- 投稿日:2019-08-29T23:46:24+09:00
LeetCode / Rotate Array
[https://leetcode.com/problems/rotate-array/]
Given an array, rotate the array to the right by k steps, where k is non-negative.
Example 1:
Input: [1,2,3,4,5,6,7] and k = 3
Output: [5,6,7,1,2,3,4]Explanation:
rotate 1 steps to the right: [7,1,2,3,4,5,6]
rotate 2 steps to the right: [6,7,1,2,3,4,5]
rotate 3 steps to the right: [5,6,7,1,2,3,4]Example 2:
Input: [-1,-100,3,99] and k = 2
Output: [3,99,-1,-100]Explanation:
rotate 1 steps to the right: [99,-1,-100,3]
rotate 2 steps to the right: [3,99,-1,-100]Note:
Try to come up as many solutions as you can, there are at least 3 different ways to solve this problem.
Could you do it in-place with O(1) extra space?Rotate Arrayということで直訳すると配列を回転させろ、ということですが、インデックスを前後にずらす操作を行う問題です。
解法を最低3つ、さらに空間計算量は$O(1)$で、と言われています。AND条件ではなくOR条件だと思いますが、意外に難しく感じました。解答・解説
解法1
私の力ではどうしても空間計算量が$O(n)$になってしまいました。
インデックスを前後にずらす=元のリストを2つのリストに分割し組み替えて再結合することになるので、以下コードで正しい値が得られます。
class Solution: def rotate(self, nums: List[int], k: int) -> None: """ Do not return anything, modify nums in-place instead. """ k %= len(nums) nums[:] = nums[-k:]+nums[:-k]今回はnumsそのものを操作して戻り値にするという指示があるため、リストに対して破壊的な操作をするためにnums[:]としてコピーを作成します。
リスト内包表記で書くこともできます。
class Solution: def rotate(self, nums: List[int], k: int) -> None: k %= len(nums) nums[:] = [nums[i] for i in range(-k,len(nums)-k)]解法2
空間計算量が$O(1)$の解法その1。
以下Solutionの転載ですが、Original List : 1 2 3 4 5 6 7
After reversing all numbers : 7 6 5 4 3 2 1
After reversing first k numbers : 5 6 7 4 3 2 1
After revering last n-k numbers : 5 6 7 1 2 3 4 --> Result3つの手順から成り、1.リスト全体を逆順にソートし、2.リスト後方のk個の要素だけで逆順にソートし、3.残りのn-k個の要素だけで逆順にソートするという手法です。
class Solution: def rotate(self, nums: List[int], k: int) -> None: k %= len(nums) self.reverse(nums, 0, len(nums)-1) self.reverse(nums, 0, k-1) self.reverse(nums, k, len(nums)-1) def reverse(self, nums, start, end): while start < end: tmp = nums[start] nums[start] = nums[end] nums[end] = tmp start += 1 end -= 1空間計算量を抑えた解法の中で、これが最も明快だと思います。
解法3
空間計算量が$O(1)$の解法その2。しかしこれは難しいと思いました。
手順は大きく分けると2つから成り、nums後方のk個の要素を正しい位置に入れ替え、次に残りのnums前方のn-k個の要素を正しい位置に入れ替えます。
入れ替え対象のリストは初めはnums全体ですが、入れ替えが完了するまで徐々に狭まっていきます。具体例で示します。以下、
n: 入れ替え対象のリストの要素数
k: インデックスをずらす要素数
j: 入れ替え対象リストの始点インデックス
とします。つまり常に n + j == len(nums) となります。nums = [1, 2, 3, 4, 5, 6, 7] を例に考えます。このとき、n = 7, k = 3, j = 0 です。
初めの入れ替えで、以下のように進みます。[5, 2, 3, 4, 1, 6, 7]
[5, 6, 3, 4, 1, 2, 7]
[5, 6, 7, 4, 1, 2, 3]ここまで来て、さらに入れ替える必要があるのは後方の [4, 1, 2, 3] です。
このとき、n = n - k, j = j + k, k %= n と計算し、n = 4, k = 3, j = 3 です。次の入れ替えは以下のように進みます。
[5, 6, 7, 1, 4, 2, 3]
[5, 6, 7, 1, 2, 4, 3]
[5, 6, 7, 1, 2, 3, 4]これで、入れ替え完了です。
先ほどと同様に、n = n - k, j = j + k, k %= nと計算し、n = 1, k = 0, j = 6 です。入れ替え完了の判定方法は、n <= 0 と k % n == 0 の2パターンがあります。
n <= 0 になると、入れ替え対象のリストが存在しないので終了し、
k % n == 0 になると、インデックスをずらしても1周回って同じリストとなってしまうので、終了します。以上をコードに落とすと、以下のようになります。
class Solution(object): def rotate(self, nums, k): n, k, j = len(nums), k % len(nums), 0 while n > 0 and k % n != 0: for i in range(0, k): nums[j + i], nums[len(nums) - k + i] = nums[len(nums) - k + i], nums[j + i] # swap n, j = n - k, j + k k = k % n初見でこの解法にたどり着く人は神なんじゃないかな。
- 投稿日:2019-08-29T23:28:40+09:00
Pythonの配列や辞書をずっと使えるようにする小技
モチベーション
Jupyter Notebookとかで重たい処理をしたり、DBから値を取ってきたりするのを毎回するのは非常に非効率。
ファイルとして保存する(永続化する)方が絶対いい。
pickleを使えばかなり簡単だった。配列
ファイルとして保存する(永続化)
pkl_array.pyimport pickle fruits_array = [] fruits= ["apple","orange","melon"] for fruit in fruits: fruits_array.append(fruit) with open("fruits_array.pkl","wb") as f: pickle.dump(fruits_array, f)読み込む
pkl_array2.pyimport pickle with open('fruits_dict.pkl', 'rb') as f: fruits_color_dict_pkl = pickle.load(f)print(fruits_color_dict_pkl) {'apple': 'red', 'orange': 'orange', 'melon': 'green'}辞書
ファイルとして保存する(永続化)
pkl_dict.pyimport pickle fruits_color_dict = {} fruits_color_dict["apple"] = "red" fruits_color_dict["orange"] = "orange" fruits_color_dict["melon"] = "green" with open("fruits_dict.pkl","wb") as f: pickle.dump(fruits_color_dict, f)読み込む
pkl_dict2.pyimport pickle with open('fruits_dict.pkl', 'rb') as f: fruits_color_dict_pkl = pickle.load(f)print(fruits_array_pkl) ['apple', 'orange', 'melon']
- 投稿日:2019-08-29T22:50:04+09:00
【トレーニングデータとテストデータ】データを分割してトレーニングデータで学習し、テストデータでフィッティングを確認
はじめに
標記の通りです。学習する際にはトレーニングデータとテストデータと分け、トレーニングデータで学習をし、テストデータで学習できているか確認してみます。
使うデータは前にも使ったアボカドデータです。
https://qiita.com/iwasaki_kenichi/items/ea580fd9498ad6950a75データ分割の方法
色々あると思いますが、ここではscikit-learnの
train_test_splitを使います。main1.py#ライブラリインポート from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(X, Y,train_size=0.8)ここで、test_sizeはテストデータのサイズです。テストデータは全体の8割としています。
コード
main1.py#ライブラリインポート %matplotlib inline import numpy as np from pylab import * import pandas as pd import matplotlib.pyplot as plt from scipy import stats #データ読み込み df = pd.read_csv("hogehoge.csv") scatter(df["Total Bags"],df["XLarge Bags"]) X = df["Total Bags"] Y = df["XLarge Bags"]
main2.pyX_train, X_test, Y_train, Y_test = train_test_split(X, Y,train_size=0.8) scatter(X_train,Y_train)
main3.pyscatter(X_test,Y_test)
main4.pyp4 = poly1d(np.polyfit(X_train,Y_train,8)) xp = np.linspace(0,20000000,50) axes = plt.axes() axes.set_xlim([0,20000000]) axes.set_ylim([0,6000000]) plt.scatter(X_train,Y_train) plt.plot(xp,p4(xp),c="r") plt.show()
main5.pyxp = np.linspace(0,20000000,50) #axes = plt.axes() axes.set_xlim([0,20000000]) axes.set_ylim([0,6000000]) plt.scatter(X_test,Y_test) plt.plot(xp,p4(xp),c="r") plt.show()
main5.pyr2 = r2_score(Y_test,p4(X_test)) print(r2) #結果は0.6496548856957747 r2 = r2_score(Y_train,p4(X_train)) print(r2) #結果は0.6945770505912501おわりに
X_train, X_test, Y_train, Y_test = train_test_split(X, Y,train_size=0.8)は覚えられない。なんかコピペバンバン使いそう。
このあたりもサラッと書けるようになりたい。





- 投稿日:2019-08-29T22:11:52+09:00
RHSCLでのPythonのバージョン切り替え
前置き
Python2.x系から3.x系にあげる際に、yumなどpython2.x系に依存したパッケージソフトがあると、該当のパッケージソフトが使用できなくなるケースがある。
https://www.logw.jp/cloudserver/8702.html
Python2.7がインストールされているCentOSに対して、
RHSCLを使用して複数のPythonを共存させ、Pythonのバージョンを2.x系→3.x系へ切り替える手順について、記載する。
RHSCL (Red Hat Software Collections) とは
CentOS向けの比較的バージョンの新しい安定版のパッケージソフトを集めたソフトウェア集。
https://www.softwarecollections.org/en/
RHEL/CentOSは、企業向けなので、
提供するパッケージを頻繁にアップデートするのではなく、特定のバージョンのパッケージを長期間に提供する、というポリシーがある.そのため、提供されているパッケージが古い。
https://www.slideshare.net/moriwaka/red-hat-software-collections
RHSCLは、RHEL/CentOSで提供しているパッケージより新らしく、なおかつ安定しているバージョンのパッケージソフトを利用することができる。
また、RHSCLからインストールしたパッケージソフトは、/usr/libではなく、/opt/rh配下にインストールされ、
環境変数PATHの切り替えによって、
利用するパッケージソフトのバージョンを切り替えることができる。そのため、Python2.x(既存パッケージソフト)と、Python3.x(RHSCL)との共存なども可能。
Pythonバージョン切り替え
RHSCLのインストール
下記の手順で、SCLおよびPythonをインストールする。
$ yum install centos-release-scl-rh scl-utils $ yum install rh-python36http://www.tooyama.org/el7/scl.html
Pythonのバージョン切り替え
方法1 : 現在のシェルのPythonバージョンを変更
# 環境変数の値を変更 $ source /opt/rh/rh-python36/enable # 変更されたPythonのバージョンを確認 $ env | egrep "^PATH=|^LD_LIBRARY_PATH=|^MANPATH=|^XDG_DATA_DIRS=|^PKG_CONFIG_PATH=" | sort LD_LIBRARY_PATH=/opt/rh/rh-python36/root/usr/lib64:/usr/local/lib MANPATH=/opt/rh/rh-python36/root/usr/share/man: PATH=/opt/rh/rh-python36/root/usr/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin PKG_CONFIG_PATH=/opt/rh/rh-python36/root/usr/lib64/pkgconfig XDG_DATA_DIRS=/opt/rh/rh-python36/root/usr/share:/usr/local/share:/usr/share # Pythonのバージョンが変更されたことを確認 $ python -V Python 3.6.1 $ which python /opt/rh/rh-python36/root/usr/bin/python
新しいシェルを起動し、新しいシェルのPythonのバージョンを切り替える
# 新しいシェルを起動し、環境変数を変更 # scl enable 'コレクション名 '‘コマンド’の形式で実行 $ scl enable rh-python36 bash # 変更されたPythonのバージョンを確認 $ env | egrep "^PATH=|^LD_LIBRARY_PATH=|^MANPATH=|^XDG_DATA_DIRS=|^PKG_CONFIG_PATH=" | sort LD_LIBRARY_PATH=/opt/rh/rh-python36/root/usr/lib64:/usr/local/lib MANPATH=/opt/rh/rh-python36/root/usr/share/man: PATH=/opt/rh/rh-python36/root/usr/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin PKG_CONFIG_PATH=/opt/rh/rh-python36/root/usr/lib64/pkgconfig XDG_DATA_DIRS=/opt/rh/rh-python36/root/usr/share:/usr/local/share:/usr/share # Pythonのバージョンが変更されたことを確認 $ python -V Python 3.6.1 $ which python /opt/rh/rh-python36/root/usr/bin/python # 元のシェルに戻る $ exit # バージョンが元に戻っていることを確認 $ which python /usr/bin/python $ python -V Python 2.7.5
- 投稿日:2019-08-29T21:57:29+09:00
flaskでhttpステータスを返却する方法
はじめに
http通信が失敗した場合に、httpステータスとメッセージを返却してユーザにエラー時の動作を通知することが良くあります。
flaskはpythonのwebフレームワークで、httpステータスやメッセージの返却する方法をまとめます。環境
- python:3.6.5
- flask:1.0.2
エンドポイントの関数からhttpステータスを指定する
URLに紐づけた関数のreturn時にhttpステータスを追加することでクライアントに返却するhttpステータスを簡単に指定できます。
サーバ側
flask_main.pyfrom flask import Flask, jsonify app = Flask(__name__) @app.route('/hello') def hello(): return jsonify({'message': 'hello internal'}), 500 app.run()クライアント側
request_url.pyimport requests response = requests.get('http://localhost:5000/hello') print('httpステータス:{}, メッセージ:{}'.format(response.status_code, response.text))実行
# python .\request_url.py httpステータス:500, メッセージ:{"message":"hello internal"}returnにhttpステータス500を指定してあげることでクライアント側にhttpステータスとメッセージが返却できました。
この方法はflaskの仕様を知っていれば、簡単でソースがシンプルになる点が利点だと思います。
一方returnがあればどこでも自由にステータスが指定できてしまうため、ちゃんとしたルールのもと作らないと思わぬところでreturnする欠点もあります。Responseクラスにhttpステータスを指定する
flaskは上のようなreturnだけでなく、ユーザへの返却にResponseクラスを使用することができます。
そのResponseクラスにhttpステータスを追加することでクライアントに返却するhttpステータスを簡単に指定できます。サーバ側
flask_main.pyfrom flask import Flask, Response import json app = Flask(__name__) @app.route('/hello') def hello(): return Response(response=json.dumps({'message': 'hello response'}), status=500) app.run()クライアント側
request_url.pyimport requests response = requests.get('http://localhost:5000/hello') print('httpステータス:{}, メッセージ:{}'.format(response.status_code, response.text))実行
# python .\request_url.py httpステータス:500, メッセージ:{"message": "hello response"}Responseクラスを生成時にhttpステータス500を指定してあげることでクライアント側にhttpステータスとメッセージが返却できました。
この方法はぱっと見でhttpステータスの指定がわかりやすい点が利点だと思います。
一方return時にクラスを生成しているため、ソースが若干見にくく、エラーだと言うイメージが持ちづらい点が欠点になります。abort関数にhttpステータスを指定する
flaskはabortと言うhttp用エクセプションのような関数を持っています。
これにhttpステータスとメッセージを追加することでクライアントに返却するhttpステータスを指定できます。サーバ側
flask_main.pyfrom flask import Flask, jsonify, abort import json app = Flask(__name__) @app.route('/hello') def hello(): abort(500, 'hello abort') return jsonify({'message': 'hello'}) app.run()クライアント側
request_url.pyimport requests response = requests.get('http://localhost:5000/hello') print('httpステータス:{}, メッセージ:{}'.format(response.status_code, response.text))実行
# python .\request_url.py httpステータス:500, メッセージ:<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN"> <title>500 Internal Server Error</title> <h1>Internal Server Error</h1> <p>hello abort</p>abort関数にhttpステータス500を指定してあげることでクライアント側にhttpステータスとメッセージが返却できました。
今までの方法と違い、flask内に定義されているhtmlに指定したメッセージを埋め込んでユーザに返却しています。
大抵は独自のエラー画面を持っているため、この方法は使用しないと思いますが、エラー画面を作成するのが手間な時は便利かもしれません。
さらに、どこからでもabortを呼べばユーザに返却されるため、上位の関数に影響を与えないのは利点だと思います。abortをpythonでキャッチする
上のabortの例だとflaskのデフォルトのhtmlが表示されました。
次はエラーハンドラーにabortを登録してメッセージを作り返して返却します。
Flaskクラスのerrorhandlerに対応するhttpステータスコードを入れればキャッチできます。
404をキャッチしたいときは@app.errorhandler(404)サーバ側
flask_main.pyfrom flask import Flask, jsonify, abort import json app = Flask(__name__) @app.route('/hello') def hello(): abort(500, 'hello abort') return jsonify({'message': 'hello'}) @app.errorhandler(500) def error_500(e): print('httpステータス:{}, メッセージ:{}, 詳細:{}'.format(e.code, e.name, e.description)) return jsonify({'message': 'internal server error', 'action': 'call me'}), 500 app.run()クライアント側
request_url.pyimport requests response = requests.get('http://localhost:5000/hello') print('httpステータス:{}, メッセージ:{}'.format(response.status_code, response.text))実行
# python flask_main.py * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) httpステータス:500, メッセージ:Internal Server Error, 詳細:hello abort# python .\request_url.py httpステータス:500, メッセージ:{"action":"call me","message":"internal server error"}エラーハンドラーにhttpステータスを入れることでabortをキャッチすることができました。
エラーハンドラーに登録した関数の引数のcodeにhttpステータス、nameにタイトル、descriptionにメッセージが入っていました。
これでabort時に独自のレスポンスを返却することができました。
abortは明示的にエラーだとわかる上に上位の関数に影響を与えないのでこの方法を使えばシンプルになるかと思います。exceptionをpythonでキャッチする
エラーハンドラーはhttpステータスだけでなく、エクセプションもキャッチすることができます。
Flaskクラスのerrorhandlerに対応するエクセプションを入れればキャッチできます。サーバ側
flask_main.pyfrom flask import Flask, jsonify, abort import json app = Flask(__name__) @app.route('/hello') def hello(): raise Exception('hello exception') return jsonify({'message': 'hello'}) @app.errorhandler(Exception) def error_except(e): print('メッセージ:{}'.format(e.args)) return jsonify({'message': 'Exception', 'action': 'call me'}), 500 app.run()クライアント側
request_url.pyimport requests response = requests.get('http://localhost:5000/hello') print('httpステータス:{}, メッセージ:{}'.format(response.status_code, response.text))実行
# python flask_main.py * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) メッセージ:('hello exception',)# python .\request_url.py httpステータス:500, メッセージ:{"action":"call me","message":"Exception"}エラーハンドラーにExceptionを入れることでExceptionをキャッチすることができました。
エラーハンドラーに登録した関数の引数のargsにメッセージが入っていました。
この方法を使えば、httpのことを意識せずにエンドポイントを作成することができます。個人的に気に入っている方法
WEBの開発をする際にhttpステータスのことを理解せずに開発する人がいる状況が大いにあります。
その際に、エクセプションをエラーハンドラーに登録することでhttpの知識がなくても開発できるのでエクセプションの方法が気に入っています。
本来はエンドポイントの処理も別ファイルにしていますが、わかりやすさのためにここでは一つのファイルにしています。
エンドポイントの別ファイル化についてはflaskのパスを指定するを見てください。利点
- httpステータスを知らなくてもエクセプションの名前で大体のエラー内容がわかる。
- pythonのエクセプションを別ファイルにまとめているため、httpのことを知らなくても作れる
- httpのことを一つのファイルに閉じ込めているため、調査が容易
- httpステータスで悩む人が減らせる
サーバ側
flask_main.pyfrom flask import Flask, jsonify, abort from myexception import MyException, InputException, ServerException import json app = Flask(__name__) @app.errorhandler(MyException) def error_my_except(e): return jsonify({'message': e.message}), e.code @app.route('/hello/<name>') def hello(name): if name == 'me': raise InputException('input exception') if name == 'my': raise ServerException('server exception') return jsonify({'message': 'hello ' + name}) app.run()myexception.pyclass MyException(Exception): code = 0 message = '' def __init__(self, code, message): self.code = code self.message = message class ServerException(MyException): def __init__(self, message): super().__init__(500, message) class InputException(MyException): def __init__(self, message): super().__init__(400, message)おわりに
httpステータスについて色々書いてきました。
httpステータスは人の解釈により値が変わってしまうので、なるべく一人の人が考えたほうが良いと思いこのような形になりました。
さらに、WEBとpythonで完全に分けて、WEB特化の人とpython特化の人で分担できたら理想だなと思っています。
何故かオールラウンダーになりがちな自分には特化のスキルを持つ人がとてもうらやましく思えてならないです。
オールラウンダーか特化かどっちがいいんだろうか・・・
- 投稿日:2019-08-29T21:52:35+09:00
【多変量回帰】多変量回帰をコードで書いてみる
はじめに
多変量回帰をプログラミングします。使うデータは前にも使ったアボカドデータです。
https://qiita.com/iwasaki_kenichi/items/ea580fd9498ad6950a75カテゴリカルデータの変換
実際に取扱うデータには、整数や実数以外にも、文字列が含まれる場合があります。
いわゆるカテゴリカルデータですが、それを変換するために下記を行うと数値に変換することができます。
文字列から数値(カテゴリ数値)に変換することで、文字列データを多変量回帰に利用することが可能です。main1.pydf["変数名"] = pd.Categorical(df.変数名).codes # コード ```python:main1.py #ライブラリインポート %matplotlib inline import numpy as np from pylab import * import pandas as pd import matplotlib.pyplot as plt from scipy import stats #データ読み込み df = pd.read_csv("hogehoge.csv") df["Categorical_type"] = pd.Categorical(df.type).codes df["Region_type"] = pd.Categorical(df.region).codes X = df[["XLarge Bags","Region_type"]] Y = df[["AveragePrice"]] X1 = sm.add_constant(X) est = sm.OLS(Y,X1).fit() est.summary()おわりに
これぐらいもササッと書けるようになりたい。
summaryで出てくる色々な変数の意味は
ここがわかりやすいです。
- 投稿日:2019-08-29T21:34:31+09:00
(Python)pandas.DataFrame の to_excel で index 列を出力しない方法
問題:pandas.DataFrame の to_excel で index が出力される
pandas.DataFrame で、Excelファイルを生成するメソッド、to_excel() を実行したときに、意図はしていなかったのですがDataFrame の index(行のアクセサ)がデフォルトで出力されるようでした。
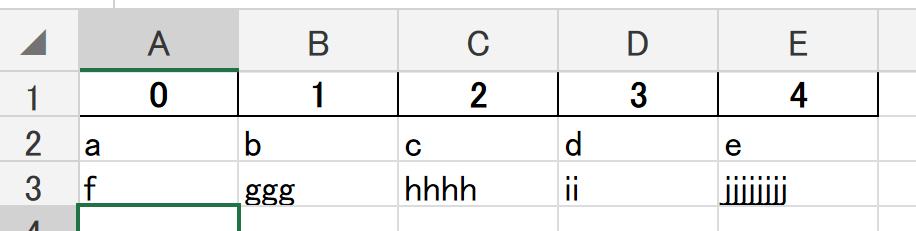
sample.pyfrom pandas import DataFrame def generateExcelFrom(dataFrame:DataFrame, filepath:str)->None: dataFrame.to_excel(filepath) return dataFrame = new DataFrame([ ['a','b','c','d','e'], ['f','ggg','hhhh','ii','jjjjjjjj'], ]) generateExcelFrom(dataFrame, './sample.xlsx')出力結果
配列データ自体は5列ですが、DataFrame が header(列のアクセサ) と index(行のアクセサ)を両方保持しており、A列にindex列を描画するようでした。
データを意図した形で出力したわけではないため、index列を出力しない方法を探したところ、公式ドキュメントに対応方法が書いてありました。
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_excel.html解決法: index=False を to_excel の引数として渡す。
参照
https://stackoverflow.com/questions/22089317/python-to-excel-without-row-names-indexsample.pyfrom pandas import DataFrame def generateExcelFrom(dataFrame:DataFrame, filepath:str)->None: dataFrame.to_excel( filepath, index=False ) return dataFrame = DataFrame([ ['a','b','c','d','e'], ['f','ggg','hhhh','ii','jjjjjjjj'], ]) generateExcelFrom(dataFrame, './sample.xlsx')出力結果
index列が消え、配列の出力ができました。
追記:Header を出力しない場合は header=False を設定する
sample.pyfrom pandas import DataFrame def generateExcelFrom(dataFrame:DataFrame, filepath:str)->None: dataFrame.to_excel( filepath, index=False, header=False ) return dataFrame = DataFrame([ ['a','b','c','d','e'], ['f','ggg','hhhh','ii','jjjjjjjj'], ]) generateExcelFrom(dataFrame, './sample.xlsx')出力結果
このように、DataFrame の to_excel() メソッドを使う際に、index と header を制御したい場合は、parameter に、
index=False及びheader=Falseを付け加えることで出力を制御できるようでした。前提条件
python --version Python 3.7.4 numpy==1.17.1 openpyxl==2.6.3 pandas==0.25.1以上です。


- 投稿日:2019-08-29T21:24:56+09:00
TensorFlowを(中途半端に)使って常微分方程式 (ODE)の数値計算をする
TensorFlowを使って常微分方程式(ODE)の初期値問題の数値計算をやってみます。速度の面では実用性はありませんが、TensorFlowに備わっている強力な自動微分を使いこなせれば色々解析に便利な面があると思われ、たとえばNeural Networkなどで複雑なモデルを作っていたとしてもヤコビ行列の計算などを自動的にしてくれることなどが利点と思います。
今回はグラフを使って微分方程式を定義してみますが、実際の数値計算はscipyに入っている
solve_ivpを使用します。 実は拡張ライブラリのTensorFlow Probability においてTensorFlow上で動くODEソルバーが実装されているようですが、理解不足もあり今回は使いません。環境
- TensorFlow 1.14
- Python 3.6.8
- scipy 1.2.1
やりたいこと
一階の常微分方程式
\frac{d \boldsymbol{x}}{dt} = f(\boldsymbol{x})の初期値問題の近似解を数値計算により求めます。 $\boldsymbol{x} \in \mathbb{R}^{d}$は$d$次元ベクトル、$f$は$\mathbb{R}^{d}$ から $\mathbb{R}^{d}$への写像(ベクトル場と呼ぶ)とします。
例として次のローレンツ方程式を以後使います。3次元の微分方程式であり、E.ローレンツがカオスを発見したことで有名です。 $\boldsymbol{x}=(x,y,z)^T$ として
\begin{equation} \frac{d \boldsymbol{x}}{dt} = \left( \begin{matrix} f_x(\boldsymbol{x}) \\ f_y(\boldsymbol{x}) \\ f_z(\boldsymbol{x}) \end{matrix}\right) = \left( \begin{matrix} \sigma(y-x) \\ x(\rho -z) -y \\ xy - \beta z \end{matrix}\right) \tag{1} \end{equation}$\sigma, \rho, \beta $ は定数のパラメータです。
この方程式をTensorFlowのグラフ上で定義し、ODEソルバーを使って数値解を求めてみたいと思います。尚,今回は倍精度で計算を行います.
グラフの定義
準備
tensorflow, scipyのodeソルバー呼び出しに使う
solve_ivp,その他をインポートします.import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D # noqa: F401 unused import import time import tensorflow as tf from scipy.integrate import solve_ivpベクトル場の定義
まず変数 $\boldsymbol{x}$ のテンソルですが外(ODEソルバー)から値を入れて使うので、今回はこんな感じでplaceholder型にします。
x = tf.placeholder(dtype=tf.float64, shape=(3), name='x')入力$x$からベクトル場を計算するグラフを作るクラスを作ります。インスタンスを作っておき,パラメータはメンバ変数に持たせるようにしておくと便利です。(参考: https://github.com/titu1994/tfdiffeq/blob/master/examples/lorenz_attractor.py )
class Lorenz(object): def __init__(self, sigma=10., beta=8 / 3., rho=28., **kwargs): self.sigma = float(sigma) self.beta = float(beta) self.rho = float(rho) def __call__(self, t, x): dx_dt = self.sigma * (x[1] - x[0]) dy_dt = x[0] * (self.rho - x[2]) - x[1] dz_dt = x[0] * x[1] - self.beta * x[2] dX_dt = tf.stack([dx_dt, dy_dt, dz_dt]) return dX_dtグラフの作成
f_lorenz = Lorenz() fx = f_lorenz(None, x) # r.h.s. of ODESessionを動かして計算
とりあえず初期値を設定しておきます.
x0 = np.array([1, 10, 10], dtype=np.float64) # initial valuesessionの開始,動作の確認
sess = tf.Session() sess.run(tf.initializers.global_variables())$\boldsymbol{x}$に初期値$(1,10,10)$を入れたときに$f(\boldsymbol{x})$を正しく計算してるか見てみます.
print('###value of f(x)###') print(sess.run(fx, feed_dict={x:x0}))結果
###value of f(x)### [ 90. 8. -16.66666667]手計算だと$(90,8,-50/3)$ですので,ちゃんと計算していることがわかります.
ODEソルバーによる数値計算
では準備ができたので,これをODEソルバーに渡して数値解を計算してみます.
scipyのsolve_ivpのドキュメントはここです.デフォルトでは(適応的時間刻み制御付)4次のルンゲ=クッタ法が実際に使われるようです.時間の設定
積分の開始,終了時刻を設定しておきます.今回きれいに図を描くため時間刻み0.01ごとの値を得たいため,配列tsを作っておきます.
dt=0.01 tstart=0.0 tend=100.0 ts=np.arange(tstart, tend+dt, dt) # 表示のため、0.01ステップで値を出力させるODEソルバーに渡すラッパー関数の作成
solve_ode に渡す関数の形式にするためのラッパー関数です.引数のxtをplaceholderに渡し,fxを評価するrunを走らせるだけです. lambdaを使えばより簡潔にすることもできます.
def f_lorenz_tf(t,xt): return sess.run(fx, feed_dict={x: xt})ソルバーによる数値解の計算
ソルバー
solve_ivpに上で作ったベクトル場を計算する関数,初期値x0,積分の開始,終了時刻,値を出力する時間のリスト,を渡して数値計算を行わせ,結果などをsol_lorenzに受け取ります.返り値のなかの['t']に時間ステップ,['y']に解が入っているので,それぞれを取り出します.start_time =time.time() # measurement of time sol_lorenz = solve_ivp(fun=f_lorenz_tf, t_span=[tstart, tend], y0=x0, t_eval=ts) integration_time_tf = time.time() - start_time t_lo = sol_lorenz['t'] # 各ステップの時刻を取得 x_lo = sol_lorenz['y'] # 各ステップのx(t)の値を取得 print("processing time (tf) %.5f" % integration_time_tf)結果の表示
解曲線を表示してみます.
fig=plt.figure(figsize=(8,6)) ax=fig.add_subplot(111) ax.plot(t_lo,x_lo[0],'-') ax.set_xlabel('time') ax.set_ylabel('x') # 3dim phase space fig3 = plt.figure(figsize=(8,6)) ax3 = fig3.add_subplot(111,projection='3d') ax3.plot(x_lo[0], x_lo[1], x_lo[2], '-', lw=0.5) ax3.set_xlabel("X Axis") ax3.set_ylabel("Y Axis") ax3.set_zlabel("Z Axis") ax3.set_title("Lorenz Attractor")
numpyとの比較
numpyのみを使って微分方程式を計算した場合と比較してみます。
まずtensorflowを使わずにローレンツ方程式のfを定義します。扱っているものはnumpy配列かtensorかで違うのですが,コード上では最後のreturn文以外は同じ処理になります。class Lorenz_np(object): def __init__(self, sigma=10., beta=8 / 3., rho=28., **kwargs): self.sigma = float(sigma) self.beta = float(beta) self.rho = float(rho) def __call__(self, t, x): """ x here is [x, y, z] """ dxdt= self.sigma * ( x[1] - x[0]) dydt= x[0] * (self.rho- x[2] ) - x[1] dzdt= x[0]*x[1]-self.beta*x[2] return np.array([dxdt,dydt,dzdt ])そしてこの関数をodeソルバーに渡して計算します.
f_lorenz_np = Lorenz_np() start_time = time.time() # measurement of time sol_lorenz_np = solve_ivp(fun=f_lorenz_np, t_span=[tstart, tend], y0=x0, t_eval=ts) integration_time_np= time.time() - start_time print("processing time (numpy) %.5f" % integration_time_np) t_lo_np = sol_lorenz_np['t'] x_lo_np = sol_lorenz_np['y']解軌道を比較してみます.
fig3=plt.figure(figsize=(8,6)) ax3=fig3.add_subplot(111) ax3.plot(t_lo,x_lo[0],'-') ax3.plot(t_lo_np,x_lo_np[0],'-')
2つの解曲線がまったく同一なので,重なってひとつにみえています.どうやら内部的には完全に同じ計算を
しているようですね. この方程式にはカオスの初期値鋭敏姓があるので,数学的には同一の式でも,計算の手順や精度を少しでも変えるだけでも数値計算の結果は変わってしまいます.たとえば
たとえばLorenz_npの__call___の1行目をdxdt= sigma * x[1] - sigma*x[0]と少し変えるだけで,丸め誤差は発生し,その誤差が時間とともに指数的に拡大するため,数値計算の結果は目に見えて変わります.
速度について
コードの中には積分にかかった時間を計算していました.手元のマシンでは
processing time (TF): 2.97551 processing time (numpy) 0.22292という結果になりました. 3秒とは...遅いですね。numpyと比べてもTensorFlowのほうが10倍遅いです。sess.run をsolve_ivpの中で10000回近く呼んでいることのオーバーヘッドでしょうか。まあnumpyもC++などに比べると100倍くらい遅いのではないかと思いますが.
尚これはCPUのみでの結果ですが、GPUを使うとさらに遅くなります。終わりに
ひとまずTensorFlowを使ってベクトル場を計算することで微分方程式の計算が可能であるということは確かめられました.
次回
今回の範囲ではTensorFlowを使う意義がまったくない感じられないと思いですので,次回は勾配を計算する機能を使ってヤコビ行列を計算することにより、不動点の安定性解析やリアプノフ指数の計算といった力学系の解析をやってみたいと思います.
TODO
- バッチ処理に対応できるようにする。
- Tensorflow上でODEsolverを動かす。
code
githubにjupyterNotebookを公開しました.
https://github.com/yymgch/ode_tf/blob/master/ode_by_tf.ipynb



- 投稿日:2019-08-29T21:10:11+09:00
pythonで株価をスクレイピング→bigqueryに取込んでlookerで可視化してみた
lookerで株価を可視化してみました
pythonでデータ加工するならmatplotlib使えよ。的な話もあると思いますが、lookerに可視化するのに必要な作業手順を一通り体験してみたかったので、やや興味本位(趣味)でやってますので、その辺はご理解よろしくお願いいたします。
利用ツール
・google colab(python3)
・bigquery
・looker株価データの取得(スクレイピング)
・まずは可視化対象のデータ取得ですが、個人的にFFとかロマサガが好きなので、スクエニの株価を取得。
・スクレイピングのコードはこちらの記事を参考にさせていただきました。
http://www.stockdog.work/entry/2016/08/28/180911import pandas import datetime def scraping_yahoo(code, start, end, term): base = "http://info.finance.yahoo.co.jp/history/?code={0}.T&{1}&{2}&tm={3}&p={4}" start = str(start) start = start.split("-") start = "sy={0}&sm={1}&sd={2}".format(start[0], start[1], start[2]) end = str(end) end = end.split("-") end = "ey={0}&em={1}&ed={2}".format(end[0], end[1], end[2]) page = 1 result = [] while True: url = base.format(code, start, end, term, page) df = pandas.read_html(url, header=0) if len(df[1]) == 0: break result.append(df[1]) page += 1 result = pandas.concat(result) result.columns = ['Date', 'Open', 'High', 'Low', 'Close', 'Volume', 'Adj Close'] return result if __name__ == "__main__": ### 取得したい株価のコードを指定する(ここを変更):9684はスクエニの株価コードです company = 9684 EndDate = datetime.date.today() StartDate = EndDate - datetime.timedelta(days=180) ## ここで何日分のデータ取得するかを指定 data = scraping_yahoo(company, StartDate, EndDate, "d") print(data)実行結果
スクエニの直近180日分の株価を取得してきました。
DBに取込む為のレイアウトの変換と、7日移動平均の項目追加
・スクレイピングしたデータをそのままbigqueryに突っ込んでみたら、日付がうまくソートできない形式だったり、インデックスの並びが微妙だった為、いい感じに取込めるように変換してます。せっかくなので7日移動平均も追加。
## スクレイピングしたデータを一時退避 df = data ## 日付項目をソートできるようにフォーマット変換 df['Date'] = pd.to_datetime(df['Date'], format='%Y年%m月%d日') ## adj CloseをDBに項目取り込みする為、スペース情報を_に変更 df = df.rename(columns={'Adj Close': 'Adj_Close'}) ## 銘柄コードを追加 df['bond_cd'] = company ## 移動平均算出の為、Date順にソートする df = df.sort_values(by=["Date"], ascending=True) ## 7日移動平均を算出して追加 df['avg_7day_Close'] = df["Close"].rolling(window=7).mean() ## indexをDateに変更 df.set_index("Date",inplace=True) ## 内容確認 df実行結果
データ定義を確認
df.dtypes実行結果
・Date はインデックスにしたので、ここでは表示されませんがCSVにするとひょっこり出てくるので大丈夫。
いちおう、matplotlibで株価データを時系列で可視化
df['Close'].plot(legend=True, grid=True)実行結果
・直近で、結構株価上がってました。
ググったら2019年4-6月期の連結営業利益は前年同期比85.8%増と好調だったみたいで調子よいみたいです。
CSVにダウンロード(google colabからローカルへ)
## CSV出力 from google.colab import files filename = "bond.csv" df.to_csv(filename) files.download(filename)CSVをBigqueryへ
ここら辺の手順はこちらを参考にし、bondというテーブルを作成しました。
bigqueryのテーブルをlookerへ反映(lookMLを自動生成する)
・lookerを開いて、開発用のDevelopment Modeに切り替える
・ProjectのViewsにbigqueryのテーブルを追加してlookMLを生成
自動生成されたlookML
view: bond { sql_table_name: sample_analysis_looker.bond ;; dimension: adj_close { type: number sql: ${TABLE}.Adj_Close ;; } dimension: avg_7day_close { type: number sql: ${TABLE}.avg_7day_Close ;; } dimension: bond_cd { type: number sql: ${TABLE}.bond_cd ;; } dimension: close { type: number sql: ${TABLE}.Close ;; } dimension_group: date { type: time timeframes: [ raw, date, week, month, quarter, year ] convert_tz: no datatype: date sql: ${TABLE}.[Date] ;; } dimension: high { type: number sql: ${TABLE}.High ;; } dimension: low { type: number sql: ${TABLE}.Low ;; } dimension: open { type: number sql: ${TABLE}.Open ;; } dimension: volume { type: number sql: ${TABLE}.Volume ;; } measure: count { type: count approximate_threshold: 100000 drill_fields: [] } }lookMLの修正その1:描画用にmeasure項目を追加
・lookerのお作法的なものですが、lookMLの自動生成では、数値項目でもmeasureではなくdimensionとして認識されます。そのため、グラフなどに描画したい情報の場合、以下のようにmeasure項目として追加する必要があります。詳細はこちら
### 追加コード measure: avg_7day_close_sum { type: sum sql: ${TABLE}.avg_7day_Close ;; ### 7日移動平均 } measure: close_sum { type: sum sql: ${TABLE}.Close ;; ### 当日終値 } measure: volume_sum { type: sum sql: ${TABLE}.Volume ;; ### 当日出来高 }lookMLの修正その2:日付け項目の修正対応
・こちらもlookML使うときのお作法です。テーブルの日付項目名に一定の文字列があると、自動で[]がつけられますが、bigqueryでは項目名に[]をつけると現時点ではエラーとなる為、コードの手直しが必要。詳細はこちら
dimension_group: Date { type: time timeframes: [ raw, date, week, month, quarter, year ] convert_tz: no datatype: date sql: ${TABLE}.[Date] ;; ### ここの[Date]というところはbigqueryでエラーになる } ### ↓ 上記を以下のように変更 dimension_group: Date{ type: time timeframes: [ raw, date, week, month, quarter, year ] convert_tz: no datatype: date sql: ${TABLE}.Date ;; ### 修正箇所:[Date] → Date に変更する }lookerで可視化
・dimension:日付/Dateを選択
・measure:7日移動平均/avg_7day_close_sum、当日終値/close_sum、当日出来高/volume_sumの3つを選択
・株価データは土日祝のデータない為、DateはNULLを除外→やり方はこちら
・当日出来高/volume_sumは2軸にする→やり方はこちら
まとめ
・サクッと可視化したいなら、colab上でmatplotlibなどを使う方が楽。
・lookMLでカスタマイズがしやすそうだが、お作法的な対処が必要なので慣れが必要。
・lookMLで分析軸を増やして、lookerのフィルタに追加可能なので、一度作ってしまえば、分析担当者でなくてもいろいろ分析出来る可能性があるので、分析の民主化的な体制を作りたい企業には良さそう。









- 投稿日:2019-08-29T21:01:23+09:00
Kaggle初参加で(すごいチームにいれてもらって)銀メダル(Top 1.1%)を手に入れた感想【Predicting Molecular Properties】
記事の概要
2ヶ月ぶりにQiitaに投稿します、Shunと申します。
以前「データ分析未経験SEがデータサイエンティストを目指す」という記事を書いていたのですが、かなり間が空いてしまい、いったい何やっているんだと言われても仕方ない状態が続いたのですが、
2か月前よりあるKaggle Masterの方からご指導いただきつつ、Kaggleの『Predicting Molecular Properties(分子コンペ)』に参加していました!
(実は、その裏でSIerを辞めて転職する決断もしています。今度記事書きます。)Predicting Molecular Properties
最終的には5人チームとなり、みなさん優秀な方ばかりで私個人の貢献度は皆無に近かったのですが、
結果としては、29位/2757チーム(Top 1.1%)で銀メダルをいただきましたので、簡単に感想を書きたいと思います。
なお、コンペの具体的な内容や使用した技術に関しての詳しい話は、今回は割愛させていただきます。
(でも、AI・Kaggle初心者で「Kaggle始めたけど何すればいいか分からない!」って人のための記事は今のうちに書いておきたい…)Kaggleを通して成長できたこと(多分に誇張が含まれます)
Before
- SIerで2年間レガシーなシステムばかりやってきたSE
- 機械学習を学び始めて3ヶ月の初学者
- PythonとそのライブラリはCodecademyの講座で学習
- ディープラーニングG検定に合格済み
- DL4USの教材は一通りColabで動かしてみた
- とりあえずTitanicコンペは見よう見まねでやってみた
ポテンシャルだけはあると勝手に思っていたAfter
- TensorFlow, Chainer, Keras, PyTorchなんでも触れるようになった
- 独自のLayer(Chain)が組めるようになった(Chainerで組んだ自作Chainはうまく動きませんでしたが…)
- 独自の損失関数を組んで学習できるようになった
- PandasやNumpyの主要な操作が自在にできるようになった
- CVスコアとLBスコアの違いや、学習データのleakについて意識できるようになった
- Ensembling、特にStackingについて(なんとなく)理解できた
- GCPでインスタンス立てて学習が回せるようになった
- チーム内のKaggle強い人の議論の内容がなんとなく分かるようになった(参加できるわけではない)
ポテンシャルだけではどうしようもないという現実にあらためて危機感を覚えた金メダルに届かなかった原因についての考察
少なくともMasterの方の協力があった以上、金メダルを目指したかったのですが、スコア的には全くと言っていいほど届きませんでしたので、原因を考えてみます。
計算資源・時間の不足
既に金メダル獲得者のsolutionが公開されつつありますが、
使用したモデル・特徴量やアイデア・工夫に関しては私たちのチームとあまり遜色なかった反面(追記:さすがに最上位の方のsolutionとなるとやってることが全然違って驚いてます)、
学習の量に関しては桁違いの差がありました。
分子コンペは名目上はtabularコンペでありながら、実際はGNN(Graph Neural Network)という計算コストの高いモデルでたくさん学習しなければ上位になれなかったため、
実態はimageコンペに近く、アイデアや工夫よりも計算資源が大きなウェイトを占めていたと考えられます。また、例え計算資源が足りないにしても、もっと早くからGNNに着手できていれば、学習時間の余裕はもっとあったかもしれません。
この点は、コンペ中盤でGNNに切り替える決断がなかなかできなかった私に責任あると思っています。コンペ内容の専門性が高い
もう一つ違った観点として、分子コンペ自体が「とっつきづらい」コンペだった、という説を挙げたいと思います。
当たり前ですが、Kaggle初心者や「とりあえず公開カーネルをsubmitしてみた人」が増えれば増えるほど、
また、ライバルの人数が減れば減るほど、メダルは取りやすくなります。分子コンペは見た目からして専門性が高く初心者が入りづらく、かと言ってチーム総数が極端に少ないわけでもありませんでした(チーム総数が少ないほど、金枠の割合自体は高い)。
また、量子物性化学を専門としているような研究者も多く参戦し、上位に入っていたようです。
ですので、他のコンペに参加していない以上推測しかできませんが、コンペの難易度自体高めだったのだろうと感じます。チームの重要性について
Kaggleが普通の競プロやマラソンマッチと異なる点はたくさんあると思うのですが(例えば他の人の公開カーネルが自由に使えるとか)、
今回実感したことの一つに「チームの重要性」があります。当初は、チームを組むメリットを「意見交換できる、作業分担できる」くらいしか思っていなかったのですが、
データ分析には「Ensembling」という手法が存在し、学習モデルは多くの種類があればあるほど(例え単体でのスコアがあまり高くなくとも)最終スコアは上がり、
かといって人数が増えたからと言ってメダルが5分割されたりするわけでもないので(Solo Goldだけは別ですが)
基本的にはチームの人数が増え、材料となるモデルがたくさん用意できるほど有利になることが分かりました(ただし、人数が増えるデメリットとして、1日5回のsubmit回数が共有化されてしまうというのもある)。一方で、他のチームとマージ申請をしようと思うと、「自身とチームを組むことの価値」を証明しなければならないので、
必然的に自分一人でもある程度のスコアが狙える必要があります。
今回の私のように、知り合いの方にご助力いただけるような場合は例外なのですが、
初心者目線として、「チーム組めば初心者であまりコミットメントしなくともメダルが取れちゃう」「Stackingよくわかんないけど他の人に任せておけばいいや」とかそういう話では決してなく、
自分の実力が一人前になることの必要性自体は競プロやマラソンマッチ等とそう変わらないということを肝に銘じておきたいと思います。
(ふと思ったのですが、この制度を悪用すれば、対戦ゲームにおける「代行」に近い形で初心者をMasterに引き上げる裏商売があってもおかしくなさそうです。そういうのって禁止されてるんでしょうか)もちろん、コンペのスコア関係なく、優秀な方と関われるのは知識の幅を広げたり、モチベーションになりますし、「私はなんて無知なんだ、もっと勉強しなければ」という焦りや危機感に突き動かされること間違いなしなので、
機会さえあれば例え初心者同士だろうとチームは積極的に組むべきだと実感しました。今後について
Kaggleは今後もやっていこうと思っています。
次のコンペとしては、現在唯一のtabularコンペ「IEEE-CIS Fraud Detection」をやってみようかなと考えています(クレカの不正利用を検知精度を上げるのが目的で、Titanicコンペなんかと性質は近そうなので、初心者にもとっつきやすそう?なにせ今回はちょっとヘンテコなコンペに手を出してしまったので正統派のものをやってみたい)。以前ロードマップとして挙げていた専門書の読破やWebアプリを作ってみる件は滞っているので、改めてスケジュールを考えます(アプリのネタはあるにはあるのですが)。
記事のネタはたくさんできたので、これからまとめていきたいです。
改めて、Kaggleに参加することはとても大きな成長になったと感じます。
最後に、チームを組んでいただいた皆様、色々とご迷惑をおかけいたしたしましたが、いろいろと勉強させていただきました。本当にありがとうございました!
- 投稿日:2019-08-29T20:47:54+09:00
【随時更新(予定)】Pythonのデータを格納するオブジェクト
はじめに
自分の備忘もかねて、基本中の基本をまとめていきます
データを格納するオブジェクト
リスト(list)
タプル(tuple)
集合(set)
辞書(dictionary)タプル(Tuple)
tuple.pylocation = (13.4125, 103.866667)集合(Set)
set.pynumbers = {1, 2, 6, 3, 1, 1, 6}リスト(List)
list.pylist_of_random_things = [1, 3.4, 'a string', True] #listはstring, int, floatすべて可能 list_of_month = ["Jan", "Feb", "Mar", "Apr", "May", "Jun", "July", "Aug", "Sep", "Oct", "Nov", "Dec"] 0 1 2 3 4 5 ...... #listのindexは0から始まる(一番初めの要素からの距離) list_of_month[1] #["Feb"] #list[(含む):(含まない)] list_of_month[1:4] #["Feb", "Mar", "Apr" ] list_of_month[:3] #["Jan", "Feb", "Mar" ] list_of_month[5:] #["Jun", "July", "Aug", "Sep", "Oct", "Nov", "Dec"] #上書き可能(可変) my_lst = [1, 2, 3, 4, 5] my_lst[0] = 'one' print(my_lst) #['one', 2, 3, 4, 5]辞書(Dictionary)
dictionary.pyelements = {"hydrogen": 1, "helium": 2, "carbon": 6} animals = {'dogs': [20, 10, 15, 15], 'cats': [3,4,2,8,2,4], 'rabbits': [2, 3, 3]} #検索1 print(animals['dogs']) #[20, 10, 15, 15] #検索2 print(animals['dogs'][3]) #15 #新しいkeyとvalueの追加 animals["birds"] = [4,5,5,6] print(animals) #{'dogs': [20, 10, 15, 15], 'cats': [3,4,2,8,2,4], 'rabbits': [2, 3, 3], 'birds': [4,5,5,6]}まとめ
データ型 順序 変更
追加
削除表記 例 タプル(Tuple) 〇 × () or tuple() (5.7, 4, 'yes', 5.7) セット(Set) × 〇 { } or set() {5.7, 4, 'yes'} リスト(List) 〇 〇 [] or list() [5.7, 4, 'yes', 5.7] 辞書(Dictionary) × 〇 { } or dict() {'Jun': 75, 'Jul': 89} 参考
はじめてにQiitaに当たって書き方を参考に
Qiita書き方これを使って練習したい(願望)
Hackerrank
- 投稿日:2019-08-29T20:42:42+09:00
プログラミング全く未経験者の初投稿
はじめに
初めまして!
奏詩と申します。
基本的には自分用のメモや後々の見返しのために記事書いてます。軽く自己紹介しますね٩(ˊᗜˋ*)و
奏詩(そうし)
1998年生まれの魚座。
学歴は高校(文系)卒。
フリーター⇨営業⇨起業⇨失敗⇨SESで全くプログラミング未経験ながら働き始める⇦イマココ
ゲーム大好き。FPS、RPG、シミュレーションなんでもやる。
Macをスタバで開くのが好き。何もできない。僕と近い境遇をもつあなたに
この記事はプログラミング未経験者(趣味で触っている)とかプログラミング初心者(学校で触っていた)などの触った経験はあるけど実務をやったことがないなんて言うエセ初心者(ごめんなさい)じゃなく、本当に触ったこともない勉強もしたことがない、じゃば?何それおいしいの?ってレベルの方達がプログラミングを勉強する後押しになればなと思って書いています。
ここからが本題
今回は初投稿なので昨日ぐらいにやっと終わった本の写経を載せたいと思います。
作成したのはヒット&ブローゲーム、ランダムな4つの数字を当てるゲームです。
自分自身書いていて半分ぐらいしか理解できてないです。# Python3 import random import tkinter as tk import tkinter.messagebox as tmsg # ボタンがクリックされたときの処理 def ButtonClick(): # テキスト入力欄に入力された文字列を取得 b = editbox1.get() # Lesson 5-4のプログラムから判定部分を借用 # 4桁の数字かどうかを判定する isok = False if len(b) != 4: tmsg.showerror("エラー","4桁の数字ではありません") else: kazuok = True for i in range(4): if (b[i] < "0") or (b[i] > "9"): tmsg.showerror("エラー","数字ではありません") kazuok = False break if kazuok: isok = True if isok: #4桁の数字であったとき #ヒットを判定 hit = 0 for i in range(4): if a[i] == int(b[i]): hit = hit + 1 #ブローを判定 blow = 0 for j in range(4): for i in range(4): if (int(b[j]) == a[i]) and (a[i] != int(b[i])) and (a[j] != int(b[j])): blow = blow + 1 break # ヒットが4つなら当たりで終了 if hit == 4: tmsg.showinfo("当たり","おめでとうございます!あたりです!") # 終了 root.destroy() else: #ヒット数とブロー数を表示 rirekibox.insert(tk.END, b + " /H:" + str(hit) + " B:" + str(blow) + "\n") # ランダムな4つの整数を作る a = [random.randint(0,9), random.randint(0,9), random.randint(0,9), random.randint(0,9)] #テストのために表示させる print(str(a[0]) + str(a[1]) + str(a[2]) + str(a[3])) # ウィンドウを作る root = tk.Tk() root.geometry("600x400") root.title("hit&blowゲーム") #履歴表示のテキストボックスを作る rirekibox = tk.Text(root, font=("Helvetica" , 14)) rirekibox.place(x = 400 , y = 0 , width = 200 , height = 400) # ラベルを作る labell = tk.Label(root, text = "数を入力してね", font=("Helvetica",14)) labell.place(x = 20, y = 20) # テキストボックスを作る editbox1 = tk.Entry(width = 4, font=("Helvetica", 28)) editbox1.place(x = 120, y = 60) # ボタンを作る button1 = tk.Button(root, text = "チェック", font=("Helvetica",14), command=ButtonClick) button1.place(x = 220, y = 60) # ウィンドウを表示する root.mainloop()これでやっと画面上にゲーム画面を出すことができました。
Progate⇨本と勉強してこのレベルです。鼻くそです。本当の初心者の方に
最初はコマンドプロンプトに慣れるところからです。文字だけの画面を見て寝ないように頑張りましょう。
僕はたまたま最初にLinuxを使う現場に回されたのでひたすらカタカタしてました。(めっちゃ寝ました)転職で未経験からエンジニアになろうとしてる方、SESに転職したけど事務みたいなことしかさせてもらえない方、一緒に頑張りましょう。諦めず地道に自分で勉強して「エンジニア」目指しましょう!
終わりに
今はなぜか業務でCobolを触っていますが(なんで?),将来のためにPythonを勉強してます。
今後また作ったものを上げていくかもしれないので応援してもらえるとやる気も上がります。(助けてください。)
- 投稿日:2019-08-29T19:45:15+09:00
Python代数演算ライブラリを使ってカオスな振る舞いをする二重振り子の運動方程式を導く
この記事の目的
Pythonの代数演算ライブラリSymPyと 数値計算用のライブラリであるSciPyやNumPyとの組み合わせが強力であることを示す例として、二重振り子を数値計算で解くということを試みます。
↓二重振り子
引用元実は、その単純な見た目からは想像できないほど、二重振り子の極座標での運動方程式は 非常に複雑です。
難しいことで有名な力学の教科書である ランダウ・リフシッツ 力学 でも出てくるぐらい有名な練習問題の一つです。今回は、Pythonを使ってマシンパワーで、サクッと極座標の運動方程式の導出をしてしまおうというわけです。
注意点
今回の記事は、ゴツイ数式が大量に出てきます。
苦手な方は、最後のGIFアニメーションだけをご覧ください。あと、解析力学の知識(特にラグランジアン)を前提としています。
ただ、知らない方も、今回の記事は、SymPyでの代数演算とSciPyを使った数値計算をPythonという単一の言語でできるのいいね(Python万歳)、というものなので、雰囲気だけでも伝われば幸いです。
「なんかやってんなー」くらいの軽い気持ちで見てください笑
二重振り子とは?
二重振り子 とは、上記の画像の通り、振り子の先にもう一つ振り子が繋がっているものです。単振り子は非常に単純な運動をしますが、そのさきにもう一つの振り子がついただけの二重振り子は カオスな振る舞い をすることが知られています。
カオス というのは、数学的には細かい定義があるものの、その特徴を大雑把にいうと、
- 初期値の小さなずれが結果的に大きなずれになること(初期値鋭敏性)
- 周期的でないこと
- 非線形であること
の3つです。
特に、初期値鋭敏性があるおかげで、二重振り子は全く予想ができない動きをします。
運動方程式を導出した後は、ついでにこれもシミュレーションしてみましょう。
本記事の流れ
- モデル設定
- 極座標のラグランジアンを導出
- 極座標の運動方程式を導出
- シミュレーション
モデル設定
水平にx軸、鉛直上向きにy軸があり、y軸負方向に重力がかかっています。
また、原点から長さ$r_1$の棒の先に1つ目の質点がついていて、そこから長さ$r_2$の棒で2つ目の質点がつながっているとします。
それぞれの棒がy軸とのなす角をそれぞれ$\theta_1, \theta_2$とします。
SymPyをimportします。
import sympy as sy sy.init_printing()
sy.init_printingの別オプションについては、
SymPyで代数演算してみるを参照してください。
文字変数や関数を定義
# 変数と関数を定義 t = sy.Symbol("t", real=True) r1, r2, m1, m2, g = sy.symbols(r"r_1 r_2 m_1 m_2 g", positive=True) # theta1, theta2 = sy.symbols(r"\theta_1 \theta_2", real=True) theta1 = sy.Function(r"\theta_1")(t) theta2 = sy.Function(r"\theta_2")(t) theta1_dot, theta2_dot = sy.symbols(r"\dot{\theta_1} \dot{\theta_2}")
ラグランジアンの極座標表示を導出
ラグランジアンの最大の特徴は、座標変換不変です。
したがって、デカルト座標でラグランジアンを作った後、それを極座標の変数で表します。
- 質点の位置・速度を極座標で表す
- デカルト座標表示のラグランジアンを座標変換(デカルト座標->極座標)して、ラグランジアンを極座標表示する
質点の位置・速度を極座標で表す
# 質点1の位置と速度 x1 = sy.Matrix([r1 * sy.sin(theta1), - r1 * sy.cos(theta1)]) v1 = x1.diff(t) x1$$\left[\begin{matrix}r_{1} \sin{\left(\theta_{1}{\left(t \right)} \right)}, - r_{1} \cos{\left(\theta_{1}{\left(t \right)} \right)}\end{matrix}\right]$$
v1$$\left[\begin{matrix}r_{1} \cos{\left(\theta_{1}{\left(t \right)} \right)} \frac{d}{d t} \theta_{1}{\left(t \right)}, r_{1} \sin{\left(\theta_{1}{\left(t \right)} \right)} \frac{d}{d t} \theta_{1}{\left(t \right)}\end{matrix}\right]$$
# 質点2の位置と速度 x2 = x1 + sy.Matrix([r2 * sy.sin(theta2), - r2 * sy.cos(theta2)]) v2 = x2.diff(t) x2$$\left[\begin{matrix}r_{1} \sin{\left(\theta_{1}{\left(t \right)} \right)} + r_{2} \sin{\left(\theta_{2}{\left(t \right)} \right)}, - r_{1} \cos{\left(\theta_{1}{\left(t \right)} \right)} - r_{2} \cos{\left(\theta_{2}{\left(t \right)} \right)}\end{matrix}\right]$$
v2$$\left[\begin{matrix}r_{1} \cos{\left(\theta_{1}{\left(t \right)} \right)} \frac{d}{d t} \theta_{1}{\left(t \right)} + r_{2} \cos{\left(\theta_{2}{\left(t \right)} \right)} \frac{d}{d t} \theta_{2}{\left(t \right)},
r_{1} \sin{\left(\theta_{1}{\left(t \right)} \right)} \frac{d}{d t} \theta_{1}{\left(t \right)} + r_{2} \sin{\left(\theta_{2}{\left(t \right)} \right)} \frac{d}{d t} \theta_{2}{\left(t \right)}\end{matrix}\right]$$デカルト座標表示のラグランジアンを座標変換(デカルト座標->極座標)して、ラグランジアンを極座標表示する
まずは、運動エネルギーを求めます。
# 運動エネルギー T1 = (m1 * (v1[0]**2 + v1[1]**2) / 2).simplify() T2 = (m2 * (v2[0]**2 + v2[1]**2) / 2).simplify() T1$$\frac{m_{1} r_{1}^{2} \left(\frac{d}{d t} \theta_{1}{\left(t \right)}\right)^{2}}{2}$$
T2$$\frac{m_{2} \left(r_{1}^{2} \left(\frac{d}{d t} \theta_{1}{\left(t \right)}\right)^{2} + 2 r_{1} r_{2} \cos{\left(\theta_{1}{\left(t \right)} - \theta_{2}{\left(t \right)} \right)} \frac{d}{d t} \theta_{1}{\left(t \right)} \frac{d}{d t} \theta_{2}{\left(t \right)} + r_{2}^{2} \left(\frac{d}{d t} \theta_{2}{\left(t \right)}\right)^{2}\right)}{2}$$
次に、ポテンシャルを求めます。
# ポテンシャル V1 = m1 * g * x1[1] V2 = m2 * g * x2[1] V1$$- g m_{1} r_{1} \cos{\left(\theta_{1}{\left(t \right)} \right)}$$
V2$$g m_{2} \left(- r_{1} \cos{\left(\theta_{1}{\left(t \right)} \right)} - r_{2} \cos{\left(\theta_{2}{\left(t \right)} \right)}\right)$$
運動エネルギーとポテンシャルが求まったので、ラグランジアン $L(\theta_1, \theta_2, \dot{\theta_1}, \dot{\theta_2})$ を得ることができます。
L = T1 + T2 - V1 - V2 L$$g m_{1} r_{1} \cos{\left(\theta_{1}{\left(t \right)} \right)} - g m_{2} \left(- r_{1} \cos{\left(\theta_{1}{\left(t \right)} \right)} - r_{2} \cos{\left(\theta_{2}{\left(t \right)} \right)}\right) + \frac{m_{1} r_{1}^{2} \left(\frac{d}{d t} \theta_{1}{\left(t \right)}\right)^{2}}{2} + \frac{m_{2} \left(r_{1}^{2} \left(\frac{d}{d t} \theta_{1}{\left(t \right)}\right)^{2} + 2 r_{1} r_{2} \cos{\left(\theta_{1}{\left(t \right)} - \theta_{2}{\left(t \right)} \right)} \frac{d}{d t} \theta_{1}{\left(t \right)} \frac{d}{d t} \theta_{2}{\left(t \right)} + r_{2}^{2} \left(\frac{d}{d t} \theta_{2}{\left(t \right)}\right)^{2}\right)}{2}$$
だんだん結果は複雑になってきましたが、人間側は相当楽をしています。
ラグランジアンから極座標の運動方程式を求める
さて、この辺りから本格的に ゴツイ数式 になってきます。
ラグランジアンから運動方程式はそれぞれ、
$$\frac{d}{dt} \frac{\partial L}{\partial \dot{\theta_1}}=\frac{\partial L}{\partial \theta_1}$$
$$\frac{d}{dt} \frac{\partial L}{\partial \dot{\theta_2}}=\frac{\partial L}{\partial \theta_2}$$
となるので、# 質点1の運動方程式 EOM_1 = sy.Eq(L.diff(theta1.diff(t)).diff(t), L.diff(theta1)) EOM_1$$m_{1} r_{1}^{2} \frac{d^{2}}{d t^{2}} \theta_{1}{\left(t \right)} + \frac{m_{2} \left(2 r_{1}^{2} \frac{d^{2}}{d t^{2}} \theta_{1}{\left(t \right)} - 2 r_{1} r_{2} \left(\frac{d}{d t} \theta_{1}{\left(t \right)} - \frac{d}{d t} \theta_{2}{\left(t \right)}\right) \sin{\left(\theta_{1}{\left(t \right)} - \theta_{2}{\left(t \right)} \right)} \frac{d}{d t} \theta_{2}{\left(t \right)} + 2 r_{1} r_{2} \cos{\left(\theta_{1}{\left(t \right)} - \theta_{2}{\left(t \right)} \right)} \frac{d^{2}}{d t^{2}} \theta_{2}{\left(t \right)}\right)}{2} = - g m_{1} r_{1} \sin{\left(\theta_{1}{\left(t \right)} \right)} - g m_{2} r_{1} \sin{\left(\theta_{1}{\left(t \right)} \right)} - m_{2} r_{1} r_{2} \sin{\left(\theta_{1}{\left(t \right)} - \theta_{2}{\left(t \right)} \right)} \frac{d}{d t} \theta_{1}{\left(t \right)} \frac{d}{d t} \theta_{2}{\left(t \right)}$$
# 質点2の運動方程式 EOM_2 = sy.Eq(L.diff(theta2.diff(t)).diff(t), L.diff(theta2)) EOM_2$$\frac{m_{2} \left(- 2 r_{1} r_{2} \left(\frac{d}{d t} \theta_{1}{\left(t \right)} - \frac{d}{d t} \theta_{2}{\left(t \right)}\right) \sin{\left(\theta_{1}{\left(t \right)} - \theta_{2}{\left(t \right)} \right)} \frac{d}{d t} \theta_{1}{\left(t \right)} + 2 r_{1} r_{2} \cos{\left(\theta_{1}{\left(t \right)} - \theta_{2}{\left(t \right)} \right)} \frac{d^{2}}{d t^{2}} \theta_{1}{\left(t \right)} + 2 r_{2}^{2} \frac{d^{2}}{d t^{2}} \theta_{2}{\left(t \right)}\right)}{2} = - g m_{2} r_{2} \sin{\left(\theta_{2}{\left(t \right)} \right)} + m_{2} r_{1} r_{2} \sin{\left(\theta_{1}{\left(t \right)} - \theta_{2}{\left(t \right)} \right)} \frac{d}{d t} \theta_{1}{\left(t \right)} \frac{d}{d t} \theta_{2}{\left(t \right)}$$
運動方程式が求められましたが、数値計算まで見越すと、もう少し単純な式にしたいですね。
$\ddot{\theta_1}, \ddot{\theta_2}$について解くと、時間についての2階連立常微分方程式が得られます。
EOMs = sy.solve([EOM_1, EOM_2], (theta1.diff(t, 2), theta2.diff(t, 2))) EOMs$\ddot{\theta}_1$ について解いたものは、
$$\frac{g m_{1} \sin{\left(\theta_{1}{\left(t \right)} \right)} + \frac{g m_{2} \sin{\left(\theta_{1}{\left(t \right)} - 2 \theta_{2}{\left(t \right)} \right)}}{2} + \frac{g m_{2} \sin{\left(\theta_{1}{\left(t \right)} \right)}}{2} + \frac{m_{2} r_{1} \sin{\left(2 \theta_{1}{\left(t \right)} - 2 \theta_{2}{\left(t \right)} \right)} \left(\frac{d}{d t} \theta_{1}{\left(t \right)}\right)^{2}}{2} + m_{2} r_{2} \sin{\left(\theta_{1}{\left(t \right)} - \theta_{2}{\left(t \right)} \right)} \left(\frac{d}{d t} \theta_{2}{\left(t \right)}\right)^{2}}{r_{1} \left(- m_{1} + m_{2} \cos^{2}{\left(\theta_{1}{\left(t \right)} - \theta_{2}{\left(t \right)} \right)} - m_{2}\right)}$$
$\ddot{\theta}_2$ について解いたものは、
$$\frac{\left(m_{1} + m_{2}\right) \left(g \sin{\left(\theta_{2}{\left(t \right)} \right)} - r_{1} \sin{\left(\theta_{1}{\left(t \right)} - \theta_{2}{\left(t \right)} \right)} \left(\frac{d}{d t} \theta_{1}{\left(t \right)}\right)^{2}\right) - \left(g m_{1} \sin{\left(\theta_{1}{\left(t \right)} \right)} + g m_{2} \sin{\left(\theta_{1}{\left(t \right)} \right)} + m_{2} r_{2} \sin{\left(\theta_{1}{\left(t \right)} - \theta_{2}{\left(t \right)} \right)} \left(\frac{d}{d t} \theta_{2}{\left(t \right)}\right)^{2}\right) \cos{\left(\theta_{1}{\left(t \right)} - \theta_{2}{\left(t \right)} \right)}}{r_{2} \left(- m_{1} + m_{2} \cos^{2}{\left(\theta_{1}{\left(t \right)} - \theta_{2}{\left(t \right)} \right)} - m_{2}\right)}$$
軽く引くぐらいゴツくなりましたが、計算は一瞬で終わります。
さて、2元2階常微分方程式は、変数を増やすことで4元1階連立方程式に帰着できますね。
変数は、 $\theta_1$, $\theta_2$, $\dot{\theta}_1$, $\dot{\theta}_2$ の4つとなります。# 関数を変数に置き換える t1, t2 = sy.symbols(r"\theta_1 \theta_2") diff2dot = [(theta1.diff(t), theta1_dot), (theta2.diff(t), theta2_dot)] theta1_ddot = EOMs[theta1.diff(t, 2)].subs(diff2dot).subs([(theta1, t1), (theta2, t2)]) theta2_ddot = EOMs[theta2.diff(t, 2)].subs(diff2dot).subs([(theta1, t1), (theta2, t2)])これでようやく、運動方程式が導出できました!
シミュレーションしてみよう!
SymPyで延々代数演算してきましたが、いよいよお役御免です。
数値演算をするために、上で求めた数式を numpy.ufunc に変換します。何やってるかというと、
代数的数式 -> 数値計算用の関数
ですね。
# 運動方程式(の右辺)をNumPyの関数に変換する args = (t1, t2, theta1_dot, theta2_dot, m1, m2, r1, r2, g) func1 = sy.lambdify(args, theta1_ddot, "numpy") func2 = sy.lambdify(args, theta2_ddot, "numpy")数値計算に必要な運動方程式
func1func2が求められたので、サクッと数値計算してみましょう。ここでは、
scipy.integrate.odeという常微分方程式のソルバを使います。
データ処理のところでPandasを使っています。# 数値計算 from scipy.integrate import ode def time_evolve(t, y, params): theta1, theta2, theta1_dot, theta2_dot = y return [theta1_dot, theta2_dot, func1(*y, *params), func2(*y, *params)] y0 = [np.pi * 1.01, np.pi * 1.01, 0, 0] params = {"m1": 1, "m2": 1, "r1": 0.1, "r2": 0.1, "g": 9.8} solver = ode(time_evolve).set_initial_value(y0, 0).set_f_params(params.values()) dt = 0.01 tmax = 100 results = [] while solver.t < tmax: y = solver.integrate(solver.t + dt) results.append([solver.t, *y]) # Pandasでデータを扱いやすくする import pandas as pd results = pd.DataFrame(results, columns=["t", "theta1", "theta2", "theta1_dot", "theta2_dot"]) results["x1"] = params["r1"] * np.sin(results.theta1) results["x2"] = results.x1 + params["r2"] * np.sin(results.theta2) results["y1"] = -params["r1"] * np.cos(results.theta1) results["y2"] = results.y1 - params["r2"] * np.cos(results.theta2)データが得られたので、これをGIFアニメーションで出力してみます。
matplotlib.animation を使えば簡単にGIFを作成できます(imagemagickはインストールが必要)。import matplotlib.animation as animation import matplotlib.patches as patches def gen(): for i, vals in results[["t", "x1", "x2", "y1", "y2"]].iterrows(): yield vals.values def plot_double_pendulum(data): t, x1, x2, y1, y2 = data ax.cla() R = params["r1"] + params["r2"] ax.set_xlim(-R, R) ax.set_ylim(-R, R) ax.scatter([x1, x2], [y1, y2]) ax.add_patch(patches.Arrow(0, 0, x1, y1, width=0.01)) ax.add_patch(patches.Arrow(x1, y1, (x2-x1), (y2-y1), width=0.01)) ax.set_aspect("equal") fig, ax = plt.subplots() ani.save("double_pendulum.gif", writer="imagemagick", dpi=100) plt.show()
結果
出力したGIFがこちらです。かなり予想しづらい動きをしていることがわかりますね。
まとめ
この二重振り子のカオス性を試すところまではやっていません。
例えば、 初期値鋭敏性 を調べるためには、ほんの少しだけ初期値をずらしたものをシミュレートし、その差がだんだんと大きくなる様子を見れれば良さそうです。興味がある方は、この辺りを自分の目で確かめて欲しいと思います。
参考になれば幸いです!
コードをまとめると
本記事のコードをまとめると以下のように書けます。これだけみると単純ですね。
import sympy as sy # 変数と関数を定義 t = sy.Symbol("t", real=True) r1, r2, m1, m2, g = sy.symbols(r"r_1 r_2 m_1 m_2 g", positive=True) # theta1, theta2 = sy.symbols(r"\theta_1 \theta_2", real=True) theta1 = sy.Function(r"\theta_1")(t) theta2 = sy.Function(r"\theta_2")(t) theta1_dot, theta2_dot = sy.symbols(r"\dot{\theta_1} \dot{\theta_2}") # 質点1の位置と速度 x1 = sy.Matrix([r1 * sy.sin(theta1), - r1 * sy.cos(theta1)]) v1 = x1.diff(t) # 質点2の位置と速度 x2 = x1 + sy.Matrix([r2 * sy.sin(theta2), - r2 * sy.cos(theta2)]) v2 = x2.diff(t) # 運動エネルギー T1 = (m1 * (v1[0]**2 + v1[1]**2) / 2).simplify() T2 = (m2 * (v2[0]**2 + v2[1]**2) / 2).simplify() # ポテンシャル V1 = m1 * g * x1[1] V2 = m2 * g * x2[1] # ラグランジアン L = T1 + T2 - V1 - V2 # 質点1、2の運動方程式 EOM_1 = sy.Eq(L.diff(theta1.diff(t)).diff(t), L.diff(theta1)) EOM_2 = sy.Eq(L.diff(theta2.diff(t)).diff(t), L.diff(theta2)) # 加速度について解く EOMs = sy.solve([EOM_1, EOM_2], (theta1.diff(t, 2), theta2.diff(t, 2))) # 関数を変数に変換 t1, t2 = sy.symbols(r"\theta_1 \theta_2") diff2dot = [(theta1.diff(t), theta1_dot), (theta2.diff(t), theta2_dot)] theta1_ddot = EOMs[theta1.diff(t, 2)].subs(diff2dot).subs([(theta1, t1), (theta2, t2)]) theta2_ddot = EOMs[theta2.diff(t, 2)].subs(diff2dot).subs([(theta1, t1), (theta2, t2)]) # NumPy関数化 args = (t1, t2, theta1_dot, theta2_dot, m1, m2, r1, r2, g) func1 = sy.lambdify(args, theta1_ddot, "numpy") func2 = sy.lambdify(args, theta2_ddot, "numpy") # 数値計算 from scipy.integrate import ode def time_evolve(t, y, params): theta1, theta2, theta1_dot, theta2_dot = y return [theta1_dot, theta2_dot, func1(*y, *params), func2(*y, *params)] # 初期値 y0 = [np.pi * 1.01, np.pi * 1.01, 0, 0] params = {"m1": 1, "m2": 1, "r1": 0.1, "r2": 0.1, "g": 9.8} solver = ode(time_evolve).set_initial_value(y0, 0).set_f_params(params.values()) dt = 0.1 tmax = 50 results = [] # 微分方程式を解く while solver.t < tmax: y = solver.integrate(solver.t + dt) results.append([solver.t, *y]) import pandas as pd results = pd.DataFrame(results, columns=["t", "theta1", "theta2", "theta1_dot", "theta2_dot"]) results["x1"] = params["r1"] * np.sin(results.theta1) results["x2"] = results.x1 + params["r2"] * np.sin(results.theta2) results["y1"] = -params["r1"] * np.cos(results.theta1) results["y2"] = results.y1 - params["r2"] * np.cos(results.theta2)参考URL



- 投稿日:2019-08-29T19:14:03+09:00
正規表現の基礎
この記事は昔正規表現について調べた時のメモをqiitaにあげ直したものです。前提としてmac, linuxを使っていることが前提になっている内容が一部あります。
正規表現とは
正規表現とは、特定のルールを満たす文字列の集合を一つの文字列で表現するための方法。
例えば、「英小文字の一回以上の繰り返し」はpythonの正規表現では"[a-z]+"で表現することができ、数式で表現するなら、
{“a”, “abc”, “hogehoge”} ⊂ "[a-z]+” = { x | xは英小文字の一回以上の繰り返し}みたいな関係が成り立ちます。
------ Pythonの公式ページの説明
正規表現 regular expressions (REs や regexes または regex patterns と呼ばれます) は本質的に小さく、Python 内部に埋め込まれた高度に特化したプログラミング言語でreモジュールから利用可能です。この小さな言語を利用することで、マッチさせたい文字列に適合するような文字列の集合を指定することができますPOSIX基本/拡張正規表現とは
POSIXとは
---------- Wikipedia
POSIX(ポシックス、ポジックス、英: Portable operating system interface)は、各種UNIXを始めとする異なるオペレーティングシステム (OS) 実装に共通のアプリケーションプログラミングインタフェース (API) を定め、移植性の高いアプリケーションソフトウェアの開発を容易にすることを目的としてIEEEが策定したAPI規格である。POSIXという名前はリチャード・ストールマンがIEEEに提案したものである[1]。末尾の「X」はUNIX互換OSに「X」の字がつく名前が多いことからつけられた。ISO/IEC JTC 1/SC 22でISO/IEC 9945として国際規格になっている。POSIX基本正規表現(BRE)とは
----------- Wikipedia
この文法では、ほとんどの文字はリテラル(機能を意味せず書かれたそのまま)に扱われる。つまり、ある文字はその文字にのみマッチする。例えば、正規表現「a」は文字「a」にマッチし、正規表現「(bc」は文字列「(bc」にマッチするなど。例外はメタ文字と呼ばれる。メタ文字とは、リテラルとしての意味とは異なる意味を持つ文字のことです。BREではメタ文字の機能を呼び出すためにバックスラッシュを用いる。
https://www.regular-expressions.info/posix.html#bre
POSIX拡張正規表現 (ERE)とは
------- Regular-Expresions.info
Extended Regular ExpressionsまたはEREフレーバーは、UNIXのegrepコマンドで使用されるものと同様のフレーバーを標準化しています。最新の正規表現フレーバーのほとんどはEREフレーバーの拡張です。今日の標準では、POSIX EREフレーバーはExtendedとはいえかなりbasicなものです。POSIX標準は1986年に定義され、それ以来、正規表現は長い道のりを歩んできました。https://www.regular-expressions.info/posix.html#ere
要するに
POSIX準拠の正規表現を覚えていれば、ほとんどのUNIX系OSのコマンドで共通の正規表現が使える。
大抵のプログラミング言語もPOSIX正規表現と同等の表現が使える。
コマンド例 BRE sed, vi, more, grep ERE egrep, awk, bash 正規表現の細かい仕様は言語ごとにに異なるhttps://gist.github.com/CMCDragonkai/6c933f4a7d713ef712145c5eb94a1816
EREの仕様の確認方法
ターミナルを起動して以下を実行
$ man 7 re_format使い方メモ
1.hキーを押す
2.qキーを押す
3./\*を入力してエンターEREの仕様(一部)
メタ文字 意味 *後ろに *が付いている正規表現はその正規表現の0回以上の繰り返しにマッチする
$${abc, abcababab, abcab} \subset (abc)(ab)*$$+後ろに +が付いている正規表現はその正規表現の1回以上の繰り返しにマッチする
$${abcababab, abcab} \subset (abc)(ab)+$$?後ろに ?が付いている正規表現はその正規表現の0から1回の繰り返しにマッチする
$${hog, hoge} = hoge?$${繰り返しは {の後に符号なし10進整数が続き、場合によっては,と別の符号なし10進整数が続き、最後に}で閉じられる.
$${hoghog, hoghoge, hogehog, hogehoge} = (hoge?){2}$$
$${aa, aaa, aaaa} = a{2, 4}$$}同上 (()で閉じられた部分は正規表現に対するマッチにマッチする.
$${abcababab, abcab} \subset (abc)(ab)+$$)同上 ..は任意の一文字にマッチする.
$${hoge, hogeasdkoasdk} \subset hoge.*$$^^は行のはじめのnull文字にマッチする.
例えば、
“^bb.”
にマッチする文字列を
“””
aabbaa
bbccbb
“””
から検索すると、”bbc”のみがマッチする.$$は行の終わりのnull文字にマッチする.
例えば、
“.bb$”
にマッチする文字列を
“””
aabbaa
bbccbb
“””
から検索すると、”cbb”のみがマッチする.\エスケープシーケンス [[]で閉じられた部分にリストされた任意の文字にマッチする. ただし、文字のリストが^で始まる場合はリストされた^以外の任意の文字にマッチする. ただし、リスト内の2文字が-で区切られている場合、2つの間の全範囲の文字の省略形として扱われる. (両端も含まれる)
$${a, b, c, d, e, z} \subset [a-z]$$
$${d, e, f, g, z} \subset [^abc]$$]同上 \数字
※拡張されたEREでのみ使えるn番目に記した包括指定子でマッチした文字列にマッチする.
$${abc123abc, hoge123hoge} \subset ([a-z]*)123\1$$pythonで正規表現を使う際に注意しないといけないこと
注意しないといけないこと
- パターンと検索文字列の文字コードは一致させること
- 使える文字コード一覧
- Unicode文字列:
str- 8ビット文字列:
bytes- バックスラッシュ感染症を起こさないようにパターン文字列にraw string記法を行う
- EREでは正規表現
$(^)は行末(行の先端)を表すけどpythonでは文字列の終端(先端)を表す\sを使えば改行とマッチできるバックスラッシュ感染症とは
正規表現パターンはキャラクタリテラルと特殊文字で構成される. 特殊文字の一つにエスケープシーケンス
\があり、\特殊文字で特殊文字の効果を消した特殊文字自体を表現する際に使用される. 従って、正規表現"\\w"は正規表現エンジンにより"\w"に置き換えられる(ここでの\はエスケープシーケンスではなく文字そのもの). しかし、pythonのパーサーもまた文字列中の\はエスケープシーケンスとして扱うため、正規表現エンジンに"\\w"を渡す前にエスケープシーケンスが評価されてしまう. つまり、"\w"が正規表現エンジンに渡されてしまうため、結果的に[a-zA-Z0-9_]を正規表現エンジンに渡した時と同じ結果が得られることになる. これはプログラマの意図とは異なるかもしれない. このような現象をバックスラッシュ感染症という.バックスラッシュ感染症を回避する方法としては、re.compileの引数にする正規表現パターン文字列にraw string記法を用いるのが一般的. 上の例で言えば、re.comple(r"\w")とすれば良い.
蛇足: バックスラッシュ感染症が起きないように改善しない理由
-----Python公式ページの説明
正規表現は文字列としてre.compile()に渡されます。正規表現は文字列として扱われますが、それは正規表現が Python 言語のコアシステムに含まれないためです、そのため正規表現を表わす特殊な構文はありません。 (正規表現を全く必要としないアプリケーションも存在します、そのためそれらを含めて言語仕様を無駄に大きくする必要はありません)pythonの正規表現パターンを調べる方法
pythonの正規表現を調べるツールを使うと便利かもしれません.
$curl https://raw.githubusercontent.com/python/cpython/3.6/Tools/demo/redemo.py > ~/Desktop/redemo.py $python ~/Desktop/redemo.py関数とインスタンスメソッド、どっちを使うべき?
------- Python公式ページ
パターンオブジェクトを作ってそのメソッドを呼び出す、とする必要は必ずしもありません。reモジュールはトップレベルの関数としてmatch(),search(),findall(),sub()などを用意しています。これら関数は、対応するメソッドの最初の引数に RE が追加されただけで後は同じで、Noneか Match オブジェクト インスタンスを返すのも同じです内部的には、これら関数は単にあなたのためにパターンオブジェクトを生成し、対応するメソッドを呼び出すだけのことです。とともに、将来の呼び出しで同じ RE のパースが何度も何度も必要とならないよう、コンパイル済みオブジェクトはキャッシュされます。
- 投稿日:2019-08-29T19:02:54+09:00
Pythonでimportしたモジュールの明らかに存在するクラスや関数が見つからない時
- 投稿日:2019-08-29T18:52:40+09:00
GAEでgoとpythonを共存させる
1. これは何?
Google Appengine(以下GAE)で、URLによってgoのアプリケーションサーバーとpythonのアプリケーションサーバーにリクエストを振り分ける方法。
2. Hello World
Python
公式を参考に進める。
適当なフォルダにpython用ファルダを作成する。$ gcloud components install app-engine-python $ mkdir python $ cd pythonファイルを作成する。
app.yamlruntime: python37 entrypoint: gunicorn --bind 0.0.0.0:$PORT -c gunicorn_conf.py main:app handlers: - url: /.* script: auto secure: alwaysmain.pyimport responder app = responder.API() @app.route('/') def index(request, response): resp.text = "Hello, Python!" if __name__ == '__main__': app.run(host='127.0.0.1', port=8080, debug=True)requirements.txtresponder gunicornlocalで動作確認する。
$ dev_appserver.py app.yamlhttp://localhost:8080/
で表示を確認する。
staticとtemplatesのフォルダが自動生成されるので、それぞれに中身が空のindex.htmlを作成する。
GAEへデプロイし、表示を確認する。$ gcloud app deploy $ gcloud app browseGo
pythonフォルダと同じ階層にgoフォルダを作成する。$ mkdir goファイルを作成する。
app.yamlruntime: go api_version: go1 handlers: - url: /.* script: automain.gopackage main import ( "fmt" "net/http" "google.golang.org/appengine" ) func main() { http.HandleFunc("/", handle) appengine.Main() } func handle(w http.ResponseWriter, r *http.Request) { fmt.Fprintln(w, "Hello, Go!") }localで動作確認する。
$ dev_appserver.py app.yamlhttp://localhost:8080/
で表示を確認する。
GAEへデプロイし、表示を確認する。$ gcloud app deploy $ gcloud app browse3. 共存
一番上の階層にサービス振分の設定を追加する。
dispatch.yamldispatch: - url: "*/go/*" service: go - url: "*/python/*" service: defaultサービスを追加する。
go/app.yamlruntime: go api_version: go1 service: go handlers: - url: /.* script: autopythonサーバーをdefaultサービスにする。
app.yamlruntime: python37 service: default entrypoint: gunicorn --bind 0.0.0.0:$PORT -c gunicorn_conf.py main:app handlers: - url: /python/.* script: auto secure: alwaysルーティングも修正する。
python/main.pyimport responder app = responder.API() @app.route('/python/') def index(req, resp): resp.text = "Hello, Python!" if __name__ == '__main__': app.run(host='127.0.0.1', port=8080, debug=True)localで動作確認する。
$ dev_appserver.py dispatch.yaml go/app.yaml python/app.yamlhttp://localhost:8080/go/
で、Hello, Go!
http://localhost:8080/python/
で、Hello, Python!の表示を確認する。GAEへデプロイする。
$ gcloud app deploy go/ $ gcloud app deploy python/ $ gcloud app dispatch.yamlhttps://<プロジェクトID>.appspot.com/go/
https://<プロジェクトID>.appspot.com/python/
で、それぞれ表示を確認する。
- 投稿日:2019-08-29T18:46:56+09:00
【kaggleで機械学習勉強・第五回】3-clusters-per-class【kaggle,python,超楕円体クラスタリング】
前回と同じくInstant Gratificationに対してchris dotteさんがアプローチしている手法の開設を。
今回は、前回と同様に疑似ラベルを使いつつ、二次判別分析や多変量ガウス分布を考慮しながらモデルを作っていく。
内容がかなり難しかったので翻訳できている自身が"全く"ありません。早速本編へ
二次判別分析 (Quadratic Discriminant Analysis, QDA) + 疑似ラベル + 混合正規? を使ったモデル化
このデータセットはsklearnのmake_classificationで作成されたと思われる512のデータのあつまりです。 EDAしてみたら、こんなパラメータで作成したのではないかと推測できました。
X, y = make_classification(n_samples=1024, n_features=255, n_informative=33+x, n_redundant=0, n_repeated=0, n_classes=2, n_clusters_per_class=3, weights=None, flip_y=0.05, class_sep=1.0, hypercube=True, shift=0.0, scale=1.0, shuffle=True, random_state=None) # where 0<=x<=14重要なパラメータはn_clusters_per_class=3 と n_informative=33+x です。 この意味は、データを六次元空間の超楕円体の33+xにすみわけさせたことである。
各超楕円は、multivariate Gaussian distributionなので、 クラス分けには、QDAと疑似ラベリングと混合正規分布を使った手法を選んだ。 (multivariate Gaussian distribution)は、多変量正規分布のこと。 平均と分散を持つ分布が例えば二次元で重なったとする。 そうすると、データには共分散が表れる。 多変量正規分布のなかでも多変量ガウス分布という表現をすると高次元のものを指していることが多い。
付録を見て。クラスごとに、3クラスタに分けているから。
ガウス過程回帰ってのは 正規分布から確率が一つ取り出せるけど、 ある時点の時にはあるパラメータを持った確率が取り出せて、 またある時には別のパラメータの確率分布が取り出せて、 というような考え方で、確率分布自体が抽出されていくようなもの。
なにが良いかというと、各時点で異なる分布を仮定してやって、それぞれの分布に重みをつけたら、 それらしい値が出てくるモデルが作れるのではないかって話。だと思う
完璧よりもさらに良き分類のために
もし、このコンペがmake_classificationでデータを作ったと仮定すると、 多くの参加者はGM(グラフィカルモデリング?)やQDAを使えばカンペキな分類ができるでしょう。 それゆえ、このコンペで勝つには、カンペキ以上の分類を行う必要があります。 このカーネルの分類器は、完璧なものよりも0.0005だけスコアを上げるランダム性を含んだモデル化をしています。
以下で説明。
もし、データがmake_classificationでつくられていたら、2.5%のランダムな要素以外を完全に予測できるでしょう。 この2.5%はどうしたって正しく予測はできないです。 ただし、予測モデルにもランダム性を加えてみたら、予測精度が少し上昇することがあります。 (時に悪化することもありますが。)
以下に示す図は精度を表しています。 点線はカンペキな分類器であり、各点はカーネルが、データセットに対して行った試みです。compのデータににている。 compってなに?????
200のどっとは10の試みによって作られた。20の異なるランダム性をもとに作成されたでーたセット。 黒の点線は完全に分類したときのAUCを出力するようにしたもの。詳細は付録3へ。
こんな感じです。
ほかには、平均で完璧に分類している?散布図は、相関を示していて、自分で確かめたスコアと投稿した時のスコアの関係である。
そんなこんなで、我々の最終的な成果物は、投稿時の最高スコアのものを使用している 30回くらいカーネルを走らせてみて、二つの成果物から選び、このスコアになった。
指を交差させ、二つのスコアが良く分類されるよう祈る。
import numpy as np np.random.seed(42) x = np.random.choice(np.arange(30),2) print('We will submit versions',x[0],'and',x[1]) np.random.seed(None)ちょっと追記
ラッキー! np.random.seed(42)を選んでよかった。コンペが終わった後、プライベートスコアと提出スコアの30個を比較した。 二つの緑の点は、ランダム性が6,19という値の時である。 19を見ると、プライベートスコアが良いのがわかるでしょう。 投稿したスコアの最高点は0.97481で、25個目の試行の時だった。 最も低いのは0.97439で、7回目の時だった。 プライベートスコアでは、19回目が最もよく、23回目が悪かった。 黒の点線は施行したスコアたちの平均値を表している。 詳細は付録3をみて。
import matplotlib.pyplot as plt, numpy as np pu = np.array([68,53,70,67,54,54,39,68,60,65,46,62,62,55,54, 60,59,55,43,52,63,68,51,75,81,56,68,55,60,48]) pr = np.array([58,54,68,54,48,61,59,49,60,57,70,54,53,69,72, 56,64,44,88,63,74,70,43,48,77,65,51,70,51,48]) plt.scatter(0.974+pu/1e5,0.975+pr/1e5) plt.scatter(0.974+pu[5]/1e5,0.975+pr[5]/1e5,color='green',s=100) plt.scatter(0.974+pu[18]/1e5,0.975+pr[18]/1e5,color='green',s=100) mpu = 0.974 + np.mean(pu)/1e5 mpr = 0.975 + np.mean(pr)/1e5 plt.plot([mpu,mpu],[mpr-0.0005,mpr+0.0005],':k') plt.plot([mpu-0.0005,mpu+0.0005],[mpr,mpr],':k') plt.xlabel('Public LB'); plt.xlim((mpu-0.0005,mpu+0.0005)) plt.ylabel('Private LB'); plt.ylim((mpr-0.0005,mpr+0.0005)) plt.title("Public and private LB scores from 30 runs of this kernel.\n \ The green dots were the two randomly chosen submissions") plt.show()
ライブラリの読み込み
# IMPORT LIBRARIES import numpy as np, pandas as pd, os from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis from sklearn.mixture import GaussianMixture from sklearn.model_selection import StratifiedKFold from sklearn.feature_selection import VarianceThreshold from sklearn.metrics import roc_auc_score import matplotlib.pyplot as plt from sklearn.datasets import make_classification# LOAD TRAIN AND TEST df_train = pd.read_csv('train.csv') df_test = pd.read_csv('test.csv') df_train.head()使えるデータの選別
使える特徴量をさがす。
分散の大きい特徴量がつかえる。# IDENTIFY USEFUL FEATURES PER MAGIC SUB-DATASET useful = np.zeros((256,512)) for i in range(512): partial = df_train[ df_train['wheezy-copper-turtle-magic']==i ] useful[:,i] = np.std(partial.iloc[:,1:-1], axis=0) useful = useful > 1.5 useful = np.sum( useful, axis=0 )カテゴリカルデータの0~512までの値でデータを取ってくる。 取ってきたデータの標準偏差を計算して、usefulに入れる
標準偏差が1.5以上であるものを残す。
512個の値にして、行の総和を計算。モデルと予測
まず、QDAと疑似ラベルをtestに対して使ったところ、0.97の値が得られた。 疑似ラベルについてはひとつ前のカーネルを見て。 次に、三つの予測を作った(疑似ラベルで)、6楕円を見つけるために。 我々は3楕円が1を、ほかの3楕円が0を担当するようにsklearnの混合正規を使って分離しました。 0~5のラベルをそれぞれの楕円につけました。 最終的に、trainのQDAを6楕円を使って行い、予測しました。 ターゲットが1である、ということは、楕円3,4,5に当てはまるということ。というように。 付録2を見て。
確認として。 k-folds CVはつかってないです。 代わりに、合成データを生成し、最適化を適応させています。 そのほうがCVを改善させるんです。 モデルを作るとき1024行の予備データセットを使えます。 我々のモデルはmake_classのデータに対して、平均的に完璧な分類ができています。 しかし、多くの参加者もできるでしょう。
なのでランダム性を加えてよりよいものを生成するのです。
以下のコードは 合成データを作り、AUCを計算しています。 test.csvを予測してみましょう
# RUN LOCALLY AND VALIDATE models = 512 RunLocally = True # RUN SUBMITTED TO KAGGLE if len(df_test)>512*300: repeat = 1 models = 512 * repeat RunLocally = False # INITIALIZE all_preds = np.zeros(len(df_test)) all_y_pu = np.array([]) all_y_pr = np.array([]) all_preds_pu = np.array([]) all_preds_pr = np.array([]) # MODEL AND PREDICT for k in range(models): # IF RUN LOCALLY AND VALIDATE # THEN USE SYNTHETIC DATA if RunLocally: obs = 512 X, y = make_classification(n_samples=1024, n_features=useful[k%512], n_informative=useful[k%512], n_redundant=0, n_repeated=0, n_classes=2, n_clusters_per_class=3, weights=None, flip_y=0.05, class_sep=1.0, hypercube=True, shift=0.0, scale=1.0, shuffle=True, random_state=None) # IF RUN SUBMITTED TO KAGGLE # THEN USE REAL DATA else: df_train2 = df_train[df_train['wheezy-copper-turtle-magic']==k%512] df_test2 = df_test[df_test['wheezy-copper-turtle-magic']==k%512]#数字%512をやると、512の時に0にもどる sel = VarianceThreshold(1.5).fit(df_train2.iloc[:,1:-1]) df_train3 = sel.transform(df_train2.iloc[:,1:-1]) df_test3 = sel.transform(df_test2.iloc[:,1:]) #k=0のとき #pd.DataFrame(df_train3) #534 rows × 46 columns (使える変数) obs = df_train3.shape[0] X = np.concatenate((df_train3,df_test3),axis=0)#787*46 単純に結合させる関数っぽい y = np.concatenate((df_train2['target'].values,np.zeros(len(df_test2))))#testにはtargetが入っていないので、ゼロを入れておく #XとyはどちらもRunLocally = Trueのとき毎回値が変化する #Faulsの時は値は変化しない # TRAIN AND TEST DATA train = X[:obs,:] train_y = y[:obs]#534行 test = X[obs:,:] test_y = y[obs:]#testの中の使える変数 comb = X #くっつけてcombという名前にする # FIRST MODEL : QDA #二次判別分析でモデルを作っている #予測値をtest_predに入れている clf = QuadraticDiscriminantAnalysis(priors = [0.5,0.5]) clf.fit(train,train_y) test_pred = clf.predict_proba(test)[:,1] # SECOND MODEL : PSEUDO LABEL + QDA #0から1の間の乱数を発生させて、その値よりも大きい値をtest_predに入れる #この状態はTFが入っている #これが疑似ラベルだと思われる #この状態のデータを使ってQDAを行う test_pred = test_pred > np.random.uniform(0,1,len(test_pred)) clf = QuadraticDiscriminantAnalysis(priors = [0.5, 0.5]) clf.fit(comb, np.concatenate((train_y,test_pred)) ) test_pred = clf.predict_proba(test)[:,1] # THIRD MODEL : PSEUDO LABEL + GAUSSIAN MIXTURE #三つ目のモデルは疑似ラベルと混合ガウス test_pred = test_pred > np.random.uniform(0,1,len(test_pred)) #またランダムで乱数を発生させて疑似ラベルとして all_y = np.concatenate((train_y,test_pred)) #予測したyの値とtrainのyの値を結合させる #TFのブール型は01のバイナリに変換される least = 0; ct = 1; thx=150 while least<thx: # STOPPING CRITERIA if ct>=10: thx -= 10 else: thx = 150 # FIND CLUSTERS clusters = np.zeros((len(comb),6)) # FIND THREE TARGET=1 CLUSTERS train4 = comb[ all_y==1, :] clf = GaussianMixture(n_components=3).fit(train4) #randomness clusters[ all_y==1, 3:] = clf.predict_proba(train4) # FIND THREE TARGET=0 CLUSTERS train4 = comb[ all_y==0, :] clf = GaussianMixture(n_components=3).fit(train4) #randomness clusters[ all_y==0, :3] = clf.predict_proba(train4) # ADJUST CLUSTERS (EXPLAINED IN KERNEL COMMENTS) for j in range(5): clusters[:,j+1] += clusters[:,j] rand = np.random.uniform(0,1,clusters.shape[0]) for j in range(6): clusters[:,j] = clusters[:,j]>rand #randomness clusters2 = 6 - np.sum(clusters,axis=1) # IF IMBALANCED TRY AGAIN least = pd.Series(clusters2).value_counts().min(); ct += 1 # FOURTH MODEL : GAUSSIAN MIXTURE + QDA clf = QuadraticDiscriminantAnalysis(priors = [0.167, 0.167, 0.167, 0.167, 0.167, 0.167]) clf.fit(comb,clusters2) pds = clf.predict_proba(test) test_pred = pds[:,3]+pds[:,4]+pds[:,5] # IF RUN LOCALLY, STORE TARGETS AND PREDS if RunLocally: all_y_pu = np.append(all_y_pu, test_y[:256]) all_y_pr = np.append(all_y_pr, test_y[256:]) all_preds_pu = np.append(all_preds_pu, test_pred[:256]) all_preds_pr = np.append(all_preds_pr, test_pred[256:]) # IF RUN SUBMIT TO KAGGLE, PREDICT TEST.CSV else: all_preds[df_test2.index] += test_pred / repeat # PRINT PROGRESS if ((k+1)%64==0)|(k==0): print('modeled and predicted',k+1,'magic sub datasets') # IF RUN LOCALLY, COMPUTE AND PRINT VALIDATION AUCS if RunLocally: all_y_pu_pr = np.concatenate((all_y_pu,all_y_pr)) all_preds_pu_pr = np.concatenate((all_preds_pu,all_preds_pr)) auc1 = roc_auc_score(all_y_pu_pr, all_preds_pu_pr) auc2 = roc_auc_score(all_y_pu, all_preds_pu) auc3 = roc_auc_score(all_y_pr, all_preds_pr) print('Validation AUC =',np.round(auc1,5)) print('Approx Public LB =',np.round(auc2,5)) print('Approx Private LB =',np.round(auc3,5))modeled and predicted 1 magic sub datasets modeled and predicted 64 magic sub datasets modeled and predicted 128 magic sub datasets modeled and predicted 192 magic sub datasets modeled and predicted 256 magic sub datasets modeled and predicted 320 magic sub datasets modeled and predicted 384 magic sub datasets modeled and predicted 448 magic sub datasets modeled and predicted 512 magic sub datasets Validation AUC = 0.97538 Approx Public LB = 0.97543 Approx Private LB = 0.97533aucをprintして
最後にsubmit
sub = pd.read_csv('../input/sample_submission.csv') sub['target'] = all_preds sub.to_csv('submission.csv',index=False) plt.hist( test_pred ,bins=100) plt.title('Model 512 test predictions') plt.show() #予測結果をplotすると図のようになる
whileあたりからわけわからん!
least = 0; ct = 1; thx=150 #こんなパラメータを用意して while least<thx: # STOPPING CRITERIA #もしもleastがthxよりも小さかった時で、 if ct>=10: thx -= 10 #さらにもしもctが10よりも大きければ、thxにはthx-10を入力する else: thx = 150 #もしもctがこの条件に当てはまらなければthxには150を入れる # FIND CLUSTERS clusters = np.zeros((len(comb),6)) #クラスタという名前の変数にはcombと同じ長さの0を6つ作る # FIND THREE TARGET=1 CLUSTERS train4 = comb[ all_y==1, :] #1の時の値を入れて clf = GaussianMixture(n_components=3).fit(train4) #randomness #ガウシアンミクスチャーでtrain4についてのモデルを作って clusters[ all_y==1, 3:] = clf.predict_proba(train4) #train4にモデルを適応させてやったものを #clustersの中の0が6個入っているものの、後半3つに予測値を代入していく # FIND THREE TARGET=0 CLUSTERS train4 = comb[ all_y==0, :] clf = GaussianMixture(n_components=3).fit(train4) #randomness clusters[ all_y==0, :3] = clf.predict_proba(train4) #こっちは前半3つに入れている # ADJUST CLUSTERS (EXPLAINED IN KERNEL COMMENTS) for j in range(5): clusters[:,j+1] += clusters[:,j]#クラスタの(787, 6)のうち、すべての列の隣の列に、左の列を足したものを代入していく rand = np.random.uniform(0,1,clusters.shape[0])#クラスタの次元に合うだけの乱数を発生させる for j in range(6): clusters[:,j] = clusters[:,j]>rand #randomness #クラスタの中の値でrandよりも大きいものを代入する clusters2 = 6 - np.sum(clusters,axis=1) #clustersには合計値を入れているので、6を引いてやる #すると0~5の6個のクラスタに分けられる # IF IMBALANCED TRY AGAIN least = pd.Series(clusters2).value_counts().min(); ct += 1 #6クラスに分けたが、少なくとも120個のデータは各クラスが持っているようにするまで繰り替えす # FOURTH MODEL : GAUSSIAN MIXTURE + QDA clf = QuadraticDiscriminantAnalysis(priors = [0.167, 0.167, 0.167, 0.167, 0.167, 0.167]) #QDAの判別は0.167を入れている。合計するとほぼ1 clf.fit(comb,clusters2) #クラスタ2で何番目の楕円に含まれているか定義してあるので適応させてる pds = clf.predict_proba(test) #testに対してモデルを使って予測している test_pred = pds[:,3]+pds[:,4]+pds[:,5] #pdsの後半3つを足してる。後半3つといえばclustersにはtarget=1の時の値だったと思う #クラスタ分けしておいて、その確率を足し合わせて1,0を判断させる仕組みか? # IF RUN LOCALLY, STORE TARGETS AND PREDS if RunLocally: all_y_pu = np.append(all_y_pu, test_y[:256])#trainの列かな? all_y_pr = np.append(all_y_pr, test_y[256:])#testの列かな? all_preds_pu = np.append(all_preds_pu, test_pred[:256]) all_preds_pr = np.append(all_preds_pr, test_pred[256:]) # IF RUN SUBMIT TO KAGGLE, PREDICT TEST.CSV else: all_preds[df_test2.index] += test_pred / repeat # PRINT PROGRESS if ((k+1)%64==0)|(k==0): print('modeled and predicted',k+1,'magic sub datasets') #64回目ごとに表示させていく。合計9回表示されることになるこれで予測スコア0.975という高い値が出ました。
内容もよく分からないので付録解説やコメントを読んでいきます。
いや、超立方体とか出てきてホント分からないのでわかるようになってから出直すと思います。付録1
今回のデータはsklearnのmake_classificationで作られたと考えています。
ここで重要なのは、kaggleが「n_clusters_per_class」をいくつで設定してデータを作ったのか?ということです。これは、長さ「2 * class_sep」の辺を持つn次元のハイパーキューブの頂点について正規分布(std = 1)されたポイントのクラスターを最初に
作成し、各クラスに同数のクラスターを割り当てます。つまり、3つの次元では、クラスターはこれらの8つの場所のいずれかに集中します。
(-1, -1, -1), (-1, -1, 1), (-1, 1, -1), (-1, 1, 1), (1, -1, -1), (1, -1, 1), (1, 1, -1), (1, 1, 1)
1をすべて「class_sep」に置き換えます。1024行のデータを作成し、1クラスごとに2つのクラスターを持ちます。
target = 1の場合、(-1、1、-1)を中心とする256ポイントと(1、1、-1)を中心とする256ポイントの2つの集団があります。
target=0の時、256ポイントが(1、1、1)を中心に、256ポイントが(-1、-1、1)を中心とする集団があります。EDAを使用して、実データのクラスとクラスター数を決定していきます。
Sklearnのmake_classificationは、ハイパーキューブの角でデータ(楕円)を生成します。
したがって、n_clusters_per_class = 1のみが存在する場合、データの各楕円(target = 1およびtarget = 0)の中心には、すべての座標1と-1が含まれます。たとえば、(1,1、-1,1、-1、-1,1 、...)。
したがって、すべての変数の平均(中心座標)のヒストグラムをプロットすると、1と-1にbumpが見られます。
(変数によって各サブデータセット内を意味します。これは768行のtrainとtestです。元のtrainの列の262144行すべてを意味するわけではありません)。←ここは262144を256変数で割ると1024になる。
n_clusters_per_class = 2の場合、1つのサブデータセット内で、target = 1に2つの楕円ができます。
たとえば、(-1,1、...)を中心とする1つの楕円と(1,1、...)を中心とする楕円があり、変数の計算時に1と-1の最初の座標は平均0になります。
したがって、clusters = 2の場合、-1、0、および1でヒストグラムバンプが表示されます。n_clusters_per_class= 3の場合、4つのバンプが表示されます。
これは合成データで確認できます。 wheezy-magicサブデータセットごとに768行しかない比較対象のトレーニングデータと公開テストデータしかないため、n_samples = 768を使用します。
その後、実データの変数平均(サブデータセット内)のヒストグラムをプロットし、どのn_clusters_per_classが一致するかを確認します。 または、モデルを構築し、n_clusters_per_classが1、2、3、または4に等しいと仮定することができます。次に、どのn_clusters_per_classが最大のCVを持つかを確認します。 これらのメソッドは両方とも、n_clusters_per_class = 3であると判断します。
for clusters in range(4): centers = np.array([]) for k in range(512): X, y = make_classification(n_samples=768, n_features=useful[k], n_informative=useful[k], n_redundant=0, n_repeated=0, n_classes=2, n_clusters_per_class=clusters+1, weights=None, flip_y=0.05, class_sep=1.0, hypercube=True, shift=0.0, scale=1.0, shuffle=True, random_state=None) centers = np.append(centers,np.mean(X[ np.argwhere(y==0).flatten() ,:],axis=0)) centers = np.append(centers,np.mean(X[ np.argwhere(y==1).flatten() ,:],axis=0)) plt.hist(centers,bins=100) plt.title('Variable means if clusters='+str(clusters+1)) plt.show()
実際のデータをplotしてみる
まず、QDAを使用してtestデータの擬似ラベルを作成します。
次に、すべてのトレーニングおよび擬似ラベル付きtestデータを組み合わせて(サブデータセットごとに768行)使用して、target = 0およびtarget = 1の変数平均(データセンターの座標)のヒストグラムをプロットします。 以下のプロットは、Kaggleがn_clusters_per_class = 3を使用したことを示しています。centers = np.array([]) for k in range(512): # REAL DATA df_train2 = df_train[df_train['wheezy-copper-turtle-magic']==k] df_test2 = df_test[df_test['wheezy-copper-turtle-magic']==k] sel = VarianceThreshold(1.5).fit(df_train2.iloc[:,1:-1]) df_train3 = sel.transform(df_train2.iloc[:,1:-1]) df_test3 = sel.transform(df_test2.iloc[:,1:]) obs = df_train3.shape[0] X = np.concatenate((df_train3,df_test3),axis=0) y = np.concatenate((df_train2['target'].values,np.zeros(len(df_test2)))) # TRAIN AND TEST DATA train = X[:obs,:] train_y = y[:obs] test = X[obs:,:] test_y = y[obs:] comb = X # FIRST MODEL : QDA clf = QuadraticDiscriminantAnalysis(priors = [0.5,0.5]) clf.fit(train,train_y) test_pred = clf.predict_proba(test)[:,1] # SECOND MODEL : PSEUDO LABEL + QDA test_pred = test_pred > np.random.uniform(0,1,len(test_pred)) clf = QuadraticDiscriminantAnalysis(priors = [0.5, 0.5]) clf.fit(comb, np.concatenate((train_y,test_pred)) ) test_pred = clf.predict_proba(test)[:,1] # PSEUDO LABEL TEST DATA test_pred = test_pred > np.random.uniform(0,1,len(test_pred)) y[obs:] = test_pred # COLLECT CENTER COORDINATES centers = np.append(centers,np.mean(X[ np.argwhere(y==0).flatten() ,:],axis=0)) centers = np.append(centers,np.mean(X[ np.argwhere(y==1).flatten() ,:],axis=0)) # PLOT CENTER COORDINATES plt.hist(centers,bins=100) plt.title('Real Data Variable Means (match clusters=3)') plt.show()
付録2
上記のコードでmake_classificationで完全に分類できていた。
さらに改善させるためのアイディアを書いていきます。案1
4分類器?4つ目の分類器?を作成しtrainを分類させることが出来ます。
その場合、abs(oof-true)> 0.9のすべてのトレーニングデータは、ラベルがフリップされた誤ったトレーニングデータです。次に、これらのトレーニングラベルを修正し、カーネル全体をもう一度実行します。案2
各クラスターの中心はハイパーキューブコーナーであるため、meang [np.argwhere(meang> = 0)] = 1.0およびmeang [np.argwhere(meang <0)] = -1.0を追加することにより、Sklearnの2次判別分析コードを変更できます。これにより、すべてのクラスターの中心がハイパーキューブコーナーに移動します。案3
コンピューターの精度では、1に近い予測を区別できません。6桁の精度の例を使用すると、1.000001と1.000002の数値は両方とも1.00000になるため同じです。 AUCを改善するために、このカーネルに次のコードを追加できます。 temp = np.log(pds [:、0] + pds [:、1] + pds [:、2]); temp [np.isinf(temp)] = -1e6; test_pred-= temp。これにより、1に近い予測を区別することでAUCが改善されます。0.0000001と0.0000002の数値は1.0e-7と2.0e-7であり、コンピューターはすでにそれらを区別できるため、0に近い予測の問題ではないことに注意してください。案4
test.csvの予測を行った後、それらを擬似ラベルとして使用し、カーネル全体を2回実行できます。次に、これらのラベルを使用して、カーネルを3回実行します。反復ごとにわずかに増加する可能性があります。案5
このカーネルを複数回実行して、平均を取ることができます。または、kフォールドを使用します。これにより、このコードの分散(ランダム性)が除去され、毎回プリフェクションに近い結果が得られますが、LB 0.00050が完璧よりも多かれ少なかれ得点される可能性もなくなります。案6
また、二次判別分析と混合ガウスのSklearnのコードを変更することにより、このコードの分散(ランダム性)を削除できます。これらの各モデルは、0または1のトレーニングラベルのみを受け入れます。数行のコードを追加することにより、これらのモデルが連続確率を受け入れ、重みとして使用できるようになります。これにより、ランダム化ラインtest_pred = test_pred> np.random.uniform(0,1、len(test_pred))を削除できます。代わりに、0〜1の確率として擬似ラベルを残し、QuadraticDiscriminantAnalysis.fit(test_data、test_pred)を呼び出すことができます。これらの追加の高度な手法を組み合わせて使用することで、このカーネルはこのコンペティションの公開リーダーボードでLB 0.97489を獲得することができました。しかし、検証により、これらの手法は基本的な完全な分類器をそれ以上完璧にしないことが示されました。したがって、最終提出には、基本分類子が使用されました。
付録3
モデルを合成データに適用することにより、シミュレートされたパブリックリーダーボードとプライベートリーダーボードでどのように機能するかを学習できます。 このカーネルが平均して完全性を達成することを確認します(Kaggleが疑わしいパラメーターでmake_classificationを使用した場合)。 make_classificationのSklearnのコードには以下が含まれます
# Randomly replace labels if flip_y >= 0.0: flip_mask = generator.rand(n_samples) < flip_y y[flip_mask] = generator.randint(n_classes, size=flip_mask.sum())変数yが書き換えられる前に、y_orig = y.copy()を追加して保存できます。 次に、シャッフル行をX、y、y_orig = util_shuffle(X、y、y_orig、random_state = generator)に更新します。 次に、make_classificationの最後の行を変更して、X、y、y_origを返します。 これを行うことにより、prefect = roc_auc_score(y、y_orig)を使用して完全な分類器のAUCを計算できます。
これで、このコンペティションのデータに類似した数百の合成データセットを作成し、このカーネルを適用して、完璧な分類器と比較してどれだけうまく機能するかを確認できます。合成データセットごとに、このカーネルを10回実行します。これはパターンを示し、2つの最終提出物の選択方法を決定するのに役立ちます。
私たちは、このケネルが完璧よりも優れている場合と、完璧よりも悪い場合があることを観察します。興味深いのは、パブリックLBとプライベートLBのパフォーマンスに相関関係がないことです。以下のプロット例では、完全な分類は黒い点線で表されています。
多くのシンセティックデータセットでこのカーネルのパフォーマンスの平均を取ると、完全な分類が達成されます。したがって、このカーネルを改善する理由はありません。平均的な完璧な分類よりも優れたパフォーマンスを期待することはできません。考慮できる唯一の変更は、このカーネルの完全性からの標準偏差を変更することです。カーネルを実行するたびに完全性を達成しようとするか、(そのままにして)いくつかのカーネル実行で所望の量だけ完全性をランダムに超えることを試みることができます。
Synthetic Dataset 1
Synthetic Dataset 2
Synthetic Dataset 3
Synthetic Dataset 4
Synthetic Dataset 5
Many Synthetic Datasets Together
わからんったらわからん!
コメント
Q:なんで疑似ラベル作るときのランダム性を
test_pred = test_pred > np.random.uniform(0,1,len(test_pred))
で判別してるの?
前回投稿してたカーネルでは
( >0.99 or <0.01 )
で判別してなかった?A:
262144のテスト(パブリックとプライベート)の観測があります。 0.99以上0.01以下を使用すると、85%の疑似ラベルのみを使用します。 しかし、私はそれらのすべてをGMM用にしたいです。問題は、テストの観測値に0.65の予測がある場合、0または1の擬似ラベルを付ける必要がありますか? 確率で決めます。 まず、r = np.random.uniform(0,1)を呼び出します。 0.6> rの場合、テスト観測1に疑似ラベルを付けます。0.6<rの場合、テスト観測0に疑似ラベルを付けます。
その後、すべての262144テスト観測に疑似ラベルを付けます。
さらに続けてQ:しかし、ランダムに "RANDOM.uniform"で確率を生成すると(テスト観測の予測値は0.65であり、確率は0になる場合があります。56(擬似ラベルはTRUE)、次回は確率が0.99(擬似ラベルFALSE)になります。 ランダムに生成された確率がデータ全体に影響を与えるかどうかはわかりません。)
私は次のコードを数回実行します(512個のモデルの1つ)、合計がちょうど数の周りにあることがわかります(合計の差はランダムな確率によって作成されました。)
np.sum(testpred> np.random.uniform(0,1、len(testpred))))
申し訳ありませんが、私の英語は苦手です。
詳しく説明してもらえますか?
確率をランダムに生成すると、Pseudoラベルにランダム性が追加される可能性があると思います。ランダム性は、プライベートデータでモデルをより良くすることができますか?
それが正しいかどうかはわかりません。A:はい、正確に。 ランダム性を追加することにより、カーネルは、プライベートLB 0.97588をスコアリングすることで達成した、完全なプライベートLB 0.97579よりも優れたパフォーマンスを実現する可能性があります。 (完全な分類はここで説明されています)。
https://www.kaggle.com/c/instant-gratification/discussion/97047Q:ラベルを平滑化する理由は何ですか?
A:predict_proba()の代わりにpredict()を使用して、コードを6行短縮できました。 たとえば、clusters2 [all_y == 0、:3] = clf.predict(train4)を使用して、ラベルを「平滑化」または「調整」とラベル付けしたセクション全体を削除します。
クラスごとに2つのクラスターしかないことを考慮してください。 クラスター0とクラスター1は、ターゲット= 0用であるとします。 次に、Pr(cluster = 0)<0.5のすべてのポイントはクラスター0とラベル付けされます。Pr(cluster = 0)> = 0.5のすべてのポイントはクラスター1とラベル付けされます。Pr(cluster = 0)= 0.25の場合、クラスター1に入る確率は0.25です。
したがって、ラベルを「スムージング」または「調整」する目的は、すべてのポイントにクラスター0または1のいずれかになる機会を与えることです。各ポイントに対して、0〜1の乱数を選択します。Pr(cluster = 0 )>乱数の場合、ラベルはクラスター1です。それ以外の場合、ラベルはクラスター0です。
Q:クラスごとのnクラスターの推定に関して:3Dの例を取り上げて、クラスごとに3つのクラスターがあると仮定します。 target = 1のクラスターの中心が(1,1,1)、(-1、-1、-1)、(1,1、-1)にあると想像してください。 その場合、変数を計算すると、1/3と-1/3でのみバンプが表示されます。 そこで、クラスごとの正しいnクラスターがclass_sep = 1/3で2ではなく3であることをどのように識別しますか?
A:3Dとサブデータセットが1つしかない場合は難しいでしょう。 変数の平均が3つしかないため、4つの値(-1、-1 / 3、1 / 3、1)を持つことはできません。 幸いなことに、40のディメンションと512のサブデータセット(20480の可変平均)があるため、-1、-1 / 3、1 / 3、および1にバンプがあります。
3Dおよび512のサブデータセットがある場合、合計1536の変数平均の各サブデータセットから3つの変数平均を結合できます。 次に、-1、-1 / 3、1 / 3、および1でバンプが表示されます。
Q:test_pred = pds [:、3] + pds [:、4] + pds [:、5]
target = 1がクラスター3,4および5にあることをどのようにして知りましたか? 0,1,2に該当する可能性がありますA:バイナリ分類では、1つのクラスに属する観測値の確率のみを予測します(この場合、ターゲット= 1またはクラスター3,4,5にあります)。
次に、任意の特定の観測について、クラスター0,1,2(またはターゲット= 0)にある確率は、単純に1-Pr(ターゲット= 1)です。
ここで、target = 0に関係なくtarget = 1のクラスターを見つけます
train4 = comb[ np.argwhere(all_y==1).flatten(), :] clf = GaussianMixture(n_components=3).fit(train4) #randomness clusters[ np.argwhere(all_y==1).flatten(), 3:] = clf.predict_proba(train4)このclfは、all_y = target = 1のクラスターのみを検出します。その後、predict_proba()は、これら3つのクラスターのいずれかにある確率を変数クラスターの列3、4、5に入れます。 与えられた観測値がクラスターの列3、4、または5にある可能性が最も高い場合(つまり、これらの列の値が最大である場合)、後の変数cluster2は3、4、または5になります。 したがって、clusters2 = 3、4、5はtarget = 1を表します。
Q:可能であれば、以下のコード、特に最初の行と4番目のコードがどのように、何をしているのかを教えてください
for j in range(5): clusters[:,j+1] += clusters[:,j] rand = np.random.uniform(0,1,clusters.shape[0]) for j in range(6): clusters[:,j] = clusters[:,j]>rand #randomness clusters2 = 6 - np.sum(clusters,axis=1) # IF IMBALANCED TRY AGAIN least = pd.Series(clusters2).value_counts().min(); ct += 1A:
変数クラスターには6つの列があります。各列の値(0、1、2、3、4、5)は、そのクラスター内にある確率(0、1、2、3、4、5)を表します。ここに例があります0.99 0.01 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.85 0.0 0.15 0.0 0.0行0、1、2は観測0、1、2です。観測0がクラスター0に存在する確率0.99とクラスター1に存在する確率0.01を持っていることに注意してください。
ここで、各観測がどのクラスターにあるかを判断する必要があります。簡単な方法は、各行の最大値を見つけることです(すなわち、clusters2 = np.argmax(clusters、axis = 1)、clusters2 = [0、3、1] )。その代わりに、私はトリッキーなことをします。
最初に、各列とその前の列を繰り返し追加します
0.99 1.0 1.0 1.0 1.0 1.0 0.0 0.0 0.0 1.0 1.0 1.0 0.0 0.85 0.85 1.0 1.0 1.0次に、0から1の間のx個の乱数を選択します。xは行数です。たとえば、0.7、0.5、および0.1を選択します。次に、行0のどの数字が0.7より大きいかをマークします。行1のどの数字が0.5より大きいか。行2のどの数値が0.1より大きいか
True True True True True True False False False True True True False True True True True True最後に、観測0はクラスター6-行0のTrueの数= 0です。観測1はクラスター6-行1のTrueの数= 3観測2はクラスター6-行2のTrueの数= 1 。したがって、clusters2 = [0、3、1]は上記のcluster2と同じです。ただし、この方法ではランダム性のため、結果がわずかにランダム化されます。
では、今度は不均衡な場合の再試行について説明します。すべての観測がどのクラスターにあるかを決定した後、6つのクラスターのそれぞれに含まれる観測の数をカウントします。理想的には、各クラスターに1024/6 = 170の観測値があるはずです。 150未満のグループがある場合、GMMが台無しになったため、プロセス全体を再度実行します。
















- 投稿日:2019-08-29T17:47:11+09:00
pipを使えないライブラリ(FBXSDK)をインストールするのに手間取った話(Win/Mac)
AutoDeskが定める3Dデータ標準形式であるfbxは、アバター等の3D形式を扱う際においてデファクトスタンダードとなっていますが、これを扱うためのSDKがAutoDeskにより公開されています。本来はC++のためのものらしいですが、Python用で同じ操作をするための(バインディングというらしいです)ライブラリもあり、そちらの方が簡単そうなので導入してみることにしてみます。
ただしこのSDK、
- Python3.3系または2.7系しか対応していない
- pipでインストールすることが出来ない
という代物でして、最新のPythonをインストールしてpipで一発だぜイェーイという感じではなかったので、Win/Mac両環境において備忘録代わりに手順を示しておきたいと思います。
Windowsの場合
基本的な手順はこの方の記事にあるのですが、一点躓いたポイントがあるのでそこを中心に解説。
まずは https://www.python.org/downloads/ からPythonをインストールする必要がありますが、最新のものだとライブラリが使えないので、旧式のものをインストールする必要があります。また上に挙げた2バージョンのうち、なぜか3.3系はインストーラが公開されていないという謎の状態なので、実質的には2.7系しか選択肢がないということになります。
https://www.python.org/downloads/release/python-2716/
上の画像は現時点での2.7系での最新(ややこしいな)である2.7.16のインストーラの配布ページになります。予めネタバレをすると、ここで「64bitOSだから当然x64でしょ!」と
Windows x86-64 MSI installerをDLすると後で詰みます。理由はよくわかりません。ぱっと見AMDとIntelの違いかな……と思いましたが、他のライブラリは余裕で動いているので違いそうです。詳しい人教えてください。
「Windows x86-64 MSI installer」の方(x64って書いてるのに……)ではなく「Windows x86 MSI installer」の方をDLしてください。
さて、インストーラを回すと、
C:\Python27というフォルダが出来ているはずなので、その下にあるC:\Python27\Lib\site-packagesにライブラリファイルを入れていきます。FBXSDKのインストーラを回すと以下のようなフォルダが出来るはずなので、
「Python27_x86」(2.7系の32bit)(わかりづらいですがx86は32bitを表します)を選択して、
中のファイルを……
こんな感じにPythonの方のファイルに入れます。
PATH(追加ライブラリを参照するパス)についてはPythonをインストールした時点で通っているはずですが(以下は、sys.pathで確認した図)
もしなければ、
sys.path.append(追加したいパス)で追加できるはず。あまりない状況だとは思いますが……。さて、これでライブラリがインストールできたので、Python上で
from fbx import *を打ってエラーがなければインストール完了。
ちなみに最初64bit版のPythonインストーラでやった所、以下のようなエラーが出ました。
ImportError: DLL load failed: 指定されたモジュールが見つかりません?ちなみに赤丸の部分が、成功したバージョンとの相違点。「手順は解説ページと完全に合っているはずなのに、なぜ……」と半日ぐらい悩み続けていましたが、「このAMD64ってのがよくなさそうだな(適当)」という仮説を基に、ためしに32bitを入れてみたら上手くいった、というのが実際の流れになります。ちなみにOSはWindows10、もちろん64bitです。CPUは(たぶんあまり関係ないですが)Intel Core i9-9900K。
Macの場合
Macの場合は
pyenvを使えるので、導入さえしてしまえばもう少し簡単になります。3.3にも入れられます。pyenvの導入方法についてはこの方の記事とかがわかりやすいです。ただ、pyenvを使うとPATHでややこしい点があって、簡単にいうと上の解説ページにあったPATHを追加しても通りませんでした。ちなみにPATHについてはMacは、
ユーザーディレクトリ直下にある
.bash_profileというファイルで管理していて、他の解説記事だとコマンドだけでオシャレにこれをPATHを追加する方法がのっていますが、ファイル自体を開いた方がわかりやすいと思うのでその方法でいきます。ターミナルを開いた状態で
open .bash_profileと打つと
こんな感じのテキストファイルが開かれると思います。要はここに乗っているテキストがそのままPATH群となる訳です。(といった感じでファイルが目に見えた方が、初めての人は安心するのではないでしょうか?)(少なくとも私はそう?)
で、ここの末尾に直接テキストで
export PATH="$HOME/.pyenv/shims:$PATH"を打ち込んで保存! 私の環境ではとりあえずこれでうまくいきました。後は、pyenvに3.3系のpythonを入れた後、
~/.pyenv/versions/3.3.7/libにFBXSDKのライブラリファイルを置きます。
こんな感じ。
インポートも上手くいきました。ところでWindowsだとOS環境を示していたところにある
[GCC 4.2.1 Compatible Apple LLVM 10.0.1 (clang-1001.0.46.4)] on darwinなる文字列の意味がまったくわかりませんが、いずれわかりたいと思います。環境は、MacBook Pro (13-inch, 2018)、macOS Mojave 10.14.6、プロセッサ 2.3 GHz Intel Core i5といった感じです。












- 投稿日:2019-08-29T17:47:11+09:00
pipを使えないライブラリ(FBXSDK)をインストールするのに成功したけど手間取った話(Win/Mac)
AutoDeskが定める3Dデータ標準形式であるfbxは、アバター等の3D形式を扱う際においてデファクトスタンダードとなっていますが、これを扱うためのSDKがAutoDeskにより公開されています。本来はC++のためのものらしいですが、Python用で同じ操作をするための(バインディングというらしいです)ライブラリもあり、そちらの方が簡単そうなので導入してみることにしてみます。
ただしこのSDK、
- Python3.3系または2.7系しか対応していない
- pipでインストールすることが出来ない
という代物でして、最新のPythonをインストールしてpipで一発だぜイェーイという感じではなかったので、Win/Mac両環境において備忘録代わりに手順を示しておきたいと思います。
Windowsの場合
基本的な手順はこの方の記事にあるのですが、一点躓いたポイントがあるのでそこを中心に解説。
まずは https://www.python.org/downloads/ からPythonをインストールする必要がありますが、最新のものだとライブラリが使えないので、旧式のものをインストールする必要があります。また上に挙げた2バージョンのうち、なぜか3.3系はインストーラが公開されていないという謎の状態なので、実質的には2.7系しか選択肢がないということになります。
https://www.python.org/downloads/release/python-2716/
上の画像は現時点での2.7系での最新(ややこしいな)である2.7.16のインストーラの配布ページになります。予めネタバレをすると、ここで「64bitOSだから当然x64でしょ!」と
Windows x86-64 MSI installerをDLすると後で詰みます。理由はよくわかりません。ぱっと見AMDとIntelの違いかな……と思いましたが、他のライブラリは余裕で動いているので違いそうです。詳しい人教えてください。
「Windows x86-64 MSI installer」の方(x64って書いてるのに……)ではなく「Windows x86 MSI installer」の方をDLしてください。
さて、インストーラを回すと、
C:\Python27というフォルダが出来ているはずなので、その下にあるC:\Python27\Lib\site-packagesにライブラリファイルを入れていきます。FBXSDKのインストーラを回すと以下のようなフォルダが出来るはずなので、
「Python27_x86」(2.7系の32bit)(わかりづらいですがx86は32bitを表します)を選択して、
中のファイルを……
こんな感じにPythonの方のファイルに入れます。
PATH(追加ライブラリを参照するパス)についてはPythonをインストールした時点で通っているはずですが(以下は、sys.pathで確認した図)
もしなければ、
sys.path.append(追加したいパス)で追加できるはず。あまりない状況だとは思いますが……。さて、これでライブラリがインストールできたので、Python上で
from fbx import *を打ってエラーがなければインストール完了。
ちなみに最初64bit版のPythonインストーラでやった所、以下のようなエラーが出ました。
ImportError: DLL load failed: 指定されたモジュールが見つかりません?ちなみに赤丸の部分が、成功したバージョンとの相違点。「手順は解説ページと完全に合っているはずなのに、なぜ……」と半日ぐらい悩み続けていましたが、「このAMD64ってのがよくなさそうだな(適当)」という仮説を基に、ためしに32bitを入れてみたら上手くいった、というのが実際の流れになります。ちなみにOSはWindows10、もちろん64bitです。CPUは(たぶんあまり関係ないですが)Intel Core i9-9900K。
Macの場合
Macの場合は
pyenvを使えるので、導入さえしてしまえばもう少し簡単になります。3.3にも入れられます。pyenvの導入方法についてはこの方の記事とかがわかりやすいので割愛させてください。一点PATHで躓いた点があって、簡単にいうと上の解説ページにあったPATHを追加しても通りませんでした。ちなみにPATHについてはMacは、
ユーザーディレクトリ直下にある
.bash_profileというファイルで管理していて、他の解説記事だとコマンドだけでオシャレにこれをPATHを追加する方法がのっていますが、ファイル自体を開いた方がわかりやすいと思うのでその方法でいきます。ターミナルを開いた状態で
open .bash_profileと打つと
こんな感じのテキストファイルが開かれると思います。要はここに乗っているテキストがそのままPATH群となる訳です。(といった感じでファイルが目に見えた方が、初めての人は安心するのではないでしょうか?)(少なくとも私はそう?)
で、ここの末尾に直接テキストで
export PATH="$HOME/.pyenv/shims:$PATH"を打ち込んで保存! 私の環境ではとりあえずこれでうまくいきました。後は、pyenvに3.3系のpythonを入れた後、
~/.pyenv/versions/3.3.7/libにFBXSDKのライブラリファイルを置きます。
こんな感じ。
インポートも上手くいきました。ところでWindowsだとOS環境を示していたところにある
[GCC 4.2.1 Compatible Apple LLVM 10.0.1 (clang-1001.0.46.4)] on darwinなる文字列の意味がまったくわかりませんが、いずれわかりたいと思います。環境は、MacBook Pro (13-inch, 2018)、macOS Mojave 10.14.6、プロセッサ 2.3 GHz Intel Core i5といった感じです。
- 投稿日:2019-08-29T17:39:42+09:00
e-Gov法令APIとXML 特定ワードが含まれる条文抽出
きっかけ
201910 Business Law Journalに,”XMLによる情報整理の薦め”という記事あり.
興味があったためまず法令XMLをいじってみた.他記事で全くコードを記載していないことに対する代償行為ではない.ないってば.
*なお,”XMLによる情報整理の薦め”の著者は,
判例等を含めて閲覧可能としたXMLを作成しており,次で公開している.
民法体系XML http://cyberlawschool.jp/kagayama/civ_ver1.xml
http://cyberlawschool.jp/kagayama/内容
- e-Gov法令APIから指定する法令入手
- 法令表示.
- 特定のワードを含む条文のみ抽出することも可.(個人的にはよく使う)
参照 https://qiita.com/sakaia/items/c787aa6471e70000d253
問題あり.
- 遅い.「条の~」を処理する部分はより良く記載できるはず.
- 基礎からおかしいので,指摘していただけると,本当に,助かります.
コード
import requests import xml.etree.ElementTree as ET #e-Gov 法令API 仕様書 #https://www.e-gov.go.jp/elaws/pdf/houreiapi_shiyosyo.pdf #法令選択 def lawName2No(KEYWORD, TAG='LawName'): url = 'https://elaws.e-gov.go.jp/api/1/lawlists/2' r = requests.get(url) root = ET.fromstring(r.content.decode(encoding='utf-8')) iflag = 0 for i,e in enumerate(root.getiterator()): if (TAG==e.tag): iflag = 0 if (KEYWORD==e.text): iflag = 1 if(iflag==1 and e.tag=='LawNo'): return e.text #法令表示・抽出 def lawTextExtractor(lawnum, wordn=0, word=''): url = 'https://elaws.e-gov.go.jp/api/1/articles;lawNum='+str(lawName2No(KEYWORD))+';article='+str(lawnum) r = requests.get(url) #if r.status_code!=requests.codes.ok: #break root = ET.fromstring(r.content.decode(encoding='utf-8')) lawstrs = [] for i,e in enumerate(root.getiterator()): for xtag in ['ArticleCaption', 'ArticleTitle', 'ParagraphNum', 'ItemTitle', 'Sentence']: if e.tag==xtag : if wordn==1 and xtag=='Sentence':#ワード指定する場合 if e.text.find(word)>-1: lawstrs.append(e.text[0:e.text.find(word)]+'●'+e.text[e.text.find(word):]) #lawstrs.append(e.text.replace(word, '●'+word)) else: lawstrs.append(str(e.text)) if lawstrs==[]: pass else: print('\n'.join(lawstrs))#法令指定 KEYWORD = '著作権法' #ワード抽出する場合 1 wordn = 1 #抽出ワード word = '映画' #条文設定 今回は14条から29条 for lawnum in range(14,30): lawTextExtractor(lawnum, wordn, word) #「条の~」を無理やり処理.後で対策を考える. [lawTextExtractor(str(lawnum)+'.'+str(i), wordn, word) for i in range(15)]出力結果
- ワード抽出した場合,たとえば,映画では譲渡権等が頒布権に変換されているのだな,などよく分かる.
(著作者の推定)
第十四条
None
(職務上作成する著作物の著作者)
第十五条
None
2
(映画の著作物の著作者)
第十六条
None
●映画の著作物の著作者は、その映画の著作物において翻案され、又は複製された小説、脚本、音楽その他の著作物の著作者を除き、制作、監督、演出、撮影、美術等を担当してその映画の著作物の全体的形成に創作的に寄与した者とする。
(著作者の権利)
第十七条
None
2
(公表権)
第十八条
None
2
一
二
三
第二十九条の規定によりその●映画の著作物の著作権が映画製作者に帰属した場合
3
一
二
三
四
五
4
一
二
三
四
五
六
七
八
(氏名表示権)
第十九条
None
2
3
4
一
二
三
(同一性保持権)
第二十条
None
2
一
二
三
四
(複製権)
第二十一条
None
(上映権)
第二十二条の二
None
(上演権及び演奏権)
第二十二条
None
(上映権)
第二十二条の二
None
(公衆送信権等)
第二十三条
None
2
(口述権)
第二十四条
None
(展示権)
第二十五条
None
(譲渡権)
第二十六条の二
None
著作者は、その著作物(●映画の著作物を除く。以下この条において同じ。)をその原作品又は複製物(映画の著作物において複製されている著作物にあつては、当該映画の著作物の複製物を除く。以下この条において同じ。)の譲渡により公衆に提供する権利を専有する。
2
一
二
三
四
五
(貸与権)
第二十六条の三
None
著作者は、その著作物(●映画の著作物を除く。)をその複製物(映画の著作物において複製されている著作物にあつては、当該映画の著作物の複製物を除く。)の貸与により公衆に提供する権利を専有する。
(頒布権)
第二十六条
None
著作者は、その●映画の著作物をその複製物により頒布する権利を専有する。
2
著作者は、●映画の著作物において複製されているその著作物を当該映画の著作物の複製物により頒布する権利を専有する。
(譲渡権)
第二十六条の二
None
著作者は、その著作物(●映画の著作物を除く。以下この条において同じ。)をその原作品又は複製物(映画の著作物において複製されている著作物にあつては、当該映画の著作物の複製物を除く。以下この条において同じ。)の譲渡により公衆に提供する権利を専有する。
2
一
二
三
四
五
(貸与権)
第二十六条の三
None
著作者は、その著作物(●映画の著作物を除く。)をその複製物(映画の著作物において複製されている著作物にあつては、当該映画の著作物の複製物を除く。)の貸与により公衆に提供する権利を専有する。
(翻訳権、翻案権等)
第二十七条
None
著作者は、その著作物を翻訳し、編曲し、若しくは変形し、又は脚色し、●映画化し、その他翻案する権利を専有する。
(二次的著作物の利用に関する原著作者の権利)
第二十八条
None
第二十九条
None
●映画の著作物(第十五条第一項、次項又は第三項の規定の適用を受けるものを除く。)の著作権は、その著作者が映画製作者に対し当該映画の著作物の製作に参加することを約束しているときは、当該映画製作者に帰属する。
2
専ら放送事業者が放送のための技術的手段として製作する●映画の著作物(第十五条第一項の規定の適用を受けるものを除く。)の著作権のうち次に掲げる権利は、映画製作者としての当該放送事業者に帰属する。
一
二
3
専ら有線放送事業者が有線放送のための技術的手段として製作する●映画の著作物(第十五条第一項の規定の適用を受けるものを除く。)の著作権のうち次に掲げる権利は、映画製作者としての当該有線放送事業者に帰属する。
一
二
- 投稿日:2019-08-29T17:16:28+09:00
djangogirlチュートリアル 個人的に詰まったところとその対処法
どうも未来電子でインターンをしているものです。
今回はdjangogirlチュートリアルで詰まったところとその対処法を備忘録としてまとめたいと思います。
プログラミング初心者ですので間違っているかもしれません。
お手柔らかにお願いします。目次
・dockerでpythonanywhereが使用できない
・ローカル環境通りに本番環境で表示されないdockerでpythonanywhereが使用できない
チュートリアルはdokcerを使っていませんが、せっかくと思ってdockerを使用してやることにしました。
しかし以降時にエラーが起こりわけわからなくなりました。
まだ対処方がわからないため、後に挑戦します。ローカル環境通りに本番環境で表示されない
ローカル環境でいくつかサンプルとしてブログを投稿し、きちんと表示されていました。
しかし本番環境(ここではpythonanywhere)ではヘッダーだけ表示され、サンプルは表示されていませんでした。調べてみると本番環境ではローカル環境と同じモデルとユーザーが適用されているが、内容までは共有されていないことがわかりました。
そのためブログ投稿数が0で、何も表示されていなかったのです。実際に本番環境でサンプルを投稿するときちんと表示されました。
参考
- 投稿日:2019-08-29T17:04:09+09:00
【初心者】pythonで0から Project Euler を解いてみた22
今回はEuler22問目で―す。
http://odz.sakura.ne.jp/projecteuler/index.php?cmd=read&page=Problem%2022
「名前のスコア」
まず。問題を見たときに解ける気がしなった。
でも初心者にとってこんなもの無理やろ!!と思ったけど分解して考えて一つずつ進めていったら出来たのでくじけず頑張りましょう!!コード
names_deta = open('names.txt') names = sorted(names_deta.read().replace('"','').split(','),key=str) alp_num = {"A":1,"B":2,"C":3,"D":4,"E":5,"F":6,"G":7,"H":8,"I":9,"J":10,"K":11,"L":12,"M":13,"N":14,"O":15,"P":16,"Q":17,"R":18,"S":19,"T":20,"U":21,"V":22,"W":23,"X":24,"Y":25,"Z":26} for i in range(len(names)): names[i] = list(names[i]) scoer = 0 for cha_No in range(len(names)): for cha_sc in range(len(names[cha_No])): tenp = 0 tenp += alp_num[names[cha_No][cha_sc]] scoer += tenp * (cha_No + 1) print(scoer)まず一行でtxtを読み込み二行目で("")を取り除き、(,)で一つ一つをリストの要素にします次にalp_numでアルファベットに数値を関連付けておきます。
次のfor文で二次元配列にします
次は二重ループを使い何番目なのか、そして名前のtenpはいくつになるのかを計算して頂きます
それによって出たtenpをscoerに足していき最後に出力させて完成ですこんな感じにやってみると案外解けましたね
皆様もぜひ!w
- 投稿日:2019-08-29T16:41:02+09:00
【初心者】pythonで0から Project Euler を解いてみた12
今回はeuler12問目を解いていきます!
問題はこちらへ!!
http://odz.sakura.ne.jp/projecteuler/index.php?cmd=read&page=Problem%2012
今回は三角数の約数が500を超える一番小さい三角数は何ですか的な問題ですねー。。。
じゃ、頑張って解いていきますか!コード
import sympy n = 0 while True: n += 1 Tri = n * (n + 1) // 2 #print(Tri) div_cout = sympy.divisor_count(Tri) if div_cout >= 500: print(Tri) break最初に三角数とは何ぞやと思う人のために少し解説!
今絵にしたのは三角関数の3項目の6です
nに3を入れてもらうと答えは6になります
これは高さ(段数)×(段数+1)÷2になります
絵のように二つの三角形を使い四角形を作りその半分が三角数の項になるということですまず私はwhile True:で無限ループを作り問題の答えになる数を探しに行く旅に出ました。
次にsympyのdivisor_countを使い約数の数を出します
次のif文でそのdiv_coutが500より大きいときにループを止めるコードを書いて終わりです!!

- 投稿日:2019-08-29T16:40:47+09:00
Numpy 1.17リリースでGensim 2.2.0インストールでエラー
背景
requirements.txtでnumpy1.15.4を指定していても、gensimのinstall時にnumpyの1.17を使っていたのを発見したのでメモ
(circleCIでキャッシュが効いてなかったことも発見した。)参考
https://mag.osdn.jp/19/07/30/170000
https://pypi.org/project/gensim/
- 投稿日:2019-08-29T15:53:10+09:00
windowsでpythonを扱うときに気を付けたこと
今後会社などでpythonを扱いたくなった時のためのメモです
結論 visual studioを使うとよい
他には
cp932' codec can't decode byte 0x8e in position 18: illegal multibyte sequenceが出るとき
以下のコードを先頭に書く
import io, sys sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding=sys.stdout.encoding, errors='backslashreplace', line_buffering=sys.stdout.line_buffering)さらに
ファイルを扱うopenファイルでunicodeエラーが起きた時
with open(path) as f:こんな感じのを
with open(path, encoding="utf-8") as f:に変える
- 投稿日:2019-08-29T15:52:30+09:00
粒子群最適化法(PSO)入門
適宜更新していきます。
0. はじめに
秋田大学で
- 群知能(メイン)
- 競技プログラミング(趣味・メイン)
- DeepLearning(来年からやりそう)
を主に研究している学生のガナリヤです。
群知能という最適化分野は、海外だとメジャーですが、日本ではかなり影が薄い分野です(工学系の方が多いので数理最適化などが多いのかもしれません)。
このままだと寂しいので、今回は、群知能のメジャーなフレームワークPSOについてまとめようと思います。
(PSOは第2節からです)
2. 粒子群最適化法(PSO)
2-1. 粒子群最適化法とは?
粒子群最適化法とは、鳥や魚の群れの行動にヒントを得た最適化フレームワーク・アルゴリズムです。
2-2. そもそも現実の鳥の群れの動きって?
粒子群最適化法が、鳥の群れの行動にヒントを得たアルゴリズムらしいですが、そもそも現実の鳥の群れはどのように行動しているのでしょうか。
群れで行動する鳥は、例えば白鳥などの渡り鳥などがいます。
これらの群れで飛ぶ鳥は
- できる限り外敵から襲われる危険を避けたい
- 集団で飛べば「自分が食べられる」確率は減ります。
- つがいなどを探したい
- より目を増やしたい
- 外敵をすばやく察知できます
などの理由から、わざわざ群れで行動します。
では、どうしてこれらの現実の鳥の群れは互いにぶつからないのでしょうか?
これら現実の鳥の群れにはリーダーがいません。リーダーが「左に行くぞ!」と言って、全員で左に進んでいるからぶつからない、ということはありません。
全員が全員自分勝手に考えて、勝手に飛んでいます。
それでもぶつからない理由はなんでしょうか?これは、鳥の群れの動きを「シュミレーション化」することでわかります。
2-2-1. 鳥の群れの動き
boidsというアルゴリズムが、現実の鳥の群れの動きを、プログラム上で再現することに成功しました。
現実の鳥の群れは、各個体がすべての個体を見ているわけではありません。
各個体が見ている他の鳥の個体数はせいぜい6~7体と呼ばれています。
これを最近傍の定理といいます。そして、この最近傍の定理に当てはまる周囲の鳥の動きを以下の3つの法則で捉えて、コンピュータ上では、boidsとして各個体の動き方をシュミレーションしています。
(現実の鳥もおそらく似たような動きをしています。)
2-2-1-1. flock centering
各個体は、自分の周辺の仲間の鳥の、ちょうど重心を狙った方向に飛びます。
2-2-1-2. collision avoidance
各個体は、自分の周辺の仲間の鳥とぶつからないような方向に飛びます。
2-2-1-3. velocity matching
各個体は、自分の周辺の仲間の鳥のベクトルの平均にあうような方向に飛びます。
2-2-2. 鳥の群れの動きから分かること
このように鳥の群れは単純なルールで動いており、「近くの鳥」と「情報を共有すること」で、群れとしての行動を成り立たせています。
この、「近くの鳥」と「互いの位置やベクトルを共有すること」、という発想をモデル化・フレームワーク化したものがPSOであり、連続的な関数の最小値を求めることができます。
2-3. PSOの直感的発想
2-4. PSOで使用する変数
2-5. PSOのアルゴリズム
2-6. PSOのソースコード(Python)

- 投稿日:2019-08-29T15:48:16+09:00
今日のpythonエラー:Permission denied
https://github.com/adobe-fonts/source-han-mono
ダウンロードして文書を読むと
https://github.com/adobe-type-tools/afdko/
を入れろという。やってみた。
$ pip3 install --user afdko Collecting afdko Downloading https://files.pythonhosted.org/packages/9e/0a/991bb8a4a4535e1bc030e40dd34d4d44b9b4915c4d4132c1868b87489e67/afdko-3.0.1-py3-none-macosx_10_6_intel.whl (2.4MB) |████████████████████████████████| 2.4MB 745kB/s Collecting ufonormalizer==0.3.6 (from afdko) Downloading https://files.pythonhosted.org/packages/16/49/48feb64327266a7147a8683f1bc547d9997499afff724251657f542702f0/ufonormalizer-0.3.6-py2.py3-none-any.whl Collecting cu2qu[cli]==1.6.5 (from afdko) Downloading https://files.pythonhosted.org/packages/cd/57/112e1af07fbf01b4e838cb5afac797048de30d4cf36586e945554abf996d/cu2qu-1.6.5-cp36-cp36m-macosx_10_6_intel.macosx_10_9_intel.macosx_10_9_x86_64.macosx_10_10_intel.macosx_10_10_x86_64.whl (250kB) |████████████████████████████████| 256kB 40.5MB/s Collecting booleanOperations==0.8.2 (from afdko) Downloading https://files.pythonhosted.org/packages/3d/67/05961a78573d5d4a710939bb9e0de6b828fd2902635db6ea66c0a54bafc5/booleanOperations-0.8.2-py2.py3-none-any.whl Collecting ufoProcessor==1.0.6 (from afdko) Downloading https://files.pythonhosted.org/packages/c4/82/d489a23a4081cf05685276f1fca5115d8103fe5af7558b005943bfc47931/ufoProcessor-1.0.6-py2.py3-none-any.whl Collecting psautohint==2.0.0a1 (from afdko) Downloading https://files.pythonhosted.org/packages/d6/15/552a379f988a9ed95f1db1779e761af3f220eec70a4854a7f8bb4f335bb4/psautohint-2.0.0a1-cp36-cp36m-macosx_10_6_intel.macosx_10_9_intel.macosx_10_9_x86_64.macosx_10_10_intel.macosx_10_10_x86_64.whl (386kB) |████████████████████████████████| 389kB 35.4MB/s Collecting mutatorMath==2.1.2 (from afdko) Downloading https://files.pythonhosted.org/packages/13/ee/662f841aa324b36f5cd12907e6f695cf831dfdbbc526cda4a2ccc20e812e/MutatorMath-2.1.2-py2.py3-none-any.whl Collecting fontMath==0.5.0 (from afdko) Downloading https://files.pythonhosted.org/packages/65/1c/11bebe5b9586b41060618251c593fd1eb70e7143a4e68cea1b7f1e369fe2/fontMath-0.5.0-py2.py3-none-any.whl Collecting fontTools[lxml,ufo,unicode,woff]==4.0.0 (from afdko) Downloading https://files.pythonhosted.org/packages/8d/cf/d2d6ca6aa22a1d6a6f064290a7bf0d4a3b1c2eb5f38f2a64a4341c36b12f/fonttools-4.0.0-py3-none-any.whl (716kB) |████████████████████████████████| 716kB 46.4MB/s Collecting lxml==4.4.1 (from afdko) Downloading https://files.pythonhosted.org/packages/32/3f/e4a551ce12890da4bed75000e0e11757ed9d962aeeee862db42092d4ec82/lxml-4.4.1-cp36-cp36m-macosx_10_6_intel.macosx_10_9_intel.macosx_10_9_x86_64.macosx_10_10_intel.macosx_10_10_x86_64.whl (9.0MB) |████████████████████████████████| 9.0MB 41.5MB/s Collecting defcon[lxml,pens]==0.6.0 (from afdko) Downloading https://files.pythonhosted.org/packages/59/f1/b55f04cb96239ec77ea712f867af30fdbe546280bad3743a3c3ebe4295e6/defcon-0.6.0-py2.py3-none-any.whl (191kB) |████████████████████████████████| 194kB 31.2MB/s Collecting pyclipper>=1.0.5 (from booleanOperations==0.8.2->afdko) Downloading https://files.pythonhosted.org/packages/f4/21/4c13db060c2e44ab0d17973d8188ccc42c28f358659d9bc39eddf987db96/pyclipper-1.1.0.post1-cp36-cp36m-macosx_10_6_intel.macosx_10_9_intel.macosx_10_9_x86_64.macosx_10_10_intel.macosx_10_10_x86_64.whl (276kB) |████████████████████████████████| 276kB 31.6MB/s Collecting fontParts>=0.8.2 (from ufoProcessor==1.0.6->afdko) Downloading https://files.pythonhosted.org/packages/ef/70/e50c80a6b8ffd63898be61223231ca64cb36716e0fcdfce583a3e9092bbb/fontParts-0.8.9-py2.py3-none-any.whl (160kB) |████████████████████████████████| 163kB 39.2MB/s Collecting fs<3,>=2.2.0; extra == "ufo" (from fontTools[lxml,ufo,unicode,woff]==4.0.0->afdko) Downloading https://files.pythonhosted.org/packages/23/32/c094850e008527d88226e56848683894e5daac0fef079e1de2318f3ad699/fs-2.4.10-py2.py3-none-any.whl (125kB) |████████████████████████████████| 133kB 39.7MB/s Collecting unicodedata2>=12.0.0; (python_version < "3.8" and platform_python_implementation != "PyPy") and extra == "unicode" (from fontTools[lxml,ufo,unicode,woff]==4.0.0->afdko) Downloading https://files.pythonhosted.org/packages/d9/49/d82da8911f989dbe08f602f4cebeb4c9e67791df6237b4ebf995139d0a6b/unicodedata2-12.0.0-cp36-cp36m-macosx_10_6_intel.macosx_10_9_intel.macosx_10_9_x86_64.macosx_10_10_intel.macosx_10_10_x86_64.whl (811kB) |████████████████████████████████| 819kB 38.1MB/s Collecting zopfli>=0.1.4; extra == "woff" (from fontTools[lxml,ufo,unicode,woff]==4.0.0->afdko) Downloading https://files.pythonhosted.org/packages/a8/5a/c0dea41694db785450e664c94722394a99466d149f049d825dc3f637d838/zopfli-0.1.6-cp36-cp36m-macosx_10_6_intel.macosx_10_9_intel.macosx_10_9_x86_64.macosx_10_10_intel.macosx_10_10_x86_64.whl (72kB) |████████████████████████████████| 81kB 22.4MB/s Collecting brotli>=1.0.1; platform_python_implementation != "PyPy" and extra == "woff" (from fontTools[lxml,ufo,unicode,woff]==4.0.0->afdko) Downloading https://files.pythonhosted.org/packages/75/23/792326ae9071ca6b691d1f0c5cd707c316980146236f99dcf971a6146317/Brotli-1.0.7-cp36-cp36m-macosx_10_6_intel.macosx_10_9_intel.macosx_10_9_x86_64.macosx_10_10_intel.macosx_10_10_x86_64.whl (796kB) |████████████████████████████████| 798kB 44.7MB/s Collecting fontPens>=0.1.0; extra == "pens" (from defcon[lxml,pens]==0.6.0->afdko) Downloading https://files.pythonhosted.org/packages/ba/9d/d084c2760c735e8f81c2a3c9e0d403cfacb811daf5166fbaa353e6d647c5/fontPens-0.2.4-py2.py3-none-any.whl Requirement already satisfied: pytz in ./.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages (from fs<3,>=2.2.0; extra == "ufo"->fontTools[lxml,ufo,unicode,woff]==4.0.0->afdko) (2017.2) Requirement already satisfied: setuptools in ./.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages (from fs<3,>=2.2.0; extra == "ufo"->fontTools[lxml,ufo,unicode,woff]==4.0.0->afdko) (41.0.1) Collecting appdirs~=1.4.3 (from fs<3,>=2.2.0; extra == "ufo"->fontTools[lxml,ufo,unicode,woff]==4.0.0->afdko) Downloading https://files.pythonhosted.org/packages/56/eb/810e700ed1349edde4cbdc1b2a21e28cdf115f9faf263f6bbf8447c1abf3/appdirs-1.4.3-py2.py3-none-any.whl Requirement already satisfied: six~=1.10 in ./.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages (from fs<3,>=2.2.0; extra == "ufo"->fontTools[lxml,ufo,unicode,woff]==4.0.0->afdko) (1.10.0) Installing collected packages: ufonormalizer, lxml, appdirs, fs, unicodedata2, zopfli, brotli, fontTools, fontPens, defcon, cu2qu, pyclipper, booleanOperations, fontMath, mutatorMath, fontParts, ufoProcessor, psautohint, afdko WARNING: The script ufonormalizer is installed in '/Users/administrator/.local/bin' which is not on PATH. Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location. WARNING: The scripts fonttools, pyftmerge, pyftsubset and ttx are installed in '/Users/administrator/.local/bin' which is not on PATH. Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location. WARNING: The script cu2qu is installed in '/Users/administrator/.local/bin' which is not on PATH. Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location. WARNING: The scripts psautohint and psstemhist are installed in '/Users/administrator/.local/bin' which is not on PATH. Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location. WARNING: The scripts autohint, buildcff2vf, buildmasterotfs, charplot, checkoutlinesufo, comparefamily, digiplot, fontplot, fontplot2, fontsetplot, hintplot, makeinstancesufo, makeotf, otc2otf, otf2otc, otf2ttf, stemhist, ttfcomponentizer, ttxn and waterfallplot are installed in '/Users/administrator/.local/bin' which is not on PATH. Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location. Successfully installed afdko-3.0.1 appdirs-1.4.3 booleanOperations-0.8.2 brotli-1.0.7 cu2qu-1.6.5 defcon-0.6.0 fontMath-0.5.0 fontParts-0.8.9 fontPens-0.2.4 fontTools-4.0.0 fs-2.4.10 lxml-4.4.1 mutatorMath-2.1.2 psautohint-2.0.0a1 pyclipper-1.1.0.post1 ufoProcessor-1.0.6 ufonormalizer-0.3.6 unicodedata2-12.0.0 zopfli-0.1.6 WARNING: You are using pip version 19.1.1, however version 19.2.3 is available. You should consider upgrading via the 'pip install --upgrade pip' command. cp: /Users/administrator/.pyenv/shims/gettext.sh: Permission denied $ pip3 install --upgrade pip Collecting pip Downloading https://files.pythonhosted.org/packages/30/db/9e38760b32e3e7f40cce46dd5fb107b8c73840df38f0046d8e6514e675a1/pip-19.2.3-py2.py3-none-any.whl (1.4MB) |████████████████████████████████| 1.4MB 1.1MB/s Installing collected packages: pip Found existing installation: pip 19.1.1 Uninstalling pip-19.1.1: ERROR: Could not install packages due to an EnvironmentError: [Errno 13] Permission denied: '/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/pip-19.1.1.dist-info/entry_points.txt' Consider using the `--user` option or check the permissions. WARNING: You are using pip version 19.1.1, however version 19.2.3 is available. You should consider upgrading via the 'pip install --upgrade pip' command.
- 投稿日:2019-08-29T15:24:02+09:00
Djangoの入力フォームにCSSを適用する方法
はじめに
Djangoのtemplateで入力フォームを
{{ form.username }}のように作る時、入力フォームにCSSを適用する方法が分からず、調べてみたのでまとめてみたいと思います。
入力フォームにCSSを適用したい
例えば、ユーザー登録をするフォームを作るために、views.pyでUserCreationFormをformという名前でtemplateに渡してフォームの画面を作るとします。
usernameを記入する欄を{{ form.username }}のように作ると、class名をつけることができず、CSSを適用することができません。
CSSを適用させる方法
CSSを適用するための方法を解説します。
まず、仮想環境で$ pip install django-widgets-improvedというコマンドを実行します。
次に、プロジェクトのsettings.pyで
INSTALLED_APPS = [ ... 'widget_tweaks', ... ]のように追加します。
そして、templateの最初の方に以下を追加します。
{% load widget_tweaks %}そしたら、
{{ form.username|add_class:'class-name' }}のように書くことでclass名を設定できます。
あとはCSSで自由に装飾してください。
- 投稿日:2019-08-29T14:25:41+09:00
【初心者】pythonで0から Project Euler を解いてみた23
今回はEuler23問目解くわ!!!
問題はここ
http://odz.sakura.ne.jp/projecteuler/index.php?cmd=read&page=Problem%2023
この問題は正直完璧ではないわ( ^ω^)・・・
もし、いいコードやアルゴリズムがあるならコメントで教えていただきたいでそうろうコード
import sympy limit = 20161 #28123 exc_num = [] #過剰数 cre_num = [] result_num = [] for i in range(1,limit+1): if sum(sympy.divisors(i)[:-1]) > i: exc_num.append(i) for n in range(len(exc_num)-1): for m in range(n,len(exc_num)): temp = exc_num[n] + exc_num[m] if temp < limit: if temp not in cre_num: cre_num.append(temp) print(exc_num) print(cre_num) for i in range(1,limit+1): if i not in cre_num: result_num.append(i) print(result_num) print(len(exc_num)) print(len(cre_num)) print(sum(result_num))問題では上限が28123だったのだけどwikiで過剰数について調べていたら上限が20161と書いてあったのでそれを使いました
あと、20161だと正解するのに28123だと正解しないのがこのプログラムの不完成なところであります
私は、まずexc_numにlimitまでの過剰数をリスト化したわ!!
そしてここで二つの過剰数で出来る数をリスト化したわfor n in range(len(exc_num)-1): for m in range(n,len(exc_num)): temp = exc_num[n] + exc_num[m] if temp < limit: if temp not in cre_num: cre_num.append(temp)そして最後にないものだけ足したのが答えだわ
もしここが違うやこうしたらうまくいったなどぜひぜひコメントいただきたいです。
- 投稿日:2019-08-29T14:12:31+09:00
【Anaconda+VSCode】Pythonの環境設定で詰まったところ【Windows10】
1. はじめに
ご覧いただきありがとうございます。
インターン先のMacでAnacondaとVSCodeを使っていてその環境を
家でも設定したいと思い、いろいろな記事をみて試行錯誤しても
うまくいかず格闘した部分があったため、備忘録を兼ねて記事にさせていただきました。基本の環境設定については
Windows10環境にAnaconda+Visual Studio CodeでPython環境を構築【2017年9月】
がとても分かり易いかと思いますのでこの環境設定で詰まった際に
この記事を参照していただければと思います。初投稿となりますので至らない点がありましたらすみません。
2. conda activateができない
上記の記事などを参考に環境設定をし、
さてconda activateを実行しようと思ってターミナル(power shell)に入力したところ
以下のようなエラーメッセージが出てきました。error_messageconda activate py36 CommandNotFoundError: Your shell has not been properly configured to use 'conda activate'. If using 'conda activate' from a batch script, change your invocation to 'CALL conda.bat activate'. To initialize your shell, run $ conda init <SHELL_NAME> Currently supported shells are: - bash - cmd.exe - fish - tcsh - xonsh - zsh - powershell See 'conda init --help' for more information and options. IMPORTANT: You may need to close and restart your shell after running 'conda init'.とりあえず、
$ conda init <SHELL_NAME>をしろと言われているのでしてみると
error_messageconda init powershell Traceback (most recent call last): File "C:\Users\chuo2\Anaconda3\lib\site-packages\conda\exceptions.py", line 1062, in __call__ return func(*args, **kwargs) File "C:\Users\chuo2\Anaconda3\lib\site-packages\conda\cli\main.py", line 84, in _main exit_code = do_call(args, p) File "C:\Users\chuo2\Anaconda3\lib\site-packages\conda\cli\conda_argparse.py", line 82, in do_call exit_code = getattr(module, func_name)(args, parser) File "C:\Users\chuo2\Anaconda3\lib\site-packages\conda\cli\main_init.py", line 16, in execute from ..core.initialize import initialize, initialize_dev, install File "C:\Users\chuo2\Anaconda3\lib\site-packages\conda\core\initialize.py", line 61, in <module> from ..gateways.disk.create import copy, mkdir_p File "C:\Users\chuo2\Anaconda3\lib\site-packages\conda\gateways\disk\create.py", line 17, in <module> import conda_package_handling.api File "C:\Users\chuo2\Anaconda3\lib\site-packages\conda_package_handling\api.py", line 3, in <module> from libarchive.exception import ArchiveError as _LibarchiveArchiveError File "C:\Users\chuo2\Anaconda3\lib\site-packages\libarchive\__init__.py", line 1, in <module> from .entry import ArchiveEntry File "C:\Users\chuo2\Anaconda3\lib\site-packages\libarchive\entry.py", line 6, in <module> from . import ffi File "C:\Users\chuo2\Anaconda3\lib\site-packages\libarchive\ffi.py", line 48, in <module> libarchive = ctypes.cdll.LoadLibrary(libarchive_path) File "C:\Users\chuo2\Anaconda3\lib\ctypes\__init__.py", line 434, in LoadLibrary return self._dlltype(name) File "C:\Users\chuo2\Anaconda3\lib\ctypes\__init__.py", line 356, in __init__ self._handle = _dlopen(self._name, mode) TypeError: LoadLibrary() argument 1 must be str, not None During handling of the above exception, another exception occurred: Traceback (most recent call last): File "C:\Users\chuo2\Anaconda3\Scripts\conda-script.py", line 12, in <module> sys.exit(main()) File "C:\Users\chuo2\Anaconda3\lib\site-packages\conda\cli\main.py", line 150, in main return conda_exception_handler(_main, *args, **kwargs) File "C:\Users\chuo2\Anaconda3\lib\site-packages\conda\exceptions.py", line 1354, in conda_exception_handler return_value = exception_handler(func, *args, **kwargs) File "C:\Users\chuo2\Anaconda3\lib\site-packages\conda\exceptions.py", line 1065, in __call__ return self.handle_exception(exc_val, exc_tb) File "C:\Users\chuo2\Anaconda3\lib\site-packages\conda\exceptions.py", line 1109, in handle_exception return self.handle_unexpected_exception(exc_val, exc_tb) File "C:\Users\chuo2\Anaconda3\lib\site-packages\conda\exceptions.py", line 1120, in handle_unexpected_exception self.print_unexpected_error_report(error_report) File "C:\Users\chuo2\Anaconda3\lib\site-packages\conda\exceptions.py", line 1190, in print_unexpected_error_report from .cli.main_info import get_env_vars_str, get_main_info_str File "C:\Users\chuo2\Anaconda3\lib\site-packages\conda\cli\main_info.py", line 19, in <module> from ..core.index import _supplement_index_with_system File "C:\Users\chuo2\Anaconda3\lib\site-packages\conda\core\index.py", line 9, in <module> from .package_cache_data import PackageCacheData File "C:\Users\chuo2\Anaconda3\lib\site-packages\conda\core\package_cache_data.py", line 15, in <module> from conda_package_handling.api import InvalidArchiveError File "C:\Users\chuo2\Anaconda3\lib\site-packages\conda_package_handling\api.py", line 7, in <module> from .tarball import CondaTarBZ2 as _CondaTarBZ2 File "C:\Users\chuo2\Anaconda3\lib\site-packages\conda_package_handling\tarball.py", line 7, in <module> import libarchive File "C:\Users\chuo2\Anaconda3\lib\site-packages\libarchive\__init__.py", line 1, in <module> from .entry import ArchiveEntry File "C:\Users\chuo2\Anaconda3\lib\site-packages\libarchive\entry.py", line 6, in <module> from . import ffi File "C:\Users\chuo2\Anaconda3\lib\site-packages\libarchive\ffi.py", line 48, in <module> libarchive = ctypes.cdll.LoadLibrary(libarchive_path) File "C:\Users\chuo2\Anaconda3\lib\ctypes\__init__.py", line 434, in LoadLibrary return self._dlltype(name) File "C:\Users\chuo2\Anaconda3\lib\ctypes\__init__.py", line 356, in __init__ self._handle = _dlopen(self._name, mode) TypeError: LoadLibrary() argument 1 must be str, not Noneこれがエラー地獄の始まりでした。
3. 解決方法
試した方法
・anacondaの再インストール
➡ 変化なし
・エラー文をググる
➡ 英語のソースしか出てこない上、日本語のソースではPythonコードのエラーしか出てこない
・環境変数のPath設定
➡ 変化なし
・Setting.jsonのPath設定
➡ 変化なしと何をやってもダメで、あきらめようと思ったとき
エラーコードに引っかかったサイトでanaconda と pyenv は相性が悪いとの記事がありました。power shellとpyenvは別物ですが同じエラーコードが出るということは
power shellとanacondaの相性も悪いのではないかと思い、
ターミナルをコマンドプロンプト(cmd.exe)に変更してconda activateを実行してみると(base) C:\Users\chuo2\Documents\Python Scripts>conda activate py36 (py36) C:\Users\chuo2\Documents\Python Scripts>無事に実行することができました。
試してみたところ、conda installなどのコマンドも問題なく使えました。4. 終わりに
地獄のエラーに悩まされること3時間、こんな簡単なことで解決してしまって怒りのやり場がなく
むしゃくしゃしてQiitaに投稿してみました。同じことに悩まされている人が時間を無駄にしないよう活用していただければと思います。