- 投稿日:2019-03-27T22:46:36+09:00
ディープラーニングで競馬予想
競馬に機械学習を使った試みはありますが、ディープラーニング(畳み込みニューラルネットワーク)を使った事例はあまり見かけません。
本稿では、畳み込みニューラルネットワーク(CNN)を使った競馬予想チャレンジをしてみます。
競馬×機械学習
機械学習で競馬をガチで予想すると、70%くらいの的中率が出るようです。
こちらのリンクは大変参考になりますので、興味ある方はご覧ください。
https://exploratory.io/note/6412637879363595/2756560754330101/note_content/note.htmlこちらの方は的中率80%くらいで、この前テレビにも出ていました。
https://logmi.jp/tech/articles/313650
https://www.youtube.com/watch?v=I1eSN6mPANs条件設定
今回競馬データを分析するに当たり、以下の条件を設定しました。
1着の馬を当てる
単勝のみで勝負します。簡単で分かりやすいです。
人気データは使わない
実際に運用することを考えると、当日の人気やオッズを調べる時間がない場合もあります。
常にパドックやPCの前に張り込んでいるわけにはいきませんので。従って、レース前の人気は入力データとして使わないことにしました。
この場合、前日までに情報収集(スクレイピング)と機械学習で予想をして
余裕をもって馬券を購入することができます。ただ、後述するように回収率を上げるためにはやはり、人気データは必須で
簡単な式を作ることで、人気データを使うことも検討してみました。血統データは使わない
血統データを入れるとデータが膨大になってしまうので、今回は割愛しました。
ただ、以前に血統データのみを使って機械学習で予想してみたことがあり、結構
良いところまで予想できたので、これを入れると的中率は上がると思われます。騎手データは使わない
血統データと同様に、騎手データも入れるとデータが膨大になってしまうので、今回は割愛しました。
対象レースは東京の春のレース(未勝利及び500万以下)
東京の春のレース(未勝利及び500万以下)は比較的当てやすいと聞きます。
そこで、今回はこの時期のレースに絞って予想します。データの準備
情報収集
情報収集は、以下に記事を参考にスクレイピングで集めました。
https://qiita.com/ishizakiiii/items/3b894b6e987fdf87093e集めたデータの内訳は以下のとおりです。
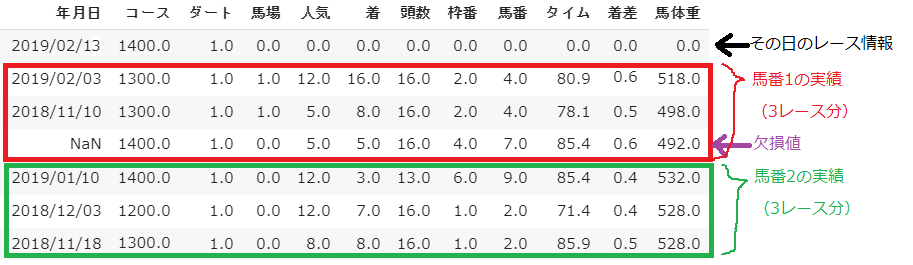
データ数 用途 1998年~2017年 911 学習データ及びバリデーションデータ 2018年 65 回収率シミュレーション用 データの形式は以下のとおりです。
1行目にはその日のレース情報が入っています。ただし、「馬場」以降の列は0で埋めています。
2行目以降は各馬番の実績が入っています。上から1レース前、2レース前、3レース前と
なっています。そして、全部の行数は18頭分×3+「その日のレース情報」となっており、
全部で55行になっています。列数は年月日を除くと11列あります。
まとめると、一レースにつき$55\times11$のデータ形式となっています。各列の情報は以下のとおりです。
年月日
CNNに投げるときに消しています。ダート
ダートであれば「1」、芝であれば「0」です。馬場
良であれば「0」、それ以外なら「1」です。タイム
秒単位に変換しています。欠損値の扱い
実績がないレースは「各列」の平均値で埋めています。
また、18頭に満たないレースも18頭になるように平均値で埋めています。データの前処理
CNNに入れる入力は0~1の間にあるとうまくいくため、各列の値は最小値0、最大値1に
なるように変換しています。特徴量エンジニアリング
今のところ、生データの特徴量は「605」となっています。
不要な特徴量を減らすと、精度が上がることが報告されており、
今回はBorutaというパッケージを使って特徴量を減らしてみました。Borutaについては、以下のリンクを参照ください。
https://qiita.com/KROYO/items/5ecabf99254f19818d8e
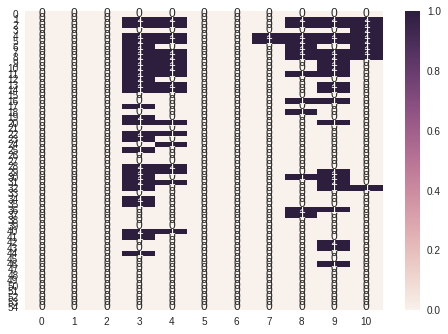
https://aotamasaki.hatenablog.com/entry/2019/01/05/195813前述したようにデータのサイズは$55\times11$となっています。
下の図はこのデータサイズに対し、Borutaで重要だと認められたものを色付けしたヒートマップです。
ヒートマップより「その日のレース情報」(1行目)は重要ではないということが分かりました。
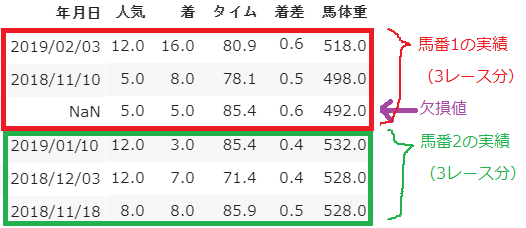
そして、各列について「人気」「着」「タイム」「着差」「馬体重」が重要な要素といえそうです。以上の検討から、最終的な入力データは以下の形式としました。
だいぶすっきりしました。当初、$55\times11$だったデータが$54\times5$まで圧縮できました。
本稿では、このデータを画像としてとらえてCNNで処理することにより一着になる馬を予想します。一番意外だったのが「過去のレースの人気」が重要だということです。
過去のレースの人気は、潜在的な馬の能力(血統)を示唆しているのでしょうか。ちなみに今回Borutaで特徴量を削減すると、精度が2%向上しました。
Boruta凄い!CNNで予想
ディープラーニングに興味のない方はここを読み飛ばして、回収率シミュレーションをご覧ください。
ここからはCNNを使っており、全て同一のものを使っています。
CNNのコードは付録に記載しています。CNNの比較対象として、一番人気の馬券を買うことが挙げられるでしょうか。
一番人気の馬券は約30%の的中率が出ます。単純に予想してみる
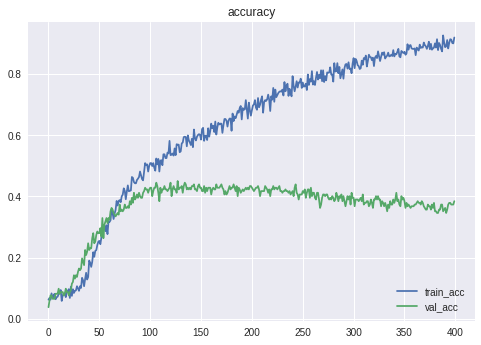
まずは、CNNで一着になる馬を予想してみます。
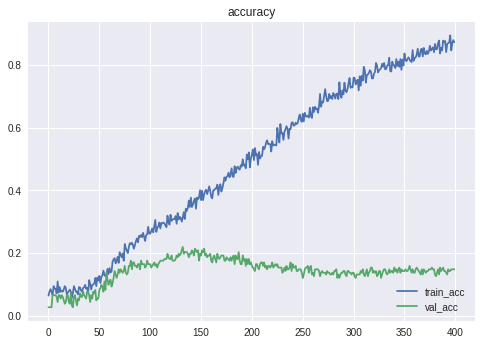
Epoch 133/400 729/729 [==============================] - 0s 335us/step - loss: 2.0631 - acc: 0.3128 - val_loss: 2.6475 - val_acc: 0.2198 Epoch 00133: val_acc improved from 0.20879 to 0.21978, saving model to weights.h5精度は21.98%となりました。
残念ながら、一番人気の的中率には届きませんでした。ちなみにXGBoostなどでも同程度の精度となりました。
CNNが過学習しているため、L2正則化などを盛り込んでみましたが、あまり効果はありませんでした。
また、CNNのフィルター(カーネル)サイズを横長や縦長に変えてみましたが、精度は悪化してしまいました。一番人気を予想してみる
単純に一着の馬を予想しても、一番人気の的中率に届きませんでした。
考え方を少し変えてみます。一番人気の的中率が高いのであれば、一番人気をCNNに
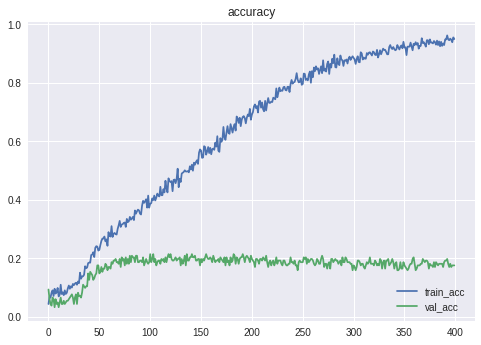
予想させてその馬券を買えば、的中率が上がるのではないでしょうか。ということで、一番人気を予想してみます。
Epoch 00127: val_acc did not improve from 0.44505 Epoch 128/400 729/729 [==============================] - 0s 318us/step - loss: 1.3221 - acc: 0.5693 - val_loss: 1.8868 - val_acc: 0.4505 Epoch 00128: val_acc improved from 0.44505 to 0.45055, saving model to model/weights_pop.h5「一番人気」の的中精度は45.06%となりました。
そして、一番人気だと予想した馬券を購入すると
test accuracy 0.24175824175824176「一着」の的中精度は24.18%となりました。
単純に一着を予想するよりも、一番人気を予想させて馬券を購入した方が
的中率が高くなるとは...何とも不思議な現象です。割ってみる
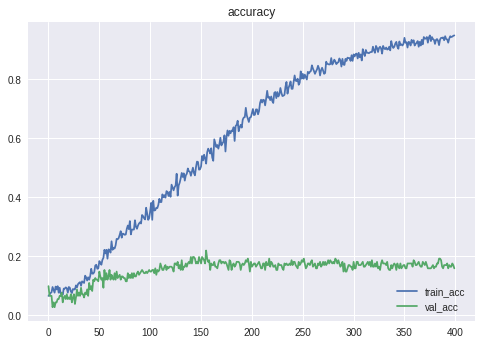
今度はデータをいじってみます。
「人気」を「着」で割ると、人気通りであれば1に近くなり、人気から外れると
1より大きいあるいは、小さいものになります。何となく役立ちそうなデータです。そこで、全ての列に対し総当たりで割り算を行いました。
ただし、データは0~1に変換しているため、分母に0.1を加算して演算します。$X$を新たに作る特徴量、$x$を既存の特徴量とすると、以下の式になります。
X_{ij}=\frac{x_{ik}}{0.1+x_{il}}ただし、$i$=1~54は行の番号、$j$は新たに作るデータの列の番号とします。
また、$k$と$l$($k\neq l$)には「人気」「着」「タイム」「着差」「馬体重」が入ります。そして、割り算したデータ$(54\times10)$を元データ$(54\times5)$に連結し、
$(54\times15)$のデータとしてCNNで判定させます。
Epoch 104/400 729/729 [==============================] - 0s 351us/step - loss: 1.8688 - acc: 0.3992 - val_loss: 2.7059 - val_acc: 0.2143 Epoch 00104: val_acc improved from 0.21429 to 0.21429, saving model to model/weights_divide.h5この時の精度は21.43%となりました。
単純に一着を予想させるのと、ほとんど変わらない精度になりました。
掛けてみる
今度は掛け算を行ってみます。
さきほどと同じように、全ての列に対し総当たりで掛け算をしました。
$X$を新たに作る特徴量、$x$を既存の特徴量とすると、以下の式になります。X_{ij}=x_{ik}x_{il}ただし、$i$=1~54は行の番号、$j$は新たに作るデータの列の番号とします。
また、$k$と$l$($k\neq l$)には「人気」「着」「タイム」「着差」「馬体重」が入ります。そして、掛け算したデータ$(54\times10)$を元データ$(54\times5)$に連結し、
$(54\times15)$のデータとしてCNNで判定させます。
Epoch 156/400 729/729 [==============================] - 0s 345us/step - loss: 1.3909 - acc: 0.5144 - val_loss: 2.8907 - val_acc: 0.2198 Epoch 00156: val_acc improved from 0.19780 to 0.21978, saving model to model/weights_times.h5この時の精度は21.98%となりました。
結果の比較
ここまでの結果をまとめておきます。
通常予想 人気予想 除算(divide) 積(times) 一番人気 21.98% 24.18% 21.43% 21.98% 30%くらい 残念ながら、CNNの予想は一番人気の的中率には届きませんでした。
次に、これらをアンサンブル学習してどこまで伸びるのか見てみます。ボツになった案
アンサンブル学習に行く前に、ボツになった案をご紹介します。
DataAugmentation
一着の馬のデータだけを他のレースデータとトレードしたり、ノイズを付与したり
mixupしたりしてデータを水増ししましたが、精度は上がりませんでした。metric learning
今回は学習データが1000以下と少なく、少ないデータ量でうまくいくと言われる
metric learningを試しました。しかし、精度は上がりませんでした。他の機械学習手法とアンサンブル
XGBoostやCATBoost、ロジスティクス回帰やSVMとのアンサンブル学習を試みましたが、
精度はほとんど変わりませんでした。二段回学習
CNNを特徴抽出器として利用し、抽出した特徴量をSVMやロジスティクス回帰で分類しましたが、
精度は上がりませんでした。アンサンブル学習
もう少し悪あがきをしてみます。
運良く「一番人気」が分かったとして、CNNに何とか組み込めないか考えてみます。
そこで、一番人気とCNNでアンサンブル学習(Voting)してみます。Votingについては、以下の記事をご覧ください。
https://qiita.com/shinmura0/items/bcc8c4a06b9a49c943d6#voting%E3%81%A8%E3%81%AF式は独断で以下のとおりとしました。
Argmax(10\times popularity + CNN_{normal} + CNN_{times} + CNN_{divide} + CNN_{popularity})(1)ただし、popularityは次式のようなone-hot表現になった18次元のベクトルです。
popularity = [0, 1, 0, ..., 0]$CNN_{***}$は18頭の馬がそれぞれ一着になる確率が入った18次元のベクトルとなっています。
CNN_{***} = [0.1, 0.8, 0.1, ..., 0](1)式で最大のスコアになった馬を単勝予想馬とします。
お気づきのとおり、一番人気の係数が「10」になっており、一番人気を買うしか
選択肢はありません。従って、CNNの投票は全く関係ないようにみえますが
回収率を上げるときに大きな役割を果たします。馬券の買い方
回収率を上げる馬券の買い方について考察します。
一番人気が既知の場合
(1)式の単勝予想馬について、その馬のスコアが高いとしたら信頼度は高いかもしれません。
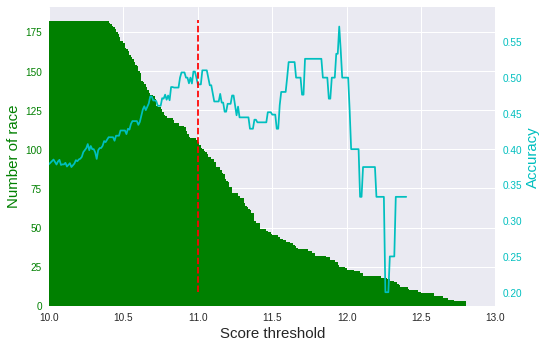
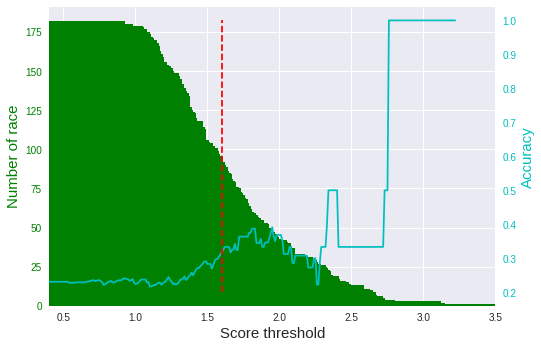
スコアに閾値を設け、その値以上であれば、馬券を買う戦略をとってみます。まずは、テストデータを使って、スコアの閾値と精度の関係を見てみます。
ご覧のとおり、スコアの閾値が高いほど精度も上がる傾向にあります。
ただ、閾値が高すぎると対象となるレース数が少なくなります(緑の棒グラフ)。そこで、今回は閾値を「11」に定め(赤の点線)、ある程度レース数を確保することにしました。
テストデータだと50%くらいの精度が出ています。一番人気が未知の場合
一番人気が未知の場合、(1)式でpopularityの項がなくなります。
その場合も同じ戦略をとってみます。テストデータを使って、スコアの閾値と精度の関係を見てみます。
さきほどと同じく、レース数を確保するために閾値を「1.8」に定めました(赤の点線)。
テストデータだと30%くらいの精度が出ています。回収率シミュレーション
最後に2018年のデータを使って、回収率シミュレーションをしてみます。
一番人気が既知の場合
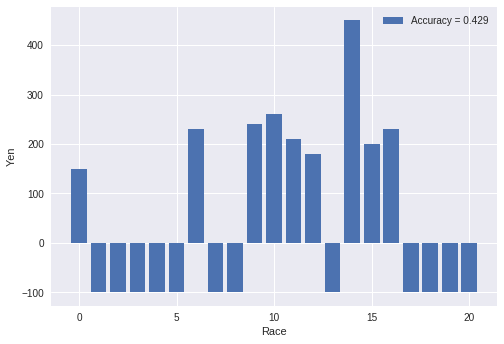
ここでは(1)式がそのまま使えます。そして、閾値を「11」にして
スコアがそれ以上であれば、馬券を買う戦略をとります。
上の図は上記の戦略で単勝の馬券を買った場合の利益です。¥100で馬券を買ったとして、
当たれば「¥100×倍率」、負ければ「-¥100」としています。一番人気の馬券を
買っているため、的中しても倍率が非常に低いです。
全レース 対象レース 的中 的中率 回収率 一番人気 65 65 20/65 30.8% 74.2% アンサンブル学習 65 21 9/21 42.9% 102% 一番人気と比較した場合、アンサンブル学習の方が的中率も回収率も高いのですが、
回収率が102%なので、やる価値はあまりないです。
銀行に預金するより若干良いくらい!?一番人気が未知の場合
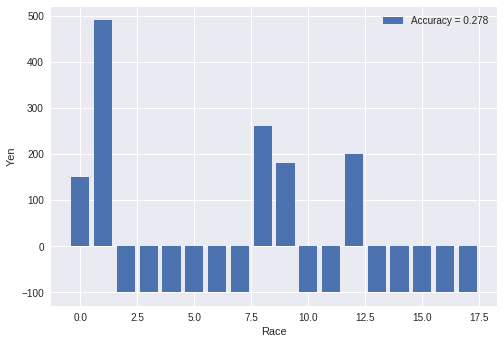
ここでは(1)式のpopularityがなくなっています。そして、閾値を「1.8」にして
スコアがそれ以上であれば、馬券を買う戦略をとります。
上の図は、上記の戦略で単勝の馬券を買った場合の利益を示しています。
2レース目の倍率は高いのですが、その他のレースは当たったとしても
一番人気っぽいので、利益が低くなっています。
全レース 対象レース 的中 的中率 回収率 一番人気 65 65 20/65 30.8% 74.2% アンサンブル学習 65 18 5/18 27.8% 71.0% 一番人気が未知の場合は回収率が100%を下回ってしまうので、買わない方が良いですね。
一番人気の情報は絶対必要です!まとめ
- ディープラーニングによる競馬データの予測は、的中率43%、回収率102%になりました。
- 今回のチャレンジでは、機械学習のモデルやハイパーパラメータをいじるより、特徴量をいじった方が精度が上がりやすかったです。やはり特徴量エンジニアリングが肝といえそうです。
- 1番人気のデータの重要性が良く分かりました。
付録
最後にCNNのコードを示します。
import keras from keras.models import Model from keras.layers import Input, Dense, Activation, Dropout from keras.layers import Conv2D, GlobalAveragePooling2D from keras.layers import BatchNormalization, Add from keras.callbacks import ModelCheckpoint from keras.utils import to_categorical from keras.initializers import he_normal import keras.backend as K # redefine target data into one hot vector classes = 19 Y_train = to_categorical(y_train, classes) Y_test = to_categorical(y_test, classes) def cba(inputs, filters, kernel_size, strides): x = Conv2D(filters, kernel_size=kernel_size, strides=strides, padding='same', kernel_initializer=he_normal())(inputs) #x = BatchNormalization()(x) #バッチノーマライゼーションは入れない方が精度が出る x = Activation("relu")(x) return x # define CNN inputs = Input(shape=(X_train_.shape[1:])) x = cba(inputs, filters=32, kernel_size=(3,3), strides=(2,2),) x = Dropout(0.2)(x) x = cba(x, filters=64, kernel_size=(3,3), strides=(2,2)) x = Dropout(0.2)(x) x = cba(x, filters=128, kernel_size=(3,3), strides=(2,2)) x = Dropout(0.2)(x) x = cba(x, filters=128, kernel_size=(3,3), strides=(2,2)) x = Dropout(0.2)(x) x = cba(x, filters=256, kernel_size=(3,3), strides=(2,2)) x = Dropout(0.2)(x) x = cba(x, filters=256, kernel_size=(3,3), strides=(2,2)) x = Dropout(0.2)(x) x = GlobalAveragePooling2D()(x) #x = keras.layers.Lambda(lambda xx: alpha*(xx)/K.sqrt(K.sum(xx**2)))(x) #metrics learning x = Dense(classes)(x) x = Activation("softmax")(x) model = Model(inputs, x) #model.summary() # initiate Adam optimizer opt = keras.optimizers.adam(lr=0.0001, decay=1e-6, amsgrad=True) # Let's train the model using Adam with amsgrad model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy']) hist = model.fit(X_train_,Y_train, validation_data=(X_test_,Y_test), epochs=400, callbacks=[ ModelCheckpoint(path + 'weights.h5', monitor='val_acc', verbose=1, mode='auto', save_best_only='true')], verbose=1, batch_size=50) model_json = model.to_json() open(path + 'model.json', 'w').write(model_json) #結果描画 plt.figure() plt.title("loss") plt.plot(hist.history['loss'],label="train_loss") plt.plot(hist.history['val_loss'],label="val_loss") plt.legend() plt.show() plt.figure() plt.title("accuracy") plt.plot(hist.history['acc'],label="train_acc") plt.plot(hist.history['val_acc'],label="val_acc") plt.legend(loc="lower right") plt.show()

- 投稿日:2019-03-27T18:07:45+09:00
TVMに量子化がやってきた
TVM v0.5で8bit整数型へのpost-training量子化がサポートされました。
現時点(2019-3-27)ではAPIドキュメント・チュートリアルが公開されていないため、簡単に使い方をまとめておきます。ソースコードはこちら
手順
Keras公式のResNet50モデルを例に進めていきます。
import keras model = keras.applications.resnet50.ResNet50(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)モデル変換
まずはこのモデルをRelayIRの関数に変換しましょう。v0.5で正式サポートされたRelayIRですが、既にKerasを含め多くのDLフレームワークからのモデル変換機能が用意されています。
import tvm.relay as relay input_name = 'input_1' image_shape = (1, 3 , 224, 224) # NCWH func, params = relay.frontend.from_keras(model, image_shape)量子化
早速この関数を量子化してみましょう。
import tvm import tvm.relay as relay with relay.quantize.qconfig(global_scale=8.0): func_quant = relay.quantize.quantize(func, params) print(str(func_quant))... %9 = round(%8) %10 = clip(%9, a_min=-127, a_max=127) %11 = cast(%10, dtype="int8") %12 = nn.conv2d(%11, meta[relay.Constant][4], channels=64, kernel_size=[1, 1], out_dtype="int32") %13 = add(%12, meta[relay.Constant][5]) %14 = add(%13, meta[relay.Constant][6]) %15 = nn.relu(%14) %16 = add(%15, 64) %17 = right_shift(%16, 7) %18 = clip(%17, a_min=-127, a_max=127) %19 = cast(%18, dtype="int8") ...conv2dへの入力値が8bit整数化されていることが分かります。量子化アルゴリズムの詳細はこの機能のコミッタであるZiheng JiangさんのLT資料がシンプルかつ直観的にまとまっています。
コンパイル
生成されたRelay関数をコンパイルします。ターゲットはLLVM(x86 CPU)としましょう。比較のため量子化前の関数も併せてコンパイルしておきます。
target = 'llvm' # 量子化有無による差異のみチェックするため,グラフ最適化は無効に with relay.build_config(opt_level=0): modules = relay.build_module.build(func, target, params=params) modules_quant = relay.build_module.build(func_quant, target, params=params)推論
一般にpost-training量子化を施したモデルは、元のモデルに比べ多少精度が低下する傾向にあります。TVMの量子化はどうでしょうか。
おなじみImageNetは tabby cat の画像でテストしてみます。
def predict_tvm(modules, data): # create module graph, lib, params = modules module = tvm.contrib.graph_runtime.create(graph, lib, tvm.cpu()) # set input and parameters module.set_input(input_name, tvm.nd.array(data.astype(np.float32))) module.set_input(**params) # get output module.run() return module.get_output(0, tvm.nd.empty((1, 1000))).asnumpy() def show_top5_accuracy(y_pred, synset): top5_ids = y_pred.flatten().argsort()[::-1][:5] for i, c in enumerate(top5_ids): print(f'{i+1} : {c} {synset[c]}') y_pred_tvm = predict_tvm(modules, data) y_pred_tvm_quant = predict_tvm(modules_quant, data) print('\nw/o quantization') show_top5_accuracy(y_pred_tvm, synset) print('\nwith quantization') show_top5_accuracy(y_pred_tvm_quant, synset)w/o quantization 1 : 278 kit fox, Vulpes macrotis 2 : 277 red fox, Vulpes vulpes 3 : 282 tiger cat 4 : 285 Egyptian cat 5 : 356 weasel with quantization 1 : 263 Pembroke, Pembroke Welsh corgi 2 : 282 tiger cat 3 : 285 Egyptian cat 4 : 281 tabby, tabby cat 5 : 722 ping-pong ball量子化の影響か両者の推論結果が若干変わっているものの、傾向としては似たようなクラスが出力されているようです。コーギーと子狐、どちらがよりこの茶トラの子猫に近しいかは議論の別れるところですが...
その他、いくつか別クラスの画像でも試してみましたが、概ね量子化前後で同等の推論結果が得られました。
ファイルサイズ
最後に重みファイルのサイズも比較してみましょう。
# save weight model.save_weights('weight_keras.h5') params = modules[2] with open("deploy_param.params", "wb") as f: f.write(relay.save_param_dict(params)) params_quant = modules_quant[2] with open("deploy_param_quant.params", "wb") as f: f.write(relay.save_param_dict(params_quant))
Keras(weights) TVM(未量子化) TVM(量子化) 99MB 98MB 31MB ばっちり軽量化できました!実質コードに2行追加しただけで、重みのサイズが約1/3になったのは中々インパクトがあるのではないでしょうか。
推論速度
最後に推論速度を計っておきましょう。注意点として、
今回のモデルはTVMのキモであるグラフ最適化を行っておらず、ターゲットデバイス向けのチューニングも施していません。絶対的な推論速度は参考程度にとどめてください。print('w/o quantization') %timeit -n10 module.run() print('\nwith quantization') %timeit -n10 module_quant.run()w/o quantization 141 ms ± 447 µs per loop (mean ± std. dev. of 7 runs, 10 loops each) with quantization 192 ms ± 77.4 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)量子化後の方が僅かに遅くなっていることが分かります。今回ターゲットとしたx86-64 CPUのようにFPU性能やキャッシュ容量が十分大きいデバイスでは、サイズの縮小による高速化よりも、量子化時のキャストやクリッピング処理による負荷の方が大きいようです。ARM CPUやFPGAでも改めて検証してみたいところですね。
終わりに
今回はTVM v0.5の新機能、post-training量子化を試してみました。既存コードに数行追加するだけで量子化にトライできる手軽さには驚かされるばかりです。既にエッジ向け推論フレームワークとして関心が高まりつつあるTVMですが、量子化の実装で今後ますます注目を集めそうです。
環境
- Ubuntu 16.04 LTS
- AMD Ryzen 7 1700
- TVM master a7c90ee579e0e830e349f372f3783a0bd31ac605 (0.6.dev)
- Python 3.6.8
- Keras 2.2.4
- tensorflow-gpu 1.12.0
参考資料
TVM Conference 2018, Automatic Quantization for TVM
https://sampl.cs.washington.edu/tvmconf/slides/11-Ziheng-Jiang.pdfTVM tutorials, Compile Keras Models
https://docs.tvm.ai/tutorials/frontend/from_keras.html#compile-keras-models


- 投稿日:2019-03-27T18:07:45+09:00
TVMとKerasで試す量子化ニューラルネットワーク
TVM v0.5で8bit整数型へのpost-training量子化がサポートされました。
現時点(2019-3-27)ではAPIドキュメント・チュートリアルが公開されていないため、簡単に使い方をまとめておきます。ソースコードはこちら
手順
Keras公式のResNet50モデルを例に進めていきます。
import keras model = keras.applications.resnet50.ResNet50(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)モデル変換
まずはこのモデルをRelayIRの関数に変換しましょう。v0.5で正式サポートされたRelayIRですが、既にKerasを含め多くのDLフレームワークからのモデル変換機能が用意されています。
import tvm.relay as relay input_name = 'input_1' image_shape = (1, 3 , 224, 224) # NCWH func, params = relay.frontend.from_keras(model, image_shape)量子化
早速この関数を量子化してみましょう。
import tvm import tvm.relay as relay with relay.quantize.qconfig(global_scale=8.0): func_quant = relay.quantize.quantize(func, params) print(str(func_quant))... %9 = round(%8) %10 = clip(%9, a_min=-127, a_max=127) %11 = cast(%10, dtype="int8") %12 = nn.conv2d(%11, meta[relay.Constant][4], channels=64, kernel_size=[1, 1], out_dtype="int32") %13 = add(%12, meta[relay.Constant][5]) %14 = add(%13, meta[relay.Constant][6]) %15 = nn.relu(%14) %16 = add(%15, 64) %17 = right_shift(%16, 7) %18 = clip(%17, a_min=-127, a_max=127) %19 = cast(%18, dtype="int8") ...conv2dへの入力値が8bit整数化されていることが分かります。量子化アルゴリズムの詳細はこの機能のコミッタであるZiheng JiangさんのLT資料がシンプルかつ直観的にまとまっています。
コンパイル
生成されたRelay関数をコンパイルします。ターゲットはLLVM(x86 CPU)としましょう。比較のため量子化前の関数も併せてコンパイルしておきます。
target = 'llvm' # 量子化有無による差異のみチェックするため,グラフ最適化は無効に with relay.build_config(opt_level=0): modules = relay.build_module.build(func, target, params=params) modules_quant = relay.build_module.build(func_quant, target, params=params)推論
一般にpost-training量子化を施したモデルは、元のモデルに比べ多少精度が低下する傾向にあります。TVMの量子化はどうでしょうか。
おなじみImageNetは tabby cat の画像でテストしてみます。
def predict_tvm(modules, data): # create module graph, lib, params = modules module = tvm.contrib.graph_runtime.create(graph, lib, tvm.cpu()) # set input and parameters module.set_input(input_name, tvm.nd.array(data.astype(np.float32))) module.set_input(**params) # get output module.run() return module.get_output(0, tvm.nd.empty((1, 1000))).asnumpy() def show_top5_accuracy(y_pred, synset): top5_ids = y_pred.flatten().argsort()[::-1][:5] for i, c in enumerate(top5_ids): print(f'{i+1} : {c} {synset[c]}') y_pred_tvm = predict_tvm(modules, data) y_pred_tvm_quant = predict_tvm(modules_quant, data) print('\nw/o quantization') show_top5_accuracy(y_pred_tvm, synset) print('\nwith quantization') show_top5_accuracy(y_pred_tvm_quant, synset)w/o quantization 1 : 278 kit fox, Vulpes macrotis 2 : 277 red fox, Vulpes vulpes 3 : 282 tiger cat 4 : 285 Egyptian cat 5 : 356 weasel with quantization 1 : 263 Pembroke, Pembroke Welsh corgi 2 : 282 tiger cat 3 : 285 Egyptian cat 4 : 281 tabby, tabby cat 5 : 722 ping-pong ball量子化の影響か両者の推論結果が若干変わっているものの、傾向としては似たようなクラスが出力されているようです。コーギーと子狐、どちらがよりこの茶トラの子猫に近しいかは議論の別れるところですが...
その他、いくつか別クラスの画像でも試してみましたが、概ね量子化前後で同等の推論結果が得られました。
ファイルサイズ
最後に重みファイルのサイズも比較してみましょう。
# save weight model.save_weights('weight_keras.h5') params = modules[2] with open("deploy_param.params", "wb") as f: f.write(relay.save_param_dict(params)) params_quant = modules_quant[2] with open("deploy_param_quant.params", "wb") as f: f.write(relay.save_param_dict(params_quant))
Keras(weights) TVM(未量子化) TVM(量子化) 99MB 98MB 31MB ばっちり軽量化できました!実質コードに2行追加しただけで、重みのサイズが約1/3になったのは中々インパクトがあるのではないでしょうか。
推論速度
最後に推論速度を計っておきましょう。注意点として、
今回のモデルはTVMのキモであるグラフ最適化を行っておらず、ターゲットデバイス向けのチューニングも施していません。絶対的な推論速度は参考程度にとどめてください。print('w/o quantization') %timeit -n10 module.run() print('\nwith quantization') %timeit -n10 module_quant.run()w/o quantization 141 ms ± 447 µs per loop (mean ± std. dev. of 7 runs, 10 loops each) with quantization 192 ms ± 77.4 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)量子化後の方が僅かに遅くなっていることが分かります。今回ターゲットとしたx86-64 CPUのようにFPU性能やキャッシュ容量が十分大きいデバイスでは、サイズの縮小による高速化よりも、量子化時のキャストやクリッピング処理による負荷の方が大きいようです。ARM CPUやFPGAでも改めて検証してみたいところですね。
終わりに
今回はTVM v0.5の新機能、post-training量子化を試してみました。既存コードに数行追加するだけで量子化にトライできる手軽さには驚かされるばかりです。既にエッジ向け推論フレームワークとして関心が高まりつつあるTVMですが、量子化の実装で今後ますます注目を集めそうです。
環境
- Ubuntu 16.04 LTS
- AMD Ryzen 7 1700
- TVM master a7c90ee579e0e830e349f372f3783a0bd31ac605 (0.6.dev)
- Python 3.6.8
- Keras 2.2.4
- tensorflow-gpu 1.11.0
参考資料
TVM Conference 2018, Automatic Quantization for TVM
https://sampl.cs.washington.edu/tvmconf/slides/11-Ziheng-Jiang.pdfTVM tutorials, Compile Keras Models
https://docs.tvm.ai/tutorials/frontend/from_keras.html#compile-keras-models
- 投稿日:2019-03-27T13:41:13+09:00
主成分分析(PCA)を題材にした線形代数の総復習
Ice Break
線形代数を思い出すために勉強したんで書き留めておきます。
本稿では機械学習のbasicな手法であるPCAを題材に線形代数を復習していきます。
参考にした文献は(Deep learning by Ian Goodfellow )です。
翻訳が正確じゃないところがあるかもしれないです。
$\newcommand{\argmin}{\mathop{\rm arg~min}\limits}$
$\newcommand{\argmax}{\mathop{\rm arg~max}\limits}$主成分分析についてざっくり
統計解析を行うにあたって用いるデータの選択は重要です。
たくさんのデータがあれば解析の精度は向上するが一般にメモリ制約を受けます。(ほんまか?)
そのような状況においてデータをなるべく情報を欠落させずに圧縮する手法が主成分分析です。
身近な例としてはBMIがわかりやすくて、身長と体重の2次元データから1次元データに圧縮していますよね。あんな感じで圧縮することで指標としてわかりやすくなったりすることもあります。主成分分析の導出
概念の整理
$\mathbb{R}^n$空間におけるm個の点について考えます。(1)
\boldsymbol{X} = \{\boldsymbol{x}^{(1)},...,\boldsymbol{x}^{(m)}\}\cdots(1)このベクトル集合をl次元(n>l)に圧縮することが主成分分析のざっくりした捉え方です。(2)
\boldsymbol{f}:\boldsymbol{x}^{(i)} \in \mathbb{R}^{n}\ \longmapsto \boldsymbol{c}^{(i)} \in \mathbb{R}^{l}\cdots(2)(2)より主成分分析では$f(\boldsymbol{x})=\boldsymbol{c}$を満たす符号化関数$f$及び、$\boldsymbol{c}\ {\simeq}\ g(f(\boldsymbol{x}))$を満たす復号化関数$g$を探索します。
主成分分析では復号化関数$g$の探索を容易にするために符号$\boldsymbol{c}$を$\mathbb{R}^n$空間に逆写像するアプローチを取ります。このことは以下の式で表現できます。
g(\boldsymbol{c})=\boldsymbol{D}\boldsymbol{c}\ {\simeq}\ \boldsymbol{x} \ where\ \boldsymbol{D}\ \in \mathbb{R}^{n\times l}\cdots(3)この行列を探索する際、解が一義的に定まらない可能性があるため2つ制約を設けています。(クラピカのあれです)
①$\boldsymbol{D}$の列ベクトルが互いに直交すること
②$\boldsymbol{D}$の列ベクトルが単位ノルムを有すること符号化関数fと復号関数gの探索
$①入力\boldsymbol{x}$に対する最適な$g(\boldsymbol{c})$の探索
ここまでの説明でなぜ符号化関数$\boldsymbol{f}$から探索しないのか不思議に思う人もいると思いますが天下り的な導出をお許し下さい。さて、今回の導出手法では最適な$\boldsymbol{g}$を探索するために$\boldsymbol{c^*}$を導入します。{\boldsymbol{c^*} = \argmin_{\boldsymbol{c}} \|\|\boldsymbol{x} - g(\boldsymbol{c})\|\|_{2}\cdots(4)}またL2ノルムが非負の値を取り、なおかつ同じ$\boldsymbol{c}$において最小化されることを用いて、L2ノルムの二乗を使用します。(式の展開を容易に行うため)
{\boldsymbol{c^*} = \argmin_{\boldsymbol{c}} \|\|\boldsymbol{x} - g(\boldsymbol{c})\|\|_{2}^2\cdots(4)'}このことより最小化する関数は以下のように単純化されます。
\begin{align} \|\|\boldsymbol{x} - g(\boldsymbol{c})\|\|_{2}^2 &= (\boldsymbol{x} - g(\boldsymbol{c}))^{\mathrm{T}}(\boldsymbol{x} - g(\boldsymbol{c}))\cdots(5)\\\\ &=\boldsymbol{x}^{\mathrm{T}}\boldsymbol{x}-\boldsymbol{x}^{\mathrm{T}}g(\boldsymbol{c}) -g(\boldsymbol{c})^{\mathrm{T}}\boldsymbol{x}+g(\boldsymbol{c})^{\mathrm{T}}g(\boldsymbol{c})\cdots(6)\\\\ &=\boldsymbol{x}^{\mathrm{T}}\boldsymbol{x}-2\boldsymbol{x}^{\mathrm{T}}g(\boldsymbol{c}) +g(\boldsymbol{c})^{\mathrm{T}}g(\boldsymbol{c})\cdots(7) \end{align}式変形に使用した性質
(5)L2ノルムの定義
(6)分配法則
(7)転置後のスカラーが等しいことを利用$\boldsymbol{c^*}$は$\boldsymbol{c}$に依存する関数であることを思い出して式(4)を少し書き直す。
\boldsymbol{c^*} = \argmin_{\boldsymbol{c}}-2\boldsymbol{x}^{\mathrm{T}}g(\boldsymbol{c}) +g(\boldsymbol{c})^{\mathrm{T}}g(\boldsymbol{c})\cdots(8)また式(3)の定義を利用して
\begin{align} \boldsymbol{c^*} &= \argmin_{\boldsymbol{c}}-2\boldsymbol{x}^{\mathrm{T}}\boldsymbol{Dc} +(\boldsymbol{Dc})^{\mathrm{T}}\boldsymbol{Dc}\cdots(9)\\\\ &=\argmin_{\boldsymbol{c}}-2\boldsymbol{x}^{\mathrm{T}}\boldsymbol{Dc} +\boldsymbol{c}^{\mathrm{T}}\boldsymbol{D}^{\mathrm{T}}\boldsymbol{Dc}\cdots(10)\\\\ &=\argmin_{\boldsymbol{c}}-2\boldsymbol{x}^{\mathrm{T}}\boldsymbol{Dc} +\boldsymbol{c}^{\mathrm{T}}\boldsymbol{I_{l}}\boldsymbol{c}\cdots(11)\\\\ &=\argmin_{\boldsymbol{c}}-2\boldsymbol{x}^{\mathrm{T}}\boldsymbol{Dc} +\boldsymbol{c}^{\mathrm{T}}\boldsymbol{c}\cdots(12) \end{align}式変形に使用した性質
(9) 式(3)より$g(\boldsymbol{c})=\boldsymbol{Dc}$
(10)行列の積の転置の定義より$(\boldsymbol{Dc})^{\mathrm{T}}=\boldsymbol{c}^{\mathrm{T}}\boldsymbol{D}^{\mathrm{T}}$
(11)直交性と単位ノルムの制約より
(12)単位行列の性質よりこの最小化問題に対してgradientベースの解法が存在しています(機械学習の常套手段)
ざっくり説明すると微分して0になるところって最小値だよねっていう考え方。鋭い人からすれば極小値$\neq$最小値や極大値を示す可能性について議論が必要だと感じるかもしれませんが、また今度やるので一旦このアプローチで進めます。(線形代数で議論しきれないので)\nabla_{c}(-2\boldsymbol{x}^{\mathrm{T}}\boldsymbol{Dc} +\boldsymbol{c}^{\mathrm{T}}\boldsymbol{c})= 0\cdots(13)-2\boldsymbol{D}^{\mathrm{T}}\boldsymbol{x} +2\boldsymbol{c}= 0\cdots(14)\boldsymbol{c}= \boldsymbol{D}^{\mathrm{T}}\boldsymbol{x}\cdots(15)式変形に使用した性質
(13) 最小化問題の典型的アプローチ
(14)$\boldsymbol{c}$で微分した
(15)2で割って移項しただけここがすごい慣性が大きい話になるんですが、最適な復号関数$\boldsymbol{g}$を探索していたら最適な符号化関数$\boldsymbol{f}$が導出されます。
また、このことにより$
\boldsymbol{f(x)}=\boldsymbol{c}
$を$\boldsymbol{f(x)}=\boldsymbol{D}^{\mathrm{T}}\boldsymbol{x}$で表現できます。
また復号関数$g$は式(3)より\begin{align} r(\boldsymbol{x})&=g(f(\boldsymbol{x}))\\ &=\boldsymbol{D}\boldsymbol{c}\\ &=\boldsymbol{D}\boldsymbol{D}^{\mathrm{T}}\boldsymbol{x}\cdots(16) \end{align}と定義できる。
符号化行列Dの探索
ここでもう一度、入力$\boldsymbol{x}$と$\boldsymbol{c}$のL2を最小化するアプローチをとる。先程と異なる点はすべての$\boldsymbol{x}^{(i)}$に対して同一の$\boldsymbol{D}$を作用させるため、今まで一つの$\boldsymbol{x}$ついて考えてきた誤差の概念をi個の$\boldsymbol{x}$に拡張する必要があるります。そのためフロペニウスノルムを用いて誤差関数を定義し、最小化を試みます。
\boldsymbol{D}^{*}=\argmin_{\boldsymbol{D}}\sqrt{\sum_{i,j}(x_{j}^{(i)}-r(\boldsymbol{x}^{(i)})_j)^{2}}\ subject \ to \ \boldsymbol{D}^{\mathrm{T}}\boldsymbol{D}=\boldsymbol{I}_{l}\cdots(17)この式(17)に式(16)を代入すると
\boldsymbol{D}^{*}=\argmin_{\boldsymbol{D}}\sqrt{\sum_{i,j}(x_{j}^{(i)}-\boldsymbol{D}\boldsymbol{D}^{\mathrm{T}}(\boldsymbol{x}^{(i)})_j)^{2}}\cdots(17)^{'}式(17)を最小化するために、まずl = 1 について考えます。
\boldsymbol{d}^{*}=\argmin_{\boldsymbol{d}}\sum_{i,j}||\boldsymbol{x}_{j}^{(i)}-\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}}\boldsymbol{x}^{(i)}||_{2}^{2}\ subject \ to \ ||\boldsymbol{d}||_{2}=1\cdots(18)ここでスカラーである$\boldsymbol{d}^{\mathrm{T}}(\boldsymbol{x}^{(i)})$がベクトルの右に表記されている、マナー上良くない書き方らしいので以下のように書き直します。
\boldsymbol{d}^{*}=\argmin_{\boldsymbol{d}}\sum_{i,j}||\boldsymbol{x}_{j}^{(i)}-\boldsymbol{d}^{\mathrm{T}}\boldsymbol{x}^{(i)}\boldsymbol{d}||_{2}^{2}\ subject \ to \ ||\boldsymbol{d}||_{2}=1\cdots(18)^{'}またスカラー部の転置行列の性質を利用して以下のように書き下すことができます。
\boldsymbol{d}^{*}=\argmin_{\boldsymbol{d}}\sum_{i,j}||\boldsymbol{x}_{j}^{(i)}-\boldsymbol{x}^{(i)T}\boldsymbol{d}\boldsymbol{d}||\ subject \ to \ ||\boldsymbol{d}||_{2}=1\cdots(18)^{''}このように機械学習の論文では行列を含む式を書き下しているときがあるので慣れておくと、ひるまなくて済みます。
そしてここで式を展開しすぎて訳が分からなくなってきたので、一度整理します。
\boldsymbol{X} = \{\boldsymbol{x}^{(1)},...,\boldsymbol{x}^{(m)}\}\ subject\ to \ \ \boldsymbol{x}^{(i)}\in \mathbb{R}^{n}の関係を思い出して式$(18)^{''}$を$\boldsymbol{X}$を用いて書き直すと
\boldsymbol{d}^{*}=\argmin_{\boldsymbol{d}}||\boldsymbol{X}-\boldsymbol{X}\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}}||_{F}^{2}\ \ subject \ to \ ||\boldsymbol{d}||_{2}=1\cdots(19)この式(19)を更に展開していく
\begin{align} \argmin_{\boldsymbol{d}}||\boldsymbol{X}-\boldsymbol{X}\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}}||_{F}^{2} &=\argmin_{\boldsymbol{d}}Tr((\boldsymbol{X}-\boldsymbol{X}\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}})^{\mathrm{T}}(\boldsymbol{X}-\boldsymbol{X}\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}}))\cdots(20)\\ &=\argmin_{\boldsymbol{d}}Tr((\boldsymbol{X}^\mathrm{T}\boldsymbol{X}-\boldsymbol{X}^\mathrm{T}\boldsymbol{X}\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}}-\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}}\boldsymbol{X}^\mathrm{T}\boldsymbol{X}+\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}}\boldsymbol{X}^\mathrm{T}\boldsymbol{X}\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}})\dots(21)\\ &=\argmin_{\boldsymbol{d}}Tr(\boldsymbol{X}^\mathrm{T}\boldsymbol{X})-Tr(\boldsymbol{X}^\mathrm{T}\boldsymbol{X}\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}})-Tr(\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}}\boldsymbol{X}^\mathrm{T}\boldsymbol{X})+Tr(\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}}\boldsymbol{X}^\mathrm{T}\boldsymbol{X}\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}})\dots(22)\\ &=\argmin_{\boldsymbol{d}}-Tr(\boldsymbol{X}^\mathrm{T}\boldsymbol{X}\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}})-Tr(\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}}\boldsymbol{X}^\mathrm{T}\boldsymbol{X})+Tr(\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}}\boldsymbol{X}^\mathrm{T}\boldsymbol{X}\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}})\dots(23)\\ &=\argmin_{\boldsymbol{d}}-2Tr(\boldsymbol{X}^\mathrm{T}\boldsymbol{X}\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}})+Tr(\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}}\boldsymbol{X}^\mathrm{T}\boldsymbol{X}\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}})\dots(24)\\ &=\argmin_{\boldsymbol{d}}-2Tr(\boldsymbol{X}^\mathrm{T}\boldsymbol{X}\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}})+Tr(\boldsymbol{X}^\mathrm{T}\boldsymbol{X}\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}}\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}})\dots(25)\\ \end{align}式変形に使用した性質
(20)フロペニウスノルムの性質 $||\boldsymbol{A}||_{F}=\sqrt{Tr(\boldsymbol{A}\boldsymbol{A}^\mathrm{T})}$
(21)(22)分配法則
(23)$\boldsymbol{d}$に影響しない項を排除
(24)(25)Trace行列の巡回可能な法則を利用ここで制約条件 $subject\ to\ \boldsymbol{d}^{\mathrm{T}}\boldsymbol{d}=1$ を思い出して式を整理していく
\begin{align} \argmin_{\boldsymbol{d}}-2Tr(\boldsymbol{X}^\mathrm{T}\boldsymbol{X}\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}})+Tr(\boldsymbol{X}^\mathrm{T}\boldsymbol{X}\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}}\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}})\ subject\ to\ \boldsymbol{d}^{\mathrm{T}}\boldsymbol{d}=1\dots(26)\\ \end{align}\begin{align} \argmin_{\boldsymbol{d}}-2Tr(\boldsymbol{X}^\mathrm{T}\boldsymbol{X}\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}})+Tr(\boldsymbol{X}^\mathrm{T}\boldsymbol{X}\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}})\ subject\ to\ \boldsymbol{d}^{\mathrm{T}}\boldsymbol{d}=1\dots(27)\\ \end{align}\begin{align} \argmin_{\boldsymbol{d}}-Tr(\boldsymbol{X}^\mathrm{T}\boldsymbol{X}\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}})\ subject\ to\ \boldsymbol{d}^{\mathrm{T}}\boldsymbol{d}=1\dots(28)\\ \end{align}\begin{align} \argmax_{\boldsymbol{d}}\ Tr(\boldsymbol{X}^\mathrm{T}\boldsymbol{X}\boldsymbol{d}\boldsymbol{d}^{\mathrm{T}})\ subject\ to\ \boldsymbol{d}^{\mathrm{T}}\boldsymbol{d}=1\dots(29)\\ \end{align}\begin{align} \argmax_{\boldsymbol{d}}\ Tr(\boldsymbol{d}^{\mathrm{T}}\boldsymbol{X}^\mathrm{T}\boldsymbol{X}\boldsymbol{d})\ subject\ to\ \boldsymbol{d}^{\mathrm{T}}\boldsymbol{d} =1\dots(30)\\ \end{align}式変形に使用した性質
(26)制約条件の追加
(27)制約条件より$\boldsymbol{d}^{\mathrm{T}}\boldsymbol{d}$を1とみなした
(28)加算則
(29)符号を反転させ、最大値問題に転換(よくやる)
(30)固有値問題に落とし込むための並び替え式(30)は固有値問題として解くことができます。行列$\boldsymbol{X}^\mathrm{T}\boldsymbol{X}$の最大固有値に対応する固有ベクトルが$\boldsymbol{d}$に対応するためです。今回は1次の場合について導出しましたが、行列$\boldsymbol{D}$においても最大固有値に対応するl個のベクトルを格納したものに対応することが知られています。
$\LaTeX$楽しかった