- 投稿日:2019-09-29T23:57:25+09:00
[python]numpy,listでappendするときにかかる時間の比較
[python]numpy,listでappendするときにかかる時間の比較
np.append
np.random.seed(seed=32) array1 = np.random.randn(1000,100,10) print(array1.shape) %time array1 = np.append(array1, array1, axis = 0) %time array1 = np.append(array1, array1, axis = 0) %time array1 = np.append(array1, array1, axis = 0) %time array1 = np.append(array1, array1, axis = 0) %time array1 = np.append(array1, array1, axis = 0) %time array1 = np.append(array1, array1, axis = 0) %time array1 = np.append(array1, array1, axis = 0) %time array1 = np.append(array1, array1, axis = 0) print(array1.shape)(1000, 100, 10) Wall time: 48.2 ms Wall time: 30 ms Wall time: 51 ms Wall time: 109 ms Wall time: 168 ms Wall time: 527 ms Wall time: 2.84 s Wall time: 11.6 s (256000, 100, 10)extend(array1とarray2を同じ配列にするため)
np.random.seed(seed=32) array2 = np.random.randn(1000,100,10).tolist() %time array2.extend(array2) %time array2.extend(array2) %time array2.extend(array2) %time array2.extend(array2) %time array2.extend(array2) %time array2.extend(array2) %time array2.extend(array2) %time array2.extend(array2) %time array2 = np.array(array2) print(array2.shape)Wall time: 0 ns Wall time: 1.26 ms Wall time: 1 ms Wall time: 978 µs Wall time: 999 µs Wall time: 5 ms Wall time: 534 µs Wall time: 4 ms Wall time: 25.9 s (256000, 100, 10)ものすごい数をappendしたわけではないので正確なことは言えないが、
numpyを用いるとappendする配列の大きさを増やせば増やすほど時間がかかるが、
listではそのような影響は出てこないようにみえる。私自身機械学習などでnumpyの配列を使うことから
listからnumpy配列にかかる時間も計測も気になり計算させたが25.9 sもかかってしまって
numpy配列を欲しい場合はどちらがいいとは結論づけられなかった。%time (array1 == array2).all()Wall time: 21.3 s Truearray1とarray2は同じ配列であるらしい(今回だけな可能性があるのかどうかはわかりません。)
- 投稿日:2019-09-29T23:34:50+09:00
PyTorchでEncoder-Decoderモデル(Seq2Seq)を実装してみた
はじめに
LSTMに引き続き、今度はPytorchでEncoder-Decoderモデル(seq2seq)の実装してみました。
以下の参考記事や書籍で仕組みや実装方法を勉強させていただきました。
※独学ゆえ、説明や実装が間違っている可能性があります。変なこと書いてたらぜひご指摘ください!参考記事/書籍
- PyTorchによるSeq2seqの実装
- ゼロから作るDeep Learning ❷ ―自然言語処理編
- Sequence to Sequence Learning with Neural Networks
Encoder-Decoderモデルとは?
その名の通り下記で説明するEncoderとDecoderをつなげたモデルを言います。
Encoder
InputData(画像、テキスト、音声、動画etc)を何かしらの(固定長)特徴ベクトルに変換する機構のことを言います。
そのまんまですが、InputDataを抽象的なベクトルにエンコードしてるイメージ。
Decoder
Encoderでエンコードされた特徴ベクトルをデコードして何か新しいデータを生む機構のことをいいます。
OutputDataはInputDataと同じデータ形式である必要はなく、画像、テキスト、音声いろいろ
Encoder-Decoderモデル
- 上のEncoderとDecoderをつなげると、Encoder-Decoderモデルの完成
- Encoder-Decoderモデルはいわゆる生成系のモデルであり、画像をテキストにしたり、音声からテキストを生成したり、日本語から英語(テキストから別のテキスト)に変換したりと用途は様々
Seq2Seq
Seq2Seq(sequence to sequence)はEncoder-Decoderモデルのうち、系列データを別の系列データに変換するモデルのことを指します。
ご想像の通り、seq2seqで翻訳をしたり、対話モデルを作ったりすることが可能になります。今回はこのSeq2Seqを使って系列データを別の系列データに変換するモデルを実装を通して解説してきます。
問題設定
参考記事に挙げた1.や2.で取り上げられている足し算モデルを扱おうと思ったけど、同じだと面白くないので、少し変更して最大3桁の非負整数同士の引き算をSeq2Seqに学習させてみようと思います。
つまりどういうことかというと、「123-95」をインプットにして「28」をアウトプットに返すようなモデルを作成します。
123-95や28を文字の系列データとみなしているわけです。系列データを扱うということはLSTMやGRUのような再帰的ニューラルネットワークが使えそうです。
もちろん今回もバッチ化して学習させたいので系列の長さをすべて揃えます。インプットの最大の長さは「xxx - yyy」で7文字、アウトプットは負の数にもなり得るのでマイナスの記号も含めて最大4文字(ex. -457とか)となりますが、下で説明するように系列生成開始を表す文字列(ここではハイフン"_"とします)を1つ先頭に足す必要があるので最大5文字(_-457とか)になります。「123-95=28」を例に絵で書くと次のような感じ
Encoder
- Encoder側はいたってシンプルです。以下のようにただLSTMで最後の隠れ層のベクトルを生成すればOK。
- LSTM層の部分はもちろんsimpleなRNNでもGRUでもOK
- Many to One のモデルです!

Decoder
Decoder側がいろいろややこしいです。推論時と学習時で考え方が異なります。
ここはゼロから作るDeep Learning ❷ ―自然言語処理編にとてもわかりやすく説明があります。下の説明もゼロ作を参考にしているので、わかりにくかったらぜひゼロ作を読んでください!推論(文字列生成)
- 文字列を生成方法は、以下のようにEncoderの隠れ層と文字生成開始を表す"_"を与えて出力された文字を次のインプットの文字とし、生成された文字を次のインプットに...という操作を生成すべき文字の数だけ繰り返して実行します。
学習
- 上の推論のようなモデルを作成したいわけなので、どのように学習すれば上の推論のようなことが実現できるかを考えます。
- 今回の例は答えが「"28 "」なので、インプットは「"_"」「"2"」「"8"」「" "」の4文字をまとめて与えて、それぞれの層の結果と「"2"」「"8"」「" "」「" "」の損失を計算します。
- Linearの層の値が一番大きいものを予測値とみなせばよいので、softmaxをかます必要はありません。
- Many to Many のモデルです!
実装
- あとは問題設定で説明した内容をひたすら実装するだけ。
- ソースコードはPyTorchによるSeq2seqの実装をがっつり参考にさせていただきました。
データ準備
引き算データセットの準備はどこかから入手する必要もなく、自前で準備すればOK。
from sklearn.model_selection import train_test_split import random from sklearn.utils import shuffle # 数字の文字をID化 char2id = {str(i) : i for i in range(10)} # 空白(10):系列の長さを揃えるようのパディング文字 # -(11):マイナスの文字 # _(12):系列生成開始を知らせる文字 char2id.update({" ":10, "-":11, "_":12}) # 空白込みの3桁の数字をランダムに生成 def generate_number(): number = [random.choice(list("0123456789")) for _ in range(random.randint(1, 3))] return int("".join(number)) # 確認 print(generate_number()) # 753 # 系列の長さを揃えるために空白パディング def add_padding(number, is_input=True): number = "{: <7}".format(number) if is_input else "{: <5s}".format(number) return number # 確認 num = generate_number() print("\"" + str(add_padding(num)) + "\"") # "636 " # 7 # データ準備 input_data = [] output_data = [] # データを50000件準備する while len(input_data) < 50000: x = generate_number() y = generate_number() z = x - y input_char = add_padding(str(x) + "-" + str(y)) output_char = add_padding("_" + str(z), is_input=False) # データをIDにに変換 input_data.append([char2id[c] for c in input_char]) output_data.append([char2id[c] for c in output_char]) # 確認 print(input_data[987]) print(output_data[987]) # [1, 5, 11, 2, 6, 6, 10] (←"15-266") # [12, 11, 2, 5, 1] (←"_-251") # 7:3にデータをわける train_x, test_x, train_y, test_y = train_test_split(input_data, output_data, train_size= 0.7) # データをバッチ化するための関数 def train2batch(input_data, output_data, batch_size=100): input_batch = [] output_batch = [] input_shuffle, output_shuffle = shuffle(input_data, output_data) for i in range(0, len(input_data), batch_size): input_tmp = [] output_tmp = [] for j in range(i, i + batch_size): try: input_tmp.append(input_shuffle[j]) output_tmp.append(output_shuffle[j]) except: break input_batch.append(input_tmp) output_batch.append(output_tmp) return input_batch, output_batchモデル定義
Encoder
- Encoderは簡単。隠れ層を返すだけでOK。
- ちょっと気にしているのが今回はLSTMの第二戻り値 $(h, c)$ をまとめて使っています。 $h$ だけでいいのか $c$ もいるのか、むしろいらないのかは、まだよくわかっていません...
import torch import torch.nn as nn import torch.optim as optim embedding_dim = 200 # 文字の埋め込み次元数 hidden_dim = 128 # LSTMの隠れ層のサイズ vocab_size = len(char2id) # 扱う文字の数。今回は13文字 # GPU使う用 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # Encoderクラス class Encoder(nn.Module): def __init__(self, vocab_size, embedding_dim, hidden_dim): super(Encoder, self).__init__() self.hidden_dim = hidden_dim self.word_embeddings = nn.Embedding(vocab_size, embedding_dim, padding_idx=char2id[" "]) self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True) def forward(self, sequence): embedding = self.word_embeddings(sequence) # Many to Oneなので、第2戻り値を使う _, state = self.lstm(embedding) # state = (h, c) return stateDecoder
Decoderの予測値は最大値をそのまま使えばいいので、softmaxは不要
# Decoderクラス class Decoder(nn.Module): def __init__(self, vocab_size, embedding_dim, hidden_dim): super(Decoder, self).__init__() self.hidden_dim = hidden_dim self.word_embeddings = nn.Embedding(vocab_size, embedding_dim, padding_idx=char2id[" "]) self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True) # LSTMの128次元の隠れ層を13次元に変換する全結合層 self.hidden2linear = nn.Linear(hidden_dim, vocab_size) def forward(self, sequence, encoder_state): embedding = self.word_embeddings(sequence) # Many to Manyなので、第1戻り値を使う。 # 第2戻り値は推論時に次の文字を生成するときに使います。 output, state = self.lstm(embedding, encoder_state) output = self.hidden2linear(output) return output, stateモデル宣言、損失関数、最適化
# GPU使えるように。 encoder = Encoder(vocab_size, embedding_dim, hidden_dim).to(device) decoder = Decoder(vocab_size, embedding_dim, hidden_dim).to(device) # 損失関数 criterion = nn.CrossEntropyLoss() # 最適化 encoder_optimizer = optim.Adam(encoder.parameters(), lr=0.001) decoder_optimizer = optim.Adam(decoder.parameters(), lr=0.001)学習
Decoderの部分が参考にしている記事とちょっと違うけど、PyTorchの仕様的にこれでいいよね?
BATCH_NUM = 100 EPOCH_NUM = 100 all_losses = [] print("training ...") for epoch in range(1, EPOCH_NUM+1): epoch_loss = 0 # epoch毎のloss # データをミニバッチに分ける input_batch, output_batch = train2batch(train_x, train_y, batch_size=BATCH_NUM) for i in range(len(input_batch)): # 勾配の初期化 encoder_optimizer.zero_grad() decoder_optimizer.zero_grad() # データをテンソルに変換 input_tensor = torch.tensor(input_batch[i], device=device) output_tensor = torch.tensor(output_batch[i], device=device) # Encoderの順伝搬 encoder_state = encoder(input_tensor) # Decoderで使うデータはoutput_tensorを1つずらしたものを使う # Decoderのインプットとするデータ source = output_tensor[:, :-1] # Decoderの教師データ # 生成開始を表す"_"を削っている target = output_tensor[:, 1:] loss = 0 # 学習時はDecoderはこのように1回呼び出すだけでグルっと系列をループしているからこれでOK # sourceが4文字なので、以下でLSTMが4回再帰的な処理してる decoder_output, _ = decoder(source, encoder_state) # decoder_output.size() = (100,4,13) # 「13」は生成すべき対象の文字が13文字あるから。decoder_outputの3要素目は # [-14.6240, -3.7612, -11.0775, ..., -5.7391, -15.2419, -8.6547] # こんな感じの値が入っており、これの最大値に対応するインデックスを予測文字とみなす for j in range(decoder_output.size()[1]): # バッチ毎にまとめてloss計算 # 生成する文字は4文字なので、4回ループ loss += criterion(decoder_output[:, j, :], target[:, j]) epoch_loss += loss.item() # 誤差逆伝播 loss.backward() # パラメータ更新 # Encoder、Decoder両方学習 encoder_optimizer.step() decoder_optimizer.step() # 損失を表示 print("Epoch %d: %.2f" % (epoch, epoch_loss)) all_losses.append(epoch_loss) if epoch_loss < 1: break print("Done") # training ... # Epoch 1: 1889.10 # Epoch 2: 1395.36 # Epoch 3: 1194.29 # Epoch 4: 1049.05 # Epoch 5: 931.19 # Epoch 6: 822.30 # 〜略〜 # Epoch 96: 4.47 # Epoch 97: 126.06 # Epoch 98: 32.81 # Epoch 99: 12.69 # Epoch 100: 6.20 # Done損失可視化
いい感じに損失減ってますが、最後らへんがちょっと迷った感じ?もう少し学習回数増やしたほうが良さそう
import matplotlib.pyplot as plt %matplotlib inline plt.plot(all_losses)
予測
ここらへんから完全に我流で書いちゃっているので急に読みにくくなるかもです...
# Decoderのアウトプットのテンソルから要素が最大のインデックスを返す。つまり生成文字を意味する def get_max_index(decoder_output): results = [] for h in decoder_output: results.append(torch.argmax(h)) return torch.tensor(results, device=device).view(BATCH_NUM, 1) # 評価用データ test_input_batch, test_output_batch = train2batch(test_x, test_y) input_tensor = torch.tensor(test_input_batch, device=device) predicts = [] for i in range(len(test_input_batch)): with torch.no_grad(): # 勾配計算させない encoder_state = encoder(input_tensor[i]) # Decoderにはまず文字列生成開始を表す"_"をインプットにするので、"_"のtensorをバッチサイズ分作成 start_char_batch = [[char2id["_"]] for _ in range(BATCH_NUM)] decoder_input_tensor = torch.tensor(start_char_batch, device=device) # 変数名変換 decoder_hidden = encoder_state # バッチ毎の結果を結合するための入れ物を定義 batch_tmp = torch.zeros(100,1, dtype=torch.long, device=device) # print(batch_tmp.size()) # (100,1) for _ in range(5): decoder_output, decoder_hidden = decoder(decoder_input_tensor, decoder_hidden) # 予測文字を取得しつつ、そのまま次のdecoderのインプットとなる decoder_input_tensor = get_max_index(decoder_output.squeeze()) # バッチ毎の結果を予測順に結合 batch_tmp = torch.cat([batch_tmp, decoder_input_tensor], dim=1) # 最初のbatch_tmpの0要素が先頭に残ってしまっているのでスライスして削除 predicts.append(batch_tmp[:,1:]) # バッチ毎の予測結果がまとまって格納されてます。 print(len(predicts)) # 150 print(predicts[0].size()) # (100, 5)
- 上でまとめたpredictsをDataFrameにまとめるための処理を以下で実行
- ついでにaccuracyも計算
import pandas as pd id2char = {str(i) : str(i) for i in range(10)} id2char.update({"10":"", "11":"-", "12":""}) row = [] for i in range(len(test_input_batch)): batch_input = test_input_batch[i] batch_output = test_output_batch[i] batch_predict = predicts[i] for inp, output, predict in zip(batch_input, batch_output, batch_predict): x = [id2char[str(idx)] for idx in inp] y = [id2char[str(idx)] for idx in output] p = [id2char[str(idx.item())] for idx in predict] x_str = "".join(x) y_str = "".join(y) p_str = "".join(p) judge = "O" if y_str == p_str else "X" row.append([x_str, y_str, p_str, judge]) predict_df = pd.DataFrame(row, columns=["input", "answer", "predict", "judge"]) # 正解率を表示 print(len(predict_df.query('judge == "O"')) / len(predict_df)) # 0.8492 # 間違えたデータを一部見てみる print(predict_df.query('judge == "X"').head(10))
- input: 予測対象
- answer: 正解
- predict: 予測結果
- judge: 予測が正しければ"O"、間違っていたら"X"
これを見る限り、なんか結果の10の桁が1つずれてしまう傾向がある気がする。人間ではしなさそうな計算ミスをしているような。
おわりに
- もっとepoch数を増やすと90数%くらいの精度まで上がります
- ゼロ作にも書いてますが、精度を更に上げるには覗き見(Peeky)という方法が有効なようです。Encoderの隠れ層をDecoderの最初の層だけに渡すのではなく、各DecoderのLSTM層すべてに渡してしまう、という方法のようです。
- ゼロ作に紹介されている反転の方法は、引き算のパターンでは使えないですね。データを反転すると答えが変わってしまうので...
- 次はAttentionを扱います!
おわり







- 投稿日:2019-09-29T23:22:47+09:00
試し割り法による素因数分解
概要
素因数(prime factor)とは、ある自然数の約数となる素数のことです。また素因数分解 (prime factorization) とは、自然数を素因数の積の形で表すことを指します。例えば360を素因数分解すると、$2^3$ × $3^2$ × $5^1$と表すことができます。本記事では2以上の自然数の素因数を試し割り法で列挙する手法を紹介します。
方針
基本的な考え方としては、与えられた2以上の自然数nに対して、nより小さい数で割り切れるかどうかを順番に確かめることで素因数判定を行っていきます。nを割り切る素因数を見つけた際、その素因数の累乗でも割り切れるかどうかも同時に確認しておくと効率的です。素因数候補として確かめるべき値の範囲は、2以上$\sqrt{n}$以下で十分です。
実装例
# Return a list of the prime factors for a natural number bigger than 1 def trial_division(n): if n < 2: return [] prime_factors = [] for i in range(2, int(n**0.5)+1): # nがi(の累乗)で割り切れるかを調べる while n % i == 0: # nがiで割り切れる場合、iを素因数としてリストに追加する prime_factors.append(i) # nをiで割った商で更新しておく n //= i # nの平方根より大きい素因数が存在する場合 if n > 1: prime_factors.append(n) return prime_factors n = int(input()) print(trial_division(n))実行結果
# 入力 12 # 出力 [2, 2, 3] # 入力 100 # 出力 [2, 2, 5, 5] # 入力 600851475143 # 出力 [71, 839, 1471, 6857]参考
試し割り法(Wikipedia)
Pythonで素因数分解(試し割り法)
Pythonで競技プログラミング 〜基本的なアルゴリズム 〜
[Python]試し割法で素因数分解する
- 投稿日:2019-09-29T23:04:36+09:00
tensorflow+kerasを扱うためのPython仮想環境はvenvとAnacondaどちらを使うべきか
結論
Anacondaを使おう
環境
OS:Ubuntu 18.04
背景
今日のディープラーニング界隈では技術の進化が飛躍的に早く、それに合わせて
tensorflowやkerasといったフレームワークの更新が頻繁に行われている。
ここで問題となるのが各モジュール間のバージョンには依存関係があり、適切なバージョンの組み合わせでないとプログラムが動作しないといったことが頻繁に発生する。
特にCUDA,cuDNN,tensorflow-gpu間の依存関係はかなりシビアで、バッチレベルが少しでも異なると平気で動かなくなる。
tensorflow公式がテスト済みの依存関係を発表しているが、このバージョンに合わせてライブラリをインストールしてもうまく動作しないことがある。
現にtensorflow-gpu-1.31.1, cuDNN-7.4, CUDA-10.0, Python3.6の組み合わせだとうまく動作しなかった。
特に厄介なのが、一見うまく動いているようで実はうまく動いていない場合がある。
たとえばtensorflow-gpuを使っているのにもかかわらず、GPUが認識されずCPUでモデルの学習が行われてしまうといった症状がある。
これは一見正常に学習が進んでいるように見えるのだが、実際はCPUで学習が行われてしまうため、学習に莫大な時間がかかってしまう。
fit()した際に以下のメッセージが表示されている場合はGPUで学習が行われていない。2019-09-22 14:52:41.548583: E tensorflow/stream_executorcuda /cuda_dnn.cc:329] Could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERRORなぜ仮想環境を使うのか
こういった背景がある中で、仮想環境を使っていない場合、
特定のモジュールを更新した際に過去に作成したプログラムのモジュールバージョンの依存関係を満たせなくなり動かなくなる。といったことがある。
そのため、Pythonを使う場合仮想環境を使うことが一般的である。
仮想環境といってもVMwareやVirtualBoxのようなハイパーバイザー型仮想環境とは異なり、
venvやAnacondaはライブラリのパスの切り方を変えているだけなので、ホストマシンの性能を最大限に活かすことができる。なぜAnacondaを使うのか
Pythonの仮想環境といえばvenvを使うのが一般的だが、ディープラーニングをやりたいのであればAnacondaが最良だという結論に至った。
Anacondaを使う理由は次の通り。
- 環境構築が楽
- モジュールのバージョン変更が楽
- 複数バージョンのCUDAを扱うことができる
特に大きな理由が3番目の"複数バージョンのCUDAを扱うことができる"部分である。
Anacondaを使わずに複数バージョンのCUDAを同一環境で共存させようとすると環境変数の管理が大変なことになる。
更にCUDAのバージョンアップさせる際にも癖があり、最悪ホストマシンが起動しなくなるといったこともある(経験済み)。
そのため、同一環境でCUDAを複数管理したい場合はAnacondaが最良の選択となる。
venvではこれが実現できない(パスの切り方工夫したらできるかも?)。Anacondaを扱う上で注意する点
- pipは使わない
- conda install "モジュール名"ではモジュールが見つからない時がある。
Anaconda環境下でpipを使うと環境が壊れてしまうことがあるため、Anaconda環境下ではpipは使わない方が良い
これに関しては以下の記事が参考になる。
condaとpip:混ぜるな危険
また、conda installでモジュールが見つからない場合はAnaconda Cloudで探せば大抵見つかる。
現時点ではAnaconda Cloudで使いたいモジュールが見つからなかったことはない。Anacondaでモジュールのバージョンを変更する
Anacondaで仮想環境作成済み、モジュールインストール済みを前提として説明する。
以下のコマンドでAnaconda-Navigatorを起動するanaconda-navigatorEnvironments→作成した仮想環境を選択→右側のコンボボックスが"Installed"になっていることを確認し、バージョンを変更したいモジュール名をSearch Packagesから検索する
モジュールがインストールされていれば表示されるので、☑のところを右クリックし、"mark for specific version installation"内から変更先のバージ
ョンを選択する。すると☑がオレンジ色になるのでApply→Applyを選択するとバージョンの変更が完了となる。
2019/09/29時点でのおすすめ組み合わせ
上記でも述べた通り、各モジュールには依存関係があるため、tensorflow(-gpu), cudatoolkit, cudnnの組み合わせは適切なバージョン同士でなければ動作しない。
そのため、最新のモジュールを入れても動作しないことがある。
また、公式発表のテスト済みの依存関係の表通りに導入しても動かないことがある。
Anaconda環境下で動作確認済み(GPU環境)のバージョンの組み合わせは次の通り
モジュール名 バージョン keras-gpu 2.2.4 tensorflow-gpu 1.12.0 cudatoolkit 9.0 cudnn 7.3.1 ※Python3.6を使用




- 投稿日:2019-09-29T22:11:38+09:00
pyTorchのNetworkのパラメータの閲覧と書き換え
2019/9/29 投稿
0. この記事の対象者
- pyTorchをある程度触ったことがある人
- pyTorchによる機械学習でNetworkのパラメータを閲覧,操作したい人
1. はじめに
昨今では機械学習に対してpython言語による研究が主である.なぜならpythonにはデータ分析や計算を高速で行うためのライブラリ(moduleと呼ばれる)がたくさん存在するからだ.
その中でも今回はpyTorchと呼ばれるmoduleを使用し,Networkからパラメータを取得する閲覧,書き換えする方法を説明する.ただしこの記事は自身のメモのようなもので,あくまで参考程度にしてほしいということと,簡潔に言うために間違った表現や言い回しをしている場合があるかもしれないが,そこはどうかご了承していただきたい.
また,この記事ではNetworkを定義,そこから操作するだけであって,実際にNetworkを使って学習をしたりはしない.
そちらに興味がある場合は以下のURLを参照してほしい.https://qiita.com/mslive/private/8e1f9a8467fff8dfd03c
2. 事前知識
pythonには他言語同様,「型」というものが定義した変数には割り当てられており,中でも「list型」,「tuple型」,「dictionary型」が今回の記事ではよく出てくるように思う.さらに,moduleとして「numpy」というものもあり,このnumpyが持つ特殊な型,「ndarray型」もよく出てくる.
ここではあえて説明はしないが,わからない人は是非検索をしてそれぞれをしっかり理解しておいてほしい.
3. pyTorchのインストール
pyTorchを初めて使用する場合,pythonにはpyTorchがまだインストールされていないためcmdでのインストールをしなければならない.
下記のURLリンクに飛び,ページの下の方にある「QUICK START LOCALLY」で自身の環境のものを選択し,現れたコマンドをcmd等で入力する(コマンドをコピペして実行で良いはず).4. pyTorchに用意されている特殊な型
numpyにはndarrayという型があるようにpyTorchには「Tensor型」という型が存在する.
ndarray型のように行列計算などができ,互いにかなり似ているのだが,Tensor型はGPUを使用できるという点で機械学習に優れている.
なぜなら機械学習はかなりの計算量が必要なため計算速度が早いGPUを使用するからだ.
Tensor型の操作や説明は下記URLより参照していただきたい.https://qiita.com/mslive/private/241bfb42d852bb801b96
ただし,機械学習においてグラフの出力や画像処理などでnumpyも重要な役割を持つ.そのためndarrayとTensorを交互に行き来できるようにしておくことがとても大切である.
5. pyTorchによるNetworkの作成
5-1. pyTorchのimport
ここからはcmd等ではなくpythonファイルに書き込んでいく.
下記のコードを書くことでmoduleの使用をする.filename.rbimport torch import torch.nn as nnここで「import torch.nn as nn」はNetwork内で使用する関数のためのものである.
torch.nn moduleはたくさんの関数を保持している.5-2. Networkの作成
以下に簡単なConvolutional Neural Networks(CNNs)を作成したコードを示す.
filename.rbclass Net(nn.Module): def __init__(self): super(Net, self).__init__() self.relu = nn.ReLU() self.pool = nn.MaxPool2d(2, stride=2) self.conv1 = nn.Conv2d(1,16,3) self.conv2 = nn.Conv2d(16,32,3) self.fc1 = nn.Linear(32 * 5 * 5, 120) self.fc2 = nn.Linear(120, 10) def forward(self, x): x = self.conv1(x) x = self.relu(x) x = self.pool(x) x = self.conv2(x) x = self.relu(x) x = self.pool(x) x = x.view(-1, 32 * 5 * 5) x = self.fc1(x) x = self.relu(x) x = self.fc2(x) return x以下にNetworkの説明をする.
5-2-1. classとしてNetworkを作成
Networkをclassとして作成する.
雛形で言えばこんな形になる.filename.rbclass Net(nn.Module): def __init__(self): super(Net, self).__init__() ...... def forward(self, x): ......以下各行の説明.
1行目の 「Net」はただの名前だから好きなもので良い.
その名前の後の「nn.Module」はこのclassがnn.Moduleというclassを継承していることを意味する.
なぜ継承するかというとnn.ModuleがNetworkを操作する上でパラメータ操作などの重要な機能を持つためである.2行目の「def __init__(self)」は初期化関数の定義で,コンストラクタなどと呼ばれる.初めてclassを呼び出したときにこの中身のものが実行される.
3行目の「super(Net, self).__init__()」は継承したnn.Moduleの初期化関数を起動している.superの引数の「Net」はもちろん自身が定義したclassの名前である.
最後の「def forward(self, x)」には実際の処理を書いていく.
5-2-2. 初期化関数の定義
この中で定義した「self.xxxxx」という変数はずっと保持される.
なので,convolutionやfully connectなどのパラメータを保持したいものなどをここに書いていく.
以下にexampleコードの説明をする.
「nn.ReLU()」は活性化関数というもので,各層の後に必ずと言っていいほど使用されている.種類はたくさんある.
「nn.MaxPool2d(2, stride=2)」はプーリング用でこのパラメータの場合データサイズが半分になるような処理をする(サイズの小数点以下は切り下げられる).
「nn.Conv2d(1,16,3)」はconvolution(畳み込み)の定義で,第1引数はその入力のチャネル数,第2引数は畳み込み後のチャネル数,第3引数は畳み込みをするための正方形フィルタ(カーネルとも言う)の1辺のサイズである.入力dataのH×Wと出力のH×Wは通常異なるものとなり,Convolutionのカーネルサイズなどから計算できる.計算方法は以下URLを見てほしい.
https://pytorch.org/docs/stable/nn.html#torch.nn.Conv2d「nn.Linear(32 * 5 * 5, 120)」はfully connectの定義で,第1引数は入力のサイズ(ただし入力は行列ではなくベクトルでなければならない),第2引数は出力後のベクトルサイズを示す.この場合の第1引数の意味は入力ベクトルがベクトルになる前のdataでは32 Channel×5 Height×5 Widthとなっていたことがわかる.どうやってベクトルにしたかは4-4-3で説明する.
これらの他にも多数の関数をpyTorchは用意しており,それらは以下のURLから参照してほしい.
https://pytorch.org/docs/stable/nn.html
5-2-3. 処理内容の定義
「def forward(self, x)」の引数xがこのネットワークに対しての入力dataである.もちろんこのxはdataloaderから取得したバッチサイズ数のdata群である.
exampleコードのように入力xを__init__()で定義した各層に入力していく.
このxは「x = xxxx(x)」のように毎回更新されていることに注意して欲しい.
ここで「x.view(-1, 32 * 5 * 5)」はTensor型の形を変換するもので,引数を 縦×横 とみた行列に変換される(縦サイズが-1となっている場合,横サイズがその値になるように自動で縦サイズを調整する)5-3. Networkの使用
Networkの使用宣言を以下に示す.
filename.rbnet = Net()これはNet() classのインスタンスとなるnetを生成している.
この瞬間に定義した初期化関数「__init__()」が実行している.
このnetがパラメータやNetworkの構造を保持していることとなるのだ.
netを出力してみるとその詳細が以下のように確認できる.filename.rbprint(net) ------'''以下出力結果'''-------- Net( (relu): ReLU() (pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (conv1): Conv2d(1, 16, kernel_size=(3, 3), stride=(1, 1)) (conv2): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1)) (fc1): Linear(in_features=800, out_features=120, bias=True) (fc2): Linear(in_features=120, out_features=10, bias=True) )6. Networkのパラメータ閲覧
今,netがNetworkの情報を持っている.
Networkのパラメータの閲覧方法は複数あり,今回はその中でも以下の閲覧方法を説明する.
- net.parameters()の使用
- net.state_dict()の使用
- net.xxxxx.weightの使用
- optimizerの使用
6-1. net.parameters()の使用
単純にパラメータを閲覧したい場合は「net.parameters()」を使用し,以下のようにすればよい.
filename.rbfor param in net.parameters(): print(param) ------'''以下出力結果'''-------- Parameter containing: tensor([[パラメータ1],[パラメータ2],...,[パラメータ16]],requires_grad=True) Parameter containing: tensor([パラメータ1のバイアス,パラメータ2のバイアス,...,パラメータ16のバイアス], requires_grad=True) Parameter containing: tensor([[パラメータ1],[パラメータ2],...,[パラメータ32]],requires_grad=True) Parameter containing: tensor([パラメータ1のバイアス,パラメータ2のバイアス,...,パラメータ32のバイアス], requires_grad=True) Parameter containing: tesnor([[パラメータ1],[パラメータ2],...,[パラメータ120]], requires_grad=True) Parameter containing: tesnor([[パラメータ1のバイアス],[パラメータ2のバイアス],...,[パラメータ120のバイアス]],requires_grad=True) Parameter containing: tesnor([[パラメータ1],[パラメータ2],...,[パラメータ10]],device='cuda:0', requires_grad=True) Parameter containing: tesnor([[パラメータ1のバイアス],[パラメータ2のバイアス],...,[パラメータ10のバイアス]],requires_grad=True)上から順に,この出力は以下のようになっている.
- conv1のパラメータ
- conv1のバイアス
- conv2のパラメータ
- conv2のバイアス
- fc1のパラメータ
- fc1のバイアス
- fc2のパラメータ
- fc2のバイアス
各パラメータの個数(パラメータ16とか書いてる)が異なっていてNetworkのそれぞれの層の定義に依存している.
この「net.parameters()」がパラメータの情報を引き出しているのだが,単純に出力せず,for文を使用していることに注意してほしい.
単純に出力してしまうと以下のようになってしまう.filename.rbprint(net.parameters()) ------'''以下出力結果'''-------- <generator object Module.parameters at 0x7fb663b45c00>これは「net.parameters()」がnetのパラメータを参照しているわけではなく,netのパラメータを持ったiteratorを返しているからである.
つまり「in」というのを使用しないと値を取り出せないのである.
もちろん,これはただの出力のために値を取り出しているだけであるため,パラメータの書き換えなどはできない.6-2. net.state_dict()の使用
以下に出力を示す.
filename.rbprint(net.state_dict()['conv1.weight']) ------'''以下出力結果'''-------- tensor([[conv1のチャネル1のパラメータ], [conv1のチャネル2のパラメータ], .... [conv1のチャネル16のパラメータ]])この「['conv1.weight']」のように閲覧したいパラメータを指定する.
つまり「['定義した名前.weight']」とすることでそのパラメータが閲覧できる.
このように配列参照のようにして,かつそれが数字ではなく文字列での参照であるから「net.state_dict()」は辞書型(collections.OrderedDict型)であることがわかり,もちろん辞書のインデックス名も以下のように確認できる.filename.rbprint(net.state_dict().keys()) ------'''以下出力結果'''-------- odict_keys(['conv1.weight', 'conv1.bias', 'conv2.weight', 'conv2.bias', 'fc1.weight', 'fc1.bias', 'fc2.weight', 'fc2.bias'])6-3. net.xxxxx.weightの使用
以下に出力を示す.
filename.rbprint(net.conv1.weight) ------'''以下出力結果'''-------- Parameter containing: tensor([[conv1のチャネル1のパラメータ], [conv1のチャネル2のパラメータ], .... [conv1のチャネル16のパラメータ]],requires_grad=True)この「net.conv1.weight」のように閲覧したいパラメータを指定する.
前のパラメータ参照と違う点は出力に「requires_grad」があるかないかであるが,だからと言って前の参照法では勾配情報がないというわけではない.
要はどちらでもよい.また,バイアス情報を見たいときは以下のようにする.
filename.rbprint(net.conv1.bias) ------'''以下出力結果'''-------- Parameter containing: tensor([conv1のバイアス1,conv1のバイアス2,...,conv1のバイアス16],requires_grad=True)6-4. optimizerの使用
optimizerとは最適化手法のことで,学習をする際に使用するものである.
以下にその使用方法を示す.filename.rbimport torch.optim as optim optimizer = optim.SGD(net.parameters(), lr=0.0001, momentum=0.9, weight_decay=0.005)この詳しい説明は気になる場合下記URLより参照してほしい.
https://qiita.com/mslive/private/8e1f9a8467fff8dfd03c
要はこの最適化手法の定義の際に「net.parameters()」を渡していることから,この変数optimizerはパラメータ情報を見ることができるのである.
以下に閲覧方法を示す.filename.rbprint(optimizer.param_groups) ------'''以下出力結果'''-------- [{'params': [Parameter containing: tensor([[conv1のチャネル1のパラメータ], [conv1のチャネル2のパラメータ], ... [conv1のチャネル16のパラメータ]], requires_grad=True), Parameter containing: tensor([conv1のバイアス1,conv1のバイアス2,...,conv1のバイアス16], requires_grad=True), Parameter containing: tensor([[conv2のチャネル1のパラメータ], ... ... tensor([fc2のベクトル1のパラメータ], [fc2のベクトル2のパラメータ], ... [fc2のベクトル10のパラメータ], requires_grad=True), Parameter containing: tensor([fc2のバイアス1,fc2のバイアス2,...,fc2のバイアス10], requires_grad=True)], 'lr': 0.0001, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0.005, 'nesterov': False}]このように「optimizer.param_groups」とすることでoptimizerが持つ情報をほぼ全て確認できる.
余談だが,このoptimizer.param_groupsの形は一番外側はカッコ「[...]」で囲まれており,中の要素は「'xxx':要素」となっていることからlist型の中に辞書型が入っている形となっている.
このことから中へのアクセスは以下のようにすればよい.filename.rbprint(optimizer.param_groups[0]) ------'''以下出力結果'''-------- {'params': [Parameter containing: tensor([[conv1のチャネル1のパラメータ], [conv1のチャネル2のパラメータ], ... [conv1のチャネル16のパラメータ]], requires_grad=True), Parameter containing: tensor([conv1のバイアス1,conv1のバイアス2,...,conv1のバイアス16], requires_grad=True), Parameter containing: tensor([[conv2のチャネル1のパラメータ], ... ... tensor([fc2のベクトル1のパラメータ], [fc2のベクトル2のパラメータ], ... [fc2のベクトル10のパラメータ], requires_grad=True), Parameter containing: tensor([fc2のバイアス1,fc2のバイアス2,...,fc2のバイアス10], requires_grad=True)], 'lr': 0.0001, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0.005, 'nesterov': False}出力してみるとわかるようにほとんど前の出力と同じ結果になっている.
違いと言えば出力の先頭と最後にカッコ「[...]」があるかないかである.
実はoptimizer.param_groupsは辞書型の要素を1つしかもたないlist型だったわけだ.さらに中へアクセスする.
filename.rbprint(optimizer.param_groups[0]['lr']) print(optimizer.param_groups[0]['params'][0]) ------'''以下出力結果'''-------- 0.0001 Parameter containing: tensor([[conv1のチャネル1のパラメータ], [conv1のチャネル2のパラメータ], ... [conv1のチャネル16のパラメータ]], grad_fn=<CopySlices>)このように辞書型への普通の参照法で中を見ることができる.
ここで,conv1のパラメータ出力に「grad_fn=<CopySlices>」というのが初めて出てきていると思うが,これは勾配情報を計算するために必要なもので,あまり気にしなくてもよい.6-5. おまけ,勾配情報の閲覧
各Networkの層であるconv1,conv1のバイアス,fc1,....等はパラメータを更新するために勾配情報を持つことができる.
今までの出力時に「requires_grad=True」とあるのがその証拠である.勾配情報は以下のように閲覧できる.
filename.rbprint(net.state_dict()['conv1.weight'].grad) print(net.conv1.weight.grad) print(optimizer.param_groups[0]['params'][0].grad) ------'''以下出力結果'''-------- None None None「None」と出ているが,勾配情報を計算するためのbackward()をしていないとこれが出てくる.
つまり勾配情報がまだ計算されていないことを示しており,正しい出力結果なのである.7. Networkのパラメータ書き換え
Networkのパラメータを書き換える方法はいくつかあり,以下にそれを示す.
- 普通に代入をする
- net.load_state_dict()を使う
以下にそれぞれの説明をする.
7-1. 普通に代入する
前に説明したパラメータの閲覧方法をそのまま使用し,そのまま代入する.
以下に例としてチャネルの書き換えを示す.filename.rbnet.state_dict()['conv1.weight'][0] = torch.tensor([conv1の新しいパラメータ]) print(net.state_dict()['conv1.weight']) ------'''以下出力結果'''-------- tensor([conv1の新しいチャネル1のパラメータ], [conv1のチャネル2のパラメータ], ... [conv1のチャネル16のパラメータ])もちろん以下も可能である.
filename.rbnet.conv1.weight[0] = torch.tensor([conv1の新しいチャネル1のパラメータ]) print(net.conv1.weight) ------'''以下出力結果'''-------- Parameter containing: tensor([conv1の新しいチャネル1のパラメータ], [conv1のチャネル2のパラメータ], ... [conv1のチャネル16のパラメータ] grad_fn=<CopySlices>)これはあくまでconv1のある1つのチャネルの書き換えを行っている.
実はconv1などの層の全チャネルを書き換える方法は少し特殊で,以下のようにやるとうまくできない.filename.rbnet.state_dict()['conv1.weight'] = torch.ones(16,1,3,3) print(net.state_dict()['conv1.weight']) ------'''以下出力結果'''-------- 書き換わっていないパラメータが出力されるこれは全てが1である同サイズのTensor型を代入している.
しかし,エラーは出ないもののパラメータは書き換わらない.
またもう一方の方ではエラーが出力される.filename.rbnet.conv1.weight = torch.ones(16,1,3,3) print(net.conv1.weight) ------'''以下出力結果'''-------- TypeError: cannot assign 'torch.FloatTensor' as parameter 'weight' (torch.nn.Parameter or None expected)解決方法として,以下のようにすると書き換えることができる.
filename.rbnet.state_dict()['conv1.weight'][0:16] = torch.ones(16,1,3,3) print(net.state_dict()['conv1.weight']) ------'''以下出力結果'''-------- tensor([同サイズで全て1の要素])これは「[0:16]」とすることで無理やり全チャネルを参照しているのだ.
ただしもう一方の方ではこのやり方でもエラーが出ることに注意してほしい.filename.rbnet.conv1.weight[0:16] = torch.zeros(16,1,3,3) print(net.conv1.weight) ------'''以下出力結果'''-------- RuntimeError: a leaf Variable that requires grad has been used in an in-place operation.とにかくこの方法ではデータの一括変換に難があるのだ.
7-2. net.load_state_dict()を使う
この方法はNetworkのパラメータを事前に外部に保存しておき,それをloadすることでパラメータを書き換えるという方法である.
まず,以下にsaveの方法を示す.
7-2-1. torch.save()によるパラメータsave
以下にsave方法を示す.
filename.rbtorch.save(net.state_dict(), 'ファイル名.pth')これにより,「net.state_dict()」によるnetのパラメータを「ファイル名.pth」というファイル名で保存する.
なお,この場合のnetは先ほどから使っているものとは別のもの(例えば事前に何か学習したパラメータとか)である.7-2-2. net.load_state_dict()によるパラメータload
上で保存したファイルをまず以下のように参照してloadする.
filename.rbparam = torch.load('ファイルのpath')これでparamという変数にloadしたパラメータを格納した.
このparamを以下のように使用する.filename.rbnet.load_state_dict(param)これでnetのパラメータを書き換える.
ちなみに部分的に書き換える場合は以下のようにすればよい.filename.rbparam = torch.load('ファイルのpath') param2 = net.state_dict() param2['conv1.weight'] = param['conv1.weight'] net.load_state_dict(param2)少々回りくどいが,事前に保存したパラメータをparamに取得し,さらに今のパラメータをparam2に取り出す.
そのparam2のconv1だけをparamのものに書き換え,それを今のnetに適応する.8. ひとこと
今回はnetworkのパラメータの閲覧と書き換えの方法を説明した.
不透明な部分や回りくどい部分もあったが何かの参考程度になっていただけると幸いである.
読みづらい点も多かったと思うが読んでいただきありがとうございます.
- 投稿日:2019-09-29T22:04:32+09:00
データサイエンティストが知っておくべき5つのグラフアルゴリズムのコピー
こちらの記事は、2019年 8月に公開された『 Data Scientists, The 5 Graph Algorithms that you should know』の和訳になります。
本投稿は転載であり、本記事はこちらになります。はじめに
私たちデータサイエンティストは、Pandas、SQL、他のどんなリレーショナルデータベースでも非常に満足しています。
私たちは、ユーザーの情報を列で表現し、ユーザを行として並べることに見慣れています。
しかし、現実の世界は本当にそのようになっているでしょうか?コネクテッドワールドでは、ユーザーを独立したエンティティと見なすことはできません。
ユーザーはお互いが一定の繋がりをもっているため、機械学習モデルを構築するときに、関係性を含めたい場合があります。リレーショナルデータベースでは、異なる行(ユーザー)の間でこのような関係性を使用することはできませんが、グラフデータベースでは非常に簡単に使用できます。
この記事では、知っておくべき最も重要なグラフアルゴリズムと、Pythonでの実現方法をいくつか説明します。
また、CourseraでUCSANDiegoが提供しているビッグデータのグラフ分析コースでグラフ理論の基礎を学ぶことを強くお勧めします。
1.連結成分(Connected Components)
クラスタリングの仕組みを知っていますか?
連結成分は、ごく一般的な用語で、関連/接続されたデータ内のクラスター/アイランドを見つける一種のハードクラスタリングアルゴリズムと考えることができます。
具体的な例:世界中の2つの都市を結んでいる任意の道路のデータを持っていて、そこからすべての大陸と、大陸にどの都市が含まれるのか探り当てたいとします。
どうやって実現しますか?考えてみてください。
これを行うために使用する連結成分アルゴリズムは、BFS / DFSの特殊なケースに基づいています。
ここではどのように機能するかについてはあまり説明しませんが、Networkxを使用してコードを起動して実行する方法について説明します。用途
小売業の観点:多くの顧客がいて、多くのアカウントを使用しているとしましょう。私たちは、Connected Componentsアルゴリズムを使用して、データセット内の異なるグループを見つけることができます。クレジットカードの使い方、住所または携帯電話番号などが同じだということに基づいて辺(エッジ)を推定することができます。
一度これらのつながりがわかれば、グループIDを割り当てるクラスタを作成するために連結成分アルゴリズムを実行することができます。そうすると、このグループIDを使用して、各グループのニーズにあった推奨事項を提供できます。
また、グループIDを使用して、グループごとの特徴を作成し、分類アルゴリズムを強化することもできます。財務の観点:別のユースケースは、これらのグループIDを使用して詐欺を見つけることです。
アカウントが過去に不正を行った場合、繋がりがあるアカウントも不正を行う可能性が高いです。あなたの想像力次第で、用途の可能性は無限大です。
コード
Networkxグラフの作成と分析にPython のモジュールを使用します。
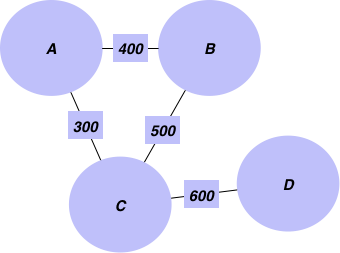
目的を達成するために使うグラフの例から始めましょう。都市とそれらの間の距離情報が含まれています。
まず、辺の重みとして追加する距離と辺のリストを作成することから始めます。edgelist = [['Mannheim', 'Frankfurt', 85], ['Mannheim', 'Karlsruhe', 80], ['Erfurt', 'Wurzburg', 186], ['Munchen', 'Numberg', 167], ['Munchen', 'Augsburg', 84], ['Munchen', 'Kassel', 502], ['Numberg', 'Stuttgart', 183], ['Numberg', 'Wurzburg', 103], ['Numberg', 'Munchen', 167], ['Stuttgart', 'Numberg', 183], ['Augsburg', 'Munchen', 84],['Augsburg', 'Karlsruhe', 250], ['Kassel', 'Munchen', 502], ['Kassel', 'Frankfurt', 173], ['Frankfurt', 'Mannheim', 85], ['Frankfurt', 'Wurzburg', 217], ['Frankfurt', 'Kassel', 173], ['Wurzburg', 'Numberg', 103], ['Wurzburg', 'Erfurt', 186], ['Wurzburg', 'Frankfurt', 217], ['Karlsruhe', 'Mannheim', 80], ['Karlsruhe', 'Augsburg', 250], ["Mumbai", "Delhi",400],["Delhi", "Kolkata",500], ["Kolkata", "Bangalore",600],["TX", "NY",1200], ["ALB", "NY",800]]Networkxを使用してグラフを作成しましょう
g = nx.Graph() for edge in edgelist: g.add_edge(edge[0],edge[1], weight = edge[2])次に、このグラフから異なる大陸とその都市を見つけ出します。
connected componentsアルゴリズムを使用することができます:
for i, x in enumerate(nx.connected_components(g)): print("cc"+str(i)+":",x) ------------------------------------------------------------ cc0: {'Frankfurt', 'Kassel', 'Munchen', 'Numberg', 'Erfurt', 'Stuttgart', 'Karlsruhe', 'Wurzburg', 'Mannheim', 'Augsburg'} cc1: {'Kolkata', 'Bangalore', 'Mumbai', 'Delhi'} cc2: {'ALB', 'NY', 'TX'}このように、データ内の個別の成分を見つけることができます。エッジと頂点を使用するだけです。異なるデータでこのアルゴリズムを実行して前述したユースケースを満たすことができます。
2.最短経路
上記の例を続けるだけで、ドイツの都市とそれぞれの距離を示すグラフを作ることができます。
最短距離をとって、フランクフルト(出発ノード)からミュンヘンへの行き方を調べたいと思います。
この問題に使用するアルゴリズムは、ダイクストラ法と呼ばれます。ダイクストラ自身の言葉で次のように語られています:ロッテルダムからフローニンゲンに移動する最短経路:
一般的には特定の都市から特定の都市へ移動するということは、最短パスのアルゴリズムであり、約20分で設計しました。ある朝、私はアムステルダムで若い婚約者と買い物をして疲れていました。私はコーヒーを飲むためにカフェテラスに座って最短経路のアルゴリズムを設計しました。先ほど言ったように、20分の発明でした。3年後の1959年に公開されました。この発表は読みやすく、非常に素晴らしいものです。優れたものになった理由の1つは、鉛筆と紙なしでデザインしたことです。鉛筆と紙なしでデザインしたため、回避可能な複雑さをすべて避けることができることが後になってわかりました。驚いたことに、このアルゴリズムは私の名声の礎石の1つになりました。— Edsger Dijkstra、ACMコミュニケーションズ、2001年のフィリップL.フラナとのインタビュー
用途
・最短ルートを見つけるために、ダイクストラアルゴリズムの一種がGoogleマップで広く使用されています。
・ウォルマートストアでは、すべての通路の間に異なる距離の通路があるため、通路 Aから通路 Dに移動する最短経路を顧客に提供したいと考えるでしょう。
・LinkedInでは一次的なつながりと二次的なつながりなど、つながりの度合いを表示しています。表示するために裏側で何が起こっているのでしょうか?
コード
print(nx.shortest_path(g, 'Stuttgart','Frankfurt',weight='weight')) print(nx.shortest_path_length(g, 'Stuttgart','Frankfurt',weight='weight'))次の方法で、すべてのペア間の最短パスを見つけることができます。
for x in nx.all_pairs_dijkstra_path(g,weight='weight'): print(x) -------------------------------------------------------- ('Mannheim', {'Mannheim': ['Mannheim'], 'Frankfurt': ['Mannheim', 'Frankfurt'], 'Karlsruhe': ['Mannheim', 'Karlsruhe'], 'Augsburg': ['Mannheim', 'Karlsruhe','Augsburg'], 'Kassel': ['Mannheim', 'Frankfurt', 'Kassel'], 'Wurzburg': ['Mannheim', 'Frankfurt', 'Wurzburg'], 'Munchen': ['Mannheim', 'Karlsruhe', 'Augsburg', 'Munchen'], 'Erfurt': ['Mannheim', 'Frankfurt', 'Wurzburg', 'Erfurt'], 'Numberg': ['Mannheim', 'Frankfurt', 'Wurzburg', 'Numberg'], 'Stuttgart': ['Mannheim', 'Frankfurt', 'Wurzburg', 'Numberg', 'Stuttgart']}) ('Frankfurt', {'Frankfurt': ['Frankfurt'], 'Mannheim': ['Frankfurt', 'Mannheim'], 'Kassel': ['Frankfurt', 'Kassel'], 'Wurzburg': ['Frankfurt', 'Wurzburg'], 'Karlsruhe': ['Frankfurt', 'Mannheim', 'Karlsruhe'], 'Augsburg': ['Frankfurt', 'Mannheim', 'Karlsruhe', 'Augsburg'], 'Munchen': ['Frankfurt', 'Wurzburg', 'Numberg', 'Munchen'], 'Erfurt': ['Frankfurt', 'Wurzburg', 'Erfurt'], 'Numberg': ['Frankfurt', 'Wurzburg', 'Numberg'], 'Stuttgart': ['Frankfurt', 'Wurzburg', 'Numberg', 'Stuttgart']})3.最小スパニングツリー
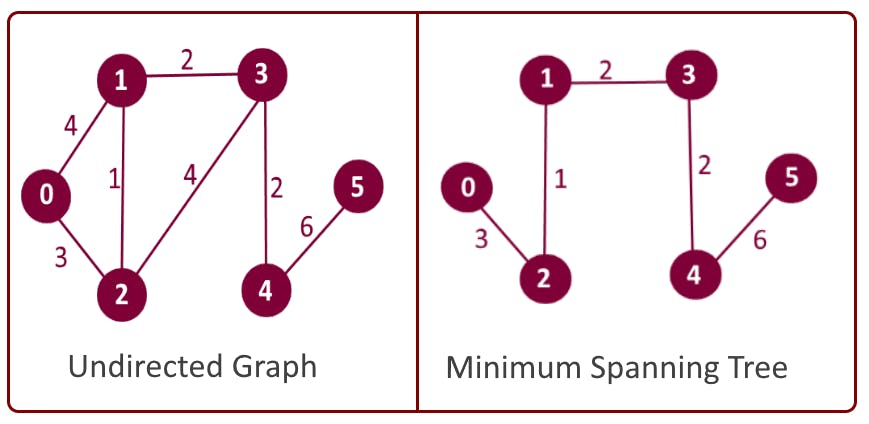
今度は別の問題です。私たちは水道管敷設会社またはインターネットの設備会社で働いています。最小限のワイヤ/パイプを使用して、グラフ内のすべての都市を接続する必要があります。どうやって実現するのでしょうか?
仕様事例
最小スパニングツリーは、コンピューターネットワーク、通信ネットワーク、運送ネットワーク、給水ネットワーク、および送電網(最初に発明された)を含むネットワークの設計に直接適用されます。・MSTは巡回セールスマン問題の近似に使用されます。
・クラスタリング—最初にMSTを構築してから、クラスター間距離とクラスター内距離を使用してMSTの一部のエッジを分割するためのしきい値を決定します。
・画像セグメンテーション—ピクセルをノードとして、類似性の測度(色、強度など)をピクセル間の距離としてグラフを作成し、画像セグメンテーションを最初のMSTとして構築しました。コード
# nx.minimum_spanning_tree(g) returns a instance of type graph nx.draw_networkx(nx.minimum_spanning_tree(g))
ごらんのとおり、ワイヤを横展開することができます。4.ページランク
これは、Googleに長い間使用されているページソートアルゴリズムです。入力リンクと出力リンクの数と品質に基づいてページにスコアを割り当てます。用途
ページランクは、ネットワーク内のノードの重要度を推定する任意の場所で使用できます。
・引用を使って、最も影響力のある論文を見つけるために使用されています。
Googleがページのランキングに使用しています。
・ツイート-ユーザーおよびツイートをランク付けするために使用できます。ユーザーAがユーザーBをフォローしている場合はユーザー間のリンクを作成し、ユーザーがツイートをツイート/リツイートする場合はユーザーとツイート間のリンクを作成します。
・推奨をするためのエンジンコード
この例では、私たちが持っているFacebookユーザー間のエッジ/リンクのファイルをもとに、Facebookのデータを利用します。まず、以下を使用してFacebookのグラフを作成します。# reading the dataset fb = nx.read_edgelist('../input/facebook-combined.txt', create_using = nx.Graph(), nodetype = int)次のようにして可視化します:
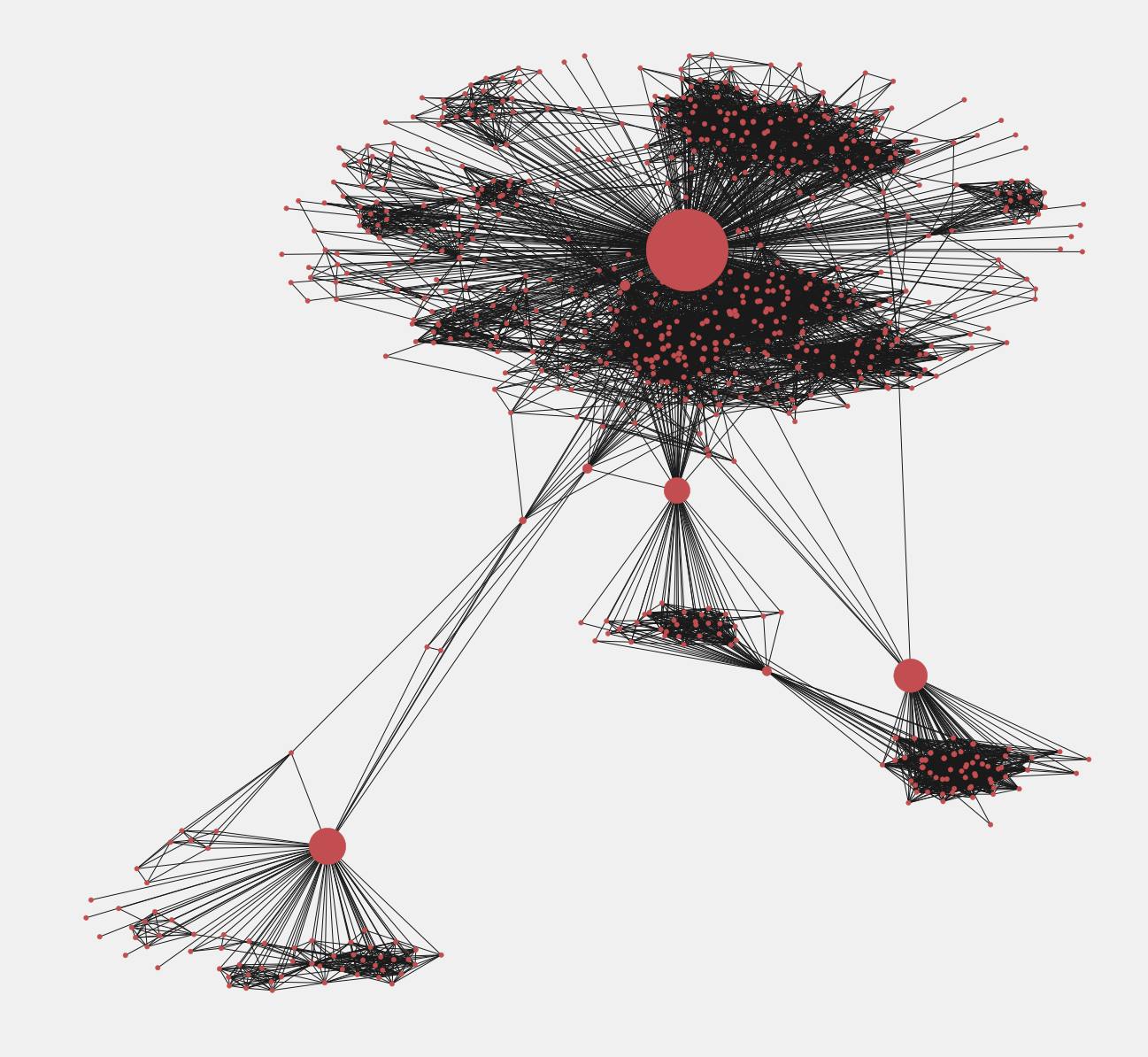
pos = nx.spring_layout(fb) import warnings warnings.filterwarnings('ignore') plt.style.use('fivethirtyeight') plt.rcParams['figure.figsize'] = (20, 15) plt.axis('off') nx.draw_networkx(fb, pos, with_labels = False, node_size = 35) plt.show()
次に、影響力の高いユーザーを探します。
直観的には、ページランクアルゴリズムは「友達が多い友達」が多いユーザーに高いスコアを与えます。pageranks = nx.pagerank(fb) print(pageranks)次の方法で、最も影響力のあるユーザー(ソートされたページランク)を取得できます。
import operator sorted_pagerank = sorted(pageranks.items(), key=operator.itemgetter(1),reverse = True) print(sorted_pagerank) ------------------------------------------------------ [(3437, 0.007614586844749603), (107, 0.006936420955866114), (1684, 0.0063671621383068295), (0, 0.006289602618466542), (1912, 0.0038769716008844974), (348, 0.0023480969727805783), (686, 0.0022193592598000193), (3980, 0.002170323579009993), (414, 0.0018002990470702262), (698, 0.0013171153138368807), (483, 0.0012974283300616082), (3830, 0.0011844348977671688), (376, 0.0009014073664792464), (2047, 0.000841029154597401), (56, 0.0008039024292749443), (25, 0.000800412660519768), (828, 0.0007886905420662135), (322, 0.0007867992190291396),......]上のIDはもっとも影響のあるユーザーです。
私達はもっとも影響のあるユーザーの部分グラフをみることができます。first_degree_connected_nodes = list(fb.neighbors(3437)) second_degree_connected_nodes = [] for x in first_degree_connected_nodes: second_degree_connected_nodes+=list(fb.neighbors(x)) second_degree_connected_nodes.remove(3437) second_degree_connected_nodes = list(set(second_degree_connected_nodes)) subgraph_3437 = nx.subgraph(fb,first_degree_connected_nodes+second_degree_connected_nodes) pos = nx.spring_layout(subgraph_3437) node_color = ['yellow' if v == 3437 else 'red' for v in subgraph_3437] node_size = [1000 if v == 3437 else 35 for v in subgraph_3437] plt.style.use('fivethirtyeight') plt.rcParams['figure.figsize'] = (20, 15) plt.axis('off') nx.draw_networkx(subgraph_3437, pos, with_labels = False, node_color=node_color, node_size=node_size ) plt.show()
5. 中心性測定
機械学習モデルの機能として使用できる中心性の尺度は多数あります。そのうち2つを説明します。ここで他の尺度を参照できます。
媒介中心性:重要な友人ばかりをもつユーザーだけではなく、ユーザーがさまざまな地域からコンテンツを表示できるように、ある地域を別の地域に接続するユーザーも重要です。Betweenness Centralityは、特定のノードが他の2つのノード間で選択された最短のパスに入ってくる回数を定量化します。
次数中心性:単純にノードの接続数です。用途
中心性測定は、あらゆる機械学習モデルの機能として使用できます。
コード
次はサブグラフの媒介中心性を見つけるためのコードです。pos = nx.spring_layout(subgraph_3437) betweennessCentrality = nx.betweenness_centrality(subgraph_3437, normalized=True, endpoints=True) node_size = [v * 10000 for v in betweennessCentrality.values()] plt.figure(figsize=(20,20)) nx.draw_networkx(subgraph_3437, pos=pos, with_labels=False, node_size=node_size ) plt.axis('off')
ノード間の中心性の値で大きさが決まったノードを確認できます。それらは情報の伝達者と考えることができます。中心性の値が大きいノードで分割すると、複数のグラフに分割できます。結論
この記事では、私たちの生活を変えた最も影響力のあるグラフアルゴリズムについて説明しました。
大量のソーシャルデータが出現したことで、ネットワーク分析はモデルの改善と価値の創出に大いに役立つ可能性があります。
そして、もう少し世の中が理解できます。
多くのグラフアルゴリズムがありますが、本記事で紹介したものは私が最も気に入っているアルゴリズムです。
必要に応じて、アルゴリズムを詳細に調べてください。
この記事は、より知識を広めることを目的としています。
お気に入りのアルゴリズムが他にあれば著者に教えてください。
ここにKaggleカーネルの全てのコードがあります。
この記事で紹介したグラフアルゴリズムがもっと知りたければ、CourseraでUCSANDiegoが提供しているビッグデータのグラフ分析コースでグラフ理論の基礎を学ぶことを強くお勧めします。読んでくれてありがとうございます。
今後も初心者向けの投稿を書く予定です。
Mediumでフォローアップするか、ブログをサブスクライブして、通知を受けてください。
いつもでも、フィードバックと建設的な批判を歓迎しています。
Twitterの @mlwhizアカウントに連絡してください。翻訳協力
Author: Rahul Agarwal
Thank you for letting us share your knowledge!記事選定: @yokomichi
翻訳/技術監査: @aoharu / @nyorochan
Markdown化: @ricky





- 投稿日:2019-09-29T22:04:32+09:00
データサイエンティストが知っておくべき5つのグラフアルゴリズム
こちらの記事は、2019年 8月に公開された『 Data Scientists, The 5 Graph Algorithms that you should know』の和訳になります。
本投稿は転載であり、本記事はこちらになります。はじめに
私たちデータサイエンティストは、Pandas、SQL、他のどんなリレーショナルデータベースでも非常に満足しています。
私たちは、ユーザーの情報を列で表現し、ユーザを行として並べることに見慣れています。
しかし、現実の世界は本当にそのようになっているでしょうか?コネクテッドワールドでは、ユーザーを独立したエンティティと見なすことはできません。
ユーザーはお互いが一定の繋がりをもっているため、機械学習モデルを構築するときに、関係性を含めたい場合があります。リレーショナルデータベースでは、異なる行(ユーザー)の間でこのような関係性を使用することはできませんが、グラフデータベースでは非常に簡単に使用できます。
この記事では、知っておくべき最も重要なグラフアルゴリズムと、Pythonでの実現方法をいくつか説明します。
また、CourseraでUCSANDiegoが提供しているビッグデータのグラフ分析コースでグラフ理論の基礎を学ぶことを強くお勧めします。
1.連結成分(Connected Components)
クラスタリングの仕組みを知っていますか?
連結成分は、ごく一般的な用語で、関連/接続されたデータ内のクラスター/アイランドを見つける一種のハードクラスタリングアルゴリズムと考えることができます。
例えば、世界中の2つの都市を結んでいる任意の道路のデータを持っていて、そこからすべての大陸と、大陸にどの都市が含まれるのか探り当てたいとします。
どうやって実現しますか?考えてみてください。
これを行うために使用する連結成分アルゴリズムは、BFS / DFS の特殊なケースに基づいています。
ここではどのように機能するかについてはあまり説明しませんが、Networkxを使用してコードを起動して実行する方法について説明します。用途
小売業の観点:多くの顧客がいて、多くのアカウントを使用しているとしましょう。私たちは、Connected Componentsアルゴリズムを使用して、データセット内の異なるグループを見つけることができます。
クレジットカードの使い方、住所または携帯電話番号などが同じだということに基づいて辺(エッジ)を推定することができます。
一度これらのつながりがわかれば、グループIDを割り当てるクラスタを作成するために連結成分アルゴリズムを実行することができます。そうすると、このグループIDを使用して、各グループのニーズにあった推奨事項を提供できます。
また、グループIDを使用して、グループごとの特徴を作成し、分類アルゴリズムを強化することもできます。財務の観点:別のユースケースは、これらのグループIDを使用して詐欺を見つけることです。
アカウントが過去に不正を行った場合、繋がりがあるアカウントも不正を行う可能性が高いです。あなたの想像力次第で、用途の可能性は無限大です。
コード
Networkxグラフの作成と分析にPython のモジュールを使用します。
目的を達成するために使うグラフの例から始めましょう。都市とそれらの間の距離情報が含まれています。
まず、辺の重みとして追加する距離と辺のリストを作成することから始めます。edgelist = [['Mannheim', 'Frankfurt', 85], ['Mannheim', 'Karlsruhe', 80], ['Erfurt', 'Wurzburg', 186], ['Munchen', 'Numberg', 167], ['Munchen', 'Augsburg', 84], ['Munchen', 'Kassel', 502], ['Numberg', 'Stuttgart', 183], ['Numberg', 'Wurzburg', 103], ['Numberg', 'Munchen', 167], ['Stuttgart', 'Numberg', 183], ['Augsburg', 'Munchen', 84],['Augsburg', 'Karlsruhe', 250], ['Kassel', 'Munchen', 502], ['Kassel', 'Frankfurt', 173], ['Frankfurt', 'Mannheim', 85], ['Frankfurt', 'Wurzburg', 217], ['Frankfurt', 'Kassel', 173], ['Wurzburg', 'Numberg', 103], ['Wurzburg', 'Erfurt', 186], ['Wurzburg', 'Frankfurt', 217], ['Karlsruhe', 'Mannheim', 80], ['Karlsruhe', 'Augsburg', 250], ["Mumbai", "Delhi",400],["Delhi", "Kolkata",500], ["Kolkata", "Bangalore",600],["TX", "NY",1200], ["ALB", "NY",800]]Networkxを使用してグラフを作成しましょう
g = nx.Graph() for edge in edgelist: g.add_edge(edge[0],edge[1], weight = edge[2])次に、このグラフから異なる大陸とその都市を見つけ出します。
connected componentsアルゴリズムを使用することができます:
for i, x in enumerate(nx.connected_components(g)): print("cc"+str(i)+":",x) ------------------------------------------------------------ cc0: {'Frankfurt', 'Kassel', 'Munchen', 'Numberg', 'Erfurt', 'Stuttgart', 'Karlsruhe', 'Wurzburg', 'Mannheim', 'Augsburg'} cc1: {'Kolkata', 'Bangalore', 'Mumbai', 'Delhi'} cc2: {'ALB', 'NY', 'TX'}このように、データ内の個別の成分を見つけることができます。エッジと頂点を使用するだけです。異なるデータでこのアルゴリズムを実行して前述したユースケースを満たすことができます。
2.最短経路
上記の例を続けるだけで、ドイツの都市とそれぞれの距離を示すグラフを作ることができます。
最短距離をとって、フランクフルト(出発ノード)からミュンヘンへの行き方を調べたいと思います。
この問題に使用するアルゴリズムは、ダイクストラ法と呼ばれます。ダイクストラ自身の言葉で次のように語られています:
ロッテルダムからフローニンゲンに移動する最短経路:
一般的には特定の都市から特定の都市へ移動するということは、最短パスのアルゴリズムであり、約20分で設計しました。ある朝、私はアムステルダムで若い婚約者と買い物をして疲れていました。私はコーヒーを飲むためにカフェテラスに座って最短経路のアルゴリズムを設計しました。先ほど言ったように、20分の発明でした。3年後の1959年に公開されました。この発表は読みやすく、非常に素晴らしいものです。優れたものになった理由の1つは、鉛筆と紙なしでデザインしたことです。鉛筆と紙なしでデザインしたため、回避可能な複雑さをすべて避けることができることが後になってわかりました。驚いたことに、このアルゴリズムは私の名声の礎石の1つになりました。— Edsger Dijkstra、ACMコミュニケーションズ、2001年のフィリップL.フラナとのインタビュー
用途
・最短ルートを見つけるために、ダイクストラアルゴリズムの一種がGoogleマップで広く使用されています。
・ウォルマートストアでは、すべての通路の間に異なる距離の通路があるため、通路 Aから通路 Dに移動する最短経路を顧客に提供したいと考えるでしょう。
・LinkedInでは一次的なつながりと二次的なつながりなど、つながりの度合いを表示しています。表示するために裏側で何が起こっているのでしょうか?
コード
print(nx.shortest_path(g, 'Stuttgart','Frankfurt',weight='weight')) print(nx.shortest_path_length(g, 'Stuttgart','Frankfurt',weight='weight'))次の方法で、すべてのペア間の最短パスを見つけることができます。
for x in nx.all_pairs_dijkstra_path(g,weight='weight'): print(x) -------------------------------------------------------- ('Mannheim', {'Mannheim': ['Mannheim'], 'Frankfurt': ['Mannheim', 'Frankfurt'], 'Karlsruhe': ['Mannheim', 'Karlsruhe'], 'Augsburg': ['Mannheim', 'Karlsruhe','Augsburg'], 'Kassel': ['Mannheim', 'Frankfurt', 'Kassel'], 'Wurzburg': ['Mannheim', 'Frankfurt', 'Wurzburg'], 'Munchen': ['Mannheim', 'Karlsruhe', 'Augsburg', 'Munchen'], 'Erfurt': ['Mannheim', 'Frankfurt', 'Wurzburg', 'Erfurt'], 'Numberg': ['Mannheim', 'Frankfurt', 'Wurzburg', 'Numberg'], 'Stuttgart': ['Mannheim', 'Frankfurt', 'Wurzburg', 'Numberg', 'Stuttgart']}) ('Frankfurt', {'Frankfurt': ['Frankfurt'], 'Mannheim': ['Frankfurt', 'Mannheim'], 'Kassel': ['Frankfurt', 'Kassel'], 'Wurzburg': ['Frankfurt', 'Wurzburg'], 'Karlsruhe': ['Frankfurt', 'Mannheim', 'Karlsruhe'], 'Augsburg': ['Frankfurt', 'Mannheim', 'Karlsruhe', 'Augsburg'], 'Munchen': ['Frankfurt', 'Wurzburg', 'Numberg', 'Munchen'], 'Erfurt': ['Frankfurt', 'Wurzburg', 'Erfurt'], 'Numberg': ['Frankfurt', 'Wurzburg', 'Numberg'], 'Stuttgart': ['Frankfurt', 'Wurzburg', 'Numberg', 'Stuttgart']})3.最小スパニングツリー
今度は別の問題です。私たちは水道管敷設会社またはインターネットの設備会社で働いています。 最小限のワイヤ/パイプを使用して、グラフ内のすべての都市を接続する必要があります。どうやって実現するのでしょうか?
用途
最小スパニングツリーは、コンピューターネットワーク、通信ネットワーク、運送ネットワーク、給水ネットワーク、および送電網(最初に発明された)を含むネットワークの設計に直接適用されます。
・MSTは巡回セールスマン問題の近似に使用されます。
・クラスタリング—最初にMSTを構築してから、クラスター間距離とクラスター内距離を使用してMSTの一部のエッジを分割するためのしきい値を決定します。
・画像セグメンテーション—ピクセルをノードとして、類似性の測度(色、強度など)をピクセル間の距離としてグラフを作成し、画像セグメンテーションを最初のMSTとして構築しました。コード
# nx.minimum_spanning_tree(g) returns a instance of type graph nx.draw_networkx(nx.minimum_spanning_tree(g))
ごらんのとおり、ワイヤを横展開することができます。4.ページランク
これは、Googleに長い間使用されているページソートアルゴリズムです。入力リンクと出力リンクの数と品質に基づいてページにスコアを割り当てます。用途
ページランクは、ネットワーク内のノードの重要度を推定する任意の場所で使用できます。
・引用を使って、最も影響力のある論文を見つけるために使用されています。
・Googleがページのランキングに使用しています。
・ツイート-ユーザーおよびツイートをランク付けするために使用できます。ユーザーAがユーザーBをフォローしている場合はユーザー間のリンクを作成し、ユーザーがツイートをツイート/リツイートする場合はユーザーとツイート間のリンクを作成します。
・レコメンドエンジンとして使用されています。コード
この例では、私たちが持っているFacebookユーザー間のエッジ/リンクのファイルをもとに、Facebookのデータを利用します。まず、以下を使用してFacebookのグラフを作成します。
# reading the dataset fb = nx.read_edgelist('../input/facebook-combined.txt', create_using = nx.Graph(), nodetype = int)次のようにして可視化します:
pos = nx.spring_layout(fb) import warnings warnings.filterwarnings('ignore') plt.style.use('fivethirtyeight') plt.rcParams['figure.figsize'] = (20, 15) plt.axis('off') nx.draw_networkx(fb, pos, with_labels = False, node_size = 35) plt.show()
次に、影響力の高いユーザーを探します。
直観的には、ページランクアルゴリズムは「友達が多い友達」が多いユーザーに高いスコアを与えます。pageranks = nx.pagerank(fb) print(pageranks)次の方法で、最も影響力のあるユーザー(ソートされたページランク)を取得できます。
import operator sorted_pagerank = sorted(pageranks.items(), key=operator.itemgetter(1),reverse = True) print(sorted_pagerank) ------------------------------------------------------ [(3437, 0.007614586844749603), (107, 0.006936420955866114), (1684, 0.0063671621383068295), (0, 0.006289602618466542), (1912, 0.0038769716008844974), (348, 0.0023480969727805783), (686, 0.0022193592598000193), (3980, 0.002170323579009993), (414, 0.0018002990470702262), (698, 0.0013171153138368807), (483, 0.0012974283300616082), (3830, 0.0011844348977671688), (376, 0.0009014073664792464), (2047, 0.000841029154597401), (56, 0.0008039024292749443), (25, 0.000800412660519768), (828, 0.0007886905420662135), (322, 0.0007867992190291396),......]上のIDはもっとも影響のあるユーザーです。
私達はもっとも影響のあるユーザーの部分グラフをみることができます。first_degree_connected_nodes = list(fb.neighbors(3437)) second_degree_connected_nodes = [] for x in first_degree_connected_nodes: second_degree_connected_nodes+=list(fb.neighbors(x)) second_degree_connected_nodes.remove(3437) second_degree_connected_nodes = list(set(second_degree_connected_nodes)) subgraph_3437 = nx.subgraph(fb,first_degree_connected_nodes+second_degree_connected_nodes) pos = nx.spring_layout(subgraph_3437) node_color = ['yellow' if v == 3437 else 'red' for v in subgraph_3437] node_size = [1000 if v == 3437 else 35 for v in subgraph_3437] plt.style.use('fivethirtyeight') plt.rcParams['figure.figsize'] = (20, 15) plt.axis('off') nx.draw_networkx(subgraph_3437, pos, with_labels = False, node_color=node_color, node_size=node_size ) plt.show()
5. 中心性測定
機械学習モデルの機能として使用できる中心性の尺度は多数あります。そのうち2つを説明します。ここで他の尺度を参照できます。
媒介中心性:重要な友人ばかりをもつユーザーだけではなく、ユーザーがさまざまな地域からコンテンツを表示できるように、ある地域を別の地域に接続するユーザーも重要です。Betweenness Centralityは、特定のノードが他の2つのノード間で選択された最短のパスに入ってくる回数を定量化します。
次数中心性:単純にノードの接続数です。用途
中心性測定は、あらゆる機械学習モデルの機能として使用できます。
コード
次はサブグラフの媒介中心性を見つけるためのコードです。
pos = nx.spring_layout(subgraph_3437) betweennessCentrality = nx.betweenness_centrality(subgraph_3437, normalized=True, endpoints=True) node_size = [v * 10000 for v in betweennessCentrality.values()] plt.figure(figsize=(20,20)) nx.draw_networkx(subgraph_3437, pos=pos, with_labels=False, node_size=node_size ) plt.axis('off')
ノード間の中心性の値で大きさが決まったノードを確認できます。それらは情報の伝達者と考えることができます。中心性の値が大きいノードで分割すると、複数のグラフに分割できます。結論
この記事では、私たちの生活を変えた最も影響力のあるグラフアルゴリズムについて説明しました。
大量のソーシャルデータが出現したことで、ネットワーク分析はモデルの改善と価値の創出に大いに役立つ可能性があります。
そして、もう少し世の中が理解できます。
多くのグラフアルゴリズムがありますが、本記事で紹介したものは私が最も気に入っているアルゴリズムです。必要に応じて、アルゴリズムを詳細に調べてください。この記事は、より知識を広めることを目的としています。
お気に入りのアルゴリズムが他にあれば著者に教えてください。
こちらにKaggleカーネルの全てのコードがあります。
この記事で紹介したグラフアルゴリズムがもっと知りたければ、CourseraでUCSANDiegoが提供しているビッグデータのグラフ分析コースでグラフ理論の基礎を学ぶことを強くお勧めします。原著者からのメッセージ
読んでくれてありがとうございます。
今後も初心者向けの投稿を書く予定です。
Mediumでフォローアップするか、ブログをサブスクライブして、通知を受けてください。
いつもでも、フィードバックと建設的な批判を歓迎しています。
Twitterの @mlwhizアカウントに連絡してください。翻訳協力
Author: Rahul Agarwal
Thank you for letting us share your knowledge!記事選定: yokomichi
翻訳/技術監査: @aoharu / @nyorochan
Markdown化: @ricky私達と一緒に記事を作りませんか?
私たちは海外の良質な記事の日本語訳を行い、複数人の優秀なエンジニアの方の協力を経て記事を公開しています。
活動に共感し良い記事を公開することに興味のある方はぜひご連絡ください!
MailやTwitter等でメッセージを頂ければ、選考のちSlackチームにご招待いたしますのでご連絡頂けますと幸いです。
- 投稿日:2019-09-29T21:55:45+09:00
PythonとOpenCVでリアルタイムで顔検出する(Windows10)
環境
Windows 10 Pro
行程
- Anacondaをインストール
- Anaconda Navigatorで仮想環境を作成
- 作成した仮想環境にOpenCVをインストール
- 顔のカスケードファイルをダウンロード
- ページを参考にコードをコピペ
1.Anacondaをインストール
適当にググってやりました。
2.Anaconda Navigatorで仮想環境を作成
コチラの記事を参照のこと。
Anaconda navigatorで仮想環境を作ってターミナルを開く(Windows10)3.作成した仮想環境にOpenCVをインストール
コチラのページを参考にさせていただいた。
pip で OpenCV のインストール4.顔のカスケードファイルをダウンロード
GitHubのOpenCVのページ からダウンロードできる。
5.ページを参考にコードをコピペ
このページ( Python, OpenCVで顔検出と瞳検出(顔認識、瞳認識) )の下の方にある、
「カメラを使ってリアルタイムで顔検出と瞳検出」を参考にさせていただいた。結果
カメラ画像の顔にリアルタイムで四角形を表示することができました。
(動作画像はすっぴんなので載せられません)
- 投稿日:2019-09-29T21:46:30+09:00
【顔認識入門】haar cascades+vgg16で「まゆゆ」の顔識別♪
昨夜とほぼ同様だが、以前収集したAKBメンバーの顔を学習して、顔識別したら名前を表示するようにした。
最終的には、顔識別したら音声で「おはよう、うわんさん」みたいなことをやろうと思っていますが、今回は表示までで記事にします。やったこと
・AKBメンバーの顔学習
・組み込んで名前表示する
・結果・AKBメンバーの顔学習
学習は以前総選挙メンバー学習のときに利用したアプリとデータを使用しました。
データ読込は以下のコードを使っています。
・face_recognition/getDataSet.py./train_images |--0 | 1.jpg ... |--1 . .今回は、
name_list=['まゆゆ','さっしー','きたりえ','じゅりな','おぎゆか','あかりんだーすー']
の人たちの顔写真を利用いたしました。
顔写真の抽出は以下で実施しています。ここでも以下を使っています。
cascade_path = "/Users/user/haarcascade/haarcascade_frontalface_alt2.xml"
・DataManage/face_detect.py
学習はvgg16のFinetuningです。
・face_recognition/akb_VGG16.py
100epochの時点で以下のようなval_lossとval_accです。
学習データが少ないのでこれ以上学習しても精度が上がるわけもないので、これで動画になったときの精度を見たいと思います。
いずれにしても静的識別というレベルでは、6人の顔認識はほぼ出来ていると思います。Train on 360 samples, validate on 60 samples Epoch 1/1 360/360 [==============================] - 4s 12ms/step - loss: 2.7682e-04 - acc: 1.0000 - val_loss: 0.4305 - val_acc: 0.9167・組み込んで名前表示する
今回作成したアプリはいかに置きました。
・face_recognition/recognize_vgg16_camera.py
まず、識別した後の名前は前回はvgg16の表示を利用しましたが、それが使えないので、以下のように変更しました。
すなわち、学習のフォルダに合わせて名前リストを作成し、それを識別結果に合わせて表示することとしました。def yomikomi(model,img): name_list=['まゆゆ','さっしー','きたりえ','じゅりな','おぎゆか','あかりんだーすー'] x = image.img_to_array(img) x = np.expand_dims(x, axis=0) preds = model.predict(x) index=np.argmax(preds) print(index,name_list[index]) return name_list[index]modelは学習で利用したmodelを使います。
def model_definition(): batch_size = 2 num_classes = 6 img_rows, img_cols=224,224 input_tensor = Input((img_rows, img_cols, 3)) # 学習済みのVGG16をロード # 構造とともに学習済みの重みも読み込まれる vgg16 = VGG16(weights='imagenet', include_top=False, input_tensor=input_tensor) # FC層を構築 top_model = Sequential() top_model.add(Flatten(input_shape=vgg16.output_shape[1:])) #vgg16,vgg19,InceptionV3, ResNet50 top_model.add(Dense(256, activation='relu')) top_model.add(Dropout(0.5)) top_model.add(Dense(num_classes, activation='softmax')) # VGG16とFCを接続 model = Model(input=vgg16.input, output=top_model(vgg16.output)) model.summary() # 新たに学習した重みを読み込む model.load_weights('params_model_VGG16L3_i_100.hdf5') return model日本語の表示を動画中にするのが少し大変です。
この技術は以前QRコードの日本語を画面に表示させるときに利用しました。
【参考】
・Python + OpenCV でWindowsの日本語フォントを描画する
ということで、以下のように変更します。
※変更を理解するのに必要な部分だけ記載しますdef main(): #カスケード分類器の特徴量を取得する cascade = cv2.CascadeClassifier(cascade_path) color = (255, 255, 255) #白 ... model=model_definition() ## Use HGS創英角ゴシックポップ体標準 to write Japanese. fontpath ='C:\Windows\Fonts\HGRPP1.TTC' # Windows10 だと C:\Windows\Fonts\ 以下にフォントがあります。 font = ImageFont.truetype(fontpath, 16) # フォントサイズが32 font0 = cv2.FONT_HERSHEY_SIMPLEX #fps表示に利用 while True: b,g,r,a = 0,255,0,0 #B(青)・G(緑)・R(赤)・A(透明度) ... #グレースケール変換 image_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) facerect = cascade.detectMultiScale(image_gray, scaleFactor=1.1, minNeighbors=2, minSize=(30, 30)) img=frame if len(facerect) > 0: #検出した顔を囲む矩形の作成 for rect in facerect: y,x=tuple(rect[0:2]) y2,x2=tuple(rect[0:2]+rect[2:4]) print(y,x,y2,x2) cv2.rectangle(frame, tuple(rect[0:2]),tuple(rect[0:2]+rect[2:4]), color, thickness=2) roi = frame[y:y2, x:x2] #frame[y:y+h, x:x+w] try: roi = cv2.resize(roi, (int(224), 224)) #cv2.imshow('roi',roi) #確認のために表示 txt=yomikomi(model,roi) #print("txt",txt) #確認のために表示 except: txt="" continue img_pil = Image.fromarray(frame) # 配列の各値を8bit(1byte)整数型(0~255)をPIL Imageに変換。 draw = ImageDraw.Draw(img_pil) # drawインスタンスを生成 position = (y, x) # テキスト表示位置 draw.text(position, txt, font = font , fill = (b, g, r, a) ) # drawにテキストを記載 fill:色 BGRA (RGB) img = np.array(img_pil) # PIL を配列に変換 cv2.imshow('test',img) key = cv2.waitKey(1)&0xff if is_video=="True": img_dst = cv2.resize(img, (int(224), 224)) #1280x960 out.write(img_dst) print(is_video)結果
ここまでやったが、どうも精度が悪い。
もともと傾いていると顔さえ認識できないが、さらに認識しても誰なのかの識別がどうもできない。
以下に「あかりんだーすーさん」の画像を変化させて見せた時の記録された動画を貼っておく。face recognition by vgg16
※画像をクリックするとYouTube動画につながりますまとめ
・顔画像を学習して顔識別してみた
・識別結果の日本語を動画に貼り付けた・識別結果はいいはずなのに精度が悪い理由が不明である

- 投稿日:2019-09-29T21:46:30+09:00
【顔認識入門】haar cascades+vgg16でカメラ動画で「まゆゆ」の顔識別♪
昨夜とほぼ同様だが、以前収集したAKBメンバーの顔を学習して、顔識別したら名前を表示するようにした。
最終的には、顔識別したら音声で「おはよう、うわんさん」みたいなことをやろうと思っていますが、今回は表示までで記事にします。やったこと
・AKBメンバーの顔学習
・組み込んで名前表示する
・結果・AKBメンバーの顔学習
学習は以前総選挙メンバー学習のときに利用したアプリとデータを使用しました。
データ読込は以下のコードを使っています。
・face_recognition/getDataSet.py./train_images |--0 | 1.jpg ... |--1 . .今回は、
name_list=['まゆゆ','さっしー','きたりえ','じゅりな','おぎゆか','あかりんだーすー']
の人たちの顔写真を利用いたしました。
顔写真の抽出は以下で実施しています。ここでも以下を使っています。
cascade_path = "/Users/user/haarcascade/haarcascade_frontalface_alt2.xml"
・DataManage/face_detect.py
学習はvgg16のFinetuningです。
・face_recognition/akb_VGG16.py
100epochの時点で以下のようなval_lossとval_accです。
学習データが少ないのでこれ以上学習しても精度が上がるわけもないので、これで動画になったときの精度を見たいと思います。
いずれにしても静的識別というレベルでは、6人の顔認識はほぼ出来ていると思います。Train on 360 samples, validate on 60 samples Epoch 1/1 360/360 [==============================] - 4s 12ms/step - loss: 2.7682e-04 - acc: 1.0000 - val_loss: 0.4305 - val_acc: 0.9167・組み込んで名前表示する
今回作成したアプリはいかに置きました。
・face_recognition/recognize_vgg16_camera.py
まず、識別した後の名前は前回はvgg16の表示を利用しましたが、それが使えないので、以下のように変更しました。
すなわち、学習のフォルダに合わせて名前リストを作成し、それを識別結果に合わせて表示することとしました。def yomikomi(model,img): name_list=['まゆゆ','さっしー','きたりえ','じゅりな','おぎゆか','あかりんだーすー'] x = image.img_to_array(img) x = np.expand_dims(x, axis=0) preds = model.predict(x) index=np.argmax(preds) print(index,name_list[index]) return name_list[index]modelは学習で利用したmodelを使います。
def model_definition(): batch_size = 2 num_classes = 6 img_rows, img_cols=224,224 input_tensor = Input((img_rows, img_cols, 3)) # 学習済みのVGG16をロード # 構造とともに学習済みの重みも読み込まれる vgg16 = VGG16(weights='imagenet', include_top=False, input_tensor=input_tensor) # FC層を構築 top_model = Sequential() top_model.add(Flatten(input_shape=vgg16.output_shape[1:])) #vgg16,vgg19,InceptionV3, ResNet50 top_model.add(Dense(256, activation='relu')) top_model.add(Dropout(0.5)) top_model.add(Dense(num_classes, activation='softmax')) # VGG16とFCを接続 model = Model(input=vgg16.input, output=top_model(vgg16.output)) model.summary() # 新たに学習した重みを読み込む model.load_weights('params_model_VGG16L3_i_100.hdf5') return model日本語の表示を動画中にするのが少し大変です。
この技術は以前QRコードの日本語を画面に表示させるときに利用しました。
【参考】
・Python + OpenCV でWindowsの日本語フォントを描画する
ということで、以下のように変更します。
※変更を理解するのに必要な部分だけ記載しますdef main(): #カスケード分類器の特徴量を取得する cascade = cv2.CascadeClassifier(cascade_path) color = (255, 255, 255) #白 ... model=model_definition() ## Use HGS創英角ゴシックポップ体標準 to write Japanese. fontpath ='C:\Windows\Fonts\HGRPP1.TTC' # Windows10 だと C:\Windows\Fonts\ 以下にフォントがあります。 font = ImageFont.truetype(fontpath, 16) # フォントサイズが32 font0 = cv2.FONT_HERSHEY_SIMPLEX #fps表示に利用 while True: b,g,r,a = 0,255,0,0 #B(青)・G(緑)・R(赤)・A(透明度) ... #グレースケール変換 image_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) facerect = cascade.detectMultiScale(image_gray, scaleFactor=1.1, minNeighbors=2, minSize=(30, 30)) img=frame if len(facerect) > 0: #検出した顔を囲む矩形の作成 for rect in facerect: y,x=tuple(rect[0:2]) y2,x2=tuple(rect[0:2]+rect[2:4]) print(y,x,y2,x2) cv2.rectangle(frame, tuple(rect[0:2]),tuple(rect[0:2]+rect[2:4]), color, thickness=2) roi = frame[y:y2, x:x2] #frame[y:y+h, x:x+w] try: roi = cv2.resize(roi, (int(224), 224)) #cv2.imshow('roi',roi) #確認のために表示 txt=yomikomi(model,roi) #print("txt",txt) #確認のために表示 except: txt="" continue img_pil = Image.fromarray(frame) # 配列の各値を8bit(1byte)整数型(0~255)をPIL Imageに変換。 draw = ImageDraw.Draw(img_pil) # drawインスタンスを生成 position = (y, x) # テキスト表示位置 draw.text(position, txt, font = font , fill = (b, g, r, a) ) # drawにテキストを記載 fill:色 BGRA (RGB) img = np.array(img_pil) # PIL を配列に変換 cv2.imshow('test',img) key = cv2.waitKey(1)&0xff if is_video=="True": img_dst = cv2.resize(img, (int(224), 224)) #1280x960 out.write(img_dst) print(is_video)結果
ここまでやったが、どうも精度が悪い。
もともと傾いていると顔さえ認識できないが、さらに認識しても誰なのかの識別がどうもできない。
以下に「あかりんだーすーさん」の画像を変化させて見せた時の記録された動画を貼っておく。face recognition by vgg16
※画像をクリックするとYouTube動画につながりますまとめ
・顔画像を学習してカメラ動画で顔識別してみた
・識別結果の日本語を動画に貼り付けた・静的識別結果はいいはずなのに精度が悪い理由が不明である
- 投稿日:2019-09-29T21:06:02+09:00
PythonでEither実装してみた
これまでPythonをメインに書いてきたのですが、最近Haskellを学んでいて、EitherはPythonでどう実装するんだろう、と思い自分で実装してみました。
実装
PythonによるEitherの実装を示します。
Functorとして扱えるように、fmapを実装しています。
※Monadとして扱うようにするためには、さらなる関数の実装が必要ですが、今後の課題としたいと思います。pither.pyfrom typing import Any, Callable class Either: pass class Right(Either): def __init__(self, v: Any): self.__v = v def value(self) -> Any: return self.__v class Left(Either): def __init__(self, v: Any): self.__v = v def value(self) -> Any: return self.__v def fmap(f: Callable[[Any], Any], x: Either) -> Either: ''' >>> fmap(lambda x: x + 1, Right(2)).value() 3 >>> fmap(lambda x: x + 1, Left('string')).value() 'string' >>> fmap(lambda x: x + 1, Right('string')).value() 'must be str, not int' ''' if not isinstance(f, Callable): raise TypeError('f should be Callable instance') if not isinstance(x, Either): raise TypeError('x should be Either instance') if isinstance(x, Right): try: return Right(f(x.value())) except Exception as e: return Left(str(e)) if isinstance(x, Left): return x if __name__ == '__main__': import doctest doctest.testmod()構造としていたってシンプルです。
Eitherという親クラスを継承したRightクラスとLeftクラスを実装しています。
そして、Right、Leftクラスともに1つの値をコンストラクタの引数に渡し、その値を参照するvalueメソッドが実装されているのみです。
fmapでは第2引数がRightインスタンスのときはラップされた値に関数を適用し、結果をRightインスタンスで返す一方、Leftインスタンスの場合は、そのまま返すような実装となっています。
また、Pythonは動的型付け言語であるため、型チェックを自前で実装しています。
fはCallableであることをチェックしていますが、fの引数の型まではチェックできないため、不完全です。
もう少しいいやり方があるか考えてみようと思っています。
(いざ静的型付け言語を学んでみると動的型付け言語は機能不足に感じてきてしまいますね…)まとめ
PythonでEitherの実装をしてみました。
先に述べた通り、Monadとして扱うようにするためには、さらなる関数の実装が必要なので、今後残りの関数の実装をしていきたいと思います。
- 投稿日:2019-09-29T20:53:07+09:00
PythonでKintoneとTwilioを結合する
今回は壮大なテーマがあったんですが。ちょっと外れてPythonでKintoneとTwilioを結合するバックエンドを作ったので書いておこうと思います。
なぜこの部分を作ったのか?
それは今後必要になってくるために作っていました。
『大垣Pythonハッカソン@ヒーローズ・リーグ 2019 by MA』 に参加しておりました。
そのときにふとしたタイミングでPythonでKintonとTwilioを結合するプログラムを作成することになりました。
そのときに利用させていただきました@RyBBさんの『kintone REST API について (GET編)』のPythonコードを利用させていただきました。
念の為おさらいの意味で載せておこうと思います。kintone_output.py#!/usr/bin/python # _*_ coding: utf-8 _*_ import requests #APIトークン画面のREST APIでこのアプリを操作するためのトークンを生成できますの例に書かれたURLとAPIトークンを利用してください URL = "https://サブドメイン/k/v1/record.json?app=4&id=1" API_TOKEN = "APIトークンを記述" def get_kintone(url, api_token): """kintoneのレコードを全件取得する関数""" headers = {"X-Cybozu-API-Token": api_token} resp = requests.get(url, headers=headers) return resp if __name__ == "__main__": RESP = get_kintone(URL, API_TOKEN) print(RESP.text)でここでKintoneのデータがまるごと取得できます。
ここでいつもの間違いがURLと書きながら実際のURLを記載してはいけません。
REST API用のURLが準備されています。
APIトークン設定画面に記載されています。
そちらを利用してください。お次はKintoneからデータを取得後の操作を記載します。
このコードはハッカソン界の赤い芸人@mobilebizことTwilioの高橋さんの『Twilio with Python』のコールバック用コードを流用・魔改造しながら作成しました。
連結させるためKintoneのURL情報の生成とAPIトークンを利用していますので気をつけてください。
JSONの部分とKintone接続部分はオリジナルに書かれていませんので下記のコードで実装できます。callback.pyfrom twilio.rest import Client import kintone_output #この部分に上記で実装したkintone_outputをインポートしてくる import json #PythonのJSONライブラリーをインポートする #Twilio SID & auth_token(Twilioのコンソールにて取得可能) account_sid = "" # Your Account SID from www.twilio.com/console auth_token = "" # Your Auth Token from www.twilio.com/console #kintone API用(この記載はkintone_output.pyからコピーして生成させる) URL = "https://サブドメイン/k/v1/record.json?app=4&id=1" API_TOKEN = "APIトークン" #Twilio API Call client = Client(account_sid, auth_token) #Kintone data get(Kintoneからデータを引っ張ってくる上記のkintone_outputを変数として実行する) to_client_json = kintone_output.get_kintone(URL,API_TOKEN) #json取得(これを実装するとJSONパースができる(KintoneからのデータはJSON形式なので気をつけること)) to_client = json.loads(to_client_json.text) #JSONをロードする to_direct_tel = to_client['record']['tel'] #JSONから一部レコードを取得する(TELを取得する) to_client_tel = to_direct_tel['value'] #JSON['TEL']レコードから値を取得する #電話番号の生成(国別番号付きコールバック用電番(E.164形式)の生成) to_contory = "+81" #国別コード to_tel = to_client_tel[1:] #電番の頭一桁を削る to_tel_number = to_tel.replace("-","") #−を削る to_client = to_contory + to_tel_number #国別番号と電番を直結 #call back call = client.calls.create( to = to_client, #E.164形式形式の電話番号を記載 from_ = "", #コールバック用電話番号をTwilioコンソールから記載 url = "http://demo.twilio.com/docs/voice.xml" ) print(call.sid)このコードにてKintoneからのデータの取得からE.164形式の電話番号の生成Twilioからのコールバックまで実装できます。
注意ですがこれは実装してしまうと実際に電話をかけることができますのでご注意ください。テストには必ずToは自分の携帯電話の電話番号を設定してください。
これができないと他人に迷惑をかけることになるので気をつけてください。
これからはというと次の壮大なテーマ災害をハックに入ります。
というのは『災害時に何を考えるのか?』で書きましたOpenStreetMapでクライシスマッピングに役立つツール作りに取り掛かりたいと思います。
これも多分このコードで実装は可能なのでKintoneからGetの部分で流用する予定です。うーん。 コードは奥深いですね。
- 投稿日:2019-09-29T20:46:42+09:00
Python 機械学習プログラミングの備忘録その5(主成分分析)
1.はじめに
Python機械学習プログラミング[第2版] という本を買って勉強を始めました。効率的な学習を進める為には、勉強した内容をアウトプットするのが効果的ということで、勉強した内容を備忘録の形でここに残すことを進めています。
なお、本ではコードを一部 jupyter notebook形式で記載しているようですが、ここでは.py形式でも実行できるような形式で記載したいと思います。
今回は、第5章次元削減の中の主成分分析です。
2.主成分分析(wineデータ)
主成分分析の目的は、分散が最大となる方向を複数見つけ出し、寄与率の高いものに絞り込み(次元削減し)、データを新たな空間に射影することです。
まず、テキストにあるコードを実行してみましょう。
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler import numpy as np import matplotlib.pyplot as plt # データセットの読み込みとサマリー表示 df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/' 'machine-learning-databases/wine/wine.data', header=None) df_wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols', 'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue', 'OD280/OD315 of diluted wines', 'Proline'] print(df_wine.head()) print() # データセットのトレーニングデータとテストデータへの分割(7:3) X, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, stratify=y, random_state=0) print('X_train.shape = ', X_train.shape) print('y_train.shape = ', y_train.shape) # Xデータの標準化 sc = StandardScaler() X_train_std = sc.fit_transform(X_train) X_test_std = sc.transform(X_test) # 固有値と固有ベクトルの計算 cov_mat = np.cov(X_train_std.T) # 共分散行列を計算 eigen_vals, eigen_vecs = np.linalg.eig(cov_mat) # 共分散行列から固有値と固有ベクトルを計算 print('\nEigenvalues \n%s' % eigen_vals) # 固有値の表示 print('\nEigenvectors \n%s' % eigen_vecs) # 固有ベクトルの表示
wineデータセットを読み込み、トレインとテストに7:3で分割します。ここで実際に使うのはトレインデータのみです。X_train.shape = (124, 13)なので、13次元のデータが124個あるわけです。X_trainデータを標準化し、共分散行列(cov_mat)から固有値(Eigenvalues)と固有ベクトル(Eigenvectors)を計算します。13次元のデータなので、固有値は13個、それに対応する固有ベクトルは、13次元のものが13個得られます。
# 主成分のパレート図表示 tot = sum(eigen_vals) var_exp = [(i / tot) for i in sorted(eigen_vals, reverse=True)] cum_var_exp = np.cumsum(var_exp) plt.bar(range(1, 14), var_exp, alpha=0.5, align='center', label='individual explained variance') plt.step(range(1, 14), cum_var_exp, where='mid', label='cumulative explained variance') plt.ylabel('Explained variance ratio') plt.xlabel('Principal component index') plt.legend(loc='best') plt.tight_layout() plt.show() # 射影行列wの作成 eigen_pairs = [(np.abs(eigen_vals[i]), eigen_vecs[:, i]) # 固有対(固有値と固有ベクトルのセット)を作成 for i in range(len(eigen_vals))] eigen_pairs.sort(key=lambda k: k[0], reverse=True) # 固有対のソート w = np.hstack((eigen_pairs[0][1][:, np.newaxis], eigen_pairs[1][1][:, np.newaxis])) # 上位2つのベクトルを取得 print('Matrix W:\n', w) # 射影行列w(13行×2列)を表示 # データセットを射影行列wで変換 X_train_pca = X_train_std.dot(w) # 変換したデータをプロット colors = ['r', 'b', 'g'] markers = ['s', 'x', 'o'] for l, c, m in zip(np.unique(y_train), colors, markers): plt.scatter(X_train_pca[y_train == l, 0], X_train_pca[y_train == l, 1], c=c, label=l, marker=m) plt.xlabel('PC 1') plt.ylabel('PC 2') plt.legend(loc='lower left') plt.tight_layout() plt.show()
13個ある固有値の個々の大きさは、全体への寄与度を表すので、パレート図にしてみます。折れ線グラフは累積寄与度を表すので、上位2つの固有値で、全体の6割近くに寄与することが分かります。固有対(固有値と固有ベクトルをセットしたもの)をソートし、上位2つの固有ベクトルを抽出し、射影行列W(13行×2列)を作成します。
13次元のトレイニングデータと2次元の射影行列の内積を取ることで、トレイニングデータが2次元に変換されます。これで、2次元グラフにプロット出来るようになるわけです。
実際に、2次元グラフにプロットすると、一目でこれなら線形分割できそうな感じが分かると思います。
3.主成分分析(irisデータ)
テキストには載っていませんが、シンプルなirisデータセットでも、やってみます。せっかくなので、共分散行列と固有値、固有ベクトルの関係も確認してみましょう。
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler import numpy as np import matplotlib.pyplot as plt from sklearn import datasets # irisデータセットの読み込み iris = datasets.load_iris() X = iris.data y = iris.target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, stratify=y, random_state=0) print('X_train.shape = ', X_train.shape) print('y_train.shape = ', y_train.shape) # Xデータの標準化 sc = StandardScaler() X_train_std = sc.fit_transform(X_train) X_test_std = sc.transform(X_test) # 固有値と固有ベクトルの計算 cov_mat = np.cov(X_train_std.T) # 共分散行列を計算 eigen_vals, eigen_vecs = np.linalg.eig(cov_mat) # 共分散行列から固有値と固有ベクトルを計算 print('\ncov_mat \n%s' % cov_mat) # 共分散行列を表示 print('\nEigenvalues \n%s' % eigen_vals) # 固有値の表示 print('\nEigenvectors \n%s' % eigen_vecs) # 固有ベクトルの表示 array = np.array([[eigen_vals[0], 0, 0, 0], [0, eigen_vals[1], 0, 0], [0, 0, eigen_vals[2], 0], [0, 0, 0, eigen_vals[3]]]) # eigen_valsからarrayを作成 print('\narray \n%s' % array) print('\nEigenvectors(-1) \n%s' % np.linalg.inv(eigen_vecs)) # eigen_vecsの逆行列 results = eigen_vecs.dot(array).dot(np.linalg.inv(eigen_vecs)) print('\nEigenvectors * array * Eigenvectors(-1) = \n%s' % results)
train.shape = (105, 4)なので、トレインデータは4次元です。なので、固有値(Eigenvalues)は4個、固有ベクトル(Eigenvectors)は4次元が4個です。さて、共分散行列(cov_mat)、固有値(Eigenvalues)、固有ベクトル(Eigenvectors)の関係を見てみましょう。
固有値(Eigenvalues)を対角に入れ、その他を0とした行列を array、固有ベクトル(Eigenvectors)の逆行列を Eigenvectors(-1)とします。
そうすると、共分散行列 = 固有ベクトル * array * 固有ベクトルの逆行列 という関係にあることが分かると思います (*は内積)。ちなみに、ある正方行列をこの様な形に分解することを固有値分解と言います。
さて、この後は、
# 主成分のパレート図表示 tot = sum(eigen_vals) var_exp = [(i / tot) for i in sorted(eigen_vals, reverse=True)] cum_var_exp = np.cumsum(var_exp) plt.bar(range(1, 5), var_exp, alpha=0.5, align='center', label='individual explained variance') plt.step(range(1, 5), cum_var_exp, where='mid', label='cumulative explained variance') plt.ylabel('Explained variance ratio') plt.xlabel('Principal component index') plt.legend(loc='best') plt.tight_layout() plt.show() # 射影行列wの作成 eigen_pairs = [(np.abs(eigen_vals[i]), eigen_vecs[:, i]) # 固有対(固有値と固有ベクトルのセット)を作成 for i in range(len(eigen_vals))] eigen_pairs.sort(key=lambda k: k[0], reverse=True) # 固有対のソート w = np.hstack((eigen_pairs[0][1][:, np.newaxis], eigen_pairs[1][1][:, np.newaxis])) # 上位2つのベクトルを取得 print('Matrix W:\n', w) # 射影行列w(4行×2列)を表示 # データセットを射影行列wで変換 X_train_pca = X_train_std.dot(w) # 変換したデータをプロット colors = ['r', 'b', 'g'] markers = ['s', 'x', 'o'] for l, c, m in zip(np.unique(y_train), colors, markers): plt.scatter(X_train_pca[y_train == l, 0], X_train_pca[y_train == l, 1], c=c, label=l, marker=m) plt.xlabel('PC 1') plt.ylabel('PC 2') plt.legend(loc='lower left') plt.tight_layout() plt.show()
上位2つの固有ベクトルを抽出し、射影行列w(4行×2列)を作成し、トレイニングデータと射影行列の内積を取ると、4次元のトレイニングデータが2次元に変換されます。2次元に変換されたデータをみると、クラス0は明確に線形分離できそうですが、クラス1と2は少し混じってしまっている感じですね。
4.主成分分析(sklearnライブラリー)
さて、sklearnには、主成分分析(PCA)がライブラリーにあるので、テキストのコードにある様に、これを使ってwineデータを主成分分析し、決定領域を表示をしてみましょう。
from sklearn.decomposition import PCA from sklearn.linear_model import LogisticRegression from matplotlib.colors import ListedColormap # 決定領域表示関数 def plot_decision_regions(X, y, classifier, resolution=0.02): # setup marker generator and color map markers = ('s', 'x', 'o', '^', 'v') colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan') cmap = ListedColormap(colors[:len(np.unique(y))]) # plot the decision surface x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1 x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1 xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution)) Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T) Z = Z.reshape(xx1.shape) plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap) plt.xlim(xx1.min(), xx1.max()) plt.ylim(xx2.min(), xx2.max()) # plot class samples for idx, cl in enumerate(np.unique(y)): plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1], alpha=0.6, c=cmap(idx), edgecolor='black', marker=markers[idx], label=cl) # sklearnによるPCA pca = PCA(n_components=2) X_train_pca = pca.fit_transform(X_train_std) X_test_pca = pca.transform(X_test_std) lr = LogisticRegression(solver='lbfgs', multi_class='auto') # 引数追加 lr = lr.fit(X_train_pca, y_train) # 学習データの決定領域表示 plot_decision_regions(X_train_pca, y_train, classifier=lr) plt.title('PCA for traning_data') plt.xlabel('PC 1') plt.ylabel('PC 2') plt.legend(loc='lower left') plt.tight_layout() plt.show() # テストデータの決定領域表示 plot_decision_regions(X_test_pca, y_test, classifier=lr) plt.title('PCA for test_data') plt.xlabel('PC 1') plt.ylabel('PC 2') plt.legend(loc='lower left') plt.tight_layout() plt.show() # 主成分の寄与率表示 pca = PCA(n_components=None) X_train_pca = pca.fit_transform(X_train_std) print('\npca.explained_variance_ratio_\n%s' %pca.explained_variance_ratio_)
sklearn のライブラリーを使うと簡単ですね。なお、sklearnのバージョン(私が使っているのは 0.21.3)の関係で、テキストのコードのままだとワーニングが出るので、lr = LogisticRegression()に引数を追加しています。






- 投稿日:2019-09-29T20:12:55+09:00
さくらのレンタルサーバーにpyenvを構築する方法
なんか間違ってたり、難しい方法でやってるの多かったから。あと、自分のブログで書くほどのことでもないから。
bashに変更
$ chsh -s /usr/local/bin/bash $ cat << EOS > ~/.bash_profile if [ -f ~/.bashrc ]; then . ~/.bashrc fi PATH=$PATH:$HOME/bin:$HOME/usr/local/bin EOS $ exec $SHELL -lpyenvをインストール
$ git clone https://github.com/pyenv/pyenv.git ~/.pyenv $ cat << EOS >> ~/.bash_profile export PATH export PYENV_ROOT="$HOME/.pyenv" export PATH="$PYENV_ROOT/bin:$PATH" export TMPDIR=/home/nashio/tmp eval "$(pyenv init -)" pyenv rehash EOS $ source ~/.bash_profilepyenv を使って好きなバージョンをインストール
$ pyenv install --list $ pyenv install 3.7.4 $ pyenv global 3.7.4 $ which python /home/ユーザー名/.pyenv/shims/python
- 投稿日:2019-09-29T19:20:55+09:00
█║▌ Distributed Fault-Tolerant Authentication Management & Identification Control System
At the rate at which technology today is moving forward with the Internet speeds increasing manifold, with IoT gaining prominence and organizations more distributed across the globe than before, the authentication software, systems and architectures remain fairly primitive.
Among the many reasons attributing to this is corporates that build these authenticating systems and software hold on to these products as their main source of income. The insight and research in these areas has also been fairly mundane. Though there's been enough research funding, what's missing has been the intellect and knowledge required to build large-scale distributed and decentralized authentication systems and architectures.
Large-scale authentication systems and architectures used in building them must allow both manned [computers, tablets, phones, virtual machines etc] and unmanned [IoT devices etc] to authenticate and authorize themselves without a centralized bottleneck, as seen in authentication systems like LDAP, Active Directory and others.
As experienced on a daily basis, these centralized authentication systems are not scalable or fault-tolerant without a sane fail-over MTBF [Mean Time Between Failure] causing business disruptions on a regular and long-lasting basis.
■ What can be done about this?
Let us acquaint ourselves with AuthControl. SynchroKnot designed and developed AuthControl as a result of realizing inadequacies in the centralized authentication systems [LDAP & Active Directory].
AuthControl was designed with the following flexibility in mind:
- Ability for authentication to be either centralized, distributed, decentralized or a combination of these.
- Ability to be seamlessly and transparently scaled on-demand across the globe with no downtime.
- Ability to be used by standard operating systems within their security framework without custom or proprietary software, enhancements, modifications or hacks.
- Ability to be used across all devices that can make a simple https call. and much more.
■ What is AuthControl?
AuthControl is SynchroKnot's unique Distributed Fault-Tolerant Authentication Management & Identification Control System that serves as a scalable, secure and simple alternative to LDAP, Active Directory and other authentication systems.
In AuthControl, the user[s] can be delegated and made responsible for managing their password. Furthermore, the user's password SHA512/GOST checksum is kept encrypted.
■ Password + Pin
The user[s] can log in to their virtual machines or physical hardware [eg. computers, tablets, mobile phones etc] with their standard username and password + 5 digit unique pin.
This 5 digit pin is not set by the user, but is rather auto or manually generated per the preference of the organization. Without having to manage separate pins for each user, and the ability to change them on a regular basis, makes logging into systems and authentication for various purposes more secure without adding the burden of lengthy procedures/steps.
Depending on the nature of the circumstance, user access can be restricted/limited by simply changing the PIN.
■ Algorithmically-ascertained decentralized numeric User and Group ID
Authcontrol also has the unique capability of creating operating system specific user and group identities that are unique. For example, AuthControl can create a Linux User ID and Group ID that are unique and always return the same numeric value for the ID.
This unique numeric user and group ID is algorithmically created in a decentralized manner without having to generate, store and poll centralized or distributed databases.
Due to the uniqueness of the user and group IDs, they can be instantly checked for changes/manipulations and reinstated automatically if changed without having to poll, check and compare with central or distributed databases. It can also report/alert in the similar manner.
AuthControl's strong security is strengthened with the use of inter-leaved mapping of Usernames to their Blockchain IDs and further using blockchain cryptography [not the blockchain network] to ascertain authenticity. This is another unique feature you will not find anywhere else but with SynchroKnot.
■ Fault Tolerant
AuthControl algorithmically checks for failures across multiple geographically-dispersed locations [configurable up to 10] before returning unreachable.
■ Load Balanced
Each user or groups of users can be assigned different geographically-dispersed locations for load balancing [with additional option of fault-tolerance].
■ Scalable
Enable AuthControl in virtual or physical machines, point more users to them, and scale seamlessly and transparently across the globe.
■ Simple
Very easy to set up and manage. Works transparently with Linux PAM without modifying standard PAM modules, and is end-to-end encrypted [uses standard HTTPS for communication].
Since this is just an article for getting acquainted with AuthControl, we refrain from getting into technicalities which might be better reflected in a whitepaper.
■ Below are examples of different methods that users can log in or access resources transparently with their standard Username and Password + 5 Digit PIN:
│
├─> Graphical Login
├─> Graphical Screen Saver Login [eg. screen lock]
├─> Non-Graphical Login
├─> SUDO - Execute a command as another user
├─> SU - Super User
├─> SSH - Secure Shell
├─> SCP - Secure Copy
├─> SFTP - Secure File Transfer Protocol
├─> SSHFS - Secure Shell File System
├─> FTP - File Transfer Protocol
├─> VNC - Virtual Network Computing
├─> RDP - Remote Desktop Protocol
├─> CUPs - standards based open source printing system
├─> CRON - Execution of scheduled commands
├─> SAMBA - Windows AD and SMB/CIFS fileserver for UNIX
├─> File Manager - Create Network Place with SFTP, SAMBA and FTP
├─> All password requirements via Control Center
├─> Practically anything that uses Standard PAM for authentication!Below is a direct link to the demonstration video:
http://synchroknot.tokyo/AuthControl.mp4
Description of the demonstration:
This is a very basic impromptu demonstration of AuthControl. Here both of the virtual machines are enabled with AuthControl and show the following:
■ Login via Graphical Interface
■ Login via Non-Graphical Interface
■ Run a command with SU as another user
■ Run a command with SUDO as another user
■ Login to a remote system via SSH
■ Mount a remote filesystem via SSHFS
■ Use File Manager to create a Network Place using SFTP
All these different types of logins use AuthControl with standard Linux users and password + 5 digit pin. The basic HTTPS traffic is captured using TCPDUMP to show realtime interaction with the SynchroKnot AuthControl when the password is entered in the virtual machines for the purposes of authentication.
Note: This demo was recorded on a severely resource-constrained system. It is up to you to determine the performance.
- 投稿日:2019-09-29T18:44:05+09:00
【競プロ】Pythonで複数の値を出力する
概要
競技プログラミングでは,形式に沿った出力を行う必要があります.出力する値が1,2個の場合は簡単ですが,これが可変個の場合はやや大変です.そこで,いくつかの出力方法を紹介し,またその実行速度の比較を行います.
空白区切り
次のような出力方法が考えられます:
ans = [1, 2, 3, 4, 5] # その1 for for a in ans[:-1]: print(a, end=' ') print(ans[-1]) # その2 join結合 print(' '.join(map(str, ans))) # その3 アンパック print(*ans)どう考えてもアンパックが簡単に書けて,バグも生じにくいように思えます.ちなみに
*ansはの意味するところは以下のようになります.# 以下2つは同じ print(*[1, 2, 3, 4, 5]) print(1, 2, 3, 4, 5)次に速度比較を見てみます:上のコードにて
ans = list(range(10**6))として,AtCoderのコードテストで実行した結果です.
種類 実行時間(ms) for 1000 join 250 *ans 450 forは遅いようです.一方で
joinで結合したほうが*ansより2倍程度高速です.ですが$10^6$個も出力しない限りは*ansで十分でしょう.改行区切り
こちらは空白区切りと殆ど変わりません:
ans = [1, 2, 3, 4, 5] # その1 for for a in ans: print(a) # その2 join結合 print('\n'.join(map(str, ans))) # その3 アンパック print(*ans, sep='\n')実行速度は次のようになりました:
種類 実行時間(ms) for 700 join 240 *ans 450 forがかなり早くなりました.どうやら
endを指定すると遅くなる様子です.しかしながら実行時間は空白区切りのときと一緒で,join < *ans < for の順です.ですが先程と同様に$10^6$個を出力しない限りは好みの問題となりそうです.まとめ
いくつか複数の値を出力する方法を紹介しました.実行時間に差はあるものの,大量に出力しない限りはお好みの出力方法を選べば大丈夫だと思います.
- 投稿日:2019-09-29T18:42:05+09:00
Pythonを使った衛星軌道LSTの計算
Local Sun Timeの計算方法
人工衛星の軌道において、特に地球観測衛星では昇交点通過地方時(LTAN)または降交点通過地方時(LTDN)の計算が必要となります。しかし、計算方法について詳細に記述されている文献は少ないと思われます(筆者が知る限り、無い)。
STKなど既存のツールを使えば簡単にわかりますが、Pythonで軌道計算を含むシステムを構築しているような場合でPythonだけで計算する方法を示します。今回はPython用の軌道計算ライブラリであるSkyfieldを使いました。
準備
軌道情報を用意します。今回はALOS-2(だいち2号)のTLE(Two Line Element,2行要素)を用います。TLEはテキストファイルで保存しておきます。
1 39766U 14029A 19271.21643628 .00000056 00000-0 14378-4 0 9997 2 39766 97.9225 6.5909 0001371 85.1486 274.9890 14.79472450288774計算
TLEを軌道6要素に変換して計算します。太陽方向ベクトルの赤経と昇交点赤経
raの差分をとって、時刻に変換するだけです。skyfieldだと
184deg 09' 18.9"のように度分秒で表示されてしまうので、無理やり文字列操作しました。import sys import math import numpy as np import datetime from skyfield.api import Loader, Star, Topos, load from skyfield.api import EarthSatellite def loc_time_calc(elements): ra = elements[5] # raan[rad] planets = load('de421.bsp') earth = planets['earth'] sun = planets['sun'] astrometric = earth.at(elements[0]).observe(sun) #earth->sun vector true_sun_direction_ra, dec, distance = astrometric.radec() true_sun_direction_ra = math.radians(_to_10deg(true_sun_direction_ra.dstr(warn=False))) # get angle true_sun_angle = ra - true_sun_direction_ra true_loc_time = _to_str(true_sun_angle * 12/math.pi + 12) print(true_loc_time) return true_loc_time def _to_10deg(val): spl1 = val.split() spl2 = spl1[0].split("deg",1) spl3 = spl1[1].split("'",1) spl4 = spl1[2].split('"',1) degrees = (float(spl4[0]) / 3600) + (float(spl3[0]) / 60) + float(spl2[0]) return degrees def _to_str(hour): h_str = datetime.datetime.strftime(datetime.datetime.strptime((str(int(hour))), "%H"),"%H") m_str = datetime.datetime.strftime(datetime.datetime.strptime(str(int((hour-int(hour))*60)), "%M"),"%M") return h_str + ":" + m_str結果
local sun timeの計算結果は以下の一番下のように
00:09と出ています。これは昇交点(LTAN)のほうですね。なお、ここでは真太陽として計算しています。赤道面に対する平均をとった平均太陽というのもあるようですが、それはまた次回に。## Osculating elements ## 7015.425994912874 0.001286689682089908 97.91723648761032 68.19812963098178 6.590899852150618 291.9395153724111 [<Time tt=2458754.717237021>, 7015.425994912874, 0.001286689682089908, 1.708978171162728, 1.1902819057625376, 0.11503290308923575, 5.095305759925173] 6.590899852150618 00:09
- 投稿日:2019-09-29T18:23:04+09:00
AtCoder Beginners Contest 過去問チャレンジ3
AtCoder Beginners Contest 過去問チャレンジ3
ABC120D - Decayed Bridges
木のサイズを持つ Union Find を実装したのに、サイズを使ってないのが残念なので類題調査で見つけてやった. Union Find には unite はあっても separate はないので、逆順にして、くっつけた時に不便さがどれだけ減るかを計算することによって解いた.
from sys import setrecursionlimit def find(parent, i): t = parent[i] if t < 0: return i t = find(parent, t) parent[i] = t return t def unite(parent, i, j): i = find(parent, i) j = find(parent, j) if i == j: return parent[j] += parent[i] parent[i] = j setrecursionlimit(10 ** 5) N, M = map(int, input().split()) AB = [[int(c) - 1 for c in input().split()] for _ in range(M)] parent = [-1] * N inconvenience = N * (N - 1) // 2 result = [] for a, b in AB[::-1]: result.append(inconvenience) pa, pb = find(parent, a), find(parent, b) if pa != pb: inconvenience -= parent[pa] * parent[pb] unite(parent, a, b) print(*result[::-1])ABC125D - Flipping Signs
負の数が偶数だったら全消しできるので絶対値の総和になる. 負の数が奇数の場合には、絶対値が一番小さい値を負にすればいいので、絶対値の総和から一番絶対値が小さい値の絶対値×2を引けばいい.
N = int(input()) A = list(map(int, input().split())) negatives = len([a for a in A if a < 0]) if negatives % 2 == 0: m = 0 else: m = min(abs(a) for a in A) print(sum(abs(a) for a in A) - 2 * m)ABC124D - Handstand
「逆立ちした人を連続で最大何人」なので、直立した人と逆立ちした人を同時にひっくり返すことには意味がなく、直立した人のブロックK個をひっくり返した 2K + 1 ブロックの最大長になる. 最初にブロックを連長カウントして、あとはしゃくとり法で最大長を求めることによって解いた.
N, K = map(int, input().split()) S = list(map(int, input())) j = 1 r = 0 t = [] for i in range(N): if S[i] == j: r += 1 else: t.append(r) r = 1 j ^= 1 t.append(r) if j == 0: t.append(0) if K >= (len(t) - 1) // 2: print(sum(t)) else: result = sum(t[:2 * K + 1]) j = result i = 2 while i + 2 * K < len(t): j += t[i + 2 * K - 1] + t[i + 2 * K] - (t[i - 2] + t[i - 1]) result = max(result, j) i += 2 print(result)ABC119D - Lazy Faith
ひたすら西に行くパターン、西に行って東に行くパターン、東に行って西に行くパターン、ひたすら東に行くパターンを、最初に神社に行ってから寺に行くパターン、最初に寺に行ってから神社に行くパターンについて、全パターン(つまり4×2で8パターン)計算し、最小値を答えとすることによって解いた. 位置は二分探索で見つける.
from bisect import bisect_left INF = float('inf') def f(x, s, t): result = INF i = bisect_left(s, x) if i > 0: j = bisect_left(t, s[i - 1]) if j > 0: result = min(result, (x - s[i - 1]) + (s[i - 1] - t[j - 1])) if j < len(t): result = min(result, (x - s[i - 1]) + (t[j] - s[i - 1])) if i < len(s): j = bisect_left(t, s[i]) if j > 0: result = min(result, (s[i] - x) + (s[i] - t[j - 1])) if j < len(t): result = min(result, (s[i] - x) + (t[j] - s[i])) return result A, B, Q = map(int, input().split()) s = [int(input()) for _ in range(A)] t = [int(input()) for _ in range(B)] for i in range(Q): x = int(input()) print(min(f(x, s, t), f(x, t, s)))ABC123D - Cake 123
1, 2, 3 の美味しさをそれぞれソートして、まずそれぞれの一番美味しいのを取ったのを出力し、1だけ次に美味しいのに差し替えたもの、2だけ次に美味しいのに差し替えたもの、3だけ次に美味しいのに差し替えたもの3パターンを作って優先度付きキューに突っ込み、その3パターンで1番美味しいものを出力し、出力したものをベースにまた3パターンを作って優先度付きキューに突っ込みを繰り返すことによって解いた.
from heapq import heappush, heappop X, Y, Z, K = map(int, input().split()) A = list(map(int, input().split())) B = list(map(int, input().split())) C = list(map(int, input().split())) for l in [A, B, C]: l.sort() exists = set() q = [(-(A[X - 1] + B[Y - 1] + C[Z - 1]), (X - 1, Y - 1, Z - 1))] for _ in range(K): v, n = heappop(q) print(-v) for i in range(3): if n[i] > 0: t = [n[j] for j in range(3)] t[i] -= 1 nn = tuple(t) if nn not in exists: exists.add(nn) nv = A[nn[0]] + B[nn[1]] + C[nn[2]] heappush(q, (-nv, nn))
- 投稿日:2019-09-29T18:11:17+09:00
日本語版wikipediaのデータ取得と整形
概要
web上からwikipediaのテキストデータを取得。
取得したwikipediaのダンプファイルは、Wiki記法で記載されているため、そのままでは自然言語処理に不向き。
そのためWikipedia Extractorというpythonスクリプトを使って、シンプルな日本語に直す。具体的には以下の2点を導出する。
1. 日本語版wikipediaのテキストデータを取得
2. データ形式の整形手順
使用環境python3.7.21. 日本語版wikipediaのテキストデータを取得
- 日本語のwikipedia情報ダウンロードページにアクセス
jawiki-latest-pages-articles.xml.bz2というファイル名のダンプファイルをダウンロード2. データ形式の整形
- Wikipedia ExtractorのGithubをclone
- wikipediaのダンプファイルと
WikiExtractor.pyを同一フォルダに配置- GithubのUsageを参考に、wikipediaデータを整形
サンプルpython WikiExtractor.py -b 500K -o wiki_data jawiki-latest-pages-articles.xml.bz2
- bオプション: 分割する1ファイル辺りのサイズ容量
- oオプション: 書き出しするフォルダ名
結果
出力される階層構成 (wiki_01などがxml形式のファイル)└── wiki_data ├── AA │ ├── wiki_00 │ ├── wiki_01 │ │ ・ │ │ ・ │ └── wiki_99 ├── AB │ ・ │ ・ └── CE出力ファイルサンプル (wiki_01の一部抜粋)<doc id="56" url="https://ja.wikipedia.org/wiki?curid=56" title="地理"> 地理 地理(ちり、英: Geography) 「地理」という表現は古くからあり、有名なところでは漢書の『地理志』がある。 地理学とは、地球の表面と住民の状態、その相互関係を研究する学問である。 「地理」は、日本の学校で設置されている、「人間の生活に影響を与える地域的、社会的な構造」を学ぶための科目である。自然環境や産業環境などを含む環境を学習対象としている。小学校および中学校においては、歴史や公民と並び、社会科の一分野である。高等学校においては、最近は「地理歴史科」という教科の中の一科目となっており、「地理A」「地理B」に細分されている。 </doc>上記のように、wikipediaの各記事ごとに<doc>タグで囲まれている。
結論
まずは単純にオープンに公開されているwikipediaのデータを取得した。
次に、自然言語処理をしやすくするためのデータ整形を行った。参考
- 投稿日:2019-09-29T18:02:17+09:00
ベストなお昼ご飯の組み合わせを求める(セブンイレブン編)
モチベーション
消費税が上がるこのタイミングで、ワンコインで満足いくお昼ご飯の組み合わせを考えてみたいと思います。
※ワンコイン:税込500円
※満足いく:満腹感重視(本当は体積や重さで求めたいが、今回はカロリーで)今回は、セブンイレブンで持ち帰り(消費税8%)を前提とします。
また、1種類の商品は1つだけしか買えないこととします。
(塩むすび×5個とかは避けたい ^^;)データ収集
セブンイレブンの全商品はこちらで調べることができます。がしかし、ここにはカロリー表示が無い...
ここに栄養成分情報があるが、お弁当やおにぎりの情報が無い...
かろうじてここにいくつか載っているが全部ではない...FAQを見ると、「使用する原材料は規格変更や調達の都合により断りなく変わります。アレルギー情報はお客様の健康に関わる重要な情報ですので、正確な情報を確認していただくため、店頭にて商品の表示をご確認のうえ、ご利用いただきたくお願いいたします。」とのことですので、カロリー等の情報も公開していない模様。
ということで、カロリーの値はググって出てきた情報(ここが中心)も利用することにします。
残念ながらこれらすべてCSV等電子データで提供されておらず、またHTMLをスクレイピングしたくなかったので、地道に手打ちします。
※2019/09/28時点の情報で作成しています
※以下は含めません
- セブンプレミアム
- セブンプレミアムゴールド
- スイーツ
- セブンカフェ
- チルドカップドリンク
- こだわり特性弁当
※販売エリアが限られている商品がありますが、今回は全部手に入るものとしてデータを作成しました
※同じ商品が地域別に複数登録されています
で、こんな感じに出来上がりました。
欠損値は、後で行ごと消します。
問題設定
今回は以下のような条件になります。
- 税込500円以下(消費税8%で計算)
- よりカロリーが高くなる組み合わせ
- 1品目1つだけ
コーディング
さっそくPythonでコーディングしてみます。
数理最適化のモジュールは「PuLP」を使用してみます。# データの読み込み import pandas as pd df = pd.read_csv("se.csv", index_col=0, encoding="SHIFT-JIS")作成したデータ(CSVファイル)をPandasで読み込み、DataFrameに保存します。
日本語バリバリなので、SHift-JISにエンコードしています。# 必要な情報だけ抜き出し df_ = df[['商品名', '金額(円、税抜)', 'カロリー(kcal)']] # 欠損値のある行は削除 df_ = df_.dropna()必要な情報は金額とカロリーだけ(最後の表示で商品名も使用)なので、それだけ抜き出します。
また欠損値のある行は消します。# モデル作成 from pulp import * # 金額 w = df_['金額(円、税抜)'] # カロリー v = df_['カロリー(kcal)'] # 制約:税込500円 W = 500 / 1.08 r = range(len(w)) # 数理モデル(最大値取得) m = LpProblem(sense=LpMaximize) # 変数(あり/なし) x = [LpVariable('x%d'%i, cat=LpBinary) for i in r] # 目的関数(カロリーの加算) m += lpDot(v, x) # 制約条件(金額の加算≦税込500円) m += lpDot(w, x) <= Wまず金額とカロリーだけ抜き出しています。
その後、モデルを作成します。今回はカロリーが最大となるように数理モデルは最大値を求めるように設定します。
変数は、その品目を含めるか含めないか(0 or 1)になります。
目的関数として、カロリーを加算する式をしてします。
制約条件は、金額を加算した結果が税抜500円以下となるように指定します。# 計算 m.solve()作成した条件で計算を行います。
問題が無ければ「1」が返ってきます。print('総カロリー:', value(m.objective), 'kcal') print('組み合わせ:') total = 0 for i in r: if value(x[i]) > 0.5: print(' ', df_['商品名'][i], '(', df_['金額(円、税抜)'][i], '円)') total += df_['金額(円、税抜)'][i] print('総額:', total, '円(税抜)')結果を出力します。
結果
総カロリー: 1836.0 kcal 組み合わせ: 北海道産じゃがいものコロッケパン ( 130 円) もちもちチョコブレッド ( 110 円) しっとりチョコチップスティックケーキ ( 120 円) 口どけチョコのオールドファッション ( 90 円) 総額: 450 円(税抜)
とっても口の中が甘くなりそうな結果となりました。
ちょっとこれでは昼食としてはつらいので、もうちょっと絞った品目で試してみたほうがよさそうです。感想
「PuLP」などモジュールを利用することで、簡単に組み合わせ最適化ができるって、ちょっと感動してしまいました。






- 投稿日:2019-09-29T17:49:26+09:00
/proc/meminfoのviewerをつくった
やりたいこと
/proc/meminfoの内容を理解するために、色々実験しながら各要素の変遷が見たい。
ただ、メモリ使用状況を可視化するツールはたくさんあるがどれも抽象度が高く、
/proc/meminfoの粒度での変遷を表示するツールを見つけられなかった。やったこと
/proc/meminfoをできるだけそのまま表示するmiviewerをつくった。
といっても/proc/meminfoを取得して積み上げグラフにしただけ。
miviewer
$ ./miviewer.py -h usage: miviewer.py [-h] [-a] [-i INTERVAL] [-c COUNT] [--check] [-w WINDOW] [-t {active,buff-cache,available,user-kernel}] optional arguments: -h, --help show this help message and exit -a, --adb Get meminfo via adb. -i INTERVAL, --interval INTERVAL The delay between updates in milli-seconds. Default is 200. -c COUNT, --count COUNT Number of updates. Default is infinite. --check Check some formulas. -w WINDOW, --window WINDOW Shown period time in seconds. Default is 60. -t {active,buff-cache,available,user-kernel}, --type {active,buff-cache,available,user-kernel} Graph type. Default is active.デフォルトでは、スクリプトを実行したPCの
/proc/meminfoを、200ms間隔で取得し、グラフにプロットする。
--adbオプションを指定することで、adb経由でAndroid端末の/proc/meminfoを取得することも可能。
また、/proc/meminfoの要素はそれぞれ重なりがあり、一つの積み上げグラフですべての要素を表示することはできないので、
4つの選択肢からグラフタイプを選択できるようにしている。グラフタイプ
activeデフォルト。
Activeかどうか、つまり、LRUリストに乗ってるかどうかで分類された要素を積み上げている。
冒頭のグラフはこのタイプ。
なお、凡例の要素名が@で始まるものは、それそのものが/proc/meminfoにあるわけではなく、何らかの方法で算出した値であることを示す。
グラフタイプ
buff-cache
BuffersとCached、つまりバッファキャッシュ(メタデータやraw I/O用のキャッシュ)とページキャッシュ(ファイル自体のページのキャッシュ)の変遷を見るとき用。
グラフタイプ
availableシンプルに
MemAvailableとそれ以外を表示する。
Linux観点でSwappingが始まるまでの余力をザクッと見るとき用。
グラフタイプ
user-kernelユーザ空間とカーネル空間のどちらで使っているかで分類してプロットする。
なんか使うことがあるかなとおもって用意したものの、デフォルトのactiveがあれば必要ない気がしないでもない。
環境
動作確認環境は、以下のとおり。
- Ubuntu 18.04
- Linux 5.0.0-29-generic
- Python 3.6.8
- matplotlib 2.1.1
とはいえあまり環境に依存する実装ではないので、
MemAvailableがある(3.14以降)Linux環境なら動くんじゃないかと。
もしかしたらadbモードならMac/Windowsでも動くかもしれない(未確認)。おわりに
なにかお気づきの点やご要望などありましたらぜひご指摘ください。
参考
/proc/meminfo
matplotlib.animation
matplotlib.stackplot




- 投稿日:2019-09-29T17:04:58+09:00
Pythonでバンド計算コードを書くーセルラー法
バンド計算を行うための手法は多数生み出されているが、その中でも最初期に登場したセルラー法(Wigner-Seitz法)に基づいてナトリウム金属の価電子帯の最低エネルギー準位を計算するコードをPythonで書いてみた。
解くべき式
詳細については参考文献[1][2]を見てもらうことにして、解くべき式を原子単位系で書くと
\frac{d^2R(r)}{dr^2}=\left(-\frac{2Q(r)}{r^2}-E\right)R(r)\tag{1}となる。ここで$R(r)=r\chi(r)$であり、求めたい波動関数が$\chi(r)$である。
$Q(r)$は文献[2]にあるように\begin{eqnarray} Q(r)=\left\{ \begin{array}{ll} 11r & (0\leq r<0.01) \\ -26.4 r^2+11.53r-0.00264 & (0.01\leq r <0.15) \\ -2.84r^2+4.46r+0.5274 & (0.15\leq r<1.00) \\ \vdots\\ \end{array} \right. \end{eqnarray}と非常に複雑な関数になっている(Naの3s軌道の電子が感じるポテンシャルになるように実験値から決定されたようだ)。
式(1)の微分方程式を4次のルンゲクッタ法で解けば$R(r)$が求まる。すなわち次の二つの微分方程式に分割して、これらを連立させて解く。
\frac{dR(r)}{dr} = p\\ \frac{dp}{dr} = \left(-\frac{2Q(r)}{r^2}-E\right)R(r) = F_1(r,R,p)ただし、セルラー法の仮定から導かれる境界条件を課す必要がある。$r_0$をウィグナー・サイツ基本格子と同じ体積を持つ球体の半径であるとすると境界条件は以下のようになる。
\left.\frac{dR(r)}{dr}\right|_{r_0} = \frac{R(r_0)}{r_0} \tag{2}この境界条件を満たす解を探すために論文[2]中では次のような戦略がとられた。
- $E$に適当な値を代入して式(1)を解く。
- 得られた$R(r)$を$r$に対してプロットし、式の境界条件が満たされる$r_0$を作図によって探す。すなわち点($r_0$,$R(r_0)$)での$R(r)$の接線が原点を通るかどうかを判断すればよい。
- 1. 2.を繰り返して$r_0$とそのときのエネルギー$E$をプロットして曲線$E(r_0)$を得る。これは境界条件の導入によって、ある$r_0$に対してあるエネルギー固有値(そして波動関数)が決まることを示している。
- 金属Naを計算したい場合は$r_0=3.95$でのエネルギーを読み取り、再度式(1)に代入することで波動関数$\chi(r)$を得る。
ただし、2. のプロセスについては$r_i$での微分を差分に置き換えて、それとその点での傾きとの差の絶対値${\rm abs}$が小さい点を抽出するようにした。$r_i$は離散化した$i$番目の$r$の値である。
{\rm abs}=\left|\frac{R(r_{i+1})-R(r_{i-1})}{2h} - \frac{R(r_i)}{r_i}\right|\tag{3}プログラム
import numpy as np import matplotlib.pyplot as plt import matplotlib from scipy.optimize import curve_fit h = 0.002 hinv = 1 / h xmin = h xmax = 10.0 h2 = h * h dh = h * 0.5 num = int((xmax - xmin)/h) pot = [] def Make_pot(h): mw = 0 w = int(0.01*hinv) for i in range(mw+1,w+1): pot.append(11.0*i*h) mw = w w = mw + int(0.14*hinv) for i in range(mw+1,w+1): pot.append(-26.4*i*i*h2+11.53*i*h-0.00264) mw = w w = mw + int(0.85*hinv) for i in range(mw+1,w+1): pot.append(-2.84*i*i*h2+4.46*i*h+0.5275) mw = w w = mw + int(0.55*hinv) for i in range(mw+1,w+1): pot.append(1.508*i*i*h2-4.236*i*h+4.876) mw = w w = mw + int(1.75*hinv) for i in range(mw+1,w+1): pot.append(0.1196*i*i*h2+0.2072*i*h+1.319) mw = w w = mw + int(3.44*hinv) for i in range(mw+1,w+1): pot.append(0.0005*i*i*h2+0.9933*i*h+0.0222) mw = w w = mw + int(3.26*hinv) for i in range(mw+1,w+1): pot.append(i*h) print(len(pot)) Make_pot(h) pa = np.array(pot) xa = np.arange(xmin,xmax+h,h) v = -pa/xa/xa print(v) def Solv(e): def F1(x,y,p): nd = int(x*hinv)-1 return (2.0*v[nd]-e)*y x = xmin y = x p = 1.0 for i in range(num): dp1 = h * F1(x,y,p) dy1 = h * p dp2 = h * F1(x+dh,y+dy1*0.5,p+dp1*0.5) dy2 = h * (p+dp1*0.5) dp3 = h * F1(x+dh,y+dy2*0.5,p+dp2*0.5) dy3 = h * (p+dp2*0.5) dp4 = h * F1(x+h,y+dy3,p+dp3) dy4 = h * (p+dp3) xl.append(x) yl.append(y) x = x + h y = y + (dy1 + 2.0*dy2 + 2.0*dy3 + dy4)/6.0 p = p + (dp1 + 2.0*dp2 + 2.0*dp3 + dp4)/6.0 results = [] for j in range(30,76): xl = [] yl = [] ex = -j * 0.01 Solv(ex) mdif1 = 50.0 mdif2 = 51.0 mem1 = 0.0 mem2 = 0.0 for k in range(200,num-1): dif = (yl[k+1]-yl[k-1])/h*0.5 tes = abs(dif-yl[k]/xl[k]) if tes < mdif1: mdif2 = mdif1 mem2 = mem1 mdif1 = tes mem1 = xl[k] elif tes < mdif2 and xl[k]-mem1 > 0.02: mdif2 = tes mem2 = xl[k] if abs(mem1-mem2) > 0.02: results.append([mem1,ex,mdif1]) results.append([mem2,ex,mdif2]) else: results.append([mem1,ex,mdif1])$h$は微分方程式を解く際の離散化の幅である。
プログラムのはじめの部分ではポテンシャル関数を生成している(Make_pot)。
つづいてあるエネルギーの値に対して4次のルンゲクッタ法によって式(1)を解く関数Solvが定義されている。$r=r_{\rm min}(=h)$から解き始めるが、初期値については$R(r)$が原点近傍で
R(r) \sim rとなることから求めた(参考)。
その後の$j$に関するループではエネルギーを-0.3から-0.75の間で0.01ずつ変えながら式(1)を解いている。続く処理では式(3)で評価される絶対値が小さい点を抽出している。ただし、$r$の値が近い2点が選ばれないようにif文による条件分岐がある。
結果はresultsというリストに
[r_0,\ E,\ {\rm abs}]の形で格納される。
解析
まず$E$と$r_0$のグラフを見てみる。きれいな曲線関係が見て取れる。
rl = np.array(results) sc = plt.scatter(rl[:,0],rl[:,1],c=rl[:,2],norm=matplotlib.colors.LogNorm()) plt.colorbar(sc) plt.show()
この図では$\log({\rm abs})$の大きさによって点の色分けがなされている。$E\leq-0.69$の点については絶対値がほかの点に比べて大きいため境界条件が満たされていないと判断し、以下の解析では除くことにする。
ちなみに、いくつかの$E$について$R(r)$を$r$に対してプロットした図が下図である。上の図と比較してみると境界条件(2)が満たされているところでの$r$が$r_0$となっていることがわかる。
続いて得られた点に対して曲線あてはめを行う。いろいろな関数式を試した結果
f(r\ ;\ e,r_0,n_1,n_2,n_3,a,b) = e\left\{ \left( \frac{r_0}{r} \right)^{n_1} - a \left( \frac{r_0}{r} \right)^{n_2} - b\left(\frac{r_0}{r} \right)^{n_3} \right\}\tag{4}で比較的よくフィットできることがわかった。ただし変数を$r_0$から$r$に変えた。以下はカーブフィッティングのコード。
rl2 = rl[rl[:,1]>-0.69] fitx = rl2[:,0] fity = rl2[:,1] def Fit_func(x,ep,x0,n1,n2,n3,a,b): return ep*((x0/x)**n1 - a*(x0/x)**n2 - b*(x0/x)**n3) popt, pcov = curve_fit(Fit_func,fitx,fity,maxfev=10000) plt.scatter(fitx,fity,s=15,zorder=2) rr = plt.axis() ra = np.arange(rr[0],rr[1],0.01) plt.ylim(rr[2],rr[3]) plt.xlabel(r"$r$") plt.ylabel(r"$E$") plt.plot(ra,Fit_func(ra,*popt),c="orange",zorder=1,label="f(r)") plt.legend() plt.show()フィッティングの結果を示す。点が非常によく曲線上にのっていることがわかる。
最後に$r=3.95$について、求められたパラメータのもとで式(4)を計算すると$E=-0.6175$となった。
これを再び式(1)に代入して波動関数$\chi(r)$を計算する。
r0 = 3.95 xl = [] yl = [] ex = Fit_func(r0,*popt) print(ex) Solv(-0.6175) xa = np.array(xl) ya = np.array(yl) plt.plot(xa,ya/xa) plt.xlim(0,r0) plt.ylim(-0.2,0.2) plt.hlines(0,0,r0,"black",linewidth=0.5) plt.xlabel(r"$r$") plt.ylabel(r"$\chi(r)$") plt.show()
規格化をしていないので絶対値は合わないが、[1]や[3]のグラフと非常によく似たものが得られた。
最後に
文献[2]に
The calculation of a wave function took about two afternoons, and five wave functions were calculated on the whole, giving the ten points of the figure.
という一節がある。コンピュータなしでこの問題を解くのはさぞ骨の折れる作業だっただろう。それにも関わらず正しく結果が求められていてすごいなと思った。
現代ではこのような手計算をする必要はないにせよ、自分の計算力が圧倒的に不足しているような気がしてならない、、、
参考文献
[1] アシュクロフト・マーミン,固体物理の基礎上・IIー固体のバンド構造ー
[2] E. Wigner and F. Seitz, Phys. Rev. 43:804, 1933.
[3] E. Wigner and F. Seitz, Phys. Rev. 46:509, 1934.また、ルンゲクッタ法の実装については
https://nemuneko-gensokyou.blog.so-net.ne.jp/2015-04-14
を参考にした。




- 投稿日:2019-09-29T16:21:20+09:00
python開発環境のファイル構造
リモートで開発する際にどのようなファイル構造が一番良いのか?
今回試したのは
/home/username/src
をホームディレクトリとして、
その下に各プロジェクトを作り、そこにソースコードをすべて入れていくスタイル。
Githubのレポジトリもそこに入れてしまう。
そして、開発はDockerを用いて行い、docker-compose.ymlでマウントを以下のように指定する。
docker-composeはgitレポジトリのものをコピーして/home/username/src/projectA/src下に置く。volumes: - /home/username/src/projectA:/rootこうすると、リモートサーバーの構造もすっきりするし、一つのコンテナ内ではそのプロジェクトに関わるもののみが見えて綺麗。
完成イメージ
リモートサーバーhome └─ username └─ src ├─ projectA │ ├─ git_repository │ └─ src │ ├─ docker-compose.yml │ └─ other source codes └─ projectB ├─ git_repository └─ srcDockerコンテナroot ├─ git_repository └─ srcsrcディレクトリを整備
srcディレクトリ下に
notebookディレクトリとpythonfileディレクトリを作成し、そこに入れる。
- 投稿日:2019-09-29T16:17:48+09:00
keras model表示で活性化関数名を表示する
pythonのkerasで、model.summary()によりモデルを表示できるが、
活性化関数名(Activation)が、
'activation_1 (Activation)'
のように表示された。
'ReLU'など、どの活性化関数を用いたのか表示したい。修正前
以下が、修正前のコード(モデル定義部分)。
活性化関数の定義を
'model.add(Activation('relu'))' とした。.......(A)model = Sequential() model.add(Dense(4, input_shape=(784, 1))) model.add(Activation('relu')) # A:活性化関数定義 model.add(Dense(10, activation='softmax')) model.summary()モデル表示結果。
Layer (type) Output Shape Param # ================================================================= dense_1 (Dense) (None, 784, 4) 8 _________________________________________________________________ activation_1 (Activation) (None, 784, 4) 0 _________________________________________________________________ dense_2 (Dense) (None, 784, 10) 50 ================================================================= Total params: 58 Trainable params: 58 Non-trainable params: 0 _________________________________________________________________活性化関数名が、
'activation_1 (Activation)'
と表示され、どの活性化関数を用いたのかわからない状態。修正後
kerasのAdvanced activationsを用いる。
Keras Documentation : Advanced ActivationsレイヤーAdvanced activationsのReLU関数をインポート。
from keras.layers import ReLU活性化関数の定義を
'model.add(ReLU())' とする。......(B)model = Sequential() model.add(Dense(4, input_shape=(784, 1))) model.add(ReLU()) # B:活性化関数定義 model.add(Dense(10, activation='softmax')) model.summary()モデル表示結果。
Layer (type) Output Shape Param # ================================================================= dense_1 (Dense) (None, 784, 4) 8 _________________________________________________________________ re_lu_1 (ReLU) (None, 784, 4) 0 _________________________________________________________________ dense_2 (Dense) (None, 784, 10) 50 ================================================================= Total params: 58 Trainable params: 58 Non-trainable params: 0 _________________________________________________________________活性化関数名が、
're_lu_1 (ReLU)'
と表示され、ReLU関数を用いたことがわかる。他の活性化関数についても、同様に可能。
補足
Advanced activationsを用いることにしたとき、
最初は、活性化関数の定義を以下のようにしていた。model.add(Activation(ReLU()))これだと、うまくいかない上に、以下の警告も表示されるので注意。
どうやら、'ReLU()'をActivationの引数として与えるのではなく、直接model.add()に渡すべきらしい。UserWarning: Do not pass a layer instance (such as ReLU) as the activation argument of another layer. Instead, advanced activation layers should be used just like any other layer in a model.
- 投稿日:2019-09-29T16:15:17+09:00
PythonでOpenWeatherのJSONファイルをテキスト化する
はじめに
OpenWeatherのAPIが天気の情報量に長けていたので登録して無料版を使ってみました。
天気APIを叩く方法は
・都市ID
・都市名
・郵便番号
・地図座標
の4パターンです
詳しくはこちらの記事がわかりやすいですこの記事ではOpenWeatherの世界の都市リストのJSONファイルを
Pythonで都市を日本にフィルタリングしてテキスト化した内容を共有したいと思います♪世界の都市リストのファイルをダウンロードする
私はWindows環境です
gzファイル は Lhaplusで解凍しましたMacの解凍方法はわからないのでググってくださいw
PythonでJSONファイルをテキスト化する
import json Jplist = []#JSONを読み取る listrows = []#出力用リスト f = open('任意の.jsonファイル', 'r' ,encoding='utf-8') jsn = json.load(f)#JSONファイルを開く for key in jsn:#JSONファイルを読み取る if key['country'] == 'JP':#日本のみに絞る for value in key:#日本の内容を行ごとに読み取る Jplist.append(str(value) + ':' + str(key[value]))#行毎に読み取る listrows.extend(Jlist)#リストを二次元配列として追記 with open("任意の.txtファイル", 'w', encoding='utf-8') as tx: for values in listrows:#行ごとにテキスト出力する tx.write(str(values) + '\n')#テキストファイルに書き込む print('完了')ポイント
- JSONファイルをなぜか辞書で読込めなかったのでリストで読込んだ
※JSONファイルがリストで作られてるのかな?
※辞書できれいに処理したかったがやむなくリストで処理
※いや、楽勝で辞書で読み込めたよって方いたら教えてくださいw)
- リスト+リストで二次元配列化しテキスト出力した
※extendメソッドでリストにリストを追加してテキストへ追記
こんな感じでテキスト化できました。
おわりに
日本のみにフィルタリングしたので、マスター化すれば日本全国の拠点を抑えられるかと思います
今後は天気のAPIを活用した記事を書いていきたいと思います♪
- 投稿日:2019-09-29T16:07:42+09:00
XMLをpandas.DataFrameにする
データ分析の過程でAPIを利用することは多いと思います。
APIの結果がXMLで返ってくるとき、扱いにちょっとこまって時間がかかったのでやり方をメモしておきます。
input
例として、こんな感じのXMLっぽいデータがあったとします。
# 例 response = """ <INFO> <RESULT> <STATUS>0</STATUS> <ERROR_MSG>SUCCESS</ERROR_MSG> <DATE>2019/09/29T06:21:15+9:00</DATE> </RESULT> <PARAMETER> <lang>ja</lang> <code>01</code> </PARAMETER> </INFO> """code
以下のコードでpd.DataFrameに変換できます。
# parse xml from lxml import etree root = etree.fromstring(response) # convert xml to dict import xmljson data_dict = xmljson.yahoo.data(root) # convert dict to pd.DataFrame import pandas as pd pd.io.json.json_normalize(data_dict)output
結果はこんな感じになります。
pd.io.json.json_normalize()の引数等は元のXMLのネスト具合に応じて調整する必要があります。

- 投稿日:2019-09-29T15:10:00+09:00
AtCoder Beginner Contest 142 参戦記
AtCoder Beginner Contest 142 参戦記
A - Odds of Oddness
2分半で突破. A問題なのにあってるのかなと考える時点でいつものA問題より難しい. これは書くだけとは言えない.
N = int(input()) print(int(N / 2 + 0.5) / N)B - Roller Coaster
3分で突破. 書くだけ. 今回はある意味A問題よりB問題のほうが簡単だった.
N, K = map(int, input().split()) h = list(map(int, input().split())) print(sum(1 if t >= K else 0 for t in h))C - Go to School
7分半で突破. 問題そのものは簡単なんだけど、タプルの第二要素でソートするのどうやるんだっけみたいな部分を調べるのに時間を使った.
from operator import itemgetter N = int(input()) A = list(map(int, input().split())) print(*[t[0] + 1 for t in sorted(enumerate(A), key=itemgetter(1))])D - Disjoint Set of Common Divisors
WA が消せず. 最大公約数を取り、その約数のうち素数のものを数え上げるという方針は合っていたのだけど、TLE 対策で
sqrt(gcd(A, B))までしかループを回さないようにした時に、sqrt(gcd(A, B))より大きい素数が1つだけ存在しうることを見落としたせいで、すべてがパーに. この問題を飛ばして、次の問題をやったら解けた可能性が高かったので、今回の ABC は完全に事故った感じに.from fractions import gcd from math import sqrt def prime_factorize(n): result = [] for i in range(2, int(sqrt(n)) + 1): if n % i != 0: continue t = 0 while n % i == 0: n //= i t += 1 result.append((i, t)) if n == 1: break if n != 1: result.append((n, 1)) return result A, B = map(int, input().split()) print(len(prime_factorize(gcd(A, B))) + 1)E - Get Everything
手を付けれず. ナップサック問題が解ける人なら大体解けるのではないか.
def read_key(): a, b = map(int, input().split()) m = 0 for c in map(int, input().split()): m |= 1 << (c - 1) return (a, m) INF = float('inf') N, M = map(int, input().split()) keys = [read_key() for _ in range(M)] dp = [INF] * (1 << N) dp[0] = 0 for i in range(M): a, m = keys[i] for j in range((1 << N) - 1, -1, -1): if dp[j] == INF: continue if dp[j] + a < dp[j | m]: dp[j | m] = dp[j] + a if dp[(1 << N) - 1] == INF: print(-1) else: print(dp[(1 << N) - 1])
- 投稿日:2019-09-29T14:56:36+09:00
Python3で平均・分散・標準偏差のプログラムを作ってみる
はじめに
テストを行う際に以下のページにある問題を参考にしています.
練習問題(6. 分散と標準偏差)問題に用いるデータ
data = [14, 2, 13, 20, 16]Pythonで求める
平均
$ print(sum(data) / len(data)) 13.0分散
def variance(data): square = [] for i in data: square.append(i * i) square_mean = sum(square) / len(data) #2乗の平均を計算する mean = sum(data) / len(data) #平均を計算する return square_mean - mean * mean↓確認
$ print(variance(data)) 36.0標準偏差
$ import math $ print(math.sqrt(variance(data))) 6.0
- 投稿日:2019-09-29T14:34:24+09:00
Anacondaのプロキシ設定
はじめに
OS:Windows10
Anaconda:2019.07職場等、プロキシ環境下でAnacondaを使うための設定。
設定しないと、conda install コマンド等が失敗する。1. 設定ファイル(.condarc)の作成
Anacondaのルートディレクトリに、".condarc"という名前のファイルを作成する。
※Anacondaのルートディレクトリは、デフォルトだと<C:\Users\ユーザー名\Anaconda3>になっている。ファイル作成の際にエクスプローラーに怒られた場合は、PowerShellで下記コマンドを使用して作成する。
※Linuxのtouchコマンドに相当New-Item -Type File .condarc2. プロキシの設定
1で作成した".condarc"に、下記を追記する。
proxy_servers: http: http://[ユーザーID]:[パスワード]@[プロキシサーバのアドレス]:[ポート番号] https: https://[ユーザーID]:[パスワード]@[プロキシサーバのアドレス]:[ポート番号]※インデントはスペースですること。タブでインデントすると動かない。
下記コマンドを実行し、proxy_servers:に設定した内容が表示されていれば正しく設定できている。
conda config --showあとがき
使わせてもらえるならLinuxのほうがPython開発では使いやすい気がする。
Macはスタバで仕事しない限り不要です。
- 投稿日:2019-09-29T14:34:01+09:00
Project Euler 031を解いてみる。「硬貨の和」
Project Euler 031
イギリスでは硬貨はポンド£とペンスpがあり,一般的に流通している硬貨は以下の8種類である.
1p, 2p, 5p, 10p, 20p, 50p, £1 (100p) and £2 (200p).
以下の方法で£2を作ることが可能である.
1×£1 + 1×50p + 2×20p + 1×5p + 1×2p + 3×1p
これらの硬貨を使って£2を作る方法は何通りあるか?->[次の問題]
考え方
プログラミングらしくて楽しい問題ですね。問が再帰関数を使えと言っています。
設問の£2=200pをmoneyとして
大きい硬貨から順に、0~(money/コインの価値)枚のパターンで分け使った分をmoneyから引きます。残ったお金を残りの硬貨で作れるパターンを再帰関数で取得します。
今回は1pがあるので、再帰関数の最後は必ず1を返しますが、例えば[3,7,11]でmoney=100になる組み合わせのように、再帰関数の最後で組み合わせが成立しない場合も考慮し1または0を返すようにしています。
実はリストは昇順じゃなくても同じ結果を返しますが、無駄な計算が増えるので遅くなります。euler031.pydef combo_of_coin(money: int, coin_list: list): """コインの組み合わせ数を返す再帰関数 Args: money: 金額 coin_list: 組み合わせに使用するコインの価値、昇順で記載。 Returns: int: コインの組み合わせ数 """ result = 0 # リストの最後に来たら if len(coin_list) == 1: # 基本的には1を返す。 # moneyを割り切れない場合=組み合わせが成立しない場合0を返す return 1 if money % coin_list[0] == 0 else 0 # 検証に使用するコインを末尾から取り出す coin = coin_list[-1] # coinを使う枚数は0~(money//coin)の(money//coin +1)通り for i in range(money // coin + 1): # coinの分をmoneyから差し引き、 # 残りのcoin_listから再帰的に組み合わせを取得しresultに加算 result += combo_of_coin(money - coin * i, coin_list[:-1]) return resultコード
euler031.pydef main(): money = 200 coin_list = [1, 2, 5, 10, 20, 50, 100, 200] print(combo_of_coin(money, coin_list)) def combo_of_coin(money: int, coin_list: list): """コインの組み合わせ数を返す再帰関数 Args: money: 金額 coin_list: 組み合わせに使用するコインの価値、昇順で記載。 Returns: int: コインの組み合わせ数 """ result = 0 # リストの最後に来たら if len(coin_list) == 1: # 基本的には1を返す。 # moneyを割り切れない場合=組み合わせが成立しない場合0を返す return 1 if money % coin_list[0] == 0 else 0 # 検証に使用するコインを末尾から取り出す coin = coin_list[-1] # coinを使う枚数は0~(money//coin)の(money//coin +1)通り for i in range(money // coin + 1): # coinの分をmoneyから差し引き、 # 残りのcoin_listから再帰的に組み合わせを取得しresultに加算 result += combo_of_coin(money - coin * i, coin_list[:-1]) return result if __name__ == '__main__': from time import time as t st = t() main() print(t() - st, 'sec')paizaにて実行
結果
73682
0.019005775451660156 sec