- 投稿日:2019-08-11T23:55:56+09:00
AWS 無料枠でEC2インスタンスの作成
はじめに
ポートフォリオ用のサイトをAWSでデプロイ使用と思いましたが、毎回忘れてしまうので自分用備忘録。
アカウントは持っているのでEC2インスタンスの作成からやっていきます。
何方かの参考になればなお良しと言うことで。以前、まとめた記事も合わせて貼っておきます。何かしらヒントになればと思います。
Capistranoで、EC2+S3への自動デプロイで起きたエラー集と基礎用語
https://qiita.com/fukaya_path/items/45014e50980dd31b24ffでは、早速やって行きます。
以前作成したアカウントで新しいインスタンスを作成して作業を進めているので、1からやるのとでは多少差異があるかもしれません。EC2インスタンスの作成〜設定
AMIの選択
まずEC2インスタンスの作成ボタンを押して進んでいきます。無料でやりたいので今回はRails+MysqlなのでAMIは『Amazon Linux AMI 2018.03.0 (HVM), SSD Volume Type』を使用します。
Amazon Linux 2 AMI (HVM), SSD Volume Typeも無料ですが、5年保証やオンプレミスの開発およびテスト用の仮想マシンイメージとして利用可能であったりと違いはあるみたいですが、特に使わないので使いません。こっちでも行けるのでしょうか?わかる人いたら教えてください。インスタンスタイプの選択~起動
インスタンスタイプは無料枠が一つしかないので『t2.micro』一択ですね。
『確認と作成』を押すと確認画面まで飛ぶので、『起動』を押すとキーペアの設定画面が出てきます。
今回は既存のキーがないので新しいのを作成し、ダウンロードします。
作成したキーは、インスタンスへのログイン時に必要なので、重要かつ厳重に扱いましょう。
間違えて消してしまうとインスタンスに入れなくなり、面倒臭いことになっちゃいます。
出来たら、『インスタンスの作成』を押します。
完了したらEC2ダッシュボードに行き、出来ているか確認してみてください。問題がなければ、インスタンスの状態がrunningになっているはずです。ElasticIP〜EC2ログイン
ElasticIPの設定
ダッシュボードから、ElasticIPを選択し、新しいアドレスを作成します。
出来たら、アドレスの関連付けを選択し、先ほど作成したEC2インスタンスとの紐付けを行います。
プライベートIPは使用しないので選択しません。セキュリティグループの設定
現状SSHでのアクセスしか出来ない状況になっているので、セキュリティグループのインバウンドの設定を行なっていきます。
ルールの追加をし、HTTPを追加し、保存するだけです。EC2にログインしてみる
これで一通り終わったので、EC2にログインしてみます。先ほどダウンロードしたkeyの移動と権限の付与をしてあげて、
$ ssh -i ダウンロードしたキー ec2-user@設定されたElasticIPで、ログイン出来れば成功です。
まとめ
最初はデプロイまで、まとめて書こうと思いましたが、あまりに長くなってしまうのでとりあえずここまでにしました。
個人的には大体何をしているのかもわかってきたので、手順さえ間違えなければすんなり出来るなという感じです。
蛇足ですが、良くEC2が止まるなと思っていたのですが、インスタンスタイプでt2.microを使っているのが原因じゃないか?と思いましたが、お金がかかるのは嫌だったので、実験は出来ませんでした。
何かと止まる原因がわかるかたいたら教えてください。
デプロイ周りは書ききれないので、credentials.yml.encとmaster.keyと自動デプロイは別記事で書いておこうと思います!参考サイト
- 投稿日:2019-08-11T23:15:55+09:00
AWS CloudFormation RDS Auroraサンプルテンプレート
はじめに
部品作成(RDS Auroraだけの作成)としての位置づけのCloudFormationのサンプルテンプレートを作成しました。
テンプレートはGitHubにあるので、こちらをご参照ください。
テンプレートはyamlパージョンとjsonバージョンがありますが、同じものを作成するので、お好きなほうをご利用ください。構成イメージ
コメント
細かい部分はGitHubの方を見ていただけると幸いです。
本稿はサンプルとしてご参考になればと記したものです。ご自分の環境にそぐわない場合もございますことご承知おきください。

- 投稿日:2019-08-11T21:53:41+09:00
CloudTrailLogをGlue経由してQuickSightで分析するやり方その1(Trail証跡作成→Glueジョブ作成まで)
ごあいさつ
AWS管理者の皆さま、こんにちは。
世の中、AWSエンジニアは数あれど、なかなかマネジメントについて書かれた記事はありません。
特にTrailに関しては集めると良いとはよく書かれていますが「それからどした?」の部分の解決が見つからないことが多いです。今回最終的にやりたいことは、自社所有AWSアカウントの全てのCloudTrail証跡ログを一つのアカウントにまとめて、QuickSightで分析してしまおうというものです。
代表的なところで、IAMユーザーの作成や、ポリシーアタッチが検出できるようになるのが目標になります。
しかし、ご存知のように、TrailLogというものはJSONで記載されていますから、そのままではQuickSightに取り込めません。
そのため、実に長大な作業を踏むことになります。今回やる作業
Trail証跡ログの集約→AWS glueでathenaが理解できる形に→QuickSight取込→分析こうやって書くと短いですが、何もない状態から私がこれを作り上げるまで一か月くらいかかってます。
AWSサポートへの問合せ期間も含めてですが。こんなやり方も
ちなみに下記のような公式ブログでのやり方も乗っています。
AWS Cloudtrail Logs を AWS Glue と Amazon Quicksight 使って可視化する
しかし、このブログのやり方を実装しようとすると、Trailログの発行API部分が入れ子構造になっており、glueジョブが全てのログを確認するまでDB構造を理解できず、結果タイムアウトで終了してしまいます。
ですので、今回のやり方は若干不便ですが実装が速く、確実なやり方です。【各アカウントからCloudTrailの証跡を、一つのアカウントのS3に集約する】
作業は二つです。
・受け入れ側S3バケットの設定
・送り側Trailでの証跡作成●受け入れ側S3バケットの設定
バケットを作成します。
バケット名は後ほどの設定で嫌というほど使いますので、使いやすい方が良いと思います。
また、証跡を集めるのですから、削除ができる環境は避けたいところです。
バージョニングを有効化し、オブジェクトのロックも完全に有効化しておきましょう。
パブリックアクセスコントロールについても全てオンにしておいて問題ありません。
最後にバケットポリシーです。
下記のようなものを用意しましょう。
※注:xxx部分には自分のアカウントIDやバケット名を入れてください。s3-backet-policy{ "Version": "2012-10-17", "Statement": [ { "Sid": "AWSCloudTrailAclCheck20150319", "Effect": "Allow", "Principal": { "Service": "cloudtrail.amazonaws.com" }, "Action": "s3:GetBucketAcl", "Resource": "arn:aws:s3:::xx-xx-account-traillog-xxx" }, { "Sid": "AWSCloudTrailAclCheck20150222", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::xxxxxxxxxxx:root" }, "Action": "s3:*", "Resource": [ "arn:aws:s3:::xx-xx-account-traillog-xxx", "arn:aws:s3:::xx-xx-account-traillog-xxx/*" ] }, { "Sid": "AWSCloudTrailWrite20150319", "Effect": "Allow", "Principal": { "Service": "cloudtrail.amazonaws.com" }, "Action": "s3:PutObject", "Resource": [ "arn:aws:s3:::xx-xx-account-traillog-xxx/AWSLogs/76xxxxxxxxxx/*", "arn:aws:s3:::xx-xx-account-traillog-xxx/AWSLogs/77xxxxxxxxxx/*", "arn:aws:s3:::xx-xx-account-traillog-xxx/AWSLogs/22xxxxxxxxxx/*", "arn:aws:s3:::xx-xx-account-traillog-xxx/AWSLogs/24xxxxxxxxxx/*", "arn:aws:s3:::xx-xx-account-traillog-xxx/AWSLogs/06xxxxxxxxxx/*", "arn:aws:s3:::xx-xx-account-traillog-xxx/AWSLogs/62xxxxxxxxxx/*", "arn:aws:s3:::xx-xx-account-traillog-xxx/AWSLogs/08xxxxxxxxxx/*", "arn:aws:s3:::xx-xx-account-traillog-xxx/AWSLogs/66xxxxxxxxxx/*", "arn:aws:s3:::xx-xx-account-traillog-xxx/AWSLogs/68xxxxxxxxxx/*", "arn:aws:s3:::xx-xx-account-traillog-xxx/AWSLogs/01xxxxxxxxxx/*", "arn:aws:s3:::xx-xx-account-traillog-xxx/AWSLogs/06xxxxxxxxxx/*", "arn:aws:s3:::xx-xx-account-traillog-xxx/AWSLogs/55xxxxxxxxxx/*" ], "Condition": { "StringEquals": { "s3:x-amz-acl": "bucket-owner-full-control" } } } ] }●送り側Trailでの証跡作成
各アカウントで、Trailを開きます。
「証跡情報」から「証跡の作成」をクリックします。
上部の必須項目を埋めた後に、「ストレージの場所」を埋めていきます。
新しいS3バケットを作成しますか? → いいえ
S3バケット → 先ほど作成したバケット名を直接入力※
詳細から「ログのプレフィックス」 → 何でもよいですが、「/AWSLogs/AccountID/CloudTrail/ap-northeast-1」の部分は変えられません。※AWSでは、S3のみアカウントの壁に守られていません。
バケット名を指定することで、相手が公開状態であればアクセス可能になります。
S3のバケット名がリージョン、アカウントを越えて一意でなくてはならない理由はここにあります。
この部分が、後ほどの作業の煩雑さに影響してきます。
その下の詳細項目についてはお好きな設定でどうぞ。上記二つの設定を行うことで、しばらくしたらS3バケットにログが集まり始めます。
もし集まらないログがあれば、バケットポリシーか証跡のバケット指定が怪しいところです。【集約したTrailログをAWS glue ETLジョブを使ってathenaでクエリ発行できるようにする】
公開されている、glueジョブからathenaDBを作成するスクリプトを実行します。
AWSログ解析Gitgit-cmd$ git clone https://github.com/awslabs/athena-glue-service-logs今回利用するのは
./scripts/example_glue_jobs.json
./scripts/sample_cloudtrail_job.py
./athena_glue_service_logs/cloudtrail.py
./Makefileで、これらの全てに手を加える必要があります。
●ファイルコピー
cmd$ cp ./scripts/example_glue_jobs.json ./scripts/glue_jobs.jsonサンプルファイルから実行ファイルを作成するためにコピーします。
●./scripts/glue_jobs.jsonを修正
修正箇所は下記の通りです。
・defaultsセクション
glueジョブで作成されるathenaデータベースの名称を決めます。
こだわりが無ければそのままで問題なしです。・cloudtrail
ジョブ名とバケット名を修正します。
ジョブ名は複数アカウントのtrailを解析するのであれば、各アカウントごとに名称を分ける必要があります。
S3_SOURCE_LOCATIONについてはパスを省略させることはできず(glueジョブのパラメーターが正規表現に対応していないため)、Trailファイルのprefixまで指定する必要があります。
「S3_CONVERTED_TARGET」については、Trailを集約するバケットを指定して問題ないです。●./scripts/sample_cloudtrail_job.pyは特に修正箇所無し
glueジョブのスクリプト実行部分。sampleというファイル名のままで問題ありません(MakeFile内で指定してあるため)。
●./athena_glue_service_logs/cloudtrail.pyを必要があれば修正
glueジョブからathenaDBを作成する際のテーブル構造を決定します。
必要があればTypeを修正します。修正しなくてもジョブは問題なく動きます。
json部分(json_requestparametersなど)についてはTrailのAPI内容によって入れ子構造が異なっており、ここを修正するとジョブが完了しなくなります。●./Makefileの修正
RELEASE_BUCKETにスクリプトなどをアップするためのバケット名を記載します。
ここはTrailを集約したバケットで無く、別途専用のバケットを作った方が良いです。このファイルのcreate_job部分がそのままでは上手く動きません。
--default-arguments部分の改行を無くし、ワンラインにすると手っ取り早く実行が可能になります。Makefile--default-arguments '{ \ "--extra-py-files":"$(RELEASE_LATEST_PATH)", \ "--TempDir":"$(GLUE_TEMP_S3_LOCATION)", \ "--job-bookmark-option":"job-bookmark-enable", \ "--raw_database_name":"$(RAW_DATABASE_NAME)", \ "--raw_table_name":"$(RAW_TABLE_NAME)", \ "--converted_database_name":"$(CONVERTED_DATABASE_NAME)", \ "--converted_table_name":"$(CONVERTED_TABLE_NAME)", \ "--s3_converted_target":"$(S3_CONVERTED_TARGET)", \ "--s3_source_location":"$(S3_SOURCE_LOCATION)" \ }'上記を下記のように変更します。
Makefile-remake--default-arguments '{ "--extra-py-files":"$(RELEASE_LATEST_PATH)", "--TempDir":"$(GLUE_TEMP_S3_LOCATION)", "--job-bookmark-option":"job-bookmark-enable", "--raw_database_name":"$(RAW_DATABASE_NAME)","--raw_table_name":"$(RAW_TABLE_NAME)", "--converted_database_name":"$(CONVERTED_DATABASE_NAME)", "--converted_table_name":"$(CONVERTED_TABLE_NAME)","--s3_converted_target":"$(S3_CONVERTED_TARGET)","--s3_source_location":"$(S3_SOURCE_LOCATION)" }'また、roleが必要になりますが、記述箇所は「create_job」の項目の--roleです。
--role AWSGlueServiceRoleDefault \と、さもデフォルトでありますよ、的な雰囲気を出していますが、このロールは存在しません。
ロールを作成するときは、・AWS管理ポリシーである「AWSGlueServiceRole」をアタッチ
・Trailログとglueジョブ作成ツールの両方で使用するバケットへのアクセス権限
s3:ListBucket
s3:GetObject
s3:PutObject
s3:DeleteObject
・ロールの信頼関係は「glue.amazonaws.com」に与えましょう●ジョブ作成ツールの実行
ジョブの作成は、下記のコマンドを実行することで行われます。
必ずMakeFileのある場所で実行しましょう。release-cmd$ RELEASE_BUCKET=<YOUR_BUCKET_NAME> make private_releaserelease-cmd$ RELEASE_BUCKET=<YOUR_BUCKET_NAME> make create_job service=<SERVICE_NAME>ちなみに今回の場合、SERVICE_NAMEは「cloudtrail」になります。
実行したら、ジョブができているか確認し、実行してみましょう。
上手くいっていれば数分でジョブが完了し、カタログデータが出来上がっているはずです。
●全てのアカウントでジョブが成功したら、トリガーで定期実行する
ジョブは一度回しただけでは追加されていくTrailデータに対応できないため、トリガーを定期実行して常にカタログデータを更新する必要があります。
更新頻度はTrailログがどの程度最新でない状態を許容するかによります。
例えば、定期実行を5時間ごとにすれば、最大で5時間前までのデータしか見れないことになります。
一方でglueジョブを実行するにはそれなりの費用がかかるため、コストとセキュリティポリシーの兼ね合いで実行間隔を決めてください。
タイプはスケジュールタイプが良いと思います。定期実行ですね。クーロン式では、曜日に指定が無い場合は「?」にする必要があります。
linux形式ではなく、CloudWatchEventと同じ形式です。
一つのトリガーで複数のジョブが実行できますので、この際、まとめて実行してしまいます。
それぞれのジョブに対するカスタマイズ実行が可能ですが、数分で終わってしまうジョブなので、変更の必要性はそれほどありません。
最安値を目指すのであればチューニングしてみるのも良いかもしれませんね。そして、データカタログができた時点で、Athenaによるクエリ投入が可能になっています。
Athenaに移動して、クエリを投入すると、データを引けることが分かります。
もうちょっとだけ続くんじゃ
ここから先はQuickSightにデータを投入して、解析する部分になります、が。
まあこれがまた少々長くなります。単純なやり方だけならすぐに終わるんですが、QuickSightの癖がある部分までお伝えしようと思うと微妙に大変な感じです。
ということで、もうちょっとだけ続くんじゃ。










- 投稿日:2019-08-11T21:05:18+09:00
AWS で WordPress ブログを構築、ドメインを取得して公開するまで(Part 3)
前回の続きです。
AWS で WordPress ブログを構築、ドメインを取得して公開するまで(Part 2)EC2 / WordPress のサーバーにドメイン名でアクセスできるように
Amazon Route53 でドメイン名を取得して、パブリックホストゾーンを設定します。ここから先は有料です。
はい。無料ではございません。ドメインは無料でも取得できますが、結局パブリックホストゾーンの設定で有料になるという感じです。
料金表(2019年8月現在)
ドメイン名の取得、および更新料
.com - 12.00 USD/年
.net - 11.00 USD/年ホストゾーン
ホストゾーンごとに 0.50 USD/月 – 最初の 25 個のホストゾーン
ホストゾーンごとに 0.10 USD/月 – それ以上のホストゾーン標準的クエリ
100 万件のクエリごとに 0.400 USD – 最初の 10 億件のクエリ/月
100 万件のクエリごとに 0.200 USD – 10 億件を超えた分のクエリ/月.com の場合は 0.50 + (12.00 / 12) = 1.50 USD(160 JPY/月)
月で100万件のクエリなんて、そのくらいコンテンツが成長できたら素敵ですけどね。
月で100万件超えてもおよそ 200 JPY/月。ドメイン名の取得とホストゾーンの設定って何してるの?
お金を払うのなら、ちゃんと理解していないといけないですね。
つまり、こういうことらしいです。
注:AWS 公式を見る限り Route53 はレジストラではないらしい?
(話を分かりやすくするため、無理やり Route53 をレジストラに仕立てあげてます)クライアント「example.com ドメインが欲しいんですけど」
Route53「わかりました問い合わせてみます」
・・・
Route53「example.com ってまだ登録できます?」
root TLD「gTLD に確認してみます」
gTLD「ああ、それなら登録できますよ」
root TLD「登録できるみたいです」
Route53「承知しました。クライアントに登録可能と伝えます」
・・・
クライアント「じゃあ取得してください」
Route53「かしこまりました。ドメイン名を申請します」
・・・
gTLD「登録しました。登録は1年間有効です。ドメインを継続したい場合は更新してください」要するに、
世界で唯一の(被らない)ドメイン名を一手に管理しているレジストリという組織があって、TLD(トップレベルドメイン)のサーバーに登録することをドメイン名の取得というらしいです。
で、レジストリとクライアントの仲介役がレジストラ。
クライアント「ドメイン名 example.com と EC2 のグローバル(世界に唯一の)IP アドレスを紐付けたい」
Route53「わかりました。ネームサーバーに登録しておきます」
・・・
訪問者「example.com のブログが見たい」
ブラウザ「最寄りの Name Server に確認してみます」
Name Server「わかりました。example.com の IP アドレスは・・・はい、ご案内します」
EC2「承知しました。ブログの内容を転送しますね」
・・・
ブラウザ「転送されてきました。表示します」
訪問者「・・・ example.com のブログってあまり面白くないわね」つまり、
訪問者がドメイン名でアクセスしてきたら、内部で IP アドレスに変換して
目的のサーバー(EC2 / WordPress)へトラフィックを誘導し、応答として訪問者の画面にブログの内容を転送・ブラウザで表示させるという仕組みのようです。理屈はわかったので、やってみましょう。
ドメイン名取得
まずは、EC2 のいつ変わってもおかしくない IP アドレスを固定します。
IP 固定には Elastic IP を利用します。
これは EC2 インスタンスに関連付けられている限り無料のようです。Elastic IP 画面にアクセスします。
「新しいアドレスの割り当て」ボタンを押して進めます。
「割り当て」ボタンを押します。
新しい Elastic IP アドレスが発行されます。
これを EC2 インスタンス ID に関連付けます。
「アクション」から「アドレスの関連付け」を選択します。
リソースタイプ:インスタンス
インスタンス:EC2 / WordPress のインスタンス ID
プライベート IP:EC2 / WordPress のプライベート IP
をそれぞれ選択・入力したら「関連付け」ボタンを押します。
はい。これで Elastic IP アドレスと EC2 / WordPress のインスタンスが関連付けられました。
Elastic IP アドレスで WordPress にアクセスできるはずですが、できないときはインスタンスの再起動を行います。※注意!
インスタンスの停止・終了はエフェメラル(短命)ストレージを揮発させます。
データは全て失われるので注意しましょう。
次に、Route53 にアクセスして「ドメインの登録」を行います。
「ドメインの登録」ボタンを押して先に進みます。
取得したいドメイン名を入力します。
TLD は比較的お安い「.net」を選択しました。
取得可能なら、カートに入れて「続行」ボタンを押します。
登録者の連絡先は入力が必要です。
ここは日本語で入力してみました。「続行」ボタンで先に進みます。
ドメインを自動的に更新しますか:有効化
規約に同意(残念ながら、日本語ではなかったです)
「購入の完了」ボタンで申し込みできます。キャンセルはできないのでよく確認しましょう。
この辺はなんだか Amazon で買い物をしているみたいな感覚ですね。
登録が完了すると、メールが届きます。
今回の場合、あまり混み合ってなかったのか 20 分もかからないうちに完了メールが来ました。
登録完了すると、下図のような画面になります。
パブリックホストゾーンの設定
ここまでくれば後もう少しです。
頑張りましょう。ホストゾーンの画面では、ドメイン取得と同時に AWS によって自動的に設定されている項目があるので、これに A レコード(IPv4 アドレス)を追加して、ドメイン名でサーバーにアクセスできるようにします。
NS レコードと、SOA レコードはすでに登録済みです。
これに A レコードを追加するため、「レコードセットの作成」ボタンを押します。
名前:空白
タイプ:A-IPv4 アドレス
エイリアス:いいえ
TTL(秒):300
値:Elastic IP アドレス
ルーティングポリシー:シンプル
以上のように設定して、「作成」ボタンを押します。
A レコードが追加されました。
これで、ようやく取得したドメイン名でブログページを表示することができます。
ところが問題発生。
確かにブログページは表示されるようになったんですが・・・次回に続く。


![Screenshot_20190812[1].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2F6b5d2437-7b71-a051-c06c-aa689082c235.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=fc1aefab3d1b5c6ec0c7d85bf3e7d09c)
![Screenshot_20190812[2].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2F22444ce1-47be-47c7-b12e-1e44699d4333.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=242cf74a1663810112b5141395ee514a)
![Screenshot_20190812[3].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2Fcab75a26-8fb5-bd03-c28a-31046b47851e.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=b7e163a635c406e428a02f9b97260e22)
![Screenshot_20190812[4].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2Fd005669f-9f38-e8f5-409d-bfd15f83a511.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=6ed0f252c73f85f7d15bfa071158ca63)
![Screenshot_20190812[5].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2F5a04bf5e-970c-4277-ec59-fdfbbc99120d.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=54e94e406b1fd15166aeb89d73f2a125)
![Screenshot_20190812[6].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2Fdd630a28-d433-f1b6-2bc0-a1ecec3be89a.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=58d4f2bd9a78f190996129217b27a557)
![Screenshot_20190812[7].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2F23646f5b-a4dd-b7a1-fa38-105fc5e7a9c7.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=500966fa5bb669216b47f5ff97d95d22)
![Screenshot_20190812[8].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2Fda2dec2a-aa1e-0255-9131-e45965b977e0.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=073452c2dc8d95163bac84c7920fbbf0)
![Screenshot_20190812[9].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2Fbb235c65-77b4-4bf3-7053-1209ae2e4098.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=574c112d4be9a2d5fee85fa34d427411)
![Screenshot_20190812[10].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2F85d6f305-ac4d-fbf2-fe40-8c10fba5e8f9.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=d8fb95568da4435492661ca695d3ac76)
![Screenshot_20190812[11].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2Fe0d960d6-844b-7c64-8433-4adbffd69a57.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=1edaa47cac241e72d0ed77c33f31d5a4)
![Screenshot_20190812[12].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2F56d509e3-9194-cb68-0a1e-018d8e701e91.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=058648b796ce36dfb3e12beeabfb0a85)
![Screenshot_20190812[13].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2F33bf62e5-ccda-170a-11d7-663a44bdaeb0.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=51425ab71acd4ab93125826ee5413c13)
![Screenshot_20190812[14].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2F12a5f091-7f87-8e10-5fce-572c57a93272.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=f68097e78a478337fcd718953806f2a8)
![Screenshot_20190812[15].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2F5914af41-7cd9-df72-0930-0ef32ce96508.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=ac22a0a3ba458bd7a174f992ee406d73)
![Screenshot_20190812[16].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2Fb86793bb-3e3b-5d77-17bb-3443c3cf8213.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=1e119b8923b404c098e031fe31ae3bfe)
- 投稿日:2019-08-11T17:44:32+09:00
【初心者】AWS Elastic Beanstalk を使ってみる
目的
- AWS Elastic Beanstalkについて話題になり、知ったかぶりするため、基本動作を確認することにした。(目標:なんとなくアプリのデプロイまでできること)
AWS Elastic Beanstalk とは(自分の理解)
- インフラ(EC2、ELB等)の構築、運用を自動化し、アプリケーションの実行環境として一元管理できるサービス。
やったこと
- Elastic Beanstalk によるサンプルアプリ実行環境(python)の作成
- 構成変更(EC2*1 ⇒ ELB+EC2*2)
- アプリケーションのデプロイ(追加バッチとローリング)
構成図
動作確認
Elastic Beanstalk 「アプリケーション」の作成
Elastic Beanstalk の画面で、「今すぐ始める」を選択する。設定値としては、「アプリケーション名:mksamba-ebtalk-sample」、「プラットフォーム:Python」とする。
数分で環境が構成され、アプリケーション「MksambaEbtsample-env」の作成が完了する。デフォルト構成(最小構成)のため、EC2インスタンス(t2.micro) 1台、ELBなしとなり、その1台のインスタンス上のみでPythonの実行環境が動作する。
- WEBアクセス用のURLが用意されるため、ブラウザからアクセスして初期画面を確認する。apacheとかと同様の「無事インストールできましたね」的な画面が表示される。
アプリケーションのデプロイ
- 公式ガイド:チュートリアル及びサンプルのところに、pythonのソース(python-v1.zip)が配布されており、このソースが初期状態として使われている様子。
- zipファイルの中にある application.py の中身(表示文言および背景色)を少し変更し、再度cron.yaml(こちらは変更なし)と合わせてzipファイルにする。
- 「アップロードとデプロイ」のボタンから、zipファイルをアップロードしてデプロイを行う。
- デプロイが無事完了し、文言と色が変わったことを確認する。
構成の変更
- EC2 1台構成だとローリングでのデプロイができないため、ELB + EC2 2台の構成に変更する。
- 「設定」-「容量の変更」のところで、値を以下に変更する。他の値はデフォルト値とする。
- 環境タイプ: 単一のインスタンス ⇒ 負荷分散
- インスタンス: (設定なし) ⇒ 最小2, 最大2
- 設定を更新すると、ELB(CLB)が作成され、EC2も2台に増加する。
アプリケーションのデプロイ(追加バッチとローリング)
- 「設定」-「ローリング更新とデプロイの変更」のところで、値を以下に変更する。他の値はデフォルト値とする。
- デプロイメントポリシー: 1回にすべて ⇒ 追加バッチとローリング
- バッチサイズ: (設定なし) ⇒ 固定 1インスタンス/1回
- 再度「アプリケーションとデプロイ」のボタンから、デプロイ(色を変えるだけの更新)を行う。
- ポリシーを「追加バッチとローリング」としたため、まずバッチ(追加の1台)を作成し、そこに新しいアプリをデプロイしてELBに組み込む。その後で既存のEC2インスタンスへのデプロイを行い、一番古い?インスタンスが削除される。
- アプリが更新されていることを確認する。
所感
- いろいろ奥が深そうだがこの辺にしておき、実案件で使うことがあれば深堀したい。
参考記事
- AWS Elastic Beanstalkのデプロイメントポリシーについて
- 各デプロイポリシーの動作仕様がが分かりやすく記載されている。








- 投稿日:2019-08-11T16:49:22+09:00
AWSソリューションアーキテクトを受験した時の話
この記事の概要
2019/04/29に
AWS認定ソリューションアーキテクトアソシエイト
(AWS Certified Solutions Architect - Associate (SAA))
を受験したので、その時の記録試験の概要
アソシエイトレベル(下から2番目)のアーキテクト向け試験です。「この試験に合格すると、AWS のテクノロジーを使用して安全で堅牢なアプリケーションを構築およびデプロイするための知識を効果的に証明できます。
可用性、優れたコスト効率、耐障害性を備え、スケーラブルな AWS上での分散システムの設計に関して、少なくとも1年の実務経験のある方が対象です。」
AWS公式より引用:引用元◼︎ 試験要項
問題数 :65問
試験時間 :130分
受験料 :¥15,000(税別)
合格ライン:100~1000点中720点(約69%)
受験資格 :なし◼︎ 出題範囲
分野 出題割合 分野 1: 回復性の高いアーキテクチャを設計する 34% 分野 2: パフォーマンスに優れたアーキテクチャを定義する 24% 分野 3: セキュアなアプリケーションおよびアーキテクチャを規定する 26% 分野 4: コスト最適化アーキテクチャを設計する 10% 分野 5: オペレーショナルエクセレンスを備えたアーキテクチャを定義する 6% 2019/08時点の最新バージョン(Ver.1.5)のものです。
バージョンアップで範囲等は変更されるので、受験時は公式で確認してください。
AWS 認定ソリューションアーキテクト – アソシエイト | AWS勉強開始前の状態
AWSで動いているアプリ開発の業務を1年以上しているけど、インフラじゃなくアプリ開発の方の担当なので、どちらかというとSDKを使ったコードを書くのがメイン。
EC2とかVPCとかのインフラ系のサービスはほぼ使い方がわからない状態。
よく触るのは、DynamoDB, S3, Lambdaとかそのへん。勉強に使ったもの
1. 対策本①
合格対策 AWS認定ソリューションアーキテクト - アソシエイト
試験要項など全体的に情報が古く、ページ数的にも少し薄いのでこれだけだと不安
追加で問題集などの活用がおすすめ。2. 対策本②
徹底攻略 AWS認定 ソリューションアーキテクト – アソシエイト教科書
比較的新しめの発行で、内容もサービス別ではなく目的別に書かれているため、何のためにそのサービスを使うかがわかりやすい。3. Web問題集
AWS WEB問題集で学習しよう – 赤本ではなく黒本の問題集から学習する方向
無料でもそれなりの問題数でおすすめ。4. AWS公式模擬試験
5. AWSアカウント
1~4の順で勉強、
対策本①と②はどちらもKindle版で通勤電車の中で勉強、①を読み終わった後内容が少し古く不安だったので、②を追加で購入しました。
③のWeb問題集はフリープランと有料プランがあり、対策本を読み終わった後、フリープランの問題集だけ利用。
最後に実力を確認する意味も兼ねて、模試を受験。受験料¥2,000とお手頃なので、何度か受験して練習問題代わりにするのもありかも。
公式の模試は本番同様スコアと分野別の正解率のみしか確認できないため、後で見直して答え合わせをするために画面キャプチャで動画に残しておくことをおすすめします。
※問題の公開はもちろん禁止されています。AWSアカウントは勉強した内容をイメージしやすくするために、無料枠の範囲内でちょこちょこ利用。
勉強時間
トータルで30時間ぐらい?一応AWS自体触ってはいたので、わりとのんびり勉強。
知識不足を補うため読書+練習問題がメイン、座学だけだとイメージしづらいので、触れたことがないサービスは、公式のチュートリアルなどを見ながら一度触れてみる時間も少し作ると、一気に理解が深まった。
公式チュートリアルソリューションアーキテクトはAWS認定の中でおそらく一番受験者が多いので、対策本なども比較的多く勉強しやすい方かと思います。
受験後
結果として、スコアは849で合格。可もなく不可もなく。
正直、ネットなんかで受験前にやったこと〜っていう記事で「BlackBelt読んで触りまくった」とか書いてる人が多いですが、試験の内容的に「アーキテクチャ設計時はこういう考え方をするべき」みたいな問題も多いので、触るのはあくまでイメージを深めてより理解するためで、座学と半々ぐらいがちょうどいいのかなという感想。
EC2, ELB, VPCなんかのインフラ周りの基本サービスは出題が多いので、EC2,ELBやらで冗長構成の構築とかやってみた方が、楽になるかと思います。
次回は、アプリエンジニアとしてはとっておきたいってことで、デベロッパーアソシエイトを受験予定です。
ちなみに、AWS認定試験は合格するとその他の試験に利用できる模擬試験の無料バウチャーと本番試験の50%OFFバウチャーがもらえるので、次回は半額です。

- 投稿日:2019-08-11T15:44:25+09:00
【初心者】Amazon EFS を使ってみる
目的
- Amazon EFS について、向学のために実機で動作確認を行う。
Amazon EFS とは(自分の理解)
- linuxサーバ(EC2インスタンスもしくオンプレサーバ)に対してNFSを提供するサービス。
やったこと
- EC2インスタンス(Amazon Linux 2) にEFSのファイルシステムをマウントして利用する。
構成図
動作確認
EFS ファイルシステムの作成
- VPC、Subnetを指定して EFS ファイルシステムを作成する(各種設定値はデフォルト)。
EC2(Amazon Linux 2)でEFSファイルシステムをマウント
AWS公式ドキュメント:EFS ファイルシステムをマウントする の手順に従い、amazon-efs-utils パッケージをインストールする。
mount コマンドを実行する。
[ec2-user@ip-10-0-1-248 mnt]$ sudo mount -t efs fs-12345678:/ /mnt/efs Failed to resolve "fs-12345678.efs.ap-northeast-1.amazonaws.com" - check that your file system ID is correct.
- 名前解決に失敗しているようなため、AWS公式ドキュメント:VPCでのDNS の使用 を参考に、該当のVPCの「DNS解決」「DNSホスト名」を両方とも有効に変更する。
- 再度mountコマンドを実行し、/mnt/efs ディレクトリとして使用可能なことを確認する(一番下の行に追加されていることを確認)。
[ec2-user@ip-10-0-1-248 mnt]$ df Filesystem 1K-blocks Used Available Use% Mounted on devtmpfs 485712 0 485712 0% /dev tmpfs 503664 0 503664 0% /dev/shm tmpfs 503664 396 503268 1% /run tmpfs 503664 0 503664 0% /sys/fs/cgroup /dev/xvda1 8376300 1347096 7029204 17% / tmpfs 100736 0 100736 0% /run/user/1000 fs-12345678.efs.ap-northeast-1.amazonaws.com:/ 9007199254739968 0 9007199254739968 0% /mnt/efs
- マウントしたディレクトリに1GBのファイルを作成する。
[ec2-user@ip-10-0-1-248 efs]$ sudo dd if=/dev/zero of=1Gfile01 bs=1M count=1000 1000+0 records in 1000+0 records out 1048576000 bytes (1.0 GB) copied, 9.0702 s, 116 MB/s [ec2-user@ip-10-0-1-248 efs]$ ls -l total 1024000 -rw-r--r-- 1 root root 1048576000 Aug 6 16:01 1Gfile01
- EFS の画面でも、容量が認識されていることを確認する。
所感
- 簡単に容量可変、かつスループットも自動拡張されるNFSが作れるということで、自分でNFSサーバ立てるよりかなり楽と感じた。
参考記事



- 投稿日:2019-08-11T15:22:25+09:00
AWS/IAMユーザーの作成方法
先日AWSのS3を使う上で、セキュリティ対策を行わなければいけないということで、
その手順をまとめましたが、IAMというサービスとS3の登録方法と言ったところも深掘りしていかないとなかなか辻褄の合いにくい箇所もあっただろうということで、今日はIAMについて書きます。
下記記事と連携して当記事をご覧ください。
IAMとは
AWS Identity and Access Management (IAM) は、AWS リソースへのアクセスを安全にコンソールするためのウェブサービスです。
要は、できることを制限した擬似アカウントを作れるということみたいです。
このアカウントを他人と共有して使うこともできるみたいですよ。
今回はS3機能だけが使えるIAMユーザーを作成したいと思います。
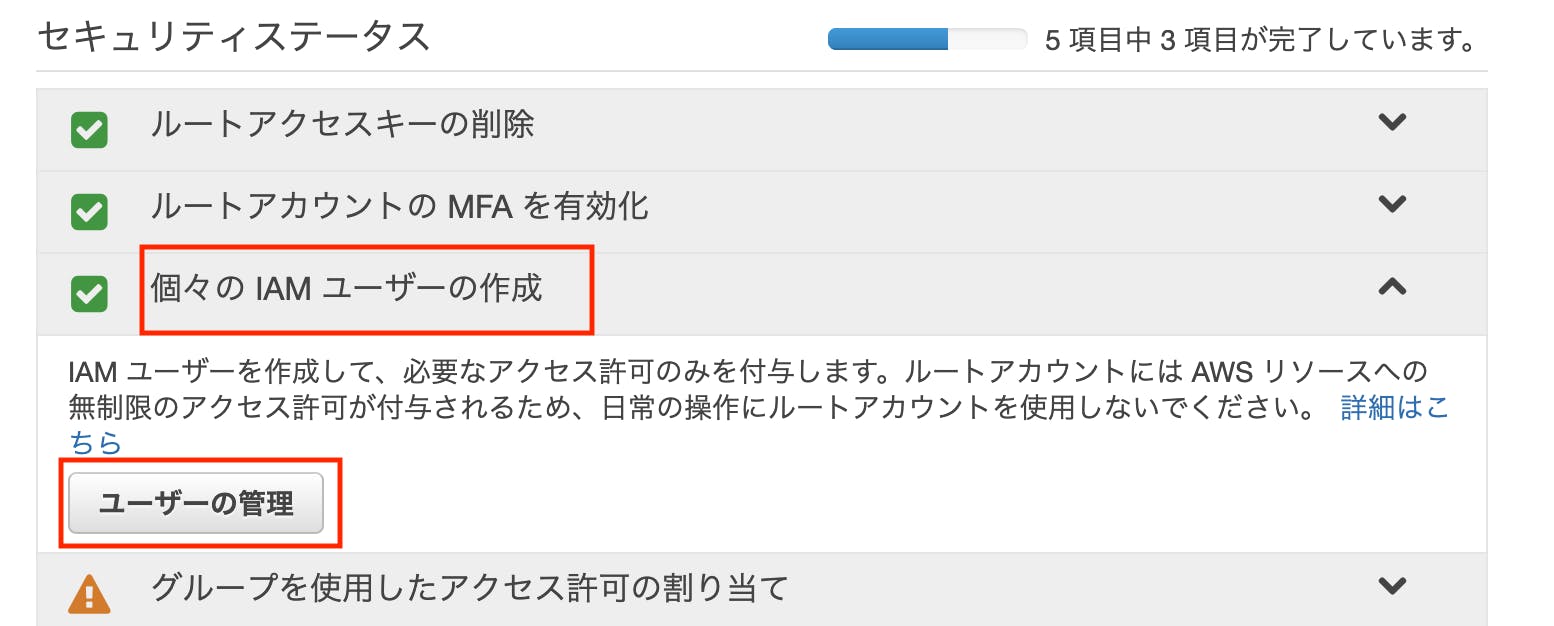
権限を制限したユーザーを作成する
ログインしているユーザーの権限は一番強いものはrootになります。AWS上の、どんな操作も可能であるため、もしこのアカウントを不正利用されたら、高額な請求が来てしまう可能性もあります。
代わりに、使える権限を制限したユーザーをIAMを利用して作成します。
AWSにログインしたら、サービスからIAMを開きます。
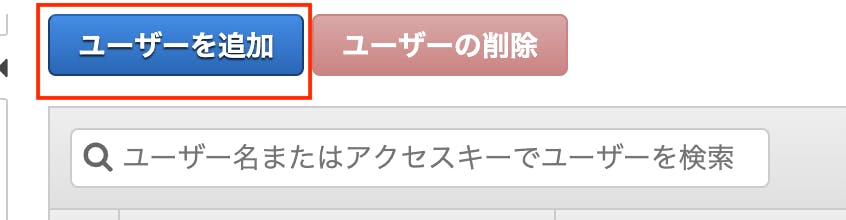
遷移先のページで下記をクリックします。
左上のユーザーを追加を選択。
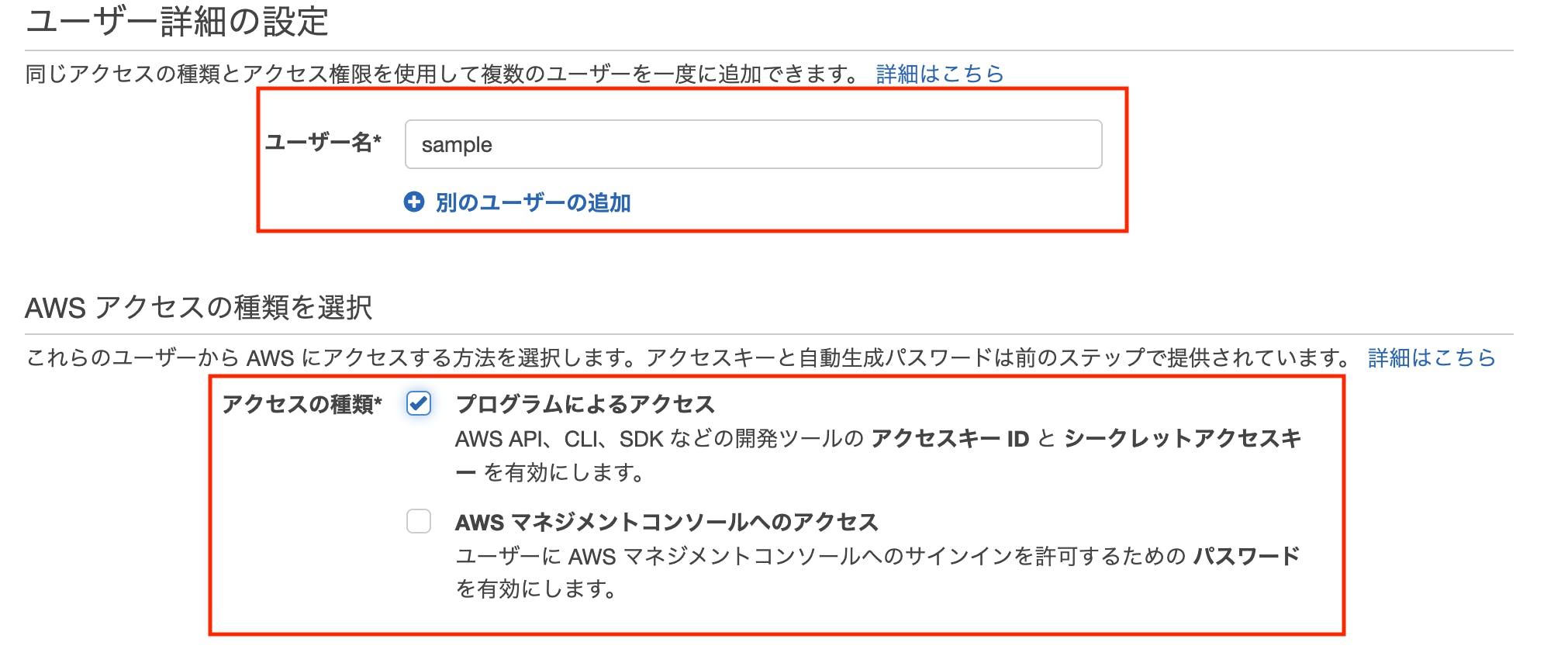
ここで作成するユーザー名を登録します。
次はアクセス権限の設定です。
「AmazonS3FullAccess」を選択してください。
選択したら、「次のステップ:タグ」をクリックします。
ここでは何もせずに、「次のステップ:確認」を押します。
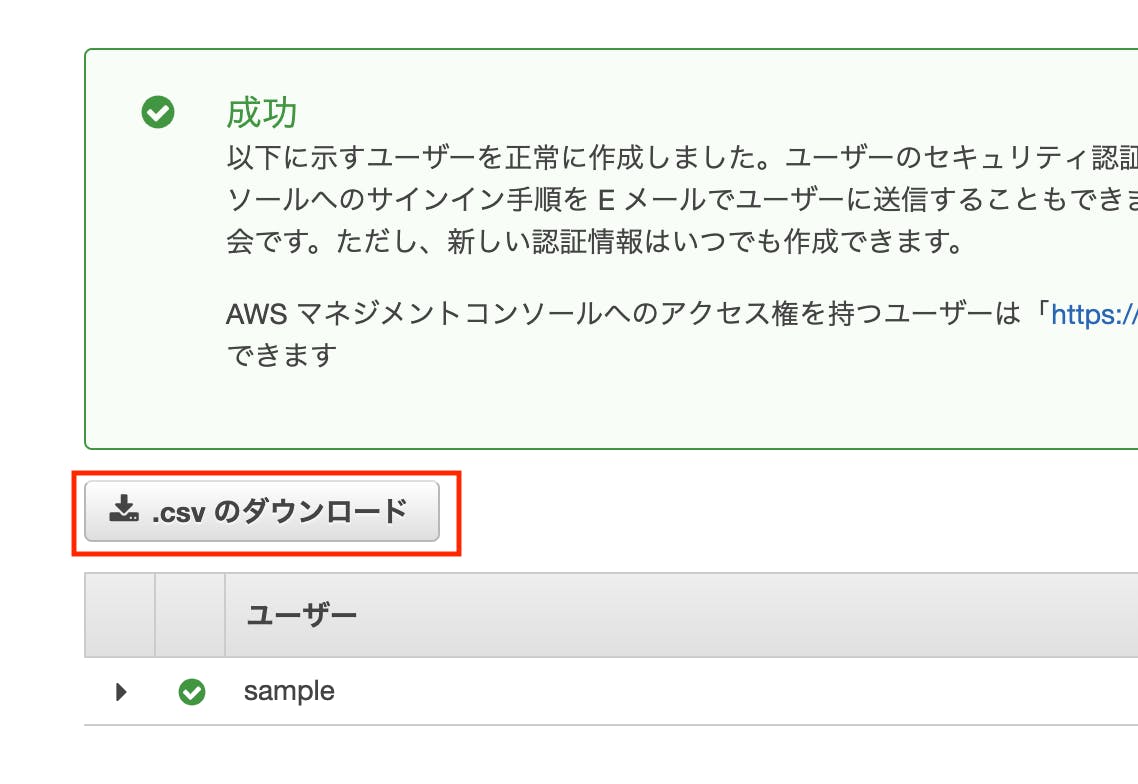
この画面まできたら、ユーザーの作成をクリックします。
※忘れずに認証情報をダウンロードしてください
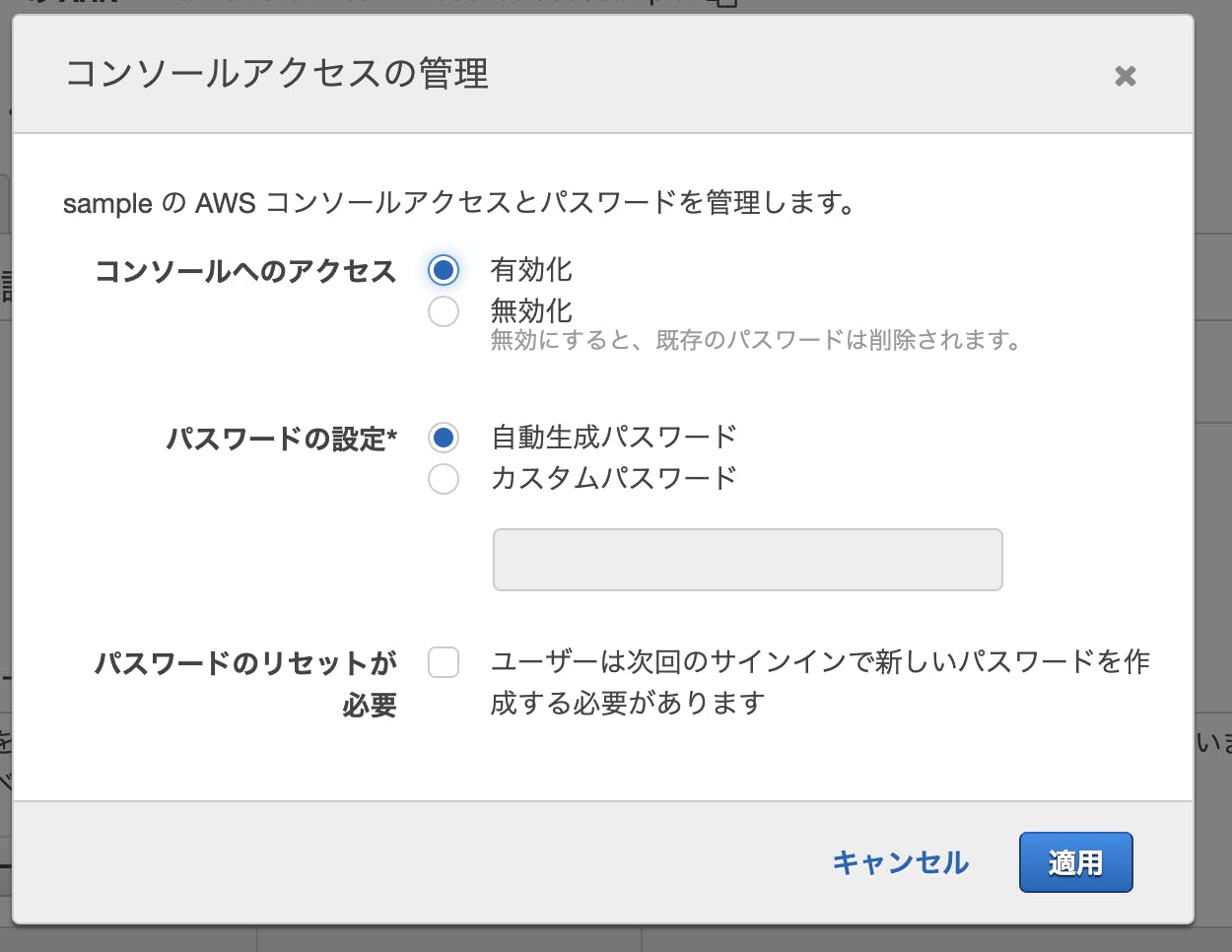
IAMユーザーにパスワードを持たせる
IAMのメニューから作成したIAMユーザーをクリックします。
遷移したページで「管理」をクリックします。
そのまま下の画像のように「有効化」「自動生成パスワード」をクリックします。
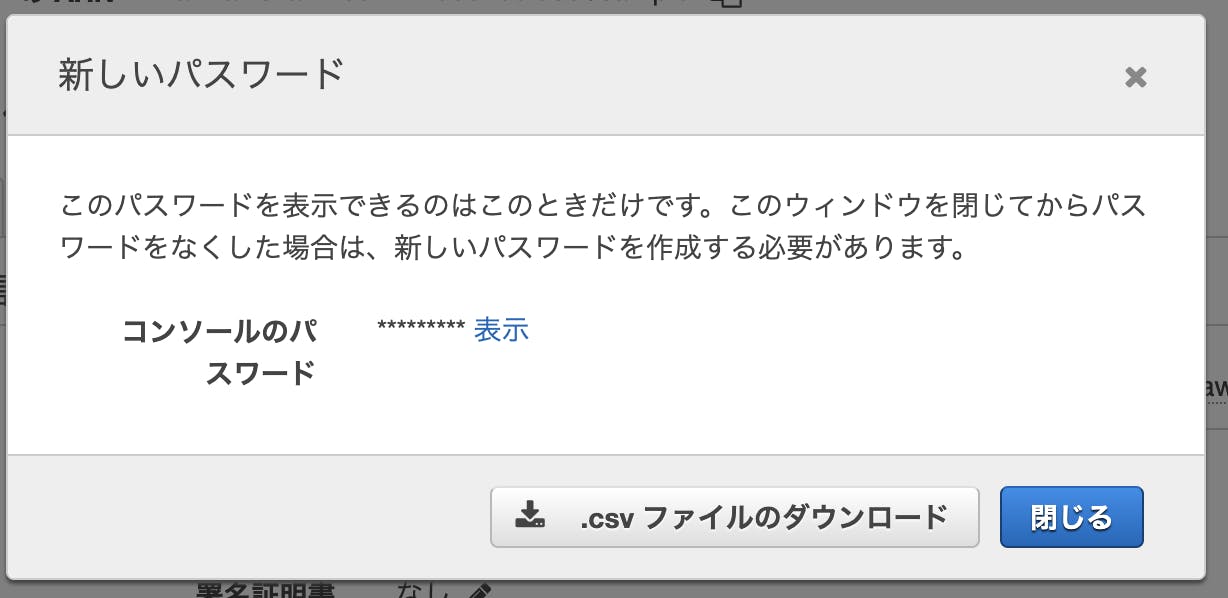
ここでもおなじように認証情報をダウンロードしておきます。
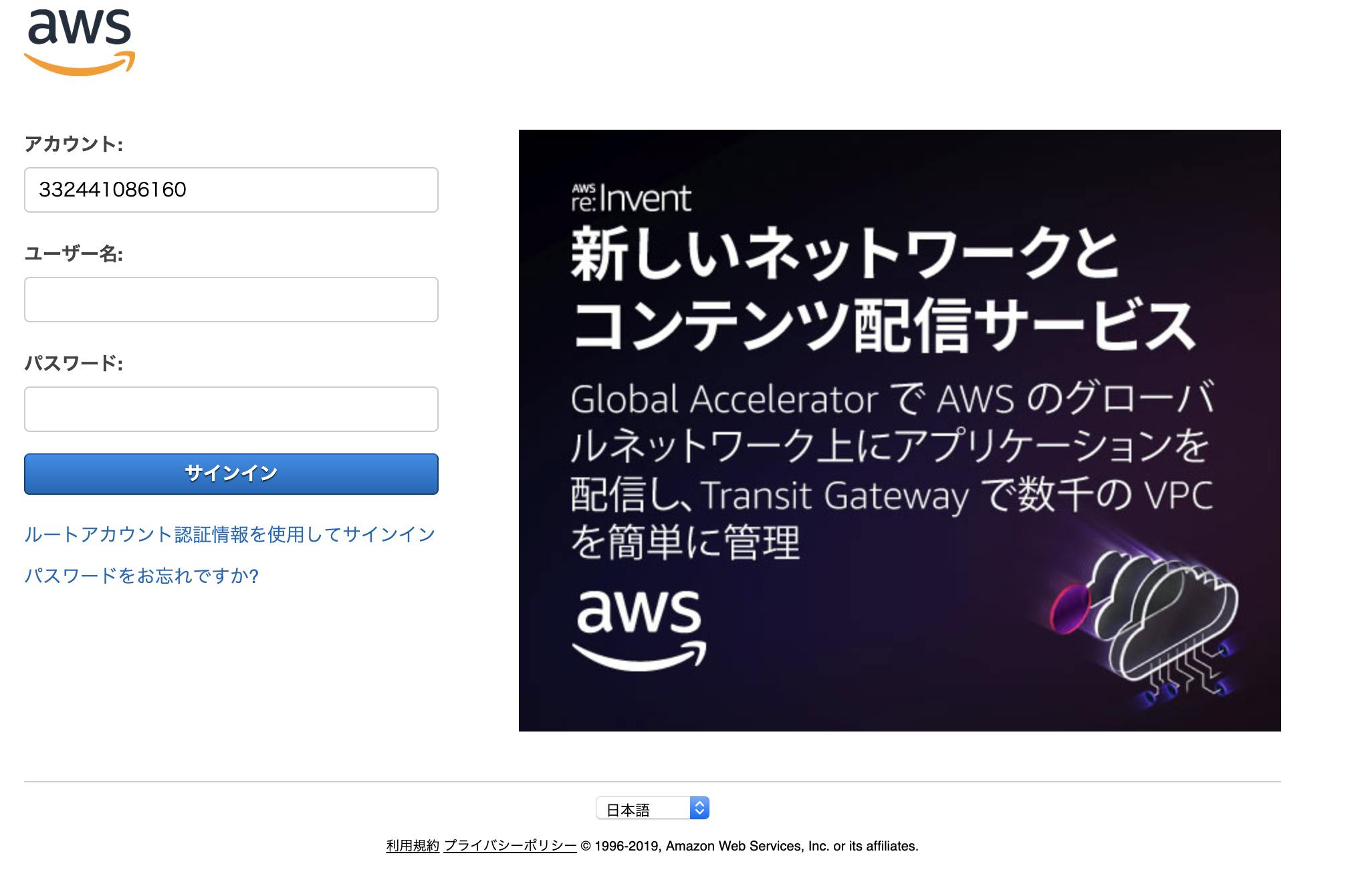
作成したIAMユーザーにログインする
今作成した、制限つきユーザーでログインしてみます。
IAMのトップページの以下のリンクをコピーし、URL欄に貼り付けて遷移します
下記画面に遷移するので、ユーザー名とパスワード、それぞれダウンロードした認証情報を入力してサインインすることができます。
hogehogefugafuga書き疲れた。






- 投稿日:2019-08-11T11:25:32+09:00
サーバレスでRSSを取得しDynamoDBに登録する30行
とあるサイトの情報をRSSで取得し、DynamoDBに突っ込むだけの処理。最初、ライブラリとかをアップロードしないとできないかなと思ったが、標準ライブラリだけで大丈夫だった。CloudWatch Eventsから起動して使う。
import urllib.request import xml.etree.ElementTree as ET import boto3 import json from boto3.dynamodb.conditions import Key, Attr dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('xxxxxxxx') def lambda_handler(event, context): cnt = 0 url = 'https://note.mu/usop/m/m79fbb598dd82/rss' with urllib.request.urlopen(url) as response: html = response.read() root = ET.fromstring(html) for item in root.iter('item'): link = item.find('link').text res = table.scan( FilterExpression=Attr('url').eq(link) ) if res["Count"] == 0: resall = table.scan() cnt = resall["Count"] table.put_item(Item={"id":cnt+1,"url":link}) return { 'count': cnt }
- 投稿日:2019-08-11T10:53:03+09:00
CloudWatch Logs Insights の分析結果をLambdaで監視する
はじめに
CloudWatch Insightsの分析結果を監視するLambdaを作成しました。
CloudWatch Logs Insightsとは
CloudWatch Logs Insightsとは、2018年のre:Inventで発表されたサービスです。
詳細に関しては、以下のサイトをご覧いただければと思いますが、一言で説明すればCloudWatch Logs内のログデータを簡単に集計・分析できるサービスです。
ロググループに対する専用のクエリ言語がサポートされており、そのクエリを投げることで簡単にログの集計・分析が行え、さらにグラフを作成して結果を可視化することもできます。これらの分析結果をCloudWatchダッシュボードに追加することもできます。
新機能 – Amazon CloudWatch Logs Insights – 高速でインタラクティブなログ分析
CloudWatch Logs Insights を使用したログデータの分析やったこと
今回、CloudWatch Insightsで得られた分析結果を監視するLambdaを作成しました。
具体的には、APIGatwayのアクセスログのステータスコードに400以上のものがある場合にSlackに通知する
ということを行いました。
注:「LambdaでInsightsの分析結果を使う」ことをしたかったため、そのままCloudWatchのメトリクスを使えばもっと簡単にできます。以下、構成図です。
APIGatewayのアクセスログをCloudWatch Logsに吐き出し、
LambdaでCloudWatch Logs Insightsのクエリを実行し分析結果を取得、
その分析結果の内容にしたがってSlackに通知するということを行います。
なお、2019年8月現在、Insightsの分析結果をCloudWatch Alermのメトリクスに指定することはできなかったため、LambdaはCloudwatch Eventsによって5分ごとに動かすようにしました。
事前準備
Lambdaを作成する前に、いくつかの事前準備を行います。
SlackWebhookのURLを取得する。
Slack通知を行う場合、SlackWebhookのURLを取得しておいてください。
IAMロールの作成
今回使用するIAMロールは以下の2つあるので、それらを作成します。
1.APIGateway用IAMロール
後述しますが、APIGatewayはデフォルト状態ではアクセスログをCloudWatch Logsに書き出す仕様ではないためその設定を行う必要があります。その際、APIGatewayがCloudWatch Logsにログを書き込む権限が必要となるためそのIAMロールを作成します。
デフォルトで存在するポリシー「AmazonAPIGatewayPushToCloudWatchLogs」をアタッチしたロールを作成し、ARNをコピーしておいてください。2.Lambda用IAMロール
Lambdaに割り当てるロールを作成します。今回、CloudWatchLogsへのアクセス権限が必要なため、以下のIAMポリシーをアタッチしたロールを作成しました。IAMポリシー{ "Version": "2012-10-17", "Statement": [ { "Action": [ "logs:*" ], "Effect": "Allow", "Resource": "*" } ] }ロググループの作成
APIGatewayのアクセスログを書き出すためのCloudWatch Logsのロググループを作成しておきます。
APIGatewayの設定
APIGatewayの対象APIのアクセスログの設定を行います。デフォルト状態では、アクセスログは取得しない設定になっているためアクセスログをCloudWatch Logsに吐き出す設定を行います。
サービス > APIGateway > 設定
でARNにAPIGatway用に作成したIAMロールのARNを設定します。アクセスログを取得するAPIを選択 > ステージを選択 > ログのトレース
CloudWatch ログを有効化し、アクセスログを有効化、ログの形式を設定 (今回は、JSONにしました)。これでAPIGatwayの設定は完了です。
Lambdaの設定
環境変数
今回、以下の環境変数を設定しました。
CHANNEL_LIST :通知するSlackのチャンネル名をカンマ区切りで設定。
LOGGROUP_NAMES : 監視するCloudWatchLogsのロググループをカンマ区切りで設定。Insightsの結果をLambdaで監視するimport os import datetime import time import ast import slackweb import boto3 at_color = "danger" client = boto3.client('logs') channel_list = os.environ.get('CHANNEL_LIST').split(',') logGroupNames = os.environ.get('LOGGROUP_NAMES').split(',') slack_api = "Slack WebhookのURLを記載" def lambda_handler(event, context): five_minutes_ago = datetime.datetime.now() - datetime.timedelta(minutes = 5) startTime = five_minutes_ago.replace(second = 0, microsecond = 0) endTime = startTime + datetime.timedelta(minutes = 5) - datetime.timedelta(milliseconds = 1) queryString = 'fields @timestamp, @message | sort @timestamp desc | filter (status >= 400)' for logGroupName in logGroupNames: error_logs = results(logGroupName, startTime, endTime, queryString) if len(error_logs) > 0: for error_log in error_logs: dict_message = ast.literal_eval(error_log[1]['value']) text = str(logGroupName) + '\n' + str(dict_message) for channel in channel_list: try: post_slack(channel,text) except Exception as e: post_slack(channel,text) def results(logGroupName, startTime, endTime, queryString): start_query_res = client.start_query( logGroupName=logGroupName, startTime=int(startTime.timestamp()), endTime=int(endTime.timestamp()), queryString=queryString ) queryId = start_query_res['queryId'] get_results_res = client.get_query_results( queryId=queryId ) while get_results_res['status'] == 'Running': #or 'Scheduled': time.sleep(5) get_results_res = client.get_query_results( queryId=queryId ) return get_results_res['results'] def post_slack(channel,text): slack = slackweb.Slack(url=slack_api) slack.notify( username="API-accesslog", channel=channel, attachments = [{ "color" : at_color, "text" : text }] )参考サイト

- 投稿日:2019-08-11T10:52:18+09:00
AWS で WordPress ブログを構築、ドメインを取得して公開するまで(Part 2)
前回の続きです。
AWS で WordPress ブログを構築、ドメインを取得して公開するまで(Part 1)今回は初期設定と固定ページの設定、
あと WordPress テーマとして有名な「STINGER8」を追加します。では張り切っていきましょう。
事前準備
AWS と WordPress の管理アカウントは持っている想定です。
初期設定
WordPress にログインして、日本にローカライズします。
[Settings]
Site Language → 日本語
Timezone → UTC+9
Data Format → Y-m-d
Time Format → H:i
Week Starts On → Sunday
「Save Changes」ボタンを押すと、日本語化されます。
いらない記事があったのでゴミ箱に捨てます。
参加サイト → サイトネットワーク管理 → 更新
とりあえず、更新できるプラグインがあれば「すべて選択 → プラグインを更新」しておきます。
STINGER8 テーマのインストールと設定
STINGER8 テーマを取得しておきます。
下記のページから、ありがたく使わせていただきます。
https://wp-fun.com/dl/#st-toc-h-6ちょっと分かりにくいんですが「※注意事項に同意の上、ダウンロードして下さい。」をクリックすると stinger8.zip がダウンロードされます。
参加サイト → サイトネットワーク管理 → テーマ → 新規追加
(サイトネットワーク管理のテーマじゃないと、新規追加がなくてアレ?ってなります)
テーマのアップロード → ファイルの選択「stinger8.zip」→ 今すぐインストール
インストールが完了したら「サイトネットワークで有効化」します。
ブログページでも有効化しておきます。
ブログを表示すると、テーマが適用されています。
シンプルでいい感じですね。
プライバシーポリシーとお問い合わせフォーム
マイナーブログならあまり必要ないかもしれませんが、
一応御守り程度に、プライバシーポリシーページとお問い合わせフォームを持っておくと良いかもしれません。プライバシーポリシーの文面は下記のサイトを参考にさせていただきました。
ありがとうございます。プライバシーポリシーの雛形(ひな形)【作り方はコピペして穴埋めするだけ】 - マーケのじかん
https://blog-tip.com/wordpress/privacy-policy-template/プライバシーポリシーページは固定ページに置きます。
まず、要らなそうな Sample Page はゴミ箱に捨てちゃいます。
新規追加でページを作ります。
雛形のおかげで、それっぽい感じに仕上がりました。
プライバシーポリシーページは設定になんかあるので忘れずに指定しておきます。
で、プライバシーポリシーにて問い合わせフォームがあるのでそれを使ってください。
と公言してしまったので作りましょう。
参加サイト → サイトネットワーク管理 → プラグイン → 新規追加
Contact Form 7 で検索すると、和風なイラストが付いたプラグインが引っかかるので
今すぐインストール → サイトネットワークで有効化します。
インストールすると、ブログのサイドメニューに「お問い合わせ」が追加されます。
コンタクトフォーム 1 が作成されているので、コレをちょっといじります。
そういえば、パーマリンクを設定し忘れたので、設定します。
日本語のプライバシーポリシーページを作ると、パーマリンクは自動的に「プライバシーポリシー」になるので URL としてはエンコード文字列の状態「%e3%83%97%e3%83%a9%e3%82%a4%e3%83%90%e3%82%b7%e3%83%bc%e3%83%9d%e3%83%aa%e3%82%b7%e3%83%bc」になるのでリンクしづらくなります。
というわけで URL スラッグを「privacy」に変更します。更新を忘れないように・・・。
基本的に、フォームはこのままでいいんですが
一応プライバシーポリシーは見てから送信してね、という注意書きを追加しておきます。
固定ページに埋め込みます。
タイトルとショートコードを追加するだけで完成します。
パーマリンクは「contact」が良いと思います。
それなりにお問い合わせフォームができたのではないでしょうか。
さて、このお問い合わせフォーム。
送信ができません。それは何故か。
メールアドレスを設定していない。
まあそれはそうなんですが、フォームからメールを送信するには AWS にメールサーバーを設定する必要があります。次回に続く。
![Screenshot_20190811[1].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2F3a85dcb8-7efc-2340-bd32-5e208fa64f50.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=661b95f146bed031544f1ba0f29756c7)
![Screenshot_20190811[2].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2Ff9821a9d-6e57-87fa-96de-839305b40a62.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=344ffb56a203660e0b589d316ee01ce2)
![Screenshot_20190811[3].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2F01ae7563-ae00-c97e-4d42-f0703ab6faa7.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=82112a887baaba18e3dc88b2aee2e617)
![Screenshot_20190811[4].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2Fa07c92de-c647-b6c5-8431-1107b5c418a0.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=065d28d3efbfb46a3c55c79825f1cd81)
![Screenshot_20190811[5].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2Fe5c6f97e-1b47-a7e5-b2b7-47d1614f55ac.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=eb7f526ba60f7dad8bc4ce97d8f6e554)
![Screenshot_20190811[6].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2F681e5635-05b5-f774-3c99-f3bda7c9946b.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=3926f3956f2eb7b25009f296e8c9ea19)
![Screenshot_20190811[7].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2Fb7bffc1c-233e-8f98-fb5b-9ce823c9c172.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=10484cae98c00a57ddb5a90948cc6ea2)
![Screenshot_20190811[8].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2F2f0f442d-82aa-4448-c232-fd5f6275bb51.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=29155dfd47a151f2008736ef2b835ae4)
![Screenshot_20190811[9].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2F224c042f-0b89-9416-4c2a-a5ee5c2b07b6.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=b2d77deb197ce6b8e017bde33067c261)
![Screenshot_20190811[10].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2F8c47ae2a-0575-d3fd-8362-548a72e60fd9.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=4677a3dcc0f31aa5db8fedda2a96f56e)
![Screenshot_20190811[11].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2F85fdc861-0bb9-b334-0038-f581442c38e7.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=ec2d6442583dbe1974e63f548fb174c4)
![Screenshot_20190811[12].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2Ff7a50e44-a525-fa8e-cc83-3190a514782f.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=6dfda65fd6968f24419ef53188f183f1)
![Screenshot_20190811[13].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2Fbf963e24-8916-34b0-9793-f9f076775654.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=948bd671d7a049d0ebbdf0ea369961bb)
![Screenshot_20190811[14].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2F26fbf11a-d9dd-c59f-a112-5e542240378b.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=e9221cfac8c8003b294668e81301153b)
![Screenshot_20190811[15].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2F2567b90d-ba66-6e44-745a-655bdb08f42d.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=0f94227ad7a6da194300f94cc1486089)
![Screenshot_20190811[16].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2F7216f84f-7252-6c91-2dfb-ef69f6e22654.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=a0b6cd73068848b46ac9571956a0d83a)
![Screenshot_20190811[17].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2Fc3a7ccd1-278d-4289-04a7-3867cdd59b62.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=a7c8048a5cccac68aec00b8f4fc531f0)
![Screenshot_20190811[18].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2F845c77f7-3799-38a1-cc90-5122e96809dd.png?ixlib=rb-1.2.2&auto=compress%2Cformat&fit=max&s=c4d5d7acc2fb34b7dc3d3f64da635c99)