- 投稿日:2019-05-12T23:12:36+09:00
Linuxでファイルをもっとさわる
いくつかおさらい。
削除、コピー、移動、リネイム、圧縮、アーカイブ削除
rm filename #ファイルを削除 rm -r dir #ディレクトリー削除 rm -f filename #確認なしでファイル削除 ls a* #aから始まるファイルを検索して消す項目を確認しておく rm a* #aから始まるファイルを削除コピー
cp sourceName destinationPath #コピーしたい(sourcename)ファイルをコピーしたい先(destinationPath/Name)にコピー cp sourceName [sourceName ...] destinationDirName #コピーしたいファイルを指定のフォルダにコピー sourceNameを羅列していけば複数コピーされる。 cp -i #インタラクティブモードが走る cp -r sourceDir destinationPath/Nam_ #ソースディレクトリが指定先に強制的にコピー移動、リネイム
mv mv sourceName destinationPath/Name mv -i sourceName destinationPath/Name mv sourceName sourceName2 #sourceName2がsourceNameに差し替えられる(リネイム) -iで動作を確認できるソート
sort filename #ファイルのテキストをアルファベット順にソート sort -k G #Gを元にソート sort -k2 #例) 2コラム目の値をソート sort -r #ソートを逆順に sort -u #重複を除いた、単体をソート複数ファイルを一つにまとめるアーカイブファイルの作成
tar [-] c|x|t f tarfileName [pattern] #c(tar作成)、x(ファイル抽出)、t(内容をリスト表示)、v()、z(圧縮を使う)、f(ファイルを使う)$ sample sebec$ tree . ├── SNSinfo ├── nanosample.txt ├── reports │ ├── archivesample │ └── dir.renamed $ tar cf tarsample.tar reports #レポートフォルダをtarsampleとして圧縮 $ tar tf tarsample.tar #tarsampleの内容を表示 reports/ reports/archivesample reports/dir.renamed/ iMac:sample sebec$アーカイブファイルの展開はこちら
tar xf zipsample.tarzip圧縮とDisk使用
gzip #ファイルを圧縮 gunzip #ファイルを解凍 gzcat #圧縮ファイルを結合 zcat #圧縮ファイルを結合 du #ファイル使用量の見積 du -k #キロバイトで表示 du -h #人間が読める単位で表示やってみます。
$ ls zipsample dir.renamed $ gzip zipsample $ ls zipsample.gz $ du -k zipsample.gz 4 zipsample.gz $ gunzip zipsample.gz $ du -k zipsample 0 zipsample少し混乱しますが、本来であれば圧縮した方が軽いデータサイズになるのですが、こちらの例では4に増えてしまっていますが、これはファイル内容がほぼゼロなのに対して、zipファイルにする内容が入るからかと。。
tarをzip圧縮したいときは
$ ls SNSinfo nanosample.txt reports $ tar zcf zipsample.tgz reports $ ls SNSinfo nanosample.txt reports zipsample.tgz← #中身をみたいときは $ tar ztvf zipsample.tgz drwxr-xr-x 0 sebec staff 0 5 12 18:19 reports/ -rw-r--r-- 0 sebec staff 0 5 12 14:56 reports/archivesample drwxr-xr-x 0 sebec staff 0 5 12 14:20 reports/dir.renamed/
- 投稿日:2019-05-12T19:48:16+09:00
Jetson NanoでGPGPU (CUDA) プログラミング ~ライフゲームの開発~
この記事について
Conway's Game of Life (ライフゲーム) をCUDA実装して高速化します。さらに、Shared MemoryやStream等の最適化手法を試し、PCとJetson Nanoでの挙動の違いを確認します。
最近、Deep Learningが非常に流行っています。その影響もあり、GPUといえば機械学習とセットで語られることが多いです。しかし、もともとはGenral Purpose GPUという言葉の通り、Deep Learningに限らず一般の計算用途に使用できるものです。ひと昔前は仮想通貨のマイニングが流行りましたね。今回は初心に戻って、Jetson NanoでGPGPUしてみようと思います。
実は、Windows PC用にCUDA実装したライフゲームのプロジェクトは以前作ったことがあります。今回は、そのプロジェクトをベースに、CMakeを使いマルチプラットフォーム化して、Jetson Nanoでも動くようにしました。
I created Conway's Game of Life on Jetson Nano.
— iwatake (@iwatake2222) 2019年5月11日
500 Generations Per Second for 1024 x 1024 thanks to CUDA. https://t.co/nrXj9zMgIi pic.twitter.com/HVITJS7Xa2ソースコードの場所
ソースコードとビルド、実行手順です
https://github.com/iwatake2222/LifeGameFast昔つくったビデオ
このビデオを見れば、雰囲気がつかめると思います。
環境
- Windows PC
- Core i7-6400 @3.4GHz x 4 cores (8 logical cores)
- GeForce GTX 1070 @1.531GHz
- Pascal
- 1920 CUDA Cores
- 256GByte/s (256 bit x 8Gbps)
- VRAM: 8GByte
- Windows 10 64-bit
- CUDA 10.0
- Visual Studio 2017 64-bit
- Jetson Nano
- ARM Cortex A57 @1.43GHz x 4 cores
- GPU @921MHz
- Maxwell
- 128 CUDA Cores
- 25.6GByte/s (64 bit x 1.6GHz x dual rate?)
- 共有VRAM: 4GByte
- jetson-nano-sd-r32.1-2019-03-18 (Ubuntu 18.04.2 LTS)
- CUDA 10.0
- GCC 7.4.0
今回作るライフゲームについて
基本的なルールは通常のConway's Life Gameと同じです。ただ、単にセルが生きているか死んでいるかだけだと面白くないので、今の年齢も併せて分かるように色分けで表示しました。年齢は、今の世代数を100として正規化した数字です。
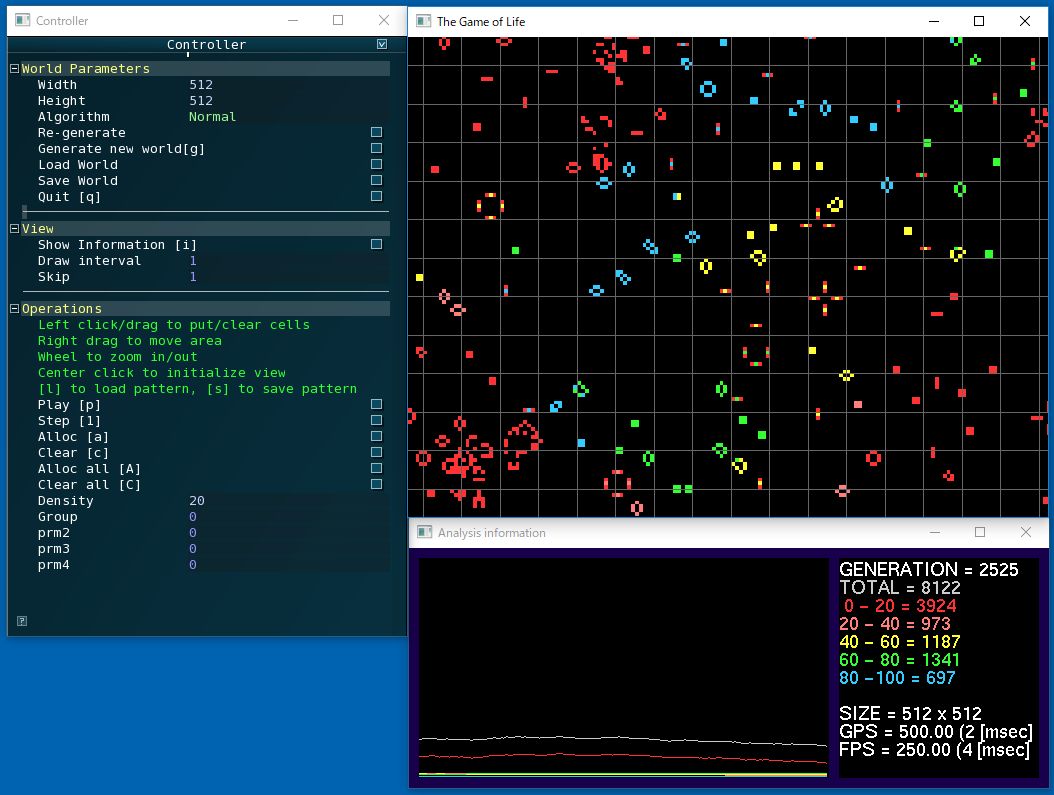
各年代のセルがどれくらいいるかといった統計情報を別ウィンドウに表示するようにしました。また、画面の大きさやパラメータ、アルゴリズム選択を行うためのコントローラUIも表示しています。
下記はWindows上でのCapture画面ですが、左側がコントローラUI、右上がゲーム画面、下が統計情報画面です。統計情報には計算速度が分かるように、Generation Per Second (GPS)と、Frame Per Second (FPS) も表示しています。
このGPSが今回の指標となる数字です。大きいほど計算が速いことになります。
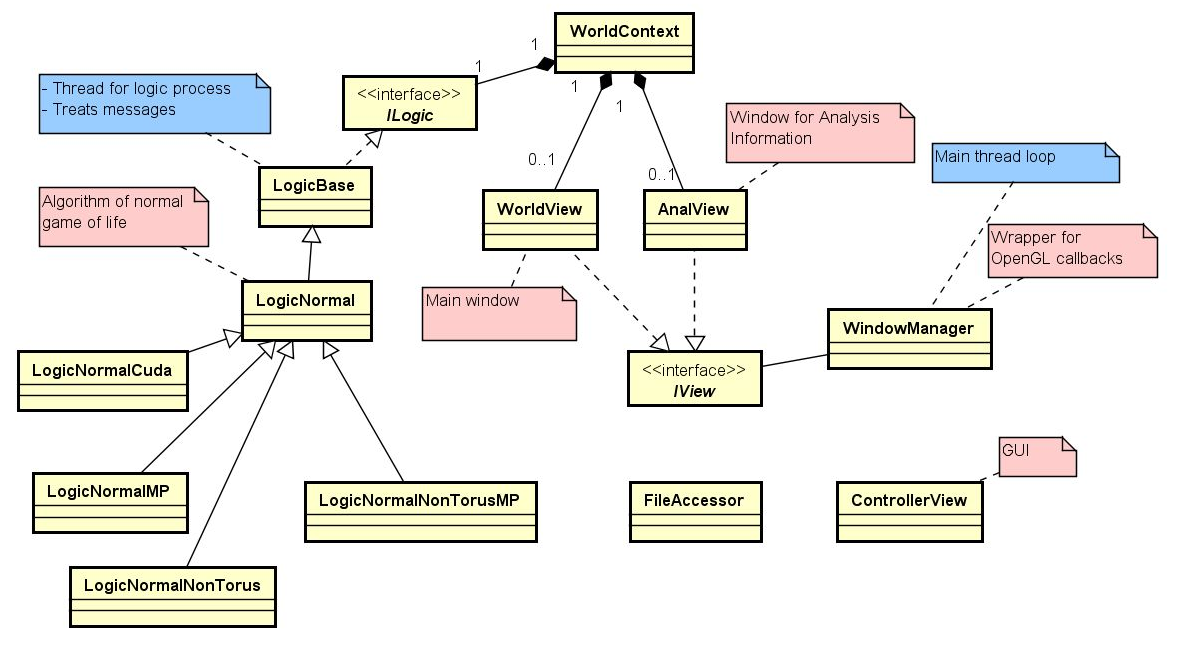
ソフトウェア構造
1年以上前に書いたコードなので、思い出しながら記事を書いています。。。
上の図が全体のクラス図です。左下にLogicNormalXXXというクラスがあります。Strategyパターンのように、色々なアルゴリズムを切り替えられるようにしています。今回は、通常のCPU実装、OpenMP実装、CUDA実装、とその他アルゴリズム色々(本記事では触れない)を切り替えています。CUDA実装内での最適化手法の切り替えは、格好悪いけどifdefで切り替えています。
LogicNormalCudaクラス(とそこから呼び出しているCudaコード)が今回の主戦場になります。一番上にあるWorldContextというクラスが全体を管理するクラスです。使用するアルゴリズムと、ライフゲームのゲーム画面(WorldView)と統計情報画面(AnalVew)を持ちます。
画面描画にはOpenGLのWrapperであるFreeGlutを使用しています。また、UIのためにAntTweakBarを外部ライブラリとして使用しています。
まずはざっくり比較
まずは、OpenMPやCUDAといった、大きな粒度で分類した高速化結果を比較します。
高速化手法
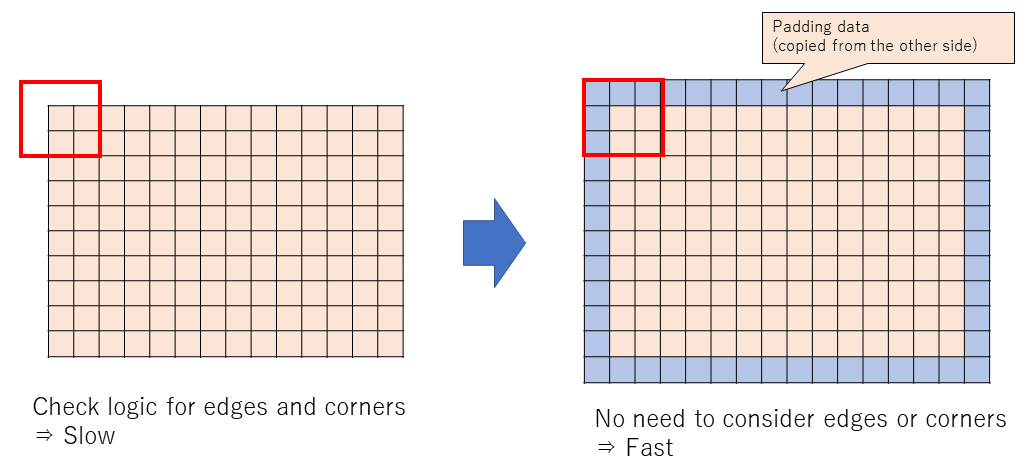
1. 境界チェックの削除
通常、ライフゲームではトーラス平面を考えます。つまり、ドラクエなどのRPGのように画面端まで行ったら反対側につながっているとします。そのため、画面端にあるセルを計算するときには特別な対応が必要になります。
しかし、これをif文で書いていると遅くなります。そのため、処理の最初にパディングを付けてしまいます(上図の青い部分)。この領域は、トーラス平面であれば反対側のセルの状態をコピー、非トーラス平面であれば0を設定します。これによって、各セルの計算をするときには余計なことは考えずに周囲8セルの状態をみるだけでOKになります。
以後、基本的には常にこの手法を使用します。2. OpenMP
通常のC/C++実装でプログラムを作成したら、1つのCPUしか使われません。
ライフゲームでは多くのforループ処理が出てきます。それらを複数のCPUで並列実装することで高速化します。
OpenMPを使用して、各for文に#pragma omp parallel forを付けるだけで簡単に並列化が可能となります。3. CUDA
今回の本題です。
OpenMPではCPUを用いた並列化であるため、せいぜい4~8並列にしかなりません。
CUDAではGPUを用いるため、CUDAコアの数だけ並列化されます。GTX 1070なら1920、Jetson Nanoなら128並列になります。理論的には、ですが。CPUに比べて圧倒的な並列度であることが分かります。4. CUDA + 最適化
詳細は後で出てきますが、CUDA実装の中でも様々な実装方法があります。それによってさらに高速化が可能となります。
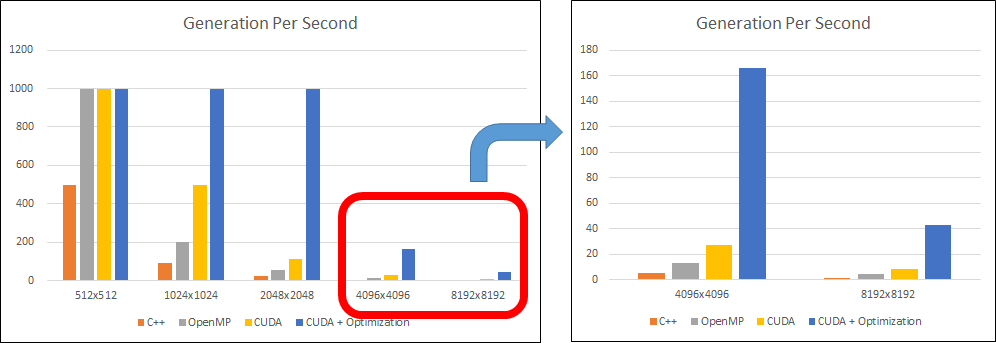
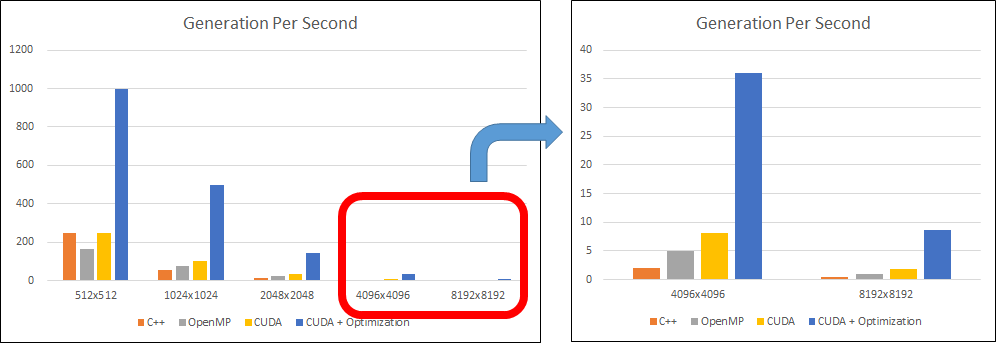
結果
GTX 1070 (PC)
Generation Per Second 512x512 1024x1024 2048x2048 4096x4096 8192x8192 C++ 500 90 24 5.5 1.3 OpenMP 1000 200 55 13 4.6 CUDA 1000 500 111 27 8 CUDA + Optimization 1000 1000 1000 166 43
Jetson Nano
Generation Per Second 512x512 1024x1024 2048x2048 4096x4096 8192x8192 C++ 250 55 12 2.1 0.4 OpenMP 166 76 26 4.9 1 CUDA 250 100 32 8.2 1.9 CUDA + Optimization 1000 500 142 36 8.7
PC, Jetson Nanoどちらも、通常のC++実装 < OpenMP < CUDA < CUDA + 最適化 の順に高速化され、傾向はほぼ同じでした。
PC(GTX1070)とJetson Nanoの性能を比べると、3~5倍程度の差でした。スペック上での性能差に比べると、そこまで大きな差にはなりませんでした。(リソースを限界まで使用した実装になっていない、ということでもありますが。)
※ GPSが500や1000と一気に飛んでいるのは、処理時間が1msec, 2msecなど非常に小さいケースです。
※ JetsonでOpenMPで512x512のケースだけ何故か傾向が違いました。何回か試したのですが毎回同じ結果になりました。謎。CUDA最適化実装
先ほどまではざっくり「CUDA + 最適化実装」と書いていましたが、実は色々なテクニックがあります。それだけで本が書けてしまうレベルですし、僕も簡単なことしか分かっていません。
ここでは、基本的なレベルの最適化を試してみます。また、一般に遅いといわれているZero Copy Memoryも試してみます。これは、PC(GTX 1070)とJetson Nanoでのアーキテクチャの違いによる挙動差を確認するためです。データフローの基本
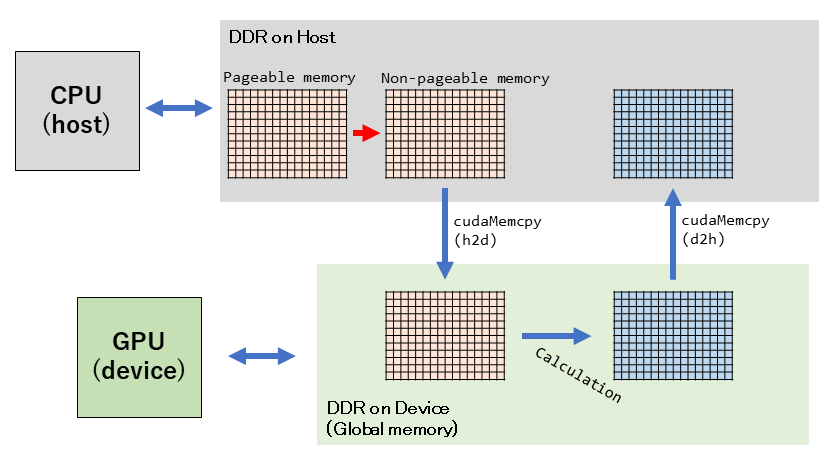
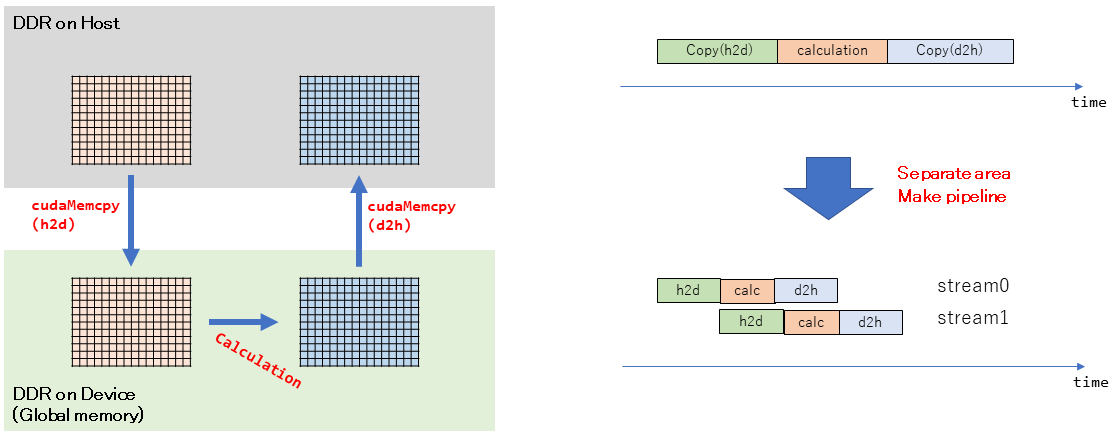
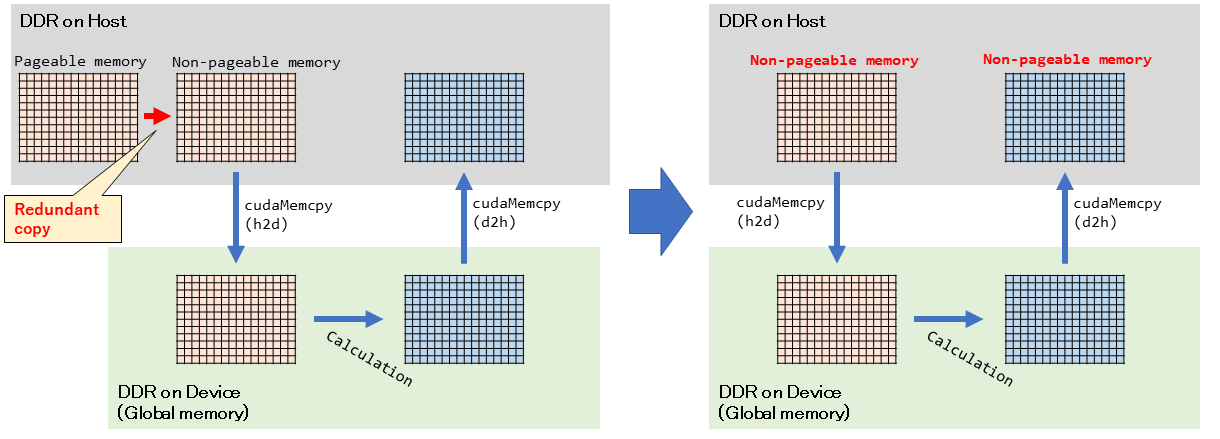
上の図が、CUDAプログラミングする際の最も基本的なデータの流れです。常にこの流れを意識しておく必要があります。
上部の灰色がCPU側(Host側)です。C言語上でallocやnewをしたら確保される領域になります。メモリはPCスペックなどに出てくる所謂「メモリ」です。
下部の緑色がGPU側(Device側)です。こちらのメモリは「一般的には」CPU側とは物理的に異なるものになります。いわゆる「VRAM」です。
ここで、「一般的には」と書きましたが、PCではPCIeバスを介して物理的に離れています。そのため遅いです。一方、、JetsonNanoのような組み込み型では物理的に近い場所だったり、共有しているケースもあります。データの流れを左上から見ていきます。
まずCPUが元となるデータをホストのDDR上に書き込みます。このデータをGPUで処理するためにはGPU側のデバイスメモリに転送する必要があります。しかし、通常のnew/alloc等で確保した領域では論理的には連続していても物理的には連続でない可能性があります。DMA転送などを使う都合だと思うのですが、物理的に連続である必要があります。また、ページアウトされてそもそも物理メモリ上に存在しなくなる可能性もあります。そのため、まずはNon-pageable memory(Pinned memory)として確保した領域にコピーされます。これはプログラマが意識せずとも勝手にやってくれます(やられてしまいます。)その後、ホストメモリからデバイスメモリにデータを転送します(
cudaMemcpyHostToDevice)。GPUはこのデータを用いて何らかの計算をして結果をデバイスメモリ上に書き込みます。計算が完了したら、デバイスメモリからホストメモリにデータを転送して完了です(
cudaMemcpyDeviceToHost)。高速化手法
高速化として、大きく2つの軸に分けました。
1つは制御変更を伴うもの(以下のALGORITHM_X)、もう1つはメモリ確保方法に関係するものです。結果はこの2つの組み合わせで見てみようと思います。
※Shared Memoryも、もろメモリに関することなのですが、実装変更が大きいので別枠にしました。ALGORITHM_0: 境界チェック有 + パディング無し
先ほど、「境界チェックがあるから遅くなるのでパディングを付けてif文をなくします」みたいなことを書きましたが、僕の中で、実はそっちの方が遅いのではないか疑惑があり、このケースも試してみました。
ALGORITHM_1: 境界チェック無し + パディング有り
周囲にパディングを付けて、境界チェックロジックを削除したアルゴリズムです。
このアルゴリズムを基準として考えます。先ほどの表・グラフの「CUDA」実装はこれですALGORITHM_2: Shared Memory
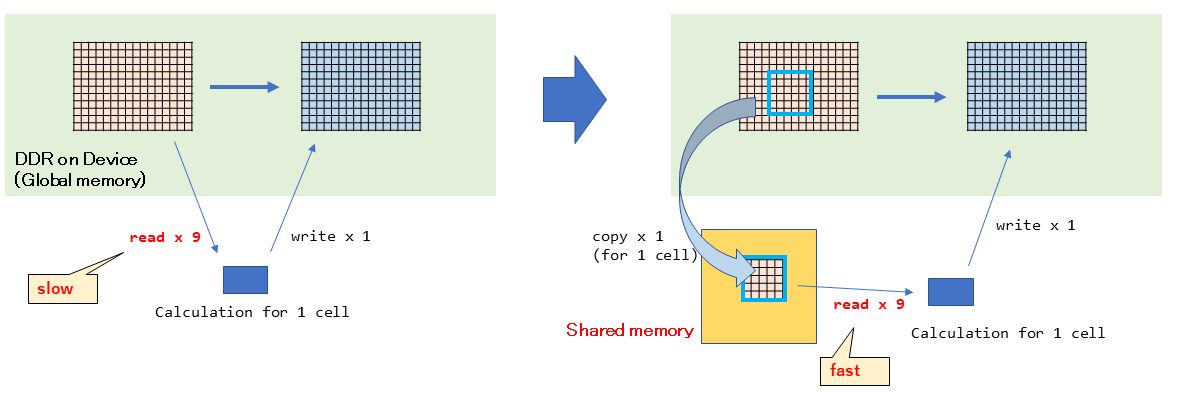
先ほどのデータフローの説明の図では、GPU(デバイス)側のメモリとして、Global Memoryを記載しました。これは、いわゆるVRAMで8GByteなど大きな容量を持っています。これはオンボード上のDDRであるため、遅いです。GPU内にも当然キャッシュ機構がありますが、さらに低遅延のオンチップメモリであるShared Memoryというものがあります。
Shared Memoryは、同一ブロック内のスレッドで共有される小容量だけど高速なオンチップメモリです。今回、ブロックサイズを32x32としました。そのため、32x32セル単位で共有するメモリを使用します。Shared Memoryを使用しないと、1つのセルの計算に対して、Global MemoryへのReadが9回、結果のWriteが1回発生します。
一方、Shared Memoryを使用すると、Global MemoryへのReadは1回だけになります。この1回でまずGlobal Memory -> Shared Memoryへコピーして、計算時にはコピーしたShared MemoryのデータをReadします。これによって、Global Memoryへのアクセス回数を減らして、高速化を狙います。Shared Memoryを使うには、カーネル関数内で
__shared__キーワードを付けた領域(配列)を宣言します。ALGORITHM_2_STREAM: Shared Memory + Stream
先ほどのデータフローの所で説明した通り、基本的には以下の流れで処理が進みます。
- Host -> Device(GPU) へのデータコピー
- GPU側で計算
- Device(GPU) -> Host へのデータコピー
何も考えずに実装すると、上記のフローはシーケンシャルに実行されます。
Streamでは、これらの操作を非同期に実行し、パイプライン化して処理を並列化させます。パイプライン化する粒度として、フレーム単位でやるのが一般的だと思います。例えば、
n-1フレーム目のcalculation中に、nフレーム目のデータ転送をする、など。
今回は簡単のために、1枚のフレームを、横長の長方形に8等分して、各エリアのデータ転送、計算、データ転送をStream化しました。Streamを使うには、
cudaStreamCreateで生成したstreamに対して、cudaMemcpyAsyncを設定することで非同期に処理を進めてくれます。(同じstream内での操作順序は維持してくれます)ALGORITHM_3_STREAM: Shared Memory + Stream + host2deviceコピー抑制
この方法はライフゲームだから適用できる手段です。
繰り返しになりますが、基本的には以下の流れで処理が進みます。
- Host -> Device(GPU) へのデータコピー
- GPU側で計算
- Device(GPU) -> Host へのデータコピー
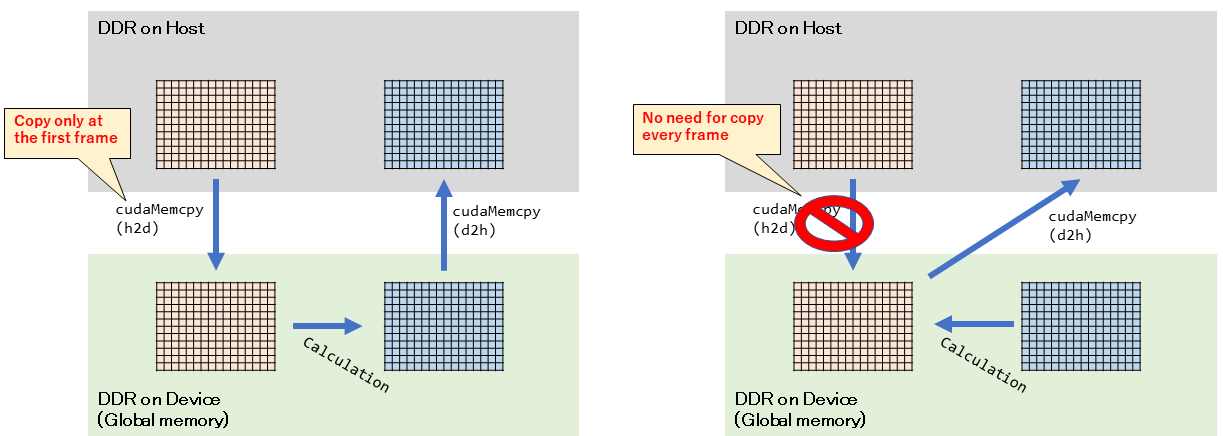
ここで、1番の「Host -> Device(GPU) へのデータコピー」は不要なのではないかと考えました。
nフレーム目の入力画像は、n-1フレーム目の出力であり、そのデータは既にデバイス側メモリにあるのだから、それをそのまま使います。その結果、1番の「Host -> Device(GPU) へのデータコピー」は不要になります。1番の「Host -> Device(GPU) へのデータコピー」は、一番最初と、ユーザが操作してセルの配置状態を変更した時だけ行います。
ALGORITHM_3_REPEAT: Shared Memory + Stream + host2deviceコピー抑制 + device2hostコピースキップ
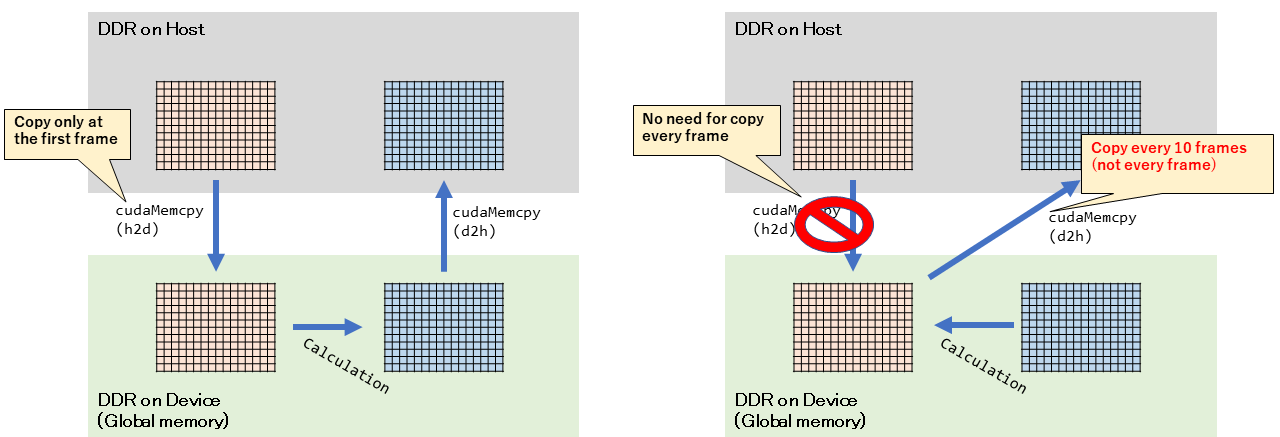
先ほどの続きで、そもそも結果の出力(3番の「Device(GPU) -> Host へのデータコピー」)も毎回やらないでいいんじゃない? という考えです。
例えば、ライフゲームのロジック計算で100GPS出たとしても、描画処理やディスプレイ出力部分で結局60fps程度に抑えられます。であれば、結果出力用のデータ転送は少しくらい間引いても問題ないはずです。
こうすると、Host<->Device間のデータ転送がほとんどなくなります。今回は、10フレーム間隔で間引くことにしました。
※
今回はライフゲームなので結果をそこそこの頻度で取得して表示する必要がありました。
Tensorflow等を用いたDeep Learningの学習は、一度データをDevice側に転送したら学習中はずっとDevice側だけで行い、本当にすべての処理が完了したタイミングでHost側に結果を返すことで、高速実行されているのだと思います。メモリ確保: Pinned Memory
メモリの確保方法でも最適化が出来ます。
左上の図は最初に説明したものと同じです。Host側のCアプリケーションでnew/allocすると、その領域はDDR上のPageable memoryとして確保されます。しかし、これだとDeviceへの転送に使えないため、暗黙的にNon-pageable memoryにコピーされます。これが無駄です。
コピーされるくらいなら、最初からNon-pageable memoryとして確保すればいいじゃない、という考えです。これを、Pinned Memoryというようです。
Pinned Memoryとして領域を確保するには、
cudaMallocHostを使用します。デメリットとしては、一般に論理アドレス導入によってもたらされる恩恵が無くなる点があります。Pinned Memoryとして領域確保すると、実アドレス空間がそれだけ占有されます。とはいえ、これは今の時代そんなに大きなデメリットではないかと思います。
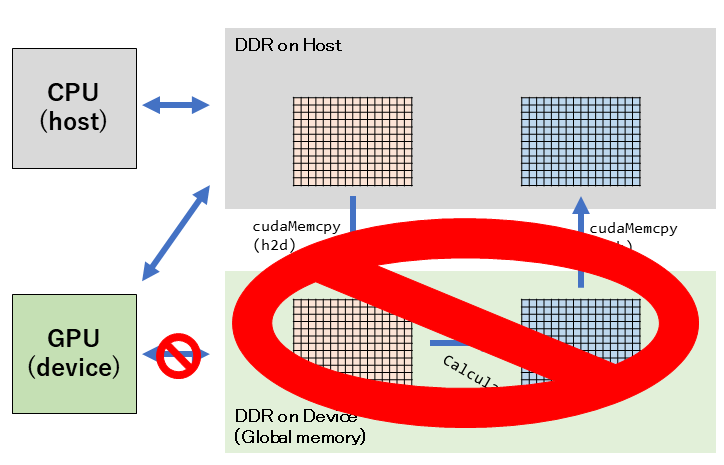
メモリ確保: Zero Copy Memory
これまで教科書通りに、Host->Deviceへデータ転送して、GPU側はDeviceメモリに対してアクセスをするようにしていました。しかし、実はGPUはHostメモリに対してもアクセス可能です。
こうすることで、Host<->Deviceのデータ転送が不要になります(Zero Copy)。
一方、GPUがHostメモリにアクセスするコストが大きい場合、計算途中のレイテンシも非常に大きくなってしまい、結果としてパフォーマンスが低下します。一般に、PCの場合は、GPUとHostメモリはPCIeでつながっているため遅いです。ハイスペックなPCIe3.0 x 16でも16GByte/sであり、GTX 1070のVRAM帯域256GByte/sに比べるとはるかに遅いです。
一方で、Jetson Nanoの場合は、共有メモリなので、実はデメリットはないのではないかな? と思っています。これについてはこれから結果を見ていきたいと思います。Zero Copy Memoryを使うには、ホストメモリを
cudaHostAllocMappedフラグを付けて取得して、cudaHostGetDevicePointerでデバイス側からアクセスできるポインタを取得します。結果
GTX 1070 (PC)
画面サイズは8192x8192
Generation Per Second Normal Pinned Memory Zero Copy Memory ALGORITHM_0 Normal without padding 8.5 20 2.8 ALGORITHM_1 Normal 8.4 20.8 2.3 ALGORITHM_2 Shared Memory 8.5 21.7 7.3 ALGORITHM_2_STREAM Shared Memory + Stream 8.5 29.4 7.3 ALGORITHM_3_STREAM Shared Memory+ Stream+ No Copy(h2d) unless update 16.3 43.5 7.3 ALGORITHM_3_REPEAT Shared Memory+ No Copy(h2d) unless update+ No Copy(d2h) while skipping (10 times) 100 150 9.4 まずは列方向に結果を見てみます。Pinnec Memoryを使うことで、全体的にパフォーマンスが向上しています。一方、Zero Copy Memoryを使うと、非常に遅くなっています。使用するアルゴリズムに依らず遅くなっていることから、GPU-Host間のMemory転送がボトルネックになっているのだと思われます。
次に、アルゴリズムの違いによる結果を見てみます。
まず、境界チェックではあまり違いはありませんでした。むしろ少し遅くなってる???。パディング領域を作るためのデータ転送が遅いのが原因かもしれません。
Shared Memoryも、高速化にはあまり貢献していないように見えます。ただ、Zero Copy Memoryのケースでは明らかに改善しているので、実装を間違えているとかではないようです。GTX1070ではGlobal Memoryがそんなに遅くないのかもしれません。そのため、Shared Memoryにしてもあまり変化がなかったのではないかと考えています。これなら、Zero Copy Memory(ホストメモリ)のケースで速くなっていることも納得です。イメージ的には、Shared Memory >= Global Memory >>> Host Memory といった感じでしょうか? あくまで今回の測定結果からですが。
Stream化することで、さらに高速化することが出来ています。効果があるのはPinned Memoryを使ったケースだけなのですが、おそらく他のケースではメモリ転送時間が支配的で効果が実感できないのだと思われます。
ALGORITHM_3_STREAM(ホストメモリからデバイスメモリへの転送をしない)では、明らかに高速化しています。Normal(Pinned Memoryを使わない)のケースで約2倍になっていることから、メモリ転送時間がほぼ全体の処理時間を占めていることが分かります。(h2dで50%、d2hで50%)。Pinned Memoryを使用するケースでもかなりの改善が見られました。一方、Zero Copy Memoryのケースでは変化有りませんでした。これは、Zero Copy Memoryではそもそも転送がされないためです。
最後のALGORITHM_3_REPEATは、デバイスメモリからホストメモリへの転送間隔が1/10に間引かれたのでさらに高速化しています。Jetson Nano
画面サイズは4096x4096
Generation Per Second Normal Pinned Memory Zero Copy Memory ALGORITHM_0 Normal without padding 7.6 13 8.4 ALGORITHM_1 Normal 8.2 17 4.0 ALGORITHM_2 Shared Memory 9.6 27 33 ALGORITHM_2_STREAM Shared Memory + Stream 6.4 22 31 ALGORITHM_3_STREAM Shared Memory+ Stream+ No Copy(h2d) unless update 12 36 32 ALGORITHM_3_REPEAT Shared Memory+ No Copy(h2d) unless update+ No Copy(d2h) while skipping (10 times) 38 45 33 Jetson Nanoの結果はPCと異なるところが多々あります。
ALGORITHM_0/1 境界チェック処理の有無ですが、結局は以下2つの処理のどちらが遅いか、ということだと思います。
- 全セルの処理時に境界チェック(if文)をする
- 処理の最初にパディング領域を作る
これを考えると、メモリアクセスが遅いZero Copy MemoryのケースでALGORITHM_1(パディング領域作成)が大幅に遅くなっているのは納得がいきます。
NormalとPinned Memoryのケースでは、PCでは差はなかったのですが、Jetson Nanoでは少し高速化しています。これは、Jetson NanoのGPU計算能力がGTXに比べて低いため、if文ロジックを大量に行うよりも、一度パディング領域を作る方が速度的に有利になったのだと思われます。次にShared Memoryです。Normal、Pinned Memoryどちらも高速化しています。また、改善幅はPCよりも大きいです。これは、Jetson NanoではShared MemoryはGlobal Memoryに比べてだいぶ速いといことなんだと思います。というよりも、Global Memoryが遅いという方が正しいかもしれません。これは、共有VRAMだからではないかと思います。この共有VRAMは、次のZero Copy Memoryの結果にも影響します。Zero Copy Memoryでは33GPSにまで高速化され、この3つの中では一番速いです。
この結果の受け止め方ですが、Jetson NanoではVRAMが共有ということを思い出す必要があります。そのため、GPUのGlobal Memory = ホストメモリとなります。Pinned Memoryを使い、いつも通りcudaMemcpyでh2d,d2hとコピーしても物理的に同じメモリ上でコピーしているだけなので、メリットはありません。むしろ無駄です。Zero Copy Memory使用時にはこのコピー処理が不要になるため、最も速くなったのだと思われます。次のStreamの結果はいずれも遅くなってしまっています。なぜだか理由がさっぱり分かりません。
想像ですが、バスが非常に混んでしまうせいではないかと疑っています。ホストとデバイスでメモリが分かれているPCでは転送とGPU計算がStreamによってパイプライン化され並列実行しても、リソースの競合は起きずらいと思います。しかし、共有VRAMであるJetson Nanoでは、メモリ転送でも計算時でも、物理的に同じメモリアクセスが起きます。そこが混雑しているのではないかな~と思っています。ALGORITHM_3_STREAM, REPEATを用いることで、Normal、Pinned Memoryどちらもさらに高速化されます。これは、データ転送回数が減るので当然の結果ですね。一方、Zero Copy Memoryのケースでは変化有りませんでした。これは、Zero Copy Memoryではそもそも転送がされないためです。
ただ、ここで気になったのが、NormalとPinned Memoryの速度がZero Copyの速度を上回ることです。結局データ転送時間が支配的で、メモリアクセス時間は変わらないのだから、データ転送を行わないZero Copy Memoryの31GPS付近が上限になると思っていました。しかし、実際にはZeroCopyMemoryの速度を超えています。Zero Copy Memoryだと何らかのオーバーヘッドがついてくるのかもしれません。
(キャッシュのコヒーレンシ保つために毎回キャッシュクリアしてるとか? でもそれならPinned-memoryも同じか。。。というか、CPU側ってどうやってキャッシュコヒーレンシ保ってるんだろう。dirty bitが立つのかな。。。ということは、Zero CopyだとGPUが処理するたびにDirty bitが立つからキャッシュヒット率が落ちるということ? 一方、Pinned memoryだとmemcpyしたときだけDirby bitが立つからそこまでヒット率は落ちないとか。 であればこの結果も納得。)PCとJetson Nanoを比較すると、色々と異なる部分はありましたが、どちらもALGORITHM_3_STREAM + Pinned Memory が最速でした。先ほどの表・グラフ内の「CUDA + Optimization」はこの結果です。
(ALGORITHM_3_REPEATは、反則的なので除く)おわりに
残った謎
- Jetson Nanoだとプログラム全体の動きが遅い。例えば8192x8192だとライフゲームの計算が36GPS、描画が20fps程度だったので1 / (1/36+1/20) = 12.8fps程度は全体で出るはず。なのに、実際の動作だと明らかに遅くカクついているように見える。どこかでストールしているのか、freeglutのメインループ処理が回っていないっぽい
- Pinned MemoryやZero Copy Memoryで、GPUが書き込んだ場合、キャッシュコヒーレンシはどうやって保たれるのだろうか。
- PC(GTX1070) でShared Memoryを使用した実装で、あまり高速化されなかった。バンク衝突とかが起きているのかな? それとも、単にGlobal Memoryが十分速いからShared Memoryの効果を感じられないだけ?
- Jetson NanoでStreamを使用した実装で、速度が低下した
まとめ
- マルチプラットフォームで動くライフゲームプロジェクトを作りました
- Open MPやCUDAを使って高速化しました
- 動作をPC, Jetson Nanoで比較しました
- CUDAの実装最適化の結果は、PCとJetsonNanoで異なることが分かりました。また、別のシステム/アーキテクチャでは、別の結果になりそうです
- 最適化実装には一つの正解があるものではないので、システム構成や状況を見て、都度検討が必要そうです
- 投稿日:2019-05-12T06:50:52+09:00
Conoha VPS + VSCodeでSSH Remote開発
はじめに
2019/5/2 に MicrosoftによりRemote機能の追加がアナウンスされました。
2019/5/12 現在ではInsiders版のみでのリリースとなっており、現在VSCodeを使っている方でも別途Insiders版のインストールが必要になります。リリース詳細
https://code.visualstudio.com/blogs/2019/05/02/remote-developmentこちらの記事にも詳しい使用方法が書かれています(英文)
https://devblogs.microsoft.com/python/remote-python-development-in-visual-studio-code/何ができるようになったの?
VSCodeの拡張機能によって、開発環境やツールをリモート環境内で利用できるようになりました。簡単に言えば、ローカルでプログラミング環境を構築せずとも用意したホストに接続することで、VSCodeさえローカルにインストールされていれば開発が可能になったということです。接続環境は以下の三つが利用可能なようです。
・Remote-Containers (Docker)
・SSH
・Remote-WSL何が嬉しいの?
例えばPythonで書かれたプログラムを開発するとき、私は現在複数のPCと1つのスマートフォンを所持していて、それぞれのコンピュータでデバッグを行うには全てにプログラミング環境を用意する必要があります。しかもそれぞれインストールされているOSもWindowsだったりUbuntuだったりDebianだったりと全然違います。それぞれの環境ごとにプログラミング環境を構築するのは大変手間な上ストレージ容量も大きく食ってしまうので、帰省中にちょっとしたテストを行うといったことが簡単にできない状況でした。この拡張機能を使えば、インターネット環境とVSCodeさえインストールしてしまえばどこでもどんな環境でもデバッグを行うことができるので便利!ということです。
他にも、Hugoのような静的サイトジェネレータを使うとき、ちょっとした更新を行う際にも毎回GitHubからクローンしてそれを編集してプッシュして…といった作業の手間が軽くなるといった使い方も便利そうです。方針
Remote機能を利用するためには接続先となるホスト環境が必要です。自宅のサーバに接続したりAWS等のクラウドを使ったりといったことが考えられますが、とりあえず今回はVPS+SSH接続を利用してテストを行うことにしました。ただ、Docker環境での使用がおそらくRemote開発の利点を最も活かせると思います(またトライします)。
VPS業者はいろいろありますが、今回は
・時間課金制である
・クラウドライクにスペック変更が容易にできる
・慣れている
というアドバンテージからConoha VPS( https://www.conoha.jp/vps/?btn_id=top_vps )を選択しました。クラウド慣れしている人ならAWSやAzureあたりから選択した方がいいかもしれません。用意するもの
・Conoha VPS
・VSCode Insiders
・インターネット接続VSCode Insidersは以下のURLよりローカルPCにインストールしておいてください。
https://code.visualstudio.com/insiders/VPS環境を構築する
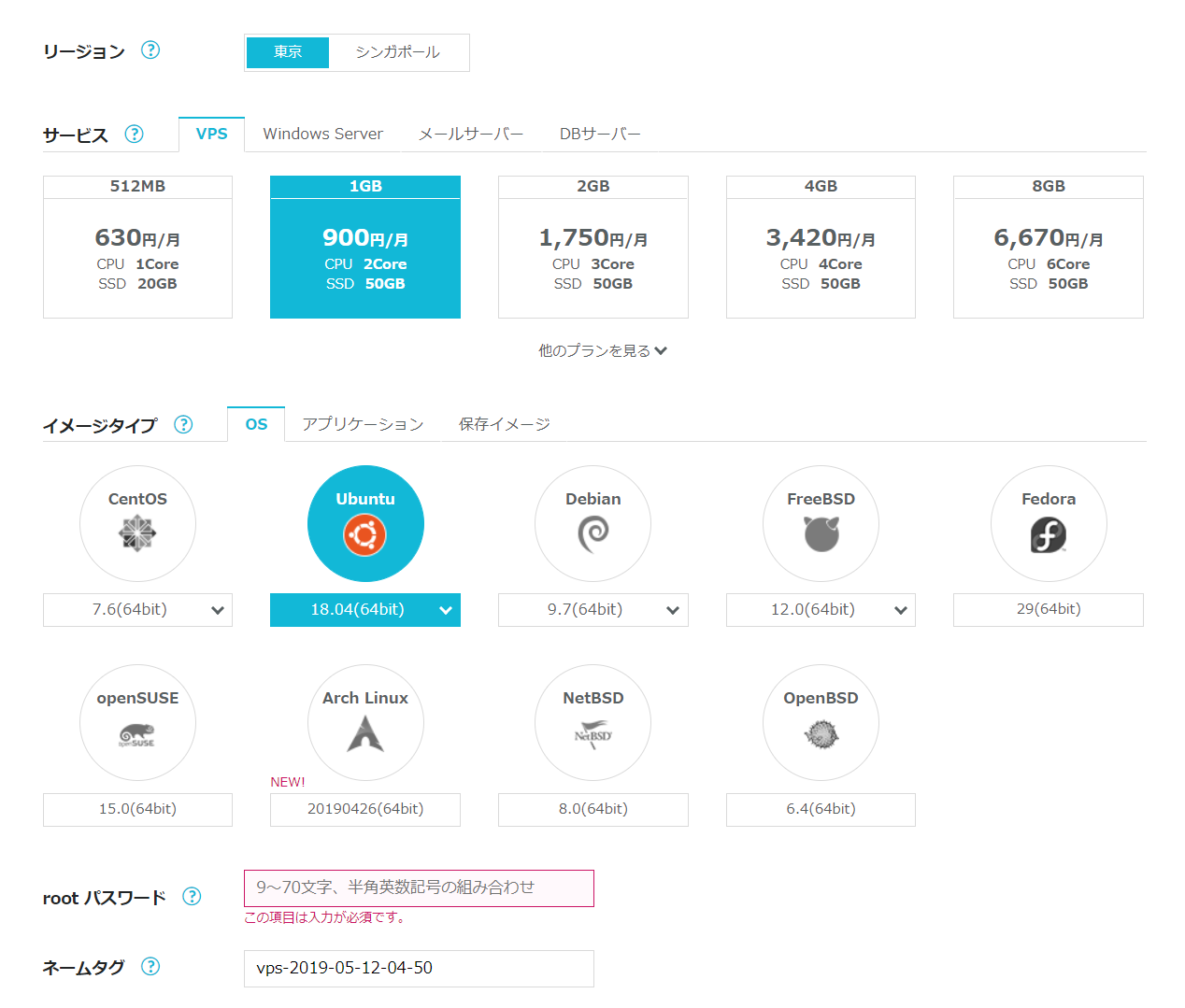
Conohaの公式サイト https://www.conoha.jp/vps/?btn_id=top_vps よりアカウントを取得します。左上のサーバ追加パネルから利用する環境を選択します。私は以下のように構築しました。
メモリ容量はテストであれば512MBで十分かと思いますが、Conohaの仕様上1GBメモリ以上でないとサーバスペックの変更ができないので、1GBを選択。
OSはDebianと悩みましたが、とりあえず簡単さを求めUbuntuを選択。CentOSもよさそうです。サーバの情報が表示されますので、IPアドレス等の情報を控えます。
サーバを立てることができたら、Webコンソールなどのターミナルより
apt update
をとりあえず実行。
また、最初はrootでログインすることになると思うので、ユーザーを追加します。
adduser ユーザー名Enter new UNIX password: # パスワード Retype new UNIX password: # パスワード(確認) passwd: password updated successfully Changing the user information for user_name Enter the new value, or press ENTER for the default Full Name []: # 全部空欄でOKです Room Number []: Work Phone []: Home Phone []: Other []: Is the information correct? [Y/n] Y # Yessudo権限も追加。
gpasswd -a ユーザー名 sudo公開鍵認証を行う
SSHでRemote開発を行うためには公開鍵認証が必要です。ここでハマりました。
まずはVPS側で鍵を作成します
mkdir ~/.ssh cd ~/.ssh/ ssh-keygen -t rsa conoha_rsaここでパスフレーズの設定が要求されますが、パスワードを設定するとVSCodeからSSH接続ができません
パスワードは空欄にして、公開鍵を生成します。
/.ssh/ディレクトリにconoha_rsa(秘密鍵)とconoha_rsa.pub(公開鍵)が生成されたかと思います。
公開鍵を登録
cat conoha_rsa.pub >> ~/.ssh/authorized_keys
生成したconoha_rsaとconoha_rsa.pubをローカルPCに転送します。転送方法は色々ありますが、viなどのエディタを利用しコピペでローカルのテキストファイルにはっつけるのが一番楽かと思います。
コピーが完了したら、VPS内の鍵ファイルは削除してかまいません。VSCode側の設定
先ほどローカルに転送してきた秘密鍵ファイル(conoha_rsa)を
C:\Users\ユーザー名\.sshに転送します。場所はどこでも構いませんが権限によるエラーが多発するので素直にここに置くのが良いです。VSCode Insiders を起動し、拡張機能をインストールします。
これです。インストールができたら、SSH-remoteの設定ファイルを書き換えます。
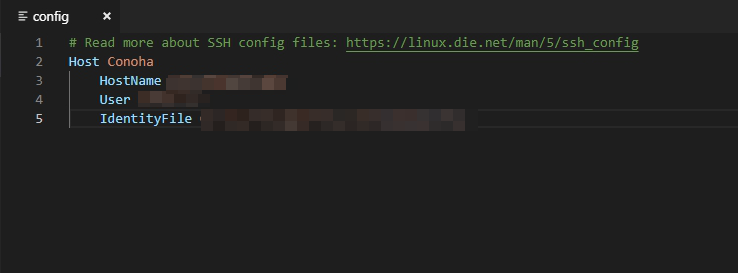
F1を押し、Remote-SSH: Open Configuration File…から開きます。
Hostは好きな名前を
HostnameにはVPSのIPアドレス
UserにはVPS内で作成したユーザー名
IdentityFileには作成した秘密鍵のパスを指定します、今回の例ではC:\Users\ユーザー名\.ssh\conoha_rsaとなります。
以上の設定を保存しF1を押してRemote-SSH: Connect to Hostから接続すると…
起動!やったぜ!
拡張機能もリモート環境にインストールしていくことができます。
とりあえずVPSにPythonをインストールし、簡単なプログラムを実行してみました。
想像以上にリモートであることを意識せずに開発ができています。
まとめ
これまでにもクラウド開発環境としてCodeanywhereやCoderなどがありましたが、VSCodeのリモート対応によりますます開発のクラウド化が進んでいくと思います。リモートホストを自分で用意しないといけない部分はややハードルが高いですが、トライする価値は十分にありそうです。何よりローカルPCにはVSCodeを入れるだけで何とかなってしまうというのが良いです。
VPSを利用した運用では重い処理は無理ですが、簡単なプログラムやシームレスな更新が必要になるソフトの開発にはよく適合するかと思います。正規版のリリースが楽しみですね。
- 投稿日:2019-05-12T01:33:03+09:00
Linuxでのファイルやフォルダを検索
findコマンドで検索
検索コマンドは指定のパスでexpressionを指定してマッチしたものを検索できる。引数を渡さない場合は、全てのファイルが現ディレクトリーで検索される。
find [path...] [expression]optionとしては
-name pattern #パターンで指定して検索 find /bin -name *v find . -name s* -ls -iname pattern #大小文字関係なく検索 -ls #見つかった項目をlsしてくれる。 -mtiime days #古い順からファイルを検索 find . -mtime +10 -mtime -15 -size num #サイズ順でファイルを検索 find . -size +1G -newer file #新しい順からファイルを検索 find . -typed d -newer sample.txt -exec command {} \; #検索した全ファイルに対してコマンドを実行locateを使うと
locate pattern
マッチした条件のファイルを一覧。findより早く、クエリーをindexするが、結果はリアルタイムではないので直近のものは表示しない可能性ある。全てのシステムで動くわけではない。初めてlocateを実行すると、下記が表示されるので、そのまま書いてある通りにコマンドを実行しておく。
WARNING: The locate database (/var/db/locate.database) does not exist. To create the database, run the following command: sudo launchctl load -w /System/Library/LaunchDaemons/com.apple.locate.plist Please be aware that the database can take some time to generate; once the database has been created, this message will no longer appear.データベース作成には少し時間がかかるので、待てない場合は、下記を実行。それでも時間がかかる。
sudo /usr/libexec/locate.updatedb実行すると検索ができる。
$locate name ... /usr/share/man/man1/uname.1 /usr/share/man/man1/uuname.1 /usr/share/man/man4/fsnameservers.4 /usr/share/man/man7/hostname.7 /usr/share/man/mann/filename.ntcl /usr/share/man/mann/namespace.ntcl /usr/share/man/mann/namespacex.n /usr/share/man/mann/rename.ntcl ...かなり早い。
findやlocate等の違いなどは、下記の記事が参考になりました。
Mac/Linuxの「locate」コマンドで高速ファイル検索|「find」コマンドとの違いから「mdfind」の紹介まで
- 投稿日:2019-05-12T01:33:03+09:00
Linuxdファイルやフォルダを検索
findコマンドで検索
検索コマンドは指定のパスでexpressionを指定してマッチしたものを検索できる。引数を渡さない場合は、全てのファイルが現ディレクトリーで検索される。
find [path...] [expression]optionとしては
-name pattern #パターンで指定して検索 find /bin -name *v find . -name s* -ls -iname pattern #大小文字関係なく検索 -ls #見つかった項目をlsしてくれる。 -mtiime days #古い順からファイルを検索 find . -mtime +10 -mtime -15 -size num #サイズ順でファイルを検索 find . -size +1G -newer file #新しい順からファイルを検索 find . -typed d -newer sample.txt -exec command {} \; #検索した全ファイルに対してコマンドを実行locateを使うと
locate pattern
マッチした条件のファイルを一覧。findより早く、クエリーをindexするが、結果はリアルタイムではないので直近のものは表示しない可能性ある。全てのシステムで動くわけではない。初めてlocateを実行すると、下記が表示されるので、そのまま書いてある通りにコマンドを実行しておく。
WARNING: The locate database (/var/db/locate.database) does not exist. To create the database, run the following command: sudo launchctl load -w /System/Library/LaunchDaemons/com.apple.locate.plist Please be aware that the database can take some time to generate; once the database has been created, this message will no longer appear.データベース作成には少し時間がかかるので、待てない場合は、下記を実行。それでも時間がかかる。
sudo /usr/libexec/locate.updatedb実行すると検索ができる。
$locate name ... /usr/share/man/man1/uname.1 /usr/share/man/man1/uuname.1 /usr/share/man/man4/fsnameservers.4 /usr/share/man/man7/hostname.7 /usr/share/man/mann/filename.ntcl /usr/share/man/mann/namespace.ntcl /usr/share/man/mann/namespacex.n /usr/share/man/mann/rename.ntcl ...かなり早い。
findやlocate等の違いなどは、下記の記事が参考になりました。
Mac/Linuxの「locate」コマンドで高速ファイル検索|「find」コマンドとの違いから「mdfind」の紹介まで
- 投稿日:2019-05-12T00:57:19+09:00
Linuxでファイルを触る
Linuxでファイルを閲覧、編集するときに使うコマンド
cat filename #ファイルの内容を表示 more filename #テキストファイルを見る less filename #他の機能を head filename #ファイルの最初部分だけを確認(10行 tail filename #ファイルの最後部分だけを確認(10行変更が多く走るファイルもの、例えばログファイルなどを見るときは、
tail -f filename
でリアルタイムのようなものをみられる。
cat filename
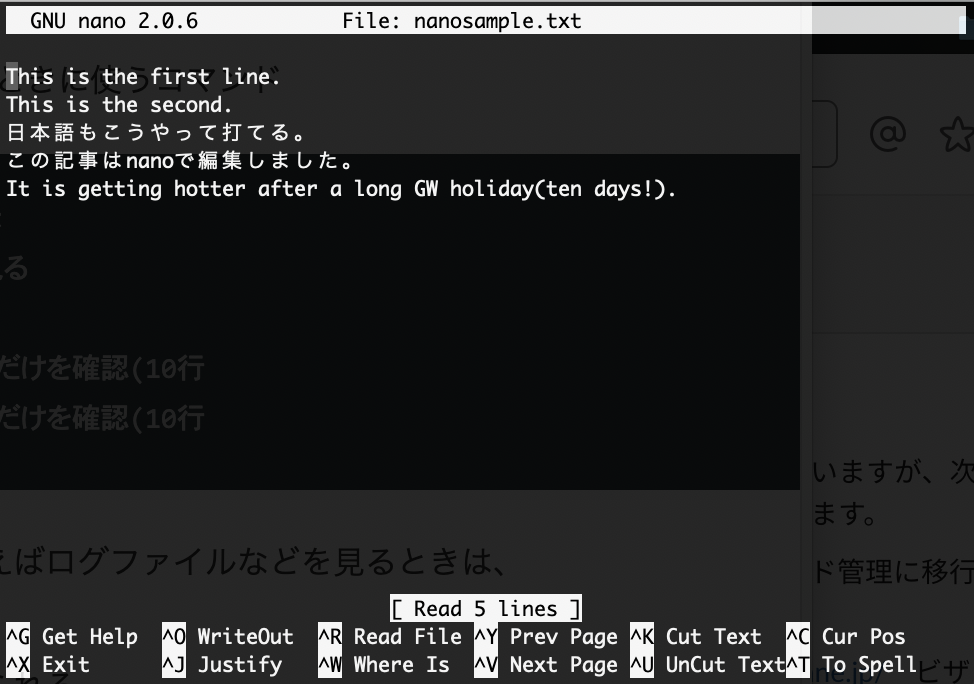
catコマンドを実行するとファイルが多すぎる場合、[enter]を押してファイルを1行ごとにスクロールできる。[q]でcatを終了できる。それが面倒なときは、tail -f filenameで自動スクロールできる。Nano editerを使ってみる。
他にも便利な編集ツールがあるが、nanoはとてもシンプル。
nano filename
画面下に編集コマンドがあるので便利。nano nanosample.txt
保存は[control]+O。Enterで。[control]+Xで終了できる。
より便利な編集ツール、VIを使う。
コマンドは
vi filename #ファイルを編集 vim filname #ファイルをより機能をもって編集 view filname #viのread-onlyのみいくつかNavigationがある。
k #一行上へ j #一行下へ h #一文字左へ l #一文字右へ w #一単語右へ b #一単語左へ ^ #最初の行へ $ #最後の行へ #挿入モード i #行の挿入 I #行の最初に挿入 a #カーソルの後から編集 A #行の最後から編集 #Vi行モード :w #ファイルを保存 :w! #ファイルを強制的に保存 :q #中止 :q! #強制的に中止 :wq! #保存して保存 :x #:wqと同じ(じゃあなんであるんや。。) #text削除 x #文字削除 dw #単語削除 dd #行を削除 D #現在の位置から削除 #text変更 r #現文字を差し替え cw #現単語を変更 cc #現行を変更 c$ #現在の一からテキストを変更 C #c$と同じ ~ #文字の小文字大文字を差し替える #コピペ yy #現行をコピ y<位置> #<位置>をコピ p #直近で切り取りした/コピーしたテキストをペースト #Undo / Redo u #Undo [ctrl}+R #Redo #検索 /<パターン> #フォアワード検索開始 ?<パターン> #リバース検索開始他にも
:n、:$、:set nu、:set nonu、:helpなどがある。まとめとしては
[Esc]で戻り、i, I, a, Aで挿入、:で行モード繰り返しのコマンドもある。
10kとやれば10行分上にいくし、100iとやれば、で指定したテキストが100回繰り返して挿入されるし、100i_で"_"にはいる文字が挿入される。その他わからないことは
vimtutor
でガイドを読み込む。Viの代わりとしてはEmacsがあるが、それは気が向いたら記事を書く。
グラフィック編集ツールは
emacs、gedit、gvim、keditなどがある。MS文書系とかはAbiWord, LibreOffice, Kateなどがある。
デフォルトで入っているものも多くある。