- 投稿日:2021-01-12T23:04:10+09:00
TensorFlowを動かすためのJupyterのDocker環境
環境
MacBookPro
OS:Catalina内容
DockerHubからimageをPull
$ docker pull tensorflow/tensorflow:latest-jupyterimageからコンテナを起動
ホスト側で8888ポートを使用していたので、私は、8889:8888で行った。$ docker run -it -p 8889:8888 --name tf_test tensorflow/tensorflow:latest-jupyter上記実行後、表示されたURLにアクセスしてJupyterのページが表示されていればOK。(8888番ポートを使用していなければ、置き換える)
- 投稿日:2021-01-12T16:40:16+09:00
Apple Silicon M1でのTensorFlowの動作速度検証
はじめに
発売当初の絶賛ムードに対して、若干時間がたった現在では「そうでもないのでは?」的な記事も増えている気がするM1 Mac。
TensorFlowのM1対応に関しても、なんとも評価しづらいような結果の記事が出てきているが、ここでは筆者が購入したMac Miniでの簡単な検証結果を記事にする。基本的にGPUを使うと遅い
M1に最適化されたというTensorFlowでは、使用するデバイスを下記のように指定できる。
from tensorflow.python.compiler.mlcompute import mlcompute mlcompute.set_mlc_device(device_name="gpu") # 'any' or 'cpu' or 'gpu'デフォルトでは'any'で最適なデバイスを勝手に選んでくれるという。
VGG19をCIFAR10で学習させた場合の1エポックの学習時間は以下の通りだった。(バッチサイズは100)
any cpu gpu 247s 243s 458s 'gpu'が一番遅い。'any'と'cpu'が同じくらい。ResNet50でも似たような結果になる。
アクティビティモニタでGPUやCPUの履歴を見ると、GPUを使うのは'gpu'とした場合のみで、'any'としてもCPUしか使わないようだ。
ちなみに、CPUを使用している際にもCPUの使用率としては割と余裕があり100%使い切っていない(使いきれていないというべきか?)。M1はNeural Engineというのも搭載しているが、私の理解ではこれは推論でしか使われないもので、今回のように訓練では関係ないと思われる。
つまり、'any'とした際にはCPUが'最適なデバイス'として選択されていることになるだろう。
実際GPUを使うと遅くなるわけだから、最適と言われればその通りだけれど、これでいいのか?という疑問は感じざるを得ない。今後のアップデートで改善されるかもしれないが。GPUを使った方が早い場合もある
以下のようなコードでモデルを作成すると、GPUとCPUの処理時間が逆転した。
def make_model(): model = tf.keras.models.Sequential() model.add(tf.keras.layers.Conv2D(64, (3,3), padding='same', activation='relu',input_shape=(32,32,3))) model.add(tf.keras.layers.BatchNormalization()) model.add(tf.keras.layers.MaxPooling2D((2,2), padding='same')) model.add(tf.keras.layers.Conv2D(128, (3,3), padding='same', activation='relu')) model.add(tf.keras.layers.BatchNormalization()) model.add(tf.keras.layers.MaxPooling2D((2,2), padding='same')) model.add(tf.keras.layers.Conv2D(256, (3,3), padding='same', activation='relu')) model.add(tf.keras.layers.BatchNormalization()) model.add(tf.keras.layers.MaxPooling2D((2,2), padding='same')) model.add(tf.keras.layers.Conv2D(512, (3,3), padding='same', activation='relu')) model.add(tf.keras.layers.BatchNormalization()) model.add(tf.keras.layers.GlobalMaxPooling2D()) model.add(tf.keras.layers.Dense(10, activation='softmax')) return model
any cpu gpu 43s 43s 35s これはGPUが早い。Conv2Dの数を減らすとGPUが有利になるようだ。
GPUの方が早いので、'any'で最適なデバイスが選択できていないとも言える。わざわざモデルの内容をみてデバイスを決める処理が入っているとも思えないので、現状常に'any'ではCPUが選択されるのだろう。Intel CPUに比べれば速い(はず)
筆者はIntel版Macを持っていないので、WindowsPCとGoogleColabのGPUなしでの比較とする。
上にあげた、簡単なモデルで訓練を実行した結果がこちら。
デバイス 時間(s) M1 Mac (CPU) 43 M1 Mac (GPU) 35 Google Colab (Xeon 2.20GHz 2cores) 537 Windows(i7-4710MQ 2.50GHz 4cores) 505 CPUでの処理速度としては圧倒的に速かった。
Intel版Macと比較しても、それなりに速いのではなかろうかと推測する。NvidiaのGPUと比べると厳しい
上記と同じ実験をGoogleColabのP100で実施すると1エポックが5秒程度で終わる(初回は12秒ぐらいだが)。
K80ならもう少し時間がかかりそうだが、それでもM1よりは速いだろう。Geforce GT730Mというモバイル向けのチップでCUDA対応のTensorFlowで実行すると104秒だった。
M1の方が速いのは立派だが、これは古いチップでcoreが384しかないので、最近のものならばM1より早くなるだろう。テストコード全文
import tensorflow as tf import sys def make_model(): model = tf.keras.models.Sequential() model.add(tf.keras.layers.Conv2D(64, (3,3), padding='same', activation='relu',input_shape=(32,32,3))) model.add(tf.keras.layers.BatchNormalization()) model.add(tf.keras.layers.MaxPooling2D((2,2), padding='same')) model.add(tf.keras.layers.Conv2D(128, (3,3), padding='same', activation='relu')) model.add(tf.keras.layers.BatchNormalization()) model.add(tf.keras.layers.MaxPooling2D((2,2), padding='same')) model.add(tf.keras.layers.Conv2D(256, (3,3), padding='same', activation='relu')) model.add(tf.keras.layers.BatchNormalization()) model.add(tf.keras.layers.MaxPooling2D((2,2), padding='same')) model.add(tf.keras.layers.Conv2D(512, (3,3), padding='same', activation='relu')) model.add(tf.keras.layers.BatchNormalization()) model.add(tf.keras.layers.GlobalMaxPooling2D()) model.add(tf.keras.layers.Dense(10, activation='softmax')) return model def test(device_name='any', model_name='VGG19'): from tensorflow.python.compiler.mlcompute import mlcompute mlcompute.set_mlc_device(device_name=device_name) train_data, validation_data = tf.keras.datasets.cifar10.load_data() batch_size = 100 ds_train = tf.data.Dataset.from_tensor_slices(train_data).repeat(50000) ds_train = ds_train.batch(batch_size).prefetch(tf.data.experimental.AUTOTUNE) ds_validation = tf.data.Dataset.from_tensor_slices(validation_data) ds_validation = ds_validation.batch(batch_size).prefetch(tf.data.experimental.AUTOTUNE) if model_name=='VGG19': from tensorflow.keras.applications import VGG19 model = VGG19(weights=None, input_shape=(32,32,3), classes=10) elif model_name=='ResNet50V2': from tensorflow.keras.applications import ResNet50V2 model = ResNet50V2(weights=None, input_shape=(32,32,3), classes=10) else: model = make_model() model.summary() steps_per_epoch = 50000//batch_size loss = tf.keras.losses.SparseCategoricalCrossentropy() acc = tf.keras.metrics.SparseCategoricalAccuracy(name='acc') model.compile(optimizer=tf.keras.optimizers.Adam(), loss=loss, metrics=[acc]) model.fit(ds_train, epochs=3, steps_per_epoch=steps_per_epoch, validation_data=ds_validation) test( sys.argv[1], sys.argv[2])まとめ
現状ではM1に最適化したTensorFlowはCPU処理の最適化がメインで、GPUは有効に使えていないようである。
それでもCPU処理のみを考えると、かなり速いのではないか。
ただし、TensorFlow関係では色々と不具合の報告もあるようなので、現状では積極的におすすめはしない。参考
- 投稿日:2021-01-12T10:12:36+09:00
TensorFlowで簡単に画像分類
はじめに
久しぶりにTensorFlow(Keras)を触ったら忘れていることが多かったので、簡単にメモとして残しておきます。
学習の流れ
TensorFlow(以下TF)では、
① データセットの準備
② モデルの準備
③model.compileでoptimizer, loss, metricsの指定
④ callbacksの指定
⑤model.fitで学習開始
⑥model.evaluateでテストの評価
⑦ 画像の予想確率だけ得るときはmodel.predictのような流れです。
これは比較的簡単な書き方です。もう少し細かいところまで記述したい場合は、以前に記事を書きましたので参考にしてみてください。① データセットの準備
ディレクトリに画像を保存しておいてそこから読み込むには、
flow_from_directory()を用います。
その前にImageDataGeneratorを使用し、augmentationの中身を記述します。train_datagen = ImageDataGenerator( rescale=1./255, zoom_range=0.2, horizontal_flip=True, rotation_range=20, width_shift_range=0.2, height_shift_range=0.2, ) val_datagen = ImageDataGenerator(rescale=1./255) train_generator = train_datagen.flow_from_directory( TRAIN_DIR, target_size=(img_size, img_size), batch_size=batch_size, classes=classes, class_mode='categorical') val_generator = val_datagen.flow_from_directory( VAL_DIR, target_size=(img_size,img_size), batch_size=batch_size, classes=classes, class_mode='categorical')*クラスラベルについては、
train_generator.class_indicesのようにすると取得可能。クラスの対応表が出力できます。基本的にはアルファベット順。以下のように使用できる augmentationは多いので各自タスクに合わせて決めてください。
詳しく知りたい人は、公式ドキュメントで確認してください。tf.keras.preprocessing.image.ImageDataGenerator( featurewise_center=False, samplewise_center=False, featurewise_std_normalization=False, samplewise_std_normalization=False, zca_whitening=False, zca_epsilon=1e-06, rotation_range=0, width_shift_range=0.0, height_shift_range=0.0, brightness_range=None, shear_range=0.0, zoom_range=0.0, channel_shift_range=0.0, fill_mode='nearest', cval=0.0, horizontal_flip=False, vertical_flip=False, rescale=None, preprocessing_function=None, data_format=None, validation_split=0.0, dtype=None )
flow_from_directoryでは、ディレクトリのパスを指定して、オーギュメントされた画像がバッチサイズごとに生成されます。flow_from_directory( directory, target_size=(256, 256), color_mode='rgb', classes=None, class_mode='categorical', batch_size=32, shuffle=True, seed=None, save_to_dir=None, save_prefix='', save_format='png', follow_links=False, subset=None, interpolation='nearest' )
class_mode: categorical, binary, sparse, input, None が選択可能。デフォは,categorical.
shuffle: Flaseならアルファベット順
save_to_dir: None or str(default:None). ディレクトリを指定することによって augmented data を保存してくれる。可視化に役に立つ。
save_prefix: str. 保存された画像のファイル名に使う。(save_to_dirが設定されている場合有効)
save_format: png or jpeg (Default:'png')
interpolation: nearest(デフォルト), bilinear, bicubic② モデルの準備
今回は例として、MobileNetv2を使います。
tf.keras.applicationsに他の学習済みモデルもあります。IMG_SHAPE = (img_size, img_size, channels) base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE, include_top=False, weights='imagenet') global_average_layer = tf.keras.layers.GlobalAveragePooling2D() prediction_layer = tf.keras.layers.Dense(n_classes, activation='softmax') model = tf.keras.Sequential([ base_model, global_average_layer, prediction_layer ])③ model.compile で optimizer, loss, metricsの指定
modelに対して学習の詳細を設定します。
model.compile(optimizer=optimizers.SGD(lr=0.0001, momentum=0.99, decay=0, nesterov=True), loss='categorical_crossentropy', metrics=['accuracy'])compile( optimizer='rmsprop', loss=None, metrics=None, loss_weights=None, weighted_metrics=None, run_eagerly=None, steps_per_execution=None, **kwargs )
optimizer: string or optimizer instance (default: rmsprop)
画像系のタスクだと個人的には、SGDかな?ex) SGD, RMSprop, Adam, Adadelta,...
sgd = tf.keras.optimizers.SGD( learning_rate=0.01, momentum=0.0, nesterov=False, name='SGD', **kwargs )*この
sgdを model.compileのoptimizerに設定する
loss: string, object function ortf.keras.losses.Lossinstance
metrics: trainingとtestで使用するmetricsのリスト
loss_weights: ロスに重み付けする④ callbacksの指定
CSVLogger, History, ProgbarLogger, TensorBoard, EarlyStopping, ReduceLROnPlateau など設定できます。
model.fitで学習する際に渡すことができます。詳しくは公式ドキュメントをご確認ください。例をいくつか挙げておきます。
tf.keras.callbacks.EarlyStopping( monitor='val_loss', min_delta=0, patience=0, verbose=0, mode='auto', baseline=None, restore_best_weights=False )tf.keras.callbacks.ModelCheckpoint( filepath, monitor='val_loss', verbose=0, save_best_only=False, save_weights_only=False, mode='auto', save_freq='epoch', options=None, **kwargs )
filepath: string or PathLike, モデルを保存するパス。指定できる変数は、epoch, loss, acc, val_loss, val_accです。
ex) filepath = '{val_loss:.2f}-{val_acc:.2f}.hdf5'
monitor: 何を基準にモデルを保存するか。accuracy, val_accuracy, loss, val_loss
*もし metrics name が分からなかったら、history = model.fit()でhistory.historyを確認。
mode: {auto, min, max}
save_best_only: もし、filepathが{epoch}のようなフォーマットを含んでいなかったら、filepathはオーバーライドされる
save_weights_only: modelの重みのみ保存
save_freq: epoch, or integer.tf.keras.callbacks.LearningRateScheduler( schedule, verbose=0 )tf.keras.callbacks.ReduceLROnPlateau( monitor='val_loss', factor=0.1, patience=10, verbose=0, mode='auto', min_delta=0.0001, cooldown=0, min_lr=0, **kwargs )tf.keras.callbacks.RemoteMonitor( root='http://localhost:9000', path='/publish/epoch/end/', field='data', headers=None, send_as_json=False )tf.keras.callbacks.CSVLogger( filename, separator=',', append=False )⑤ model.fitで学習開始
例
history = model.fit( train_generator, steps_per_epoch=steps_per_epoch, validation_data=val_generator, validation_steps=validation_steps, epochs=CONFIG.epochs, shuffle=True, callbacks=[cp_callback])fit( x=None, y=None, batch_size=None, epochs=1, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0, steps_per_epoch=None, validation_steps=None, validation_batch_size=None, validation_freq=1, max_queue_size=10, workers=1, use_multiprocessing=False )
validation_split: [0~1]. training dataの一部をa validation data とする。x, yの後ろのデータが用いられる(シャッフルする前)。
validation_data: validation data. validation_splitがある場合はオーバーライドされる
class_weight: データが少ないクラスのlossに重きを置く方法。辞書型で渡す。例) {0:0.66, 1:1.33}
steps_per_epoch: Integer or None. training data // batch_size で求められる。
validation_steps: Integer or None. validation data // batch_size で求められる。⑥ model.evaluate でテストの評価
test_loss, test_acc = model.evaluate(test_generator, steps=test_steps)evaluate( x=None, y=None, batch_size=None, verbose=1, sample_weight=None, steps=None, callbacks=None, max_queue_size=10, workers=1, use_multiprocessing=False, return_dict=False )
x: 入力データ。 Numpy array, tensor, tf.data.dataset, (inputs, targets) or (inputs, targets, sample_weights)
y: ターゲットデータ。
batch_size: Integer or None.
verbose: 0 or 1. Verbosity mode. 0 = silent, 1 = progress bar.
sample_weight:
steps: Integer or None
callbacks: list ofkeras.callbacks.Callbackinstances
max_queue_size: Integer.
workers: Integer.
use_multiprocessing: boolean
return_dict: もしTrueなら、metric results をdictで返す⑦ 画像の予想確率だけ得るときは model.predict
predict( x, batch_size=None, verbose=0, steps=None, callbacks=None, max_queue_size=10, workers=1, use_multiprocessing=False )+α
<<モデルを保存した際に作成されるファイルについて>>
checkpoint : 1ファイルのみ作成。どのファイルが最新か確認可能。学習の際に必要なのでテストの際はなくても大丈夫。保存したデータから再度学習を始める場合に必要。
XXXXX.data-0000-of-00001 : 変数名をテンソル値としてマッピングした独自のフォーマット。
XXXXX.index : このファイルはバイナリファイル。複数のステップでデータを保存した際に同名の「.data-0000-of-00001」ファイルが、どのステップのどのデータであるか一意に定まる。
終わりに
細かい設定まで今回目を通すことができて良い機会になりました。
参考文献
- 投稿日:2021-01-12T06:38:29+09:00
Deep Q-Networkを使って道路の誘導灯を制御しよう!
はじめに
友人たちと簡単な強化学習を使ったプロジェクトに取り組んだので、その記録もかねて記事にまとめてみた。
背景
混雑した市街地において駐車場探しに悩まされた経験のある方は多いだろう。一説によると市街地における交通量の約30%は駐車場探しのための徘徊らしい1。
道路状況(状態)を考慮して、各車両の駐車場選択をリアルタイムで指示(行動選択)できれば、道路の混雑緩和を達成できるのではないかと考えた。
そこで、リアルタイムで駐車場への入庫を指示する誘導灯を導入し、Deep Q-Networkを用いてそれらを学習させた。アイデア
既往研究
強化学習を用いた信号制御の研究としては
Pol and Oliehoek(2016), Coordinated Deep Reinforcement Learners for Traffic Light Control, NIPS'16 Workshop on Learning, Inference and Control of Multi-Agent Systems
などが挙げられる。
この研究では2次元道路ネットワーク上でDQNを用いて信号制御を学習しているわけだが、報酬関数の設計がミソで、渋滞や車両の待ち時間、急停止の有無などをうまく報酬関数に組み込んでいる。参考:既往研究で用いられた報酬関数
$ r_t = -0.1c - 0.1 \sum_{i=1}^N j_i - 0.2 \sum_{i=1}^N e_i - 0.3 \sum_{i=1}^N d_i - 0.3\sum_{i=1}^N w_i$$i = 1, \dots, N$:エージェント(車両)
$r$:報酬
$c$:信号が変わったか否か
$j$:車両が渋滞に巻き込まれたか否か
$e$:車両が急停止したか否か
$d$:車両のスピードが一定の速度(制限速度)以下か否か
$w$:車両が赤信号で停止したか否かしかし、この研究では車両が単純に道路を通過するだけで、渋滞の一因である駐車とそれに伴う一時停止などは扱えていない。さらに、交通シミュレーションにSUMO2というシミュレータを使っており、少々扱いが面倒。
このプロジェクトのアイデア
そこで本プロジェクトでは
- 車両の駐車行動に対象を絞り、駐車場の誘導灯を学習
- 道路ネットワークおよび駐車・渋滞の表現にセルオートマトンを導入し、より扱いやすく
- 渋滞を低減しながら駐車時間を短くするよう、各誘導灯を動的に制御
を念頭に実装をおこなった。
モデル
Environment
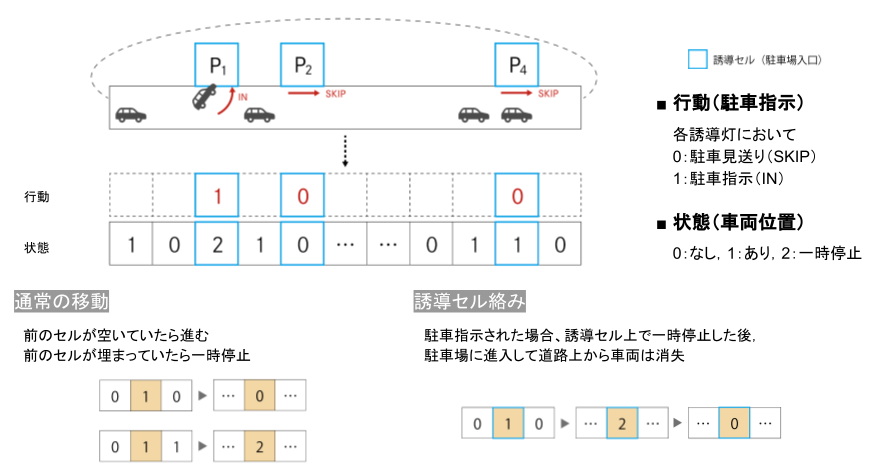
1次元の簡単な道路空間を想定し、セルオートマトンを用いて環境を表現した。
状況設定は上の図の通り。
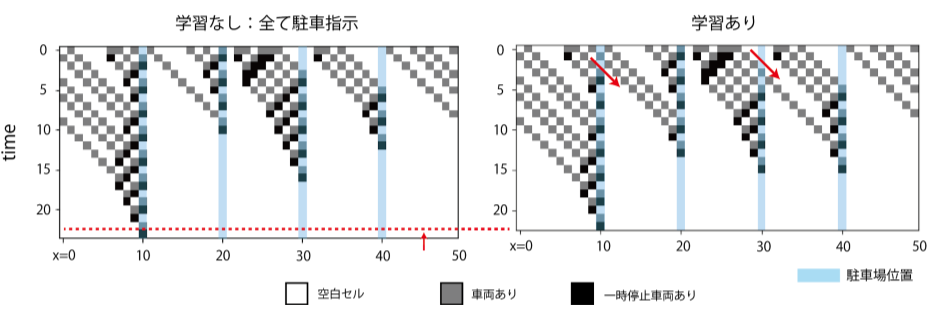
t=0時点において1次元道路空間上に車が初期位置に並ぶ。道路空間沿いにはいくつかの駐車場が設けられており、すべての車はいずれかに入庫したいと考えている。車は道路空間上を進みながら、いずれかの駐車場に入庫する。ここで全ての車にとって駐車場は無差別、つまりどの車もどこの駐車場でもいいから入庫したいと考えている。各車両は駐車場前に設置された誘導灯の指示(IN / SKIP)に従い入庫or見送り。セル上の状態は
0:車なし
1:車(走行中)あり
2:車(一時停止中)誘導灯の行動は
0:入庫見送り(SKIP)
1:入庫指示(IN)遷移規則は
通常移動:前のセルが空いていたら進む。前のセルに車がいたら一時停止。
誘導セル:入庫指示された場合、そのセルで一時停止した後、駐車場に進入して道路上から消失。以上を踏まえたPythonのコードは以下の通り3。
environment.pyimport os import numpy as np import random class Parking: def __init__(self, test = False): self.name = os.path.splitext(os.path.basename(__file__))[0] self.n_cells = 50 # number of cells self.n_cars = 20 # number of cars at t=0 self.n_parking = 4 # number of parking self.enable_actions = ([0, 0, 0, 0], [0, 0, 0, 1], [0, 0, 1, 0], [0, 0, 1, 1], [0, 1, 0, 0], [0, 1, 0, 1], [0, 1, 1, 0], [0, 1, 1, 1], [1, 0, 0, 0], [1, 0, 0, 1], [1, 0, 1, 0], [1, 0, 1, 1], [1, 1, 0, 0], [1, 1, 0, 1], [1, 1, 1, 0], [1, 1, 1, 1]) self.pre_action = [0, 0, 0, 0] self.parking_position = [10, 20, 30, 40] # fixed parking locations self.frame_rate = 5 self.rules = [ "000222000000222000000222000", # 111 "000222000000222000000222000", # 110 "220220000220220000220220000", # 101 "220220000220220000220220000", # 100 "000222111000222111000222000", # 011 "000222111000222111000222000", # 010 "220220111220220111220220000", # 001 "220220111220220111220220000" # 000 ] self.frame_rate = 5 self.test = test # variables self.reset() def update(self, action): # update navigation for i, p in enumerate(self.parking_position): self.navigation[p] = action[i] # update car position self.car_cells = self.cellautomaton(self.car_cells, self.navigation) # calculate reward self.reward = 0 self.terminal = False self.n_remain = self.count_remain(self.car_cells) self.n_stop = self.count_stop(self.car_cells) c = np.sum(np.abs(np.array(action) - np.array(self.pre_action))) / self.n_parking # reward function self.reward = - self.n_remain/self.n_init - self.n_stop/self.n_init if self.n_remain == 0: self.terminal = True self.pre_action = action def rule_choice(self, l, x, r): # decide the transition rule by the parking navigation bin_num = int(str(l)+str(x)+str(r), 2) return self.rules[-(bin_num+1)] def transition(self, l, x, r, rule): # decide the next state tri_num = int(str(l)+str(x)+str(r), 3) return int(rule[-(tri_num+1)]) def count_remain(self, state): #count remaining cars return len([i for i in state if i > 0]) def count_stop(self, state): # count stopping cars return len([i for i in state if i == 2]) def cellautomaton(self, state, navigation): state_new = [] # add 1 cell at the edge for periodic boundary conditions state = [state[-1]] + state state.append(state[1]) navigation = [navigation[-1]] + navigation navigation.append(navigation[1]) # calculate the next state of each cell for i in range(1, len(state)-1): rule = self.rule_choice(navigation[i-1], navigation[i], navigation[i+1]) state_new.append(self.transition(state[i-1], state[i], state[i+1], rule)) # delate added edge cells del navigation[-1] del navigation[0] return state_new def draw(self): # reset screen self.screen = np.array(self.car_cells) def observe(self): self.draw() return self.screen, self.reward, self.terminal, self.n_remain, self.n_stop def execute_action(self, action): self.update(action) def reset(self): random.seed(300) # car position at t=0 is fixed self.car_cells = [1] * self.n_cars + [0] * (self.n_cells - self.n_cars) random.shuffle(self.car_cells) self.n_init = len([i for i in self.car_cells if i > 0]) self.n_remain = self.count_remain(self.car_cells) self.n_stop = self.count_stop(self.car_cells) self.navigation = [0] * self.n_cells # reset other variables self.reward = 0 self.terminal = FalseAgent
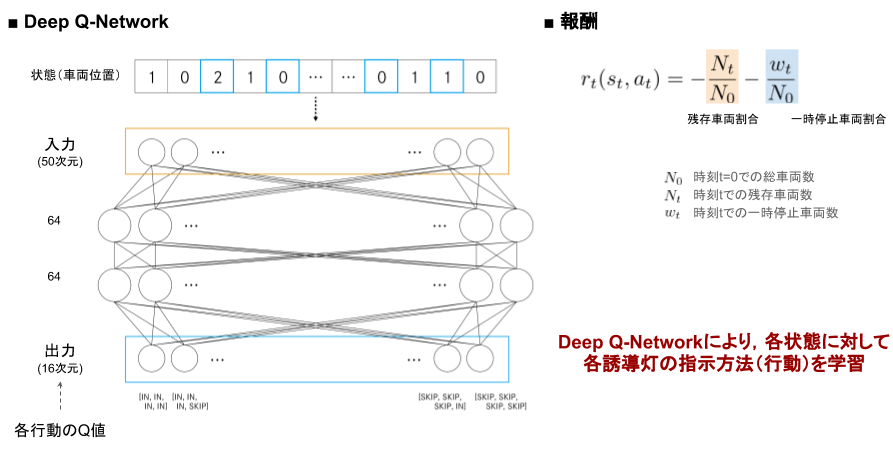
Agentの学習および報酬の設計のイメージは上の図の通り。
状態(車両位置)を入力とし、全結合層を2つはさんで行動(誘導灯指示の組み合わせ)のQ値を出力とする。報酬は
・総車両数に対する時刻 t での残存車両数の割合
・総車両数に対する時刻 t での一時停止車両数の割合
を用いた。以上を踏まえたPythonコードは以下の通り。
agent.pyfrom collections import deque import os import numpy as np import tensorflow as tf # it is necessary if tensorflow version > 2.0 import tensorflow.compat.v1 as tf tf.disable_v2_behavior() class DQNAgent: """ Multi Layer Perceptron with Experience Replay """ def __init__(self, enable_actions, environment_name, n_cells): # parameters self.name = os.path.splitext(os.path.basename(__file__))[0] self.environment_name = environment_name self.enable_actions = enable_actions self.n_actions = len(self.enable_actions) self.minibatch_size = 32 self.replay_memory_size = 1000 self.learning_rate = 0.001 self.discount_factor = 0.9 self.exploration = 0.1 self.model_dir = os.path.join(os.path.dirname(os.path.abspath(__file__)), "models") self.model_name = "{}.ckpt".format(self.environment_name) self.n_cells = n_cells # replay memory self.D = deque(maxlen=self.replay_memory_size) # model self.init_model() # variables self.current_loss = 0.0 def init_model(self): # input layer (1 x n_cells) self.x = tf.placeholder(tf.float32, [None, self.n_cells]) # flatten (n_cells) x_flat = tf.reshape(self.x, [-1, self.n_cells]) # fully connected layer 1 W_fc1 = tf.Variable(tf.truncated_normal([self.n_cells, 64], stddev=0.01)) b_fc1 = tf.Variable(tf.zeros([64])) h_fc1 = tf.nn.relu(tf.matmul(x_flat, W_fc1) + b_fc1) # fully connected layer 2 W_fc2 = tf.Variable(tf.truncated_normal([64, 64], stddev=0.01)) b_fc2 = tf.Variable(tf.zeros([64])) h_fc2 = tf.nn.relu(tf.matmul(h_fc1, W_fc2) + b_fc2) # output layer (n_actions) W_out = tf.Variable(tf.truncated_normal([64, self.n_actions], stddev=0.01)) b_out = tf.Variable(tf.zeros([self.n_actions])) self.y = tf.matmul(h_fc2, W_out) + b_out # loss function self.y_ = tf.placeholder(tf.float32, [None, self.n_actions]) self.loss = tf.reduce_mean(tf.square(self.y_ - self.y)) # train operation optimizer = tf.train.RMSPropOptimizer(self.learning_rate) self.training = optimizer.minimize(self.loss) # saver self.saver = tf.train.Saver() # session self.sess = tf.Session() self.sess.run(tf.global_variables_initializer()) def Q_values(self, state): # Q(state, action) of all actions return self.sess.run(self.y, feed_dict={self.x: [state]})[0] def select_action(self, state, epsilon): if np.random.rand() <= epsilon: # random indice = np.random.choice(self.n_actions) return self.enable_actions[indice] else: # max_action Q(state, action) return self.enable_actions[np.argmax(self.Q_values(state))] def store_experience(self, state, action, reward, state_1, terminal): self.D.append((state, action, reward, state_1, terminal)) def experience_replay(self): state_minibatch = [] y_minibatch = [] # sample random minibatch minibatch_size = min(len(self.D), self.minibatch_size) minibatch_indexes = np.random.randint(0, len(self.D), minibatch_size) for j in minibatch_indexes: state_j, action_j, reward_j, state_j_1, terminal = self.D[j] action_j_index = self.enable_actions.index(action_j) y_j = self.Q_values(state_j) if terminal: y_j[action_j_index] = reward_j else: # reward_j + gamma * max_action' Q(state', action') y_j[action_j_index] = reward_j + self.discount_factor * np.max(self.Q_values(state_j_1)) # NOQA state_minibatch.append(state_j) y_minibatch.append(y_j) # training self.sess.run(self.training, feed_dict={self.x: state_minibatch, self.y_: y_minibatch}) # for log self.current_loss = self.sess.run(self.loss, feed_dict={self.x: state_minibatch, self.y_: y_minibatch}) def load_model(self, model_path=None): if model_path: # load from model_path self.saver.restore(self.sess, model_path) else: # load from checkpoint checkpoint = tf.train.get_checkpoint_state(self.model_dir) if checkpoint and checkpoint.model_checkpoint_path: self.saver.restore(self.sess, checkpoint.model_checkpoint_path) def save_model(self): self.saver.save(self.sess, os.path.join(self.model_dir, self.model_name))学習
上で見てきた設定でモデルの学習をおこなった上で実験をおこない、学習しない場合(=誘導灯がすべて入庫指示)と比べてどれほど車両を効率的に制御できているかを確認する。
学習および実験のPythonコードは以下の通り。
train.pyimport numpy as np from environment import Parking from agent import DQNAgent if __name__ == "__main__": # parameters n_epochs = 1000 # environment, agent env = Parking(test = False) agent = DQNAgent(env.enable_actions, env.name, env.n_cells) for e in range(n_epochs): # reset frame = 0 loss = 0.0 Q_max = 0.0 env.reset() state_t_1, reward_t, terminal, state_remain, state_stop = env.observe() while not terminal: state_t = state_t_1 # execute action in environment action_t = agent.select_action(state_t, agent.exploration) env.execute_action(action_t) # observe environment state_t_1, reward_t, terminal, state_remain, state_stop = env.observe() # store experience agent.store_experience(state_t, action_t, reward_t, state_t_1, terminal) # experience replay agent.experience_replay() # for log frame += 1 loss += agent.current_loss Q_max += np.max(agent.Q_values(state_t)) print("EPOCH: {:03d}/{:03d} | FRAME: {:d} | LOSS: {:.4f} | Q_MAX: {:.4f}".format( e, n_epochs - 1, frame, loss / frame, Q_max / frame)) # save model agent.save_model()test.pyimport matplotlib.pyplot as plt import argparse import datetime import os from environment import Parking from agent import DQNAgent import csv import pprint if __name__ == "__main__": # args parser = argparse.ArgumentParser() parser.add_argument("-m", "--model_path") parser.add_argument("--load_model", default=True) # 学習したモデル使用→True, 不使用→False parser.add_argument("-s", "--save", dest="save", action="store_true") parser.set_defaults(save=False) args = parser.parse_args() # environmet, agent env = Parking(test = True) agent = DQNAgent(env.enable_actions, env.name, env.n_cells) if args.load_model: agent.load_model(args.model_path) # variables score = 0 state_t_1, reward_t, terminal, state_remain, state_stop = env.observe() result_state = [] result_remain = [] result_stop = [] n_cars = state_remain while not terminal: result_state.append(list(state_t_1)) result_remain.append(state_remain) result_stop.append(state_stop) state_t = state_t_1 # execute action in environment if args.load_model: action_t = agent.select_action(state_t, 0.0) else: action_t = [1,1,1,1] env.execute_action(action_t) state_t_1, reward_t, terminal, state_remain, state_stop = env.observe() result_remain.append(state_remain) result_stop.append(state_stop) print("conversion time = " + str(len(result_remain))) # total time print("average time = " + str(sum(result_remain) / n_cars)) # average parking time print("extra stopping time = " + str(sum(result_stop) - n_cars)) # extra stopping time # output for csv with open('output/result.csv', 'a') as f: writer = csv.writer(f) writer.writerow([len(result_remain), sum(result_remain) / n_cars, sum(result_stop) - n_cars]) # mkdir for output dirname_n_remain = "output/figure/n_remain/" dirname_n_stop = "output/figure/n_stop/" dirname_state = "output/figure/state/" os.makedirs(dirname_n_remain, exist_ok=True) os.makedirs(dirname_n_stop, exist_ok=True) os.makedirs(dirname_state, exist_ok=True) # file name is date+time now = datetime.datetime.now() n_remain_filename = dirname_n_remain + now.strftime('%Y%m%d_%H%M%S') + '.png' n_stop_filename = dirname_n_stop + now.strftime('%Y%m%d_%H%M%S') + '.png' state_filename = dirname_state + now.strftime('%Y%m%d_%H%M%S') + '.png' # make the graph of number of remaining cars epoch = range(len(result_remain)) plt.figure() plt.xlabel("time") plt.ylabel("number of remained cars") plt.plot(epoch, result_remain); plt.show() # make the graph of stopping cars epoch = range(len(result_stop)) plt.figure() plt.xlabel("time") plt.ylabel("number of stopping cars") plt.plot(epoch, result_stop); plt.show() # make the figure of state transition plt.figure() plt.title("State Transition") plt.imshow(result_state, cmap="binary") plt.show()結果
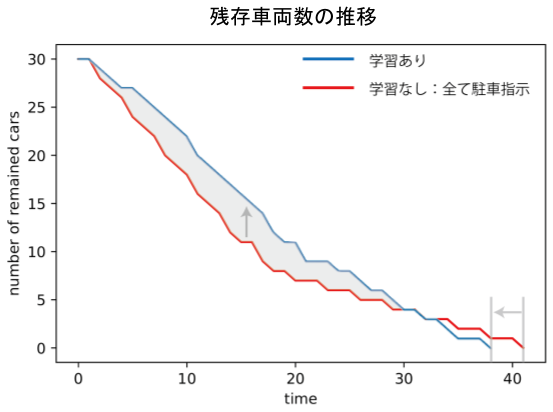
残存車両数の推移
残存車両数の推移は上の図の通り(初期車両数30)。
学習をおこなった場合、初期段階では車がなかなか減らないが、全ての車が駐車完了するまでの時間は短縮できた。これは、特定の駐車場に偏った場合に起こる渋滞を防ぐために、いくつかの車について「あえて見送り」という指示を出していることに起因する。一部車両の利益を犠牲にして社会最適をとった形だ。状態推移(初期車両数30)
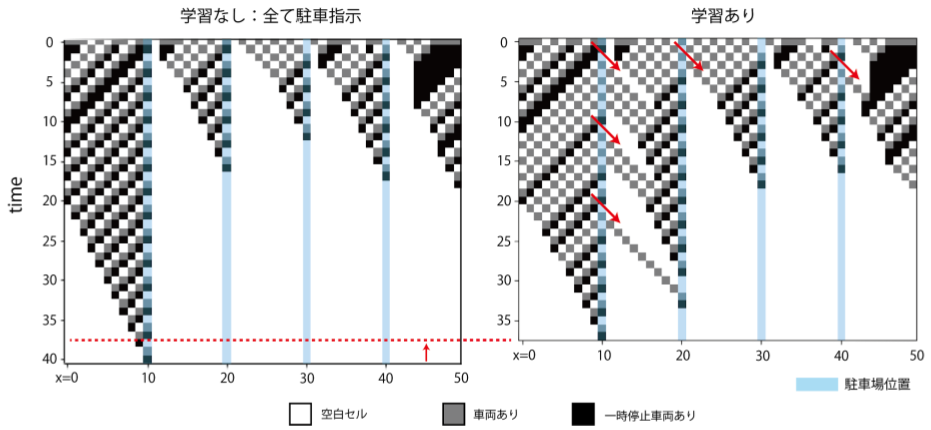
実際の車両の動きがどうなっているのか、状態遷移の様子を見てみる。縦軸方向が時間、横軸方向が各時刻での状態。t=0での初期状態を与えて、時間発展させた際の状態変化を下方向に積み上げたもの。初期車両数30の場合の状態遷移は上の図の通り。残存車両数の推移で見たように、いくつかの車両に対し「あえて見送り」の指示を与えていることで将来の渋滞が緩和され、結果的に全車両の駐車完了が早まっている。
状態推移(初期車両数20)
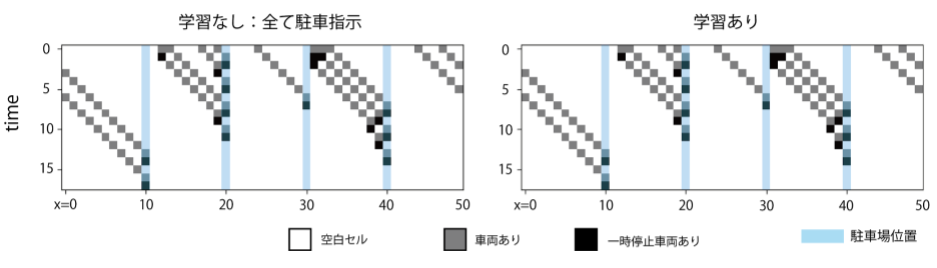
初期車両数20の場合の状態遷移は上の図の通り。初期車両数30の場合と同様に、「あえて見送り」を指示することで将来の渋滞が緩和され、結果的に全車両の駐車完了が早まっている。このことから、車両数に対してある程度学習は頑健であることがわかる。状態遷移(初期車両数10)
初期車両数10の場合の状態遷移は上の図の通り。初期車両数が少ない場合は渋滞が発生せず、「あえて見送り」の指示をする必要がないと判断している。結論
・駐車行動を伴う道路空間をセルオートマトンでシンプルに記述した。
・「見つけた駐車場にとりあえず入庫する」戦略はかえって全車両が駐車完了する時間を増大させてしまうことがある。
・駐車場への入庫を指示する誘導灯を導入し、DQNを用いて学習することで、全車両が駐車完了する時間を短くできる。
Donald C. Shoup (2006), Cruising for parking, Transport Policy, vol.13 issue.6, pp479-486. ↩
Simulation of Urban MObilityの略。交通流などを扱えるオープンソースのシミュレータ。https://github.com/eclipse/sumo ↩
今回の実装はDQNの基本的な実装例を提示している https://github.com/algolab-inc/tf-dqn-simple を参考におこなった。Agent以降のコードも同様。 ↩