- 投稿日:2021-01-23T23:20:35+09:00
Lambda(Python)でDynamo DBに接続しようとした際に"Unable to marshal response: Object of type SSLError is not JSON serializable"が出た件について
下記の記事を参考にして、Amplifyプロジェクト内にDynamo DBに接続するLambda関数を実装していたところ、タイトルにあるエラーが出ました。
AWS API GatewayとLambdaでDynamoDB操作
この記事では、その対処方法を備忘録代わりに記載します。
環境
- Windows10 20H2
- WSL2 - Ubuntu-20.04
- Amplify CLI 4.41.0
- Python 3.8.5
- pipenv 2020.11.15
症状
冒頭の記事を参考にして、一部を書き換えながら試していたとき、タイムアウトのエラーが起こりました。
START RequestId: 04359089-637f-48f3-aa2b-e7649c53e4d1 Version: $LATEST {'OperationType': 'SCAN'} END RequestId: 04359089-637f-48f3-aa2b-e7649c53e4d1 REPORT RequestId: 04359089-637f-48f3-aa2b-e7649c53e4d1 Duration: 25025.37 ms Billed Duration: 25000 ms Memory Size: 128 MB Max Memory Used: 73 MB Init Duration: 350.04 ms 2021-01-23T11:46:56.775Z 04359089-637f-48f3-aa2b-e7649c53e4d1 Task timed out after 25.03 secondsLambda関数デフォルトのタイムアウトが25秒だったので、それを+1分して実行したところ、下記のエラーが根本のエラーであることがわかりました。
Response: { "errorMessage": "Unable to marshal response: Object of type SSLError is not JSON serializable", "errorType": "Runtime.MarshalError" } Request ID: "7dceb7ee-1a1c-4361-b22e-00e489d1264f" Function logs: START RequestId: 7dceb7ee-1a1c-4361-b22e-00e489d1264f Version: $LATEST {'OperationType': 'SCAN'} Error Exception. [ERROR] Runtime.MarshalError: Unable to marshal response: Object of type SSLError is not JSON serializableEND RequestId: 7dceb7ee-1a1c-4361-b22e-00e489d1264f REPORT RequestId: 7dceb7ee-1a1c-4361-b22e-00e489d1264f Duration: 25721.98 ms Billed Duration: 25722 ms Memory Size: 128 MB Max Memory Used: 74 MB Init Duration: 388.41 msSSL関係でエラーが出ているようですね。
原因
調べてみると、以下の記事にヒントがあり、
certifiのバージョンによって不具合があるとのことでした。Lambdaでboto3を使ってDevice Shadowを取得しようとしたらSSLでエラーが起きたから応急処置をする
自身の環境を確認してみると、
certifi==2019.11.28でした。$ pipenv graph ... certifi==2019.11.28 ...対処
ということで、Pipfileに最新のバージョンを設定してみました。
Pipfile
[[source]] name = "pypi" url = "https://pypi.org/simple" verify_ssl = true [dev-packages] [packages] certifi = "2020.12.5" [requires] python_version = "3.8"Lambdaのテストを実行してみたところ、問題なくDynamodbに接続することができました。
START RequestId: f7c621d7-ee5b-41ca-a4c3-5ab78c8fa103 Version: $LATEST Received event: "{\r\n\"OperationType\": \"SCAN\"\r\n}" END RequestId: f7c621d7-ee5b-41ca-a4c3-5ab78c8fa103 REPORT RequestId: f7c621d7-ee5b-41ca-a4c3-5ab78c8fa103 Duration: 283.60 ms Billed Duration: 284 ms Memory Size: 128 MB Max Memory Used: 76 MB Init Duration: 353.24 msまとめ
自分の環境だけ、たまたま古いパッケージが入っていたのか、Amplifyで作ったパッケージがすべてこうなるのかはよくわかりません。
Pythonを触るのはLambdaを書くときだけなので、解決にも時間がかかってしまいました。ただ、このトラブルシュートでPythonにもAmplifyにも少し詳しくなることができたのでよかったです。
- 投稿日:2021-01-23T22:38:45+09:00
AWS re:Invent 2019: SaaS Tenant Isolation Patterns(SaaS テナント分離パターン) (ARC372-P)
動画 https://www.youtube.com/watch?v=fuDZq-EspNA
テナント分離は、SaaS アーキテクチャーの最も基本的な側面の 1 つです。すべての SaaS プロバイダーは、提供するテナントリソースの分離と安全を確保する手段について考察する必要があります。その際の課題となるのは、各リソースタイプ(コンピューティング、ストレージ、その他)で、異なる分離アプローチが要求されるということです。このセッションでは、分離オプションの全体像を概観できる、明確なロードマップを作成します。さまざまなマルチテナントモデルと AWS のサービスに広がる分離を達成するための、戦略についてもハイライトしていきます。SaaS ソリューションに分離を導入する際のアプローチに影響を与え得る考慮事項についての、包括的な理解を得ることを目標にします。
descriptionより
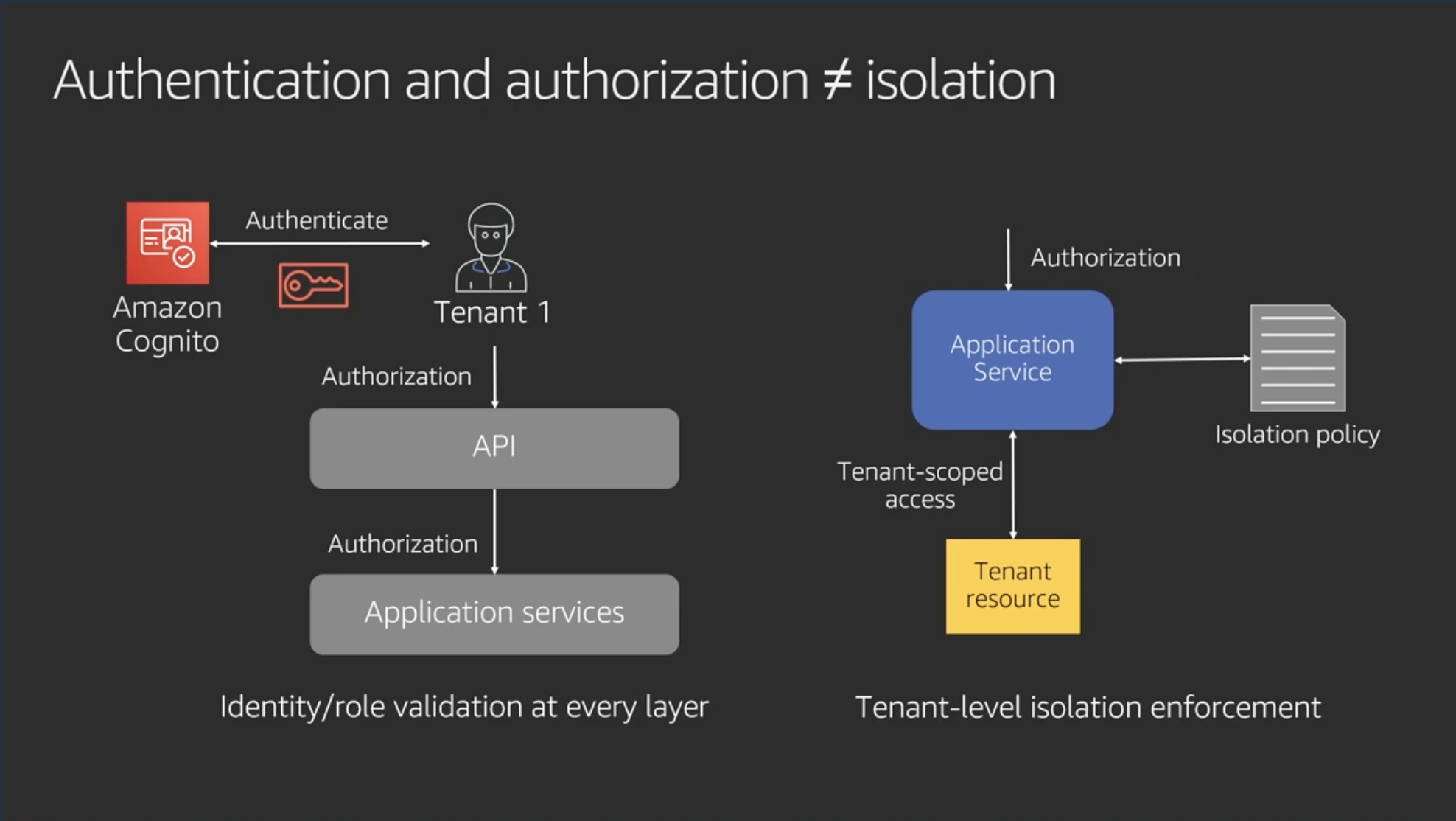
Authentication and authorization ≠ isolation
認証認可とは異なる新たなテナント分離のレイヤを追加することにより、各テナントのリソースを分離する
Isolation strategy drivers
- Tiering Strategy: 複数の方法でテナント分離する
- Noisy neighbor: あるテナントのアクセス(DoS等?) を他のテナントに影響させない
- Compliance requirements: 金融とかで各種レギュレーションに従うため、テナント分離の方法に制約がかかるかもしれない。設計に影響するのでよく確認してね
- Legacy architecture: 現在の実装も考慮してね
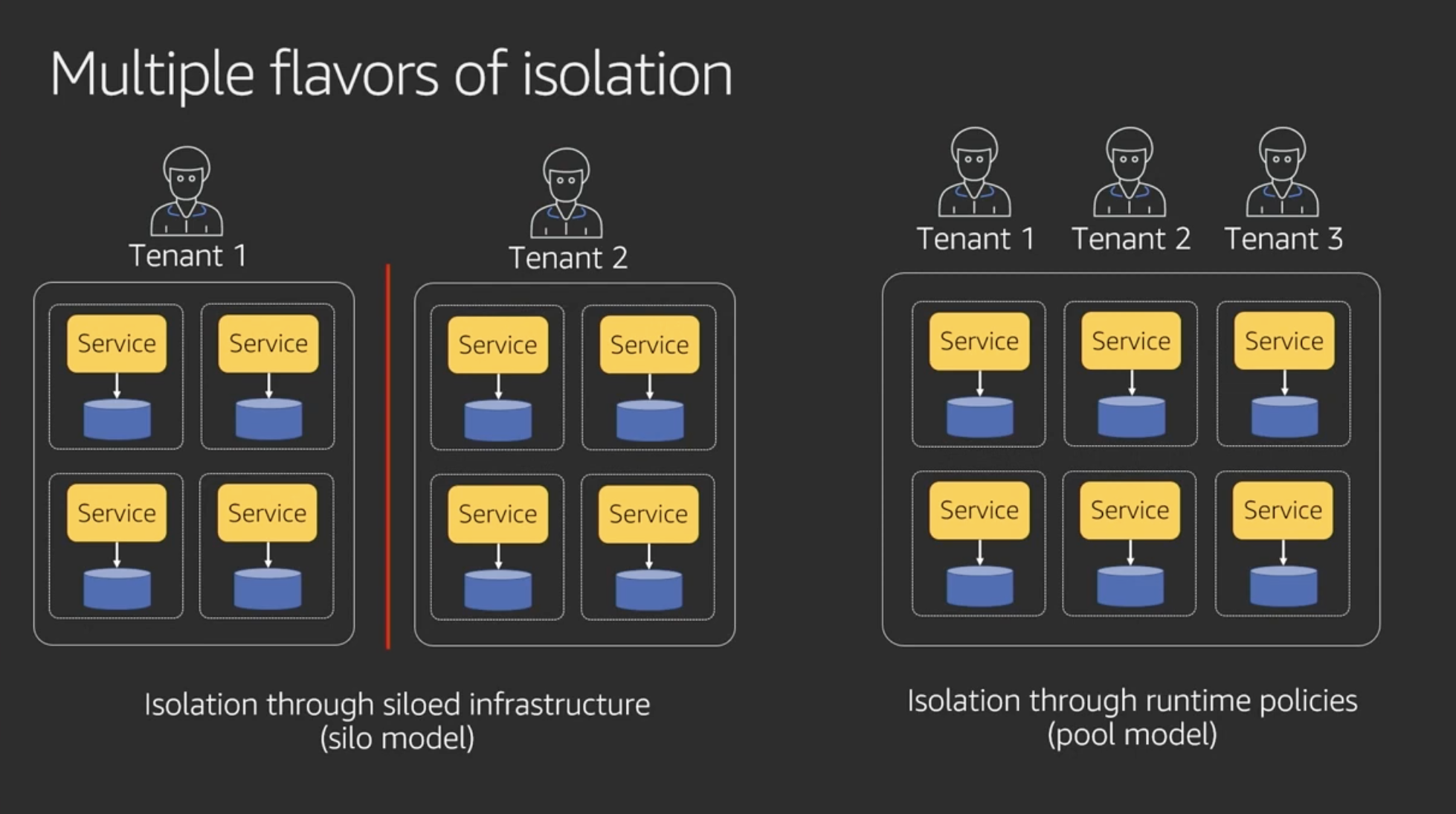
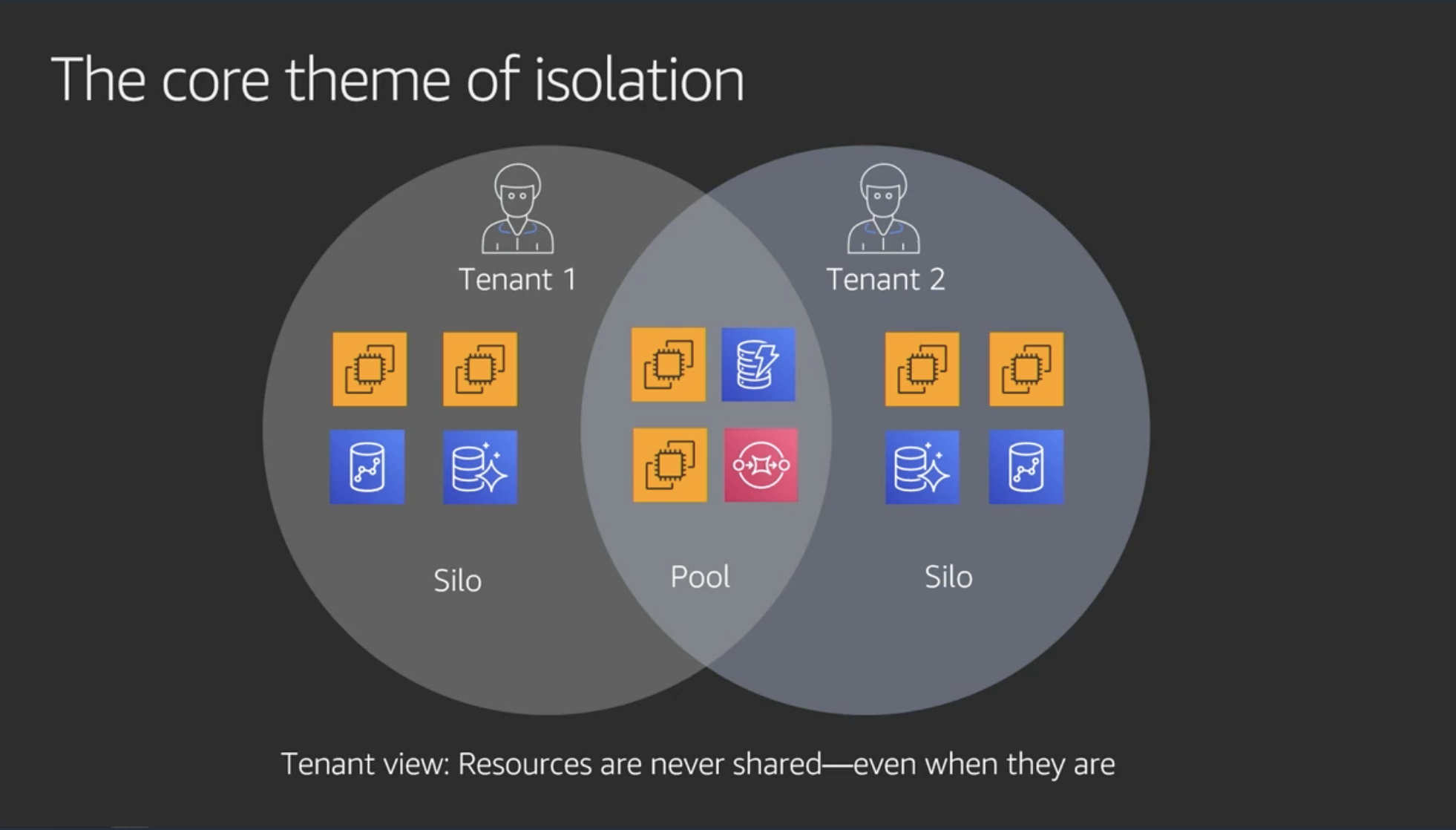
Multiple flavors of isolation
- Silo model: リソース全部分離する。VPCとかも
- Pool model: リソースを共有する。ポリシーで分離する
- メモ:なるほどなあ。顧客によって要求が違うから、サービスによっては両方の方式でテナント分離を提供できないといけないと
- メモ:両方の方式で提供はかなりハードになるだろうな
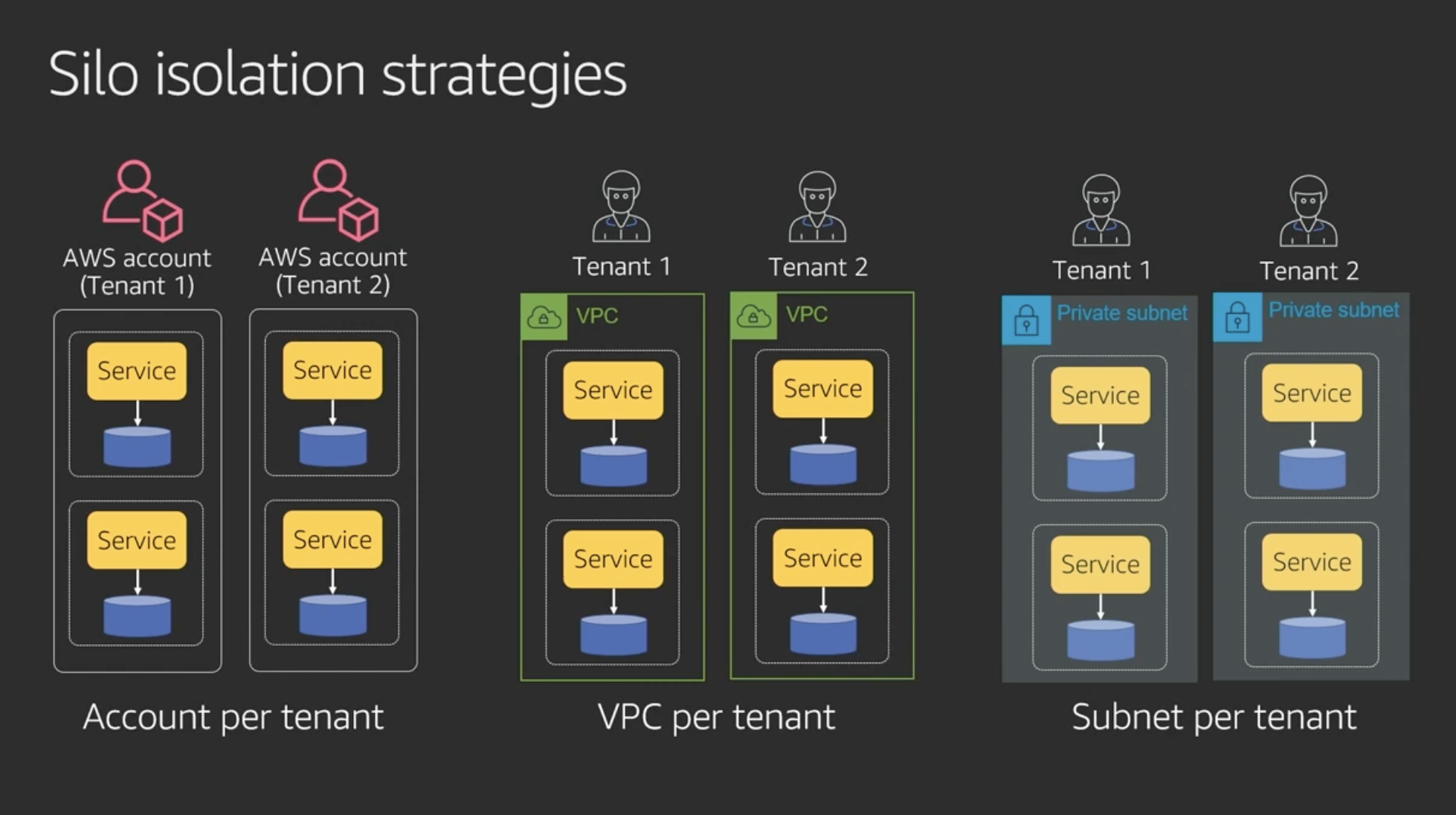
Silo isolation strategies
Silo modelの戦略。それぞれメリデメあるが、VPCレベルが一番common
統合すべきところと分離すべきところ
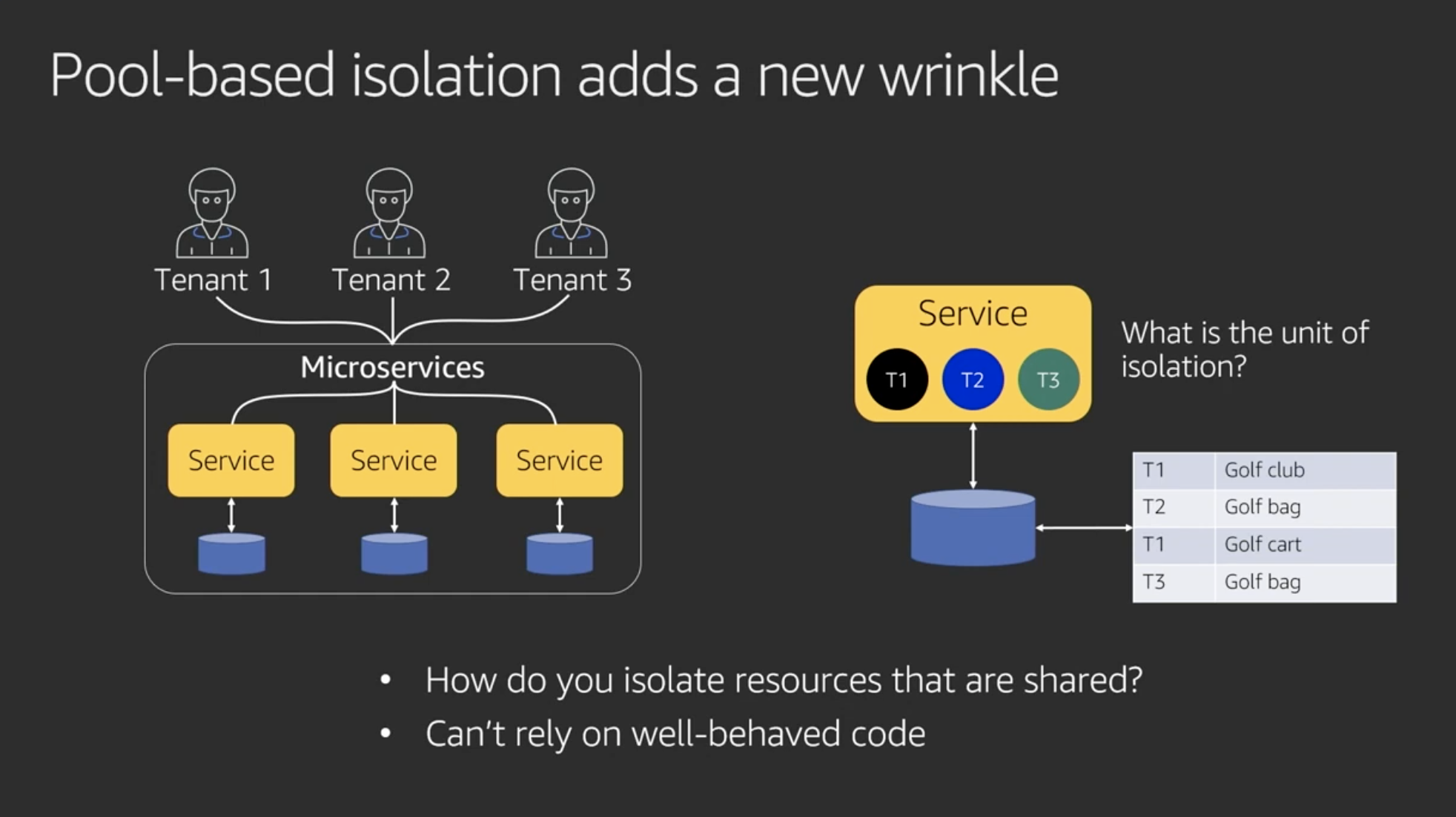
Pool-based isolation adds a new wrinkle
ベストプラクティスとは言えない
自然には全く分離されてない。コンプライアンス的にもよくない。分離されるかどうか開発者に委ねられる。
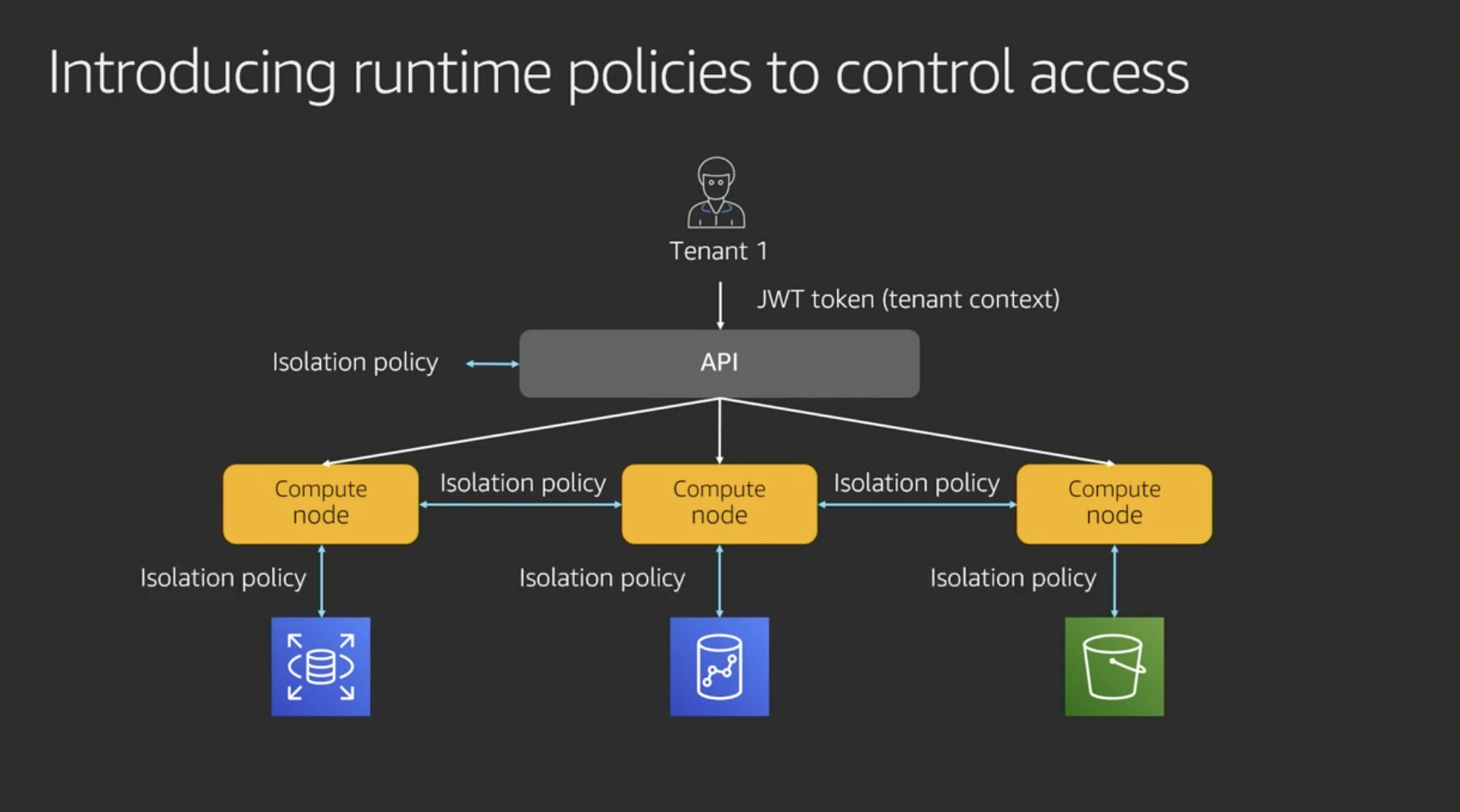
認証レイヤや各リソースで分離ポリシーを共有することによりテナントを分離する(いったん概念のみ)
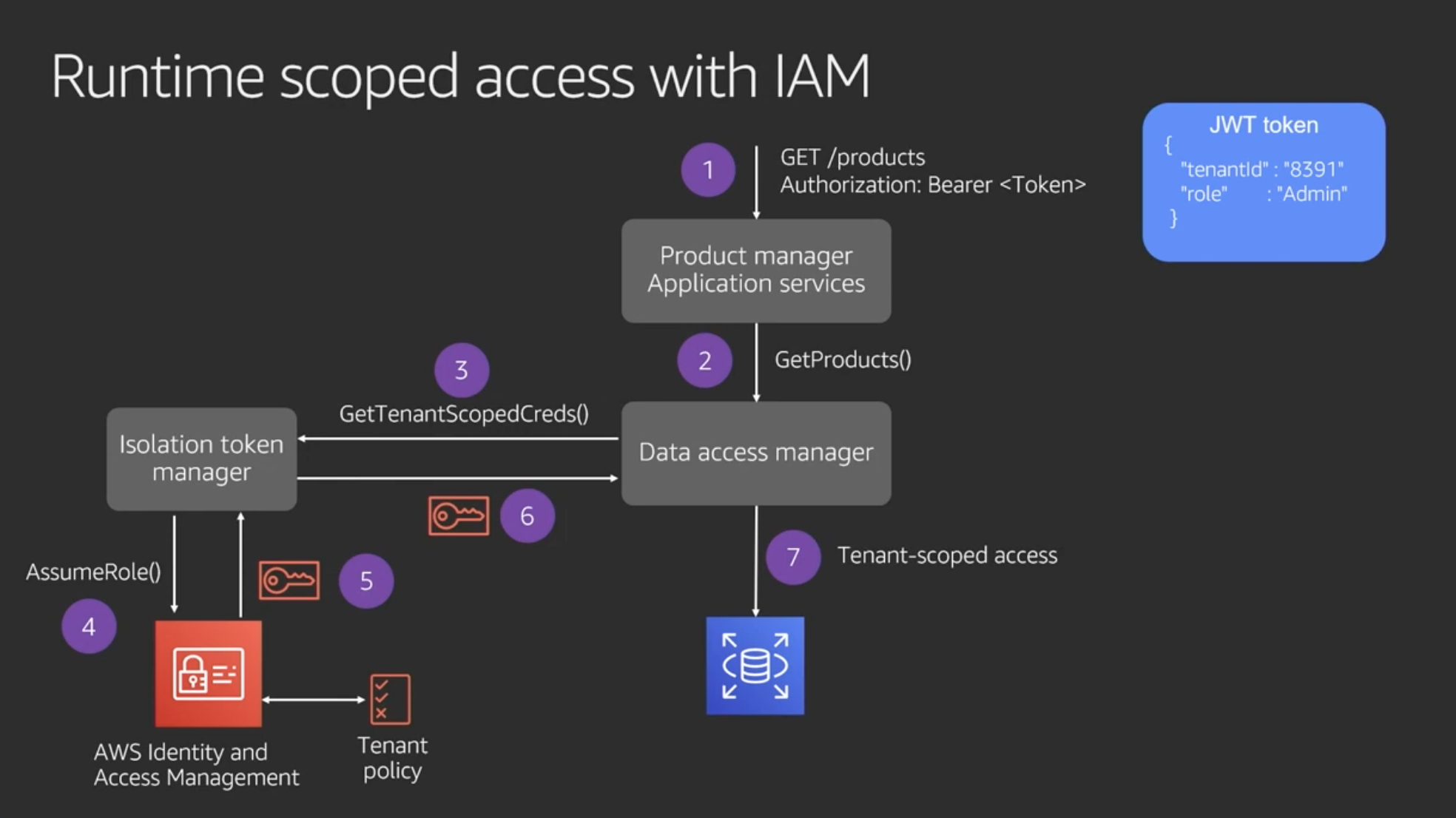
Runtime scoped access with IAM
実装の概要(ビデオ 19:47 あたりから)
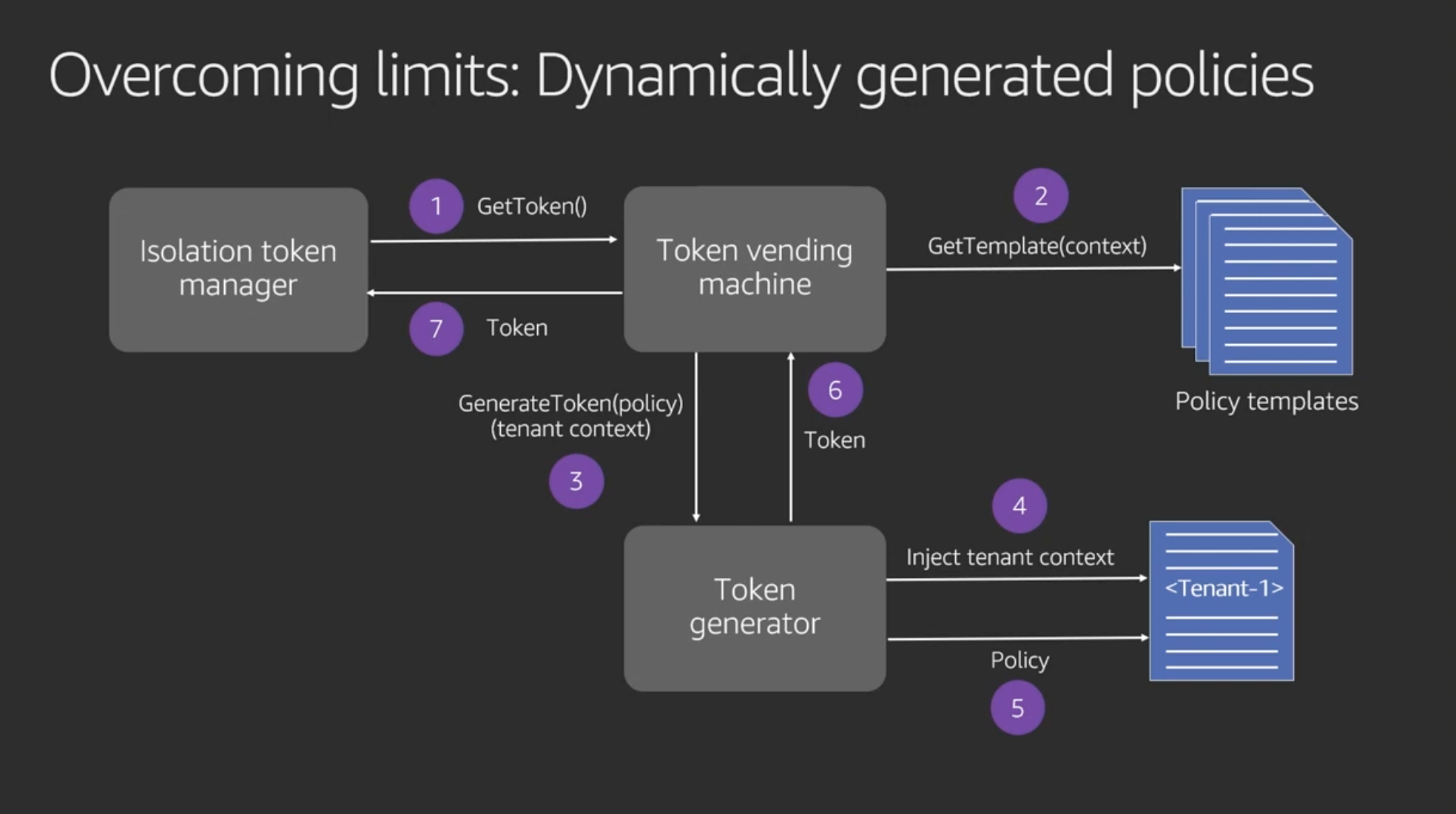
動的ポリシー生成
現実的には、顧客は自分のデータは自分が持っていると思っている。SiloだろうとPoolだろうとどんなテナント分離戦略を取ったとしても、このシステムは他のテナントにデータが保存されたり、他のテナントのデータが見えたりすることがないということをことを保証しないといけない。
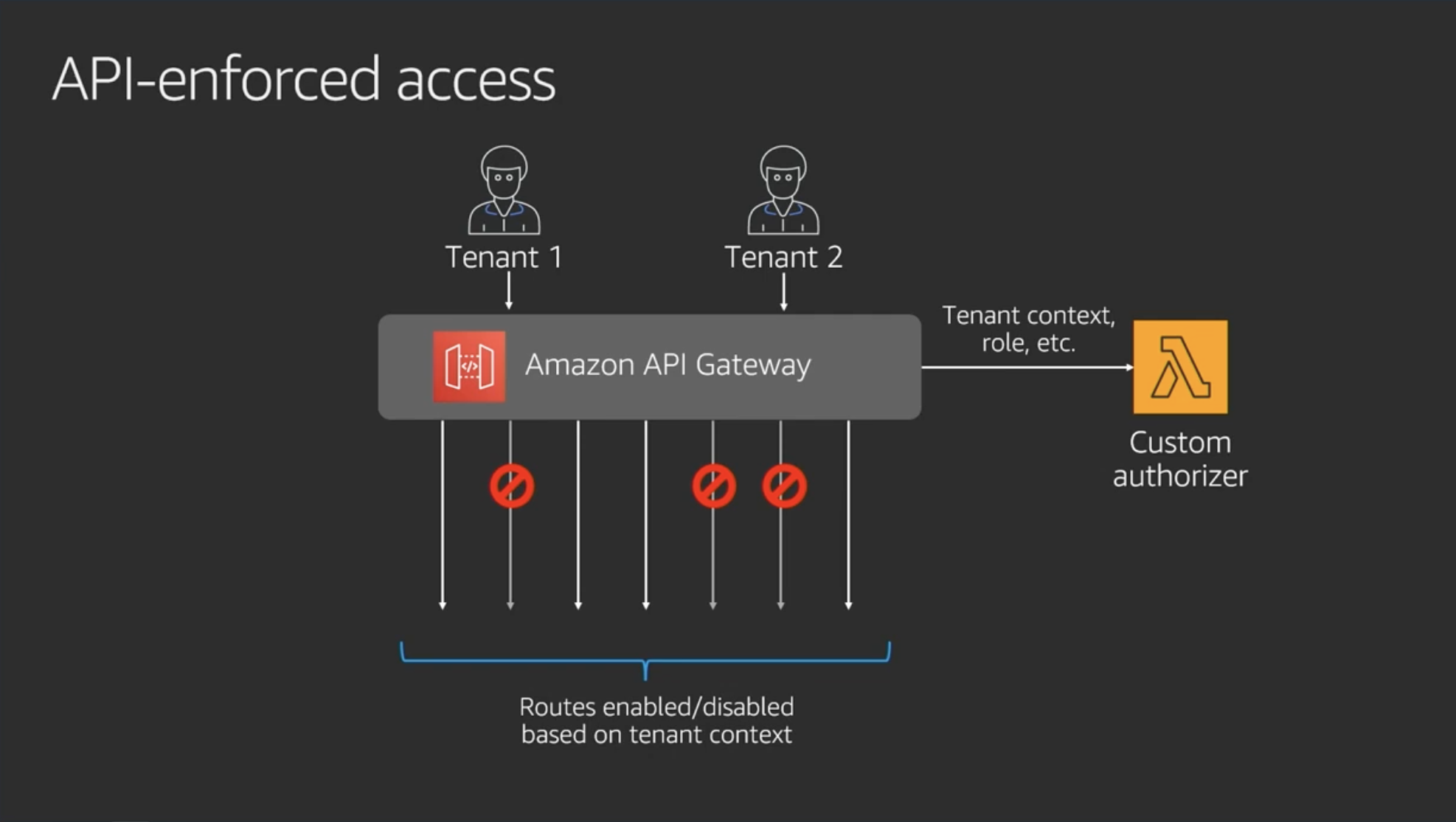
API-enfoced access
API GatewayにLambdaカスタム認証を入れることでテナントポリシーを付与
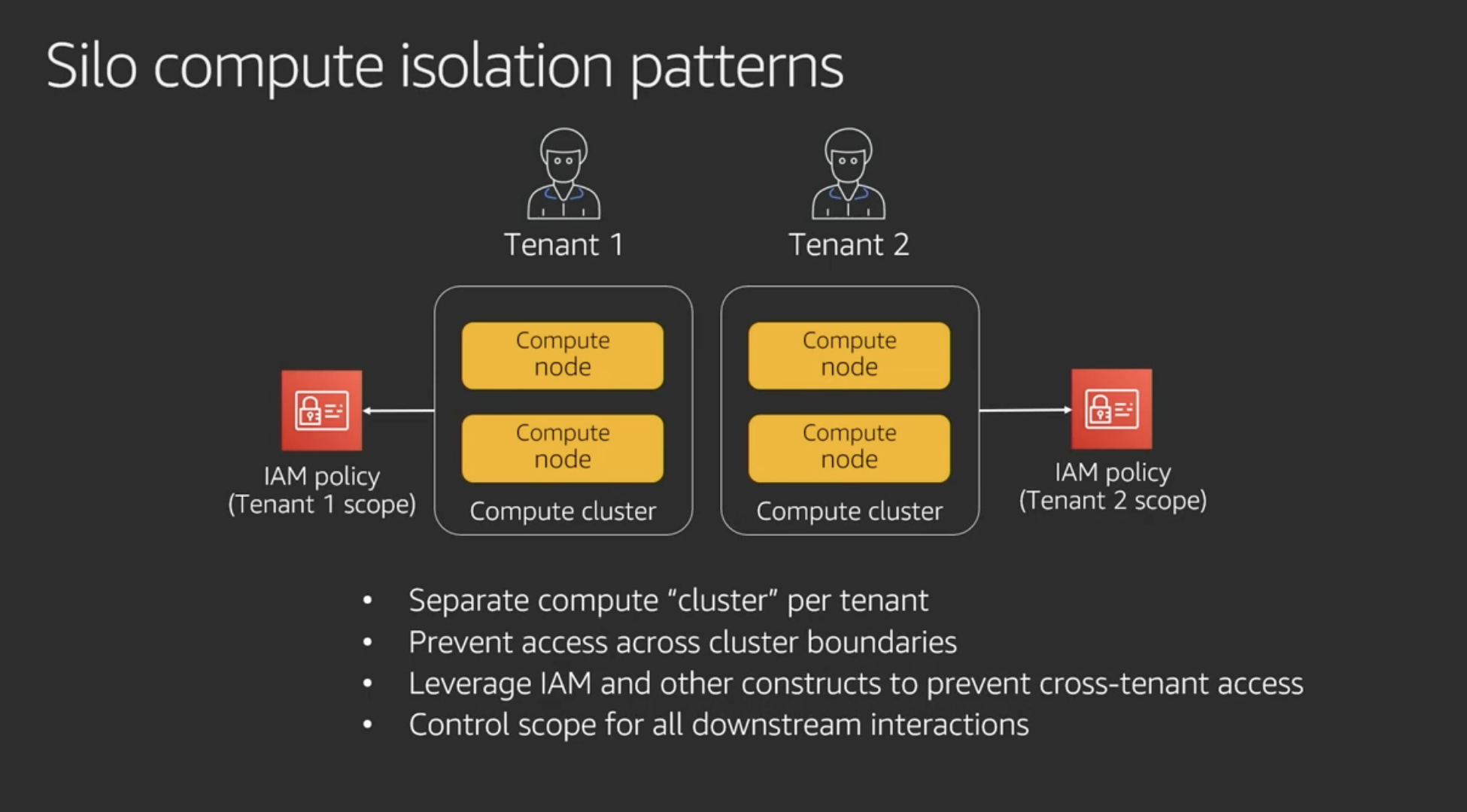
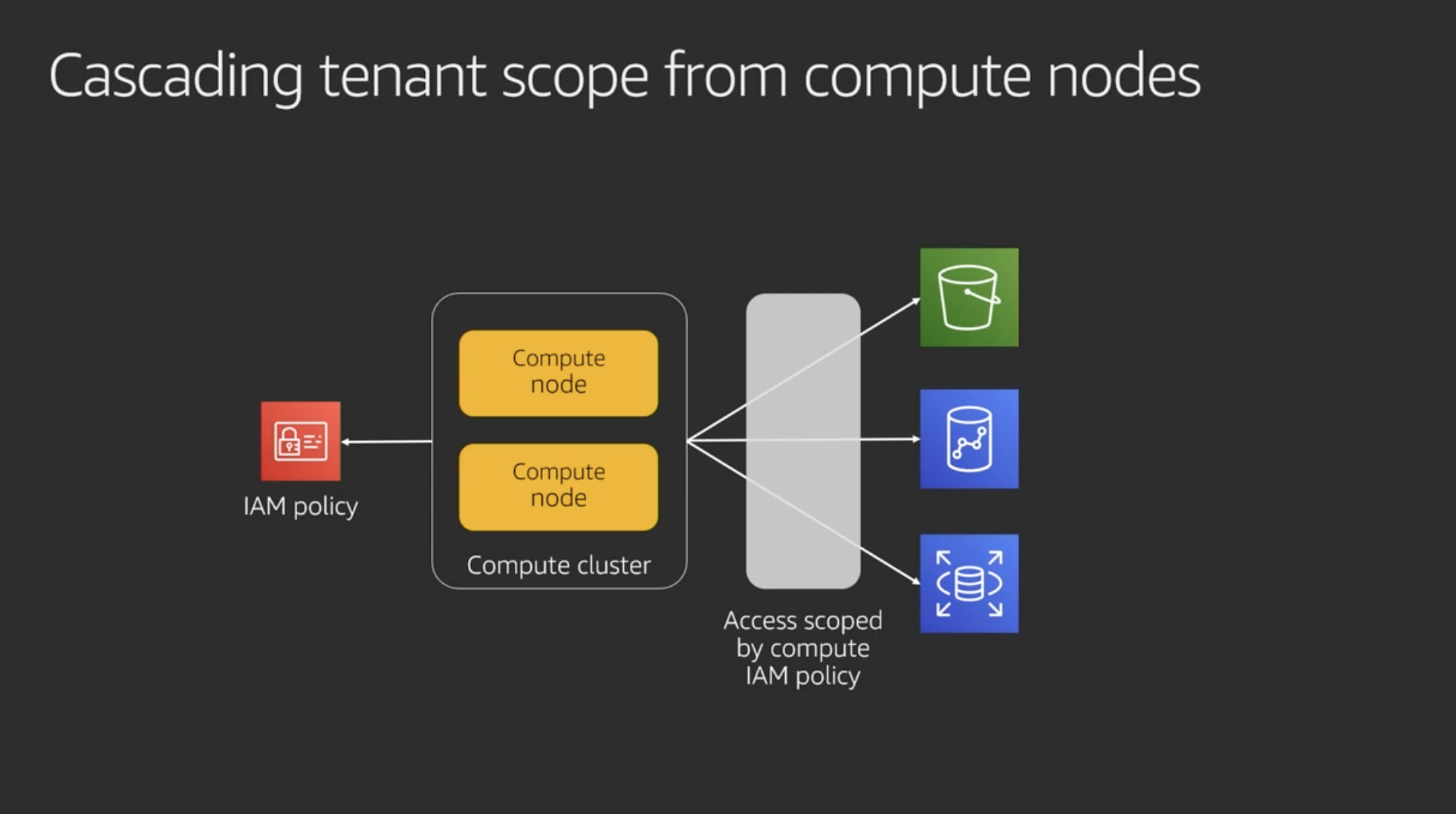
Silo compute isolation patterns
Silo modelでやるにしてもIAMで制御すべき
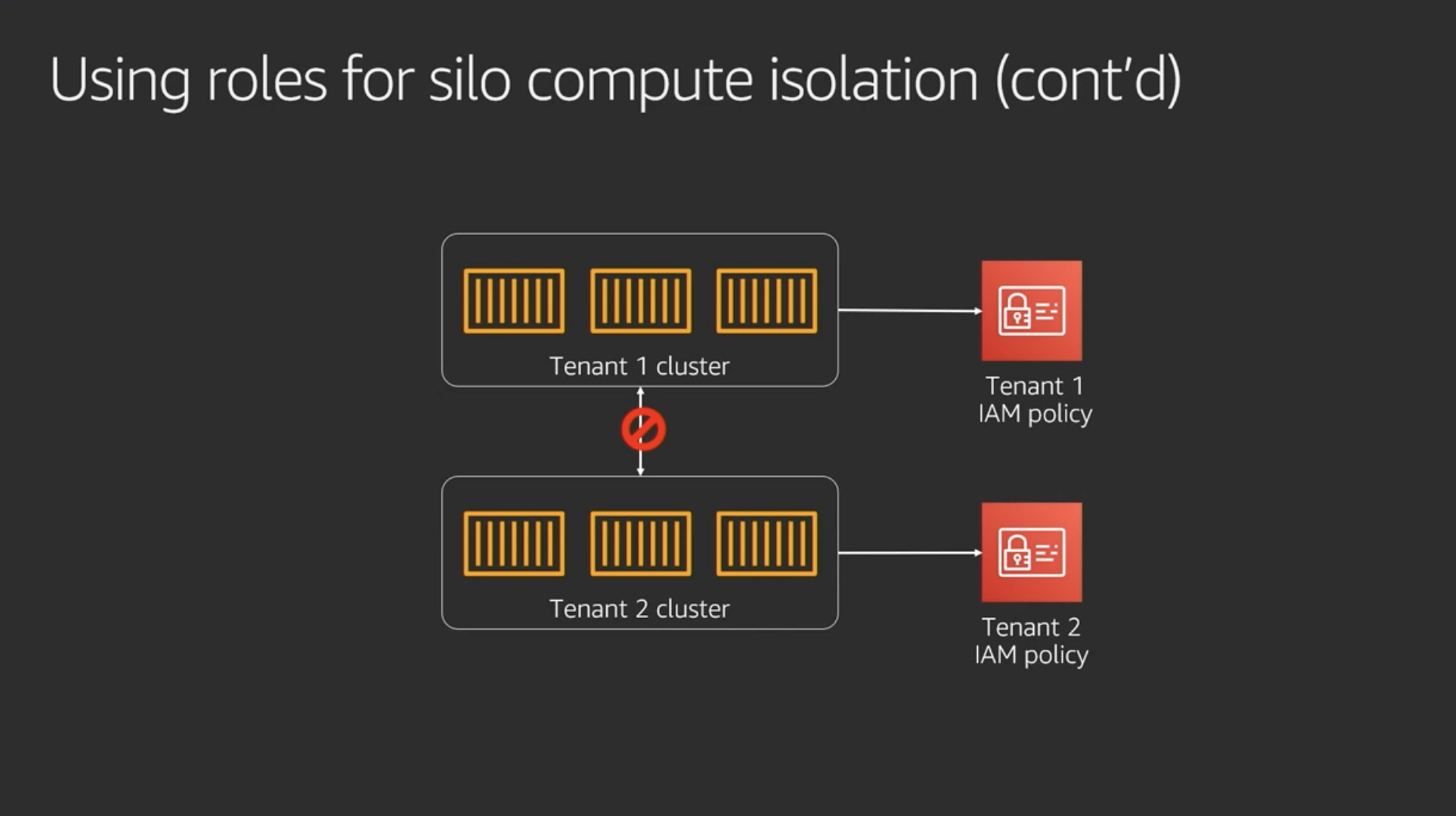
Using roles for silo compute isolation
コンピュートリソースの分離
コンテナの場合も同様
ポリシーをリソースをまたいで連動 (cascading) させることでテナント分離の管理がシンプルになる
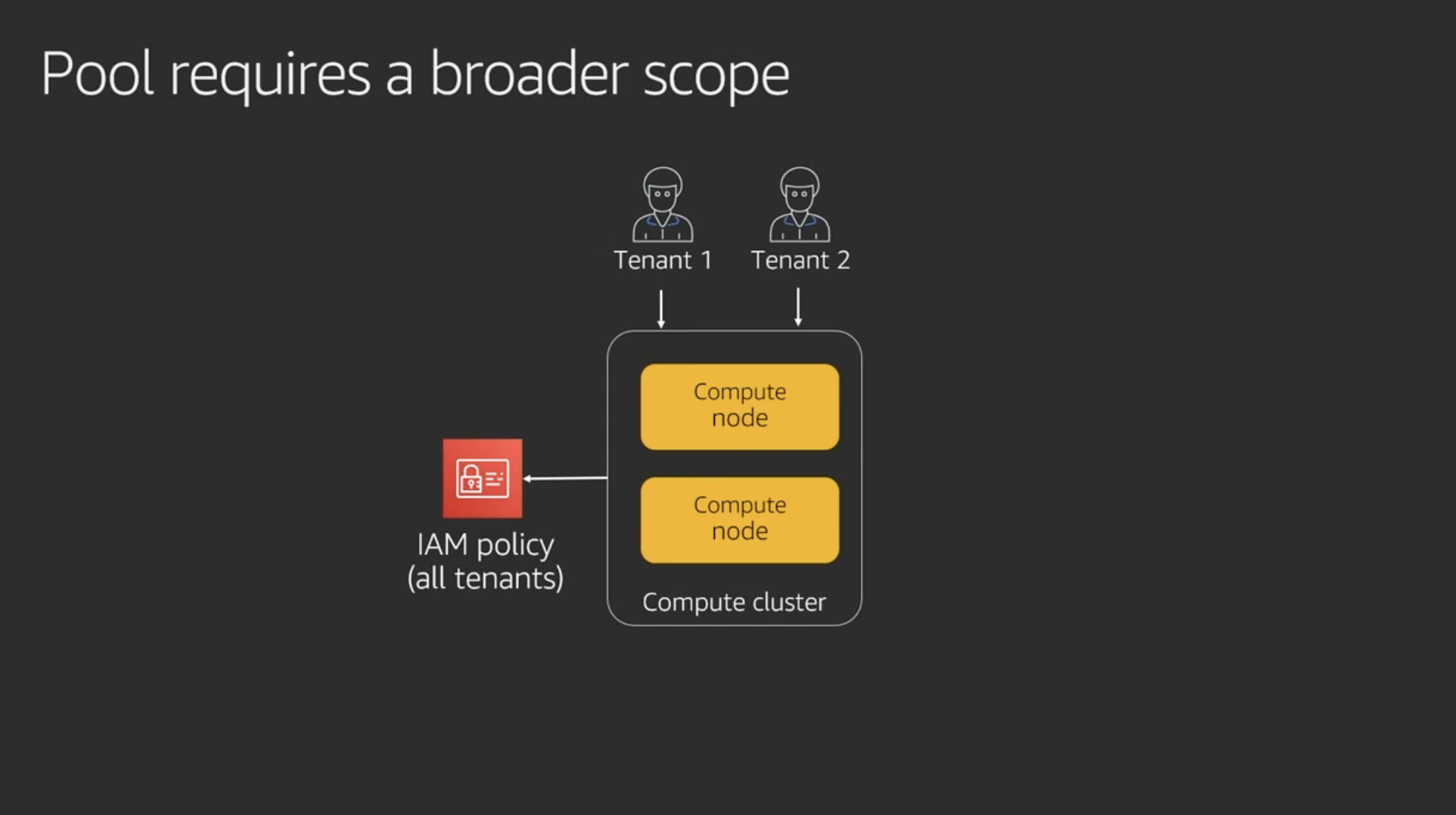
Pool requires a broader scope
Poolの場合、IAMポリシーはSiloの場合よりも許可の範囲が広くなる
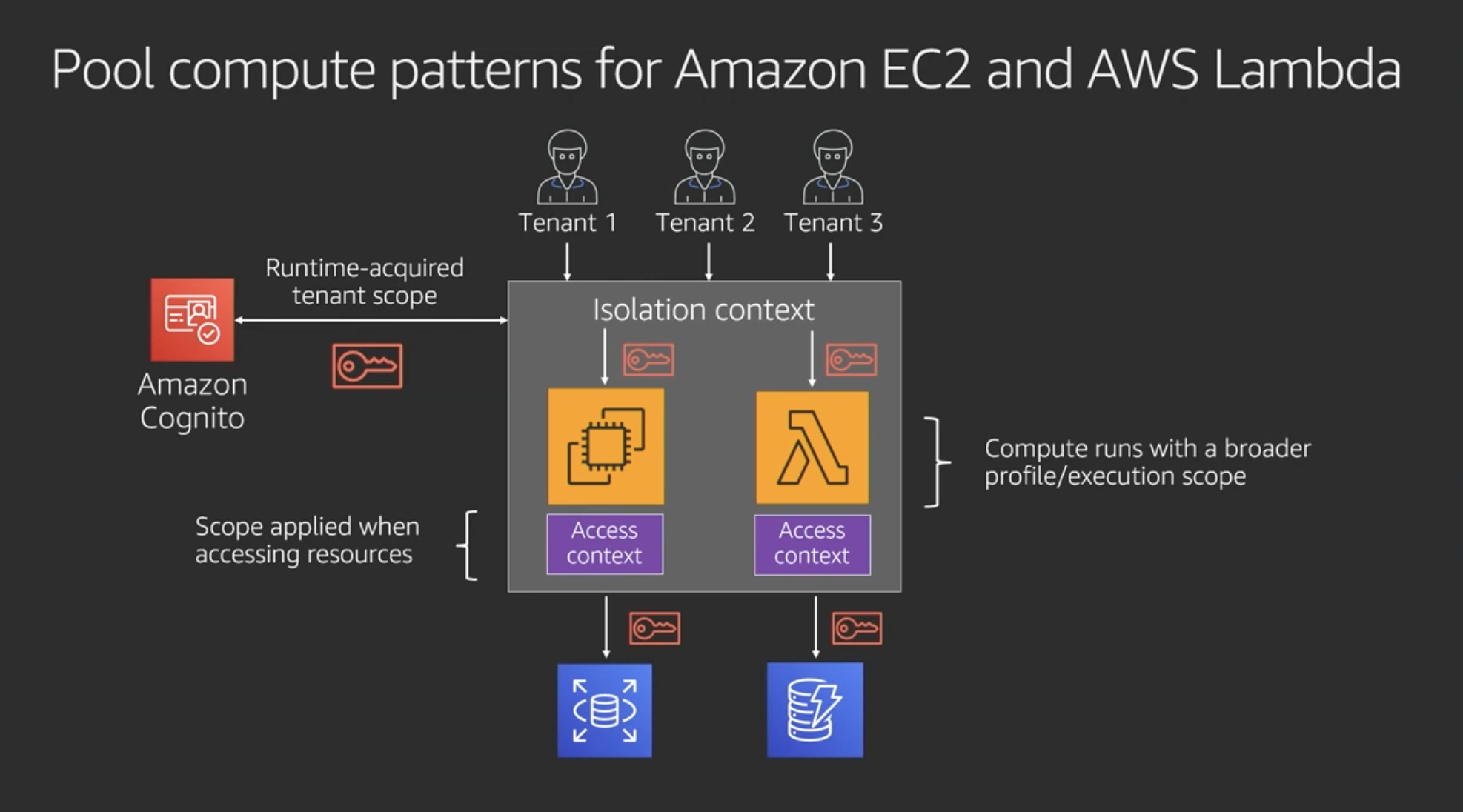
Pool compute patterns for Amazon EC2 and AWS Lambda
EC2とLambdaでpoolするパターン
- CognitoからEC2やLambdaを実行するIAMポリシー取ってくる(多くのテナントで利用できるよう幅広なポリシーが設定されてる)
- 分離コンテキストの外にあるRDSやDynamoDBといったリソースにアクセスする時は別のアクセスコンテキストが適用される
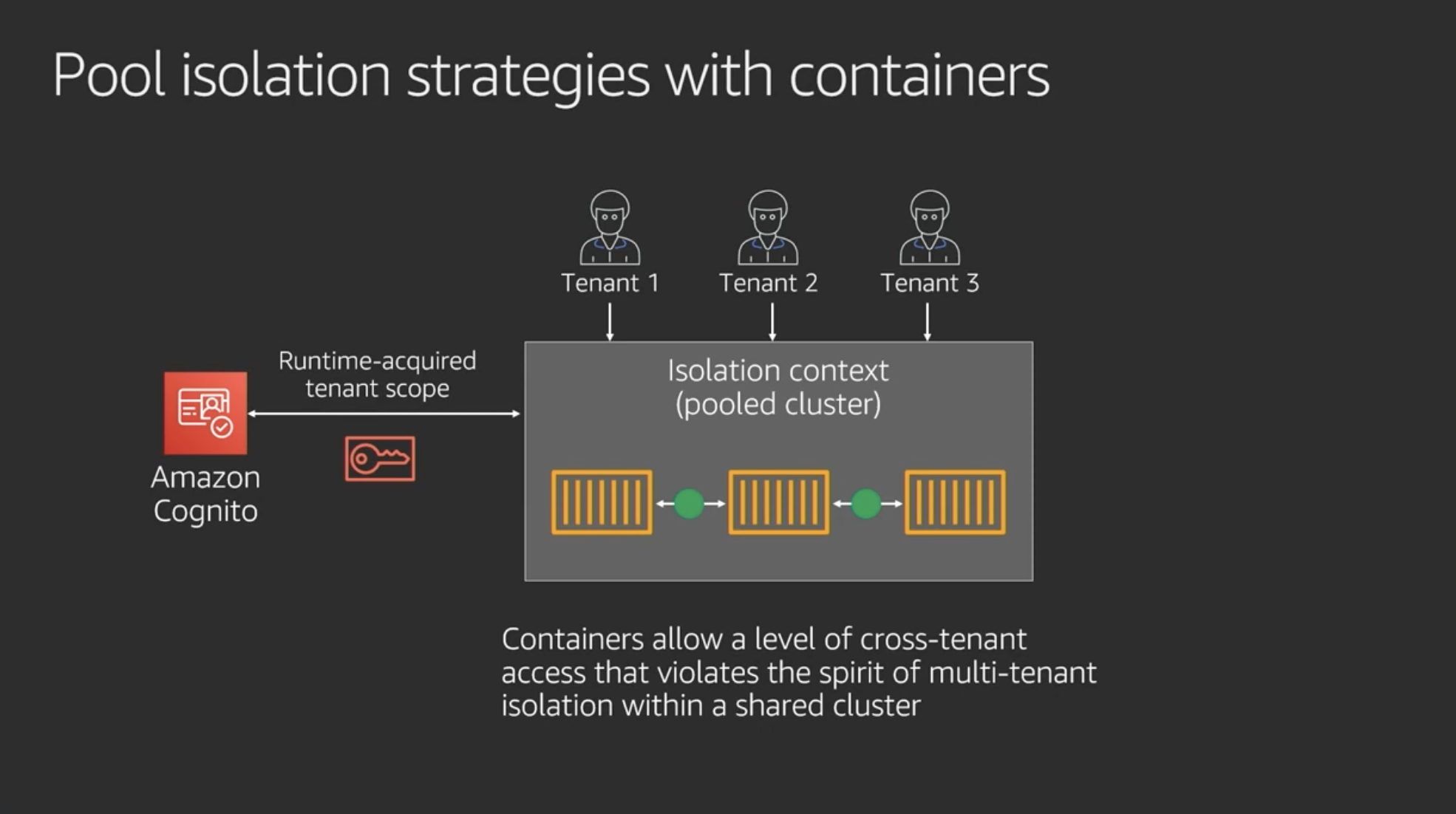
コンテナだと違った分離の方法になる
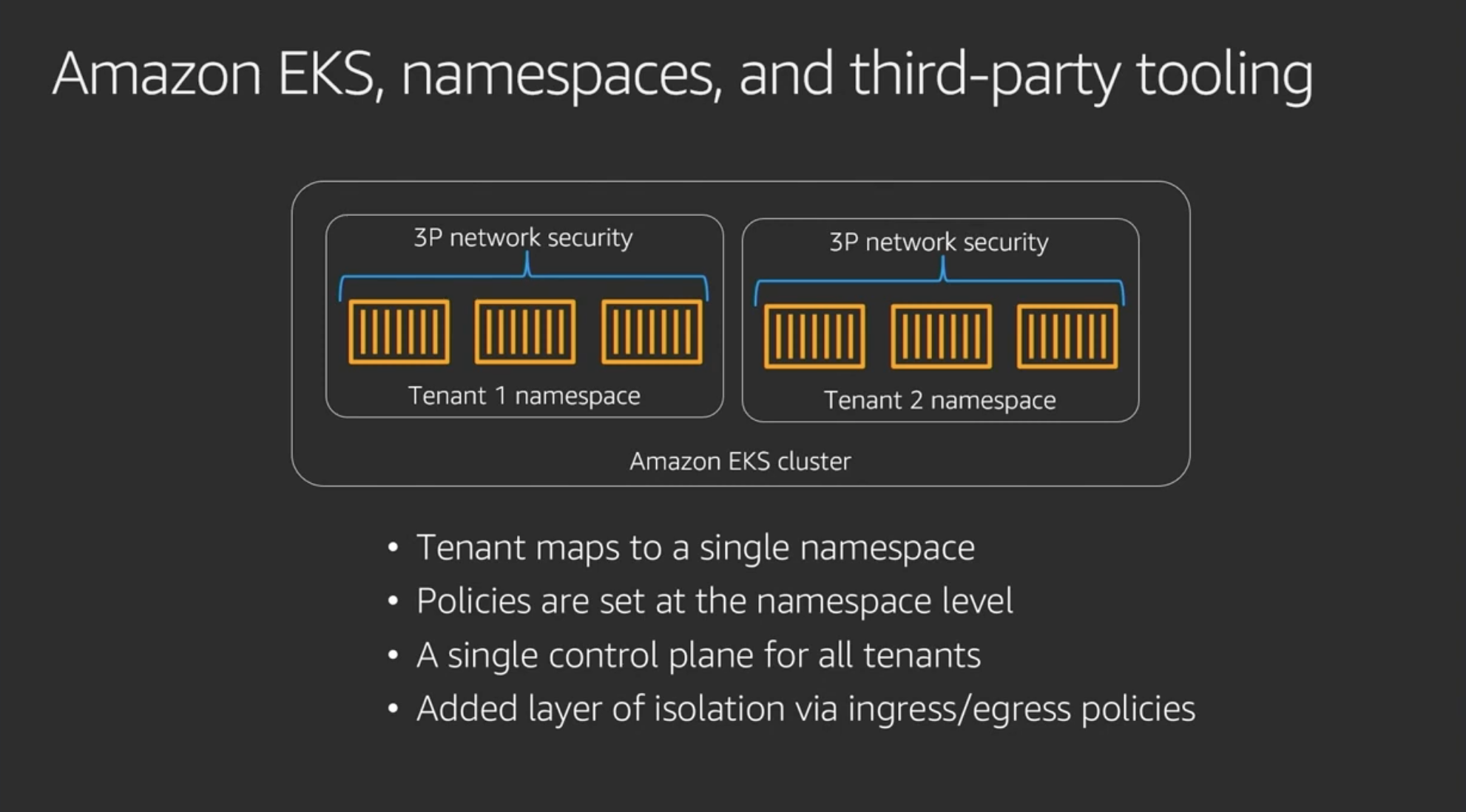
テナントそれぞれにnamespaceをつくる
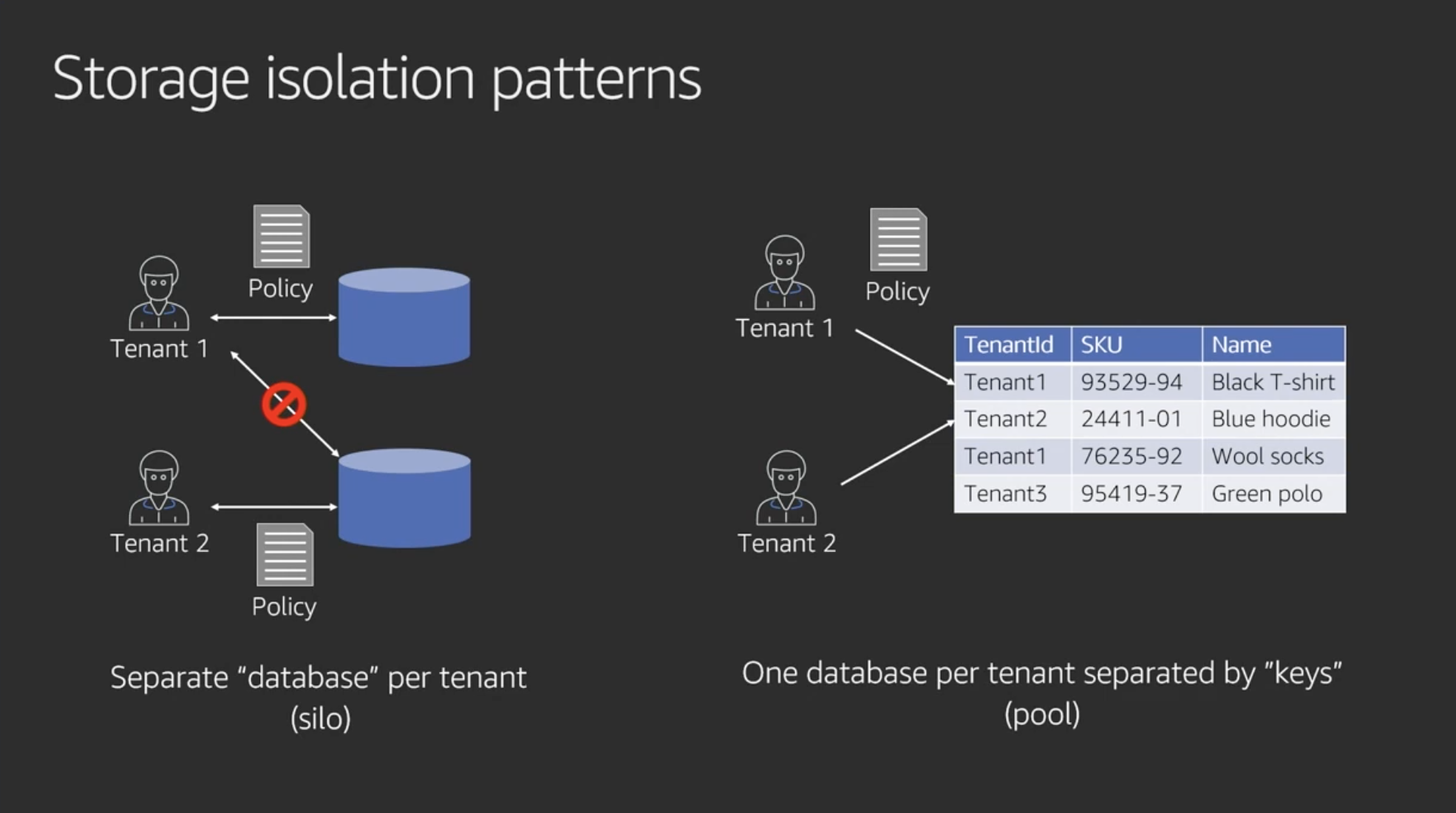
Storage isolation patterns
ストレージ(DB)の分離はもっとシンプル
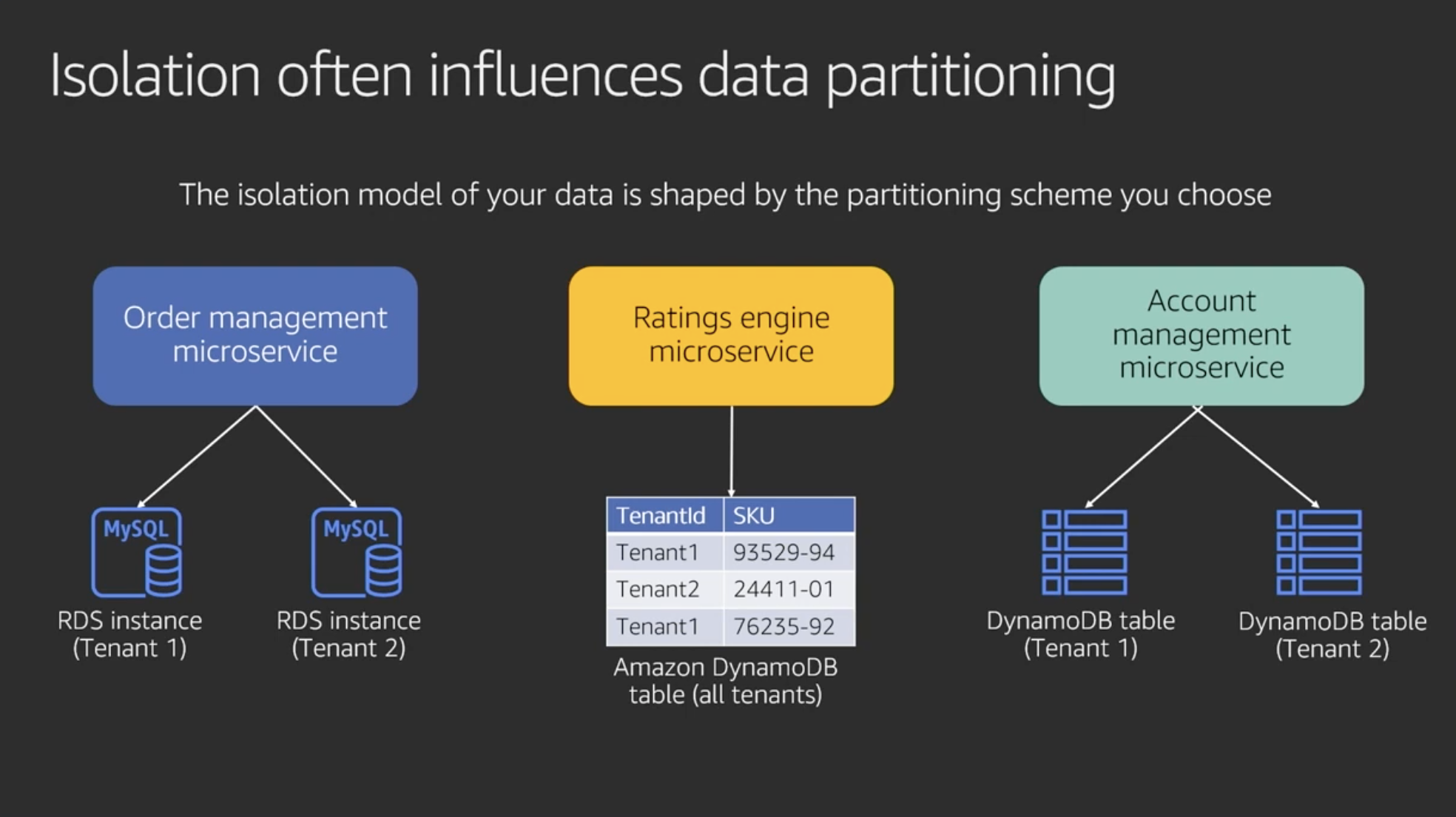
分離戦略がパフォーマンスやスケーリングのためのpartitioning戦略に影響するので注意
Pool isolation with Amazon DynamoDB
DynamoDBでpool分離するときのIAMポリシー
Pool with RLS and Amazon Aurora PostgreSQL
Aurora PostgreSQLでpool分離するときのポリシー
- RLSを有効にする
- メモ:MySQLにはRLS機能がないが、View機能を活用することで実現できる
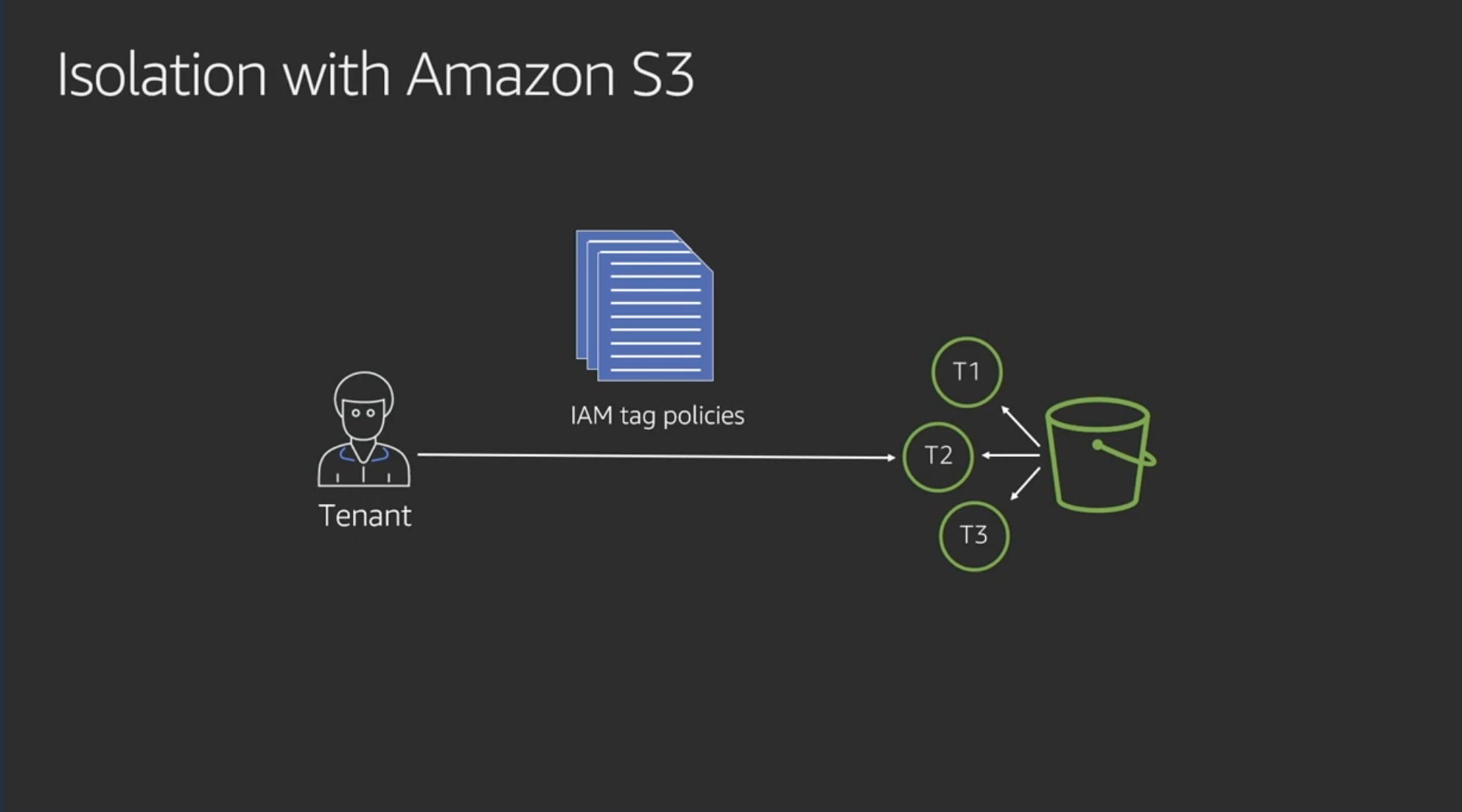
Isolation with Amazon S3
S3の分離はIAM tag policyで実現できる
その他のストレージはそれぞれ色々方法あるので試してみてね
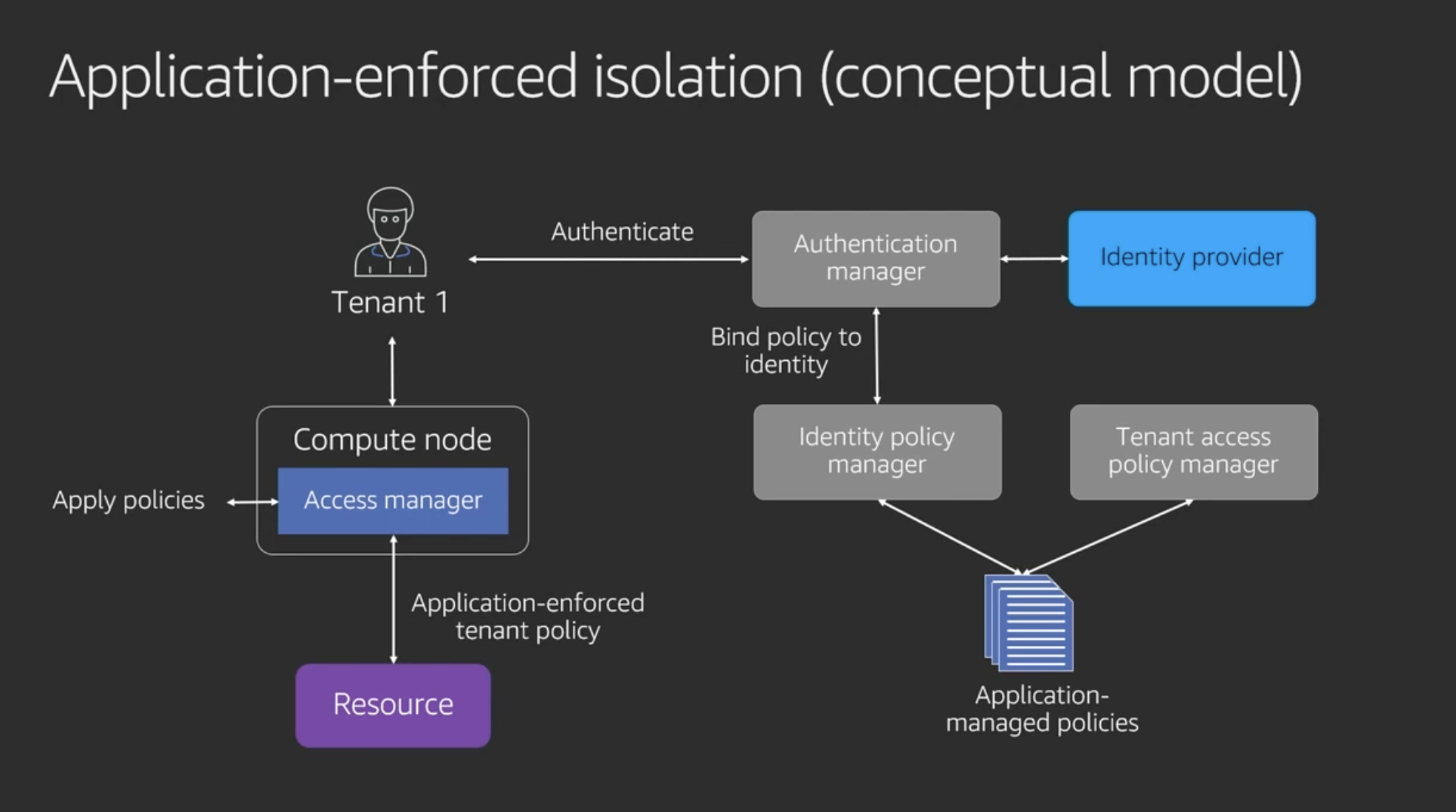
Application-enforced isolation (conceptual model) / Applicationによる分離の概念モデル
- IAMを使わない場合の分離の代替手段
- リソースへのアクセスポリシーの適用をアプリケーションで強制する
- JavaやNode.jsで実装したり、ツールやライブラリ、フレームワークなどを用いて実現する
Weighing your options / 分離方法の選び方
- Siloは顧客の厳しい要件にも耐えられるしツールも色々あるが、管理コストや費用が増える
- ポリシーによる分離はSiloよりも細かい単位での分離ができ運用も柔軟になるが、顧客の要望に応えられなかったり、技術の発展に依存したり、複数の技術を組み合わせたりと実装が大変
- サービスやリソースごとに分離方法を変えるハイブリッドもあるよね
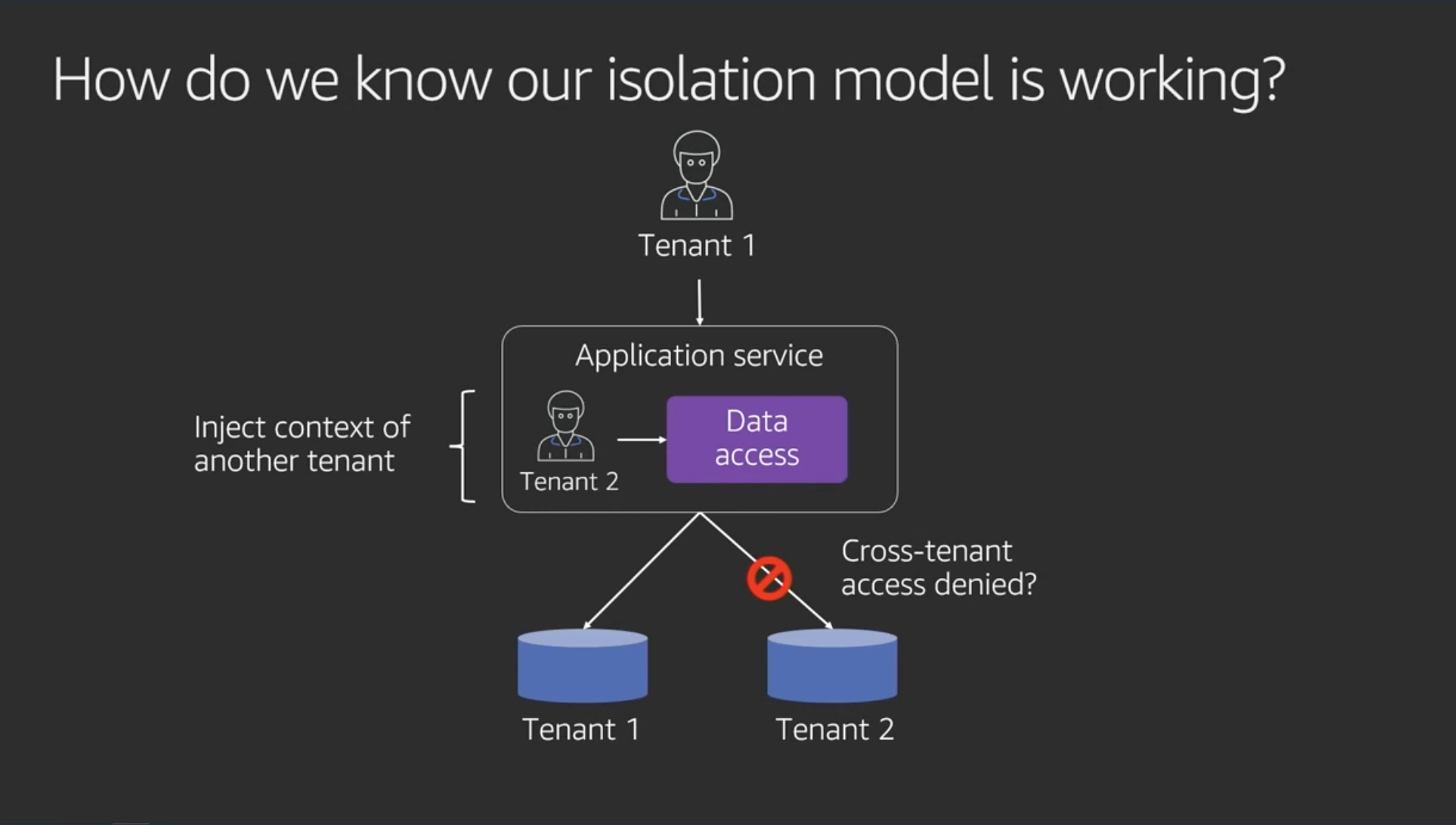
How do we know ouri isolation model is working? / テナント分離のテスト(検証)について
- 6ヶ月かけて分離のテストのシナリオとtesting framework作った(マジか)
- テナント1のポリシーでアクセスし、テナント2のコンテキストを注入する(メモ:SQLならwhere文に tenant_id = 2 等を仕込む感じなのかな)
まとめ
所感
- 確かに、厳密にデータを分離するよう顧客からの強い要求があった場合、Siloモデルを取らざるを得ないのかな
- 運用がハードすぎるので、非常に高額なエンタープライズプランとかでないと対応するのは難しそう
- SOCとか取ってデータ保護の安全性が認証されてる場合でも、Siloモデルによるデータ分離が求められることあるんだろうか?
- PoolでSQLのWhere句だけによって分離されてる場合でも、PostgreSQLのRLS (Row Level Security) やMySQLのViewテーブル、S3のタグベースでのアクセスポリシーなど、着手しやすいテナント分離の方法は早期に実施しておいた方が良さそう
- 事故が起きてから信頼を取り戻すのは難しい









- 投稿日:2021-01-23T22:21:56+09:00
AWS ソリューションアーキテクト 資格取得タイムトライアル 1日目
始めること
AWS ソリューションアーキテクトの資格取得に向けた勉強にタイムトライアル的な要素を加えて、何日で資格取得なるかを計測することで楽しくお勉強しようという試みです!
目標は勉強時間20時間でクリアしてみたいと思っています(適当)
また、勉強した内容をここにアウトプットして、メモ&復習用途としても利用しています。筆者の人物像
- 普段はフロントエンドとバックエンドがメイン(reactとnode.js)
- AWSの実務経験はなし
- 個人学習で紫本とudemyの教材を1本実施
- dockerやk8s、rhelなどのインフラ業務経験はあり
学習の動機
- 単純にAWSの知識が欲しい
- 実務経験がない部分を客観的な知識として資格で補いたい
- 転職を考え始めたので、少しでも有利な状況にしたい
使う教材
模試は受ける予定ですが、基本的には改訂新版 徹底攻略 AWS認定 ソリューションアーキテクト − アソシエイト教科書のみをインプットとして進める予定です。
※リンク先はAmazonですがアドセンスは付いてないです!本日(2021/01/23)の学習時間
- 8:30〜10:00までの約1時間30分
以下勉強内容
AWS Well Architected 5つの柱がある
- 運用の優秀性
- セキュリティ
- 信頼性
- パフォーマンス効率
- コスト最適化
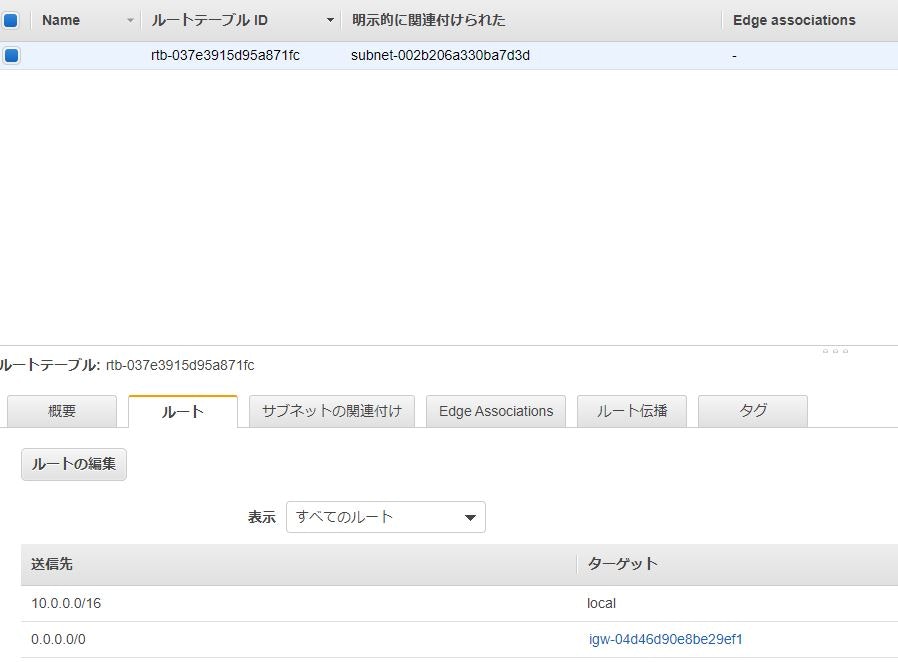
インターネットゲートウェイとは
VPC内のリソースからインターネットにアクセスするためのゲートウェイ
パブリックサブネットとは(重要)
ルートテーブル内のデフォルトゲートウェイ(0.0.0.0/0)へのルーティングにインターネットゲートウェイを指定したサブネット
プライベートサブネットとは(重要)
インターネットゲートウェイを指定していないサブネット
NATゲートウェイとは(重要)
- ネットワークアドレス変換 (NAT) ゲートウェイを使用して、プライベートサブネットのインスタンスからはインターネットや他の AWS のサービスに接続できるが、インターネットからはこれらのインスタンスとの接続を開始できないようにすることができる
セキュリティグループとは
EC2インスタンスなどに適応するファイアーウォール機能
* デフォルト設定の場合、アウトバウンド通信は全て許可、インバウンド通信は全て拒否
* インバウンド・アウトバウンドの種別、プロトコル、ポート範囲、アクセス元IP、アクセス先IPといった、許可するルールのみを定義する
* EC2インスタンスに複数のSGを適応可能
* 設定追加、変更は即座に反映される
* ステートフルな制御が可能ネットワークACLとは(SGとの違いを理解しておく必要あり)
サブネット単位で設定するファイアーウォール機能
AWS Direct Connectとは(DXという略称で呼ばれることがある)
オンプレ環境とAWSを専用線で接続するサービス。基本は1対1での接続だが、Direct Connect ゲートウェイを利用すると1対多での接続が実現できる。
Site to Site VPNとは
DXよりコスパはいいが、品質が低い
* 仮想プライベートゲートウェイ(VGW)というオンプレ環境とAWSを接続するゲートウェイをあらかじめVPCにアタッチしておく必要がある
- 投稿日:2021-01-23T21:05:54+09:00
簡単Webサイトホスティング④CloudFrontのリアルタイムログをKibanaで可視化する
はじめに
Amazon Web Services(AWS)が提供する、
Amazon CloudFrontやAmazon S3と呼ばれるサービスを組み合わせることで、 HTMLやJavaScript、画像、ビデオなどで構成される静的Webサイトの配信基盤 を安価に構築することができます。本記事では、リソースのセットアップを自動で行うことのできる、AWS CloudFormationを用いることで、これらの配信基盤を ミスなく迅速に構築 する手順をご説明します。なお、今回使用する CloudFormation テンプレートは、以下の GitHub リポジトリで公開しています。TL;DR
以下の
CloudFormationテンプレートを実行することで、 静的Webサイトのホスティング基盤 を 迅速かつお手軽に実現 します。下にあるボタンをクリックすると、自身のAWSアカウント(Asia Pacific Tokyo - ap-northeast-1)で、このCloudFormationテンプレートを実行することが可能となります。

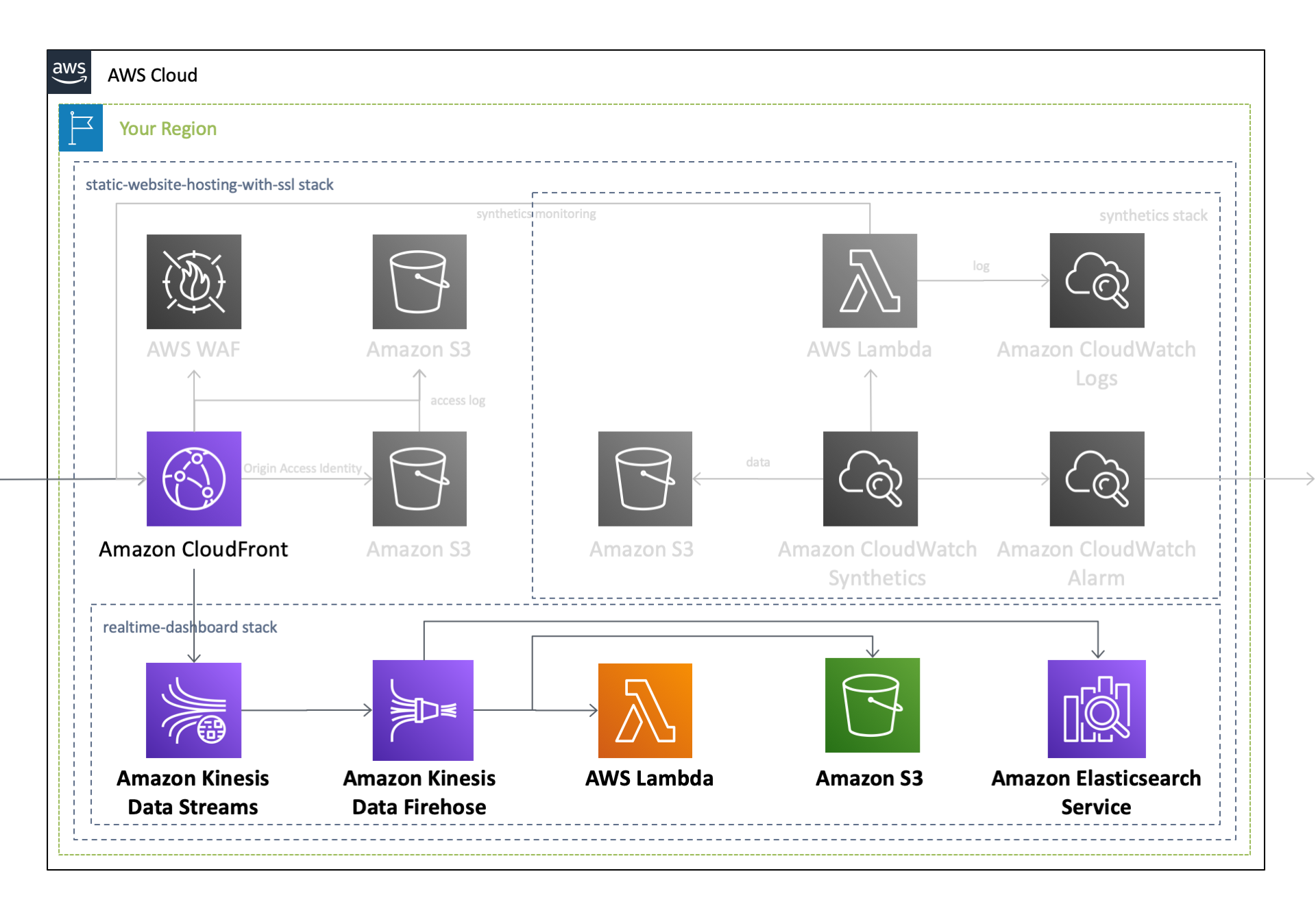
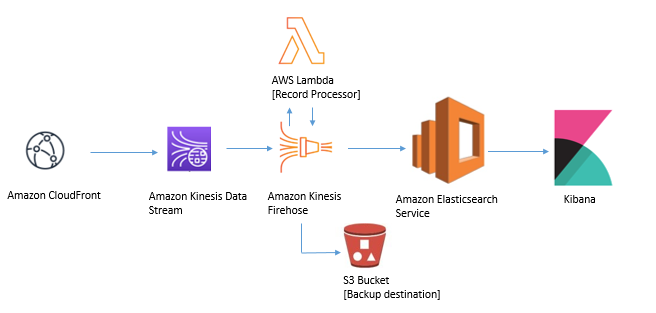
作成されるAWSリソース全体のアーキテクチャ図は、過去の記事をご覧ください。このうち本記事では、以下のリソースに焦点を当ててご説明します。
Kibana を用いた CloudFront リアルタイムログの可視化
ログが生成されてから利用できるまでに数分を要していた従来の
標準ログに加えて、生成されてからわずか数秒でアクセス可能 となる CloudFront のリアルタイムログ が提供開始 となり、これを用いることで より詳細かつ迅速なモニタリング と 発生した事象に合わせた迅速なリソース設定の変更 を行えるようになりました。このリアルタイムログは、
- 取得するログのサンプリング率
- 取得するログのフィールド
- どのCloudFront Behavior に適用するか
を指定することが可能で、指定した 任意のログを Kinesis Data Streams に送信する ことができます。 また、Kinesis ストリームに到達したログは、
Kinesis Data Firehoseを経由してElasticsearch Serviceに蓄積することが可能で、さらに Kibanaを用いることで、ログの中身を簡単に可視化 することができます。
これらの手順は、 Amazon CloudFront ログを使用したリアルタイムダッシュボードの作成 というタイトルで、 Amazon Web Services ブログに公開されており、ここに掲載されている手順に沿ってリソースを作成することで、以下のアーキテクチャを構成することができます。
本記事では、 上記のアーキテクチャ を CloudFormationテンプレートを用いてワンクリックで作成 するとともに、それぞれのAWSサービスに掛かる負荷に対して どの程度のリソースをプロビジョニングしておけば良いか についても合わせてご説明します。
Amazon Kinesis Data Streams
まず最初に、 CloudFrontから送られた リアルタイムログを受信する Kinesis ストリームを作成 します。
Parameters: KinesisShardCount: Type: Number Default: 1 MinValue: 1 Description: The shard count of Kinesis [required] Resources: Kinesis: Type: 'AWS::Kinesis::Stream' Properties: Name: !Ref AWS::StackName RetentionPeriodHours: 24 StreamEncryption: EncryptionType: KMS KeyId: alias/aws/kinesis ShardCount: !Ref KinesisShardCountここで重要となるのは、 Kinesisストリームを何シャードで構えておくか についてです。この値をどう算出するのかについては、 公式ドキュメントの Kinesis データストリームのシャード数を推定するには という項に推定方法の記述があり、全てのフィールドを含んだリアルタイムログを出力する場合には、
1,000 Byte x 秒間リクエスト数 / 1000,000 * 1.25 = シャード数として算出できます。
例えば最大秒間5,000リクエストのアクセスが発生する可能性がある場合は、
5,000 x 1,000 / 1,000,000 * 1.25 = 7となり、バッファも含めて約7シャード必要になることが分かります。
ただし、 バーストトラフィックが発生するようなサイト の場合は、 特定の1秒にログの出力が集中することで受信できるデータ量を超過 してしまい、 ProvisionedThroughputExceededExceptionが発生 するケースがあり得ることから、ドキュメントに記載のある値より大きなバッファ値、例えば 想定するデータ量を処理できるシャード数の倍のシャードをプロビジョニング しておくなどしておいた方が安全です。
トラフィックに合わせてシャード数を変更する
CloudFrontへのトラフィックは、時間帯やイベントの有無によって変動します。
Kinesis Data Streamsが、シャード数単位(シャード時間)で課金されること、キャパシティを超えたリアルタイムログを受信できないことなどから、 CloudFrontへのトラフィック量に応じて 、 Kinesis ストリームの シャード数を変更する 必要があります。ただし、シャード数を変更する際には、 いくつかの制約事項が存在 します。まず、シャード数を変更する際にコールされる
UpdteShardCountAPIは、 現在のシャード数を2倍にするか、もしくは1/2にするかの操作しかできません 。したがって、3シャードのKinesisストリームを7シャードに変更するといったことはできません。そこで シャード数は、2の階乗(1, 2, 4, 8, 16, 32, 64, 128...)に設定しておく ことをオススメします。また、 1リージョンあたりのシャード数 の初期値は、北部バージニア(us-east-1)リージョンで500シャード、それ以外のリージョンで 200シャード です。これに加えて、シャード数の変更を行うUpdteShardCountAPIの実行回数にも上限 があります。これらの上限値を超えた利用を希望する場合には、 クオータ制限の緩和申請 が必要となります。Kinesis Data Streams に設定したキャパシティが負荷に対して適切であるかどうかを確認するためには、以下のCloudWatchメトリクスを監視してください。こちらのリンク から、これらのメトリクスを基にしたCloudWatchアラームを一括で有効化することができます。
ネームスペース メトリクス 閾値 AWS/Kinesis GetRecords.IteratorAgeMilliseconds テンプレートで指定した値 AWS/Kinesis PutRecord.Success テンプレートで指定した値 AWS/Kinesis WriteProvisionedThroughputExceeded 1分間に1回以上 Amazon CloudFront
次に、CloudFront から出力する リアルタイムログの設定 を行います。
まずは、 CloudFront が Kinesis Data Streams に対してログを出力 できるように、IAM Role を用いて権限の付与を行います。 CloudFront に与える権限は、 Kinesisへの書き込み権限 と、データを暗号化する際に使用する KMSキーを作成する権限 です。
Resources: IAMRoleForCloudFrontRealtimeLog: Type: 'AWS::IAM::Role' Properties: AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: cloudfront.amazonaws.com Action: 'sts:AssumeRole' Policies: - PolicyName: !Sub '${AWS::StackName}-KinesisPutPolicy-${AWS::Region}' PolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Action: - 'kinesis:DescribeStreamSummary' - 'kinesis:DescribeStream' - 'kinesis:PutRecord' - 'kinesis:PutRecords' Resource: - !GetAtt Kinesis.Arn - Effect: Allow Action: - 'kms:GenerateDataKey' Resource: - !GetAtt KMSKey.Arn RoleName: !Sub '${aws::StackName}-CloudFrontRealtimeLog-${AWS::Region}'次に、先ほど作成した
Kinesis Data StreamsとIAM RoleのARNを指定して、 リアルタイムログの設定を行います。Fieldsでは ログに出力するフィールド を選択することができますが、本テンプレートでは以下の 全てのフィールドを出力 する設定としています。
フィールド名 内容 timestamp エッジサーバーがリクエストへの応答を終了した日時 c-ip リクエスト元のビューワーの IP アドレス time-to-first-byte サーバー上で測定される、要求を受信してから応答の最初のバイトを書き込むまでの秒数 sc-status サーバーのレスポンスの HTTP ステータスコード sc-bytes サーバーがリクエストに応じてビューワーに送信したデータのバイトの合計数 cs-method ビューワーから受信した HTTP リクエストメソッド cs-protocol ビューワーリクエストのプロトコル cs-host CloudFront ディストリビューションのドメイン名 cs-uri-stem パスとオブジェクトを識別するリクエスト URL の部分 cs-bytes ビューワーがリクエストに含めたデータのバイトの合計数 x-edge-location リクエストを処理したエッジロケーション x-edge-request-id リクエストを一意に識別する不透明な文字列 x-host-header ビューワーが、このリクエストの Host ヘッダーに追加した値 time-taken サーバーが、ビューワーのリクエストを受信してからレスポンスの最後のバイトを出力キューに書き込むまでの秒数 cs-protocol-version ビューワーがリクエストで指定した HTTP バージョン c-ip-version リクエストの IP バージョン cs-user-agent リクエスト内の User-Agentヘッダーの値cs-referer リクエスト内の Refererヘッダーの値cs-cookie リクエスト内の Cookie ヘッダー cs-uri-query リクエスト URL のクエリ文字列の部分 x-edge-response-result-type ビューワーにレスポンスを返す直前にサーバーがレスポンスを分類した方法 x-forwarded-for リクエスト元のビューワーの IP アドレス ssl-protocol リクエストとレスポンスを送信するためにビューワーとサーバーがネゴシエートした SSL/TLS プロトコル ssl-cipher リクエストとレスポンスを暗号化するためにビューワーとサーバーがネゴシエートした SSL/TLS 暗号 x-edge-result-type サーバーが、最後のバイトを渡した後で、レスポンスを分類した方法 fle-encrypted-fields サーバーが暗号化してオリジンに転送したフィールドレベル暗号化フィールドの数 fle-status リクエストボディが正常に処理されたかどうかを示すコード sc-content-type レスポンスの HTTP Content-Type ヘッダーの値 sc-content-len レスポンスの HTTP Content-Length ヘッダーの値 sc-range-start 範囲の開始値 sc-range-end 範囲の終了値 c-port 閲覧者からのリクエストのポート番号 x-edge-detailed-result-type x-edge-result-type と同じ値 c-country ビューワーの IP アドレスによって決定される、ビューワーの地理的位置を表す国コード cs-accept-encoding ビューワーリクエスト内の Accept-Encoding ヘッダーの値 cs-accept ビューワーリクエスト内の Accept ヘッダーの値 cache-behavior-path-pattern ビューワーリクエストに一致したキャッシュ動作を識別するパスパターン cs-headers ビューワーリクエスト内の HTTP ヘッダー cs-header-names ビューワーリクエスト内の HTTP ヘッダーの名前 cs-headers-count ビューワーリクエスト内の HTTP ヘッダーの数 また、
SamplingRateの値を変更することで、CloudFront が Kinesis Data Streams に送信する ログのサンプリングレートを、1%から100%の間で指定 することができます。Parameters: SamplingRate: Type: Number Default: 100 MinValue: 1 MaxValue: 100 Description: The sampling rate of logs sent by CloudFront [required] Resources: CloudFrontRealtimeLogConfig: Type: 'AWS::CloudFront::RealtimeLogConfig' Properties: EndPoints: - KinesisStreamConfig: RoleArn: !GetAtt IAMRoleForCloudFrontRealtimeLog.Arn StreamArn: !GetAtt Kinesis.Arn StreamType: Kinesis Fields: - timestamp - c-ip - time-to-first-byte - sc-status - sc-bytes - cs-method - cs-protocol - cs-host - cs-uri-stem - cs-bytes - x-edge-location - x-edge-request-id - x-host-header - time-taken - cs-protocol-version - c-ip-version - cs-user-agent - cs-referer - cs-cookie - cs-uri-query - x-edge-response-result-type - x-forwarded-for - ssl-protocol - ssl-cipher - x-edge-result-type - fle-encrypted-fields - fle-status - sc-content-type - sc-content-len - sc-range-start - sc-range-end - c-port - x-edge-detailed-result-type - c-country - cs-accept-encoding - cs-accept - cache-behavior-path-pattern - cs-headers - cs-header-names - cs-headers-count Name: RealtimeLogConfig SamplingRate: !Ref SamplingRateなお、プロビジョニングした Kinesis ストリームのキャパシティを超える リアルタイムログが生成された場合は、 キャパシティを超えた分のリアルタイムログが欠落 します。しかし、それによって、 CloudFront ディストリビューションの挙動に異常が発生することはありません 。
また、 CloudFront はグローバルに提供されるAWSサービスですが、 リアルタイムログを受信する Kinesis ストリームには全てのエッジロケーションのアクセスログが出力 されます。どのエッジロケーションでリクエストを処理したかについては、
x-edge-locationフィールドで確認することができます。そして、 過去に作成したCloudFrontディストリビューション に上記の リアルタイムログの設定をアタッチ すると、 今設定したばかりの リアルタイムログの出力がCloudFront上で有効 となります。
CloudFront: Type: 'AWS::CloudFront::Distribution' Properties: DistributionConfig: DefaultCacheBehavior: RealtimeLogConfigArn: !GetAtt CloudFrontRealtimeLogConfig.ArnAmazon Elasticsearch Service
Elasticsearchは、 分散型の分析エンジン で、構造化、非構造化、地理情報、メトリックなどの 様々なタイプの検索 を行なったり、 大規模なデータに対して分析 を行うことができます。この Elasticsearch を簡単かつ大規模にデプロイ、保護、実行を可能とするマネージドサービスが、
Amazon Elasticsearch Serviceです。この Elasticsearch Service を使用することで、 アプリケーションやインフラストラクチャのログを保存、分析して問題を迅速に発見 したり、 アプリケーションに検索機能を追加 したりすることができます。そこで今回は、 Elasticsearch を用いて CloudFront のリアルタイムログを分析し、 Elasticsearch で使えるグラフツールとして知られる Kibanaを用いてこれを可視化 します。
Parameters: ElasticSearchVolumeSize: Type: Number Default: 10 MinValue: 10 Description: The volume size (GB) of ElasticSearch Service [required] ElasticSearchDomainName: Type: String Default: cloudfront-realtime-logs AllowedPattern: .+ Description: The domain name of ElasticSearch Service [required] ElasticSearchInstanceType: Type: String Default: r5.large.elasticsearch AllowedValues: - t3.small.elasticsearch - t3.medium.elasticsearch - t2.micro.elasticsearch - t2.small.elasticsearch - t2.medium.elasticsearch - m5.large.elasticsearch - m5.xlarge.elasticsearch - m5.2xlarge.elasticsearch - m5.4xlarge.elasticsearch - m5.12xlarge.elasticsearch - m4.large.elasticsearch - m4.xlarge.elasticsearch - m4.2xlarge.elasticsearch - m4.4xlarge.elasticsearch - m4.10xlarge.elasticsearch - c5.large.elasticsearch - c5.xlarge.elasticsearch - c5.2xlarge.elasticsearch - c5.4xlarge.elasticsearch - c5.9xlarge.elasticsearch - c5.18xlarge.elasticsearch - c4.large.elasticsearch - c4.xlarge.elasticsearch - c4.2xlarge.elasticsearch - c4.4xlarge.elasticsearch - c4.8xlarge.elasticsearch - r5.large.elasticsearch - r5.xlarge.elasticsearch - r5.2xlarge.elasticsearch - r5.4xlarge.elasticsearch - r5.12xlarge.elasticsearch - r4.large.elasticsearch - r4.xlarge.elasticsearch - r4.2xlarge.elasticsearch - r4.4xlarge.elasticsearch - r4.8xlarge.elasticsearch - r4.16xlarge.elasticsearch - r3.large.elasticsearch - r3.xlarge.elasticsearch - r3.2xlarge.elasticsearch - r3.4xlarge.elasticsearch - r3.8xlarge.elasticsearch - i3.large.elasticsearch - i3.xlarge.elasticsearch - i3.2xlarge.elasticsearch - i3.4xlarge.elasticsearch - i3.8xlarge.elasticsearch - i3.16xlarge.elasticsearch Description: The instance type of ElasticSearch Service [required] ElasticSearchMasterUserName: Type: String AllowedPattern: .+ Description: The user name of ElasticSearch Service [required] ElasticSearchMasterUserPassword: Type: String AllowedPattern: .+ NoEcho: true Description: The password of ElasticSearch Service [required] Resources: KMSKey: Type: AWS::KMS::Key Properties: Description: Encrypt CloudTrail Logs Enabled: true EnableKeyRotation: true KeyPolicy: Version: 2012-10-17 Id: DefaultKeyPolicy Statement: - Sid: Enable IAM User Permissions Effect: Allow Principal: AWS: !Sub arn:aws:iam::${AWS::AccountId}:root Action: 'kms:*' Resource: '*' - Effect: Allow Principal: Service: cloudtrail.amazonaws.com Action: - 'kms:GenerateDataKey*' Resource: - '*' Condition: StringLike: kms:EncryptionContext:aws:cloudtrail:arn: - !Sub arn:aws:cloudtrail:*:${AWS::AccountId}:trail/* - Effect: Allow Principal: Service: cloudtrail.amazonaws.com Action: - 'kms:DescribeKey' Resource: - '*' KeyUsage: ENCRYPT_DECRYPT PendingWindowInDays: 30 ElasticSearchDomain: Type: 'AWS::Elasticsearch::Domain' Properties: AccessPolicies: Version: '2012-10-17' Statement: - Effect: Allow Principal: AWS: - '*' Action: - es:* Resource: !Sub arn:aws:es:${AWS::Region}:${AWS::AccountId}:domain/${ElasticSearchDomainName}/* AdvancedSecurityOptions: Enabled: true InternalUserDatabaseEnabled: true MasterUserOptions: MasterUserName: !Ref ElasticSearchMasterUserName MasterUserPassword: !Ref ElasticSearchMasterUserPassword DomainEndpointOptions: EnforceHTTPS: true DomainName: !Ref ElasticSearchDomainName EBSOptions: EBSEnabled: true VolumeSize: !Ref ElasticSearchVolumeSize VolumeType: gp2 ElasticsearchClusterConfig: DedicatedMasterCount: 3 DedicatedMasterEnabled: true DedicatedMasterType: c5.large.elasticsearch InstanceCount: 3 InstanceType: !Ref ElasticSearchInstanceType ZoneAwarenessConfig: AvailabilityZoneCount: 3 ZoneAwarenessEnabled: true ElasticsearchVersion: 7.8 EncryptionAtRestOptions: Enabled: true KmsKeyId: !GetAtt KMSKey.Arn NodeToNodeEncryptionOptions: Enabled: true SnapshotOptions: AutomatedSnapshotStartHour: 0本テンプレートの構成と注意点は、以下の通りです。
DomainNameには、「アカウントおよびリージョンに固有」「先頭が小文字」「3~28文字」「小文字のアルファベット、数字、ハイフンのみ使用可能」という制約が課せられています。EBSOptionsにて、アタッチするEBSボリュームのタイプとサイズを指定しています。ElasticsearchClusterConfigにて、本番稼働用として奨励されている、マルチAZ + 専用データノード構成を規定しており、 データノード3台 + マスターノード3台 の構成としています。AvailabilityZoneCountを3に設定しているため、 インスタンスは3つのAZに分散配置 されます。EncryptionAtRestOptionsにて、 保管時のデータ暗号化 を指定しています。 これと同時に 暗号化の際に使用するAWS KMSのカスタマーマスターキー(CMK)も作成 しています。NodeToNodeEncryptionOptionsにて、 ノード間の暗号化 を指定しています。AutomatedSnapshotStartHourにて、 UTC時刻の午前0時にスナップショットが作成 されます。アクセスコントロール
本テンプレートは きめ細かなアクセスコントロール (= FGAC) を有効化しており、以下の設定としています。
- パブリックアクセスを許可 します。
DomainEndpointOptionsにて、 HTTPSによるアクセスを強制 します。InternalUserDatabaseEnabledにて 内部ユーザデータベースを有効化 した上で、MasterUserOptionsにて、 マスターユーザのユーザ名およびパスワードを規定 します。AccessPoliciesにて、 Elasticsearch Service の全ての操作を許可 します。上記の設定によりこのドメインおよびKibanaへは、 事前に設定したユーザ名とパスワードを用いて外部からアクセスする ことが可能となります。
ドメインのサイジング
Elasticsearch Service を使用するに当たって注意すべき点は、 どのインスタンスタイプにすべきか、そして EBSボリュームはどの程度の大きさを用意しておけばよいか 、についてです。これについては、公式ドキュメントの Amazon ES ドメインのサイジングの項に記載があります。
例えば、ストレージサイズについては、
ソースデータ x (1+ レプリカの数) x 1.45 = 最小ストレージ要件という式が掲載されています。秒間5,000リクエストのトラフィックが発生するCloudFrontディストリビューションのリアルタイムログを24時間保存する場合は、
5,000(件) x 3,600(秒)x 24(時間) x 1,000(byte) = 432(GB)ソースデータは432GBとなり、上記の式を適用すると、
432(GB) x (1 + 1) x 1.45 = 1252 (GB)1252GBのストレージが必要となります。
なお、上記の例では 1時間あたり18GBの割合でソースデータが増加する 計算となり、これは Elasticsearch Service にとって大きな負荷となります。。公式ドキュメントに、「高負荷の集計処理、頻繁なドキュメント更新、または大量のクエリ処理が発生している場合 、それらのリソースではニーズを満たせない可能性があります。クラスターがこのようなカテゴリに分類される場合はまず、 ストレージ要件の 100 GiB ごとに vCPU x 2 コア、メモリの 8 GiB に近い構成」を勧める旨の記載があり、上記例にこれを当てはめると、
1252(GB)/ 100(GB)x 2 = 25(コア) 1252(GB)/ 100(GB)x 8 = 100(GBメモリ)が必要になると考えられます。上述のように、本テンプレートでは データノードを3台用意 しているため、1インスタンスあたりで必要とされるコア数およびメモリサイズは、
25(コア)/ 3 (台) = 8.3(コア) 100(GBメモリ)/ 3 (台) = 33.3(GBメモリ)となり、1インスタンスあたりに必要なEBSボリュームは、
1252(GB) / 3(台) = 417(GB)となります。これを満たす インスタンスタイプ は、
- m5.2xlarge.elasticsearch 以上のインスタンスタイプ
- c5.4xlarge.elasticsearch 以上のインスタンスタイプ
- r5.2xlarge.elasticsearch 以上のインスタンスタイプ
- i3.2xlarge.elasticsearch 以上のインスタンスタイプ
となりますが、経験上 データノードはヒープ領域が枯渇することが多い ため、 上記例の場合は、 メモリ最適化 インスタンスである R5インスタンスを選択 するのが良いかもしれません。なお、マスターノードに関しては、 専用マスターノードの項に、
Instance Count 推奨される最小専用マスターインスタンスタイプ 1–10 c5.large.elasticsearch との記述があるため、本テンプレートが構築する構成では
c5.large.elasticsearchで問題なさそうです。なお、これらの値はあくまで計算上の値であることから、データノードおよびマスターノードのインスタンスタイプを決定する際には、 事前に想定と同程度の負荷を掛けて挙動を検証する必要 があります。ドメイン作成後にこれらの設定を変更する場合、Blue/Greenデプロイメントプロセスが実行 されて新たな環境が作成されます。この 設定変更には時間が掛かる上にマスターノードに大きな負荷が掛かる ため、このデプロイプロセスに関連した オーバヘッドを処理するための十分なリソース が必要となります。十分なリソースが無い状態で設定変更した場合、 設定変更(In Progress)に数時間掛かる こともあります。
Elasticsearch Service に設定したキャパシティが負荷に対して適切であるかどうかを確認するためには、以下のCloudWatchメトリクスを監視してください。こちらのリンク から、これらのメトリクスを基にしたCloudWatchアラームを一括で有効化することができます。
ネームスペース メトリクス 閾値 AWS/ES ClusterStatus.green 0だった場合 AWS/ES ClusterIndexWritesBlocked 1分間に1回以上 AWS/ES MasterReachableFromNode 0だった場合 AWS/ES AutomatedSnapshotFailure 1分間に1回以上 AWS/ES KibanaHealthyNodes 0だった場合 AWS/ES FreeStorageSpace テンプレートで指定した値 AWS/ES MasterCPUUtilization 50%を超えた場合 AWS/ES MasterJVMMemoryPressure 80%を超えた場合 AWS/ES CPUUtilization 50%を超えた場合 AWS/ES JVMMemoryPressure 80%を超えた場合 AWS/ES SysMemoryUtilization 80%を超えた場合 Kinesis Data Firehose
最後に
Kinesis Data Firehoseの設定を行います。Firehoseは、ストリーミングデータを取り込んで変換し、 Amazon S3、Amazon Redshift、Amazon Elasticsearch Service、汎用 HTTP エンドポイントなどに配信できるサービスで、今回は Kinesisストリームに配信されたリアルライムログをElasticsearch Service に配信 します。なお、Kinesisストリームでは、レコードを格納する際に Base64エンコードする必要がある ため、 リアルタイムログもBase64エンコードされた状態で格納 されています。そこで、 Firehoseが持つデータ変換機能を用いて、対象のカラムをBase64デコード します。Firehoseのデータ変換機能は、変換処理を記述したAWS Lambdaを紐づけることで実現します。
このLambda関数にアタッチするIAM Roleは、以下の通りです。Lambda関数に与える権限は、CloudWatch Logs への書き込み権限 です。
Resources: IAMRoleForLambda: Type: 'AWS::IAM::Role' Properties: AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: lambda.amazonaws.com Action: 'sts:AssumeRole' Description: A role required for Lambda to execute. Policies: - PolicyName: !Sub '${AWS::StackName}-AWSLambdaCloudWatchLogsPolicy-${AWS::Region}' PolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Action: - 'logs:CreateLogStream' Resource: '*' - Effect: Allow Action: - 'logs:PutLogEvents' Resource: '*' RoleName: !Sub '${AWS::StackName}-Lambda-${AWS::Region}'また、データ変換処理を行う Lambda 関数は、以下の通りです。
Resources: Lambda: Type: 'AWS::Lambda::Function' Properties: Code: ZipFile: | import logging import base64 import json logger = logging.getLogger() logger.setLevel(logging.INFO) logger.info("Loading function") def lambda_handler(event, context): output = [] # Based on the fields chosen during the creation of the Real-time log configuration. # The order is important and please adjust the function if you have removed certain default fields from the configuration. realtimelog_fields_dict = { "timestamp": "float", "c-ip": "str", "time-to-first-byte": "float", "sc-status": "int", "sc-bytes": "int", "cs-method": "str", "cs-protocol": "str", "cs-host": "str", "cs-uri-stem": "str", "cs-bytes": "int", "x-edge-location": "str", "x-edge-request-id": "str", "x-host-header": "str", "time-taken": "float", "cs-protocol-version": "str", "c-ip-version": "str", "cs-user-agent": "str", "cs-referer": "str", "cs-cookie": "str", "cs-uri-query": "str", "x-edge-response-result-type": "str", "x-forwarded-for": "str", "ssl-protocol": "str", "ssl-cipher": "str", "x-edge-result-type": "str", "fle-encrypted-fields": "str", "fle-status": "str", "sc-content-type": "str", "sc-content-len": "int", "sc-range-start": "int", "sc-range-end": "int", "c-port": "int", "x-edge-detailed-result-type": "str", "c-country": "str", "cs-accept-encoding": "str", "cs-accept": "str", "cache-behavior-path-pattern": "str", "cs-headers": "str", "cs-header-names": "str", "cs-headers-count": "int", } for record in event["records"]: # Extracting the record data in bytes and base64 decoding it payload_in_bytes = base64.b64decode(record["data"]) # Converting the bytes payload to string payload = "".join(map(chr, payload_in_bytes)) # dictionary where all the field and record value pairing will end up payload_dict = {} # counter to iterate over the record fields counter = 0 # generate list from the tab-delimited log entry payload_list = payload.strip().split("\t") # perform the field, value pairing and any necessary type casting. # possible types are: int, float and str (default) for field, field_type in realtimelog_fields_dict.items(): # overwrite field_type if absent or '-' if payload_list[counter].strip() == "-": field_type = "str" if field_type == "int": payload_dict[field] = int(payload_list[counter].strip()) elif field_type == "float": payload_dict[field] = float(payload_list[counter].strip()) else: payload_dict[field] = payload_list[counter].strip() counter = counter + 1 # JSON version of the dictionary type payload_json = json.dumps(payload_dict) # Preparing JSON payload to push back to Firehose payload_json_ascii = payload_json.encode("ascii") output_record = { "recordId": record["recordId"], "result": "Ok", "data": base64.b64encode(payload_json_ascii).decode("utf-8"), } output.append(output_record) logger.info("Successfully processed {} records.".format(len(event["records"]))) return {"records": output} Description: CloudFrontログを変換します FunctionName: realtimeLogsTransformer Handler: index.lambda_handler MemorySize: 512 Role: !GetAtt IAMRoleForLambda.Arn Runtime: python3.8 Timeout: 60 TracingConfig: Mode: Active LambdaLogGroup: Type: 'AWS::Logs::LogGroup' Properties: LogGroupName: !Sub /aws/lambda/${Lambda} RetentionInDays: 60次に、Firehose から Elasticsearch Service への配信が失敗した場合に、 代わりにリアルタイムログを格納するS3バケットも事前に作成 しておきます。
Resources: S3ForKinesisFirehose: Type: 'AWS::S3::Bucket' UpdateReplacePolicy: Retain DeletionPolicy: Retain Properties: BucketEncryption: ServerSideEncryptionConfiguration: - ServerSideEncryptionByDefault: SSEAlgorithm: AES256 BucketName: !Sub ${ElasticSearchDomainName}-${AWS::Region}-${AWS::AccountId} LifecycleConfiguration: Rules: - Id: ExpirationInDays ExpirationInDays: 60 Status: Enabled PublicAccessBlockConfiguration: BlockPublicAcls: true BlockPublicPolicy: true IgnorePublicAcls: true RestrictPublicBuckets: trueさらに、Firehoseに付与する権限をIAM Roleで規定します。
IAMRoleForKinesisFirehose: Type: 'AWS::IAM::Role' Properties: AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: firehose.amazonaws.com Action: 'sts:AssumeRole' Description: A role required for KinesisFirehose to access Glue, S3, Lambda, CloudWatch Logs, Kinesis and KMS. Policies: - PolicyName: !Sub '${AWS::StackName}-FirehoseDelivery-${AWS::Region}' PolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Action: - 's3:AbortMultipartUpload' - 's3:GetBucketLocation' - 's3:GetObject' - 's3:ListBucket' - 's3:ListBucketMultipartUploads' - 's3:PutObject' Resource: - !Sub 'arn:aws:s3:::${S3ForKinesisFirehose}' - !Sub 'arn:aws:s3:::${S3ForKinesisFirehose}/*' - Effect: Allow Action: - 'kms:Decrypt' - 'kms:GenerateDataKey' Resource: - !GetAtt KMSKey.Arn Condition: StringEquals: 'kms:ViaService': s3.region.amazonaws.com StringLike: 'kms:EncryptionContext:aws:s3:arn': !Sub 'arn:aws:s3:::${S3ForKinesisFirehose}/*' - Effect: Allow Action: - 'es:DescribeElasticsearchDomain' - 'es:DescribeElasticsearchDomains' - 'es:DescribeElasticsearchDomainConfig' - 'es:ESHttpPost' - 'es:ESHttpPut' Resource: - !Sub 'arn:aws:es:${AWS::Region}:${AWS::AccountId}:domain/${ElasticSearchDomainName}' - !Sub 'arn:aws:es:${AWS::Region}:${AWS::AccountId}:domain/${ElasticSearchDomainName}/*' - Effect: Allow Action: - 'es:ESHttpGet' Resource: - !Sub 'arn:aws:es:${AWS::Region}:${AWS::AccountId}:domain/${ElasticSearchDomainName}/_all/_settings' - !Sub 'arn:aws:es:${AWS::Region}:${AWS::AccountId}:domain/${ElasticSearchDomainName}/_cluster/stats' - !Sub 'arn:aws:es:${AWS::Region}:${AWS::AccountId}:domain/${ElasticSearchDomainName}/realtime*/_mapping/*' - !Sub 'arn:aws:es:${AWS::Region}:${AWS::AccountId}:domain/${ElasticSearchDomainName}/_nodes' - !Sub 'arn:aws:es:${AWS::Region}:${AWS::AccountId}:domain/${ElasticSearchDomainName}/_nodes/stats' - !Sub 'arn:aws:es:${AWS::Region}:${AWS::AccountId}:domain/${ElasticSearchDomainName}/_nodes/*/stats' - !Sub 'arn:aws:es:${AWS::Region}:${AWS::AccountId}:domain/${ElasticSearchDomainName}/_stats' - !Sub 'arn:aws:es:${AWS::Region}:${AWS::AccountId}:domain/${ElasticSearchDomainName}/realtime*/_stats' - Effect: Allow Action: - 'kinesis:DescribeStream' - 'kinesis:GetShardIterator' - 'kinesis:GetRecords' - 'kinesis:ListShards' Resource: !GetAtt Kinesis.Arn - Effect: Allow Action: - 'logs:PutLogEvents' Resource: - !Sub 'arn:aws:logs:${AWS::Region}:${AWS::AccountId}:log-group:${CloudWatchLogsGroupForFirehose}:log-stream:${CloudWatchLogsStreamForFirehoseElasticSearch}' - !Sub 'arn:aws:logs:${AWS::Region}:${AWS::AccountId}:log-group:${CloudWatchLogsGroupForFirehose}:log-stream:${CloudWatchLogsStreamForFirehoseS3}' - Effect: Allow Action: - 'lambda:InvokeFunction' - 'lambda:GetFunctionConfiguration' Resource: - !GetAtt Lambda.Arn - Effect: Allow Action: - 'kms:Decrypt' Resource: - !GetAtt KMSKey.Arn Condition: StringEquals: 'kms:ViaService': kinesis.ap-northeast-1.amazonaws.com StringLike: 'kms:EncryptionContext:aws:kinesis:arn': !GetAtt Kinesis.Arn RoleName: !Sub '${AWS::StackName}-Firehose-${AWS::Region}'最後に、リアルタイムログの配信先となる Elasticsearch Service と S3、データ変換機能を提供するLambda関数、それぞれを指定して Firehoseを作成 します。なお、Elasticsearch Serviceへの データ配信に係る遅延量をできるだけ少なくするため、
BufferingHintsを設定可能な最小の値 にしています。また、S3BackupModeの値をFailedDocumentsOnlyとすることで、 Elasticsearch Serviceへの配信が失敗した場合のみ、S3にリアルタイムログを保存 する挙動にしています。AWS::KinesisFirehose::DeliveryStreamの一部属性は更新時の動作がReplacement、つまり 更新時にはFirehoseリソースが再作成され物理IDも新規で作成 する必要があります。このため、当該属性の値を更新する場合はDeliveryStreamNameの値も同時に更新してください。Resources: KinesisFirehose: Type: 'AWS::KinesisFirehose::DeliveryStream' Properties: DeliveryStreamName: !Sub ${AWS::StackName}-${KinesisFirehoseStreamNameSuffix} DeliveryStreamType: KinesisStreamAsSource KinesisStreamSourceConfiguration: KinesisStreamARN: !GetAtt Kinesis.Arn RoleARN: !GetAtt IAMRoleForKinesisFirehose.Arn ElasticsearchDestinationConfiguration: BufferingHints: IntervalInSeconds: 60 SizeInMBs: 1 CloudWatchLoggingOptions: Enabled: true LogGroupName: !Ref CloudWatchLogsGroupForFirehose LogStreamName: !Ref CloudWatchLogsStreamForFirehoseS3 DomainARN: !GetAtt ElasticSearchDomain.DomainArn IndexName: realtime IndexRotationPeriod: NoRotation ProcessingConfiguration: Enabled: true Processors: - Parameters: - ParameterName: LambdaArn ParameterValue: !GetAtt Lambda.Arn Type: Lambda RetryOptions: DurationInSeconds: 300 RoleARN: !GetAtt IAMRoleForKinesisFirehose.Arn S3BackupMode: FailedDocumentsOnly S3Configuration: BucketARN: !GetAtt S3ForKinesisFirehose.Arn CloudWatchLoggingOptions: Enabled: true LogGroupName: !Ref CloudWatchLogsGroupForFirehose LogStreamName: !Ref CloudWatchLogsStreamForFirehoseElasticSearch RoleARN: !GetAtt IAMRoleForKinesisFirehose.Arn TypeName: '' CloudWatchLogsGroupForFirehose: Type: 'AWS::Logs::LogGroup' Properties: LogGroupName: !Sub '/aws/kinesisfirehose/${AWS:StackName}' RetentionInDays: 60 CloudWatchLogsStreamForFirehoseS3: Type: 'AWS::Logs::LogStream' Properties: LogGroupName: !Ref CloudWatchLogsGroupForFirehose LogStreamName: S3 CloudWatchLogsStreamForFirehoseElasticSearch: Type: 'AWS::Logs::LogStream' Properties: LogGroupName: !Ref CloudWatchLogsGroupForFirehose LogStreamName: ElasticSearch以上で、CloudFront のリアルタイムログを可視化するために必要な全てのリソースの設定が完了しました。この CloudFormation テンプレートを実行することで、それぞれのリソースがデプロイされます。
なお、Firehose が正常に動作しているかどうかを確認するためには、以下のCloudWatchメトリクスを監視してください。こちらのリンク から、これらのメトリクスを基にしたCloudWatchアラームを一括で有効化することができます。
ネームスペース メトリクス 閾値 AWS/Firehose DeliveryToElasticsearch.DataFreshness テンプレートで指定した値 AWS/Firehose ThrottledGetShardIterator 1分間に1回以上 AWS/Firehose ThrottledGetRecords 1分間に1回以上 AWS/Firehose DeliveryToElasticsearch.Success 1より小さい場合 Kibana の設定
上記のリソースのデプロイが完了したあとは、 Elasticsearch に取り込んだデータにインデックスを指定し、Kibana を用いてこれを可視化する ための設定を行います。この手順の詳細については、 こちら にも記載がありますので、本記事と合わせてご一読ください。下記の作業を行うことで、 Firehose が Elasticsearch に対してデータを投入できるようになる とともに、 可視化に必要なグラフおよびダッシュボードが自動で作成 されます。
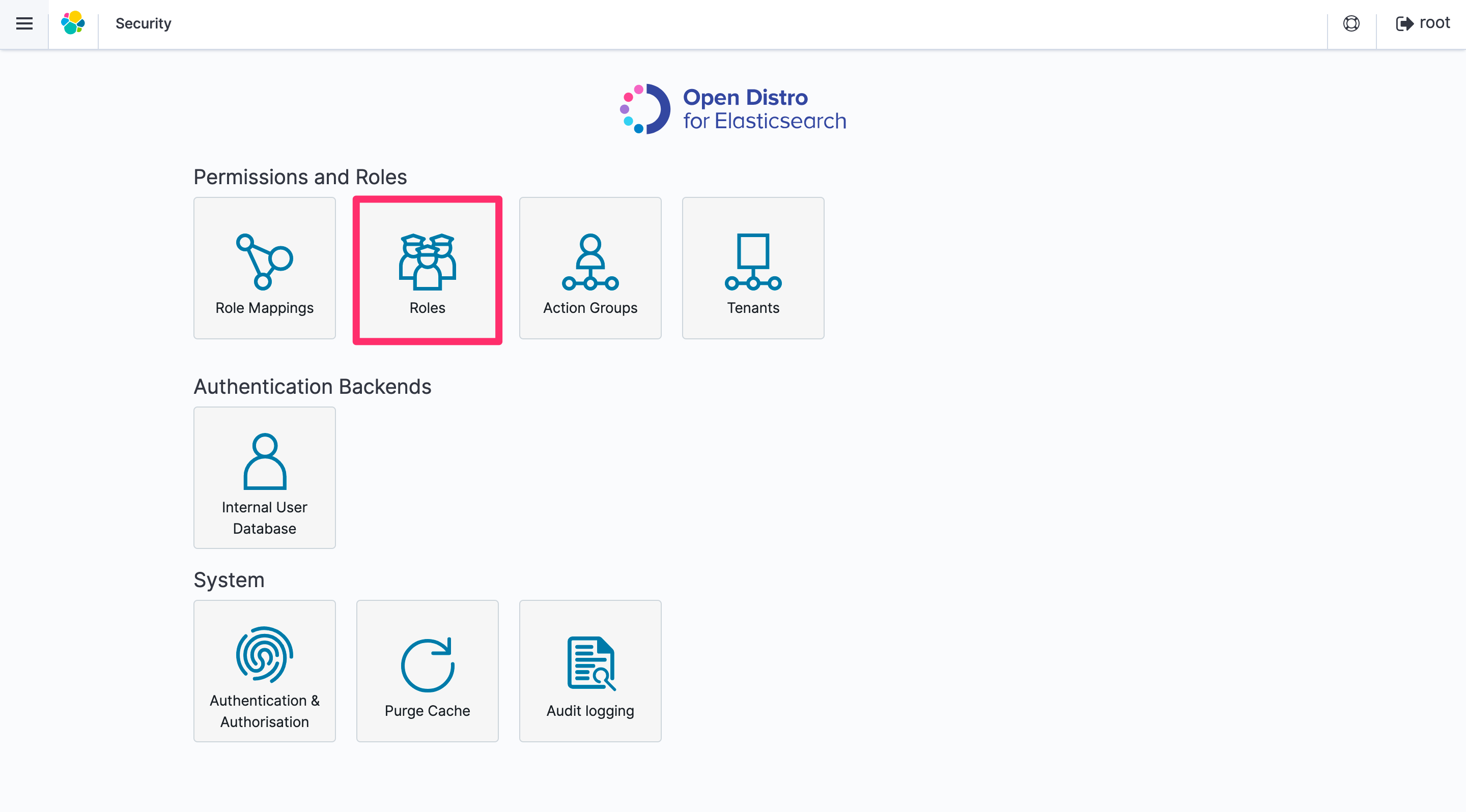
- Security の Roles を選択します。
+アイコンをクリックして新しいロールを追加します。- 作成したロールに
firehoseという名前をつけます。
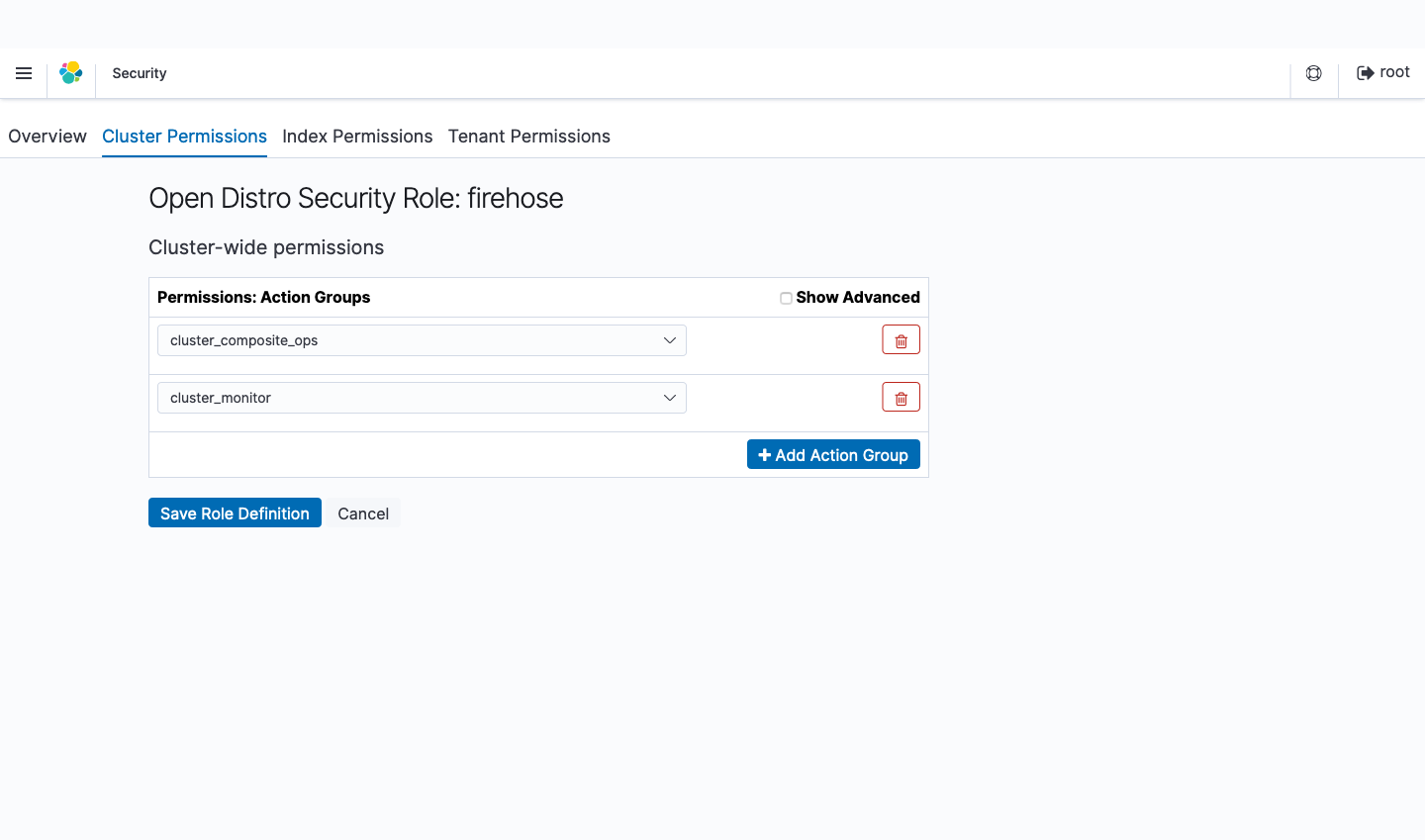
- Cluster Permissions タブの Cluster-wide permissions で
cluster_composite_opscluster_monitorグループを追加します。
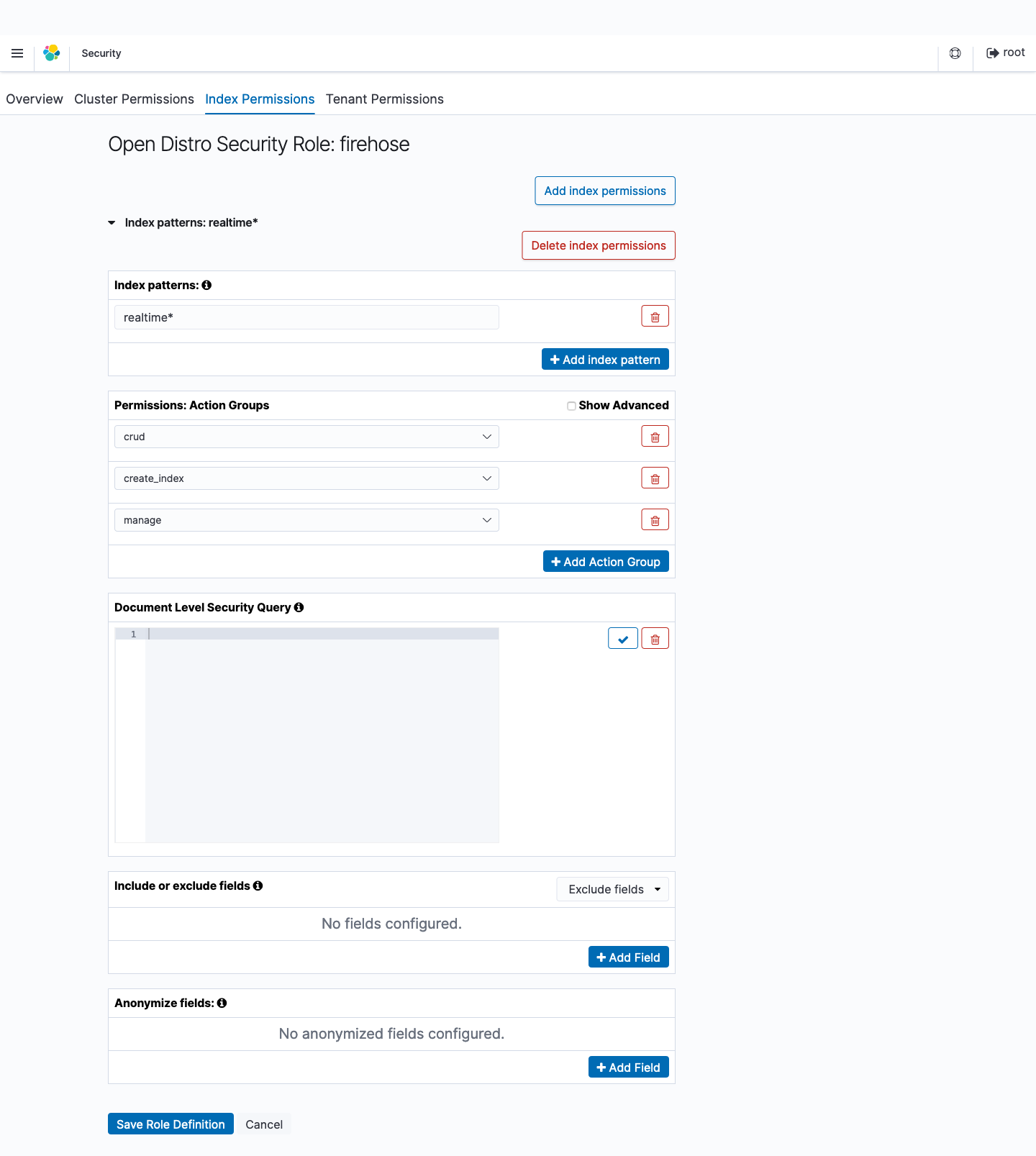
- Index Permissions タブの Add index permissions から Index Patterns を選んで
realtime*を入力します。Permissions: Action Groups でcrudcreate_indexmanageアクショングループを追加します。
- Save Role Definition をクリックします。
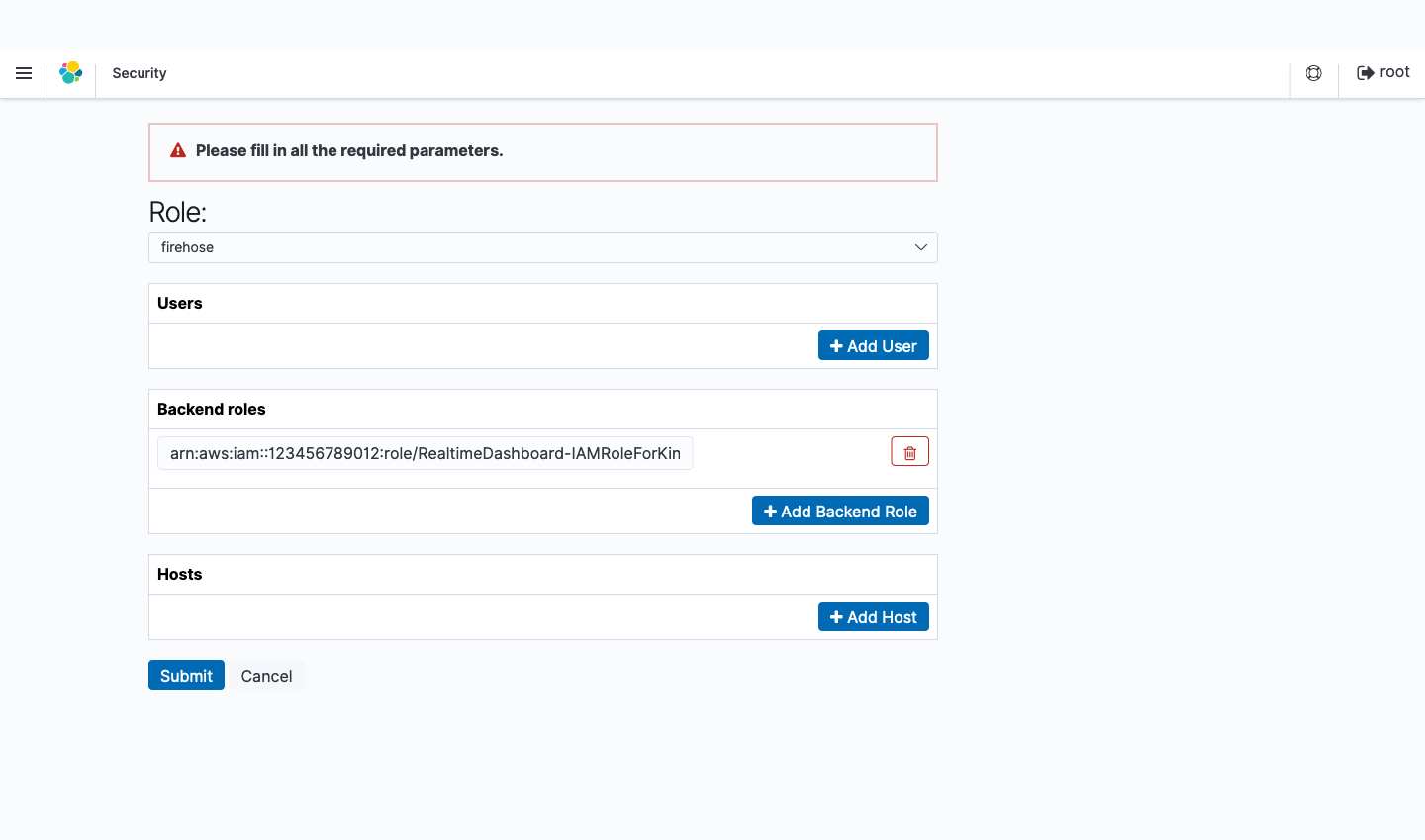
- Security の Role Mappings を選択します。
- Add Backend Role をクリックします。
- 先ほど作成した
firehoseを選択します。- Backend roles に Kinesis Data Firehose が Amazon ES および S3 に書き込むために使用する IAM ロールの ARN を入力します。
- Submit をクリックします。
- Dev Tools を選択します。
timestampフィールドをdateタイプと認識させるために、以下のコマンドを入力して実行します。PUT _template/custom_template { "template": "realtime*", "mappings": { "properties": { "timestamp": { "type": "date", "format": "epoch_second" } } } }
- インデックス および visualizes と dashboard の設定ファイル をインポートします。
以上で、 Kibanaを用いてCloudFrontのログをリアルタイムに確認できる環境 を、AWS上に構築することができました。
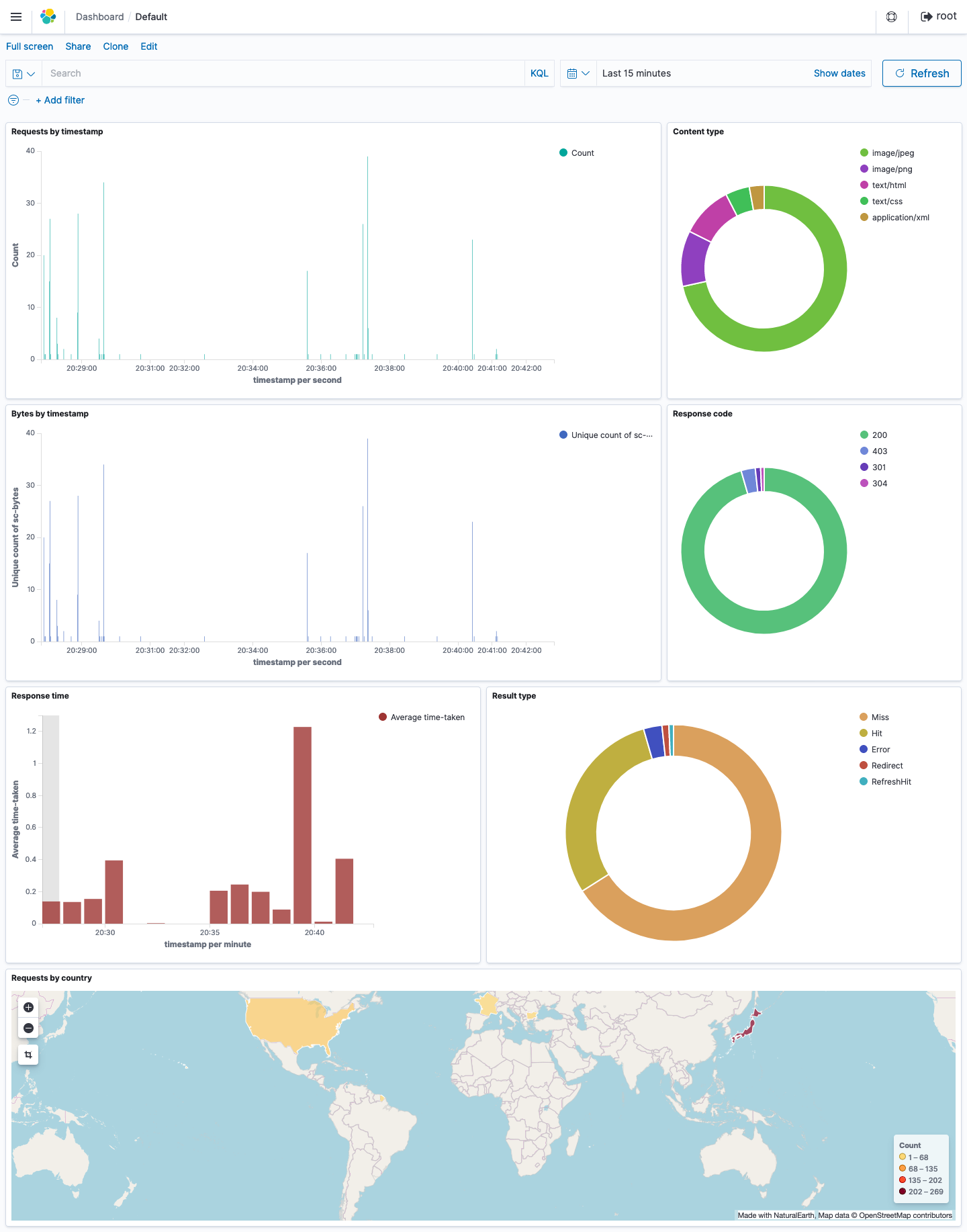
リアルタイムダッシュボード
上記の設定が完了したあとにKibanaにログインすると、 以下のデータをグラフ等でリアルタイムに確認することが可能 となります。
Dashboard
作成した 全てのグラフを一画面で確認 することができます。
Vizualize
それぞれのグラフは以下の通りです。
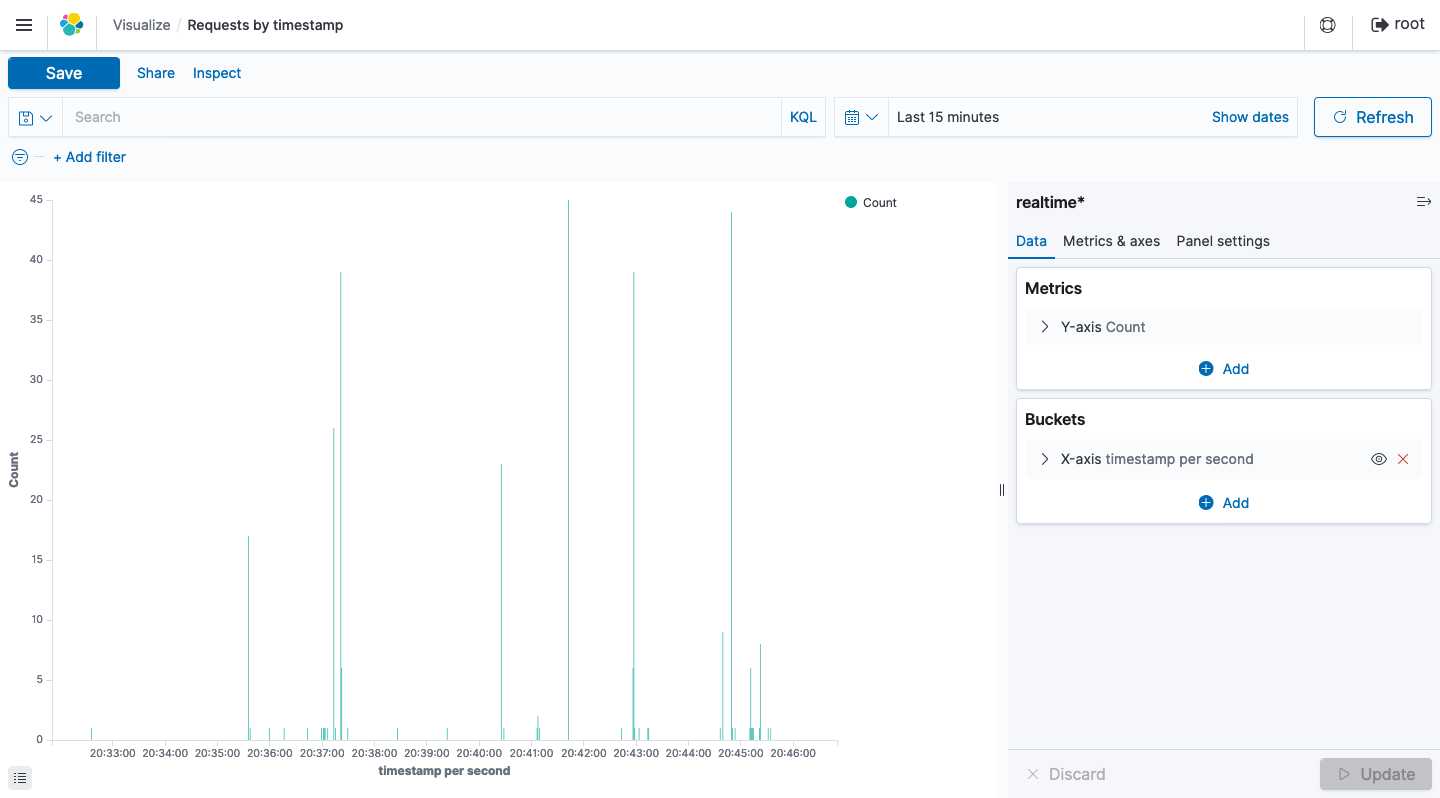
Requests per second
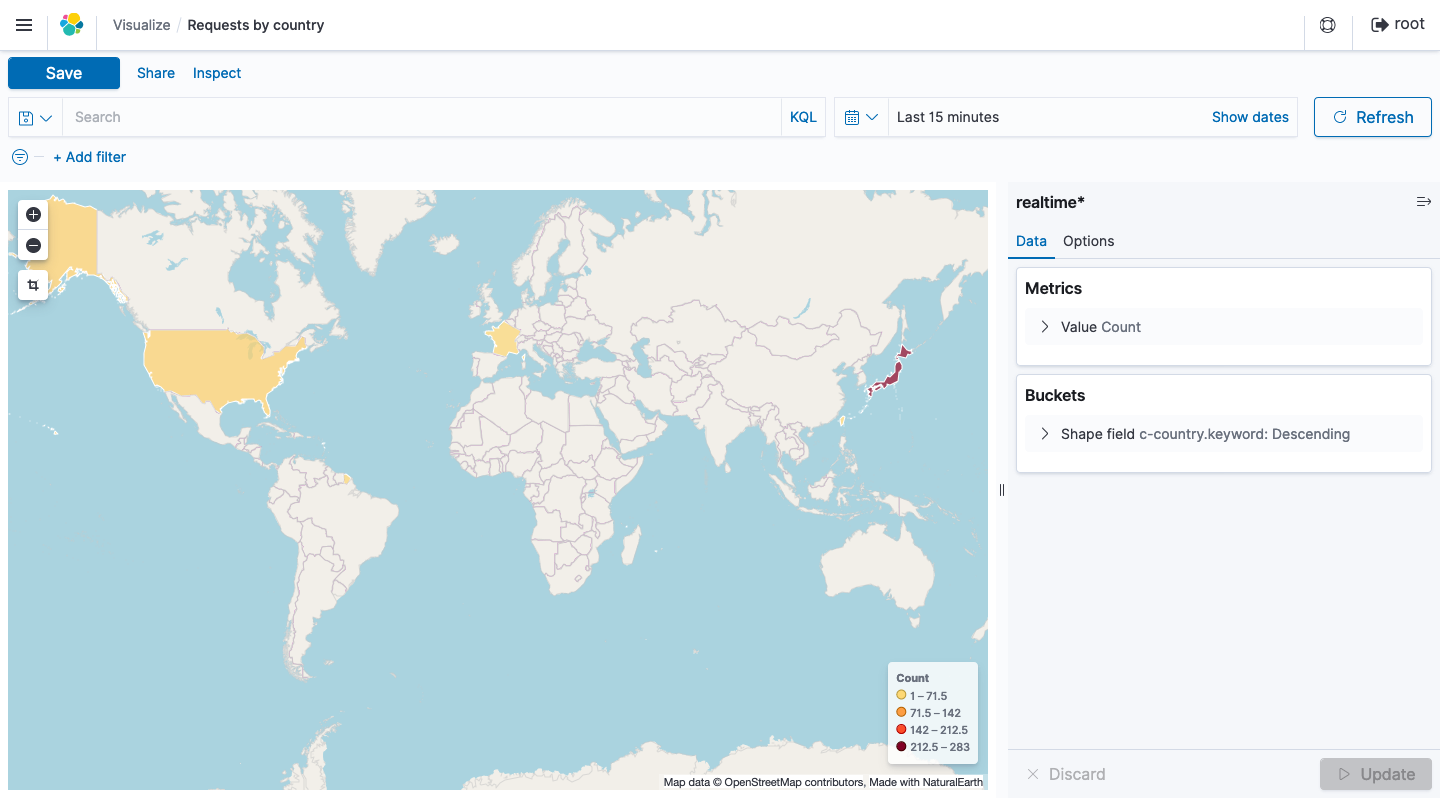
Country
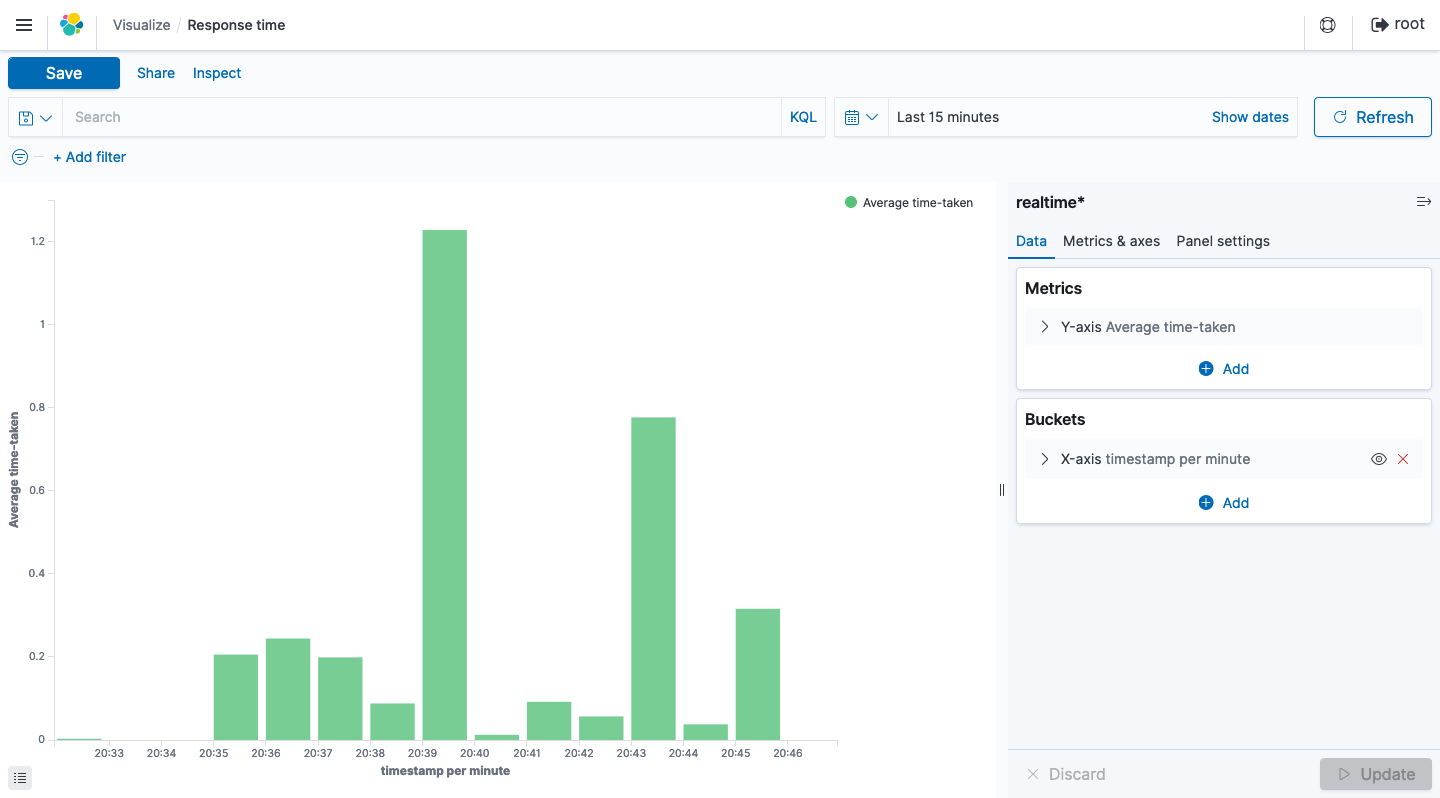
Response time
Content type
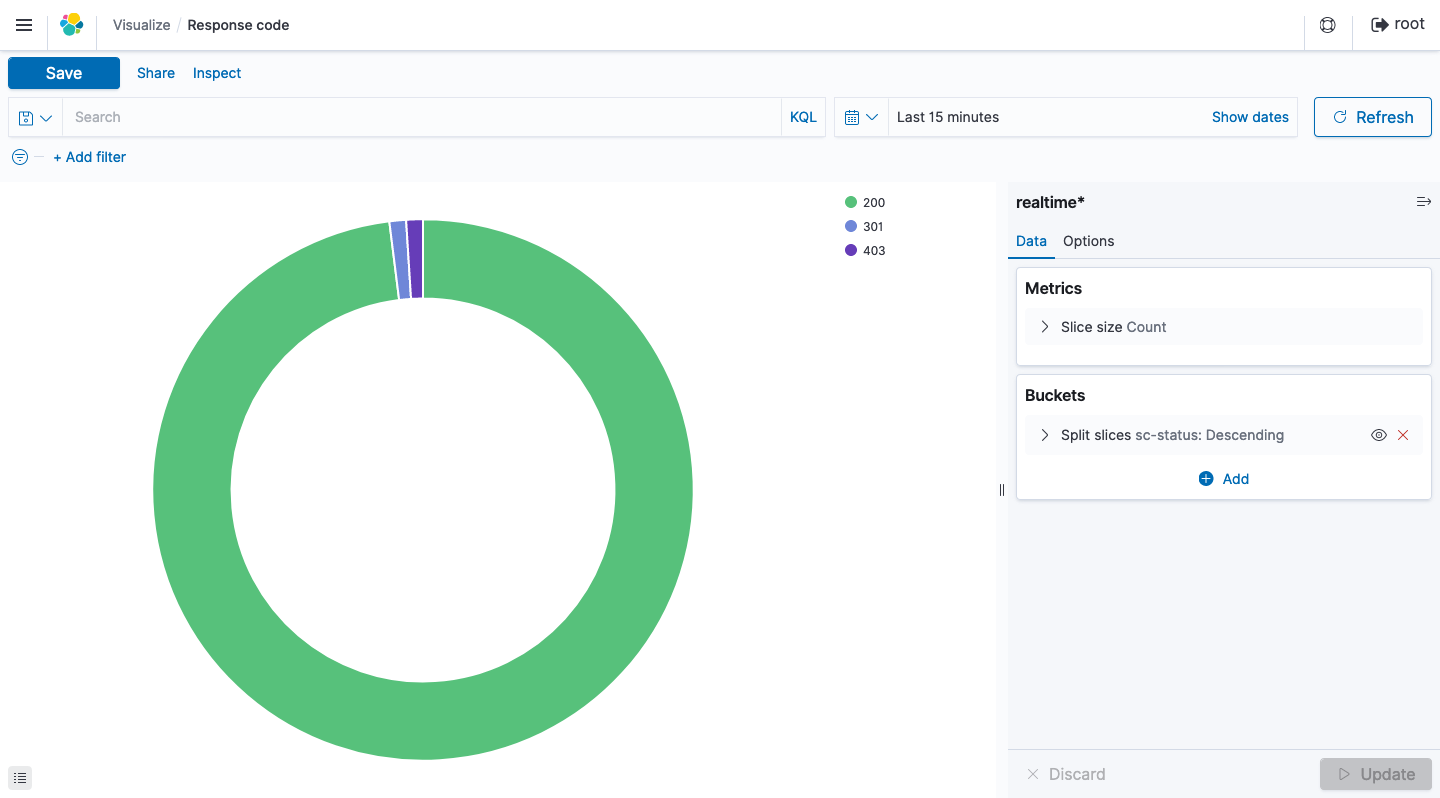
Response Code
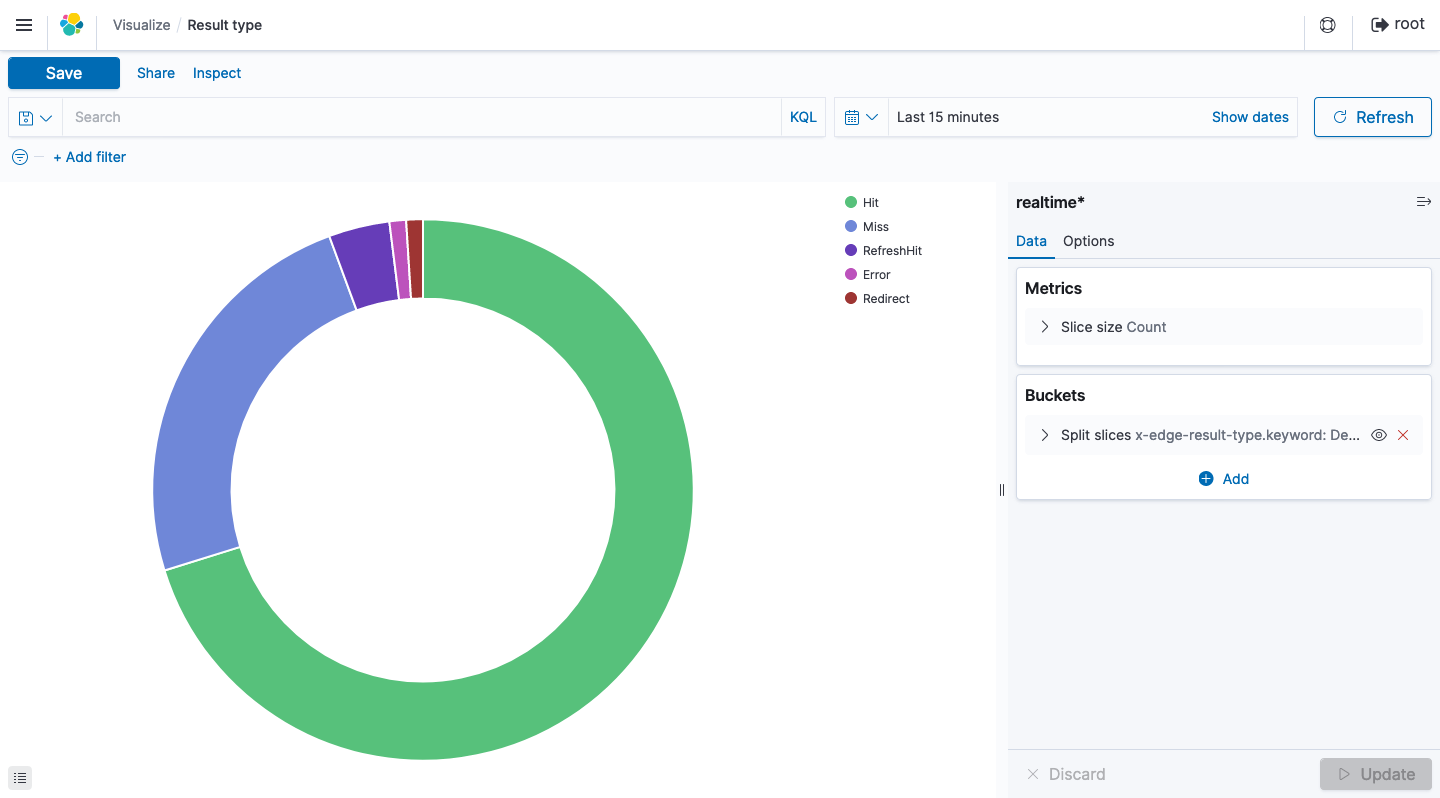
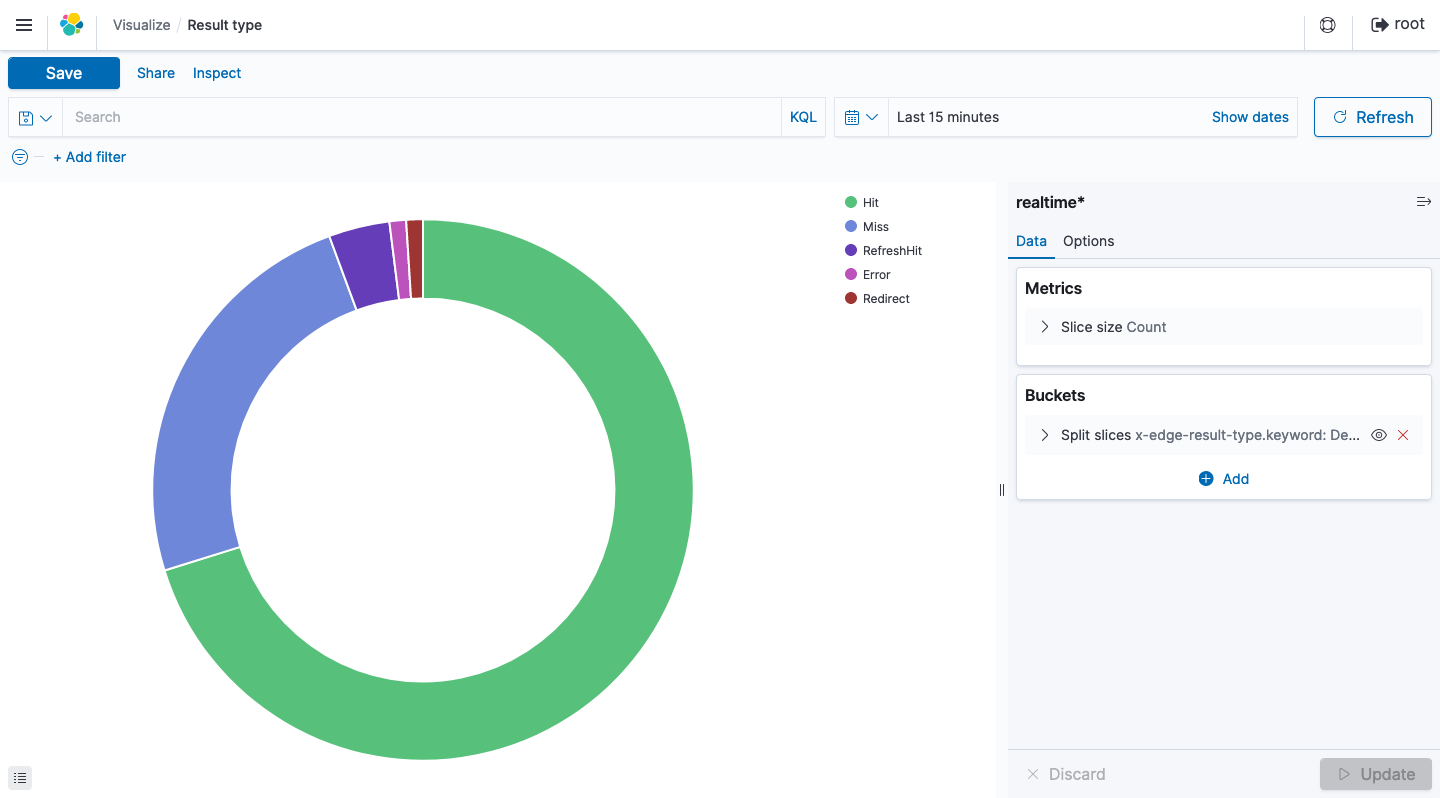
Result type
リアルタイムログの任意のフィールドを抽出することで、これ以外にも 様々なデータを可視化し、リアルタイムにその変化を確認することができます 。これにより従来より機動性が高く、きめ細やかなWebサイトの運用監視体制が構築できるのではないかと思います。
関連リンク
- ワンクリックで配信基盤を構築 - CloudFormation を用いて簡単Webサイトホスティング
- CloudFrontにWAFをアタッチ - CloudFormation を用いて簡単Webサイトホスティング
- 特定のURLを定期的にモニタリングする - CloudFormation を用いて簡単Webサイトホスティング
- CloudFrontのリアルタイムログをKibanaで可視化する - CloudFormation を用いて簡単Webサイトホスティング
- 投稿日:2021-01-23T20:31:49+09:00
最安値に挑戦!AWSとRTX1210の拠点間VPN接続
AWSで拠点間VPN接続をするのであれば、通常はマネージドサービス(AWSサイト間VPN接続)を使います。しかし、0.048USD/hourの費用、1か月(744時間)で35ドル強の費用が掛かり、個人で使うには厳しい金額です。
そこで、できるだけ安く拠点間VPNを行うための方法を模索し、定期的にQiitaに載せていたのですが、ようやく実現したのでこの記事でまとめておきます。節約のポイント
- AWS側のVPNサーバとしてEC2を利用し、ソフトウェアはLinuxベースのstrongSwanを使用
EC2のインスタンスタイプは、現状AWSで最安値であるT4g.nanoを利用
- リザーブドインスタンスが余っていたため、今回はt3.nanoで構築しています
- OSはminimalイメージを活用し、EBS 2GBで運用
- 自宅側の固定IP費用を削減するため、IPv6で接続
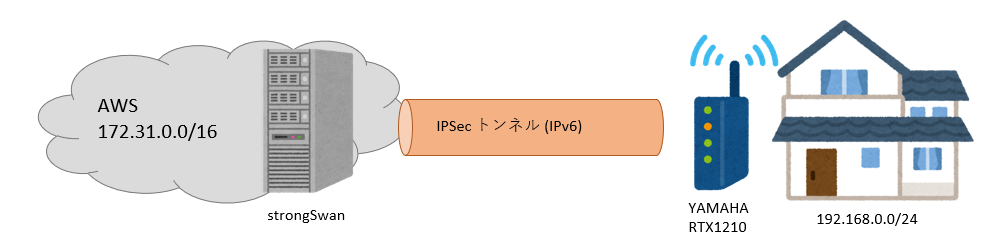
接続構成
AWS側
EC2にLinuxインスタンスを立て、strongSwanを利用してIPSecトンネルを張ります。T3に比べて20%OFFで利用できる、Arm系のT4gインスタンスを使う、、、予定だったのですが、t3.nanoのリザーブドインスタンスが手持ちに余っていたため、今回はそちらを利用しています。
自宅側
VPNルータとしてYAMAHAのRTX1210を利用し、光回線はIPoE接続のフレッツ光コラボを利用します。固定IPは費用が掛かるため、半固定で付与されているIPv6アドレスを利用してVPNトンネルを張ります。IPv6アドレスが変更されることは滅多にないと予想されるため、その際は、再度一から設定をし直すこととします。
strongSwanのインストール・設定
strongswanを設定する際は、strongswan5.8より推奨化されているswanctlを利用します。OSにubuntu 20.04 LTSを利用すると、strongSwan5.8系がインストールされ、swanctlも容易に利用できるのですが、EBSで8GB課金されてしまうという問題があります。
今回はできるだけ安く運用するという方針のもと、Amazon Linux 2のminimalインスタンスを利用し、EBS 2GBで運用します。(0.576USD≒約60円の節約)strongSwanのインストール方法は以下の記事を参照してください。
Amazon Linux 2 minimalイメージにstrongSwan5.9.1をインストールstrongSwanとRTX1210間でIPSecトンネルを張るための設定方法は以下の記事を参照してください。
strongSwanとRTX1210の拠点間VPN接続(IKEv2, IPv4 over IPv6)費用
通信費を除き、3.042 USD(約320円)になりました。なんと91%OFFです!T4g系を利用して3年分の利用契約をすればさらに安くなります!新規で購入するのであれば、リザーブドインスタンスよりもSaving Planを利用すると安いインスタンスタイプが出た際に容易に対応できるようになるかと思います。
- T3.nanoリザーブドインスタンス コンバーチブル3年間 2.85USD
- EBS 0.096USD/GB × 2(GB) = 0.192 USD
参考:過去に投稿したQiitaのリンク
- LightsailでSecureNATを有効化したSoftEther VPN Serverを構築する
- 当初はSoftEther VPN Serverを利用しようと考えていました。通信料削減のためにLightsailを利用できないか検証しましたが、ルートテーブルがいじれないので VPNServer側でNATが必要なことに気づき、LightSailの利用は諦めました。
- T4gインスタンスにIPv6を有効にしてSoftEther VPN Server を構築する
- SoftetherでL2TPv3を利用して接続する作戦でしたが、VPNトンネルは張れても、トンネルとブリッジ接続をしようとするとインターネットにつながらなくなったため諦めました。。。
- strongSwanでIPv4 over IPv6のVPNトンネルを構成する
- SoftEtherは諦め、strongSwanに切り替え。strongSwanのインストールに手間取りましたが、strongSwan同士の検証は特にトラブルもなく利用できました。
- strongSwanとRTX1210の拠点間VPN接続(IKEv2, IPv4 over IPv6)
- strongSwanとYAMAHAルータで検証。ちょっと設定変える必要がありましたが何とか接続成功。調べるときにIKEv1とIKEv2の情報が入り乱れていて、結局信用できるのは公式サイトの情報だと改めて感じた次第。
- Amazon Linux 2 minimalイメージにstrongSwan5.9.1をインストール
- strongSwanの検証ではUbuntuを利用していたため、AmazonLinux2のminimalイメージに入れられないか検証。
- 投稿日:2021-01-23T19:54:54+09:00
AWS Translateを使ってGo言語で翻訳するサンプル
タイトルの通りですが、公式ドキュメントにサンプルが含まれていなかったので記事にしました。
サンプルソースはGithubにも置いてあります。
https://github.com/yuukimiyo/go-aws-translate簡単なコードですが、73言語(2021年1月現在)の双方向翻訳が可能な簡易ツールとして使えます。
Public Domainですので、コピペなどご自由に。package main import ( "flag" "fmt" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/translate" ) func main() { sourceText := flag.String("text", "これは翻訳のテストです", "source text") sourceLC := flag.String("slc", "ja", "source language code [en|ja|fr]...") targetLC := flag.String("tlc", "en", "target language code [en|ja|fr]...") flag.Parse() sess := session.Must(session.NewSession()) trs := translate.New(sess) result, err := trs.Text(&translate.TextInput{ SourceLanguageCode: aws.String(*sourceLC), TargetLanguageCode: aws.String(*targetLC), Text: aws.String(*sourceText), }) if err != nil { panic(err) } fmt.Printf(*result.TranslatedText) }上記ドキュメントを読み、Text()関数で翻訳を実施するんだ、という事さえわかれば難しいことは何もないです。
手元で試したい人向け
前提
AWSアカウントと、次のポリシーをアタッチしたユーザが必要です。
- TranslateFullAccess
無料期間もありますがAWS Translateは有料サービスです、公式サイトの料金表は必ず確認してください。
AWS TranslateGo言語の実行環境が必要です。
厳密にどのバージョンからかは把握していませんが、開発/確認には次の環境を利用しています。Ubuntu20.04(WSL2)
go1.15.7.linux-amd64環境変数の設定
他言語のAWS SDKでも同じですが、次の環境変数をセットしておきます。
- AWS_REGION
- AWS_ACCESS_KEY_ID
- AWS_SECRET_ACCESS_KEY
bashの場合
export AWS_REGION=ap-northeast-1 export AWS_ACCESS_KEY_ID=<access key id> export AWS_SECRET_ACCESS_KEY=<Secret access key>fish shellの場合
set -x AWS_REGION ap-northeast-1 set -x AWS_ACCESS_KEY_ID <access key id> set -x AWS_SECRET_ACCESS_KEY <Secret access key>Download
git clone git@github.com:yuukimiyo/go-aws-translate-example.git動かしてみる
デフォルトでは、日本語ー>英語の翻訳を行います。
go run main.go --text="翻訳のテストです" > Testing the translation言語を指定したい場合は次のように言語コードを指定します。
(例えば英語ー>日本語の場合)go run main.go --text="This is test of AWS Translate" --slc="en" --tlc="ja" > これは AWS 翻訳のテストです利用可能な言語コードの一覧は次のURLにあります。
Supported Languages and Language Codes
- 投稿日:2021-01-23T17:48:41+09:00
AWSへDockerホストのプロビジョニングをする際にcredentialsがない旨のエラーが表示される
AWSへDockerホストのプロビジョニングをする際に、アクセスキーやシークレットキーを記述したcredentialsファイルを作成して、AWSにDocker Engineが動作するインスタンス作成するコマンドを実行したところ、下記エラーが出力されました。
$ docker-machine create --driver amazonec2 --amazonec2-open-port 8000 --amazonec2-region ap-northeast-1 aws-sandbox Error setting machine configuration from flags provided: amazonec2 driver requires AWS credentials configured with the --amazonec2-access-key and --amazonec2-secret-key options, environment variables, ~/.aws/credentials, or an instance roleこれはcredentialsのファイルがないか、もしくは作成する権限がおかしいことを意味するエラーの模様。
AWSで作成したIAMユーザの権限はadmin権限を渡しているので特に問題がないため、credentialsファイルがどうやら悪さしているみたいです。対策
調べたところ、credentialsファイルの置き場所が悪かったようです。
credentialsファイルはユーザのホームディレクトリ配下に作成しなければいけませんでした。mkdir ~/.aws vi ~/.aws/credentials適当な作業ディレクトリにawsディレクトリを作成して、その配下にcredentialsファイルを作成しておりましたが、ユーザのホームディレクトリ配下にcredentialsファイルを作成してコマンドの実行ユーザに紐付けしなければ、当然AWSへインスタンス作成はできないですよね。
これで無事AWSへインスタンス作成が完了です。
$ docker-machine create --driver amazonec2 --amazonec2-open-port 8000 --amazonec2-region ap-northeast-1 aws-sandbox Running pre-create checks... Creating machine... (aws-sandbox) Launching instance... Waiting for machine to be running, this may take a few minutes... Detecting operating system of created instance... Waiting for SSH to be available... Detecting the provisioner... Provisioning with ubuntu(systemd)... Installing Docker... Copying certs to the local machine directory... Copying certs to the remote machine... Setting Docker configuration on the remote daemon... Checking connection to Docker... Docker is up and running! To see how to connect your Docker Client to the Docker Engine running on this virtual machine, run: docker-machine env aws-sandbox $最後に
教材ではサラッと流されてしまうところ、一つ一つ重要視して進めていかないとうまくいかないですね。
- 投稿日:2021-01-23T17:24:33+09:00
はじめてのAmazon EKS (k8s経験者向け )
k8sは使ってるがAmazon EKSは使ったことないので気になったポイントまとめ
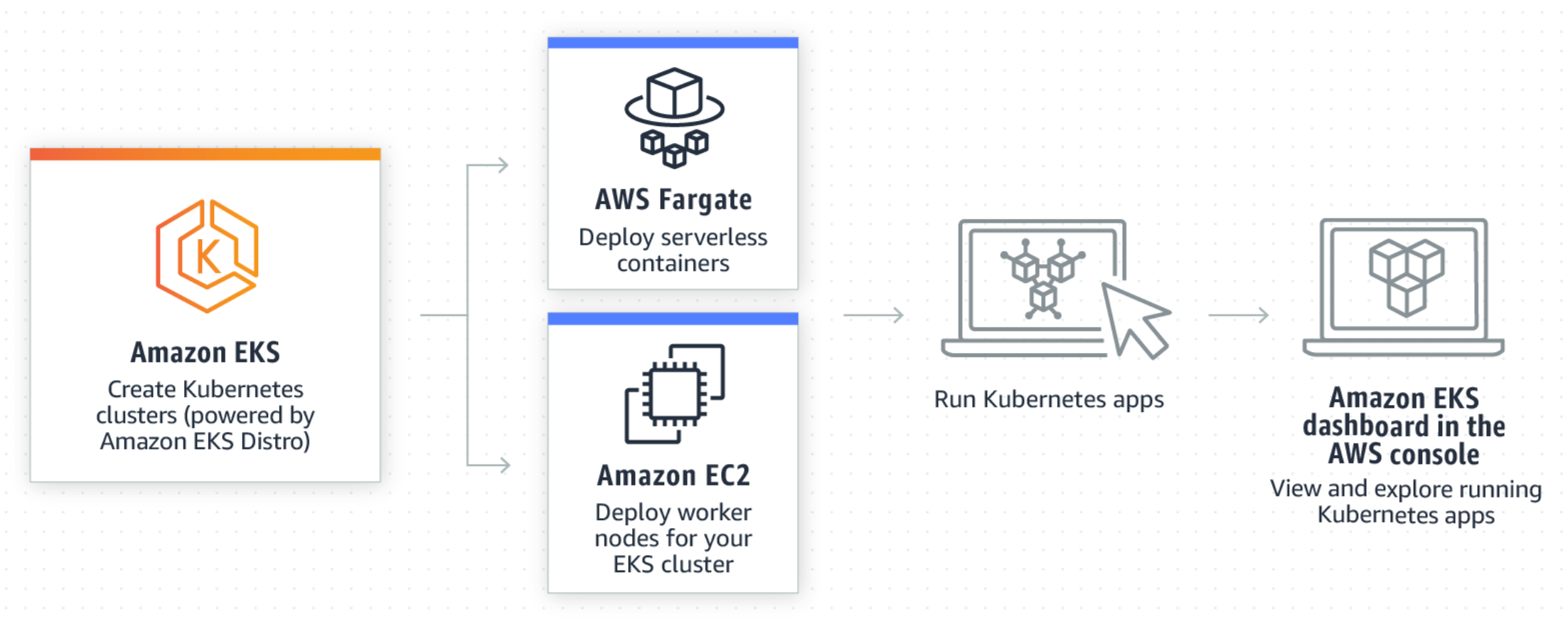
※2021年1月時点[1] Amazon EKSとは
- AWSが提供する
マネージドKubernetesサービス(2018 GA)- Masterにあたるコントロールプレーン(etcd含む)がサーバレス的に提供され、Worker部分は統合されたEC2(NodeGroup)かFargateでクラスタを構成する
- re:Invent 2020にてEKS Anywhereという新サービスが発表され、オンプレミス環境のKubernetesの管理拡張も可能になる予定(GCPのAnthos的な感じ)
- 参考:オンプレ利用想定のディストリビューション EKS Distro:https://github.com/aws/eks-distro
Kubernetesバージョンについて
- 本家アップストリームの最新版はすぐに使えない
- 半年ほど遅れてEKSはサポートしている模様(目安的には1~2世代古い)
- 本家では最新3世代サポートだが、
EKSは最新4世代までサポート可用性/耐障害性とSLAについて
- リージョン内の 3 つのアベイラビリティーゾーンにまたがって動作する
2 つ以上の API サーバーノードと 3 つの etcd ノードで構成されている99.95%のSLAが規定されている価格について
- 基本はクラスタごとに
毎時課金 0.10USDと、ワーカーノード(EC2 or Fargate)の利用料- その他暗号化のKMSやCloudWatch、S3、ECR(コンテナレジストリ)利用料など関連サービスを利用した料金
Amazon EKS利用のメリット
- マネージドかつHA構成のコントロールプレーン(etcd含む)が容易に構築できる
- WorkerノードのAuto Scalingが利用できる(PodではなくNodeレベルのCluster Autoscaler)
- 使った分だけの従量課金
- 認証認可をKubernetesのRBACとAWS IAMを統合できる(AWSユーザ向けの利点)
- その他のAWSサービスとの統合(例:KMS、Cloud Watch、EFS、などなど)
[2] クラスタ作成関連
実際にクラスタを作成する際に気になったポイント
※所感としてはGKEより複雑な印象Kubernetesバージョン
- k8sバージョンは2021/1時点でアップストリーム最新版は1.20だが、EKSでは1.18
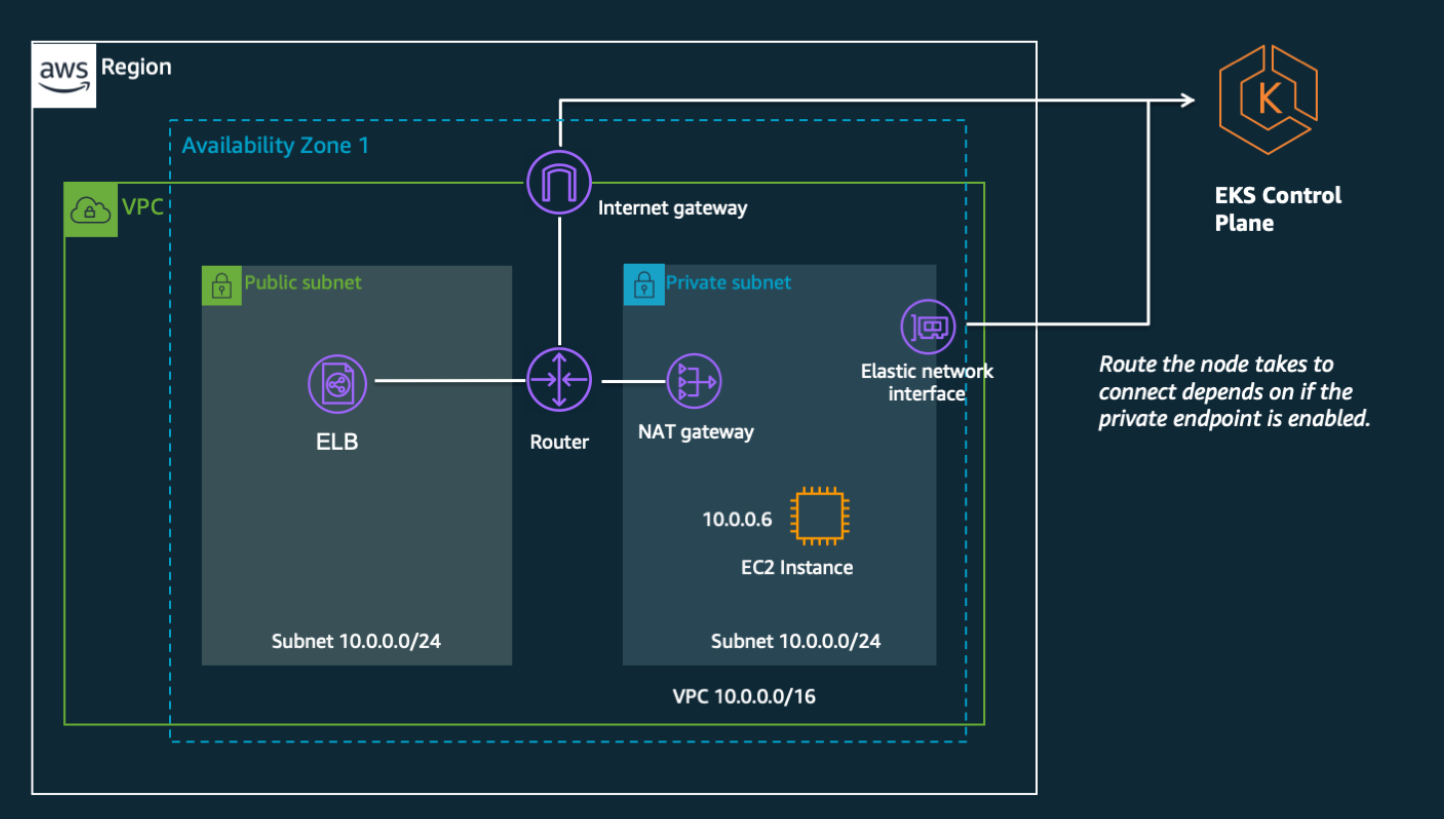
アーキテクチャ
- パブリック、プライベート、パブリック&プライベートの3パターンがある
- Master(コントロールプレーン)~Worker間は、サブネット内のENIを経由する
- Master(コントロールプレーン)のAPIエンドポイントは、パブリックかプライベートか選択できる
- 下記は標準的なパブリック&プライベートの例
https://aws.amazon.com/jp/blogs/news/de-mystifying-cluster-networking-for-amazon-eks-worker-nodes/
VPC
- クラスタ全体では基本2つ
- 1) Master/コントロールプレーンは「Amazon EKS管理VPC」と呼ばれるユーザが意識しない領域に作成される(サーバーレス)
- 2) Workerノードは指定したVPCに作成できる
サブネット
- Workerノード用に2つ以上のアベイラビリティーゾーンでサブネット作成が必要
- パターンは3つ
- パブリックのみ
- プライベートのみ
- パブリックとプライベートの併用(上の図)
SG
- 基本的に2つ
- 各Workerノード用
- Workerノードが存在するVPCサブネット内から、EKSコントロールプレーンへアクセスするためのENIに設定されるSG(eks-cluster-sg-XXXという名前でEKSが自動作成)
- https://docs.aws.amazon.com/eks/latest/userguide/sec-group-reqs.html
IAM ROLE
- MASTER(コントロールプレーン)用とWorker(Node Group)用の2つ
- https://docs.aws.amazon.com/ja_jp/eks/latest/userguide/using-service-linked-roles.html
CNIプラグイン
- 基本はAWS提供のamazon-vpc-cni-k8s
- FlannelやCalicoをセットアップすることもできる模様
ワーカーノードのイメージ
- EC2 起動テンプレートが利用でき、ベースイメージ(AMI)やインスタンスタイプなどを規定できる
コンテナイメージの利用
- ECRを利用する場合は、ワーカーノードのIAM ROLEにECR利用のための以下の権限を付与しておく必要あり
- "ecr:BatchCheckLayerAvailability"
- "ecr:BatchGetImage"
- "ecr:GetDownloadUrlForLayer"
- "ecr:GetAuthorizationToken"
[3] クラスタ接続方法
1. kubectlインストール
https://docs.aws.amazon.com/ja_jp/eks/latest/userguide/install-kubectl.html
例)
curl -o kubectl https://amazon-eks.s3.us-west-2.amazonaws.com/1.18.9/2020-11-02/bin/linux/amd64/kubectl chmod +x ./kubectl mkdir -p $HOME/bin && cp ./kubectl $HOME/bin/kubectl && export PATH=$PATH:$HOME/bin echo 'export PATH=$PATH:$HOME/bin' >> ~/.bash_profile2. kubeconfigファイルの更新
https://aws.amazon.com/jp/premiumsupport/knowledge-center/eks-cluster-connection/
例)
aws eks --region リージョン update-kubeconfig --name クラスタ名
- 投稿日:2021-01-23T17:24:33+09:00
はじめてのAmazon EKS (k8s経験者用 )
今更ながら、k8sは使ってるがAmazon EKSはちゃんと使ったことないので気になったポイントまとめ
※2021年1月時点[1] Amazon EKSとは
- AWSが提供する
マネージドKubernetesサービス(2018 GA)- Masterにあたるコントロールプレーン(etcd含む)がサーバレス的に提供され、Worker部分は統合されたEC2(NodeGroup)かFargateでクラスタを構成する
- re:Invent 2020にてEKS Anywhereという新サービスが発表され、オンプレミス環境のKubernetesの管理拡張も可能になる予定(GCPのAnthos的な感じ)
- 参考:オンプレ利用想定のディストリビューション EKS Distro:https://github.com/aws/eks-distro
Kubernetesバージョンについて
- 本家アップストリームの最新版はすぐに使えない
- 半年ほど遅れてEKSはサポートしている模様(目安的には1~2世代古い)
- 本家では最新3世代サポートだが、
EKSは最新4世代までサポート可用性/耐障害性とSLAについて
- リージョン内の 3 つのアベイラビリティーゾーンにまたがって動作する
2つ以上の APIサーバーノードと3つのetcdノードで構成されている99.95%のSLAが規定されている価格について
- 基本はクラスタごとに
毎時課金 0.10USDと、ワーカーノード(EC2 or Fargate)の利用料- その他暗号化のKMSやCloudWatch、S3、ECR(コンテナレジストリ)利用料など関連サービスを利用した料金
Amazon EKS利用のメリット
- マネージドかつHA構成のコントロールプレーン(etcd含む)が容易に構築できる
- WorkerノードのAuto Scalingが利用できる(PodではなくNodeレベルのCluster Autoscaler)
- 使った分だけの従量課金
- 認証認可をKubernetesのRBACとAWS IAMを統合できる(AWSユーザ向けの利点)
- その他のAWSサービスとの統合(例:KMS、Cloud Watch、EFS、などなど)
[2] クラスタ構築関連
実際にクラスタを作成する際に気になったポイント
※所感としてはGKEより複雑な印象クラスタ作成手段
- クラスタ作成方法は3種類の方法がある
- ①AWSコンソールからGUIポチポチ
- ②AWS標準CLIツール「aws cli」を利用
- ③公式のEKSクラスタ構築用CLIツール「eksctl」を利用
eksctlとは?
- 標準的なAWSサービスはAWSコンソールかaws cliで操作するが、EKSのk8sクラスタ構築は煩雑なためか、EKS k8sクラスタ作成用のCLIが別途提供されている
- 普通にコンソールからEKS k8sクラスタを作成する場合、Master要素(コントロールプレーン)の他にもVPC/Subnet/SGやIAM、Workerノードの作成など多くの操作手順が必要だが、eksctlはコマンド1つでそれらを自動的に生成し、クラスタ構築してくれる
- もともとWeaveworks社がGo言語ベースで開発し、OSSとして公開されている
- 裏でCloud Formationが連携していて、各種必要なAWSリソース生成を行っている
- GCP GKEでいうとgcloudコマンド相当
eksctlインストール
$ curl --silent --location "https://github.com/weaveworks/eksctl/releases/latest/download/eksctl_$(uname -s)_amd64.tar.gz" | tar xz -C /tmp $ sudo mv /tmp/eksctl /usr/local/binhttps://github.com/weaveworks/eksctl
eksctlでEKS k8sクラスタ作成
- 極論でいえば、
eksctl create clusterコマンドだけで作成できる- 実際は色々なオプションを付ける
eksctl create cluster --helpでオプションは参照可能クラスタ作成例)
eksctl create cluster \ --name=test-cluster \ #クラスタ名 --region=ap-northeast-1 \ #リージョン --version=1.18 \ #バージョン --node-type=t3.medium \ #Workerインスタンスタイプ --nodes=2 \ #Workerノード数 --nodes-min=2 \ #Workerオートスケール最小 --nodes-max=2 \ #Workerオートスケール最大 --node-volume-size=20 #Workerディスクサイズ※参考:2020/12にリリースされたAWS CloudShellから、kubectlとeksctlをセットアップすればクラスタ作成(CLIコマンド実行)がすぐに試せます
https://aws.amazon.com/jp/blogs/news/aws-cloudshell-command-line-access-to-aws-resources/
- eksctlで上記コマンドで自動生成された主なAWSリソース
- Cloud Formationスタック(KSクラスタとWorker(NodeGroup)の2つ)
- EKSクラスタ
- VPC
- サブネット
- SG
- InternetGWとNAT-GW
- IAM ROLE
- EC2(NodeGroup)
- etc.
eksctlでEKS k8sクラスタ削除
eksctl delete cluster --name クラスタ名Kubernetesバージョン
- k8sバージョンは2021/1時点でアップストリーム最新版は1.20だが、EKSでは1.18
アーキテクチャ
- 基本的に①パブリック、②プライベート、③パブリック&プライベート の3パターンがある
- Master(コントロールプレーン)~Worker間は、サブネット内のENIを経由する(ENIは自動生成される)
- Master(コントロールプレーン)のAPIエンドポイントは、パブリックかプライベートか選択できる
- 下記は標準的なパブリック&プライベートの例
https://aws.amazon.com/jp/blogs/news/de-mystifying-cluster-networking-for-amazon-eks-worker-nodes/
VPC
- クラスタ全体では基本2つ
- 1) Master/コントロールプレーンは「Amazon EKS管理VPC」と呼ばれるユーザが意識しない領域に作成される(サーバーレス)
- 2) Workerノードは指定したVPCに作成できる
サブネット
- Workerノード用に2つ以上のアベイラビリティーゾーンでサブネット作成が必要
- パターンは3つ
- パブリックのみ
- プライベートのみ
- パブリックとプライベートの併用(上の図)
SG
- 基本的に2つ
- 各Workerノード用
- Workerノードが存在するVPCサブネット内から、EKSコントロールプレーンへアクセスするためのENIに設定されるSG(eks-cluster-sg-XXXという名前でEKSが自動作成)
- https://docs.aws.amazon.com/eks/latest/userguide/sec-group-reqs.html
IAM ROLE
- MASTER(コントロールプレーン)用とWorker(Node Group)用の2つ
- https://docs.aws.amazon.com/ja_jp/eks/latest/userguide/using-service-linked-roles.html
CNIプラグイン
- 基本はAWS提供のamazon-vpc-cni-k8s
- FlannelやCalicoをセットアップすることもできる模様
ワーカーノードのイメージ
- EC2 起動テンプレートが利用でき、ベースイメージ(AMI)やインスタンスタイプなどを規定できる
コンテナイメージの利用
- ECRを利用する場合は、ワーカーノードのIAM ROLEにECR利用のための以下の権限を付与しておく必要あり
- "ecr:BatchCheckLayerAvailability"
- "ecr:BatchGetImage"
- "ecr:GetDownloadUrlForLayer"
- "ecr:GetAuthorizationToken"
[3] クラスタ接続設定
1. kubectlインストール
https://docs.aws.amazon.com/ja_jp/eks/latest/userguide/install-kubectl.html
例)
curl -o kubectl https://amazon-eks.s3.us-west-2.amazonaws.com/1.18.9/2020-11-02/bin/linux/amd64/kubectl chmod +x ./kubectl mkdir -p $HOME/bin && cp ./kubectl $HOME/bin/kubectl && export PATH=$PATH:$HOME/bin echo 'export PATH=$PATH:$HOME/bin' >> ~/.bash_profile2. kubeconfigファイルの更新
https://aws.amazon.com/jp/premiumsupport/knowledge-center/eks-cluster-connection/
例)
aws eks --region リージョン update-kubeconfig --name クラスタ名[4] おまけ
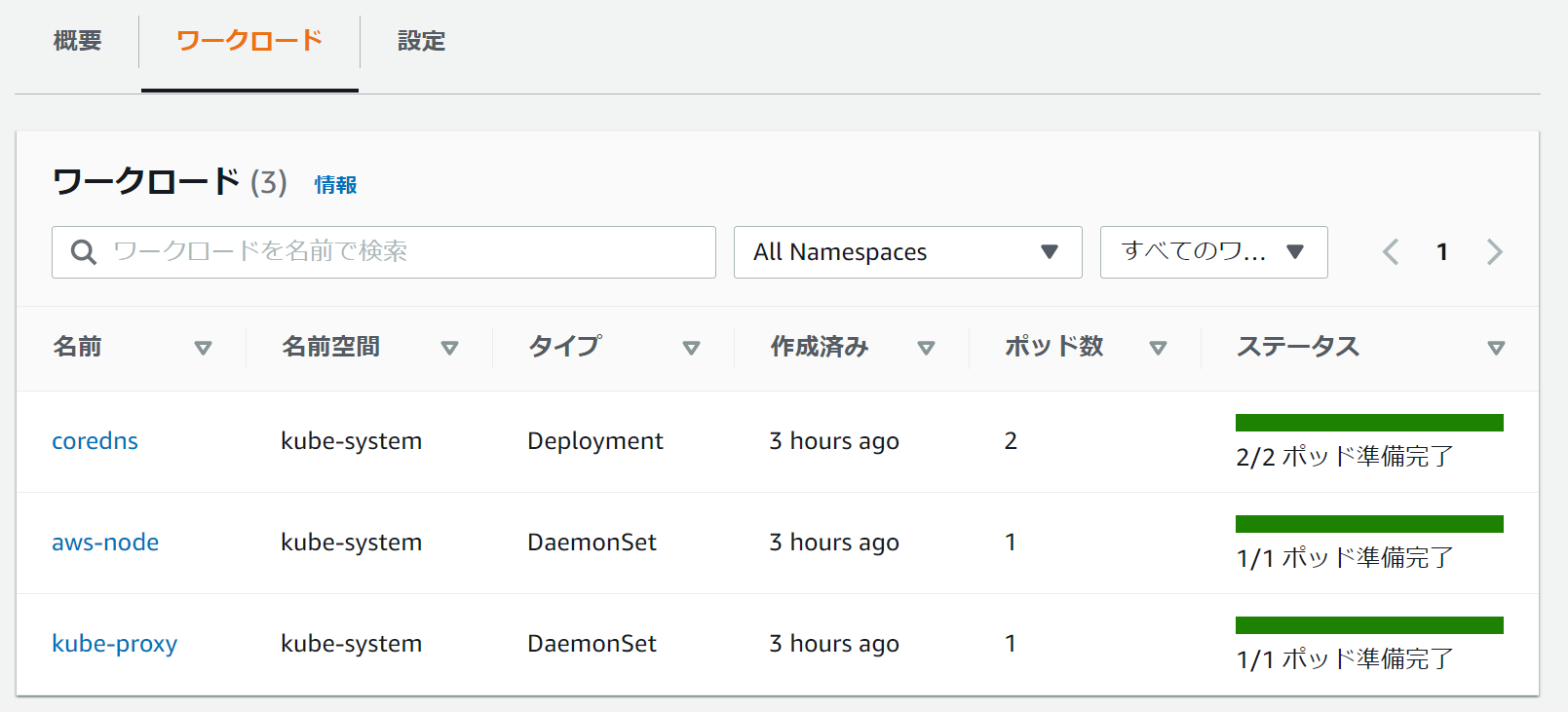
モニタリング
EKSコンソール上からのワークロードのモニタリングができる

- 投稿日:2021-01-23T17:11:33+09:00
CloudFront+API Gateway構成ではHostヘッダに気をつけよう
TL;DR
CloudFrontのオリジンにAPI Gatewayを追加したい時には、
Origin Request Policyにて、AllViewerの設定で全てのヘッダをバイパスするように設定するとエラーとなる。
原因はCloudFront向きのHostヘッダの情報をAPI Gatewayにそのままバイパスしてしまうため。はじめに
よく知られていることですが、API Gatewayは内部的にCloudFrontの仕組みを利用しているため、
レスポンスデータのキャッシュやスケーラビリティの確保については、CloudFrontをユーザー側で用意しなくても、
CloudFrontのメリットを受けられるようになっています。
しかしながら、例えば
- WAFによるアクセス制限の仕組みを利用したい
- キャッシュ設定をより細かく設定したい (
Maximum TTL,Minimum TTL、Invalidation等)などのユースケースにて、意図的にAPI Gatewayの前段にCloudFrontを置きたくなることがあります。
今回自分もキャッシュ設定のメリットを受けるためにこの構成を採用しましたが、表題の通りヘッダ設定周りでハマったので残しておこうと思います。
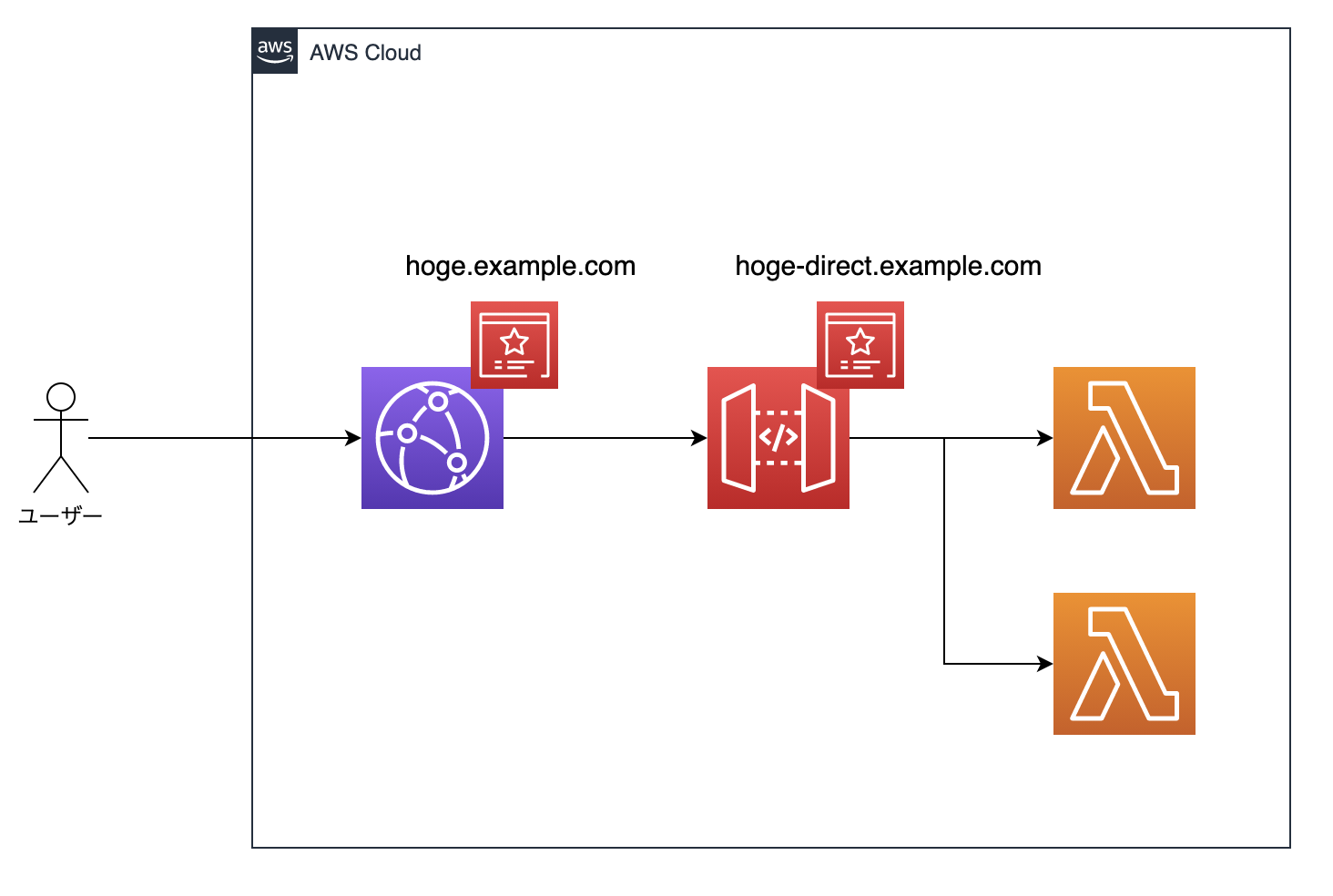
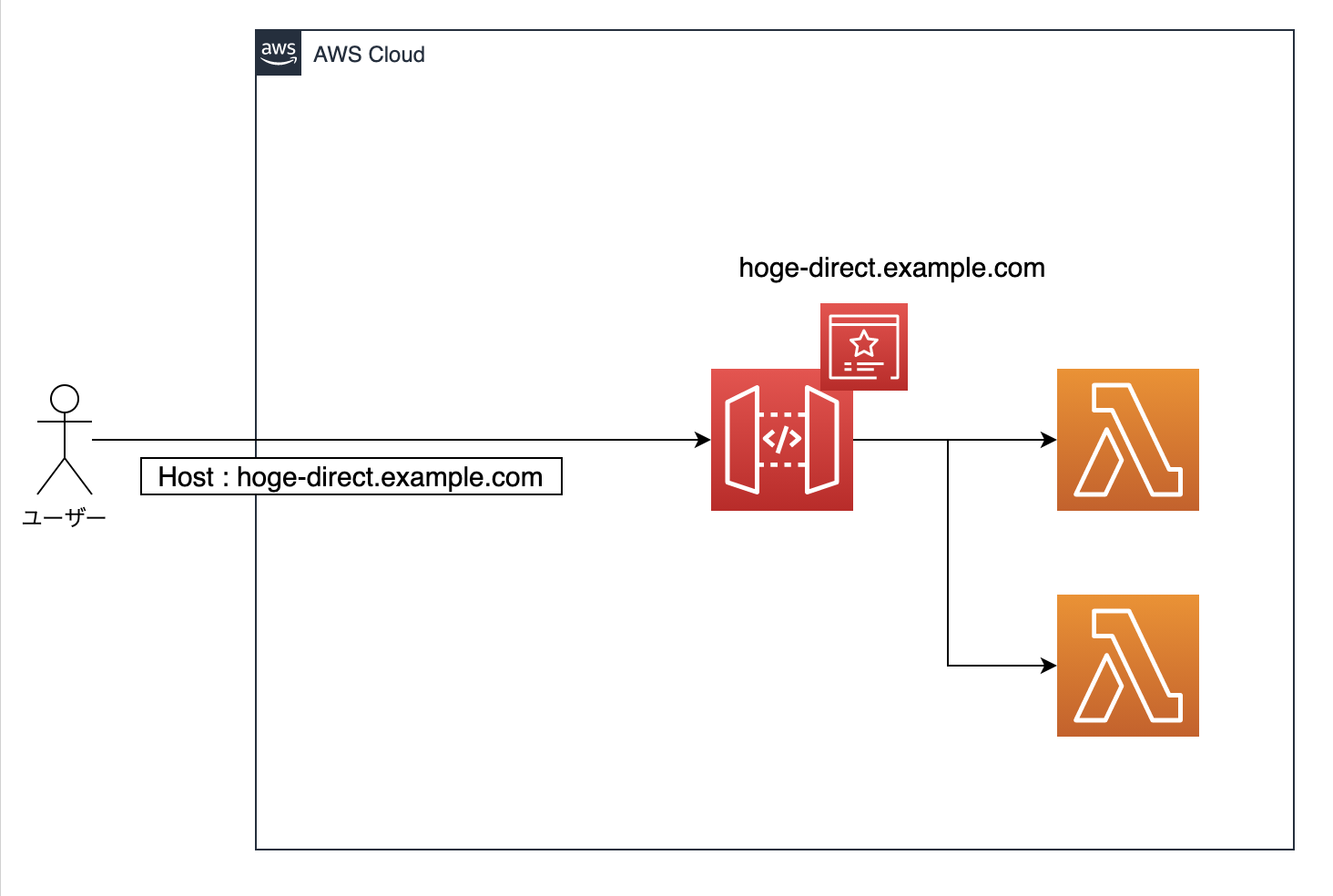
今回実施した構成
今回実施した構成は以下のようなイメージです。
ユーザーはAPIにアクセスする際はCloudFrontを経由します。
CloudFrontにキャッシュデータがある場合はキャッシュを返し、キャッシュがない場合のみAPI Gateway経由で各Lambdaに配置されたAPI関数を実行します。
また、CloudFrontとAPI Gatewayにはそれぞれドメインを用意します。ドメインはRoute53でAレコード、ACMによってSSL証明書とCNAMEレコードを発行します。
API Gatewayにもカスタムドメインを用意するのは、自動で着くステージ名のパスが要求仕様的に不要で、カスタムドメインによって内包するためです。最初に行った設定
早速CloudFrontのDistributionを作成します。
最初は、おおよそ以下のような設定で作成を行いました。(主要部分の抜粋)Origin Settings
Origin Domain Name: <API Gatewayのカスタムドメイン>Origin Pass: *Cache Policy
- Cache Key Content
Headers:whitelistAuthorization(↑BASIC認証の成功有無でキャッシュするか決定するため)QueryString:All(←全てのパターンで識別するため)- 圧縮は行わない
Origin Request Policy
- Origin Request contents
- Headers : AllViewer
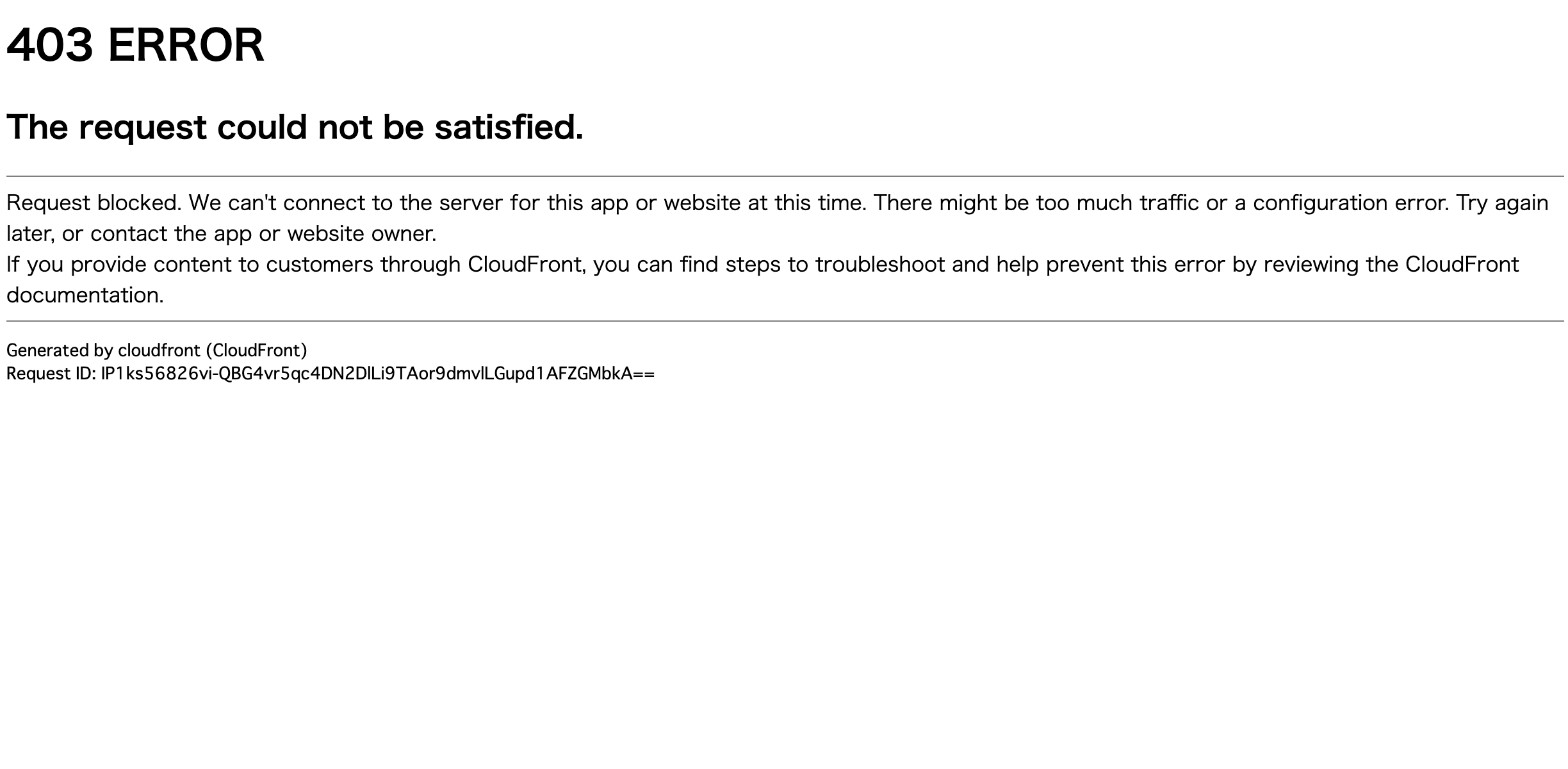
QueryString:All(↑元々のリクエスト同等のリクエスト内容となるように)さて、上記のような設定でDistributionを作成し、早速アクセスをしてみました。すると、以下のようなHTMLページがレスポンスで帰ってきました。
うーん困った...
APIは全てjsonを返すものなので、HTMLが帰ってきていると言うことはCloudFrontとAPI Gateway部分でのエラーだろうと考え設定周りを調べました。原因
調査を行ったところ、原因は設定内でも太字にしていた、Origin Request PolicyにてHeadersを
AllViewerとして、リクエストの全てのヘッダをオリジンへバイパスしていることが原因でした。今回のキーとなったのは、リクエストにて自動的に付与される、
Hostヘッダの内容です。
Hostヘッダとは、リクエストが送信される先のサーバーのホスト名とポート番号を指定するためのヘッダ情報です。HTTP/1.1だと唯一の必須ヘッダになっています。
(参考:https://developer.mozilla.org/ja/docs/Web/HTTP/Headers/Host)API Gatewayに直接アクセスしようとしていた時は(当たり前ですが)
Hostヘッダの宛先はAPI Gatewayのドメインになっています。
しかし今回、CloudFrontからAPI Gatewayにアクセスする際、
AllViewerの設定によって、ユーザーがCloudFrontへリクエストを投げる際に付与されていたHostヘッダもそのままバイパスしてAPI Gatewayにリクエストするようになっています。
ここからは確認できていませんが恐らく、
HostヘッダにCloudFrontのドメインを設定したままAPI Gatewayのドメインにアクセスしようとした- CloudFrontアクセス時の
Hostヘッダに加え、API Gatewayアクセス時のHostヘッダが作成され、2つのHostヘッダがある不正なリクエストとなってしまったかのいずれかでアクセスエラーとなっていたのでしょう。その結果、CloudFrontがエラーを検知して403のHTMLを返していた、ということです。
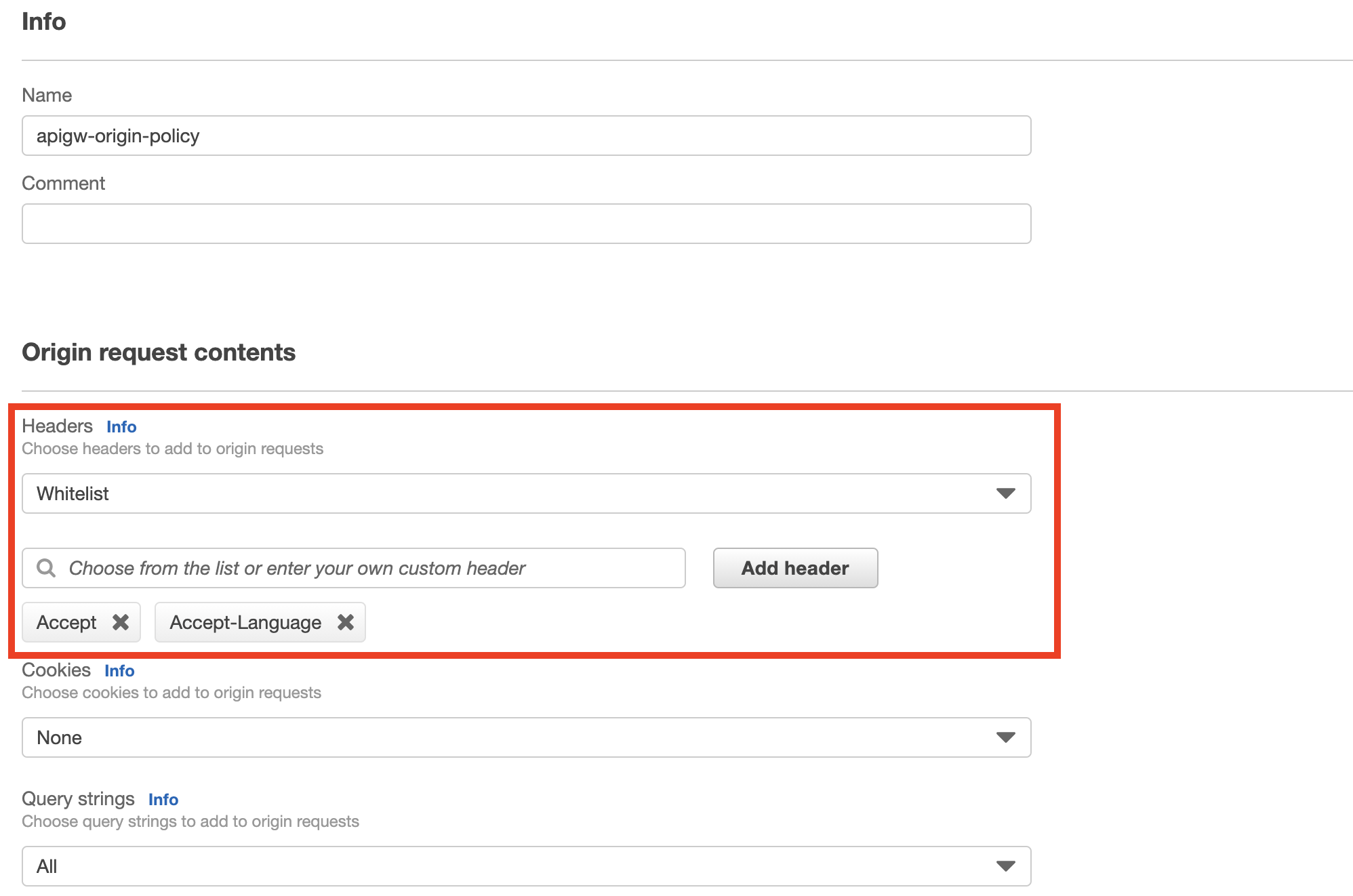
対応方法
原因がわかったので対策として、Headersの設定を
whitelistにし、必要なヘッダのみをバイパスするように設定を変更しました。今回はAcceptとAccept-Languageを追加しています。
なお、AuthorizationヘッダについてはCache Policyにて識別対象に設定しているため、こちらで設定を行わなくともオリジンへのリクエスト時にはバイパスされています。
これによって、CloudFrontからオリジンとしてAPI Gatewayにアクセスする際に適切な
Hostヘッダが再設定されるようになり、正常にアクセスができるようになりました。まとめ
原因の調査には時間がかかりましたが、おかげで普段あまり意識しきれていなかったHTTP/1.1の仕様部分まで理解を深められて良かったです。
低レベルなコンピューターサイエンスの知識はやはり重要です。

- 投稿日:2021-01-23T16:42:02+09:00
【AWS】用語を整理しながら学ぶAWS - part4 VPC構築編-1
はじめに
この記事では AWS Cloud Tech を通して VPC を学習して実践していく記事です。
主な内容としては実践したときのメモを中心に書きます。(忘れやすいことなど)
誤りなどがあれば書き直していく予定です。AmazonVPC とは
Amazon が提供するクラウドサービスの一つ
Amazon Virtual Private Cloud の略Amazon Web Services の中でネットワークを構築できるサービスである。
ネットワークだけでなくセキュリティグループの作成やネットワーク ACL を作成して
セキュリティを構築することができる。どのようなときに用いるか
AWS 内にネットワークを構築する際に利用します。
利用する方法としては
パブリックサブネットとプライベートサブネットの二つに分けて使うのがベーシックな使い方です。学習するときに必要な知識
- IPv4 アドレスの計算
- サブネットの計算
- ルーティングの構築
- ファイアウォールの知識
- OSI 参照モデル(L2 から L7)
おおむね、基本情報処理技術者試験の内容が理解できるのであればおおむねイケます。
ネットワークの基礎(IP アドレスとサブネット)
IP アドレスの計算で用いられるのは主に 2 進数によるビット計算
オクテッド毎に 8 ビットあります。※オクテッドというのは IP アドレスそれぞれの桁の名前を指します。
例)192.168.0.0 /24 のとき
第一オクテッドは 192
第二オクテッドは 168
第三オクテッドは 0
第四オクテッドは 0となります。
この時のアドレスの範囲は
192.168.0.1 ~ 192.168.0.255 となりますが実際にホストアドレスとして利用できるアドレスは 2^8 -2 個となる。
192.168.0.2 ~ 192.168.0.254第 4 オクテッドが 1 のアドレスはネットワークアドレス
第 4 オクテッドが 255 のアドレスはブロードキャストアドレス
となります。※※ブロードキャストアドレスは範囲の中でも一番終端にあるアドレスがそう呼ばれる為
必ずしも 255 になるとは限りません。IP アドレスの計算 実践問題
実際に問題を解いて考えてみよう。
問題 1)10.0.0.0/21 の範囲を計算してください。
答え) 10.0.0.1 ~ 10.0.7.255
解き方)
まずは CIDER 表記に着目/21 はサブネットマスクに直すといくつになるかといえば
/24 が以下のように表せるので
11111111.11111111.11111111.00000000/21 はサブネットに直すと
11111111.11111111.11111000.00000000
となります。そうするとネットワークを分割するサブネットマスクは以下のようになります。
255.255.248.0ここの第 3 オクテッドの計算はいろんな方法がありますが
255 のビット列を覚えている人が直感的にわかりやすい方法としてはビットの引き算を利用することです。計算式:
11111111 - 00000111 = 11111000
255 - 7 = 248サブネット表記に表すと問題の IP アドレスの範囲は
10.0.0.0 255.255.248.0アドレスの範囲を計算すると
10.0.0.1 ~ 10.0.7.255 となります。ここで忘れやすいのがネットワークアドレスとブロードキャストアドレスの存在
実際に利用できる IP アドレスはサブネットで切られた全体の IP アドレスの個数 -2 で考えましょう。
問題 2)10.0.0.0/21 の範囲を利用して実際にホストアドレスとして利用できる IP アドレスの個数はいくつか
答え ) さらにサブネットとして分割しなかった場合は 2046 個の IP アドレスが利用できる。
解き方)
第 4 オクテッドの数は 256 個となるのが確定なので今回は第 3 オクテッドに注目
第 3 オクテッドで利用できる数値の個数は 0 から 7 までの数値である為、8 個となります。あとは組み合わせの計算で 256 × 8 = 2048
ネットワークアドレスとブロードキャストアドレスを除くと 2046 個となります。VPC を構築しよう
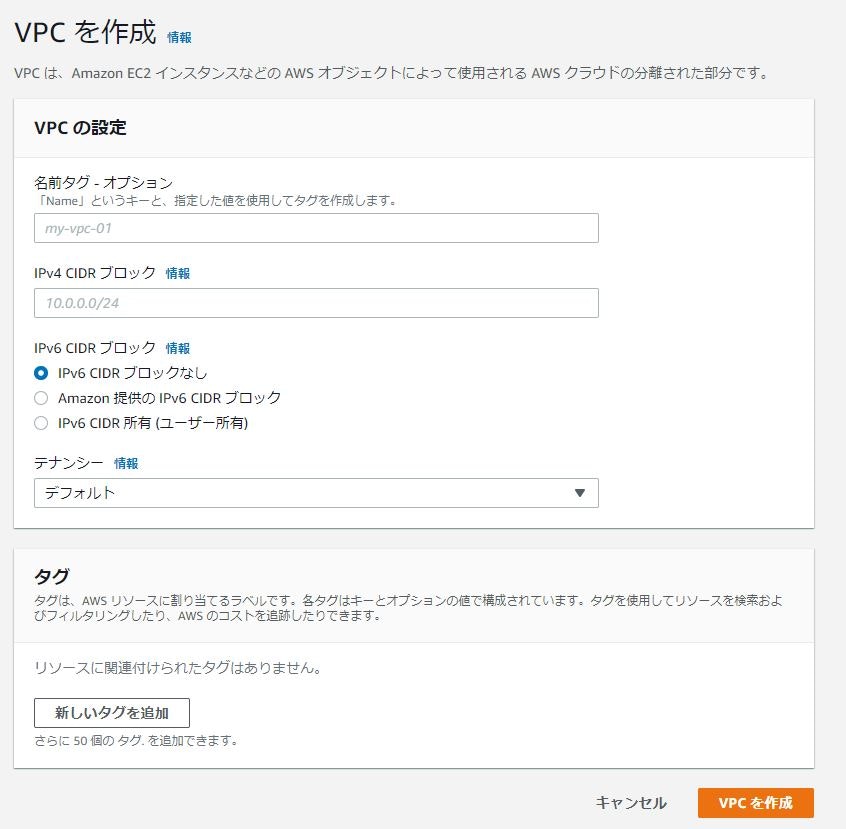
VPC を構築する場合はサービスから VPC を検索する。
コンソール画面の左側からVPCを選択する。
Name タグ:構築する VPC の前を指定
IPv4 CIDER ブロック:プレフィックス表記(短縮表記)で記載
IPv6 CIDER ブロック:IPV6 のアドレスを使うかどうか基本はなしでダイジョブ
Name タグ:ここを設定すると VPC に識別子をつけることができる。たくさん VPC を作る予定ならばしっかりつけておく。
最後に VPC を作成をクリック
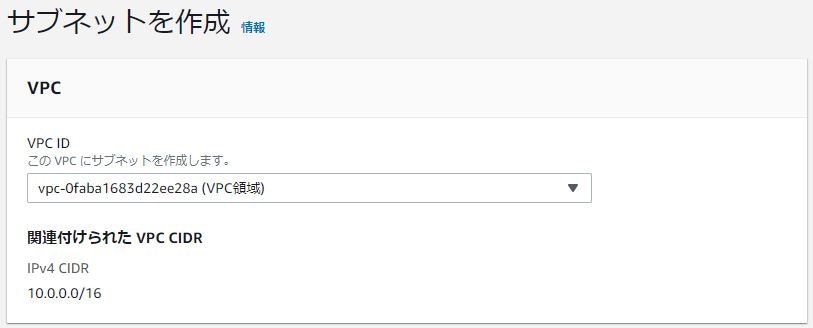
サブネットを切ろう
VPC 領域と名付けた VPC をサブネットで切ろう。
実際のネットワークエンジニアリングではサブネットを切る時
そのネットワークでいくつのサブネットを切るつもりかを先に検討する。今回はパブリックネットワークに 2 つ、プライベートネットワークに 2 つという合計 4 つになる想定であり
今後の拡張に備えて 8 にサブネットが切れるようにする。
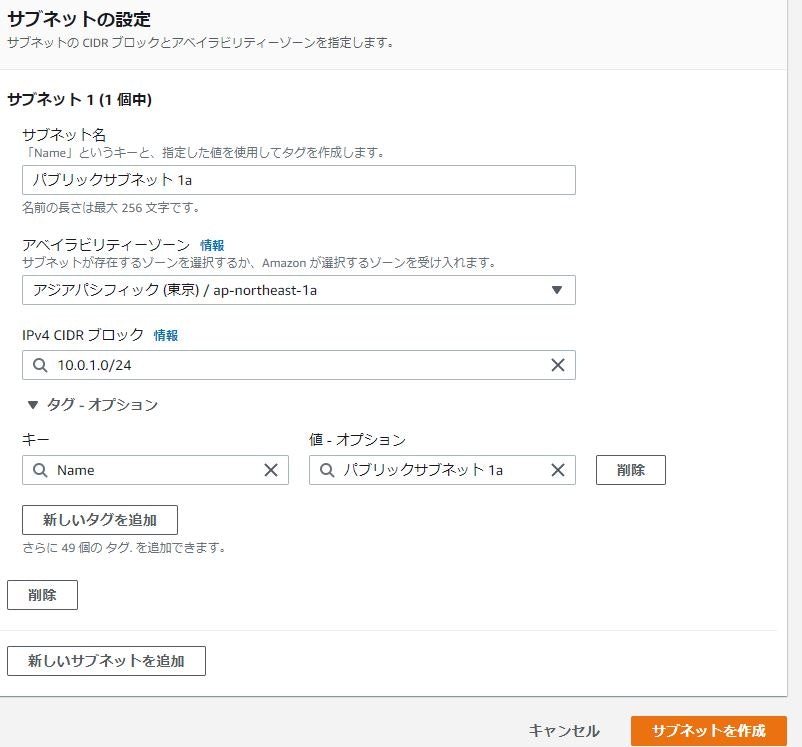
VPCID は先ほど作成した VPC を指定
サブネット名:パブリックサブネット 1a
アベイラビリティゾーン:リージョンを分割して距離をおいたファシリティを使うゾーンのこと
IPv4 CIDR ブロック:サブネットのネットワークをプレフィックス表記で指定※ファシリティやアベイラビリティゾーンの説明はここに書きました
※サブネットは VPC の範囲内で作成すること。
インターネットゲートウェイの構築
シンプルにネットワークを構築することができました。
とはいえ、この状態のネットワークだとインターネットに接続されていない
クラウド内におけるプライベートネットワークに過ぎないのでインターネットの出入り口である。
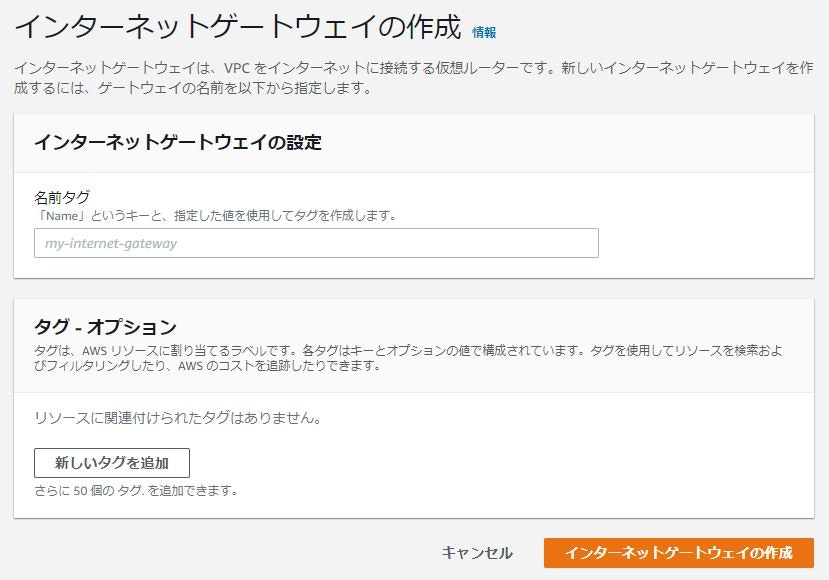
インターネットゲートウェイをつなぐ必要があります。インターネットゲートウェイから「インターネットゲートウェイを選択」
インターネットゲートウェイの設定:ゲートウェイの名前(任意の名前)を入力
タグ:たくさん インターネットゲートウェイ を作る予定ならばしっかりつけておく。インターネットゲートウェイをデフォルトゲートウェイに登録
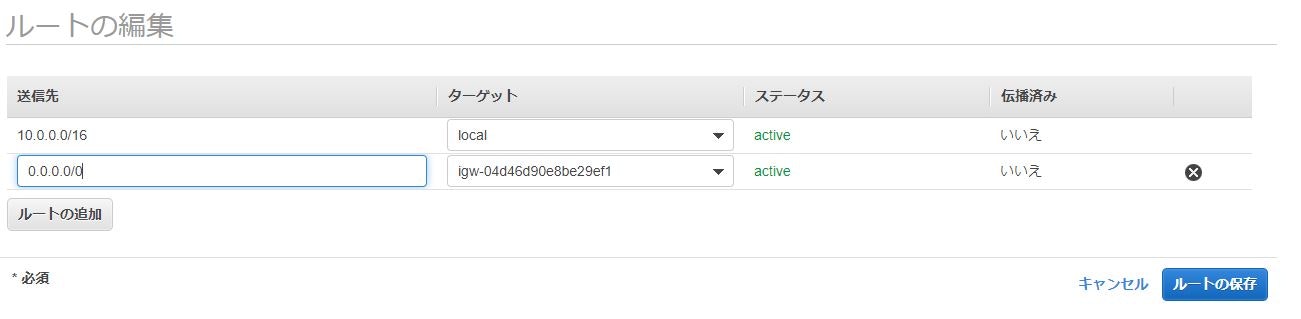
インターネットゲートウェイ向けのルーティングを持つルートテーブルを作成する。
サブネットを作成するとルートテーブルも自動で作成される為
自動で作成されたルートテーブルを編集してインターネットゲートウェイを設定します。
上記のような状態になれば、設定できています。
意味としては向かってきた全てのアドレスをインターネット側に向けるという意味です。
実際に登録する為には送信先に「0.0.0.0/0」のアドレスを入力して
先ほど作成したインターネットゲートウェイを指定します。ここまででインターネットにつながるパブリックネットワークの構築は以上です。
おわり
VPC は他のサービスを触るうえでとても重要な技術になります。
今回記載した内容ではパブリックネットワークの作成までですので
せいぜい、Web サーバの配置くらいでしか用途がありません。
※画像などのメディアは S3 に格納することが一般的ですので、くれぐれも重要な DB を配置しないようにしましょう。
- 投稿日:2021-01-23T15:54:21+09:00
Amazon Linux 2のhostname変更方法
はじめに
AmazonLinux2でEC2を立ち上げ、
hostsファイルとnetworkファイルを編集してhostnameを変更後にLinuxを再起動後に再度SSH接続してもhostnameが変更されていないという場面で遭遇しました。
そのため、AmazonLinux2でのhostname変更方法の忘備録を残しておきたいと思います。変更方法
hostnamectlコマンドでhostnameを変更する# hostnamectlコマンドで変更前のhostnameを確認する [ec2-user@ip-10-0-11-229 ~]$ hostnamectl Static hostname: ip-10-0-11-229.ap-northeast-1.compute.internal ←変更前のhostname Icon name: computer-vm Chassis: vm Machine ID: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx Boot ID: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx Virtualization: xen Operating System: Amazon Linux 2 CPE OS Name: cpe:2.3:o:amazon:amazon_linux:2 Kernel: Linux 4.14.209-160.339.amzn2.x86_64 Architecture: x86-64 # hostnameコマンドでhostnameを変更 [ec2-user@ip-10-0-11-229 ~]$ sudo hostnamectl set-hostname hogehoge # hostsファイルの変更 [ec2-user@ip-10-0-11-229 ~]$ cat /etc/hosts 127.0.0.1 hogehoge localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost6 localhost6.localdomain6 # インスタンスの再起動 [ec2-user@ip-10-0-11-229 ~]$ sudo reboot # SSH接続 $ ssh -i hogehoge.pem ec2-user@XX.XXX.XXX.XXX __| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ [ec2-user@hogehoge ~]$まとめ
hostnameを変更するにはhostnamectlを使って変更しないと反映されないみたいなんですね。
- 投稿日:2021-01-23T15:20:08+09:00
AWSアクセスキーをGithubにあげてしまった時の対処方法
WEBサービス開発歴7ヶ月目に突入しましたにこと申します。
先日、GithubにAWSアクセスキーをあげてしまいました。
その時は事の重大さをわかっておらず、言われるがままにコマンドをうち対処が出来たのですが、調べれば調べるほど「とんでもないことをしていた・・・!」ということがわかりました。
AWSで不正利用され80000ドルの請求が来た話
初心者がAWSでミスって不正利用されて$6,000請求、泣きそうになったお話。もう今後アクセスキーをあげることはないですが、愚かな人間なのでまた何らかを間違えてやってしまうかもしれません・・・。
二度とないことを誓いつつ、もし万が一やらかしてしまった場合、また同じようにアクセスキーをあげてしまったような方に向け、手順をしっかり残したいと思います。
まずはざっくりと手順の確認
- アクセスキーが書かれている該当部分を削除し、コミットする
- git rebase -i HEAD~~ で過去のコミットを表示する
- 先ほどコミットしたものを[pick]→[f]に修正する
- フォースプッシュをする
ざっくりだと4STEPで終わります。あれ、思ったより簡単・・・?
ただ上記だけだと初心者にとって「???」なる部分があると思います。
私もいつか見返した時にこれしか書いていなかったら、理解出来ずにMacをぶん投げると思うので、詳しく書いていきます。
1. 該当ファイルからアクセスキーの削除
該当ファイルからアクセスキーを削除します。
(サンプルファイルのため適当です、お許しください。)アクセスキー入りファイルconst awsKeys = { AWS_ACCESS_KEY_ID: AgetaraAkanYatsu,git AWS_SECRET_ACCESS_KEY: DakaraAgetaraAkantte888888 } function littleTwoos (status) { return status ? 'littleTwoos' : 'notLittleTwoos' }アクセスキーを削除したファイルfunction littleTwoos (status) { return status ? 'littleTwoos' : 'notLittleTwoos' }この状態で通常通りコミットします。
git add index.js git commit -m "アクセスキー削除"2.git rebase -i HEAD~~ で過去のコミットを表示する
続いて
git rebase -i HEAD~~で過去のコミットを表示します。
HEAD~~で2つ分のコミットを編集することになります。先ほどコミットした履歴が表示されていますね。
pick ab1eb2b 関数を追加 pick 66b6df1 アクセスキー削除 # Rebase 3866636..66b6df1 onto 3866636 (2 commands) # # Commands: # p, pick <commit> = use commit # r, reword <commit> = use commit, but edit the commit message # e, edit <commit> = use commit, but stop for amending # s, squash <commit> = use commit, but meld into previous commit # f, fixup <commit> = like "squash", but discard this commit's log message # x, exec <command> = run command (the rest of the line) using shell # b, break = stop here (continue rebase later with 'git rebase --continue') # d, drop <commit> = remove commit # l, label <label> = label current HEAD with a namegit rebaseってなに?
git rebase についてまとめてみた3.commitしたものを「f」に修正する
ターミナルがvimのノーマルモードになっているので、
iキーを押してインサートモードにします。
これで文字入力や削除ができるようになりました。先頭の
pickをfに変更しましょう。
f(fixup)は直前のpickにコミットを統合してくれます。この場合は
f 66b6df1 アクセスキー削除が直前のpick ab1eb2b 関数を追加に統合されることになります。変更前pick ab1eb2b 関数を追加 pick 66b6df1 アクセスキー削除変更後pick ab1eb2b 関数を追加 f 66b6df1 アクセスキー削除変更後
escキーを押してインサートモードからノーマルモードに戻ります。
:wq→Enterを押して、保存して終了します。そうするとターミナルに以下が表示されます!これでOKです!
Successfully rebased and updated refs/heads/branch_namevimってなに?
Vim初心者に捧ぐ実践的入門4. フォースプッシュをする
最後にリモートの履歴を上書きするために、フォースプッシュをします。
git push -f origin branch_nameのコマンドを打ち込んで、削除は完了です。きちんと削除できているかGithubも確認して一連の作業は終わりです。
お疲れ様でした!
まとめ
万が一アクセスキーをあげてしまった場合は、落ち着いて上記を実施しましょう。
またこちらの対処方法で間違いや他の方法があれば、優しく!コメントやTwitterで教えていただけますと幸いです。
- 投稿日:2021-01-23T14:08:32+09:00
【自分用メモ】AWS認定SysOpsアドミニストレーター-アソシエイト試験対策メモ
はじめに
本記事は、AWS-SOA試験の対策をしている上で覚えておくべきだと感じたことをメモとして残しておくものです。
主に問題演習中に連続して間違えたものを記載しています。
SOA試験に関する記事はこちらAWS CLI
・Auto Scalingグループを削除したい場合
最小サイズと希望する容量を0に → delete - auto -scaling - group コマンドを使用EC2
・インスタンスタイプ
R - RAMのR メモリが必要
C - CPUのC 高性能なCPUが必要
M - MidiumのM バランスの取れたインスタンス郡
I - I/OのI またはInstance storrageのI 主にデータベース用
G - GPUのG ビデオレンダリングもしくは機械学習用
T2/T3 - バースト可能なインスタンス 無制限のバーストが可能(クレジットの制限がない)
・Linux Amazon Machine Imagesは、準仮想化(PV)またはハードウェア仮想マシン(HVM)の2種類の仮想化がある。
・Linux準仮想(PV)AMIは、すべてのAWSリージョンでサポートされているわけではありませんVPC
・VPCフローログを使用して[access error]が出た場合
1. フローログのIAMロールに、フローログレコードをCloudWatchロググループに公開するための十分な権限がありません
2. IAMロールには、フローログサービスとの信頼関係がありません
3. 信頼関係では、フローログサービスがプリンシパルとして指定されていません
のいずれかが原因。
・フローログを作成したあとに構成の変更をすることはできない。フローログを削除して再度ログを作成する必要がある。
・VPCピアリング - 手動でVPCルートテーブルに追加する必要ありEBS
・スナップショット作成中 - 読み書き可能
・新しいEBSボリューム(スナップショットから作成された)のデータに初めてアクセスすると、レイテンシが大幅に増加する
→EBSボリュームを初期化する or 事前にウォームアップするAutoScaling
・競合がある場合 - エラーメッセージ表示
・CLIからデフォルトの設定でグループ作成 - 詳細モニタリングが自動的に有効化
・ec2の再起動はできないCloudWatch
・Aggregateは集計できない
・カスタムメトリクス - 独自のメトリクスを利用可能
・カスタムメトリクス - コンソールからはアップロード不可
・ELBの1分間隔のメトリクス送信 課金なし
・Auto scallingの1分間隔のメトリクス 課金なし
・Route53ヘルスチェックのメトリクス 課金なしCloudFormation
・作成中に一つエラーがおきたら? - 全てフォールパック
・EC2およびAutoScalingを使用し、一つのインスタンスが起動するまで次のインスタンスを待機させたい - creationPolicyをリソースに関連付ける
[resource import]を使用して既存のリソースをCloudFromation管理に取り組むことが可能
・AMIにCloudWatchエージェントが含まれている場合、EC2 AutoScalingグループを作成するとEC2インスタンスに自動的にインストールされる
・スタックポリシーは、スタックの更新中にのみ適用され、アクセス制御は提供しません。開発者はIAMポリシーを介してアクセスを提供する必要ELB
・いつでもAZを追加可能
・アクセスログで取得不可 - フロントエンドの処理時間
・クライアント - elb間はipv4でもipv6でも可能
・elb - ec2間の通信はipv4のみSNS
・SESを送信先には出来ないElastic Beanstalk
・Perlはサポート外SQS
・デフォルトキューで順序性を保証したい - 各メッセージにシーケンスを使用するOpsworks
・トラブルシューティング方法 - インスタンスにログインS3
・正常に格納されたかチェックする方法 - HTTPステータスコード200が返ってくるのを確認orMD5チェックサムにて損傷を検出
・マルチパートアップロードが途中終了した場合のパートファイル処理方法 - ライフサイクルポリシーがベストプラクティス
・MFA delete を有効化する方法 - ルートアカウントとAWSCLI
・各ファイル毎にパスワードを設定する方法はない
・オブジェクトにフェデレートを用いてアクセスさせるユースケース
ユーザが企業に所属している - SAMLを利用してssoできるようにフェデレート
ユーザが一般ユーザ - cognitoを利用してフェデレート
・Clacierに保存するためには、S3に一旦保存→Glacierに保存という手順がいる
・「x-」で始まるクエリ文字列パラメーターを無視するDirectConnect
・パブリック仮想インスタンスとプライベート仮想インスタンスのユースケースAWS System Manager
・Session Managerを使用すると、インバウンドポートを開いたり、踏み台ホストを維持したりせずにインスタンスに接続可能AWS KMS
・カスタマーマスターキー(CMK)の自動ローテーションを有効にすると、暗号化マテリアルを毎年作成し、
・古い暗号化マテリアルを永続的に保持する。X-Ray
・統合されていない主要サービス - ELBAWS Secrets Manager
・AWS Secrets Manager は、アプリケーション、サービス、IT リソースへのアクセスに必要なシークレットの保護を支援する

















- 投稿日:2021-01-23T13:06:32+09:00
Amazon ECS (Fargate起動) 構築方法メモ
- AWS CLIからAmazon ECSのクラスター構築、タスク登録、サービス登録をFargate起動設定で行う方法についてのメモ。
作成手順
前提条件
シェルスクリプトからAWS CLIを実行して作成する。
クラスター構築~サービス設定まで。アプリデプロイは別途実施する。
1. クラスター構築
- ECSクラスター
test-fargate-clusterを作成する。aws ecs create-cluster --cluster-name test-fargate-cluster2. Fargate起動用タスク定義登録
- Fargate起動タスク定義を登録する。
task_definition_path=$(dirname $0)/json/TestTaskDefinition.json task_definition_json=$(cat ${task_definition_path}) tempfile=$(mktemp) echo ${task_definition_json} | envsubst > ${tempfile} aws ecs register-task-definition --cli-input-json file://${tempfile} rm -f ${tempfile}
タスク定義
TestTaskDefinition.json
- 要件に合わせて設定。
{ "family": "test-fargate", "containerDefinitions": [ { "name": "test-fargate-app", //... } ], "requiresCompatibilities": [ "FARGATE" ], // .. }3. Fargate起動用サービス登録
service_definition_path=$(dirname $0)/json/TestServiceDefinition.json service_definition_json=$(cat ${service_definition_path}) tempfile=$(mktemp) echo ${service_definition_json} | envsubst > ${tempfile} aws ecs create-service --cluster test-fargate-cluster --service-name test-fargate-service --cli-input-json file://${tempfile} rm -f ${tempfile}
- サービス定義ファイル
TestServiceDefinition.json
- 作成済みロードバランサーにつなぐことを想定。
- デプロイはCodeDeployを指定。
- 要件に合わせて設定。
{ "serviceName": "test-fargate-service", "taskDefinition": "test-fargate", "loadBalancers": [ { "targetGroupArn": "${TG_ARN}", "containerName": "test-app", "containerPort": 10080 } ], "launch-type":"FARGATE", "deployment-controller":{ "type":"CODE_DEPLOY" } //.. }参考情報
- 投稿日:2021-01-23T12:49:47+09:00
AWS セキュリティグループ 作成方法 メモ
- AWS CLIを用いたセキュリティグループ作成方法をメモする。
用語メモ
インバウンド(送信元)
- 外部から対象セキュリティグループへのアクセス設定
アウトバウンド(宛先)
- 対象セキュリティグループ内部から外部へのアクセス設定
セキュリティグループ作成
- シェルスクリプトからセキュリティグループを作成し、以下のようなインバウンド・アウトバウンド設定を行う。
- VPCはすでに作成済みとする。
1. セキュリティグループ作成
- 作成後、セキュリティグループIDを取得し、デフォルト設定を削除する。
RES=$(aws ec2 create-security-group --vpc-id ${YOUR_VPC_ID} --group-name sg-test --description "SG for Test") SG_TEST=$(echo ${RES} | jq -r ".GroupID") aws ec2 revoke-security-group-egress --group-id ${SG_TEST} --cidr 0.0.0.0/0 --protocol -1
- 作成したセキュリティグループを確認する場合。
aws ec2 describe-security-groups --group-ids ${SG_TEST}2.セキュリティグループ設定
①インバウンド設定
- 80番、443番ポートへのインバウンドTCP通信を設定する。
aws ec2 authorize-security-group-ingress --group-id {SG_TEST} --protocol tcp --port 80 --cidr 0.0.0.0/0 aws ec2 authorize-security-group-ingress --group-id {SG_TEST} --protocol tcp --port 443 --cidr 0.0.0.0/0
--source-group ${SG_TEST2}のように通信元にセキュリティグループを指定することも可能。②アウトバウンド設定
- 80番、443番ポートからのアウトバウンドTCP通信を設定する。
aws ec2 authorize-security-group-egress --group-id {SG_TEST} --cidr 0.0.0.0/0 --protocol tcp --port 80aws ec2 authorize-security-group-egress --group-id {SG_TEST} --cidr 0.0.0.0/0 --protocol tcp --port 443参考情報
- 投稿日:2021-01-23T11:33:52+09:00
AWS EBで「Unhandled exception during build: invalid literal for int() with base 8: '493'」エラーの対処
概要
AWSのElastic Beanstalkで.ebextensionsを利用時にデプロイでエラー発生
(ちなみにPHPでLaravel)/var/log/cfn-init.log2021-01-23 02:10:56,395 [ERROR] -----------------------BUILD FAILED!------------------------ 2021-01-23 02:10:56,395 [ERROR] Unhandled exception during build: invalid literal for int() with base 8: '493' Traceback (most recent call last): File "/opt/aws/bin/cfn-init", line 171, in <module> worklog.build(metadata, configSets) File "/usr/lib/python2.7/site-packages/cfnbootstrap/construction.py", line 129, in build Contractor(metadata).build(configSets, self) File "/usr/lib/python2.7/site-packages/cfnbootstrap/construction.py", line 530, in build self.run_config(config, worklog) File "/usr/lib/python2.7/site-packages/cfnbootstrap/construction.py", line 542, in run_config CloudFormationCarpenter(config, self._auth_config).build(worklog) File "/usr/lib/python2.7/site-packages/cfnbootstrap/construction.py", line 251, in build changes['files'] = FileTool().apply(self._config.files, self._auth_config) File "/usr/lib/python2.7/site-packages/cfnbootstrap/file_tool.py", line 103, in apply file_is_link = "mode" in attribs and stat.S_ISLNK(int(attribs["mode"], 8)) ValueError: invalid literal for int() with base 8: '493'今回解消した方法
.ebextensions/hogehoge.configファイルの内容を修正(modeのパラメータを"で囲む)
files: "/hoge/fuga.txt": mode: 000755files: "/hoge/fuga.txt": mode: "000755"
- 投稿日:2021-01-23T09:57:48+09:00
re:Invent 2020 ストレージ関連の新サービス、アップデートまとめ
re:Invent2020で発表されたEBS、EFS、S3等のストレージ関連サービスのアップデートをまとめてみました。
re:Invent スペシャル企画 まだまだやるよ!宇宙一 回数の多い re:Cap week8
でこのあたりをキャッチアップしますので是非ご参加ください!EBS
gp3 volumes for EBS
- 3,000 IOPS、125MB/sのベースライン・パフォーマンス
- 最大16000IOPS
JAWS-UG横浜のre:Cap week1で発表した資料に詳しいことは残しています。
https://www.slideshare.net/akifuminiida/jawsug-yokohama-recapweek1gp3io2 Block Express
- 最大 256 K IOPS と 4000 MBps のスループット
- 最大 64 TiB のボリュームサイズ
スループット最適化 HDD (ST1) とコールド HDD ボリューム (SC1) の最小ボリュームサイズを75%削減
- 最小ボリュームサイズ125GBから作成可能に(従来は500GB)
EFS
Amazon EFS ストレージの使用状況がモニタリング可能に
- EFSコンソールからStorageBytes メトリクスが確認可能
- CloudWatch コンソール、その API、CLI、および AWS SDK からモニタリング可能
S3
Amazon S3が強力な書込み後の読み取り整合性
- S3 の GET、PUT、LIST 操作のすべて、およびオブジェクトタグ、ACL、またはメタデータを変更する操作に強力な整合性を適用
- 既存および新規の S3 オブジェクトすべてに適用
https://aws.amazon.com/jp/blogs/news/amazon-s3-update-strong-read-after-write-consistency/
Amazon S3 Replication が複数の宛先バケットのサポートを開始
- 異なるストレージクラス、異なる暗号化タイプ、または異なるアカウント全体でデータの複数のコピーを保存
- [レプリケーションステータス] を確認可能
Amazon S3 Replication 双方向レプリケーションのサポート
- オブジェクトアクセス制御リスト(ACL)、オブジェクトタグ、複製されたオブジェクトのオブジェクトロックなどのメタデータの変更を簡単に複製
- S3管理コンソールまたはAmazonCloudWatchでオブジェクトとオブジェクトメタデータのレプリケーションの進行状況を監視
Amazon S3 Bucket Keys
- KMSで行っていたデータキーの生成、暗号化操作をS3バケットキーが実施
- SSE-KMSで暗号化する場合のコストが最大99%下がる
- 投稿日:2021-01-23T09:57:36+09:00
AWSでproduction.logが肥大化した時の対処方法 & ログローテート方法
AWS初学者です。
Railsで個人的にアプリを作っておりまして、AWSにデプロイしています。
昨日も新しい機能を追加したため、変更内容をAWSにデプロイしようとしたところエラーが発生しました。EC2にSSH接続し、「df -h」で容量を確認したところ、
「/dev/xvda1」の使用率が100%に…「どこの容量が多いのか」をさらに深掘りして調べてみたところ、
「/var/www/アプリのディレクトリ名/shared/log/production.log」
というログファイルがかなり多いことがわかりました。その容量はなんと3G!?
今まで放っておいた自分を反省しました?そして、何とかproduction.logを軽量化し、正常にデプロイさせることができたので、その方法をアウトプットしていきたいと思います。
(ちなみに、「どこの容量が多いか」を調べる方法については、こちらの記事で説明しています:容量がいっぱいでAWSにデプロイできなかった時の対処方法)
production.logの軽量化
まずは、この肥大化したproduction.logを軽量化していきます。
「/var/www/アプリのディレクトリ名/shared/log」
まで移動したら次のコマンドを実行します。ターミナル[log]$ echo '' > ./production.log「echo 文字列 > ファイル名」とすることで、指定したファイルに文字列を出力(上書き)できるようです。
上記のコマンドを実行すれば、production.log内は''という空の文字で上書きされます。つまり、production.logの中身を一度空にすることができるわけです。これを実行した後したところ、無事容量を約3Gまるまる減らすことに成功しました!
ターミナル①まず容量を確認 [log]$ sudo du -sm ./* | sort -rn | head -3 3162 ./production.log 73 ./unicorn.stderr.log 0 ./unicorn.stdout.log ②空の文字で上書き [log]$ echo ' ' > ./production.log ③prodction.logの容量を減らすことに成功! [log]$ sudo du -sm ./* | sort -rn | head -3 73 ./unicorn.stderr.log 1 ./production.log 0 ./unicorn.stdout.logこの後、無事デプロイすることができました!
ログローテートの設定
しかし、安心するのはまだ早いです。
まだ、ログローテートの設定が残っています。ログローテートとは、ログを定期的に削除することで、ログが肥大化することを防ぐことを言います。
僕が使用しているRails6の場合は、
「config/environments/production.rb」
に以下の設定を追加することで、ログローテートの設定をすることができました。production.rb# production.rb内で、「一週間より前のログを切り捨てる」というログローテートを設定 config.logger = Logger.new("log/production.log", 'weekly')上記の場合ですと、「一週間より前のログを切り捨てる」というログローテートを設定していますが、weeklyの部分は、
「daily(一日で切り捨て)」
「monthly(一ヶ月で切り捨て)」に変更することもできます。
参考にした記事
以下、参考にさせていただきました。
ありがとうございました。以上です。
もしご指摘などありましたら、教えていただけますと幸いです。ここまで読んでくださりありがとうございました?♂️
- 投稿日:2021-01-23T08:16:28+09:00
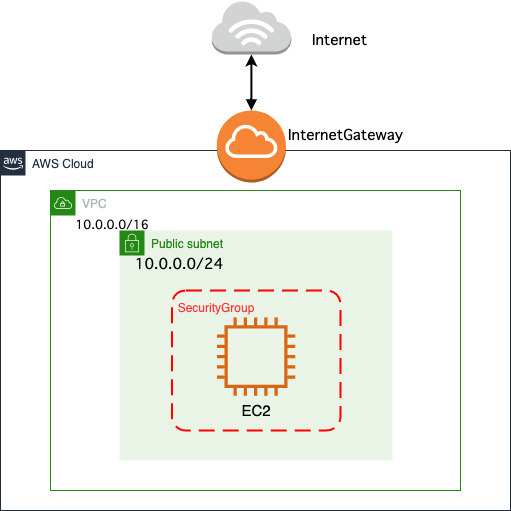
CloudFormationで起動テンプレートとEC2の構築
はじめに
CloudFormationで起動テンプレートを構築する資料があまりなかったので、
解説をつけてまとめました。対象者
- AWSの管理コンソールから起動テンプレートを構築された経験がある方
- CloudFormationの知見がある方
構築されるもの
- VPC
- InternetGateway
- Subnet
- RouteTable
- EC2
- SecurityGroup
- 起動テンプレート
構成図
セクション説明
セクション 意味 備考 AWSTemplateFormatVersion テンプレートバージョン 2010-09-09 であり、現時点で唯一の有効な値 Description テンプレートを説明するテキスト ---- Metadata テンプレートバージョン ---- Parameters パラメーターの定義 ---- Resources スタックに含める AWS リソースの宣言 ---- Outputs 出力値を宣言 他のスタックでインポートできる 組み込み関数説明
組み込み関数 意味 備考 Ref 指定したパラメータまたはリソースの値 --- Sub 特定した値の入力文字列にある変数の代わりになる 文字列内に変数を挿入する GetAtt テンプレートのリソースから属性の値を返す --- その他用語説明
起動テンプレート
EC2インスタンス起動時に指定するAmazon マシンイメージ (AMI) の ID、インスタンスタイプ、キーペアなどのパラメータを事前に定義し、再利用可能な形で保管するサービス
テンプレートファイル
下記においてあります。ご自由にお使いください
https://github.com/toyoyuto/cloudformation_templateテンプレートファイル(解説付き)
launchtemplate.ymlAWSTemplateFormatVersion: "2010-09-09" Description: Amazon Web Services LaunchTemplate & Network & server construction Metadata: # コンソールでパラメータをグループ化およびソートする方法を定義するメタデータキー "AWS::CloudFormation::Interface": # パラメーターグループとそのグループに含めるパラメーターの定義 ParameterGroups: # Project名に関するグループ - Label: default: "Project Name Prefix" Parameters: - PJPrefix # ネットワーク設定に関するグループ - Label: default: "Network Configuration" # 記述された順番に表示される Parameters: - KeyName # ------------------------------------------------------------# # Input Parameters # ------------------------------------------------------------# Parameters: PJPrefix: Type: String KeyName: Type: "AWS::EC2::KeyPair::KeyName" Resources: # ------------------------------------------------------------# # VPC # ------------------------------------------------------------# # VPC Create VPC: Type: "AWS::EC2::VPC" Properties: CidrBlock: "10.0.0.0/16" # VPC に対して DNS 解決がサポートされているか EnableDnsSupport: "true" # VPC 内に起動されるインスタンスが DNS ホスト名を取得するか EnableDnsHostnames: "true" # VPC 内に起動されるインスタンスの許可されているテナンシー InstanceTenancy: default Tags: - Key: Name Value: !Sub "${PJPrefix}-vpc" # InternetGateway Create InternetGateway: Type: "AWS::EC2::InternetGateway" Properties: Tags: - Key: Name Value: !Sub "${PJPrefix}-igw" # IGW Attach InternetGatewayAttachment: Type: "AWS::EC2::VPCGatewayAttachment" Properties: InternetGatewayId: !Ref InternetGateway VpcId: !Ref VPC # ------------------------------------------------------------# # Subnet # ------------------------------------------------------------# # Public Subnet Create PublicSubnet: Type: "AWS::EC2::Subnet" Properties: AvailabilityZone: "ap-northeast-1a" CidrBlock: "10.0.0.0/24" VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "${PJPrefix}-public-subnet" # ------------------------------------------------------------# # RouteTable # ------------------------------------------------------------# # Public RouteTable Create PublicRouteTable: Type: "AWS::EC2::RouteTable" Properties: VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "${PJPrefix}-public-route" # ------------------------------------------------------------# # Routing # ------------------------------------------------------------# # PublicRoute Create PublicRoute: Type: "AWS::EC2::Route" Properties: RouteTableId: !Ref PublicRouteTable DestinationCidrBlock: "0.0.0.0/0" GatewayId: !Ref InternetGateway # ------------------------------------------------------------# # RouteTable Associate # ------------------------------------------------------------# # PublicRouteTable Associate PublicSubnet PublicSubnetRouteTableAssociation: Type: "AWS::EC2::SubnetRouteTableAssociation" Properties: SubnetId: !Ref PublicSubnet RouteTableId: !Ref PublicRouteTable # ------------------------------------------------------------# # EC2 # ------------------------------------------------------------# # 起動テンプレート Ec2InstanceLaunchTemplate: Type: AWS::EC2::LaunchTemplate Properties: # 起動テンプレートの名前 LaunchTemplateName: !Sub "${PJPrefix}-web-server-template" # 起動テンプレートの情報 LaunchTemplateData: # リソースの作成時にリソースに適用するタグを指定 TagSpecifications: # ------------------------------------------------------ # タグ付けするリソースのタイプ。 # 現在、作成中のタグ付けをサポートするリソースタイプは、instance および volume # ------------------------------------------------------ - ResourceType: instance Tags: - Key: Name Value: !Sub "${PJPrefix}-web-server" UserData: Fn::Base64: | #!/bin/bash sudo yum -y update sudo yum -y install httpd sudo systemctl start httpd.service sudo systemctl enable httpd.service KeyName: !Ref KeyName ImageId: ami-01748a72bed07727c InstanceType: t2.micro NetworkInterfaces: # IPv4 アドレスを割り当てるか - AssociatePublicIpAddress: "true" # ------------------------------------------------------ # アタッチの順序におけるネットワークインターフェイスの位置。 # ネットワークインターフェイスを指定する場合必須 # ------------------------------------------------------ DeviceIndex: "0" SubnetId: !Ref PublicSubnet Groups: - !Ref WebServerSG # WebServerセキュリティグループ WebServerSG: Type: AWS::EC2::SecurityGroup Properties: GroupName: web-sg-cf GroupDescription: web server sg VpcId: !Ref VPC SecurityGroupIngress: - IpProtocol: tcp FromPort: 22 ToPort: 22 CidrIp: 0.0.0.0/0 - IpProtocol: tcp FromPort: 80 ToPort: 80 CidrIp: 0.0.0.0/0 Tags: - Key: Name Value: !Sub "${PJPrefix}-web-server-sg" # EC2インスタンス Ec2Instance: Type: AWS::EC2::Instance Properties: # 起動テンプレートの設定 LaunchTemplate: # 起動テンプレートのID LaunchTemplateId: !Ref 'Ec2InstanceLaunchTemplate' # 起動テンプレートのバージョン番号 Version: !GetAtt 'Ec2InstanceLaunchTemplate.LatestVersionNumber' NetworkInterfaces: # IPv4 アドレスを割り当てるか - AssociatePublicIpAddress: "true" # ------------------------------------------------------ # アタッチの順序におけるネットワークインターフェイスの位置。 # ネットワークインターフェイスを指定する場合必須 # ------------------------------------------------------ DeviceIndex: "0" SubnetId: !Ref PublicSubnet GroupSet: - !Ref WebServerSG # # # ------------------------------------------------------------# # # # Output Parameters # # # ------------------------------------------------------------# Outputs: VPC: Value: !Ref VPC Export: Name: !Sub "${PJPrefix}-vpc" PublicSubnet: Value: !Ref PublicSubnet Export: Name: !Sub "${PJPrefix}-public-subnet" Ec2InstanceLaunchTemplate: Value: !Ref Ec2InstanceLaunchTemplate Export: Name: !Sub "${PJPrefix}-web-server-template" Ec2Instance: Value: !Ref Ec2Instance Export: Name: !Sub "${PJPrefix}-web-server"参考
- 投稿日:2021-01-23T06:22:19+09:00
AWS ALB の LCU の料金計算方法の備忘録
AWS ALB の LCU の料金計算方法のメモ
https://aws.amazon.com/jp/elasticloadbalancing/pricing/ から LCU の計算方法が個人的にわかりにくかった(僕の頭が悪いだけなのですが…)ので整理したメモ。
ただし、例 1 しか整理してない。
金額は アジア・パシフィック/東京 リージョンをベースにした。
例1の条件
- (a) アプリケーションが 1 秒あたり平均 1 個の新しい接続を受信
- (b) それぞれ 2 分間継続する
- (c) クライアントは毎秒平均 5 つのリクエストを送信
- (d) リクエストと応答の合計処理バイト数は毎秒 300 KB
- (e) クライアントのリクエストをルーティングする 60 個のルールを設定
新しい接続(1秒あたり)
LCU は 1 秒あたり 25 個の新しい接続を提供する ← 既定値
アプリケーションは 1 秒あたり1この新しい接続を受信する ← (a)
つまり
1 / 25 = 0.04 LCU
と評価する
アクティブ接続(1分あたり)
LCU は 1 分辺り 3000 このアクティブな接続を提供する ← 既定値
アプリケーションは 1 秒あたり 1 個の新しい接続を受信し、 ← (a)
それぞれ 2 分間継続する ← (b)
つまり
1 分辺り 120 個のアクティブ接続が存在する状態となる
つまり
120 / 3000 = 0.04 LCU
と評価する
プロセスされたバイト数(GB / 時)
LCU は 1 時間辺り 1 GB の処理バイトを提供する ← 既定値
アプリケーションのレスポンスは平均 300 KB であり ← (d)
1時間あたりの応答総量は、
(d) 応答 300 KB * 60 * 60 = 1080000 KB = 1.08 GB
となる
つまり、
1.08 GB / 既定値である LCU 1時間あたり 1 GB = 1.08 LCU
と評価される
ルール評価(1秒あたり)
LCU 1 秒あたり1000 個のルール評価を提供します( 1 時間あたり / 設定されたルールが全て処理される前提) ← 既定値
このアプリケーションは 1 秒あたり 5 個のリクエストを受信する ← (c)
ので、各リクエストに対して 60 個のルールが評価れます ← (e)
その結果、
1 秒あたり ( 60 個のルール - 無料分 10 のルール) * 5 = 最大 250 個のルール評価
となり、
上記 250 個のルール評価 / 既定値容量の 1000 個のルール評価 = 0.25 LCU
と評価される
最終評価
これらの評価の結果、最も LCU の値が大きい プロセスされたバイト数( GB / 時) = 1.08 LCU が計算軸となる
この結果、以下の利用金が算定される
- 1 時間あたりは 1.08 LCU * 0.008 USD = 0.00864 USD となり
- 1ヶ月換算すると 0.00864 USD * 24 * 30 = 6.22 USD となる
- 投稿日:2021-01-23T00:00:35+09:00
【受験記】AWS 認定 機械学習 – 専門知識
はじめに
この記事は、先日合格したAWS 認定 機械学習 – 専門知識の受験記録になります。
準備のためのメイン教材に英語教材を使用したという点で、内容的にはレアケースになるかと思います。それでも、この記事がどなたかの参考になれば幸いです。
公式情報
- 試験ついてはこちらの公式サイトでご確認ください。
一般的な準備方法
こちらの記事(AWSの機械学習エンジニア認定試験を受けてきた)に上手くまとめられていると思います。*試験を受けた感想としても、こちらの内容はいまだ有効だと感じました。
ただ、私は機械学習はもとよりAWS自体実務経験がないことから、上記の記事で紹介されているような(公式ドキュメントやブログを読む)学習方では、試験範囲に対する体系的で効率的な知識の習得は難しいと判断しました。それで、いっそのことなら英語教材を使えばいいのではないかと思うに至りました。
因みに、私は関連する資格としてこれまでに以下のものを取得していました。
- AWS 認定 クラウドプラクティショナー
- AWS 認定 ソリューションアーキテクト – アソシエイト
- JDLA G検定
- 英検1級
試験準備で使用した教材一覧
① Udemy: AWS Certified Machine Learning Specialty 2020 - Hands On! (英語)
- 広範囲にわたる知識を効率よく学ぶことができました。
- 英語は大変聞きとりやすく、テンポよく、程よい集中力が要求される速さで進んでいきます。(英語字幕の表示ができます。)
- 多くはないものの、ハンズオンも含まれています。
- 私は講義の内容を自分なりにノートにまとめることを通じて、概要を把握し、知識を定着させました。
② Udemy: AWS Certified Machine Learning Specialty: 3 PRACTICE EXAMS (英語)
- 模擬試験はあえて①とは異なる講師が作成したものを購入しました。
- それによって、より多角的な試験準備ができたと考えています。
- 模擬試験の得点率は1周目が概ね5割、2周目が概ね9割でした。
- 実施後は全ての問題を選択肢まで含めて見直して、分からないところは解説に貼ってあるリンクも参考にしながら調べました。
- なお、説明欄に「技術寄りだった25題をユースケース/シナリオベース寄りに改訂した」とありますが、本試験を受けた後の感想としては、この点はまだ弱いと感じました。
③ 公式サンプル問題(日本語)
- ①を行う前に、試験の雰囲気を把握するために一度行いました。
- また、②の1周目が終わった後で2回目を行いました。
④ 公式模擬試験(日本語/英語)
- 無料クーポンを利用して②の一周目の後で行いました。
- 得点率は7割程度でした。
- 問題をキャプチャして、全て解き直しをしました。
結果
結果は自分の予想をはるかに上回る、890点台で合格することができました。
今後も英語教材を積極的に有効活用していこうと思う、いいきっかけになりました。(学習自体は楽しめたのですが、システムの影響で終了まで4時間以上かかった本試験は大変な苦痛でした。。)
最後まで読んできただきまして、ありがとうございました!