo.bar.bazのobj?.foo部分がまず評価されてundefinedになる。- すると
undefined.bar.bazが評価されることになる。undefinedのbarプロパティを読もうとしてエラーになる。繰り返しますが、この誤解を避けるために抑えるべきポイントは
obj?.foo.bar.bazでobjがnullishな値の場合は?.foo.bar.baz全体が飛ばされるということです。ちなみに、このように
?.から始まるプロパティアクセス(または関数呼び出し)の列のことをオプショナルチェーン (optional chain)と呼びます。?.foo.bar.bazは一つのオプショナルチェーンです。この用語を使うと、?.の評価は左側がnullishな値の場合はオプショナルチェーン全体を無視してundefinedを返すものだと言うことができます。オプショナルチェーンは
[ ]によるプロパティアクセスや()による関数呼び出しを含むことができるので、次のようなものも一つのオプショナルチェーンです。?.foo.bar["hoge fuga"](1, 2, 3).bazオプショナルチェーンと括弧
上の例を少し変えてこうしてみましょう。
(obj?.foo.bar).bazこの場合、括弧で区切られているので
?.foo.barまでがオプショナルチェーンであり.bazはチェーンに含まれません。よって、objがnullishな値だった場合はまずobj?.foo.barがundefinedに評価され、undefined.bazを計算しようとしてエラーになります。このように、括弧によってオプショナルチェーンが区切られてプログラムの意味が変わることがある点は要注意です。これはオプショナルチェーンの新しい特徴です。従来は
obj.foo.bar.bazを(obj.foo.bar).bazに変えても意味は変わりませんでした。オプショナルチェーンに間違えて括弧をはさむ人はあまり居ないと思いますが、3ヶ月に1回くらいこんな罠を踏むかもしれませんから気をつけましょう。
複数のオプショナルチェーン
ところで、次のような式を考えることもできます。
obj?.foo.bar?.baz(123)
?.が2箇所に出てきました。この式はどのように解釈できるでしょうか。実は、これは
objのあとに2つのオプショナルチェーンが続いている形になっています。1つ目は?.foo.barで、2つ目が?.baz(123)です。先ほどオプショナルチェーンという概念を紹介しましたが、これは先頭のみに
?.が来るものであり、次の?.が来た時点でそこから先は次のオプショナルチェーンになります。上の式は以下のように括弧を付けても同じことです。(obj?.foo.bar)?.baz(123)途中で
undefinedやnullが発生する可能性があるときは複数のオプショナルチェーンを繋げる意味もあります。例えばobjが{ foo: { bar: null } }だった場合を考えましょう。このとき、上の式の結果はundefinedとなります。まずobj?.foo.barがnullになり、それに対して次のオプショナルチェーン?.baz(123)が適用されますが、?.の左はnullなので全体の結果はundefinedとなります。一方で、
?.がひとつだけの場合は違った結果になります。上のobjに対してobj?.foo.bar.baz(123)を評価した場合を考えると、これはobj?.foo.barまで評価してnullを得たところでそれのbazプロパティを取得しようとしてエラーになります。
?.[ ]と?.( )
?.という構文は一貫しているとはいえ、特にobj?.[expr]とかfunc?.()という構文は.の後に括弧が来る点が気持ち悪いと思えるかもしれません。どちらかというとobj?[expr]とかfunc?()のほうがきれいです。しかし、もちろんそうはできない理由がありました。それは条件演算子
cond ? expr1 : expr2の存在です。どちらも?を使っていることがあり、両方の構文があるとたいへん紛らわしくなります(:があるので多分文法が曖昧になるというわけではなさそうですが)。プロポーザル文書に載っている例を引用します。
obj?[expr].filter(fun):04文字目の
?は条件演算子の?なのですが、:を見るまではobj?[expr].filter(fun)というオプショナルチェーンである可能性を捨て切れません。このように判断を遅延しなければいけないのは人間にも処理系にも負担になります。これを避けるために
?.というトークンを使っているのです。
?.と数値リテラル実は、
?.を用いてもなお文法上の問題が多少残っています。それは、.1のような数値リテラルが関わる場合です。実は数値リテラルは.1のようにいきなり少数点から始めることができます。これは0.1と同じ意味です。これまたプロポーザルから引用しますが、次のような場合が問題になります。foo?.3:0これの正しい解釈は
foo ? .3 : 0、つまり条件演算子です。コード中に?.の並びがありますが、これはoptional chainingの構文ではなく?と.3が並んだものです。このことを表現するために、「Optional Chainingの
?.構文の直後に数字(0〜9)が来ることはない」という規則が用意されています。これにより、?.3という並びを見た時点で即座にこれは?. 3ではなく? .3であることが判断できるようになっています。そもそも
obj.3のようなプロパティアクセスは文法上不可能ですからobj?.3と書いてあってもobj ?. 3と解釈する必要はないように思えます。それにも関わらず上記のような規則があるのは、極力分岐を減らしてパーサーの負担を減らすためでしょう。そもそも、JavaScriptの文法というのは原則として前から順番に読んでいけば常に解釈が1通りに定まり、複数の可能性が同時に存在しないように定義されています(これが達成できていないところもあるのですが、そういうところは仕様上ではカバー文法を用いて明示的な配慮がされています)。
今回も、パーサーがプログラムを前から読んで
?.まで読んだ瞬間に、これが?.というトークンなのかそれとも?が条件演算子でその後に何か別の.が続いているのかを決定できるのが理想です。ただ、foo?.3:0とfoo?.barというプログラムが両方存在する可能性がある以上、これだけの情報からではこれは不可能です。しかし、実は1文字先読みをすることでこれが可能になります。つまり、
.の次の文字が数値ならばその時点で?.の?が条件演算子であることが確定し、そうでなければ?.はOptional Chaningの開始であることが確定します。一般に長く先読みするほどパースが大変になりますが、まあ1文字先読みくらいなら許容範囲です。
以上がOptional Chainingの基本でした。おおよそプロポーザルの文書に書いてあることを説明した感じです。この文書も分かりやすく書かれていますので一度目を通してみてもよいかもしれません。
他の言語との比較
CoffeeScriptを始めとして、Optional Chainingに類似の言語機能をすでに持っているプログラミング言語はいくつか存在します。ここでは、他の言語とJavaScriptのOptional Chainingとの違いや共通点を明らかにします。
以下の言語はプロポーザルの文書に言及があったものを列挙しています。他にこんな言語にもあるよという情報は大歓迎です。
CoffeeScript
一番手はCoffeeScriptです。CoffeeScriptではこの機能はExistential Operatorと呼ばれ、Optional Chainingの3種類の構文は以下で表現されます。
obj?.fooobj?[expr]func?(arg)(または関数呼び出しの括弧を省略してfunc? arg)まずは構文を比較します。CoffeeScriptでも
?.という演算子を用いてobj?.fooのように書くことができま。ただ、[ ]と( )に関してはJavaScriptとは異なり、obj?[expr]やfunc?(arg)のように書くことができました。JavaScriptとは異なりこれらの場合に
?.[expr]としなくても良かった理由は、CoffeeScriptが条件演算子?:を採用していないからです。代わりにifが式となっており、条件演算子のように使用できます。挙動については、現在のJavaScriptのものと基本的に同じです。つまり、
obj?.a.b.cでobjがundefinedの場合はチェーン全体が飛ばされるという挙動をします。短絡評価についても同じであるほか、括弧でチェーンを切ることができる点も同じです。ただ、CoffeeScriptでは今のJavaScriptにはないいくつかの追加機能を備えていました。ひとつはオプショナルな代入です。
obj?.foo = 123このようなプログラムが可能であり、これは
if (obj != null) obj.foo = 123;とおおよそ同じ意味でした。また、タグ付きテンプレートリテラルの関数部分でも
?.が使用可能です。obj?.foo"""123"""JavaScriptでは、前者は仕様が複雑になることから、後者はユースケースの欠如から採用されていない仕様です。CoffeeScriptの大胆さと言語デザインが伝わってくる例ですね。
長くなりましたが、他の言語はあまり詳しいわけではないのでさらっと流します。
C#
C#ではこれはNull-conditional operator(Null条件演算子)と呼ばれています。2015年リリースのC# 6で追加されたようです。
C#では
obj?.fooとobj?[expr]の2種類の構文がサポートされています。C#にも条件演算子? :があるはずですが、前述の問題にも関わらずobj?[expr]の形が採用されています。その理由は調べられていませんが、まあ仕様よりも実装が先行する言語であることや主にコンパイルして使う言語であることなど、事情の違いがあるのでしょう。短絡評価周りの挙動も、基本的に今回解説したJavaScriptのものと同様です。
なお、C#は(というかほとんどの言語は)
undefinedとnullが別々にあるみたいな意味不明な状況にはありません。C#ではnullがあり、?.の左辺がnullのときに結果がnullになるという仕様です。オプショナル関数呼び出し
func?.()にあたる構文はありませんが、C#ではデリゲート(thisを覚えている関数オブジェクトのようなものらしいです)がInvokeを持っており、func?.Invoke()のようにして代替可能です。JavaScriptでも関数オブジェクトがcallメソッドなどを持ってはいますが、thisを渡さないといけないせいで微妙に使い勝手が悪くなっています。
obj?.foo = 123はサポートされていません。Swift
Swiftではこの機能はOptional Chainingです。同じ名前ですね。Swiftでは
nilがこの機能の対象です。Swiftでも構文はやはり
obj?.fooとobj?[expr]です。オプショナル関数呼び出しは無いようです。挙動はJavaScriptと同じく、チェーンの短絡評価および括弧でチェーンを切る挙動ができます。
また、代入におけるOptional Chaining(
obj?.foo = 123)もサポートしています。面白い点はこの代入式の返り値がVoid?型であり、代入が成功したか失敗したかが返り値から分かるようになっている点ですね。Kotlin
Kotlinも
?.演算子を持ち、これはSafe Callと呼ばれているようです。Kotlinでは、これまでの言語とは異なりオプショナルチェーンの概念は存在しません。
obj?.foo.barは(obj?.foo).barと同じであり、objがnullの場合は.fooは飛ばされますが.barは飛ばされません。これはobj?.foo?.barと書く必要があります(Kotlinはいわゆるnull安全な型システムを持っているので、こう書かないとコンパイルエラーとなります)。なお、
obj?[expr]に相当する記法は無いようです。例えばList<Int>?型からInt?を取り出したい場合、list?.get(0)4のようにするかlist?.let { it[0] }とする必要があります(あまり自信がないので間違っていたらぜひ訂正をお願いします)。
obj?.foo = 123は可能です。Dart
Conditional Member Accessと呼ばれ、
?.演算子のみが存在するようです。代入も可能です。また、Kotlinと同様に一段階のみのサポートです。
Ruby
RubyではSafe Navigation Operatorと呼ばれており、Ruby 2.3で導入された機能のようです。
Rubyではこれは
&.という名前です。これまでの言語で唯一?を含んでいませんが、まあこれは仕方ありませんね。Rubyは識別子(メソッド名など)に?や!を含むことができる言語なので、演算子に?を使うのはさすがに都合が悪そうです。Kotlinなどと同様に
&.は一段階しか作用しません。Rubyはドキュメントにこのことが明記してあってたいへんありがたいですね。余談:Elm
ちょっと趣向を変えて、というか趣味に走っていますが、関数型言語との比較もしてみます。そもそも関数型言語はオブジェクトとかプロパティという概念を持たないこともあるので比較の意味がそこまで大きいわけではありません。なので余談ということにしてみました。
さて、値が無いかもしれない(
nullかもしれない)という状況に対して、これから説明するように関数型言語はかなり異なる方法で対処します。関数型言語の場合しっかりとした代数的データ型を備えていることが多く、
nullのような概念の代わりになるものとしてMaybe型のようなデータ構造を持つのが典型的です。ElmのMaybe型はHaskellと同じ定義で、例えばMaybe Int型はJust 42のようなInt型の値をラップした値とNothingから成ります。また、Elmの場合はJavaScriptのオブジェクトに比較的近い概念としてレコードというものがあります。レコードはこのように使用します。
import Html exposing (text) -- Person 型を定義(実態はただのレコード型) type alias Person = { name: String , age: Int } -- Person型の変数pを定義(型宣言は省略可) p: Person p = { name = "John Smith" , age = 100 } main = text (p.name) -- "John Smith" が表示される
Personが存在するかもしれないししないかもしれないという状況はMaybe Preson型で表現します。p1: Maybe Person p1 = Just { name = "John Smith" , age = 100 } p2: Maybe Person p2 = Nothing main = text (p1.name) -- これはコンパイルエラー
Maybe PersonはPersonとは別の型でありレコードではためp1.nameのようなアクセス方法はできません。また、Elmは
?.nameのようなことができる機能はありません。筆者はElmに詳しくありませんが、やるとしたら恐らくこうでしょう。n1 = Maybe.map .name p1 -- Just "John Smith" n2 = Maybe.map .name p2 -- Nothing
Maybe.mapは与えられた関数をJustの中身に適用する関数です(NothingのときはそのままNothingが返る)。.nameはこれでひとつの関数であり、与えられたレコードのnameフィールドを返します。ポイントは、無いかもしれない値(
Maybe Person型の値)を操作するにあたって2つの一般的な関数(Maybe.mapと.name)を用いて対処している点です。むやみに演算子を増やすよりも関数の組み合わせで対処する点に関数型言語らしさが現れています。真に何もない値であり関数・メソッド等のサポートを受けにくいnullと比べると、Maybeは代数的データ型を用いて表現される値でありMaybe.mapに代表されるような標準ライブラリレベルでのサポートが受けやすい点が大きく異なっています。ちょっと話が横道に逸れましたが、以上が他の言語との比較でした。他の言語の情報をお持ちの方はお寄せいただけるとたいへん幸いです。
TypeScriptとOptional Chaining
さて、ではJavaScriptに話を戻しましょう。……と言いたいところですが、次はTypeScriptに話を移します。TypeScriptは言わずと知れたJavaScriptの型付きバージョンです。
TypeScriptは、プロポーザルがStage 3になったらその機能を導入するという方針があるようです。ということで、Optional ChainingがTypeScriptに導入されるのは11月リリースのTypeScript 3.7です。現在すでにベータ版が出ており、これでTypeScriptのOptional Chainingサポートを体験できます。
ここではTypeScriptにおけるOptional Chainingの挙動を解説します。もはやTypeScriptがJavaScript開発における必須ツールとなりつつある今日この頃ですから、JavaScriptの新機能とあればTypeScriptにどう影響するのか気になるのは必然です。ということで、この記事では欲張りなことにTypeScriptにも手を伸ばして解説します。
とはいえTypeScriptなんか興味ありませんよという硬派(安全性的にはむしろ軟派?)な方もいるでしょうから、そのような方は次のセクションまで飛ばしましょう。また、TypeScriptの用語で分からないところがあればTypeScriptの型入門が参考になるかもしれません(宣伝)。
では、さっそく
?.の例をお見せします。interface HasFoo { foo: number; } const obj: HasFoo | undefined = Math.random() < 0.5 ? { foo: 123 } : undefined; // これはエラー (objがundefinedかもしれないので) const v1 = obj.foo; // これはOK(v2はnumber | undefined型) const v2 = obj?.foo;
HasFoo型は、fooというプロパティを持つオブジェクトの型です。今回は変数objをHasFoo | undefined型として宣言しました。これは、objの中身はHasFoo型のオブジェクトかもしれないしundefinedかもしれないということです。この
objに対してobj.fooとすると、TypeScriptにより型エラーが発生します。これは、objがundefinedかもしれない状況でobj.fooを実行するとエラーになるかもしれなくて危険だからです。TypeScriptは型エラーにより、そのような危険なコードを事前に警告してくれます。一方、
obj?.fooは型エラーになりません。これは、?.ならばたとえobjがundefinedでもエラーが発生することはなく安全だからです。その代わり、
obj?.fooの結果はnumber | undefined型となります。これは、number型かもしれないしundefined型かもしれないという意味です。実際、objがundefinedのときはobj?.fooの結果はundefinedになるし、objがundefinedでないときは(objがHasFoo型になるので)obj?.fooはnumberになるためこの結果は妥当です。型推論のしくみ
上では言葉でそれっぽい説明をしましたが、型推論の挙動を整理するのはそれほど難しくありません。これに関してはTypeScriptの当該プルリクエストも参考になるでしょう。
例えば、
expr?.fooという式の型を推論するにあたってはおよそ以下のような過程を減ることになります。
- 普通に
exprの型を推論する(Tとする)。Tがnullやundefinedを含むunion型の場合:
Tからnullとundefinedを除いた型T2を作る。T2のfooプロパティの型Uを得る。(fooプロパティが無ければ型エラー)expr?.fooの型をU | undefinedとする。Tがnullやundefinedを含むunion型ではない場合:
- 普通に
expr.fooの型を返す。(無いなら型エラー)要するに、
exprから一旦nullやundefinedの可能性を除いて考えて、もしそういう可能性があるなら結果の型にundefinedをつけるということです。never型に関する注意
知らないと少し混乱するかもしれない例がひとつありますのでここで紹介しておきます。それは、
expr?.fooでexprがただのundefined型(あるいはnull型とかundefined | null型)だった場合です。const obj = undefined; // 型エラーが発生 // error TS2339: Property 'foo' does not exist on type 'never'. const v = obj?.foo;この例では
objはundefined型です(もはやオブジェクトではないので変数の命名が微妙な気もしますが)。したがって、obj?.fooは常に結果がundefinedとなり、fooプロパティへのアクセスが発生することはありません。となると
obj?.fooの型はundefined型になりそうな気がしますが、実際はそうではありません。というか、実はこの式は型エラーとなります。そもそも、
objがundefinedであると判明しているのであればobj?.fooは絶対にundefinedにあるのであり、わざわざこんな書き方をする意味はありません。何かを勘違いしている可能性が非常に高いでしょう。その意味では、これが型エラーになるのはどちらかといえば嬉しい挙動です。問題なのはエラーメッセージです。エラーメッセージは「
never型の値にfooというプロパティはないのでobj?.fooはだめですよ」と主張しています。ここで突如登場した
never型の意味が分からないとエラーの意味がよく分からないのではないでしょうか。
never型は「値が存在する可能性が無いことを表す型」です。obj?.fooは「objがnullやundefinedでないときはobj.fooにアクセスする」という意味を持ちますが、ではobjがundefinedのときにそこからnull型やundefined型の可能性を除外すると何が残るでしょうか。そう、何も残りませんね。この「何も可能性がない」状況を表してくれる概念がnever型です。要するに、「
objがHasFoo | undefined型のときは、fooプロパティへのアクセスが発生するのはobjがHasFoo型のときである」のと同様に、「objがundefined型のときは、fooプロパティへのアクセスが発生するのはobjがnever型のときである」という理屈です。そして結局のところ、
never型に対するプロパティアクセスは許可されません5。これが型エラーの原因です。ここで言いたいことは、エラーメッセージにnever型が出てきたら「絶対に走らない処理」を書いていることを疑うべきだということです。今回の場合はobj?.fooと書いても絶対にfooプロパティへのアクセスは発生しないのでした。Optional Chainingと型の絞り込み
TypeScriptのたいへん便利な機能のひとつは、条件分岐の構造を理解し自動的に型の絞り込みを行なってくれることです(type narrowing)。実は、Optional Chainingも型の絞り込みに対応しています。
※ この内容は記事執筆時点でまだTypeScript 3.7 betaに入っていませんが、このプルリクエストで実装されているためTypeScript 3.7に導入されることが期待されます。また、現在は実装されていませんがTypeScript 3.7のリリースまでには対応されそうなものもあります(issue)。以下のサンプルはmasterブランチをビルドして動作を確認しました。
従来の型の絞り込みはこういう感じです。
function func(v: string | number) { if (typeof v === "string") { // ここではvはstring型 console.log(v.length); } }この関数では
string | number型の変数vに対してtypeof演算子を使った条件分岐を書きました。TypeScriptはこれを検知し、if文の中ではvをstring | number型ではなくstring型として扱います。vが数値である可能性を排除出来たことになりますね。これが型の絞り込みです。では、Optional Chainingを混ぜてみましょう。
interface HasFoo { foo: number; } const obj: HasFoo | undefined = Math.random() < 0.5 ? { foo: 123 } : undefined; if (typeof obj?.foo === "number") { // ここではobjがundefinedの可能性が消えているのでこれはOK console.log(obj.foo) }さっきと同様に
HasFoo | undefined型を持つ変数objに対してtypeof obj?.foo === "number"というチェックを行っています。実は、このチェックを通ったif文の中では
objがundefinedである可能性が消えてHasFoo型となります。なぜなら、objがundefinedだった場合はobj?.fooは必ずundefinedとなり、typeof obj?.foo === "number"が満たされることはないからです。他にも
if (obj?.foo === 123)とかif (obj?.foo)のような判定でも同様に型の絞り込みが行われます。これはたいへん助かりますね。このように、optional chainingを含んだ条件分岐を行うことでオブジェクトがnullishな値である可能性を消すことができます。
発展:Optional Chainの型推論の実装
これはTypeScriptコンパイラの内部処理に関する話なので、興味がない方は飛ばしても問題ありません。
Optional Chainingの型推論にあたっては、愚直に実装するとうまくいかない点があります。TypeScriptではその点をoptional typeと呼ばれる内部的な型の表現を導入することで乗り越えています。optional typeは「
?.由来のundefined型」です。基本的には通常のundefined型と同じ振る舞いをする型であり、通常のundefinedとの違いはOptional Chainingの型推論の内部でのみ表れます。Optional typeのはたらきを理解するために、次の例を見てみましょう。
interface HasFoo { foo: number; } interface HasFoo2 { foo?: number; } const obj: HasFoo | undefined = Math.random() < 0.5 ? { foo: 123 } : undefined; const obj2: HasFoo2 | undefined = Math.random() < 0.5 ? { foo: 123 } : undefined; // obj?.foo と obj2?.foo はどちらも number | undefined 型 const v1: number | undefined = obj?.foo; const v2: number | undefined = obj2?.foo; // これはOK obj?.foo.toFixed(2) // これは型エラー obj2?.foo.toFixed(2)
HasFoo型とHasFoo2型はどちらもfooプロパティを持つオブジェクトですが、fooがundefinedの可能性があるかどうかという違いがあります。その違いは
obj?.fooとかobj2?.fooでは可視化されません。この2つはどちらもnumber | undefined型を持ちます。しかし、
obj?.foo.toFixed(2)とobj2?.foo.toFixed(2)のようにさらにチェーンを繋げるとその違いが表れ、前者はコンパイルが通る一方で後者は型エラーとなります。まずこの理由を理解しましょう。まず前者を考えます。
objはundefinedの場合とHasFooの場合があり、前者の場合はobj?.foo.toFixed(2)は即座にundefinedとなり終了します。objがHasFooだった場合は、obj?.fooがnumberとなり、よってobj?.foo.toFixed(2)の呼び出しは可能です。次に
obj2の場合を考えてみます。obj2がundefinedの場合は先ほどと同様です。一方でobj2がHasFoo2の場合ですが、HasFoo2自体のfooがundefinedの可能性を秘めているためobj2?.fooは依然としてnumber | undefined型です。これにより、obj2?.foo.toFixed(2)はobj2?.fooがundefinedの可能性があるため型エラーとなります。ここで問題となるのは、
obj?.fooとobj2?.fooの型だけを見るとどちらもnumber | undefined型となってしまい、それに対する.toFixed(2)呼び出しを許可していいのかどうか判断できないという点です。obj?.foo.toFixed(2)という一連の式を見た場合、コンパイラはまずobj?.foo部分の型推論を行い、その結果に対して.toFixed(2)の推論を行います。少なくとも今のTypeScriptの実装では、(式).toFixed(2)というノードの型推論を行うときに得られる(式)部分の情報はその型のみです。しかし、上で見たようにそれだけだと情報が不足しており適切な判断ができないというわけです。この問題に対するワークアラウンドとして、コンパイラの内部でoptional typeが導入されました。これを便宜上
optionalと書くことにします(実際のTypeScriptプログラムでそう書けるわけではありません)。具体的には、
?.由来のundefinedに対してはoptional型を付与します。そして、Optional Chain内部の型推論においてはoptional型を無視してプロパティアクセス等が可能かどうか判断します。すなわち、
obj?.fooの型推論結果はnumber | optionalとなります。これに対して.toFixed(2)のメソッド呼び出しの型推論を行うときは、一時的にoptionalを無視してnumberとして扱います。そうするとメソッド呼び出しは許可され、結果はstringとなります。optionalは伝播するので結果にoptionalを戻し、obj?.foo.toFixed(2)の型はstring | optionalとなります。一方、
HasFoo2の場合はfooプロパティがもともとnumber | undefinedでした。これにより、obj2?.fooの型はnumber | undefined | optionalとなります。これに対する.toFixed(2)呼び出しを考えると、optionalを取り除いても依然としてundefined型の可能性が残っているため型エラーとなります。このようにして上記の2種類の式を区別しているのです。型の世界で話を終わらせるために内部的に特殊な型を導入するといいうことはTypeScriptのコンパイラでは結構行われています。
以上でTypeScriptの話は終わりです。
Optional Chainingの歴史
ここからは、Optional Chainingの歴史を見ましょう。この概念がどれだけ昔からあったのか正確に知ることは難しいものの、JavaScriptの文脈からするとまず語るべきはCoffeeScriptでしょう。CoffeeScriptでは
?.はExistential Operatorと呼ばれています。CoffeeScript
CoffeeScriptのChangelogによれば、
?.は2010年1月5日リリースのCoffeeScript 0.2.0で導入されました。紆余曲折を経て、JavaScriptのOptional Chainingの挙動はこのときのCoffeeScriptのものに非常に近くなっています。さすが
?.の原点(推測)ですね。ただ、先述のように構文はJavaScriptとは微妙に違っています。JavaScriptにおいて
?という記号が条件演算子のせいで扱いにくいものになっていることを考えると、条件演算子を廃して?をフリーにしたのは英断と言えると感じられます。ちなみに、CoffeeScriptは
?はnullish関連のいろいろな場面で使われます。例えばfoo?という式はJavaScriptのfoo != nullに相当します。また、JavaScriptでfoo ?? barと書く式もCoffeeScriptではfoo ? barと書けます。初期の議論
これをJavaScriptに入れたいという議論は2013〜2014年ごろからあったようです。メーリングリストでの議論がesdiscuss.orgにまとまっています。他にも何個かスレッドがあり、プロポーザル文書からリンクが貼られています。
読むと分かりますが、初期からすでに
?.という構文が優勢だったようです。obj?[expr]のようなものも模索されましたがやはり前述の理由でうまくいきません。他の構文の候補やセマンティクスなど一通りの議論がここでなされました。TC39ミーティング
その後舞台はTC39ミーティングへと移ります。TC39というのはJavaScript (ECMAScript) の仕様を策定する委員会で、仕様をJavaScriptに採用するかどうかはここで決められます。
採用候補の仕様はプロポーザルという形で管理されます。Optional Chainingもひとつのプロポーザルです。
プロポーザルはいくつかのステージに分類されます。ステージは0から4までの5段階あり、ステージ0は有象無象のアイデア、ステージ4は採用決定という段階です。現在Optional Chainingはステージ3です。ステージ3はほぼプロポーザルの内容が固まったので正式採用前だけど実装してみようぜという段階で、ここまで来ると我々が使えるようになり正式採用も近くなります。
ステージの上げ下げはTC39のミーティングによって決定されます。基本的にはステージが上がるかそのままかですが、稀にステージが下げられてしまうこともあります。
ここからは、ステージ上昇を賭けた各ミーティングの様子をざっくり振り返ります。
Stage 1: 2017年1月
Optional ChainingがTC39ミーティングに最初に登場したのは2017年1月の回です。このプロポーザルは当初はNull Propagation Operatorという名前でした。
プロポーザルの最初の関門は、TC39の興味を惹きつけてStage 1に認定されることです。
議事録の初っ端に
All: having a hard time reading the screen
と書いてあって笑いました。実際のスライドを見るとたしかに文字が小さいですね。
結論から言えばStage 1になることができたので終わりよければ全てよしですが。
Stage 1になるためには仕様の詳細まで決まっている必要はありません。実際、Stage 1になるためのスライドでは
?.という演算子のコンセプトのみが述べられています。ただ、スライドとは別に今回の場合は初期から比較的詳細な案が用意されており、よい叩き台となったようです。全体的に
?.は好評でしたが、?.[ ]や?.( )は何か見た目が微妙だし本当に必要だろうかとか、短絡評価のセマンティクスが微妙とか、( )のあるなしで意味が変わってしまうのが微妙といった議論がありました。また、ES2015で導入されたオプショナル引数が
undefinedのみに対応していることを考えると、?.がnullとundefinedに両対応すべきかそれともundefinedに対応すべきかも一考の余地がありそうでした。とはいえ、これらの内容はStage 1になってから議論しても遅くはありません。ということで、無事にこのプロポーザルはStage 1になりました。今後Stage 2を目指すにあたってはこれらの内容が議論の焦点になります。
2017年7月
次にこのプロポーザルがTC39ミーティングに登場したのは7月です。前回のミーティングで挙げられた課題について回答をまとめ、Stage 2の承認を得ることが目的です。
ここで説明されたセマンティクスはおおよそ最終的なものと同じですが、
(a?.b).cがa?.b.cと同じになる点が今と違いました。また、代入のサポートをするかどうかもまだ未定という段階でした。このときのスライドはCoffeeScriptで書かれた既存のコードに対する利用状況調査などが含まれており面白いです。
結論としては、このミーティングでプロポーザルがStage 2に進むことはできませんでした。特に短絡評価周りで混乱が起こり、参加者を納得させられるより明確な説明が必要という結論になりました。次回の宿題ですね。
2018年1月
その2つ後のミーティングでOptional Chainingが再び議題にあがりました。これはStage 2が目標というよりはTC39に意見を聞きたいという意図のほうが強いようです。
今回、なぜか
?.が??.に変わりました(GitHub上で投票を行ってみた結果のようです)。この場合[ ]や( )はobj??[expr]やfunc??(arg)となり少し見た目が良くなるので、そちら側に寄せた変更といえます。そのほかは前回の課題であった短絡評価のセマンティクスの明確化がおもな議題です。多くのスライドや具体例を用いてセマンティクスが説明されました。また、分かりやすくする目的で仕様テキストも大きく書きなおされました。ちゃんと読んでいないのですが以前はNil Referenceというやばそうな概念があったらしく、改訂でそれが消されて現在のものに近くなりました(仕様書についてはあとで解説があります)。
TC39の反応としては
?.でも??.でもどちらでも良さそうな感じでどちらかに決まることはありませんでした。短絡評価に関してはしっかりと説明したことで納得度が向上したようです。2018年3月
TC39ミーティングは2〜3ヶ月に1回なので、前回に引き続いての登場です。前回比較的良い手応えを得たので今回はStage 2を目指しての議論となりました。なお、構文は
?.に戻りました。もう一度投票してみたら?.が優勢になったことと、??にするとnullish coalescing operatorが??:になってしまうのが辛かったようです。しかし、結論としては今回もStage 2に進むことができませんでした。
?.[ ]や?.( )という構文に対する強烈な反対があり全然話が進まなかったようです。2018年11月
今回は発表者がこれまでと違うのでスライドの雰囲気が今までと全然違います。一見の価値があるかもしれません。
内容としては、まずオプショナルな関数呼び出し
func?.()が消えてしまいました。obj?.[expr]は依然として残っています。obj?.fooも含めた三者がセットでなければいけないと主張していた勢力が折れた形です。これに対する反応はまずまずといったところで、強い賛成も反対も見られない様子です。今回のミーティングでは話が右往左往してあまり進まなかった印象です。
Stage 2: 2019年6月
おまたせしました、約2年に渡った停滞を乗り越えてOptional ChainingがStage 2となったのが今年の6月のことです。つい最近ですね。ちなみに、今回はまた発表者が別の人です。
内容としては、
?.()が復活しました。今回の議論の争点もそこだったらしく、これを入れるか入れないかがひとしきり議論されました。反対意見もありましたが結局
?.()を含んだままStage 2への移行が決定する形となりました。Optional Chainingに対するコミュニティの強い期待と、構文に関して長い時間をかけて解決策を模索したが何も見つからなかったことへの諦めから、やっとプロポーザルが次の段階に進むことができたという感じです。ちなみに、Nullish Coalescing (
??演算子)も同じミーティングでStage 2に移行しました。まあ、この2つはセットで扱われるのが自然ですからそんなに不思議ではありません。Stage 3: 2019年7月
スケジュールの都合で2ヶ月連続となったTC39ミーティング(6月頭と7月終わりなので実際は1ヶ月半くらい間があります)です。前回Stage 2となったOptional Chainingはスピード出世でStage 3となりました。
今回のスライドでは、前回未だに争点となっていた
?.()に関して重点的に説明されています。?.()のユースケースを集めてその必要性を説く形です。そして今回の争点もやはり
?.()でした。今回、?.()の見た目よりはその挙動が争点となったことで議論が白熱しました。123?.()のようなものもエラーではなく無視されるべきではないかというような話がされました。色々と議論がありましたが結局周りに説得され、全会一致でStage 3への昇格が決まりました。めでたしめでたし。
その後
プロポーザルがStage 3になると、実装が動き始めます。先述のようにTypeScriptがOptional Chainingの実装に向けて動き、3.7でリリースされます。
また、WebkitもStage 3への昇格直後に動き始め、8月のうちに対応を完了しています。Chrome (V8) も同様に8月のうちに対応しています。Chromeは9月に公開されたGoogle Chrome 78 ベータ版にフラグ付きですがOptional Chainingのサポートが含まれています。
以上がOptional Chainingの歴史でした。Stage 4への昇格が楽しみですね。
Optional Chainingの仕様
最後に、この節ではOptional Chainingを仕様の観点から見ていきます。やや難易度が高いので興味の無い方は飛ばしても大丈夫です(あと残っているのはまとめだけですが)。
なお、仕様書という場合は以下の文書を指しています。
OptionalExpression
さて、仕様の観点から見ると、このプロポーザルは文法にOptionalExpressionという非終端記号を追加するものです。OptionalExpressionの定義を仕様から引用します(画像)。
読むと分かるように、OptionalExpressionは左側の部分(MemberExpression, CallExpression, OptionalExpressionのいずれか)にOptionalChainがくっついた形になっています。このOptionalChainという非終端記号が上で説明したオプショナルチェーンにちょうど対応します。
例えば
obj?.foo.barが文法上どう解釈されるかを表で表すと、このようになります。
OptionalExpression MemberExpression
PrimaryExpression
IdentifierReference
Identifier
IdentifierNameOptionalChain OptionalChain IdentifierName IdentifierName obj?.foo.barポイントは、先に説明したように
?.foo.barという部分全体がひとつのOptionalChainとして扱われていることです。OptionalChainの中身は左再帰で定義されており、先頭が?.であとは通常の.や[ ]、そしてArguments(これは関数呼び出しの( )を表しています)が続くことで構成されていることが分かります。また、この文法から「チェーンの一部を括弧で囲むと意味が変わる」ということも読み取れます。括弧で囲まれた式はParenthesizedExpressionになりますが、これはPrimaryExpressionの一種であり直接OptionalChainになることはできません。
例えば、
(obj?.foo).barの解釈は以下に定まります。
MemberExpression MemberExpression
PrimaryExpression
ParnthesizedExpressionIdentifierName Expression
(中略)
OptionalExpressionMemberExpression
(中略)
IdentifierNameOptionalChain
(内訳は省略)(obj?.foo).bar
obj?.foo.barと(obj?.foo).barでは構文木の形が大きく違うことが分かりますね。Optional Chainingの構文が前述のような木の形で定義される理由は、主に前述のセマンティクスを説明しやすいからです(逆に、構文上の表現に合致するようにセマンティクスを決めたとも言えます)。特に、括弧でオプショナルチェーンを切ることができるという構文上の事象とセマンティクスがちょうど合致していて扱いやすいものになっています。OptionalExpressionとタグ付きテンプレートリテラル
注意深い読者の方は、上で引用されたOptionalExpressionを見てあることに気づいたかもしれません。OptionalExpressionの定義にこのようなものが混ざっています。
これはすなわち、
func?.`abc`のような式がOptionalExpressionとして解釈されるということです。こればfunc`abc`というタグ付きテンプレートリテラルのオプショナル版に見えます。
OptionalExpression MemberExpression OptionalChain TemplateLiteral
NoSubstitutionTemplateTemplateCharacters func?.`abc`しかし、先述の通り、Optional Chainingはタグ付きテンプレートリテラルをサポートしていないはずです。実際のところこう書いた場合はエラーが発生します。このことは、仕様書の以下の場所に書かれています(画像で引用)。
要するに、
func.`abc`のような形は定義してあるけど実際には文法エラーになるよということです。また、ここに書いてある通りobj?.func`abc`のような形も同様です。わざわざ定義してから構文エラーにしなくても、最初から定義しなければいいと思われるかもしれません。そうしなかった理由は上記引用中にNOTEとして書かれています。これについて少し解説します。
理由を一言で説明すると、ここで明示的に定義しておかないと、かの悪名高きセミコロン自動挿入によって別の解釈が可能になってしまうからです。仕様書に書かれている例を引用します。
a?.b `c`現在の定義では、これは2行でひとつの式として解釈されます。すなわち、
a?.b`c`というOptionalExpressionとして解釈され、上記の規則により構文エラーとなります。一方で、これをOptionalExpressionとして扱う構文規則がなかった場合を考えてみます。まず、改行がない場合は
a?.b`c`というコードは解釈することができずにやはり構文エラーとなります。タグ付きテンプレートリテラルはMemberExpression TemplateLiteralという並びによって定義されますが、上で見たようにOptionalExpressionはMemberExpressionの一種ではないからです。これを踏まえて、上の2行のプログラムを見てみます。1行目の
a?.bを読み終わって2行目に入り`を読んだ時点で構文エラーが発生することになります。ここで自動セミコロン挿入が発動します。ここで適用されるルールをざっくり言うと「改行の直後でコードが解釈不能な状況に陥ったら直前にセミコロンを挿入してみる」というものです。これにより、上のプログラムの解釈はこれと同じになります。a?.b; `c`この解釈においては大まかに分けて2つの問題があります。ひとつは、将来的な拡張が困難になる点です。現在
a?.b`c`がサポートされていないのはユースケースの欠如が理由とされています。つまり、関数が存在するときだけタグ付き関数呼び出しが出来るという機能の需要が無さそうなのです。もし将来的に需要が発見されたらこの機能をサポートする道もあるわけですが、上記のプログラムに別の解釈が与えられてしまうと将来的にその解釈を上書きすることができなくなってしまいます。それを避けるために、わざと文法エラーにすることで将来的な拡張の余地を残しているのです。もうひとつの問題は通常の(オプショナルでない)タグ付きテンプレートリテラルとの対称性です。現在、以下のプログラムは
a.b`c`として解釈されます。a.b `c`
a.bをa?.bに変えるといきなり解釈が変わって文が2つになるというのはたいへん微妙だし非直感的ですね。思わぬミスが発生するのを避けるために.と?.の場合で解釈が大きく変わらないようになっています。OptionalExpressionとLeftHandSideExpression
OptionalExpressionの定義をもう一度振り返りましょう。
一番下にすこし気になることが書いてあります。OptionalExpressionは、NewExpressionやCallExpressionと並んで、LeftHandSideExpressionの一種であるとされています。
LeftHandSideExpressionとは何の左側のことを指しているのでしょうか。実は、これは
=の左側です。これが意味することは、obj?.foo = 123のような式が構文上可能であるということです。
AssignmentExpression LeftHandSideExpression
OptionalExpression
(詳細は省略)AssignmentExpression
(中略)
IdentifierNameobj?.foo=123やはり、これも構文上認められるとはいえ実際には文法エラー扱いになります。このことは仕様書の既存のEarly Error定義12.15.1 Static Semantics: Early Errorsに定義されています(該当部分を以下に引用)。
It is an early Syntax Error if LeftHandSideExpression is neither an ObjectLiteral nor an ArrayLiteral and AssignmentTargetType of LeftHandSideExpression is strict.
実はプロポーザル文書のほうを見るとAssignmentTargetTypeではなくIsSimpleAssignmentTargetというものが定義されています。ちゃんと追っていないのですが、仕様執筆時にちょうどこのあたりの改稿が議論されていて齟齬があったようです。多分そのうち直るでしょう。
まとめ
お疲れ様でした。この記事ではOptional Chainingの機能面を解説し、さらにStage 3に上がるまでの歴史と仕様の中身にも少し触れました。
機能面では短絡評価をちゃんと理解することがポイントとなります。一度理解すれば大したことはありませんのでぜひ今のうちに予習しておきましょう。
歴史に関しては、当初はセマンティクスで少し揉めたもののすぐに沈静化し、
?.( )という構文が激しい反発を呼んで2年ものあいだ停滞したことがお分かりになったと思います。TC39の面々が年単位で考えぬいてベストだと判断された(というかは妥協して受け入れるまでに年単位の時間がかかった)?.( )構文ですから、素人考えで構文にああだこうだと文句を付けるのはあまり意味が無いことがお分かりでしょう。仕様に関しては構文がどのように扱われているのかなどに興味がある方向けに解説しました。よく分からなくてもOptional Chainingの使用に問題はないと思いますのでご安心ください。
この記事執筆時にはStage 3プロポーザルであるOptional Chainingですが、多分ES2020か遅くともES2021くらいでStage 4に上がるものと思われます。楽しみですね。この記事を読んだみなさんはOptional Chainingに関して大抵のことは聞かれても答えられることでしょう。ぜひ周りにOptional Chainingを布教しましょう。
おおよそというのは、
objを評価するのは1回だけであるとか、document.allとの兼ね合いといったことを指しています。 ↩
objがnullのときはobj?.fooがnullになってほしいという意見もありそうですが、このときの結果がundefinedである理由付けは一応あります。それは「obj?.fooはobjについての情報を得るためのものではなくfooの情報を得るためのものである。nullもundefinedもどちらもfooを持たないという点で同じなのだから、結果はundefinedに統一してobjの情報が伝播しないようにすべきである」というものです。個人的にはまあ一理あると思っています。また、JavaScript本体の言語仕様はそもそもnullよりもundefinedに偏重しているため(DOMは逆にnullに寄っていますが)、undefinedに統一されるのもまあ妥当に思えます。 ↩厳密に言えば、ゲッタがエラーを発生させた場合や
Proxyの場合など、プロパティアクセスに起因してエラーになる可能性は他にもあります。とはいっても、今はそういう話をしているのではないことはお分かりですよね。 ↩
obj[expr]はobj.get(expr)の糖衣構文。 ↩
never型のボトム型的な性質を考えると「never型に対しては任意のプロパティアクセスを許可してその結果もnever型になる」というような推論も理論的には可能だと思いますが、ユーザーに対する利便性を考えて今の仕様になっているのだと思われます。 ↩



- 投稿日:2019-10-20T16:59:45+09:00
Cypressテストレポート出力でハマった件
Cypress導入とレポート出力
cypressを導入をしてみてついでにレポート出力しようとしたところハマったためメモしておきます。
環境
windows10
node v12.2.0
Nuxt.js 2.10.1ハマった内容
PS > npx mochawesome-merge > mochawesome.json PS > npx marge mochawesome.json ✘ Some files could not be processed: mochawesome.json Unexpected token � in JSON at position 0やったこと
1.cypressインストール
npm install cypress --save-dev2.環境周りの設定
cypress.json{ "baseUrl": "http://localhost:3000", "fixturesFolder": "test/e2e/fixtures", "integrationFolder": "test/e2e/integration", "pluginsFile": "test/e2e/plugins/index.js", "supportFile": "test/e2e/support/index.js" }3.sample.jsの作成
- sample2.jsも同じファイルで作成test/e2e/integration/sample.js/// <reference types="Cypress" /> describe('Sample tests', () => { it('Visits index page', () => { cy.visit('/'); cy.contains('h2', 'Nuxt'); }); });4.scripts設定
package.json"scripts": { "e2e": "cypress run", "e2e:open": "cypress open" }5.動作確認
npm run e2e6.レポート関連インストール
npm install --save-dev mocha mochawesome mochawesome-merge mochawesome-report-generator7.cyperss設定更新
cypress.json{ "baseUrl": "http://localhost:3000", "fixturesFolder": "test/e2e/fixtures", "integrationFolder": "test/e2e/integration", "pluginsFile": "test/e2e/plugins/index.js", "supportFile": "test/e2e/support/index.js", "reporter": "mochawesome", "reporterOptions": { "overwrite": false, "html": false, "json": true } }8.e2e実行
* mochawesome-reportフォルダにjsonが出力されるnpm run e2e9.出力された結果のマージ
npx mochawesome-merge > mochawesome.json npx marge mochawesome.jsonここでハマる
解決方法
npx mochawesome-merge | Out-File -Encoding Default mochawesome.json npx marge mochawesome.jsonなぜハマったか
- 「mochawesome-merge」で出力された「mochawesome.json」がUTF-16LEとなっていた(VScode上で) *バイナリで先頭FFFE
- PowerShellでやるとNG、コマンドプロンプトだとOK ⇒ PowerShellのリダイレクトの仕様にハマっていた
ということでPowerShellでUTF8で出力する方法を探したところ上記の解決方法となりました。
*ちなみにEncodingがUTF8指定だとBOM付になりNGでした。
- 投稿日:2019-10-20T16:57:10+09:00
Reactのdebounceとthrottleのhooksをそれぞれ試してみた
Reactのdebounceとthrottleをhooksがないかとそれぞれググってみて検索の上の方に出てきたのをただ試してみただけの投稿です、よろしくお願いします
私が試したコードはこちらです
https://github.com/okumurakengo/react_debounce_throttle
debounce
debounceはこちらを試しました
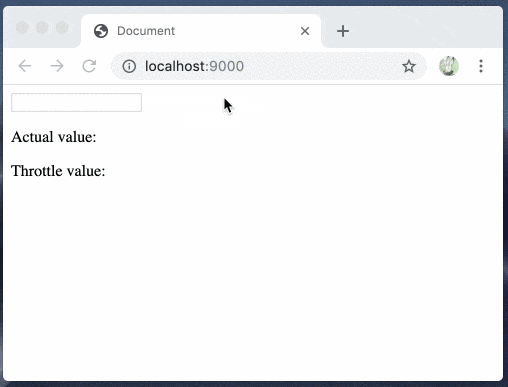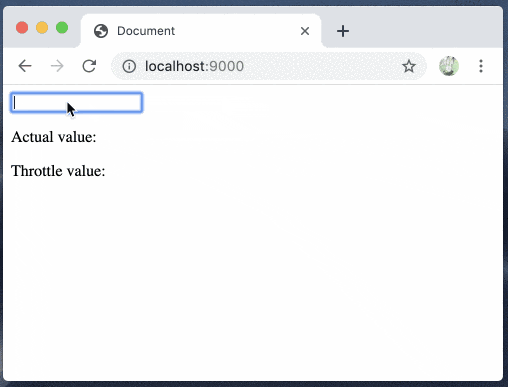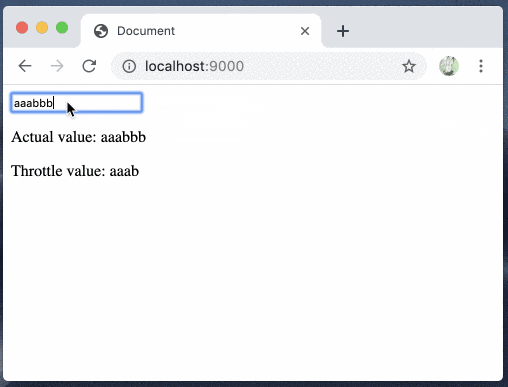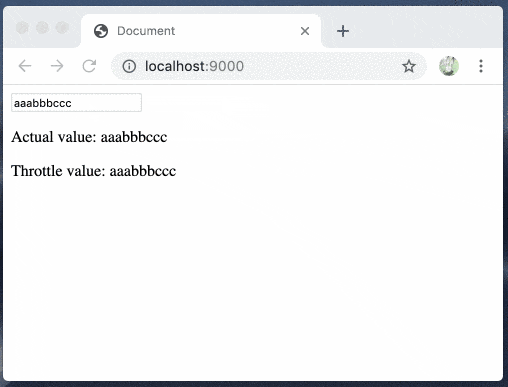
yarn add use-debounceimport React, { useState } from "react"; import { useDebounce } from "use-debounce"; const App = () => { const [text, setText] = useState(""); const [value] = useDebounce(text, 1000); return ( <> <input onChange={e => setText(e.target.value)} /> <p>Actual value: {text}</p> <p>Debounce value: {value}</p> </> ); }; export default App;
debounceが簡単に試せました
throttle
throttleはこちらを試しました
bhaskarGyan/use-throttle - github
yarn add use-throttleimport React, { useState } from "react"; import { useThrottle } from "use-throttle"; const App = () => { const [text, setText] = useState(""); const value = useThrottle(text, 1000); return ( <> <input onChange={e => setText(e.target.value)} /> <p>Actual value: {text}</p> <p>Throttle value: {value}</p> </> ); }; export default App;
throttleが簡単に試せました
以上です。みていただいてありがとうございました。m(_ _)m

- 投稿日:2019-10-20T16:56:29+09:00
【JavaScript】Object とは似て非なる Array の異常さを明らかにする ~exotic object とは~
イントロダクション
そもそも array とは0番目の値、1番目の値、...と一列に値を並べたもので、 object は key-value のペアの集まりであり、まったく異なるデータ構造である。
しかし、array は object としての性質も持っており、自由にプロパティの追加などができる。
const arr = [1, 2, 3] arr.prop = "value"一方で、
lengthプロパティに代入できる値に制限があるなど、object とは異なる部分もある。const a = [] a.length = -2 // Uncaught RangeError: Invalid array length「単に setter/getter 持ちのプロパティ(acessor property1)なのでは?」と思うかもしれないが、実はそうではなく、普通の data property1 である。この記事では、このような array の異常性を列挙した上で、それを実現する仕組みを説明する。
1. 持っているメソッドが違う
array object は
.slice()メソッドなど、通常のオブジェクトにはないメソッドを持っているが、これは簡単に説明がつく。array object は
Array.prototypeを継承しており、さらにこれはObject.prototypeを継承している。Array.prototypeがいくつかのメソッドを定義しているため、array object は object が持つメソッドだけでなく array 特有のメソッドにもアクセスできるのである。array が iterable であるのも、Array.prototypeが[Symbol.iterator]メソッドを持っているからである。また、以下のように
toString()メソッドの挙動が異なることも、「Object.prototypeが持つtoString()メソッドをArray.prototypeがオーバーライドしているから」と説明がつく。const obj = {0: 1, 1: 2} const arr = [1, 2] obj.toString() // "[object Object]" <- Object.prototype.toString() arr.toString() // "1,2" <- Array.prototype.toString()
2.
lengthプロパティarray object の
lengthプロパティは特別なものであり、普通のプロパティとは異なる振る舞いをする。ここで、lengthが data property であることを確認しておこう。Object.getOwnPropertyDescriptor([], "length") // {value: 0, writable: true, enumerable: false, configurable: false}もし data property ではなく accessor property であれば、
valueの代わりにgetとsetが存在するはずである。lengthプロパティには getter も setter もないことが分かる。3.
length以上のインデックスに代入するとlengthも増える
length以上のインデックスに対して代入をすると、lengthの値はそのインデックス+1になる。const arr = [] arr.length // 0 arr[2] = 10 arr.length // 3 arr // [empty, empty, 10]当たり前と言えばそうだが、object として考えると異常な振る舞いである。新しいプロパティを追加しただけで、別のプロパティの値が変わるというのは、普通の object ではありえない。
ちなみに、要素を
deleteしてもlengthは変わらない。const arr = [1, 2, 3] arr.length // 3 delete arr[2] arr.length // 3 arr // [1, 2, empty]4.
lengthプロパティを non-writable にするとlength以上のインデックスに代入できない
lengthプロパティのwritable属性をfalseにして2値を変更できなくすると、length以上のインデックスに対する代入ができなくなる。const arr = Object.defineProperty([], "length", {writable: false}) arr[3] = 10 arr // [] arr.length // 0strict モードならエラーが発生する。
"use strict" const arr = Object.defineProperty([], "length", {writable: false}) arr[3] = 10 // Uncaught TypeError3. のことを考えれば納得できるが、やはり普通の object ではありえない挙動である。
5.
lengthプロパティを変えると実際の要素数も変わる
lengthを減らすと、length以上のインデックスを持つ要素は削除される。const arr = [1, 2, 3, 4, 5] arr.length = 3 arr // [1, 2, 3]該当するプロパティも消えていることが分かる。
Object.getOwnPropertyNames(arr) // [ '0', '1', '2', 'length' ]このように、
lengthプロパティを変えることで他のプロパティに影響を与えるという点においても、array object が異常であることが伺えるだろう。逆に
lengthを増やすと、empty な要素が末尾に追加される。const arr = [1, 2, 3] arr.length = 6 arr // [1, 2, 3, empty, empty, empty]しかし、プロパティの数が増えるわけではない。
lengthは 6 であるのに、345のプロパティは存在しないことが分かる。Object.getOwnPropertyNames(arr) // [ '0', '1', '2', 'length' ]empty な要素というのは、該当するプロパティが存在しないということを意味するのである。
6.
lengthを減らすときに non-configurable な要素があるとそこで止まる
lengthを減らそうとすると、削除される予定の要素の中にもしconfigurable属性がfalseであるものがいくつかあれば、その中で最も大きいインデックスの所でlengthが止まる。これは、non-configurable なプロパティは削除できないからであるが、それでも中途半端に長さが減るというのは意外である。const arr = ["a", "b", "c", "d", "f"] // プロパティ "2" を non-configurable にする Object.defineProperty(arr, "2", { configurable: false }) arr.length = 0 arr.length // 3 arr // ["a", "b", "c"]
これも、strict モードではエラーが発生するが、
lengthが減らなくなるわけではない。"use strict" const arr = ["a", "b", "c", "d", "f"] Object.defineProperty(arr, "2", { configurable: false }) arr.length = 0 // Uncaught TypeError: Cannot delete property '2' of [object Array] arr.length // 37.
lengthは 0 から 2^32 - 1 までarray object の 長さは 0 から 2^32 - 1 までの整数値しかとれない。これも array の長さを表すという点では不思議なことではないが、setter があるわけでもないのにある種の validation が行われるのはやはり異常である。
const arr = [] arr.length = -1 // Uncaught RangeError: Invalid array length arr.length = 1.5 // Uncaught RangeError: Invalid array length arr.length = 2 ** 32 // Uncaught RangeError: Invalid array lengthちなみに、上記の条件さえみたせば数値の string 表現でもよい。
const arr = [] arr.length = "3" arr.length // 3もっと言えば、
Number()関数に渡して有効な数値になる値ならばなんでもよい。const arr = [] const length = { valueOf: () => 3 } Number(length) // 3 arr.length = length arr.length // 3ちなみに内部的にはこの数値変換はなぜか2回行われる。
const arr = [] const length = { valueOf: () => { console.log("oops"); return 3 } } arr.length = length // "oops" が2回出力される8. インデックスは 0 から 2^32 - 2 まで
lengthと同様に、 array インデックスとして有効な整数は0から2^32 - 2までであり、それ以外の値をキーにもつプロパティを作っても、配列の要素とはならない。const arr = [] arr[2 ** 32 - 1] = 1 arr.length // 0 Object.getOwnPropertyNames(arr) // ["length", "4294967295"] (プロパティとしては追加されている) arr[2 ** 32 - 2] = 1 arr.length // 4294967295タネ明かし
ここまでで述べたような array object の特殊な挙動はいったいどのようにして実現されているのだろうか?
実は JavaScript の object は「プログラマーからは一切見えない内部的なメソッド」を持っている。これらのメソッドはその object に対して何らかの操作をしたときにそれに対応したものが呼び出されるようになっている。Array object はこのうち
[[DefineOwnProperty]]というメソッドだけ、通常の object とは異なった定義がされているのである。下記のリンクは ECMAScript 2019 の仕様の該当部分である。内部メソッドは object が作られるときに、その object の内部スロットに明示的にセットされる。例えば array が作られるときは下のように、通常 object とは異なる
[[DefineOwnProperty]]メソッドがセットされるのである。...
5. Let A be a newly created Array exotic object.
6. Set A's essential internal methods except for [[DefineOwnProperty]] to the default ordinary object definitions specified in 9.1.
7. Set A.[[DefineOwnProperty]] as specified in 9.4.2.1.
...
(from 9.4.2.2 ArrayCreate)Side Note: 普通のプロパティやメソッドと異なり、内部メソッドは継承されない。例えば array の
sliceメソッドはArray.prototypeから継承したものであり、array が作られるたびにわざわざメソッドをセットしているわけではない。しかし、内部メソッドは object を作るたびに毎回その内部スロットにセットするようになっている。このように、通常の object の内部メソッドをオーバーライドしているような object を exotic object といい(exotic=風変わりな)、例としては Array、TypedArray、
arguments、bindした function、proxy object などがある。この
[[DefineOwnProperty]]メソッドは下の図のように、プロパティへの代入が行われるときに呼び出される(あくまで仕様を追うときに参考になればいいという図)。
下のように、array object は
[[DefineOwnProperty]]メソッドにおいてプロパティ名がlengthのときとインデックスであるときに特別な処理をしていることが分かる。ここまでで説明した array object の特殊な挙動は、この内部メソッドを見ればすべて説明がつく。
まとめ
array object は基本的には object であるが、普段使う JavaScript の知識だけでは説明できないような振る舞いをする。このような奇妙な振る舞いを理解するためには、言語仕様で定義されている内部メソッドなどの低レベルな所まで見なければいけない。筆者は array の「object っぽいけど違う」所が気持ち悪く感じ、ネット上で調べても答えが得られなかったため、自分で言語仕様を読んで理解し記事を書くに至ったが、もし他の誰かの参考になれば幸いである。
仕様の該当箇所
本文中にあげた部分は除く。
- 代入式: 12.15.4 Runtime Semantics: Evaluation
- exotic object: 4.3.7 exotic object
- array index の定義: 6.1.7 The Object Type
- 数値への変換処理: 7.1.3 ToNumber ( argument )
プロパティには2種類あり、data property と accessor property である。前者は普通のプロパティで、一つの値を格納するだけである。後者は getter と setter と呼ばれる関数によってそれぞれ"値の代入"、"値の取得"を実現するものである。 ↩
array の
lengthプロパティは最初から non-configurable なのでwritable属性を変更できないはずでは?と思うかもしれないが、実は一般的に non-configurable であってもwritableをtrueからfalseにすることは特別に許されている。仕様の該当部分: 9.1.6.3 ValidateAndApplyPropertyDescriptor ↩
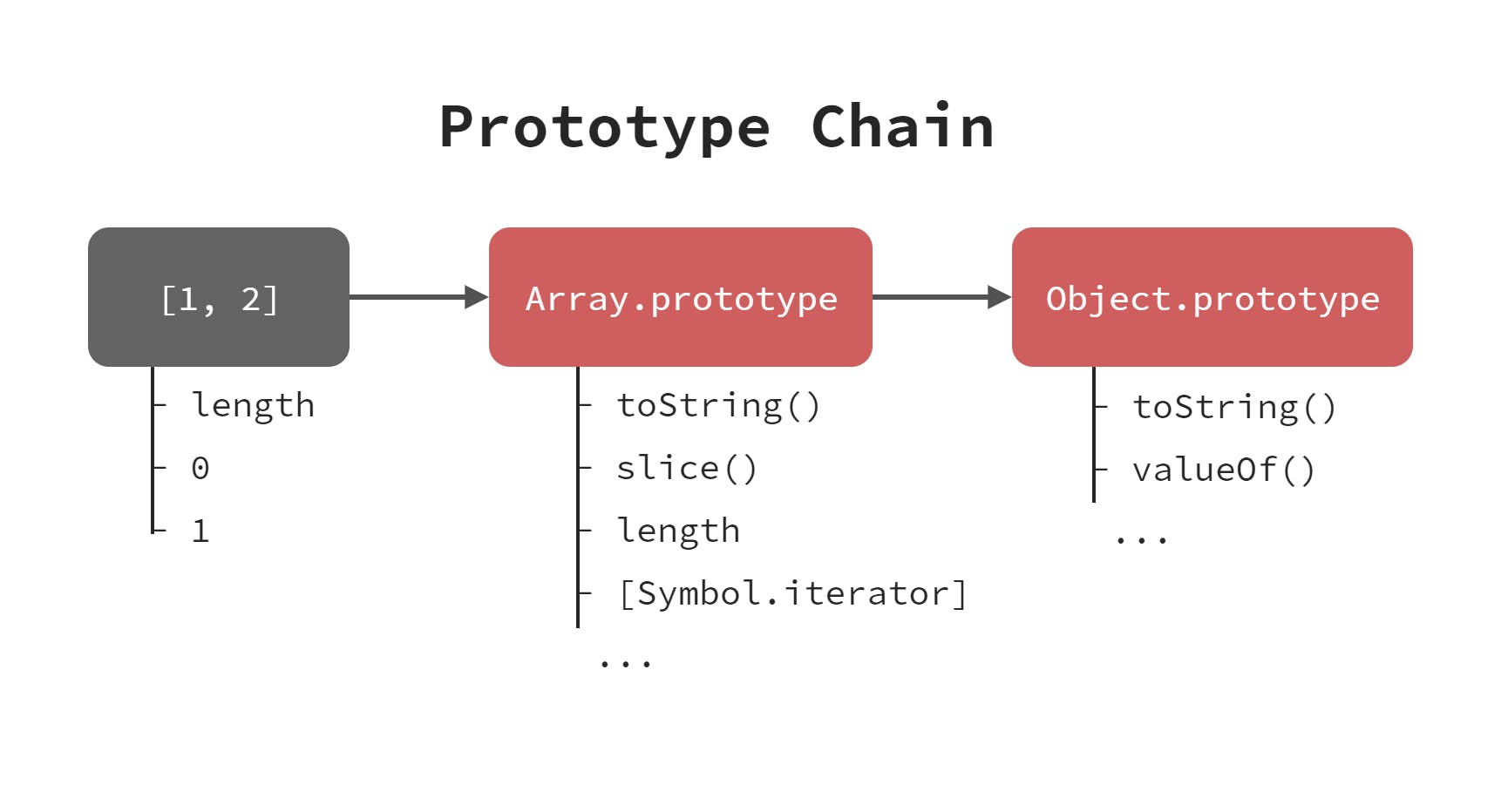

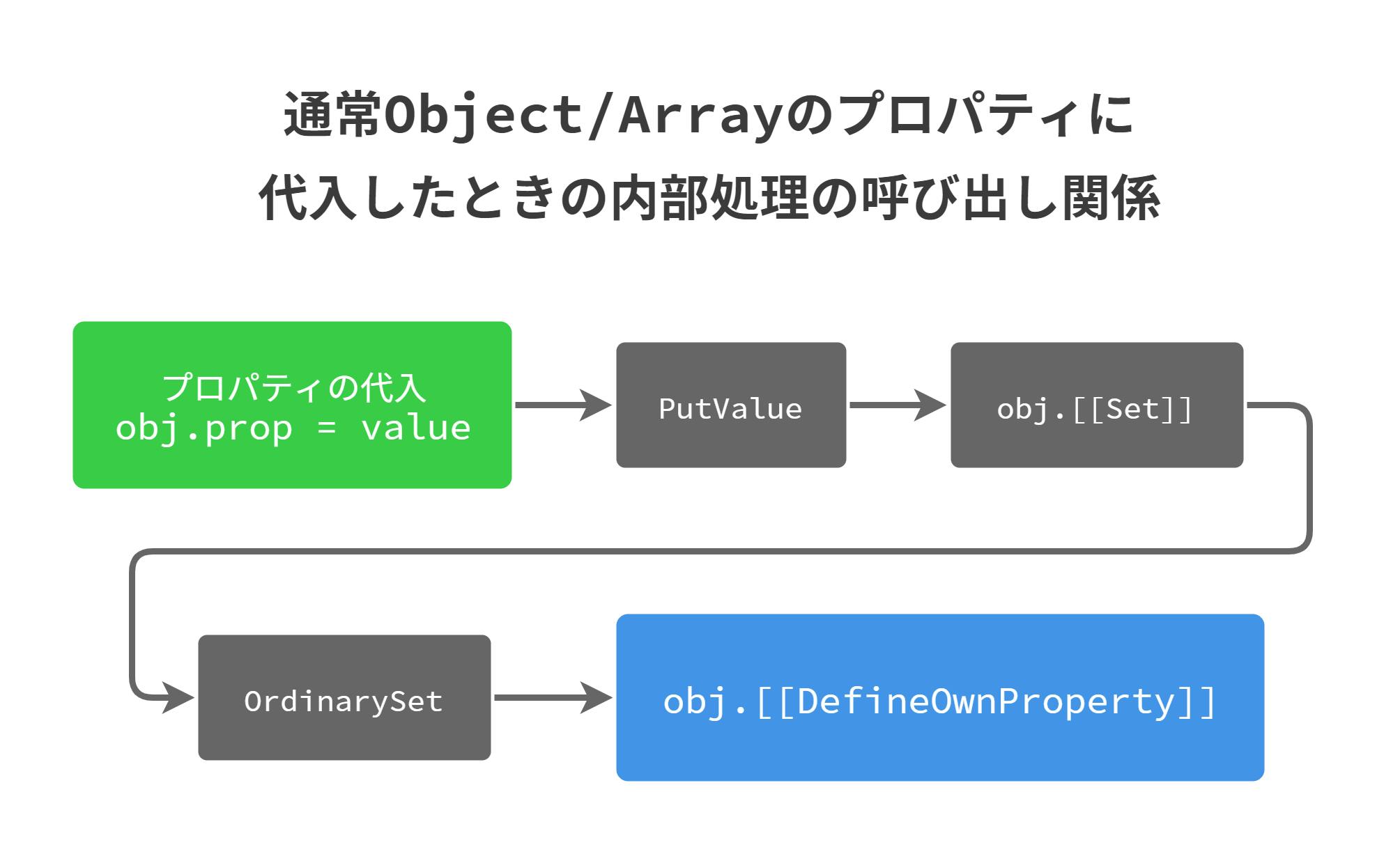

- 投稿日:2019-10-20T15:40:15+09:00
CometD 4.0.4でネットワーク・エラーのメッセージが変わっていた
CometDを使った情報配信Webアプリケーションの開発プロジェクトにて、結合テストで不具合が発生したので備忘録として書き留めておきます。
私はフロントエンド機能の開発を担当していたのですが、ネットワーク・エラー発生時にアプリのリカバリー処理を実行するために、Bayeuxレスポンスのerrorフィールドに設定される(はずだった)下記メッセージを検知するようにリスナー(JavaScript)を実装していました。
402::Unknown client上記メッセージを検知したら、アプリのリカバリー処理がコールされるはずだったのですが...
サーバー・サイド機能との結合テストを実施してみるとリカバリー処理がコールされず、実際にサーバー・サイドから受信したエラー・メッセージを確認してみると以下のとおりでした。402::unknown_session最新のCometD 4.0.4 リファレンス・マニュアル 8.5.2. Long Network Failures or Server Failuresには確かに
402::unknown_sessionと記載されています。「おやっ?」と思い、
CometD 4.0.3以前のリファレンス・マニュアルの同じ箇所を確認したところ、402::Unknown clientと記載されており、CometD 4.0.4からメッセージ文言が変わっていることが判りました。
単体テストで使っていたのはCometD 4.0.2、結合テストではCometD 4.0.4が使用されていたことにより、メッセージ文字列がマッチしなくなり、結合テストでエラーが検知できなくなってしまったようです。メッセージ先頭の
402::で検知するように修正して解決。以上。
- 投稿日:2019-10-20T15:29:53+09:00
【JavaScript】関数の基礎を勉強した
JavaScriptを勉強してる時に最初につまずいたのが関数。
最初はなんとなく読めたけど「え、人によって書き方が違う・・?」「アロー関数・・・?矢?え、矢?」ってなったのでちゃんとお勉強した関数ってなに
function(関数)は色んな処理を一つにまとめて名前をつけたもの
例えばよく使う処理を関数にしておくことで、コードの再利用性が上がってスッキリする基本の関数
関数はいろいろな形があるがまずは基本の形
基本的な書き方
関数を定義して、プログラム内で呼び出すことができる
function hoge() { console.log("hello"); } hoge();引数を利用した書き方
定義した関数に引数を渡すこともできる
function hoge(fruit,Number) { console.log('私は' + fruit + 'を' + Number + '個買った') ; } hoge('リンゴ',5);コールバック
引数に関数を指定することもできる
function hoge2 (){ console.log('hoge2が実行されました'); } function hoge1() { console.log('hoge1が実行されました'); hoge2(); } hoge1(hoge2);この時、hoge1()にはhoge2の関数式が渡される
function hoge2 (){ console.log('hoge2が実行されました'); testだよ } function hoge1(result) { console.log('hoge1が実行されました'); console.log(result); hoge2(); } hoge1(hoge2);consolehoge1が実行されました ƒ hoge2 (){ console.log('hoge2が実行されました'); testだよ } hoge2が実行されましたreturn(戻り値)
returnを利用することで、関数から戻り値を取得できる
function hoge1(num1,num2) { var answer; answer = num1 * num2 ; return answer; } console.log(hoge1(4,6));無名関数
無名関数は名前を定義しない関数(そのまんま)
関数名をつける手間が省かれるのがメリット無名関数の書き方
無名関数は変数に関数を代入して使用する
var result = function() { console.log("hello"); } result();引数を利用した書き方
無名関数にも引数を渡すことができる
var hoge = function (fruit,Number) { return(('私は' + fruit + 'を' + Number + '個買った')) ; } var my = hoge('リンゴ',5); console.log(my);即時関数
関数を定義すると同時に実行するための構文。
即時関数はスコープを汚染しないため、再利用しないような処理に使われる。即時関数の書き方
無名関数をさらに()で覆うような書き方をする
var hoge = (function () { console.log("hello") ; }());引数を利用した書き方
即時関数も引数を使用できる
var hoge = (function (fruit,Number) { return(('私は' + fruit + 'を' + Number + '個買った')) ; }('リンゴ',5)); console.log(hoge);アロー関数
ES2015から導入された書き方。
「=>」この矢みたいな書き方をすることで「function」を省略することができるアロー関数の書き方
まずは普通の関数の書き方
var result = function() { console.log("hello"); } result();アロー関数を使うことでfunctionを省略できる
var result = () => { console.log("hello"); } result();さらに処理が1行の場合は{}を省略することができる
var result = () => console.log("hello"); result();引数を利用した書き方
アロー関数も当然引数を指定できる
var result = (idle) => console.log(idle); result('坂道');さらに引数がある場合のみ、()を省略することもできる
var result = idle => console.log(idle); result('坂道');
- 投稿日:2019-10-20T14:14:59+09:00
C/Java/C#(SI系)なエンジニアに贈るTypeScript事始め その3(型の整理(基本編))
TypeScriptにおける型をもう少しだけ。
だいぶ仕事にかまけてサボってしまいましたが、ゆっくり続けていきます。
型の基本
だいたい想像通りです。オブジェクト指向な言語を触ってきた私たちなら問題なく対応可能です!
型の種類
型 属性 説明 number 基本型 数値型(整数/浮動小数点数) string 基本型 文字列型 boolean 基本型 真偽型(true/false) symbol 基本型 シンボル型 any オブジェクト型 配列、タプル、クラス、インターフェイス、関数など Java脳だとsymbolとanyがよくわからないですね。オブジェクト型は別途整理します。
オブジェクト型ってなに?
オブジェクト指向言語をやってきた人たちならなんとなくわかると思いますが、カンタンに整理します。
配列
配列です、、、宣言の仕方が複数種類あリます。[]で宣言するやり方とArrayで宣言するやり方。Array使うと混乱するケースがあるようなので普通に[]で宣言する、と覚えましょう。
ArraySample.js//配列 let neta: string[] = ['マグロ','イカ','車海老','ウニ','サーモン']; //これも配列(ジェネリックス記法)) let sake: Array<string> = ['ビール','焼酎','日本酒','ワイン']; //多次元配列はArrayでは宣言できないよ let neta_from: string[][] = [ ['マグロ', '大間'], ['イカ', '三崎'], ['ウニ', '淡路島'], ]; //Arrayだと混乱する例。初期値を期待しているのかサイズを期待しているのかが不明瞭。 let array1: number[] = new Array(5); //サイズ5の空配列 let array2: number[] = new Array(5,10,15); //要素5,10,15からなるサイズ3の配列 let array3: number[] = new Array(-1); //これは実行時エラー! //空配列を宣言するときはこう書こう let array4: number[] = [];連想配列(ハッシュ)
JavaでいうHashMapです。ハッシュをカンタンに取り扱えるのはスクリプト言語の有利な点だと勝手に思っています。Perlの連想配列とかすごくお世話になりました。
HashSample.ts//連想配列 let neta_prices: {[index: string]: number; } ={ 'マグロ': 100, 'イカ': 200, '穴子': 250, 'キュウリ': 50, }; neta_prices.ウニ = 500; //こんなにラクに要素を足せるよ! console.log(neta_prices.マグロ); //100 console.log(neta_prices['イカ']); //200 console.log(neta_prices['ウニ']); //500interfaceキーワードを使えば名前付きの型をあらかじめ用意しておくことができます。C言語でいうtypedefです笑。
InterfaceSample.tsinterface animal_colors {[index: string]: string;};連想配列においても型推論による問題が発生する可能性があります。インデックスシグニチャは省略しない!と覚えておきます。先ほどのネタの値段リストで試すとこうなります。
HashSampleError.tslet neta_prices2 = { 'マグロ': 100, 'イカ': 200, '穴子': 250, 'キュウリ': 50, }; neta_prices2.ウニ = 500; //コンパイルエラー! //- error TS2339: Property 'ウニ' does not exist on type // '{ 'マグロ': number; 'イカ': number; '穴子': number; 'キュウリ': number; }'.これはどういうことかというと、インデックスシグニチャが存在しないため、型推論がされた結果、ハッシュではなく、4つのメンバー(マグロ、イカ、穴子、キュウリ)を持ったオブジェクト型である、と推論されてしまったということなのです。なので、ウニというメンバーはいませんぜ!というエラーが発生するわけですね。
列挙型(enum)
これも他の言語でもよくありますよね。普段通りに使えます。
EnumSample.tsenum Sex { MALE, //初期値を指定しない場合は0からの連番 FEMALE, //1 UNKNOWN = 9, //初期値を指定したので9 }; let m: Sex = Sex.MALE; console.log(m); //0 console.log(Sex[m]); //MALEタプル(Tuple)
複数の異なる型の集合を表現するためのデータ型です。これは意外だったのですがタプルもあんまり使わない方が良いんですって。クラスオブジェクトとして定義した方が自然で管理がラク、という評価のようです。
さらに、先頭の要素を削除する等、データの構造を変えたりするとパニックになります。要素を削除してもデータ型には反映されないため、容易に実行時エラーが発生することとなってしまいます。
TupleSample.tslet tuple_data:[string, number, boolean] = ['獺祭',1200, false]; console.log(tuple_data); //[ '獺祭', 1200, false ] //各要素の肩に応じたメソッドの呼び出しが可能です console.log(tuple_data[0].length); // 2 console.log(tuple_data[1].valueOf()); // 1200 console.log(tuple_data[2] === false); // true tuple_data.shift(); //先頭要素の削除はできるが、、 // 実データと型データがズレてしまう・・・ console.log(tuple_data[0].length); // undefined console.log(tuple_data[1].valueOf()); // false console.log(tuple_data[2] === false); // falseSymbol型ってなに?
ECMAScript 2015で導入されたもので、number, stringと同様に使えます。
以下の特徴を持った型です。オブジェクトのプロパティのキー値に使ったりするらしい。
色々な使い方ができそうなので、別途まとめます。今はさわりだけ。
- 不変(immutable)
- 一意(unique)
SymbolSample.tsconst NAME = Symbol('kuzukawa') const NICKNAME = Symbol('kuzukawa') // if(NAME === NICKNAME) はコンパイルエラー。trueになることはない console.log(NAME) //Symbol(kuzukawa) console.log(NAME.toString()) //Symbol(kuzukawa) console.log(NAME.valueOf()) //Symbol(kuzukawa)型アサーション, TypeAssertion(キャスト)
以下の2通りの書き方ができます。とりあえず使ってはいけない機能、とだけ覚えておきます笑
Javaでもキャストは止めようねって話でしたよね。TypeAssertiionSample.tsfunction show(result: string) { return `今日は${result}点な気分です。`; } console.log(show('100')); console.log(show(<any>100)); // <Type> Value console.log(show(100 as any)); // Value as Typeまとめ
今回は基本的な型の整理だけを行いました。まだ整理できていない型の話がいっぱいあるのでまだまだ型の話を続けようと思っています。SI業界の方は静的型付けな世界で育っていることが多いような気がしていますが、時代は静的型付け言語!ですし、意外とスムーズに頭に入ってくる初見です。
おまけ(リテラルの書き方ざっくり)
数値リテラル
種類 概要 例 10進数 一般的な10進数表現 1, 392, 10012 16進数 0xをプレフィックスに 0xFF, 0x31b1 8進数 0oをプレフィックスに 0o123, 0o777 2進数 0bをプレフィックスに 0b0101010101 指数 仮数 E 符号 指数 3.5E2 いつもと対して変わらないので説明は省略しますね。
文字列リテラル
種類 概要 例 シングルクォート ' でくくる 'Hello Sushi!' ダブルクォート " でくくる ”マグロうまい” バッククォート ` でくくる ${neta}一貫バッククォートでくくる形を「テンプレート文字列」と言います。
- 文字列に変数を埋め込める
- 複数行も表現可能
といういいヤツです。+で文字列連結!なんてもう今は昔。
let sushi = "寿司"; let sushi2 = "鮨"; let msg: String = ` 世の中で一番ウマい食べ物が鰻なのは いうまでもないが、スシ勢という勢力もおり ${sushi} と書くのか ${sushi2} と書くのか 今でも局地的に論争がされている`; console.log(msg);それではまた次回。
- 投稿日:2019-10-20T12:17:34+09:00
Vue + VuexでREST APIを叩いてリスト表示する方法
1. はじめに
だいぶ前にReact + ReduxでREST APIを叩いてリスト表示する方法という記事を書いたのですが、実際自分はVue派だったりするので、Vueでも同じことできるよっていうのを書いておこうと思います。
1-2. 作りたい機能概要
作るのは,React + ReduxでREST APIを叩いてリスト表示する方法でやったのと基本的には同じで、ユーザの投稿(Post)の一覧を表示する機能です。
サーバー側はGETリクエストすると、[ { id: '1', body: '朝ごはん食べた' }, { id: '2', body: '昼ごはん食べた' }, { id: '3', body: '夜ごはん食べた' }, ]という投稿の一覧を返します。それをリスト表示できればOKという感じです。
2. Vuexとは?
Vuex公式のドキュメントには、以下のようにあります。
Vuex は Vue.js アプリケーションのための 状態管理パターン + ライブラリです。
これは予測可能な方法によってのみ状態の変異を行うというルールを保証し、アプリケーション内の全てのコンポーネントのための集中型のストアとして機能します。Vueは、コンポーネントが一つであれば非常にシンプルなのですが、共通の状態を共有する複数のコンポーネントを持ったときに急に複雑になってしまいます。
プロパティ(props)が増えたり、それを孫でも使う、とかになると急に管理が面倒になりますし、親子コンポーネント間のデータの参照とかも必要になってくると、もう大変です。それを解決するのが、Vuexです。
Vuexでは、コンポーネントから共有している状態を抽出し、それをグローバルシングルトンで管理します。
つまり、どのコンポーネントも状態(data)にアクセスしたり、アクション(methods)をトリガーしたりできるようになります。イメージで言うと、手渡しでメモを回しながら管理すると、人が増えたりすると大変なので、ホワイトボードに張り出して管理しよう、って感じでしょうか。
この記事では実際にユーザの投稿をリスト表示するサンプルを作ってどんなものか理解したいと思います。
3. Vueプロジェクト生成
なにはともあれ、Vueのプロジェクトを作成してVuexを入れます。
プロジェクト作成は、vue-cliを使用すると簡単なので、それを使います。vue init vuex-sampleVuexは、yarnで。
yarn add vuex4. APIの準備
APIの準備は今回の記事では直接関係ないので、axiosでGETリクエストのモックを作成する
に切り出しておきます。
練習がてら同じ環境でやりたい方はこちらを参考にしてください。5. ストアの実装
store/index.jsを作成して、そこにStoreを以下の定義します。store/index.jsimport Vue from 'vue' import Vuex from 'vuex' Vue.use(Vuex) export default new Vuex.Store({ state: { posts: [ { id: 1, body: 'test1' }, { id: 2, body: 'test2' }, { id: 3, body: 'test3' } ] } });本当はAPIを叩いてデータ取得したいですが、まずはStoreの定義が出来ているかを確認するために、stateのpostsにダミーでデータを仕込んでいます。
そして、
main.jsでstoreを読み込みます。main.jsimport Vue from 'vue' import App from './App.vue' import store from './store'; Vue.config.productionTip = false new Vue({ store, render: h => h(App), }).$mount('#app')こうすることで、以下のようにして
storeをVueコンポーネントで使用することができるようになります。Post.vue<template> <div class="post"> <ul> <li v-for="post in posts" :key="post.id">{{ post.body }}</li> </ul> </div> </template> <script> export default { name: 'Post', computed: { posts () { return this.$store.state.posts }, } } </script>複数のステートを扱いはじめると、全部に対して算出プロパティを宣言すると冗長になるので、mapStateヘルパーが用意されています。
以下のようにすると、postsというプロパティを使用することが出来ます。Post.vue<script> import { mapState } from 'vuex'; export default { name: 'Post', computed: { ...mapState(['posts']) } } </script>ここまでで、一旦、サーバを起動して見ると、
postsが取得できていることがわかるかと思います。6. ミューテーションの実装
ミューテーションは、イベントみたいなもので、それをコミットすることでストアの状態を変更できます。
まず、Fluxでは、ミューテーションのタイプに定数を使用することが多いので、タイプを切り出して定義しておきます。
store/mutation-types.jsconst MUTATION_TYPES = { GET_POSTS_REQUEST: 'GET_POSTS_REQUEST', GET_POSTS_SUCCESS: 'GET_POSTS_SUCCESS', GET_POSTS_FAILURE: 'GET_POSTS_FAILURE' } export default MUTATION_TYPES次に、ミューテーションを実装します。
ここでは、リクエスト開始、成功、失敗というミューテーションを実装します。
↓のように、ES2015の算出プロパティ名を使用して、[定数]とすることで、定数を関数名として使用できます。
(定数にしなくても、普通にgetPostsRequest(state) {....}みたいな形でも定義できます。store/mutations.jsimport MUTATION_TYPES from './mutation-types' export const mutations = { [MUTATION_TYPES.GET_POSTS_REQUEST] (state) { state.isFetching = true }, [MUTATION_TYPES.GET_POSTS_SUCCESS] (state, posts) { state.isFetching = false state.posts = posts }, [MUTATION_TYPES.GET_POSTS_FAILURE] (state, err) { state.isFetching = false state.posts = null state.error = err } }ミューテーションがコミットされたときの処理を記述しています。
GET_POSTS_REQUESTでFetch中かどうかのフラグを変更し、GET_POSTS_SUCCESSで成功時にpostsにデータをセットし、GET_POSTS_FAILUREでエラー時の処理を実装しています。7. アクションの実装
次にアクションの実装です。
アクションは、
- ミューテーションをコミット
- 非同期処理を組み込める
ので、APIはここで叩きます。
store/actions.jsimport Api from '../apis/api' import MutationTypes from './mutation-types' export default { getPosts ({ commit }) { commit(MutationTypes.GET_POSTS_REQUEST) return Api.getPosts() .then(res => commit(MutationTypes.GET_POSTS_SUCCESS, res.data)) .catch(err => commit(MutationTypes.GET_POSTS_FAILURE, err)) } }リクエストの開始と、終了(成功と失敗)でミューテーションをコミットして状態を変更してます。
8. コンポーネントへの導入
コンポーネントへ導入する前に、ミューテーションとアクションを
store/index.jsでセットしてあげないといけません。store/index.jsimport Vue from 'vue' import Vuex from 'vuex' import { mutations } from './mutations' import actions from './actions' Vue.use(Vuex) export default new Vuex.Store({ state: { isFetching: false, posts: [], error: null }, mutations, actions });そして、
components/Post.vueで以下のようにして使用します。components/Post.vue<template> <div class="post"> <ul> <li v-for="post in posts" :key="post.id">{{ post.body }}</li> </ul> </div> </template> <script> import { mapState, mapActions } from 'vuex' export default { name: 'Post', computed: { ...mapState(['posts']) }, mounted () { this.$store.dispatch('getPosts') }, methods: { ...mapActions (['getPosts']) } } </script>算出プロパティで状態を監視し、メソッドでアクションを読み込んで、必要なタイミングでディスパッチしてあげると状態が更新されます。
ここまでやると、↓のような感じで表示できるようになったかと思います。
9. まとめ
これで簡単なVuexのアプリを実装できるようになりました。ソースコードも共有します。
これを機に、 Vuex公式ドキュメントを結構読み込んだんですが、Reduxのときと比べて楽でした。なんせ、日本語で書いてあるので。実装自体もReduxより個人的にはシンプルな気がしました。
参考

- 投稿日:2019-10-20T11:09:47+09:00
老眼と加齢性難聴のチェックができるLINEbotとIotの作成
概要
プログラムの勉強を始めて3か月程の開業医です。最近ディスプレイを見る時間が長くなったせいか、年齢のせいか、近くの文字が見えにくくなってきました。
リーディンググラス(老眼鏡)について調べていると、人差し指の指紋が一番鮮明に見える距離(近点)が30cm以上離れると老眼鏡が必要で、近点の長さによってピント調節力が年齢相応かどうかや老眼度数もある程度わかるようです。
今回、近点距離(人差し指の指紋が見える距離)を入力すると、ピント調節力がどの年齢相当か?老眼かどうか?老眼度数はどの程度か?がわかるLINE botを作成してみようと思いました。
同時にobnizでIotを作る勉強を始めたので、老眼判定LINE botと連携させて、判断された年齢でぎりぎり聴きとることができる高音(モスキート音)をスピーカーから出し、自分の可聴周波数がわかる加齢性難聴判定Iotを作成しました。
※老眼や加齢性難聴の診断を行う為には医療機関での検査が必要です。今回の記事の医療情報に関しては参考程度にして頂きたいと思います。
実装内容
・LINE上に近点距離を入力すると老眼かどうか返答されるFAQBOT。
・返答と同時にその年齢でぎりぎり聞きとることができる高音(モスキート音)を出すIot。概念図
node.js expressでLINE bot APIとobnizを連携しました。
作成方法
前回はGoogle Spread Sheet × Google Apps Script × LINE の組み合わせでLINE botを作成しました。
保育園・小中学校での感染症流行状況がわかる Line Botの作成今回はこちらの記事を参考にnode.js express × LINE bot API × obnizの組み合わせでLINE botとIotを作成しました。
1時間でLINE BOTを作るハンズオン (資料+レポート) in Node学園祭20171. Botアカウントを作成する
2. Node.jsでBot開発
3. ngrokでトンネリング
上記の1~3を参考記事の通りに行います。初めての方でも1~2時間ほどで質問をオウム返しされるLINE botを作ることができます。
4.obnizとの連携
ここから先は、参考記事に掲載されている以下のコードに変更を加えていきます。
'use strict'; const express = require('express'); const line = require('@line/bot-sdk'); const PORT = process.env.PORT || 3000; const config = { channelSecret: '作成したBOTのチャンネルシークレット', channelAccessToken: '作成したBOTのチャンネルアクセストークン' }; //////////////////////////////////////////////////////////////// ここにコードAをコピペしてください //////////////////////////////////////////////////////////////// const app = express(); app.get('/', (req, res) => res.send('Hello LINE BOT!(GET)')); //ブラウザ確認用(無くても問題ない) app.post('/webhook', line.middleware(config), (req, res) => { console.log(req.body.events); //ここのif分はdeveloper consoleの"接続確認"用なので削除して問題ないです。 if(req.body.events[0].replyToken === '00000000000000000000000000000000' && req.body.events[1].replyToken === 'ffffffffffffffffffffffffffffffff'){ res.send('Hello LINE BOT!(POST)'); console.log('疎通確認用'); return; } Promise .all(req.body.events.map(handleEvent)) .then((result) => res.json(result)); }); const client = new line.Client(config); function handleEvent(event) { if (event.type !== 'message' || event.message.type !== 'text') { return Promise.resolve(null); } ///////////////////////////////////////////////////////////////// ここにコードBをコピペしてください。 ///////////////////////////////////////////////////////////////// return client.replyMessage(event.replyToken, { type: 'text', text: event.message.text //実際に返信の言葉を入れる箇所 }); } app.listen(PORT); console.log(`Server running at ${PORT}`);コードA
このコードをコピペすることでobnizが準備され、接続したスピーカーが使えるようになります。// コードA // Obnizの準備 var Obniz = require("obniz"); var obniz = new Obniz("Obniz ID"); // Obniz ID を入力 var speaker; // 全体で使えるようにするスコープ obniz.onconnect = async function () { speaker = obniz.wired("Speaker", {signal:0, gnd:1}); }コードB
このコードをコピペすることで近点距離によってLINE botからの回答を変え、スピーカーから出る音の周波数も変えます。//コードB // LINE botのプログラム let ans = ""; let question = event.message.text; let distance = parseInt(question); let hz;//モスキート音のhz if (distance>=80) { ans = "ピント調整力は61歳以上相当です。老眼の可能性が高いです。老眼度数は3以上と思われます。今流れているモスキート音は8000Hzです。"; hz = 8000; }else if (distance >= 60){ ans = "ピント調整力は56~60歳相当です。老眼の可能性が高いです。老眼度数は2.5程度と思われます。今流れているモスキート音は8000Hzです。"; hz = 8000; }else if (distance >= 50){ ans = "ピント調整力は51~55歳相当です。老眼の可能性が高いです。老眼度数は2程度と思われます。今流れているモスキート音は10000Hzです。"; hz = 10000; }else if(distance >= 40){ ans = "ピント調整力は46~50歳相当です。老眼の可能性が高いです。老眼度数は1.5程度と思われます。今流れているモスキート音は12000Hzです。"; hz = 12000; }else if(distance >= 30){ ans = "ピント調整力は41~45歳相当です。老眼の可能性が高いです。老眼度数は1程度と思われます。今流れているモスキート音は15000Hzです。"; hz = 15000; } else if(distance<30) { ans = "ピント調整力は40歳未満相当です。老眼の可能性は低いです。今流れているモスキート音は16000Hzです。"; hz = 16000; }else { ans = "指先にピントが合い、人差し指の指紋がはっきりと見えた距離を数字で入力してください。"; } speaker.play(hz);最後に textの部分をansに変更して完了です。
return client.replyMessage(event.replyToken, { type: 'text', text: ans });動作確認
ちゃんと返信されています。
音もちゃんと出ていました。
— 病気のセルフチェック (@Selfcheckhealt1) 2019年10月20日
考察
今回node.jsでLINE botを作成しました。前回のGoogle Spread Sheet × Google Apps Script × LINE の組み合わせに比べるとやや面倒なところはありますが、他のAPIと連携しやすいので応用が利きやすいと感じました。
また、初めてのobnizでしたが、スピーカーはピンを入れるだけで使えるので作成は驚くほど簡単でした。今度は超音波センサーを使って近点距離を自動で取得できるようにしたいと思いました。
ちなみに私は老眼は大丈夫そうでしたが、15000Hz以上の音は耳をスピーカーに近づかないと聞こえませんでした。



- 投稿日:2019-10-20T01:08:54+09:00
ajaxを活用した非同期通信について
ajaxを使った非同期通信
10月19日現在、ajaxによる非同期通信を学習しているところですが、なかなか理解が追いつかないので自分なりにJavaScriptの復習をかねて中身を確認していきたいと思います。かなり自分向けに書いていますので、語弊がある部分もあるかもしれません。
今回は、ブログに対して投稿されるコメントが非同期通信にて行われるようにしていきます。
イベントの発火
まずは動作のきっかけ部分を記述します。きっかけはコメントを入力し、投稿ボタンをクリックした時です。
comment.js$(function(){ $('#newcomment').on('submit', function(e){ e.preventDefault(); var formdata = new FormData(this); }) })
$(function(){
jQuery(JavaScript)のコードが読み込まれる際に、まだHTMLが読み込まれていないとエラーが発生します。1行目、$(function(){から書き始めることで、HTMLのページ情報が読み込み完了してからコードが実行されます。
ちなみにこのfunctionメソッド(書き方あっているのかな・・・)では引数は不要ですが、引数がない場合でも()括弧を書く必要があります。
$('#newcomment')
jQueryでどのボタンがトリガーになるかは、HTMLタブ内のclassもしくはidから探します。
2行目の$('#newcomment').はHTML内のid(newcomment)を探します。#はidを探す書き方です。
$('.〜')といったように、.を使うとclass要素から探されます。
.on('submit', function(e){
イベントsubmitが起こった際に以下の関数を実施する、という部分。
ちなみにfunction(e)のeはイベントの頭文字。
次の行のe.preventDefaultは実行されるべきイベントをキャンセルさせます。
var 〜〜 = 〇〇
変数〜〜に〇〇を代入します。
Rubyだと頭のvarなんて要りませんでしたが、他のプログラム言語では必要な場合も多いようです。
new FormData(this)
フォームの情報を取得します。引数がthisの場合、イベントが発生した部分、今回はコメント投稿の部分からの取得になります。コメントの保存
非同期通信の中で、入力したコメントがcreateメソッドで保存されるようにします。
comment.js$(function(){ $('#newcomment').on('submit', function(e){ e.preventDefault(); var formdata = new FormData(this); $.ajax({ url: $(this).attr('action'), type: "POST", data: formData, dataType: 'json', proseccData: false, contentType: false }) }) })
$.ajax({
ajaxで非同期通信をする際のオプションを記述します。
1.type HTTP通信の種類を記述。GETもしくはPOST。
2.url リクエスト送信先のURLを記述。
3.data 送信する値を記述。
4.dataType データの種類を記述。今は基本的にjson
5.processData
6.contentType データのファイル形式を指定。基本false
attr
要素が持つ属性から、指定した属性の値を返します。
今回では投稿ボタンを含むformタグの中からaction要素を探し、その値となるURLを取得するようにします。以上の記述で、ajaxで扱われるデータは
「json形式でテキストボックス内の文字をPOSTでコメント投稿のアドレスへ送信」
となります。すなわちコメントが投稿される形となります。返ってくる結果を受け取る
.doneメソッドで非同期通信の結果を受け取ります。
comment.js.done(function(data){ $('.comments').append(〜〜) $('.textbox').val('') }) .fail(function(){ alert('error') })
.doneメソッドで、受け取った結果を元に処理を行います。
commentsクラスの後ろに()内の記述を追加します。詳細は省略。
textboxクラスの値を空にします。今回はフォームボックスの中をクリアします。
.failメソッドは、エラーが発生した時に表示させる処理です。
alertメソッドはポップアップを表示させます。こんな感じなんでしょうか。
まだなんとなく程度の理解ですので、もっと精進していきます。
- 投稿日:2019-10-20T01:08:54+09:00
Ajaxを活用した非同期通信について
ajaxを使った非同期通信
10月19日現在、ajaxによる非同期通信を学習しているところですが、なかなか理解が追いつかないので自分なりにJavaScriptの復習をかねて中身を確認していきたいと思います。かなり自分向けに書いていますので、語弊がある部分もあるかもしれません。
今回は、ブログに対して投稿されるコメントが非同期通信にて行われるようにしていきます。
イベントの発火
まずは動作のきっかけ部分を記述します。きっかけはコメントを入力し、投稿ボタンをクリックした時です。
comment.js$(function(){ $('#newcomment').on('submit', function(e){ e.preventDefault(); var formdata = new FormData(this); }) })
$(function(){
jQuery(JavaScript)のコードが読み込まれる際に、まだHTMLが読み込まれていないとエラーが発生します。1行目、$(function(){から書き始めることで、HTMLのページ情報が読み込み完了してからコードが実行されます。
ちなみにこのfunctionメソッド(書き方あっているのかな・・・)では引数は不要ですが、引数がない場合でも()括弧を書く必要があります。
$('#newcomment')
jQueryでどのボタンがトリガーになるかは、HTMLタブ内のclassもしくはidから探します。
2行目の$('#newcomment').はHTML内のid(newcomment)を探します。#はidを探す書き方です。
$('.〜')といったように、.を使うとclass要素から探されます。
.on('submit', function(e){
イベントsubmitが起こった際に以下の関数を実施する、という部分。
ちなみにfunction(e)のeはイベントの頭文字。
次の行のe.preventDefaultは実行されるべきイベントをキャンセルさせます。
var 〜〜 = 〇〇
変数〜〜に〇〇を代入します。
Rubyだと頭のvarなんて要りませんでしたが、他のプログラム言語では必要な場合も多いようです。
new FormData(this)
フォームの情報を取得します。引数がthisの場合、イベントが発生した部分、今回はコメント投稿の部分からの取得になります。コメントの保存
非同期通信の中で、入力したコメントがcreateメソッドで保存されるようにします。
comment.js$(function(){ $('#newcomment').on('submit', function(e){ e.preventDefault(); var formdata = new FormData(this); $.ajax({ url: $(this).attr('action'), type: "POST", data: formData, dataType: 'json', proseccData: false, contentType: false }) }) })
$.ajax({
ajaxで非同期通信をする際のオプションを記述します。
1.type HTTP通信の種類を記述。GETもしくはPOST。
2.url リクエスト送信先のURLを記述。
3.data 送信する値を記述。
4.dataType データの種類を記述。今は基本的にjson
5.processData
6.contentType データのファイル形式を指定。基本false
attr
要素が持つ属性から、指定した属性の値を返します。
今回では投稿ボタンを含むformタグの中からaction要素を探し、その値となるURLを取得するようにします。以上の記述で、ajaxで扱われるデータは
「json形式でテキストボックス内の文字をPOSTでコメント投稿のアドレスへ送信」
となります。すなわちコメントが投稿される形となります。返ってくる結果を受け取る
.doneメソッドで非同期通信の結果を受け取ります。
comment.js.done(function(data){ $('.comments').append(〜〜) $('.textbox').val('') }) .fail(function(){ alert('error') })
.doneメソッドで、受け取った結果を元に処理を行います。
commentsクラスの後ろに()内の記述を追加します。詳細は省略。
textboxクラスの値を空にします。今回はフォームボックスの中をクリアします。
.failメソッドは、エラーが発生した時に表示させる処理です。
alertメソッドはポップアップを表示させます。こんな感じなんでしょうか。
まだなんとなく程度の理解ですので、もっと精進していきます。
- 投稿日:2019-10-20T00:53:57+09:00
【React】Context APIとHooksでReduxを駆逐する!
はじめに
進撃の巨人もついに最終回が見えてきましたね。来年には完結しそう。
さてタイトルはReduxを駆逐するとか書いてますが、エレンしたかっただけです。すいません。
今回は業務でContext APIとHooksを使ってみて、「あれ?Reduxいらなくね?」「Hooksは神」と感じることが多かったので筆をとろうと思った次第です。筆者のReact歴
React初めて半年のペーペーです。
Reduxは個人で簡単なCRUDアプリを作った時しか使ってなくて業務では使ってないので、Reduxじゃないと辛いケースやReduxを使っていて辛いケースについてはあまり詳しくないので、偏りはあるかもしれません(大規模になってくるとReduxじゃなきゃやってられない、みたいな話も聞きますが実際どうなんだろう)。Context APIとHooksの概要
Context API
Contextを使うとコンポーネントツリーの中でグローバルにデータを管理することができます。
親コンポーネントで定義したContextを子や孫コンポーネントで簡単に参照できます。Hooks
今までStateを管理したり、ライフサイクルメソッドを使ったりできるのはクラスコンポーネントだけでしたが、それを関数コンポーネントでも可能にしたのがHooksです。
関数コンポーネントとHooksを使うとクラスコンポーネントに比べて記述量が少なく、可読性の高いシンプルなコードが書けます(特にクラスコンポーネントだとthisの取り扱いがややこしい…)。Context APIとHooksの使い方の実例
今回記事を書くにあたって「自己紹介サイト」を作ってみたので、そのコードをもとにContext APIとHooksの使い方を解説していきます。
自己紹介サイトは以下のような感じです。
コードは以下で見れます。
https://github.com/yutaroadachi/i_amContextを使うときはコンポーネントツリーのトップでContextを定義します。
IAm.es6.jsxexport const IAmContext = createContext();Contextを下の階層で使うには
Context.Providerを使います。
valueにグローバルに管理したいデータを渡します。ここではさらに
useReducerHooksを使ってStateとReducerを作成し、それらをvalueに渡しています。
useReducerの第一引数にはStateを書き換えるReducerを、第二引数にはStateの初期値を渡します。
ここではReducerにsaveとdeleteアクションを定義し、初期値は空文字にしています。IAm.es6.jsxconst nameReducer = (name, action) => { switch (action.type) { case "save": return action.name; case "delete": return ""; default: return name; } }; const hobbyReducer = (hobby, action) => { switch (action.type) { case "save": return action.hobby; case "delete": return ""; default: return hobby; } }; const [name, nameDispatch] = useReducer(nameReducer, ""); const [hobby, hobbyDispatch] = useReducer(hobbyReducer, ""); const iAmContext = { name, nameDispatch, hobby, hobbyDispatch }; return ( <div> <IAmContext.Provider value={iAmContext}> <IAmHeader /> <IAmBody /> </IAmContext.Provider> </div> ); };コンポーネントツリーの中でContextを参照したいときは参照したいコンポーネントの中で
useContextHooksを使います。以下のたった1行のコードを書くだけでOKです。IAMBody.es6.jsxconst iAmContext = useContext(IAmContext);ここではコンポーネントツリーのトップでvalueにオブジェクトとしてデータを渡しているので
iAmContextを普通のオブジェクトのように扱うことができます。// name Stateの値を参照 iAmContext.name // name Stateの値を削除 iAmContext.nameDispatch({ type: "delete" });以上のようにContext APIとHooksを使えば簡単にグローバルにデータを管理できます。
Context APIとHooksを使うメリット、デメリット
ここからは業務で実際に使ってみて感じたContext APIとHooksを使うメリット、デメリットについて書いていきます。
メリット
- 記述量が少なくて済む
- 可読性が高く、シンプルなコードが書ける
- Contextがローカライズされているため、コンポーネント指向で書ける
デメリット
- Contextをコンポーネントツリーの中で乱立させるとコードの見通しが悪くなる
- Reduxのような非同期の鉄板ライブラリがない(redux-thunkやredux-saga)
総じてシンプルなコードが書けるのがメリットだと思います。
あと個人的にはReduxのようにstoreを集中管理するのではなく、コンポーネントごとに管理する方がコンポーネント指向で書けて好みです。デメリットも設計に気をつけたり、複雑なことをやろうとしすぎたりしなければ問題にならない気がします。
Contextをコンポーネントツリーのデータベースのように扱い、子や孫以下の階層ではそれを単純に参照し、フォームなどで編集するときはフォーム専用のLocal Stateを定義することで切り分けて管理すれば書きやすく、読みやすいコードになるんじゃないかなと思います。
おわりに
Context APIとHooksを使えば、大体のことがシンプルに書けるので、これからは関数コンポーネントで書くのがReactの鉄板になりそうです。Hooks本当に書きやすい。

- 投稿日:2019-10-20T00:26:13+09:00
HTML+JavaScriptを駆使して"全角XX文字"地獄を脱するツールを作ってみた
社内の各種申請に利用するシステムは、多くの入力欄が全角文字のみ入力可能という仕様になっています。これは開発時のテスト行程を少なく出来るなど開発者側にとっての大きな利点を生みます。しかし、困ってしまうのが意図せず半角英数字記号が混ざってしまい、「全角XX文字で入力してください。」地獄に陥った時・・・
また、文字数の指定も明示されていない上にカウントも表示されないので、ここでも「全角XX文字」地獄に陥ります・・・
開発の動機及び開発言語の選定理由
上述の様に社内申請システムで毎度"全角XX文字"地獄に陥るため(なかなか脱出できない)
システムの利用環境に開発環境がインスール出来ないのでブラウザさえ有れば動くHTML+JavaScriptを選択
世の中に出回っているツールは「不要な親切機能」が有る代わりに「必要な」機能が無かったため
最近ひょんなことからWebプログラミングに凝ってしまったので勉強も兼ねて実装
ツールを構成する各種スクリプト
今回の開発ではそもそも使える言語が大幅に制限された環境で利用することを考慮して実装する必要が有ったため、HTML5 + JavaScript+正規表現のみを駆使して実装しました。Pythonが使える環境ならもっと楽に開発が出来た可能性も有ります・・・。(pyperclip等を利用して)
半角英数字記号スペースを全角文字に変換するスクリプト
半角スペースが混じっている場合まず半角から全角に変換してから変換しないと文字コードをずらす方法で先に変換してしまうと別の記号になってしまうので先に変換しています。
function toFullWidth(value){ return value.replace(/\u0020/g,"\u3000").replace(/[ -~]/g, s => { return String.fromCharCode(s.charCodeAt(0) + 0xfee0) }) }
- このスクリプトで以下の様にすると全角英数字記号スペースを半角に変換するスクリプトになります。
function toFullWidth(value){ return value.replace(/\u3000/g, "\u0020").replace(/[ -~]/g, s => { return String.fromCharCode(s.charCodeAt(0) - 0xfee0) }) }スペースは取り除くスクリプト
後述の文字数上限を超えている場合に超えない文字数にするスクリプト内で利用します。
function deleteSpace(value){ return value.replace(/\s+/g,""); }文字数上限までを切り出すスクリプト
function cutString(value, length){ return value.substr(0, length); }文字数上限を考慮した全角変換スクリプト
まずはスペースを取り除き、それでも文字数上限を超えている場合は切り出すという方法を採用しました。
function full_and_length(value, length){ const conv_value = toFullWidth(value); if(conv_value.length > length){ let temp_str = deleteSpace(conv_value); if(temp_str.length > length){ return cutString(temp_str, length); } } return conv_value; }ボタンを押すと自動的に編集結果がコピーされる機能も追加
const result1 = document.getElementsByTagName("input")[0]; result1.select(); document.execCommand("copy");
- このスクリプトを応用することで、今回はクリップボードをクリアする機能も実装しました。
まとめ
制約の多い環境下での利用を考慮したツールの設計・実装は大変勉強になりました。また、実装を通してHTMLやJavaScriptへの理解も深まりました。また、ブラウザを上手く利用することで、ゼロから実装するととてつもなく大変なGUIの実装をHTML標準の部品だけで実現出来てしまうことの便利さに気が付きました。今後、HTMLで実装したUIも紹介できればと思っています。また、便利ツールを継続して開発して紹介出来ればと思います。
Reference
http://www.koikikukan.com/archives/2013/08/28-015555.php
https://blog.yug1224.com/archives/580e07c974d0d51807ee1295/
https://www.nishishi.com/javascript-tips/trim-space-chars.html
http://catprogram.hatenablog.com/entry/2013/05/13/231457
https://qiita.com/butakoma/items/642c0ec4b77f6bb5ebcf