- 投稿日:2021-01-05T23:52:55+09:00
Amazon EC2でStreamlitを使った簡単な「新規感染者数可視化アプリ」を動かしてみる
はじめに
- Python3で簡単にデータを可視化できるAPI「Streamlit」を使ってみます
- 対象となるデータはNHKが公開しているコロナウイルスの県別新規感染者数データです
- 本記事ではStreamlitをEC2サーバで稼働させ、Webアプリケーションとして公開する手順を書きます
- VPCやEC2の構築方法については過去記事をご参照ください
- プログラムだけみたい!という方は「streamlitを動かす」までスクロールしてください
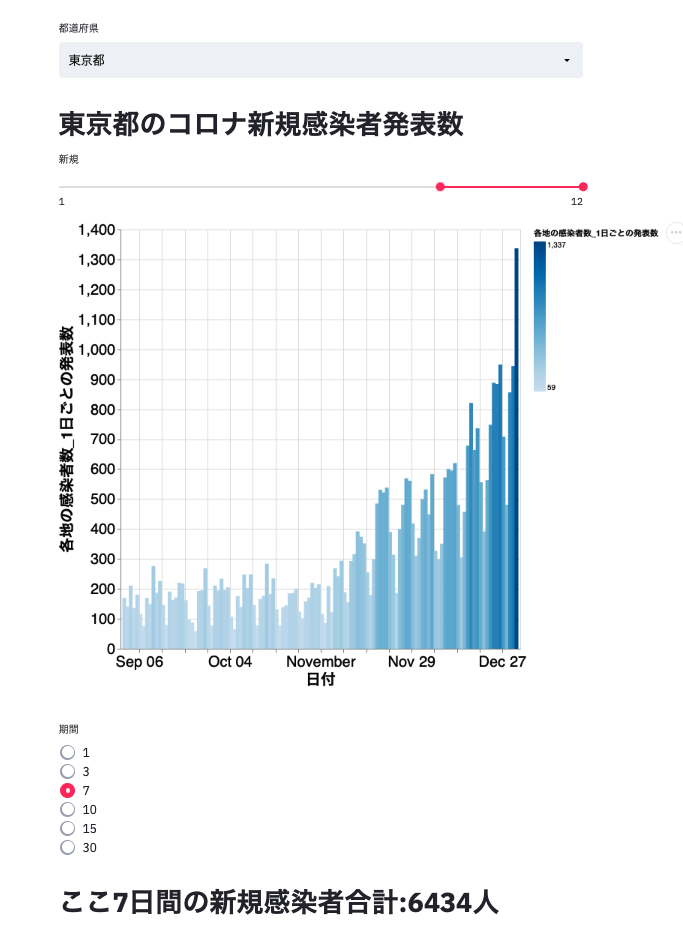
完成イメージ
環境構築
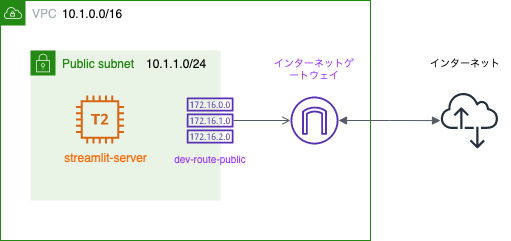
ネットワーク構成図
streamlit-serverインスタンスの生成
- EC2サービス
- [左タブ] インスタンス
- 下記設定のみ変更し、他はデフォルトでインスタンスを作る
インスタンスの詳細の設定
- ネットワーク: Develop(10.1.0.0/16)
- サブネット: public-subnet-1a-dev
- 自動割り当てパブリックIP: 有効
タグの追加
- タグの追加
- キー: Name
- 値: Streamlit-server
- 次のステップ
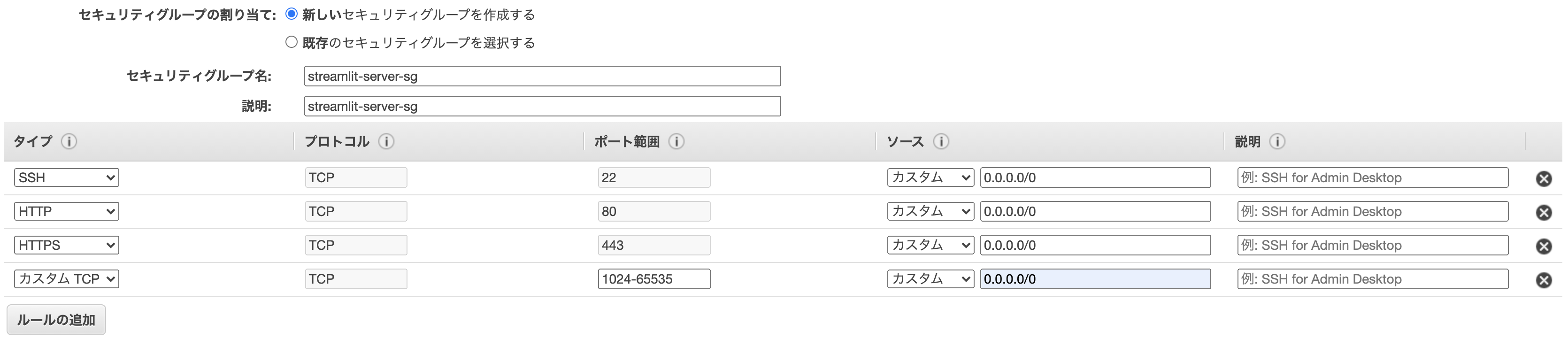
セキュリティグループの設定
新しいセキュリティグループ
- グループ名: streamlit-server-sg
- 説明: streamlit-server-sg
ルールの追加
HTTP、HTTPS、カスタムTCPを追加
確認と作成
キーペア
- 既存のキーを使うことを想定
streamlitをインストールする
- streamlit-serverインスタンスにsshアクセスする
- ssh -i ~/.ssh/develop.pem ec2-user@[パブリックIPv4アドレス]
- streamlitを入れる
sudo suyum update -yyum install python3 -ypip3 install streamlitStreamlitを動かす
- csvファイルをcurlでダウンロードする
curl -O https://www3.nhk.or.jp/n-data/opendata/coronavirus/nhk_news_covid19_prefectures_daily_data.csv
vi corona.pyで下記をペーストcorona.pyimport pandas as pd import streamlit as st import altair as alt # グラフを描画するためのパッケージ DF = pd.read_csv('nhk_news_covid19_prefectures_daily_data.csv') PREFACTURES = DF['都道府県名'].unique() # セレクトボックス用に都道府県名リストを取得しておく class GraphMakerNewly(): '''新規感染者のグラフを作成するクラス''' def __init__(self, dataframe, prefacture_name): self.df = self.__read_prefacture(dataframe, prefacture_name) def __read_prefacture(self, df, name): '''都道府県を指定して読み込み、結果を返すメソッド''' result = df[df['都道府県名'] == name].reset_index(drop=True) result['日付'] = pd.to_datetime(result['日付']) return result def alt_graph(self, slider): '''指定された期間のコロナウイルス新規感染者のグラフを返すメソッド''' begin = self.df['日付'].dt.month >= slider[0] end = self.df['日付'].dt.month <= slider[1] df_slider = self.df[begin == end] graph_slider = alt.Chart(df_slider).mark_bar().encode(x='日付', y='各地の感染者数_1日ごとの発表数', color='各地の感染者数_1日ごとの発表数').properties( width=800, height=640 ).configure_axis( labelFontSize=20, titleFontSize=20 ) return graph_slider def get_ndays_cum(self, ndays): '''直近ndaysの新規感染者の合計を返すメソッド''' return sum(self.df.tail(ndays)[self.df.columns[3]]) # 都道府県が選べるセレクトボックスを定義 prefacture_name = st.selectbox('都道府県', (PREFACTURES)) st.write('# ' + prefacture_name + 'のコロナ新規感染者発表数') # 期間を指定できるスライダーを定義 mslider_new = st.select_slider( '新規', options=range(1, 13, 1), value=(9, 12)) gm_n = GraphMakerNewly(DF, prefacture_name) st.altair_chart(gm_n.alt_graph(mslider_new)) ndays = st.radio("期間", (1, 3, 7, 10, 15, 30), index=2) st.write('# ここ' + str(ndays) + '日間の新規感染者合計:' + str(gm_n.get_ndays_cum(ndays))+'人')管理者権限から抜ける
exit
streamlit run corona.pyで実行You can now view your Streamlit app in your browser. Network URL: http://[プライベートIP]:8501 External URL: http://[パブリックIP]:8501
- ブラウザで
http://[パブリックIP]:8501にアクセスしてみる
- アプリケーションが表示できれば成功
終わりに
- Streamlitを用いることで時間をかけずに簡単なデータの可視化することができました
- 年を跨いだ1月のデータが出力されないことが課題ですが...
- 間違いや改善点等ありましたらコメントいただければ幸いです
- 投稿日:2021-01-05T23:37:30+09:00
どうせ起動してるPCを使って、宣伝ツイートを自動でRTする
概要
いちいちリツイートボタンを押しに行くのがめんどくさいので、
せや!自動化したろ!というおはなし。リツイート何度も繰り返すのは案外めんどくさい
僕は音楽とかそういったのを作るのがすきなんですけど、
先日、新曲を発表しました。
宣伝になりますが、ぜひ聞いてみてください。イロメガネの人生論 / Sotono
— MushroomRecord (Sotono) (@MushroomRecord) January 4, 2021
色だらけの世界で僕はどう生きるべきか?という曲です。
そして僕の人生もついでに歌いました。
Youtube : https://t.co/athRiiOjN5
Niconico: https://t.co/lwdPODf7mJ#vocaloPost #vocanew #vocaloid #Sotono pic.twitter.com/zgcoQD27O6…
これ何度も宣伝するのめんどくさくね?とふと思いました。
めんどくさいので、じゃあ自動化しましょう。Twitter API使えるように準備
Twitter API使用権限を用意する
このへんを参考に取得してください。
取得したものを、とりあえずわかりやすく
key.pyにぶちこんでおきましょう。key.pyAPI_KEY = 'hoge' API_SECRET = 'hoge' ACCESS_TOKEN = 'hoge' ACCESS_TOKEN_SECRET = 'hoge'次に
Twitter_API.pyを作成して、APIを使えるようにしましょう。Twitter_api.pyimport key API_KEY = key.API_KEY API_SECRET = key.API_SECRET ACCESS_TOKEN = key.ACCESS_TOKEN ACCESS_TOKEN_SECRET = key.ACCESS_TOKEN_SECRET def api_proc(): # TwiterのAPIを使えるようにする api = OAuth1Session( API_KEY, API_SECRET, ACCESS_TOKEN, ACCESS_TOKEN_SECRET ) return apiこれで
Twitter_api.api_proc()を実行すると返り値としてTwitterのAPI使用権限が渡されます。実際にAPIを動かしてみよう
やりたいことをまとめる
したいことをわかりやすくまとめるとこうなります。
- 指定したツイートIDを、自分のアカウントでRT解除する。
- 指定したツイートIDを、自分のアカウントでRTする。なぜ解除が必要か?と言うと、同じツイートを2回リツイートすることはできないので、
同じツイートをリツイートしたい場合は一度解除する必要があるからです。
ちなみに、エラーなどは一切発生しません。(厳密にはexceptionが発生しない)当該ツイートのIDを取得する
Twitterの当該ツイートのページへ飛びます。
PCなら適当なツイートのどこでもいいのでクリックすれば飛ぶと思います。
そうでない場合、だいたい日付をクリックすれば当該ツイートへ移動できます。そのページのURLは以下の通りになっていると思います。
https://twitter.com/MushroomRecord/status/1346128262871744512これの
statusの右側、つまりこのURLだと1346128262871744512が該当IDとなります。
これを使用するので控えておきましょう。APIを動かす
今回は
POSTでAPIを動かすだけで簡単に終わるので、
スクリプトも簡単になります。main.pyimport Twitter_API def main(tweet_id: int): TWITTER = Twitter_API.api_proc() URL_TWITTER = 'https://api.twitter.com/1.1/statuses' URL_RT = f'{URL_TWITTER}/retweet/{tweet_id}.json' URL_UNRT = f'{URL_TWITTER}/unretweet/{tweet_id}.json' TWITTER.post(URL_UNRT) TWITTER.post(URL_RT) if __name__ == '__main__': tweet_id = 1346128262871744512 main(tweet_id)これを実行すると、僕の宣伝ツイートがRTされると思います。
tweet_idを変更すれば非公開アカウントでない限りどんなツイートもRTすることができるはずです。どうせ起動しているPCを使って定期的に実行する
僕はずっとPCもといMacをつけっぱなしにしているので、
このズボラな点を使って定期的に実行できるようにします。
cronとかあったよなーと思いつつも調べたら、
MacだとLaunchdのほうが良いみたいです、よくわからんけど。というわけで
Launchdを使って定期実行を行います。autoself_retweet.plist<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE plist PUBLIC "-//Apple Computer//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd"> <plist version="1.0"> <dict> <key>Label</key> <string>autoself_retweet</string> <key>ProgramArguments</key> <array> <string>pythonのパス</string> <string>スクリプトのパス</string> </array> <key>StartInterval</key> <integer>3600</integer> </dict> </plist>
keyとなんかの属性がセットになっていると考えながら構築します。
Labelは任意の名前をセットします。
Labelとファイル名は同一である必要があります。
ProgramArgumentsに実行したいコマンドとパラメータを入れます。ここがよくわからなくて、本当は「cdで移動して、そこのスクリプトを読み込んで〜」と汎用性ある記述にしたかったんですが、
うまく行かなかったので、実用性重視でコマンドとして一行にまとめるような記述になってるんですが、
詳しい方いたらご教授いただけると幸いです。
StartIntervalで何秒おきに実行するかを決めます。定期実行できるようにセットする
これでn秒おきにPythonスクリプトを実行する環境が整ったので、実際にMacに仕込みます。
~/Library/LaunchAgentsにautoself_retweet.plistを設置します。- ターミナルで以下コマンドを入力すると、定期実行が開始されます。
Terminal$ launchctl load ~/Library/LaunchAgents/autoself_retweet.plist
- もし、上記手順を踏んでもスクリプトが実行されない、テストに失敗していると思ったときは以下コマンドでunloadします。
Terminal$ launchctl unload ~/Library/LaunchAgents/autoself_retweet.plistそれでは、良い定期実行ライフを。
参考
- 投稿日:2021-01-05T23:16:11+09:00
Error: pg_config executable not found
WSLの Linux 環境で
psycopg2-binaryをpip経由でインストールしたときに出たエラー。Pythonのバージョンは3.9.1Error: pg_config executable not found. pg_config is required to build psycopg2 from source. Please add the directory containing pg_config to the $PATH or specify the full executable path with the option: python setup.py build_ext --pg-config /path/to/pg_config build ... or with the pg_config option in 'setup.cfg'. If you prefer to avoid building psycopg2 from source, please install the PyPI 'psycopg2-binary' package instead.
pg_configというコマンドが見当たらないと言われている。pg_config が使えればいいtということ。検索すると PostgreSQL のコマンドらしいので、 Linux 環境に PostgreSQL をインストールすればいいと見当がつく。ソースからビルドすることになるので、シェアドライブラリなどのインストールが必要になりそう。一旦、ライブラリのリポジトリを見に行く。
Issues を眺めてみると、 pg_config について言及されているものがいくつか見つかる。
https://github.com/psycopg/psycopg2/issues/1200 によれば、 Python 3.9 以降の場合は、 2.8.6 以降じゃないと動作しないようだ。試してみる。まずは2.8.5がインストールできないことを確認する。
$ docker run -it --rm python:3.9-slim bash $ python -m pip install psycopg2-binary==2.8.5
エラー詳細
Collecting psycopg2-binary==2.8.5 Downloading psycopg2-binary-2.8.5.tar.gz (381 kB) |████████████████████████████████| 381 kB 8.0 MB/s ERROR: Command errored out with exit status 1: command: /usr/local/bin/python -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-install-qcdbyewy/psycopg2-binary_6829b82052994eb083b5f67ce9537531/setup.py'"'"'; __file__='"'"'/tmp/pip-install-qcdbyewy/psycopg2-binary_6829b82052994eb083b5f67ce9537531/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' egg_info --egg-base /tmp/pip-pip-egg-info-dt29jovq cwd: /tmp/pip-install-qcdbyewy/psycopg2-binary_6829b82052994eb083b5f67ce9537531/ Complete output (23 lines): running egg_info creating /tmp/pip-pip-egg-info-dt29jovq/psycopg2_binary.egg-info writing /tmp/pip-pip-egg-info-dt29jovq/psycopg2_binary.egg-info/PKG-INFO writing dependency_links to /tmp/pip-pip-egg-info-dt29jovq/psycopg2_binary.egg-info/dependency_links.txt writing top-level names to /tmp/pip-pip-egg-info-dt29jovq/psycopg2_binary.egg-info/top_level.txt writing manifest file '/tmp/pip-pip-egg-info-dt29jovq/psycopg2_binary.egg-info/SOURCES.txt' Error: pg_config executable not found. pg_config is required to build psycopg2 from source. Please add the directory containing pg_config to the $PATH or specify the full executable path with the option: python setup.py build_ext --pg-config /path/to/pg_config build ... or with the pg_config option in 'setup.cfg'. If you prefer to avoid building psycopg2 from source, please install the PyPI 'psycopg2-binary' package instead. For further information please check the 'doc/src/install.rst' file (also at <https://www.psycopg.org/docs/install.html>). ---------------------------------------- ERROR: Command errored out with exit status 1: python setup.py egg_info Check the logs for full command output.予想通り、失敗。続いて2.8.6をインストールしてみる。Issue の報告通りなら成功するはず。
$ python -m pip install psycopg2-binary==2.8.6 Collecting psycopg2-binary==2.8.6 Downloading psycopg2_binary-2.8.6-cp39-cp39-manylinux1_x86_64.whl (3.0 MB) |████████████████████████████████| 3.0 MB 7.9 MB/s Installing collected packages: psycopg2-binary Successfully installed psycopg2-binary-2.8.6解決。
pip install psycopg2-binary>=2.8.6でインストールできる。
- 投稿日:2021-01-05T22:56:00+09:00
PythonでHEICファイルをPNGファイルに変換
iPhoneのライブフォトで撮影した写真はHEICファイルで保存される.
このファイルはJPEGやPNGに比べて対応しているソフトウェアが少なく扱いにくい.
そこでHEICファイルをPNGファイルに変換する方法をメモしておく.Google Colaboratoryを使えばブラウザから実行できる.
環境
- Ubuntu 20.04.1 LTS on WSL2
- Python 3.8.5
ソースコード
変換したいファイルと同一の階層にconv.pyを配置して実行する.
conv.pyfrom PIL import Image import pyheif def conv(image_path): new_name = image_path.replace('heic', 'png') heif_file = pyheif.read(image_path) data = Image.frombytes( heif_file.mode, heif_file.size, heif_file.data, "raw", heif_file.mode, heif_file.stride, ) data.save(new_name, "PNG") import glob lst = glob.glob("*.heic") for l in lst: conv(l)利用パッケージ
- pyheif
- PIL
pipコマンドでインストールをする.
pip install pyheif Pillow実行結果
$ python conv.py $ ls IMG_3488.heic* IMG_3494.heic* IMG_3497.heic* IMG_3499.heic* IMG_3503.heic* IMG_3510.heic* IMG_3514.heic* a.py* IMG_3488.mov* IMG_3494.mov* IMG_3497.mov* IMG_3499.mov* IMG_3503.mov* IMG_3510.mov* IMG_3514.mov* env/参考URL
- 投稿日:2021-01-05T22:34:57+09:00
Spotify APIで曲を解析したい 2
始めに
前回の続きです。
アルバム単位のAPI取得、曲の項目などをみていきます。アルバム情報の取得
前回取得した任意のアーティストのidを利用します。
main.pyimport spotipy from spotipy.oauth2 import SpotifyClientCredentials client_id = 'クライアントid' client_secret = 'クライアントシークレット' spotify_client_credentials = spotipy.oauth2.SpotifyClientCredentials(client_id, client_secret) spotify = spotipy.Spotify(client_credentials_manager=spotify_client_credentials) artist_uri = 'spotify:artist:5PalnqYJTpnO5wt00jf0um' results = spotify.artist_albums(artist_uri, album_type='album') print(results)これでidで指定したアーティストのアルバム情報が取得できます。実行してみると...
{ "album_type": "album", "name": "再生の風景", "external_urls": { "spotify": "https://open.spotify.com/album/2evf6T9osScdVnhVrL7tXX" }, "release_date": "2013-01-23", "uri": "spotify:album:2evf6T9osScdVnhVrL7tXX", "total_tracks": 10, "href": "https://api.spotify.com/v1/albums/2evf6T9osScdVnhVrL7tXX", "artists": [ { "name": "the cabs", "external_urls": { "spotify": "https://open.spotify.com/artist/5PalnqYJTpnO5wt00jf0um" }, "uri": "spotify:artist:5PalnqYJTpnO5wt00jf0um", "href": "https://api.spotify.com/v1/artists/5PalnqYJTpnO5wt00jf0um", "type": "artist", "id": "5PalnqYJTpnO5wt00jf0um" } ], "images": [ { "url": "https://i.scdn.co/image/ab67616d0000b273c4f2e7d76207985faf2427c5", "width": 640, "height": 640 }, { "url": "https://i.scdn.co/image/ab67616d00001e02c4f2e7d76207985faf2427c5", "width": 300, "height": 300 }, { "url": "https://i.scdn.co/image/ab67616d00004851c4f2e7d76207985faf2427c5", "width": 64, "height": 64 } ], "album_group": "album", "type": "album", "id": "2evf6T9osScdVnhVrL7tXX", "available_markets": [ "JP" ], "release_date_precision": "day" }, { "album_type": "album", "name": "saisei no hukei", "external_urls": { "spotify": "https://open.spotify.com/album/6koCjq9UGVZFa9YjJgCLok" }, "release_date": "2013-01-23", "uri": "spotify:album:6koCjq9UGVZFa9YjJgCLok", "total_tracks": 10, "href": "https://api.spotify.com/v1/albums/6koCjq9UGVZFa9YjJgCLok", "artists": [ { "name": "the cabs", "external_urls": { "spotify": "https://open.spotify.com/artist/5PalnqYJTpnO5wt00jf0um" }, "uri": "spotify:artist:5PalnqYJTpnO5wt00jf0um", "href": "https://api.spotify.com/v1/artists/5PalnqYJTpnO5wt00jf0um", "type": "artist", "id": "5PalnqYJTpnO5wt00jf0um" } ], "images": [ { "url": "https://i.scdn.co/image/ab67616d0000b27371b964ec832c791e2e880428", "width": 640, "height": 640 }, { "url": "https://i.scdn.co/image/ab67616d00001e0271b964ec832c791e2e880428", "width": 300, "height": 300 }, { "url": "https://i.scdn.co/image/ab67616d0000485171b964ec832c791e2e880428", "width": 64, "height": 64 } ], "album_group": "album", "type": "album", "id": "6koCjq9UGVZFa9YjJgCLok", "available_markets": [ "AD", "AE", "AL", "AR", "AT", "AU", "BA", "BE", "BG", "BH", "BO", "BR", "BY", "CA", "CH", "CL", "CO", "CR", "CY", "CZ", "DE", "DK", "DO", "DZ", "EC", "EE", "EG", "ES", "FI", "FR", "GB", "GR", "GT", "HK", "HN", "HR", "HU", "ID", "IE", "IL", "IN", "IS", "IT", "JO", "KW", "KZ", "LB", "LI", "LT", "LU", "LV", "MA", "MC", "MD", "ME", "MK", "MT", "MX", "MY", "NI", "NL", "NO", "NZ", "OM", "PA", "PE", "PH", "PL", "PS", "PT", "PY", "QA", "RO", "RS", "RU", "SA", "SE", "SG", "SI", "SK", "SV", "TH", "TN", "TR", "TW", "UA", "US", "UY", "VN", "XK", "ZA" ], "release_date_precision": "day" } ]かなり長いですがアルバム取得ができました。
気になる部分をみていきます。available_markets
視聴可能な国を表しているみたいです。見たところISOのcountry codeで記述してありますね。
つまり国によっては聴けないところもあるということらしいです。total_tracks
アルバムに含まれている楽曲の総数です。
album_type
上の結果では
albumのみですが、他にsingleやcompilationがあり、これによってSpotifyの画面上で分類をしています。次に楽曲の取得をしてみます。
楽曲の取得
先ほど使った
album_idを使用します。私は先ほどと違うアルバムを調べますが、idの取得方法は変わりません。main.py. . . album_id = 'spotify:album:61Xe5yDSI4IrIqPdYqXxMJ' results = spotify.album(album_id)['tracks']['items'][1] #アルバムの2曲目を取得 print(results){ 'is_local': False, 'name': 'camn aven', 'external_urls': { 'spotify': 'https://open.spotify.com/track/7gA5tchFTCxarNIt3JGDhD' }, 'uri': 'spotify:track:7gA5tchFTCxarNIt3JGDhD', 'explicit': False, 'preview_url': 'https://p.scdn.co/mp3-preview/84b9a4c8f35fd36b8884d003ee17836265fb47f3?cid=6551068e9be94d4bb07c29cb25fa84f0', 'track_number': 2, 'disc_number': 1, 'href': 'https://api.spotify.com/v1/tracks/7gA5tchFTCxarNIt3JGDhD', 'artists': [ { 'name': 'the cabs', 'external_urls': { 'spotify': 'https://open.spotify.com/artist/5PalnqYJTpnO5wt00jf0um' }, 'uri': 'spotify:artist:5PalnqYJTpnO5wt00jf0um', 'href': 'https://api.spotify.com/v1/artists/5PalnqYJTpnO5wt00jf0um', 'type': 'artist', 'id': '5PalnqYJTpnO5wt00jf0um'}], 'duration_ms': 214000, 'type': 'track', 'id': '7gA5tchFTCxarNIt3JGDhD', 'available_markets': ['JP'] }ここから取得した楽曲のidを利用して、楽曲の特徴を見ていきます。
特徴を取得
上記のtrack_idを利用していきます。audio_featuresというオブジェクトで取得可能みたいです。
main.py. . . track_id = 'spotify:album:7gA5tchFTCxarNIt3JGDhD' results = spotify.audio_features(track_id) print(results)[ { 'track_href': 'https://api.spotify.com/v1/tracks/7gA5tchFTCxarNIt3JGDhD', 'analysis_url': 'https://api.spotify.com/v1/audio-analysis/7gA5tchFTCxarNIt3JGDhD', 'energy': 0.941, 'liveness': 0.0952, 'tempo': 100.324, 'speechiness': 0.052, 'uri': 'spotify:track:7gA5tchFTCxarNIt3JGDhD', 'acousticness': 8.32e-05, 'instrumentalness': 0.0512, 'time_signature': 3, 'danceability': 0.449, 'key': 5, 'duration_ms': 214000, 'loudness': -2.499, 'valence': 0.538, 'type': 'audio_features', 'id': '7gA5tchFTCxarNIt3JGDhD', 'mode': 1 } ]楽曲のより詳しい情報が見れました。普段spotifyを使っていても見慣れない項目がいくつかありますね。
公式リファレンスを後で載せておきますが、いくつか紹介していきます。energy
0~1の間で評価される項目です。速く、うるさく、ノイジーな曲ほど高く評価されるみたいです。
time_signature
曲の拍子を表します。私が抽出したcamm avenという曲は変拍子なので、おそらく正しく評価できていないと思います。
instrumentalness
インスト(演奏時間の長さ)の項目です。0.5を超えてくるとインストゥルメンタルトラックに近いと言えます。
danceability
曲の踊りやすさを表しています。どうやって評価しているのかは謎です。
終わりに
今回は楽曲といった、より細かい単位で分析してみました。
結構隠されたパラメーターがいっぱいあるので、これを使ってどうにか類似したバンドを見つけてみるのも面白いと思います。参考にさせていただいた記事
Get Audio Features for a Track ← 楽曲のパラメーターについて解説が載っています。
Get an Album
- 投稿日:2021-01-05T22:24:40+09:00
Pythonで正規表現
使い方
モジュールのimport
import re正規表現オブジェクトの生成・マッチング
正規表現オブジェクトを生成してから、マッチングする方法
# 生成 cmpObj = re.compile(r'a.c') # マッチング ret = cmpObj.match('abc')正規表現オブジェクトを生成しなくても、マッチングできる。
しかし、プログラム中で何度も同じ正規表現パターンを使用する場合は、正規表現オブジェクトを生成して使用するほうが効率的に処理できる。# マッチング ret = re.match(r'a.c', 'abc')正規表現パターンに文字列がマッチしている場合には、
match()の戻り値として、マッチオブジェクトを返却する。
マッチしなかった場合は、Noneが返却される。
match()は文字列の先頭がマッチするかを見ているため、以下のような場合はマッチしない# これはマッチしない ret = re.match(r'a.c', 'babc')文字列の先頭だけでなく、途中でもマッチしているかを確認する場合は、
search()を使用する。# これはマッチする ret = re.search(r'a.c', 'babc') # 正規表現オブジェクトを使用する場合 ret = cmpObj.search('babc')マッチしたか確認する
if ret : print(ret) # マッチした場合 else : print('not match') # マッチしなかった場合注意点
- パターンと検索する文字列は
strまたはbytesを使用するが、strとbytesの混在はできない。- 正規表現パターンの文字列を指定するときには、raw文字列記法を使用する。(
\を特殊文字として扱いたくないため)
- 投稿日:2021-01-05T22:19:41+09:00
初学者ロードマップ
私は、大学(非情報学部)に入ってからプログラミングをやり始めて、現在、小学生から大人の方まで色んな方がPythonやJavaScriptで色んなプロダクトを作りながら勉強していくところのバイトのメンターのようなことをしています。
私自身、勉強にかなり手こずった方だと思っているので、初心者の参考になればと思います。
1.初心者の心構え
まずはこの動画をみてください。
https://youtu.be/5MgBikgcWnYプログラミングに限らず、初心者は「完璧を目指さない、6〜7割できたらどんどん次に進む!」というような心構えで学習するべきです。
動画でもわかった通り、ある程度理解しているぐらいのレベルに達するには約20時間必要だとのこと。
逆に言えば、目安としてこのぐらいの学習量で進むべきということですね。もし、さらに専門的な知識が必要になったらまたその時に学習すればいいと思います。
私は、昔からちゃんと理解してから進むような勉強の方法をしていたので、大学に入ってより専門性の高いものを勉強するようになってから、めちゃくちゃ学習効率が下がりました。そして、モチベーションも駄々下り。
みなさんがどうかはわかりませんが、意外とこれになりがちな印象。
2.ロードマップ(暫定版)
今のところこんな感じのルートで勉強していけば、割と効率よく勉強できそうです。
2.1.勉強法
これまで勉強してきて、「勉強したことを使って、プロダクトを作りながら勉強していく」以外はモチベが下がってまじで勉強が続かないです...
2.2.エンジニアの種類・使用言語を把握
https://www.indeed.com/career-advice/finding-a-job/types-of-software-engineer
まずはこれをみて、どんなエンジニアがいて、どんな言語を使っているのか全体像を把握する。
先に言っておくと、コンピューターサイエンスの世界は奥が深すぎるので色んなところに手を出そうとすると痛い目を見ますw
特に初心者のうちは、やることを絞っておくことがかなり効率をあげると経験的に感じています。
2.3.エンジニアとして絶対必要になること
2.3.1.Git
これは、プログラムのソースコードなどぼバージョン管理をするシステムです。
2.3.2.Docker
開発をする時、必ず開発環境を整える必要があります。
ローカル環境に直接構築するのでもあまり問題ありませんが、ローカルのソフト同士がコンフリクトしてエラーになったりすることがあるかも知れませんし、なにより数行のコマンドを打つだけでどこにでも環境構築ができるのはかなり便利です。色んなところで聞く話ですが、今やDockerは色んな企業で採用されている技術だそうなので、やっておく必要があります。
2.4.基本的な文法を学ぶ(Python、Ruby、PHP)
プログラミング言語にもそれぞれの言語ごとに文法があります。
ですが、一つの言語の文法がわかれば、だいたい他の言語でも対応可能と言われているので、Python、Ruby、PHPの3つから1つ選んで勉強するので十分でしょう。
なんでも良ければ、Pythonがおすすめです。(自分がそうだったので)2.5.分野ごとにやることを選定
2.2.でみたサイトに分野ごとに必要な技術が書いてあるので、それを中心に勉強を進めていくのがいいでしょう。
2.6.随時更新...
3.おすすめの教材
・海外のサイト(日本のサイトでは見つけられなかったことも見つけることができる)
4.まとめ
・完璧主義はモチベ低下の原因。(絶対挫折します)バンバン先に進みましょう。
・形にしながら勉強すべし。
・手を出しすぎない。
少しでも参考になればと思います!
- 投稿日:2021-01-05T22:12:31+09:00
2021年のPython仮想環境〜いまやvenvを使わない理由はありません〜
Python仮想環境、どうしていますか?
さまざまなライブラリがあるのがPythonの魅力の1つですが、それゆえ、ライブラリ互換性や安定性を考えると、開発目的にあわせたライブラリセットとPythonバージョンを組み合わせて、必要に応じて、切り替えたいものです。それを実現するのがPython仮想環境です。
Python仮想環境については、いろいろな選択肢がありますが、よほどのコダワリが無いのであれば、venvの選択を強くお勧めします。理由を3つにまとめてみました。
仮想環境の比較紹介については、「pyenv、pyenv-virtualenv、venv、Anaconda、Pipenv。私はPipenvを使う。」が、非常によくまとまっています。ただし、venvはPythonインタプリタバージョンの切り替えはできない、という分類がされていますが間違いです。venvはvirtualenvとほぼ同等なのは書かれている通りです。ですので、○の位置もvirtualenvと同等であるべきで、Pythonインタプリタバージョンの切り替えは可能です。仮想環境ごとに別バージョンの利用ができるものの、同じ仮想環境のバージョンを後から切り替えることはできないところも、virtualenvと同等です(アップグレードはできます)。
理由1. Python仮想環境でありつつ、公式だから
当たり前ですが、venvはPython3.5以降のPython公式に付属する推奨仮想環境です。
venv非対応なPython3.4のサポートが2019年4月に完了し、Python2系のサポートが2020年1月1日に終了して実際の最終リリースが2020年4月となりました。これまでは「venvは公式だけど、自分の使いたいPythonバージョンには対応していない」と言われて、他のPython仮想環境を使う理由がありましたが、2021年においては否定的理由はなくなりました。いまやvenvを使わない理由はありません。
理由2. 公式系の関連エコシステムが充実しているから
資格試験・教育コース・企業系発信といった「公式系」のPythonエコシステムでは、前提とする仮想環境はvenvになってきています。
- Python3エンジニア認定基礎試験の主教材である、オライリー・ジャパン「Pythonチュートリアル 第3版」では、仮想環境の項では公式の1世代前であるpyvenvが掲載されています。実は、この本は結構古く、英語最新版の「Pythonチュートリアル」では、記述がvenvに切り替わっています。
- 2020年から開始したCicso DevNet試験では、Cisco DevNetのmacOS向け学習環境構築に記載されているように、試験対策チュートリアルがvenv前提で記述されています。
- VSCodeのPython環境構築の公式チュートリアルでは、仮想環境としてvenvが説明されています。
数年前と異なり公式系のエコシステムが成長し、いまやvenvを使わない理由はありません。
なお、注意したいのは、ここQiitaをはじめとしたユーザ参加型コンテンツのような「非公式系」では、pyenvなどの他のPython仮想環境が優勢であることです。こういったユーザ参加型コンテンツでは、以前に流行った方式がなかなか下火にならない、という特性があります。古くても人気があったコンテンツは検索上位に来ますし、それを見た別の人が、新たにコンテンツを生成する、という循環が生まれるためです。よって、現時点の2021年では、公式系のコンテンツではvenvが使われ、非公式系ではvenvはほとんど使われない、という歪んだ状態にあります。
理由3. pipが使えるから
機械学習が流行った現在、さまざまなライブラリを追加インストールする機会が増えました。その際、ライブラリインストール例はpipで記述されています。また、機械学習の流行により、Juypterを使った例が非常に増えました。Jupyterでも!pipで追加ライブラリのインストールをさせる例が多いです。すなわち、pipを使うように誘導される機会が、非常に増えています。
Jupyterでのpipによるライブラリ追加インストールは、Jupyterを立ち上げた環境に作用します。そのため、Jupyerはvenv環境から立ち上げるべきであり、かつ、別ライブラリセットを使いたいJupyterはベースとなるvenv環境も分けるべきです。この事実はあまり認識されていないようです。
一方、anacondaユーザがこれらをそのまま見て、anacondaにpipでパッケージインストールして、システムを不安定にさせる、という事故が頻発しています(teratailでのQA動向の感覚値に基づきます)。
venvはもちろんpipをそのまま使えますので、このような問題もありません。pipを使う機会が増えた中、いまやvenvを使わない理由はありません。
おまけ. 3つの理由を満足するさらなる仮想環境
実は、これら3つの理由を満足する仮想環境が、まだ存在します。厳密に言うと、「Python仮想環境」ではありません。そのため、理由1は命題として真になります。なぜなら、前提条件である「Python仮想環境でありつつ」が命題として偽なので、「Python仮想環境でありつつ、公式だから」は、公式かどうかにかかわらず真になるためです。
1つは、Dockerです。Docker上で生Pythonを実行させ、コンテナ環境ごと切り替えて使うというやり方です。なお書籍「自走プログラマー」では、プロが選択する仮想環境としては、venvかDockerである、と言い切っています。
もう1つは、Google Colabです。Jupyter+Ubuntu+VMをクラウド提供するセットです。機械学習に使えるライブラリはプレインストールされており、さらに追加ライブラリをpipでインストールすることが可能です。好みは分かれますが、追加ライブラリ等の環境は、VMの最大利用時間をすぎるとリセットされますので、あたかも仮想環境のように使えます。Google Colabが前提環境となっている教育コースが増えています。
いずれにしても、「Python仮想環境には、いまやvenvを使わない理由はありません」は、命題として真なのです。
- 投稿日:2021-01-05T22:06:14+09:00
datetime.indexで設定される週を修正する
はじめに
時系列データを処理するに辺り、pandasでindexをdatetimeにすると便利だが、indexから週を抽出する際に、例えば2019/12/30と12/31など最終週が2019年の第1週となってしまうため、これを修正する方法を調べた備忘録である。
問題点
12月最終週と翌年1月最初の週は同じ週となる。週番号の付け方は色々あるらしいが、pandasではISO準拠のヨーロッパ式のようであり、その週の平日から第1週目と認識される。
しかし、2019/12/30, 31は df.index.yaer -> 2019、df.index.week -> 1 となるため、2019年の第1週と認識されてしまうため、週単位でのデータ集計などの処理に都合が悪い。
下記のようなdatetime形式のindexを例に示す。
df.indexDatetimeIndex(['2019-12-29 22:00:00+00:00', '2019-12-29 22:00:00+00:00', '2019-12-29 22:00:00+00:00', '2019-12-29 22:00:00+00:00', '2019-12-29 22:00:00+00:00', '2019-12-29 22:08:00+00:00', '2019-12-29 23:00:00+00:00', '2019-12-30 01:47:00+00:00', '2019-12-30 02:48:00+00:00', '2019-12-30 02:48:00+00:00', '2019-12-30 12:34:00+00:00', '2019-12-30 14:51:00+00:00', '2019-12-30 14:53:00+00:00', '2019-12-30 14:56:00+00:00', '2019-12-31 04:50:00+00:00', '2019-12-31 13:41:00+00:00', '2019-12-31 14:42:00+00:00', '2019-12-31 14:45:00+00:00', '2019-12-31 15:56:00+00:00', '2019-12-31 15:56:00+00:00', '2019-12-31 15:58:00+00:00', '2019-12-31 15:58:00+00:00'], dtype='datetime64[ns, UTC]', name='date', freq=None)このデータフレームに対して、下記のようにMultiIndexを設定すると、12/29は52週なのに対して、12/30, 31は2019年の第1週になってしまう事が確認できる。
df_w = df.set_index([df.index.year, df.index.month, df.index.week, df.index]) df_w.index.names = ['year', 'month', 'week', 'date'] df_w.sort_index(inplace=True) df_w.indexMultiIndex([(2019, 12, 1, '2019-12-30 01:47:00+00:00'), (2019, 12, 1, '2019-12-30 02:48:00+00:00'), (2019, 12, 1, '2019-12-30 02:48:00+00:00'), (2019, 12, 1, '2019-12-30 12:34:00+00:00'), (2019, 12, 1, '2019-12-30 14:51:00+00:00'), (2019, 12, 1, '2019-12-30 14:53:00+00:00'), (2019, 12, 1, '2019-12-30 14:56:00+00:00'), (2019, 12, 1, '2019-12-31 04:50:00+00:00'), (2019, 12, 1, '2019-12-31 13:41:00+00:00'), (2019, 12, 1, '2019-12-31 14:42:00+00:00'), (2019, 12, 1, '2019-12-31 14:45:00+00:00'), (2019, 12, 1, '2019-12-31 15:56:00+00:00'), (2019, 12, 1, '2019-12-31 15:56:00+00:00'), (2019, 12, 1, '2019-12-31 15:58:00+00:00'), (2019, 12, 1, '2019-12-31 15:58:00+00:00'), (2019, 12, 52, '2019-12-29 22:00:00+00:00'), (2019, 12, 52, '2019-12-29 22:00:00+00:00'), (2019, 12, 52, '2019-12-29 22:00:00+00:00'), (2019, 12, 52, '2019-12-29 22:00:00+00:00'), (2019, 12, 52, '2019-12-29 22:00:00+00:00'), (2019, 12, 52, '2019-12-29 22:08:00+00:00'), (2019, 12, 52, '2019-12-29 23:00:00+00:00')], names=['year', 'month', 'week', 'date'])改善策
参考サイトに私の求める解決策があり、自分のケースにあてはめました。
1. 一旦indexを解除
2. dt.weekで週を抽出
3. 強制的に52週に変更
4. indexを再設定df.reset_index(inplace=True) df["year"] = df["date"].dt.year df["month"] = df["date"].dt.month df["week"] = df["date"].dt.week df["week"] = df["date"].apply( lambda x: 52 if x.year == 2019 and x.day in [30, 31] else x.week) df_w = df.set_index([df["year"], df["month"], df["week"], df["date"]]) df_w.index.names = ['year', 'month', 'week', 'date'] df_w.sort_index(inplace=True) df_w.indexMultiIndex([(2019, 12, 52, '2019-12-29 22:00:00+00:00'), (2019, 12, 52, '2019-12-29 22:00:00+00:00'), (2019, 12, 52, '2019-12-29 22:00:00+00:00'), (2019, 12, 52, '2019-12-29 22:00:00+00:00'), (2019, 12, 52, '2019-12-29 22:00:00+00:00'), (2019, 12, 52, '2019-12-29 22:08:00+00:00'), (2019, 12, 52, '2019-12-29 23:00:00+00:00'), (2019, 12, 52, '2019-12-30 01:47:00+00:00'), (2019, 12, 52, '2019-12-30 02:48:00+00:00'), (2019, 12, 52, '2019-12-30 02:48:00+00:00'), (2019, 12, 52, '2019-12-30 12:34:00+00:00'), (2019, 12, 52, '2019-12-30 14:51:00+00:00'), (2019, 12, 52, '2019-12-30 14:53:00+00:00'), (2019, 12, 52, '2019-12-30 14:56:00+00:00'), (2019, 12, 52, '2019-12-31 04:50:00+00:00'), (2019, 12, 52, '2019-12-31 13:41:00+00:00'), (2019, 12, 52, '2019-12-31 14:42:00+00:00'), (2019, 12, 52, '2019-12-31 14:45:00+00:00'), (2019, 12, 52, '2019-12-31 15:56:00+00:00'), (2019, 12, 52, '2019-12-31 15:56:00+00:00'), (2019, 12, 52, '2019-12-31 15:58:00+00:00'), (2019, 12, 52, '2019-12-31 15:58:00+00:00')], names=['year', 'month', 'week', 'date'])これにより、各年毎に週単位の集計が可能になりました。
参考サイト
同じ悩みに対する解決策が大変参考になりました。感謝!
Pandas - wrong week extracted week from date

- 投稿日:2021-01-05T22:06:14+09:00
datetime形式のindexで設定される週を修正する
はじめに
時系列データを処理するに辺り、pandasでindexをdatetimeにすると便利だが、indexから週を抽出する際に、例えば2019/12/30と12/31など最終週が2019年の第1週となってしまうため、これを修正する方法を調べた備忘録である。
問題点
12月最終週と翌年1月最初の週は同じ週となる。週番号の付け方は色々あるらしいが、pandasではISO準拠のヨーロッパ式のようであり、その週の平日から第1週目と認識される。
しかし、2019/12/30, 31は df.index.yaer -> 2019、df.index.week -> 1 となるため、2019年の第1週と認識されてしまうため、週単位でのデータ集計などの処理に都合が悪い。
下記のようなdatetime形式のindexを例に示す。
df.indexDatetimeIndex(['2019-12-29 22:00:00+00:00', '2019-12-29 22:00:00+00:00', '2019-12-29 22:00:00+00:00', '2019-12-29 22:00:00+00:00', '2019-12-29 22:00:00+00:00', '2019-12-29 22:08:00+00:00', '2019-12-29 23:00:00+00:00', '2019-12-30 01:47:00+00:00', '2019-12-30 02:48:00+00:00', '2019-12-30 02:48:00+00:00', '2019-12-30 12:34:00+00:00', '2019-12-30 14:51:00+00:00', '2019-12-30 14:53:00+00:00', '2019-12-30 14:56:00+00:00', '2019-12-31 04:50:00+00:00', '2019-12-31 13:41:00+00:00', '2019-12-31 14:42:00+00:00', '2019-12-31 14:45:00+00:00', '2019-12-31 15:56:00+00:00', '2019-12-31 15:56:00+00:00', '2019-12-31 15:58:00+00:00', '2019-12-31 15:58:00+00:00'], dtype='datetime64[ns, UTC]', name='date', freq=None)このデータフレームに対して、下記のようにMultiIndexを設定すると、12/29は52週なのに対して、12/30, 31は2019年の第1週になってしまう事が確認できる。
df_w = df.set_index([df.index.year, df.index.month, df.index.week, df.index]) df_w.index.names = ['year', 'month', 'week', 'date'] df_w.sort_index(inplace=True) df_w.indexMultiIndex([(2019, 12, 1, '2019-12-30 01:47:00+00:00'), (2019, 12, 1, '2019-12-30 02:48:00+00:00'), (2019, 12, 1, '2019-12-30 02:48:00+00:00'), (2019, 12, 1, '2019-12-30 12:34:00+00:00'), (2019, 12, 1, '2019-12-30 14:51:00+00:00'), (2019, 12, 1, '2019-12-30 14:53:00+00:00'), (2019, 12, 1, '2019-12-30 14:56:00+00:00'), (2019, 12, 1, '2019-12-31 04:50:00+00:00'), (2019, 12, 1, '2019-12-31 13:41:00+00:00'), (2019, 12, 1, '2019-12-31 14:42:00+00:00'), (2019, 12, 1, '2019-12-31 14:45:00+00:00'), (2019, 12, 1, '2019-12-31 15:56:00+00:00'), (2019, 12, 1, '2019-12-31 15:56:00+00:00'), (2019, 12, 1, '2019-12-31 15:58:00+00:00'), (2019, 12, 1, '2019-12-31 15:58:00+00:00'), (2019, 12, 52, '2019-12-29 22:00:00+00:00'), (2019, 12, 52, '2019-12-29 22:00:00+00:00'), (2019, 12, 52, '2019-12-29 22:00:00+00:00'), (2019, 12, 52, '2019-12-29 22:00:00+00:00'), (2019, 12, 52, '2019-12-29 22:00:00+00:00'), (2019, 12, 52, '2019-12-29 22:08:00+00:00'), (2019, 12, 52, '2019-12-29 23:00:00+00:00')], names=['year', 'month', 'week', 'date'])改善策
参考サイトに私の求める解決策があり、自分のケースにあてはめました。
1. 一旦indexを解除
2. dt.weekで週を抽出
3. 強制的に52週に変更
4. indexを再設定df.reset_index(inplace=True) df["year"] = df["date"].dt.year df["month"] = df["date"].dt.month df["week"] = df["date"].dt.week df["week"] = df["date"].apply( lambda x: 52 if x.year == 2019 and x.day in [30, 31] else x.week) df_w = df.set_index([df["year"], df["month"], df["week"], df["date"]]) df_w.index.names = ['year', 'month', 'week', 'date'] df_w.sort_index(inplace=True) df_w.indexMultiIndex([(2019, 12, 52, '2019-12-29 22:00:00+00:00'), (2019, 12, 52, '2019-12-29 22:00:00+00:00'), (2019, 12, 52, '2019-12-29 22:00:00+00:00'), (2019, 12, 52, '2019-12-29 22:00:00+00:00'), (2019, 12, 52, '2019-12-29 22:00:00+00:00'), (2019, 12, 52, '2019-12-29 22:08:00+00:00'), (2019, 12, 52, '2019-12-29 23:00:00+00:00'), (2019, 12, 52, '2019-12-30 01:47:00+00:00'), (2019, 12, 52, '2019-12-30 02:48:00+00:00'), (2019, 12, 52, '2019-12-30 02:48:00+00:00'), (2019, 12, 52, '2019-12-30 12:34:00+00:00'), (2019, 12, 52, '2019-12-30 14:51:00+00:00'), (2019, 12, 52, '2019-12-30 14:53:00+00:00'), (2019, 12, 52, '2019-12-30 14:56:00+00:00'), (2019, 12, 52, '2019-12-31 04:50:00+00:00'), (2019, 12, 52, '2019-12-31 13:41:00+00:00'), (2019, 12, 52, '2019-12-31 14:42:00+00:00'), (2019, 12, 52, '2019-12-31 14:45:00+00:00'), (2019, 12, 52, '2019-12-31 15:56:00+00:00'), (2019, 12, 52, '2019-12-31 15:56:00+00:00'), (2019, 12, 52, '2019-12-31 15:58:00+00:00'), (2019, 12, 52, '2019-12-31 15:58:00+00:00')], names=['year', 'month', 'week', 'date'])これにより、各年毎に週単位の集計が可能になりました。
参考サイト
同じ悩みに対する解決策が大変参考になりました。感謝!
Pandas - wrong week extracted week from date
- 投稿日:2021-01-05T21:37:22+09:00
Python+Nimのハイブリッド環境(Nimporter)で、PyInstallerによる実行ファイル(EXE)を作成する
ずっと気になっていたハイブリッド環境
こちらの記事にて、nimporterなるクールなライブラリがあると知り、ほんわかなコメントをしたものの、ずっと気になっていたので検証してみました。
サンプルソースはこちら。
PyInstallerの記事もQiita内にたくさんありますので、そちらも参照いただければと。
環境
PyInstallerとpyenvやらvirtualenv系とは相性が悪いらしいので、Pythonは仮想環境なしで動作させています。
- Windows 10
- Nim 1.4.2
- Python 3.9
- PyInstaller 4.1
- Nimporter 1.0.2
- Visual Studio Community 2019
開発時のトラブルなど
- NimporterがWindows環境だとVCCを使う設定になっているようなので、VisualStudioのCommunity Editionを入れました。
- PyInstallerが起動しないため、PythonインストールフォルダのScriptsフォルダにもパスを通したりしていました。
まずはNimporterで遊ぶ
今回のサンプルのディレクトリ構成はこちら。
ファイル・フォルダ 説明 └─ nimporter-sample プロジェクトディレクトリ ├─nimutils nimソース用パッケージ │ ├─ __init__.pyお約束ファイル │ ├─ calc.nim 計算サンプル │ ├─ thread_test.nim スレッドサンプル │ └─ uuid.nim 別ライブラリ呼び出しサンプル ├─ nimporter_sample.py メインのPythonスクリプト └─ nimporter_sample.spec.sample PyInstaller用Specファイルのサンプル Pythonからパッケージ内のNimモジュールをインポートする
Pythonファイルと同じディレクトリになくても、パッケージ(フォルダ)内にあるNimのメソッドへのアクセスも、通常のPythonと同じようにできます。
nimutils/calc.nimimport nimpy import strformat proc add(a: int, b: int): int {.exportpy.} = echo fmt("{ a + b = }") return a + bnimporter_sample.pyimport nimporter from nimutils import calc # nimutils/calc.nimをインポート # call nim method print(calc.add(2, 4)) # 6Nimbleでインストールしたモジュールを利用してみる
あらかじめnimbleコマンドでインストールした
nuuidというモジュールを、nimソースでインポートし、実行結果をPythonに返すということもできます。# モジュールインストール $ nimble install nuuidnimutils/uuid.nimimport nimpy import strformat import nuuid # import uuid library proc generate(): string {.exportpy.} = return generateUUID()nimporter_sample.pyimport nimporter from nimutils import uuid print(uuid.generate())PythonからNimのマルチスレッドを実行してみる
こちらも問題なく動作しました。
nimutils/calc.nimimport nimpy import strformat import os proc threadFunc(param: tuple[a, b: int]) {.thread.} = echo fmt("This is Thread-{param.a}") proc threadTest(): int {.exportpy.} = var thr: array[0..1, Thread[tuple[a, b: int]]] echo "start threads" defer: echo "wait threads" thr[0].createThread(threadFunc, (1, 1000)) thr[1].createThread(threadFunc, (2, 1000)) sleep(1000) joinThreads(thr)nimporter_sample.pyfrom nimutils import thread_test # スレッド生成&実行しているメソッドを呼び出す thread_test.threadTest()ただし、PythonのスレッドからNimのメソッドは呼べないようです。(Issueはこちら)
そのため、現在のところNimporterを利用する場面においては、Pythonのメインスレッドからしか呼べないようです。
Webフレームワークでリクエストハンドラの中からNimのモジュールを呼ぶっていうことはできないみたいですね。PyInstallerによるシングルExeファイルの作成
上記3パターンの呼び出しを行ったPythonファイルを、PyinstallerにてExe化し、別のWindows10環境でも動作することを確認します。
1発でExeが出来上がらないので、以下の手順で作成していきます。
- Pyinstallerを起動し、Specファイルを作成
- Pydファイル情報をSpecファイルに追加する
- PyinstallerをSpecファイルで起動し、Exeファイルを作成
- エラーが出たら足りないモジュールをSpecファイルに追加
以下、Exe起動時にエラーが出なくなるまで、3,4を繰り返します。
Specファイルの作成
シンプルな構成のPythonスクリプトであれば、Pyinstallerで1発でEXEファイルができるかもしれませんが、Pyinstallerを起動して生成されるSpecファイルを適切に修正して、Exeを作る環境を整えていきます。
まずは、エントリポイントとなるPythonスクリプトを指定して、PyInstallerを実行すると、スクリプトと同じフォルダにspecファイルが生成され、distフォルダにもExeファイルが出来上がります。
ただし、出来上がったExeファイルを起動してもエラーが出て終了してしまうため、生成されたSpecファイルに足りないモジュールなどを記述していきます。$ pyinstaller nimporter_sample.py --onefile ・・・ $ dir dist 2021/01/04 19:36 <DIR> . 2021/01/04 19:36 <DIR> .. 2021/01/04 19:36 7,725,805 nimporter_sample.exe 1 File(s) 7,725,805 bytes 2 Dir(s) 232,853,856,256 bytes free $ dist\nimporter_sample.exe # 起動するとエラーが発生してしまう Traceback (most recent call last): File "nimporter_sample.py", line 1, in <module> import nimporter File "c:\apps\python\python39\lib\site-packages\PyInstaller\loader\pyimod03_importers.py", line 493, in exec_module exec(bytecode, module.__dict__) File "nimporter.py", line 13, in <module> File "c:\apps\python\python39\lib\site-packages\PyInstaller\loader\pyimod03_importers.py", line 493, in exec_module exec(bytecode, module.__dict__) File "setuptools\__init__.py", line 24, in <module> File "c:\apps\python\python39\lib\site-packages\PyInstaller\loader\pyimod03_importers.py", line 493, in exec_module exec(bytecode, module.__dict__) File "setuptools\depends.py", line 6, in <module> ModuleNotFoundError: No module named 'setuptools.py33compat' [431764] Failed to execute script nimporter_samplePydファイルをSpecのbinariesに追加する
Nimporterが生成するのは、Python拡張モジュール(拡張子がpyd)なので、これをPyinstallerがExeモジュールに含めるように修正します。
Specファイルは、実際はPythonスクリプトであるため、Pythonのコードを記述して設定ファイルを修正することができます。今回のサンプルでは、
nimutilsフォルダ内にNimファイルを配置したので、nimutils\__pycache__フォルダにpydが出力されたので、Specファイルを以下のように修正します。nimporter_sample.spec# -*- mode: python ; coding: utf-8 -*- import os curDir = os.getcwd() cacheDir = os.path.join(curDir, 'nimutils', '__pycache__') pydDir = os.path.join('.', 'nimutils') block_cipher = None a = Analysis(['nimporter_sample.py'], pathex=[curDir], # nimporter が生成したpydファイルをバイナリとして追加する binaries=[ (os.path.join(cacheDir, 'calc.pyd'), pydDir), (os.path.join(cacheDir, 'thread_test.pyd'), pydDir), (os.path.join(cacheDir, 'uuid.pyd'), pydDir), ],バイナリファイルの設定は複数指定でき、ファイル毎にタプルで指定
(Pydファイルの場所, EXE起動時にどこに配置するか)します。
今回の例だと、nimutils/__pycache__/に入っているpydファイルを、Exe起動時にはnimutilsフォルダに展開せよという指定です。
展開後も__pycache__フォルダなのでは?と思ったのですが、Exe実行時は__pycache__フォルダにpydがあったとしてもそちらからは読み込まないようです。PyinstallerをSpecファイルで起動し、Exeファイルを作成
PyInstaller の引数に、Specファイルを指定して実行します。
# Specファイルを指定して実行 $ pyinstaller nimporter_sample.spec # distにできたExeを起動する $ dist\nimporter_sample.exeエラーが出たら足りないモジュールをSpecファイルに追加
PyInstallerで作成したExeを起動した際に、以下のようなエラーが出た場合、PyInstallerのSpecファイルの
hiddenimportsに、モジュール名を追加することで、エラーが解消されます。ModuleNotFoundError: No module named 'setuptools.py33compat'何度か繰り返し、2つのモジュールをhiddenimportsに追加することでエラーが出なくなりました。
nimporter_sample.spechiddenimports=['setuptools.py33compat','setuptools.py27compat'],実行の様子
雑なキャプチャですが、ご参考まで。
まとめ
Nimporterを利用したPythonスクリプトをPyInstallerでExe化する手順を紹介しました。
ポイントとしては、Nimporterが生成したPydファイルをバイナリとして含めてあげることでしたね。PythonのマルチスレッドからはNimporterで作成したモジュールは呼べない制限があるものの、Pythonの魅力的なライブラリを利用し、高速処理させたい部分をNimで作成するなど、ちょっとしたユーティリティをExeとして配布できるのは魅力的な環境ではないでしょうか。
とはいえ、本番で利用できる技術ではなく、ホビーユース(趣味的)な利用に限られるとは思いますが。
参考にしたサイト
https://qiita.com/rebellious-wimp/items/61f16389f957b2ace163

- 投稿日:2021-01-05T21:13:14+09:00
【競プロ】株の売り買い問題総まとめ
実世界での株取引では,刻一刻と変化する株の値を見ながら,新たな株を買ったり自分の所有する株を売ったりしてより多くの利益を得ることを目指します.
もちろん株の値動きを予測するのはとても難しく,この記事もそれを目指している訳ではありません.実際の状況では未来の値動きはわからないのですが,今回はこれを単純化し,値動きを記録した数値の列が与えられたときに,いつ「売り」や「買い」を行えば最も高い利益を得られるかを考えます.
問題設定
これは,各時刻での株価が入った配列を入力として,そこから得られる最大利益を出力するような関数を設計する問題になります.
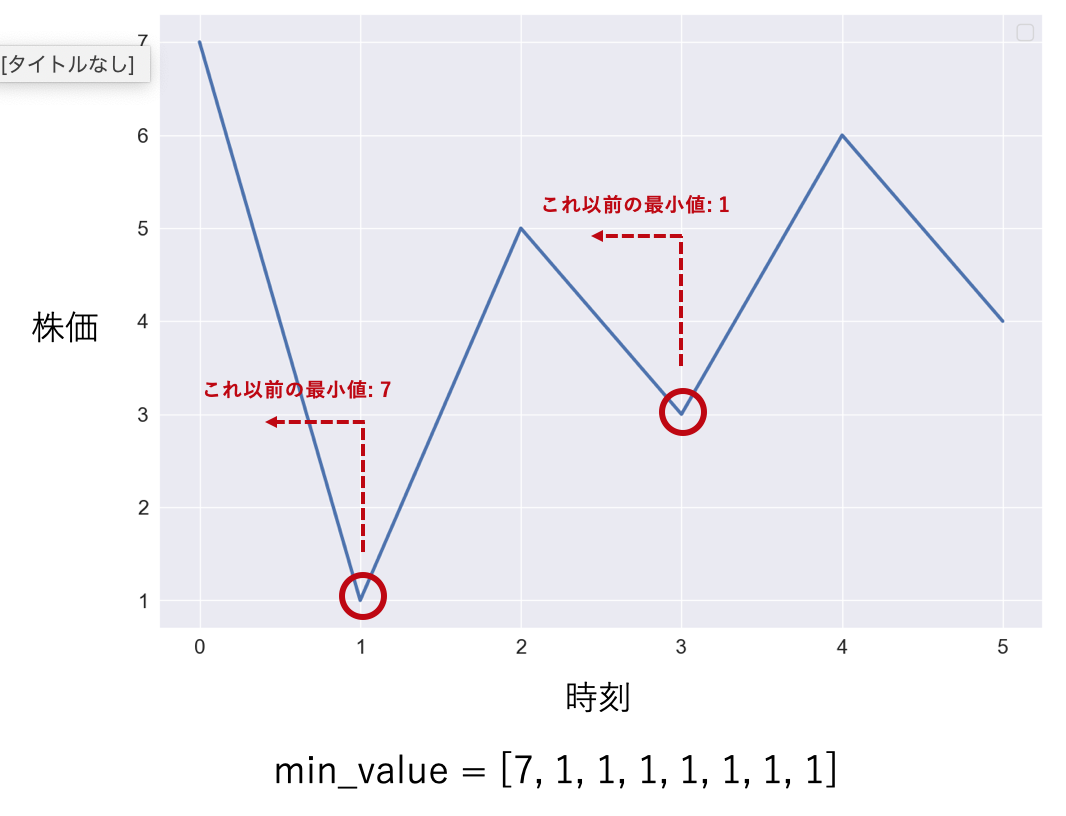
def calculate_max_profit(prices: List[int]) -> int: ... return max_profit例えば上のグラフだと入力は
prices = [7,1,5,3,6,4]のようになります.基本的なルールは以下のようなものです.
- 各時刻で買う操作と売る操作のどちらかを行うことができる(何もしなくても良いが両方同時刻にはできない).
- 買う前に売ることはできない
- 買う操作と売る操作は交互にしなければならない(買う→売る→買う→売る...としなければいけない).
- ある時刻に株を買えばその時刻での株価が持ち金から引かれ,ある時刻に株を売ればその時刻での株価分のお金を得ることができる.
- 最初の持ち金は0.持ち金は0以下になってもよい.
- 最終的な持ち金の額を最大化したい.
あらかじめ各時刻の値段がわかっていればすぐ計算できそう感じもしますが,問題が複雑になればそう簡単にはいきません.条件の違いによって様々なパターンがあるので,この記事ではそれを一挙に紹介します.
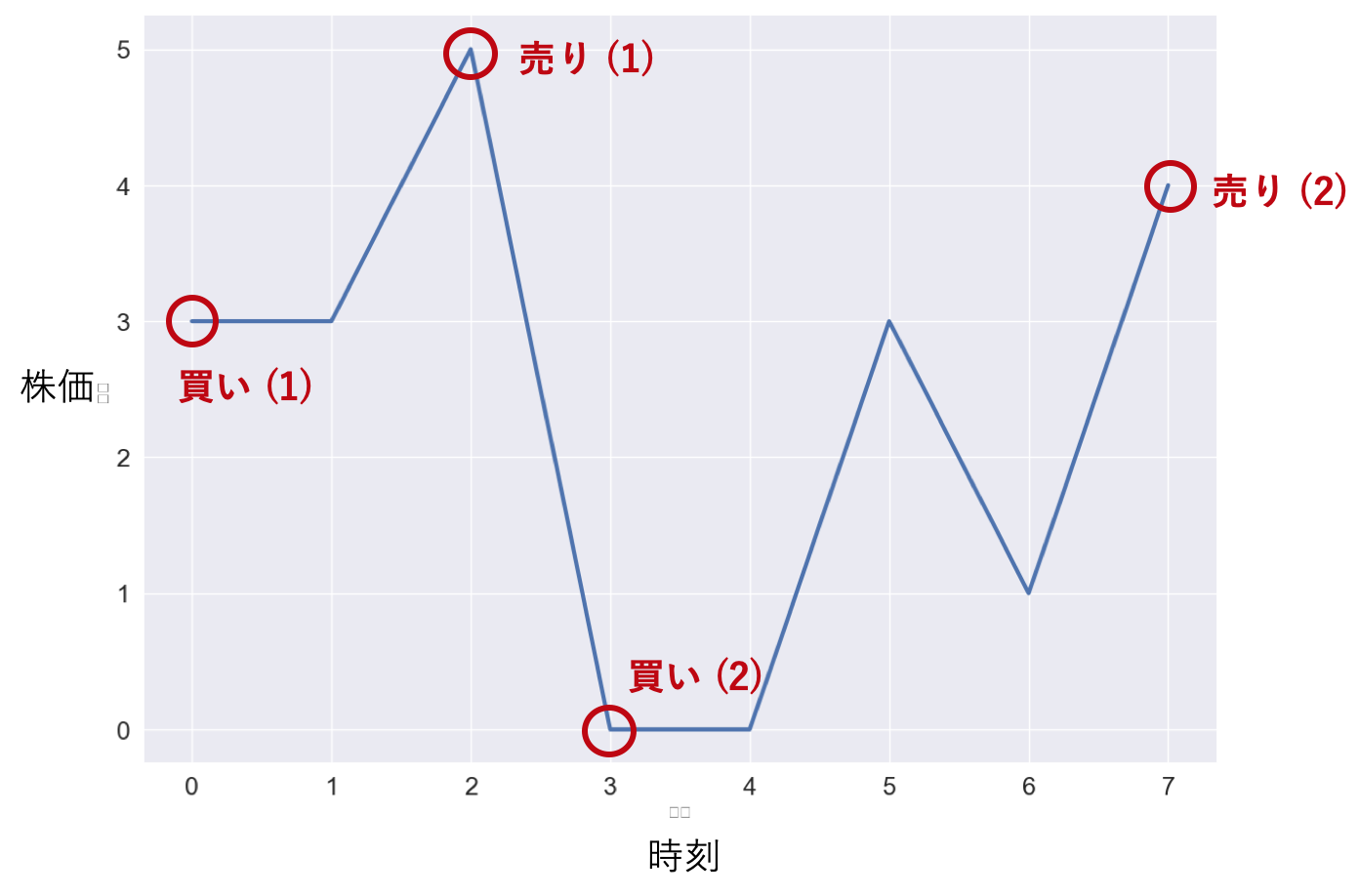
Case 1: 1回だけ売り買いできる場合
まず,最も基本的な場合として,買う操作と売る操作を1度ずつしかできない場合を考えます.例えば,$prices = [7,1,5,3,6,4]$の場合は,最初の図に書いたように時刻$t=1$で買い,時刻$t=4$で売ることで最大利益5を得ることができます(最初を$t=0$としています).ルール上,先に$t=0$で売って$t=1$で買うことで利益6を得る,というようなことはできません.一方,もし$prices = [7,6,4,3,1]$であれば,一度も売り買いをしない場合に利益が0で最大になることがわかります.
最も基本的な解き方は,買う時刻と売る時刻を全探索することです.
def calculate_max_profit(prices: List[int]) -> int: n = len(prices) max_profit = 0 for i in range(n): # 買う時刻 for j in range(i+1, n): # 売る時刻 max_profit = max(max_profit, prices[j] - prices[i]) # 最大利益を更新 return max_profitこの方法では,$prices$の長さを$n$として$O(n^2)$の時間計算量となります.
ここから時間計算量を抑える方法を考えます.まず,ある時点$t = i$で株を売ることを考えます.ここで売ることを決めている場合,いつ株を買っていることが望ましいでしょうか?それは$t = i$より前で最も株価が安い時です.つまり,$t = i$以前での株価の最小値がわかっていれば,その差が得られる利益の最大値となるのです.ということは$prices$を走査する間,最小値さえ保持していれば計算することができます.
def calculate_max_profit(prices: List[int]) -> int: n = len(prices) min_value = float("inf") max_profit = 0 for i in range(n): # iは売る時刻 max_profit = max(max_profit, prices[i] - min_value) min_value = min(min_value, prices[i]) # 最小値を更新 return max_profitこれで時間計算量は$O(n)$,空間計算量は$O(1)$に抑えられます.また,各時点での利益が0以下になる場合は$max\_profit = 0$となり,売り買いをしないほうがいいという結果が得られます.
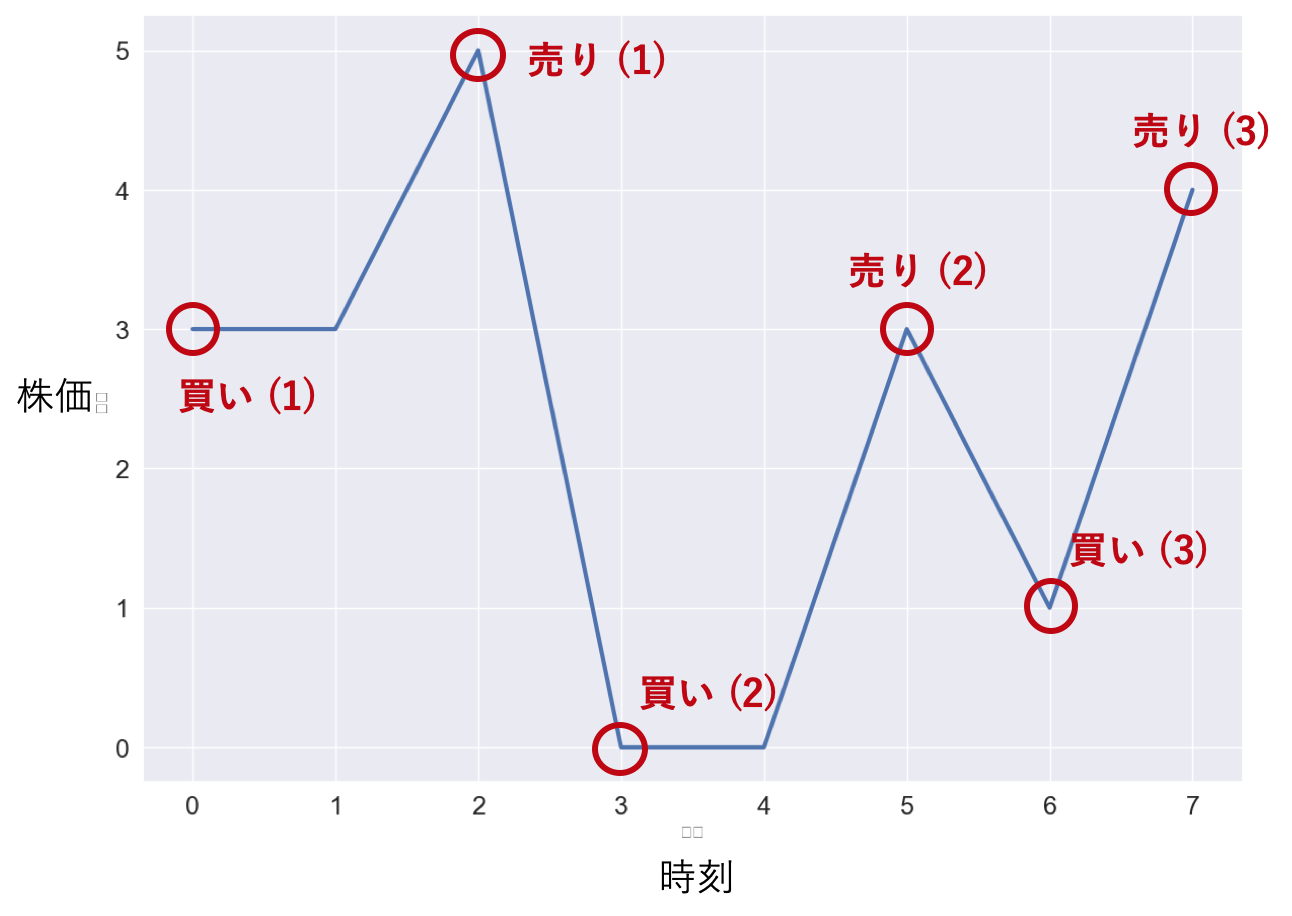
Case 2: 2回まで売り買いできる場合
次は,売り買いできる回数を2回ずつまでという条件に変えてみます.$prices$の中で「買→売→買→売」を行うことができます.例えば,
prices = [3,3,5,0,0,3,1,4]に対しては,$t=0$で買(-3)→$t=2$で売(+5)→$t=3$で買(-0)→$t=7$で売(+4),の手順で最大利益6を得ることができます.
1回のみの取引に対して複雑さが増しました.最も単純な計算方法はやはりそれぞれの操作のタイミングを全探索することですが,計算量は$O(n^4)$となり現実的ではありません.ここで,ある時点$t=i$で1度目の「売り」を行うことを考えます.この売りに対して1度目の「買い」をいつ行えば良いのかはCase 1と同じ方法で求めることができます.では,これ以降2回目の売り買いの最大利益はどのように計算できるでしょうか?それは,$prices$の$t=i+1$以降の部分に対してもう一度同じ操作をしてやればいいのです.
擬似的には以下のようなコードになるでしょう.def calculate_max_profit_twice(prices: List[int]) -> int: min_value = float("inf") max_profit = 0 for i in range(n): current_profit = (prices[i] - min_value) + calculate_max_profit_once(prices[i+1:]) max_profit = max(max_profit, current_profit) min_value = min(min_value, prices[i]) return max_profit$calculate\_max\_profit\_once()$関数はCase 1の関数だと考えてください.この場合計算量は$O(n^2)$まで抑えることができました.
しかしまだ無駄な操作があります.$calculate\_max\_profit\_once()$は毎回同じような計算をしているのです.例えば,$t = i$以降の最大利益の計算と$t = i+1$以降の最大利益の計算はほとんど同じような操作を行なっているはずです.
この部分の無駄な計算を削減するために,ある時点$t = j$で2回目の株の「買い」を行うことに決めた場合を考えます.すると,この株を売るタイミングはいつが最適でしょうか?もちろん$t = j$以降で株が最も高くなる時刻です.これはCase 1と逆の状況と言えます.つまり,$t = j$以降の最大値を記録しておくことで,$t = j$での株を買うときの最大利益が求まります.
よって具体的には,はじめに各$j$以降で行われる2回目の取引の最大利益を配列$second\_trans\_max$に保存しておきます.その後$t = i$における1回目の取引の最大値をCase 1のように求め,$second\_trans\_max[i+1]$を加算することで,2回分の最大利益を求めることができるのです.def calculate_max_profit(prices: List[int]) -> int: n = len(prices) if n < 2: return 0 # 2回目の取引の最大利益を先に計算 second_trans_max = [0]*(n+1) max_after = float("-inf") for i in reversed(range(n)): second_trans_max[i] = max(max_after - prices[i], second_trans_max[i+1]) # 2回目の取引の最大利益 max_after = max(max_after, prices[i]) # これ以降の最大値の更新 # 1回目の取引の最大利益を計算 max_profit = first_trans_max = 0 min_before = prices[0] for i in range(1, n): first_trans_max = max(prices[i]-min_before, first_trans_max) # 1回目の取引の最大利益 max_profit = max(first_trans_max + second_trans_max[i+1], max_profit) # 全体の最大利益 min_before = min(min_before, prices[i]) # これ以前の最小値の更新 return max_profitなお,このコードには取引回数が0回,1回の場合も包含されています.これによって時間計算量は$O(n)$に減らすことができました.一方$second\_trans\_max$を保持する分,空間計算量は$O(n)$となります.
Case 3: 何回でも売り買いできる場合
続いて,何度でも制限なく売り買いができる場合を考えます.回数制限がなくなった分あらゆる可能性を考える必要が出てきて,問題がより複雑になったように感じますが,実はこの設定は難しくはありません.値が下がりそうになったらその前に売り,値が上がりそうになったら一番安い時に買う,という操作を繰り返すだけで良いのです.
def calculate_max_profit(prices: List[int]) -> int: n = len(prices) valley = peak = prices[0] max_profit = 0 idx = 0 while idx < n-1: while idx < n-1 and prices[idx] >= prices[idx+1]: idx += 1 valley = prices[idx] while idx < n-1 and prices[idx] <= prices[idx+1]: idx += 1 peak = prices[idx] max_profit += peak - valley return max_profitこのコードは要するに値動きの頂上と谷底を探して記録しているだけです.これは直感的にも妥当な戦略ですが,次のように考えることもできます.例えば,$t = i$で株を買い,$t = j$で株を売るとします.もし,$i$から$j$までの間で(広義の)単調増加ではなく$prices[a] > prices[b] ~~(a < b)$となっていた時,$t=a$で売り,$t=b$で買いの操作を入れたほうがより利益を大きくすることができます.つまり,増減が入れ替わる点で常に売り買いを行うべきということになります.
なお,これは結局,「隣の株価が現時刻より大きければ利益に加算し,小さければ加算しない」という計算を行なっているのと同じです.これを凝縮すると解答を1行で書くこともできます.def calculate_max_profit(prices: List[int]) -> int: return sum([max(a-b, 0) for a, b in zip(prices[1:], prices[:-1])]) if prices else 0ここでは増加分のみを足し合わせるために,隣接する値の差を取っています.いずれのコードも時間計算量は$O(n)$,空間計算量は$O(1)$となります.
Case 4: k回まで売り買いできる場合
続いてはいよいよこの記事の山場,売り買いの回数の上限が$k$回と決まっている場合です.これはCase 1やCase 2の一般形と言えます.ただし,$k$が3,4,5...となっていった場合,Case 1や2と同じように計算することはできません.またCase 3のようにただ増減のみを見て決定することができません.
ここで,解法を考える前にまず整理しておきたいのは,$k$が大きい時です.極端な話,$n = 10, k = 100$だった場合,実質的にこれは制限なく取引できるCase 3と同じ状況です.Case 3とCase 4の境界線はどこでしょうか?それは$k = \frac{n}{2}$の時です.長さ$n$の中で取引できる最大回数は$\frac{n}{2}$回なので,$k$がそれより大きい場合はCase 3を解けば十分です.
それでは$k$がそこまで大きくない場合について改めて考えていきます.例えば,ある$t = i$において,$t = i$までに$j$回目の「売り」を終えた後の最大利益$max\_sell[i][j]$,$j$回目の「買い」を終えた後の最大利益$max\_buy[i][j]$がそれぞれの$j$についてわかっているとします.すると$t = i+1$における$max\_sell$や$max\_buy$は以下のように計算できます.
\begin{align} max\_buy[i+1][j] &= \max(max\_buy[i][j], max\_sell[i][j-1] - prices[i+1]) \\ max\_sell[i+1][j] &= \max(max\_sell[i][j], max\_buy[i][j] + prices[i+1]) \end{align}これは一体どういうことでしょうか?まず$max\_buy$について,$j$回目の「買い」はルール上$j-1$回目の「売り」の後に行われます.よって,$i$地点での$j-1$回目の「売り」が終わった段階での最大利益$max\_sell[i][j-1]$から,$i+1$地点での$j$回目の「買い」にかかった費用$prices[i+1]$を引きます.これを$i$地点の$j$回目の「買い」が終わった時点での最大利益$max\_buy[i][j]$と比較しているのです.同様に,$max\_sell$について,$j$回目の「売り」は$j$回目の「買い」の後に行われるので,$i$地点での$j$回目の「買い」が終わった段階での最大利益$max\_buy[i][j]$に,$i+1$地点での$j$回目の「売り」で得た利益$prices[i+1]$を足します.これを$i$地点の$j$回目の「売り」が終わった時点での最大利益$max\_sell[i][j]$と比較しています.
これはまさしく$i$と$j$に関する動的計画法(DP)です.初期値と漸化式を適切に設定すれば,あらゆる$i$と$j$に関する値を効率的に計算できます.def calculate_max_profit(prices: List[int]) -> int: n = len(prices) if k == 0: return 0 if k >= n//2: # Case 3の場合 max_profit = 0 for i in range(1, n): max_profit += max(0, prices[i] - prices[i-1]) return max_profit else: # 初期化 max_buy = [[float("-inf")]*(k+1) for _ in range(n)] max_sell = [[float("-inf")]*(k+1) for _ in range(n)] for i in range(n): max_sell[i][0] = max_sell[i][0] = 0 max_buy[0][1] = -prices[0] # DP for i in range(1,n): for j in range(k): max_sell[i][j+1] = max(max_sell[i-1][j+1], max_buy[i-1][j+1]+prices[i]) max_buy[i][j+1] = max(max_buy[i-1][j+1], max_sell[i-1][j]-prices[i]) # 全jのうちの最大利益を返す return max(max_sell[n-1])これの時間計算量,空間計算量はともに$O(nk)$です.また計算の順序をうまく考えることで,DPの際に使うメモリを削減することができます.
def calculate_max_profit(prices: List[int]) -> int: ## これ以前は上と同じ else: # 初期化 max_buy = [float("-inf")]*(k+1) max_sell = [float("-inf")]*(k+1) max_sell[0] = 0 for i in range(n): for j in reversed(range(k)): max_sell[j+1] = max(max_sell[j+1], max_buy[j+1] + prices[i]) max_buy[j+1] = max(max_buy[j+1], max_sell[j] - prices[i]) return max(max_sell)やっていること自体はどちらも同じですが,$max\_sell$と$max\_buy$を上書きすることで空間計算量を$O(k)$にできました.
※DPによる他の問題の解法
さて,この解法では「$i$地点で($k$回目の)「売り」「買い」をした後それぞれの状態での最大利益」を記録することで問題を解いています.この考え方を使ってこれまでの問題を解いてみます.Case 2に関しては,Case 4で$k = 2$になった特殊なケースなので,同じようにして解くことができます.
def calculate_max_profit(prices: List[int]) -> int: n = len(prices) max_buy1 = max_buy2 = float("-inf") max_sell1 = max_sell2 = 0 for i in range(n): max_sell2 = max(max_sell2, max_buy2 + prices[i]) max_buy2 = max(max_buy2, max_sell1 - prices[i]) max_sell1 = max(max_sell1, max_buy1 + prices[i]) max_buy1 = max(max_buy1, -prices[i]) return max(sell1, sell2)変数が4個で済み,空間計算量は$O(1)$になりました.また,Case 3も以下のように解くことができます.
def calculate_max_profit(prices: List[int]) -> int: max_sell, max_buy = 0, float("-inf") for i in range(n): sell, buy = max(sell, buy+prices[i]), max(buy, sell-prices[i]) return max_sell何回でも取引が可能なため回数$k$を考える必要がなくなり,$sell$と$buy$を同時に計算しています.
Case 5: 売り買いに料金がかかる場合
Case 4がこの記事のメインテーマだったのですが,それ以外のやや変化球の設定を2つほど紹介します.1つ目は「1回の取引(売り買い)に手数料がかかる」場合です.このケースでは何回でも自由に取引が可能としますが,得られる利益が少額だと手数料によって逆に損失が発生してしまいます.どのように考えれば良いのでしょうか?
実はこれは簡単で,Case 3において$max\_sell$を更新する際に$fee$を引くだけです.$max\_buy + prices[i] - fee$の大小に応じて取引を行うかを決めれば良いのです.
def calculate_max_profit(prices: List[int], fee: int) -> int: n = len(prices) max_sell, max_buy = 0, float("-inf") for i in range(n): max_sell, max_buy = max(max_sell, max_buy + prices[i] - fee), max(max_buy, max_sell - prices[i]) return max_sellCase 6: 連続では売り買いできない場合
最後に,「株を売ってから次買うまでに少なくとも一回分の間を入れないといけない」という条件を考えてみます.
この場合は,Case 3に対して休憩を表す状態$max\_stay$を追加します.そして更新式を以下のようにすれば,休憩を挟んでいる様子を表現できます.\begin{align} max\_sell[i+1] &= \max(max\_sell[i], max\_buy[i] + prices[i+1]) \\ max\_buy[i+1] &= \max(max\_buy[i], max\_stay[i] - prices[i+1]) \\ max\_stay[i+1] &= \max(max\_stay[i], max\_sell[i]) \end{align}max_sell[i+1]は$i$地点までの「買い」の最大利益$max\_buy[i]$に$i+1$地点での「売り」の利益$prices[i+1]$を足したもの,max_buy[i+1]は$i$地点までの休憩を挟んだ後の最大利益$max\_stay[i]$から$i+1$地点での「買い」のコスト$prices[i+1]$を引いたもの,max_stay[i+1]は$i$地点までの「売り」の最大利益$max\_sell[i]$から休憩状態に移行したものです.これをメモリを節約する形で書くと以下のようになります.
def calculate_max_profit(prices: List[int]) -> int: n = len(prices) max_stay, max_sell, max_buy = 0, 0, -float("inf") for i in range(n): max_stay, max_sell, max_buy = max(max_stay, max_sell), max(max_sell, max_buy + prices[i]), max(max_buy, max_stay - prices[i]) return max(max_stay, max_sell)まとめ
ここまで網羅的に株価売り買い系問題を見てきましたが,「各座標$i$までの$k$回目の売り買いの最大利益」を表す状態を計算することで多くの問題に対応できることがわかりました.この記事を読んだ方は万が一未来が見通せている状況なら株取引で最大利益をゲットできるようになったはずです.参考にした以下のサイトでコードを実際に動かしてみることができますので,興味を持った方は試してみてください!
参考(LeetCodeより)
Best Time to Buy and Sell Stock
Best Time to Buy and Sell Stock II
Best Time to Buy and Sell Stock III
Best Time to Buy and Sell Stock IV
Best Time to Buy and Sell Stock with Cooldown
Best Time to Buy and Sell Stock with Transaction Fee








- 投稿日:2021-01-05T21:12:21+09:00
root権限のないサーバーでpipでpython モジュールをインストールする
- 投稿日:2021-01-05T20:08:09+09:00
たのしいアスタリスク三角形
アスタリスクで三角形描きました。
Pythonは文字列がアスタリスクで繰り返しできるのでfor文ネストしなくていいから楽ですね。for i in range(1, 11, 1): print("*" * i) print() for i in range(10, 0, -1): print("*" * i) print() for i in range(1, 11, 1): print(" " * (10 - i) + "*" * i) print() for i in range(10, 0, -1): print(" " * (10 - i) + "*" * i)実行結果
* ** *** **** ***** ****** ******* ******** ********* ********** ********** ********* ******** ******* ****** ***** **** *** ** * * ** *** **** ***** ****** ******* ******** ********* ********** ********** ********* ******** ******* ****** ***** **** *** ** *
- 投稿日:2021-01-05T19:52:26+09:00
Rhinoceros with Python でLattice Hingeを書くプログラム
使い方
- drawlatticehinge.pyをdownload
- drawlatticehinge.pyを同じメインプログラムと同じディレクトリに保存
- メインプログラムでdrawlatticehinge.pyをimport
- パラメータを設定してdraw_lattice_follow_crosspointで描画
サンプルプログラム
SampleProgram.pyimport rhinoscriptsyntax as rs import drawlatticehinge as lh import math def clear_all(): all_obs = rs.ObjectsByType(0) rs.DeleteObjects(all_obs) clear_all() parameter = [37.5,0.2,0.4,1.5,10] lattice = lh.LatticeHinge(parameter) startPoint = (0,0,0) endPoint = (200,200,0) lattice.draw_lattice_follow_crosspoint(startPoint,endPoint)パラメータ
parameter = [37.5,0.2,0.4,1.5,10] LINE_LENGTH = parameter[0] #37.5# LINE_WIDTH = parameter[1] #0.2# OVERLAP_RATE = parameter[2] #0.4# LINE_INTERVAL = parameter[3] #1.5# INTERVAL_LIMIT = parameter[4] #10# cutAngle = (math.radians(90),math.radians(90),math.radians(90),math.radians(90))※コメント
LINE_LENGTH = 1本の線の長さ
LINE_WIDTH = 1本の線の幅( レーザーのカット幅なので0.2mm )
OVERLAP_RATE = 線の長さの重なり具合
LINE_INTERVAL = 線と線の間隔
INTERVAL_LIMIT = Latticeの繰り返し回数(この数値でlatticeの幅と数が決まる)実行結果
startPoint = (0,0,0) から endPoint = (200,200,0) までの間でLattice Hingeが描かれた


- 投稿日:2021-01-05T19:34:34+09:00
Linked List Cycleを理解する
はじめに
leetcodeでアルゴリズムの勉強を始めた際、Linked list(連結リスト)というデータ構造について勉強したのでメモしました。
配列と連結リストの違い
配列と連結リストについては、以下の記事が参考になります。
https://qiita.com/BumpeiShimada/items/522798a380dc26c50a50連結リストのイメージを掴むには、以下の記事が参考になります。
https://astrostory.hatenablog.com/entry/2020/02/24/070213LeetCodeの問題を解いてみる
問題文の詳細は、leetcodeにアクセスして確認してみてください。
https://leetcode.com/problems/linked-list-cycle/問題文の抜粋
Given a linked list, determine if it has a cycle in it.To represent a cycle in the given linked list, we use an integer pos which represents the position (0-indexed) in the linked list where tail connects to. If pos is -1, then there is no cycle in the linked list.
Example 1:
Input: head = [3,2,0,-4], pos = 1
Output: true
Explanation: There is a cycle in the linked list, where tail connects to the second node.
この問題では、与えられた連結リストが循環(ループ)している場合にTrueを返し、していない場合にFalseを返すという問題です。
この問題は他の記事でも解かれているのを見かけましたが、どういう風に連結リストを生成し、出力結果を返すかどうかという記事は見られなかったので、その部分の処理についても記述しました。
この問題で重要なのは、ListNodeで生成したノードオブジェクトのアドレスの繋がりを理解することです。
処理結果に関係のない部分はコメント文にしていますが、アドレスの繋がりを理解するためには適宜コメント文を外して確認すると良いと思います。
解法1 (HashSetを利用)
この解き方では、空集合にノードオブジェクト(アドレス)を頭から順番に追加していきます。集合に追加しようと思ったノードオブジェクトが既に入っていた場合、連結リストは循環しているとみなします。
class ListNode(object): def __init__(self, x): self.val = x self.next = None class Solution: def hasCycle(self, head): seen = set() curr = head # print(curr) while curr: # currがNoneでない限りループ if curr in seen: # print(curr) return True seen.add(curr) # print(seen) curr = curr.next # print(curr) return False # head = [3,2,0,-4] # pos = 1 # posはパラメータではなく、最後の要素がどこに戻るかを示す。(この場合、最後の-4は1番目の要素の2に戻る) # 循環する連結リストの作成 links = ListNode(3) # print(vars(links)) links.next = ListNode(2) # print(vars(links)) # print(vars(links.next)) links.next.next = ListNode(0) # print(vars(links.next)) # print(vars(links.next.next)) links.next.next.next = ListNode(-4) links.next.next.next.next = links.next # 2に戻る(循環させる) # print(vars(links.next.next.next)) # print(vars(links.next.next.next.next)) # 循環を確認 # print(vars(links.next.next.next.next.next)) obj = Solution() print(obj.hasCycle(links)) # 循環している場合、True解法2 (速度の違うポインタを利用)
この解き方では、一つ一つノードを遷移するslowと、一つ飛ばしでノードを遷移するfastというポインタを用意します。連結リストが循環している場合、異なる速度で遷移するslowとfastはやがて同じアドレスを指します。このことより、循環しているかを判断します。
class ListNode(object): def __init__(self, x): self.val = x self.next = None class Solution: def hasCycle(self, head: ListNode) -> bool: if not head: # leetcodeではtestcaseにnullを含む場合あるので記述 return False slow = head #一つ先のポインタへ fast = head.next #二つ先のポインタへ # print(slow, fast) while slow != fast: # slowとfastが同じアドレスを指さない限りループ(循環していれば、速度の違うslowとfastはいずれ同じアドレスを指す) if not fast or not fast.next: # fastとfastの次がnullの場合はlinked-listは終わっているのでFalseを返す return False slow = slow.next fast = fast.next.next print(slow, fast) return True # slowとheadが同じノードに到達すればループ # head = [3,2,0,-4] # pos = 1 # posはパラメータではなく、最後の要素がどこに戻るかを示す。(この場合、最後の-4は1番目の要素の2に戻る) # 循環ex links = ListNode(3) # print(vars(links)) links.next = ListNode(2) # print(vars(links)) # print(vars(links.next)) links.next.next = ListNode(0) # print(vars(links.next)) # print(vars(links.next.next)) links.next.next.next = ListNode(-4) links.next.next.next.next = links.next # 2に戻る(循環させる) # print(vars(links.next.next.next)) # print(vars(links.next.next.next.next)) # 循環を確認 # print(vars(links.next.next.next.next.next)) # 最初のslowとfastのアドレスがそれぞれlinksとlinks.nextに一致するか確認 # print(links) # print(links.next) obj = Solution() print(obj.hasCycle(links)) # 循環している場合、True # 遷移の確認 # slow(一個一個進む):3,2,0,-4 # fast(一つとばし): 2,-4,0 (2,0,-4でループより) # よって、slowとfastは2回の遷移で同じノード0のアドレスになり、循環を確認追記
連結リストの作成は、以下のようにループ処理でも可能です。上記のlinksがheadに対応しています。
# 循環する連結リストの作成方法2 data = [3,2,0,-4] # pos = 1 # posはパラメータではなく、最後の要素がどこに戻るかを示す。(この場合、最後の-4は1番目の要素の2に戻る) # ループで連結リストを作成 tail = head = ListNode(data[0]) for i in data[1:]: tail.next = ListNode(i) # アドレスは1回目でhead.next、2回目でhead.next.next,3回目でhead.next.next.next tail = tail.next head.next.next.next.next = head.next # # 確認 # print(vars(head)) # print(vars(head.next)) # print(vars(head.next.next)) # print(vars(head.next.next.next)) # print(vars(head.next.next.next.next))まとめ
最初、アドレスの遷移をイメージするまでに時間がかかったが、わかると結構単純でした。leetcodeを利用してどんどんアルゴリズムの勉強を進めていきたいです。
参考

- 投稿日:2021-01-05T19:23:10+09:00
Python PCA 主成分分析
PointCloudからロボットアームで把持をするのに使えそうな第二主成分を求める
pca.pyimport numpy as np import scipy as sp from sklearn.datasets import make_classification from sklearn.decomposition import PCA import matplotlib.pyplot as plt # サンプルデータを生成 X, y = make_classification(n_samples=200, n_features=2, n_redundant=0, n_informative=2, n_classes=1, n_clusters_per_class=1, random_state=0) # 主成分分析 pca = PCA(n_components=2) pca.fit(X) # 可視化 plt.scatter(X[:, 0], X[:, 1], alpha=0.5) l = pca.explained_variance_[1] vector = pca.components_[1] v = vector * 3 * np.sqrt(l) plt.annotate('', pca.mean_ + v, pca.mean_ - v, arrowprops=dict(connectionstyle='arc3', width=2)) plt.axis('equal') plt.show()結果
参考
https://hawk-tech-blog.com/python-machine-learning-basic-pca/

- 投稿日:2021-01-05T19:23:10+09:00
ロボットの把持位置(Python PCA 主成分分析)
- 2次元のデータの第二主成分を求める
- PointCloudで認識した物体の点群からロボットの把持位置を求めるときに使えそう
pca.pyimport numpy as np import scipy as sp from sklearn.datasets import make_classification from sklearn.decomposition import PCA import matplotlib.pyplot as plt # サンプルデータを生成 X, y = make_classification(n_samples=200, n_features=2, n_redundant=0, n_informative=2, n_classes=1, n_clusters_per_class=1, random_state=0) # 主成分分析 pca = PCA(n_components=2) pca.fit(X) # 可視化 plt.scatter(X[:, 0], X[:, 1], alpha=0.5) l = pca.explained_variance_[1] vector = pca.components_[1] v = vector * 3 * np.sqrt(l) plt.annotate('', pca.mean_ + v, pca.mean_ - v, arrowprops=dict(connectionstyle='arc3', width=2)) plt.axis('equal') plt.show()結果
参考
https://hawk-tech-blog.com/python-machine-learning-basic-pca/
- 投稿日:2021-01-05T19:08:27+09:00
manimの作法 その10
概要
manimの作法、調べてみた。
add_updater、使ってみた。サンプルコード
from manimlib.imports import * class test(Scene): def construct(self): self.t_offset = 0 dot = Dot() rate = 0.25 orbit = Circle() def around_circle(mob, dt): self.t_offset += (dt * rate) mob.move_to(orbit.point_from_proportion(self.t_offset % 1)) dot.add_updater(around_circle) self.add(dot) self.wait(5)動画
https://www.youtube.com/watch?v=c5djg93rWjg
以上。
- 投稿日:2021-01-05T18:46:04+09:00
UIFlowでM5Stackはじめーる
はじめに
積まれていたM5Stackをすぐに始めるための備忘録です。
開発環境
- M5Stack
- Windows 10 PC
導入
1.UIFlow Quick Startを参考にします
2.ドライバーをインストールします
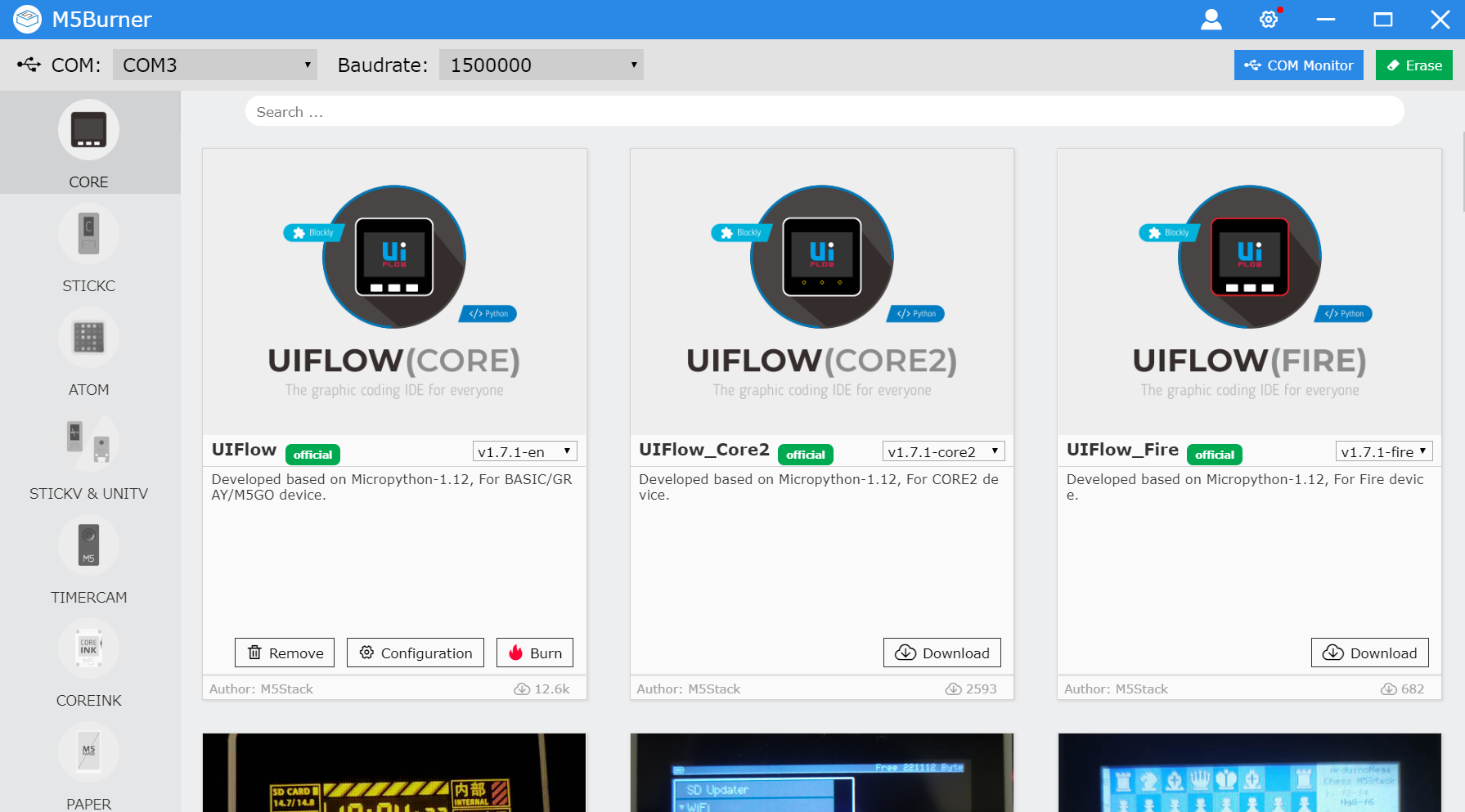
3.M5Burnerを起動します
4.UIFLOW(CORE)のファームウェアをBurnします
5.自宅のWiFiを設定します
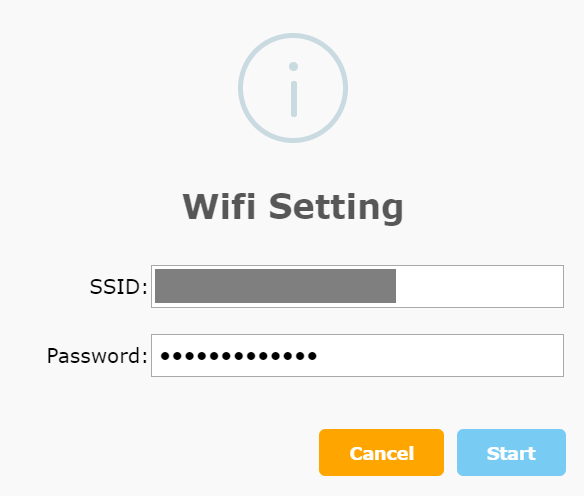
6.Burn成功です
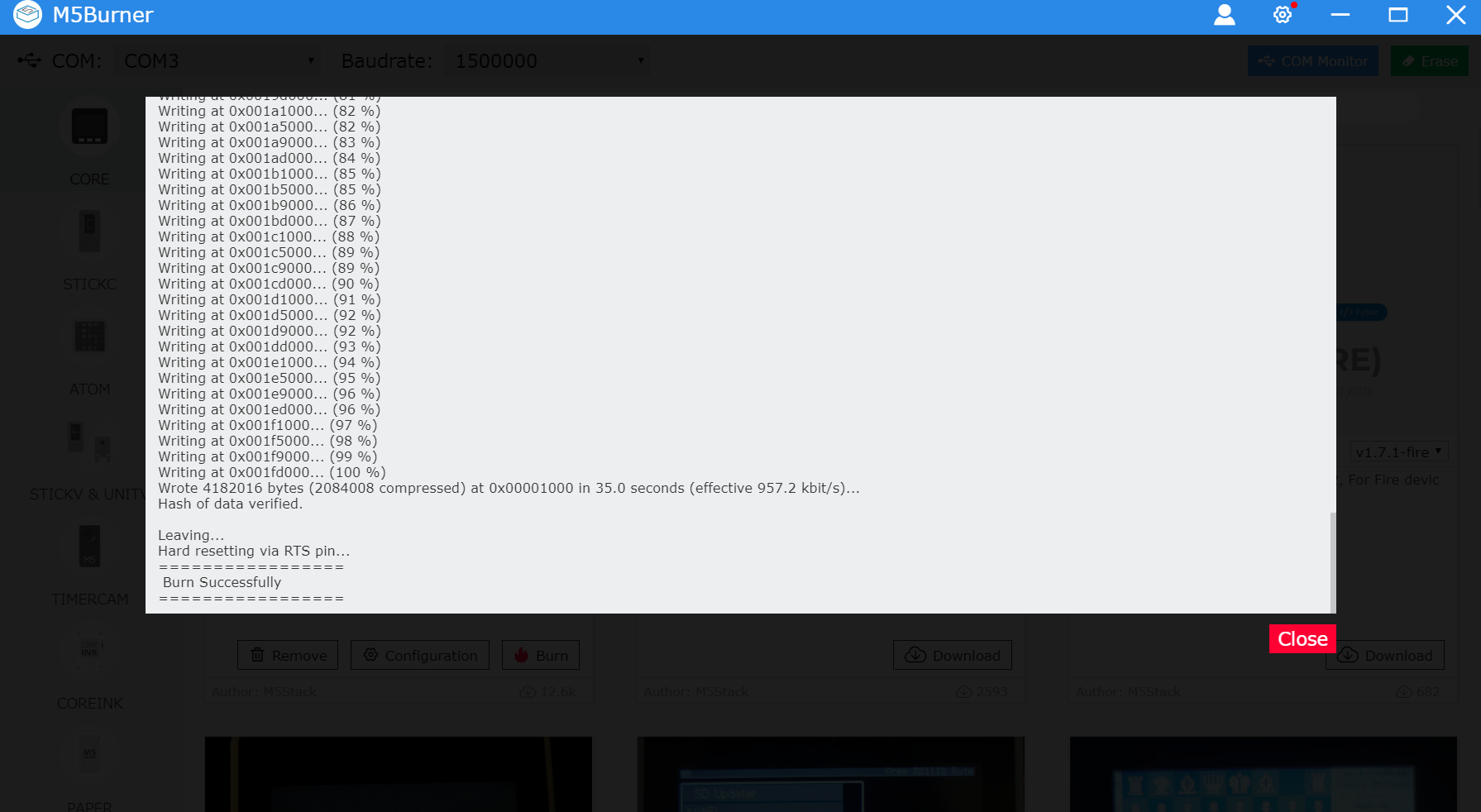
7.PCをm5stackのwifiに接続します
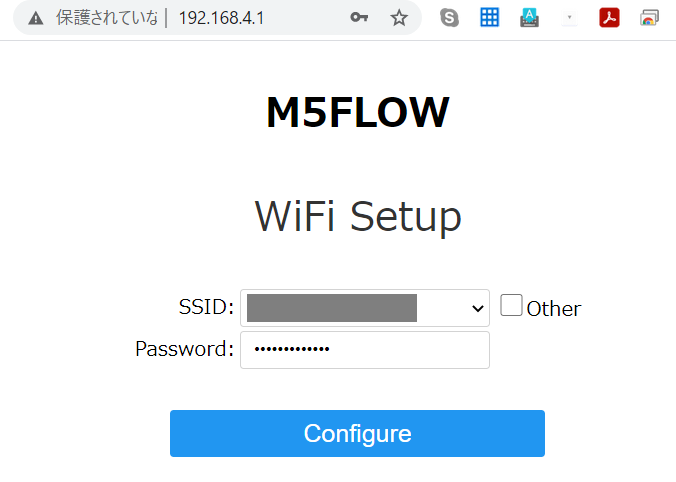
8.PCのブラウザからm5stackに表示されているIPアドレスを開きます
9.自宅のWiFiを選択し、パスワードを入力します
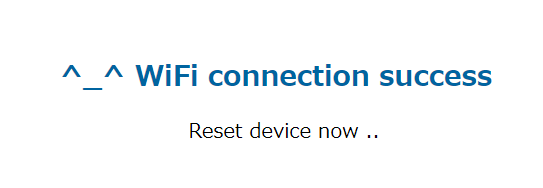
10.WiFi接続成功です
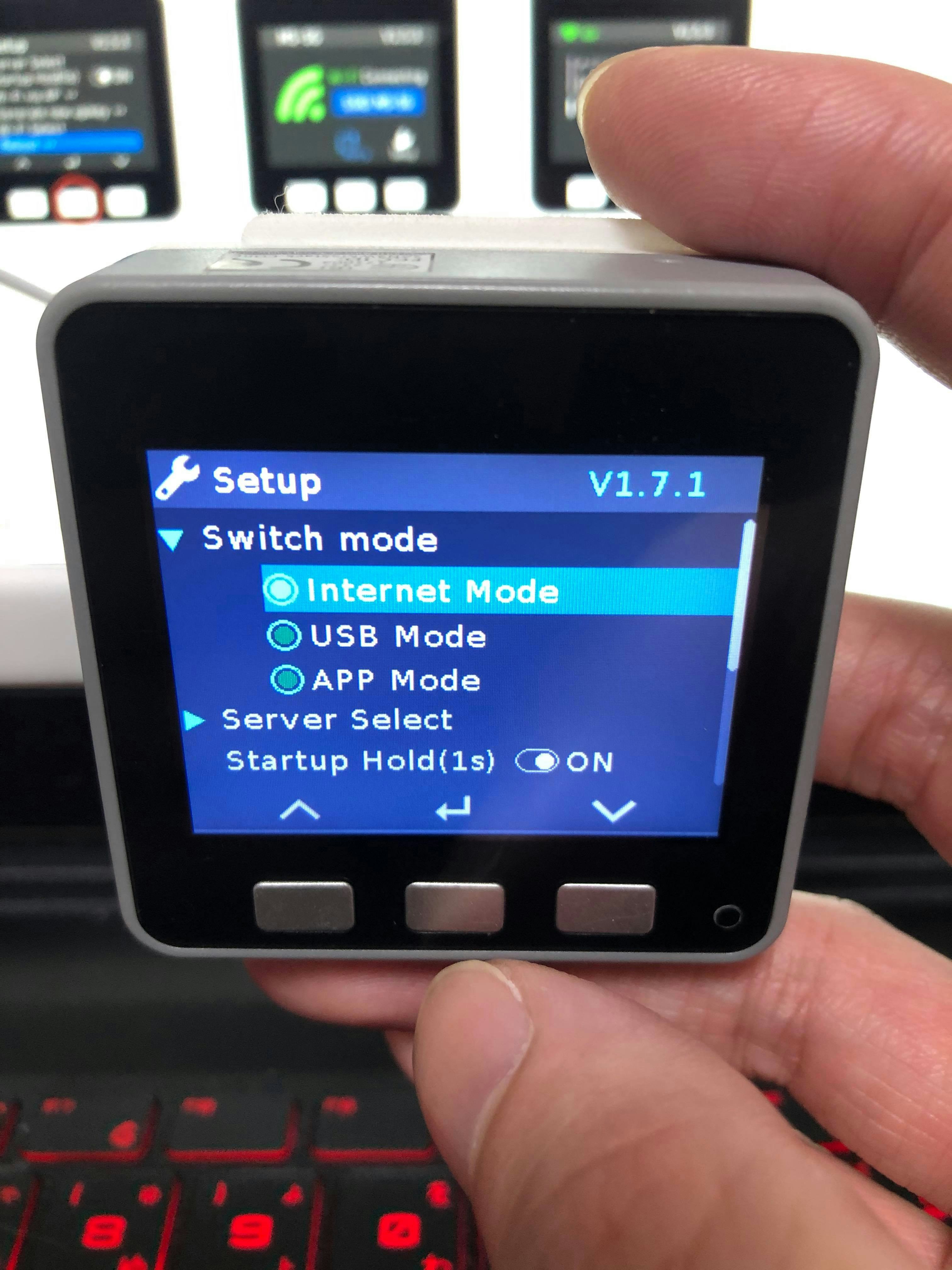
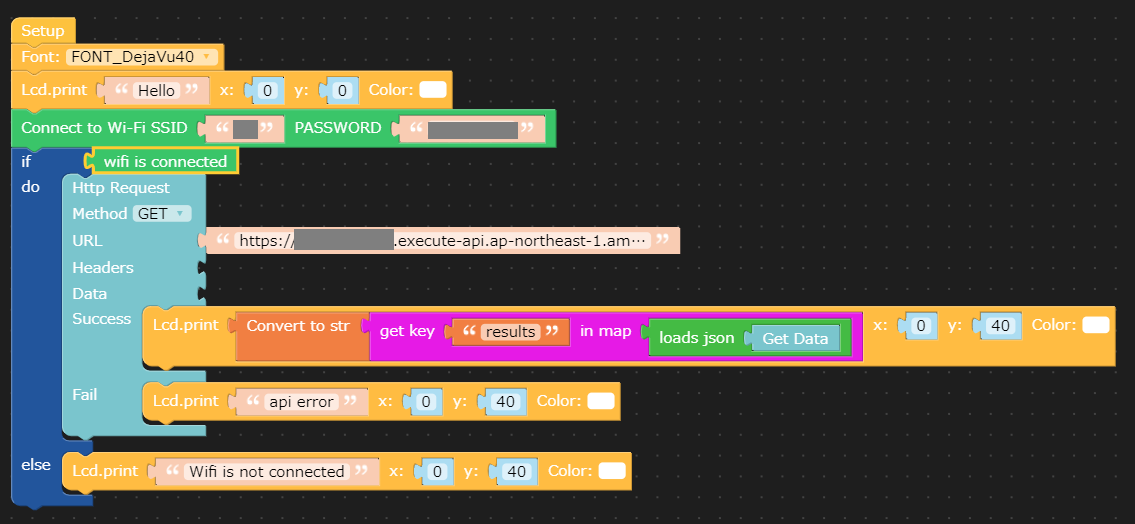
11.M5Stackをinternet modeにし、RebootするとAPIキーが表示されます
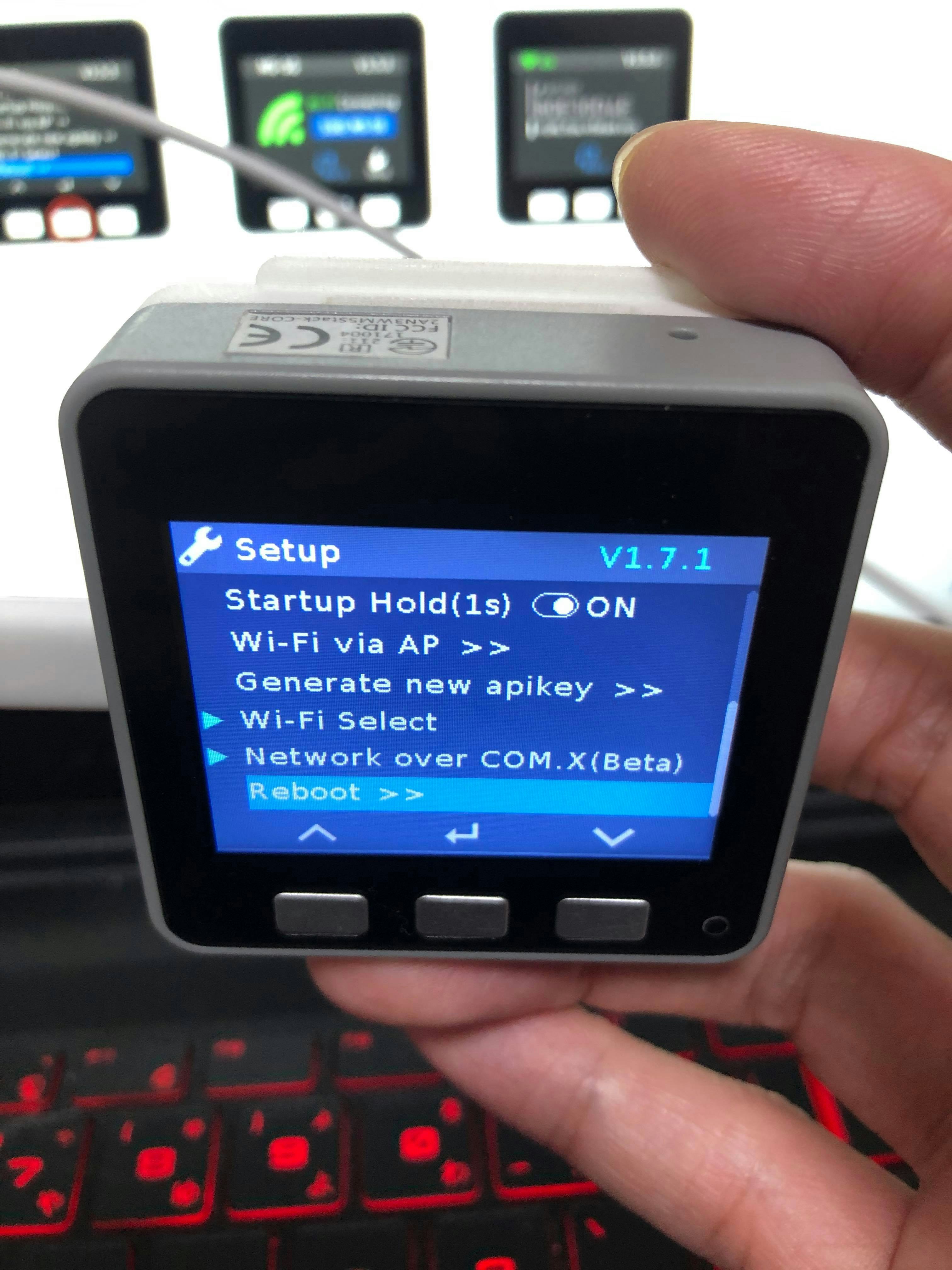
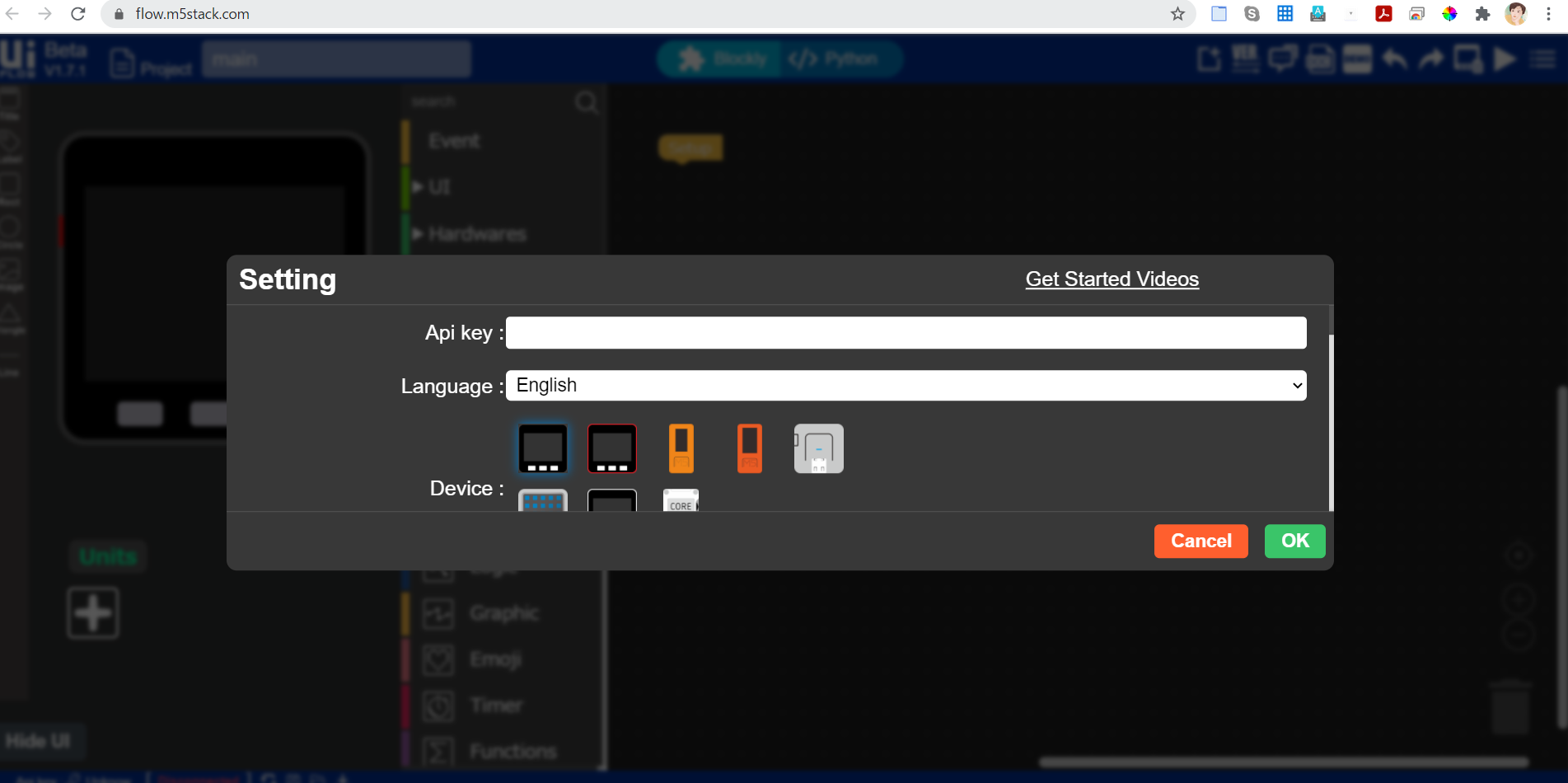
12.M5Flowを開き、APIキーを入力します
13.作ったAWS LambdaのAPIを叩いてみましょう。レスポンスはJSONで {"results":値}となっています。
14.結果です。
いつものバス停にあと何分でバスが到着するか表示するやつ作った。超便利なやつができた!がバスがもうないw #UIFlow #m5stack #Python #AWS #Lambda #API pic.twitter.com/Rl2hnTnIRn
— がちもとさん@あけおめことよろ (@sotongshi) January 4, 2021これは良いものだ! #m5stack pic.twitter.com/Iol4fAoicT
— がちもとさん@あけおめことよろ (@sotongshi) January 5, 2021お疲れ様でした。


- 投稿日:2021-01-05T18:10:58+09:00
CUDA及びnvidia-driverのインストール方法
CUDA及びnvidia-driverのインストール方法
CUDA(Compute Unified Device Architecture)とは、Nvidiaが開発しているGPUアクセラレーションアプリケーションを作成するための開発環境です。
nvidia-driverはその名の通り、
GTXやRTXシリーズを始めとするNvidia製のGPUを制御するためのドライバです。これら2つの役割を簡単に説明すると、nvidia-driverがハードとOSの仲介役となり、その上でCUDAというツールキット(アプリケーション郡)が
pythonなどのプログラムにGPUリソースを提供します。インストール方法
昔は動作しているグラフィックドライバを停止したり、
dkms等でカーネルを焼き直す等々の作業が必要でしたが、今日はdebファイル一つで簡単にインストール可能です。
CUDA11.2をUbuntu 16.04にインストールする場合の手順を示します。1. CUDA toolkit配布サイトより自分の環境を選択していき、
.debファイルのダウンロードコマンドを確認するまず、CUDA Toolkit 11.2 Downloads にアクセスします。
Linux->x86_64->Ubuntu->16.04->deb(local)の順に選択して行くと
Download Installer for Linux Ubuntu 16.04 x86_64というコンテンツボックス内に
.debファイルのダウンロード方法が表示されます。
2.
debファイルを用いてCUDAのインストール実際に表示されたコマンドを以下に示しますが、あくまで一例なので必ず自分で操作した時のコンテンツボックスに表示されたコマンドを入力して下さい。
コンテンツボックスの中身# リポジトリに優先度の登録 wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-ubuntu1604.pin sudo mv cuda-ubuntu1604.pin /etc/apt/preferences.d/cuda-repository-pin-600 # debファイルのダウンロード wget https://developer.download.nvidia.com/compute/cuda/11.2.0/local_installers/cuda-repo-ubuntu1604-11-2-local_11.2.0-460.27.04-1_amd64.deb # debファイルを用いてシステムにパッケージのインストール sudo dpkg -i cuda-repo-ubuntu1604-11-2-local_11.2.0-460.27.04-1_amd64.deb sudo apt-key add /var/cuda-repo-ubuntu1604-11-2-local/7fa2af80.pub # パッケージ一覧を更新 sudo apt-get update3. 自分の環境に合ったメタパッケージのインストール
dpkg -iにてパッケージのインストールできましたが、まだシステムには反映されていません。最後にsudo apt installコマンドを用いてパッケージをシステムに適用させるのですが、ここで注意が必要です。コンテンツボックスではsudo apt install cudaとなっていますが、自分の用途に合わせて反映させるメタパッケージは変える必要があります。メタパッケージの一覧を公式サイト(3.10.3. Meta Packages)より抜粋、さらに和訳して以下に示します。
主に指定するメタパッケージは以下の2つです。
cuda-11-2
- CUDA自体を新規でインストールする時。
cuda-toolkit-11-2
- 既に
nvidia-driverがインストール済みの時- 既に他のCUDAが存在していて、別バージョンのCUDAをインストールしたい時。
- 下手にドライバーを上書きすると、マシンが動作しなくなります。
ちなみに
CUDA10.1の場合はcuda-10-1というメタパッケージ名になります。臨機応変に変換して下さい。
Meta Package Purpose cuda すべてのCUDAツールキットとドライバーパッケージをインストールします。新しいcudaパッケージのリリース時に、自動で次のバージョンへのアップグレードを処理します。 cuda-11-2 すべてのCUDAツールキットとドライバーパッケージをインストールします。追加バージョンのCUDAがインストールされるまで、バージョン 11.2のままで固定されます。cuda-toolkit-11-2 CUDAアプリケーションの開発に必要なすべてのCUDAツールキットパッケージをインストールします。ドライバーは含まれていません。 cuda-tools-11-2 すべてのCUDAコマンドラインとビジュアルツールをインストールします。 cuda-runtime-11-2 CUDAアプリケーションの実行に必要なすべてのCUDAツールキットパッケージとドライバーパッケージをインストールします。 cuda-compiler-11-2 すべてのCUDAコンパイラパッケージをインストールします。 cuda-libraries-11-2 すべてのランタイムCUDAライブラリパッケージをインストールします。 cuda-libraries-dev-11-2 すべての開発CUDAライブラリパッケージをインストールします。 cuda-drivers すべてのドライバーパッケージをインストールします。リリース時に、次のバージョンのドライバーパッケージへのアップグレードを処理します。 sudo apt install cuda-11-2または、
sudo apt install cuda-toolkit-11-2でCUDAパッケージをシステムに適用します。
複数のCUDAを管理したい。
CUDAとnvidia-driverには互換性があります。詳しく知りたい場合は下記の公式サイトを参照して下さい。
CUDA Toolkit Linux x86_64 Driver Version CUDA 11.1 (11.1.0) >= 450.80.02 CUDA 11.0 (11.0.3) >= 450.36.06 CUDA 10.2 (10.2.89) >= 440.33 CUDA 10.1 (10.1.105) >= 418.39 CUDA 10.0 (10.0.130) >= 410.48 CUDA 9.2 (9.2.88) >= 396.26 CUDA 9.1 (9.1.85) >= 390.46 CUDA 9.0 (9.0.76) >= 384.81 CUDA 8.0 (8.0.61 GA2) >= 375.26 CUDA 8.0 (8.0.44) >= 367.48 CUDA 7.5 (7.5.16) >= 352.31 CUDA 7.0 (7.0.28) >= 346.46
nvidia-driver==410.48がインストールされている場合
CUDA 10.0,9.2,9.1...等がインストールできますが、CUDA11.0はインストールできません。事前に自分が今からインストールするCUDAとdriverの互換性があるかは確認して下さい。ちなみに、これらのことを考えるのは以下のような状況にある時です。
nvidia-driverのバージョンを変えられないor変えたく無い時
- Google colabで作業している時
- 既に環境構築済みのマシンに追加でCUDAをインストールする時
下手に
nvidia-driverを操作すると環境を破壊してOSの再インストールをする羽目になります。面倒です。CUDAのインストール場所と切り替え方
CUDAの実態は
/usr/localにあります。/usr/local/cuda11-2や/usr/local/cuda10-2です。しかし、python等のプログラムはそれらを直接参照しません。cudaという、シンボリックリンクを参照します。Consolehoge@hoge:/usr/local$ ls -la drwxr-xr-x 12 root root 4096 10月 15 10:10 . drwxr-xr-x 13 root root 4096 10月 15 10:10 .. ~~~ lrwxrwxrwx 1 root root 9 10月 15 10:10 cuda -> cuda-11.2 drwxr-xr-x 16 root root 4096 12月 31 23:59 cuda-11-2 drwxr-xr-x 16 root root 4096 10月 15 10:10 cuda-10-2 ~~~上の状態では、
cudaディレクトリを参照することはcuda-11-2を参照するのと等価であることがわかります。もしcuda10-2に変更したい場合はln -nfs cuda-10-2 cudaコマンドでcudaへのリンクを貼り直して下さい。こうすることで複数のバージョンのCUDAを管理運用することができます。cudnnのインストール場所
余談ですが、
cudnnというライブラリは/usr/include/cudnn.hにあります。これらのバージョンを確認する場合、以下のように入力するとバージョンの確認ができます。cat /usr/include/cudnn.h | grep CUDNN_MAJOR -A 2cudnnはCUDAのバージョンに依存しています。なので、CUDAのバージョンを変えた場合、cudnnをアンインストールした後に適切なバージョンをインストールする必要があります。

- 投稿日:2021-01-05T18:08:39+09:00
【Python】TypeError: 'int' object is not subscriptable が出たとき
今日からUdemyの超人気コース『100 Days of Code - The Complete Python Pro Bootcamp』にてPythonの学習を始めました!
これからここでの学習のアウトプットとしてつまづいたところなどを中心にまとめていきます

というわけで初回は基本の基本からいきます。
使用環境
Repl.it
URL: https://repl.it/~やっていたこと
コースの課題で
「数字を二つ入力したらそれを足し合わせた結果を返してくれる」
というプログラムを書いていました。その課題のコードは以下になります。
▼課題
# ? Don't change the code below ? two_digit_number = input("Type a two digit number: ") # ? Don't change the code above ? #################################### #Write your code below this line ?▼期待する結果
Type a two digit number: 63 9 >
▼自分が書いたコード
# ? Don't change the code below ? two_digit_number = input("Type a two digit number: ") # ? Don't change the code above ? #################################### #Write your code below this line ? new_two_digit_number = int(two_digit_number) print(new_two_digit_number[0] + new_two_gigit_number[1])▼出力結果
Type a two digit number: 13 Traceback (most recent call last): File "main.py", line 10, in <module> print(new_two_digit_number[0] + new_two_gigit_number[1]) TypeError: 'int' object is not subscriptable input()で返される値が必ずstr(文字列)になるのを学んでいたので、まずはintに変換するために
new_two_digit_number = int(two_digit_number)としました。それから、そこでint化した値の最初の値と2番目の値を足し合わせるために
print(new_two_digit_number[0] + new_two_gigit_number[1])としました。しかし、出力結果のようなエラーになりました。
エラーの原因
まずはこの
TypeError: 'int' object is not subscriptableこれが何を言っているのが調べました。
日本語に直してみると
「"int"オブジェクトは下付き文字にできません」
と言っています。
ちなみにSubscriptは「下付き文字・添え字」という意味らしいです。
どうやら、int(整数)オブジェクトに対しては[0]や[1]などの添え字をつけることができないというルールがあるみたいです。
そもそもこの[0]や[1]などの添え字はstr(文字列)に使うのであって、intには使わないようです。
整数値に対して添え字を付けているとは例えば、5[1] のようなことしているということですね。
そりゃコンピューターさんも困りますね。(ごめんね。)
解決策
これがわかったところで、どうすればいいのか考え思いつきました。
「
two_digit_numberがstr(文字列)のうちに配列[0][1]で取得すればいいかも!その後にそれをint(整数)化すればいけそう!」というわけで、以下のコードを試しました。
number_1 = two_digit_number[0] number_2 = two_digit_number[1] result = int(number_1 + number_2) print(result) -- #出力結果 Type a two digit number: 63 63 >あれ?
足されていない??
print(type(result))でdata typeを調べてもちゃんとintになっているのに?!よくみてみると、
int(number_1 + number_2)はintに変換する前に中でstr同士を足してしまっているようです。 (爪が甘かった・・・)これはint("6" + "3") = int(63)をしていることと同じですね。
結果的にtype()で確認するとこの63はintになっていたわけです。
これが理解できたらもうゴールに近づいてきました。
number_1 = two_digit_number[0] number_2 = two_digit_number[1] result = int(number_1) + int(number_2) print(result) -- Type a two digit number: 63 9 >きたーーー!!!嬉しいっ!!!

1つの課題で多くのことを知れました

Data typeは奥が深いですね〜〜
少しずつ身につけていきたいと思いますっ!
何か書き方や説明の仕方で不足や間違えがあればご教授いただけると幸いです

参考ソース
- 投稿日:2021-01-05T17:53:26+09:00
manimの作法 その9
概要
manimの作法、調べてみた。
ParametricSurface、使ってみた。サンプルコード
from manimlib.imports import * class DSurface(ParametricSurface): def __init__(self, **kwargs): kwargs = { "u_min": -1.5, "u_max": 1.5, "v_min": -1.5, "v_max": 1.5, "checkerboard_colors": [GREEN, BLUE], "checkerboard_opacity": 0.5 } ParametricSurface.__init__(self, self.func, **kwargs) def func(self, x, y): return np.array([x, y, x ** 2 + y ** 2]) class test(ThreeDScene): def construct(self): sphere = ParametricSurface(lambda u, v: np.array([1.5 * np.cos(u) * np.cos(v), 1.5 * np.cos(u) * np.sin(v), 1.5 * np.sin(u)]), v_min = 0, v_max = TAU, u_min = -PI / 2, u_max = PI / 2, checkerboard_colors = [RED_D, RED_E], resolution = (15, 32)) def param_plane(u, v): x = u y = v z = 0 return np.array([x, y, z]) plane = ParametricSurface(param_plane, resolution = (22, 22), v_min = -2, v_max = +2, u_min = -2, u_max = +2, ) def param_gauss(u, v): x = u y = v d = np.sqrt(x * x + y * y) sigma, mu = 0.4, 0.0 z = np.exp(-((d - mu) ** 2 / (2.0 * sigma ** 2))) return np.array([x, y, z]) gauss_plane = ParametricSurface(param_gauss, resolution = (22, 22), v_min = -2, v_max = +2, u_min = -2, u_max = +2, ) cylinder = ParametricSurface(lambda u, v: np.array([np.cos(TAU * v), np.sin(TAU * v), 1.0 * (1 - u)]), resolution = (6, 32)) surface = DSurface() axes = ThreeDAxes() self.set_camera_orientation(phi = 75 * DEGREES, theta = 30 * DEGREES) self.add(axes) self.play(ShowCreation(sphere)) self.wait() self.remove(sphere) self.play(ShowCreation(plane)) self.wait() self.remove(plane) self.play(ShowCreation(gauss_plane)) self.wait() self.remove(gauss_plane) self.play(ShowCreation(cylinder)) self.wait() self.remove(cylinder) self.play(ShowCreation(surface)) self.wait()動画
https://www.youtube.com/watch?v=HATdDHmnmD8
以上。
- 投稿日:2021-01-05T17:32:36+09:00
なぜDLが普及したのか?(用語を使って簡単に説明)
はじめに
今更な内容ですが、課題でまとめたものをせっかくなので記事として投稿します。
間違いや不適切な表現があればコメントでお知らせください。前置き:DeepLearningの登場まで
第3次AIブームのビッグウェーブ
出典:『人工知能は人間を超えるか ディープラーニングの先にあるもの』
松尾 豊(著)KADOKAWA発行しばしばAIと呼ばれることのあるDeepLearning(MachineLearning)ですが、
最近になって登場した技術というイメージとはギャップがありその歴史は60年前まで遡ります。第1次AIブーム
第1次AIブームは 「推論・探索の時代」 と呼ばれており、探索木をしらみつぶしに探ったり行動計画を与えあたかも知能があるかのように見せるような手法がメインで現在のようなリッチな技術はありませんでした。それでも迷路や言葉で指示を与え積み木を操作させたり、チェスや将棋に挑戦させることは可能でした。しかし冷静に現実を見つめ直すと、
知能があるかのように振る舞えていたのは限定的な状況で実際に問題には対応できないことが判ってきました
チェスの例では場面ごとに次の手を選択することは可能でも相手の手のパターンまで考慮し戦略的に戦うことができないことが判りました。期待された人工知能でしたが限界を感じられ第1次AIブームは冬の時代を迎えました。
第2次AIブーム
第2次AIブームではAIに「知識」を与えることがメインの時代です。
病気の知識を与えれば医者の代わりになり、法律の知識を与えれば犯罪を裁けるのでは!?
と探索では限界があったタスクに対して期待が高まりました。しかし、現実は甘くなくいくつかの問題が浮き出て来ました。
1. 知識を与えることの難しさ
知識を与えることの難しさというのは、知識を体系的に評価することの難しさと言えます。
言葉には上下関係があり、大きく分けてpart of関係とis-a問題があります。
詳しくは書きませんが
例えば「車輪は自転車の一部」ですが「車輪」は自転車が無くても成り立つが「自転車」は車輪がないと成り立ちません。
また「木は森の一部」ですが、自転車の例とは違い木が1本無くなっても森は森です。
このような知識の体系的な評価をすべて記述しコンピュータに与えると言うのはとても難しく、これ自体が現在も研究となっています。(オントロジー研究)2. 知識を与えた上での難しさ
これは知識を与えたとしても、「人間が無意識に行っている処理」を行えないことが原因の問題です。
これには必要な知識だけを取り出せずに永遠に考え出してしまう「フレーム問題」と
「特徴+科名」でモノがなんなのか判断できな「シンボルグラウンディング問題」の二つが挙げられます。これらの知識を与える方針の難しさに直面し、AIブームは二度目の冬に入りました。
機械学習の登場
限界を感じられ世間が忘れていた人工知能ですがここ最近で第3次ブームが来ました。
その着火剤となったのが 「コンピュータの普及とそれに伴う膨大なデータ」 です。イメージは容易だと思いますが、ここ数年でパソコンをはじめインターネットやスマートフォン、各種ネットサービスなどのITが爆発的に普及しました。そのことにより多種多様なデータの取得が容易になり、データを基盤とする機械学習の分野が急成長しました。
その中で機械学習に含まれる深層学習(DeepLearning)も成長しました。DeepLearningの普及
DeepLearningはニューラルネットを利用しており、これは古くから研究が行われていました。
DeepLearning自体もパーセプトロンという前身が1957年に始まりそれなりに歴史がありますが、有用なメカニズムが考案されていなかったりそもそも脳の解明が足りず1990年代後半に冬の時代を迎えていました。普及したのはここ最近です。DeepLearningの衝撃
DeepLearningは機械学習の一部で分類や回帰を根幹としていますが、その応用先は言語処理や画像認識、音声認識など現代の技術に大きく貢献しています。
代表的な出来事としては
・2012年トロント大学のヒントン教授らが世界的な人工知能の競技会でDLを用いたシステムで圧勝
・2016年人工知能囲碁プログラム「AlphaGo」が韓国のプロ棋士に勝利
などがあります。こういった局所的なところから注目を浴びはじめビジネスで用いられ界隈は盛り上がり始めました。
そして昨今では「ML/DLやデータサイエンスを根幹とした教育」にまで波及しています。
そこにはどういった背景があったのか調査しました。ビッグデータの登場による火付け
これまで一部の業界でしか確保できなかった 「大量のデータ」 がデジタル化で生み出されました。
またそれに伴い詳細なデータも採れるようになり、有用な特徴量の確保が可能になりました。
あらゆる分野がデジタル化することで幅広い分野で成果を見込めることで注目を浴びました。コンピュータ性能の向上
DLは大量のデータでニューラルネットの演算(脳の再現)を行うため大量の計算が必要となります。
分かりやすい例でいえば 「スパコン」 や 「量子コンピュータ」 が挙げられます。
スパコンは従来のノイマン型コンピュータの最高峰で、
現在世界1位の富岳の計算速度は1秒間に41京5530兆回です。
さらに量子コンピュータは全く異なる原理で大きな単位の演算を可能としています。昨秋、グーグル社を中心とする研究グループは、当時の世界最速のスーパーコンピュータが1万年を要する計算を、同社が開発した量子コンピュータが3分20秒で実行したことを発表しました。特筆すべきは計算速度だけでなく、両者を構成する素子数の違いです。たった53個の量子素子が、1京個を超える半導体素子を持つスーパーコンピュータを桁違いのスピードで凌駕した点です。
(引用:国産スパコン「富岳」が世界1位に! 量子コンピュータはそれよりスゴい?)トップ性能が上がると共に一般レベルのマシンも性能が飛躍的に向上しています。
こういったマシンのパワーアップによって将来性と技術者の養成ハードルが改善されたことが
DL普及の前提にあると考えます。① GPU
DLでは非常に大量の演算を行うため、CPUでは力不足な場合がほとんどです。
そのためコア数の多いGPUに並列処理をさせることで演算の高速化をします。
近年ではGPUの発展もすさまじくゲーム用途と思われがちなGPUですが、DLに大きく貢献しています。
GPU大手のNVIDIAが覇権を握っており、アルゴリズムもNVIDIAのCUDAに最適化されている場合が多いです。② TPU
TPUはGoogleが開発した機械学習用に特別開発された集積回路です。
Tensor Processing Unitの略でTensor(多次元配列)に特化しています。
同社が提供する機械学習ライブラリ「Tensor Flow」に最適化されています。
2018年12月に行われた機械学習ベンチマーク「MLPerf v0.5」の結果でトップに立ちました。
※現在はNVIDIAのGPU A100がトップ
NVIDIA が最新の MLPerf ベンチマークで 16 の AI 性能の記録更新③ intel FPGA
FPGAとはその場でハードウェア言語にて修正が出来る集積回路です。
新人エンジニアの赤面ブログ 『FPGAとは?超初級編』これの高性能製品をIntelが開発しました。
Intelの新FPGA「Agilex」、高い柔軟性を実現 (1/3)
これにより高速なデータ活用コンピューティングが可能となります。④ IBM ASIC
ASICはユーザに合わせてカスタマイズされた集積回路です。
FPGAと同様にハードウェア開発されますが修正ができません。また開発費と開発期間を要します。
しかしユーザに合わせて最低限の構成なため高性能かつ部品コストを抑えることが可能です。
実装面積も抑えられます。このASICの開発はIBMが先導しています
IBM由来の5nm ASIC、Marvellがビジネスを開始優秀なネットワークの考案
ML/DLに取り組むハード的なハードルと心理的なハードルの両方が改善されたことで研究者が増えました。そのおかげか、分野内での発明と改良が加速します。
パーセプトロンの存在と限界
DLの全身としてパーセプトロンが存在しました。
最も簡易的なアルゴリズムであるパーセプトロンから掘り下げてみようと思います。第1世代:単純パーセプトロン(1960~)
入力値の線形結合+活性化関数による非線形変換
出典:農学情報科学 - パーセプトロン
$$y = f(v)\v = W_t x - θ$$
原理的に非線形な識別が不可能という限界がありました。
第2世代:多層パーセプトロン(1980~)
多数の単純パーセプトロンを階層的に組み合わせ、活性化関数にシグモイド関数を採用しました。
誤差逆伝播法でパラメータの更新を行います。
線形分離できなかったデータもパーセプトロンを組み合わせることで分離可能になりました。
しかし実際には逆伝播が遅かったり過学習しやすいなどの問題点がありました。
(訓練データへの過度な適応)
ここで順伝播、逆伝播、誤差関数、勾配などの仕組みが登場します。
順伝播(フィードフォワードニューラルネットワーク)
構築されたネットワークに沿って計算を行い予測値を求める。
入力層→中間層→出力層→確率逆伝播(バックプロパゲーション)
順伝播で誤差を求めたら誤差関数を元に逆伝番でパラメータ更新を行う。(誤差逆伝播)
名の通り出力層←確立へと逆に伝播を行う。誤差関数(目的関数)
ネットワークを評価する指標を目的関数といい、その中でも誤差関数(予測値と真値の誤差)
が用いられ事が多いです。
・分類では交差エントロピー
・回帰では平均二乗誤差
など目的に応じて使い分けます。勾配
関数のある地点の傾き
傾きが0=関数の最小値である。
誤差関数の最小値を求めるために勾配法が用いられる最適化アルゴリズム
前述の目的関数(誤差関数)を最適化(勾配を最小に)するためのアルゴリズムが
最適化アルゴリズムです。最急効果法をはじめとし様々な派生形が存在します。
ニューラルネットワークの学習プロセスの問題
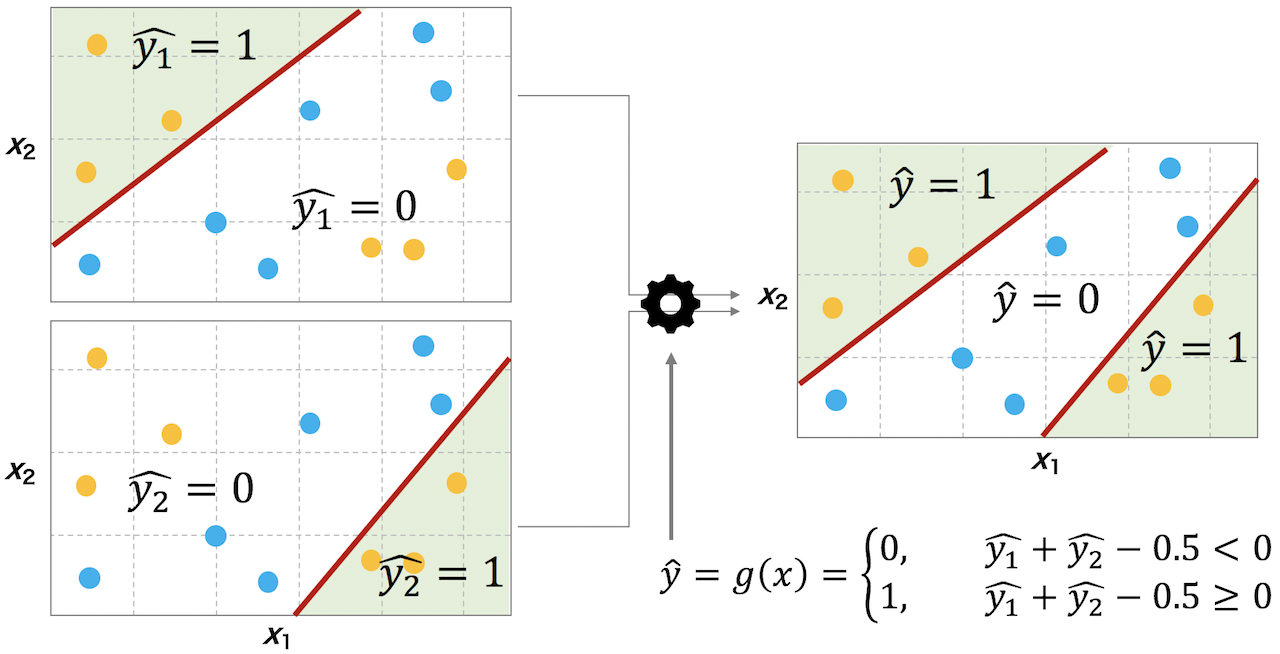
パーセプトロンの層を増やすことで決定境界も形が直線からドーナツ型に近づくことが段々わかり多層にする手法に光を見ましたが他にも大きな問題がありました。
それが 「局所最適化」と「勾配消失」 です。
従来の最適化手法では勾配を減らしきれず、局所的な最小値に収束してしまったり過学習を起こすことがありました。
また勾配消失(+勾配爆発)はシグモイド関数のS字の端に勾配が寄ってしまい誤差の減少が止まる不具合がありました。
実際にはこれらの問題が原因で英語の過去形を識別できない不具合などが生じていたそうです。まだネットワークに問題があることに加えSVMやランダムフォレストといった新しい統計的学習モデルの波もあり停滞期に入りました。
第3世代:Deep Learning(深層学習)
従来よりも多層のニューラルネット(現在は20層を超えるものも)の考案により
音声認識や画像認識、自然言語処理など様々な分野で性能を発揮しました。代表的なブレークスルーとしては画像認識や囲碁で人間に勝った事例があります
これ以後DLは安定期に入り、精度向上や効率化のフェーズに移行しました。
大企業や大学の力と恩恵
マシン性能の部分でGoogleやNVIDIAに触れましたが、それらの会社は広く深く昨今のDL界に貢献しています。
DLフレームワークの提供
ML/DLには多くの手法やパラメータが存在しておりすべてをプログラムで構築するのは大変です。
そこで活躍するのが DLフレームワーク です。
フレームワークは数多のアルゴリズムを内包しており、メソッドを呼び出すだけで簡単に利用することができるようになっています。
代表的なものを例に挙げると
- TensorFlow (Google)
- Chainer (PFN)
- Caffe (Yangqing Jia, UC Barkeley)
- MXNet (ワシントン大学)
- PyTorch (Facebook)
- The Microsoft Cognitive Toolkit (CNTK) (Microsoft)
- Theano (モントリオール大学)などが挙げられます。
参考:Qiita - Deep Learning フレームワークざっくり一覧
DL界隈ではこれらのツールを無料で利用でき、またリファレンスも充実しています。
最前線を走る研究者の方々がライバルとして切磋琢磨しており、
さらに技術の利用ハードルを下げるために相当な労力を費やしています。
このことからも業界の勢いと発展に対する姿勢が分かります。各種手法の改善
DLでは手順の中でいくつかの役割が分かれており組み合わせることで機能しますが
完璧な手法というのは存在していません。目的に応じて最適な手法を選択する必要があります。
その上で、いくつか課題をなるべく抑えるようにアルゴリズムの考案、改良が行われています。
活性化関数の改善
出力の要となる活性化関数では主に
- 精度
- 計算速度
- 勾配消失・勾配爆発
- 苦手な入力値などが挙げられます。精度と計算速度についてはトレードオフという認識で問題ありませんが、
最近ではReLU関数のようなシンプルで高精度な関数も登場しています。勾配消失は勾配が偏ることで起きる誤差変動の停止です。これもReLU関数で解決されました。
勾配爆発は、層を重ねることで活性化関数の行列積が繰り返され勾配サイズが大きくなってしまう問題です。これはクリッピングという操作を加え勾配に上限を付けることで解決しています。目的関数の改善
ここでは損失関数について扱います。
予測値を評価するための損失関数にも種類があり、それぞれ特徴があります。
考慮しなければいけないのは
- 外れ値の影響
- 計算速度
- 適切かなどが挙げられます。
代表的な手法は
- 平均二乗誤差 / Mean Squared Error
- もっともメジャー。分かりやすいが外れ値に弱い。
- 平均絶対誤差 / Mean Absolute Error
- 外れ値に強い。
- 平均二乗対数誤差 / Mean Squared Logarithmic Error
- 予測値が実値を上回りやすい。
- 交差エントロピー誤差 / cross entropy error
- 分類問題用。などがあります。回帰と分類で枠組みが違うのでタスクとその性質ごとに選択が必要です。
最適化手法の改善
目的関数の最小化に用いられる最適化(optimizer)にも種類があり
- 精度(局所解)
- 収束速度
- 安定性などが挙げられます。
最適化の難しさは以下の図が分かりやすいです
引用:最適化アルゴリズムを評価するベンチマーク関数まとめ
詳しくは最適化超入門
過学習の抑制:重み減衰(Weight Decay)
ネットワークが教師データに過度に適応する過学習を防ぐために
重み減衰(Weight Decay) という操作も考案されています。正則化とも呼ばれます。
厳密には目的関数で作用します。
最適化と重み減衰の組み合わせによって過学習を防止します。過学習の抑制:Dropout
DLはモデルの複雑さと過学習が比例します。
そのためシンプルなモデルの方が汎化性能が高くなります。
この原理を元に考案されたのがDropoutで、
いくつかのノードを無効化し強制的にモデルの自由度を下げ過学習を防ぎます。過学習の抑制:Batch Normalization
勾配消失・爆発を防ぐための手法です。
これまでの目的関数や最適化、重み減衰、Dropoutとは違い
ネットワーク全体を安定化させることが目的です。ネットワーク全体を安定させることで
- 学習の高速化
- 初期値の依存からの脱却
- 過学習抑制などが見込めます。
こういった手法の考案や改善がハイスピードで行われています。
ニューラルネットワークの種類
NN(ニューラルネットワーク)にも種類があり、こちらも考案、改良が研究されています。
タスクごとに特化したモデルがあります。特化したアルゴリズムの開発が幅広い分野への適応に繋がり、DLの普及につながっているとも言えます。
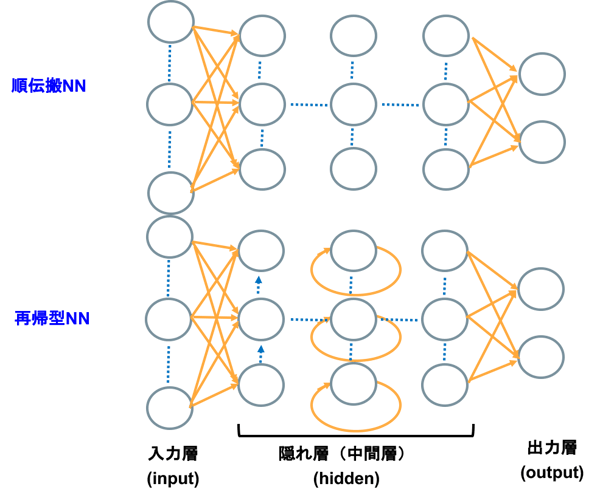
CNN(畳み込みニューラルネットワーク)
NNでは各層のノードが密に結合する全結合層がありますが、
CNNではそれらに加え畳み込み層,プーリング層というフィルタ処理により特徴量を処理します。主に画像データや非連続データの解析に用いられます。
出典:DeepAge - 定番のConvolutional Neural Networkをゼロから理解するRNN(再帰型ニューラルネットワーク)
RNNは時系列データを得意とするネットワークです。
連続データの他データポイントを利用することでよりよい予測を行います。
出典:AISIA - リカレントニューラルネットワーク_RNN (Vol.17)
その他
上記2種類の代表的なネットワークのほかに
- LSTM : 長期の時系列データに特化。自然言語処理で活躍
- BERT : 最近登場した双方向Transformer。多くのベンチマークで記録更新。
- GAN : 最新の生成モデル。2つのNNで構成されている。など様々なネットワークがあり、派生形を含めかなりの数のネットワークが提案されています。
高めあいの精神
同じタスクでもデータセットごとに適したアルゴリズムが違います。
ML/DL界ではSOTA(state-of-the-art:最新技術)を目標に研究されることが多く、
タスクごとのベンチマークを指標にアルゴリズムのランク付けが行われています。自然言語処理のテキスト分類だけでもいくつものデータセットが用意されており
絶対的なアルゴリズムが存在しないこと、アルゴリズムの種類が豊富であることが判ります。参考:
Browse SoTA > Natural Language Processing > Text Classificationまたデータ分析コンペというのも頻繁に開催されており、
論文が出たばかりの新手法はコンペ内で試され話題になるということも多いです
例:XGBoost(アンサンブル手法というアルゴリズムたちに多数決させる手法)まとめ
DLの普及の流れをまとめると
といった感じだと認識しています。





- 投稿日:2021-01-05T17:32:36+09:00
なぜDeepLearningが普及したのか?(用語を使って簡単に説明)
はじめに
今更な内容ですが、課題でまとめたものをせっかくなので記事として投稿します。
間違いや不適切な表現があればコメントでお知らせください。前置き:DeepLearningの登場まで
第3次AIブームのビッグウェーブ
出典:『人工知能は人間を超えるか ディープラーニングの先にあるもの』
松尾 豊(著)KADOKAWA発行しばしばAIと呼ばれることのあるDeepLearning(MachineLearning)ですが、
最近になって登場した技術というイメージとはギャップがありその歴史は60年前まで遡ります。第1次AIブーム
第1次AIブームは 「推論・探索の時代」 と呼ばれており、探索木をしらみつぶしに探ったり行動計画を与えあたかも知能があるかのように見せるような手法がメインで現在のようなリッチな技術はありませんでした。それでも迷路や言葉で指示を与え積み木を操作させたり、チェスや将棋に挑戦させることは可能でした。しかし冷静に現実を見つめ直すと、
知能があるかのように振る舞えていたのは限定的な状況で実際に問題には対応できないことが判ってきました
チェスの例では場面ごとに次の手を選択することは可能でも相手の手のパターンまで考慮し戦略的に戦うことができないことが判りました。期待された人工知能でしたが限界を感じられ第1次AIブームは冬の時代を迎えました。
第2次AIブーム
第2次AIブームではAIに「知識」を与えることがメインの時代です。
病気の知識を与えれば医者の代わりになり、法律の知識を与えれば犯罪を裁けるのでは!?
と探索では限界があったタスクに対して期待が高まりました。しかし、現実は甘くなくいくつかの問題が浮き出て来ました。
1. 知識を与えることの難しさ
知識を与えることの難しさというのは、知識を体系的に評価することの難しさと言えます。
言葉には上下関係があり、大きく分けてpart of関係とis-a問題があります。
詳しくは書きませんが
例えば「車輪は自転車の一部」ですが「車輪」は自転車が無くても成り立つが「自転車」は車輪がないと成り立ちません。
また「木は森の一部」ですが、自転車の例とは違い木が1本無くなっても森は森です。
このような知識の体系的な評価をすべて記述しコンピュータに与えると言うのはとても難しく、これ自体が現在も研究となっています。(オントロジー研究)2. 知識を与えた上での難しさ
これは知識を与えたとしても、「人間が無意識に行っている処理」を行えないことが原因の問題です。
これには必要な知識だけを取り出せずに永遠に考え出してしまう「フレーム問題」と
「特徴+科名」でモノがなんなのか判断できな「シンボルグラウンディング問題」の二つが挙げられます。これらの知識を与える方針の難しさに直面し、AIブームは二度目の冬に入りました。
機械学習の登場
限界を感じられ世間が忘れていた人工知能ですがここ最近で第3次ブームが来ました。
その着火剤となったのが 「コンピュータの普及とそれに伴う膨大なデータ」 です。イメージは容易だと思いますが、ここ数年でパソコンをはじめインターネットやスマートフォン、各種ネットサービスなどのITが爆発的に普及しました。そのことにより多種多様なデータの取得が容易になり、データを基盤とする機械学習の分野が急成長しました。
その中で機械学習に含まれる深層学習(DeepLearning)も成長しました。DeepLearningの普及
DeepLearningはニューラルネットを利用しており、これは古くから研究が行われていました。
DeepLearning自体もパーセプトロンという前身が1957年に始まりそれなりに歴史がありますが、有用なメカニズムが考案されていなかったりそもそも脳の解明が足りず1990年代後半に冬の時代を迎えていました。普及したのはここ最近です。DeepLearningの衝撃
DeepLearningは機械学習の一部で分類や回帰を根幹としていますが、その応用先は言語処理や画像認識、音声認識など現代の技術に大きく貢献しています。
代表的な出来事としては
・2012年トロント大学のヒントン教授らが世界的な人工知能の競技会でDLを用いたシステムで圧勝
・2016年人工知能囲碁プログラム「AlphaGo」が韓国のプロ棋士に勝利
などがあります。こういった局所的なところから注目を浴びはじめビジネスで用いられ界隈は盛り上がり始めました。
そして昨今では「ML/DLやデータサイエンスを根幹とした教育」にまで波及しています。
そこにはどういった背景があったのか調査しました。ビッグデータの登場による火付け
これまで一部の業界でしか確保できなかった 「大量のデータ」 がデジタル化で生み出されました。
またそれに伴い詳細なデータも採れるようになり、有用な特徴量の確保が可能になりました。
あらゆる分野がデジタル化することで幅広い分野で成果を見込めることで注目を浴びました。コンピュータ性能の向上
DLは大量のデータでニューラルネットの演算(脳の再現)を行うため大量の計算が必要となります。
分かりやすい例でいえば 「スパコン」 や 「量子コンピュータ」 が挙げられます。
スパコンは従来のノイマン型コンピュータの最高峰で、
現在世界1位の富岳の計算速度は1秒間に41京5530兆回です。
さらに量子コンピュータは全く異なる原理で大きな単位の演算を可能としています。昨秋、グーグル社を中心とする研究グループは、当時の世界最速のスーパーコンピュータが1万年を要する計算を、同社が開発した量子コンピュータが3分20秒で実行したことを発表しました。特筆すべきは計算速度だけでなく、両者を構成する素子数の違いです。たった53個の量子素子が、1京個を超える半導体素子を持つスーパーコンピュータを桁違いのスピードで凌駕した点です。
(引用:国産スパコン「富岳」が世界1位に! 量子コンピュータはそれよりスゴい?)トップ性能が上がると共に一般レベルのマシンも性能が飛躍的に向上しています。
こういったマシンのパワーアップによって将来性と技術者の養成ハードルが改善されたことが
DL普及の前提にあると考えます。① GPU
DLでは非常に大量の演算を行うため、CPUでは力不足な場合がほとんどです。
そのためコア数の多いGPUに並列処理をさせることで演算の高速化をします。
近年ではGPUの発展もすさまじくゲーム用途と思われがちなGPUですが、DLに大きく貢献しています。
GPU大手のNVIDIAが覇権を握っており、アルゴリズムもNVIDIAのCUDAに最適化されている場合が多いです。② TPU
TPUはGoogleが開発した機械学習用に特別開発された集積回路です。
Tensor Processing Unitの略でTensor(多次元配列)に特化しています。
同社が提供する機械学習ライブラリ「Tensor Flow」に最適化されています。
2018年12月に行われた機械学習ベンチマーク「MLPerf v0.5」の結果でトップに立ちました。
※現在はNVIDIAのGPU A100がトップ
NVIDIA が最新の MLPerf ベンチマークで 16 の AI 性能の記録更新③ intel FPGA
FPGAとはその場でハードウェア言語にて修正が出来る集積回路です。
新人エンジニアの赤面ブログ 『FPGAとは?超初級編』これの高性能製品をIntelが開発しました。
Intelの新FPGA「Agilex」、高い柔軟性を実現 (1/3)
これにより高速なデータ活用コンピューティングが可能となります。④ IBM ASIC
ASICはユーザに合わせてカスタマイズされた集積回路です。
FPGAと同様にハードウェア開発されますが修正ができません。また開発費と開発期間を要します。
しかしユーザに合わせて最低限の構成なため高性能かつ部品コストを抑えることが可能です。
実装面積も抑えられます。このASICの開発はIBMが先導しています
IBM由来の5nm ASIC、Marvellがビジネスを開始優秀なネットワークの考案
ML/DLに取り組むハード的なハードルと心理的なハードルの両方が改善されたことで研究者が増えました。そのおかげか、分野内での発明と改良が加速します。
パーセプトロンの存在と限界
DLの全身としてパーセプトロンが存在しました。
最も簡易的なアルゴリズムであるパーセプトロンから掘り下げてみようと思います。第1世代:単純パーセプトロン(1960~)
入力値の線形結合+活性化関数による非線形変換
出典:農学情報科学 - パーセプトロン
$$y = f(v)\v = W_t x - θ$$
原理的に非線形な識別が不可能という限界がありました。
第2世代:多層パーセプトロン(1980~)
多数の単純パーセプトロンを階層的に組み合わせ、活性化関数にシグモイド関数を採用しました。
誤差逆伝播法でパラメータの更新を行います。
線形分離できなかったデータもパーセプトロンを組み合わせることで分離可能になりました。
しかし実際には逆伝播が遅かったり過学習しやすいなどの問題点がありました。
(訓練データへの過度な適応)
ここで順伝播、逆伝播、誤差関数、勾配などの仕組みが登場します。
順伝播(フィードフォワードニューラルネットワーク)
構築されたネットワークに沿って計算を行い予測値を求める。
入力層→中間層→出力層→確率逆伝播(バックプロパゲーション)
順伝播で誤差を求めたら誤差関数を元に逆伝番でパラメータ更新を行う。(誤差逆伝播)
名の通り出力層←確立へと逆に伝播を行う。誤差関数(目的関数)
ネットワークを評価する指標を目的関数といい、その中でも誤差関数(予測値と真値の誤差)
が用いられ事が多いです。
・分類では交差エントロピー
・回帰では平均二乗誤差
など目的に応じて使い分けます。勾配
関数のある地点の傾き
傾きが0=関数の最小値である。
誤差関数の最小値を求めるために勾配法が用いられる最適化アルゴリズム
前述の目的関数(誤差関数)を最適化(勾配を最小に)するためのアルゴリズムが
最適化アルゴリズムです。最急効果法をはじめとし様々な派生形が存在します。
ニューラルネットワークの学習プロセスの問題
パーセプトロンの層を増やすことで決定境界も形が直線からドーナツ型に近づくことが段々わかり多層にする手法に光を見ましたが他にも大きな問題がありました。
それが 「局所最適化」と「勾配消失」 です。
従来の最適化手法では勾配を減らしきれず、局所的な最小値に収束してしまったり過学習を起こすことがありました。
また勾配消失(+勾配爆発)はシグモイド関数のS字の端に勾配が寄ってしまい誤差の減少が止まる不具合がありました。
実際にはこれらの問題が原因で英語の過去形を識別できない不具合などが生じていたそうです。まだネットワークに問題があることに加えSVMやランダムフォレストといった新しい統計的学習モデルの波もあり停滞期に入りました。
第3世代:Deep Learning(深層学習)
従来よりも多層のニューラルネット(現在は20層を超えるものも)の考案により
音声認識や画像認識、自然言語処理など様々な分野で性能を発揮しました。代表的なブレークスルーとしては画像認識や囲碁で人間に勝った事例があります
これ以後DLは安定期に入り、精度向上や効率化のフェーズに移行しました。
大企業や大学の力と恩恵
マシン性能の部分でGoogleやNVIDIAに触れましたが、それらの会社は広く深く昨今のDL界に貢献しています。
DLフレームワークの提供
ML/DLには多くの手法やパラメータが存在しておりすべてをプログラムで構築するのは大変です。
そこで活躍するのが DLフレームワーク です。
フレームワークは数多のアルゴリズムを内包しており、メソッドを呼び出すだけで簡単に利用することができるようになっています。
代表的なものを例に挙げると
- TensorFlow (Google)
- Chainer (PFN)
- Caffe (Yangqing Jia, UC Barkeley)
- MXNet (ワシントン大学)
- PyTorch (Facebook)
- The Microsoft Cognitive Toolkit (CNTK) (Microsoft)
- Theano (モントリオール大学)などが挙げられます。
参考:Qiita - Deep Learning フレームワークざっくり一覧
DL界隈ではこれらのツールを無料で利用でき、またリファレンスも充実しています。
最前線を走る研究者の方々がライバルとして切磋琢磨しており、
さらに技術の利用ハードルを下げるために相当な労力を費やしています。
このことからも業界の勢いと発展に対する姿勢が分かります。各種手法の改善
DLでは手順の中でいくつかの役割が分かれており組み合わせることで機能しますが
完璧な手法というのは存在していません。目的に応じて最適な手法を選択する必要があります。
その上で、いくつか課題をなるべく抑えるようにアルゴリズムの考案、改良が行われています。
活性化関数の改善
出力の要となる活性化関数では主に
- 精度
- 計算速度
- 勾配消失・勾配爆発
- 苦手な入力値などが挙げられます。精度と計算速度についてはトレードオフという認識で問題ありませんが、
最近ではReLU関数のようなシンプルで高精度な関数も登場しています。勾配消失は勾配が偏ることで起きる誤差変動の停止です。これもReLU関数で解決されました。
勾配爆発は、層を重ねることで活性化関数の行列積が繰り返され勾配サイズが大きくなってしまう問題です。これはクリッピングという操作を加え勾配に上限を付けることで解決しています。目的関数の改善
ここでは損失関数について扱います。
予測値を評価するための損失関数にも種類があり、それぞれ特徴があります。
考慮しなければいけないのは
- 外れ値の影響
- 計算速度
- 適切かなどが挙げられます。
代表的な手法は
- 平均二乗誤差 / Mean Squared Error
- もっともメジャー。分かりやすいが外れ値に弱い。
- 平均絶対誤差 / Mean Absolute Error
- 外れ値に強い。
- 平均二乗対数誤差 / Mean Squared Logarithmic Error
- 予測値が実値を上回りやすい。
- 交差エントロピー誤差 / cross entropy error
- 分類問題用。などがあります。回帰と分類で枠組みが違うのでタスクとその性質ごとに選択が必要です。
最適化手法の改善
目的関数の最小化に用いられる最適化(optimizer)にも種類があり
- 精度(局所解)
- 収束速度
- 安定性などが挙げられます。
最適化の難しさは以下の図が分かりやすいです
引用:最適化アルゴリズムを評価するベンチマーク関数まとめ
詳しくは最適化超入門
過学習の抑制:重み減衰(Weight Decay)
ネットワークが教師データに過度に適応する過学習を防ぐために
重み減衰(Weight Decay) という操作も考案されています。正則化とも呼ばれます。
厳密には目的関数で作用します。
最適化と重み減衰の組み合わせによって過学習を防止します。過学習の抑制:Dropout
DLはモデルの複雑さと過学習が比例します。
そのためシンプルなモデルの方が汎化性能が高くなります。
この原理を元に考案されたのがDropoutで、
いくつかのノードを無効化し強制的にモデルの自由度を下げ過学習を防ぎます。過学習の抑制:Batch Normalization
勾配消失・爆発を防ぐための手法です。
これまでの目的関数や最適化、重み減衰、Dropoutとは違い
ネットワーク全体を安定化させることが目的です。ネットワーク全体を安定させることで
- 学習の高速化
- 初期値の依存からの脱却
- 過学習抑制などが見込めます。
こういった手法の考案や改善がハイスピードで行われています。
ニューラルネットワークの種類
NN(ニューラルネットワーク)にも種類があり、こちらも考案、改良が研究されています。
タスクごとに特化したモデルがあります。特化したアルゴリズムの開発が幅広い分野への適応に繋がり、DLの普及につながっているとも言えます。
CNN(畳み込みニューラルネットワーク)
NNでは各層のノードが密に結合する全結合層がありますが、
CNNではそれらに加え畳み込み層,プーリング層というフィルタ処理により特徴量を処理します。主に画像データや非連続データの解析に用いられます。
出典:DeepAge - 定番のConvolutional Neural Networkをゼロから理解するRNN(再帰型ニューラルネットワーク)
RNNは時系列データを得意とするネットワークです。
連続データの他データポイントを利用することでよりよい予測を行います。
出典:AISIA - リカレントニューラルネットワーク_RNN (Vol.17)
その他
上記2種類の代表的なネットワークのほかに
- LSTM : 長期の時系列データに特化。自然言語処理で活躍
- BERT : 最近登場した双方向Transformer。多くのベンチマークで記録更新。
- GAN : 最新の生成モデル。2つのNNで構成されている。など様々なネットワークがあり、派生形を含めかなりの数のネットワークが提案されています。
高めあいの精神
同じタスクでもデータセットごとに適したアルゴリズムが違います。
ML/DL界ではSOTA(state-of-the-art:最新技術)を目標に研究されることが多く、
タスクごとのベンチマークを指標にアルゴリズムのランク付けが行われています。自然言語処理のテキスト分類だけでもいくつものデータセットが用意されており
絶対的なアルゴリズムが存在しないこと、アルゴリズムの種類が豊富であることが判ります。参考:
Browse SoTA > Natural Language Processing > Text Classificationまたデータ分析コンペというのも頻繁に開催されており、
論文が出たばかりの新手法はコンペ内で試され話題になるということも多いです
例:XGBoost(アンサンブル手法というアルゴリズムたちに多数決させる手法)まとめ
DLの普及の流れをまとめると
といった感じだと認識しています。
- 投稿日:2021-01-05T17:17:01+09:00
機械学習による競馬予測
はじめに
みなさんは競馬は競馬をしたことがありますか?
私は機械学習を勉強して初めて、競馬に触れました。
プログラミングを勉強する上で「手を動かしながら学ぶ」というのがあります。私は、勉強するなら楽しくかつビジネスに貢献できる題材がいいと思いました。
そこで色々調べた結果、特徴量(予測する際に使う要素)が多くかつビジネスに関係あるということで競馬を選びました。
最初は「馬が早いか遅いかなんて馬にしか分からないでしょ。」と思っていましたが、機械学習を使うことである程度は予測できるということを知って、今回の記事を書きました。
初めての記事なので、分かりにくい部分が多々あるかと思いますが、その際はご指摘いただけると幸いです。行ったこと
競馬データを分析し、予測精度(AUCという指標)を出すところまで行いました。本当は実際に予測した後に、回収率などを出せるともっと面白そうですが、そこまでの技術はないので「データの取得→前処理→学習→AUCの算出→考察」まで行いました。
環境
mac OS
Python
Google Colab(初めはローカルのJupyter labで行っていましたが、私のPCでは学習時にメモリ不足となりGoogle colabを使用しました。)手順
1 netkeiba.comよりスクレイピング
2 前処理
3 lightGBMで学習、予測1 netkeiba.comよりスクレイピング
この工程は https://qiita.com/penguinz222/items/6a30d026ede2e822e245 を参考にさせていただきました。
2 前処理
スクレイピングしてきたCSVファイルは以下のとおりです。
データの大きさは535594行×20列です。
これらに対して前処理を行っていきます。先に、一般には馴染みのない列名があるので解説します。
・c_weight...前回のレースからの体重差
・j_weight...ジョッキーの体重
・popu...人気(運営側が事前情報によって馬それぞれに人気をつけます)
・odds...払い戻し額÷掛け金(人気な馬ほどoddsは低いです。)2-1 データを扱いやすくする
一番左の列がUnnamed:0となっています。この列は開催された日付、レース番号、馬番が連なっていますので、これは2列に分解します。
# データの読み込み # Unnamed0のカラムは日付、レース番号、馬番号なのでrenameして分割。 keiba_data = pd.read_csv('/content/drive/MyDrive/競馬.csv', encoding = "shift-jis") keiba_data.rename(columns={"Unnamed: 0":"date_num"},inplace=True) keiba_data["date_num"]=keiba_data["date_num"].astype(str) keiba_data["race_num"]=keiba_data["date_num"].str[0:12].astype(int) keiba_data["horse_num"]=keiba_data["date_num"].str[12:14].astype(int) keiba_data.drop(columns=["date_num"],inplace=True) # 扱いやすいようにrace_numとhorse_numは一番左に配置。 keiba_data=keiba_data.reindex(columns=["race_num","horse_num",'age', 'c_weight', 'course', 'date', 'field', 'gender', 'head_count', 'horse_name', 'j_weight', 'jackie', 'odds', 'popu', 'race', 'race_name', 'rank', 'trainerA', 'trainerB', 'weight', 'year'])2-2 欠損値処理
データに欠損値があるか確認します。
keiba_data.isnull().sum()
いくつか欠損値があるみたいです。今回、学習に使うモデルはlightGBMという欠損値の処理をしなくていいモデルなのですが、どこかでlightGBMも欠損値処理をした方が精度があがるという記事をみたので(すいません、どの記事かは忘れてしまいました。)欠損値処理を行います。
intのカラムは0や平均値で埋めていき、objectのカラムなどはdropしていきます。
popuとoddsはかなり重要な要素となることが予想されるので、欠損値は平均値や中央値では埋めずdropしました。#欠損値処理 keiba_data["c_weight"].fillna(0,inplace=True) keiba_data["j_weight"].fillna(keiba_data["j_weight"].mean(),inplace=True) keiba_data["weight"].fillna(keiba_data["weight"].mean(),inplace=True) keiba_data.dropna(subset=["race_name"],inplace=True) keiba_data.dropna(subset=["odds"],inplace=True) keiba_data.dropna(subset=["popu"],inplace=True)2-3 データ型の確認
keiba_data.dtypes
object型は全てLabel Encoderによってint型に変換します。
その後、yearなどの不要な列を削除します。#labelencoderを使って、カテゴリ変数を変換。 le=LabelEncoder() keiba_categorical = keiba_data[["gender","field","horse_name","course","head_count","trainerA","trainerB","race","jackie","race_name"]].apply(le.fit_transform) keiba_categorical = keiba_categorical.rename(columns={"race_name":"race_name_c","filed":"field_c","gender":"gender_c","horse_name":"horse_name_c","course":"course_c","head_count":"head_count_c","trainerA":"trainerA_c","trainerB":"trainerB_c","jackie":"jackie_c"}) keiba_data = pd.concat([keiba_data,keiba_categorical],axis=1) # 変換前と不要な列を削除 keiba_data.drop(columns=["race_num","horse_num","date","year","race_name","race","trainerA","trainerB","course","field","gender","jackie","head_count","horse_name"],inplace=True)2-4 特徴量生成
oddsとpopuはかなり重要な特徴量と考え、それらの積をとった特徴量とc_weightから前回の体重が分かるので前回の体重を新たに特徴量として追加しました。
# 特徴量生成 # 1つ目はoddsとpopuの積 # 2つ目は前回の体重 keiba_data["odds_popu"]=keiba_data["odds"]*keiba_data["popu"] keiba_data["pre_weight"]=keiba_data["weight"]-keiba_data["c_weight"]2-5 目的変数の処理
ここから目的変数であるrankの処理を行います。
# rankの確認 keiba_data["rank"].unique()
すると順位以外に中止、失格の行があります。rankが分からなければ、学習もできないのでこの行は全てdropします。count()で数えると約2000と数も少ないのでdropしても大丈夫そうです。#中止、失格の行は全て削除する。 delete_index = keiba_data.index[((keiba_data["rank"]=="中止") | (keiba_data["rank"]=="失格")] keiba_data.drop(delete_index,inplace=True)さて、順位を予測したいところですが、競馬は基本的には3着以内に入るかが賞金に関わってきます。逆に言えば、7位や8位の馬をドンピシャで当てる必要は全くありません。
ということで、3着以内かそれより下位かの二値分類問題にしようと思います。要は勝つか負けるかですね。
他の方の記事では上位、中位、下位と3つに分けて多値分類問題にしてる方もいらっしゃいました。# 1,2,3着かそれ以外かに分割して、二値分類問題にする。 keiba_data["rank"]=keiba_data["rank"].astype(int) keiba_data = keiba_data.assign(target = (keiba_data['rank'] <= 3).astype(int))targetという新しい列を作り、3着以内であれば1,それより下位であれば0と振った列を作りました。
ここまでが前処理になります。次はlightGBMを使って、学習→予測まで行います。
ここまで処理したデータは以下のとおりです。3 学習、予測
特徴量と目的変数をXとyに分割して、さらに学習用データと評価用データに分割します。
またそれらのデータをlgb.DatasetでlightGBMで読めるデータに変換します。# trainデータおよびtestデータの分割と特徴量および目的変数の分割 import lightgbm as lgb X = keiba_data.drop(['rank','target'], axis=1) y = keiba_data['target'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0) # データの変換 lgb_train = lgb.Dataset(X_train, y_train) lgb_eval = lgb.Dataset(X_test, y_test)パラメータチューニングに関してはoptunaというフレームワークを使って、自動で決めます。
# ハイパーパラメータをoptunaで自動設定 %%time !pip install optuna from optuna.integration import lightgbm as lgb params = { 'objective': 'binary', 'metric': 'auc' } best_params, history = {}, [] model = lgb.train(params, lgb_train, valid_sets=[lgb_train,lgb_eval], verbose_eval=False, num_boost_round=10, early_stopping_rounds=10) best_params_ = model.params # モデルの作成 import lightgbm as lgb_orig model = lgb_orig.train(best_params_, lgb_train, valid_sets=lgb_eval, num_boost_round=100, early_stopping_rounds=10)最終的なAUCは
でした。AUCなので82%当てているということではないですが、思ったよりいい数値が出てくれました。
(AUCについてはこちらのサイトが分かりやすかったです。
https://techblog.gmo-ap.jp/2018/12/14/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%81%AE%E8%A9%95%E4%BE%A1%E6%8C%87%E6%A8%99-roc%E6%9B%B2%E7%B7%9A%E3%81%A8auc/)最後に特徴量の重要度をみてみます。
#特徴量の重要度を表示。 keiba_data.drop(columns = ["rank","target"],inplace=True) importance = pd.DataFrame(model.feature_importance(), index=keiba_data.columns,columns=['importance']) importance=importance.sort_values(by="importance",ascending=False) display(importance)
やはりoddsはかなり重要な特徴量であるようです。また馬に乗るジョッキー(jackie_c)も重要なようです。
意外だったのはpopuやtrainerAの重要度が低いという点です。しかしtrainerBは重要度が高いです。この辺りは競馬に詳しい人に聞いた方が良いかもしれないです。筆者は競馬を数回しかやったことがないのに、この辺りはまだまだ勉強が必要です。おわりに
今回、前処理について基礎的なことしか行っていませんが、AUCは0.816736という割と良い数値がでました。
結構当てくれるので、これを使えば儲かるかと言われるとまたそれは別の問題になってきます。モデルは3着以内に入るか否かだけを判定してくれてるので、いくら賭けていくら戻ってくるなどの回収率は一切考慮していません。
人気な馬に賭けておけば的中しやすくなりますが、その分oddsは低いので払い戻し金額も少なくなってしまいます。
要するに「当たるけど、戻ってくるお金は少ない」ということです。
理想は穴馬(oddsが高い不人気な馬)にもかけつつ、人気な馬で安定的に稼ぐみたいな感じがいいのかなと思います。
最終的にできたモデルはDjangoなどで実装して日付とレース番号を入れると、予測を返してくれるようなものを作りたいと思っています。これを作ってて思いましたが、好きな題材でプログラミングの勉強ができるのは良いですね。プログラミングを勉強する上で、実際に何かを作りながら勉強するのが大事だなと改めて実感しました。
最後までご覧いただきありがとうございました。参考にさせていただいた記事
・https://qiita.com/Mshimia/items/6c54d82b3792925b8199
・https://qiita.com/km_takao/items/0a448543961a97fc9c94
・https://qiita.com/km_takao/items/70f7a7c3c9c533d7bee4
・https://techblog.gmo-ap.jp/2018/12/14/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%81%AE%E8%A9%95%E4%BE%A1%E6%8C%87%E6%A8%99-roc%E6%9B%B2%E7%B7%9A%E3%81%A8auc/




- 投稿日:2021-01-05T16:29:30+09:00
レコメンドシステムの実装〜TF-IDFを使って映画の概要から類似度を求めてみました〜
はじめに
レコメンドシステムのコンテンツベースフィルタリングを、TF-IDFを用いて実装してみます。前回の記事では、One-Hot Encodingを用いてアニメのジャンルデータから類似度を計算しています。良ければこちらもご覧ください。
今回は以下のような実装を行います。
- 映画の概要(文章)をTF-IDFでベクトル化
- コサイン類似度を使って類似度を計算
- 類似度の高いアイテムをレコメンド
scikit-learnを使って簡単に実装していきます。
TF-IDF
TF-IDFは前回One-Hot Encodingで行ったようなアイテムのベクトル化の手法の一つです。今回はアイテムの概要(文章のもの)をベクトル化するため、TF-IDFを使ってみます。
TF-IDFはTF(Term Frequency)とIDF(Inverse Document Frequency)の積で求められます。以下の式で表されますが、単語がレアなほどその文章の特徴を表す際にその単語の重要度が上がるというものです。
$$IDF = \log \frac{全文章数}{単語Xを含む文章数}$$$$TF = \frac{文章Aにおける単語Xの出現頻度}{文章Aにおける全単語の出現頻度の和}$$
$$TFIDF = TF \cdot IDF$$こちらの記事がTF-IDFに関して詳しく書かれていたので紹介しておきます。
実装
今回はこちらのデータを使って実装します。まずはデータを確認します。
(カラムが多いので、今回使うカラムだけ取り出します。)コードimport pandas as pd import numpy as np #データの読み込み movies = pd.read_csv("movies_metadata.csv") #必要なカラムだけ取り出す movies = movies[['id', 'original_title', 'overview']] #データの長さを確認 print('データ数:',len(movies.id)) movies.head()実行結果データ数: 45466 id original_title overview 0 862 Toy Story Led by Woody, Andys toys live happily in his ... 1 8844 Jumanji When siblings Judy and Peter discover an encha... 2 15602 Grumpier Old Men A family wedding reignites the ancient feud be... 3 31357 Waiting to Exhale Cheated on, mistreated and stepped on, the wom... 4 11862 Father of the Bride Part II Just when George Banks has recovered from his ...overviewカラム(概要)に欠損値があるので、欠損値を含む行を削除します。今回はTF-IDFを試すのが目的なので、処理が雑ですがご了承ください。
コード#欠損値の確認 movies.isnull().sum() #欠損値のある行を削除 movies = movies.dropna(how='any') print('データ数:',len(movies.id))実行結果#欠損値 id 0 original_title 0 overview 954 dtype: int64 データ数: 44512次は実際にTF-IDFでアイテムをベクトル化します。TF-IDFの計算はscikit-learnのTfidfVectorizerを使って簡単に実装します。
コード#overview(概要)のカラムをTF-IDFでベクトル化 from sklearn.feature_extraction.text import TfidfVectorizer tf = TfidfVectorizer() tfidf_matrix = tf.fit_transform(movies['overview']) #作成した行列のサイズを確認 tfidf_matrix.shape実行結果(44512, 76132)映画のデータ数が44512で、出現する単語数が76132単語と確認できます。
今回は類似度行列もscikit-learnを使って求めます。コサイン類似度の説明は前回の記事で書いたので省略します。コード#類似度行列を作成 from sklearn.metrics.pairwise import pairwise_distances cosine_sim = 1 - pairwise_distances(tfidf_matrix, metric = 'cosine') cosine_sim対角成分が1の類似度行列ができます。
実行結果[[1. , 0.0306972 , 0.01283222, ..., 0.00942304, 0.03492933, 0.01737238], [0.0306972 , 1. , 0.05674315, ..., 0.00944854, 0.06448034, 0.03307954], [0.01283222, 0.05674315, 1. , ..., 0.01271578, 0.05854697, 0.02767532], ..., [0.00942304, 0.00944854, 0.01271578, ..., 1. , 0.02566797, 0.01480498], [0.03492933, 0.06448034, 0.05854697, ..., 0.02566797, 1. , 0.0590926 ], [0.01737238, 0.03307954, 0.02767532, ..., 0.01480498, 0.0590926 , 1. ]]このままだとどの映画がどの行にあるか分かりづらいので、indexと映画のidの対応表をキーバリュー型で作成します。そして、映画のidから類似度の高いアイテムを検索します。ここでは、Toy Story(id:862)と類似度の高いアイテムを抽出します。
コード#indexと映画のidの対応表を作成 itemindex = dict() for num, item_id in enumerate(movies.id): itemindex[item_id] = num #映画のid(Toy Storyなので862)を指定してindexを検索、row_numに格納 row_num = itemindex['862'] #類似度の高いアイテム(トップ10)の行数をtop10_indexに格納 top10_index = np.argsort(sim_mat[row_num])[::-1][1:11] top10_index #top10_indexに格納したindexと対応する映画のidを検索 rec_id = list() for search_index in top10_index: for id, index in itemindex.items(): if index == search_index: rec_id.append(id) rec_id実行結果['10193', '863', '6957', '82424', '92848', '181801', '364123', '250434', '42816', '355984']このidの映画は以下の通りです。
id original_title overview 2997 863 Toy Story 2 Andy heads off to Cowboy Camp, leaving his toy... 8327 42816 The Champ Dink Purcell loves his alcoholic father, ex-he... 10301 6957 The 40 Year Old Virgin Andy Stitzer has a pleasant life with a nice a... 15348 10193 Toy Story 3 Woody, Buzz, and the rest of Andy's toys haven... 23843 92848 Andy Hardy's Blonde Trouble Andy is going to Wainwright College as did his... 24523 82424 Small Fry A fast food restaurant mini variant of Buzz fo... 29202 181801 Hot Splash Matt and Woody's summer in Cocoa Beach is goin... 38476 250434 Superstar: The Life and Times of Andy Warhol Documentary portrait of Andy Warhol. 42721 355984 Andy Peters: Exclamation Mark Question Point Exclamation Mark Question Point is the debut s... 43427 364123 Andy Kaufman Plays Carnegie Hall Andy Kaufman's legendary sold-out Carnegie Hal... 補足
ちなみに2つのアイテム間の類似度を求めるだけなら、scikit-learnのcosine_similarityを使うと便利です。
コードfrom sklearn.metrics.pairwise import cosine_similarity print(cosine_similarity(tfidf_matrix[0:1], tfidf_matrix)[0,1])上で求めたTF-IDFの処理をした行列で0行目と1行目(Toy StoryとJumanji)のコサイン類似度を求めると、上で計算した類似度行列の値と一致していることがわかります。
実行結果0.0306972031053245最後に
映画の概要(文章)を特徴ベクトルにし、Toy Storyと類似度の高い映画Top10を求めてみました。Toy Story2,3やSmall Fryのように似ている映画もあるものの、The 40 Year Old VirginやAndy Kaufman Plays Carnegie Hallなどあまり似ていない映画もありました(おそらく登場人物の名前がAndyでヒットしたんだと思います・・・)。
映画や本の場合は純粋にジャンルで類似度を求めた方が精度が高いかもしれません。今回TF-IDFを用いて文章の類似度を計算してみて、精度に関して詳しく勉強したいと感じました。
- 投稿日:2021-01-05T15:27:48+09:00
pytestでテスト中にprintで標準出力したいとき
結論から -s オプション追加でOK
pytestでテストするとき、単純に結果だけでなく途中の変数の値などを調べたいときがあります。
結論から言うと-sオプションを追加すれば出力されます。$ pytest -s例1 -sを使わない場合
以下のようなコードを考えます。
test_one.py# test_one.py def test_good(): for i in range(5): print(i) assert True def test_bad(): print('this should fail!') assert False-sオプションなしでテストすると、ループの中のアウトプットは出ません。
$ pytest =========================================================== test session starts =========================================================== platform darwin -- Python 3.7.0, pytest-6.2.1, py-1.10.0, pluggy-0.13.1 rootdir: /Users/reishimitani/Desktop/d2xx/D2XX collected 2 items test_one.py .F [100%] ================================================================ FAILURES ================================================================= ________________________________________________________________ test_bad _________________________________________________________________ def test_bad(): print('this should fail!') > assert False E assert False test_one.py:10: AssertionError ---------------------------------------------------------- Captured stdout call ----------------------------------------------------------- this should fail! ========================================================= short test summary info ========================================================= FAILED test_one.py::test_bad - assert False ======================================================= 1 failed, 1 passed in 0.37s =======================================================例2 -sを使う場合
同じコードで-sを追加して試してみます。ループの中のアウトプットが出力されます。
$ pytest -s =========================================================== test session starts =========================================================== platform darwin -- Python 3.7.0, pytest-6.2.1, py-1.10.0, pluggy-0.13.1 rootdir: /Users/reishimitani/Desktop/d2xx/D2XX collected 2 items test_one.py 0 1 2 3 4 .this should fail! F ================================================================ FAILURES ================================================================= ________________________________________________________________ test_bad _________________________________________________________________ def test_bad(): print('this should fail!') > assert False E assert False test_one.py:10: AssertionError ========================================================= short test summary info ========================================================= FAILED test_one.py::test_bad - assert False ======================================================= 1 failed, 1 passed in 0.34s =======================================================
- 投稿日:2021-01-05T15:20:48+09:00
Pythonのwith文に複数のcontext managerを指定した場合の実行順序
PythonのLanguage Referenceによると、
withには複数のcontext managerを指定できます。Language_Referenceより抜粋with A() as a, B() as b: SUITEこれはネストした
with文と同等とのこと。Language_Referenceより抜粋with A() as a: with B() as b: SUITEとなると、
__exit__()が呼ばれる順序は書いた順の逆(B→A)になるはずです。実際にサンプルを書いて確かめました。
my_context_manager.pyclass MyContextManager: def __init__(self, name): self.name = name def __enter__(self): print(f'{self.name} enter') def __exit__(self, exc_type, exc_val, exc_tb): print(f'{self.name} exit') with MyContextManager('A') as a, MyContextManager('B') as b: print('do something')実行結果$ python my_context_manager.py A enter B enter do something B exit A exit確かに、逆順になっています。
- 投稿日:2021-01-05T15:11:37+09:00
【Python】iPadのカメラでリアルタイム物体検知
最近のスマホはカメラ,加速度・角速度センサ,気圧センサなどセンサーの塊です.これとpythonを組み合わせれば簡単に実世界の状態を観測することが可能になります.
本記事では,pythonでiPadのカメラから見えている物体が何かを認識させる方法の解説を行います.必要なものは以下の通りです.
① iOSのデバイス
iPadまたはiPhone.iPadの方が画面が大きいため操作しやすいです② iOS環境でpythonを実行するためのアプリ「Pyto」
デフォルト状態で画像解析に用いられるモジュール(Open CV)がインストールされているため便利です.有料1220円(2020.11月現在)ですが,3日のお試し期間でも下記のスクリプトは実行可能ですのでお試しください.1.Pytoのインストール
app storeから"Pyto -Python 3"をインストールします.
有料または,3日限定の試用が選択できます.試用でも問題ありません.https://apps.apple.com/jp/app/pyto-python-3/id1436650069
環境
端末:iPad Air 3 OS:iPad OS 14.1 Pyto:14.1.12.ファイルの作成
サンプルコードは以下の通りです.OpenCVとは画像や動画を処理するために必要な機能が実装されたライブラリです.こちらを使ってiPadのカメラに映る物体が何かを検知します.
objectDitection.pyimport cv2 from cv2 import dnn import numpy as np import time import os inWidth = 224 inHeight = 224 WHRatio = inWidth / float(inHeight) inScaleFactor = 0.017 meanVal = (103.94, 116.78, 123.68) prevFrameTime = None currentFrameTime = None device = 0 if __name__ == "__main__": modelfolder = "./MobileNet-Caffe-master" net = dnn.readNetFromCaffe( os.path.join(modelfolder, "mobilenet_v2_deploy.prototxt"), os.path.join(modelfolder, "mobilenet_v2.caffemodel"), ) cap = cv2.VideoCapture(device) f = open(os.path.join(modelfolder, "synset.txt"), "r") classNames = f.readlines() showPreview = True while cap.isOpened(): # capture frame-by-frame ret, frame = cap.read() # check if frame is not empty if not ret: # print("continue") continue frame = cv2.autorotate(frame, device) rgbFrame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) blob = dnn.blobFromImage(rgbFrame, inScaleFactor, (inWidth, inHeight), meanVal) net.setInput(blob) detections = net.forward() maxClassId = 0 maxClassPoint = 0 for i in range(detections.shape[1]): classPoint = detections[0, i, 0, 0] if classPoint > maxClassPoint: maxClassId = i maxClassPoint = classPoint className = classNames[maxClassId] # print("class id: ", maxClassId) # print("class point: ", maxClassPoint) # print("name: ", className) prevFrameTime = currentFrameTime currentFrameTime = time.time() if prevFrameTime != None: i = 1 # print(1.0 / (currentFrameTime - prevFrameTime), "fps") if showPreview: font = cv2.FONT_HERSHEY_SIMPLEX size = 1 color = (255, 255, 255) weight = 2 cv2.putText(frame, className, (10, 30), font, size, color, weight) cv2.putText(frame, str(maxClassPoint), (10, 60), font, size, color, weight) cv2.imshow("detections", frame)3.物体検知の学習済ファイルをiPadにダウンロード
今回は以下の物体検知ライブラリを使わせていただきます。
https://github.com/shicai/MobileNet-CaffeからMobileNet-Caffe-master
をダウンロード.これを実行ファイルと同じディレクトリに保存します.① iOS上で上記リンク先からファイルをダウンロード
② zipファイルを展開(iOS13以降で可能です)
③ ファイルを実行ファイルのあるディレクトリに移動(デフォルトではicloud/pytoです)4.フォルダへのアクセス許可
pyto内の設定から以下の手順で「pyto実行ファイルの存在するフォルダ」,「MobileNet-Caffe-masterの存在するフォルダ」にアクセス許可を与えます.
5.実行
右上,実行ボタンを押すだけでコンソール上に画面が表示されます.
環境構築やモジュールのインストールさえ必要ないため本当に3分できます!
また,Pytoの機能としてSiriからのスクリプト実行呼び出しなどにも対応しています.参考にさせていただいた記事
https://github.com/shicai/MobileNet-Caffe
https://qiita.com/yamamido0268/items/e1172d25072da1687c49
http://asukiaaa.blogspot.com/2018/03/opencvdnnpythonmobilenet.html


