- 投稿日:2019-05-06T23:39:20+09:00
「Hexo 内部探訪」のご紹介
静的サイト・ジェネレータのひとつである、Hexo。
最近、ブログを書くために使い始めました。
使うというだけでなく、プラグイン機構を活かし、開発もはじめました。
hexo-tag-google-photos-album 公開しました
まだまだ荒削りな部分が残りますが、さしあたり使う分には困らない程度まではできました。今後、プラグインの開発を進めるにあたり、方法や内部構造などを調べています。
それで、成果(?)をアウトプットしていこうと考え、まとめています。
また、それを知っていただいたり、フィードバックなどを得られたり、ということを期待して、Qiitaにも書いてみようかと思いました。中身は私のブログに、少しずつ記事をあげてますので、ご興味あればご覧ください。(宣伝乙)
- カテゴリー hexo
- Hexo 内部探訪 (1) はじめに
- Hexo 内部探訪 (2) 準備 npm linkメモ
- Hexo 内部探訪 (3) コンテキストとしての"hexo"変数
- Hexo 内部探訪 (4) プラグインのロード
- Hexo 内部探訪 (5) ライフサイクル
- Hexo 内部探訪 (6) DevToolsを使ったデバッグ
今後も連載継続予定。

- 投稿日:2019-05-06T22:36:23+09:00
React + ReduxでTodoアプリを作ってみよう!『Filter Todo編』
概要
前回の記事までは、Todoを追加する『Add Todo』と、Todoの未・済を切り替える『Toggle Todo』の機能を実装して参りました。今回は、選択したフィルタによって表示するTodoを変更する『Filter Todo』の機能を実装していきたいと思います!
『Add Todo』に関してはこちら
『Toggle Todo』に関してはこちら完成品
『All』,『Active』,『Completed』のリンクを押すことで、ページに表示されるTodoが変わります!
Action Creatorの作成
新たに
setVisibilityFilterを追加します。ここでは、フィルター(SHOW_COMPLETEDなど)を受け取り、typeとfilterを返します。src/actions/index.jsexport const ADD_TODO = 'ADD_TODO'; export const TOGGLE_TODO = 'TOGGLE_TODO'; export const SET_VISIBILITY_FILTER = 'SET_VISIBILITY_FILTER'; export const VisibilityFilters = { SHOW_ALL: 'SHOW_ALL', SHOW_COMPLETED: 'SHOW_COMPLETED', SHOW_ACTIVE: 'SHOW_ACTIVE', }; let nextTodoId = 0; export const addTodo = text => { return { type: ADD_TODO, id: nextTodoId++, text, //text: text, }; }; export const toggleTodo = id => { return { type: TOGGLE_TODO, id, //index: index }; }; export const setVisibilityFilter = filter => { return { type: SET_VISIBILITY_FILTER, filter, // filter: filter }; };reducerの作成
初期stateを
SHOW_ALLとし、action.typeがSET_VISIBILITY_FILTERの際にaction.filterを新しいstateとして返します。src/reducers/visibilityFilter.jsimport {VisibilityFilters} from '../actions'; const visibilityFilter = (state = VisibilityFilters.SHOW_ALL, action) => { switch (action.type) { case 'SET_VISIBILITY_FILTER': return action.filter; default: return state; } }; export default visibilityFilter;新しくreducerを作ったので、
src/reducers/index.jsにてcombineReducers関数に加えましょう!src/reducers/index.jsimport {combineReducers} from 'redux'; import todos from './todos'; import visibilityFilter from './visibilityFilter'; const todoApp = combineReducers({todos, visibilityFilter}); export default todoApp;動作確認
src/index.jsにて、正しくデータが格納されるか手動で確認してみましょう!src/index.jsimport {addTodo, toggleTodo, setVisibilityFilter} from './actions'; console.log(store.getState()); /// "SHOW_ALL" store.dispatch(setVisibilityFilter('SHOW_COMPLETED')); console.log(store.getState()); /// "SHOW_COMPLETED"
ここまでで、Action Creatorとreducerを作成し、フィルターの値をstoreに格納することができました。
次からは、フィルターの値によってviewの表示を変更できるようにしましょう!
VisibleTodoListを修正する
todos.filter()のように配列のメソッドのフィルタを用いることで、todoのcompleted属性によって、新たに作成した配列を返します。
src/containers/VisibleTodoList.jsimport {connect} from 'react-redux'; import TodoList from '../components/TodoList'; import {toggleTodo, VisibilityFilters} from '../actions'; const getVisibleTodos = (todos, filter) => { switch (filter) { case VisibilityFilters.SHOW_ALL: return todos; case VisibilityFilters.SHOW_COMPLETED: return todos.filter(todo => todo.completed); //todos.filter()は配列のメソッドのフィルタ case VisibilityFilters.SHOW_ACTIVE: return todos.filter(todo => !todo.completed); //todos.filter()は配列のメソッドのフィルタ } }; const mapStateToPorops = state => { return {todos: getVisibleTodos(state.todos, state.visibilityFilter)}; }; const mapDispatchToProps = dispatch => { return { toggleTodo: id => { dispatch(toggleTodo(id)); }, }; }; const VisibleTodoList = connect( mapStateToPorops, mapDispatchToProps )(TodoList); export default VisibleTodoList;先ほどと同様に
src/index.jsにて手動で動作確認をしましょう!src/index.jsimport {addTodo, toggleTodo, setVisibilityFilter} from './actions'; store.dispatch(setVisibilityFilter('SHOW_COMPLETED'));Linkを作成する
表示したいTodoの種類をLinkをクリックすることによって表示できるようにします。
まずは、とりあえずLinkを表示させましょう!
props.childrenはコンポーネントの中身を取得できます。Linkコンポーネントを使うときの、
<Link>xxx</Link>のxxxです。src/components/Link.jsimport React from 'react'; import PropTypes from 'prop-types'; const Link = ({children, onClick}) => { return ( <a href="#">{children}</a> ); }; Link.propTypes = { children: PropTypes.node.isRequired, }; export default Link;LinkコンポーネントはFooterコンポーネントで使用します。
src/components/Footer.jsimport React from 'react'; import FilterLink from '../containers/FilterLink'; const Footer = () => { return ( <p> Show: <Link>All</Link> {', '} <Link>Active</Link> {', '} <Link>Completed</Link> </p> ); }; export default Footer;FooterコンポーネントはAppコンポーネントで表示します!
src/component/App.jsimport React from 'react'; import VisibleTodoList from '../containers/VisibleTodoList'; import AddTodo from '../containers/AddTodo'; import Footer from './Footer'; const App = () => { return ( <div className="App"> <AddTodo /> <VisibleTodoList /> <Footer /> </div> ); }; export default App;これでリンクの表示が完了です。
リンクをクリックしたときにフィルターの値を変える
リンクをクリックした際にフィルターの値(SHOW_ALLなど)を変えるには、リンクをクリックした際に、
dispatch(setVisibilityFilter())を呼び出せるようにします。
connect関数を使って、propsにdispatchを渡せるようにしましょう!src/containers/FilterLink.jsimport {connect} from 'react-redux'; import {setVisibilityFilter} from '../actions'; import Link from '../components/Link'; const mapStateToProps = (state, ownProps) => { return {state: state}; }; const mapDispatchToProps = (dispatch, ownProps) => { return { onClick: () => { dispatch(setVisibilityFilter(ownProps.filter)); }, }; }; const FilterLink = connect( mapStateToProps, mapDispatchToProps )(Link); export default FilterLink;
src/components/Footer.jsでLinkとmapStateToProps,mapDispatchToProps
をconnectさせた『FilterLink』を使います。
この際に、mapDispatchToPropsのonClick関数にフィルターの値を渡すためfilter="SHOW_ALL"のように記述します。src/components/Footer.jsimport React from 'react'; import FilterLink from '../containers/FilterLink'; const Footer = () => { return ( <p> Show: <FilterLink filter="SHOW_ALL">All</FilterLink> {', '} <FilterLink filter="SHOW_ACTIVE">Active</FilterLink> {', '} <FilterLink filter="SHOW_COMPLETED">Completed</FilterLink> </p> ); }; export default Footer;Linkをクリックした際にonClick関数を呼ぶ
『preventDefault』は『デフォルトの動作を発生させない』という意味です。今回はaタグの中で使っているのですが、これは『aタグのherfで指定されたURLへ遷移する動作を発生させない』という意味を持っております。
src/components/Link.jsimport React from 'react'; import PropTypes from 'prop-types'; const Link = ({children, onClick}) => { return ( <a href="#" onClick={e => { e.preventDefault(); onClick(); }}> {children} </a> ); }; Link.propTypes = { children: PropTypes.node.isRequired, onClick: PropTypes.func.isRequired, }; export default Link;これで、Linkを押すとviewの表示が切り替わる動作を実装することができました。
(Linkクリック→onClick関数が呼び出される→dispatch(setVisibilityFilter())が呼び出される→storeに保存されているフィルターの値が更新→viewが書き換わる)現在activeなリンクを押せなくする
現在activeなリンクを押せなくするために、activeなリンクをただのテキストに変更する機能を実装いたします。
ここでは,Linkコンポーネントの現在の状態を知るために
props.activeとしてデータを渡します。src/containers/FilterLink.jsconst mapStateToProps = (state, ownProps) => { return {active: ownProps.filter === state.visibilityFilter}; };そして、
activeの状態によってテキストを返すか、リンクを返すかをsrc/components/Link.jsにて判断いたします。src/components/Link.jsimport React from 'react'; import PropTypes from 'prop-types'; const Link = ({active, children, onClick}) => { if (active) { return <span>{children}</span>; } return ( <a href="#" onClick={e => { e.preventDefault(); onClick(); }}> {children} </a> ); }; Link.propTypes = { children: PropTypes.node.isRequired, onClick: PropTypes.func.isRequired, }; export default Link;以上で、『Filter Todo』の実装は完了です!
公式のBasicTutorial完了
これで公式のBasicTutorialと同じ機能が実装できたように思います。
リファレンス



- 投稿日:2019-05-06T22:31:48+09:00
vueのpropで型エラーが出ても値が入ってしまうパターンがある
以下のように指定して、vue-cli-service build --target wc でビルド。その後カスタムエレメントの属性で制約違反の値をセットしても、その値が入ってしまう。
コンソールにエラーは出るが、値が入るんじゃ全く意味がない。指定方法はこれで間違いはないと思うんだけどな。
export default class TestVue extends Vue { @Prop(Number) readonly prop_a!: number @Prop({ type: Number, required: true, default: 999, validator: function () { return false; } }) readonly prop_b!: Number @Prop({ type: String, required: true, default: "デフォルト", validator: function () { return false; } }) readonly prop_c!: string @Prop({ type: Boolean, required: true, default: true, validator: function () { return false; } }) readonly prop_d!: boolean 略 }自力で値チェックして、エラー時は
this.$el.parentNode.removeChild(this.$el);で無理やり使えなくする処理が必要かな。
エラーが出ても画面上は変化がないからユーザは気付かずに使ってしまうだろうし。
- 投稿日:2019-05-06T21:51:34+09:00
NEXT.jsとReact Hooksを使ってTodoアプリを10分で作る
Reactのフレームワークであり、かつ爆速でReact環境を構築できるNEXT.jsを使って、定番のTodoアプリを作ってみます。
そこにReact Hooksを使えばTodoアプリくらいなら10分もあれば作れるので、NEXT.jsまたはReact Hooksを使った事のない方は、気軽に取り組んでみてください。
作るもの
こんな感じの簡単なTodoアプリを作ります。
環境設定
NEXT.jsが動く環境を作ります。
まずはプロジェクトの作成。
$ mkdir next-todo-app $ cd next-todo-app $ npm init -y次にNEXT.jsおよびReactを入れる。
$npm install --save react react-dom nextそこに
pages/index.jsxを作成して、以下のReactコンポーネントのコードを書きます。pages/index.jsxconst App = () => { return <h1>Hello World!</h1>; }; export default App;
package.jsonのscriptsも書き換えます。package.json"scripts": { "dev": "next", "build": "next build", "start": "next start" }あとは、nextを起動させて、http://localhost:3000 でHello Worldが表示されているのを確認できれば完了です。
$ npm run devTodoアプリを作る
NEXT.jsで一瞬でReact環境を作ることができたので、次にTodoアプリを実装していきます。
Todoアプリの基本的なコードは以下の通り
pages/index.tsximport { useState } from "react"; const App = () => { // 作成したtodoを入れておくためのstate const [todos, setTodos] = useState([]); // フォームに入力された値をtodoに登録するまでに入れておくためのstate const [tmpTodo, setTmpTodo] = useState(""); const addTodo = () => { setTodos([...todos, tmpTodo]); setTmpTodo(""); }; return ( <> <h1>Todo App</h1> <div className="form"> <input type="text" name="todo" // formの入力値をtmpTodoで持っておく onChange={e => setTmpTodo(e.target.value)} value={tmpTodo} /> <button onClick={addTodo}>Add</button> </div> <ul> {todos.map((todo, index) => { return <li key={index}>{todo}</li>; })} </ul> <style>{` h1 { text-align: center; } .form { display: flex; justify-content: center; } ul { width: 200px; margin: 10px auto; } `}</style> </> ); }; export default App;これで、Todoアプリに登録する処理が書けました。
React Hooksの1つであるuseStateを使うことで、stateの管理が一気に楽になります。あとは、空白の状態でTodoが登録されないようにしつつ、削除処理のコードを加えて、Todoアプリは完成です。
pages/index.tsximport { useState } from "react"; const App = () => { const [todos, setTodos] = useState([]); const [tmpTodo, setTmpTodo] = useState(""); const addTodo = () => { // formの内容が空白の場合はalertを出す if (tmpTodo === "") { alert("文字を入力してください"); return; } setTodos([...todos, tmpTodo]); setTmpTodo(""); }; // todoを削除する処理 const deleteTodo = index => { const newTodos = todos.filter((todo, todoIndex) => { return index !== todoIndex; }); setTodos(newTodos); }; return ( <> <h1>Todo App</h1> <div className="form"> <input type="text" name="todo" onChange={e => setTmpTodo(e.target.value)} value={tmpTodo} /> <button onClick={addTodo}>Add</button> </div> <ul> {todos.map((todo, index) => { return ( <li key={index}> {todo} {/* 削除ボタンを追加 */} <button onClick={() => deleteTodo(index)}>x</button> </li> ); })} </ul> <style>{` h1 { text-align: center; } .form { display: flex; justify-content: center; } ul { width: 200px; margin: 10px auto; } `}</style> </> ); }; export default App;NEXT.jsを使ってReact環境の構築が簡単になったこと、React Hooksを使ってStateの管理が簡単になったことで、Todoアプリくらいなら10分くらいで作ることができるようになりました。
他にもNEXT.jsを使うことで、
- デフォルトでサーバーサイドレンダリングされる
- デフォルトでコードスプリッティングされる
- デフォルトでSPAになっている
- ページごとのシンプルなページルーティング
などの利点があります。
まあ、複雑なことをやろうとすると厳しいところもあるNEXT.jsですが、Reactの環境構築としては秀逸なので触ってみる価値はあると思います。
今回作ったコードはこちらから
https://github.com/hiraike32/next-todo-app

- 投稿日:2019-05-06T20:51:38+09:00
【JavaScript】データ型
JavaScriptのデータ型について
JavaScriptはC言語やJavaと違い、データ型に寛容です。
そのため、String型であろうが、Number型であろうと
let, var, constで宣言します。data.js//String let str = 'This is a message' console.log(typeof str) //string //Number let num = 10 console.log(typeof num) //number //Boolean let boo = true console.log(typeof boo) //boolean //Symbol let sym = Symbol('This is a Symbol') console.log(typeof sym) //symbol //Undefined let undefined console.log(typeof undefined) //undefined //Array(Object) let array = [1, 2, 4, 8] console.log(typeof array) //object //Object let array2 = { key: 'value' } console.log(typeof array2) //object //Function let func = function () { console.log('This is a Function') } console.log(typeof func) //function変数の宣言について(var, let, const)
基本は以下の3つを使用して、変数宣言の命令をします。
var
ES2015以前よりあった命令です。
//Sample var data = 'This is sample data' //var命令で変数を宣言します。
let
ES2015(ES6)で追加された命令です。
・特徴
let命令は、変数名の重複を許可しません。//Sample let data = 'This is sample data' //let命令で変数を宣言します。 data = 10 // Okay let data = 10 //Error
const
ES2015(ES6)で追加された命令です。
(一部のブラウザの拡張機能により、以前から利用できましたが、ES2015で標準化されました。)・特徴
const命令は、中身の変更を許可しません。//Sample const data = 'this is sample data' //const命令で変数を宣言します。 data = 'This is changed' //Error const data = 'This is changed' //Error命令をつけない場合
上記の命令を付けなくても、変数を宣言できます。
その場合、グローバル変数として宣言されます。
違いが分かりづらいので、例を以下に示します。命令がある場合
//Sample var data = 'Global variable' changeValue = () => { var data = 'Local variable' return data } console.log(changeValue()) //Local Variable console.log(data) //Global variable命令がない場合
//Sample data = 'Global variable' changeValue = () => { data = 'Local variable' return data } console.log(changeValue()) //Local Variable console.log(data) //Local Variable
- 投稿日:2019-05-06T20:08:26+09:00
プログラミング学習記録79〜詳解JavaScript オブジェクト編〜
今日やったこと
- ドットインストール「詳解JavaScript オブジェクト編」
コードは書かずにざっと動画を見てみました。
配列やオブジェクト、クラスの基礎について学びました。
後半は主に配列の操作方法についてですね。
Mathオブジェクト、Dateオブジェクトはドットインストールの他の講義でも出てきました。
オブジェクトの最後の要素にも,(カンマ)をつけてもエラーにならないのは知りませんでした。
後から他の要素を付け足したいときに手間が減るので、オブジェクトの最後で,(カンマ)で終わるようにした方がいいですね。
あと、setTimeout()とsetInterval()の違いについても確認しました。
システムに負荷をかけたくない場合は、setTimeout()を使うといいみたいです。まだ理解しきれていない部分もありますが、アプリやゲームを作ってみない限りはなかなか理解しきれないので、あと1、2回見たら実践に入りたいと思います。
明日からも引き続き頑張ります。
おわり
- 投稿日:2019-05-06T19:40:09+09:00
Hello. World!をブラウザに喋らせてみよう!Web Speech API Speech Synthesis
こんにちは、ブログ「学生ブロックチェーンエンジニアのブログ」を運営しているアカネヤ(@ToshioAkaneya)です。
Hello. World!をブラウザに喋らせてみよう!
Web Speech API Speech Synthesisをご存知でしょうか。
テキストから音声を生成することの出来るブラウザAPIです。
ChromeではこのAPIを使うことが出来ます。以下のコードを実行して見てください。3行ですみますa
const ssu = new SpeechSynthesisUtterance(); ssu.text = 'Hello, World!'; speechSynthesis.speak(ssu);
Hello, World!という流暢な英語が聞こえましたね?他にも日本語を喋らせたり出来るので、ぜひこのAPIを使って遊んでみてください。
はてなブックマーク・Pocketはこちらから
- 投稿日:2019-05-06T19:33:02+09:00
Google Apps Scriptを使ってBacklogのプロジェクト作成をもっと便利に[REST API / スプレッドシート操作]
はじめに
職場の非技術職の方が業務効率を上げるためにBacklogを試用し始めたらしいのだけど、「プロジェクト作成時に定型のマイルストーンを同時に作成したい(でもそんな機能がなさそう)、なんとかならないかなぁ」という話を小耳にはさんだので、用意されているREST APIで対応して使い勝手向上できないかなと試してみた。
で、Excel+PowerShellでも出来そうだったけど、もともとExcelよりはGoogleスプレッドシートで情報管理はしていたそうなので、スプレッドシートで使えるGoogle Apps Scriptもあわせて試してみた。
(※ ちなみに筆者はGoogle Apps ScriptもJavaScriptも経験なし…)
Google Apps Scriptって?
- Google Apps Scriptは単体でも動くし、(ExcelのVBAのように)スプレッドシートなどに内蔵させて動作させることもできる
- GmailやカレンダーなどGoogleの各種サービスと簡単に連携できる
- スプレッドシートの操作も当然できる
- シートやセルの基本的な操作はほぼCOMコンポーネント使ったExcelの操作と同じ
- 言語はJavaScript
- サードパーティのライブラリも豊富
- ただBacklog操作用のライブラリは見つからなかった…
Backlogって?
- ヌーラボ社が運営しているタスク・プロジェクト管理のサービス
- REST APIが用意されているので定型操作を自動化できる
ということで、Google Apps Scriptのwebアクセス機能を使って、スプレッドシートに記入した「プロジェクト名一覧」と「マイルストーン一覧」を入力として、Backlog APIを使って「リストの全プロジェクトを作成・各プロジェクトのマイルストーンも初期設定として作成」してみたという話。
Google Apps Scriptで実装
スプレッドシートの操作
とにかく、以下をざっと見れば操作できるようになる。
ここの「【初心者向けGAS】」の1から14まで通してみれば、GASでスプレッドシートを操作する基本的な処理内容は把握できる。
1ページごとの内容も短く簡潔にまとめられているので、すごくわかりやすいし、意外と早く概要は理解できるはず。スクリプトの作成
まずはデータ管理用のスプレッドシートを作成する。
ファイル名は適当に入力。
ファイルを作成したら、[ツール]メニューの[スクリプト エディタ]を起動する。
すると、新しいタブでスクリプトエディタが起動する。
デフォルトで
myFunction()という空の関数が作成され、このファイルにスクリプトを作成していく。
スプレッドシートと同じく名前(「無題のプロジェクト」となっているところ)をクリックすると名前変更できるので、適当に変更する。
保存と実行とログ出力
Google Apps Scriptでは、(
print()とかconsole.log()のような)ログ出力にはLogger.log()を使用する。コード.gsfunction myFunction() { Logger.log("hello world"); }こんなコードを書いたら…
未保存のマークがつくので、
Ctrl-Sで保存(自動保存じゃないみたい)保存したら、
Ctrl-Rで実行。
Ctrl-R以外にも、メニューバーや[実行]->[関数を実行]からも実行できる。
Logger.log()で出力した内容は、Ctrl-Enterか[表示]->[ログ]で出力内容を確認する。
関数が複数ある場合は、実行する関数を選択して実行することもできる。(個人的にこの仕組みはびっくりしたw)
参考: 【初心者向けGAS】はじめてのスクリプトを作成し、保存し、実行する
スプレッドシートの基本操作
基本的な操作は以下の通り。
(実はExcelの操作とまったく同じ)
- スプレッドシートを開く
- シートを開く
- セルを取得する
- 取得したセルに対して読み書きを行う
スプレッドシートを開く
スプレッドシートのスクリプトエディタで作成したスクリプトであれば、とにかく以下のコードで「開いているスプレッドシートのオブジェクト」が取れる。
var ss = SpreadsheetApp.getActiveSpreadsheet()GASやJavaScript固有の単語はまだちょっと把握できてないけど、C++/Java的にいうとSpreadsheetAppクラスの
getActiveSpreadsheet()staticメソッドを呼んでいる感じ。スプレッドシートに対する操作は、すべてこのメソッドで取得できるオブジェクト(ここでは
ss変数)に対して行う。参考: 【初心者向けGAS】Spreadsheetサービスの「オブジェクト」の基礎の基礎を知ろう
シートを開く
スプレッドシートは(Excelも同様に)複数のシートで構成されているので、処理対象のシートを選択する。
スプレッドシートを開くときに使用したgetActiveSpreadsheet()と同じように、現在アクティブなシートを開くgetActiveSheet()もあるが、複数シートがあると制御が難しい。
複数シートのうちどれかを開く場合は、シート名を指定してgetSheetByName("シート名")を使うとよい。
例えばこのシートを開くのであれば、以下の通り。
var ss = SpreadsheetApp.getActiveSpreadsheet() var sheet = ss.getSheetByName("マイルストーン")参考: 【初心者向けGAS】スプレッドシートのシートを取得する2つの方法
セルを取得する
セルを取得するには何通りか方法があるが、基本はまず
getRange()でセルの範囲を指定する。
getRange()にも使い方が複数あり、
- セルの範囲が1つの場合
getRange('B1')で「B1セル」を取得するgetRange(1, 2)で、「1行目2列目」を取得する (数字は0でなく1開始)- 範囲が複数の場合
getRange('A1:B5')で「A1からB5までの範囲を取得するgetRange(1, 2, 3, 5)で「1行目2列目から3行目5列目」を取得するvar cell = sheet.getRange("A1")シート内のデータ件数がいくつあるか不明の場合でも、
getLastRow()で、データが入力されている最終行を取得できる。var lastRow = sheet.getLastRow();セルに対して読み書きする
getRange()で取得したセルに対してgetValue()を行うことでセルの内容を取得できる。
セルの範囲が複数の場合はgetValues()(複数形)で、リスト形式で内容を取得できる。var cell = sheet.getRange("A1") Logger.log("cell A1: %s", cell.getValue()) // A1セル内の値が取得できるvar list = sheet.getRange(dataRowIndex, dataColumnIndex, lastRow, dataColumnIndex).getValues();セルに値を書き込むには、
setValue()を使用する。sheet.getRange(i, checkedColumnIndex).setValue("登録済")参考: 【初心者向けGAS】スプレッドシートのセル・セル範囲とその値を取得する方法
メニューの追加
function onOpen(e)を使うことで、スプレッドシートにオリジナルのメニューを追加して任意の関数を簡単に呼び出せるように設定できる。スクリプト内に、
onOpen(e)という関数を定義することで、スプレッドシートを開いたタイミングでこの関数が読み込まれるので、ここにメニューを追加する処理を定義すればOK。function onOpen(e) { var ui = SpreadsheetApp.getUi(); ui.createMenu('Backlog') .addItem('プロジェクト作成', 'createBacklogProject') .addItem('プロジェクト情報取得', 'getBacklogProjects') .addToUi(); }
createMenu("メニュー用文字列")にメソッドチェーン(関数の戻り値にさらに関数をつなげて書ける書き方のこと)でaddItem()で項目を追加する。
追加時の注意として、メニューを選択されたときに実行する関数名を文字列としてセットする。
(createBacklogProjectでなく'createBacklogProject'ということ)参考: スプレッドシートとGASでTrelloのリストにカードを作成するツール / スプレッドシートのメニューに項目追加
REST APIの実行
RESTの操作で使用するのは、webアクセスを行う
UrlFetchApp.fetch()と、JSONをparseするJSON.parse()。BacklogのAPIを実行するには、APIキーを作成し、リクエストするURLに付加してアクセスすればよい。
(OAuth2も使えるけど、キーの期限切れ時の処理とかの処理とかが増えるので、今回はAPIキーで実装)認証と認可 | Backlog Developer API | Nulab
APIキーの設定
Backlogの「個人設定」のメニューからAPIキーを作成する。
メモには用途など適当に入力して[登録]を押下。
このAPIキーの文字列を使えば、作成したユーザの権限であらゆる操作ができるようになるので他人に漏れたりしないようにしっかり管理する。
万一漏れてしまった場合は、×ボタンから削除し、再作成を行う。APIキーをスクリプト内にそのまま書いても良いが、その場合はスクリプトをほかの人と共有設定するとAPIキーもほかの人に漏れてしまうので注意。
(共有する場合は、外部ファイルに設定ファイルとして持たせて、GAS実行時に外部ファイルを読み込む仕組みなどが必要)参考: GASでテキストファイルの内容を読み取る - Qiita
プロジェクト一覧の取得
まずはお試しで自分が見えるプロジェクトの一覧を取得してみる。
プロジェクト一覧の取得 | Backlog Developer API | Nulabメソッドは
GETでURLは/api/v2/projects、クエリパラメーターは必須項目はないのでまずは省略してアクセスしてみる。URLのベース部分は、ダッシュボードを開いたときのこの部分。
といっても、これだけ。
var base_url = 'https://***.backlog.com' var endpoint = base_url + '/api/v2/projects'; var apiKey = '*** api key ***'; var url = endpoint + '?' + 'apiKey=' + apiKey; var resp = UrlFetchApp.fetch(url);これで、
https://***.backlog.com//api/v2/projects?apiKey=********にGETアクセスしたレスポンスがrespに入る。
レスポンスの内容はオブジェクトになっており、ステータスコード(getResponseCode())やレスポンスヘッダ(getAllHeaders())などいろいろセットされているが、APIからの応答であるレスポンスボディを参照するにはresp.getContentText()で取り出せる。
レスポンスの内容はAPI仕様の通りで、JSONの連想配列になっているプロジェクト情報が配列形式になっている。これを
JSON.parse()に通せば、オブジェクトとして操作できる。
プロジェクト名(name)とプロジェクトキー(projectKey)を出力する例。var json = JSON.parse(resp.getContentText()) for(var i = 0; i < json.length; i++) { Logger.log("%s (key:%s)", json[i].name, json[i].projectKey) }参考:
プロジェクトの作成
プロジェクトの追加 | Backlog Developer API | Nulab
URLはプロジェクト一覧の取得と同じ。
ただし、POSTメソッドを使って作成するプロジェクトのパラメタを付加する。リクエストパラメーターが
Content-Type:application/x-www-form-urlencodedとなっているので、HTTPリクエストヘッダにこれを設定。そしてリクエストボディに表に記載されている項目を指定する。
curlコマンドであれば以下のような感じ。(APIキーは環境変数${API_KEY}にある前提)$ curl -XPOST \ -d 'name=PROJECT_NAME' \ -d 'key=PJ_KEY' \ -d 'chartEnabled=true' \ -d 'subtaskingEnabled=true' \ -d 'textFormattingRule=markdown' \ -H 'Content-Type: application/x-www-form-urlencoded' \ "https://******.backlog.com/api/v2/projects?apiKey=$API_KEY"プロジェクト名などで日本語を使用する場合は、(いろいろ試した結果)UTF-8エンコードの文字列をURLエンコーディングすればOK
GASのコードで書こうとするとこんな感じ。
(プロジェクト名「ぼくのプロジェクト」、プロジェクトキー「PJKEY」で作成)参考: Google Apps Script UrlFetchApp で Http Header を設定する | Monotalk
var base_url = 'https://***.backlog.com' var endpoint = base_url + '/api/v2/projects'; var apiKey = '*** api key ***'; var url = endpoint + '?' + 'apiKey=' + apiKey; var params = { 'name': 'ぼくのプロジェクト', 'key': 'PJKEY', 'chartEnabled': 'true', 'subtaskingEnabled': 'true', 'textFormattingRule': 'markdown', } var options = { 'method': 'POST', 'contentType': 'application/x-www-form-urlencoded', 'payload': createQuery(params), } var resp = UrlFetchApp.fetch(url, options)
key1=value1&key2=value2&...の形式のリクエストボディを作成する標準関数的なものがあるのかどうかわからなかったので、以下のような関数を作成。(上記のpayloadの値に指定している部分)日本語のURLエンコードについては標準で用意されている
encodeURI()が使用できる。参考: パーセント記号を使ったURL(URI)エンコード・デコード方法 - JavaScript TIPSふぁくとりー
// 連想配列をqueryにする関数 function createQuery(obj) { var query = [] for(var key in obj) { query.push(key + '=' + encodeURI(obj[key])) //Logger.log(key) } return query.join('&') }これでプロジェクトの作成をAPIで実行できるようになった。
これだけだとwebの画面から手動で登録作業を行うのとあまり変わらないかもしれないけど、たとえば10件まとめて登録したい場合なんかは、登録したいプロジェクトの一覧のリストを用意し、ループで処理すればさくっと10件のプロジェクト作成ができるようになる。
マイルストーンの作成
ここから(「プロジェクト作成時に初期設定として定型のマイルストーンを作成したい」という要望の)本題。
といっても対象プロジェクトに対してマイルストーンを作成するBacklog APIを使用すればよい。バージョン(マイルストーン)の追加 | Backlog Developer API | Nulab
API仕様をみると、「URLパラメーター」と「リクエストパラメーター」の二種類のパラメーターがあるが、要は「対象プロジェクトのプロジェクトキーをURLの一部に指定」「その他のパラメーターはリクエストボディに指定」という構成。
「URL」の仕様に
:が入ってて紛らわしいけど、プロジェクトキー指定時は:は付けずに'https://***.backlog.com/api/v2/projects/'+ project_id + '/versions'って指定すればOK
ということで、指定プロジェクトに対して固定のマイルストーンを作成するには…
var milestones = ["朝起きる", "学校へ行く", "授業受ける", "部活に行く", "帰宅する"]というリスト形式のマイルストーンがあったとして、GASで指定プロジェクトに対してこの5つのマイルストーンを(必須項目のみで)作成するには以下のような感じ。
var base_url = 'https://***.backlog.com' var endpoint = base_url + '/api/v2/projects/'+ project_id + '/versions' for (var i in milestones) { Logger.log("milestone: %s", milestones[i]) var milestone_param = { 'name': milestones[i] } var url = endpoint + '?' + 'apiKey=' + apiKey var milestone_option = { 'method': 'POST', 'contentType': 'application/x-www-form-urlencoded', 'payload': createQuery(milestone_param), } var resp = UrlFetchApp.fetch(url, milestone_option) }前述のプロジェクト作成もリスト処理できるようにして、このマイルストーン作成と組み合わせれば、初期設定として同じマイルストーン設定の複数のプロジェクトを、ワンアクションで一気に作成できるようになる。














- 投稿日:2019-05-06T19:00:59+09:00
npmでsimplemdeを使いたい!
前提:simplemde とは
簡単に組み込めるマークダウンエディタとして紹介されてる記事がいくつか上がってるライブラリ。
npm経由で使おうとした
$ npm i simplemdeapp.jsimport SimpleMDE from 'simplemde' const simplemde = new SimpleMDE()ら、
崩れた。どうみてもスタイルがあたってない。
対処:直接CSSをimportする
app.jsimport SimpleMDE from 'simplemde' import 'simplemde/dist/simplemde.min.css' const simplemde = new SimpleMDE()
本当に一瞬で実装できました。
esaあたりで見覚えあるこの画面。おすすめです。


- 投稿日:2019-05-06T18:57:14+09:00
Vue.jsとfirebaseでライツアウト作ってみたからちょっと見てってよ
言いたいこと
vue.jsとvuetifyとfirebaseでライツアウトっていうゲーム作ったので遊んでってください。
実物
https://custom-bond-167105.firebaseapp.com/github
https://github.com/tanakatanao/lightsout前日談
ある日プログラミングコンテストの過去問を解いていた筆者はライツアウトという問題にぶち当たる。全然解けず仕方なく解法をネットで調べるもさっぱり意味がわからないため「解法がわからないなら作ればいいじゃない」という信条に基づいてvscodeを起動したのであった。
ライツアウトとは
ライツアウトは、5×5の形に並んだライトをある法則にしたがってすべて消灯 (lights out) させることを目的としたパズル。特徴としてはライトを押すと上下左右全てのボタンが押ささってしまう(北海道弁)
(出展wikipedia https://ja.wikipedia.org/wiki/%E3%83%A9%E3%82%A4%E3%83%84%E3%82%A2%E3%82%A6%E3%83%88)
こんな感じ解法
下記のサイトが詳しいです。
http://www.ic-net.or.jp/home/takaken/nt/light/light2.html自分が理解に時間がかかった部分だけここで補足すると
ライツアウトの原則として
- 二回押したら元に戻る(初期の状態に対して、押したか押していないかの状態しか存在しない)
- 押す順番は関係ない
という二点があります。そのため取りうる状態は
みたいな初期状態に対して
押す押さないの組み合わせだけです。
そのため、押す押さないのパターンの組み合わせを全て求めればライツアウトは解けます。
ただこの解法だと状態が爆発するので、今回実装した解法はもう少し簡略化したもの。今回の解法
ライトを押すと上下左右が点灯するということは、上のライトを消すためには一つ下のライトを押さなければなりません。
一つ上行の押す押さないが決定した場合、その一つ下の行からは上のライトの点灯状態によって押す押さないが自動的に決まります。
というちょっと組み合わせ数が減った解法でやってみたいと思います。
(ちなみにもっと計算数が少なくなる解法もありますけど直感的にわかりやすいこの解法を採用)環境
- vue.js
- vuetify
- firebase
実装
詳しくは下記にて。
https://github.com/tanakatanao/lightsoutちょこちょこ解説してきます。
状態を二次元配列でもつ
現在点いているかどうかを二次元配列で確保。
items: [ [true, true, true, true, true], [true, true, true, true, true], [true, true, true, true, true], [true, true, true, true, true], [true, true, true, true, true] ],押したら上下左右も変化させる
switch_on(y, x) { if (this.items[y][x]) { //直接値を入力すると変更が検知されないためこんな感じ this.$set(this.items[y], x, false); } else { this.$set(this.items[y], x, true); } }, arround_change(y, x) { if (y > 0) { this.switch_on(y - 1, x); } this.switch_on(y, x); if (y + 1 < this.items.length) { this.switch_on(y + 1, x); } if (x > 0) { this.switch_on(y, x - 1); } if (x + 1 < this.items[y].length) { this.switch_on(y, x + 1); } },シャッフルする
shuffle() { this.dialog = false; this.init_guide(); let i = 0; while (i < 5) { let j = 0; while (j < 5) { if (this.random_marubatsu()) { this.arround_change(i, j); } j = j + 1; } i = i + 1; } }, random_marubatsu() { if (Math.random() >= 0.5) { return true; } else { return false; } },判定する
二次元配列の中に一つもtrueが含まれていなかったらゲーム終了。
二次元配列の中身全部チェックするのの良いやり方が見つからなかったため、とりあえず一列に直してから判定しております。judge() { let judge_array = []; // 二次元配列を直列にする for (const i in this.items) { judge_array = judge_array.concat(this.items[i]); } // 配列に含まれているかを確認 if (judge_array.includes(true)) { return true; } else { return false; } },答えをだす
ようやく今回の本当にやりたかったところ。
今回は全通り試してみて、成功に至る組み合わせの中で一番ボタンを押す回数が少ないものを答えとします。先頭の押す押さないの組み合わせパターンを作る
correct_answer(now_array) { let n = 1; let front_array_pattern = []; let minimum_push_number = -1; let minimum_push_order = []; //先頭の組み合わせ作成 while (n <= now_array.length) { front_array_pattern = front_array_pattern.concat( this.kumiawase([0, 1, 2, 3, 4], n) ); n = n + 1; }先頭のパターンの数だけ試行してみる
//先頭のパターン分実施する for (let pattern in front_array_pattern) { //試行回数 let push_number = 0; //初期化 now_array = this.$lodash.cloneDeep(this.items); //先頭のパターン押下する for (let pattern2 in front_array_pattern[pattern]) { push_number = push_number + 1; now_array = this.math_arround_change( now_array, 0, front_array_pattern[pattern][pattern2] ); } // 二段目より下をやる; // 自分の上の段が光ってたら押下; let i = 1; while (i < now_array.length) { let j = 0; while (j < now_array[i].length) { if (now_array[i - 1][j]) { push_number = push_number + 1; now_array = this.math_arround_change(now_array, i, j); } j = j + 1; } i = i + 1; } //最後に判定 if (this.math_judge(now_array)) { if (minimum_push_number == -1 || minimum_push_number > push_number) { minimum_push_number = push_number; minimum_push_order = front_array_pattern[pattern]; } } } if (minimum_push_number != -1) { return minimum_push_order; } }これで一番押す回数が少なく済む一行目の押すパターンが手に入ります。
minimum_push_orderの値が-1の場合は解決できるパターンがなかったということです。
そういう日もあります。ちなみにそれではゲームとしては面白くないので、これでは解けるやつしか出してません。
感想
ようやくライツアウトの解法が分かりました。正直これ作り出してから30分くらいでわかってしまったのですが、途中でそんなことも言えず最後まで作りきるはめになってしまいました。vueから一年くらい離れていてリハビリがてら久しぶりに書いたんですが全て忘れていました。びっくりですね。もうどうせ全て忘れたのだから次はtypescriptとreactを新たに学ぼうと思います。




- 投稿日:2019-05-06T17:02:43+09:00
JavaScriptの数値型完全理解
数値というのはプログラミングにおいて極めて基本的な対象です。ほとんどのプログラミング言語は何らかの形で数値の操作を行うことができ、もちろんJavaScriptにおいても例外ではありません。
プログラミングにおける数値の特徴的な点は、往々にしてその性質に応じた複数の型1が与えられている点です。まず、数値は整数か小数かによって分類されます。さらに、値を表すのに使われるビット数、また整数に関しては符号ありか符号なしかという分類ができます。例えば、Rustという言語ではこれらの分類が分かりやすく表れています2。Rustにおける数値の型は
i32,i64,u32,u64,f32,f64などがあり、見ただけでどのような特徴を持つ数値なのかが分かりやすくなっています。iというのは符号あり整数、uというのは符号なし整数、fは小数で、その後の数字がビット数ですね。では、JavaScriptにおいては数値はどのように扱われているのでしょうか。この記事では、JavaScriptの数値はどのように表されるのか、計算はどのように行われるのかなど、JavaScriptの数値に関するトピックを網羅します。
JavaScriptの数値は(今のところ)1種類
実は、JavaScriptの数値は型が1種類しかありません。熱心な方は
BigIntの存在についてご存知かと思いますが、まだこれはぎりぎりJavaScriptに入っていないのでここでは1種類とカウントします。(BigIntについてはこの記事の後半で触れます。)1種類しかないということは、上で紹介した「整数か小数か」「ビット数」などによる区別を持たないということです。結論から言ってしまえば、JavaScriptの数値は64ビットの浮動小数点数です。つまり、JavaScriptの数値は全てが小数なのです。
以下のようなプログラムではJavaScriptで整数を扱っているように見えますが、実はこれも
1.0や2.0などのデータを扱っていることになります(整数と小数を区別する言語では1.0のように小数点を明示することでそれが小数データであることを明示することがあり、この記事でもそれに倣っています)。const x = 1; const y = 2; console.log(x + y); // 3
3などと表示されるのも処理系が気を利かせているのであり、内部的には3.0というデータになっています3。IEEE 754 倍精度浮動小数点数 (double)
より詳細に言えば、JavaScriptの数値型はIEEE 754 倍精度浮動小数点数です(長いので以降はdoubleと呼ぶことにします)。これは何かというと、64ビットの範囲内でどのように小数を表現するかを定めた規格のひとつです。doubleによる小数(浮動小数点数)の表現は極めて広く使用されており、コンピュータにおける小数の表現のスタンダードとなっています。
まず前提として、64ビットという限られたデータ量で任意の小数を表すのは不可能です。それゆえ、プログラムで表せる数値の精度には限りがあります。このことは、以下のよく知られた例に表れています。
// 0.30000000000000004 と表示される console.log(0.1 + 0.2); // false と表示される console.log(0.3 === 0.1 + 0.2);これは、
0.1とか0.2という数が(2進数で数値を扱うコンピュータにとっては)きりの悪い数なので正確に表すことができないことが原因です。なので、0.1と書いた時点で、コンピュータはそれをぴったり0.1という数ではなく0.1000000000000000055511151231257827021181583404541015625という数として認識します。64ビットという限られたデータ量ではこれが精一杯で、これ以上正確に0.1を表すことはできないのです(doubleという規格を用いるならばの話ですが)。0.2についても同様で、コンピュータはこれを0.200000000000000011102230246251565404236316680908203125と認識します。この時点で、0.1も0.2もともに、実際よりもわずかに大きいほうに誤差が発生しています。
0.1 + 0.2という計算の結果は0.3000000000000000444089209850062616169452667236328125です4。ポイントは、0.1や0.2と書いた時点で発生していた誤差、そして加算で発生した丸め誤差がこの計算結果に蓄積しているということです。一方で、プログラムに
0.3と書いた場合もやはりすでに誤差が発生しており、コンピュータは実際の0.3に最も近いdoubleで表現可能な数である0.299999999999999988897769753748434595763683319091796875を採用します。ここで運悪く、
0.3をdoubleで表現しようとすると負の方向に誤差が発生しています。0.1と0.2はともに正の誤差を持っていたこともあり、これらが蓄積した結果0.1 + 0.2は0.3から離れすぎてしまいます。その結果、0.1 + 0.2の結果は0.3(に最も近いdoubleで表現可能な数)からずれてしまうのです。このずれはビット表現でいうとわずか1ビットです。実際、0.3にちょうど1ビットぶんの値である$2^{-54}$を足すと0.1 + 0.2になります。// true と表示される console.log(0.3 + 2 ** (-54) === 0.1 + 0.2);結局ここで何が言いたいかというと、このような挙動はJavaScriptとは関係のない浮動小数点数の仕様であり、コンピュータで(固定長のデータで)小数を表そうとする限り避けようのないものであるということです。
ゆえに、JavaScriptの数値型を理解するには、IEEE 754由来の挙動はどれかということも知らなければなりません。というわけで、もう少しだけIEEE 754(double)について見てみましょう。
doubleによる小数の表現では、64ビットのうち最初の1ビットを符号ビット(0なら正の数、1なら負の数を表す)、次の11ビットを指数部、残りの52ビットを仮数部として用います。本質的には、指数部と仮数部はそれぞれ2進数で表された整数であると解釈されます。仮数部が$x$という整数で指数部が$y$という整数であるとき、その小数表現が表すのは$x \times 2^y$となります(実際には$x$はいわゆるけち表現を加味して決められることや、$y$は正負をバランスよく表せるように調整されることに注意が必要です)。ここから分かることは、指数部のビット数というのは小数で表せるスケール(どれくらい大きな/小さな範囲の数を表せるか)、そして仮数部のビット数というのは小数で表せる精度(小数を表すのにどれくらいの桁数を使えるか)に関わるということです。
特に、doubleにおける仮数部の精度は53ビットであることは覚えておくに値するでしょう(52ビットからなぜ1つ増えているのかは調べてみてください)。
そろそろ話をJavaScriptに戻しますが、JavaScriptの数値がdoubleによって表されているという話と上記のdoubleの仕様を組み合わせて言えることは、JavaScriptの数値の精度は53ビット分であるということです。
JavaScriptの数値の精度は53ビット
JavaScriptは整数と小数という区別が無いということは冒頭でお話ししましたね。これは、繰り返しになりますが、整数だろうと小数だろうと全部doubleで表しているということです。
ということはJavaScriptの整数の精度も53ビットということです。整数と小数を区別するプログラミング言語では整数の精度は32ビットだったり64ビットだったりしますから、それに比べると随分中途半端に思えます。ただ、それらの言語と比べると、JavaScriptでの整数はdoubleであることに由来する面白い挙動をします。それはだんだん下の桁から大ざっぱになっていくという挙動です。まずこの辺りを見ていきましょう。
整数の精度が53ビットということは、$0$から$2^{53}-1$までの整数は正確に表せるということを意味します。ただし、ここで正確に表せるというのは1つ違うとなりの整数と区別できるということを意味します。次の例は、$2^{53}-1$が両隣の数と区別できることを確かめています。
// false と表示される(2^53 - 2 と 2^53 - 1は違うものと認識されている) console.log(2 ** 53 - 2 === 2 ** 53 - 1); // false と表示される(2^53 - 1 と 2^53は違うものと認識されている) console.log(2 ** 53 - 1 === 2 ** 53);この範囲を超えると、となりの整数と区別することができなくなります。例えば、$2^{53}$と$2^{53}+1$は区別することができません。両者をdoubleで表すと同一のビット列となるためです。
// true と表示される(2^53 と 2^53 + 1は同じと認識されている) console.log(2 ** 53 === 2 ** 53 + 1);$2^{53}$を2進数で表すと
100000000000000000000000000000000000000000000000000000(1の後に0が53個)である一方、$2^{53}+1$は100000000000000000000000000000000000000000000000000001です。どちらも整数としての表現に54ビット必要としていることが分かります。doubleは数の精度を53ビットしか確保できませんから、53ビットになるように丸められます(このときの丸めモードは最近接(偶数)丸めです)。これにより、両者はどちらも$2^{53}$に丸められて等しいと扱われるのです。一方、$2^{53}+2$という数を考えてみます。これは
100000000000000000000000000000000000000000000000000010ですから、53ビットに情報が減らされた後も依然として$2^{53}$とは異なります。console.log(2 ** 53 === 2 ** 53 + 2); // falseこの例では、整数として表すのに54ビット必要になったことで整数の精度が1ビット分大ざっぱになりました。さらに数を大きくしていくことで、下のほうからどんどんビットが削られて大ざっぱになっていくわけです。
このような事情から、JavaScriptにはsafe integer(安全な整数?)という概念があります。これは絶対値が$2^{53}-1$以下の整数を指し、計算結果がsafe integerならばずれが発生していない(上述の現象により正しい答えを表す整数からずれていない)ことが分かります5。
JavaScriptには与えられた数がsafe integerかどうか判定する
Number.isSafeInteger関数が用意されています。console.log(Number.isSafeInteger(2 ** 53 - 1)); // true console.log(Number.isSafeInteger(2 ** 53)); // falseこう真面目に解説するとJavaScriptはアホな言語なのではないかと思われるかもしれませんが(そして整数もdoubleで表さないといけないのが実際アホなことは否定しませんが)、整数を浮動小数点数で表そうとしたときにこのように情報が落ちていくことはdoubleの仕様から来る話でJavaScriptに特有の話ではないということは理解しておくべきでしょう。
NaNとInfinity,+0と-0JavaScriptには
NaNとInfinityという特別な数値が存在します。NaNはNot a Number(数ではない)の略であることは知られていますが、JavaScriptでは数値の一種なので型を調べると数値型です。console.log(typeof NaN); // "number"言うまでもなく、これもIEEE 754由来の概念です。ですから、「JavaScriptにはNaNとかいう意味不明な値がある」などとは思わないでくださいね。
ただ、doubleはNaNを表すビットパターンを大量に($2^{53}-2$個くらい)持ちますが、JavaScriptにおいては
NaNはただ一種類であり区別はありません。
NaNは数値が必要だけどどうしても無理な場合に表れます。例えば、parseInt(後述)で文字列を数値に変換しようとしたけど無理だった場合はNaNが結果となります。console.log(parseInt("foobar!")); // NaNまた、
0 / 0という計算をした場合もNaNとなります。
NaNの面白い(もちろんIEEE 754由来の)点は、NaN === NaNという比較がfalseとなることです。NaN < NaNなど、NaNを含む比較演算はすべてfalseとなります。ある数値がNaNかどうか判定した場合はisNaN(後述)を使うのがよいでしょう。
Infinityも同様です。これは「無限大」を表す特別な数値であり、IEEE 754由来です。無限大には正の無限大と負の無限大があります。さらに、doubleは
+0と-0という2種類の0が存在し、JavaScriptにおいても2種類の0が確認できます(普通の0は+0です)。+0と-0は===で比較しても等しいのが特徴です。このように、JavaScriptにおいて広く使われる等値比較演算子である
===もIEEE 754の影響を受けています。ES2015以降では、IEEE 754の影響を排除した等値比較の手段としてObject.isという関数が用意されています(cf. JavaScriptの等値比較を全部理解する)。console.log(0 === -0); // true console.log(Object.is(0, -0)); // false以上でJavaScriptの数値型が裏ではどのようになっているか分かりました。これを踏まえてJavaScriptにおける数値に関連する演算を見ていきたいのですが、その前に数値リテラルの話を挟みます。
JavaScriptの数値リテラル
数値リテラルとは、プログラム中で数値を表現する方法です。プログラム中に
123とか0.45と書いたら当然123とか0.45という数値になりますが、これらが数値リテラルです。これはJavaScriptに限った話ではありませんが、
0.123のように0.で始まる小数を書きたい場合は最初の0を省略して.123のように書けます。見かけても驚かないようにしましょう。console.log(.123); // 0.123また、整数を書きたい場合は
123.0の最後の0を省略して123.とできます。JavaScriptではただ123とすればいいので特に意味はありませんが、整数と浮動小数点数を区別する言語では123と123.0が別の意味になるために後者を省略したい場合の記法として需要があるようです。なお、数値のメソッドを呼びたい場合には注意してください。
123のtoFixedメソッド(後述)を呼びたい場合には、123.toFixed()とするとエラーとなります。なぜなら、123.という数値の直後にtoFixedが並んでいる(123 toFixed()と書いたのと同じ)と解釈されるからです。これを回避するひとつの方法は(123).toFixed()ですが、文字数の少なさと見た目の面白さからこれを123..toFixed()とするのをよく見ます。こうすることで、123.が数値、.toFixed()でメソッド呼び出しと解釈されます。もちろん、123.0.toFixed()なども動作します。さらに、数値リテラルは指数表記をサポートしています。これは
1.23e5のように整数または小数のうしろにeと整数を付けるリテラルです。eの後ろは10の指数と解釈されます。よって、1.23e5は$1.23 \times 10^5$、すなわち123000と解釈されます。1e-4(0.0001と同じ)のようにeの後ろは負の整数も可能です。また、ここまでは10進数表記でしたが、他に16進数・8進数・2進数のリテラルがサポートされています。それぞれ
0xabcdef、0o755、0b1010111のようなリテラルです。これらの10進数以外のリテラルは小数点やeによる指数表記はサポートされていません。また、桁数の多い数値リテラルを見やすく
1_234_567のように書ける提案がもう少しで完成しそうです(cf. JavaScriptで数値の区切り文字を使いたい物語)。以上が数値リテラルの話でした。まあ、特におかしな所はありませんでしたね。では、いよいよ数値演算の話に入っていきます。
JavaScriptにおける数値演算
とはいえ、JavaScriptの数値演算は、それほど特筆すべき点があるわけではありません。まず、普通の四則演算(
+,-,*,/及び余り%)と累乗(**)が備えられています。ただし、
+は文字列の連結にも使われるので"5" + 1が"51"になったりする点はやや注意が必要でしょうか。-とかは両辺を数値に変換するので"5" - 1は4です。これらの演算子にオブジェクトを渡してしまったときの挙動はちょっと面白かったりするのですが(cf. JavaScriptのプリミティブへの変換を完全に理解する)、いまは関係のない話です。やや注意が必要なのはビット演算です。JavaScriptは一般的なビットごと演算(
&,|,~)やビットシフト(<<,>>,>>>)を備えていますが、これらを使う場合は突然数値が32ビット整数に変換されます。このとき小数は0に近いほうへ丸められます。この結果として、32ビットを超える範囲の整数は下位32ビットのみが残されて他は捨てられます。また、負数は普通の2の補数表現によって表されます。そして、32ビット整数に対してビット演算が適用され、結果が32ビット符号あり整数として再解釈されます(ただし、
>>>のみ32ビット符号なし整数として解釈します)。以上の説明で以下の結果が理解できることでしょう。
console.log((2 ** 32) | 0); // 0 console.log(2 ** 31); // 2147483648 console.log((2 ** 31) | 0); // -2147483648 console.log((2 ** 32) >> 0); // 0 console.log((2 ** 31) >> 0); // -2147483648 console.log((2 ** 31) >>> 0); // 2147483648また、
<<などのビットシフト演算の右オペランド(シフト量を指定する数)についても右側は32ビット整数として扱われます。また、対象が32ビット整数ということで32個以上シフトするのは意味がないと考えられることから、32以上の数については32で割った余りが取られます。よって、次のような結果となります。console.log(1 << 33); // 2 console.log(1 << (-1)); // -2147483648数値から文字列への変換
数値の計算に関する話は終わりにして、数値を文字列に変換したいときの話をしましょう。実は、JavaScriptは数値から文字列への変換メソッドを5種類提供しています。いずれも数値が持つメソッドとして利用可能です。
toExponentialこのメソッドは数値を指数表現で文字列に変換します。指数表現というのは
1.23e+5($1.23 \times 10^5$を表す)のようにeを用いた表現です。toExponentialはどのような数値でもこの表現に変換します(NaNとかInfinityは除く)。引数で、小数点以下の桁数を指定できます。省略すると数値を表現するのに最低限必要な分を適切に選んでくれます。console.log(150..toExponential(3)); // "1.500e+2" console.log(0.1234.toExponential(1)); // "1.2e-1"
toFixed
toFixedは、逆に指数表現を用いない文字列表現を得たいときに使います。引数は小数点以下の桁数で、省略の場合は0(整数部分のみ)扱いです。また、絶対値が$10^{21}$以上の数は諦めてしまいます(後述のtoStringと同じになります)。console.log(100..toFixed(3)); // "100.000" console.log(0.000999.toFixed(5)); // "0.00100"特筆すべき点として、safe integerの範囲を超える(しかし$10^{20}$を超えない)範囲の整数に対しては
toString(後述)よりもtoFixedのほうがより正確な610進表現を求めてくれます。小数についても同様の場合があります。console.log((2 ** 60).toString()); // "1152921504606847000" console.log((2 ** 60).toFixed()); // "1152921504606846976"
toPrecision
toPrecisionは、引数で渡した数を有効数字の桁数とする文字列表現に直してくれます。必要に応じて指数表現が使われます。console.log(1.234.toPrecision(3)); // "1.23" console.log(1234..toPrecision(3)); // "1.23e+3" console.log(0.00123.toPrecision(2)); // "0.0012" console.log(0.0000000123.toPrecision(2)); // "1.2e-8"
toString
toStringは数値から文字列への暗黙の変換の場合に使われる標準的な方法です。結果は数値を普通に(必要最小限の桁数で)表現したものですが、toPrecisionの場合と同様に必要に応じて指数表現も使われます。
toStringには大きな特徴が2つあります。1つ目は、10進表示への変換を適度にサボることです。toFixedの例を再掲します。2 ** 60($2^{60}$)に対する結果がtoStringとtoFixedで違っているという例でしたね。console.log((2 ** 60).toString()); // "1152921504606847000" console.log((2 ** 60).toFixed()); // "1152921504606846976"$2^{60}$は正確に
1152921504606846976ですが、(2 ** 60).toString()は最後の4桁が7000と大ざっぱになっています。しかし、JavaScriptの整数の精度が53ビットしかないことを考えれば、実は
1152921504606847000も2 ** 60になることが分かります。console.log(2 ** 60 === 1152921504606846976); // true console.log(2 ** 60 === 1152921504606847000); // true$2^{60}$という61ビットの数が53ビットに情報を減らされる場合、8ビット分情報が落ちます。こうなると、丸めのことを考えてもその半分(7ビット)程度の違いは意味を成さなくなります。$2^7$は128ですから、
6976と7000の間のたった24の差は無視できるのです。このように、
toStringは無視できる範囲で情報を落としてもよいことになっています。ちなみに、小数の場合でもこれは同じです。次の例を見れば分かるように、これはわりと人間に優しい仕様であるといえますね。console.log(0.3.toString()); // "0.3" console.log(0.3.toFixed(20)); // "0.29999999999999998890"この場合、わざわざ
0.2999999999999999889と書いても0.3と書いても結果は同じであるため、より少ない桁数で表されるほうが選ばれています。console.log(0.2999999999999999889 === 0.3); // true
toStringにはもうひとつ特徴があります。それは、引数で基数を指定できる点です。これにより、10進数以外の表現を得ることができます。console.log(12345.67.toString(16)); // "3039.ab851eb852" (Google Chrome 74の場合)ちなみに、10進数以外は文字列を生成する具体的なアルゴリズムは実装依存です。
toLocaleStringこれは
IntlAPIの一部で、言語や地域等の慣習に合わせて数値を文字列に変換してくれるメソッドです。詳しく説明するのは別の機会に譲るとして、ひとつだけ例を出しておきます。console.log(1234567..toLocaleString("ja-JP", { style: "currency", currency: "JPY"}); // "¥1,234,567"文字列から数値への変換
逆に、文字列をいい感じに解釈して数値に変換するという機能にも需要がありますよね。JavaScriptにはそのための方法がいくつかあります。
parseIntその一つは
parseIntです。Intというのはinteger(整数)のことですから、これは整数を表す文字列を数値に変換してくれます。
parseIntは大きな特徴が2つあり、1つは数値の後ろの余計な文字列を無視してくれることです。数値として解釈できない文字列はNaNとなります。console.log(parseInt("55000")); // 55000 console.log(parseInt("123px")); // pxが無視されて結果は 123 console.log(parseInt("123.45")); // 小数はパースしないので.45が無視されて 123 console.log(parseInt("foobar")); // NaNもうひとつは、第2引数で基数を指定できる点です。2から36まで可能です。
console.log(parseInt("ff", 16)); // abcdef を16進数で解釈すると 255 console.log(parseInt("100zzzzzz", 16)); // 256ちなみに、16進数の場合は
parseIntは特殊な挙動をします。それは、0xで始まる文字列をいい感じに解釈してくれるというものです。とてもいい迷惑ありがたい機能ですね。console.log(parseInt("0xff", 16)); // 255では、
parseIntの第2引数を省略した場合はどうなるのでしょうか。この場合は先の例からも分かるように10進数として扱われますが、省略した場合はひとつ特殊な挙動があります。それは0xで始まる文字列を渡された場合で、この場合だけ気を利かせて16進数として解釈してくれるのです。console.log(parseInt("0xff")); // 255 console.log(parseInt("0xff", 10)); // 0 (第2引数を指定するとこの挙動はオフになるため)最後に、
parseIntは文字列前後の空白文字を無視してくれます。console.log(parseInt(" 123 ")); // 123 console.log(parseInt(" 1 2 3 ")); // 1 (1の後の空白以降は全部余計な文字と見なされるので)ちなみに、グローバル変数の
parseIntではなくNumber.parseIntもあります(ES2015で追加)。こちらも同じ挙動となります。
parseFloat
parseFloatは、整数だけでなく小数も解釈してくれる関数です。まず、文字列前後の空白文字を無視してくれたり、後ろに余計なものが付いていても無視してくれるという点はparseIntと同じです。
parseFloatについては、10進の数値リテラルを文字列として表したものを解釈できます。console.log(parseFloat(" 123.45px")); // 123.45 console.log(parseFloat("1.23e4")); // 12300 console.log(parseFloat(" .456")); // 0.45616進など、他の基数のリテラルは無理です。
console.log(parseFloat("0x123")); // 0加えて、
parseFloatはInfinityに対する特別なサポートがあります。console.log(parseFloat("Infinity")); // Infinity
Infinityと書くとInfinityという数が得られますがこれはInfinityというグローバル変数が存在するからこそなので、parseFloatが"Infinity"に対応しているのはなかなか面白いですね。実に簡単ですね。なお、
Number.parseFloatをグローバルのparseFloatと同様に使えるのもparseIntと同じです。
Number
Numberは渡したものをなんでも数値に変換してくれる関数です。また、+"123"のように数値への暗黙の変換が要求される場合もこの変換が使われます。
Numberは、parse系メソッドと同様に前後に空白文字があっても許容します。ただし、それ以外の余計な文字が後ろにくっついているのはNaNとなります。console.log(Number("1234")); // 1234 console.log(Number(" 1234 ")); // 1234 console.log(Number("1234px")); // NaNこの点を除いて、
Numberは全ての数値リテラルを受け付けます7。また、parseFloatと同様にInfinityも受け付けます。すなわち、
parseFloatが受け付けてくれた全てのリテラルに加えて"0xff"や0b10101なども受け付けられるということです。parseIntと挙動が揃っていないのはご愛嬌です。console.log(Number("0xff")); // 255 console.log(Number("0b101")); // 5その他の数値関係メソッド
他にもいくつか数値関係のメソッドがあるので紹介します。
isNaN・isFinite
isNaNは引数で与えられた数がNaNかどうか判定するメソッドです。console.log(isNaN(123)); // false console.log(isNaN(Infinity)); // false console.log(isNaN(NaN)); // true
NaNはNaN === NaNがfalseになってしまうため、isNaNがNaNかどうか判定する簡単な方法です。また、
isFiniteは与えられた数がNaNかInfinityまたは-Infifityだったらfalseで他はtrueを返すメソッドです。これは意外と使いどころがある関数です。console.log(isFinite(123.45)); // true console.log(isFinite(NaN)); // false console.log(isFinite(Infinity)); // false
parseIntなどと同様にこれらにもNumberの下にあるバージョン、すなわちNumber.isNaNとNumber.isFiniteがありますが、何とこれらはisNaNやisFiniteとは微妙に挙動が違います。
Numberバージョン、すなわちNumber.isNaNやNumber.isFiniteは、与えられたものが数値でない場合は即座にfalseを返します。一方、グローバルのisNaNやisFiniteはまず与えられたものを(Numberで)数値に変換しようとします。その結果、以下のような違いが現れることになります。console.log(isNaN("foobar")); // true ("foobar"を数値に変換したらNaNなので) console.log(Number.isNaN("foobar")); // false ("foobar"は数値ではないので) console.log(isFinite("1234")); // true console.log(Number.isFinite("1234"));// false
Number.isInteger,Number.isSafeInteger
Number.isIntegerは単純ですね。与えられた数値が整数かどうかを判定します。Number.isSafeIntegerは少し前に話題にのぼりました。絶対値が$2^{53}-1$以下の整数に対してtrueを返します。これらはNumber.isFiniteなどと同様に、数値以外には即falseを返します。console.log(Number.isInteger(1234)); // true console.log(Number.isInteger(123.4)); // false console.log(Number.isInteger(Infinity)); // false
Numberの定数数値に関連するメソッドは以上ですが、
Numberにはいくつか付随する定数があります。
Number.MAX_SAFE_INTEGERは$2^{53}-1$です。つまり最大のsafe integerですね。同様に、Number.MIN_SAFE_INTEGERは$-(2^{53}-1)$です。
Number.MAX_VALUEはJavaScriptの数値型で(すなわちdoubleで)表現可能な最大の数です(Infinityは除く)。console.log(Number.MAX_VALUE); // 1.7976931348623157e+308これは約$1.7976931348623157 \times 10^{308}$のようですね。
同様に、
Number.MIN_VALUEはdoubleで表現可能な最小の正の数です。console.log(Number.MIN_VALUE); // 5e-324
Number.MAX_VALUEに比べると有効数字が少ないような気がしますが、それはdoubleの0に近い部分では非正規化数(精度を落とすことで通常の小数(正規化数)よりも絶対値が0に近い数を表現する仕組み)が現れるからです。実際、この5e-324という数は精度を1ビットまで落とすことでぎりぎりまで0に近づけた数です。0より大きく5e-324より小さい数はJavaScript(あるいはdouble)には存在しません。例えば、5e-324 / 2は0となります。他には
Number.POSITIVE_INFINITY(Infinityが入っている)とNumber.NEGATIVE_INFINITY(-Infinityが入っている)、そしてNumber.NaNがあります(NaNが入っている)があります。グローバル変数のNaNやInfinityが信用ならないときに使いましょう。最後に、
Number.EPSILONという定数もあります。これは、「1」と「(doubleで表せる)1よりも大きい最小の数」の差です。doubleの仕組みを理解していれば、これが$2^{-52}$であることはすぐに分かるでしょう。console.log(Number.EPSILON === 2 ** (-52)); // true以上で、数値に関する話はだいたい語りつくしました。他には
Mathオブジェクト以下で提供されるさまざまな数学関数もあります(ES2015でいろいろ追加されたのでまだ調べていない人は調べてみてください)。ここでは全ては紹介しませんが、少しだけ触れておきます。面白いところでは、
Math.clz32という関数があります。これは、与えられた数を32ビット(符号なし)整数に変換してleading zeroesを数える(2進表現における一番左の1よりも左にある0の数を数える)関数です。console.log(Math.clz32(1)); // 31 console.log(Math.clz32(2 ** 31)); // 0 console.log(Math.clz32(-(2 ** 31))); // 0また、
Math.imulは2つの引数を符号なし32ビット整数に変換したあと乗算を行い、結果の下部32ビット(を符号あり32ビット整数として解釈したもの)を返します。console.log(Math.imul(2 ** 15, 2 ** 16)); // -2147483648他は普通の数学関数なので調べてみてください。
BigIntの話さて、以上で数値の話は終わりました。しかし、この記事はこれだけでは終わりません。JavaScriptには
BigIntがあります。これはまだJavaScriptに正式採用されていないものの現在Stage 3のプロポーザルです。これは要するにJavaScriptにもうそろそろ正式に追加されそうということで、恐らく2020年にリリースされるES2020で正式にJavaScriptの仕様に追加されると思います。
BigIntはこれまで説明してきた普通の数値(number型)とは別の型であり、任意精度の整数を表す型です。ざっくり言えば、ビット数という制限に囚われずに好きなだけ大きい整数を表すことができるという、従来の数値とはまったく異なる特徴を持つ値です。ただし、小数は範疇外です。あくまで整数のみが対象となります。BigInt型の値を作るには主に2つの方法があります。一つはBigIntリテラルを使う方法です。これは
123nのように整数の後にnを付けるリテラルを用います。もう一つは
BigInt()関数を使う方法です。これはNumber()のように、与えられた値をBigInt型の値に変換してくれます。整数を表す数値や文字列をBigInt()に与えることでBigInt型の値を作ることができるのです。BigInt型の値は
typeof演算子で調べると"bigint"という結果になります。console.log(123n); // 123n console.log(typeof 123n); // "bigint" console.log(BigInt(123) === 123n); // true console.log(BigInt("123") === 123n); // true
BigInt型の値は、普通の数値と同様に四則演算が可能です。ただし、これはBigInt同士の計算に制限されています。BigIntと普通の数値を混ぜるとエラーになります。また、BigIntは小数を表しませんので、割り算が割り切れない場合は切り捨てられます。console.log(2n + 3n); // 5n console.log(2n * 3n); // 6n console.log(5n / 2n); // 2n
BigIntが普通の数値とは異なり精度に制限がないことを確かめてみましょう。console.log(2 ** 60 + 10 === 2 ** 60); // true (普通の数値は精度が53ビットしかないので) console.log(2n ** 60n + 10n === 2n ** 60n); // false (BigIntはどんな大きさの整数も正確に表現可能)このような挙動はたいへんうれしいですね。とりわけ、これまでJavaScriptで扱うのが難しかった64ビット整数が
BigIntを使えば自然に表せるのがとても偉いです。BigIntの導入以降は、53ビット以上に大きな整数が必要な場面でBigIntが活用されていくことになります(cf. JavaScriptの日時処理はこう変わる! Temporal入門)。また、
BigIntは任意精度のビット演算ができるのも嬉しい点です。従来の数値型では32ビットに制限されていたビット演算が、BigIntでは任意の精度で可能です。console.log((2n ** 60n | 2n ** 55n === 2n ** 60n + 2n ** 55n); // true
BigInt関連のメソッド以上が
BigIntの基本機能です。また、以下の2つのメソッドがBigIntに関連して提供される予定です。
BigInt.asUintN,BigInt.asIntN
BigIntの値を指定したビット数に制限して得られる新しいBigInt値を返します。例えばBigInt.asUintN(64, n)はnの下位64ビットの値を表すBigIntです。asUintNとasIntNの違いは、得られた下位nビット分の値を符号なし整数として解釈するか符号あり整数として解釈するかの違いです。console.log(BigInt.asUintN(64, 7n * (2n ** 62n)) === 2n ** 63n + 2n ** 62n); // true
BigIntの上限ちなみに、
BigIntはどれくらい大きな整数を表せるのでしょうか。実は、仕様ではBigIntの上限は定められていません。理想的な処理系では、どんなに大きなBigIntでも表せることになります。ところが、現実にはそうもいきません。最悪のケースでも、コンピュータのメモリを全部食いつぶしてしまえばそれ以上の大きさの
BigIntは作れないわけです。もちろん、現実の処理系はそういう事態になるより前に何らかのエラーを発生させるでしょう。
これについては、BigIntの上限を調べてみた方がいるようです。それによれば、Google ChromeではBigIntの上限$M$は$2^{2^{30}-1} \leq M \leq 2^{2^{30}}$を満たすようです。恐らくビット数で制限されているであろうことを考えると、Chromeでは
BigIntの最大精度は$2^{30}$ビットと考えてよさそうです。$2^{30}$ビットというのは1GBですから、ChromeはひとつのBigIntに対して1GBまでの使用を許してくれるようです(複数のBigIntを同時に作る実験は行われていないので、複数のBigIntの合計が1GBとかそういう話かもしれません。未検証です)。もっとも、
BigIntの演算というのは定数時間ではないので、実際の1GBのメモリを使って表されたBigIntに対して計算を行うのは非常に時間がかかることでしょう(前述の記事でも実際にそのような結果が報告されています)。まとめ
この記事ではJavaScriptの数値型について概観しました。
ポイントは、(
BigIntではない従来の)数値型は整数と小数を区別せず、IEEE 754倍精度浮動小数点数で表されているという点です。その結果、整数が53ビットという一見中途半端な精度を持っていたり、浮動小数点数に特有の(0.1 + 0.2 !== 0.3のような)挙動が表れます。特に、どの挙動がJavaScriptに特有の話でどの挙動がIEEE 754由来の話なのかはよく考えておくべきでしょう。万一にもIEEE 754をバカにするつもりでJavaScriptをバカにしてしまったら末代までの恥です。とはいえ、JavaScriptも歴史ある言語ですから、数値周りの挙動も中々面白いものが出来上がっています。そのあたりをこの記事で楽しんでいただけたなら嬉しいです。
これは静的型にも動的型にも言えることですね。 ↩
usizeとかisizeがちょっと厄介なのですが、ここではあまり関係がないので触れるのを避けることにします。 ↩本当の処理系の内部では最適化して整数として扱われている可能性もありますが、仕様上は全て浮動小数点数として扱われています。 ↩
筆算してみたけど結果が全然違うじゃないかと思われる方がいるかもしれませんが、
0.1と0.2では指数部(後述)が異なるのでそれによる丸め誤差が発生しているからです。なので、本当はこうやって割り切れるまで10進展開した値を書くことにはそこまで意味がないのですが、ここでは何となく誤差があるんだよということを認識してもらうのが目的なので大目に見てください。 ↩複雑な計算の場合は途中の計算もsafe integerになっていないといけませんが。 ↩
正確なというのは、53ビットで表せない範囲の部分をちゃんと最後まで10進展開してくれるという意味です(詳しくは
toStringのところで説明します)。 ↩ただし、前述のnumeric separators(
1_234_567みたいなやつ)が導入された場合はNumberはこれを解釈してくれないという仕様になる予定のようです。 ↩
- 投稿日:2019-05-06T17:02:01+09:00
JavaScriptの日時処理はこう変わる! Temporal入門
日時の処理は様々なアプリケーションにおいて避けては通れないタスクです。JavaScriptにおいてもそれは例外ではありません。
JavaScriptでは最初期から
Dateオブジェクトが日時を表すオブジェクトとして存在していましたが、これは非常に使いにくいAPIで知られています。その結果、momentに代表されるような日時処理ライブラリを使うのが事実上スタンダードとなっています。この記事では、将来的に日時処理の有力な選択肢になると期待されるモジュールであるTemporalについて解説します。Temporalでは、既存の
Dateによる日時処理のつらい部分が解消されることが期待されています。なお、例によってTemporalはまだ策定中の仕様です。現在Stage 2というフェーズにあり、APIを鋭意策定中という状況です。よって、この記事にかかれている内容は確定までにまだ変化するかもしれません。この記事でTemporalの雰囲気を理解し、実際に使う際はご自分での情報収集が必要です。覚えていればこの記事もちゃんとアップデートしますが。
Temporalの特徴
Temporalについて詳説する前に、Temporalの特徴的な部分をまとめておきます。具体的なひとつひとつのAPIがまだ今後変わりそうなことを考えれば、この記事で一番重要なのはここです。特に、Temporalについてどのようなデザイン上の決定が為されているのかを知るのはTemporal、ひいては今後のJavaScriptの展望を理解するのに役立つでしょう。
1. 標準ライブラリに含まれている
Temporalは標準ライブラリに含まれるモジュールです。標準ライブラリについては筆者の別記事で詳しく解説しているのでぜひチェックしてください。
外部ライブラリを使うという選択肢はTemporalの登場後も消えることは無いでしょうが、それらと比べたTemporalの利点はTemporalが標準ライブラリに含まれていることです。特にブラウザ環境では、Temporalで事足りるならば外部ライブラリが不要になり、JavaScriptのダウンロードサイズを削減することができます。
標準ライブラリの概念の登場によってこれまで最低限だったJavaScriptの機能を拡充しようという動きがあり、Temporalもその一環だといえます。
2. オブジェクトがイミュータブル
Temporalが提供するオブジェクトはイミュータブルです。つまり、オブジェクトを作成した後でそれが表す日時情報を書き換えることはできません。別の日時情報を表したい場合は別のオブジェクトを作ることになります。
これと対称的に、既存の
Dateオブジェクトはミュータブルでした。つまり、setFullYearやsetHoursなどのメソッドを使ってDateオブジェクトの日時情報を書き換えることができたのです。なぜミュータブルなオブジェクトよりもイミュータブルなオブジェクトのほうがよいのかは今さら言うまでもありません。特に今回扱うのは日時情報という「データ」の側面が強いものを表すオブジェクトです。例えば日時データを他の関数に渡すような場合に、その関数の中でオブジェクトが書き換えられてしまわないかどうかをわざわざ心配するのは無駄ですね。
// 日付データを引数で受け取る function foo(date) { // 別の関数に渡す bar(date); // dateはイミュータブルなのでbarによって書き換えられている心配はない console.log(date); }そもそも単なる日時データとしても
Dateが使いにくかったことがTemporalが登場する動機のひとつとなっています。3. 意味に応じて異なるオブジェクトを使用
既存の
Dateオブジェクトの最大の問題点はタイムゾーンの扱いがとても適当であるという点です。Dateオブジェクトは自分のタイムゾーンはどこかという情報を持っています1。明示していない場合タイムゾーンは環境依存です。また、(特にタイムゾーンが1つしかない日本では)タイムゾーンが特に必要でない日時処理もあり、そのような場合でもDateの仕様上タイムゾーンを意識しなければならないのはバグの元だし残念です。そこで、Temporalではタイムゾーンの情報を持つデータとタイムゾーンの情報を持たないデータを別々のオブジェクトで表現します。タイムゾーンの情報を持たない日時情報は
CivilDateTime、タイムゾーンの情報を持つ日時情報はZonedDateTimeというオブジェクトで表現します。また、詳しくは後述しますが他にもいくつかの種類のオブジェクトが利用可能です。4. ナノ秒単位のデータが扱える
読んで字のごとしです。既存の
Dateオブジェクトの時刻データはミリ秒単位の精度ですが、Temporalでは精度が6桁増えてナノ秒単位になりました。Temporalの使い方
では、いよいよTemporalの使い方を解説していきます。
Temporalを読み込む
Temporalは標準ライブラリに加えられる見込みですので、
import文を用いて読み込むことになります。例えばCivilDateTimeというオブジェクトを使用したいときは次のようにします。import { CivilDateTime } from "std:temporal";
"std:temporal"の部分は未確定です。"js:temporal"とかになるかもしれません。もちろんこれはまだブラウザ等には実装されていません。公式のPolyfillが存在しますが、仕様が変更されるにつれてPolyfillにも変更が加えられることになっていますので安定したものではありません2。また、現状ではこのPolyfillも少し古い情報(2019年3月以前の仕様)に基づいており、最新の情報を反映していません。以降のサンプルでは可能なものはこのPolyfillで動作を確認しています。
オブジェクトの種類
Temporalが提供するオブジェクトは現在のところ以下の種類があります。
- Civil系:
CivilDateTime,CivilTime,CivilDate,CivilYearMonth,CivilMonthDay- 絶対時間系3:
Instant,OffsetDateTime,ZonedDateTimeCivil系オブジェクト
Civil系というのはタイムゾーン情報を持たないデータで、持っている情報によってオブジェクトの種類が細分化されています。例えば
CivilDateというのは日付の情報、すなわち年・月・日を持つオブジェクトです、CivilTimeは時計、すなわち時間・分・秒及びそれ以下です。CivilDateTimeは日付と時計の両方の情報を持っています。また、CivilYearMonthというのは年と月のみで日及び時計の情報を持たないデータです。CivilMonthDayも同様に月と日のみで年の情報を持ちません。重要なのは、これらのCivil系オブジェクトは絶対的な(全世界的に一意の)ひとつの時刻を指し示すものではないということです。Civil系オブジェクトは例えば「2019年5月1日12時0分0秒」のように暦(こよみ)上の情報、すなわちカレンダーや時計の表示を表すものですが、このデータだけでは全世界的に一意の時刻を表すことはできません。例えば、日本とイギリスではこのデータが表す絶対時刻は9時間4ずれています。
要するに、Civil系オブジェクトはタイムゾーンあるいはオフセットの情報を持たないデータであるということです。これらのオブジェクトはタイムゾーンと関係ないローカルなデータや、カレンダーの処理をしたい場合に適しています。
絶対時間系オブジェクト
Civil系以外の残りの3つのオブジェクトは絶対時間を表すことができます。
Instantオブジェクトはその中でも「生データ」に近いオブジェクトであり、時刻を1970年1月1日0時0分0秒(世界標準時)からの経過時間(ナノ秒単位)で保持しています5。このように1970年1月1日からの経過時間で絶対時刻を表す方法はコンピュータにおける時刻表現として広く使われており、UNIX時間として知られています。
InstantはこのUNIX時間を表すオブジェクトであるといえます。さて、
Instantにより絶対時刻を表すことができますが、これは不便です。なぜなら、オフセットの情報が無いと実際にはこれが何月何日の何時何分なのか分からないからです。これも先ほどと同じ話で、例えば「1970年1月1日0時0分0秒(世界標準時)から100秒後」という時刻はイギリスでは1970年1月1日の0時1分40秒ですが、日本では1970年1月1日の9時1分40秒を表しており、ひとつに定まりません。オフセットは、世界標準時からどれだけ時差があるかということを表す分単位の情報です。例えば日本は世界標準時よりも9時間進んでいるのでオフセットは
+09:00です。イギリスは世界標準時と同じなので+00:00となります。絶対時刻とオフセットの2つの情報を組み合わせることで日時(カレンダー・時計の値)をひとつに定めることができます。例えば「1970年1月1日0時0分0秒(世界標準時)から100秒後」という時刻は
+09:00というオフセットにおいては「1970年1月1日9時1分40秒」という日時を表すのです。逆に言えば、日時とオフセットがあれば絶対時刻を特定することができます。つまり、「オフセット
+09:00における1970年1月1日9時1分40秒」というデータは「1970年1月1日0時0分0秒(世界標準時)から100秒後」という絶対時刻を一意に表しています。前置きが長くなりましたが、このような「日時とオフセット」の情報を持つオブジェクトが
OffsetDateTimeです。最後の
ZonedDateTimeはOffsetDateTimeと同様に日時の情報を持つオブジェクトですが、オフセットの代わりにタイムゾーンを持っています。タイムゾーンは地域名により表現されるデータであり、例えば日本のタイムゾーンは
Asia/Tokyoです。そして、Asia/Tokyoのオフセットは+09:00であるというデータがtz databaseに保存されているためタイムゾーンからはオフセットを得ることができます。これにより、ZonedDateTimeもやはり絶対時刻を表すことができます。
OffsetDateTimeとZonedDateTimeの大きな違いは、後者はタイムゾーン内でのオフセットの変化に対応可能だということです。日本ではあまり馴染みがありませんが、典型的には夏時間の影響により、時季によって同じタイムゾーン内でもオフセットが変わる可能性があるのです。これにより、ZonedDateTimeに対して日時の操作を行う場合、同じタイムゾーンでもオフセットが勝手に変動することがあります。一方のOffsetDateTimeは常に固定のオフセットを持ちます。一般に、タイムゾーンに寄り添った日時処理を行いたい場合はZonedDateTimeが便利ですね。まとめると、Civil系オブジェクトは暦により表された情報のみを持ちオフセットやタイムゾーンの情報を持たないオブジェクトで、絶対時刻を表すものではありません。
Instant,OffsetDateTime,ZonedDateTimeはいずれも絶対時刻を表すもので、さらにOffsetDateTimeはオフセットの情報を、ZonedDateTimeはタイムゾーンの情報を持っています。なお、Temporalが採用している暦は先発グレゴリオ暦であり、これは我々が慣れ親しんでいる暦(グレゴリオ暦)をグレゴリオ暦が実際に使われるよりも以前にも適用するようにしたものです。この暦は古い日付も統一的に扱えて簡単であるという利点からプログラミング言語での採用例があり、日時の表記の国際規格であるISO 8601にもこれが採用されています。Temporalは基本的にISO 8601に準拠して作られています。
では、ここからは各オブジェクトを見ていきます。とはいえ、TemporalのAPIはまだ変化の途上にあり、何ヶ月もすればAPIが別物になっているということも普通にあります。ですから以下の話はおまけ程度に考えてください。どちらかといえばここまで説明したコンセプトのほうが重要です。
CivilDateTimeつい先程述べたように、
CivilDateTimeは暦の上での日時情報を表すオブジェクトです。具体的には、年・月・日・時間・分・秒・そして秒以下の数値で日時を表します。CivilDateTimeオブジェクトを作る方法の1つはCivilDateTimeコンストラクタを使うものです。例えば、過ぎし2019年5月1日の0時0分0秒を表すCivilDateTimeは次のように作ります。// 年, 月, 日, 時, 分の順でコンストラクタに数値を渡す const startOfReiwa = new CivilDateTime(2019, 5, 1, 0, 0);まず最初に気づいていただきたいのは、月は1始まりということです。古い
Dateオブジェクトでは月は0〜11の整数で表され、0が1月、1が2月、……11が12月というとても間違えやすい仕様になっていたのですが、Temporalでは1〜12の数値になっています。上の例ではコンストラクタの引数は5個ですが、最大9個まで数値を指定可能です。意味は順に年、月、日、時、分、秒、ミリ秒、マイクロ秒、ナノ秒です。ミリ秒以下は0から999の数値で指定します。例えば、2019年5月1日の2時34分56.789012345秒という時刻を表したい場合は次のようにします。
const time = new CivilDateTime(2019, 5, 1, 2, 34, 56, 789, 12, 345);
CivilDateTimeコンストラクタの引数は最低5個必要です。つまり、秒以下は省略可能ですが分以上は省略できません。省略したところは当然0になります。
CivilDateTimeのプロパティこうして作られた
CivilDateTimeオブジェクトからはいくつかのプロパティを通して情報を取得可能です。基本的なプロパティはyear、month、date、hour、minute、second、millisecond、microsecond、nanosecondで、上記のコンストラクタの引数にちょうど対応した情報を持っています。console.log(time.year); // 2019 console.log(time.day); // 1 console.log(time.millisecond); // 789
DateではgetFullYear()などとする必要があったのに比べると簡潔で嬉しいですね。また、いくつか追加の情報を取得できるプロパティがあります。
dayOfWeekはその日付の曜日を表す数値であり、1(月曜日)〜7(日曜日)の整数で表されます。dayOfYearはその日がその年の1月1日から数えて何日目かを表す数値です(1月1日は1日目です)。そしてweekOfYearは週番号、すなわちその日を含む週がその年の何週目かを表す数値です。console.log(time.dayOfWeek); // 3 (2019年5月1日は水曜日) console.log(time.dayOfYear); // 121 console.log(time.weekOfYear); // 18なお、週番号についてはISO 8601で規定されているものであり、「年の最初の木曜日を含む週がその年の第1週である」とされています。その結果、次の例のように年始の日付が前の年の最終週に属するという判定になることがあります。
const wah = new CivilDateTime(2010, 1, 3, 0, 0); console.log(wah.weekOfYear); // 522010年最初の木曜日は1月7日ですから、1月7日を含む週が2010年の第1週です。
dayOfWeekで月曜日が1であることからも分かるように週は月曜日〜日曜日が1つの週という数え方になりますから、2010年の第1週は1月4日(月)〜1月10日(日)ということになります。よって、それより前の1月3日は週番号上は2009年の最終週に属することになるのです。文字列への変換
日時データというのは頻繁にコンピュータ間でやり取りされます。そのためには日時データを表現する共通の方法が必要であり、それはやはりISO 8601によって規定されています。
CivilDateTimeはtoString()によってISO 8601に適合する文字列に変換可能です。toString()は文字列への暗黙の変換の際も呼ばれます。const startOfReiwa = new CivilDateTime(2019, 5, 1, 0, 0); console.log(startOfReiwa.toString()); // "2019-05-01T00:00:00.000000000"ちなみに、ISO 8601では秒未満(
.以降の部分はオプショナルで桁数の規定はありませんが、Temporalでは9桁、すなわちナノ秒の精度で文字列化することが規定されています。なお、日時データを機械ではなく人間が読みやすい形で表示できる機能というのも需要がありますが、それは現在議論中でまだ固まっていないようです。
文字列からの変換
上で紹介したメソッドたちとは逆に、文字列から
CivilDateTimeオブジェクトを得るための方法も用意されています。それがCivilDateTime.fromString()です。CivilDateTime.fromStringの例console.log(CivilDateTime.fromString("2019-05-01T00:00:00.000000000"));なお、ISO 8601文字列はもう少しバリエーションがありますが、
CivilDateTime.fromStringはそれらの文字列も受け付けてくれそうな雰囲気があります。雰囲気というのはどういうことかというと、正確に何が受け付けられて何が受け付けられないのかは仕様策定者たちの頭の中にしかない(あるいは決まっていないかもしれない)ということです。
plus: 時刻の加算
CivilDateTimeオブジェクトはplusメソッドを持ち、ある時刻に対して加算を行うことができます。CivilDateTimeオブジェクトはイミュータブルですから、結果は新しいCivilDateTimeオブジェクトとして得られます。さっそく例を見ましょう。const startOfReiwa = new CivilDateTime(2019, 5, 1, 0, 0); // 12時間足して正午にする const noon = startOfReiwa.plus({ hours: 12 }); console.log(noon.toString()); // "2019-05-01T12:00:00.000000000" // 1年戻して5000秒進める const time2 = noon.plus({ years: -1, seconds: 5000 }); console.log(time2.toString()); // "2018-05-01T13:23:20.000000000"このように、
plusにはオブジェクトを渡します。オブジェクトはyears,months,days,hours,minutes,milliseconds,microseconds,nanosecondsを持つことができます。プロパティ名が複数形である点に注意してください。2番目の例のように、負の数を渡すことで時間を戻すこともできます。
with: 部分的な上書き
withメソッドは、既存のCivilDateTimeオブジェクトの情報を部分的に書き換えて得られる新しいCivilDateTimeオブジェクトを返します。const startOfReiwa = new CivilDateTime(2019, 5, 1, 0, 0); // 年を2100年に、日を31日に変更する const maybeNotReiwa = startOfReiwa.with({ year: 2100, day: 31 }); console.log(maybeNotReiwa.toString()); // "2100-05-31T00:00:00.000000000"渡すのはやはりオブジェクトであり、
CivilDateTimeと同名のプロパティたちを用いて上書き箇所を指定します。
minus: 2つの日時の差を得る2つの
CivilDateTimeの間の期間を得ることができるminusメソッドも用意されています。使い方は多分こんな感じです。const startOfReiwa = new CivilDateTime(2019, 5, 1, 0, 0); const startOfHeisei = new CivilDateTime(1989, 1, 8, 0, 0); const diff = startOfReiwa.minus(startOfHeisei); console.log(diff); /* { years: 31, months: 3, days: 23, hours: 0, minutes: 0, seconds: 0, (以下略) } */多分こんな感じというのは、メソッドの存在だけとりあえず決まっていそうな感じがして具体的な計算方法はまだ決まっていなそうな感じがしていることを意味しています。
CivilDate他のCivil系のオブジェクトは基本的に
CivilDateTimeより情報が少ないバージョンです。CivilDateは年・月・日の情報だけを持ち、コンストラクタの引数は年・月・日の3つです。const startOfReiwa = new CivilDate(2019, 5, 1);プロパティとしては
year,month,dayを持ちます。また、dayOfWeek,dayOfYear,weekOfYearも日付だけあれば計算可能なので持っています。持っているメソッドたちも同様で、with,plus,minusがあります。注意すべき点は、
plusでは渡されたオブジェクトのyears,months,daysのみ見られるということです。次のようにしても日付が1日進んだりはしません。// hoursは無視されるのでこれはstartOfReiwaと同じ const tomorrow = startOfReiwa.plus({ hours: 24 });また、
CivilDateは日付の情報のみを持っているオブジェクトでしたが、次に紹介するCivilTime(一日の中の時刻情報だけを持つ)と組み合わせることでCivilDateTimeを作ることができます。そのためにはwithTimeメソッドを用います。const startOfReiwa = new CivilDate(2019, 5, 1); const clock = new CivilTime(12, 34, 56); const dateTime = startOfReiwa.withTime(clock); console.log(dateTime.toString()); // "2019-05-01T12:34:56.000000000"文字列への変換
CivilDateで特筆すべき点は文字列への変換メソッドを3種類持っている点です。実はISO 8601では日付の表現方法が3種類規定されています。1つは2019-05-01のように年-月-日で表現する方法、2つ目は2019-W18-03のように年-週番号-曜日で表現する方法、そして最後は2019-121のように年とその年の1月1日からの日数で表す方法です。この3種類の変換はそれぞれ
toDateString(),toWeekDateString(),toOrdinalDateString()で可能です。toString()はtoDateString()と同じになります。
fromString()は3種類の表現の全てを受け付けてくれます。
CivilTime
CivilTimeのコンストラクタは2〜6引数です。最初の2つ、すなわち時と分は省略不可能で、それ以下(秒、ミリ秒、マイクロ秒、ナノ秒)は省略可能です。また、
withDateにCivilDateを渡すことでCivilDateTimeに変換することができます。
CivilYearMonth
CivilYearMonthは年と月だけの情報を持ちます。コンストラクタの引数もその2つです。withDay()メソッドでCivilDateに変換できます。
CivilMonthDay
CivilMonthDayは月と日だけの情報を持ちます。withYear()メソッドでCivilDateに変換できます。なんだか後半駆け足でしたが、以上でCivil系の説明は終わりです。
Instant
Instantは前述の通り、UNIXエポック(1970年1月1日0時0分0秒(世界標準時))からの経過時間(ナノ秒)によって絶対時刻を表すデータです。よって、InstantコンストラクタにはUNIXエポックからの経過時間を渡します。例えば、UNIXエポックから1556636400000000000ナノ秒後の絶対時刻を表すInstanceオブジェクトを作りたい場合は次のようにします。const inst = new Instant(1556636400000000000n);なお、
1556636400000000000nというのはBigIntのリテラルです。普通の数値型ではナノ秒単位の秒数を扱うには精度が小さいのでBigIntが使われています。数値型の精度とかBigIntの話は筆者の別記事がありますのでよろしければそちらもご覧ください。
Instantオブジェクトからは、UNIXエポックからの経過時間を秒・ミリ秒・マイクロ秒・ナノ秒単位で得ることができます。console.log(inst.epochSeconds); // 1556636400 console.log(inst.epochMilliseconds); // 1556636400000 console.log(inst.epochMicroseconds); // 1556636400000000n console.log(inst.epochNanoseconds); // 1556636400000000000nマイクロ秒とナノ秒はBigIntになっています。ミリ秒くらいなら普通の数値で行けるだろという判断のようです。ちなみに、ミリ秒をBigIntではなく普通の数値で表した場合、西暦約29万年問題の発生が懸念されます。今からとても心配ですね。
また、
InstantにもtoStringとfromStringがありますが、何に変換されるのかはよく分かりません。多分ZタイムゾーンのISO 8601表現とかだと思いますが。
Instantにはオフセットやタイムゾーンの情報がないため具体的な日付や時刻の数値が分からないのでした。そのため、上記のように得られる情報は人間には分かりにくいものとなっています。そこで、
withOffsetやwithZoneメソッドでこれらの情報を付加することでOffsetDateTimeやZonedDateTimeに変換することができます。withOffsetには"+09:00"のようなオフセットを表す文字列を、withZoneには"Asia/Tokyo"のようなタイムゾーンを表す文字列を渡します。
OffsetDateTime
OffsetDateTimeはオフセット情報のついた時刻データです。API的にはCivilDateTimeプラスアルファだと思えば間違いありません。作り方は
InstantのwithOffsetを使う方法やnew OffsetDateTime(instant, offset)のようにする方法があります。どちらにせよInstantのインスタンスが必要ですね。CivilDateTimeにもwithOffsetがある気がするのですがはっきりとは分かりませんでした。また、OffsetDateTime.fromStringで文字列から作る方法もあります。
OffsetDateTimeは自分のタイムゾーンの元で自分が何年何月何日の何時何分かということを知っていますから、CivilDateTimeの機能は全て利用可能です。year,monthなどのプロパティで数値を取得したりplus,with,minusメソッドを使用できます。加えて、
instantプロパティで自分の絶対時刻を表すInstantオブジェクトを取得可能です。また、offsetプロパティはオフセットを表す文字列です。toStringに関してはISO 8601に従ってオフセット情報が付加された文字列を返します。const inst = new Instant(1556636400000000000n); const datetime = new OffsetDateTime(inst, "+09:00"); console.log(datetime.year); // 2019 console.log(datetime.month); // 5 console.log(datetime.day); // 1 console.log(datetime.offset);// "+09:00" console.log(datetime.toString()); // "2019-05-01T00:00:00.000000000+09:00"なお、なぜか
OffsetDateTime.fromZonedDateTimeが用意されておりZonedDateTimeからOffsetDateTimeへの変換ができます。
ZonedDateTime
ZonedDateTimeはタイムゾーンの情報を持ったオブジェクトで、OffsetDateTimeのさらに上位互換です。作り方は先ほど説明したInstantのwithZoneか、new ZonedDateTime(instant, zone)です(あとZonedDateTime.fromString)。
OffsetDateTimeの機能は全て使える上に、timeZoneプロパティでタイムゾーンを取得できます。また、toString()の結果は下のようにタイムゾーンの情報が付加されます。const inst = new Instant(1556636400000000000n); const datetime = new ZonedDateTime(inst, "Asia/Tokyo"); console.log(datetime.year); // 2019 console.log(datetime.month); // 5 console.log(datetime.day); // 1 console.log(datetime.offset);// "+09:00" console.log(datetime.timeZone); // "Asia/Tokyo" console.log(datetime.toString()); // "2019-05-01T00:00:00.000000000+09:00[Asia/Tokyo]"
[Asia/Tokyo]のように角括弧で囲まれたタイムゾーン名があるのが特徴的です。また、オフセットの情報もついています。補足:現在時刻の取得について
古い
Dateは引数なしでDateコンストラクタを呼ぶと初期値が現在時刻になったり、Date.now()でミリ秒の形で現在時刻を取得できたりします。Temporalでは同様の方針は採用されませんでした。一時期は「JavaScriptの言語仕様自体に外界の情報を得る手段をこれ以上増やすべきではない」との観点から仕様としてはそのような手段を用意しないべきではという議論もされましたが、さすがに何かあったほうがいいだろうという方向に話が進んでいるように見えます(参考)。一案として以下のようなAPIが出ています。import { now, timeZone } from "std:temporal/now"; now(); // 現在時刻を表すInstantが返る timeZone(); // 現在地のタイムゾーンを表す文字列が返る // この2つの情報から現在時刻を表すZonedDateTimeが作れる const currentTime = new ZonedDateTime(now(), timeZone();まとめ
というわけで、現在使用策定中のTemporalについて紹介しました。旧来の
Dateに比べると様々な点で改良されています。日付の計算はplusとminusくらいしかありませんが、結構それで事足りることもあるでしょう。また、記事中でちらっと触れた通り、人間向けのフォーマッティングについても別個に議論されるようです(それ系はIntlという別の仕様の範疇となる可能性が高いです)。後半のAPIの話をよく読んだ方は
CivilDateTimeからZonedDateTimeにどうやって変換すんのこれなどの鋭い疑問を持ったかもしれません。自分も持ちましたが、まだAPIが整理されていないということで勘弁してあげましょう。実はこの記事がベースとしているのはつい2週間ほど前にドラフトが書き上がったばかりの文書で、実際自分も読んでいる途中にいくつもおかしな箇所を見つけました。仕様化が終わるまでには直っているでしょう。それよりも、おおよそのTemporalの方向性をこの記事で理解していただけたら幸いです。Civil系、
Instant、OffsetDate、そしてZonedDateTimeというようにオブジェクトを細分化し、今どの情報を持っていてどの情報を持っていないのかということを明示できるようにしたのはDateからの大きな進歩です。個人的には、Temporalが実際に利用可能になるには速く進んでもあと2〜3年はかかりそうだと考えています。
いざTemporalがブラウザに搭載されたときに解説記事を書こうとした人がn年前に書かれたこの記事を見て悔しがるのが今から楽しみです。リンク
- Temporal Proposal - プロポーザルの文書です。
- What about Temporal in JavaScript - Temporalを紹介する恐らく唯一の既存日本語資料です。2019年2月のスライドなのでAPIが少し古いです(
ZonedTimeZOneではなくZonedInstantになっていたりOffsetDateTimeが存在しないなど)。- Fixing JavaScript Date - Getting Started - Temporalを作るモチベーションを解説する文書です。
厳密には
Dateはオフセット(世界標準時からの時差を数値で表したもの)でタイムゾーンを表しています。Temporalはタイムゾーンをそのまま扱うことができる点で進化しています。 ↩このPolyfillは仕様の策定を担当している方が片手間に作った感じのもので、めちゃくちゃしっかり作られているわけではありません。実際、この記事を書いている間に筆者は1個バグを見つけました。 ↩
ここでは「全世界で共通の時間軸」や「その上の時刻」という程度の意味で絶対時間と言っています。この言葉で検索すると哲学とか物理学の話題が出てきて怖いのですが、あまりその方面から突っ込みを入れてくださらないようにお願いします。 ↩
イギリスが夏時間の場合は8時間ですが。 ↩
なお、この情報は閏秒を考慮していないため、その分だけ実際の経過時間(物理的に1970年1月1日0時0分0秒から経過した時間)とはずれがあります。コンピュータにおける時刻表現は基本的に閏秒を考えていないのでTemporalが特別に劣っているわけではありませんが。閏秒を厳密に処理する必要がある場合は閏秒のデータを用意して自分で処理する(あるいはそういう処理をやってくれるライブラリを使用する)必要があります。 ↩
- 投稿日:2019-05-06T17:01:33+09:00
WeakRef: JavaScriptに弱参照がやってくる(ついでにFinalizationも)
WeakRef、すなわち弱参照は多くの(ガベージコレクションを持つ)プログラミング言語に存在する機能です。ちょっと「weakref」でGoogle検索するだけで、Python, Ruby, PHP, Javaにこの概念が存在することが確認できます。
皆さんもよくご存知の通り、JavaScriptもガベージコレクションを持つ言語のひとつです。しかし、残念なことに弱参照はいまだJavaScriptにありませんでした。
もちろん、そんな状況に置かれているJavaScriptに弱参照を導入しようという動きもしっかりとあります。それがWeakRefプロポーザルです。このプロポーザルは現在Stage 2、つまり方向性はおおよそ定まって絶賛仕様策定中という状況です。それゆえに、この記事で解説することの委細は今後変わるかもしれません。しかし大きな方向性はよほどのことがないと変わらないと考えられます。このことを理解し、ぜひWeakRefの登場に備えましょう。
※記事タイトルに「JavaScriptに弱参照がやってくる」とありますが、実際にやってくるのは多分年単位で先です。なお、node.js(v12以上)は
--harmony-weak-refsオプションをつけることで実験的な実装を利用可能です。WeakRefとは何か
では、いよいよWeakRefとは何かについて解説します。日本語では先程も述べたとおり弱参照ですが、これは参照先のオブジェクトがガベージコレクション対象になってしまうかもしれないような参照です。
参照
ここで「参照」という言葉が出てきましたが、ここでは何らかの方法でオブジェクトにアクセス可能な手段を参照と呼んでいます。この概念を掴むために、次の例を見てみましょう。
let obj = { name: "object 1" }; obj = { name: "object 2" };変数
objに{ name: "object 1" }を入れたあと、次に{ name: "object 2" }を入れました。最初のオブジェクトをオブジェクト1、次のオブジェクトをオブジェクト2とすると、objはまずオブジェクト1が入った後にオブジェクト2が入りました。このとき、オブジェクト2はobjに入っているのでobjを通じてアクセス可能ですが、オブジェクト1はもう変数objに入っていないので、どうやってもプログラムからアクセス不能です。つまり、オブジェクト2へは参照があり、オブジェクト1へは参照が無いという状態になっています。ところで、オブジェクト1やオブジェクト2がプログラムに登場した時点で、それらの実体がマシンのメモリ上に作成されます。そもそもプログラム中に登場する全ての値(数値とかも)はマシンが覚えている必要があり、覚えておくために情報を置いておく場所がメモリです。
参照されなくなったオブジェクトはもうプログラムにとっては有っても無くても関係ないどうでもよい存在ですから、メモリから消しても構いません。ところが、ガベージコレクションのある言語では、参照されなくなったオブジェクトを即座にメモリから消去することはあまりありません。もう参照されていない不要なオブジェクトがメモリ上に溜まってからまとめて消す処理をするのが普通です。この処理がガベージコレクションです。
上のプログラムの実行後は、ガベージコレクションによってオブジェクト1が消去されるかもしれません。その一方、オブジェクト2は消去されません。なぜなら、変数
objを使ったらオブジェクト2を触ることができるからです。参照されているオブジェクトは触られる可能性があるのでメモリ上にデータが無ければいけません。弱参照
では、話を弱参照に戻しましょう。これはその名の通り弱い参照です。つまり、オブジェクトへの参照はあるけど、弱いので参照先がオブジェクトがガベージコレクションされているかもしれないというものです。よって、いざ参照先のオブジェクトを使おうとしたらもう捨てられていて使えませんという事態になることがあります。
WeakRefの使い方
WeakRefのAPIはとても単純です。まず、何らかのオブジェクトobjへの弱参照を表すWeakRefオブジェクトはnew WeakRef(obj)として作成します。WeakRefの使用例let obj = { name: "object 1" }; const wref = new WeakRef(obj);そして、
WeakRefオブジェクトの参照先を得るにはderefメソッドを用います。上の例の直後にderef()メソッドを呼ぶと当然返り値はobjです。console.log(wref.deref() === obj); // trueもし
wref.deref()を呼ぶまでの間にwrefの参照先がガベージコレクションの対象になって捨てられた場合は、wref.deref()の返り値はundefinedとなります。ただし、上の例で
wrefの参照先がガベージコレクションの対象となるには、まずobjを通じた当該オブジェクトへの参照を消す必要があります。let obj = { name: "object 1" }; // objにオブジェクト1を代入 const wref = new WeakRef(obj); console.log(wref.deref()); // { name: "object 1" }; // オブジェクト1への(弱ではない)参照を無くす obj = null; // ここではオブジェクト1への参照はwrefによる弱参照のみ // しばらくするとwrefの参照先がガベージコレクトされるかも // するとwref.deref()の返り値はundefinedになる console.log(wref.deref()); // undefined
WeakRefの基本はこれだけです。とても簡単ですね。
FinalizationGroupしかし、実はガベージコレクションに関連してもうひとつセットで提案されているAPIがあります。それが
FinalizationGroupです。このAPIを使うと、オブジェクトがガベージコレクトされた(メモリから消去された)タイミングを検知することができます。これの使い方もそんなに難しくありません。まず
new FinalizationGroup(callback)として新しいFinalizationGroupオブジェクトを作成します。callbackというのは値がガベージコレクトされたときに呼ばれるコールバックですが、これの詳細はあとで説明します。そして、できたオブジェクトの
registerメソッドを呼ぶことで、ガベージコレクトされたのを検知したいオブジェクトを登録します。FinalizationGroupの使用例// オブジェクトが捨てられたときに呼ばれるコールバック(詳細は後述) const handler = iterator => { for (const key of iterator) { console.log(key, "がガベージコレクトされました"); } }; // FinalizationGroupオブジェクトを作成 const group = new FinalizationGroup(handler); // 適当なオブジェクトを作成 const obj = { name: "object 1" }; // 監視対象に登録 group.register(obj, "オブジェクト1");このように、
registerメソッドの第1引数に監視対象のオブジェクトを渡します。これにより、objがガベージコレクトされたらhandlerが呼ばれることになります。ポイントは第2引数です。これは、第1引数のオブジェクトを表す何らかの値です(別のオブジェクトでも構いませんが)。実は、第1引数のオブジェクトがガベージコレクトされた場合に実際にコールバックに渡されるのは第2引数に指定したほうの値です(holdingsと呼ばれるらしいです)。その理由は、第1引数のオブジェクトはそのタイミングでは既にガベージコレクトされており利用不能になっているからです。そのため、代わりに(既にガベージコレクトされて消えてしまった)オブジェクトを識別するためのものとしてholdingsの値を利用します。
では、いよいよ
FinalizationGroupに渡すコールバックの解説をします。何らかのオブジェクト(複数まとめてかもしれません)がガベージコレクトされて消されたとき、コールバック関数にはそれらのオブジェクトに対応するholdingsたちのイテレータが渡されます。イテレータの詳細な説明は省きますが、for-ofでループしたりArray.from(iterator)で配列に変換できると思っておけば大丈夫です1。上の例でいえば、
objがガベージコレクトされた場合はhandlerが呼び出されて、最終的にfor-ofループのkeyに"オブジェクト1"が入ってくることになります。今回はconsole.logするだけですが、この得られたholdingsをどう使うかはあなた次第です。次の例で以上の動作を試すことができます(
--harmony-weak-refsに加えて、ガベージコレクションを起動するgc()関数を利用可能にする--expose-gcオプションをnodeに与える必要があります)。// オブジェクトが捨てられたときに呼ばれるコールバック const handler = iterator => { for (const key of iterator) { console.log(key, "がガベージコレクトされました"); } }; // FinalizationGroupオブジェクトを作成 const group = new FinalizationGroup(handler); // 適当なオブジェクトを作成(GCされやすいように1GBのメモリを確保) let obj = new ArrayBuffer(1024 ** 3); // 監視対象に登録 group.register(obj, "でかいメモリ"); // objへの(弱くない)参照を消す obj = null; // ガベージコレクションを起動 gc();これを実行すると、(ガベージコレクションの挙動にもよりますが)普通は
でかいメモリ がガベージコレクトされましたというログが表示されるはずです。これは、gc()により1GBのArrayBufferがガベージコレクトされて、それに反応してFinalizationGroupのコールバックが呼ばれたことを意味しています。以上が
FinalizationGroupの機能です。ちなみに、registerを取り消すunregisterメソッドもあります(使用するためには取り消し用のトークンを新たに用意してregisterの第3引数に渡す必要がありますが詳細は省略します)。
WeakRefの使いみちここまで解説したように、
WeakRefの機能は「弱参照を作る」というたいへんシンプルなものです。また、FinalizationGroupも「オブジェクトがガベージコレクトされたら教えてくれる」という同じくらいのシンプルさです。上では別々に紹介しましたが、両方ともガベージコレクションに関わる機能ですからもちろん組み合わせられる場面もあるでしょう。機能がシンプルな分だけ、その使いみちは幅広いでしょう。とはいえ、
WeakRefの典型的な使い道としてはキャッシュを挙げざるを得ません。
WeakRefは「いつ消えるか分からないオブジェクトへの参照」を持つのが基本的な役割ですから、WeakRefで弱参照されているオブジェクトは「あったら嬉しいけど無くてもまあ大丈夫なオブジェクト」ということになります。これに当てはまるのがまさにキャッシュでしょう。例えばネットワークからダウンロードしたファイルをキャッシュしておくことで、そのファイルが再び必要になったときに再びダウンロードする時間をかけずにファイルを利用することができます。もしキャッシュしておいたファイルが消えていても、再びダウンロードすればまあ大丈夫です2。特に、キャッシュは一般に容量を喰いますから、全てのキャッシュをメモリに溜め込んでおくことはできません。不要なキャッシュは捨てることでメモリ使用量を少なくすることができます。
キャッシュされた値を
WeakRefを用いて弱参照で保持しておくことで、このような(メモリが埋まってきたらいらないものを消すという)動作をガベージコレクションに任せることができます。また、FinalizationGroupと組み合わせることによって、キャッシュされたデータ本体に付随するメタデータの掃除などもできるでしょう。もう少し具体的な実装例がプロポーザルのページにたくさん載っていますので、気になる方は見てみてください。
WeakMap・WeakSetとの関係実は、JavaScriptの既存機能にも弱参照に関連するものはあります。それは
WeakMapやWeakSetです。WeakMapは好きなオブジェクトに対して好きな値を紐付けられるデータ構造でしたね。特徴は、WeakMapからキーとなるオブジェクトへの参照が弱参照であるという点です。つまり、何らかのオブジェクトがWeakMapのキーとして登録されていてもそのオブジェクトがガベージコレクトされることは妨げられません。WeakMapの例const wmap = new WeakMap(); let obj = { name: "object 1" }; // objにオブジェクト1を代入 // objに対して"foobar"を覚えておく wmap.set(obj, "foobar"); // ... // objに対応する値を取り出す console.log(wmap.get(obj)); // "foobar" // オブジェクト1への参照を消すとそのうちガベージコレクトされる(wmapからオブジェクト1への参照は弱いので) obj = null;ただし、
WeakMap等は自身に登録されているキーを露出するAPIを持ちませんので、「当該オブジェクトを取り出そうとしたけどもう捨てられていた」のような事態は発生しません。これがWeakRefとの大きな違いです。このように、これまでは
WeakMap等の内部でのみ用いられていた弱参照の概念を我々が直に利用できるようにする新しいAPIがWeakRefであると言えます。まとめ
この記事ではWeakRefsプロポーザルで提案されている
WeakRefおよびFinalizationGroupというAPIを紹介しました。これらは両方ともガベージコレクションに関するAPIで、オブジェクトがガベージコレクトされるかどうか、あるいはされた場合はどうするかといったことに切り込める面白いAPIです。使用する場面は限られているかもしれませんが、いざ実用化されたらぜひ一回くらいは使ってみたいですね。
- 投稿日:2019-05-06T15:11:36+09:00
LinebotとGASとアニメで1日100フレーズの英文を復習してみる
はじめに
この記事では、「英語を勉強している」という大義によって、他にやるべきことがあるにも関わらず、アニメや映画を見ることを正当化し、一見意識高そうに堕落する方法を紹介しています
やりたいこと
「ねえ、確率の計算って知ってる?」
「かずまが3回連続で勝つとかすごく無茶振りなんですけどー笑」
「スゥー。俺、じゃんけんで負けたことねえから」
みたいな英語のフレーズをスラスラと言えるようになりたい出典:KONOSUBA -God's blessing on this wonderful world! 2 Episode 7 – An Invitation for This Knucklehead!
※違法サイトは使っておりません。英語ネイティブ向けの有料ストリーミングサービスからの引用です
作ったもの
スプレッドシートに入れた英文を15分ごとにLINEに通知してくれるlinebot
英語を見て、対応する日本語を忘れてしまっていた場合、リンクをクリックする
該当行にジャンプするので、対応する日本語を復習する
15分ごとに通知するようにすれば1日100フレーズ復習できます
これで3ヶ月で最低限冗談言い合いながら会話できるようになりました夜寝てる間には通知が30ほどたまるので、朝にまとめて復習します
寝る前と寝起きすぐの復習は記憶の定着率がいいそうです。linebot(Line Messaging API)の登録
Line Developersから登録できます
登録方法は富士通さんの解説がわかりやすかったのでご参考ください
記事の頃から見た目が少し変わってますがわかる範囲だと思いますbotのchannel accsess tokenと自分のuser idの取得、botへの友達登録まで済ませてください
スプレッドシート作成
なんでもいいので名前をつけて新規作成しましょう。作れたら1行目はスクショのようにします。
A列は復習したい外国語、B列は対応する日本語、C列は通知がどこまでされたかを表す数字です。
C列は最初は1と記入しておいてください。1つ通知が送られると数字が1ずつ加算されますタイにいたためタイ語も入ってることご容赦ください。本来はタイ語が話せないという死活問題を解決することに始まり、英語に派生しました。ちなみに、タイ語は会話ができればよかったので発音記号とひらがなで覚えてました
gasの記述
こちらの方のスクリプトを参考にさせていただきました
コメントなど大変わかりやすかったため一部そのままのところもあります。ありがとうございますGoogle Spread Sheetは1シートに対して1つのスクリプトを紐づけることができます
海外にかぶれてブラウザが英語設定なのもご容赦ください。
開けたらJavascriptを記述していきましょう
画像を参考にbotのchannel access tokenとuser id、スプレッドシートのリンクの3つを自分のものに変えてお使いください
z,y,zの羅列の部分ですhttps://script.google.com/hogefuga/** * @OnlyCurrentDoc */ // LINE Developersに書いてあるChannel Access Token var access_token = "xxxxxxxxxxxxxxxxxxxxxxxxxxxx"; // 自分のユーザーIDを指定します。LINE Developersの「Your user ID」の部分です var to = "yyyyyyyyyyyyyyyyyyyyyyyyy"; function text_message(text){ return { "type": "text", "text": text } } function choose_in_order(arrayData,isChange){ var ss = SpreadsheetApp.getActiveSpreadsheet(); var sheet = ss.getActiveSheet(); var arrayIndex = sheet.getRange(1,3,1,1).getValue(); var index = arrayIndex+1; if(isChange == true){ if(index < sheet.getLastRow()){ sheet.getRange(1,3,1,1).setValue(arrayIndex+1); }else{ sheet.getRange(1,3,1,1).setValue(1); } } return index+':'+arrayData[arrayIndex-1][0]; } function getEngs() { var ss = SpreadsheetApp.getActiveSpreadsheet(); var sheet = ss.getActiveSheet(); var range = sheet.getRange(2,1,sheet.getLastRow()-1); var values = range.getValues(); return values; } function getJaps() { var ss = SpreadsheetApp.getActiveSpreadsheet(); var sheet = ss.getActiveSheet(); var range = sheet.getRange(2,2,sheet.getLastRow()-1); var values = range.getValues(); return values; } function messagePush(){ //これは皆同じなので、修正する必要ありません。 var url = "https://api.line.me/v2/bot/message/multicast"; var headers = { "Content-Type" : "application/json; charset=UTF-8", 'Authorization': 'Bearer ' + access_token, }; //toのところにメッセージを送信したいユーザーのIDを指定します。(toは自分のtokenを指定したので、linebotから自分に送信されることされます) var eng = choose_in_order(getEngs(),true); /* 日本語も添えて送りたければこちらコメントアウト外してください var jap = choose_in_order(getJaps(),true); */ var ss = SpreadsheetApp.getActiveSpreadsheet(); var sheet = ss.getActiveSheet(); var arrayIndex = sheet.getRange(1,3,1,1).getValue(); var postData = { "to" : [to], "messages" : [ text_message(eng+'\n'+'https://docs.google.com/spreadsheets/zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz/edit#gid=0&range=A'+arrayIndex) // スプレッドシートではurlにrangeというクエリをつけることで指定したセルに飛ぶことができます ] }; /* 日本語も添えて送りたければこちらコメントアウト外して代わりにお使いください var postData = { "to" : [to], "messages" : [ text_message(eng+'\n'+jap+'\n'+'https://docs.google.com/spreadsheets/zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz/edit#gid=0&range=A'+arrayIndex) ] }; */ var options = { "method" : "post", "headers" : headers, "payload" : JSON.stringify(postData) }; return UrlFetchApp.fetch(url, options); }再掲
15分おきに通知(メッセージ送信)の設定
最後に、あるタイミングでスクリプトを走らせるバッチの設定です
同じように設定してください
15分おきだと多いと感じる方はここで変更することができます
編集リクエスト、解説して欲しいところなどのコメントお待ちしております
参考
事前準備 LINE Messaging APIアクセストークンの取得 | 富士通
LINE Messaging API を使用して、会話の「くっころ」という言葉に反応して「くっころ」してしまうBOTを作成する方法 | Qiita















- 投稿日:2019-05-06T15:11:36+09:00
LinebotとGASとアニメで1日100フレーズの英文を復習してみた
はじめに
この記事では、「英語を勉強している」という大義によって、他にやるべきことがあるにも関わらず、アニメや映画を見ることを正当化し、一見意識高そうに堕落する方法を紹介しています
やりたいこと
「ねえ、確率の計算って知ってる?」
「かずまが3回連続で勝つとかすごく無茶振りなんですけどー笑」
「スゥー。俺、じゃんけんで負けたことねえから」
みたいな英語のフレーズをスラスラと言えるようになりたい出典:KONOSUBA -God's blessing on this wonderful world! 2 Episode 7 – An Invitation for This Knucklehead!
※違法サイトは使っておりません。英語ネイティブ向けの有料ストリーミングサービスからの引用です
作ったもの
スプレッドシートに入れた英文を15分ごとにLINEに通知してくれるlinebot
英語を見て、対応する日本語を忘れてしまっていた場合、リンクをクリックする
該当行にジャンプするので、対応する日本語を復習する
15分ごとに通知するようにすれば1日100フレーズ復習できます
これで3ヶ月で最低限冗談言い合いながら会話できるようになりました夜寝てる間には通知が30ほどたまるので、朝にまとめて復習します
寝る前と寝起きすぐの復習は記憶の定着率がいいそうです。linebot(Line Messaging API)の登録
Line Developersから登録できます
登録方法は富士通さんの解説がわかりやすかったのでご参考ください
記事の頃から見た目が少し変わってますがわかる範囲だと思いますbotのchannel accsess tokenと自分のuser idの取得、botへの友達登録まで済ませてください
スプレッドシート作成
なんでもいいので名前をつけて新規作成しましょう。作れたら1行目はスクショのようにします。
A列は復習したい外国語、B列は対応する日本語、C列は通知がどこまでされたかを表す数字です。
C列は最初は1と記入しておいてください。1つ通知が送られると数字が1ずつ加算されますタイにいたためタイ語も入ってることご容赦ください。本来はタイ語が話せないという死活問題を解決することに始まり、英語に派生しました。ちなみに、タイ語は会話ができればよかったので発音記号とひらがなで覚えてました
gasの記述
こちらの方のスクリプトを参考にさせていただきました
コメントなど大変わかりやすかったため一部そのままのところもあります。ありがとうございますGoogle Spread Sheetは1シートに対して1つのスクリプトを紐づけることができます
海外にかぶれてブラウザが英語設定なのもご容赦ください。
開けたらJavascriptを記述していきましょう
画像を参考にbotのchannel access tokenとuser id、スプレッドシートのリンクの3つを自分のものに変えてお使いください
z,y,zの羅列の部分ですhttps://script.google.com/hogefuga/** * @OnlyCurrentDoc */ // LINE Developersに書いてあるChannel Access Token var access_token = "xxxxxxxxxxxxxxxxxxxxxxxxxxxx"; // 自分のユーザーIDを指定します。LINE Developersの「Your user ID」の部分です var to = "yyyyyyyyyyyyyyyyyyyyyyyyy"; function text_message(text){ return { "type": "text", "text": text } } function choose_in_order(arrayData,isChange){ var ss = SpreadsheetApp.getActiveSpreadsheet(); var sheet = ss.getActiveSheet(); var arrayIndex = sheet.getRange(1,3,1,1).getValue(); var index = arrayIndex+1; if(isChange == true){ if(index < sheet.getLastRow()){ sheet.getRange(1,3,1,1).setValue(arrayIndex+1); }else{ sheet.getRange(1,3,1,1).setValue(1); } } return index+':'+arrayData[arrayIndex-1][0]; } function getEngs() { var ss = SpreadsheetApp.getActiveSpreadsheet(); var sheet = ss.getActiveSheet(); var range = sheet.getRange(2,1,sheet.getLastRow()-1); var values = range.getValues(); return values; } function getJaps() { var ss = SpreadsheetApp.getActiveSpreadsheet(); var sheet = ss.getActiveSheet(); var range = sheet.getRange(2,2,sheet.getLastRow()-1); var values = range.getValues(); return values; } function messagePush(){ //これは皆同じなので、修正する必要ありません。 var url = "https://api.line.me/v2/bot/message/multicast"; var headers = { "Content-Type" : "application/json; charset=UTF-8", 'Authorization': 'Bearer ' + access_token, }; //toのところにメッセージを送信したいユーザーのIDを指定します。(toは自分のtokenを指定したので、linebotから自分に送信されることされます) var eng = choose_in_order(getEngs(),true); /* 日本語も添えて送りたければこちらコメントアウト外してください var jap = choose_in_order(getJaps(),true); */ var ss = SpreadsheetApp.getActiveSpreadsheet(); var sheet = ss.getActiveSheet(); var arrayIndex = sheet.getRange(1,3,1,1).getValue(); var postData = { "to" : [to], "messages" : [ text_message(eng+'\n'+'https://docs.google.com/spreadsheets/zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz/edit#gid=0&range=A'+arrayIndex) // スプレッドシートではurlにrangeというクエリをつけることで指定したセルに飛ぶことができます ] }; /* 日本語も添えて送りたければこちらコメントアウト外して代わりにお使いください var postData = { "to" : [to], "messages" : [ text_message(eng+'\n'+jap+'\n'+'https://docs.google.com/spreadsheets/zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz/edit#gid=0&range=A'+arrayIndex) ] }; */ var options = { "method" : "post", "headers" : headers, "payload" : JSON.stringify(postData) }; return UrlFetchApp.fetch(url, options); }再掲
15分おきに通知(メッセージ送信)の設定
最後に、あるタイミングでスクリプトを走らせるバッチの設定です
同じように設定してください
15分おきだと多いと感じる方はここで変更することができます
編集リクエスト、解説して欲しいところなどのコメントお待ちしております
参考
事前準備 LINE Messaging APIアクセストークンの取得 | 富士通
- 投稿日:2019-05-06T15:11:36+09:00
LinebotとGASとアニメで1日100フレーズの英文を3ヶ月復習してみた
はじめに
この記事では、「英語を勉強している」という大義によって、他にやるべきことがあるにも関わらず、アニメや映画を見ることを正当化し、一見意識高そうに堕落する方法を紹介しています
やりたいこと
「ねえ、確率の計算って知ってる?」
「かずまが3回連続で勝つとかすごく無茶振りなんですけどー笑」
「スゥー。俺、じゃんけんで負けたことねえから」
みたいな英語のフレーズをスラスラと言えるようになりたい出典:KONOSUBA -God's blessing on this wonderful world! 2 Episode 7 – An Invitation for This Knucklehead!
※違法サイトは使っておりません。英語ネイティブ向けの有料ストリーミングサービスからの引用です
作ったもの
スプレッドシートに入れた英文を15分ごとにLINEに通知してくれるlinebot
英語を見て、対応する日本語を忘れてしまっていた場合、リンクをクリックする
該当行にジャンプするので、対応する日本語を復習する
15分ごとに通知するようにすれば1日100フレーズ復習できます
これで3ヶ月で最低限冗談言い合いながら会話できるようになりました夜寝てる間には通知が30ほどたまるので、朝にまとめて復習します
寝る前と寝起きすぐの復習は記憶の定着率がいいそうです。linebot(Line Messaging API)の登録
Line Developersから登録できます
登録方法は富士通さんの解説がわかりやすかったのでご参考ください
記事の頃から見た目が少し変わってますがわかる範囲だと思いますbotのchannel accsess tokenと自分のuser idの取得、botへの友達登録まで済ませてください
スプレッドシート作成
なんでもいいので名前をつけて新規作成しましょう。作れたら1行目はスクショのようにします。
A列は復習したい外国語、B列は対応する日本語、C列は通知がどこまでされたかを表す数字です。
C列は最初は1と記入しておいてください。1つ通知が送られると数字が1ずつ加算されますタイにいたためタイ語も入ってることご容赦ください。本来はタイ語が話せないという死活問題を解決することに始まり、英語に派生しました。ちなみに、タイ語は会話ができればよかったので発音記号とひらがなで覚えてました
gasの記述
こちらの方のスクリプトを参考にさせていただきました
コメントなど大変わかりやすかったため一部そのままのところもあります。ありがとうございますGoogle Spread Sheetは1シートに対して1つのスクリプトを紐づけることができます
海外にかぶれてブラウザが英語設定なのもご容赦ください。
開けたらJavascriptを記述していきましょう
画像を参考にbotのchannel access tokenとuser id、スプレッドシートのリンクの3つを自分のものに変えてお使いください
z,y,zの羅列の部分ですhttps://script.google.com/hogefuga/** * @OnlyCurrentDoc */ // LINE Developersに書いてあるChannel Access Token var access_token = "xxxxxxxxxxxxxxxxxxxxxxxxxxxx"; // 自分のユーザーIDを指定します。LINE Developersの「Your user ID」の部分です var to = "yyyyyyyyyyyyyyyyyyyyyyyyy"; function text_message(text){ return { "type": "text", "text": text } } function choose_in_order(arrayData,isChange){ var ss = SpreadsheetApp.getActiveSpreadsheet(); var sheet = ss.getActiveSheet(); var arrayIndex = sheet.getRange(1,3,1,1).getValue(); var index = arrayIndex+1; if(isChange == true){ if(index < sheet.getLastRow()){ sheet.getRange(1,3,1,1).setValue(arrayIndex+1); }else{ sheet.getRange(1,3,1,1).setValue(1); } } return index+':'+arrayData[arrayIndex-1][0]; } function getEngs() { var ss = SpreadsheetApp.getActiveSpreadsheet(); var sheet = ss.getActiveSheet(); var range = sheet.getRange(2,1,sheet.getLastRow()-1); var values = range.getValues(); return values; } function getJaps() { var ss = SpreadsheetApp.getActiveSpreadsheet(); var sheet = ss.getActiveSheet(); var range = sheet.getRange(2,2,sheet.getLastRow()-1); var values = range.getValues(); return values; } function messagePush(){ //これは皆同じなので、修正する必要ありません。 var url = "https://api.line.me/v2/bot/message/multicast"; var headers = { "Content-Type" : "application/json; charset=UTF-8", 'Authorization': 'Bearer ' + access_token, }; var eng = choose_in_order(getEngs(),true); /* 日本語も添えて送りたければこちらコメントアウト外してください var jap = choose_in_order(getJaps(),true); */ var ss = SpreadsheetApp.getActiveSpreadsheet(); var sheet = ss.getActiveSheet(); var arrayIndex = sheet.getRange(1,3,1,1).getValue(); var postData = { "to" : [to], "messages" : [ text_message(eng+'\n'+'https://docs.google.com/spreadsheets/zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz/edit#gid=0&range=A'+arrayIndex) // スプレッドシートではurlにrangeというクエリをつけることで指定したセルに飛ぶことができます ] }; /* 日本語も添えて送りたければこちらコメントアウト外して代わりにお使いください var postData = { "to" : [to], "messages" : [ text_message(eng+'\n'+jap+'\n'+'https://docs.google.com/spreadsheets/zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz/edit#gid=0&range=A'+arrayIndex) ] }; */ var options = { "method" : "post", "headers" : headers, "payload" : JSON.stringify(postData) }; return UrlFetchApp.fetch(url, options); }再掲
15分おきに通知(メッセージ送信)の設定
最後に、あるタイミングでスクリプトを走らせるバッチの設定です
同じように設定してください
15分おきだと多いと感じる方はここで変更することができます
編集リクエスト、解説して欲しいところなどのコメントお待ちしております
参考
事前準備 LINE Messaging APIアクセストークンの取得 | 富士通
- 投稿日:2019-05-06T14:51:08+09:00
岡田を切る技術
これはとある回顧録
何度も諦めかけましたが、数年の歳月を経て遂に岡田を切る技術が一旦の完成へと至りました。その技術を巡る奮闘の歴史と成果について、ここに記録を残していきたいと思います。
画像時代
まずは「切る」という動作が何を指すかを明確にしておきます。
厳密な定義というよりは、切った感を得るために必要そうなふるまいとして定義します。
- 平面上のある領域が、任意の直線を境界として分割されること
- 分割された領域は物理法則に準じてふるまうこと
要するに気持ちよく岡田を切ることができれば目標は無事達成です。
物理エンジン
切った感を高めるためにはやはり「物理法則」に準じたふるまいが欲しくなります。つまりブラウザ上で動く物理エンジンが必要です。
世の中にはフルスクラッチで物理エンジンを作れる人間と作れない人間が居ると思われますが、残念ながら私は後者でした。勝ち目の薄い勝負は避け、素直に巨人の方にすがります。今回採用したのはmatter.jsというjavascript製の2D物理エンジンです。
http://brm.io/matter-js/リンク先のデモを見てもらうと分かりますが、めっちゃ物理エンジンしています。描画機能も内蔵しているのでそのまま使うだけで物理エンジン制御下の世界をさっとwebページ上に作り出せます。
「でもこの物理エンジンだけでは岡田は切れないから・・」と自分がやるべきことはまだ残っているんだと必死に言い聞かせて先に進みます。
最古の岡田
作図系な処理において最も基本的かつ扱いやすいのは矩形でしょう。そして矩形に「岡田」と書いた画像を貼れば最もシンプルに岡田を物理エンジンの世界に登場させることが可能です。
成功しました、最古の岡田です。まだまだ先は長いですが、小さな成功体験の積み上げこそが大事です。
matter.jsを使えば一瞬で終わりそうに見えますが、画像を矩形に貼り付けるために、matter.jsの描画機能は使わず自前で
canvasに描画する処理を作っています。
とはいえ今回扱う図形は全て剛体なので、物理エンジン世界における図形の中心と回転角さえ分かればcanvasの変形描画機能をそのまま使うことができます。そして勿論matter.jsはそれらのプロパティを提供してくれます。ctx.save() ctx.translate(body.position.x, body.position.y) ctx.rotate(body.angle) ~~ 物理演算の考慮不要な描画処理 ~~ ctx.restore()両断
次は早速一刀両断していきます。ここからは物理エンジンは無関係で、座標をいじくり倒してポリゴンを直線で両断します。
しかしこの時点ではそれほど複雑な計算は必要ありません。なぜなら登場しているポリゴンは凸多角形であることが保証されているからです。
凸多角形であることの何が良いかというと、両断した後のポリゴンが必ず2つの凸多角形になることです。
(証明や出展は探していないですが、直感的に正しそうなのでそう信じておきます。)図だとこんな感じで、左が非凸多角形、右が凸多角形です。
断面となる頂点を2つ追加し、その断面が辺となるように他の頂点を拾い集めて2つのポリゴンを作れば両断処理の完成です。
そして新たに生まれた2つのポリゴンも凸多角形なので、両断前と後で物理エンジンの世界に存在するポリゴンの特性は何も変化していません。それっぽく言うと、凸多角形は切るという処理において完備なわけです。
こうして最古の岡田は無事に切ることができました。
両断後のポリゴンに若干の動きを加えたりすれば、切った感はさらに高まります。
SVG時代
葛藤
「それ岡田じゃなくて画像切っただけじゃない?」
わかる。
ただ岡田と書かれた画像を貼り付けた矩形を切っただけだ、これでは岡田を切ったなんて到底言えない。
画像を切りたいんじゃないんだ、岡田を切りたいんだ。岡田を求めて
岡田を切るためには、とにかくまずは物理エンジンの世界に岡田を登場させなくてはいけません。
手段は色々あると思いますが、2Dでの表現ができ、かつ座標が扱いやすそうなSVGを入力として採用しました。SVGを入力に使うと決めたはいいものの、もちろんSVGのデータ表現をそのまま物理エンジンの世界に突っ込むことはできません。最終的には両断計算をする必要もあるので座標としてパースする必要があります。
というわけでSVGの仕様を懇切丁寧にまとめてくださっていていつもお世話になっているサイトを熟読しながらパース処理を作ります。
http://defghi1977.html.xdomain.jp/tech/svgMemo/svgMemo_03.htm
<path>エレメントはコマンドと座標の羅列で図形を表現するのが若干ややこしいものの、M x yやL x yなどのコマンドはそのまま座標として抜き出せます。曲線という強敵
しかしここで、SVGを入力として使うことに潜んでいた問題に気づきます。ベジェ曲線、円弧、楕円の存在です。
物理エンジンが対応しているのだろうか、両断するときにどんな計算が必要になるのだろうかと瞬時に様々な問題が頭をよぎります。そして早々にそれは無理だと諦め、直線で近似する方針をとりました。
ただでさえ面倒な座標計算にさらに曲線も考慮に入れるなんてやり遂げられる気がしません。まともに勝負するには多角形の世界に持ち込むしかありません。2次ベジェは2次方程式を、3次ベジェは3次方程式を、楕円は楕円方程式を近似用の頂点を導出していきます。ここは気合で計算していくしかありません。
特に<path>エレメントにおける楕円の表現は、楕円の中心ではなく弧上の始点と終点を指定するという特殊なものだったため、楕円方程式を求めるまでにも手間がかかりました。https://triple-underscore.github.io/SVG11/implnote.html#ArcImplementationNotes
W3Cのドキュメントからも楕円の面倒くささが伺えます。ただでさえ式が難しいのにさらに特殊ケースの分岐まで豊富でとにかく気合が求められます。岡田を切るには気合が必要なのです。こうして曲線の近似も乗り越え、遂にSVGからポリゴンを座標リストとしてパースすることに成功しました。
3次ベジェの近似サンプルはこんな感じです。近似に使う頂点数を増やせば違和感もかなり減っていきます。
非凸多角形の両断
SVGパースという頭の体操を乗り越え、ついに岡田を物理エンジンの世界に登場させることができました。なんと岡田にはベジェも楕円も必要なかったという事実から目をそらすために、飾り付けも入念に行います。
上の画像を見れば明らかなように、非凸な多角形が世界に溢れ出します。かつて凸多角形の完備性に頼って実装した両断処理にも調整が必要となってくるわけです。
と思わせぶりに書いたものの、実は違いは分割後のポリゴン数が3以上の場合もあり得るというだけです。
一気に分割しようとするとなかなかややこしいですが、やることは2つのポリゴンへの分割を繰り返すだけです。手順はこうです。
- 直線とポリゴンの各辺との交点を求め、直線の方向順に並べる
- 並べた交点のうち先頭2点だけを分断面として採用してポリゴンを2つに分割する
- 分割したポリゴンそれぞれで1からの処理を繰り返す(分割されなくなったら終わり)
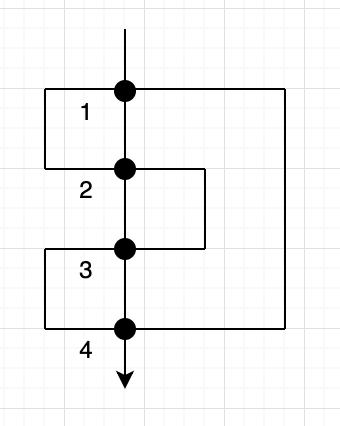
1で並び替えるときは、直線がx軸と重なるような回転を交点にかけるとx座標の比較だけで済んで楽です。雰囲気は下記のような感じ。
const rad = getRadian(line[0], line[1]) crossList.sort((a, b) => rotate(a, -rad).x - rotate(b, -rad).x)非凸多角形を凸多角形に分解する余談
実はこれを作った当初(2016年頃?)は、matter.jsが非凸な多角形に対応していませんでした。なのでSVGからパースした多角形を三角分割し、分割された三角形をグループ化することで無理やり物理エンジンに食わせていたりしました。
しかし現在のmatter.jsはpoly-decomp.jsという外部モジュールと一緒に使うことで非凸な多角形でも問題なく扱えるようになっています。
結局やっていることは同じく凸多角形への分割とグループ化なのですが、凸多角形の最小単位である三角形ではなく、パーツ数が少なくなるよう最適化された分割をしてくれます。すごい。
matter.jsの進化を喜ぶ共に、いらなくなってしまったかつての処理をここで供養しておきます。
欲しかったのはバッサリ感
準備は整いました。いきましょう、バッサリと。
フォント時代
葛藤と妥協
「それ岡田っぽい形をした図形を切っただけじゃない?」
わかる。
見て見ぬふりをしていましたが、SVGから作り出した岡田っぽい図形には多くの制限事項がありました。
「岡」はまぁ許せなくはないです。
しかし「田」には大きな誤魔化しがあります。不自然な隙間が所々に存在しています。
隙間が気になるなら無くせばいいと思われるかもしれませんが、この隙間には大きな意味がありました。もしこの隙間をなくし、「田」という字そのままを表現しようとすると、ポリゴンに穴が空いてしまうのです。
物理エンジンが対応しているのだろうか、両断するときにどんな計算が必要になるのだろうかと瞬時に様々な問題が頭をよぎる以前に、そもそもデータ構造として今のままでは穴空きポリゴンを表現することはできません。
岡田っぽい図形が切れて満足してしまったこともあり、この難題に再び立ち向かうまでにはさらに3年ほどの年月を待つこととなりました。転機
月日は流れ、岡田を切ることへの情熱も忘れ去っていたある日、複雑GUI会という名前の通りディープな集会に参加する機会に恵まれました。
そしてその場で、opentype.jsというライブラリの存在を知りました。
https://github.com/opentypejs/opentype.js/blob/master/README.md
注目の機能は、上の画像のようにフォントからパスを取得することができる機能です。
特に理由はありませんが岡田のパスを取得すべく早速試してみます。とりあえずREADME通りに使ってみてパスがどんな形式になっているのか調べてみます。
一部界隈の方ならこの画像だけでどんなデータフォーマットなのか一目瞭然でしょう。そうです、これはSVGの
<path>エレメントにおけるd属性フォーマットに違いありません。まるで運命だったかのように、SVGから座標をパースする処理はすでに手元にあります。
しかもこの半年ほど前に、typescriptの素振りをしようとパース処理をリプレイスし、かつては無かったテストまでも大幅に充実させていました。若干のインタフェース調整は必要でしたが、それほど苦もなく岡田のフォントパースに成功します。
穴あきポリゴンの正体
岡田フォントのパースに成功すると共にあることに気づきました。フォントのパスデータにはポリゴンがフラットな配列で存在するのみなのにも関わらず、opentype.jsは穴の空いたポリゴンもしっかりと描画しています。
穴あきポリゴンを表現するには特別なデータ構造を用意しなければいけないと思い込んでいた身からすると、これは大きな衝撃でした。
もしかしてSVGには白抜き描画用のコマンドも用意されているのではと調べていたら、SVGの教科書としていつも大活用させてもらっているサイトにてその答えを見つけました。> path要素においてはfill-ruleがnonzeroであっても,白抜きとなるケースが発生する.複数のパスから構成されたpash図形であった場合,互いにパスの向きが逆向きであった場合は,内側と外側とが打ち消し合い,fill対象の領域から除外される.https://t.co/0abg9y1qWA
— robokomy (@robokomy) 2019年5月2日つまり、ポリゴンにはパスの向きという概念が存在し、逆向きなポリゴンを内包している場合、その内容ポリゴン部分は白抜きされます。この仕様によって、特別なデータ構造を用意しなくとも穴の空いたポリゴンを表現することが可能となっています。
穴空きポリゴンの描画
SVGの仕様から発覚した穴空きポリゴンの表現ですが、これはcanvasでも同様です。
描画方法は既にこちらで記事化しています。
https://qiita.com/miyanokomiya/items/c0e9f2ea8d05945d58b3物理エンジン世界での穴あきポリゴン
描画方法は分かりましたが、物理エンジン世界で穴あきポリゴンをどう扱うか考える必要があります。
アイディアはいくつかありそうですが、実装がシンプルそうなので外枠以外は模様として扱うことにしました。例えばこのような図形があった場合、物理エンジン世界での実態はただの矩形です。そして内部の穴あき矩形はただの模様であり、外枠から独立した物理計算をされることはありません。
ポリゴンの包含判定
この模様方針を実現するために面倒だったのは、物理エンジンに入れ込む外枠ポリゴンと、その内部模様となるポリゴンをグルーピングする必要があることです。
一般的にある面が他の面に含まれているかを判定するのは様々なケースが考えられてとても面倒です。シンプルなケースは下図左のようなものです。この場合、全ての頂点があるポリゴンに含まれているならば、その頂点から構成されるポリゴンも包含されているとみなすことができます。
しかし右のケースでは早くもその判定が破綻します。同じく全ての頂点が他のポリゴンに含まれているのに、明らかにはみ出している部分が存在しています。
辺の交差判定も加えたらいけるかもしれません。それでは下図左のように、凹のくぼみにぴったり嵌まり込んでいるようなケースはどうでしょうか。
頂点は全て大きいポリゴンの辺上にあり、辺同士での交差もしていません。しかし内包関係にないことは目で見れば明らかです。
中心点がポリゴンに含まれているかの判定も加えたらいけるかもしれません。しかし右のケースから分かるように、中心点が含まれるかどうかはポリゴンの形次第でとても頼りにはできません。このように一般的なポリゴンの包含判定はとても面倒です。やっぱり手に負えないと投げ出したくもなりましたが、幸運なことにとある抜け道を見つけることができました。
その抜け道とは、今回扱っているポリゴンがフォント由来のものであることでした。
要するに、包含関係は最もシンプルな上記のパターンしかないはずなのです。これも証明などは無く直感的に正しそうだという程度のものですが、先に挙げた面倒なケースのどれも、フォントとしての表現で使われることはないはずです。
このことを前提とするならば、ポリゴンの包含判定は、頂点全てが他のポリゴンに含まれているかを判定するだけで十分となります。点の包含判定
ある点がポリゴンに包含されているかは、その点から任意の方向に伸ばしたベクトルがポリゴンの辺と何回交差するかを数えることで判定可能です。奇数回なら内部、偶数回なら外部とみなします。
Crossing Number Algorithmと呼ぶそうです。
https://www.nttpc.co.jp/technology/number_algorithm.html
この手法についてはweb上にも多くの資料があるので紹介程度に留めておきます。頭の体操兼素振りと思って手を動かしてみるのも楽しいと思います。
グルーピング
判定の準備は整ったので、あとは外枠用ポリゴンと模様用ポリゴンをグルーピングしていくだけです。複数グループに所属するというケースはないので、意外と単純にグルーピングが可能です。
具体的な手順はこのような感じになりました。
- ポリゴンを面積の大きい順にソート
- 面積最大のポリゴンから順に、その内部に他のポリゴンを含むか判定
- 含むなら同じグループとして確定、含まないならグループ未確定として保留
- 面積最小のポリゴンまでループを回せば全てのグループが確定する
フォント to 物理エンジン世界
こうしてまずは、フォントからパースした岡田を物理エンジン世界に登場させることに成功しました。
穴あきポリゴンの両断
最後の砦です。岡田を切るには、穴あきポリゴンを両断する処理を作らなければなりません。
まずはやるべきことを整理します。
このような穴あきポリゴンを両断したら、
こういうポリゴンの破片が欲しいわけです(もう一方の破片は一旦無視しておきます)。
ここで注目したいのは、穴としての役割を担っていたポリゴンが両断対象になった場合、その穴は消滅して窪みになるということです。
やるべきことが段々と見えてきました。下図を使ってさらに整理します。
- 下向きの矢印: 両断線
- 左側の図: 外枠ポリゴンを両断した後のポリゴン
- 中央の図: 両断線がヒットした元々の穴用ポリゴン
- 右側の図: 穴開きポリゴンを両断した後に欲しいポリゴン
もうお分かりのように、「両断後の外枠ポリゴン」から「両断線がヒットした穴用ポリゴン」を差し引くことで「両断後のポリゴン」が手に入るということです。所謂ポリゴンのブーリアン演算です。
ブーリアン演算
今回やりたい演算はこれです。
https://upload.wikimedia.org/wikipedia/commons/1/16/Boolean_operations_on_shapes.png
例によって一般的なポリゴンに対するブーリアン演算を実装するのはとても面倒で心が折れそうになるのですが、今回はある程度状況が限定されています。
ブーリアン判定を行うことになる2つのポリゴンは先述の通り、「両断後の外枠ポリゴン」と「両断線がヒットした穴用ポリゴン」という組み合わせのみです。つまり多少の形の違いはあれど、下記のようにシンプルな状況のみを考えれば十分となります。
さらに外枠ポリゴンと穴用ポリゴンという特性から、両者の回転方向は逆向きであることも保証されています。
両断後の外枠ポリゴンの辺で穴用ポリゴンの辺と交差しうるものは、両断線によって作られた辺だけであることにも注目です。ここまで条件が揃えばあとは地道に頂点を拾い集めるだけです。
- 両断後の外枠ポリゴンの頂点をインデックス順に拾っていく
- 両断線による辺の始点に辿り着いたら、交点を経由して穴用ポリゴンに移る
- 穴用ポリゴンの頂点をインデックス順に拾っていく
- 両断線による辺と交差する辺の始点に辿り着いたら、交点を経由して両断後の外枠ポリゴンに移る
- 両断後の外枠ポリゴンの残りの頂点を全て拾い集めて完了
両断されなかった穴
先程後回しにしておいたもう片方の破片についても考えます。
両断される穴部分の扱いはすでに解決しました。
残りの両断されなかった穴の扱いですが、両断処理の際は何もする必要はありません。そして両断後のポリゴンが出揃ったタイミングで、外枠用ポリゴンと模様用ポリゴンのグルーピング処理を再適用すれば、両断後の外枠ポリゴンの模様としてあり続けることに成功します。ありがとう、岡田
こうして、数年に渡った岡田を切るための全ての準備は整いました。様々な困難がありましたが、全てはここへと繋がる道だったのだと考えると感慨深いものがあります。
ここまでの道のり全てに感謝を込めて、バッサリいきます。
さらば、岡田。
付録
計算系リポジトリ
幾何計算や、SVGのパース処理などは使い回しやすいようライブラリ化しています。テストもそれなりに頑張って書いたので、もしSVGから図形をパースしてポリゴン化したいという稀有な希望をお持ちの方が居たらご活用ください。
https://github.com/miyanokomiya/okageoアプリ用リポジトリ
アプリとしての形を整えたものはここにあります。ただこちらは試行錯誤のままに作っていたのであまり整理はされていないです。
https://github.com/miyanokomiya/okadaphy最終成果物は静的サイトとして公開もしてあるので、俺も岡田を切りたいという欲求をお持ちの方はご活用ください。
https://hopeful-visvesvaraya-3dafb6.netlify.com/





























- 投稿日:2019-05-06T14:02:23+09:00
あなたのお役に立てるかもしれないアプリを、フロントエンド開発でついにリリースを迎えることが出来ました!
気づいたら10連休最終日!!
会社員になって中々まとまった休みが無い中、やってきたゴールデン10連休!!!ここぞとばかり徹夜でアプリ作成に挑戦し、つい先日Appleの審査が通り本日リリースを迎えることが出来ました!!
何とも言えない達成感です。その紹介も兼ねて、どういった技術を使用してこのアプリを作ったのかを簡単にまとめましたので読んでいただけると嬉しくて飛び跳ねます。
EndeLinkとは
Apple Storeの紹介にも記載してますが、このアプリはデザイナーとエンジニアに特化したお仕事探しアプリです。登録されたエンジニアまたはデザイナーの作品、金額、頻度で適切な仕事パートナーを探し出すことができます。
つまり、読んで字のごとくエンジニアとデザイナーを探すのにフォーカスしたSNSアプリです。作った背景
昔、フリーランスを少しかじっていた時期があるのですが、知人のエンジニアやデザイナーさんに頼みたいけど金額面で気を使わせたり、可動日数が合わず調整が難しかったり…苦労しました…。
その頃からエンジニアやデザイナーさんを探すことに注力した良い感じのSNSをいつか作りたいなと思っていました。
現在はフリーではなく会社員ですが、会社が副業OKなので自分も仕事相手を探す機会も出てくるだろうと思い、思い切ってこの10連休を活かして開発しようと思いました。EndeLinkはどのようにして作られたのか
デザイン
色々コーディングをやってきましたが、デザインを作ったことは一度もなくセンスもないと認識しているためにAdobe XDでちゃちゃっとワイヤーフレームを作りました。
(軌道に乗れば、デザイナーさんにちゃんと制作を依頼したいです)
一番注意して作ったのが、このアプリの使用目的を明確にすることです。
そこでこのアプリは仕事パートナーを見つけるのに大事になってくる、お金や可動日数の入力を必須にし、そこをソート出来るようにしました。
またポートフォリオのURLやポートフォリオ画像も数点貼れるようにしときました。あと、スペースはなるべく統一して作りました。
例えば上記リストページはiPhoneのファーストビューで自己紹介をMax数書いても2つのリストは最低でも見せれるように空きを調整しました。
空きをきちんと取ることにより、見た目が綺麗に見える?感じがします。
あとは実際に作りながらかなり調整していきました。開発するプラットフォーム選び
フロントエンドの技術だけでアプリが開発できるプラットフォームとして国内で開発している会社として有名な Monaca を選びました。
フロントエンドだけのアプリ開発も徐々に選択できるようになりましたが、自分はこのMonacaのプラットフォームを利用して良かったと思うところは、日本語のドキュメントが充実している所です。
国内で開発している会社なので当たり前かもしれませんが、日頃英語のドキュメント見るのが当たり前なので、日本語のドキュメントが充実しているのは何より新鮮でしたし、大変助かりました。
あと国内産ってなぜか安心するんですよね、まー食べませんが( º﹃º` )…… はい。ちなみに当たり前ですが、お問い合わせも日本語で出来るのでこれも非常に助かります。
ただしお問い合わせがテクニカルだと、お金をがっつり取られる場合があるのでそこは注意していただきたいです。興味がある方は、下記料金プランを見ていただけると大体いくら掛かるのかが分かります。
https://ja.monaca.io/pricing.html使用したバックエンドサービス
Qiitaでもかなりの頻度で取り上げられる Firebase を使用しました。
Firebaseで利用したプロダクトは下記4つで、
- データベースの用意として「Realtime Database」
- 画像などのデータアップ先として「Cloud Storage」
- その次がSNS認証として「Authentication」
- あと一部アプリからデータを送信する技術を使用しているため「Cloud Functions」
以上のプロダクトを用いて開発しました。
見て分かるように、Firebase一つで多種多様なプロダクトを使用できるので大変助かります。
話が少しそれるのですがFirebaseの中で色々なプロダクトが年々増えてきているのですが、最近気になるのが Google の機械学習技術を用いた「ML Kit」
まだベータなのですが、このAPIを利用することによテキスト認識(OCR)はもちろん顔認識を利用した技術も使用することが出来ます。
Firebaseの母体はGoogleなので、Googleで開発された技術がFirebaseでも使用できるのも嬉しいですね。・データベースのセキュリティについて
Firebase Realtime Databaseではセキュリティ設定を細かく設定することができますが、、、ここで唐突に問題です!
管理権限を持たない一般ユーザは下記 grandchild のルートには読み取りアクセスできますでしょうか?{ "rules":{ ".read":false, "parent":{ "child":{ ".read":true, "grandchild":{ ".read":false } } } } }
正解は「出来ます」
なぜならその親の child ルートで読み取りを許可したので、その権限が子に引き継かれるからです。
なので読み取り先である grandchild の読み取りを不可にしても、親のアクセス権限が適用されます。ということは仮にトップルートで読み取りがアクセス許可されていた場合は、いくら子が読み取りアクセス不可にしても全体にアクセスできてしまうことになります。
{ "rules":{ ".read":true, "parent":{ "child":{ //アクセス出来てしまう ".read":false, "grandchild":{ //アクセス出来てしまう ".read":false } } } } }まーこんなことしないでしょうが。。
このようにアクセス権限は親ルートにアクセス権限をもたせた場合、それは子に影響されます。
なので今回作ったアプリではアクセス出来るルート権限ごとに細かく分けてルールを定義し、権限通りに動いてるかチェック表をつけました。
ご存知の方も多いと思いますが、Firebaseではデータのアクセス権限の確認をコンソールからシミュレートすることが出来ます。
より詳しく知りたい方は、下記ドキュメントを見てください。
https://firebase.google.com/docs/database/security/securing-data?hl=ja#read_and_write_rules_cascade
・メール認証について
今回ログイン認証としてパスワード認証とメール認証を組み合わせてログインできるようにしてます。
メール認証はログイン後に下記方法で送ることが出来ます。firebase.auth().currentUser.sendEmailVerification().then(function() { //success }).catch(function(error) { window.alert(error); });送られてきたメールのパラメータには mode や oobCode、apiKeyが付属してます。
メール認証の場合は mode は 'verifyEmail'になります。
他にもパスワード変更やメールアドレス変更などの際の mode があります。
参照 : https://firebase.google.com/docs/auth/custom-email-handler#create_the_email_action_handler_page例えばメール認証の一例として
auth.checkActionCode(actionCode).then(function() { //ワンタイムコード(oobCode)の確認 auth.applyActionCode(actionCode).then(function() { //メールアドレス認証を確認 }).catch(function(error) { window.alert(error); }); }).catch(function(error) { window.alert(error); });checkActionCodeでワンタイムコードを確認し有効であれば、applyActionCodeにてメールアドレス認証を確認することができます。
実際にメール認証されたかどうかは、Firebaseのログイン認証から一度ログアウトする必要があります。
メール認証の確認は firebase.auth().currentUser.emailVerified を使用します。firebase.auth().signOut().then(function(){ firebase.auth().signInWithEmailAndPassword(email, pass).then(function (info) { if(firebase.auth().currentUser.emailVerified) { //メールアドレス認証済み } else { //メールアドレス認証エラー } }).catch(function (error) { window.alert(error); }); });
使用したJSフレームワーク
おなじみの Vue.js、今回SPAで開発しているためにVue.jsでコーディングさせていただきました。
またSPAを構築する際に Vue Router を使用するかと思いますが、自分は知らなかったので共有として下記方法で一つのコンポーネントに対して複数のパス(alias)を関連付けることもできます。const Vue = require('vue'); const VueRouter = require('vue-router'); const Main = require('./Main'); Vue.use(VueRouter); const routes = [{ path: '/main', component: Main, alias: ['/page1', '/page2', '/page3'] }];基本的に path と component は対になってますが、例えば alias に設定した /page1 にアクセスした際に component の Main を共有して使うことが出来ます。
ユーザーから見ると /main と /page1 は別々のURLの為に当然別のページを見てると思うのですが、裏側では共通のページに見ていることになります。Appleからの審査について
今回アプリの審査で2回リジェクトを食らったのですが、作ったのがSNSアプリということもあり下記基準に満たしていませんでした。
これは書いてあるように、ユーザーがユーザーに対して不適切な行為をされた場合、それを防ぐ/報告手段を実装しなければならいということでした。
そこでユーザーのブロック機能と報告機能を実装して報告したところ、無事通りました。
最後に
このEndeLinkはApple Storeに公開されようやくスタートしたばかりなので、機能拡張やデザイン改修も含めてこれからやりたいことだらけです。
あともし可能であればぜひ知り合いのデザイナーさんやエンジニアさんに紹介してもらえると有り難いです( ´^`° )
以上、読んで頂きありがとうございました。
また「いいね」を押していただけると大変励みになります(っ_ _)っ
※Firebaseの料金プランの兼ね合いから、会員数によって会員登録に制限をかける可能性があります。
※今の所、このアプリは全て無料でご利用できます(広告無)バグ報告/ご意見は、Twitterからダイレクトメッセージにてご連絡ください!
※些細なことでも言っていただけると嬉しいです(´∩ω∩`)
※唯の批判などはスルーします、人としても。











- 投稿日:2019-05-06T14:02:23+09:00
エンジニアとデザイナー向けのSNSアプリを作りました!
気づいたら10連休最終日!!
会社員になって中々まとまった休みが無い中、やってきたゴールデン10連休!!!ここぞとばかり徹夜でアプリ作成に挑戦し、つい先日Appleの審査が通り本日リリースを迎えることが出来ました!!
何とも言えない達成感です。その紹介も兼ねて、どういった技術を使用してこのアプリを作ったのかを簡単にまとめましたので読んでいただけると嬉しくて飛び跳ねます。
EndeLinkとは
Apple Storeの紹介にも記載してますが、このアプリはデザイナーとエンジニアに特化したお仕事探しアプリです。登録されたエンジニアまたはデザイナーの作品、金額、頻度で適切な仕事パートナーを探し出すことができます。
つまり、読んで字のごとくエンジニアとデザイナーを探すのにフォーカスしたSNSアプリです。作った背景
昔、フリーランスを少しかじっていた時期があるのですが、知人のエンジニアやデザイナーさんに頼みたいけど金額面で気を使わせたり、可動日数が合わず調整が難しかったり…苦労しました…。
その頃からエンジニアやデザイナーさんを探すことに注力した良い感じのSNSをいつか作りたいなと思っていました。
現在はフリーではなく会社員ですが、会社が副業OKなので自分も仕事相手を探す機会も出てくるだろうと思い、思い切ってこの10連休を活かして開発しようと思いました。EndeLinkはどのようにして作られたのか
デザイン
色々コーディングをやってきましたが、デザインを作ったことは一度もなくセンスもないと認識しているためにAdobe XDでちゃちゃっとワイヤーフレームを作りました。
(軌道に乗れば、デザイナーさんにちゃんと制作を依頼したいです)
一番注意して作ったのが、このアプリの使用目的を明確にすることです。
そこでこのアプリは仕事パートナーを見つけるのに大事になってくる、お金や可動日数の入力を必須にし、そこをソート出来るようにしました。
またポートフォリオのURLやポートフォリオ画像も数点貼れるようにしときました。あと、スペースはなるべく統一して作りました。
例えば上記リストページはiPhoneのファーストビューで自己紹介をMax数書いても2つのリストは最低でも見せれるように空きを調整しました。
空きをきちんと取ることにより、見た目が綺麗に見える?感じがします。
あとは実際に作りながらかなり調整していきました。開発するプラットフォーム選び
フロントエンドの技術だけでアプリが開発できるプラットフォームとして国内で開発している会社として有名な Monaca を選びました。
フロントエンドだけのアプリ開発も徐々に選択できるようになりましたが、自分はこのMonacaのプラットフォームを利用して良かったと思うところは、日本語のドキュメントが充実している所です。
国内で開発している会社なので当たり前かもしれませんが、日頃英語のドキュメント見るのが当たり前なので、日本語のドキュメントが充実しているのは何より新鮮でしたし、大変助かりました。
あと国内産ってなぜか安心するんですよね、まー食べませんが( º﹃º` )…… はい。ちなみに当たり前ですが、お問い合わせも日本語で出来るのでこれも非常に助かります。
ただしお問い合わせがテクニカルだと、お金をがっつり取られる場合があるのでそこは注意していただきたいです。興味がある方は、下記料金プランを見ていただけると大体いくら掛かるのかが分かります。
https://ja.monaca.io/pricing.html使用したバックエンドサービス
Qiitaでもかなりの頻度で取り上げられる Firebase を使用しました。
Firebaseで利用したプロダクトは下記4つで、
- データベースの用意として「Realtime Database」
- 画像などのデータアップ先として「Cloud Storage」
- その次がSNS認証として「Authentication」
- あと一部アプリからデータを送信する技術を使用しているため「Cloud Functions」
以上のプロダクトを用いて開発しました。
見て分かるように、Firebase一つで多種多様なプロダクトを使用できるので大変助かります。
話が少しそれるのですがFirebaseの中で色々なプロダクトが年々増えてきているのですが、最近気になるのが Google の機械学習技術を用いた「ML Kit」
まだベータなのですが、このAPIを利用することによテキスト認識(OCR)はもちろん顔認識を利用した技術も使用することが出来ます。
Firebaseの母体はGoogleなので、Googleで開発された技術がFirebaseでも使用できるのも嬉しいですね。・データベースのセキュリティについて
Firebase Realtime Databaseではセキュリティ設定を細かく設定することができますが、、、ここで唐突に問題です!
管理権限を持たない一般ユーザは下記 grandchild のルートには読み取りアクセスできますでしょうか?{ "rules":{ ".read":false, "parent":{ "child":{ ".read":true, "grandchild":{ ".read":false } } } } }
正解は「出来ます」
なぜならその親の child ルートで読み取りを許可したので、その権限が子に引き継かれるからです。
なので読み取り先である grandchild の読み取りを不可にしても、親のアクセス権限が適用されます。ということは仮にトップルートで読み取りがアクセス許可されていた場合は、いくら子が読み取りアクセス不可にしても全体にアクセスできてしまうことになります。
{ "rules":{ ".read":true, "parent":{ "child":{ //アクセス出来てしまう ".read":false, "grandchild":{ //アクセス出来てしまう ".read":false } } } } }まーこんなことしないでしょうが。。
このようにアクセス権限は親ルートにアクセス権限をもたせた場合、それは子に影響されます。
なので今回作ったアプリではアクセス出来るルート権限ごとに細かく分けてルールを定義し、権限通りに動いてるかチェック表をつけました。
ご存知の方も多いと思いますが、Firebaseではデータのアクセス権限の確認をコンソールからシミュレートすることが出来ます。
より詳しく知りたい方は、下記ドキュメントを見てください。
https://firebase.google.com/docs/database/security/securing-data?hl=ja#read_and_write_rules_cascade
・メール認証について
今回ログイン認証としてパスワード認証とメール認証を組み合わせてログインできるようにしてます。
メール認証はログイン後に下記方法で送ることが出来ます。firebase.auth().currentUser.sendEmailVerification().then(function() { //success }).catch(function(error) { window.alert(error); });送られてきたメールのパラメータには mode や oobCode、apiKeyが付属してます。
メール認証の場合は mode は 'verifyEmail'になります。
他にもパスワード変更やメールアドレス変更などの際の mode があります。
参照 : https://firebase.google.com/docs/auth/custom-email-handler#create_the_email_action_handler_page例えばメール認証の一例として
auth.checkActionCode(actionCode).then(function() { //ワンタイムコード(oobCode)の確認 auth.applyActionCode(actionCode).then(function() { //メールアドレス認証を確認 }).catch(function(error) { window.alert(error); }); }).catch(function(error) { window.alert(error); });checkActionCodeでワンタイムコードを確認し有効であれば、applyActionCodeにてメールアドレス認証を確認することができます。
実際にメール認証されたかどうかは、Firebaseのログイン認証から一度ログアウトする必要があります。
メール認証の確認は firebase.auth().currentUser.emailVerified を使用します。firebase.auth().signOut().then(function(){ firebase.auth().signInWithEmailAndPassword(email, pass).then(function (info) { if(firebase.auth().currentUser.emailVerified) { //メールアドレス認証済み } else { //メールアドレス認証エラー } }).catch(function (error) { window.alert(error); }); });
使用したJSフレームワーク
おなじみの Vue.js、今回SPAで開発しているためにVue.jsでコーディングさせていただきました。
またSPAを構築する際に Vue Router を使用するかと思いますが、自分は知らなかったので共有として下記方法で一つのコンポーネントに対して複数のパス(alias)を関連付けることもできます。const Vue = require('vue'); const VueRouter = require('vue-router'); const Main = require('./Main'); Vue.use(VueRouter); const routes = [{ path: '/main', component: Main, alias: ['/page1', '/page2', '/page3'] }];基本的に path と component は対になってますが、例えば alias に設定した /page1 にアクセスした際に component の Main を共有して使うことが出来ます。
ユーザーから見ると /main と /page1 は別々のURLの為に当然別のページを見てると思うのですが、裏側では共通のページを見ていることになります。Appleからの審査について
今回アプリの審査で2回リジェクトを食らったのですが、作ったのがSNSアプリということもあり下記基準に満たしていませんでした。
これは書いてあるように、ユーザーがユーザーに対して不適切な行為をされた場合、それを防ぐ/報告手段を実装しなければならいということでした。
そこでユーザーのブロック機能と報告機能を実装して報告したところ、無事通りました。
最後に
このEndeLinkはApple Storeに公開されようやくスタートしたばかりなので、機能拡張やデザイン改修も含めてこれからやりたいことだらけです。
あともし可能であればぜひ知り合いのデザイナーさんやエンジニアさんに紹介してもらえると有り難いです( ´^`° )
以上、読んで頂きありがとうございました。
また「いいね」を押していただけると大変励みになります(っ_ _)っ
※Firebaseの料金プランの兼ね合いから、会員数によって会員登録に制限をかける可能性があります。
※今の所、このアプリは全て無料でご利用できます(広告無)バグ報告/ご意見は、Twitterからダイレクトメッセージにてご連絡ください!
※些細なことでも言っていただけると嬉しいです(´∩ω∩`)
※唯の批判などはスルーします、人としても。
- 投稿日:2019-05-06T12:38:57+09:00
分かりそうで分かっていないVue.jsワード
DOM(Document Object Model)
「JavaScriptでhtmlの要素を操作するための仕組み」
Webページは文書であり、HTMLを操作することで表示されます。
そのHTMLをJavaScriptを用いて操作することができる仕組みのこと。データバインディング
「データと描画を同期する仕組み」
JavaScriptのデータを変えるだけで描画内容も一緒に変わる仕組みのこと。こんなかんじ
①Vue.jsでデータを表示
<!DOCTYPE html> <html> <body> <div id="app"> <h1>{{ message }}</h1> </div> <script src="https://cdn.jsdelivr.net/npm/vue@2.5.13"></script> <script> var app = new Vue({ el: '#app', data: { message: 'Hello Mt.everest!' } }) </script> </body> </html>
②コンソールからデータを変更
③データを変更したタイミングで画面が変更される



- 投稿日:2019-05-06T12:08:47+09:00
canvasをつかってみよう!【初心者】
プログラミング学習を初めて2ヶ月!
canvasが面白そうだなとペイントみたいなものを作りました。
その際学んだ基礎的な部分を記事にしています。
※この記事では、canvasによる三角形の描画を目指します。
canvasとは
「ブラウザ上で描画を可能にする仕様」
HTML5から追加された仕様です。
対応しているブラウザが必要ですが、ほとんど対応しているのでご安心を!HTMLではcanvasという描画エリアを生成して終了です。
JavaScriptを組み合わせてはじめて描画できます。描画エリアを作る
<canvas id="draw-area" width="300" height="300"></canvas>注意:canvas要素に直接CSSをあててサイズを変更するとデフォルトサイズ(300*150)からの変更になり描画が引き延ばされたりします。
jsで縦横の大きさを柔軟に操作が可能!今回はこの300*300のcanvasに図形を描画するサンプルで仕組みを理解できればと思います。
JavaScriptで描画する
描画の準備
var canvas = document.getElementById("draw-area"); var canvasCtx = canvas.getContext('2d');.Context('2d')
CanvasRenderingContext2Dオブジェクト
2D描画をするためのコンテキストを生成しています。
引数をwebglとすると3D描画用のコンテキストに!!
(WebGLは筆者が今後勉強していきたいコンテンツです。)CanvasRenderingContext2Dオブジェクトに様々なメソッドを使い図を描画します。
このメソッド、たくさんありますので調べてみてください。三角形を描画する
先ほど作った300×300のcanvasに三角形を描画します。
canvasCtx.beginPath(); //描画を始める宣言 canvasCtx.moveTo(125, 50); //描き始める始点の座標 canvasCtx.lineTo(210, 210); //終点の座標 canvasCtx.lineTo(40, 210); canvasCtx.closePath(); //始点に戻る(直接指定でも可) canvasCtx.stroke(); //描画する.beginPath()
パスをリセットする。
だとわからないので、描画するための宣言だ捉えて良いと思います。.moveTo(x, y)
直線を描画するための始点の座標です。
canvasは左上を基準とした座標空間になるため、メソッドの引数には座標を与えます。.lineTo(x, y)
終点の座標です。
連続で記述している場合、一つ前のlineToで指定した座標から直線で結びます。.closePath()
moveToで指定した座標に戻るような指示です。
直接lineTo(始点の座標)でも同じ処理になります。.stroke()
直線を描く処理をする指示です。
この処理をする前はプログラムが線を描くための準備をしていただけで、canvasには何も表示されていません。
.strokeをして初めて、描画され見えるようになります。イベントハンドリなどを設定して、ボタンを押したら三角形を描画するようにすると描いている実感が湧くかもしれません。
まとめ
すごくシンプルですが、考え方の基礎の理解に繋がったり
canvasが楽しそうだなと思える記事になればと思います。ちなみに、載せているGIFは上記の線を引く処理をマウスの座標で設定し、繰り返すことで実現しています。
おかしな点があればご指摘ください。

- 投稿日:2019-05-06T11:46:57+09:00
jenkinsのジョブ実行結果を、ajaxでwebスクレイピングしてxml形式で取得し、一覧表示してみよう
はじめに
Jenkinsの管理コンソール、、、見づらくないですか?
ビルド履歴番号で成功とか言われても、それは誰がどのパラメータで実行したジョブ?ってなりますよね。
そこで、Jenkinsのビルド情報をwebスクレイピングで取得し、一覧表示したいと思います!
WebスクレイピングといえばPythonとBeautiful Soupの組み合わせが主流のようですが、
前回の記事同様に、Javascriptと基本的なライブラリのみを使用して解決できないか試した所、
なんとかなったので、メモを残したいと思います。
(webスクレイピングの注意事項 https://qiita.com/nezuq/items/c5e827e1827e7cb29011)
取得先とリクエスト頻度は計画的に、、、、課題整理
まず、Jenkinsから情報を取得出来なければ話になりません。
そこで調査したところ、APIが用意されている事がわかりました。
使い方もシンプルで、httpリクエストメソッドオンリーで取得可能でした。
今回はジョブの実行結果を取得したいだけなので、getメソッドで対応します。とりあえず実行
どのようなデータが取れるのか確認する為、
google chromeにて、自身が立てたjenkinsへ以下のリクエストを投げてみました。http://localhost:9090/api/json?
※xml形式で取得したい場合は、jsonの部分をxmlにするだけで可能{ "assignedLabels": [ { } ], "mode": "NORMAL", "nodeDescription": "ノード", "nodeName": "", "numExecutors": 2, "description": null, "jobs":[ { "name": "testJob", "url": "http://<jenkins host>/job/testJob/", "color": "blue" }, { "name": "hoge", "url": "http://<jenkins host>/job/hoge/", "color": "blue" } ], "overallLoad": { }, "primaryView": { "name": "All", "url": "http://<jenkins host>/" }, "quietingDown": false, "slaveAgentPort": 0, "unlabeledLoad": { }, "useCrumbs": false, "useSecurity": false, "views":[ { "name": "All", "url": "http://<jenkins host>/" } ] }え?この程度の情報しか取得できないの、、、?
うーん、、、情報収集、、
更に調査を進めた所、
クエリパラメータで情報量を操作できることがわかりました。・depth
値を増やす事で、より深い階層情報を取得できるようになります。
例えば「1」と指定すると、job配下のdisplayName(ジョブ名称が入ってる)などが取得できるようになります。
あまり大きな値を入力すると、情報量が増えますが、それに比例して時間が、、、・tree
指定する事で、取得する要素名でフィルタリングをかける事ができます。
depthを指定する際は情報量が増加するので、こちらも指定する事をお勧めします
ちなみにですが、同一要素名称が複数存在する場合、末に「s」をつける仕様のようです。jobが複数ある→jobs
jobの中のdisplayNameを取りたい→jobs[displayName]
※カンマで区切ると複数指定が可能になります。・xpath
指定した要素の内容でフィルタリングをかける事ができます。色々ありましたが、自身の求める情報を取得する為のリクエストは以下になりました。
http://localhost:9090/api/xml?depth=2&tree=jobs[displayName,builds[number,result,actions[parameters[name,value]],timestamp]]&xpath=//job[displayName='testJob']ただ、取得して分かったのですが、JenkinsのタイムスタンプってUNIXタイムスタンプなんですね、、
取得した値に以下の関数を通して、馴染みやすい形式(yyyy/MM/dd)に変換しちゃいましょう!function convTimestamp(intTime) { var date = new Date(intTime); var year = date.getFullYear(); var month = ('0'+(date.getMonth()+1)).slice(-2); var day = ('O'+date.getDate()).slice(-2); var hour = ('0'+date.getHours()).slice(-2); var min = ('O'+date.getMinutes()).slice(-2); return(year + '/' + month + '/' day + ' ' + hour + ':' + min); }ちなみにですが、無効なリクエストを投げると、、、、
紳士的なイメージのjenkinsマスコットキャラ(名前不明)がメッチャ怒ります!
真面目なツールだと思っていたのですが、エンジニアの遊び心が伺えました!
やっぱり仕事は楽しくしたいですよね!webスクレイピング一覧化
必要な情報の取得方法が確認できたので、ajaxによるwebスクレイピングを行い、
取得・加工して一覧表示用のhtni文字列を作成しましょう!今回は、画像の読み込み等がない、そして、ビルド毎で一覧をしたかったので、以下のコードになりました。
// html読み込み完了後に呼び出すよう設定 $(document).ready(function(){ // 一覧表示 getList(); }); // 一覧表示 function getList(){ // 一覧取得 $.ajax({ type: "GET", dataType: "xml", url: "http://localhost:9090/api/xml?depth=2&tree=jobs[displayName,builds[number,result,actions[parameters[name,value]],timestamp]]&xpath=//job[displayNane='testJob']" ]).done(function (getData){ // build要素数分繰り返し処理を実施 $(getData).find("build").each(function(){ // 実行日時の変換・取得 convTimestamp(Number($(this).find("timestamp").text())); // パラメータは深い階層に格納されているので、 // findを繰り返して取得する $(this).find("action").each(function(){ $(this).find("parameter").each(function(){ if($.inArray($(this).find("name").text(), Unnecessary) == -1){ // naneとvalueの関係になっているので、以下のように取得し、 // 配列かhtml文字列作成用変数に格納していく $(this).find("name").text(); //要素名 $(this).find("value").text(); //要素値 } }); }); }); }); // html書き換え // 挿入先のhtmlタグは、idを設定して記載しておく $("#挿入先のid").html("先ほど作成したhtml文字列"); }; // 個人的にリフレッシュ処理を行いたくなったので // 一定間隔で繰り返し処理を行う「setIntervalメソッド」を組み込み、 // そこからも呼び出すようにする $(function(){ setInterval(function(){ getList(); }, 5000); });最後に
とりあえず、基本的なライブラリでもなんとかなる事がわかりました。
次は新しいツールも試してみたいと思います。

- 投稿日:2019-05-06T11:30:37+09:00
クロージャーの4言語比較(Python, JavaScript, Java, C++)
概要
クロージャーといえばJavaScriptという感じだけど、Pythonでクロージャーを使ってみる機会があったので、色々な言語で比較してみる。
間違えている部分があったらコメントにてお教えください!
もちろん間違いがないように努力します。JavaScriptの場合
function outer(){ let a = 0; let inner = () => { console.log(a++); }; return inner; } let fn = outer(); >>> fn(); 0 >>> fn(); 1 >>> fn(); 2innerがaへの参照を保持しているので、変数aがGCに回収されないままである。
シンプルで分かりやすい。
ただ、以下のようにaがouterの引数として渡される場合でもaが保持されることに注意する。function outer(a){ let inner = () => { console.log(a++); }; return inner; } let fn = outer(0); >>> fn(); 0 >>> fn(); 1 >>> fn(); 2クロージャーを定義時と異なる場所で実行してみる
結論から言えば、もちろん定義時と異なる場所でも定義時の変数を参照出来る。
nodeでimport文を実行するために.mjsファイルにし、node --experimental-modulesコマンドを用いる。
module.mjs// export let a = 1; // aはエクスポートしない let a = 1; export function outer(){ let b = 1000; let inner1 = ()=>{ console.log(b++); } return inner1; } //関数内関数ではない export function inner2(){ console.log(a++) }closure.mjsimport * as m from "./module.mjs"; let fn = m.outer(); fn(); fn(); fn(); m.inner2(); m.inner2(); m.inner2(); console.log(a)出力:
$ node --experimental-modules closure.mjs (node:12980) ExperimentalWarning: The ESM module loader is experimental. 1000 1001 1002 1 2 3 file:///***********/closure.mjs:11 console.log(a) ^ ReferenceError: a is not definedこのようにaは定義されていないと出るのに、inner2で参照出来ている。
ということは、JavaScriptでは関数内関数でなくとも、関数はクロージャーになる。firefox(66.0.3)で実際に実行してみる。
$ cp closure.mjs closure.js $ cp module.mjs module.jsclosure.jsのインポート文をimport * as m from "./module.js";と書き換えておく。
closure.html<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <script type="module" src="closure.js"></script> <title>test</title> </head> <body> </body> </html>closure.htmlにfirefoxでアクセスし、ログを確認。
1000 1001 1002 1 2 3 ReferenceError: a is not defined[詳細]全く同じ結果になった。
Pythonだとグローバル変数のスコープはそのファイル限りであるが、import/export機能を使い、その変数をexportしないのであればJavaScriptでも同じっぽい?(exportしないのだから当然か)Pythonの場合
def outer(): a = 0 def inner(): nonlocal a print(a) a += 1 return inner fn = outer() >>> fn() 0 >>> fn() 1 >>> fn() 2Pythonもほぼ同じで分かりやすいが、一つ余分なものが入っている。その名はnonlocal。
一つ外側のスコープの変数を変更しようとする時に必須となる。
ちなみにnonlocalではなくglobal aとすると今度はaはグローバル変数aを参照するようになる。nonlocal 文は、列挙された識別子がグローバルを除く一つ外側のスコープで先に束縛された変数を参照するようにします。
global 文は、列挙した識別子をグローバル変数として解釈するよう指定することを意味します。
(引用元:Python 言語リファレンス)
a = 111 def outer(): a = 0 def inner1(): # 参照するだけならnonlocal aとしなくてもOK print(a) # nonlocal aとしないとa+=1でエラーが出る # a += 1 def inner2(): #global aとするとa = 111の定義を参照する global a print(a) return (inner1, inner2) inner1, inner2 = outer() >>> inner1() 0 >>> inner2() 111 # 当たり前だがクロージャーから # 参照しているouter関数内部のa=0は外部からアクセス出来ず、 # この場合global変数であるa=111がprintされる >>> print(a) 111定義時と異なる場所で実行してみる
module.pya = 1 def outer(): b = 1000 def inner1(): nonlocal b print(b) b += 1 return inner1 #inner2は関数内関数ではない def inner2(): #global aとしないとエラーが出る global a print(a) a += 1closure.pyfrom module import * inner1 = outer() inner1() inner1() inner1() inner2() inner2() inner2()出力:
$ python closure.py 1000 1001 1002 1 2 3JavaScriptと同様にできた!
(inner2でglobal aとしないままエラーを出して、エラーが出るからJavaScriptとは違うと書いていましたが、コメントでご指摘を頂き修正しました。)
Javaの場合
Java(7以前)にはクロージャーがないらしい。関数内で無名クラス(匿名クラス)を使うことによって似たようなことが出来る(ただし制限あり)。
Java8からはラムダ式が導入されたが、それもまたクロージャーではないらしい。
それらの経緯等含めて以下のリンクが詳細かつ非常に読みやすくおすすめ。
- Java 8:ラムダ式、パート1
- Java 8:ラムダ式、パート2パート2はまだ読んでないが一応貼っておく。
以下ではざっくりした説明をしていく。
まずは無名クラスを使う例を試してみる。
Javaでは関数が第一級オブジェクトではないので、代わりに一つの関数のみをメンバーとして持つ無名クラスオブジェクトをouter関数からリターンしてみたらどうなるか、みたいなイメージでいいのだろうか。interface Inner { public void print(); } public class ClosureTest { public Inner outer() { //ここはfinal使わないとエラー final int a = 0; return new Inner() { public void print() { System.out.println(a); //finalなのでa++できない } } } public static void main(String[] args) { ClosureTest ct = new ClosureTest(); Inner inner = ct.outer(); inner.print(); } }上の例の通り、finalをつけなければならないので、JavaScriptやPythonのようには出来ない。ただし、finalは参照に対してのfinalに過ぎないので、変数aを配列かArrayList等にして、要素の値を実行ごとに変えることは出来る。つまり同じことを実現すること自体は出来る。
次にラムダ式。
ラムダ式の場合は、スコープ外の変数を参照する場合、その変数はfinalにしなくてもいい。しかし、値を変更するとエラーが出る。public class Closure { public static void main(String... args) { //無名クラスと違ってfinalでなくともいい! int a = 0; //しかしa++の部分でエラーが出る Runnable r = () -> System.out.println(a++); r.run(); } }エラー内容は以下の通り。
Exception in thread "main" java.lang.Error: Unresolved compilation problem:
Local variable a defined in an enclosing scope must be final or effectively finalということは、変数aはfinalか、実質的にfinalでなくてはならないということ。実質的にfinalというのは、上の例のような変更を施さないこと。
つまり、スコープ外の変数を参照する場合の取扱いは、無名クラスとラムダ式で(ほぼ)同じ。
以前、無名クラスやら関数型インターフェースやらラムダ式の表記法やら学んだ当初はなんなんだこれと思っていたが、クロージャーの観点で見ると理解出来てきてくるような気がする。
C++の場合
C++11のラムダ式を使って簡単に書けるようだ。
まず、ラムダ式はこれ。
[](int a, int b) -> int { return a + b; }以下のように使う。
auto fn = [](int a, int b) -> int { return a + b; } int c = fn();「-> int」の部分はこの関数の戻り値の型を示している。次のように省略してもいい。
[](int a, int b) { return a + b; }[]は後述。
そして、
このラムダ式によって、その場に以下のような関数オブジェクトが定義される:
struct F { auto operator()(int a, int b) const -> decltype(a + b) { return a + b; } };(引用元:cpprefjp - C++日本語リファレンス)
()をオーバーロードして関数オブジェクトを実現しているのが面白い。
戻り値がautoとdecltype(a+b)の二つになっている理由はここ参照。[]はキャプチャのこと。
ラムダ式には、ラムダ式の外にある自動変数を、ラムダ式内で参照できるようにする「キャプチャ(capture)」という機能がある。キャプチャは、ラムダ導入子(lambda-introducer)と呼ばれる、ラムダ式の先頭にある[ ]ブロックのなかで指定する。
キャプチャには、コピーキャプチャと参照キャプチャがあり、デフォルトでどの方式でキャプチャし、個別の変数をどの方式でキャプチャするかを指定できる。
(引用元:cpprefjp - C++日本語リファレンス)
以下キャプチャの例
#include <iostream> using namespace std; int main(){ int a = 1; int b = 2; //aをコピーキャプチャ auto fn1 = [a] () { cout << a << endl; }; //aを参照キャプチャ auto fn2 = [&a] () { cout << a << endl; }; //aとbをコピーキャプチャ auto fn3 = [=] () { cout << a + b << endl; }; //aとbを参照キャプチャ auto fn4 = [&] () { cout << a + b << endl; }; a = 1000; b = 2000; fn1(); fn2(); fn3(); fn4(); }出力:
1 1000 3 3000コピーキャプチャの時は以下のようになるんだろうか。詳しい方いたらお教えください。
これは想像上のコードです struct F { //変数名はaとbにはならなそう? int a = 1; int b = 2; auto operator()() const -> decltype(a + b) { cout << a + b << endl; } };そして、クロージャー(っぽいもの)はこのように書ける。
#include <iostream> #include <functional> std::function<int()> outer() { int a = 0; //aをコピーキャプチャ auto inner = [a]() mutable -> int { return a++; }; return inner; } int main() { auto inner = outer() std::cout << inner() << std::endl; std::cout << inner() << std::endl; std::cout << inner() << std::endl; return 0; }mutableに関しては、
キャプチャした変数はクロージャオブジェクトのメンバ変数と見なされ、クロージャオブジェクトの関数呼び出し演算子は、デフォルトでconst修飾される。そのため、コピーキャプチャした変数をラムダ式のなかで書き換えることはできない。
コピーキャプチャした変数を書き換えたい場合は、ラムダ式のパラメータリストの後ろにmutableと記述する。
(引用元:cpprefjp - C++日本語リファレンス)
とのこと。この例では、外部スコープにあるaをコピーし、それをラムダ式(関数オブジェクト)の中でメンバー変数として保存する。
Javaのようにコピーされた変数aはconst(final)なわけだが、mutableという語句によって変更可能にしてしまう。もちろん、上の例で
auto inner = [&a]() mutable -> int {}のように参照キャプチャをするとouter()実行終了時に参照先が解放されてしまうのでコピーキャプチャでなければならない。
おまけ
Pythonで面白いクロージャーの使い方が出来る。
http.serverというライブラリがあり、簡易なwebサーバーをたてられる。
以下のようにして使うのだが、HTTPServer()の第二引数のhdはクラスオブジェクトでなければならない。しかし、hdがクロージャーでもうまくいく。server = HTTPServer(('', int(port)), hd) server.serve_forever()hdがクロージャーの場合:
def handler_wrapper(): counter = [0] def handler(*args): counter[0] += 1 return HandleServer(counter, *args) return handler hd = handler_wrapper()なぜこのようにしていいのか等含めて時間があったら別記事として書きたい。
まとめ
クロージャーって難しいなあ。
- 投稿日:2019-05-06T10:53:48+09:00
AMP Conf 2019 @ tokyo ハイライト
2019/04/17-18に六本木アカデミーヒルズで開催された、AMP Conf 2019の参加レポートです。
2017年アメリカ・ニューヨーク、2018年オランダ・アムステルダムと続き、第3回目は日本開催ということで、初参戦してきました。
新ガバナンスモデル
2018年11月に発表した新ガバナンスモデルについての説明。
そもそもガバナンスって?って話しですが、Wikipediaによると、ガバナンス(governance)とは、統治のあらゆるプロセスをいう。政府、企業などの組織のほか、領土、ITシステム、権力などにも用いられる広い概念である
Wikipediaとあるので、AMPのコミュニティを今後どうやって統制していくかって話だと思います。
セッション内での説明では、Technical Steering Committee (TSC)とよばれる、技術面と製品面の方向性を定めるメンバー。Advisory Committee(AC)とよばれるTSCにアドバイスする関連ビジネスの代表者。また、特定分野の知識、関心を持つWorking Group(WG)の3つの構成でよりオープンに意見を求めてAMPの方向性を議論していくとのこと。
References
amp-script
AMPのデメリットとして挙げられる厳しい制限。その1つがJavascriptの一切の禁止。これが緩和される。
まだ
Experimentalだが、<amp-script />を利用することで、web worker上で開発者が用意したJavascriptを実行することができるようになる。web workerは仕様上、DOMの操作ができないが、AMPプロジェクトのworker-domというライブラリのおかげて、worker内でDOM APIを再現し本体のDOMに反映することができる。
仕様上できないDOM操作をどうやってやってるか気になる人はぜひセッション動画を見てほしい。
ムリクリ実現させた方法が解説されている。注意点
Javascriptの利用ができるようになったからと言って無制限に利用できるわけではない。
- 合計のファイルサイズが150KB以内(利用ライブラリ等含む)
- ユーザーの操作起因で動く処理のみ許可
- スクリプトの動作時間は5秒以内
- 外部リソースの取得等があった場合はレスポンスのfirst byteが帰って来たときから更に5秒以内
References
Google Domainからの開放
AMPのデメリットとして挙げられる厳しい制限。もう1つがAMPとして配信されるドメインがgoogle.comになてしまう問題。それを自ドメインで配信できるようになる。
AMPページを高速に表示するために、
- CDNエッジサーバからの配信
- サーチ検索結果であれば、結果表示時点での事前読み込み
を行いたく、そのためにはどうしてもGoogleドメインで配信せざるを得ないらしい。
(詳しくはセッション動画参照ちょっと難しかった。。。)
配信はGoogleドメインだが、ユーザーに表示するドメインを自ドメインにさせる方法が
webpackaging(webpackではない)という仕様。webpackagingは
Signed ExchangeとBundle Exchangeからなる仕様で、AMPを自ドメインで表示するためには、Signed Exchangeを利用する。この仕様はchrome 73から利用可能。Signed ExchangeはHTTPのrequest,responseに対して証明書付きでひとまとめにすることで、配信ドメインに関係なく自ドメインを証明できるようにする技術。これによりコンテンツ(web page)が
- どこから、だれからでも入手可能
- オフラインでも利用可能
- コンテンツの所有者のURLで表示可能
- Cookieなんかも操作可能
になる。
Signed Exchangeをサポートしているプラットフォームは、Googleの検索結果と、Yahoo Japanの検索結果。
Signed ExchangeをサポートしているPublisherは現在のところ日本では、Yahoo トラベルや一休など。Signed Exchangeを利用するには、
CanSignHttpExchangesをサポートしている証明書を別で発行する必要があり、現在発行できるベンダーはDigiCertだけある。また、CloudFlareはBeta機能としてSigned Exchangeを利用してのAMP配信を利用でき、機能をON後、CloudFlareからの返信があれば機能を利用できる。
https://blog.cloudflare.com/announcing-amp-real-url/
Signed Exchangeを利用すれば実際の配信はGoogle CDNで、ブラウザに表示されるドメインが自ドメインにすることができるが、注意点も必要。
- AMPの有効期限が短時間(最大1週間)
- 証明書の有効期限は90日
- 端末に保存され参照されるのでAMPの内容がキャッシュ可能なものか(個人情報を含んでないか)を確認することが求められる
References
- 解説ブログ
- 関連セッション
amp-story
カンファレンスの目玉の一つ。前から発表されていたコンポーネントだが、利用者からのfeedback等をもとに改善された点などの報告。
ストーリーは今や、インスタグラム、Facebook、Snapchat等に実装されている新しいメディアのフォーマット。
プラットフォーム内だけでの公開であったり、制限がいろいろあったりする。AMP StoryはこのストーリーというメディアをWebで簡単に構築できるコンポーネントを用意している。
とはいえ結局のところただのWeb pageに過ぎない。AMP StoryはAMPを利用することで、ストーリーっぽいUIのWeb Pageを簡単につくることを可能にしてくれる。主な特徴、機能としては、
- シェア可能
- リンク可能
- 検索可能
- アタッチメント可能
- 情報のEmbed可能(tweetやyoutube、google mapなどがサポート予定)
- レスポンシブ対応
- 広告を表示可能
百聞は一見にしかず。下記はメディアが作った実際のAMP Story。
レスポンシブ未対応のAMP Story
- https://www.bbc.co.uk/news/ampstories/africafish/index.html
- https://edition.cnn.com/ampstories/entertainment/the-matrix-turns-20-a-look-back
- https://www.pcgamesn.com/amp-stories/best-battle-royale-games.html
- https://www.usatoday.com/amp-stories/beyonce-rule-the-world/
レスポンシブ対応のAMP Story
- https://projects.sfchronicle.com/2019/visuals/guerneville-russian-river-flooding/
- https://www.telegraph.co.uk/visual-stories/best-islands-to-visit/
アタッチメント
ストーリーに載せた情報のより詳細をスワイプアップして表示可能
情報のEmbed
検索可能
ストーリーはWeb pageなのでGoogle検索での検索も可能。
詳細はこちらの動画参照。
https://youtu.be/i7Br9GmpQWs?t=1003ベストプラクティス
導入事例をもとに、Storyを作る上での、ベストプラクティスも公開しているので参考になる。
これは、AMPでなくても例えばインスタグラムのStoryを作る上でも参考になるかもしれない。https://amp.dev/documentation/guides-and-tutorials/develop/amp_story_best_practices
ツール
AMP Storyを作るツールを提供するサービス公開されているので、ゴリゴリコードを書かずとも作ることは可能。
References
- ドキュメント
- 関連セッション
AMP Email
カンファレンスの目玉の一つ。まだ
Experimentalだが、先行して実装している企業からのフィードバックの紹介が多くあった。
AMP EmailはAMPのコンポーネントをEmailに埋め込んで利用できるようにするもの。現在EmailはTextタイプのものと、HTMLタイプのものがあるが、HTMLタイプのEmailはレイアウトが難しかったり、JavaScriptが使えないため動的な表現がまったくできなかったが、AMP Emailを利用することでそれができるようになる。
互換性
送るときのMIME-typeは
text/x-amp-htmlとして送るため、現状のEmailの互換性が保たれていて、AMP Emailが表示できるサービスならAMP Emailを表示して、できないサービスなら、HTML Emailを見せるということができる。主なコンポーネント
ドキュメントによると、、、、フォームによる情報の送信、カルーセル、light-box、アコーディオンなんかも表示可能。
Google DocのEmail内でのコメント返信
Ecwid(ECのキャンペーンEmailでの画像のカルーセル表示)
効果
- Indeedは、job alert Emailのクリック数が2倍に
- OYOは+57%のCTR、+60%のCVR
パートナー
- AMP Emailを配信できるサービス
- SendGrid
- SPARKPOST
- AMP Emailを表示できるクライアント
- Gmail
- Yahoo mail
- Outlook
開発
- 開発するならプレビュー機能がある下記を利用できる
- AMP Emailを試しに送信するなら下記が利用できる
References
今後について
2019年はAMPでの
- 決済機能
- CSSの50KB制限の条件付きでの緩和
- optimizerで最適化処理したAMPファイルもvalidにする予定
- Stateful ページの実装
- 例えば商品検索ページでいろいろ絞り込みして商品詳細ページへ遷移して、戻るボタンで商品検索ページに戻るとさっき絞り込みした状態が復元するとか
長期的視点
AMPを実装するときは2つの構成がある。
- Paired AMP
- 非AMPと対になるAMPページの2つを用意する
- AMP First
- AMPページだけ用意する
あくまで目標はAMP Firstな実装なのでそれに足りない機能を検討、実装していく。
AMP Bento ?
AMPは、アクセシビリティやUXが考えられた素晴らしいコンポーネントが多数存在する。
これらをAMPページ以外でも気軽に利用できるようにしていきたい。現在は、AMP runtimeである https://cdn.ampproject.org/v0.js がページには必須だが、これがなくても動くようにしたいし、VueやReactといった別コンポーネントと相互にインタラクトできるようにしていきた。
そのコンセプトの名前が AMP Bento ?
References
- 関連セッション

- 投稿日:2019-05-06T10:12:49+09:00
Express v4 と log4js v4 で実践的なロガーを実装
はじめに
node.jsでアプリケーションログを出力する際に、業務でありがちなログのローテーションや、ログレベル毎にファイルを分けるとかの設定をlog4jsで実装してみました。
実装時の環境
以下の環境で実装しました。
・OS:Mac OS X v10.14.4
・Node:v12.1.0
・npm:v6.9.0log4jsで指定できるログの種別
log4jsでは以下のログレベルを指定できます。
ログレベル 詳細 OFF 全てのログを取得しない。(使うことがあるのか疑問です) MARK エラーではないが常に表示しておきたい情報を出力。(使ったことないので憶測です) FATAL 致命的なエラーの情報を出力。(システムの動作に影響を与えるエラー) ERROR 予期しない実行時エラーの情報を出力。 WARN 使用が終了となった機能の使用、APIの不適切な使用等に対する警告を出力。(エラーではないが正常とは言い難いものはこちらに分類されます) INFO 通常のログ。サーバーの起動、停止、ユーザーの操作情報等を出力。 DEBUG デバッグ用のログレベル。システムの動作状況に関する詳細な情報を出力したい時に使用。 TRACE トレース用のログレベル。デバッグでは出力しきれない詳細な情報を出力。 ALL 全てのログを取得 簡単なコードで実装してみる
ひとまず、簡単に出力するしてみます。
Expressとlog4jsをインストールします。# package.jsonを生成 $ npm init -y # Expressインストール(実装時の最新版です) $ npm install express@4.16.4 # log4jsインストール(実装時の最新版です) $ npm install log4js@4.1.0以下のようなコードでログを出力できます。
const express = require ('express'); const app = express (); const log4js = require ('log4js'); const logger = log4js.getLogger (); logger.level = 'debug'; app.get ('/', (req, res) => { logger.debug ('デバッグログが出力されます'); res.send ('log test'); }); app.listen (3000);出力結果は以下の通り。
このログの出力では、console.log()と変わらないですね。[2019-05-05T19:44:34.037] [Level { level: 10000, levelStr: 'DEBUG', colour: 'cyan' }] default - デバッグログが出力されます実践的なログ出力
業務で使用するログの出力方式としては以下の基準は満たしておきたいです。
・ログはファイルに出力する。
・ログの種別毎に分ける。(システムログ、アプリケーションログ、アクセスログ)
・ログローテーションを行う。 (30日分保持とか5MB毎にファイル生成等)ログファイルの出力設定について
ログをファイルに出力するには、log4x系によくあるappnedersとcategoriesを使用します。
以下はnodejsで実装する場合の一例です。
appendersには、logのタイプを指定します。下の例では、console出力用のAppenderを設定しています。
categoriesには、appendersで設定したAppenderを指定して、どのレベルで出力を行うかを指定します。// <APP ROOT>/config/log4js-config.js const log4js = require('log4js'); // ログ出力設定 log4js.configure({ appenders: { consoleLog: { type: "console" } }, categories: { "default": { // appendersで設定した名称を指定する // levelは出力対象とするものを設定ここではALL(すべて) appenders: ["consoleLog"], level: "ALL" } } }); // ログカテゴリはdefaultを指定する const logger = log4js.getLogger("default"); // infoとかerrorとかで出力 logger.error("error message");Appenderに設定するtypeでよく利用するものは以下の通り。
タイプ 詳細 console コンソールログを出力する。 file ファイルサイズによるローテーションと何ファイル保持するかを設定できる。 multiFile 主にAPIルート毎などログファイルの分離を行いたい時に使用する。 dateFile 日時でログローテーションするログの管理に使用する。何日分保持するかを設定できる。 上のコードを実行すると以下のような出力となります。
categoriesに設定したdefaultというカテゴリでログの内容が出力されます。[2019-05-05T20:30:24.433] [Level { level: 40000, levelStr: 'ERROR', colour: 'red' }] default - error messageモジュールの設計
システムログ、アプリケーションログ、アクセスログの設計は以下の通りです。
. ├── config │ └── log4js-config.js ←ログ設定モジュール ├── lib │ └── log │ ├── logger.js ←ルートロガーモジュール(各設定モジュールを統合する) │ ├── accessLogger.js ←アクセスログ出力モジュール │ └── systemLogger.js ←システムログ出力モジュール ├── log │ ├── access ←アクセスログが出力されるディレクトリ │ ├── application ←アプリケーションログが出力されるディレクトリ │ └── system ←システムログが出力されるディレクトリ ├── package-lock.json ├── package.json └── server.js ←Expressアプリケーションシステムログの実装
まずはシステムログから実装します。
今回作成するシステムログの要件は以下の通りです。・エラーログのみを出力。
・1ファイルが一定のサイズになった時にローテーションする。(5MBでローテーション)
・/log/system/system.log に出力する。
・世代管理は5ファイルまでとする。File Appenderを使う
システムログの出力設定には、File Appenderを使用します。
File Appenderで指定できる設定は以下の通りです。
設定 型 詳細 type string 設定できる値は file のみ。 filename string 出力ファイルのパスを設定。 maxLogSize number ログファイルの最大サイズ(byteで指定)この数値に達するとローテーションが実行されます。 backups number ログファイルの最大保持数を指定。 layout object ログ出力のレイアウトを指定。(日付のフォーマット等の設定) compress boolean ログファイルの保持数が上限に達した場合に古いログを削除するかの設定(trueに設定すると削除) 実装
ファイルを出力する際に、パスの指定をする必要があるので、pathモジュールをインストールします。
$ npm install pathログ設定モジュールにシステムログ用の設定を追加します。
// <APP ROOT>/config/log4js-config.js const path = require("path"); // ログ出力先は、サーバー内の絶対パスを動的に取得して出力先を設定したい const APP_ROOT = path.join(__dirname, "../"); // ログ出力設定 // log4jsはルートロガーで使用するので、エクスポートに変更 module.exports = { appenders: { consoleLog: { type: "console" }, // ADD systemLog: { type: "file", filename: path.join(APP_ROOT, "./log/system/system.log"), maxLogSize: 5000000, // 5MB backups: 5, // 世代管理は5ファイルまで、古いやつgzで圧縮されていく compress: true } }, categories: { default: { // appendersで設定した名称を指定する // levelは出力対象とするものを設定ここではALL(すべて) appenders: ["consoleLog"], level: "ALL" }, // ADD system: { appenders: ["systemLog"], level: "ERROR" } } };ルートロガーモジュールを作成します。
このモジュールは、ログ設定モジュールを元にロガーを生成します。// <APP ROOT>/lib/log/logger.js const log4js = require("log4js"); const config = require("../../config/log4js-config.js"); log4js.configure(config); // それぞれのログ種別ごとに作成 const console = log4js.getLogger(); const system = log4js.getLogger("system"); // 上で作成したcategoriesのsystemで作成します。 // ログ種別のエクスポート module.exports = { console, system };ログ出力モジュールは、上で作成したモジュールとは別に作成します。
// <APP ROOT>/lib/log/systemLogger.js const logger = require("./logger").system; module.exports = (options) => (err, req, res, next) => { logger.error(err.message); next(err); }Expressアプリに実装します。
// <APP ROOT>/server.js const express = require("express"); const app = express(); app.get('/', (req, res) => { logger.debug('デバッグログが出力されます'); res.send('log test'); }); // 意図的にエラーを起こすルート app.get("/error", (req, res) => { throw new Error("システムログの出力テスト Errorです"); }); // systemロガー const systemLogger = require("./lib/log/systemLogger"); // ロガーをExpressに実装 app.use(systemLogger()); app.listen(3000);ログ出力をテストしてみます。
# サーバー起動 $ node server.js # curlでerrorルートにアクセス $ curl localhost:3000/errorcurlでアクセスすると、以下のようなログが出力されます。
また、systemディレクトリ、system.logファイルが存在しない場合は自動生成されます。# <APP ROOT>/log/system/system.log [2019-05-05T21:53:57.674] [Level { level: 40000, levelStr: 'ERROR', colour: 'red' }] system - システムログの出力テスト Errorです次は、ログローテーションの機能を確認してみましょう。
以下のコマンドを実行して5MBのファイルを生成しておきます。$ mkfile 5m ./log/system/system.logログ出力をテストしてみます。
# サーバー起動 $ node server.js # curlでerrorルートにアクセス $ curl localhost:3000/errorsystem.log(5MB)のファイル名がsystem.log.1に変更され、新しくsystem.logファイルが生成されるはずです。
次は、ログの保持は5ファイルまでにしていたので、こちらを確認してみましょう。
system.log.1~5までの5ファイル(5MB)、system.log(5MB)を用意します。ログ出力のテストをしてみます。
# サーバー起動 $ node server.js # curlでerrorルートにアクセス $ curl localhost:3000/error一番古いログ(作成日付が古いもの)がgzで生成され、system.logがsystem.log.1へと名前が変更されるはずです。
以上でシステムログの実装は完了です。アプリケーションログの実装
アプリケーションログの要件は以下の通りです。
・エラーログのみ出力。
・機能毎にログファイルを分割する。
・1ファイルが一定のサイズになった時にローテーションする。(5MBでローテーション)
・/log/application/.log に出力する。
・世代管理は5ファイルまでとする。Multi File Appenderを使う
アプリケーションログの実装には Multi File Appenderを使用します。
Multi File Appenderで指定できる設定は以下の通りです。
設定 型 詳細 type string 設定できる値は multiFile のみ。 base string 出力ファイルのパスを設定。(ファイル名は記述しない) property string ログを分離する条件を設定。 extension string ログファイル名のサフィックスを設定。(拡張子のこと) layout object ログ出力のレイアウトを指定。(日付のフォーマット等の設定) maxLogSize number ログファイルの最大サイズ(byteで指定)この数値に達するとローテーションが実行されます。 backups number ログファイルの最大保持数を指定。 compress boolean ログファイルの保持数が上限に達した場合に古いログを削除するかの設定(trueに設定すると削除) 実装
ログ設定モジュールにシステムログ用の設定を追加します。
// <APP ROOT>/config/log4js-config.js const path = require('path'); // ログ出力先は、サーバー内の絶対パスを動的に取得して出力先を設定したい const APP_ROOT = path.join(__dirname, '../'); // ログ出力設定 module.exports = { appenders: { consoleLog: { type: 'console', }, systemLog: { type: 'file', filename: path.join(APP_ROOT, './log/system/system.log'), maxLogSize: 5000000, backups: 5, compress: true, }, // ADD applicationLog: { type: "multiFile", base: path.join(APP_ROOT, "./log/application/"), property: "key", extension: ".log", // ファイルの拡張子はlogとする maxLogSize: 5000000, // 5MB backups: 5, // 世代管理は5ファイルまで、古いやつからgzで圧縮されていく compress: true, }, }, categories: { default: { appenders: ["consoleLog"], level: "ALL" }, system: { appenders: ["systemLog"], level: "ERROR" }, // ADD application: { appenders: ["applicationLog"], level: "ERROR" } }, };ルートロガーモジュールに追加します。
// <APP ROOT>/lib/log/logger.js const log4js = require("log4js"); const config = require("../../config/log4js-config.js"); log4js.configure(config); // それぞれのログ種別ごとに作成 const console = log4js.getLogger(); const system = log4js.getLogger("system"); const application = log4js.getLogger("application"); // ADD // ログ種別のエクスポート module.exports = { console, system, application, // ADD };Expressアプリに実装します。
// <APP ROOT>/server.js const express = require("express"); const app = express(); app.get('/', (req, res) => { logger.debug('デバッグログが出力されます'); res.send('log test'); }); // 意図的にエラーを起こすルート app.get("/error", (req, res) => { throw new Error("システムログの出力テスト Errorです"); }); // systemロガー const systemLogger = require("./lib/log/systemLogger"); // ロガーをExpressに実装 app.use(systemLogger()); //=== const logger = require("./lib/log/logger").application; logger.addContext("key", "test"); logger.error("アプリケーションログの出力テスト Errorです"); //=== app.listen(3000);サーバーを起動すると、test.logという名前のファイルが作成されるはずです。
$ node server.js# <APP ROOT>/log/application/test.log [2019-05-06T07:50:08.500] [Level { level: 40000, levelStr: 'ERROR', colour: 'red' }] application - アプリケーションログの出力テスト Errorですこの実装で、アプリケーションログは出力できますが、アプリケーションログだけ
logger.addContext()とlogger.error()の2行を書くのはダサいので修正します。以下のような指定で出力できるようにしたい。
logger.error("test", "1行で出力できるようにしたい");ルートロガーを修正します。
アプリケーションロガーを拡張して、アプリケーションID(key)と出力内容(message)を取得して、ログを出力できるようにします。
// <APP ROOT>/lib/log/logger.js const log4js = require("log4js"); // log4jsの中からlevelを設定しているファイルを指定 // https://github.com/log4js-node/log4js-node/blob/master/lib/levels.js を参照 const levels = require("log4js/lib/levels").levels; const config = require("../../config/log4js-config.js"); log4js.configure(config); // それぞれのログ種別ごとに作成 const console = log4js.getLogger(); const system = log4js.getLogger("system"); // アプリケーションロガー拡張 const ApplicationLogger = function () { this.logger = log4js.getLogger("application"); }; const proto = ApplicationLogger.prototype; for (let level of levels) { // log4jsのソースコード見ると、大文字になっているので小文字にします。 level = level.toString().toLowerCase(); proto[level] = (function (level) { return function (key, message) { const logger = this.logger; logger.addContext("key", key); // logger.Context("key", "test") で実装していたところをこちらで任意の値が設定できるようにする logger[level](message); }; })(level); } // 新たにロガーを生成 const application = new ApplicationLogger(); // ログ種別のエクスポート module.exports = { console, system, application, };Expressアプリケーションを修正します。
// <APP ROOT>/server.js const logger = require("./lib/log/logger").application; // ADD const express = require("express"); const app = express(); app.get('/', (req, res) => { logger.debug('デバッグログが出力されます'); res.send('log test'); }); // 意図的にエラーを起こすルート app.get("/error", (req, res) => { throw new Error("システムログの出力テスト Errorです"); }); // systemロガー const systemLogger = require("./lib/log/systemLogger"); // ロガーをExpressに実装 app.use(systemLogger()); //=== logger.error("test", "1行で出力できるようにしたい"); // 今度はkeyとメッセージのみで出力できる logger.error("app1","こちらは別のログファイルで出力される"); // ついでなのでこちらの確認もします //=== app.listen(3000);以下のログが出力されるはずです。
# <APP ROOT>/log/application/test.log [2019-05-06T08:14:33.930] [Level { level: 40000, levelStr: 'ERROR', colour: 'red' }] application - 1行で出力できるようにしたい # <APP ROOT>/log/application/app1.log [2019-05-06T08:18:45.057] [Level { level: 40000, levelStr: 'ERROR', colour: 'red' }] application - こちらは別のログファイルで出力される以上でアプリケーションログの実装は完了です。
アクセスログの実装
アクセスログの要件は以下の通りです。
・INFOログを出力。
・ファイルは日付でローテーションする。
・/log/access/access.log に出力する。
・世代管理は5ファイル(5日分)までとする。Date Rolling File Appenderを使う
アクセスログの実装には、Date Rolling File Appenderを使用します。
Date Rolling File Appenderで指定できる設定は以下の通りです。
設定 型 詳細 type string 設定できる値は、dateFile のみ。 filename string 出力ファイルのパスを設定。 pattern string ログローテーションする際にサフィックス。(yyyy-MM-dd 等) daysTokeep number ログファイル名のサフィックスを設定。(拡張子のこと) layout object ログ出力のレイアウトを指定。(日付のフォーマット等の設定) compress boolean ログファイルの保持数が上限に達した場合に古いログを削除するかの設定(trueに設定すると削除) keepFileExt boolean patternで指定したサフィックスを.logの後につけるか前につけるかを指定。 Expressでアクセスログを出力するために
公式ドキュメントを見ると、
log4js.connectLogger(logger,options)で指定できるようです。
loggerにはログ出力に使用するロガーを指定、optionsにはログレベルやログフォーマットを指定します。optionsは指定できるものが多いので、まとめました。
①levelオプション
詳細 ログレベルを指定する。
"auto"または任意の値が設定できそうです。
"auto"を指定した場合、
・3xx→WARNログ
・4xx、5xx→ERRORログ
・その他→INFOログ
として出力されます。②formatオプション
設定値 詳細 :date[フォーマット] 現在日時(サーバーサイド)、format指定にはelf/iso/webのいずれかを指定。 :http-version リクエストHTTPのバージョンを表示。 :method リクエストメソッド(POST、GET)を表示。 :referrer リクエストのリファラを表示。 :remote-addr リクエストのリモートアドレスを表示。 :remote-user Basic認証を使用していた場合、リクエストユーザー名を表示。 :req[取得したいリクエストヘッダー] 指定したリクエストヘッダーを表示。 :res[取得したいレスポンスヘッダー] 指定したレスポンスヘッダーを表示。 :response-time[桁数指定] レスポンス時間を指定した桁数で表示。 :status レスポンスステータスを表示。 :url リクエストURLを表示。 :user-agent リクエストのUser-Agentを表示。 実装
ログ設定モジュールにアクセスログ用の設定を追加します。
// <APP ROOT>/config/log4js-config.js const path = require('path'); // ログ出力先は、サーバー内の絶対パスを動的に取得して出力先を設定したい const APP_ROOT = path.join(__dirname, '../'); // ログ出力設定 module.exports = { appenders: { consoleLog: { type: 'console', }, systemLog: { type: 'file', filename: path.join(APP_ROOT, './log/system/system.log'), maxLogSize: 5000000, backups: 5, compress: true, }, applicationLog: { type: "multiFile", base: path.join(APP_ROOT, "./log/application/"), property: "key", extension: ".log", maxLogSize: 5000000, backups: 5, compress: true, }, // ADD accessLog: { type: "dateFile", filename: path.join(APP_ROOT, "./log/access/access.log"), pattern: "yyyy-MM-dd", // 日毎にファイル分割 daysToKeep: 5, // 5日分の世代管理設定 compress: true, keepFileExt: true, } }, categories: { default: { appenders: ["consoleLog"], level: "ALL" }, system: { appenders: ["systemLog"], level: "ERROR" }, application: { appenders: ["applicationLog"], level: "ERROR" }, // ADD access: { appenders: ["accessLog"], level: "INFO" } }, };ルートロガーモジュールに追加します。
// <APP ROOT>/lib/log/logger.js const log4js = require("log4js"); const levels = require("log4js/lib/levels").levels; const config = require("../../config/log4js-config.js"); log4js.configure(config); // それぞれのログ種別ごとに作成 const console = log4js.getLogger(); const system = log4js.getLogger("system"); const access = log4js.getLogger("access"); // ADD const ApplicationLogger = function () { this.logger = log4js.getLogger("application"); }; const proto = ApplicationLogger.prototype; for (let level of levels) { level = level.toString().toLowerCase(); proto[level] = (function (level) { return function (key, message) { const logger = this.logger; logger.addContext("key", key); logger[level](message); }; })(level); } const application = new ApplicationLogger(); // ログ種別のエクスポート module.exports = { console, system, application, access, // ADD };ログ出力モジュールは、ルートロガーモジュールとは別に作成します。
// <APP ROOT>/lib/logger/accessLogger.js const log4js = require("log4js"); const logger = require("./logger").access; module.exports = (options) => { options = options || {}; // オプションを指定する場合はそちらを使う options.level = options.level || "auto"; // ない場合、autoを設定 return log4js.connectLogger(logger, options); // ログ設定 Expressのアクセスログと結びつける };Expressアプリに実装します。
loggerの設定で、levelにautoを設定したので、ステータス毎にどのように出力されるかも確認してみます。
// <APP ROOT>/server.js const accessLogger = require("./lib/log/accessLogger"); // ADD const logger = require("./lib/log/logger").application; const systemLogger = require("./lib/log/systemLogger"); const express = require("express"); const app = express(); app.use(systemLogger()); // ADD app.use(accessLogger()); app.get('/', (req, res) => { logger.debug('デバッグログが出力されます'); res.send('log test'); }); // ADD app.get("/access1", (req, res) => { res.status(200).send("access test 200"); }); // ADD app.get("/access2", (req, res) => { res.status(304).send("access test 304"); }); // ADD app.get("/access3", (req, res) => { res.status(404).send("access test 404"); }); // ADD app.get("/access4", (req, res) => { res.status(500).send("access test 500"); }); app.get("/error", (req, res) => { throw new Error("システムログの出力テスト Errorです"); }); app.listen(3000);curlでaccess1~4にアクセスすると、以下のようにステータス毎にログレベルの表示が変化します。
# <APP ROOT>/log/access/access.log [2019-05-06T09:39:28.034] [Level { level: 20000, levelStr: 'INFO', colour: 'green' }] access - ::1 - - "GET /access1 HTTP/1.1" 200 15 "" "curl/7.54.0" [2019-05-06T09:40:06.079] [Level { level: 30000, levelStr: 'WARN', colour: 'yellow' }] access - ::1 - - "GET /access2 HTTP/1.1" 304 - "" "curl/7.54.0" [2019-05-06T09:40:10.745] [Level { level: 40000, levelStr: 'ERROR', colour: 'red' }] access - ::1 - - "GET /access3 HTTP/1.1" 404 15 "" "curl/7.54.0" [2019-05-06T09:40:16.519] [Level { level: 40000, levelStr: 'ERROR', colour: 'red' }] access - ::1 - - "GET /access4 HTTP/1.1" 500 15 "" "curl/7.54.0"以上でアクセスログの実装は完了です。
今回作成したデモアプリはこちら に格納しました。
参考資料
紹介しきれていない設定がまだあるので、こちらを参考にすると細かい設定ができると思います。
- 投稿日:2019-05-06T09:31:17+09:00
Nuxt.js(Vue.js)とGoでSPA + API(レイヤードアーキテクチャ)でチャットアプリを実装してみた
概要
Nuxt.js(Vue.js)とレイヤードアーキテクチャのお勉強のために簡単なチャットアプリを実装してみた。
SPA + APIと言った形になっている。機能
機能はだいたい以下のような感じ。
- ログイン機能
- サインアップ機能
- スレッド一覧表示機能
- スレッド作成機能
- ログインしたユーザーは誰でもスレッドを作成できること
- コメント一覧表示機能
- スレッドをクリックすると、そのスレッド内のコメント一覧が表示されること
- スレッド内でのコメント作成機能
- ログインしたユーザーは誰でもどのスレッド内でもコメントできること
- スレッド内でのコメント削除機能
- 自分のコメントのみ削除できること
- ログアウト機能
コード
- コード全体はここ
- コードは一例でもっと他の実装や良さそうな実装はありそう
技術
サーバーサイド
アーキテクチャ
DDD本に出てくるレイヤードアーキテクチャをベースに以下の書籍や記事を参考にさせていただき実装した。超厳密なレイヤードアーキテクチャというわけではない。
- Goを運用アプリケーションに導入する際のレイヤ構造模索の旅路 | Go Conference 2018 Autumn 発表レポート - BASE開発チームブログ
- GoでのAPI開発現場のアーキテクチャ実装事例 / go-api-architecture-practical-example - Speaker Deck
- ボトムアップドメイン駆動設計 │ nrslib
- エリック・エヴァンス(著)、今関 剛 (監修)、和智 右桂 (翻訳) (2011/4/9)『エリック・エヴァンスのドメイン駆動設計 (IT Architects’Archive ソフトウェア開発の実践)』 翔泳社
- pospome『pospomeのサーバサイドアーキテクチャ
実際のpackage構成は以下のような感じ。
├── interface │ └── controller // サーバへの入力と出力を扱う責務。 ├── application // 作業の調整を行う責務。 ├── domain │ ├── model // ビジネスの概念とビジネスロジック(正直今回はそんなにビジネスロジックない...) │ ├── service // EntityでもValue Objectでもないドメイン層のロジック。 │ └── repository // infra/dbへのポート。 ├── infra // 技術に関すること。 │ ├── db // DBの技術に関すること。 │ ├── logger // Logの技術に関すること。 │ └── router // Routingの技術に関すること。 ├── middleware // リクエスト毎に差し込む処理をまとめたミドルウェア ├── util └── testutilpackageの切り方は以下を大変参考にさせていただいている。
- エリック・エヴァンス(著)、今関 剛 (監修)、和智 右桂 (翻訳) (2011/4/9)『エリック・エヴァンスのドメイン駆動設計 (IT Architects’Archive ソフトウェア開発の実践)』 翔泳社
- pospome『pospomeのサーバサイドアーキテクチャ』
- Goを運用アプリケーションに導入する際のレイヤ構造模索の旅路 | Go Conference 2018 Autumn 発表レポート - BASE開発チームブログ
- ボトムアップドメイン駆動設計 │ nrslib
- GoでのAPI開発現場のアーキテクチャ実装事例 / go-api-architecture-practical-example - Speaker Deck
上記のpackage以外に
application/mock、domain/service/mock、infra/db/mockというmockを格納する用のpackageもあり、そこに各々のレイヤーのmock用のファイルを置いている。(詳しくは後述)依存関係
依存関係としてはざっくり、
interface/controller→application→dmain/repositoryordmain/service←infra/dbという形になっている。参考: GoでのAPI開発現場のアーキテクチャ実装事例 / go-api-architecture-practical-example - Speaker Deck
domain/~とinfra/dbで矢印が逆になっているのは、依存関係が逆転しているため。
詳しくは その設計、変更に強いですか?単体テストできますか?...そしてクリーンアーキテクチャ - Qiitaを参照。先ほどの矢印の中で、
domain/modelは記述しなかったが、domain/modelは、interface/controllerやapplication等からも依存されている。純粋なレイヤードアーキテクチャでは、各々のレイヤーは自分の下のレイヤーにのみ依存するといったものがあるかもしれないが、それを実現するためにDTO等を用意する必要があって、今回の実装ではそこまで必要はないかなと思ったためそうした。(厳格にやる場合は、実装した方がいいかもしれない)各レイヤーでのinterfaceの定義とテスト
applicaion、domain/service、infra/db(定義先は、/domain/repository) にはinterfaceを定義し、他のレイヤーからはそのinterfaceに依存させるようにしている。こうするとこれらを使用する側は、抽象に依存するようになるので、抽象を実装する具象を変化させても使用する側(依存する側)はその影響を受けにくい。実際に各レイヤーを使用する側のレイヤのテストの際には、使用されるレイヤーを実際のコードではなく、Mock用のものに差し替えている。各々のレイヤーに存在する
mockというpackageにmock用のコードを置いている。このモック用のコードは、gomockを使用して自動生成している。この辺のことについては、
その設計、変更に強いですか?単体テストできますか?...そしてクリーンアーキテクチャ - Qiita という記事を以前書いたので、詳しくはこちらを参照いただきたい。エラーハンドリング
エラーハンドリングは以下のように行なっている。
- 以下のような形で
errors.Wrapを使用してオリジナルのエラーを包むif err := Hoge(); err != nil { return errors.Wrap(オリジナルエラー, "状況の説明" }
- 独自のエラー型を定義している
- エラーは基本的に各々のレイヤーで握りつぶさず、
interface/controllerレイヤーまで伝播させる- 最終的には、
interface/controllerでエラーの型によって、レスポンスとして返すメッセージやステータスコードを選択する参考
Golangのエラー処理とpkg/errors | SOTAログイン周り
- 外部サービスを使用せず、自前で簡単なものを実装した
- パスワードのハッシュ化には bcryptを使用した
- 普通にCookieとSessionを使用した
- ログインが必要なAPIには
ginのmiddlewareを使用して、ログイン済みでないクライアントからのリクエストは401 Unauthorizedを返すようにしたDB周り
- MySQLを使用した
- DBテスト部分は、DBサーバを立てたわけではなく、DATA-DOG/go-sqlmockを使用し、モックで行なった
- GoのAPIのテストにおける共通処理 – timakin – Mediumにあるように以下等を使用してDBサーバーを立てて行うのも良いかも
- ory/dockertest
- Dockerを使う場合
- lestrrat-go/test-mysqld
- Dockerを使わない場合
- DB操作周りの実装に関しては、database/sql packageをそのまま使用し、ORMやその他のライブラリは特に使用していない
- トランザクションは、
applicationレイヤでかける- 以下のようなSQL周りの
interfaceを作成package query import ( "context" "database/sql" ) // DBManager is the manager of SQL. type DBManager interface { SQLManager Beginner } // TxManager is the manager of Tx. type TxManager interface { SQLManager Commit() error Rollback() error } // SQLManager is the manager of DB. type SQLManager interface { Querier Preparer Executor } type ( // Executor is interface of Execute. Executor interface { Exec(query string, args ...interface{}) (sql.Result, error) ExecContext(ctx context.Context, query string, args ...interface{}) (sql.Result, error) } // Preparer is interface of Prepare. Preparer interface { Prepare(query string) (*sql.Stmt, error) PrepareContext(ctx context.Context, query string) (*sql.Stmt, error) } // Querier is interface of Query. Querier interface { Query(query string, args ...interface{}) (*sql.Rows, error) QueryContext(ctx context.Context, query string, args ...interface{}) (*sql.Rows, error) } // Beginner is interface of Begin. Beginner interface { Begin() (TxManager, error) } )
applicationレイヤーでは以下のようにフィールドでquery.DBManagerを所持する
- そうすることで
SQLManagerとTxManager(Begin()で生成)のどちらもapplicationレイヤーで扱うことができる(applicationレイヤで直接使用するわけではなく、domain/repositoryに渡す)// threadService is application service of thread. type threadService struct { m query.DBManager service service.ThreadService repo repository.ThreadRepository txCloser CloseTransaction }
domain/repositoryの引数ではquery.SQLManagerを受け取る
query.TxManagerは、query.SQLManagerも満たしているので、query.TxManagerは、query.SQLManagerのどちらも受け取ることができる// ThreadRepository is Repository of Thread. type ThreadRepository interface { ListThreads(ctx context.Context, m query.SQLManager, cursor uint32, limit int) (*model.ThreadList, error) GetThreadByID(ctx context.Context, m query.SQLManager, id uint32) (*model.Thread, error) GetThreadByTitle(ctx context.Context, m query.SQLManager, name string) (*model.Thread, error) InsertThread(ctx context.Context, m query.SQLManager, thead *model.Thread) (uint32, error) UpdateThread(ctx context.Context, m query.SQLManager, id uint32, thead *model.Thread) error DeleteThread(ctx context.Context, m query.SQLManager, id uint32) error }
- 以下のようなRollbackやCommitを行う関数を作成しておく
// CloseTransaction executes post process of tx. func CloseTransaction(tx query.TxManager, err error) error { if p := recover(); p != nil { // rewrite panic err = tx.Rollback() err = errors.Wrap(err, "failed to roll back") panic(p) } else if err != nil { err = tx.Rollback() err = errors.Wrap(err, "failed to roll back") } else { err = tx.Commit() err = errors.Wrap(err, "failed to commit") } return err }
applicationレイヤでは、deferでCloseTransactionを呼び出す(ここではa.txCloserになっている)// CreateThread creates Thread. func (a *threadService) CreateThread(ctx context.Context, param *model.Thread) (thread *model.Thread, err error) { tx, err := a.m.Begin() if err != nil { return nil, beginTxErrorMsg(err) } defer func() { if err := a.txCloser(tx, err); err != nil { err = errors.Wrap(err, "failed to close tx") } }() yes, err := a.service.IsAlreadyExistTitle(ctx, tx, param.Title) if yes { err = &model.AlreadyExistError{ PropertyName: model.TitleProperty, PropertyValue: param.Title, DomainModelName: model.DomainModelNameThread, } return nil, errors.Wrap(err, "already exist id") } if _, ok := errors.Cause(err).(*model.NoSuchDataError); !ok { return nil, errors.Wrap(err, "failed is already exist id") } id, err := a.repo.InsertThread(ctx, tx, param) if err != nil { return nil, errors.Wrap(err, "failed to insert thread") } param.ID = id return param, nil }
- 上記の処理ができるように
CloseTransactionをapplicationレイヤの構造体にDIしておく
- Goでは関数もDIできる
// threadService is application service of thread. type threadService struct { m query.DBManager service service.ThreadService repo repository.ThreadRepository txCloser CloseTransaction }所感
- レイヤードアーキテクチャは
- 依存関係がはっきりするのが良い
- 各レイヤが疎結合なので変更しやすく、テストもしやすいのは良い
- 各レイヤの責務がはっきり別れているので、どこに何を書けばいいかはわかりやすい
- コード量は増えるので、実装に時間がかかる
- 決まったところは自動化できると良いかも
- CRUDだけの小さなアプリケーションでは、大げさすぎるかもしれない
フロントエンド
アーキテクチャ
- 基本的には、Nuxt.jsのアーキテクチャに沿って実装を行なった
- 状態管理に感じては、Vuexを使用した
- 各々の
Component側(pagesやcomponents)からデータを使用したい場合には、Vuexを通じて使用した- データ、ロジックとビュー部分が綺麗に別れる
見た目
- Vue.jsに全面的に乗っかった
- コメントの一覧部分のCSSは CSSで作る!吹き出しデザインのサンプル19選 を参考にさせていただいた
大きな流れ
大きな流れとしては、以下のような流れ。
pasgesやcomponents等のビューでのイベントの発生 →actions経由でAPIへリクエスト →mutationsでstate変更 →pasgesやcomponents等のビューに反映される他の流れもたくさんあるが、代表的なList処理とInput処理の流れを以下に記す。
List処理
pagesやcomponentsのasyncData内で、store.dispatchを通じて、データ一覧を取得するアクション(actions)を呼び出すstoreのactions内での処理を行う
- axiosを使用してAPIにリクエストを送信する
- APIから返却されたデータを引数に
mutationsをcommitする。mutationsでの処理を行う
stateを変更するpagesやcomponentsのビューで取得したデータが表示されるInput処理
pagesやcomponentsでstoresに定義したactionやstateを読み込んでおくpagesやcomponentsのdata部分とformのinput部分等にv-modelを使用して双方向データバインディングをしておくpagesやcomponentsで表示しているビュー部分でイベントが生じる
- form入力→submitなど
- sumitする時にクリックされるボタンに
@click=hogeという形でイベントがそのElementで該当のイベントが生じた時に呼び出されるメソッド等を登録しておく
- 上記の例では、
clickイベントが生じるとhogeメソッドが呼び出される- イベントハンドリング — Vue.js
- 呼び出されたメソッドの処理を行う
- formのデータを元にデータを登録するアクション(
actions)を呼び出すstoreのactions内での処理を行う
- axiosを使用してAPIにリクエストを送信する
- APIから返却されたデータを引数に
mutationsをcommitする。mutationsでの処理を行う
stateを変更する- 登録した分のデータを一覧の
stateに追加するpagesやcomponentsのビューで登録したデータが追加された一覧表示される非同期部分
async/awaitで処理所感
- Nuxt.jsを使用すると、レールに乗っかれて非常に楽
- どこに何を実装すればいいか明白になるので迷わないで済む
- 特にVuexを使用すると
- データの流れが片方向になるのはわかりやすくて良い
- ビュー、ロジック、データの責務がはっきりするのが良い
- Vuetifyを使用するとあまり凝らない画面であれば、短期間で実装できそう
- Componentの切り方をAtomic Designに則ったやり方とかにするともっといい感じに切り分けられたかもしれない
参考文献
サーバーサイド
- InfoQ.com、徳武 聡(翻訳) (2009年6月7日) 『Domain Driven Design(ドメイン駆動設計) Quickly 日本語版』 InfoQ.com
- エリック・エヴァンス(著)、今関 剛 (監修)、和智 右桂 (翻訳) (2011/4/9)『エリック・エヴァンスのドメイン駆動設計 (IT Architects’Archive ソフトウェア開発の実践)』 翔泳社
- pospome『pospomeのサーバサイドアーキテクチャ』
フロントエンド
- 花谷拓磨 (2018/10/17)『Nuxt.jsビギナーズガイド』シーアンドアール研究所
- 川口 和也、喜多 啓介、野田 陽平、 手島 拓也、 片山 真也(2018/9/22)『Vue.js入門 基礎から実践アプリケーション開発まで』技術評論社
参考にさせていただいた記事
サーバーサイド
Goを運用アプリケーションに導入する際のレイヤ構造模索の旅路 | Go Conference 2018 Autumn 発表レポート - BASE開発チームブログ
GoでのAPI開発現場のアーキテクチャ実装事例 / go-api-architecture-practical-example - Speaker Deck
フロントエンド
関連記事
- 投稿日:2019-05-06T05:01:25+09:00
ワイ「スリープソート? 寝ている間に小人さんがソートしてくれるんでっか?」
社長「やめ太郎くん」
ワイ「なんでっか社長」
社長「画期的なソートアルゴリズムをJavaScriptで書いたから見てくれや」
ワイ「ソートアルゴリズムちゅうのは配列を数字が小さい順に並べ替えてくれるやつでんな」
ワイ「(どうせバブルソートとかやろ)」
社長「これや」
function sleep(duration) { return new Promise(resolve => setTimeout(resolve, duration)); } function sleepSort(arr) { const result = []; return Promise.all( arr.map(elm => sleep(elm * 100).then(() => result.push(elm))) ).then(() => result); } sleepSort([1, 3, 6, 2, 1, 4, 10, 1, 4, 3]).then(console.log); // 1秒後に [1, 1, 1, 2, 3, 3, 4, 4, 6, 10] と表示されるワイ「スリープソートやないかい!」
※この記事は全編やめ太郎さんリスペクトでお送りします。(3週間ぶり2回目)
スリープソートを読み解く
ワイ「思わず突っ込んでもうたけど何やっとんのか全然分からんで」
ワイ「スリープソートっちゅうんは寝ている間に小人がソートしてくれるっちゅうことでっか?」
社長「んなわけあるかい!」
社長「これはタイマーを使うことで複雑なロジックを書かんでもソートができる画期的なアルゴリズムや」
ワイ「それだけ聞いてもどんなソートなのか全然分かりまへんわ」
社長「仕方あらねんなあ、ワイ自ら解説したるで(ワイって一人称ワイで合っとるんか? みんな一人称同じやんけ)」
社長「まず結果の配列を用意する。これはまあええやろ」
const result = [];社長「そして与えられた配列の各要素に対して
sleep(elm * 100).then(() => result.push(elm))を実行するんや」社長「ここでいくらか時間がかかるからそれを待つんや」
社長「
Promise.allっちゅうのは全部の要素が終わるまでしっかり待つっちゅうことやな」社長「そして全部終わったら
resultを返す」ワイ「社長アホになったんでっか?
sleepSortにreturn result;なんて書いとらんやん」社長「お前本当にJavaScript書いとんのか? 非同期処理なんだからPromiseに包んで値を返すのは当たり前やん」
社長「最後の
.then(() => result)で処理が全部終わったらresultっちゅう結果をPromiseに包んで返すことを表しとるんや」ワイ「(そもそもソートを非同期処理にする方がどうかしとるんちゃうか)」
ハリー先輩「(こいつソートを並列化したこと無いんか)」
ワイ「じゃあ
sleep(elm * 100).then(() => result.push(elm))はどういう意味でっか」社長「
sleepってのは与えられたミリ秒数だけ経ったら解決されるPromiseを返す関数や」社長「そしてそのPromiseが解決されたら
resultにelmを追加する」社長「つまり
elm * 100ミリ秒後にresultにelmを追加するっちゅうことや」ワイ「
elmってのは配列の要素やから」ワイ「
elmが1なら100ミリ秒後、2なら200ミリ秒後にresultに1とか2が追加されるわけでんな」社長「せや」
社長「小さい数ほど先に
resultに追加されるから全部追加し終えたらソートが完了しとるっちゅうわけや」ワイ「この
sleepっちゅうのはarr.mapで各要素に対して実行されとるけど」ワイ「配列の各要素に対して順番に実行されるんでっか」
社長「ちゃうで」
社長「
Promiseで表されるのは非同期処理や」ハリー先輩「非同期処理っちゅうのは終わるまでボケっと待っとらんでもええってことやで」
社長「つまり一つ一つが終わるのを待たんでも全部同時に
sleep(elm * 100)が走るんや」ハリー先輩「つまり
elm * 100秒後にresultにelmを追加するっちゅう処理が全要素同時に始まるっちゅうことや」社長「どや、画期的やろ」
ワイ「これ負の数はどうするんでっか」
社長「適当にゲタ履かせときゃええやろ」
ワイ「1000000とか渡されたら1日以上待つんでっか」
社長「あー忙し、仕事しよ」
ワイ「社長!」
スリープソートを高速化してみた
ハスケル子「やめ太郎さん」
ワイ「何や(この筆者ハスケル子好きやな……)」
ハスケル子「スリープソートを高速化してみたんですけど」
ワイ「ほう、見せてみい」
async function sleep(duration) { for (let i = 0; i < duration; i++) { await null; } } function sleepSort(arr) { const result = []; return Promise.all( arr.map(elm => sleep(elm).then(() => result.push(elm))) ).then(() => result); } sleepSort([1, 3, 6, 2, 1, 4, 10, 1, 4, 3]).then(console.log); // すぐに [1, 1, 1, 2, 3, 3, 4, 4, 6, 10] と表示されるハスケル子「これです」
ワイ「
sleep関数が変わっただけやな」ワイ「おお、一瞬でソートが終わったで」
ワイ「でも
sleep関数の意味が分からんわ」ハスケル子「これは
async関数です」ワイ「返り値が自動的に
Promiseになるやつやな」ハスケル子「
await null;がポイントで」ハスケル子「これは一瞬待つって意味です」
ワイ「ほお」
ハスケル子「つまり
elmが1なら一瞬待って」ハスケル子「
elmが2なら二瞬、elmが3なら三瞬待ちます」ワイ「は?」
ハスケル子「つまり
elm * 100ミリ秒待つ代わりにelm瞬待つようにして高速化したんです」ワイ「説明聞いてもやっぱり意味が分からんわ」
イベントループ
ハスケル子「最近のJavaScript処理系はイベントループという仕組みを持っています」
ハスケル子「JavaScriptは非同期といっても全部シングルスレッドで動くので」
ハスケル子「非同期処理のコールバックが呼ばれる場合は今実行している処理が終わってからそっちに移るんです」
ワイ「溜まっとる一個一個の処理をループで順番に処理していくからイベントループってわけやな」
ハスケル子「
await nullはループ一周分待つってことなんです」ワイ「はあ」
ワイ「でもそれがスリープソートと何の関係があるんや」
ハスケル子「まだ理解できないんですか…… じゃあちょっとさっきのコードを書きなおしてみましょう」
function sleep(duration) { let i = 0; const loop = () => { if (i < duration) { i++; return Promise.resolve(null).then(loop); } else { return null; } }; return loop(); } function sleepSort(arr) { const result = []; return Promise.all( arr.map(elm => sleep(elm).then(() => result.push(elm))) ).then(() => result); } sleepSort([1, 3, 6, 2, 1, 4, 10, 1, 4, 3]).then(console.log); // すぐに [1, 1, 1, 2, 3, 3, 4, 4, 6, 10] と表示されるワイ「
sleepの中がますます意味不明になったで」ハスケル子「さっきのコードを
asyncとawaitを使わずに生のPromiseを使うように書きなおしただけです」ワイ「async/awaitが分かとっらん読者もおるかもしれんけど本題とは関係ないから省略するで」
ハスケル子「こういうふうに
Promise.resolveで作られたPromiseは一瞬で解決されます」ハスケル子「つまり、それに
thenでつなげた関数はイベントループの次のループで呼び出されるんです」ワイ「はあ」
ハスケル子「じゃあイベントループを自分で再現してみましょう」
const events = []; // ソートの結果 const result = []; // 最初に実行する処理を登録 events.push(() => sleepSort([1, 3, 6, 2, 1, 4, 10, 1, 4, 3])); // ここからイベントループの処理 while (events.length > 0) { // eventsの先頭から1つ取り出して呼び出す const nextEvent = events.shift(); nextEvent(); } // イベントループが終わったらresultを表示 console.log(result); function sleep(elm, callback) { let i = 0; const loop = () => { // イベントループ1回の処理 if (i < elm) { i++; events.push(loop); } else { // ループが終了したのでコールバックを呼ぶ callback(); } }; return loop(); } function sleepSort(arr) { for (const elm of arr) { // 各elmに対する処理を実行 sleep(elm, () => result.push(elm)); } }ワイ「一気にコードが長くなって読むのがつらいで」
ワイ「でもイベントループっちゅうのがどこかは分かるで」
ワイ「
while (events.length > 0)のところやな」ハスケル子「そうです、イベントループは
eventsに登録された関数を順番に呼び出すだけです」ハスケル子「
sleepSort関数はarrの各要素に対する処理を別々にイベントループに登録します」ワイ「
sleep(elm).then(()=> result.push(elm))がsleep(elm, ()=> result.push(elm))になっとるで」ハスケル子「
thenを実装するのが面倒なのでsleepにコールバックを渡す形にしたんです」ワイ「
sleep関数の中はPromise.resolve(null).then(loop)がevents.push(loop)に変わっとるで」ハスケル子「
Promise.resolve(null)は一瞬で解決されるので、それにthenしたloopは次のイベントループで呼び出されるんです」ハスケル子「だから自前のイベントループを使うためにこう直しました」
ワイ「なるほどな」
スリープソートを最適化してみる
ワイ「何となく分かったから自分でちょっとコードをいじってみるで」
ワイ「まずイベントループは
sleepSort関数の中に押し込んでもええやろ」const result = sleepSort([1, 3, 6, 2, 1, 4, 10, 1, 4, 3]); console.log(result); function sleepSort(arr) { const result = []; const events = []; for (const elm of arr) { // 各elmに対する処理を実行 sleep(elm, () => result.push(elm)); } while (events.length > 0) { // eventsの先頭から1つ取り出して呼び出す const nextEvent = events.shift(); nextEvent(); } return result; function sleep(elm, callback) { let i = 0; const loop = () => { // イベントループ1回の処理 if (i < elm) { i++; events.push(loop); } else { // ループが終了したのでコールバックを呼ぶ callback(); } }; loop(); } }ワイ「
events配列の中に関数を突っ込むのはようわからんわ」ワイ「スリープソート専用にして
iとelmを覚えといてくれるオブジェクトにするで」const result = sleepSort([1, 3, 6, 2, 1, 4, 10, 1, 4, 3]); console.log(result); function sleepSort(arr) { const result = []; const events = []; for (const elm of arr) { // 各elmに対する処理を実行 sleep(elm); } while (events.length > 0) { // eventsの先頭から1つ取り出して呼び出す const { i, elm } = events.shift(); if (i < elm) { events.push({ i: i + 1, elm }); } else { result.push(elm); } } return result; function sleep(elm) { events.push({ i: 0, elm }); } }ハスケル子「なんか
sleepの中身がすっきりしてイベントループの中にベタ書きになりましたね」ワイ「もう
sleepとか要らんから消すわ」const result = sleepSort([1, 3, 6, 2, 1, 4, 10, 1, 4, 3]); console.log(result); function sleepSort(arr) { const result = []; const events = []; for (const elm of arr) { // 各elmに対する処理を実行 events.push({ i: 0, elm }); } while (events.length > 0) { // eventsの先頭から1つ取り出して呼び出す const { i, elm } = events.shift(); if (i < elm) { events.push({ i: i + 1, elm }); } else { result.push(elm); } } return result; }ハスケル子「あの」
ハスケル子「この
iってオブジェクトの中に入れる必要無くないですか?」ワイ「せやろか」
ハスケル子「
iは最初みんな0で」ハスケル子「みんな一緒に
iが増えていってelmに達したやつがresult.push(elm)されるんですよね」ハスケル子「なので
iは別々に持つんじゃなくて共通にしましょう」const result = sleepSort([1, 3, 6, 2, 1, 4, 10, 1, 4, 3]); console.log(result); function sleepSort(arr) { const result = []; let events = []; for (const elm of arr) { // 各elmに対する処理を実行 events.push({ elm }); } for (let i = 0; events.length > 0; i++) { const nextEvents = []; while (events.length > 0) { const { elm } = events.shift(); if (i < elm) { nextEvents.push({ elm }); } else { result.push(elm); } } events = nextEvents; } return result; }ワイ「なんか随分変わりよったなあ」
ハスケル子「次のイベントループに登録するものは
eventsに直にpushするんじゃなくてnextEventsを作ってそっちにpushするようにしました」ワイ「なんで?」
ハスケル子「今の
iの処理が終わったらiを増やしてから次のイベントループに行きたいので今のiに対する処理と混ざらないようにするためです」ワイ「さよか(難しくなってきたで、若者の考えることはよう分からんわ)」
ワイ「でもこれ
eventsの中身のオブジェクトがelmしか値を持たんから数値を直に入れてもええやろ」const result = sleepSort([1, 3, 6, 2, 1, 4, 10, 1, 4, 3]); console.log(result); function sleepSort(arr) { const result = []; let events = []; for (const elm of arr) { events.push(elm); } for (let i = 0; events.length > 0; i++) { const nextEvents = []; while (events.length > 0) { const elm = events.shift(); if (i < elm) { nextEvents.push(elm); } else { result.push(elm); } } events = nextEvents; } return result; }ハスケル子「でも」
ワイ「今度は何や」
ハスケル子「これもう
i要らなくないですか?」ワイ「なんでや」
ハスケル子「
iがどんどん増えていってelmに到達したやつからresultにpushされるんですよね」ワイ「せやな(これそういう意味なんか、やっと分かったで)」
ハスケル子「ということは一番小さい
elmが最初にresultにpushされますよね」ワイ「せやな」
ハスケル子「じゃあ一番小さい
elmを直接探せばいいんじゃないですか?」ハスケル子「
iは要らない子ですね」ワイ「(
iを要らない子にしたのはお前やろ!)」const result = sleepSort([1, 3, 6, 2, 1, 4, 10, 1, 4, 3]); console.log(result); function sleepSort(arr) { const result = []; let events = []; for (const elm of arr) { events.push(elm); } while (events.length > 0) { // 一番小さいelmを探す let minElm = Infinity; for (const elm of events) { if (elm < minElm) { minElm = elm; } } // eventsの中から一番小さいelmをresultに入れて他はnextEventsに入れる const nextEvents = []; for (const elm of events) { if (minElm === elm) { result.push(elm); } else { nextEvents.push(elm); } } events = nextEvents; } return result; }ワイ「やっとることは分かったけど」
ワイ「なんか
nextEventsを毎回作っとるのが気に入らんで」ハスケル子「じゃあ作らないようにしましょう」
const result = sleepSort([1, 3, 6, 2, 1, 4, 10, 1, 4, 3]); console.log(result); function sleepSort(arr) { const result = []; const events = []; for (const elm of arr) { events.push(elm); } while (events.length > 0) { // 一番小さいelmを探す let minElm = Infinity; for (const elm of events) { if (elm < minElm) { minElm = elm; } } // eventsの中から一番小さいelmを抜き出してresultに入れる for (let k = 0; k < events.length; k++) { const elm = events[k]; if (minElm === elm) { result.push(elm); // eventsからk番目を抜く events.splice(k, 1); // 次の要素がk番目に来るので調整のためにkを減らす k--; } } } return result; }ハスケル子「
nextEventsを作る代わりにeventsからspliceを使って抜き出していくようにしました」ワイ「なるほどな」
ハリー先輩「動くな、計算量警察や」
ワイ「は?」
ハリー先輩「
spliceは$O(N)$かかる計算や」ハリー先輩「さっきまで$O(N^2)$だったアルゴリズムが$O(N^3)$になったんとちゃうか?」
ハスケル子「くっ……」
ワイ「(なんの話しとるのかさっぱり分からんで)」
ワイ「(前回の話では英語の仕様書を一瞥しただけで理解できる天才だったのにどうしてこうなったんや)」
(1時間後)
ハスケル子「!!!」
ハスケル子「待ってください、
splice(k, 1)は配列のk番目以降を全部前にずらすのが$O(N)$の理由です」ハスケル子「ということは
for (let k = 0; k < events.length; k++)というforループと合わせればこれは全体として配列全体を1回舐めているだけ、よって$O(N)$です」ワイ「(ちくわ大明神)」
ハリー先輩「だとしたら
splice(k, 1)の後にbreak;が必要なんとちゃうか?」ハスケル子「あっ……」
ハスケル子「でも
spliceを呼ぶと一番外側のループの回数がひとつ減るから……」(1時間後)
ハスケル子「でも
minElmを持つelmが複数あったときにもう一度最小値を探しなおすのは無駄ですよね」ワイ「(話についていけなくて飽きてきたで)」
ハリー先輩「じゃあこういうときに使えるテクニックを教えたるで」
ハリー先輩「要素を全部動かすんやなくて要素の入れ替えを使うんや」
ワイ「お、やっと2人が次のコードを書き始めたで」
const result = sleepSort([1, 3, 6, 2, 1, 4, 10, 1, 4, 3]); console.log(result); function sleepSort(arr) { const result = []; for (const elm of arr) { result.push(elm); } // まだソートされていない部分の開始位置 let start = 0; while (start < result.length) { // 一番小さいelmを探す let minElm = Infinity; for (let k = start; k < result.length; k++) { const elm = result[k]; if (elm < minElm) { minElm = elm; } } // eventsの中から一番小さいelmを探す for (let k = start; k < result.length; k++) { const elm = result[k]; if (minElm === elm) { // elmをstart番目に入れて代わりに今start番目にあるやつをk番目も移動 result[k] = result[start]; result[start] = elm; // start番目はソート済み start++; } } } return result; }ワイ「なんか元のコードの面影はあるけどまた大分変わってもうたで」
ワイ「
eventsもnextEventsも消えてresultだけになってもうたわ」ハリー先輩「このコードでは
resultは2つの意味を持つで」ハリー先輩「前半、つまり
start番目より前はソート済みでそれより後は未ソートや」ワイ「最初
startが0ってことはまだなんもソートされてないっちゅうことでんな」ハスケル子「配列から最小値を見つける部分は同じですが」
ハスケル子「
start番目より前は既に処理済みなのでstart番目以降から探すようになってます」ハリー先輩「そして最小値
elmを見つけたらそれを処理済み部分に付け足すんや」ハリー先輩「つまり
start番目に移動させてやってstartを1増やしてやる」ハスケル子「もともと
start番目にあったresult[start]はまだソートされていないですが」ハスケル子「ちょうど
elmがあった位置であるk番目が空いてるのでそこに入れておきます」ハリー先輩「ここがポイントやな」
ハスケル子「要素の入れ替えによりソートを進めることで
spliceによる配列をずらす操作を無くしているんです」ハリー先輩「これなら誰が見ても計算量は$O(N^2)$や」
まとめ
ワイ「ところで」
ハリー先輩「ん?」
ワイ「これだとソートの安定性が失われるんとちゃいますか?」
ハスケル子「えっ……確かにそうですが」
ハリー先輩「誰やお前、さっきまでアホ面して半分寝とったあいつはどこに行ったんや」
ワイ「お前人様のキャラに向かって言っていいことと悪いことがあるで」
ワイ「てかなあ」
ハリー先輩「おう」
ワイ「これただの選択ソートやんけ!」
スリープソートを最適化したら選択ソートになった話 〜完〜
おまけ
ハスケル子「というか」
ワイ「なんや」
ハスケル子「計算量警察以降の話って無駄じゃないですか?」
ワイ「せやな」
ワイ「正直、
iが消えた段階(↓)で既に選択ソートになっとると思うんやけど」const result = sleepSort([1, 3, 6, 2, 1, 4, 10, 1, 4, 3]); console.log(result); function sleepSort(arr) { const result = []; let events = []; for (const elm of arr) { events.push(elm); } while (events.length > 0) { // 一番小さいelmを探す let minElm = Infinity; for (const elm of events) { if (elm < minElm) { minElm = elm; } } // eventsの中から一番小さいelmをresultに入れて他はnextEventsに入れる const nextEvents = []; for (const elm of events) { if (minElm === elm) { result.push(elm); } else { nextEvents.push(elm); } } events = nextEvents; } return result; }ワイ「選択ソートでググっても要素の入れ替えを使って並び替えるのが選択ソートやっちゅう説明しか出てこんかったから無理やりそこまで持ってったんや」
ハスケル子「まあメモリ使用量が違いますからね」
ワイ「てか要素の入れ替えを使うとかプログラム書き換えすぎやろ、それでスリープソートが選択ソートになってもなんも面白ないで」
ワイ「見た目変わってるけど考え方は変わってないでってアピールするのが大変だったわ」
ハスケル子「アピール失敗してますよそれ」
ハスケル子「最後だけ説明が長くてコードが全然出てこないし」
ワイ「まあソートアルゴリズムの本質を分かっとる奴はあの段階でピンと来とったやろ」
ワイ「そうでない奴らから何言われたって痛くないで」
ハスケル子「(何で最後の最後に喧嘩売るんですかこの人は)」
〜完〜
- 投稿日:2019-05-06T05:01:17+09:00
JavaScriptで数値の区切り文字を使いたい物語
桁数の多い数値をプログラム中に書く場合は、
1_234_567のように間に区切りを入れることで桁数を分かりやすくしたいことがありますよね。実際、既に多くのプログラミング言語でこれが可能です。Java, Kotlin, Swift, Perl, Ruby, Rustなどの言語で1_234_567が可能です。また、C++は1'234'567のように_ではなく'を用いて区切るのが特徴的です。JavaScriptにおいてはまだこれは不可能ですが、できるようにしようという提案は古くから知られていました。それがnumeric separatorというプロポーザル(提案)です。日本語に直すと「数値区切り文字」とかでしょうが、何となくしっくり来ないのでこの記事ではnumeric separatorと呼ぶことにします。当該のプロポーザルは2017年4月に起草され、同5月にはStage 1に認定されています。そして、何やかんやがあって2019年3月にStage 3に昇格しました。
そんなに実装が難しいものでもありませんし、今年中にブラウザ等の実装が出揃ってES2020に正式採用という流れかなあと見ています。また、今すぐ使いたい場合はBabelのプラグインを使いましょう。またTypeScriptもすでに対応済みです。
numeric separatorの使用法
では、もう少し詳しくnumeric separatorのルールを見ていきましょう。区切り文字は10進数だけでなく全ての数値リテラルで使用可能です。
_は何個でも使用できます。1_234_567 // 10進リテラル 1_234.567_89 // 小数も可能 0xdead_beef // 16進リテラル 0o7_5_5 // 8進リテラル 0b0101_0111 // 2進リテラルただし、
_が使用可能なのは数字と数字の間です。端に使うことはできません。また、_を複数連続させることもできません。_123_456 // これは_が左端にあるので不可 123_456_ // これは_が右端にあるので不可 123__456 // これは_が2個連続しているので不可 123_.456 // . の隣も端と見なされるので不可また、コーナーケースとしては、JavaScriptでは実は
2.3e5のような数値リテラルも可能です(これは230000になります)が、eの直前直後も端となるのでだめです。2.3e1_0 // これは可能 2.3_e10 // これは不可話はこれだけです。とても簡単ですね。
文字列から数値への変換に対する影響
ところで、JavaScriptでは文字列から数値への変換を行う言語機能があります。大きく分けて、
parseIntやparseFloatによるものとNumberによるものです。文字列から数値への暗黙の変換は後者に含まれます。今回数値リテラルで_が許されるようになったということで、これらにはどのように影響するのでしょうか。結論から言うと、影響しません。言うまでもなく、これは後方互換性を維持するための措置ですね。
この結果として、
parseInt、Number、そして生のソーステキストの3つが文字列に対してそれぞれ異なる解釈を持つこととなります。まず、
parseIntは10進リテラル(1e5のような指数部分を含むものを除く)と16進リテラルを解釈可能ですが、8進と2進は解釈できません。これは後ろ2つがES2015で追加されたものであり、そこで後方互換性を壊さない判断をされたことが理由です。// 10進と16進は対応 console.log(parseInt("123")); // 123 console.log(parseInt("0x123")); // 291 // 8進と2進は未対応 console.log(parseInt("0o755")); // 0 console.log(parseInt("0b101")); // 0一方、
Numberによる変換は8進・2進リテラルにも対応しています。console.log(Number("123")); // 123 console.log(Number("0x123")); // 291 console.log(Number("0o755")); // 403 console.log(Number("0b101")); // 5では、今回
_が追加されてどうなかったといえば、parseIntもNumberも未対応となります。console.log(parseInt("1_234_567")); // 1 console.log(Number("1_234_567")); // NaN歴史が感じられるなかなか素晴らしい仕様ですね。
numeric separatorの歴史
さて、やっていることはわりかし簡単なこの提案ですが、実はこの提案が現在の状態になるまでには紆余曲折がありました。この記事ではその部分にスポットを当てて解説しようと思います。
起草〜Stage 3への出世
最初に述べた通り、このプロポーザルは2017年4月にStage 1となりました。StageというのはJavaScriptへの機能追加の提案が通る承認フローであり、Stage 0からStage 4までの段階があります。仕様が具体化されているかどうかなど、ステージを上がるごとに必要な条件は厳しくなっていきます。Stage4になればその提案は完成と見なされ、JavaScriptに正式採用となります。Stage 1というのはアイデアはまあ良いんじゃないと認められた状態です。Stage 2は具体的な仕様をちゃんと作ろうという状態、Stage 3は仕様がほぼ完成して実際に試してみたいという状態です。この承認フローを司るのがTC39という委員会です。
区切り文字の提案を作るにあたって区切り文字の有力な候補は
_ですが、C++の'のように他の候補も一度ありました。また、_が複数連続するのが許されるかどうかなどの細かい論点もありました。しかし、Stage 1に上がったときの議事録やStage 2のときの議事録を見るに、この辺は特に異論なくすんなりと進んだようです。最後の
Numberの挙動についてはStage 3に上がるときの議論ではNumber("1_234_567")が1234567になるという話だったのですが、その後ひっそりと現在の仕様に変更されたようです。このように、numeric seprator自体の議論は特に大きな波乱もなく順調に策定が進み、2017年11月にはStage 3に上がりました。これは提案が起草されてからわずか半年というスピード感ある出世です。Stage 3というのは仕様がほぼ完成している段階であり、ブラウザやnode.jsなどの実行環境が実装を始める段階です。また、TypeScriptもStage 3まで上がった仕様は取り入れるという方針を取っており、2018年2月に登場したTypeScript 2.7で利用可能になりました。
この流れならES2018とかES2019に正式採用されてもおかしくはなかったのですが、そうはなりませんでした。ライバルが出現したのです。
ライバルの出現
颯爽と現れたnumeric separatorのライバル、それはextended numeric literalsです。この提案は、2017年9月にStage 1に入りました。numeric separatorがStage 3に上がるすこし前ですね。
これはやはり数値リテラルを拡張する提案で、およそ以下のような提案でした。数値のあとにこのように
_pxなどの接尾辞を付けます。const length = 10_px; const imaginary = 13_i;ポイントは、この
_pxや_iなどを自分で定義できる点です。関数として_pxなどを予め定義しておくことで、10_pxのようなリテラルを自分で定めることができるのです。const _px = ({ number })=> ({ type: "px", length: number }); const length = 10_px; console.log(length); // { type: "px", length: 10 }初期には
_pxではなくpxのように任意の変数名を接尾辞に使用可能な提案でしたが、さすがに無理があるということで最初に_を付けることになりました。ちなみに、この
_pxなどは10進だけでなく16進・2進・8進などの数値リテラルにも付けることができます。さて、ここでひとつの問題が発生しました。それは文法に曖昧性が発生してしまうというものです。具体例としては
0x123_abcが挙げられます。そう、これは0x123abcの間に区切り文字が入ったという解釈と、0x123に_abcという接尾辞がついたという解釈の2通りが可能なのです、この問題が発生してしまった以上、2つの提案はどちらかが変更される必要があります。この問題をめぐって2つの提案は膠着状態に入りました。
numeric separatorの降格
この問題が2018年5月のTC39ミーティングで取り上げられた際、numeric separatorはStage 2に降格となってしまいました。プロポーザルのステージが下がるのはなかなかレアな現象です。
解決策として
_pxを__pxにする(アンダースコア2個)や`pxにする、_pxは10進数のリテラルのみに許すなどの案もありましたが、どの案も合意に達することはなく、2つの提案は協調しながら仕様を再設計することなりました。そして、Stage 3だったnumeric separatorも仕様が変動する可能性があるということでstage 2に戻されました。
ところで、numeric separatorは一度Stage 3に上がったのでTypeScriptに取り入れられていました。これがStage 2に戻ってしまったということで、これはTypeScript側に打撃を与えました。TypeScriptユーザーが既にこれを使用しているかもしれず、この機能がStage 2に戻ったからといって削除してしまうのは破壊的変更となります。また、そもそもnumeric separatorの仕様自体が変更となってしまう可能性もあり、その場合TypeScriptは非標準のものを実装していることとなってしまいます。直す場合はやはり破壊的変更です。
では、TypeScript側はどうしたのでしょうか。答えは、TypeScriptチーム主要メンバーのRyanCavanaughさんがちゃぶ台を投げました。
そして、その後は見て見ぬふりを貫きました。まあ、実際に事が起こってから(どうしようもない仕様変更が起こってから)動こうという考えだったのでしょう。
解決編
しばらく2つの提案が水面下で動いたあと、2019年1月のミーティングで動きがありました。
概要は、extended numeric literalsを変更して
100~pxのようにするというものです。すなわち、チルダを使って_pxではなく~pxとするようになりました。100~pxというリテラルを解釈するときにはnumeric__pxという関数が呼ばれます。この新提案がTC39のミーティングにかけられましたが、あまり受けは良くありませんでした。特に、
~pxに対してnumeric__pxという関数を作らなければいけないのが微妙です。このような仕様となっている理由は例えば
~iとしたい場合にiという関数を用意しないといけないのはそれはそれで微妙(ループ変数にiという変数名を迂闊に使えなくなるので)だからでしたが、やはりnumeric__は受け入れがたかったようです(議事録を見ると賛否両論があったようですが)。こうなってくると、もはや他の変数たちと同じ名前空間でやっていくのは無理がある気がします。再び無理難題をつきつけられてしまったextended numeric literalsでした。
しかし、ここである存在が救いの手を差し伸べました。それにより、extended numeric literalsは2019年3月のTC39ミーティングに早くも返り咲くことができたのです。このミーティングでは、extended numeric literalsはみたび新たな姿を見せました。
今回の新提案では、
~pxは@pxとなりました。記号が変わっただけじゃんと思うかもしれませんが、熱心なJavaScriptユーザーはあることにお気づきでしょう。そう、@というのはデコレータの記号です。デコレータは現在Stage 2の提案ですが、@を用いて関数やクラスのメンバーを修飾できるという提案でした。実は、123@pxと書いた場合は@pxというデコレータが参照されることになります。スライドから例を引用しましょう。decorator @i { @numericTemplate(impl) } 1234@iこのように、
@iという接尾辞を使うためには事前にデコレータ宣言により@iというデコレータを宣言しておきます。その実態は@numericTemplateという組み込みデコレータです。こう書くと、1234@iはimpl(Object.freeze({string: "1234", number: 1234}))という意味になります。ポイントは、デコレータは変数名とは別の名前空間を持つため
@iというデコレータを作ってもそんなに問題とならないだろうという点です。デコレータは変数に比べてそれほど頻繁には作られないため、プログラマが十分制御できると考えられます。グローバルデコレータ名前空間にデコレータを増やして解決するという方向性は、少し怖く見えるかもしれません(標準ライブラリ導入の動機と一見逆行しています)。しかし、デコレータ宣言もスコープを持つため同盟の組み込みデコレータが増えてもエラーが発生しないこと、デコレータの存在確認をランタイムで行う方法は(恐らく)提供されないことからこれは問題にはならなそうです。また、将来的には組み込みデコレータも標準ライブラリから提供できるようになるでしょう。
まあ、extended numeric literalsに関してはまだStage 1なので、基本はこの方向性でいきつつまだまだ大きな変化があると考えられます。とはいえ、これによりわざわざ
_を使う理由は無くなりました。そろそろ話をnumeric separatorに戻しましょう。上述の変更により2つの提案の衝突は解消されました。よって、2019年3月のミーティングでnumeric separatorはそのままの形で晴れてStage 3への復帰を果たしたのです。
さすがにもう邪魔する者はないと信じたいですね。そのうちブラウザ等にも実装されるでしょう。
まとめ
数値リテラルの数字の間に
_を挟めるという単純な話でしたが、その裏にはこのようなドラマがありました。numeric separatorsを救ってくれたデコレータへの感謝の気持ちを込めて_を数字の間に挟みましょう。関連リンク
- Numeric Separators - プロポーザル文書です。
- 投稿日:2019-05-06T05:01:10+09:00
モジュール時代のJavaScriptにおける必需品「import.meta」の総復習
import.metaはJavaScriptに追加予定の新機能です。すでにStage 3プロポーザル(内容がほぼ確定している状態)となってから2年近く経っている仕様で、Google Chrome, Firefox, Safariで実装済みです。また、node.jsではexperimentalな扱いで実装されています(import.metaが前提とするESモジュールがそもそもまだnode.jsではexperimentalという事情がありますが)。Stage 3になってから長いこともありすでに広く知られているこのプロポーザルですが、まとまった日本語資料が見当たらなかったのでこの記事を用意してみました。では、さっそく
import.metaとは何かから解説していきます。ちなみに、import.metaのプロポーザルはこちらです。
import.metaとは何か一言で言えば、
import.metaはモジュールに固有の情報を持つメタプロパティです。メタプロパティ
まずメタプロパティから解説します。これは、プロパティアクセスっぽく見えるけどそうではない構文のことを指します。実際、
import.metaという構文はimportというオブジェクトのmetaというプロパティに見えますが、そうではありません。なぜなら、importは予約語であり変数名ではないからです。これはあくまでimport.metaというひとつの構文であり、これに外れる形(例えばimport.foobarなど)は構文エラーとなります。
import.metaは現在提案中のメタプロパティですが、実はすでに現在JavaScriptに採用されているメタプロパティが1つだけあります。それはnew.targetです。new.targetもあまり日本語記事がありませんが、こちらの記事が詳しいので読んでみるとよいでしょう。また、現在提案中(Stage 2)のfunction.sentというメタプロパティもあります。いずれも、予約語.プロパティ名という構文になっているのがメタプロパティの特徴です。メタプロパティは、特定のコンテキストに固有の情報を表すのに使用される傾向があります。これは、仕様がグローバルに提供する何らかのAPIを使用するのに比べてコンテキスト依存であることが分かりやすいからだと思われます。そのため、メタプロパティは特定の状況でしか使用できないことがほとんどです。例えば
new.targetは関数がコンストラクタとして呼ばれたときに意味があるものですから、関数の中でしか使用できません。また、アロー関数はコンストラクタとして使用できないため、アロー関数の中でも使用できません。モジュール
では
import.metaが使用できるのはどこかというと、モジュールの中です。モジュールについての詳細な説明は省きますが、これはJavaScriptプログラムを複数のファイルに分割するための仕組みです。この分割された各ファイルが一つ一つのモジュールとなります。モジュール
export文を用いて自身から何らかの値を他のモジュールに対して提供したり、import文を用いて他のモジュールが提供する値を読みこんだりできます。モジュールでない従来のJavaScriptプログラムはスクリプトと呼んで区別されます。import.metaはモジュールの中では使えますがスクリプトの中では使えないのです。HTMLでは、
script要素を用いてモジュールを読み込む場合はtype="module"という属性を付ける必要があります。例えば以下のようにすることで、module.jsがモジュール扱いで読みこまれます。<script type="module" src="./module.js"></script>一方、
type="module"を付け忘れるとmodule.jsはスクリプト扱いで読みこまれます。スクリプト扱いの場合はmodule.jsの中でimport文やexport文、そしてimport.metaは使えません。モジュールの動作例はこんな感じです。
/// module.js import { fooFunction } from './foo.js'; fooFunction(123); /// foo.js export function fooFunction(arg) { console.log(arg * 10); }上記のHTMLで
module.jsが読みこまれると、module.jsがimport文でさらにfoo.jsを読み込んで、結果としてコンソールに1230が表示されることになります。以上がモジュールの簡単な復習でした。
import.metaの中身では、いよいよ本題に入りましょう。
import.metaが持つモジュールに固有の情報とは何でしょうか。実を言えば、JavaScriptの仕様ではimport.metaの中身は決まっていません(オブジェクトであるということは決まっています)。そもそも、モジュールという概念自体、定義しているのはJavaScriptの仕様であるもののその具体的な仕組みは実行環境に委ねられています。例えばnode.jsの場合は、
import './foo.js'と書いた場合はファイルシステムからfoo.jsが読みこまれるでしょう。一方Webの場合は、import './foo.js'はfoo.jsへのHTTPリクエストを発生させるでしょう。このように、import文で指定された読み込み先モジュールが具体的にどのように解決されるかということは環境に依存します。ですから、「モジュール」というものの実体が環境によって異なるために、
import.metaが提供すべき「モジュールに固有の情報」というのも環境によって異なるのです。ここまで抽象的な話が続いてきたので、ここからは具体的に
import.metaを使ってどんな情報が得られるのかを見ていきます。Webにおける
import.meta先ほども述べたように、
import.metaによって提供される情報というのは環境ごとに異なります。まずは、Web(すなわちブラウザ上)におけるimport.metaについて解説します。Webにおける
import.metaの挙動はHTML仕様書において定められています。それによれば、import.meta(によって得られるオブジェクト)はurlというプロパティをひとつだけ持っています。これは、そのモジュールのURLです。次の例で考えてみます。module.mjsconsole.log(import.meta.url);index.html<script type="module" src="./module.mjs"></script>このHTMLファイルが
http://localhost:8001/index.htmlでアクセスできるとしましょう。ここからmodule.mjsを読み込んだ場合、コンソールに表示されるのは"http://localhost:8001/module.mjs"です。このように、モジュール内でimport.meta.urlを取得した場合はそのモジュールのURLが取得できるのです。これは特に、モジュールからの相対パスを絶対URLに変換したい場合に有用です。また、Webでは必然的にひとつのURLがひとつのモジュールに対応しているという事実は覚えておく価値があるかもしれません。Webにおける
import.metaの拡張案現在のところ仕様で定められている
import.metaのプロパティはurlだけですが、もうひとつscriptElementというプロパティを入れようという議論がされています。ところが、これはさまざまな理由から難航しています。かなりうまく作らないと使い物にならなそうだということが分かってきたからです。
import.meta.scriptElementというのは、そのモジュールが読みこまれるきっかけとなったscript要素を得ることができるプロパティです(名前は変わるかもしれません)。上の例を少しいじってみましょう。module.mjsconsole.log(import.meta.scriptElement.id); // "abc"が表示されるindex.html<script id="abc" type="module" src="./module.mjs"></script>
index.htmlはscript要素を用いてmodule.mjsを読み込みます。そうして実行されたmodule.mjsがimport.meta.scriptElementを見ると、index.html内のscript要素が得られるというわけです。なんとなく便利そうに見えますが、すでに問題が見えています。
index.htmlを次のようにすると何が表示されるでしょうか。<script id="abc" type="module" src="./module.mjs"></script> <script id="def" type="module" src="./module.mjs"></script>実は、この場合は
"abc"だけが表示されます。同じモジュールを2回読み込んでも2回実行されることはないからです。これだけで使いやすさが半減していますね。モジュールを複数回実行できないという根本的な制限に加えて、わざわざ
import.meta.scriptElementを使うということは「自分の読み込み元」を詳細に(単にdocumentにアクセスするのでは不足するくらいに)知りたい場面のはずなのに、読み込み先をひとつしか取れないというのは問題です。他にも、script要素がshadowRootの中にある場合などの問題が議論されていたようですが、とにかく難航しており標準化には至っていません。
既に仕様化されている
url、そして議論されているscriptElementくらいしか現状では見当たりません。もし他にこんな情報もimport.metaに必要だろうと思うものがあれば提案してみるともしかしたら採用されるかもしれませんね。node.jsにおける
import.metaWebとは別のJavaScript実行環境として有力なのがnode.jsです。node.jsも既に
import.metaを実装しています。node.jsのimport.metaにどんなプロパティがあるのかについては特に仕様化されていません。node.jsが自分で欲しい情報を好き勝手に実装すればいいだけです。議論したい場合、場所はGitHubのissueになります。結論から言ってしまえば、node.jsに現在実装されているのは
import.meta.urlだけです。Webと同じですね。node.jsにおいてはES Modules以前からCommonjsによるモジュールシステム(
requireとかのやつですね)が広く利用されており、自身のファイル名の取得に関しては__dirnameや__filenameが(モジュールに対するローカル)変数として提供されるという独自仕様により行ってきました。node.jsにおいてはこれが結構便利で利用される場面も多かったのですが、JavaScriptの標準に準拠したモジュールを実装するにあたってこれらの独自仕様は排除される(スクリプトの中では依然使用可能だがモジュールの中では使用不可になる)こととなり、その代替としてimport.metaが必要となりました。では、
import.meta.urlの例を見ましょう。module.mjsconsole.log(import.meta.url);node.jsで動作を確認するには次のようにします。
node --experimental-modules module.mjs結果はこんな感じになります。
file:///tmp/test-module/module.mjsポイントは、結果が単なるパスではなく
file:スキームを持つURLとして得られることです。なんとなくWebの場合と一貫性があっていいですね。ちなみに、import文でもこのようなfile:スキームがサポートされるようです。node.jsにおいても
import.meta.url以外のプロパティの議論はあまり活発ではないようです(全く無いわけではないようですが)。そもそもまだnode.jsにおけるモジュール自体がexperimentalということもあり、先にそちらに注力するのでしょう。まとめ
この記事では
import.metaというプロポーザルを紹介しました。将来的な拡張は考えられますが現時点ではimport.meta.urlのみしかWeb・node.jsともに存在しないようです。今後モジュールの利用が本格化するにつれて
import.metaの利用は避けて通れなくなるでしょう。今後起こるかもしれないimport.metaへの拡張に目を光らせておくのも悪くはありません。尤も、生のモジュールなど使わずに
webpackでモジュールたちを1つのスクリプトにまとめる人ばかりの現状では実用化はしばらく先となりそうですが。関連リンク
import.metaへの言及を含む日本語記事を探したところ以下の3つが見つかりました。
- 投稿日:2019-05-06T04:08:19+09:00
JavaでPromiseを使った非同期処理を記述したい ~ JavaScriptのPromiseライクな文法の試行~
概要
- Java言語で「JavaScriptのPromiseライクな文法で、非同期処理・並行処理を記述してみたい」と思いやってみました。
- ソースは以下リポジトリにあります
https://github.com/riversun/java-promiseコード例
「非同期処理1が終わったら、その結果を使った非同期処理2が実行される」処理はJavaではどのように書けば良いでしょうか?
- 解1:Java1.4時代の解:Threadクラスの機能でがんばる
- Threadを入れ子式に持つとか、joinで終了待ちとか。並列処理黎明期。
- 解2:Java5(1.5)時代の解:Callable/Futureで幸せになれたのかな・・・
- Future/Callableで結果返せてうれしい、加えセマフォやラッチなど小道具そろったがそれなりに頑張る必要あり。
解3:Java8時代の解:CompletableFutureで幸せになる、はず。
- ついに待望?!のFuture/Promiseパターン的な仕組みが標準で登場!
本稿では上の3つの解とは別の切り口で、以下のコードのようにJavaScriptのPromiseライクに書いてみました。
JavaでPromiseのサンプルPromise.resolve() .then((action, data) -> { //非同期処理1 new Thread(() -> {System.out.println("Process1");action.resolve("Result-1");}).start(); }) .then((action, data) -> { //非同期処理2 new Thread(() -> {System.out.println("Process2");action.resolve("Result-2");}).start(); }) .start();本稿でやりたいこと
- やりたいことは以下のような処理を「JavaScriptのPromiseライクに記述すること」となります
- 複数あるAPIを非同期に呼んで、結果を受け取ったら次のAPIを呼ぶ、という一連の処理
- 複数の処理を同時に(並列に)に動かし、それがすべて完了したら次の処理に移るような処理
本稿で対象としないこと
- (アカデミックな)Future/Promiseパターンの具現化
- Java標準のコンカレント処理の使い方
- Java5(1.5.0)以降から使えるExecutorServiceやCallable
- Java8以降から使えるCompletableFutureを使って書く方法
対象環境
- Java5以降
- ライブラリはJava1.6ベースのAndroidでも動作します
- Java8のコンカレント系APIはつかっていません
使い方(依存関係)
ライブラリjava-promiseとしてMavenレポジトリにありますので、以下を追加すればすぐに使えます。
Maven
POM.xmlのdependency<dependency> <groupId>org.riversun</groupId> <artifactId>java-promise</artifactId> <version>1.1.0</version> </dependency>Gradle
build.gradledependencies { compile 'org.riversun:java-promise:1.1.0' }build.gradle(Android)dependencies { implementation 'org.riversun:java-promise:1.1.0' }本編
JavaScriptで書くPromiseと、本稿で紹介するJavaで書く方法との比較
まず、比較のためにJavaScriptでPromiseを書いてみる
以下のコードは'foo'という文字列に非同期に実行された処理結果('bar')を連結するだけのJavaScriptのサンプルコードとなる。MDNでPromiseのサンプルとして公開されているものから抜粋した。
Example.jsPromise.resolve('foo') .then(function (data) { return new Promise(function (resolve, reject) { setTimeout(function () { const newData = data + 'bar'; resolve(newData); }, 1); }); }) .then(function (data) { return new Promise(function (resolve, reject) { console.log(data); resolve(); }); }); console.log("Promise in JavaScript");実行結果は以下のとおり
Promise in JavaScript foobar次にJava8でjava-promiseを使って書く
Example.javaimport org.riversun.promise.Promise; public class Example { public static void main(String[] args) { Promise.resolve("foo") .then(new Promise((action, data) -> { new Thread(() -> { String newData = data + "bar"; action.resolve(newData);//#resolveで次の処理に移行 }).start();//別スレッドで実行 })) .then(new Promise((action, data) -> { System.out.println(data); action.resolve(); })) .start();//処理開始のトリガー System.out.println("Promise in Java"); } }実行結果は以下のとおり
Promise in Java foobarPromise以下の実行は非同期(別スレッド)で行われるので、この例では
System.out.println("Promise in Java");が実行されているのがわかる。処理の都合最後に
.start()を呼び出してPromiseチェインのトリガーをしている以外はJavaScriptのPromiseライクな文法に近づけてみた。記法
ラムダ式を使わないで書く(Java7以前)
ラムダ式を使わなければ以下のようになる
ラムダ式を使わないで書いた場合Promise.resolve("foo") .then(new Promise(new Func() { @Override public void run(Action action, Object data) throws Exception { new Thread(() -> { String newData = data + "bar"; action.resolve(newData); }).start(); } })) .then(new Promise(new Func() { @Override public void run(Action action, Object data) throws Exception { new Thread(() -> { System.out.println(data); action.resolve(); }).start(); } })) .start();
(action,data)->{}となっていた部分の正体はJavaScriptでいうところの function を表すインタフェースとなる。Func.javapublic interface Func { public void run(Action action, Object data) throws Exception; }さらにシンプルに書く
Promise.then(new Promise())ではなくPromise.then(new Func())でもOK。new Funcはラムダ式におきかえるとPromise.then((action,data)->{})となり、さらにシンプルになる。then(Func)をつかって書くPromise.resolve("foo") .then((action, data) -> { new Thread(() -> { String newData = data + "bar"; action.resolve(newData); }).start(); }) .then((action, data) -> { System.out.println(data); action.resolve(); }) .start();Promiseをつかった並行実行の各種パターン紹介
(1) Promise.then:非同期処理を順番通り実行する
コード:
public class Example20 { public static void main(String[] args) { // 処理1(別スレッド実行) Func function1 = (action, data) -> { new Thread(() -> { System.out.println("Process-1"); Promise.sleep(1000);// Thread.sleepと同じ action.resolve("Result-1");// ステータスを"fulfilled"にして、次の処理に結果("Result-1")を伝える }).start();// 別スレッドでの非同期処理開始 }; // 処理2 Func function2 = (action, data) -> { System.out.println("Process-2 result=" + data); action.resolve(); }; Promise.resolve()// 処理を開始 .then(function1)// 処理1実行 .then(function2)// 処理2実行 .start();// 開始 System.out.println("Hello,Promise"); }実行結果:
Hello,Promise Process-1 Process-2 result=Result-1説明:
thenの文法は Promise.then(onFulfilled[, onRejected]); つまり引数を2つまでとることができる
最初の引数onFulfilledは前の実行がfulfilled(≒成功)ステータスで終了した場合に実行される。
2つめの引数onRejectedはオプションだが、こちらは前の実行がrejected(≒失敗)ステータスで終了した場合に実行される。このサンプルは1つめの引数のみを指定している。処理フロー:
- Promise.resolveでステータスをfullfilledにしてthenにチェインする。
- fullfilledなのでthenでは第一引数に指定されたfunction1を実行する
- function1もaction.resolveによりステータスをfullfilledにする
- function1はaction.resolveにString型引数"Result-1"をセットする
- 次のthenもステータスがfullfilledなのでfunction2が実行される
- function2実行時の引数dataにはfunction1の結果"Result-1"が格納されている
(2) action.resolve,action.reject:実行結果によって処理を分岐する
コード:
public class Example21 { public static void main(String[] args) { Func function1 = (action, data) -> { System.out.println("Process-1"); action.reject();// ステータスを "rejected" にセットして実行完了 }; Func function2_1 = (action, data) -> { System.out.println("Resolved Process-2"); action.resolve(); }; Func function2_2 = (action, data) -> { System.out.println("Rejected Process-2"); action.resolve(); }; Promise.resolve() .then(function1) .then( function2_1, // ステータスが fulfilled のときに実行される function2_2 // ステータスが rejected のときに実行される ) .start(); System.out.println("Hello,Promise"); } }実行結果:
Hello,Promise Process-1 Rejected Process-2説明:
function1は
action.reject();で完了しているので、ステータスがrejectedとなる。
次のthenは.then( function2_1, // ステータスが fulfilled のときに実行される function2_2 // ステータスが rejected のときに実行される )としている。
前述のとおり、thenの文法は Promise.then(onFulfilled[, onRejected]);であるので、
function1の完了ステータスがrejectedであるため、ここではthenの2つめの引数であるfunction2_2が実行される。処理フロー:
(3)Promise.always: resolve、rejectどちらの処理結果も受け取る
コード:
public class Example30 { public static void main(String[] args) { Func function1 = (action, data) -> { action.reject("I send REJECT"); }; Func function2 = (action, data) -> { System.out.println("Received:" + data); action.resolve(); }; Promise.resolve() .then(function1) .always(function2)// ステータスが"fulfilled"でも"rejected"でも実行される .start(); } }実行結果:
Received:I send REJECT説明:
.always(function2)のようにalways((action,data)->{})は、その前の処理が resolvedによるステータスfulfilledであろうと、rejectedによるステータスrejectedであろうと必ず実行される。
処理フロー:
(4)Promise.all:複数の並列な非同期処理の完了待ちをして次に進む
コード:
public class Example40 { @SuppressWarnings("unchecked") public static void main(String[] args) { //非同期処理1 Func function1 = (action, data) -> { new Thread(() -> { Promise.sleep(1000); System.out.println("func1 running");action.resolve("func1-result"); }).start(); }; //非同期処理2 Func function2 = (action, data) -> { new Thread(() -> { Promise.sleep(500);System.out.println("func2 running"); action.resolve("func2-result"); }).start(); }; //非同期処理3 Func function3 = (action, data) -> { new Thread(() -> { Promise.sleep(100);System.out.println("func3 running");action.resolve("func3-result"); }).start(); }; //最後に結果を受け取る処理 Func function4 = (action, data) -> { System.out.println("結果を受け取りました"); List<Object> resultList = (List<Object>) data; for (int i = 0; i < resultList.size(); i++) { Object result = resultList.get(i); System.out.println("非同期処理" + (i + 1) + "の結果は " + result); } action.resolve(); }; Promise.all(function1, function2, function3) .always(function4) .start(); } }実行結果:
func3 running func2 running func1 running 非同期処理の結果を受け取りました 非同期処理1の結果は func1-result 非同期処理2の結果は func2-result 非同期処理3の結果は func3-result説明:
Promise.all(function1,function2,・・・・functionN)はfunction1~functionNの複数の処理を引数にとることができ、それらを並列実行する
並列実行が終わると、チェインされたthen(ここではalways)に処理が移行する。
上の例では function1,function2,function3が並列に実行されるが、function1~function3すべてがfulfilledで完了した場合は、各function1~function3の結果がListに格納されthenに渡る。その際、格納順序は、引数に指定された function1,function2,function3の順番となる。(この仕様もJavaScriptのPromiseと同一)
function1~function3のうち、どれか1つでも失敗≒rejectになった場合、いちばん最初にrejectになったfunctionの結果(reject reason)が次のthenに渡る。(fail-fast原則)
処理フロー:
(5)Promise.all:その2スレッドプールを自分で指定する
(4)で説明したとおり、Promise.allでFuncを並列動作をさせることができるが、事前に並列動作を行うときのスレッド生成ポリシーをExecutorをつかって定義可能。また、既に別の用途で使うために用意したスレッドプールをPromise.allに転用しても良い。
コード例:
public class Example41 { @SuppressWarnings("unchecked") public static void main(String[] args) { final ExecutorService myExecutor = Executors.newFixedThreadPool(2); // 非同期処理1 Func function1 = (action, data) -> { System.out.println("No.1 " + Thread.currentThread()); new Thread(() -> { Promise.sleep(1000);System.out.println("func1 running");action.resolve("func1-result"); }).start(); }; // 非同期処理2 Func function2 = (action, data) -> { System.out.println("No.2 " + Thread.currentThread()); new Thread(() -> { Promise.sleep(500);System.out.println("func2 running");action.resolve("func2-result"); }).start(); }; // 非同期処理3 Func function3 = (action, data) -> { System.out.println("No.3 " + Thread.currentThread()); new Thread(() -> { Promise.sleep(100);System.out.println("func3 running");action.resolve("func3-result"); }).start(); }; // 最後に結果を受け取る処理 Func function4 = (action, data) -> { System.out.println("No.4 final " + Thread.currentThread()); System.out.println("結果を受け取りました"); List<Object> resultList = (List<Object>) data; for (int i = 0; i < resultList.size(); i++) { Object result = resultList.get(i); System.out.println("非同期処理" + (i + 1) + "の結果は " + result); } myExecutor.shutdown(); action.resolve(); }; Promise.all(myExecutor, function1, function2, function3) .always(function4) .start(); } }実行結果:
No.1 Thread[pool-1-thread-2,5,main] No.2 Thread[pool-1-thread-2,5,main] No.3 Thread[pool-1-thread-2,5,main] func3 running func2 running func1 running No.4 final Thread[pool-1-thread-1,5,main] 結果を受け取りました 非同期処理1の結果は func1-result 非同期処理2の結果は func2-result 非同期処理3の結果は func3-result結果から、Funcは同じスレッドプールから取り出されたスレッドで実行されていることがわかる。
(Funcの中であえてさらに非同期処理(new Thread)しているので、その非同期処理は指定したスレッドプールの外側になる)説明:
- Promise.allの実行に使うExecutorを定義する。以下はプールサイズが2のスレッドプール。
final ExecutorService myExecutor = Executors.newFixedThreadPool(2);
- Promise.all(executor,func1,func2,func3,・・・・funcN)のようにしてExecutorを指定できる
Promise.all(myExecutor, function1, function2, function3) .always(function4) .start();
- 独自にExecutorを指定した場合は、忘れずにshutdownする
Func function4 = (action, data) -> { //中略 myExecutor.shutdown(); action.resolve(); };スレッド生成ポリシー:
- スレッドプールのサイズは2以上を指定する必要がある。(つまり、singleThreadExecutorは利用不可。)
- java-promiseでは、Promise.allを行う場合、非同期実行のため1スレッドを使う。
- さらに、Promise.allで並列実行をおこなうため、並列実行用に最低1スレッドが必要。(1スレッドだと並列とはいわないが)
- この2つを合計すると2スレッド以上必要になる。
まとめ
- JavaでPromiseを「JavaScriptライクに記述」する方法を試行しました
- Java8ラムダ式をうまくとりいれるとJavaScriptの記法に近いカタチでPromiseを実行できました
- 簡潔な記法で気の利いた処理ができるという点はJavaScript(ES)他スクリプト系言語の進化に学びたいとおもいます
(非同期実行もJavaScriptではasync/awaitまで進化しました)JavaでPromise(java-promise)のライブラリ側ソースコードは以下にあります
https://github.com/riversun/java-promise
git clone https://github.com/riversun/java-promise.gitしてmvn testすると単体テスト動確ができますまた、本稿内に掲載したサンプルコードは以下にあります
https://github.com/riversun/java-promise-examples/tree/master-ja



