- 投稿日:2021-01-05T23:52:55+09:00
Amazon EC2でStreamlitを使った簡単な「新規感染者数可視化アプリ」を動かしてみる
はじめに
- Python3で簡単にデータを可視化できるAPI「Streamlit」を使ってみます
- 対象となるデータはNHKが公開しているコロナウイルスの県別新規感染者数データです
- 本記事ではStreamlitをEC2サーバで稼働させ、Webアプリケーションとして公開する手順を書きます
- VPCやEC2の構築方法については過去記事をご参照ください
- プログラムだけみたい!という方は「streamlitを動かす」までスクロールしてください
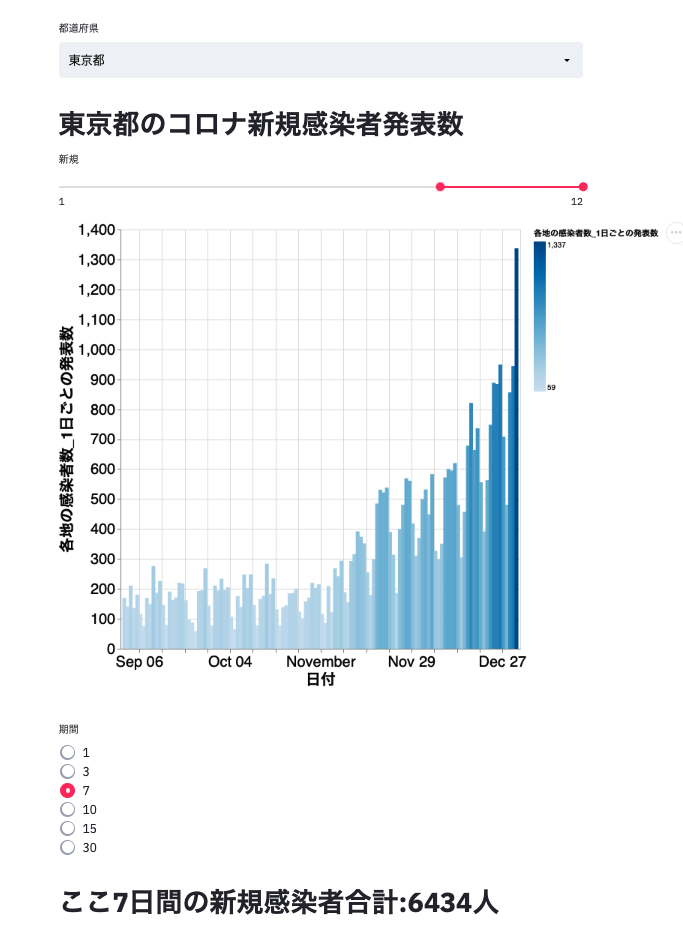
完成イメージ
環境構築
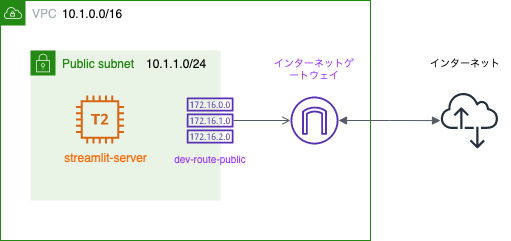
ネットワーク構成図
streamlit-serverインスタンスの生成
- EC2サービス
- [左タブ] インスタンス
- 下記設定のみ変更し、他はデフォルトでインスタンスを作る
インスタンスの詳細の設定
- ネットワーク: Develop(10.1.0.0/16)
- サブネット: public-subnet-1a-dev
- 自動割り当てパブリックIP: 有効
タグの追加
- タグの追加
- キー: Name
- 値: Streamlit-server
- 次のステップ
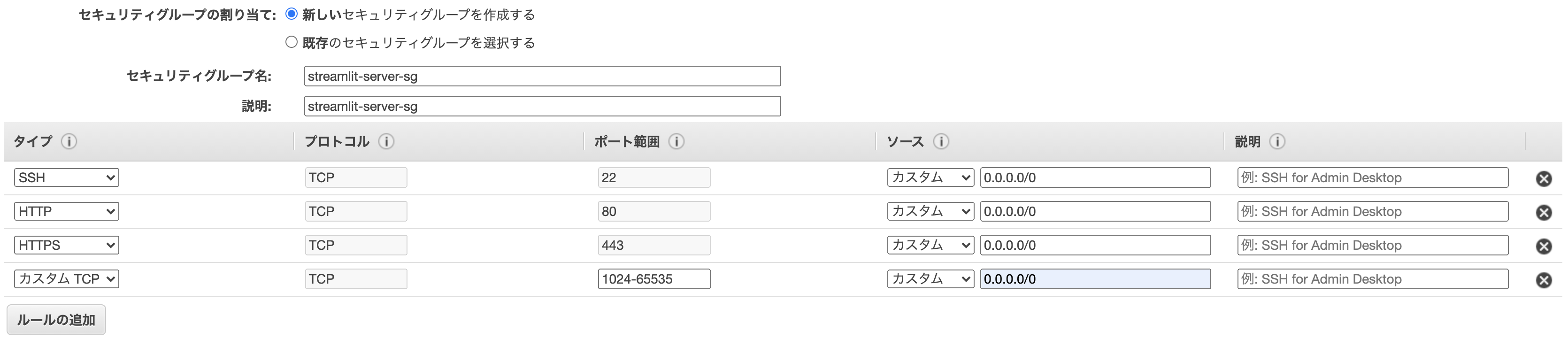
セキュリティグループの設定
新しいセキュリティグループ
- グループ名: streamlit-server-sg
- 説明: streamlit-server-sg
ルールの追加
HTTP、HTTPS、カスタムTCPを追加
確認と作成
キーペア
- 既存のキーを使うことを想定
streamlitをインストールする
- streamlit-serverインスタンスにsshアクセスする
- ssh -i ~/.ssh/develop.pem ec2-user@[パブリックIPv4アドレス]
- streamlitを入れる
sudo suyum update -yyum install python3 -ypip3 install streamlitStreamlitを動かす
- csvファイルをcurlでダウンロードする
curl -O https://www3.nhk.or.jp/n-data/opendata/coronavirus/nhk_news_covid19_prefectures_daily_data.csv
vi corona.pyで下記をペーストcorona.pyimport pandas as pd import streamlit as st import altair as alt # グラフを描画するためのパッケージ DF = pd.read_csv('nhk_news_covid19_prefectures_daily_data.csv') PREFACTURES = DF['都道府県名'].unique() # セレクトボックス用に都道府県名リストを取得しておく class GraphMakerNewly(): '''新規感染者のグラフを作成するクラス''' def __init__(self, dataframe, prefacture_name): self.df = self.__read_prefacture(dataframe, prefacture_name) def __read_prefacture(self, df, name): '''都道府県を指定して読み込み、結果を返すメソッド''' result = df[df['都道府県名'] == name].reset_index(drop=True) result['日付'] = pd.to_datetime(result['日付']) return result def alt_graph(self, slider): '''指定された期間のコロナウイルス新規感染者のグラフを返すメソッド''' begin = self.df['日付'].dt.month >= slider[0] end = self.df['日付'].dt.month <= slider[1] df_slider = self.df[begin == end] graph_slider = alt.Chart(df_slider).mark_bar().encode(x='日付', y='各地の感染者数_1日ごとの発表数', color='各地の感染者数_1日ごとの発表数').properties( width=800, height=640 ).configure_axis( labelFontSize=20, titleFontSize=20 ) return graph_slider def get_ndays_cum(self, ndays): '''直近ndaysの新規感染者の合計を返すメソッド''' return sum(self.df.tail(ndays)[self.df.columns[3]]) # 都道府県が選べるセレクトボックスを定義 prefacture_name = st.selectbox('都道府県', (PREFACTURES)) st.write('# ' + prefacture_name + 'のコロナ新規感染者発表数') # 期間を指定できるスライダーを定義 mslider_new = st.select_slider( '新規', options=range(1, 13, 1), value=(9, 12)) gm_n = GraphMakerNewly(DF, prefacture_name) st.altair_chart(gm_n.alt_graph(mslider_new)) ndays = st.radio("期間", (1, 3, 7, 10, 15, 30), index=2) st.write('# ここ' + str(ndays) + '日間の新規感染者合計:' + str(gm_n.get_ndays_cum(ndays))+'人')管理者権限から抜ける
exit
streamlit run corona.pyで実行You can now view your Streamlit app in your browser. Network URL: http://[プライベートIP]:8501 External URL: http://[パブリックIP]:8501
- ブラウザで
http://[パブリックIP]:8501にアクセスしてみる
- アプリケーションが表示できれば成功
終わりに
- Streamlitを用いることで時間をかけずに簡単なデータの可視化することができました
- 年を跨いだ1月のデータが出力されないことが課題ですが...
- 間違いや改善点等ありましたらコメントいただければ幸いです
- 投稿日:2021-01-05T22:39:07+09:00
EC2インスタンスをWebサーバとして起動し、Hello, worldを出力する
はじめに
- Amazon EC2を起動し、Macのターミナルからssh接続してみるの続きです
- 今回はEC2インスタンスにApacheを入れてブラウザでHello,worldを表示してみます
構造図
- 特に変更なし
手順
1. Apacheをインストールする
- ターミナルを開く
- ec2インスタンスにsshアクセスする
ssh -i ~/.ssh/develop.pem ec2-user@[パブリックIPv4アドレス]- 管理者権限に移動
sudo su- インストールされているソフトウェアを最新のものに更新
yum update -y- apacheサーバをインストール
yum install httpd -y2. index.htmlを作成する
/var/www/htmlに移動
cd /var/www/html- htmlファイルを作る
vi index.html
- 下記をコピー&ペースト
<html><h1>Hello, world!</h1></html>- 上書き保存
esc→:wq- apacheを起動
systemctl start httpd- インスタンスの起動時にapacheが起動するように設定
systemctl enable httpd3.ブラウザでインスタンスにアクセスする
- EC2インスタンスのパブリックIPアドレスをコピー
- 任意のブラウザでアドレスをペースト
Hello, world!が出力されれば成功
完了
終わりに
- EC2インスタンスは無料枠には時間制限があるので、使用しない場合は停止しておきましょう
- 次回はStreamlitというPythonのAPIを使って、コロナウイルス感染者の人数を可視化するWebアプリケーションを作ってみます
- 間違いや改善点等ございましたらコメントをいただければ幸いです
作図ツール
- 投稿日:2021-01-05T22:21:01+09:00
1か月の試験勉強でAWS 認定 デベロッパー – アソシエイト (DVA) に合格した話
AWS SAA(ソリューションアーキテクトアソシエイト)を取得できたエンジニアが
1か月の試験対策でAWS DVA(デベロッパーアソシエイト)に合格できた話です。
AWS DVAについては、他の方が説明されていたり、AWS HPに記載されているので、
ここでは省略させて頂きます。SAA取得時の話は下記となります。
AWS SAA取得時の話
※SAA取得から1年以上、受験をしておらずコンスタントに取り組めば、
もっと良かったと、思ったりしました。(今年は、ステップアップしたいと思います。)個人的な経験ですが備忘録として投稿いたします。
ちょっとは、役に立てばうれしいです。
年末年始の休み中、比較的勉強ができたこともあるため、1ヶ月の試験とはいえ、
比較的、取り組み時間が長く取れたかと思います。
下記、試験結果です。
背景
経歴
組込系(ARMアーキテクチャ)エンジニアとして働いています。
IoT機器のアプリケーション開発、ネットワーク環境構築がメインの業務としてます。
また、AWSを使用した、IoT機器の保守システム開発などをしてきました。受験きっかけ
前回、SAAを取得できて、少し満足したところがあり、他の資格取得は目指しておりませんでした。しかし、今年はAWS re:Inventがオンライン配信ということもあり、気軽に新しいサービスを知るきっかけができました。こういったこともあって、秋以降、AWSへの興味が再熱してきました。そこで、他の資格も取得してみようと思ったのがきっかけです。
取り組んだこと
(1)本による"試験対象サービスの知識習得"
デベロッパーアソシエイト取得後、
SysOpsアドミニストレーターも取得したい思いがあったため、
下記を試験対策本としました。この本の中で、DVAが対象としている章(サービス)を
一通り確認し理解できるよう読み込みました。
AWS認定アソシエイト3資格対策~ソリューションアーキテクト、デベロッパー、SysOpsアドミニストレーター本という形のため、以後に記載するもの(Udemy,BlackBelt)よりも、情報量は少ないですが、
体系的に説明されているため初めに試験勉強として取り組むものとしては良いと思います。
(2)Udemyによるオンライン学習
セールをやっていたので、下記購入しました。
AWS 認定デベロッパー アソシエイト模擬試験問題集(5回分325問)
⇒正直なところ、実際の試験よりもやや難しいと感じるところもあります。
また、若干ですが、試験には出てこない範囲も含まれます。
しかし、この問題集は解説も細かく記載されているため、これらを合格点がとれるまで
繰り返すと、とても自信がつきました。(3)BlackBelt Online Seminarをみる
Amazon Web Services Japan 公式
たくさんの動画がupされているため、全部を見るのは難しいかと思います。
問題集ばかりをやっていると、飽きてくるのもあったため、
DVAの試験対象のサービスに関して、動画をチェックいたしました。
(Lambda,API Gateway,CodePipelineあたり)
本やUdemy講座などで各サービスの概要を知った上でBlackBeltを
観ると理解が深まると思いました。(4)実際にAWSサービスに触れる
やはり、これが一番だと思います。文字を追うだけよりも実際に触ってみたら、理解が
早いです。手軽にサービスに触れるところがクラウドの良いところだなと改めて思いました。スケジュール
* 1週目
本を中心に全体像を理解
勉強時間:平日-通勤時間の30分ぐらい
土日-なし
* 2週目
Udemyのオンライン講座で理解
※勉強時間:平日-通勤時間の30分ぐらい
土日-2時間/日ぐらい
* 3週目
本とUdemyの問題集を繰り返し実施し、3周程度いたしました。
この時、年明け最初に受験するよう、申込をいたしました。
* 4週目(年末年始)
BlackBeltを観始めました。
Udemyの問題集で間違えたサービスについて、BlackBeltを観て、不明点を補う作業
飽きてきたら、本/Udemy/BlackBeltの教材をチェンジしながら勉強してました。
また、AWSサービスに触れ、理解を進めました。
※勉強時間:1日3時間程度試験当日
運転免許証とクレジットカードをもって、テストセンターへ
コロナ禍のため、マスクしたままでした。席も間が空いており、人はまばらでした。
ホワイトボードを渡され、試験を開始しました。
■1周目
約50分かけて、まずは全問題を解きました。
あやふやなところ含めて、確信できない問題にチェックをいれていきました。
■2周目
見直しフェーズ。
約30分かけて、見直ししました。
落ち着いて見直しを行い、1問ずつ、大丈夫かなと思えるようになってきました。
⇒時間が長い試験ですが、2周問題をチェックするとあっという間でした。
アンケートを答えたら、"合格"となっていたので、うれしかったです。
3時間後程度に試験結果のリンクのメールがきておりました。その他
ホワイトペーパーやベストプラクティスなど、いろいろありましたが、ボリュームに圧倒されて、題材に使うのは諦めました。。
感想
やはり、受験料も安くないので、1発で合格出来てよかったです。
今年は、この流れで他の資格も取れていければなと思います。
新しいサービスがどんどん出てきて、興味が沸く一方、
キャッチアップも大変なところもあるなと感じました。
でもできることが増えるのはやはり楽しいです。以上です。

- 投稿日:2021-01-05T21:58:35+09:00
Amazon EC2を起動し、Macのターミナルからssh接続してみる
はじめに
- Amazon VPCでシンプルなネットワークを構築するの続きです
- 今回はパブリックサブネットにEC2インスタンスを作成し、sshでアクセスしてみます
- 本記事ではMacのターミナルからアクセスします
- Windowsの方はTeraTerm等をお使いください
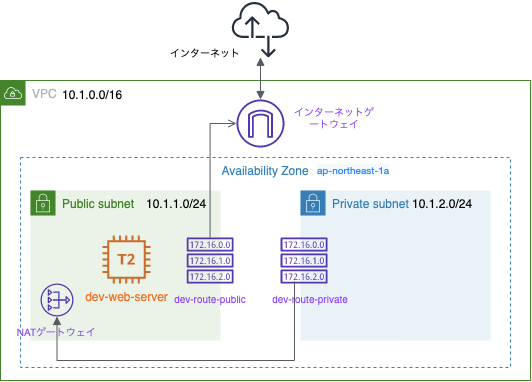
構造図
- Publicサブネット(10.1.1.0/24)にdev-web-serverを追加
手順と設定
1. EC2の起動
- EC2サービスを開く
- [左タブ] インスタンス
- 下記設定でインスタンスを起動
AMI
- Amazon Linux 2 64ビット(x86) → 次のステップ
インスタンスタイプ
- t2.micro → 次のステップ
インスタンスの詳細の設定
- ネットワーク: Develop(10.1.0.0/16)
- サブネット: public-subnet-1a-dev
- 自動割り当てパブリックIP: 有効 → 次のステップ
ストレージの追加
- 特に変更なし → 次のステップ
タグの追加
- タグの追加
- キー: Name
- 値: dev-web-server
- 次のステップ
セキュリティグループの設定
新しいセキュリティグループ
- グループ名: web-server
- 説明: web-server
ルールの追加
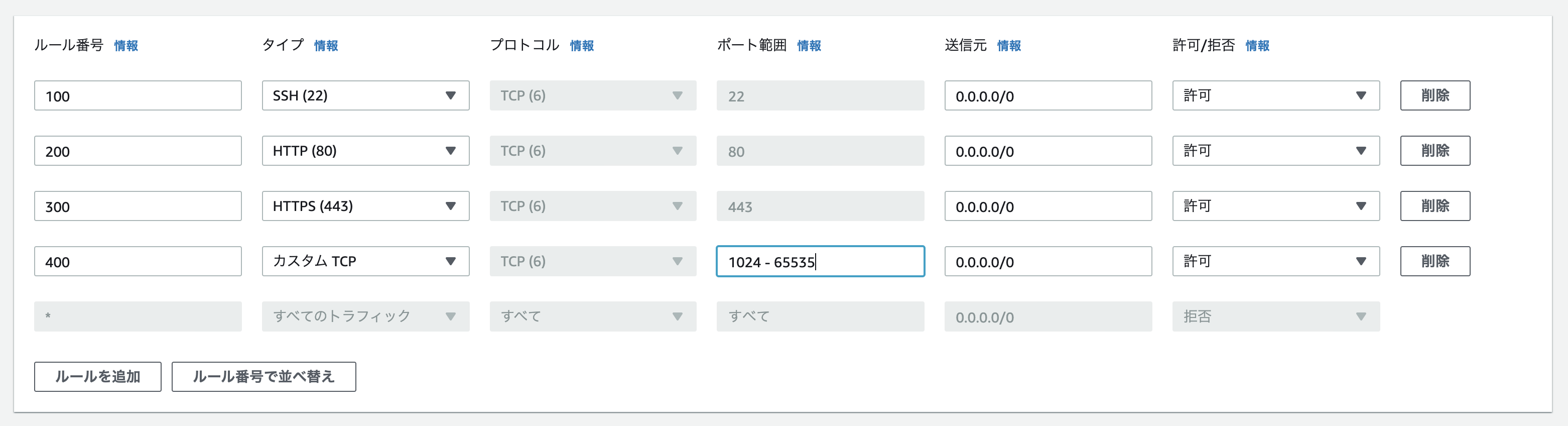
HTTPとHTTPSを追加
タイプ プロトコル ポート範囲 ソース 説明 SSH TCP 22 カスタム 0.0.0.0/0 HTTP TCP 80 カスタム 0.0.0.0/0 HTTPS TCP 443 カスタム 0.0.0.0/0
- 確認と作成
起動
- キーペアの作成
- 新しいキーペアの作成
- キーペア名: develop
- キーペアのダウンロード
2. キーの移動
- ターミナルを起動
- develop.pemを保存した場所に移動
cd /Downloads/- キーを
~/.sshに移動
mv develop.pem ~/.ssh/- カレントディレクトリを
~/.sshに移動
cd ~/.sshlsでファイルを確認- develop.pemを読み取り専用ファイルにする
chmod 400 develop.pemls -lでrのみ有効になっていることを確認
-r--------3. ネットワークACLの設定
- VPCサービス
- [左タブ] ネットワークACL
- ネットワークACLを作成
- Name: Develop-NACL
- VPC: Develop
- 作成
Develop-NACLを選択、アクション「サブネットの関連づけを編集」
- public-subnet-1a-dev
- private-subnet-1a-dev
- 変更を保存
Develop-NACLを選択、アクション「インバウンドルールを編集」
- 下記の通り設定する
Develop-NACLを選択、アクション「アウトバウンドルールを編集」
- インバウンドルールと同様の設定にする
4. ssh接続
EC2サービス
- [左タブ] インスタンス
- 起動したインスタンスを選択
- 画面下にスクロールし、パブリック IPv4 アドレスを確認、コピー
ターミナル
ssh -i ~/.ssh/develop.pem ec2-user@[コピーしたIPv4アドレス]Are you sure you want to continue connecting
yes完了
終わりに
- EC2インスタンスは無料枠に時間制限があるので、使用しない場合は停止しておきましょう
- 次回はEC2インスタンスにWebサーバとしての機能を与え、ブラウザでHello,worldを表示してみます
- 間違いや改善点等ございましたらコメントをいただければ幸いです。
作図ツール
- 投稿日:2021-01-05T21:53:26+09:00
CloudFront + S3 の環境で、IPアドレスの制限を行う
はじめに
S3 に配置されたファイルを CloudFront を使って配信しているときに、特定の IP アドレスに限定して配信したいときがあります。次の3つの要素を組み合わせることで、実現できます。
- S3 で Public Access を Block
- S3 で Bucket Policy を設定し、CloudFront の OAI(Origin Access Identity) を使い、特定の Distributions のみアクセス許可
- CloudFront に WAF ACL を設定し、特定の IP アドレスのみアクセス許可
詳細な設定手順を備忘録として残しておきます。
S3 にファイルを配置
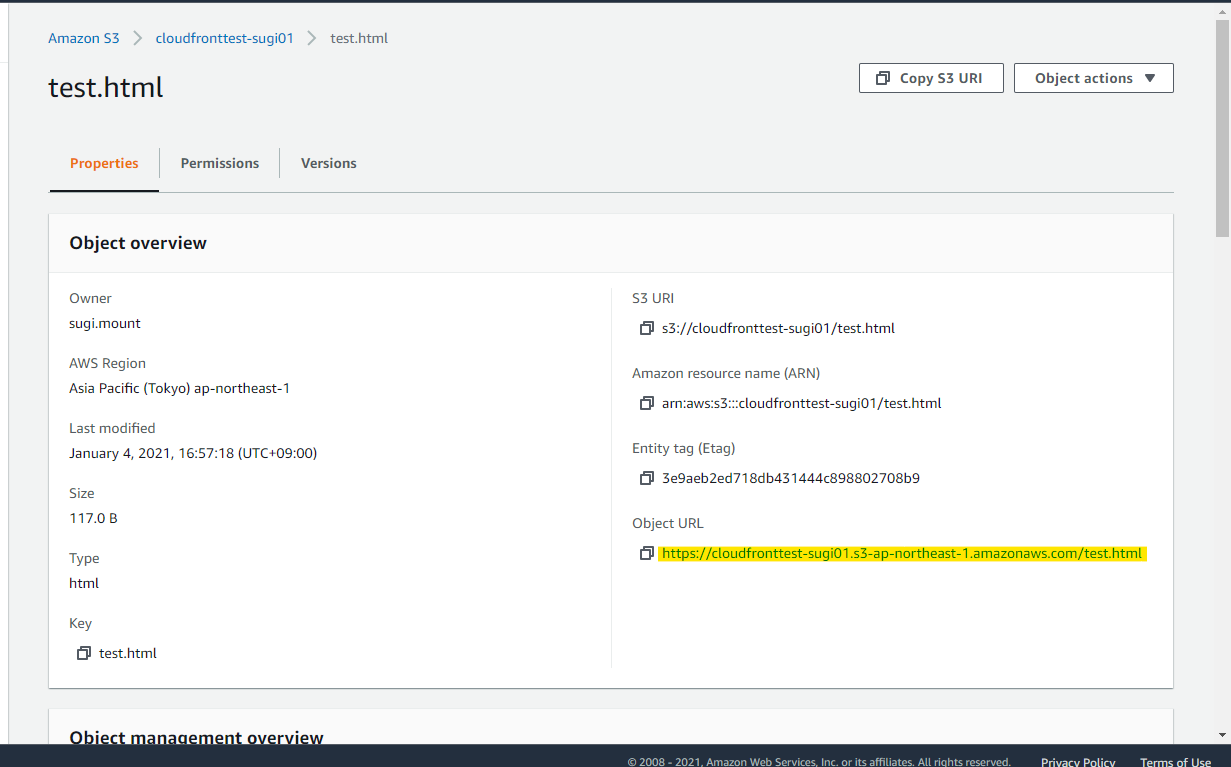
まず、S3 Bucket にテスト用のファイルを配置します。適当に作成した Bucket を開きます
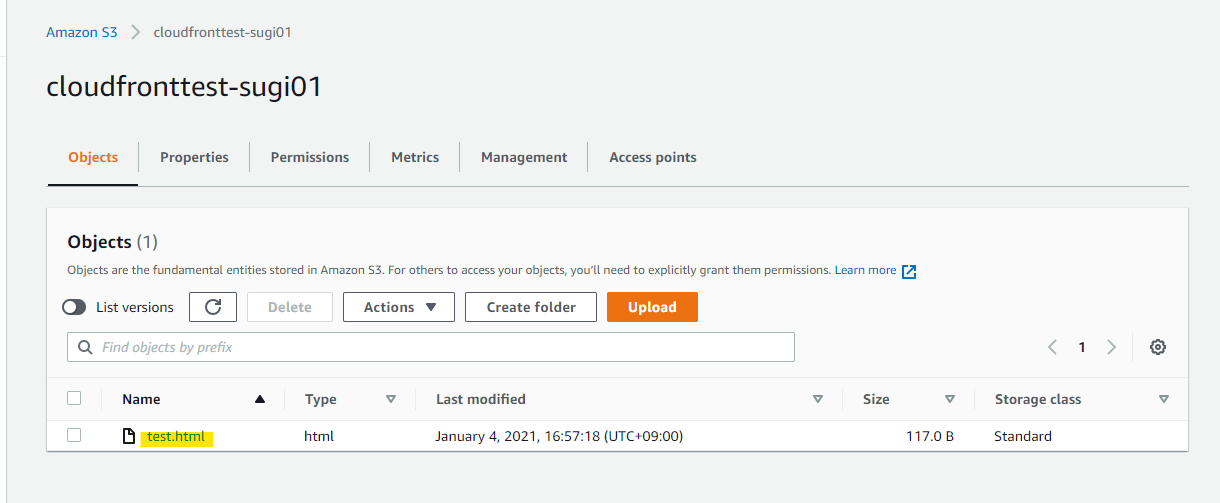
こんな感じのテストファイルを格納します
<html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"/> <title>CloudFront用制限</title> </head> <body> <h1>CloudFront用制限</h1> </body> </html>このように test.html としてアップロードしています
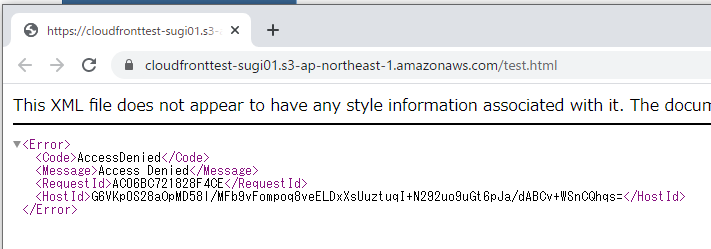
ObjectURLをクリックしても、、、
Access Denied となり、アクセスできません。Public Access をブロックしているので、正しい動作です。
CloudFront Distribution 作成
CloudFront で、Create Distribution
Get Started
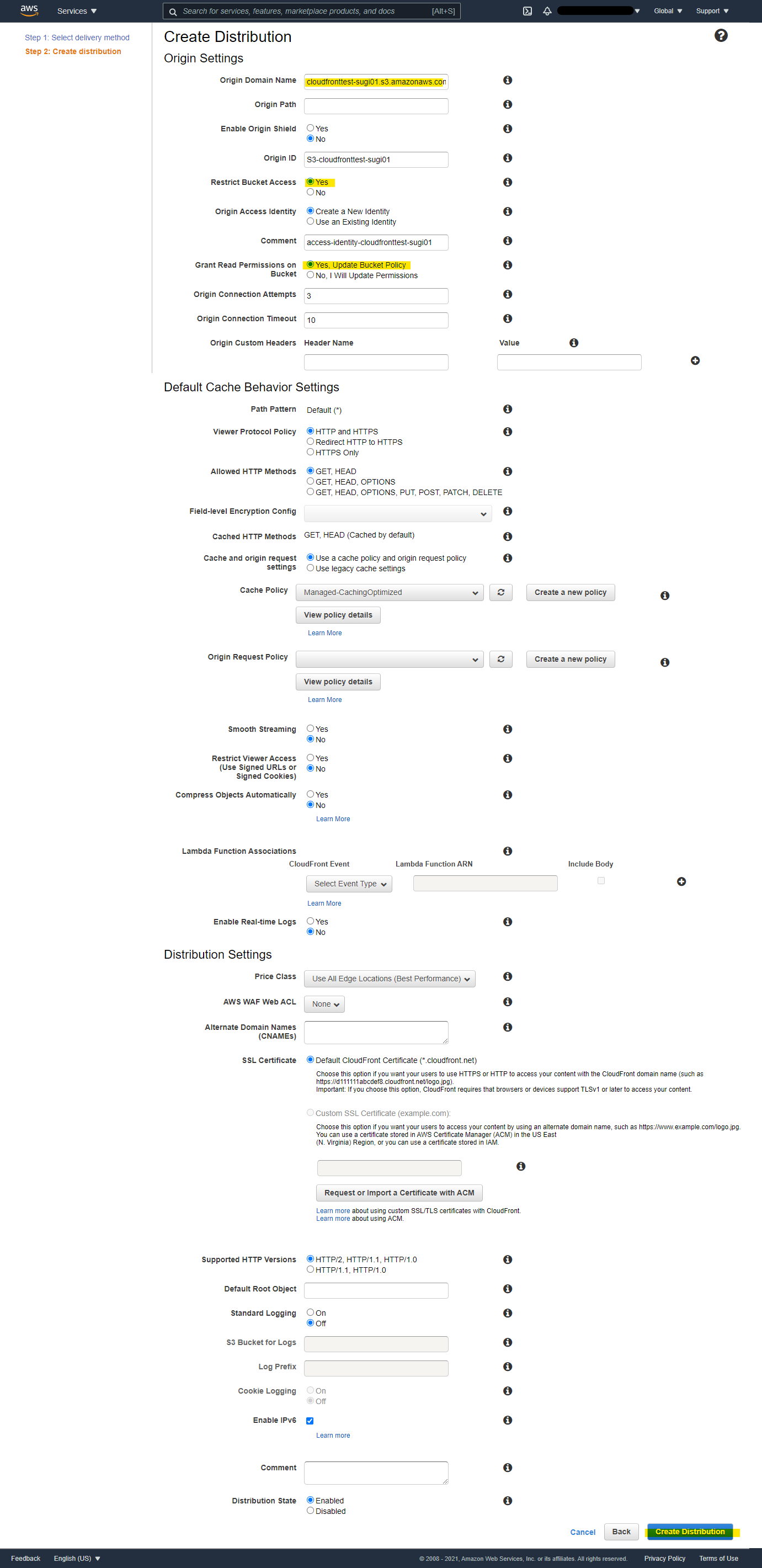
パラメータを入れて Create を押します
- Origin Domain Name : S3 の名前を選択
- Restrict Bucket Access : Yes にすると、OAI (Origin Access Identity) などの設定項目が現れます
- Grant Read Permission on Bucket : S3 Bucket Policy を自動的に設定し、新たに作成する Distribution のみアクセス許可
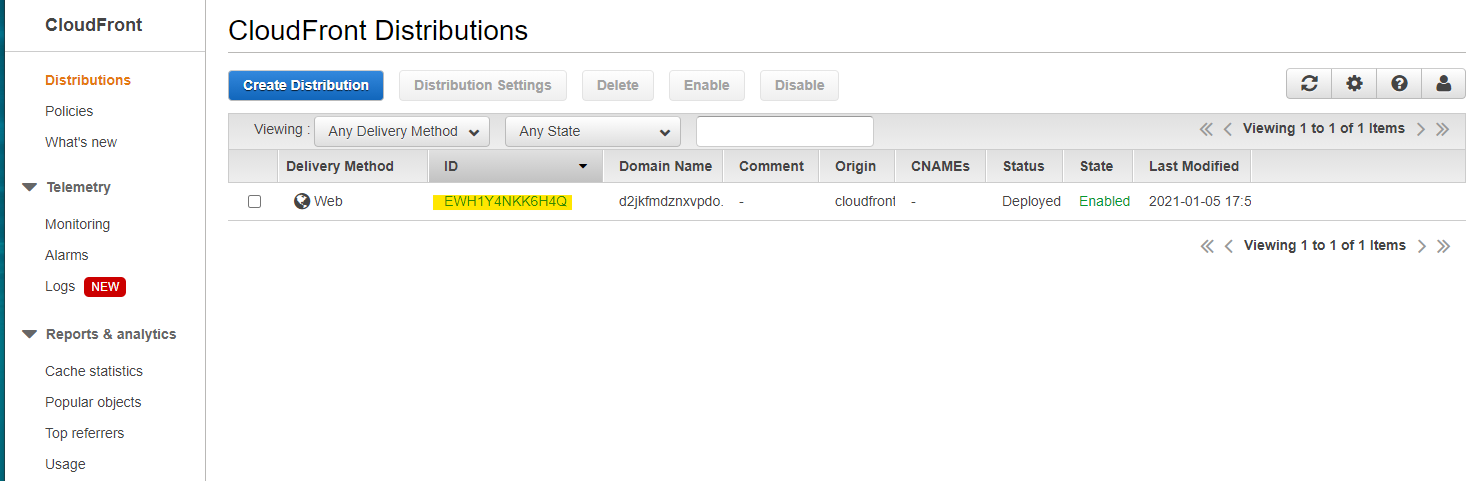
作成完了 (Enabled)
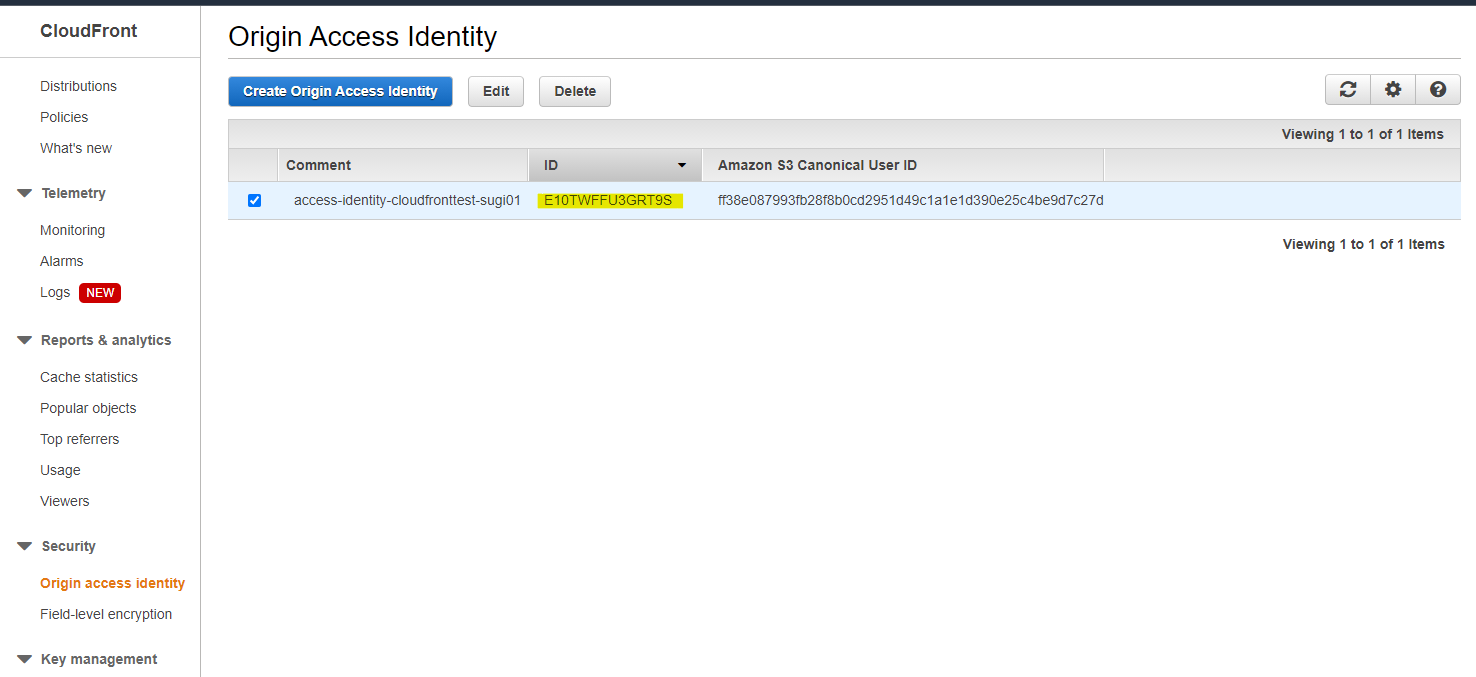
OAI(Origin Access Identity) の ID は
E10TWFFU3GRT9Sで生成されている
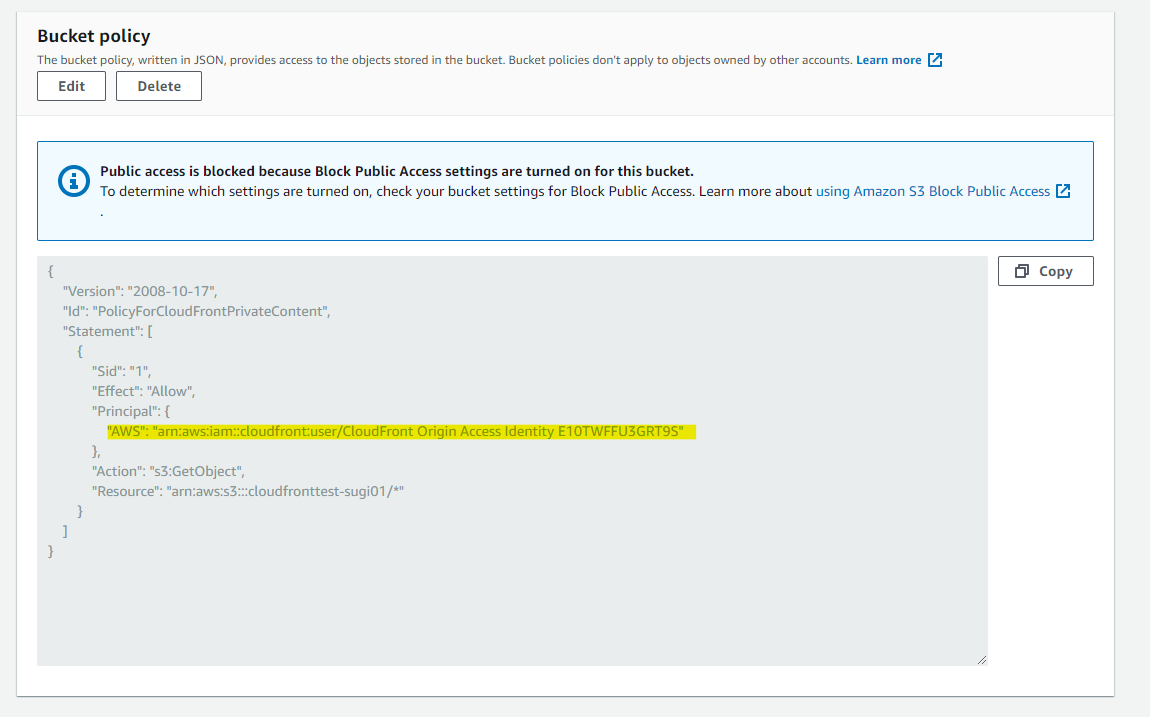
S3 の Bucket Policy には自動的に設定されている
Bucket Policy を文字列でもメモ
{ "Version": "2008-10-17", "Id": "PolicyForCloudFrontPrivateContent", "Statement": [ { "Sid": "1", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::cloudfront:user/CloudFront Origin Access Identity E10TWFFU3GRT9S" }, "Action": "s3:GetObject", "Resource": "arn:aws:s3:::cloudfronttest-sugi01/*" } ] }WAF ACL 作成
CloudFront に IP アドレスのアクセス制限を付与するために、WAF ACL を設定します
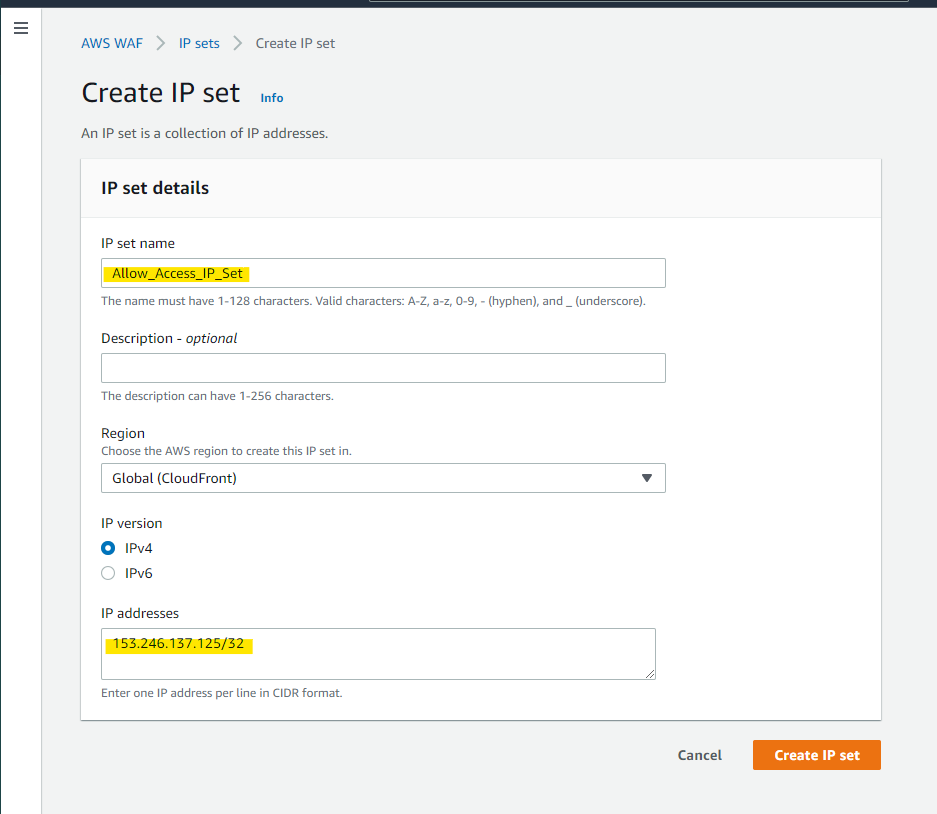
まず、アクセスを許可する IP アドレスを、IP set として定義します
Create IP set
自分が持っている環境の IP アドレスを指定
作成完了
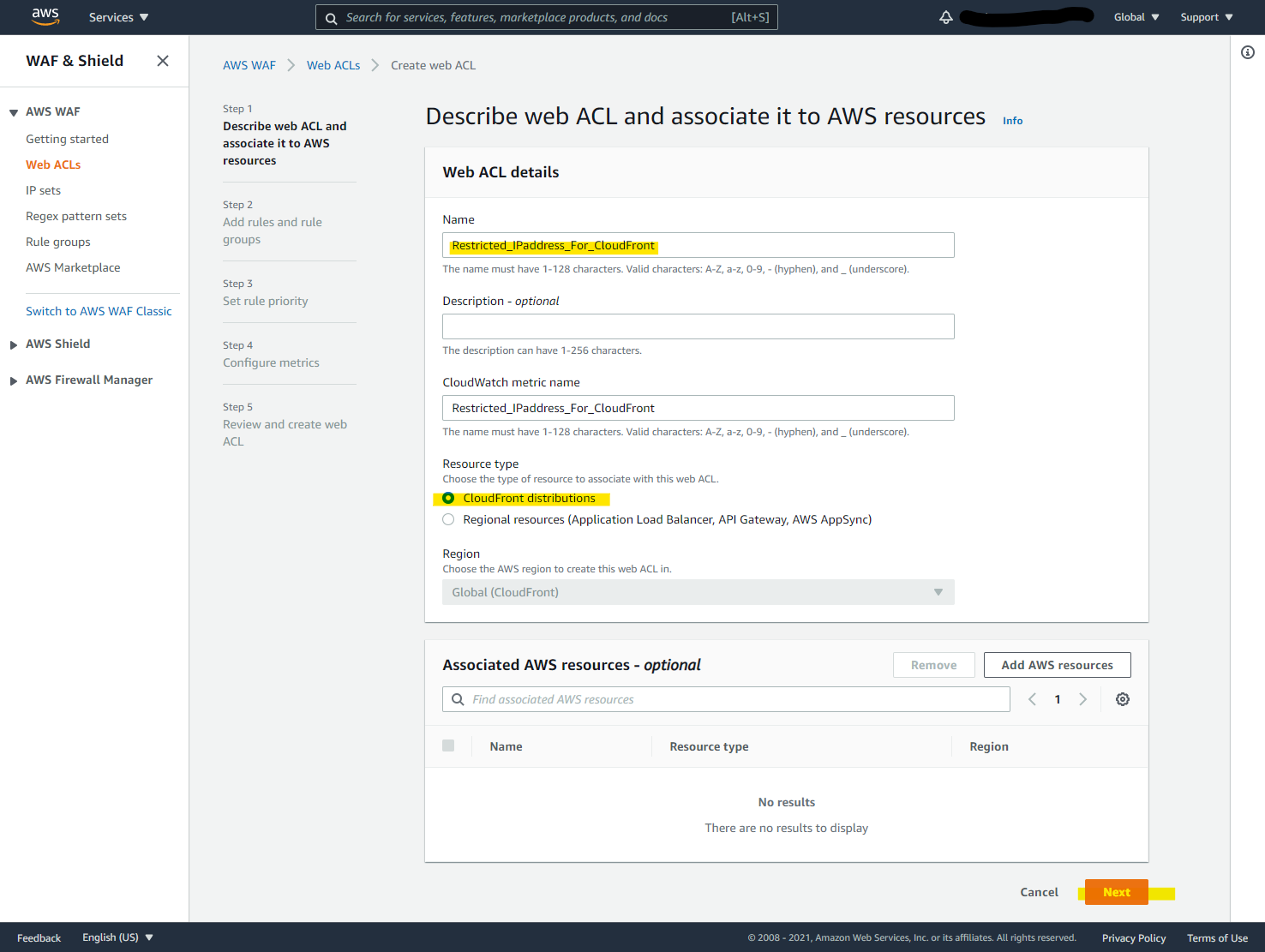
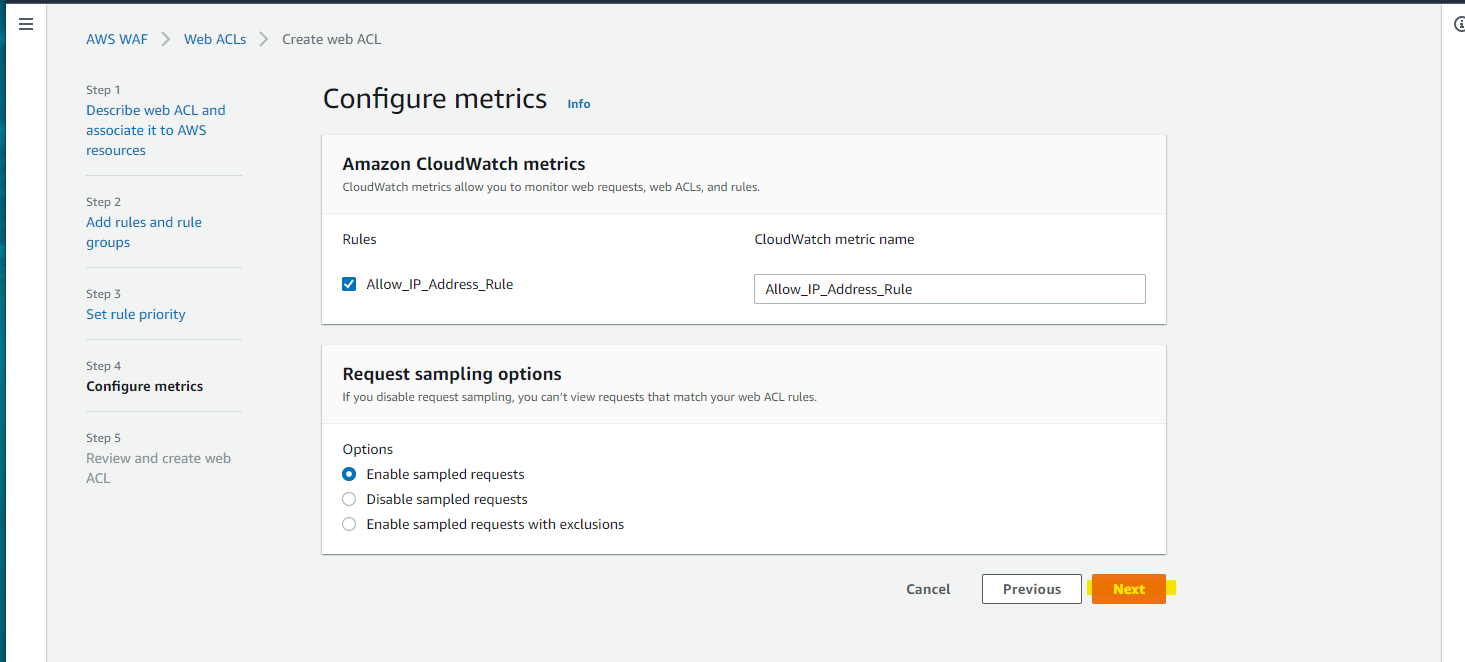
Web ACL を作成します
パラメータ指定して Next
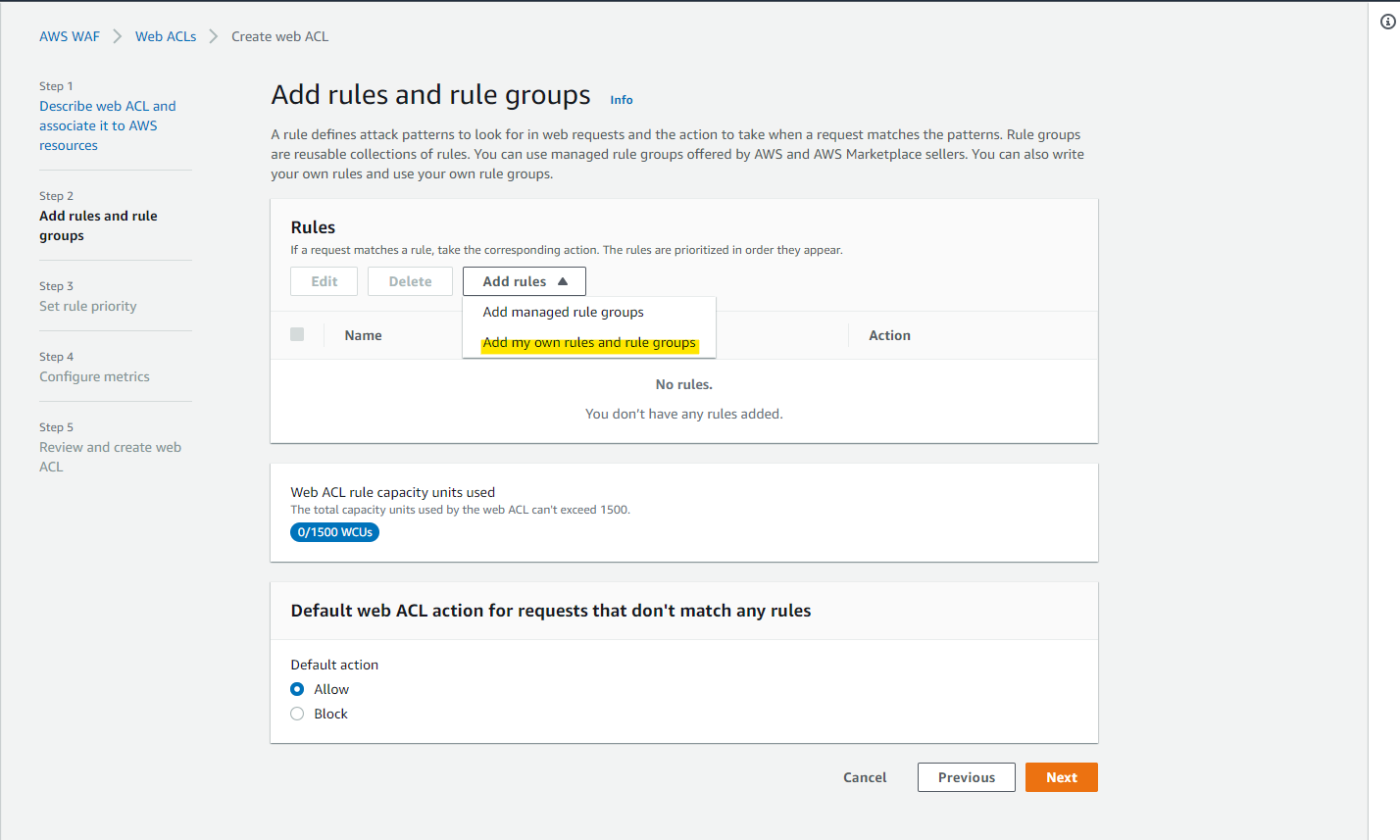
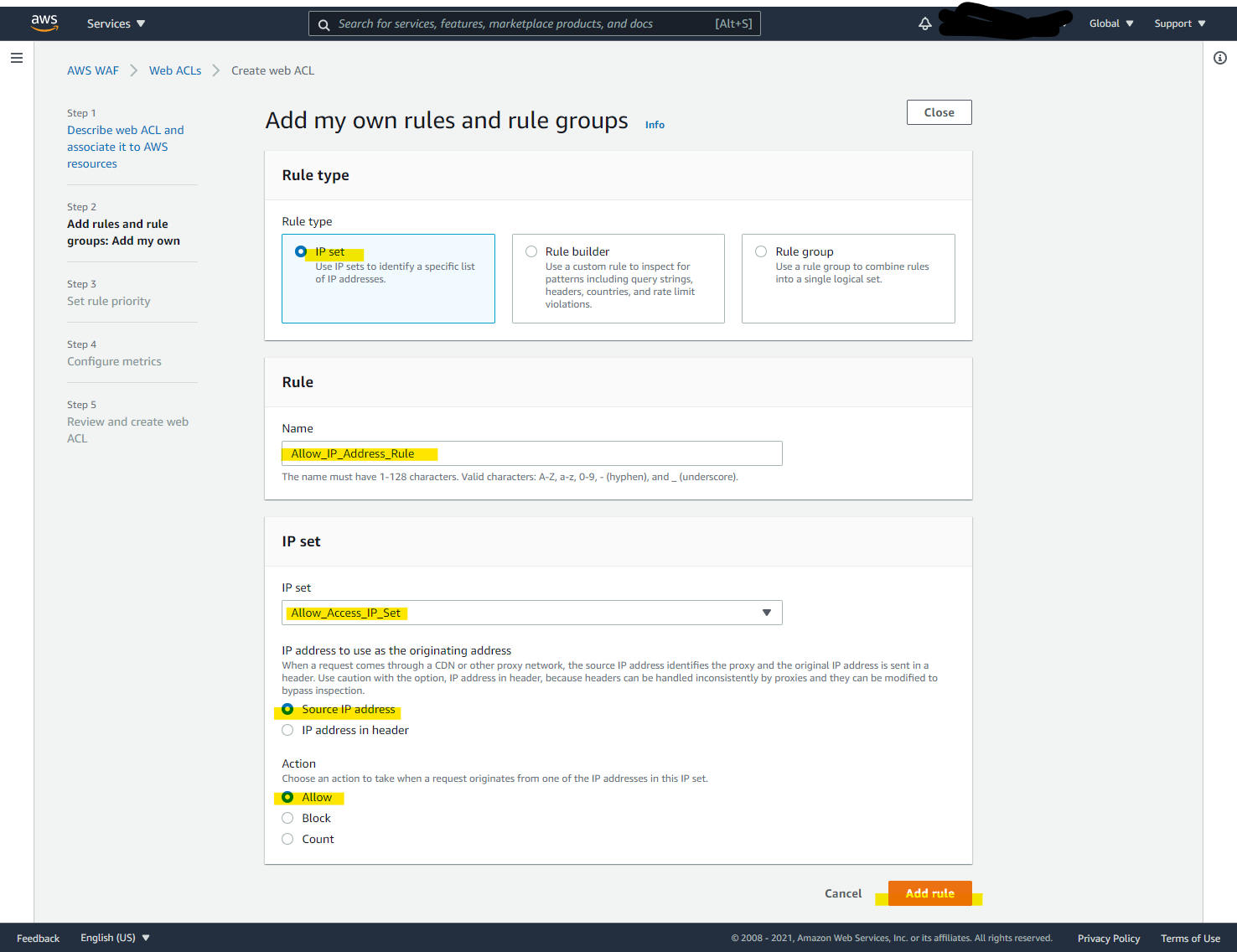
Add my own rules and rule groups
IP set を選択して、定義された IP アドレスのみアクセスを許可します。
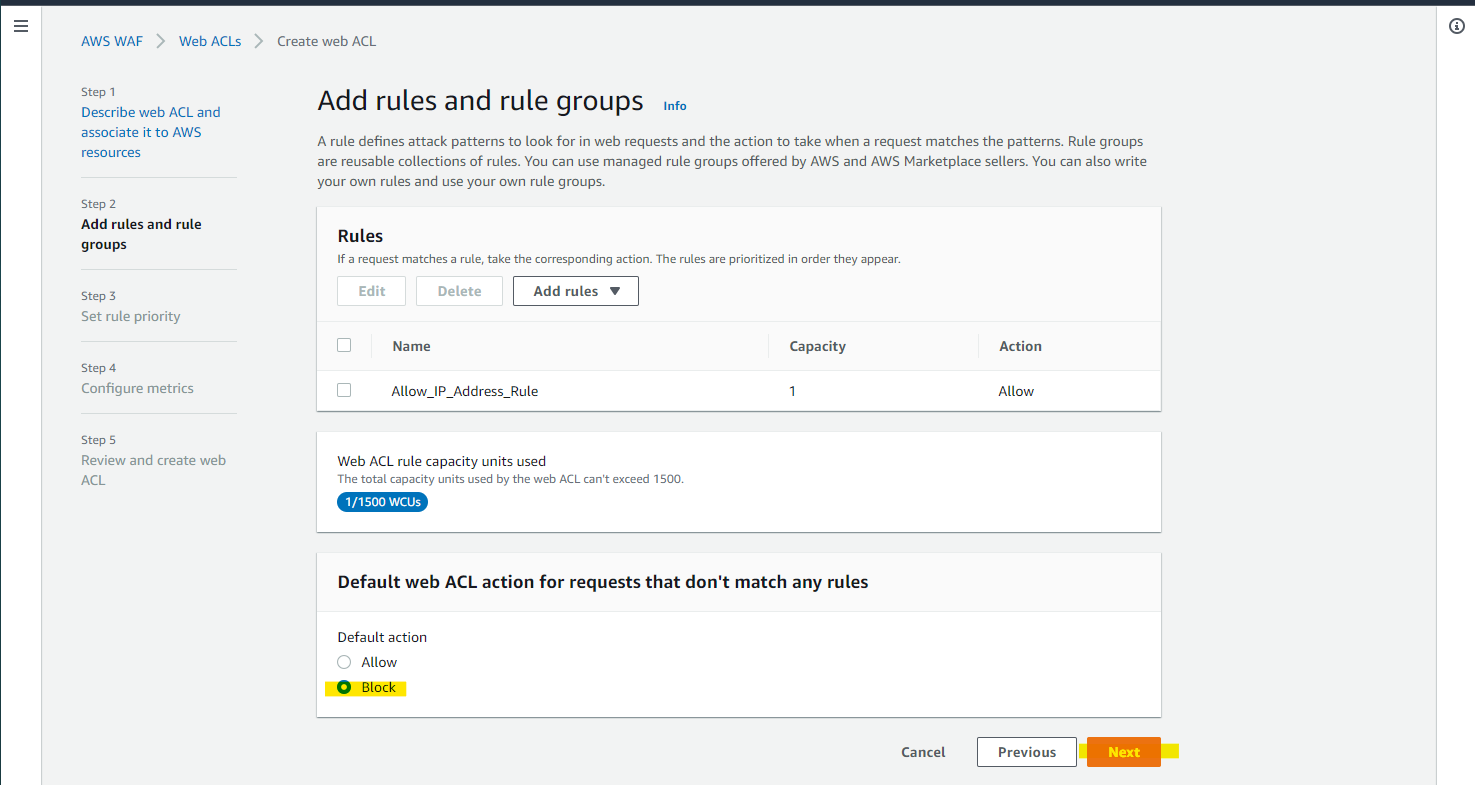
Default Block にすることで、IP set の IP アドレスのみアクセス可能です
Next
Next
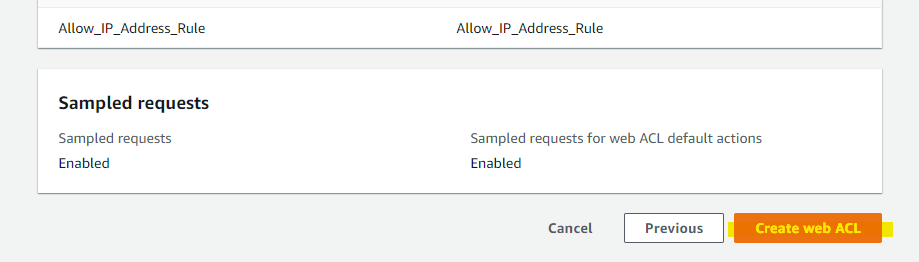
Create ACL
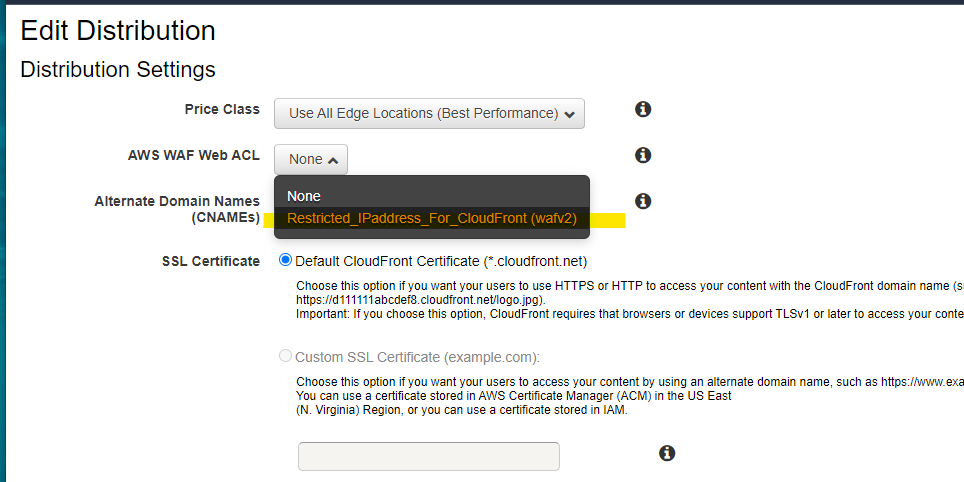
Distribution に WAF ACL をアタッチ
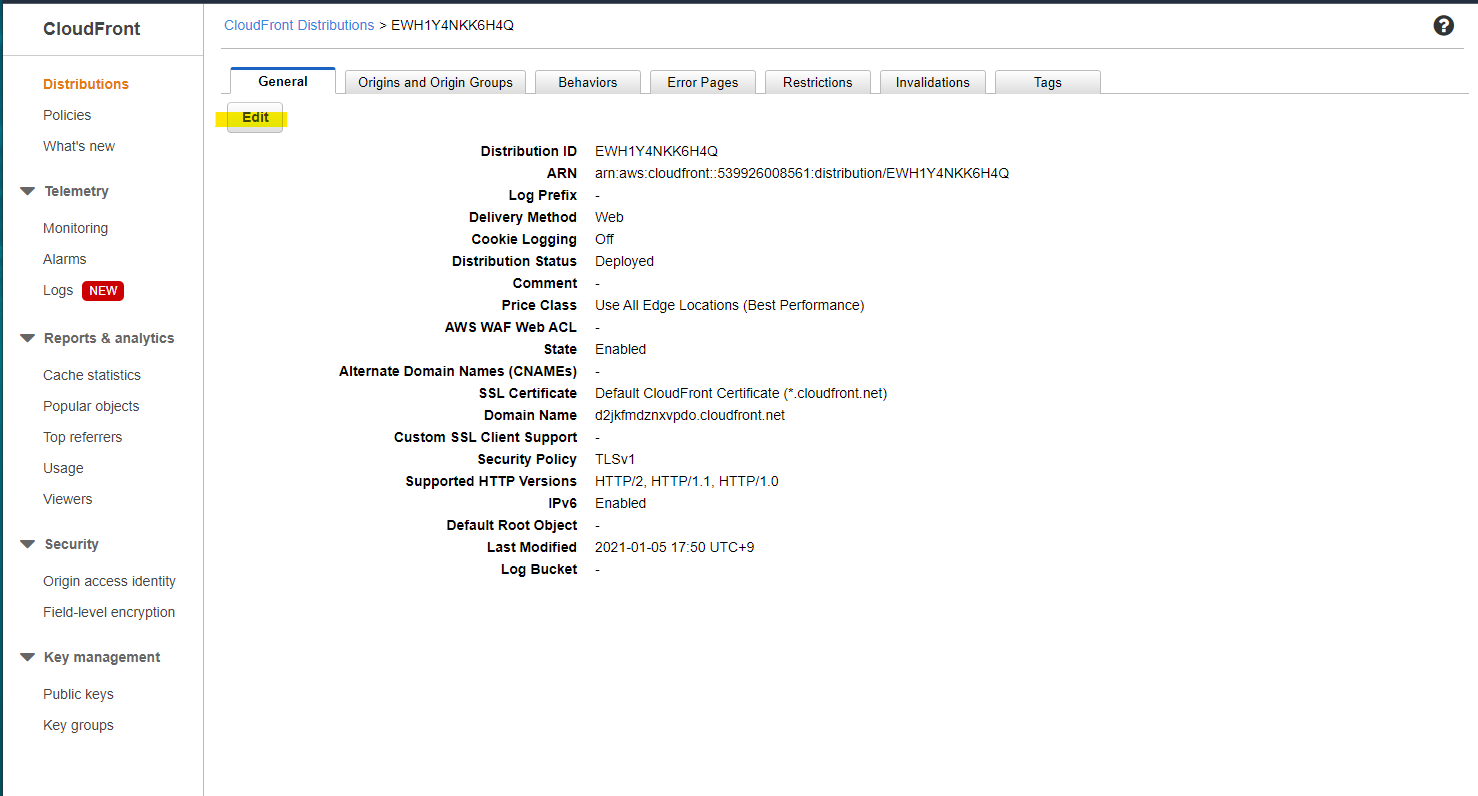
Distribution の詳細画面に移動
Edit
新たに作成した、WAF Web ACL を紐づけます
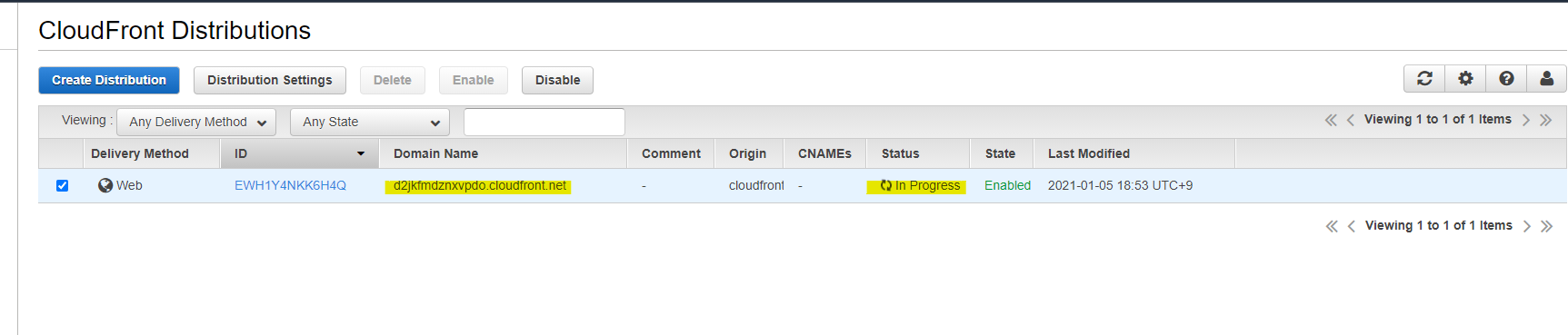
Progress となり、一定時間後に Deployed になります。
動作確認
CloudFront の Domain Name は
d2jkfmdznxvpdo.cloudfront.netなので、次のようにアクセス可能です
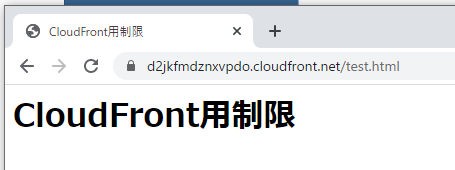
https://d2jkfmdznxvpdo.cloudfront.net/test.html許可した IP アドレスから、CloudFront 経由で S3 へアクセス
正常に表示されています
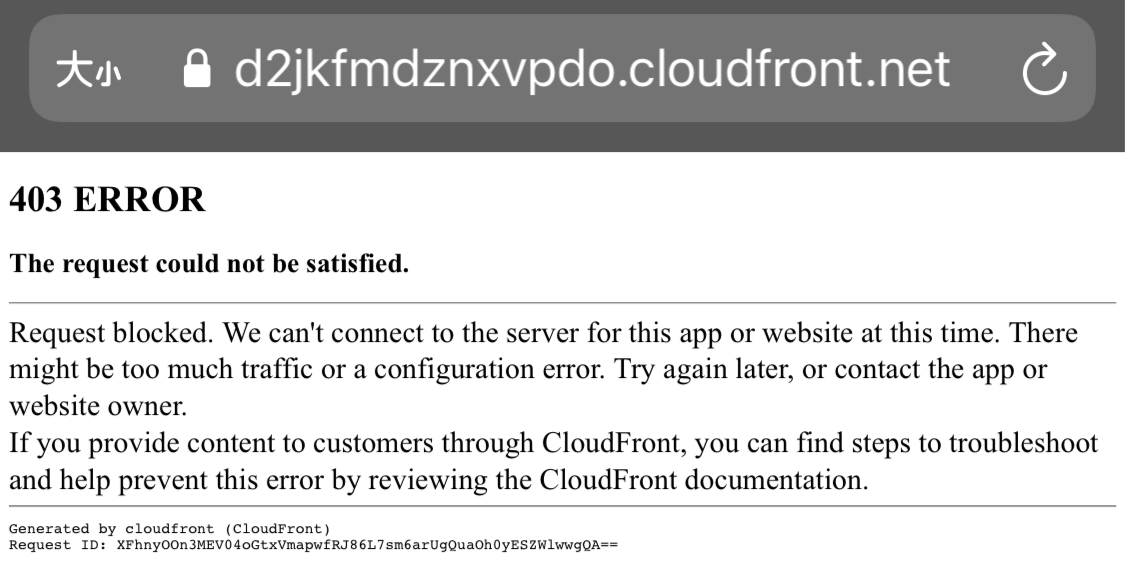
許可していない IP アドレスから、CloudFront 経由で S3 へアクセス
403 ERROR となっており、正常な動作です
S3 直接アクセスはもちろん禁止されているので、エラーになります
https://cloudfronttest-sugi01.s3-ap-northeast-1.amazonaws.com/test.html
参考URL


- 投稿日:2021-01-05T19:51:02+09:00
AWS Organizations の SCP を使って利用可能サービスを制限してみよう
こんにちは。
今回も前回と同様 AWS Organizations を使ってハンズオン、サンドボックス環境を作っていた際に出てきた要件の対応です。
高額なインスタンスタイプの指定やリザーブドインスタンスの購入、ハンズオンやサンドボックスには不要そうなサービスの使用を防ぐといったいった内容です。ホワイトボックスリスト、ブラックボックスリストともにメリットデメリットがありますが、本稿ではブラックボックスリストでの制限としています。
正直、どちらでもよかったのですが、ハンズオン、サンドボックス環境という性格上、できるかぎり新サービス・新機能リリース後、即時に学習や体験ができるようにしておきたかったので、追加サービスがでても自動的に制限がかからないブラックボックスリストとしました。
今回使用に制限をかけたサービスや機能
一例として以下に列挙します。また、社内のハンズオンやサンドボックスという性格上、お楽しみ系サービス(DeepRacerやDeepComposer)についても制限をかける対象としました。
ほかにもこれを制限しているよ!とか、これをいれるといいよ!といったものがあったら、こっそりコメントで教えていただけると幸いですm(_ _)m
- Amazon EC2 の一部の高額なインスタンスタイプ
- Amazon EBS のプロビジョンド IOPS
- Amazon EBS の一定容量以上の割り当て
- Amazon EC2 のリザーブドインスタンス
- Amazon RDS のリザーブドインスタンス
- Amazon RDS のプロビジョンド IOPS
- Amazon Redshift のリザーブドインスタンス
- Amazon ElastiCacheのリザーブドノード
- Amazon DynamoDB のリザーブドキャパシティ
- Amazon Bracket
- AWS Outposts
- AWS DeepRacer
- AWS DeepComposer
- AWS DeepLens
- AWS Organizations
- AWS Snowball
- Amazon IVS
- Amazon SES
- Amazon Workspaces などの work シリーズ各種
- Amazon Route53 Domains
- AWS アカウント情報へのアクセス(請求情報や個人情報など) など
制限をかけてみよう
前回の記事と同様の流れで設定します。
ポリシーは以下の通りです。denyServiceAndFunctions.json{ "Version": "2012-10-17", "Statement": [ { "Sid": "notUseExpensiveService", "Effect": "Deny", "Action": [ "ec2:PurchaseReservedInstancesOffering", "ec2:ModifyReservedInstances", "ec2:GetReservedInstancesExchangeQuote", "ec2:DescribeReservedInstancesOfferings", "ec2:DescribeReservedInstancesModifications", "ec2:DescribeReservedInstancesListings", "ec2:DescribeReservedInstances", "ec2:CreateReservedInstancesListing", "ec2:CancelReservedInstancesListing", "ec2:AcceptReservedInstancesExchangeQuote", "ec2:CancelCapacityReservation", "ec2:CreateCapacityReservation", "ec2:DescribeCapacityReservations", "ec2:DescribeHostReservationOfferings", "ec2:DescribeHostReservations", "ec2:ModifyCapacityReservation", "ec2:ModifyInstanceCapacityReservationAttributes", "ec2:PurchaseHostReservation", "outposts:*", "s3-outposts:*", "rds:DescribeReservedDBInstances", "rds:DescribeReservedDBInstancesOfferings", "rds:PurchaseReservedDBInstancesOffering", "redshift:PurchaseReservedNodeOffering", "redshift:GetReservedNodeExchangeOfferings", "redshift:DescribeReservedNodes", "redshift:DescribeReservedNodeOfferings", "redshift:AcceptReservedNodeExchange", "dynamodb:DescribeReservedCapacity", "dynamodb:DescribeReservedCapacityOfferings", "dynamodb:PurchaseReservedCapacityOfferings", "elasticache:DescribeReservedCacheNodes", "elasticache:DescribeReservedCacheNodesOfferings", "elasticache:PurchaseReservedCacheNodesOffering", "aws-portal:ModifyAccount", "aws-portal:ModifyBilling", "aws-portal:ModifyPaymentMethods", "aws-portal:ViewAccount", "aws-portal:ViewBilling", "aws-portal:ViewPaymentMethods", "aws-portal:ViewUsage", "deepracer:*", "braket:*", "deepcomposer:*", "deeplens:*", "organizations:*", "snowball:*", "ivs:*", "ses:*", "workmailmessageflow:*", "workmail:*", "worklink:*", "workdocs:*", "workspaces:*", "route53domains:*" ], "Resource": [ "*" ] }, { "Sid": "notUseExpensiveInstanceType", "Effect": "Deny", "Action": [ "ec2:RunInstances", "ec2:RunScheduledInstances" ], "Resource": [ "*" ], "Condition": { "StringLike": { "ec2:InstanceType": [ "p*.*", "x*.*", "f*.*", "i*.*", "g*.*", "h*.*", "r*.*xlarge", "c*.*xlarge", "m*.*xlarge", "z*.*xlarge", "a*.*xlarge", "*.metal" ] } } }, { "Sid": "notUsePIOPSEBS", "Effect": "Deny", "Action": [ "ec2:CreateVolume", "ec2:ModifyVolume" ], "Resource": [ "*" ], "Condition": { "StringLike": { "ec2:VolumeType": [ "io1", "io2", "gp3" ] } } }, { "Sid": "notUse1000overEBS", "Effect": "Deny", "Action": [ "ec2:CreateVolume", "ec2:ModifyVolume" ], "Resource": [ "*" ], "Condition": { "NumericGreaterThanEquals": { "ec2:VolumeSize": [ "1000" ] } } }, { "Sid": "notUseRDSPIOPSVolume", "Effect": "Deny", "Action": [ "rds:CreateDBInstance", "rds:CreateDBCluster", "rds:CreateDBInstanceReadReplica", "rds:ModifyDBInstance" ], "Resource": [ "*" ], "Condition": { "NumericGreaterThan": { "rds:Piops": [ "250" ] } } }, { "Sid": "notUseRDSOverStorage", "Effect": "Deny", "Action": [ "rds:CreateDBCluster", "rds:CreateDBInstance", "rds:ModifyDBInstance", "rds:ModifyDBCluster" ], "Resource": [ "*" ], "Condition": { "NumericGreaterThan": { "rds:StorageSize": [ "500" ] } } } ] }動作確認
- まずは、SCP を割り当てた AWS アカウントへスイッチするなりログインするなりします。
- 制限をかけていないサービスにアクセスし、操作します(例:Amazon EC2の制限をかけていないインスタンスタイプの起動)
- 制限をかけたサービスにアクセスする(例:Amazon EC2の制限をかけていないインスタンスタイプの起動、AWS DeepRacer)
制限をかけていないサービス
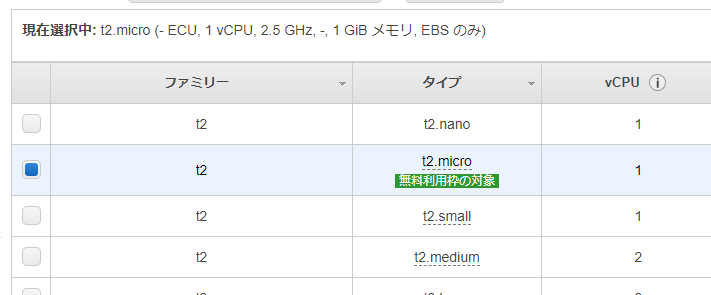
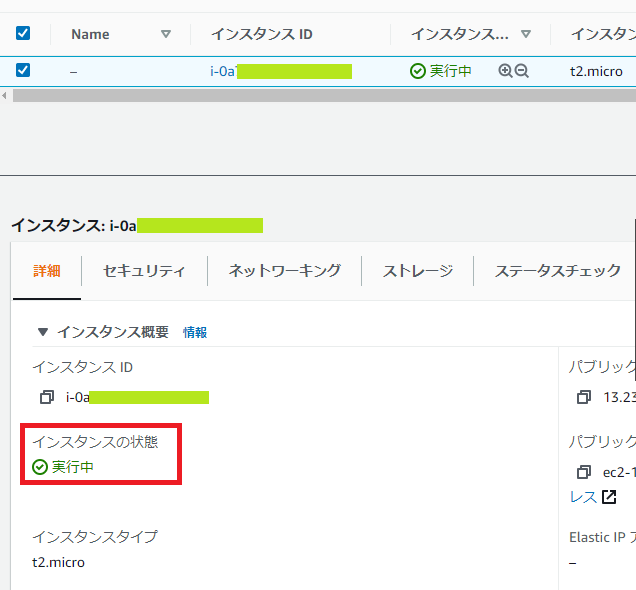
Amazon EC2 で t2.micro のインスタンスを起動してみます。
問題なく、起動できました。
制限をかけたサービス
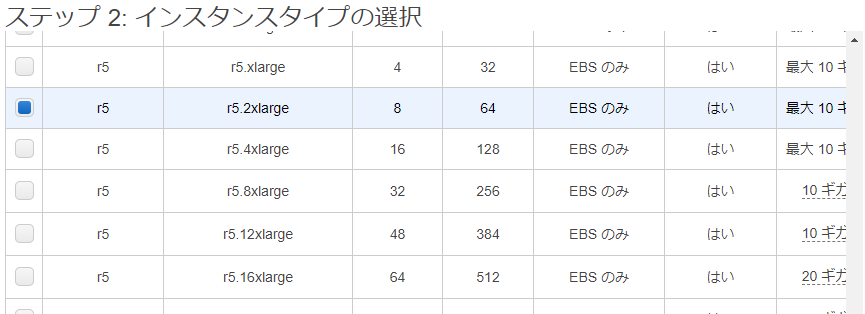
Amazon EC2 で 制限をかけた、"r*.*large" に該当する r5.2xlarge を起動しようとしてみます。
期待した通り、起動できませんでした。
伏字にしているところは、以下のコマンドでデコードできるので、サクッと、 AWS CloudShell を使って確認します。
aws sts decode-authorization-message --encoded-message <encoded-message>こんな感じで出てきました。見やすくするために少し整形し、省略もしています。
まず、冒頭で explicitDeny (明示的な拒否)が true と出力されています。また、どのステートメント(この場合は SCP で定義したポリシー/条件)に合致したかも出力されています。
このことから、定義した通りに制限が正しく動作したことがわかります。{ "allowed":false, "explicitDeny":true, "matchedStatements":{ "items":[ { "statementId":"notUseExpensiveInstanceType", "effect":"DENY", "principals":{ "items":[ { "value":"AROAS46SY7***********" } ] }, "principalGroups":{ "items":[] }, "actions":{ "items":[ { "value":"ec2:RunInstances" },{ "value":"ec2:RunScheduledInstances" } ] }, "resources":{ "items":[ { "value":"*" } ] }, "conditions":{ "items":[ { "key":"ec2:InstanceType", "values":{ "items":[ { "value":"p*.*" },{ "value":"x*.*" },{ "value":"f*.*" },{ "value":"i*.*" },{ "value":"g*.*" },{ "value":"h*.*" },{ "value":"r*.*xlarge" },{ "value":"c*.*xlarge" },{ "value":"m*.*xlarge" },{ "value":"z*.*xlarge" },{ "value":"a*.*xlarge" },{ "value":"*.metal" } ] } } ] } } ] } (後略)まとめ
2回続けて、SCP まわりのお話でした。前回と今回でお伝えした内容は、ほんの一部であり、奥が深い機能であります。
今回はハンズオンやサンドボックスといった環境向けに、使われたら困るような高額サービスや不要なサービスの停止をメインにしましたが、例えば、セキュリティ周りのサービスの設定変更(ex. AWS CloudTrail の設定変更など)を防いだりももちろんできます。各環境の要件に応じたポリシーを作って、アカウントを適切に運用していきましょう!
記載されている会社名、製品名、サービス名、ロゴ等は各社の商標または登録商標です。
- 投稿日:2021-01-05T19:29:49+09:00
【AWS初心者向け】お嬢様と学ぶAWS基礎
ことの経緯(読まなくていい)
発狂しそうな程のどかな昼下がり。ランチタイムの後のティータイム(午後の紅茶ペットボトル500ml)。
私はベランダに座り優雅にプログラミングを致します。
小鳥たちはさえずり、花々は咲き乱れ、美しい空が広がり、私のコードは長文のエラーを吐いています。
「はぁ」
ため息をつきながら長文のエラーをおGoogleに貼り付け、エンターを爆発音と勘違いされる勢いでおぶちかまします。
ヒットした記事を調べるも解決できず膝から崩れ落ち、頭髪にはその時に零した紅茶が降り注ぐ。脳内にはライアーゲームの圧倒的な絶望BGMが流れている。
「ふぅ、いったん諦めてAWSの勉強としましょう。分からないことはあとでセバスに聞けばいいですわ」
そう思って紅茶臭いまま技術書を開くが、なんと退屈なことでしょう!
技術書に書かれた文章は、高校生が英語を頑張って翻訳したかのような日本語の羅列。よくわからねぇ図。
私は目蓋の裏側が拝見したくてしょうがなくなって参りました。
しかしそういう訳には参りません。ここで一発気合を入れてモンスターを注入。俺様がモンスターだ。
ただ本を読むだけでは気絶してしまいますわ。そうだ! Qiitaでアウトプットすれば良いのですわァ!目次
クラウドとはなんでしょう?
クラウドとは、何か動かしたいもの(Webアプリケーションとか)があった時にインターネット経由でその動かしたいものを動かす環境を与えてくださるものですわ。
しかも基本的にはオンデマンド、つまり利用したい時に利用しただけお金を払えばいいんですのよ。ネカフェみたいなものですわ。サブスクライブと言われる月額課金とは違って、使った分だけで良いので、"""庶民"""の方々にとってはお得ですわね。クラウドが出来る前まではオンプレミスという自前でサーバーを用意する方式でしたの。我が家でも10年前に5億円のサーバーを導入しましたが大変だったらしいですわ……。というのも、自前サーバですと、不動産、非常用発電機、冷却設備への投資。そして、それらを維持するための人件費がかかってしまいますわ。その時はわたくしのお小遣いも200万円程度に減ってしまって驚いたものです。
AWSさんの長所はなんでしょう?
AWSさんは一応公式では6つの長所を上げられていますわ。
- [設備投資費が柔軟な変動費に]
- [スケールによる大きなコストメリット]
- [キャパシティ予測が不要に]
- [速度と俊敏性の向上]
- [データセンターの運用と保守への投資が不要に]
- [わずか数分で世界中にデプロイ]
ちょーっと分かりづらいですわね。ですがご安心くださいませ。わたくしが解説いたしますわ。
【1.設備投資費が柔軟な変動費に】
これはさっき説明したのと同じですわ。サーバーを自前で購入する設備投資費が無くなり、代わりに、使った分だけ支払う方式にできますわ。
スタートアップ企業さんなんかは嬉しいですわね。小さく始めて、大きくなってきたら増やせばいいので、少額の資金で始めることが可能ですわ。【2.スケールによる大きなコストメリット】
スケールというのは企業のスケールのことですわ。つまりAmazonさんのことですわね。クソバカアルティメットゴールデンまろびだしストロングに大きな会社ですので、規模の経済というのが発生いたします。
規模の経済というのは、品の生産量が増えれば増えるほど、製品1つあたりの平均費用が下がる状態のことですわ。AWSは多くの方がご利用になりますから、1人あたりの料金も安く済むということですわね。
まぁ資本主義社会では大きい会社が有利って思っておけばいいですわ。【3.キャパシティ予測が不要に】
キャパシティというのはサーバーの台数や性能のことですわ。自前のサーバーでは、どれくらいのアクセスがあるのか、どれくらい利用されるのか、いつ利用されるのか、1つのデータはどれくらい大きくて、どれくらいの時間で処理しなければならないのか、綿密に計算をしてキャパシティを予測しています。プロの方でも3か月以上かかるそうですわ。
しかし、AWSを利用すればそれがいらないと。えぇ、ホンマに?
ここで思い出して頂きたいのが”従量課金制”というシステム。使った分だけ払えば良い。この”使った分”というところが自由に改変しやすいということですわ。サーバーの性能が低すぎたり高すぎたりした場合には、設定をし直せばいいのですわ。【4.速度と俊敏性の向上】
スピードいずパワーということですわ。自前のサーバーを使用する場合、そこに環境を構築して~、セキュリティつけて~など、面倒なことが多く時間がかかってしまいがちですわ。しかし、AWSを利用すれば短い時間で”素早い”実装が可能ということです。【5.データセンターの運用と保守への投資が不要に】
従来のオンプレミス(自前サーバー)には、人件費、電気代、サーバのラック代、ライセンス費用など様々な費用がかかっていましたわ。でも、AWSでしたら、そこに工数や時間や費用を割かなくても全てAWS側でやってくれるということらしいですわ。【6.わずか数分で世界中にデプロイ】
例えばそうですわね、「アメリカにWebサーバを1台設置してくる」というミッションを受けたとしましょう。
まず、自家用ジェット機を用意しますわね。そこからビザやら何やらいろいろ申請して、アメリカへランデブー。アメリカへ到着し、時差ボケに酔う暇もなくデータセンターへタクシー。高いチップの代わりに折り紙で折った手裏剣をドライバーに渡し、歓喜のあまりドブに落ちる様子を横目で見ながらデータセンター内へ。ケーブル引いて設置してOSインストールして……。気を失いそうなほど時間がかかりますわ。
でもAWSなら数回のクリックで終わるのですわ。
参考文献
あぁ、眠くなってきましたわ。またどこかでお会いしましょう。おやすみなさいませ。
- 投稿日:2021-01-05T19:23:45+09:00
Amazon VPCでシンプルなネットワークを構築する
はじめに
- AWS無料枠のお勉強記録です
- 今回はAmazon VPCを作成し、サブネットで分割してみます
- VPC内にパブリック、プライベートのサブネットを作成します
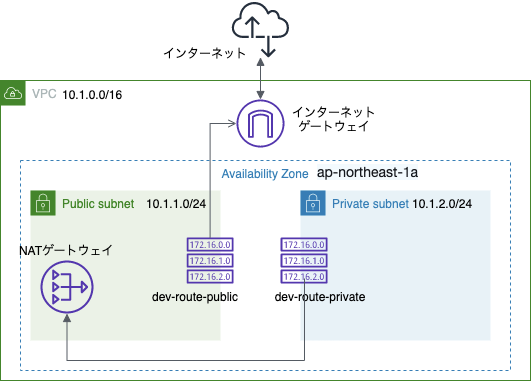
構成図
- パブリックサブネットはインターネットにつながる
- プライベートサブネットからの返信はプライベートサブネットを介して行う
- パブリックサブネットにNATゲートウェイを設置する
手順と各種設定
1. VPCの作成
- Name: Develop
- IPv4 CIDR ブロック: 10.1.0.0/16
- IPv6 CIDR ブロック: なし
2. サブネットの作成
- [左側タブ] サブネットをクリック
- サブネットの作成をクリック
- 下記設定でサブネットを作成
2.1 public-subnet-1a-devの作成
- VPC: Develop(10.1.0.0/16)
- AZ : ap-northeast-1a
- IPv4 CIDR: 10.1.1.0/24
- Name: public-subnet-1a-dev
2.2 private-subnet-1a-devの作成
- VPC: Develop(10.1.0.0/16)(パブリックと同じ)
- AZ : ap-northeast-1a(パブリックと同じ)
- IPv4 CIDR : 10.1.2.0/24
- Name: private-subnet-1a-dev
3. インターネットゲートウェイの作成
- [左タブ] インターネットゲートウェイ
- インターネットゲートウェイの作成
- Name: Develop
- 作成
- 作成したインターネットゲートウェイを選択
- アクション
- VPCにアタッチ
- 使用可能なVPC: Develop
- 保存
4. ルートテーブルの設定 -パブリック-
パブリックサブネットの宛先をインターネットゲートウェイに向ける
[左タブ]: サブネット
- public-subnet-1a-devをクリック
- 画面下部にスクロール
- 「詳細」内から「ルートテーブル」を見つける
- ID(rtb-hogehoge)をクリック
アクション:ルートの編集
- ルートの追加
送信先 ターゲット 0.0.0.0/0 Internet Gateway
- ルートの保存
サブネットの関連づけ:サブネットの関連づけの編集
- public-subnet-1a-devを関連づけて保存
Nameを「dev-route-public」に変更
5. NATゲートウェイの作成
- [左タブ]: NATゲートウェイ
- NATゲートウェイを作成
- Name: dev-nat
- サブネット: public-subnet-1a-dev
- Elastic IPの割り当てをクリック
- NATゲートウェイを作成
6. ルートテーブルの設定 -プライベート-
- ルートテーブルの作成
- Name: dev-route-private
- VPC: Develop
[左タブ]: サブネット
- private-subnet-1a-devをクリック
- 画面下部にスクロール
- 「詳細」内から「ルートテーブル」を見つける
- ID(rtb-hogehoge)をクリック
- サブネットの関連づけでprivate-subnet-1a-devを対象外にする
dev-route-privateをクリック
- サブネットの関連づけでprivate-subnet-1a-devを対象にする
ルートの編集
ルートの追加
送信先 ターゲット 0.0.0.0/0 NAT Gateway ルートの保存
7. 完成
終わりに
- NATゲートウェイは有料ですので、使用しない場合は削除することをオススメします
- 次回はサブネット内にEC2インスタンスを配置し、sshで疎通を確認していきます
- 間違いや改善点等ございましたらコメントを頂ければ幸いです
作図ツール
- draw.io (https://www.draw.io/?splash=0&libs=aws4)
- 投稿日:2021-01-05T18:46:04+09:00
UIFlowでM5Stackはじめーる
はじめに
積まれていたM5Stackをすぐに始めるための備忘録です。
開発環境
- M5Stack
- Windows 10 PC
導入
1.UIFlow Quick Startを参考にします
2.ドライバーをインストールします
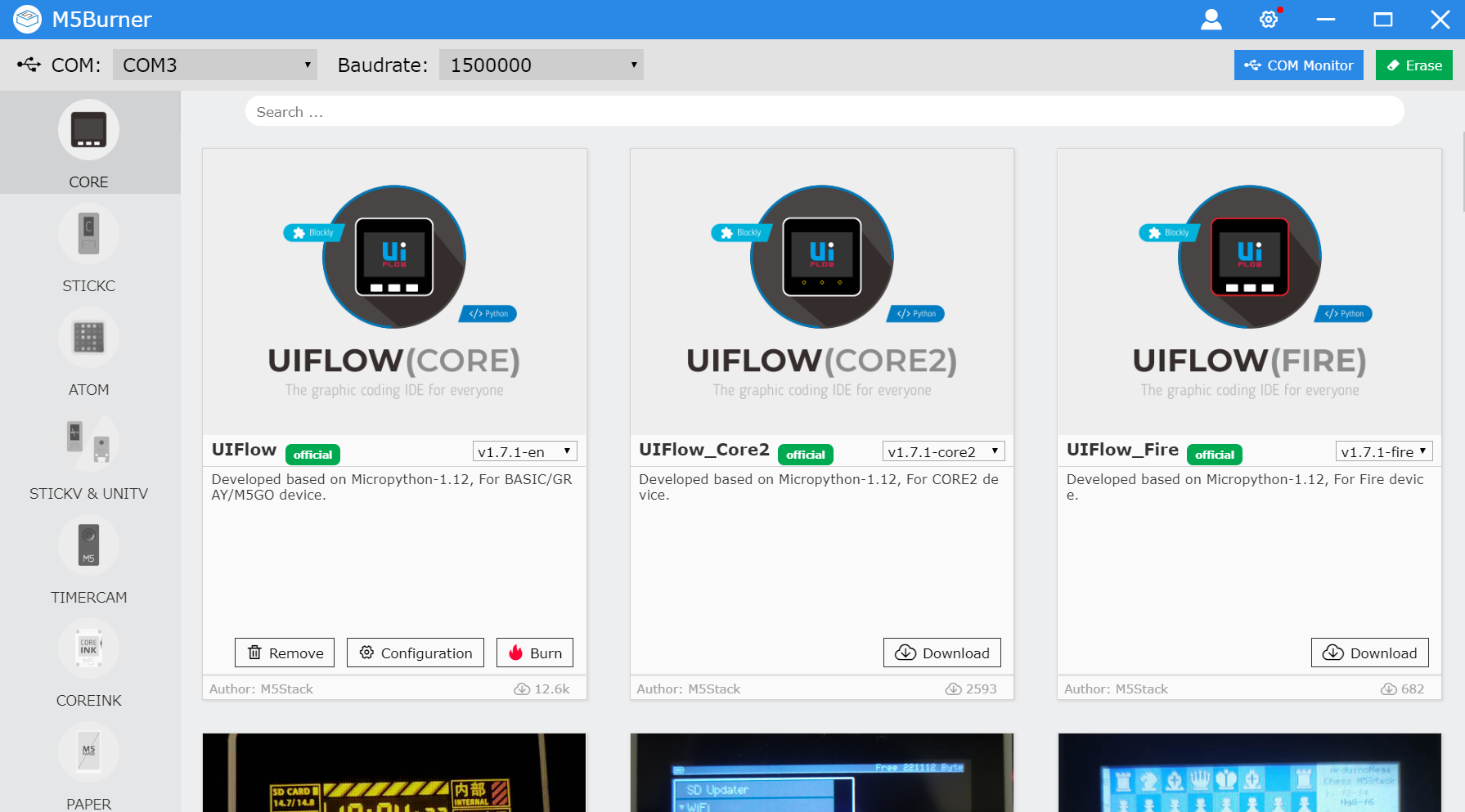
3.M5Burnerを起動します
4.UIFLOW(CORE)のファームウェアをBurnします
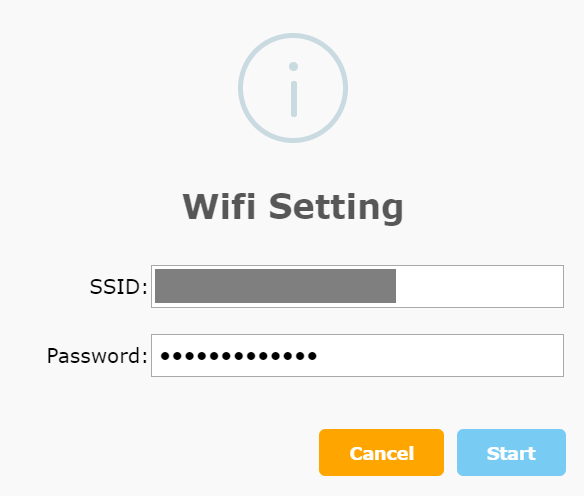
5.自宅のWiFiを設定します
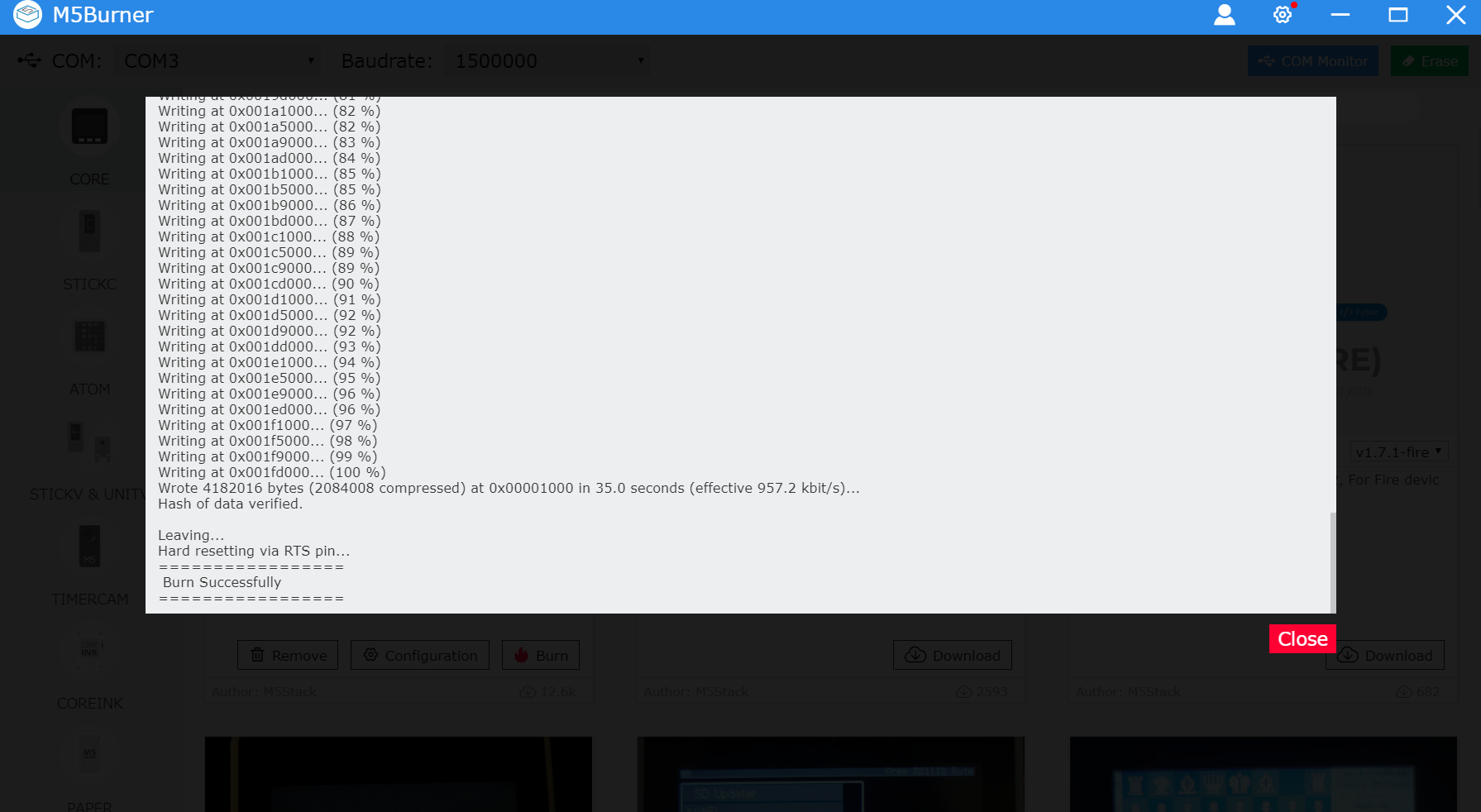
6.Burn成功です
7.PCをm5stackのwifiに接続します
8.PCのブラウザからm5stackに表示されているIPアドレスを開きます
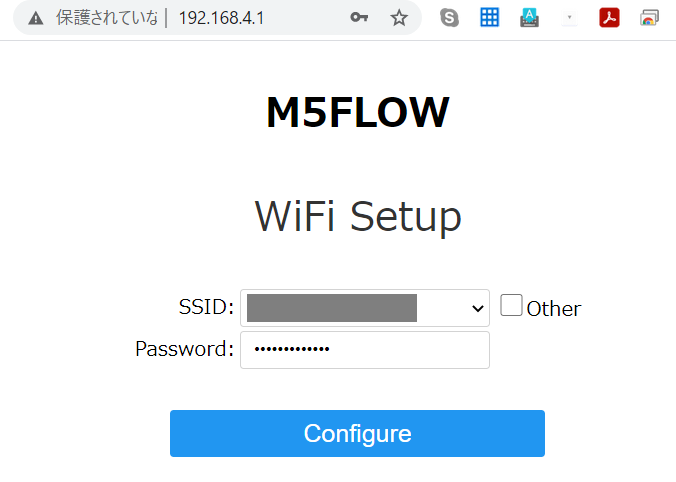
9.自宅のWiFiを選択し、パスワードを入力します
10.WiFi接続成功です
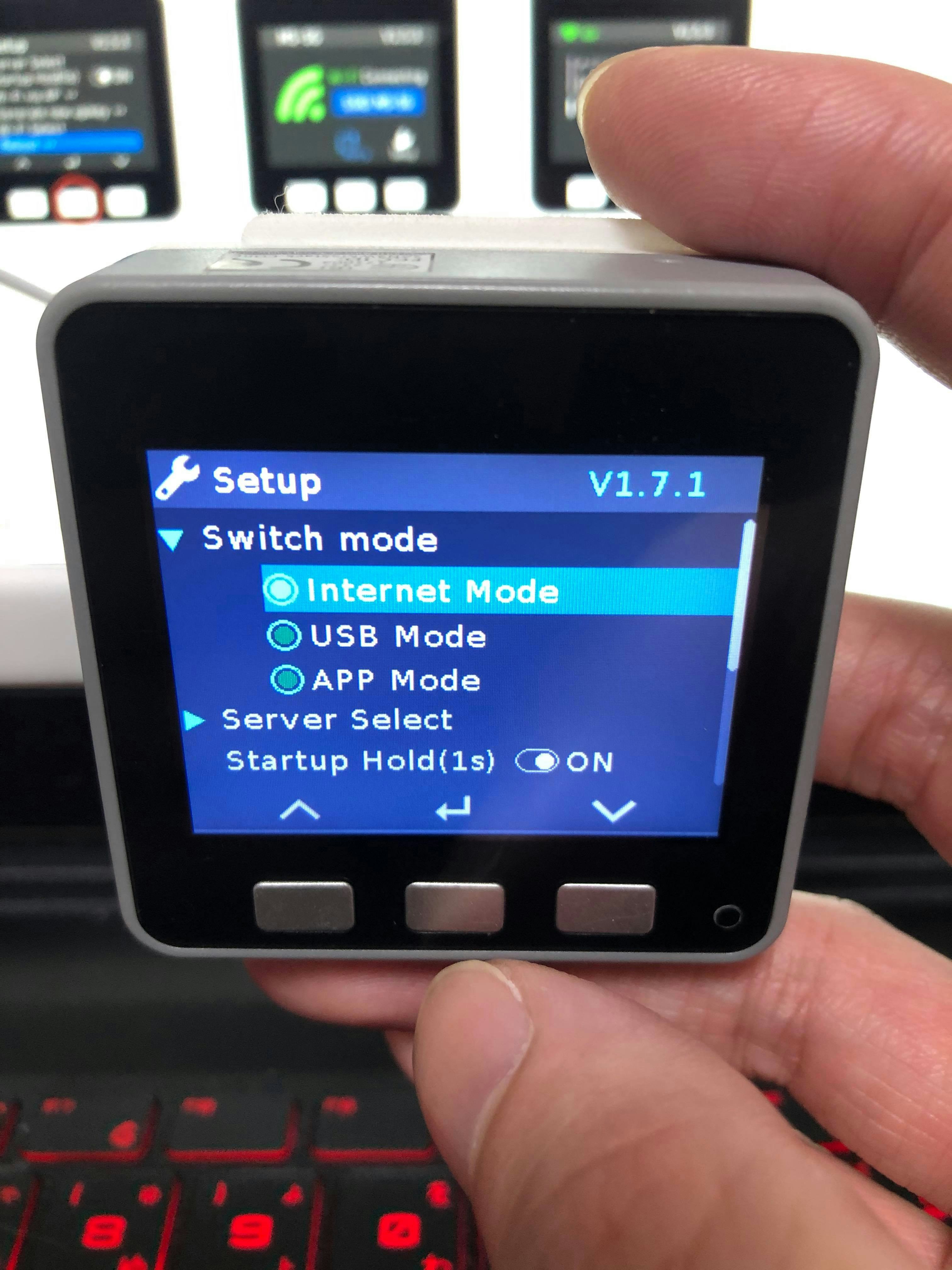
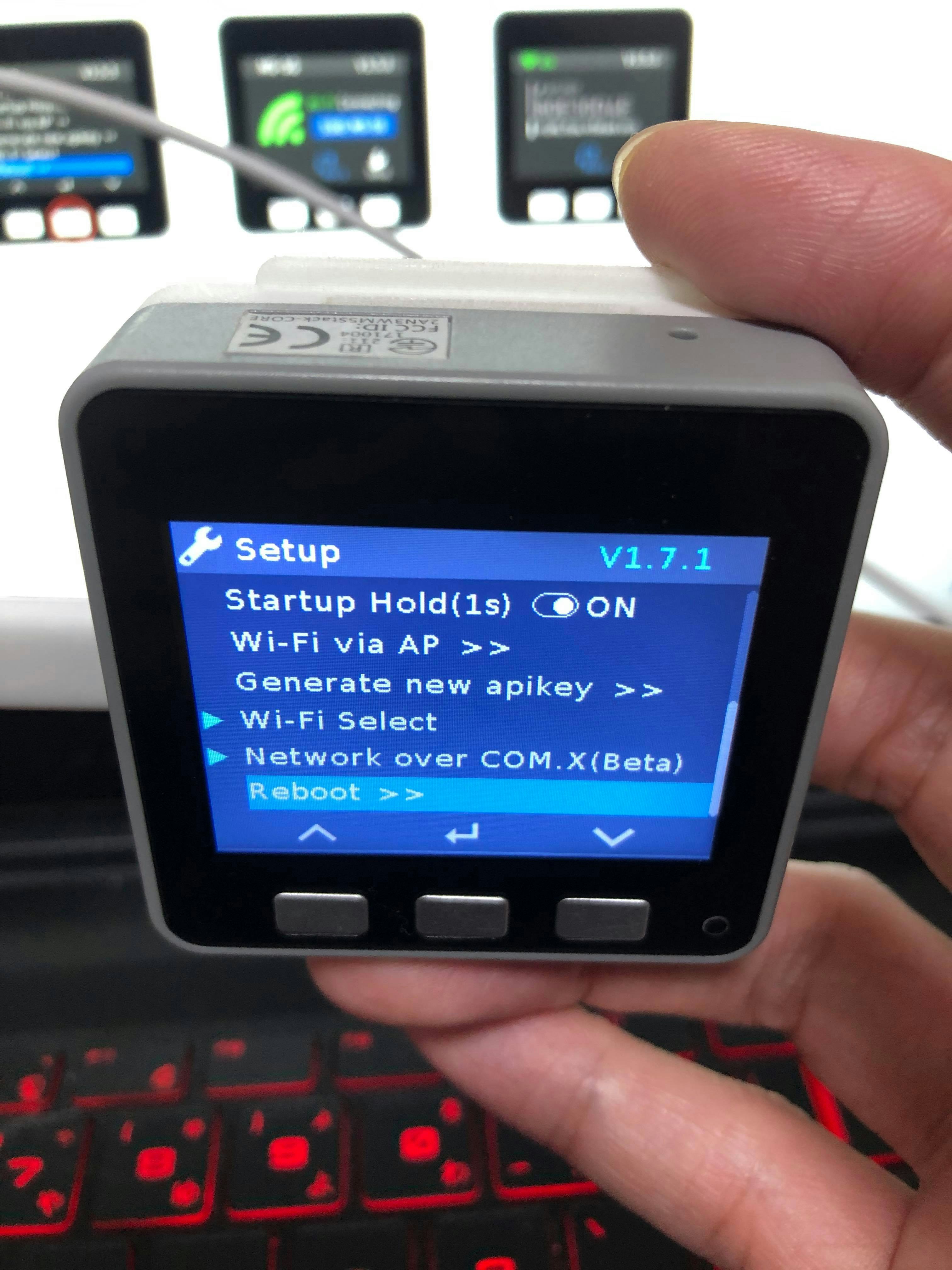
11.M5Stackをinternet modeにし、RebootするとAPIキーが表示されます
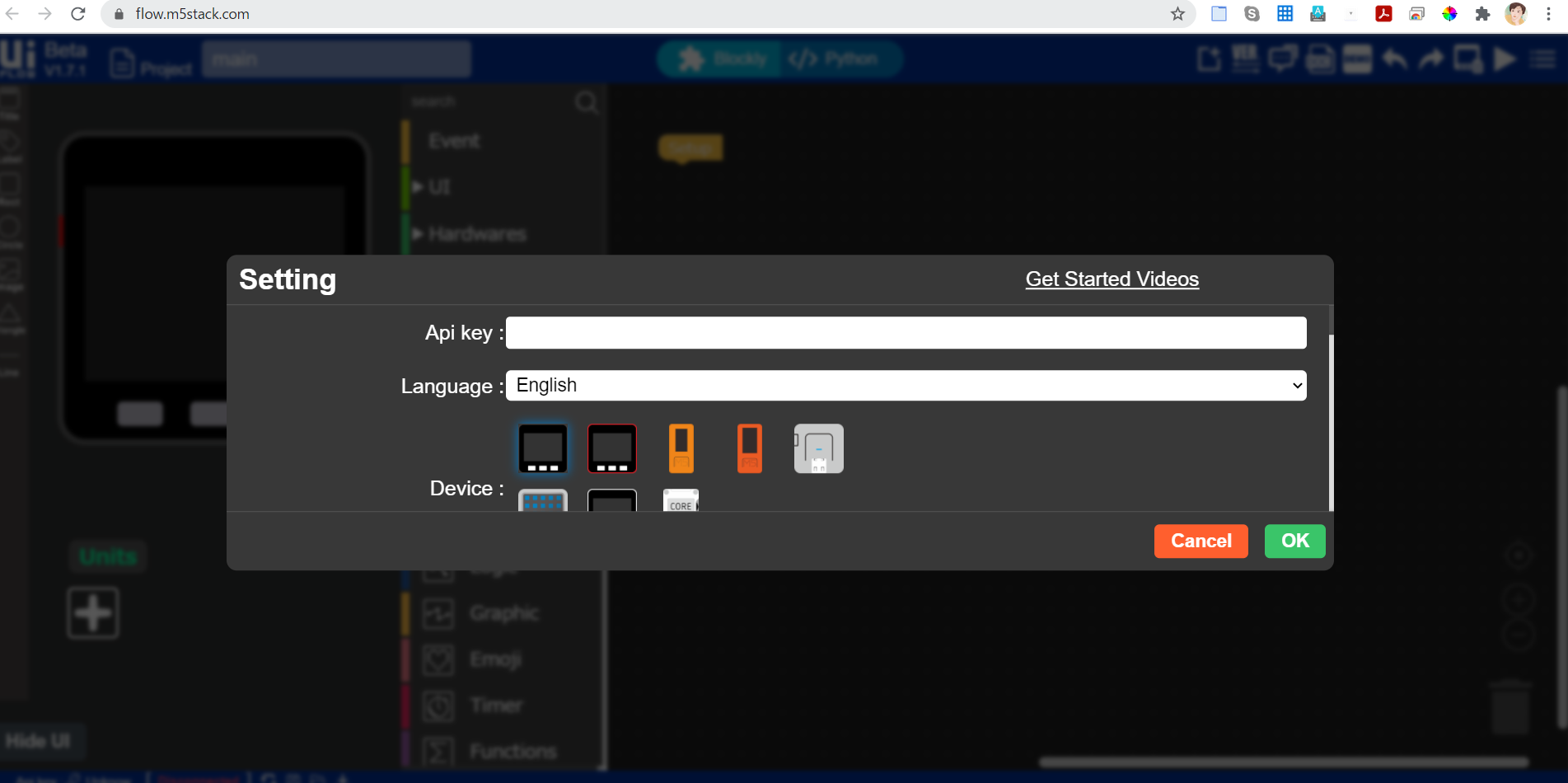
12.M5Flowを開き、APIキーを入力します
13.作ったAWS LambdaのAPIを叩いてみましょう。レスポンスはJSONで {"results":値}となっています。
14.結果です。
いつものバス停にあと何分でバスが到着するか表示するやつ作った。超便利なやつができた!がバスがもうないw #UIFlow #m5stack #Python #AWS #Lambda #API pic.twitter.com/Rl2hnTnIRn
— がちもとさん@あけおめことよろ (@sotongshi) January 4, 2021これは良いものだ! #m5stack pic.twitter.com/Iol4fAoicT
— がちもとさん@あけおめことよろ (@sotongshi) January 5, 2021お疲れ様でした。


- 投稿日:2021-01-05T17:43:00+09:00
opensslとmosquittoでAWS IoT Coreの "CAを登録せずにクライアント証明書を登録する" を試す
AWS IoT EduKitの動作を理解するためには、 2020年4月に一般提供開始となった「マルチアカウント登録による複数の AWS アカウントでの X.509 クライアント証明書の使用」で使えるようになった機能「CAを登録せずにクライアント証明書を登録する」を知っておく必要があったので、opensslとMQTTクライアントであるmosquittoを使って動作を確認してみました。
論よりコード
独自CAのプライベートキーと証明書の作成
$ openssl req -x509 -newkey rsa:2048 -sha256 -nodes -keyout CA.key -out CA.crt -subj "/CN=example.com" -days 3650 $ ls CA.* CA.crt CA.keyクライアント用のプライベートキーと証明書(CSR経由)の作成
$ openssl genrsa -out device1.key 2048 $ openssl req -new -key device1.key -out device1.csr -subj "/CN=device1" $ openssl x509 -req -in device1.csr -CA CA.crt -CAkey CA.key -CAcreateserial -days 365 -sha256 -out device1.crt $ ls device1.* device1.crt device1.csr device1.keyAWS IoT Core への登録
(CLIを使用、Webコンソールの方法はこちら)
※
$certificateIdと$certificateArnはaws iot register-certificate-without-caの返却値を利用。
※ AllowAll" ポリシーは作成済み
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "iot:*", "Resource": "*" } ] }$ aws iot register-certificate-without-ca --certificate-pem file://device1.crt $ aws iot update-certificate --certificate-id $certificateId --new-status ACTIVE $ aws iot attach-policy --target $certificateArn --policy "AllowAll"AWS IoT Core への接続
※
endpointAddressはaws iot describe-endpoint --endpoint-type IoT:Data-ATSで入手$ curl -O https://www.amazontrust.com/repository/AmazonRootCA1.pem $ mosquitto_sub -d --cert device1.crt --key device1.key --cafile AmazonRootCA1.pem -h $endpointAddress -p 8883 -t my/topic片付け
※ いきなり delete-certificate しても動きますが、まあお作法として。
$ aws iot detach-policy --target $certificateArn --policy "AllowAll" $ aws iot update-certificate --certificate-id $certificateId --new-status INACTIVE $ aws iot delete-certificate --certificate-id $certificateId手元にクライアントのプライベートキーがある場合の AWS IoT Core に MQTTS 接続する方法
AWS IoT Core へMQTTS接続する際に必要なのは以下の情報です。
- 証明書(クライアント毎)
- プライベートキー(クライアント毎)
- クライアント毎の証明書に署名をしたCA証明書
- AWS IoT Core のエンドポイントアドレス
この情報をmosquittoに当てはめると以下のようになります。
$ mosquitto_pub \ --cert 証明書(クライアント毎) \ --key プライベートキー(クライアント毎) \ --cafile クライアント毎の証明書に署名をしたCA証明書 \ -h AWS IoT Core のエンドポイントアドレス \ -p 8883 -t TOPIC -m MESSAGEクライアントのプライベートキーが手元にある状態においてAWS IoT Coreに接続する場合、本機能ができる前までは以下のような選択肢がありました。
- A: クライアントのプライベートキーからCSRを作成し、AWS IoT Coreの "証明書" > "CSR による作成" [create-certificate-from-csr] で登録しつつ、証明書をダウンロード
- B: 「独自CA」の証明書をAWS IoT Coreに登録 [register-ca-certificate] しておき、証明書(クライアント毎)の登録 [register-certificate] の際に登録済みの独自CAを選択
本機能はAとBの中間に位置するようなものです。
Aはクライアント証明書の作成はAWS IoT Coreが行いますが、本機能はクライアント証明書は作成済みであることを前提としています。
Bはクライアント証明書に署名したCAをAWS IoT Coreに登録の必要がありますが、本機能はCAの登録は不要です。プライベートキーが手元にあるなら、証明書もあるよね、、、という前提ですが。AWS IoT サービス アップデートのご紹介 / P25でも解説されている通り、CA登録をしなくともクライアント証明書さえあればAWS IoT Coreに登録できるのがポイントです。
※実際の登録には IAM ポリシーのiot:RegisterCertificateWithoutCA権限も必要となるため、むやみやたらに登録できるわけじゃありません、ご安心を。おわりに
AWSブログにも書かれている通り、この機能は証明書とプライベートキーが格納されているセキュアエレメントを搭載したデバイスで活用できます。
AWS re:Invent 2020 で発表となったAWS IoT EduKitはMicrochip ATECC608Aを搭載しており、本機能を使うことでプライベートキーをネットワークに流すことなくAWS IoT Coreに登録できるようになっています。
ということがわかり、元々AWS IoT EduKitについて書いていたら、この話だけで1エントリーできてしまったのでかき揚げたという次第です。
AWS IoT EduKitについては別途書きます。参考資料
- RSA鍵、証明書のファイルフォーマットについて / Qiita
- AWS IoT 証明書のJust In Time登録 / Qiita
- AWS IoT Deep Dive #1 2020 上半期 AWS IoT アップデート 資料と録画、Q&Aを公開 / AWSブログ
- register-certificate-without-ca / AWS CLI 2.1.15 Command Reference
EoT
- 投稿日:2021-01-05T17:01:57+09:00
特定のEC2の起動、停止、再起動のみを行えるIAMユーザーを作成する。
問題
プロジェクトメンバーA君に、プロジェクトで使用するEC2インスタンスの起動、停止、再起動を行う権限を与えたい。
ただ、起動、停止、再起動以外の操作と、プロジェクトに関係のないEC2の操作は行えないようにしたい。作業の流れ
①IAMポリシーを作成する。
②IAMユーザーを作成し、作成したポリシーを割り当てるIAMポリシー
対象のEC2に対してキー「Project」、値「****」のタグを設定します。
以下、ポリシー。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:Describe*" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "ec2:StartInstances", "ec2:StopInstances", "ec2:RebootInstances" ], "Resource": "*", "Condition": { "StringEquals": { "ec2:ResourceTag/Project": "****" } } } ] }以上になります。
参考:
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/list_amazonec2.html
- 投稿日:2021-01-05T16:38:11+09:00
Kinesis Data StreamsとLambda連携でのCloudWatchメトリクスの読み方[Lambda編]
Kinesis Data StreamsのレコードをLambda関数で処理するアプリケーションについて、CloudWatchメトリクスを分析することで以下の様な用途に役立てることができます。
- アプリケーションの動作におけるエラーの兆候を見つける
- 入力されるデータ量が増えるに従ってKinesis Data Streamのシャードを拡張するといった例にみられるように、リソースの拡張が必要な兆候を見つける
- AWSサービス利用料が適正であるかを分析し、コスト削減につなげる
上記の様な目的でCloudWatchメトリクスを分析した経験から、Kinesis Data StreamsとLambda関数のCloudWatchメトリクスをどのように分析するのかをまとめてみたいと思います。
Lambda関数のCloudWatchメトリクス
ここでは、Kinesis Data Streamsのレコードを処理するLambda関数に関連するCloudWatchメトリクスの中でコスト、エラー検知、拡張性の観点で注目すべきメトリクスを取り上げたいと思います。
Invocations
InvocationsはLambda関数の起動回数を示すメトリクスになります。Kinesis Data StreamsからLambda関数がレコードを読み込む場合、デフォルトで1秒おきにレコードを読み込むため、100シャードのストリームの場合、各シャード毎に1秒間隔で1回Lambda関数が起動されますので、合計して1秒間に100回のLambda関数が起動されることになります。ただし、1回のLambda関数の起動でシャードから読み込んだレコードを処理するのに1秒以上かかる可能性があります。この場合は、処理完了後にLambda関数が起動されますので、Lambda関数の起動は1秒間隔でないケースがあります。この場合は、秒間あたりのLambda関数の起動回数も減少していきます。
Duration
Invocationのメトリクスで説明しましたように各シャードごとに1秒ごとにLambda関数が1回起動されますが、Durationは起動されたLambda関数内での処理時間になります。1回のLambda関数の起動でシャードから読み込んだレコードの処理に時間がかかる場合にはDurationも長くなります。レコードの処理内容が複雑で処理に時間がかかるような場合はDurationが延びていくことになります。
Concurrent executions
Concurrent executionsは同時実行しているLambda関数の数になります。Kinesis Data Streamsで複数のシャードを使用する場合、1つのシャードに投入されるレコードを処理するLambda関数の数を指定できます1。シャード数をM、シャードあたりのLambda関数をNとした場合、全てのシャードを処理するLambda関数の同時並行数(Concurrent executions)は最大でMxNになります。投入されるレコードのPartition Keyを適切に設定しないと、Kinesis Data Streamsの各シャード及びシャードに割り当てられた複数のLambda関数にバランスよくレコードが振り分けられません2。Concurrent executionsの数値がシャード数やシャードあたりのLambda関数の設定に比較して小さい場合にはPartition Keyの設定によりレコードの振り分けがうまくいっていないことも一因として考えられます。
IteratorAge
シャードにレコードが投入されてからその後にLambda関数によりそのレコードが取得される(読み込まれる)までの所要時間になります。シャードからレコードを読み込んだ後にLambda関数の処理が遅延した場合、その処理が終わるまでLambda関数によりシャード内のレコードは読み取られないため、シャード内のレコードがLambda関数に読み込まれるまでの所要時間(IteratorAge)が長くなります。逆に言えばIteratorAgeが長くなっている場合は何等かの理由でLambda関数の処理が遅延している(Lambda関数のdurationが延びている)ことになります。
Error count and success rate
Lambda関数またはLambda関数が稼働するLambda runtime内で想定外のエラーが発生している場合はError countのメトリクスにカウントされます。Error countがカウントされている場合はLambda関数内に実装したユーザーコードのエラー処理で拾えていないような想定外のエラーが発生していることになります。Error countがカウントされている場合はLambda関数が出力するCloudWatch Logsを解析することによりエラー内容の詳細に解析して下さい。
各メトリクスの活用方法
コスト観点
Lambdaの料金はInvocationsの回数とDurationの長さにより課金されます。運用の中でLambda関数の単位時間当たりのInvocationsの回数の合計と平均Durationが上昇してきた場合はLambda関数の課金が増えてきている兆候になります。
エラー確認の観点
Lambda関数またはLambda runtimeでの想定外のエラーを検知する場合にはError countのメトリクスに対してCloudWatchアラームを設定することで検知することができます。
拡張性の観点
Lambda関数の処理時間(Duration)が長くなっている、Kinesis Data Streamの投入されたレコードが処理されるまでの時間(IteratorAge)が長くなってきている、Lambda関数の同時実行数(Concurrent Executions)が増加してきているといった兆候が見られる場合にはKinesis Data Streamのシャードの数を増やすまたはシャードあたりのLambda関数の数を増やす等、パラメーターチューニングによる拡張を考慮する必要があります。
拡張性の観点やコスト削減の観点ではCloudWatchメトリクスの値を参考にどのようにパラメーターをチューニングするかは別の記事でまとめてみたいと思います。
- 投稿日:2021-01-05T16:38:11+09:00
Kinesis Data StreamsをLambda関数で処理する場合のCloudWatchメトリクスの読み方[Lambda編]
Kinesis Data StreamsのレコードをLambda関数で処理するアプリケーションについて、CloudWatchメトリクスを分析することで以下の様な用途に役立てることができます。
- アプリケーションの動作におけるエラーの兆候を見つける
- 入力されるデータ量が増えるに従ってKinesis Data Streamのシャードを拡張するといった例にみられるように、リソースの拡張が必要な兆候を見つける
- AWSサービス利用料が適正であるかを分析し、コスト削減につなげる
上記の様な目的でCloudWatchメトリクスを分析した経験から、Kinesis Data StreamsとLambda関数のCloudWatchメトリクスをどのように分析するのかをまとめてみたいと思います。
Lambda関数のCloudWatchメトリクス
ここでは、Kinesis Data Streamsのレコードを処理するLambda関数に関連するCloudWatchメトリクスの中でコスト、エラー検知、拡張性の観点で注目すべきメトリクスを取り上げたいと思います。
Invocations
InvocationsはLambda関数の起動回数を示すメトリクスになります。Kinesis Data StreamsからLambda関数がレコードを読み込む場合、デフォルトで1秒おきにレコードを読み込むため、100シャードのストリームの場合、各シャード毎に1秒間隔で1回Lambda関数が起動されますので、合計して1秒間に100回のLambda関数が起動されることになります。ただし、1回のLambda関数の起動でシャードから読み込んだレコードを処理するのに1秒以上かかる可能性があります。この場合は、処理完了後にLambda関数が起動されますので、Lambda関数の起動は1秒間隔でないケースがあります。この場合は、秒間あたりのLambda関数の起動回数も減少していきます。
Duration
Invocationのメトリクスで説明しましたように各シャードごとに1秒ごとにLambda関数が1回起動されますが、Durationは起動されたLambda関数内での処理時間になります。1回のLambda関数の起動でシャードから読み込んだレコードの処理に時間がかかる場合にはDurationも長くなります。レコードの処理内容が複雑で処理に時間がかかるような場合はDurationが延びていくことになります。
Concurrent executions
Concurrent executionsは同時実行しているLambda関数の数になります。Kinesis Data Streamsで複数のシャードを使用する場合、1つのシャードに投入されるレコードを処理するLambda関数の数を指定できます1。シャード数をM、シャードあたりのLambda関数をNとした場合、全てのシャードを処理するLambda関数の同時並行数(Concurrent executions)は最大でMxNになります。投入されるレコードのPartition Keyを適切に設定しないと、Kinesis Data Streamsの各シャード及びシャードに割り当てられた複数のLambda関数にバランスよくレコードが振り分けられません2。Concurrent executionsの数値がシャード数やシャードあたりのLambda関数の設定に比較して小さい場合にはPartition Keyの設定によりレコードの振り分けがうまくいっていないことも一因として考えられます。
IteratorAge
シャードにレコードが投入されてからその後にLambda関数によりそのレコードが取得される(読み込まれる)までの所要時間になります。シャードからレコードを読み込んだ後にLambda関数の処理が遅延した場合、その処理が終わるまでLambda関数によりシャード内のレコードは読み取られないため、シャード内のレコードがLambda関数に読み込まれるまでの所要時間(IteratorAge)が長くなります。逆に言えばIteratorAgeが長くなっている場合は何等かの理由でLambda関数の処理が遅延している(Lambda関数のdurationが延びている)ことになります。
Error count and success rate
Lambda関数またはLambda関数が稼働するLambda runtime内で想定外のエラーが発生している場合はError countのメトリクスにカウントされます。Error countがカウントされている場合はLambda関数内に実装したユーザーコードのエラー処理で拾えていないような想定外のエラーが発生していることになります。Error countがカウントされている場合はLambda関数が出力するCloudWatch Logsを解析することによりエラー内容の詳細に解析して下さい。
各メトリクスの活用方法
コスト観点
Lambdaの料金はInvocationsの回数とDurationの長さにより課金されます。運用の中でLambda関数の単位時間当たりのInvocationsの回数の合計と平均Durationが上昇してきた場合はLambda関数の課金が増えてきている兆候になります。
エラー確認の観点
Lambda関数またはLambda runtimeでの想定外のエラーを検知する場合にはError countのメトリクスに対してCloudWatchアラームを設定することで検知することができます。
拡張性の観点
Lambda関数の処理時間(Duration)が長くなっている、Kinesis Data Streamの投入されたレコードが処理されるまでの時間(IteratorAge)が長くなってきている、Lambda関数の同時実行数(Concurrent Executions)が増加してきているといった兆候が見られる場合にはKinesis Data Streamのシャードの数を増やすまたはシャードあたりのLambda関数の数を増やす等、パラメーターチューニングによる拡張を考慮する必要があります。
拡張性の観点やコスト削減の観点ではCloudWatchメトリクスの値を参考にどのようにパラメーターをチューニングするかは別の記事でまとめてみたいと思います。
- 投稿日:2021-01-05T15:43:03+09:00
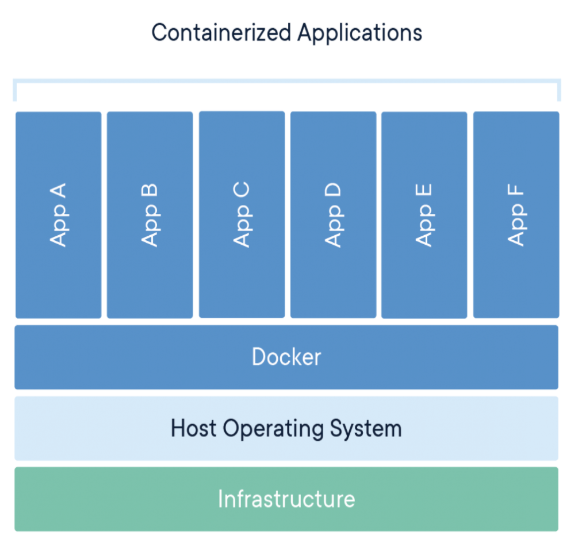
【AWS】ECRとECSとは?それぞれの違いとAWS上でDockerを運用する方法について。
AWSのECRとECSを使うとDockerをAWS上で運用することができる。
AWSのすべてのサービス一覧をみると、一番右端の隅にちょこんと記載されている。
Elastic Container RegistryがECR、Elastic Container ServiceがECS。
目次
ECRとECSとは?
・ECRはDocker hubのAWSバージョン。レポジトリを作成しイメージをプッシュ・プルできる。
・ECSはDockerをAWSで起動させる場所**。ECRのイメージからコンテナを起動する。
Docker hubではなくAWS上にDockerイメージをプッシュしてチーム全体で共有したり(ECR)、AWS上でコンテナを起動して運用することができる(ECS)。
ECR
- Elastic Container Registryの略。
- Dockerのレジストリサービス。
- Docker hubのAWS版。
Elasticは弾性のある。ここでは要領変化への追従自由度が高いといった意味。
ContainerはDockerのコンテナ。Registryは保存場所。
まとめると、自由度の高いコンテナ保存場所といったニュアンス。作成したイメージをECRにプッシュし、保存することができる。
ECRの詳細
ECRでできることは、
- レポジトリの作成
- イメージのプッシュ・プル
- イメージの詳細確認
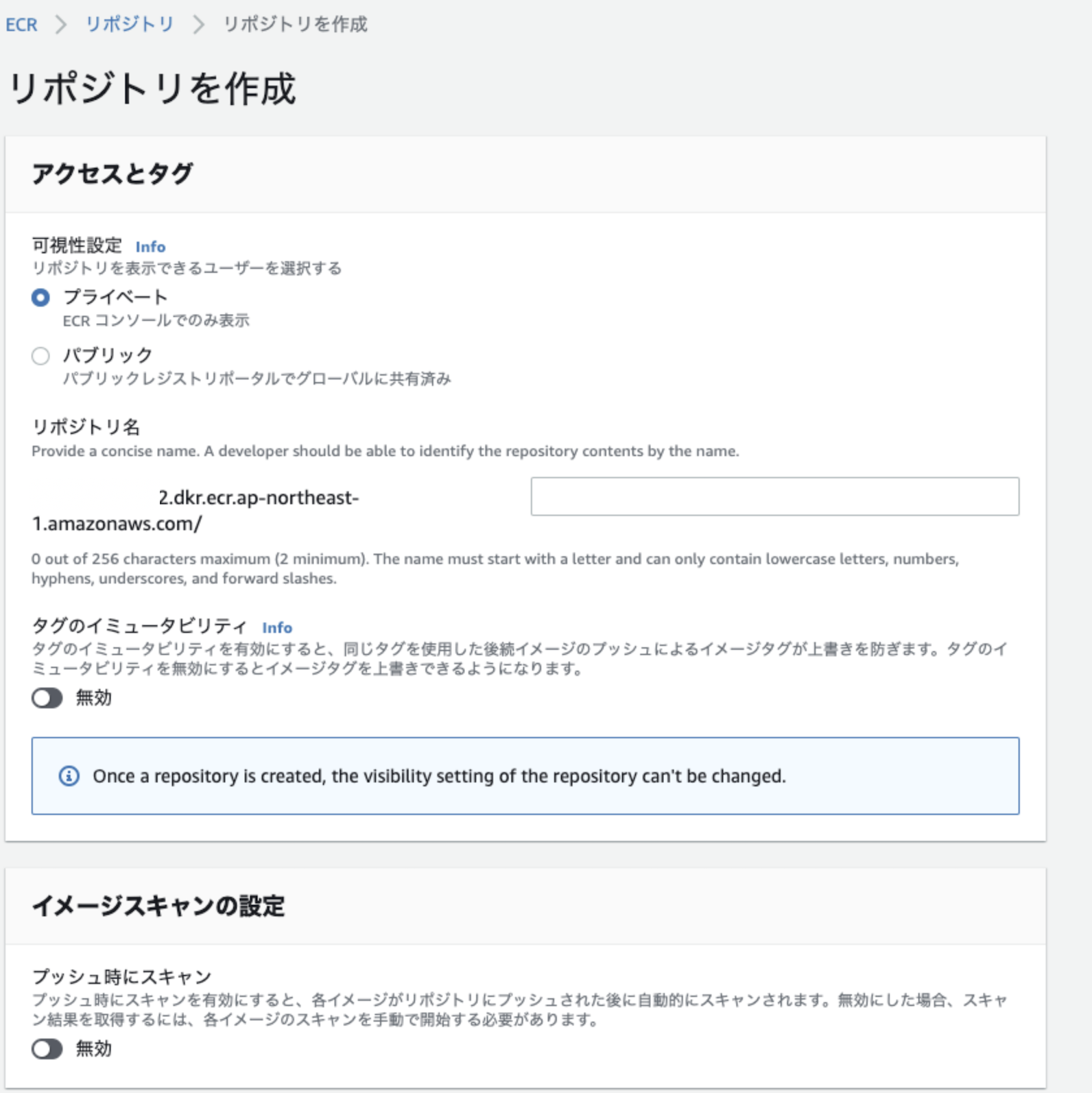
PrivateとPublicを選択してレポジトリを作成することができる。
レポジトリ名をクリックすると作成されたイメージの一覧をみることができる。
イメージをクリックすると、その詳細が確認できる。レポジトリの作成
画面右上のレポジトリの作成ボタンから作成画面に入れる。
作成は非常に簡単。基本的には、
- Private or Publicの選択
- リポジトリ名を入力
- リポジトリの作成
の3stepのみ。
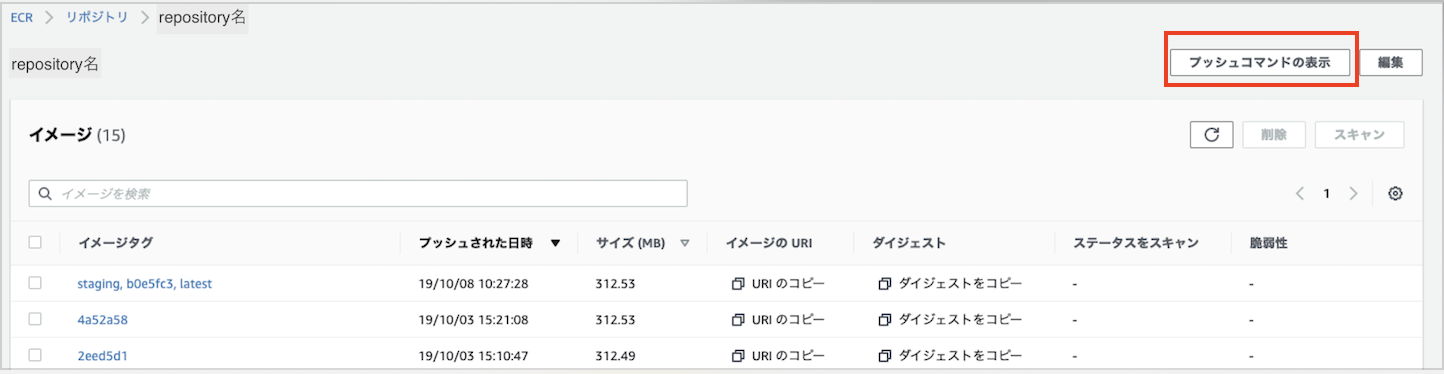
レポジトリにイメージをプッシュする
レポジトリに入り右上のプッシュコマンドの表示をクリックすると、イメージをレポジトリ にプッシュするための手順が確認できる。
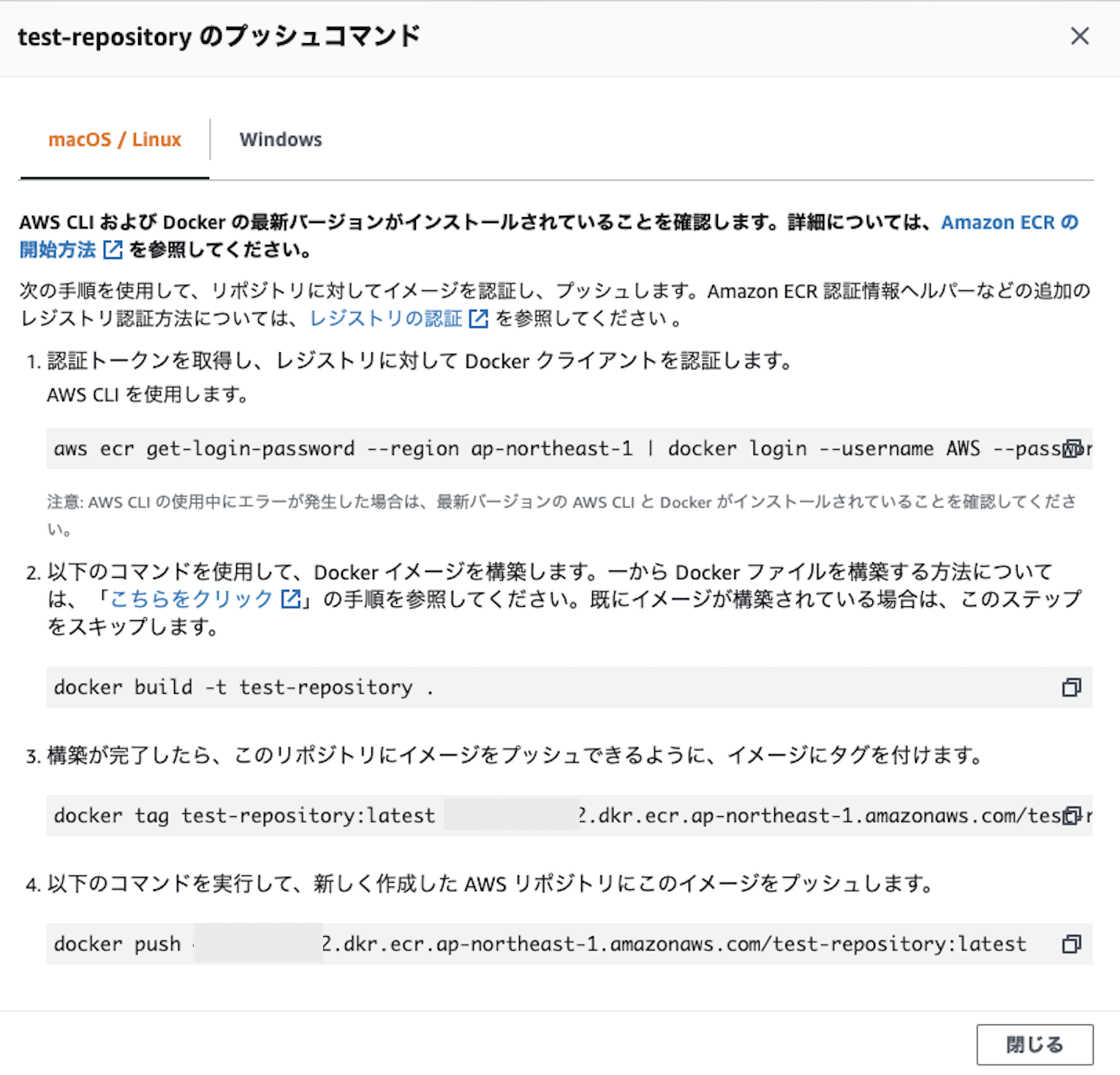
step1 Dockerレジストリサーバーにログイン
step1#AWSの認証トークンを取得し、dockerのレポジトリサーバーにログイン aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin [aws_account_id].dkr.ecr.[region].amazonaws.com・
aws ecr get-login-password --region ap-northeast-1
aws ecrコマンドで指定リージョンのPW(トークン)を取得。・
コマンドA | コマンドB
コマンドを「|」パイプで繋ぐと、コマンドAで取得したデータをコマンドBに渡す処理になる。・
docker login [オプション] [サーバー]
--username AWS:ユーザー名をAWSとしてログイン
--password-stdin:パスワードは先ほど取得したトークンを標準入力(-stdin)
で渡す。
[aws_account_id].dkr.ecr.[region].amazonaws.com
サーバーにはawsのアカウントを指定。
サーバーの指定がない場合はDocker hubに接続する。
step2 Dockerファイルからイメージを作成
現在作業中のディレクトリにDockerfileがある場合に以下コマンドを実行する。
step2docker build -t [レポジトリ名] .・
docker build [オプション] [Dockerファイルのパス]
-t [イメージ名:タグ名]:作成したイメージにタグを付与する。ここではレポジトリ名をタグとして指定している。タグ名を指定しない場合は
latestとなる。例えば、
docker build -t test-repository .の場合、
イメージ名はtest-repository:latestとなる。・
.
Dockerfileのあるディレクトリのパス。現在のディレクトリにあると指定。
step3 イメージにレポジトリ名を設定
step3docker tag [レポジトリ名]:latest [aws_account_id].dkr.ecr.[region].amazonaws.com/[レポジトリ名]:latestイメージにリポジトリ名を設定する。
docker tag [イメージ名] [リポジトリ名:タグ名]
[イメージ名]はイメージIDでも、イメージ:タグのどちらでも指定可能。設定後の例$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE [aws_account_id].dkr.ecr.[region].amazonaws.com/[AWS上のレポジトリ名] latest test-repository:latest 33 minutes ago 802MB
step4 イメージをECRにプッシュ
docker push [aws_account_id].dkr.ecr.[region].amazonaws.com/test-repository:latest
docker push [レポジトリ名:タグ名]
指定したレポジトリに該当するタグ名のイメージをプッシュする。以上でイメージのpushが完了。
ECS
- Elastic Container Serviceの略
- Dockerコンテナの実行環境
(参考)Docker公式 概要説明
ECSの詳細
ECSではAWSにプッシュしたイメージからコンテナを起動できる。
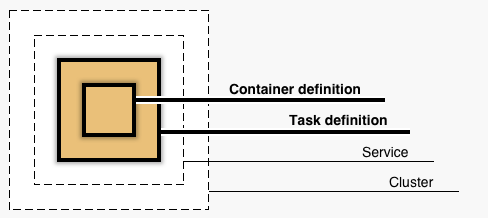
処理には大きく(1)クラスターと(2)タスク定義の二つの項目がある。
簡単にいうと、クラスターはサイトやアプリケーション、タスク定義はコンテナ作成の設定
▼ECSオブジェクトの関係性
クラスターとは?
クラスターとはタスクリクエストを実行できる1つ以上のコンテナ
つまり、1つのアプリケーションのこと。例えば、ブログサイトとコーポレートサイトを別々のサーバーで運用している場合、クラスターはブログサイトとコーポレートサイトの2つになる。
ブログサイトの中には、 Ruby on RailsとPostgreSQLなどのDBなど複数コンテナが動いているといったイメージ。
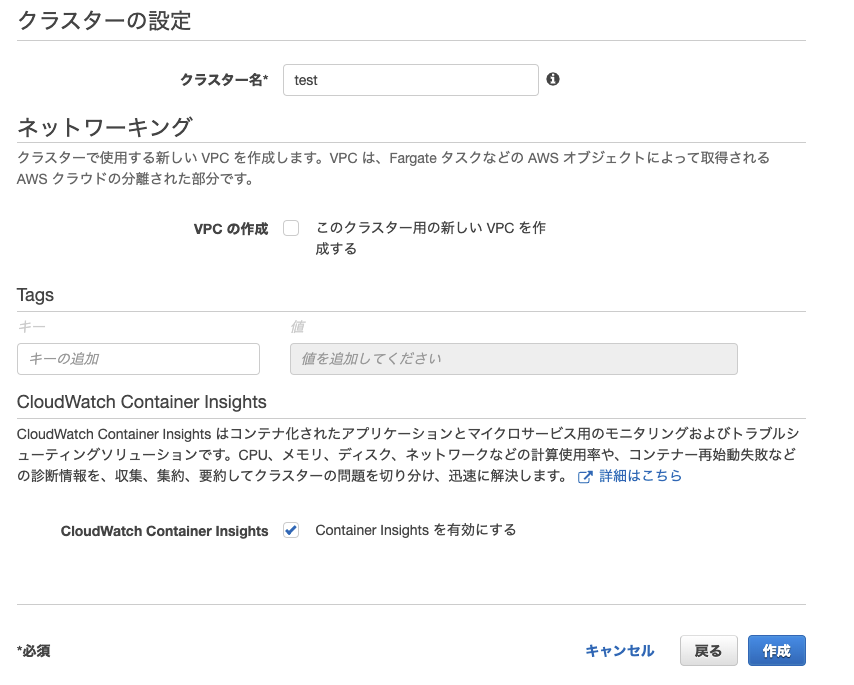
クラスターの作成
step1 クラスターテンプレートの選択
クラスターを簡単に作成するためのテンプレートを選択。
AWS Fargateとは?
ファーゲートと読む。ECS(およびEKS)専用のサービスでEC2サーバーやクラスターの管理をすることなく、コンテナを実行できるサービス。
step2 クラスター名を指定して作成
・VPCとは?
Amazon Virtual Private Cloud (Amazon VPC)の略で、コンテナを起動する専用スペースのこと。
・Container Insightsとは?
AWSの運用状況監視サービスCloudWatchに特定のデータ追加で送信できるようになる。
送信できるデータはいくつかああるが例えば、CpuUtilized(使用中のCPUユニット数)など。
以上でクラスターの作成が完了。
タスク定義とは?
タスク定義は、コンテナを起動するためのイメージやCPUなどの基本設定の定義。
ECSでDockerコンテナを実行するには、タスク定義が必須。
▼タスク定義の内容
- タスク内の各コンテナーで使用するDockerイメージ
- 各タスクまたはタスク内の各コンテナで使用するCPUとメモリの量
- 使用する起動タイプ。タスクがホストされるインフラストラクチャを決定します。
- タスクのコンテナーに使用するDockerネットワークモード
- タスクに使用するログ構成
- コンテナが終了または失敗した場合にタスクを実行し続けるかどうか
- コンテナの起動時に実行する必要のあるコマンド
- タスクのコンテナで使用する必要のあるデータボリューム
- タスクが使用する必要があるIAMロール
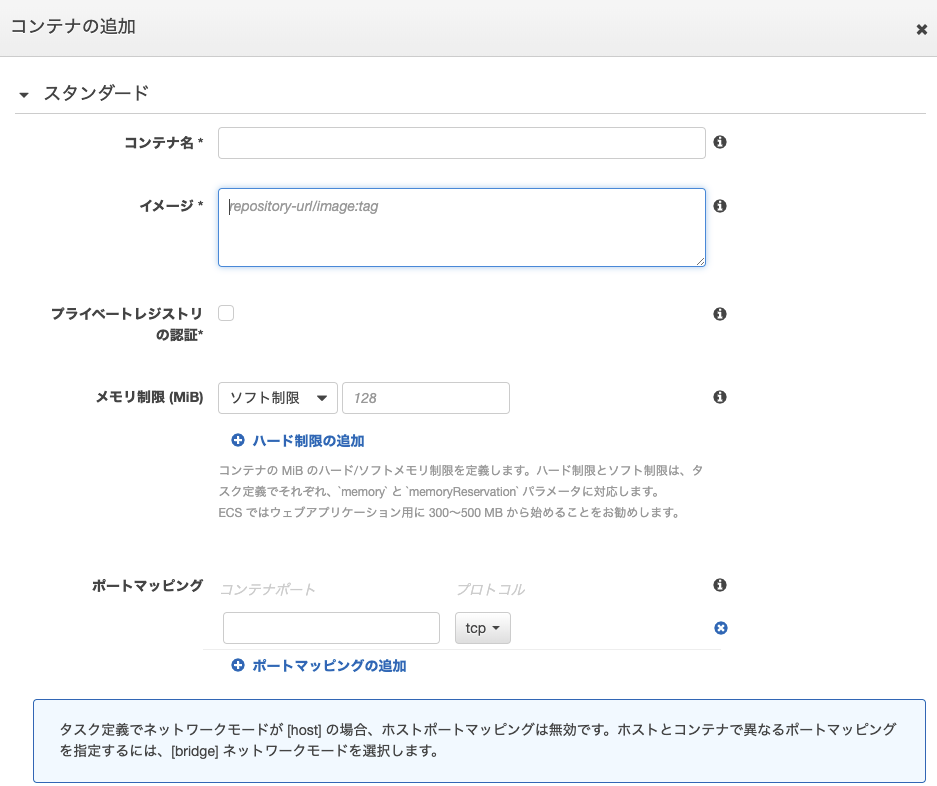
タスクの作成方法
step1 起動タイプの選択
↓
step2 タスクとコンテナの定義の設定
タスク名やコンテナに割り当てるCPUやメモリ量、コンテナの名前などを設定する。
▼主な設定内容
コンテナを起動するイメージをECRから指定。








- 投稿日:2021-01-05T15:24:24+09:00
AWS SSMエージェント起動
SSMエージェントを起動する。
自分はFargateを利用してRailsアプリケーションをデプロイしました。
そこで、Fargateでサーバ内にターミナルで入る手段にSSMというのを発見したので、
これを活用しましたが、少し躓いた点があったので共有します。自分の場合ディレクトリ構成はこんな感じです。
今回使用するのはDockerfile.producionとentrypoint.shのみです。
※Dockerfileはdevelopment用で、Dockerfile.productionが今回利用するものです。
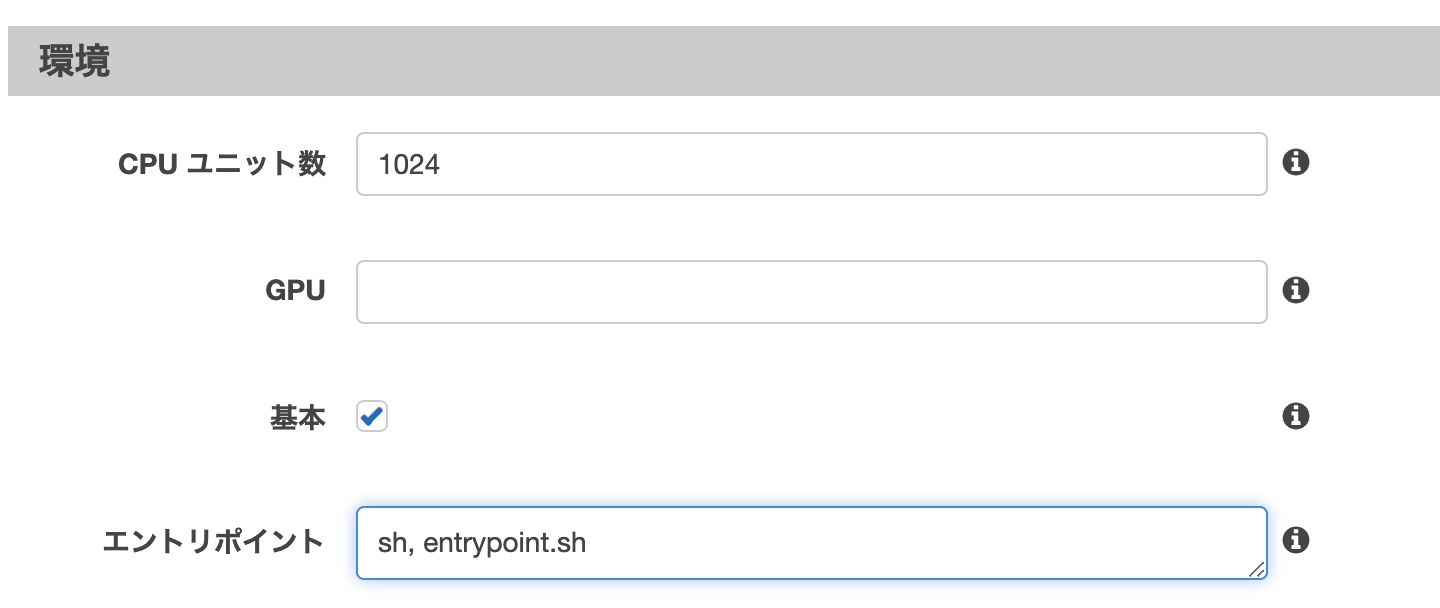
staging環境は用意していません。/application L /app L /bin ... L Dockerfile L Dockerfile.production L entrypoint.sh ...1.entrypoint.shからハイブリットアクティベーションを作成する。
まず、SSMエージェントを起動するにはハイブリットアクティベーションというのを作成する必要があります。
AWS→SystemsManager→ハイブリッドアクティベーションから手動で作成することもできますが、自分はentrypoint.shでハイブリットアクティベーションを作成しました。entrypoint.shSSM_ACTIVATE_INFO=`aws ssm create-activation --iam-role service-role/AmazonEC2RunCommandRoleForManagedInstances --registration-limit 1 --region ap-northeast-1 --default-instance-name medley-blog-fargate-container` SSM_ACTIVATE_CODE=`echo $SSM_ACTIVATE_INFO | jq -r '.ActivationCode'` SSM_ACTIVATE_ID=`echo $SSM_ACTIVATE_INFO | jq -r '.ActivationId'`2.マネージドインスタンスを登録する。
次に先程作成したハイブリットアクティベーションを使いマネージドインスタンスを登録します。
entrypoint.sh# 一番下に次を追加 amazon-ssm-agent -register -code $SSM_ACTIVATE_CODE -id $SSM_ACTIVATE_ID -region "ap-northeast-1"※自分でハイブリットアクティベーションを作成した場合は環境変数にIDとCODEを保存し利用してください。
3.SSMエージェントを起動
entrypoint.sh# 一番下に次を追加 amazon-ssm-agent &これでSSMエージェントが起動できるはずですがECSのタスク定義から起動しようとしても起動しませんでした。
そこでDockerfileからentrypint.shを起動するとどうかと思い、Dockerfileから起動してみたところ無事起動しました。
Dockerfile.productionCOPY entrypoint.sh /usr/bin/ RUN chmod +x /usr/bin/entrypoint.sh ENTRYPOINT ["entrypoint.sh"]原因は定かではありませんが、ハイブリットアクティベーションの登録まではECSのタスク定義からでも出来ていたので、「Dockerコンテナ自体はECS側にデプロイされていて、ただそのコンテナが動くようなコマンドがコンテナ内にない」という感じでしょうか?
ただ、他の記事ではECSタスク定義のエントリポイントからも出来ている記事があったので謎です。
もし、分かる人がいれば教えて下さい。まあ、DockerfileからENTRYPOINTで起動できたので良かったです。
参考記事
- 投稿日:2021-01-05T15:12:17+09:00
【AWS認定資格】取れたてホヤホヤ!AWS CloudPractitioner合格体験記(2021/01/05)
合格しました!
本日午前にAWSクラウドプラクティショナーを受験し、無事合格しました!
記憶が新しいうちに実際に受験した所感と、AWSクラウドプラクティショナー受験にあたっての勉強法・申し込み方法・当日の心構えを紹介します。筆者のバックグラウンド
文系大学出身の20卒です。都内のIT企業で働いています。
◆業務経歴
4月 主にPython初級レベルの新人研修を受ける
5月 部署でJava研修を受ける
6月~ 環境移行・オープン化案件でテストや運用監視業務を担当
11月末 AWSのAPNパートナー向け新人研修を受け、AWSに出会う実はAWSを業務・プライベート共に全く触ったことがありません。
弊社がAWSのAPNパートナーであり、動画研修が無料で受けられたので、ちょっとやってみようかな、くらいのノリで勉強を始めました笑私のIT知識は基本情報レベルです。
クラウドプラクティショナーは基本情報レベルのIT知識があれば、AWSのことが何も分からなくても恐れるに足りない試験だと思います。所感
試験時間90分で65問でした。
かなりゆっくり解きましたが、1周終わった時点で50分残っていました。
一問一答形式で、長い文章の設問や選択肢は少なかったです。公式のサンプル問題やネットに転がっている問題等いくつか見ましたが、それらに比べると本番の試験の方が難しく感じます。
ただ問題自体のレベルが高いというよりは、「聞かれ方が複雑」という感じでした。
日本語訳が間違っている出題もちらほらあるので、変な文章があったら「原文を見る」ボタンで英語の設問を確認した方が良いです。勉強法
勉強を始めたのは12月から、期間は1か月です。
その間JavaSilverや基本情報の勉強をメインで行っていたので、クラウドプラクティショナー対策に費やした総学習時間は30時間くらいだと思います。おすすめ教材はAPNパートナー向けになってしまいますが、AWS CloudPractitioner Essentialsの動画です。図や例を用いてわかりやすく説明してくれます。
AWSが何も分からなくても勉強を始められ、これだけやれば合格できるレベルに達せる良い教材です。申し込み方法
割と簡単に申し込めました。
- AWS認定クラウドプラクティショナーのページ
- 「試験のスケジュールを立てる」
- サインイン
- 「新しい試験の予約」
- 試験形態を選択
といった流れです。
私はピアソンVUEのテストセンターで受験しました。
当日の心構え
10日前にJavaSilverの試験を受験したときと同じ会場(地元のテストセンター)での受験でした。
ピアソンVUEテストセンター受験における注意点としては、以下の3点です。
①身分証明書は2種類必要
有効な身分証明書を確認し、必ず2種類持っていきましょう。
②試験会場では勉強不可
早めに到着することは大事ですが、会場に入ってしまうともう勉強できないので注意。
③証明書に掲載される写真撮影がある
メイクはちゃんとしていきましょう!
おわりに
現時点で伝えたいことは以上です!
クラウドプラクティショナーの試験はかなり初歩的なので、それ自体にあまり価値はないかもしれません。
しかし「クラウド初心者でも少し勉強すれば合格できる試験」という点でハードルが低く、資格勉強の過程でAWSの全体像がつかめるようになるので、クラウドの世界に一歩踏み出したい人には最適な試験なのではないかと思います。
次は1月10日に基本情報技術者試験を受験します。
シラバス改定後初回かつ基本情報史上初のCBT試験となるのでドキドキですが、合格目指して頑張ります!
- 投稿日:2021-01-05T15:10:30+09:00
Amazon AthenaのDDL(CREATE TABLE)でパーティションを指定してもパーティションが利用できない問題
事象
AthenaのDDLでパーティションを指定しても、それだけでは実際のSELECTクエリで結果は返ってきません。これはGlueのAPIでCREATE TABLEした場合でも同様です。
解決策
DDL実行後に下記クエリを実行する。
MSCK REPAIR TABLE table_nameこれは解決策というよりか普通に必要な手順になります。以下公式Docsにも記載されています。
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/partitions.html解説
CREATE TABLEしただけでは、そのパーティションキーがこのテーブルにはあるよ、という情報がデータカタログに渡されるだけで、実際にそのパーティションキーにはどんな値のものがあるかということが知らされないため、パーティションキーはスキーマに記載されているがパーティションはカタログ上存在しないという状態になります。
例えばnameというパーティションキーがスキーマに登録されても、実際のパーティションにname=yamadaとかname=satoがあるかどうかはカタログ側はまだ知らないのでパーティション使えませんという状態ということです。
なのでMSCK REPAIR TABLEコマンドでS3パスと照合して実際に存在するパーティションをスキャンしてメタ情報がカタログに登録され、ようやくクエリできるということです。その他
上記のコマンドは自動的にパーティションをスキャンさせる方法ですが、単体のパーティションを個別で登録するには
ALTER TABLE table_name ADD PARTITION xxxxxxを使う方法があります。
- 投稿日:2021-01-05T14:56:49+09:00
AWSにてPdfの日本語が表示されなかったのでフォントを追加する
概要
AWS内でPhpSpreadsheetを用いてExcelを出力。
LibreOfficeを使用しExcelをPdfへ変換したところ、日本語が出力されませんでした。
フォントを設定したところ解消したので設定方法を記載します。
(ちなみに筆者はWindows環境です。)フォントのzipファイルダウンロード
Google Noto Fonts
https://www.google.com/get/noto/
から以下をダウンロードします。
Noto Sans CJK JP
Noto Serif CJK JP
ダウンロードしたzipファイルの解凍
NotoSansCJKjp-hinted.zip
NotoSerifCJKjp-hinted.zip
がダウンロードされたかと思いますのでローカルの任意の場所で解凍します。
(解凍したファイルの拡張子が.otfのものだけ使いますので、どこかわかりやすい場所にまとめておくと良いと思います。)
例 C:\Users\ユーザー名\Desktop\japanese
AWSに作業フォルダ配置
Win-SCPなどを用いて、先ほどの.otfファイルをわかりやすい場所へ配置します。
例 /home/ec2-user/japanese
フォントの設定
先ほどの作業フォルダをフォント設定フォルダへコピーします。
例 sudo cp -r /home/ec2-user/japanese /usr/share/fonts/japanese
設定を適用
sudo fc-cache -fv
Pdfの表示確認
システムで表示できていなかった日本語が表示できているか確認します。
作業フォルダ削除
日本語の表示が確認できたら作業終了ですので、作業フォルダを削除します。
例 sudo rm -rf /home/ec2-user/japanese
あとがき
作業ユーザーがrootなら直で/usr/share/fontsへ配置できるかと思います。
- 投稿日:2021-01-05T14:37:42+09:00
【AWS】CloudWatchとは?名前空間やメトリクスなど専門用語の解説とグラフの作成まで。
個人メモです。
CouldWatchの用途
AWSで使用しているサービスの稼働状況をモニタリングできるシステム。
閾値を設定しておけばアラート通知もできる。
表示するデータは折れ線や円グラフなど好きな形式を選択できる。
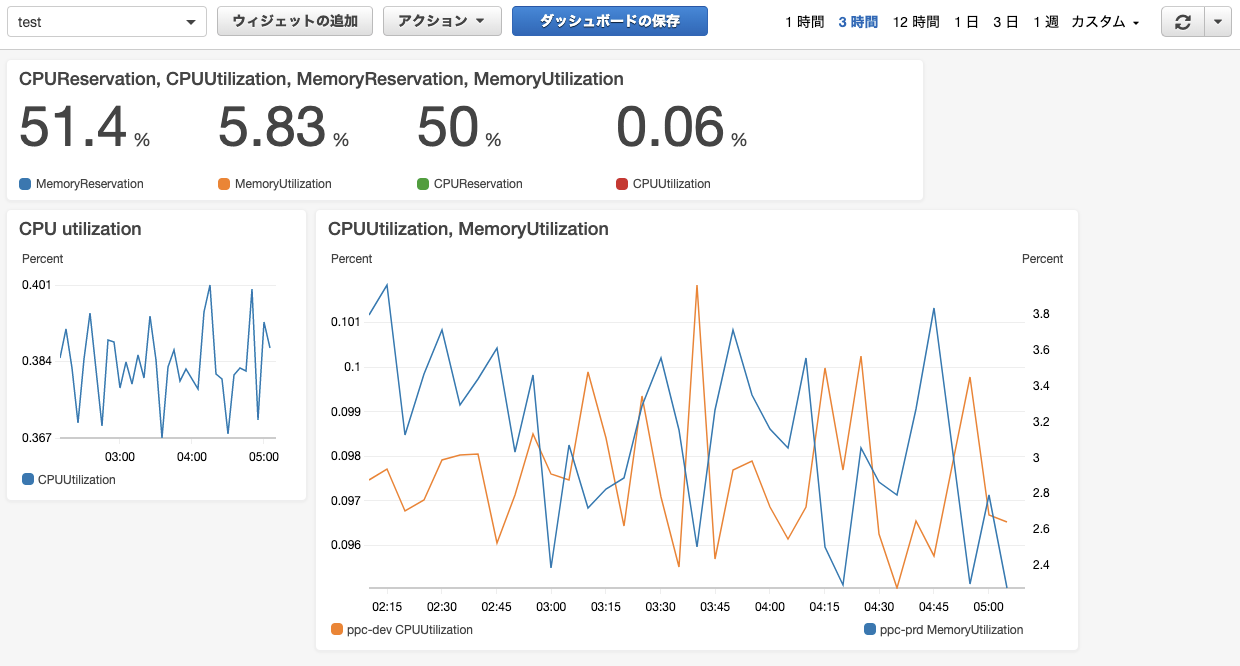
▼CloudWatchダッシュボード画面の例
上記のようなグラフや数値などの好きなウィジェットを好きな場所に表示できる。
各ウィジェットの表示サイズの変更はドラッグで簡単にできる。
CloudWatchと連携できるサービス一覧
EC2、ECS、S3などの多くのサービスのデータを集計できる。
CloudWatchの関連用語
- Namespaces(名前空間)
- Widget(ウィジェット)
- Dimensions(ディメンション)
- Metrics(メトリクス)
- Statics(統計)
名前空間とは?(Namespaces)
ここでの名前空間は、EC2, ECSなどのAWSのサービス名を指す。
ウィジェットとは?(widget)
データの表示方法は折れ線、面積、数値、棒グラフなどが選択できる。これらをウィジェットとして選択する。
グラフの自由度はとても高い。例えば折れ線の場合、2軸表示、凡例の位置、グラフの最大値・最少値の設定、注釈の表示などができる。
ディメンションとは?(Dimensions)
ここでのディメンションは集計方法の切り分け方のこと。
例えば、EC2のメモリ使用率をグラフ化したい場合、各インスタンス毎のメモリ使用率を表示するか、EC2全体のメモリ使用率を出すかなど。
Auto Scalingグループ別や、イメージID別、すべてのインスタンスにわたり、などがディメンションとなる。
メトリクスとは?
集計するデータのこと。CPUの使用率、メモリの使用率、エラー発生数などのこと。
▼メトリクスの一例
メトリクス選択の流れ
ダッシュボードを選択する。今回はtestを選択
↓ ウィジェットの追加を選択
↓ 線を選択
↓ メトリクスを選択(これでメトリクスを使ってグラフ作成ができる)
↓ 名前空間はEC2を選択
↓ ディメンションはすべてのインスタンスにわたりを選択
↓ メトリクスはCPU Utilization(CPU使用率)を選択
以上で指定したメトリクスでウィジェットの作成が完了。
周期とは?(Period)
データの集計周期。例えば1時間、1日、1ヶ月(30日)単位とか。
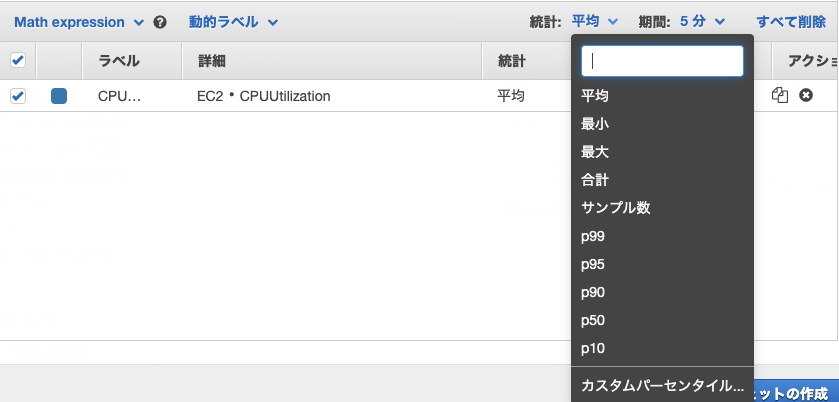
統計とは?(Statistic)
データの集計方法。例えば平均とか、最大値とか。
Sum
Max
Min
Average
Sample count
Percentile
Percentileとは?
すべてのデータを小さい方から大きい方に並べ替え、全体を100%とした場合に、指定した%のデータ。
p10や、p85といった形で表す。(p10 = 10%)例えば、指定期間でCPU使用率が100個のデータがあった場合に、p10だと、使用量の低い方から10%目に当たるデータとなる。
p50ならパーセンタイルでした場合の中央部のデータとなる。(平均値Averageの値とは異なる)
Percentileを使うメリット
Average(平均)だと、突発的な異常値も平均化されてしまい、実像が見えにくい場合がある。
%を使えば、より実際に近い値が得られる。
アラーム
アラームの状態
アラームの状態は3つある。
- OK
- NG
- Insufficient data(データ量不十分)
アラームの設定
アラームの設定には主に3つの指標がある。
- 期間(Period)
- 最新データを基点として期間(Evaluation Period)
- 設定した閾値を超えたデータ数(Datapoints to Alarm)
実際の設定例
例えば、以下のように設定した場合、直近の3つのデータすべてが閾値を超えたときにアラームが発動する。
・最新データを基点として期間(Evaluation Period)= 3
・設定した閾値を超えたデータ数(Datapoints to Alarm)= 3データ欠損した場合
データが欠損している場合(送信されてこない場合)の対応以下から選択することができる。
- Good(not breaching): 欠損データは閾値内とする。
- Bad (breaching): 欠損データは閾値外とする。
- Ignore: 直近のアラーム状態をいじ
- Missing: 過去の期間に遡る
breachingとは違反状態。ここでは閾値を超えた状態のこと。
設定例としては、CPU使用率のようにクリティカルでなければGoodとし、エラーのように異常を即座に検知する必要があるものはBadと設定する。









- 投稿日:2021-01-05T11:17:30+09:00
AWS データベース
Amazon Relational Database Service(Amazon RDS)
VPCにEC2同様にDBインスタンスを配置する(MySQL、MariaDB等)
Amazon Aurora
RDSで使用できるDBエンジン
Amazon Aurora以外の場合
EC2インスタンスに自前でインストールして使用する
ブロックストレージ(DBの保存スペースをボリュームという単位で確保する方法)で構築される※AmazonAuroraのDBを使用すると、EC2に保存されるのではなく、アベイラビリティーゾーンに保存される(それもゾーン(1a、1c、1d)それぞれが通信しており、1つのアベイラビリティーゾーンが障害が起きても、代替え、代替えしてるあいだに自動修復するような仕組みになっている)
Amazon ElasticCache
Redis及Memcachedと互換性のあるインメモリデータストアを提供する
Redis= めっさ早くDBを検索してくれる&それなりに検索機能がある
Memcached= めっさめっさ早くDBを検索してくれる
※RDBMS(リレーション・DB・マネジメントサービス)=複雑操作可能だから遅い
※同時多発的なゲームなどの集計など、今後多くのミリ秒以下を扱うもの
(運転?手術?とかの開発に使われてくるのかね?)
- 投稿日:2021-01-05T09:45:55+09:00
Amplifyの基礎知識と使い方メモ
基礎知識
- Amplifyとは「AWSの様々なサービスをより簡単に扱えるツール」のこと
- Firebaseに似てる
- AmplifyはWebブラウザ用のコンソールと呼ばれる画面上でも一部操作可能だが、基本的にはCLIで操作する
- CLIの各種コマンドを実行すると裏でCloudFormationが動く仕組みになっている
【重要】CLIコマンド実行中に途中で強制停止するとトラブルの元になり、最悪の場合元に戻せないので注意- Amplifyにはプロジェクトという概念があり、基本的には一つのプロダクトにつき一つのプロジェクトを作成
- プロジェクトを作成すると、リポジトリ内にamplifyという名前のフォルダが生成される
CLIインストール
- ローカルでAWSの認証情報を設定する
- 任意のprofile名を付ける
- 下記コマンドでCLIインストール
npm install -g @aws-amplify/cliCategory (カテゴリ)
- Amplifyには「category (カテゴリ)」という概念がある
- api、auth、functionなど様々なカテゴリが用意されている
- 例えばapiカテゴリはGraphQL APIやREST APIを作るときに使う
- GraphQL APIは裏でAppSyncが動き、REST APIではAPI GatewayやLambda等が動く
- 他にも、authはCognito、functionはLambda、hostingはRoute53やS3、storageはS3が動く
- CLIで
amplify api addを実行すれば apiを追加でき、amplify api removeで削除できる- functionなら
amplify function add、authならamplify auth addといったように実行するamplifyフォルダ
- amplifyフォルダ内には、amplify関連の各種設定やLambda関数のソースコードファイル、GraphQLスキーマファイル等が配置される
- amplifyフォルダにはGit管理下のファイルと、そうでないファイルがある
/amplify/.configには基本的な設定ファイルが配置される/amplify/backendにはカテゴリ毎にフォルダが配置され、それぞれに関連ファイルが配置される/amplify/team-provider-info.jsonは環境設定を記述するJSONファイル(詳しくは後述)env (環境)
- Amplifyには「env (環境)」という概念がある
- これは例えば本番環境、ステージング環境、開発環境といったように環境を分けたい場合に役立つ
- 環境ごとに全く別々のAWSリソースが構築される
- 例えばLambda関数(function)を作り、2つの環境(stgとdev)を作ると、AWSコンソールを見ると同じソースコードのLambda関数が2つ生成されていることが確認できる
- 同様に、DyanmoDBのテーブルやS3のバケット等も全て環境ごとに生成される
- 現在存在する環境一覧をリスト表示するには
amplify env listを実行- 現在選択中の環境には名前の横にマークが付く
- 環境を切り替えるには
amplify env checkout stgのように最後に環境名を指定して実行- 新たに環境を追加するにはCLIで
amplify env addを実行- 環境の削除は
amplify env removeで簡単に実行できるが、再度作り直してもIDが変わってしまい、全く同じ環境ではなくなるので注意- 環境関連コマンドを実行すると
/amplify/team-provider-info.jsonの内容が書き換わる- 前述のJSONファイルに環境が存在しなければ、
amplify env checkout {環境名}コマンドを実行できないamplify codegen
- GraphQLスキーマを
/amplify/backend/api/{API_NAME}/schema.graphqlに書くamplify codegenというコマンドを実行すると、GraphQLスキーマファイルに基づいたJSファイルが生成される- 生成先は
/srcフォルダ(設定で変更可)- 生成されたJSファイルをアプリケーション側でimportすることでGraphQL APIを扱うことができる
- 基本的にcodegen後のファイルはGit管理下にするべきではない(GraphQLスキーマファイルとの不一致を防ぐため)
- 生成された以外のGraphQLを書きたい場合は、別途ファイルを作成してimportする
- 投稿日:2021-01-05T09:24:28+09:00
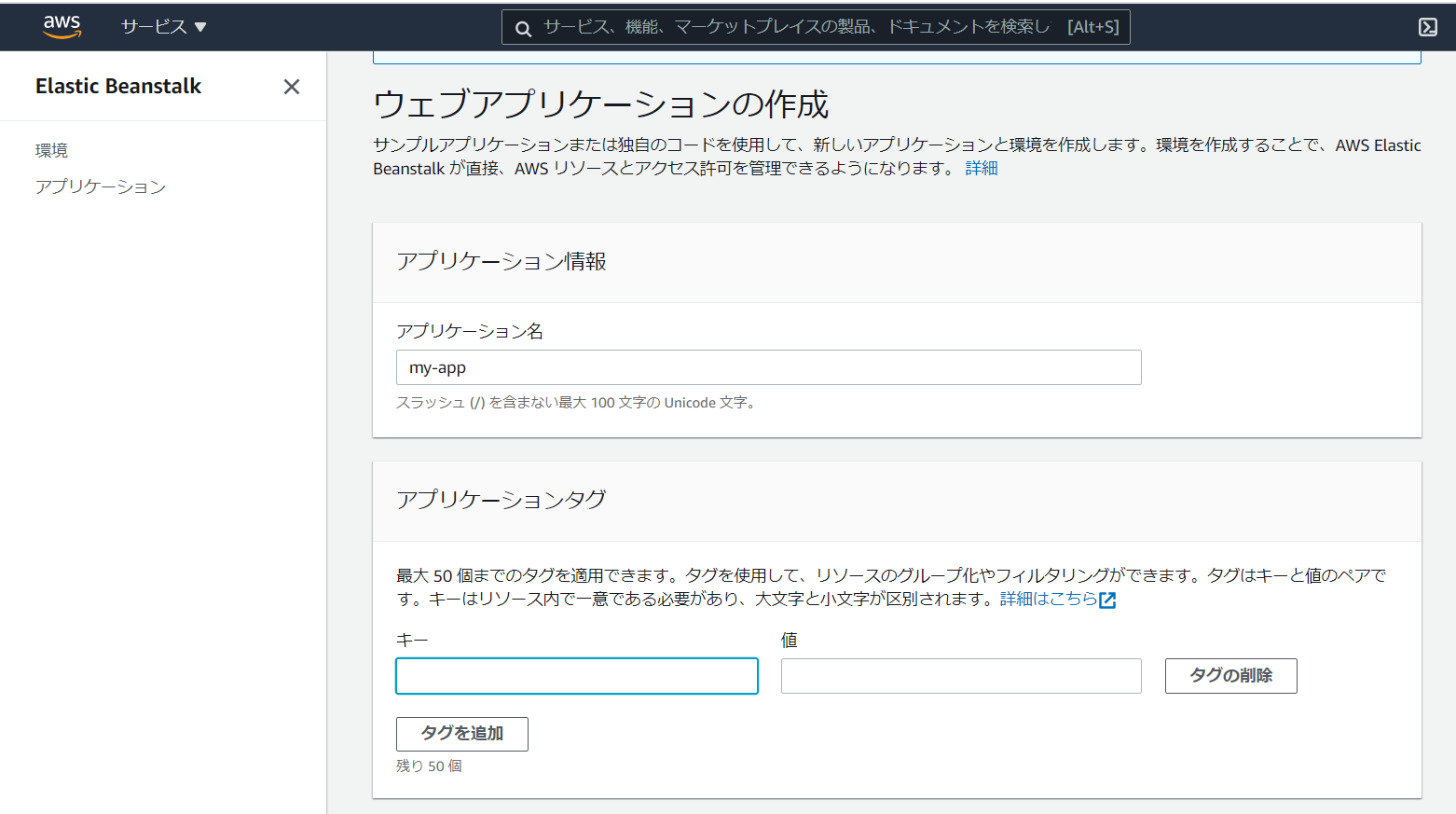
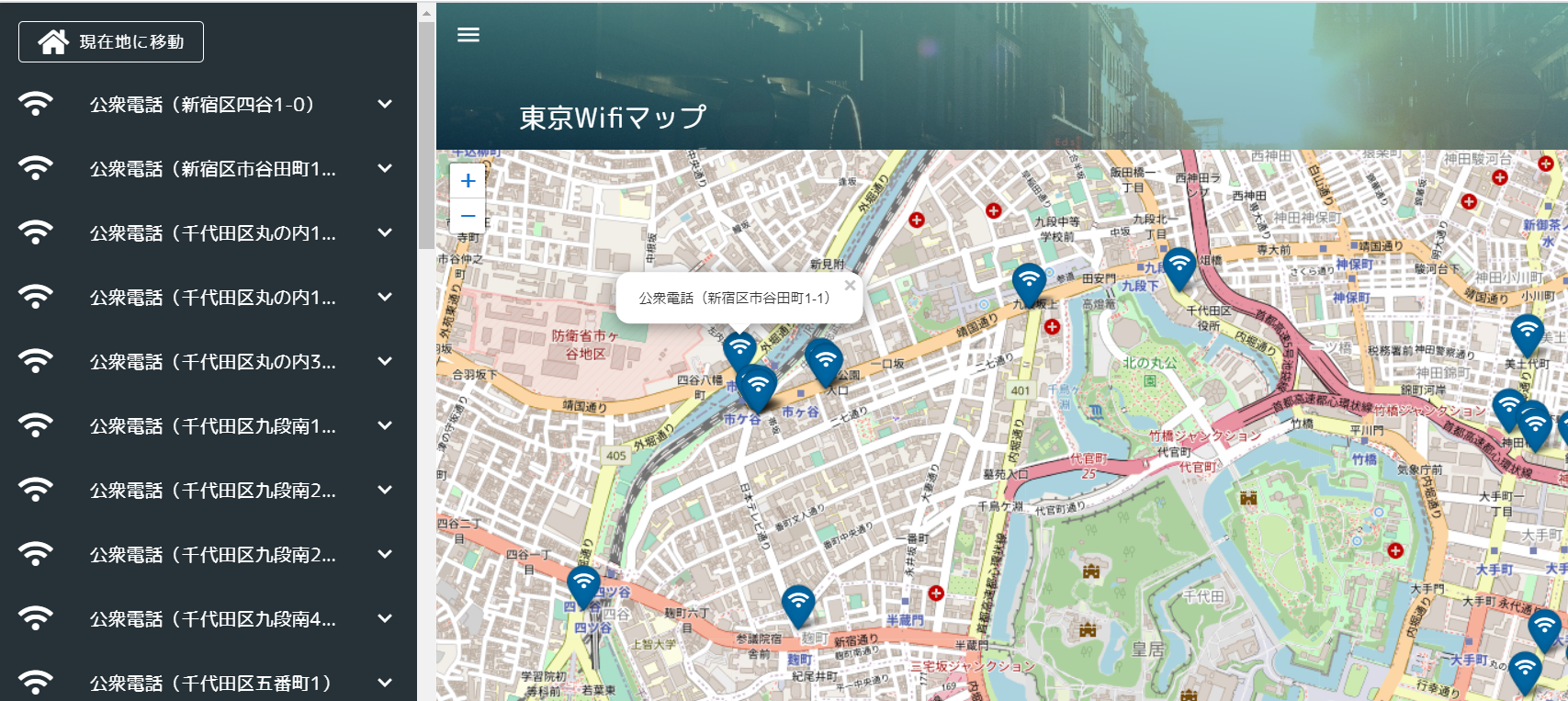
AWS Elastic BeanstalkでサクッとWiFiマップアプリをデプロイする(Vue/Leaflet)
この記事はリンク情報システムの2021新春アドベントカレンダー Tech Connect!のインデックス記事です。
Tech Connect! は勝手に始めるアドベントカレンダーとして、engineer.hanzomon のグループメンバによってリレーされます。
アドベントカレンダー2日目です。好きにアプリを作ってAWSにデプロイしてみました。1.アプリケーションを作る
作成したアプリは下記のような感じ。データの元ネタは東京都オープンデータの公衆無線LANアクセスポイント。
- Vue:2.5.2
- Vuetify:2.3.19
- vuex:3.0.1
- leaflet:1.7.1
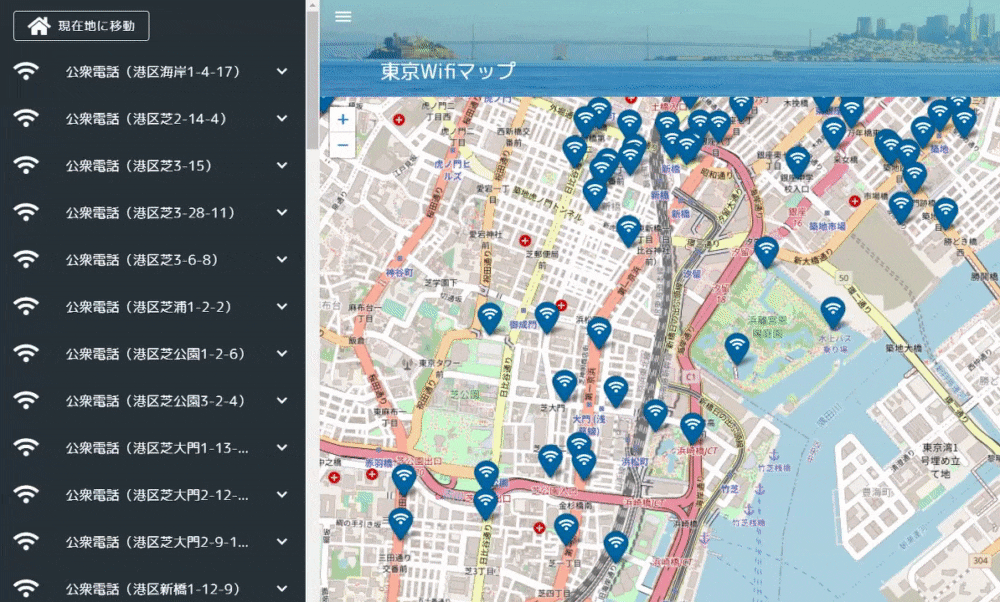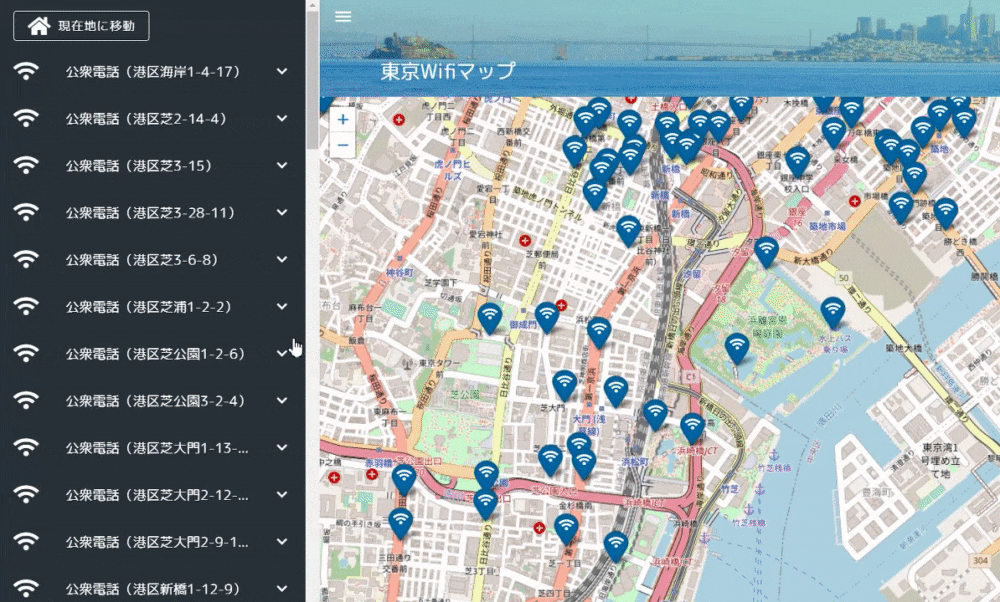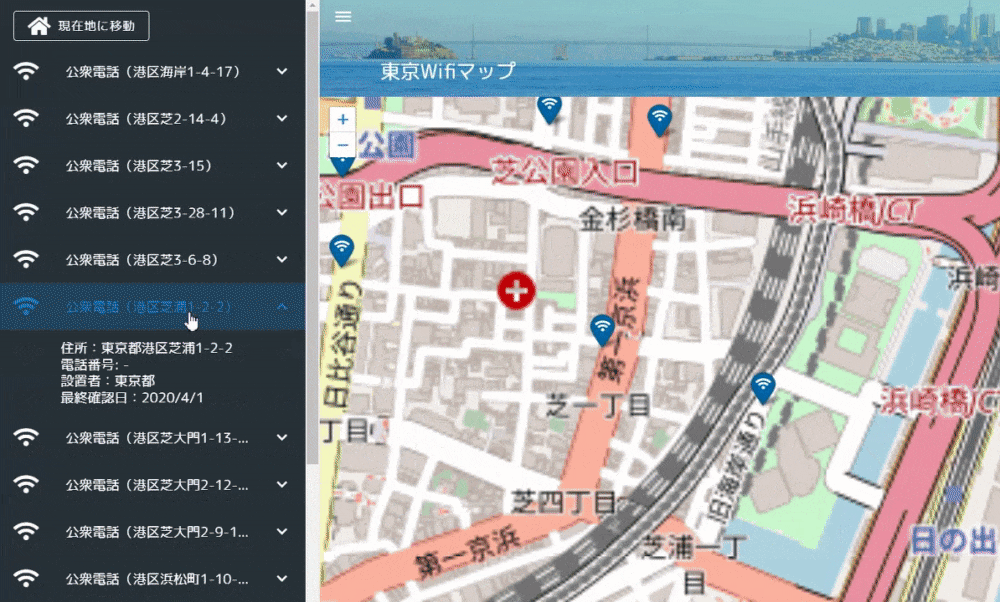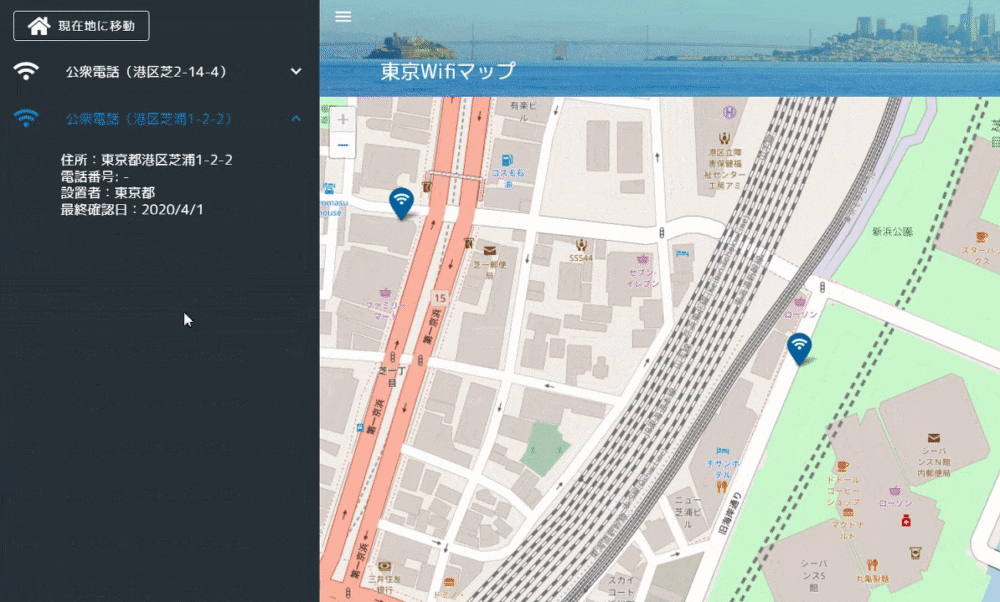
Leaflet含めたMapの実装は下記となります。地図が動いて緯度経度情報が変わったら、storeに情報をセットします。mount時に現在値情報を取得し、現在地情報があれば地図描画時に付近を表示するように実装しました。
マーカーアイコンはLeaflet.awesome-markers、アイコンはFont Awesomeです。
Leaflet.awesome-markersはLeaflet後に宣言する必要があります。(「Uncaught ReferenceError: L is not defined」になる)Map.vue<template> <v-container id="mapid" class="com-map"> </v-container> </template> <script> import "leaflet/dist/leaflet.css"; import L from "leaflet"; import "../../static/js/leaflet.awesome-markers.js"; export default { name: "map", data() { return { map: null, twnCd: 130001 }; }, mounted() { // Wifi情報と現在地情報を取得する this.getWifiList(); this.getLocation(); }, computed: { /** Wifi情報 */ wifiList: { get() { return this.$store.state.Map.wifiList; } }, /** 地図表示範囲 */ bounds: { get() { return this.$store.state.Map.bounds; } }, /** 現在地 */ crtLocation: { get() { return this.$store.state.Map.crtLocation; } }, /** 現在地ズームフラグ */ crtZmFlg: { get() { return this.$store.state.Map.crtZmFlg; } }, /** ズーム情報 */ zmInfo: { get() { return this.$store.state.Map.zmInfo; } } }, methods: { /** WiFi情報を取得する */ getWifiList() { setTimeout(() => { this.$store.dispatch("Map/getWifiList", { twnCd: this.twnCd }); }, 500); }, /** Map情報を設定する */ setMapConfig() { let zmLat = 35.6825; let zmLon = 139.752778; if (this.crtLocation != null) { // 現在地が取得できた場合は現在地を設定する zmLat = this.crtLocation.latitude; zmLon = this.crtLocation.longitude; } this.map = L.map("mapid").setView([zmLat, zmLon], 13); // map情報を取得する const map = this.map; // mapの表示緯度経度を設定する this.setBounds(); L.tileLayer("http://{s}.tile.osm.org/{z}/{x}/{y}.png", { maxZoom: 18 }).addTo(map); // ダブルクリック時のズームをOFFにする map.doubleClickZoom.disable(); // マップ動作時にmap表示範囲を設定する map.on("move", this.setBounds); // アイコンの設定をする var wifiMarker = L.AwesomeMarkers.icon({ icon: "fa-wifi", markerColor: "darkblue", prefix: "fa" }); for (var wifi of this.wifiList) { if (wifi.lat !== undefined && wifi.lon !== undefined) { let mark = L.marker([wifi.lat, wifi.lon], { icon: wifiMarker }).addTo( map ); mark.on("click", function(e) { map.setView(e.latlng, 16); }); mark.bindPopup(wifi.equipName); } } }, /** 表示範囲情報を設定する */ setBounds() { let bounds = this.map.getBounds(); this.$store.commit("Map/setBounds", bounds); }, /** 現在地を取得する */ getLocation() { if (!navigator.geolocation) { return; } const options = { enableHighAccuracy: false, timeout: 5000, maximumAge: 0 }; navigator.geolocation.getCurrentPosition( this.success, this.error, options ); }, success(position) { // 成功した場合は現在の表示情報を取得する this.$store.commit("Map/setCrtLocation", position.coords); }, error(error) { console.warn(`ERROR(${error.code}): ${error.message}`); } }, watch: { /** Wifi情報を監視 */ wifiList() { this.setMapConfig(); }, /** 現在地ズームフラグを監視 */ crtZmFlg() { if (this.crtZmFlg && this.crtLocation != null) { // ズームフラグON、かつ現在地情報が取得できた場合 let zmLat = this.crtLocation.latitude; let zmLon = this.crtLocation.longitude; const map = this.map; // 現在地にズームする map.flyTo([zmLat, zmLon], 15); } // エラー処理 // 現在地ズームフラグOFF this.$store.commit("Map/setCrtZmFlg", false); }, /** ズーム情報を監視 */ zmInfo() { const map = this.map; // 公衆Wifiリスト押下時にズームする map.flyTo([this.zmInfo.lat, this.zmInfo.lon], 18); } } }; </script>横のWifiリスト一覧は下記のような感じ。地図の表示範囲情報を監視し、緯度経度情報が変わったら、actionを呼んで表示範囲内のWifiリストを生成します。
Panel.vue<template> <v-card class="mx-auto blue-grey darken-4" height="100%"> <v-spacer></v-spacer> <v-btn class="mt-4 ml-4" dark depressed outlined justify="center" @click="setCrtZmFlg" > <v-icon dark large class="mr-2 fas fa-home home_icon"> </v-icon> <span>現在地に移動</span> </v-btn> <v-list> <v-list-group v-for="item in dispRangeWifiList" :key="item.no" v-model="item.active" :prepend-icon="item.action" no-action @click="setZmInfo(item.lat, item.lon)" > <template v-slot:activator> <v-list-item-icon> <v-icon class="fas fa-wifi"></v-icon> </v-list-item-icon> <v-list-item-content> <v-list-item-title v-text="item.equipName"></v-list-item-title> </v-list-item-content> </template> <v-list-item> <v-list-item-content> <div>住所:{{ item.address }}</div> <div v-if="item.phoneNum">電話番号: {{ item.phoneNum }}</div> <div v-else>電話番号: -</div> <div>設置者:{{ item.installer }}</div> <div>最終確認日:{{ item.updateDate }}</div> </v-list-item-content> </v-list-item> </v-list-group> </v-list> </v-card> </template> <script> export default { name: "panel", data() { return { clickFlg: true }; }, mounted() {}, computed: { /** Wifi情報 */ wifiList: { get() { return this.$store.state.Map.wifiList; } }, /** 地図表示範囲 */ bounds: { get() { return this.$store.state.Map.bounds; } }, /** Wifi情報 */ dispRangeWifiList: { get() { return this.$store.state.Map.dispRangeWifiList; } }, /** 現在地 */ crtLocation: { get() { return this.$store.state.Map.crtLocation; } }, /** 現在地ズームフラグ */ crtZmFlg: { get() { return this.$store.state.Map.crtZmFlg; } }, /** ズーム情報 */ zmInfo: { get() { return this.$store.state.Map.zmInfo; } } }, methods: { /** 表示範囲内のWifiの情報を取得する */ getDispRangeWifiList() { setTimeout(() => { this.$store.dispatch("Map/getDispRangeWifiList", { wifiList: this.wifiList, bounds: this.bounds }); }, 500); }, /** 現在地ズームフラグON */ setCrtZmFlg() { this.$store.commit("Map/setCrtZmFlg", true); }, /** Wifi一覧押下時のズーム */ setZmInfo(lat, lon) { if (this.clickFlg) { let info = { lat: lat, lon: lon }; this.$store.commit("Map/setZmInfo", info); // リストを閉じる時はズームは動作しない this.clickFlg = false; } else { this.clickFlg = true; } } }, watch: { /** 地図表示範囲を監視 */ bounds() { if (this.wifiList.length) { this.getDispRangeWifiList(); } } } }; </script>2.AWS Elastic Beanstalkデプロイ用にアプリを構成する
AWS Elastic BeanstalkでVue(静的コンテンツ)をデプロイする場合は下記のような構成になります。Nginx側に静的コンテンツを配置するのではなく、HTTPサーバとしてExpressを立てて動くイメージです。
(ここを誤解していて随分時間を無駄にしました。。)
Vueとは別にExpressのプロジェクトを作成し、index.htmlにルーティングするように設定します。
AWS Elastic Beanstalkにデプロイするにあたっては2つ注意点があります。
- package.jsonに「start」コマンドを定義すること
- AWS Elastic Beanstalkではポート8080で動くので、expressの起動を3000ポートで固定しないこと
package.jsonは下記のような感じです。
{ "name": "proxy", "version": "1.0.0", "description": "", "main": "app.js", "scripts": { "start": "node app.js", "test": "echo \"Error: no test specified\" && exit 1" }, "author": "", "license": "ISC", "dependencies": { "del": "^6.0.0", "express": "^4.17.1", "fancy-log": "^1.3.3", "gulp": "^4.0.2", "gulp-zip": "^5.0.2", "nodemon": "^2.0.4", "webpack": "^4.43.0", "webpack-cli": "^3.3.11", "webpack-stream": "^5.2.1" } }ルーティング設定は下記の様にしました。
静的コンテンツがある場合(static)、定義を入れる必要があります。(入れないとGET http://~.js net::ERR_ABORTED 404 (Not Found)になり、画面が真っ白になる。)app.jsconst express = require("express"); const app = express(), port = process.env.PORT || 3000; // 静的コンテンツを定義 app.use("/static", express.static(__dirname + "/wifi-map-app/dist/static")); // ルートアクセスはindex.htmlを参照するようにする app.get("/", (req, res) => { res.sendFile(process.cwd() + "/wifi-map-app/dist/index.html"); }); app.listen(port, () => { console.log(`Server listening on the port::${port}`); });最終的にはExpressとVue合わせてzip圧縮した資材をAWSにアップロードします。自動で圧縮ファイルを構築できるようにgulpを利用してビルド定義を書きます。配置先はpackage.jsonと同ディレクトリです。
この辺の話しは下記サイトが詳しいので、ご参照ください。
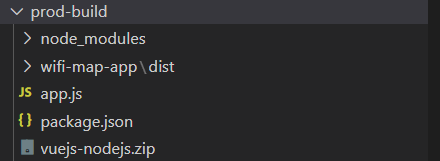
https://medium.com/bb-tutorials-and-thoughts/aws-deploying-vue-js-with-nodejs-backend-on-elastic-beanstalk-e055314445c5gulpfile.jsconst { src, dest, series, parallel } = require("gulp"); const del = require("del"); const fs = require("fs"); const zip = require("gulp-zip"); const log = require("fancy-log"); var exec = require("child_process").exec; const paths = { prod_build: "../prod-build", server_file_name: "./app.js", server_package_json: "package.json", server_module: "node_modules/**/*", server_module_dist: "../prod-build/node_modules", vue_src: "../wifi-map-app/dist/**/*", vue_dist: "../prod-build/wifi-map-app/dist", zipped_file_name: "vuejs-nodejs.zip", }; function clean() { log("removing the old files in the directory"); return del("../prod-build/**", { force: true }); } function createProdBuildFolder() { const dir = paths.prod_build; log(`Creating the folder if not exist ${dir}`); if (!fs.existsSync(dir)) { fs.mkdirSync(dir); log("folder created:", dir); } return Promise.resolve("the value is ignored"); } function buildVueCodeTask(cb) { log("building Vue code into the directory"); return exec("cd ../wifi-map-app && yarn build", function ( err, stdout, stderr ) { log(stdout); log(stderr); cb(err); }); } function copyVueCodeTask() { log("copying Vue code into the directory"); return src(`${paths.vue_src}`).pipe(dest(`${paths.vue_dist}`)); } function copyNodeJSCodeTask() { log("building and copying server code into the directory"); return src([ `${paths.server_file_name}`, `${paths.server_package_json}`, ]).pipe(dest(`${paths.prod_build}`)); } function copyNodeJSModules() { log("copying nodejs modules into the directory"); return src(`${paths.server_module}`).pipe(dest(`${paths.server_module_dist}`)); } function zippingTask() { log("zipping the code "); return src(`${paths.prod_build}/**`) .pipe(zip(`${paths.zipped_file_name}`)) .pipe(dest(`${paths.prod_build}`)); } exports.default = series( clean, createProdBuildFolder, buildVueCodeTask, parallel(copyVueCodeTask, copyNodeJSCodeTask, copyNodeJSModules), zippingTask );Expressプロジェクト配下で「glup」コマンドを実行して、ビルドします。
下記のようにVueのビルド資材とexpressが配置できたらOKです。vuejs-node.zipがAWS Elastic Beanstalkでアップロードする資材となります。
3.AWS Elastic Beanstalkでインフラ環境をつくる
AWS Elastic Beanstalkを利用すれば下記が自動で生成されます。
※詳しいチュートリアルはこちらから・Amazon Elastic Compute Cloud (Amazon EC2) インスタンス (仮想マシン)
・Amazon EC2 セキュリティグループ
・Amazon Simple Storage Service (Amazon S3) バケット
・Amazon CloudWatch アラーム
・AWS CloudFormation スタック
・ドメイン名Elastic Beanstalkの画面を開いて、ウェブアプリケーションを作成します。
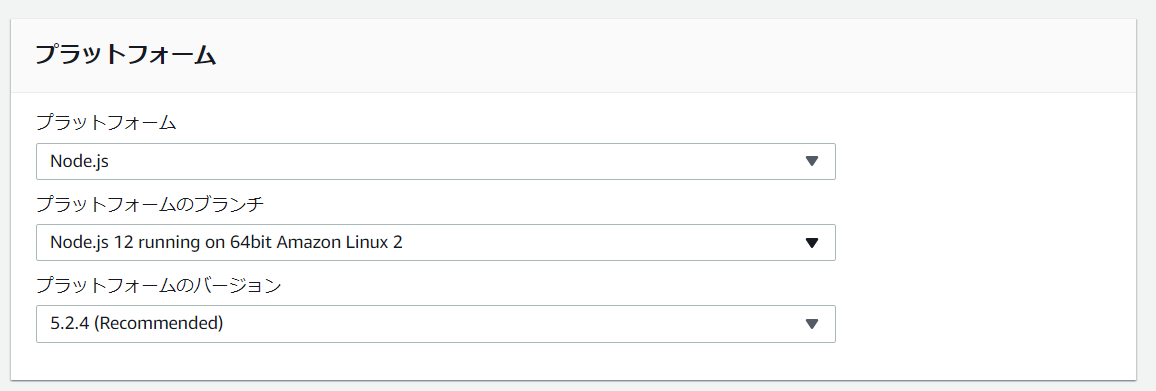
プラットフォームはNode.jsを選択します。デプロイするアプリケーションは、上記で作成したvuejs-node.zipでも良いですが、一旦サンプルアプリケーションで動作確認をするのをお勧めします。
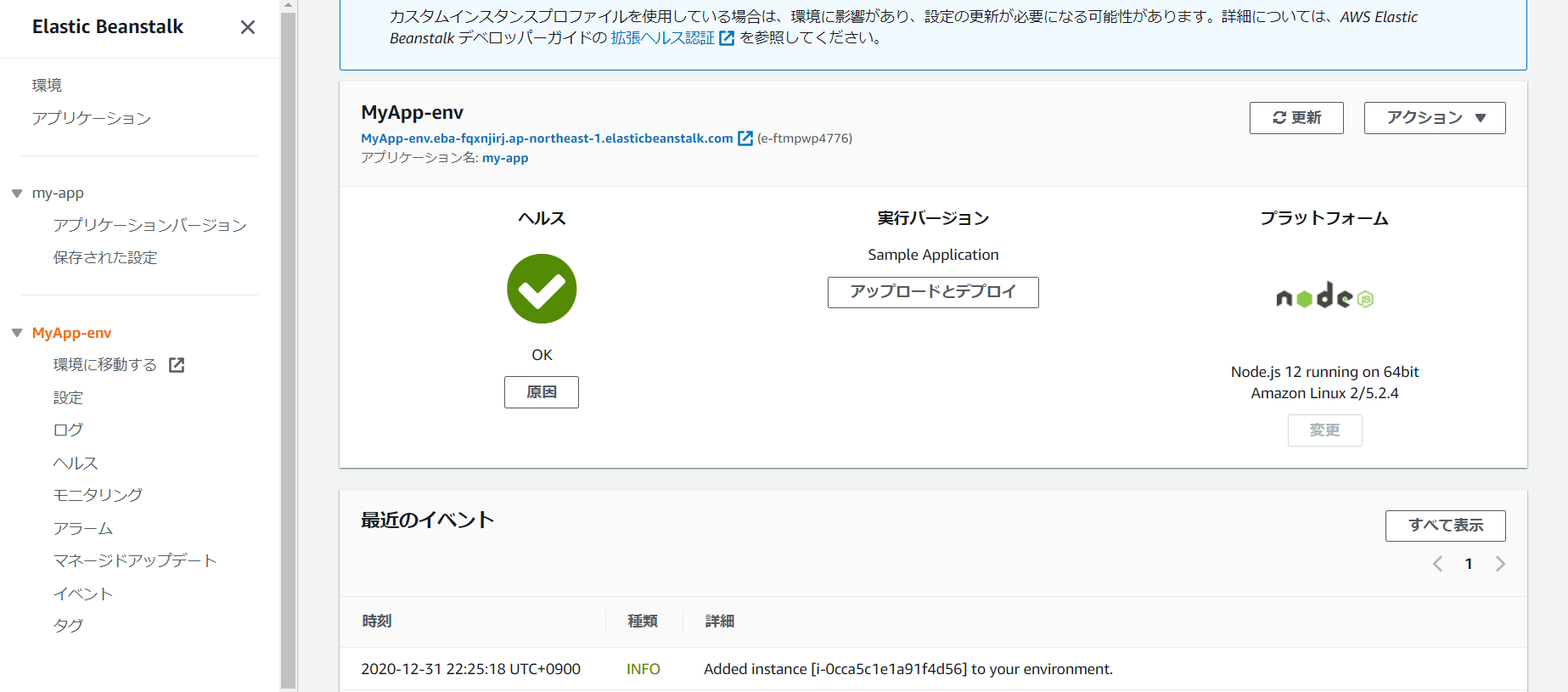
「環境の作成」を押下し、完了するまでしばし待ちます。
無事に作成が完了すると下記のような画面になります。
EC2に行ってみるとインスタンスも追加されています。
4.アプリをデプロイする
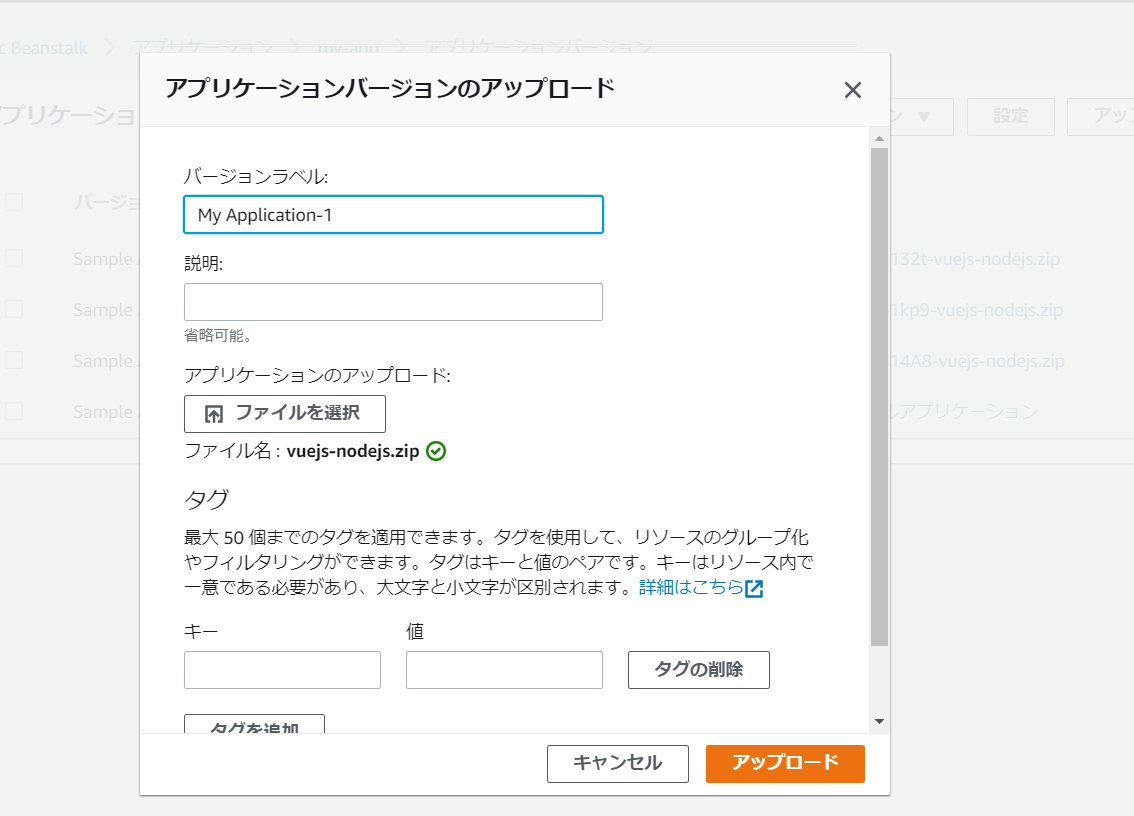
アプリケーションバージョン>アップロードで、glupでビルドした資材を選択して、アップロードを押下します。
アップロードした資材を選択して「デプロイ」を押下すると、環境の変更が開始されます。
アプリは履歴になっているので前のバージョンに戻ってデプロイすることも可能です。(便利!)
http://作成されたドメイン/でアクセスすると、アプリがデプロイできていることを確認できます。
AWS Elastic Beanstalkを利用したインフラ構築+デプロイは以上です。
あとがき
フロント側の仕事が増えたので、今回画面も作ってみました。AWS Elastic Beanstalkを利用すればインフラ気にしないでアプリのデプロイが可能なので手っ取り早いです。オートスケールとかLB、ドメインも自動設定されるので便利だと思いました。IP制限とかすれば、開発用の環境としても使い勝手良さそうです。
3日目は@usankusaiさんです!引き続きよろしくお願いします!
リンク情報システム株式会社では一緒に働く仲間を随時募集しています!
また、お仕事のご依頼、ビジネスパートナー様も募集しております。お気軽にご連絡ください。
Facebookはこちら。



- 投稿日:2021-01-05T02:19:34+09:00
AWS Session Manager SSH接続時に俺の考えた最高の名前でつなぐためのメモ
俺です。
AWS EC2使うにあたって踏み台潰さないと2021年はじめられないけどインスタンスIDで接続するの辛いなあと思ったのでメモを残します。~/.ssh/config
Host 最高-prod-app Hostname i-0123456789ABCDEF Host 最高-prod-* User ec2-user IdentityFile ~/.ssh/saikou.pem ProxyCommand sh -c "aws ssm start-session --target %h --document-name AWS-StartSSHSession --parameters 'portNumber=%p'"いざssh
❯ ssh 最高-prod-app __| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ [ec2-user@ip-XX-XX-XX-XX ~]$最高。