- 投稿日:2021-01-23T23:42:12+09:00
AtCoder Beginner Contest 189 参戦記
AtCoder Beginner Contest 189 参戦記
終了50秒前に書けたE問題を投げたら奇跡的に一発 AC が出て久々に大勝利!
ABC189A - Slot
1分半で突破. 書くだけ.
S = input() if S[0] == S[1] and S[1] == S[2]: print('Won') else: print('Lost')ABC189B - Alcoholic
3分で突破. double でやるのは嫌な予感がしたので、思考停止で Decimal で. 30秒考えれば100倍すればいいじゃんと気づいただろうに(笑).
from decimal import Decimal N, X = map(int, input().split()) c = 0 for i in range(N): V, P = map(Decimal, input().split()) c += V * (P / 100) if c > X: print(i + 1) break else: print(-1)ABC189D - Logical Expression
20分くらいで突破. C問題に一旦敗退してこちらを先に. 普通に AND のほうが OR より優先順位が高いんだろうと思いつつ問題文を読んだら優先順位が同じで、何この簡単な問題ってなった.
N, *S = open(0).read().split() t = 1 f = 1 for s in S: if s == 'AND': f = t + f * 2 elif s == 'OR': t = t * 2 + f print(t)ABC189C - Mandarin Orange
20分くらいで突破、WA1. N≤104 だから O(N2) だと駄目だよなと思いつつ、順位表を見ると正当者数が多いので、多分テストケースが制限いっぱいに攻めてないんだろうと投げたら AC が出て一安心. 公式解法も O(N2) で、そもそも制限時間も2秒ではなく、1.5秒だったことに気づいて目が白黒してる.
N, *A = map(int, open(0).read().split()) def f(x): result = 0 i = 0 j = 0 while i < N: while j < N and x <= A[j]: j += 1 result = max(result, x * (j - i)) i = j + 1 j = i return result result = 0 for x in set(A): result = max(result, f(x)) print(result)ABC189E - Rotate and Flip
56分で突破. アフィン変換、なんでしたっけ?(まて)
情報学科卒にも関わらずアフィン変換という単語は出てこなかったものの、行列とは気づかずに行列の遷移を書けたおかげで AC できた.
from sys import stdin readline = stdin.readline N = int(readline()) XY = [tuple(map(int, readline().split())) for _ in range(N)] M = int(readline()) op = [readline() for _ in range(M)] Q = int(readline()) AB = [tuple(map(int, readline().split())) for _ in range(Q)] # (x, y) # 1 -> (y, -x) # 2 -> (-y, x) # 3 p -> (2p - x, y) # 4 p -> (x, 2p - y) def e(x, i): result = x[0] if x[1] == 1: result += XY[i][x[2]] elif x[1] == -1: result -= XY[i][x[2]] return result x = (0, 1, 0) y = (0, 1, 1) applied = 0 result = [None] * Q for a, b, i in sorted(((AB[i][0], AB[i][1], i) for i in range(Q)), key=lambda x: x[0]): while applied < a: o = op[applied] if o[0] == '1': t = x x = (y[0], y[1], y[2]) y = (-t[0], -t[1], t[2]) if o[0] == '2': t = x x = (-y[0], -y[1], y[2]) y = (t[0], t[1], t[2]) if o[0] == '3': p = int(o[2:]) x = (2 * p - x[0], -x[1], x[2]) if o[0] == '4': p = int(o[2:]) y = (2 * p - y[0], -y[1], y[2]) applied += 1 result[i] = '%d %d' % (e(x, b - 1), e(y, (b - 1))) print(*result, sep='\n')
- 投稿日:2021-01-23T23:39:11+09:00
学習型じゃんけん (Python)
はじめに
- Python を少し囓った素人が、「学習型じゃんけん」を作ってみました。
- 学習型といっても、強化学習とかではありません。単純な統計です。
- 「こう書いた方がスマートだ」など、突っ込み大歓迎です。
環境
- Jupyter Notebook 6.1.4
- Python 3.8.5 (default, Sep 3 2020, 21:29:08) [MSC v.1916 64 bit (AMD64)]
アルゴリズム
- 人間は、単純な選択を短時間に繰り返したときに、無意識に癖が出ます。
- 直近4回の手の並びの出現頻度を記録して、直近3回の並びから最も頻度の高い次の手を予測とします。
- 最初に出現履歴と頻度表を適当な乱数で埋めてあります。
使い方
- 人間が手を入力する前に、プログラムは手の内を見せます。
- 人間側の手を
1~3の数字で入力します。
- 機械側の手を見ずに入力するとフェアです。
- 見たくない場合は、
0を入力するとゲームを終了します。- 人間が手を選ぶと、勝敗を判定し、結果と戦績を表示します。
コード
janken.pyimport random as rnd # 初期化 log = [rnd.randrange(3) for _ in range(4)] # 履歴 frequency = [[[[rnd.randrange(3) for _ in range(3)] for _ in range(3)] for _ in range(3)] for _ in range(3)] # 頻度 handName = { 0:'Goo', 1:'Choki', 2:'Par' } # 手の名前 human = 0 # 人間の勝利数 computer = 0 # 機械の勝利数 draw = 0 # 引き分け数 # メインループ while True: print(f"--- {human + computer + draw + 1} ---") # 機械の次の手の算出 f = frequency[log[1]][log[2]][log[3]] # 人間の次の手の出現頻度 com = (f.index(max(f)) + 2) % 3 # 最頻手に勝てる手 print(f"Computer hand: {handName[com]} (secret)") # 先に見せてしまう # 人間の次の手の取得 while True: try: hand = int(input("[1:Goo, 2:Choki, 3:Par, 0:End]? ")) except: pass else: if hand >= 0 and hand <= 3: hand -= 1 break print("input error") if hand < 0: break print(f"Human hand: {handName[hand]}") #print(f"Computer hand: {handName[com]}") # 後で見せる # 判定 if com == hand: result = 'draw' draw += 1 elif com == hand - 1 or com == hand + 2: result = 'Human lose!' computer += 1 else: result = 'Human win!!' human += 1 print(f"{result} (computer:{computer} human:{human} draw:{draw})") # 履歴と頻度の更新 log.append(hand) log = log[-4:] frequency[log[0]][log[1]][log[2]][log[3]] += 1
- 投稿日:2021-01-23T23:39:02+09:00
【パターン認識】k-means clustering
はじめに
突然ですが、パターン認識についていろいろ書いていこうと思います。
用語について
パターン認識という言葉を使います。いろいろな流派?があり、機械学習、人工知能などいろいろありますが、ここではパターン認識として考えます。それぞれ、突っ込みどころのある用語ですが、まぁそれはおいておいて。
流れ
パターン認識の全てについてですが、モデルを用いて行いことをします。
モデルを用意します。モデルのパラメータを求める必要があります。これを「学習」と呼びます。
モデルを用いて、観測が何であるかを推定します。
K-means algorithm
たくさんのデータがあり、それらが分類されていたとします。
新しく入ってきたデータが、それまでに分類されていたどのクラスに属するかを考える、というタスクを考えます。そうすると、学習として求めたいモデルは各クラスの代表値、認識は観測値が属するクラスを求める、ことに当たります。
使い方として、
- たくさんのサンプルを分類する(クラスタリング)
- 分類したクラスタをもとに、新しいサンプルがどのクラスタに属するか求める
というのを考えてみたいと思います。
サンプルデータ
ここでは、次のように分布している2次元データを考えます。
この例だと、何となく4つのクラスタに分類されそうだなー、と思うと思います。
そういう分類を行いたいと思います。実際には多次元のデータですし、クラスタの分類が明確ではない場合もあります。さらに、クラスタ数がいくつかも普通は分からない状態で使います。(そういう場合の「学習」を「教師無し学習」と呼ぶことがあります。)
これらの学習用のN個の観測を
$x_n$と書くことにします。今、クラスタ数をK=4とします。各クラスタは代表値をがあるとします。各学習サンプルは、4個あるクラスタのどれかに属します。最も自然な考え方として、代表値に対して最も近くにあるクラスタに属すると考えます。n番目のサンプルが属するクラスタのインデックスk[n] は
k[n] = \arg \min_k ||x_n - \mu_k||^2とする。自乗は無くてもあってここでは同じであるが、後の目的関数の最小化で説明しやすいのでつけることにする。
もし、クラスタの代表値が分かっていれば、各サンプルがどこに属するかを求めることができます。一方で、各サンプルがどのクラスタに属するかが分かれば、各クラスタに属するサンプルを用いて代表値を更新することができます。これを繰り返すことが、k-means clustering です。
以下は実行結果です。
最初に乱数で初期の代表値を与えました。初期値の与え方はいろいろありますし、実はかなりデリケートな問題です。それは実際に動かすと出てきますが、ここではとりあえず置いておきます。
☆が各クラスタの代表値の推定値です。繰り返しのステップをくりかえすごとに各クラスタの中心に収束していくことが分かります。
実装は、いろいろあるでしょうが、ここでは変数を全て保持して計算を行う、以下のようにしました。
def kmeans_update_alignment(x:ndarray, mu:ndarray) -> ndarray: """ サンプルがどのクラスタに属するかを求める。 parameters ---------- x[N, D]: samples mu[K, D]: centroids """ N, D = x.shape r = np.zeros((N, K)) for n in range(N): r[n, argmin([ sum(v*v for v in x[n, :] - mu[k, :]) for k in range(K)])] = 1 return r def kmeans_update_centroid(x:ndarray, r:ndarray) -> ndarray: """ 各クラスタの平均値を求める Parameters ---------- x, training data (N, D) r, alignment information(K, D) """ mu = dot(r.transpose(), x) for k in range(K): if sum(r[:,k]) < 0.01: continue mu[k,:] = mu[k,:] / sum(r[:,k]) return mu各クラスタの平均を求めるとき、もしそのクラスタに属するサンプルが一つもない場合があり得ます。そのときは更新しないような実装になっています。
目的関数の最小化
このようにad hoc に更新を行い、無事に収束するところを紹介しましたが、このクラスタリングはいつでも収束します。そのことを確認するために、定式化して考えます。
J = \sum_{n=1}^N \sum_{k=1}^K r_{n,k} || x_n - \mu_k ||^2を最小化します。
(1) 各サンプルが属するクラスタを求める
$\mu$ を固定したときの$r_{n,k}$の最適化です。かならず目的関数が減少します。
(2) クラスタの中心の更新
$r_{n,k}$固定したときに最適な目的関数を最小にする$\mu_k$を求めます。これは、各クラスタごとに独立に最適化することができます。
J = \sum_{x_n\in C_1} || x_n - \mu_k||^2 + \cdots + \sum_{x_n\in C_1} || x_n - \mu_k||^2自乗誤差を最小にするベクトルは平均ベクトルです。形をみると、各クラスタを正規分布と思い、その正規分布の平均の最尤推定値を求めることと同じ計算をしていますね。
\hat{\mu_k} = \frac{1}{N_k}\sum_{x_n \in C_k} x_n以上から、単調に減少し、かつ、これは下限があるので、結果として必ず収束することが分かります。(「収束」の定義が何かはおいておいて^^;)先の計算での目的関数は、下記のように収束しています。最初は代表値が遠くにあるので目的関数は大きいですが、あとは単調に収束していきます。k-means ではサンプルがどのクラスタに属するかという01なので、全てのサンプルのクラスタへの帰属が更新により変化しなくなった時が、クラスタリングの処理が終了したときになります。
行列による表現
実は、これらの計算を行列で書くことができます。さきに書いたpython コードは行列表現で書いています。これらは何となく昔からある慣習?なのかな、と思っていますが、ここでは一応紹介だけしました。(時間があれば後で式も追加)
まとめ
K-means 法の概要と実装を復習しました。いろいろ思い出してきました。
緒言
アルゴリズムについては:
- 初期値の設定について:初期値はデリケートな問題です。クラスタを徐々に増やしていく方法に、LBGアルゴリズムというのがあります。余力があれば紹介したい
- 制約条件がある場合:分布について、ノルムが1など、制約がある場合は応用例として考えらえれる。spherical k-means と呼ばれるものがこれに当たるのか?
実際にいろいろ動かすと分かることですが:
サンプル数が多いと収束までのステップが長くなる。(境界のサンプルの取り合いでセントロイドが微妙に更新される)
- サンプルが割り当てられないクラスタもある。
- シミュレーションの場合、ガウス分布の平均値に収束するわけではない。(サンプルの割り当ての最適性とは異なる。生成モデルが異なるので。)
- 実装を公開
- グラフの余白の調整
等々。
今日はここまで。次回はGMMの予定。
(2021/01/23)



- 投稿日:2021-01-23T23:39:02+09:00
【パターン認識】k-means
はじめに
突然ですが、パターン認識についていろいろ書いていこうと思います。
用語について
パターン認識という言葉を使います。いろいろな流派?があり、機械学習、人工知能などいろいろありますが、ここではパターン認識として考えます。それぞれ、突っ込みどころのある用語ですが、まぁそれはおいておいて。
流れ
パターン認識の全てについてですが、モデルを用いて行いことをします。
モデルを用意します。モデルのパラメータを求める必要があります。これを「学習」と呼びます。
モデルを用いて、観測が何であるかを推定します。
K-means algorithm
たくさんのデータがあり、それらが分類されていたとします。
新しく入ってきたデータが、それまでに分類されていたどのクラスに属するかを考える、というタスクを考えます。そうすると、学習として求めたいモデルは各クラスの代表値、認識は観測値が属するクラスを求める、ことに当たります。
使い方として、
- たくさんのサンプルを分類する(クラスタリング)
- 分類したクラスタをもとに、新しいサンプルがどのクラスタに属するか求める
というのを考えてみたいと思います。
サンプルデータ
ここでは、次のように分布している2次元データを考えます。
この例だと、何となく4つのクラスタに分類されそうだなー、と思うと思います。
そういう分類を行いたいと思います。実際には多次元のデータですし、クラスタの分類が明確ではない場合もあります。さらに、クラスタ数がいくつかも普通は分からない状態で使います。(そういう場合の「学習」を「教師無し学習」と呼ぶことがあります。)
これらの学習用のN個の観測を
$x_n$と書くことにします。今、クラスタ数をK=4とします。各クラスタは代表値をがあるとします。各学習サンプルは、4個あるクラスタのどれかに属します。最も自然な考え方として、代表値に対して最も近くにあるクラスタに属すると考えます。
k[n] = argmin_k (x_n, mu_k)もし、クラスタの代表値が分かっていれば、各サンプルがどこに属するかを求めることができます。一方で、各サンプルがどのクラスタに属するかが分かれば、各クラスタに属するサンプルを用いて代表値を更新することができます。これを繰り返すことが、k-means clustering です。
以下は実行結果です。
最初に乱数で初期の代表値を与えました。初期値の与え方はいろいろありますし、実はかなりデリケートな問題です。それは実際に動かすと出てきますが、ここではとりあえず置いておきます。
☆が各クラスタの代表値の推定値です。繰り返しのステップをくりかえすごとに各クラスタの中心に収束していくことが分かります。
実装は、いろいろあるでしょうが、ここでは変数を全て保持して計算を行う、以下のようにしました。
def kmeans_update_alignment(x:ndarray, mu:ndarray) -> ndarray: """ サンプルがどのクラスタに属するかを求める。 parameters ---------- x[N, D]: samples mu[K, D]: centroids """ N, D = x.shape r = np.zeros((N, K)) for n in range(N): r[n, argmin([ sum(v*v for v in x[n, :] - mu[k, :]) for k in range(K)])] = 1 return r def kmeans_update_centroid(x:ndarray, r:ndarray) -> ndarray: """ 各クラスタの平均値を求める Parameters ---------- x, training data (N, D) r, alignment information(K, D) """ mu = dot(r.transpose(), x) for k in range(K): if sum(r[:,k]) < 0.01: continue mu[k,:] = mu[k,:] / sum(r[:,k]) return mu各クラスタの平均を求めるとき、もしそのクラスタに属するサンプルが一つもない場合があり得ます。そのときは更新しないような実装になっています。
目的関数の最小化
このようにad hoc に更新を行い、無事に収束するところを紹介しましたが、このクラスタリングはいつでも収束します。そのことを確認するために、定式化して考えます。
J = \sum_{n=1}^N \sum_{k=1}^K r_{n,k} || x_n - \mu_k ||^2を最小化します。
(1) 各サンプルが属するクラスタを求める
$\mu$ を固定したときの$r_{n,k}$の最適化です。かならず目的関数が減少します。
(2) クラスタの中心の更新
$r_{n,k}$固定したときに最適な目的関数を最小にする$\mu_k$を求めます。これは、各クラスタごとに独立に最適化することができます。
J = \sum_{x_n\in C_1} || x_n - \mu_k||^2 + \cdots + \sum_{x_n\in C_1} || x_n - \mu_k||^2自乗誤差を最小にするベクトルは平均ベクトルです。形をみると、各クラスタを正規分布と思い、その正規分布の平均の最尤推定値を求めることと同じ計算をしていますね。
\hat{\mu_k} = \frac{1}{N_k}\sum_{x_n \in C_k} x_n以上から、単調に減少し、かつ、これは下限があるので、結果として必ず収束することが分かります。(「収束」の定義が何かはおいておいて^^;)先の計算での目的関数は、下記のように収束しています。最初は代表値が遠くにあるので目的関数は大きいですが、あとは単調に収束していきます。k-means ではサンプルがどのクラスタに属するかという01なので、全てのサンプルのクラスタへの帰属が更新により変化しなくなった時が、クラスタリングの処理が終了したときになります。
行列による表現
実は、これらの計算を行列で書くことができます。さきに書いたpython コードは行列表現で書いています。これらは何となく昔からある慣習?なのかな、と思っていますが、ここでは一応紹介だけしました。(時間があれば後で式も追加)
まとめ
K-means 法の概要と実装を復習しました。いろいろ思い出してきました。
緒言
アルゴリズムについては:
- 初期値の設定について:初期値はデリケートな問題です。クラスタを徐々に増やしていく方法に、LBGアルゴリズムというのがあります。余力があれば紹介したい
- 制約条件がある場合:分布について、ノルムが1など、制約がある場合は応用例として考えらえれる。spherical k-means と呼ばれるものがこれに当たるのか?
実際にいろいろ動かすと分かることですが:
サンプル数が多いと収束までのステップが長くなる。(境界のサンプルの取り合いでセントロイドが微妙に更新される)
- サンプルが割り当てられないクラスタもある。
- シミュレーションの場合、ガウス分布の平均値に収束するわけではない。(サンプルの割り当ての最適性とは異なる。生成モデルが異なるので。)等々。
今日はここまで。次回はGMMの予定。
(2021/01/23)
- 投稿日:2021-01-23T23:20:35+09:00
Lambda(Python)でDynamo DBに接続しようとした際に"Unable to marshal response: Object of type SSLError is not JSON serializable"が出た件について
下記の記事を参考にして、Amplifyプロジェクト内にDynamo DBに接続するLambda関数を実装していたところ、タイトルにあるエラーが出ました。
AWS API GatewayとLambdaでDynamoDB操作
この記事では、その対処方法を備忘録代わりに記載します。
環境
- Windows10 20H2
- WSL2 - Ubuntu-20.04
- Amplify CLI 4.41.0
- Python 3.8.5
- pipenv 2020.11.15
症状
冒頭の記事を参考にして、一部を書き換えながら試していたとき、タイムアウトのエラーが起こりました。
START RequestId: 04359089-637f-48f3-aa2b-e7649c53e4d1 Version: $LATEST {'OperationType': 'SCAN'} END RequestId: 04359089-637f-48f3-aa2b-e7649c53e4d1 REPORT RequestId: 04359089-637f-48f3-aa2b-e7649c53e4d1 Duration: 25025.37 ms Billed Duration: 25000 ms Memory Size: 128 MB Max Memory Used: 73 MB Init Duration: 350.04 ms 2021-01-23T11:46:56.775Z 04359089-637f-48f3-aa2b-e7649c53e4d1 Task timed out after 25.03 secondsLambda関数デフォルトのタイムアウトが25秒だったので、それを+1分して実行したところ、下記のエラーが根本のエラーであることがわかりました。
Response: { "errorMessage": "Unable to marshal response: Object of type SSLError is not JSON serializable", "errorType": "Runtime.MarshalError" } Request ID: "7dceb7ee-1a1c-4361-b22e-00e489d1264f" Function logs: START RequestId: 7dceb7ee-1a1c-4361-b22e-00e489d1264f Version: $LATEST {'OperationType': 'SCAN'} Error Exception. [ERROR] Runtime.MarshalError: Unable to marshal response: Object of type SSLError is not JSON serializableEND RequestId: 7dceb7ee-1a1c-4361-b22e-00e489d1264f REPORT RequestId: 7dceb7ee-1a1c-4361-b22e-00e489d1264f Duration: 25721.98 ms Billed Duration: 25722 ms Memory Size: 128 MB Max Memory Used: 74 MB Init Duration: 388.41 msSSL関係でエラーが出ているようですね。
原因
調べてみると、以下の記事にヒントがあり、
certifiのバージョンによって不具合があるとのことでした。Lambdaでboto3を使ってDevice Shadowを取得しようとしたらSSLでエラーが起きたから応急処置をする
自身の環境を確認してみると、
certifi==2019.11.28でした。$ pipenv graph ... certifi==2019.11.28 ...対処
ということで、Pipfileに最新のバージョンを設定してみました。
Pipfile
[[source]] name = "pypi" url = "https://pypi.org/simple" verify_ssl = true [dev-packages] [packages] certifi = "2020.12.5" [requires] python_version = "3.8"Lambdaのテストを実行してみたところ、問題なくDynamodbに接続することができました。
START RequestId: f7c621d7-ee5b-41ca-a4c3-5ab78c8fa103 Version: $LATEST Received event: "{\r\n\"OperationType\": \"SCAN\"\r\n}" END RequestId: f7c621d7-ee5b-41ca-a4c3-5ab78c8fa103 REPORT RequestId: f7c621d7-ee5b-41ca-a4c3-5ab78c8fa103 Duration: 283.60 ms Billed Duration: 284 ms Memory Size: 128 MB Max Memory Used: 76 MB Init Duration: 353.24 msまとめ
自分の環境だけ、たまたま古いパッケージが入っていたのか、Amplifyで作ったパッケージがすべてこうなるのかはよくわかりません。
Pythonを触るのはLambdaを書くときだけなので、解決にも時間がかかってしまいました。ただ、このトラブルシュートでPythonにもAmplifyにも少し詳しくなることができたのでよかったです。
- 投稿日:2021-01-23T23:14:07+09:00
BeautifulSoup,Selenium備忘録
はじめに
スクレイピングの基本操作を備忘録用として投稿します。
対象ページ、クラスのスクレイピング
qiita.rbimport sys from selenium import webdriver import os from bs4 import BeautifulSoup options = webdriver.ChromeOptions() options.add_argument('--headless') options.add_argument('--no-sandbox') options.add_argument('--disable-dev-shm-usage') browser = webdriver.Chrome('chromedriver',options=options) # 対象のWebページURLを宣言します url = "https://qiita.com/" # 対象URLを取得 browser.get(url) html = browser.page_source.encode('utf-8') soup = BeautifulSoup(html,'html.parser') list = soup.find_all(class_ = "css-1laxd2k") print(list)結論こちらに対象URLと取得したいクラスやidをいれたら取得できる。
本来requests.get()で取得した方が楽ですけどね。BeautifulSoupとは
requestsなどによってHTMLのデータをスクレイピングした後に
そのHTMLを整形するために使用。
所謂BeautifulSoupだけではスクレイピングはできない。
これ使えばスクレイピングしたデータに色々できるSeleniumとは
Webページの自動化を行うためのフレームワーク
今回はoptionに色々やっているのでclickなどによるページ遷移も
すぐできたり
- 投稿日:2021-01-23T23:06:50+09:00
Djangoをとりあえず動かす ~pythonインストールからstartprojectまで~
どんな記事?
- Djangoの環境構築手順書を毎回忘れるので、自分用メモとして作成。
- 環境構築が完了した状態から遡って手順を確認したので、抜け漏れがあるかも。
環境構築手順
python インストール
何はともあれpythonのインストール。
(参照|https://www.python.jp/install/windows/install.html)今回はubuntsu経由?でインストールしたので、下コマンドを実行。
sudo apt-get install python3
pip インストール
pipのインストール。
(参照|https://qiita.com/suzuki_y/items/3261ffa9b67410803443)ubuntsuでpipをインストールする前には、ubuntsuの付属パッケージ?の更新をしておいた方が良いらしい。
sudo apt-get updatepipインストールは以下。
sudo apt-get install python3-pip仮想環境構築
必須ではないが、設定しておくと何かと便利。
個人開発では必要ないかもしれないが、製品開発では動作環境が問題になることがあるので必須だと思う。
(参考|https://www.acrovision.jp/career/?p=2254)今回はvenvで仮想環境を構築した。
(参考|https://qiita.com/fiftystorm36/items/b2fd47cf32c7694adc2e)Django インストール
pipでDjangoのライブラリをインストールするだけでOK。
注意点として、作成した仮想環境のディレクトリを覗いている状態でインストールする。
pip3 install djangoプロジェクト作成
プロジェクトを作成したいディレクトリへ移動する。
プロジェクトを作成するコマンドは以下。
jango-admin startproject [プロジェクト名]プロジェクトの作成を確認
Djangoのプロジェクトは、初期状態でもアクセスできるページが存在する。
サーバーを起動して、指定されたURLにアクセスする。
python3 manage.py runserverつまづいたところ
adminページへのアクセス不可
問題
初期状態では、アクセスできていたadminページに対して、ある段階から以下のようなメッセージが出てアクセス不可になった。エラーメッセージ:「no such table: django_session」
原因
viewに新たなメソッドを作成したが、DBに登録されていなかった対策
migrationする
python manage.py makemigrations
python manage.py migrate
- 投稿日:2021-01-23T23:00:33+09:00
Python で保存する Excel ファイルのハッシュ値を固定する
(結論だけ知りたい方は「解決方法」のセクションまでお進みください)
はじめに
Excel ファイルは、表形式の情報を整理する用途では(特に「テキストファイル」に馴染みのない方たちにとっては)もっとも親しまれている形式です。
いっぽうで各種プログラミング言語から読み書きするためのライブラリも存在しており、こと「非エンジニアに情報を提示する」という目的に絞れば、Excel ファイルで出力するのは悪い選択肢ではありません。
ところが、そのファイルを Git 管理しようとするとさぁ大変。中身が全く同じでも、バイナリレベルでは異なる Excel ファイルが生成されてしまうことがあるのです。おかげで「何も変更していないのにコンフリクトした!」という事象が多々発生します。
分かっています、Excel ファイルを Git 管理しようとするのが正気の沙汰ではないことくらい。でもそういう案件があったんですよ。本当に。そのときに学んだことを供養させてください。
素朴に書き出すと何が問題か
ここでは Python 3 で
openpyxl(記事執筆時点で 3.0.6 が最新)を使ってファイルを書き出すことにします。バージョン管理が Mercurial なので一瞬面食らいますが、今でもきちんとメンテされているようですし、Pandas でも採用されているので問題ないでしょう。
- ドキュメント: https://openpyxl.readthedocs.io/en/stable/
- ソースコード: https://foss.heptapod.net/openpyxl/openpyxl
- PyPI: https://pypi.org/project/openpyxl/
こんな感じに、ちょっと間を置いて2回ファイルを書き出してみます。
from time import sleep from openpyxl import Workbook if __name__ == "__main__": book = Workbook() book.active["A1"] = "Hello world" book.save("hello1.xlsx") sleep(1) book.save("hello2.xlsx")書き出したファイルのハッシュ値を比較してみると、異なっているのが分かります。
$ sha1sum hello*.xlsx 091a1922ac5f2dc58e91ac3bbae32e3ca58c5ca5 hello1.xlsx ed51a9901eed0a5d2f2c21dd6664bb8a07a9563c hello2.xlsxファイルの中身が同じなら、ハッシュ値も全くおなじになっていてほしいですよね。
それをどう実現するか、というのが本記事の趣旨です。解決方法:タイムスタンプの固定
種明かしをしてしまえば、ファイルコンテンツに含まれるタイムスタンプを固定するというのが解決方法になります。テキストファイルであれば OS が管理するファイル属性にタイムスタンプが含まれるだけですが、Excel の場合はファイルの中身にもタイムスタンプが書き込まれているんですね。
下記のようにすれば、常に完全に同一な(バイナリレベルで一致する)Excel ファイルが生成できます。
from datetime import datetime from time import sleep from zipfile import ZipFile from openpyxl import Workbook def save_workbook(book: Workbook, path: str) -> None: # タイムスタンプをこの値に固定する timestamp = datetime(1980, 1, 1, 00, 00, 00) # Excel 管理のタイムスタンプ固定 book.properties.created = timestamp book.properties.modified = timestamp # ファイル保存 book.save(path) # ZIP 管理のタイムスタンプ固定 with ZipFile(path, mode="a") as f: for info in f.infolist(): info.date_time = timestamp.timetuple()[:6] f.fp.seek(info.header_offset) # ファイルの途中だが、タイムスタンプ変更してもヘッダー長変わらないので OK f.fp.write(info.FileHeader()) f._didModify = True if __name__ == "__main__": book = Workbook() book.active["A1"] = "Hello world" save_workbook(book, "hello_fixed1.xlsx") sleep(1) save_workbook(book, "hello_fixed2.xlsx")固定できていますね!
$ sha1sum hello_fixed*.xlsx 49f5b2f7b9e637ded7c3d81bdf2522b0d14d2e79 hello_fixed1.xlsx 49f5b2f7b9e637ded7c3d81bdf2522b0d14d2e79 hello_fixed2.xlsx処理内容について、簡単に解説したいと思います。
なお前提知識として「xlsx ファイルは XML ファイルを Zip で固めたもの」というのを知っておくといいでしょう。
$ unzip -d hello_fixed1.xlsx.d hello_fixed1.xlsx Archive: hello_fixed1.xlsx inflating: hello_fixed1.xlsx.d/docProps/app.xml inflating: hello_fixed1.xlsx.d/docProps/core.xml inflating: hello_fixed1.xlsx.d/xl/theme/theme1.xml inflating: hello_fixed1.xlsx.d/xl/worksheets/sheet1.xml inflating: hello_fixed1.xlsx.d/xl/styles.xml inflating: hello_fixed1.xlsx.d/_rels/.rels inflating: hello_fixed1.xlsx.d/xl/workbook.xml inflating: hello_fixed1.xlsx.d/xl/_rels/workbook.xml.rels inflating: hello_fixed1.xlsx.d/[Content_Types].xml参考:
- Officeファイルの成り立ちと最新形、そして標準化 (1/2):XMLを取り込んだ最新Officeフォーマットとは(前編) - @IT
- ECMA376のリファレンスを使ってxlsxファイルの中身を見る。 - 好きなことを書いていく
- Excelファイル操作をプログラミングする前に、まずはxlsxをzipに変えて内部構造を見てみよう | ソフトウェア開発のギークフィード
Excel 管理のタイムスタンプ固定
1つ目は Excel のレイヤーで管理されているプロパティで、作成日時と更新日時が記録されています。
技術的に言うと
docProps/core.xmlというファイルに記載されています。ファイルの中身を覗いてみるとこんな感じ(整形済み)。<cp:coreProperties xmlns:cp="http://schemas.openxmlformats.org/package/2006/metadata/core-properties" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:dcterms="http://purl.org/dc/terms/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <dc:creator>openpyxl</dc:creator> <dcterms:created xsi:type="dcterms:W3CDTF">1980-01-01T00:00:00Z</dcterms:created> <dcterms:modified xsi:type="dcterms:W3CDTF">1980-01-01T00:00:00Z</dcterms:modified> </cp:coreProperties>
openpyxlではこれはWorkbook#properties.created,Workbook#properties.modified属性で設定されるようですので(ソース: workbook/workbook.py#L67, packaging/core.py#L76-78)、それを保存直前に上書きしてあげればいいという寸法です。book.properties.created = timestamp book.properties.modified = timestamp book.save(path) # ...ZIP 管理のタイムスタンプ固定
上記によって「ZIP 圧縮前」のファイルのレベルでは完全に固定できましたが、最終的な xlsx ファイルはまだ固定しきれていません。
それは ZIP ファイルのレイヤーでもタイムスタンプを保持しているからです。
そのタイムスタンプを固定するために、いったん
Workbook#save()したあとにzipfile.Zipfileを使ってファイルを開き直してタイムスタンプを書き換えます(save()をいじって保存処理に手を加えようとしたのですが、思ったより該当処理が深かったため、トリッキーなこの形になりました)。なお ZIP ファイルの形式は MS-DOS 由来なため、タイムスタンプの起点は1980年1月1日です。それ以前の日付は保持することができないため、固定値を UNIX timestamp の起点である1970年1月1日にするとエラーになるので注意してください。
まずファイルを
mode="a"で開きます("w"だと中身が消えてしまいます)。# ... book.save(path) with ZipFile(path, mode="a") as f:開くと各ファイルのプロパティ情報が
zipfile.ZipInfoクラスで保持されているので、このdate_time属性を変更します。for info in f.infolist(): info.date_time = timestamp.timetuple()[:6]変更した値を反映する必要があるのですが、注意点として、ZIP のファイルプロパティは2箇所に重複して書き込まれています。齟齬がある場合は後者が尊重されるようですが、ファイルを固定するという意味では両方に反映する必要がありますね。
- ローカルファイルヘッダー……各ファイルエントリーの先頭に書き込まれたプロパティ
- セントラルディレクトリ……ZIP ファイル全体の末尾に書き込まれたプロパティ
参考:
ローカルファイルヘッダーについては、各ファイルエントリーごとに該当箇所まで
seekしてwriteします。f.fp.seek(info.header_offset) # ファイルの途中だが、タイムスタンプ変更してもヘッダー長変わらないので OK f.fp.write(info.FileHeader())セントラルディレクトリについては
ZipFile#_didModifyをTrueに設定しておくことで、自動で反映されるようです(ソース: Lib/zipfile.py#L1821-L1825)。f._didModify = Trueおわりに
以上、ファイルの中身が同じならハッシュ値も同じになるように保存する方法を解説しました。
ただし執筆にあたっては Excel や ZIP の仕様には当たっておらず、実装レベルで試行錯誤した結果となります。書き出しに用いたソフトウェアのバージョンや対象ファイルのサイズなどによってはうまく動かない可能性があることをご理解ください。
- 投稿日:2021-01-23T21:15:42+09:00
【合格体験記】Pythonエンジニア認定基礎試験(2021/01/23)
合格しました!
1/10に受けた基本情報はおそらく合格しました。
しかし、選択したPythonでひどい正答率をたたき出してしまいました(泣)
悔しかったのでPythonエンジニア認定基礎試験を受験し、無事雪辱を果たしました^^
この記事では、Pythonエンジニア認定基礎試験の申込方法・勉強法・所感を紹介します。筆者のバックグラウンド
文系大学出身の20卒です。都内のIT企業で働いています。
◆業務経歴
4月 主にPython初級レベルの新人研修を受ける
5月 部署でJava研修を受ける
6月~ 環境移行・オープン化案件でテストや運用監視業務を担当入社前や新人研修でPythonの基礎を学び、簡単な関数を組めるレベルになりました。
しかし昨年5月でPythonの勉強を中断したため、年末にはPythonの書き方を大方忘れてしまっている状態でした。
一方、Pythonの勉強を中断している間にJavaを勉強し、JavaSilverの資格を取得しました。
つまり資格勉強開始時には、Python初心者・Java中級者程度のプログラミングスキルでした。申し込み方法
①OdesseyIDの作成
1分ほどで登録が完了する簡単なものでした。
申し込みには必要ありませんが、受験時や結果確認に必要です。②試験会場を探す
ざっと見たところ、パソコン教室が会場になっている場合が多いようです。
毎日受験できる会場もあれば、土日のみの会場もあります。会場を選択すると、「※受験希望の方は、試験会場へお問い合わせください」と書いてありますが、結局教室のHP(ISAオンラインショップ等)から直接申し込むことになります。
会場と日時を選択すると、支払い方法の案内が来ます。銀行振込を指定されました。
支払いを済ませたところで申し込み完了です!勉強法
使用教材は3つです。
①スッキリわかるPython入門(学習期間:3日)
Pythonが全くの初心者ではなかったうえに、プログラミングの基礎知識はJavaで身につけていたので一瞬で終わりました。
この教材があればPythonについて一通りは学べるので、プログラミング初心者・他言語経験者におすすめです。
Pythonの知識が少しでもある人には少々物足りない内容だと思います。②Pythonチュートリアル第3版(学習期間:1週間)
Pythonエンジニア認定基礎試験公式の教材で、試験概要にてどの章から何問出るかまで公開されています。試験概要:https://www.pythonic-exam.com/exam/basic
これが本当に曲者。内容が難しいというか、翻訳がおかしいというか、とにかくわかりづらくて腹が立ちます。
半年前に購入したときは、本当に読めなくて途中でギブアップしました。
Javaをしっかり学んだ今でも7割くらいしか理解できません。でもそれでいいんです。
試験対策という観点だと、この教材は流し読み程度で十分。
事実試験概要の動画で公式の人が、「この本は学校の教材でいう教科書だから、勉強は問題集(他の教材)を使ってください」とおっしゃっていますから。if この教材を読んだときに言っていることが1ミリもわからない: スッキリわかるPython入門等他教材で再度勉強 else: 教材での勉強終了でいきましょう!
③DIVE INTO EXAM(回数:3回)
会員登録するだけで受けられる無料の模擬試験です。
1回目を受験した時点で800点(合格700点)だった時点で察しました。(簡単と聞いていたけどここまでとは…)
他言語履修してたらPython全く分からなくても合格できるのでは、レベルです。
結局、2回目も800点、3回目925点で試験に臨みました。所感
模試よりは多少難しかったですが、模試で合格点を取れれば十分合格できると思います。
60分40問の試験でしたが、見直しも含め30分ほどで終わり、結果875点でした。気を付けるべきことが2点ほどあります。
①メモ用紙は使えない
まあメモするほどのこともないですけど、メモできるつもりでいたのでちょっと動揺しました。②地味に「複数選べ」がある
これは見直しの時に気が付いて一命を取り留めました。
複数選択で1つしか選んでいなくても通知されないのでご注意を!おわりに
Pythonって簡単に使えるのが売りだから、なかなか中上級レベルの試験を作るのは難しいんですかね…
もうちょっと試験の質を高めていただきたいところですね。最後まで読んでいただき、ありがとうございました。
皆さんが合格できますように!
- 投稿日:2021-01-23T20:26:26+09:00
Googleの検索結果をpecoりたい「Google Fuzzy Search」の開発
はじめに
pecoとかfzfとかskimとかいろんな
fuzzy findツールがある中、 googleの検索結果だけfuzzy findするツールがなかったので作ってみました。Google Fuzzy Search とは
とってもシンプルなツールで 「標準入力から受けたjsonをインクリメンタルサーチして、選択したアイテムをブラウザで開くためのツールです。jsonはgooglerで用意したものを使います。」
百聞は一見にしかずということで動いているものをご覧ください。(拡大してご覧ください。)
fixtures/tokyo.jsonに東京をキーワードにgooglerで調べたものを保存しておいて、それを標準入力として渡して使ってます。QUERY>となっている部分に絞りたい単語コロナを入れて検索結果を絞り、Enterを押してブラウザで開いている様子です。実際、使ってみたくなったでしょうか?
仮想環境でデモを試す
まずはトライアル!
仮想環境を作ることで、ローカルの環境を汚さずに試すことができます。
以下のコマンドを順番に入力して下さい。python3 -m venv .venv source .venv/bin/activate pip install gfzs==0.2.1 gfzs init gfzs demoこんな風に表示されたら正しく動いてます。
閉じるときは、
Ctrl-cで閉じます。気にったら
pip install gfzs==0.2.1で入れて使って貰えると幸いです。googlerを使った例
googlerを使った例を試すには1つお約束事項があります。
googlerでは検索結果をデフォルトで10件までしか取得できませんが、オプションを渡す事で一応100件とか取得できるように作られています。
だがしかし...
????????????????????????????????????????????
100件とか1000件とか取得しようとするとGoogle側にIPをブロックされるかもしれない事を忘れないでください。(試してIPがブロックされても責任は負えません。)
????????????????????????????????????????????
これは動作確認の時、私がやらかしてしまった時のgooglerのレスポンスをご覧ください。
$ googler --json -n 1000 東京 [ERROR] Connection blocked due to unusual activity. THIS IS NOT A BUG, please do NOT report it as a bug unless you have specific information that may lead to the development of a workaround. You IP address is temporarily or permanently blocked by Google and requires reCAPTCHA-solving to use the service, which googler is not capable of. Possible causes include issuing too many queries in a short time frame, or operating from a shared / low reputation IP with a history of abuse. Please do NOT use googler for automated scraping.[エラー]異常なアクティビティが原因で接続がブロックされました。これはバグではありません。回避策の開発につながる可能性のある特定の情報がない限り、バグとして報告しないでください。お客様のIPアドレスはGoogleによって一時的または永続的にブロックされており、サービスを使用するにはreCAPTCHAを解決する必要がありますが、Googlerではできません。考えられる原因には、短期間で発行するクエリが多すぎる、または悪用の履歴がある共有/レピュテーションの低いIPから操作することが含まれます。自動スクレイピングにグーグルを使用しないでください。
という感じでIPがブロックされました。「あぁ... もう一生使えないかも...」って思ったのですが、2〜3日おいたら使えるようになりました。内心良かったーって思いました。?
という事で...
???????????????????????????????????????????
googlerがデフォルトで取得してくる件数をオプションでいじれなくした状態で使う事を激しく推奨します。
???????????????????????????????????????????
私はこんな感じでaliasを貼って使ってます。
function gfzs_google_fuzzy_search(){ # 結果を取得しすぎてロボット判定されないようにgooglerの-nと--countオプションを渡せなくする FLAG_N=0 FLAG_S=0 GFZS_SCORE=30 googler_input=() for OPT in "$@" do case $OPT in -n | --count) FLAG_N=1 ;; -s | --score) FLAG_S=1 GFZS_SCORE=$2 shift ;; *) googler_input+=($1) ;; esac if [ $# -ne 0 ]; then shift; fi done echo $googler_input if [ "$FLAG_N" -eq 1 ]; then echo "Can't use -n(--count) option" else local res if [ "$FLAG_S" -eq 1 ]; then res=$(googler --json $googler_input | gfzs -s $GFZS_SCORE) else res=$(googler --json $googler_input | gfzs) fi if [ "$res" != "" ]; then echo $res fi fi } alias ggr=gfzs_google_fuzzy_search使う時はこんな感じです。
typoしてても大丈夫です。googlerが勝手にそこらへん良しなにしてくれます。ggr -s 30 python machne lerning
Ctrl-Cを押して閉じてみましょう。$ ggr python machne lerning ** Showing results for python machine learning; use -x, --exact for an exact search.typoしてたから、「
python machine learning」で探してみたよって言ってますね。
素晴らしい!コマンドに関して
使えるコマンドは
gfzs -hで確認できます。
ここまでで二つほど使ってないコマンドがあります。
gfzs editgfzs validedit
editコマンドは、初期化の際、作られた設定ファイル(~/.gfzrc)を編集するために使われるコマンドです。EDITORという環境変数にエディタを開くためのコマンドを設定して下さい。例)
export EDITOR=code # vscodeで開く場合 gfzs edit詳しい設定に関してはこちらで確認して下さい。
valid
validコマンドは、~/.gfzrcが有効な設定ファイルかどうかを調べるためのコマンドです。# 有効な場合 $ gfzs valid Config is valid.無効な場合を試すために、
gfzs editで設定ファイルを以下のように修正してみて下さい。
コピペ用
{
"view": {
"hoge": {},
"fuga": [],
"footer": {
"messageaaa": "QUERY>",
"color": {
"message": {
"text": 8,
"background": 0,
"style": "normalaaaaa"
},
"hline": {
"text": 7,
"background": 0,
"styleaaaaaaaa": "linkbbbbbbbb"
}
}
},
"header": {
"color": {
"hline": {
"text": 7,
"background": 0,
"style": "normal"
}
}
},
"search_result": {
"color": {
"index": {
"text": 6,
"background": 0,
"style": "normal"
},
"title": {
"text": 2,
"background": 0,
"style": "bold"
},
"url": {
"text": 3,
"background": 0,
"style": "link"
},
"abstract": {
"text": 7,
"background": 0,
"style": "normal"
},
"markup_partial": {
"text": 2,
"background": 5,
"style": "normal"
},
"markup_char": {
"text": 1,
"background": 0,
"style": "normal"
}
}
},
"paging": {
"color": {
"common": {
"text": 2,
"background": 0,
"style": "bold"
}
}
}
}
}
この状態でコマンドを試すと以下のように表示されどこがおかしい設定かあたりをつけれるようになってます。
$ gfzs valid Config is invalid. Error: Contains unsupported key. (key_path, value) = (view.hoge, {}). Error: Contains unsupported key. (key_path, value) = (view.fuga, []). Error: Contains unsupported key. (key_path, value) = (view.footer.messageaaa, QUERY>). Error: Contains unsupported value. (key_path, value) = (view.footer.color.message.text, 8). Error: Contains unsupported value. (key_path, value) = (view.footer.color.message.style, normalaaaaa). Error: Contains unsupported key. (key_path, value) = (view.footer.color.hline.styleaaaaaaaa, linkbbbbbbbb).設定がおかしい状態で、
demoコマンドを試してみましょう。$ gfzs demo Config is invalid. Error: Contains unsupported key. (key_path, value) = (view.hoge, {}). Error: Contains unsupported key. (key_path, value) = (view.fuga, []). Error: Contains unsupported key. (key_path, value) = (view.footer.messageaaa, QUERY>). Error: Contains unsupported value. (key_path, value) = (view.footer.color.message.text, 8). Error: Contains unsupported value. (key_path, value) = (view.footer.color.message.style, normalaaaaa). Error: Contains unsupported key. (key_path, value) = (view.footer.color.hline.styleaaaaaaaa, linkbbbbbbbb).こんな風に設定がおかしいと起動しないようになってます。
実行時オプションに関して
キーワードでの絞りこみには、fuzzywuzzy を使って実装しており、このライブラリーが返してくるスコア〇〇以上の結果だけ画面に表示するための
-s(--score)オプション(デフォルト値は30)が用意されています。実際に使ってみたらよくわかります。
スコアを上げすぎると全く検索に引っかからなくなります。
gfzs -s 90 demo
逆に下げすぎると全く絞れなくなります。
gfzs -s 5 demo
なんか欲しいオプションあったらIssueを英語で起案して下さい。
まとめ
Googleの規制が緩くなって、一気に100件くらい取得できるようになったら本当に面白いツールになるかなって思ってます。(望み薄)
簡単に使えるので使ってみて下さい。(^ ^)






- 投稿日:2021-01-23T20:26:26+09:00
Googleの検索結果をpecoりたい「Google Fuzzy Search」を作った
はじめに
peco, percol, fzf, skimとかいろんな
fuzzy findツールがある中、 googleの検索結果だけfuzzy findするツールがなかったので作ってみました。Google Fuzzy Search とは
とってもシンプルなツールで 「標準入力から受けたjsonをインクリメンタルサーチして、選択したアイテムをブラウザで開くためのツールです。jsonはgooglerで用意したものを使います。」
百聞は一見にしかずということで動いているものをご覧ください。(拡大してご覧ください。)
実行しているコマンドはこれです。
cat fixtures/tokyo.json | gfzs
fixtures/tokyo.jsonに東京をキーワードにgooglerで調べたものを保存しておいて、それを標準入力として渡して使ってます。QUERY>となっている部分に絞りたい単語コロナを入れて検索結果を絞り、Enterを押してブラウザで開いている様子です。実際、使ってみたくなったでしょうか?
仮想環境でデモを試す
まずはトライアル!
仮想環境を作ることで、ローカルの環境を汚さずに試すことができます。
以下のコマンドを順番に入力して下さい。python3 -m venv .venv source .venv/bin/activate pip install gfzs==0.2.1 gfzs init gfzs demoこんな風に表示されたら正しく動いてます。
閉じるときは、
Ctrl-cで閉じます。気にったら
pip install gfzs==0.2.1で入れて使って貰えると幸いです。googlerを使った例
googlerを使った例を試すには1つお約束事項があります。
googlerでは検索結果をデフォルトで10件までしか取得できませんが、オプションを渡す事で一応100件とか取得できるように作られています。
だがしかし...
????????????????????????????????????????????
100件とか1000件とか取得しようとするとGoogle側にIPをブロックされるかもしれない事を忘れないでください。(試してIPがブロックされても責任は負えません。)
????????????????????????????????????????????
これは動作確認の時、私がやらかしてしまった時のgooglerのレスポンスをご覧ください。
$ googler --json -n 1000 東京 [ERROR] Connection blocked due to unusual activity. THIS IS NOT A BUG, please do NOT report it as a bug unless you have specific information that may lead to the development of a workaround. You IP address is temporarily or permanently blocked by Google and requires reCAPTCHA-solving to use the service, which googler is not capable of. Possible causes include issuing too many queries in a short time frame, or operating from a shared / low reputation IP with a history of abuse. Please do NOT use googler for automated scraping.[エラー]異常なアクティビティが原因で接続がブロックされました。これはバグではありません。回避策の開発につながる可能性のある特定の情報がない限り、バグとして報告しないでください。お客様のIPアドレスはGoogleによって一時的または永続的にブロックされており、サービスを使用するにはreCAPTCHAを解決する必要がありますが、Googlerではできません。考えられる原因には、短期間で発行するクエリが多すぎる、または悪用の履歴がある共有/レピュテーションの低いIPから操作することが含まれます。自動スクレイピングにグーグルを使用しないでください。
という感じでIPがブロックされました。「あぁ... もう一生使えないかも...」って思ったのですが、2〜3日おいたら使えるようになりました。内心良かったーって思いました。?
という事で...
???????????????????????????????????????????
googlerがデフォルトで取得してくる件数をオプションでいじれなくした状態で使う事を激しく推奨します。
???????????????????????????????????????????
私はこんな感じでaliasを貼って使ってます。
function gfzs_google_fuzzy_search(){ # 結果を取得しすぎてロボット判定されないようにgooglerの-nと--countオプションを渡せなくする FLAG_N=0 FLAG_S=0 GFZS_SCORE=30 googler_input=() for OPT in "$@" do case $OPT in -n | --count) FLAG_N=1 ;; -s | --score) FLAG_S=1 GFZS_SCORE=$2 shift ;; *) googler_input+=($1) ;; esac if [ $# -ne 0 ]; then shift; fi done if [ "$FLAG_N" -eq 1 ]; then echo "Can't use -n(--count) option" else local res if [ "$FLAG_S" -eq 1 ]; then res=$(googler --json $googler_input | gfzs -s $GFZS_SCORE) else res=$(googler --json $googler_input | gfzs) fi if [ "$res" != "" ]; then echo $res fi fi } alias ggr=gfzs_google_fuzzy_search # 自分の場合 function ggr(){ command=$1 shift case $command in "abema") googler_input=($@) googler_input+=(-w abema.tv) gfzs_google_fuzzy_search $googler_input ;; "hulu") googler_input=($@) googler_input+=(-w hulu.jp) gfzs_google_fuzzy_search $googler_input ;; "amazon") googler_input=($@) googler_input+=(-w amazon.co.jp) gfzs_google_fuzzy_search $googler_input ;; "zenn") googler_input=($@) googler_input+=(-w zenn.dev) gfzs_google_fuzzy_search $googler_input ;; "qiita") googler_input=($@) googler_input+=(-w qiita.com) gfzs_google_fuzzy_search $googler_input ;; *) gfzs_google_fuzzy_search ;; esac }使う時はこんな感じです。
typoしてても大丈夫です。googlerが勝手にそこらへん良しなにしてくれます。ggr -s 30 python machne lerning
Ctrl-Cを押して閉じてみましょう。$ ggr python machne lerning ** Showing results for python machine learning; use -x, --exact for an exact search.typoしてたから、「
python machine learning」で探してみたよって言ってますね。
素晴らしい!コマンドに関して
使えるコマンドは
gfzs -hで確認できます。
ここまでで二つほど使ってないコマンドがあります。
gfzs editgfzs validedit
editコマンドは、初期化の際、作られた設定ファイル(~/.gfzrc)を編集するために使われるコマンドです。EDITORという環境変数にエディタを開くためのコマンドを設定して下さい。例)
export EDITOR=code # vscodeで開く場合 gfzs edit詳しい設定に関してはこちらで確認して下さい。
valid
validコマンドは、~/.gfzrcが有効な設定ファイルかどうかを調べるためのコマンドです。# 有効な場合 $ gfzs valid Config is valid.無効な場合を試すために、
gfzs editで設定ファイルを以下のように修正してみて下さい。
コピペ用
{
"view": {
"hoge": {},
"fuga": [],
"footer": {
"messageaaa": "QUERY>",
"color": {
"message": {
"text": 8,
"background": 0,
"style": "normalaaaaa"
},
"hline": {
"text": 7,
"background": 0,
"styleaaaaaaaa": "linkbbbbbbbb"
}
}
},
"header": {
"color": {
"hline": {
"text": 7,
"background": 0,
"style": "normal"
}
}
},
"search_result": {
"color": {
"index": {
"text": 6,
"background": 0,
"style": "normal"
},
"title": {
"text": 2,
"background": 0,
"style": "bold"
},
"url": {
"text": 3,
"background": 0,
"style": "link"
},
"abstract": {
"text": 7,
"background": 0,
"style": "normal"
},
"markup_partial": {
"text": 2,
"background": 5,
"style": "normal"
},
"markup_char": {
"text": 1,
"background": 0,
"style": "normal"
}
}
},
"paging": {
"color": {
"common": {
"text": 2,
"background": 0,
"style": "bold"
}
}
}
}
}
この状態でコマンドを試すと以下のように表示されどこがおかしい設定かあたりをつけれるようになってます。
$ gfzs valid Config is invalid. Error: Contains unsupported key. (key_path, value) = (view.hoge, {}). Error: Contains unsupported key. (key_path, value) = (view.fuga, []). Error: Contains unsupported key. (key_path, value) = (view.footer.messageaaa, QUERY>). Error: Contains unsupported value. (key_path, value) = (view.footer.color.message.text, 8). Error: Contains unsupported value. (key_path, value) = (view.footer.color.message.style, normalaaaaa). Error: Contains unsupported key. (key_path, value) = (view.footer.color.hline.styleaaaaaaaa, linkbbbbbbbb).設定がおかしい状態で、
demoコマンドを試してみましょう。$ gfzs demo Config is invalid. Error: Contains unsupported key. (key_path, value) = (view.hoge, {}). Error: Contains unsupported key. (key_path, value) = (view.fuga, []). Error: Contains unsupported key. (key_path, value) = (view.footer.messageaaa, QUERY>). Error: Contains unsupported value. (key_path, value) = (view.footer.color.message.text, 8). Error: Contains unsupported value. (key_path, value) = (view.footer.color.message.style, normalaaaaa). Error: Contains unsupported key. (key_path, value) = (view.footer.color.hline.styleaaaaaaaa, linkbbbbbbbb).こんな風に設定がおかしいと起動しないようになってます。
実行時オプションに関して
キーワードでの絞りこみには、fuzzywuzzy を使って実装しており、このライブラリーが返してくるスコア〇〇以上の結果だけ画面に表示するための
-s(--score)オプション(デフォルト値は30)が用意されています。実際に使ってみたらよくわかります。
スコアを上げすぎると全く検索に引っかからなくなります。
gfzs -s 90 demo
逆に下げすぎると全く絞れなくなります。
gfzs -s 5 demo
なんか欲しいオプションあったらIssueを英語で起案して下さい。
まとめ
Googleの規制が緩くなって、一気に100件くらい取得できるようになったら本当に面白いツールになるかなって思ってます。(望み薄)
簡単に使えるので使ってみて下さい。(^ ^)
- 投稿日:2021-01-23T20:21:55+09:00
Atcoder Beginner Contest 163 躓いたところまとめ
Atcoderについて
AtCoder(アットコーダー)とは、「競技プログラミング」と呼ばれるコンピュータプログラムのコンテストを行うサービス、および高橋直大が代表を務めるその運営会社を指す。(Wikipediaより)
今回プログラミングの練習でいい機会と思い登録してみました。163回目のコンテストで躓いたところについてまとめていきます。環境
Windows10
python 3.8.2問題A
円周率について
いつも忘れてしまうのが円周率。表記方法がいくつかあります。
mathモジュールを使用する方法
mathimport math print(math.pi)numpyを使用する方法
nupyimport numpy as np print(np.pi)mpmathを使用する方法
mpmathfrom mpmath import * mp.dps = 10 print(pi)
- 投稿日:2021-01-23T20:20:34+09:00
Pythonのinput関数
- 投稿日:2021-01-23T19:49:02+09:00
ディープラーニングまとめ(これから学習する人向け)
はじめに
今回はディープラーニングの基本をまとめました。
※これからディープラーニングを学習する人向けの記事です。ニューラルネットワークについて
まずはディープラーニングの前身となるニューラルネットワークについて。
ニューラルネットワークとは、簡単にいうと人間の脳の中をマネしたアルゴリズム。
脳の中にはニューロンと呼ばれる神経細胞が何十億個とあり、それらが互いに結びつくことで神経回路という巨大なネットワークのようなものを作り上げている。
一つの情報が脳内に入ってくると、ニューロンに電気信号で伝わる。この電気信号が脳内の神経回路を駆け巡り、脳内のどの部分にどれだけの電気信号を伝えるかによって、情報を処理している。
この神経回路の仕組みを再現すれば、最高の機械学習ができるのではないか?
と考えて生まれたのがニューラルネットワークです。単純パーセプトロン
単純なニューラルネットワークのモデル。
※参考図
複数の入力を受け取り、一つの出力を行う。
入力を受け取る部分を入力層、出力する部分を出力層と言う。
入力層と出力層とのつながりは「重み」というもので調整され、どれだけの特徴を出力層に伝えるかを調整している。※入力層と出力層のみでは回路が単純すぎるため、線形分類しか行うことしかできない。
多層パーセプトロン
単純パーセプトロンの線形分類しかできないという弱点を解決するために、入力層と出力層の間に更に層を追加するというアプローチをとったものを多層パーセプトロンと言います。
※参考図
入力層と出力層の間の層のことを中間層(隠れ層)と言います。層が追加させただけで、単純パーセプトロンと仕組みは変わりません。
しかし、層が追加されたことでネットワーク全体の表現が向上し、非線形分類も行うことができるようになりました。ディープラーニング
ディープラーニングとは、多層パーセプトロンの中間層(隠れ層)をより増やしたモデルになります。(一般的に中間層2つ以上)
※層が「深い」から、ディープラーニング(深層学習)と言われている。
ディープラーニングの学習の流れ
図で表すと以下のとおり
①順伝播
与えられた入力を重みで調整し、予測値を出力する。
(一般的に初期値の重みはランダムで設定される)②誤差の計算(損失関数)
予測値と教師データである正解値の誤差を計算する。具体的な計算方法は以下のとおり。
回帰:平均2乗誤差
分類:交差エントロピー誤差③逆伝播(誤差逆伝播法)
損失関数(誤差)を最小化するために逆向きに学習し、パラメーター(重み等)を更新する。④ ①〜③を繰り返すことでディープラーニングの予測精度を高めていきます。
誤差逆伝播法(バックプロパゲーション)とは
損失関数(誤差)を最小化するために逆向きに学習し、パラメーター(重み等)を更新する作業。
パラメーターの更新の際に重要なことは大きく2つ!
○パラメーターを増やすか減らすか決める。
(勾配降下法)
○どれくらい増減させるか
(学習率)※ディープラーニングの実装の際にはオプティマイザー(optimizer)と言われる。
ADam,RMSPropなどが使われる。ディープラーニングの特徴まとめ
メリット
・予測精度が圧倒的に高い
・パラメーターの数が多い
・特徴エンジニアリングが不要(学習に影響を与えそうなデータを抽出する作業)デメリット
・単純な問題の場合は単純なモデル(重回帰分析)の方が性能が良い
・計算コストが非常に高い
・大量の学習データが必要おわりに
以上です。
ディープラーニングの基本をまとめました。




- 投稿日:2021-01-23T17:55:44+09:00
macでpythonの仮想環境作成
macでpythonの仮想環境を構築する
前提
・macOSでpythonの仮想環境を構築する
・今までanacondaで仮想環境を作っていたが、ふとターミナルで仮想環境を作るには?と思い調べた手順
1.仮想環境の作成
1-1.仮想環境を作りたいディレクトリまで移動
お馴染みのcdで
1-2.ターミナルに以下のコードを入力
python3 -m venv 環境名(例:.venv)2.仮想環境の起動
. .venv/bin/activate3.終了
deactivate最後に
今までpythonの実行をanacondaのspyderというIDEを使っていたため、急にターミナルやVScodeで実行するのに少し抵抗があったが、少しずつ慣れていきたい
- 投稿日:2021-01-23T17:51:21+09:00
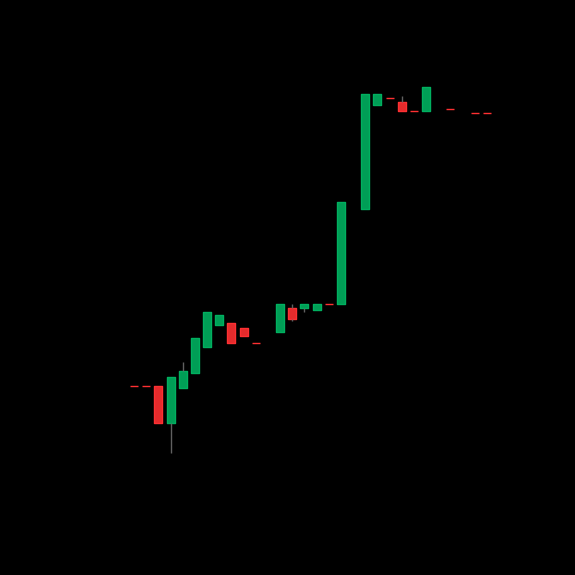
2次元CNNによるBitcoin価格予測
個別銘柄のBitcoinを対象として,2次元CNNを用いた予測を行いました.
5分先の価格の騰落を予測する,2値分類問題としました.
1. データセット
入力データは,上記のようなローソク足チャート画像としました.
2016年1月1日~2016年3月31日までのBitcoin/USD価格,1分足の131,040件を取得しました.
1枚の画像に30件のデータを用いた為,4368枚の画像が生成されました.
前半の3968枚を訓練データとして分割し,後半の400枚をテストデータとして分割しました.
Google Colaboratoryへ全ての訓練データをアップロードすることができなかった為,前半の2800枚を訓練データとしました.
訓練データにはデータ拡張を行い,最終的には11,200枚の訓練データと400枚のテストデータを用いました.
2. 2次元CNNアーキテクチャ
(Conv2D relu + MaxPooling2D)2層 + Flatten + Dropout(0.3) + Dense relu + Dense sigmoid
エポック数は,200としました.
また,Dropoutを低い割合で組み込むことで,精度の向上が見られました.
3. 結果
最終的なtest accuracyは,0.575となりました.
学習データを増やすことで,精度の向上を図ることができる可能性があります.
4. 参考文献
Ashwin Siripurapu: Convolutional Networks for Stock Trading.
Rosdyana Mangir Irawan Kusuma, Trang-Thi Ho, Wei-Chun Kao, Yu-Yen Ou, Kai-Lung Hua: Using Deep Learning Neural Networks and Candlestick Chart Representation to Predict Stock Market, arXiv, 2019.
池田欽一: 株価ローソク足チャート画像を用いた畳み込みニューラルネットワークによる株価変動予測, 北九州市立大学「商経論集」第54巻第1・2・3・4巻合併号, 2019.
白方健司,津田博史: 畳み込みニューラルネットワークによる株価インデックス騰落予測, THE HARRIS SCIENCE REVIEW OF DOSHISHA UNIVERSITY, VOL.59, NO.2 July 2018.
宮崎邦洋,松尾豊: 深層学習を用いた株価予測の分析,一般社団法人 人工知能学会,2017.
- 投稿日:2021-01-23T17:05:20+09:00
TweepyでPINベース認証する方法
TweepyでPINベース認証をやったのでメモ程度に
前提条件
Python 3.7.4
tweepy 3.10.0PINベース認証する方法
tewwpy_auth.pyimport tweepy import webbrowser TWITTER_CONSUMER_KEY = 'xxxxxxxxxxxxxxxxxxxxxx' TWITTER_CONSUMER_SECRET = 'xxxxxxxxxxxxxxxxxxxxxxxxx' # ここで oob と入力することで、アクセス許可後にPINが表示される様になる auth = tweepy.OAuthHandler(TWITTER_CONSUMER_KEY, TWITTER_CONSUMER_SECRET, 'oob') # 認証用URLを取得後ブラウザで開く authorization_url= auth.get_authorization_url() webbrowser.open(authorization_url) # アクセスを許可後出てきたPINを入力 print('PIN CODE >>', end='') pin_code = input() # PINコードを元にトークンなどを取得 auth.get_access_token(pin_code) print(f"ACCESS_TOKEN = {auth.access_token}") print(f"ACCESS_SECRET = {auth.access_token_secret}") # 取得した情報を認証情報に追加 auth.set_access_token(auth.access_token, auth.access_token_secret) api = tweepy.API(auth) username = api.me().name print(f"ユーザー名: {username}")
- 投稿日:2021-01-23T16:29:45+09:00
herokuを使ってpythonのflaskアプリをデプロイ
概要
FlaskでWebアプリを作り、herokuを使って公開します。
今回は世の中でもっとも簡単なアプリケーションである、Hello worldを表示するアプリケーションを作ります。
そのため、HTMLとflaskの連携等のお話はしません。pythonのコード
flaskをインストールしていない場合はpipでインストールします。
pip install flaskpythonのコードは以下です。
from flask import Flask app = Flask(__name__) @app.route('/') def index(): return ('Hello world') if __name__ == '__main__': app.run()これをapp.pyとして保存します。
簡単にコードの説明を。まずは、Flaskを使ったアプリ名をappとします。
('/')はホーム画面的な意味で、このURLにindexという関数を適用しますよーということになります。Hello worldを返り値とするわけです。
最後のif文はおまじないみたいなもので、基本的にmainという名前のものが実行されるのですが、このmainがnameならアプリを実行するという意味です。
最初にFlask(name)としていますから、mainと一致して、アプリが起動するわけです。
デプロイの準備
gunicornのインストール
herokuを使ってデプロイする際に必要となるものです。
pip install gunicornrequirements.txtの作成
デプロイする側に、このアプリはこんなライブラリやモジュールを使っていますよーと教えてあげる必要があります。
pip freeze > requirements.txtこれで作成されます。ローカルでこのコマンドを実行すると、ローカルに入っているモジュールが全て吐き出されるので、必要なもののみを残せば良いです。消さないとエラーの原因にもなりますし、何よりアプリが重くなります。(pandasやnumpyはかなり重いので、使わないならない方がいい)
今回はflaskとgunicornのみですね。heroku cliのインストール
コマンドラインを使ってデプロイする際に必要となるものです。
GoogleでHeroku cliと検索すればいいです。一応URL貼っておきます。
https://devcenter.heroku.com/ja/articles/heroku-cli#download-and-installMACならHomebrewでインストールした方が楽ですね。
brew tap heroku/brew && brew install herokuProcfileの作成
app.pyと同じ階層にProcfileという名前のファイルを作成し、以下の内容を書いて保存します。
web: gunicorn app:app --log-file=-デプロイ
まずはGitレポジトリの準備をしましょう。ここではGitの細かい説明はしません。
git init git add . git commit -m "first commit"herokuにアクセスしましょう。以下の作業はheroku cliがダウンロードできていないとできません。確認したいなら
heroku -vを実行してバージョンが返ってくればOKです。
heroku loginなんかでてきますが、構わずEnterで問題ありません。するとブラウザーが立ち上がって、Herokuのログイン画面が出てきます。登録していない人はSign upしたあと、再度heroku login を実行します。
ブラウザーでLoginボタンを押してログインできたら、ブラウザーは消して結構です。
次のステップでアプリケーションのURLを決めます。
heroku create test-test-test今回はtest-test-testというURLにしました。他の人と重複していたり、URLとして使用できない文字があるとエラーになります。
ちなみにアンダーバー _ は使用できないっぽいです。あともう少し。
一応プッシュ先の確認をしましょうgit remote -v先ほどcreateで作成したURLが返ってくると思います。そうなれば最後のステップ...
git push heroku masterこれでアプリケーションのデプロイは完了です。ブラウザーでURLを叩くか、
heroku openで確認できます。
ファイルを変更した場合
app.pyを変更した場合は以下のコマンドでOKです。
git add app.py git commit -m "change app.py" git remote -v git push heroku master以上。
- 投稿日:2021-01-23T16:28:16+09:00
CRFモデルで時系列データからある時点の状態を推定する
これを読んで得られること
- CRF(条件付き確率場)を用いた時系列データの分類
- 自分のためにまとめておこうというモチベーション
- まとめているうちに自分の中で整理されてきて、記事にするほどじゃないよねという気になっている
これを読んでも書いていないこと
- 自然言語のCRFによる分類の方法
- 各ライブラリにあるチュートリアルが詳しいのでそちらへ
- CRFの詳細説明
- これも大学の講義資料とか書籍とかたくさん詳しい方がいらっしゃるのでそちらへ...
CRFとは
深層学習がはやる前に流行っていた教師あり学習のひとつ。例えば、文章中の固有表現の抽出といった系列に対するラベルの付与(系列ラベリング)問題を解く際に適用される。
系列ラベリング
- 系列ラベリング
- 系列に対してラベルを付与するもの
- 隠れマルコフモデル(HMM)やCRFや深層学習のLSTMがある
- 系列データ
- 自然言語処理や時系列データ(前後関係がある)
- 画像(周辺情報も大事)
- ラベリング
- 自然言語処理は分類で何かを分類すること(MeCabで形態素解析するとか)
- 時系列データの場合は回帰で今の時点から次の時点を予測すること
- 画像のピクセル毎の分類(セマンティックセグメンテーション)
今回やりたいことは、時系列データを用いてある時点での挙動を分類すること。
例えば、人の速度と歩数から歩いているか、走っているか、自転車に乗っているかといった推定をしたり、心臓の周波数データから緊張しているとかリラックスしているとかを推定すること。HMMやCRFの関係性をまとめると次のような図となる。(日本語を付した。一部意訳。)
(引用: An Introduction to Conditional Random Fields https://arxiv.org/abs/1011.4088 )CRFとは
- マルコフ確率場の一種
- マルコフ確率場とは依存関係を無向グラフで表すもの(上図の下段)
- 学習で最大化する対象
- 設計する事後確率
- 教師あり学習
実装手順
ライブラリ候補
- PyStruct
- CRFSuite
- sklearn_crfsuite
sklearn_crfsuiteはCRFSuiteのラッパーでsklearnのモデルセレクションのパッケージが利用できるようになっている。つまりはハイパーパラメーターチューニングが楽。なので今回はsklearn-crfsuiteを用いる。ちなみに線形連鎖条件付き確率場を実現しているライブラリである。
実装ステップ
- データを集める
- データを学習データとテストデータに分割する train_test_split
- 学習データとテストデータを整形する
- 系列データに分割する for文を用いて切ったりくっつけたり
- CRFのモデルを決めるsklearn_crfsuite.CRF()で最適化アルゴリズムを設定したり
- 学習データを学習させる crf.fit(X_train, y_train)
- テストデータで推論する crf.predict(X_test)
- テストデータの正解率を確認する metrics.flat_classification_report() recallとかもこれ
- ハイパーパラメータのチューニング RandomizedSearchCV
- ハイパーパラメーターと正解のスコアのばらつきを可視化
手順は公式チュートリアルを見ながら時系列データに応用
https://sklearn-crfsuite.readthedocs.io/en/latest/tutorial.html1. データを集める
今回は気象庁の気温と気圧から天気を予測する。
2020年1月1日から2021年1月22日までの3時間毎の気温と気圧と天気をお借りした。
https://www.data.jma.go.jp/gmd/risk/obsdl/index.phpdf = pd.read_csv('202001data.csv', encoding='shift-jis', skiprows=3) df = df.append(pd.read_csv('202004data.csv', encoding='shift-jis', skiprows=3)) df = df.append(pd.read_csv('202007data.csv', encoding='shift-jis', skiprows=3)) df = df.append(pd.read_csv('202010data.csv', encoding='shift-jis', skiprows=3)) df.columns = ['datetime', 'temparature', 'weather', 'pressure'] df = df[['datetime', 'temparature', 'pressure', 'weather']] df = df.dropna(how='any') df = df.reset_index(drop = True)
2. データを学習データとテストデータに分割する
X_df = df[['temparature', 'pressure']] y_s = df['weather'] X_train, X_test, y_train, y_test = train_test_split(X_df, y_s, random_state=0)3. 学習データとテストデータを整形する
入力データはdictionary型にする。
X_train = X_train.to_dict(orient='records') X_test = X_test.to_dict(orient='records')正解ラベルはリスト型
y_train = y_train.to_list() y_test = y_test.to_list()4. 系列データに分割する
全データを等間隔のwindow幅を持つ系列データに整形する。
これは辞書型の集合の配列とする。
学習データとテストデータは[[{}{}{}], [{}{}{}], [{}{}{}]]こんなイメージ。
正解ラベルは[[], [], []]こんなイメージ。from_i = 0 step = 10 # window幅 to_i = len(X_train) - step X_trains = [] for i in range(from_i, to_i, step): X_trains.append(X_train[i:i+step]) y_trains = [] for i in range(from_i, to_i, step): y_trains.append(y_train[i:i+step]) to_i = len(X_test) - step X_tests = [] for i in range(from_i, to_i, step): X_tests.append(X_test[i:i+step]) y_tests = [] for i in range(from_i, to_i, step): y_tests.append(y_test[i:i+step])5. CRFのモデルを決める
crf = sklearn_crfsuite.CRF( algorithm='lbfgs', c1=0.1, c2=0.1, max_iterations=100, all_possible_transitions=True )6. 学習データを学習させる
crf.fit(X_trains, y_trains)7. テストデータで推論する
labels = list(crf.classes_) y_pred = crf.predict(X_tests) metrics.flat_f1_score(y_tests, y_pred, average='weighted', labels=labels)8. テストデータの正解率を確認する
sorted_labels = sorted( labels, key=lambda x: (x[1:], x[0]) ) print(metrics.flat_classification_report( y_tests, y_pred, labels=sorted_labels, digits=3 ))
9. ハイパーパラメータのチューニング
# define fixed parameters and parameters to search crf = sklearn_crfsuite.CRF( algorithm='lbfgs', max_iterations=100, all_possible_transitions=True ) params_space = { 'c1': scipy.stats.expon(scale=0.5), 'c2': scipy.stats.expon(scale=0.05), } # use the same metric for evaluation f1_scorer = make_scorer(metrics.flat_f1_score, average='weighted', labels=labels) # search rs = RandomizedSearchCV(crf, params_space, cv=2, verbose=1, n_jobs=-1, n_iter=50, scoring=f1_scorer) rs.fit(X_trains, y_trains)10. ハイパーパラメーターと正解のスコアのばらつきを可視化
_x = [s['c1'] for s in rs.cv_results_['params']] _y = [s['c2'] for s in rs.cv_results_['params']] _c = [s for s in rs.cv_results_['mean_test_score']] fig = plt.figure() fig.set_size_inches(6, 6) ax = plt.gca() ax.set_yscale('log') ax.set_xscale('log') ax.set_xlabel('C1') ax.set_ylabel('C2') ax.set_title("Randomized Hyperparameter Search CV Results (min={:0.3}, max={:0.3})".format( min(_c), max(_c) )) ax.scatter(_x, _y, c=_c, s=60, alpha=0.9) print("Dark blue => {:0.4}, dark red => {:0.4}".format(min(_c), max(_c)))
結果より気温と気圧だけでは最大で28%の予測精度であった。
つまり気温と気圧からCRFで天候を予測することは難しい。
本記事の目的としては予測精度を上げることではなく、CRFで時系列データのある点の予測を行うことである。何かありましたらコメントいただけると幸いです。
参考ページ
sklearn-crfsuite
https://sklearn-crfsuite.readthedocs.io/en/latest/index.htmlUsing CRF in Python
http://acepor.github.io/2017/03/06/CRF-Python/An Introduction to Conditional Random Fields
https://arxiv.org/abs/1011.4088




- 投稿日:2021-01-23T16:15:04+09:00
csvファイルに書かれた語をgoogle翻訳に掛け、csv出力するプログラム
はじめに
前回(https://qiita.com/syunpeta/private/63d2de6faef992bbad39) に引き続きseleniumで遊んでみようということでcsvファイルに書かれた文または語句を自動的にgoogle翻訳に掛け、それを同じcsvファイルに出力するプログラムを作成しました。seleniumとChromeDriverの導入は前回を参考にしてください。
動作環境
Windows 10 Home (64bit)
python 3.8.7
ChromeDriver 87.0.4280.88
selenium 3.141.0ソースコード
import csv from pathlib import Path from selenium import webdriver import time #翻訳して出力を配列に格納する関数 def translate(*tl): tmp=[] for i in range(len(tl)): #csv上から順に入力 before_in.send_keys(tl[i]) time.sleep(2) #出力部を取得 after_out = driver.find_element_by_css_selector("span[jsname='W297wb']") tmp.append(after_out.text) before_in.clear() return tmp #csvファイルを開く filepath = Path(r"翻訳したいcsvファイルのあるディレクトリの絶対パス") csv_file = list(filepath.glob("*.csv")) csv_file_op = csv_file.pop() #csvファイルの一列目を2次元配列で読み込み with open(csv_file_op,'r',encoding='utf-8-sig') as fp: translate_list = list(csv.reader(fp)) print(translate_list) #翻訳言語を選択 print("翻訳する前の言語を入力してください.(ex. 英語:en 日本語:ja 韓国語:ko 中国語:zh-CN") before_lang = input() print("翻訳した後の言語を入力してください.(ex. 英語:en 日本語:ja 韓国語:ko 中国語(簡体):zh-CN) 中国語(繁体):zh-TW") after_lang = input() #google翻訳をChromeで開く driver = webdriver.Chrome(r"chromedriverの格納されているディレクトリの絶対パス/chromedriver.exe") url = "https://translate.google.co.jp/?hl=ja&sl="+ before_lang +"&tl="+ after_lang +"&op=translate" driver.get(url) #2秒待機 time.sleep(2) #入力部を取得 before_in = driver.find_element_by_xpath("//*[@id='yDmH0d']/c-wiz/div/div[2]/c-wiz/div[2]/c-wiz/div[1]/div[2]/div[2]/c-wiz[1]/span/span/div/textarea") ans_arr = translate(*translate_list) #csv書き込み with open(csv_file_op, 'w', encoding= 'utf-8-sig', newline= "") as fp2: i=0 #結果と翻訳前を結合 for row in translate_list: row.append(ans_arr[i]) i+=1 writer = csv.writer(fp2) for k in translate_list: writer.writerow(k) #ブラウザ閉じる driver.close()部分的に解説
#csvファイルの一列目を2次元配列で読み込み with open(csv_file_op,'r',encoding='utf-8-sig') as fp: translate_list = list(csv.reader(fp)) print(translate_list)with 構文を使ってファイルを開いています。encodingはutf-8-sigとして下さい。sigを付けた理由はBOMありのcsvファイルを読み込むためです。(参考資料[1]を参照してください)また、list(csv.reader(fp))でcsvファイルの中身を2次元配列で得ています。これは後に翻訳後の結果と結合して一行に書き込むためです。
#翻訳して出力を配列に格納する関数 def translate(*tl): tmp=[] for i in range(len(tl)): #csv上から順に入力 before_in.send_keys(tl[i]) time.sleep(2) #出力部を取得 after_out = driver.find_element_by_css_selector("span[jsname='W297wb']") tmp.append(after_out.text) before_in.clear() return tmp翻訳する文字を入力し、翻訳結果を取得する関数です。翻訳したい文字列の配列を引数に渡して、forループで配列の長さ分だけ繰り返し翻訳をしています。google翻訳の翻訳結果の出力部はfind_element_by_css_selector("span[jsname='W297wb']")で取得しています。また、一回一回入力をクリアするためにclear()を実行しています。戻り値は出力結果を要素とした配列です。
with open(csv_file_op, 'w', encoding= 'utf-8-sig', newline= "") as fp2: i=0 #結果と翻訳前を結合 for row in translate_list: row.append(ans_arr[i]) i+=1 writer = csv.writer(fp2) for k in translate_list: writer.writerow(k)書き込みのためにもう一度csvファイルをwith構文で開いています。この時、オプションでnewline=""とすることでcsvファイルの出力時に一行空くことを防いでいます。#以下のforループでは翻訳前と翻訳語の配列を結合しています。結合した配列を一行ずつ書き込むことで翻訳前と翻訳語を横並びで書き込めるようになっています。
csvファイルの書式
翻訳したい文字列を一列目に書き込んでください。
例:
翻訳したい文字列 空欄 空欄・・・ 大学 東京 月 太陽 etc・・・ 翻訳結果は次の列(2列目)に出力されます。
おまけ
個人的に自動入力されていく様子が面白いのでHeadlessモードは使いませんでしたが、使うと少し処理が早くなるかも?・・・
参考資料
以下のサイトを参考にさせていただきました。
[1]https://qiita.com/showmurai/items/60d32006d13512ffeaff
[2]https://note.nkmk.me/python-file-io-open-with/
[3]https://qiita.com/ryokurta256/items/defc553f5165c88eac95
- 投稿日:2021-01-23T15:18:05+09:00
flickr APIで富士山の画像を自動取得
Udemyで【画像判定AIアプリ開発・パート2】Django・TensorFlow・転移学習による高精度AIアプリ開発を受講した。オリジナルの機械学習プログラムを作る際に、インターネット上から画像を取得するのが非常に手間だと感じていたので、画像取得自動化の方法を記録しておく。
flicker APIのKey取得
flickerのホームページ
→ フッターのナビゲーションバーからDevelopersを選択
→ 画面上部からAPIを選択
→ Getting Startedの①にあるRequest an API keyを選択
→ ①のGet your API keyにあるRequest an API keyを選択
→ 商用利用ではないので、APPLY FOR A NON-COMMERCIAL KEYを選択
→ 作りたいアプリケーションの名前、アプリケーションの説明を入力
→ チェックボックスを埋めて、SUBMITを選択
→ KeyとSecretの取得完了!
画像をダウンロードするPythonファイル
これから目的の画像を取得する。
flickr APIのパッケージを仮想環境内にインストールする。私はAnaconda仮想環境を使っており、パッケージのインストールには
pip installではなくconda installを使うようにしているが、Anaconda Cloudで「flickrapi」で検索しても情報がほとんどなかったため、pip installを使った。(それっぽいパッケージもあるにはあるが、300ダウンロードにも満たないものだったので避けた。)$ pip install flickrapi今回は
download.pyというファイルで富士山の画像のダウンロードを自動でおこなう。download.pyと同じディレクトリにdataというディレクトリを作成し、さらにその内部にmt.fujiというディレクトリを作成した。このmt.fujiの中に画像をダウンロードする。ソースコードは以下の通りである。from flickrapi import FlickrAPI from urllib.request import urlretrieve import os, time, sys key ="**************************" # 先ほど取得したKeyをコピー&ペースト secret = "****************" # 先ほど取得したSecretをコピー&ペースト wait_time = 1 keyword = sys.argv[1] savedir = "./data/" + keyword flickr = FlickrAPI(key, secret, format='parsed-json') result = flickr.photos.search( text = keyword, per_page = 400, media = 'photos', sort = 'relevance', extras = 'url_q, license', ) photos = result['photos'] for i, photo in enumerate(photos['photo']): url_q = photo['url_q'] filepath = savedir + '/' + photo['id'] + '.jpg' if os.path.exists(filepath): continue urlretrieve(url_q, filepath) time.sleep(wait_time)このように書いたうえでターミナルで
$ python download.py mt.fujiと入力すると画像のダウンロードが始まる。数分後、
mt.fujiの中身を確認すると、以下のように画像がダウンロードされている。
これで、画像を手作業でダウンロードするという手間を大幅に省くことができた。しかしこのままでは関係ない画像も多く混じっているため、もっと工夫が必要である。
- 【画像判定AIアプリ開発・パート2】Django・TensorFlow・転移学習による高精度AIアプリ開発 https://www.udemy.com/course/django-ai-app/learn/lecture/14733746


- 投稿日:2021-01-23T15:05:24+09:00
ゲシュタルトパターンマッチングを用いた文字列の類似度計算
はじめに
2つの文字列の類似度を計算するアルゴリズムの1つである、
ゲシュタルトパターンマッチング
について調べたので、内容をまとめました。※本記事は、Wikipedia(英語版)の内容をベースとしています。
目次
実装
ゲシュタルトパターンマッチングは、Pythonのdifflibで以下のように実装できます。
import difflib word = 'appel' possibilities = ['ape', 'apple', 'peach', 'puppy'] print(difflib.get_close_matches(word, possibilities, n=3, cutoff=0.6)) # ['apple', 'ape']ある文字列(
word = 'appel')と似ているものを、文字列のリスト(possibilities = ['ape', 'apple', 'peach', 'puppy'])のなかから取り出すことができます。get_close_matchesの引数と戻り値の詳細は以下です。
- 引数
- word:マッチさせたい文字列
- possibilities:wordにマッチさせる文字列のリスト
- n(デフォルト3):マッチさせる文字列の最大数。1以上を指定。
- cutoff(デフォルト0.6):wordとの一致率。0以上1以下を指定。
- 戻り値
- マッチした文字列のリスト。cutoff以上の一致率の文字列リストを、一致率の高い順(似ている順)にソートして返却。
マッチさせる文字列の数はn、マッチングの厳しさはcutoffで調整できます。
# n=1 print(difflib.get_close_matches(word, possibilities, n=1, cutoff=0.6)) # ['apple'] # cutoff=0.8 print(difflib.get_close_matches(word, possibilities, n=3, cutoff=0.8)) # ['apple']マッチの一致率は以下で調べることができます。cutoffの参考にすると良いかもしれません。
str1 = 'appel' possibilities = ['ape', 'apple', 'peach', 'puppy'] for str2 in possibilities: ratio = difflib.SequenceMatcher(None, str1, str2).ratio() print(str2, ratio) # ape 0.75 # apple 0.8 # peach 0.4 # puppy 0.4ゲシュタルトパターンマッチングとは
『ゲシュタルトパターンマッチング(Gestalt Pattern Matching)』とは、2つの文字列の類似度を判定するためのアルゴリズムです。Ratcliff, Obershelpによって1983年に考案されました。Ratcliff/Obershelp Pattern Recognitionとも呼ばれているようです。
(以下、その頭文字をとって$D_{ro}$などと表記する)「ゲシュタルト(Gestalt)」は、「形」「形態」「状態」といった意味を表すドイツ語です。
「ゲシュタルト崩壊」という言葉を聞いたことがある方も多いのではないでしょうか。ずっと同じ文字を眺めていると、それが何を表す文字なのかわからなくなってしまう感覚のことです。
ゲシュタルト崩壊(ゲシュタルトほうかい、独: Gestaltzerfall)とは、知覚における現象のひとつ。 全体性を持ったまとまりのある構造(Gestalt, 形態)から全体性が失われてしまい、個々の構成部分にバラバラに切り離して認識し直されてしまう現象をいう。幾何学図形、文字、顔など、視覚的なものがよく知られているが、聴覚や皮膚感覚、味覚、嗅覚においても生じうる。
Wikipediaより引用「ゲシュタルト」のこれらの意味より、
「ゲシュタルトパターンマッチング」は、細かい部分は気にせず、あくまで文字列全体のまとまりに重きを置いて類似度を計算する手法
というのが個人的な印象です。アルゴリズム
ゲシュタルトパターンマッチングによる、2つの文字列$S_1, S_2$の類似度$D_{ro}$は、以下で表されます。
D_{ro}(S_1, S_2)=\frac{2K_m}{|S_1|+|S_2|}ここで
- $K_m$:マッチした文字数
- $|S_1|, |S_2|$:それぞれ$S_1, S_2$の文字列の長さ
であり、類似度$D_{ro}$の取り得る値の範囲は
0 \leq D_{ro} \leq 1となります。
1に近いほど類似度は高く、0に近いほど類似度は低くなります。ちなみに、
- $D_{ro}=1$:完全一致
- $D_{ro}=0$:1文字もマッチしない
となります。
例
$S_1$ S I M I L A R I T Y $S_2$ S I M I R E L I T Y 左から順に見ていくと、最長で
SIMIの4文字がマッチしています。
残った文字列に対して再び見ていくと、最長でITYの3文字がマッチしています。よって、この場合の類似度は以下になります。
\begin{align} D_{ro}&=\frac{2K_m}{|S_1|+|S_2|}\\ &=\frac{2\cdot(\mbox{|"SIMI"|+|"ITY"|})}{|S_1|+|S_2|}\\ &=\frac{2\cdot(4+3)}{10+10}\\ &=\frac{7}{10}=0.7 \end{align}性質
非可換性
ゲシュタルトパターンマッチングは非可換(non-commutative)、すなわち交換できません。
D_{ro}(S_1, S_2) \neq D_{ro}(S_2, S_1)以下の例で確認してみましょう。
2つの文字列を
- $S_1$:
Gestalt Pattern Matching- $S_2$:
Gestalt Practiceとすると、マッチする文字列は以下のように異なります。
- $D_{ro}(S_1, S_2)$:
Gestalt P,a,t,e- $D_{ro}(S_2, S_1)$:
Gestalt P,r,a,c,iよって、それぞれ類似度を計算すると
\begin{align} D_{ro}(S_1, S_2)&=\frac{2K_m}{|S_1|+|S_2|}\\ &=\frac{2\cdot(\mbox{|"Gestalt P"|+|"a"|+|"t"|+|"e"|})}{|S_1|+|S_2|}\\ &=\frac{2\cdot(9+1+1+1)}{24+16}\\ &=\frac{24}{40}=0.6\\ \\ D_{ro}(S_2, S_1)&=\frac{2K_m}{|S_2|+|S_1|}\\ &=\frac{2\cdot(\mbox{|"Gestalt P"|+|"r"|+|"a"|+|"c"|+|"i"|})}{|S_2|+|S_1|}\\ &=\frac{2\cdot(9+1+1+1+1)}{16+24}\\ &=\frac{26}{40}=0.65\\ \end{align}\begin{align} \end{align}となり、確かに
D_{ro}(S_1, S_2) \neq D_{ro}(S_2, S_1)と非可換となっています。
実際に、コードで確認すると
str1 = 'GESTALT PATTERN MATCHING' str2 = 'GESTALT PRACTICE' print(difflib.SequenceMatcher(None, str1, str2).ratio()) print(difflib.SequenceMatcher(None, str2, str1).ratio()) # 0.6 # 0.65と同様の結果を得ることができます。
参考文献
- 投稿日:2021-01-23T15:05:24+09:00
ゲシュタルトパターンマッチングによる文字列類似度の計算
はじめに
2つの文字列の類似度を計算するアルゴリズムの1つである、
ゲシュタルトパターンマッチング
について調べたので、内容をまとめました。※本記事は、Wikipedia(英語版)の内容をベースとしています。
目次
実装
ゲシュタルトパターンマッチングは、Pythonのdifflibで以下のように実装できます。
※環境は、Google Colaboratoryを使用import difflib word = 'appel' possibilities = ['ape', 'apple', 'peach', 'puppy'] print(difflib.get_close_matches(word, possibilities, n=3, cutoff=0.6)) # ['apple', 'ape']ある文字列(
word = 'appel')と似ているものを、文字列のリスト(possibilities = ['ape', 'apple', 'peach', 'puppy'])のなかから取り出すことができます。get_close_matchesの引数と戻り値の詳細は以下です。
- 引数
- word:マッチさせたい文字列
- possibilities:wordにマッチさせる文字列のリスト
- n(デフォルト3):マッチさせる文字列の最大数。1以上を指定。
- cutoff(デフォルト0.6):wordとの一致率。0以上1以下を指定。
- 戻り値
- マッチした文字列のリスト。cutoff以上の一致率の文字列リストを、一致率の高い順(似ている順)にソートして返却。
マッチさせる文字列の数はn、マッチングの厳しさはcutoffで調整できます。
# n=1 print(difflib.get_close_matches(word, possibilities, n=1, cutoff=0.6)) # ['apple'] # cutoff=0.8 print(difflib.get_close_matches(word, possibilities, n=3, cutoff=0.8)) # ['apple']マッチの一致率は以下で調べることができます。cutoffの参考にすると良いかもしれません。
str1 = 'appel' possibilities = ['ape', 'apple', 'peach', 'puppy'] for str2 in possibilities: ratio = difflib.SequenceMatcher(None, str1, str2).ratio() print(str2, ratio) # ape 0.75 # apple 0.8 # peach 0.4 # puppy 0.4ゲシュタルトパターンマッチングとは
『ゲシュタルトパターンマッチング(Gestalt Pattern Matching)』とは、2つの文字列の類似度を判定するためのアルゴリズムです。Ratcliff, Obershelpによって1983年に考案されました。Ratcliff/Obershelp Pattern Recognitionとも呼ばれているようです。
(以下、その頭文字をとって$D_{ro}$などと表記する)「ゲシュタルト(Gestalt)」は、「形」「形態」「状態」といった意味を表すドイツ語です。
「ゲシュタルト崩壊」という言葉を聞いたことがある方も多いのではないでしょうか。ずっと同じ文字を眺めていると、それが何を表す文字なのかわからなくなってしまう感覚のことです。
ゲシュタルト崩壊(ゲシュタルトほうかい、独: Gestaltzerfall)とは、知覚における現象のひとつ。 全体性を持ったまとまりのある構造(Gestalt, 形態)から全体性が失われてしまい、個々の構成部分にバラバラに切り離して認識し直されてしまう現象をいう。幾何学図形、文字、顔など、視覚的なものがよく知られているが、聴覚や皮膚感覚、味覚、嗅覚においても生じうる。
Wikipediaより引用「ゲシュタルト」のこれらの意味より、
「ゲシュタルトパターンマッチング」は、細かい部分は気にせず、あくまで文字列全体のまとまりに重きを置いて類似度を計算する手法
というのが個人的な印象です。アルゴリズム
ゲシュタルトパターンマッチングによる、2つの文字列$S_1, S_2$の類似度$D_{ro}$は、以下で表されます。
D_{ro}(S_1, S_2)=\frac{2K_m}{|S_1|+|S_2|}ここで
- $K_m$:マッチした文字数
- $|S_1|, |S_2|$:それぞれ$S_1, S_2$の文字列の長さ
であり、類似度$D_{ro}$の取り得る値の範囲は
0 \leq D_{ro} \leq 1となります。
1に近いほど類似度は高く、0に近いほど類似度は低くなります。ちなみに、
- $D_{ro}=1$:完全一致
- $D_{ro}=0$:1文字もマッチしない
となります。
例
$S_1$ S I M I L A R I T Y $S_2$ S I M I R E L I T Y 左から順に見ていくと、最長で
SIMIの4文字がマッチしています。
残った文字列に対して再び見ていくと、最長でITYの3文字がマッチしています。よって、この場合の類似度は以下になります。
\begin{align} D_{ro}&=\frac{2K_m}{|S_1|+|S_2|}\\ &=\frac{2\cdot(\mbox{|"SIMI"|+|"ITY"|})}{|S_1|+|S_2|}\\ &=\frac{2\cdot(4+3)}{10+10}\\ &=\frac{7}{10}=0.7 \end{align}性質
非可換性
ゲシュタルトパターンマッチングは非可換(non-commutative)、すなわち交換できません。
D_{ro}(S_1, S_2) \neq D_{ro}(S_2, S_1)以下の例で確認してみましょう。
2つの文字列を
- $S_1$:
Gestalt Pattern Matching- $S_2$:
Gestalt Practiceとすると、マッチする文字列は以下のように異なります。
- $D_{ro}(S_1, S_2)$:
Gestalt P,a,t,e- $D_{ro}(S_2, S_1)$:
Gestalt P,r,a,c,iよって、それぞれ類似度を計算すると
\begin{align} D_{ro}(S_1, S_2)&=\frac{2K_m}{|S_1|+|S_2|}\\ &=\frac{2\cdot(\mbox{|"Gestalt P"|+|"a"|+|"t"|+|"e"|})}{|S_1|+|S_2|}\\ &=\frac{2\cdot(9+1+1+1)}{24+16}\\ &=\frac{24}{40}=0.6\\ \\ D_{ro}(S_2, S_1)&=\frac{2K_m}{|S_2|+|S_1|}\\ &=\frac{2\cdot(\mbox{|"Gestalt P"|+|"r"|+|"a"|+|"c"|+|"i"|})}{|S_2|+|S_1|}\\ &=\frac{2\cdot(9+1+1+1+1)}{16+24}\\ &=\frac{26}{40}=0.65\\ \end{align}\begin{align} \end{align}となり、確かに
D_{ro}(S_1, S_2) \neq D_{ro}(S_2, S_1)と非可換となっています。
実際に、コードで確認すると
str1 = 'GESTALT PATTERN MATCHING' str2 = 'GESTALT PRACTICE' print(difflib.SequenceMatcher(None, str1, str2).ratio()) print(difflib.SequenceMatcher(None, str2, str1).ratio()) # 0.6 # 0.65と同様の結果を得ることができます。
参考文献
- 投稿日:2021-01-23T15:05:24+09:00
ゲシュタルトパターンマッチングによる文字列の類似度の計算
はじめに
2つの文字列の類似度を計算するアルゴリズムの1つである、
ゲシュタルトパターンマッチング
について調べたので、内容をまとめました。※本記事は、Wikipedia(英語版)の内容をベースとしています。
目次
実装
ゲシュタルトパターンマッチングは、Pythonのdifflibで以下のように実装できます。
※環境は、Google Colaboratoryを使用import difflib word = 'appel' possibilities = ['ape', 'apple', 'peach', 'puppy'] print(difflib.get_close_matches(word, possibilities, n=3, cutoff=0.6)) # ['apple', 'ape']ある文字列(
word = 'appel')と似ているものを、文字列のリスト(possibilities = ['ape', 'apple', 'peach', 'puppy'])のなかから取り出すことができます。get_close_matchesの使い方は以下です。
- 引数
- word:マッチさせたい文字列
- possibilities:wordにマッチさせる文字列のリスト
- n(デフォルト3):マッチさせる文字列の最大数。1以上を指定。
- cutoff(デフォルト0.6):wordとの一致率。0以上1以下を指定。
- 戻り値
- マッチした文字列のリスト。cutoff以上の一致率の文字列リストを、一致率の高い順(似ている順)にソートして返却。
マッチさせる文字列の数はn、マッチングの厳しさはcutoffで調整できます。
# n=1 print(difflib.get_close_matches(word, possibilities, n=1, cutoff=0.6)) # ['apple'] # cutoff=0.8 print(difflib.get_close_matches(word, possibilities, n=3, cutoff=0.8)) # ['apple']マッチの一致率は、difflibのSequenceMatcherで調べることができます。cutoffを決める際の参考になるかと思います。
str1 = 'appel' possibilities = ['ape', 'apple', 'peach', 'puppy'] for str2 in possibilities: ratio = difflib.SequenceMatcher(None, str1, str2).ratio() print(str2, ratio) # ape 0.75 # apple 0.8 # peach 0.4 # puppy 0.4ゲシュタルトパターンマッチングとは
『ゲシュタルトパターンマッチング(Gestalt Pattern Matching)』とは、2つの文字列の類似度を判定するためのアルゴリズムです。Ratcliff, Obershelpによって1983年に考案されました。Ratcliff/Obershelp Pattern Recognitionとも呼ばれているようです。
(以下、その頭文字をとって$D_{ro}$などと表記する)「ゲシュタルト(Gestalt)」は、「形」「形態」「状態」といった意味を表すドイツ語です。
「ゲシュタルト崩壊」という言葉を聞いたことがある方も多いのではないでしょうか。ずっと同じ文字を眺めていると、それが何を表す文字なのかわからなくなってしまう感覚のことです。
ゲシュタルト崩壊(ゲシュタルトほうかい、独: Gestaltzerfall)とは、知覚における現象のひとつ。 全体性を持ったまとまりのある構造(Gestalt, 形態)から全体性が失われてしまい、個々の構成部分にバラバラに切り離して認識し直されてしまう現象をいう。幾何学図形、文字、顔など、視覚的なものがよく知られているが、聴覚や皮膚感覚、味覚、嗅覚においても生じうる。
Wikipediaより引用「ゲシュタルト」のこれらの意味より、
「ゲシュタルトパターンマッチング」は、細かい部分は気にせず、あくまで文字列全体のまとまりに重きを置いて類似度を計算する手法
というのが個人的な印象です。アルゴリズム
ゲシュタルトパターンマッチングによる、2つの文字列$S_1, S_2$の類似度$D_{ro}$は、以下で表されます。
D_{ro}(S_1, S_2)=\frac{2K_m}{|S_1|+|S_2|}ここで
- $K_m$:マッチした文字数
- $|S_1|, |S_2|$:それぞれ$S_1, S_2$の文字列の長さ
であり、類似度$D_{ro}$の取り得る値の範囲は
0 \leq D_{ro} \leq 1となります。
1に近いほど類似度は高く、0に近いほど類似度は低くなります。ちなみに、
- $D_{ro}=1$:完全一致
- $D_{ro}=0$:1文字もマッチしない
となります。
例
$S_1$ S I M I L A R I T Y $S_2$ S I M I R E L I T Y 左から順に見ていくと、最長で
SIMIの4文字がマッチしています。
残った文字列に対して再び見ていくと、最長でITYの3文字がマッチしています。よって、この場合の類似度は以下になります。
\begin{align} D_{ro}&=\frac{2K_m}{|S_1|+|S_2|}\\ &=\frac{2\cdot(\mbox{|"SIMI"|+|"ITY"|})}{|S_1|+|S_2|}\\ &=\frac{2\cdot(4+3)}{10+10}\\ &=\frac{7}{10}=0.7 \end{align}性質
非可換性
ゲシュタルトパターンマッチングは非可換(non-commutative)、すなわち交換できません。
D_{ro}(S_1, S_2) \neq D_{ro}(S_2, S_1)以下の例で確認してみましょう。
2つの文字列を
- $S_1$:
Gestalt Pattern Matching- $S_2$:
Gestalt Practiceとすると、マッチする文字列は以下のように異なります。
- $D_{ro}(S_1, S_2)$:
Gestalt P,a,t,e- $D_{ro}(S_2, S_1)$:
Gestalt P,r,a,c,iよって、それぞれ類似度を計算すると
\begin{align} D_{ro}(S_1, S_2)&=\frac{2K_m}{|S_1|+|S_2|}\\ &=\frac{2\cdot(\mbox{|"Gestalt P"|+|"a"|+|"t"|+|"e"|})}{|S_1|+|S_2|}\\ &=\frac{2\cdot(9+1+1+1)}{24+16}\\ &=\frac{24}{40}=0.6\\ \\ D_{ro}(S_2, S_1)&=\frac{2K_m}{|S_2|+|S_1|}\\ &=\frac{2\cdot(\mbox{|"Gestalt P"|+|"r"|+|"a"|+|"c"|+|"i"|})}{|S_2|+|S_1|}\\ &=\frac{2\cdot(9+1+1+1+1)}{16+24}\\ &=\frac{26}{40}=0.65\\ \end{align}\begin{align} \end{align}となり、確かに
D_{ro}(S_1, S_2) \neq D_{ro}(S_2, S_1)と非可換となっています。
実際に、コードで確認すると
str1 = 'GESTALT PATTERN MATCHING' str2 = 'GESTALT PRACTICE' print(difflib.SequenceMatcher(None, str1, str2).ratio()) print(difflib.SequenceMatcher(None, str2, str1).ratio()) # 0.6 # 0.65と同様の結果を得ることができます。
参考文献
- 投稿日:2021-01-23T14:49:12+09:00
初心者 初めてのWEBアプリ(FASTAPI)
初めてWEBアプリを開発しています。
FASTAPIをお薦めされ、このフレームワークを使用していますが、なかなか参考資料が少なく開発難航中です。(笑)現在の困りごと:
トレーニングの計画や実施事項をまとめたスポーツのコンデションプランを視覚化できるアプリケーションを作っています。
ユーザーをスポーツチームでお互いのプランやトレーニング内容を確認できるようにアプリ内でユーザーをグループ化できるようにしたいのですが、どのようにコードを書くかに困っています。
グループ機能を組み込むには、どのようなロジックで書くか模索中!記事として書いてますが、何か参考にグループ機能についてコメントに書いていただけますと嬉しいです!
絶賛、猛勉強中!!
- 投稿日:2021-01-23T14:27:47+09:00
manimの作法 その28
概要
manimの作法、調べてみた。
animation、全部使ってみた2。サンプルコード
from manimlib.imports import * class test(Scene): def construct(self): mobjects = VGroup(Circle(), Circle(fill_opacity = 1), TextMobject("Text0").scale(2)) mobjects.scale(1.5) mobjects.arrange_submobjects(RIGHT, buff = 2) self.play(*[ShowCreation(mob) for mob in mobjects]) self.wait() self.play(FadeOut(mobjects)) mobjects = VGroup(Circle(), Circle(fill_opacity = 1), TextMobject("Text1").scale(2)) mobjects.scale(1.5) mobjects.arrange_submobjects(RIGHT, buff = 2) self.add(mobjects) self.wait(0.3) self.play(*[Uncreate(mob) for mob in mobjects]) self.wait() self.play(FadeOut(mobjects)) vmobjects = VGroup(Circle(), Circle(fill_opacity = 1), TextMobject("Text2").scale(2)) vmobjects.scale(1.5) vmobjects.arrange_submobjects(RIGHT, buff = 2) self.play(*[DrawBorderThenFill(mob) for mob in vmobjects]) self.wait() self.play(FadeOut(vmobjects)) mobjects = VGroup(Circle(), Circle(fill_opacity = 1), TextMobject("Text3").scale(2)) mobjects.scale(1.5) mobjects.arrange_submobjects(RIGHT, buff = 2) self.play(*[Write(mob) for mob in mobjects]) self.wait() self.play(FadeOut(mobjects)) mobjects = VGroup(Circle(), Circle(fill_opacity = 1), TextMobject("Text4").scale(2)) mobjects.scale(1.5) mobjects.arrange_submobjects(RIGHT, buff = 2) self.add(mobjects) self.wait(0.3) self.play(*[FadeOut(mob) for mob in mobjects]) self.wait() self.play(FadeOut(mobjects)) mobjects = VGroup(Circle(), Circle(fill_opacity = 1), TextMobject("Text5").scale(2)) mobjects.scale(1.5) mobjects.arrange_submobjects(RIGHT, buff = 2) self.play(*[FadeIn(mob) for mob in mobjects]) self.wait() self.play(FadeOut(mobjects)) mobjects = VGroup(Circle(), Circle(fill_opacity = 1), TextMobject("Text6").scale(2)) mobjects.scale(1.5) mobjects.arrange_submobjects(RIGHT, buff = 2) directions = [UP, LEFT, DOWN, RIGHT] for direction in directions: self.play(*[FadeInFrom(mob,direction) for mob in mobjects]) self.wait() self.play(FadeOut(mobjects)) mobjects = VGroup(Circle(), Circle(fill_opacity = 1), TextMobject("Text7").scale(2)) mobjects.scale(1.5) mobjects.arrange_submobjects(RIGHT, buff = 2) self.play(*[FadeInFromDown(mob) for mob in mobjects]) self.wait() self.play(FadeOut(mobjects)) mobjects = VGroup(Circle(), Circle(fill_opacity = 1), TextMobject("Text8").scale(2)) mobjects.scale(1.5) mobjects.arrange_submobjects(RIGHT, buff = 2) directions = [UP, LEFT, DOWN, RIGHT] self.add(mobjects) self.wait(0.3) for direction in directions: self.play(*[FadeOutAndShift(mob,direction) for mob in mobjects]) self.wait() self.play(FadeOut(mobjects)) mobjects = VGroup(Circle(), Circle(fill_opacity = 1), TextMobject("Text9").scale(2)) mobjects.scale(1.5) mobjects.arrange_submobjects(RIGHT, buff = 2) self.play(*[FadeOutAndShiftDown(mob) for mob in mobjects]) self.wait() self.play(FadeOut(mobjects)) mobjects = VGroup(Circle(), Circle(fill_opacity = 1), TextMobject("Texta").scale(2)) mobjects.scale(1.5) mobjects.arrange_submobjects(RIGHT, buff = 2) scale_factors = [0.3, 0.8, 1, 1.3, 1.8] for scale_factor in scale_factors: t_scale_factor = TextMobject(f"\\tt scale\\_factor = {scale_factor}") t_scale_factor.to_edge(UP) self.add(t_scale_factor) self.play(*[FadeInFromLarge(mob, scale_factor) for mob in mobjects]) self.remove(t_scale_factor) self.wait(0.3) self.play(FadeOut(mobjects)) mobjects = VGroup(Circle(), Circle(fill_opacity = 1), TextMobject("Textb").scale(2)) mobjects.arrange_submobjects(RIGHT, buff = 2) directions = [UP, LEFT, DOWN, RIGHT] for direction in directions: self.play(*[GrowFromPoint(mob, mob.get_center() + direction * 3) for mob in mobjects]) self.wait() self.play(FadeOut(mobjects)) mobjects = VGroup(Circle(), Circle(fill_opacity = 1), TextMobject("Textc").scale(2)) mobjects.scale(1.5) mobjects.arrange_submobjects(RIGHT, buff = 2) self.play(*[GrowFromCenter(mob) for mob in mobjects]) self.wait() self.play(FadeOut(mobjects)) mobjects = VGroup(Circle(), Circle(fill_opacity = 1), TextMobject("Textd").scale(2)) mobjects.arrange_submobjects(RIGHT, buff = 2) directions = [UP, LEFT, DOWN, RIGHT] for direction in directions: self.play(*[GrowFromEdge(mob, direction) for mob in mobjects]) self.wait() self.play(FadeOut(mobjects)) mobjects = VGroup(Arrow(LEFT, RIGHT), Vector(RIGHT * 2)) mobjects.scale(3) mobjects.arrange_submobjects(DOWN, buff = 2) self.play(*[GrowArrow(mob) for mob in mobjects]) self.wait() self.play(FadeOut(mobjects)) mobjects = VGroup(Square(), RegularPolygon(fill_opacity = 1), TextMobject("Texte").scale(2)) mobjects.scale(1.5) mobjects.arrange_submobjects(RIGHT, buff = 2) self.play(*[SpinInFromNothing(mob) for mob in mobjects]) self.wait() self.play(FadeOut(mobjects)) mobjects = VGroup(Square(), RegularPolygon(fill_opacity = 1), TextMobject("Textf").scale(2)) mobjects.scale(1.5) mobjects.arrange_submobjects(RIGHT, buff = 2) self.play(*[ShrinkToCenter(mob) for mob in mobjects]) self.wait() self.play(FadeOut(mobjects)) mobjects = VGroup(Dot(), TexMobject("x")) mobjects.arrange_submobjects(RIGHT, buff = 2) mobject_or_coord = [*mobjects, mobjects.get_right() + RIGHT * 2] colors = [GRAY, RED, BLUE] self.add(mobjects) for obj,color in zip(mobject_or_coord, colors): self.play(FocusOn(obj, color = color)) self.wait() self.play(FadeOut(mobjects)) formula = TexMobject("f(", "x", ")") dot = Dot() VGroup(formula, dot).scale(3).arrange_submobjects(DOWN, buff = 3) self.add(formula, dot) for mob in [formula[1], dot]: self.play(Indicate(mob)) self.wait() self.remove(formula) self.remove(dot) mobjects = VGroup(Dot(), TexMobject("x0")).scale(2) mobjects.arrange_submobjects(RIGHT, buff = 2) mobject_or_coord = [*mobjects, mobjects.get_right() + RIGHT * 2] colors = [GRAY, RED, BLUE] self.add(mobjects) for obj,color in zip(mobject_or_coord,colors): self.play(Flash(obj, color = color, flash_radius = 0.5)) self.wait() self.play(FadeOut(mobjects)) mobjects = VGroup(Dot(), TexMobject("x1")).scale(2) mobjects.arrange_submobjects(RIGHT, buff = 2) self.add(mobjects) self.wait(0.2) for obj in mobjects: self.play(CircleIndicate(obj)) self.play(FadeOut(mobjects)) mobjects = VGroup(Circle(), Circle(fill_opacity = 1), TextMobject("Textg").scale(2)) mobjects.scale(1.5) mobjects.arrange_submobjects(RIGHT, buff = 2) self.play(*[ShowCreationThenDestruction(mob) for mob in mobjects]) self.wait() self.play(FadeOut(mobjects)) mobjects = VGroup(Circle(), Circle(fill_opacity = 1), TextMobject("Texth").scale(2)) mobjects.scale(1.5) mobjects.arrange_submobjects(RIGHT, buff = 2) self.play(*[ShowCreationThenFadeOut(mob) for mob in mobjects]) self.wait() self.play(FadeOut(mobjects)) mobjects = VGroup(Circle(), Circle(fill_opacity = 1), TextMobject("Texti").scale(2)) mobjects.scale(1.5) mobjects.arrange_submobjects(RIGHT, buff = 2) self.add(mobjects) self.play(*[ShowPassingFlashAround(mob) for mob in mobjects]) self.wait() self.play(FadeOut(mobjects)) mobjects = VGroup(Circle(), Circle(fill_opacity = 1), TextMobject("Textj").scale(2)) mobjects.scale(1.5) mobjects.arrange_submobjects(RIGHT, buff = 2) self.add(mobjects) self.play(*[ShowCreationThenDestructionAround(mob) for mob in mobjects]) self.wait() self.play(FadeOut(mobjects)) mobjects = VGroup(Circle(), Circle(fill_opacity = 1), TextMobject("Textk").scale(2)) mobjects.scale(1.5) mobjects.arrange_submobjects(RIGHT, buff = 2) self.add(mobjects) self.play(*[ShowCreationThenFadeAround(mob) for mob in mobjects]) self.wait() self.play(FadeOut(mobjects)) mobjects = VGroup(Circle(), Circle(fill_opacity = 1), TextMobject("Textl").scale(2)) mobjects.scale(1.5) mobjects.arrange_submobjects(RIGHT, buff = 2) self.add(mobjects) self.play(*[ApplyWave(mob) for mob in mobjects]) self.wait() self.play(FadeOut(mobjects)) mobjects = VGroup(Circle(), Circle(fill_opacity = 1), TextMobject("Textm").scale(2)) mobjects.scale(1.5) mobjects.arrange_submobjects(RIGHT, buff = 2) self.add(mobjects) self.play(*[WiggleOutThenIn(mob) for mob in mobjects]) self.wait() self.play(FadeOut(mobjects)) mobjects = VGroup(Circle(), Circle(fill_opacity = 1), TextMobject("Textn").scale(2)) mobjects.scale(1.5) mobjects.arrange_submobjects(RIGHT, buff = 2) self.add(mobjects) self.play(*[TurnInsideOut(mob) for mob in mobjects]) self.wait() self.play(FadeOut(mobjects)) mobject = RegularPolygon(3).scale(2) self.add(mobject) for n in range(4, 9): self.play(Transform(mobject, RegularPolygon(n).scale(2))) self.wait(0.3) self.play(FadeOut(mobject)) polygons = [*[RegularPolygon(n).scale(2) for n in range(3, 9)]] self.add(polygons[0]) for i in range(len(polygons) - 1): self.play(ReplacementTransform(polygons[i], polygons[i + 1])) self.wait(0.3) self.remove(polygons[0]) self.remove(polygons[1]) self.remove(polygons[2]) self.remove(polygons[3]) self.remove(polygons[4]) self.remove(polygons[5]) polygons = VGroup(*[RegularPolygon(n).scale(0.7) for n in range(3, 9)]).arrange_submobjects(RIGHT, buff = 1) self.add(polygons[0]) for i in range(len(polygons) - 1): self.play(ClockwiseTransform(polygons[0], polygons[i + 1])) self.wait(0.3) self.play(FadeOut(polygons)) polygons = VGroup(*[RegularPolygon(n).scale(0.7) for n in range(3, 9)]).arrange_submobjects(RIGHT, buff = 1) self.add(polygons[0]) for i in range(len(polygons) - 1): self.play(CounterclockwiseTransform(polygons[0], polygons[i + 1])) self.wait(0.3) self.play(FadeOut(polygons)) mobject = Square() mobject.generate_target() VGroup(mobject, mobject.target).arrange_submobjects(RIGHT, buff = 3) mobject.target.rotate(PI / 4).scale(2).set_stroke(PURPLE, 9).set_fill(ORANGE, 1) self.add(mobject) self.wait(0.3) self.play(MoveToTarget(mobject)) self.wait(0.3) self.play(FadeOut(mobject)) dot = Dot() text = TextMobject("Texto") dot.next_to(text, LEFT) self.add(text, dot) self.play(ApplyMethod(text.scale, 3, { "about_point": dot.get_center() })) self.wait(0.3) self.remove(dot) self.remove(text) text = TextMobject("Textp") self.add(text) def spread_out(p): p = p + 2 * DOWN return (FRAME_X_RADIUS + FRAME_Y_RADIUS) * p / get_norm(p) self.play(ApplyPointwiseFunction(spread_out, text)) text = TextMobject("Text").set_width(FRAME_WIDTH) colors = [RED, PURPLE, GOLD, TEAL] self.add(text) for color in colors: self.play(FadeToColor(text, color)) self.wait(0.3) self.remove(text) text = TextMobject("Textq").set_width(FRAME_WIDTH / 2) scale_factors = [2, 0.3, 0.6, 2] self.add(text) for scale_factor in scale_factors: self.play(ScaleInPlace(text, scale_factor)) self.wait(0.3) self.remove(text) text = TextMobject("Original").set_width(FRAME_WIDTH / 2) text.save_state() text_2 = TextMobject("Modified").set_width(FRAME_WIDTH / 1.5).set_color(ORANGE).to_corner(DL) self.add(text) self.play(Transform(text, text_2)) self.play(text.shift, RIGHT, text.rotate, PI / 4) self.play(Restore(text)) self.wait(0.7) self.remove(text) self.remove(text_2) text = TextMobject("Texts").to_corner(DL) self.add(text) def apply_function(mob): mob.scale(2) mob.to_corner(UR) mob.rotate(PI / 4) mob.set_color(RED) return mob self.play(ApplyFunction(apply_function, text)) self.wait(0.3) self.remove(text) def plane_wave_homotopy(x, y, z, t): norm = get_norm([x, y]) tau = interpolate(5, -5, t) + norm / FRAME_X_RADIUS alpha = sigmoid(tau) return [x, y + 0.5 * np.sin(2 * np.pi * alpha) - t * SMALL_BUFF / 2, z] mobjects = VGroup(TextMobject("Text").scale(3), Square(), ).arrange_submobjects(RIGHT, buff = 2) self.add(mobjects) self.play(*[Homotopy(plane_wave_homotopy, mob) for mob in mobjects]) self.wait(0.3) self.play(FadeOut(mobjects)) def func(t): return t * 0.5 * RIGHT mobjects = VGroup(TextMobject("Textt").scale(3), Square(), ).arrange_submobjects(RIGHT, buff = 2) self.play(*[PhaseFlow(func, mob, run_time = 2,) for mob in mobjects]) self.wait() self.play(FadeOut(mobjects)) line = Line(ORIGIN, RIGHT * FRAME_WIDTH, buff = 1) line.move_to(ORIGIN) dot = Dot() dot.move_to(line.get_start()) self.add(line, dot) self.play(MoveAlongPath(dot, line)) self.wait(0.3) self.remove(line) self.remove(dot) square = Square().scale(2) self.add(square) self.play(Rotating(square,radians = PI / 4, run_time = 2)) self.wait(0.3) self.play(Rotating(square,radians = PI, run_time = 2, axis = RIGHT)) self.wait(0.3) self.remove(square) square = Square().scale(2) self.add(square) self.play(Rotate(square, PI / 4, run_time = 2)) self.wait(0.3) self.play(Rotate(square, PI, run_time = 2, axis = RIGHT)) self.wait(0.3) self.remove(square) self.wait() mobject = RegularPolygon(3).scale(2) self.add(mobject) for n in range(4, 9): self.play(TransformFromCopy(mobject, RegularPolygon(n).scale(2))) self.wait(0.3) self.play(FadeOut(mobject)) self.wait()生成した動画
https://www.youtube.com/watch?v=a3blYTllCF0
以上。
- 投稿日:2021-01-23T14:04:36+09:00
Python の __name__ を理解する
Python で 以下のようなコードをよく目にする。
if __name__ == "__main__":これについては色々な記事があるが、自分なりにコードを実行してみてみるのが理解し易いため、ハンズオン形式で理解できるようにメモ。
結論
__name__ は、
実行ファイル内では __main__
外部から読み込まれた場合は 拡張子なしのファイル名
となる。
上記のことをつらつらと確認していく。
ディレクトリ構成
下記の構成を用意して動作確認した。
. ├── test1.py └── test2.py__name__ を出力してみる
test1.py 内で __name__ を出力するようにして実行する。
test1.pyprint('test1: ' + __name__)> .% python test1.py > test1: __main____name__ は __main__ と出力された。
外部ファイルから読み込んでみる
test2.py から test1.py を読み込んだ上で、test2.py 内でも __name__ を出力するようにして、test2.py を実行する。
test2.pyimport test1 print('test2: ' + __name__)> .% python test2.py > test1: test1 > test2: __main__test1.py の __name__ は test1 と出力され、test2.py の __name__ は __main__ と出力された。
つまり、実行ファイル内では __name__ が __main__ となり、外部から読み込まれた場合は __name__ が 拡張子なしのファイル名 となる。
結論
__name__ は、
実行ファイル内では __main__
外部から読み込まれた場合は 拡張子なしのファイル名
となる。
- 投稿日:2021-01-23T13:08:35+09:00
【Python】エラーメッセージの内容を理解する(2)
背景
自身がPython習得をすすめる上での備忘録ではありますが、エラーメッセージの読み解き方を、ここにまとめておきます。
前回、掲載しきれなかったエラーを掲載した『第二弾』です。先人たちの知恵をお借りするなどして解決できたことを、この場をお借りして感謝するとともに、大変恐縮ですが自分のメモとしても、こちらへまとめておきます。
開発環境
- Windows 10 Pro
- Python 3.9.0, 3.8.5
- Django 3.1.3
- PostgreSQL 13.1
- Nginx 1.19.5
- Gunicorn
- Putty 0.74
エラーメッセージ
9. ImportError(インポート・エラー)
from <モジュール名> import <オブジェクト名、関数名 など)>でモジュールに含まれていないオブジェクトをインポートしようとした場合などに発生する。大文字・小文字も区別されるため、タイプミスに注意。pythonfrom bs4 import BeautifulSoap # 誤...Soap→Soup from bs4 import BeautifulSoup # 正ターミナルImportError: cannot import name 'BeautifulSoap' from 'bs4' (/usr/local/~/python/3.9.0/・・・)【訳】
インポート(取り込み)エラーが発生:「bs4」から「BeautifulSoap」という名前のモジュールを取り込めません。
↓
『「BeautifulSoap」って名前のモジュールが取り込めないよ~!』ということ。※綺麗な石鹸(Soap)じゃなくて、美味しいスープ(Soup)ですよ~!^^
<注>
モジュール名やオブジェクト名は正しいか、対象のモジュールにそのオブジェクトが含まれているかは、公式ドキュメントなどを確認する癖を付けましょう
稀にライブラリがバージョンアップされた際に、そのオブジェクト名が変わったり、無くなったり(廃止されたり)します10. IndexError(インデックス・エラー)
- リストやタプルなどシーケンスオブジェクトに格納された値を
[インデックス]で取得する際、その範囲外の位置(要素数を超えたインデックス値)を指定することで起こる。pythonlist1 = ["あ", "い", "う", "え", "お"] print(list1[5]) # 誤...末尾の "お" は、インデックスでは [ 要素数-1] であるため、4 と指定するのが正解 print(list1[4]) # 正 # おターミナルIndexError: list index out of range【訳】
索引エラーが発生:リストの索引は範囲外です。
↓
『リスト型の索引の範囲外だよ~(...だから探しに行けないの...)』ということ。
リストやタプルの要素数はlen()関数で確認可能です。よく確認してからインデックスを指定しましょう。
ちなみに、インデックスは0から数えはじめますので、末尾は要素数-1番目になります。pythonlist1 = ["あ", "い", "う", "え", "お"] print(len(list1)) # 511. KeyError(キー・エラー)
- 辞書型(dict型)の値をキー指定して取得する際、存在しないキーを指定してしまうと起こる。
pythondict1 = {1 : "りんご" , 2 : "みかん", 3 : "ぶどう" , 4 : "バナナ"} print(dict1[5]) # 誤...'5' は、Key として存在しない print(dict1[4]) # 正 # バナナターミナルKeyError: 5【訳】
キーエラーが発生:'5'(が、キーエラーです。)
↓
(そのまま)『5 は キーエラーですな~』ということ。
キーの一覧は、keys()メソッドで確認しましょう。pythondict1 = {1 : "りんご" , 2 : "みかん", 3 : "ぶどう" , 4 : "バナナ"} print(dict1) # {1: 'りんご', 2: 'みかん', 3: 'ぶどう', 4: 'バナナ'} print(list(dict1.keys())) # [1, 2, 3, 4]
裏技?
get()メソッドを使うと、存在しないキーに対してもエラーになりません。
この場合、デフォルト値を取得することができます!pythonprint(dict1.get[5]) # None辞書に含まれるキーや、指定したキーが正しいかを、よく確認しましょう。
(指差し確認、安全よーし!!)12. AttributeError(アトリビュート・エラー)
- 属性(Attribute)の参照に関して起こる。
「<オブジェクト>.<識別子>」のようにメソッドなどを呼び出す際、オブジェクトや識別子(属性やメソッド)の名前、オブジェクトの型を間違えた場合に発生する。
大文字・小文字も区別されるため、タイプミスに注意。12-1.
- 識別子の名前を間違えた例:
pythonimport math print(math.PI) # 誤...PI→pi print(math.pi) # 正ターミナルAttributeError: module 'math' has no attribute 'PI'【訳】
属性エラー発生:'math' モジュールは 'PI' という属性を持ち合わせません。
↓
『「math」は「PI」なんて、持ってないってさ!』ということ。12-2.
- オブジェクトの型が想定と違った例:
pythoncounter = 60 counter.append(120)ターミナルAttributeError: 'int' object has no attribute 'append'【訳】
属性エラー発生:'int' オブジェクト(数値型オブジェクト)は 'append' という属性を持ち合わせません。
↓
『数値型オブジェクトに「append」なんて、備わってないってよ~』ということ。オブジェクト名、識別子名や、オブジェクトの型は想定通りか、をよく確認しましょう。
13. FileNotFoundError(ファイル・ノット・ファンド・エラー)
- ファイルを読み込む際など
open()で指定したファイルが見つからないときに起こる。pythonwith open('sample1.txt') as f: # sample1.txt は存在しない print(f.read())ターミナルFileNotFoundError: [Errno 2] No such file or directory: 'sample1.txt'【訳】
ファイルが見付からないエラーが発生:'sample1.txt' というファイルまたはディレクトリはありません。
↓
『「sample1.txt」 は ありまへんがな~』ということ。
指定したファイルやディレクトリは本当に存在している?
指定したパスは正しい?特に、相対パスで指定したときのカレントディレクトリは正しい?
(相対パスで指定した際、Pythonのカレントディレクトリが想定と異なっている可能性も考えられます。)14. FileExistsError(ファイル・イグジスツ・エラー)
- ファイルやディレクトリを作成しようとした際に、それが既に存在したときに起こる。(13.の逆パターン)
pythonimport os os.mkdir('sub_dir') # 'sub_dir' は既に存在しているターミナルFileExistsError: [Errno 17] File exists: 'sub_dir'【訳】
ファイルは存在するエラーが発生:'sub_dir' というファイル(またはディレクトリ)は存在します。
↓
『「sub_dir」 は もう在るやん!』ということ。指定したファイル(またはディレクトリ)はすでに存在していない?
<注>
python 3.2.x 以降では、os.makedirs()に引数exist_okが追加されています。
このため、exist_ok=Trueとした際には、既に存在しているディレクトリの作成を試みてもエラーとなりません。
(編集後記)
よく遭遇するエラーを集めてまとめてみました、の第二弾です。
エラーの内容、原因・理由を理解して、複雑なプログラミングをする際に、エラーが出ても慌てないようすることと、対処を適切に素早く施せるようにしたいですね。VS Code には、リアルタイムに文法をチェックしてくれる拡張機能もあるようですので、いろいろ試してみようと思います。
- 投稿日:2021-01-23T12:31:46+09:00
Flask APIでNo 'Access-Control-Allow-Origin...エラーの対処法
ReactからFlaskAPIを呼び出そうとしたらこんなエラーが。
No 'Access-Control-Allow-Origin.Origin 'null' is therefore not allowed access.' header is present on the requested resource errorJavaScriptが別のプロセスでホストされているHTTPリクエストを送ろうとすると出るエラーなので、Flask側で
CORS(Cross-Origin Resource Sharing)を有効にする。1.flask-corsをインストール
pip install -U flask-cors2.設定
main.py# -*- coding: utf-8 -*- from flask import Flask, jsonify from flask_cors import CORS # <-追加 import json app = Flask(__name__) CORS(app) # <-追加 @app.route('/', methods=['GET']) def sample(): ...これだけ!
Enjoy Hacking!?
- 投稿日:2021-01-23T12:03:02+09:00
サーマルカメラ(サーモ AI デバイス TiD) Python ヒートマップ作成
はじめに
サーマルカメラとしては、取得した温度データをヒートマップにしたいのです。
MH ソフトウェア&サービスでは、Raspberry Piを使用して実現したいので、温度データ -> ヒートマップ変換は、4種類ほど作成してみました。(高速化が必要だったのです。)使用機材
サーマルカメラ(サーモ AI デバイス TiD) Python AMG8833 番外編で使用したwebカメラとPanasonic AMG8833、Raspberry Piを使用して取得した温度データを使用してみます。
テスト用にwebカメラのレンズ付近に、Panasonic AMG8833を取り付けているだけの簡素な仕様です。
温度データは
この動画の一部の、指を開いている個所の温度データです。回転処理をしていませんので、ヒートマップの画像は180度回転しています。メインクラス(HeatMap)
このクラスからversion1.py ~ version4.pyを開きます。
それぞれ10回の処理を実行して、処理速度を比較します。処理はRaspberry Pi 4を使用しています。#!/usr/bin/env python # -*- coding:utf-8 -*- import numpy as np import PIL import PIL.Image import PIL.ImageTk import time import cv2 from version1 import Version1 from version2 import Version2 from version3 import Version3 from version4 import Version4 class HeatMap(): def __init__(self): self.heat_map = [ None, Version1(), Version2(), Version3(), Version4() ] def __call__(self): img = None timer = ProcessingTime() # Version1から4まで処理速度を比較してみます for version in range(1, 5): # 計測タイマリセット timer.get() # 処理回数は10回です for _ in range(10): img = self.heat_map[version](self.parameters) message = f'Version{version} {timer.get():.02f}[msec]' print(message) img = resize(img, self.parameters.size, self.parameters.size) cv2.imshow(message, img) cv2.waitKey(5000) while True: pass class parameters(): gain = 10 max = 40 min = 20 offset_x = 0.2 offset_green = 0.6 pixels = 8 * 8 size = 320 class ProcessingTime(): """ Return processing time [msec]. """ def __init__(self): self._start = time.time() def get(self) -> float: result = (time.time() - self._start) * 1000 self._start = time.time() return result def resize(image: np.ndarray, width: int, height: int) -> np.ndarray: result = cv2.resize(image, (width, height), cv2.INTER_CUBIC) return result if __name__ == '__main__': heat_map = HeatMap() heat_map()Version1クラス
webからサンプルを取得して作成したクラスです。ごめんなさい。引用元が不明になってしまいました。
処理時間: 3,907[msec]
ヒートマップは、指だな?と感じられます。
for文を多用しているせいか、これ以上の高速化は望めませんでした。色のブレンドはカッコ良いと思います。元ソースに感謝です。version1.py
#!/usr/bin/env python # -*- coding:utf-8 -*- import math from colour import Color import numpy as np from scipy.interpolate import griddata from temp_data import temp_data class Version1(): # クラスにする必要は無いと思います def __call__(self, parameters: dict) -> np.array: color_depth = 1024 pixels = temp_data() pixels = [ map_value( p, parameters.min, parameters.max, 0, color_depth - 1) for p in pixels] sqrt = int(parameters.pixels ** 0.5) points = [( math.floor(ix / sqrt), (ix % sqrt)) for ix in range(0, sqrt * sqrt)] grid_x, grid_y = np.mgrid[ 0: (sqrt - 1): 32j, 0: (sqrt - 1): 32j] bicubic = griddata( points, pixels, (grid_x, grid_y), method='cubic') low = Color('darkblue') high = Color('red') colors = list(low.range_to(high, color_depth)) img = [[[255] * 3] * bicubic.shape[0]] * bicubic.shape[1] img = np.asarray(img) # やはりfor文を使うと時間がかかります for ix, row in enumerate(bicubic): for jx, pixel in enumerate(row): rgb = colors[ constrain( int(pixel), 0, color_depth- 1 )].rgb img[ix, jx, 0] = rgb[2] * 255 img[ix, jx, 1] = rgb[1] * 255 img[ix, jx, 2] = rgb[0] * 255 img = img.astype('uint8') return img def constrain(val: int, min_val: int, max_val: int) -> int: return min(max_val, max(min_val, val)) def map_value(x: int, in_min: int, in_max: int, out_min: int, out_max: int) -> float: result = 0 try: result = (x - in_min) * (out_max - out_min) / (in_max - in_min) + out_min except: pass return result if __name__ == '__main__': passVersion2クラス
Version1クラスで、高速化が望めず、それならばnumpyで処理!と意気込んで作成したクラスです。
処理時間: 25[msec]
ヒートマップは、なんとか指だな?と感じられます。
黄色が足らない・・・。と感じます。ほぼ、青と赤ですね・・・。
数値と色変換が甘く、赤成分と青成分のみ演算しています。#!/usr/bin/env python # -*- coding:utf-8 -*- import numpy as np from temp_data import temp_data class Version2(): # クラスにする必要は無いと思います def __call__(self, parameters: dict) -> np.array: sqrt = int(parameters.pixels ** 0.5) img = np.zeros((sqrt, sqrt, 3), dtype='uint8') pitch = (parameters.max - parameters.min) / 255 for x in range(sqrt): for y in range(sqrt): temp = temp_data()[x * 8 + y] img[x, y, 2] = (temp - parameters.min) / pitch img[x, y, 0] = (parameters.max - temp) / pitch return img if __name__ == '__main__': passVersion3クラス
処理時間: 3[msec]
もはや、何が表示されているかわかりません。
緑成分を入れようと作成を始めたのですが、温度から緑ってどうするんだろう?と悩んだ結果です。#!/usr/bin/env python # -*- coding:utf-8 -*- import numpy as np from temp_data import temp_data class Version3(): # クラスにする必要は無いと思います def __call__(self, parameters: dict) -> np.array: temp = np.array(temp_data()) temp *= 1.5 temp = temp.reshape(8, 8) blue = temp - parameters.min green = 0 red = parameters.max - temp sqrt = int(parameters.pixels ** 0.5) img = np.zeros((sqrt, sqrt, 3), dtype='uint8') pitch = (parameters.max - parameters.min) / 255 img[:, :, 0] = 255 - blue / pitch img[:, :, 1] = green img[:, :, 2] = 255 - red / pitch return img if __name__ == '__main__': passVersion4クラス
処理時間: 10[msec]
ヒートマップは、指だな?と感じられます。
webでいろいろ情報を集めたところ、シグモイド関数を使うと、良いらしいことが分かりました。
画像データをnumpy.ndarrayで処理できるように、def sigmoid()を作成しました。現在のサーモ AI デバイス TiDは、この処理を用いています。
#!/usr/bin/env python # -*- coding:utf-8 -*- import numpy as np from temp_data import temp_data class Version4(): def __call__(self, parameters: dict) -> np.array: self.parameters = parameters width = self.parameters.max - self.parameters.min temp = np.array(temp_data()) temp = temp - self.parameters.min temp = temp / width temp = temp.reshape(8, 8) sqrt = int(self.parameters.pixels ** 0.5) img = np.zeros((sqrt, sqrt, 3), dtype='uint8') img[:, :, 0]\ = self.color_bar_rgb(temp)[0] img[:, :, 1]\ = self.color_bar_rgb(temp)[1] img[:, :, 2]\ = self.color_bar_rgb(temp)[2] return img def color_bar_rgb(self, x: np.ndarray) -> list: """ Return list of numpy.ndarray. """ x = (x * 2) - 1 red = sigmoid(x, self.parameters.gain, -1 * self.parameters.offset_x) blue = 1 - sigmoid(x, self.parameters.gain, self.parameters.offset_x) green = sigmoid(x, self.parameters.gain, self.parameters.offset_green) green += (1 - sigmoid( x, self.parameters.gain, -1 * self.parameters.offset_green)) green = green - 1.0 blue = blue * 255 green = green * 255 red = red * 255 return [blue, green, red] def sigmoid(x: np.ndarray, gain=1, offset_x=0) -> np.ndarray: return ((np.tanh(((x + offset_x) * gain) / 2) + 1) / 2) if __name__ == '__main__': passまとめ
Version1 Version2 Version3 Version4 指です 指です なんとなく指かも? 指です





