- 投稿日:2021-01-12T23:25:33+09:00
自作のTransformの作成方法
参考ページ:Pytorch – torchvision で使える Transform まとめ
画像データの前処理に利用する
transformsでは、Lambda関数を渡すことでユーザ定義のTransformが作れる。from torchvision import transforms import cv2 import matplotlib.pyplot as plt img = cv2.imread("sample.jpeg") plt.imshow(img)
def gray(img): """ RGBに変換してグレースケール化 """ img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY) return img transform = transforms.Lambda(gray) img_transformed = transform(img) plt.imshow(img_transformed)
この処理をComposeでつなげれば、pytorchのtransformのpipelineに組み込むことができる。


- 投稿日:2021-01-12T22:35:58+09:00
pythonでcsvいじいじ
ファイルのコピー
copy.pyimport shutil shutil.copy('コピー元パス', 'コピー先パス')ファイルの移動
move.pyimport shutil shutil.move('移動前のパス', '移動後のパス')ファイルのエンコード(utf8→shift_jis)
encode.pyimport codecs def main(): # UTF-8 ファイルのパス utf8_csv_path = 'utf8のファイルパス' # Shift-jis ファイルのパス shiftjis_csv_path= 'shift-jisのファイルパス' # 文字コードをshiftjisに変換して保存 fin = codecs.open(utf8_csv_path, "r", "utf-8") fout_jis = codecs.open(shiftjis_csv_path, "w", "shift_jis") for row in fin: fout_jis.write(row) fin.close() fout_jis.close() if __name__ == "__main__": main()ファイルの削除
remove.pyimport os os.remove('削除したいファイルパス')ファイル名の変更
renameFile.pyimport os os.rename('変更前ファイルパス', '変更後ファイルパス')csvのカラム名変更
renameColumns.pyimport pandas as pd df = pd.read_csv('202101.csv') print("Before Column\t"+str(df.columns)) #カラム名確認 df = df.rename(columns = {'A':'aaa', 'B':'bbb', 'C':'ccc', 'D':'ddd', 'E':'eee', 'F':'fff', 'G':'ggg', 'H':'hhh', 'I':'iii', }) print("After Column\t"+str(df.columns)) #変更後のカラム名確認 df.to_csv('202101_changeColumnName.csv', index = False) #csvへの変更書き込み日付の取得(今回はYYYYMM)
today = datetime.date.today() print(today.strftime('%Y%m'))
- 投稿日:2021-01-12T22:34:11+09:00
Pythonで学ぶアルゴリズム 第18弾:並べ替え(スタックとキュー)
#Pythonで学ぶアルゴリズム< スタックとキュー >
はじめに
基本的なアルゴリズムをPythonで実装し,アルゴリズムの理解を深める.
その第18弾としてスタックとキューを扱う.今回も並べ替えのカテゴリとしているが,スタックとキューは次回の並べ替え(ヒープソート)との比較のため学ぶのであり,決して並べ替えアルゴリズムということではないことを述べておく.スタック(stack)
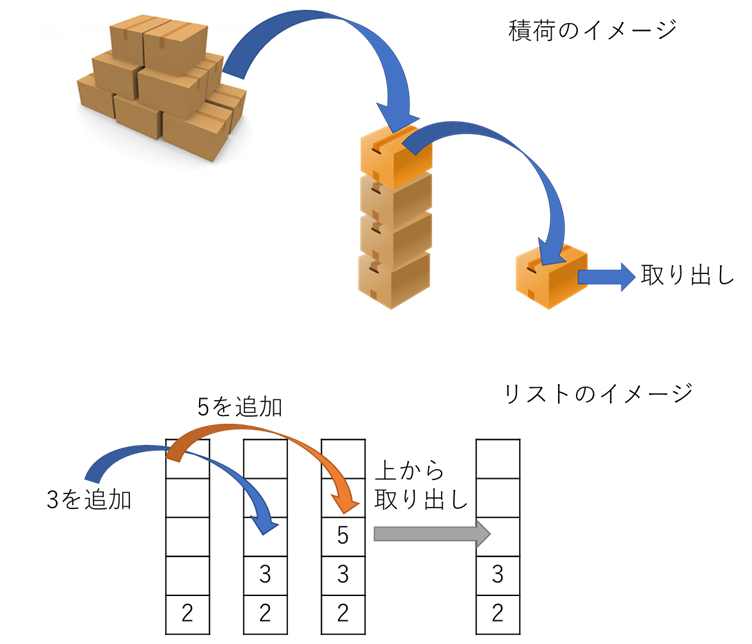
データの格納されたリストにおいて,末尾(最後に入れたもの)から取り出すこと.
スタック(stack)は積み上げるという意味で,その名前の通りである.積荷におけるイメージとリストでのイメージの図を次に示す.
キュー(queue)
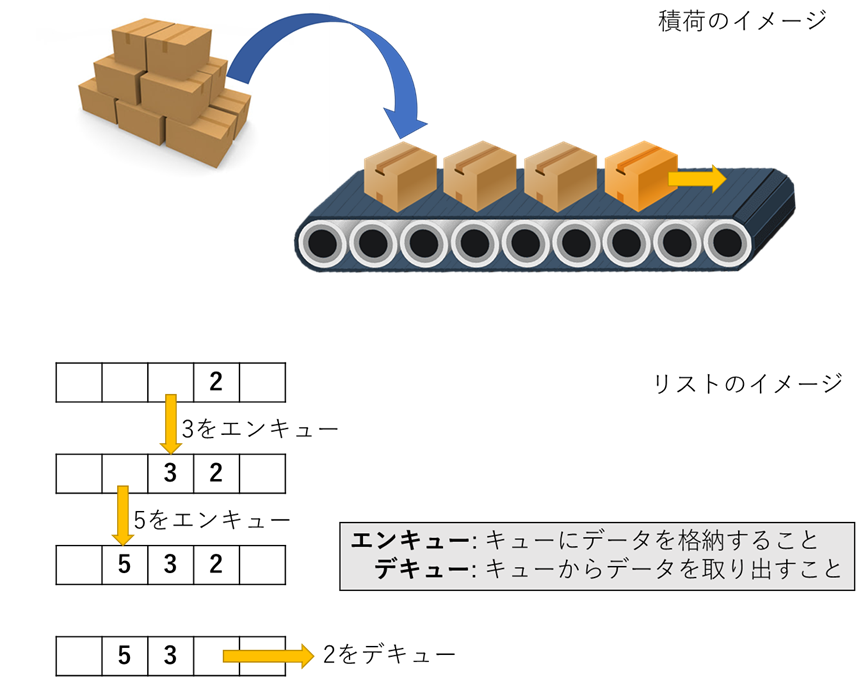
データの格納されたリストにおいて,先頭(先に入れたもの)から取り出すこと.
キュー(queue)は「列」という意味で,その名前の通り入れたものは反対から出てくるというイメージである.先ほどと同様に積荷におけるイメージとリストでのイメージの図を次に示す.
また,図に示すように,キューにおいてはデータの格納,取り出しに対して,エンキューとデキューという名称がつけられている.スタックの実装
以下にスタックのコードとその出力を示す.
コード
stack.py""" 2021/01/12 @Yuya Shimizu スタック(stack) """ List = [] List.append(3) #stackに[3]を追加 List.append(5) #stackに[5]を追加 List.append(2) #stackに[2]を追加 print(List) temp = List.pop() #stackから取り出し print(f"\n取り出し: {temp}\n") print(List) temp = List.pop() #stackから取り出し print(f"\n取り出し: {temp}\n") print(List) List.append(4) #stackに[4]を追加 print(f"\n追加: 4\n") print(List) temp = List.pop() #stackから取り出し print(f"\n取り出し: {temp}\n") print(List)出力
[3, 5, 2] 取り出し: 2 [3, 5] 取り出し: 5 [3] 追加: 4 [3, 4] 取り出し: 4 [3]キューの実装
以下にキューのコードとその出力を示す.
コード
queue_program.py""" 2021/01/12 @Yuya Shimizu キュー(queue) """ import queue q = queue.Queue() q.put(3) #キューに[3]を追加 q.put(5) #キューに[5]を追加 q.put(2) #キューに[2]を追加 print(q.queue) temp = q.get() #キューから取り出し print(f"\nデキュー: {temp}\n") print(q.queue) temp = q.get() #キューから取り出し print(f"\nデキュー: {temp}\n") print(q.queue) q.put(4) #キューに[4]を追加 print(f"\nエンキュー: 4\n") print(q.queue) temp = q.get() #キューから取り出し print(f"\nデキュー: {temp}\n") print(q.queue)出力
deque([3, 5, 2]) デキュー: 3 deque([5, 2]) デキュー: 5 deque([2]) エンキュー: 4 deque([2, 4]) デキュー: 2 deque([4])キューに関しては,Pythonにqueueというモジュールが用意されており,Queueクラスを使うことで,putメソッドすなわちエンキュー,getメソッドすなわちデキューを実装することができる.注意としては,
queue.pyという名前ではqueueモジュールが読み込めないことである.感想
今回はスタックとキューについて学んだ.直接,並べ替えを学んだわけではないが,データの取り扱いについて,新たなキューというものを知った.また,スタックにおいては,
pop()を再び扱い,pop()の使い方にも慣れて気がする.次回のヒープソートで,今回学んだことよりも優れた方法が学べるということで楽しみである.参考文献
Pythonで始めるアルゴリズム入門 伝統的なアルゴリズムで学ぶ定石と計算量
増井 敏克 著 翔泳社
- 投稿日:2021-01-12T22:33:16+09:00
Kubeflow PipelinesでBigQueryにクエリを投げてその結果を保存する方法と注意点
はじめに
Kubeflow PipelinesからBigQueryにクエリを投げ、クエリ結果を以下の3パターンで保存する方法をまとめます。
1. CSVファイル
2. GCS
3. BigQuery併せて実装上の注意点も思いついたものを書いていきます。
環境
import sys sys.version """ '3.7.7 (default, May 6 2020, 04:59:01) \n[Clang 4.0.1 (tags/RELEASE_401/final)]' """ import kfp kfp.__version__ """ '1.0.0' """2021年1月現在Kubeflow PipelinesのPython SDKであるkfpの最新バージョンは
1.3.0ですが、筆者の実行環境(AI Platform Pipelines)にインストールされているのが1.0.0だったため、このバージョンを利用しています。ベースイメージについて
BigQueryにクエリを投げるKFPのコンポーネントは2020年7月頃から存在していましたが、ベースイメージにpython2.7を使っていたためクエリ文に日本語が入っているとエンコーディングエラーが出ていました。
それがつい先日のP-Rマージでベースイメージがpython3.7に更新されたことで、クエリに日本語が入っていても正しくクエリを処理できるようになりました。
つまり2021年1月現在、クエリに日本語が入っている場合は以下のようなコンポーネントURLを指定しない場合、python2系のイメージを使ったコンポーネントが指定されてエンコーディングエラーで落ちるので注意が必要です。
'https://raw.githubusercontent.com/kubeflow/pipelines/ここが1.3.0のものを使う/components/gcp/bigquery/query/...'準備
この記事で示すサンプルは以下の宣言がされているものとします。
import kfp from kfp import dsl from kfp import components as comp from kfp.components import func_to_container_op from kfp.components import InputPath HOST = 'Kubeflow PipelinesのURL' PROJECT_ID = 'GCPを使っている場合は実行先のProject Id' QUERY = ''' SELECT * FROM `bigquery-public-data.stackoverflow.posts_questions` LIMIT 10 -- これはテストです '''実行は全部これです。
result = kfp.Client(host=HOST).create_run_from_pipeline_func(pipeline, arguments={}) result """ Experiment link here Run link here RunPipelineResult(run_id=ee82166c-707b-4e5f-84d2-5d98d7189023) """CSVファイルに保存
コード
保存するファイル名とコンポーネントを宣言します。
# CSVのファイル名 FILENAME = 'query_result.csv' # BigQuery to CSVのコンポーネントURL bigquery_op_url = 'https://raw.githubusercontent.com/kubeflow/pipelines/1.3.0/components/gcp/bigquery/query/to_CSV/component.yaml' bigquery_query_op = comp.load_component_from_url(bigquery_op_url) help(bigquery_query_op) """ Help on function Bigquery - Query: Bigquery - Query(query: str, project_id: 'GCPProjectID', job_config: dict = '', output_filename: str = 'bq_results.csv') Bigquery - Query A Kubeflow Pipeline component to submit a query to Google Cloud Bigquery and store the results to a csv file. """
help関数を使うとそのコンポーネントに渡すべき引数がわかるので、ここを見ながら引数を設定してやります。CSVに出力されたことは以下の2つの手順で確認してみます。
task 1. 出力先パスを確認
task 2. 出力先パスからCSVを読んでshapeを出力# task 1 @func_to_container_op def print_op(text: InputPath('CSV')) -> None: print(f"text: {text}") print(f"type: {type(text)}") # task 2 @func_to_container_op def handle_csv_op(path: InputPath('CSV')) -> None: print(f'path: {path}') print(f'type: {type(path)}') import subprocess subprocess.run(['pip', 'install', 'pandas']) import pandas as pd df = pd.read_csv(path) print(f'shape: {df.shape}') # おまけ @func_to_container_op def print_op_non_type(text) -> None: print(f"text: {text}") print(f"type: {type(text)}") # pipeline @dsl.pipeline( name='Bigquery query pipeline name', description='Bigquery query pipeline' ) def pipeline(): bq_task = bigquery_query_op( query=QUERY, project_id=PROJECT_ID, output_filename=FILENAME) print_op(bq_task.outputs['table']) # task 1 handle_csv_op(f"{bq_task.outputs['table']}/{FILENAME}") # task 2 print_op_non_type(bq_task.outputs['table']) # おまけ実行結果
# print_opのログ text: /tmp/inputs/text/data type: <class 'str'> # handle_csv_opのログ path: /tmp/inputs/path/data type: <class 'str'> shape: (10, 20) # print_op_non_typeのログ text: ,id,title,body,accepted_answer_id,answer_count,comment_count,community_owned_date,creation_date,favorite_count,last_activity_date,last_edit_date,last_editor_display_name,last_editor_user_id,owner_display_name,owner_user_id,parent_id,post_type_id,score,tags,view_count 0,65070674,NewRelic APM cpu usage shows incorrect values in comparison to K8S cluster cpu chart,"<p>Here goes charts of CPU usage of same pod. <strong>chart 1</strong> is from k8s cluster, <strong>chart 2</strong> is from APM.</p> <ol></ol>" ... type: <class 'str'>実行結果のログから、以下のことがわかります。
InputPath('CSV')で受け取ったパスは/tmp/inputs/変数名/dataのようになる- 引数で指定したファイル名はコンポーネントの出力(
bq_task.outputs['table'])に表示されない# print_opのログ text: /tmp/inputs/text/data # handle_csv_opのログ # 引数としてf"{bq_task.outputs['table']}/{FILENAME}"を渡しているがFILENAMEは出力されない path: /tmp/inputs/path/data
- 次のコンポーネントにクエリ結果を渡す際、引数の型を
InputPath('CSV')で指定しないとクエリ結果が文字列として渡る# print_op_non_typeのログ text: ,id,title,body,accepted_answer_id,answer_count,comment_count,community_owned_date,creation_date,favorite_count,last_activity_date,last_edit_date,last_editor_display_name,last_editor_user_id,owner_display_name,owner_user_id,parent_id,post_type_id,score,tags,view_count 0,65070674,NewRelic APM cpu usage shows incorrect values in comparison to K8S cluster cpu chart,"<p>Here goes charts of CPU usage of same pod. <strong>chart 1</strong> is from k8s cluster, <strong>chart 2</strong> is from APM.</p> <ol></ol>" ...中略 type: <class 'str'>注意点
その1
クエリ結果を文字列として渡す際に渡し先のコンポーネントの引数の型を
strにすると型の不一致で落ちるため、InputPath('xxx')以外の形でコンポーネントの出力を受け渡すことは非推奨と思われます。...略 # 引数の型をstrに指定 @func_to_container_op def print_op(text:str) -> None: print(f"text: {text}") print(f"type: {type(text)}") def pipeline(): bq_task = bigquery_query_op( query=QUERY, project_id=PROJECT_ID, output_filename=FILENAME) # コンポーネントの出力はPipelineParam型で引数はstrを指定しているため、以下のタスクは引数の型の不一致で落ちる print_op(bq_task.outputs['table']) # task 1その2
上で述べたようにコンポーネントの出力(
bq_task.outputs['table'])はPipelineParam型というプレースホルダになっているため、文字列との連結や演算などはできません。そのため、上のプログラムではf-stringでの代入をしていたというわけです。
def pipeline(): bq_task = bigquery_query_op( query=QUERY, project_id=PROJECT_ID, output_filename=FILENAME) # PipelineParam型はstringにキャストできないため以下の方法は落ちる # print_op(bq_task.outputs['table'] + "/" + FILENAME) # task 1 # これは通る print_op(f"{bq_task.outputs['table']}/{FILENAME}") # task 1実際に値が割り当てられるのはパイプライン実行時なので、コンポーネントの出力の扱いには注意が必要です。
参考:Kubeflow - Pipeline Parameters
GCSに保存
コード
保存するファイル名とコンポーネントを宣言します。
help関数の出力を見てわかるように、CSVファイルを保存する時とは違った引数が必要です。# GCSに保存するファイルへのパス BUCKET = 'バケット名' GCS_PATH = f'gs://{BUCKET}/query_from_kfp/query_result.csv' bigquery_op_url = 'https://raw.githubusercontent.com/kubeflow/pipelines/1.3.0/components/gcp/bigquery/query/to_gcs/component.yaml' bigquery_query_op = comp.load_component_from_url(bigquery_op_url) help(bigquery_query_op) """ Help on function Bigquery - Query: Bigquery - Query(query: str, project_id: 'GCPProjectID', dataset_id: str = '', table_id: str = '', output_gcs_path: 'GCSPath' = '', dataset_location: str = 'US', job_config: dict = '', output_kfp_path: str = '') Bigquery - Query A Kubeflow Pipeline component to submit a query to Google Cloud Bigquery service and dump outputs to a Google Cloud Storage blob. """GCSに出力されたことは先ほどと同様に、以下の2つの手順で確認します。
task 1. 出力先のGCSパスを確認
task 2. 出力先のGCSパスからCSVを読んでshapeを出力# task 1 @func_to_container_op def print_op(text: InputPath('GCSPath')) -> None: print(f"text: {text}") print(f"type: {type(text)}") # task 2 @func_to_container_op def handle_csv_op(gcs_file_path: InputPath('GCSPath'), project:str) -> None: print(f'path: {gcs_file_path}') print(f'type: {type(gcs_file_path)}') import subprocess subprocess.run(['pip', 'install', 'google-cloud-storage', 'pandas']) from google.cloud import storage from io import BytesIO import pandas as pd client = storage.Client(project) # point 1 with open(gcs_file_path, 'r') as f: path = f.read() # point 2 with BytesIO() as f: client.download_blob_to_file(path, f) content = f.getvalue() df = pd.read_csv(BytesIO(content)) print(f'shape: {df.shape}') # pipeline @dsl.pipeline( name='Bigquery query pipeline name', description='Bigquery query pipeline' ) def pipeline(): bq_task = bigquery_query_op( query=QUERY, project_id=PROJECT_ID, output_gcs_path=GCS_PATH}) print_op(bq_task.outputs['output_gcs_path']) # task 1 handle_task = handle_csv_op(gcs=bq_task.outputs['output_gcs_path'], project=PROJECT_ID) # task 2実行結果
# print_opのログ text: /tmp/inputs/text/data type: <class 'str'> # handle_csv_opのログ path: /tmp/inputs/gcs/data type: <class 'str'> shape: (10, 20)注意点
その1
handle_csv_opコンポーネントでの処理のクセが強い気がしてます。今回のケースではクエリ結果がGCSに保存されているため、bigquery_query_opコンポーネントからの出力はstr型のパスではなく、GCSのパスが記述されたファイルへのパスになっています。そのため、以下のようにGCSのパスを読み込んでから、
# point 1 with open(gcs_file_path, 'r') as f: path = f.read() # gs://{BUCKET}/query_from_kfp/query_result.csv以下のようにGCSからファイルの中身を取得します。
# point 2 with BytesIO() as f: client.download_blob_to_file(path, f) content = f.getvalue() df = pd.read_csv(BytesIO(content))この挙動はコンポーネントの定義ファイルで
output_gcs_pathをOutputPath型で定義していることに拠ります。素直にstringにしてくれよ…と思いますが、その理由は謎に包まれています。その2
コンポーネントの引数の型に
InputPathを指定した場合、引数名から特定の文字列が除外されます。例えば
handle_csv_opコンポーネントの引数でgcs_file_pathがありますが、参照するときにはgcsとして参照しています。# gcs_file_path=bq_task.outputs['output_gcs_path']ではない handle_task = handle_csv_op(gcs=bq_task.outputs['output_gcs_path'], project=PROJECT_ID) # task 2一応以下のようにドキュメント?はあるのですが如何せん探しにくいので地味にハマりどころです。Kubeflowのドキュメントだったりチュートリアルが色んなところに散っていて探すのが大変です。
参考:Building Python function-based components - passing parameters by value
BigQueryに保存
BigQueryにクエリを投げてその結果をBigQueryの任意のテーブルに書き出します。
コード
保存先のテーブルとコンポーネントを宣言します。
# クエリ結果の保存先 DATASET_ID = 'mail_retention_pipeline' TABLE_ID = 'query_result' FILENAME = 'query_result.csv' # クエリ結果の確認用クエリ VERIFY_QUERY = f''' SELECT * FROM `{PROJECT_ID}.{DATASET_ID}.{TABLE_ID}` ''' # クエリ結果をBigQueryに保存するコンポーネント bigquery_table_op_url = 'https://raw.githubusercontent.com/kubeflow/pipelines/1.3.0/components/gcp/bigquery/query/to_table/component.yaml' bigquery_query_table_op = comp.load_component_from_url(bigquery_table_op_url) # クエリ結果をCSVに出力するコンポーネント bigquery_csv_op_url = 'https://raw.githubusercontent.com/kubeflow/pipelines/1.3.0/components/gcp/bigquery/query/to_CSV/component.yaml' bigquery_query_csv_op = comp.load_component_from_url(bigquery_csv_op_url) help(bigquery_query_table_op) """ Help on function Bigquery - Query: Bigquery - Query(query: str, project_id: 'GCPProjectID', table: str, dataset_id: str = '', table_id: str = '', dataset_location: str = 'US', job_config: dict = '') Bigquery - Query A Kubeflow Pipeline component to submit a query to Google Cloud Bigquery service and dump outputs to new table. """BigQueryに出力されたことは以下の3つの手順で確認します。
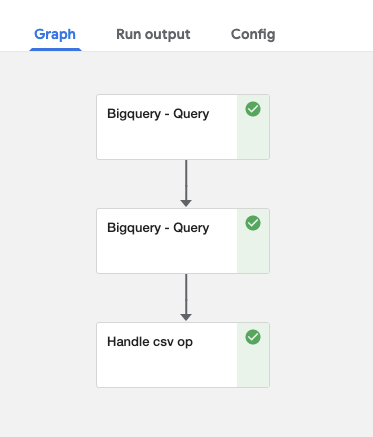
task 1. BigQueryにクエリを投げてBigQueryに結果を保存
task 2. クエリ結果をBigQueryから取得しCSVで保存
task 3. CSVファイルを読んでshapeを確認# task 3 @func_to_container_op def handle_csv_op(path: InputPath('CSV')) -> None: import subprocess subprocess.run(['pip', 'install', 'pandas']) import pandas as pd df = pd.read_csv(path) print(f'shape: {df.shape}') @dsl.pipeline( name='Bigquery query pipeline name', description='Bigquery query pipeline' ) def pipeline(): # task 1: クエリ結果をBigQueryに保存 bq_table_task = bigquery_query_table_op( query=QUERY, project_id=PROJECT_ID, dataset_id=DATASET_ID, table_id=TABLE_ID, table='') # task 2: クエリ結果をCSVで保存 bq_csv_task = bigquery_query_csv_op( query=VERIFY_QUERY, project_id=PROJECT_ID, output_filename=FILENAME).after(bq_table_task) handle_task = handle_csv_op(f"{bq_csv_task.outputs['table']}/{FILENAME}") # task 3実行結果
# handle_csv_opのログ path: /tmp/inputs/gcs/data type: <class 'str'> shape: (10, 20)DAGがパイプラインっぽい形になりました。
注意点
その1
bq_table_taskコンポーネントにはtableという謎の引数があり、この引数に何かしらのstringを入れないと動作しません。ソースコードを見る限りこのパラメータは使われていないので修正漏れと思われます。# クエリ結果をBigQueryに保存するコンポーネント bigquery_table_op_url = 'https://raw.githubusercontent.com/kubeflow/pipelines/1.3.0/components/gcp/bigquery/query/to_table/component.yaml' bigquery_query_table_op = comp.load_component_from_url(bigquery_table_op_url) ... # table というpositional argumentがある help(bigquery_query_table_op) """ Help on function Bigquery - Query: Bigquery - Query(query: str, project_id: 'GCPProjectID', table: str, dataset_id: str = '', table_id: str = '', dataset_location: str = 'US', job_config: dict = '') Bigquery - Query A Kubeflow Pipeline component to submit a query to Google Cloud Bigquery service and dump outputs to new table. """Kubeflow Pipelinesのリポジトリを確認したところ修正PRが出ていたので、マージされればこの問題は解消されます。
その2
クエリ結果をBigQueryに保存する処理は、実はGCSにクエリ結果を保存するコンポーネントでも実現できます。
helpの出力からわかるように、クエリ結果をGCSに保存するコンポーネントにもdataset_idとtable_idという引数があります。# クエリ結果をBigQueryに保存するコンポーネント """ Help on function Bigquery - Query: Bigquery - Query(query: str, project_id: 'GCPProjectID', table: str, dataset_id: str = '', table_id: str = '', dataset_location: str = 'US', job_config: dict = '') Bigquery - Query A Kubeflow Pipeline component to submit a query to Google Cloud Bigquery service and dump outputs to new table. """ # クエリ結果をGCSに保存するコンポーネント """ Help on function Bigquery - Query: Bigquery - Query(query: str, project_id: 'GCPProjectID', dataset_id: str = '', table_id: str = '', output_gcs_path: 'GCSPath' = '', dataset_location: str = 'US', job_config: dict = '', output_kfp_path: str = '') Bigquery - Query A Kubeflow Pipeline component to submit a query to Google Cloud Bigquery service and dump outputs to a Google Cloud Storage blob. """つまり「クエリ結果はパイプライン内だけで使うからどこにも保存する必要はない」という状況以外は、クエリ結果をGCSに保存するコンポーネントを使えばOKということです。
まとめ
- BigQueryにクエリを投げる公式コンポーネントを使う際はバージョンに注意
- 古いとクエリのコメントに日本語が使えない
- コンポーネントの入力と出力の型に注意
- コンポーネントのキーワード引数には省略される文字列がある
- クエリ結果をパイプライン内で完結させる場合以外はGCSに保存するコンポーネントを使う
以上。
- 投稿日:2021-01-12T22:32:40+09:00
【初心者向け】Pythonで作成したライブラリをPyPIに登録する方法
はじめに
ブログの自動投稿に興味があったのだが、Pythonには使い勝手のいいライブラリがなかったので自作した。せっかくなら
pip install hogehogeてやりたいのでその方法についてまとめてみた。環境
- Mac OS Big Sur 11.1
- Python 3.8.2
- pip 20.3.3
- Pipenv 2020.11.15
- twine 3.3.0
忙しい人向け
PyPIってところに登録するといいよ!
アップロードにはtwineを使ってね!手順
以下はPipenvを使用時のコマンドになりますが参考を見るなりして適宜置き換えてください。
0. 前提
1. twineのインストール
PyPIへのアップロードは
twineを使用するため予めインストールしておきます。pipenv install --dev twine2. 登録ファイルの作成
以下を実行すると
dist/以下に.whlと.tar.gzが作成されます。python setup.py sdist bdist_wheel3. Test PyPIへアップロード
本番のPyPIへアップロードする前にTest環境のPyPIが使用できます。
絶対に使わなければいけないってことはないですが、慣れないうちは使用する方がいいでしょう。python -m twine upload --repository testpypi dist/*これでTest PyPIへのアップロードが完了しました。
せっかくなのでTest PyPIからインストールを行なってみましょう。pipenv install --pypi-mirror https://test.pypi.org/simple/ <PACKAGE_NAME>4. PyPIへアップロード
Test PyPIへアップロードしたライブラリの動作確認ができたら最後は本番のPyPIに登録しましょう。誰かに審査されるわけではないのでお気軽にどうぞ。
python -m twine upload dist/*これで本番のPyPIへアップロードが完了しました。
最後に例のやつを試して終了です。お疲れさまでした。pipenv install <PACKAGE_NAME>参考
- 投稿日:2021-01-12T22:29:01+09:00
競技プログラミングをやってみた
エンジニアになりたいと思い勉強しているのだけれど、これがなかなか就職先が見つからない
(ポートフォリオが駄作なのは承知)ということで暇つぶしにpythonであそんでみてる(その時間使ってポートフォリオ改修しろ!)
3日前くらいから淡々とPaizaのDランクから一問づつ解いてみてるんだけど
楽しい!!!
基礎勉強はしてきたけどアウトプットはほとんどやってきてない
そんな自分にとってはいいアウトプットの場所だなと思う。
ただ競技プログラミングができる=エンジニアとして通用する わけではないので注意なのかな?
え?Paizaは競技プログラミングではないって?
問題形式が似ているから実質競技プログラミング!ということで
自分はPaizaの問題を解いていて構文について調べてるときに競技プログラミングを知ったわけだけど
画面ひとつでできるPaizaで一通り遊び終わってからAtCoderに挑戦してみようと思う
(決してツールを用意するのが面倒とかではない)ここからはその中でも経験になった問題、構文
まず初歩的なFizzBuzz問題から
1から100までの数字を出力する時、
3の倍数の時'Fizz',5の倍数の時'Buzz',3と5の倍数の時'FizzBuzz'を数字の代わりに出力する
という問題プログラミング学習してる人ならやったことがある人が多いと思う
まず一般的な書き方から.pyfor i in range(1, 101): if i % 3 == 0 and i % 5 == 0: print('FizzBuzz') elif i % 3 == 0: print('Fizz') elif i % 5 == 0: print('Buzz') else: print(i)この問題の肝は最初に判定を3と5の倍数かどうかにすること。(詳しい解説は各自調べてね)
簡単にいうと 「15で割ったあまりが0」 ⊃ 「3(5)で割ったあまりが0」 だから
残りの3の倍数、5の倍数の判定の順は関係ないからどちらから書いても正解であるさあこれをもっと簡潔に書いてみようっていうのが競技プログラミングである
最初にかけた時は感動した.pyfor i in range(1, 101): print('Fizz' * (i % 3 == 0) + 'Buzz' * (i % 5 == 0) or i)なんと2行で書ける
ただ1行で書けるのでまだ改良できるけどこれくらい綺麗に描ければ十分感動ものであるひとつ目
入力される2つの値M,N(半角スペース区切り)が与えられるとき、
M,Nの偶奇が一致するときは'YES'、しないときは'NO'と出力普通に書くと長くなるので割愛
自分が書いたのはこれn, m = map(int, input().split()) print('NO' * (n % 2 == m % 2) or 'YES')コーダー100人いたら100通りの書き方があるので参考程度に
何個か紹介しようとしたけど振り返ってみたら何もすごいこと書いてなかったのにメモされていたので省略します
以上 競プロ楽しいって話ですた
P.S. 競プロにおいてC++が最速らしいのでC++触り始めました(就活しろ)
- 投稿日:2021-01-12T22:06:50+09:00
GoogleのSpeech to textをDjangoで実装してみた
AWSでは、WEB操作で文字起こしをすることが可能ですが、GCPではAPIからしか操作することができません。なので、djangoを勉強するとともに簡易的に実施してみました。理由は、Googleの音声認識の精度はかなり高いから。流れとしては、GoogleStorageにアップロードして文字起こしをします。なぜ、GoogleStorageなのかは、ローカルだとファイルサイズが10MB未満など条件がつくからです。
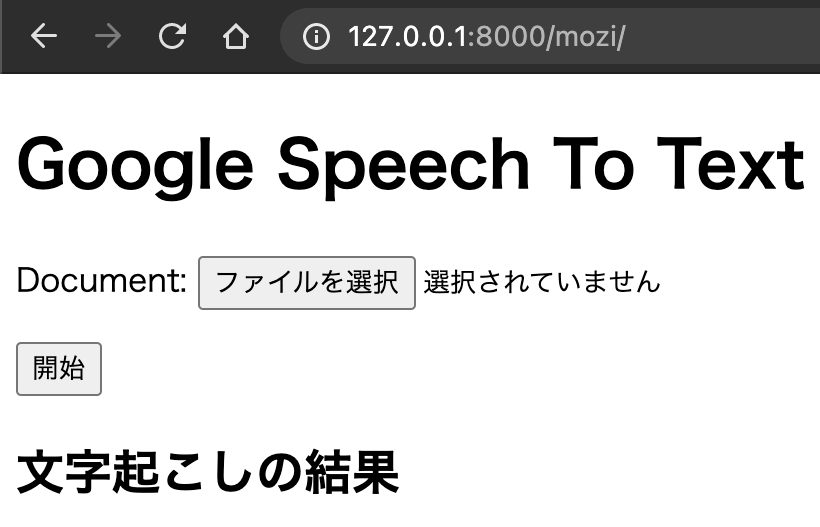
完成図
開発環境
MacBook
Python(3.7.7)
Django(3.1.5)
google-cloud-storage(1.35.0)
google-cloud-speech(2.0.1)
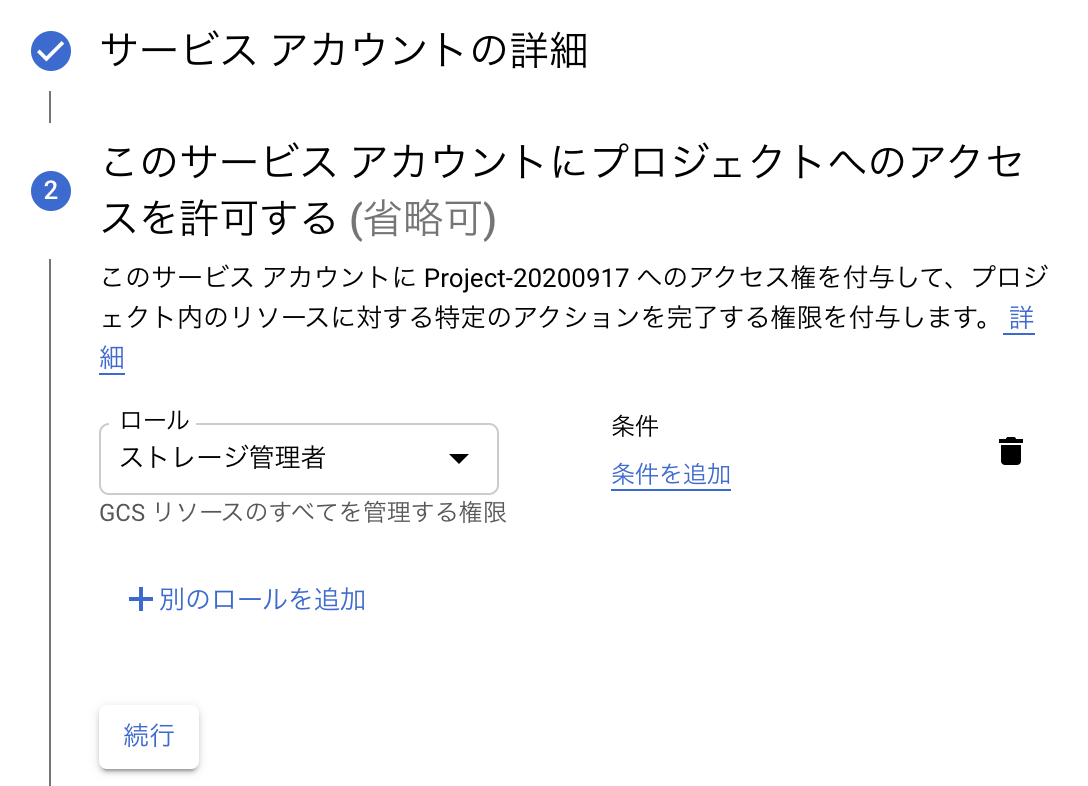
pydub(0.24.1)Googleの認証用jsonを取得
サービスアカウント作成時に、"Google Storage"の管理者権限を付与する.
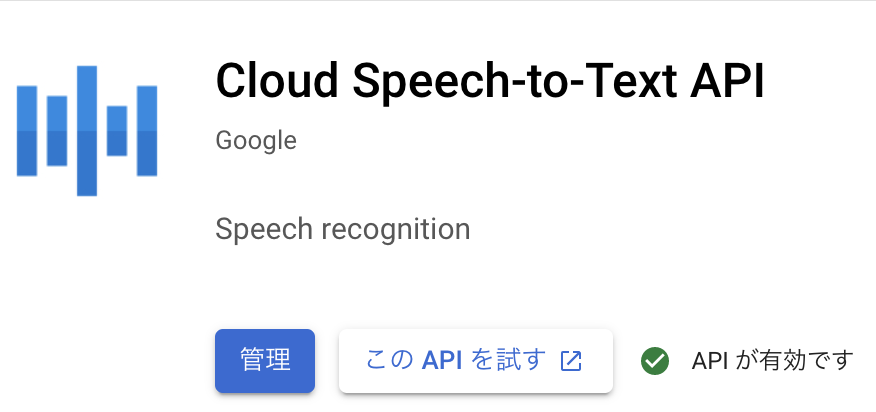
Speech to TextのAPI有効化
GCPのライブラリからAPIを有効化する
環境設定
#Django pip3 install django==3.1.5 #google-cloud-storage pip3 install google-cloud-storage==1.35.0 #google-cloud-storage pip3 install google-cloud-speech==2.0.1 #pydub pip3 install pydub==0.24.1Django設定
プロジェクト作成
projectフォルダが作成されます.
#プロジェクト名(project) django-admin startproject projectアプリケーションの作成
projectフォルダに移動しアプリケーションを作成します.
※今回は"mozi"というアプリケーションを作成#アプリケーション作成 python3 manage.py startapp mojiDjango(WEBサーバ)の基本設定
projectフォルダにあるprojectフォルダのファイルを設定.
settings.py#誰からでもアクセスできるように ALLOWED_HOSTS = ['*'] #htmlファイルを使用するために INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'mozi', #アプリケーションの追加(mozi内のtemplatesの検索するようになる) ]urls.pyfrom django.contrib import admin from django.urls import path,include urlpatterns = [ path('admin/', admin.site.urls), path('mozi/', include('mozi.urls')), #moziアプリ内でurls.pyを設定できるように ]アプリケーション(mozi)の基本設定
projectフォルダ内のmoziフォルダ内のファイルを設定.
アプリケーション側で画面遷移を設定できるようにurls.pyを新規作成urls.pyfrom django.urls import path from . import views urlpatterns = [ path('', views.index, name='index'), ]メイン機能を作成
projectフォルダ内のsettings.pyにアップロード先を追記.
BASE_DIRは、manage.pyがあるところなので、そこにuploadフォルダを作成する.settings.py#FILE_UPLOAD import os MEDIA_ROOT = os.path.join(BASE_DIR, 'upload') MEDIA_URL = '/upload/'projectフォルダ内のurls.pyにおまじないを追記.
urls.pyif settings.DEBUG: urlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)フォームに必要な情報をmoziフォルダ配下のmodels.pyに追記します.
ここの"media"は、uploadフォルダの配下に作成されその中にファイルが保存されます.models.pyfrom django.db import models class Upload(models.Model): document = models.FileField(upload_to='media') uploaded_at = models.DateTimeField(auto_now_add=True) konosuke@konosuke mozi %フォームからファイルをアップロードするためmoziフォルダ配下にforms.pyを新規作成.
forms.pyfrom django import forms from .models import Upload class UploadForm(forms.ModelForm): class Meta: model = Upload fields = ('document',)WEB画面作成のためにhtmlを作成する.
※mozi/templates/mozi/inde.html --> template以下を新規作成
※{{}}でくくると変数扱いになるinde.html<!DOCTYPE html> <html lang="ja-JP"> <head> <meta charset="UTF-8"> <title>文字起こし君</title> </head> <body> <h1>Google Speech To Text</h1> <form method="post" enctype="multipart/form-data"> {% csrf_token %} {{ form.as_p }} <button type="submit">開始</button> </form> <h2>文字起こしの結果</h2> <p>{{ transcribe_result }}</p> </body> </html>画面表示の核となるviews.pyを設定.
views.pyfrom django.http import HttpResponse from django.shortcuts import render,redirect from .forms import UploadForm from .models import Upload def index(request): import os import subprocess #保存PATH source = "ファイルがアップロードされるpath" #GCS_URL GCS_BASE = "gs://バケット名/" #結果保存 speech_result = "" if request.method == 'POST': #GoogleStorageの環境準備 from google.cloud import storage os.environ["GOOGLE_APPLICATION_CREDENTIALS"]='jsonのPATH' client = storage.Client() bucket = client.get_bucket('GoogleStorageのバケット名') #アップロードファイルの保存 form = UploadForm(request.POST,request.FILES) form.save() #アップロードしたファイル名を取得 #ファイル名と拡張子を分割(ext->拡張子(.py)) transcribe_file = request.FILES['document'].name name, ext = os.path.splitext(transcribe_file) if ext==".wav": #GoogleStorageへアップロード blob = bucket.blob( transcribe_file ) blob.upload_from_filename(filename= source + transcribe_file ) #再生時間を取得 from pydub import AudioSegment sound = AudioSegment.from_file( source + transcribe_file ) length = sound.duration_seconds length += 1 #作業用ファイルの削除 cmd = 'rm -f ' + source + transcribe_file subprocess.call(cmd, shell=True) #文字起こし from google.cloud import speech client = speech.SpeechClient() gcs_uri = GCS_BASE + transcribe_file audio = speech.RecognitionAudio(uri=gcs_uri) config = speech.RecognitionConfig( encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16, #sample_rate_hertz=16000, language_code="ja_JP", enable_automatic_punctuation=True, ) operation = client.long_running_recognize(config=config, audio=audio) response = operation.result(timeout=round(length)) for result in response.results: speech_result += result.alternatives[0].transcript #GoogleStorageのファイル削除 blob.delete() else: #ファイルの変換処理 f_input = source + transcribe_file f_output = source + name + ".wav" upload_file_name = name + ".wav" cmd = 'ffmpeg -i ' + f_input + ' -ar 16000 -ac 1 ' + f_output subprocess.call(cmd, shell=True) #GoogleStorageへアップロード blob = bucket.blob( upload_file_name ) blob.upload_from_filename(filename= f_output ) #再生時間を取得 from pydub import AudioSegment sound = AudioSegment.from_file( source + transcribe_file ) length = sound.duration_seconds length += 1 #作業用ファイルの削除 cmd = 'rm -f ' + f_input + ' ' + f_output subprocess.call(cmd, shell=True) #文字起こし from google.cloud import speech client = speech.SpeechClient() gcs_uri = GCS_BASE + upload_file_name audio = speech.RecognitionAudio(uri=gcs_uri) config = speech.RecognitionConfig( encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16, #sample_rate_hertz=16000, language_code="ja_JP", ) operation = client.long_running_recognize(config=config, audio=audio) response = operation.result(timeout=round(length)) for result in response.results: speech_result += result.alternatives[0].transcript #GoogleStorageのファイル削除 blob.delete() else: form = UploadForm() return render(request, 'mozi/index.html', { 'form': form, 'transcribe_result':speech_result })最後にアプリケーションを同期します.
django-admin makemigrations mozi django-admin migrateこれで準備が整ったので、WEBサーバを起動します.
python3 manage.py runserver サーバのIP:8000PythonでWEBサーバ構築から内部処理を記述できたので構築しやすかったです。
触れてみた程度かつメモ程度の記録となります。参考サイト
https://noumenon-th.net/programming/2019/10/28/django-forms/
https://qiita.com/peijipe/items/009fc487505dfdb03a8d
https://cloud.google.com/speech-to-text/docs/async-recognize?hl=ja
- 投稿日:2021-01-12T21:49:25+09:00
【Pyhton】MacOS11でtkinterが動かない問題を解消したい
最近MacをBigSurにメジャーアップデートをしたらPythonがGUI系のモジュールが動かなくなったので直した。
brewのPythonは3.9.1にできなかったので公式からインストールする。
Python Release Python 3.9.1 | Python.org
最新のMacじゃないのでIntel版でインストール
公式のGUIインストーラでインストールされるPythonは以下に配置されているので
バージョンを確認して3.9.1になっていればOK$ /usr/local/bin/python3 --version Python 3.9.1venvとかを使っている場合は適宜エイリアスなどでPATHを変えるといいと思う。
development/Python
- 投稿日:2021-01-12T21:49:07+09:00
最適化アルゴリズムを実装していくぞ(差分進化)
はじめに
最適化アルゴリズムの実装シリーズです。
まずは概要を見てください。コードはgithubにあります。
差分進化
差分進化(Differential evolution:DE)は、生物の進化をもとに考案された遺伝的アルゴリズムと似ている手法です。
大きく、Mutation(突然変異)、Crossover(交叉)、Selection(生存選択)の3つのフェーズがあります。
遺伝的アルゴリズムみたいにフェーズ毎にアルゴリズムがいろいろあるようですが、本記事では一番簡単なアルゴリズムで実装しています。参考
・差分進化法でハイパーパラメータチューニング
・差分進化(Wikipedia)
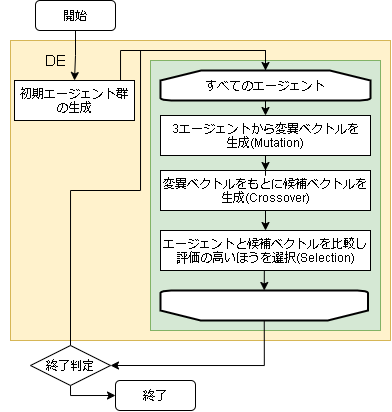
- アルゴリズムのフロー
- 用語の対応
問題 差分進化 入力値の配列 エージェントの位置 入力値 エージェント 評価値 エージェントの評価値
- ハイパーパラメータに関して
変数名 意味 所感 crossover_rate 交叉する確率 変異ベクトルになる確率 scaling 変異ベクトルのスケール率(長さ) 大きいほど移動範囲が大きい Mutation(突然変異)
ランダムに選んだ3人のエージェントから変異ベクトルを作成します。
import random i = 自分を表すindex # i番目を除いた3エージェントをランダムに選択 r1, r2, r3 = random.sample([ j for j in range(len(agents)) if j != i ], 3) pos1 = agents[r1].getArray() pos2 = agents[r2].getArray() pos3 = agents[r3].getArray()変異ベクトルは以下の式で出します。
$$ \vec{v} = \vec{x_1} + F (\vec{x_2} - \vec{x_3}) $$
$F$ は変異差分の適用率(スケール因子:scaling factor)を表す0~2の実数です。
pythonコードだと以下になります。# ベクトル計算しやすいようにnumpy化 import numpy as np pos1 = np.asarray(pos1) pos2 = np.asarray(pos2) pos3 = np.asarray(pos3) m_pos = pos1 + scaling * (pos2 - pos3)Crossover(交叉)
一様交叉(binary crossover)で交叉します。
ある確率(crossover_rate)で成分を入れ替える交叉となります。また交叉は、変異ベクトル側の要素を1成分だけ必ず取り入れます。
import random # 変異ベクトルで交叉させる(一様交叉) pos = agent.getArray() ri = random.randint(0, len(pos)) # 1成分は必ず変異ベクトル for j in range(len(pos)): if ri == j or random.random() < self.crossover_rate: pos[j] = m_pos[j] else: pass # 更新しない # 新しい位置のエージェントを作成 new_agent = problem.create(pos)生存選択
交叉でできた新しいエージェントと今のエージェントを比べ、更新されていれば置き換えます。
# 優れている個体なら置き換える if agents[i].getScore() < new_agent.getScore(): agents[i] = new_agentコード全体
コード全体です。
クラス化しているので上記コードと少し違います。import math import random import numpy as np class DE(): def __init__(self, agent_max, # エージェント数 crossover_rate=0.5, # 交叉率 scaling=0.5, # 差分の適用率 ): self.agent_max = agent_max self.crossover_rate = crossover_rate self.scaling = scaling def init(self, problem): self.problem = problem # 初期位置の生成 self.agents = [] for _ in range(self.agent_max): self.agents.append(problem.create()) def step(self): for i, agent in enumerate(self.agents): # iを含まない3個体をランダムに選択 r1, r2, r3 = random.sample([ j for j in range(len(self.agents)) if j != i ], 3) pos1 = self.agents[r1].getArray() pos2 = self.agents[r2].getArray() pos3 = self.agents[r3].getArray() # 3個体から変異ベクトルをだす pos1 = np.asarray(pos1) pos2 = np.asarray(pos2) pos3 = np.asarray(pos3) m_pos = pos1 + self.scaling * (pos2 - pos3) # 変異ベクトルで交叉させる(一様交叉) pos = agent.getArray() ri = random.randint(0, len(pos)) # 1成分は必ず変異ベクトル for j in range(len(pos)): if ri == j or random.random() < self.crossover_rate: pos[j] = m_pos[j] else: pass # 更新しない # 優れている個体なら置き換える new_agent = self.problem.create(pos) self.count += 1 if agent.getScore() < new_agent.getScore(): self.agents[i] = new_agentハイパーパラメータ例
各問題に対して optuna でハイパーパラメータを最適化した結果です。
最適化の1回の試行は、探索時間を2秒間として結果を出しています。
これを100回実行し、最適なハイパーパラメータを optuna に探してもらいました。
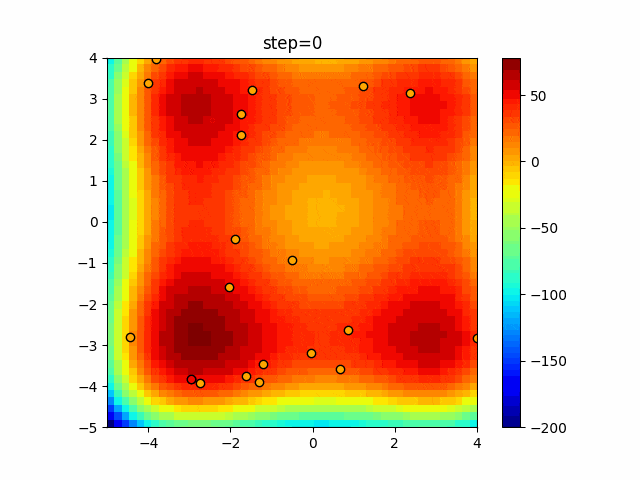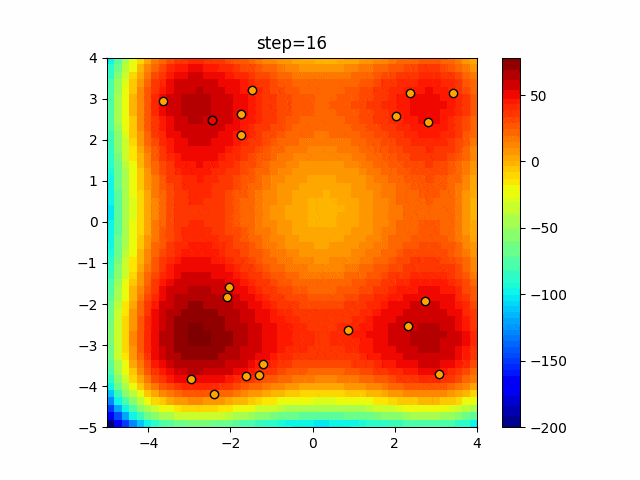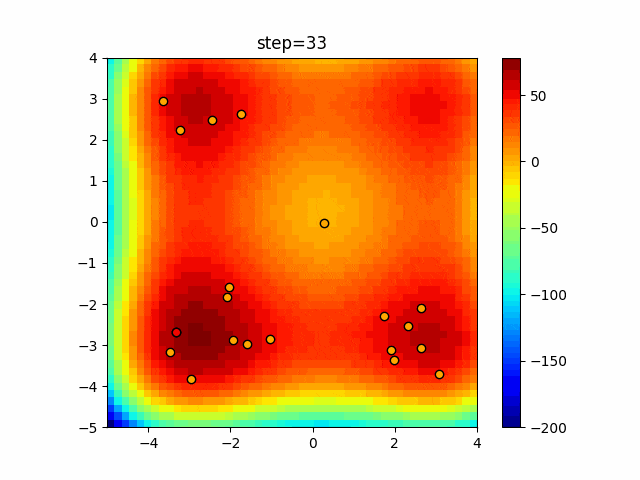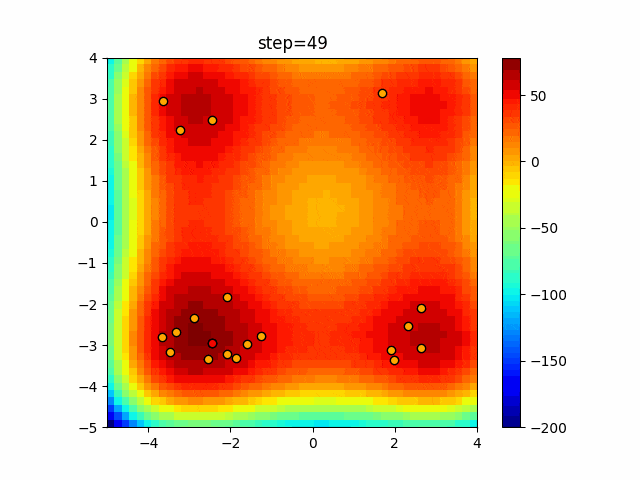
問題 agent_max crossover_rate scaling EightQueen 5 0.008405098138137779 1.7482804860765253 function_Ackley 36 0.4076390525351224 0.2908895854800526 function_Griewank 14 0.27752386128521395 0.4629100940098222 function_Michalewicz 12 0.1532879607238835 0.0742830755371933 function_Rastrigin 28 0.33513859646880306 0.0754225020709786 function_Schwefel 13 0.00032331965923372563 0.13153649005308807 function_StyblinskiTang 39 0.21247741932099348 0.08732185323441227 function_XinSheYang 33 0.0955103914325307 0.008270969294347359 LifeGame 39 0.6612227467897149 1.136453380180552 OneMax 4 0.1190487045395953 1.1581036102901494 TSP 23 0.41212989299137665 0.014644735558753091 実際の動きの可視化
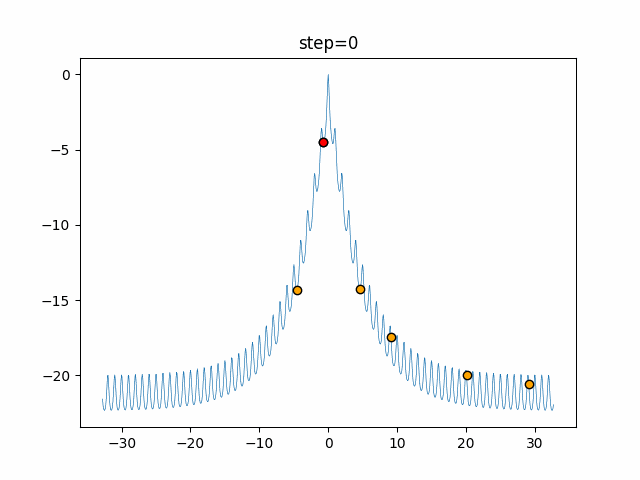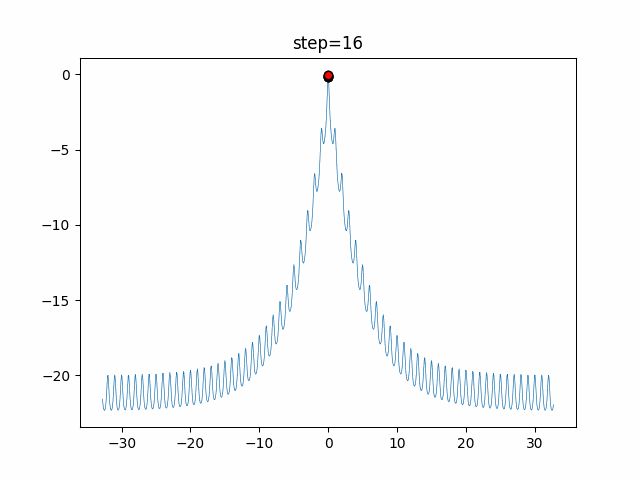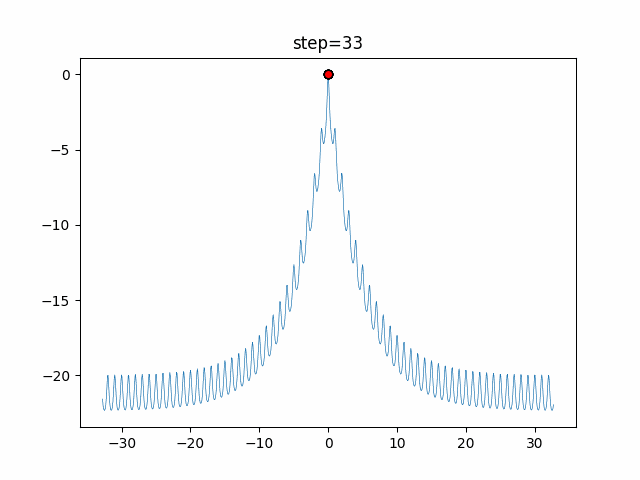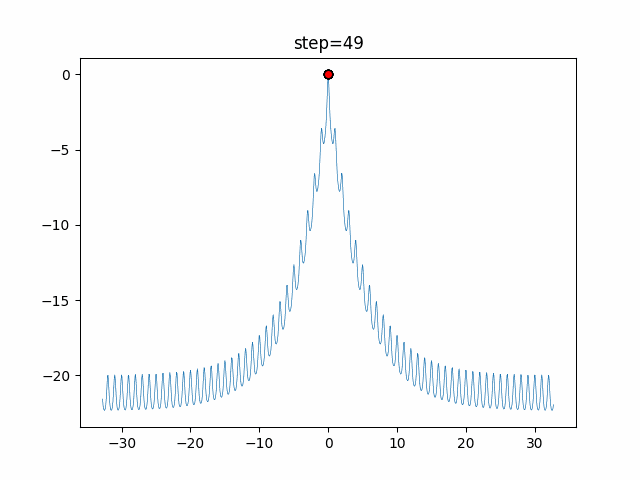
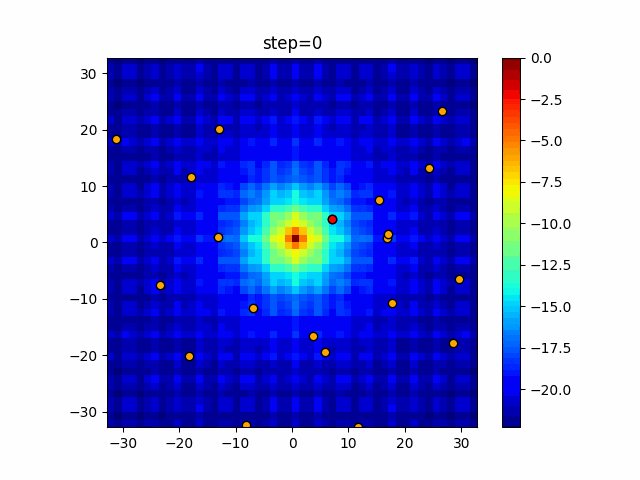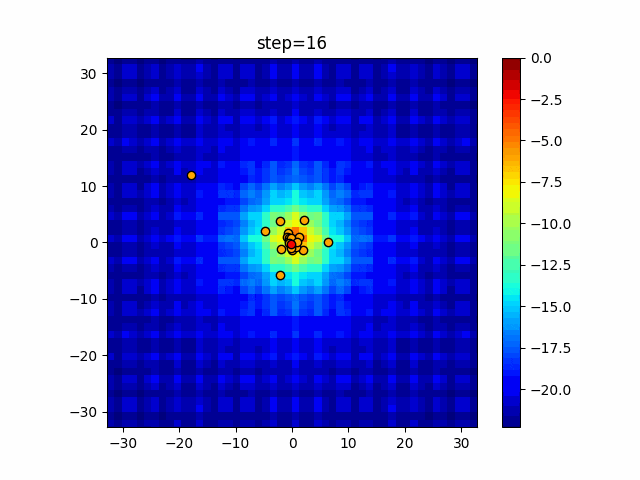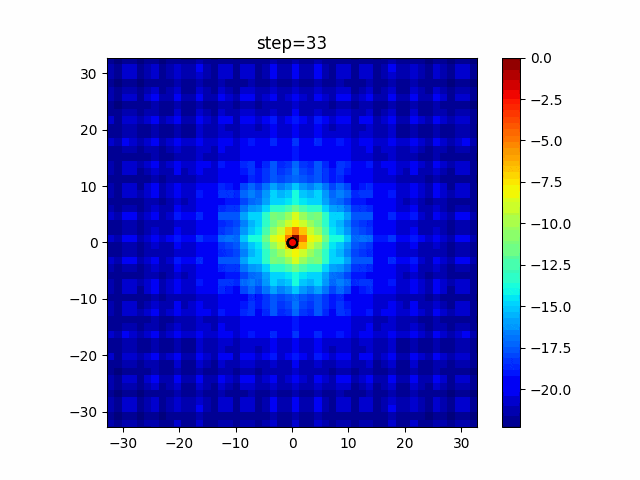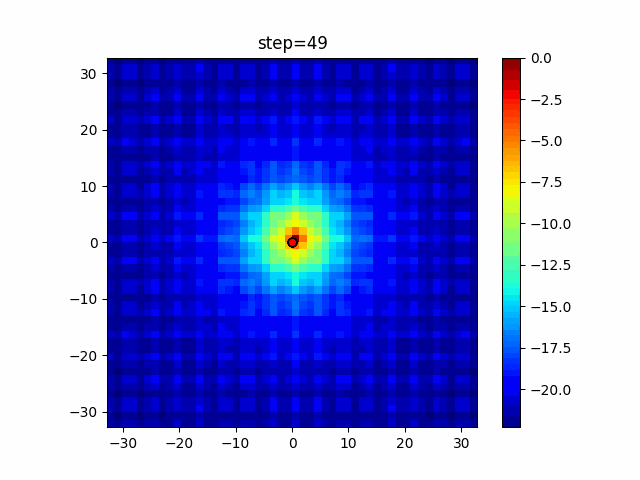
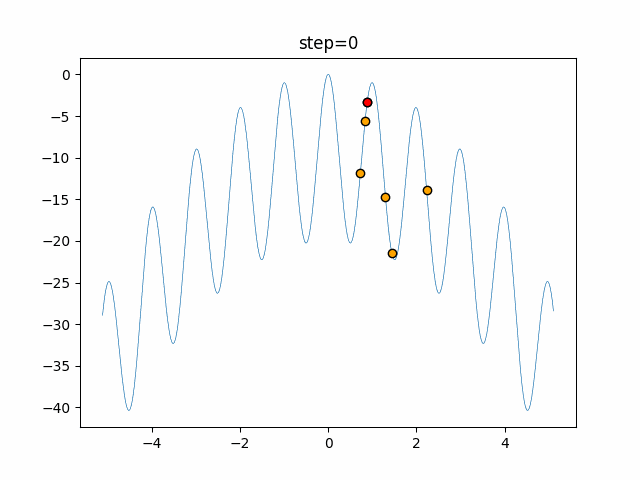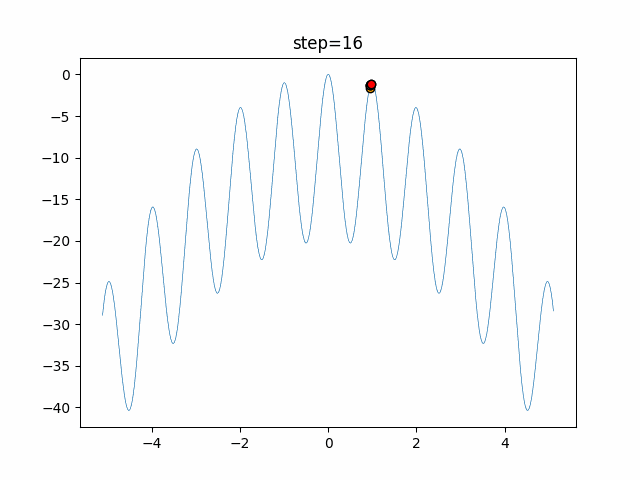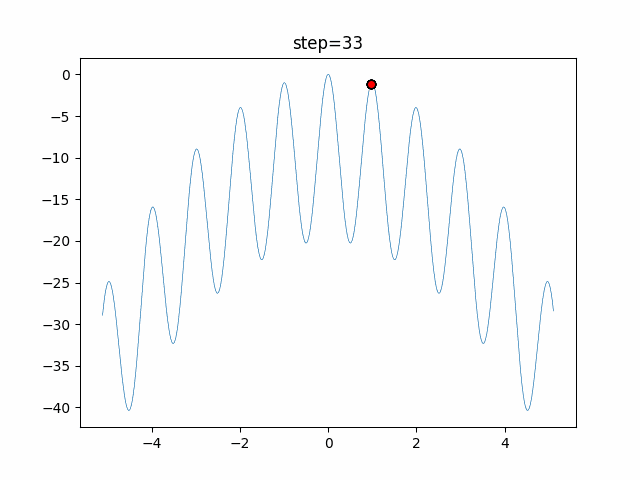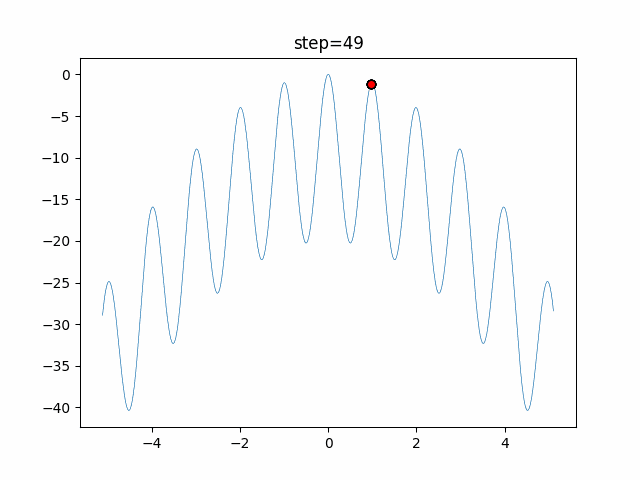
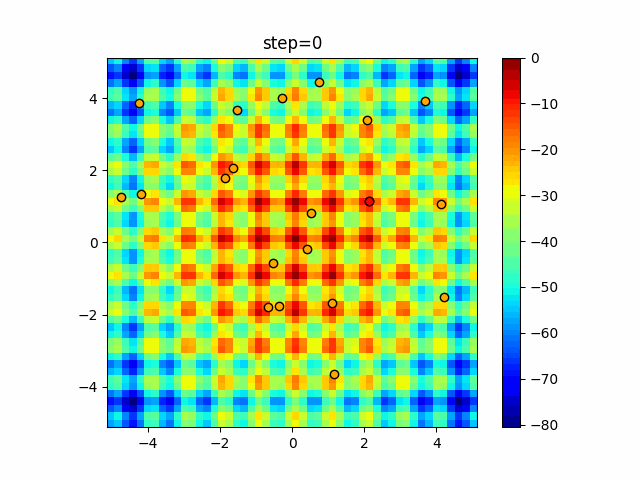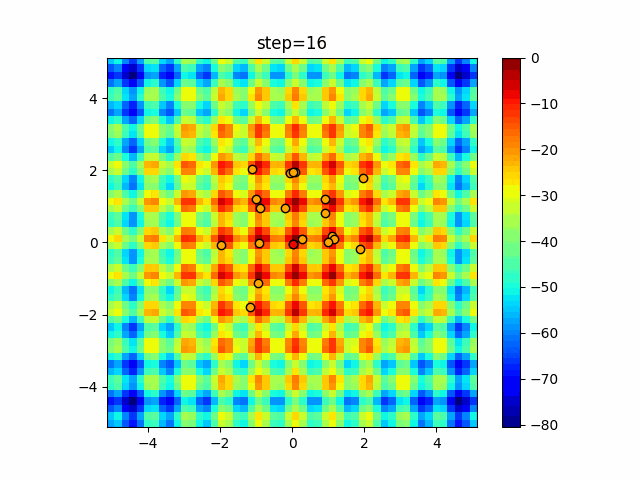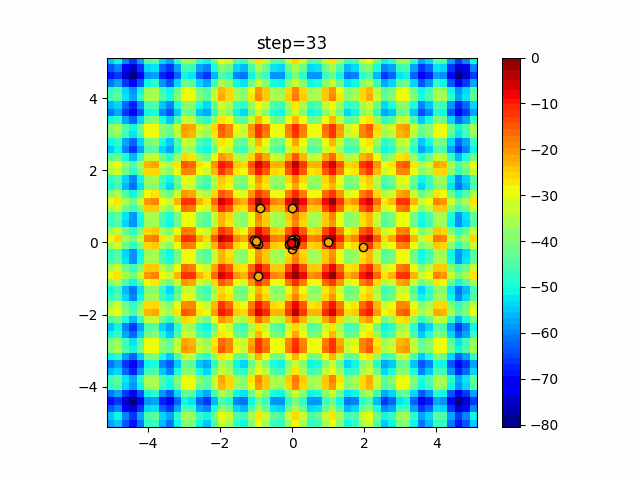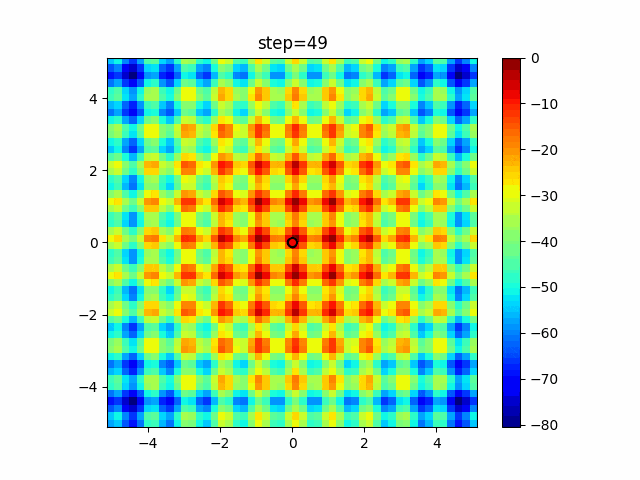
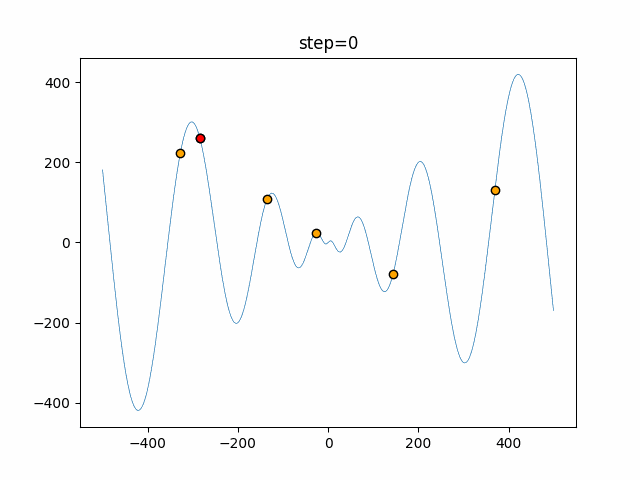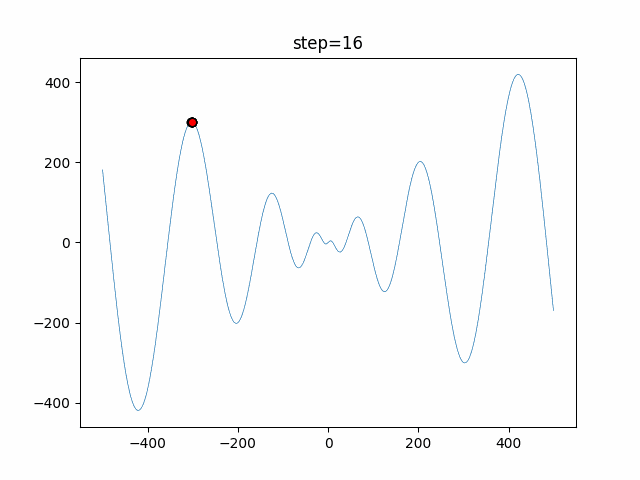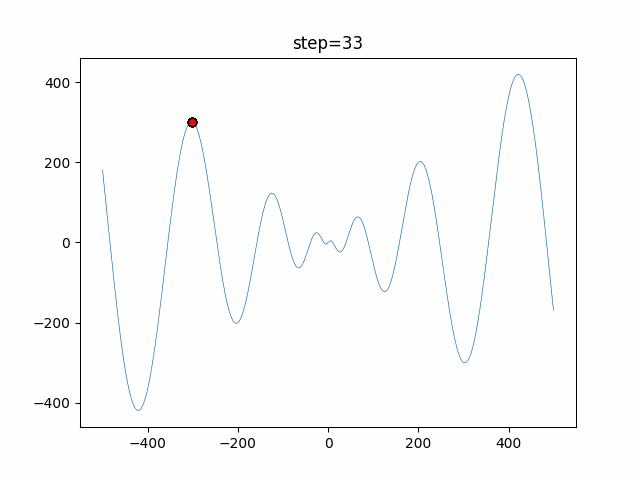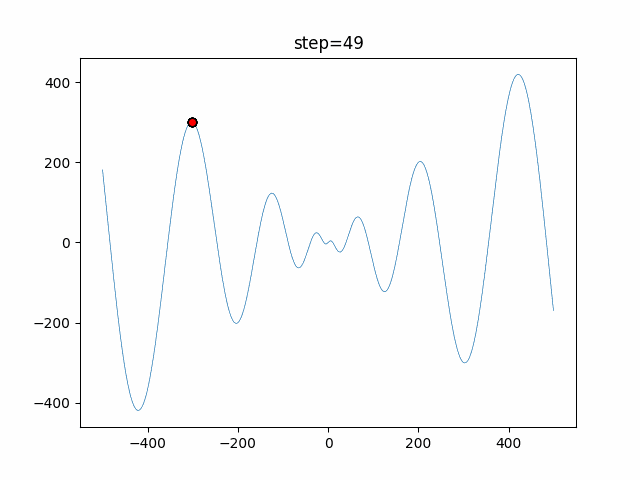
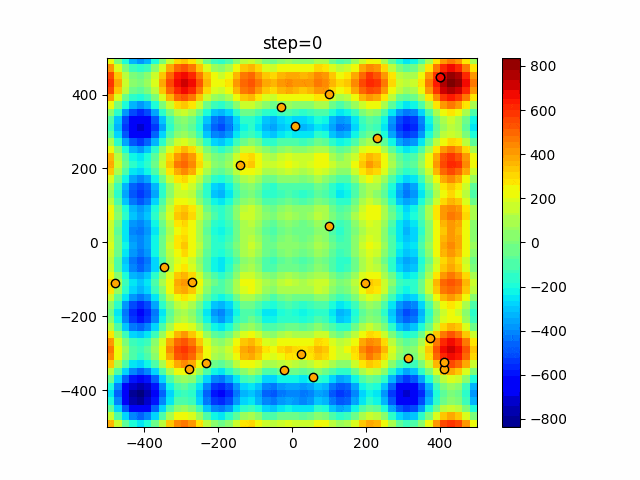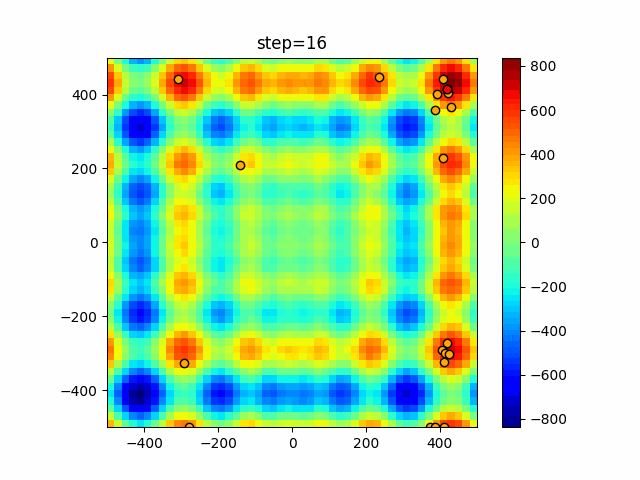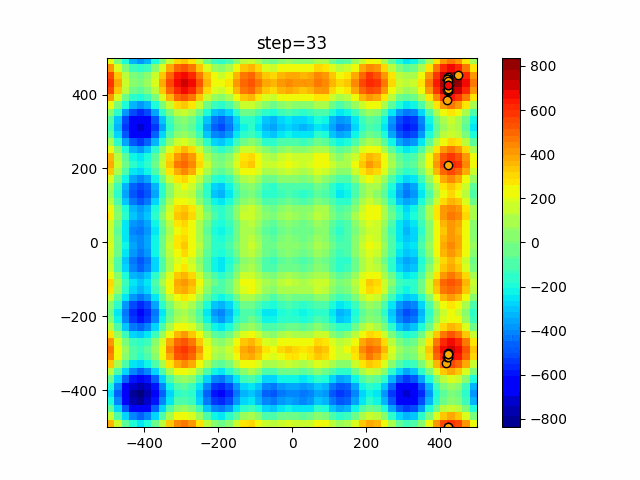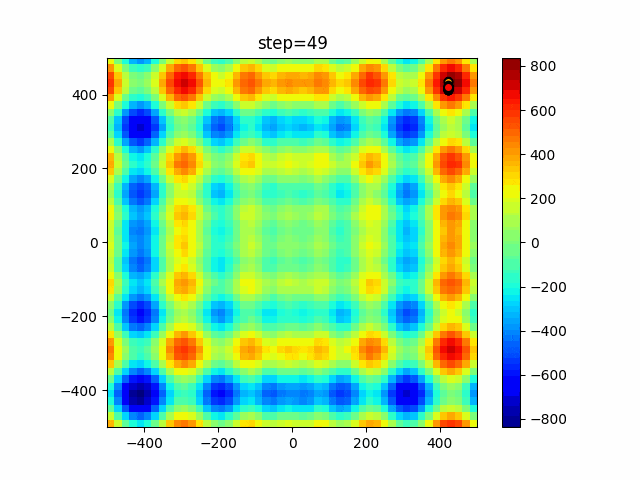
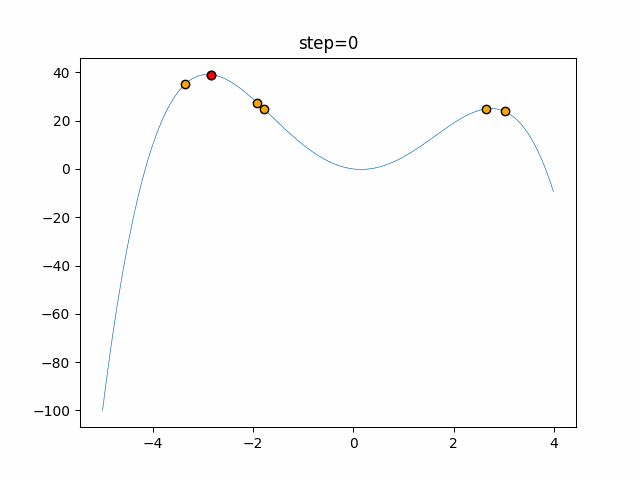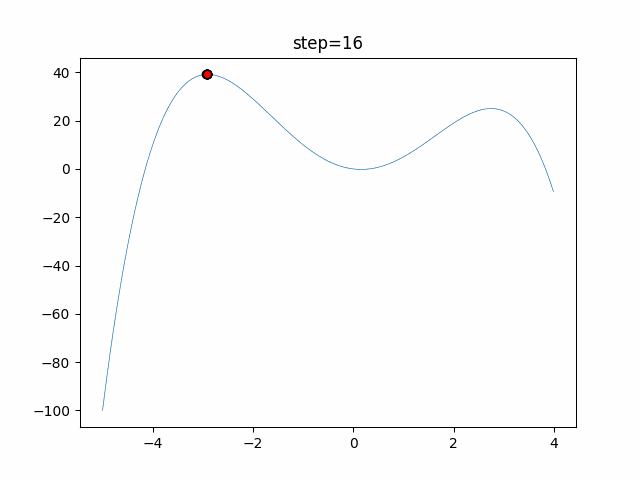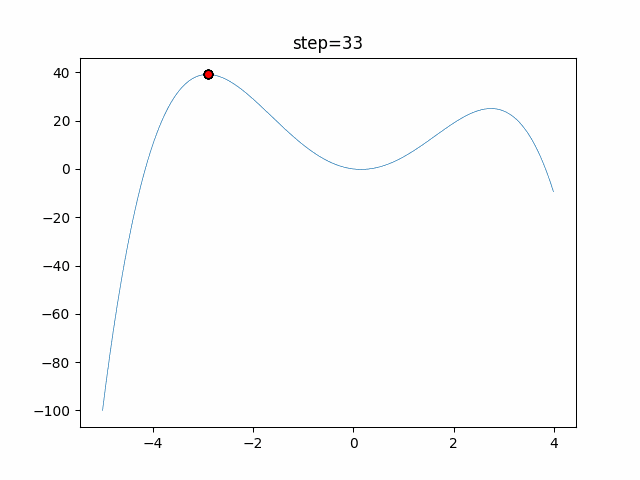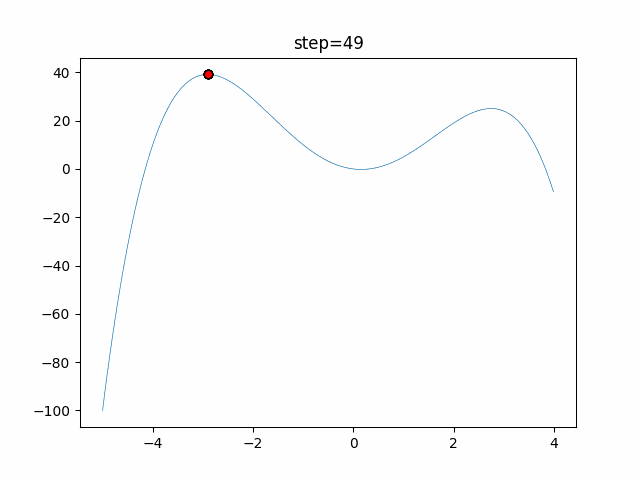
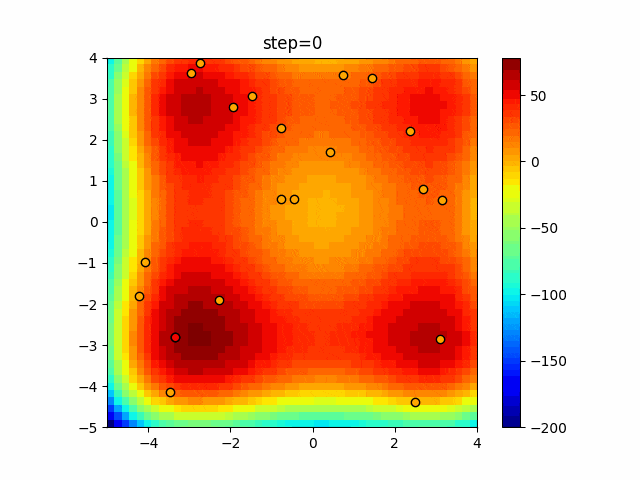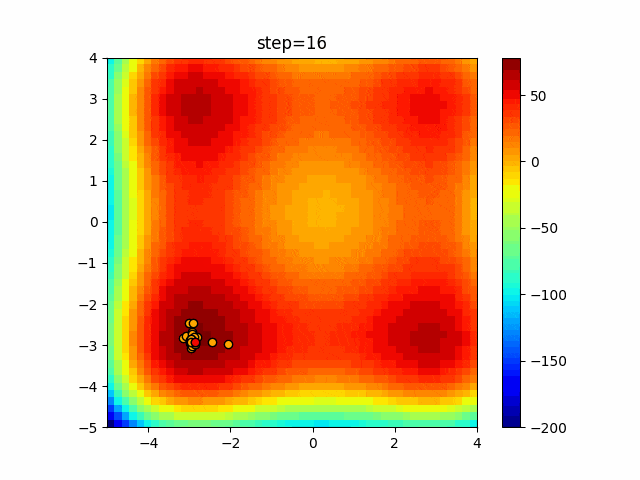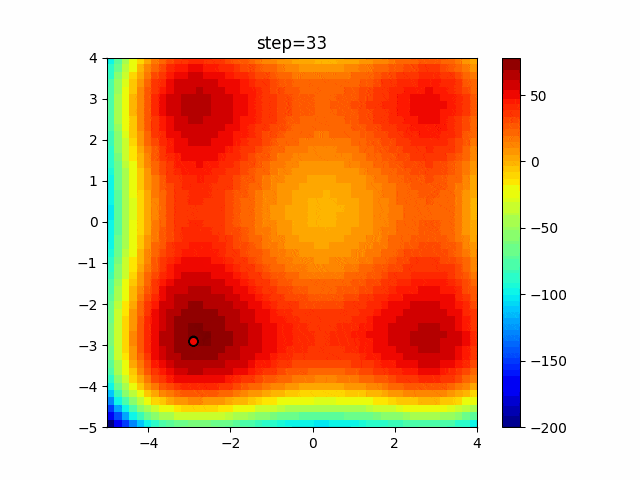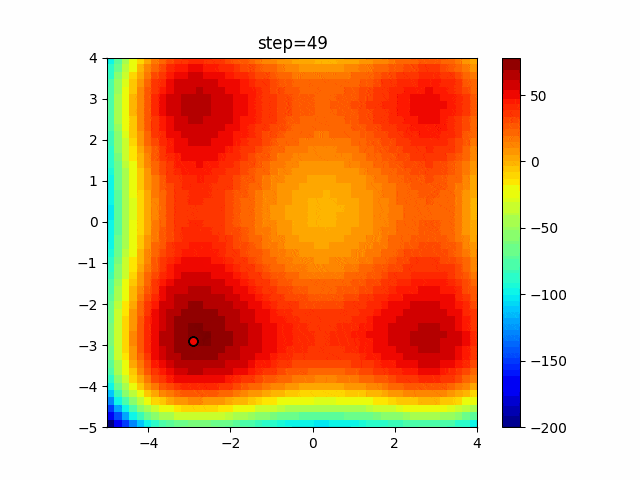
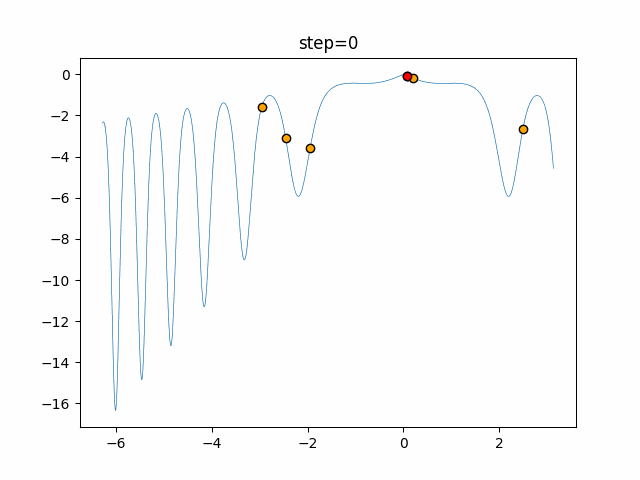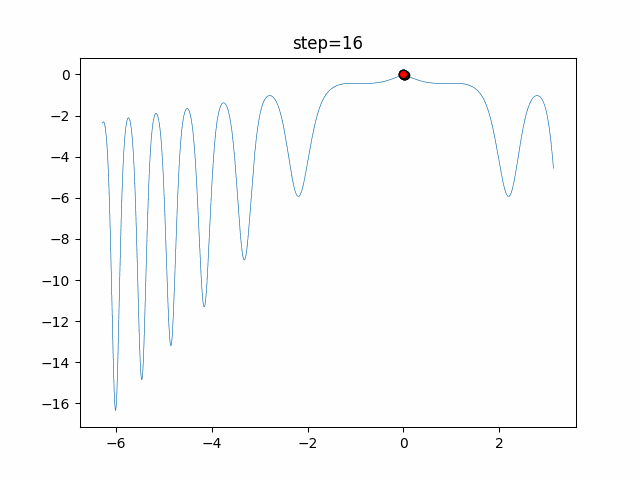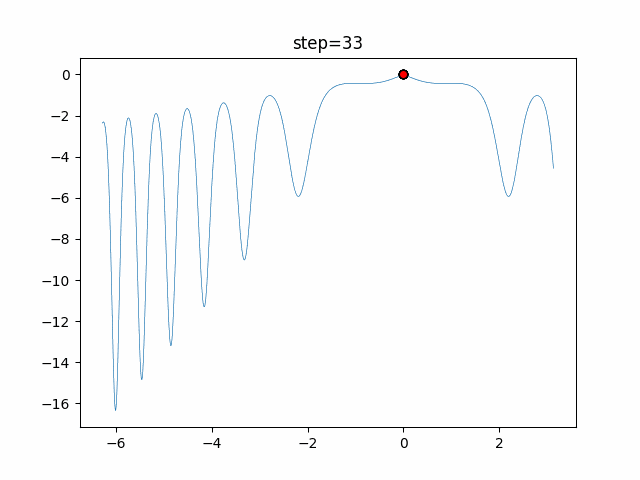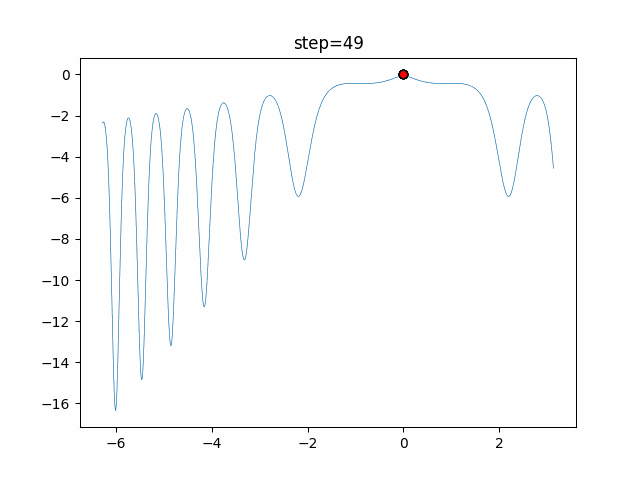
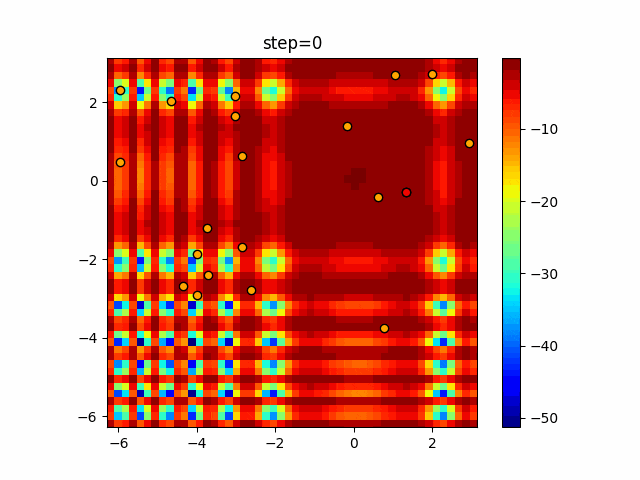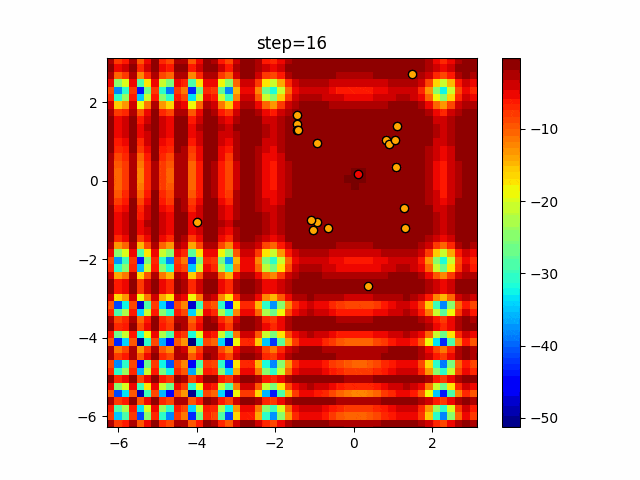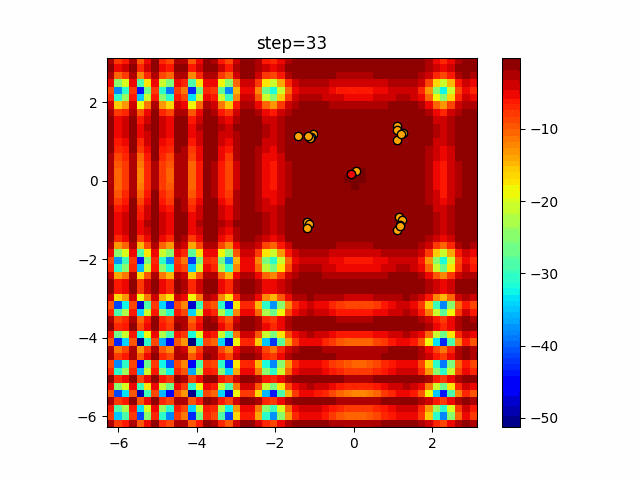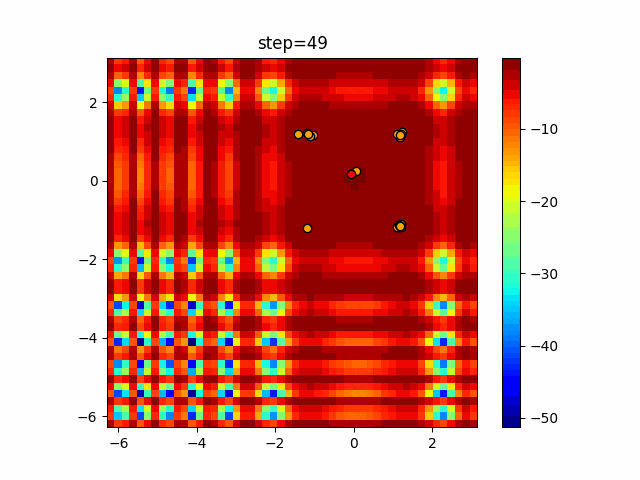
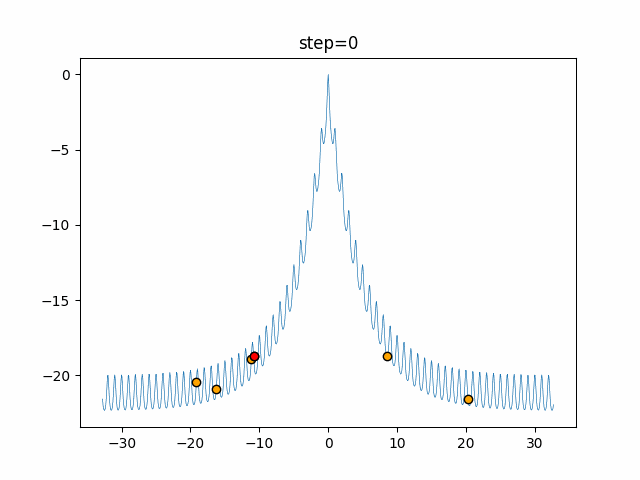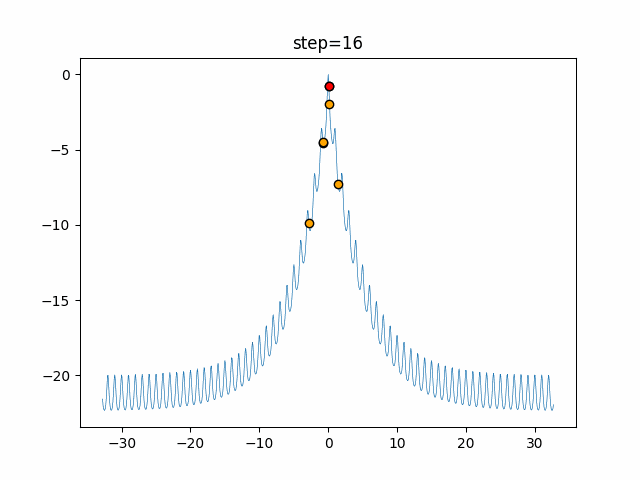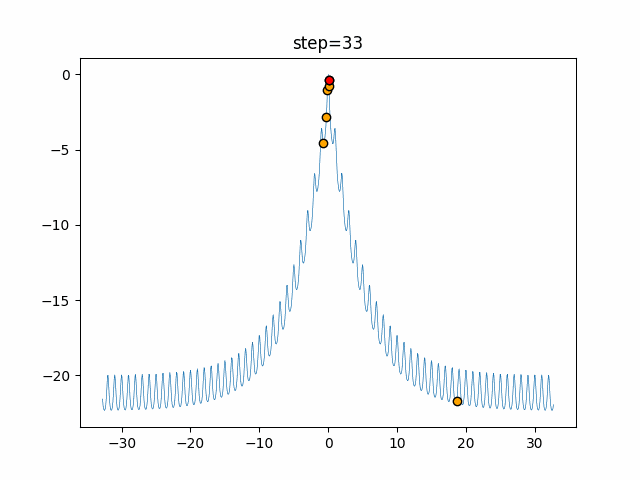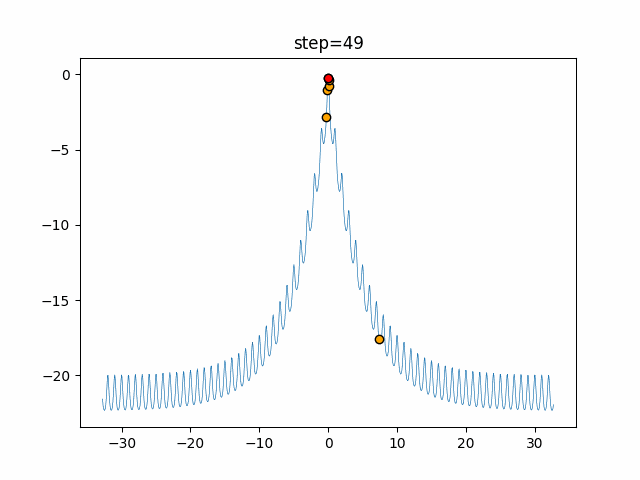
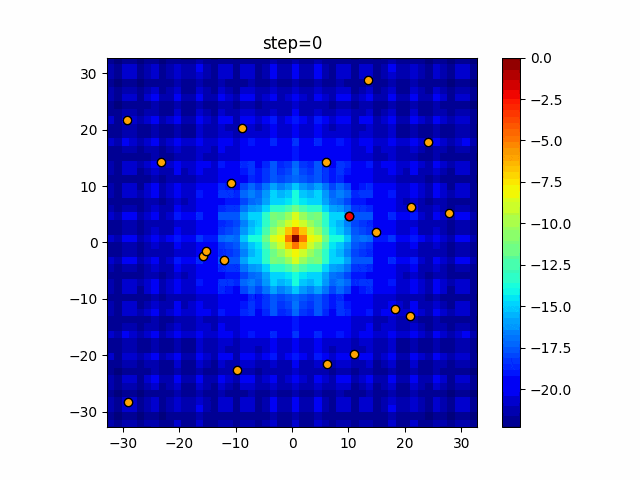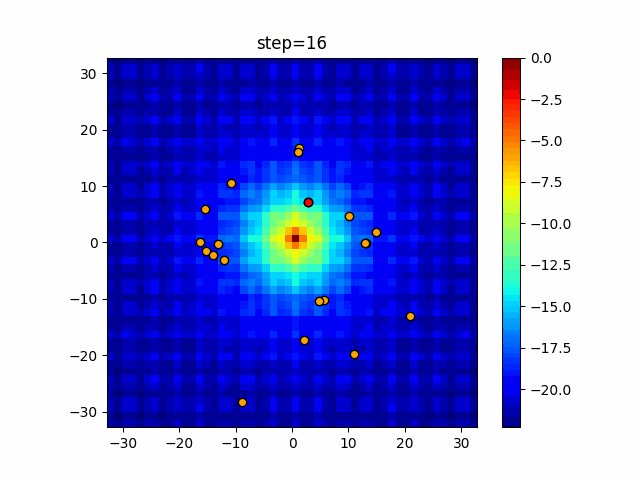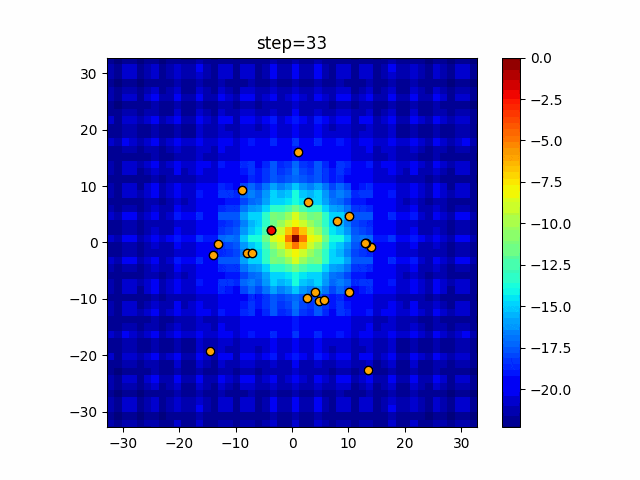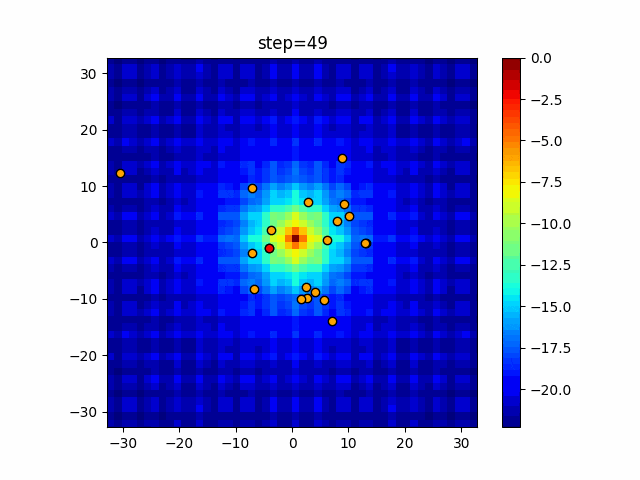
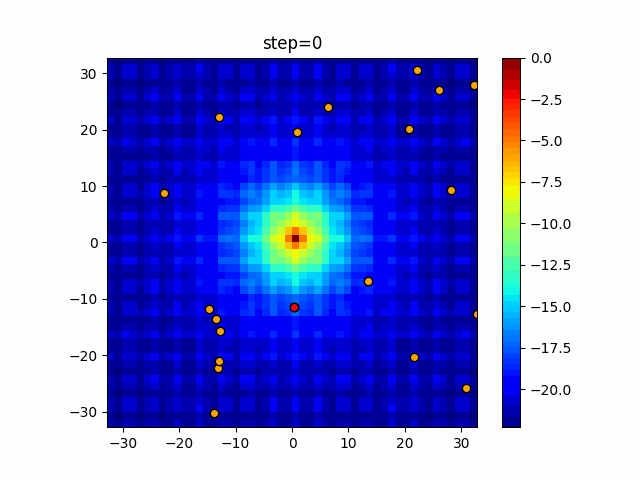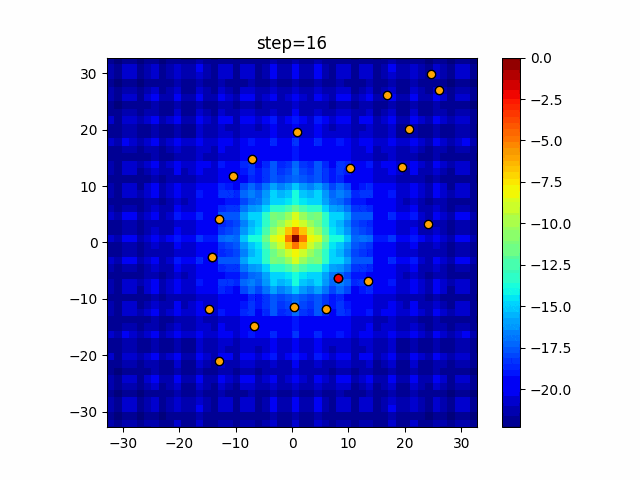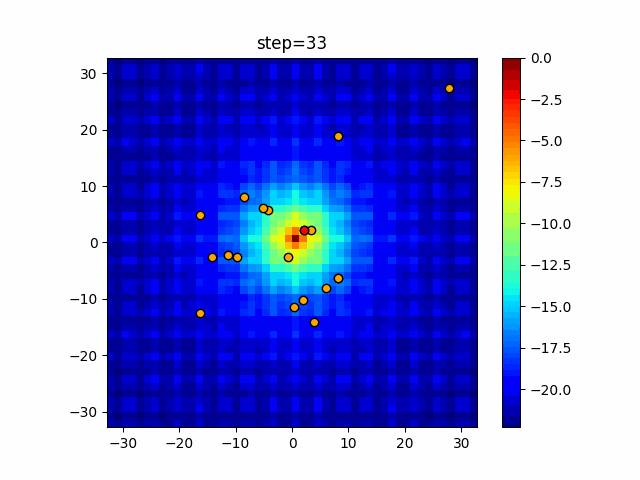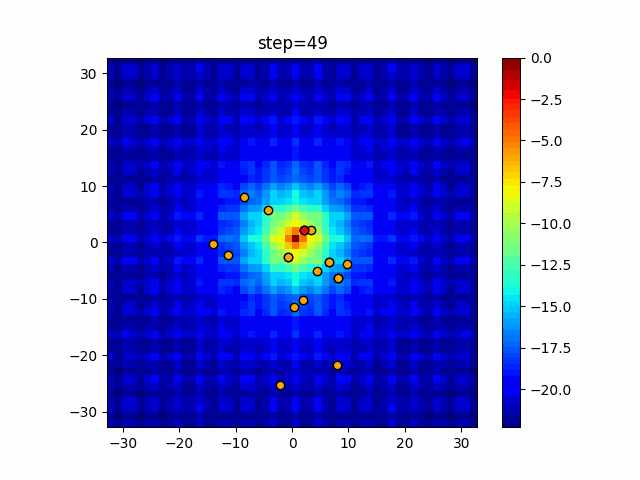
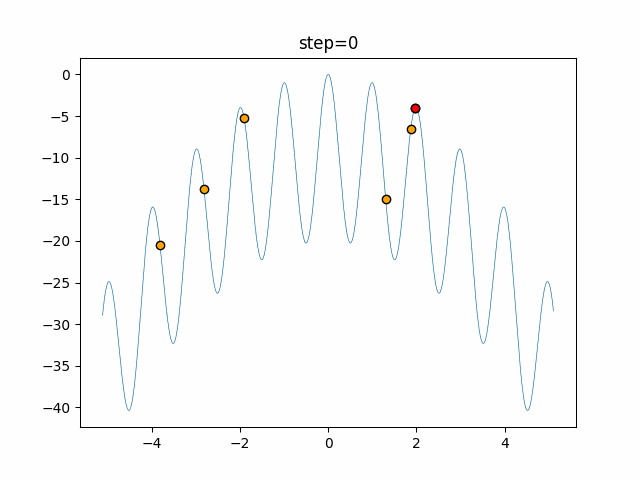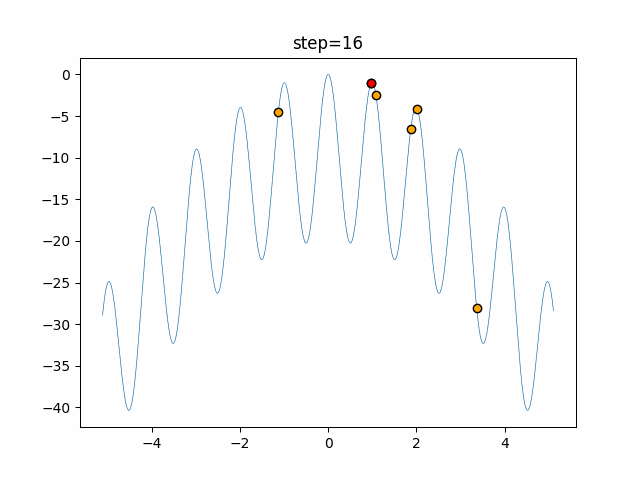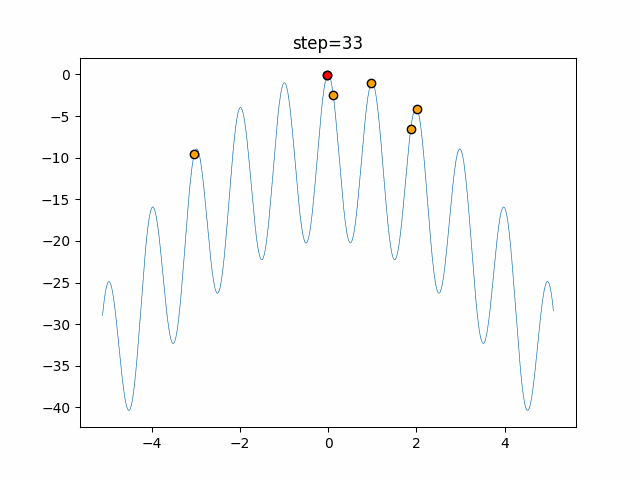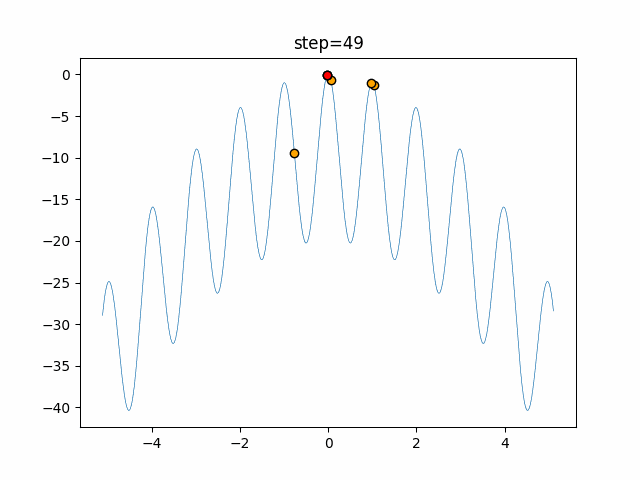
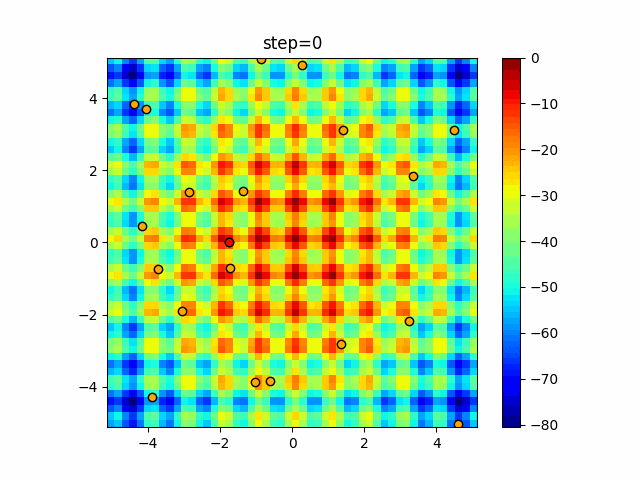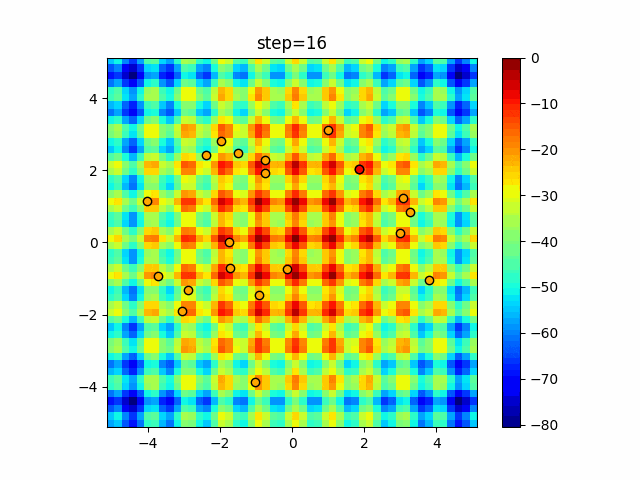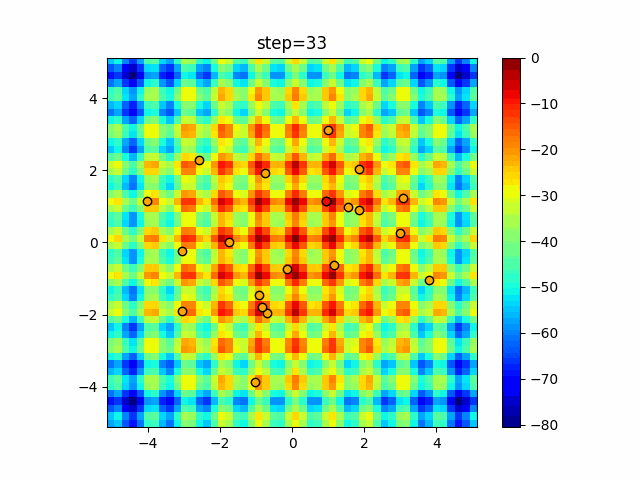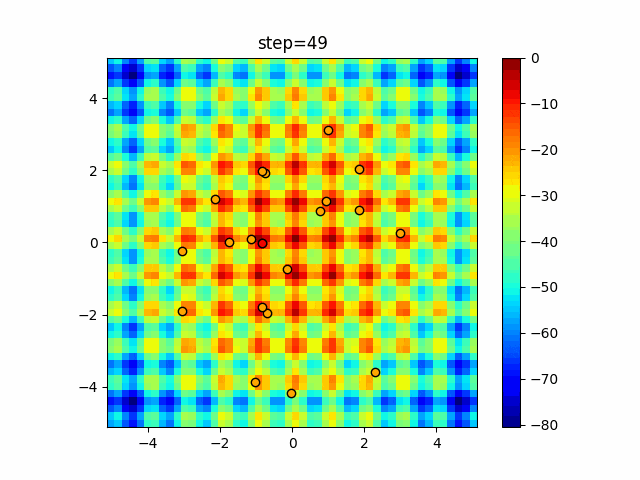
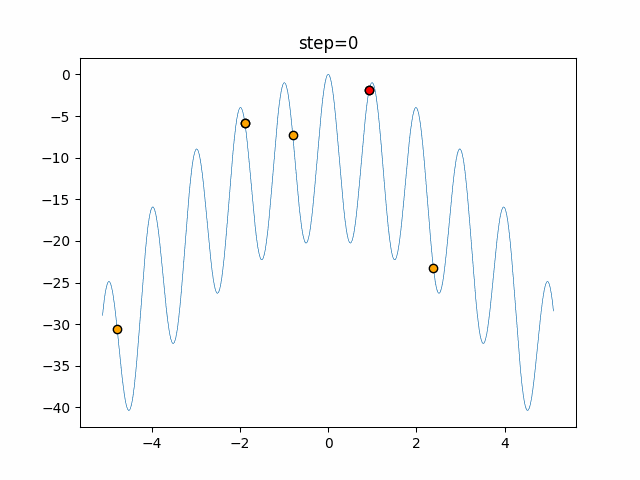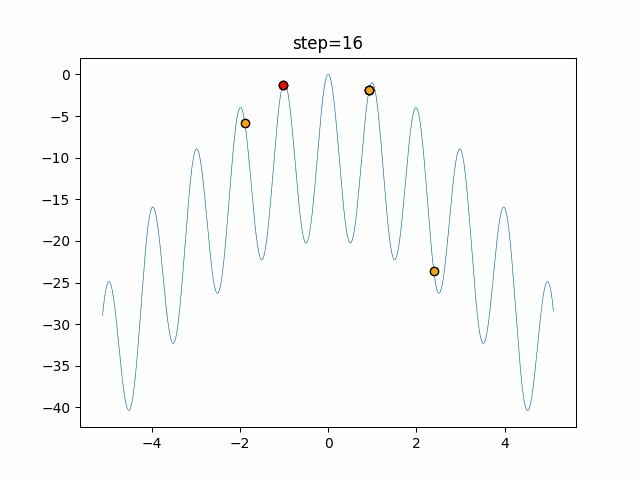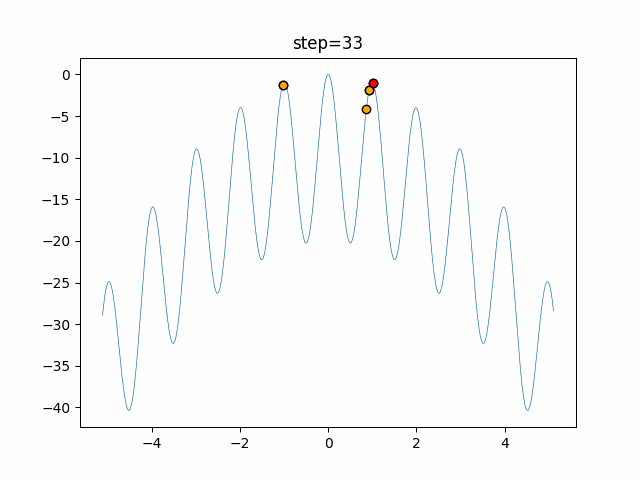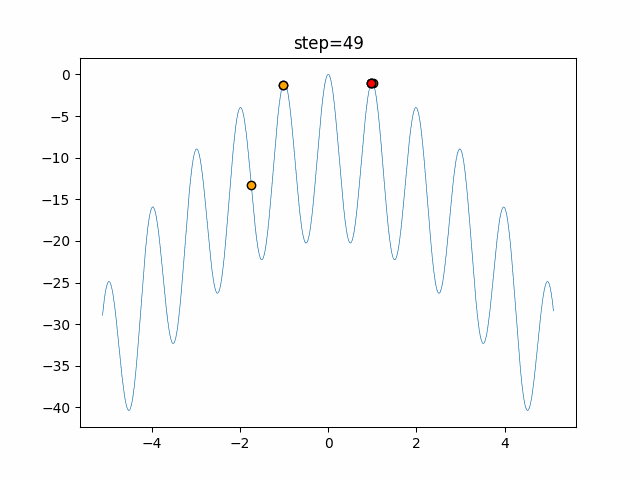
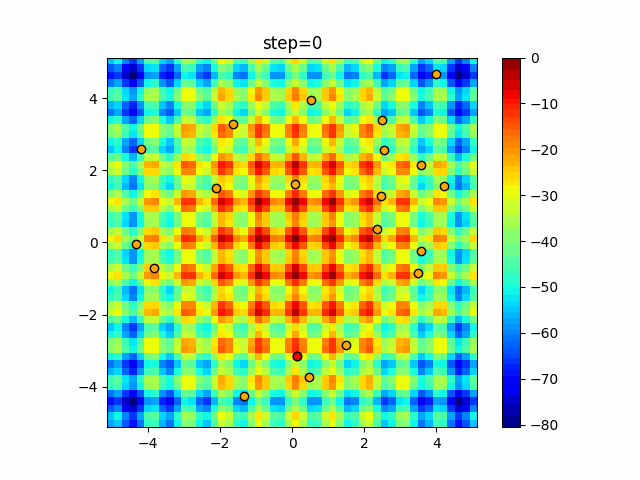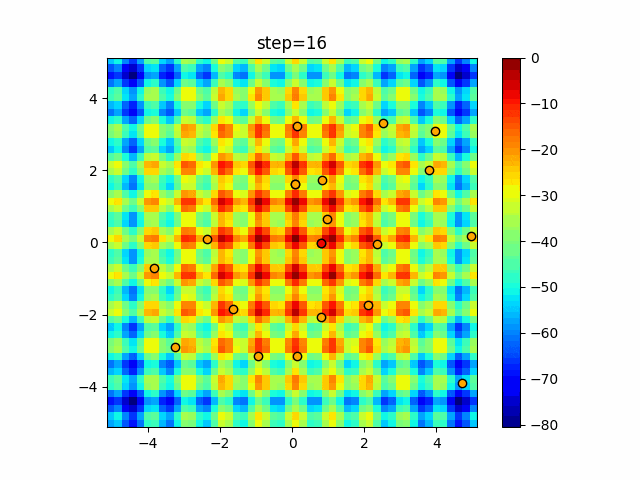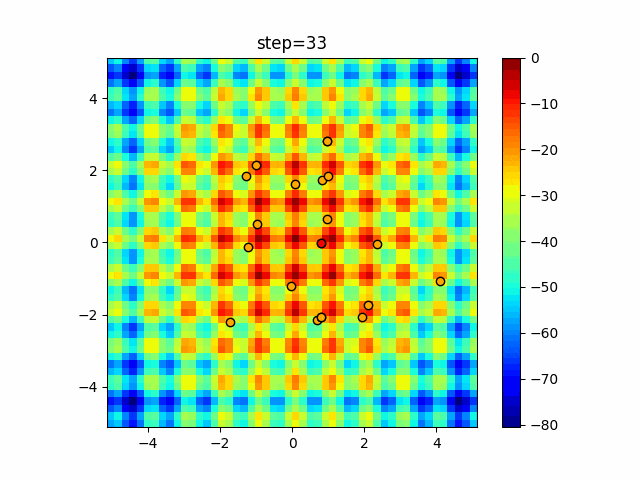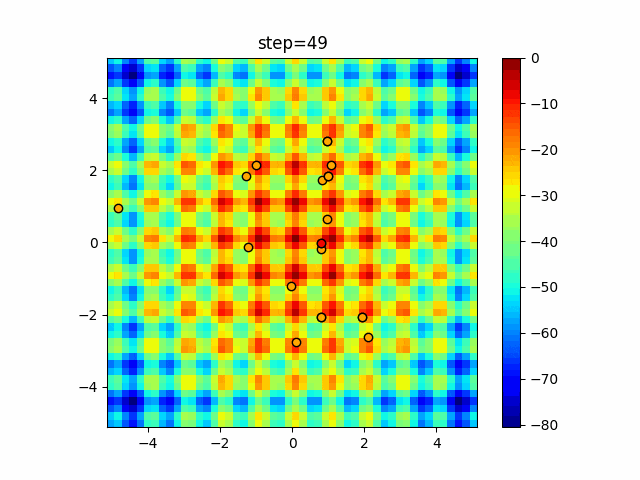
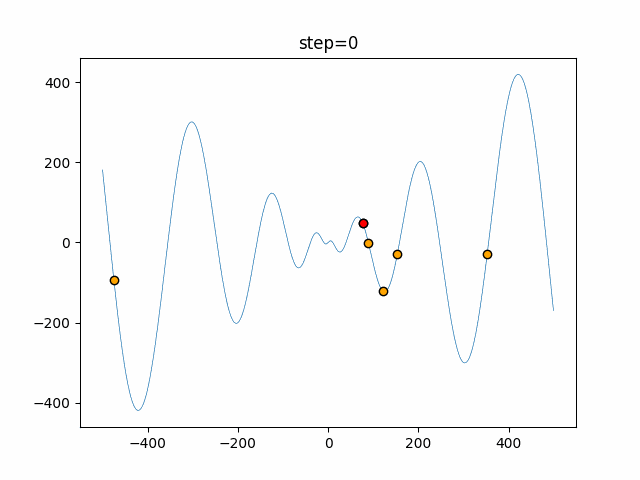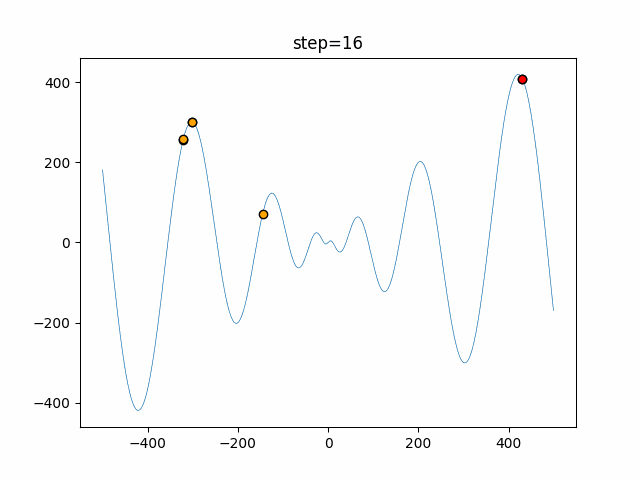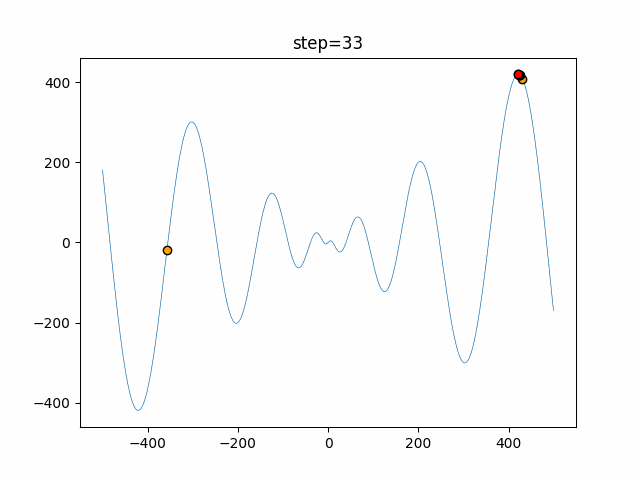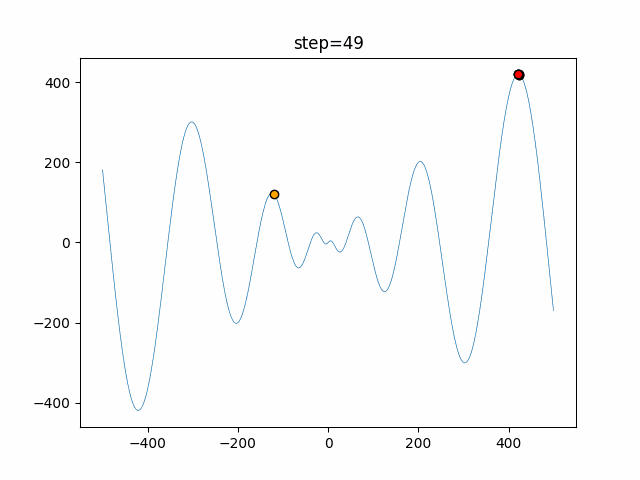
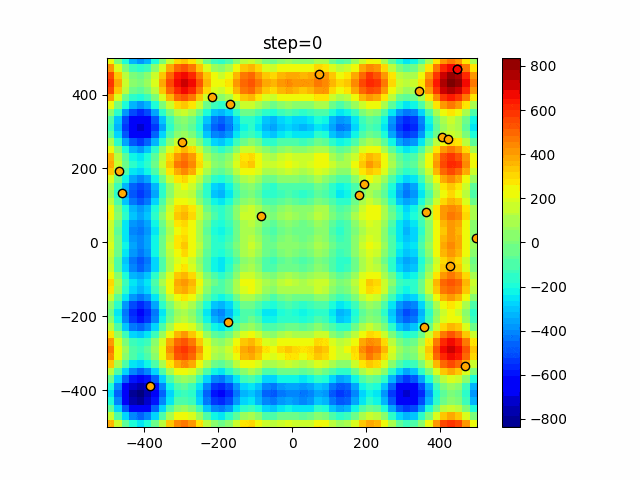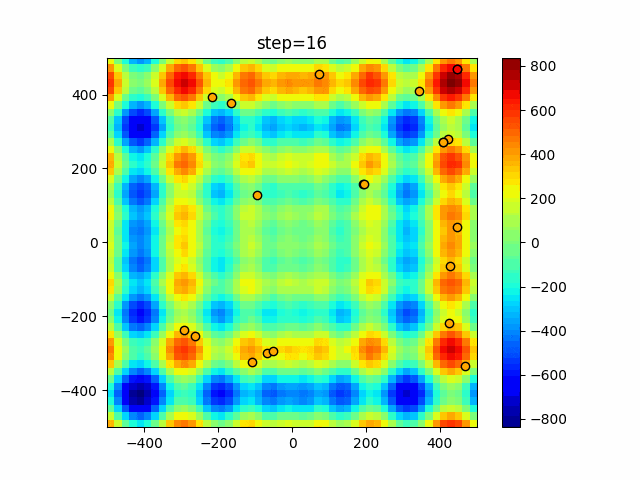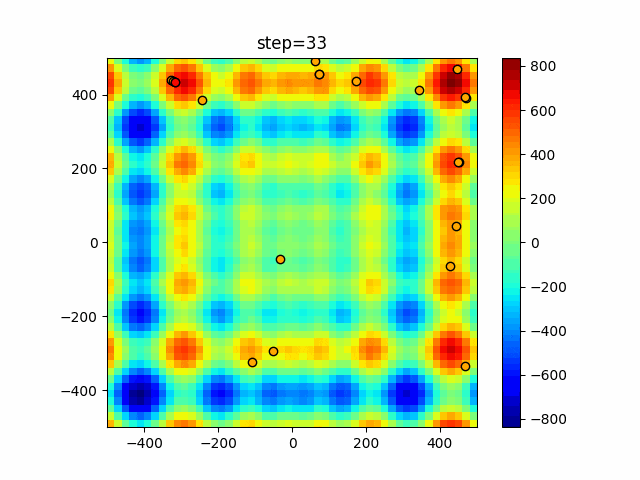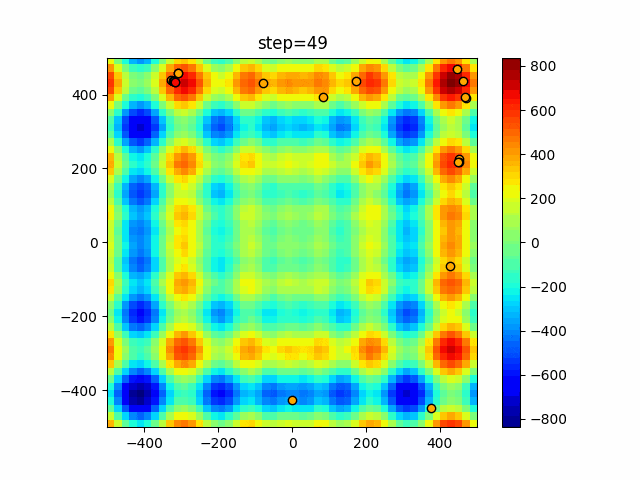
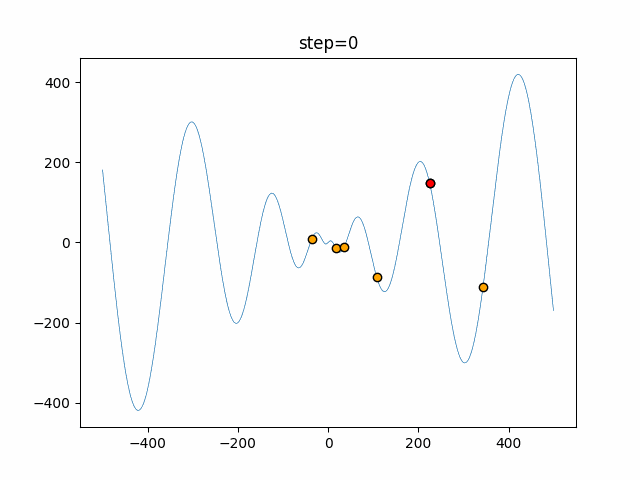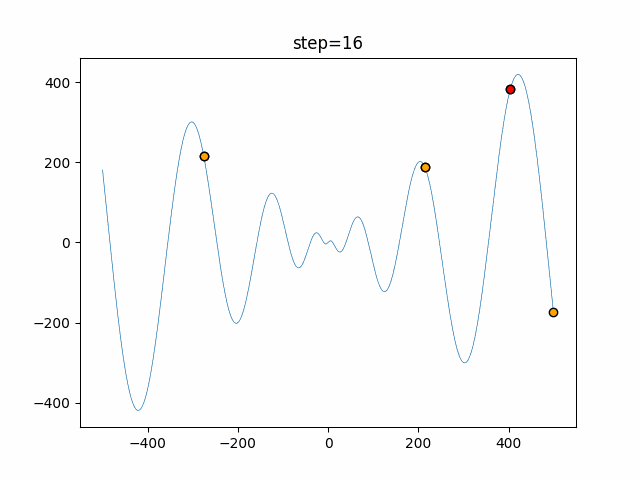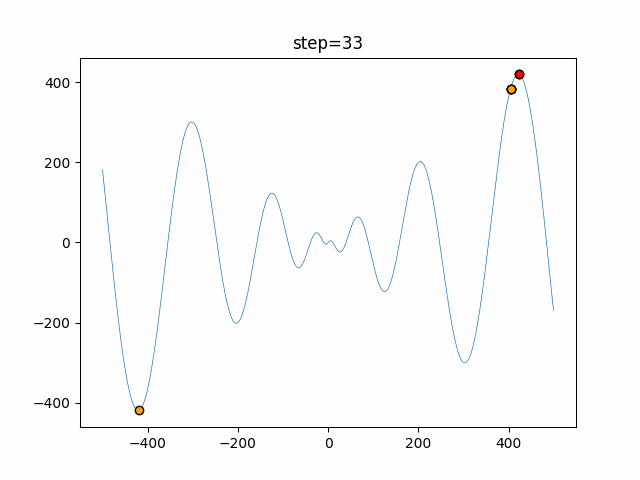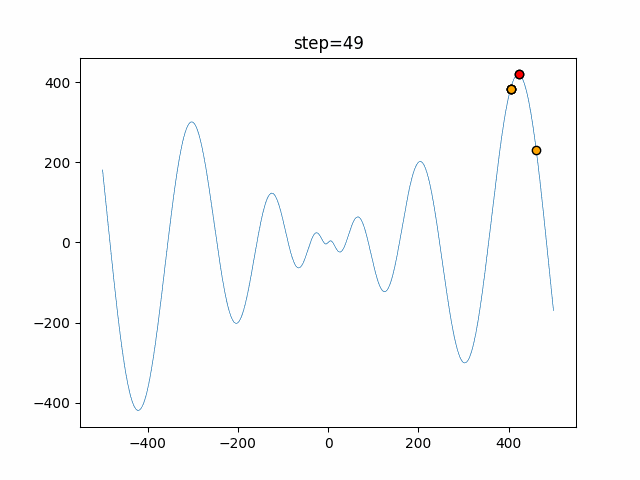
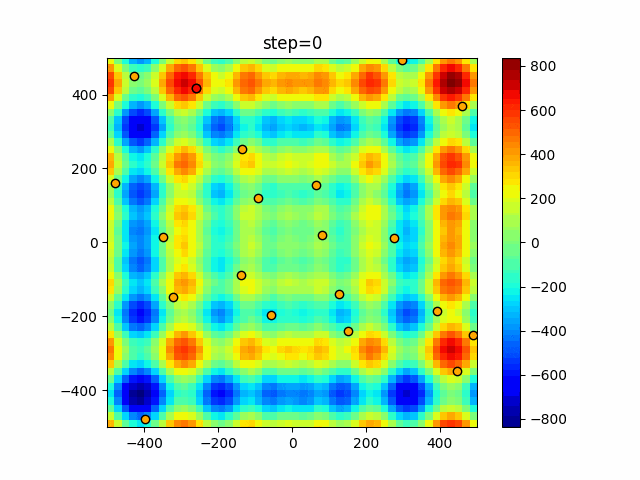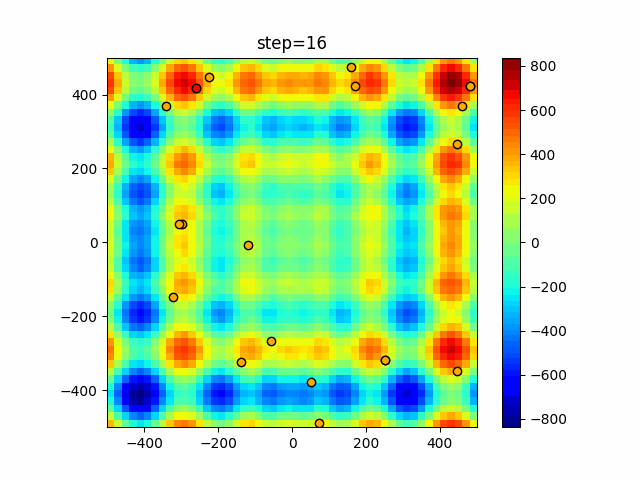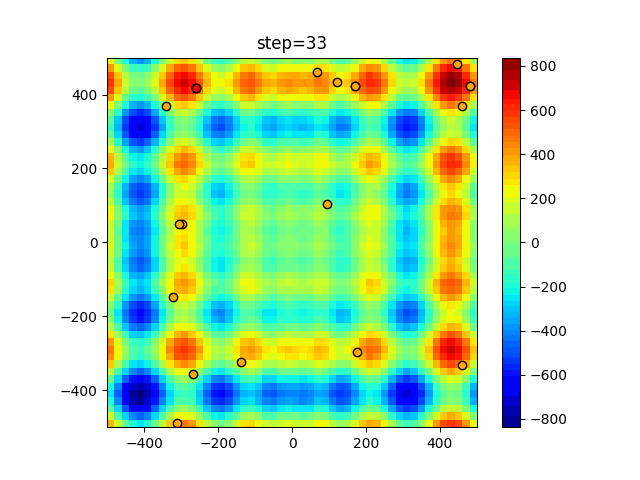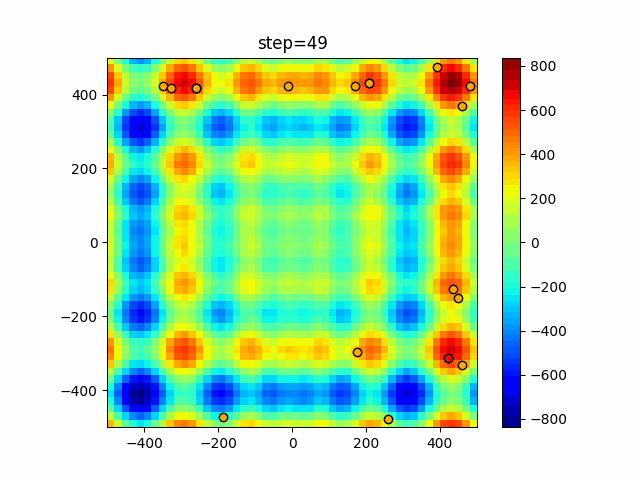
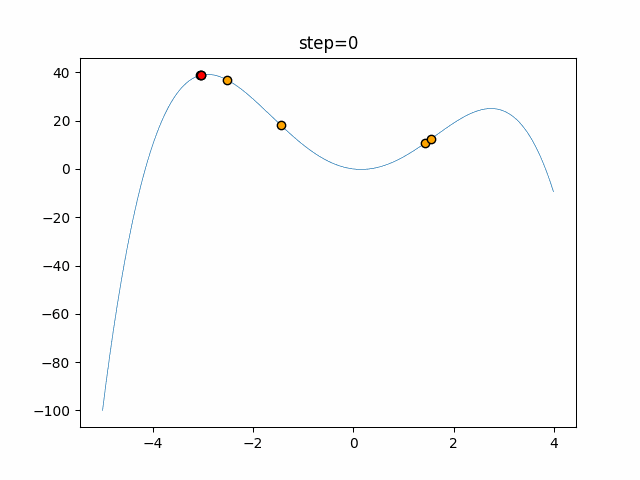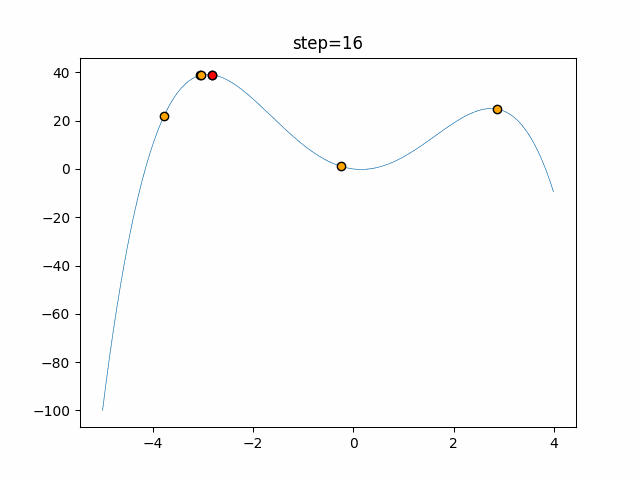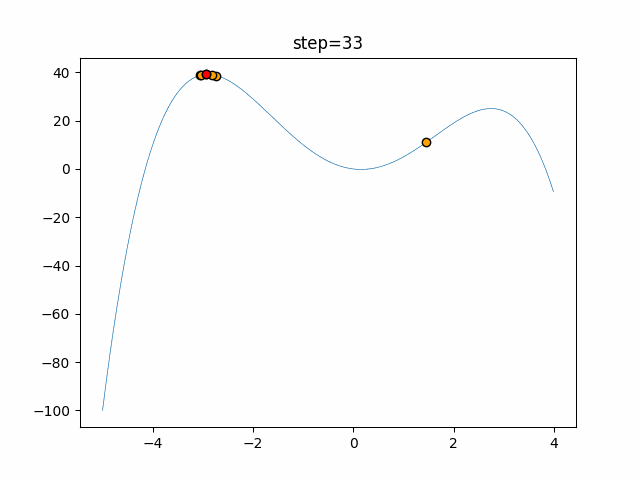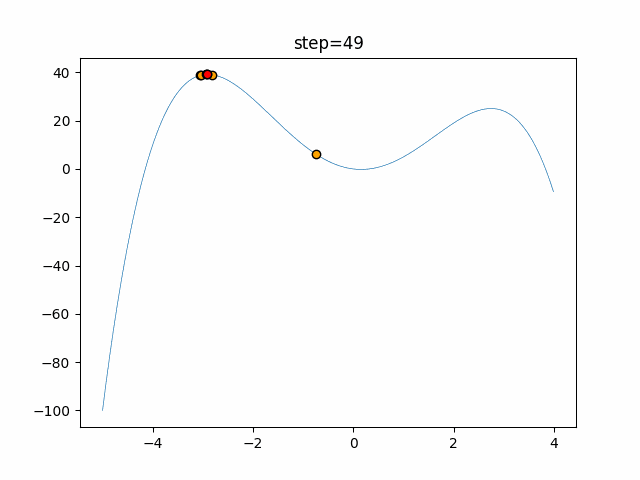
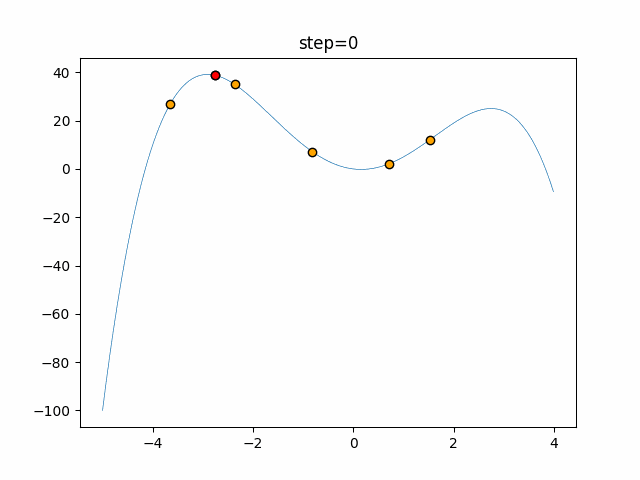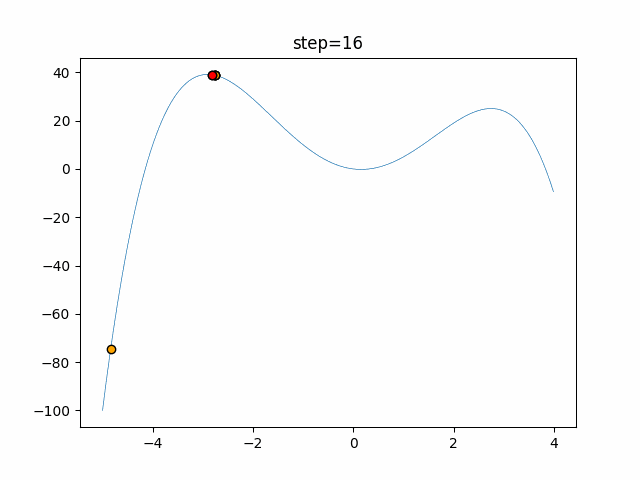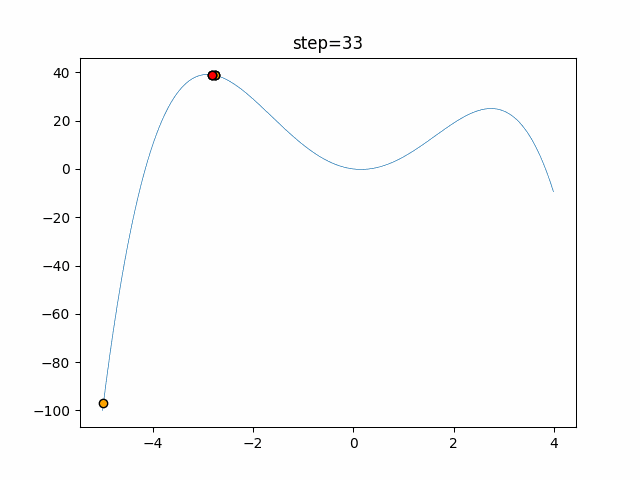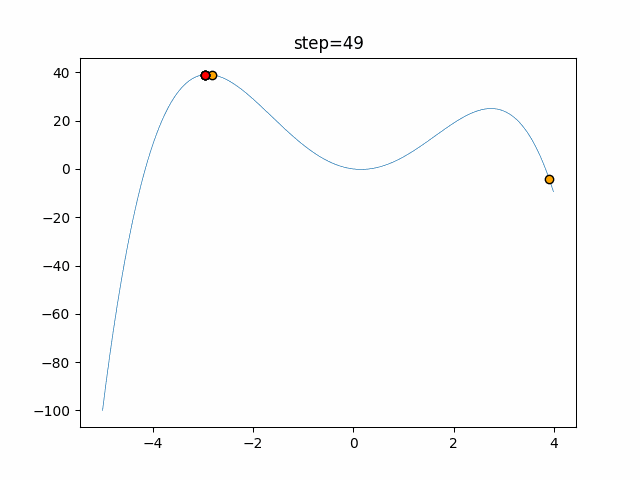
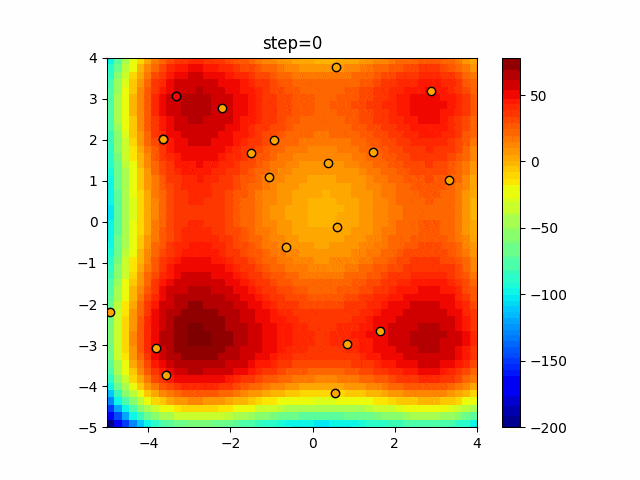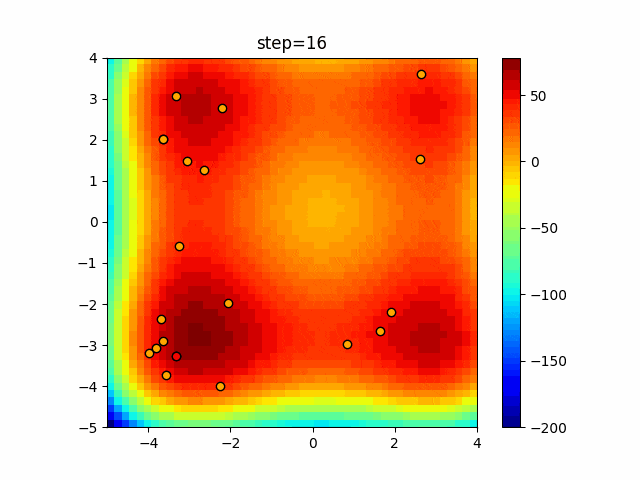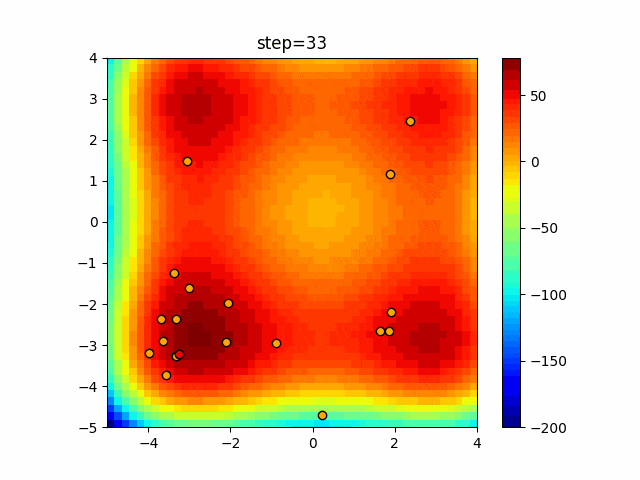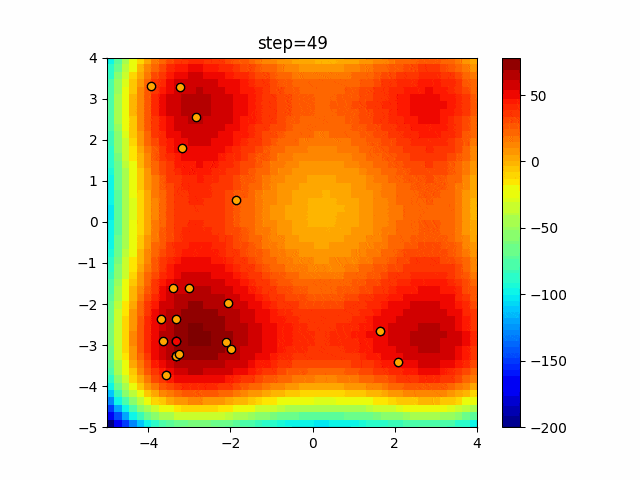
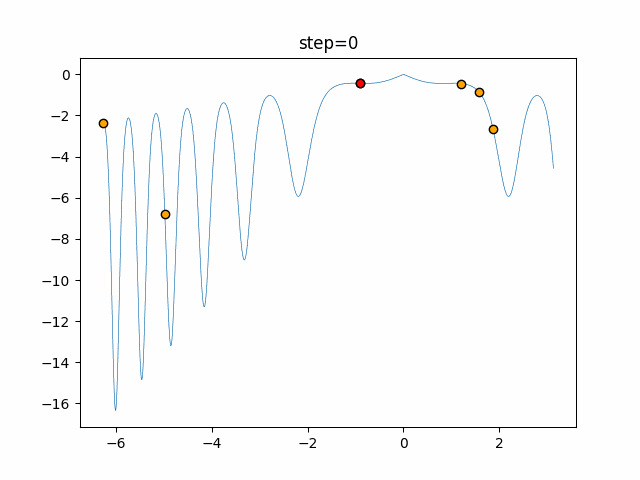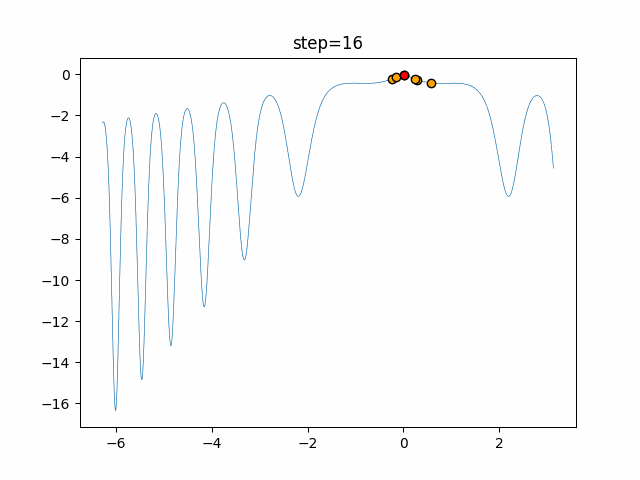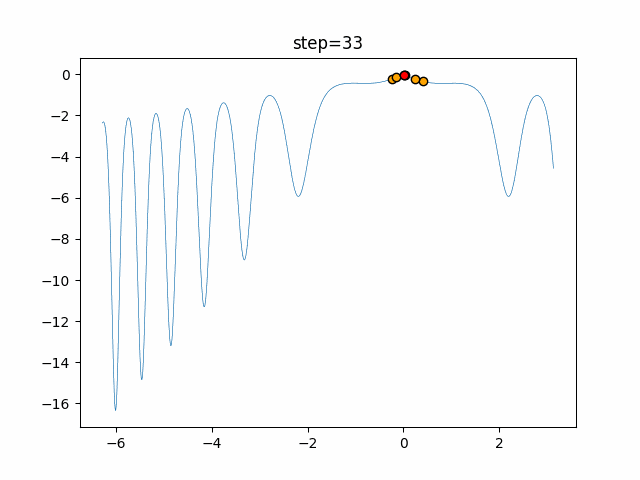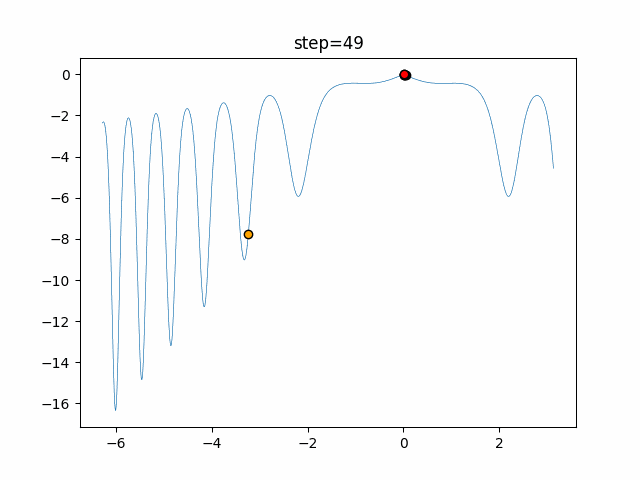
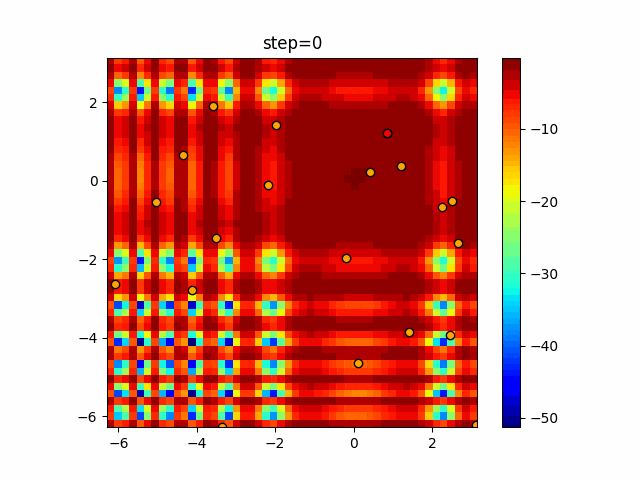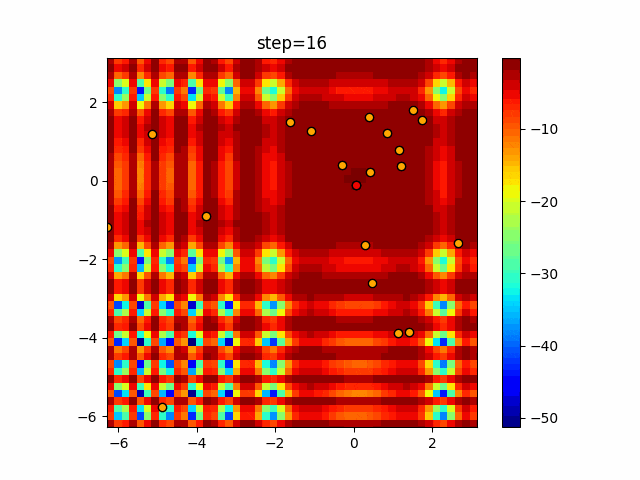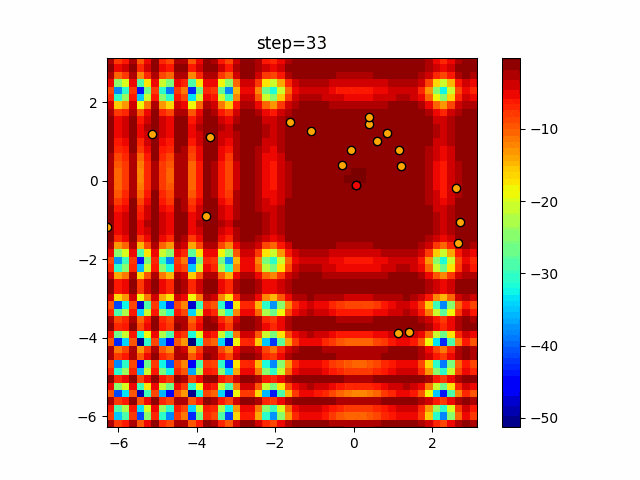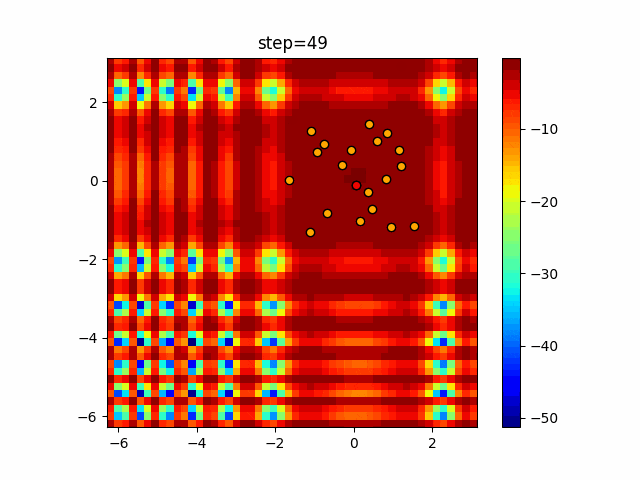
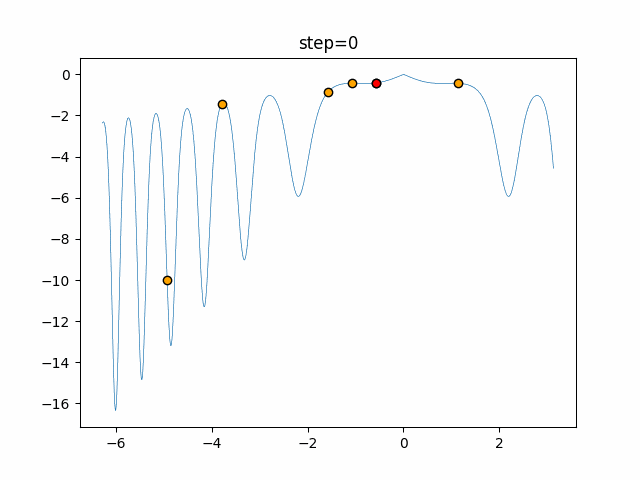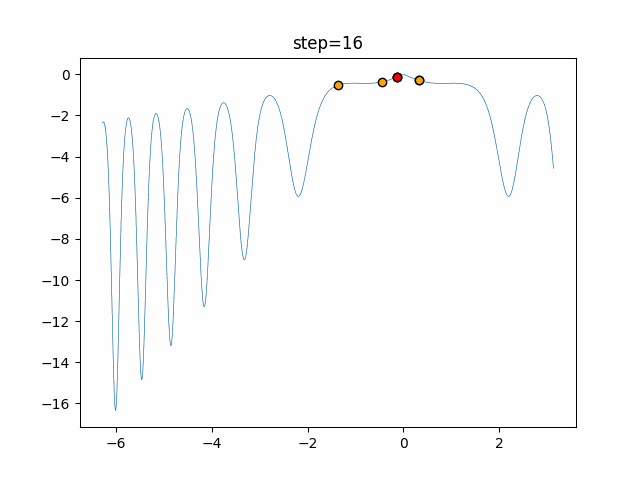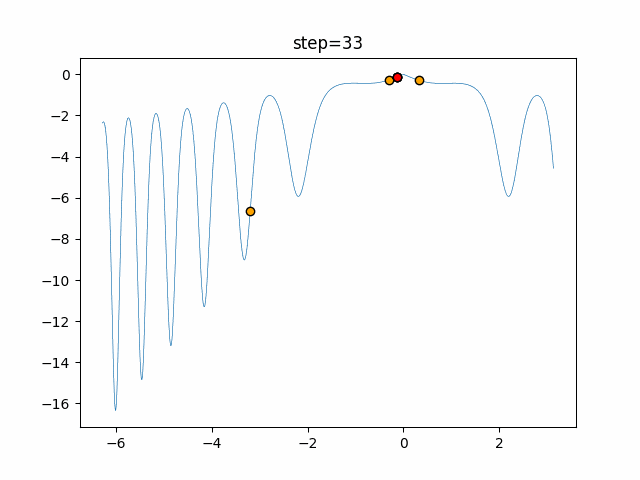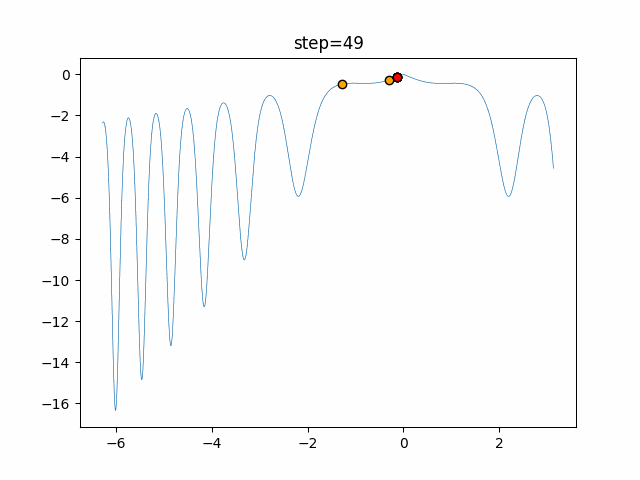
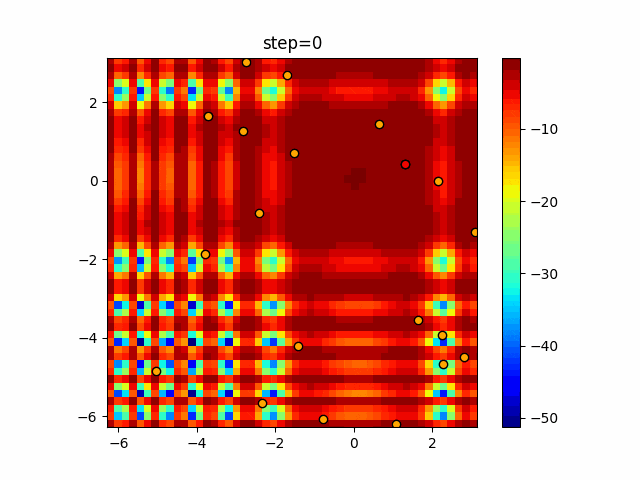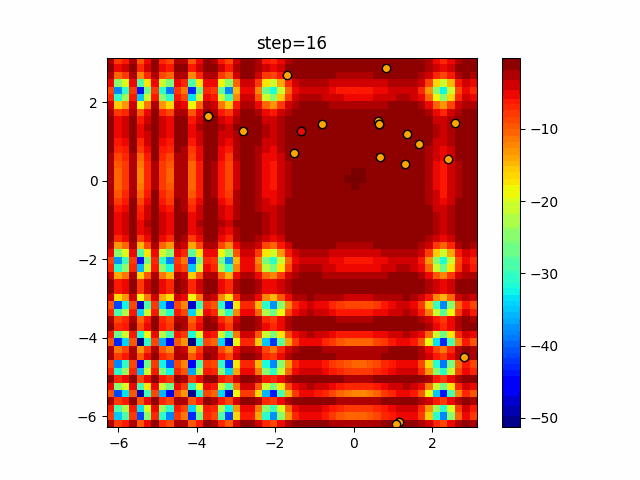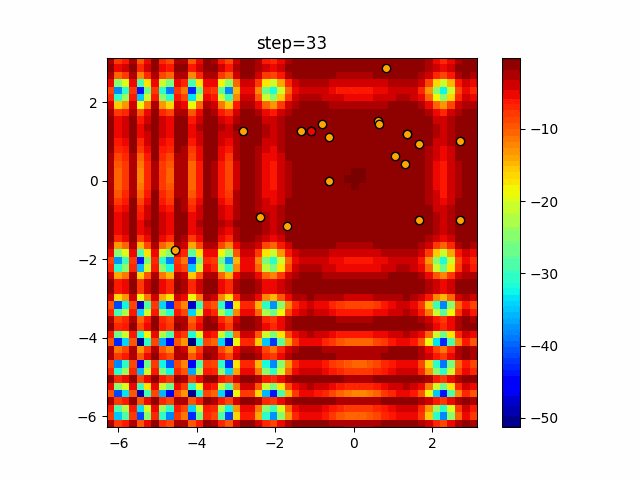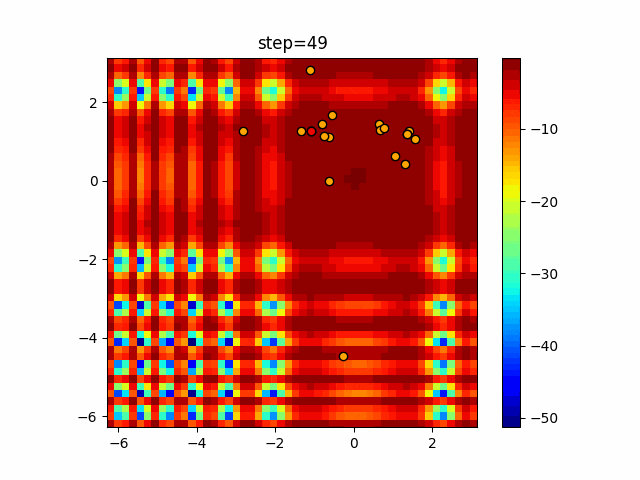
1次元は6個体、2次元は20個体で50step実行した結果です。
赤い丸がそのstepでの最高スコアを持っている個体となります。パラメータは以下で実行しました。
DE(N, crossover_rate=0, scaling=0.4)function_Ackley
- 1次元
- 2次元
function_Rastrigin
- 1次元
- 2次元
function_Schwefel
- 1次元
- 2次元
function_StyblinskiTang
- 1次元
- 2次元
function_XinSheYang
- 1次元
- 2次元
あとがき
いい感じに収束していきますね。
ただランダム移動がないので局所解に陥りやすい気はします。
- 投稿日:2021-01-12T20:50:35+09:00
【競プロ】必勝法の無い石取りゲームはPythonにやらせよう
石取りゲームとは
盤面に石がいくつか置かれており,プレーヤが石を取っていった後に勝ち負けが決まるようなものが石取りゲームです.石取りゲームには様々な種類がありますが,この記事では,
- プレーヤーは2人
- 2人は交互に一つずつ石を取る
- それぞれの石には得点が書かれている
- 石を取りきった後の総得点を競う
というようなものを考えていきます.
石取りゲームの難しさは,両プレーヤーそれぞれが自分にとって最適な戦略を取ることです.自分一人で石を取るだけなら常に思い通りの(自分にとって最適な)盤面を作ることができますが,2人でゲームをすると相手も最適なプレーをするため,逆にそれは自分にとっては最悪な盤面になってしまいます.
大抵こういったゲームには各盤面で取るべき最適な戦略や必勝法が決まっていたりします.しかし,非常に複雑な盤面では必勝法がわからないこともありますし,そもそも必勝法がないこともあります.そんなときに,コンピュータの力で勝敗を導き出すのが本記事の目的です.ここではいくつかのゲームパターンにおいて,勝敗や得点を計算する方法を考えていきます.Game 1: 両端から取るゲーム(1)
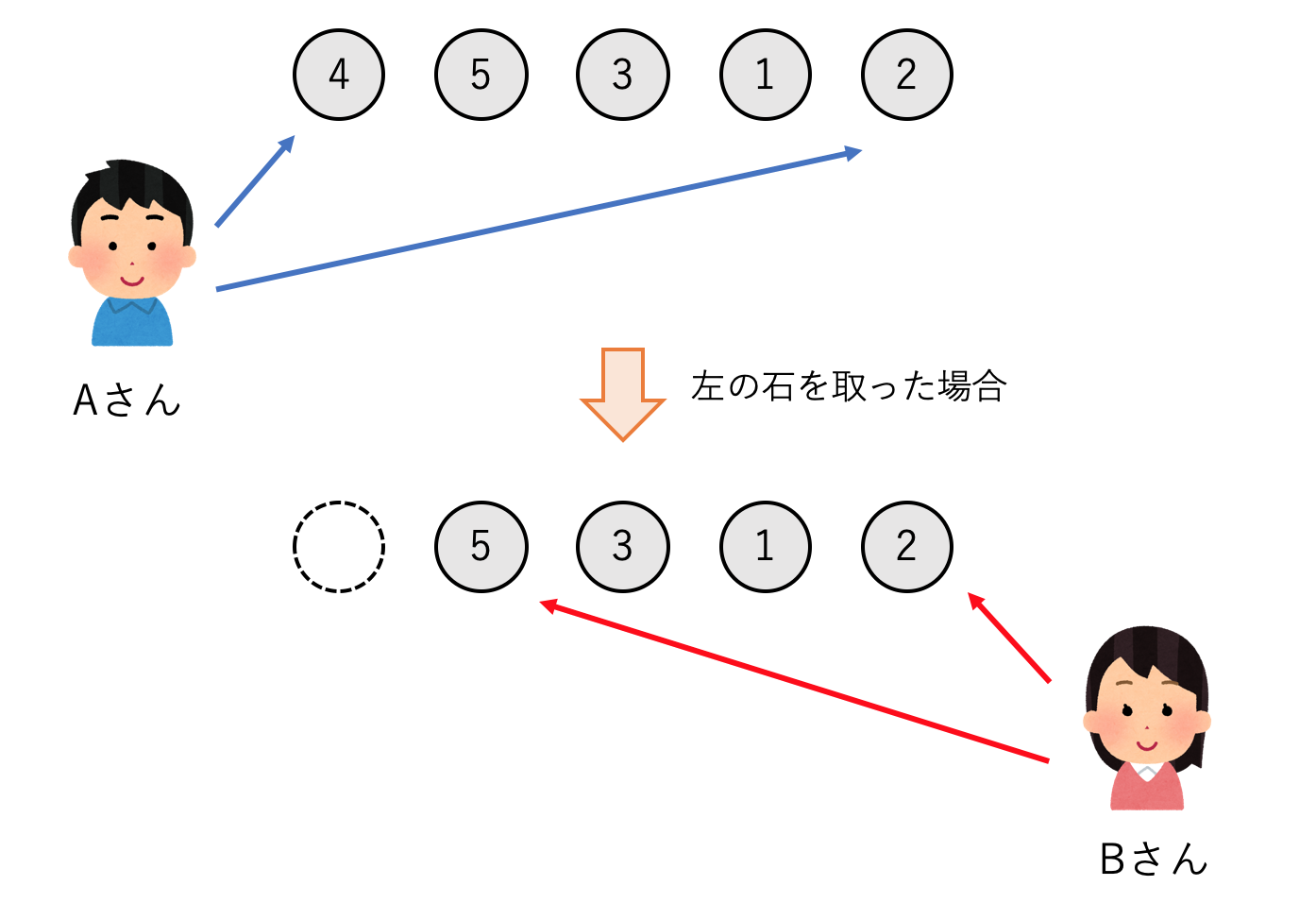
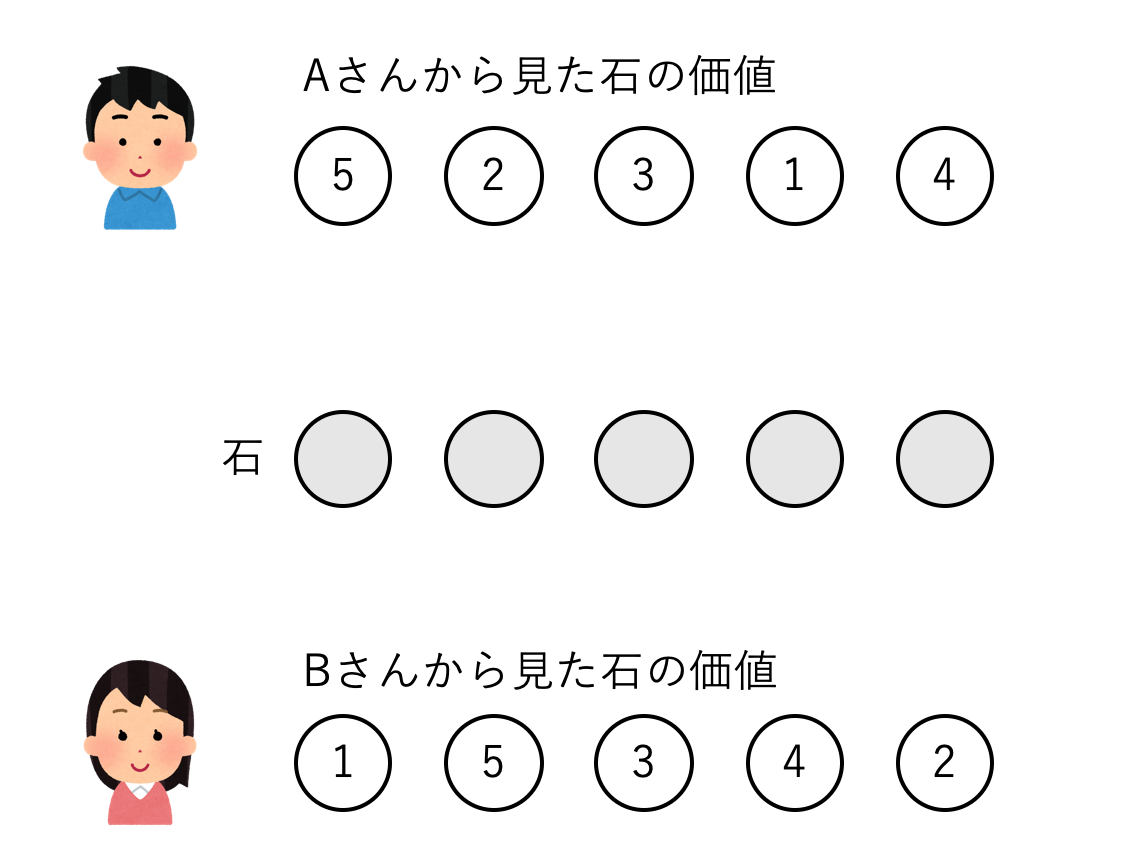
石が一列に並べられており,それぞれの石には得点が書かれています.2人のプレーヤーは交互に石を取りますが,このとき列の両端にある石のどちらかしか取ることができません.石がなくなったら終わりです.2人のプレーヤーがそれぞれ常に最適な戦略を取るとき,どちらが勝つでしょうか?
ここでは,一列に並んだ石の得点を配列で表現します.上の画像の例だと配列はstones = [4,5,3,1,2]のようになります.2人のプレーヤーのうち先攻をA,後攻をBとします.まずAは4の石を取るか2の石を取るか2種類の選択肢があります.4の石をとった方が得点は高くなりますが,次に相手に5の石を取られてしまいます.逆に2の石をとれば得点は少ないですが,次に相手が取れるようになるのは1の石です.また極端な例として,$stones = [1,100,2,3]$のような石列であれば,100の石を取れるかどうかが勝敗を決めるでしょう.
この問題を解くために,左右の石をそれぞれ取っていった全ての場合を全探索すればいいのでしょうか?それでは自分の得られる最大の利益を求めることはできるかもしれませんが,相手が最適な戦略をとっているとは限らないので,ゲームが成立していません.そう考えるとそもそも最適な戦略というものがなんなのかよくわからなくなります.
解法1
ここで,何かしらの最適な戦略があると仮定し,それを$strategy$とおいてしまいます.配列に対して$strategy$を適用すると,先攻の人が得られる得点が返ってくるとします.
max\_score = strategy(stones[:])$strategy$の中では何が行われているのでしょうか.それは,右の石を取った時と左の石を取った時の得点を比較し,より得点が大きくなる方を選ぶような操作だと思われます.
max\_score = \max \left\{ \begin{array}{l} stones[0] + strategy\_inv(stones[1:]) \\ stones[-1] + strategy\_inv(stones[:-1]) \end{array} \right.ここで$strategy\_inv$は,プレーヤーBが残っている石に対して最適なプレイングをした際にAが得られる得点です.Bが自分の得点を最大化することとAの得点を最小化することは同じなので,Aからすると最悪な戦略を取られていることになります.具体的に$strategy\_inv$は,残っている石列のうち左右の石を取った場合に,よりAの得点が低くなる石を選ぶようなものです.
max\_score = \max \left\{ \begin{array}{l} stones[0] + \min \left\{ \begin{array}{l} stones[1] + strategy(stones[2:]) \\ stones[-1] + strategy(stones[1:-1]) \end{array} \right. \\ stones[-1] + \min \left\{ \begin{array}{l} stones[0] + strategy(stones[1:-1]) \\ stones[-2] + strategy(stones[:-2]) \end{array} \right. \end{array} \right.$\min$,$\max$が出てきてややこしくなってきましたが,式の中に再び$strategy$が現れました.Bの前に石を取るのはAなので,この$strategy$は再びAの得点を最大化するようなものです.重要なのは,これが漸化式の形になっていることです.つまり,この$strategy$関数を定義して入れ子のように計算すれば,具体的な最適戦略を知らなくても計算を行なっていくことができます.
def stone_game(stones: List[int]) -> int: n = len(stones) def strategy(i, j): if i > j: return 0 if i == j: return stones[i] left = min(stones[i+1] + strategy(i+2, j), stones[j] + strategy(i+1, j-1)) # プレーヤーが左の石を取った時 right = min(stones[i] + strategy(i+1, j-1), stones[j-1] + strategy(i, j-2)) # プレーヤーが右の石を取った時 return max(stones[i] + left, stones[j] + right) return strategy(0, n - 1) # Aの得られる総得点コードでは部分配列を入力する代わりに配列の開始点と終了点のインデックス$i, j$を引数にしています.漸化式には初期値が必要ですが,残りの石が0個,1個になったような場合は最適戦略は明らかなのでそれは別に定義しています.最終的にAとBの得点を比べれば勝敗がわかります.
解法2
解法1によって最適戦略を毎回具体的に考えることなく問題を解くことができましたが,式がやや複雑なのが難点です.プレーヤーAとBは最適な戦略を取っているという点で同じなので,それをどうにかして統一できないでしょうか?
$strategy$の返り値を,Aの総得点ではなく,AとBの最大得点差ということにしてみます.
score\_dif = strategy(stones[:])すると,解法1の式を以下のように変更できます.
score\_dif = \max \left\{ \begin{array}{l} stones[0] - strategy(stones[1:]) \\ stones[-1] - strategy(stones[:-1]) \end{array} \right.得点差なので足し算だった部分が引き算になります.そしてその結果,ここに$strategy\_inv$ではなく$strategy$が現れました.これで漸化式がだいぶ簡単になりました.
def stone_game(stones: List[int]) -> int: n = len(stones) def strategy(i, j): if i > j: return 0 return max(stones[i] - strategy(i+1, j), stones[j] - strategy(i, j-1)) return strategy(0, n - 1) # AとBの得点差なお,$strategy$関数は入力する配列,つまり$i, j$が決まれば返り値は一つに定まります.計算の過程で,違うルートから同じ部分配列に達する場合も頻繁にあるはずなので,これを毎回計算するのは無駄です.よってここではメモ化再帰を行います.メモ化再帰は既に見た関数の入力と出力を記録しておくようなもので,同じ関数を何度も計算することを避け,大きな計算時間節約に繋がります.
メモ化再帰は辞書$dict$で値を保持するような方法もありますが,pythonでは関数の前に$@functools.lru\_cache()$をつけることでメモ化された関数にすることができます.
def stone_game(stones: List[int]) -> int: n = len(stones) @functools.lru_cache(None) # メモ化再帰 def strategy(i, j): if i > j: return 0 return max(stones[i] - strategy(i+1, j), stones[j] - strategy(i, j-1)) return strategy(0, n - 1)この結果,各$i, j$の組み合わせに対して1度ずつだけ$strategy$の計算を行うことになりました.組み合わせの個数は$O(n^2)$,$strategy$内の計算量は$O(1)$なので,全体の時間計算量は$O(n^2)$となります.また空間計算量もメモ化によって$O(n^2)$となります.
勝敗を求める
解法2で勝敗を求めるときには,最終的な$score\_dif$が正なのか負なのかを見ます.得点差なので,$score\_dif$が0より大きければ先攻のAの勝ち,0より小さければBの勝ちになります.0なら引き分けです.
def stone_game(stones: List[int]) -> str: def strategy(i, j): # 中身は同じ score = strategy(0, n - 1) if score > 0: return "A win" elif score < 0: return "B win" else: return "draw"総得点を求める
一方Aの総得点を求める際は,$score\_dif$を利用して,
score\_A = \frac{\sum_{i=1}^n stones[i] + score\_dif}{2}と計算できます.
def stone_game(stones: List[int]) -> int: def strategy(i, j): # 中身は同じ return (sum(stones) + strategy(0, n - 1)) // 2(おまけ)必勝になる場合
ちなみにコーディングとは無関係ですが,石の数が偶数の場合は先手必勝になる簡単な戦略があります.
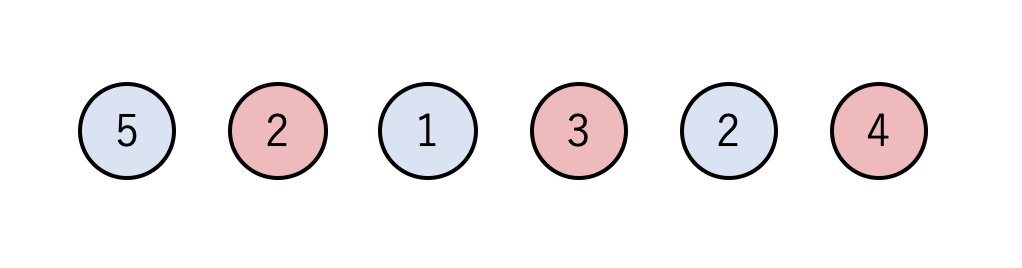
偶数個の石を以下のように交互に2色に塗り分けます.
赤色と青色の石を足すと赤色の方が総和が大きいことがわかります.ここで,先手のAが右側にある赤色の石(4)を取ったとき,Bは次に青色の石(5か2)しか取ることができません.Bがどちらの石をとっても,Aは赤色の石を取ることができ,Bはまた青色の石しか取れません.このようにしてAが全ての赤い石を取れば,Aが必ず勝つ(少なくとも負けない)ようにできます.Game 2: 両端から取るゲーム(2)
Game 1を少し変えて,「石を取った時に,取った石ではなく残っている石の点の総和がもらえる」というゲームも考えることができます.この場合はどうなるでしょうか?
解法1
得られる得点が「取った石の点数」→「残りの石の点数の和」に変わるだけなので,Game 1の関数からその部分だけ変えれば良いです.例えば左の石を取った時の得点が
score = stones[i] - strategy(i+1, j)だったものが
score = sum(stones[i+1:j]) - strategy(i+1, j)になります.簡単ですね.
def stone_game(stones: List[int]) -> int: n = len(stones) @functools.lru_cache(None) def strategy(i, j): if i >= j: return 0 left = sum(stones[i+1:j]) - strategy(i+1, j) right = sum(stones[i:j-1]) - strategy(i, j-1) return max(left, right) return strategy(0, n-1)解法2
しかし,解法1には致命的な欠点があります.部分配列の和を求める部分$sum(stones[i:j])$には$O(n)$の時間がかかるため,全体の計算量が$O(n^2)$になってしまうのです.これを防ぐため累積和を計算しておきます.累積和は先頭からの値の合計をあらかじめ配列として保持しておくことで,部分配列の和を$O(1)$で求めることができるものです.pythonでは,$itertools.accumulate()$関数が勝手に累積和を求めてくれます.これを$prefix\_sum$とおいて,改善されたコードは以下のようになります.
def stone_game(stones: List[int]) -> int: n = len(stones) prefix_sum = [0] + list(itertools.accumulate(stones)) # 累積和 @functools.lru_cache(None) def strategy(i, j): if i >= j: return 0 left = (prefix_sum[j+1] - prefix_sum[i+1]) - strategy(i+1, j) # 左の石を取った場合 right = (prefix_sum[j] - prefix_sum[i]) - strategy(i, j-1) # 右の石を取った場合 return max(left, right) return strategy(0, n-1)これで計算量が$O(n)$になりました.
解法3
メモ化再帰以上に最適な解法があるわけではないのですが,別の書き方も紹介しておきます.メモ化再帰によって入れ子的に関数を呼び出すのではなく,得られた結果を配列に格納して適宜読み取ることを考えます.本質的にはメモ化再帰とやっていることは同じですが,こちらの方がいわゆる動的計画法のイメージに近い方法です.
ここでは縦横の長さ$n$の2次元配列$dp$を用意します.$dp[i][j]$には解法2における$strategy(i, j)$の出力が入ることになります.コードの上ではほぼ解法2の$strategy(i, j)$が$dp[i][j]$に変わるだけです.しかし,$dp$を計算する順序には注意する必要があります.$dp[i][j]$を計算する際にはその内側にあるインデックス$a, b~(i <= a <= b <= j)$に対して$dp[a][b]$が求まっていなければなりません.よって,$dif$を$i$から$j$の差として,$dif$が小さい方から順に$dp[i][j]$を計算していきます(これはいわゆる「区間DP」という方法です).
def stone_game(stones: List[int]) -> int: n = len(stones) prefix_sum = [0] + list(itertools.accumulate(stones)) dp = [[0]*n for _ in range(n)] # 値を格納する配列 for dif in range(1, n): # 求める配列の幅, 順に長くしていく for i in range(n-dif): # 配列の開始地点 j = i+dif # 配列の終了地点 left = (prefix_sum[j+1] - prefix_sum[i+1]) - dp[i+1][j] right = (prefix_sum[j] - prefix_sum[i]) - dp[i][j-1] dp[i][j] = max(left, right) return dp[0][n-1]解法2と3の理論的な計算量は同じですが,実際は解法3の方がたいてい計算時間は速くなります.解法2で遅すぎる場合は3で書き直すとうまくいったりします.
区間DPを使ったGame 1の解法
ちなみにGame 1も区間DPを使えば解法3のように解くことができます.
def stone_game(stones: List[int]) -> int: n = len(stones) dp = [[0]*n for _ in range(n)] for dif in range(1, n): for i in range(n-dif): j = i + dif dp[i][j] = max(stones[i] - dp[i+1][j], stones[j] - dp[i][j-1]) return dp[0][n-1]Game 3: 端から順に取るゲーム(1)
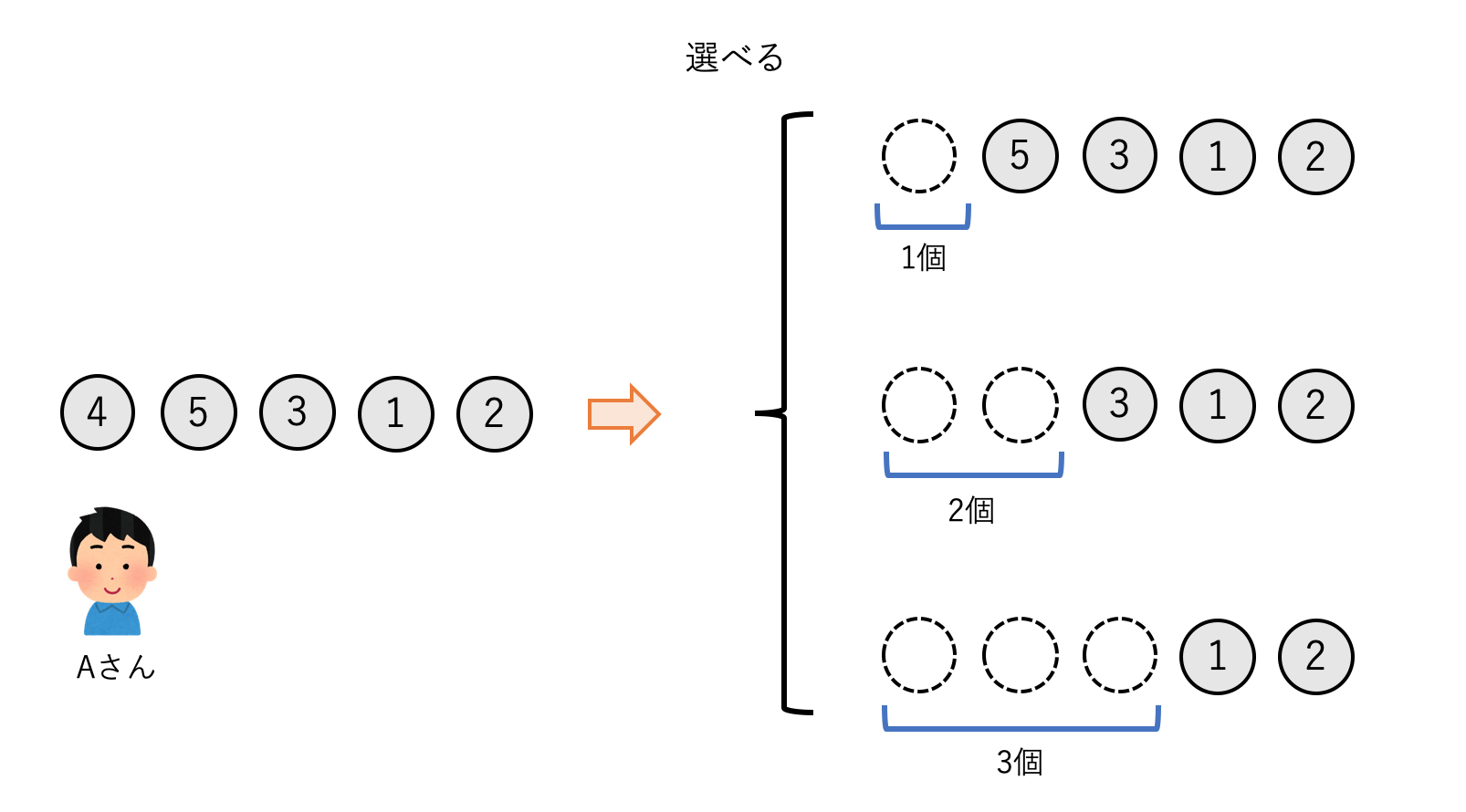
続いては,両端から石を取るのではなく,一方の端からのみ順に石を取っていく設定を考えます.ただ,1個ずつ石を取っていては何のゲーム性もないので,一回に取れる石の数を1,2,3個いずれかから選択できるとします.今回も石を最後まで取りきった時総得点が高い方が勝ちです.
解法1
Game 1やGame 2の解説から.部分配列を入力,得点差を出力とし,最適戦略を再帰的に表現する$strategy$関数を構築することで問題を解けることがわかりました.その戦略をこのゲームに対しても適用します.
この場合$strategy$関数は,取る石の数が1~3個の場合に得られる最大得点差をそれぞれ計算し,それらの最大値を返すようなものになります.
score\_dif = \max \left\{ \begin{array}{l} stones[0] - strategy(stones[1:]) \\ stones[0] + stones[1] - strategy(stones[2:]) \\ stones[0] + stones[1] + stones[2] - strategy(stones[3:]) \end{array} \right.これを初期値や境界条件に注意しながら,Game 1と同じようにメモ化再帰で書くだけです.
def stone_game(stones: List[int]) -> int: n = len(stones) @functools.lru_cache(None) def strategy(i): if i >= n-1: return sum(stones[i:]) return max(sum(stones[i:i + k]) - strategy(i + k) for k in (1, 2, 3)) # sumとfor文を使ってまとめた return strategy(0)今回は関数の引数が1つのインデックスだけなので,時間計算量,空間計算量は$O(n)$で済みます.
解法2
Game 2で見たように,配列に計算結果を格納する方法での解法も見ておきます.ここでは長さ$n$の1次元配列$dp$を用意し,$dp[i]$には$strategy(i)$の出力が入ります.今回はインデックスが1つしかないのでGame 2よりシンプルですが,計算する順序にはやはり注意する必要があります.$dp[i]$を計算する際にはより大きなインデックス$i < j$での$dp[j]$が求まっていなければなりません.よって,インデックスの大きい方から$dp[i]$を計算していきます.
def stone_game(stones: List[int]) -> int: n = len(stones) dp = [0] * (n+3) # インデックスエラーを防ぐため配列を長めに用意しておく for i in reversed(range(n)): # i = n-1 ~ 0 の順でループ dp[i] = max(sum(stones[i:i + k]) - dp[i + k] for k in (1, 2, 3)) return dp[0]こちらも理論的な計算量は同じですが,実際には解法2の方が計算時間は速くなると思います.
Game 4: 端から順に取るゲーム(2)
ここで少しゲームルールを変えて,「プレーヤーはこれまで取られた石の最大個数の2倍を超えない数の石を取ることができる」としてみます.つまり,これまでに最大で$M$個の石が取られた時,次のプレーヤーは$1 \leq X \leq 2M$を満たす$X$個の石を取ることができ,この範囲であれば好きな$X$を選択できます.さらにその次のプレーヤーに対しては$M = max(X, M)$となります.なお,はじめは$M=1$からスタートするものとします.
ここまでの内容を理解された方は,このような複雑な問題を見てももう解法がイメージできるのではないでしょうか?$strategy$の状態は,開始するインデックスと取れる石の最大個数$2M$によって決まります.コードは以下のようになります.
def stone_game(stones: List[int]) -> int: n = len(stones) @functools.lru_cache(None) def strategy(i, M): if i + 2 * M >= n: return sum(stones[i:]) return max(sum(stones[i:i + X]) - strategy(i + X, max(M, X)) for X in range(1, 2 * M + 1)) return strategy(0, 1) # 初めはX = 1, M = 1関数の入力と更新式が変わりましたが,やっていることはGame 3とほぼ同じです.
Game 5: 石の価値が違う場合のゲーム
最後に,また違ったルールのゲームを考えてみます.大きなルール変更は次の2つです.
- 場にある石のどれでも取っていい.
- 石の価値は2人のプレーヤーで異なる
例えば場に石が5個あった時,Aから見た石の価値は順に5,2,3,1,4であり,Bから見た石の価値は順に1,5,3,4,2というように,同じ石でも両者の得られる得点が異なります.なお,両プレーヤーは相手の得点配分も見えているものとします.例えばAは1つ目の石(5点)を取れば最も得られる得点は高いですが,そうすれば次にBは2番目の石を取って5点を得るはずなので,先に2番目の石(2点)を取っておくべきかもしれません.
解法1
ただ我々は既に,得点差を出力とし最適戦略を再帰的に表現する$strategy$関数を構築することで問題を解けることを知っています.今回は列のどの位置から石を取ってもいいので,既に残っている石と取られた石の場所を表す$state$配列を導入します.$i$番目の石が既に取られていれば$state[i] = False$,残っていれば$True$とします.プレーヤー名と$state$を入力として,まだ残っている石をそれぞれ取った時の得点を求め,最大得点を返す関数を書きます.
def stone_game(values_A: List[int], values_B: List[int]) -> int: n = len(values_A) state = [True]*n @lru_cache(None) def strategy(player, state): if max(state) == 0: # 全てFalse, つまり全ての石が取られているなら0を返す return 0 max_value = float("-inf") state = list(state) for i in range(n): if state[i]: # もし石iが残っていれば state[i] = False # 石iを取ったことにする if player == "A": # プレーヤーAとBで場合分け max_value = max(max_value, values_A[i] - strategy("B", tuple(state))) else: max_value = max(max_value, values_B[i] - strategy("A", tuple(state))) state[i] = True # 石iを取られていない状態に戻す return max_value return strategy("A", tuple(state)) # 先攻はA, stateは全てTrueなお,pythonにおいて配列はhashableではなくメモ化できないので,$state$を関数に入力する際はtupleに変換しています.これで各$state$に対して得られる得点が求まり,計算できるようになりました.
しかしこれで本当にいいのでしょうか?今までは配列の両端からしか石を取らなかったものが,どこからでも石を取ってもよくなったことで,$state$のバリエーションは膨大になっています.具体的には$n$個それぞれの地点が$True$か$False$を取れるため,組み合わせの個数のオーダーは$O(2^n)$になってしまいます.これではせいぜい$n=30$くらいまでしか気軽に計算できないでしょう.
解法2
実はこのゲーム,はるかに簡単に計算できます.まず問題を単純化して,石の価値が両者で同じ場合を考えてみます.この場合,再帰をするまでもなく,一番得点の高い石から順に取っていくのが最適です.これは直感的には以下の2つの理由によるものです.
- 得点の大きい石を取れば自分の得点を大きくできる.
- 得点の大きい石を取れば相手はその石を取れず,相手の得点を減らせる.
これが,両者の石の価値が違う場合にも成り立ちます.一つの石を取った場合に生まれる相手との得点差は,(自分が得た得点)+(その石がなくなったことで相手が得られなくなった得点)と考えることができます.それはつまり,自分から見た石の得点と相手から見た得点の和です.得点差を大きくするためには結局,両者にとっての価値を石ごとに足して,価値の大きい石から順に取っていくのが最適になります.
def stone_game(values_A: List[int], values_B: List[int]) -> int: sorted_sum_value = sorted(zip(values_A, values_B), key=sum, reverse=True) # 石ごとの価値の和を降順に並べている sum_A = sum(a for a, b in sorted_sum_value[::2]) # 先頭の石から一つおきに取れる sum_B = sum(b for a, b in sorted_sum_value[1::2]) # 2個目の石から一つおきに取れる return sum_A - sum_Bこれなら計算量は$O(n)$になりました.この問題に関しては定石メソッドを適応するよりさらに良い方法があるということで,石取りゲームの奥深さが感じられます.
まとめ
ここまで,得点の異なるいくつかの石があり,2人でその石を取り合う場合に,どちらがより多くの得点を取れるのか,また何点取れるのかという問題を考えてきました.ポイントは,
- 各状態を単純な形(インデックスなど)で表す
- 各状態を入力,得られる得点(の差)を出力とし,最適な行動をとる関数を再帰的に書く
- メモ化やDPによって計算量を減らす
でした.今後もし他人から石取りゲームを申し込まれた場合は,確実に勝てるか見極めてから応じるようにしましょう.
参考(Leetcodeより)
Stone Game
Stone Game VII
Stone Game III
Stone Game II
Stone Game VI




- 投稿日:2021-01-12T20:43:55+09:00
django-sesで「No handler was ready to authenticate」エラー
事象
No handler was ready to authenticate. 1 handlers were checked. ['HmacAuthV3Handler'] Check your credentials
- EC2では動く
- ECS(Fargate)で上記エラー
- IAM Roleには正しく設定されている(AdminRoleを設定しても解決されない)
解決策
このエラー自体はRoleの設定ミス等の他の原因でも発生するのですが(そのため調査に時間がかかりました・・)、ライブラリのバージョンが古いと発生する可能性があります。
具体的には、
django-sesが1.0未満(0.X)の場合に、認証ライブラリのbotoが古いために(botoではなくboto3である必要がある)、ECSのRoleをうまく扱えずにエラーが発生します。
他のライブラリでも、ECS環境で認証エラーが発生した場合は疑ってみてください。
- 投稿日:2021-01-12T20:30:37+09:00
最適化アルゴリズムを実装していくぞ(カッコウ探索)
はじめに
最適化アルゴリズムの実装シリーズです。
まずは概要を見てください。コードはgithubにあります。
カッコウ探索
概要
カッコウ探索(Cucko Search)は、カッコウの托卵という行動をもとに作られたアルゴリズムです。
托卵は他の種類の鳥の巣に卵を産み、その巣の親に育成を頼む行為です。また、カッコウを含めた野生動物は獲物を探すときにレヴィフライトというレヴィ分布と呼ばれる分布に従って移動することが知られています。
参考
・Cuckoo search
・進化計算アルゴリズム入門 生物の行動科学から導く最適解アルゴリズム
ランダムな巣を元に卵を作成し、別の巣を作ります。
この時に作成される卵は、レヴィ分布に従って生成されます。作成された巣はさらに別のランダムな巣と比較し、良ければ置き換えられます。
最後に評価値の悪い巣は破棄され、新しい巣に置き換えられます。
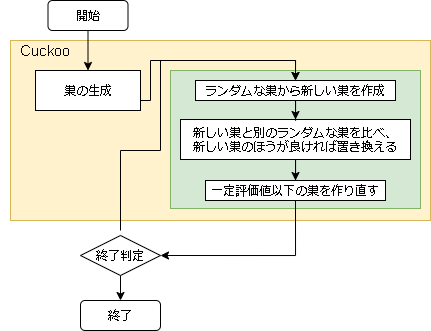
- アルゴリズムのフロー
- 用語の対応
問題 カッコウ探索 入力値の配列 巣 入力値 卵 評価値 巣の評価値
- ハイパーパラメータに関して
変数名 意味 所感 scaling_rate レヴィ分布の尺度 大きいほど遠くに移動しやすくなる levy_rate レヴィフライトの反映率 大きいほどレヴィフライトによる移動が大きい bad_nest_rate 悪い巣の割合 高いほど巣の入れ替え(探索範囲)が多くなる 巣の作成
ランダムに選んだ巣からレヴィ分布に従って新しい巣を作成します。
$$ x^{new}_i = x^{r}_i + \alpha s $$
$s$ はレヴィ分布に従った乱数(レヴィフライト)で、$\alpha$ はレヴィフライトの反映率となります。
この巣の生成がカッコウ探索のすべてですが、レヴィフライトがちょっと厄介です。レヴィ分布は以下です。
$$ f(x; \mu, c) = \sqrt{ \frac{c}{2 \pi} } \frac{ \exp^{\frac{-c}{2(x - \mu)}} }{ (x - \mu)^{\frac{2}{3}}} $$
import math def levy(x, u=0, c=1): if x == 0: return 0 t = math.exp((-c/(2 * (x-u)))) t /= (x-u) ** (3/2) return math.sqrt(c/(2*math.pi)) * tこのレヴィ分布に従った乱数を生成する必要があります。
レヴィ分布に従った乱数は Mantegna アルゴリズムで求めます。$$ s = \frac{u}{|v|^{\frac{1}{\beta}}} $$
ここで $\beta$ はスケーリング指数で0~2の実数をとります。
$u$ は平均0,分散 $\sigma^2$の正規分布に従う乱数、
$v$ は標準正規分布に従う乱数です。$\sigma$ は以下の式で求まります。
$$ \sigma = \Biggl( \frac{ \Gamma(1+\beta) \sin(\frac{\pi \beta}{2}) }{ \Gamma(\frac{1+\beta}{2}) \beta 2^{\frac{(\beta-1)}{2}} } \Biggr)^{\frac{1}{\beta}} $$
$\Gamma$ はガンマ関数を表します。
$$ \Gamma(x) = \int_{0}^{\infty} t^{x-1}e^{-t} dt $$
- 正規分布の乱数
正規分布の乱数ですが、pythonのnumpyライブラリを使うと以下で簡単に出せます。
import numpy as np np.random.randn() # 標準正規分布の一様乱数を生成 np.random.normal(0, sigma) # 平均0、分散sigma^2の正規分布に従う乱数が、他の言語(主にluaとか)での実装も考えているのでライブラリを使わない方法も書いておきます。
標準正規分布の乱数はボックス=ミュラー法で出すことができます。
$$ z = \sqrt{-2 \log{X}} \cos{2\pi Y} $$
ここで X と Y は互いに独立した一様乱数になります。
pythonだと以下です。import math def random_normal(): r1 = random.random() r2 = random.random() return math.sqrt(-2.0 * math.log(r1)) * math.cos(2*math.pi*r2)
- ガンマ関数
ガンマ関数も math を使うと簡単に出せます。
import math math.gamma(x)使わない場合はここのサイトのコードを使わせてもらいました。
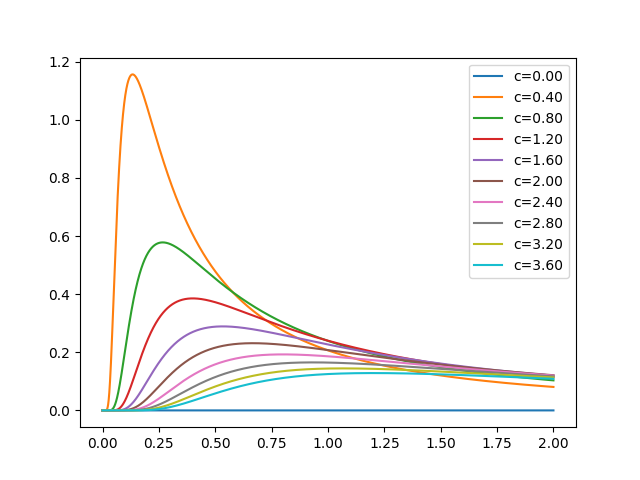
(コードは全体コードに記載しています)レヴィ分布に関して
レヴィ分布のグラフです。
レヴィ分布ですが見てわかるように範囲が 0~∞ です。
これは卵を生成する場合に少しネックになります。例えばOneMaxの問題だと範囲が0~1しかとりません。
この問題に対してレヴィ分布で生成された1以上の値をどうするかは決まっていません。
ここで、例えば1以上の値は1にするとした場合、生成された乱数がレヴィ分布に従わなくなります。
(1の生成確率だけ高くなってしまう)これはどうなんでしょうかね。
解決方法もよくわからないので今のところは放置しています。コード全体
import math import random import numpy as np ############################################ # Γ(x)の計算(ガンマ関数,近似式) # ier : =0 : normal # =-1 : x=-n (n=0,1,2,・・・) # return : 結果 # coded by Y.Suganuma # https://www.sist.ac.jp/~suganuma/programming/9-sho/prob/gamma/gamma.htm ############################################ def gamma(x): if x <= 0: raise ValueError("math domain error") ier = 0 if x > 5.0 : v = 1.0 / x s = ((((((-0.000592166437354 * v + 0.0000697281375837) * v + 0.00078403922172) * v - 0.000229472093621) * v - 0.00268132716049) * v + 0.00347222222222) * v + 0.0833333333333) * v + 1.0 g = 2.506628274631001 * math.exp(-x) * pow(x,x-0.5) * s else: err = 1.0e-20 w = x t = 1.0 if x < 1.5 : if x < err : k = int(x) y = float(k) - x if abs(y) < err or abs(1.0-y) < err : ier = -1 if ier == 0 : while w < 1.5 : t /= w w += 1.0 else : if w > 2.5 : while w > 2.5 : w -= 1.0 t *= w w -= 2.0 g = (((((((0.0021385778 * w - 0.0034961289) * w + 0.0122995771) * w - 0.00012513767) * w + 0.0740648982) * w + 0.0815652323) * w + 0.411849671) * w + 0.422784604) * w + 0.999999926 g *= t return g def random_normal(): """ 正規分布の乱数 ボックス=ミュラー法 """ r1 = random.random() r2 = random.random() return math.sqrt(-2.0 * math.log(r1)) * math.cos(2*math.pi*r2) def mantegna(beta): """ mantegna アルゴリズム """ #beta: 0.0 - 2.0 if beta < 0.005: # 低すぎると OverflowError: (34, 'Result too large') beta = 0.005 # siguma t = gamma(1+beta) * math.sin(math.pi*beta/2) t = t/( gamma((1+beta)/2) * beta * 2**((beta-1)/2) ) siguma = t**(1/beta) u = random_normal()*siguma # 平均0 分散siguma^2 の正規分布に従う乱数 v = random_normal() # 標準正規分布に従う乱数 s = (abs(v)**(1/beta)) if s < 0.0001: # 低すぎると ValueError: supplied range of [-inf, inf] is not finite s = 0.0001 s = u / s return s class Cuckoo(): def __init__(self, nest_max, scaling_rate=1.0, levy_rate=1.0, bad_nest_rate=0.1 ): self.nest_max = nest_max self.scaling_rate = scaling_rate self.levy_rate = levy_rate # 悪い巣の割合から悪い巣の個数を算出 self.bad_nest_num = int(nest_max * bad_nest_rate + 0.5) if self.bad_nest_num > nest_max-1: self.bad_nest_num = nest_max-1 if self.bad_nest_num < 0: self.bad_nest_num = 0 def init(self, problem): self.problem = problem self.nests = [] for _ in range(self.nest_max): self.nests.append(problem.create()) def step(self): # ランダムに巣を選択 r = random.randint(0, self.nest_max-1) # a<=x<=b # 新しい巣を作成 arr = self.nests[r].getArray() for i in range(len(arr)): # レヴィフライで卵を作る arr[i] = arr[i] + self.levy_rate * mantegna(self.scaling_rate) new_nest = self.problem.create(arr) # ランダムな巣と比べてよければ変える r = random.randint(0, self.nest_max-1) # a<=x<=b if self.nests[r].getScore() < new_nest.getScore(): self.nests[r] = new_nest # 悪い巣を消して新しく作る self.nests.sort(key=lambda x:x.getScore()) for i in range(self.bad_nest_num): self.nests[i] = self.problem.create()カッコウ探索(ε-greedy)
これは本記事オリジナルです。(探せばあるかも?)
カッコウ探索はとてもシンプルなアルゴリズムですが、レヴィフライトの実装がすごく厄介です。そこでレヴィフライトをε-greedyに置き換えてみました。
ε-greedyに置き換えることで実装がすごい簡単になりましたね。ε-greedyでもそこそこの精度がでるような気がします。
コード全体
import math import random class Cuckoo_greedy(): def __init__(self, nest_max, epsilon=0.1, bad_nest_rate=0.1 ): self.nest_max = nest_max self.epsilon = epsilon # 悪い巣の割合から悪い巣の個数を算出 self.bad_nest_num = int(nest_max * bad_nest_rate + 0.5) if self.bad_nest_num > nest_max-1: self.bad_nest_num = nest_max-1 if self.bad_nest_num < 0: self.bad_nest_num = 0 def init(self, problem): self.problem = problem self.nests = [] for _ in range(self.nest_max): self.nests.append(problem.create()) def step(self): # ランダムに巣を選択 r = random.randint(0, self.nest_max-1) # a<=x<=b # 新しい巣を作成 arr = self.nests[r].getArray() for i in range(len(arr)): # ε-greedy で卵を新しく作成する if random.random() < self.epsilon: arr[i] = self.problem.randomVal() new_nest = self.problem.create(arr) # ランダムな巣と比べてよければ変える r = random.randint(0, self.nest_max-1) # a<=x<=b if self.nests[r].getScore() < new_nest.getScore(): self.nests[r] = new_nest # 悪い巣を消して新しく作る self.nests.sort(key=lambda x:x.getScore()) for i in range(self.bad_nest_num): self.nests[i] = self.problem.create()ハイパーパラメータ例
各問題に対して optuna でハイパーパラメータを最適化した結果です。
最適化の1回の試行は、探索時間を2秒間として結果を出しています。
これを100回実行し、最適なハイパーパラメータを optuna に探してもらいました。
- カッコウ探索
問題 bad_nest_rate levy_rate nest_max scaling_rate EightQueen 0.09501642206708413 0.9797131483689493 14 1.9939515457735189 function_Ackley 0.0006558326608885681 0.3538825414958845 4 0.9448539685962172 function_Griewank 0.23551408245457767 0.30150681160121073 2 0.9029863706820189 function_Michalewicz 0.00438839398648697 0.0004796264527609298 2 1.5288609934193742 function_Rastrigin 0.13347040982335695 0.031401149135082206 7 1.6949622109706082 function_Schwefel 0.0003926596935418525 0.02640034426449156 4 0.5809451877075759 function_StyblinskiTang 0.08462936367613791 0.0633939067767827 5 1.7236388666366773 LifeGame 0.8819375718376719 0.015175414454036936 33 1.3899842408715666 OneMax 0.89872646833605 0.1261650035421213 17 0.04906594355889626 TSP 0.024559598255857823 0.008225444982304852 4 1.8452535160497248
- カッコウ探索(ε-greedy)
問題 bad_nest_rate epsilon nest_max EightQueen 0.004374125594794304 0.03687227169502155 7 function_Ackley 0.5782260075661492 0.031195954391595435 2 function_Griewank 0.23314007403872794 0.05206930732996057 2 function_Michalewicz 0.11845570554906226 0.02242832420874199 3 function_Rastrigin 0.009725819291390304 0.025727770986639094 3 function_Schwefel 0.22978641596753258 0.048159183280607774 2 function_StyblinskiTang 0.14184473157004032 0.01965829867603547 2 LifeGame 0.7358005558643367 0.9115290938258255 39 OneMax 0.0016700608620328905 0.006003869128710593 2 TSP 0.00023997215188062415 0.030790166824531992 29 実際の動きの可視化
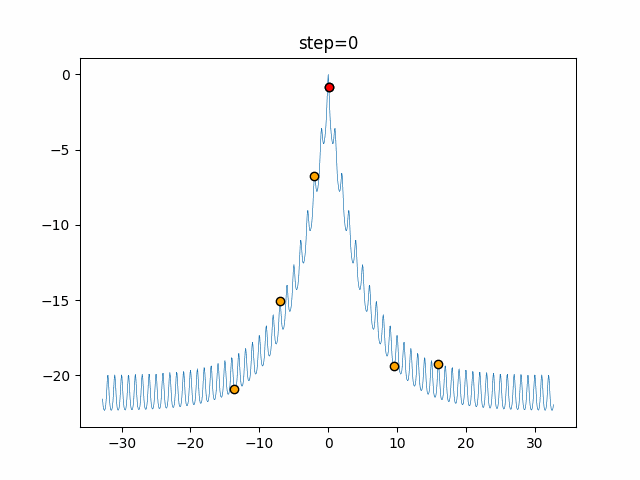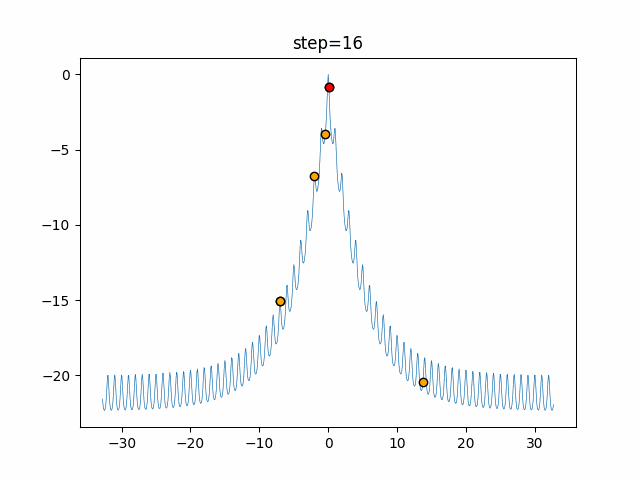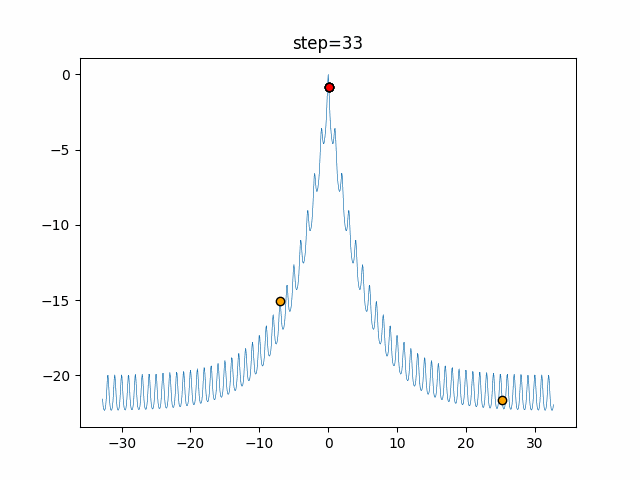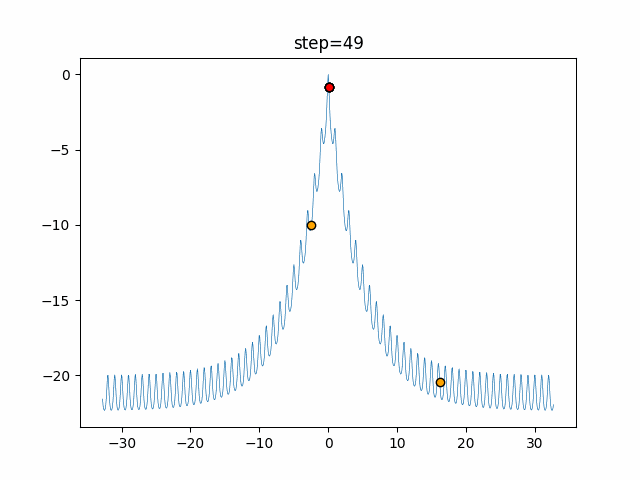
1次元は6個体、2次元は20個体で50step実行した結果です。
赤い丸がそのstepでの最高スコアを持っている個体となります。パラメータは以下で実行しました。
Cuckoo(N, scaling_rate=1.0, levy_rate=1.0, bad_nest_rate=0.1) Cuckoo_greedy(N, epsilon=0.5, bad_nest_rate=0.1)function_Ackley
- Cuckoo
- 1次元
- 2次元
- Cuckoo_greedy
- 1次元
- 2次元
function_Rastrigin
- Cuckoo
- 1次元
- 2次元
- Cuckoo_greedy
- 1次元
- 2次元
function_Schwefel
- Cuckoo
- 1次元
- 2次元
- Cuckoo_greedy
- 1次元
- 2次元
function_StyblinskiTang
- Cuckoo
- 1次元
- 2次元
- Cuckoo_greedy
- 1次元
- 2次元
function_XinSheYang
- Cuckoo
- 1次元
- 2次元
- Cuckoo_greedy
- 1次元
- 2次元
あとがき
アルゴリズム自体はかなり簡単で精度もかなりいいらしいです。
レヴィ分布に従った乱数の生成が一番難しかったです…。
- 投稿日:2021-01-12T20:10:03+09:00
Twitter api とLine api使ってみた
はじめに
apiの勉強をしたいと思い、テストで作ってみました。
Twitterのトレンド(1~5位)を取得して、Lineで通知するbotを作ります。環境構築
pip install line-bot-sdk //Line apiを使うライブラリー pip install requests requests_oauthlib//twitter apiを使うためのライブラリーそれぞれをインストールする。
import json from requests_oauthlib import OAuth1Session from linebot import LineBotApi from linebot.models import TextSendMessage CONSUMER_KEY='*****' CONSUMER_SECRET='*****' ACESS_TOKEN='*****' ACESS_TOKEN_SECRET='*****' twitter=OAuth1Session(CONSUMER_KEY,CONSUMER_SECRET,ACESS_TOKEN,ACESS_TOKEN_SECRET)//自分のapikeyを入力してください url='https://api.twitter.com/1.1/trends/place.json' params={'id':23424856} //日本のidの値を設定する。 res=twitter.get(url,params=params) json=res.json() trends=json[0]['trends'] names=[] urls=[] for i,trend in enumerate(trends): if i>=5: break name=trends[i]['name'] url=trends[i]['url'] names.append(name) urls.append(url) CHANNEL_ACCESS_TOKEN="*****" line_bot_api=LineBotApi(CHANNEL_ACCESS_TOKEN) texts=[] number=0 def main(): USER_ID="*****" for i in range(len(names)): texts.append(str(i+1)+" "+names[i]+"\n"+urls[i]) line_bot_api.push_message(USER_ID, TextSendMessage(text=texts[number]+'\n'+texts[number+1]+'\n'+texts[number+2]+'\n'+texts[number+3]+'\n'+texts[number+4])) main()終わりに
APIの利用はなれたらとても簡単にできると思います。
わからないところがあれば、気軽に言ってください!!
この記事に関することなら、なんでもお答えします!!
ダメなところなどもあれば言ってください
- 投稿日:2021-01-12T19:58:58+09:00
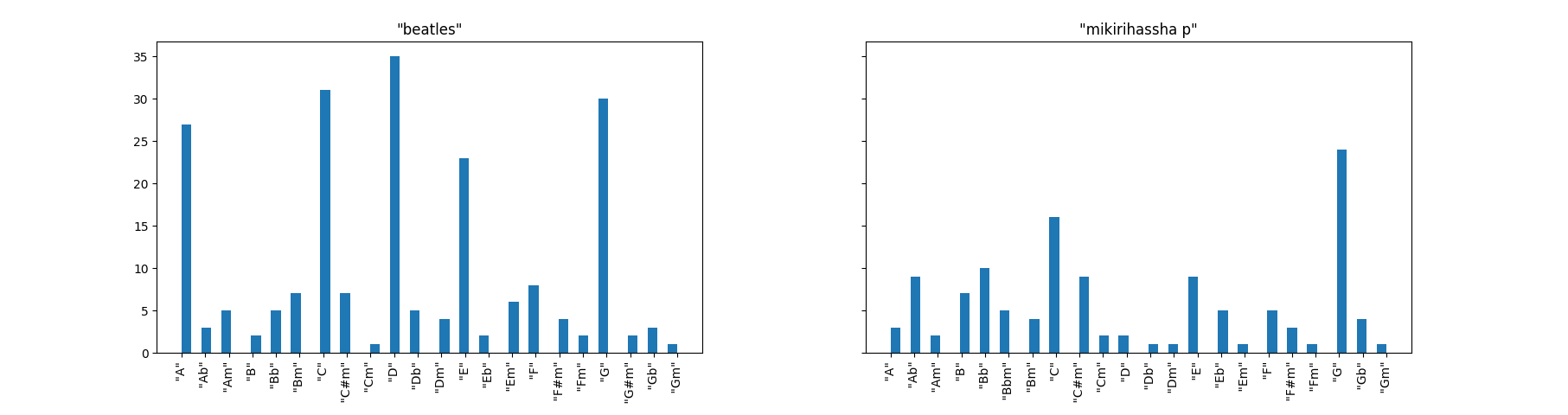
ビートルズ楽曲と自作曲の違いをSpotifyに分析してもらってプロットした
前説
ビートルズが50年経っても未だにポピュラーなのは、
(クオリティの高さは前提として)
把握しやすいキャリアの長さだということもあると思います。
約10年で約200曲という、膨大ながらついていけなくもない曲数。
分析するのにうってつけですね(強引な話の切り替え)。
自分語り
ところで自分も楽曲を作っていて、Spotifyにもあるわけですが、
自分の曲とビートルズの曲を比べてみると何か分かるかもしれないというあやふやな動機の元、
Pythonを走らせてみました。
Spotipy
と言ってもPythonで分析したわけではなく、
Spotifyが(レコメンドのために?)分析しているデータをAPIを通じて取ってきただけです。
取ってくるためのライブラリもあって、
Spotipyといいます。https://spotipy.readthedocs.io/en/2.16.1/
認証情報
Spotifyの開発者ポータルから、APPを作ります。
このときクライアントIDとSecretをメモっておきます。
Spotipy的には環境変数を使ってほしいみたいですが、うまく行かなかったので 直打ち でIDとSecretを渡します。
import spotipy from spotipy.oauth2 import SpotifyClientCredentials spotify = spotipy.Spotify(client_credentials_manager=SpotifyClientCredentials( client_id='hogehoge', client_secret='fugafuga'))これでSpotifyのAPIが叩ける…というかSpotipyを通じて単に取ってくる感じになるので、
取ってきます。
ちなみにビートルズ213曲を集めたプレイリストを見つけたので使わせてもらいました。
beatles_uri = 'spotify:playlist:57z71mWZeq5xy0zEBvO5Cx' results1 = spotify.playlist_items(beatles_uri) songs1 = results1["items"] results2 = spotify.playlist_items(beatles_uri, offset=100) songs2 = results2["items"] results3 = spotify.playlist_items(beatles_uri, offset=200) songs3 = results3["items"] songs1.extend(songs2) songs1.extend(songs3) songs = songs1213曲あるけど、同時に取れるのは100曲までのようなので3回に分けました。
for song in songs: ana = spotify.audio_features(song["track"]["uri"])audio_featuresは先程のplaylist_itemsとはまた別なAPIで、
ここに分析情報が格納されています。
いろいろ含まれているのですが今回は楽曲の「調」を調べます。
213曲ぶんなので
time.sleep(1)を入れて負荷がかからないようにしました。csvRow = f'"{i}", "{song["track"]["name"].replace(",", " ")}", "{keymode[ana[0]["key"]][ana[0]["mode"]]}"' with open('beatles.csv', 'a') as f: print(csvRow, file=f)あとはファイルへの書き込みです。
ちなみに
keymodeというのは、Spotifyの分析ではキー(AとかBとか)とモード(長調、短調)が別のところに入っているので、うまくマップするための自作リストです。
keymode = [ ["Cm", "C"], ["C#m", "Db"], ["Dm", "D"], ["D#m", "Eb"], ["Em", "E"], ["Fm", "F"], ["F#m", "Gb"], ["Gm", "G"], ["G#m", "Ab"], ["Am", "A"], ["Bbm", "Bb"], ["Bm", "B"] ]余談1: Bbm にすべきか A#m にすべきか迷ったんですけど、たぶんBbmが一般的? かな?
余談2: bじゃなくて♭を使いたかったけど、文字化けで断念しました。
csvmod.py
さて、これで
beatles.csvができました。ほぼ同じ要領で
mikiri.csvも作りました。しかしながらプロットする段になって2つは同じCSVにあったほうが設定しやすいことが判明しました!
なのでマージです。
import pandas as pd beatles_csv = pd.read_csv("beatles.csv") mikiri_csv = pd.read_csv("mikiri.csv") beatles_csv["artist"] = '"beatles"' mikiri_csv["artist"] = '"mikirihassha p"' beatles_csv.to_csv("analyze.csv", index=False, columns=["name", "key", "artist"]) mikiri_csv.to_csv("analyze.csv", mode="a", header=False, index=False, columns=["name", "key", "artist"])
pandasのread_csvを使用しCSVからデータフレームを作成。データフレームに新たなカラム "artist" を追加。
to_csv()で吐き出し。
ただし2つ目はheaderをFalse、modeをaとする。
こんなもんでしょう!
できたCSVは 見せたくないけど 見せます。
name,key,artist " ""Love Me Do - Mono / Remastered"""," ""C""","""beatles""" " ""P.S. I Love You - Remastered"""," ""D""","""beatles""" " ""Please Please Me - Remastered"""," ""E""","""beatles""" " ""Ask Me Why - Remastered"""," ""E""","""beatles""" " ""I Saw Her Standing There - Remastered"""," ""E""","""beatles""" " ""Misery - Remastered"""," ""C""","""beatles""" " ""Anna (Go To Him) - Remastered"""," ""D""","""beatles""" " ""Chains - Remastered"""," ""Bb""","""beatles""" " ""Boys - Remastered"""," ""E""","""beatles""" " ""Baby It's You - Remastered"""," ""Em""","""beatles""" " ""Do You Want To Know A Secret - Remastered"""," ""E""","""beatles""" " ""A Taste Of Honey - Remastered"""," ""C#m""","""beatles""" " ""There's A Place - Remastered"""," ""E""","""beatles""" " ""Twist And Shout - Remastered"""," ""D""","""beatles"""なんかクォーテーションが多すぎて煩雑なことになってしまいました。
しかしこのままGOします。
plot.py
次はいよいよプロットです。
import matplotlib.pyplot as plt import pandas as pd csv = pd.read_csv( "analyze.csv" ) csv = csv.sort_values("key") csv["key"].hist(bins=50, by=csv["artist"], sharey=True) plt.show()これだけです!
csv["key"].hist()に渡す値は多少試行錯誤しましたが、あとは素直に書けました。
by=columnを指定するとそのカラムの値によって比較するプロットが描写できます。つまりこんな感じ。
見た感じちゃんとしたデータになってくれたようです。
分析
シンガーソングライターギタリスト
beatlesのグラフを見て直ちに気づくのは、こいつらギターで曲を作ってるなということです。
突出している、A, C, D, E, G はそれぞれ、ギターに於いて押さえやすいフォームがあるコードです。
つまり、バレーコード(弦をガバっと押さえるやつ)ではなく、ローコードで作曲しているのではないでしょうか。
その後演奏時にはバレーコードに変えたりしてるかもしれませんが…
ネアカ
また2番めに気づくのは、メジャー系のキーが多くマイナー系は少ないということです。
これはビートルズのイメージから言っても納得できます。
また、個人的にビートルズにはDのキーが多い気がしていたのですが、実際多かったようです。
比較
mikirihassha p(自分)はGにピークがあるもののあまり波がなく、傾向が掴みづらいグラフになっていました。よく言えばバランスの取れたグラフです。
調のバランスを取ってどうなるんだって感じですが…
AよりAbが多かったのはちょっと意外。
あと、ビートルズでは多かったDが自作では少ない。
結論
あまり参考にならない
みなさんカラオケで音を半音単位で上げ下げとかするかと思いますが、
半音上にしたからと言って違う曲になったりはしませんよね。
それと同様に、例えばキーをDにしたからといって即ビートルズになれるかというとなれそうにないです。
でもDキーの曲が少なすぎる気がしたので今後ちょっと増やしてみようかなと思いました。
- 投稿日:2021-01-12T19:33:29+09:00
[pyqtgraph] カーソルを追いかける十字線とその座標を表示するクラスを作った
やりたい事
この動作をやってくれるクラスの作成
- カーソルを追従する十字線の作成
- ラベルにx, y座標を表示
- ラベルの色はプロット線と同じになる
- y軸の範囲外の場合はNone表示
環境
Mac OS
Python 3.8.5PyQt5 5.15.2
PyQt5-sip 12.8.1
pyqtgraph 0.11.1
pip install PyQt5 PyQt5-sip pyqtgraphpyqtgraph.exsamples
import pyqtgraph.examples as ex ex.run()で色々なサンプルグラフが見れます。今回参考にしたのはCrosshair / Mouse interactionです。
作ったもの
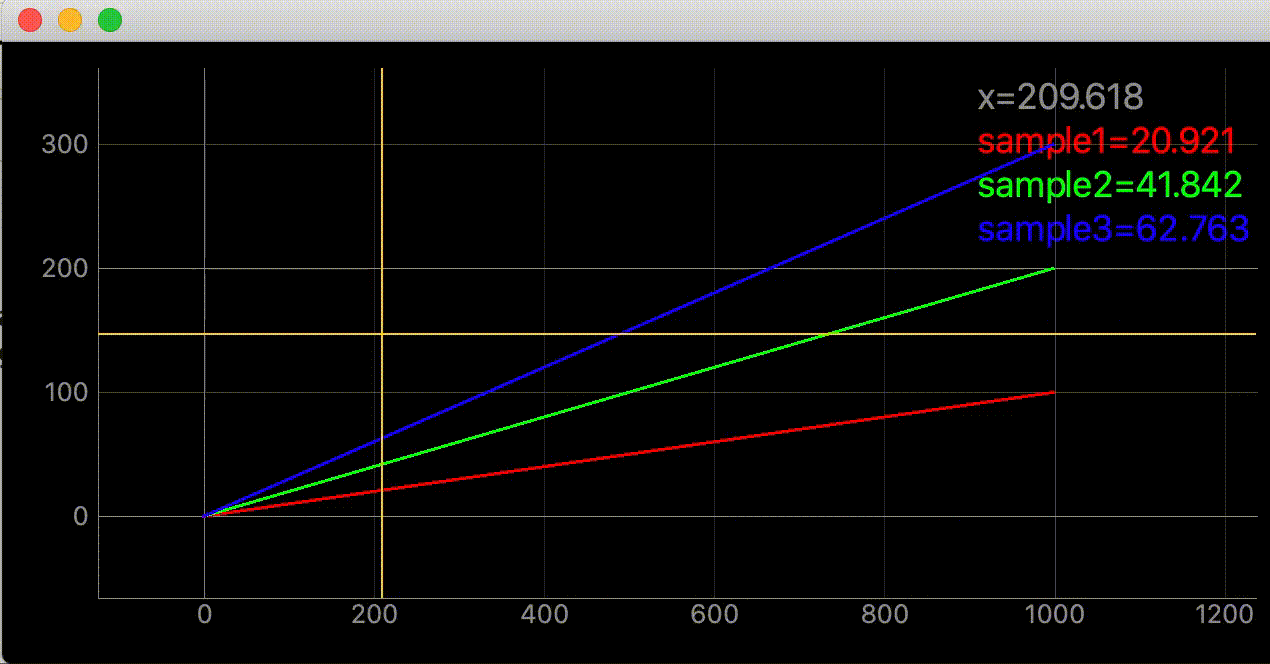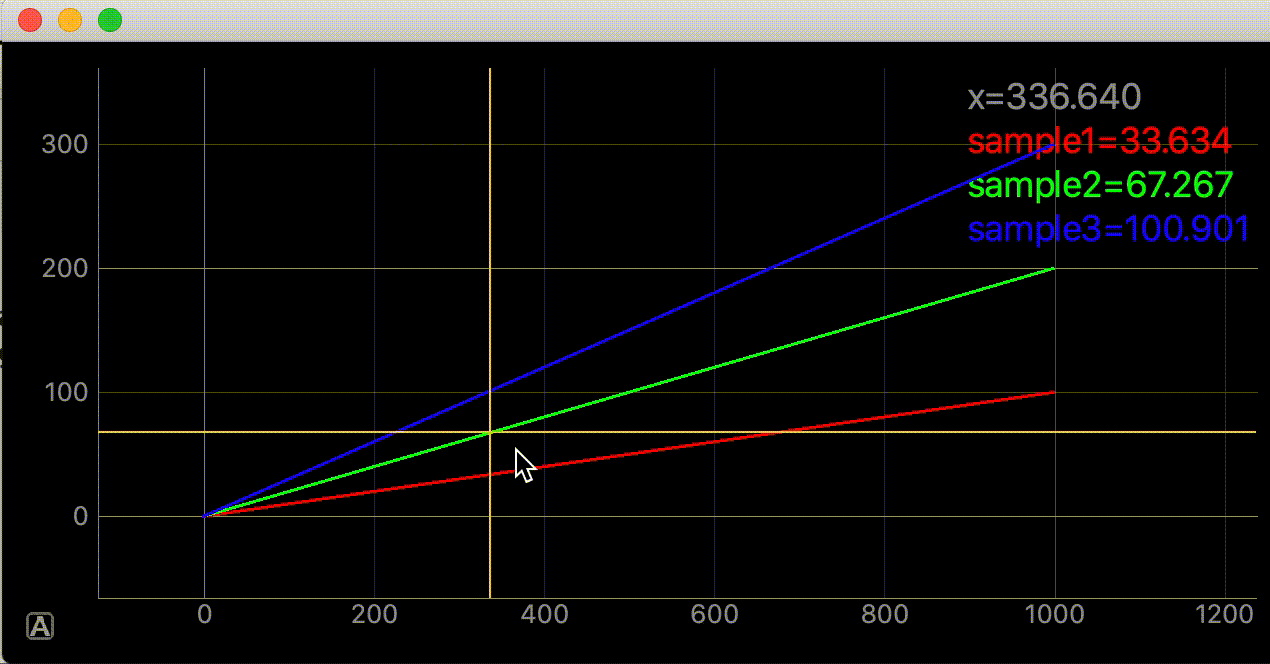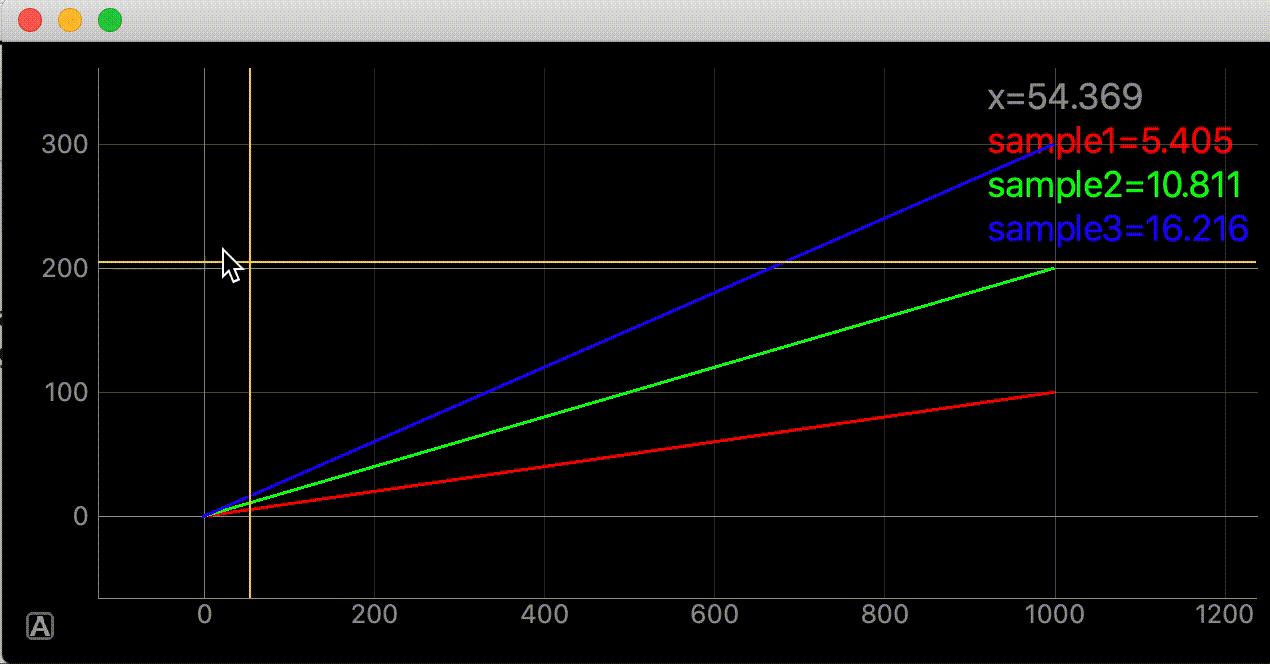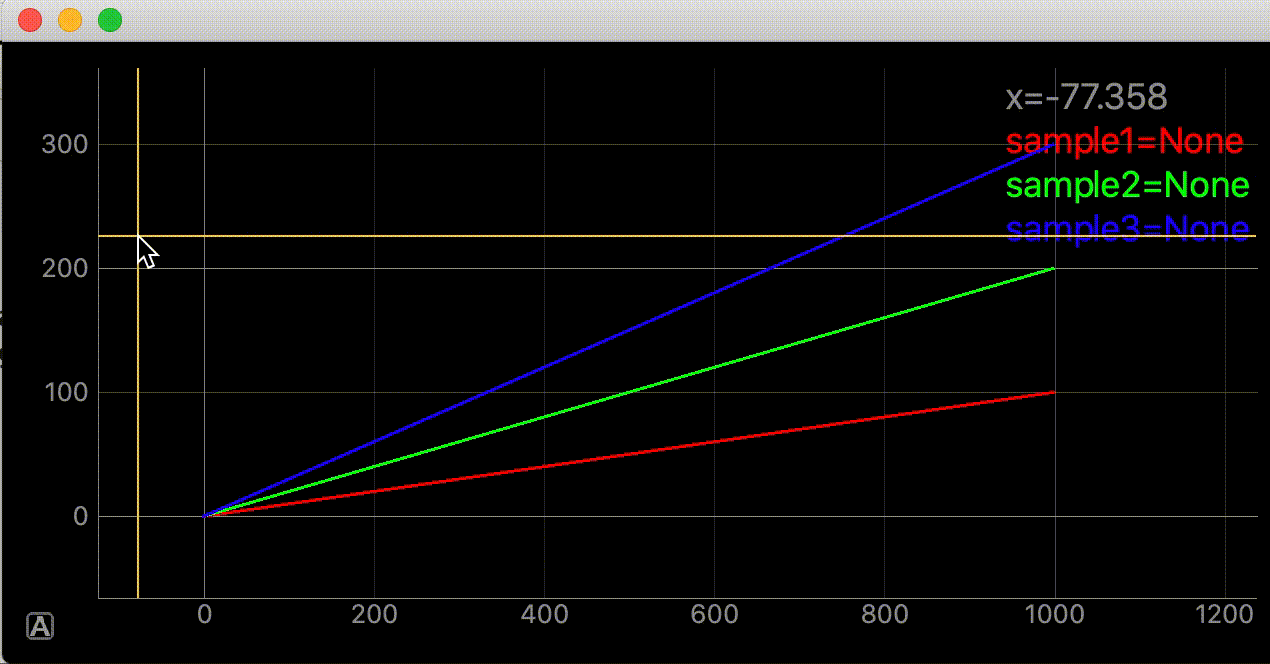
import dataclasses from typing import Union import sys from PyQt5 import QtWidgets import pyqtgraph as pg @dataclasses.dataclass class CursorCrossHairLabel(object): """カーソルを追従する十字線を作成してグラフに追加するクラス カーソルが座標内にあれば座標を表示する Attributes # ---------- plotter: pg.PlotItem 十字線を追加するグラフ label: pg.LabelItem 座標を表示するラベル vertical_line: pg.InfiniteLine カーソルを追いかける縦線 horizontal_line: pg.InfiniteLine カーソルを追いかける横線 proxy: pg.SignalProxy self.cursor_movedの実行間隔を制御するオブジェクト y_label: str default='y' y値凡例の文字列 label_font_size: Union[int, float] default=14 ラベルフォントサイズ digit :int default=3 座標の小数点以下表示を指定 Examples ---------- import dataclasses from typing import Union import sys from PyQt5 import QtWidgets import pyqtgraph as pg app = QtWidgets.QApplication(sys.argv) graph_widget = pg.GraphicsLayoutWidget() label = pg.LabelItem(justify='right') graph_widget.addItem(label) plotter = graph_widget.addPlot(row=0, col=0) plotter.showGrid(x=True, y=True, alpha=1) curve1 = pg.PlotCurveItem([i ** 2 for i in range(10)], pen=pg.mkPen('#f00')) curve2= pg.PlotCurveItem([2*i ** 2 for i in range(10)], pen=pg.mkPen('#0f0')) plotter.addItem(curve1) plotter.addItem(curve2) cross_hair = CursorCrossHairLabel(plotter, label) graph_widget.show() sys.exit(app.exec_()) """ plotter: pg.PlotItem label: pg.LabelItem y_label: str = 'y' label_font_size: Union[int, float] = 14 digit: int = 3 v_color: dataclasses.InitVar[str] = '#ffd700' v_width: dataclasses.InitVar[Union[int, float]] = 2 h_color: dataclasses.InitVar[str] = '#ffd700' h_width: dataclasses.InitVar[Union[int, float]] = 2 def __post_init__(self, v_color: str, v_width: Union[int, float], h_color: str, h_width: Union[int, float]) -> None: """コンストラクタの続き Parameters ---------- v_color: str default='#ffd700' 縦線の色 v_width: Union[int, float] default=2 縦線の幅 h_color: str default='#ffd700' 横線の色 h_width: Union[int, float] default=2 横線の幅 """ self.vertical_line = pg.InfiniteLine(angle=90, movable=False, pen=pg.mkPen(v_color, width=v_width)) self.horizontal_line = pg.InfiniteLine(angle=0, movable=False, pen=pg.mkPen(h_color, width=h_width)) # plotterに追加 self.plotter.addItem(self.vertical_line, ignoreBounds=True) self.plotter.addItem(self.horizontal_line, ignoreBounds=True) self.proxy = pg.SignalProxy(self.plotter.scene().sigMouseMoved, rateLimit=60, slot=self.cursor_moved) self.set_label() def set_label(self): """座標の初期値(None)をラベルにセット""" coord_text = f"<span style='font-size: {self.label_font_size}pt'>x=None<br>" for y_index, curve in enumerate(self.plotter.curves, 1): curve_color: str = curve.opts['pen'].color().name() coord_text += f" <span style='color: {curve_color}'>{self.y_label}{y_index}=None</span><br>" self.label.setText(coord_text) def cursor_moved(self, window_coord) -> None: """カーソル位置に十字線移動と座標を表示する カーソルの座標がグラフ内であればx値を表示する カーソルのy座標にデータがあればy値を表示する。範囲外であればNoneを表示する。 y座標ラベルはcurveと同じ色 Parameters ---------- window_coord: tuple 画面のピクセル単位の座標, ex) (PyQt5.QtCore.QPointF(2.0, 44.0),) Notes ---------- curveはpyqtgraph.PlotCurveItem()で作成しないとcurve_colorの個所でエラーが発生する ex) OK import pyqtgraph as pg window = pg.PlotWidget() curve = pg.PlotCurveItem(pen=pg.mkPen('#ff0000)) window.addItem(curve) ex) Error import pyqtgraph as pg window = pg.PlotWidget() curve = window.plot(pen=...) 関数内変数の説明=================== pos: PyQt5.QtCore.QPointF カーソルの画面内の座標 ex) PyQt5.QtCore.QPointF(2.0, 44.0) cursor_point: QtCore.QPointF カーソルのグラフ内の座標 ex) PyQt5.QtCore.QPointF(269.0678171506131, 0.695852534562212) self.parent.curves: List[pg.PlotCurveItem] parent内にあるcurveのリスト ex) [<pg.PlotCurveItem object at ...>, ...] curve_color: str curveの色 ex) '#ff0000', 関係無いけどcurve.opts['pen'].color()の型はQtGui.QColor ================================= """ pos = window_coord[0] if self.plotter.sceneBoundingRect().contains(pos): cursor_point = self.plotter.vb.mapSceneToView(pos) x_cursor_point: float = cursor_point.x() coord_text = f"<span style='font-size: {self.label_font_size}pt'>x={x_cursor_point:.{self.digit}f}<br>" data_index = int(x_cursor_point) for label_index, curve in enumerate(self.plotter.curves, 1): curve_color = curve.opts['pen'].color().name() if len(curve.yData) != 0 and 0 <= data_index < len(curve.yData): y_value = curve.yData[data_index] coord_text += f" <span style='color: {curve_color}'>" \ f"{self.y_label}{label_index}={y_value:.{self.digit}f}</span><br>" else: coord_text += f" <span style='color: {curve_color}'>{self.y_label}{label_index}=None</span><br>" self.label.setText(coord_text) # 十字線移動 self.vertical_line.setPos(cursor_point.x()) self.horizontal_line.setPos(cursor_point.y())引数
必須引数
- plotter: pyqtgraph.PlotItem, 十字線を表示するグラフ
- label: pyqtgraph.LabelItem, 座標を表示するラベル
その他
- y_label: str, y値の凡例文字変更, デフォルト='y'
- label_font_size: Union[int, float], ラベルフォントサイズ, デフォルト=14
- digit :int 座標の小数点以下表示を指定, デフォルト=3
あとは十字線の色とか幅とか
使用例
実行結果が上のgifです
import dataclasses from typing import Union import sys import numpy as np from PyQt5 import QtWidgets import pyqtgraph as pg app = QtWidgets.QApplication(sys.argv) graph_widget = pg.GraphicsLayoutWidget() label = pg.LabelItem(justify='right') graph_widget.addItem(label) plotter = graph_widget.addPlot(row=0, col=0) plotter.showGrid(x=True, y=True, alpha=1) data = np.linspace(0, 100, 1000) curve = pg.PlotCurveItem(data, pen=pg.mkPen('#f00', width=3)) curve2 = pg.PlotCurveItem(data * 2, pen=pg.mkPen('#0f0', width=3)) curve3 = pg.PlotCurveItem(data * 3, pen=pg.mkPen('#00f', width=3)) plotter.addItem(curve) plotter.addItem(curve2) plotter.addItem(curve3) # これ cross_hair = CursorCrossHairLabel(plotter, label, y_label='sample', label_font_size=18) graph_widget.show() sys.exit(app.exec_())ラベルとグラフが重なってほしく無い時
graph_widget = pg.GraphicsLayoutWidget() plotter = graph_widget.addPlot() plotter.showGrid(x=True, y=True, alpha=1) label = pg.LabelItem(justify='right') graph_widget.addItem(label)ラベル無いver
import dataclasses from typing import Union import sys from PyQt5 import QtWidgets import pyqtgraph as pg @dataclasses.dataclass class CursorCrossHair(object): """カーソルを追従する十字線を作成してグラフに追加するクラス Attributes # ---------- parent: pg.PlotItem 十字線を追加するグラフ vertical_line: pg.InfiniteLine カーソルを追いかける縦線 horizontal_line: pg.InfiniteLine カーソルを追いかける横線 proxy: pg.SignalProxy self.cursor_movedの実行間隔を制御するオブジェクト Examples ---------- import dataclasses from typing import Union import sys from PyQt5 import QtWidgets import pyqtgraph as pg app = QtWidgets.QApplication(sys.argv) graph_widget = pg.GraphicsLayoutWidget() plotter = graph_widget.addPlot(row=0, col=0) plotter.showGrid(x=True, y=True, alpha=1) curve1 = pg.PlotCurveItem([i ** 2 for i in range(10)], pen=pg.mkPen('#f00')) curve2= pg.PlotCurveItem([2*i ** 2 for i in range(10)], pen=pg.mkPen('#0f0')) plotter.addItem(curve1) plotter.addItem(curve2) cross_hair = CursorCrossHair(plotter) graph_widget.show() sys.exit(app.exec_()) """ parent: pg.PlotItem v_color: dataclasses.InitVar[str] = '#ffd700' v_width: dataclasses.InitVar[Union[int, float]] = 2 h_color: dataclasses.InitVar[str] = '#ffd700' h_width: dataclasses.InitVar[Union[int, float]] = 2 def __post_init__(self, v_color: str, v_width: Union[int, float], h_color: str, h_width: Union[int, float]) -> None: """コンストラクタの続き Parameters ---------- v_color: str default='#ffd700' 縦線の色 v_width: Union[int, float] default=2 縦線の幅 h_color: str default='#ffd700' 横線の色 h_width: Union[int, float] default=2 横線の幅 """ self.vertical_line = pg.InfiniteLine(angle=90, movable=False, pen=pg.mkPen(v_color, width=v_width)) self.horizontal_line = pg.InfiniteLine(angle=0, movable=False, pen=pg.mkPen(h_color, width=h_width)) # parentに追加 self.parent.addItem(self.vertical_line, ignoreBounds=True) self.parent.addItem(self.horizontal_line, ignoreBounds=True) self.proxy = pg.SignalProxy(self.parent.scene().sigMouseMoved, rateLimit=60, slot=self.cursor_moved) def cursor_moved(self, window_coord) -> None: """カーソル位置に十字線を移動させる Parameters ---------- window_coord: tuple 画面のピクセル単位の座標, ex) (PyQt5.QtCore.QPointF(2.0, 44.0),) Notes ---------- 関数内変数の説明=================== pos: PyQt5.QtCore.QPointF カーソルの画面内の座標 ex) PyQt5.QtCore.QPointF(2.0, 44.0) cursor_point: QtCore.QPointF カーソルのグラフ内の座標 ex) PyQt5.QtCore.QPointF(269.0678171506131, 0.695852534562212) ================================= """ pos = window_coord[0] if self.parent.sceneBoundingRect().contains(pos): cursor_point = self.parent.vb.mapSceneToView(pos) self.vertical_line.setPos(cursor_point.x()) self.horizontal_line.setPos(cursor_point.y())
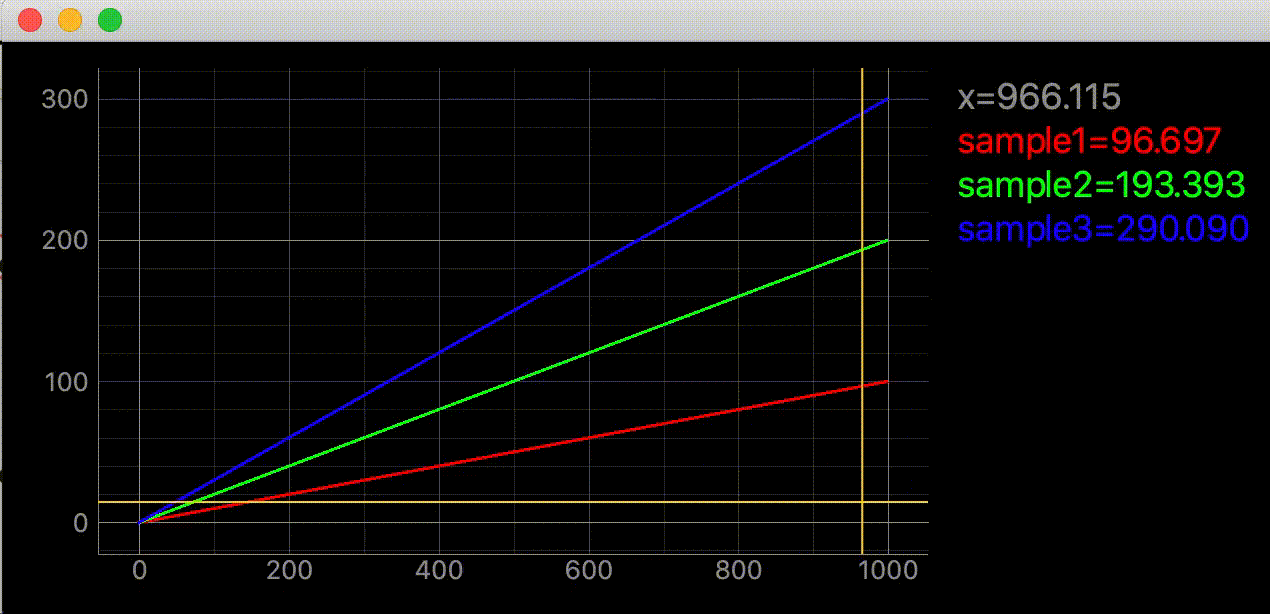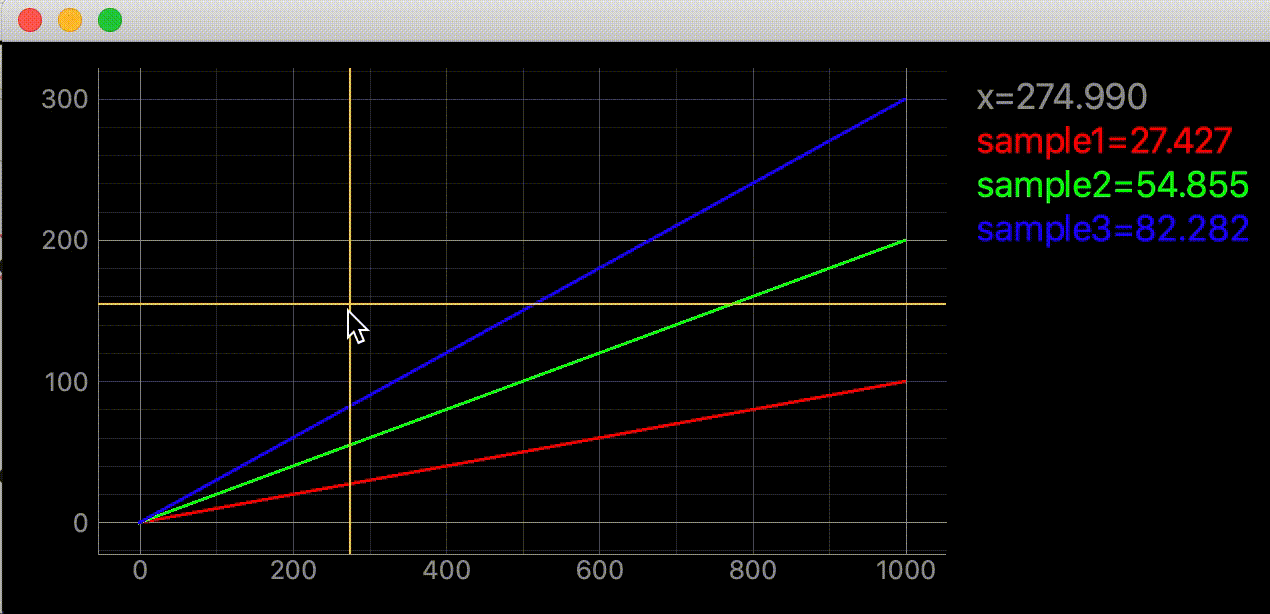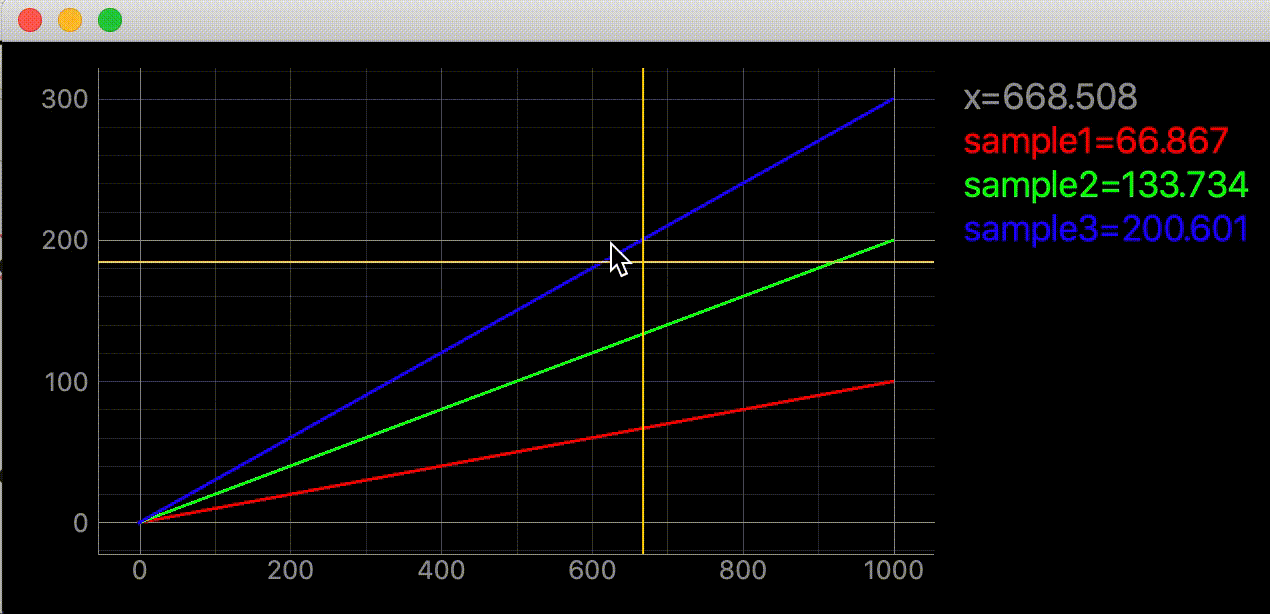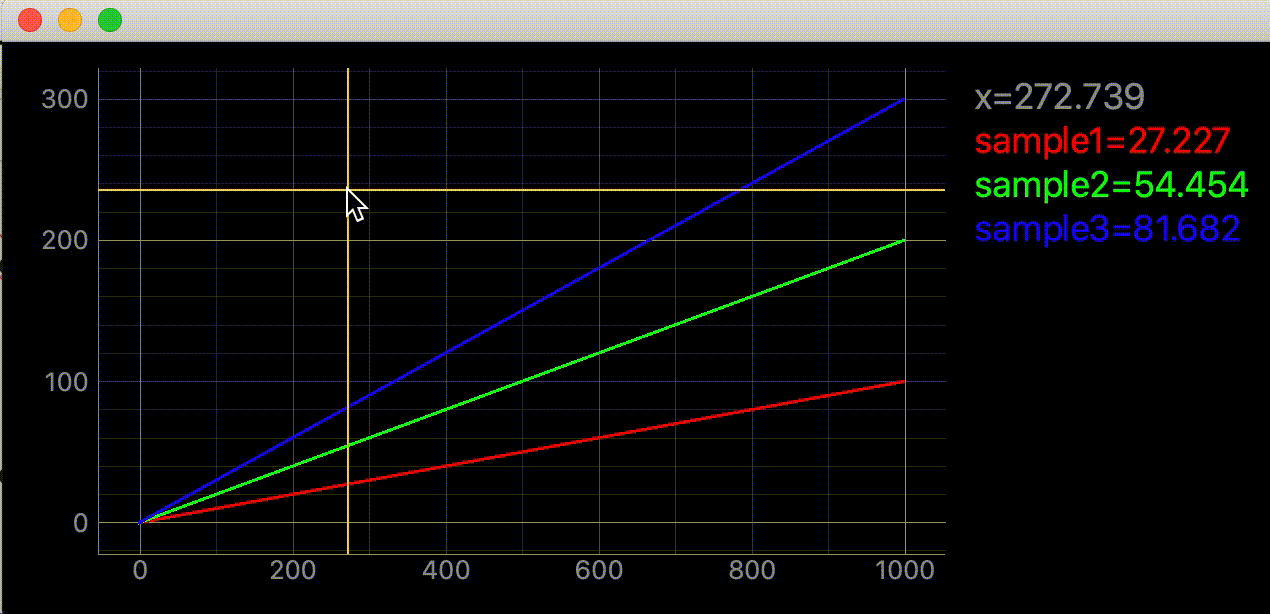
- 投稿日:2021-01-12T18:16:10+09:00
[Python] 環境変数を取得する
- 投稿日:2021-01-12T17:29:19+09:00
楽天APIと連動したサーバーレスchatbotをTeamsに導入してみた
はじめに
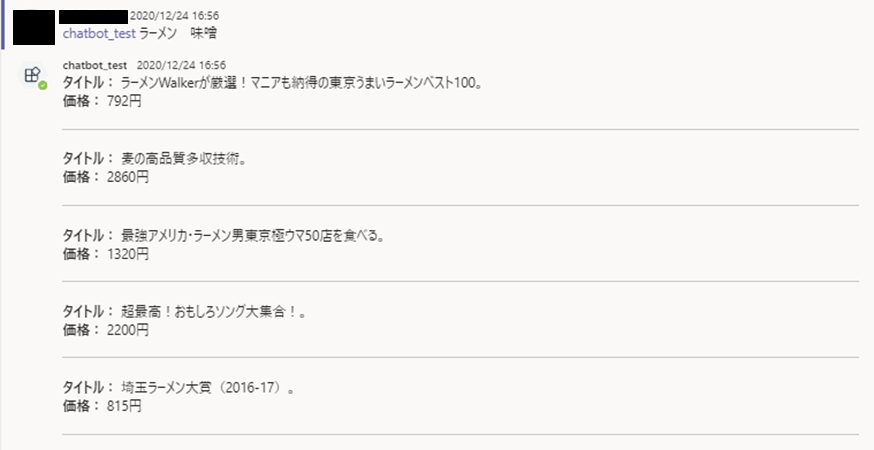
今回私は、書籍検索ができるサーバーレスなchatbotを作成しTeamsに導入しました。
ユーザーがTeamsにキーワードを入力すると、キーワードに関連する書籍のタイトルと価格が5件表示されるchatbotを作成しました。
本記事では、サーバーレスなchatbotをTeamsに導入する方法を紹介します。背景
私がchatbotを作成するに至った背景を説明します。
弊社は、新卒育成を目的とした新しい取り組みを探していました。
探していく中で、「新卒と先輩社員でペアプログラミングをしてアプリを作ってみるのはどうか?」という案が出ました。この案の目的は以下の2つです。
- 先輩社員の技術力を使えば短期間でモノを作れる
- 新卒への学習意欲向上の刺激になる。
- 先輩社員とペアプログラミングをすることでコードを書く際の思考回路など様々な知見が得れる
- コーディング経験の浅い新卒からすると、先輩社員が何を考えてコーディングしているのか知ることは貴重な経験になる。
この案を一旦、新卒である私と先輩社員で取り組んでみようという流れで今回のchatbot作成に至りました。
ちなみにペアプログラミングは、Live Shareを使用しました。
Live ShareはVS Codeで使用できるペアプログラミング用のツールです。
一緒に作業している人がどこを操作しているのかを視覚的に把握できますし、動作も重くないため、快適にペアプログラミングができます。Live Shareの詳細は、Visual Studio Live Shareでペアプロしてみた(Developers.IOより引用)を参照ください。
作成したchatbotの構成図
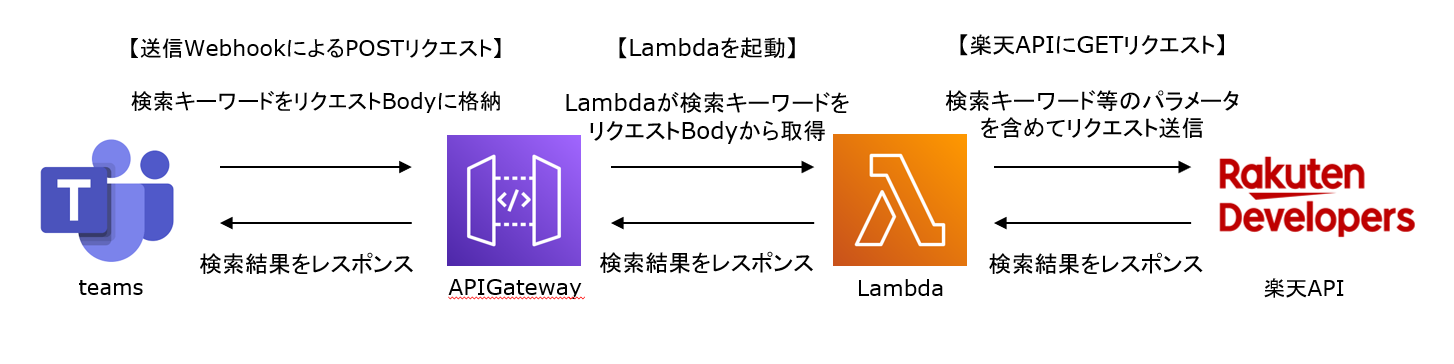
作成したchatbotの処理内容は以下です。
1.Teamsでキーワードを送信する。
2.キーワードの送信をトリガーに送信Webhook1が起動する。
3.送信WebhookがキーワードをリクエストBodyに詰めてAPIGatewayにPOSTリクエストする。
4.APIGatewayへのリクエストをトリガーに、Lambda関数が起動する。
5.Lambda関数内で楽天APIにGETリクエストする。
6.楽天APIが書籍を検索する。
7.検索結果をTeamsにレスポンスする。楽天APIは楽天ブックス総合検索APIを使用しています。
楽天ブックス総合検索APIの詳細は
楽天ブックス総合検索API (version:2017-04-04)(Rakuten Developersより引用)を参照ください。以下構成図です。
作成手順
1.AWS環境の準備
今回は主に2つのAWSサービスを使用します。
- AWS Lambda
- 特定のイベントをトリガーにLambda関数が実行されます。
サーバーを設置しなくても関数の実行が可能なサーバーレスアプリケーションを実現します。- Amazon API Gateway
- LambdaのトリガーにはAPI Gatewayを使用します。
API Gatewayは簡単にAPIを作成できるAWSのフルマネージドサービスです。Lambda関数はpythonで実装します。実装内容は3.スクリプトの記述(pythonを使用)で紹介します。
API GatewayのURLにPOSTリクエストすると、Lambda関数が実行される設定をします。
設定方法はAPI GatewayとLambdaでAPI作成のチュートリアル(@vankobeさんより引用)を参照ください。2.楽天APIの準備
楽天APIを使用するためには、楽天の会員登録とアプリIDの発行が必要です。
アプリIDの発行方法は楽天商品検索APIの使い方-最安値の商品を見つけよう(PHP)-(HPcodeより引用)を参照ください。アプリIDの発行や楽天APIの使用は無料です。
3.スクリプトの記述(pythonを使用)
処理を実装するにあたって、以下の3つの関数を作成しました。
1.ユーザーが入力したキーワードで書籍を検索する関数
2.1の関数の処理結果からタイトルと価格のパラメータのみ抽出する関数
3.1,2の関数を呼び出し、chatbotの一連の処理を記載する関数3-1.ユーザーが入力したキーワードで書籍を検索する関数
この関数では、ユーザーが入力したキーワードで書籍を検索しています。
関数が呼び出された際に、ユーザーが入力したキーワードを引数で受け取ります。
また、書籍の検索結果をjsonで楽天APIから受け取り、dict型でreturnします。
以下、pythonスクリプトです。
REQUEST_URL = "https://app.rakuten.co.jp/services/api/BooksTotal/Search/20170404" APP_ID="ここに発行したアプリIDを記載" def search_books(keyword): serch_params={ "applicationId" : [APP_ID], "formatVersion": 2, "keyword" : keyword, "hits": 5, "availability": 0, "sort": "reviewAverage" "booksGenreId": "001" } response = requests.get(REQUEST_URL, serch_params) result = response.json() return result
search_paramsに楽天APIの入力パラメータを格納します。今回は以下のパラメータを指定しました。
- formatVersion
- 出力フォーマットのバージョンを指定。
- hits
- 1ページあたりの取得件数を指定。
- availability
- 検索結果の書籍の在庫状況を指定。
- sort
- 検索結果をどの順で並び替えるかを指定。
- booksGenreId
- 楽天ブックス内のジャンルを指定。
その他の入力パラメータは楽天ブックス総合検索API 入力パラメーター version:2017-04-04(Rakuten Developersより引用)を参照ください。
3-2.1の関数の処理結果からタイトルと価格のパラメータのみ抽出する関数
この関数では、1の関数で処理した検索結果からタイトルと価格のパラメータのみを抽出しています。
関数が呼び出された際に、1の関数の処理結果を引数で受け取ります。
また、タイトルと価格のパラメータで抽出した結果をlist型でreturnします。
以下、pythonスクリプトです。
def extract_books(result): item_list = [{'title': item['title'], 'price': item['price']} for item in result['Items']] return item_list1の関数で取得した書籍でループを回し、タイトルと価格のパラメータで抽出した結果を
item_listにlist型で格納します。
また上記の処理は、内包表記を使用しています。3-3.1,2の関数を呼び出し、chatbotの一連の処理を記載する関数
この関数では、1,2の関数を呼び出してchatbotに必要な一連の処理を実行し、APIGatewayにレスポンスします。
以下、pythonスクリプトです。
app = Chalice(app_name='ここにAPI名を記載') def search(): json_text = app.current_request.json_body['text'] keyword = json_text[json_text.find('</at>')+5:] keyword = html.unescape(keyword) result = search_books(keyword) text = '' for item in extract_books(result): text += f'**タイトル**: {item["title"]}。\n\n**価格**: {item["price"]}円\n\n------------------------------------------\n\n' return {'text':text}
json_textにTeamsで入力されたキーワードを格納します。
TeamsからAPIGatewayへのリクエスト内容はCloudWatch Logsを参考にしながら記載しました。
(appの格納に使用しているChaliceは4.pythonスクリプトをLambdaにデプロイで説明しています。)TeamsからAPIGatewayにキーワードを送る際、特定の文字列をhtml文字列でエスケープしてしまうため、
unescape関数を使用してエスケープしないよう設定した上でkeywordにキーワードを格納しています。
resultにlist型で欲しい情報を格納した後に、list型をString型に変換する処理をします。最後にkeyをtextで設定したdict型オブジェクト2をreturnすれば、pythonスクリプトの処理は終了です。
3-4.全てのpythonスクリプト
今回のchatbotに必要な全てのスクリプトを改めて以下に記載します。
import requests import html from chalice import Chalice app = Chalice(app_name='ここにAPI名を記載') REQUEST_URL = "https://app.rakuten.co.jp/services/api/BooksTotal/Search/20170404" APP_ID="ここに発行したアプリIDを記載" @app.route('/bookSearch', methods = ['POST']) def search(): json_text = app.current_request.json_body['text'] keyword = json_text[json_text.find('</at>')+5:] keyword = html.unescape(keyword) result = search_books(keyword) text = '' for item in extract_books(result): text += f'**タイトル**: {item["title"]}。\n\n**価格**: {item["price"]}円\n\n------------------------------------------\n\n' return {'text':text} def search_books(keyword): serch_params={ "applicationId" : [APP_ID], "formatVersion": 2, "keyword" : keyword, "hits": 5, "availability": 0, "sort": "reviewAverage" "booksGenreId": "001" } response = requests.get(REQUEST_URL, serch_params) result = response.json() return result def extract_books(result): item_list = [{'title': item['title'], 'price': item['price']} for item in result['Items']] return item_list4.pythonスクリプトをLambdaにデプロイ
AWS Chaliceを使用してLambdaにデプロイしました。
chaliceは、コマンド一つでLambdaにコードをデプロイできるAWSのアプリケーションフレームワークです。
AWS Chaliceの詳細はAWS Chaliceとは(builders.flashより引用)を参照ください。デプロイするスクリプトとLambdaを関連付けるために以下を記載します。
from chalice import Chalice app = Chalice(app_name='ここにAPI名を記載') @app.route('/bookSearch', methods = ['POST']) # 以下処理コードを記載上記のスクリプトを記載した後にターミナルで
chalice deployとコマンドを打つとLambdaにデプロイできます。
AWS ChaliceはAWS credentialファイルが必要なのでご注意を。
5.動作確認
chatbotの作成が終了したらTeamsに導入します。
chatbotをTeamsに導入する方法は以下を参照ください。
Microsoft TeamsのOutgoing Webhooksを使ってAWS Lambda(Python), Amazon API Gatewayとbot(ヤマムギより引用)Teamsのチームにアプリを導入すると、チームに所属している全てのチャネルからchatbotの起動が可能になります。
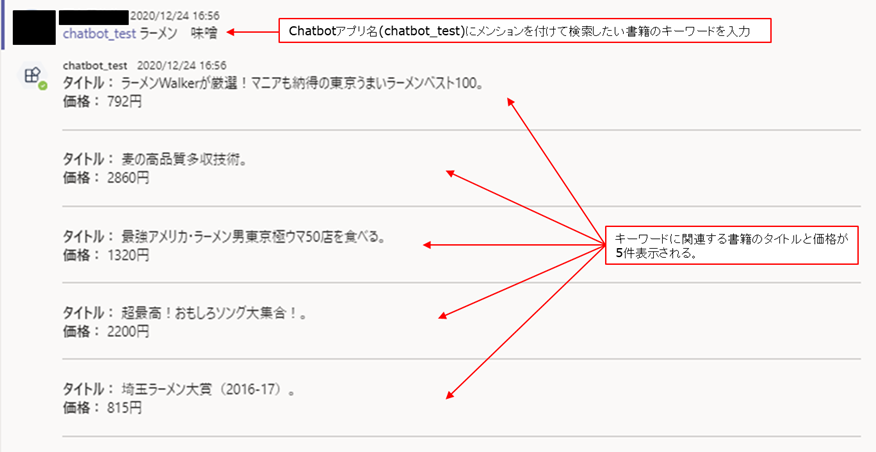
実際にチャネルの中で、chatbotアプリ名にメンションを付けて、キーワードを入力すると書籍の検索結果が表示されます。
また、CloudWatch Logsに表示されているログを見ると、入力したキーワードで検索していることが確認できます。
最後に
自分は今までAWSサービスは、EC2を立てたり、ELBを使用して負荷分散したり、という目的でしか使用したことがありませんでした。
また、言語もJavaしか触ったことのないようなエンジニア初心者でした。そんな自分が、今回初めてAPIGatewayやLambda、Python、外部APIを使用して一つのアプリを作れたことは、とても貴重な経験でした。
先輩社員とペアプログラミングすることで自分では気づかない冗長なコーディングであったり、色んなパターンのコーディング方法を知ることができました。
また、先輩社員が助言をくれるので、長時間悩んだり調べたりして全くコーディングが進まないという新卒含め若手が陥りがちな現象を回避できます。ペアプログラミングは、自分含め新卒社員の教育にとても有意義な教育方法だと実感しました。是非皆さんもペアプログラミングをやってみることをお勧めします。
pythonの環境構築(pipenvを用いるなど)やAWS Chaliceなど座学すらしたことのないようなサービスをいきなり使うことは苦戦しましたが、今回の弊社の取り組みによって多くのことを学べました。
また、AWSや外部APIを使うことで簡単にアプリを作成できるんだと実感できました。次は先輩社員がいなくても自分で何かアプリを作成したいと思います。是非皆さんも本記事を参考に、様々なchatbotを作成して欲しいと思います。
送信WebhookとはTeamsと外部アプリに対してPOST要求をするTeamsの機能です。
詳細は送信 Webhook を使用して Microsoft Teams にカスタム ボットを追加する(Microsoft Officeデベロッパーセンターより引用)を参照ください。 ↩Teamsにレスポンスする際は、keyにtextを含める必要があります。
keyを含めなかった場合、テキストとして扱われずエラーとなってしまいます。 ↩

- 投稿日:2021-01-12T16:24:18+09:00
[Day 7]テンプレートの継承とinclude
January 12, 2021
←前回:Day 6 staticファイルを扱う今回のテーマは「テンプレートの継承とinclude」です。
現時点でtemplate/base/top.htmlはフッダー、ヘッター、サイドバーとコンテンツを全て有する1つのHTMLファイルとして生成されました。
しかし、ヘッダー、フッター、サイドバー等は他のページでも使い回すことが想定されるものです。
また、ログインページにはサイドバーを出したくないなど、必要に応じて取り込んだり、外したりする部品もあります。
このような要望に対してDjangoテンプレートは継承とインクルードという二つの方法でテンプレートを使い回す方法を提供しています。
では、実際に見ていきましょう。テンプレートの継承
まず、templates/base/base.htmlを用意し、ここに全ページで共通して使う部品を配置します。
他のページではこのbase.htmlを継承して変更部分のみをはめ込むことにします。base.htmlはこんな感じになります。templates/base/base.html{% load static %} <!DOCTYPE html> <head> <meta charset="UTF-8"> <meta http-equiv="content-language" content="ja"> <meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0"> {% block meta_tag %}{% endblock %} <link href="{% static 'css/semantic.css' %}" rel="stylesheet"> {% block css %}{% endblock %} <title> {% block title %}IT学習ちゃんねる{% endblock %} </title> </head> <body> <div class="ui stackable inverted menu"> <div class="header item"> IT学習ちゃんねる </div> <a class="item"> このサイトはなに? </a> <div class="right menu"> <a class="item"> Log in </a> <a class="item"> Sign up </a> </div> </div> <div class="ui container" style="min-height:100vh;"> {% block content %} {% endblock %} </div> <div class="ui inverted stackable footer segment"> <div class="ui container center aligned"> <div class="ui horizontal inverted small divided link list"> <a class="item">© 2019 Django学習ちゃんねる(仮)</a> <a class="item">利用規約</a> <a class="item">プライバシーポリシー</a> </div> </div> </div> <script src="https://code.jquery.com/jquery-3.1.1.min.js"></script> <script type="text/javascript" src="{% static 'js/semantic.js' %}"></script> {% block js %}{% endblock %} </body>{% block hogehoge %}{% endblock %}で囲まれた部分の中身をbase.htmlを継承した各テンプレートファイルで作成していきます。templates/base/top.htmlは次のように変更されました。
templates/base/top.html{% extends 'base/base.html' %} {% block title %}ITについて切磋琢磨する掲示板 - {{ block.super }}{% endblock %} {% block content %} <div class="ui grid stackable"> <div class="eleven wide column"> <div class="ui breadcrumb"> <a class="section">TOP</a> <i class="right angle icon divider"></i> <a class="section">category</a> <i class="right angle icon divider"></i> <div class="active section">thread</div> </div> <div class="ui segment"> <div class="content"> <div class="header"><h3>新着スレッド</h3></div> <div class="ui divided items"> <div class="item"> <div class="content"> <div class="header"> <a><h4>dummy thread</h4></a> </div> <div class="meta"> <span class="name">投稿者名</span> <span class="date">2019-2-1 00:00</span> </div> </div> </div> <div class="item"> <div class="content"> <div class="header"> <a><h4>dummy thread</h4></a> </div> <div class="meta"> <span class="name">投稿者名</span> <span class="date">2019-2-1 00:00</span> </div> </div> </div> <div class="item"> <div class="content"> <div class="header"> <a><h4>dummy thread</h4></a> </div> <div class="meta"> <span class="name">投稿者名</span> <span class="date">2019-2-1 00:00</span> </div> </div> </div> <div class="item"> <div class="content"> <div class="header"> <a><h4>dummy thread</h4></a> </div> <div class="meta"> <span class="name">投稿者名</span> <span class="date">2019-2-1 00:00</span> </div> </div> </div> </div> </div> </div> </div> {% include 'base/sidebar.html' %} </div> {% endblock %}この場合は{% block content %}の中身をtop.htmlで作ってはめ込んでいるんですね。
尚、今回{% block meta_tag %}や{% block css %}, {% block js %}等を用意したのはページによって特殊に加えたいMETAタグやCSS,JSが出てくることを想定しているためです。
またページタイトルに関しては常にbase.htmlのタイトルをハイフンつなぎで表示する目的でblock.superを使ってbase.htmlのタイトルを呼び出しています。テンプレートのインクルード
今度はサイドバーも別パート化してみましょう。templates/base/sidebar.htmlとします。
templates/base/sidebar.html<div class="five wide column"> <div class="ui action input" style="width: 100%;"> <input type="text" placeholder="検索"> <button class="ui button"><i class="search icon"></i></button> </div> <div class="ui segment"> <div class="content"> <div class="header"><h4>話題のトピック</h4></div> <div class="ui relaxed list small divided link"> <a class="item">dummy</a> <a class="item">dummy</a> <a class="item">dummy</a> <a class="item">dummy</a> <a class="item">dummy</a> </div> </div> </div> </div>ここでDjango学習帳ではtemplates/base/top.htmlにhogehogeを入れましょうと記述がありますが、先程top.htmlを変更した際にすでに追加済みなのでスルーしました。
(のちに重要な箇所になってこないことを祈ります♪(´ε` ))見た目に関してはstaticファイルを扱うから変化していません。
ただしテンプレートが部品化されたことでより効率的な開発が出来ると思います。さいごに
今回はテンプレートの継承とincludeをしました。
プログラミングにおいて継承やincludeというワードはよく聞きます。
私もC言語をはじめ、さまざまなプログラミング言語を学習してきたので言葉の意味は理解していました。
ブログの方はDjangoのテンプレートにはまだ便利な機能があるといっていますが、
今の私は、現段階でテンプレートの何を使用したのかよくわかっていません。
今後が若干心配です。それではまたまた。
- 投稿日:2021-01-12T16:24:09+09:00
寒いね
今年の冬は寒いですね。
という事で、アレクサに寒いねと話しかけたら寒いねと答えてくれるスキルの開発をやってみた。作成
開発者のページ
https://developer.amazon.com/ja上記URLからスキル作成ページへ進み
下記を選択してスキルを作成を押す。
スクラッチで作成を選択し、テンプレートで続けるを押す。
開発
デフォルトのHelloWorldIntentを削除
その後、インデントを追加を押し、
SpeakIntentを作成。
サンプル発話に話題を入力する。
入力後はモデルをビルドを押す。
ビルド完了後、コードエディタを開き、以下を修正する。修正箇所は3箇所。
lambda_function.py# speak_output = "Welcome, you can say Hello or Help. Which would you like to try?" speak_output="寒いね。" # return ask_utils.is_intent_name("HelloWorldIntent")(handler_input) return ask_utils.is_intent_name("SpeakIntent")(handler_input) # speak_output = "Hello World!" speak_output = "そういう時は暖かい飲み物でもいかがですか?"修正後デプロイを押す。
テスト
まずは、スキル名の「寒いね」を入力する。
アレクサは「寒いね」と返してくれた!
その後、SpeakIntentのサンプル発話で作った「雪が降ったね」を入力。
「そういう時は暖かい飲み物でもいかがですか?」と答えてくれた。
実機確認
https://alexa.amazon.co.jp/spa/index.html#skills/?ref-suffix=nav_nav
で有効なスキルを押す。
開発スキルタブで「寒いね」スキルが登録されている事を確認。これで、
「アレクサ、寒いね」
と話しかけると答えてくれるようになる。

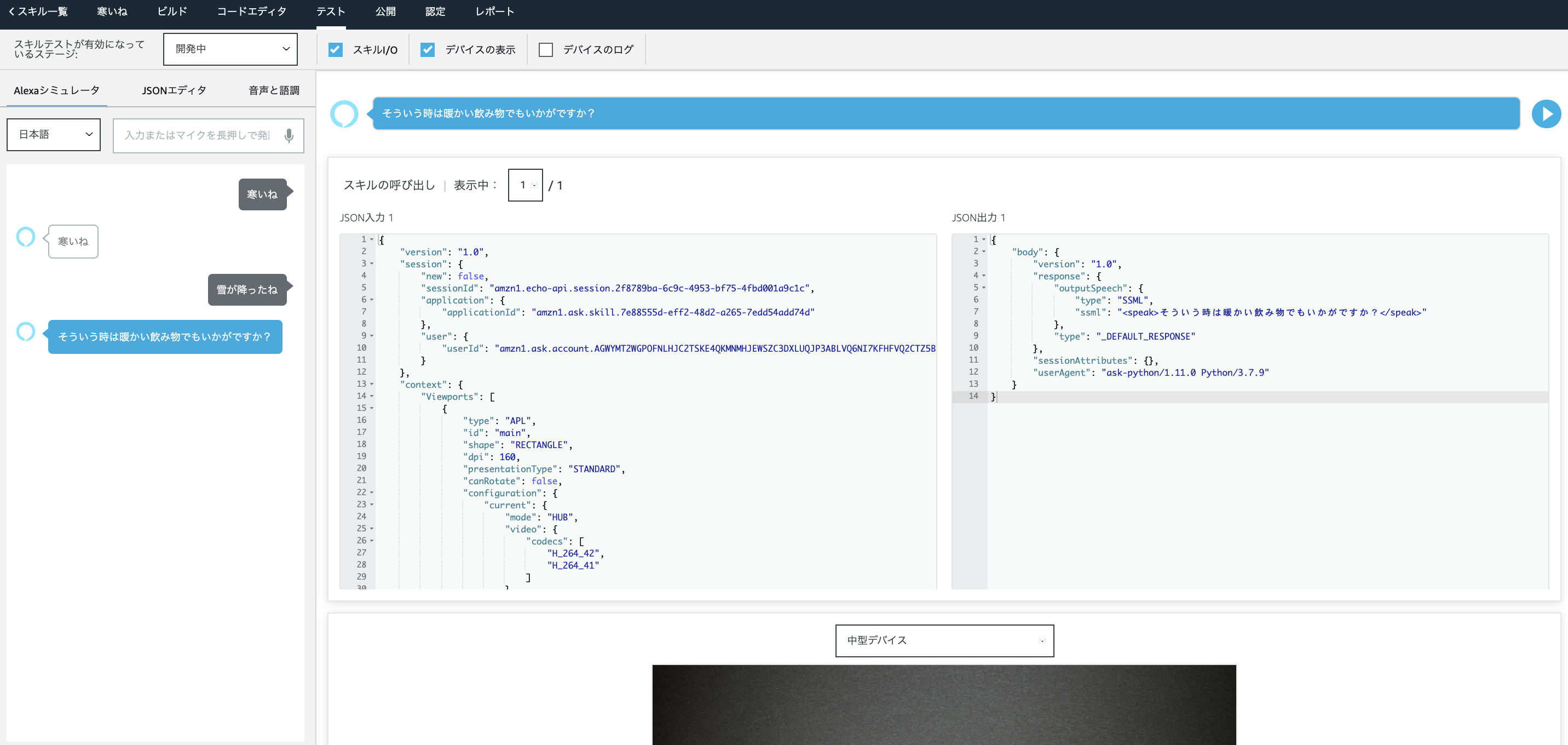
- 投稿日:2021-01-12T16:24:09+09:00
アレクサが寒いねと返してくれるスキルを作ってみた
今年の冬は寒いですね。
という事で、アレクサに寒いねと話しかけたら寒いねと答えてくれるスキルの開発をやってみた。作成
開発者のページ
https://developer.amazon.com/ja上記URLからスキル作成ページへ進み
下記を選択してスキルを作成を押す。
スクラッチで作成を選択し、テンプレートで続けるを押す。
開発
デフォルトのHelloWorldIntentを削除
その後、インデントを追加を押し、
SpeakIntentを作成。
サンプル発話に話題を入力する。
入力後はモデルをビルドを押す。
ビルド完了後、コードエディタを開き、以下を修正する。修正箇所は3箇所。
lambda_function.py# speak_output = "Welcome, you can say Hello or Help. Which would you like to try?" speak_output="寒いね。" # return ask_utils.is_intent_name("HelloWorldIntent")(handler_input) return ask_utils.is_intent_name("SpeakIntent")(handler_input) # speak_output = "Hello World!" speak_output = "そういう時は暖かい飲み物でもいかがですか?"修正後デプロイを押す。
テスト
まずは、スキル名の「寒いね」を入力する。
アレクサは「寒いね」と返してくれた!
その後、SpeakIntentのサンプル発話で作った「雪が降ったね」を入力。
「そういう時は暖かい飲み物でもいかがですか?」と答えてくれた。
実機確認
https://alexa.amazon.co.jp/spa/index.html#skills/?ref-suffix=nav_nav
で有効なスキルを押す。
開発スキルタブで「寒いね」スキルが登録されている事を確認。これで、
「アレクサ、寒いね」
と話しかけると答えてくれるようになる。
- 投稿日:2021-01-12T15:33:39+09:00
リストの処理について(Ruby学習後のPython初学)
リスト処理
リスト処理の一部補足
list.py#split関数 与えられたデータを指定の引数で分割し、リストとして戻す。以下今回は特に使用せず。 #random.randrange関数 引数のリストの要素の中でランダムに取り出す # coding: utf-8 inport sys dice = [] for line in sys.stdin.readlines(): dice.append(line.rstrip()) #入力される値(例) 1 2 3 4 5 6 #行ごとに入力された1から6までの数字がdice変数のリストに格納される num = len(dice) print(dice[random.randrange(num)) #diceの中身の0番目の1から5番目の6までの間のいづれかが出力される。入力時に関しての処理補足
line = input().rstrip() #rstrip関数 文字列の末尾の改行コードを取り覗く。
import sys
line = sys.stdin.readlines() #sys.stdin.readlines関数 ファイル・複数行の入力値を全て読み込み、1行毎に処理する
- 投稿日:2021-01-12T14:43:29+09:00
pytest の導入と簡単な使い方
pythonでテストコード実装のためにpytestを使用したので、その導入方法と最低限の使い方についてまとめます。
環境
Mac OSX
Python 3.7.7,
pytest-6.1.2,
py-1.9.0,
pluggy-0.13.1pytestの導入方法(インストール)
ターミナル$ pip install pytestこれでインストール完了です。
ファイル構成
.test/ ├── A │ └── test_a.py └── B └── test_b.py(後でまとめて実行する場合には、ファイル名を一意に定まるようにする。()<注意点>
- テストファイル名は
testで始まるようにする(例:test_integration.py, test_unit.py)- テストファイル(.py)のファイル名は一意に定まるようにする(他のテストファイルと名前が被らないようにする)
- テスト対象の関数名は
testで始まるようにする<関数の記述方法>
import os import sys sys.path.append(os.getcwd()) # pytestはカレントディレクトリをsys.pathに追加しないためカレントディレクトリ上にあるファイルを読み込みたい場合はimport os, import sysと一緒に明記 def test_a(): assert 6 == multiplication(2, 3) def multiplication(x, y): return x * yテストコード実行方法
フォルダ別で実行する場合
ターミナル$ pytest test/A上階層から複数のフォルダに対してまとめて実行することもできます。
ターミナル$ pytest testファイル別で実行する場合
ターミナル$ pytest test/A/test_a.pyもしくは、ディレクトリを移動して
ターミナル$ pytest test_a.pyでも大丈夫です。
実行してテストに合格するとこのようになります。(グリーン表記)

- 投稿日:2021-01-12T14:25:05+09:00
スマートロックを自作したので難所をまとめる
IoT開発初心者がスマートロックを作ってみました。詰まった箇所をまとめます。
作製したもの
スマートロックを作製しました。開錠・施錠の方法は2つあります。
- あるエンドポイントにリクエストを送った後、ドアノブを一回ガチャっと回す
- 指定のリズムでドアノブをガチャガチャする
内側はこのようになっています。ブレッドボードやジャンパワイヤを使ったままですが、この方が新しい機能をつけやすいのでこのままにします。
構成
エンドポイントを利用した開錠・施錠を実現するため、以下のような構成を作りました。
使用した技術
バックエンドはサーバーレスにしています。私しか利用しないので、サーバーを借りるとコストがかさむからです。デプロイにServerless Frameworkを利用しました。
WiFiを利用したかったのでESP32-WROOM-32を選択しました。初めて利用したのですが開発は非常に楽でした。Arduino IDEで開発可能です。
難所
今回の開発で難しかった点を書いていきます。
消費電力を抑えながら可用性を確保する必要があった
今回はバッテリーから給電することにしました。頻繁に電池切れを起こすとスマートロックとして大変不便ですし、最悪家から締め出されてしまう原因にもなります。そのため消費電力をできる限り抑える必要がありました。
対策として、ESP32-WROOM-32の選定により解決を目指しました。ESP32-WROOM-32にはDeepSleepという機能があり、スリープ状態での消費電流を10uA~150uAに抑えることが出来ます。
しかしながら、実際に運用してみると1週間程度でバッテリーがきれてしまいます。そのため商用のスマートロックと同等の製品にすることはできませんでした。
モバイルバッテリーが自動停止してしまう
モバイルバッテリーはもともと携帯などを充電するために作られており、過充電を防いだり無駄な電力を消費しないように自動停止する機能がついているみたいです。家電量販店で売られているものには基本的にこの機能がついています。
この問題はこのモバイルバッテリーを利用するすることで解決しました。
cheero Canvas 3200mAh IoT機器対応 モバイルバッテリー ホワイト CHE-061スマートロックを設置する方法に戸惑った
当然、サーボモータをカギに取り付けると以下のようにサーボモータの方が回ってしまいます。
これをしっかりと固定するために、L字の金具などを使いました。しかし自分にこのような金具を使う経験が乏しく見栄えは悪くなってしまいました。
DynamoDBをboto3で操作するのが大変
本筋ではないのですが、Pythonのboto3のAPIを使ってDynamoDBにリクエストを送るのが大変でした。APIの仕様が複雑で、私には理解するのに非常に時間がかかりました。
途中でPynamoDBを利用することにしました。開発が非常に楽になりました。
開発の感想
ドアノブをガチャガチャするだけで開錠できるので、生活は非常に楽になりました。
また友達が一時的に自分の部屋を出入りする場合、物理的な鍵を共有せずに開錠・施錠ができるため、今後も便利なシチュエーションがありそうです。
ESP32-WROOM-32開発ボードを利用した開発は非常にスムーズでした。お金が少し高くても、開発の速度や快適さを求めるなら開発ボードを買うべきだと実感しました。以前はお金をケチってPICを使ったり、ESP-WROOM-02 DIP化キットを使ったりしていました。
スマートロックをドアに取り付けるのに苦労しました。ネット上の先人はよく3Dプリンタを使ってこの問題に取り組んでいるので、私も3Dプリンタを購入しました。次の開発から使ってみたいと思います。
実際に商品を開発する場合は、小さくて安価で高品質に作るなど、多くの基準を満たすことが求められます。また量産などのノウハウも必要です。将来は組み込み系の仕事をしたいと思っているので、このようなノウハウをもっと蓄積できたら嬉しいです。


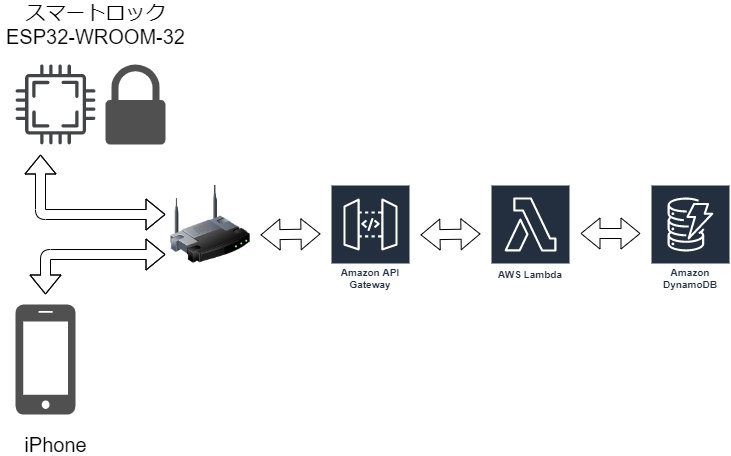


- 投稿日:2021-01-12T13:57:05+09:00
ubuntu のターミナルからanacondaの仮想環境を呼ぶ 備忘録
- 投稿日:2021-01-12T13:03:18+09:00
TensorFlowLiteとLINE Messaging APIを組み合わせて画像分類BOTを作ってみた
TensorFlow等の機械学習ライブラリの使い方を勉強していくと「何か動くものを作ってみたい!」と考えると思います。
今回はTensorFlowLiteとLINE Messaging API、Herokuを組み合わせて画像分類BOTを作ってみたいと思います。Herokuを使う理由
作成したアプリのデプロイ先にはAWSやGCPなど様々な選択しがあります。
Herokuは無料枠が用意されており比較的簡単に使い始めることができます。
無料枠には起動できる仮装環境の数や一月あたりの使用時間制限など制約がありますが、
サンプルのAPPをデプロイする環境としてはおすすめです。TensorFlowLiteを使う理由
本記事ではデプロイ先にHerokuの無料枠を使用しています。
無料枠では保存容量が300MB程度に制限されています。
そのため、モデルの容量を小さくできるTensorFlowLiteを使用しています。LINE Messaging APIを使う理由
機械学習を組み込むアプリにはAndroidやiOSのスマホアプリやWEBアプリなどいろいろあると思います。
TensorFlowには、AndroidやiOSのそれぞれの環境に対応したライブラリがありますが、
それらを使用するためにはもちろんアプリ開発の知識が必要となります。
また、TensorFlow.jsを使えばブラウザまたはNode.jsでアプリを作成することもできます。今回作成するアプリは「ユーザーから送られてきた画像に写っているものを分類する」ものです。
スマホアプリとして作成する場合には、スマホアプリとバックエンドの両方を開発する必要があります。
ブラウザで動作させるアプリではないのではないこと、最小限のコードでアプリ開発を行いたいとの理由からLINE Messaging APIを使うことにしました。オウム返しBOTを作成してみる
BOTの動作を確認するために簡単なオウム返しBOTを作ってみたいと思います。
LINE Messaging APIの動作の流れを簡単に説明したいと思います。
- ユーザーがLINEプラットフォームへメッセージを送信する。
- LINEプラットフォームからBOTサーバに対してイベントオブジェクトを含むHTTP POSTリクエストが送られる。
- リクエストがLINEプラットフォームから送られたことを確認するために、BOTサーバで検証が行われる。
- 検証にクリアしたらユーザーから送られてきたコンテンツ(テキストメッセージや画像メッセージなど)が取得できるようになる。
- ユーザーリクエストに対して必要な処理を行いメッセージを送信する。
この流れだけをみると実装するのは大変だと思うかもしれませんが、LINE Messaging API SDKを使えば比較的簡単に実装することができます。
実際に廃発が必要なのは「ユーザーから送られてきたメッセージの処理」の部分です。LINE Messaging API SDKとオウム返しBOTのサンプルコードは公式ドキュメントをご確認ください。
今回はPythonを使っていますがそれ以外にもJAVA、PHP、GO、Node.jsなどいろいろな言語のSDKが用意されています。
LINE Messaging API SDK
https://github.com/line/line-bot-sdk-python作成したオウム返しBOTはHerokuへデプロイすればLINEから使用することができます。
Herokuへのデプロイ方法は別の長くなるので別の記事にしたいと思います。画像分類BOTの実装
今回作成する画像分類BOTはオウム返しBOTを応用することで実装することができます。
実際に実装する部分としては、
- ユーザーから送られてきた画像を取得する。
- 画像分類モデルで画像に写っているものラベリングする。
- ラベルをテキストメッセージとしてユーザーへ送信する。
実装したコードは以下です。
# モデルのロード model = Interpreter(model_path='モデルパス') model.allocate_tensors() # モデルのインプット、アウトプットの形状を取得 input_details = model.get_input_details()[0] output_details = model.get_output_details()[0] @handler.add(MessageEvent, message=ImageMessage) def handle_image(event): # ユーザーから送られてきたコンテンツを取得する image_url = f'https://api.line.me/v2/bot/message/{event.message.id}/content/' header = { "Content-Type": "application/json", "Authorization": "Bearer " + YOUR_CHANNEL_ACCESS_TOKEN } res = requests.get(image_url, headers=header) # 画像の前処理 image = Image.open(BytesIO(res.content)) input_data = process_image(input_details['shape'], image) # 画像に写っているもののラベルを予測 model.set_tensor(input_details["index"], input_data) model.invoke() label = model.tensor(output_details["index"])().argmax() # 画像のラベルをテキストメッセージでユーザーに送信する。 line_bot_api.reply_message( event.reply_token, TextSendMessage(text=f'たぶん...{label}'))オウム返しBOTの下記の箇所を置き換えることで画像分類BOTとして動作させることができます。
@handler.add(MessageEvent, message=TextMessage) def handle_message(event): line_bot_api.reply_message( event.reply_token, TextSendMessage(text=event.message.text))サンプル:
- 投稿日:2021-01-12T11:29:10+09:00
Python: Google Drive APIで共有ドライブからファイル情報を取り出す
内容
Google Drive APIを使って指定の共有ドライブのディレクトリからファイル一覧を抜き出すためのメモ
コード
Python Quickstartと同じ関数の引数を変更すればOK
import pickle import os.path from googleapiclient.discovery import build from google_auth_oauthlib.flow import InstalledAppFlow from google.auth.transport.requests import Request from typing import Final from typing import List # If modifying these scopes, delete the file token.pickle. SCOPES: Final[List] = [ 'https://www.googleapis.com/auth/drive.metadata.readonly' ] SHARED_DRIVE_ID: Final[str] = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxx" DIRECTORY_ID: Final[str] = "yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy" FILENAME: Final[str] = "zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz" def get_credentials(scopes: List): credentials = None if os.path.exists('token.pickle'): with open('token.pickle', 'rb') as token: credentials = pickle.load(token) if not credentials or not credentials.valid: if credentials and credentials.expired and credentials.refresh_token: credentials.refresh(Request()) else: flow = InstalledAppFlow.from_client_secrets_file( 'credentials.json', scopes) credentials = flow.run_local_server(port=0) # Save the credentials for the next run with open('token.pickle', 'wb') as token: pickle.dump(credentials, token) return credentials def directory_files(filename: str, directory_id: str, pages_max: int = 10) -> List: """ 対象のディレクトリ配下からファイル名で検索した結果を配列で返す :param filename: ファイル名 :param directory_id: ディレクトリID :param pages_max: 最大ページ探索数 :return: ファイルリスト """ credentials = get_credentials(SCOPES) service = build("drive", "v3", credentials=credentials) items: List = [] page = 0 while True: page += 1 if page == pages_max: break results = service.files().list( corpora="drive", driveId=SHARED_DRIVE_ID, includeItemsFromAllDrives=True, includeTeamDriveItems=True, q=f"'{directory_id}' in parents and " f"name = '{filename}' and " "trashed = false", supportsAllDrives=True, pageSize=10, fields="nextPageToken, files(id, name)").execute() items += results.get("files", []) page_token = results.get('nextPageToken', None) if page_token is None: break return items items = drive_util.directory_files( filename=FILENAME, directory_id=DIRECTORY_ID) for item in items: print(f"{item['id']} : {item['name']}")参考
https://developers.google.com/drive/api/v3/reference/files/list
https://developers.google.com/drive/api/v3/search-files
- 投稿日:2021-01-12T10:39:26+09:00
Pythonを使う人がJavaScriptの空辞書の判定ではまった話
普段は機械学習系のプログラミングでPythonを使うことが多いのですが、画面回りもやる必要があり、その時JavaScriptの辞書を
if文で判定するコードであれ?と思ったこと。勘違いと言ってしまうとそれまでですが。Pythonの場合
Python で辞書が空かどうか判定するのに以下のような
if文を書いていました。xが空辞書やnullの時はFalseになります。sample.pyx = {} if x: print("xは空ではない"); else: print("xは空です");実行結果
xは空ですJavaScriptの場合
一方で JavaScript だと空辞書の場合
Trueになります。sample.jsvar x = {}; if (x) { console.log("xは空ではない"); } else { console.log("xは空です"); }xは空ではない空かどうか判定する方法はいろいろあるようですが
Object.keys(x)でキーの数を調べることでできるようです。sample.jsvar x = {}; if (Object.keys(x).length) { console.log("xは空ではない"); } else { console.log("xは空です"); }つい、うっかりPythonと同じように考えてコーディングしてしまい、「うまく動かないな」と悩んでしまいました・・・
参考文献
JavaScriptの
if(x)での判定結果がオブジェクトごとTrue/Falseどちらになるかはこちらに纏められていてわかりやすいです。
- [JavaScript] null とか undefined とか 0 とか 空文字(”) とか false とかの判定について
- 投稿日:2021-01-12T10:12:36+09:00
TensorFlowで簡単に画像分類
はじめに
久しぶりにTensorFlow(Keras)を触ったら忘れていることが多かったので、簡単にメモとして残しておきます。
学習の流れ
TensorFlow(以下TF)では、
① データセットの準備
② モデルの準備
③model.compileでoptimizer, loss, metricsの指定
④ callbacksの指定
⑤model.fitで学習開始
⑥model.evaluateでテストの評価
⑦ 画像の予想確率だけ得るときはmodel.predictのような流れです。
これは比較的簡単な書き方です。もう少し細かいところまで記述したい場合は、以前に記事を書きましたので参考にしてみてください。① データセットの準備
ディレクトリに画像を保存しておいてそこから読み込むには、
flow_from_directory()を用います。
その前にImageDataGeneratorを使用し、augmentationの中身を記述します。train_datagen = ImageDataGenerator( rescale=1./255, zoom_range=0.2, horizontal_flip=True, rotation_range=20, width_shift_range=0.2, height_shift_range=0.2, ) val_datagen = ImageDataGenerator(rescale=1./255) train_generator = train_datagen.flow_from_directory( TRAIN_DIR, target_size=(img_size, img_size), batch_size=batch_size, classes=classes, class_mode='categorical') val_generator = val_datagen.flow_from_directory( VAL_DIR, target_size=(img_size,img_size), batch_size=batch_size, classes=classes, class_mode='categorical')以下のように使用できる augmentationは多いので各自タスクに合わせて決めてください。
詳しく知りたい人は、公式ドキュメントで確認してください。tf.keras.preprocessing.image.ImageDataGenerator( featurewise_center=False, samplewise_center=False, featurewise_std_normalization=False, samplewise_std_normalization=False, zca_whitening=False, zca_epsilon=1e-06, rotation_range=0, width_shift_range=0.0, height_shift_range=0.0, brightness_range=None, shear_range=0.0, zoom_range=0.0, channel_shift_range=0.0, fill_mode='nearest', cval=0.0, horizontal_flip=False, vertical_flip=False, rescale=None, preprocessing_function=None, data_format=None, validation_split=0.0, dtype=None )
flow_from_directoryでは、ディレクトリのパスを指定して、オーギュメントされた画像がバッチサイズごとに生成されます。flow_from_directory( directory, target_size=(256, 256), color_mode='rgb', classes=None, class_mode='categorical', batch_size=32, shuffle=True, seed=None, save_to_dir=None, save_prefix='', save_format='png', follow_links=False, subset=None, interpolation='nearest' )
class_mode: categorical, binary, sparse, input, None が選択可能。デフォは,categorical.
shuffle: Flaseならアルファベット順
save_to_dir: None or str(default:None). ディレクトリを指定することによって augmented data を保存してくれる。可視化に役に立つ。
save_prefix: str. 保存された画像のファイル名に使う。(save_to_dirが設定されている場合有効)
save_format: png or jpeg (Default:'png')
interpolation: nearest(デフォルト), bilinear, bicubic② モデルの準備
今回は例として、MobileNetv2を使います。
tf.keras.applicationsに他の学習済みモデルもあります。IMG_SHAPE = (img_size, img_size, channels) base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE, include_top=False, weights='imagenet') global_average_layer = tf.keras.layers.GlobalAveragePooling2D() prediction_layer = tf.keras.layers.Dense(n_classes, activation='softmax') model = tf.keras.Sequential([ base_model, global_average_layer, prediction_layer ])③ model.compile で optimizer, loss, metricsの指定
modelに対して学習の詳細を設定します。
model.compile(optimizer=optimizers.SGD(lr=0.0001, momentum=0.99, decay=0, nesterov=True), loss='categorical_crossentropy', metrics=['accuracy'])compile( optimizer='rmsprop', loss=None, metrics=None, loss_weights=None, weighted_metrics=None, run_eagerly=None, steps_per_execution=None, **kwargs )
optimizer: string or optimizer instance (default: rmsprop)
画像系のタスクだと個人的には、SGDかな?ex) SGD, RMSprop, Adam, Adadelta,...
sgd = tf.keras.optimizers.SGD( learning_rate=0.01, momentum=0.0, nesterov=False, name='SGD', **kwargs )*この
sgdを model.compileのoptimizerに設定する
loss: string, object function ortf.keras.losses.Lossinstance
metrics: trainingとtestで使用するmetricsのリスト
loss_weights: ロスに重み付けする④ callbacksの指定
CSVLogger, History, ProgbarLogger, TensorBoard, EarlyStopping, ReduceLROnPlateau など設定できます。
model.fitで学習する際に渡すことができます。詳しくは公式ドキュメントをご確認ください。例をいくつか挙げておきます。
tf.keras.callbacks.EarlyStopping( monitor='val_loss', min_delta=0, patience=0, verbose=0, mode='auto', baseline=None, restore_best_weights=False )tf.keras.callbacks.ModelCheckpoint( filepath, monitor='val_loss', verbose=0, save_best_only=False, save_weights_only=False, mode='auto', save_freq='epoch', options=None, **kwargs )
filepath: string or PathLike, モデルを保存するパス。指定できる変数は、epoch, loss, acc, val_loss, val_accです。
ex) filepath = '{val_loss:.2f}-{val_acc:.2f}.hdf5'
monitor: 何を基準にモデルを保存するか。accuracy, val_accuracy, loss, val_loss
*もし metrics name が分からなかったら、history = model.fit()でhistory.historyを確認。
mode: {auto, min, max}
save_best_only: もし、filepathが{epoch}のようなフォーマットを含んでいなかったら、filepathはオーバーライドされる
save_weights_only: modelの重みのみ保存
save_freq: epoch, or integer.tf.keras.callbacks.LearningRateScheduler( schedule, verbose=0 )tf.keras.callbacks.ReduceLROnPlateau( monitor='val_loss', factor=0.1, patience=10, verbose=0, mode='auto', min_delta=0.0001, cooldown=0, min_lr=0, **kwargs )tf.keras.callbacks.RemoteMonitor( root='http://localhost:9000', path='/publish/epoch/end/', field='data', headers=None, send_as_json=False )⑤ model.fitで学習開始
例
history = model.fit( train_generator, steps_per_epoch=steps_per_epoch, validation_data=val_generator, validation_steps=validation_steps, epochs=CONFIG.epochs, shuffle=True, callbacks=[cp_callback])fit( x=None, y=None, batch_size=None, epochs=1, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0, steps_per_epoch=None, validation_steps=None, validation_batch_size=None, validation_freq=1, max_queue_size=10, workers=1, use_multiprocessing=False )
validation_split: [0~1]. training dataの一部をa validation data とする。x, yの後ろのデータが用いられる(シャッフルする前)。
validation_data: validation data. validation_splitがある場合はオーバーライドされる
class_weight: データが少ないクラスのlossに重きを置く方法。
steps_per_epoch: Integer or None. training data // batch_size で求められる。
validation_steps: Integer or None. validation data // batch_size で求められる。⑥ model.evaluate でテストの評価
test_loss, test_acc = model.evaluate(test_generator, steps=test_steps)evaluate( x=None, y=None, batch_size=None, verbose=1, sample_weight=None, steps=None, callbacks=None, max_queue_size=10, workers=1, use_multiprocessing=False, return_dict=False )
x: 入力データ。 Numpy array, tensor, tf.data.dataset, (inputs, targets) or (inputs, targets, sample_weights)
y: ターゲットデータ。
batch_size: Integer or None.
verbose: 0 or 1. Verbosity mode. 0 = silent, 1 = progress bar.
sample_weight:
steps: Integer or None
callbacks: list ofkeras.callbacks.Callbackinstances
max_queue_size: Integer.
workers: Integer.
use_multiprocessing: boolean
return_dict: もしTrueなら、metric results をdictで返す⑦ 画像の予想確率だけ得るときは model.predict
predict( x, batch_size=None, verbose=0, steps=None, callbacks=None, max_queue_size=10, workers=1, use_multiprocessing=False )終わりに
細かい設定まで今回目を通すことができて良い機会になりました。
参考文献
- 投稿日:2021-01-12T10:04:17+09:00
【メモ】不要な変数を"_"(アンダースコア)へ代入する
- 製造業出身のデータサイエンティストがお送りする記事
- 今回は自分のメモとして記事に残しておきます。
はじめに
Pythonのコードを読んでいて返り値が"_"(アンダースコア)になっているコードを見てなんだろう?と不思議に思って調べたので、メモとして残しておきます。
Return値を無視する
いろいろと調べたら下記のような文章を発見しました。
Pythonはライブラリが沢山あって、関数をインポートして使う事が多いです。そういう時、もし関数からのreturn値が複数あって使わない部分があったらアンダースコアを使ってreturn値のメモリの占用をしないまま廃棄ができます。
つまり、return値を無視しますという意味だったそうです。
例としては下記のような使い方をするそうです。
def get_tuple(): return ('amedama', 'Japan/Tokyo') def print_name(): name, _ = get_tuple() print name if __name__ == '__main__': print_name()関数の返り値がタプルである以上、タプルで受けるしかないありませんが、アンダーバーから始まる変数の値は意識しなくて良い (使われない) という意図を伝えることができるそうです。
参考文献
- 投稿日:2021-01-12T09:45:52+09:00
FastAPIで任意のヘッダーをレスポンスに追加する方法
FastAPIで、脆弱性対策のためにレスポンスヘッダーを追加する必要がありました。
すべてのレスポンスに同じヘッダーを追加したかったのですが、FastAPIのドキュメントには記述がなく、path operation関数 (例:
@app.post("/comment")デコレータ) ごとの設定だけでした。
今回メインで紹介したいのはすべてのレスポンスに追加する方法ですが、ここではせっかくなので両方の方法について紹介します。以下の例では、画像などを返却するAPIを想定して、
Cache-Controlを設定してみます。
もちろん、Content-Security-PolicyだろうがX-Frame-Optionsだろうが、同様に設定可能です。1. あるpath operation関数に対して追加する方法
こちらはFastAPIの 公式ドキュメント にある方法です。
以下のように、path operation関数の引数に
Response型のクラスを追加します。from fastapi import Response @app.get("/image") def image(response: Response) response.headers["Cache-Control"] = "no-cache, no-store" ... return image_instanceこれによって、もともとこうだったレスポンスに、
"Cache-Control" が追加されたのがわかります。
2. すべてのリソースに追加する方法
こちらで紹介されている、FastAPIが依存しているStarletteというライブラリの、
BaseHTTPMiddlewareというクラスを利用します。from starlette.middleware.base import BaseHTTPMiddleware class MyHeadersMiddleware(BaseHTTPMiddleware): async def dispatch(self, request, call_next): response = await call_next(request) response.headers["Cache-Control"] = "no-cache, no-store" return response
response.headersのキーを変更すれば、複数のヘッダーを設定することも可能です。こちらのクラスを、main.pyなどで定義しているFastAPIのインスタンスに対して設定してあげます。
app = FastAPI() app.add_middleware(MyHeadersMiddleware)ちなみに、CORSに関しては専用の
CORSMiddlewareが用意されていて、regexによるホワイトリストなどに対応しているので、上記のような実装をせずにこちらを利用するのがよいでしょう。
これに関しては FastAPIのチュートリアル にも詳しく書かれています。(fastapi.middleware.cors.CORSMiddlewareクラスは実は単なるstarlette.middleware.cors.CORSMiddlewareのエイリアスです。)エラー処理に注意
Exceptionがraiseされたり、Pydanticのバリデーションによってエラーハンドリングされる場合、2の方法ではエラーケースでも問題なくヘッダーが追加されるのに対し、1の方法だと、設定したヘッダーが出力されません。
もちろん1の方法であっても、FastAPIの公式ドキュメントにあるように、以下のように直接エラーハンドリングをpath operation関数の中で処理してあげれば問題なく出力されます。
if error: return JSONResponse( {}, status_code=404, headers={"Cache-Control": "no-cache, no-store"} )しかし、すべてのエラーケースに対してこれを処理するとなると処理漏れが発生するリスクがありますので、多くの場合
@app.exception_handlerを定義して処理することになるかと思います。この中でpath operation関数ごとの処理を書いていくと複雑化すると思いますので、多くの場合は1の方法よりも2の方法を採用して、レスポンスの中身やエラー内容に応じてヘッダーを書き換えてあげるのが良いのではないかと考えます。まとめ
以上、FastAPIのレスポンスに任意のHTTPヘッダーを追加する方法を2つ紹介しました。
FastAPIは業務でガッツリ使っていますので、今後もシリーズ化していくつか記事を書きたいと思います。