- 投稿日:2019-05-12T23:44:29+09:00
だれでもdocker-composeで楽々Django(Python)環境構築(DBなし)
Docker環境作成用のディレクトリ内構成
docker-django -- Dockerfile | -- requirements.txt | -- docker-compose.yml | -- pythonProject(中身空のディレクトリを作成しておく)それでは、requirements.txtを作成します。こちらは、djangoで使用するパッケージを記述していきます。
requirements.txt
requirements.txtDjango==2.2Djangoフレームワーク(バージョン2.1.1)を指定しています。DB関係のパッケージをインストールしたい場合こちらで記述します。
Dockerfile
DockerfileFROM python:3.7 ENV PYTHONUNBUFFERED 1 WORKDIR /code COPY requirements.txt /code/ RUN pip install -r requirements.txt
- FROM ベースイメージの設定(今回はPython)
- ENV 環境変数の設定(コンソールのstdout(標準出力)とstderr(標準エラー出力)のバッファーを無効にする設定)
- WORKDIR コマンドのcd(移動) + ディレクトリ作成をしてくれる
- COPY requirements.txtを/code/にコピー
- RUN コマンド実行 pip install -r requirements.txtはrオプションでファイルの中身のパッケージをまとめてインストールしてくれます。pipはPythonのパッケージ管理ツール
docker-compose.yml
docker-compose.ymlversion: "3" services: python37: build: . volumes: - ./pythonProject/:/code tty: true ports: - 8000:8000
- volumns ファイル同期(マウント)
- tty 起動したコンテナを起動しっぱなしにできる
- portsホストOSからコンテナへポートフォワード(あらかじめ指定したコンテナのポート番号へホストOSのポート番号に届いたパケットを届ける)
◆注意点◆
PHPの経験がある人は、環境構築の際に/var/wwwの場所にコードを配置したと思いますが、PythonコードをWebサーバーのドキュメントルート下に置いてしまうと、他人がWebを通して、コードを読めるようになってしまうため、安全性に欠けてしまいます。そのため、今回はcode下に置いています。コードの置き場所参考記事docker compose up -d
docker-compose.ymlに記述しているすべてのサービスを起動します
コマンドdocker compose up -d完了したら、コマンド打ってコンテナが作成されているか確認してみましょう。できてたら環境構築終わり
コマンド$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 33378ade007f dockerdjango_python37 "python3" 15 minutes ago Up 12 minutes 0.0.0.0:8000->8000/tcp dockerdjango_python37_1Djangoで初期画面を表示する
Djangoでいうアプリケーションとプロジェクトの違い
- アプリケーション 処理を行う
- プロジェクト 設定記述・アプリケーションを配下にもつ$ docker-compose exec python37 bashDjangoプロジェクト作成
コンテナ内に入れましたら、プロジェクトを作成します。
コマンドroot@bc8400473a8a:/code# django-admin startproject djangoProject .最後に.(ドットをつけるのは、階層を深くしたくないからそうしています)(今回プロジェクト名 = djangoProject)
Djangoアプリ作成
プロジェクトと同階層でアプリを作成します。(アプリ名 = sampleApp)
コマンドroot@bc8400473a8a:/code# python manage.py startapp sampleAppDjango初期画面表示
Djangoでは、公開するホストを指定する必要があります。djangoProject下にあるsettings.pyを編集します。
settings.pyALLOWED_HOSTS = ['192.168.99.100']今回は、Dockerを使用していて、192.168.99.100(デフォルトのものを指定)
それではdjangoの開発用のサーバを起動します。
root@bc8400473a8a:/code# python manage.py runserver 0.0.0.0:8000http://192.168.99.100:8000/
にアクセスできて、画面が表示されれば完了です。おめでとうございます!
- 投稿日:2019-05-12T23:44:29+09:00
だれでもdocker-composeで楽々Django(Python)環境構築(DBなし)#1
Docker環境作成用のディレクトリ内構成
pythonProject docker-django -- Dockerfile | -- requirements.txt | -- docker-compose.ymldocker-django(環境用)とpythonProjectは同階層です。
それでは、requirements.txtを作成します。こちらは、djangoで使用するパッケージを記述していきます。requirements.txt
requirements.txtDjango==2.1.1Djangoフレームワーク(バージョン2.1.1)を指定しています。DB関係のパッケージをインストールしたい場合こちらで記述します。
Dockerfile
DockerfileFROM python:3.7 ENV PYTHONUNBUFFERED 1 WORKDIR /code COPY requirements.txt /code/ RUN pip install -r requirements.txt
- FROM ベースイメージの設定(今回はPython)
- ENV 環境変数の設定(コンソールのstdout(標準出力)とstderr(標準エラー出力)のバッファーを無効にする設定)
- WORKDIR コマンドのcd(移動) + ディレクトリ作成をしてくれる
- COPY requirements.txtを/code/にコピー
- RUN コマンド実行 pip install -r requirements.txtはrオプションでファイルの中身のパッケージをまとめてインストールしてくれます。pipはPythonのパッケージ管理ツール
docker-compose.yml
docker-compose.ymlversion: "3" services: python37: build: . volumes: - ../pythonProject/:/code tty: true ports: - 8000:8000
- volumns ファイル同期(マウント)
- tty 起動したコンテナを起動しっぱなしにできる
- portsホストOSからコンテナへポートフォワード(あらかじめ指定したコンテナのポート番号へホストOSのポート番号に届いたパケットを届ける)
docker compose up -d
docker-compose.ymlに記述しているすべてのサービスを起動します
:コマンド
docker compose up -d
完了したら、コマンド打ってコンテナが作成されているか確認してみましょう。できてたら環境構築終わり
コマンドdocker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 33378ade007f dockerdjango_python37 "python3" 15 minutes ago Up 12 minutes 0.0.0.0:8000->8000/tcp dockerdjango_python37_1Djangoで初期画面を表示する
Djangoでいうアプリケーションとプロジェクトの違い
- アプリケーション 処理を行う
- プロジェクト 設定記述・アプリケーションを配下にもつdocker-compose exec python37 bashDjangoプロジェクト作成
コンテナ内に入れましたら、プロジェクトを作成します。
コマンドdjango-admin startproject djangoProject .最後に.(ドットをつけるのは、階層を深くしたくないからそうしています)(今回プロジェクト名 = djangoProject)
Djangoアプリ作成
アプリを作成します。
:コマンド(アプリ名 = sampleApp)
python manage.py startapp sampleApp
Django初期画面表示
Djangoでは、公開するホストを指定する必要があります。djangoProject下にあるsettings.pyを編集します。
settings.pyALLOWED_HOSTS = ['192.168.99.100']今回は、Dockerを使用していて、192.168.99.100(デフォルトのものを指定)
それではdjangoの開発用のサーバを起動します。
python manage.py runserver 0.0.0.0:8000http://192.168.99.100:8000/
にアクセスできて、画面が表示されれば完了です。おめでとうございます!
- 投稿日:2019-05-12T23:33:20+09:00
scheduleライブラリで定期的にTwitter
はじめに
今回はscheduleモジュールを使用して, Twitterにて定期的な処理を自動的に実行できるようにしていきます.
scheduleモジュール
まずは, インストールしましょう.
pip install schedule公式ドキュメントを参考にして使い方を確認しましょう.
import schedule import time # 実行したい処理 def job(): print("I'm working...") # 10分ごと schedule.every(10).minutes.do(job) # 1時間ごと schedule.every().hour.do(job) # 毎日10:30 schedule.every().day.at("10:30").do(job) # 毎週月曜日 schedule.every().monday.do(job) # 毎週水曜13:15 schedule.every().wednesday.at("13:15").do(job) # 毎時17分 schedule.every().minute.at(":17").do(job) while True: schedule.run_pending() time.sleep(1)まずはjob()関数の中で実行したい処理を設定します.
def job(): print("I'm working...")そしてschedule.every()で実行したいjobをライブラリに登録します.
様々な時間単位で登録できるようですね.# 10分ごと schedule.every(10).minutes.do(job) # 1時間ごと schedule.every().hour.do(job) # 毎日10:30 schedule.every().day.at("10:30").do(job) # 毎週月曜日 schedule.every().monday.do(job) # 毎週水曜13:15 schedule.every().wednesday.at("13:15").do(job) # 毎時17分 schedule.every().minute.at(":17").do(job)最後にschedule.run_pending()で登録したjobを実行しています. 1度の呼び出しで1度実行するので, while分でループさせて呼び出しています.
while True: schedule.run_pending() time.sleep(1)Twitterで定期的に検索andいいね
それではscheduleモジュールを用いて, Twitterの定期的な検索といいねを実装しましょう.
今回は6時間ごとに「大谷翔平」と検索して, いいねをするという仕様にしています.
Twitterの検索といいねに関しては, こちらを参照してください.# coding: utf-8 import tweepy import time import schedule # 先ほど取得した各種キーを代入する CK="Consumer Key" CS="Consumer Secret" AT="Access Token" AS="Access Token Secret" # Twitterオブジェクトの生成 auth = tweepy.OAuthHandler(CK, CS) auth.set_access_token(AT, AS) api = tweepy.API(auth) # 処理関数 def job(): # 1ツイートずつループ for status in api.search(q='大谷翔平', count=50): tweet_id = status.id # 例外処理をする try: # いいね実行 api.create_favorite(tweet_id) except: print('error') def main(): # 6時間ごと schedule.every(6).hours.do(job) while True: schedule.run_pending() time.sleep(1) main()参考サイト
- 投稿日:2019-05-12T23:33:20+09:00
scheduleライブラリで定期的にTwitterの検索andいいね
はじめに
今回はscheduleモジュールを使用して, Twitterにて定期的な処理を自動的に実行できるようにしていきます.
scheduleモジュール
まずは, インストールしましょう.
pip install schedule公式ドキュメントを参考にして使い方を確認しましょう.
import schedule import time # 実行したい処理 def job(): print("I'm working...") # 10分ごと schedule.every(10).minutes.do(job) # 1時間ごと schedule.every().hour.do(job) # 毎日10:30 schedule.every().day.at("10:30").do(job) # 毎週月曜日 schedule.every().monday.do(job) # 毎週水曜13:15 schedule.every().wednesday.at("13:15").do(job) # 毎時17分 schedule.every().minute.at(":17").do(job) while True: schedule.run_pending() time.sleep(1)まずはjob()関数の中で実行したい処理を設定します.
def job(): print("I'm working...")そしてschedule.every()で実行したいjobをライブラリに登録します.
様々な時間単位で登録できるようですね.# 10分ごと schedule.every(10).minutes.do(job) # 1時間ごと schedule.every().hour.do(job) # 毎日10:30 schedule.every().day.at("10:30").do(job) # 毎週月曜日 schedule.every().monday.do(job) # 毎週水曜13:15 schedule.every().wednesday.at("13:15").do(job) # 毎時17分 schedule.every().minute.at(":17").do(job)最後にschedule.run_pending()で登録したjobを実行しています. 1度の呼び出しで1度実行するので, while分でループさせて呼び出しています.
while True: schedule.run_pending() time.sleep(1)Twitterで定期的に検索andいいね
それではscheduleモジュールを用いて, Twitterの定期的な検索といいねを実装しましょう.
今回は6時間ごとに「大谷翔平」と検索して, いいねをするという仕様にしています.
Twitterの検索といいねに関しては, こちらを参照してください.# coding: utf-8 import tweepy import time import schedule # 先ほど取得した各種キーを代入する CK="Consumer Key" CS="Consumer Secret" AT="Access Token" AS="Access Token Secret" # Twitterオブジェクトの生成 auth = tweepy.OAuthHandler(CK, CS) auth.set_access_token(AT, AS) api = tweepy.API(auth) # 処理関数 def job(): # 1ツイートずつループ for status in api.search(q='大谷翔平', count=50): tweet_id = status.id # 例外処理をする try: # いいね実行 api.create_favorite(tweet_id) except: print('error') def main(): # 6時間ごと schedule.every(6).hours.do(job) while True: schedule.run_pending() time.sleep(1) main()参考サイト
- 投稿日:2019-05-12T23:16:18+09:00
httpによるev3devモータ駆動サーバ
0.何のメモか
モータ駆動実験の目標:
先週までの実験で、加速度センサが置かれた状態、あるいは加速度センサにより計測できる「動き」を検出し、出力につなげる基本的な仕組みを理解した。
今週は、より高度な状態や「動き」を検出し、ユニークな出力に繋げるIoTシステムの設計・実装を行う。1. ev3dev-lang-pythonの動作確認
1.1 インストール済のパッケージの確認
宿題にしてあったソフトのインストールと設定を前提に作業を行います。
https://qiita.com/takelab/items/ebde398893d05ca7a56a
OpenDHCPサーバでクロスケーブルにより有線接続されたev3がIPを自動取得。
その後、TeraTermでSSHアクセスを行う(ユーザ名:robot パスワード:maker)リスト表示
dpkg -l |grep ev3ii python3-ev3dev 1.2.0 all Python language bindings for ev3dev ii python3-ev3dev2 2.0.0~beta3 all Python language bindings for ev3devこんな結果が出るはず。
基本的に、最初にインストールされているpython3-ev3dev2の2.0.0~beta3を基準に実験を進める。つまり、'apt-get update'等はしない。一応、何をセレクトしているか表示
dpkg --get-selectionsrobot@ev3dev:~$ dpkg --get-selections |grep ev3 ev3-config install ev3-systemd install ev3dev-adduser-config install ev3dev-base-files install ev3dev-bluez-config install ev3dev-connman-config install ev3dev-media install ev3dev-rules install ev3dev-tools install ev3devkit-data install firmware-ev3 install gir1.2-ev3devkit-0.5 install jri-11-ev3:armel install libev3devkit-0.5-0 install linux-image-4.14.96-ev3dev-2.3.2-ev3 install linux-image-ev3dev-ev3 install micropython-ev3dev2 install python3-ev3dev install python3-ev3dev2 install rtl8188eu-modules-4.14.96-ev3dev-2.3.2-ev3 install rtl8812au-modules-4.14.96-ev3dev-2.3.2-ev3 install1.2 ev3devでのpython動作確認
公式資料の内容で確認する。
https://github.com/ev3dev/ev3dev-lang-python/blob/ev3dev-stretch/README.rst
コマンドラインから
python3で起動。
先頭の「>>>」は対話入力をしている印。
その後ろに以下の各行を一行づつ入力し、Enterキーを押す。
pythonの対話モード終了の際は「>>>」の後にexit()でEnterキーを押す。>>> from ev3dev2.sound import Sound >>> sound = Sound() >>> sound.speak('Hello World')1.3 ev3devでのモータ動作確認
同様にモータの動作も確認する。AポートとBポートにモータを接続する。
ここで、レポートのために、モータの接続図を作成するためのメモを取っておくこと。>>> from ev3dev2.motor import LargeMotor, OUTPUT_A, OUTPUT_B, SpeedPercent >>> m1 = LargeMotor(OUTPUT_A) >>> m2 = LargeMotor(OUTPUT_B) >>> m1.on(SpeedPercent(-10),brake=False) >>> m1.on(SpeedPercent(0),brake=False) >>> m2.on(SpeedPercent(10),brake=False) >>> m1.on(SpeedPercent(0),brake=False) >>> m1.on(SpeedPercent(-10),brake=False) >>> m2.on(SpeedPercent(0),brake=False) >>> m1.on(SpeedPercent(0),brake=False)ちなみに、各要素は次のような結果を返す。
>>> print(LargeMotor) <class 'ev3dev2.motor.LargeMotor'> >>> print(OUTPUT_A) ev3-ports:outAモータ動作の仕様は、以下の通り(今回はサーバ経由で制御するので直接制御は行わない)
https://python-ev3dev.readthedocs.io/en/ev3dev-stretch/motors.html#ev3dev.motor.Motor.on_for_degrees
https://sites.google.com/site/ev3devpython/learn_ev3_python/using-motors1.4 ev3devでhttpサーバ
python3 -m http.server 8000
が使える。robot@ev3dev:~/dist-pack-ev3dev$ cd robot@ev3dev:~$ python3 -m http.server 8000 Serving HTTP on 0.0.0.0 port 8000 ... 192.168.137.5 - - [04/Mar/2019 09:11:57] "GET / HTTP/1.1" 200 - 192.168.137.5 - - [04/Mar/2019 09:11:57] code 404, message File not found 192.168.137.5 - - [04/Mar/2019 09:11:57] "GET /favicon.ico HTTP/1.1" 404 - ^C Keyboard interrupt received, exiting.2. HTTPサーバの部分
1.4のようにpythonの標準ライブラリである、http.serverを使うことができることまで確認した。
2.1 デモにあるEV3D4のwebコントロール
デモ中のEV3D4WebControl.pyの先頭部分
WebControlledTankをimportして、それをEV3D4WebControlledに継承させて使っている。EV3D4WebControl.py#!/usr/bin/env python3 import logging import sys from ev3dev2.motor import OUTPUT_A, OUTPUT_B, OUTPUT_C, MediumMotor from ev3dev2.control.webserver import WebControlledTank class EV3D4WebControlled(WebControlledTank): def __init__(self, medium_motor=OUTPUT_A, left_motor=OUTPUT_C, right_motor=OUTPUT_B): WebControlledTank.__init__(self, left_motor, right_motor) self.medium_motor = MediumMotor(medium_motor) self.medium_motor.reset() #この後まだ数行続くimportされているWebControlledTankがある。ev3dev2.control.webserver.pyの先頭部分を見る。
from http.server import BaseHTTPRequestHandler, HTTPServerの行を見ると分かるように、やはりhttp.serverからimportをしているので、python3の標準的な実装を行っている様子。具体的には、/usr/lib/python3.5/の下のhttp/server.pyを見てやると具体的なことは分かる。
Webを検索すると、from BaseHTTPServer import BaseHTTPRequestHandler, HTTPServerとやっている例があるが、python2とpython3の違いか?webserver.py#!/usr/bin/env python3 import logging import os import re from ev3dev2.motor import MoveJoystick, list_motors, LargeMotor from http.server import BaseHTTPRequestHandler, HTTPServer継承しているWebControlledTankの確認
具体的には、MoveJoyStickの継承をして、TankWebHandlerをハンドラにして、RobotWebServerを使ったサーバ起動を行う。具体的なソース。
WebControlledTank.pyclass WebControlledTank(MoveJoystick): """ A tank that is controlled via a web browser """ def __init__(self, left_motor, right_motor, port_number=8000, desc=None, motor_class=LargeMotor): MoveJoystick.__init__(self, left_motor, right_motor, desc, motor_class) self.www = RobotWebServer(self, TankWebHandler, port_number) def main(self): # start the web server self.www.run()サーバ部分のRobotWebServer
サーバは
self.content_server = HTTPServer(('', self.port_number), self.handler_class)でハンドラを分岐する。
具体的には、’’は自分のIPアドレス、ポート番号は8000, self.handler_classはTankWebHandlerになる。RobotWebServer.pyclass RobotWebServer(object): """ A Web server so that 'robot' can be controlled via 'handler_class' """ def __init__(self, robot, handler_class, port_number=8000): self.content_server = None self.handler_class = handler_class self.handler_class.robot = robot self.port_number = port_number def run(self): try: log.info("Started HTTP server (content) on port %d" % self.port_number) self.content_server = HTTPServer(('', self.port_number), self.handler_class) self.content_server.serve_forever() # Exit cleanly, stop both web servers and all motors except (KeyboardInterrupt, Exception) as e: log.exception(e) if self.content_server: self.content_server.socket.close() self.content_server = None for motor in list_motors(): motor.stop()2.2 HTTPメソッドハンドラ
2.1で説明したようにWebサーバのハンドラ制御部分が中心的になる。
TankWebHandlerはRobotWebHandlerを継承している。
RobotWebHandlerは後述のソースように標準的なBaseHTTPRequestHandlerを継承している。
TankWebHandler.pyclass TankWebHandler(RobotWebHandler): def __str__(self): return "%s-TankWebHandler" % self.robot def do_GET(self): """ Returns True if the requested URL is supported """ if RobotWebHandler.do_GET(self): return True実際のRobotWebHandlerは以下の通り。
RobotWebHandler.pylog = logging.getLogger(__name__) # ================== # Web Server classes # ================== class RobotWebHandler(BaseHTTPRequestHandler): """ Base WebHandler class for various types of robots. RobotWebHandler's do_GET() will serve files, it is up to the child class to handle REST APIish GETs via their do_GET() self.robot is populated in RobotWebServer.__init__() """ # File extension to mimetype mimetype = { 'css' : 'text/css', 'gif' : 'image/gif', 'html' : 'text/html', 'ico' : 'image/x-icon', 'jpg' : 'image/jpg', 'js' : 'application/javascript', 'png' : 'image/png' } def do_GET(self): """ If the request is for a known file type serve the file (or send a 404) and return True """ if self.path == "/": self.path = "/index.html" # Serve a file (image, css, html, etc) if '.' in self.path: extension = self.path.split('.')[-1] mt = self.mimetype.get(extension) if mt: filename = os.curdir + os.sep + self.path # Open the static file requested and send it if os.path.exists(filename): self.send_response(200) self.send_header('Content-type', mt) self.end_headers() if extension in ('gif', 'ico', 'jpg', 'png'): # Open in binary mode, do not encode with open(filename, mode='rb') as fh: self.wfile.write(fh.read()) else: # Open as plain text and encode with open(filename, mode='r') as fh: self.wfile.write(fh.read().encode()) else: log.error("404: %s not found" % self.path) self.send_error(404, 'File Not Found: %s' % self.path) return True return False def log_message(self, format, *args): """ log using our own handler instead of BaseHTTPServer's """ # log.debug(format % args) pass2.3 簡易do_GET実装
以上までのソースを参考に、プログラム的には褒められないが、馬鹿正直なハンドラ部分を作ると次のようになる。
もちろんテストはブラウザからテストできる。test.pyfrom http.server import HTTPServer, BaseHTTPRequestHandler class MyHandler(BaseHTTPRequestHandler): def do_GET(self): print(self.path) if self.path == "/": self.send_response(200) self.end_headers() self.wfile.write("OK".encode('utf-8')) return elif self.path == "/command": self.send_response(200) self.end_headers() self.wfile.write("OK".encode('utf-8')) return else: self.send_response(200) self.end_headers() self.wfile.write("OK".encode('utf-8')) return if __name__ == "__main__": host = '' port = 8181 server = HTTPServer((host, port), MyHandler) server.serve_forever()3. モータ制御との連携
3.1 Python(ev3dev側)のサーバプログラム
2.3のプログラムに単にモータ管理用オブジェクトをグローバル変数化してif-elifで制御する単純プログラム。
まずはここから。これから良いプログラムにしてください。実行は、
python3 motorHttp.pyでOK。
終了はCtrl+C。motorHttp.py#!/usr/bin/env python3 # # import logging import sys from ev3dev2.motor import LargeMotor, OUTPUT_A, OUTPUT_B, SpeedPercent from http.server import HTTPServer, BaseHTTPRequestHandler class MyHandler(BaseHTTPRequestHandler): def do_GET(self): global m1 global m2 print(self.path) if self.path == "/": self.send_response(200) self.end_headers() self.wfile.write("MotorA: OFF B: OFF".encode('utf-8')) m1.on(SpeedPercent(0),brake=False) m2.on(SpeedPercent(0),brake=False) return elif self.path == "/a0": self.send_response(200) self.end_headers() self.wfile.write("MotorA: OFF B:x".encode('utf-8')) m1.on(SpeedPercent(0),brake=False) return elif self.path == "/a1": self.send_response(200) self.end_headers() self.wfile.write("MotorA: ON B:x".encode('utf-8')) m1.on(SpeedPercent(10),brake=False) return elif self.path == "/a-1": self.send_response(200) self.end_headers() self.wfile.write("MotorA: RV B:x".encode('utf-8')) m1.on(SpeedPercent(-10),brake=False) return elif self.path == "/b0": self.send_response(200) self.end_headers() self.wfile.write("MotorA:x B:OFF".encode('utf-8')) m2.on(SpeedPercent(0),brake=False) return elif self.path == "/b1": self.send_response(200) self.end_headers() self.wfile.write("MotorA:x B:ON".encode('utf-8')) m2.on(SpeedPercent(10),brake=False) return elif self.path == "/b-1": self.send_response(200) self.end_headers() self.wfile.write("MotorA:x B:RV".encode('utf-8')) m2.on(SpeedPercent(-10),brake=False) return else: self.send_response(200) self.end_headers() self.wfile.write("OK".encode('utf-8')) return if __name__ == "__main__": host = '' port = 8181 m1 = LargeMotor(OUTPUT_A) m2 = LargeMotor(OUTPUT_B) m1.on(SpeedPercent(0),brake=False) m2.on(SpeedPercent(0),brake=False) server = HTTPServer((host, port), MyHandler) server.serve_forever()3.2 Windows側のクライアントプログラム
キーボード入力の先頭文字列を使い、3.1のサーバプログラムと連携する。
IPアドレスを固定で書いてあるので、IPアドレスで置換をかけるべき。key2HTTP.csusing System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Data; using System.Net; using System.Net.Sockets; using System.Threading.Tasks; using System.IO.Ports; using System.IO; namespace key2HTTP { class Program { static void Main(string[] args) { ConsoleKeyInfo k; for (int i = 0; i < 100; i++) { //Console.WriteLine("InputInt Number"); k = Console.ReadKey(true); string s = k.KeyChar.ToString(); //この段階でiは文字列sが数字なら数字に、0とそれ以外は0になっている。 Console.WriteLine("KEYBOARD INPUT: {0}", s); if (!string.IsNullOrEmpty(s)) { WebClient wc = new WebClient(); Stream st; StreamReader sr; //受信データに関する処理 if (s.StartsWith("0")) { st = wc.OpenRead("http://192.168.137.7:8181/"); sr = new StreamReader(st, Encoding.GetEncoding("UTF-8")); Console.WriteLine(sr.ReadToEnd()); } else if (s.StartsWith("a")) { st = wc.OpenRead("http://192.168.137.7:8181/a1"); sr = new StreamReader(st, Encoding.GetEncoding("UTF-8")); Console.WriteLine(sr.ReadToEnd()); } else if (s.StartsWith("b")) { st = wc.OpenRead("http://192.168.137.7:8181/a-1"); sr = new StreamReader(st, Encoding.GetEncoding("UTF-8")); Console.WriteLine(sr.ReadToEnd()); } else if (s.StartsWith("c")) { st = wc.OpenRead("http://192.168.137.7:8181/a0"); sr = new StreamReader(st, Encoding.GetEncoding("UTF-8")); Console.WriteLine(sr.ReadToEnd()); } else if (s.StartsWith("e")) { st = wc.OpenRead("http://192.168.137.7:8181/b1"); sr = new StreamReader(st, Encoding.GetEncoding("UTF-8")); Console.WriteLine(sr.ReadToEnd()); } else if (s.StartsWith("f")) { st = wc.OpenRead("http://192.168.137.7:8181/b-1"); sr = new StreamReader(st, Encoding.GetEncoding("UTF-8")); Console.WriteLine(sr.ReadToEnd()); } else if (s.StartsWith("g")) { st = wc.OpenRead("http://192.168.137.7:8181/b0"); sr = new StreamReader(st, Encoding.GetEncoding("UTF-8")); Console.WriteLine(sr.ReadToEnd()); } else { Console.WriteLine("We don't define the command"); } wc.Dispose(); } } Console.WriteLine("Press Enter Key"); Console.ReadLine(); } } }3.3 シリアル通信との連携
3.2節のプログラムを改造し、シリアル通信の基礎プログラムである以下のプログラムを作成せよ。
ComReceive.csusing System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Data; using System.Net; using System.Net.Sockets; using System.Threading.Tasks; using System.IO.Ports; namespace ComReceive { class Program { static void Main(string[] args) { SerialPort sp = new SerialPort(); sp.BaudRate = 9600; //sp.BaudRate = 115200; sp.PortName = "COM5"; //自分たちのCOMポート番号にすること // extra sp.Parity = Parity.None; sp.StopBits = StopBits.One; sp.DataBits = 8; //Start Send Charctor Console.Write("Press EnterKey to start!"); Console.ReadLine(); string req = "s"; //PCからのキー入力トリガー try { sp.Open();//シリアルポートのオープン sp.WriteLine(req); Console.WriteLine("send :" + req); } catch (Exception e) { Console.WriteLine("Unexpected exception: ", e.ToString()); } //受信処理 50回のループにしてある for (int i = 0; i < 50; i++) { string data = sp.ReadLine(); Console.WriteLine(data); } Console.WriteLine("loop was over"); sp.Close();//シリアルポートのクローズ } } }
- 投稿日:2019-05-12T22:36:21+09:00
【WIP】リスト型の関数まとめ
以下のリストを元に関数をまとめます
list.pyv = ["a", "b", "c", "d"]要素を追加したいとき
append
appendは〜を…に付け加えるという意味の動詞
文字通り要素をリストの末尾に追加するlist.pyv.append("e") v ['a', 'b', 'c', 'd', 'e']追加する要素の順番を指定したい場合はinsertを使用する
insert
vというリストの頭にfという要素を追加したい場合、コードは
v.insert(0, f)``となる
一つ目の引数で値の位置を指定、二つ目の引数で追加する要素を宣言するlist.pyv.insert(0,"f") v ['f', 'a', 'b', 'c', 'd', 'e']要素を削除したいとき
remove
指定した要素をリストから削除する
list.pyv.remove('f') v ['a', 'b', 'c', 'd', 'e']pop
指定された位置にある要素をリストから削除する
list.pyv.pop(0) 'a' v ['b', 'c', 'd', 'e']リストを一掃する
clear
list.pyv.clear() v []
- 投稿日:2019-05-12T22:22:41+09:00
tsfreshで時系列データの統計的処理を簡単に
概要
時系列データを処理する機会があり、便利そうなものを発見したので、使い方のメモ。
以下の公式を参照。
tsfreshtsfresh is a python package. It automatically calculates a large number of time series characteristics, the so called features. Further the package contains methods to evaluate the explaining power and importance of such characteristics for regression or classification tasks.
使い方
以下はJupyter Notebook上で実行しています。
ライブラリのインポート
!pip install tsfresh import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline時系列データの作成
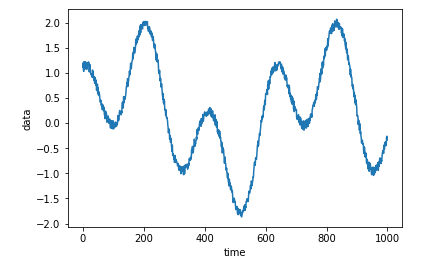
適当なダミーデータを作成。
timeline = np.arange(10000) data = np.sin(timeline/100) + np.cos((timeline/100) * 3) + (np.random.rand(len(timeline)))*0.2 plt.plot(timeline[:1000], data[:1000]) plt.xlabel('time') plt.ylabel('data') plt.show()
feature_extractionで特徴量を計算
feature_calculatorsという関数があるので、これを使うと様々な特徴量を計算できる。
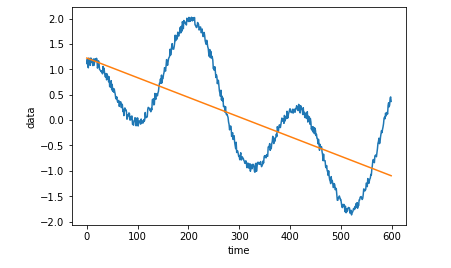
feature_extractionimport tsfresh.feature_extraction.feature_calculators as feature_calculators range_data = data[:600] mean_abs_change = feature_calculators.mean_abs_change(data) # 前後のポイント間での差分の平均値 # np.mean(np.abs(np.diff(x))) と等しい first_location_of_maximum = feature_calculators.first_location_of_maximum(data) # 最大値が観測される位置 fft_aggregated = feature_calculators.fft_aggregated(data, [{'aggtype': 'skew'}]) # フーリエ変換 number_peaks = feature_calculators.number_peaks(data[:1000], 50) # ピークの数 index_mass_quantile = feature_calculators.index_mass_quantile(data[:1000], [{'q': 0.5},{'q': 0.1}]) # パーセンタイル処理 linear_trend = feature_calculators.linear_trend(range_data, [{'attr': "slope"},{'attr': 'intercept'},{'attr': 'rvalue'}]) # 単純なトレンド分析。attrに関しては下記を参照 # https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.linregress.html autocorrelation = feature_calculators.autocorrelation(data, 100) # 自己相関の計算この中のlinear_trendを使って、時系列データのトレンドを計算してみる。
trend = linear_trend[0][1] * timeline + linear_trend[1][1] plt.plot(timeline[:600], data[:600]) plt.plot(timeline[:600], trend[:600]) plt.xlabel('time') plt.ylabel('data') plt.show()
当たり前だが、正しく計算できていそう。
まとめて特徴量を計算
個別にではなくて、とりあえずたくさん特徴量を計算したい場合は、extract_featuresを使えばよさそう。
from tsfresh import extract_features # こちらはDataFrameではないといけないようなので変換する。 # 1つのデータフレーム内に複数の時系列データがある形を想定しているらしく、どのデータが時系列としてひとまとまりなのか識別するカラムが必要(column_idで指定) # 今回は1種類しか入っていないので、すべて1にした temp = pd.DataFrame(data, columns=['value'], dtype='float') temp['id'] = 1 temp.head() extracted_features = extract_features(temp, column_id='id') display(extracted_features.columns)Index(['value__abs_energy', 'value__absolute_sum_of_changes', 'value__agg_autocorrelation__f_agg_"mean"__maxlag_40', 'value__agg_autocorrelation__f_agg_"median"__maxlag_40', 'value__agg_autocorrelation__f_agg_"var"__maxlag_40', 'value__agg_linear_trend__f_agg_"max"__chunk_len_10__attr_"intercept"', 'value__agg_linear_trend__f_agg_"max"__chunk_len_10__attr_"rvalue"', 'value__agg_linear_trend__f_agg_"max"__chunk_len_10__attr_"slope"', 'value__agg_linear_trend__f_agg_"max"__chunk_len_10__attr_"stderr"', 'value__agg_linear_trend__f_agg_"max"__chunk_len_50__attr_"intercept"', ... 'value__symmetry_looking__r_0.9', 'value__symmetry_looking__r_0.9500000000000001', 'value__time_reversal_asymmetry_statistic__lag_1', 'value__time_reversal_asymmetry_statistic__lag_2', 'value__time_reversal_asymmetry_statistic__lag_3', 'value__value_count__value_-1', 'value__value_count__value_0', 'value__value_count__value_1', 'value__variance', 'value__variance_larger_than_standard_deviation'], dtype='object', name='variable', length=794)これだけで794個も特徴量が計算できたらしい。
まとめ
numpy1行で終わるようなものも多いが、まとめて特徴量計算したいときには便利かもしれない。特にextract_features。
時間を見つけてもう少し使ってみたい。
- 投稿日:2019-05-12T22:20:08+09:00
進化計算ライブラリDEAPで実数値GA
はじめに
前職の業務で遺伝的アルゴリズムを用いた数理最適化を行っており、その際にPythonの進化計算ライブラリDEAPを用いる機会があったので実装例をまとめておきたいと思いました。
DEAPを用いた実数値遺伝的アルゴリズムの実装例はネットで探しても見かけなかったので、役に立てば良いなと思います。遺伝的アルゴリズム(Genetic Algorithm, GA)
遺伝的アルゴリズムは自然淘汰の仕組みを最適化問題に応用したアルゴリズムです。
生命進化の場合、周囲の自然環境に適応できた個体の遺伝子は子孫へと受け継がれ、適応できなかった個体の染色体は受け継がれずに途絶えてしまいます。また、突然変異などにより他の個体よりも環境への適応度の高い個体が生まれた場合は、その遺伝子はより子孫へと受け継がれやすくなります。これらが繰り返されることで、環境への適応度が高い個体が最終的に残ります。これが自然淘汰のメカニズムです。
遺伝的アルゴリズムでは解きたい問題の解の候補(個体)をランダムに生成して多数の個体からなる個体集団を作成します。個体集団内の個体に対して交叉(2つの個体から新しい個体を生成する操作)や変異(個体をランダムに変更する操作)といった操作を行い適応度(問題における解の良さ)の高い個体を選出します。これら一連の操作を繰り返し実行することで集団内の個体は淘汰されていき、最終的に最適解を得る事ができます。問題設定
解きたい問題
本記事ではDEAPに入っているベンチマーク関数Ackleyの2次元空間における最小値探索を行います。
Ackley関数
関数式は以下です。
f(x, y) = 20 - 20\exp\Biggl(-0.2\sqrt{\frac{x^2 + y^2}{2}}\Biggl) + e - \exp\Biggl(\frac{\cos(2\pi x) + \cos(2\pi y)}{2}\Biggl)この関数を3次元プロットしたものが下図です。
公式ドキュメントでは変数の定義域は[-15, 30]となっていましたが、今回は[-500, 500]とします。
左図は[-30, 30]の範囲で、右図は[-500, 500]の範囲で表示しています。
図を見て分かる通り曲面が非常にギザギザしており、(x, y)=(0, 0)において最小値0.0を取る関数です。
(公式ドキュメント, Ackley関数)
https://deap.readthedocs.io/en/master/api/benchmarks.html遺伝子
個体の遺伝子は解の候補となる2次元空間上の点のx, y座標とします。
また個体遺伝子はそれぞれ[-500, 500]の範囲で一様に生成します。交叉
交叉はブレンド交叉(BLX-α)を用います。
ブレンド交叉では下図のように親子体によってできる矩形領域に対して各軸を1+2α倍した矩形領域内で一様に次世代個体候補を生成します。
変異
変異はガウス変異を用います。
個体に変異を行う際には個体の遺伝子に、指定した平均値、分散のガウス分布から発生した乱数が加算されます。個体選択
トーナメント方式による個体選択を行います。
トーナメント方式では指定された個数の個体が集団からランダムに選出され、その中で最良の個体が次世代個体の候補となります。ランダムに選出される個体数はトーナメントサイズと呼ばれます。実行環境
- Python 3.7.3
- deap 1.2
実装
実装コード : https://github.com/t-yoshitake/ga-sample/blob/master/ga.py
実装は公式ドキュメントにあるOne Max Problem(バイナリ値の最適化問題)の実装をベースに実数値関数の最小値探索を行うように修正しています。
(One Max Problemの実装コード https://deap.readthedocs.io/en/master/examples/ga_onemax.html)コードの解説
import random from deap import base, creator, tools from deap.benchmarks import ackleyまず最初にDEAPモジュールのインポートを行っています。
今回用いるベンチマーク関数はackleyとして読み込んでいます。# 適応度クラスの作成 creator.create("FitnessMin", base.Fitness, weights=(-1.0,))creatorはclass factoryというもので、createメソッドにより指定した名前、親クラス、属性を持つクラスを作成します。
creator.createの引数は順に、作成するクラス名、継承するクラス、クラスの属性第1、第2引数は必須で第3以降の引数は任意です。
base.Fitnessは抽象クラスであり、weights属性を必ずオーバーライドする必要があります。
なのでここではweightsが必須になります。
weightsはタプルで渡します。
関数値を最小化する場合は(-1.0, )、最大化する場合は(1.0, )。サイズが2以上のタプルを渡すことで複数の関数の最適化ができるようです。# 個体クラスの作成 creator.create("Individual", list, fitness=creator.FitnessMin)ここでは個体クラスIndividualを作成しています。Individualはlistクラスを継承し、先程作成したcreator.FitnessMinを属性として持ちます。
# Toolboxの作成 toolbox = base.Toolbox()Toolboxには様々な関数を指定した名前で登録することができます。
ここでは以下の関数を登録します。
- attr_gene : 遺伝子を生成する関数
- individual : 個体を生成する関数
- population : 個体集団を生成する関数
- evaluate : 評価関数
- mate : 交叉を実行する関数
- mutate : 変異を実行する関数
- select : 次世代の個体を選択する関数
# 遺伝子を生成する関数"attr_gene"を登録 toolbox.register("attr_gene", random.uniform, -500, 500)toolbox.registerで関数の登録を行っています。引数は順に関数の登録名、登録する関数、登録する関数の引数(任意)です。
上の例では遺伝子を生成する関数の登録を行っており、初期個体の遺伝子を-500から500の間でランダムに作成するために一様乱数を生成する関数random.uniformと引数を登録しています。# 個体を生成する関数”individual"を登録 toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.attr_gene, 2)個体を生成する関数の登録を行っています。tools.initRepeatの引数としてcreator.Individual, toolbox.attr_gene, 2を登録しています。tools.initRepeatはtoolbox.attr_geneを2回実行することでcreator.Individualクラスを初期化します。
今回の問題では個体は2つの遺伝子を持ち、各遺伝子が2次元空間上の点のx, y座標に対応するように設定しています。# 個体集団を生成する関数"population"を登録 toolbox.register("population", tools.initRepeat, list, toolbox.individual)個体集団を生成する関数の登録を行っています。上で定義したtoolbox.inidividualを繰り返し実行する処理を行っていますが、繰り返し回数(集団内の個体数)は実行時に引数として指定したいため、登録時には指定していません。
# 評価関数"evaluate"を登録 toolbox.register("evaluate", ackley)個体の評価関数の登録を行っています。
# 交叉を行う関数"mate"を登録 toolbox.register("mate", tools.cxBlend, alpha=0.2)交叉を実行する関数の登録を行っています。
cxBlendはブレンド交叉を行う関数で、第1, 2引数が交叉対象の個体、第3引数が交叉パラメータαになります。
ここでは交叉パラメータを指定し、対象個体は実行時に指定します。# 変異を行う関数"mutate"を登録 toolbox.register("mutate", tools.mutGaussian, mu=[ 0.0, 0.0], sigma=[200.0, 200.0], indpb=0.2)変異を実行する関数の登録を行っています。
mutGaussianは個体にガウス変異を加える関数で、引数は順に対象個体、ガウス分布の平均値(mu)、ガウス分布の標準偏差(sigma)、独立変異確率(indpb)です。ここで独立変異確率は個体の1つの遺伝子に変異がかかる確率です。ここでも対象個体は指定せずに実行時に引数として与えます。# 個体選択法"select"を登録 toolbox.register("select", tools.selTournament, tournsize=3)個体選択を実行する関数の登録を行っています。
selTournamentは個体選択を行う関数で対象個体集団、選択個体数、トーナメントサイズ(tournsize)を引数として受けます。
ここではトーナメントサイズを指定し、対象個体集団、選択個体数は実行時に指定します。def main(): random.seed(1) # GAパラメータ N_GEN = 100 # 繰り返し世代数 POP_SIZE = 1000 # 集団内の個体数 CX_PB = 0.5 # 交叉確率 MUT_PB = 0.2 # 変異確率ここからmain関数の説明に入ります。
GAの制御のためのパラメータを定義しています。# 個体集団の生成 pop = toolbox.population(n=POP_SIZE) print("Start of evolution") # 個体集団の適応度の評価 fitnesses = list(map(toolbox.evaluate, pop)) for ind, fit in zip(pop, fitnesses): ind.fitness.values = fit print(" Evaluated %i individuals" % len(pop)) # 適応度の抽出 fits = [ind.fitness.values[0] for ind in pop]ここで記述した処理は進化ループ処理に入る前の前処理です。
まず個体集団の生成を行っています。個体の生成はtoolboxに登録した関数"population"に集団内の個体数POP_SIZEを渡して実行しています。
個体は前に定義したIndividualクラスのインスタンスですが、生成時はfitness属性が設定されていないので2段目の処理で各個体のfitness属性を設定しています。設定する値はtoolboxに登録した関数"evaluate"の出力値(個体を引数としたackley関数の出力値)です。
最後の段の処理では各個体の適応度を抽出しリスト化しています。# 進化ループ開始 g = 0 while g < N_GEN: g = g + 1 print("-- Generation %i --" % g) # 次世代個体の選択・複製 offspring = toolbox.select(pop, len(pop)) offspring = list(map(toolbox.clone, offspring))進化ループに入ります。
上記コードの最後の2行の1行目は次世代に引き継ぐ個体の選択を行うためにtoolbox.selectを実行しています。
しかしこのままではoffspringはpop内の個体への参照となっているので、2行目で参照を切ることでoffspringをpopとは独立したコピーとして作成しています。# 交叉 for child1, child2 in zip(offspring[::2], offspring[1::2]): # 交叉させる個体を選択 if random.random() < CX_PB: toolbox.mate(child1, child2) # 交叉させた個体は適応度を削除する del child1.fitness.values del child2.fitness.values交叉処理の部分です。
次世代個体候補から個体を2個ずつ選択肢、確率CX_PBで個体同士の交叉を行っています。
交叉を実行した個体のfitness属性は後で再設定するために一旦削除しています。# 変異 for mutant in offspring: # 変異させる個体を選択 if random.random() < MUT_PB: toolbox.mutate(mutant) # 変異させた個体は適応度を削除する del mutant.fitness.values変異処理を行っています。
# 適応度を削除した個体について適応度の再評価を行う invalid_ind = [ind for ind in offspring if not ind.fitness.valid] fitnesses = map(toolbox.evaluate, invalid_ind) for ind, fit in zip(invalid_ind, fitnesses): ind.fitness.values = fit print(" Evaluated %i individuals" % len(invalid_ind)) # 個体集団を新世代個体集団で更新 pop[:] = offspring交叉あるいは変異を行った個体は遺伝子が変化しているので、適応度(fitness属性)を再評価する必要があります。
上記の部分ではfitness属性の再設定を行い、個体集団popを次世代の個体集団offspringで更新しています。# 新世代の全個体の適応度の抽出 fits = [ind.fitness.values[0] for ind in pop] # 適応度の統計情報の出力 length = len(pop) mean = sum(fits) / length sum2 = sum(x*x for x in fits) std = abs(sum2 / length - mean**2)**0.5 print(" Min %s" % min(fits)) print(" Max %s" % max(fits)) print(" Avg %s" % mean) print(" Std %s" % std)ここでは各世代の全個体について適応度を抽出し、統計情報を出力しています。
以上で進化ループ処理は終わりです。# 最良個体の抽出 best_ind = tools.selBest(pop, 1)[0] print("Best individual is %s, %s" % (best_ind, best_ind.fitness.values))最後に最終世代の個体集団内の最良個体を抽出し、遺伝子と適応度を出力しています。
結果
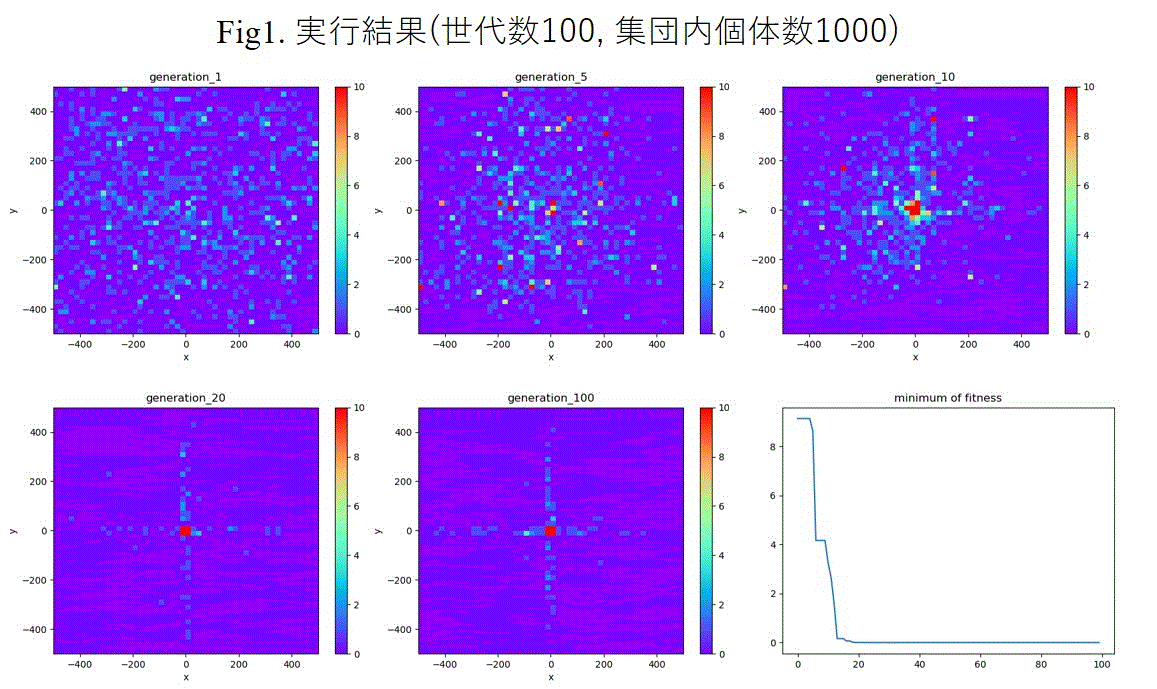
繰り返し世代数100, 集団内個体数1000で実行した結果、最終世代の最良個体は(x, y)=(-4.014e-17, 7.845e-17)でこのときのackley関数値は0.0となりました。
また、進化過程の結果を図示したものが下です。個体分布のヒストグラムをヒートマップ図で表しており横軸がx座標遺伝子、縦軸がy座標遺伝子に対応しヒストグラムのカウント数を0から最大10までを色付けしています(赤い所ほど個体が密集しています)。ヒートマップ図は1, 5, 10, 20, 100世代目の結果を出力しています。最初はまばらに生成された個体が世代を経るごとに最適解(0, 0)密集していることがわかります。最後の図は集団内個体のfitness値の最小値を世代ごとにプロットしたもので(横軸:世代、縦軸:fitness最小値)、20世代くらいでfitnessの最小値はほぼ0となっており、最小値探索は上手くいったことがわかります。
条件を厳しくして探索がうまくいくかやってみました。先の例では初期個体を[-500, 500]の範囲で一様に生成していましたが、個体生成の座標の範囲を[400, 500]に変更しました。また実行条件は繰り返し世代数20000, 集団内個体数1000でその他の条件は同じです。結果は最終世代の最良個体は(x, y)=(1.892e-17, -3.985e-17)で関数値は0.0となり、最小値を求めることができました。
下図は第1, 20000世代のヒストグラムとfitnessの最小値の世代推移図です。
その他
探索したい領域が有限領域の場合は、個体遺伝子が探索区間から外れた場合に適応度を大幅に悪くすることで探索区間に制限をかけることができます。DEAPにはそのためのメソッドが用意されており、簡単に制限をかけることができます。
https://deap.readthedocs.io/en/master/tutorials/advanced/constraints.html?highlight=constraint実際の業務ではもっと複雑な最適化問題を扱っていて、良い解が得られるハイパーパラメータ(繰り返し世代数、集団内個体数、交叉確率、変異確率など)を探すのに苦労しました。この辺はディープラーニングでも用いられているベイズ最適化などが使えるのではないかと考えているのですが、ベイズ最適化の仕組みを理解できていないので今後勉強して試してみたいと思っています。
ベイズ最適化:https://www.slideshare.net/hoxo_m/ss-77421091参考
https://deap.readthedocs.io/en/master/index.html
https://qiita.com/neka-nat@github/items/0cb8955bd85027d58c8e
https://qiita.com/simanezumi1989/items/4f821de2b77850fcf508
Cによる探索プログラミング―基礎から遺伝的アルゴリズムまで 伊庭 斉志



- 投稿日:2019-05-12T22:15:41+09:00
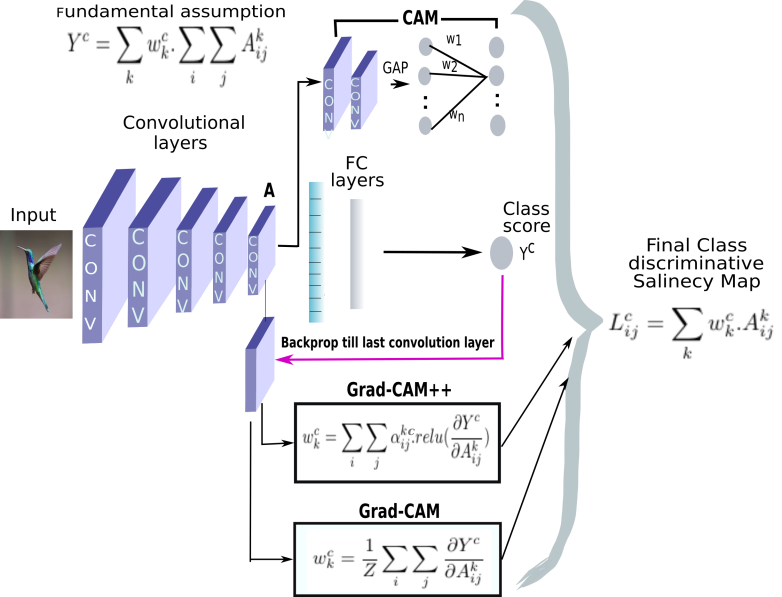
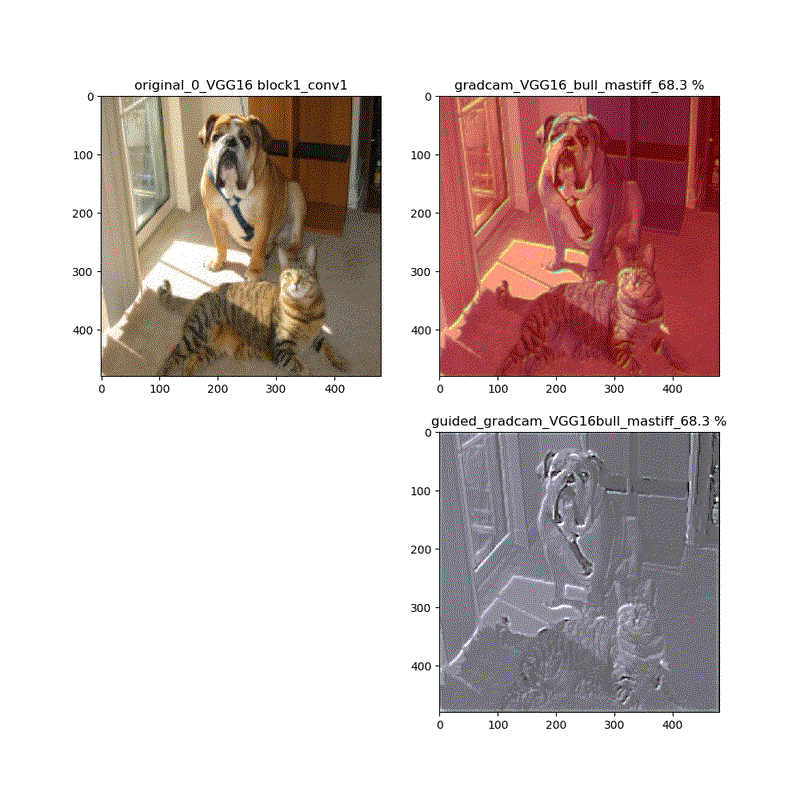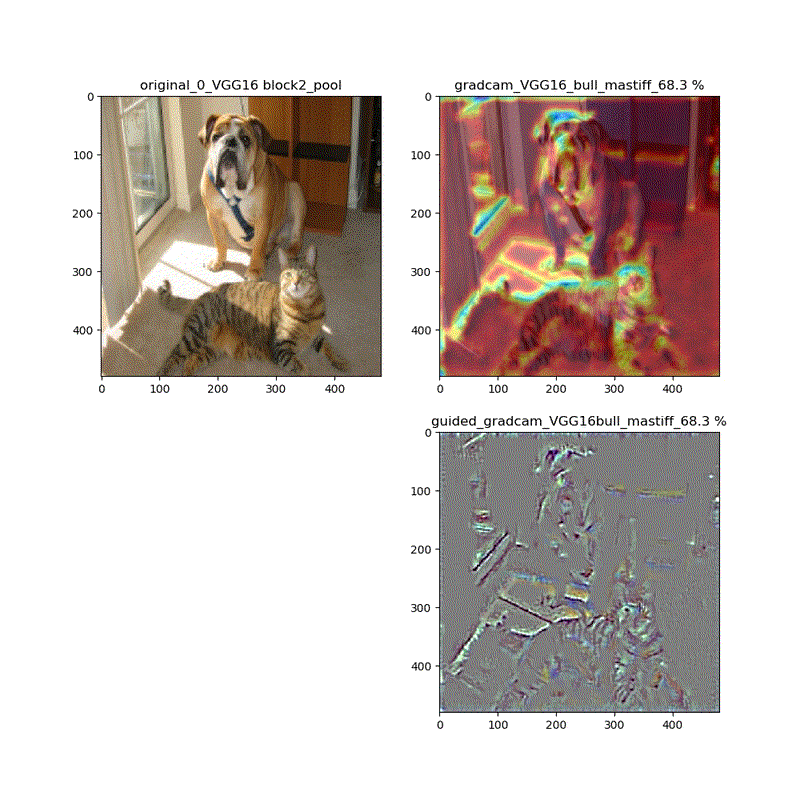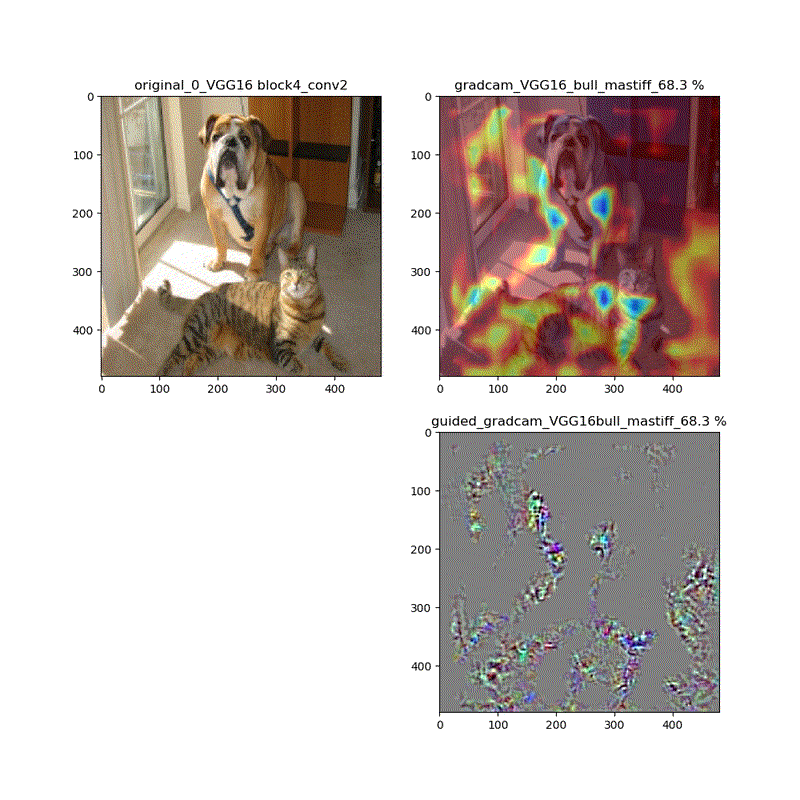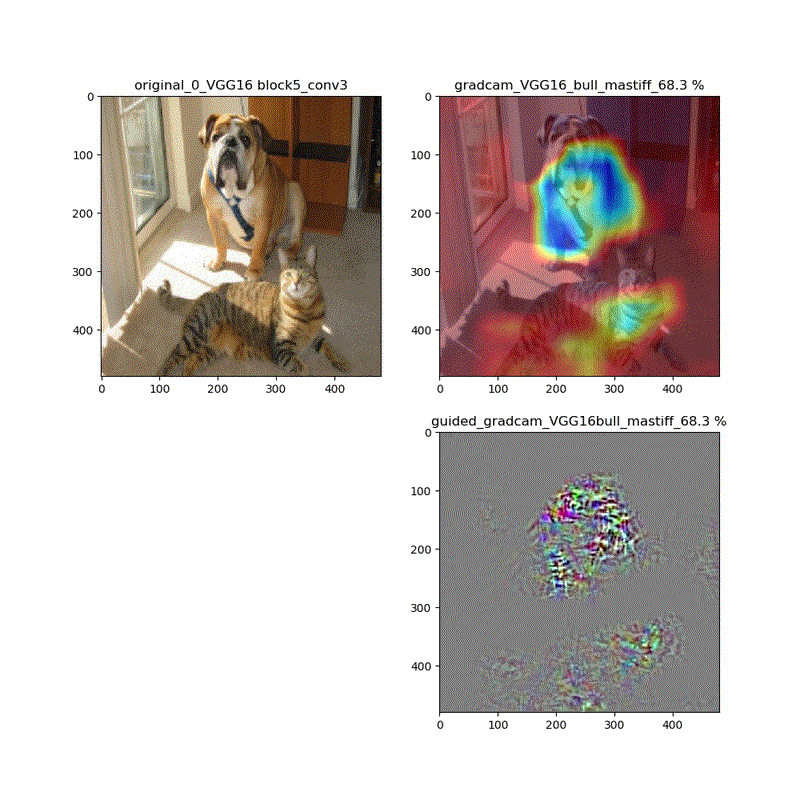
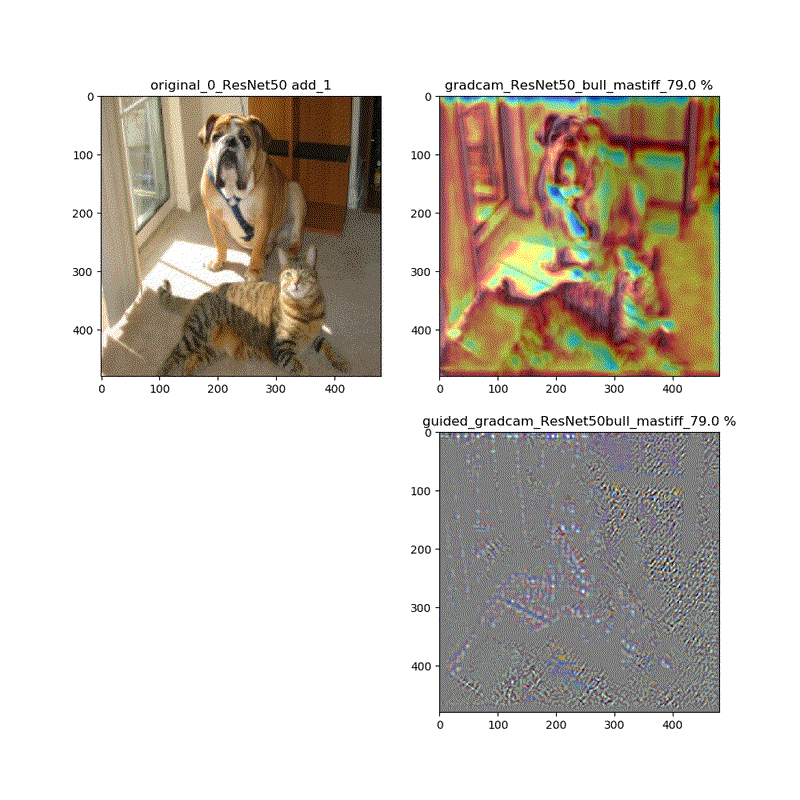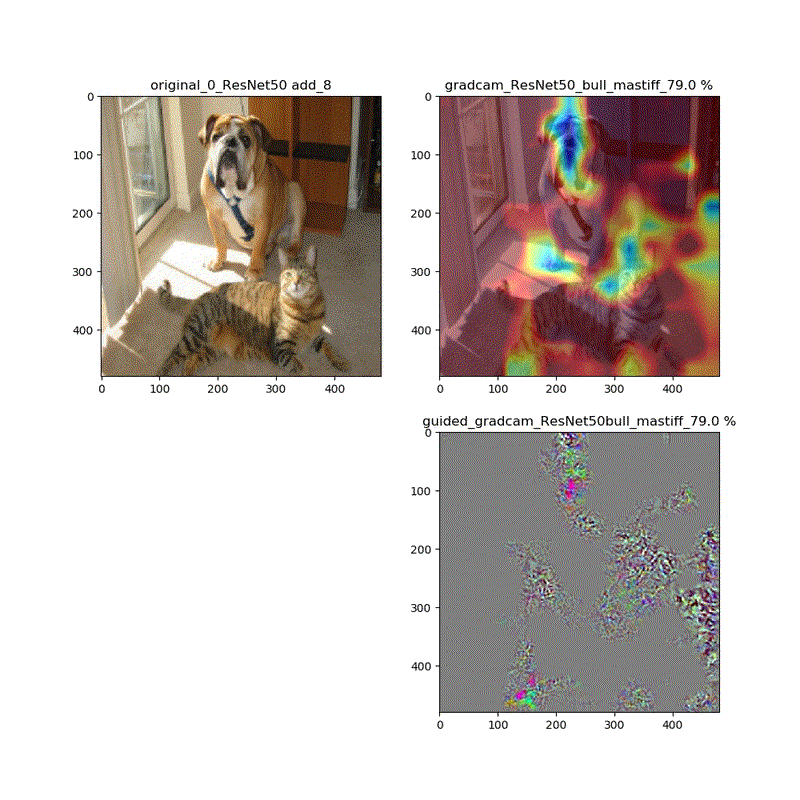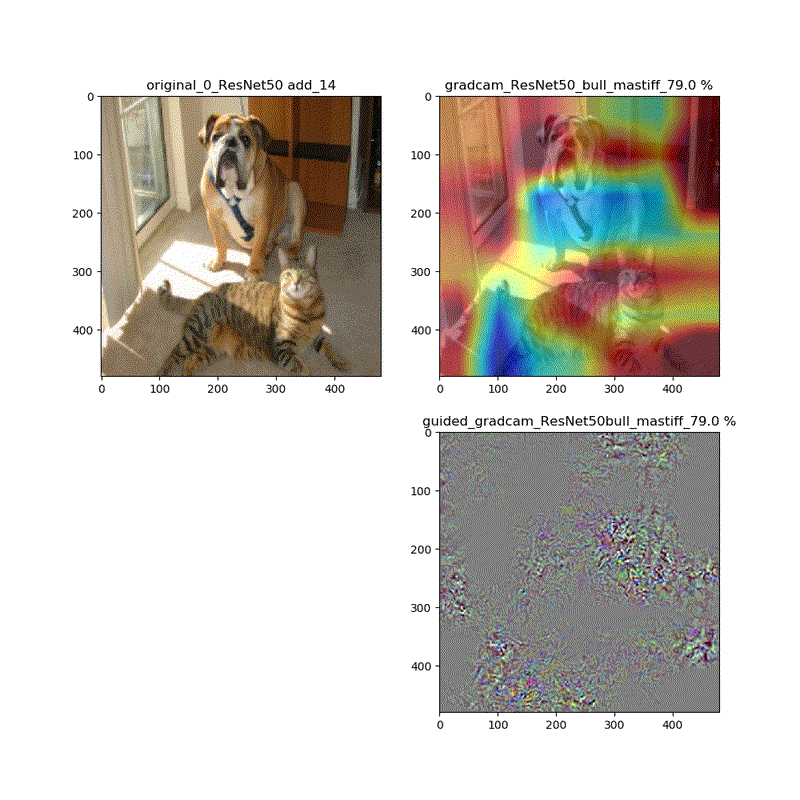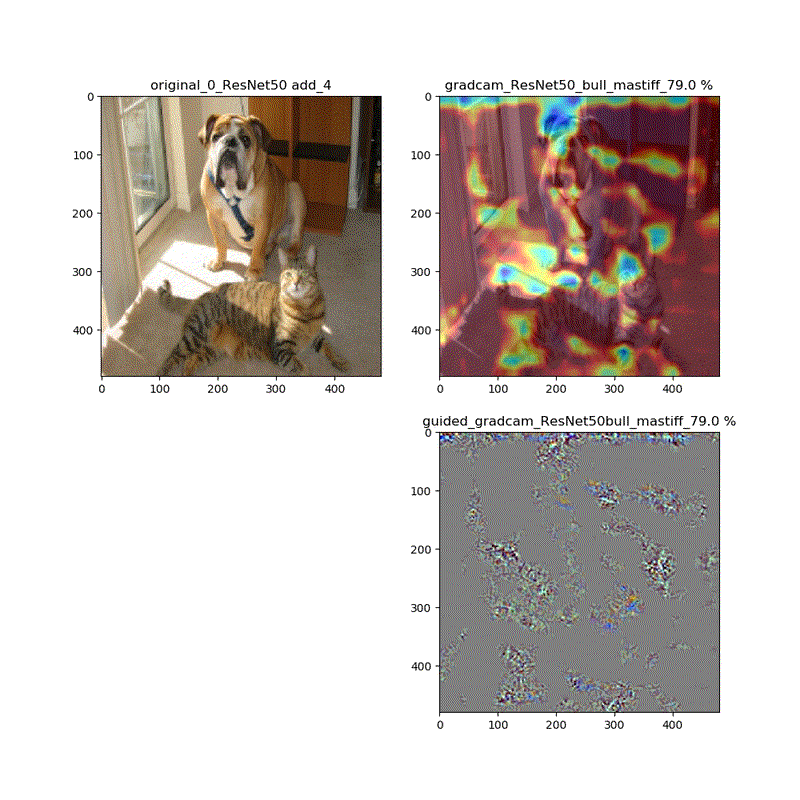
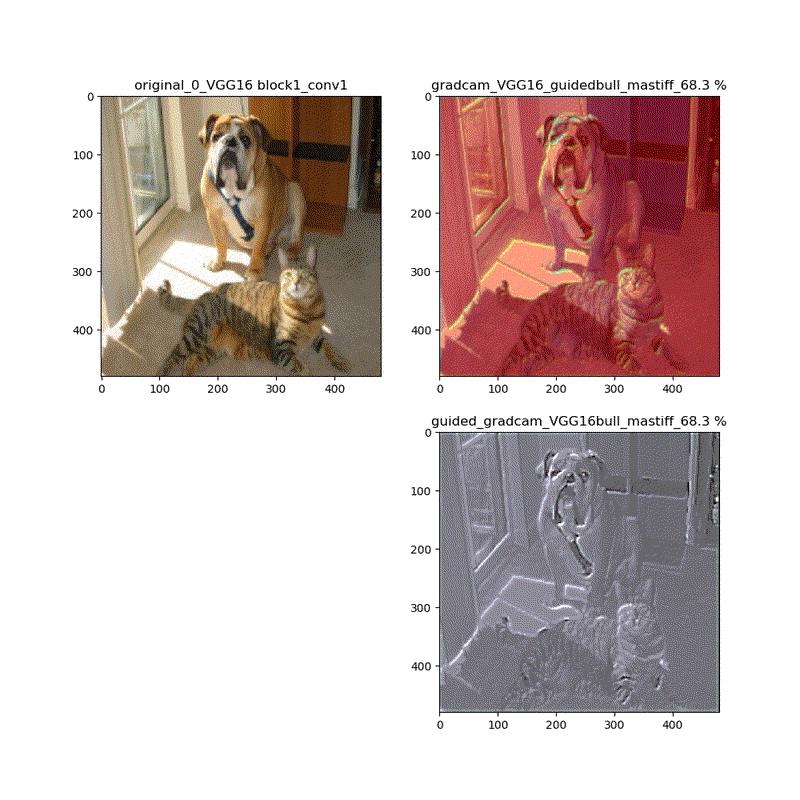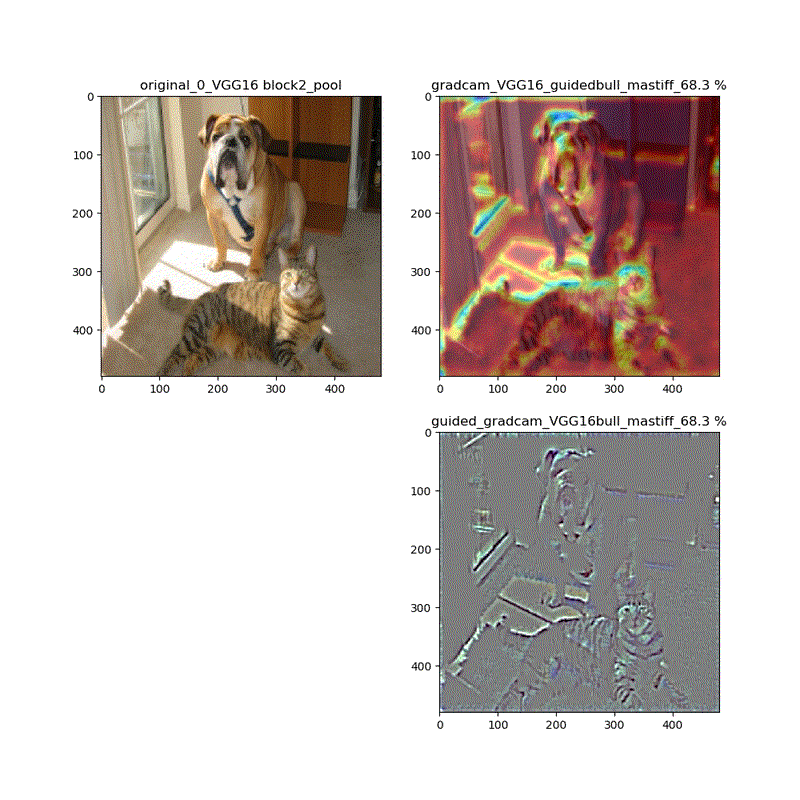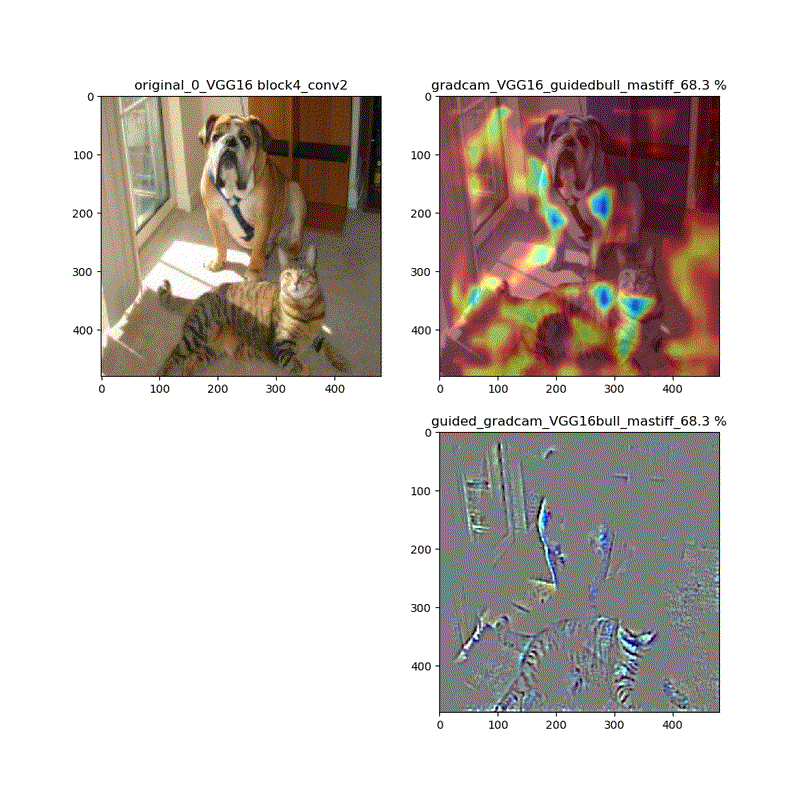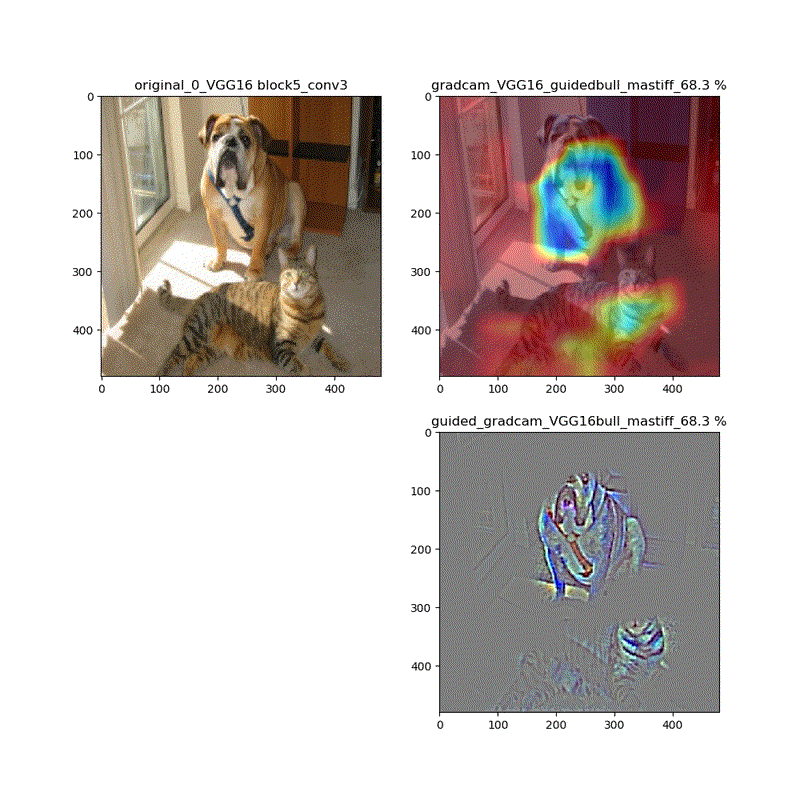
【特徴部位可視化】Grad-CAMとGuided Grad-CAMで各Layer可視化ムービー!
このシリーズもこれが四本目で、どうにかやっていることもキャッチアップ出来つつあり、今回は深い層が何をみているかを描画可視化することとします。
※実際にはその層から最終層へ一番寄与する勾配の大きさを評価する技術がGrad-CAMでその視覚的な描画がGuided-Grad-CAMということになります
上記の説明図のAにあたる層を上流に変化させたときのそれぞれの寄与をインプット画像に重畳して示しているものになります。
代表的なものとしてVGG16(weights='imagenet')に適用し、以下の動画が得られました。
やったこと
・各モデルに適用するための工夫
・適用にあたってのコードのポイント
・適用・結果・各モデルに適用するための工夫
これは前回の「【文字列リスト】条件を満たす要素の一括抽出の仕方」のおまけにコードを置きましたが、モデルを変更するのは、Fine-tuningより簡単です。しかも、学習するのでなければメモリーもあまり必要ありません。
ただし、各モデルはそれなりに大きく特徴(使っている層)がかなり異なります。また、学習データは同じものを学習しているものと思っていましたが、そうでもないようです。
※つまり同一のあのCat_Dogの画像に対して予測されたカテゴリが同じものもありますが、基本異なりました。(というか比較的最近のモデルでは犬や猫を学習していないようです)
しかし、ここではそれを無視して適当に出てきたものを解析することとしました。
そして、何よりモデル構成が異なるのでそれに対応するのが最大の工夫ですが、昨夜のコードを利用してうまく対応できましたので、以下のコードのポイントで述べることとします。・適用にあたってのコードのポイント
適用するにあたって、コードを整理してリンクのような構成にしました。
1.できるだけ関数化する
前回のカテゴリの動画から変更したコードは以下のとおりです。
今回は、モデルを変更したら、それに合うように解析するLayerを自動的に求めるのが肝であるが、それにともなって処々変更した。
①def preprocessed()の引数にlayer_nameを追加、その層のgrad_camを計算する。そのネットワークモデル(グラフ)としてmodelも入力できるようにし、
model = ResNet50(weights='imagenet')の定義をdef main()に移動した。
②一応、カテゴリの入力sを残した
③以下の関数で一番悩ましかったのは、grad_camのモデルとcompile_saliency_functionのモデルを何にするかといういことである。
本来なら、grad_camは元のmodel、compile_saliency_functionはguided_model(keras.activation.reluをtf.nn.reluに変更したモデル)とすべきだが、ResNet50やXceptionなどの長ーいモデルではactivation層とadd層などがlayer.nemeがmodelとguided_modelで同一でないためgrad_camのところでエラーではじかれる。以下の結果で例と理由を示すが、最終的に以下のコードのようにどちらもguided_modelを入力するのが妥当であるという結論となった。def preprocessed(model,guided_model,preprocessed_input,s,layer_name='block5_conv3'): predictions = model.predict(preprocessed_input) top_1 = decode_predictions(predictions)[0][s] predicted_class = predictions.argsort()[0][::-1][s] cam, heatmap = grad_cam(guided_model, preprocessed_input, predicted_class, layer_name=layer_name) #guided_model saliency_fn = compile_saliency_function(guided_model,activation_layer=layer_name) saliency = saliency_fn([preprocessed_input, 0]) gradcam = saliency[0] * heatmap[..., np.newaxis] return predictions, top_1, cam, gradcam最初に利用するmodelとguided_model(Guided Grad-CAM計算用)を定義する。
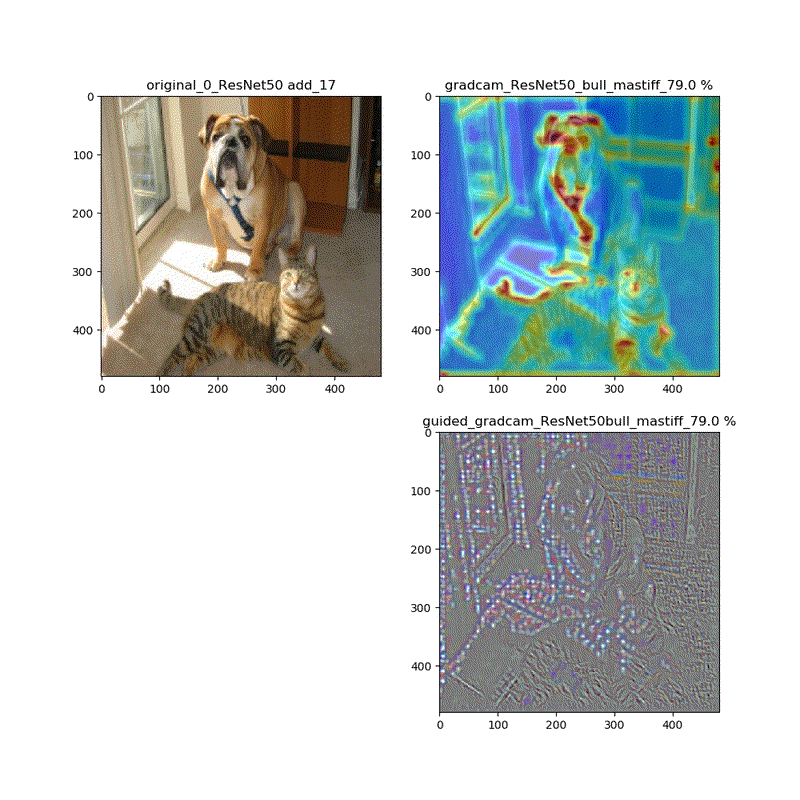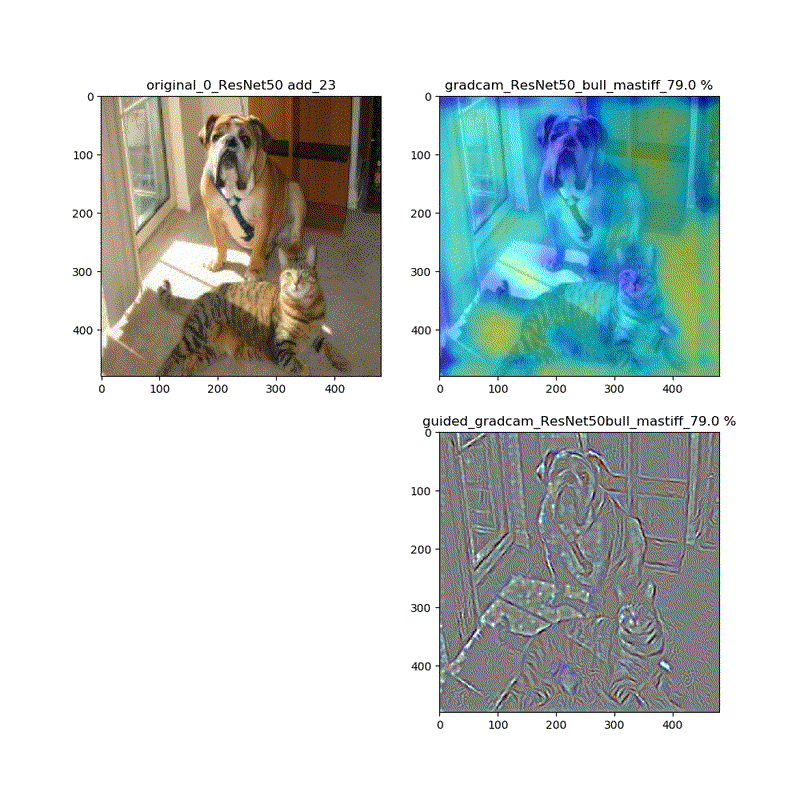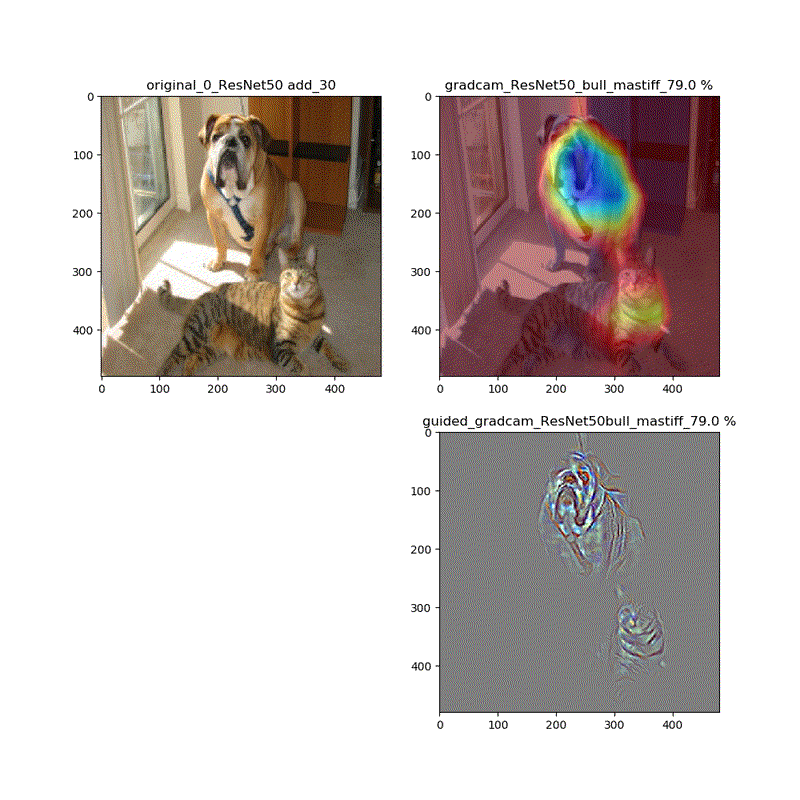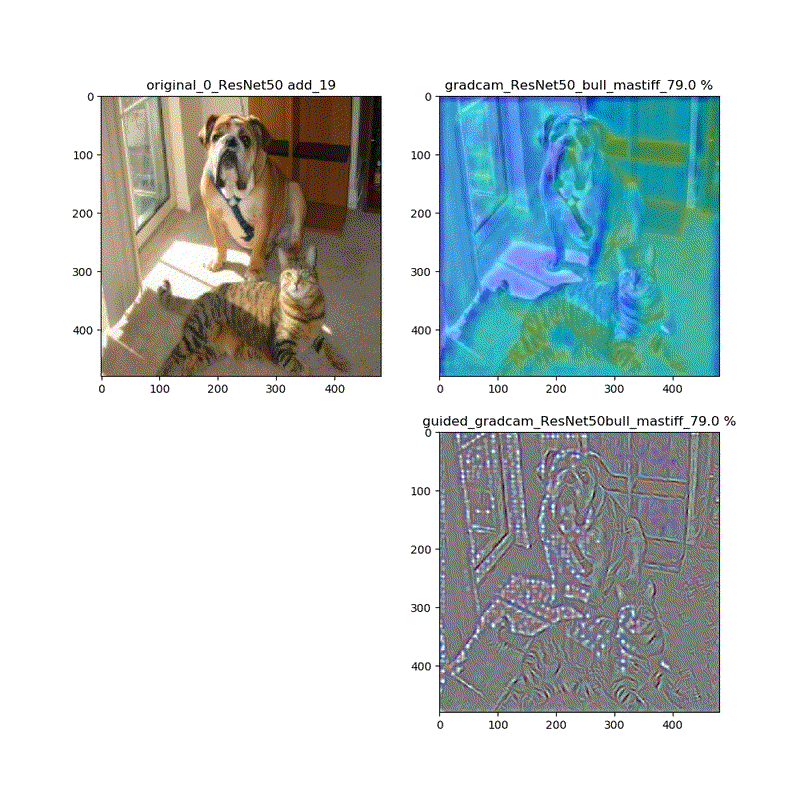
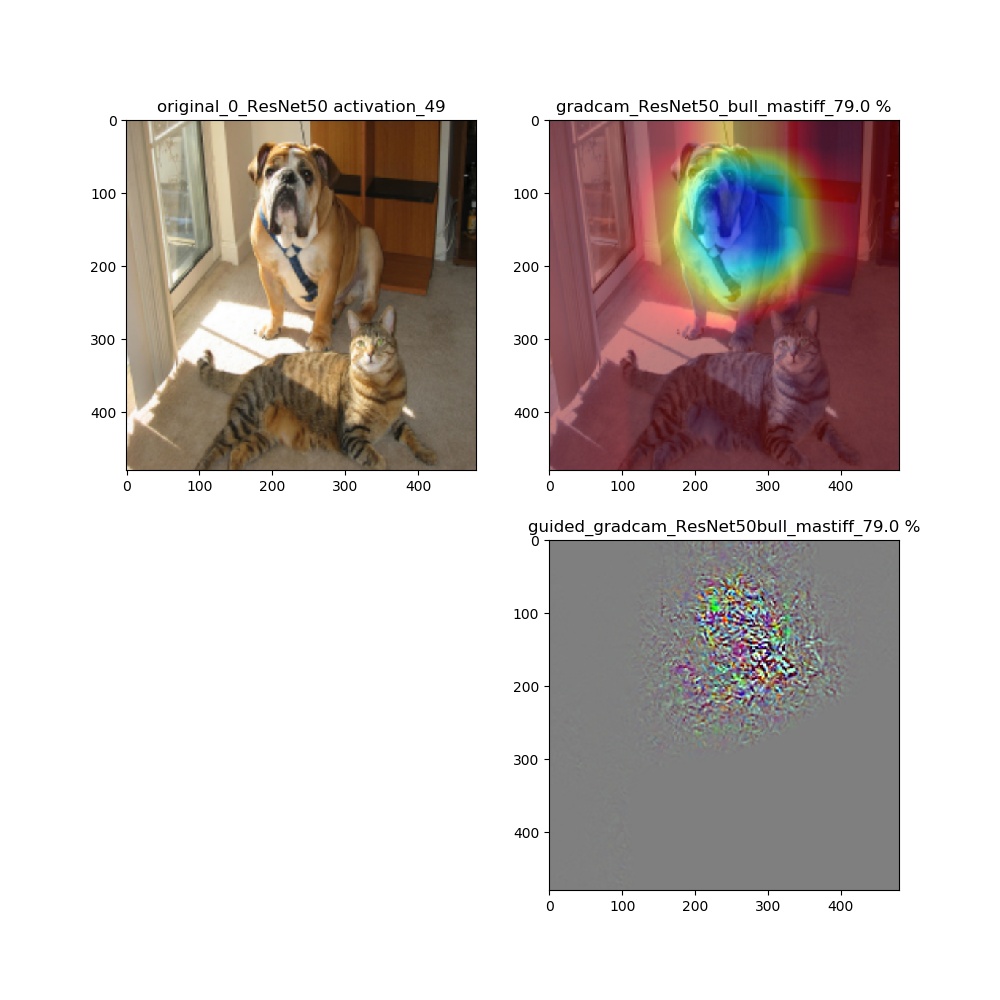
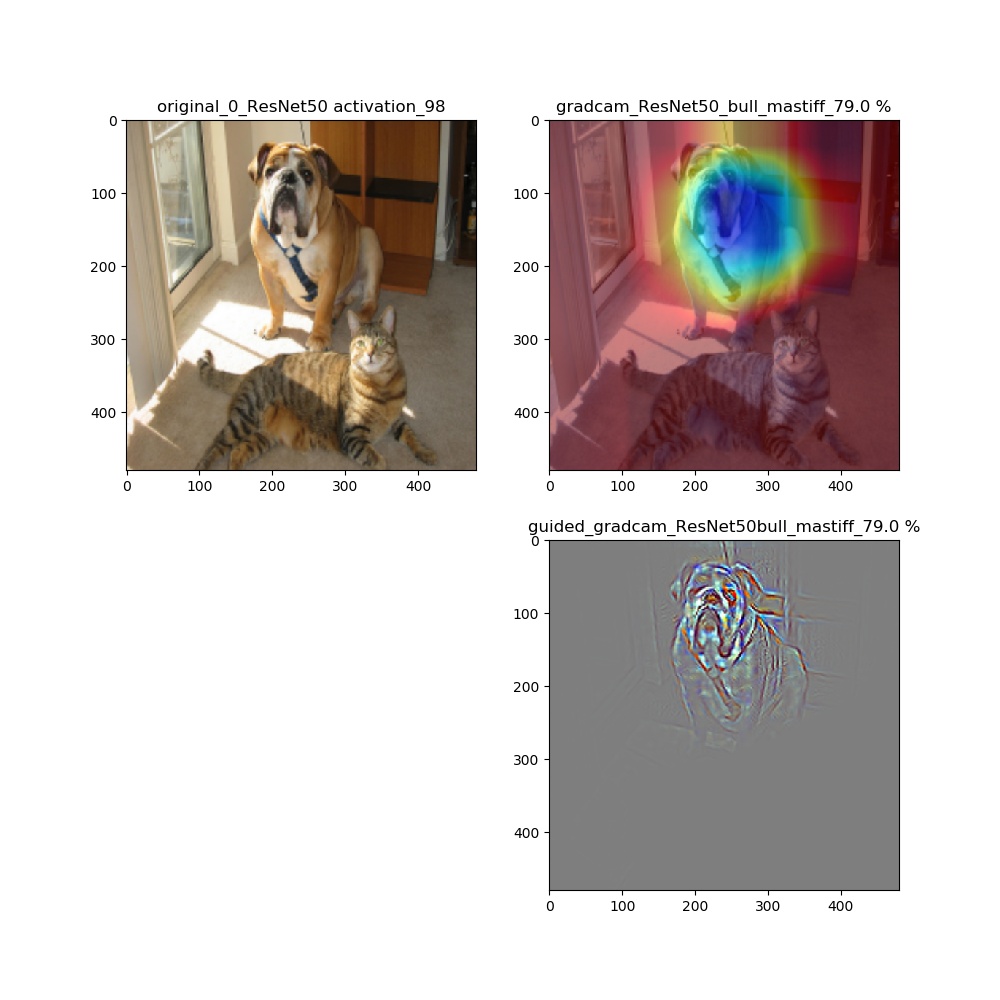
そして、解析する画像をインプットする。def main(): model = ResNet50(weights='imagenet') #ResNet50 VGG16 model.summary() category=0 ... s1=0 size=(224,224) register_gradient() guided_model = modify_backprop(model, 'GuidedBackProp') frame = cv2.imread("cat_dog.png") ...そして昨夜の記事で解説した以下のコードを利用して、解析したいlayer.nameをリスト化する。ここでは、ResNet50の場合のものを示している。このモデルは、おまけに置いたようにかなり深いがそのうちaddと最終層のactivation_98という層を抽出している。本来activation_49が最終層なのだが、上記のguided_modelを作成するとaddとactivation層はmodelからの通し番号が振られ、guided_modelではこんなに大きな値になる。
name_list=[l.name for l in guided_model.layers[1:]] #guided_model name_list = [layer for layer in name_list if 'add' in layer or 'activation_98' in layer] print(len(name_list),name_list)以下のような結果が得られます。
17 ['add_17', 'add_18', 'add_19', 'add_20', 'add_21', 'add_22', 'add_23', 'add_24', 'add_25', 'add_26', 'add_27', 'add_28', 'add_29', 'add_30', 'add_31', 'add_32', 'activation_98']動画は時間で切っています。
層の種類の変更はs =s1%(len(name_list))で繰り返すようにしています。このsを使って上記のリストから指定してactivation_layerに代入してgrad-camなどを計算します。timer0=time.time() while True: s =s1%(len(name_list)) activation_layer=name_list[s] print(s) input= cv2.resize(frame, (480,480)) input = cv2.cvtColor(input, cv2.COLOR_BGR2RGB) ax1.imshow(input) ax1.set_title("original_"+str(category)+"_ResNet50 "+str(activation_layer))まず、画像を4次元に変更してpreprocessed()関数に入力します。
preprocessed_input= cv2.resize(frame, size) preprocessed_input= np.expand_dims(preprocessed_input, axis=0) predictions, top_1, cam, gradcam = preprocessed( model, guided_model, preprocessed_input, category, layer_name=activation_layer)動画はcv2版もできますが、ここではplt版にしています。タイトルにいろいろな属性を記載しています。
input= cv2.resize(cam, (480,480)) ax2.imshow(input) ax2.set_title("gradcam_ResNet50_"+str(top_1[1])+"_"+ str(int(top_1[2]*1000)/10)+" %") input= cv2.resize(deprocess_image(gradcam), (480,480)) ax3.imshow(input) ax3.set_title("guided_gradcam_ResNet50"+str(top_1[1])+"_"+ str(int(top_1[2]*1000)/10)+" %") plt.pause(1) cv2.imshow("guided_gradcam_"+str(top_1[1])+"_"+ str(int(top_1[2]*1000)/10)+" %",input) s1 += 1 plt.savefig("output/image_ResNet50_"+str(s1)+".jpg") dst = cv2.imread('output/image_ResNet50_'+str(s1)+'.jpg') img_dst = cv2.resize(dst, (int(480), 480)) out.write(img_dst)動画にするには、上記のcv2.imshowが大切で、これを描画すると以下のキー入力が安定して使えます。実際にはその下のifの部分で120秒記録して終了します。
ここで、上記の大量なjpg画像ファイルとoutで出力したmp4ファイルが保存されています。
そして、jpg画像ファイルから綺麗なGifアニメーションを生成したのが、最初に掲示した動画です。ほぼ同じような動画がmp4で保存されています。
※動画保存のおまじないなどのコードは今回は示していませんが、コード全体には含まれているので、参考にしてくださいk = cv2.waitKey(1)&0xff if k == ord('q'): cv2.destroyAllWindows() break else: cv2.destroyAllWindows() print(time.time()-timer0) if time.time()-timer0>=120: out.release() break if __name__ == '__main__': main()コードは以下に置きました
・cheating_DL/plot_grad-cam_categoryC_layer.py
適用・結果
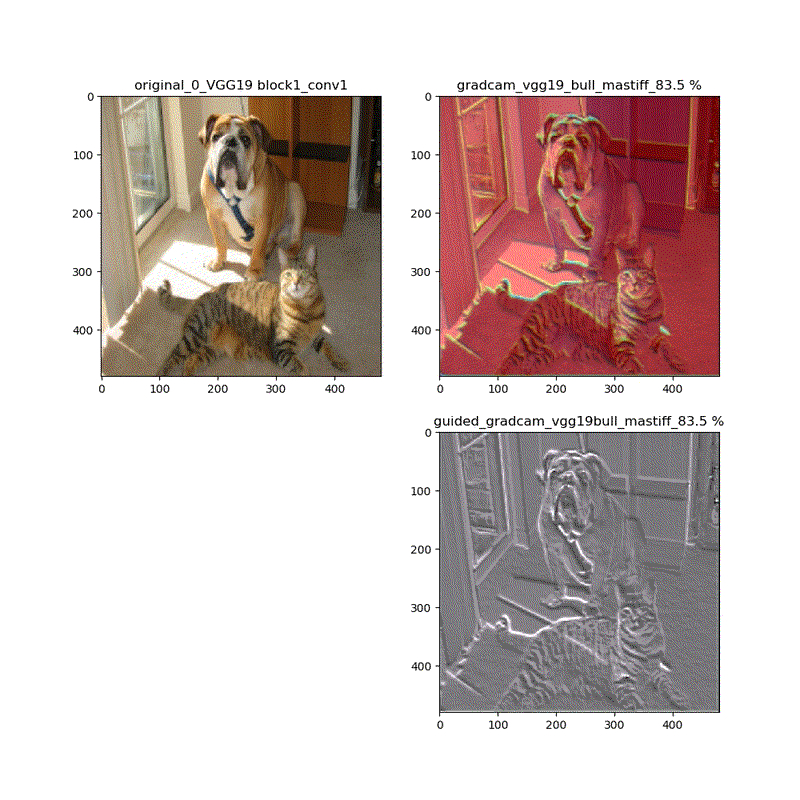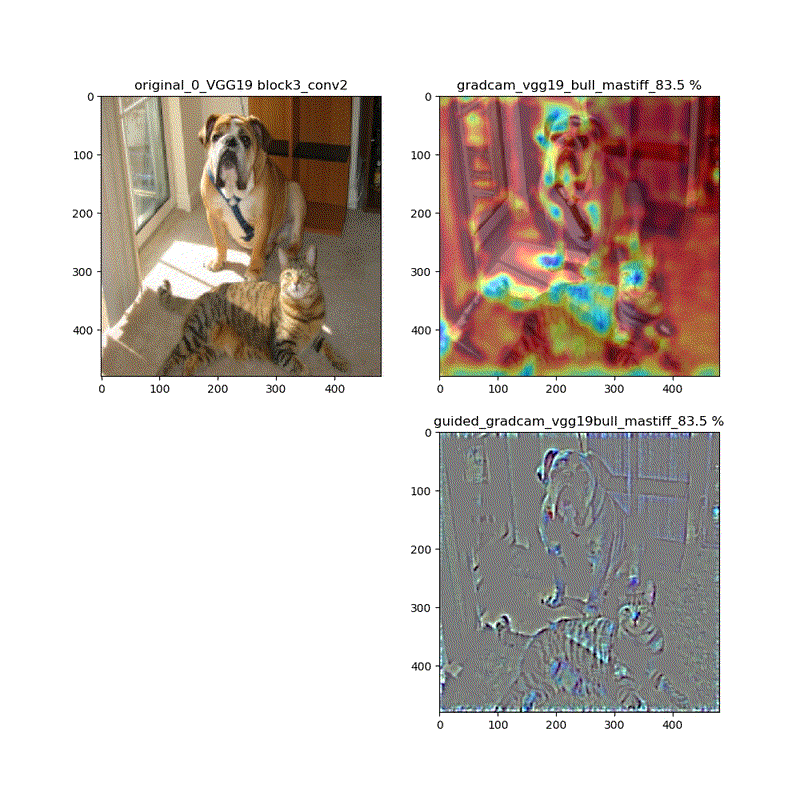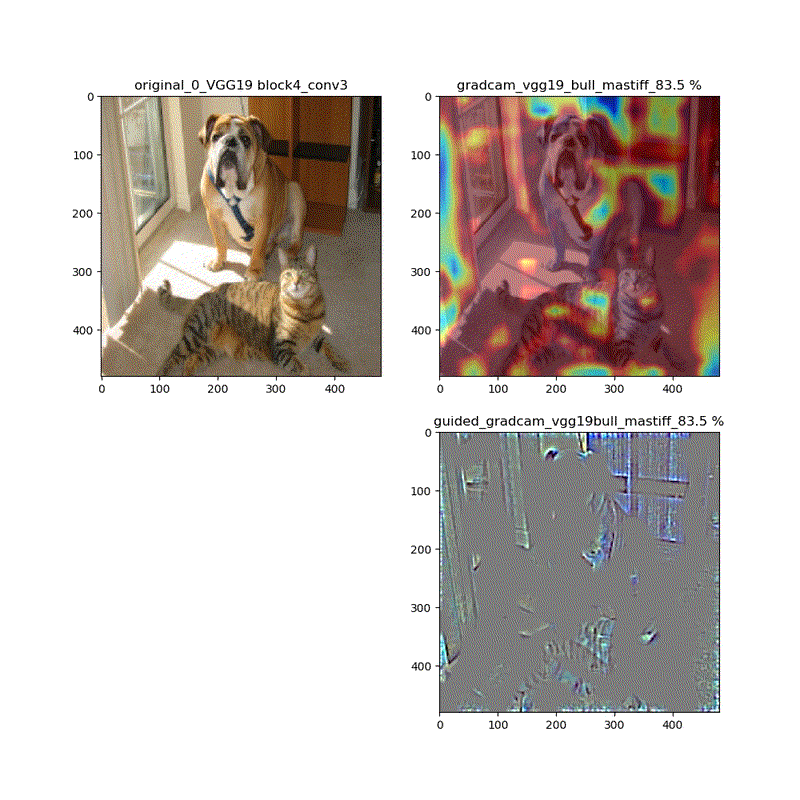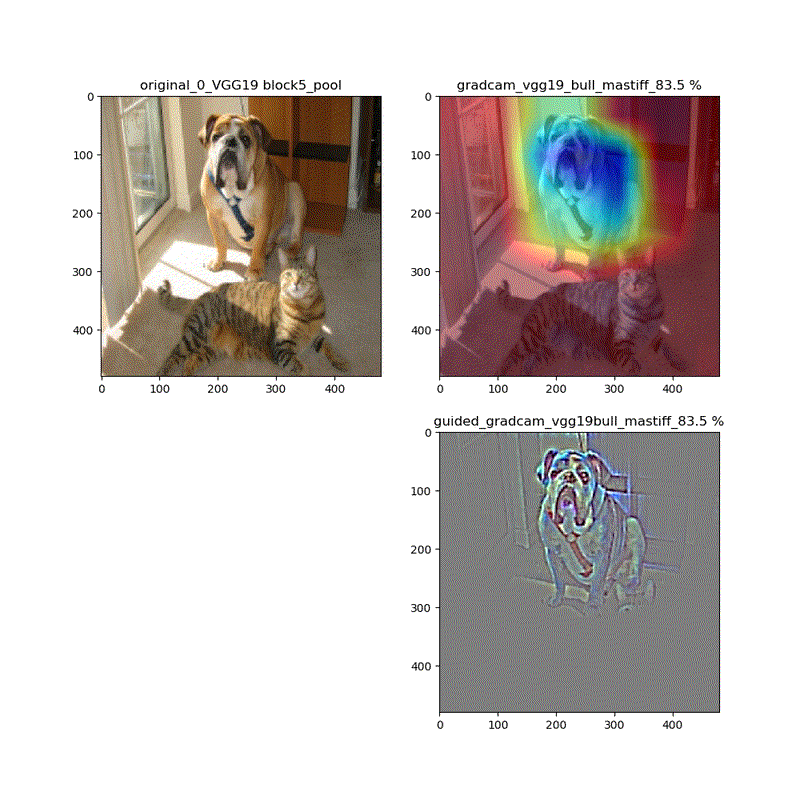
VGG16:guided_modelは上記のとおりです。
VGG16 model compile_saliency_function;modelで実施
これだと、Guided-Grad-CAMの画像がつぶれています。
そして、VGG16、VGG19モデルでは、どちらもmodelとguided_modelは同じlayer.nameを持っているので、model compile_saliency_function;にguided_modelを使えばどちらを使っても同じような画像が得られました。
しかし、それ以外ではこれらは異なります。以下、ResNet50の場合を比較します。
grad-cam;model compile_saliency_function;modelの場合
grad-cam,compile_saliency_function;guided_modelの場合
上記の動画はgrad-camはほぼ同じ動画が得られていますが、Guided-Grad-CAMはmodel-modelではVGG16と同じように、元の下絵が再現できていないのが分かります。
このことは、やはり先日の記事でreluの差し替えの問題で指摘しています。
ということで、直接画像を見ると以下のとおりになっています。
最後に、VGG19とVGG16を並べて貼っておきます。比較的似ている画像が動いているのが分かります。
VGG16 VGG19 まとめ
・いろいろなモデルの層毎のGrad-camとGuidel-Crad-camの可視化を実施した
・VGG16とVGG19だと、だいたい最後の二層程度で急激に選んだカテゴリに集中する
・そしてResNet50でさえ最後の層のGrad-camやGuided-Grad-CAMの画像は酷似している。
・compile_saliency_function;はguided_model(tf.nn.relu)でないと綺麗な画像は得られない・この技術をAdversarialAttackの分析に応用したいと思う
・確率が低いカテゴリも綺麗に覚えていることもあるので、さらに利用の仕方を考えようと思うおまけ
__________________________________________________________________________________________________ Layer (type) Output Shape Param # Connected to ================================================================================================== input_1 (InputLayer) (None, 224, 224, 3) 0 __________________________________________________________________________________________________ conv1_pad (ZeroPadding2D) (None, 230, 230, 3) 0 input_1[0][0] __________________________________________________________________________________________________ conv1 (Conv2D) (None, 112, 112, 64) 9472 conv1_pad[0][0] __________________________________________________________________________________________________ bn_conv1 (BatchNormalization) (None, 112, 112, 64) 256 conv1[0][0] __________________________________________________________________________________________________ activation_1 (Activation) (None, 112, 112, 64) 0 bn_conv1[0][0] __________________________________________________________________________________________________ pool1_pad (ZeroPadding2D) (None, 114, 114, 64) 0 activation_1[0][0] __________________________________________________________________________________________________ max_pooling2d_1 (MaxPooling2D) (None, 56, 56, 64) 0 pool1_pad[0][0] __________________________________________________________________________________________________ res2a_branch2a (Conv2D) (None, 56, 56, 64) 4160 max_pooling2d_1[0][0] __________________________________________________________________________________________________ bn2a_branch2a (BatchNormalizati (None, 56, 56, 64) 256 res2a_branch2a[0][0] __________________________________________________________________________________________________ activation_2 (Activation) (None, 56, 56, 64) 0 bn2a_branch2a[0][0] __________________________________________________________________________________________________ res2a_branch2b (Conv2D) (None, 56, 56, 64) 36928 activation_2[0][0] __________________________________________________________________________________________________ bn2a_branch2b (BatchNormalizati (None, 56, 56, 64) 256 res2a_branch2b[0][0] __________________________________________________________________________________________________ activation_3 (Activation) (None, 56, 56, 64) 0 bn2a_branch2b[0][0] __________________________________________________________________________________________________ res2a_branch2c (Conv2D) (None, 56, 56, 256) 16640 activation_3[0][0] __________________________________________________________________________________________________ res2a_branch1 (Conv2D) (None, 56, 56, 256) 16640 max_pooling2d_1[0][0] __________________________________________________________________________________________________ bn2a_branch2c (BatchNormalizati (None, 56, 56, 256) 1024 res2a_branch2c[0][0] __________________________________________________________________________________________________ bn2a_branch1 (BatchNormalizatio (None, 56, 56, 256) 1024 res2a_branch1[0][0] __________________________________________________________________________________________________ add_1 (Add) (None, 56, 56, 256) 0 bn2a_branch2c[0][0] bn2a_branch1[0][0] __________________________________________________________________________________________________ 。。。 __________________________________________________________________________________________________ add_15 (Add) (None, 7, 7, 2048) 0 bn5b_branch2c[0][0] activation_43[0][0] __________________________________________________________________________________________________ activation_46 (Activation) (None, 7, 7, 2048) 0 add_15[0][0] __________________________________________________________________________________________________ res5c_branch2a (Conv2D) (None, 7, 7, 512) 1049088 activation_46[0][0] __________________________________________________________________________________________________ bn5c_branch2a (BatchNormalizati (None, 7, 7, 512) 2048 res5c_branch2a[0][0] __________________________________________________________________________________________________ activation_47 (Activation) (None, 7, 7, 512) 0 bn5c_branch2a[0][0] __________________________________________________________________________________________________ res5c_branch2b (Conv2D) (None, 7, 7, 512) 2359808 activation_47[0][0] __________________________________________________________________________________________________ bn5c_branch2b (BatchNormalizati (None, 7, 7, 512) 2048 res5c_branch2b[0][0] __________________________________________________________________________________________________ activation_48 (Activation) (None, 7, 7, 512) 0 bn5c_branch2b[0][0] __________________________________________________________________________________________________ res5c_branch2c (Conv2D) (None, 7, 7, 2048) 1050624 activation_48[0][0] __________________________________________________________________________________________________ bn5c_branch2c (BatchNormalizati (None, 7, 7, 2048) 8192 res5c_branch2c[0][0] __________________________________________________________________________________________________ add_16 (Add) (None, 7, 7, 2048) 0 bn5c_branch2c[0][0] activation_46[0][0] __________________________________________________________________________________________________ activation_49 (Activation) (None, 7, 7, 2048) 0 add_16[0][0] __________________________________________________________________________________________________ avg_pool (GlobalAveragePooling2 (None, 2048) 0 activation_49[0][0] __________________________________________________________________________________________________ fc1000 (Dense) (None, 1000) 2049000 avg_pool[0][0] ================================================================================================== Total params: 25,636,712 Trainable params: 25,583,592 Non-trainable params: 53,120 __________________________________________________________________________________________________guided_model ResNet50
Layer (type) Output Shape Param # Connected to ================================================================================================== input_2 (InputLayer) (None, 224, 224, 3) 0 __________________________________________________________________________________________________ conv1_pad (ZeroPadding2D) (None, 230, 230, 3) 0 input_2[0][0] __________________________________________________________________________________________________ conv1 (Conv2D) (None, 112, 112, 64) 9472 conv1_pad[0][0] __________________________________________________________________________________________________ bn_conv1 (BatchNormalization) (None, 112, 112, 64) 256 conv1[0][0] __________________________________________________________________________________________________ activation_50 (Activation) (None, 112, 112, 64) 0 bn_conv1[0][0] __________________________________________________________________________________________________ pool1_pad (ZeroPadding2D) (None, 114, 114, 64) 0 activation_50[0][0] __________________________________________________________________________________________________ max_pooling2d_2 (MaxPooling2D) (None, 56, 56, 64) 0 pool1_pad[0][0] ________________________________________________________________________________ 。。。 ________________________________________________________________________________ __________________ add_31 (Add) (None, 7, 7, 2048) 0 bn5b_branch2c[0][0] activation_92[0][0] __________________________________________________________________________________________________ activation_95 (Activation) (None, 7, 7, 2048) 0 add_31[0][0] __________________________________________________________________________________________________ res5c_branch2a (Conv2D) (None, 7, 7, 512) 1049088 activation_95[0][0] __________________________________________________________________________________________________ bn5c_branch2a (BatchNormalizati (None, 7, 7, 512) 2048 res5c_branch2a[0][0] __________________________________________________________________________________________________ activation_96 (Activation) (None, 7, 7, 512) 0 bn5c_branch2a[0][0] __________________________________________________________________________________________________ res5c_branch2b (Conv2D) (None, 7, 7, 512) 2359808 activation_96[0][0] __________________________________________________________________________________________________ bn5c_branch2b (BatchNormalizati (None, 7, 7, 512) 2048 res5c_branch2b[0][0] __________________________________________________________________________________________________ activation_97 (Activation) (None, 7, 7, 512) 0 bn5c_branch2b[0][0] __________________________________________________________________________________________________ res5c_branch2c (Conv2D) (None, 7, 7, 2048) 1050624 activation_97[0][0] __________________________________________________________________________________________________ bn5c_branch2c (BatchNormalizati (None, 7, 7, 2048) 8192 res5c_branch2c[0][0] __________________________________________________________________________________________________ add_32 (Add) (None, 7, 7, 2048) 0 bn5c_branch2c[0][0] activation_95[0][0] __________________________________________________________________________________________________ activation_98 (Activation) (None, 7, 7, 2048) 0 add_32[0][0] __________________________________________________________________________________________________ avg_pool (GlobalAveragePooling2 (None, 2048) 0 activation_98[0][0] __________________________________________________________________________________________________ fc1000 (Dense) (None, 1000) 2049000 avg_pool[0][0] ================================================================================================== Total params: 25,636,712 Trainable params: 25,583,592 Non-trainable params: 53,120 __________________________________________________________________________________________________ 17 ['add_17', 'add_18', 'add_19', 'add_20', 'add_21', 'add_22', 'add_23', 'add_24', 'add_25', 'add_26', 'add_27', 'add_28', 'add_29', 'add_30', 'add_31', 'add_32', 'activation_98']
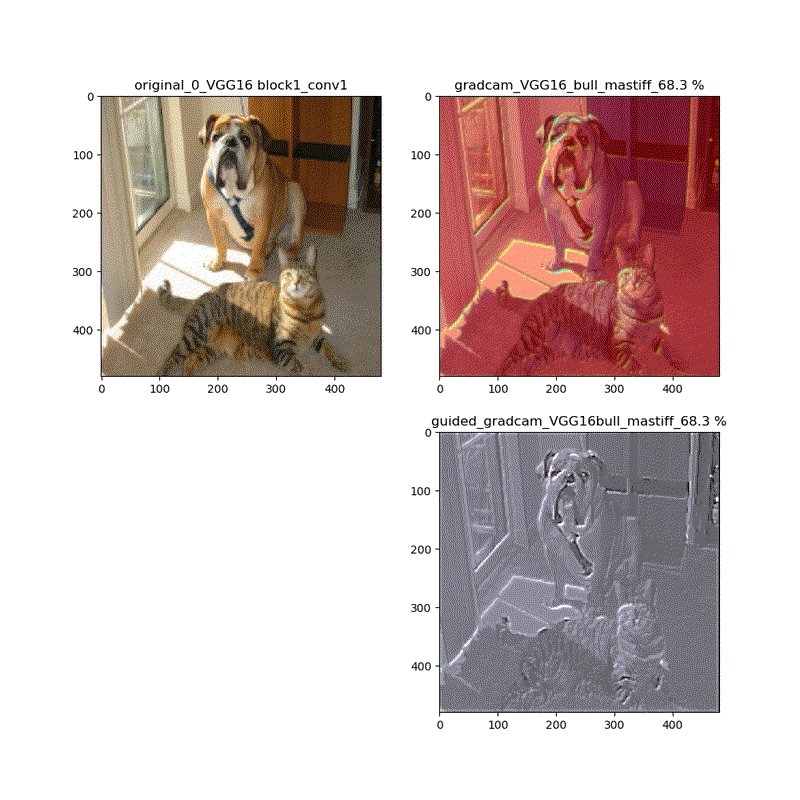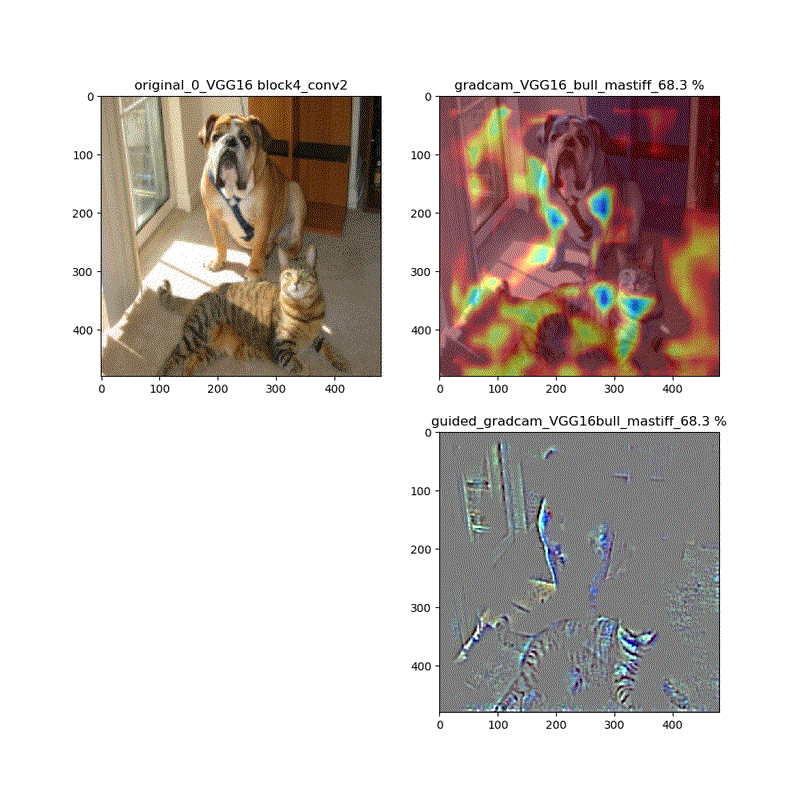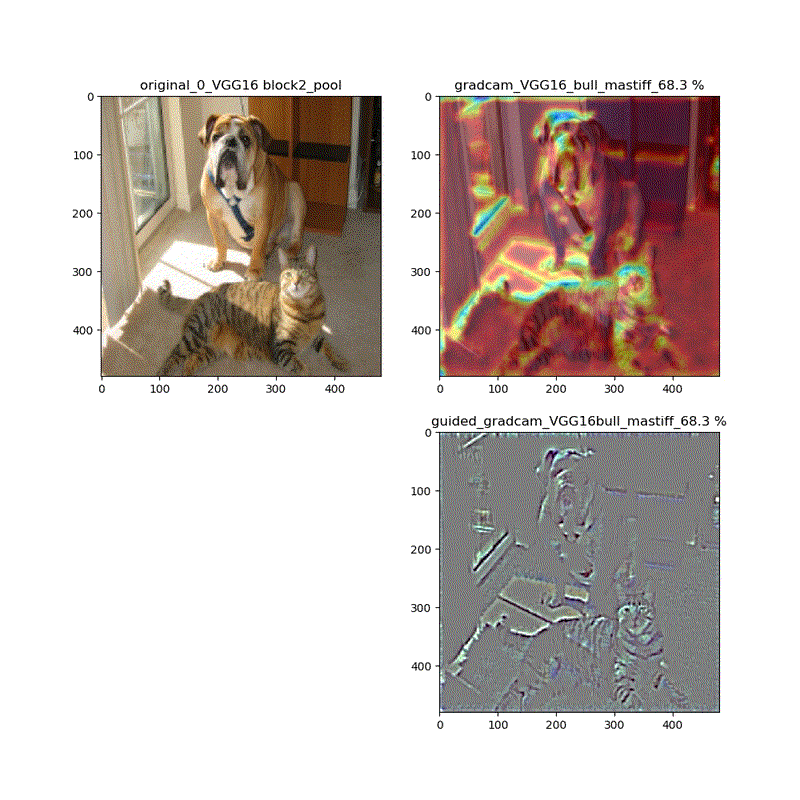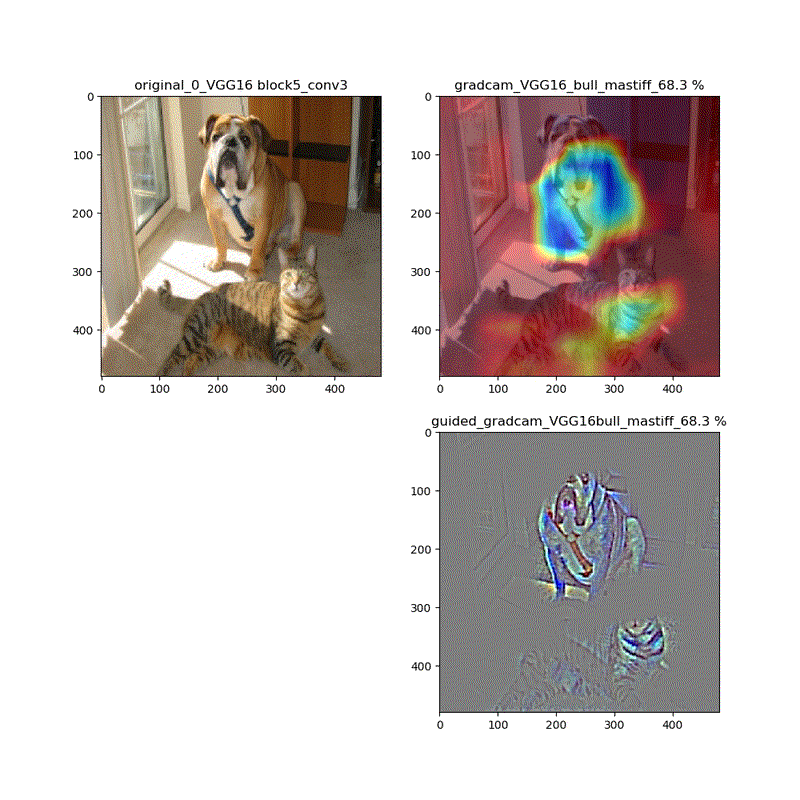
- 投稿日:2019-05-12T21:41:26+09:00
[pyglet] プロシージャルオーディオが少し重いのでmultiprocessingを使う
プロシージャルオーディオ
pygletには簡単な波形を生成しそれを再生する機能があり、現在
Sine,Sawtooth,Square,FM,Silence,WhiteNoise,Digitarが利用できます。
これらを使ってゲームで曲を演奏できたら面白いかなと思い色々試しているのですが、重いというか再生開始時に負荷が一瞬高くなるという感じなので、multiprocessingを使って別プロセスでやってもらうことにしました。サンプル
from multiprocessing import Process, Pipe import pyglet from pyglet.window import key from pyglet.media.sources.procedural import FlatEnvelope, Sine, Silence if pyglet.compat_platform in ('win32', 'cygwin'): pyglet.options['audio'] = ('openal', 'directsound', 'silent') elif pyglet.compat_platform.startswith('linux'): pyglet.options['audio'] = ('openal', 'pulse', 'silent') elif pyglet.compat_platform == 'darwin': pass class MainHundler: def __init__(self, window, process, connection): self.window = window self.process = process self.connection = connection def on_draw(self): self.window.clear() def on_key_press(self, symbol, modifiers): if symbol == key.A: self.connection.send('play') def on_close(self): self.connection.send('close') self.process.join() def note_to_frequency(note): i = 'CcDdEFfGgAaB'.index(note[0]) octave = int(note[1]) return 440 * (2 ** ((octave * 12 + i - 57) / 12)) def sound_player(conn): player = None volume = 0.2 flat_env = FlatEnvelope(0.3) duration = 0.32 score = ['C4', 'D4', 'E4', 'F4', 'G4', 'A4', 'B4', 'C5'] while True: if conn.poll(0.05): message = conn.recv() if message == 'close': conn.close() break elif message == 'play': if player: if player.playing: player.pause() player = pyglet.media.Player() player.volume = volume for note in score: if note[0] == ' ': source = Silence(duration) else: freq = note_to_frequency(note) source = Sine( duration, frequency=freq, envelope=flat_env) player.queue(source) player.play() def main(): parent_conn, child_conn = Pipe() pcs = Process(target=sound_player, args=(child_conn,)) pcs.start() window = pyglet.window.Window(caption='multiprocessing test') handler = MainHundler(window, pcs, parent_conn) window.push_handlers(handler) pyglet.app.run() if __name__ == '__main__': main()動作環境
Windows10, python3.7.2, OpenAL
LinuxMint18.1, python3.5.2, OpenAL
pyglet1.3.2使用で動作確認。操作
Aキーでメロディーを再生。
ESCキーでウィンドウを閉じる。注意点等
LinuxはPulseAudioでは動作しませんでした。OpenALを別途インストールする必要があります。Macは未所持なのでわかりません。WindowsはDirectSoundでも動作すると思います、DirectSoundはイヤホンジャックに何か刺さっていないと起動に失敗します。
scoreが楽譜で音名とオクターブのセットです。CDEFGABがドレミファソラシになり、CDFGAの#は小文字のcdfgaであらわします。スペースは休符です。周波数の求め方は440HzをA4基準にして
440 * (2 ** (n / 12))で求めています。nにはA4から幾つ隣なのかを入れます。音量に注意してください。PCによって音が大きかったり小さかったりするかもしれません。
volumeやエンベロープに1.0〜0.0の値をいれて音量を調節できます。プチプチと音と音の間にノイズが入るのはたぶん仕様です、そのあたりの対処方法は次回にでも書きます。
Windowsではウィンドウが非アクティブ状態で起動します。子プロセスの方にフォーカスが移っているからだと思うので、子プロセスの方でウィンドウを起動するようにしたものがこちらです。
from multiprocessing import Process, Pipe import pyglet from pyglet.window import key from pyglet.media.sources.procedural import FlatEnvelope, Sine, Silence if pyglet.compat_platform in ('win32', 'cygwin'): pyglet.options['audio'] = ('openal', 'directsound', 'silent') elif pyglet.compat_platform.startswith('linux'): pyglet.options['audio'] = ('openal', 'pulse', 'silent') elif pyglet.compat_platform == 'darwin': pass class MainHundler: def __init__(self, window, connection): self.window = window self.connection = connection def on_draw(self): self.window.clear() def on_key_press(self, symbol, modifiers): if symbol == key.A: self.connection.send('play') def on_close(self): self.connection.send('close') def note_to_frequency(note): i = 'CcDdEFfGgAaB'.index(note[0]) octave = int(note[1]) return 440 * (2 ** ((octave * 12 + i - 57) / 12)) def window_setup(conn): window = pyglet.window.Window(caption='multiprocessing test') handler = MainHundler(window, conn) window.push_handlers(handler) pyglet.app.run() def main(): parent_conn, child_conn = Pipe() pcs = Process(target=window_setup, args=(child_conn,)) pcs.start() player = None volume = 0.3 flat_env = FlatEnvelope(0.5) duration = 0.32 score = ['C4', 'D4', 'E4', 'F4', 'G4', 'A4', 'B4', 'C5'] while True: if parent_conn.poll(0.05): message = parent_conn.recv() if message == 'close': break elif message == 'play': if player: if player.playing: player.pause() player = pyglet.media.Player() player.volume = volume for note in score: if note[0] == ' ': source = Silence(duration) else: freq = note_to_frequency(note) source = Sine( duration, frequency=freq, envelope=flat_env) player.queue(source) player.play() parent_conn.close() pcs.join() if __name__ == '__main__': main()これでコアが複数あるCPUであればメインの処理に影響を与えないはずです。
以上です。
- 投稿日:2019-05-12T21:34:27+09:00
ログから処理時間を算出する #4(開始日時と終了日時の計算)
はじめに
Androidのlogcatコマンドで出力されたログファイルを解析し、端末の処理時間を算出したい。
開始日時と終了日時の差分を計算する。
実装
from datetime import datetime from datetime import timedelta start_time = datetime.strptime('2019-03-26 01:43:37', '%Y-%m-%d %H:%M:%S') end_time = datetime.strptime('2019-03-27 02:34:29', '%Y-%m-%d %H:%M:%S') date_dat = end_time - start_time print( date_dat )結果
1 day, 0:50:52結果は取得できた。
あとは#〜#4を全部足せば、最低レベルの機能は完成する。
- 投稿日:2019-05-12T21:31:20+09:00
PythonによるTkinterを使った雛形(MVCモデル)
はじめに
最近はPythonのTkinterを使ってGUIアプリケーションを作ることが楽しい日々です。
そして、ただプログラムを組むのではなく、可動性を高めるために、MVCモデルでプログラムを構築しようとしています。ある程度、MVCモデルでの実装で最初の形が定まってきたので、ここに記そうと思います。環境
- Windows 10 home
- Python 3.7.1
MVCモデルによる雛形
Tkinter.pyimport tkinter as tk class Model(): def __init__(self, master): self.master = master class View(): def __init__(self, master, m, c): self.master = master self.m = m self.c = c class Controller(): def __init__(self, master, m): self.master = master self.m = m class Application(tk.Frame): def __init__(self, master): super().__init__(master) self.pack() master.geometry("300x300") master.title("雛形") self.m = Model(master) self.c = Controller(master, self.m) self.v = View(master, self.m, self.c) self.m.c = self.c self.m.v = self.c.v = self.v def main(): win = tk.Tk() app = Application(master = win) app.mainloop() if __name__ == "__main__": main()実行
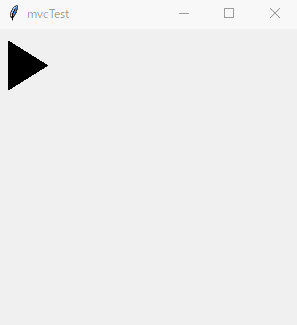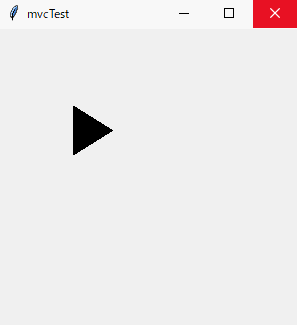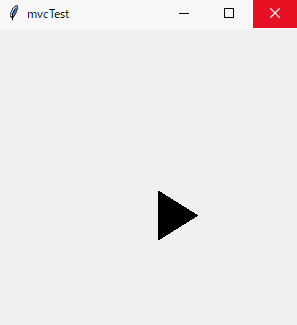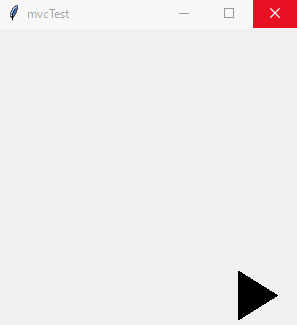
このような画面が出れば、成功です。
実装例
上記の雛形を拡張した例を下記に記します。
スペースキーを押すと三角形の図形が右斜め下に動くものです。
mvcTest.pyimport tkinter as tk class Model(): def __init__(self, master): self.master = master def moveModel(self, canvas, id): canvas.move(id,5,5) class View(): def __init__(self, master, m, c): self.master = master self.m = m self.c = c self.canvas = tk.Canvas(self.master, width=500, height=500) self.canvas.pack() self.canvas.create_polygon(10,10,10,60,50,35,tag="id1") master.bind("<space>",self.c.moveController) class Controller(): def __init__(self, master, m): self.master = master self.m = m def moveController(self, event): self.m.moveModel(self.v.canvas, "id1") class Application(tk.Frame): def __init__(self, master): super().__init__(master) self.pack() master.geometry("300x300") master.title("mvcTest") self.m = Model(master) self.c = Controller(master, self.m) self.v = View(master, self.m, self.c) self.m.c = self.c self.m.v = self.c.v = self.v def main(): win = tk.Tk() app = Application(master = win) app.mainloop() if __name__ == "__main__": main()終わりに
まだ私も勉強中なので、この形が完璧なMVCモデルかどうかは保障できません。
参考程度に使ってください。
ここまでこの記事を読んでいただき、ありがとうございました。その他書き方

- 投稿日:2019-05-12T21:09:18+09:00
【python】instagramでフォローを自動化するツール
インスタグラムで特定のタグのうち、100以上のいいねを獲得している投稿者をフォローする自動化ツールを作りました。
人気の投稿を探してフォローするので、バズりそうな投稿主をいち早く探すことが出来るツールになります。これはインフルエンサーになりそうな人材を確保したり、マーケティングにも使えます。
ニッチなハッシュタグでも、人気投稿になりそうな人をいち早く察知して、フォローすることが出来ます。
過去にいいね自動化ツールも作りました。
https://note.mu/merukari_/n/nbe588104bd4c
フォロー自動化ツール
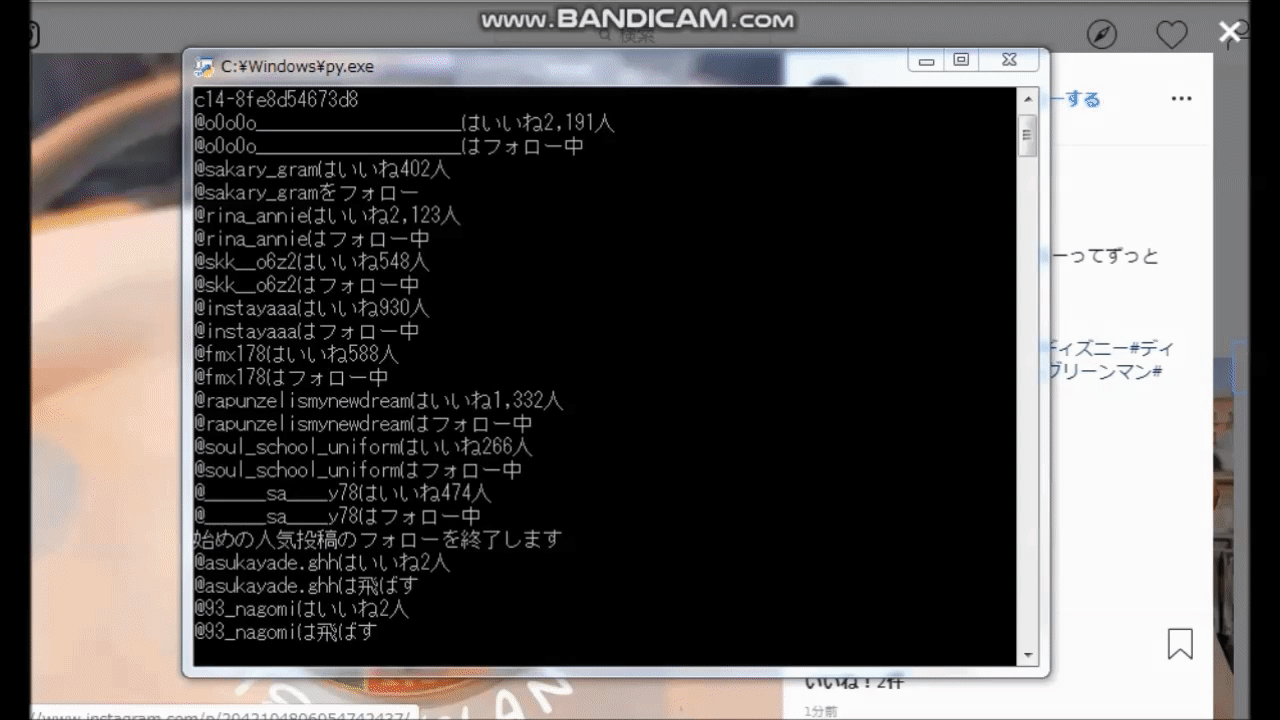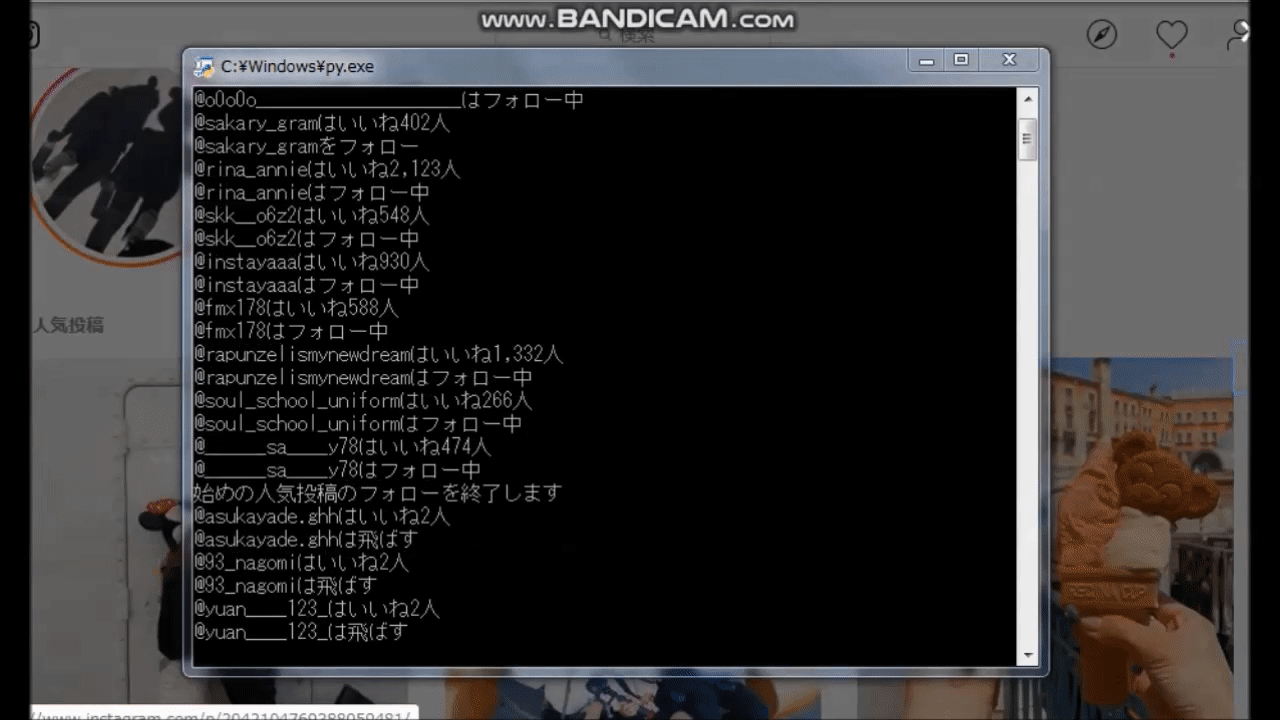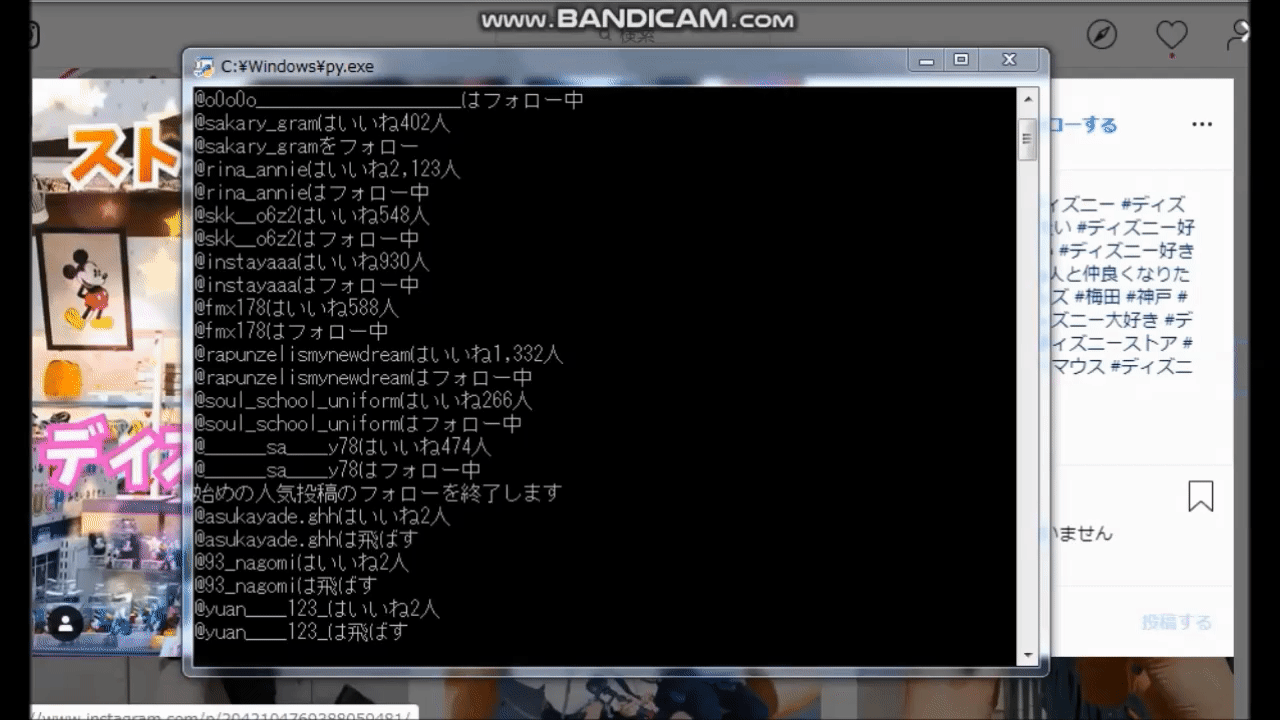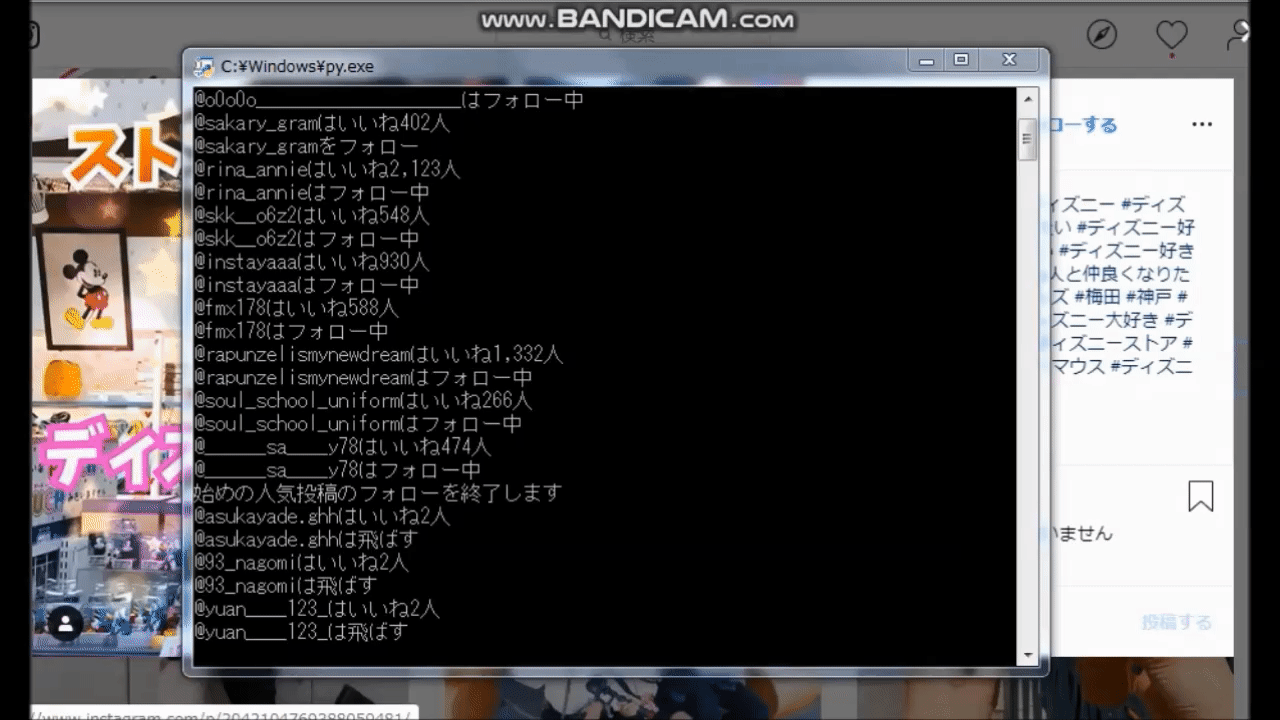
ログイン→タグ検索→トップ画像から順番に100いいね以上を獲得している人をフォローします。実際のログイン画面
必ず出てくる「お知らせをオンにする」のポップアップを取り払います。
どのように動くのか
実行結果がコマンドラインに書き込まれていきます。
・アカウント名
・いいね数
・行動
続きはこちらからお願いします。
https://note.mu/merukari_/n/n18c6db183b09
- 投稿日:2019-05-12T21:00:21+09:00
SQLAlchemyのautoflushについて
概要
SQLAlchemyのautoflushについて理解できてなかったので調査しました。
調査した時の各バージョン
* SQLAlchemy : 1.3.3
* MySQL : 8.0.16modelの作成
シンプルなuser_listテーブルを作成しこのテーブルをSQLAlchemyから操作することでautoflushの挙動を確認します。
model.pyfrom sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String Base = declarative_base() class User(Base): __tablename__ = 'user_list' id = Column('id', Integer, primary_key=True) name = Column('name', String(100))autoflushの検証①(autoflush=True)
autoflushをTrueにして動作検証してみます。autoflushの影響があるのはSessionクラスの"add"、"delete"メソッドを使った時やモデルのプロパティに書き込みをした時(update)ですが、とりえあずaddメソッドで検証してみます。
main.pyfrom sqlalchemy.orm import Session from model import User # ~ 中略 ~ session = Session( bind = ENGINE, autocommit = False, autoflush = True) #1 user_listテーブルのレコード数確認 user_list = session.query(User) print(user_list.count()) # ⇒ "0"出力 #2 1レコード追加 user = User(id = 1, name = 'hoge') session.add(user) #3 user_listテーブルのレコード数確認 print(user_list.count()) # ⇒ "1"出力上記のコードを実行した場合、autoflush=Trueにしていると自動でinsert文が実行されるので#3の時点で"1"と出力されます。但し、実際にinsert文が実行されるタイミングは#3の"user_list.count()"が実行された時です。(この挙動はflushの処理をできるだけ遅延させる為、だろうか?)
autoflushの検証②(autoflush=False、明示的にflush実行)
autoflushをFalseにして明示的にflushメソッドを呼ぶパターンで動作検証してみます。
main.pyfrom sqlalchemy.orm import Session from model import User # ~ 中略 ~ session = Session( bind = ENGINE, autocommit = False, autoflush = False) #1 user_listテーブルのレコード数確認 user_list = session.query(User) print(user_list.count()) # ⇒ "0"出力 #2 1レコード追加 user = User(id = 1, name = 'hoge') session.add(user) session.flush() # 明示的にflushメソッドを実行(insert文が実行される) #3 user_listテーブルのレコード数確認 print(user_list.count()) # ⇒ "1"出力上記のコードを実行した場合、autoflush=Falseではあるが明示的に"session.flush()"を実行しているので、この場合も#3の時点で"1"と出力されます。但し、実際にinsert文が実行されるタイミングはautoflush=Trueの時と異なり"session.flush()"の時点です。
autoflushの検証③(autoflush=False、flush無し)
autoflushをFalseにしてflushメソッドを呼ばないパターンで動作検証してみます。
main.pyfrom sqlalchemy.orm import Session from model import User # ~ 中略 ~ session = Session( bind = ENGINE, autocommit = False, autoflush = False) #1 user_listテーブルのレコード数確認 user_list = session.query(User) print(user_list.count()) # ⇒ "0"出力 #2 1レコード追加 user = User(id = 1, name = 'hoge') session.add(user) #3 user_listテーブルのレコード数確認 print(user_list.count()) # ⇒ "0"出力上記のコードを実行した場合、autoflush=Falseで"session.flush()"も実行していないのでinsert文は実行されず、#3の時点ではレコードが追加されていないので"0"が出力されます。ではこの場合は"session.add()"がなかったことになるのかというとそういうわけでもなく、最終的に"session.commit()"してやればそのタイミングでinsert文は実行されます。
autoflushはTrue、Falseのどちらが良いか?
基本的にautoflush=Trueにしておいたほうがうっかりミスも発生せずコードもシンプルになり良さそうです。Sessionクラスのデフォルト値もautoflush=Trueですし。逆にautoflush=Falseにしたほうが良い場合が思いつかない。。(SQL実行のタイミングを明示的にしたい場合とか?)
- 投稿日:2019-05-12T20:30:18+09:00
今更だけどSlackBotを作ってみた
作ったツールは、PythonのツールでSlackで単純な受け答えするツール。
使用するPythonのライブラリは、「slackbot」を使用する。ライブラリの場所
https://github.com/lins05/slackbot
Slack側の設定
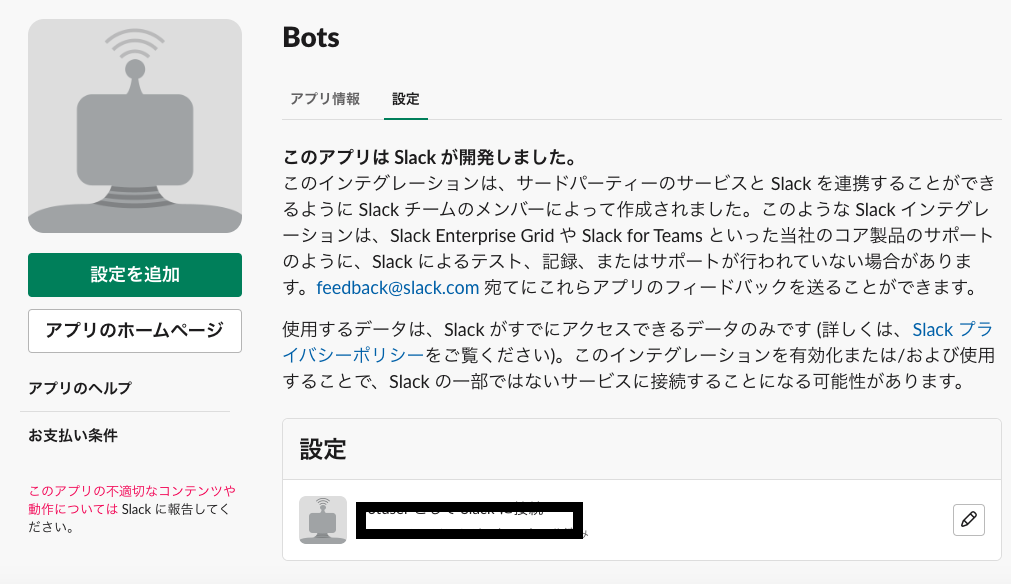
Slackの管理画面
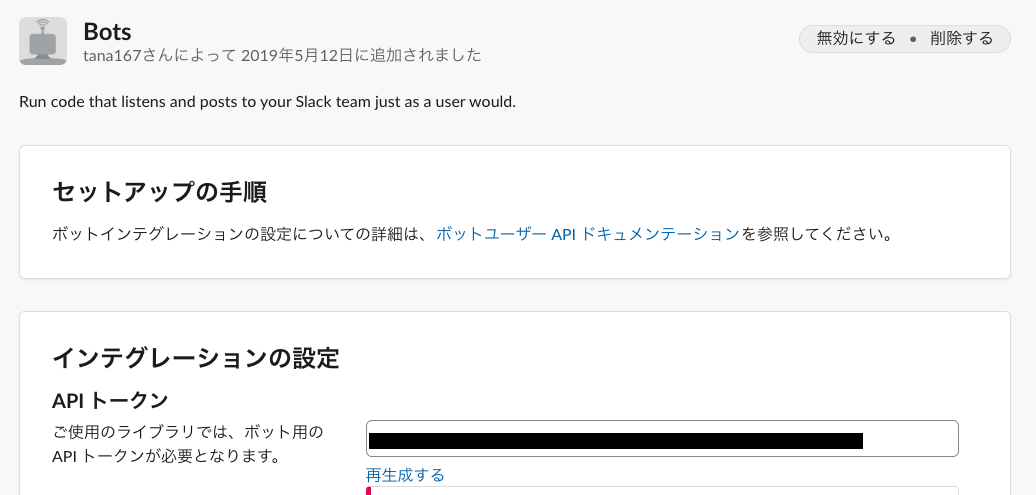
検索から「Bots」入力
Botsの設定確認
BotsのAPIトークンをメモする
Python側の設定
ライブラリをダウンロード
pip install slackbot以下の構造道理作成する
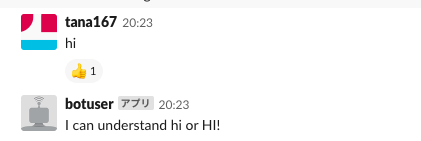
slackbot └── run.py :初期起動の設定 └── slackbot_settings.py :ここに先程の上でメモしたAPI_TOKENをセットする。 └── plugins └── __init__.py └── custom.py :カスタマイズするファイルSlackでメッセージをやりとりしてみるカスタマイズファイルを作成する。
Githubのサンプルをつかって、「Hi」とメッセージしたら「I can understand hi or HI!」をレスポンスするcustom.py@respond_to('hi', re.IGNORECASE) def hi(message): message.reply('I can understand hi or HI!') message.react('+1')Slackボットを起動するコマンド
python run.pyコマンドで起動したらSlackでボットに「hi」とメッセージを行う
以下にGithubに使用したファイルアップ

- 投稿日:2019-05-12T20:20:58+09:00
windowsでプログラミングを始めようとしている初学者さんたちへ
この記事の対象
- windowsでプログラミングを始めようとしている人
昨今のITブームの流れから、プログラミングに興味を持ち始めた人は多いと思います。
僕もそのうちの中の一人であり、プログラミングを本格的に始めて2か月ほどが経ちました。
僕はwindows環境で開発を行っているのですが、windowsだからこそ混乱した事などがちょいちょいあり、これからプログラミングをしたいと考えている人たちにこんなことで悩んでほしくないと思っています。
今回はこの2か月でわかってきた事や、2か月前にほしかった情報を書いていきます。webアプリ作成のために1か月目で知りたかったこと
その1 windowsはwebアプリ開発にあまり向いていない。
windowsは現状、webアプリ開発にあまり向いていないと言われています。
これは、いろいろ理由があり、全てに言及すると分量が多くなってしまうので、詳しくは他サイトに譲ります。
簡単に言えば
windows固有の問題が発生する事があり、windowsでは何時間もかかる場合がある。
Macであれば上記の固有の問題が発生しないどころか、発生してもMacでの開発者が非常に多く、調べればすぐに解決する事が多い。その2 ターミナルとコマンドプロンプトの違い
コマンドプロンプトがwindowsで、ターミナルがMacです。
pythonなどのインストールのために用いられるbrewコマンドなどはコマンドプロンプトでは使えません。
windowsの方はGitbashなどの別のツールを入れる事で、Unixコマンドを使えるようになります。
この辺りのツールは他にも多く存在しますが、初学者の方はとりあえず入れておくといいのではないでしょうか?その3 IDEとは何か?
IDEとは統合開発環境の事です。つまりwebアプリのコードを書くための作業場です。
これも非常に多く存在していますが、とりあえずVScodeを使うといいと思います。その4 GitとGithub
web開発に絶対に欠かせないGitとGithub。一度は目にしたことがあるのではないでしょうか?
この2つは実は別物であり、ローカル(自分の使っているPC)環境がGitであり、これをhub(共有)するのがgithubです。
バージョン管理ツールとして説明されることが多く、少しややこしい部分もありますが
自分の開発するwebアプリが完成に近づくにつれ、重要度が増していくツールです。言語を学んだあと、何をすればいいのか
基本的にプログラミング言語はアプリケーションを作るためのツールになります。
つまり自分の作りたいアプリケーションを制作する事が次に行うことになります。まとめ
大体以上の4点が初学者の人が調べると次の目標を立てやすい項目になるのかなと思います。
これらの項目については、Qiitaで色々な方が詳しく解説されており、調べれば多くの情報が得られると思います。
- 投稿日:2019-05-12T20:16:48+09:00
あるデータの列から、教師データとテストデータを重複なくランダムに取得する方法(Python/NumPy)
さてさて ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装 を絶賛学習中です。。
あるデータの列から、教師データとテストデータを重複なくランダムに取得したい
Pythonでニューラルネットワークをあつかっていると、自前でテストデータの列を用意したいときがたびたびあります。
「あー、$y = 0.5x +3$ のデータ$(x,y)$を $(-5,5)$の区間で100コ欲しいなぁ、ランダムに取り出して90コは教師データ、10コはテストデータとしたいなぁ。。テストデータは学習にはつかえないので、重複なく取り出したいなぁ。。」なんてケースですね。。やってみる
まずはx軸側。Python の数値計算ライブラリであるNumPyは
>>> import numpy as np >>> targets = np.array([10,20,30,40,50]) >>> index = [1,2,3] >>> targets[index] array([20, 30, 40])のようにnumpy配列に対して配列番号の列
[1,2,3]などを渡すことで、その配列番号のデータだけを取得することができます。よってたとえば、データ数
data_size=10、教師データ数train_size=6、-5.0〜5.0で、1.0 刻みのデータを作成し、教師データ列とテストデータ列に分けるにはこんな感じにします。>>> import numpy as np >>> data_size = 10 >>> train_size = 6 >>> train_index = np.sort(np.random.choice(data_size, train_size, replace=False)) >>> train_index array([1, 2, 3, 4, 6, 7]) >>> x_all = np.arange(-5.0,5.0, 10.0/data_size) >>> x_all array([-5., -4., -3., -2., -1., 0., 1., 2., 3., 4.]) >>> x_train = x_all[train_index] >>> x_train array([-4., -3., -2., -1., 1., 2.]) >>> >>> x_test = np.delete(x_all, train_index) >>> x_test array([-5., 0., 3., 4.]) >>>
np.random.choice(data_size, train_size, replace=False)で0〜data_size -1からtrain_sizeコのデータを取り出すことで、教師データ用の配列番号の列train_indexを作成しました。replace=Falseは重複を許可しないオプションです。そしてそれをソートしておきます。
そしてtrain_indexを用いて全データx_allから教師データx_trainを作成しました。残りのデータをテストデータ
x_testとしたいですが、ちょっとスマートなやり方が見つからず、、、下記の通り、x_allから、train_indexのデータを除去して、残りを取得しました。x_test = np.delete(x_all, train_index)結果、
>>> x_train array([-4., -3., -2., -1., 1., 2.]) >>> x_test array([-5., 0., 3., 4.]) >>>と振り分けることができましたー。。
関数を呼び出して、x_train,x_testから、t_train,t_testを作成する
つづいてy軸側。
def f(x): return 0.5 * x + 3.0などを用いて、
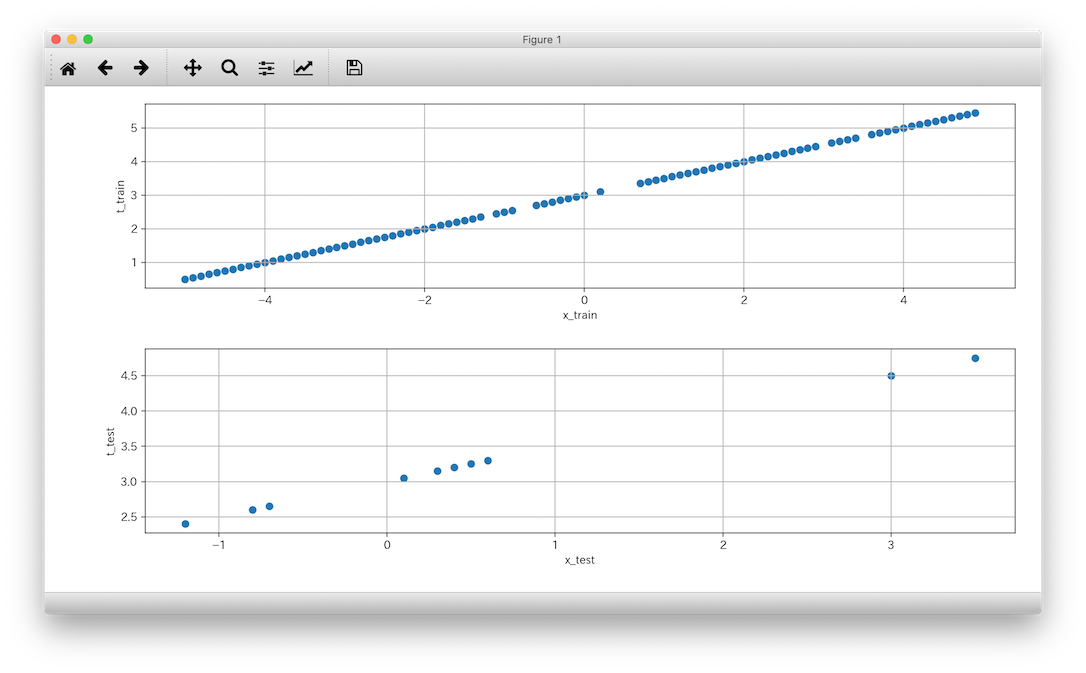
t_train,t_testを作成します。コードの全体はこんな感じです。test_data_samples.py#!/usr/bin/env python # -*- coding: utf-8 -*- import sys from matplotlib import pyplot as plt import numpy as np def f(x): return 0.5 * x + 3.0 def get_data(data_size, train_size=None, train_ratio=0.9, start=-5.0, end=5.0): if train_size is None: # 教師データ数が引数から取れない場合は、 train_size = int(data_size * train_ratio) # うち教師データの割合から、教師データ数を計算 train_index = np.sort(np.random.choice(data_size, train_size, replace=False)) # data から train だけの配列番号をつくる # まずdata_sizeコの、全データを作成 x_all = np.arange(start, end, (end - start) / data_size) # 数直線を作成。 t_all = f(x_all) # 全体のyのデータを算出 # t_all += np.random.normal(0, 0.3, data_size) # ちょっとだけノイズをたす # 全データ作成、以上 x_train = x_all[train_index] t_train = t_all[train_index] x_test = np.delete(x_all, train_index) t_test = np.delete(t_all, train_index) # つくったデータ達は横向きになってるのでreshapeして、縦向きに。 x_train = x_train.reshape(len(x_train), 1) t_train = t_train.reshape(len(t_train), 1) # つくったデータ達は横向きになってるのでreshapeして、縦向きに。 x_test = x_test.reshape(len(x_test), 1) t_test = t_test.reshape(len(t_test), 1) return (x_train, t_train), (x_test, t_test) def main(args): data_size = 100 # 母集団のデータ数 (x_train, t_train), (x_test, t_test) = get_data(data_size, train_ratio=0.9) print(f'教師データ数:{x_train.shape}') print(f'テストデータ数:{x_test.shape}') print('xの値:' + str(x_train)) print('yの値:' + str(t_train)) fig = plt.figure() ax1 = fig.add_subplot(2, 1, 1) ax2 = fig.add_subplot(2, 1, 2) ax1.scatter(x_train, t_train, label='教師データ') ax1.set_xlabel('x_train') ax1.set_ylabel('t_train') ax1.grid(True) # グリッド線 ax2.scatter(x_test, t_test, label='テストデータ') ax2.set_xlabel('x_test') ax2.set_ylabel('t_test') ax2.grid(True) # グリッド線 plt.tight_layout() # タイトルの被りを防ぐ # グラフに情報を表示 plt.show() # plt.scatter(x_test, t_test, label='テストデータ') # plt.show() if __name__ == "__main__": main(sys.argv)実行してみます。
(venv) $ python test_data_samples.py 教師データ数:(90, 1) テストデータ数:(10, 1) xの値:[[-5.00000000e+00] [-4.90000000e+00] [-4.80000000e+00] [-4.70000000e+00] [-4.60000000e+00] [-4.50000000e+00] ... [ 4.50000000e+00] [ 4.60000000e+00] [ 4.70000000e+00] [ 4.80000000e+00] [ 4.90000000e+00]] yの値:[[0.5 ] [0.55] [0.6 ] [0.65] [0.7 ] [0.75] ... [5.25] [5.3 ] [5.35] [5.4 ] [5.45]]
うん、ちゃんと分けられてそうだし、関数の結果を
t_train,t_testとして取得できていそうですね。もうすこしデータにバラツキをくわえる
さて作成したy軸側のデータは、
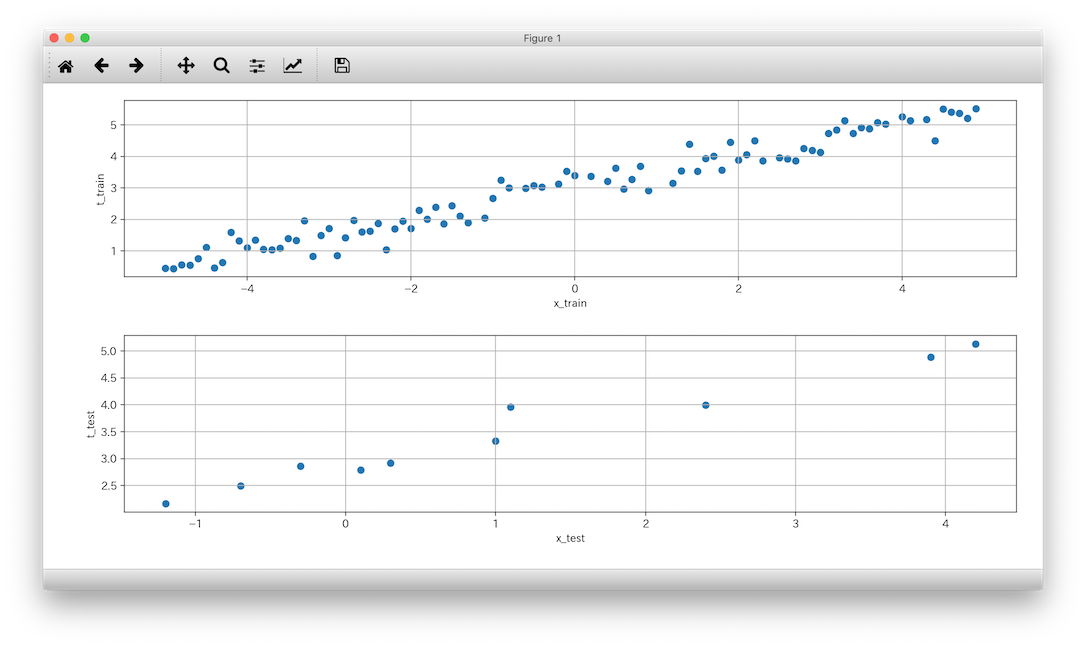
def f(x): return 0.5 * x + 3.0コレで作成したテストデータなのでキレイに並んじゃってますが、y方向にバラツキをくわえるには、
t_all = f(x_all) # 全体のyのデータを算出 # t_all += np.random.normal(0, 0.3, data_size) # ちょっとだけノイズをたすこのコメントを外して実行してみます。正規分布(上記だと平均0,標準偏差0.3にしたがう)に従った値を各要素に加味したデータになります。
おつかれさまでした。。
関連リンク
- 投稿日:2019-05-12T20:00:46+09:00
Python Seleniumでtwitterのログインからリプライするbot
はじめに
Python Seleniumでログインから特定の投稿に対して自動リプライするbotを作りました。TwitterAPI無しでログインからリプライまで一連の動作です。
投稿のURLの取得も自動で行えば、完全に自動で返答するbotになります。
意外と日本語のドキュメント無かったのでこちらに記載しました。※あまり頻度多いと、twitterからスパム判定食らう可能性が高いので、用法・用量を気をつけて使いましょう。
参考:Twitterでスパムに引っかからない対策と判定されないための予備知識 | スタートアップSNS環境
Python3.x
Mac OS Mojave
Google Chrome
Chrome Chrome Web Driverコード
python3import time from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.keys import Keys # 各種設定 # twitterアカウント account = 'xxxxxxxxxxxx@xxxxxxxxx' password = 'xxxxxxxx' # 返答したい投稿のURL tweet_url = "https://twitter.com/xxxxxxxx/status/xxxxxxxxxxxxxxxxx" # 返答したいテキスト reply_text = '''こんにちは〜!''' # Twitterログイン実行する処理 def twitterlogin(): # ログインページを開く driver.get('https://twitter.com/login/') time.sleep(3) # 動作止める # accountを入力する element_account = driver.find_element_by_class_name("js-username-field") element_account.send_keys(account) time.sleep(3) # 動作止める # パスワードを入力する element_pass = driver.find_element_by_class_name("js-password-field") element_pass.send_keys(password) time.sleep(3) # 動作止める # ログインボタンをクリックする element_login = driver.find_element_by_xpath('//*[@id="page-container"]/div/div[1]/form/div[2]/button') driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") element_login.click() time.sleep(3) # 動作止める # Tweetリプライ実行する処理 def tweetreply(URL): # ツイートIDを取得する tweetID = URL[-19:] driver.get(URL) try: # 投稿文を挿入 driver.find_element_by_id("tweet-box-reply-to-" + tweetID).click() time.sleep(3) # 動作止める driver.find_element_by_id("tweet-box-reply-to-" + tweetID).click() time.sleep(3) # 動作止める driver.find_element_by_id("tweet-box-reply-to-" + tweetID).send_keys(reply_text) time.sleep(3) # 動作止める driver.find_element_by_id("tweet-box-reply-to-" + tweetID).send_keys(Keys.CONTROL + "\n") except: print("Error") # selenium起動 options=Options() driver=webdriver.Chrome(chrome_options = options) # Twitterログイン処理 twitterlogin() # Tweetリプライ処理 tweetreply(tweet_url) # seleniumを終了 driver.close() driver.quit()
- 投稿日:2019-05-12T19:36:23+09:00
プログラミング言語作成 〜1日目〜
- 投稿日:2019-05-12T19:33:17+09:00
Django Form のデザインのカスタマイズ
Django Form のデザインのカスタマイズの方法はこちらが参考になった
結論から言うと「widget_tweaks」を用いるのが一番簡単らしいhttps://hodalog.com/how-to-use-bootstrap-4-forms-with-django/
- 投稿日:2019-05-12T18:40:57+09:00
pytorch学習メモ
Pytorchを学習する中で分からなくて調べた知識をまとめました。随時追加していきます。
ネットワーク関連
torch.nn.Conv2d
畳み込み層の定義
torch.nn.Conv2d(入力チャネル数, 出力チャネル数, カーネルサイズ)torch.nn.Linear
線形層($y=Wx+b$)の定義
torch.nn.Linear(in_features, out_features, bias=True)例えば, 次元数3のデータを2つ用意してこれを5次元に変換する場合
x = torch.randn(2, 3) W = torch.nn.Linear(3, 5, False) y = m(x) print(y.size()) #torch.Size([2, 5])x= \begin{bmatrix} x_{11} & x_{12} & x_{13}\\ x_{21} & x_{22} & x_{23} \end{bmatrix},\\ W= \begin{bmatrix} w_{11} & w_{12} & w_{13} & w_{14} & w_{15}\\ w_{21} & w_{22} & w_{23} & w_{24} & w_{25}\\ w_{31} & w_{32} & w_{33} & w_{34} & w_{35} \end{bmatrix},\\ y=xW = \begin{bmatrix} y_{11} & y_{12} & y_{13} & y_{14} & y_{15}\\ y_{21} & y_{22} & y_{23} & y_{24} & y_{25} \end{bmatrix}\\torch.nn.functional.max_pool2d
プーリング処理を行う関数1
torch.nn.functional.max_pool2d(入力, カーネルサイズ)勾配
net.zero_grad()
netの各パラメータの勾配を0で初期化
(初期化するのは, 勾配がイテレーション毎に加算される仕様であるため)backward()
出力や損失に対する各パラメータの勾配を計算する.
y.backward()
backward()はbackward(torch.Tensor([1]))の省略形である.
そのため, 例えば出力が[1,10]次元のベクトルである場合y.backward(torch.randn(1, 10))のようにする.
損失
nn.MSELoss()
平均二乗誤差関数
criterion=nn.MSELoss() loss=criterion(output,target)Tensor関連
torch.empty()
Tensorを作成する. 作成したTensorは初期化されておらず何らかの値が入っている.
x = torch.empty(5, 3) print(x) #tensor([[ 0.0000e+00, 1.5846e+29, -2.6611e-27], # [-3.6902e+19, -2.6884e-27, 1.5849e+29], # [ 0.0000e+00, 1.5846e+29, 5.6052e-45], # [ 0.0000e+00, 0.0000e+00, 1.5846e+29], # [ 0.0000e+00, 1.5846e+29, -2.6615e-27]])どうやって決まるのか何の値かは謎…
torch.rand()
ランダムなTensorを作成する.
x = torch.rand(5, 3) print(x) #tensor([[0.5934, 0.8821, 0.2641], # [0.3726, 0.3678, 0.2573], # [0.2761, 0.6679, 0.7228], # [0.9908, 0.5877, 0.5313], # [0.4664, 0.1699, 0.0252]])torch.zeros()
要素が0で初期化されたTensorを作成する.
x = torch.zeros(5, 3, dtype=torch.long) print(x) #tensor([[0, 0, 0], # [0, 0, 0], # [0, 0, 0], # [0, 0, 0], # [0, 0, 0]])torch.tensor()
値を直接指定してTensorを作成する.
x = torch.tensor([5.5, 3]) print(x) #tensor([5.5000, 3.0000])new_*
既存のTensorを上書きする. ちなみに元のshapeと揃える必要は無い.
x = torch.tensor([5.5, 3]) x = x.new_ones(5, 3, dtype=torch.double) print(x) #tensor([[1., 1., 1.], # [1., 1., 1.], # [1., 1., 1.], # [1., 1., 1.], # [1., 1., 1.]], dtype=torch.float64)
- new_zeros, new_ones, new_emptyは動いた.
- new_randはエラー
torch.randn_like()
Tensorの値をランダムに書き換え, 型を変換する
下の例では5*3のゼロ行列を, 5*3の値がランダムなフロート型に変換x = x.new_zeros(5, 3, dtype=torch.double) print(x) #tensor([[0, 0, 0], # [0, 0, 0], # [0, 0, 0], # [0, 0, 0], # [0, 0, 0]]) x = torch.randn_like(x, dtype=torch.float) print(x) #tensor([[ 0.4074, -0.4801, -1.7652], # [ 0.9456, -0.8796, -0.5751], # [-1.5125, -2.3049, 0.7683], # [ 0.8419, -0.6031, -0.2340], # [ 0.7071, 0.8503, 0.5636]])transpose
転置
x = torch.randn(4,3) #4行3列 torch.transpose(x)#3行4列view
サイズ変更
x = torch.randn(4,3) #4行3列 x.view(12,1) #12行1列 x.view(-1,2) #n行2列(この場合n=6)size
tensorのサイズを取得
x = torch.randn(4,3) x.size() #torch.Size([4,3])numpy()
Tensorをndarrayに変換
a = torch.ones(5) print(a) #tensor([1., 1., 1., 1., 1.]) b = a.numpy() print(b) #[1. 1. 1. 1. 1.]ちなみに
a.add_(1) print(a) print(b) # tensor([2., 2., 2., 2., 2.]) # [2. 2. 2. 2. 2.]aの値の変更がbにも反映される.
torch.from_numpy()
ndarrayをTensorに変換
a = np.ones(5) b = torch.from_numpy(a) np.add(a, 1, out=a) print(a) print(b) # [2. 2. 2. 2. 2.] # tensor([2., 2., 2., 2., 2.], dtype=torch.float64)その他用語
- Affine(アフィン) : 全結合層, 線型層
プーリング層を定義するクラス(torch.nn.MaxPool2d)もある ↩
- 投稿日:2019-05-12T18:16:47+09:00
Pythonでcsvファイルの内容を標準出力(sys.stdout)に出す
概要
ちょっとcsvファイルを確認したくなったときに標準出力(sys.stdout)に出すときのメモ
コード
test.csv12345,あいうえお,abcdefg 56789,かきくけこ,hijklmncsv_out.pyimport sys import csv with open("test.csv") as f: reader = csv.reader(f) writer = csv.writer(sys.stdout) writer.writerows(reader)12345,あいうえお,abcdefg 56789,かきくけこ,hijklmn解説?
csv.writerにsys.stdoutを渡すと出力先を標準出力にすることができる.
sys.stdoutはファイルオブジェクトなのでcsv.writerに渡すことができる.import sys import csv writer = csv.writer(sys.stdout)また, writerows()は iterable of row objects を受け取れる.
csv.reader()で作成したreaderオブジェクトもiterable of row objectsなのでを渡すことができる.reader = csv.reader(f) writer.writerows(reader)参考
Use Python to write CSV output to STDOUT - Stack Overflow
csv --- CSV ファイルの読み書き — Python 3.7.3 ドキュメント
Python3ではcsvモジュールを使わなくてもCSVを出力できる - Qiita
Pythonでcsvファイルに出力 - Qiita
- 投稿日:2019-05-12T18:07:16+09:00
カプランマイヤー曲線(Kaplan-Meier curves)
はじめに
初めてQiita書いてみます。
基本的にはバイオインフォマティクス中心のトピックスとなると思います。
非エンジニアですので、コードが乱雑なのはお手柔らかに・・・。また、未来の自分へ向けた備忘録的な書き方をしているのでちょっとくどめに見えるかもしれませんが宜しくおねがいします。基本的にはWindowsとLinuxに「Python」の「anaconda」を入れ、「jupyter notebook」をメインに使ってます。
今回はモデルデータを用いて 「乳癌患者の生存率を示すカプランマイヤー曲線」 を描きます。
基本的には下記リンクの方「junyasato」さんや「sinhrks」さんのトレースです。anacondaにはpythonの lifelines ライブラリが入っていなかったのでまずインストールします(以下はLinuxの場合)。
・Linuxターミナルのコンソールで次のように打ってlifelinesライブラリが入っていないことを確認。conda list---結果省略---
その後、同じくコンソールで次のようにインストール。
conda install -c conda-forge lifelines<参考>
lifelinesライブラリインストール後、コンソールで jupyter notebook を立ち上げ。
jupyter notebookこれ以降は jupyter notebook での作業となります。
Lifelinesライブラリを用いたカプランマイヤー曲線の作成
プログラム環境
import sys sys.version '3.6.5 |Anaconda, Inc.| (default, Apr 29 2018, 16:14:56) \n[GCC 7.2.0]'使用ライブラリ(モデルデータ含む)
import pandas as pd import numpy as np import matplotlib.pyplot as plt from lifelines import KaplanMeierFitter from lifelines.datasets import load_gbsg2 # test data of breast cancer with hormone treatment from lifelines import CoxPHFitter # Cox model %matplotlib inlineモデルデータについて
モデルデータとなる乳癌患者の治療データを入手します。
#test data for breast cancer with hormone treatment df = load_gbsg2() type(df)本データはpythonのpandasのDataFrame形式のデータです。
#type of "df" data pandas.core.frame.DataFrame(一応下記に参考文献を載せてますが読んでません・・・)
Original paper: Schumacher, M., Basert, G., Bojar, H., et al. “Randomized 2 × 2 trial evaluating hormonal treatment and the duration of chemotherapy in node-positive breast cancer patients.” Journal of Clinical Oncology 12, 2086–2093. (1994) まず、dfデータフレームの最初の10行をざっくり見てみます。
df.head(10)
主なパラメータとして、「horTh」がホルモン治療の有無,
「tgrade」は(恐らく)癌のグレード、timeが生存期間、
「cens」がcensoring、つまりある時点での打ち切りがあったかどうかです。もう少し詳細にパラメータを見てみると、
print(df.shape)686症例、10パラメータ。
(686, 10)print(df.nunique())例えば「horTh」は2種類,「tgrade」は3種類、「cens」は2種類のuniqueパラメータが存在します。
horTh 2 age 54 menostat 2 tsize 58 tgrade 3 pnodes 30 progrec 242 estrec 244 time 574 cens 2 dtype: int64df.isnull().all()では各列の要素に欠損があるかを調べます。
boolの返り値が"False"の場合は、「欠損がある、わけではない」、つまり要素に欠損がない、という意味です。#欠損値の判定 print(df.isnull().all())本データには欠損値はないためこのまま進めますが、実施中の臨床データでは欠損値が出てくるケースがあると思います。そのため、実臨床データの解析では、ここから更にデータクリーニングのステップが入ります。
horTh False age False menostat False tsize False tgrade False pnodes False progrec False estrec False time False cens False dtype: bool3つのパラメータの内訳。dtype(データ型)もついで調べている理由は後述します。
#パラメータの種類 print("horTh: ", df["horTh"].unique(), df["horTh"].dtype) print("tgrade: ", df["tgrade"].unique(), df["tgrade"].dtype) print("cens: ", df["cens"].unique(), df["cens"].dtype)「horTh」は治療の有無として'no'と'yes'、「tgrade」として'I'、'II'、'III'、「cens」では打ち切りの有無として'1'と'0'、のパラメータが存在することがわかります。
horTh: ['no' 'yes'] object tgrade: ['II' 'III' 'I'] object cens: [1 0] int64どれくらいの生存期間の患者を対象にしているかをざっくり把握します。
#臨床研究期間における最小と最大のsurvival time print(" min of viable time: ", df["time"].min()) print(" max of viable time: ", df["time"].max())最大7年間の観察期間のようです。
min of viable time: 8 max of viable time: 2659686人を60分割してsurvival timeのヒストグラムを描くと次のようになります。
df["time"].hist(bins=60)
686人を60分割して年齢層のヒストグラムを描くと次のようになります。
df["age"].hist(bins=60)40代後半から60代前半にかけての患者が多いようですね。
基本的に大半の癌は高齢者の方が罹患率が高い傾向にあるということがここからわかりますね。
50代半ばの患者の方がやや少ないのは何かしら理由があるのでしょうか。
ちなみにこれは1994年のデータセットなので、治療法が改善されている現在では
これとはやや異なるプロファイルになる可能性はあります。
カプランマイヤー曲線の作成前のデータ分割結果の検証
「horTh」がホルモン治療の有無により、生存率が変わるかをカプランマイヤー曲線によりチェックします。
その前に、groupby機能により、どのようにデータを分割できるかを見てみます。# group classification by with or without hormone therapy("horTh") for name, group in df.groupby('horTh'): print("name =", name) print("group =") print(group.shape) print(group.head(10)) print("")name = no group = (440, 10) horTh age menostat tsize tgrade pnodes progrec estrec time cens 0 no 70 Post 21 II 3 48 66 1814 1 4 no 73 Post 35 II 1 26 65 772 1 5 no 32 Pre 57 III 24 0 13 448 1 7 no 65 Post 16 II 1 192 25 2161 0 8 no 80 Post 39 II 30 0 59 471 1 9 no 66 Post 18 II 7 0 3 2014 0 13 no 50 Post 27 III 1 16 12 1842 0 15 no 54 Post 30 II 1 135 6 1371 1 16 no 39 Pre 35 I 4 79 28 707 1 19 no 55 Post 65 I 4 312 76 865 1name = yes group = (246, 10) horTh age menostat tsize tgrade pnodes progrec estrec time cens 1 yes 56 Post 12 II 7 61 77 2018 1 2 yes 58 Post 35 II 9 52 271 712 1 3 yes 59 Post 17 II 4 60 29 1807 1 6 yes 59 Post 8 II 2 181 0 2172 0 10 yes 68 Post 40 II 9 16 20 577 1 11 yes 71 Post 21 II 9 0 0 184 1 12 yes 59 Post 58 II 1 154 101 1840 0 14 yes 70 Post 22 II 3 113 139 1821 0 17 yes 66 Post 23 II 1 112 225 1743 0 18 yes 69 Post 25 I 1 131 196 1781 0「horTh」の状態(ホルモン治療が'no' or 'yes')によりデータを分割し、"shape"により分割後のデータ数(行×列)を表示させたのち、それぞれデータを10症例ずつ表示させた結果です。
分割した2つのグループ「no」と「yes」の行数の合計が(440 + 246) = 686、とオリジナルデータの行数と一致しているのがわかります。
これをみるとホルモン治療を行っていない対称群の方が症例数が2倍程度多いようですね。数百症例規模の研究だと大きな問題にはならない気がしますが、 症例数が少ない場合は「Stratified Sampling (層化サンプリング) 」等をした方が良いのかも・・・# tgrade after grouping by with or without hormone therapy("horTh") for name, group in df.groupby('horTh'): print("name =", name) print(group["tgrade"].value_counts()) print("")name = no II 281 III 111 I 48 Name: tgrade, dtype: int64 name = yes II 163 III 50 I 33 Name: tgrade, dtype: int64ホルモン治療の有無によりグループ分けしたあとの、「tgrade」の3種類のグレードの割合について見てみました。多少ばらつきはあるものまあ許容範囲なのかもしれません。
これが例えば、別治療群のみステージIの比率が圧倒的に多い、とかいう結果になると、そもそも比較が成立しない可能性がありますしね。このあたりはじっくりチェックしておきたいところです。カプランマイヤー曲線の作成
いよいよカプランマイヤーまできました。
「horTh」がホルモン治療の有無により、生存率が変わるかをカプランマイヤー曲線によりチェックします。
先ほどgroupby機能により「horTh」によりグループ分けした結果がほどほどにきちんと分割されている(ような気がする)ことを確認したので、この2種類のグループでカプランマイヤー曲線を描写します。kmf = KaplanMeierFitter() ax = None for name, group in df.groupby('horTh'): kmf.fit(group['time'], event_observed=group['cens'], label = 'hormone therapy =' + str(name)) # 描画する Axes を指定。None を渡すとエラーになるので場合分け if ax is None: ax = kmf.plot() else: ax = kmf.plot(ax=ax) plt.title('Kaplan-Meier Curve') plt.show()
なんとなく、ホルモン治療群の方が生存率は高そうな感じですね。
次は、「tgrade」で層別化してカプランマイヤーを描いてみます。ax = None for name, group in df.groupby('tgrade'): kmf.fit(group['time'], event_observed=group['cens'], label = 'tgrade =' + str(name)) # 描画する Axes を指定。None を渡すとエラーになるので場合分け if ax is None: ax = kmf.plot() else: ax = kmf.plot(ax=ax) plt.title('Kaplan-Meier Curve') plt.show()
こちらもtgrade=IIとIIIの差はやや微妙ですが、Iの予後が良いのは間違いなさそうですね。
ちなみに下記でtgradeで分類したグループI,II,IIIそれぞれの年齢に関する要約統計量を算出していますが、だいたい均等分布していることがわかります。
この2点の情報から、(本検証の結果からは)年齢に関わらず、癌は早期発見するほど予後は良くなるであろう、ということが推測できます。# age after grouping by ("tgrade") for name, group in df.groupby('tgrade'): print("name =", name) print(group["age"].describe()) print("")name = I count 81.000000 mean 54.000000 std 9.648834 min 37.000000 25% 47.000000 50% 51.000000 75% 61.000000 max 79.000000 Name: age, dtype: float64 name = II count 444.000000 mean 53.364865 std 10.059742 min 21.000000 25% 46.000000 50% 53.000000 75% 62.000000 max 80.000000 Name: age, dtype: float64 name = III count 161.000000 mean 51.714286 std 10.452529 min 29.000000 25% 45.000000 50% 52.000000 75% 60.000000 max 77.000000 Name: age, dtype: float64しかし、年齢についてこのままカプランマイヤー曲線を描写するととんでもないことに・・・・
ax = None for name, group in df.groupby('age'): kmf.fit(group['time'], event_observed=group['cens'], label = 'age =' + str(name)) # 描画する Axes を指定。None を渡すとエラーになるので場合分け if ax is None: ax = kmf.plot() else: ax = kmf.plot(ax=ax) plt.title('Kaplan-Meier Curve') plt.show()
この理由はuniqueな年齢ごとにカプランマイヤーが層別化してしまうからです。
前の方で本データセットに関して、「age」には54種類の異なる年齢が登録されていることがわかっていましたので、カプランマイヤーでは54種類の層別化をおこなっている(はず)です。そこで、データセットに関して年齢を35歳区分で区切って、3分割(0〜34,35〜69,70〜)してみます。
3分割した「age」の要素(df2["age"])はそれぞれ(0,1,2)へと変換されていることがわかると思います。df2 = df.copy() df2["age"] = (df2["age"]//35) # 35歳ずつ区切る print(df2["age"].value_counts()) df2.head(10)1 631 0 29 2 26 Name: age, dtype: int64
# tgrade after grouping by ("age") for name, group in df2.groupby('age'): print("name =", name) print(group["tgrade"].value_counts())name = 0 II 18 III 11 Name: tgrade, dtype: int64 name = 1 II 409 III 144 I 78 Name: tgrade, dtype: int64 name = 2 II 17 III 6 I 3 Name: tgrade, dtype: int64しかし分割した年齢区分には厄介な問題が・・・・。
上記で3分割した年齢層ごとにtgradeのサブタイプの数を見てみたのですが、若年層(0〜34歳)のサブタイプにはtgradeがIの患者が含まれていません。つまり、分割後の若年層グループは潜在的に癌が進行している患者が多くを占めていると予想されます。
そのため、年齢3分割後のカプランマイヤーを描写すると・・・ax = None for name, group in df2.groupby('age'): kmf.fit(group['time'], event_observed=group['cens'], label = 'age =' + str(name)) # 描画する Axes を指定。None を渡すとエラーになるので場合分け if ax is None: ax = kmf.plot() else: ax = kmf.plot(ax=ax) plt.title('Kaplan-Meier Curve') plt.show()
一見、age=0(0〜34歳までの患者)の生存率が悪いような気がするのですが、これは前述したように層別化後に若年層ではtgrade=Iの患者がいない影響もあるためだと考えられます(筆者の勝手な推測です)。
かといって、tgrade=Iの患者を排除して解析すると症例数が少なくなっていきますし、なかなか臨床試験の解析は難しいですね(とりあえずこの解析は年齢に関してはこれ以上深入りしません)。ここで言いたかったのは、分類項目が多すぎるものに関しては、何らかの方法で分類項目を減らして解析することが可能だということです(その結果が良いか悪いかは別として)。
コックス比例ハザードモデル(Cox proportional hazard model)
上記まででカプランマイヤー曲線を作成して、なんとなくホルモン治療の有無やtgradeの違いによって、患者の生存率(≒予後)に影響を与えることがわかってきましたが、では 「どの程度」 影響があるのでしょうか?
それを調べる手法の一つが「コックス比例ハザードモデル」です。コックス比例ハザードモデルでは、各パラメータが目的変数(今回だと生存率)に与える影響度を数値で比較します(間違ってたらすみません・・・)。
そして、数値で比較することにより、ではこの疾患ではこのパラメータに注目してフォローアップしていこう、という治療方針が立ちます(と思います)。しかし、ここで元データの要素に少し厄介な性質があることに気づきます。
それは「文字データ」の取り扱いです。
前の方でdtype(データ型)を調べていた時に、いくつかのパラメータは数値型(例:int64)ではなく、object型だったことを覚えているでしょうか?
色々なコマンドにデータを引き渡す場合、結構な頻度でobject型のデータは拒絶されることあります。horTh: ['no' 'yes'] object tgrade: ['II' 'III' 'I'] object cens: [1 0] int64実際に今回のオリジナルデータをコックス比例ハザードモデルで分析してみると、、、
cph = CoxPHFitter() cph.fit(df, duration_col='time', event_col='cens', show_progress=True)--------------------------------------------------------------------------- TypeError Traceback (most recent call last) ...<中略>... TypeError: DataFrame contains nonnumeric columns: ['horTh', 'menostat', 'tgrade']. Try 1) using pandas.get_dummies to convert the non-numeric column(s) to numerical data, 2) using it in stratification `strata=`, or 3) dropping the column(s).でた!素人殺しのエラーメッセージ。。。
心が折れて諦めそうになりますが、いやいや読むとどうも['horTh', 'menostat', 'tgrade']、の3種類が問題なんじゃないかという予想がつきます。
そして、その3種類のデータはobjectデータです。そしてよくよく読むと、Pythonもそれらについて、
1) using pandas.get_dummies to convert the non-numeric column(s) to numerical data
2) using it in stratificationstrata=,
3) dropping the column(s).
をTryしろよ、って言っていることに気づきます。でもこういうのって、エラー出た直後は冷静に読めないよね。手順としては、
A) ['horTh', 'menostat', 'tgrade']の3種類のobject型データに関して、「get_dummies」を使用して、要素の種類に関してカテゴリ変数から数値型(→ダミー変数(例:0、1))に変換します。
通常、get_dummies()関数ではk個の要素がk個のダミー変数に変換されるため、引数でdrop_first=Trueし、k-1個のダミー変数に変換するようにします。
k-1個にする理由は下記リンク参照して頂ければと思います。ただし、「junyasato」さんのブログでは、['horTh', 'menostat']に関しては、ダミー変数化しているのですが ['tgrade']に関しては列ごと削除してCox比例ハザードモデルに投入しています。
その理由はいくつかある気がするのですが、理由の一つは['tgrade']の要素の種類としては「I, II, III」の3種類があり、そのままダミー変数化してしまうと、オリジナルデータでは「'tgrade'」が1列だったのが2列になってしまうためだと思います。ごちゃごちゃ書いていますが実際のデータを見たほうが早いので、実際のデータに関して変換前後の10行のデータを見てみましょう。
df3_pre = df.copy() df3_pre2 = pd.get_dummies(df3_pre,columns=['horTh','menostat','tgrade'],drop_first=True) #ダミーデータ変換前 df3_pre.head(10) #ダミーデータ変換後 df3_pre2.head(10)df3_pre #ダミーデータ変換前
df3_pre2 #ダミーデータ変換後
これを見ると、例えば「horTh」に関しては、ホルモン治療があった人(='yes')の人が「1」、治療がなかった人が「0」になっていることがわかります。
また、「menostat」に関しては、'Pre'が「1」、'Post'が「0」になっていることがわかります。一方、「tgrade」に関しては、列が「tgrade_II」,[tgrade_III]の2列にわかれています。
そして、元々のtgrade='II'の人は、「tgrade_II,tgrade_III:1,0],元々のtgrade='III'の人は、「tgrade_II,tgrade_III:0,1],そしてここには表示していませんが、元々のtgrade='I'の人は、「tgrade_II,tgrade_III:0,0]に変換されることになります。ただこう変換すると、Cox比例ハザードモデルは通常、列データごとの影響度を調べることになるため、恐らくですが、「tgrade_II」の列ではtgrade='II'の人と、'I'+'III'の人の比較、「tgrade_III」の列ではtgrade='III'の人と、'I'+'II'の人の比較をすることになります。
ブログを書きながら、まあでもそれぞれtgradeの影響度を判別できるからこれはこれで良いのかも・・・、と思ったのですが(汗)、元々の自分のポリシー(謎)は「tgrade」という変数そのものを評価したいということでした。<参考:この状態でCOX比例ハザードモデルに投入した結果>
cph = CoxPHFitter() cph.fit(df3_pre2, duration_col='time', event_col='cens', show_progress=True) cph.print_summary() cph.plot()<lifelines.CoxPHFitter: fitted with 686 observations, 387 censored> duration col = 'time' event col = 'cens' number of subjects = 686 number of events = 299 log-likelihood = -1735.73 time fit was run = 2019-05-12 08:25:34 UTC --- coef exp(coef) se(coef) z p -log2(p) lower 0.95 upper 0.95 age -0.01 0.99 0.01 -1.02 0.31 1.69 -0.03 0.01 tsize 0.01 1.01 0.00 1.98 0.05 4.39 0.00 0.02 pnodes 0.05 1.05 0.01 6.55 <0.005 34.03 0.03 0.06 progrec -0.00 1.00 0.00 -3.87 <0.005 13.14 -0.00 -0.00 estrec 0.00 1.00 0.00 0.44 0.66 0.60 -0.00 0.00 horTh_yes -0.35 0.71 0.13 -2.68 0.01 7.10 -0.60 -0.09 menostat_Pre -0.26 0.77 0.18 -1.41 0.16 2.65 -0.62 0.10 tgrade_II 0.64 1.89 0.25 2.55 0.01 6.55 0.15 1.12 tgrade_III 0.78 2.18 0.27 2.90 <0.005 8.08 0.25 1.31 --- Concordance = 0.69 Log-likelihood ratio test = 104.75 on 9 df, -log2(p)=59.01
そこで、元々の自分のポリシーに従うため、「tgrade」の要素「'I','II','III'」をダミー変数ではなく、数値型「'1','2','3'」に変換します。
df3 = df.copy() df3["tgrade"] = df3["tgrade"].replace({'I': 1,'II': 2,'III': 3}) df3_2 = pd.get_dummies(df3,columns=['horTh','menostat'],drop_first=True) df3_2.head(10)
[tgrade]がobject型から数値型に変換されているのが確認できます。
それではこの状態でこの状態でCOX比例ハザードモデルに投入してみましょう。cph.fit(df3_2, duration_col='time', event_col='cens', show_progress=True) cph.print_summary() cph.plot()--- coef exp(coef) se(coef) z p -log2(p) lower 0.95 upper 0.95 age -0.01 0.99 0.01 -1.01 0.31 1.68 -0.03 0.01 tsize 0.01 1.01 0.00 1.95 0.05 4.30 -0.00 0.02 tgrade 0.28 1.32 0.11 2.64 0.01 6.93 0.07 0.49 pnodes 0.05 1.05 0.01 6.73 <0.005 35.82 0.04 0.06 progrec -0.00 1.00 0.00 -3.89 <0.005 13.26 -0.00 -0.00 estrec 0.00 1.00 0.00 0.37 0.71 0.50 -0.00 0.00 horTh_yes -0.34 0.71 0.13 -2.61 0.01 6.81 -0.59 -0.08 menostat_Pre -0.27 0.77 0.18 -1.46 0.14 2.79 -0.63 0.09 --- Concordance = 0.69 Log-likelihood ratio test = 101.86 on 8 df, -log2(p)=58.96
めでたく「tgrade」が一つの指標として評価されましたね!
ただ、データをよく見ると、「age」の項はそんなにCOXモデルで生存率に影響を与える指標としては評価されていません。
そのため、前述したように「35歳区分」で「age」を分けて、再び評価してみましょう。df3_3 = df3_2.copy() df3_3["age"] = (df3_3["age"]//35) # 35歳ずつ区切る cph.fit(df3_3, duration_col='time', event_col='cens', show_progress=True) cph.print_summary() cph.plot()coef exp(coef) se(coef) z p -log2(p) lower 0.95 upper 0.95 age -0.35 0.70 0.21 -1.66 0.10 3.37 -0.77 0.06 tsize 0.01 1.01 0.00 2.09 0.04 4.77 0.00 0.02 tgrade 0.28 1.32 0.11 2.60 0.01 6.73 0.07 0.48 pnodes 0.05 1.05 0.01 6.62 <0.005 34.69 0.03 0.06 progrec -0.00 1.00 0.00 -3.88 <0.005 13.25 -0.00 -0.00 estrec 0.00 1.00 0.00 0.45 0.65 0.61 -0.00 0.00 horTh_yes -0.34 0.71 0.13 -2.67 0.01 7.04 -0.60 -0.09 menostat_Pre -0.19 0.83 0.13 -1.45 0.15 2.76 -0.44 0.07 --- Concordance = 0.69 Log-likelihood ratio test = 103.58 on 8 df, -log2(p)=60.14
プロファイルが大分かわりましたね!
まあ、いずれのグラフでもlog(HR)(95% CI)をまたいでいるので、「age」は影響度がそんなに大きいパラメータではなさそうですが、これを見るともうちょっと層別化して解析してみようかな、という気にもなりますね。このように、今回は同一データから出発しても、データの区切り方を変えるだけで、全く別の結果が得られる、ということを確認できたためよいモデル実験となりました。それにしてもやはり臨床データの解析はなかなか難しいですね。。。
ちなみに、cox比例ハザードモデルは仮定のもとに成立しているようなので、本来は仮定が成立しているか検証すべきようですがちょっとそこまでフォローできていませんので悪しからず・・・
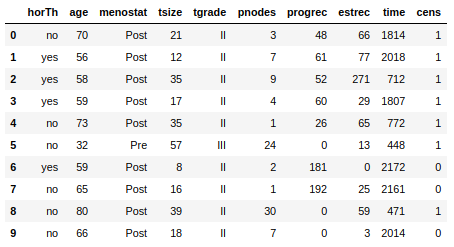
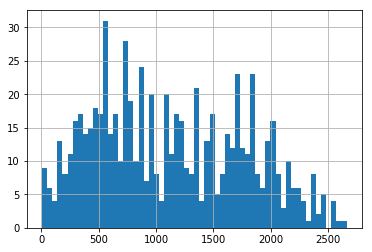
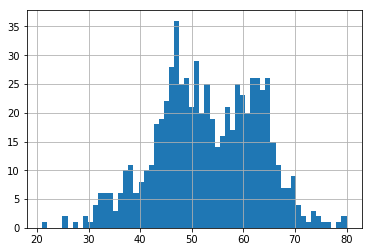
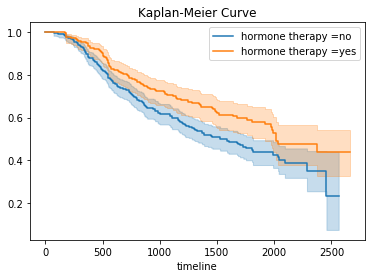
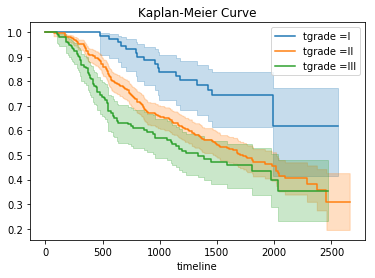


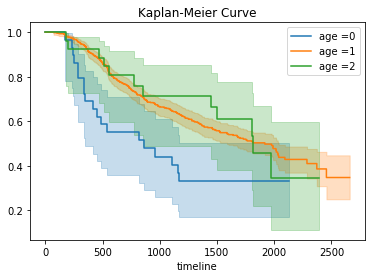
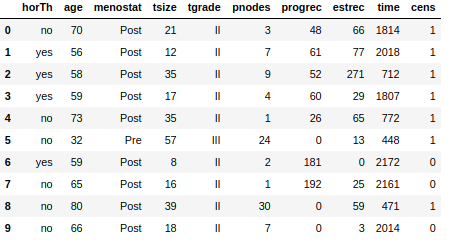
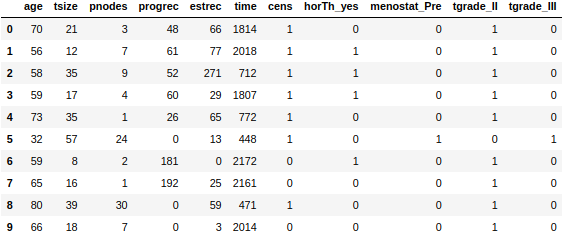

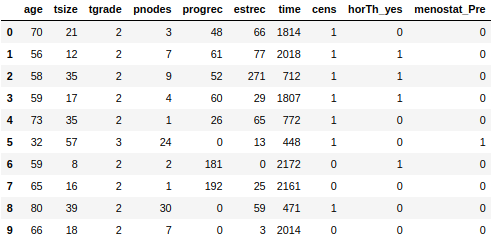


- 投稿日:2019-05-12T17:21:05+09:00
沖本本をもとに、製薬企業のPERの時系列データをグレンジャー因果性検定する
自分の備忘録のために、沖本本4章の「グレンジャー因果性検定」「インパルス応答関数」「分散分解」のコードを投稿する。
なお、上記3つの手法部分のコードは下記投稿を参考にした(ほぼコピペの箇所もあり)
(感謝しています!!!ありがとうございます!!)
https://qiita.com/mckeeeen/items/4afa1167008c1f315d0b使用データ
下記サイトから取得。今回は、武田薬品、中外製薬、第一三共、大塚製薬、タカラバイオ、アステラス、塩野義製薬、エーザイ、田辺三菱製薬、小野薬品の10社の2018年の株価データを使用した。
https://kabuoji3.com/stock/前処理
まず、日別の株価データを週次に変換した
(日別、月別も試したが、週次が一番良さそうだった)。company_list = ["takeda", "chugai", "sankyo", "otsuka", "takara_bio", "astellas", "shionogi", "eisai", "tanabe", "ono"] company_stock_list = [pd.read_csv(f"../Desktop/株価/{com}.csv", encoding="shift-jis", header=1) for com in company_list] comp_df = pd.DataFrame(columns=company_list) for i, comp in enumerate(company_list): comp_df[comp] = company_stock_list[i]["終値"] comp_df.index = pd.to_datetime(company_stock_list[0]["日付"]) comp_df["week"] = comp_df.index - comp_df.index.weekday.map(lambda x: datetime.timedelta(x)) comp_df = comp_df.groupby("week").mean()図示
fig = plt.figure(figsize=(15, 10)) ax = fig.add_subplot(1, 1, 1) comp_df.plot(ax=ax) plt.title("製薬企業の株価の時系列変化", fontsize=20) plt.legend(["武田薬品", "中外製薬", "第一三共", "大塚製薬", "タカラバイオ", "アステラス", "塩野義製薬", "エーザイ", "田辺三菱製薬", "小野薬品"])
PERに変換
対数差分系列を作成
per = pd.DataFrame(np.log(comp_df).diff(), index=comp_df.index)[1:] fig = plt.figure(figsize=(15, 10)) ax = fig.add_subplot(1, 1, 1) per.plot(ax=ax) plt.title("製薬企業のPERの時系列変化", fontsize=20) plt.legend(["武田薬品", "中外製薬", "第一三共", "大塚製薬", "タカラバイオ", "アステラス", "塩野義製薬", "エーザイ", "田辺三菱製薬", "小野薬品"])
グレンジャー因果性検定
VARモデル作成
AICが一番小さかったモデルを使用(maxlags=3)。
var_3 = VAR(per).fit(maxlags=3)グレンジャー因果性検定
names = ["武田薬品", "中外製薬", "第一三共", "大塚製薬", "タカラバイオ", "アステラス", "塩野義製薬", "エーザイ", "田辺三菱製薬", "小野薬品"] stat = [] pval = [] null = [] for i in range(10): for j in range(10): if i != j: test = var_3.test_causality(i, j, kind='f',signif=0.05, verbose=False) stat.append(test['statistic'].round(1)) pval.append(test['pvalue'].round(3)) null.append(f'{names[j]}->{names[i]}') else: pass calc = pd.DataFrame({'Statistics': stat, 'P_value' : pval}, index=null, columns=['Statistics', 'P_value'])こんな結果になりました(P値0.05以下のみ表示)
以下の結果から、
アステラスは他社の株価予測に有用であるのに対して、アステラスの株価予測に有用な製薬企業はなさそうであることがわかります。アステラスが製薬企業のトレンドに対して大きな影響力を持っていそうだと推察されます。
インパルス応答関数
irf=var_3.irf(10).orth_irfs interval=var_3.irf_errband_mc(orth=True,T=10,signif=0.05) fig,ax=plt.subplots(10, 10, figsize=[50, 50]) for i in range(10): for j in range(10): ax[i,j].plot(irf[:, i, j] * 100, linewidth=2) ax[i,j].plot(interval[0][:, i, j] * 100, linestyle='dashed', color='green', linewidth=1) ax[i,j].plot(interval[1][:, i, j] * 100, linestyle='dashed', color='green', linewidth=1) ax[i,j].hlines(0, 0, 10) ax[i,j].set_xlim(0, 10) ax[i,j].set_ylim(-0.2, 1.2) ax[i,j].set_xlabel('lag', fontsize=12) ax[i,j].set_ylabel('IRF', fontsize=12) ax[i,j].set_title(f'{names[j]}->{names[i]}') plt.subplots_adjust(wspace=0.3, hspace=0.3) plt.show()信頼区間(緑)がだいぶ広いので、精度は荒そうです。
分散分解
decomp=var_3.fevd(11).decomp fig, ax=plt.subplots(10, 10, figsize=[50, 50]) for i in range(10): for j in range(10): ax[i,j].plot(decomp[i, :, j] * 100, linewidth=2) ax[i,j].set_xlim(0, 10) ax[i,j].set_ylim(0, 100) ax[i,j].set_xlabel('lag', fontsize=12) ax[i,j].set_ylabel('RVC', fontsize=12) ax[i,j].set_title(f'{names[j]}->{names[i]}') plt.subplots_adjust(wspace=0.3, hspace=0.3) plt.show()
終わりに
重複になりますが、今回の投稿内容では、下記サイトにお世話になりました。
ありがとうございました。
https://qiita.com/mckeeeen/items/4afa1167008c1f315d0b時系列解析について、理論的枠組をもっとしっかり理解したいです。


- 投稿日:2019-05-12T17:02:50+09:00
pyenvのPythonにOpnecvが入らなかったから、既存のPythonの方から持ってくる
経緯
RaspberryPiの既存のPythonでopencv入れると、/usr/local/lib/python3.5/dist-packages/cv2 の中にcv2.cpython-35m-arm-linux-gnueabihf.so が入るんだけど、pyenvのpython(3.4.1)の中には違うやつが入ってて動かしてみると、色々無いよと言われ一つずつ足りないやつを入れてたけど落ちていない...
て事で、シンボリック貼ればええやんとなった。環境
RaspberryPi3b+
stretch(Release 9.9)
Python3.5(元々)
Python3.4(pyenv)導入
まずは既存のpythonの方にopencvを入れる
前処理
$ sudo apt-get install -y cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev python-dev python-numpy libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libjasper-dev libdc1394-22-dev$ sudo pip3 install opencv-python ・ ・ ・ TypeError: unsupported operand type(s) for -=: 'Retry' and 'int'なんか、色々怒られた
pip3 install opencv-python出来た。もうわからん
これで出来なければstack overflow実行前処理
$ sudo apt-get install -y libcblas-dev libatlas3-base libilmbase12 libopenexr22 libgstreamer1.0-0 libqtgui4 libqttest4-perl実行
$ python3 >>> import cv2 >>>通った
pyenvでも使えるようにしよう
まずはシンボリックを貼る ここでcv2.soとすることが大事
ln -s /usr/local/lib/python3.5/dist-packages/cv2/cv2.cpython-35m-arm-linux-gnueabihf.so /home/pi/.pyenv/versions/3.4.1/lib/python3.4/site-packages/cv2.soあとは、opencv-pythonを入れた際についでに入るsixパッケージなどのpathを追加して再起動
pathの追加の仕方(下の方に書いてる)$ pyenv global 3.4.1 $ python >>> import cv2はい、終わり
- 投稿日:2019-05-12T16:57:50+09:00
ゲーム画面の画像認識 → 文字認識 → 文字起こし の流れをリアルタイムに行う
1. はじめに
PyOCRを利用した文字認識に挑戦中のメモ書きです。
こういった場での公開は初めてなので、至らない点もあるかと思いますがよろしくお願いします。
好きなゲームの布教・翻訳を目的に作り始めたのでこんな記事タイトルをしてますが、記事の文字起こしや動画の字幕など何にでも使えると思います。
読み上げソフトに打ち込む際にちょっとだけ便利かもしれません。2. ざっくりフロー
PyAutoGuiで指定範囲のスクリーンショットを撮影
OpenCVでグレースケール、拡大
PyOCRで文字認識、テキスト出力
左上隅の座標を取得します 658,502 右下隅の座標を取得します 1196,602 【原文】 ------------------------------------ いつ頃からか出来上がった召喚という技術は、 様々な世界から技術、 人、 物を運んできたが、 この画期的な技術に少々浮かれすぎた人々は、 用もないのに多くの者を呼びすぎた。4.指定範囲の画像認識~テキスト出力の動作を3秒周期で繰り返す(リアルタイム要素)
【ポイント】
★ページ送りして読み進めながらでも、すぐさま次のテキストを文字認識して出力してくれます。3. PyOCR、PyAutoGui、OpenCVをそれぞれ導入
PyOCRの導入 【PyOCR】画像から日本語の文字データを抽出する
こちらを参考に。大変勉強になりました。この場を借りて感謝を。PyAutoGuiの導入
以下のコマンドを実行します。
pip install pyautogui
* OpenCVの導入
以下のコマンドを実行します。
pip install opencv-python
4. ソースコード
import sys import os import pyocr import pyocr.builders import pyautogui import cv2 from PIL import Image from time import sleep TESSERACT_PATH = 'C:\Program Files (x86)\Tesseract-OCR' TESSDATA_PATH = 'C:\Program Files (x86)\Tesseract-OCR\\tessdata' os.environ["PATH"] += os.pathsep + TESSERACT_PATH os.environ["TESSDATA_PREFIX"] = TESSDATA_PATH tools = pyocr.get_available_tools() if len(tools) == 0: print("No OCR tool found") sys.exit(1) # The tools are returned in the recommended order of usage tool = tools[0] print("Will use tool '%s'" % (tool.get_name())) # Ex: Will use tool 'libtesseract' langs = tool.get_available_languages() print("Available languages: %s" % ", ".join(langs)) lang = langs[0] print("Will use lang '%s'" % (lang)) # Ex: Will use lang 'fra' # Note that languages are NOT sorted in any way. Please refer # to the system locale settings for the default language # to use. # ↑PyOCR使う時の呪文、おまじない。 # 範囲指定のためのマウスカーソル座標取得関数。メッセージボックスの左上隅と右下隅で囲まれた範囲をスクリーンショット def PosGet(): # クリックを検知したらそこの座標を取得 ←なんか難しいからやめました # 3秒待ってからカーソル位置の座標を取得 print("左上隅の座標を取得します") sleep(3) x1, y1 = pyautogui.position() print(str(x1) + "," + str(y1)) # 3秒待ってからカーソル位置の座標を取得 print("右下隅の座標を取得します") sleep(3) x2, y2 = pyautogui.position() print(str(x2) + "," + str(y2)) # PyAutoGuiのregionの仕様のため、相対座標を求める x2 -= x1 y2 -= y1 return(x1, y1, x2, y2) # スクリーンショット撮影 → グレースケール → 画像を拡大 def ScreenShot(x1, y1, x2, y2): sc = pyautogui.screenshot(region=(x1, y1, x2, y2)) # PosGet関数で取得した座標を使用 sc.save('TransActor.jpg') # あとは画像拡大してみましょうか グレースケールも有効? OpenCVにも頼ってみよう img = cv2.imread('TransActor.jpg') gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) tmp = cv2.resize(gray, (gray.shape[1]*2, gray.shape[0]*2), interpolation=cv2.INTER_LINEAR) cv2.imwrite('TransActor.jpg', tmp) # Image.openメソッドで画像が開かれる。PyOCRで文字認識、文字起こし # 関数名は翻訳実装の名残 def TranslationActors(): txt = tool.image_to_string( Image.open('TransActor.jpg'), lang="jpn", builder=pyocr.builders.TextBuilder(tesseract_layout=6) ) # 英文を読み取る時はlang="eng" print("【原文】\n------------------------------------") print(txt) ''' ここまでが文字認識→出力のゾーン ''' # 読み取る範囲を決める x1, y1, x2, y2 = PosGet() while True: ScreenShot(x1, y1, x2, y2) TranslationActors() sleep(3) # 3秒ごとに繰り返す5. 改善点
- 原文を出力した後に英語への翻訳機能。そのままグーグル翻訳に投げつけると通信が多すぎて怒られてしまうので現在模索中です。
- メッセージボックスの配置が変わった場合とっても気まずいです。めげずに範囲を再度指定してます。
- 出力テキストを見比べて、全く同様の内容なら破棄する。
- リアルタイム(?)
次回予告!
出力したテキストを翻訳!(Pythonパッケージのgoogletransが便利でした)
GUI化!(TKinterと戦ってるけど今のところ1ミリもわかりません)リンク
- はむすたブログ様 記事内で紹介したフリーゲーム「ざくざくアクターズ」のDLはこちらから

- 投稿日:2019-05-12T16:57:36+09:00
IDEを多用し初心者に優しいROSの開発環境を作る
以下,intellisenseとデバッガは健康で文化的な最低限度の生活として保証されるべき,と考えているあじのりがお送りいたします.
はじめに
「弘法筆を選ばず」なんて言いますけれど,プログラミング初心者にとって開発環境の良し悪しは学習意欲に大きく影響します.
そこでこの記事では『ROSを初めて触る方が,挫折せずに入門書を一周できる環境を作る』ことを目標として設定し,Roboware Studioを使用したROS開発環境の構築方法と簡単な使用方法をご紹介します.
なお,Roboware公式からIDEの使い方が表記されたPDF資料が配布されているので,詳細についてはそちらをご覧ください.免責事項
一個人のQiita記事であることを理解してください.
環境
- OS: Ubuntu 16.04.5
- ROSのバージョン: ROS Kinetic
- 使用する言語: Python, C++
- 導入するIDE: Roboware Sudio
ROSのインストール
ROS Wikiに従って作業をすれば詰まることは無いと思います.
http://wiki.ros.org/kinetic/Installation/Ubuntudashimaki360さんが作成したこちらのスクリプトをダウンロードする方法でも問題なくインストールできるはずです.
https://gist.github.com/dashimaki360/4d612c845db65a3746e2caab39cf295b#file-ros_kinetic_install-shRobowareを導入する
Robowareとは
公式ホームページ: http://www.roboware.me/#/home
Roboware StudioはVSCodeベースのROS開発に特化したIDEです.
Robowareを使うことでプログラミングの本質以外のパッケージ管理や動作中のノードの管理が簡単になります.下ごしらえ
以下を実行しておきます.pylintのインストールで
sudo apt-get install build-essential sudo apt-get install python-pip sudo python -m pip install pylint sudo apt-get install clang-format-3.8なお,pylintのインストールをするとき
ERROR: Cannot uninstall 'enum34'. It is a distutils installed p roject and thus we cannot accurately determine which files belo ng to it which would lead to only a partial uninstall.と出てきた場合は,
sudo /usr/bin/python -m pip install pylint --ignore-installed
を実行して無理やり強引にインストールしました.Robowareのインストール
まず公式ホームページのトップページからRoboware Studioをダウンロードしてきます.
ついでにManual pdfもダウンロードしておくと捗るのでオススメです.
ファイルをダブルクリックすれば自動的にUbuntu Softwareが立ち上がり,インストールが進むはずです.ライセンス事項によく目を通し,同意する場合はチェックをつけてForwardを押します.
しばらくして画面右上当たりにインストール完了を知らせる文字が出ればインストール完了です.
すでに古いバージョンのRoboware Studioがインストールされている場合もこの手順で問題ないです.Robowareを使ってみる
ROSのワークスペースを開くor新規作成する
ダッシュボードにRobowareとタイプするか,ターミナルにroboware-studioとタイプすれば起動します.
画面真ん中にあるStartからNew Workspace...かOpen Workspace...を選択します.
通常,入門書ではユーザのホームディレクトリ直下にcatkin_wsというディレクトリを作成するよう書かれていると思いますのでそちらに従ってください.
無事ワークスペースを開けたら,画面の左側にワークスペース名とその中にいくつかフォルダやファイルが表示されます.
ここでとりあえず一度左上のEXPLORERのすぐ横の選択肢をDebugにした後,緑のハンマーマークを押してcatkin_makeしておきます.
ROSパッケージを新規作成する
画面左側のsrcフォルダを右クリックし,Add ROS Pacageを押します.
パッケージ名を入力すればパッケージが新規作成されます.
PublisherとSubscriberを作成する
- C++: パッケージ名を右クリックし,Add C++ ROS Nodeを選択して,ノード名を入力すれば完了です.
- Python: パッケージ名を右クリックし,Add Python ROS Nodeを選択して,ノード名を入力すれば完了です.
自動生成ではC++もPythonもsrcフォルダ内にコードが生成されますが,pythonファイルは<パッケージ>/scriptsフォルダに入れることが多そうなので,scriptsフォルダを作り,その後自動生成されたPythonファイルをドラッグアンドドロップしておきます.
(任意)Pythonファイルに実行権限がないため,ターミナルから自動生成したファイルのディレクトリまで進んで実行権限を渡してあげます.
下の図のようにchmod +x <ファイル名>としてあげればOKです.
Roboware StudioではPub/Subのサンプルプログラムが自動生成されます.
ファイルが生成されたのを確認できれば再度緑のハンマーマークを押してcatkin_makeします.
C++でコードを書いた場合,画面左側のNodeという部分に生成したパッケージ名とノード名が現れます.(Pythonで書いた場合は,ここにノード名は表示されないっぽいですが詳細は不明です)ノードの実行・デバッグ
まずはじめに画面上のROSタブからRun roscoreを押しroscoreを実行します.
C++
先にデバッグしたい対象のノードのcppファイルを開き,適当な場所にブレークポイントを1つ置いておきます.ブレークポイントは行数が表記されている部分のすぐ左側をクリックすれば設置できます.赤い丸が表示されれば準備完了です.
それでは,先ほどの手順でNodeタブ内にノード名が追加されたと思いますので,そちらをクリックします.
その画面の一番上にある「Debug this file」を選択します.先ほど選択したブレークポイントの箇所で処理が止まり,行が黄色くなれば成功です.
あとは画面左側の上から4つめの虫マークを押せば各種デバッグ情報を閲覧することができます.Python
画面左側の上から4つめの虫マークか画面上側のDebugタブからデバッグを開始します.
デバッグの設定は初期設定ではC++となっているのでPythonを使用している場合は変更したのち緑の矢印を押すとデバッグを開始できます.
デバッグ画面の使い方の詳細についてはVSCodeの解説サイトを見てください.
その他各種作業
パッケージを右クリックすれば各種作業が行えます.
Launchファイルは以下のように?マークで表示されるので,右クリックし,Run Launch fileを押せば実行されます.
画面左側の,点が9個並んでいるところをクリックすれば現在実行されているノードや,トピックなどを表示することができます.
画面左側の,上から5番目の四角っぽいアイコンを押せば,各種ROSパッケージを管理することができます.
Robowareをアンインストールする
ターミナルで
sudo apt remove roboware-studioを実行すれば終わり.
こんなところでしょうか.
とにかくインストールしてからデバッグ機能を使うところまでサクッと進めるので,とりあえずROSを触ってみたいと思う人にとってはなかなか魅力的ではないかと思います.以上,あじのりがお送りしました.何かあればTwitter(@hakumai_no_tomo)まで.
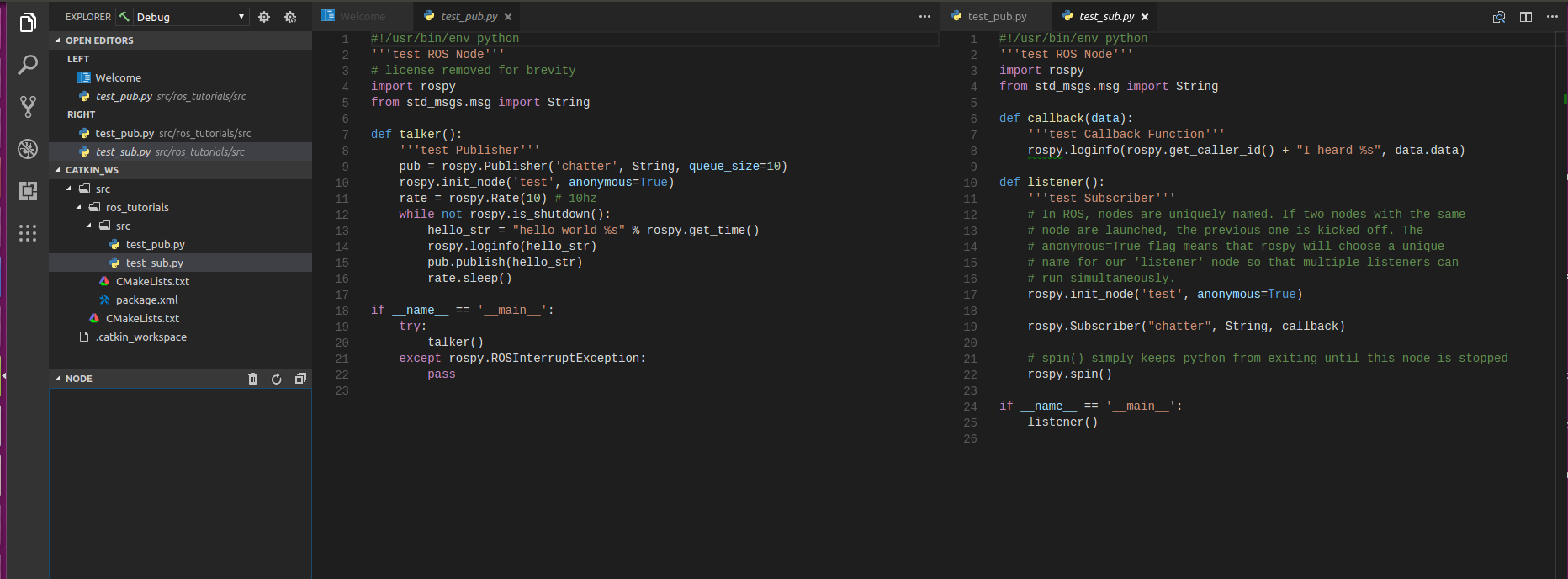
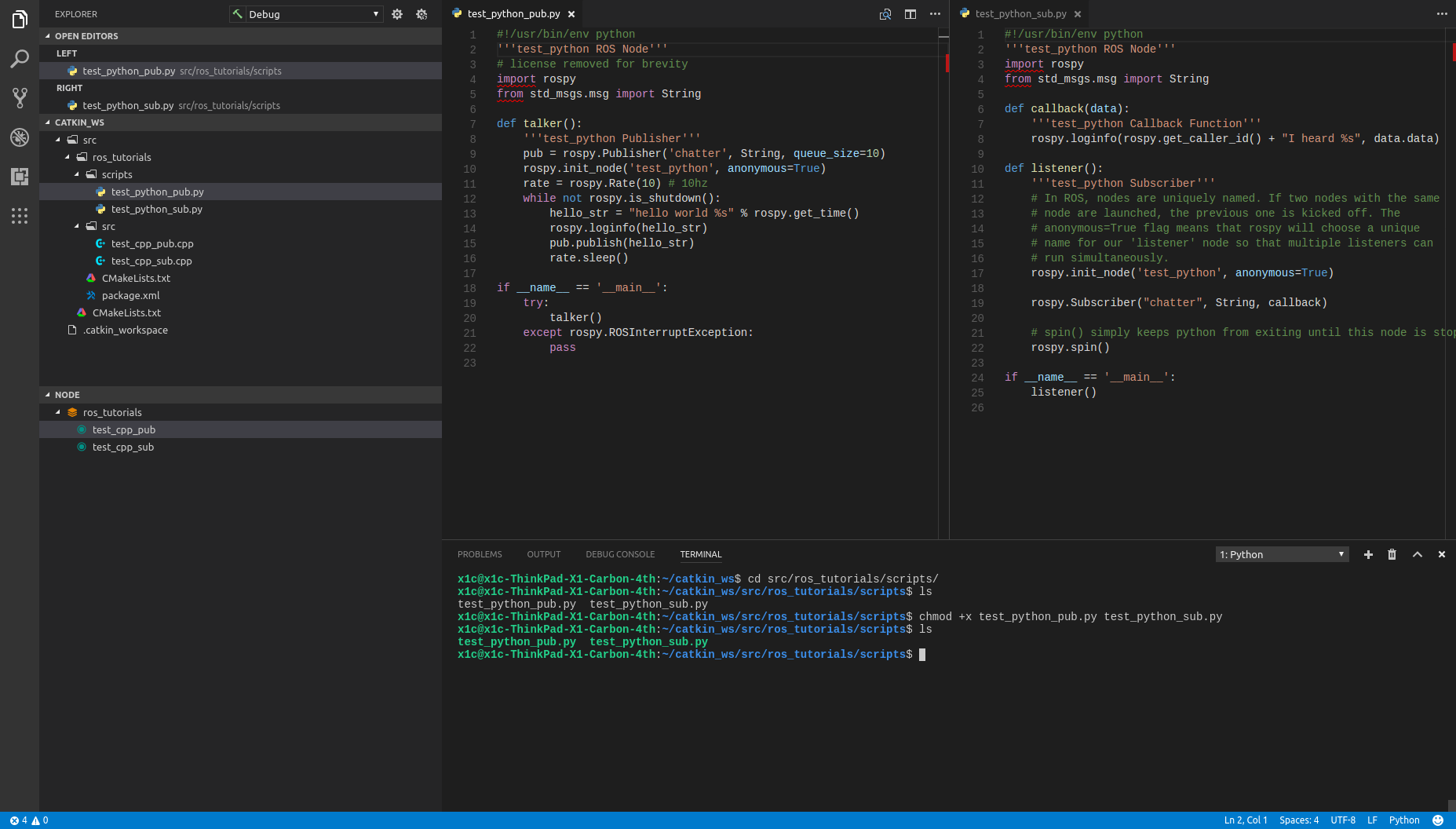
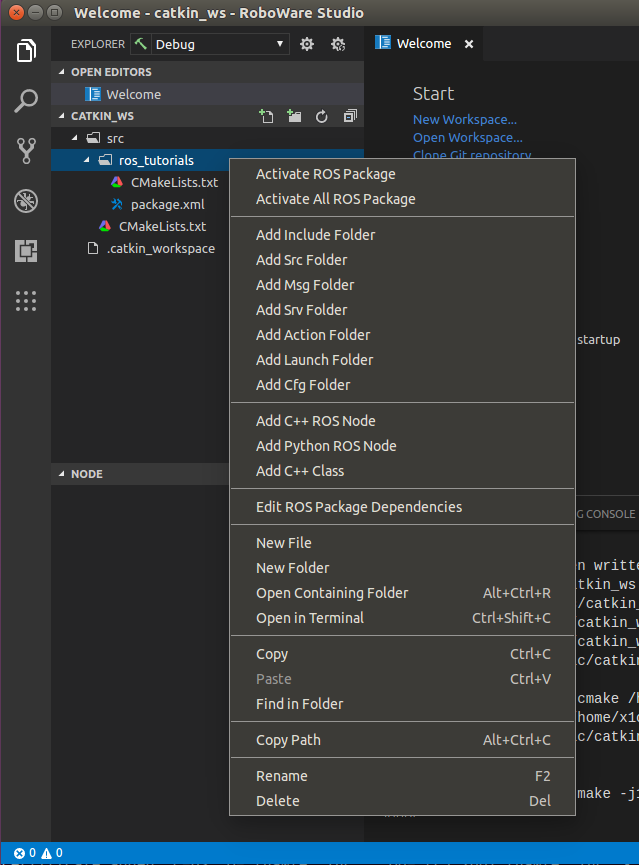
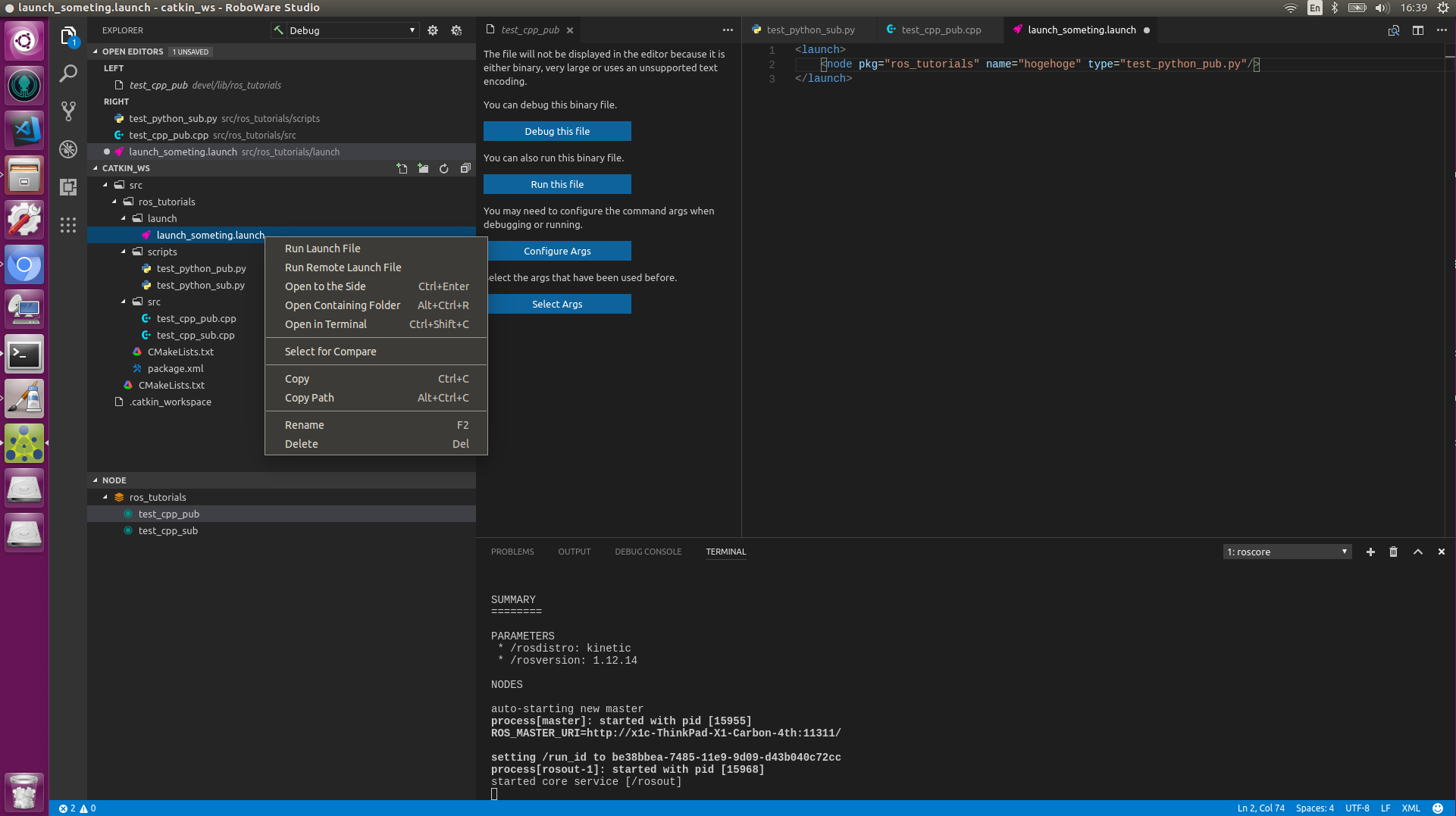
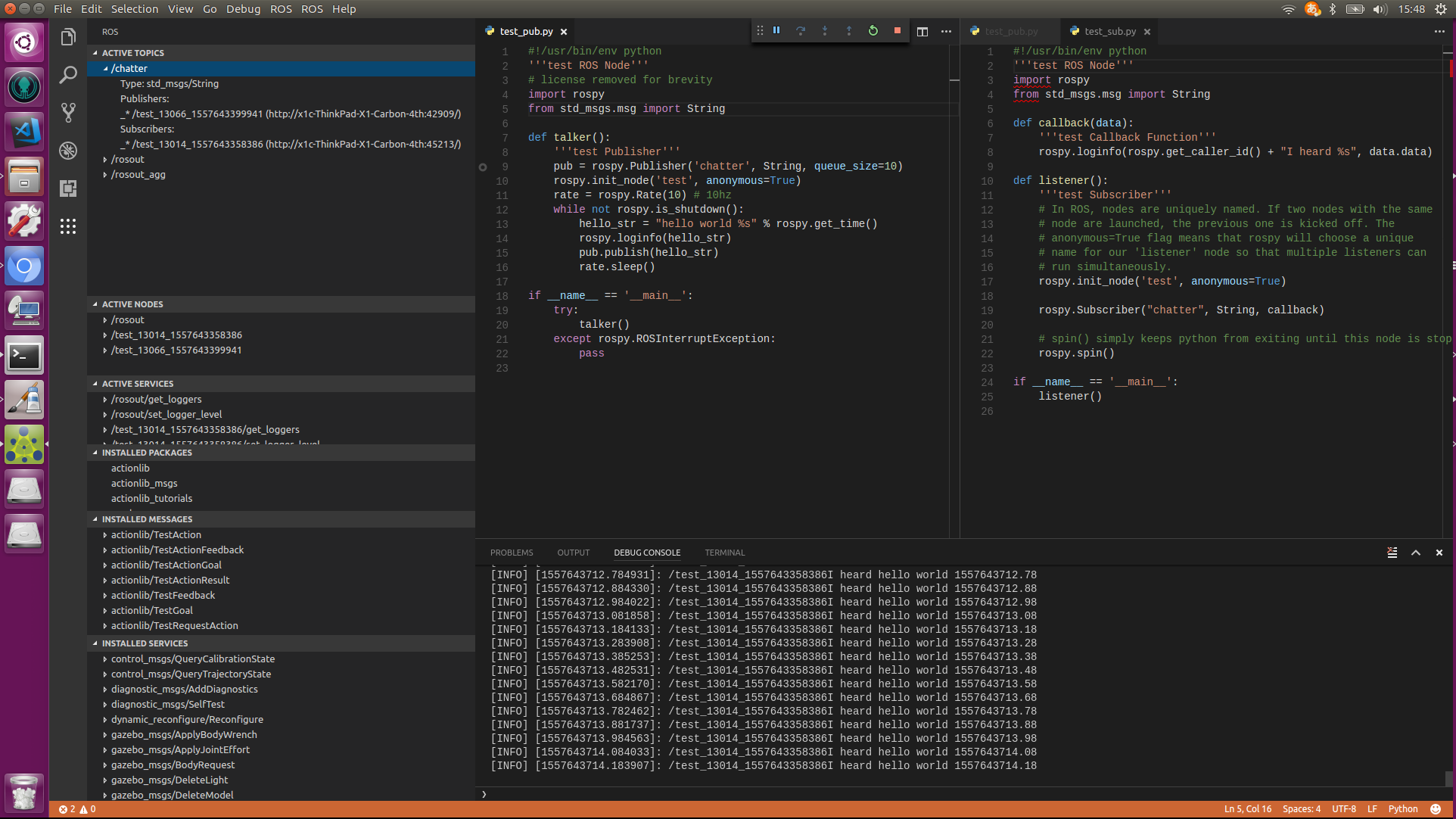
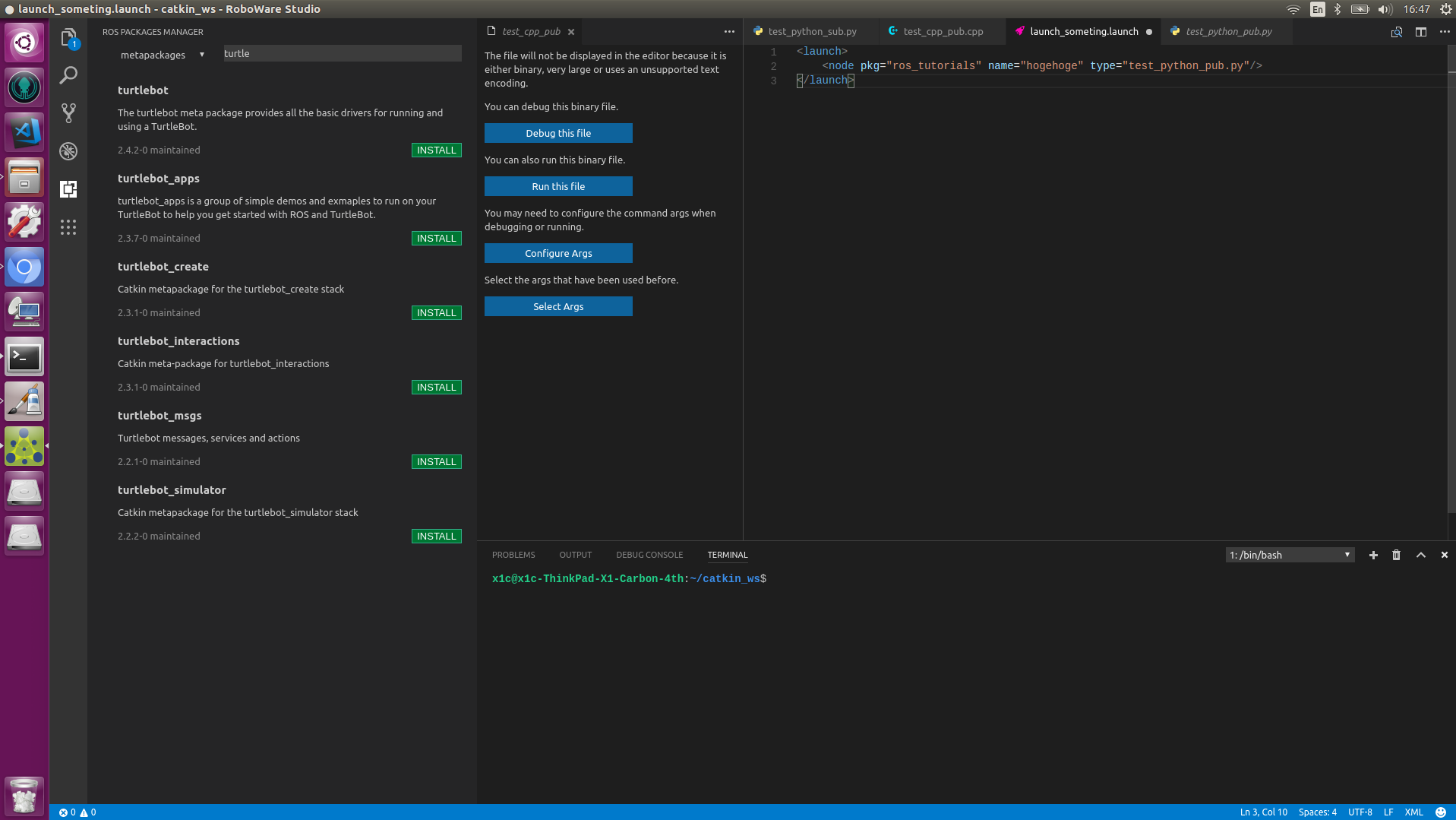
- 投稿日:2019-05-12T16:35:03+09:00
RaspberryPiでNumpyをインポートした際のエラー ImportError: numpy.core.multiarray failed to import
経緯
pythonでnumpyをインポートした際、ImportError: numpy.core.multiarray failed to importと言われたのでNumPyをアップグレードしたものの、なかなかこのエラーが消えてくれなかったので色々考えた。
解決法1
pipが古い
そもそものpipが古かったら、最新のnumpyをアップグレード出来ないのでpipをアップグレード
$ pip3 install --upgrade pip $ pip3 install numpy --upgradeこれでもダメ?
解決法2
いくつかNumpyが入っていて、古いやつが呼ばれている
例えば、
$ python3 >>>import sys >>>sys.path ['', '/home/pi/.pyenv/versions/3.4.1/lib/python34.zip', '/home/pi/.pyenv/versions/3.4.1/lib/python3.4', '/home/pi/.pyenv/versions/3.4.1/lib/python3.4/plat-linux', '/home/pi/.pyenv/versions/3.4.1/lib/python3.4/lib-dynload', '/home/pi/.pyenv/versions/3.4.1/lib/python3.4/site-packages']上記のように打つと、パッケージを探してくれるディレクトリをずらずらと並べ立ててくれる。
この時に注目するべきところは、この記述の順番である。これはパッケージを探す順番である。
例えば、初めの '/home/pi/.pyenv/versions/3.4.1/lib/python34.zip'のディレクトリにnumpyが入っていればこいつを読み込まれてしまう。無ければ、次のディレクトリを探す。という感じだ。過去に適当に他のディレクトリのpathを追加していてそいつが呼ばれているということもあり得る。
私は何も考えずに古いnumpyが入っている/usr/lib/python3/dist-packagesを追加していた。追加するのはいいが、一番最後に探してくれる追加の仕方をしていなかった。なので、最新のnumpyが入っている/home/pi/.pyenv/versions/3.4.1/lib/python3.4/site-packagesよりも早く呼び出されてしまっていたという事
対策
pathの追加方法な何通りかあるが、方法によって動きが微妙に違う。
追加方法1 .bashrcに追記
これは一番手っ取り早くpath追加できるが、パッケージの探索の際一番早く探索される
$ vi ~/.bashrc # 以下の内容を追記 export PYTHONPATH="/usr/lib/python3/dist-packages"保存して、再起動してpath一覧を見ると
$ python3 >>>import sys >>>sys.path ['', '/usr/lib/python3/dist-packages', '/home/pi/.pyenv/versions/3.4.1/lib/python34.zip', '/home/pi/.pyenv/versions/3.4.1/lib/python3.4', '/home/pi/.pyenv/versions/3.4.1/lib/python3.4/plat-linux', '/home/pi/.pyenv/versions/3.4.1/lib/python3.4/lib-dynload', '/home/pi/.pyenv/versions/3.4.1/lib/python3.4/site-packages']はい、一番先頭に来ましたね。
追加方法2 .pth ファイルの追加
これは、検索してくれるディレクトリに.pthファイルを作成及びpathを追記しておくと、pthファイルのpathのディレクトリを一番最後に探索してくれるというものだ。
#検索対象ディレクトリに移動 $ cd /home/pi/.pyenv/versions/3.4.1/lib/python3.4/site-packages $ vi path.pth # 以下の内容を追記 /usr/lib/python3/dist-packages保存して、再起動してpath一覧を見ると
$ python3 >>>import sys >>>sys.path ['', '/home/pi/.pyenv/versions/3.4.1/lib/python34.zip', '/home/pi/.pyenv/versions/3.4.1/lib/python3.4', '/home/pi/.pyenv/versions/3.4.1/lib/python3.4/plat-linux', '/home/pi/.pyenv/versions/3.4.1/lib/python3.4/lib-dynload', '/home/pi/.pyenv/versions/3.4.1/lib/python3.4/site-packages', '/usr/lib/python3/dist-packages']最後に来ていることがわかりますね。他にも方法があるみたいなので、その辺は他のサイトにお任せします...
- 投稿日:2019-05-12T16:30:27+09:00
Cisco機器の設定変更をBotで通知させた時のメモ
はじめに
前回と同じくEEMとOn-Box Pythonを組み合わせ、設定変更をAPI経由でWebex Teams Botへ通知させてみました。
手順は以下を参考にし、変更部分をメモとして残しています。
POC: Catalyst 9000 Sandbox integration with Spark.1) 用意した環境
AWS MarketplaceのCSR1000Vを使用しました。
Cisco Cloud Services Router (CSR) 1000V - AX Pkg. Max Performance30日間はFree Trial期間のため、CSRのソフトウェア費用はかかりません。
ただしEC2利用料はかかります。
バージニアリージョンのEC2(t2.medium)の場合、0.046ドル/時間でした。
EC2起動後、セキュリティグループでSSHを許可し、SSHログインします。2) Webex Teams Botの作成
Cisco Webex for Developersにログインし、[Start Building Apps] > [Create a New App] > [Create a Bot] にてBotを作成します。
詳しい手順は2)の通りです。3) ゲストシェルのセットアップ
詳しい手順は3)の通りです。
ただしAWSの場合、DNSサーバの設定変更は不要です。4) Pythonスクリプトの作成とBotのテスト
基本的に4)と同じですが、対象ホスト名と変更内容をBotに表示させるコードを追加しています。
具体的には、get_hostnameメソッドでホスト名を取得し、diffiosモジュールでStartup ConfigとRunning Configの差分を抽出しています。
別途ignore.txtを作成し、無視して構わない差分を定義しています。myscript.pyfrom ciscosparkapi import CiscoSparkAPI from cli import cli import diffios def get_hostname(): sh_run_host = cli('show run | include hostname') host_strip = sh_run_host.strip() hostname = host_strip.lstrip('hostname ') return hostname if __name__=='__main__': # Get hostname of device hostname = get_hostname() # Get diffs of startup-config and running-config with open('sh_start.log', 'w') as f1: sh_start = cli('show startup-config') f1.write(sh_start) with open('sh_run.log', 'w') as f2: sh_run = cli('show running-config') f2.write(sh_run) baseline = 'sh_start.log' comparison = 'sh_run.log' ignore = 'ignore.txt' diff = diffios.Compare(baseline, comparison, ignore) print diff.delta() # Use ArgParse to retrieve command line parameters. from argparse import ArgumentParser parser = ArgumentParser("Spark Check In") # Retrieve the Spark Token and Destination Email parser.add_argument( "-t", "--token", help="Spark Authentication Token", required=True ) # Retrieve the Spark Token and Destination Email parser.add_argument( "-e", "--email", help="Email to Send to", required=True ) args = parser.parse_args() token = args.token email = args.email message = "**Alert:** Config Changed \n**Hostname:** " + hostname + " \n```\n" + diff.delta() + "\n```" api = CiscoSparkAPI(access_token=token) api.messages.create(toPersonEmail=email, markdown=message)ignore.txt^Using Building configuration Current configuration crypto pki certificate ^end$5) NW機器側のEEM設定
5)と同じです。アクセストークンとメールアドレスは用意したものに書き換えます。
変更箇所をBotで表示させるために、一旦設定保存した後、以下の設定変更を行いました。
conf t ip domain lookup ip access-list extended Test permit ip host 10.10.10.1 host 10.10.10.2Webex Teamsにログインし、Botからの通知を確認します。
対象のホスト名、変更箇所が表示されました!
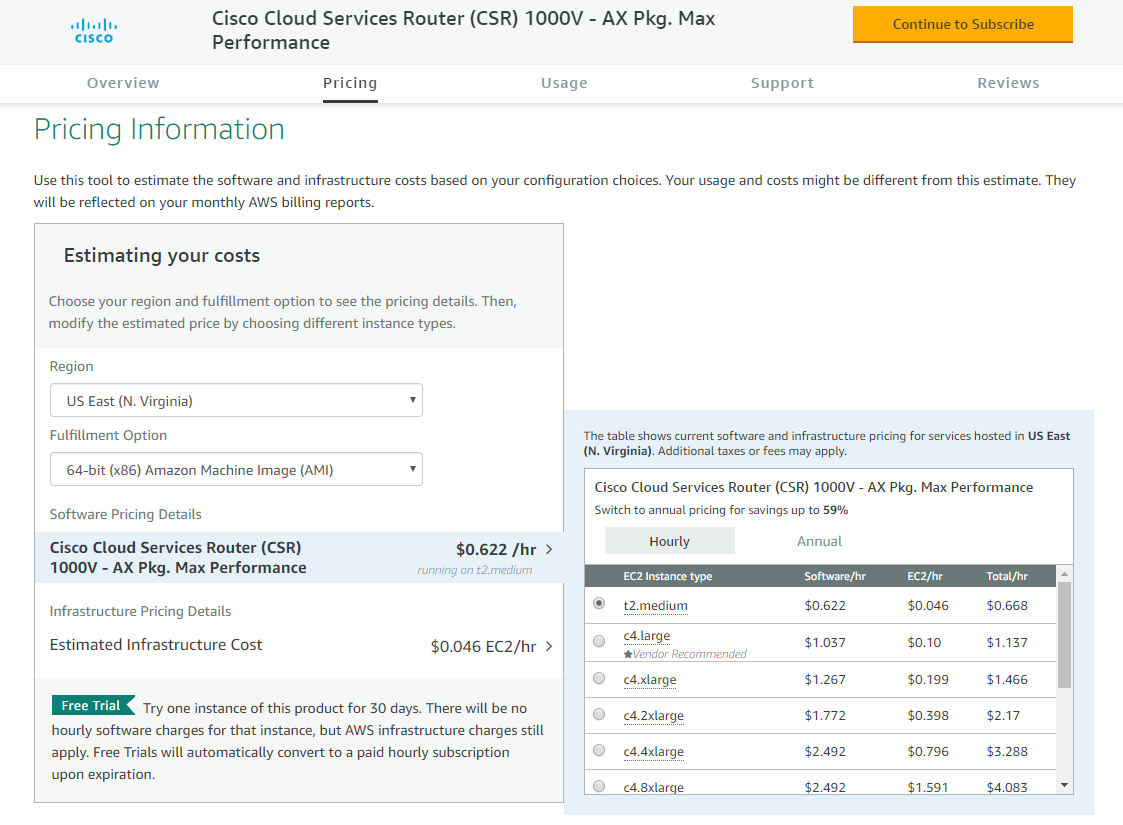
- 投稿日:2019-05-12T15:23:46+09:00
RaspberryPiにpyenvを入れて複数のPython動かすよ
経緯
事の発端はPyaudioを使おうとしたが、Python3.4より後に出たバージョンでは動かない。
なので、Python3.4をぶち込む環境
RaspberryPi3b+
stretch(Release 9.9)
Python3.5(元々)
GCC 4.8.5導入
RaspberryPiにpyenvでPython3環境を作るを参考にして入れていく。
前処理
$ sudo apt-get install -y git openssl libssl-dev libbz2-dev libreadline-dev libsqlite3-devpyenvインストール
$ git clone https://github.com/yyuu/pyenv.git ~/.pyenv終わったら、path設定
$ sudo vi ~/.bashrc # 以下の内容を追記 export PYENV_ROOT="$HOME/.pyenv" export PATH="$PYENV_ROOT/bin:$PATH" eval "$(pyenv init -)"Pythonをインストール
$ pyenv install 3.4.1 ・ ・ ERROR: The Python ssl extension was not compiled. Missing the OpenSSL lib? ・ ・ Ignoring ensurepip failure: pip 2.1.1 requires SSL/TLSまあ、なんかエラーが出る。
pyenv Ubuntu16.04 ERROR:
色々、入れていなかったみたい$ sudo apt-get install -y make build-essential libssl-dev zlib1g-dev libbz2-dev \ libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev libncursesw5-dev \ xz-utils tk-dev libffi-dev liblzma-dev python-opensslでは再び、インストール
$ pyenv install 3.4.1 ・ ・ ERROR: The Python ssl extension was not compiled. Missing the OpenSSL lib? ・ ・ Ignoring ensurepip failure: pip 2.1.1 requires SSL/TLS冗談だろ...
ラズパイ python3.5.1 インストール エラー
Debian 9 Stretchでは、libssl-devは、OpenSSL 1.1.xベースになっているので、あったlibsslを入れろとの事みたいです。$ sudo apt install -y libssl1.0-dev3度目の正直で、出来ました。
あとは、バージョン変更です。$ pyenv global 3.4.1確認
pi@raspberrypi:~ $ python -V Python 3.4.1元のPythonに戻るなら
$ pyenv global systemあとは、自分の環境だとPython3.4のpipが古かったのでpipの更新をしておく
$ pyenv global 3.4.1 $ pip install --upgrade pip $ pip3 install --upgrade pip $ pip --version pip 19.1.1 from /home/.pyenv/versions/3.4.1/lib/python3.4/site-packages/pip (python3.4)うん、いい感じ
余談
$ sudo pip3 --version pip 9.0.1 from /usr/lib/python3/dist-packages (python3.5) $ pip3 --version pip 19.1.1 from /home/.pyenv/versions/3.4.1/lib/python3.4/site-packages/pip (python3.4)癖でsudo付けてたらImportErrorになりまくった