- 投稿日:2019-09-15T23:54:06+09:00
自分用だからを言い訳に、顔画像データセットを怠惰に作る
モチベーション
- GANとかに使える顔画像を集めたい
- せっかくだから、自分の好きな声優や芸能人で学習させたい
- ラクしたい
サマリ
- ライブラリ(icrawler)で、画像収集します。
- Google、Bingから画像をガーっと集めます。しかし、関係ない画像(風景や別人)だったり、同じ画像(重複データ)も集まってきます.
- ライブラリ(MTCNN)で、顔画像を抽出します。
- 欲しいのは顔画像なので、集めた画像から顔画像をひと通り抽出します。ただし、別人や重複画像の情報は残っています。
- 顔識別関係の学習済みモデル(Keras VGGFace)を利用し、分類します。
- 学習済みモデルから得られる特徴量から類似度を利用し、上記の顔画像内でクラスタリング、人ごとのクラス形成を試みます。重複情報もここで削除します。
- 最後に、自分の手で微調整(ここだけガンバル)
実行結果イメージ
クローリングで、こんな感じに集まってきたデータを、
分類して、まとめていきます。(対象人物でない人や、アニメキャラが分けられます)
一部、誤分類や重複が残るのでパラメータ調整や、手作業で修正します。機械学習のために、機械学習(深層学習)の成果物を使うという、鶏と卵になってますが、、自分用だから・・・
今回作成したプログラムは、こちらで公開しています。
以下、簡易使用説明です。Readmeにある内容の転記です。
必須ライブラリのインストール# GPUを利用しない場合は、tensorflow-gpu -> tensorflow に変更 pip3 install -r requirements.txtクローリング# 第一引数:出力先ディレクトリ # それ以降:検索クエリ この場合、「TrySail」「麻倉もも」「雨宮天」「夏川椎菜」をそれぞれ検索 # オプション: --flatten 最後に画像をひとつのディレクトリにまとめる # --src 検索先 google, bing, baidu が使える # --max_num 1クエリごとで、ダウンロードする最大数 python3 crawling.py resource TrySail 麻倉もも 雨宮天 夏川椎菜 --flatten --src google bing --max_num 100顔画像抽出&分類# 第一引数:元データ格納ディレクトリ 直下にあるイメージのみ読込む # 第二引数:作業用ディレクトリ 途中結果、最終結果の格納先 # オプション: -n プロセス数(最低 2) # --min_face 検知する顔画像の最小領域の一辺 python3 clustering.py resource/TrySail resource/work -n 4 --min_face 100
以下、利用ライブラリのサンプルや説明。
クローリング
icrawlerというライブラリを利用します。Build-inでGoogle、Bing、Baidu向けクローラーが完備されており、使いやすいです。
icrawler: https://github.com/hellock/icrawler
Google用クローラーのサンプルを以下に示します。ちなみに、1,000件超のダウンロードになる場合はライブラリ内部で止めているようです。
import pathlib from datetime import datetime from icrawler.builtin import GoogleImageCrawler def example_google(): keyword = 'TrySail' pathlib.Path('output/trysail').mkdir(parents=True, exist_ok=True) crawler = GoogleImageCrawler( feeder_threads=1, parser_threads=1, downloader_threads=2, storage={'root_dir': 'output/trysail'}) filter_ = { 'size': 'large', 'date': ((2015, 5, 13), (datetime.today().year, datetime.today().month, datetime.today().day)), } crawler.crawl(keyword=keyword, max_num=500, offset=0, file_idx_offset=0, min_size=(250, 250), max_size=None, filters=filter_)
keywordが検索クエリになります。- 個人的に、迷惑をあまりかけないように・・という意味で、
downloader_threadsは低く設定しています。顔検出
MTCNNというライブラリを利用します。FacenetのMTCNN実装としてTensorFlowで書かれたライブラリです。
MTCNN: https://github.com/ipazc/mtcnn
詳しい使い方は、GitHubにあります。https://github.com/ipazc/mtcnn#usage
MTCNNで顔検出import cv2 import mtcnn.mtcnn as mtcnn img = cv2.cvtColor(cv2.imread('path/to/your-image.png'), cv2.COLOR_BGR2RGB) model = mtcnn.MTCNN(min_face_size=128) faces = model.detect_faces(img)
min_face_sizeを利用し、128x128以上の領域のみ顔と判定するように指定しています。- 返り値は、
boxが顔の領域(x, y, 幅, 高さ)、confidenceが顔である確率を示しています。特徴量抽出
学習済みモデルから対象画像の特徴量を抽出し、コサイン類似度を利用して、イメージの類似度を測ることを試みます。
ライブラリは、Keras VGGFaceを利用します。このライブラリを導入することで、Kerasと同じ使用感で、VGGFaceで学習されたモデルを利用することができます。
Keras VGGFace: https://github.com/rcmalli/keras-vggface
Kerasで学習済みモデルを利用した特徴量抽出の方法は、公式にサンプルがあります。
https://keras.io/ja/applications/Imagenetで学習済みVGG19を利用してコサイン類似度計算from keras.preprocessing import image from keras.applications.vgg19 import VGG19 from keras.applications.vgg19 import preprocess_input def calc_sim_trained_model(path_a: str, path_b: str, size=(224, 224, 3)): model = VGG19(weights='imagenet', include_top=False, input_shape=size, pooling='avg') inputs = np.array([image.img_to_array(image.load_img(path, target_size=size[:2])) for path in (path_a, path_b)]) feats = model.predict(preprocess_input(inputs)) return np.dot(feats[0] / np.linalg.norm(feats[0]), feats[1] / np.linalg.norm(feats[1]))
- モデル生成時に
poolingを指定し、プーリング層を含めるようにしています。
プーリング層によって特徴量をベクトルで抽出できるので、コサイン類似度を行いやすくなります。keras.preprocessingのimage.load_imgを利用すると、リサイズなど簡単に行えて便利です。inputsは、(サンプル数, Width, Height, チャンネル数(色))の形状になる配列です。
多数のイメージを対象にし、バッチで高速に処理したい場合は、inputsにサンプル数を追加ことで対応できます。- 学習済みモデルを利用するので、
preprocess_inputによる処理後に、predictを利用します。- numpyにて、$[-1.0, 1.0]$になるように、正規化しつつ、コサイン類似度を計算します。
Keras VGGFaceの場合は、以下を参考に、
model, preprocess_inputを入れ替えます。from keras_vggface.vggface import VGGFace from keras_vggface.utils import preprocess_input model = VGGFace(model='senet50', input_shape=(224, 224, 3), include_top=False, pooling='avg') ... model.predict(preprocess_input(inputs), version=2)
- 利用可能モデル:https://github.com/rcmalli/keras-vggface#example-usage
- 利用モデルによって、
preprocess_inputにversion指定が必要なことに注意。https://github.com/rcmalli/keras-vggface#predictionおまけ
別途利用できるライブラリのサンプルもついでに。
OpenCV: カスケード型分類器
OpenCVには顔検出に利用できる分類器がデフォルトで用意されています。
Haarカスケード分類器を利用した顔検出のサンプルimport cv2 import pathlib def face_detect_cascade(path: str, cascade: cv2.CascadeClassifier, **kwargs): # https://docs.opencv.org/3.4.1/d7/d8b/tutorial_py_face_detection.html img_gs = cv2.imread(path, cv2.IMREAD_GRAYSCALE) return cascade.detectMultiScale(img_gs, **kwargs) # インストール先のdataディレクトリに、デフォルトの分類器が用意されているので、 # 以下のようにパスを指定すればアクセスできます。 cascade = cv2.CascadeClassifier(str( pathlib.Path(cv2.__file__).parent / 'data/{}.xml'.format('haarcascade_frontalface_default') )) face_detect_cascade('path/to/image.png', cascade, scaleFactor=1.1, minNeighbors=10, minSize=(32, 32))OpenCV: ヒストグラム比較
N階級(下記だと200)のカラーヒストグラムを作成し、その類似度を指定メソッド(HISTCMP_CORRELなど)で計算して求めます。
https://docs.opencv.org/3.4/d6/dc7/group__imgproc__hist.html で利用できるメソッド名が確認できます。import numpy as np import cv2 def calc_sim_hist(path_a: str, path_b: str, method='HISTCMP_CORREL'): # https://docs.opencv.org/3.4/d6/dc7/group__imgproc__hist.html def make_vec(img): hists = np.array([cv2.calcHist([img], [ch], None, histSize=[200], ranges=[0, 256]) for ch in range(3)]) return np.reshape(hists, (hists.shape[0] * hists.shape[1], 1)) img_a, img_b = cv2.imread(path_a), cv2.imread(path_b) hist_a, hist_b = make_vec(img_a), make_vec(img_b) return cv2.compareHist(hist_a, hist_b, getattr(cv2, method))ImageHash
画像の類似度判定に、
ImageHash: https://github.com/JohannesBuchner/imagehash
を利用できます。画像からハッシュ値を算出し、そのハミング距離から類似度を判断します。import imagehash from PIL import Image def calc_sim_imagehash(path_a: str, path_b: str): img_a, img_b = Image.open(path_a), Image.open(path_b) hash_a, hash_b = imagehash.average_hash(img_a), imagehash.average_hash(img_b) return hash_a - hash_b


- 投稿日:2019-09-15T23:31:55+09:00
AtCoder Beginner Contest 141 参戦記
AtCoder Beginner Contest 141 参戦記
A - Weather Prediction
3分半で突破. ボーッとしてて開始に気づかなく、40秒くらい損している. もったいない. 書くだけ.
S = input() if S == 'Sunny': print('Cloudy') elif S == 'Cloudy': print('Rainy') else: print('Sunny')B - Tap Dance
3分で突破. 0-indexed と 1-indexed で偶奇がひっくり返ることだけ気にした.
S = input() if all(c in 'RUD' for c in S[::2]) and all(c in 'LUD' for c in S[1::2]): print('Yes') else: print('No')C - Attack Survival
10分半で突破. 制約を見るに、素直に N - 1 人のスコアを -1 して回ると TLE になるのは明々白々なので、正解者を +1 点する方向性で書いたらあっさり通りました.
N, K, Q = map(int, input().split()) score = [K - Q] * (N + 1) for _ in range(Q): score[int(input())] += 1 for i in range(1, N + 1): if score[i] > 0: print('Yes') else: print('No')D - Powerful Discount Tickets
13分半で突破. ABC137D からそんなに経ってないのにまた優先度付きキューですかーと思いながら実装. Dだから素直にM回一番大きいやつを割るのではなく、まとめ割がいるかなあと思ったけどそんなことはなかった.
from heapq import heapify, heappop, heappush N, M = map(int, input().split()) a = [-int(a) for a in input().split()] heapify(a) for _ in range(M): heappush(a, heappop(a) / 2) print(-sum(int(x) for x in a))
- 投稿日:2019-09-15T23:30:52+09:00
Python3.7でCrean Architectureを実現する
先日あるプロジェクトで、python 3.7を利用したクリーンアーキテクチャの設計を行いました。
その時に得た知見を紹介したいと思います。
基本的に、この記事ではDDDに関しての説明はこの連載を参考していきます。
Domainモデル
ValueObject
参考記事によるとValueObjectでは、次の6つの要素を持つものである、と定義されています。
No 値オブジェクトの特徴 説明 1 計測/定量化/説明 ドメイン内の何かを計測したり定量化したり説明したりする 2 不変性 状態を不変に保つことができる 3 概念的な統一体 関連する属性を不可欠な単位として組み合わせることで、概念的な統一体を形成する 4 交換可能性 計測値や説明が変わったときには、全体を完全に置き換えられる 5 等価性 値が等しいかどうかを、他と比較できる 6 副作用のない振る舞い 協力関係にあるその他の概念に「副作用のない振る舞い」を提供する python 3.7からはValue Objectを作成する際にdataclassを利用するのが最もシンプルに記載できます。
from dataclasses import dataclass @dataclass(frozen=True) class MonetaryValue(): amount: Decimal currency: strdataclassを利用することで、先程の特性の2. 編成、4. 交換可能性、5. 透過性、6. 副作用のない振る舞いを手に入れることができます。 1. の計測/定量化/説明及び3. の概念的な統一体は設計に依存する箇所であるため、これでValueObjectを記述することができました。
注意事項
個人情報に該当する箇所はreprで出力されないようにマスクする
例えば次のようなクラスがあった場合に、何かの拍子にパスワードがログに書かれて、更に何かの拍子に流出する、という事がないように、ハッシュ化前のパスワード等の重要なものはログに出力されないようにしましょう。from dataclasses import dataclass, field @dataclass(frozen=True) class UserPassword(): name: str password: str = field(repr=False) user = UserPassword(name="foo", password="bar") print(user) >>> UserPassword(name='foo')例えばテナントIDのような、単一の値を持つValueObjectを作成する場合は、継承と委譲と2種類の実装があります。
継承の場合:class TenantId(str): @classmethod def __new__(cls, value): # do some validation return cls(value)委譲の場合:
class TenantId(): def __init__(self, value): super().__init__() this.__value = value # 他に必要なメソッドをvalueからdelegateする(色々) def __eq__(self, value): ...委譲のほうが設計としては良いのですが、記述は継承のほうがシンプルです
Entity
Entityも基本的には同じで設計可能ですが、dataclassでは特定のフィールドだけ書き換え不可能、という書き方ができません。
そのため、idの不変性を持つためのEntity classを作成し、それを継承してEntityを作るようにします。from dataclasses import dataclass, field @dataclass class Entity(): id: str = field(compare=True) def __setattr__(self, name, value): if (name == 'id' and hasattr(self, name) ): raise SystemError() super().__setattr__(name, value) @dataclass class User(Entity): name: str = field(compare=False) jon = User(id='foo', name='jon') pochi = User(id='foo', name='pochi') jon == pochi >>> Trueこれにより、idに初期値を代入後再代入することが不可能となるため、idの不変性を得ることができました。
と、楽したいためにここまでdataclassを利用して来ましたが、特にエンティティのValidationがうまくできないため、dataclassを利用しない実装も検討の余地がありそうです。
Dependency Injection
pythonは静的型付け言語ではないため、DIコンテナの利用は必須では無いです。しかし、クラスのインスタンス化の手間を考えると、DIコンテナを利用して依存性の解決を行う方が良いと思います。
Dependency Injectionのおすすめライブラリはinjectorです。シンプルな記述で必要最低限の機能を持つため、簡単にDIコンテナによる依存性注入を実現できます。
from injector import inject, singleton, Injector, Module from abc import ABC, abstractmethod class IARepo(ABC): @abstractmethod def get_user(self): raise NotImprementedError('not impremented') @singleton class ARepo(IARepo): def get_user(self): return User(id='aaa', name='bbb') @singleton class Usecase(): @inject def __init__(self, repo: IARepo): super().__init__() self.__repo = repo def get_user(self): return self.__repo.get_user() class InjectConfig(Module): def configure(self, binder): binder.bind(IARepo, to=ARepo, scope=singleton) inj = Injector(InjectConfig()) usecase = inj.get(Usecase) usecase.get_user()DIを利用した単体テスト
また、DIコンテナを利用することで、例えばユースケース等、十分なテストを行いたいモジュールの単体テストも簡単にできるようになります。
from unittest.mock import create_autospec def test_run(): repo_mock = create_autospec(IARepo) usecase = Usecase(repo=repo_mock) user = User(id='baz', name='hoge') repo_mock.get_user.return_value = user result = usecase.get_user() assert result == user test_run()
- 投稿日:2019-09-15T23:17:47+09:00
python 正規表現で奇数番目、偶数番目の文字のパターンを見る
正規表現を使った偶数、奇数番目の文字判定
pythonで文字列の奇数番目、偶数番目文字を判定した方法を共有します。
例えば
RDULULDURURLRDULRLRこのような文字列で奇数番目の文字にLが入っていないことを、また偶数番目の文字にRが入っていないことを確認したいです。
そこで今回は正規表現を使いました。
import re string = input() pattern = re.compile(r'^([^L][^R])*[^L]?$') if pattern.match(string): print('Yes') else: print('No')re.compileとしておくと繰り返しそのパターンを探していく場合に高速になります。
上記の正規表現の意味は以下の通りです。
r:文字列の先頭に書いておくとバックスラッシュ等がエスケープされます
^:行の先頭を表す
:0回以上の繰り返し 例:ab 合致パターン: a,ab,abb,abbb,...
$:行の末尾
- 投稿日:2019-09-15T22:35:21+09:00
RealSence D435をPythonで使う【画角を合わせる編】(Windows10)
お詫び
半年くらい全く更新がありませんでしたが飽きたわけではなくて
あるイベントのロボット製作が忙しく更新できていませんでした。VAEとかもほったらかしですし単眼カメラのSLAMとかもやりたいなぁ・・・
・・・
・・・・・・(過労死)はじめに
先日PythonでD435を動かすラッパーのビルド方法とかとりあえず表示する方法をアップしたので
この記事からの方は上記もご参照いただきたく・・・「とりあえず表示編」のスクリプトでIR,RGB,Depthの画像を得ることが出来ましたが
実はRGBとDepthの画角がずれているという問題がありますので、その辺を解決したいと思います環境
windows10
python:3.6.6とか3.6.7とか3.6.8
OpenCV:3.4.2
pyrealsense2:2.19.0
numpy:1.15.1RGB+Depthを表示するスクリプト
まずどのくらいずれているのかを見てみたいと思います
いちいち作るのも面倒かと思いますのでRGBとDepthのカラーマップを並べて表示する
スクリプトを下記に示しますimport pyrealsense2 as rs import numpy as np import cv2 # ストリーム(Color/Depth)の設定 config = rs.config() config.enable_stream(rs.stream.color, 640, 480, rs.format.bgr8, 30) config.enable_stream(rs.stream.depth, 640, 480, rs.format.z16, 30) # ストリーミング開始 pipeline = rs.pipeline() profile = pipeline.start(config) try: while True: # フレーム待ち frames = pipeline.wait_for_frames() #RGB RGB_frame = frames.get_color_frame() RGB_image = np.asanyarray(RGB_frame.get_data()) #depyh depth_frame = frames.get_depth_frame() depth_image = np.asanyarray(depth_frame.get_data()) depth_colormap = cv2.applyColorMap(cv2.convertScaleAbs(depth_image, alpha=0.08), cv2.COLORMAP_JET) # 表示 images = np.hstack((RGB_image, depth_colormap)) cv2.namedWindow('RealSense', cv2.WINDOW_AUTOSIZE) cv2.imshow('RealSense', images) if cv2.waitKey(1) & 0xff == 27:#ESCで終了 cv2.destroyAllWindows() break finally: # ストリーミング停止 pipeline.stop()結果
見ての通りDepthの方が明らかに広角で画角が合っていません
このままのDepthを使用してRGB側にマスクをかけるとずれたり
単眼SLAMの学習データに出来ないという問題が・・・
対策
と書きましたが、私が何かを作ったわけでもなく普通にライブラリにコマンドがありますw
とりあえず動かしてみましょうimport pyrealsense2 as rs import numpy as np import cv2 # ストリーム(Depth/Color)の設定 config = rs.config() #config.enable_stream(rs.stream.color, 1280, 720, rs.format.bgr8, 30) #config.enable_stream(rs.stream.depth, 1280, 720, rs.format.z16, 30) # config.enable_stream(rs.stream.color, 640, 360, rs.format.bgr8, 30) # config.enable_stream(rs.stream.depth, 640, 360, rs.format.z16, 30) # ストリーミング開始 pipeline = rs.pipeline() profile = pipeline.start(config) # Alignオブジェクト生成 align_to = rs.stream.color align = rs.align(align_to) try: while True: # フレーム待ち(Color & Depth) frames = pipeline.wait_for_frames() aligned_frames = align.process(frames) color_frame = aligned_frames.get_color_frame() depth_frame = aligned_frames.get_depth_frame() if not depth_frame or not color_frame: continue #imageをnumpy arrayに color_image = np.asanyarray(color_frame.get_data()) depth_image = np.asanyarray(depth_frame.get_data()) #depth imageをカラーマップに変換 depth_colormap = cv2.applyColorMap(cv2.convertScaleAbs(depth_image, alpha=0.08), cv2.COLORMAP_JET) #画像表示 color_image_s = cv2.resize(color_image, (640, 360)) depth_colormap_s = cv2.resize(depth_colormap, (640, 360)) images = np.hstack((color_image_s, depth_colormap_s)) cv2.namedWindow('RealSense', cv2.WINDOW_AUTOSIZE) cv2.imshow('RealSense', images) if cv2.waitKey(1) & 0xff == 27:#ESCで終了 cv2.destroyAllWindows() break finally: #ストリーミング停止 pipeline.stop()無事に画角が揃いました!!
おわり・・・解説したいと思います解説
ストリーミングを開始した後に下記の2行を追記し画角を合わせます
# Alignオブジェクト生成 align_to = rs.stream.color align = rs.align(align_to)今まではカメラに格納されていたデータを取りに行っていましたが
alignを行ったので処理後のデータを下記のように取得しますaligned_frames = align.process(frames) color_frame = aligned_frames.get_color_frame() depth_frame = aligned_frames.get_depth_frame()正直「標準でこの状態で出力してくれ」と思いますが何か不都合があるんでしょうか?
兎にも角にも、これでRGB+Dデータを正しく取得できることが出来ました。
次回は深度情報を使った簡単な事例を・・・紹介できるといいなぁ・・・


- 投稿日:2019-09-15T21:42:14+09:00
Pythonのバージョン確認方法
いつも忘れてしまう、バージョンの確認方法
$ python --version Python 3.7.4$ python -V Python 3.7.4
- 投稿日:2019-09-15T20:08:43+09:00
メモ:俺なりのLakeCounting
記事の見てくれとか何も気にせず他の人の書いたコードをもとにして自分なりに書いたのをここに保存。
a = list(map(int,input().split()))
n = a[0]
m = a[1]print("n=",n,"m=",m)
field=[]
for i in range(n):
field.append(list(input()))
def dfs(x,y):
#print("x=",x,"y=",y)
field[x][y] = '.'
for dx in [-1,0,1]:
for dy in [-1,0,1]:
nx = x + dx
ny = y + dy
#print("nx=",nx,"ny=",ny)
if(0<=nx and nx<n and 0<=ny and ny<m and field[nx][ny] == 'W'):
dfs(nx,ny)
res = 0
for j in range(n):
for k in range(m):
print("j=",j,"k=",k,"field[",j,"][",k,"]=",field[j][k])
if(field[j][k]=='W'):
#print("so dfs starts!!")
dfs(j,k)
res +=1
- 投稿日:2019-09-15T20:08:01+09:00
だらだら転職日記 (4) Pythonのツールチェインを整理する
モチベーション
パッケージ管理ツールというとJavaScriptならnpm,1 Rustならcage, Rubyならgems, ElixirならHexというのがあります. ではPythonにはとpipというのがあります. それぞれ"管理"という言葉にこめられた意味が違っているのですが, pipの場合は公式にはパッケージ・インストーラとありプロジェクトの作成などは含んでいないようです.
pip is the package installer for Python2
そのほかにも様々なツールがあってブログやら記事やらの日付を見て古いやつだと後で気付いたりして混乱している次第です.3 そもそもの原因は個々のツールの目的を曖昧にしたまま, とりあえず動かせているから理解した気になっていることが原因なのです. 特にpipenvというのが便利そうなんですが他のツールとの使い分け・共存などで混乱したことが大きなきっかけです.
簡単な用語の整理
Pythonのモジュール・システムを解説するわけではないのでかなり適当ですが何を対象にしているのかが分かるようにモジュールとパッケージについて説明します.
モジュール
Pythonファイルを定義するとそれはそのままモジュールという単位になる.
greet.pydef sayHello(): print("Hello, World")つまりこのファイルを他のファイルから読み込めるということだ.
sample.pyimport greet一方このファイルをスクリプトとして実行することもできる.
python greet.pyこの場合ブートストラップとしてコードを呼び出す場所が必要になる.
sample.pyif __name__ == "__main__": sample();スクリプトとして実行した場合はmainという文字列が設定されてとしてとトップレベルのモジュールとして実行される. 一方モジュールとして読み込まれた場合はモジュール名が格納されている.4
モジュールとパッケージの違い
公式ドキュメントにはパッケージとモジュールは以下のように定義されている. 5
A Python module which can contain submodules or recursively, subpackages. Technically, a package is a Python module with an __path__ attribute.
An object that serves as an organizational unit of Python code. Modules have a namespace containing arbitrary Python objects. Modules are loaded into Python by the process of importing.
パッケージもモジュールの一つですが, __path__という属性があるようです. 大雑把にいうとPythonファイルを定義すればモジュールで, それが入ったフォルダがパッケージです.
パッケージ管理に関する基本的な問題点
Q. パッケージの取得
パッケージを取得できないとまずは意味がありません. Batteries-includedと言えど, Pythonをメインストリームに押し上げた科学技術計算用のパッケージとかは欠かせないはずです.
A. pip
すでに説明しましたがパッケージのインストール・ツールです. pip installでパッケージを取得します. パッケージはsite-packagesというフォルダにインストールされます.
Q. 依存性の管理
pipでパッケージをインストールできました. しかし他のパッケージの機能をインポートして利用するパッケージというのもあります. この他所から機能を提供してくれるパッケージを依存性(依存パッケージ)と言います.依存性は単にパッケージの名前を知っていれば良いというわけではなくて, バージョンに関する情報も必要になります. つまりAという依存パッケージが存在してもバージョン1.0と1.1に互換性が無いという状況が想定されまう. したがってパッケージの名前とバージョンという二つの情報を管理する必要があります. もしこの情報が何らかの形で定義されていないとコードの中から依存性となるパッケージを抽出するという作業が出てきます.
A. setuptools
パッケージの配布とビルドのためのパッケージです. pipを通じてパッケージを配布したいときにこのツールを使ってsetup.pyやsetup.cfgなどを書く必要があります. setuptooslのオプションにinstall_requiresがあってここに必要な依存性を記述することになります. 問題は手動なことです.
Q. 開発環境の再現
もう1つの注意点は開発環境が変わるような場合です. マシンが古くなってきたので新しいのに変えるという時に問題が生じます. 依存性が解決されても環境が再現されないと問題になる場合もあるのです. これも間接的な依存性と言えます.
A. 環境のダンプ
開発するときはpipでパッケージをインストールしています. pipはインストール済みのパッケージ一覧を表示してくれます. これを保存しておけばとりあえずは同じ環境が再構築できます. 一般にrequirements.textと呼ばれるファイル名が使われます.
# Save dependencies pip freeze > requirements.txt # Retrieve dependencies pip install -r requirements.txtinstall_requiresと形式は同じなのでrequirements.txtをそのまま指定することもできます.
ここまでのまとめ
パッケージの取得に関してはおおよそpipでオッケーです.
requirements.txtの問題点
requirements.txtを用いた環境のダンプには二つの問題がありそうです.
- 依存パッケージのバージョンが微妙に違う場合
- 依存性のレベルをコントロールできない
Q. 依存パッケージのバージョンが微妙に違う場合
全て最新のバージョンにしておけば良いと言えそうですが, 依存パッケージが何百とあってアップデートのたびにその全ての変更に対応しないといけないのは煩雑に過ぎるわけです. バージョンを固定したいわけですが, 新しいプロジェクトでは新しいバージョンを使い始めるなんてこともありそうです. このように管理するプロジェクトが増えていくとrequirements.txtのような依存性の列挙では解決できないケースが出てきます.
A. venv/virtualenv
仮想環境は仮想Pythonを作ってその中で開発を行います. Python自体はインストールされたインタプリタを使いますが, site-packagesなどが環境ごとに違ってきます. よって依存パッケージのバージョンが違おうが種類が違おうが関係なく開発を行えます.
Q. 依存性のレベルをコントロールできない
依存性と一口に言っても, 直接依存しているのか依存パッケージがさらに依存しているのかということがrequirements.txtでは区別がつきません. 依存性の解決なのか開発時の環境の再現なのかが分かりにくいのです. これはそのそもpipでインストールしたパッケージをダンプしているだけだからです. 他にもdev-dependenciesのよな開発時にのみ必要なツールなどが分けられません.
A. Pipenv
Pipenvはpipとvirtualenvを組み合わせたツールです. このツールを使うとpipで導入する依存パッケージをPipfileというtoml形式のファイルで管理できます. 基本的にプロジェクトが直接依存するパッケージだけが記述されます. またdev-dependenciesの管理もできます.
Pipenvの問題点
Pipenvは便利なツールに見えますが内部はpipです. つまりsetuptoolsを使った依存関係の定義が背後にはあります. このため他の言語のツールとは違いアプリケーション用途では使えても基本的なパッケージ管理はpipの形式で記述する必要があるわけです. これはpipenvの問題点というよりはpip自体の問題点ともなのですが, 開発対象ごとにツールが二重になってしまいます.
またpipenvは仮想環境を使いますが, 今度は複数の環境の切り替えが問題になります. プロジェクト間を移動するたびに環境を切り替える作業を忘れずにできるでしょうか?
更に仮想環境を作る際のpythonインタプリタのインストールは誰もしてくれません. 仮想環境の元になる本体は別途調達する必要があります.
Q. 環境の切り替え & 複数のPythonインタプリタの管理
プロジェクトごとに環境が設定できて, 指定したPythonがなければインストールしてくれれば助かります.
A. direnv & pyenv
direnvは環境の切り替えをしてくれます. pyenvは両方してくれます. 言い換えるとプロジェクトごとに環境が設定できるわけです.
結局pipの問題点
pipは便利ツールでした. それをうまく利用したpipenvでアプリ開発に関する準備が簡素化されたと言えます. ただ他の言語と比べると少し物足りない感じはします.
Q. パッケージ管理はインストールだけじゃない
pipはパッケージ・インストーラーでした. 実際の多くのことはsetuptoolsが行ってくれたわけです. ただ, あまり便利なツールとは言えません.6
ぶっちゃけcagoとかnpmみたいのが欲しいです.7
A. Poetry & Pyenv?
Rustとの比較
用途 Rust Python パッケージ管理 Cargo poetry ツールチェインの管理 rustup pyenv? rustupの部分的な機能はpyenvで代替できそうな気もします.
まとめ(新しいモチベーション)
Poetryとpyenvをやってみる.

- 投稿日:2019-09-15T20:08:01+09:00
だらだら転職日記 (4) Pythonのツールチェインを整理する ~pipからPoetryへ~
モチベーション
パッケージ管理ツールというとJavaScriptならnpm,1 Rustならcage, Rubyならgems, ElixirならHexというのがあります. ではPythonにはとpipというのがあります. それぞれ"管理"という言葉にこめられた意味が違っているのですが, pipの場合は公式にはパッケージ・インストーラとありプロジェクトの作成などは含んでいないようです.
pip is the package installer for Python2
そのほかにも様々なツールがあってブログやら記事やらの日付を見て古いやつだと後で気付いたりして混乱している次第です.3 そもそもの原因は個々のツールの目的を曖昧にしたまま, とりあえず動かせているから理解した気になっていることが原因なのです. 特にpipenvというのが便利そうなんですが他のツールとの使い分け・共存などで混乱したことが大きなきっかけです.
簡単な用語の整理
Pythonのモジュール・システムを解説するわけではないのでかなり適当ですが何を対象にしているのかが分かるようにモジュールとパッケージについて説明します.
モジュール
Pythonファイルを定義するとそれはそのままモジュールという単位になる.
greet.pydef sayHello(): print("Hello, World")つまりこのファイルを他のファイルから読み込めるということだ.
sample.pyimport greet一方このファイルをスクリプトとして実行することもできる.
python greet.pyこの場合ブートストラップとしてコードを呼び出す場所が必要になる.
sample.pyif __name__ == "__main__": sample();スクリプトとして実行した場合はmainという文字列が設定されてとしてとトップレベルのモジュールとして実行される. 一方モジュールとして読み込まれた場合はモジュール名が格納されている.4
モジュールとパッケージの違い
公式ドキュメントにはパッケージとモジュールは以下のように定義されている. 5
A Python module which can contain submodules or recursively, subpackages. Technically, a package is a Python module with an __path__ attribute.
An object that serves as an organizational unit of Python code. Modules have a namespace containing arbitrary Python objects. Modules are loaded into Python by the process of importing.
パッケージもモジュールの一つですが, __path__という属性があるようです. 大雑把にいうとPythonファイルを定義すればモジュールで, それが入ったフォルダがパッケージです.
パッケージ管理に関する基本的な問題点
Q. パッケージの取得
パッケージを取得できないとまずは意味がありません. Batteries-includedと言えど, Pythonをメインストリームに押し上げた科学技術計算用のパッケージとかは欠かせないはずです.
A. pip
すでに説明しましたがパッケージのインストール・ツールです. pip installでパッケージを取得します. パッケージはsite-packagesというフォルダにインストールされます.
Q. 依存性の管理
pipでパッケージをインストールできました. しかし他のパッケージの機能をインポートして利用するパッケージというのもあります. この他所から機能を提供してくれるパッケージを依存性(依存パッケージ)と言います.依存性は単にパッケージの名前を知っていれば良いというわけではなくて, バージョンに関する情報も必要になります. つまりAという依存パッケージが存在してもバージョン1.0と1.1に互換性が無いという状況が想定されまう. したがってパッケージの名前とバージョンという二つの情報を管理する必要があります. もしこの情報が何らかの形で定義されていないとコードの中から依存性となるパッケージを抽出するという作業が出てきます.
A. setuptools
パッケージの配布とビルドのためのパッケージです. pipを通じてパッケージを配布したいときにこのツールを使ってsetup.pyやsetup.cfgなどを書く必要があります. setuptooslのオプションにinstall_requiresがあってここに必要な依存性を記述することになります. 問題は手動なことです.
Q. 開発環境の再現
もう1つの注意点は開発環境が変わるような場合です. マシンが古くなってきたので新しいのに変えるという時に問題が生じます. 依存性が解決されても環境が再現されないと問題になる場合もあるのです. これも間接的な依存性と言えます.
A. 環境のダンプ
開発するときはpipでパッケージをインストールしています. pipはインストール済みのパッケージ一覧を表示してくれます. これを保存しておけばとりあえずは同じ環境が再構築できます. 一般にrequirements.textと呼ばれるファイル名が使われます.
# Save dependencies pip freeze > requirements.txt # Retrieve dependencies pip install -r requirements.txtinstall_requiresと形式は同じなのでrequirements.txtをそのまま指定することもできます.
ここまでのまとめ
パッケージの取得に関してはおおよそpipでオッケーです.
requirements.txtの問題点
requirements.txtを用いた環境のダンプには二つの問題がありそうです.
- 依存パッケージのバージョンが微妙に違う場合
- 依存性のレベルをコントロールできない
Q. 依存パッケージのバージョンが微妙に違う場合
全て最新のバージョンにしておけば良いと言えそうですが, 依存パッケージが何百とあってアップデートのたびにその全ての変更に対応しないといけないのは煩雑に過ぎるわけです. バージョンを固定したいわけですが, 新しいプロジェクトでは新しいバージョンを使い始めるなんてこともありそうです. このように管理するプロジェクトが増えていくとrequirements.txtのような依存性の列挙では解決できないケースが出てきます.
A. venv/virtualenv
仮想環境は仮想Pythonを作ってその中で開発を行います. Python自体はインストールされたインタプリタを使いますが, site-packagesなどが環境ごとに違ってきます. よって依存パッケージのバージョンが違おうが種類が違おうが関係なく開発を行えます.
Q. 依存性のレベルをコントロールできない
依存性と一口に言っても, 直接依存しているのか依存パッケージがさらに依存しているのかということがrequirements.txtでは区別がつきません. 依存性の解決なのか開発時の環境の再現なのかが分かりにくいのです. これはそのそもpipでインストールしたパッケージをダンプしているだけだからです. 他にもdev-dependenciesのよな開発時にのみ必要なツールなどが分けられません.
A. Pipenv
Pipenvはpipとvirtualenvを組み合わせたツールです. このツールを使うとpipで導入する依存パッケージをPipfileというtoml形式のファイルで管理できます. 基本的にプロジェクトが直接依存するパッケージだけが記述されます. またdev-dependenciesの管理もできます.
Pipenvの問題点
Pipenvは便利なツールに見えますが内部はpipです. つまりsetuptoolsを使った依存関係の定義が背後にはあります. このため他の言語のツールとは違いアプリケーション用途では使えても基本的なパッケージ管理はpipの形式で記述する必要があるわけです. これはpipenvの問題点というよりはpip自体の問題点ともなのですが, 開発対象ごとにツールが二重になってしまいます.
またpipenvは仮想環境を使いますが, 今度は複数の環境の切り替えが問題になります. プロジェクト間を移動するたびに環境を切り替える作業を忘れずにできるでしょうか?
更に仮想環境を作る際のpythonインタプリタのインストールは誰もしてくれません. 仮想環境の元になる本体は別途調達する必要があります.
Q. 環境の切り替え & 複数のPythonインタプリタの管理
プロジェクトごとに環境が設定できて, 指定したPythonがなければインストールしてくれれば助かります.
A. direnv & pyenv
direnvは環境の切り替えをしてくれます. pyenvは両方してくれます. 言い換えるとプロジェクトごとに環境が設定できるわけです.
結局pipの問題点
pipは便利ツールでした. それをうまく利用したpipenvでアプリ開発に関する準備が簡素化されたと言えます. ただ他の言語と比べると少し物足りない感じはします.
Q. パッケージ管理はインストールだけじゃない
pipはパッケージ・インストーラーでした. 実際の多くのことはsetuptoolsが行ってくれたわけです. ただ, あまり便利なツールとは言えません.6
ぶっちゃけcagoとかnpmみたいのが欲しいです.7
A. Poetry & Pyenv?
Rustとの比較
用途 Rust Python パッケージ管理 Cargo Poetry ツールチェインの管理 rustup pyenv? rustupの部分的な機能はpyenvで代替できそうな気もします.
まとめ(新しいモチベーション)
Poetryとpyenvをやってみる.
- 投稿日:2019-09-15T20:06:45+09:00
setup.pyの中からnvccを使う方法
はじめに
TL;DR
C++向けにCUDAを使ったライブラリを開発している中で、pybind11を使えばpythonからでも比較的簡単に使えることに気が付いたまでは良かったのですが、いざsetup.pyを作ろうとしたら苦労したので、備忘録として記載しております。殆ど自分用のメモなので需要はあまりないと思いますが、もし同じようなことをされる方の参考になれば幸いです。
なお、私は普段はC++メインでpythonは初心者なのでもっと良いやり方があるのかもしれません。やりたいこと
下記に対応できるsetup.pyを作るのが目標です。
- Windows と Linxu(ubuntu) に対応したい
- nvccのインストールされていない環境ではCPU版がビルドされるようにしたい
ということで、状況に応じて4パターンに対応できれば良いということになります。
参考にしたもの
結局いろいろ見ましたが、下記のソースコードを読むのが一番理解に繋がりました。
unixccompiler と msvccompiler は共に ccompiler を継承したクラスで、それぞれunix(gcc)用とwindows(cl.exe)用となっているようです。
また、探した限りこちらの記事や、CuPyのソースコードも参考になりました。
ただし、前者はWindowsに未対応で、後者はやや大掛かりでした。今回は自分の必要な部分だけなるべくシンプルに動くように作成を試みて、PyPIに登録するところまで試すことができました。事前準備
まず始めに nvcc が動く状態になっていることは前提とします。
また、Pythonは Python3 を前提として、windows環境には64bit版がインストールされているものとします。Windows においては、msvc (Microsoft Visual C++) の cl.exe の 64bit 版がコマンドラインから使えるようになっている必要があります。
これは例えばコマンドラインから
"C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Auxiliary\Build\vcvarsall.bat" x64のように実行することで設定できます(実際のインストール先は環境によって異なると思いますので読み替えてください)。
このとき x64 オプションを忘れないことが重要です。
windowsの場合、pip を使ってインストールする場合であっても、バイナリではなくソースコード(sdist)からのインストールとなる場合は事前設定しておかないといけないので注意が必要です。setup.py の作成
結果的に私が作成したのは、このソースコードとなります。
hook_compilerメソッドの箇所が今回のメインの箇所となります。
(プロジェクト特有の無関係の処理や、解析過程のprintなどが残っていますがご容赦ください)方針
基本的に ccompiler クラスのメソッドをオーバーライドしてフックすることで、'.cu' ファイルが来たときのみ処理を切り替えることで対応しました。
pybind11のsetup.pyサンプルがここにあるので、これをC++コードのコンパイルの基本形として対応を行っていきました。
unix と msvc の切り分け
ccompiler クラスの compiler_type メンバ変数を見れば、派生クラスで 'unix' や 'msvc' と設定されるようなのでここで判定が出来ます。
compile処理
次にコンパイル時のフックなのですが、unixccompiler では compileメソッド -> compileメソッド の順で処理されます。compileメソッドでpython用に必要なincludeパスやライブラリパスが追加されて、compileメソッドが呼ばれるので、_compileメソッドをフックするのが簡単なようです。
一方で、msvccompiler では、_compileメソッドは呼ばれず compileメソッド の中で完結しています。
もともと cl 用のオプションが得られても、nvcc の形式に変換するのが逆に大変なので、msvc 時はcompileメソッドをフックして、代替処理を作成することを考えます。このとき、親クラスである ccompiler の _setup_compile メソッドを活用することで楽が出来ます。 _setup_compile メソッドを呼び出すとその中でpythonに必要な項目を追加して出力先のディレクトリの作成などをしてくれるようです。
あとは、cl.exe 用であれば /D"(マクロ定義)" や /I"(インクルードパス)" のように、nvccやgccであれば -D(マクロ定義) や -I(インクルードパス) のようにの加工を行っていけばよい事になります。
Windowsでは空白のパス名の対策で "(ダブルクォーテーション)で囲う必要があるので注意ください。link処理
リンクに関しては _linkメソッドのようなものはなく、メタデータの解釈が必要になりそうです。
linkはオリジナルのまま使うことも考えたのですが、nvcc を使う場合、CUDA関連のライブラリ関連の設定を考えるとリンクにも nvcc を使う方が楽そうです。
私の場合は cuBLAS や OpenMP を使っていたのですが、-lcublas オプションを nvcc に、-fopenmp は -Xcompiler オプションを使って、gcc に投げるようにしたことで、それぞれに適切なライブラリをリンクしてもらえました。link に関しても同様に、親クラスの ccompiler の _fix_lib_args メソッドを使うことで楽が出来るようです。
その他
今回基本的に4パターンに応じたオプションを手動で用意しておくことでいろいろと簡略化しています。
コンパイラクラス自体を複数生成させるわけではないので、先人に習って extra_compile_args に、辞書として両方入れておき、フック先で切り替えています。
また、今回は nvcc を探すのにもいろいろコードを入れていますが、結果的に nvcc 経由で呼び出せば不要な情報もあり、もっと省略できそうにも思います。
おわりに
今後、setuptoolsなどが進化した場合に同じ手法が使えるかどうかわかりませんが、このあたりを活用したい人の参考になれば幸いです。
nvcc自体は unix 用とwindows用で使い方は近いのですが、unixccompiler と msvccompiler とで、意外に共通項が少なく思っていたより苦労しました。
- 投稿日:2019-09-15T18:00:41+09:00
Pygameを使ってテトリスを作った
Pygameでゲームを色々作れるらしかったので今回はテトリスを作りました。
プログラム本体
import pygame from pygame.locals import * import sys import random import copy # 定数 MAX_ROW = 20 MAX_COL = 10 class Block: def __init__(self, block_type): self.shapes = [[], [], # empty block and wall [[0, -1], [0, 0], [0, 1], [0, 2]], # I block [[-1, -1], [0, -1], [0, 0], [0, 1]], # J block [[0, -1], [0, 0], [0, 1], [-1, 1]], # L block [[0, -1], [0, 0], [-1, 0], [-1, 1]], # S blosk [[-1, -1], [-1, 0], [0, 0], [0, 1]], # Z block [[0, -1], [0, 0], [-1, 0], [0, 1]], # T block [[0, 0], [-1, 0], [0, 1], [-1, 1]]] # square self.block_type = block_type self.shape = copy.deepcopy(self.shapes[block_type]) self.row = 1 # initial position self.col = 5 self.level = 0 self.drop_rate = [60, 50, 45, 42, 39, 36, 35, 34, 33, 32, 31, 30, 29, 28, 27, 26, 25, 24, 23, 22, 21, 20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0] self.count = 60 self.hold_flag = True # key command movement def move(self, board, direction): # direction down:0 left:1 right:2 bottom:3 if direction == 0 and self.moveable(board, [1, 0]): self.row += 1 elif direction == 1 and self.moveable(board, [0, -1]): self.col -= 1 elif direction == 2 and self.moveable(board, [0, 1]): self.col +=1 elif direction == 3: self.row += self.bottom(board) self.count = 60 def bottom(self, board): # direction = [1, 0] while self.moveable(board, direction): direction[0] += 1 return direction[0]-1 def rotate(self, board, direction): # clockwise:0 anticloskwise:1 # long bar rotates differently if self.block_type == 2: if direction == 0: for dx in self.shape: dx[0], dx[1] = dx[1], 1-dx[0] elif direction == 1: for dx in self.shape: dx[0], dx[1] = 1-dx[1], dx[0] # square doesn`t rotate elif self.block_type == 8: pass # other blocks elif direction == 0: for dx in self.shape: dx[0], dx[1] = dx[1], -dx[0] elif direction == 1: for dx in self.shape: dx[0], dx[1] = -dx[1], dx[0] self.rotate_correction(board) # moving downward due to time def drop(self, screen, board): if self.count < self.drop_rate[self.level]: self.count += 1 return 0 elif self.moveable(board, [1, 0]): self.count = 0 self.row += 1 return 0 else: return 1 # make new block def moveable(self, board, direction): drow, dcol = direction for dx in self.shape: row = self.row + dx[0] + drow col = self.col + dx[1] + dcol if 0 <= row < MAX_ROW + 3 and 0 <= col < MAX_COL + 2 and board[row][col] != 0: return False return True def rotate_correction(self, board): move_priority = [[0, 0], [0, -1], [0, 1], [-1, 0], [1, 0], [2, 0], [-1, 1], [1, 1]] for direction in move_priority: if self.moveable(board, direction): self.row += direction[0] self.col += direction[1] return direction = [0, 2] while not self.moveable(board, direction): direction[1] += 1 self.row += direction[0] self.col += direction[1] def draw(self, screen, block_color, board): # prediction when dropped drow = self.bottom(board) for row, col in self.shape: row += self.row + drow col += self.col if row > 1: pygame.draw.rect(screen, block_color[self.block_type], Rect(30+35*col, 30+35*(row-2), 35, 35)) pygame.draw.rect(screen, block_color[10], Rect(32+35*col, 32+35*(row-2), 31, 31)) for row, col in self.shape: row += self.row col += self.col if row > 1: pygame.draw.rect(screen, (0, 0, 0), Rect(30+35*col, 30+35*(row-2), 35, 35)) pygame.draw.rect(screen, block_color[self.block_type], Rect(32+35*col, 32+35*(row-2), 31, 31)) def place(self, screen, board, record): for dx in self.shape: row = self.row + dx[0] col = self.col + dx[1] if not (2 <= row < MAX_ROW+2 and 1 <= col < MAX_COL+1): # placed block outside screen gameover(screen, record) return 1 board[row][col] = self.block_type return 0 class Record: def __init__(self): self.cleared_row = 0 self.score = 0 self.level = 0 self.score_table = [0, 80, 100, 300, 1200] self.level_up = [2, 5, 8, 12, 16, 20, 25, 30, 35, 40, # level 0 to 9 46, 52, 58, 64, 70, 77, 84, 91, 98, 105, # level 10 to 19 112, 120, 128, 136, 144, 152, 160, 168, 177, 186, # level 20 to 29 195, 204, 213, 222, 231, 240, 255, 270, 285, 300, 1000] # 30 to 40 def update(self, count): self.score += self.score_table[count]*(self.level+1) self.cleared_row += count if self.level < 40 and self.level_up[self.level] <= self.cleared_row: # level 40 is max self.level += 1 def show(self, screen): font = pygame.font.Font(None, 50) text1 = font.render("LEVEL:", True, (255, 255, 255)) level = font.render("{}".format(self.level), True, (255, 255, 255)) screen.blit(text1, [500, 300]) screen.blit(level, [700, 300]) text2 = font.render("CLEARED ROW:", True, (255, 255, 255)) cleared_row = font.render("{}".format(self.cleared_row), True, (255, 255, 255)) screen.blit(text2, [500, 360]) screen.blit(cleared_row, [900, 360]) text3 = font.render("SCORE", True, (255, 255, 255)) score = font.render("{0:012d}".format(self.score), True, (255, 255, 255)) screen.blit(text3, [500, 420]) screen.blit(score, [600, 480]) def start(screen): font1 = pygame.font.Font(None, 150) title = font1.render("TETRIS", True, (255, 255, 255)) font2 = pygame.font.Font(None, 50) text = font2.render("Press ENTER to start", True, (255, 255, 255)) screen.blit(title, [100, 100]) screen.blit(text, [100, 300]) pygame.draw.rect(screen, (255, 255, 255), Rect(510, 300, 390, 400), 3) pygame.draw.rect(screen, (0, 0, 0), Rect(550, 290, 310, 40)) font1 = pygame.font.Font(None, 80) text1 = font1.render("COMMAND", True, (255, 255, 255)) screen.blit(text1, [550, 275]) font3 = pygame.font.Font(None, 40) text2 = font3.render("Arrow DOWN: Move down", True, (255, 255, 255)) screen.blit(text2, [540, 350]) text2 = font3.render("Arrow LEFT: Move left", True, (255, 255, 255)) screen.blit(text2, [540, 390]) text2 = font3.render("Arrow RIGHT: Move right", True, (255, 255, 255)) screen.blit(text2, [540, 430]) text2 = font3.render("Arrow UP: Move bottom", True, (255, 255, 255)) screen.blit(text2, [540, 470]) text2 = font3.render("A: Rotate anticlockwise", True, (255, 255, 255)) screen.blit(text2, [540, 510]) text2 = font3.render("S: Rotate clockwise", True, (255, 255, 255)) screen.blit(text2, [540, 550]) text2 = font3.render("D: Hold", True, (255, 255, 255)) screen.blit(text2, [540, 590]) text2 = font3.render("P: Pause", True, (255, 255, 255)) screen.blit(text2, [540, 630]) pygame.display.update() while(1): pygame.time.wait(50) for event in pygame.event.get(): if event.type == QUIT: pygame.quit() sys.exit() if event.type == KEYDOWN: if event.key == K_ESCAPE: pygame.quit() sys.exit() if event.key == K_RETURN: return # ブロック、次ブロック、ボード、記録の初期化 def initialize_game(): board = [[0 for i in range(MAX_COL+2)] for j in range(MAX_ROW+3)] for col in range(MAX_COL+2): board[-1][col] = 1 for row in range(MAX_ROW+3): board[row][0] = 1 board[row][-1] = 1 record = Record() block_type = random.randint(2, 8) block = Block(block_type) block.level = record.level block_type = random.randint(2, 8) next_block = Block(block_type) hold_block = None return board, record, block, next_block, hold_block # 入力 ボード # 出力 消える行数、消える行の番号 def find_deleting_row(board): count = 0 row_numbers = [] for row in range(2, MAX_ROW+2): flag = True for col in range(1, MAX_COL+1): if board[row][col] == 0: flag = False break # row filled if flag: count += 1 row_numbers.append(row) return count, row_numbers # 行削除 # 入力 スクリーン、ボード、消す行番号 # 出力 なし def delete_row(screen, board, row_number, block_color): n_col = 4 for row in row_number: for col in range(1, MAX_COL+1): board[row][col] = 0 for i in range(n_col+MAX_COL): for row in row_number: for col in reversed(range(1, MAX_COL+1)): board[row][col] = board[row][col-1] if i < n_col: board[row][1] = 9 pygame.time.wait(8) draw_board(screen, board, block_color) pygame.display.update() for deleting_row in row_number: for row in reversed(range(2, deleting_row+1)): for col in range(1, MAX_COL+1): board[row][col] = board[row-1][col] # ゲームオーバー処理 def gameover(screen, record): screen.fill((0, 0, 0)) font1 = pygame.font.Font(None, 200) gameover_text = font1.render("GAMEOVER", True, (255, 0, 0)) screen.blit(gameover_text, [100, 100]) font2 = pygame.font.Font(None, 80) result_text = font2.render("RESULT", True, (255, 255, 255)) screen.blit(result_text, [200, 300]) font = pygame.font.Font(None, 50) text1 = font.render("LEVEL:", True, (255, 255, 255)) level = font.render("{}".format(record.level), True, (255, 255, 255)) screen.blit(text1, [250, 370]) screen.blit(level, [600, 370]) text2 = font.render("CLEARED ROW:", True, (255, 255, 255)) cleared_row = font.render("{}".format(record.cleared_row), True, (255, 255, 255)) screen.blit(text2, [250, 430]) screen.blit(cleared_row, [600, 430]) text3 = font.render("SCORE", True, (255, 255, 255)) score = font2.render("{0:012d}".format(record.score), True, (255, 255, 255)) screen.blit(text3, [250, 490]) screen.blit(score, [300, 550]) restart_text = font.render("Press R to restart", True, (255, 255, 255)) screen.blit(restart_text, [350, 650]) pygame.display.update() while(1): pygame.time.wait(50) for event in pygame.event.get(): if event.type == QUIT: pygame.quit() sys.exit() if event.type == KEYDOWN: if event.key == K_ESCAPE: pygame.quit() sys.exit() if event.key == K_r: return def pause(screen, board, block_color): pygame.draw.rect(screen, (50, 50, 50), Rect(65, 32, 35*MAX_COL, 35*MAX_ROW)) font1 = pygame.font.Font(None, 100) text1 = font1.render("PAUSE", True, (255, 255, 255)) font2 = pygame.font.Font(None, 30) text2 = font2.render("Press P to resume", True, (255, 255, 255)) text3 = font2.render("Press Q to start new game", True, (255, 255, 255)) screen.blit(text1, [120, 200]) screen.blit(text2, [120, 300]) screen.blit(text3, [120, 350]) pygame.display.update() while(1): pygame.time.wait(50) for event in pygame.event.get(): if event.type == QUIT: pygame.quit() sys.exit() if event.type == KEYDOWN: if event.key == K_ESCAPE: pygame.quit() sys.exit() if event.key == K_p: draw_board(screen, board, block_color) pygame.display.update() return 0 # restart if event.key == K_r: return 1 def hold(block, next_block, hold_block, record): # no block in hold if hold_block == None: block_type = random.randint(2, 8) new_block = Block(block_type) block, next_block, hold_block = next_block, new_block, block hold_block.hold_flag = False block.row = 1 block.col = 5 hold_block.shape = hold_block.shapes[hold_block.block_type] # first hold elif block.hold_flag: block, hold_block = hold_block, block hold_block.hold_flag = False block.row = 1 block.col = 5 hold_block.shape = hold_block.shapes[hold_block.block_type] block.level = record.level return block, next_block, hold_block def draw_hold(screen, hold_block, block_color): pygame.draw.rect(screen, (255, 255, 255), Rect(700, 30, 150, 150)) pygame.draw.rect(screen, (0, 0, 0), Rect(705, 35, 140, 140)) pygame.draw.rect(screen, (0, 0, 0), Rect(720, 30, 70, 10)) font = pygame.font.Font(None, 30) text = font.render("HOLD", True, (255, 255, 255)) screen.blit(text, [730, 20]) if hold_block != None: for dx in hold_block.shape: if hold_block.block_type == 2 or hold_block.block_type == 8: pygame.draw.rect(screen, (20, 20, 20), Rect(750+25*dx[1], 105+25*dx[0], 25, 25)) pygame.draw.rect(screen, block_color[hold_block.block_type], Rect(752+25*dx[1], 107+25*dx[0], 21, 21)) else: pygame.draw.rect(screen, (20, 20, 20), Rect(762+25*dx[1], 105+25*dx[0], 25, 25)) pygame.draw.rect(screen, block_color[hold_block.block_type], Rect(764+25*dx[1], 107+25*dx[0], 21, 21)) def draw_next(screen, block, block_color): pygame.draw.rect(screen, (255, 255, 255), Rect(500, 30, 150, 150)) pygame.draw.rect(screen, (0, 0, 0), Rect(505, 35, 140, 140)) pygame.draw.rect(screen, (0, 0, 0), Rect(520, 30, 70, 10)) font = pygame.font.Font(None, 30) text = font.render("NEXT", True, (255, 255, 255)) screen.blit(text, [530, 20]) for dx in block.shape: if block.block_type == 2 or block.block_type == 8: pygame.draw.rect(screen, (20, 20, 20), Rect(550+25*dx[1], 105+25*dx[0], 25, 25)) pygame.draw.rect(screen, block_color[block.block_type], Rect(552+25*dx[1], 107+25*dx[0], 21, 21)) else: pygame.draw.rect(screen, (20, 20, 20), Rect(562+25*dx[1], 105+25*dx[0], 25, 25)) pygame.draw.rect(screen, block_color[block.block_type], Rect(564+25*dx[1], 107+25*dx[0], 21, 21)) # ゲームボードの描画 # 入力 スクリーン、ゲームボード、ブロックの色 # 出力 なし def draw_board(screen, board, block_color): for row in range(2, MAX_ROW+3): for col in range(MAX_COL+2): pygame.draw.rect(screen, (0, 0, 0), Rect(30+35*col, 30+35*(row-2), 35, 35)) if board[row][col] < 2: pygame.draw.rect(screen, block_color[board[row][col]], Rect(31+35*col, 31+35*(row-2), 34, 34)) else: pygame.draw.rect(screen, block_color[board[row][col]], Rect(32+35*col, 32+35*(row-2), 31, 31)) def main(): pygame.init() screen = pygame.display.set_mode((1000, 800)) pygame.display.set_caption("Tetris") # title bar block_color = [(50, 50, 50), (150, 150, 150), (255, 0, 0), (0, 0, 255), (255, 165, 0), (255, 0, 255), (0, 255, 0), (0, 255, 255), (255, 255, 0), (200, 200, 200), (100, 100, 100)] board, record, block, next_block, hold_block = initialize_game() start(screen) while(1): pygame.time.wait(10) screen.fill((0, 0, 0)) # fill with black R:0 G:0 B:0 draw_board(screen, board, block_color) # move command pressed_key = pygame.key.get_pressed() if pressed_key[K_k]: block.move(board, 0) if pressed_key[K_j]: block.move(board, 1) if pressed_key[K_l]: block.move(board, 2) bottom_flag = block.drop(screen, board) block.draw(screen, block_color, board) record.show(screen) draw_next(screen, next_block, block_color) draw_hold(screen, hold_block, block_color) pygame.display.update() if bottom_flag == 1: gameover_flag = block.place(screen, board, record) if gameover_flag == 1: board, record, block, next_block, hold_block = initialize_game() else: count, row_numbers = find_deleting_row(board) if count > 0: delete_row(screen, board, row_numbers, block_color) record.update(count) block_type = random.randint(2, 8) while block_type == block.block_type and block_type == next_block.block_type: block_type = random.randint(2, 8) block = next_block block.level = record.level if not block.moveable(board, [0, 0]): # new block unplaceable gameover(screen, record) board, record, block, next_block, hold_block = initialize_game() # if resume was selected next_block = Block(block_type) for event in pygame.event.get(): # close button if event.type == QUIT: pygame.quit() sys.exit() if event.type == KEYDOWN: # escape key pressed if event.key == K_ESCAPE: pygame.quit() sys.exit() # block rotetion if event.key == K_a or event.key == K_SPACE: # anti-clockwise block.rotate(board, 1) if event.key == K_s: # clockwise block.rotate(board, 0) # block movement if event.key == K_DOWN: block.move(board, 0) if event.key == K_LEFT: block.move(board, 1) if event.key == K_RIGHT: block.move(board, 2) if event.key == K_UP: # move to bottom block.move(board, 3) # pause if event.key == K_p: restart_flag = pause(screen, board, block_color) if restart_flag == 1: board, record, block, next_block, hold_block = initialize_game() # hold if event.key == K_d or event.key == K_h: block, next_block, hold_block = hold(block, next_block, hold_block, record) if __name__ == "__main__": main()おわりに
長めのコードになってしまいました。ネットで調べたら1時間ほどでテトリスを実装している動画なんかがあってかてへんってなりました。
- 投稿日:2019-09-15T17:43:46+09:00
[ブレイクタイム]全てはタイプミスから始まった(Spyderを用いたPythonの静的コード解析)
経緯
Pythonコードを書いていたときのこと.
数字の8を入力しようとしたら,間違えてF8キーを押してしまった.
そしたら・・・
右上に「静的コード分析」が現れたではないか!!
静的コード解析
C言語の場合,ポインタを扱う以上どんな人でもバッファオーバーフローの危険性をはらんでいるため,自分が作ったプログラムを他人に配布する際には必ず静的コード解析をかけていた.
Polyspace Bug Finder(学生ライセンス)で.
Pythonはインタプリタとして実行するため,構文エラーに対しては例外処理が働くこともあり,静的解析によるバグの削減の重要性はそこまでないと思っているが,この静的解析の嬉しいところは,PEP 8に準拠した記法のアドバイスもしてくれる点である.
エラーや警告については静的解析であれば出さないといけないが,記法についてここまで出してくれるものはそうない.
また,記法について10点満点で点数をつけてくれる.記法を勉強するPython初学者には嬉しい機能だ.
ちなみに,Spyder内で動いている静的解析ツールはPylintを参照のこと.
まとめ
他にもSpyderは嬉しい機能がたくさんある.他に見つけることができたらどんどん報告していきい.

- 投稿日:2019-09-15T17:19:49+09:00
【Python】数字認識APIを使って実感
機械学習といえばPython
- Pythonには機械学習に関するライブラリが豊富にそろっていて、初心者でも簡単に使い始められることが理由の1つ
使用するパッケージ
- tensorflow:機械学習に関連するもの
Flask:Webアプリ化するためのもの
pip install tensorflow==1.12.0 keras matplotlib pip install Flask flask-corsJupyter Notebookで機械学習(Google Colaboratoryを使用)
ノートブック場で機械学習を動かして、数字画像を認識させてみる。
ipython.notebookがどうもうまく動作しない。。。
ので、結局CentOS7に jupyter notebookをインストールして検証処理1# (1) 学習済みモデルの読み込み from keras.models import load_model model = load_model('/content/drive/My Drive/Colab Notebooks/cnn.h5') # (2) MNISTテスト画像の読み込み from keras.datasets import mnist (train_images, train_labels), (test_images, test_labels) = mnist.load_data() test_images = test_images.astype('float32') / 255 # (3) 予測する画像を表示 %matplotlib inline import matplotlib.pyplot as plt plt.imshow(test_images[0], cmap='gray_r') # (4) 機械学習モデルによる予測 import numpy as np pred = model.predict(test_images[0].reshape(1, 28, 28, 1)) print(pred) #=> [[6.83331218e-11 9.19927301e-10 5.45313406e-10 3.99958111e-09 1.16873996e-14 # 2.17858523e-10 2.98024704e-16 1.00000000e+00 2.00886807e-10 4.71085215e-09]] print(np.argmax(pred)) #=> 7処理2# (1) Canvasを表示する HTML html = ''' <canvas width="280" style="border:solid"></canvas> <script type="text/javascript"> var pixels = []; for (var i = 0; i < 28 * 28; i++) pixels[i] = 0; var canvas = document.querySelector("canvas"); var drawing = false; canvas.addEventListener("mousedown", function() { drawing = true; }); canvas.addEventListener("mouseup", function() { drawing = false; IPython.notebook.kernel.execute("image = [" + pixels + "]"); # <<-- Google Colab ではここがどうしても動かない }); canvas.addEventListener("mousemove", function(e) { if (drawing) { var x = Math.floor(e.offsetX / 10); var y = Math.floor(e.offsetY / 10); if (0 <= x && x <= 27 && 0 <= y && y <= 27) { canvas.getContext("2d").fillRect(x*10, y*10, 10, 10); pixels[x+y*28] = 1; } } }); </script> ''' # (2) HTMLの実行 from IPython.display import HTML HTML(html)処理3# 機械学習モデルによる予測 img = np.array(image, dtype=np.float32) <<-- 処理2で書いた文字を認識できない pred = model.predict(img.reshape(1, 28, 28, 1)) print(np.argmax(pred)) #=> 9Jupyter Notebook使用できるまで
anaconda3をダウンロード
[root@centos7 ~]# curl https://repo.continuum.io/archive/Anaconda3-4.3.1-Linux-x86_64.sh -O % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 474M 100 474M 0 0 9855k 0 0:00:49 0:00:49 --:--:-- 11.0M[root@centos7 ~]# bash ./Anaconda3-4.3.1-Linux-x86_64.shjupyter notebookの設定
[root@centos7 ~]# mkdir -p /root/.jupyter [root@centos7 ~]# touch ~/.jupyter/jupyter_notebook_config.py [root@centos7 ~]# vi ~/.jupyter/jupyter_notebook_config.py [root@centos7 ~]# cat ~/.jupyter/jupyter_notebook_config.py c = get_config() c.NotebookApp.ip = '*' c.NotebookApp.open_browser = false c.NotebookApp.port = 8888 c.NotebookApp.password = u'sha1:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' <--あとで [root@centos7 ~]#firewallの設定
[root@centos7 ~]# firewall-cmd --state Traceback (most recent call last): File "/usr/bin/firewall-cmd", line 24, in <module> from gi.repository import GObject [root@centos7 ~]# ll /usr/bin/python lrwxrwxrwx. 1 root root 16 9月 1 16:11 /usr/bin/python -> /usr/bin/python3 [root@centos7 ~]# ln -nfs /usr/bin/python2 /usr/bin/python [root@centos7 ~]# ll /usr/bin/python lrwxrwxrwx. 1 root root 16 9月 15 14:41 /usr/bin/python -> /usr/bin/python2 [root@centos7 ~]# firewall-cmd --state running [root@centos7 ~]# firewall-cmd --list-all --zone=public public (active) target: default icmp-block-inversion: no interfaces: ens999 sources: services: ssh ports: protocols: masquerade: no forward-ports: source-ports: icmp-blocks: rich rules: [root@centos7 ~]# firewall-cmd --add-port=8888/tcp --zone=public --permanent success [root@centos7 ~]# firewall-cmd --add-service=http --zone=public --permanent success [root@centos7 ~]# firewall-cmd --reload success [root@centos7 ~]# [root@centos7 ~]# firewall-cmd --list-all --zone=public public (active) target: default icmp-block-inversion: no interfaces: ens999 sources: services: ssh http ports: 8888/tcp protocols: masquerade: no forward-ports: source-ports: icmp-blocks: rich rules: [root@centos7 ~]# ipython Python 3.6.8 (default, May 2 2019, 20:40:44) Type 'copyright', 'credits' or 'license' for more information IPython 7.8.0 -- An enhanced Interactive Python. Type '?' for help. c = get_config() In [1]: from notebook.auth import passwd In [2]: passwd() Enter password: Verify password: Out[2]: 'sha1:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' In [4]: exit [root@centos7 ~]# vi ~/.jupyter/jupyter_notebook_config.py[root@centos7 ~]# jupyter notebook --allow-root [E 14:54:57.290 NotebookApp] Exception while loading config file /root/.jupyter/jupyter_notebook_config.py Traceback (most recent call last): File "/usr/lib/python3.6/site-packages/traitlets/config/application.py", line 562, in _load_config_files config = loader.load_config() File "/usr/lib/python3.6/site-packages/traitlets/config/loader.py", line 457, in load_config self._read_file_as_dict() File "/usr/lib/python3.6/site-packages/traitlets/config/loader.py", line 489, in _read_file_as_dict py3compat.execfile(conf_filename, namespace) File "/usr/lib/python3.6/site-packages/ipython_genutils/py3compat.py", line 198, in execfile exec(compiler(f.read(), fname, 'exec'), glob, loc) File "/root/.jupyter/jupyter_notebook_config.py", line 4, in <module> c.NotebookApp.open_browser = false NameError: name 'false' is not defined [I 14:54:57.498 NotebookApp] Serving notebooks from local directory: /root [I 14:54:57.498 NotebookApp] The Jupyter Notebook is running at: [I 14:54:57.499 NotebookApp] http://localhost:8888/?token=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx [I 14:54:57.499 NotebookApp] or http://127.0.0.1:8888/?token=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx [I 14:54:57.499 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation). [W 14:54:57.553 NotebookApp] No web browser found: could not locate runnable browser. [C 14:54:57.553 NotebookApp] To access the notebook, open this file in a browser: file:///root/.local/share/jupyter/runtime/nbserver-21530-open.html Or copy and paste one of these URLs: http://localhost:8888/?token=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx or http://127.0.0.1:8888/?token=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx



- 投稿日:2019-09-15T17:09:10+09:00
動かしながら学ぶPython入門~その1:ソースファイル作成から画面に表示まで~
はじめに
筆者は、仕事の都合もあって独学でPythonを勉強してきた。
自分の復習も兼ねつつ、「Pythonくらい使えるようになりたいんだよね」みたいな同僚もチラホラいるので、布教活動しやすくするために入門書替わりの記事を書いてみる。タイトルに
【コラム】とついているセクションは、動作や書式に直接の関係はありません。
なので、ちゃっちゃと動かしてみたい人は読み飛ばしても問題ありません。
もちろん、せっかく書いたので読んでもらえたほうが嬉しいです。対象
Pythonの初歩中の初歩を学習したい人執筆時の環境
- OS: Windows10
- Python: 3.7.3
- エディタ:VSCode
本文中の用語
用語 概略 ターミナル コマンドでコンピュータに命令を出すインターフェース
Windowsだと"コマンドプロンプト"や"PowerShell"が標準Pythonインタプリタ Pythonのソースコードの解釈と実行を行うアプリケーション
詳しくはコラムを参照ソースファイル アプリケーションの元となる、プログラム言語の決まった書式で書かれたファイル パス ファイルやディレクトリ(フォルダ)のコンピュータ上の場所を表す文字列 テキストエディタ テキストファイルを編集するアプリケーション Pythonを導入する
そもそもPythonの環境すら持ってない人は、まずインストールとセットアップをする。
拙著だが、筆者が書いた記事もあるので、参考にセットアップする。Pythonを実行する
対話モードで実行
対話モードは、ユーザがターミナルにて直接命令を入力し、その応答をユーザが確認しながら処理を進めていくモード。
Pythonをインストールしたときに、Add Python3.x to PATH(xはバージョン番号)にチェックしていればパスが通っているはずなので、Windowsキー+rで"ファイル名を指定して実行"を開いて、pythonと入力してEnterで起動する。
もし、起動しなかったらパスの設定が誤っている可能性がある。手で修正するか、よくわからないようであれば、一度アンインストールしてAdd Python3.x to PATHのチェックを入れて再インストールするといい。(今後ゴリゴリと使っていくようなら、PATHの設定くらいは覚えておいたほうがいいかも…) また、ターミナルからpythonと実行しても起動できる。
この方法の場合は、別ウィンドウは立ち上がらず、ターミナルの画面がそのままPythonインタプリタへのインターフェースになる。
簡易的な実行ではあるが、日常業務でちょっと計算するときに"高機能な電卓として"使えて便利だったり、"ソースコードを書いていて書式や仕様をど忘れしたときに、実際に入力して確認してみる"という使い方ができるので、割と重宝する。ソースファイルから実行
命令をソースコードとして記述したファイルを用意して、ファイルの内容を一括で実行するモード。
プログラミング自体の実務としてはこのモードでの使用がメイン。
Pythonのソースファイルは.pyの拡張子で表され、デフォルトではPythonインタプリタに紐づいているので、ファイルのダブルクリックでも起動する。 ただし、ダブルクリックで起動すると、ソース内に明示的に停止処理を書いていない限り、スクリプトの実行が終わると画面ごと終了するので、軽い処理だと画面表示が確認できない。(よく見ると、一瞬だけウィンドウが立ち上がっているのが見えるはず)
そのため、次のようにターミナルから起動することで、Pythonインタプリタが終了しても画面は終了しないようにして実行することが多い。
.pyファイルの実行アプリを変更している(エディタに紐づけてるなど)場合は、python ファイル名.pyとして実行する。
【コラム】インタプリタ型言語
読む
Pythonは"インタプリタ"型言語といわれる部類の言語で、"インタプリタ"とは
インタプリタとは、人間に分かりやすい高水準プログラミング言語(高級言語)で書かれたコンピュータプログラムを、コンピュータが解釈・実行できる形式に変換しながら同時に少しずつ実行していくソフトウェア。英語の原義は「通訳者」
出典:インタプリタとは - IT用語辞典 e-Words
とされている。対義語?としては"コンパイラ"があり、どちらもプログラムを解釈するのは同じだが、"コンパイラ"は実行を伴わない。
"インタプリタ"は解釈と同時に実行されるため、プログラムが未完成だったりエラーがあっても途中までの実行結果が確認できる反面、冗長なコードも解釈した時点で実行されるために実行速度が遅い。
"コンパイラ"は実行を伴わないおかげで、全体を解釈した内容を"処理速度優先"や"省メモリ優先"などの目的に合わせて最適化したうえで実行できる反面、未完成やエラーがある状態のプログラムは途中まででも実行結果が確認できない。
このように、"インタプリタ"と"コンパイラ"はメリットとデメリットが相反関係にあり、「どちらが優れている」ということでもない。
作りたいアプリケーションの特性に合わせて、開発言語を選べるようになるのが一番いい。
動かしながら書き方を覚えよう
ソースファイルを作る
まずは、Pythonのソースファイルを作ろう。
といっても、ただのテキストファイルなので、ソースファイルを置きたいところで右クリック -> 新規作成 -> テキストドキュメント -> 任意のファイル名.pyで作るだけ。
ただ、ファイル拡張子の表示がOFFになっていると、拡張子を.pyにできないので、ファイルエクスプローラー上で表示 -> ファイル名拡張子のチェックを入れる。
もちろん、各種エディタの新規作成やコマンドラインから作ってもいい。なお、ソースファイル自体や保存先のパスに日本語を含んでいるとトラブることもあるので、ソースファイルへのパスに日本語を含まないように作るのが無難。
文字コードを設定する
これは少し面倒なのだが、プログラム上で日本語を使う場合、そのソースファイルが書かれている文字コードを意識しないといけない。
英語が堪能でない限り、コメントなどに日本語を使うことは避けられないと思うので、覚えておく必要がある。確認と設定方法
文字コードによってコンピュータ側の認識が異なる(詳しくはコラム参照)ので、Pythonインタプリタに対しても「このファイルの文字コードは○○ですよ」と教えてあげないと、ソースファイルを正しく解読できずにエラーになってしまう。
ファイルの文字コードは、テキストエディタで開くと確認できる。
Windows標準でついてくるメモ帳ですら右下に表示される。
もちろん、プログラミング向けのリッチなエディタでも確認可能で、筆者がメインで使っている"VSCode"では右下に表示されている。
ちなみに、一応他のインストールしているエディタも見てみたがどれも表示箇所は右下だった。確認して表示された文字コードが意図していない設定だったら、エディタで文字コードを変換しておく。なんの文字コードがいいのかわからない場合は、とりあえず
参考までに、VSCodeでは次のようにutf-8にするのをオススメする。右下の文字コードをクリック -> エンコード付きで保存 -> "utf"と入力 -> utf-8を選択 -> 上書き保存で変更できる。
次にPythonへの設定方法だが、ソースファイルの先頭行に次のように記述する。.py# coding: 文字コード又は、
.py# -*- coding: 文字コード -*-2つ目の書き方は、公式ドキュメントに準拠した形だが、
-*-はなくても問題ない。先頭行にシバン(起動バージョン自動判定用のコメント)を書いている場合は2行目に書く。
.py#!/usr/bin/env python3 # coding: 文字コード又は、
.py#!/usr/bin/env python3 # -*- coding: 文字コード -*-
文字コードの部分にファイルの文字コードを記述する。基本的には
utf-8を指定して、エディタ側でファイルの文字コードをutf-8にしてしまうのがいいと思うが、Windows標準(コラムの通り、Windowsもutf-8に移行してきているので標準というかは微妙だが)を使いたければcp932と指定する。一応、デフォルトは
utf-8で認識されるので、ソースファイルをutf-8で書くなら省略しても問題はないが、"エディタの設定で別のコードとして開いてしまい、手動で正規のコードで開きなおす"際に、人が視認できるというメリットもあるので、utf-8でも書く癖をつけておいたほうがいい。【コラム】文字コードとは?
読む
コンピュータ上では、さまざまな文字は対応表に基づく数値として解釈されていて、
A to Zのアルファベット(小文字も)や数字と一部の符号に関しては普遍的な対応表(Asciiコード)があるのだが、日本語のようなアルファベットの組み合わせで表現できない言語は別途文字と数値の対応表が整備されている。この対応表にあたるのが文字コードで、Asciiコードに含まれない文字は割り当てが異なる複数の対応表が存在している。
Windowsはcp932という文字コードが標準だったが、最近はutf-8という文字コードが世界標準になりつつあって(もうなっているといってもいいのか?)、これは日本語含む様々な文字に対応しているため、Windows系も徐々に移行が進んでいる1が、過去互換性などの都合か完全移行はできていない。
ターミナルへの出力
ここまでの準備が終わったら、ようやくソースコードを書いて動かしてみる。
とりあえず、ターミナルに任意の表示ができないと始まらないので、ターミナルへの出力方法を覚えよう。文字列を出力してみよう
ターミナルへ文字列を出力するには、
書式print(出力したい文字列)と記述する。
Pythonでは"または'で囲った範囲を文字列と認識する。
文字列についての詳細は別記事にまとめたので気になる人はどうぞ。例題
実行したら、画面に
こんにちはを表示するソースコードを作ってみよう。実行画面> python .\hellow.py こんにちは回答例
次の例はVSCodeでの操作例だが、参考にして自分の環境でも試してみるといいかも。hellow.pyprint("こんにちは")
数値を出力してみよう
ターミナルへ数値を出力するには、
書式print(出力したい数値)と記述する。
文字列の出力の出力したい文字列を出力したい数値に変えるだけでいい。数値についても詳細は別記事にまとめたので気になる人はどうぞ。
例題
実行したら、画面に
10と1.25を表示するソースコードを作ってみよう。実行画面> python .\numbers.py 10 1.25
回答例
numbers.pyprint(10) print(1.25)
次回
今回はプログラム自体よりも、Pythonの実行方法やソースファイルの作り方がメインになったが、次回以降は徐々にプログラム書いてみるセクションが増えるはず。
動かしながら学ぶPython入門~その2:変数操作と画面入力~に続く…




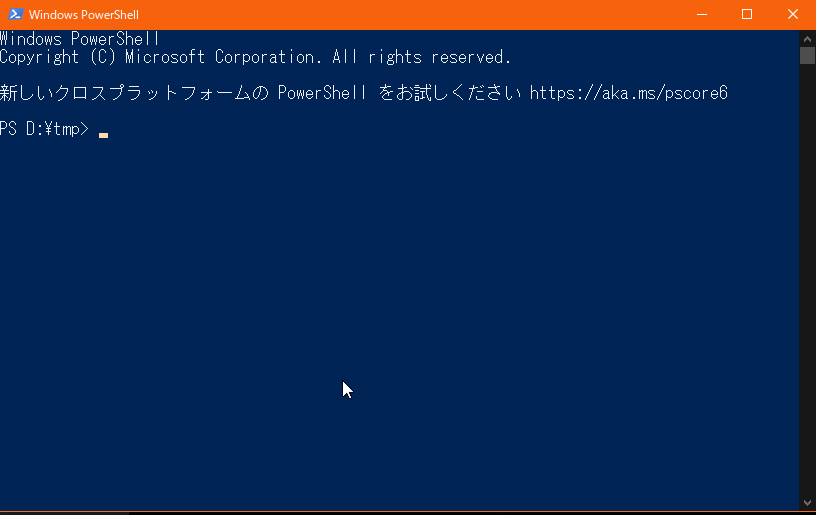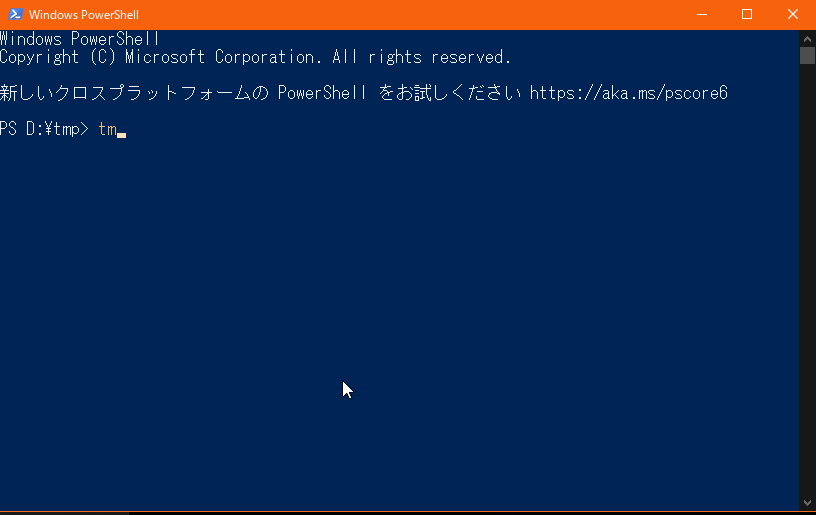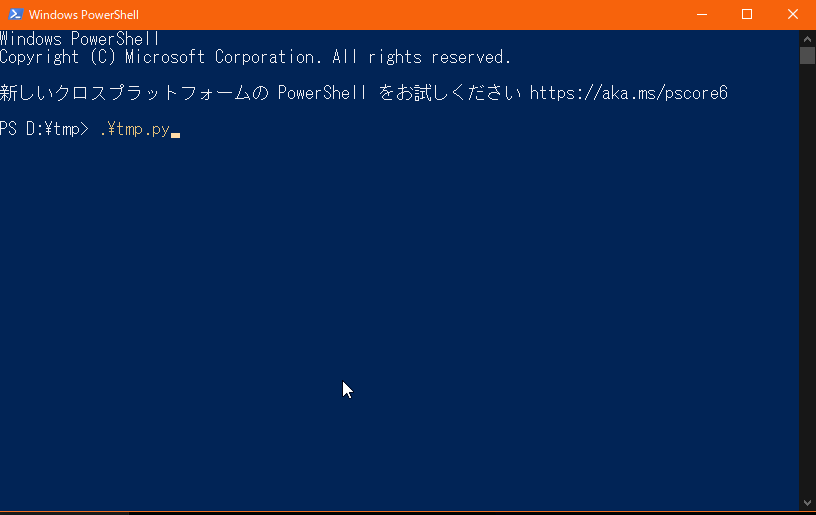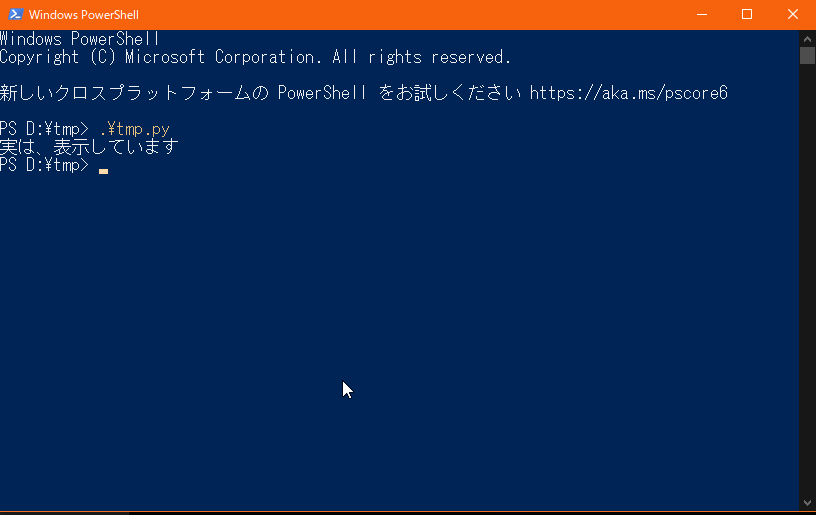





- 投稿日:2019-09-15T16:29:07+09:00
天球を描いてアニメーションを作ることで、望遠鏡の経緯台式架台や視差角の概念を理解する
はじめに
この前の記事で https://qiita.com/phyblas/items/52dc1bd113aff3745a8d
直接撮像法による系外惑星の探索について説明しました。その中で『視差角』と『経緯台式架台』について言及しましたが、あまり詳しく説明していません。
言葉で説明しても難しいことだと思うので、補充として、今回はそれについて、pythonで絵を描いてアニメーションで解説します。実装に使うモジュール
この記事の実装で以下のpythonモジュールを使います
- numpy
- matplotlib
- astropy
- imageio
astropyは主に座標変換に使います。
astropyの座標変換機能についてはこの前の記事でもよく使っていました。
https://qiita.com/phyblas/items/a801b0f319742245ad2e
https://qiita.com/phyblas/items/9a087ad1f73aca5dcbe5
https://qiita.com/phyblas/items/0d7623dbaf6866fb5bbdmatplotlibによって描かれた画像をgifアニメーションにするためにimageioを使います
地平座標と赤道座標
地平座標(equatorial coordinate)はある特定の場所から空を見る時に天体の位置を示す座標で、方位角と仰俯角で天体の位置を特定するものです。
それに対し、赤道座標(horizontal coordinate)は赤経と赤緯で天体の位置を示す座標です。
天体の位置は天の赤道座標に固定されているが、観測する人間や望遠鏡は地平座標に固定されているものです。
地球は常に回っているため、赤道座標が回っているように見えて、空を見上げたら天体は時間によって移動していくように見えます。
回転軸は赤道座標の北極と南極にあるため、空における全ての天体は赤経値の線に沿って移動するものです。
その天体の移動をmatplotlibで描いてimageioで動くgifにします。
座標変換はastropyに任せます。時間と場所を指定したらすぐ変換できるのでとても便利です。そうしたら赤道座標のグリッドと観測したい天体の位置も地平座標に表示できます。
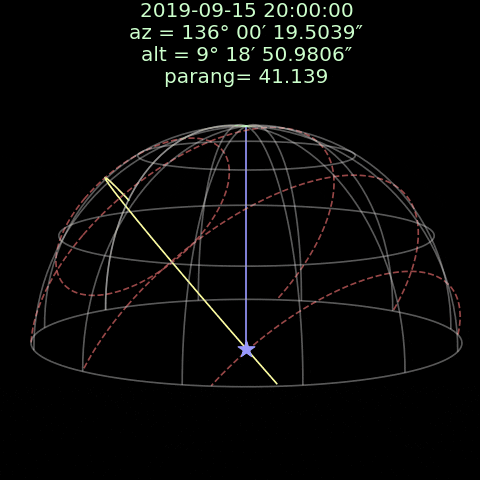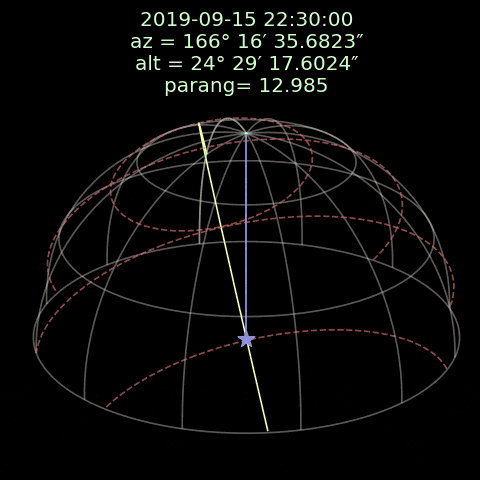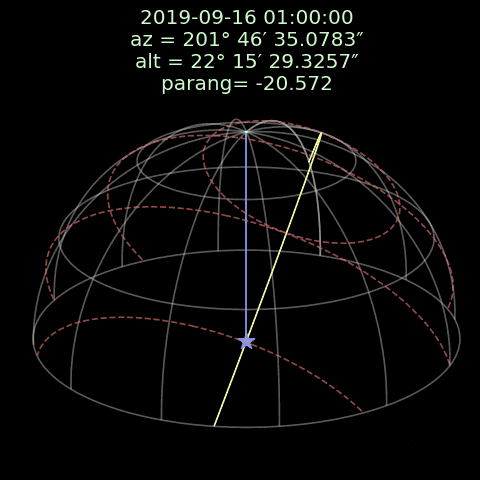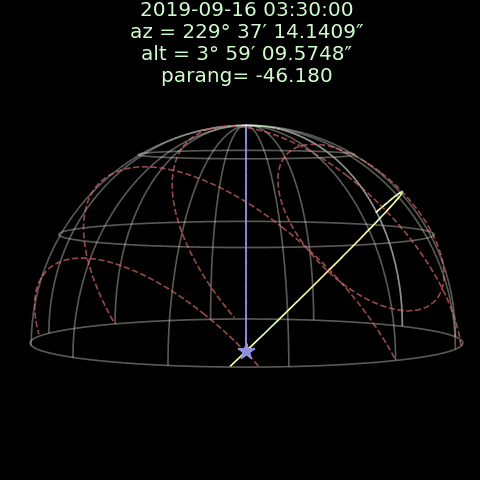
まずは観測する時間と場所と天体を決めなければならないので、ここでは
- 時間は、この記事を書いた2019年9月15日の夜
- 場所は、経度133°35′48.3″、緯度34°34′36.5″にある岡山天体物理観測所のせいめい望遠鏡
- 天体は、赤経22h57m39.04625s、赤緯-29°37′20.0533″にあるフォマルハウト
にします。
ちなみにフォマルハウトを選ぶ理由はちょうど赤緯-30°くらいにあるし、ちょうど今この時期では夜の間に空を昇るし、それにこの星は初めて直接撮像法で系外惑星も発見された星なのです。
実装
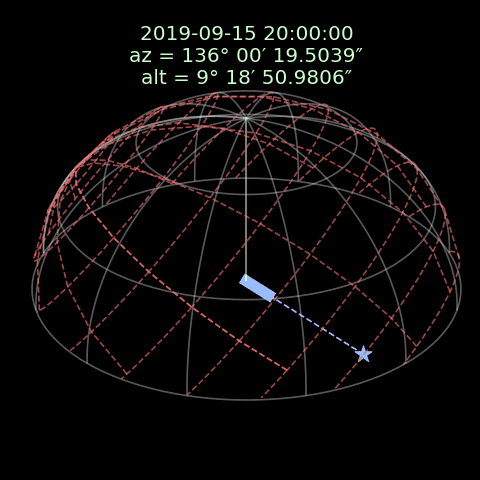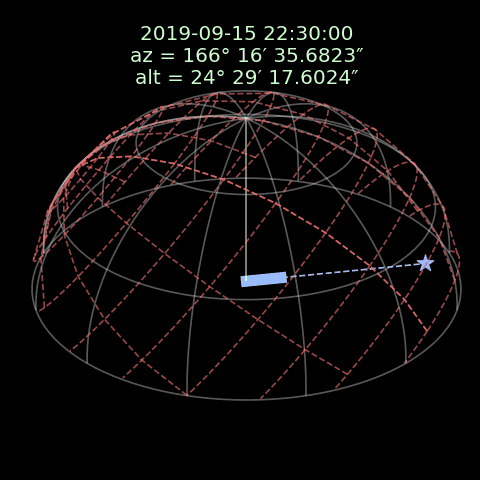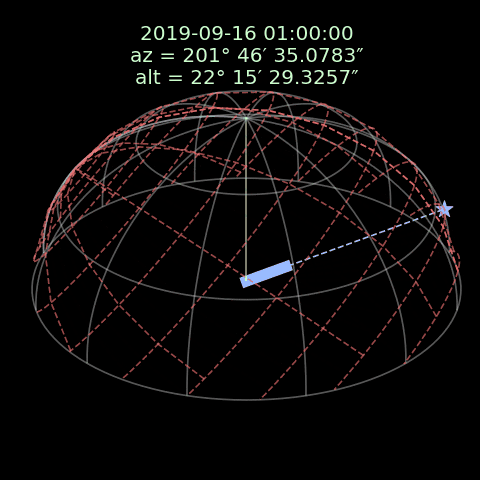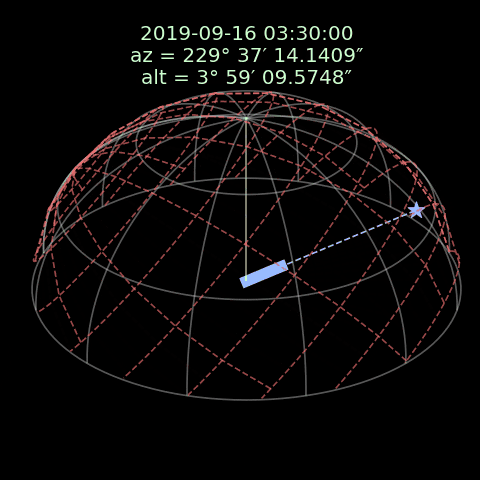
結果import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D import astropy.units as u from astropy.coordinates import SkyCoord,EarthLocation,AltAz,Angle from astropy.time import Time import imageio koko_keido = Angle('133° 35′ 48.3″') # 観測値の経度 koko_ido = Angle('34° 34′ 36.5″') # 観測値の緯度 # 観測の位置を決めるオブジェクト koko = EarthLocation(lat=koko_ido,lon=koko_keido) # 観測時間、日本の20時に始まるが、๊UTCにする必要があるので9時間でひく toki = Time('2019-09-15 20:00:00') - 9*u.hour + np.arange(0,8,0.5)*u.hour # 地平座標のグリッド az,alt = np.meshgrid(np.arange(0,360.1,3),np.arange(0,90.1,3)) chihei_grid = SkyCoord(az=az,alt=alt,unit='deg',frame='altaz').cartesian.xyz # 赤道座標のグリッド ra,dec = np.meshgrid(np.arange(0,360.1,1),np.arange(-90,90.1,15)) sekidou_grid = SkyCoord(ra=ra,dec=dec,unit='deg') # 観測したい天体の赤道による位置 hoshi_sekkei = Angle('22h 57m 39.04625s') # 赤経 hoshi_sekii = Angle('-29° 37′ 20.0533″') # 赤緯 hoshi_sekidou = SkyCoord(ra=hoshi_sekkei,dec=hoshi_sekii) gif = [] # 絵のフレームを納めるリスト # フレーム毎に繰り返し絵を描く for ima in toki: # その時間のその場所の地平座標を示すオブジェクト kokoima = AltAz(obstime=ima,location=koko) fig = plt.figure(figsize=[6,6],dpi=80) # 地平座標のグリッドを描く ax = plt.axes([0,0,1,1],projection='3d',xlim=[-0.6,0.6],ylim=[-0.6,0.6],zlim=[-0.4,1],facecolor='k') ax.plot_wireframe(*chihei_grid,rstride=10,cstride=10,color='#dddddd',alpha=0.4) # 地平座標で赤道座標のグリッドを描く sekidou_grid_xyz = sekidou_grid.transform_to(kokoima).cartesian.xyz sekidou_grid_xyz[:,sekidou_grid_xyz[2]<0] = np.nan # 地面より低いところを除外 ax.plot_wireframe(*sekidou_grid_xyz,cstride=30,color='#ff7777',linestyle='--',alpha=0.6) # 地平座標における天体の位置 hoshi_chihei = hoshi_sekidou.transform_to(kokoima) # 直交座標に変換する hoshi_xyz = hoshi_chihei.cartesian.xyz # 地平座標で天体の位置をマーク ax.scatter(*hoshi_xyz,s=250,marker='*',color='#9999ff') # 望遠鏡から天体までの線 ax.plot(*np.stack([(0,0,0),hoshi_xyz],1),color='#99bbff',ls='--') # 望遠鏡を描く ax.plot(*np.stack([(0,0,0),hoshi_xyz],1)*0.2,color='#99bbff',lw=10) # 望遠鏡から天頂までの線 ax.plot([0,0],[0,0],[0,1],color='#ffffdd',alpha=0.6) plt.axis('off') # 時間と方位角と仰俯角を書く az = hoshi_chihei.az.to_string(unit=u.degree, sep=['° ','′ ','″']) alt = hoshi_chihei.alt.to_string(unit=u.degree, sep=['° ','′ ','″']) ax.text(0,0,1.2,f'{(ima+9*u.hour).datetime}\naz = {az}\nalt = {alt}',color='#ccffcc',size=18,ha='center') ax.view_init(30,105) fig.canvas.draw() gif.append(np.array(fig.canvas.renderer._renderer)) plt.close() # .gifファイル保存 imageio.mimsave('fomalhaut_20190915.gif',gif,fps=4)
この画像では、白い線は地平座標で、赤い線は赤道座標です。フォマルハウトは赤道座標と一緒に移動していて地平座標における位置は時間によって変わります。
経緯台式架台の望遠鏡による観測
望遠鏡は回転に使う座標によって二種類分けられます。
赤道儀を使ったら回転軸は天体と同じ、赤道座標なので、天体を追う時はただ向かう方向を変えるだけで制御しやすいが、経緯台式架台の方が作りやすいため、すばる望遠鏡やせいめい望遠鏡など大型望遠鏡が大体は経緯台を使用しています。
天体は赤経値の線に沿って移動している時には方位角も仰俯角も変わっていきます。その上で、経緯台を使う望遠鏡の視野に入る天体の見かけの角度は変わっていきます。
その差分の角度は視差角(parallactic angle)と呼びます。
視差角はこの公式で計算できます。
parang = \arcsin \left(\frac{\sin(az)\cos(lat)}{\cos(dec)}\right)その視差角の変化をわかりやすくするためにアニメーションで解説します。
実装
import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D import astropy.units as u from astropy.coordinates import SkyCoord,EarthLocation,AltAz from astropy.coordinates import Angle from astropy.time import Time import imageio koko_keido = Angle('133° 35′ 48.3″') koko_ido = Angle('34° 34′ 36.5″') koko = EarthLocation(lat=koko_ido,lon=koko_keido) toki = Time('2019-09-15 20:00:00')-9*u.hour + np.arange(0,8,0.5)*u.hour az,alt = np.meshgrid(np.arange(0,360.1,3),np.arange(0,90.1,3)) chihei_grid = SkyCoord(az=az,alt=alt,unit='deg',frame='altaz').cartesian.xyz ra,dec = np.meshgrid(np.arange(0,360.1,1),np.arange(-90,90.1,30)) sekidou_grid = SkyCoord(ra=ra,dec=dec,unit='deg') hoshi_sekkei = Angle('22h 57m 39.04625s') hoshi_sekii = Angle('-29° 37′ 20.0533″') hoshi_sekidou = SkyCoord(ra=hoshi_sekkei,dec=hoshi_sekii) lis_parang = [] # 視差角を納めるリスト gif = [] for ima in toki: kokoima = AltAz(obstime=ima,location=koko) fig = plt.figure(figsize=[6,6],dpi=80) ax = plt.axes([0,0,1,1],projection='3d',xlim=[-0.6,0.6],ylim=[-0.6,0.6],zlim=[-0.1,1.1],facecolor='k') ax.plot_wireframe(*chihei_grid,rstride=10,cstride=10,color='#dddddd',alpha=0.4) sekidou_grid_xyz = sekidou_grid.transform_to(kokoima).cartesian.xyz sekidou_grid_xyz[:,sekidou_grid_xyz[2]<0] = np.nan ax.plot_wireframe(*sekidou_grid_xyz,cstride=None,color='#ff7777',linestyle='--',alpha=0.6) hoshi_chihei = hoshi_sekidou.transform_to(kokoima) hoshi_xyz = hoshi_chihei.cartesian.xyz ax.scatter(*hoshi_xyz,s=250,marker='*',color='#9999ff') # 赤道座標の北極から天体を経過して南極まで曲線 kyoku_chihei = SkyCoord(ra=hoshi_sekkei,dec=np.arange(-90,90.1,1),unit=('hourangle','deg')).transform_to(kokoima) kyoku_xyz = kyoku_chihei.cartesian.xyz kyoku_xyz[2][kyoku_xyz[2]<0] = np.nan ax.plot(*kyoku_xyz,color='#ffff99') ax.view_init(hoshi_chihei.alt.value,hoshi_chihei.az.value) # 天頂から天体までの曲線 tenchou_chihei = SkyCoord(az=hoshi_chihei.az,alt=np.linspace(hoshi_chihei.alt.value,90,101),unit='deg',frame='altaz') tenchou_xyz = tenchou_chihei.cartesian.xyz ax.plot(*tenchou_xyz,color='#9999ff') # 時間と方位角と仰俯角と視差角を書く az = hoshi_chihei.az.to_string(unit=u.degree, sep=['° ','′ ','″']) alt = hoshi_chihei.alt.to_string(unit=u.degree, sep=['° ','′ ','″']) parang = np.degrees(np.arcsin(np.sin(hoshi_chihei.az.radian)*np.cos(koko.lat.radian)/np.cos(hoshi_sekidou.dec.radian))) ax.text(0,0,1.2,f'{(ima+9*u.hour).datetime}\naz = {az}\nalt = {alt}\nparang= {parang:.3f}',color='#ccffcc',size=18,ha='center') plt.axis('off') fig.canvas.draw() gif.append(np.array(fig.canvas.renderer._renderer)) plt.close() lis_parang.append(parang) # 図1を保存 imageio.mimsave('fomalhaut_20190915_parang.gif',gif,fps=4) # 図2を描く plt.figure(figsize=[7,8],dpi=60) for i,(parang,ima) in enumerate(zip(lis_parang,toki)): plt.subplot(4,4,1+i,xlim=[-1,1],ylim=[-1,1],xticks=[],yticks=[],facecolor='k') plt.plot([0,0],[0,1],color='#9999ff') plt.text(0,0,'$\Delta$',color='#ffff99',size=70,ha='center',va='center',rotation=-parang) plt.title(f'{(ima+9*u.hour).datetime:%H:%M}',size=18) plt.xlabel('%.1f°'%parang,size=18) plt.tight_layout() plt.savefig('fomalhaut_20190915_parang1.png') plt.close() # 図3を描く plt.figure(figsize=[7,8],dpi=60) for i,(parang,ima) in enumerate(zip(lis_parang,toki)): plt.subplot(4,4,1+i,xlim=[-1,1],ylim=[-1,1],xticks=[],yticks=[],facecolor='k') plt.plot([0,-np.tan(np.radians(parang))],[0,1],color='#9999ff') plt.text(0,0,'$\Delta$',color='#ffff99',size=70,ha='center',va='center') plt.title(f'{(ima+9*u.hour).datetime:%H:%M}',size=18) plt.xlabel('%.1f°'%parang,size=18) plt.tight_layout() plt.savefig('fomalhaut_20190915_parang2.png') plt.close()実行したら3枚画像ができます
図1:黄色の線は天体を通して赤道座標の北極から南極までの大円上の曲線で、紫色の線は天頂から天体までの大円上の曲線です。
その黄色と紫色の線によって成す角度は視差角です
図2:時間によって変化していく視差角を使って回っているΔを表示したのです。地平座標における観測者から見る天体の角度はこうやって回っていきます。だから経緯台で観測する時は視差角によって視野を逆に回す場合が多いです。
図3:視野を回したら、天体の角度は固定されます。
(注意:コードや絵はここまで、以下は天文学の説明ばかり)
視野を回すべきかどうかの話
経緯台を使う望遠鏡でを天体の写真を撮る時には視差角によって視野を回転をするのが一般的ですが、そうしない場合もあります。
望遠鏡で天体を観測する時は色んなノイズが起こります。その中で、PSFやスペックルノイズなど光学系に由来する準静的なノイズであり、視野に固定されるノイズがあります。
視野を回して撮影すると、このようなノイズも天体と共に視野と一緒に移動するので、ノイズから天体の写真から分解することが難しくなります。
ノイズと天体を分解する必要がある場合視野を回転しない方が寧ろいい結果になります。
ただし、視野を回転せずに長時間露出で撮影すると天体の姿がぼけて写るためよくないのです。この場合、短時間露出で何枚もの写真を撮って後で回して合成する必要があります。
ADI方法の概念
視野を回転せずに、色んな写真を撮影したら、それらの写真の中のノイズが同じような形だが、天体だけは回っていきます。
全ての写真を分析するととノイズのパターンがわかり、そのノイズを全ての写真からひくことで、ノイズを消すことができます。
後は写真を回転して各枚の写真の中の天体の位置を一致して写真を合わせたら、天体がはっきり写る一枚の写真ができます。
これはADI(angular differential imaging)という方法です。
恒星の周りにある系外惑星を探す時には、恒星からの僅かなノイズでも惑星の光よりも強いため、惑星をはっきり見えるためにはノイズを消すことが重要なことになって、この方法で撮影することが一般的です。
参考資料


- 投稿日:2019-09-15T15:55:15+09:00
【会話入門】テキスト入力と音声応答で会話して遊んでみる♪
前回のtext2speakとTF-IDFによるQA応答の自然な発展としてテキスト入力に対するQA応答を利用するとテキスト入力に対して発話応答する会話ができる。ということで今回は会話実現に向けて、少し遊んでみました。
やったこと
・会話アプリのための環境構築
・正規表現を使う
・テキスト応答で会話
・自己自動会話・会話アプリのための環境構築
前回までは、BoW上でTF-IDFなどをやり、text2speakはKeras-gpu環境で実施してきた。
つまり、text2speakとTF-IDFを同時に使うことができなかった。
これは、BoWでは(Pyaudioなどはインストールできたが)スピーカが使えず、一方、Windows環境ではMecab(辞書)がインストールできないということが原因であった。
ということで、どちらかの環境を作る必要があるが、BoWでのスピーカ認識の仕方がわからないので、参考のあるWindows上へのMecabのインストールを実施した。
エラー内容は以下の参考と同様です。参考では解決していませんがほぼ辞書がうまくインストール出来ていないということのようです。
【参考】
・MeCabが使えない
一方、Mecabのインストールは以下の手順や辞書の手順が参考になりました。
ただし、まんまやっても実は使えませんでした。
【参考】
・WindowsでNEologd辞書を比較的簡単に入れる方法
そこで、最後に以下のバイナリーで再度Mecabをインストールして、その後もう一度Mecabをインストールしなおすと辞書ipadicが正常に使えるようになりました。
※ここはあまり論理的な記事になっていませんが後で再整理したいと思います
【参考】
・MeCab 0.996 64bit version・正規表現を使う
もう一つの問題は、適当な会話(既存のQAやドキュメント)などの場合はテンポラリに文字が選ばれるのでアルファベット以外の文字も入ってきます。
ということで、正規表現を使ってもともと録音されていない音を削除することを考えました。
【参考】
・Pythonの文字列を削除する方法まとめ
今回はpykakasiでローマ字変換されたあとの文字削除なので、このローマ字のみを残します。
コードは以下を試します。import re text = "abc123def456ghi,HP1234;: ある意味korega" new_text = re.sub(r"[a-z]", "", text) print(new_text) new_text = re.sub(r"[^a-z]", "", text) print(new_text)123456,HP1234;: ある意味g
abcdefghikorea
うまく分離されました。そして、re.sub(r"[^a-z]", "", text)のコード使います。・テキスト応答で会話
コード全体は以下のリンクのとおり
・something2speak/tfidf_speak.py
ここは前回の【NLP入門】気象庁のFAQをTF-IDFして遊んでみた♪とほぼ同様です。
単に上記の回答をtext2speakで音声に変換するだけです。
ただし、ここで正規表現による文字入力改善等を実施しています。while True: line = input("> ") if not line: break sims = cosine_similarity(vectorizer.transform([mecab.parse(line)]), vecs) index = np.argsort(sims[0]) print("({:.2f}): {}".format(sims[0][index[-1]],questions[index[-1]])) print() print(answers[index[-1]]) text2speak(answers[index[-1]]) #ここを追記 print() for i in range(2,5): print("({:.2f}): {}".format(sims[0][index[-i]],questions[index[-i]])) print()もう一点の改善はFAQでは回答が長くてつまらないので、ここは以下のような会話を作成して実施してみました。
something2speak/data/kaiwa_aruaru.txt
以下実行例です。ローマ字部分が音声で発話します。>python tfidf_speak.py -d C:\PROGRA~1\mecab\dic\ipadic kaiwa_aruaru.txt -s stop_words.txt > おはよう (1.00): おはよう ごきげんよう ごきげんよう ごきげんよう ['ご', 'き', 'げ', 'ん', 'よ', 'う'] ['go', 'ki', 'ge', 'n', 'yo', 'u'] ./pyaudio/aiueo/go.wav ./pyaudio/aiueo/ki.wav ./pyaudio/aiueo/ge.wav ./pyaudio/aiueo/n.wav ./pyaudio/aiueo/yo.wav ./pyaudio/aiueo/u.wav (0.00): そう です か 。 お忙しい の でしょ う ね (0.00): 最近 どう よ ? (0.00): どんな 感じ ?・自己自動会話
ところでやはり人が介在すると、どうも調整して質問するので、自前にどんどん会話が進むかを試してみた。
こうすることにより、会話には何が必要なのかを見るのが今回の目的である。
コードは以下のとおり
・something2speak/tfidf_cyclic.py
会話の肝心な部分は、単一なQAだと延々同様な会話が繰り返される恐れがあるということで、ちょっと前の回答はできないように制限しました。
※それでも話題が固定化する傾向が見えてきます。
ということで、ここでは三回前までの回答はできないようにしました。line = input("> ") line1=line line2=line line3=line while True: sims = cosine_similarity(vectorizer.transform([mecab.parse(line)]), vecs) index = np.argsort(sims[0]) print("({:.2f}): {}".format(sims[0][index[-1]],questions[index[-1]])) text2speak(questions[index[-1]]) print() time.sleep(2) line3=line2 line2=line1 line1=line while True: line = questions[index[-np.random.randint(1,7)]] if line1==line or line2==line or line3==line: continue else: breakまた、ここでこの自動応答では会話を目指すので、QAタイプではなく、全て文章というか質問ということにしました。
つまり、文章集vecsは以下のようなものとしました。
something2speak/data/single_sentences.txt
つまり、こういう文章空間の中で会話が進むかどうかが今回の興味です。
そのために、上記では次の質問を選ぶのに関連はあるけど、7番目までの質問をランダムに選べるようにしています。
これでも以下の実施例を見ると少し会話が回っちゃってますが、。。。>python tfidf_cyclic.py -d C:\PROGRA~1\mecab\dic\ipadic single_sentences.txt -s stop_words.txt > おはよう (1.00): おはよう (1.00): なかなか のんびり は でき ない です ね (1.00): 体重 は 減らさ ない と だめ だ ね (1.00): そう だ 、 食べ すぎる より 、 運動 し た ほう が いい ね (1.00): いい 感じ だ よ 、 そっち は (1.00): どんな 感じ ? (1.00): 危険 は ない けど 、 とにかく 忙しい 感じ です (1.00): 今 仕事 が 忙しい ので 大変 です (1.00): 仕事 は 危険 は ない の です か (1.00): しょうが ない なぁ 、 カレー 作る か (1.00): ドライブ と 食事 と どっち が 楽しい か なぁ (1.00): 箱根 も いい なぁ (1.00): でも 外 暑い から なぁ (1.00): ドライブ でも 行こ う か (1.00): ドライブ と 食事 と どっち が 楽しい か なぁ (1.00): しょうが ない なぁ 、 カレー 作る か (1.00): 仕事 は 危険 は ない の です か (1.00): 仕事 です か (1.00): 今 仕事 が 忙しい ので 大変 です (1.00): 忙しい けど 、 どうにか なっ て いる (1.00): でも 何 も 食べ られ なく なっ ちゃうまとめ
・テキスト入力と音声応答で会話して遊んでみた
・工夫として正規表現とTry~exceptを導入した
・会話が途切れない工夫として記憶を導入した・会話では、単なるQAと異なり、記憶と類似のバランスで意味空間を綺麗に遷移させる必要がある
・会話データ蓄積・学習型のアプリに拡張するおまけ
本文からの続き。。
(1.00): ドライブ でも 行こ う か (1.00): どんぶり でも いい か な (1.00): 伊豆 でも 行こ う か (1.00): そう です か 。 お忙しい の でしょ う ね (1.00): 天丼 食べよ う か (1.00): 天丼 食べ たい な (1.00): カレーライス が 食べ たい な (1.00): 何 食べ たい (1.00): 食べ たい けど 、 体 に 悪い よ (1.00): ラーメン 食べ たい な (1.00): 天丼 食べ たい な (1.00): カレーライス が 食べ たい な (1.00): おいしい もの 食べ たい な (1.00): ラーメン 食べ たい な (1.00): ラーメン 太る か な (1.00): どんぶり でも いい か な (1.00): ドライブ でも 行こ う か (1.00): 伊豆 でも 行こ う か (1.00): そう です か 。 お忙しい の でしょ う ね (1.00): 天丼 食べよ う か (1.00): 仕事 です か (1.00): お 元気 です か (1.00): ちょっと お 会い し たく て 来 まし た (1.00): 今 は IT 系 の お 仕事 やっ て い ます (1.00): IT って どんな お 仕事 です か (1.00): お 元気 です か (1.00): 仕事 です か (1.00): 仕事 は 危険 は ない の です か (1.00): しょうが ない なぁ 、 カレー 作る か (1.00): 軽井沢 が いい なぁ (1.00): IT 社長 とか 軽井沢 に 別荘 持っ て いる よ なぁ (1.00): 今 は IT 系 の お 仕事 やっ て い ます (1.00): まあ 、 ぼちぼち やっ て い ます 。 あなた は 何 を やっ て い ます か (1.00): のんびり さ れ て い て いい です ね (1.00): なかなか のんびり は でき ない です ね (1.00): 体重 は 減らさ ない と だめ だ ね (1.00): まあ 、 ね (1.00): この ところ 忙しかっ た けど 、 まあ まあ (1.00): ドライブ も 気持ちいい と 思う けど (1.00): ドライブ と 食事 と どっち が 楽しい か なぁ (1.00): しょうが ない なぁ 、 カレー 作る か (1.00): 仕事 は 危険 は ない の です か (1.00): 今 仕事 が 忙しい ので 大変 です (1.00): 危険 は ない けど 、 とにかく 忙しい 感じ です (1.00): どんな 感じ ? (1.00): どんな 御用 です か (1.00): 今日 は 何 の 御用 です か (1.00): お 元気 です か (1.00): そう いえ ば お 久しぶり です 。 今 は 何 を やっ て いる ん です か (1.00): できれ ば カレーライス 作っ て よ (1.00): いい よ 、 で そっち は ? (1.00): いい 感じ だ よ 、 そっち は (1.00): どんな 感じ ? (1.00): 軽井沢 は 夏 は 混む よ (1.00): IT 社長 とか 軽井沢 に 別荘 持っ て いる よ なぁ (1.00): 忙しい けど 、 どうにか なっ て いる (1.00): 危険 は ない けど 、 とにかく 忙しい 感じ です (1.00): 今 仕事 が 忙しい ので 大変 です (1.00): 仕事 です か (1.00): お 元気 です か (1.00): ちょっと お 会い し たく て 来 まし た (1.00): 最近 お 顔 を 拝見 し て い ない ので 会い たく なり まし た (1.00): それでも 、 何 も し て い ない という こと で は ない ので 一 日 が 早く 過ぎ ます (1.00): なんとなく 一 日 が 過ぎ て い ます (1.00): 今 は IT 系 の お 仕事 やっ て い ます (1.00): まあ 、 ぼちぼち やっ て い ます 。 あなた は 何 を やっ て い ます か (1.00): ウェブ の 開発 です 。 主 に デザイン やっ て ます (1.00): そう いえ ば お 久しぶり です 。 今 は 何 を やっ て いる ん です か (1.00): できれ ば カレーライス 作っ て よ (1.00): いい よ 、 で そっち は ? (1.00): 軽井沢 が いい なぁ (1.00): 軽井沢 は 夏 は 混む よ (1.00): いい 感じ だ よ 、 そっち は (1.00): 高血圧 と 糖尿 病 だ けど 、 食事 制限 は し て ない よ (1.00): 食事 制限 は し た ほう が いい ん じゃ ない の (1.00): 筋肉 運動 が 成人病 に は いい と 聞い た けど 、 どう な ん だろ う (1.00): そう だ 、 食べ すぎる より 、 運動 し た ほう が いい ね (1.00): いい 感じ だ よ 、 そっち は (1.00): どんな 感じ ? (1.00): 軽井沢 は 夏 は 混む よ (1.00): いい よ 、 で そっち は ? (1.00): 軽井沢 が いい なぁ (1.00): 箱根 も いい なぁ (1.00): でも 外 暑い から なぁ (1.00): どんぶり でも いい か な (1.00): それ より 血圧 心配 か な (1.00): ラーメン 食べ たい な (1.00): 天丼 食べ たい な (1.00): 天丼 食べよ う か (1.00): そう です か 。 お忙しい の でしょ う ね (1.00): はい そう です (1.00): そう だ 、 食べ すぎる より 、 運動 し た ほう が いい ね (1.00): いい 感じ だ よ 、 そっち は (1.00): 高血圧 と 糖尿 病 だ けど 、 食事 制限 は し て ない よ (1.00): 食事 制限 は し た ほう が いい ん じゃ ない の (1.00): ラーメン じゃ だめ (1.00): 体重 は 減らさ ない と だめ だ ね (1.00): そう だ 、 食べ すぎる より 、 運動 し た ほう が いい ね (1.00): 食事 制限 は し た ほう が いい ん じゃ ない の (1.00): 適度 な 運動 が いい ん じゃ ない (1.00): ラーメン じゃ だめ (1.00): ラーメン 食べ たい な (1.00): ラーメン 太る か な (1.00): どんぶり でも いい か な (1.00): ドライブ でも 行こ う か (1.00): 伊豆 でも 行こ う か (1.00): 天丼 食べよ う か (1.00): そう です か 。 お忙しい の でしょ う ね (1.00): はい そう です (1.00): 忙しい けど 、 どうにか なっ て いる (1.00): IT 社長 とか 軽井沢 に 別荘 持っ て いる よ なぁ (1.00): 軽井沢 が いい なぁ (1.00): 箱根 も いい なぁ (1.00): しょうが ない なぁ 、 カレー 作る か (1.00): ドライブ と 食事 と どっち が 楽しい か なぁ (1.00): ドライブ でも 行こ う か (1.00): どんぶり でも いい か な (1.00): ラーメン 太る か な (1.00): 仕事 です か (1.00): 今 は IT 系 の お 仕事 やっ て い ます (1.00): まあ 、 ぼちぼち やっ て い ます 。 あなた は 何 を やっ て い ます か (1.00): それでも 、 何 も し て い ない という こと で は ない ので 一 日 が 早く 過ぎ ます (1.00): それでも 体重 は 減らさ ない と いか ん なぁ (1.00): 適度 な 運動 が いい ん じゃ ない (1.00): 筋肉 運動 が 成人病 に は いい と 聞い た けど 、 どう な ん だろ う (1.00): 食堂 が いい な (1.00): いい よ 、 で そっち は ? (1.00): いい 感じ だ よ 、 そっち は (1.00): 危険 は ない けど 、 とにかく 忙しい 感じ です (1.00): どんな 感じ ? (1.00): どんな 御用 です か (1.00): IT って どんな お 仕事 です か (1.00): 今 は IT 系 の お 仕事 やっ て い ます (1.00): ウェブ の 開発 です 。 主 に デザイン やっ て ます (1.00): それでも 、 何 も し て い ない という こと で は ない ので 一 日 が 早く 過ぎ ます (1.00): なんとなく 一 日 が 過ぎ て い ます
- 投稿日:2019-09-15T13:54:58+09:00
cacheのヒット率を測定するツールを作成しました
Cacheのヒット率測定ツール
Webアプリケーションのインフラを考えるうえで、静的コンテンツ等をCDN配信にする選択肢を取ることが多いかと思います。
(例えば、さくらCDNやAWSならCloudFrontなど)運用していくうえで、画面ごと(URLごと)にキャッシュのヒット率やキャッシュされていないコンテンツを洗い出すツールを作成しました。
https://github.com/hirotoyoshidome/hit_rate
Docker化していますが、seleniumを利用していてchromediriverのバージョンによっては
上手く動かない場合があるようです。その場合は、申し訳ないですが、各自のローカル環境で動かしてみてください。
※そのうち直すかもです* selenium * requests ↑のみ利用していますもっと良いやり方があれば、ご教示ください!
では、今回はこのへんで!
- 投稿日:2019-09-15T12:00:56+09:00
Mac (macOS Mojave) の開発環境設定の記録 (Python の環境構築)
はじめに
macOS Mojave をクリーンインストールした際の記録です。
Python の環境構築の記録です。
記事作成・更新時の環境
- Model: MacBook Pro (13-inch, 2016, Four Thunderbolt 3 Ports)
- OS: macOS Mojave 10.14.6
- pyenv 1.2.13
- Anaconda 3-5.3.1 (Python 3.7.4)
Anaconda とは Python 本体に加え,科学計算やデータ分析などに使えるライブラリがセットになっているパッケージです。
pyenv のインストール
pyenv は Python のバージョン管理システムになります。
プロジェクトごとに Python のバージョンを切り替えることができるようになります。
$ brew install pyenv $ pyenv --version pyenv 1.2.13
.bash_profileに環境変数を設定します。$ echo 'alias brew="env PATH=${PATH/\/Users\/[ユーザー名]\/\.pyenv\/shims:/} brew"' >> .bash_profile $ echo 'eval "$(pyenv init -)"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ source ~/.bash_profilepyenv で Anaconda をインストールしてから
$ brew doctorを実行すると Warning が出てしまいます。1行目は
brewコマンド実行前にPATHから~/.pyenv/shimsを一時的に削除しbrewコマンドを実行するようにするためのものです。Anaconda (Python) のインストール
インストール可能な anaconda のリストを確認します。
$ pyenv install --l2019/09/15 現在 anaconda3-5.3.1 が最新安定版なのでこちらをインストールします。
$ pyenv install anaconda3-5.3.1デフォルトで利用する Anaconda のバージョンを指定します。
$ pyenv global anaconda3-5.3.1設定できているかを確認します。
$ pyenv versions system * anaconda3-5.3.1 (set by /Users/[ユーザー名]/.pyenv/version)アップデート
conda のアップデートは以下を実行します。
$ conda update condaanaconda のアップデートは以下を実行します。
$ conda update anaconda全パッケージのアップデートは以下を実行します。
$ conda update --all特定のパッケージのアップデートは以下を実行します。
$ conda update python
- 投稿日:2019-09-15T11:28:01+09:00
Windowsで誰でも好きなキャラの声になれるyukarinライブラリを動かしてみた。
はじめに
ヒホさんの開発されたyukarinライブラリ(第一段変換のyukarin 第二段変換のbecome-yukarin リアルタイム変換のrealtime-yukarinの総称)を使って、誰でも好きなキャラの声になれるという声質変換ができるのですが、推奨環境がLinuxですので、Windowsでは動かなかったところ、8月24日にヒホさんが直してくれて、動くようになりましたので、動かしてみましたので、ご報告です。
環境構築
『Yukarinライブラリ』ためのLinux環境構築(RTX対応)【Ubuntu 19.04】を参考に環境構築していきます。
実行環境
プロセッサ : Intel(R) Core(TM) i5-4590 CPU @ 3.30GHz
メモリ : 16GB
GPU : GTX 1070Ti (GPUメモリ 8GB)
ストレージ : SSD 480GB
OS : Microsoft Windows 10 ProWindows環境の整備
隠しファイルと拡張子を表示するようにしておきます。Windows 10のエクスプローラーで隠れている拡張子やシステムファイルを表示したい
シェル及びターミナルはGitBashを使用しました。エディタ系のインストール
基本サクラエディタを使用しました。
また、PythonにはPycharmを使用しました。
pycharmはWindows10 Pycharmの日本語化のやり方で、日本語化できます。ディープラーニング環境の構築
Windows 10にNVIDIA GPUを使用したDeep Learning環境をインストール。(CUDA10、VS2017、Chainerのインストール)を参考にしました。
開発系のインストール
VisualStudio(以下VS)2015のC++コマンドライン開発環境が必要なので、入れます。VS2017でもVS2019でもVSのインストーラーからチェックを入れればよいです。私はVS2019Communityが入ってましたので、インストーラーからいれましたが、新規に入れる場合、Tools for Visual Studio 2019でよいです。(入ってないとcudaのインストールが失敗します。)
Pythonのインストール
anacondaではなく、Python3.7.4を入れました。
インストール方法はこちらです。CUDAのインストール
なかなか入らなくて苦労しました。基本nvidiaのページからダウンロードして、インストールするだけなのですが、インストーラーがインストールに失敗しました。と出ます。グラフィックドライバのクリーンイントールからやりましたが、結果はダメ。結局VS2015のc++コマンドラインビルド環境がないとインストーラーがこけるようです。
CuDnnのインストール
nvidiaのサイトに登録して、ダウンロードしたものを解凍して、CUDAのフォルダにマージします。
yukarinライブラリの環境整備と実行
ここからは『Yukarinライブラリ』become-yukarin, yukarin コマンド解説を参考に実行していきます。作業ディレクトリ等はこれに準拠しました。
become-yukarinの環境整備
pip install -r requiremets.txt を実行する。cupyがなかなか入りません。入れるためには、環境変数を多数設定するなどのコツがあるようです。windows10環境でChainer2.0を動かすまでにハマった罠が参考になるかと思います。
PYTHONPATHの設定
コントロールパネル→システム→システムの詳細設定で、システム環境変数に、PYTHONPATHを設定します。become-yukarinディレクトリ、yukarinディレクトリを指定します。複数指定するときは、;(セミコロン)で区切ります。
音素バランス文の収録
まず音素バランス文を収録します。私は声優統計コーパスのものを50文使いました。100文やATR503のものをつかえば、もっとクオリティが上がるのかもしれません。あと好きなキャラの声を用意します。私はCeVIOのさとうささらを使用しました。第二段用には青空文庫の夏目漱石の『吾輩は猫である』を整形したものを約3000文使いました。
yukarinでの第一段学習
コマンドを実行するだけです。
become-yukarinでの第二段学習
pickleのエラーに悩まされました。
回避方法を教えていただきました。
C:\Usersユーザ名\Anaconda3\pkgs\python-3.6.5-h0c2934d_0\Lib\multiprocessing\http://reduction.py/
の15行目にある import pickleを
import dill as pickleに変更
dillはpipなどからインストールしてください
だそうです。Python本体のマルチスレッド部分のpickleを互換ライブラリのdillで置き換える方法になります。
これで学習ができます。おわりに
Ubuntu使わなくてもできるようになったのは大きいですが、いろいろコツがいりますね。それでもわからないことがあったら、ユーザーコミュニティのyukarinライブラリディスコードで聞いてみてください。最後に、ヒホさんをはじめ、atticさん、AIきりたんさん他の皆さんに助けていただきました。感謝申し上げます。
- 投稿日:2019-09-15T09:11:01+09:00
機械学習の学習が終わったらその結果を自動的にメールで送ってくれるモジュールを作ってみた
とりあえずpythonのモジュールを作ってみたかった
Python初心者です。
今回は自作モジュールを作ってみたい!
それだけの気持ちでやりました。
というわけで今回製作したのは、
機械学習の学習が終わったらそのロス等のログをメールで送ってくれるモジュール
です。特にfine tuneなどやってるときはロスがきちんと減っているかをすぐ知りたかったり、メールがくることで学習が終わっていることをメールで知ることができます。
1 gitから取ってきてメールアドレスを設定する
gitからcloneします。
git clone git@github.com:daikiclimate/modules.git次にメールアドレスだけ先に登録しておくと楽です。
vi Datorch/mailog.pyそして以下の部分を編集します。
#settings to_email = "aaaa@gmail.com" from_email = "bbbb@gmail.com" gmail_account = "aaaa@gmail.com" gmail_password = "cccc""aaaa@gmail.com"は送信側のメールアドレス
"bbbb@gmail.com"は受信側のメールアドレス
"cccc"はaaaaのパスワードです。(経験上)gmailでログ送信・受信専用のアカウントを作り、送信も受信も同じアカウントでやってしまうのが簡単でいいと思います。
そして送信にしようするアカウントで「安全性の低いアプリのアクセス」を許可する必要があります。
以下のURLから変更してください。(セキュリティ含め新アカウント推奨)
https://myaccount.google.com/security以上で準備は終了です。
次に以上のものをpipのライブラリに登録します。
pipでインストールしたみたいに使うためには、こうするといいようです。python setup.py develop2 使い方
mail送信用のモジュールをインポートします
import Datorch.mailog as mailog引数1がメールタイトル、引数2が本文のあるテキストファイルの名前です。
今回で言えば、"log.txt"というテキストファイルにログを記述してあります。mailog.sendmail("Sending Log!","log.txt")これでメールが送信できます。
簡単のためにテキストを作成するLogfuncクラスを作成してあります。from Datorch.printlog import Logfunc Logf = Logfunc() for epoch in range(10): ... ... Logf.update(epoch, train_loss, test_loss) Logf.print_log() Logf.write_log()updateはクラス変数に数値を更新する作業になります。引数はとりあえず以下のようになってます。
update(self, epoch, train_loss, test_loss = None, correct = None, total = None )print_log()は標準出力でlossなどをプリントします。
write_log()は"log.txt"という形でロスを記録する(追記する)テキストファイルを更新います。
自分では使ってます。
いいんです。僕は「pythonのモジュール作ったことあります」って言いたかっただけなんです
正直な感想
メールアドレスの設定とかあんまりクールではないですが、時間があれば更新していきたいと思います。
リンク
- 投稿日:2019-09-15T07:10:38+09:00
itertools.tee は57個ずつキャッシュする
Pythonでitertools.teeを使うと一つのイテレータを複数箇所で利用できますが、どうやってそれを実現しているか、メモリ効率の面でどうなっているかを見ます。
確認環境は Python 3.7.4 です。
イテレータ
イテレータは、next関数を呼ぶことで順に要素を返し、要素が尽きるとStopIterationをスローします。
Python 3.7.4 (default, Sep 12 2019, 15:40:15) [GCC 8.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> itr = iter(range(3)) >>> itr <range_iterator object at 0x7f36e189bab0> >>> next(itr) 0 >>> next(itr) 1 >>> next(itr) 2 >>> next(itr) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration >>>順次要素を生成して返すという実装が可能なため、シーケンス全体をメモリ上に保持する必要がなく、うまく使えばメモリ効率を上げられるというのが特徴です。
複数箇所での利用
イテレータは一般に一度消費されてしまうと元に戻れないため、そのままでは複数回利用できません。
>>> itr = iter(range(3)) >>> ','.join(map(str, itr)) '0,1,2' >>> ','.join(map(str, itr)) ''一つのイテレータを複数箇所で使いたい場合、ひとつのやり方は、リストにしてしまうことです。
>>> itr = iter(range(3)) >>> lst = list(itr) >>> ','.join(map(str, lst)) '0,1,2' >>> ','.join(map(str, lst)) '0,1,2'ただしこうすると最初にイテレータを消費し全ての要素をメモリ上に保持することになるため、要素が多い場合にメモリ効率がよくありません。
一方、itertools.teeを使うと、一つのイテレータから複数の独立したイテレータを作り、それぞれを利用することができます
>>> from itertools import tee >>> itr = iter(range(3)) >>> itr0, itr1 = tee(itr) >>> itr0 <itertools._tee object at 0x7fcd9d9f0320> >>> itr1 <itertools._tee object at 0x7fcd9d9fa5a0> >>> ','.join(map(str, itr0)) '0,1,2' >>> ','.join(map(str, itr0)) '' >>> ','.join(map(str, itr1)) '0,1,2' >>> ','.join(map(str, itr1)) '' >>>イテレータの消費のされ方
動きを見るため、独自のイテレータをクラスとして定義し、ログを出力してみます。
>>> class Iterator(object): ... def __init__(self): ... print('__init__', self) ... self._itr = iter(range(3)) ... def __iter__(self): ... print('__iter__', self) ... return self ... def __next__(self): ... print('__next__', self) ... return next(self._itr) ... >>> itr0,itr1 = tee(Iterator()) __init__ <__main__.Iterator object at 0x7fcd9d9f5890> __iter__ <__main__.Iterator object at 0x7fcd9d9f5890> __iter__ <__main__.Iterator object at 0x7fcd9d9f5890> >>> next(itr0) __next__ <__main__.Iterator object at 0x7fcd9d9f5890> 0 >>> next(itr1) 0 >>> next(itr1) __next__ <__main__.Iterator object at 0x7fcd9d9f5890> 1 >>> next(itr0) 1 >>>最初に消費した方(一回目はitr0、二回目はitr1)では
__next__のログが表示されているのに、他方(itr1で1要素目を取る時、itr0で2要素目を取る時)には表示されていません。つまり、teeによって作成されるイテレータは元のイテレータをラップして、最初に消費したときの戻りをキャッシュしておき、後の消費時にはキャッシュしていた値を返していると考えられます。キャッシュの生存期間
イテレータは一度に全ての要素をメモリ上に保持しないのが特徴と書いていました。teeを使った場合に最初に消費したときの戻りを全てキャッシュしているとすると、イテレータを消費していくにつれて、リストにしてしまった場合との差異はなくなっていくのでしょうか?というわけでキャッシュの生存期間を確認してみます。
sample.pyclass Foo(object): def __init__(self, n): self._n = n print(f"Foo.__init__, n={self._n}") def __str__(self): return f"Foo({self._n})" def __del__(self): print(f"Foo.__del__, n={self._n}") class FooIterator(object): def __init__(self, n): self._n = n def __iter__(self): return self def __next__(self): n = self._n if n >= 0: self._n -= 1 return Foo(n) raise StopIteration if __name__ == '__main__': from itertools import tee itr0, itr1 = tee(FooIterator(100)) for i in itr0: print('1st', i) for i in itr1: print('2nd', i)$ python sample.py Foo.__init__, n=100 1st Foo(100) Foo.__init__, n=99 1st Foo(99) ... Foo.__init__, n=0 1st Foo(0) 2nd Foo(100) 2nd Foo(99) ... 2nd Foo(45) 2nd Foo(44) Foo.__del__, n=100 Foo.__del__, n=99 ... Foo.__del__, n=45 Foo.__del__, n=44 2nd Foo(43) 2nd Foo(42) ... 2nd Foo(1) 2nd Foo(0) Foo.__del__, n=0 Foo.__del__, n=43 ... Foo.__del__, n=3 Foo.__del__, n=2 Foo.__del__, n=1 $"2nd Foo(44)" より手前では
__del__のログが表示されていないこと、"2nd Foo(44)"と"2nd Foo(43)"の間に100-44+1=57個の消費されたイテレータに対する__del__のログが表示されていないことが見て取れます。実際にcPythonのソースを確認すると、
cpython/Modules/itertoolsmodule.c#define LINKCELLS 57 typedef struct { PyObject_HEAD PyObject *it; int numread; /* 0 <= numread <= LINKCELLS */ PyObject *nextlink; PyObject *(values[LINKCELLS]); } teedataobject;という構造体でキャッシュを保持していて、一要素消費するごとにnumreadがインクリメントされ、valuesに戻りがキャッシュされる、LINKCELLS個たまったら次のteedataobjectを作ってnextlinkでリンクするという処理になっているので、teeで生成されたイテレータの複製のいずれでも消費され参照がなくなったオブジェクトは57個ずつ破棄されていくということになります。
結論
itertools.teeを使うとイテレータを複数箇所で使うことができますが、その際に消費済みリソースの解放は57個単位で行われており、一個一個の単位ではないものの、イテレータの特徴を保持している。したがって最初にリストにしてしまうのと比べるとメモリ効率の高い実装をすることが可能。
- 投稿日:2019-09-15T04:50:21+09:00
Houdiniで最初から使えるPythonのモジュールってどれだけあるの?
どうも、ゲームエフェクト屋です。
Houdiniで普通にインストールしただけの状態でPythonからどれくらいの
モジュールが利用可能なのかふと気になって少し調べました。Pythonでは利用可能なモジュールの一覧を
help('modules')で取得出来ます。
Houdini17.5.378(Windows)のメインメニューの Windows から Python Shell を起動して上記コマンドを実行するとこれだけのモジュールが出てきます。Python 2.7.15 (default, Apr 8 2019, 15:38:59) [MSC v.1916 64 bit (AMD64)] on win32 Houdini 17.5.378 hou module imported. Type "help", "copyright", "credits" or "license" for more information. >>> help('modules') Please wait a moment while I gather a list of all available modules... No handlers could be found for logger "OpenGL.Tk" BaseHTTPServer codecs itertools repr Bastion codeop itsdangerous requests CGIHTTPServer collections jinja2 rexec Canvas colorschemeutils json rfc822 ConfigParser colorsys karmautils rigtoolutils Cookie commands keyword rlcompleter Crypto compileall layermuting rmands Dialog compiler lib2to3 robotparser DocXMLRPCServer contextlib lightpanel roptoolutils EC2 contextoptionseditor linecache rpyc FileDialog cookielib loadHelpcardOTLExample runpy FixTk cop2toolutils locale sas HTMLParser copnettoolutils logging scenegraphdetails HelpCard copy loptoolutils sched MimeWriter copy_reg loputils sdl2otl OpenGL crowds lxml select PIL crowdstoolutils macpath sets PySide2 csv macurl2path setuptools Queue ctypes mailbox sgmllib ScrolledText curl mailcap sha SimpleDialog curses mako shadingutils SimpleHTTPServer datetime markupbase shelfutils SimpleXMLRPCServer dbg markupsafe shelve SocketServer dbhash marshal shlex StringIO decimal math shopclerks Tix defaultstatetools md5 shoptoolutils Tkconstants defaulttoolmenus metaexpr shutil Tkdnd defaulttools mhlib sidefx_bend Tkinter demjson mimetools sidefx_lop_edit UserDict difflib mimetypes sidefx_lop_stagemanager UserList digitalassetsupport mimify sidefx_stroke UserString dircache mmap signal _LWPCookieJar dis modulefinder simplejson _MozillaCookieJar displaymessage msilib simtracker __builtin__ distutils mssbuild site __future__ doctest msvcrt six _abcoll dopclothproxy multifile skytoolutils _ast dopclothtoolutils multiprocessing slo2otl _bisect dopfetoolutils muscletoolutils smtpd _bsddb dopgeofiltertoolutils mutex smtplib _codecs dopinstance mvexportutils sndhdr _codecs_cn dopparticlefluidtoolutils netrc snippetmenu _codecs_hk doppoptoolutils new socket _codecs_iso2022 doppyrotoolutils nntplib soptoolutils _codecs_jp doprbdtoolutils nodegraph soputils _codecs_kr dopreltoolutils nodegraphalign sqlite3 _codecs_tw dopsbdtoolutils nodegraphautoscroll sre _collections dopsmoketoolutils nodegraphbase sre_compile _csv dopstatictoolutils nodegraphconnect sre_constants _ctypes doptoolutils nodegraphdisplay sre_parse _elementtree dopwiretoolutils nodegraphdispopts ssl _functools dragdroputils nodegraphedittext stagemanager _hashlib drivertoolutils nodegraphfastfind stat _heapq ds2hda nodegraphflags stateutils _hotshot dumbdbm nodegraphfurutils statvfs _hou dummy_thread nodegraphgestures string _io dummy_threading nodegraphhooks stringold _json easy_install nodegraphhotkeys stringprep _locale ecdsa nodegraphinfo stroketoolutils _lsprof email nodegraphlayout strop _md5 encodings nodegraphpalettes struct _multibytecodec ensurepip nodegraphpopupmenus subprocess _multiprocessing errno nodegraphprefs sunau _osx_support exceptions nodegraphrename sunaudio _pdg expression_functions nodegraphselectpos symbol _pyio expressionmenu nodegraphselectposhooks symtable _random filecmp nodegraphsnap sys _sha fileinput nodegraphstates sysconfig _sha256 fileutils nodegraphtitle tabnanny _sha512 finddeprecated nodegraphtopui tarfile _socket flask nodegraphui taskgraphtable _sqlite3 flask_script nodegraphutils telnetlib _sre fnmatch nodegraphvellumutils tempfile _ssl formatter nodegraphview terraintoolutils _strptime fpformat nodesearch test _struct fractions nodeselectionutil textwrap _subprocess ftplib nodethemes this _symtable functools nodeutils thread _threading_local furtoolutils nose threading _usdHoudini furutils nt time _usdMantra future_builtins ntpath timeit _warnings gamedevutils nturl2path tkColorChooser _weakref gasresizedynamic numbers tkCommonDialog _weakrefset gc numpy tkFileDialog _winreg generateHDAToolsForOTL objecttoolutils tkFont abc generate_proto opcode tkMessageBox aifc genericpath operator tkSimpleDialog alignutils genshi opnode_sum toaiff antigravity getopt optixdownload token anydbm getpass optparse tokenize argparse gettext os toolprompts args2hda githubdownloader os2emxpath toolutils array glob paginate toptoolutils assetauthortools gzip paramiko trace assetdownload hashlib parmutils traceback ast hdefereval parser ttk asynchat heapq particletoolutils tty asyncore hjson pdb turtle atexit hjsonrpc pdg types audiodev hmac pdgjob uiutils audioop hotkeys perfmon_sum unicodedata autorig hotshot pickle unittest autorigs hou pickletools urllib bakeanimation hou_settings pipes urllib2 base64 houdiniInterpreter pkg_resources urllib3 bdb houdini_external_editor pkgutil urlparse beaker houdiniengineutils platform user binascii houdinihelp plistlib uu binhex houdiniinternals popen2 uuid bisect houpythonportion poplib vexpressionmenu bookish houxmlrpc poselib viewerstate bsddb hqrop posespacedeform viewportmeasuretool bvhviewer hqueue posixfile volumetoolutils bz2 hrender posixpath vopcallbacks cPickle hrpyc poster vopfxmenu cProfile hscp pprint vopnettoolutils cStringIO htmlentitydefs profile voptoolutils calendar htmllib pstats warnings canvaseventtypes httplib pty wave certifi husd pxr weakref cgi husdshadertranslators py_compile webbrowser cgitb hutil pyclbr webob channelwranglesnippet idlelib pycurl werkzeug charactertoolutils idna pydoc whichdb chardet ihooks pydoc_data whoosh charpicker imageop pyexpat winsound chopnettoolutils images2gif pygments wsgiref choptoolutils imaplib pyro2 xdrlib chunk imghdr pyside2uic xml click imp pythonscriptmenu xmllib cloud importlib quickplanes xmlrpclib cloudEULA imputil quopri xxsubtype cloudsubmit index_help radialmenu zipfile cloudtoolutils inlinecpp random zipimport cmath inspect re zlib cmd introspect render code io rendertracker Enter any module name to get more help. Or, type "modules spam" to search for modules whose descriptions contain the word "spam".540個程でしょうか。
__builtin_ みたいなのはほっとくとしても結構いっぱいありますね。気になったところがいくつかありました。
karmautils はもうKarmaを先取りしてあるんでしょうか。
husd はUSDを扱うものでしょうか?気になりますね。
nodegraph シリーズ、dop シリーズ は多いですね
PySide2 や TKinter などのUI系、numpy 、math などの算術系もデフォルトで使えます。
画像を扱うPIL、簡易データベースを扱うsqlite3もすぐに使える状態なので便利です。モジュールのメンバーは組み込み関数の
dirで確認出来ます。
気になる husd にdirをかけて中身を見てみると>>> for i in dir(husd): ... print i ... GetEditorNodesForLayer GetLabelForLayer GetRootLayerStackInfo GetScalarTypeFromAttr GetShortString GetValue Gf HUSD_ATTRIBUTE_TYPE_TOKEN HUSD_PARM_CONTROLLER_PREFIX HUSD_PRIMITIVE_PATH HUSD_PROPERTY_CATEGORY HUSD_PROPERTY_NAME HUSD_PROPERTY_VALUETYPE HUSD_RELATIONSHIP_TYPE_TOKEN OrderedDict QtCore QtGui QtWidgets SceneGraphDetails Sdf TEMPLATE_TYPE_MAP TYPE_TEMPLATE_MAP Tf ToString Usd UsdGeom UsdHoudini UsdMantra __builtins__ __doc__ __file__ __name__ __package__ __path__ addParmsToGroup appendSpareParm attrutils bakeAnimation convertFromGf createAttributesForParmTemplateGroup createClassForNodeType createParmForAttr createParmForRelationship createParmTemplateForAttr createParmTemplateForProperty createParmTemplateForRelationship createParmTemplateGroupForPrim createPropertyForParmTemplate createSchemaHeader fixParmName getParmForProperty getParmTemplateGroupForPrim getPropertyClassForParmTemplate getScalarValue groupby hdefereval hou houdinihelp importPropsAtPrim isGfType isUsdAttrParm isValidParm listPropsAtNode math parmValueToUsd parmutils populateScalarValue primpicker propsOnPrim re scenegraphdetails typeutils usdTypeForParmTemplate warningsやはりUSD絡みの様ですね。
更にhelp( husd.scenegraphdetails )などとしてみると>>> help( husd.scenegraphdetails ) Help on module husd.scenegraphdetails in husd: NAME husd.scenegraphdetails FILE c:\progra~1\sideef~1\houdin~1.378\houdini\python2.7libs\husd\scenegraphdetails.py CLASSES PySide2.QtWidgets.QFrame(PySide2.QtWidgets.QWidget) SceneGraphDetails class SceneGraphDetails(PySide2.QtWidgets.QFrame) | Method resolution order: | SceneGraphDetails | PySide2.QtWidgets.QFrame | PySide2.QtWidgets.QWidget | PySide2.QtCore.QObject | PySide2.QtGui.QPaintDevice | Shiboken.Object | __builtin__.object | | Methods defined here: | | __init__(self, pane) | ~~~~~~~~以下略~~~~~~~~~~なんとなくUSDのシーングラフを編集出来るインターフェイスの様に見えます。
dirでモジュールの中身を調べて使えそうなものを探していきhelpで使い方を確認しながら自分が気になるモジュールを物色していけます。
こんな風にPythonで出来ることの幅を広げていくのもオススメです。
せっかく用意して下さっているモジュールを使わない手は無いですね。というわけで皆様良きHoudini Pythonライフを。
- 投稿日:2019-09-15T04:45:28+09:00
python jsonモジュールの覚え書き データの取得、ファイルへの読み書き
Pythonでのjsonデータの処理について
Pythonのjsonモジュールでjsonファイルからの読み込み、データの文字列 ⇔ 辞書型変換、ファイルへの保存を行う。
【Python入門】JSON形式データの扱い方を参考に、複数箇所引用した上で、自分用に注釈、変更している。jsonとは
JSON は「JavaScript Object Notation」の略で、「JavaScript 言語の表記法をベースにしたデータ形式」と言えます。
JSON では、ある数値と、その数値の名前であるキーのペアをコロンで対にして、それらをコンマで区切り、全体を波かっこで括って表現します。【参考1】
(つまりPythonの辞書型に似ている)。jsonファイルの読み込みと型変換
dict型としての読み込み
↓このようなjsonファイルがある【参考1】。
test.json{ "book1":{ "title": "Python Beginners", "year": 2005 , "page": 399 }, "book2":{ "title": "Python Developers", "year": 2006 , "page": 650 } }まずはload関数を実行する。実行場所と同じディレクトリにtest.jsonがあるとする。
jikkou1import json var1 = open('test.json','r') #第一引数はtest.jsonまでのパス。jsonファイルを開く var2 = json.load(var1) #開いたファイルを JSON として読み込む var1.close() #ファイルが開いたままなので閉じる。var1,var2は任意の変数。jsonファイルを絶対パスで指定するならば、
var0=open('C:/Users/user_name/json_directory/test.json','r')
のように / でディレクトリを区切る。下は実行結果の確認
kakunin1#それぞれの変数の型を調べてみる。 In [81]: type(var1) Out[81]: _io.TextIOWrapper #これはファイルのオブジェクト In [82]: type(var2) Out[82]: dict #var2は辞書型 In [85]: import pprint #整形出力のモジュール In [86]: pprint.pprint(var2) #var2の内容を整形して出力 Out[86]: {'book1': {'page': 399, 'title': 'Python Beginners', 'year': 2005}, 'book2': {'page': 650, 'title': 'Python Developers', 'year': 2006}}In [85]: やOut[86]: はIPythonでの表示、実際には入力、出力しない。
結果から、jsonファイルを読み込んで辞書型の変数として扱うことができている。Pythonでのjsonデータの型は2種類
文字列型(str型)と辞書型(dict型)である。
文字列型では、階層の情報までを文字列に含んで、1行の文字列としてデータを格納している。辞書型では、元々持っている階層構造を活かしてjsonの情報を扱っている。jsonデータの型変換 dict → str
JSON ファイルを load 関数で読み込むと、Python で扱いやすいように辞書型で保存される。文字列型として扱いたい場合は、辞書型から文字列型へ変換する。辞書型から JSON 形式の文字列への変換は dumps 関数を使う。
jikkou2import json var1 = open('test.json', 'r') #ファイルを開く var2 = json.load(var1) #辞書型で読み出し var3 = json.dumps(var2) #文字列型に変換 var1.close() #開いたファイルは閉じる。jikkou1からdumps文が追加されている。
kakunin2In [91]: type(var1) Out[91]: _io.TextIOWrapper In [92]: type(var2) Out[92]: dict In [93]: type(var3) Out[93]: str #つまりvar2(dict型)がvar3(str型)に変換されている In [94]: print(var3) Out[94]: {"book1": {"title": "Python Beginners", "year": 2005, "page": 399}, "book2": {"title": "Python Developers", "year": 2006, "page": 650}}dumps は辞書型を引数にとり、それを文字列に変換して返す関数です。
jsonデータの変換 str → dict
逆に文字列型から辞書型への変換も行える。
loads関数を用いる。jikkou3import json var1 = open('test.json', 'r') var2 = json.load(var1) var3 = json.dumps(var2) var4 = json.loads(var3) var1.close()確認してみる。
kakunin3In [85]: import pprint #整形出力のモジュール In [97]: type(var4) Out[97]: dict In [98]: pprint.pprint(var4) Out[98]: {'book1': {'page': 399, 'title': 'Python Beginners', 'year': 2005}, 'book2': {'page': 650, 'title': 'Python Developers', 'year': 2006}}結果からvar4は辞書型になっている。
jsonデータのファイルへの書き込み&保存
辞書型を使って書き込み
読み込んだり、作成したりしたjsonデータをファイルへ書き込み、保存していく。
同じディレクトリにsave.json 、save.txtを作成して保存する。jikkou4import json var1 = open('test.json', 'r') #第一引数はtest.jsonまでのパス。読み込みたいjsonファイルを開く var2 = json.load(var1) #辞書型として読み込み var5 = open('save.json', 'w') #第一引数は保存したいファイルのパス。 #var5 = open('save.txt', 'w') #txtファイルでも同様に操作できる json.dump(var2, var5) var5.close() #close()を実行した時点で保存される。'w'モード(上書き)でopen()を実行したとき、指定したファイルが存在しなければファイルが新たに作成され、存在すれば上書きされる。続けて書きたい場合は'a'モードでファイルを開く(多分使わない)。
結果
ファイルが作成されている。
文字列型を使って書き込み
文字列型からjsonファイルを作成するときは、単純にopen()関数の機能を使えば良い。
jikkou5var1 = open('test.json', 'r') #読み込みたいjsonファイルを開く var2 = json.load(var1) #辞書型として読み込み var3 = json.dumps(var2) #文字列型へ変換 var5 = open('save.json', 'w') #第一引数は保存したいファイルのパス。 #var5 = open('save.txt', 'w') #txtファイルでも同様に操作できる var5.write(var3) var5.close() #close()を実行した時点で保存される。 #dumpsは文字列に変換するときに、下のように整形を含むこともできる。 #var3 = json.dumps(var2, sort_keys=True, indent=2)結果
jikkou4と同様のファイル出力が行われる。
まとめ
jsonを読み書きするための関数は以下の通り、
matome#読み込みと変換 import json var1 = open('test.json','r') #jsonファイルを開く、第一引数はファイルパス var2 = json.load(var1) #jsonデータを辞書型で読み取る var3 = json.dumps(var2) #辞書型を文字列型に変換 var4 = json.loads(var3) #文字列型を辞書型へ #書き込みと保存 var5 = open('save.json', 'w') #書き込みファイルを開く json.dump(var2,var5) #辞書型データを書き込み var6 = open('saves.json', 'w') #書き込みファイルを開く var6.write(var3) #文字列型データを書き込み var5.close() var6.close() #ファイルを閉じて保存loadとloads、dumpとdumpsはそれぞれ機能が違うので注意。
データの内容を書き換えたり、追加したりといった処理は#書き込みと保存の前に入れれば良さそう。おまけ
open()からclose()の処理はwith文で簡略化できる。
omake#書き込み部分にて #var5 = open('save.json', 'w') #json.dump(var2,var5) #var5.close() #だったのをwith文で with open('save.json', 'w') as var5: json.dump(var2,var5)これならclose()のし忘れを防げる。
参考リンク

- 投稿日:2019-09-15T04:28:37+09:00
Pythonで重回帰分析
TL; DR
過去記事で重回帰分析についてやりたいと書いていた割に書かなかったなと思ったので書こうと思います。
重回帰分析について
重回帰分析は、単回帰分析と異なり、説明変数が1次元ではなく、多次元のベクトルになったものです。
公式の導出
説明変数をD次元ベクトル
$$\boldsymbol{x}^{T} = (x_1, x_2, ..., x_D)$$
単回帰分析における切片におけるバイアス項を
$$w_0$$
説明変数の各次元に対する重み係数を
$$\boldsymbol{w}^T = (w_1, w_2, ..., w_D)$$
と置きます。
便宜上、
$$x_0 = 1$$
と定義し、目的変数をyとおくと、バイアス項と重みベクトルw、説明変数xをあわせてy = w_0x_0 + x_1x_1 + w_2x_2 + ... + w_Dx_D \\ y = \boldsymbol{w}^T\boldsymbol{x}と書くことができる。
N個のサンプルについて同様に並べるとy_1 = \boldsymbol{x_{1}}^T\boldsymbol{w} \\ y_2 = \boldsymbol{x_{2}}^T\boldsymbol{w} \\ \vdots \\ y_N = \boldsymbol{x_{N}}^T\boldsymbol{w} \\と書くことができるので、これを行列としてまとめると
\boldsymbol{y} = X\boldsymbol{w} \\ \\ ただし \\ \boldsymbol{y} = (y_1, y_2, ..., y_N)^T \\ X = \left( \begin{array}{ccccc} \boldsymbol{x_1}^T\\ \boldsymbol{x_2}^T \\ \vdots \\ \boldsymbol{x_N}^T \end{array} \right)このとき、目的変数と回帰した超平面の二乗誤差Eを最小にする重みwを求めます。
\begin{align} E &= \sum_{k=1}^{N}(y_k - \boldsymbol{x_k}^T\boldsymbol{w})^2 \\ &= (\boldsymbol{y} - X\boldsymbol{w})^T(\boldsymbol{y} - X\boldsymbol{w})\\ &= \boldsymbol{y}^T\boldsymbol{y} - \boldsymbol{y}^TX\boldsymbol{w} - (X\boldsymbol{w})^T\boldsymbol{y} + (X\boldsymbol{w})^TX\boldsymbol{w} \\ &= \boldsymbol{y}^T\boldsymbol{y} - \boldsymbol{y}^TX\boldsymbol{w} - \boldsymbol{w}^TX^T\boldsymbol{y} + \boldsymbol{w}^TX^TX\boldsymbol{w} \\ &(\boldsymbol{w}の最小値を求めたいので、\boldsymbol{w}についてまとめる)\\ &= \boldsymbol{y}^T\boldsymbol{y} - \boldsymbol{w}^TX^T\boldsymbol{y} - \boldsymbol{w}^TX^T\boldsymbol{y} + \boldsymbol{w}^TX^TX\boldsymbol{w} \\ & = \boldsymbol{y}^T\boldsymbol{y} - 2\boldsymbol{w}^TX^T\boldsymbol{y} + \boldsymbol{w}^TX^TX\boldsymbol{w} \end{align}二次形式とベクトルの微分の公式は以下のようになる(証明略)
\frac{∂\boldsymbol{w}^T\boldsymbol{x}}{∂\boldsymbol{w}} = \boldsymbol{x} \\ \frac{∂\boldsymbol{w}^TX\boldsymbol{w}}{∂\boldsymbol{w}} = (X + X^T)\boldsymbol{w}二乗誤差Eをwについて微分すると
\begin{align} \frac{∂E}{∂\boldsymbol{w}} &= -2X^T\boldsymbol{y} + (XX^T + X^TX)\boldsymbol{w} \\ & XX^Tは対称行列であるので \\ &= -2X^T\boldsymbol{y} + 2X^TX\boldsymbol{w} \\ &ととける。そこで、 \\ \frac{∂E}{∂\boldsymbol{w}} &= 0 になるのは \\ X^T\boldsymbol{y} &= X^TX\boldsymbol{w} \\ &のときであり、重み係数\boldsymbol{w}の解は \\ \boldsymbol{w} &= (X^TX)^{-1}X^T\boldsymbol{y} \end{align}線形代数と微分はすごい、前に書いた線形回帰の導出もこれで楽々でした。まあ一回書き下すのは無駄ではなかったと思っていますが。ただ、これは当然のこととして、サンプル間の強い相関によるrank落ち(多重共線性)などによって逆行列を持たないこともあるため、必ずこの式で求められるわけではないことに注意が必要です。
使用するデータセット
今回も、ワインのデータセットについて試してみようと思います。
アルコール濃度以外のデータを使って、アルコール濃度を回帰で求めてみます。import pandas as pd from sklearn import datasets # load datasets wine = datasets.load_wine() # データフレームに変換 wine_df = pd.DataFrame(wine.data, columns=wine.feature_names) # alcoholを除いたデータセットと、アルコールだけのデータセットを作成 wine_alcohol = wine_df['alcohol'] wine_df = wine_df.drop('alcohol', axis=1)これで準備OKです。
scikit-learnによる実装
重回帰分析は、単回帰分析の時と同様に、
LinearRegressorクラスを使うことで実装できます。
また、attributeとして
attribute contents coef_ 重み係数 intercept_ バイアス項 を持ちます。
さて、実装してみます。from sklearn.linear_model import LinearRegression regressor = LinearRegression() regressor.fit(wine_df, wine_alcohol) print("score: ", regressor.score(wine_df, wine_alcohol)) print("intercept_: ", regressor.intercept_) print("coef_: ", "\n", regressor.coef_) print("predict:", "\n", regressor.predict(wine_df))結果は以下のようになりました。predictはそのまま表示すると長いので折りたたんでます。0.6くらいなので精度としてはまあまあといったところでしょうか?
score: 0.5935573146395273 intercept_: 11.071849541591947 coef_: [ 1.31636223e-01 1.37853612e-01 -3.77877101e-02 4.17911054e-06 5.20835243e-02 9.12514513e-03 -2.07795701e-01 -1.52497193e-01 1.63034871e-01 2.16879740e-01 1.60796319e-01 1.01585935e-03]
predictの結果
predict:
[13.66661305 13.64752402 13.59563623 14.4052741 12.97482915 14.15701754
13.85663207 13.89779774 13.4709283 13.84297084 14.02101275 13.61803463
13.82154853 13.63461237 14.42345393 14.18447268 13.71908271 13.60595157
14.70283505 13.57710193 13.35817881 13.33383144 13.41843559 13.32366916
13.04824697 12.79884478 13.65533596 13.45027096 13.29175806 13.41725635
13.48293341 14.09284127 13.11146165 13.66649247 13.30414209 13.24784155
13.30314255 13.29265567 13.18334915 13.63423042 13.32684749 13.458762
13.77941017 13.15429841 13.21852136 13.82152627 13.72213254 13.53142533
13.46094036 14.2264349 13.85794468 13.76673994 14.09331536 14.03032453
13.59846737 13.48538009 13.58934323 13.89144957 13.90264255 12.33551952
12.61359476 12.67111418 12.69102457 12.56493353 12.27242088 12.72326328
12.78345378 12.74724228 12.65455758 12.49852547 12.45526705 12.31592651
12.34293859 12.76645457 12.79760956 12.49715174 12.47441694 12.50076878
12.45205875 12.47810083 12.10828489 12.83470347 12.20214895 12.58767798
12.28763989 12.33634852 12.07605997 12.30388937 12.48399939 12.17067429
12.15083621 12.20561124 12.06011357 12.28848566 12.51293363 12.49238823
12.35407668 12.36653661 12.74888564 12.31812079 12.79821893 12.27456753
12.44095121 12.02631475 12.59972888 12.11742979 12.45221563 12.12000559
11.96407592 12.45100466 12.33021851 12.10957692 12.80162616 12.11439632
12.23441205 12.05074235 12.13838057 11.93515166 12.49734291 12.31230046
12.68034483 12.78528655 12.22540335 12.57538188 12.4551593 12.28688219
12.20360252 11.96657558 11.7762624 12.56485122 12.4734682 12.7509841
12.54745097 12.78985254 12.63279097 13.09236227 12.82015943 12.80478258
12.93068582 12.74768578 12.77899086 13.13475719 12.63590754 12.95336025
13.70179728 12.7361745 12.71471967 13.37247996 13.25055405 13.36895717
13.0352707 13.37067199 12.50773895 13.57637831 12.79881705 13.369749
13.31336471 13.15447604 13.58553634 13.44927794 13.12760049 13.12063534
12.86415386 12.97903986 13.36410603 12.95310457 13.71603328 13.75424839
13.25314658 13.49374775 12.80027482 13.32119359 13.46345337 13.62814343
13.21066122 13.87543436 13.50377703 13.31372158]
自分で実装
scikit-learnライクのAPIを継承するため、scikit-learnのbase.BaseEstimatorとbase.RegressorMixinを継承して自分のクラスを作ります。RegressorMixinを継承すると、coef_やintercept_アトリビュート、また、scoreメソッドなどを継承することができます。
import numpy as np from sklearn.base import BaseEstimator, RegressorMixin from sklearn.utils.validation import check_is_fitted class MyLinearRegression(BaseEstimator, RegressorMixin): def fit(self, X, y): # バイアス項用にx_0 = 1を代入 X = np.insert(X, 0, 1, axis=1) # 解いた式に従って重み係数を算出 w = (np.linalg.inv(X.T @ X) @ X.T) @ y # バイアス項と重み係数に分解 self.coef_ = w[1:] self.intercept_ = w[0] return self def predict(self, X): # fitされてるかチェックしてくれるらしい check_is_fitted(self, 'coef_') # 予測を返す return X @ self.coef_ + self.intercept_ # 実行 pandasデータフレームの状態だと謎にエラーを吐かれるのでvaluesでnumpy arrayに変換している my_regressor = MyLinearRegression() my_regressor.fit(wine_df.values, wine_alcohol.values) print("score: ", my_regressor.score(wine_df.values, wine_alcohol.values)) print("intercept_: ", my_regressor.intercept_) print("coef_: ", "\n", my_regressor.coef_) print("predict:", "\n", my_regressor.predict(wine_df.values))完全に一致したので、自前で実装できた。
score: 0.5935573146395273 intercept_: 11.071849541591947 coef_: [ 1.31636223e-01 1.37853612e-01 -3.77877101e-02 4.17911054e-06 5.20835243e-02 9.12514513e-03 -2.07795701e-01 -1.52497193e-01 1.63034871e-01 2.16879740e-01 1.60796319e-01 1.01585935e-03]
predictの結果
predict:
[13.66661305 13.64752402 13.59563623 14.4052741 12.97482915 14.15701754
13.85663207 13.89779774 13.4709283 13.84297084 14.02101275 13.61803463
13.82154853 13.63461237 14.42345393 14.18447268 13.71908271 13.60595157
14.70283505 13.57710193 13.35817881 13.33383144 13.41843559 13.32366916
13.04824697 12.79884478 13.65533596 13.45027096 13.29175806 13.41725635
13.48293341 14.09284127 13.11146165 13.66649247 13.30414209 13.24784155
13.30314255 13.29265567 13.18334915 13.63423042 13.32684749 13.458762
13.77941017 13.15429841 13.21852136 13.82152627 13.72213254 13.53142533
13.46094036 14.2264349 13.85794468 13.76673994 14.09331536 14.03032453
13.59846737 13.48538009 13.58934323 13.89144957 13.90264255 12.33551952
12.61359476 12.67111418 12.69102457 12.56493353 12.27242088 12.72326328
12.78345378 12.74724228 12.65455758 12.49852547 12.45526705 12.31592651
12.34293859 12.76645457 12.79760956 12.49715174 12.47441694 12.50076878
12.45205875 12.47810083 12.10828489 12.83470347 12.20214895 12.58767798
12.28763989 12.33634852 12.07605997 12.30388937 12.48399939 12.17067429
12.15083621 12.20561124 12.06011357 12.28848566 12.51293363 12.49238823
12.35407668 12.36653661 12.74888564 12.31812079 12.79821893 12.27456753
12.44095121 12.02631475 12.59972888 12.11742979 12.45221563 12.12000559
11.96407592 12.45100466 12.33021851 12.10957692 12.80162616 12.11439632
12.23441205 12.05074235 12.13838057 11.93515166 12.49734291 12.31230046
12.68034483 12.78528655 12.22540335 12.57538188 12.4551593 12.28688219
12.20360252 11.96657558 11.7762624 12.56485122 12.4734682 12.7509841
12.54745097 12.78985254 12.63279097 13.09236227 12.82015943 12.80478258
12.93068582 12.74768578 12.77899086 13.13475719 12.63590754 12.95336025
13.70179728 12.7361745 12.71471967 13.37247996 13.25055405 13.36895717
13.0352707 13.37067199 12.50773895 13.57637831 12.79881705 13.369749
13.31336471 13.15447604 13.58553634 13.44927794 13.12760049 13.12063534
12.86415386 12.97903986 13.36410603 12.95310457 13.71603328 13.75424839
13.25314658 13.49374775 12.80027482 13.32119359 13.46345337 13.62814343
13.21066122 13.87543436 13.50377703 13.31372158]
まとめ
今回の実装に当たって、scikit-learn本体の実装もみたけど色々前処理がされてたりと、やはり本家はすごいなあと。そういえば二乗誤差をとるなら
numpy.linalg.lstsqを使えば良いという知見を得ました。次はPCAあたりですかね。
- 投稿日:2019-09-15T04:28:37+09:00
Pythonで重回帰分析(理論編)
TL; DR
過去記事で重回帰分析についてやりたいと書いていた割に書かなかったなと思ったので書こうと思います。
重回帰分析について
重回帰分析は、単回帰分析と異なり、説明変数が1次元ではなく、多次元のベクトルになったものです。
公式の導出
説明変数をD次元ベクトル
$$\boldsymbol{x}^{T} = (x_1, x_2, ..., x_D)$$
単回帰分析における切片におけるバイアス項を
$$w_0$$
説明変数の各次元に対する重み係数を
$$\boldsymbol{w}^T = (w_1, w_2, ..., w_D)$$
と置きます。
便宜上、
$$x_0 = 1$$
と定義し、目的変数をyとおくと、バイアス項と重みベクトルw、説明変数xをあわせてy = w_0x_0 + x_1x_1 + w_2x_2 + ... + w_Dx_D \\ y = \boldsymbol{w}^T\boldsymbol{x}と書くことができる。
N個のサンプルについて同様に並べるとy_1 = \boldsymbol{x_{1}}^T\boldsymbol{w} \\ y_2 = \boldsymbol{x_{2}}^T\boldsymbol{w} \\ \vdots \\ y_N = \boldsymbol{x_{N}}^T\boldsymbol{w} \\と書くことができるので、これを行列としてまとめると
\boldsymbol{y} = X\boldsymbol{w} \\ \\ ただし \\ \boldsymbol{y} = (y_1, y_2, ..., y_N)^T \\ X = \left( \begin{array}{ccccc} \boldsymbol{x_1}^T\\ \boldsymbol{x_2}^T \\ \vdots \\ \boldsymbol{x_N}^T \end{array} \right)このとき、目的変数と回帰した超平面の二乗誤差Eを最小にする重みwを求めます。
\begin{align} E &= \sum_{k=1}^{N}(y_k - \boldsymbol{x_k}^T\boldsymbol{w})^2 \\ &= (\boldsymbol{y} - X\boldsymbol{w})^T(\boldsymbol{y} - X\boldsymbol{w})\\ &= \boldsymbol{y}^T\boldsymbol{y} - \boldsymbol{y}^TX\boldsymbol{w} - (X\boldsymbol{w})^T\boldsymbol{y} + (X\boldsymbol{w})^TX\boldsymbol{w} \\ &= \boldsymbol{y}^T\boldsymbol{y} - \boldsymbol{y}^TX\boldsymbol{w} - \boldsymbol{w}^TX^T\boldsymbol{y} + \boldsymbol{w}^TX^TX\boldsymbol{w} \\ &(\boldsymbol{w}の最小値を求めたいので、\boldsymbol{w}についてまとめる)\\ &= \boldsymbol{y}^T\boldsymbol{y} - \boldsymbol{w}^TX^T\boldsymbol{y} - \boldsymbol{w}^TX^T\boldsymbol{y} + \boldsymbol{w}^TX^TX\boldsymbol{w} \\ & = \boldsymbol{y}^T\boldsymbol{y} - 2\boldsymbol{w}^TX^T\boldsymbol{y} + \boldsymbol{w}^TX^TX\boldsymbol{w} \end{align}二次形式とベクトルの微分の公式は以下のようになる(証明略)
\frac{∂\boldsymbol{w}^T\boldsymbol{x}}{∂\boldsymbol{w}} = \boldsymbol{x} \\ \frac{∂\boldsymbol{w}^TX\boldsymbol{w}}{∂\boldsymbol{w}} = (X + X^T)\boldsymbol{w}二乗誤差Eをwについて微分すると
\begin{align} \frac{∂E}{∂\boldsymbol{w}} &= -2X^T\boldsymbol{y} + (XX^T + X^TX)\boldsymbol{w} \\ & XX^Tは対称行列であるので \\ &= -2X^T\boldsymbol{y} + 2X^TX\boldsymbol{w} \\ &ととける。そこで、 \\ \frac{∂E}{∂\boldsymbol{w}} &= 0 になるのは \\ X^T\boldsymbol{y} &= X^TX\boldsymbol{w} \\ &のときであり、重み係数\boldsymbol{w}の解は \\ \boldsymbol{w} &= (X^TX)^{-1}X^T\boldsymbol{y} \end{align}線形代数と微分はすごい、前に書いた線形回帰の導出もこれで楽々でした。まあ一回書き下すのは無駄ではなかったと思っていますが。ただ、これは当然のこととして、サンプル間の強い相関によるrank落ち(多重共線性)などによって逆行列を持たないこともあるため、必ずこの式で求められるわけではないことに注意が必要です。
実装をscikit-learnのBaseEstimaterとRegressionMixinを使ってやろうと思ったのですが、なんかうまくいかなかったのでうまくいき次第投稿します(追記か新記事)
- 投稿日:2019-09-15T00:33:02+09:00
Project Euler 016, 020を解いてみる。「各位の数字の和」
Project Euler 016, 020
215 = 32768 であり, 各位の数字の和は 3 + 2 + 7 + 6 + 8 = 26 となる.
同様にして, 21000 の各位の数字の和を求めよ.n × (n - 1) × ... × 3 × 2 × 1 を n! と表す.
例えば, 10! = 10 × 9 × ... × 3 × 2 × 1 = 3628800 となる.
この数の各桁の合計は 3 + 6 + 2 + 8 + 8 + 0 + 0 = 27 である.
では, 100! の各位の数字の和を求めよ.->[次の問題]
考え方
016と020は類似の問題なので合わせて解きます。
桁数や第1桁、最高位の数字を出す方法はありますが、各位の数字は実際に計算する以外の方法が思いつかなかったので、単純に計算しています。
pythonはstrにすることで各桁の数字を文字列で取り出せるので便利ですね。コード
euler016.pydef main016(): number = 2 ** 1000 num_list = [int(i) for i in str(number)] print(sum(num_list)) def main020(): number = 1 for i in range(2, 101): number *= i num_list = [int(i) for i in str(number)] print(sum(num_list)) if __name__ == '__main__': from time import time as t start = t() main016() print(t() - start) start = t() main020() print(t() - start)paizaにて実行
結果
1366
6.604194641113281e-05
648
3.266334533691406e-05
シンプルな問題が続きますね