- 投稿日:2021-01-21T23:01:56+09:00
[Python] 01ナップサック問題 ABC032D
ABC032D
01ナップサック問題
- N個の荷物があり、$i(1\le i\le N)$ 番目の荷物には価値 $v_i$ と重さ $w_i$ が割り当てられている。
- 許容重量Wのナップサックが1つある。
- 重さの和がW以下となるように荷物の集合を選びナップサックに詰め込むとき、価値の和の最大値を求めよ。ただし、同じ荷物は一度しか選ぶことができない。
次の3パターンのデータセットが与えられる。
- ① $1\le N\le 30, 1\le W \le 10^9, 1\le v_i \le 10^9, 1\le w_i \le 10^9$
- ② $1\le N\le 200, 1\le W \le 10^9, 1\le v_i \le 10^9, 1\le w_i \le 1000$
- ③ $1\le N\le 200, 1\le W \le 10^9, 1\le v_i \le 1000, 1\le w_i \le 10^9$
時間計算量と空間計算量の制約に対応するために、それぞれのパターンに応じた計算方法を採る必要がある。
➀ N≦30
全列挙 $O(2^N)$ ではTLEになる。
動的計画法は、空間計算量が膨大でMLEになる。
枝刈りで行けそうだが、半分全列挙 $O(2^\frac{N}{2}\log {2^\frac{N}{2}})$ で確実に行う。
高速に探索できるように、最大値を実現できる可能性のある [重み,価値] のみを列挙する。➁ w≦1000
空間計算量に配慮し、動的計画法を次のように設計する。一般的なナップサック問題の解法となる。
時間計算量は $O(N^2 W_{max})$ で空間計算量は $O(NW_{max})$ となる。$dp[i][j]$の定義:
$i$ 番目までの荷物を選んで、重みの和 $j$ 以下を満たす、価値の和の最大値dp初期条件:
dp[0..N][0..W]=0dp漸化式の定義:
dp[i][j]=max(dp[i-1][j], dp[i-1][j-w_i]+v_i) \hspace{15pt}(j-w_i\ge 0)求める解:
dp[N][W]➂ v≦1000
空間計算量に配慮し、動的計画法を次のように設計する。
時間計算量は $O(N^2 V_{max})$ で空間計算量は $O(NV_{max})$ となる。$dp[i][j]$の定義:
$i$ 番目までの荷物を選んで、価値の和 $j$ を達成する、重みの和の最小値dp初期条件:
dp[0][0]=0, dp[0..N][0..V_{max}]=\inftydp漸化式の定義:
dp[i][j]=min(dp[i-1][j], dp[i][j-v_i]+w_i) \hspace{15pt}(j-v_i\ge 0)求める解:
max\{\ j\ |\ dp[N][j]\le W\ \}PyPy3ならACするが、Python3ではTLEとなる。
サンプルコードN,W = map(int,input().split()) vw = [list(map(int,input().split())) for _ in [0]*N] vM,wM = 0,0 for v,w in vw: vM = max(vM,v) wM = max(wM,w) if wM <= 1000: # ➁ wS = sum(w for v,w in vw) if wS <= W: ans = sum(v for v,w in vw) else: dp = [[0]*(W+1) for _ in range(N+1)] for i,vw2 in enumerate(vw,1): # イテラブルオブジェクトとインデックスを取得 v,w = vw2 for j in range(W+1): dp[i][j] = dp[i-1][j] if j>=w : dp[i][j] = max(dp[i][j],dp[i-1][j-w] + v) ans = dp[-1][W] print(ans) elif vM <= 1000: # ➂ V = sum(v for v,w in vw) dp = [[W+1]*(V+1) for _ in range(N+1)] dp[0][0] = 0 for i,vw2 in enumerate(vw,1): v,w = vw2 for j in range(V+1): dp[i][j] = dp[i-1][j] if j>=v : dp[i][j] = min(dp[i][j],dp[i-1][j-v]+w) print(max(i for i,w in enumerate(dp[-1]) if w<=W)) elif N <= 30: # ➀ w_max = W V,W = zip(*vw) # Weightでソートしたい # N <= 30 # 半分全列挙 left = [(0,0)] # weight, value right = [(0,0)] for i in range(N//2): left += [(x+W[i],y+V[i]) for x,y in left] for i in range(N//2,N): right += [(x+W[i],y+V[i]) for x,y in right] left.sort() # 重さ順 right.sort() def remove_worthless(li): temp = [] current_value = -1 for w,v in li: if w > w_max: break # wでの最大値vをリストする if v > current_value: current_value = v temp.append((w,v)) return temp left = remove_worthless(left) right = remove_worthless(right) INF = 10**18 right.append((INF,0)) # double pointer j = 0 x = 0 for wL,vL in left[::-1]: # leftを逆順 wR_max = w_max-wL while right[j+1][0] <= wR_max: j += 1 vLR = vL + right[j][1] if x < vLR: x = vLR print(x)次はNumpy version
サンプルコードN,w_max = map(int,input().split()) VW = [[int(x) for x in input().split()] for _ in range(N)] V,W = zip(*VW) def case_1(): # N <= 30 # 半分全列挙 left = [(0,0)] # weight, value right = [(0,0)] for i in range(N//2): left += [(x+W[i],y+V[i]) for x,y in left] for i in range(N//2,N): right += [(x+W[i],y+V[i]) for x,y in right] left.sort() # 重さ順 right.sort() def remove_worthless(li): temp = [] current_value = -1 for w,v in li: if w > w_max: break # valueを更新したものに制限 if v > current_value: current_value = v temp.append((w,v)) return temp left = remove_worthless(left) right = remove_worthless(right) INF = 10**18 right.append((INF,0)) # double pointer j = 0 x = 0 for wL,vL in left[::-1]: wR_max = w_max-wL while right[j+1][0] <= wR_max: j += 1 vLR = vL + right[j][1] if x < vLR: x = vLR return x def case_2(): import numpy as np L = N*1000+1 dp = np.zeros(L,dtype=np.int64) # 総重量、最大価値 for v,w in VW: dp[w:] = np.maximum(dp[w:], dp[:-w] + v) return dp[:w_max+1].max() def case_3(): import numpy as np L = N*1000+1 dp = np.zeros(L,dtype=np.int64) # 総価値、最小重量 dp[1:] = 10**18 for v,w in VW: dp[v:] = np.minimum(dp[v:], dp[:-v] + w) possible_value = (dp <= w_max).nonzero()[0] return possible_value.max() if N <= 30: print(case_1()) elif max(W) <= 1000: print(case_2()) else: print(case_3())
- 投稿日:2021-01-21T22:42:07+09:00
python-dotenvを使い環境変数を管理
python-dotenvを使い環境変数を管理
初めに
API_KEYなどPythonファイルにベタ書きだと使い勝手が悪いため
python-dotenvを使い環境変数を設定するfrom datetime import timedelta import pandas as pd import tweepy API_KEY = "xxx" API_SECRET_KEY = "xxx" ACCESS_TOKEN = "xxx" ACCESS_TOKEN_SECRET = "xxx" def twitter_api() -> tweepy.API: auth = tweepy.OAuthHandler(API_KEY, API_SECRET_KEY) auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET) return tweepy.API(auth)python-dotenvバッケージをインストール
$ pip install python-dotenv使い方
.envファイル作成
API_KEY = "xxx" API_SECRET_KEY = "xxx" ACCESS_TOKEN = "xxx" ACCESS_TOKEN_SECRET = "xxx"settigs.py作成
.envからデータを読み込むimport os from os.path import dirname, join from dotenv import load_dotenv load_dotenv(verbose=True) dotenv_path = join(dirname(__file__), ".env") API_KEY = os.environ.get("API_KEY") API_SECRET_KEY = os.environ.get("API_SECRET_KEY") ACCESS_TOKEN = os.environ.get("ACCESS_TOKEN") ACCESS_TOKEN_SECRET = os.environ.get("ACCESS_TOKEN_SECRET")元Pythonファイル変更
from datetime import timedelta import pandas as pd import tweepy from settings import API_KEY, API_SECRET_KEY, ACCESS_TOKEN, ACCESS_TOKEN_SECRET def twitter_api() -> tweepy.API: auth = tweepy.OAuthHandler(API_KEY, API_SECRET_KEY) auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET) return tweepy.API(auth)何がいいか
環境変数が散らばると参照がし難い、セキュリティ的にも良くない
python-dotenを使うと.envに集約できる
- 投稿日:2021-01-21T20:59:24+09:00
pythonのif文
pythonのif文の使用方法
基本的な使い方は以下のようになっている
if 条件式 : 条件式が真のときに実行する処理 else : 条件式が偽の場合に実行する処理Javaと比べるとスッキリとしたコードがpythonは書けるといった印象です。
また複数条件に分けて処理を行いたい場合は以下のように
elif 条件式を使って実現できるif 条件式1 : 条件式1が真の場合に実行する処理 elif 条件式2 : 条件式2が真の場合に実行する処理 else : どの条件にも当てはまらなかった場合に実行する処理これらと
input()を使って簡単なプログラムを作ってみましたnum = input("1~10のどれかを入力してください") if int(num) % 3 == 0 : print(num + "は3の倍数です") elif int(num) % 5 == 0 : print(num + "は5の倍数です") elif int(num) % 7 == 0 : print(num + "は7の倍数です") else : print(num + "はその他の倍数です")
- 投稿日:2021-01-21T20:47:04+09:00
DjangoでOneToOneKeyとForiegnKeyの違い
DjangoでのOneToOneとForiegnKeyの違い
単純に言うとOneToOneフィールドは「モデルが1:1の関係で、片方が削除されるともう片方も自動で削除される」という想定をしています。
つまり、OneToOneは設定時に「もう片方のモデルを削除するのがデフォルト動作」なのです!
OneToOneは片方が削除されると、もう片方も削除されるのがデフォ
つまり、コレはえらーになります
UserHoge.pyclass UserHoge(models.Model): id = models.BigAutoField(primary_key=True,unique=True) UserId = models.ForeignKey( settings.AUTH_USER_MODEL, related_name='UserId ', null=True, blank=True )マイグレーション結果
on_delete属性は必須だよ、と怒られます。TypeError: __init__() missing 1 required positional argument: 'on_delete'つまり、正しい書き方はこんな感じです
UserHoge.pyclass UserHoge(models.Model): id = models.BigAutoField(primary_key=True,unique=True) UserId = models.ForeignKey( settings.AUTH_USER_MODEL, related_name='UserId', on_delete=models.CASCADE, #デフォルト動作指定、UserHogeの削除時にユーザーモデルも削除される null=True, blank=True )ForeignKeyは片方が削除されても消されない
ForignKeyは片方のモデルが削除されても、削除されないのがデフォルト動作です。
UserHoge.pyclass UserHoge(models.Model): id = models.BigAutoField(primary_key=True,unique=True) UserId = models.ForeignKey( settings.AUTH_USER_MODEL, related_name='UserId', null=True, blank=True )こんな感じで、
ER図上の1:1を結構簡単に実現できるのがDjangoの強みですね。
- 投稿日:2021-01-21T20:43:31+09:00
Python 備忘録
1.デフォルトの文字コード指定
1-1.path to python/Lib/site-packagesでsitecustomize.pyを作成~/path to python/Lib/site-packages $ touch sitecustomize.py1-2.下記コードを記載
文字コードは、公式サイトを参考にする。import sys sys.setdefaultencoding('utf-8')
- 投稿日:2021-01-21T20:29:17+09:00
DjangoでOneToOne、ForiegnKeyを設定する時のTip
DjangoでForignKeyを使う時はデフォルト値を設定する必要がある
DjangoのモデルにはOneToOneFieldという便利なフィールドがありますが、
これにはNullを設定できませんそんな感じでOneToOneフィールドを追加した時、
マイグレーションに失敗する時があります。という訳で、Nullを許可するTipsの書き方です
実際の書き方
model.pyclass VideoGamePurchase(models.Model): bought_by = models.ForeignKey(Person) after_homework = models.OneToOneField(HomeWork, null=True, blank=True)はいnullとblankという属性を設定するだけですね。
こんな感じでざっくり~
Django OneToOneField with possible blank field
https://stackoverflow.com/questions/47804020/django-onetoonefield-with-possible-blank-field
- 投稿日:2021-01-21T20:09:18+09:00
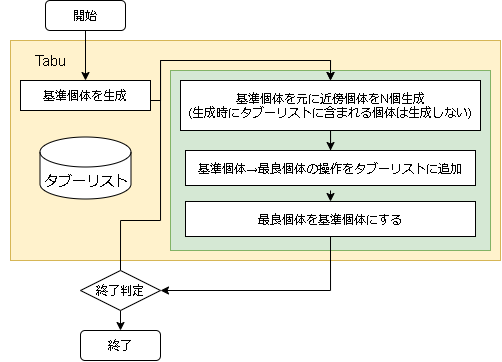
最適化アルゴリズムを実装していくぞ(タブーサーチ)
はじめに
最適化アルゴリズムの実装シリーズです。
まずは概要を見てください。コードはgithubにあります。
タブーサーチ
概要
タブーサーチ(Tabu Search)は人工知能の概念に基づいた局所探索法を一般化した手法らしいです。
アルゴリズム
- アルゴリズムのフロー
- 用語の対応
問題 タブーサーチ 問題への入力 個体の座標 評価値 個体の評価値
- ハイパーパラメータに関して
変数名 意味 備考 individual_max 生成する近傍の数 epsilon 近傍を生成する際の各成分の変更確率 tabu_list_size タブーリストのサイズ tabu_range_rate タブーとする範囲の割合(問題が取りうる値を基準) タブーリスト
タブーリストは基準個体の遷移が局所解でループしないように設定するリストです。
このリストにある遷移を一定時間しない(リストから消えるまで)ことで局所解のループから脱出する事を目的としています。タブーリストの記載方法は解自体を記述する方法と、遷移を記述する方法があるようですが、遷移を記述する方法を実装しています。
また、遷移で判断する値は実数値となるので、以下のように問題が取りうる値の割合($R$, tabu_range_rate)で指定できるようにしました。$$ X_{range} = R (Prob_{max} - Prob_{min})$$
tabu_range = tabu_range_rate * (problem.MAX_VAL - problem.MIN_VAL) # 判定する場合 if tabu_val - tabu_range < val and val < tabu_val + tabu_range: タブーリストに該当 else: タブーリストに該当しない近傍の生成
近傍の生成に決まった方法はなく、問題に依存するところが大きいようです。
本記事では各成分をε-greedy法でランダムに変更する方法にしました。
また、1要素は必ず変更するようにしています。pos = individual.getArray() # 基準個体の座標 ri = random.randint(0, len(pos)) # 1成分は必ず変更 for i in range(len(pos)): if i == ri or random.random() < epsilon: # ランダムな値に変更 pos[i] = problem.randomVal()コード全体
import math import random class Tabu(): def __init__(self, individual_max, epsilon=0.1, tabu_list_size=100, tabu_range_rate=0.1, ): self.individual_max = individual_max self.epsilon = epsilon self.tabu_list_size = tabu_list_size self.tabu_range_rate = tabu_range_rate def init(self, problem): self.problem = problem # タブー判定の範囲 self.tabu_range = (problem.MAX_VAL - problem.MIN_VAL) * self.tabu_range_rate # タブーリスト self.tabu_list = [] # 初期個体の生成 self.best_individual = problem.create() self.individuals = [self.best_individual] def step(self): # 基準となる個体(前stepの最良個体) individual = self.individuals[-1] # 個体数が集まるまで近傍を生成 next_individuals = [] for _ in range(self.individual_max*99): # for safety if len(next_individuals) >= self.individual_max: break # 近傍の座標を生成 pos = individual.getArray() ri = random.randint(0, len(pos)) # 1成分は必ず変更 trans = [] # タブーリスト用 for i in range(len(pos)): if i == ri or random.random() < self.epsilon: # ランダムな値に変更 val = self.problem.randomVal() trans.append((i, pos[i]-val)) # 変更内容を保存 pos[i] = val # タブーリストにある遷移は作らない if self._isInTabuList(trans): continue # 近傍を生成 o = self.problem.create(pos) # ソートしたいので個体と変更内容を保存 next_individuals.append((o, trans)) # 近傍が0なら新しく生成する if len(next_individuals) == 0: o = self.problem.create() if self.best_individual.getScore() < o.getScore(): self.best_individual = o self.individuals = [o] return # sort next_individuals.sort(key=lambda x: x[0].getScore()) # 次のstep用に保存 self.individuals = [x[0] for x in next_individuals] # このstepでの最良個体 step_best = next_individuals[-1][0] if self.best_individual.getScore() < step_best.getScore(): self.best_individual = step_best # タブーリストに追加 step_best_trans = next_individuals[-1][1] self.tabu_list.append(step_best_trans) if len(self.tabu_list) > self.tabu_list_size: self.tabu_list.pop(0) def _isInTabuList(self, trans): for tabu in self.tabu_list: # 個数が違えば違う if len(tabu) != len(trans): continue f = True for i in range(len(trans)): # 対象要素が違えば違う if tabu[i][0] != trans[i][0]: f = False break # 範囲内じゃないなら非該当 tabu_val = tabu[i][1] val = trans[i][1] if not(tabu_val - self.tabu_range < val and val < tabu_val + self.tabu_range): f = False break # 該当するものがある if f: return True return Falseハイパーパラメータ例
各問題に対して optuna でハイパーパラメータを最適化した結果です。
最適化の1回の試行は、探索時間を5秒間として結果を出しています。
これを100回実行し、最適なハイパーパラメータを optuna に探してもらいました。
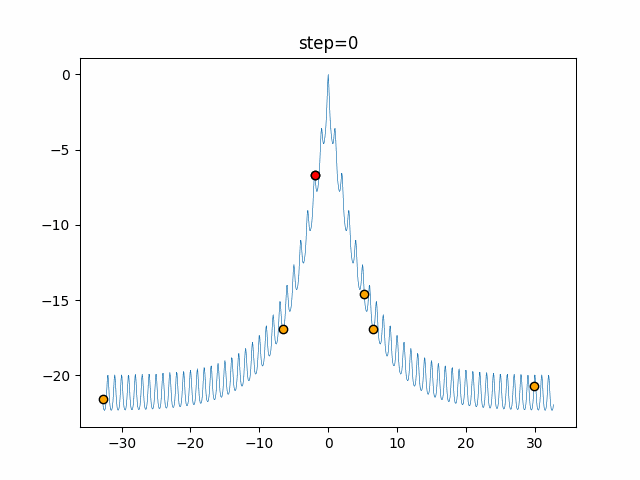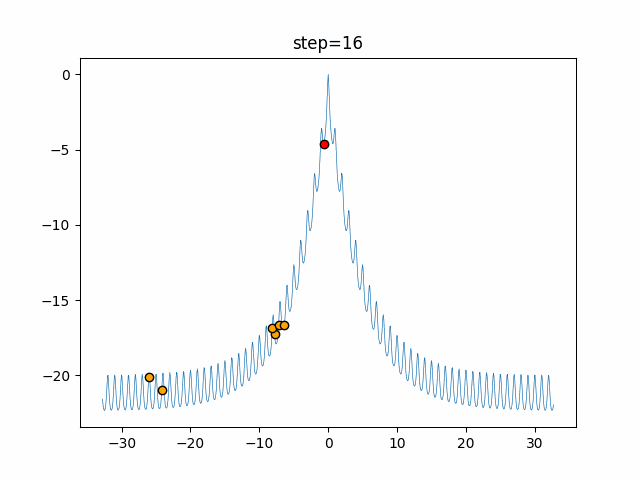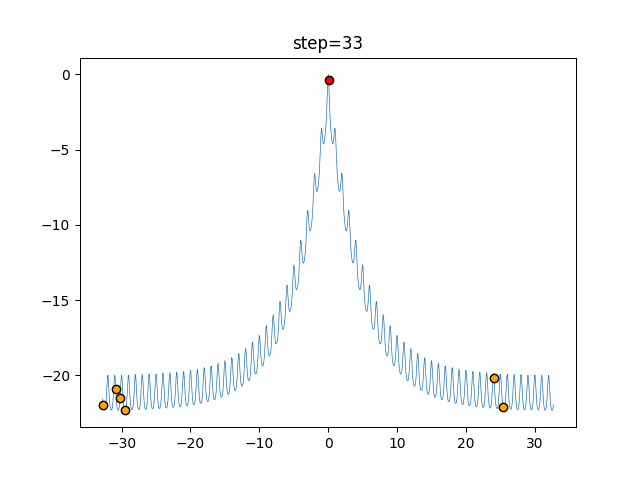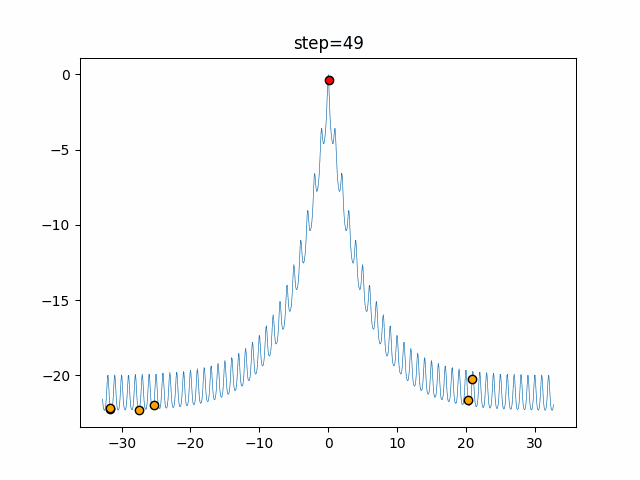
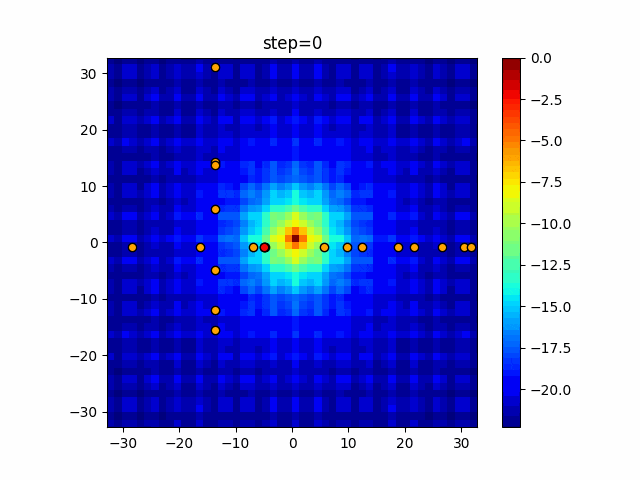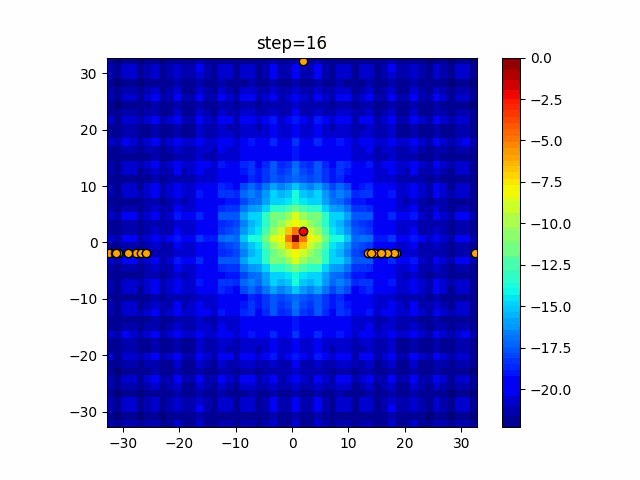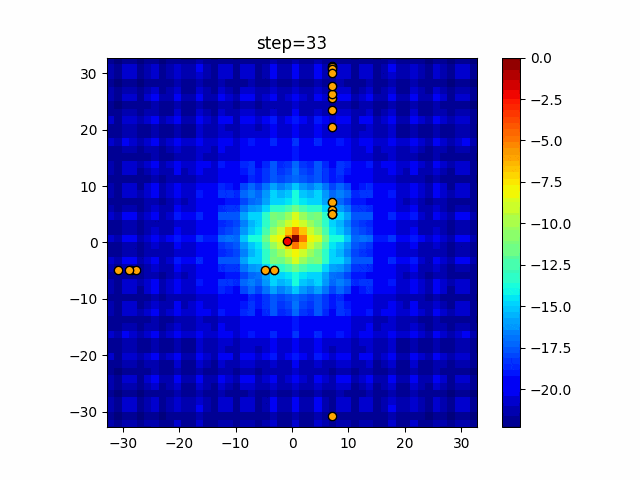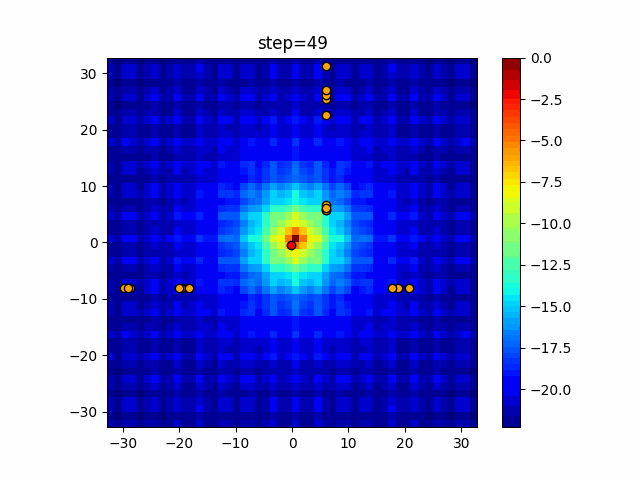
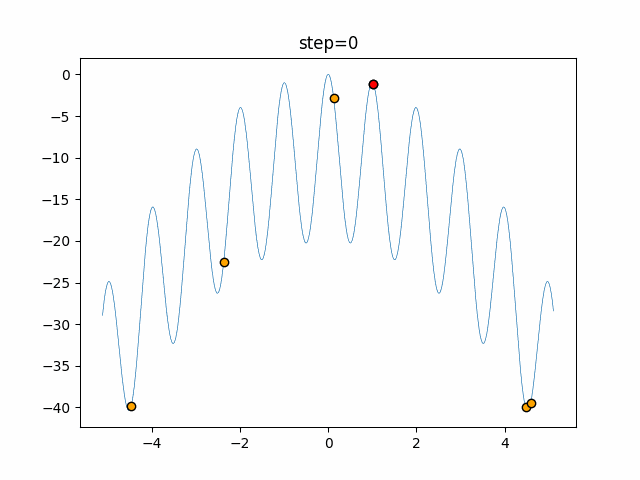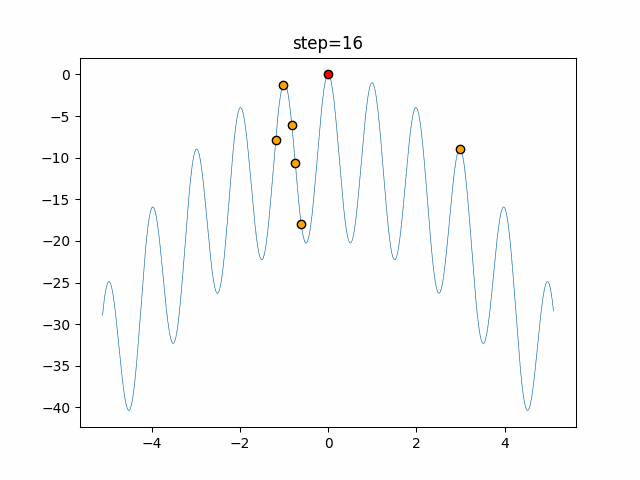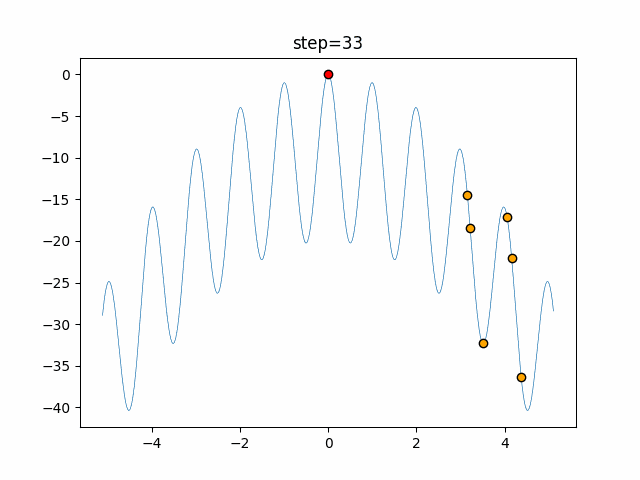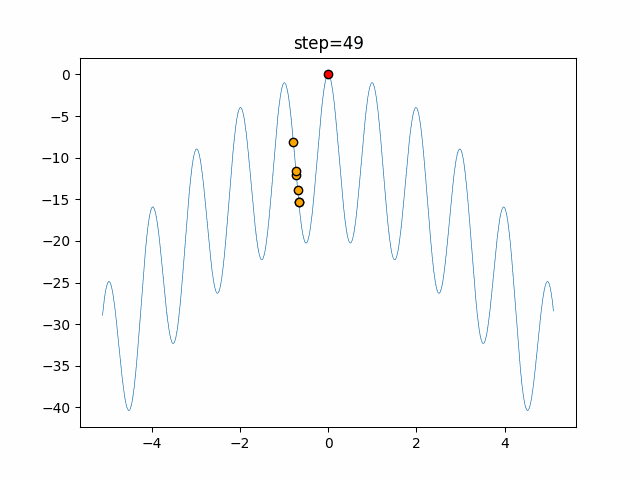
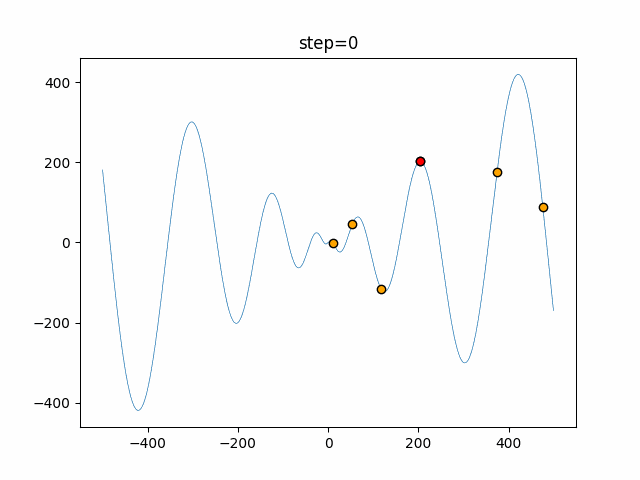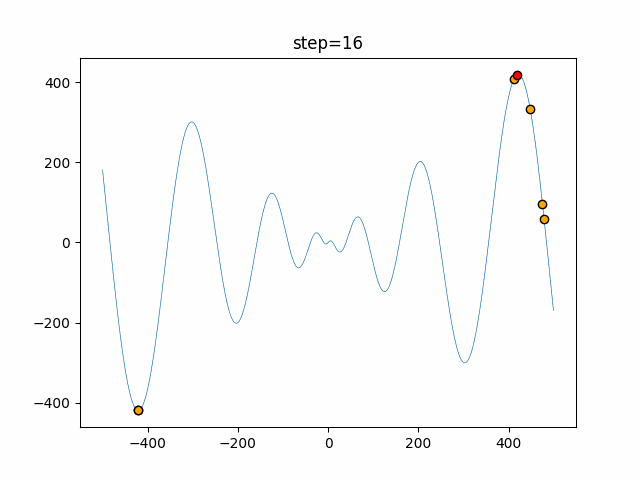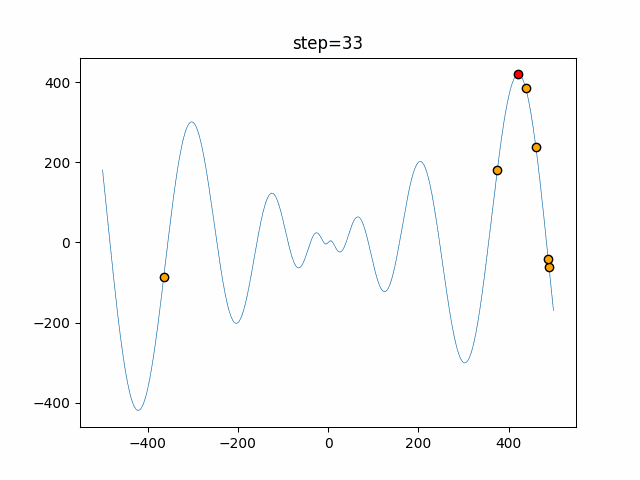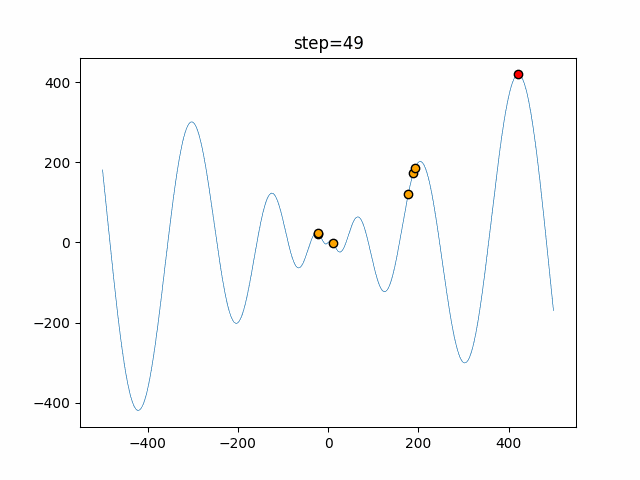
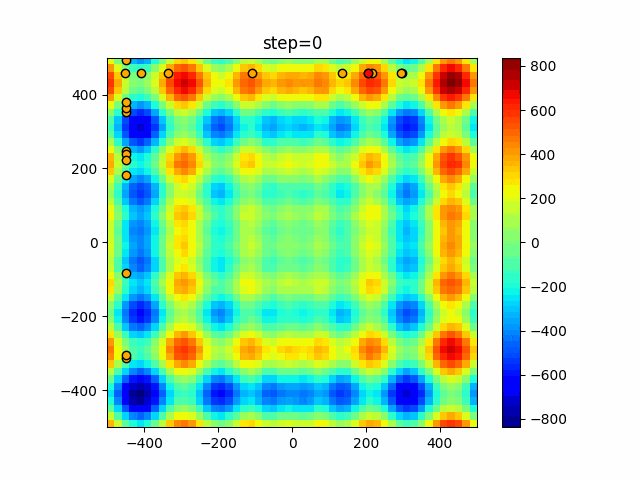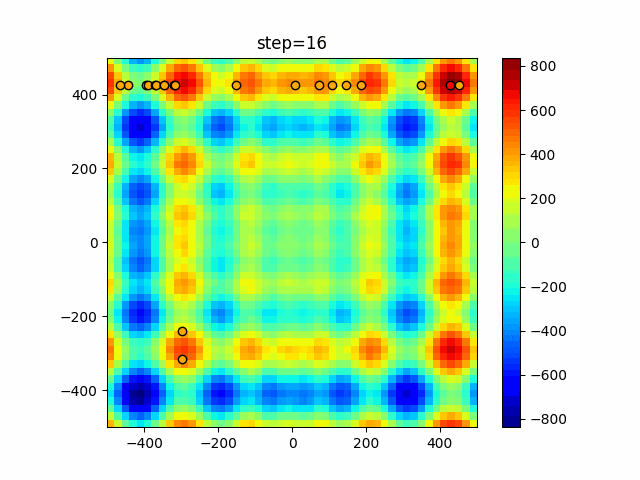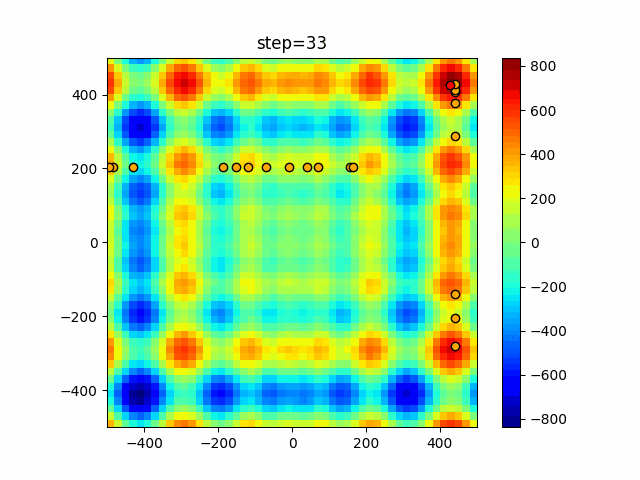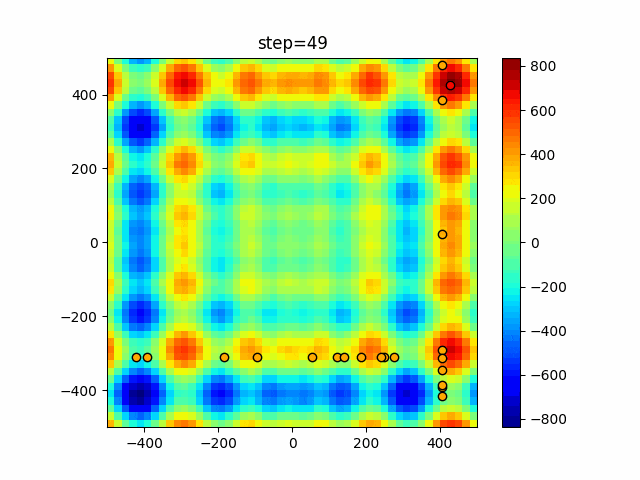
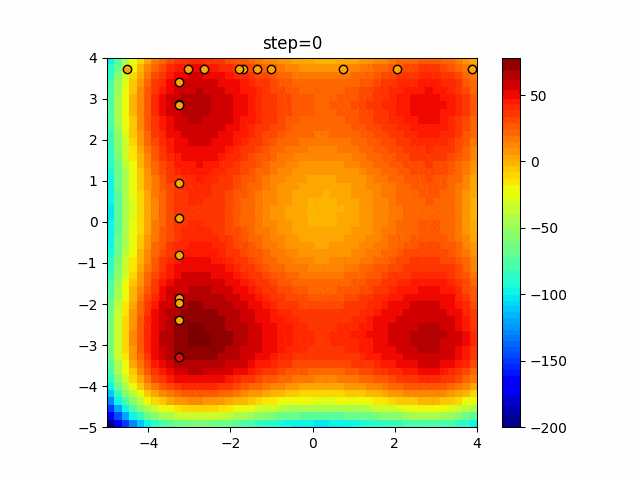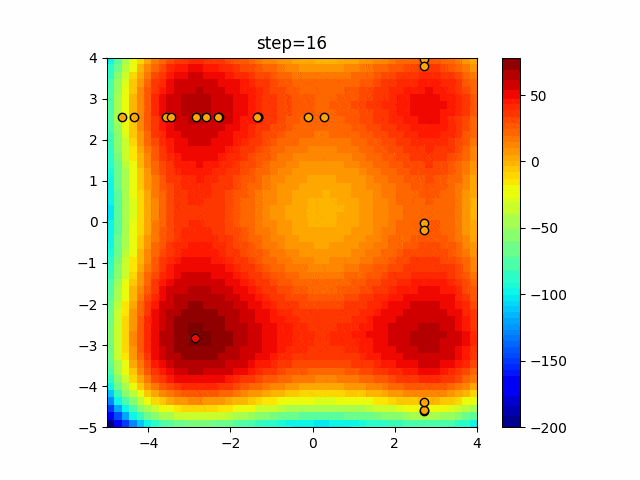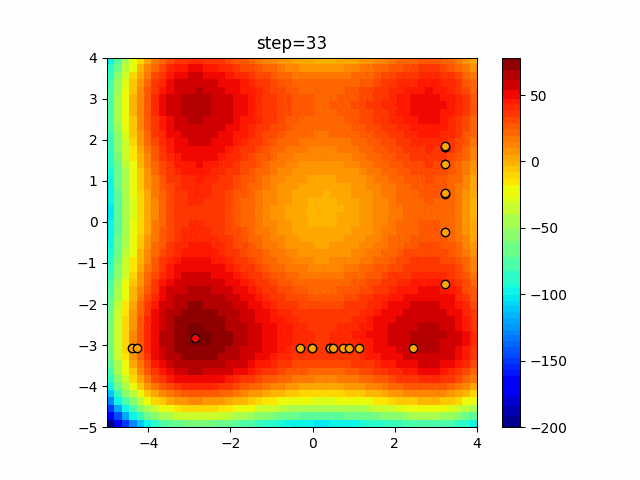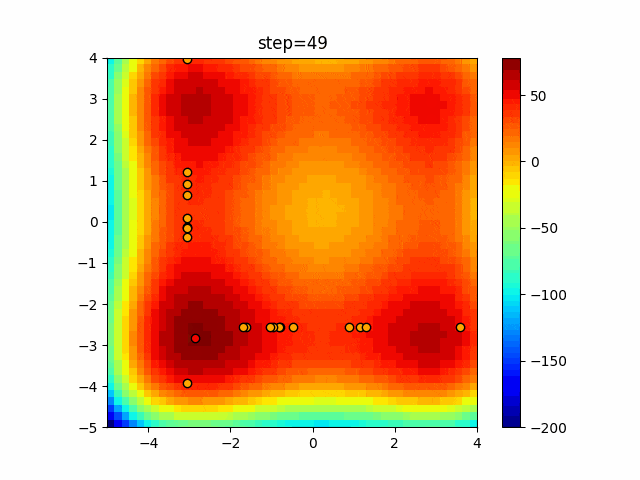
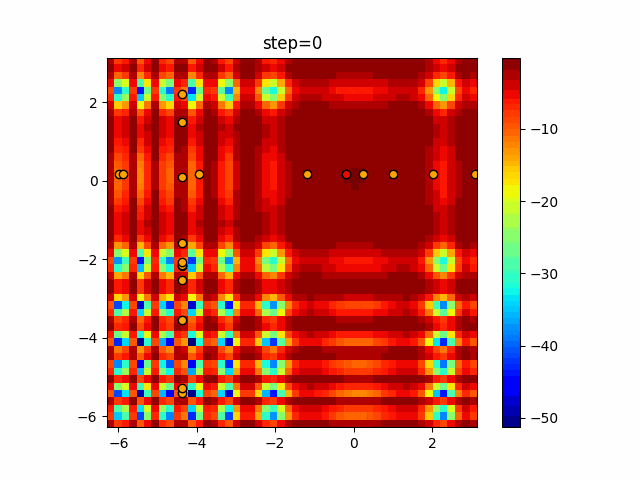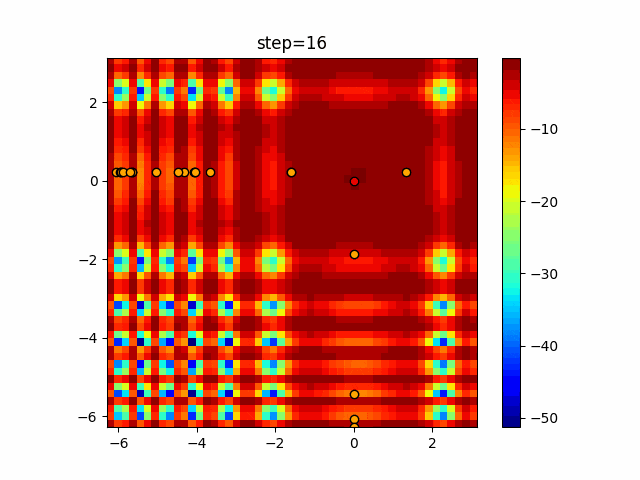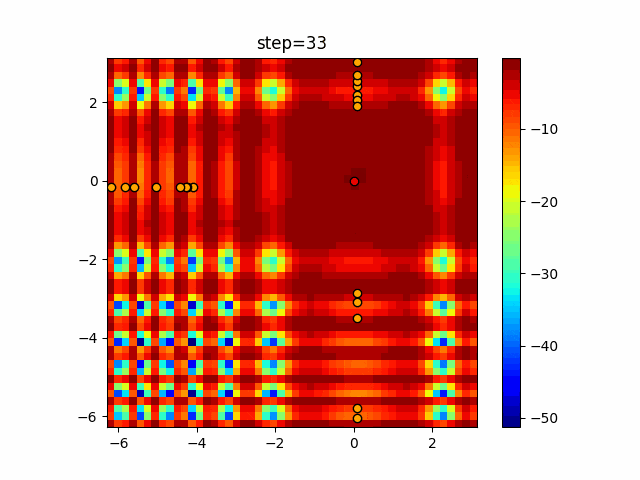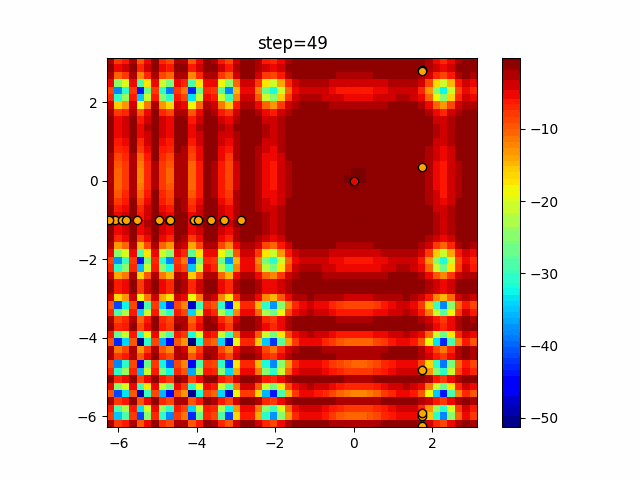
問題 epsilon individual_max tabu_list_size tabu_range_rate EightQueen 0.011151919824816751 24 33 0.003497750329001216 function_Ackley 0.000110909916091936 18 146 0.0032544838729771236 function_Griewank 0.0012284413321756848 48 6 0.8866006526200017 function_Michalewicz 0.0005626187277017018 42 300 0.7351059491323495 function_Rastrigin 0.00022273162093360693 29 15 0.03345590467119916 function_Schwefel 0.00010033345050305172 49 10 0.4450495107614175 function_StyblinskiTang 0.0019068533760369163 50 16 0.5646323547501031 function_XinSheYang 0.0005997343899621366 47 295 0.001967269783955519 g2048 0.9996213921785719 12 22 0.014073734875355126 LifeGame 0.0066786013632043895 25 259 0.6435199139608611 OneMax 0.00046850780076445296 19 60 0.9692455801618902 TSP 0.0006803511143661416 31 20 0.5199790701315284 実際の動きの可視化
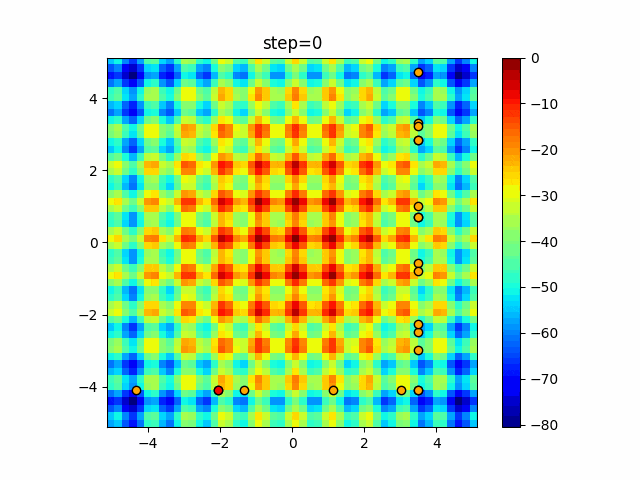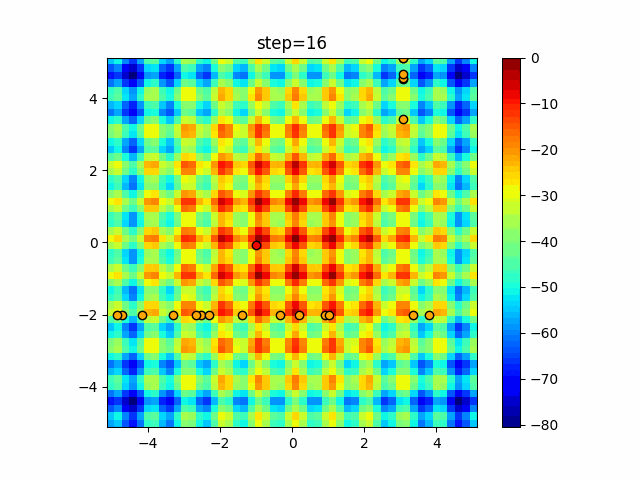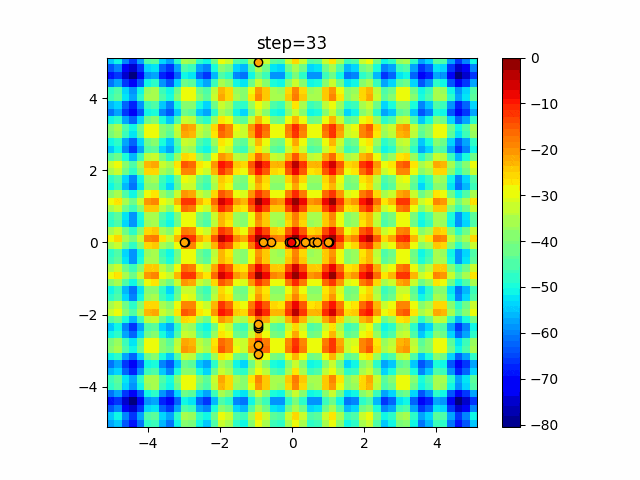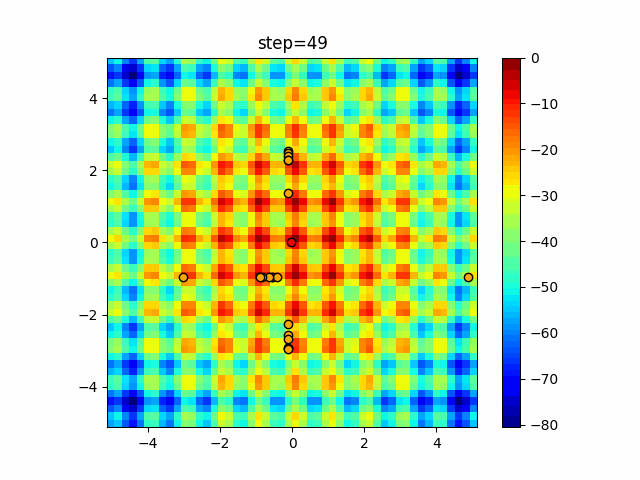
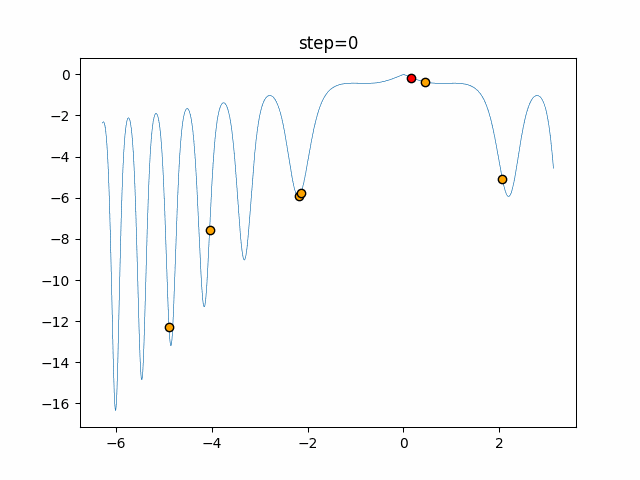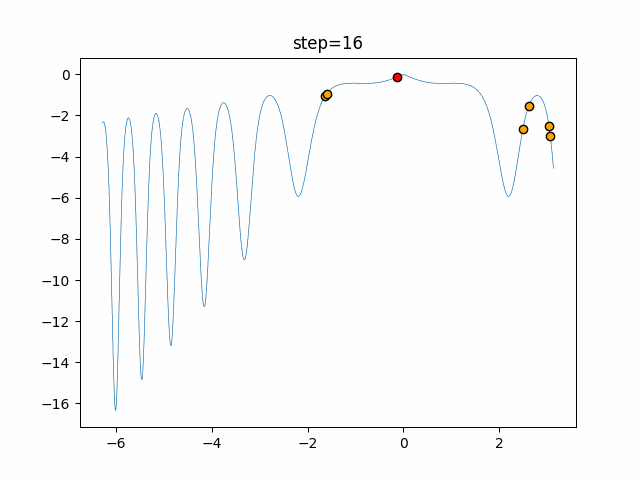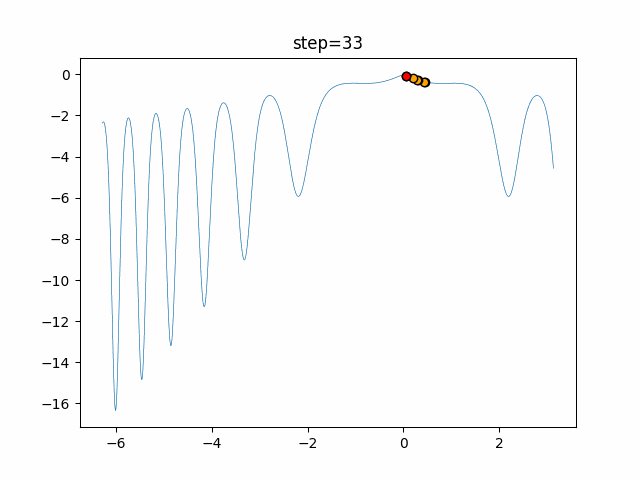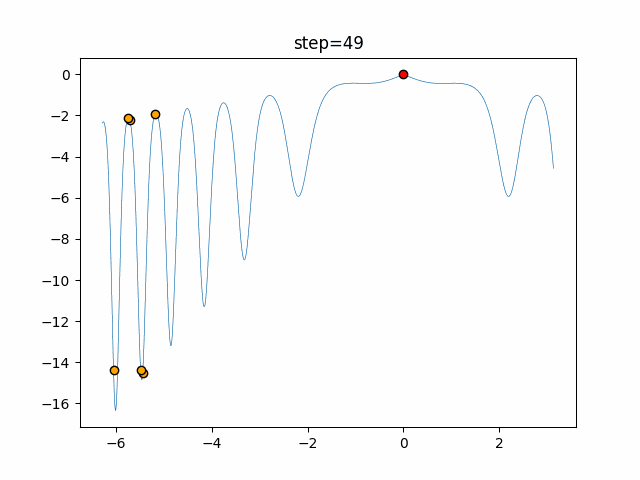
1次元は6個体、2次元は20個体で50step実行した結果です。
赤い丸がそのstepでの最高スコアを持っている個体となります。パラメータは以下で実行しました。
Tabu(N, epsilon=0, tabu_list_size=10, tabu_range_rate=0.1)function_Ackley
- 1次元
- 2次元
function_Rastrigin
- 1次元
- 2次元
function_Schwefel
- 1次元
- 2次元
function_StyblinskiTang
- 1次元
- 2次元
function_XinSheYang
- 1次元
- 2次元
あとがき
タブーリストのサイズが10なので、10stepまで空白が目立ったエリアが10stepからは埋まっていきまた20stepから埋められている感じですね。
2次元で上下に動いているのはεを0にしているので必ず1次元のみ遷移するからです。(もう1次元は元の位置を使用する)

- 投稿日:2021-01-21T18:53:02+09:00
VTuberのモザイクアートを作る
動画・配信のサムネイルを使って、VTuberのモザイクアートを作ります。
とは言えモザイクアートの作成自体はツールを使うだけなので、ここで書くのはYouTube Data APIの使い方ぐらいです。
流れとして、APIで動画データ取得→動画データ内のサムネURLから画像を取得→取得した画像を使ってモザイクアート作成といった感じです。今回対象とするVTuberさんは不条 理さんです。
https://twitter.com/AyaFujo
https://www.youtube.com/channel/UCnWY-6vdj_UaKDwGI5oLDZw
素敵な個人Vさんで、おすすめです。動画データの取得
まず、YouTube Data APIを使って動画データを取得します。
準備方法は調べればいくらでも出てくるので、今回は割愛します。from apiclient.discovery import build import json import time # APIを使うための情報を設定 DEVELOPER_KEY = "**取得したAPIキー**" YOUTUBE_API_SERVICE_NAME = "youtube" YOUTUBE_API_VERSION = "v3" youtube = build(YOUTUBE_API_SERVICE_NAME, YOUTUBE_API_VERSION, developerKey=DEVELOPER_KEY) item_list = [] search = youtube.search().list( part = "snippet", # チャンネルIDはYouTubeホーム画面URLから取得、↓の***の部分 # https://www.youtube.com/channel/***/featured channelId = "**チャンネルID**", maxResults = 50 # 一回で取得する動画情報数 ) data = search.execute() # 一回じゃ取りきれないので何回か実行する while True: item_list = item_list + data["items"] print(len(item_list)) print(data["pageInfo"]) # 取りきったら終了 if "nextPageToken" not in data: break time.sleep(1) search = youtube.search().list_next(search, data) data = search.execute() # 取得したデータを保存 with open('movieData.json', 'w', encoding="utf8") as f: json.dump(item_list, f, ensure_ascii=False)ざっくりこんな感じで動画データが取得できます。
画像の取得
続いて画像の取得です。
先ほど取得したJSONファイルですが、snippet→thumbnailsにサムネの情報が入ってます。
画像サイズごと別れており、その下のurlに画像のURLがあります。
データ構造も調べれば出てくるので割愛します。画像の保存方法としてurllibライブライを使います。
これを使うことで、URLを指定して画像を保存することができます。import json import urllib.request # さっきのJSONファイル json_file = open('movieData.json', 'r') data = json.load(json_file) json_file.close() i = 1 for line in data: # 画像ファイル名 image_file = "samune/" + str(i) + ".jpg" i += 1 # URLの場所を指定して取得 url = line["snippet"]["thumbnails"]["medium"]["url"] print(line["snippet"]["title"]) # urllibライブライを使って画像を保存 tgt = urllib.request.urlopen(url).read() with open(image_file, mode='wb') as f: f.write(tgt)モザイクアートの作成
これもプログラムでサクッとできればよかったのですが、そこまでの技術は無いので...。
最後はツールの力を借ります。
AndreaMosaicというツールになります。
使い方はリンクを貼るのでそちらから。
https://aprico-media.com/posts/3742完成したモザイクアート
元画像はツイッターのアイコンを使いました。
小さくして薄目で見ると見える気がする!元画像
モザイクアート
以上、ちょっと変わったファンアートを作りたくて遊んだ話でした。


- 投稿日:2021-01-21T16:40:28+09:00
Linux(Ubuntu or Linux Mint or Debian?)でWine!Python!Pyinstaller!!
1.はじめに
ここに書いてある手順は、Pyinstallerによって推奨されていません。(こちらを参照)
また、動作するかどうか、かなり微妙です。
出力されるファイルが正常でない可能性もあります。
それでもいいという方のみ先へお進みください。
また、すべてのこの記事の内容の実行についての責任はこの記事の読者側にあります。
環境がおかしくなったりしても、責任はとれません。
それでもいいという方のみ先へお進みください。2.前提
多分、wine_stableが入れば勝ちです。
バージョンは、6.0.0と、5.0.3で動きました。(環境に依存しそうですが。)
動作報告お待ちしてます。
Pythonは64bit and 32 bit 3.8.5はテスト済みです。
これも動作報告お待ちしてます。
また、ここでは、linux用バイナリについてではなくて、windowsのexeを生み出す方法を紹介しています。
念のため書いときます。3.wineインストール!
Ubuntuの方はこちら
Debianは、こちら
をご覧の上、Stableをインストールしてください。4.Pythonインストール!
Pythonをインストールします。
まあ、使いたいバージョンをここから落としてきてください。installerですよ?exeですからね?
Windows版Pythonはバージョンが共存できるので、複数入れるのもありです。
インストール時の設定は、弄らずに、Recommandedで入れましたが、これは別になんでもいい気もします。5.PyInstallerインストール!
う〜ん...それにしてもこの記事てきと〜だな...
えっと、以下のようにして、Pyinstallerを突っ込みます。wine py [-3-32とかのバージョン指定] -m pip install PyInstallerこれで入るでしょう。(超なげやり)
6.いざ実行。
緊張の瞬間です...
とりあえず、なんでもいいのでやってみましょう。
念のため、テスト用コード置いときます。test.pyprint("test")#適当の極みまあ、実行してみましょう。
wine py [-3-64とかのバージョン指定] -m pyinstaller [ファイル名]できたら赤飯を炊きましょう。
以上です。
- 投稿日:2021-01-21T16:33:32+09:00
機械学習における競馬予測 〜ニューラルネットワーク編〜
はじめに
前回、LightGBMを使って競馬予測行ったところ、結構良い感じのAUCが出てくれました。
今回はkerasに実装されているニューラルネットワークを使って、競馬予測を行いたいと思います。行ったこと
LightGBM編と同様に「データの取得→前処理→学習→AUCの算出→考察」を行いました。
環境
Google Colab
手順
1 https://www.netkeiba.com/ よりスクレイピング
2 前処理
3 ニューラルネットワークで学習、予測1,2 スクレイピングと前処理
スクレイピングと前処理についてはLightGBM編と全く同じ処理をしたのでそちらを見ていただければと思います。数値変数に対して、標準化の処理だけプラスして行いました。
LightGBM編の記事はこちらから見れます。3-0 そもそもニューラルネットワークって何?
ニューラルネットワークをすでに知っている人はここは飛ばしちゃってください。
ニューラルネットワークとは、人間の脳内にある神経細胞(ニューロン)とそのつながりを人工ニューロンという数式的なモデルで表現したものです。
イメージ的には以下のような感じです。
人間の脳はこんな感じでニューロンがそれぞれ相互作用し合うことで、情報伝達を行っています。
さて、機械学習では次のような図を想像してみてください。
いきなり訳の分からない図が出てきました。笑
これは何を表しているかというと、MNISTというデータセット(7万枚の手書き数字の画像とその正解ラベルが入っている。)に入っている「8」をニューラルネットワークに通して学習をしている図です。この画像は28×28=784ピクセルの画像で、そのピクセル一つ一つをネットワークにいれています。ネットワーク内で起きていることは数学的な話になるので割愛しますが、最終的にこのネットワークは「確率」を算出してくれます。
何の確率かというと入力した数字が「0」である確率、「1」である確率、、、「9」である確率をそれぞれ出してくれます。「この確率が90%以上だったら8と認識する」みたいに使われます。また、この90%という数字は人間が決め、閾値と呼ばれます。
ちなみに、一番左の層から順に入力層、中間層、出力層と呼ばれ、白丸一つ一つはノードと呼ばれます。3-1 kerasについて
kerasはTensorFlowのラッパーライブラリとして登場し、比較的分かりやすいコードで実装されています。今回使用するニューラルネットワークはこのkerasに実装されているものを使います。
また、GPUを使用することで学習を高速化することができます。ちなみにGoogle ColabではGPUが無料で使えます。3-2 必要なモジュールをimport
#モジュールのimport import keras from keras.models import Model,Sequential from keras.layers import Input, Dense, Activation, Dropout from keras.layers import BatchNormalization, Add, Dense from keras.callbacks import ModelCheckpoint from keras.utils import to_categorical from keras.initializers import he_normal import keras.backend as K3-3 モデルの定義
kerasでニューラルネットワークを実装するには2種類の実装が存在しますが、今回は簡単なSequentialモデルを使用します。Sequentialモデルというのは全結合のニューラルネットワークで、ノードが次の層のノードに全て結合しているものです。(ノードから出る矢印が次のノードに全て繋がっている。)
もう一つのFunctionalモデルは層を分岐させたり、層を飛び越えて結合することができます。こちらの方が自由度があり、複雑なモデルを定義できます。
今回はSequentialモデルを使いますが、やることはニューラルネットワークをcreate_modelという関数で定義して、学習時に呼び出すだけです。def create_model(optimizer='adam', init='glorot_normal'): model=Sequential() model.add(Dense(16, input_dim=X.shape[1], kernel_initializer=init, activation='relu')) model.add(Dense(8, kernel_initializer=init, activation='relu')) model.add(Dense(4, kernel_initializer=init, activation='relu')) model.add(Dense(1, kernel_initializer=init, activation='sigmoid')) #2値分類なのでbinary_crossentropyを使う model.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy']) return model model=create_model()書き方はこんな感じです。はじめにmodel=Sequential()として空のネットワークを生成し、そこに後からaddメソッドで層を追加していきます。
今回は入力層、中間層2層、出力層の計4つの層で学習します。3-4 学習
前処理は終わっているのでfitメソッドで学習させていくのですが、ここでkerasの便利機能を紹介しておきます。
それはコールバックという機能です。コールバックとは学習中にある条件を満たした時に作動する機能です。今回は2つのコールバックを設定します。
1つ目はEaryStoppingです。これは何エポック連続でvalidationのlossや何かしらの指標が改善しなかったら、指定したエポック数に達していなくても学習を終了してくれます。
2つ目はModelCheckpointです。これは1エポック目からのvalidationの何かしらの指標の値を内部で保持しておいて、その指標がそれまでのエポックでベストを記録した場合、そのモデルをdumpする機能です。
直感的には最終エポックが一番良いモデルになりそうですが、実際学習させると全エポックが20エポックで12エポック目がベストだったなんてことはよくあります。何も設定しないと最終エポックの20エポック目が採用されますが、ModelCheckpointを設定することで、ベストである12エポック目を採用してくれます。
※batch-size(2のn乗にするのが一般的らしい)とepochsは適当に設定してください。#checkpointとearystoppingの設定 es = EarlyStopping(monitor='val_loss', patience=3, verbose=1) cp = ModelCheckpoint(filepath = 'best_model.h5', monitor='val_loss', save_best_only=True, verbose=1) history = model.fit(x=X_train, y=y_train, validation_data=(X_test, y_test), batch_size=512, epochs=100, shuffle=True, callbacks=[es, cp] )学習を始めるとこんな感じになります。
Earystoppingのおかげで途中で学習が止まりました。
最終的には20エポック目で止まっています。
3-5 AUCの確認
最後にAUCを確認します。
pred = model.predict(X_test) print(roc_auc_score(y_test, pred))
LightGBMで予想した時とほとんど同じでした。もっと変わると思ったのですが、前処理が同じだとモデルを変えてもAUCはあまり変わらないようです。よく言われていますが、やはり機械学習は前処理が命ですね。おわりに
今回はニューラルネットワークを使って、競馬AIを実装してみました。結果はLightGBMで予想した時とあまり変わりませんでした。
LightGBMではハイパーパラメータをいじってもそこまで大きく精度が変わることはなく、特徴量生成やアンサンブル学習によって精度を上げることが課題でした。
しかし、ニューラルネットワークでは層を何層も重ねたり、Dropout層を追加したりすることで精度の向上が予想されます。ただこの辺りは経験が大事になってくると思うので、とにかくいじってみることが大事ですね。
そして、残念なことにこのモデルも回収率を一切考慮していないのでこれを使って儲けることは出来ません。
これからは回収率シュミレーションなども行い、モデルの精度を上げていきたいと思います。(頑張って精度上げて儲けたい!)
最後までご覧いただき、ありがとうございました。全コードは以下に掲載しています。
https://github.com/suzuki24/keiba参考
・https://ml4a.github.io/ml4a/jp/looking_inside_neural_nets/
・https://www.sbbit.jp/article/cont1/33345
・https://ja.wikipedia.org/wiki/%E3%83%8B%E3%83%A5%E3%83%BC%E3%83%A9%E3%83%AB%E3%83%8D%E3%83%83%E3%83%88%E3%83%AF%E3%83%BC%E3%82%AF
・Python機械学習プログラミング 達人データサイエンティストによる理論と実践




- 投稿日:2021-01-21T16:25:09+09:00
PythonのC拡張モジュールで作った関数内で引数として、なんか受け取ったから、処理したった!
はい。タイトル通りです。
やりたいこと!
下記な感じのコードを書いた時に、ゴリゴリ自作したPythonのC拡張モジュールに引数渡したい。という感じです。
と言っても、今回は処理するための前段階を書いているだけです。testobject = test.Test() testobject.helloworld("test",123)出来たもの
test.hpp#pragma once #define PY_SSIZE_T_CLEAN #include <Python.h> #include "structmember.h" #include <iostream> #include <string> static PyObject* c_helloworld(CustomObject *self, PyObject *args){ std::cout << "test test1" << std::endl; std::cout << "testtest Type:" << Py_TYPE(args)->tp_name << std::endl; std::cout << "testtest size:" << PyTuple_Size(args) << std::endl; for(Py_ssize_t i = 0 ; i < PyTuple_Size(args) ; i++ ){ auto item = PyTuple_GetItem(args, i); std::cout << "count:" << i << " , type:" << Py_TYPE(item)->tp_name << std::endl; if(std::string(Py_TYPE(item)->tp_name) == "str"){ Py_ssize_t textsize = 0; auto text = PyUnicode_AsUTF8AndSize(item, &textsize); std::cout << "text:" << text << std::endl; }if(std::string(Py_TYPE(item)->tp_name) == "int"){ auto num = PyLong_AsLong(item); std::cout << "num:" << num << std::endl; } } return Py_None; } static PyMethodDef myMethods[] = { { "helloworld", (PyCFunction) c_helloworld, METH_VARARGS, "Prints Hello World" }, { NULL } }; static PyTypeObject CustomType = { PyVarObject_HEAD_INIT(NULL, 0) .tp_name = "test.Test", .tp_basicsize = sizeof(CustomObject), .tp_itemsize = 0, .tp_flags = Py_TPFLAGS_DEFAULT | Py_TPFLAGS_BASETYPE, .tp_doc = "test objects", .tp_methods = myMethods, }; static struct PyModuleDef testModule = { PyModuleDef_HEAD_INIT, "test", "Python3 C API Module(testModule)", -1, };main.cpp#include "test.hpp" PyMODINIT_FUNC PyInit_test(void){ PyObject *m; if(PyType_Ready(&CustomType) < 0) return NULL; m = PyModule_Create(&testModule); if (m == NULL) return NULL; Py_INCREF(&test::CustomType); PyModule_AddObject(m, "test", (PyObject *) &test::CustomType); return m; }出力結果
test test1 testtest Type:tuple testtest size:2 count:0 , type:str text:test count:1 , type:int num:123解説
前書き
c_helloworld関数とmyMethods変数以外は、特に通常通りです。
これらの件については、下記の公式のリファレンスを読んでください。myMethods変数
METH_VARARGSにすることで、Python文から引数を受け取れるようにする。
c_helloworld関数
Py_TYPE(args)->tp_nameこの文で、args(引数)の型が変わると思います。
引数は、タプルということらしいので、これ以降では、タプルとして動かしてみましょう。PyTuple_Size(args)これでタプルの要素数が分かります。これでいくらfor文を回したらよいのか分かったので、次は各アイテムにアクセスします。
PyTuple_GetItem(args, i)で、指定要素にアクセスします。
そこから、また変数の型を確認しなおします。std::string(Py_TYPE(item)->tp_name) == "str"こんな感じでね。
"str"は、文字列型であったということです。Py_ssize_t textsize = 0; auto text = PyUnicode_AsUTF8AndSize(item, &textsize);こんな感じで、PyObjectからconst char*に変換します。
なお、intの場合は、下記のような感じで取得できます。
(今回は、long型で取っています)PyLong_AsLong(item);超余談
戻り値として返したいときあるよね!
[1,2,3,4,5]こんな感じのものを返したいときってあるよね!
とりあえず、なりふり構わずPyObject*で返せばいいので、
例えば、どっかの例みたいに、PyLong_FromLong(sts)で返すとかの制限はないです。なので…例えば、下記のようなintを内包したリスト型にして返すことも可能です。
PyObject* returnData = PyList_New(0); for(long i = 1; i <= 5; i++){ PyList_Append(returnData, PyLong_FromLong(i)); } return returnData;こんな感じで、PyObject*にして、返せるよ。
- 投稿日:2021-01-21T16:13:49+09:00
回帰分析その2
最小二乗法の前提の確認
---分布図の作成---
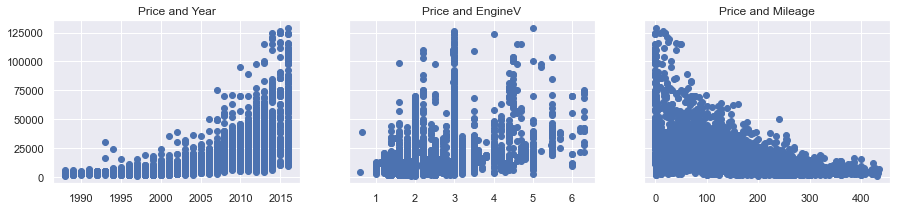
f, (ax1, ax2, ax3) = plt.subplots(1, 3, sharey=True, figsize =(15,3)) ax1.scatter(data_cleaned['Year'],data_cleaned['Price']) ax1.set_title('Price and Year') ax2.scatter(data_cleaned['EngineV'],data_cleaned['Price']) ax2.set_title('Price and EngineV') ax3.scatter(data_cleaned['Mileage'],data_cleaned['Price']) ax3.set_title('Price and Mileage') plt.show()
上記グラフから
値段と製造年数・値段と走行距離・値段と排気量を表しています。指数分布図になっている場合は、引数に対数を返します
対数に変換するメソッド
np.log(x)
# Priceを対数に変換していきます log_price = np.log(data_cleaned['Price']) # データフレームに追加します data_cleaned['log_price'] = log_price data_cleanedBrand
Price
Body
Mileage
EngineV
Engine Type
Registration
Year
log_price
0
BMW 4200.0 sedan 277 2.0 Petrol yes 1991 8.3428401
Mercedes-Benz 7900.0 van 427 2.9 Diesel yes 1999 8.9746182
Mercedes-Benz 13300.0 sedan 358 5.0 Gas yes 2003 9.4955193
Audi 23000.0 crossover 240 4.2 Petrol yes 2007 10.0432494
Toyota 18300.0 crossover 120 2.0 Petrol yes 2011 9.814656...
... ... ... ... ... ... ... ... ...3862
Volkswagen 11500.0 van 163 2.5 Diesel yes 2008 9.3501023863
Toyota 17900.0 sedan 35 1.6 Petrol yes 2014 9.7925563864
Mercedes-Benz 125000.0 sedan 9 3.0 Diesel yes 2014 11.7360693865
BMW 6500.0 sedan 1 3.5 Petrol yes 1999 8.7795573866
Volkswagen 13500.0 van 124 2.0 Diesel yes# 改めて散布図を作成します f, (ax1, ax2, ax3) = plt.subplots(1, 3, sharey=True, figsize =(15,3)) ax1.scatter(data_cleaned['Year'],data_cleaned['log_price']) ax1.set_title('Log Price and Year') ax2.scatter(data_cleaned['EngineV'],data_cleaned['log_price']) ax2.set_title('Log Price and EngineV') ax3.scatter(data_cleaned['Mileage'],data_cleaned['log_price']) ax3.set_title('Log Price and Mileage') plt.show()
多重共線性
・正規性
・平均が0 =切片の値を入れる事で対応が可能
・同分散性# データフレームの列を見ていきましょう data_cleaned.columns.valuesarray(['Brand', 'Body', 'Mileage', 'EngineV', 'Engine Type',
'Registration', 'Year', 'log_price'], dtype=object)sklearn には多重共線性を確認するメソッドはない
なら確認するには?
A、スタッツモデルを使用する (vif)
# 多重共線性を確認するためのモジュールをインポートしていきます from statsmodels.stats.outliers_influence import variance_inflation_factor # 多重共線性を確認するための列を指定した変数を作成します variables = data_cleaned[['Mileage','Year','EngineV']] # 新しいデータフレームを作成します vif = pd.DataFrame()A # それぞれのVIFの値を求めていきます vif["VIF"] = [variance_inflation_factor(variables.values, i) for i in range(variables.shape[1])] # 対応する列の名前を追加します vif["Features"] = variables.columnsVIF
VIF =1 多重共線性はない
1 < VIF < 5 問題ない値
5 < VIF 多重共線性あり# 結果の確認 vifVIF
Features
0
3.791584 Mileage1
10.354854 Year2
7.662068 EngineVYear がほかの部分と強く相関していることがわかる
DORPメソットを使い取り除いていく
# Yearに関するデータを削除します data_no_multicollinearity = data_cleaned.drop(['Year'],axis=1)多重共線性についての参考ソース
(https://statisticalhorizons.com/multicollinearity)ダミー変数の作成
カテゴリー分析は、ダミー変数に置き換える事で分析に使うことができます。
ダミーの作成
pandas pd.get_dummies(df[, drop_first])
カテゴリ変数の数がN子の場合、作成するダミー変数の数はN‐1個でなければならない
# get_dummiesメソッドを使ってダミー変数を作成します data_with_dummies = pd.get_dummies(data_no_multicollinearity, drop_first=True)# 結果を表示します data_with_dummies.head()データの並べ替え
# 全ての列の名前を表示します data_with_dummies.columns.values# 従属変数、独立変数、ダミー変数で並べかをしていきます cols = ['log_price', 'Mileage', 'EngineV', 'Brand_BMW', 'Brand_Mercedes-Benz', 'Brand_Mitsubishi', 'Brand_Renault', 'Brand_Toyota', 'Brand_Volkswagen', 'Body_hatch', 'Body_other', 'Body_sedan', 'Body_vagon', 'Body_van', 'Engine Type_Gas', 'Engine Type_Other', 'Engine Type_Petrol', 'Registration_yes']# 新しいデータフレームに並べ替えたデータを入れていきます data_preprocessed = data_with_dummies[cols] data_preprocessed.head()

- 投稿日:2021-01-21T15:27:04+09:00
manimの作法 その27
概要
manimの作法、調べてみた。
Histogram使ってみた。サンプルコード
from manimlib.imports import * def text_range(start,stop,step): numbers = np.arange(start,stop,step) labels = [] for x in numbers: labels.append(str(x)) return labels class Histogram(VMobject): CONFIG = { "start_color": RED, "end_color": BLUE, "x_scale": 1.0, "y_scale": 1.0, "x_labels": "auto", "y_labels": "auto", "y_label_position": "top", "x_min": 0, "bar_stroke_width": 5, "outline_stroke_width": 0, "stroke_color" : WHITE } def __init__(self, x_values, y_values, mode = "widths", **kwargs): digest_config(self, kwargs) if mode == "widths" and len(x_values) != len(y_values): raise Exception("Array lengths do not match up!") elif mode == "posts" and len(x_values) != len(y_values) + 1: raise Exception("Array lengths do not match up!") self.y_values = y_values self.x_values = x_values self.mode = mode self.process_values() VMobject.__init__(self, **kwargs) def process_values(self): self.y_values = np.array(self.y_values) if self.mode == "widths": self.widths = self.x_values self.posts = np.cumsum(self.widths) self.posts = np.insert(self.posts, 0, 0) self.posts += self.x_min self.x_max = self.posts[-1] elif self.mode == "posts": self.posts = self.x_values self.widths = self.x_values[1:] - self.x_values[:-1] self.x_min = self.posts[0] self.x_max = self.posts[-1] else: raise Exception("Invalid mode or no mode specified!") self.x_mids = 0.5 * (self.posts[:-1] + self.posts[1:]) self.widths_scaled = self.x_scale * self.widths self.posts_scaled = self.x_scale * self.posts self.x_min_scaled = self.x_scale * self.x_min self.x_max_scaled = self.x_scale * self.x_max self.y_values_scaled = self.y_scale * self.y_values def generate_points(self): self.process_values() for submob in self.submobjects: self.remove(submob) def empty_string_array(n): arr = [] for i in range(n): arr.append("") return arr def num_arr_to_string_arr(arr): ret_arr = [] for x in arr: if x == np.floor(x): new_x = int(np.floor(x)) else: new_x = x ret_arr.append(str(new_x)) return ret_arr previous_bar = ORIGIN self.bars = VGroup() self.x_labels_group = VGroup() self.y_labels_group = VGroup() outline_points = [] if self.x_labels == "widths": self.x_labels = num_arr_to_string_arr(self.widths) elif self.x_labels == "mids": self.x_labels = num_arr_to_string_arr(self.x_mids) elif self.x_labels == "auto": self.x_labels = num_arr_to_string_arr(self.x_mids) elif self.x_labels == "none": self.x_labels = empty_string_array(len(self.widths)) if self.y_labels == "auto": self.y_labels = num_arr_to_string_arr(self.y_values) elif self.y_labels == "none": self.y_labels = empty_string_array(len(self.y_values)) for (i,x) in enumerate(self.x_mids): bar = Rectangle(width = self.widths_scaled[i],height = self.y_values_scaled[i],stroke_width = self.bar_stroke_width,stroke_color = self.stroke_color,) if bar.height == 0: bar.height = 0.01 bar.generate_points() t = float(x - self.x_min)/(self.x_max - self.x_min) bar_color = interpolate_color(self.start_color,self.end_color,t) bar.set_fill(color = bar_color, opacity = 1) bar.next_to(previous_bar,RIGHT,buff = 0, aligned_edge = DOWN) self.bars.add(bar) x_label = TextMobject(self.x_labels[i]) x_label.next_to(bar,DOWN) self.x_labels_group.add(x_label) y_label = TextMobject(self.y_labels[i]) if self.y_label_position == "top": y_label.next_to(bar, UP) elif self.y_label_position == "center": y_label.move_to(bar) else: raise Exception("y_label_position must be top or center") self.y_labels_group.add(y_label) if i == 0: outline_points.append(bar.get_anchors()[-2]) outline_points.append(bar.get_anchors()[0]) outline_points.append(bar.get_anchors()[1]) previous_bar = bar outline_points.append(bar.get_anchors()[2]) outline_points.append(outline_points[0]) self.outline = Polygon(*outline_points,stroke_width = self.outline_stroke_width,stroke_color = self.stroke_color) self.add(self.bars, self.x_labels_group, self.y_labels_group, self.outline) self.move_to(ORIGIN) def get_lower_left_point(self): return self.bars[0].get_anchors()[-2] class BuildUpHistogram(Animation): def __init__(self, hist, **kwargs): self.histogram = hist class FlashThroughHistogram(Animation): CONFIG = { "cell_color" : WHITE, "cell_opacity" : 0.8, "hist_opacity" : 0.2 } def __init__(self, mobject, direction = "horizontal", mode = "random", **kwargs): digest_config(self, kwargs) self.cell_height = mobject.y_scale self.prototype_cell = Rectangle(width = 1,height = self.cell_height,fill_color = self.cell_color,fill_opacity = self.cell_opacity,stroke_width = 0,) x_values = mobject.x_values y_values = mobject.y_values self.mode = mode self.direction = direction self.generate_cell_indices(x_values,y_values) Animation.__init__(self,mobject,**kwargs) def generate_cell_indices(self,x_values,y_values): self.cell_indices = [] for (i,x) in enumerate(x_values): nb_cells = int(np.floor(y_values[i])) for j in range(nb_cells): self.cell_indices.append((i, j)) self.reordered_cell_indices = self.cell_indices if self.mode == "random": shuffle(self.reordered_cell_indices) def cell_for_index(self,i,j): if self.direction == "vertical": width = self.mobject.x_scale height = self.mobject.y_scale x = (i + 0.5) * self.mobject.x_scale y = (j + 0.5) * self.mobject.y_scale center = self.mobject.get_lower_left_point() + x * RIGHT + y * UP elif self.direction == "horizontal": width = self.mobject.x_scale / self.mobject.y_values[i] height = self.mobject.y_scale * self.mobject.y_values[i] x = i * self.mobject.x_scale + (j + 0.5) * width y = height / 2 center = self.mobject.get_lower_left_point() + x * RIGHT + y * UP cell = Rectangle(width = width, height = height) cell.move_to(center) return cell def interpolate_mobject(self,t): if t == 0: self.mobject.add(self.prototype_cell) flash_nb = int(t * (len(self.cell_indices))) - 1 (i,j) = self.reordered_cell_indices[flash_nb] cell = self.cell_for_index(i,j) self.prototype_cell.width = cell.get_width() self.prototype_cell.height = cell.get_height() self.prototype_cell.generate_points() self.prototype_cell.move_to(cell.get_center()) if t == 1: self.mobject.remove(self.prototype_cell) def clean_up_from_scene(self, scene = None): Animation.clean_up_from_scene(self, scene) self.update(1) if scene is not None: if self.is_remover(): scene.remove(self.prototype_cell) else: scene.add(self.prototype_cell) return self class OutlineableBars(VGroup): CONFIG = { "outline_stroke_width": 3, "stroke_color": WHITE } def create_outline(self, animated = False, **kwargs): outline_points = [] for (i, bar) in enumerate(self.submobjects): if i == 0: outline_points.append(bar.get_corner(DOWN + LEFT)) outline_points.append(bar.get_corner(UP + LEFT)) outline_points.append(bar.get_corner(UP + RIGHT)) previous_bar = bar outline_points.append(previous_bar.get_corner(DOWN + RIGHT)) outline_points.append(outline_points[0]) self.outline = Polygon(*outline_points,stroke_width = self.outline_stroke_width,stroke_color = self.stroke_color) if animated: self.play(FadeIn(self.outline, **kwargs)) return self.outline class test(Scene): def construct(self): self.probs = 1.0 / 6 * np.ones(6) x_scale = 1.3 y_labels = ["${1\over 6}$"] * 6 hist = Histogram(np.ones(6), self.probs, mode = "widths", x_labels = "none",y_labels = y_labels,y_label_position = "center",y_scale = 20,x_scale = x_scale,) hist.rotate(-TAU / 4) for label in hist.y_labels_group: label.rotate(TAU / 4) hist.remove(hist.y_labels_group) self.play(FadeIn(hist)) self.play(LaggedStartMap(FadeIn, hist.y_labels_group))生成した動画
https://www.youtube.com/watch?v=PT98_arbTz0
以上。
- 投稿日:2021-01-21T15:23:57+09:00
manimの作法 その26
概要
manimの作法、調べてみた。
ImageMobject使ってみた。サンプルコード
from manimlib.imports import * def shift_up(mobject): return mobject.shift(2 * UP) class test(Scene): def construct(self): square = ImageMobject('res10.png') anno = TextMobject("Show Creation") anno.shift(2 * DOWN) self.add(anno) self.play(ShowCreation(square)) self.remove(square) self.remove(anno) square = ImageMobject('res10.png') anno = TextMobject("Uncreate") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(Uncreate(square)) self.remove(square) self.remove(anno) square = ImageMobject('res10.png') circle = ImageMobject('res12.png') anno = TextMobject("Transform") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(Transform(square, circle)) square.generate_target() square.target.move_to(2 * UP) self.play(MoveToTarget(square)) self.remove(square) self.remove(circle) self.remove(anno) square = ImageMobject('res10.png') circle = ImageMobject('res12.png') anno = TextMobject("Replacement Transform") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(ReplacementTransform(square, circle)) circle.generate_target() circle.target.move_to(2 * UP) self.play(MoveToTarget(circle)) self.remove(square) self.remove(circle) self.remove(anno) square = ImageMobject('res10.png') circle = ImageMobject('res12.png') anno = TextMobject("Transform from copy") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(TransformFromCopy(square, circle)) self.remove(circle) self.wait(2) self.remove(square) self.remove(circle) self.remove(anno) square = ImageMobject('res10.png') circle = ImageMobject('res12.png') anno = TextMobject("Clockwise transform") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(ClockwiseTransform(square, circle)) self.remove(square) self.remove(circle) self.remove(anno) square = ImageMobject('res10.png') circle = ImageMobject('res12.png') anno = TextMobject("Counterclockwise transform") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(CounterclockwiseTransform(square, circle)) self.remove(square) self.remove(circle) self.remove(anno) square = ImageMobject('res10.png') square.generate_target() square.target.shift(2 * UP) anno = TextMobject("Move to target") anno.shift(2 * DOWN) self.add(square) self.play(MoveToTarget(square)) self.remove(square) self.remove(anno) square = ImageMobject('res10.png') anno = TextMobject("Apply pointwise function") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(ApplyPointwiseFunction(lambda x: 2 * x + UP, square)) self.remove(square) self.remove(anno) square = ImageMobject('res10.png') anno = TextMobject("Scale in place") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(ScaleInPlace(square, 0.5)) self.remove(square) self.remove(anno) square = ImageMobject('res10.png') anno = TextMobject("Shrink to center") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(ShrinkToCenter(square)) self.remove(square) self.remove(anno) square = ImageMobject('res10.png') anno = TextMobject("Restore") anno.shift(2 * DOWN) self.add(anno) square.save_state() circle = ImageMobject('res12.png') self.play(Transform(square, circle)) square.generate_target() square.target.shift(2 * UP) self.play(MoveToTarget(square)) self.play(Restore(square)) self.remove(square) self.remove(circle) self.remove(anno) square = ImageMobject('res10.png') anno = TextMobject("Apply Function") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(ApplyFunction(shift_up, square)) self.remove(square) self.remove(anno) mat = [[1.0, 0.5], [1.0, 0.0]] square = ImageMobject('res10.png') anno = TextMobject("Apply Matrix") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(ApplyMatrix(mat, square)) self.remove(square) self.remove(anno) square = ImageMobject('res10.png') anno = TextMobject("Apply Complex Function") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(ApplyComplexFunction(lambda complex_num: complex_num + 2 * np.complex(0, 1), square)) self.remove(square) self.remove(anno) square = ImageMobject('res10.png') circle = Circle() circle.shift(2 * UP + 2 * RIGHT) triangle = Triangle() triangle.shift(2 * UP + 2 * LEFT) anno = TextMobject("Cyclic Replace") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.add(circle) self.add(triangle) self.play(CyclicReplace(square, circle, triangle)) self.remove(square) self.remove(circle) self.remove(triangle) self.remove(anno) square = ImageMobject('res10.png') anno = TextMobject("Fade In") anno.shift(2 * DOWN) self.add(anno) self.play(FadeIn(square)) self.remove(square) self.remove(anno) square = ImageMobject('res10.png') anno = TextMobject("Fade Out") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(FadeOut(square)) self.remove(square) self.remove(anno) square = ImageMobject('res10.png') for label, edge in zip(["LEFT", "RIGHT", "UP", "DOWN"], [LEFT, RIGHT, UP, DOWN]): anno = TextMobject(f"Fade In from {label}") anno.shift(2 * DOWN) self.add(anno) self.play(FadeInFrom(square, edge)) self.remove(anno, square) square = ImageMobject('res10.png') for label, edge in zip(["LEFT", "RIGHT", "UP", "DOWN"], [LEFT, RIGHT, UP, DOWN]): anno = TextMobject(f"Fade Out and shift {label}") anno.shift(2 * DOWN) self.add(anno) self.play(FadeOutAndShift(square, edge)) self.remove(anno, square) square = ImageMobject('res10.png') for factor in [0.1, 0.5, 0.8, 1, 2, 5]: anno = TextMobject(f"Fade In from large scale\_factor={factor}") anno.shift(2 * DOWN) self.add(anno) self.play(FadeInFromLarge(square, scale_factor = factor)) self.remove(anno, square) square = ImageMobject('res10.png') for i in range(-6, 7, 2): anno = TextMobject(f"Fade In from point {i}") anno.shift(2 * DOWN) self.add(anno) self.play(FadeInFromPoint(square, point = i)) self.remove(anno, square) for label, edge in zip(["LEFT", "RIGHT", "UP", "DOWN"], [LEFT, RIGHT, UP, DOWN]): anno = TextMobject(f"Grow from {label} edge") anno.shift(2 * DOWN) self.add(anno) square = ImageMobject('res10.png') self.play(GrowFromEdge(square, edge)) self.remove(anno, square) square = ImageMobject('res10.png') anno = TextMobject("Grow from center") anno.shift(2 * DOWN) self.add(anno) self.play(GrowFromCenter(square)) self.remove(square) self.remove(anno) square = ImageMobject('res10.png') for diag in [UP + LEFT, UP + RIGHT, DOWN + LEFT, DOWN + RIGHT]: self.play(FadeInFrom(square, diag)) self.remove(square)生成した動画
https://www.youtube.com/watch?v=n9GjXkZ9rlA
以上。
- 投稿日:2021-01-21T15:20:57+09:00
manimの作法 その25
概要
manimの作法、調べてみた。
animation、全部使ってみた。サンプルコード
from manimlib.imports import * def shift_up(mobject): return mobject.shift(2 * UP) class CustomSquare(Square): def custom_method(self, color): self.set_color(color) self.shift(2 * UP) return self class test(Scene): def construct(self): square = Square() anno = TextMobject("Show Creation") anno.shift(2 * DOWN) self.add(anno) self.play(ShowCreation(square)) self.remove(square) self.remove(anno) square = Square() anno = TextMobject("Uncreate") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(Uncreate(square)) self.remove(square) self.remove(anno) square = Square(fill_opacity = 1.0) anno = TextMobject("Draw border then fill") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(DrawBorderThenFill(square)) self.remove(square) self.remove(anno) text = TextMobject("Hello World") anno = TextMobject("Write") anno.shift(2 * DOWN) self.add(anno) self.play(Write(text)) self.remove(text) self.remove(anno) points = [] for x in range(-5, 6): points.append(Dot(point = np.array([x, 0.0, 0.0]))) group = VGroup(*points) anno = TextMobject("Show submobjects") anno.shift(2 * DOWN) self.add(anno) self.play(ShowIncreasingSubsets(group, run_time = 3.0)) self.remove(group) self.remove(anno) points = [] for x in range(-5, 6): points.append(Dot(point = np.array([x, 0.0, 0.0]))) group = VGroup(*points) anno = TextMobject("Show submobjects one by one") anno.shift(2 * DOWN) self.add(anno) self.play(ShowSubmobjectsOneByOne(group, run_time = 3.0)) self.remove(group) self.remove(anno) square = Square() circle = Circle() anno = TextMobject("Transform") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(Transform(square, circle)) square.generate_target() square.target.move_to(2 * UP) self.play(MoveToTarget(square)) self.remove(square) self.remove(circle) self.remove(anno) square = Square() circle = Circle() anno = TextMobject("Replacement Transform") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(ReplacementTransform(square, circle)) circle.generate_target() circle.target.move_to(2 * UP) self.play(MoveToTarget(circle)) self.remove(square) self.remove(circle) self.remove(anno) square = Square() circle = Circle() anno = TextMobject("Transform from copy") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(TransformFromCopy(square, circle)) self.remove(circle) self.wait(2) self.remove(square) self.remove(circle) self.remove(anno) square = Square() circle = Circle() anno = TextMobject("Clockwise transform") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(ClockwiseTransform(square, circle)) self.remove(square) self.remove(circle) self.remove(anno) square = Square() circle = Circle() anno = TextMobject("Counterclockwise transform") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(CounterclockwiseTransform(square, circle)) self.remove(square) self.remove(circle) self.remove(anno) square = Square() square.generate_target() square.target.shift(2 * UP) anno = TextMobject("Move to target") anno.shift(2 * DOWN) self.add(square) self.play(MoveToTarget(square)) self.remove(square) self.remove(anno) square = CustomSquare() anno = TextMobject("Apply method") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(ApplyMethod(square.custom_method, RED)) self.remove(square) self.remove(anno) square = Square() anno = TextMobject("Apply pointwise function") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(ApplyPointwiseFunction(lambda x: 2 * x + UP, square)) self.remove(square) self.remove(anno) square = Square(fill_opacity = 1) anno = TextMobject("Fade to color") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(FadeToColor(square, RED)) self.remove(square) self.remove(anno) square = Square() anno = TextMobject("Scale in place") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(ScaleInPlace(square, 0.5)) self.remove(square) self.remove(anno) square = Square() anno = TextMobject("Shrink to center") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(ShrinkToCenter(square)) self.remove(square) self.remove(anno) square = Square() anno = TextMobject("Restore") anno.shift(2 * DOWN) self.add(anno) square.save_state() circle = Circle() self.play(Transform(square, circle)) square.generate_target() square.target.shift(2 * UP) self.play(MoveToTarget(square)) self.play(Restore(square)) self.remove(square) self.remove(circle) self.remove(anno) square = Square() anno = TextMobject("Apply Function") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(ApplyFunction(shift_up, square)) self.remove(square) self.remove(anno) mat = [[1.0, 0.5], [1.0, 0.0]] square = Square() anno = TextMobject("Apply Matrix") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(ApplyMatrix(mat, square)) self.remove(square) self.remove(anno) square = Square() anno = TextMobject("Apply Complex Function") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(ApplyComplexFunction(lambda complex_num: complex_num + 2 * np.complex(0, 1), square)) self.remove(square) self.remove(anno) square = Square() circle = Circle() circle.shift(2 * UP + 2 * RIGHT) triangle = Triangle() triangle.shift(2 * UP + 2 * LEFT) anno = TextMobject("Cyclic Replace") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.add(circle) self.add(triangle) self.play(CyclicReplace(square, circle, triangle)) self.remove(square) self.remove(circle) self.remove(triangle) self.remove(anno) square = Square() anno = TextMobject("Fade In") anno.shift(2 * DOWN) self.add(anno) self.play(FadeIn(square)) self.remove(square) self.remove(anno) square = Square() anno = TextMobject("Fade Out") anno.shift(2 * DOWN) self.add(anno) self.add(square) self.play(FadeOut(square)) self.remove(square) self.remove(anno) square = Square() for label, edge in zip(["LEFT", "RIGHT", "UP", "DOWN"], [LEFT, RIGHT, UP, DOWN]): anno = TextMobject(f"Fade In from {label}") anno.shift(2 * DOWN) self.add(anno) self.play(FadeInFrom(square, edge)) self.remove(anno, square) square = Square() for label, edge in zip(["LEFT", "RIGHT", "UP", "DOWN"], [LEFT, RIGHT, UP, DOWN]): anno = TextMobject(f"Fade Out and shift {label}") anno.shift(2 * DOWN) self.add(anno) self.play(FadeOutAndShift(square, edge)) self.remove(anno, square) square = Square() for factor in [0.1, 0.5, 0.8, 1, 2, 5]: anno = TextMobject(f"Fade In from large scale\_factor={factor}") anno.shift(2 * DOWN) self.add(anno) self.play(FadeInFromLarge(square, scale_factor = factor)) self.remove(anno, square) square = Square() for i in range(-6, 7, 2): anno = TextMobject(f"Fade In from point {i}") anno.shift(2 * DOWN) self.add(anno) self.play(FadeInFromPoint(square, point = i)) self.remove(anno, square) for label, edge in zip(["LEFT", "RIGHT", "UP", "DOWN"], [LEFT, RIGHT, UP, DOWN]): anno = TextMobject(f"Grow from {label} edge") anno.shift(2 * DOWN) self.add(anno) square = Square() self.play(GrowFromEdge(square, edge)) self.remove(anno, square) square = Square() anno = TextMobject("Grow from center") anno.shift(2 * DOWN) self.add(anno) self.play(GrowFromCenter(square)) self.remove(square) self.remove(anno) square = Square() for diag in [UP + LEFT, UP + RIGHT, DOWN + LEFT, DOWN + RIGHT]: self.play(FadeInFrom(square, diag)) self.remove(square) text = TextMobject(r"Hello World !\\This should be written word by word.") anno = TextMobject("Add text word by word") anno.shift(2 * DOWN) self.add(anno) self.play(AddTextWordByWord(text, run_time = 5.0)) self.remove(text) self.remove(anno)生成した動画
https://www.youtube.com/watch?v=dkqdqlS73dU
以上。
- 投稿日:2021-01-21T15:17:27+09:00
manimの作法 その24
概要
manimの作法、調べてみた。
TextMobject使ってみた。サンプルコード
from manimlib.imports import * class test(Scene): def construct(self): first_line = TextMobject('hello') second_line = TextMobject('world') third_line = TextMobject('nice', color = RED) second_line.next_to(first_line, DOWN) self.wait(1) self.play(Write(first_line), Write(second_line)) self.wait(1) self.play(ReplacementTransform(first_line, third_line), FadeOut(second_line)) self.wait(2)生成した動画
https://www.youtube.com/watch?v=mg32_XbyawA
以上。
- 投稿日:2021-01-21T14:55:25+09:00
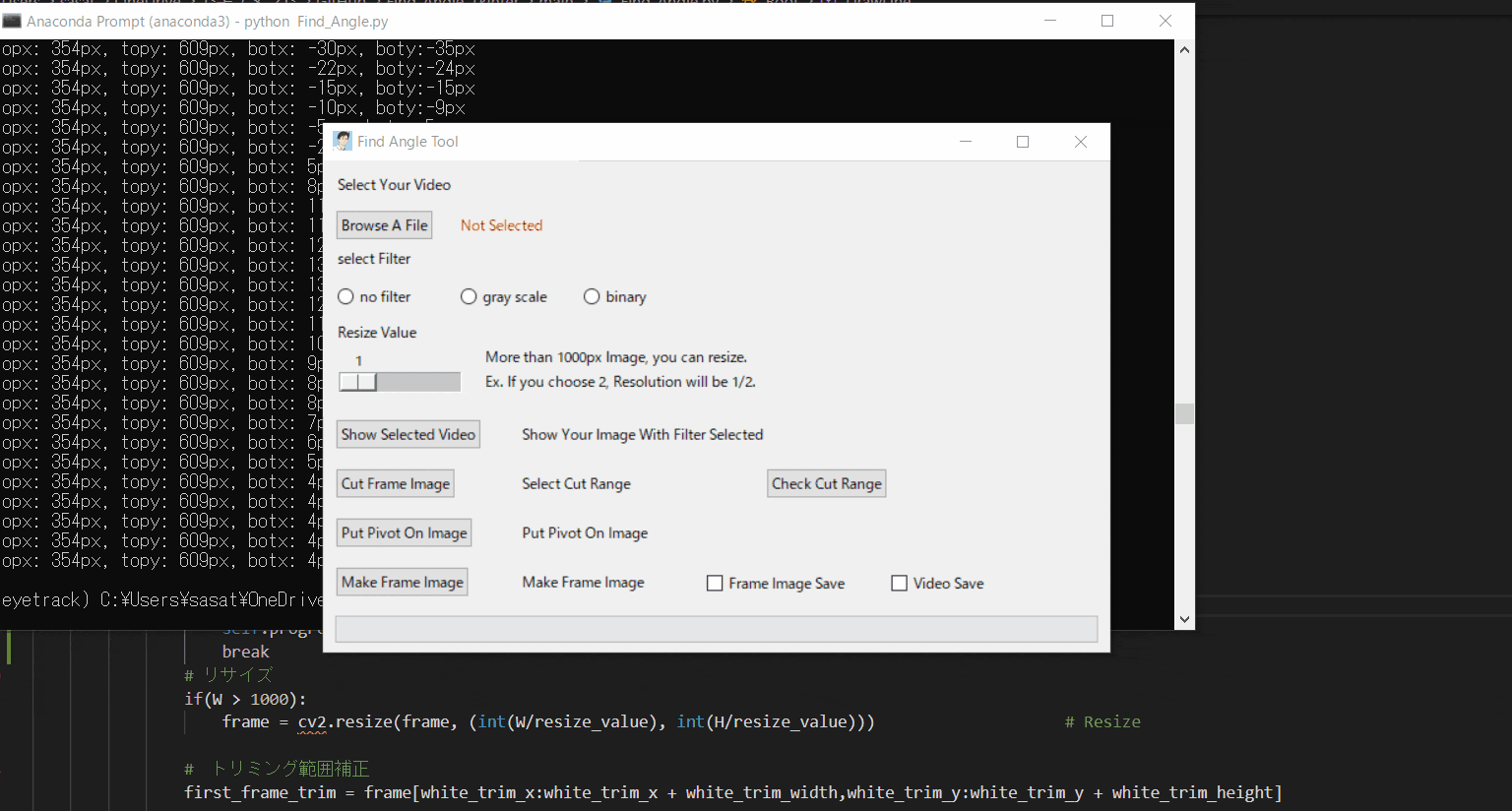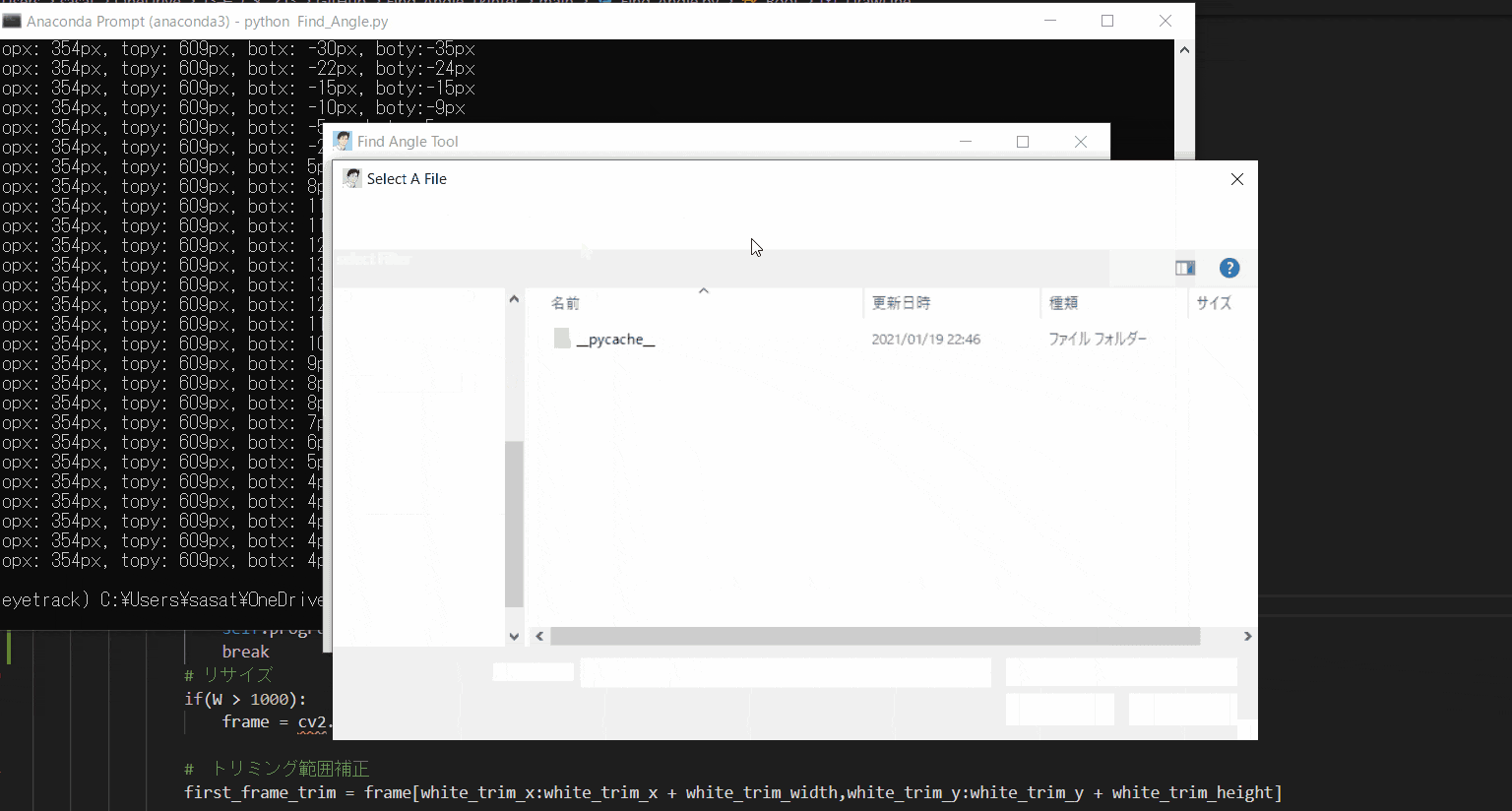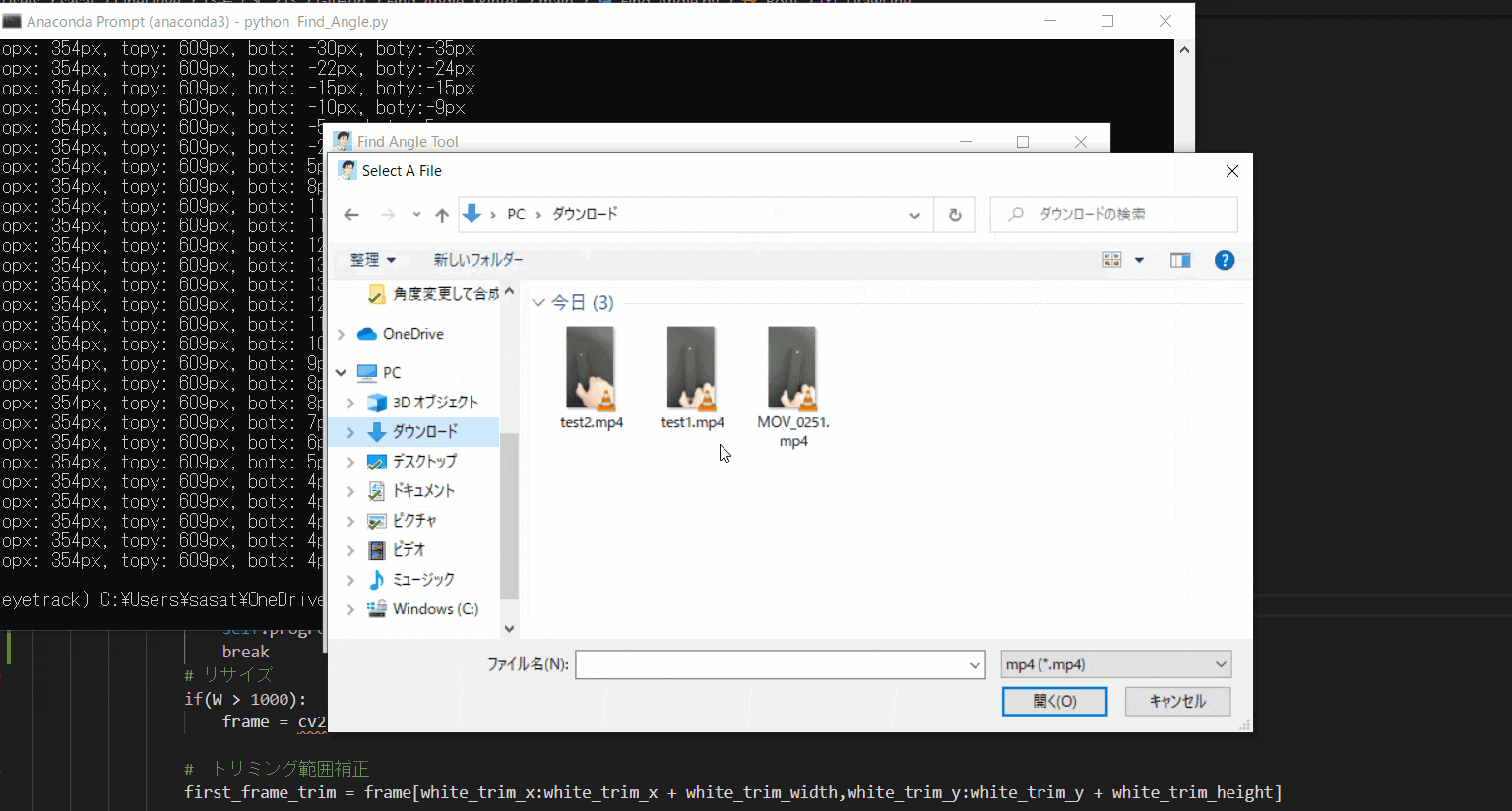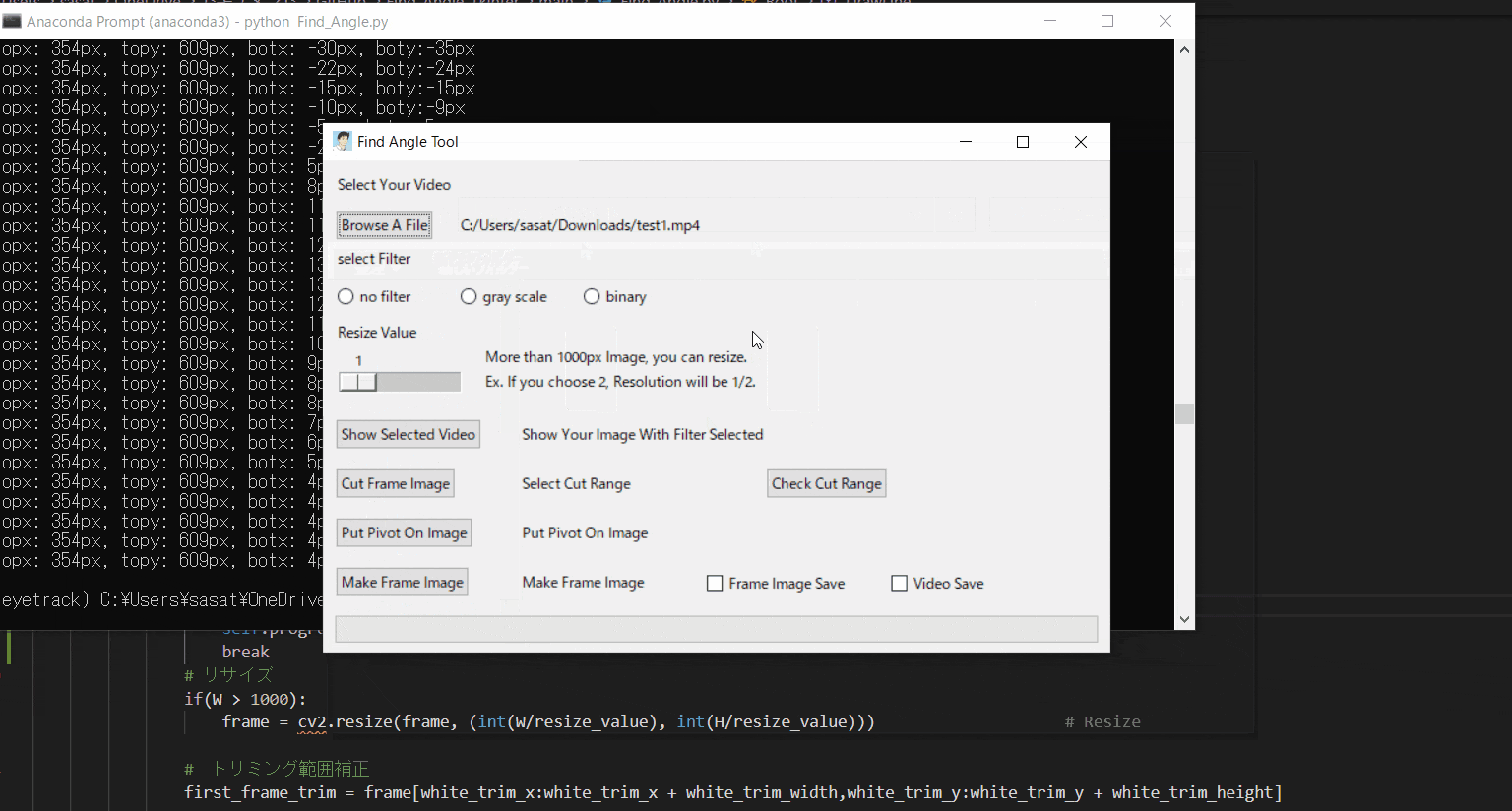
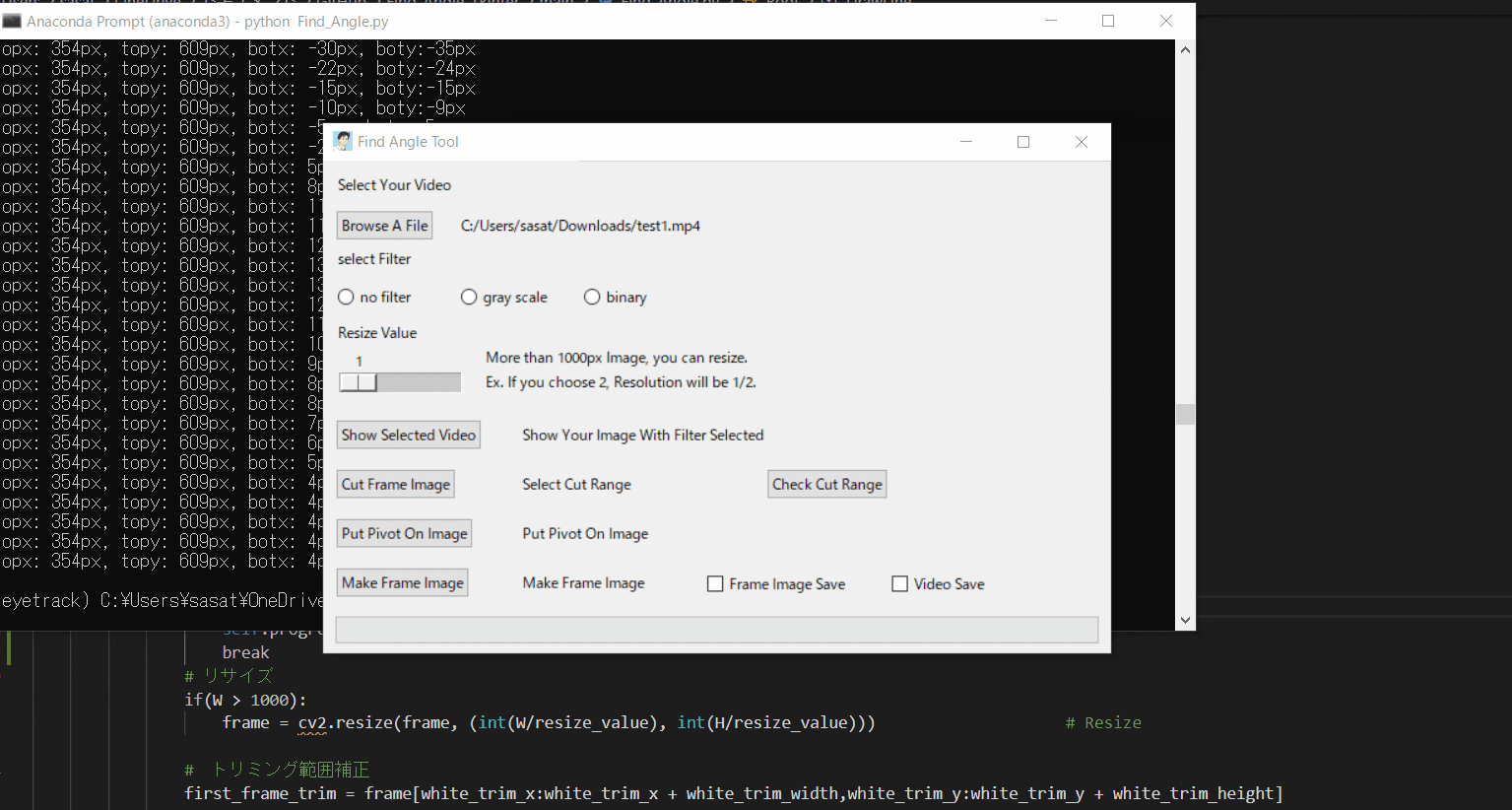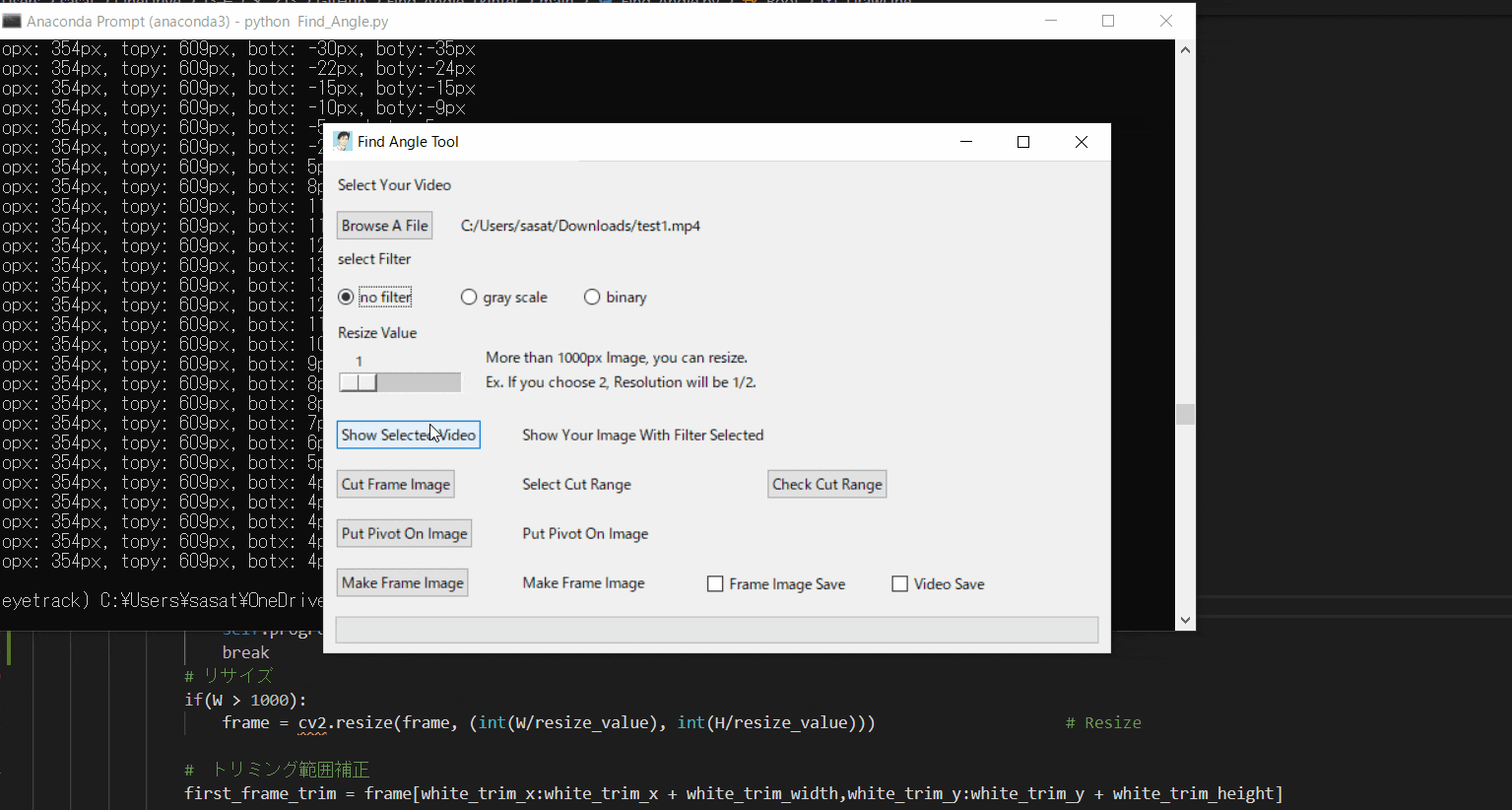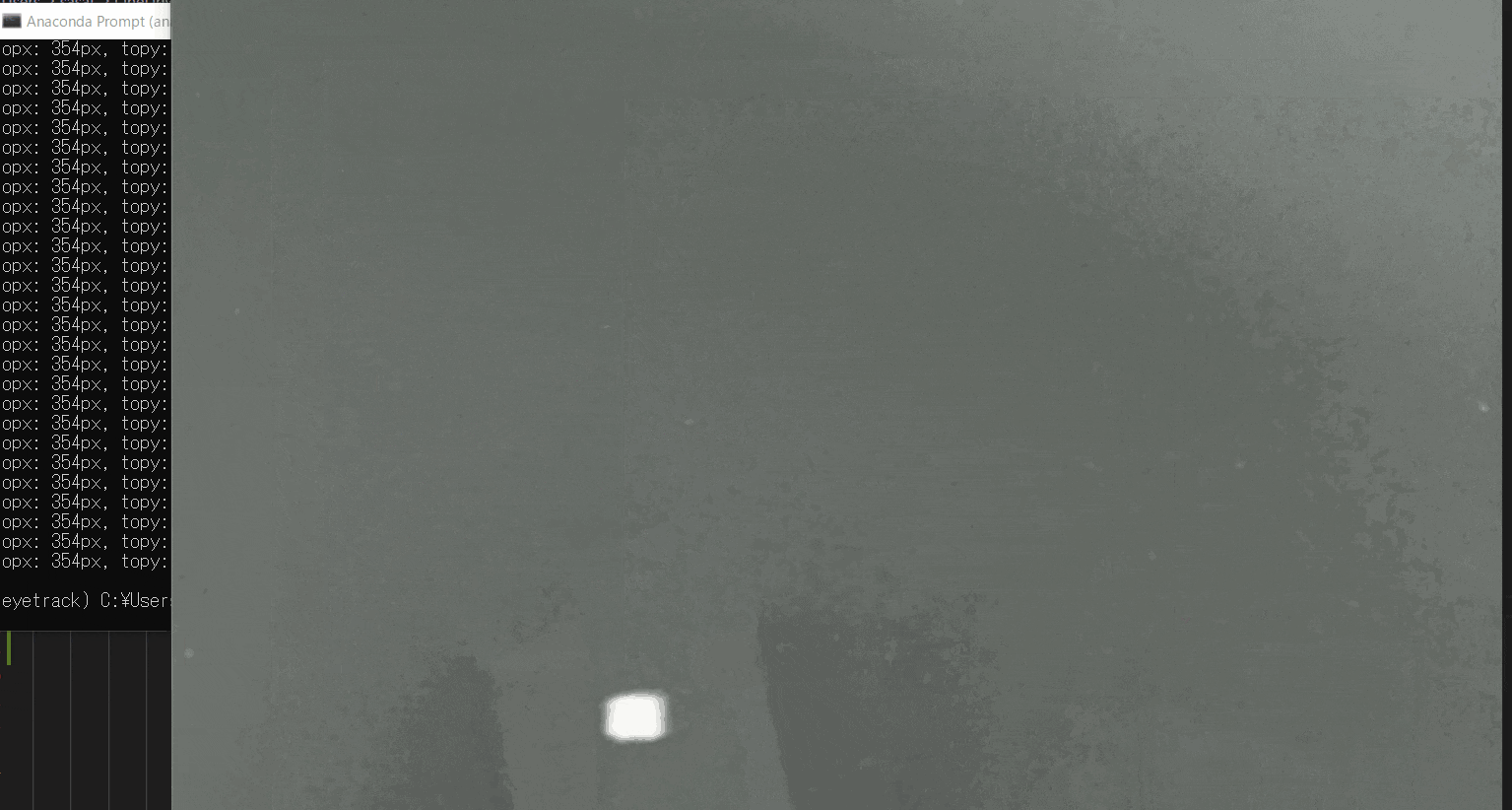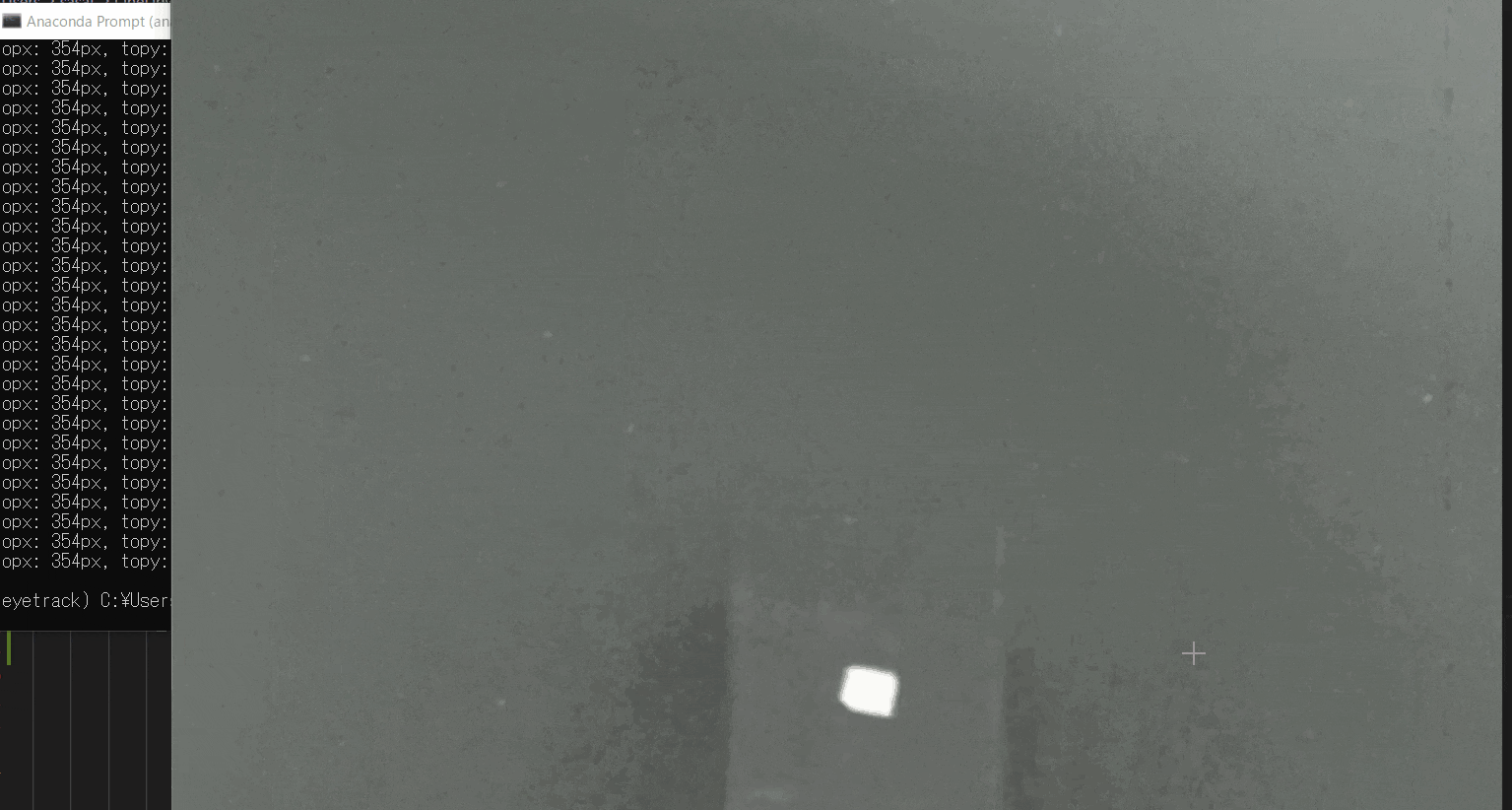
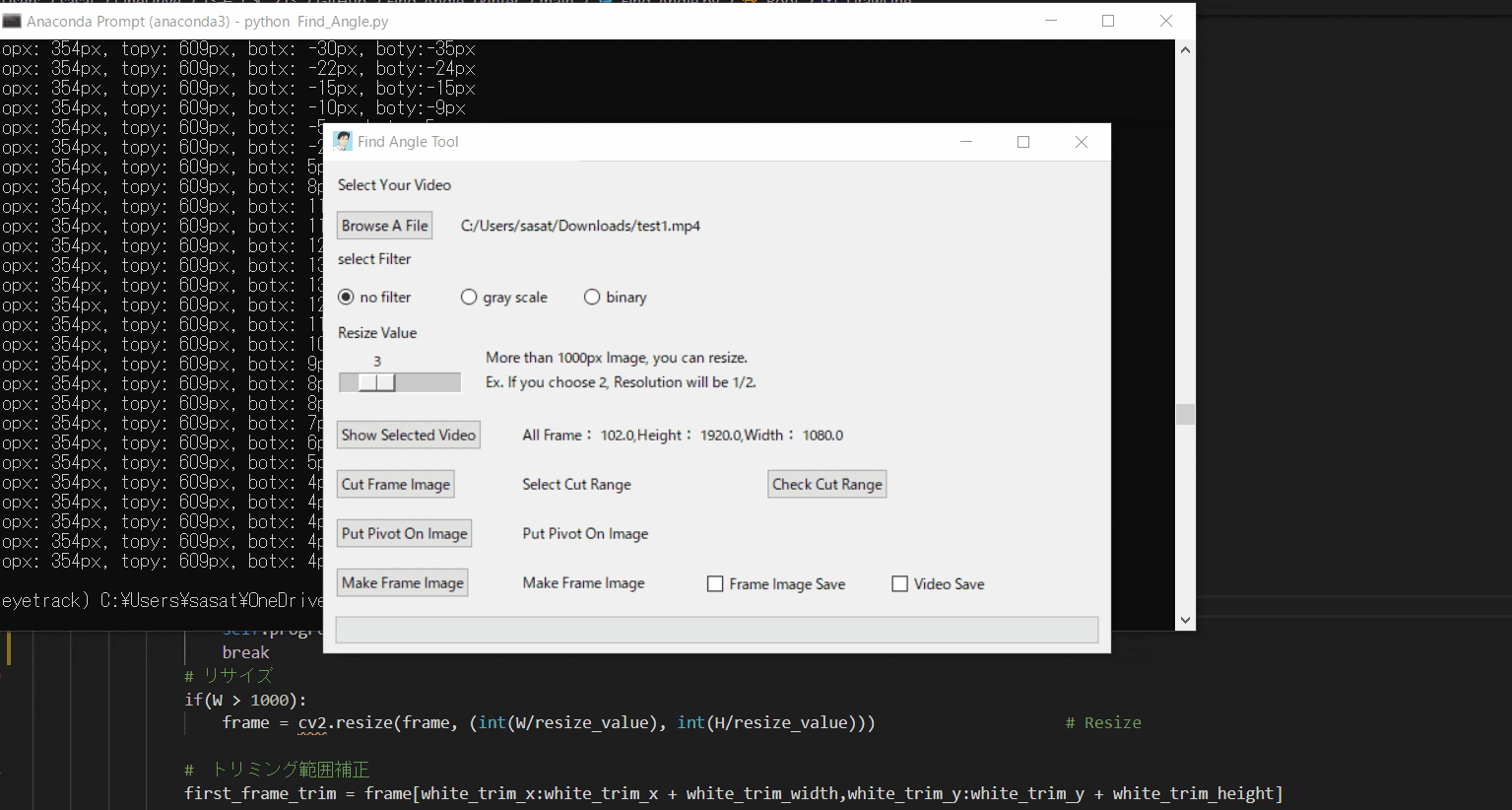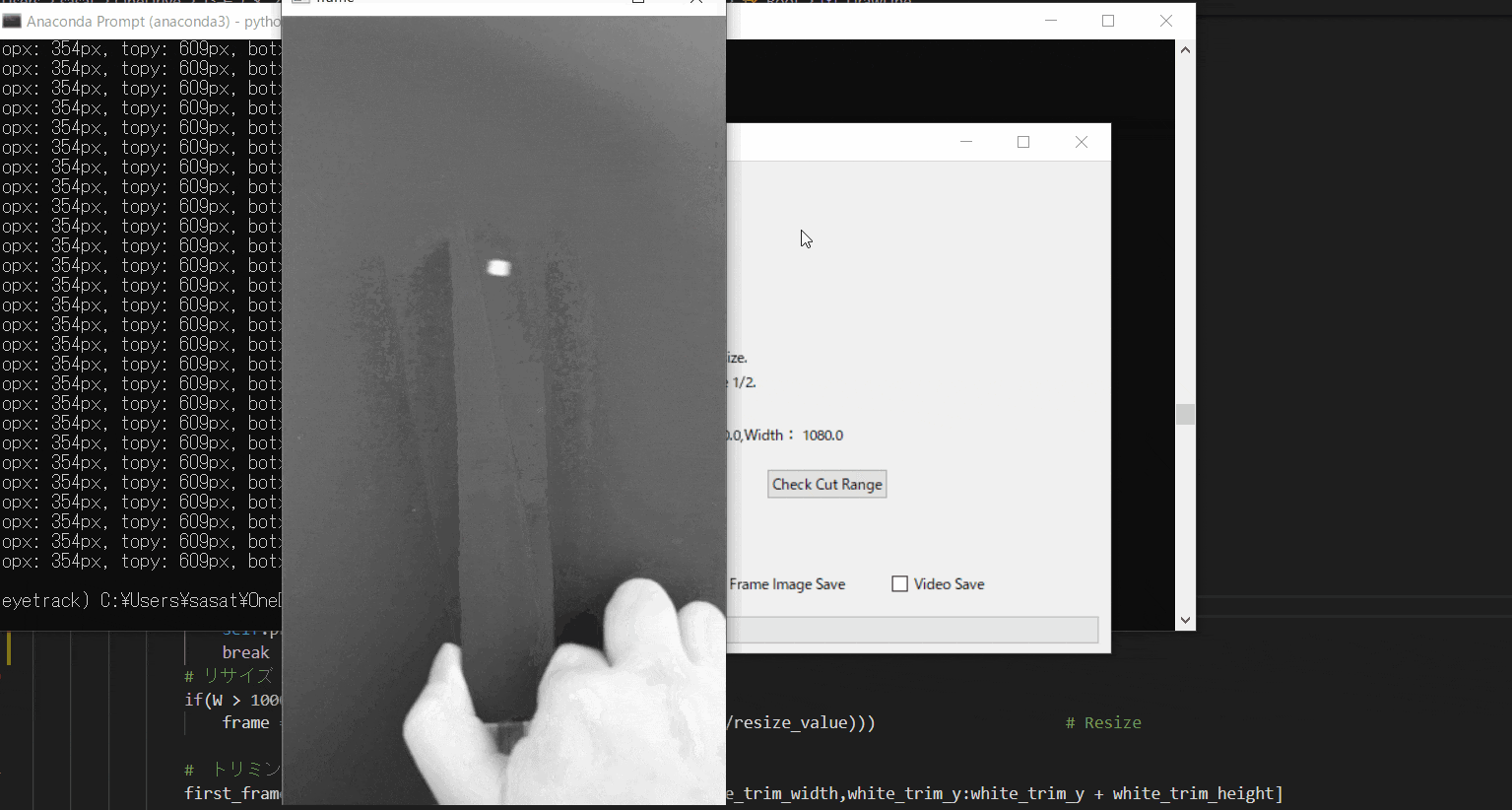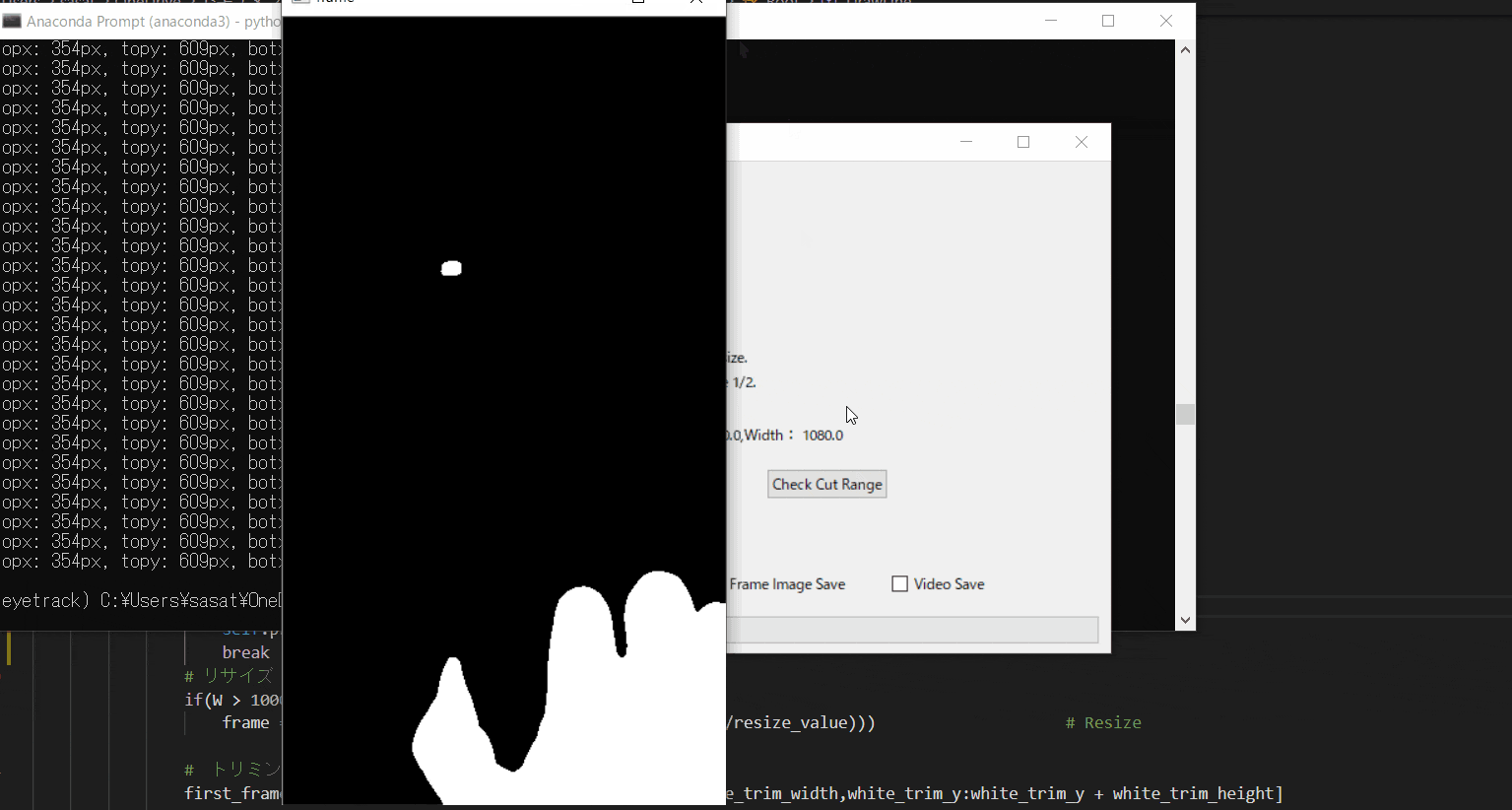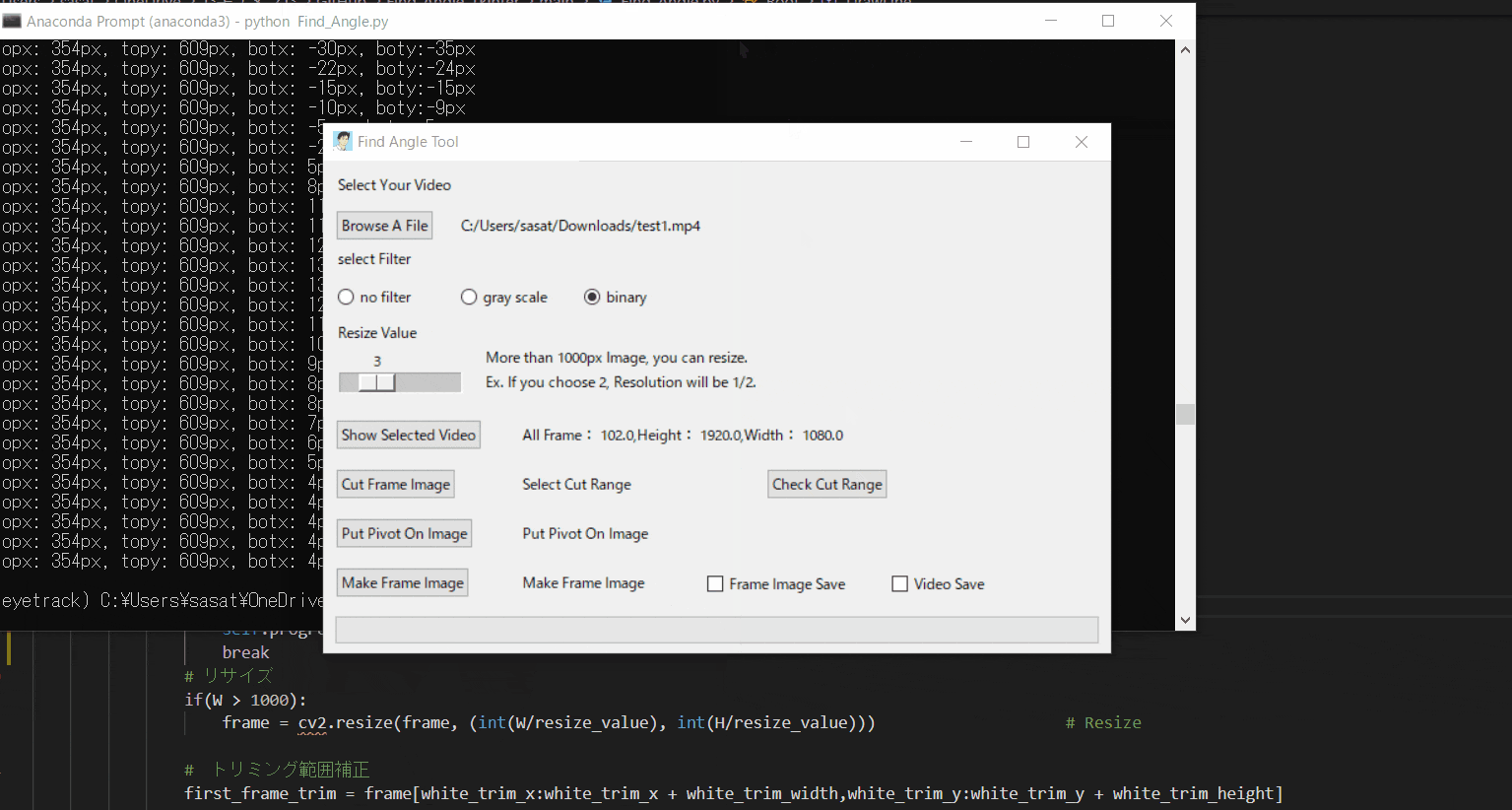
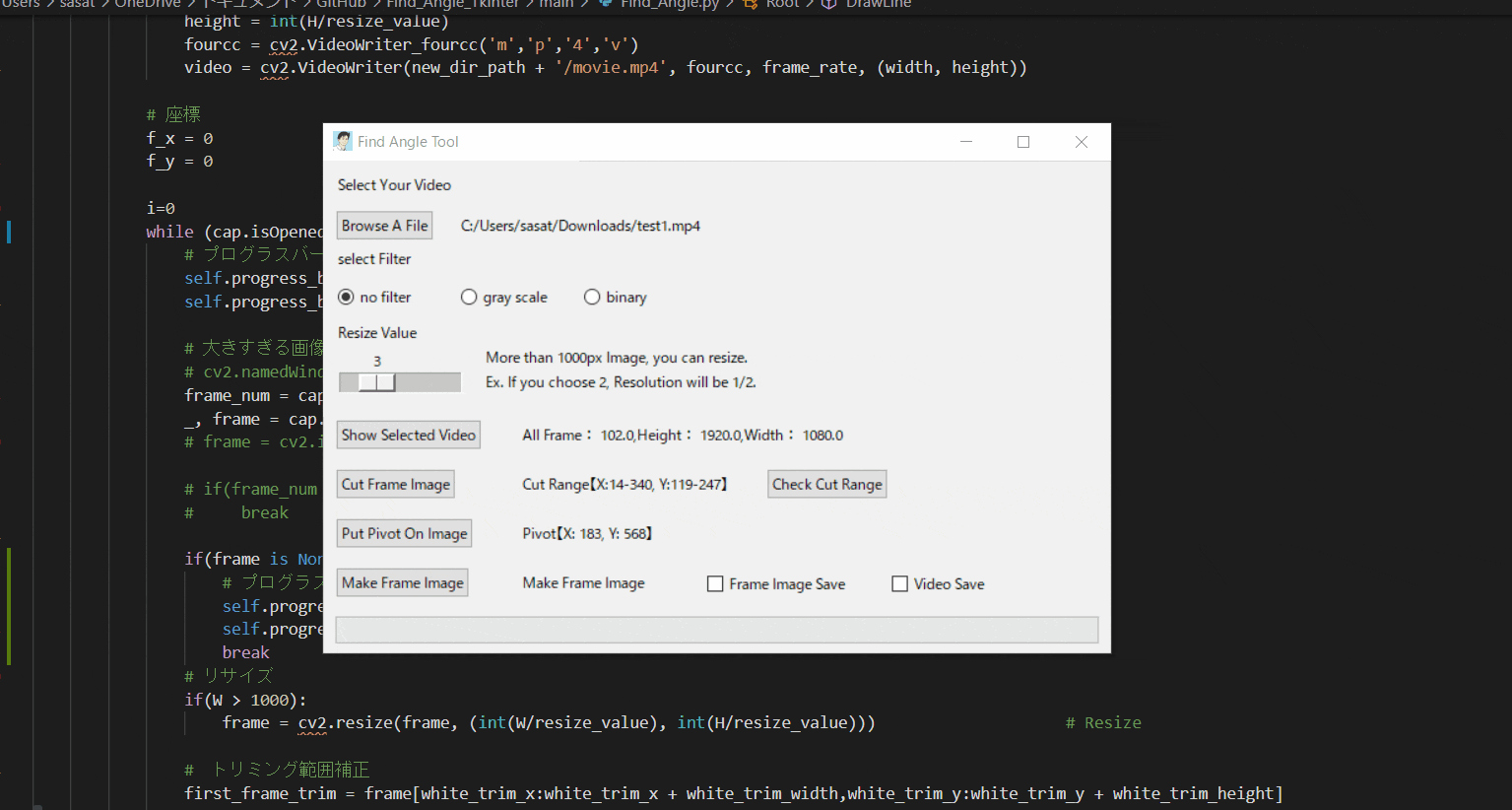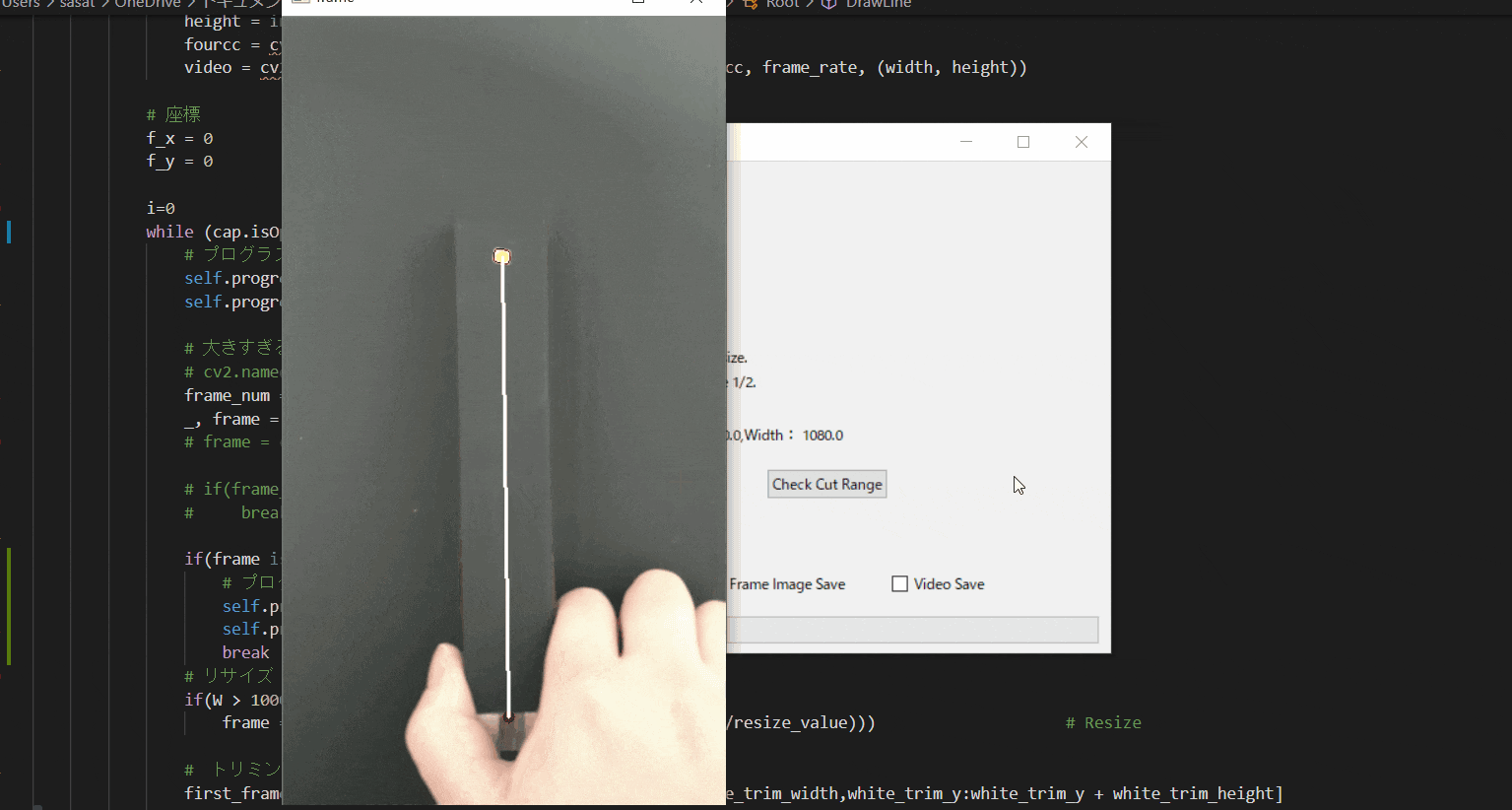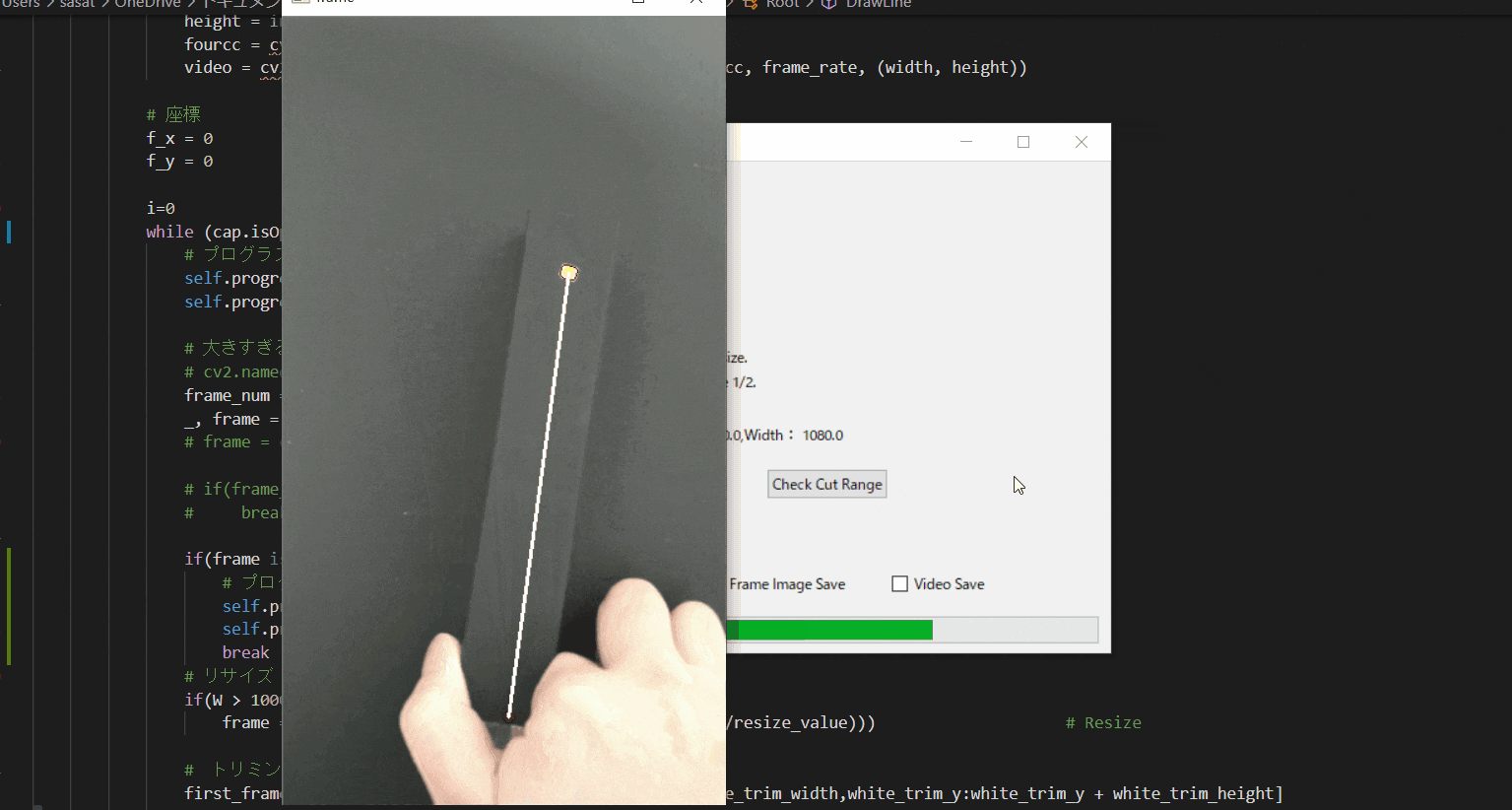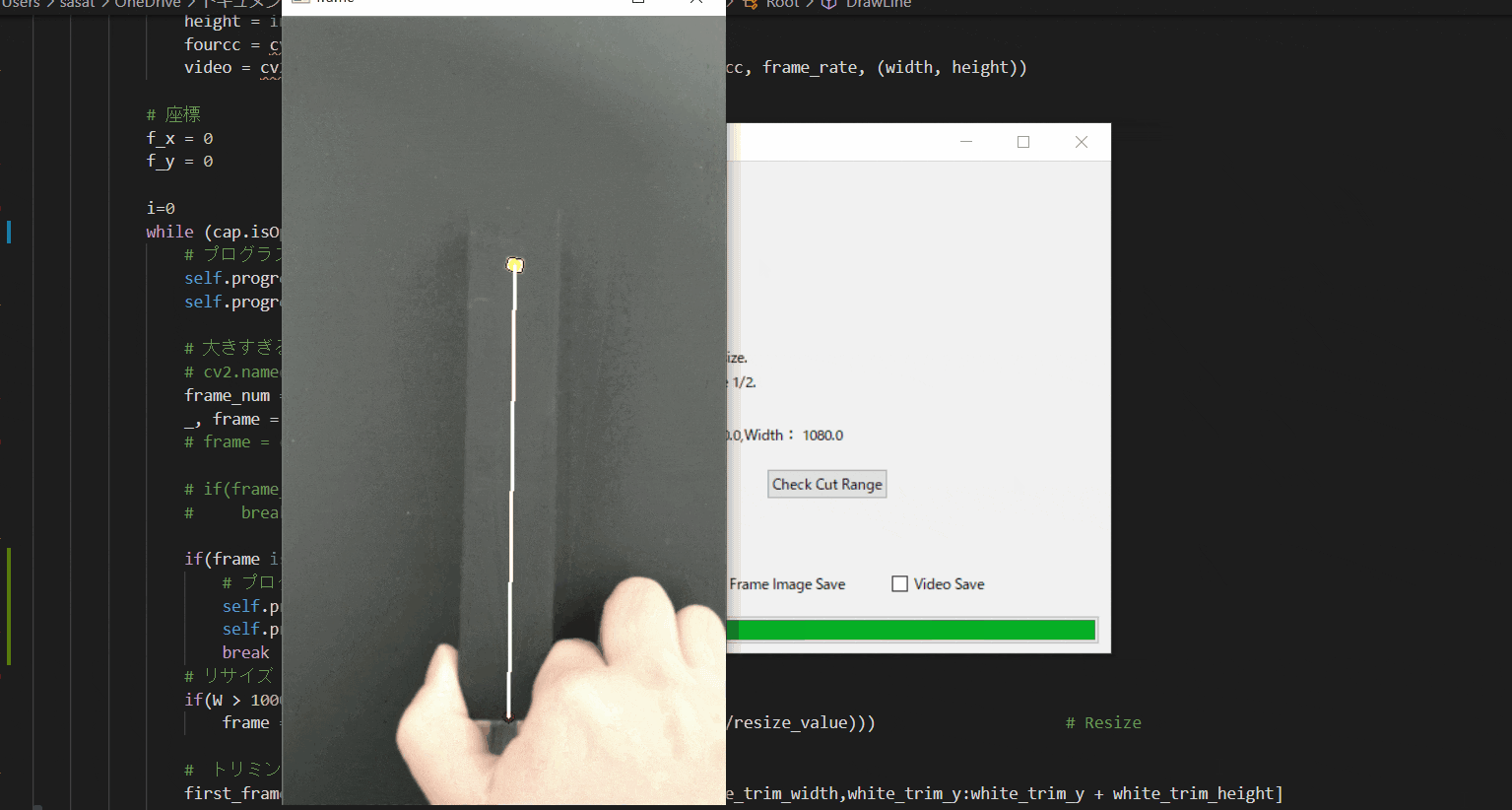
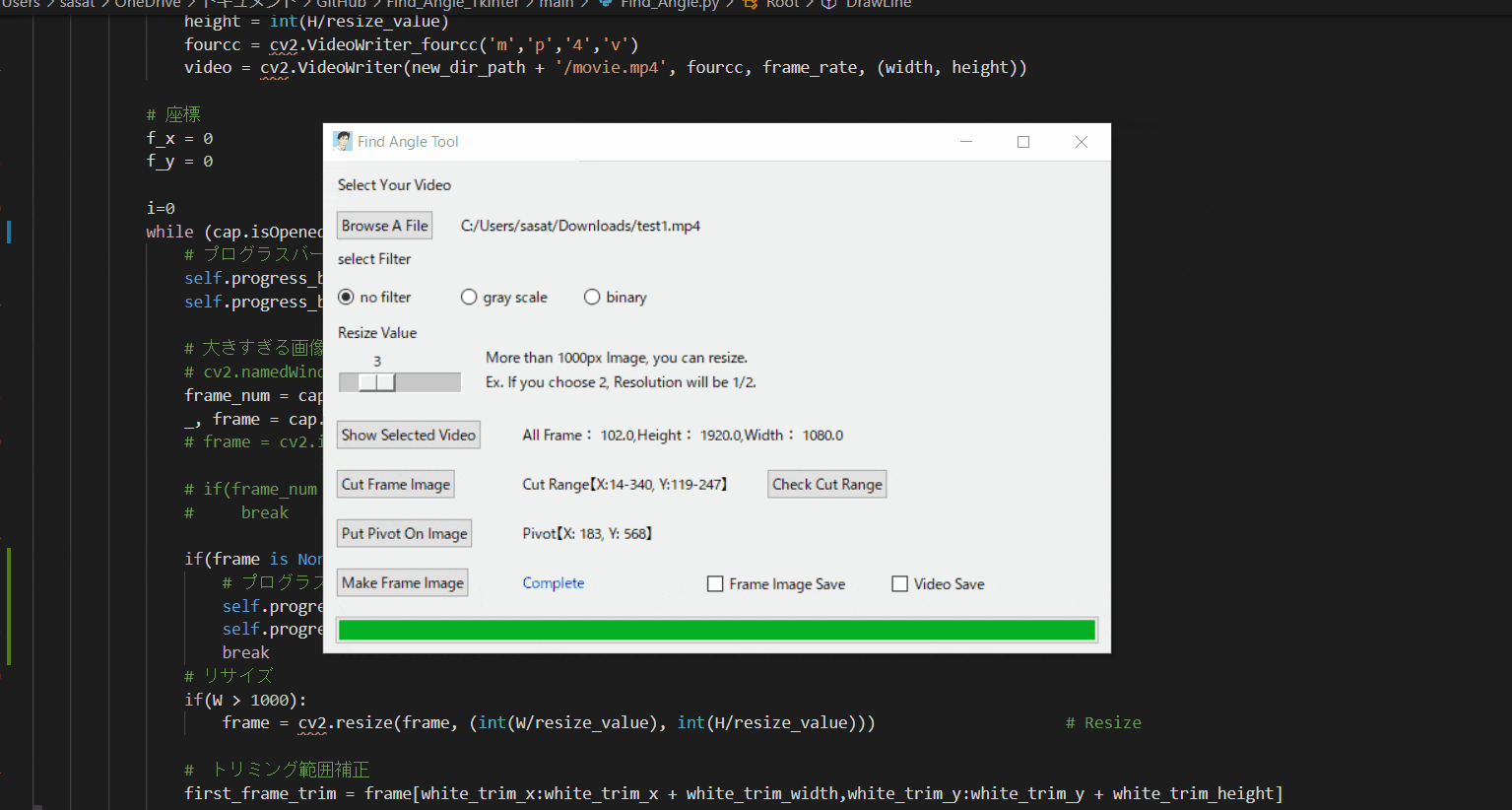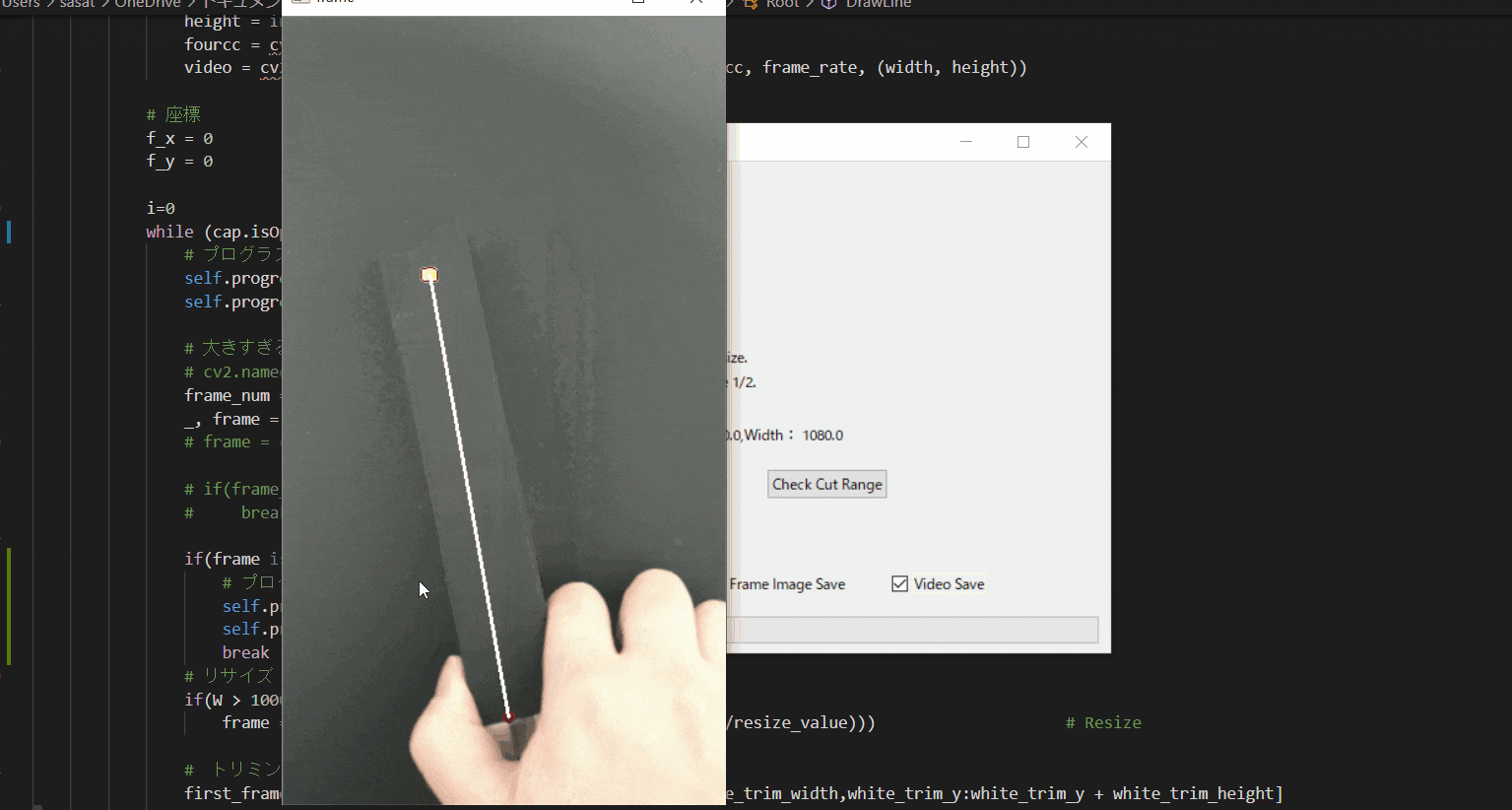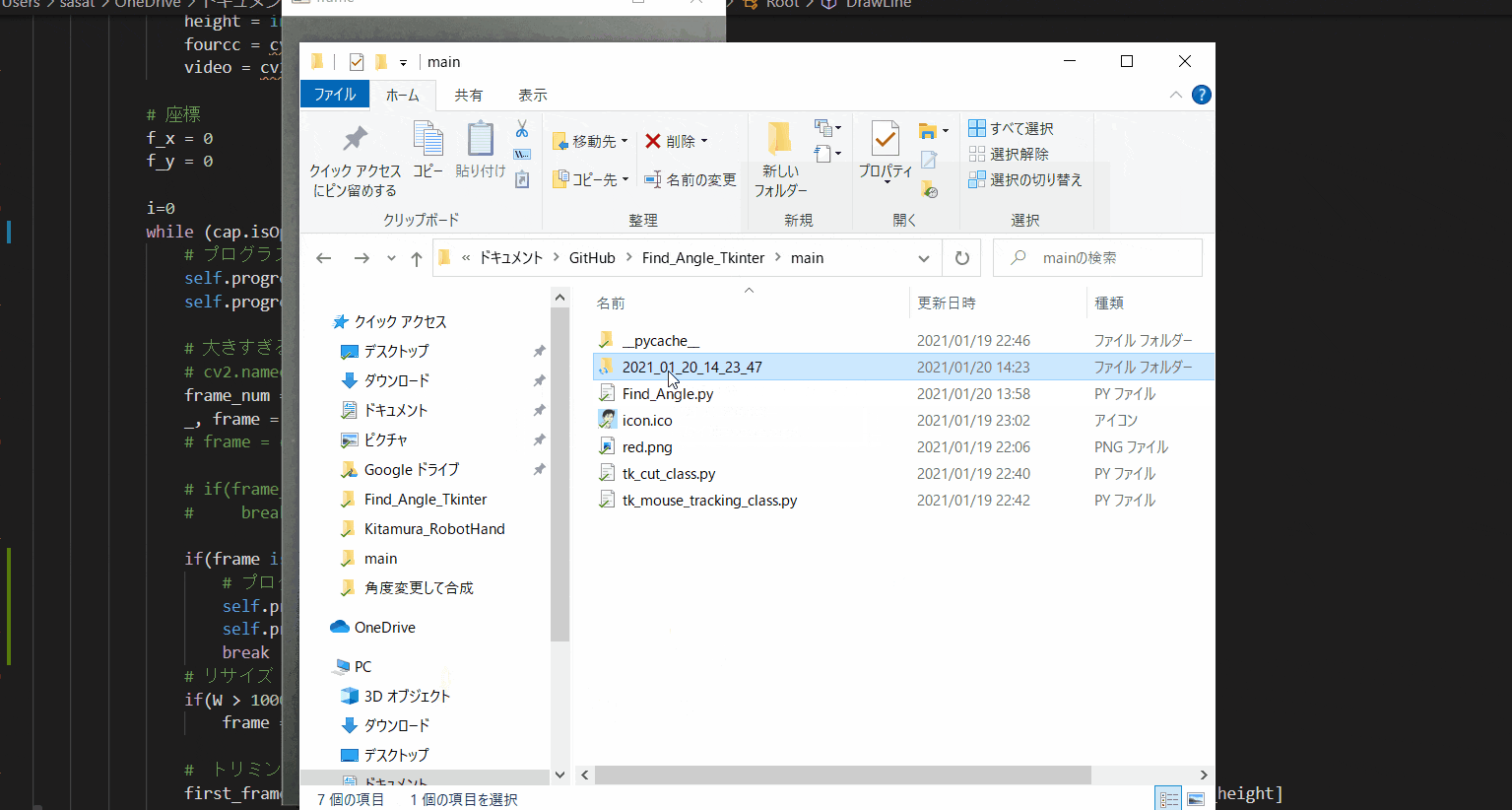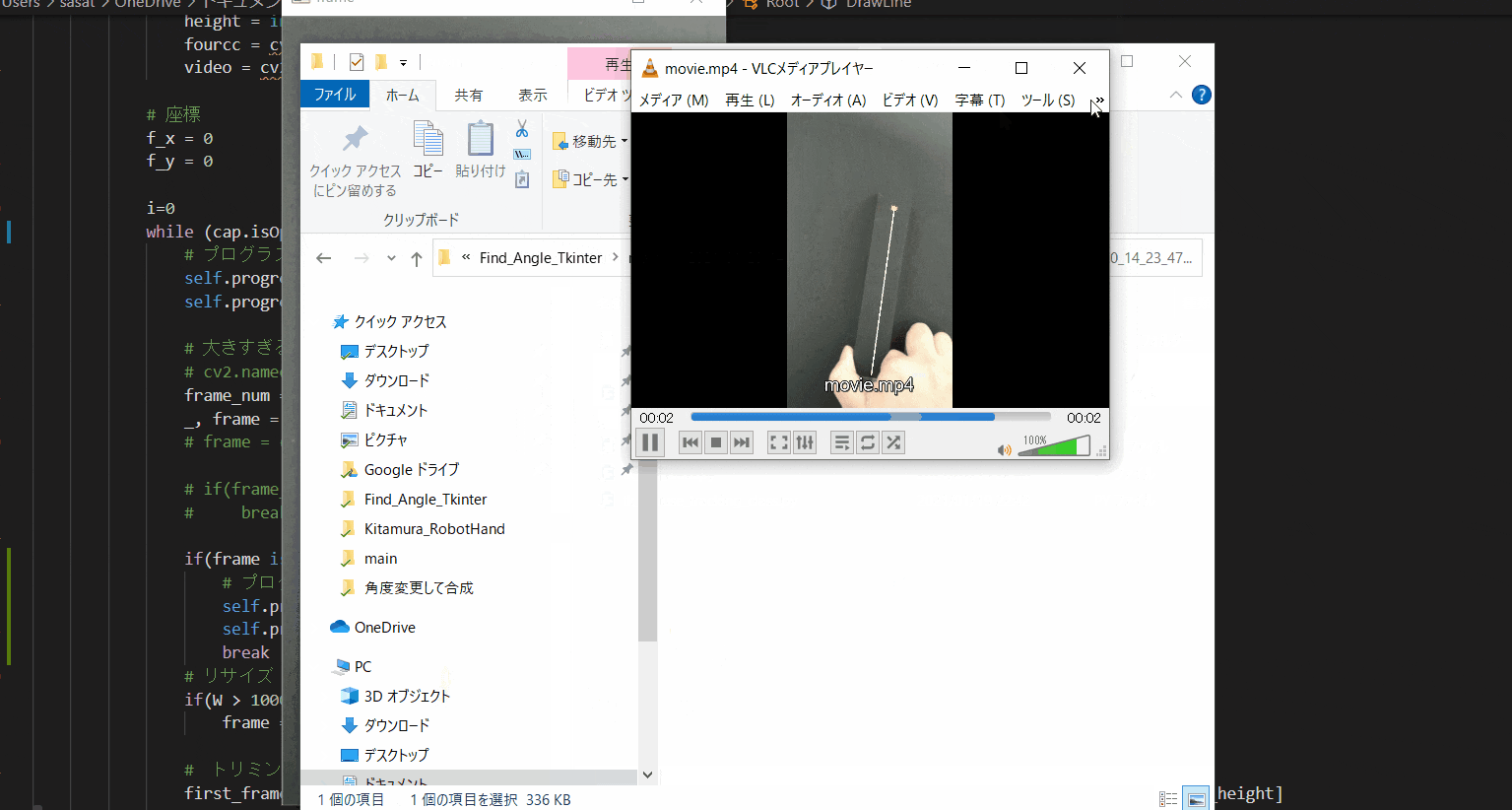
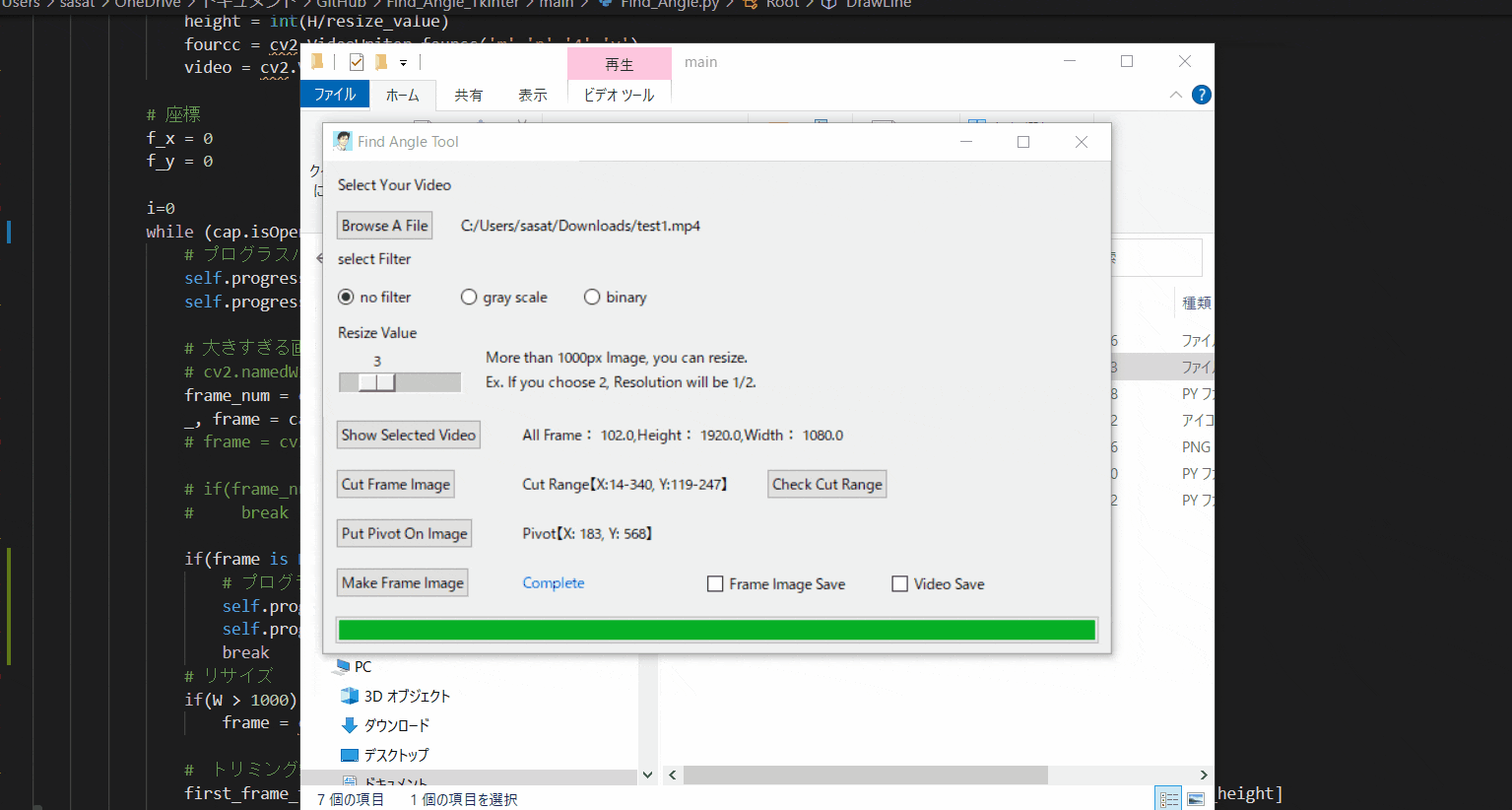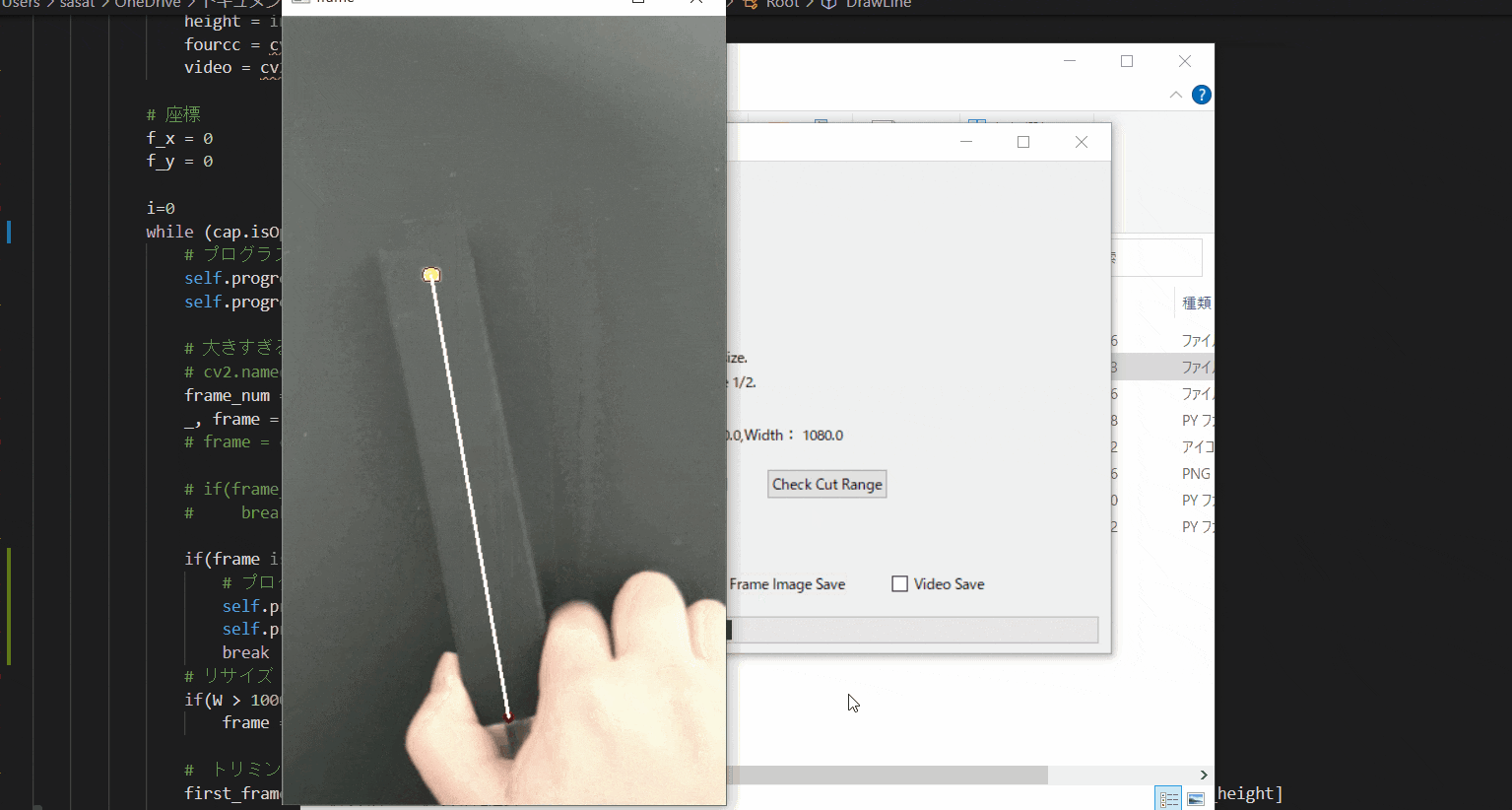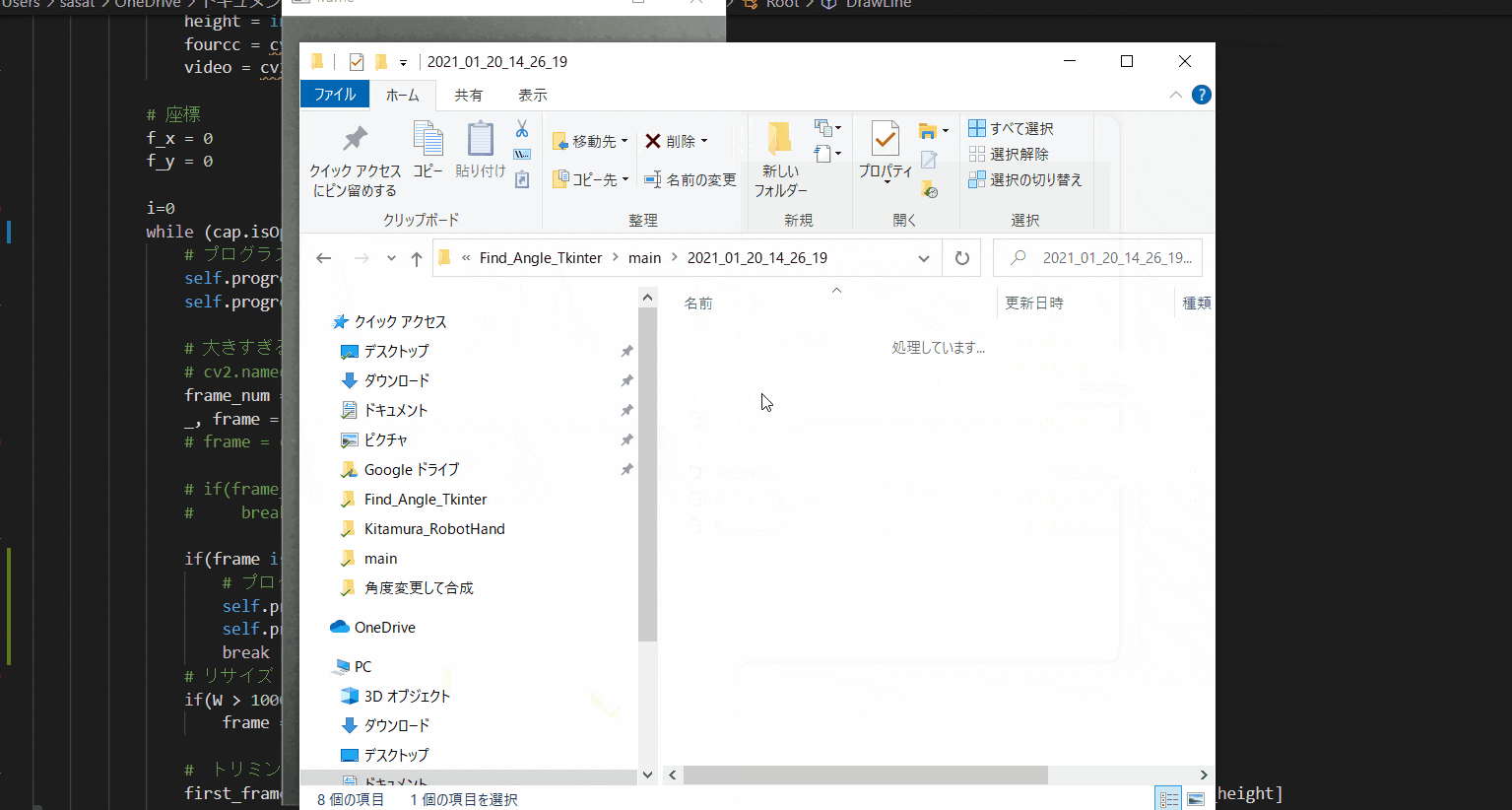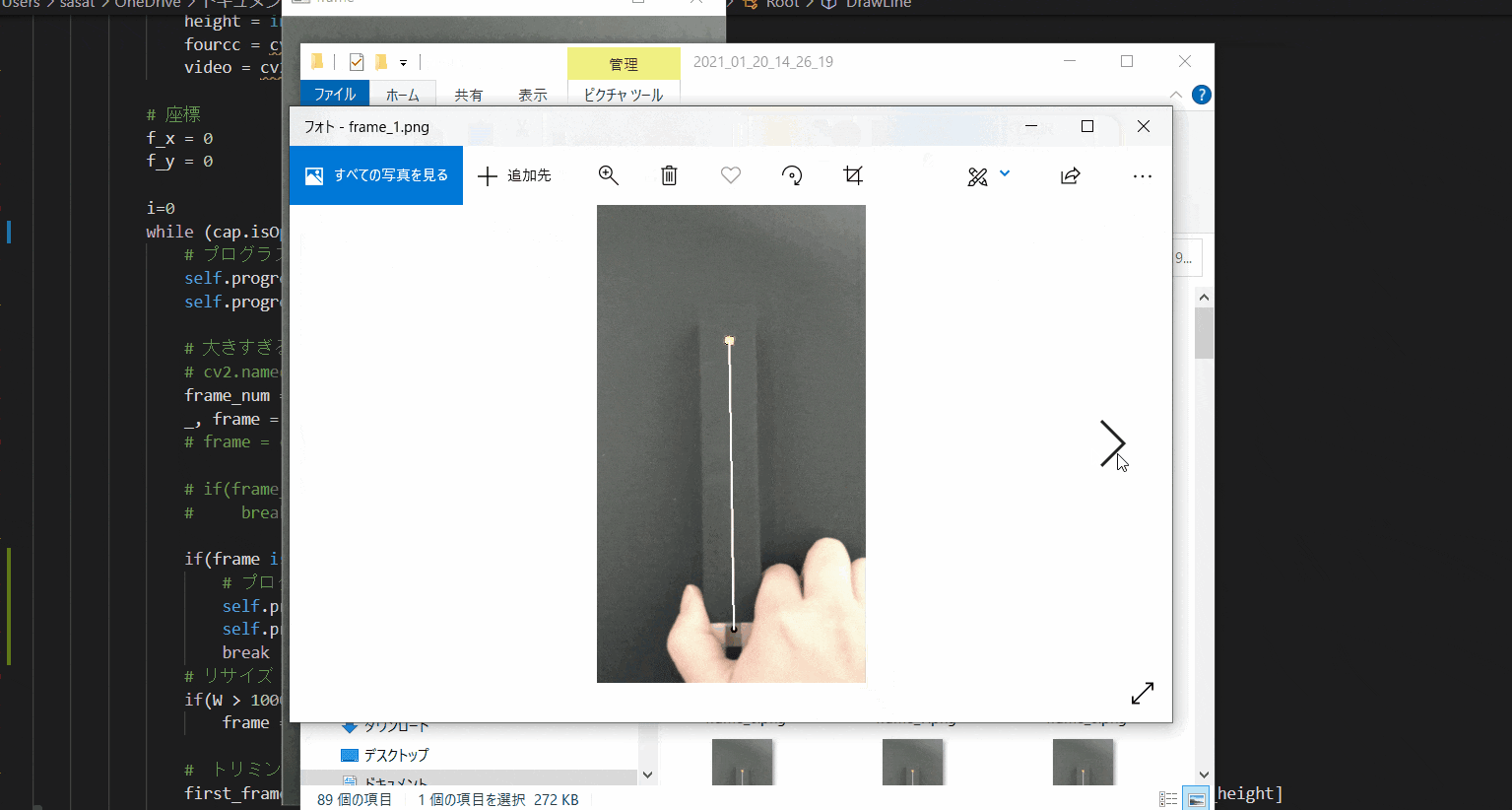
Pythonでアーム角度を自動検出して動画に追加する。(Tkinterで使いやすい画像処理ツールを作る。)※Tkinterが学べる
https://github.com/sassa4771/Find_Arm_Angle_Tkinter
ここのファイルの中身説明↑このサイトでできること
・角度・位置座標を自動検出したいアーム動画を処理して動画に骨組みを表示する。
・本ツールを通して、Tkinterでできること(ファイル読み出し、動画トリミング、マウス追従、スライダー作成などなど)
このFind Angleツールを作るまでに学んだ機能などをレッスンとして
lesson1~27までまとめてあるので参考にしてみてください。
Tkinter Lesson
<参考サイト:https://www.youtube.com/watch?v=sAu7uxW85_Y&list=PL1FgJUcJJ03sm4WuVCPMbT0RIf2uMmoAj&index=17>目次
①Tkinterとは?
②必要なライブラリ・動作環境(※とりあえず動かしてみたい人はここから)
③ツールの使い方とTkinterの機能紹介
④Tkinter学び方(参考スクリプト付き)
⑤本ツールの作り方(簡易版)①Tkinterとは?
【Tkinterとは】
Tkinterとは、「ティーキンター」や「ティーケーインター」と呼ばれ、Window,Mac,Linuxといった
主要なOSにも対応しているクロスプラットフォームなGUIライブラリです。
(参考:https://www.acrovision.jp/service/data/?p=616)要するに
GUIが作れる!
②必要なライブラリ・動作環境
【動作環境:(Let's Note)】
OS:windows10 Pro
CPU:Corei7
メモリ:12GB【必要なライブラリ】
・dlib
・opencv
・numpy
・PIL(Pillow)【Anaconda環境データ】
今回使用しているAnacondaの環境データ(yamlファイル)もGitにあるので利用してみてください。
https://github.com/sassa4771/Find_Angle_Tkinter/tree/main/Anaconda%20EnvironmentAnaconda環境インストールコマンド
cd 【find_angle.yamlがあるとディレクトリ】
conda env create -n find_arm_angle -f find_angle.yaml
環境をインストールしたらmainファイルのrun.batを起動するとソフトが起動できる。
【撮影環境】
・背景を黒色
・目標点を白色
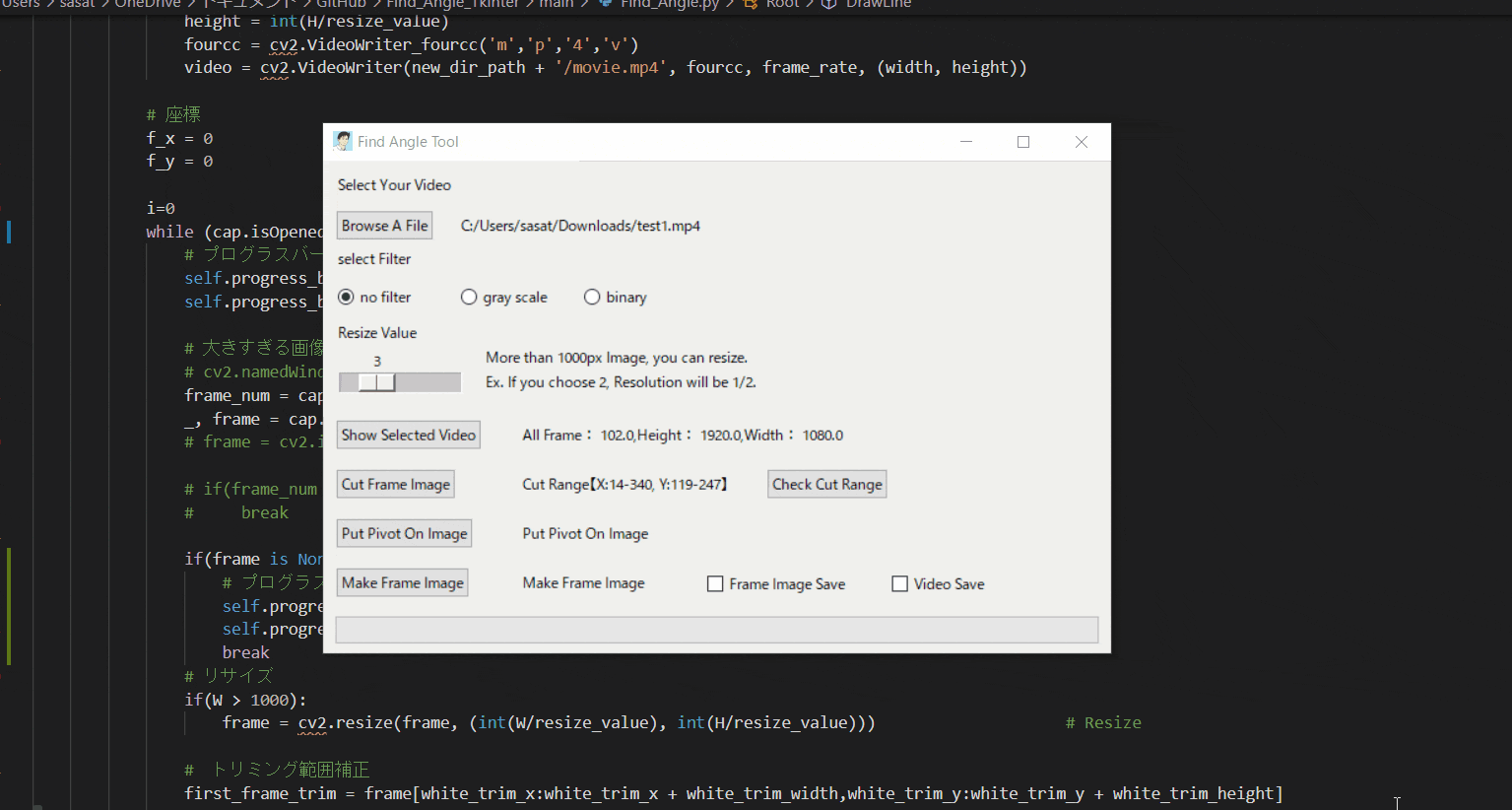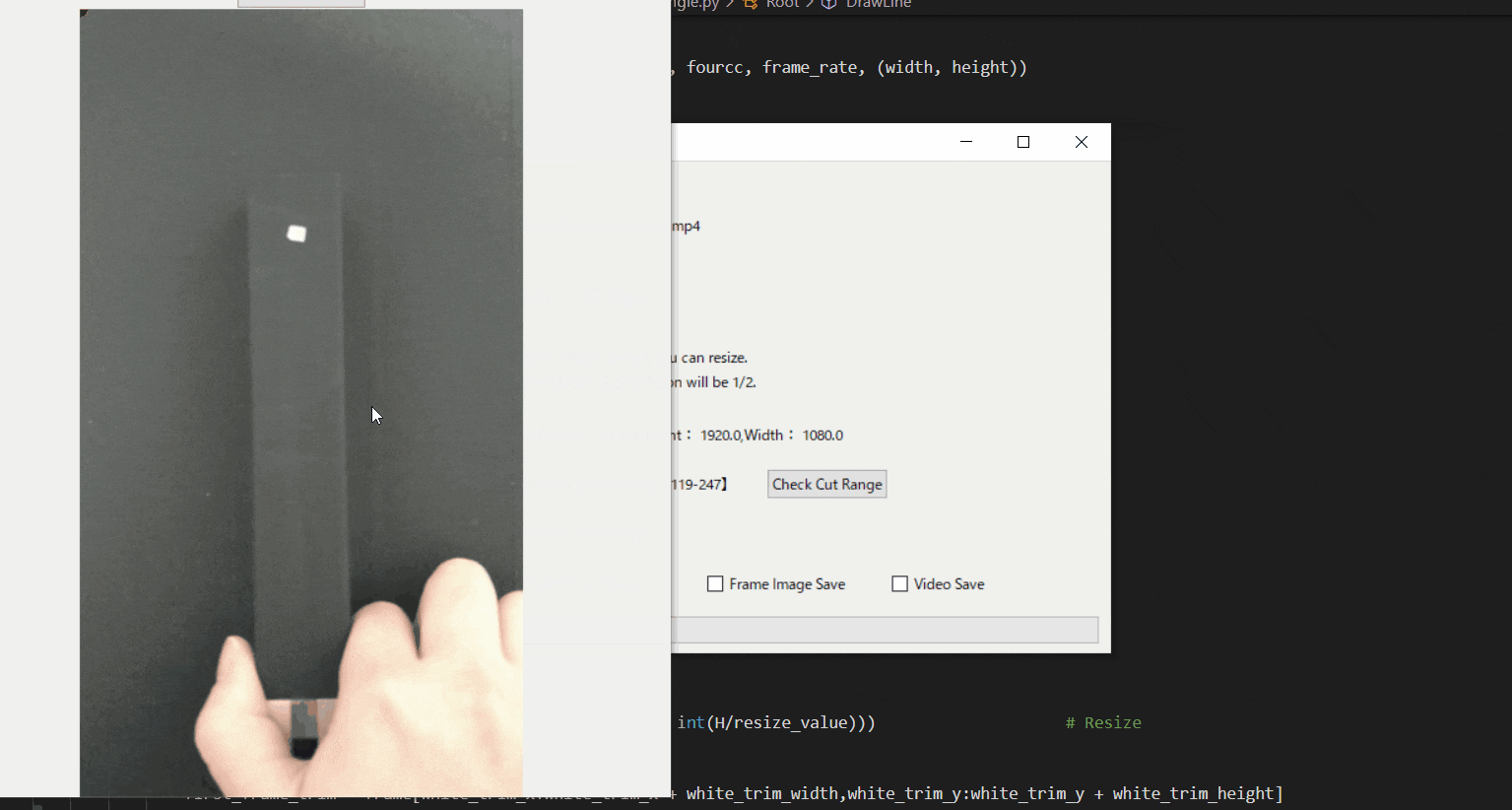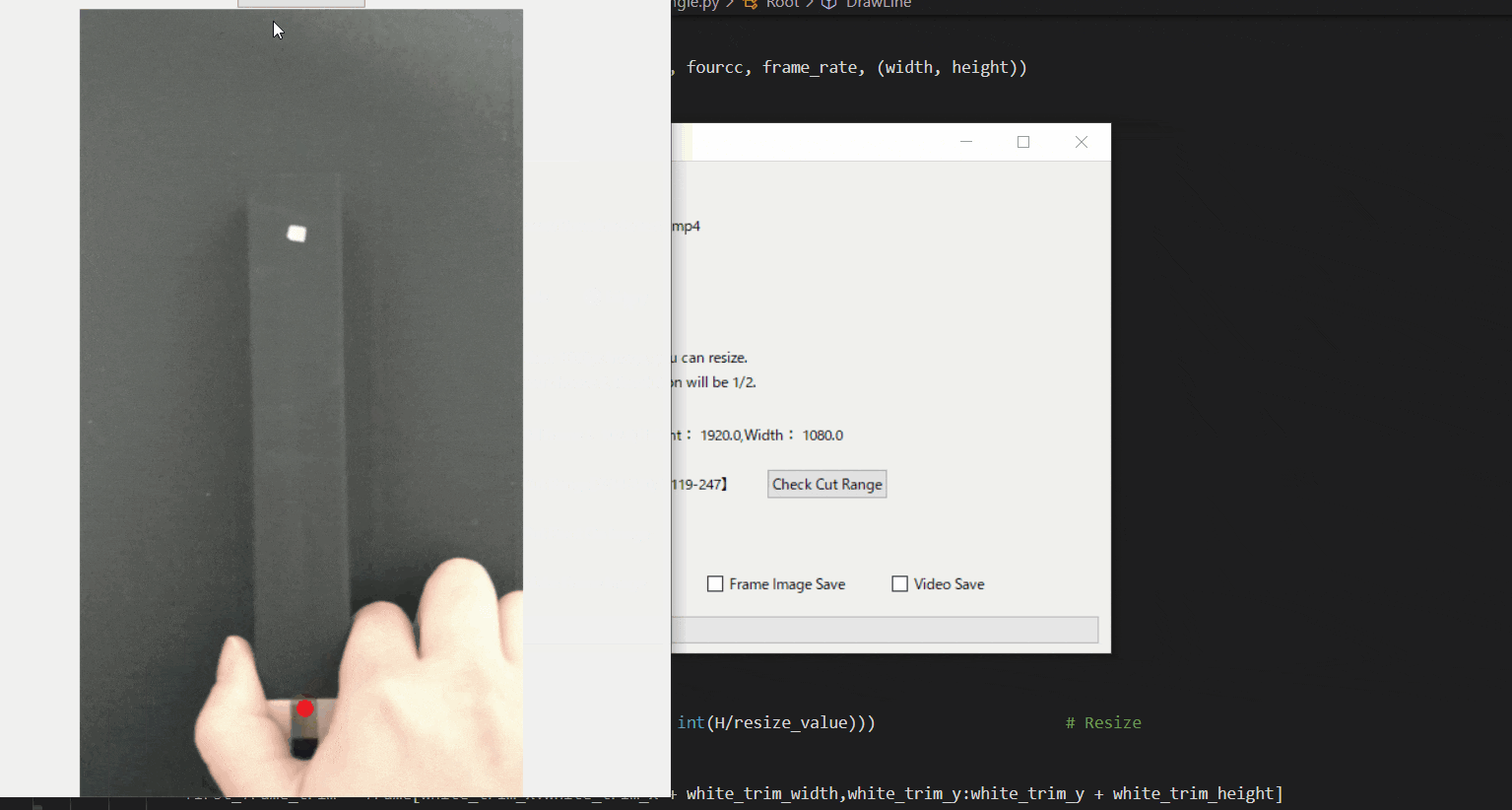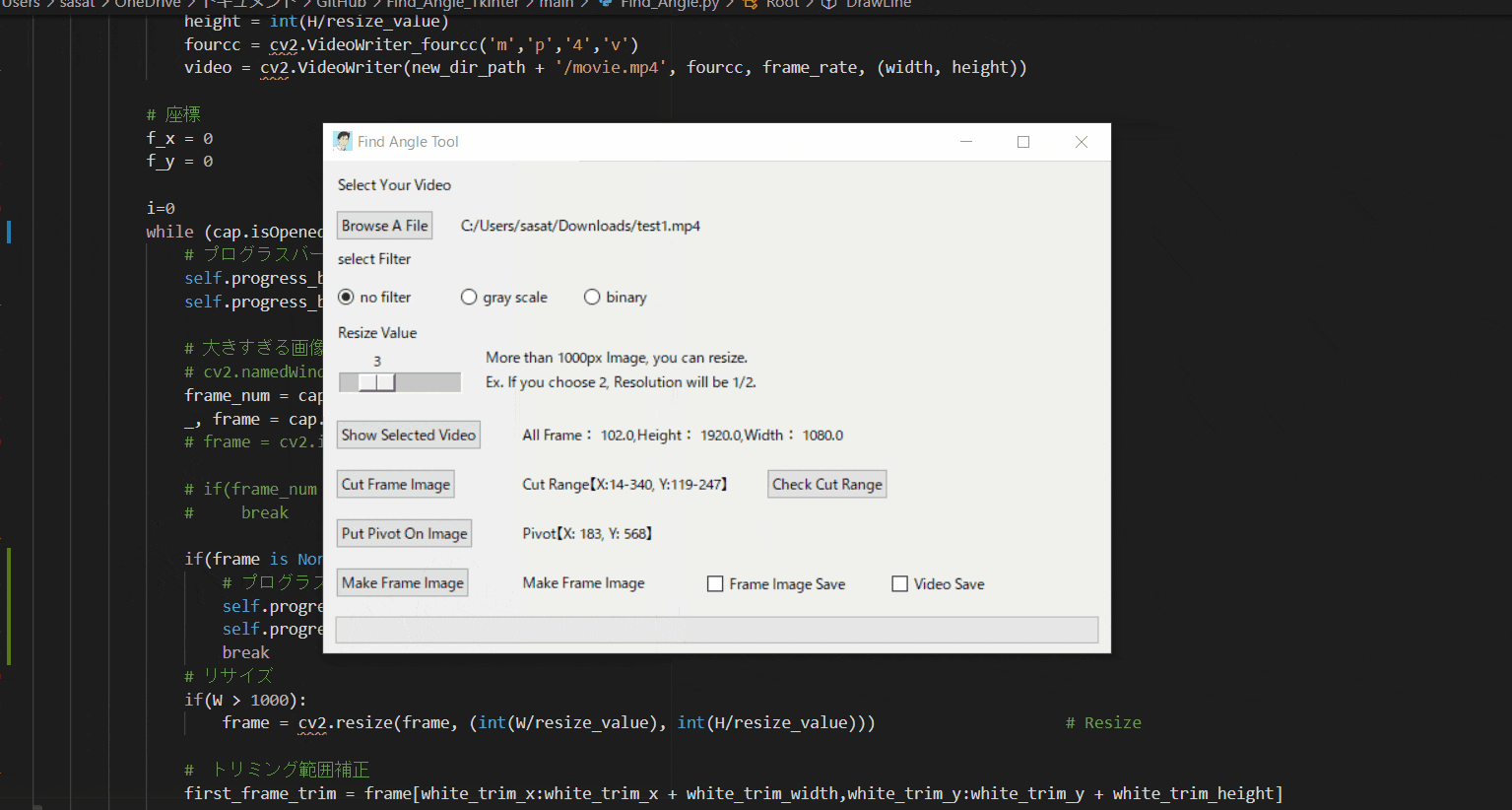
にする必要がある。(※二値化→輪郭抽出で座標を特定するため)③ツールの使い方とTkinterの機能紹介
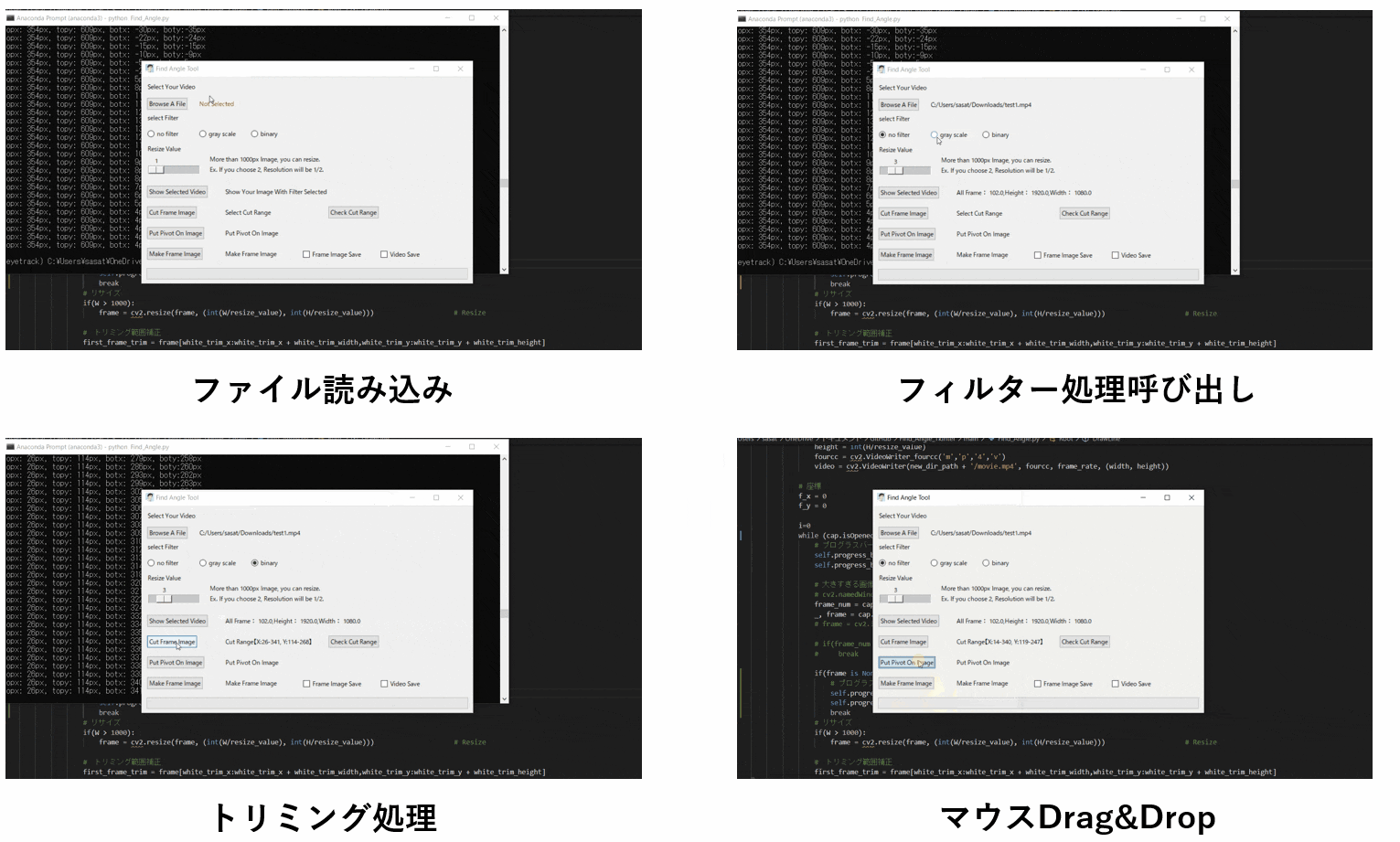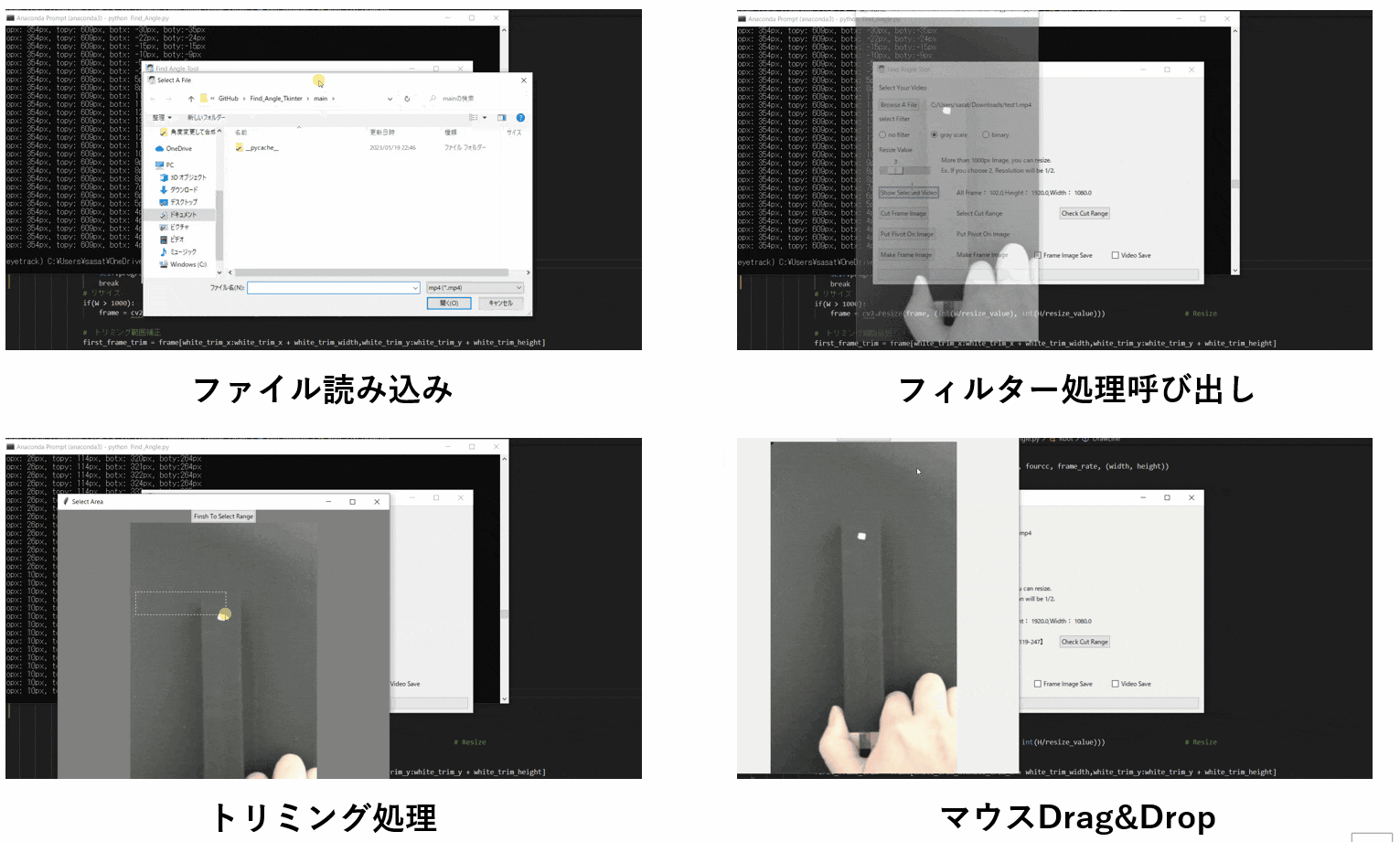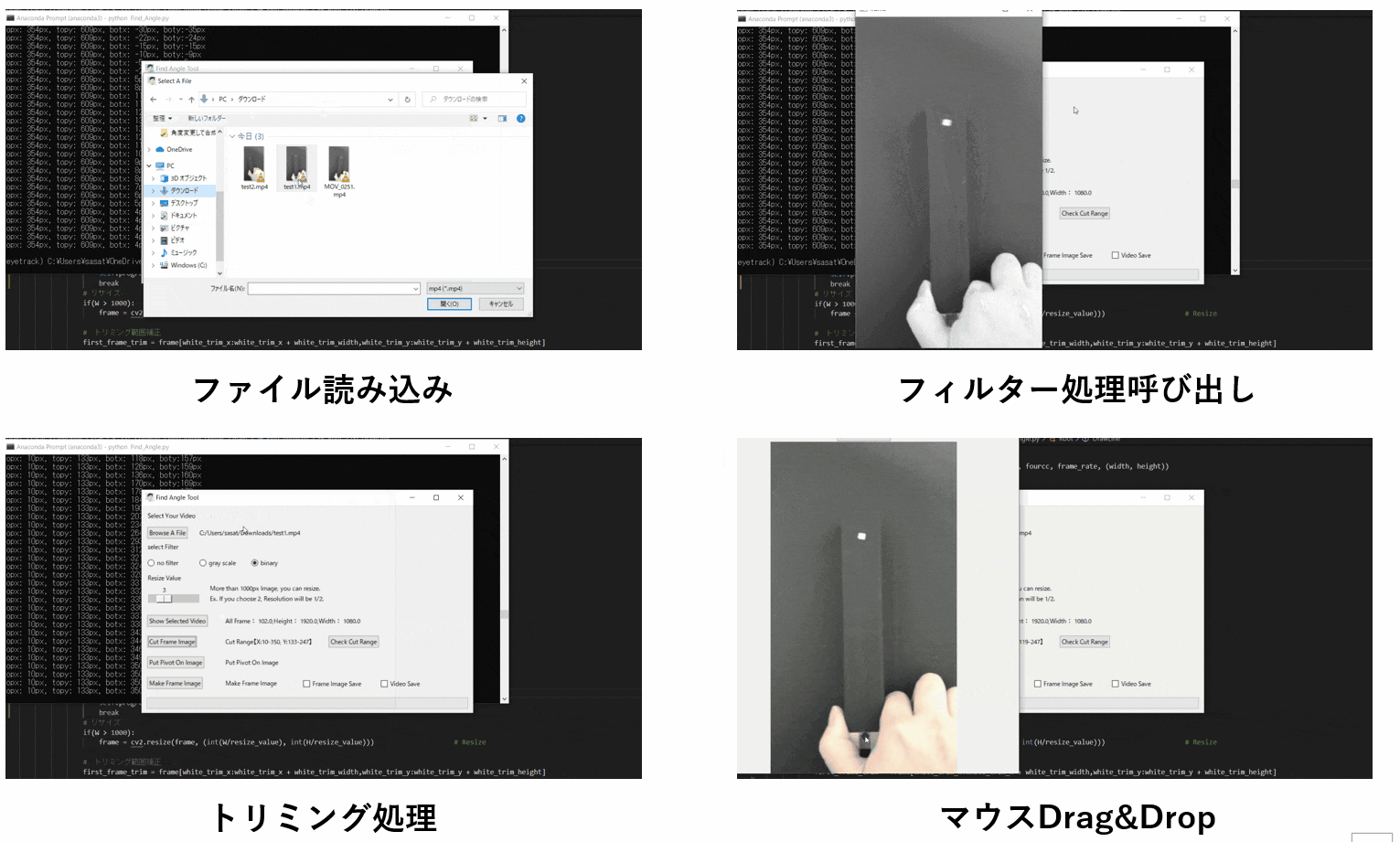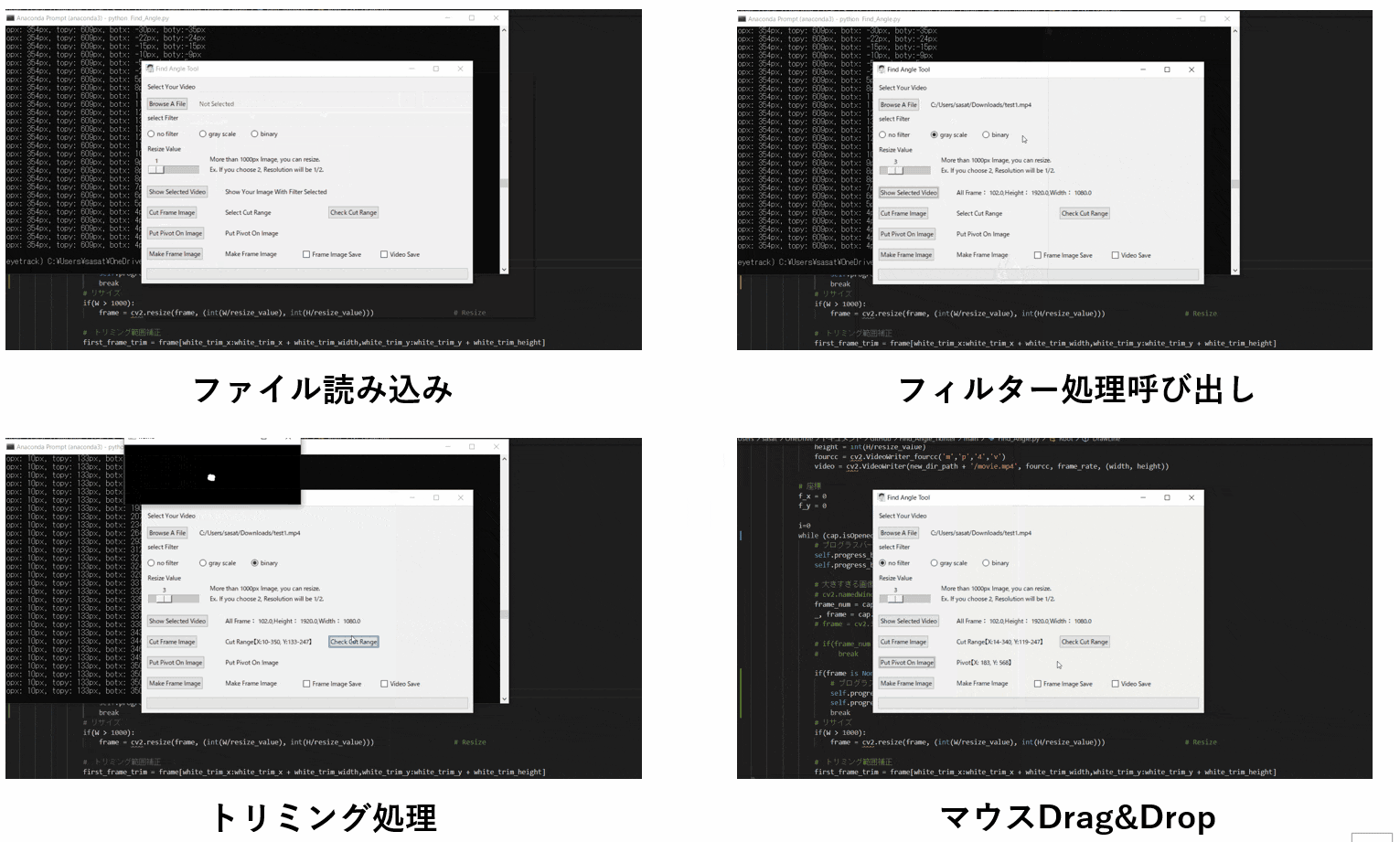
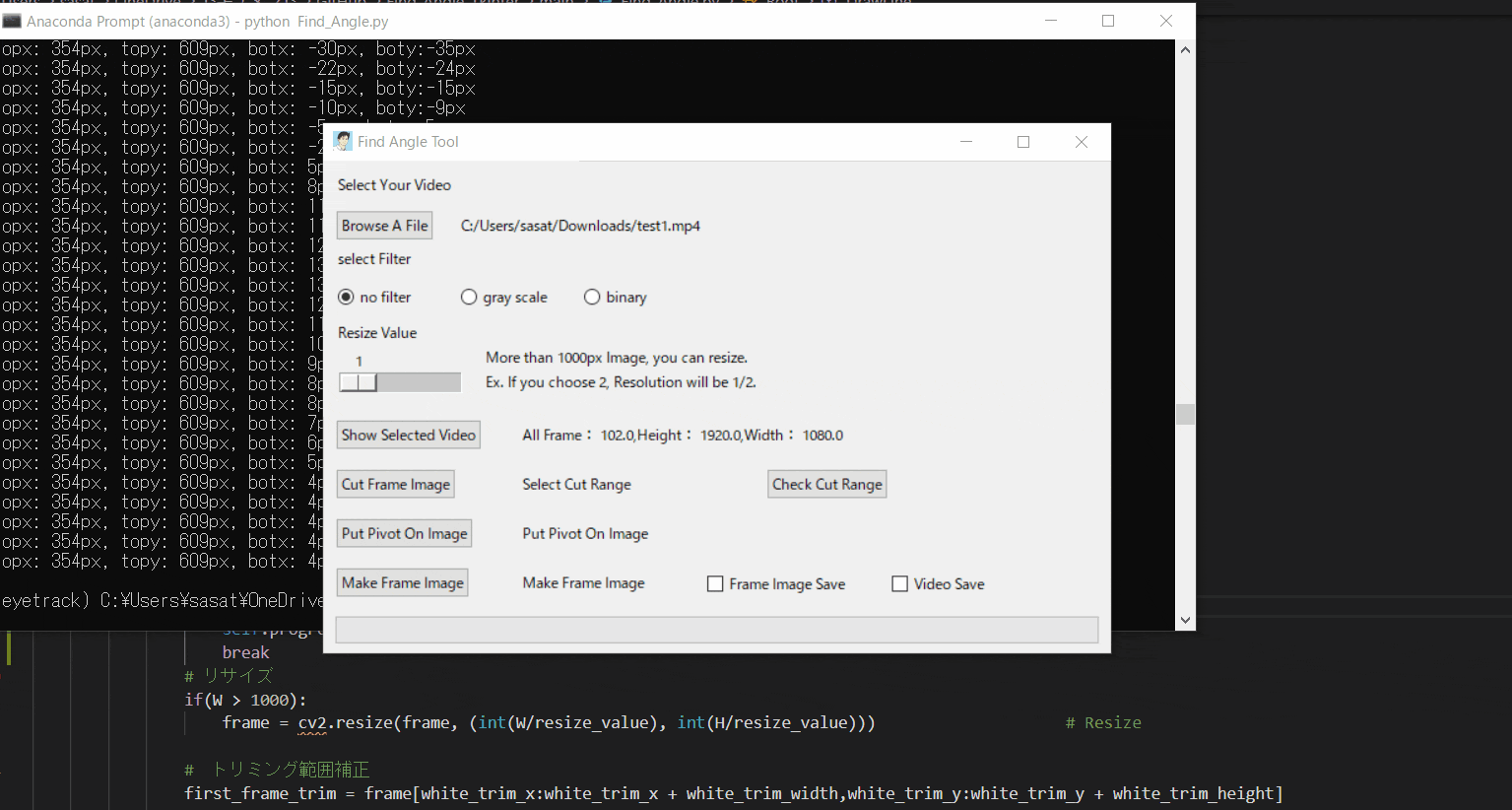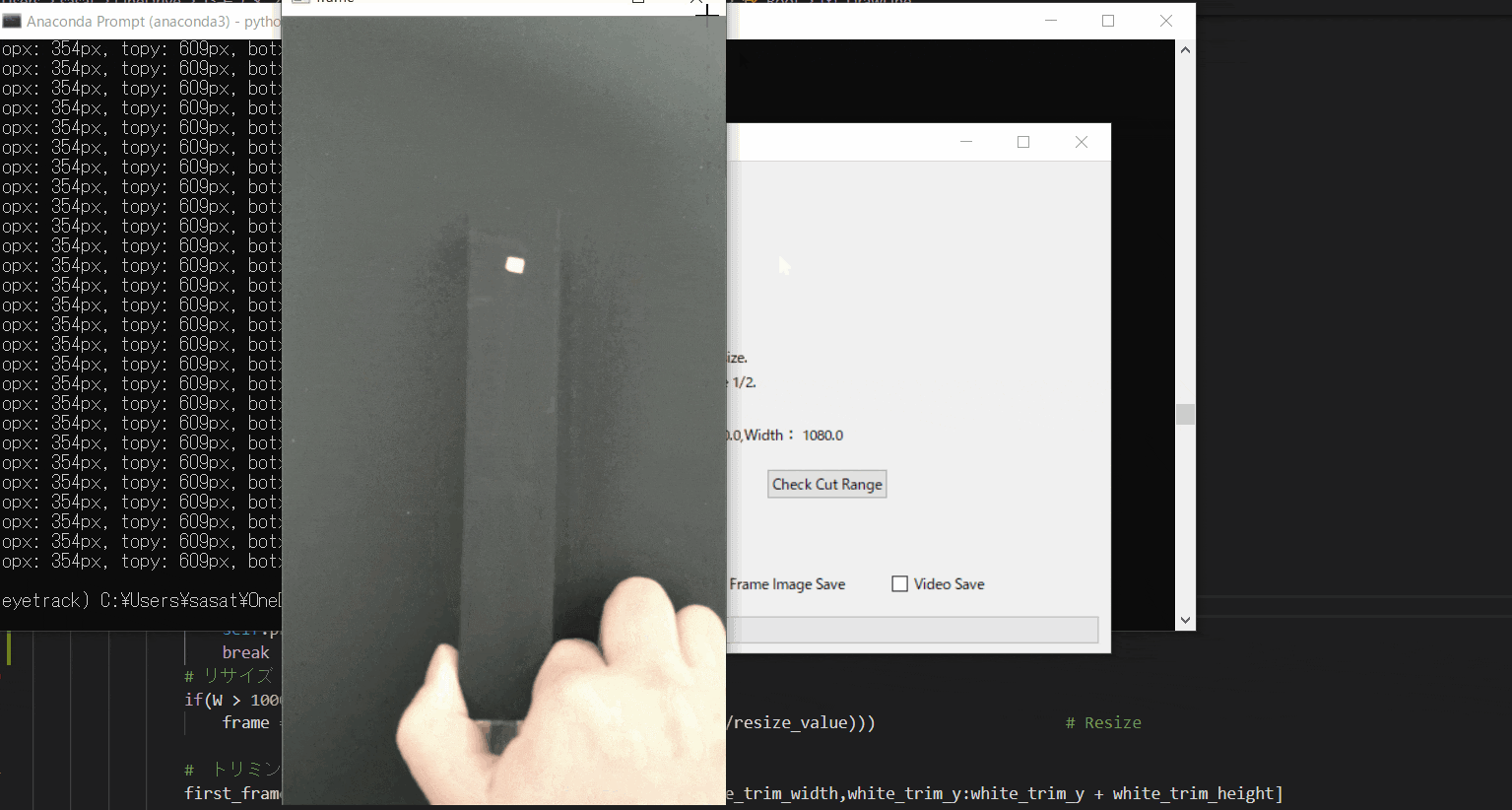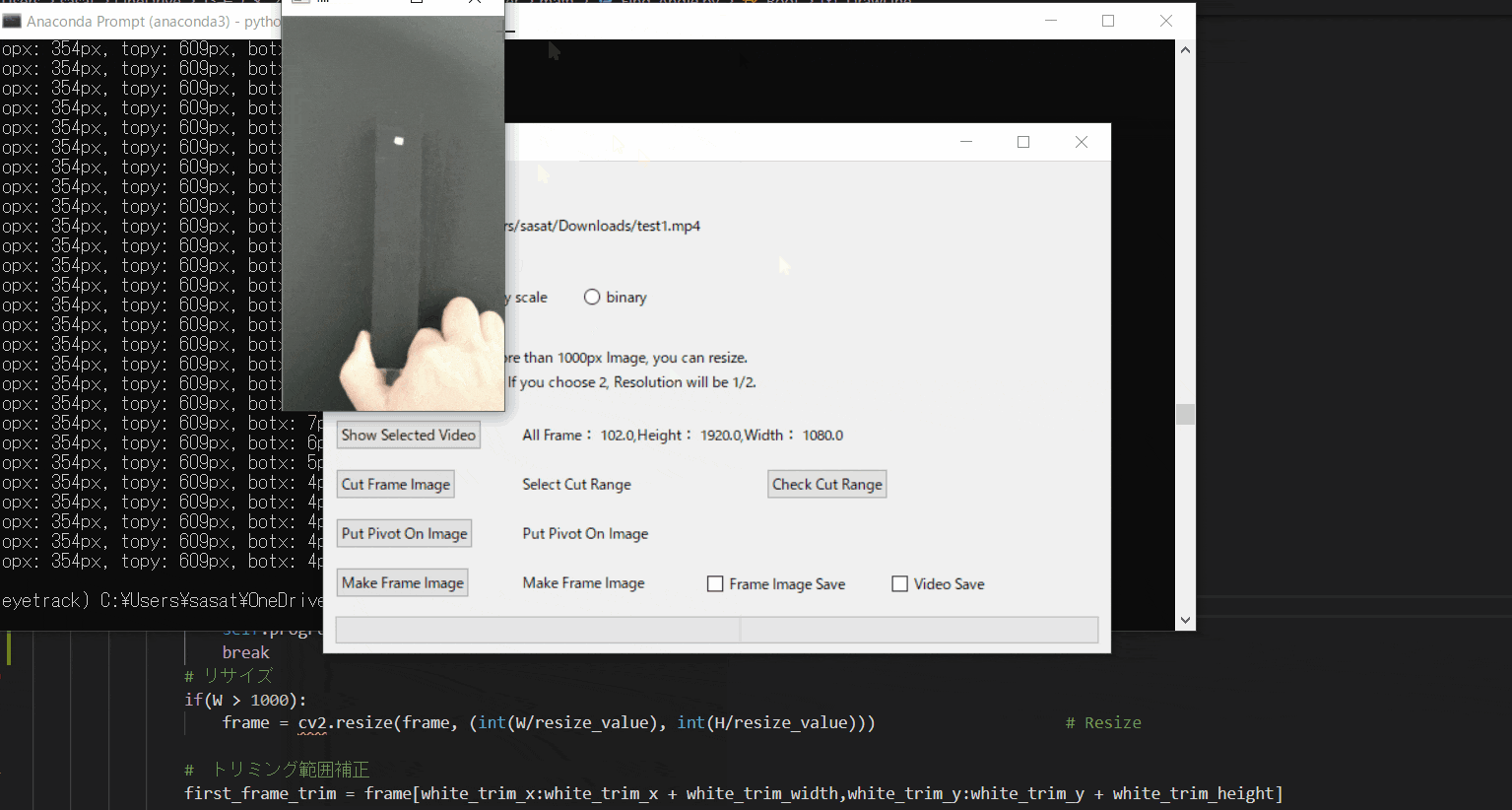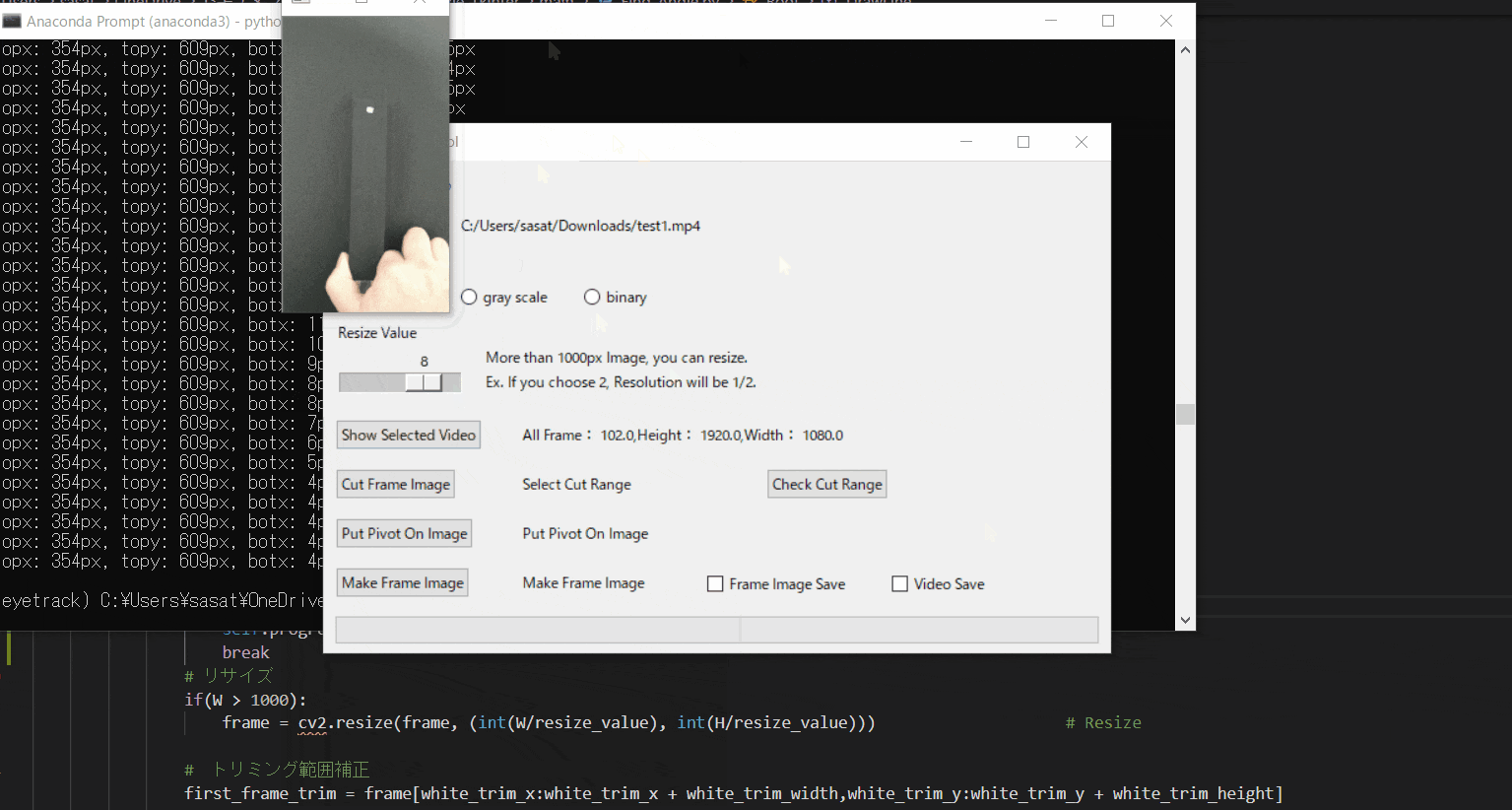
【1.ファイルを開く】
まずは、ファイルを開きましょう。このTkinter機能は、こちらのスクリプトを参考にしてください。
[ラベル] https://github.com/sassa4771/Find_Angle_Tkinter/blob/main/tk_lesson/tk_lesson2(Labels).py
[ファイル参照] https://github.com/sassa4771/Find_Angle_Tkinter/blob/main/tk_lesson/tk_lesson23(Browsing%20A%20File).py
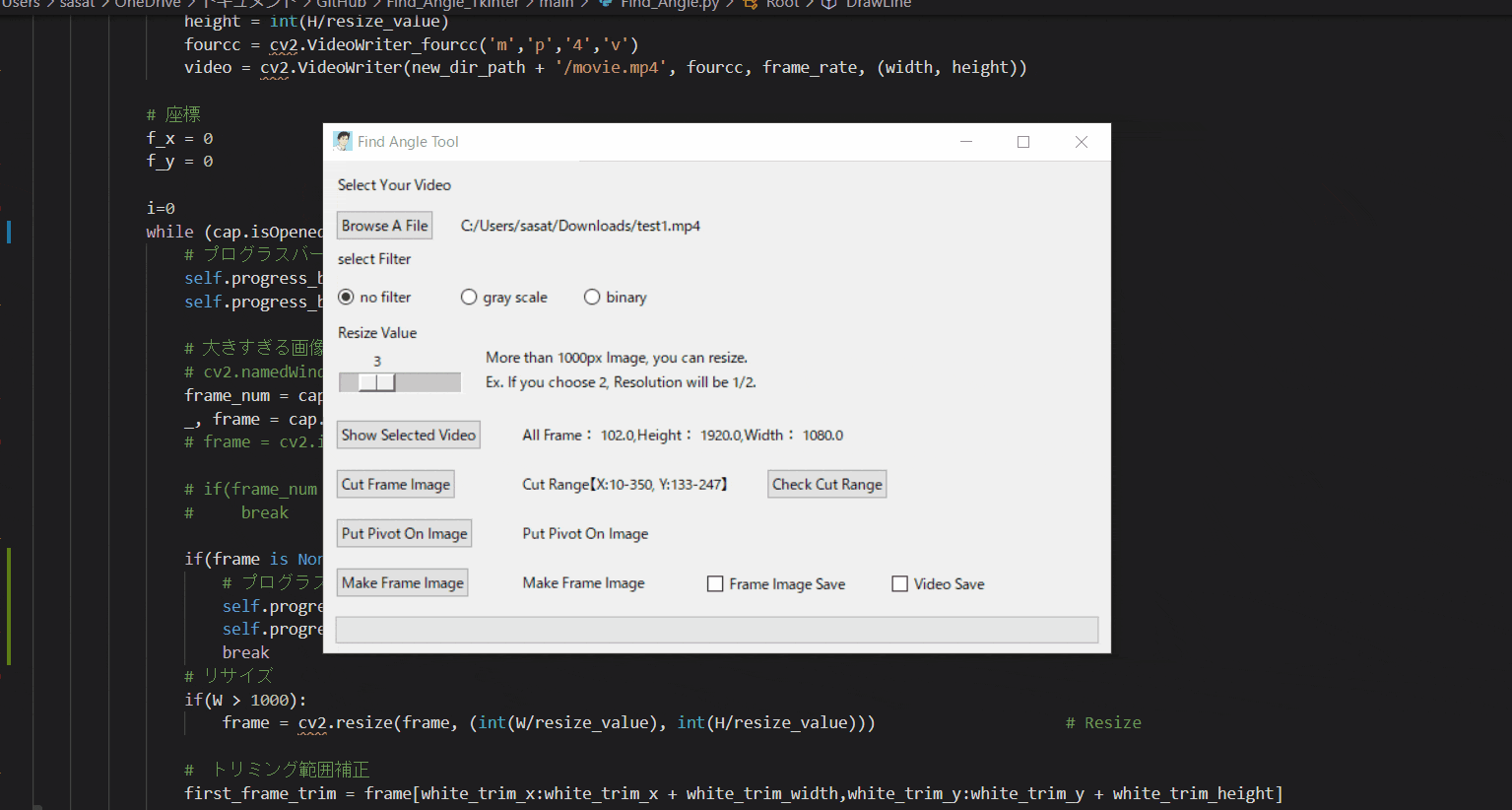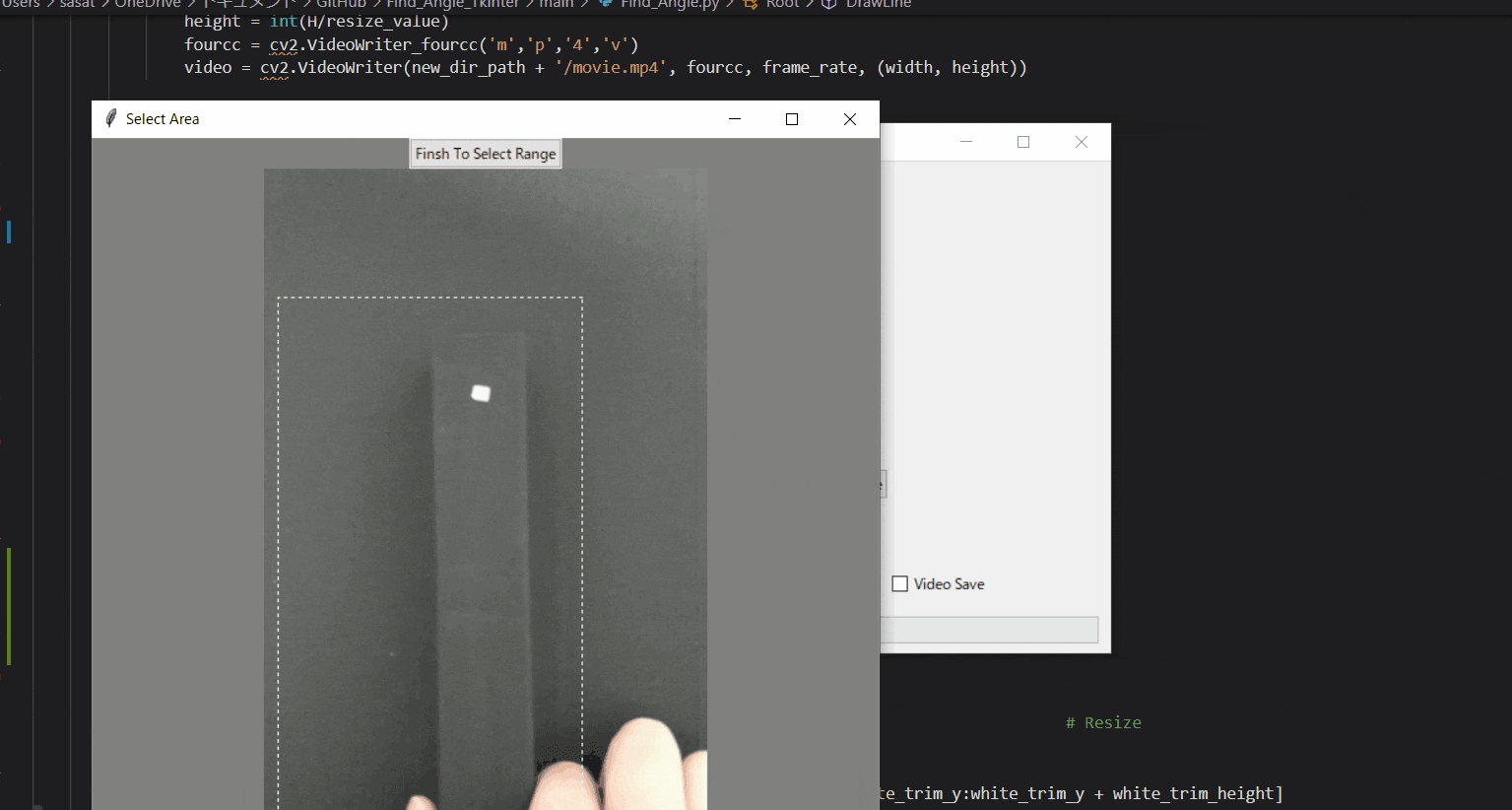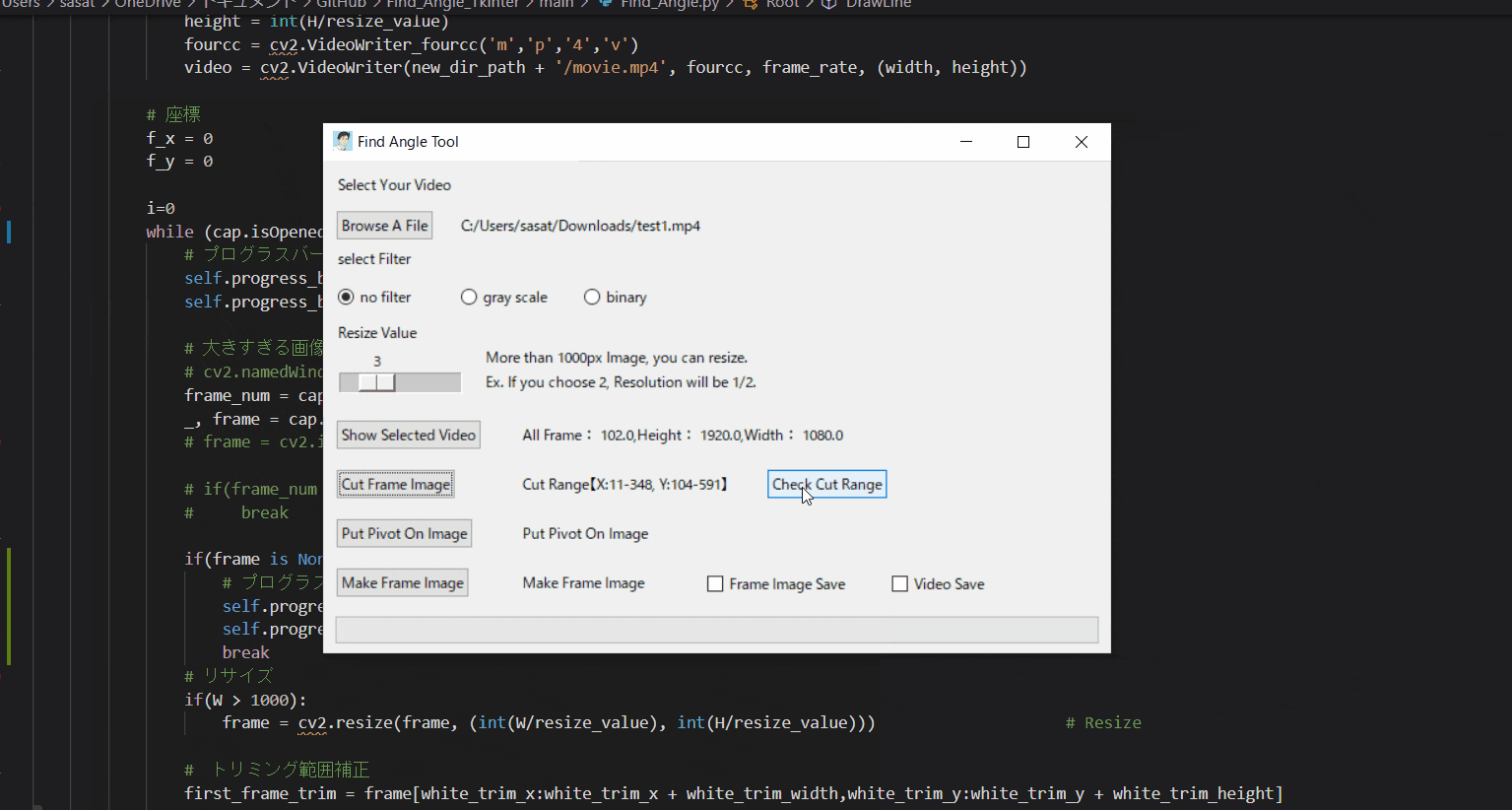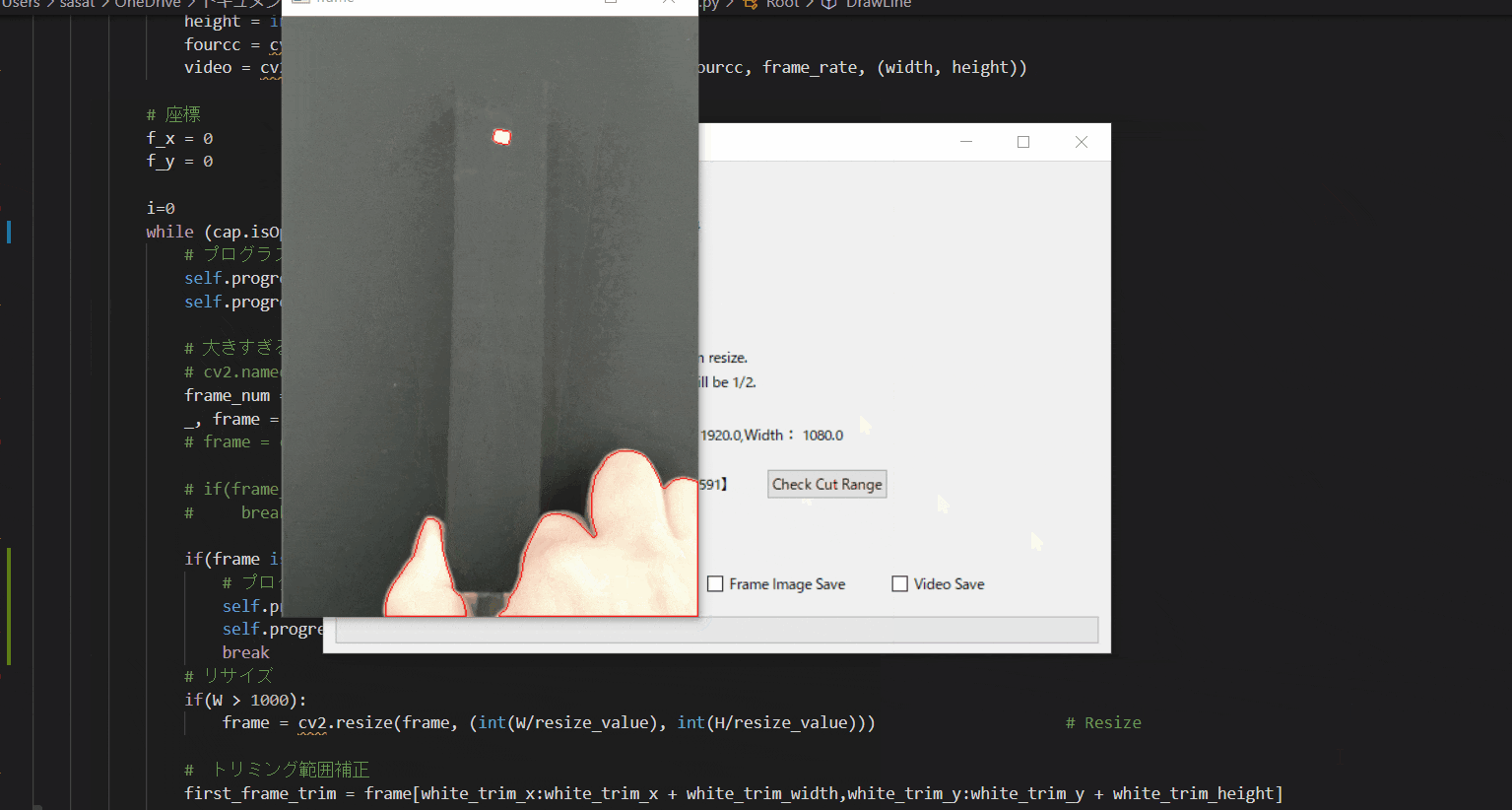
【2.選択した動画の閲覧】
no filterを選択して「Show Selected Video」を押すと表示することができる。このTkinter機能は、こちらのスクリプトを参考にしてください。
[ラベル] https://github.com/sassa4771/Find_Angle_Tkinter/blob/main/tk_lesson/tk_lesson2(Labels).py
[ラジオボタン] https://github.com/sassa4771/Find_Angle_Tkinter/blob/main/tk_lesson/tk_lesson8(Radio%20Button).py
[ボタンと機能呼び出し] https://github.com/sassa4771/Find_Angle_Tkinter/blob/main/tk_lesson/tk_lesson4(Button%20And%20Button%20Commands).py
【3.動画の縮小をする】
ただこのままだと、元の動画が大きすぎるのでリサイズをします。
スライダーを利用して、縮小割合を決定します。このTkinter機能は、こちらのスクリプトを参考にしてください。
[ラベル] https://github.com/sassa4771/Find_Angle_Tkinter/blob/main/tk_lesson/tk_lesson2(Labels).py
[スライダー] https://github.com/sassa4771/Find_Angle_Tkinter/blob/main/tk_lesson/tk_lesson27(Slider).py
【4.フィルター処理した動画の閲覧】
ラジオボタンで・フィルターなし・グレースケール・二値化の処理を選択して表示することができます。
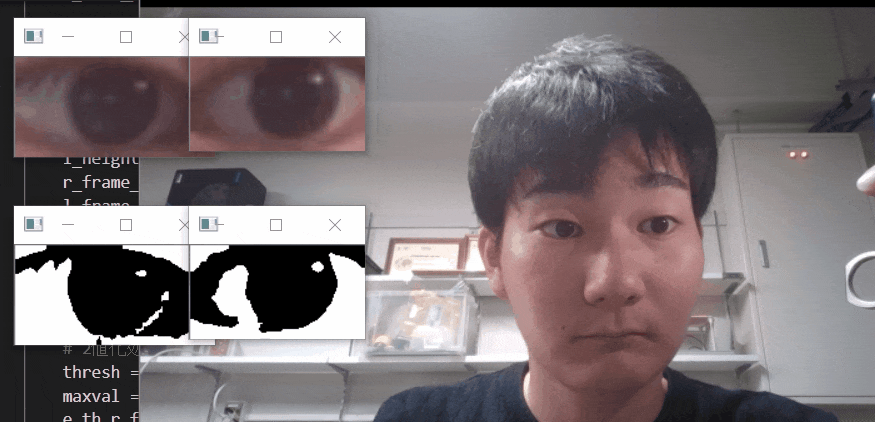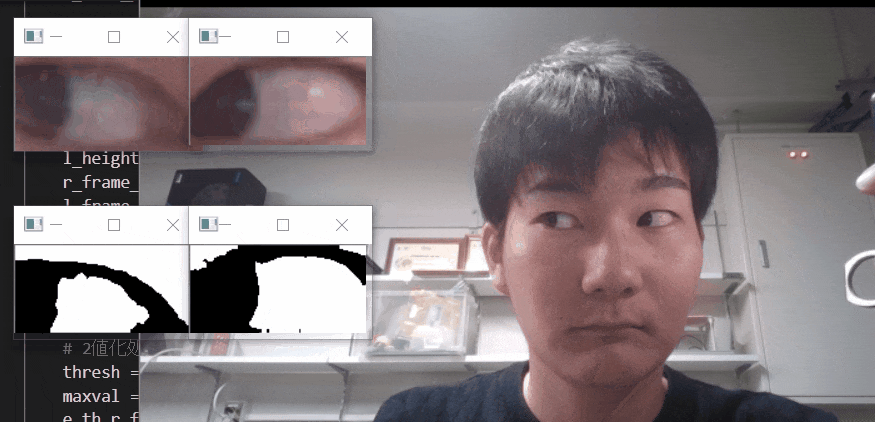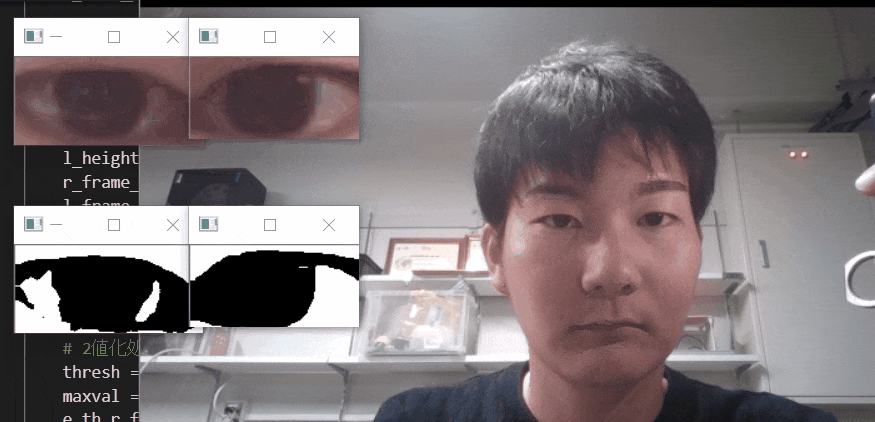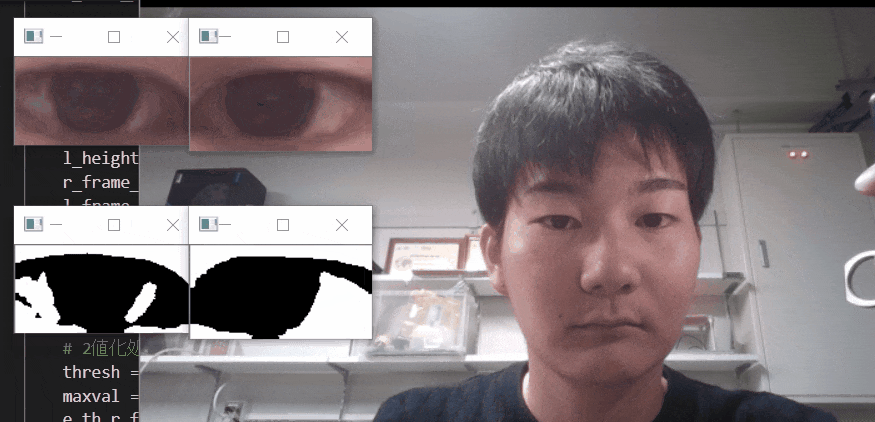
※二値化処理したものを輪郭抽出で自動追従しているため、背景が黒で、目標点が白でないといけない。
フィルターに関して詳しくは、eyetrackのところで説明しています。
Webカメラでeye tracking(アイトラッキング・視線計測)をする【Windows10】:https://github.com/sassa4771/eyetrackこのTkinter機能は、こちらのスクリプトを参考にしてください。
[ラベル] https://github.com/sassa4771/Find_Angle_Tkinter/blob/main/tk_lesson/tk_lesson2(Labels).py
[ボタンと機能呼び出し] https://github.com/sassa4771/Find_Angle_Tkinter/blob/main/tk_lesson/tk_lesson4(Button%20And%20Button%20Commands).py
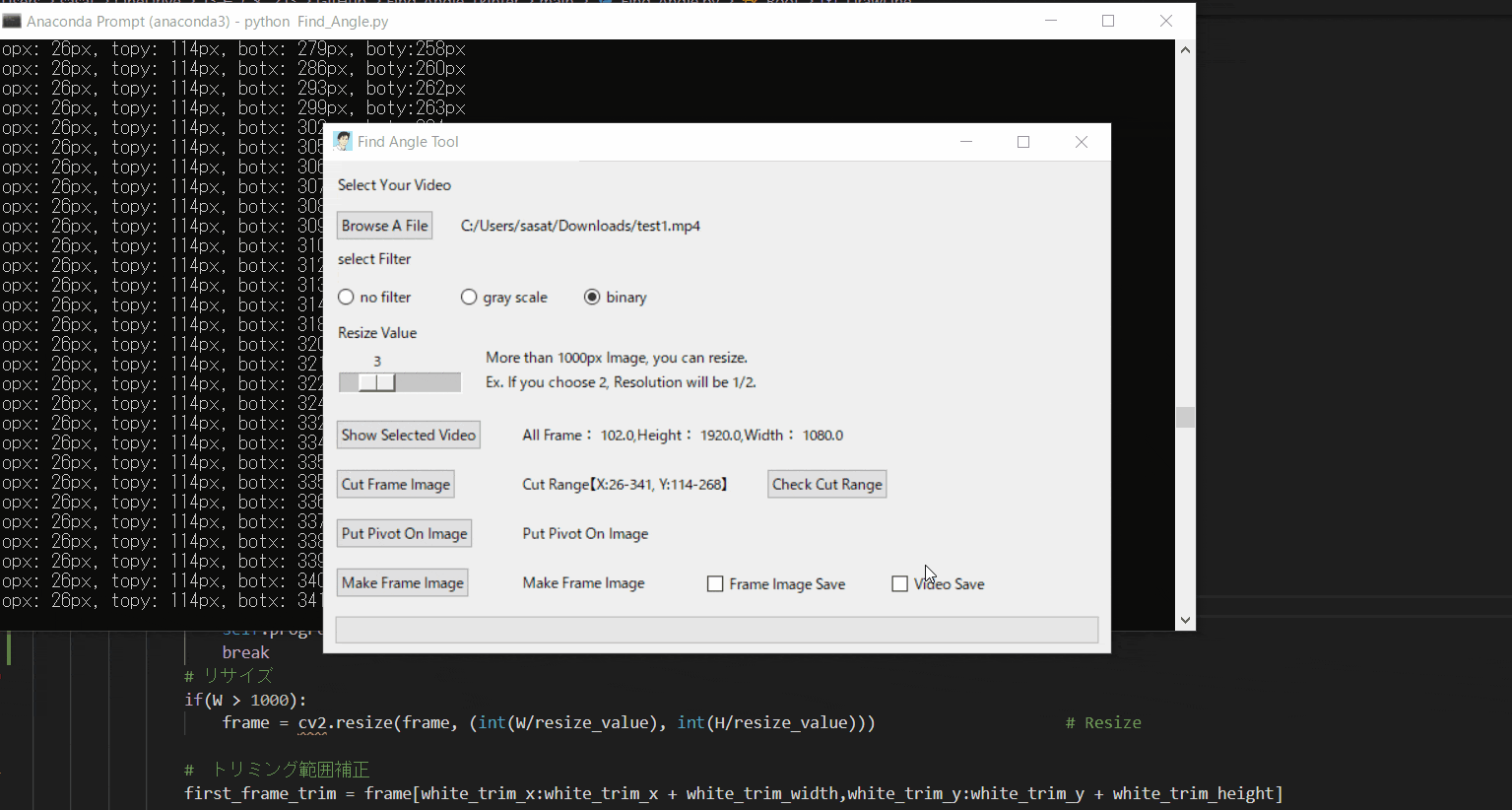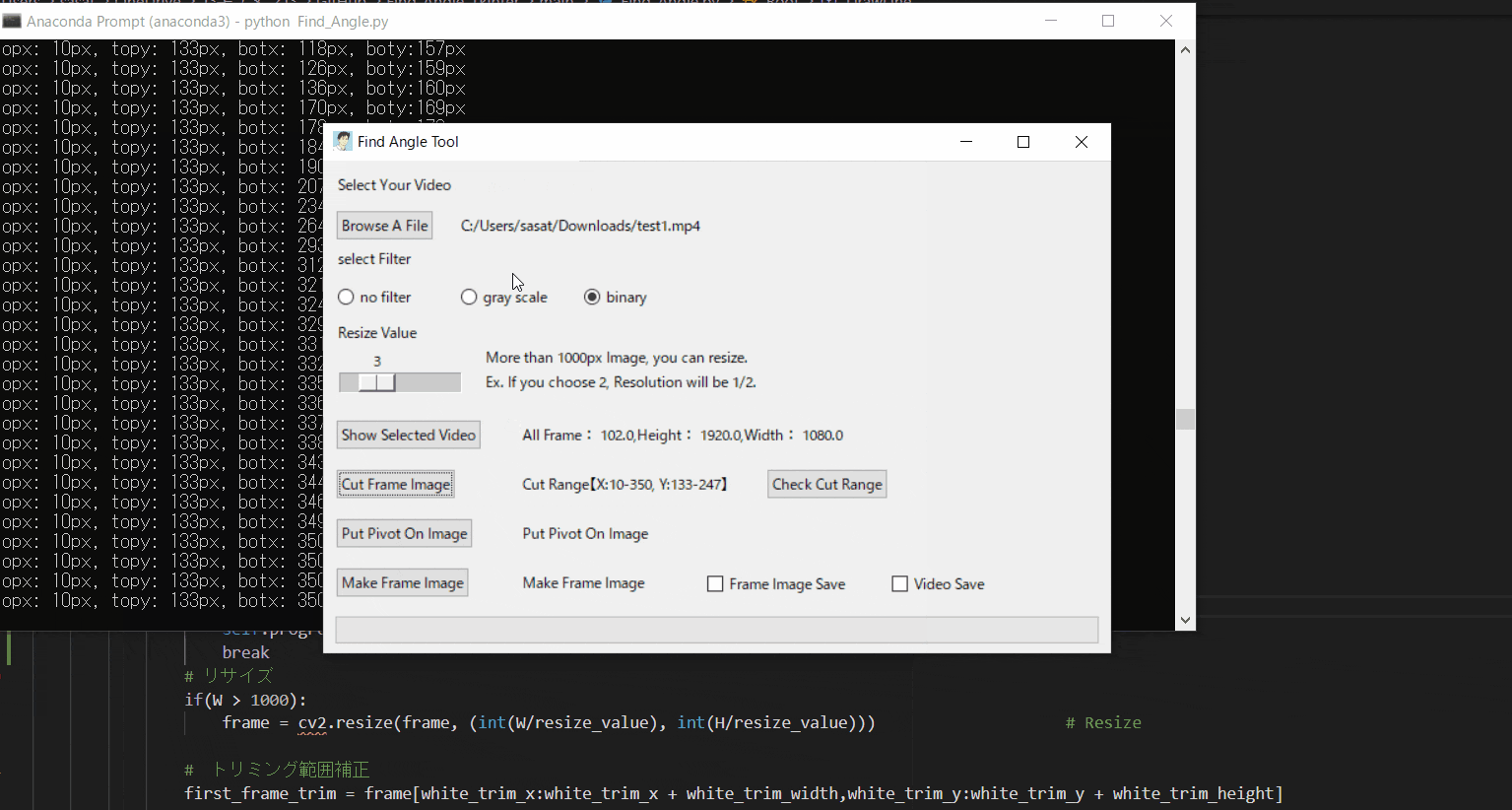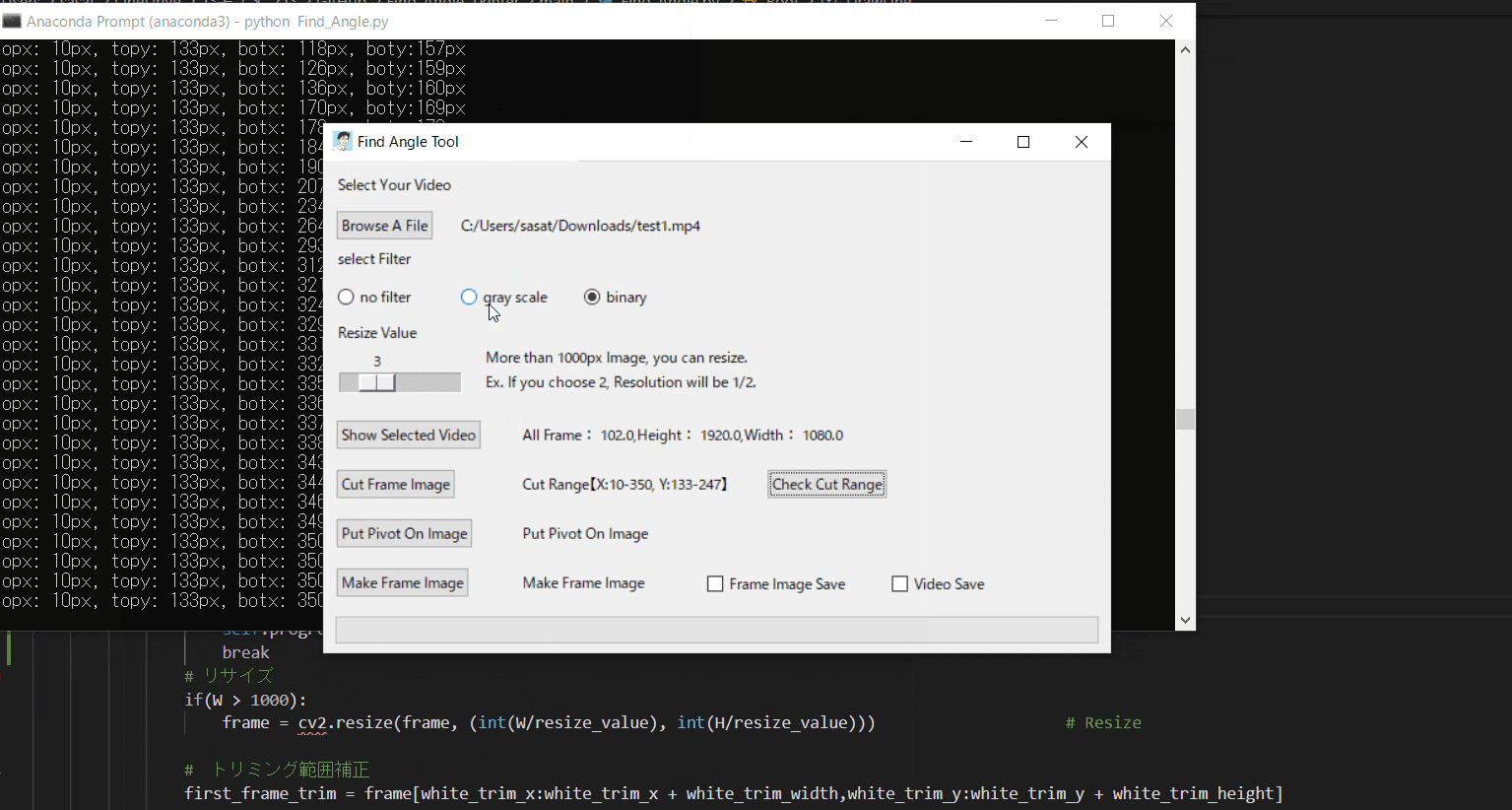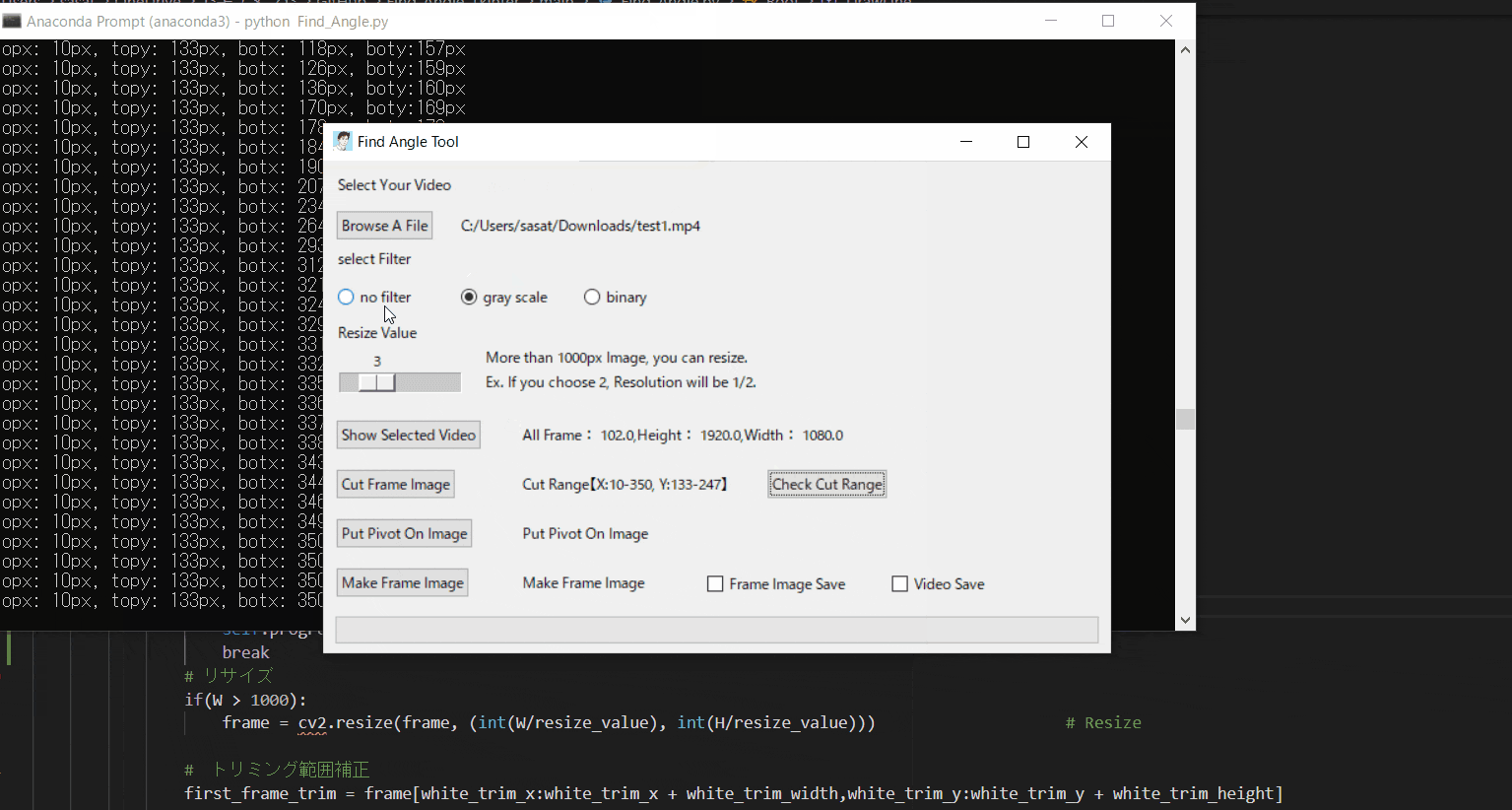
【5.動画の範囲トリミングする】
自動トラッキングしたい点(白色のみトラッキング可能。背景は黒色がベスト)が移動する範囲をトリミングしましょう。
※この処理は、目標点の追従する際に範囲を絞ってノイズが入るのを防ぐために行います。このTkinter機能は、こちらのスクリプトを参考にしてください。
[ラベル] https://github.com/sassa4771/Find_Angle_Tkinter/blob/main/tk_lesson/tk_lesson2(Labels).py
[画像トリミング] https://github.com/sassa4771/Find_Angle_Tkinter/blob/main/tk_lesson/tk_lesson25(Image_Triming).py
【6.目標点を追従できているかを確認する】
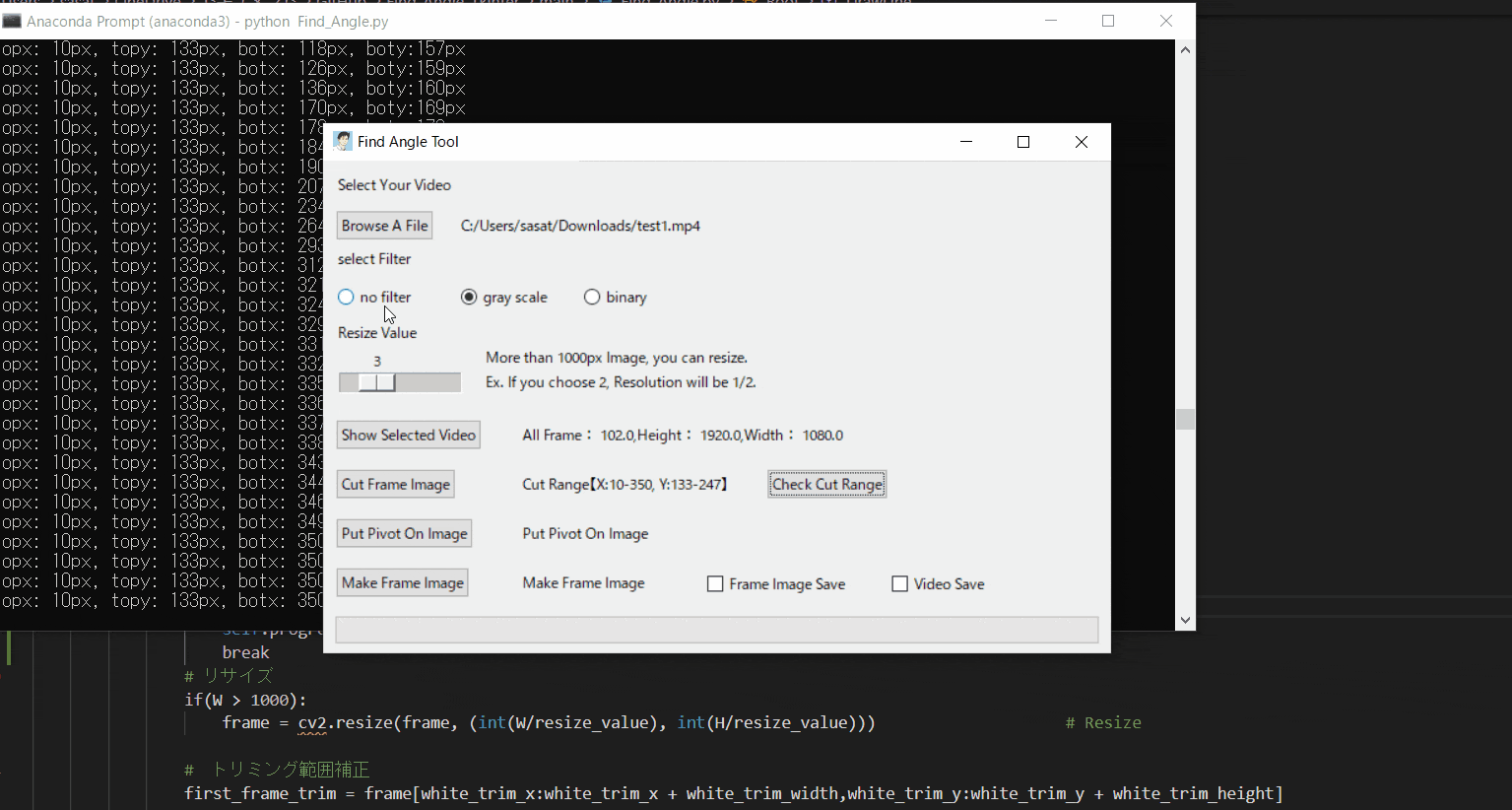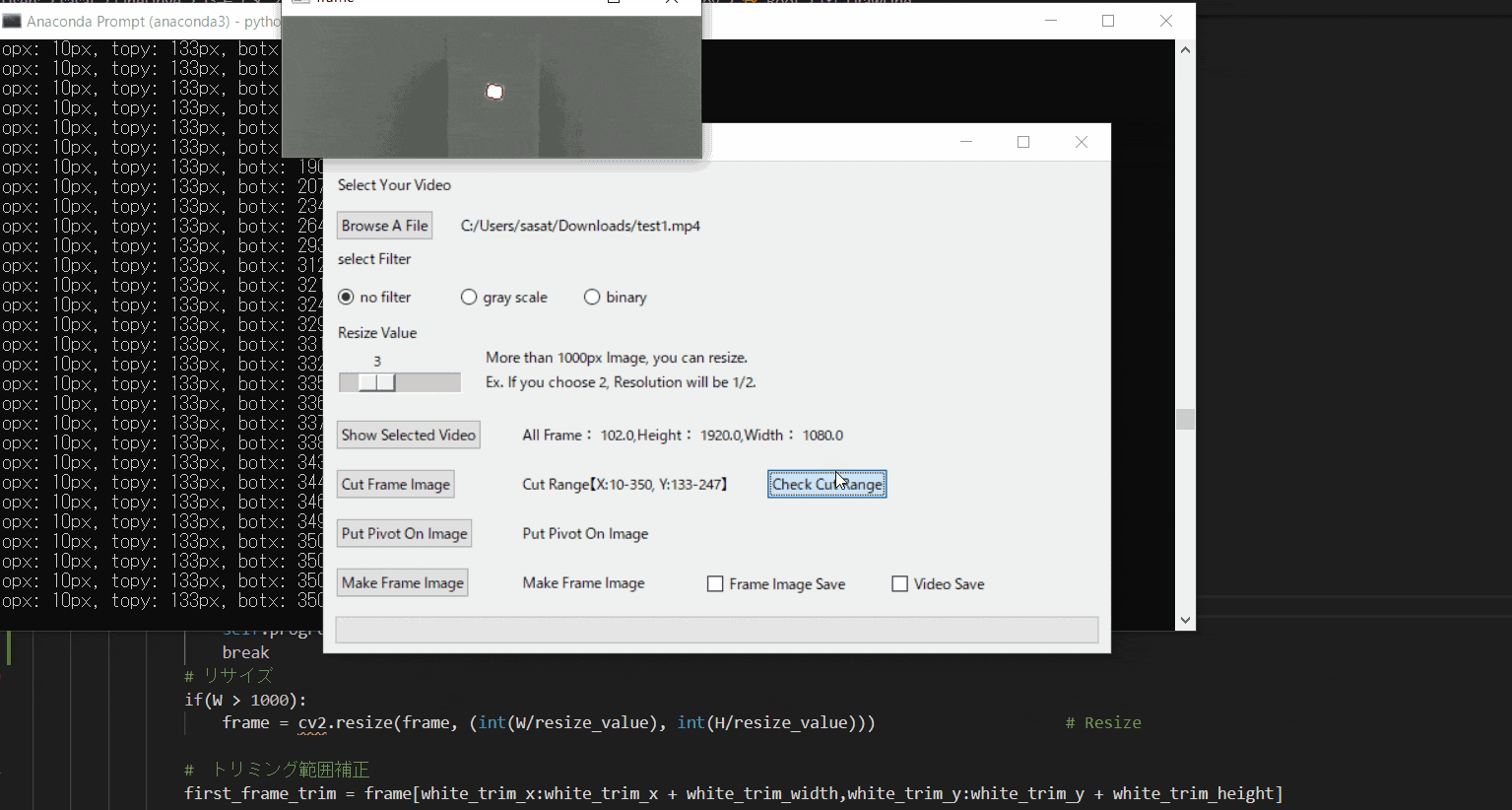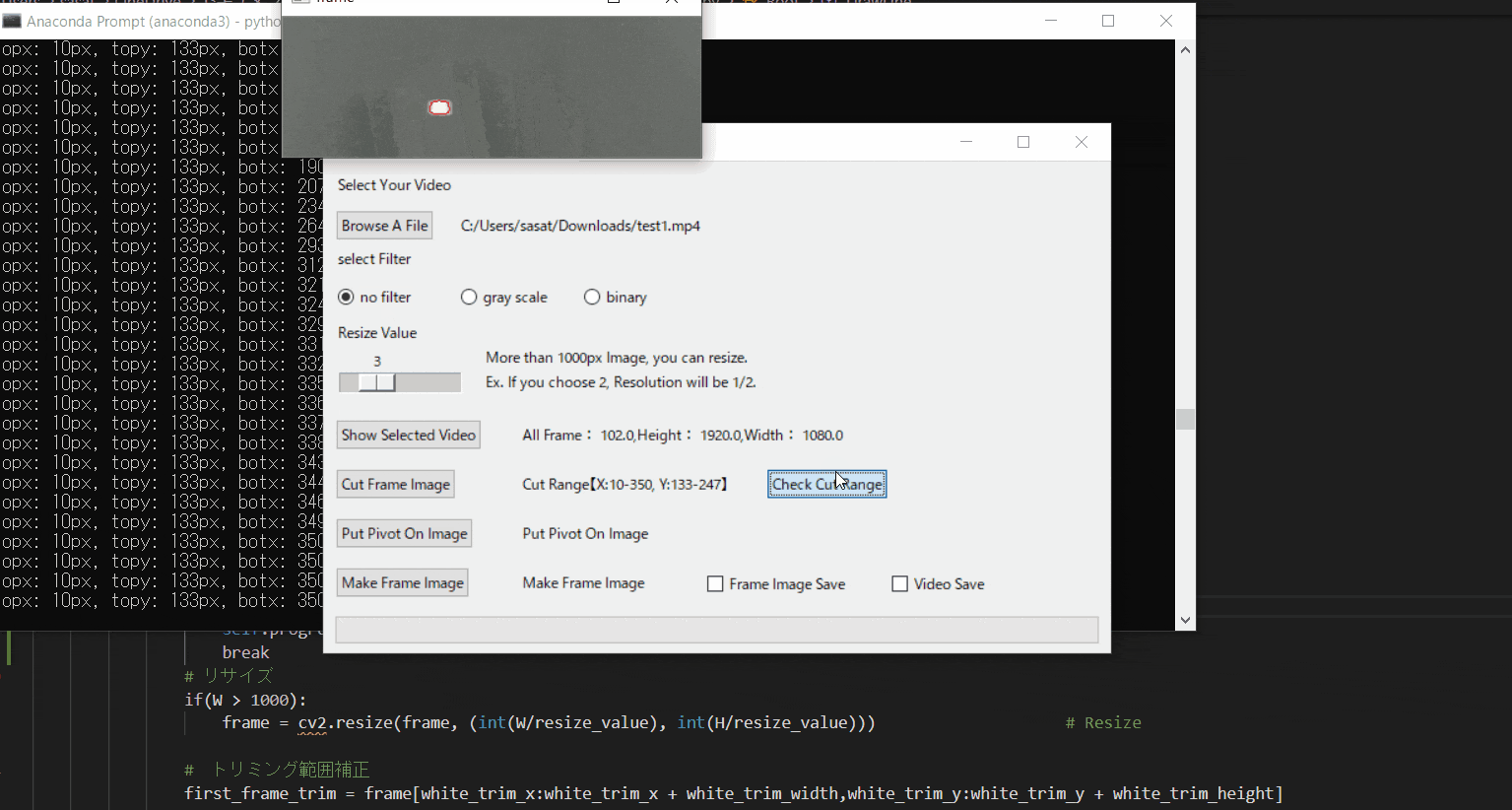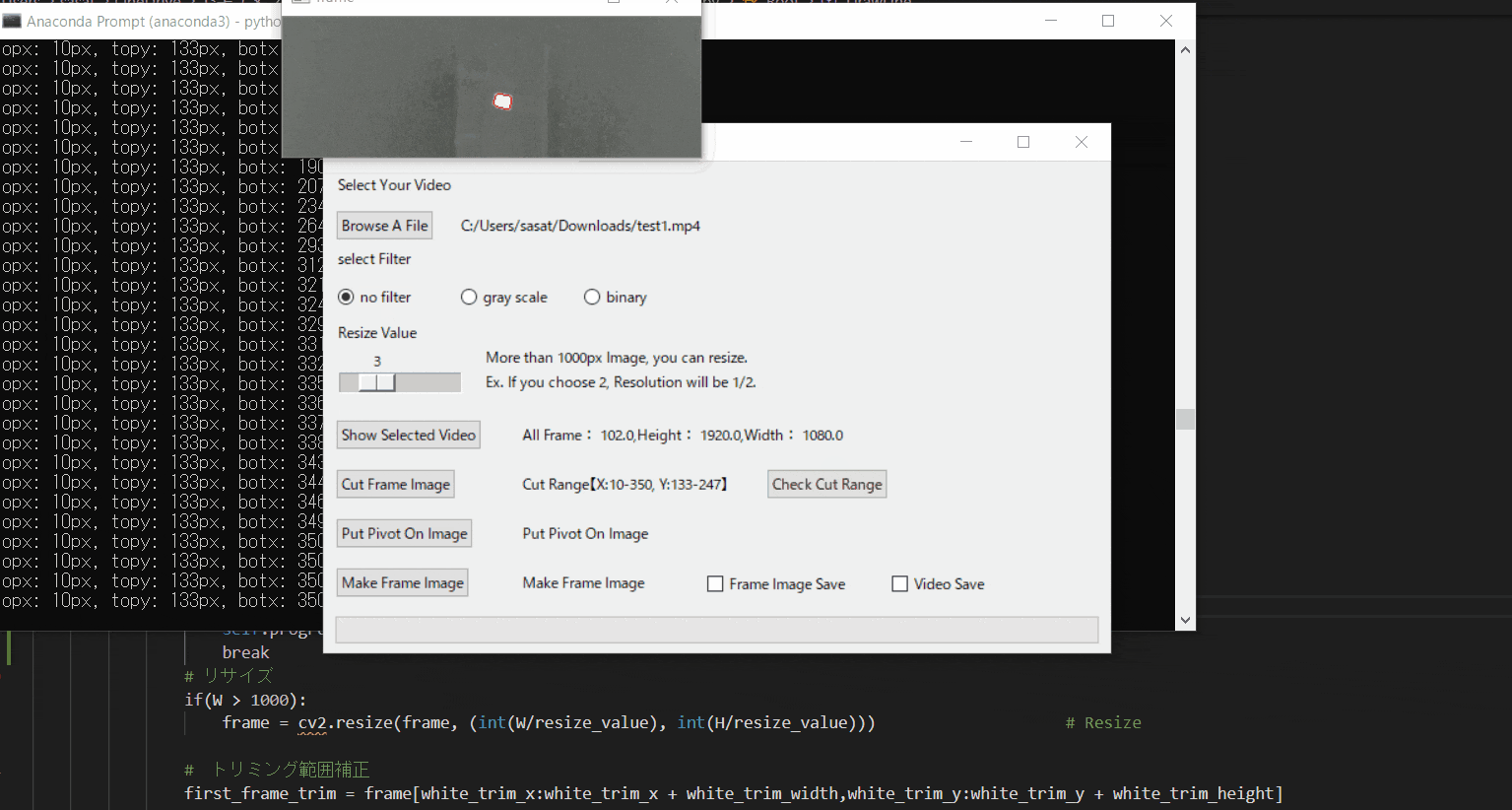
「Check Cut Range」を押して、トリミングした範囲で動画を表示します。
「no filter」を選択した場合、目標点が赤枠で囲われていることを確認できる。
この赤枠がほかの箇所にも表示されている場合は、トリミング範囲の修正が必要。または、動画の撮り直しや撮影環境の見直しが必要です。このTkinter機能は、こちらのスクリプトを参考にしてください。
[ラベル] https://github.com/sassa4771/Find_Angle_Tkinter/blob/main/tk_lesson/tk_lesson2(Labels).py
[ボタンと機能呼び出し] https://github.com/sassa4771/Find_Angle_Tkinter/blob/main/tk_lesson/tk_lesson4(Button%20And%20Button%20Commands).py
【7.自動追従が失敗する場合の例】
仮にトリミング範囲を大きくしてみましょう。
そうすると、目標点と思われる場所がプログラム上で判断できなくなってしまうため、手にも赤枠が表示されているのがわかると思います。
これを避けるために、目標点の自動追従範囲を絞る必要があります。
【8.回転中心を決定する】
次に、回転中心(Pivot)を決定します。
「Put Pivot On Image」を押して、マウスをドラックすることで赤点を操作できます。
その赤点を回転中心におきましょう。このTkinter機能は、こちらのスクリプトを参考にしてください。
[ラベル] https://github.com/sassa4771/Find_Angle_Tkinter/blob/main/tk_lesson/tk_lesson2(Labels).py
[ボタンと機能呼び出し] https://github.com/sassa4771/Find_Angle_Tkinter/blob/main/tk_lesson/tk_lesson4(Button%20And%20Button%20Commands).py
[マウストラッキング] https://github.com/sassa4771/Find_Angle_Tkinter/blob/main/tk_lesson/tk_lesson26(mouse_tracking).py
【9.角度表示を行う】
ここまで出来たら、最後の処理を行いましょう。
「Make Frame Image」を押すことで、処理された動画を確認することができます。このTkinter機能は、こちらのスクリプトを参考にしてください。
[ラベル] https://github.com/sassa4771/Find_Angle_Tkinter/blob/main/tk_lesson/tk_lesson2(Labels).py
[ボタンと機能呼び出し] https://github.com/sassa4771/Find_Angle_Tkinter/blob/main/tk_lesson/tk_lesson4(Button%20And%20Button%20Commands).py
【10.作成した動画を保存】
「Video Save」にチェックを入れて、「Check Cut Range」を押すと、動画を保存できます。
pythonのファイルがある場所に、今の日付時間のフォルダーを作成して、その中に保存されます。このTkinter機能は、こちらのスクリプトを参考にしてください。
[ラベル] https://github.com/sassa4771/Find_Angle_Tkinter/blob/main/tk_lesson/tk_lesson2(Labels).py
[ボタンと機能呼び出し] https://github.com/sassa4771/Find_Angle_Tkinter/blob/main/tk_lesson/tk_lesson4(Button%20And%20Button%20Commands).py
[チェックボタン] https://github.com/sassa4771/Find_Angle_Tkinter/blob/main/tk_lesson/tk_lesson7(Check%20Button).py
【11.作成した動画をフレームごとに分けて画像で保存】
「Frame Image Save」にチェックを入れて、「Check Cut Range」を押すと、動画をフレームごとに分けて画像で保存できます。
pythonのファイルがある場所に、今の日付時間のフォルダーを作成して、その中に保存されます。このTkinter機能は、こちらのスクリプトを参考にしてください。
[ラベル] https://github.com/sassa4771/Find_Angle_Tkinter/blob/main/tk_lesson/tk_lesson2(Labels).py
[ボタンと機能呼び出し] https://github.com/sassa4771/Find_Angle_Tkinter/blob/main/tk_lesson/tk_lesson4(Button%20And%20Button%20Commands).py
[チェックボタン] https://github.com/sassa4771/Find_Angle_Tkinter/blob/main/tk_lesson/tk_lesson7(Check%20Button).py
【12.角度情報を数値で取得】
動画で表示するだけでなく、数値で位置座標を取得したい場合はコマンドプロンプトから取得することができます。
【13.最後に全体の確認】
ここで最後に、全体の一連の流れを確認しましょう。[Something went wrong]()
④Tkinter学び方(参考スクリプト付き)
本ツールで利用した機能などはlesson1~27までを用意しているので、チェックしてください。
https://github.com/sassa4771/Find_Angle_Tkinter/tree/main/tk_lesson機能一つ一つを確認できるようにしてあるので、オリジナルを作るのに役立つと思います。
⑤本ツールの作り方(簡易版)
本ツールのフィルターや画像処理に関しては、eyetrackのところで同じフィルターについて解説をしているので参考にしてください。
https://github.com/sassa4771/eyetrackまた、Tkinterの機能に関しても前章の「④Tkinter学び方(参考スクリプト付き)」ですべてできているので参考にしてください。


- 投稿日:2021-01-21T14:38:13+09:00
QSVMの量子回路の特徴をカラーマップ化してみた
$$
\def\bra#1{\mathinner{\left\langle{#1}\right|}}
\def\ket#1{\mathinner{\left|{#1}\right\rangle}}
\def\braket#1#2{\mathinner{\left\langle{#1}\middle|#2\right\rangle}}
$$はじめに
量子サポートベクトルマシン(QSVM)は,サポートベクトルマシン(SVM)に量子計算を導入しようというものです.
ここでは,あるサンプルの分類問題を考えます.
QSVMでは量子計算を使うにあたって,各データ(古典サンプルと呼びます)を量子回路を用いて量子状態に埋め込まなくてはいけません.ここで一般的に,「どんな量子回路を用いるかで,分類の精度が変化する」といことが知られています.
つまり,量子回路には特有の特徴があるということです!
本記事は,その特徴をカラーマップで可視化してみようというものです.
※本記事では,この性質の証明とQSVMの具体的なアルゴリズムについては触れません.
これに関しては,[元論文]とこちらの[記事]を参考にしてみてください.量子回路を導入しよう
ここでは,2次元データの2クラス分類を例に挙げて説明します.
QSVMでは,以下の数式で表せる量子回路を初期状態$\ket{0}^{\otimes2}$に作用させることで,古典サンプルを量子状態に埋め込みます.
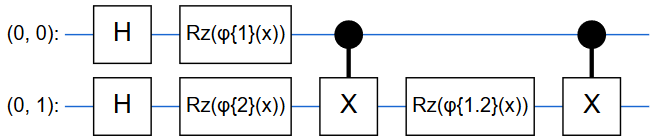
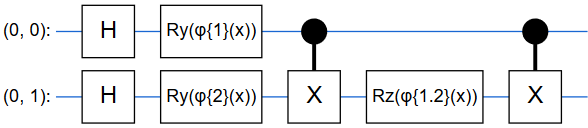
\rm \mathcal{U}_\Phi(\bf x)\rm = U_\Phi(\bf x)\rm H^{\otimes2}U_\Phi(\bf x)\rm H^{\otimes2} \tag{1}本記事では,$U_\Phi(\bf x)\rm H^{\otimes2}$のことを単に「量子回路」と呼びます.
回路の形で示した方がしっくりとくるので以下に示します.ちなみにRzゲートは任意のZ軸回転を作用させるものです.
元論文では各Rzゲートの回転角度を,
\{\phi_{\{1\}}(\bf x)\rm=x_1,\phi_{\{2\}}(\bf x)\rm=x_2, \phi_{\{1,2\}}(\bf x)\rm =(\pi-x_1)(\pi-x_2)\} \tag{2}のようにしていました.
つまり,ここで古典サンプルの情報を量子回路に埋め込んでいるということです!本記事では,この量子回路と回路に含まれる位相ゲートの位相を変化させてみました.
量子状態の特徴をとらえよう
ところで,先ほどの量子回路の持つ特徴とは何でしょうか.
まず,初期状態に(1)を作用させた,$\ket{\Phi(x)} = \mathcal{U}_{\Phi(x)}\ket{0}^{\otimes 2}$の内積$|\braket{\Phi(\bf{x})}{\Phi(\bf{z})}|^2$について考えます.
この内積を考える考え方はSVMでもありましたね!この内積が,サンプルの識別境界に影響を与えるということです.よって,次にその内積の持つ特徴について考えていきます.この際に,密度演算子の性質を用いて,
先ほどの内積は,|\braket{\Phi(\bf{x})}{\Phi(\bf{z})}|^2=2^2\sum_{i=1}^{4^2} a_i(x) a_i(z)のように変形することが出来ます.(ここでは結果だけ示します.)
つまりこの$a_i$というのが先ほどから言っている特徴でありそうです.
最後にこの$a_i$について見ていきます.
これは,密度演算子$\rho(x) = \ket{\Phi(x)}\bra{\Phi(x)}$が,($\ket{\Phi(x)}$は量子回路を通して得られた状態)
\rho(x) = \sum_{i=1}^{4^2}a_i(x)\sigma_i = \sum_{i=1}^{16}a_i(x)\sigma_iとなる性質を用いて出てきたものなのでした!(これは2量子状態の場合です.)
(簡単に示すと,密度演算子$\rho$は,$|\braket{\Phi(\bf{x})}{\Phi(\bf{z})}|^2 = tr[\rho(x)\rho(z)]$を満たし,$tr(\sigma_i\sigma_j) = 2^n\delta_{i,j}$も満たすから)
ここで,$\sigma_1, \sigma_2,..., \sigma_{16}$は$II, IX,..., ZZ$です.(I,X,Y,Zはパウリゲート)
つまり,$a_1(x), a_2(x),...,a_{16}(x)$は密度演算子をパウリゲートの線形和に表した時の各ゲートの係数だったのです!
よって古典サンプル$x$の特徴は,量子回路を通して$a_1(x), a_2(x),...,a_{16}(x)$に写像されました.
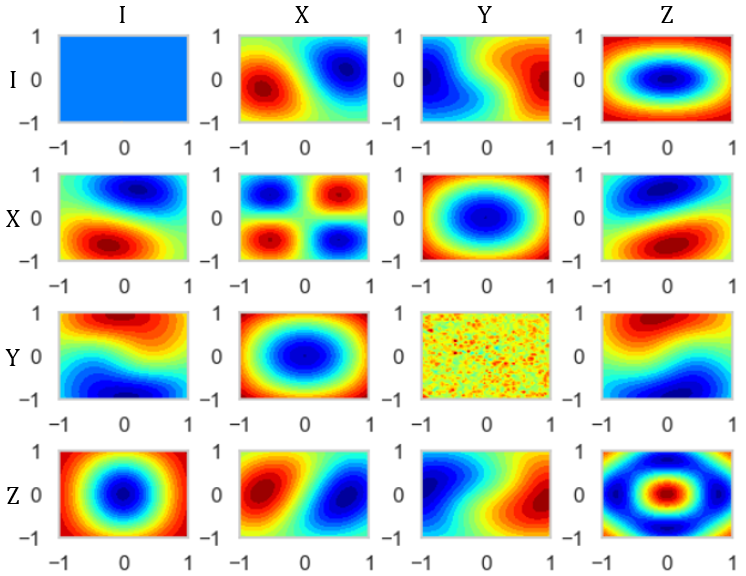
特徴をカラーマップ化してみよう
一般的に,上で示した特徴$a_1(x), a_2(x),...,a_{16}(x)$は,
a_1 = tr[\rho(x)\sigma_1(x)],a_2 = tr[\rho(x)\sigma_2(x)],...,a_{16} = tr[\rho(x)\sigma_{16}(x)]のように得ることが出来ます.
そもそも$\rho(x)=\ket{\Phi(x)}\bra{\Phi(x)}$であり,また$\ket{\Phi(x)} = \mathcal{U}_{\Phi(x)}\ket{0}^{\otimes 2}$を満たしていたので,
$\rho(x)$は作用させる(1)によって異なることがわかります.発想を転換させましょう.
$\rho(x)$は作用させる(1)によって異なる.
-> $\rho(x)$は作用させる量子回路によって異なる.
-> $\rho(x)$によって得られる$a_1(x), a_2(x),...,a_{16}(x)$は作用させる量子回路によって異なる.
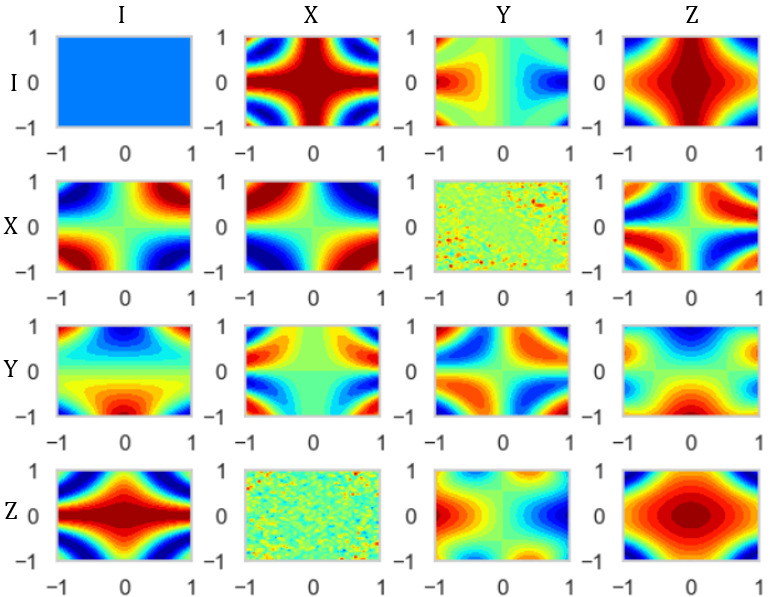
-> $a_1(x), a_2(x),...,a_{16}(x)$は量子回路の特徴でもある.この量子回路の特徴を可視化します.以下は,先ほどの量子回路と位相(2)の場合です.
まず以下のコードで係数$a_1(x), a_2(x),...,a_{16}(x)$を獲得.
circuit.pydef func(x1, x2, i): #2次元データ x12 = np.cos(x1 + x2) #$\phi{1,2}の位相$ # エンコード回路において,最初に2つのビットそれぞれに作用される位相ゲート # Rzゲート U1 = np.array([[1, 0], [0, np.cos(x1)+1j*np.sin(x1)]]) U2 = np.array([[1, 0], [0, np.cos(x2)+1j*np.sin(x2)]]) U_2 = np.kron(U1, U2) # エンコード回路において,CNOTゲートに挟まれる位相ゲート # Rzゲート U12 = np.kron(np.array([[1,0], [0,1]]), np.array([[1,0],[0,np.cos(x12) + 1j*np.sin(x12)]])) #量子回路を通す ##HはアダマールゲートでC_Sは初期状態 F_1 = np.matmul(CNOT, np.matmul(U12, np.matmul(CNOT, np.matmul(U_2, H_2)))) F_2 = np.matmul(F_1, F_1) C = np.matmul(F_2, C_S) C_H = np.conjugate(C.T) C_F = np.matmul(C, C_H) # 係数の取得 A = np.trace(np.matmul(C_F, np.kron(i[0], i[1])))/4 return Aそしてここで得られた16個の係数のカラーマップを表示します.
colormap.pyplt.style.use('default') sns.set() sns.set_style('whitegrid') sns.set_palette('gray') np.random.seed(2020) fig = plt.figure() for idx, p in enumerate(pair):#pairは\sigma_1, \sigma_2,..., \sigma_{16}のリスト a = np.linspace(-1, 1, 50) b = np.linspace(-1, 1, 50) A, B = np.meshgrid(a, b) C = [] for i in range(50): for j in range(50): c = func(A[i][j], B[i][j], p) C.append(c) C = np.array(C).reshape(50, 50) ax1 = fig.add_subplot(4, 4, idx+1) plt.subplots_adjust(wspace=0.4, hspace=0.6) ax1.contourf(A, B, C, 20, cmap="jet") plt.show()これにより得られるカラーマップは,
のようになります.一番左上が$a_1(x)$で右下が$a_{16}(x)$のカラーマップです.
これで先ほどの量子回路の特徴を捉えることが出来ました!
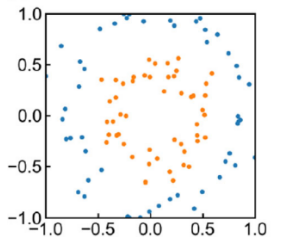
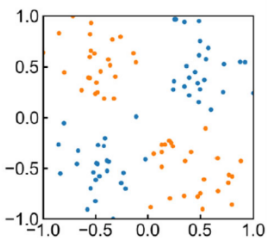
ここで$a_{16}(x)$のカラーマップに注目してみてください.真ん中が出っ張っていますよね.
つまり,この量子回路は$a_{16}(x)$を特徴として持つため,下ような散らばりを持つデータの分類に有効に働くと言えそうです!
ここらへんの,詳細は[Analysis and synthesis of feature map for kernel-based quantum classifier]に示されています.
いろいろな量子回路
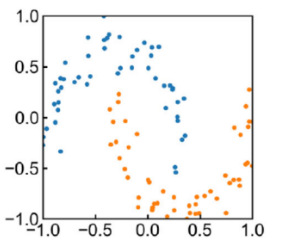
先ほどの量子回路が円の概形を散らばりにもつデータの分類に適しているということは示しました.
ここでは,例として二つほど別の量子回路を導入していきます.
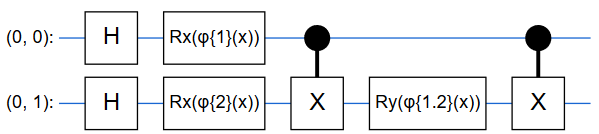
量子回路の例1
一つ目は以下の回路です.
一見最初の回路と同じように見えますが,使用している位相ゲートが異なります.
(一つ目がRxゲート,二つ目がRyゲートです)またこれらのゲートにおける位相を,
\{\phi_{\{1\}}(\bf x)\rm=x_1,\phi_{\{2\}}(\bf x)\rm=x_2, \phi_{\{1,2\}}(\bf x)\rm =\pi x_1x_2\}のように設定しました.ここも,さき程と異なります.
この回路が持つ特徴は以下のようになります.
これは以下のようなデータの分類に適してそうです.
量子回路の例2
二つ目は以下の回路です.
これも使用している位相ゲートが異なります.(一つ目がRyゲート,二つ目がRzゲートです)
これらのゲートにおける位相は,
\{\phi_{\{1\}}(\bf x)\rm=x_1,\phi_{\{2\}}(\bf x)\rm=x_2, \phi_{\{1,2\}}(\bf x)\rm =cos(x_1)cos(x_2)\}のように設定しました.
この回路が持つ特徴は以下のようになりました.
ここで,$a_9やa_{12}$をみてください.これは,以下のようなデータの分類に適してそうです.
このようにQSVMにおいて,量子回路によって,どんな散らばりを持つデータの分類に適するかが異なることがわかりました.
実際に,moon型のデータの分類を今まで示してきた三つの回路を用いたQSVMで試してみたところ,三つ目の回路を用いた時に格段に精度が高くなりました.
補足
最後にこの量子回路をQSVMにおいて導入するコードを載せておきます.
ベースはこちらの[記事]を参考にさせていただきました.この記事では,一番最初の回路を用いています.一番最初の回路はqiskitにAPIが用意してあります.
circuit1.pyfeature_map1 = ZZFeatureMap(feature_dim, reps=2)二つ目の回路は以下のコードで可能です.
circuit2.pyclass CustomFeatureMap(FeatureMap): def __init__(self, feature_dimension, depth=2, entangler_map=None): self._support_parameterized_circuit = False self._feature_dimension = feature_dimension self._num_qubits = self._feature_dimension = feature_dimension self._depth = depth self._entangler_map = None if self._entangler_map is None: self._entangler_map = [[i, j] for i in range(self._feature_dimension) for j in range(i + 1, self._feature_dimension)] # 回路の構築 def construct_circuit(self, x, qr, inverse=False): qc = QuantumCircuit(qr) for _ in range(self._depth): qc.h(qr[0]) qc.h(qr[1]) qc.rx(x[0], qr[0]) qc.rx(x[1], qr[1]) qc.cx(qr[0], qr[1]) qc.ry(np.pi * x[0] * x[1], qr[1]) qc.cx(qr[0], qr[1]) if inverse: qc.inverse() return qcこれをベースモデルの該当箇所に置き換えてあげれば実際にQSVMを動かすことが出来ます!
まとめ
本記事では,QSVMにおける量子回路のもつ特徴をカラーマップを用いて可視化しました.
これにより,どんな量子回路を用いるかで,どんな散らばりを持つデータの分類に適するかが異なることがわかりました.
つまり,あるデータが与えられたときに,どの量子回路を用いるかを選択することが出来るということです.
これは,SVMにはない興味深い知見であるとに思います.この性質を有効に活用すれば,従来のSVMに勝る精度を出すことも期待できます!
参考サイト

- 投稿日:2021-01-21T14:17:00+09:00
Python Webカメラでeye tracking(アイトラッキング・視線計測)をする【Windows10】
https://github.com/sassa4771/eyetrack/tree/main/Eye_Tracking_Program_by_dlib
ここのファイルの中身説明↑このサイトでできること
・webカメラを利用した視線計測(以下の動画のイメージ)
目次
①eyetracking(アイトラッキング・視線計測)とは?
②必要なライブラリ・動作環境(※とりあえず動かしたい人はここから)
③dlibを使った顔ランドマーク検出
④瞳の区画切り出し
⑤機械学習で検出(失敗)
⑥画像処理で検出(成功)
⑦その他試したこと(Docker接続など)
⑧完成①eyetracking(アイトラッキング・視線計測)とは?
【eye trackingとは】
eye trackingとは、ユーザーの視線の動きを計測し分析するアイトラッキング(視線計測)技術のこと。
ヒトの眼球運動を分析し、視覚的注意などを明らかにする生体計測手法です。
ヒトの視線の場所(注視点)や動きを、アイトラッカーと呼ばれる専門の機械で計測。
取得したデータを分析し、よく見られていた場所や、見る順序、反対に全く見られていなかった場所などを明らかにします。心理学や認知科学などの学術領域のほか、マーケティング領域、観光分野、医療・教育・スポーツの研究など、さまざまな分野で利活用されているほか、近年ではVR空間内での計測やAIによる視線推定などの研究も盛んに行われており、今後も成長が期待されている技術です。
(参考:https://neu-brains.co.jp/information/case-study/2020/09/25/1489.html)
要するに
視線がどこにあるかわかる!
【製品】
製品は、Tobiが有名
・https://www.tobiipro.com/ja/
・https://www.tobiipro.com/ja/service-support/learning-center/eye-tracking-essentials/what-is-dark-and-bright-pupil-tracking/【瞳孔検出方法】
赤外線を利用した検出方法が主流
・file:///C:/Users/sasat/Downloads/IPSJ-Z69-5P-08.pdf
・https://www.tobiipro.com/ja/service-support/learning-center/eye-tracking-essentials/what-is-dark-and-bright-pupil-tracking/②必要なライブラリ・動作環境
必要なものはGitHubからダウンロードしてください。
https://github.com/sassa4771/eyetrack【動作環境:(Let's Note)】
OS:windows10 Pro
CPU:Corei7
メモリ:12GB【必要なライブラリ】
・dlib
・opencv
・numpy【Anaconda環境インストールコマンド】
使用した環境はeyetrack.yamlにあります。cd 【eyetrack.yamlがあるとディレクトリ】 conda env create -n eyetrack -f eyetrack.yaml環境をインストールしたらmainファイルのrun.batを起動するとソフトが起動できる。
③dlibを使った顔ランドマーク検出
【dlibのインストール】
※インストールが若干めんどくさい(windowsの場合)
windowsでdlibを利用するにはPowerShellからCMakeをインストールしないといけない。参考にしたサイト:https://rikoubou.hatenablog.com/entry/2019/06/17/160248
【CMakeダウンロードサイト】
参考サイト:https://cmake.org/download/【opencvのダウンロード】
参考サイト:https://qiita.com/fiftystorm36/items/1a285b5fbf99f8ac82eb
よくコマンドを忘れるので、注意。④瞳の区画切り出し
【瞳の区画切り出し】
【opencvで画像の切り出し方法】
参考サイト:https://qiita.com/mo256man/items/e36797f9f44a64caf81c【opencvで画像サイズの拡大方法】
参考サイト:https://qiita.com/kenfukaya/items/dfa548309c301c7087c4【opencvウィンドウの変更】
参考サイト:https://qiita.com/Kazuhito/items/b2ebd9f9010f1ffcac5b
ウィンドウが表示される場所を固定するため。【int型をstring型に変更する方法】
参考サイト:https://www.javadrive.jp/python/string/index9.html【画像の二値化】
参考サイト:https://qiita.com/tokkuri/items/ad5e858cbff8159829e9⑤機械学習で検出(失敗)
https://github.com/sassa4771/eyetrack/tree/main/tensorflow_pictures
↑ここのファイルの中身においてある。GoogleのTeachable Machineを利用としたが、dlibに使うnumpyと機械学習で使うTensorflowのnumpyが合わなかったため断念。
Teachable Machine:https://teachablemachine.withgoogle.com/keras==2.2.4,tensorflow==1.15.0,pillow==7.0.0
をダウンロードしないと動かないらしい。⑥画像処理で検出(成功)
【画像処理で検出】
【平滑化、二値化、輪郭の抽出】
参考サイト:https://qiita.com/ankomotch/items/74884b0ca24b739159c0【抽出した座標に長方形・円を表示】
参考サイト:https://note.nkmk.me/python-opencv-draw-function/
⑦その他試したこと(Docker接続など)
【Docker】
opencvとnumpyのインストールで苦戦したので、環境のリセットが容易なDockerをしようと試みた。
Windows版のDockerでは、カメラデバイスを検出できないため断念。
(一応VirtualBoxを使えばできるらしいが、せっかくのコンテナなのにホスト型の仮想環境を使うのはナンセンスと思った。)【opencvのインポートでエラー】
ImportError: numpy.core.multiarray failed to import
がでる。opencvとnumpyのバージョンを合わせると解決する。
・pip uninstall opencv-python
・pip uninstall numpy・conda uninstall opencv-python
・conda uninstall numpyでアンインストールしてから、
・pip install opencv-python==3.4.2.17 numpy==1.14.5
をする。
※↑python=3.6じゃないとインストールできない⑧完成
次は、web版でopencvとか使いたい。
追記
【瞬きの判定を入れた】


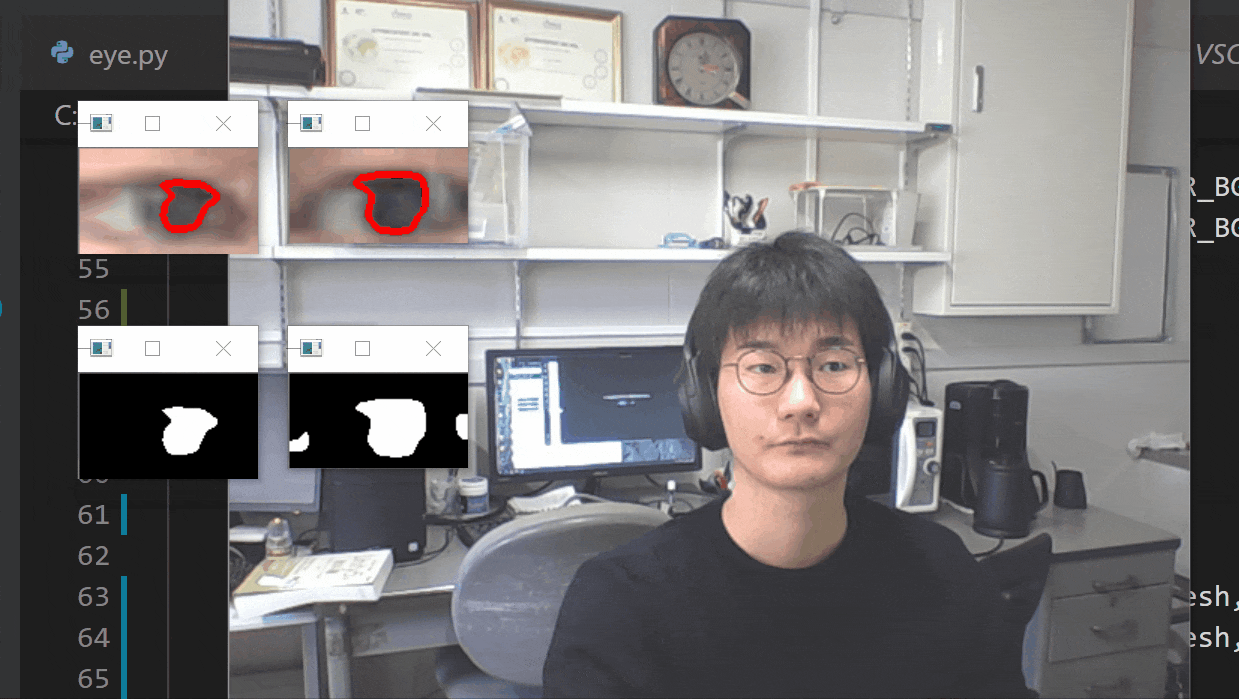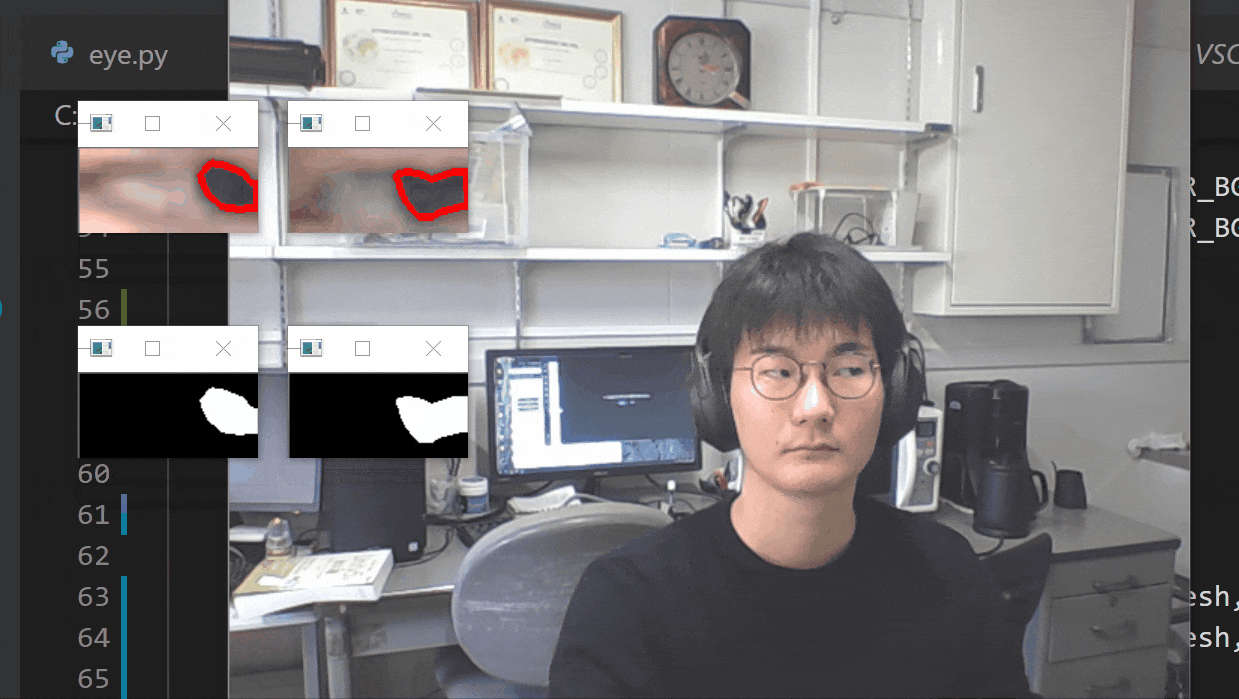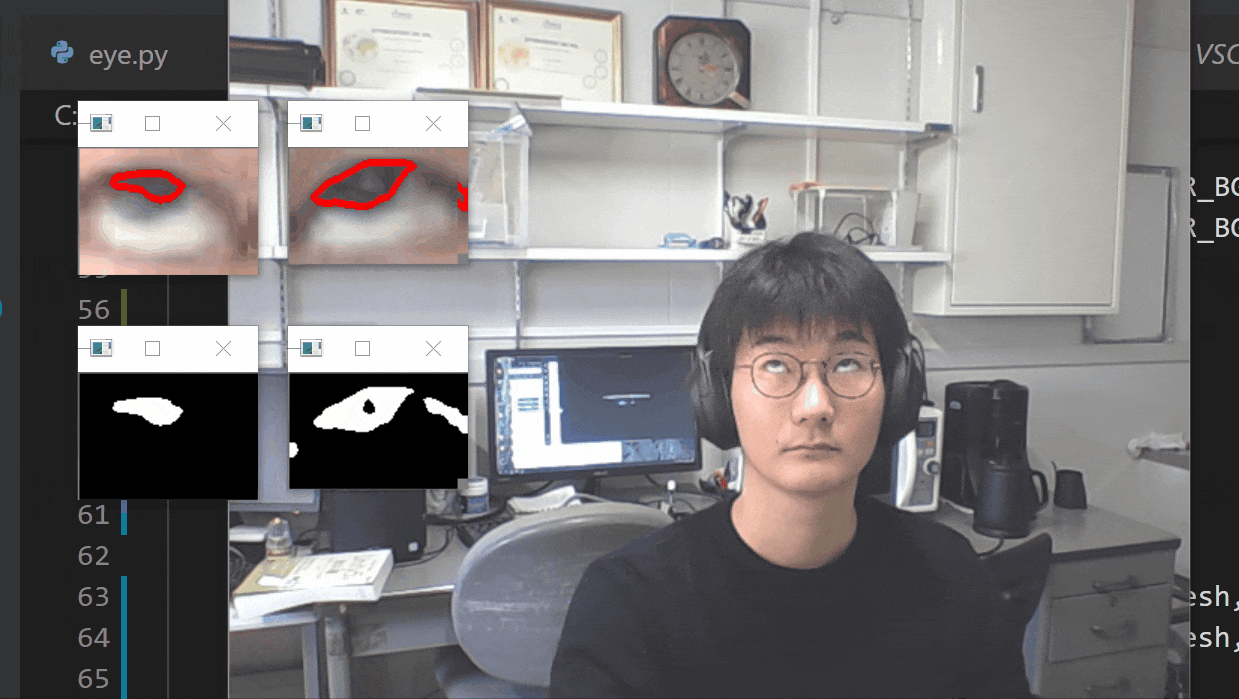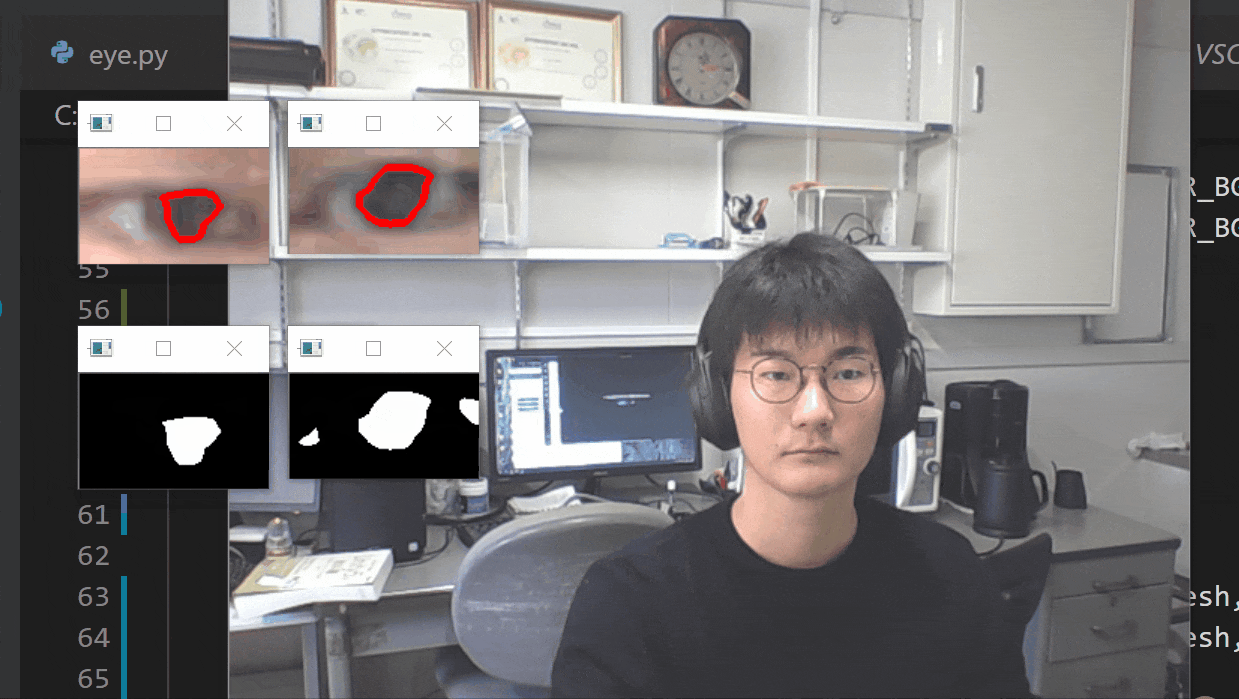



- 投稿日:2021-01-21T14:17:00+09:00
Webカメラでeye tracking(アイトラッキング・視線計測)をする【Windows10】
https://github.com/sassa4771/eyetrack/tree/main/Eye_Tracking_Program_by_dlib
ここのファイルの中身説明↑このサイトでできること
・webカメラを利用した視線計測(以下の動画のイメージ)
目次
①eyetracking(アイトラッキング・視線計測)とは?
②必要なライブラリ・動作環境(※とりあえず動かしたい人はここから)
③dlibを使った顔ランドマーク検出
④瞳の区画切り出し
⑤機械学習で検出(失敗)
⑥画像処理で検出(成功)
⑦その他試したこと(Docker接続など)
⑧完成①eyetracking(アイトラッキング・視線計測)とは?
【eye trackingとは】
eye trackingとは、ユーザーの視線の動きを計測し分析するアイトラッキング(視線計測)技術のこと。
ヒトの眼球運動を分析し、視覚的注意などを明らかにする生体計測手法です。
ヒトの視線の場所(注視点)や動きを、アイトラッカーと呼ばれる専門の機械で計測。
取得したデータを分析し、よく見られていた場所や、見る順序、反対に全く見られていなかった場所などを明らかにします。心理学や認知科学などの学術領域のほか、マーケティング領域、観光分野、医療・教育・スポーツの研究など、さまざまな分野で利活用されているほか、近年ではVR空間内での計測やAIによる視線推定などの研究も盛んに行われており、今後も成長が期待されている技術です。
(参考:https://neu-brains.co.jp/information/case-study/2020/09/25/1489.html)
要するに
視線がどこにあるかわかる!
【製品】
製品は、Tobiが有名
・https://www.tobiipro.com/ja/
・https://www.tobiipro.com/ja/service-support/learning-center/eye-tracking-essentials/what-is-dark-and-bright-pupil-tracking/【瞳孔検出方法】
赤外線を利用した検出方法が主流
・file:///C:/Users/sasat/Downloads/IPSJ-Z69-5P-08.pdf
・https://www.tobiipro.com/ja/service-support/learning-center/eye-tracking-essentials/what-is-dark-and-bright-pupil-tracking/②必要なライブラリ・動作環境
必要なものはGitHubからダウンロードしてください。
https://github.com/sassa4771/eyetrack【動作環境:(Let's Note)】
OS:windows10 Pro
CPU:Corei7
メモリ:12GB【必要なライブラリ】
・dlib
・opencv
・numpy【Anaconda環境インストールコマンド】
使用した環境はeyetrack.yamlにあります。cd 【eyetrack.yamlがあるとディレクトリ】 conda env create -n eyetrack -f eyetrack.yaml環境をインストールしたらmainファイルのrun.batを起動するとソフトが起動できる。
③dlibを使った顔ランドマーク検出
【dlibのインストール】
※インストールが若干めんどくさい(windowsの場合)
windowsでdlibを利用するにはPowerShellからCMakeをインストールしないといけない。参考にしたサイト:https://rikoubou.hatenablog.com/entry/2019/06/17/160248
【CMakeダウンロードサイト】
参考サイト:https://cmake.org/download/【opencvのダウンロード】
参考サイト:https://qiita.com/fiftystorm36/items/1a285b5fbf99f8ac82eb
よくコマンドを忘れるので、注意。④瞳の区画切り出し
【瞳の区画切り出し】
【opencvで画像の切り出し方法】
参考サイト:https://qiita.com/mo256man/items/e36797f9f44a64caf81c【opencvで画像サイズの拡大方法】
参考サイト:https://qiita.com/kenfukaya/items/dfa548309c301c7087c4【opencvウィンドウの変更】
参考サイト:https://qiita.com/Kazuhito/items/b2ebd9f9010f1ffcac5b
ウィンドウが表示される場所を固定するため。【int型をstring型に変更する方法】
参考サイト:https://www.javadrive.jp/python/string/index9.html【画像の二値化】
参考サイト:https://qiita.com/tokkuri/items/ad5e858cbff8159829e9⑤機械学習で検出(失敗)
https://github.com/sassa4771/eyetrack/tree/main/tensorflow_pictures
↑ここのファイルの中身においてある。GoogleのTeachable Machineを利用としたが、dlibに使うnumpyと機械学習で使うTensorflowのnumpyが合わなかったため断念。
Teachable Machine:https://teachablemachine.withgoogle.com/keras==2.2.4,tensorflow==1.15.0,pillow==7.0.0
をダウンロードしないと動かないらしい。⑥画像処理で検出(成功)
【画像処理で検出】
【平滑化、二値化、輪郭の抽出】
参考サイト:https://qiita.com/ankomotch/items/74884b0ca24b739159c0【抽出した座標に長方形・円を表示】
参考サイト:https://note.nkmk.me/python-opencv-draw-function/
⑦その他試したこと(Docker接続など)
【Docker】
opencvとnumpyのインストールで苦戦したので、環境のリセットが容易なDockerをしようと試みた。
Windows版のDockerでは、カメラデバイスを検出できないため断念。
(一応VirtualBoxを使えばできるらしいが、せっかくのコンテナなのにホスト型の仮想環境を使うのはナンセンスと思った。)【opencvのインポートでエラー】
ImportError: numpy.core.multiarray failed to import
がでる。opencvとnumpyのバージョンを合わせると解決する。
・pip uninstall opencv-python
・pip uninstall numpy・conda uninstall opencv-python
・conda uninstall numpyでアンインストールしてから、
・pip install opencv-python==3.4.2.17 numpy==1.14.5
をする。
※↑python=3.6じゃないとインストールできない⑧完成
次は、web版でopencvとか使いたい。
追記
【瞬きの判定を入れた】
- 投稿日:2021-01-21T13:28:06+09:00
回帰分析その1
線形回帰実装
中古車の値段を予想するモデルを作成してきます。
ライブラリーのインポート
import numpy as np import pandas as pd import statsmodels.api as sm import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression import seaborn as sns sns.set()データの読み込み
raw_data = pd.read_csv("/Users/xxx/Desktop/分析ソース/xxxx.csv") raw_data.head()----------↓結果----------
Brand Price Body Mileage EngineV Engine Type Registration Year Model
0 BMW 4200.0 sedan 277 2.0 Petrol yes 1991 320
1 Mercedes-Benz 7900.0 van 427 2.9 Diesel yes 1999 Sprinter 212
2 Mercedes-Benz 13300.0 sedan 358 5.0 Gas yes 2003 S 500
3 Audi 23000.0 crossover 240 4.2 Petrol yes 2007 Q74 Toyota 18300.0 crossover 120 2.0 Petrol yes 2011 Rav 4
このデータで確認でわかるものは
Brand Price Body Mileage EngineV Engine Type Registration Year Model が価値に影響があるのではないかと推測ができる前処理
変数の記述統計量の確認(データに何か問題がないか確認する時の方法として記述統計量を確認します)
raw_data.describe(include='all') /*←引数として全て選択 ここでデータの説明をしてもらいます ここで得られるデータはデフォルトでは量的変数に対応している*/----------↓結果----------
Brand Price Body Mileage EngineV Engine Type Registration Year Model
count 4345 4173.000000 4345 4345.000000 4195.000000 4345 4345 4345.000000 4345
unique 7 NaN 6 NaN NaN 4 2 NaN 312
top Volkswagen NaN sedan NaN NaN Diesel yes NaN E-Class
freq 936 NaN 1649 NaN NaN 2019 3947 NaN 199
mean NaN 19418.746935 NaN 161.237284 2.790734 NaN NaN 2006.550058 NaN
std NaN 25584.242620 NaN 105.705797 5.066437 NaN NaN 6.719097 NaN
min NaN 600.000000 NaN 0.000000 0.600000 NaN NaN 1969.000000 NaN
25% NaN 6999.000000 NaN 86.000000 1.800000 NaN NaN 2003.000000 NaN
50% NaN 11500.000000 NaN 155.000000 2.200000 NaN NaN 2008.000000 NaN
75% NaN 21700.000000 NaN 230.000000 3.000000 NaN NaN 2012.000000 NaN
max NaN 300000.000000 NaN 980.000000 99.990000 NaN NaN 2016.000000 NaN変数の選択
ここでモデルに対して意味のなさないデータが推測できるのでpandasのdropメソットを使って取り除いていきます
data = raw_data.drop(['Model'],axis=1) /* axisは表上列を指定する*/ data.describe(include='all')Brand
Price
Body
Mileage
EngineV
Engine Type
Registration
Year
count
4345 4173.000000 4345 4345.000000 4195.000000 4345 4345 4345.000000unique
7 NaN 6 NaN NaN 4 2 NaNtop
Volkswagen NaN sedan NaN NaN Diesel yes NaNfreq
936 NaN 1649 NaN NaN 2019 3947 NaNmean
NaN 19418.746935 NaN 161.237284 2.790734 NaN NaN 2006.550058std
NaN 25584.242620 NaN 105.705797 5.066437 NaN NaN 6.719097min
NaN 600.000000 NaN 0.000000 0.600000 NaN NaN 1969.00000025%
NaN 6999.000000 NaN 86.000000 1.800000 NaN NaN 2003.00000050%
NaN 11500.000000 NaN 155.000000 2.200000 NaN NaN 2008.00000075%
NaN 21700.000000 NaN 230.000000 3.000000 NaN NaN 2012.000000max
NaN 300000.000000 NaN 980.000000 99.990000 NaN NaN 2016.000000
ここで欠けているデータ欠けていないデータを確認する事ができたので欠損値の値を確認していきます。
data.isnullメソットを使い確認値が入ってないデータにはtureが返ってきます。
data.isnull().sum()Brand 0
Price 172
Body 0
Mileage 0
EngineV 150
Engine Type 0
Registration 0
Year 0
dtype: int64データが欠けている割合が5%よりも小さければ、そのデータはそのまま削除しても問題ない場合が多いです
影響5%未満のデータを削除していきます。
data_no_mv = data.dropna(axis=0) data_no_mv.describe(include='all')ここで結果がでたら最大値、最小値、平均値などをグラフを
つかい確認を行っていきます。
そのために、確率密度関数を作成していきます。率密度関数
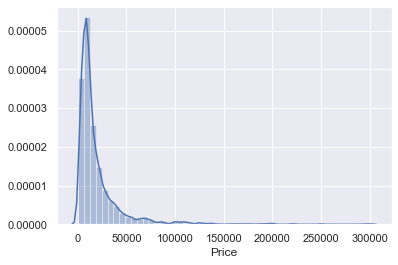
sns.distplot(data_no_mv['Price'])
値段には外れ値があることがわかります。
回帰はそれぞれのデータに近い線を引いていきますので
外れ値が存在すると線がひきづられていきますので
外れ値に対処する一つの方法として観測されたデータの1%
を取り除いていこうと思います。quantileメソット
引数を取り任意の数値をとることができる
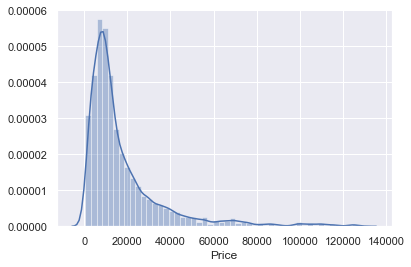
q = data_no_mv['Price'].quantile(0.99) data_1 = data_no_mv[data_no_mv['Price']<q] data_1.describe(include='all')max
NaN 129222.000000 NaN 980.000000 99.990000 NaN NaN 2016.000000max
NaN 129222.000000 が1200なのでまあ許容の範囲いないかなと思いますので
グラフで確認していきます。sns.distplot(data_1['Price'])
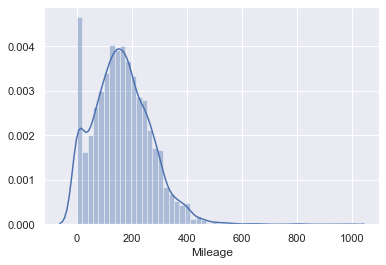
以下も上位1%を取り除いていきます。
sns.distplot(data_no_mv['Mileage'])
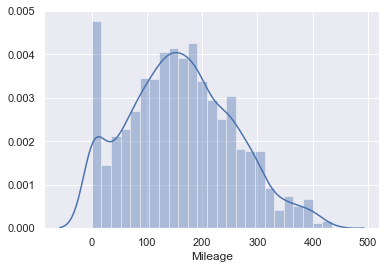
q = data_1['Mileage'].quantile(0.99) data_2 = data_1[data_1['Mileage']<q] sns.distplot(data_2['Mileage'])![4.png]
では、排気量データの99.99%と表記されているが
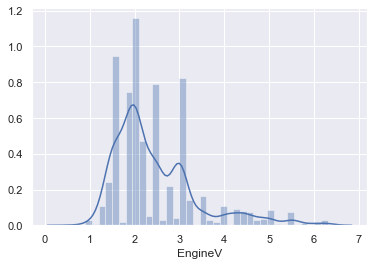
これはPC初期の記載方法であるので欠けた値を99.99%にすることは、その値の正確性についてほかの人が判断することが難しいという意味において、良い方法とは言えないと考える。今回は6.5というベンチマークに合わせて作成していきます。
data_3 = data_2[data_2['EngineV']<6.5] sns.distplot(data_3['EngineV'])
sns.distplot(data_no_mv['Year'])
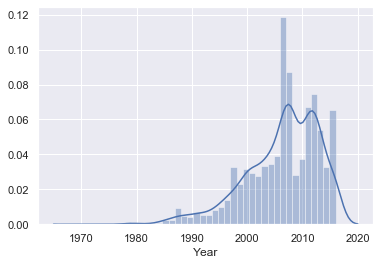
ビンテージ車などほとんど使われていないデータが確認できます。
下位1%のデータを取り除きます。q = data_3['Year'].quantile(0.01) data_4 = data_3[data_3['Year']>q] sns.distplot(data_4['Year'])
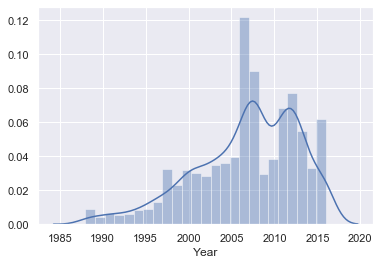
この上で再度、確率密度関数を確認していきます。
data_cleaned = data_4.reset_index(drop=True)data_cleaned.describe(include='all')Brand
Price
Body
Mileage
EngineV
Engine Type
Registration
Year
count
3867 3867.000000 3867 3867.000000 3867.000000 3867 3867 3867.000000unique
7 NaN 6 NaN NaN 4 2 NaNtop
Volkswagen NaN sedan NaN NaN Diesel yes NaNfreq
848 NaN 1467 NaN NaN 1807 3505 NaNmean
NaN 18194.455679 NaN 160.542539 2.450440 NaN NaN 2006.709853std
NaN 19085.855165 NaN 95.633291 0.949366 NaN NaN 6.103870min
NaN 800.000000 NaN 0.000000 0.600000 NaN NaN 1988.00000025%
NaN 7200.000000 NaN 91.000000 1.800000 NaN NaN 2003.00000050%
NaN 11700.000000 NaN 157.000000 2.200000 NaN NaN 2008.00000075%
NaN 21700.000000 NaN 225.000000 3.000000 NaN NaN 2012.000000max
NaN 129222.000000 NaN 435.000000 6.300000 NaN NaN 2016.000000ここで250のデータを取り除くことができました。
- 投稿日:2021-01-21T13:28:06+09:00
線形回帰実装その1
線形回帰実装
中古車の値段を予想するモデルを作成してきます。
ライブラリーのインポート
import numpy as np import pandas as pd import statsmodels.api as sm import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression import seaborn as sns sns.set()データの読み込み
raw_data = pd.read_csv("/Users/xxx/Desktop/分析ソース/xxxx.csv") raw_data.head()----------↓結果----------
Brand Price Body Mileage EngineV Engine Type Registration Year Model
0 BMW 4200.0 sedan 277 2.0 Petrol yes 1991 320
1 Mercedes-Benz 7900.0 van 427 2.9 Diesel yes 1999 Sprinter 212
2 Mercedes-Benz 13300.0 sedan 358 5.0 Gas yes 2003 S 500
3 Audi 23000.0 crossover 240 4.2 Petrol yes 2007 Q74 Toyota 18300.0 crossover 120 2.0 Petrol yes 2011 Rav 4
このデータで確認でわかるものは
Brand Price Body Mileage EngineV Engine Type Registration Year Model が価値に影響があるのではないかと推測ができる前処理
変数の記述統計量の確認(データに何か問題がないか確認する時の方法として記述統計量を確認します)
raw_data.describe(include='all') /*←引数として全て選択 ここでデータの説明をしてもらいます ここで得られるデータはデフォルトでは量的変数に対応している*/----------↓結果----------
Brand Price Body Mileage EngineV Engine Type Registration Year Model
count 4345 4173.000000 4345 4345.000000 4195.000000 4345 4345 4345.000000 4345
unique 7 NaN 6 NaN NaN 4 2 NaN 312
top Volkswagen NaN sedan NaN NaN Diesel yes NaN E-Class
freq 936 NaN 1649 NaN NaN 2019 3947 NaN 199
mean NaN 19418.746935 NaN 161.237284 2.790734 NaN NaN 2006.550058 NaN
std NaN 25584.242620 NaN 105.705797 5.066437 NaN NaN 6.719097 NaN
min NaN 600.000000 NaN 0.000000 0.600000 NaN NaN 1969.000000 NaN
25% NaN 6999.000000 NaN 86.000000 1.800000 NaN NaN 2003.000000 NaN
50% NaN 11500.000000 NaN 155.000000 2.200000 NaN NaN 2008.000000 NaN
75% NaN 21700.000000 NaN 230.000000 3.000000 NaN NaN 2012.000000 NaN
max NaN 300000.000000 NaN 980.000000 99.990000 NaN NaN 2016.000000 NaN変数の選択
ここでモデルに対して意味のなさないデータが推測できるのでpandasのdropメソットを使って取り除いていきます
data = raw_data.drop(['Model'],axis=1) /* axisは表上列を指定する*/ data.describe(include='all')Brand
Price
Body
Mileage
EngineV
Engine Type
Registration
Year
count
4345 4173.000000 4345 4345.000000 4195.000000 4345 4345 4345.000000unique
7 NaN 6 NaN NaN 4 2 NaNtop
Volkswagen NaN sedan NaN NaN Diesel yes NaNfreq
936 NaN 1649 NaN NaN 2019 3947 NaNmean
NaN 19418.746935 NaN 161.237284 2.790734 NaN NaN 2006.550058std
NaN 25584.242620 NaN 105.705797 5.066437 NaN NaN 6.719097min
NaN 600.000000 NaN 0.000000 0.600000 NaN NaN 1969.00000025%
NaN 6999.000000 NaN 86.000000 1.800000 NaN NaN 2003.00000050%
NaN 11500.000000 NaN 155.000000 2.200000 NaN NaN 2008.00000075%
NaN 21700.000000 NaN 230.000000 3.000000 NaN NaN 2012.000000max
NaN 300000.000000 NaN 980.000000 99.990000 NaN NaN 2016.000000
ここで欠けているデータ欠けていないデータを確認する事ができたので欠損値の値を確認していきます。
data.isnullメソットを使い確認値が入ってないデータにはtureが返ってきます。
data.isnull().sum()Brand 0
Price 172
Body 0
Mileage 0
EngineV 150
Engine Type 0
Registration 0
Year 0
dtype: int64データが欠けている割合が5%よりも小さければ、そのデータはそのまま削除しても問題ない場合が多いです
影響5%未満のデータを削除していきます。
data_no_mv = data.dropna(axis=0) data_no_mv.describe(include='all')ここで結果がでたら最大値、最小値、平均値などをグラフを
つかい確認を行っていきます。
そのために、確率密度関数を作成していきます。率密度関数
sns.distplot(data_no_mv['Price'])
値段には外れ値があることがわかります。
回帰はそれぞれのデータに近い線を引いていきますので
外れ値が存在すると線がひきづられていきますので
外れ値に対処する一つの方法として観測されたデータの1%
を取り除いていこうと思います。quantileメソット
引数を取り任意の数値をとることができる
q = data_no_mv['Price'].quantile(0.99) data_1 = data_no_mv[data_no_mv['Price']<q] data_1.describe(include='all')max
NaN 129222.000000 NaN 980.000000 99.990000 NaN NaN 2016.000000max
NaN 129222.000000 が1200なのでまあ許容の範囲いないかなと思いますので
グラフで確認していきます。sns.distplot(data_1['Price'])
以下も上位1%を取り除いていきます。
sns.distplot(data_no_mv['Mileage'])
q = data_1['Mileage'].quantile(0.99) data_2 = data_1[data_1['Mileage']<q] sns.distplot(data_2['Mileage'])![4.png]
では、排気量データの99.99%と表記されているが
これはPC初期の記載方法であるので欠けた値を99.99%にすることは、その値の正確性についてほかの人が判断することが難しいという意味において、良い方法とは言えないと考える。今回は6.5というベンチマークに合わせて作成していきます。
data_3 = data_2[data_2['EngineV']<6.5] sns.distplot(data_3['EngineV'])
sns.distplot(data_no_mv['Year'])
ビンテージ車などほとんど使われていないデータが確認できます。
下位1%のデータを取り除きます。q = data_3['Year'].quantile(0.01) data_4 = data_3[data_3['Year']>q] sns.distplot(data_4['Year'])
この上で再度、確率密度関数を確認していきます。
data_cleaned = data_4.reset_index(drop=True)data_cleaned.describe(include='all')Brand
Price
Body
Mileage
EngineV
Engine Type
Registration
Year
count
3867 3867.000000 3867 3867.000000 3867.000000 3867 3867 3867.000000unique
7 NaN 6 NaN NaN 4 2 NaNtop
Volkswagen NaN sedan NaN NaN Diesel yes NaNfreq
848 NaN 1467 NaN NaN 1807 3505 NaNmean
NaN 18194.455679 NaN 160.542539 2.450440 NaN NaN 2006.709853std
NaN 19085.855165 NaN 95.633291 0.949366 NaN NaN 6.103870min
NaN 800.000000 NaN 0.000000 0.600000 NaN NaN 1988.00000025%
NaN 7200.000000 NaN 91.000000 1.800000 NaN NaN 2003.00000050%
NaN 11700.000000 NaN 157.000000 2.200000 NaN NaN 2008.00000075%
NaN 21700.000000 NaN 225.000000 3.000000 NaN NaN 2012.000000max
NaN 129222.000000 NaN 435.000000 6.300000 NaN NaN 2016.000000ここで250のデータを取り除くことができました。
- 投稿日:2021-01-21T12:39:42+09:00
【強化学習】cpprb で Experience Replay を簡単に!
0. はじめに
先日「【強化学習】Ape-X の高速な実装を簡単に!」を公開しましたが、今回はその基礎となる「Experience Replay (経験再生)」に関してより入門者向けの記事を書いてみようと思います。
(インターネット上で、「Experience Replay」と検索するとPythonでフルスクラッチで実装した記事がたくさんヒットする (1、2、3、4、etc.) ので、もっと簡単に利用できることを書こうと思い)
1. cpprb
拙作の cpprb は、強化学習の Experience Replay 向けに開発しているライブラリです。
1.1 インストール
1.1.1 Linux/Windows
PyPI からそのままバイナリをインストールできます。
pip install cpprb1.1.2 macOS
残念ながらデフォルトで利用される clang ではコンパイルができないため、Homebrew なり MacPorts なりで、gcc を用意してもらいインストール時に手元でコンパイルしてもらうことが必要です。
/path/to/g++はインストールした g++ のパスに置き換えてください。CC=/path/to/g++ CXX=/path/to/g++ pip install cpprb参考: 公式サイトのインストール手順
2. Experience Replay
2.1 概要
Experience Replayは、エージェントによる環境の探索で得られたトランジションをそのままニューラルネットワークに渡して学習させるのではなく、一旦ためておいて無作為に取り出したサンプルでニューラルネットワークを学習させる方法です。
連続するトランジションに内在する自己相関の影響による学習の不安定性を低減することが知られており、off-policyの強化学習において幅広く利用されています。
2.2 サンプルコード
cpprbを利用したExperience Replayのサンプルコードを以下に掲載します。ニューラルネットワークによるモデルの実装や、可視化・モデルの保存などはこのサンプルには含まれていません。(
MockModelの部分の実装を改造してください。)import numpy as np import gym from cpprb import ReplayBuffer n_training_step = int(1e+4) buffer_size = int(1e+6) batch_size = 32 env = gym.make("CartPole-v1") class MockModel: # ここにDQNなどのモデルを実装する def __init__(self): pass def get_action(self,obs): return env.action_space.sample() def train(self,sample): pass model = MockModel() obs_shape = 4 act_dim = 1 rb = ReplayBuffer(buffer_size, env_dict ={"obs": {"shape": obs_shape}, "act": {"shape": act_dim}, "rew": {}, "next_obs": {"shape": obs_shape}, "done": {}}) # 保存するものを dict 形式で指定する。"shape" と "dtype" を指定可能。デフォルトは、{"shape": 1, "dtype": np.single} obs = env.reset() for i in range(n_training_step): act = model.get_action(obs) next_obs, rew, done, _ = env.step(act) # keyword argument として渡す rb.add(obs=obs,act=act,rew=rew,next_obs=next_obs,done=done) if done: rb.on_episode_end() obs = env.reset() else: obs = next_obs sample = rb.sample(batch_size) # dict[str,np.ndarray] 形式で、ランダムサンプルされる model.train(sample)3. Prioritized Experience Replay
3.1 概要
Prioritized Experience Replay (優先度付き経験再生) は、Experience Replay を発展させたバージョンで、TD誤差の大きかったトランジションをより優先してサンプルする手法です。
細かい説明はこの記事では省きますが、以下の記事やサイトに解説があります。
3.2 サンプルコード
Experience Replayのサンプルコード同様、ニューラルネットワークによるモデルの実装や、可視化、保存などはこのサンプルには含まれていません。
Prioritized Experience Replay を高速に実行するためには、Segment Tree を利用することが提案されていますが、独自実装するとバグに陥りやすく、またPythonで実装すると遅いということが多々あります。(cpprbでは、Segment Tree は C++ で実装してあり高速です。)
import numpy as np import gym from cpprb import PrioritizedReplayBuffer n_training_step = int(1e+4) buffer_size = int(1e+6) batch_size = 32 env = gym.make("CartPole-v1") class MockModel: # ここにDQNなどのモデルを実装する def __init__(self): pass def get_action(self,obs): return env.action_space.sample() def train(self,sample): pass def compute_abs_TD(self,sample): return 0 model = MockModel() obs_shape = 4 act_dim = 1 rb = PrioritizedReplayBuffer(buffer_size, env_dict ={"obs": {"shape": obs_shape}, "act": {"shape": act_dim}, "rew": {}, "next_obs": {"shape": obs_shape}, "done": {}}, alpha = 0.4) obs = env.reset() for i in range(n_training_step): act = model.get_action(obs) next_obs, rew, done, _ = env.step(act) # バッファに加える際に、 priority を直接指定することも可能。未指定時は最大の priority が利用される。 rb.add(obs=obs,act=act,rew=rew,next_obs=next_obs,done=done) if done: rb.on_episode_end() obs = env.reset() else: obs = next_obs sample = rb.sample(batch_size, beta = 0.4) # コンストラクタで指定したトランジションに加えて、"indexes", "weights" が np.ndarray として dict に含まれる model.train(sample) abs_TD = model.compute_abs_TD(sample) rb.update_priorities(sample["indexes"],abs_TD)4. 困ったときは
ユーザーフォーラムとして GitHub Discussions を開設しましたので、cpprbに関する質問などはこちらへ
- 投稿日:2021-01-21T11:49:51+09:00
pyppeteerで別タブを取得する
puppeteerはよく見るのですが
memoresult_page_future = asyncio.get_event_loop().create_future() browser.once( | 'targetcreated', | lambda target: result_page_future.set_result(target) ) _link = await page.J('a.hoge') await _link.click() newtab_page = await (await result_page_future).page() await newtab_page.close()
- 投稿日:2021-01-21T10:19:42+09:00
【Python】エラーメッセージの内容を理解する
背景
自身がPython習得をすすめる上での備忘録ではありますが、エラーメッセージの読み解き方を、ここにまとめておきます。
先人たちの知恵をお借りするなどして解決できたことを、この場をお借りして感謝するとともに、大変恐縮ですが自分のメモとしても、こちらへまとめておきます。
開発環境
- Windows 10 Pro
- Python 3.9.0, 3.8.5
- Django 3.1.3
- PostgreSQL 13.1
- Nginx 1.19.5
- Gunicorn
- Putty 0.74
エラーメッセージ
1. NameError(ネーム・エラー)
1-1.
- ミス・タイピングによって起こる。大文字・小文字の違いでも起こる。
pythonprlnt("Hello World !") # 誤...print→prlnt print("Hello World !") # 正ターミナルTraceback (most resent call last): file "c:/~/sample.py", line 1, in <module> pilnt("Hello World !") NameError: name 'Pilnt' is not defined【訳】
直近の最後の呼び出しにおけるモジュール内での名前エラーが発生:1行目の「pilnt」という名前は定義されていません。
↓
『スペルミスをしてるよ~!』ということ。1-2.
- 関数を呼び出しが、関数定義よりも前で行われている場合に起こる。
pythonprint(cost(100000)) # 誤...costを定義よりも前で、呼び出している def cost(bill): return int(bill * 1.1)ターミナルNameError: name 'cost' id not defined【訳】
名前エラーが発生:「cost」は定義されていません。
↓
『「cost」という関数は、まだ把握・理解していないよ~』ということ。2. SyntaxError(シンタックス・エラー)
- 文法に関するミスで起こる。
2-1.
pythonprint("Hello World !) # 誤...閉じクォート忘れ print("Hello World !") # 正ターミナルSyntaxError: EOL while scaning stringliteral【訳】
文法エラーが発生:文字列リテラルの走査中に行末(End Of Line)を見付けました。
↓
『文字列だと思ってたのに、行末になっちゃったけど!?大丈夫?』ということ。2-2.
pythonprint( Hello World ! ) # 誤...クォート忘れ print("Hello World !") # 正ターミナルSyntaxError: invalid character in identifier【訳】
文法エラーが発生:識別子の中に不正な文字を見付けました。
↓
『(クォートで囲んでないから)変数か、関数だろうと思ったけど、「!」って使っちゃダメ~』ということ。<注>
「!」(エクスクラメーション・マーク)は、変数や関数の名前として使えない文字です。このために不正な文字と指摘されています。2-3.
pythonifheight > 180: # 誤...ifの直後に半角スペースが無い if height > 180: # 正ターミナルSyntaxError: invalid systax【訳】
文法エラーが発生:不正な文法です。
↓
『そんな書き方じゃダメで~す』ということ。3. TypeError(タイプ・エラー)
- データの型に問題があるときに起こる。
pythonprint(5 + "枚") # 誤...5(数値)と、"枚"(文字列)を、+演算子で結合しようとしたが、方が異なるため連結できない print("5" + "枚") # 正...型をstr型に合わせる print(str(5) + "枚") # 正...同上ターミナルTypeError: unsupporter operand type(s) for +: 'int' and 'str'【訳】
型エラーが発生:+演算子は被演算子の型を支持していません。
↓
『データの型が、intとstrとで異なるから一緒に処理できないよ~』ということ。4. IndentaionError(インデンテーション・エラー)
- ifやfor文、関数などのネストのインデントが無かったり、ズレていたりすると起こる。
pythonif counter > 10: break # 誤...インデントが無い if counter > 10: break # 正ターミナルIndentationError: expected an indented block【訳】
インデントのエラーが発生:インデントされたブロックが必要だと予測します。
↓
『インデントしていないけど、インデントが必要だよねぇ~』ということ。※逆の場合(インデントが不要なのに、インデントしている場合)も、同様にIndentationErrorとなります。
5. ValueError(バリュー・エラー)
数字以外を含む文字列をint関数の引数とすると起こる。
対応できないデータ型が関数に渡されると起こる。
ターミナルValueError: invalid literal for int() with base 10: 'xxxxxxx'【訳】
値エラーが発生:引数baseが10であるint関数に対して、不正なリテラル:文字列「xxxxxxx」です。
↓
『10進数で変換するのに、文字列を入れてますよ~!』ということ。※int関数はbaseという引数を受けることが可能。省略した場合はデフォルト値:10が与えられます。
「with base 10」=『10進数へ変換する』ことを表します。6. ModuleNotFoundError(モジュール・ノット・ファンド・エラー)
- モジュールをimportできない場合に起こる。(主にタイプ・ミスによる)
pythonimport xxxxxxxxターミナルModuleNotFoundError: No module named 'xxxxxxxx' # 「xxxxxxxx」というモジュール名が見付からない【訳】
モジュールが見付からないエラーが発生:「xxxxxxxx」という名前のモジュールがありません。
↓
『「xxxxxxxx」って名前のモジュールなんて、ありまへんっ!』ということ。8. ZeroDivisionError(ゼロ・ディヴィジョン・エラー)
- いわゆる「ゼロ割り」した場合に起こる
python10 + 10 + 10 + 10 * 0 + 10 + 10 / 0 + 10ターミナルZeroDivisionError: division by zero【訳】
ゼロ割りエラーが発生:ゼロで割り算しました。
↓
(そのまま)『ゼロ割りじゃん!』ということ。9. KeyboradInterrupt(キーボード・インターラプト)
- 無限ループを止める際に「ctrl」+「C」キー押下で中断すると起こる。
ターミナルTraceback (most resent call last): file "c:/~/sample.py", line 120, in <module> counter += 1 KeyboardInterruput【訳】
キーボードからの割り込みが入りました。
↓
『キーボードから割り込みの入力によって、プログラムを止めたよ!』ということ。
(編集後記)
よく遭遇するエラーを集めてまとめてみました。
まずは簡単なエラーの内容、原因・理由を理解して、複雑なプログラミングをする際に、エラーが出ても慌てないようにしたいですね。VS Code には、リアルタイムに文法をチェックしてくれる拡張機能もあるようですので、いろいろ試してみようと思います。
- 投稿日:2021-01-21T10:01:43+09:00
データ分析で役立つPandas DataFrameへの置換操作のやりかた(簡単)
- 投稿日:2021-01-21T09:38:53+09:00
ArgumentParserの使い方のシンプルな例
Pythonで初めてArgumentParserを使ってみました。
使い方に関する記事はいろいろありましたが、取り急ぎやりたいことを調べるのに、時間がかかって、あきらめそうになったので、メモとして残します。
実現したいことは、
* 対象とするデイレクトリをパラメータとして渡す
* 通常は条件に一致したファイルを対象とするが--allと指定されたらすべてを対処とする下記を実行した時は、testDir内のすべてのファイルを処理対処として
$ python3 check.py testDir --all--allを指定せず実行した時は、testDir内のすべてのファイルのうち特定のファイルを処理したい
$ python3 check.py testDirディレクトリをパラーメータとして渡す
まずは初歩の初歩 最初の一歩として
parser.add_argument('directry', help='input directry') print(args.directry)実行結果
$ python3 check.py testDir testDir実行する条件も指定する
次にオプションとして“--all”を指定できるようにする
--allが指定された時は、「True」が返るように「action='store_true'」を指定した
(値を指定しないオプションの時は「action='store_true'」か「action='store_false'」を指定する)parser.add_argument('directry', help='input directry') parser.add_argument('--all', help='Existence check',action='store_true',required=False) print(args.directry) print(args.all)実行結果
$ python3 check.py testDir --all testDir True $ python3 check.py testDir testDir False
- 投稿日:2021-01-21T09:17:57+09:00
scipy.interpolate.griddataで2次元データの補間をする
やりたい事
scipy.interpolate.griddataの使い方説明x,y座標、及びその座標での値データがあるとします。
example.pyprint(sample_df) # >>> # X Y value # 0 0 0 11 # 1 0 2 17 # 2 0 4 13 # 3 0 6 12 # 4 0 8 26 # ... # 32 10 4 8 # 33 10 6 35 # 34 10 8 30 # 35 10 10 17x,y座標のみをプロット
example.pyimport matplotlib.pyplot as plt import pandas as pd fig = plt.figure() ax1 = fig.add_subplot(111) ax1.scatter(sample_df['X'], sample_df['Y']) plt.show()
scipy.interpolate.griddataを使って座標とvaluesの空白部分を補間します。
結果は等高線マップで確認していきます。補間したデータ
環境
Mac OS
Python 3.8.1matplotlib 3.3.2
numpy 1.19.2
pandas 1.1.3
scipy 1.6.0
pip install matplotlib numpy pandas scipy詳細
サンプルデータ
以下をサンプルデータとして使用します。
sample_data.pyimport itertools import numpy as np import pandas as pd # sample data x_coord_range = [i for i in range(0, 11, 2)] y_coord_range = [i for i in range(0, 11, 2)] xy_coord = list(itertools.product(x_coord_range, y_coord_range)) values = np.random.randint(1, 50, len(xy_coord)) sample_df = pd.DataFrame() sample_df['X'] = [xy[0] for xy in xy_coord] sample_df['Y'] = [xy[1] for xy in xy_coord] sample_df['value'] = values print(sample_df) # >>> # X Y value # 0 0 0 11 # 1 0 2 17 # 2 0 4 13 # 3 0 6 12 # 4 0 8 26 # ... # 32 10 4 8 # 33 10 6 35 # 34 10 8 30 # 35 10 10 17コード
sample_dfの中身は分からない想定です
import itertools # サンプルデータ作成にのみ使用 import matplotlib.pyplot as plt import numpy as np import pandas as pd from scipy.interpolate import griddata # サンプルデータ作成個所は省略 # データ範囲を取得 x_min, x_max = sample_df['X'].min(), sample_df['X'].max() y_min, y_max = sample_df['Y'].min(), sample_df['Y'].max() # 取得したデータ範囲で新しく座標にする配列を作成 new_x_coord = np.linspace(x_min, x_max, 100) new_y_coord = np.linspace(y_min, y_max, 100) # x, yのグリッド配列作成 xx, yy = np.meshgrid(new_x_coord, new_y_coord) # 既知のx, y座標, その値取得 knew_xy_coord = sample_df[['X', 'Y']].values knew_values = sample_df['value'].values # 座標間のデータを補間, method='nearest', 'linear' or 'cubic' result = griddata(points=knew_xy_coord, values=knew_values, xi=(xx, yy), method='cubic') # グラフ表示 fig = plt.figure() ax = fig.add_subplot(111) ax.set_aspect('equal', adjustable='box') ax.contourf(xx, yy, result, cmap='jet') plt.show()データ範囲取得、新しい座標作成
# データ範囲を取得 x_min, x_max = sample_df['X'].min(), sample_df['X'].max() # >>> 今回は x_min = 0, x_max = 10 y_min, y_max = sample_df['Y'].min(), sample_df['Y'].max() # >>> 今回は y_min = 0, y_max = 10 # 取得したデータ範囲で新しく座標にする配列を作成 new_x_coord = np.linspace(x_min, x_max, 101) # >>> [ 0. 0.1 0.2, ..., 10] new_y_coord = np.linspace(y_min, y_max, 101) # >>> [ 0. 0.1 0.2, ..., 10]x, yの最大、最小値を取得して、実際のx, y2次元配列作成用の座標を作成します。
下表のような配列に補間値を入れていきたいのでnew_x_coord, new_y_coordはそれ用の
座標です
0 0.1 0.2 ... 10 0 val val val ... val 0.1 val val val ... val 0.2 val val val ... val ... ... ... ... ... val 10 val val val ... val np.grid
# x, yのグリッド配列作成 xx, yy = np.meshgrid(new_x_coord, new_y_coord)ここが分かりやすいです。
配列の要素から格子列を生成するnumpy.meshgrid関数の使い方 - DeepAge簡単にnp.meshgridで作成される配列の説明をすると、
example_meshgrid.pyimport numpy as np x = np.array([1, 2, 3]) # [x1, x2, x3]とする y = np.array([1, 2, 3]) # [y1, y2, y3]とする xx, yy = np.meshgrid(x, y) xx= array([[1, 2, 3], [1, 2, 3], [1, 2, 3]]) # xx= # array([[x1, x2, x3], # [x1, x2, x3], # [x1, x2, x3]]) yy= array([[1, 1, 1], [2, 2, 2], [3, 3, 3]]) # yy= # array([[y1, y1, y1], # [y2, y2, y2], # [y3, y3, y3]]) # xxとyyを重ねるて見ると座標ができる # array([[(1, 1),(2, 1),(3, 1)], # [(1, 2),(2, 2),(3, 2)], # [(1, 3),(2, 3),(3, 3)]]) # = # array([[(x1, y1),(x2, y1),(x3, y1)], # [(x1, y2),(x2, y2),(x3, y2)], # [(x1, y3),(x2, y3),(x3, y3)]])伝われ、、、
griddata
# 既知の座標とその値 knew_xy_coord = sample_df[['X', 'Y']].values # >>>[[ 0 0] # [ 0 2] # ... # [10 8] # [10 10]] knew_values = sample_df['value'].values # >>> [14 32 4 35..., 9] # 座標間のデータを補間, method='nearest', 'linear' or 'cubic' result = griddata(points=knew_xy_coord, values=knew_values, xi=(xx, yy), method='cubic') # >>> [[43. 40.16511073 37.34503184 ... 15.18228356 13.55766151 12.] # ... # [32. 30.91846813 29.83829943 ... 7.6922715 4.85443981 2. ]]
resultに補間された2次元配列が入ります。
scipy.interpolate.griddataの引数は
- points: 既知の座標
type=np.ndarray- values: pointsで入れた座標の値
type=np.ndarray- xi: x, yのグリッド配列
type=tuple(np.ndarray, np.ndarray)- method: 補間の種類指定
type=str,'nearest','linear'or'cubic'- fill_value: 補間できなかった座標の値を指定できる。
type=floatデフォルトはnan、'nearest'には効果なし- rescale: ???
pointsとvaluesの長さは一致していないとエラーが起きます。
補間の種類
- nearest: 再近隣内挿(補間したい点から最も近いデータ値を代入する)
- linear:線形補間
- cubic: (2次元配列の場合)3次スプライン補間
グラフ表示
fig = plt.figure() ax = fig.add_subplot(111) ax.set_aspect('equal', adjustable='box') ax.contourf(xx, yy, result, cmap='jet') plt.show()座標有2次元配列なので
ax.imshowではなくax.contourfを使用しています。
xのグリッド配列、yのグリッド配列、表示したい2次元配列の順に渡します。cmapはカラーマップの種類を指定しています。
ax.set_aspect('equal', adjustable='box')はxとyのアスペクト比を同じにしたいからです。参考
- 投稿日:2021-01-21T09:09:42+09:00
公益財団法人日本薬剤師会の医薬分業進捗状況(保険調剤の動向)のPDFをCSVに変換する
公益財団法人日本薬剤師会の医薬分業進捗状況(保険調剤の動向)のPDFをCSVに変換する
import pathlib import time from urllib.parse import urljoin import pandas as pd import pdfplumber import requests from bs4 import BeautifulSoup from tqdm.notebook import tqdm headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko" } def fetch_soup(url, parser="html.parser"): r = requests.get(url, headers=headers) r.raise_for_status() soup = BeautifulSoup(r.content, parser) return soup def fetch_file(url, dir="."): p = pathlib.Path(dir, pathlib.PurePath(url).name) p.parent.mkdir(parents=True, exist_ok=True) # 同一ファイル名の場合はダウンロードしない if not p.exists(): # サーバー負荷軽減のため3秒待機 time.sleep(3) r = requests.get(url) with p.open(mode="wb") as fw: fw.write(r.content) return p # スクレイピング url = "https://www.nichiyaku.or.jp/activities/division/faqShinchoku.html" soup = fetch_soup(url) # PDFのURLを抽出 links = [urljoin(url, i.get("href")) for i in soup.select("section.section a.btn-pdf")] # PDF変換 table_settings = { "vertical_strategy": "lines", "horizontal_strategy": "text", "intersection_tolerance": 5, } for link in tqdm(links): # PDFファイルをダウンロード path_pdf = fetch_file(link, "pdf") with pdfplumber.open(path_pdf) as pdf: page = pdf.pages[0] # PDFの表をテキスト変換 table = page.extract_table(table_settings) # CSV加工用に一時pandasで読み込み df = pd.DataFrame(table) # ヘッダー1行目の結合セルを補完 df.iloc[0] = df.iloc[0].fillna(method="ffill") # 保存用にPDFファイル名の拡張子をCSVに変更 path_csv = pathlib.Path("csv", path_pdf.with_suffix(".csv").name) path_csv.parent.mkdir(parents=True, exist_ok=True) df.to_csv(path_csv, encoding="utf_8_sig", index=False, header=False)
- 投稿日:2021-01-21T01:07:28+09:00
PythonでS3バケット内の一覧を取得し、特定のKeyで検索 Key名と最終更新日、カウント数をファイルに出力
所用で必要になったので
# -*- coding: utf-8 -*- import boto3 PUBLIC_S3_BUCKET_NAME_TEST = 'バケット名' def access_count(): count = 0 with open('file.txt', 'w') as f: # バケットの一覧取得 S3 = boto3.resource('s3') S3BUCKET = S3.Bucket(PUBLIC_S3_BUCKET_NAME_TEST) for obj in S3BUCKET.objects.all(): if '検索名' in obj.key: count += 1 print(count, obj.key, obj.last_modified, file=f) print('total=' + str(count), file=f)