- 投稿日:2019-08-29T21:31:47+09:00
Jenkins pipelineでAWS CloudFormationを利用しVPCを構築する
はじめに
JenkinsからAWS CloudFormationを利用しVPCを構築するサンプルです。JenkinsからAWS CLIを利用するやり方はたくさんあります。これはあくまでひとつの例です。
検証環境
OS: CentOS7
Jenkinsのバージョン: 2.1以降
必要なプラグイン: Jenkinsの初期設定画面でインストールされるプラグイン + Pipeline: AWS StepsJenkinsの設定
必要なパッケージ
Jenkinsサーバに以下のパッケージがインストールされている必要があります。
- Git
- AWS CLI
こちらのAnsible PlaybookでJenkinsを構築することも可能です。
Pipeline: AWS Stepsをインストールする
「Jenkinsの管理」→「プラグインの管理」→「利用可能タブ」から AWS CodePipeline を選択しインストールする(Jenkinsサーバ側ではプラグイン名が「Pipeline: AWS Steps」ではないので注意!)
このプラグインをインストールすると他の依存関係にあるプラグインもインストールされる
AWS Credentialsを登録する
AWSのIAMのコンソールでEC2とCloudFormationの実行権限を付与したアクセスキーを作成する
「認証情報」→「システム」→「 認証情報の追加」→「種類」から「AWS Credentials」を選択し「Access Key ID」と「Secret Access Key」を入力する
IDの部分は入力しない
JenkinsへPipelineファイルを登録する
こちらのPipelineファイルを登録していきます。
create-stack/Jenkinsfile#!groovy pipeline { agent any parameters { string( name: 'AWS_CREDENTIALS_ID', defaultValue: '', description: 'AWS credentials id, stored in Jenkins credentials' ) string( name: 'EXTRA_ARGS', defaultValue: '', description: 'aws cloudformation create-stack command extra arguments' ) string( name: 'GIT_BRANCHES_CFN', defaultValue: '*/master', description: "Git branch or tag name or commit id to retrieve of GIT_URL of CloudFormation template file" ) string( name: 'GIT_URL', defaultValue: '', description: "GitHub URL to retrieve CloudFormation template" ) string( name: 'REGION', defaultValue: '', description: 'AWS CLI region name' ) string( name: 'STACK_NAME', defaultValue: '', description: 'CloudFormation stack name' ) string( name: 'TEMPLATE_FILE_PATH', defaultValue: '', description: 'CloudFormation template file path' ) string( name: 'WORKING_DIR', defaultValue: 'cfn', description: 'Job working directory' ) } stages { stage('Initialize wokring directory') { steps { dir ("${params.WORKING_DIR}") { cleanWs() } } } stage('Retrieve CloudFormation template file from Github') { steps { checkout( [ $class: 'GitSCM', branches: [ [ name: "${params.GIT_BRANCHES_CFN}" ] ], extensions: [ [ $class: 'RelativeTargetDirectory', relativeTargetDir: "${params.WORKING_DIR}" ] ], doGenerateSubmoduleConfigurations: false, submoduleCfg: [], userRemoteConfigs: [ [ url: "${params.GIT_URL}" ] ] ] ) } } stage('Create Stack') { steps { withAWS(credentials:"${params.AWS_CREDENTIALS_ID}", region:"${params.REGION}") { dir ("${params.WORKING_DIR}") { // Create Stack sh "aws cloudformation create-stack \ --stack-name ${params.STACK_NAME} \ --template-body file://${params.TEMPLATE_FILE_PATH} \ ${params.EXTRA_ARGS}" // Wait until Stack is created completely sh "aws cloudformation wait stack-create-complete \ --stack-name ${params.STACK_NAME}" // Print CloudFormation create command resutls sh "aws cloudformation describe-stacks \ --stack-name ${params.STACK_NAME}" } } } } } }
- 「新規ジョブ作成」→パイプライン名を入力して「パイプライン」をクリック
- パイプラインで以下を設定
リポジトリURL
Script Path
create-stack/Jenkinsfile
Jobを実行する
作成したJobを一回空実行します。一度実行するとパラメータが指定できる様になります。
パラメータ設定例です。
AWS_CREDENTIALS_IDはJenkinsで発行される一意のIDです。
利用したCloudFormationテンプレートはこちらです。
centos7-hvm.yamlAWSTemplateFormatVersion: '2010-09-09' Parameters: InstanceType: Description: EC2 instance type Type: String Default: t2.micro ConstraintDescription: must be a valid EC2 instance type. KeyName: Description: Name of an existing EC2 KeyPair to enable SSH access to the instances Type: AWS::EC2::KeyPair::KeyName ConstraintDescription: must be the name of an existing EC2 KeyPair. Mappings: StackConfigs: VPC: CidrBlock: 10.0.0.0/16 EnableDnsSupport: 'true' EnableDnsHostnames: 'true' PublicSubnet: AvailabilityZone: "ap-northeast-1a" CidrBlock: 10.0.1.0/24 Name: "10.0.1.0 - ap-northeast-1a" Resources: VPC: Type: AWS::EC2::VPC Properties: CidrBlock: !FindInMap [StackConfigs, VPC, CidrBlock] EnableDnsSupport: !FindInMap [StackConfigs, VPC, EnableDnsSupport] EnableDnsHostnames: !FindInMap [StackConfigs, VPC, EnableDnsHostnames] Tags: - Key: Name Value: !Ref AWS::StackName GatewayAttachment: Type: AWS::EC2::VPCGatewayAttachment Properties: VpcId: Ref: VPC InternetGatewayId: Ref: InternetGateway PublicSubnet: Type: AWS::EC2::Subnet Properties: AvailabilityZone: !FindInMap [StackConfigs, PublicSubnet, AvailabilityZone] CidrBlock: !FindInMap [StackConfigs, PublicSubnet, CidrBlock] MapPublicIpOnLaunch: 'true' VpcId: Ref: VPC Tags: - Key: Name Value: !FindInMap [StackConfigs, PublicSubnet, Name] centos7: Type: AWS::EC2::Instance DependsOn: InternetGateway Properties: BlockDeviceMappings: - DeviceName: /dev/sda1 Ebs: DeleteOnTermination: true VolumeType: gp2 ImageId: ami-045f38c93733dd48d InstanceType: !Ref 'InstanceType' KeyName: !Ref 'KeyName' SecurityGroupIds: - !Ref sshSG - !Ref httpSG SubnetId: Ref: PublicSubnet Tags: - Key: Name Value: !Ref AWS::StackName - Key: ansible_inventory_group_name Value: centos7 - Key: ansible_user Value: centos - Key: ansible_port Value: 22 sshSG: Type: AWS::EC2::SecurityGroup Properties: GroupName: ssh GroupDescription: SSH access rule SecurityGroupIngress: - CidrIp: 0.0.0.0/0 FromPort: 22 IpProtocol: tcp ToPort: 22 VpcId: Ref: VPC httpSG: Type: AWS::EC2::SecurityGroup Properties: GroupName: http GroupDescription: http access rule SecurityGroupIngress: - CidrIp: 0.0.0.0/0 FromPort: 80 IpProtocol: tcp ToPort: 80 VpcId: Ref: VPC InternetGateway: Type: AWS::EC2::InternetGateway Properties: Tags: - Key: Name Value: InternetGateway PublicRouteTable: Type: AWS::EC2::RouteTable Properties: VpcId: Ref: VPC Tags: - Key: Name Value: public PublicRoute: Type: AWS::EC2::Route DependsOn: InternetGateway Properties: RouteTableId: Ref: PublicRouteTable DestinationCidrBlock: 0.0.0.0/0 GatewayId: Ref: InternetGateway PublicSubnetRouteTableAssociation: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: Ref: PublicSubnet RouteTableId: Ref: PublicRouteTable Outputs: VpcId: Value: !Ref VPCJobを実行するとスタックが作成されます。






- 投稿日:2019-08-29T21:02:36+09:00
JAWS-UG コンテナ支部 #15 イベントレポート
はじめに
今日はこれにきました!
— nari@技術書典7? GoとAWSで作る本格slackbot (@fukubaka0825) August 29, 2019
JAWS-UG コンテナ支部 #15 https://t.co/FTwTlTw9op #jawsug_ct
ブログ枠で参加したので、Qiitaで概要をまとめていきたいと思います!!タイムテーブル
時間 内容 登壇者 18:30 受付開始 - 19:00 - 19:05 会場、UG 案内など 19:05 - 19:25 AWS コンテナサービスアップデート トリ / Amazon Web Services Japan 19:25 - 19:55 Amazon ECSの開発環境を動的に管理するツールを作ってみました プログラミングヤクザ / サイバーエージェント 19:55 - 20:00 休憩 --- 20:00 - 20:30 Fargate運用物語 ~ 本当にコンテナで幸せになりますか? ~ 曽根 壮大 / オミカレ 20:30 - 21:00 How Fast can your Fargate Scale? Pahud Hsieh / Amazon Web Services 21:00 終了・撤収 セッション
1. AWS コンテナサービスアップデート by トリ Twitter: @toricls
2019年の AWS コンテナ関連サービスアップデートをササササッと振り返り
- ECS EKS デプロイコントローラーの発表(これでプチカナリアリリースなどがユーザーカスタマイズで可能)
- Amazon ECS で新しいローカルのテストツールが利用可能
- AWS Fargate および Amazon ECS が ECS サービスの外部デプロイメントコントローラーをサポート
- Amazon EKS が Amazon CloudWatch への Kubernetes コントロールプレーンログの配信を開始
- Amazon ECS が awsvpc ネットワークモードの ENI の密度の上限を改善
コンテナワークロードのためのメトリクス・ログモニタリングサービス、CloudWatch Container Insights の Public Preview を発表しました!! #KubeCon
— ポジティブな Tori (@toricls) May 20, 2019
続) pic.twitter.com/pRCZtHexcp
これ、最近パブリックプレビューしてめちゃくちゃありがたい、、(ECS)
https://qiita.com/fukubaka0825/items/a6f5f528771fb63a3192
こう聞いていくとほんと目まぐるしくECS、EKS進化してる
— nari@技術書典7? GoとAWSで作る本格slackbot (@fukubaka0825) August 29, 2019
#jawsug_ct
シークレットとかコンテナ依存関係がないECSなんてもう考えられないもんな。。
— nari@技術書典7? GoとAWSで作る本格slackbot (@fukubaka0825) August 29, 2019
#jawsug_ct
「これからはawsvpcネットワークモード、ガンガンつかっちゃいなYO!!」
— ポジティブな Tori (@toricls) June 7, 2019
Yo! Yo!
/ "ECSにおけるインスタンスのENI制限が大幅に改善されました!! | DevelopersIO" https://t.co/gE5SSJhClM
Fluentdも頼むよ。。。 >Fargate logging
— nari@技術書典7? GoとAWSで作る本格slackbot (@fukubaka0825) August 29, 2019
#jawsug_ct
最近はお仕事でECS使ってるのでだいたい追いかけられてたな
— nari@技術書典7? GoとAWSで作る本格slackbot (@fukubaka0825) August 29, 2019
#jawsug_ct
- toriさんのリリースツイートで一番伸びたのが↓ 笑
これです#jawsug_ct https://t.co/skktRiWFsw
— nari@技術書典7? GoとAWSで作る本格slackbot (@fukubaka0825) August 29, 20192. Amazon ECSの開発環境を動的に管理するツールを作ってみました by プログラミングヤクザ Twitter: @prog893
- (プログラミングヤクザって勝手につけられたらしい。。)
- PRごとに専用のECS環境を動的に作成、削除できるツールを紹介 EDENというツール
- REST風APIとCLIツールの二つ
手動から自動化へ devxx方式の自動化を考える
— nari@技術書典7? GoとAWSで作る本格slackbot (@fukubaka0825) August 29, 2019
- CloudFormation/Terraform/CDK
- IaaCのソース自体がGit管理で、自動コミットとか自動apply 怖い
- のでやめて、自前で増やしたり減らしたりする
#jawsug_ct#jawsug_ct pic.twitter.com/m9M0H1G75c
— Shota Tsuge (@shotaTsuge) August 29, 2019- タップル誕生にEDENを導入
- 作成は3秒 削除は2秒 LoadBalancerを作ってないから
- 自動デプロイでlead timeが短縮できる
- Terraformのdev00以外のdevが消せる
- 今後のロードマップやOSS化について、サイバーエージェントのインフラ周りのツールのOSS化プロジェクトについて紹介
Baikonur Project サイバーエージェントのOSS Project
— nari@技術書典7? GoとAWSで作る本格slackbot (@fukubaka0825) August 29, 2019
Terraform Moduleでチェックしよう
#jawsug_cthttps://t.co/zngFXGBljF
— nari@技術書典7? GoとAWSで作る本格slackbot (@fukubaka0825) August 29, 2019
#jawsug_ctQ「環境のコピーの具体的な方法は?」A「リファレンス環境を都度describeして、可変パラメータ部分を上書きしてAPIを叩く。ここではterraformとかは使わない」 #jawsug_ct
— 濱田孝治(ハマコー) (@hamako9999) August 29, 2019本日の資料です〜https://t.co/gwjgaTKL5o#jawsug_ct
— さわやかな プログラミングヤクザ (@prog893) August 29, 20193. Fargate運用物語 ~ 本当にコンテナで幸せになりますか? ~ by 曽根 壮大(そね たけとも) Twitter: @soudai1025
JAWS-UG コンテナ支部 #15 での登壇資料です #jawsug_cthttps://t.co/RSG0j6s4xA
— そーだい@初代ALF (@soudai1025) August 20, 2019Fargateにしてみた
- 大前提はEC2で困っていること 困ってないならコンテナ、ECS、Fargate必要ない
- オミカレというサービスをやっていて、Fargateで動いている https://party-calendar.net/
- EC2よりもFargateを使いたい
- 根拠なき使用は悪 つらみを積み重ねるだけ
- よくあるEC2で辛かったこと
- AMIやAnsibleの管理
- 手元の環境
- Ansibleで冪等性担保
- どんどんオートスケール時の起動が遅くなる
- AMIのゴールデンディスクも併用する
- そうするとRoleの管理が非常に煩雑になる。。。。
- そもそも冪等性は幻想
- 複雑になったAnsibleのメンテは大変
- 最初にちゃんと設計していることは稀
- スタートアップだと特にそう思う
- 頻繁に環境に手を入れるならコンテナの方が向いている
- バチっと決まっているならAnsibleはとても便利
- VagrantとAnsibleでシンプルなLAMPを維持するのは楽だった - ただ肥大していくと、乱立するVM。。。
- だんだん開発環境と本番環境が肥大化してくる。。
- デプロイツールは昔はエースエンジニアがオレオレで作っていた
- deployをシンプルにしよう
- dockerfileメンテ、コンテナはシンプルにCDできる!!!最高
Fargateで辛かったこと
- 最初の環境構築 知見がなくて失敗。。
- 既存とVPCを容易に分けてしまった
- 作りながら学ぶ状態
- パフォーマンスの計測が甘かった
- ネットワークのdebugが大変
- トラブルシューティング
- デバッグしようとするといない。。
- ログ
- モニタリング
- 永続的に個別でとりたい、、チューニングむずい
Fargateにしてよかったこと
- 開発環境と本番環境の乖離が起きない
- デプロイがシンプルになる
- 本番にあるコンテナは全て同じ
- ロールバックが簡単
- ECRの履歴で戻せる
- コンテナの外に閉じているしホストもないので、EC2より守りやすい
- Stagingや開発環境の複製が簡単
- パートナーにも環境を提供しやすい
- CI/CDの環境構築がより簡単になる
コンテナの勘所
- コンテナの勘所を抑えないと運用は難しい - ログとかモニタリングが非常に難しい
- それ、レンタルサーバでできるよってことよくある
- テスト書く前にコンテナ化するな
- 自分たちの解決したい問題のスコープを大事にする
- コンテナ技術を使うなら仕組みかが重要(状態を持たないからこそ、仕組みかできる) ### まとめ
- 適材適所で自分のユースケースにあった部分をコンテナ化する
- 技術で課題解決する
- 運用のことは考えよう
デバックしようとするといないのめっちゃわかる。。
— nari@技術書典7? GoとAWSで作る本格slackbot (@fukubaka0825) August 29, 2019
#jawsug_ct4. How Fast can your Fargate Scale? by Pahud Hsieh Twitter: @pahudnet
AWS Fargate でスパイキーなトラフィックに対して10秒以内にオートスケーリングをトリガーする話
- Fargateが好きなのはServerless Containerだから
- しかし、どれくらい早くFargateはScaleしてくれる??
- 普通のスケールであれば1~3分くらいはかかる Monitor Detenctionだけで
- iamgeが小さければ小さいほど リージョンがかみ合っていれば それ以降は時間がかからない
- このMonitor Detectionの時間を短縮する
- CloudWatchを使わない
- Step functionがループでイテレーションを回して、監視しているっぽい
オラオラスケールアウトするマンの図 #jawsug_ct pic.twitter.com/rSf2SX9FAw
— ポジティブな Tori (@toricls) August 29, 2019- CDKで2、3行で各リソースが用意される
たったこれだけで Fargate タスクが起動して ALB まで用意されるの楽ですよね #jawsug_ct pic.twitter.com/rTz4JL7gaH
— ポジティブな Tori (@toricls) August 29, 2019- publicに今回のサンプルのソースなどを挙げる予定なので、チェックを!
本人のサンプルコードここにあった https://t.co/2dXFkkwFZO #jawsug_ct https://t.co/wrYbcaPmCl
— Ryo Nakamaru (@pottava) August 29, 2019私もCDKとGoで作るSlack botの本を、CDKの導入部分から書くので是非チェックを
— nari@技術書典7? GoとAWSで作る本格slackbot (@fukubaka0825) August 29, 2019
#jawsug_ct #技術書典7
- 投稿日:2019-08-29T20:37:00+09:00
ECS/Fargate 上のコンテナで使われている AWS Credentials を調べる
ECS/Fargate は便利ですが、この上で動作する ECS コンテナにどんな IAM 権限が割り当てられているかを調べるのは意外と面倒くさく、思わぬ落とし穴にハマりがちです。
Assume Role で動かしていたつもりが予期せず環境変数が設定されていてそちらが使われていた、みたいなことも、稀にあったりします。ここでは簡単に、割り振られている権限を調べる方法について記述していきます。
aws configure list
aws コマンドを用いて、今の動作環境でどのクレデンシャル情報が使用できるかを知ることができます。
$ aws configure list Name Value Type Location ---- ----- ---- -------- profile sada manual --profile access_key ****************SADA shared-credentials-file secret_key ****************ASHI shared-credentials-file region ap-northeast-1 config-file ~/.aws/config
- profile
- access_key
- secret_key
- region
それぞれについて、どこから情報が参照されているかが表示されます。
Type
- env : 環境変数
- shared-credentials-file : 設定ファイル
- iam-role : インスタンスプロファイル
- container-role : ECS に割り当てられたコンテナRole
Fargate で ECS を動作させる際に、 TaskRole に割り当てられた権限がただしくコンテナに AssumeRole されているか確認する場合は、このコマンドの結果で
Type = container-roleがされていることを確認します。$AWS_CONTAINER_CREDENTIALS_RELATIVE_URI
ECS で動かすタスクに TaskRole を割り当てると、その上で動作するコンテナには自動的に
AWS_CONTAINER_CREDENTIALS_RELATIVE_URIという環境変数が割り当てられます。生の EC2 インスタンスでは
169.254.169.254に curl などで接続することでクレデンシャル情報をふくむ様々なメタ情報を取得でき、 AssumeRole の仕組みをこちらを使って実現されています。Docker などのように一つのホスト上に様々に文脈の異なるコンテナを動作させる際にも、同じようにコンテナ間で独立して AssumeRole できるような仕組みを提供する工夫として、
AWS_CONTAINER_CREDENTIALS_RELATIVE_URIのようなコンテナ固有の接続文字列が提供されているのだと思います。https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/task-iam-roles.html
Amazon ECS エージェントは、ロール認証情報を含む追加のフィールドを使用してタスクを開始するペイロードメッセージを受け取ります。Amazon ECS エージェントは、一意のタスク認証情報 ID を識別トークンとして設定し、内部認証情報のキャッシュを更新して、タスクの識別トークンがペイロードで受け取ったロールの認証情報を指すようにします。Amazon ECS エージェントでは、次の相対 URI を使用して、このタスクに属するすべてのコンテナの Env オブジェクト (docker inspect container_id コマンドで利用可能) に AWS_CONTAINER_CREDENTIALS_RELATIVE_URI 環境変数を設定します。/credential_provider_version/credentials?id=task_credential_id
以下のような形で curl で呼び出すと、そのコンテナに割り当てられた TaskRole 権限に基づくクレデンシャル情報が返却されます。
$ curl --max-time 5 169.254.170.2$AWS_CONTAINER_CREDENTIALS_RELATIVE_URI { "RoleArn": "arn:aws:iam::1234567890:role/sada_masashi", "AccessKeyId" : "......", "SecretAccessKey" : "......", "Token" : "......", "Expiration": "2019-08-29T16:21:26Z" }こちらを見ることで、どの IAM Role の権限が割り当てられているか、実際のアクセスキー情報は何か、といったことを知ることができます。
また、
AWS_CONTAINER_CREDENTIALS_RELATIVE_URIに環境変数が設定されていない場合は基本的に TaskRole が設定されていないので、この環境変数の値をチェックするだけでも AssumeRole できる状況にあるのかどうかの判断ができます。ECSコンテナ上でのデバッグ
これらの仕組みを ECS で動かす Docker に仕込んでおくと、意図通りの権限が付与されず正しく動かない際のデバッグに便利です。
私が個人的に ECS を動かす際は、 Docker の entrypoint などに以下の仕組みを入れています。
echo "Verify aws configure list" aws configure list echo "Verify assume role [curl --max-time 5 169.254.170.2${AWS_CONTAINER_CREDENTIALS_RELATIVE_URI}]" curl --max-time 5 169.254.170.2${AWS_CONTAINER_CREDENTIALS_RELATIVE_URI} | jq -r ".RoleArn"
169.254.170.2${AWS_CONTAINER_CREDENTIALS_RELATIVE_URI}を叩いた結果は、すべてをログに残してしまうと Access Key などのクレデンシャル情報が丸見えになってしまうため、ここではRoleArnだけをログに残すようにしています。こういったちょっとした工夫で、期待した権限が付与されていない、もしくは予期せぬ権限が付与されている、という際の原因調査の手がかりになると思います。
Appenditx. credentials provider chain
補足資料として、一応。
AWS の認証情報の解決は、使用しているライブラリなどにより順番が決まっています。
概ね優先順位はどのツールも共通ですが、ツールにより微妙な誤差があります。boto3 (python)
https://boto3.amazonaws.com/v1/documentation/api/latest/guide/configuration.html
- Passing credentials as parameters in the boto.client() method
- Passing credentials as parameters when creating a Session object
- Environment variables
- Shared credential file (~/.aws/credentials)
- AWS config file (~/.aws/config)
- Assume Role provider
- Boto2 config file (/etc/boto.cfg and ~/.boto)
- Instance metadata service on an Amazon EC2 instance that has an IAM role configured.
python のプログラムの中で直接指定する方法が一番優先順位が高く、その後は
- 環境変数
- credential file / config file
- Assume Role
- Instance Profile
という順番は他の SDK などともおそらく共通です。 Boto2 のファイルの読み込みが Assume Role と Instance Profile の間に落ち着いたのは、どういう経緯があったのかは興味深いですが調べていません。
Java SDK
https://docs.aws.amazon.com/ja_jp/sdk-for-java/v2/developer-guide/credentials.html
- Java のシステムプロパティ
- 環境変数
- デフォルトの認証情報プロファイルファイル
- Amazon ECS コンテナの認証情報
- インスタンスプロファイル認証情報
Go SDK
https://docs.aws.amazon.com/ja_jp/sdk-for-go/v1/developer-guide/configuring-sdk.html
- Environment variables.
- Shared credentials file.
- If your application is running on an Amazon EC2 instance, IAM role for Amazon EC2.
記述は簡潔ですが、概ね挙動はほかの言語と同じです。
- 投稿日:2019-08-29T19:39:34+09:00
AWS AthenaでS3にあるCloudTrailのlogsを検索する
はじめに
CloudTrailのログをS3に配置する設定にしています。
CloudTrailでログが確認できるのは過去 7 日間までなので、7日を過ぎるとS3を確認する必要があります。
ただ、必要なファイルを見つけることが困難ですし、見つけてもJSONファイルなので、扱いづらかった感が否めません。
そこで、S3の検索をSQLでできるAthenaを利用して、検索してみましょう!前提条件
- S3バケットが用意済みであること
- S3にて検索するファイルが用意済みであること
- CloudTrailログがS3バケットに出力されるよう設定されていること
- Ahtenaのクエリ性能や課金に関しては考慮しない。なので、Athenaパーティションについては考えない
準備
CloudTrailログのフォーマットを確認して出力したい項目を決める
CloudTrailのログフォーマット{ "Records": [{ "eventVersion": "1.01", "userIdentity": { "type": "IAMUser", "principalId": "ABCDEFGHIJKLMNOPQRSTU", "arn": "arn:aws:iam::123456789012:user/Alice", "accountId": "123456789012", "accessKeyId": "ABCDEFGHIJKLMNOPQRST", "userName": "Alice", "sessionContext": { "attributes": { "mfaAuthenticated": "false", "creationDate": "2014-03-18T14:29:23Z" } } }, "eventTime": "2014-03-18T14:30:07Z", "eventSource": "cloudtrail.amazonaws.com", "eventName": "StartLogging", "awsRegion": "us-west-2", "sourceIPAddress": "72.21.198.64", "userAgent": "signin.amazonaws.com", "requestParameters": { "name": "Default" }, "responseElements": null, "requestID": "12345678-9abc-def0-1234-56789abcdef0", "eventID": "12345678-9abc-def0-1234-56789abcdef0" }, ... additional entries ... ]例では、以下の項目を抽出する。
- eventTime
- eventSource
- eventName
- awsRegion
- sourceIPAddress
- userIdentity
- type
- arn
AhtenaのDB作成
GUIから作成する場合、
Athena > Catalog Manager > Add table
からテーブル情報を入力していく。CUIから作成する場合、
Athena > Query Editor
にて、
DATABASE: (上記で作成したDB)
を選択し、以下のクエリをRun Queryする。DB作成クエリCREATE DATABASE [DB名];例)DB作成クエリCREATE DATABASE s3_cloudtrail_logs_db;Ahtenaのテーブル作成
GUIから作成する場合、
Athena > Catalog Manager > Add table
からテーブル情報を入力していく。CUIから作成する場合、
Athena > Query Editor
にて、
DATABASE: (上記で作成したDB)
を選択し、以下のクエリをRun Queryする。テーブル作成クエリCREATE EXTERNAL TABLE IF NOT EXISTS [テーブル名] ( [カラム] [カラムの型] ) ROW FORMAT SERDE '[形式]' LOCATION 's3://[バケット]/[プレフィックス]/' --region [S3のリージョン] TBLPROPERTIES ('has_encrypted_data' = 'false');
'has_encrypted_data' = 'false':指定されたテーブルのクエリに使用する S3 のデータは暗号化されていないデータであることを Athena に指定する。- 暗号化されていないデータに対してCreate TableをRun Queryすると、
The authorization header is malformed;エラーになる可能性がある。例)テーブル作成クエリCREATE EXTERNAL TABLE IF NOT EXISTS cloud_trail_logs_tokyo ( records ARRAY< STRUCT< eventTime:STRING, eventSource:STRING, eventName:STRING, awsRegion:STRING, sourceIPAddress:STRING, userIdentity:STRUCT< type:STRING, arn:STRING > > > ) ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe' LOCATION 's3://cloudtrail-log/AWSLogs/123456789012/CloudTrail/ap-northeast-1/' --region ap-northeast-1 TBLPROPERTIES ('has_encrypted_data' = 'false');検索
Athena > Query Editor
にて、
DATABASE: (上記で作成したDB)
を選択し、以下のクエリをRun Queryする。limit例SELECT record.eventTime, record.eventSource, record.eventName, record.awsRegion, record.sourceIPAddress, record.userIdentity.type, record.userIdentity.arn FROM cloud_trail_logs_tokyo CROSS JOIN UNNEST(records) AS t (record) limit 10;where例SELECT record.eventTime, record.eventSource, record.eventName, record.awsRegion, record.sourceIPAddress, record.userIdentity.type, record.userIdentity.arn FROM cloud_trail_logs_tokyo CROSS JOIN UNNEST(records) AS t (record) where record.eventTime like '2017-06-19T03:56:%' and record.eventSource = 'ec2.amazonaws.com';おまけ
パーティションの作成
AthenaはQueryでスキャンしたデータの容量による課金が発生する。
また、Athenaをデフォルトのまま利用し、かつQueryでSelect文をかけると、LOCATIONに配置されているファイル全てをスキャンしてしまう。
LOCATIONのS3の容量がかなり大きい場合、毎回検索していると、多額の費用になってしまう。
そのため、1テーブルにパーティションを区切り、QueryのSelect文でWhere句にパーティションを指定すると、パーティション範囲のみを検索することになるので、スキャンするデータの容量を抑えることができる。テーブルの作成(作り直し)
テーブル作成クエリ(パーティション有)CREATE EXTERNAL TABLE IF NOT EXISTS [テーブル名] ( [カラム] [カラムの型] ) PARTITIONED BY([パーティションのカラム] [パーティションの型]) ROW FORMAT SERDE '[形式]' LOCATION 's3://[バケット]/[プレフィックス]/' --region [S3のリージョン] TBLPROPERTIES ('has_encrypted_data' = 'false');例)テーブル作成クエリ(パーティション有)CREATE EXTERNAL TABLE IF NOT EXISTS cloud_trail_logs_tokyo ( records ARRAY< STRUCT< eventTime:STRING, eventSource:STRING, eventName:STRING, awsRegion:STRING, sourceIPAddress:STRING, userIdentity:STRUCT< type:STRING, arn:STRING > > > ) PARTITIONED BY(year string, month string, day string) ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe' LOCATION 's3://cloudtrail-log/AWSLogs/123456789012/CloudTrail/ap-northeast-1/' --region ap-northeast-1 TBLPROPERTIES ('has_encrypted_data' = 'false');パーティションの追加
Athena > Query Editor
にて、
DATABASE: (上記で作成したDB)
を選択し、以下のクエリをRun Queryする。パーティションの追加ALTER TABLE [テーブル名] ADD PARTITION (year='[設定値]',month='[設定値]',day='[設定値]') location 's3://[バケット]/[プレフィックス]/';例)パーティションの追加ALTER TABLE cloud_trail_logs_tokyo ADD PARTITION (year='2017',month='06',day='19') location 's3://cloudtrail-log/AWSLogs/123456789012/CloudTrail/ap-northeast-1/2017/06/19/';登録済みパーティションを確認する
パーティション確認クエリSHOW PARTITIONS [テーブル名];例)パーティション確認クエリSHOW PARTITIONS cloud_trail_logs_tokyo;検索(パーティション含め)
where句の最初の方にパーティションの指定をする。
where例SELECT record.eventTime, record.eventSource, record.eventName, record.awsRegion, record.sourceIPAddress, record.userIdentity.type, record.userIdentity.arn FROM cloud_trail_logs_tokyo CROSS JOIN UNNEST(records) AS t (record) where year='2017' and month='06' and day in ('18','19') and record.eventTime like '2017-06-19T03:56:%' and record.eventSource = 'ec2.amazonaws.com';Athena > History > Data scanned
にて、スキャンした容量が減っていることが確認できます。参考資料
- 投稿日:2019-08-29T16:59:57+09:00
SAM meets CDK?
ハロー、AWS! 君はもう、バッチリCDKでStackを育てたかい?
たっぷり作り込んだ君もまだまだの君も、IaCの歓びに貴賤はない! 一緒にノウハウを分かち合おう!
今回はCDKの運用にAWS SAMを絡めるとどーなるのか、いってみよう!CDKの基本についてはこのへんを頭から読んでもらうのがイチバンだけど、SAMやCFnに不慣れな場合には、かんたんにでもCFnから始めてもらう方がいいかも知れないね。
先にまとめ
- StackおよびLambda関数のコードはCDKで管理
- 主にローカルでのデバッグ、実行にSAM CLIを使う
- CDKから
synthしてCFnテンプレートを生成した後、sam local系のコマンドが使える
- invoke
- start-lambda
- start-api (
AWS::Serverless::Functionリソースの定義が必要)- その他、LambdaのパッケージングやデプロイはCDKから実行する・・・ことになりそう
そもそもSAMでできることおさらい
- CFnリソースタイプの拡張機能
- 統合されたAPI Gateway + Lambdaのリソースタイプ等
- CDKで言うところの
AWS Constructに近いもの- このへん
- Lambda関数およびAPI Gatewayをローカル環境にデプロイ、実行する機能
- ランタイム環境のコンテナ作成と実行
- 定義したLambda関数および周辺リソースを含めたStackのデプロイ
- その他
- AWS Serverless Application Repository にpublishする機能とか
この中で、CDKは1, 3の機能をカバーしている(要プラグイン)から、CDKからSAMが2の機能を実行するために使えるCFnテンプレートを生成して、それをSAM CLIで使うことになるんだよ。ワクワクするね!
やってみた
まずはサンプルプロジェクトの雛形を作ろう。今回はpythonを使うよ。
$ mkdir cdk-sam-sample $ cd cdk-sam-sample $ cdk init app --language=pythonvirtualenvで環境を切り替えて、
aws-samパッケージをインストールしよう。$ source .env/bin/activate (.env) $ pip install -r requirements.txtrequirements.txtはこんな感じで。
-e . aws-cdk.aws-sam生成されるpythonのソースファイルはこんな感じだ。
app.py
#!/usr/bin/env python3 from aws_cdk import core from cdk_sam_sample.cdk_sam_sample_stack import CdkSamSampleStack app = core.App() CdkSamSampleStack(app, "cdk-sam-sample") app.synth()生成されたpythonのスタック定義に、SAMの拡張リソースを作ってみよう!
cdk_sam_sample/cdk_sam_sample_stack.py
from aws_cdk import core, aws_sam as sam class CdkSamSampleStack(core.Stack): def __init__(self, scope: core.Construct, id: str, **kwargs) -> None: super().__init__(scope, id, **kwargs) function = sam.CfnFunction( self, "HelloWorldFunction", runtime="python3.7", handler="app.lambda_handler", code_uri="lambda_functions/", events={ "HelloWorld": { "type": "Api", "properties": {"method": "get", "path": "/hello"}, } }, )CDKのコードが準備できたら、今度はLambda関数を準備するよ。
$ mkdir lambda_functionslambda_functions/app.py
import json def lambda_handler(event, context): return { "statusCode": 200, "body": json.dumps( { "message": "hello world", } ), }さぁ、準備はいいかな? 早速、テンプレートを生成してみよう!
(.env) $ cdk synth --no-staging > template.ymltemplate.yml
Transform: AWS::Serverless-2016-10-31 Resources: HelloWorldFunction: Type: AWS::Serverless::Function Properties: CodeUri: lambda_functions/ Handler: app.lambda_handler Runtime: python3.7 Events: HelloWorld: Properties: {} Type: Api Metadata: aws:cdk:path: cdk-sam-sample/HelloWorldFunction CDKMetadata: Type: AWS::CDK::Metadata Properties: Modules: aws-cdk=1.6.0,@aws-cdk/aws-sam=1.6.0,@aws-cdk/core=1.6.0,@aws-cdk/cx-api=1.6.0,jsii-runtime=Python/3.7.4(2019-08-29現在)
Propertiesが意図した通り生成されないようなので、下記のように修正。Properties: Path: /hello Method: getちゃんとテンプレートは生成できたかな? いよいよ、SAM CLIでローカル環境にAPIサーバを起動するよ!
$ sam local start-apiこの状態で、
http://127.0.0.1:3000/helloにGETリクエストを送ると、コンテナが起動してレスポンスが返ってくるはずだ。$ curl http://127.0.0.1:3000/hello {"message": "hello world"}やったね!
( ・∀・)イイ!!
- CDKでSAMの拡張リソースタイプも使える
- API Gateway + Lambdaのローカル環境が簡単に作れる
- SAMではやりきれなかったStackの管理がCDKでできる
( ・A・)イクナイ!!
aws_cdk.aws_samパッケージがまだベータ版
Propertiesフィールドが上手く生成されないので、まだ使えない・・・こーするのがいいと思う
- Stackの管理、運用はCDKに乗っていくのが良さそう
- SAMの拡張も使えるけど、もうちょい様子見
- ローカル開発環境はSAM CLIでサクサク作っていこう
使い終わったStackは、30分以内に
cdk destroyだ!
- 投稿日:2019-08-29T16:27:08+09:00
CodeCommitの認証エラー(403)で躓いたのでドキュメントを読んで対応したときの作業ログ
Github でソースコードを管理している、サーバー環境は AWS で、 CodeCommit へ push したら CodePipelineが動くよう設定されている。
という状況で、CodeCommitにpush(もpullも)できず認証エラーで悩んだときの作業記録https://docs.aws.amazon.com/ja_jp/codecommit/latest/userguide/troubleshooting-ch.html
AWSのドキュメントを読んだ
$ git config -l --show-origin |grep osxkeychain file:/usr/local/etc/gitconfig credential.helper=osxkeychaingitconfigの親玉が見つかったので、開いて編集
[credential] # helper = osxkeychainhelperの設定をコメントアウトした。
さらに
Keychain Access.appで CodeCommit の該当のエントリー(有効期限が切れている)を削除。これで CodeCommit へは gitアクセスできるようになった。
しかし代わりに Githubへgitコマンドでアクセスすると、毎度ユーザー名とパスワードを聞かれるようになってしまった。
さすがにそれは煩わしい。~/.gitconfig へこれを追加
[credential "https://github.com"] helper = osxkeychain無事、いままでどおりにgithubを使えるように戻った。
個人的にはGitlabも使うのでgitlab.comへも同じように osxkeychain を使うように設定しておいた。
- 投稿日:2019-08-29T16:11:16+09:00
猿でもできるOpenShift4インストール編
はじめに
OpenShift4クラスターをAWS上に構築してみます。
多少AWSの知識は必要になるものの,インストール手順は(ガチで)猿でも分かるレベルで簡単でした。少しばかりその手順を記載してみます。
ご注意:
2019/6/10時点の私のインストールメモをベースに記載しています。
適宜アップデートしていますが古い情報もあります。ご了承ください。OpenShift4のインストール方法について
IPIによるインストール,UPIによるインストールの2つの方法があります。
詳しくは公式ドキュメントを参照ください。
- IPI (Installer-Provisioned Infrastructure)
- デフォルト設定を使用してOpenShift4インストーラーがインフラ環境を準備してインストールする方法
- 対応クラウドプロバイダー
- AWS
- Azure
- GCP (Tech Preview)
- UPI (User-Provisioned Infrastructure)
- ユーザー独自に準備したインフラ環境にインストールする方法
- 対応プラットフォーム
- AWS (CloudFormationテンプレート利用)
- vSphere
- ベアメタル
事前準備
- Emailアドレス
- クレジットカード
- ブラウザ (Chrome or Firefox)
- ターミナル (e.g. iTerm2)
※わざわざ書くべきか悩みましたが一応・・・
OpenShift4クラスターの構築手順
IPIでOpenShift4をAWS上にインストールする場合は以下のように進めます。
- Red Hat Customer Portalのアカウントの準備 ※初回のみ
- AWSアカウントの準備 ※初回のみ
- AWS IAMユーザーの作成と権限,認証情報の確認
- AWS Route53サービスの作成
- AWSリソースの制限緩和
- AWS CLIのセットアップ
- OpenShift4のインストール
- インストーラー(openshift-install)取得
- install-config.yaml作成
- インストール
1) Red Hatアカウント Customer Portalアカウントの準備
OpenShift4のインストールに必要なクレデンシャル情報などを取得するために必要です。
Red Hatページにアクセスし,[Log in your Red Hat account] > [Red Hat アカウントをお持ちでないお客様] からいくつかの項目を入力し,アカウントを作成します。
図: Red Hat Customer Portal アカウントの作成2) AWSアカウントの準備
2-1) AWSアカウントの作成
OpenShift4をインストールする際に必要なEC2やロードバランサーなどのAWSリソースを利用するために必要です。AWSページにアクセスして作成しましょう。
2-2) AWS IAMユーザーの作成と権限,認証情報の確認
インストール作業を行うユーザー用にIAMユーザーを作成します。作成時に適切な権限(“Programmatic access” のアクセス権限と,“AdministratorAccess” のポリシー)を付与しましょう。なお,IAMユーザーの作成は必須ではありませんが,AWSアカウントにはアカウント作成に使用したメールアドレスに基づくrootユーザーアカウントが含まれており,高い権限が含まれています。このため,初期アカウントおよび請求設定のみに使用することが推奨されています。
参考までに以下にて,IAMユーザーの作成および権限付与について手順を記載しますが,基本的にはAWS公式ドキュメントに従ってユーザー作成などの操作を行ってください。
- IAMユーザーの作成と権限付与の手順
- IAMページを開き,[ユーザー]>[ユーザーを追加]を開きます。ユーザー名に任意の名前(図例では “capsmalt-aws”)を指定し,「プログラムによるアクセス」,「AWSマネジメントコンソールへのアクセス」にチェックを入れ,[次のステップ:アクセス権限]に進みます。
- [既存のポリシーを直接アタッチ]を開き,「AdministratorAccess」にチェックを入れて,[次のステップ:タグ]に進みます。
- デフォルト値のままで,[次のステップ:確認]に進みます。
- デフォルト値のままで,[ユーザーの作成]と進みます。
図: AWS IAMユーザーの作成と権限設定以上の操作でIAMユーザーが作成され,“AWS IAMユーザー認証情報” が表示されます。
図: AWS IAMユーザー認証情報“アクセスキーID”,”シークレットアクセスキー” はAWS CLI(後述)からAWSリソースを制御するために必要になりますので,忘れずにメモしておきましょう。「.csvのダウンロード」を選択して認証情報をローカルに保存しておくと便利です。
(参考) OpenShift4インストールに必要なパーミッション
2-3) AWS Route53のサービスの作成
OpenShift4クラスターに外部から接続するために必要です。既に利用可能なドメインがあれば新規に取得する必要はありません。取得したドメインは,後ほどOpenShift4インストーラーを実行する際に指定しますのでメモしておきましょう。(e.g. “capsmalt.net”)
- Route 53でドメイン登録
- AWSにログインし,[サービス]>[Route 53]>[ドメインの登録-今すぐ始める]>[ドメインの登録]を開きます。
- 任意のドメイン名を決めて,[チェック]>[カートに入れる]>[続行]と進めて,決済など契約手続きを行います。
- ドメインの自動更新の[無効化]を選択し,規約を確認してチェックを入れます。また登録者のメールアドレスに送られる通知の確認も行います。最後に[購入の完了]を選択します。
- ドメイン登録のステータスが進行中から成功に変わるのを待ちましょう。(30分程度かかりました)
図: Route 53サービスでドメイン登録(参考) Route 53サービス
2-4) AWSリソースの制限緩和 (デフォルト構成の場合は不要 as of 2019/8/16)
AWSアカウント作成直後の状態ではリソース利用量に対して制限がかかっているため,制限緩和の作業が必要になる場合があります。OpenShift4をインストールするために必要なリソースは “OpenShift Limits Calculator” で確認できます。2019年8月16日時点では,AWSアカウントの初期状態でもOpenShift4をデフォルト構成でインストール可能です。一方で,カスタマイズ構成でクラスター構築する場合や,複数クラスターを構築するなど,多量のリソースが必要になる場合は事前にAWSサポート窓口経由で制限緩和リクエスト挙げる必要があります。
(参考) OpenShift4のインストールおよび実行に影響を与えうるAWSリソース制限
(参考) OpenShift Limits Calculator
(参考) AWS東京リージョンの制限
(参考) AWS制限緩和のリクエストページ2-5) AWS CLIのセットアップ
OpenShift4インストーラー(3-1にて後述)がAWSアカウントの認証情報を使用するために構成しておく必要があります。
$ aws configureを実行して,2-2で取得したアクセスキーID,シークレットアクセスキーを指定します。またリージョン(東京の場合は ap-northeast-1)も指定しましょう。
図: AWSアカウントの認証情報の構成(CLI)3) OpenShift4のインストール
3-1) インストーラー取得とクレデンシャルの準備
最初にIPIインストールを実行するためのインストーラーと,クレデンシャル情報を用意します。Red Hat Customer Portalアカウントにログインし,AWSへのIPIインストールから取得します。
OpenShift4インストーラー(openshift-installコマンド) は,OpenShift4をIPIという方法でインストールする際に必要です。インストール操作を行うクライアントOS(linux or mac)に合わせたインストーラーを取得します。
図: OpenShift4インストーラー (linux or mac)以下のように実行して展開し,openshift-installコマンドを実行できるようにしておきます。
$ tar xzf openshift-install-mac-4.1.9.tar.gzクレデンシャル情報(Pull-Secret) は,OpenShiftクラスターを管理する際に使用されるためRed Hat アカウント毎に異なります。openshift-installコマンドを実行した際に入力します。
図: クレデンシャル情報(Pull-Secret)3-2) インストール用Configファイルの作成 (install-config.yaml)
必要な情報は揃いましたので,図の実行例を参考にOpenShift4をAWS上にインストールしてみましょう。
まずはインストールに使用する構成情報(install-config.yaml)を作成します。
図: openshift-install create install-config 実行イメージ上記を実行した際に作成されるinstall-config.yamlは以下です。
apiVersion: v1 baseDomain: capsmalt.net compute: - hyperthreading: Enabled name: worker platform: {} replicas: 3 controlPlane: hyperthreading: Enabled name: master platform: {} replicas: 3 metadata: creationTimestamp: null name: ocp4-aws networking: clusterNetwork: - cidr: 10.128.0.0/14 hostPrefix: 23 machineCIDR: 10.0.0.0/16 networkType: OpenShiftSDN serviceNetwork: - 172.30.0.0/16 platform: aws: region: ap-northeast-1 pullSecret: '{"auths":{"cloud.openshift.com":{"auth":"XXX","email":"capsmalt@gmail.com"},"quay.io":{"auth":"XXX","email":"capsmalt@gmail.com"},"registry.connect.redhat.com":{"auth":"XXX","email":"capsmalt@gmail.com"},"registry.redhat.io":{"auth":"XXX","email":"capsmalt@gmail.com"}}}'OpenShift4を構築するコマンドを実行した際にinstall-config.yamlは,自動削除されてしまいますのでバックアップを取っておきましょう。(例:
$ cp -p install-config.yaml{,.org})Tips:
クラスター構成のカスタマイズ
$ openshift-install create install-configで作成された install-config.yamlを編集してから,$ openshift-install create clusterを実行することで行なえます。初期状態ではMasterノード3台,Workerノード3台の計6台構成でOpenShift4クラスターは構築されます。例えば,Workerノードを6台に変更する場合は以下のようにyamlを編集します。編集前: compute: - hyperthreading: Enabled name: worker platform: {} replicas: 3 編集後: compute: - hyperthreading: Enabled name: worker platform: {} replicas: 6他にもEC2インスタンスのタイプをm4.largeからm4.xlargeに変更したり,リージョンやゾーンを指定するなど様々なカスタマイズが行えます。
3-3) OpenShift4クラスターのインストール
AWS上にOpenShift4を構築するコマンド(
$ openshift-install create cluster)を実行します。
クラスター構築完了までに3-40分ほどかかります。
図: $ openshift-install create cluster 実行イメージTips:
ログの確認 (.openshift_install.log)ログはコマンド実行ディレクトリに生成されます。
$ tail -f .openshift_install.logなどでログを追ってみるのも良いかもしれません。以下のような文字列(URLおよびログイン情報)の出力が確認できればクラスター構築は完了です。
- Kubernetes API (Master):
https://api.ocp4-aws.capsmalt.net:6443- Console:
https://console-openshift-console.apps.ocp4-aws.capsmalt.net- ログインユーザー: kubeadmin
- ログインパスワード: Nmp83-XXXXX-XXXXX-YHtst
図: クラスター構築完了時点の出力イメージインストールに失敗した場合は,「Tips: OpenShift4インストールに失敗した場合の前処理」を参照ください。AWSリソース不足では無い場合は,何度か繰り返しトライしてみてください。
AWSアカウントを作成した直後の状態では,リージョンやリソースの準備ができていないせいか,うまくクラスター作成できない場合があります。あくまで経験上の話にはなりますが,作成したばかりのAWSアカウントの場合は,2,3回トライするとクラスター作成が無事成功するようになりました。Tips:
OpenShift4インストールに失敗した場合の前処理
OpenShift4のインストールに失敗し,エラー末尾に以下のようなメッセージが出力される場合があります。
"failed to fetch Cluster: failed to generate asset \"Cluster\": failed to create cluster: failed to apply using Terraform"例えば,AWSの指定リージョンの準備が出来ていない場合や,AWSリソースの制限にかかるケースなどいくつかのパターンが考えられます。
この場合,エラーメッセージを参考に対処した上で再インストールの作業が必要です。再インストールする際は,以下を忘れずに実施しましょう。$ openshift-install destroy cluster # AWS上のOpenShift4関連のリソースを削除 $ rm terraform.tfstate # Terraformのstateファイルの削除 $ cp install-config.yaml.org install-config.yaml # OpenShift4構成ファイルのコピー 上記を実行後に,再度インストールコマンドを実行 $ openshift-install create cluster # 再インストールOpenShift4のアンインストール
ずっと放置するとコストがかかるので,不要になれば削除しておきましょう。
インストールコマンド(
$ openshift-install create cluster)を実行したディレクトリで以下を実行します。Terraformでいっきに削除されます。$ openshift-install destroy cluster念の為,AWSのダッシュボード上で,EC2やESB,ELBなどが削除(あるいはTerminatingで削除中)になっていることも確認しておきましょ〜。もしミスったら・・・・ポチポチとAWSコンソールで削除しましょう。
まとめ
OpenShift4クラスターは,インストール用のConfig作成(コマンド実行)と,インストール(コマンド実行)だけでAWS上に構築できました。同じようにAzureやGCP(Tech Preview)にも構築できるようなのでトライしてみようと思います。
Kubernetesクラスターのインストール,アンインストール,バージョンアップ,マイグレーション,などクラスター自体の運用のツラミを減らせそうなのは嬉しいです。その辺はまた今度試してみます。
余談
AWS経験も無く,Red Hatにゆかりも無い私の友人Aも迷うこと無くOpenShift4を無事インストールできました。
(猿ではないですがw)「マネージドKubernetesみたいに使える(使えそうな)のは良いですな〜」 by 友人B











- 投稿日:2019-08-29T15:27:51+09:00
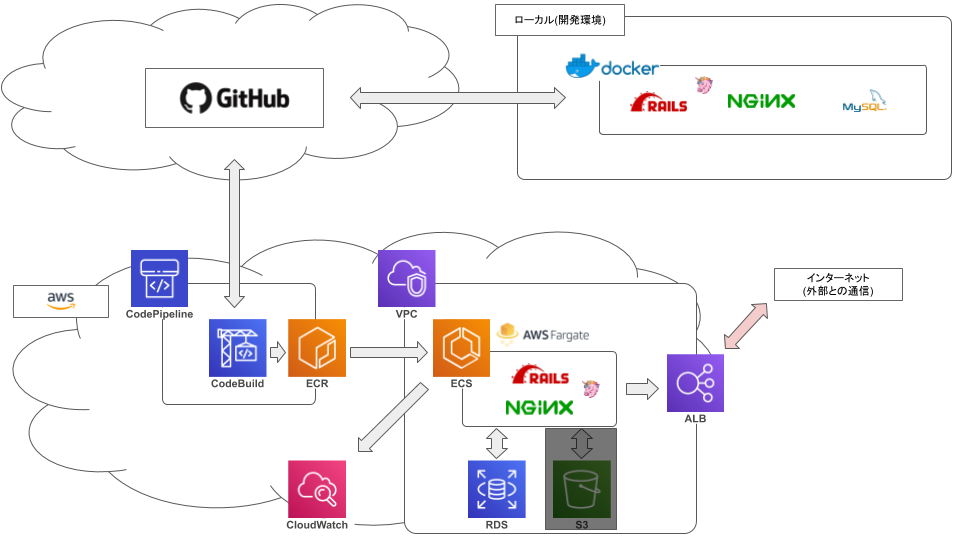
ECS FargateでRails動かそうとして2ヶ月かかって手元に残ったもの【3.Fargate編】
弊社の基幹システムをVPSからAWSに移行するにあたって、まずはrailsを動かしてみる、という段階で無事に死にました☆
今後のための備忘録です。前記事:ECS FargateでRails動かそうとして2ヶ月かかって手元に残ったもの【2.Build編】
前回まででやったこと
今回やったこと
今回はいよいよコンテナをfargteで動かして、ALBも用いて公開してみようと思います。
VPC
今回はデフォルトのものを使います。
RDS
- エンジンのタイプはmysqlで設定して、バージョンも合わせます。
- データベースの承認情報は
docker-composeファイルなどで設定した環境変数と合わせます。- VPCはデフォルトのもの、セキュリティグループはデフォルトを消して新規作成します。
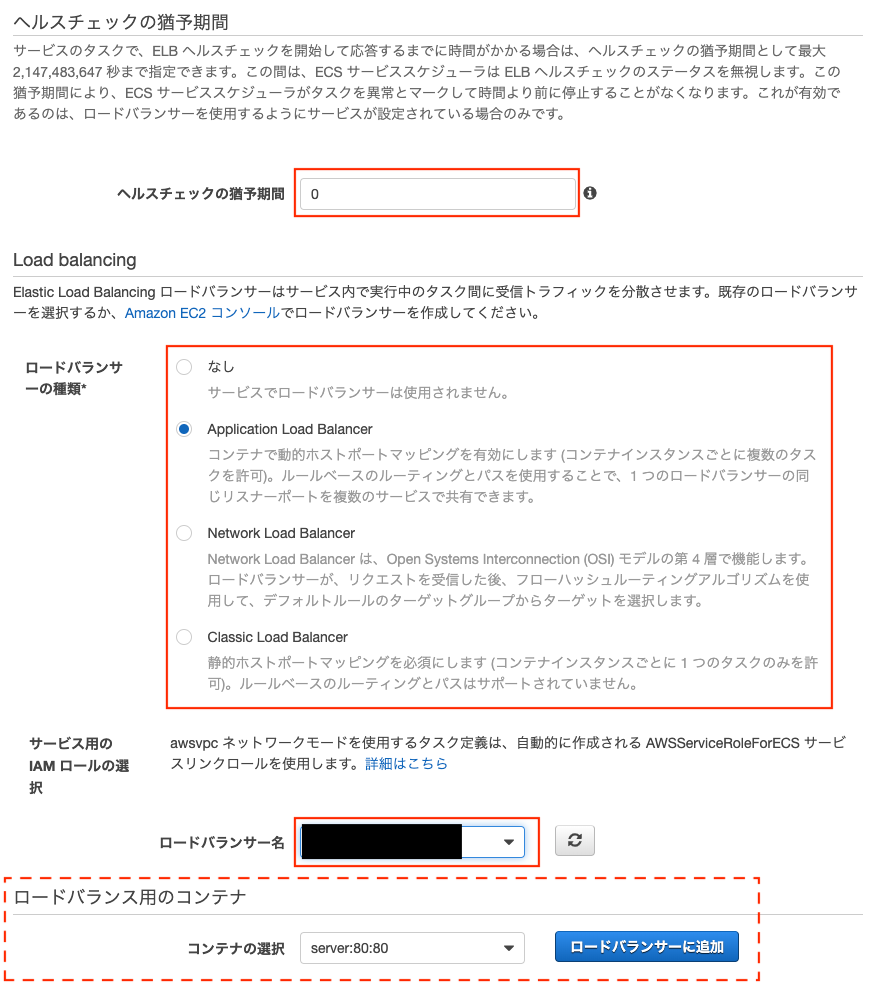
ALB
「サービス」 → 「ES2」 → 「ロードバランサー」を選ぶ。
アベイラビリティーゾーンは全てにチェックを入れます。
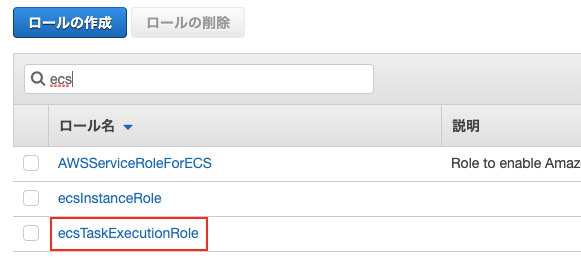
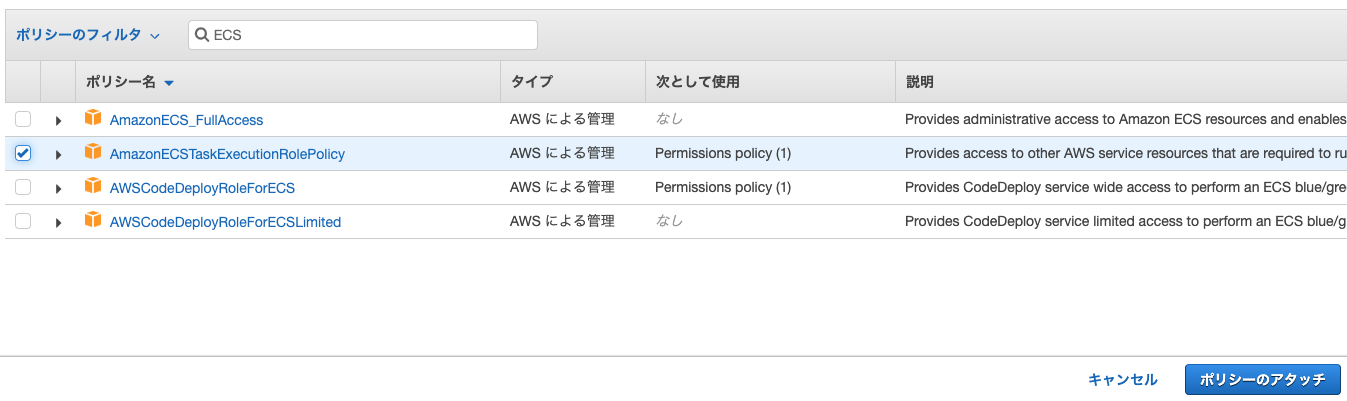
IAM
ECSのアクセス権限を設定します。
「サービス」 → 「IAM」 → 「ロール」 → 検索ボックスに「ecs」と入力して、「ecsTaskExecutionRole」を選択
ECS
「サービス」 → 「ECS」
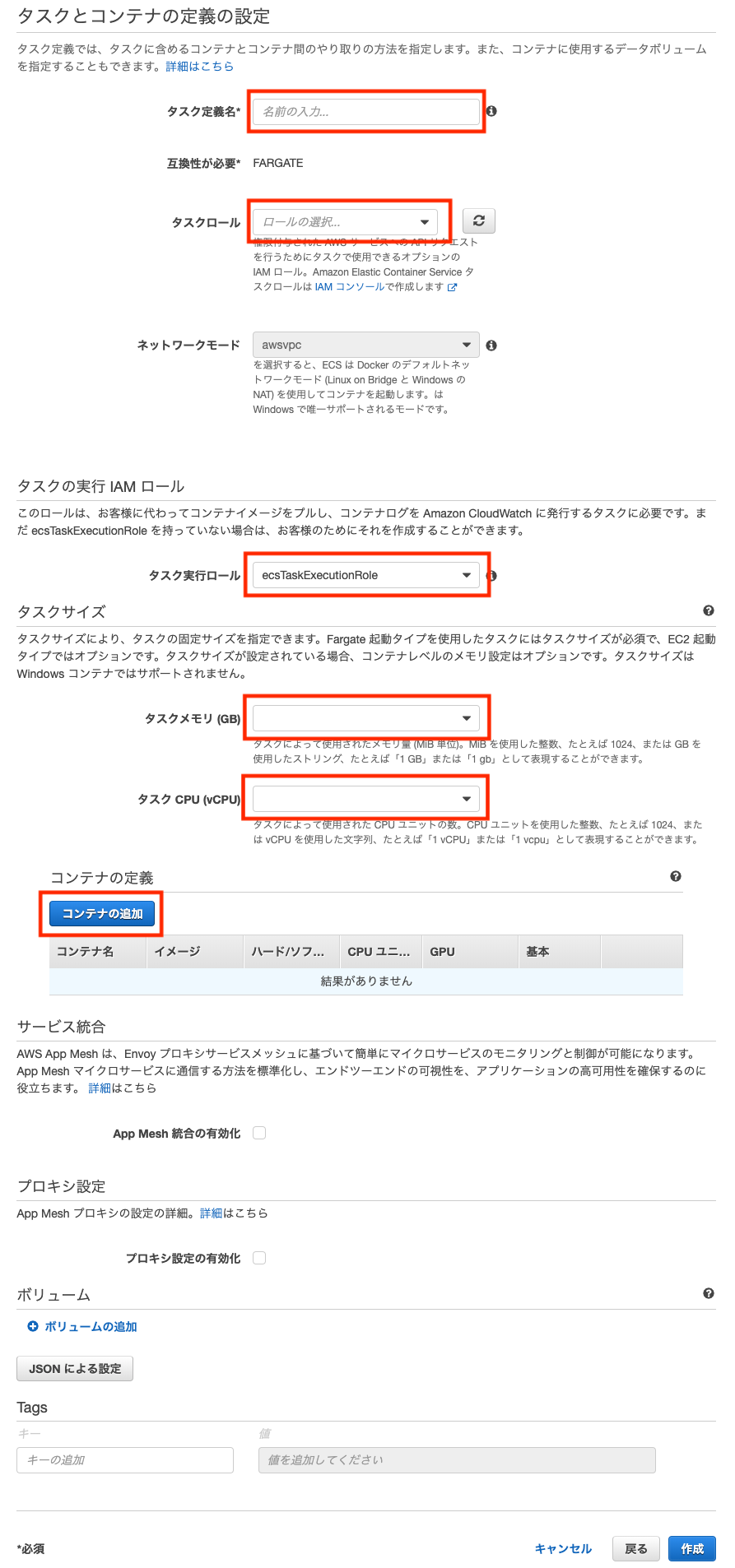
タスク定義
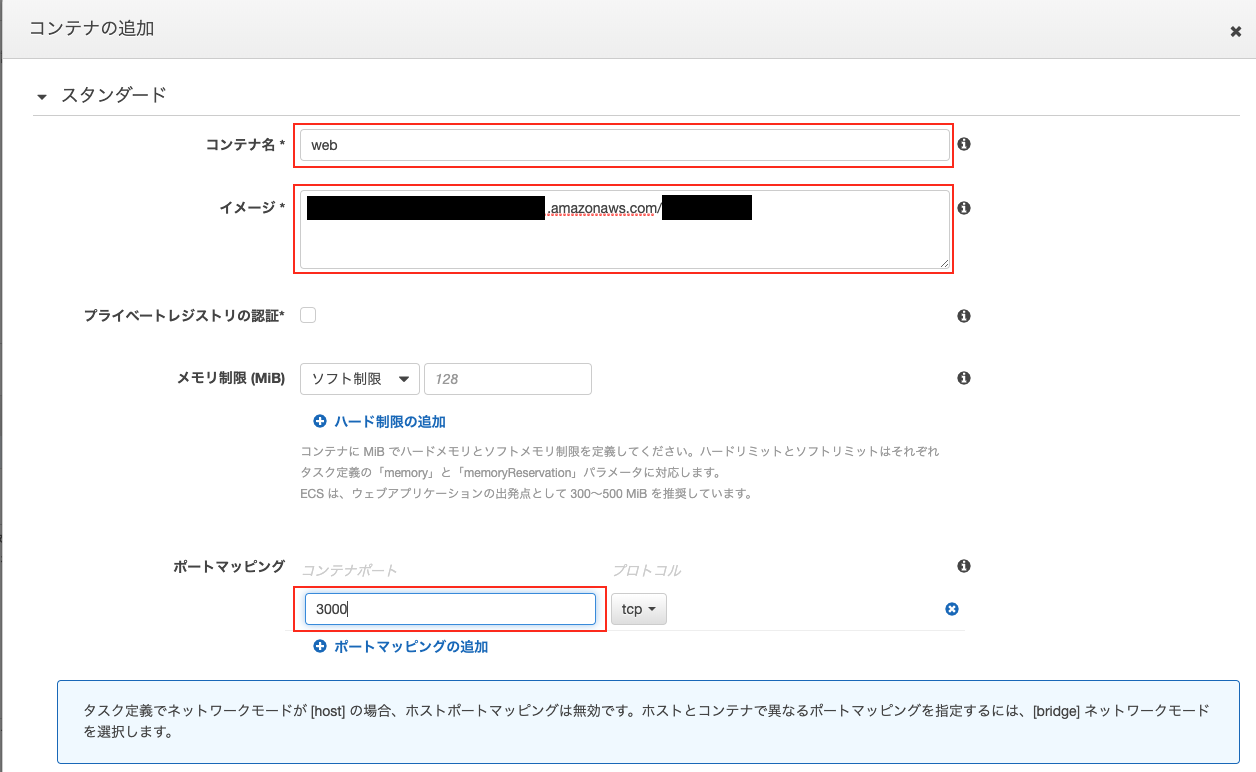
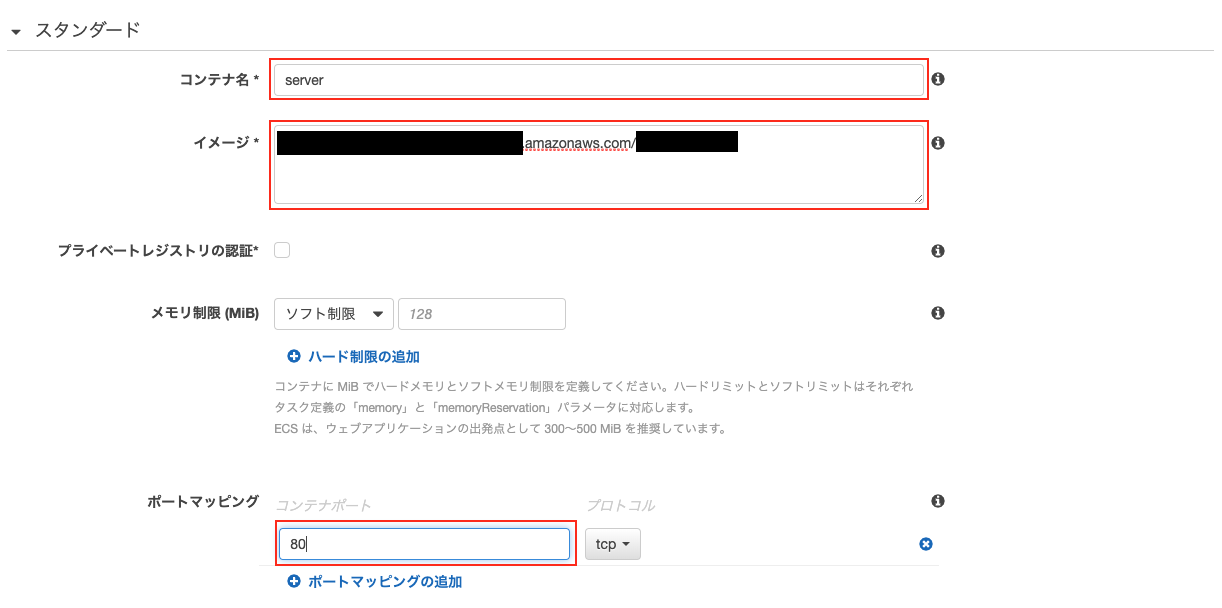
「コンテナの追加」がポイントになります。
ECRで設定した「web」と「server」のリポジトリをそれぞれ指定します。
web
server
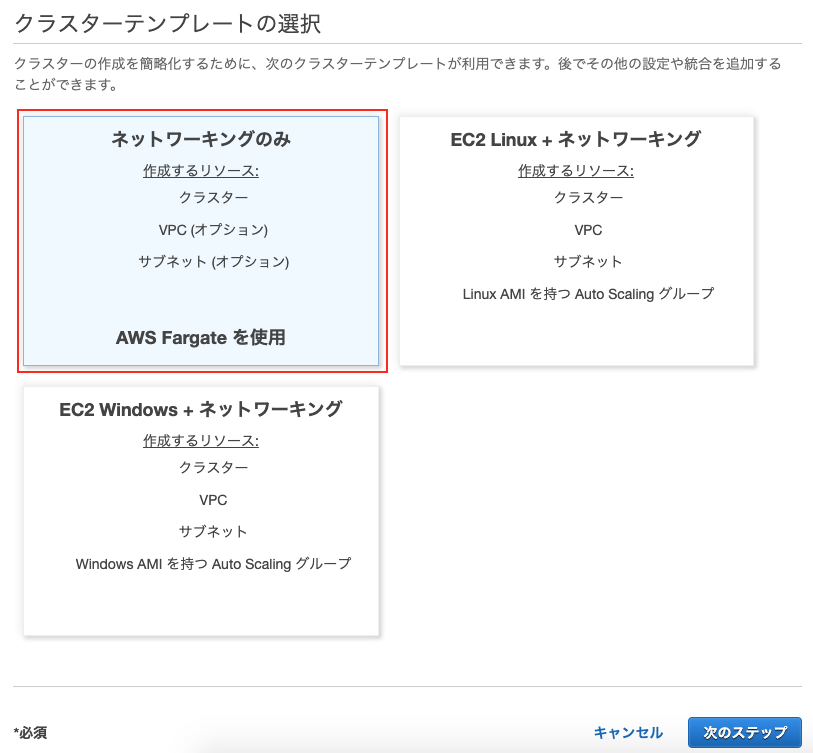
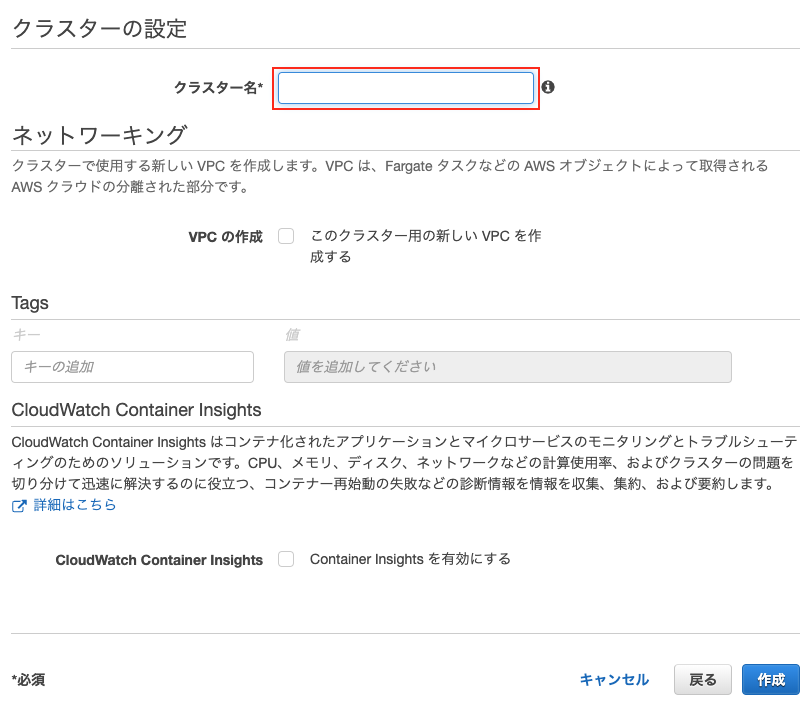
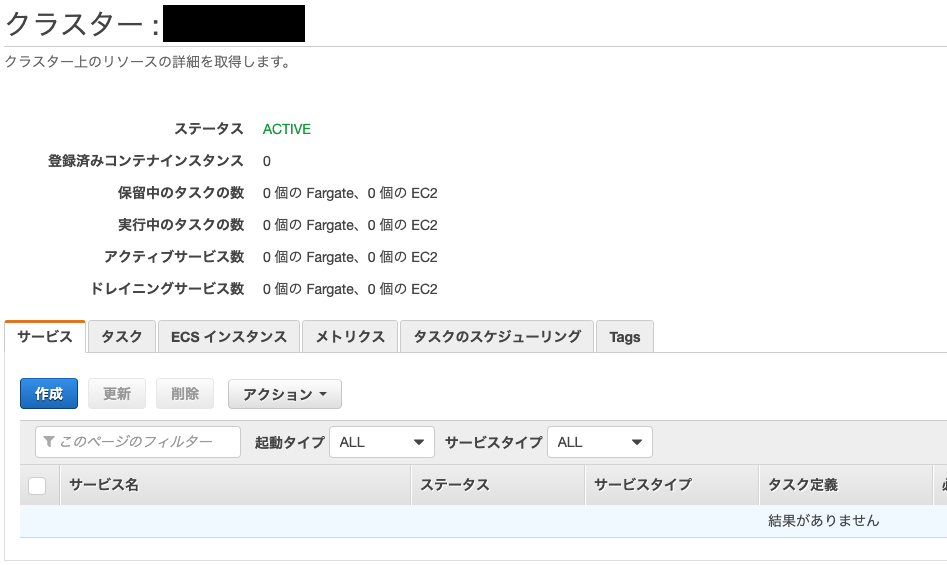
クラスター
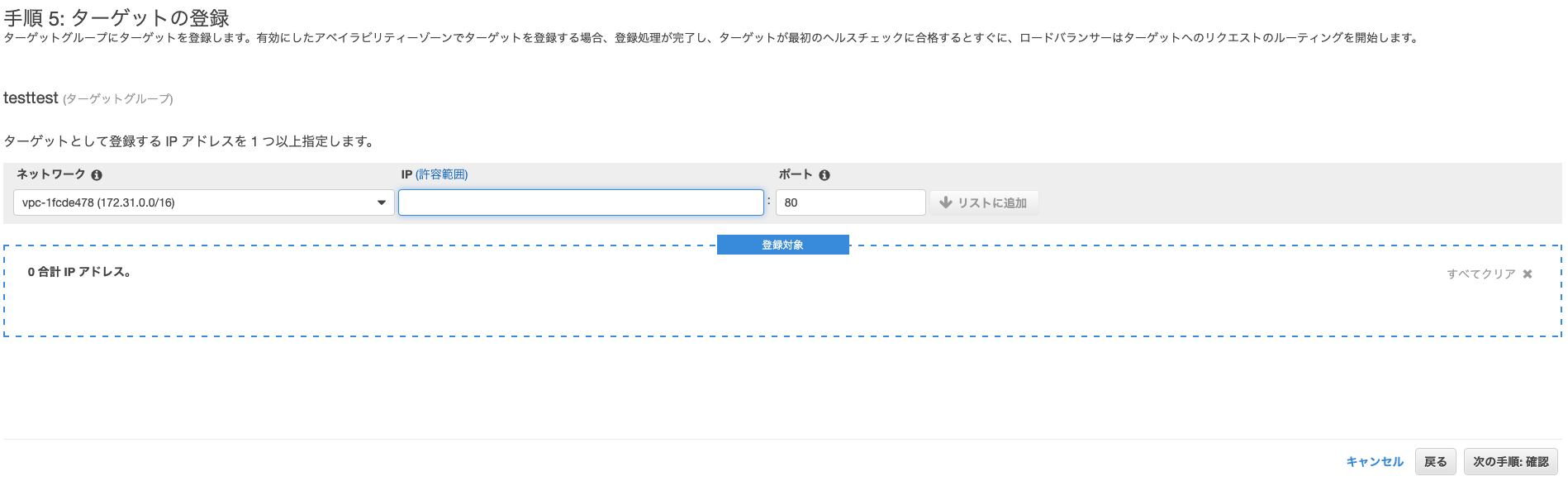
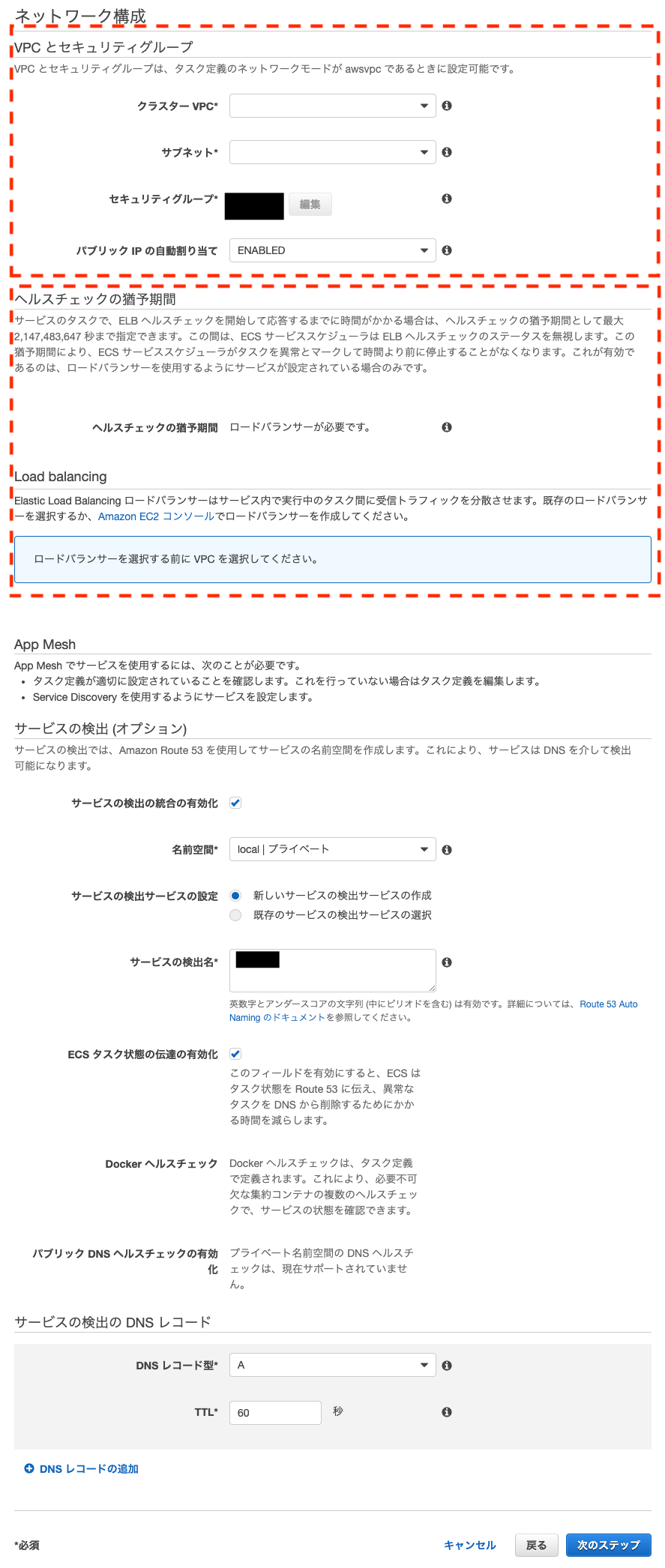
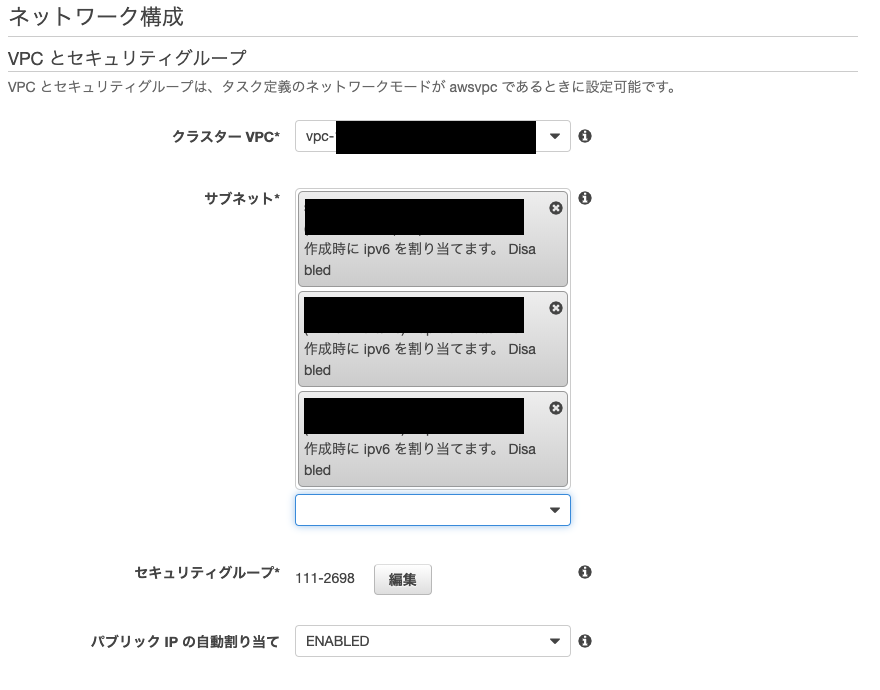
サービス
VPCを設定します。(点線部上)
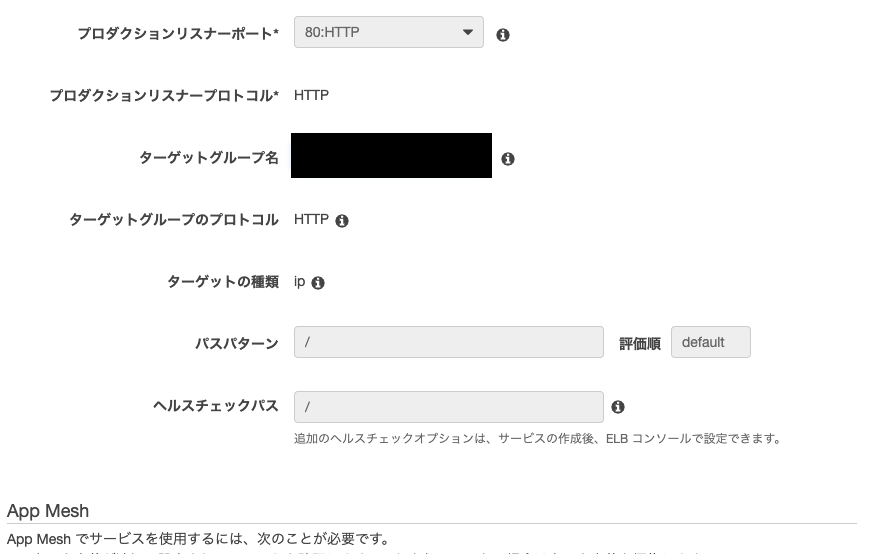
次にロードバランサーも設定します。
これでサービスを動かせば、ひとまず設定は完了です。
起動確認
「サービス」 → 「EC2」 → 「ロードバランサー」 を選択して下部のメニューにアドレスがあるのでそこからコピペしましょう。
最後に
私自身、手探りで2ヶ月かかって、やっと起動にこぎつけました。
まだまだ設定が十分でない部分はあると思います。
今後も自分自身の備忘録として、更新を続けていきたいと思います。ここまでできたこと
次記事:S3編。。。?
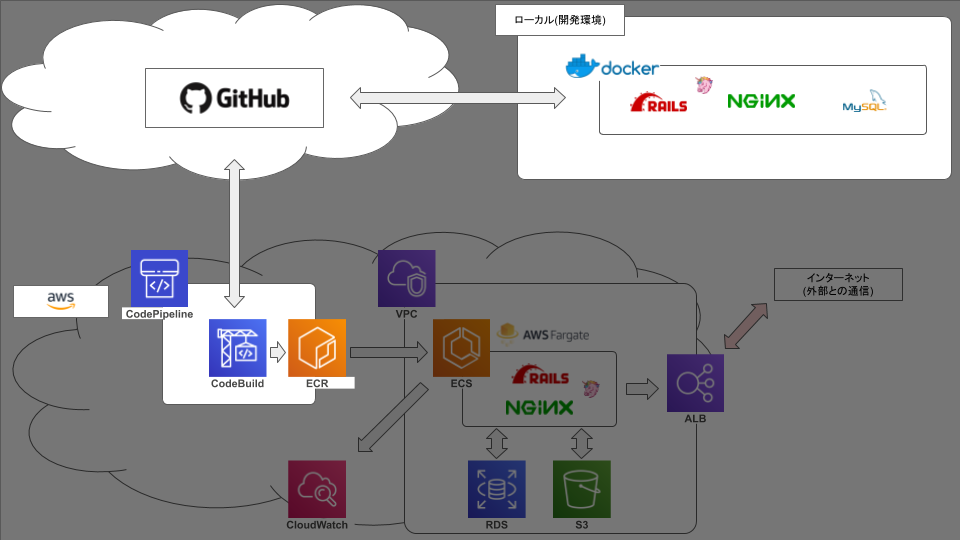
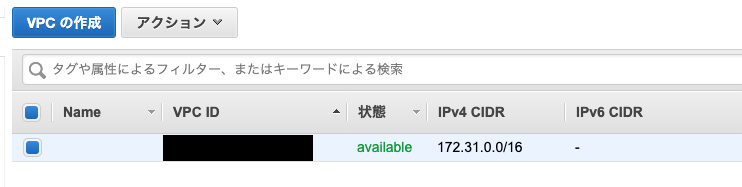


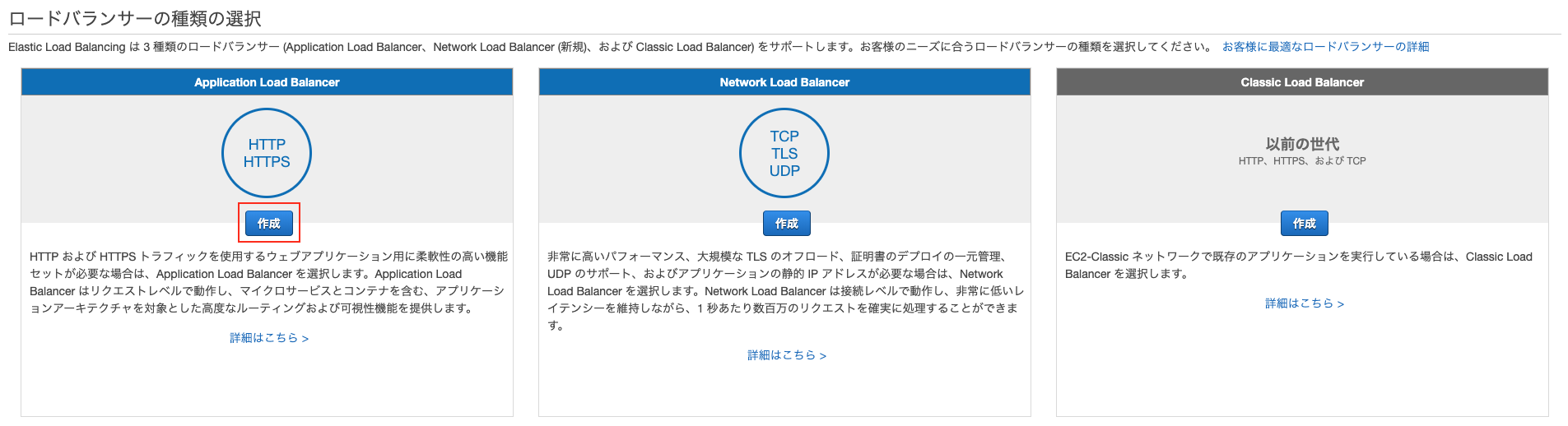
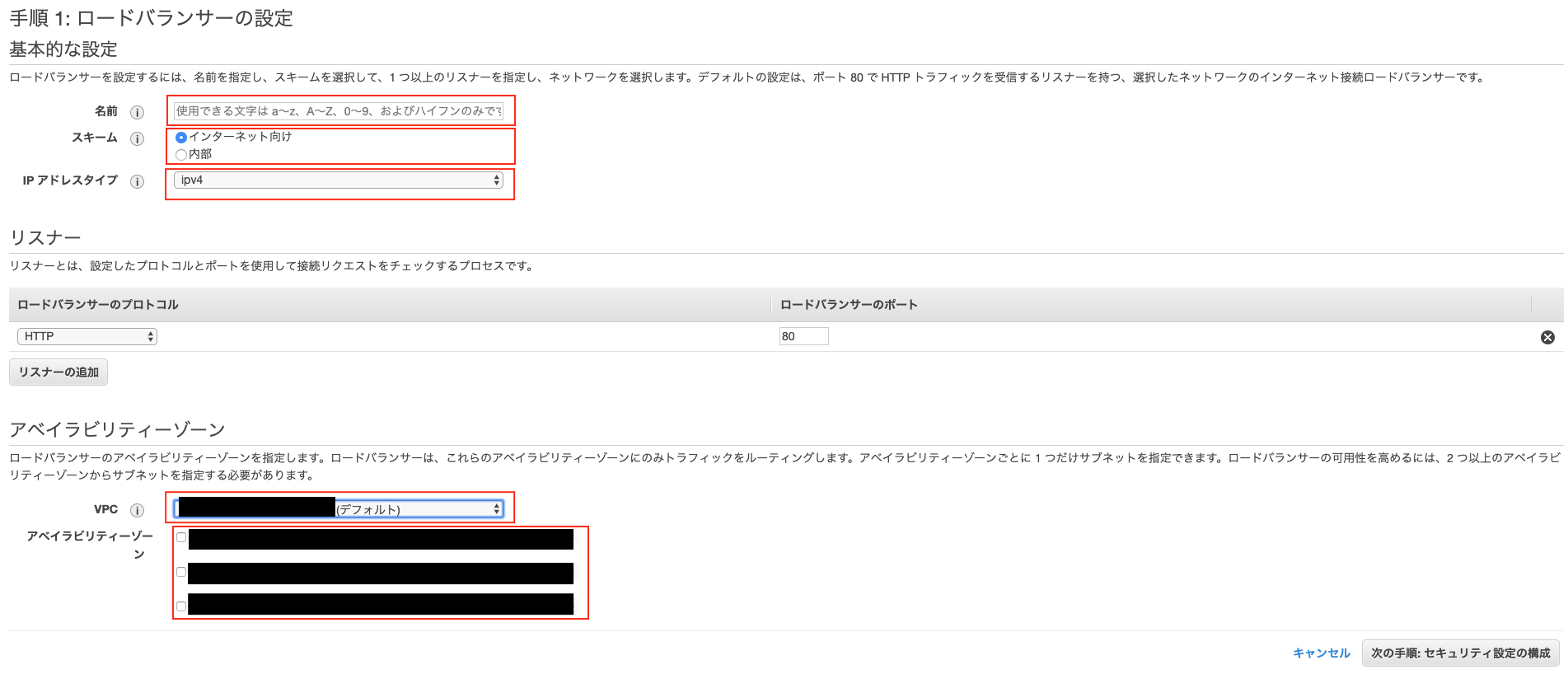

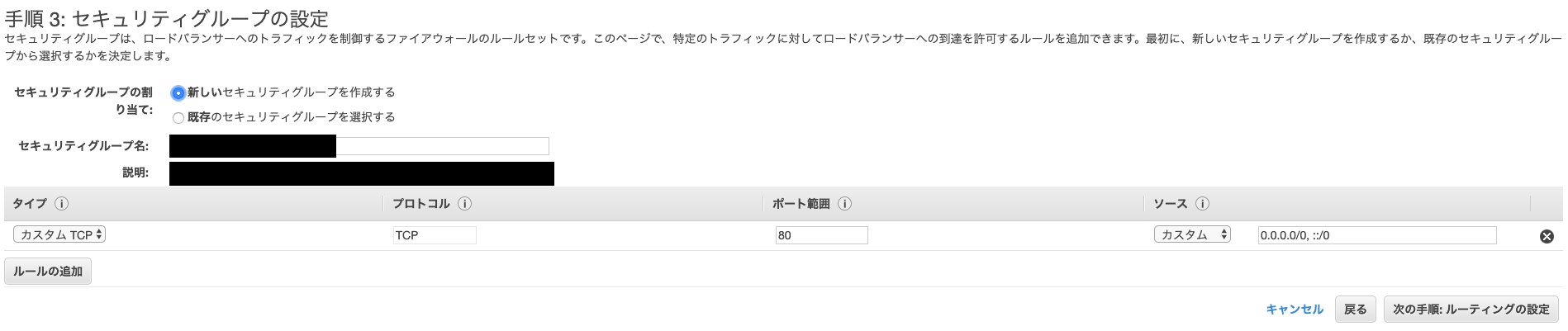
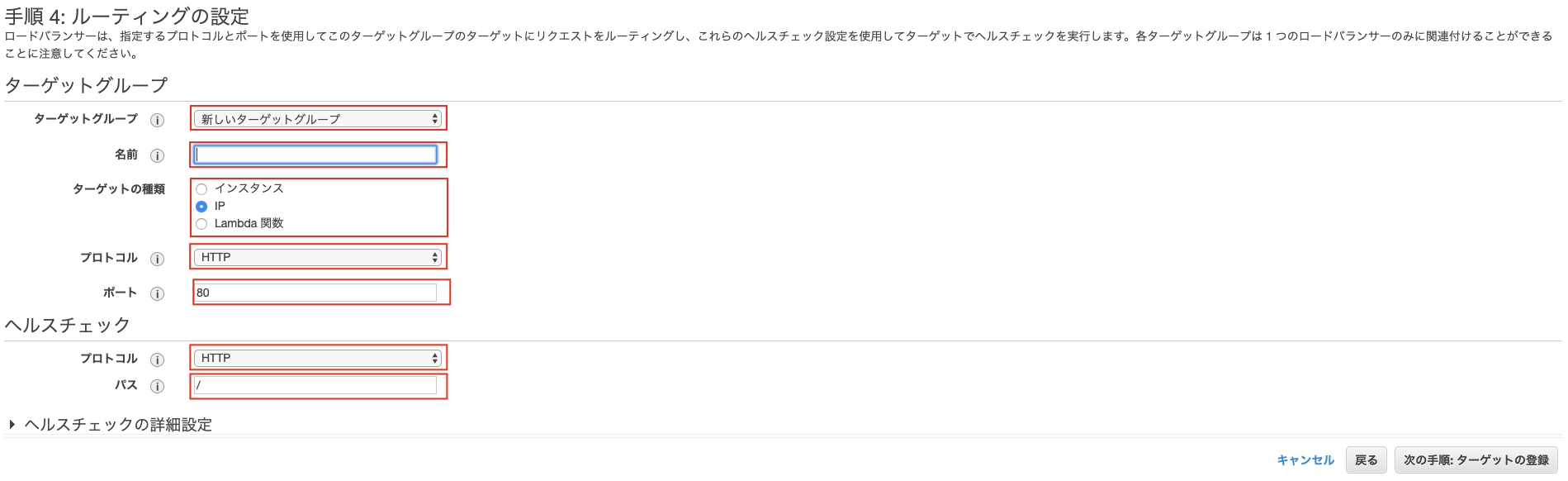





- 投稿日:2019-08-29T15:24:00+09:00
CloudWatch Eventのアラートメールにグラフを添付する
Amazon CloudWatchスナップショットグラフとアラートで解決までの時間を短縮
をやってみたのでメモ。1.EC2
監視するEC2インスタンスを用意しておく。
2.IAMロール
LambdaへアタッチするIAMロールを準備しておく。
CloudWatchReadOnlyAccess
AmazonSESFullAccess
AmazonSNSReadOnlyAccess
AWSLambdaBasicExecutionRole3.Lambda
コードは以下のgithubのものを使います。
https://github.com/aws-samples/aws-cloudwatch-snapshot-graphs-alert-contextGithubからサンプルコードをクローンし、npm installしてからZIPを作成します。
git clone https://github.com/aws-samples/aws-cloudwatch-snapshot-graphs-alert-context cd aws-cloudwatch-snapshot-graphs-alert-context/ npm install zip -r snapshotgraphsalarmdemo.zip ./*設定は、githubに記載されているとおりに設定します。
・ランタイム:Node.js
・ハンドラ:emailer.myHandler
・タイムアウト:30秒
・環境変数:EMAIL_TO_ADDRESS、EMAIL_FROM_ADDRESS、MAIL_SERVER_REGIONzip圧縮の際は注意!階層が合わないと"Unable to import module '...': No module named ..."などとなる。
参考:Lambda(Python) を実行すると "Unable to import module '...': No module named ..."4.SNS
SNSトピックを作成し、Lambdaへサブスクリプションします。
5.SMS
[Email Address]で認証しておく。
6.CloudWatch
EC2のCPUUtilizationが0以上(ここではテストのため)の場合に通知するように設定します。
7.テスト
メールが届いていることと、CloudWatchlogsの実行結果を確認してみましょう。

- 投稿日:2019-08-29T14:35:21+09:00
AWS 認定 - 試験対策 「ソリューションアーキテクト - アソシエイト」(2
パフォーマンスに優れたアーキテクチャを定義する
AWS Innovate オンラインカンファレンス
* AWS 認定 - 試験対策 「ソリューションアーキテクト - アソシエイト」
* セッション1:回復性の高いアーキテクチャを設計する
* セッション 2:パフォーマンスに優れたアーキテクチャを定義する高パフォーマンスなストレージおよびデータベースを選択する
- Amazon EBSのボリュームタイプ
- 汎用SSD * 低コストで高いIOPS
- プロビジョンドSSD
- 非常に高いIOPSとスループット
- コストが高い
- スループット最適化HDD
- スループット性能に対してコスト効率が良い
- コールドHDD
- スループット性能に対してコスト効率が良い
- マグネティック
パフォーマンスとコストは、トレードオフ
Amazon S3 バケット
- インターネットからアクセス可能なデータストレージ
- 静的コンテンツの配信が可能
- パフォーマンス懸念が無くなる
- 完全マネージド型
- 最大限活用するには
- ライフサイクルポリシー
- 手動の管理は、現実的でない
- データ格納されてからの経過時間にともないストレージタイプを自動で変更することができる
- S3標準 -> 30日経過 S3標準低頻度 -> 60日後 Glacier -> 1年後 削除
- オブジェクトごと、バケットごとに設定が可能
Amazon のデータベース
要件に応じたデータベースを選択する
- Amazon RDS
- 最適なワークロード(ユースケース
- 複雑なトランザクションや複雑なクエリ
- 単一のワーカーノード
- 高耐久性
- 最適でないワークロード
- 超高速な読取・書込み
- シャーディングが必要
- 簡単なGET/PUTリクエスト
- RDBMSのカスタマイズ
- RDSリードレプリカ
- 水平スケール
- Amazon DynamoDB
- 完全マネージド型の NoSQL
- Amazon Redshift
- データウェアハウス向け
- 構造化
パフォーマンス向上のためキャッシュを使用する
AmazonCloudFront
- エッジロケーション上で提供
- 低レイテンシー
- エンドユーザーに近い最適なエッジロケーションにルーティングされる
Amazon ElastiCache
- システム内部でキャッシュする
- 読込みの多いワークロード
- コンピューティング負荷の高いワークロード
- memcached, redis をマネージドサービスとして利用できる
- Memcached
- マルチスレッド
- 永続性は無い
- redis である必要性が無い場合は、memcached
- Redis
- シングルスレッド
- 構造化データのサポート
- 永続性をサポート
伸縮性とスケーラビリティに優れたソリューションを設計する
- 垂直スケーリング
- インスタンスのスペックを変更する
- インスタンスのスペックに限界がある
- インスタンスの再起動が必要になる
水平スケーリング
- インスタンスの数の変更
- 理論上、限界が無い
- インスタンスの再起動が必要にならない
Amazon Auto Scaling
- EC2インスタンスを増やしたり減らしたりする機能
- ひとつ以上のロードバランサーを既存のオートスケーリンググループにアタッチできる
Amazon CloudWatch
- 標準メトリクス
- カスタムメトリクス
- 投稿日:2019-08-29T14:33:40+09:00
AWS 認定 - 試験対策 「ソリューションアーキテクト - アソシエイト」(1
回復性の高いアーキテクチャを設計する
AWS Innovate オンラインカンファレンス
* AWS 認定 - 試験対策 「ソリューションアーキテクト - アソシエイト」
* セッション1:回復性の高いアーキテクチャを設計する信頼性と回復性に優れたストレージを選択する
EC2インスタンスストア
- 一時的なブロックレベルストレージ *
- ライフサイクルによっては、データが消えてしまうエフェメラルボリューム
- ホストコンピューターに直結されているので他のストレージに比べて高いパフォーマンスを発揮
- 頻繁に変更される情報の一次ストレージに適している
- EC2料金に含まれる
Elastic Block Store(EBS)
- EC2インスタンスで利用
- 同じAZにあるEC2にアタッチできる
- 可用性、信頼性に優れたストレージボリューム
- 永続性を持つストレージボリューム
- EC2料金とは別で利用料金がかかる
- 汎用SSD
- プロビジョンドSSD
- スループット最適化HDD
- コールドHDD
ホワイトペーパー(英語)
- AWS Storage Services Overview
Amazon Simple Storage Service (S3)
- インターネット経由で利用できるオブジェクトストレージ
- 耐久性は、イレブンナイン=99.999999999%)
- ストレージクラス
- Amazon S3 標準 (S3 標準)
- アクセス頻度の高いデータ向けに高い耐久性、可用性、パフォーマンスのオブジェクトストレージを提供します。
- クラウドアプリケーション、動的なウェブサイト、コンテンツ配信、モバイルやゲームのアプリケーション、ビッグデータ分析など、幅広いユースケースに適しています。
- 複数のアベイラビリティーゾーンにわたってオブジェクトに耐久性 99.999999999%
- 1 年で可用性が 99.99% になるように設計
- Amazon S3 Intelligent-Tiering (S3 Intelligent-Tiering)
- パフォーマンスの低下や、オペレーション上のオーバーヘッドを発生させることなく、最もコスト効率の高いアクセス階層に自動的にデータを移動することで、コストを最小限に抑えるように設計されています。
- 複数のアベイラビリティーゾーンにわたってオブジェクトに耐久性 99.999999999%
- 1 年で可用性が 99.9% になるように設計
- Amazon S3 標準 – 低頻度アクセス (S3 標準 – IA)
- アクセス頻度は低いが、必要に応じてすぐに取り出すことが必要なデータに適しています
- 複数のアベイラビリティーゾーンにわたってオブジェクトに耐久性 99.999999999%
- 1 年で可用性が 99.9% になるように設計
- Amazon S3 1 ゾーン – 低頻度アクセス (S3 1 ゾーン – IA)
- アクセス頻度は低いが、必要に応じてすぐに取り出すことが必要なデータに適しています。
- ひとつの AZ にデータを保存するため、S3 標準 – IA よりもコストを 20% 削減できます。
- 複数のアベイラビリティーゾーンにわたってオブジェクトに耐久性 99.999999999%
- 1 年で可用性が 99.5% になるように設計
- 再作成可能なデータのセカンダリバックアップのコピーを保存するのに適しています
- Amazon S3 Glacier
- データのアーカイブに適しています。
- 複数のアベイラビリティーゾーンにわたってオブジェクトに耐久性 99.999999999%
- 3 種類の取り出しオプション
- 取得時間を設定可能 (数分~数時間)
- Amazon S3オブジェクトのライフサイクルポリシーと連携して動作することができる
- Amazon S3 Glacier Deep Archive
- 1 年のうち 1 回か 2 回しかアクセスされないようなデータを対象とした長期保存やデジタル保存をサポート
- 7〜10 年間保持されるデータの長期保存用に設計された低コストのストレージクラス
- 複数のアベイラビリティーゾーンにわたってオブジェクトに耐久性 99.999999999%
- 取り出し時間は 12 時間以内
- Amazon S3オブジェクトのライフサイクルポリシーと連携して動作することができる
- ライフサイクルポリシー
- オブジェクトが格納されてからの経過時間によってストレージクラスを自動で変更することが可能
- データの暗号化
- 保管中のデータ暗号化
- バージョンニング
- マルチパートアップロード
Amazon Elastic File System
- EC2インスタンスで使用できるAWSクラウド上のファイルストレージ
- フルマネージドサービス
- ギガバイトからペタバイトにスケール可能
- 数10~数1000のEC2インスタンスから同時にアクセスできる
- 使用したストレージにのみ料金がかかる
AWSのサービスを使用した疎結合化メカニズムの設計方法を決定する
多層アーキテクチャソリューションの設計方法を決定する
- システムの可用性を向上させるメリット
- スケーラビリティの疎結合化
- 相互に密接に依存しない疎結合なコンポーネントで構築する
- 独立したコンポーネントは、容易に増強できる
- コンポーネント同士を非同期で連携する
コンポーネントをブラックボックス化する
AWS CloudFormation
- コンポーネントのスタックを作成するサービス
Amazon Simple Queue Service
AWS CloudTrail
- ログ記録サービス
Elastic Load Balancing
Amazon Elastic MapReduce
- マネージド型Hadoopサービス
可用性や耐障害性に優れたソリューションの設計方法を決定する
- 「あらゆるものはいつ故障してもおかしくない」という前提でシステムを構築する
- 高可用性とは、システムを構成するいずれかのコンポートネントが故障しても長時間停止することなく自動的に復旧する
- 自己修復して可用性を継続する
- 単一障害点を無くす
- 複数のAZ、リージョンを利用する
- AutoScaring する
マネージドサービスを利用する
耐障害性(フォールトトレランス性)
- アプリケーション内のコンポートネントが備える冗長性のこと
- 疎結合性を促進することでスケーリングが容易になり、耐障害性が向上する
- 高可用性と耐障害性の考え方の違い
- 前提として SLAを満たすには4つのEC2インスタンスが必要。AZで障害があった場合を考える
- 高可用性
- 二つのAZを利用し、個々のAZに2台のEC2インスタンスを配置
- AZの一つが障害となった場合、AutoScaringで2台のEC2を起動する
- 一時的にSLAが満たせない
- 耐障害性
- 二つのAZを利用し、個々のAZに4台のEC2インスタンスを配置
- AZの一つが障害となった場合でもSLAを満たせる
- 8台のEC2インスタンス費用が掛かる
CloudFormation
- AWSリソースをデプロイするための宣言型プログラミング言語
- テンプレートとスタックを使用
AWS Lambda
- サーバレスなアーキテクチャを実現できるサービス
- あらかじめ用意したコードを関数として実行させることができる
- 実行タイミングをAWSのイベントと紐づけることができる
- 二つの大きなメリット
- 運用上の様々な操作を自動化できる
- 障害イベントをトリガーに自動回復させる
- アプリケーションとして利用する
- 可用性、運用性をAWSに任せることができる
- 投稿日:2019-08-29T11:45:18+09:00
CloudFormation のパラメーターのデフォルト値を更新した時の動作
tl; dr
update-stack と deploy で挙動が違うのだ
本文
やっていく。
サンプルの CloudFormation
test.cfn.ymlAWSTemplateFormatVersion: 2010-09-09 Parameters: EnableDnsHostnames: Type: String Default: true Resources: TestVPC: Type: AWS::EC2::VPC Properties: CidrBlock: 10.0.0.0/16 EnableDnsHostnames: !Ref EnableDnsHostnames初回デプロイ
$ aws cloudformation deploy --stack-name test --template-file test.cfn.yml Waiting for changeset to be created.. Waiting for stack create/update to complete Successfully created/updated stack - test $ aws cloudformation describe-stacks --stack-name test --query 'Stacks[].Parameters[?ParameterKey==`EnableDnsHostnames`].ParameterValue | [0][0]' "true"
aws cloudformation deploy値を
trueからfalseに書き換えて、aws cloudformation deployをしてみる。$ aws cloudformation deploy --stack-name test --template-file test.cfn.yml Waiting for changeset to be created.. No changes to deploy. Stack test is up to date $ aws cloudformation describe-stacks --stack-name test --query 'Stacks[].Parameters[?ParameterKey==`EnableDnsHostnames`].ParameterValue | [0][0]' "true"Default 値を変更しても、スタック自体に変更があったとはみなされないし、パラメーターにも反映されない。パラメーター自体を書き換えたい場合には、もちろん
--parameter-overridesオプションを使用する。$ aws cloudformation deploy --stack-name test --template-file test.cfn.yml --parameter-overrides EnableDnsHostnames=false Waiting for changeset to be created.. Waiting for stack create/update to complete Successfully created/updated stack - test
aws cloudformation update-stackでは
update-stackではどうか。$ aws cloudformation update-stack --stack-name test --template-body file://test.cfn.yml { "StackId": "arn:aws:cloudformation:ap-northeast-1:123456789012:stack/test/xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" } $ aws cloudformation describe-stacks --stack-name test --query 'Stacks[].Parameters[?ParameterKey==`EnableDnsHostnames`].ParameterValue | [0][0]' "false"Default 値の変更がスタックのパラメーターに反映される。
で、どっちがええんや
テンプレートを書き換えてそれを反映したい場合、基本的には
aws cloudformation deployをオススメする。Change Set を作成しているため、些細なミスでロールバックが行われることはないからだ (とはいえ、ロールバックの可能性がゼロというわけでもない)。
aws cloudformation update-stackはスタックポリシーやロールバック設定などスタック自体の設定の変更に使用すると良いだろう。
- 投稿日:2019-08-29T11:27:10+09:00
AWS ELB(ALB)で起きた謎現象(筆者がnginxの仕様を理解していない可能性あり)
構成:
インターネット => ELB(ALB) => EC2 => nginx => puma => rails参考サイト:
https://qiita.com/himatani/items/b6c267dfb330a47fea9fこちらの参考サイトを元にnginxを設定
upstream puma { server unix:///var/www/my-app-name/shared/tmp/sockets/puma.sock; } server { listen 80; listen [::]:80 default_server; server_name my.server.com; location / { proxy_pass http://puma; } ...これで my.server.com にアクセスするとなぜか http://puma にリダイレクトし DNS_PROBE_FINISHED_NXDOMAIN になってしまう。
ちなみにserver_nameをec2のドメインに変えて直接アクセスすると問題なくアクセスできる。
(と思い込んでいる可能性は否めないけど)で、これを以下のように修正したら動くようになった。
(かも)upstream my.server.com { server unix:///var/www/my-app-name/shared/tmp/sockets/puma.sock; } server { listen 80; listen [::]:80 default_server; server_name my.server.com; location / { proxy_pass http://my.server.com; } ...もうちょっとちゃんと調べよう...
- 投稿日:2019-08-29T11:08:59+09:00
AWSのESCを使ってデプロイ(Docker&Goのアプリを)
- 投稿日:2019-08-29T10:53:53+09:00
起動時に Amazon EC2 Linux インスタンスへ (手動で)SSM エージェントをインストールする方法(要点のみ)
- Amazon EC2 Linux インスタンスに SSM エージェント を手動でインストールする
- 起動時に Amazon EC2 Linux インスタンスへ SSM エージェントをインストールする方法
上記の内容の 要点のみ です。
Amazon Linux 2 で SSMエージェントはデフォルトでインストールされる様ですが、
起動時から最新版を使用したいケースのメモです。TL;DR
EC2起動時に「ユーザーデータ」にスクリプトを設定します。
環境
OS:Amazon Linux 2です。
SSM エージェント を Amazon Linux 2 にインストールするには..
次のコマンドを実行します。
sudo yum install -y https://s3.amazonaws.com/ec2-downloads-windows/SSMAgent/latest/linux_amd64/amazon-ssm-agent.rpmSSM エージェント が実行中であるかどうかを調べるには..
次のコマンドを実行します。
sudo systemctl status amazon-ssm-agent「ユーザーデータ」に設定するスクリプトは..
#!/bin/bash cd /tmp sudo yum install -y https://s3.amazonaws.com/ec2-downloads-windows/SSMAgent/latest/linux_amd64/amazon-ssm-agent.rpm sudo systemctl start amazon-ssm-agent実際に比べてみた
AMI: amzn2-ami-hvm-2.0.20190618-x86_64-gp2 (ami-0c3fd0f5d33134a76)
でユーザーデータの設定無しと有りで比較した結果です。
設定の有無 SSMエージェントのバージョン あり 2.3.701.0 なし 2.3.372.0 重要
新しい機能が Systems Manager に追加されるか、既存の機能が更新されると必ず、更新されたバージョンの SSM エージェント がリリースされます。古いバージョンのエージェントがインスタンスで実行されていると、SSM エージェント プロセスによっては失敗することがあります。そのため、インスタンス上で SSM エージェント を最新に維持するプロセスを自動化することをお勧めします。詳細については、SSM エージェント への更新の自動化 を参照してください。SSM エージェント の更新に関する通知を受け取るには、SSM エージェント のリリースノートのページをサブスクライブします。
- 投稿日:2019-08-29T01:29:10+09:00
パブリッククラウドの大規模ゾーン障害について考える
先日AWSで発生した大規模ゾーン障害について考えてみました。
今までは、パブリッククラウドでは下記対応すれば、可用性が担保できると思ってました。
- リージョン内は、Multi-AZ構成で冗長化
- リージョン間は、別リージョンで迅速にサービスが復旧できるようにDR対策
ところが今回の障害でどうもそうでもないような気がしてきました。
Multi-AZ構成ではインスタンス障害やインスタンスへの接続障害がトリガーとなって、自動縮退・自動復旧しますが
ゾーン障害が直接のトリガーとなる訳ではありません。
「ゾーン全体で中途半端に接続障害が発生した場合はどうなるのだろう」という疑問を解消すべく考えてみることにしました。考察内容
そこで以下の状況が発生した場合どのような対応ができるか、考察したいと思います。
- 1つのゾーンで10%のトラフィックがエラーになる
- ヘルスチェックに引っかからないため、自動縮退・自動復旧しない
注) 上記想定は、実際に発生した障害と同じという訳ではありません。
1. ゾーン障害とMulti-AZの有効性
今回の障害が発生するまでは、ゾーン障害というと
「地震や火災でデータセンターが壊滅的な状態になる」
ようなイメージを持っていました。
Multi-AZ構成であれば、正常なゾーンに縮退しサービスを継続することができます。
もちろん、特定のインスタンス障害の場合でも、Multi-AZ構成は効果があります。Multi-AZ構成:正常時
正常時は2ゾーンに冗長化されています。
Multi-AZ構成:縮退時
ゾーン障害時またはインスタンス障害時は正常なゾーンに縮退します。
ところが、今回発生した障害は
- EC2とEBSのパフォーマンス劣化
- 当初はEC2の接続障害と説明
- RDSの接続障害
とのことでした。
ここでは接続障害に注目して、特定のゾーンで10%のトラフィックがエラーになるような
接続障害が発生したとします。Multi-AZ構成:特定のゾーンで10%位のトラフィックでエラー
3回中3回エラーになるかチェックするようなヘルスチェックだとヘルスチェックをすり抜けて、縮退・自動復旧しません。
全体で 10 / 2 = 5%のトラフィックがエラーになってしまいます。
Multi-AZ構成:両方のゾーンで10%のトラフィックでエラー
両方のゾーンで10%のトラフィックがエラーになるとすると、そもそもゾーンの縮退ができません。
2. 対応策の考察
上記を踏まえ、以下の障害が発生した時の対応策について考察します。
- 1つのゾーンで10%のトラフィックがエラーになる
- ヘルスチェックに引っかからないため、自動縮退・自動復旧しない
1) アプリで対応
以下のような対応を実装して、多少遅延はあるものサービスが継続できる、一部機能が提供できなくてもサービスは停止しないようにするのがあるべき論だと思います。
- exponential backoffを実装する
- circuit breakerを実装する
AWSは昔からexponential backoffの実装を啓蒙し続けているように思えるのですが、個人的な感覚ではまだまだ実装されてないシステムが多い感じがします。
ただMulti-AZやヘルスチェックと組み合わせないでアプリだけで対応しようとすると、ヘルスチェックに引っかかるレベルのネットワーク・インスタンス障害が発生してもcircuit breakerでブロックするまで、トラフィックが流れてしまいます。
ですのでアプリで対応する場合も、Multi-AZとの組み合わせは必須だと考えます。次からはインフラレイヤーでの対応策を検討したいと思います。
2) Multi-AZ
上で述べたとおり、10%のトラフィックがエラーになる状況では(設定次第ではありますが)
- ヘルスチェックをすり抜けるため、状況は変わらない。
- ヘルスチェックにかかった場合でも、縮退・復旧・縮退・復旧・・・を繰り返す可能性がある
ようになってしまいます。
また、縮退・復旧したとしても復旧先のゾーンが障害中のゾーンだとすると、同じことの繰り返しになります。この状況をインフラレイヤーだけで回避するためには、「ゾーン障害をトリガーにして、ゾーンごと縮退させる」ことが必要だと考えます。
Multi-AZの本質は、「インスタンス障害をトリガーにしてインスタンス単位で縮退させることによりゾーン障害に対応する」ことではないかと思っているのですが、自分の知る限り「ゾーン障害をトリガーにして」の部分は標準機能として提供されていないため、その部分を自前で実装する必要があると思っています。
ただ、インフラレイヤーを抽象化したLambdaやFargateは、そもそもそのような実装を組み入れること自体困難かつナンセンスです。
IaaSやコンテナにおけるゾーン全体の縮退の実現性は別の機会に検討したいと思っています。RDSの例
RDSのMulti-AZはゾーン障害に対応できますが、2インスタンスが別ゾーンにあって、インスタンス障害により別ゾーンのインスタンスにフェイルオーバするため、結果ゾーン障害に対応できているとも考えられます。
また複数ゾーンにそれぞれRDSのリードレプリカが複数ある構成を考えた場合、インスタンス単位で縮退した結果としてゾーン障害に対応できることはあっても、ゾーン障害をトリガーにして対象ゾーンの全てのインスタンスを縮退するといった機能は標準では提供されていません。3) 3ゾーン冗長化
Multi-AZと状況は変わりませんが、エラーが3ゾーンに分散される分全体のエラー率は下がる点が、Multi-AZより若干優れていると考えられます。
またAuroraのストレージレイヤーは3ゾーン6箇所に冗長化して多数決をとるような仕組みになっていますが、まさに今回のような障害のためにあるような仕組みだと言えます。
Auroraの後発でリリースされたAmazon NeptuneやAmazon DocumentDBも同じようなストレージレイヤーを備えていますが、今後このような耐障害性の高いサービスが増えていくことが期待できます。ただ、EC2やECSにAuroraのストレージレイヤーのような多数決による冗長化を導入するのはかなり無理があるので、現状は1) アプリで対応で述べたような対応と組み合わせるしかないと考えます。
4) リージョン間DR
ゾーン障害を含むリージョンから別リージョンへフェイルオーバするリージョン間DRであれば、このような障害に完全に対応可能です。
フェイルオーバーのダウンタイムとデータの欠損を考慮しなければならない所がデメリットですが、逆にダウンタイムとデータの欠損を最小化(またはゼロ)にするシステムを作るところが面白い所ではないでしょうか。5) 他クラウドへ移行
こういった大規模障害が発生すると、他クラウドに移行した方が良いのではといった考えが浮かんでくるかもしれませんが、仮にAzureやGCPへ移行してもAからBへ移しただけで何も状況は変わりません。それよりもこういった障害をクラウドの特性と捉えて、前向きに対応を検討するべきだと考えます。
ただ、AWSの補完として、DR先やクラウド間冗長化のために他クラウドを利用することを検討するのはアリだと思います。3. 結論
以下の障害が発生した時の対応について、考察した結果をまとめます。
想定する障害
- 1つのゾーンで10%のトラフィックがエラーになる
- ヘルスチェックに引っかからないため、自動縮退・自動復旧しない
対応案と効果
対応案 上記障害に対応できるか 補足 デメリット アプリ対応 ○ ヘルスチェックに引っかかるレベルの障害もアプリ対応になる Multi-AZ △ エラーの分散は可能 縮退できない 3ゾーン冗長化 △+ Multi-AZよりもエラーの分散は可能 縮退できない アプリ対応+Multi-AZ ◎ リージョン間DR ◎ フェイルオーバのダウンタイム アプリ対応+Multi-AZが王道だと考えます。素直にあるべき論に従い正しい実装することが、結局一番の近道ではないかと思います。
またリージョン間DRも合わせて実装し、リージョン障害だけでなくゾーン障害時でも利用できるように常に準備しておけばさらに良い対策だと考えます。ただ、上記に合わせてゾーン全体の縮退が容易にできる対応策を準備しておいても良いのではと感じています。
実現性については別の機会に検討したいと思います。




