- 投稿日:2020-12-01T23:49:03+09:00
PythonでQRコード読み取りをしてみる。 第一章・ただ読み取るだけ
はじめに
今やQRコードって色々なところで使われていると思います。
電子決済や、最近だと大阪府がコロナウィルスの追跡でもQRコードを利用しています。
こんなにQRコードが普及しているのだから、PythonでもQRコードを利用できないかと調べた所・・・
ありました。もう何でも出来るなPythonって経緯
経緯と書いて"いきさつ"と読む。かっこいいね。
実は身内の会社は未だに紙で出退勤登録をしているそうなので、以前不要になったPCとPythonを利用して出退勤登録をするシステムを作成しました。
ところが!最近のスマートフォンにはNFC装備がないものがあるらしく、新人さんのスマートフォンにはなんとNFCが搭載されていないとの連絡が来ました。
そこで社員全員に振り当てているID等のデータをQRにして出退勤登録できないかという話が出てきました。
と、言うわけで急遽プログラムをアップグレードすることに。
第一章である今回は、QRコードを読み取れるまでがゴールとしていきます。QRを作りたい
とはいっても既存のプログラムなんかとある程度の整合性を取るために、決められたデータのフォーマットのQRを生成するプログラムを作りたいよねってことで・・・
作りました。
私の十八番「Tkinter」を用いて簡単なQRコード作成ツールを用意しました。
ソースコードはこちら↓import sys import tkinter as tk import qrcode from PIL import Image def connect(): name = inputbox.get() empid = inbox.get() other = ibox.get() makeqr = qrcode.QRCode(box_size=3) makeqr.add_data(name+","+empid+","+other) makeqr.make() qr_makeimage = makeqr.make_image() qr_makeimage.save('qr'+name+empid+".png") root = tk.Tk() root.title('QRコード生成 NewCommer For Release Observer') root.geometry('600x400') maintext = tk.Label(text='名前・社員ID・備考を入力してください。') maintext.pack(anchor='center', expand=1) inputtext = tk.Label(text='名前') inputtext.pack(anchor='center', expand=1) inputbox = tk.Entry() inputbox.pack() inboxtext = tk.Label(text='社員ID') inboxtext.pack(anchor='center', expand=1) inbox = tk.Entry() inbox.pack() iboxtext = tk.Label(text='備考') iboxtext.pack(anchor='center', expand=1) ibox = tk.Entry() ibox.pack() enterbutton = tk.Button(text='生成', command=connect) enterbutton.pack(anchor='center',expand=1) root.mainloop()やっていることはとっても簡単。
テキストボックスの値を取得・カンマ区切りで連結しているだけ。
その連結した物をQR化して.pngファイルで出力しているだけ。
今回はセキュリティーデータを持ち運んでいるわけではないので、この程度でいいかなって感じです。
どうしてカンマ区切りにしたかというと、後々リストとして取得したいためです。読み取り
QRの読み取りは相当難しかったです。
はじめ自分でイチから組み立ててみたのですが、Pythonがクラッシュしてしまいシステムが停止します。
原因はわかりませんでしたが、こちらのサイト様を参考にしてコードを改良しました。from pyzbar.pyzbar import decode import cv2 from pygame import mixer systemonly = "" cap = cv2.VideoCapture(0) while cap.isOpened(): system,frame = cap.read() if system == True: dec = decode(frame) if dec: for qr in dec: x,y,w,h = qr.rect cv2.rectangle(frame,(x,y),(x+w,y+h),(0,255,0),2) commer = qr.data.decode('utf-8') if(systemonly != commer): mixer.init() qrlist = commer.split(",") mixer.music.load("sound/recognized.mp3") mixer.music.play(1) systemonly = commer print(qrlist[0]+"registrate completed.") cv2.imshow('Release Observer QRCode Recognize System',frame) if cv2.waitKey(1) & 0xFF == ord('q'): break cap.release()個人的な予想では、これと同時に動作させていたTkinterが悪さをしてそうでした。
今回は参考元サイト様を参考に「枠付け」を行いました。
参考元サイト様では認識枠の上に文字列を表示していましたが、日本語の文字化けが発生すること・単なる出退勤情報の登録だけということで、今回は行いませんでした。systemonly変数は、この読み取りシステムだとコンソール画面に認識している間無限にメッセージが表示されてしまうので、「1度読み取ったら変数に入れて表示を禁止する」コードにしました。
cv2.VideoCaptureは0番が内蔵カム・1番が確か外部カムだった気がします。
後は恐らく説明不要だと思います。
pygameは「読み取りが完了したら音を鳴らす」仕様にしたかったので採用しました。フリー音源を利用しています。
それで今回はまだ「読み取ること」が目標なので、データベースへの登録は行っていません。
その代わり、認識されたことがはっきりと分かるようにコンソール画面に「社員名 registrate completed.」を表示するようにしています。
本番環境でもこのシステムは残そうかと思っています。そして実際の動作がこちら↓
https://www.youtube.com/watch?v=PSU53UyISLs&feature=youtu.be
いいですねぇ。読み取れてます。次回予...告?
次回は実際にこのデータをデータベース登録ができるようにしていきたいと思います。
Pythonからのデータベースの操作は以前行ったことがあるので、非常にスムーズに事が運ぶ・・・と思いたい。

- 投稿日:2020-12-01T23:31:06+09:00
【Python】WebスクレイピングでYahoo!ニュースのコメントを取得する
はじめに
Yahoo!ニュースのコメントをたまに見るのですが、見ても5ページくらいですね。
返信コメントがあってもクリックしないと見れないので、見逃してしまうことがあります。この前、「【Python】Youtube Data Apiを使ってコメントを全取得する」を書いたのですが、
それならと今度はYahoo!ニュースのコメントも一括取得に挑戦しようと考えました。調査
Yahoo!ニュースのコメントの取得については、Youtube Data Apiのような提供しているAPIがありませんでした。
そこでネットで検索してみると下記の2記事を見つけました。どうやらWebスクレイピングするしかコメント取得の方法はないようです。
環境
今回は誰でも手軽にコメント取得が出来ればいいなと思って、Googleアカウントさえあれば直ぐに使える「Google Colaboratory」を使ってやりたかったので、プログラム言語としてはPythonにしたかった。
Webスクレイピング方法
PhantomJSブラウザの開発が中断しているため、下記を参考にSeleniumにてGoogle Chromeをヘッドレスモードを使用します。
静岡のGoToEat公式サイトをスクレイピング、伊豆のキャンペーン対象店をリスト化するPythonのスクレイピングライブラリに「Beautifulsoup4」がありますが、これだとJavaScriptの実行ができません。
返信のコメントを取得するには返信ボタンをクリックしてコメントデータを取得することになるので、JavaScriptの実行ができる「Selenium」を使用します。環境準備
Google Colaboratory にて、Selenium と ChromeDriver をインストールします。
下記を実行すれば動かせます。ただし、90分と12時間ルールで初期化されるので、その際にはインストールし直します。!apt-get update !apt install chromium-chromedriver !cp /usr/lib/chromium-browser/chromedriver /usr/bin !pip install seleniumGoogle Colaboratoryでは以下の条件を満たす場合、実行中のプログラムがあってもインスタンスの状態がすべてリセットされていまいます。
* 【12時間ルール】新しいインスタンスを起動してから12時間経過
* 【90分ルール】ノートブックのセッションが切れてから90分経過【簡単】GoogleColabの制限とは?90分と12時間ルール
Yahoo!ニュースのコメント仕様
Yahoo!ニュースは1ページに10件のコメントが表示されます。1ページ目に認証されたユーザーのコメントがあった場合はその分だけ多くなります。
「返信」ボタンの横に0以外の数値があれば、「返信」ボタンをクリックするとコメントが10件取得されて表示されます。10件以上あれば「もっと見る」のリンクが付き、それをクリックすれば次のコメントが10件単位で取得され表示されます。認証されたユーザーがコメントした場合、「返信」ボタンではなく「参考になった」ボタンが表示されます。この場合には返信はできません。
掲載期間
Yahoo!ニュースに掲載されている記事の掲載期間は、情報提供元により異なります。掲載期間を過ぎると、記事は削除されて読めなくなります。
トピックス一覧では、ニュース編集部がピックアップした話題を確認できますが、掲載開始から1週間以上経過したトピックスは読めません。また、掲載から1週間以内であっても、情報提供元により記事詳細を表示できない場合もあります。
記事の掲載期間 - Yahoo! JAPANヘルプセンター記事の掲載期間が終了した場合、コメントも削除されます。
仕様
タブ区切りでコメントの改行は半角空白に置換しています。
親連番は4桁、子の連番は3桁にしているので桁数を超えるコメントを取得したい場合は表示する桁数を変更増やすといいでしょう。000X (コメント) (グッド数/参考になった数) (バッド数) (ユーザー名) (日時) (返信数) 000X-00X (子コメント) (グッド数) (バッド数) (ユーザー名) (日時)使用方法
Google Colaboratoryを開いて上記サイトの「getYahooNewsComments.py」をコピペで貼り付け、指定URLを書き換えて実行します。
環境準備のところに記載しましたが、使用前にSelenium と ChromeDriver をインストールしてください。指定URL
「漫画家の水島新司さんが引退表明 野球漫画「ドカベン」など」の場合、アドレスバーのURLを指定します。
URL = "https://news.yahoo.co.jp/articles/c3fe0c9976b8a84b89ffa07bbd27890f944369fc/comments?order=recommended"ページ番号の「&page=2」の部分は、プログラムで付け加えているので外してセットしてください。
ページ範囲
プログラム上では開始(start)1ページ〜終了(end)2ページとしています。当然、終了ページを増やせば取得できます。
返信ボタンやもっと見るリンクをクリックする際に2秒待機していますので、ページ数を増やせば多少は時間がかかります。start = 1 end = 2プログラム
getYahooNewsComments.pyimport time from selenium import webdriver from selenium.webdriver.chrome.options import Options # ブラウザをバックグラウンド実行 options = webdriver.ChromeOptions() options.add_argument('--headless') options.add_argument('--no-sandbox') options.add_argument('--disable-dev-shm-usage') # ブラウザ起動 driver = webdriver.Chrome('chromedriver',options=options) URL = 'URLを入力' # 対象要素のテキスト取得 def getItem(element, name, name2): result = "" elem = element.find_elements_by_class_name(name) if len(elem) > 0: if name2 == "": result = elem[0].text.strip() else: result = elem[0].find_element_by_class_name(name2).text.strip() return result; # 認証者コメント出力 def print_authorComment(no): comment_boxes = driver.find_elements_by_css_selector('li[id^="authorcomment-"]') for comment_box in comment_boxes: #コメント取得 elem_comment = comment_box.find_element_by_class_name("comment") comment = elem_comment.text.strip().rstrip('...もっと見る') comment += comment_box.find_element_by_class_name("hideAthrCmtText").get_attribute("textContent") #ユーザー名取得 name = getItem(comment_box, "rapidnofollow", "") #日付取得 date = getItem(comment_box, "date", "") #参考になった数取得 refcnt = comment_box.find_elements_by_css_selector('li.reference a em')[0].text no += 1 print('{:0=4}\t{}\t{}\t{}\t{}\t{}\t{}'.format(no,comment.replace('\n', ' '), refcnt, "0", name, date, "0")) return no # 一般者コメント出力 def print_generalComment(no): comment_boxes = driver.find_elements_by_css_selector('li[id^="comment-"]') for comment_box in comment_boxes: #コメント取得 comment = getItem(comment_box, "cmtBody", "") #ユーザー名取得 name = getItem(comment_box, "rapidnofollow", "") #日付取得 date = getItem(comment_box, "date", "") #good数取得 agree = getItem(comment_box, "good", "userNum") #bad数取得 disagree = getItem(comment_box, "bad", "userNum") #返信数 reply = int(getItem(comment_box, "reply", "num") or "0") no += 1 print('{:0=4}\t{}\t{}\t{}\t{}\t{}\t{}'.format(no, comment.replace('\n', ' '), agree, disagree, name, date, reply)) if reply == 0: continue #返信出力 print_reply(comment_box, reply, no) return no # 返信コメント出力 def print_reply(element, reply, no): # 「返信」 リンクを click rep_links = element.find_elements_by_css_selector('a.btnView.expandBtn') for rep_link in rep_links: rep_link.click() time.sleep(2) # 「もっと見る」 リンクを click response_boxes = element.find_elements_by_class_name("response") for i in range(int(reply/10)): if len(response_boxes) > 0 and (reply % 10) > 0: rep_links = response_boxes[0].find_elements_by_css_selector('a.moreReplyCommentList') for rep_link in rep_links: rep_link.click() time.sleep(2) # 返信コメント 取り出し replys = response_boxes[0].find_elements_by_css_selector('li[id^="reply-"]') cno = 1 for reply in replys: cmtBodies = reply.find_elements_by_css_selector('div.action article p span.cmtBody') if len(cmtBodies) == 0: continue #コメント取得 comment = cmtBodies[0].text.strip() #ユーザー名取得 name = getItem(reply, "rapidnofollow", "") #日付取得 date = getItem(reply, "date", "") #good数取得 agree = getItem(reply, "good", "userNum") #bad数取得 disagree = getItem(reply, "bad", "userNum") print('{:0=4}-{:0=3}\t{}\t{}\t{}\t{}\t{}'.format(no, cno, comment.replace('\n', ' '), agree, disagree, name, date)) cno += 1 # コメント取り出し start = 1 end = 2 no = 0 for page in range(start, end + 1): driver.get(URL + "&page={}".format(page)) iframe = driver.find_element_by_class_name("news-comment-plguin-iframe") driver.switch_to.frame(iframe) #認証者コメント if page == 1: no = print_authorComment(no) #一般者コメント no = print_generalComment(no)プログラムの説明
Pythonは、たまに記述しないのでプログラム的にはベタに書いています。その方が他の言語に移植しやすいかな。
返信コメントは「もっと見る」がなくなるまでクリックしてから、一気にコメントを取得しています。
改行を半角スペースに置換してるので読みやすさは特に考慮してません、Excelに貼り付けて折り返して見ればいい。「...もっと見る」の後のテキストがあるのに属性が「display:none」になっていることで取得できなくて困っていたのですが、下記サイトの方法で解決できました。ありがとうございます。
Seleniumでタグに囲まれた文字列を.textで取得すると空文字が返ってくる#コメント取得 elem_comment = comment_box.find_element_by_class_name("comment") comment = elem_comment.text.strip().rstrip('...もっと見る') comment += comment_box.find_element_by_class_name("hideAthrCmtText").get_attribute("textContent")実行結果
「漫画家の水島新司さんが引退表明 野球漫画「ドカベン」など」のYahoo!ニュースのコメントを取得すると、下記のようになります。
コメント取得例0001 10年近く前、・・・ます。 4792 0 菊地高弘 11時間前 0 0002 いつかは・・・言えるでしょう。 2938 0 河村鳴紘 11時間前 0 0003 10年ほど前、・・・あります。 1282 0 阿佐智 10時間前 0 0004 ユニークな・・・お疲れ様でした。 5978 649 dck***** 12時間前 61 0004-001 YahooTOP記事・・・お過ごしください。 101 0 p******* 12時間前 0004-002 水島先生・・・思います。 63 0 gtj***** 11時間前最後に
Advent Calendarが始まりました。今年も「Visual Basic Advent Calendar 2020」を記事を募集しています。
これでPythonではなく Visual BasicやExcelでやってみるなどのネタができそうです。
- 投稿日:2020-12-01T23:17:42+09:00
画像処理100本ノック!!(031 - 040)まだまだここから
1. はじめに
画像の前処理の技術力向上のためにこちらを実践 画像処理100本ノック!!
とっかかりやすいようにColaboratoryでやります。
目標は2週間で完了できるようにやっていきます。丁寧に解説します。質問バシバシください!
001 - 010 は右のリンク 画像処理100本ノック!!(001 - 010)丁寧にじっくりと
011 - 020 は右のリンク 画像処理100本ノック!!(011 - 020)序盤戦
021 - 030 は右のリンク 画像処理100本ノック!!(021 - 030)一息入れたい・・・2. 前準備
ライブラリ等々を以下のように導入。
# ライブラリをインポート from google.colab import drive import numpy as np import matplotlib.pyplot as plt import cv2 from google.colab.patches import cv2_imshow # 画像の読み込み img = cv2.imread('画像のパス/imori.jpg') img_noise = cv2.imread('画像のパス/imori_noise.jpg') img_dark = cv2.imread('画像のパス/imori_dark.jpg') img_gamma = cv2.imread('画像のパス/imori_gamma.jpg') # グレースケール画像 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) gray_noise = cv2.cvtColor(img_noise, cv2.COLOR_BGR2GRAY) gray_dark = cv2.cvtColor(img_dark, cv2.COLOR_BGR2GRAY) # 画像保存用 OUT_DIR = '出力先のパス/OUTPUT/'3.解説
Q.31. アフィン変換(スキュー)
1)アフィン変換を用いて、出力(1)のようなX-sharing(dx = 30)画像を作成せよ。
(2)アフィン変換を用いて、出力2のようなY-sharing(dy = 30)画像を作成せよ。
(3)アフィン変換を用いて、出力3のような幾何変換した(dx = 30, dy = 30)画像を作成せよ。
このような画像はスキュー画像と呼ばれ、画像を斜め方向に伸ばした画像である。
出力(1)の場合、x方向にdxだけ引き伸ばした画像はX-sharingと呼ばれる。
出力(2)の場合、y方向にdyだけ引き伸ばした画像はY-sharingと呼ばれる。
それぞれ次式のアフィン変換で実現できる。 ただし、元画像のサイズがh x wとする。A31def affine_skew(img, dx, dy): """ params ------------------------------ param1: numpy.ndarray形式のimage param2: x軸方向のスキュー param2: y軸方向のスキュー returns ------------------------------ numpy.ndarray形式のimage """ # 画像の高さ、幅、色を取得 H, W = img.shape[:2] # xy座標をnp.float32型(3点分のxy座標) src = np.array([[0.0, 0.0],[0.0, 1.0],[1.0, 0.0]], np.float32) dest = src.copy() # 変換後の3点の座標 dest[:,0] += (dx / W * (src[:,1])).astype(np.float32) dest[:,1] += (dy / H * (src[:,0])).astype(np.float32) """ アフィン変換の変換行列を生成: cv2.getAffineTransform(src, dest) src: 変換前の3点の座標 dest: 変換後の3点の座標をNumPy配列ndarrayで指定 """ affine = cv2.getAffineTransform(src, dest) """ アフィン変換 cv2.warpAffine(src, M, dsize[, dst[, flags[, borderMode[, borderValue]]]]) 第一引数に元画像(NumPy配列ndarray)、 第二引数に2 x 3の変換行列(NumPy配列ndarray)、 第三引数に出力画像のサイズ(タプル)を指定する。 """ return cv2.warpAffine(img, affine, (W+dx, H+dy)) # X-sharing(dx = 30)画像 out1 = affine_skew(img, 30, 0) # Y-sharing(dy = 30)画像 out2 = affine_skew(img, 0, 30) # 幾何変換した(dx = 30, dy = 30)画像 out3 = affine_skew(img, 30, 30) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans31_1.jpg', out1) cv2.imwrite(OUT_DIR + 'ans31_2.jpg', out2) cv2.imwrite(OUT_DIR + 'ans31_3.jpg', out3) # 画像を表示 cv2_imshow(out1) cv2_imshow(out2) cv2_imshow(out3) cv2.waitKey(0) cv2.destroyAllWindows()座標の変換イメージは下記参照


参考: 完全に理解するアフィン変換
Q.32. フーリエ変換
二次元離散フーリエ変換(DFT)を実装し、imori.jpgをグレースケール化したものの周波数のパワースペクトルを表示せよ。 また、逆二次元離散フーリエ変換(IDFT)で画像を復元せよ。
二次元離散フーリエ変換(DFT: Discrete Fourier Transformation)とはフーリエ変換の画像に対する処理方法である。
通常のフーリエ変換はアナログ信号や音声などの連続値かつ一次元を対象に周波数成分を求める計算処理である。
一方、ディジタル画像は[0,255]の離散値をとり、かつ画像はHxWの二次元表示であるので、二次元離散フーリエ変換が行われる。
二次元離散フーリエ変換(DFT)は次式で計算される。
K = [0, W-1], l = [0, H-1], 入力画像を I として
ここでは画像をグレースケール化してから二次元離散フーリエ変換を行え。
パワースペクトルとは Gは複素数で表されるので、Gの絶対値を求めることである。 今回のみ画像表示の時はパワースペクトルは[0,255]にスケーリングせよ。
逆二次元離散フーリエ変換(IDFT: Inverse DFT)とは周波数成分Gから元の画像を復元する手法であり、次式で定義される。
x = [0, W-1], y = [0, H-1] として
上が定義式ですがexp(j)は複素数の値をとってしまうので、実際にコードにするときはぜ下式のように絶対値を使います
シンプルに全部for文で回すと128^4の計算になるので、時間がかかってしまいます。numpyをうまく活用すれば計算コストを減らすことができます。(解答は128^2まで減らしました。)
A32# 2次元離散フーリエ変換 (DFT)のハイパーパラメーター K, L = 128, 128 channel = 3 def dft(img): """ 2次元離散フーリエ変換 (DFT) params -------------------------------------- param: numpy.ndarray形式のimage returns ------------------------------ 周波数成分G """ # 画像の高さ、幅を取得 H, W = img.shape[:2] # DFT係数(np.complex: 複素数を扱うための型) G = np.zeros((L, K, channel), dtype=np.complex) # 元のイメージと一致(NumPy配列ndarrayをタイル状に繰り返し並べるnp.tile) x = np.tile(np.arange(W), (H, 1)) # >>> [0 1 2 ・・・・ 125 126 127] y = np.arange(H).repeat(W).reshape(H, -1) # >>> [0 0 0 0]・・・・[127 127 127・・・] # DFTの計算(周波数成分G) for c in range(channel): for l in range(L): for k in range(K): G[l, k, c] = np.sum(img[..., c] * np.exp(-2j * np.pi * (x * k / K + y * l / L))) / np.sqrt(K * L) return G # IDFT(逆二次元離散フーリエ変換) def idft(G): """ 逆二次元離散フーリエ変換 (IDFT) params -------------------------------------- param: 周波数成分G returns ------------------------------ numpy.ndarray形式のimage """ # 画像の高さ、幅を取得 H, W = G.shape[:2] # DFT係数(np.complex: 複素数を扱うための型) out = np.zeros((H, W, channel), dtype=np.float32) # 元のイメージと一致(NumPy配列ndarrayをタイル状に繰り返し並べるnp.tile) x = np.tile(np.arange(W), (H, 1)) y = np.arange(H).repeat(W).reshape(H, -1) # IDFT(逆二次元離散フーリエ変換) for c in range(channel): for l in range(H): for k in range(W): out[l, k, c] = np.abs(np.sum(G[..., c] * np.exp(2j * np.pi * (x * k / W + y * l / H)))) / np.sqrt(W * H) # clipping(NumPy配列ndarrayを任意の最小値・最大値に収めるclip) # 0 ~ 255の範囲 out = np.clip(out, 0, 255) out = out.astype(np.uint8) return out # 2次元離散フーリエ変換 G = dft(img) # 周波数のパワースペクトル ps = (np.abs(G) / np.abs(G).max() * 255).astype(np.uint8) cv2.imwrite("out_ps.jpg", ps) # 逆二次元離散フーリエ変換 out = idft(G) # 保存 cv2_imshow(out) cv2.waitKey(0) cv2.imwrite("img32.jpg", out)
OpenCVがカラーでできないのが残念参考: 【Python/OpenCV】高速フーリエ変換でパワースペクトルの算出
参考: フーリエ変換Q.33. フーリエ変換 ローパスフィルタ
imori.jpgをグレースケール化したものをDFTし、ローパスフィルタを通してIDFTで画像を復元せよ。
DFTによって得られた周波数成分は左上、右上、左下、右下に近いほど低周波数の成分を含んでいることになり、中心に近いほど高周波成分を示す。
画像における高周波成分とは色が変わっている部分(ノイズや輪郭など)を示し、低周波成分とは色があまり変わっていない部分(夕日のグラデーションなど)を表す。 ここでは、高周波成分をカットし、低周波成分のみを通すローパスフィルタを実装せよ。ここでは低周波数の中心から高周波までの距離をrとすると0.5rまでの成分を通すとする。A33# 2次元離散フーリエ変換 (DFT)のハイパーパラメーター K, L = 128, 128 channel = 3 def dft(img): """ 2次元離散フーリエ変換 (DFT) params -------------------------------------- param: numpy.ndarray形式のimage returns ------------------------------ 周波数成分G """ # 画像の高さ、幅を取得 H, W = img.shape[:2] # DFT係数(np.complex: 複素数を扱うための型) G = np.zeros((L, K, channel), dtype=np.complex) # 元のイメージと一致(NumPy配列ndarrayをタイル状に繰り返し並べるnp.tile) x = np.tile(np.arange(W), (H, 1)) # >>> [0 1 2 ・・・・ 125 126 127] y = np.arange(H).repeat(W).reshape(H, -1) # >>> [0 0 0 0]・・・・[127 127 127・・・] # DFTの計算(周波数成分G) for c in range(channel): for l in range(L): for k in range(K): G[l, k, c] = np.sum(img[..., c] * np.exp(-2j * np.pi * (x * k / K + y * l / L))) / np.sqrt(K * L) return G # IDFT(逆二次元離散フーリエ変換) def idft(G): """ 逆二次元離散フーリエ変換 (IDFT) params -------------------------------------- param: 周波数成分G returns ------------------------------ numpy.ndarray形式のimage """ # 画像の高さ、幅を取得 H, W = G.shape[:2] # DFT係数(np.complex: 複素数を扱うための型) out = np.zeros((H, W, channel), dtype=np.float32) # 元のイメージと一致(NumPy配列ndarrayをタイル状に繰り返し並べるnp.tile) x = np.tile(np.arange(W), (H, 1)) y = np.arange(H).repeat(W).reshape(H, -1) # IDFT(逆二次元離散フーリエ変換) for c in range(channel): for l in range(H): for k in range(W): out[l, k, c] = np.abs(np.sum(G[..., c] * np.exp(2j * np.pi * (x * k / W + y * l / H)))) / np.sqrt(W * H) # clipping(NumPy配列ndarrayを任意の最小値・最大値に収めるclip) # 0 ~ 255の範囲 out = np.clip(out, 0, 255) out = out.astype(np.uint8) return out def lpf(G, ratio=0.5): """ ローパスフィルタ: 信号の低周波数成分のみを通過 params -------------------------------------- param1: 周波数成分G param2: 割合 returns ------------------------------ 周波数成分G """ # 画像の高さ、幅を取得 H, W = G.shape[:2] # 元の配列と同じ形状の配列を生成 _G = np.zeros_like(G) # 第1象限と第3象限、第1象限と第4象限を入れ替え _G[:H//2, :W//2] = G[H//2:, W//2:] _G[:H//2, W//2:] = G[H//2:, :W//2] _G[H//2:, :W//2] = G[:H//2, W//2:] _G[H//2:, W//2:] = G[:H//2, :W//2] # fsrc = np.fft.fftshift(src) # 元のイメージと一致(NumPy配列ndarrayをタイル状に繰り返し並べるnp.tile) x = np.tile(np.arange(W), (H, 1)) y = np.arange(H).repeat(W).reshape(H, -1) # フィルターの作成 _x = x - W // 2 _y = y - H // 2 r = np.sqrt(_x ** 2 + _y ** 2) # マスクの作成 mask = np.ones((H, W), dtype=np.float32) mask[r > (W // 2 * ratio)] = 0 mask = np.repeat(mask, channel).reshape(H, W, channel) # フィルタリング _G *= mask # 入れ替え G[:H//2, :W//2] = _G[H//2:, W//2:] G[:H//2, W//2:] = _G[H//2:, :W//2] G[H//2:, :W//2] = _G[:H//2, W//2:] G[H//2:, W//2:] = _G[:H//2, :W//2] return G H, W, C = img.shape # 2次元離散フーリエ変換 G = dft(img) # ローパスフィルタ G = lpf(G) # 逆二次元離散フーリエ変換 out = idft(G) # 保存 cv2_imshow(out) cv2.waitKey(0) cv2.imwrite("img33.jpg", out)
参考: 【Python/OpenCV】フーリエ変換+ローパスフィルタでノイズ除去
Q.34. フーリエ変換 ハイパスフィルタ
imori.jpgをグレースケール化したものをDFTし、ハイパスフィルタを通してIDFTで画像を復元せよ。
ここでは、低周波成分をカットし、高周波成分のみを通すハイパスフィルタを実装せよ。
ここでは低周波数の中心から高周波までの距離をrとすると0.1rからの成分を通すとする。A34# 2次元離散フーリエ変換 (DFT)のハイパーパラメーター K, L = 128, 128 channel = 3 def dft(img): """ 2次元離散フーリエ変換 (DFT) params -------------------------------------- param: numpy.ndarray形式のimage returns ------------------------------ 周波数成分G """ # 画像の高さ、幅を取得 H, W = img.shape[:2] # DFT係数(np.complex: 複素数を扱うための型) G = np.zeros((L, K, channel), dtype=np.complex) # 元のイメージと一致(NumPy配列ndarrayをタイル状に繰り返し並べるnp.tile) x = np.tile(np.arange(W), (H, 1)) # >>> [0 1 2 ・・・・ 125 126 127] y = np.arange(H).repeat(W).reshape(H, -1) # >>> [0 0 0 0]・・・・[127 127 127・・・] # DFTの計算(周波数成分G) for c in range(channel): for l in range(L): for k in range(K): G[l, k, c] = np.sum(img[..., c] * np.exp(-2j * np.pi * (x * k / K + y * l / L))) / np.sqrt(K * L) return G # IDFT(逆二次元離散フーリエ変換) def idft(G): """ 逆二次元離散フーリエ変換 (IDFT) params -------------------------------------- param: 周波数成分G returns ------------------------------ numpy.ndarray形式のimage """ # 画像の高さ、幅を取得 H, W = G.shape[:2] # DFT係数(np.complex: 複素数を扱うための型) out = np.zeros((H, W, channel), dtype=np.float32) # 元のイメージと一致(NumPy配列ndarrayをタイル状に繰り返し並べるnp.tile) x = np.tile(np.arange(W), (H, 1)) y = np.arange(H).repeat(W).reshape(H, -1) # IDFT(逆二次元離散フーリエ変換) for c in range(channel): for l in range(H): for k in range(W): out[l, k, c] = np.abs(np.sum(G[..., c] * np.exp(2j * np.pi * (x * k / W + y * l / H)))) / np.sqrt(W * H) # clipping(NumPy配列ndarrayを任意の最小値・最大値に収めるclip) # 0 ~ 255の範囲 out = np.clip(out, 0, 255) out = out.astype(np.uint8) return out def hpf(G, ratio=0.1): """ ハイパスフィルタは、信号の高周波数成分のみを通過させる。 params -------------------------------------- param: 周波数成分G returns ------------------------------ 周波数成分G """ H, W = G.shape[:2] # 第1象限と第3象限、第1象限と第4象限を入れ替え _G = np.zeros_like(G) _G[:H//2, :W//2] = G[H//2:, W//2:] _G[:H//2, W//2:] = G[H//2:, :W//2] _G[H//2:, :W//2] = G[:H//2, W//2:] _G[H//2:, W//2:] = G[:H//2, :W//2] # 中心からの距離 x = np.tile(np.arange(W), (H, 1)) y = np.arange(H).repeat(W).reshape(H, -1) # フィルター作成 _x = x - W // 2 _y = y - H // 2 r = np.sqrt(_x ** 2 + _y ** 2) # マスクの作成 mask = np.ones((H, W), dtype=np.float32) mask[r < (W // 2 * ratio)] = 0 mask = np.repeat(mask, channel).reshape(H, W, channel) # フィルタリング _G *= mask # 入れ替え G[:H//2, :W//2] = _G[H//2:, W//2:] G[:H//2, W//2:] = _G[H//2:, :W//2] G[H//2:, :W//2] = _G[:H//2, W//2:] G[H//2:, W//2:] = _G[:H//2, :W//2] return G # DFT G = dft(img) # HPF G = hpf(G) # IDFT out = idft(G) # 画像表示 cv2_imshow(out) cv2.waitKey(0) cv2.imwrite("img34.jpg", out)
OpenCVでやろうとしたがうまくいかず、実行もかなり遅い。要改善。Q.35. フーリエ変換 バンドパスフィルタ
imori.jpgをグレースケール化したものをDFTし、ハイパスフィルタを通してIDFTで画像を復元せよ。
ここでは、低周波成分と高周波成分の中間の周波数成分のみを通すハイパスフィルタを実装せよ。
ここでは低周波数の中心から高周波までの距離をrとすると0.1rから0.5rまでの成分を通すとする。A35# 2次元離散フーリエ変換 (DFT)のハイパーパラメーター K, L = 128, 128 channel = 3 def dft(img): """ 2次元離散フーリエ変換 (DFT) params -------------------------------------- param: numpy.ndarray形式のimage returns ------------------------------ 周波数成分G """ # 画像の高さ、幅を取得 H, W = img.shape[:2] # DFT係数(np.complex: 複素数を扱うための型) G = np.zeros((L, K, channel), dtype=np.complex) # 元のイメージと一致(NumPy配列ndarrayをタイル状に繰り返し並べるnp.tile) x = np.tile(np.arange(W), (H, 1)) # >>> [0 1 2 ・・・・ 125 126 127] y = np.arange(H).repeat(W).reshape(H, -1) # >>> [0 0 0 0]・・・・[127 127 127・・・] # DFTの計算(周波数成分G) for c in range(channel): for l in range(L): for k in range(K): G[l, k, c] = np.sum(img[..., c] * np.exp(-2j * np.pi * (x * k / K + y * l / L))) / np.sqrt(K * L) return G # IDFT(逆二次元離散フーリエ変換) def idft(G): """ 逆二次元離散フーリエ変換 (IDFT) params -------------------------------------- param: 周波数成分G returns ------------------------------ numpy.ndarray形式のimage """ # 画像の高さ、幅を取得 H, W = G.shape[:2] # DFT係数(np.complex: 複素数を扱うための型) out = np.zeros((H, W, channel), dtype=np.float32) # 元のイメージと一致(NumPy配列ndarrayをタイル状に繰り返し並べるnp.tile) x = np.tile(np.arange(W), (H, 1)) y = np.arange(H).repeat(W).reshape(H, -1) # IDFT(逆二次元離散フーリエ変換) for c in range(channel): for l in range(H): for k in range(W): out[l, k, c] = np.abs(np.sum(G[..., c] * np.exp(2j * np.pi * (x * k / W + y * l / H)))) / np.sqrt(W * H) # clipping(NumPy配列ndarrayを任意の最小値・最大値に収めるclip) # 0 ~ 255の範囲 out = np.clip(out, 0, 255) out = out.astype(np.uint8) return out def bpf(G, ratio1=0.1, ratio2=0.5): """ バンドパスフィルタ: ある帯域のみを通したいときに使います params -------------------------------------- param1: 周波数成分G param2: 成分範囲 param3: 成分範囲 returns ------------------------------ 周波数成分G """ H, W, _ = G.shape # 第1象限と第3象限、第1象限と第4象限を入れ替え _G = np.zeros_like(G) _G[:H//2, :W//2] = G[H//2:, W//2:] _G[:H//2, W//2:] = G[H//2:, :W//2] _G[H//2:, :W//2] = G[:H//2, W//2:] _G[H//2:, W//2:] = G[:H//2, :W//2] # 中心からの距離 x = np.tile(np.arange(W), (H, 1)) y = np.arange(H).repeat(W).reshape(H, -1) # フィルター作成 _x = x - W // 2 _y = y - H // 2 r = np.sqrt(_x ** 2 + _y ** 2) # マスクの作成 mask = np.ones((H, W), dtype=np.float32) # 範囲を指定 mask[(r < (W // 2 * ratio1)) | (r > (W // 2 * ratio2))] = 0 mask = np.repeat(mask, channel).reshape(H, W, channel) # フィルタリング _G *= mask # 入れ替え G[:H//2, :W//2] = _G[H//2:, W//2:] G[:H//2, W//2:] = _G[H//2:, :W//2] G[H//2:, :W//2] = _G[:H//2, W//2:] G[H//2:, W//2:] = _G[:H//2, :W//2] return G # DFT G = dft(img) # BPF G = bpf(G) # IDFT out = idft(G) # 画像表示 cv2_imshow(out) cv2.waitKey(0) cv2.imwrite("img35.jpg", out)
参考: 画像処理におけるフーリエ変換④〜pythonによるフィルタ設計〜Q.36. JPEG圧縮 (Step.1)離散コサイン変換
imori.jpgをグレースケール化し離散コサイン変換を行い、逆離散コサイン変換を行え。
離散コサイン変換(DCT: Discrete Cosine Transformation)とは、次式で定義される周波数変換の一つである。
逆離散コサイン変換(IDCT: Inverse Discrete Cosine Transformation)とは離散コサイン変換の逆(復号)であり、次式で定義される。 ここでいう K は復元時にどれだけ解像度を良くするかを決定するパラメータである。 K = Tの時は、DCT係数を全部使うのでIDCT後の解像度は最大になるが、Kが1や2などの時は復元に使う情報量(DCT係数)が減るので解像度が下がる。これを適度に設定することで、画像の容量を減らすことができる。
ここでは画像を8x8ずつの領域に分割して、各領域で以上のDCT, IDCTを繰り返すことで、jpeg符号に応用される。 今回も同様に8x8の領域に分割して、DCT, IDCTを行え。A36# DCT hyoer-parameter T = 8 K = 8 # 復元時にどれだけ解像度を良くするかを決定するパラメータ channel = 3 # DCT weight def w(x, y, u, v): """ 離散コサイン変換(DCT: Discrete Cosine Transformation) の係数 params ------------------------------- returns ------------------------------- 係数 """ cu = 1. cv = 1. if u == 0: cu /= np.sqrt(2) if v == 0: cv /= np.sqrt(2) theta = np.pi / (2 * T) return (( 2 * cu * cv / T) * np.cos((2*x+1)*u*theta) * np.cos((2*y+1)*v*theta)) # DCT def dct(img): """ 離散コサイン変換(DCT: Discrete Cosine Transformation) params ----------------------------- img: numpy.ndarray形式のimage returns ----------------------------- 離散コサイン変換(DCT: Discrete Cosine Transformation) """ # 画像の高さ、幅を取得 H, W, _ = img.shape # 0を要素とする配列を生成する F = np.zeros((H, W, channel), dtype=np.float32) # rgbそれぞれのチャネル for c in range(channel): # 縦方向にT(8)の間隔 for yi in range(0, H, T): # 横方向にT(8)の間隔 for xi in range(0, W, T): for v in range(T): for u in range(T): for y in range(T): for x in range(T): # 各画素に対して離散コサイン変換 F[v+yi, u+xi, c] += img[y+yi, x+xi, c] * w(x,y,u,v) return F # IDCT def idct(F): """ 逆離散コサイン変換 params ----------------------------- F: 離散コサイン変換 returns ----------------------------- 逆離散コサイン変換 """ # 画像の高さ、幅を取得 H, W, _ = F.shape # 0を要素とする配列を生成する out = np.zeros((H, W, channel), dtype=np.float32) for c in range(channel): for yi in range(0, H, T): for xi in range(0, W, T): for y in range(T): for x in range(T): for v in range(K): for u in range(K): out[y+yi, x+xi, c] += F[v+yi, u+xi, c] * w(x,y,u,v) # clipping(NumPy配列ndarrayを任意の最小値・最大値に収めるclip) out = np.clip(out, 0, 255) out = np.round(out).astype(np.uint8) return out # DCT F = dct(img) # IDCT out = idct(F) # 画像表示 cv2_imshow(out) cv2.waitKey(0) cv2.imwrite("img36.jpg", out)参考: 「離散コサイン変換」4-7【4章 三角関数、数学大百科事典】
こちらに関しては説明が難しい・・・
Q.37. PSNR
IDCTで用いるDCT係数を8でなく、4にすると画像の劣化が生じる。 入力画像とIDCT画像のPSNRを求めよ。また、IDCTによるビットレートを求めよ。
PSNR(Peak Signal to Noise Ratio)とは信号対雑音比と呼ばれ、画像がどれだけ劣化したかを示す。
PSNRが大きいほど、画像が劣化していないことを示し、次式で定義される。 v_maxは取りうる値の最大値で[0,255]の表示なら v_max=255 となる。
式中のMSEはMean Squared Error(平均二乗誤差)と呼ばれ、二つの画像の差分の二乗の平均値を示す。
ビットレートとは8x8でDCTを行い、IDCTでKxKの係数までを用いた時に次式で定義される。
A37# DCT hyoer-parameter T = 8 K = 4 channel = 3 # DCT weight def w(x, y, u, v): """ 離散コサイン変換(DCT: Discrete Cosine Transformation) の係数 params ------------------------------- returns ------------------------------- 係数 """ cu = 1. cv = 1. if u == 0: cu /= np.sqrt(2) if v == 0: cv /= np.sqrt(2) theta = np.pi / (2 * T) return (( 2 * cu * cv / T) * np.cos((2*x+1)*u*theta) * np.cos((2*y+1)*v*theta)) # DCT def dct(img): """ 離散コサイン変換(DCT: Discrete Cosine Transformation) params ----------------------------- img: numpy.ndarray形式のimage returns ----------------------------- 離散コサイン変換(DCT: Discrete Cosine Transformation) """ # 画像の高さ、幅を取得 H, W, _ = img.shape # 0を要素とする配列を生成する F = np.zeros((H, W, channel), dtype=np.float32) # rgbそれぞれのチャネル for c in range(channel): # 縦方向にT(8)の間隔 for yi in range(0, H, T): # 横方向にT(8)の間隔 for xi in range(0, W, T): for v in range(T): for u in range(T): for y in range(T): for x in range(T): # 各画素に対して離散コサイン変換 F[v+yi, u+xi, c] += img[y+yi, x+xi, c] * w(x,y,u,v) return F # IDCT def idct(F): """ 逆離散コサイン変換 params ----------------------------- F: 離散コサイン変換 returns ----------------------------- 逆離散コサイン変換 """ # 画像の高さ、幅を取得 H, W, _ = F.shape # 0を要素とする配列を生成する out = np.zeros((H, W, channel), dtype=np.float32) for c in range(channel): for yi in range(0, H, T): for xi in range(0, W, T): for y in range(T): for x in range(T): for v in range(K): for u in range(K): out[y+yi, x+xi, c] += F[v+yi, u+xi, c] * w(x,y,u,v) # clipping(NumPy配列ndarrayを任意の最小値・最大値に収めるclip) out = np.clip(out, 0, 255) out = np.round(out).astype(np.uint8) return out # MSE def MSE(img1, img2): """ 平均二乗誤差 params ----------------------------- img1: numpy.ndarray形式のimage img2: numpy.ndarray形式のimage returns ----------------------------- 平均二乗誤差の値 class 'numpy.float64' """ # 画像の高さ、幅を取得 H, W, _ = img1.shape # 二つの画像の差分の二乗 mse = np.sum((img1 - img2) ** 2) / (H * W * channel) # 47.437601725260414 return mse # PSNR def PSNR(mse, vmax=255): """ 信号対雑音比: イメージ間のピーク S/N 比 (PSNR) の計算 params ------------------------------ mse: 平均二乗誤差の値 vmax: 値の最大値で[0,255] returns ------------------------------ 信号対雑音比 class 'numpy.float64' """ return 10 * np.log10(vmax * vmax / mse) # 31.369576363256535 # bitrate def BITRATE(): """ ビットレート class 'float' """ return 1. * T * K * K / T / T #2.0 # DCT F = dct(img) # IDCT out = idct(F) # MSE mse = MSE(img, out) # PSNR psnr = PSNR(mse) # bitrate bitrate = BITRATE() print("MSE:", type(mse)) print("PSNR:", type(psnr)) print("bitrate:", type(bitrate)) # 画像表示 cv2_imshow(out) cv2.waitKey(0) cv2.imwrite("img37.jpg", out)
参考: MathWorksQ.38. JPEG圧縮 (Step.2)DCT+量子化
DCT係数を量子化し、IDCTで復元せよ。また、その時の画像の容量を比べよ。
DCT係数を量子化することはjpeg画像にする符号化で用いられる手法である。
量子化とは、値を予め決定された区分毎に値を大まかに丸め込む作業であり、floorやceil, roundなどが似た計算である。
JPEG画像ではDCT係数を下記で表される量子化テーブルに則って量子化する。 この量子化テーブルはjpeg団体の仕様書から取った。 量子化では8x8の係数をQで割り、四捨五入する。その後Qを掛けることで行われる。 IDCTでは係数は全て用いるものとする。Q = np.array(((16, 11, 10, 16, 24, 40, 51, 61), (12, 12, 14, 19, 26, 58, 60, 55), (14, 13, 16, 24, 40, 57, 69, 56), (14, 17, 22, 29, 51, 87, 80, 62), (18, 22, 37, 56, 68, 109, 103, 77), (24, 35, 55, 64, 81, 104, 113, 92), (49, 64, 78, 87, 103, 121, 120, 101), (72, 92, 95, 98, 112, 100, 103, 99)), dtype=np.float32)量子化を行うと画像の容量が減っていることから、データ量が削減されたことが伺える。
A38# DCT hyoer-parameter T = 8 K = 4 channel = 3 # DCT weight def w(x, y, u, v): """ 離散コサイン変換(DCT: Discrete Cosine Transformation) の係数 params ------------------------------- returns ------------------------------- 係数 """ cu = 1. cv = 1. if u == 0: cu /= np.sqrt(2) if v == 0: cv /= np.sqrt(2) theta = np.pi / (2 * T) return (( 2 * cu * cv / T) * np.cos((2*x+1)*u*theta) * np.cos((2*y+1)*v*theta)) # DCT def dct(img): """ 離散コサイン変換(DCT: Discrete Cosine Transformation) params ----------------------------- img: numpy.ndarray形式のimage returns ----------------------------- 離散コサイン変換(DCT: Discrete Cosine Transformation) """ # 画像の高さ、幅を取得 H, W, _ = img.shape # 0を要素とする配列を生成する F = np.zeros((H, W, channel), dtype=np.float32) # rgbそれぞれのチャネル for c in range(channel): # 縦方向にT(8)の間隔 for yi in range(0, H, T): # 横方向にT(8)の間隔 for xi in range(0, W, T): for v in range(T): for u in range(T): for y in range(T): for x in range(T): # 各画素に対して離散コサイン変換 F[v+yi, u+xi, c] += img[y+yi, x+xi, c] * w(x,y,u,v) return F # IDCT def idct(F): """ 逆離散コサイン変換 params ----------------------------- F: 離散コサイン変換 returns ----------------------------- 逆離散コサイン変換 """ # 画像の高さ、幅を取得 H, W, _ = F.shape # 0を要素とする配列を生成する out = np.zeros((H, W, channel), dtype=np.float32) for c in range(channel): for yi in range(0, H, T): for xi in range(0, W, T): for y in range(T): for x in range(T): for v in range(K): for u in range(K): out[y+yi, x+xi, c] += F[v+yi, u+xi, c] * w(x,y,u,v) # clipping(NumPy配列ndarrayを任意の最小値・最大値に収めるclip) out = np.clip(out, 0, 255) out = np.round(out).astype(np.uint8) return out def quantization(F): """ DCT係数を量子化 params ------------------------------- F: DCT係数 returns ------------------------------- DCT係数を量子化 """ # 画像の高さ、幅を取得 H, W, _ = F.shape # 量子化では8x8の係数をQで割り、四捨五入 Q = np.array(((16, 11, 10, 16, 24, 40, 51, 61), (12, 12, 14, 19, 26, 58, 60, 55), (14, 13, 16, 24, 40, 57, 69, 56), (14, 17, 22, 29, 51, 87, 80, 62), (18, 22, 37, 56, 68, 109, 103, 77), (24, 35, 55, 64, 81, 104, 113, 92), (49, 64, 78, 87, 103, 121, 120, 101), (72, 92, 95, 98, 112, 100, 103, 99)), dtype=np.float32) for ys in range(0, H, T): for xs in range(0, W, T): for c in range(channel): F[ys: ys + T, xs: xs + T, c] = np.round(F[ys: ys + T, xs: xs + T, c] / Q) * Q return F def MSE(img1, img2): """ 平均二乗誤差 params ----------------------------- img1: numpy.ndarray形式のimage img2: numpy.ndarray形式のimage returns ----------------------------- 平均二乗誤差の値 class 'numpy.float64' """ # 画像の高さ、幅を取得 H, W, _ = img1.shape # 二つの画像の差分の二乗 mse = np.sum((img1 - img2) ** 2) / (H * W * channel) return mse # PSNR def PSNR(mse, vmax=255): """ 信号対雑音比: イメージ間のピーク S/N 比 (PSNR) の計算 params ------------------------------ mse: 平均二乗誤差の値 vmax: 値の最大値で[0,255] returns ------------------------------ 信号対雑音比 class 'numpy.float64' """ return 10 * np.log10(vmax * vmax / mse) def BITRATE(): """ ビットレート class 'float' """ return 1. * T * K * K / T / T # DCT F = dct(img) # quantization F = quantization(F) # IDCT out = idct(F) # MSE mse = MSE(img, out) # PSNR psnr = PSNR(mse) # bitrate bitrate = BITRATE() print("MSE:", mse) print("PSNR:", psnr) print("bitrate:", bitrate) # 画像表示 cv2_imshow(out) cv2.waitKey(0) cv2.imwrite("img38.jpg", out)
参考: 量子化行列のナゾ~その1Q.39. JPEG圧縮 (Step.3)YCbCr表色系
YCbCr表色形において、Yを0.7倍してコントラストを暗くせよ。
YCbCr表色系とは、画像を明るさを表すY、輝度と青レベルの差Cb、輝度と赤レベルの差Crに分解する表現方法である。
これはJPEG変換で用いられる。A39def y_change(img, y): """ brg => YCrCbへ変換し、コントラストを変える YCrCb => bgrへ変換 params --------------------------------- img: numpy.ndarray形式のimage y: yのコントラストの数値(倍数) returns --------------------------------- numpy.ndarray形式のimage """ # rgb => YCrCbへ変換 YCrCb = cv2.cvtColor(img, cv2.COLOR_BGR2YCR_CB) # Yを0.7倍 YCrCb[..., 0] = YCrCb[..., 0] * 0.7 # YCrCb => bgrへ変換 out = cv2.cvtColor(YCrCb, cv2.COLOR_YCrCb2BGR) return out # YCbCr表色系 out = y_change(img, 0.7) # 保存 cv2_imshow(out) cv2.waitKey(0) cv2.imwrite("img39.jpg", out)
参考: Python OpenCV:YCbCrをRGBに戻す方法は?Q.40. JPEG圧縮 (Step.4)YCbCr+DCT+量子化
YCbCr表色系にし、DCT後、Yを量子化テーブルQ1、CbとCrをQ2で量子化し、IDCTで画像を復元せよ。 また、画像の容量を比較せよ。
アルゴリズムは、
1. RGB を YCbCrに変換
2. YCbCrをDCT
3. DCTしたものを量子化
4. 量子化したものをIDCT
5. IDCTしたYCbCrをRGBに変換
これはJPEGで実際に使われるデータ量削減の手法であり、Q1,Q2はJPEGの仕様書に則って次式で定義される。A40def BGR2YCbCr(img): """ bgr => YCrCbへ変換 params --------------------------------- img: numpy.ndarray形式のimage returns --------------------------------- numpy.ndarray形式のimage """ # rgb => YCrCbへ変換 YCrCb = cv2.cvtColor(img, cv2.COLOR_BGR2YCR_CB) return YCrCb def YCbCr2BGR(img): """ YCbCr => bgrへ変換 params --------------------------------- img: numpy.ndarray形式のimage returns --------------------------------- numpy.ndarray形式のimage """ # YCbCr => bgへ変換 bgr = cv2.cvtColor(YCrCb, cv2.COLOR_YCrCb2BGR) return bgr # DCT hyoer-parameter T = 8 K = 4 channel = 3 # DCT weight def w(x, y, u, v): """ 離散コサイン変換(DCT: Discrete Cosine Transformation) の係数 params ------------------------------- returns ------------------------------- 係数 """ cu = 1. cv = 1. if u == 0: cu /= np.sqrt(2) if v == 0: cv /= np.sqrt(2) theta = np.pi / (2 * T) return (( 2 * cu * cv / T) * np.cos((2*x+1)*u*theta) * np.cos((2*y+1)*v*theta)) # DCT def dct(img): """ 離散コサイン変換(DCT: Discrete Cosine Transformation) params ----------------------------- img: numpy.ndarray形式のimage returns ----------------------------- 離散コサイン変換(DCT: Discrete Cosine Transformation) """ # 画像の高さ、幅を取得 H, W, _ = img.shape # 0を要素とする配列を生成する F = np.zeros((H, W, channel), dtype=np.float32) # rgbそれぞれのチャネル for c in range(channel): # 縦方向にT(8)の間隔 for yi in range(0, H, T): # 横方向にT(8)の間隔 for xi in range(0, W, T): for v in range(T): for u in range(T): for y in range(T): for x in range(T): # 各画素に対して離散コサイン変換 F[v+yi, u+xi, c] += img[y+yi, x+xi, c] * w(x,y,u,v) return F # IDCT def idct(F): """ 逆離散コサイン変換 params ----------------------------- F: 離散コサイン変換 returns ----------------------------- 逆離散コサイン変換 """ # 画像の高さ、幅を取得 H, W, _ = F.shape # 0を要素とする配列を生成する out = np.zeros((H, W, channel), dtype=np.float32) for c in range(channel): for yi in range(0, H, T): for xi in range(0, W, T): for y in range(T): for x in range(T): for v in range(K): for u in range(K): out[y+yi, x+xi, c] += F[v+yi, u+xi, c] * w(x,y,u,v) # clipping(NumPy配列ndarrayを任意の最小値・最大値に収めるclip) out = np.clip(out, 0, 255) out = np.round(out).astype(np.uint8) return out def quantization(F): """ DCT係数を量子化 params ------------------------------- F: DCT係数 returns ------------------------------- DCT係数を量子化 """ # 画像の高さ、幅を取得 H, W, _ = F.shape # 量子化では8x8の係数をQで割り、四捨五入 Q = np.array(((16, 11, 10, 16, 24, 40, 51, 61), (12, 12, 14, 19, 26, 58, 60, 55), (14, 13, 16, 24, 40, 57, 69, 56), (14, 17, 22, 29, 51, 87, 80, 62), (18, 22, 37, 56, 68, 109, 103, 77), (24, 35, 55, 64, 81, 104, 113, 92), (49, 64, 78, 87, 103, 121, 120, 101), (72, 92, 95, 98, 112, 100, 103, 99)), dtype=np.float32) for ys in range(0, H, T): for xs in range(0, W, T): for c in range(channel): F[ys: ys + T, xs: xs + T, c] = np.round(F[ys: ys + T, xs: xs + T, c] / Q) * Q return F def JPEG(img): """ jpeg圧縮 params ------------------------------------ img: numpy.ndarray形式のimage returns ------------------------------------ numpy.ndarray形式のimage """ # BGR -> YCbCr YCbCr = BGR2YCbCr(img) # DCT F = dct(YCbCr) # DCT係数を量子化 F = quantization(F) # IDCT YCbCr = idct(F) # Y Cb Cr -> BGR out = YCbCr2BGR(YCbCr) return out def MSE(img1, img2): """ 平均二乗誤差 params ----------------------------- img1: numpy.ndarray形式のimage img2: numpy.ndarray形式のimage returns ----------------------------- 平均二乗誤差の値 class 'numpy.float64' """ # 画像の高さ、幅を取得 H, W, _ = img1.shape # 二つの画像の差分の二乗 mse = np.sum((img1 - img2) ** 2) / (H * W * channel) return mse # PSNR def PSNR(mse, vmax=255): """ 信号対雑音比: イメージ間のピーク S/N 比 (PSNR) の計算 params ------------------------------ mse: 平均二乗誤差の値 vmax: 値の最大値で[0,255] returns ------------------------------ 信号対雑音比 class 'numpy.float64' """ return 10 * np.log10(vmax * vmax / mse) def BITRATE(): """ ビットレート class 'float' """ return 1. * T * K * K / T / T # JPEG out = JPEG(img) # MSE mse = MSE(img, out) # PSNR psnr = PSNR(mse) # bitrate bitrate = BITRATE() print("MSE:", mse) print("PSNR:", psnr) print("bitrate:", bitrate) # 画像表示 cv2_imshow(out) cv2.waitKey(0) cv2.imwrite("img40.jpg", out)
感想
内容が賀くんと難しくなった。うまく説明できていない部分は随時更新していく



















- 投稿日:2020-12-01T23:05:20+09:00
表示されたファイル内の固有表現リスト(人名、地名など)から単語選択する、該当する「主語 -> 述語」ペアが一覧表示されるGUIツール
作ったもの
Terminal% python3 tkinter_ner_sub_pred_pair_file_dialog.py1. 以下のウインドウが立ち上がります。
ファイル選択ダイアログが現れます。
"OK"を押して、任意のディレクトリから任意のテキストファイルを選択します。__
ファイル選択ダイアログの表示が、以下に変わります。
以下の画面が表示されます。
「地名」のラジオボタンを選択し、「ファイルから指定した・・・」ボタンを押す。
( 出力画面を下方向にスクロールすると、画面切れしていた解析結果の続きを確認できる )
『着目する「主語」』欄に「5」(「中国」)を入力後、「指定単語を主語に持つ・・・」ボタンを押す。
( 出力画面を下方向にスクロールすると、画面の外に表示されている解析結果を確認できる )
『着目する「主語」』欄に「2」(「ロシア」)を入力後、「指定単語を主語に持つ・・・」ボタンを押す。
『着目する「主語」』欄に「4」(「日本」)を入力後、「指定単語を主語に持つ・・・」ボタンを押す。
「組織名」のラジオボタンを選択し、「ファイルから指定した・・・」ボタンを押す。
『着目する「主語」』欄に「1」(「ロシア軍」)を入力後、「指定単語を主語に持つ・・・」ボタンを押す。
今回、ツールに読み込ませたファイル(拡張子:".txt") )
NHK NewsWebの国際面に、2020/12/1に掲載されていた記事を読み込ませてみました。
article.txtACロシア軍は、北方領土で地対空ミサイルシステム「S300」の訓練を初めて行ったと発表しました。ロシアとしては北方領土で軍備を強化している姿勢を強調するねらいがあるものとみられます。 ロシア軍の東部軍管区は1日、地対空ミサイルシステム「S300」の訓練を北方領土を含む島々で初めて行ったと発表しました。 このミサイルシステムは中国国境に近いロシア極東のユダヤ自治州に配備されていたものを移送したということで、軍のテレビ局は、北方領土の択捉島でミサイルシステムを稼働させる映像を流しました。 このミサイルシステムは、射程がおよそ400キロ、戦闘機やミサイルなどを撃ち落とす対空防衛を目的としていて、島にある演習場で訓練することが目的だとしています。 ロシアは、択捉島と国後島には地対艦ミサイルシステムを配備していますが、「S300」の訓練を北方領土で行ったのは初めてで、ロシアとしては、北方領土で軍備を強化している姿勢を強調するねらいがあるものとみられます。 日本政府は、ロシア側による北方領土での軍備の強化について「北方領土に関する日本の立場と相いれず受け入れられない」として繰り返し、抗議しています。
実装コード
tkinter_ner_sub_pred_pair_file_dialog.py# Tkinterのライブラリを取り込む import tkinter, spacy, collections, CaboCha, os import tkinter.filedialog, tkinter.messagebox from typing import List, TypeVar from tkinter import * from tkinter import ttk from tkinter import filedialog from tkinter import messagebox from spacy.matcher import Matcher # グローバル変数の宣言 exracted_entity_word_list = "" user_input_text = "" named_entity_label = "" T = TypeVar('T', str, None) Vector = List[T] # ファイルの参照処理 def click_refer_button(): fTyp = [("","*")] iDir = os.path.abspath(os.path.dirname(__file__)) filepath = filedialog.askopenfilename(filetypes = fTyp, initialdir = iDir) file_path.set(filepath) # 固有表現抽出処理 def extract_words_by_entity_label(text, named_entity_label): nlp = spacy.load('ja_ginza') text = text.replace("\n", "") doc = nlp(text) words_list = [ent.text for ent in doc.ents if ent.label_ == named_entity_label] return words_list # 出力処理 def click_export_button(): # 選択された固有表現の種別名を取得 named_entity_label = flg.get() global user_input_text f = open(file_path, encoding="utf-8") user_input_text = f.read() label_word_list = extract_words_by_entity_label(user_input_text, named_entity_label) # 指定された固有表現に該当する単語を取得した結果(単語リスト)を、{単語文字列 : 出現回数}の辞書に変換する count_per_word = collections.Counter(label_word_list) # 出現回数の多い順番に並べる freq_per_word_dict = dict(count_per_word.most_common()) #output_list = ["{k} : {v}".format(k=key, v=value) for (key, value) in freq_per_word_dict.items()] # 単語数を取得する unique_word_num = len(freq_per_word_dict) if unique_word_num > 0: message = "{num}件の{label}が見つかりました。\n\n出現回数順に並べた結果は以下です。\n\n".format(num=unique_word_num, label=named_entity_label) word_list = list(freq_per_word_dict.keys()) word_freq_list = list(freq_per_word_dict.values()) for i in range(unique_word_num): tmp = "{rank}番目の単語 : {word}\n出現回数 : {count}\n\n===================\n".format(rank=i+1, word=word_list[i], count=word_freq_list[i]) message += tmp else: message = "{num}件の{label}が見つかりました。\n\n".format(num=unique_word_num, label=named_entity_label) textBox.insert(END, message) global exracted_entity_word_list exracted_entity_word_list = word_list return exracted_entity_word_list def get_subject_predicate_pair_list(sentence: str, subject_word: str) -> Vector: T = TypeVar('T', str, None) c = CaboCha.Parser() tree = c.parse(sentence) # 形態素を結合しつつ[{c:文節, to:係り先id}]の形に変換する chunks = [] text = "" toChunkId = -1 for i in range(0, tree.size()): token = tree.token(i) text = token.surface if token.chunk else (text + token.surface) toChunkId = token.chunk.link if token.chunk else toChunkId # 文末かchunk内の最後の要素のタイミングで出力 if i == tree.size() - 1 or tree.token(i+1).chunk: chunks.append({'c': text, 'to': toChunkId}) # ループの中で出力される「係り元→係り先」文字列をlistに格納 pair_list = [] # for chunk in chunks: if chunk['to'] >= 0: pair_list.append(chunk['c'] + " → " + chunks[chunk['to']]['c']) output_list = [pair for pair in pair_list if subject_word in pair] return output_list def click_export_button2(): # 入力された主語単語の文字列を取得 order_num = int(subject_num.get())-1 #ユーザが1を入力したとき、配列の0番地を指定する。 subject_string = exracted_entity_word_list[order_num] output_list = get_subject_predicate_pair_list(user_input_text, subject_string) result = "\n".join(output_list) message = """ 単語:「{subject_word}」を主語に持つ「主語と述語」のペアは、以下が見つかりました。 ========================================================================= {result} ========================================================================= 以上です。 """.format(subject_word=subject_string, result=result) textBox.insert(END, message) if __name__ == '__main__': # ウィンドウを作成 root = tkinter.Tk() root.title("文書内容_早見チェッカー") # アプリの名前 root.geometry("730x500") # アプリの画面サイズ # ファイル選択ウインドウを作成 # root.withdraw() fTyp = [("", "*.txt")] iDir = os.path.abspath(os.path.dirname(__file__)) tkinter.messagebox.showinfo('ファイル選択ダイアログ','処理ファイルを選択してください!') file_path = tkinter.filedialog.askopenfilename(filetypes = fTyp,initialdir = iDir) # 処理ファイル名の出力 tkinter.messagebox.showinfo('以下のファイルを選択しました。',file_path) # Frame1の作成 frame1 = ttk.Frame(root, padding=10) frame1.grid() # 「」ラベルの作成 t = StringVar() t.set('着目する「主語」:') label1 = ttk.Label(frame1, textvariable=t) label1.grid(row=1, column=0) #テキストボックス2(「主語述語ペア」の「主語」入力欄)の作成 subject_num = StringVar() subject_num_entry = ttk.Entry(frame1, textvariable=subject_num, width=50) subject_num_entry.grid(row=1, column=1) # ラジオボタンの作成 #共有変数 flg= StringVar() #ラジオ1 rb1 = ttk.Radiobutton(frame1, text='人名',value="PERSON", variable=flg) rb1.grid(row=2,column=0) #ラジオ2 rb2 = ttk.Radiobutton(frame1, text='地名',value="LOC", variable=flg) rb2.grid(row=2,column=1) #ラジオ3 rb3 = ttk.Radiobutton(frame1, text='組織名', value="ORG", variable=flg) rb3.grid(row=2,column=2) #ラジオ4 rb4 = ttk.Radiobutton(frame1, text='日付',value="DATE", variable=flg) rb4.grid(row=3,column=0) #ラジオ5 rb5 = ttk.Radiobutton(frame1, text='イベント名',value="EVENT", variable=flg) rb5.grid(row=3,column=1) #ラジオ6 rb6 = ttk.Radiobutton(frame1, text='金額',value="MONEY", variable=flg) rb6.grid(row=3,column=2) # Frame2の作成 frame2= ttk.Frame(root, padding=10) frame2.grid() # 固有表現単語を抽出した結果を表示させるボタンの作成 export_button = ttk.Button(frame2, text='ファイルから指定した種類の単語を洗い出す', command=click_export_button, width=70) export_button.grid(row=0, column=0) # 「主語述語ペア」を抽出した結果を表示させるボタンの作成 export_button2 = ttk.Button(frame2, text='指定単語を主語に持つ「主語述語ペア」を表示します', command=click_export_button2, width=70) export_button2.grid(row=1, column=0) # テキスト出力ボックスの作成 textboxname = StringVar() textboxname.set('\n\n処理結果 ') label3 = ttk.Label(frame2, textvariable=textboxname) label3.grid(row=1, column=0) textBox = Text(frame2, width=100) textBox.grid(row=3, column=0) file_selected_message = """以下のファイルを選択しました。\n{filename}\n\n""".format(filename=file_path) textBox.insert(END, file_selected_message) # ウィンドウを動かす root.mainloop()











- 投稿日:2020-12-01T23:05:20+09:00
ファイルに登場する固有表現リストを表示後、選択した単語が起点となる「主語 -> 述語」ペアを一覧表示するGUIツール
作ったもの
Terminal% python3 tkinter_ner_sub_pred_pair_file_dialog.py1. 以下のウインドウが立ち上がります。
ファイル選択ダイアログが現れます。
"OK"を押して、任意のディレクトリから任意のテキストファイルを選択します。
ファイル選択ダイアログの表示が、以下に変わります。
以下の画面が表示されます。
「地名」のラジオボタンを選択し、「ファイルから指定した・・・」ボタンを押す。
( 出力画面を下方向にスクロールすると、画面切れしていた解析結果の続きを確認できる )
『着目する「主語」』欄に「5」(「中国」)を入力後、「指定単語を主語に持つ・・・」ボタンを押す。
( 出力画面を下方向にスクロールすると、画面の外に表示されている解析結果を確認できる )
『着目する「主語」』欄に「2」(「ロシア」)を入力後、「指定単語を主語に持つ・・・」ボタンを押す。
『着目する「主語」』欄に「4」(「日本」)を入力後、「指定単語を主語に持つ・・・」ボタンを押す。
「組織名」のラジオボタンを選択し、「ファイルから指定した・・・」ボタンを押す。
『着目する「主語」』欄に「1」(「ロシア軍」)を入力後、「指定単語を主語に持つ・・・」ボタンを押す。
今回、ツールに読み込ませたファイル(拡張子:".txt") )
NHK NewsWebの国際面に、2020/12/1に掲載されていた記事を読み込ませてみました。
article.txtロシア軍は、北方領土で地対空ミサイルシステム「S300」の訓練を初めて行ったと発表しました。ロシアとしては北方領土で軍備を強化している姿勢を強調するねらいがあるものとみられます。 ロシア軍の東部軍管区は1日、地対空ミサイルシステム「S300」の訓練を北方領土を含む島々で初めて行ったと発表しました。 このミサイルシステムは中国国境に近いロシア極東のユダヤ自治州に配備されていたものを移送したということで、軍のテレビ局は、北方領土の択捉島でミサイルシステムを稼働させる映像を流しました。 このミサイルシステムは、射程がおよそ400キロ、戦闘機やミサイルなどを撃ち落とす対空防衛を目的としていて、島にある演習場で訓練することが目的だとしています。 ロシアは、択捉島と国後島には地対艦ミサイルシステムを配備していますが、「S300」の訓練を北方領土で行ったのは初めてで、ロシアとしては、北方領土で軍備を強化している姿勢を強調するねらいがあるものとみられます。 日本政府は、ロシア側による北方領土での軍備の強化について「北方領土に関する日本の立場と相いれず受け入れられない」として繰り返し、抗議しています。
実装コード
tkinter_ner_sub_pred_pair_file_dialog.py# Tkinterのライブラリを取り込む import tkinter, spacy, collections, CaboCha, os import tkinter.filedialog, tkinter.messagebox from typing import List, TypeVar from tkinter import * from tkinter import ttk from tkinter import filedialog from tkinter import messagebox from spacy.matcher import Matcher # グローバル変数の宣言 exracted_entity_word_list = "" user_input_text = "" named_entity_label = "" T = TypeVar('T', str, None) Vector = List[T] # ファイルの参照処理 def click_refer_button(): fTyp = [("","*")] iDir = os.path.abspath(os.path.dirname(__file__)) filepath = filedialog.askopenfilename(filetypes = fTyp, initialdir = iDir) file_path.set(filepath) # 固有表現抽出処理 def extract_words_by_entity_label(text, named_entity_label): nlp = spacy.load('ja_ginza') text = text.replace("\n", "") doc = nlp(text) words_list = [ent.text for ent in doc.ents if ent.label_ == named_entity_label] return words_list # 出力処理 def click_export_button(): # 選択された固有表現の種別名を取得 named_entity_label = flg.get() global user_input_text f = open(file_path, encoding="utf-8") user_input_text = f.read() label_word_list = extract_words_by_entity_label(user_input_text, named_entity_label) # 指定された固有表現に該当する単語を取得した結果(単語リスト)を、{単語文字列 : 出現回数}の辞書に変換する count_per_word = collections.Counter(label_word_list) # 出現回数の多い順番に並べる freq_per_word_dict = dict(count_per_word.most_common()) #output_list = ["{k} : {v}".format(k=key, v=value) for (key, value) in freq_per_word_dict.items()] # 単語数を取得する unique_word_num = len(freq_per_word_dict) if unique_word_num > 0: message = "{num}件の{label}が見つかりました。\n\n出現回数順に並べた結果は以下です。\n\n".format(num=unique_word_num, label=named_entity_label) word_list = list(freq_per_word_dict.keys()) word_freq_list = list(freq_per_word_dict.values()) for i in range(unique_word_num): tmp = "{rank}番目の単語 : {word}\n出現回数 : {count}\n\n===================\n".format(rank=i+1, word=word_list[i], count=word_freq_list[i]) message += tmp else: message = "{num}件の{label}が見つかりました。\n\n".format(num=unique_word_num, label=named_entity_label) textBox.insert(END, message) global exracted_entity_word_list exracted_entity_word_list = word_list return exracted_entity_word_list def get_subject_predicate_pair_list(sentence: str, subject_word: str) -> Vector: T = TypeVar('T', str, None) c = CaboCha.Parser() tree = c.parse(sentence) # 形態素を結合しつつ[{c:文節, to:係り先id}]の形に変換する chunks = [] text = "" toChunkId = -1 for i in range(0, tree.size()): token = tree.token(i) text = token.surface if token.chunk else (text + token.surface) toChunkId = token.chunk.link if token.chunk else toChunkId # 文末かchunk内の最後の要素のタイミングで出力 if i == tree.size() - 1 or tree.token(i+1).chunk: chunks.append({'c': text, 'to': toChunkId}) # ループの中で出力される「係り元→係り先」文字列をlistに格納 pair_list = [] # for chunk in chunks: if chunk['to'] >= 0: pair_list.append(chunk['c'] + " → " + chunks[chunk['to']]['c']) output_list = [pair for pair in pair_list if subject_word in pair] return output_list def click_export_button2(): # 入力された主語単語の文字列を取得 order_num = int(subject_num.get())-1 #ユーザが1を入力したとき、配列の0番地を指定する。 subject_string = exracted_entity_word_list[order_num] output_list = get_subject_predicate_pair_list(user_input_text, subject_string) result = "\n".join(output_list) message = """ 単語:「{subject_word}」を主語に持つ「主語と述語」のペアは、以下が見つかりました。 ========================================================================= {result} ========================================================================= 以上です。 """.format(subject_word=subject_string, result=result) textBox.insert(END, message) if __name__ == '__main__': # ウィンドウを作成 root = tkinter.Tk() root.title("文書内容_早見チェッカー") # アプリの名前 root.geometry("730x500") # アプリの画面サイズ # ファイル選択ウインドウを作成 # root.withdraw() fTyp = [("", "*.txt")] iDir = os.path.abspath(os.path.dirname(__file__)) tkinter.messagebox.showinfo('ファイル選択ダイアログ','処理ファイルを選択してください!') file_path = tkinter.filedialog.askopenfilename(filetypes = fTyp,initialdir = iDir) # 処理ファイル名の出力 tkinter.messagebox.showinfo('以下のファイルを選択しました。',file_path) # Frame1の作成 frame1 = ttk.Frame(root, padding=10) frame1.grid() # 「」ラベルの作成 t = StringVar() t.set('着目する「主語」:') label1 = ttk.Label(frame1, textvariable=t) label1.grid(row=1, column=0) #テキストボックス2(「主語述語ペア」の「主語」入力欄)の作成 subject_num = StringVar() subject_num_entry = ttk.Entry(frame1, textvariable=subject_num, width=50) subject_num_entry.grid(row=1, column=1) # ラジオボタンの作成 #共有変数 flg= StringVar() #ラジオ1 rb1 = ttk.Radiobutton(frame1, text='人名',value="PERSON", variable=flg) rb1.grid(row=2,column=0) #ラジオ2 rb2 = ttk.Radiobutton(frame1, text='地名',value="LOC", variable=flg) rb2.grid(row=2,column=1) #ラジオ3 rb3 = ttk.Radiobutton(frame1, text='組織名', value="ORG", variable=flg) rb3.grid(row=2,column=2) #ラジオ4 rb4 = ttk.Radiobutton(frame1, text='日付',value="DATE", variable=flg) rb4.grid(row=3,column=0) #ラジオ5 rb5 = ttk.Radiobutton(frame1, text='イベント名',value="EVENT", variable=flg) rb5.grid(row=3,column=1) #ラジオ6 rb6 = ttk.Radiobutton(frame1, text='金額',value="MONEY", variable=flg) rb6.grid(row=3,column=2) # Frame2の作成 frame2= ttk.Frame(root, padding=10) frame2.grid() # 固有表現単語を抽出した結果を表示させるボタンの作成 export_button = ttk.Button(frame2, text='ファイルから指定した種類の単語を洗い出す', command=click_export_button, width=70) export_button.grid(row=0, column=0) # 「主語述語ペア」を抽出した結果を表示させるボタンの作成 export_button2 = ttk.Button(frame2, text='指定単語を主語に持つ「主語述語ペア」を表示します', command=click_export_button2, width=70) export_button2.grid(row=1, column=0) # テキスト出力ボックスの作成 textboxname = StringVar() textboxname.set('\n\n処理結果 ') label3 = ttk.Label(frame2, textvariable=textboxname) label3.grid(row=1, column=0) textBox = Text(frame2, width=100) textBox.grid(row=3, column=0) file_selected_message = """以下のファイルを選択しました。\n{filename}\n\n""".format(filename=file_path) textBox.insert(END, file_selected_message) # ウィンドウを動かす root.mainloop()
- 投稿日:2020-12-01T22:54:40+09:00
NVIDIA Triton Inference Server で推論してみた
はじめに
こんにちは。 @dcm_yamaya です。
ことしハマったキーボードは HHKB Professional HYBRID (not type-s) です。
この記事は、NTTドコモ R&D Advent Calendar 2020 7日目の記事です。
普段の業務では、画像認識やエッジコンピューティングの技術領域を担当しています。
昨年の記事 ではJetson上で画像認識モデルをTensorRT化する方法を紹介しました。
ことしはTensorRTに関連して興味があった、GTC2020で発表された NVIDIA Triton Inference Server を使って画像認識モデルの推論を試したいと思います。
「あれ、このフレームワーク前もなかったっけ?TensorRT Inference Server じゃなかったっけ?」
と思ったら、名前が変わっていました。
https://twitter.com/_ksasaki/status/1243708356419710976?s=20対象とする人
- GPUサーバで
- Triton Inference Server を使ってみたい
やること
- Triton Inference Server とは
- 分類モデルの推論
- 物体検出モデル(yolov3)の推論
Triton Inference Server で推論してみよう
Triton Inference Server とは
NVIDIA がリリースしている、GPUを使用して機械学習モデルを高速に推論させるサーバを構築するためのフレームワークです。
単に推論させるだけであれば、わざわざをサーバを立てなくても…という気もしますが、TISによって複数の学習環境の異なるモデルを高速に
動作させることができるといったメリットがあります。
Inference Server に載せたモデルを推論するには、クライアントからHTTP/RESTまたはGRPCプロトコルでリクエストを投げることで、
推論結果を得ることができます。TensorFlowはTensorFlow Serving, Pytorch は TorchServe と フレームワークごとに Serving が用意されていますが、それらとは異なりTensorRTが使えるなどより実行を高速にできる(可能性がある)のがこれらとのちがいかなと思います。
※[2]
特徴
- 様々なフレームワークで学習されたモデルを扱うことができる
- TensorRT
- TensorFlow GraphDef
- TensorFlow SavedModel
- ONNX
- Pytorch TorchScript
- 複数のモデルを同時に、1つのGPU内または複数のGPU上で実行できる(Concurent Execution)
- GPUごとに使用率やメモリ、レイテンシーの状況など各種メトリクスの監視ができる
分類モデルの推論
では早速 Triton Inference Server を使って推論してみたいと思います。
こちらにチュートリアルがあるのでこれを参考に画像分類モデルの推論を試してみます。
特にTensorRTがUbuntuやCUDAのバージョンにシビアなため、それにあったTISのバージョンを選択する必要があることが注意点です。
(筆者は最初にはまりました。。)
https://github.com/triton-inference-server/server/blob/master/docs/quickstart.md筆者の動作環境
- Docker version 19.03.13
- Ubuntu 18.04
- CUDA 10.2
- TensorRT 6.0.1.8
Docker Image のインストール
下記コマンドでngcから docker image を pull してきます。
docker pull nvcr.io/nvidia/tritonserver:<xx.yy>-py3
<xx.yy>の部分はバージョンとなっていて、Ubuntu、CUDA、TensorRTのバージョンに合わせて選択します。
リリースノートを参照しながら、筆者環境では20.03を選択しました。$ docker pull nvcr.io/nvidia/tritonserver:20.03-py3model repositoryの作成
サンプルとしていくつかモデルがダウンロードできるようになっているので、githubのコードから
./fetch_models.shを実行します。これにより複数個のモデルが配置されます。git clone https://github.com/NVIDIA/triton-inference-server cd triton-inference-server git checkout r20.03 cd docs/examples ./fetch_models.shTriton Server で推論したいモデルは model repository に置きますが、その位置は
docs/example/model_repositoryになります。サーバの実行
まずはサーバを立ち上げます。以下のコマンドで
/modelsに model_repository をマウントできるようにします。cd triton-inference-server docker run --gpus=1 --rm -p 8000:8000 -p 8001:8001 -p 8002:8002 -v $PWD/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:20.03-py3 trtserver --model-repository=/models注意するのは、20.03までは
trtserverという名前で、以降はtritonserverな点です。これでGPUの認識及び model_repository 以下にあるモデルがGPU上に展開されるログが表示されていると思います。最後にhttpserviceなど3つのサーバがスタートしていることが表示されればOKです。============================= == Triton Inference Server == ============================= NVIDIA Release 20.03 (build 11042949) Copyright (c) 2018-2019, NVIDIA CORPORATION. All rights reserved. Various files include modifications (c) NVIDIA CORPORATION. All rights reserved. NVIDIA modifications are covered by the license terms that apply to the underlying project or file. 2020-11-29 11:05:38.961638: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.2 I1129 11:05:39.008650 1 metrics.cc:164] found 1 GPUs supporting NVML metrics I1129 11:05:39.014088 1 metrics.cc:173] GPU 0: Quadro P6000 I1129 11:05:39.014403 1 server.cc:120] Initializing Triton Inference Server I1129 11:05:39.334589 1 server_status.cc:55] New status tracking for model 'densenet_onnx' I1129 11:05:39.334616 1 server_status.cc:55] New status tracking for model 'inception_graphdef' I1129 11:05:39.334640 1 server_status.cc:55] New status tracking for model 'simple' ... Starting endpoints, 'inference:0' listening on I1129 11:05:42.585518 1 grpc_server.cc:1939] Started GRPCService at 0.0.0.0:8001 I1129 11:05:42.585571 1 http_server.cc:1411] Starting HTTPService at 0.0.0.0:8000 I1129 11:05:42.629039 1 http_server.cc:1426] Starting Metrics Service at 0.0.0.0:8002これでAPIの状態などをチェックすることができます。
curl localhost:8000/api/status id: "inference:0" version: "1.12.0" uptime_ns: 6718051588331 model_status { key: "densenet_onnx" value { config { name: "densenet_onnx" platform: "onnxruntime_onnx" version_policy { latest { num_versions: 1 } } input { name: "data_0" data_type: TYPE_FP32 format: FORMAT_NCHW dims: 3 dims: 224 dims: 224 reshape { ...クライアントの実行
次にクライアント側を実行します。
docker pull nvcr.io/nvidia/tritonserver:20.03-py3-sdk docker run --rm --net=host -it nvcr.io/nvidia/tritonserver:20.03-py3-clientsdkコンテナに入ることができたら、pythonコードを実行し、画像の分類モデルのリクエストを投げて結果を表示してみます。
python /workspace/install/python/image_client.py -m densenet_onnx -c 3 -s INCEPTION /workspace/images/mug.jpg Request 0, batch size 1 Image ‘/workspace/images/mug.jpg’: 504 (COFFEE MUG) = 13.901954650878906 968 (CUP) = 12.000585556030273 967 (ESPRESSO) = 9.819758415222168これでdensenetによる画像分類ができ、
/workspace/images/mug.jpgに対しCOFFEE MUGの画像と推論ができました。
image_client.pyでは、引数でモデルを指定しています。-mでdensenetモデルを選択肢、-cで上位3つの結果を返すように設定しています。
これで、サーバ側とクライアント側の動きを試すことができました。モデルの配置の仕方
新しいモデルを配置してサーバで読むにはどうするのか?というとmodel_repositoryに設定されたルールやパスを記述して読み込ませることができます。
docs/example/model_repositoryがそのまま参考になりますが、こういった構成で配置することになります。models/ +-- densenet_onnx # モデルの名前 | +-- config.pbtxt # 設定ファイル | +-- output_labels_file.txt # クラス名のファイル | +-- 1/ # バージョン | +-- saved_model.pb ...モデル名のフォルダの下に、設定ファイルとバージョンを示すフォルダがあり、そのフォルダの下にバイナリファイル(重みパラメータであるモデルファイル)を配置します。設定ファイルは、例えばdensenet_onnxの場合はこのように記述されています。
name: "densenet_onnx" platform: "onnxruntime_onnx" max_batch_size : 0 input [ { name: "data_0" data_type: TYPE_FP32 format: FORMAT_NCHW dims: [ 3, 224, 224 ] reshape { shape: [ 1, 3, 224, 224 ] } } ] output [ { name: "fc6_1" data_type: TYPE_FP32 dims: [ 1000 ] reshape { shape: [ 1, 1000, 1, 1 ] } label_filename: "densenet_labels.txt" } ]入力と出力の形式を記述するのはもちろん、platformでモデル自体の形式を指定します。TensorRT化されたモデルであればtensorrt_plan、TFのsaved_modelであればtensorflow_savedmodelと記載します。
このようにしてモデルを配置したらもう一度サーバ側のdockerコンテナを立ち上げることで、新しく配置したモデルが読み込まれリクエストを投げて推論することができます。物体検出モデルの推論
次に、分類モデル以外の例として、みんな大好き物体検出アルゴリズムyolov3をTISに載せて推論してみます。
学習のフレームワークとしてdarknetで学習したモデルをTensorFlowのsavedmodelとしてpbで読み込む方法と、TensorRT化した上でデプロイする2つ方法がありますが、今回は前者でやってみようと思います。モデルの設定
今回のモデルはTensorFlowの savedmodel を使うこととします。この場合はdarknetの重みからpbへ変換して上げる必要がありますが、その部分は下記レポジトリが参考になります。
https://github.com/zzh8829/yolov3-tf2TensorFlow Serving の例でexportできる部分があるので、これをもとにpb化してきます。
python export_tfserving.py --output serving/yolov3/1/続いて、yolov3のモデルを配置するにあたり、設定ファイルを書く必要があります。yolov3.pbtxtはこんな感じで書くことができます。モデル名(フォルダ名)は
yolov3_tfとしています。name: "yolov3_tf" platform: "tensorflow_savedmodel" max_batch_size: 64 input [ { name: "input_1" data_type: TYPE_FP32 dims: -1 dims: -1 dims: 3 } ] output [ { name: "yolo_nms_0" data_type: TYPE_FP32 dims: -1 dims: 1 dims: 4 }, { name: "yolo_nms_1" data_type: TYPE_FP32 dims: -1 dims: -1 }, { name: "yolo_nms_2" data_type: TYPE_FP32 dims: -1 dims: -1 } ] instance_group [ { kind: KIND_GPU count: 1 gpus: [0] # 使用するGPUの指定 } ]最後の
instance_groupではCPU/GPUどちらで実行するのか、GPUの場合どのGPUで何並列で実行するのかを設定できます。ここまでできたら、サーバ側でyolov3モデルを読み込むよう再度立ち上げます。
docker run --gpus=1 --rm -p 8000:8000 -p 8001:8001 -p 8002:8002 -v $PWD/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:20.03-py3 trtserver --model-repository=/modelsクライアント側の設定
続いてクライアント側です。
yolov3のクライアント例を作っている先人のdocker image[3]を参考にしながら画像描画部分を修正しgRPC経由でリクエストを投げ推論する、ことをやってみたいと思います。docker pull srijithss/tensorrtserver_client:latest docker run -it -v $PWD/:/opt/code srijithss/tensorrtserver_client:latest bashコンテナに入ったら
python trtserver_test.pyが実行できますが、そのままだと表示が見づらいので、inference.pyとして少し修正します。def draw_outputs(self, img, outputs): boxes, objectness, classes, nums = outputs boxes, objectness, classes, nums = boxes[0], objectness[0], classes[0], nums[0] for i in range(nums): x1y1 = tuple((np.array(boxes[i][0:2]) * self.wh).astype(np.int32)) x2y2 = tuple((np.array(boxes[i][2:4]) * self.wh).astype(np.int32)) label = self.class_names[int(classes[i])] class_num = 0 for name in self.class_names: if label == name: class_num = self.class_names.index(name) break cv2.rectangle(img, x1y1, x2y2, self.class_colors[class_num], 2) text = label + " " + ('%.2f' % objectness[i]) tlx = x1y1[0] tly = x1y1[1] cv2.rectangle(img, (tlx, tly - 20), (tlx + 110, tly), self.class_colors[class_num], -1) cv2.putText(img, text, (tlx, tly-5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0,0,0), 1) return img def process(self): img = cv2.imread(self.args.img) if self.wh is None: self.wh = np.flip(img.shape[0:2],0) frame_rgb = self.bgr_to_rgb(img, self.args.yolo_size) frames = [] frames.append(frame_rgb) responses = [] yolo_generator = partial(request_generator, self.yolo_request, frames) responses = self.grpc_stub.StreamInfer(yolo_generator()) for response in responses: boxes, scores, classes, nums = process_yolo_response(response) img_out = self.draw_outputs(img, (boxes, scores, classes, nums)) cv2.imwrite('result.jpg', img_out)これでdarknetでおなじみの画像に推論してみると以下のようになります。
python inference.py --img ./dog.jpg
このように、TISにモデルを載せるためにはどのフレームワークで学習しTISがサポートするフレームワークに変換できるかどうか、設定ファイルを正しく記述しているかが重要となります。一回載せてさえしまえば、httpまたはgRPC経由でAPIとして機械学習モデルを利用することができるのは便利だなと思います。
ただし設定ファイルの書き方やクライアント側の書き方もgRPCに慣れていないと難しかったです。src/clients/python/examplesにいくつかサンプルがあるのでこの辺が参考になります。(C++, go もある)おわりに
Triton Inference Server を使って画像認識モデルの推論を試してみました。
ほかのタスク(音声認識など)をデプロイしたり、torchscript 形式での実行やonnxでの実行など検証したいことはほかにもあるので、それらが今後の課題です。
Jetsonシリーズではあまりなさそうですが、GPUクラスタでの実行において今後もServingのフレームワークは重要なポイントになりそうです。参考



- 投稿日:2020-12-01T22:53:36+09:00
PythonでJavaScriptの分割代入のようなことをする
やりたいこと
JavaScriptの分割代入のようなことがPythonでしたいです。
destructuringAssignment.jslet a, b, c; [a, b, c] = ["x", "y", "z"]; console.log(a, b, c); // x y z結論
Pythonのシーケンスのアンパックによって実現できます。
unpack.pya, b, c = ("x", "y", "z") print(a, b, c) # x y z余談
Pythonのテキストデータはテキストシーケンス型であり、シーケンスのアンパックが行えます。
textunpack.pya, b, c = "xyz" print(a, b, c) # x y zこのPythonの挙動を見て、JavaScriptではどうなるのか試したところ。。。
textDestructuringAssignment.jslet a, b, c; [a, b, c] = "xyz"; console.log(a, b, c); // x y zいけました!ただし、色々調べましたがこちらの仕様がECMAScriptのどこで定義されているのかはよくわかりませんでした。。。
さらにここから、見かけ上Pythonと同様の記法も試してみました!
textUnpack.jslet a, b, c; a, b, c = "xyz"; console.log(a, b, c); // undefined undefined xyzどうやら左辺の最後の変数に右辺の値が代入され、左辺の最後以外の変数は
undefinedとなるようです。
このあたりの仕様も一旦この記事にメモ書きして、興味が湧いたらまた調べます!参考URL
分割代入 - JavaScript | MDN
5. データ構造 — Python 3.9.1rc1 ドキュメント
組み込み型 — Python 3.9.1rc1 ドキュメント
- 投稿日:2020-12-01T22:40:47+09:00
内点法の概要と主双対内点法のアルゴリズムの解説
はじめに
凸最適化問題に使われている主双対内点法の解説を目標に、凸最適化の概要を説明します。二次計画がメインターゲットです。
この記事は
- ソルバーは使ったことあるけど、もう少しアルゴリズムの中身が知りたい
- 凸最適を学びたいけど、最適化の章までの道のりが長すぎてつらい
な方が対象です。いまどき1から凸最適アルゴリズム実装しようなんて物好きは稀だと思いますが、この記事の目的は主双対内点法を実装するための知識を全体的にふわっと理解することです。
二次計画でよく使われる 主双対内点法 と 有効制約法 を以下に可視化しました。解の求め方が全く異なることが分かります。コードはpythonです。
主双対内点法(primal dual interpoint)
- 内点法の系譜(有効領域の内部を進む)
- 徐々に相補性残差を減少させて最適解を得る
- 線形計画、二次計画、非線形計画まで幅広く対応可能
- 高次元の問題が得意
有効制約法(active set)
- 単体法の系譜(有効領域の壁に沿って進む)
- 二次計画専用
- 等式制約が成立する拘束条件を探索して最適解を得る
- 拘束条件の数が少ない場合は高速
https://github.com/TakaHoribe/python_algorithm/tree/master/convex_optimization_algorithms
※ 初学者向けの記事ですので、厳密性は欠きます。ご容赦ください。
なぜ凸最適化問題は複雑なのか
凸最適は実用性が高いツールであり、matlabやpythonなどの言語を使えば数行で凸最適を実行できます。そのため「まず使ってみる」から入る人が多数だと思います。
そこから、もう少し複雑な問題が解きたい!と勉強し始めると、双対定理、制約想定、実行可能解、スラック変数、ラグランジアン、などなど知らない単語がたくさん出てきます。アルゴリズムを知るために理解しないといけないことが多すぎます(もちろん重要なのですが)。
凸最適の理論を複雑にしている原因の1つが、「不等式制約」の存在です。
具体的な説明に入る前に、以下の3つケースについて解法をざっと比較してみます。
- 等式制約なし
- 等式制約付き
- 不等式制約付き
※ 簡単のために、この章は関数は全部1次元としてます。式は厳密ではないのでご注意を。
1. 制約なしのケース
まずは 制約なし凸最適化問題 です。
\min \ f(x) \tag{1}この解は勾配が0になる点、つまり $\nabla f(x)=0$ を満たす$x$を探すことによって最適解を得ます。これはただの方程式なので、ニュートン法などを使えば簡単に解けます。
2. 等式制約付きのケース
等式制約付きの問題設定は以下の形。
\min \ f(x),\quad {\rm s.t.}\ \ g(x) = 0. \tag{2}これはラグランジュの未定乗数法 と呼ばれるテクニックを用いて、
\begin{aligned} \nabla f(x)+ \lambda \nabla g(x) &= 0,\\ \ g(x)&=0. \end{aligned}を満たす $x, \lambda$ を計算すれば最適解が求まります。少し式が複雑になりましたが、これも結局ただの連立方程式なので、ニュートン法で解けます。低次元であれば手計算も可能で、大学の定期テストでも出てきます。ちなみに、ラグランジュの未定乗数法は18世紀(一説では1788年)には完成していました。
3. 不等式制約付きのケース
これは最も一般的な最適化の形で、問題設定は以下。
\min \ f(x),\quad {\rm s.t.}\ \ h(x) \leq 0. \tag{3}先の(2)と(3)の違いは等式制約「=」が不等式制約「<=」に変わっただけです。このケースは以下で表されるKKT条件を満たす解を計算することによって求めます。
\begin{aligned} \nabla f(x) + \lambda \nabla g(x) + \mu \nabla h(x)=0,\\[6pt] g(x) = 0,\quad \quad h(x) \leq 0,\\[6pt] \mu \geq 0,\quad \quad \mu h(x) = 0. \end{aligned}一気に式が複雑になりました。まず、このKKT条件は不等式が入っているので、これまで有効だったニュートン法が(直接は)使えません。また、このKKT条件の論文が公開されたのは1951年であり、ラグランジュの未定乗数法の発見から200年近くも経っています。等式を不等式に変えただけで200年かかるのです。このKKT条件の導出には双対などの複雑な概念が取り入れられています。また、凸最適問題のほとんどがこの不等式付きのケースであるため、凸最適化全体が難しく見えてしまっているわけです。
つまり、凸最適化の理論は研究者たち長年かけて作り上げてきたものなので、そりゃ難しいよね、という結論です。
(※無理やり近似して解く方法はもっと前から知られていたらしいですが。)
ですが、目的もよくわからない概念を勉強していたら1日が終わっていた、なんてことは避けたいので、ここからは完璧な理解よりアルゴリズムの実装に重点を置いて凸最適の概要をまとめます。
今はとりあえず、不等式ってそんなめんどくさかったんだ、程度に思っていただければ大丈夫です。
もっと詳しく知りたいなーと思った方は、コチラをどうぞ。
凸最適化とは
凸最適化問題とは、凸空間で凸関数を最小化する問題です。「凸」がここまで注目される理由は、とにかく数学的に扱いやすいからです。
凸関数
定義:関数上の任意の二点を結んだ直線が必ずもとの関数の上に存在する。
特徴:極値が1つしかない
つまり:極小値が必ず最小値になる。凸空間
定義:空間上の任意の二点を結んだ直線が必ずもとの空間の内部に存在する。
特徴:直線で任意の空間上を移動できる。
つまり:直線で移動できない領域は考えなくて良い。これらの特徴のおかげで、勾配方向に直線探索をしながら極小値を求めれば、それが最適解であることが保証されます。
逆に凸関数ではない場合は、たとえ極小値であっても最小値と確定することはできません。
また凸空間ではない場合は、直線探索で境界にぶつかった際に、その境界を回り込んだ裏の空間の存在も考えければなりません。
とりあえず定式化と標準形
凸最適化は一般的に凸関数 $f(x),\ h(x)$ を用いて以下の形で書かれます。
\min \ f(x),\ \ {\rm s.t.}\ h(x) \leq 0.ここで、$h(x)\leq 0$ は凸空間を表しています( $h(x)\leq 0$ が凸空間を表す...?ってなった方はこちら)。
これを凸最適の標準形に変形します。
ここで、下のような一次関数を考えます(凸最適ではアフィン関数という名前でよく出てきます)。
g(x)=Ax+bこの一次関数は定義上は凸関数であり、符号を逆転した $-g(x)$ も凸関数であるという特徴があります。これを利用して、
g(x) \leq 0,\ \ -g(x) \leq 0と制約を作ることによって、実質 $g(x)=0$ という等式制約条件を凸最適化の中に入れ込むことができます。
これを利用して、凸最適化問題は凸関数 $f(x)$, $h(x)$ および一次関数 $g(x)$ を用いて以下のように標準化されます。
\begin{aligned} \min \ &f(x),\\ {\rm s.t.}\ \ &g(x) = 0,\\ &h(x) \leq 0. \end{aligned} \tag{4}標準形というよりは、一次関数という特殊ケースに対応した特殊形のように思えるのですが、等式制約というのが非常に有用なので、この形式を標準形として議論を進めることが多いです。
標準形をもっと簡単な形にしたい(スラック変数による変形)
標準形(4)では $h(x)\leq 0$ という不等式制約がありますが、はじめにも述べたとおり、基本的に最適化問題において「不等式」制約は非常に厄介な代物で、「等式」制約のほうが遥かに簡単に取り扱えます。
そこで、なんとかしてこの不等式制約 $h(x)\leq 0$ を等式制約に変形します。このとき使われる変数はスラック変数と呼ばれ、変数 $s$ で表されることが多いです。
スラック変数の効果を確認します。まず、
h(x) \leq 0この不等式は、
h(x)-s=0,\quad s\geq 0と同じ意味であることを確認してください。"スラック" は日本語で "緩み" や "余裕" みたいな意味なので、 不等式を直接扱うのではなく、等式からの "余裕" に対して不等式制約を付けるイメージです。この要領で、最適化問題の標準形は、スラック変数を用いて
\begin{aligned} \min_{x,\ s}\ &f(x),\\ \ {\rm s.t.}\ \ &g(x)=0,\ h(x)-s=0,\\[5pt] & s \geq 0 \end{aligned}と書くことができます。
これの何が嬉しいかと言うと、最適化問題において最も厄介な不等式制約が、$s\geq 0$ という非常に簡単な形で書き下せることです。
ただ、今の状態では変数 $x$ とスラック変数 $s$ の2つが変数として存在し、そのうちスラック変数のみに不等式制約がついています。これではすこし使いづらいので、もう少し工夫をします。変数$x$を
x=x^+-x^-,\ \ x^+\geq 0,\ x^- \geq 0と分解してやると、最適化問題を
\begin{aligned} \min_{x^+,x^-,s}\ &f(x),\\ \ {\rm s.t.}\ \ &g(x)=0,\ h(x)-s=0,\\[5pt] & x^+\geq 0,\ x^- \geq 0,\ s \geq 0 \end{aligned}と書き換えることができます。不等式制約を見ると、最適化変数として使用されている$(x^+,x^-,s)$の全てに対して不等式制約がついています。これをまとめて $x=[x^+,x^-,s]^T$ と再定義して、等式制約もすべてまとめて $g(x)$と定義しなおせば、最終的に最適化問題は
\begin{aligned} \min_{x}\ &f(x),\\ \ {\rm s.t.}\ \ &g(x)=0,\\[5pt] & x \geq 0 \end{aligned} \tag{5}と書くことができます。変数の次元が2倍以上になりましたが、それでも厄介な不等式制約を $x\geq 0$といった単純な形にできるのは大きなメリットがあります。
(4)式、(5)式のどちらも標準形としてよく出てくる形ですが、一般論を議論するときは(4)、アルゴリズムの説明では(5)を用いることが多いです。
凸最適化で用いる用語の説明
凸最適化には双対性など色々と小難しい用語が出てきますが、計算を回すだけであれば、凸性の特徴とKKT条件の形だけ知っていればなんとかなります。
この記事でも、双対みたいな難しい用語はなるべく使いたくないのですが、このあたりの流れを知らないと、凸最適(というより最適化問題)で一番重要なKKT条件が完全にブラックボックス化してしまいます。そして論文やドキュメントの多くでは、これは双対変数の〜と言った書き方をされるので、ある程度用語を知らないと理解が進みません。なので、かなり雑ではありますが、全体の用語のつながりを説明します。(一つ一つの詳細は省きます。)
※ 表記や可解性のような厳密さは無視するのでご容赦ください
忙しい人へ
KKT条件
不等式制約付き最適化問題の最適解が満たすべき必要条件。凸最適化問題ではほとんどのケースで必要十分条件となる。式に出てくる$\lambda$や$\mu$は、導出の仮定で双対問題の変数になったり、ラグランジュ関数の係数になったりするので、双対変数とかラグランジュ乗数とか呼ばれる。双対問題
与えられた問題(主問題)に対応するラグランジュ関数を最大化する問題。この問題自体が重要と言うよりは、双対定理と組み合わせて初めて意味がある。双対定理
KKT条件の元になった定理で、最適解において双対問題と主問題の目的関数が一致するという定理。相補性条件
KKT条件に出てくる式の一つで、解釈が重要なので名前がついている。最適解においては、不等式制約の関数か、そのラグランジュ乗数のどちらかが0である、という式。双対ギャップ
主問題と双対問題の目的関数の差。双対定理から、最適解であれば差は0であるため、どれだけ最適解から離れているかの指標として使われる。これらの単語の関係性をまとめたものが下図。以下はこの図をベースに説明します。
1次最適性条件
図の左側で四角く囲まれている部分です。ここだけ先にまとめてバッと説明します。
1次最適性条件とは、最適解において1階導関数が満たすべき必要条件です。「制約なし」最適化問題では
\nabla f(x)=0となり、見慣れた形になります。
ちなみに、2次最適性条件というのもあり、制約なし最適化問題の2次最適性条件は $\nabla^2 f(x)>0$ となります。凸関数は定義から常に2次最適性条件を満たすため、凸最適に限っては特に意識しません。
ラグランジュの未定乗数法
「 "等式" 制約付き最適化問題における1次の最適性条件」を導出する方法がラグランジュの未定乗数法であり、以下の式で表されます。
\begin{aligned} \nabla f(x) + \sum_i \lambda_i \nabla g_i(x) =0,\quad g(x) = 0 \end{aligned}これは大学で習った人も多いと思います。ラグランジュ未定乗数法から得られる以下の式:
-\nabla f(x)=\sum_i \lambda_i\nabla g_i(x)これは「(左辺)コストを下げる方向が(右辺)制約条件の法線方向と同じ向きである」ということを意味しています。逆に向きが同じでない場合は、「制約を満たしながら移動可能な方向にコストを下げる方向成分がある」ことを意味し、その点は最適解ではないことになります。以下はよく出てくる幾何的解釈の図。
KKT条件
「"不等式" 制約付き最適化問題における1次の最適性条件」を KKT条件(Karush-Kuhn-Tucker condition) と言い、以下で表されます。
\begin{aligned} \nabla f(x) + \sum_i \lambda_i \nabla g_i(x) + \sum_i \mu_i \nabla h_i(x)=0,\\[6pt] g(x) = 0,\quad \quad h(x) \leq 0,\\[6pt] \mu \geq 0,\quad \quad \mu_i h_i(x) = 0. \end{aligned}式の形はラグランジュの未定乗数法に似ていますが、その他にも条件がいくつか追加されています。また、このKKT条件は常に成り立つわけではないのですが、問題が凸であればほとんどのケースで成立するので、特に考えなくてokです(制約想定について)。
KKT条件の1つ目の式:
-\nabla f(x)=\sum_i \lambda_i\nabla g_i(x) + \sum_i \mu_i \nabla h_i(x)これもラグランジュの未定乗数法と同じように幾何的な解釈が可能です。厄介なのが不等式制約の $h(x)$ なのですが、これはKKT条件の5番目の式(相補性条件):
\mu_i h(x)_i=0から、$h(x)\neq 0$ (制約が非アクティブ) のときは $\mu=0$ であるため、実際に勾配を考えるのは $h(x)= 0$ の場合だけとなります。なので結局ラグランジュの未定乗数法とイメージは同じになります。
KKT条件の導出仮定(凸最適問題の流れ)
ここからKKT条件の導出仮定を大雑把にまとめます。上の図で番号を降ったので、その順番で解説していきます。
①主問題
解きたい凸最適化問題です。後に示す双対問題と比較して、主問題と呼ばれます(Pは主:Primalの意味)。
(P)\ \ \min \ f(x),\ \ {\rm s.t.}\ \ g(x)=0,\ h(x) \leq 0.②ラグランジュ関数
主問題が与えられましたが、いきなりこれを解くのは大変です。とりあえず制約条件が厄介なので、目的関数 $f(x)$ と制約条件 $g(x)$, $h(x)$ に重みを付けて足し合わせたら、何か分からないかな?なノリで、与えられた主問題に対して、ラグランジュ変数と呼ばれる変数 $\lambda,\ \mu$ を導入してラグランジュ関数を作ります。
L(x, \lambda, \mu) = f(x)+\sum_{i=1}^m\lambda_ig_i(x)+\sum_{i=1}^l\mu_ih_i(x)難しいことはしていません。ただそれぞれの関数に変数を掛けて足しただけです。
③ラグランジュ双対関数
②で作ったラグランジュ関数は、凸関数の和なので凸関数になります。拘束条件がないので最小化しやすそうです。なのでとりあえず最小化しましょう。
ラグランジュ関数に対して、$x$ で最小化したものをラグランジュ双対関数といいます。q(\lambda, \mu) = \inf_x \ L(x, \lambda, \mu)ここでもまだ難しいことはしていません。ただ最小化した値を$q$と定義しただけです。
このラグランジュ双対関数の値$q$と主問題の目的関数 $f(x)$の値を比較することによって、次の弱双対定理が得られます。
④弱双対定理
弱双対定理は 「$\mu\geq 0$のとき、ラグランジュ双対関数の値 $q(\lambda, \mu)$ は、主問題の目的関数の値 $f(x)$ を超えない」 というものです。数式で書くと、こう。
\forall \lambda \in \mathbb{R}^m,\ \forall \mu \in \mathbb{R}^l_{+},\ \ \ f(x)\geq q(\lambda, \mu)これは簡単に証明ができます。(制約条件から $g(x)=0,\ \mu h(x)\leq 0$ であることを考えれば、すぐ導出できます。)
この定理の何が嬉しいのかというと、不等式制約のせいで解くのが難しい主問題に対して、制約条件を取り除いたラグランジュ双対関数を最適化すれば、少なくとも主問題の下界が計算できるようになります(下界:最小値以下のなんらかの値)。ラグランジュ双対関数の最適化問題は制約なし凸最適化のため、非常に簡単に実行可能です。
しかし、あくまで求まるのは下界であり、下界が10だとしても、実際の最小値は100かも1000かもしれません。
ちなみに、この下界と、実際の最小値の差 $f(x)- q(\lambda, \mu)$ を双対ギャップと呼びます。
こうなると、この下界をどこまで実際の最小値に近づけることができるのか(ラグランジュ双対関数の値はどこまで大きくできるのか?)という問題を考えたくなります。これが双対問題です。
⑤双対問題
ラグランジュ双対関数は変数として $\lambda$ と $\mu$ を持っています。なので、この変数を変化させれば、より正確に下界を見積もることができるはずです。このように、ラグランジュ双対関数の最大値を求める問題を双対問題といいます。
この問題のニーズは上の弱双対定理から来ているので、弱双対定理の前提である $\mu \geq 0$ が制約条件に入っています(Dは双対:Dualの意味)。
(D) \ \ \max \ q(\lambda, \mu),\ \ {\rm s.t.}\ \ \mu \geq 0.⑥強双対定理
主問題の最適解を $x^{\ast}$ 、双対問題の最適解を $\lambda^{\ast}, \mu^{\ast}$ とします。
強双対定理とは 「主問題の最小値 $f(x^{\ast})$ と双対問題の最大値 $q(\lambda^{\ast}, \mu^{\ast})$ は一致する」 というものです。つまり、弱双対定理のときに考えた「この下界をどこまで実際の最小値に近づけることができるのか」に対する答えは、「完全に一致できる」となります。
f(x^{\ast}) = q(\lambda^{\ast}, \mu^{\ast})主問題と双対関数の目的関数の差は双対ギャップと呼ばれるので、強双対定理は 「最適解では双対ギャップは0である」 と言い換えることもできます。
今まで何となくラグランジュ関数を作って、ゴニョゴニョしてきたのも、全てはこの強双対定理を導くためです。感覚的には、こいつがラスボスです。
この定理の何がすごいかというと、
- 双対問題を解けば、主問題の最適値も求まる
- 双対ギャップを計算するだけで、その解が最適かどうか分かる
という点です。
そもそも不等式制約がついた最適化問題は解析が難しいので、この定理が無いと、最適解かどうかを見極めるだけで一苦労です。それがこの定理のおかげで(双対問題という謎の問題を1つ余分に解かなくてはいけませんが)2つの目的関数の差を計算するだけで最適解かどうかを判定することができます。
このように、今まで何となくラグランジュ関数やら双対問題やらを定義してきましたが、この定理でそれら全てが関連付けられます。
なお、この定理は常に成り立つわけではなく、主問題が制約想定(constraint qualification)と呼ばれる条件を満たしている必要が有ります。強双対定理を使うときは、主問題がこの制約想定が満たされているか確認する必要があるのですが、凸最適化問題の場合は大抵のケースで満たされているため、ここでは深く言及しません。
⑦KKT条件
強双対定理をベースに、主問題の1次最適性条件を書き出したのがKKT条件です。
\begin{aligned} \nabla f(x) + \sum_{i=1}^m \lambda_i \nabla g_i(x) + \sum_{i=1}^l \mu_i \nabla h_i(x)=0,\\ g(x) = 0,\\ h(x) \leq 0,\\ \mu_i \geq 0,\\ \mu_i h_i(x) = 0. \end{aligned} \tag{6}2~4本目の式は、主問題と双対問題の拘束条件から持ってきたもので、1と5本目の式は強双対定理を解析すると出てきます。
基本的にすべてのアルゴリズムは、この条件を満たす解を求めるのが目標なので、最低限このKKT条件の式の形だけ知っていればなんとかなります。
⑦-2 相補性条件
KKT条件の中で5本目の式は特に解釈が重要で、 「相補性条件」 と名前がついています。これは不等式制約の関数 $h(x)$ もしくは、その制約に対応する双対変数 $\mu$ のどちらかが0でなければならない、ということを意味しており、有効制約法の有効制約の判定などに用いられます。
後ほど説明する主双対内点法では、この相補性の右辺を大きな値から徐々に0に近づけて行くことによって最適解を見つけます。
アルゴリズム
用語の説明が終わったところで、実際の最適化アルゴリズムの説明に入ります。
主双対内点法の説明がメインですが、すべての内点法は「実行可能領域の内部で解を徐々に変化させて最適解を求める」という方針のため、極論その解の変化方向と変化量をどう決めるかという問題に帰着します。その違いを確認するためにも、ここでは 主内点法 の一種であるバリア法と、主双対内点法 の一種であるパス追従法について説明します。
バリア関数法(主内点法)
バリア関数法のほうが理解しやすいため、先に説明してしまいます。
バリア法は内点法の一種で、不等式制約をlog関数で近似して、ニュートン法でゴリ押しで解く方法です。非常に直感的で、ここに双対とかラグランジュといったワードは出てきません。(現在は主双対内点法が主流なのであまり使われていないようです。)
ここではまず、凸最適化問題の標準形(5)
\min_x f(x),\quad {\rm s.t.}\ g(x)=0,\ \ x \geq 0を、以下の形
\min_x f(x) - \nu \sum_{i=1}^l\log (x_i),\quad {\rm s.t.}\ g(x)=0.に近似します。等価な変形でないことに注意してください。変化点は、不等式制約が消えたことと、目的関数に以下の関数が追加されたこと。
- \nu \sum_{i=1}^l\log (x_i)これはバリア関数と呼ばれ、$x_i$ が正の方向から0に近づくに従って無限大に発散する関数で、$x_i\geq 0$ の制約の代わりとして近似的に使うことができます。
下の図がバリア関数ですが、$\nu$ が小さくなるに従って、壁が急になり、かつ $x>0$ の部分の値はほぼ$0$であることが分かります。 なので、 $\nu$ が小さい値であれば、殆どの領域でコスト関数に影響を及ぼさず、かつ $x>0$ の制約を取り込むことが可能です。
この時点で、問題から不等式制約が消えているので、ニュートン法を適用したら解くことができます。そして $\nu$ が十分小さい値であれば近似精度も良いはずです。ただし、問題が1つ。急すぎるバリア関数は $x=0$ に近づくと勾配がほぼ無限大になってしまうため、ニュートン法のような微分を使う計算がうまく回りません。
そこで、とりあえず大きな $\nu$ の値をとって、ニュートン法で解きます。その解を初期点として、$\nu$ を少し小さくした問題に対して、またニュートン法で解きます。このように徐々に $\nu$ を小さくして行きながら、本当の解に近づけていきます。こうすると、たとえ勾配が非常に大きな値でも、目標点が初期値のすぐ近くにあるため、計算が発散することはありません。
双対のような概念も現れず、直感的に分かりやすい方法ですが、バリアパラメータ $\nu$ のイテレーションとニュートン法のイテレーションの2種類の反復計算が行われるため、あまり効率の良い方法ではありません。
主双対内点法
主双対内点法は、主問題と双対問題をまとめて解くことによって、主問題の最適解を求める方法の総称です。
そもそも、本来求めたい解を得るためには双対問題は不要であり、無駄に次元を増やしているだけに感じますが、KKT条件を使って主問題と双対問題をまとめて解いたほうが高速と言うことが知られてから頻繁に使われるようになりました。なぜ主双対内点法が高速なのかについて(個人的な)考察は後ほど。
先程で述べた主内点法では $x_{k+1}=x_k+dx_k$ のように徐々に主問題の変数 $x$ を変化させて最適値を探しました。
一方で主双対内点法は、主問題の変数 $x$ と双対問題の変数 $\lambda,\ \mu$ の3変数を同時に変化させて最適値を探す方法です。\begin{aligned} x_{k+1}&=x_k+dx_k\\ \lambda_{k+1}&=\lambda_k+d\lambda_k\\ \mu_{k+1}&=\mu_k+d\mu_k \end{aligned}特徴としては、
- 変数、拘束条件の次元が大きい場合に有利
- 非線形最適化にも適用可能
が挙げられます。
主双対内点法にも勾配計算の違いによって、アフィンスケーリング法、パス追従法、ポテンシャル法などの種類がありますが、基本方針はどれも 「KKT条件を満たす解をニュートン法で求める」 です。
1つ理解してしまえば後は似た感じです。ここではイメージしやすい パス追従法 を取り上げて説明します。
例として、二次計画問題で確認してみます。二次計画問題の標準形は以下のようになります。
\min \ \frac{1}{2}x^TQx+c^Tx,\quad Ax=b,\ x\geq 0.この問題に対するKKT条件(6)は
\begin{aligned} &Ax = b,\ \ x \geq 0,\\ &A^T \lambda+ \mu=Qx+c,\ \ \mu \geq 0,\\ &x_i \mu_i=0 \end{aligned}となります。この式が $(x, \lambda, \mu)$ について解ければ万事解決なのですが、厄介な箇所が二点。
- $x\geq 0,\ \mu \geq 0$ の不等式制約の存在
- 相補性条件が非線形項 $x_i \mu_i$ を含む
この2点がクリアされれば、このKKT条件はただの線形連立方程式になるので解析的に解くことができます。
まず、1点目の不等式制約はとりあえず無視します(あとで対応する)。2点目の双線形は、適当な解の近傍で線形近似する、といった方針で進めます。
まずは不等式制約を無視しましょう。また、相補性条件 $x_i\mu_i$ も添字 $i$ がややこしいので、行列 $X$ を導入してベクトルで形式記述しておきます。 すると、解きたい方程式はこうなります。
\begin{aligned} &Ax = b,\\ &A^T \lambda+ \mu=Qx+c,\\ &X \mu=0.\\[6pt] & {\rm where}\ \ X={\rm diag}(x_1, \cdots, x_n) \end{aligned} \tag{7}次に線形近似について考えます。KKT条件の変数 $(x, \lambda, \mu)$ に対して、適当に初期値 $(x_0, \lambda_0, \mu_0)$ を取ってやります。ちなみにこの初期値は $e$ を単位ベクトルとして $x_0=10^5e,\ \lambda=0,\ \mu_0=10^5e$ のような値を選ぶことが多いそうです。
このとき、初期値 $(x_0, \lambda_0, \mu_0)$ を、
\begin{aligned} x_{k+1} \leftarrow x_k + dx\\ \lambda_{k+1} \leftarrow \lambda_k + d\lambda \\ \mu_{k+1} \leftarrow \mu_k + d\mu \end{aligned} \tag{8}と動かして(7)式を満たす解を求めることを考えます。記述が面倒なので、変数 $z=(x, \lambda, \mu)$ を導入して、この式を下のように書いておきます。
z_{k+1}\leftarrow z_k+dz移動後の解 $z_k+dz$ には方程式(7)を満たしていてほしいので、$z=z_k+dz$ を(7)に代入すると、
\begin{aligned} &A(x_k+dx) = b,\\ &A^T( \lambda+d \lambda)+( \mu_k+d \mu)=Q(x_k+dx)+c,\\ &(X_k+dX)( \mu_k+d \mu)=0 \end{aligned} \tag{9}となります。ここで$dz$が微小であるとして2次の変分量 $dXd\mu \simeq0$ と線形近似を施してやります。すると、(9)の3本目の相補性条件の式は
\begin{aligned} &(X_k+dX)( \mu_k+d \mu) \\[6pt] & \simeq X_{k} \mu_{k} + X_{k}d \mu + \mu_{k}dX = 0 \end{aligned}と近似されます。ここまでをまとめると、解くべき式は
\begin{aligned} &A(x_k+dx) = b,\\ &A^T( \lambda+d \lambda)+( \mu_k+d \mu)=Q(x_k+dx)+c,\\ &X_{k} \mu_{k} + X_{k}d \mu + \mu_{k}dX = 0 \end{aligned}となります。ここまででやっているのは、線形近似して変化量を求めるという、通常のニュートン法の考え方です。正直これをいきなり解いても良いのですが、この式をいきなり $dz$ について解くと、目的値が適当に取った初期値から離れすぎてしまい、線形近似で用いた $dz$ が微小という仮定が破綻してします。そのためパス追従法では「現在の相補性条件の左辺値 $(x_i\mu_i)$ を大きく変化させない範囲で $z$ を動かす」という方針を取ります。
今の解 $z_k$ におけるの $X_i\mu_i$ の平均値 $\nu_k$ を計算しましょう。(とりあえずここでは 相補性残差 と呼びます)
\nu_k= \frac{1}{N}\sum_i^N \left( x_i\mu_i \right)_kこの現在の相補性残差に近い値として、スケールを掛けた相補性残差 $\sigma \nu_k,\ \sigma \in [0, 1)$ を用いて計算を行います。なので結局、KKT条件はこんな感じで近似されます。
\begin{aligned} &A(x_k+dx) = b,\\ &A^T( \lambda+d \lambda)+( \mu_k+d \mu)=Q(x_k+dx)+c,\\ &X_{k} \mu_{k} + X_{k}d \mu + \mu_{k}dX=\sigma \nu_k \end{aligned} \tag{10}これを行列形式で書いたものがこちら。
\begin{aligned} &\begin{bmatrix} A & 0 & 0 \\ -Q & A^T & I\\ M_k & 0 & X_k \end{bmatrix} \begin{bmatrix} dx \\ d \lambda \\ d \mu \end{bmatrix} = \begin{bmatrix} b-Ax_k \\ Qx_k+c-A^T \lambda_k- \mu_k\\ \sigma\nu_k e - X_k \mu_k \end{bmatrix},\\[9pt] &X_k={\rm diag}(x_{k1}, \cdots, x_{kn}),\\ &M_k={\rm diag}(\mu_{k1},\cdots,\mu_{kl}),\quad e=[1,\cdots,1]^T. \end{aligned} \tag{11}この式の左辺はKKT行列などとも呼ばれます。この式はただの $(dx, d\lambda, d\mu)$ の一次連立方程式なので、数値計算で容易に解けます。この解 $dz$ をもとに本来求めたい解 $z$ を更新していきます。(実用上 $\sigma$ は0.1や0.01といった値が用いられるそうです。)
この更新のタイミングで、一番最初に無視した不等式条件を考慮します。
ここで、式(8)から求めた変化量を $dz_k$としましょう。このときの解の更新における方針は、スカラ係数 $\alpha$ を使って、不等式制約を壊さないように $\alpha$ の値を調節しながら、
z_{k+1} \leftarrow z_k + \alpha dz_kのように解の値を更新するというものです。そして、これは簡単な計算から、 $\alpha$ が以下の式を満たしていれば、更新によって不等式制約 $x\geq0,\ \mu\geq 0$ が破られることがないことが分かります。
\alpha = \min \left\{ \min_{dx_i<0} \left(-\frac{x_i}{dx_i}\right),\ \min_{d\mu_i<0} \left( -\frac{\mu_i}{d\mu_i}\right) ,1\right\}この更新によって求められた解を新たな初期値として、(11)式を解いて徐々に双対ギャップを下げていき、ある一定値以下になったところで計算をストップし、最適解を得ます。
解の収束性などの議論はすっ飛ばしましたが、これが大まかな主双対内点法の概要になります。
線形計画、二次計画に適用した場合は以下のような方針になります。
参考記事:
- 内点法 - wikipedia
- 主双対内点法 - 線形計画におけるパス追跡法
- 2次計画問題と内点法 - 東京工業大学 講義資料
- Primal-Dual Interior-Point Methods - CMU Lecture Notes
実装例:IPOPT
バリア法と主双対内点法の共通点(なぜ主双対内点法は高速なのか)
ここを読むと、主双対内点法がなぜ高速計算可能なのかのイメージが(少し)湧きます。(若干発展的な話なので読まなくても良いです。)
バリア関数法を二次計画問題に適用します。二次計画の標準形はこの形。
\min \ \frac{1}{2}x^TQx+c^Tx,\ \ {\rm s.t.}\ \ Ax=b,\ \ x \geq 0.これに対してバリア関数の近似を入れたのが、こんな形。
\min \ \frac{1}{2}x^TQx+c^Tx - \sum_{i}\nu_i \log(x_i) \,\ \ {\rm s.t.}\ \ Ax=b.この式は等式制約条件つきの最適化問題なので、ラグランジュの未定乗数法が適用できます。すると、以下の式が得られます。
\begin{aligned} &Ax=b,\\ &\nabla \left( \frac{1}{2} x^TQx+c^Tx - \sum_{i}\nu_i \log(x_i) \right) + \nabla\lambda^T (b-Ax)=0 \end{aligned}実際に勾配の計算をすると、こうなります。
\begin{aligned} &Ax=b,\\ &Qx+c- \frac{\nu}{x}-A^T\lambda=0, \quad \frac{\nu}{x}=\left[\frac{\nu_1}{x_1}, \cdots, \frac{\nu_n}{x_n} \right] \end{aligned} \tag{12}ラグランジュの未定乗数法から出てきた式なので、これを満たす $x, \lambda$ が見つかれば、それは最適解になっています。
ここで、$\nu/x$ の部分が見にくいので、新たな変数 $\mu$ を用いて
以下の式でまとめます。\frac{\nu}{x}=\mu \quad \quad (\ \Leftrightarrow \ x_i\mu_i=\nu_i)すると(12)式は
\begin{aligned} &Ax=b,\\ &Qx+c- \mu-A^T\lambda=0,\\ &x_i\mu_i=\nu_i \end{aligned}となります。変数が増えましたが、これを満たす $x, \lambda, \mu$ が見つかれば、それは最適解です。
よく見るとこの式は、主双対内点法の各ステップで解いていた方程式(10)と全く同じものになっています。つまり、主双対内点法で求めていた解は、バリア関数法の解と等価であり、相補性残差 $X\mu$ を徐々に小さくしながら解を求めていたのは、バリア関数の係数を徐々に小さくしていきながら最適化問題を解いていたのと同じことだったということです。
バリア関数法は「バリアパラメータ $\nu$のイテレーションとニュートン法のイテレーションの2種類の反復計算が行われるため、あまり効率の良い方法ではない」がデメリットでした。また、$\nu$ の更新の仕方によっては、勾配が急すぎて計算できない or 勾配が小さすぎて解が更新されない、といった問題も起こります。
一方で主双対内点法では「バリアパラメータなどの複数の変数を、相補性残差を0に近づけるという1つの方針に従って同時に最適化する」ことによって高速な計算を可能にしています。
(※ あくまで、ざっくりした個人的考察です。厳密に何で早いかという話は内点法の幾何学とかの論文を読めば書いてあるのかな?詳しい人がいたら教えていただけると嬉しいです。)
有効制約法
ここからは申し訳ない程度に、他のアルゴリズムを載せておきます。
有効制約法は線形計画における単体法を改良して、二次計画に適用したものです(QPの解法として普及した最初のアルゴリズムだそうです)。
手法の大雑把な説明としては、複数の制約条件の中から数個のみを取り出して、その制約条件が有効な場合の解をラグランジュの未定乗数法を用いて求める。相補性条件により、有効制約のラグランジュ定数が全て非負であれば、その解は最適解となる。すべて非負でない場合は、いい感じに制約を追加したり取り除いたりして、全て非負になるまで繰り返す。
という感じです。(言葉で書くより、この記事の冒頭に載せたgifを見ていただいたほうが分かりやすそうです。)
参考記事:
- 講義資料 - 有効制約法
- Algorithms for Quadratic Programming
- 大規模最適化問題へのアプローチ - 有効制約法、内点法、外点法
- 2次計画法 Pythonと機械学習 - Hatena Blog
実装例:qpOASES
交互方向乗数法(ADMM)
特殊な構造を持つ凸最適化問題に対して高速で問題を解くことができる手法です。
最近Oxford大学が公開したOSQPというQPソルバーがADMMをベースにしており、非常に高速だと巷で有名です。このアルゴリズムの解説もしたかったのですが、肝心の何で高速なの?が論文読んでもいまいちつかめなかったので、時間がある時にまとめようと思います。
実装例:OSQP
その他備考
凸関数で凸空間を表す
教授「凸空間は凸関数 $h(x)$ を用いて $h(x)\leq 0$ で表せるよ」と言われた時に、一瞬理解できなかった経験があるのでメモ。
凸関数を平面でカットしたときの下側の空間は凸空間になります。
例えば
・凸関数:$x^2+y^2-5$ を0でカットした下側の空間 $x^2+y^2\leq 5$ は円であり、これは凸空間です。
・2つの凸関数:$x^2+y^2-5$, $(x-1)^2+(y-1)^2-5$ を0でカットした下側の空間 $x^2+y^2\leq 5 \cap (x-1)^2+(y-1)^2\leq 5$ は凸空間です。
・1つの凸関数:$x^2+y^2-5$ と 1つの非凸関数 $-(x-1)^2-(y-1)^2+5$ を0でカットした下側の空間 $x^2+y^2\leq 5 \cap (x-1)^2+(y-1)^2\geq 5$ は凸空間ではありません。
制約想定
強双対性が成り立つための十分条件。(KKT条件も強双対性から来てるので、KKT条件が成り立つための条件でもある。)
なので、KKT条件を使う場合は、最適化問題がこの制約想定を満たしているか確認する必要がある。
制約想定の中にも、1次独立条件やSlater条件などの種類があり、どれか1つでも満たしていればok。
ちなみに凸最適で頻出の Slater条件 は、以下で表される「凸最適化問題」において、
\min \ f(x),\ \ {\rm s.t.} \ \ g(x)=0,\ \ h(x)\leq 0制約の内点に実行可能解を持つ、つまり
g(x)=0,\ \ h(x)< 0を満たす $x$ が1点でも存在する、という条件です。(※ $h(x)$ の制約から等号が消えていることに注意してください。)
KKT条件を線形計画問題で確認する
KKT条件を線形計画問題で確認します。
まず、線形計画法の標準形は下の形式で与えられます。
(P)\ \ \min_x c^T x, \quad {\rm s.t}. \ Ax=b,\ \ x \geq 0よって、ラグランジュ関数は
L(x, \lambda, \mu) = c^Tx + \lambda^T (b - Ax) + \mu^T (-x)となり、ラグランジュ双対関数は
\begin{aligned} q(\lambda, \mu) &= \inf_x \left[ c^Tx + \lambda^T (b - Ax) - \mu^T x \right] \\[5pt] &= \inf_x \left[ (c^T - \lambda^TA - \mu^T) x + \lambda^T b \right]\\[5pt] &= \begin{cases} -\infty \quad (c - A^T\lambda - \mu \neq 0)\\[3pt] \lambda^T b \quad \ (c - A^T\lambda - \mu = 0) \end{cases} \end{aligned}となります。 ($\infty$が出てきたのは線形計画だけのレアケースです。)
ここで、$q=-\infty$ の場合は双対問題に実行可能解が存在しない、という意味になります。上の説明では省きましたが、双対定理が成り立つためには実行可能解が存在することが条件として必要であるため、意味があるのは2つ目の $\lambda^Tb$ になります。よって、実行可能解が存在するための拘束条件を追加して双対問題を以下のように設定します。
(D) \ \ \max \ \lambda^Tb, \ \ {\rm s.t.}\ \ c - A^T\lambda - \mu = 0,\ \mu \geq 0.これに対して、双対定理を確認してみます。双対ギャップ(主問題と双対問題の目的関数の差)は、
c^Tx - \lambda~bです。この値を(P)と(D)の拘束条件を用いて変換すると、
\begin{aligned} c^Tx - \lambda^Tb &= c^Tx - b^T \lambda \\ &= c^Tx - (Ax)^T \lambda \\ &= c^Tx - x^TA^T\lambda \\ & = c^Tx - x^T (c - \mu) \\ &= x^T\mu \end{aligned}となります。拘束条件から $x \geq0,\ \mu \geq 0$ なので、$x^T \mu \geq 0 $ が成り立ちます。よって
c^Tx \geq b^T\lambdaが示せます。これは弱双対定理そのものですね。
対して強双対定理は、最適解において
c^Tx=b^T\lambda\ \ \Leftrightarrow \ \ x^T \mu =0が成り立つことです。これも先程の式変形から
x^T \mu =0と等価であることが分かります。これは相補性条件の式そのものを表しています。
最後に、この例題に対してKKT条件を書き下してみます。
\begin{aligned} \nabla f(x) + \sum_{i=1}^m \lambda_i &\nabla g_i(x) + \sum_{i=1}^l \mu_i \nabla h_i(x) \\ = \nabla(c^Tx) + \nabla &(b - Ax)^T \lambda + \nabla (-x)^T \mu \\ = c - \lambda^TA -\mu &= 0,\\[7pt] Ax&=b,\\ -x &\leq 0, \\ \mu &\geq 0,\\ x^T\mu&=0 \end{aligned}5つの式がありますが、1つ目は双対問題の可解性を満たすために導入した条件、2~4つ目は主・双対問題の拘束条件なので無条件で満たしています。5つ目は強双対定理から得られる式となっていて、 $(x,\ \mu)$ が最適解であればこの条件が満たされます。
したがって、主・双対問題の最適解においてKKT条件が満たされていること(KKT条件が最適解の必要条件であること)が分かります。
参考
- Convex Optimization – Boyd and Vandenberghe:凸最適で最も有名な本。著者曰く初心者向けらしいですが、基本的な情報は網羅されてる。書籍、講義ノートともに無料PDF公開されてる。
- Lecture 1 | Convex Optimization I (Stanford):上の本の著者によるスタンフォード大の講義シリーズ。
- CMU Lecture Note:CMUの講義ノート。これもたぶんBoydの本がベース。
- Wisconsin Univercity - NEOS guide:実際の最適化アルゴリズムについて良くまとまってる
- NTTデータ - Numerical Optimizerアルゴリズム解説:日本語の万能記事
- KKT conditions and Duality:KKT条件の分かりやすいスライド












- 投稿日:2020-12-01T22:40:47+09:00
凸最適化の概要と主双対内点法のアルゴリズムの解説
はじめに
凸最適化問題に使われている主双対内点法の解説を目標に、凸最適化の概要を説明します。二次計画がメインターゲットです。
この記事は
- ソルバーは使ったことあるけど、もう少しアルゴリズムの中身が知りたい
- 凸最適を学びたいけど、最適化の章までの道のりが長すぎてつらい
な方が対象です。いまどき1から凸最適アルゴリズム実装しようなんて物好きは稀だと思いますが、この記事の目的は主双対内点法を実装するための知識を全体的にふわっと理解することです。
二次計画でよく使われる 主双対内点法 と 有効制約法 を以下に可視化しました。解の求め方が全く異なることが分かります。コードはpythonです。
主双対内点法(primal dual interpoint)
- 内点法の系譜(有効領域の内部を進む)
- 徐々に相補性残差を減少させて最適解を得る
- 線形計画、二次計画、非線形計画まで幅広く対応可能
- 高次元の問題が得意
有効制約法(active set)
- 単体法の系譜(有効領域の壁に沿って進む)
- 二次計画専用
- 等式制約が成立する拘束条件を探索して最適解を得る
- 拘束条件の数が少ない場合は高速
https://github.com/TakaHoribe/python_algorithm/tree/master/convex_optimization_algorithms
※ 初学者向けの記事ですので、厳密性は欠きます。ご容赦ください。
なぜ凸最適化問題は複雑なのか
凸最適は実用性が高いツールであり、matlabやpythonなどの言語を使えば数行で凸最適を実行できます。そのため「まず使ってみる」から入る人が多数だと思います。
そこから、もう少し複雑な問題が解きたい!と勉強し始めると、双対定理、制約想定、実行可能解、スラック変数、ラグランジアン、などなど知らない単語がたくさん出てきます。アルゴリズムを知るために理解しないといけないことが多すぎます(もちろん重要なのですが)。
凸最適の理論を複雑にしている原因の1つが、「不等式制約」の存在です。
具体的な説明に入る前に、以下の3つケースについて解法をざっと比較してみます。
- 等式制約なし
- 等式制約付き
- 不等式制約付き
※ 簡単のために、この章は関数は全部1次元としてます。式は厳密ではないのでご注意を。
1. 制約なしのケース
まずは 制約なし凸最適化問題 です。
\min \ f(x) \tag{1}この解は勾配が0になる点、つまり $\nabla f(x)=0$ を満たす$x$を探すことによって最適解を得ます。これはただの方程式なので、ニュートン法などを使えば簡単に解けます。
2. 等式制約付きのケース
等式制約付きの問題設定は以下の形。
\min \ f(x),\quad {\rm s.t.}\ \ g(x) = 0. \tag{2}これはラグランジュの未定乗数法 と呼ばれるテクニックを用いて、
\begin{aligned} \nabla f(x)+ \lambda \nabla g(x) &= 0,\\ \ g(x)&=0. \end{aligned}を満たす $x, \lambda$ を計算すれば最適解が求まります。少し式が複雑になりましたが、これも結局ただの連立方程式なので、ニュートン法で解けます。低次元であれば手計算も可能で、大学の定期テストでも出てきます。ちなみに、ラグランジュの未定乗数法は18世紀(一説では1788年)には完成していました。
3. 不等式制約付きのケース
これは最も一般的な最適化の形で、問題設定は以下。
\min \ f(x),\quad {\rm s.t.}\ \ h(x) \leq 0. \tag{3}先の(2)と(3)の違いは等式制約「=」が不等式制約「<=」に変わっただけです。このケースは以下で表されるKKT条件を満たす解を計算することによって求めます。
\begin{aligned} \nabla f(x) + \lambda \nabla g(x) + \mu \nabla h(x)=0,\\[6pt] g(x) = 0,\quad \quad h(x) \leq 0,\\[6pt] \mu \geq 0,\quad \quad \mu h(x) = 0. \end{aligned}一気に式が複雑になりました。まず、このKKT条件は不等式が入っているので、これまで有効だったニュートン法が(直接は)使えません。また、このKKT条件の論文が公開されたのは1951年であり、ラグランジュの未定乗数法の発見から200年近くも経っています。等式を不等式に変えただけで200年かかるのです。このKKT条件の導出には双対などの複雑な概念が取り入れられています。また、凸最適問題のほとんどがこの不等式付きのケースであるため、凸最適化全体が難しく見えてしまっているわけです。
つまり、凸最適化の理論は研究者たち長年かけて作り上げてきたものなので、そりゃ難しいよね、という結論です。
(※無理やり近似して解く方法はもっと前から知られていたらしいですが。)
ですが、目的もよくわからない概念を勉強していたら1日が終わっていた、なんてことは避けたいので、ここからは完璧な理解よりアルゴリズムの実装に重点を置いて凸最適の概要をまとめます。
今はとりあえず、不等式ってそんなめんどくさかったんだ、程度に思っていただければ大丈夫です。
もっと詳しく知りたいなーと思った方は、コチラをどうぞ。
凸最適化とは
凸最適化問題とは、凸空間で凸関数を最小化する問題です。「凸」がここまで注目される理由は、とにかく数学的に扱いやすいからです。
凸関数
定義:関数上の任意の二点を結んだ直線が必ずもとの関数の上に存在する。
特徴:極値が1つしかない
つまり:極小値が必ず最小値になる。凸空間
定義:空間上の任意の二点を結んだ直線が必ずもとの空間の内部に存在する。
特徴:直線で任意の空間上を移動できる。
つまり:直線で移動できない領域は考えなくて良い。これらの特徴のおかげで、勾配方向に直線探索をしながら極小値を求めれば、それが最適解であることが保証されます。
逆に凸関数ではない場合は、たとえ極小値であっても最小値と確定することはできません。
また凸空間ではない場合は、直線探索で境界にぶつかった際に、その境界を回り込んだ裏の空間の存在も考えければなりません。
とりあえず定式化と標準形
凸最適化は一般的に凸関数 $f(x),\ h(x)$ を用いて以下の形で書かれます。
\min \ f(x),\ \ {\rm s.t.}\ h(x) \leq 0.ここで、$h(x)\leq 0$ は凸空間を表しています( $h(x)\leq 0$ が凸空間を表す...?ってなった方はこちら)。
これを凸最適の標準形に変形します。
ここで、下のような一次関数を考えます(凸最適ではアフィン関数という名前でよく出てきます)。
g(x)=Ax+bこの一次関数は定義上は凸関数であり、符号を逆転した $-g(x)$ も凸関数であるという特徴があります。これを利用して、
g(x) \leq 0,\ \ -g(x) \leq 0と制約を作ることによって、実質 $g(x)=0$ という等式制約条件を凸最適化の中に入れ込むことができます。
これを利用して、凸最適化問題は凸関数 $f(x)$, $h(x)$ および一次関数 $g(x)$ を用いて以下のように標準化されます。
\begin{aligned} \min \ &f(x),\\ {\rm s.t.}\ \ &g(x) = 0,\\ &h(x) \leq 0. \end{aligned} \tag{4}標準形というよりは、一次関数という特殊ケースに対応した特殊形のように思えるのですが、等式制約というのが非常に有用なので、この形式を標準形として議論を進めることが多いです。
標準形をもっと簡単な形にしたい(スラック変数による変形)
標準形(4)では $h(x)\leq 0$ という不等式制約がありますが、はじめにも述べたとおり、基本的に最適化問題において「不等式」制約は非常に厄介な代物で、「等式」制約のほうが遥かに簡単に取り扱えます。
そこで、なんとかしてこの不等式制約 $h(x)\leq 0$ を等式制約に変形します。このとき使われる変数はスラック変数と呼ばれ、変数 $s$ で表されることが多いです。
スラック変数の効果を確認します。まず、
h(x) \leq 0この不等式は、
h(x)-s=0,\quad s\geq 0と同じ意味であることを確認してください。"スラック" は日本語で "緩み" や "余裕" みたいな意味なので、 不等式を直接扱うのではなく、等式からの "余裕" に対して不等式制約を付けるイメージです。この要領で、最適化問題の標準形は、スラック変数を用いて
\begin{aligned} \min_{x,\ s}\ &f(x),\\ \ {\rm s.t.}\ \ &g(x)=0,\ h(x)-s=0,\\[5pt] & s \geq 0 \end{aligned}と書くことができます。
これの何が嬉しいかと言うと、最適化問題において最も厄介な不等式制約が、$s\geq 0$ という非常に簡単な形で書き下せることです。
ただ、今の状態では変数 $x$ とスラック変数 $s$ の2つが変数として存在し、そのうちスラック変数のみに不等式制約がついています。これではすこし使いづらいので、もう少し工夫をします。変数$x$を
x=x^+-x^-,\ \ x^+\geq 0,\ x^- \geq 0と分解してやると、最適化問題を
\begin{aligned} \min_{x^+,x^-,s}\ &f(x),\\ \ {\rm s.t.}\ \ &g(x)=0,\ h(x)-s=0,\\[5pt] & x^+\geq 0,\ x^- \geq 0,\ s \geq 0 \end{aligned}と書き換えることができます。不等式制約を見ると、最適化変数として使用されている$(x^+,x^-,s)$の全てに対して不等式制約がついています。これをまとめて $x=[x^+,x^-,s]^T$ と再定義して、等式制約もすべてまとめて $g(x)$と定義しなおせば、最終的に最適化問題は
\begin{aligned} \min_{x}\ &f(x),\\ \ {\rm s.t.}\ \ &g(x)=0,\\[5pt] & x \geq 0 \end{aligned} \tag{5}と書くことができます。変数の次元が2倍以上になりましたが、それでも厄介な不等式制約を $x\geq 0$といった単純な形にできるのは大きなメリットがあります。
(4)式、(5)式のどちらも標準形としてよく出てくる形ですが、一般論を議論するときは(4)、アルゴリズムの説明では(5)を用いることが多いです。
凸最適化で用いる用語の説明
凸最適化には双対性など色々と小難しい用語が出てきますが、計算を回すだけであれば、凸性の特徴とKKT条件の形だけ知っていればなんとかなります。
この記事でも、双対みたいな難しい用語はなるべく使いたくないのですが、このあたりの流れを知らないと、凸最適(というより最適化問題)で一番重要なKKT条件が完全にブラックボックス化してしまいます。そして論文やドキュメントの多くでは、これは双対変数の〜と言った書き方をされるので、ある程度用語を知らないと理解が進みません。なので、かなり雑ではありますが、全体の用語のつながりを説明します。(一つ一つの詳細は省きます。)
※ 表記や可解性のような厳密さは無視するのでご容赦ください
忙しい人へ
KKT条件
不等式制約付き最適化問題の最適解が満たすべき必要条件。凸最適化問題ではほとんどのケースで必要十分条件となる。式に出てくる$\lambda$や$\mu$は、導出の仮定で双対問題の変数になったり、ラグランジュ関数の係数になったりするので、双対変数とかラグランジュ乗数とか呼ばれる。双対問題
与えられた問題(主問題)に対応するラグランジュ関数を最大化する問題。この問題自体が重要と言うよりは、双対定理と組み合わせて初めて意味がある。双対定理
KKT条件の元になった定理で、最適解において双対問題と主問題の目的関数が一致するという定理。相補性条件
KKT条件に出てくる式の一つで、解釈が重要なので名前がついている。最適解においては、不等式制約の関数か、そのラグランジュ乗数のどちらかが0である、という式。双対ギャップ
主問題と双対問題の目的関数の差。双対定理から、最適解であれば差は0であるため、どれだけ最適解から離れているかの指標として使われる。これらの単語の関係性をまとめたものが下図。以下はこの図をベースに説明します。
1次最適性条件
図の左側で四角く囲まれている部分です。ここだけ先にまとめてバッと説明します。
1次最適性条件とは、最適解において1階導関数が満たすべき必要条件です。「制約なし」最適化問題では
\nabla f(x)=0となり、見慣れた形になります。
ちなみに、2次最適性条件というのもあり、制約なし最適化問題の2次最適性条件は $\nabla^2 f(x)>0$ となります。凸関数は定義から常に2次最適性条件を満たすため、凸最適に限っては特に意識しません。
ラグランジュの未定乗数法
「 "等式" 制約付き最適化問題における1次の最適性条件」を導出する方法がラグランジュの未定乗数法であり、以下の式で表されます。
\begin{aligned} \nabla f(x) + \sum_i \lambda_i \nabla g_i(x) =0,\quad g(x) = 0 \end{aligned}これは大学で習った人も多いと思います。ラグランジュ未定乗数法から得られる以下の式:
-\nabla f(x)=\sum_i \lambda_i\nabla g_i(x)これは「(左辺)コストを下げる方向が(右辺)制約条件の法線方向と同じ向きである」ということを意味しています。逆に向きが同じでない場合は、「制約を満たしながら移動可能な方向にコストを下げる方向成分がある」ことを意味し、その点は最適解ではないことになります。以下はよく出てくる幾何的解釈の図。
KKT条件
「"不等式" 制約付き最適化問題における1次の最適性条件」を KKT条件(Karush-Kuhn-Tucker condition) と言い、以下で表されます。
\begin{aligned} \nabla f(x) + \sum_i \lambda_i \nabla g_i(x) + \sum_i \mu_i \nabla h_i(x)=0,\\[6pt] g(x) = 0,\quad \quad h(x) \leq 0,\\[6pt] \mu \geq 0,\quad \quad \mu_i h_i(x) = 0. \end{aligned}式の形はラグランジュの未定乗数法に似ていますが、その他にも条件がいくつか追加されています。また、このKKT条件は常に成り立つわけではないのですが、問題が凸であればほとんどのケースで成立するので、特に考えなくてokです(制約想定について)。
KKT条件の1つ目の式:
-\nabla f(x)=\sum_i \lambda_i\nabla g_i(x) + \sum_i \mu_i \nabla h_i(x)これもラグランジュの未定乗数法と同じように幾何的な解釈が可能です。厄介なのが不等式制約の $h(x)$ なのですが、これはKKT条件の5番目の式(相補性条件):
\mu_i h(x)_i=0から、$h(x)\neq 0$ (制約が非アクティブ) のときは $\mu=0$ であるため、実際に勾配を考えるのは $h(x)= 0$ の場合だけとなります。なので結局ラグランジュの未定乗数法とイメージは同じになります。
KKT条件の導出仮定(凸最適問題の流れ)
ここからKKT条件の導出仮定を大雑把にまとめます。上の図で番号を降ったので、その順番で解説していきます。
①主問題
解きたい凸最適化問題です。後に示す双対問題と比較して、主問題と呼ばれます(Pは主:Primalの意味)。
(P)\ \ \min \ f(x),\ \ {\rm s.t.}\ \ g(x)=0,\ h(x) \leq 0.②ラグランジュ関数
主問題が与えられましたが、いきなりこれを解くのは大変です。とりあえず制約条件が厄介なので、目的関数 $f(x)$ と制約条件 $g(x)$, $h(x)$ に重みを付けて足し合わせたら、何か分からないかな?なノリで、与えられた主問題に対して、ラグランジュ変数と呼ばれる変数 $\lambda,\ \mu$ を導入してラグランジュ関数を作ります。
L(x, \lambda, \mu) = f(x)+\sum_{i=1}^m\lambda_ig_i(x)+\sum_{i=1}^l\mu_ih_i(x)難しいことはしていません。ただそれぞれの関数に変数を掛けて足しただけです。
③ラグランジュ双対関数
②で作ったラグランジュ関数は、凸関数の和なので凸関数になります。拘束条件がないので最小化しやすそうです。なのでとりあえず最小化しましょう。
ラグランジュ関数に対して、$x$ で最小化したものをラグランジュ双対関数といいます。q(\lambda, \mu) = \inf_x \ L(x, \lambda, \mu)ここでもまだ難しいことはしていません。ただ最小化した値を$q$と定義しただけです。
このラグランジュ双対関数の値$q$と主問題の目的関数 $f(x)$の値を比較することによって、次の弱双対定理が得られます。
④弱双対定理
弱双対定理は 「$\mu\geq 0$のとき、ラグランジュ双対関数の値 $q(\lambda, \mu)$ は、主問題の目的関数の値 $f(x)$ を超えない」 というものです。数式で書くと、こう。
\forall \lambda \in \mathbb{R}^m,\ \forall \mu \in \mathbb{R}^l_{+},\ \ \ f(x)\geq q(\lambda, \mu)これは簡単に証明ができます。(制約条件から $g(x)=0,\ \mu h(x)\leq 0$ であることを考えれば、すぐ導出できます。)
この定理の何が嬉しいのかというと、不等式制約のせいで解くのが難しい主問題に対して、制約条件を取り除いたラグランジュ双対関数を最適化すれば、少なくとも主問題の下界が計算できるようになります(下界:最小値以下のなんらかの値)。ラグランジュ双対関数の最適化問題は制約なし凸最適化のため、非常に簡単に実行可能です。
しかし、あくまで求まるのは下界であり、下界が10だとしても、実際の最小値は100かも1000かもしれません。
ちなみに、この下界と、実際の最小値の差 $f(x)- q(\lambda, \mu)$ を双対ギャップと呼びます。
こうなると、この下界をどこまで実際の最小値に近づけることができるのか(ラグランジュ双対関数の値はどこまで大きくできるのか?)という問題を考えたくなります。これが双対問題です。
⑤双対問題
ラグランジュ双対関数は変数として $\lambda$ と $\mu$ を持っています。なので、この変数を変化させれば、より正確に下界を見積もることができるはずです。このように、ラグランジュ双対関数の最大値を求める問題を双対問題といいます。
この問題のニーズは上の弱双対定理から来ているので、弱双対定理の前提である $\mu \geq 0$ が制約条件に入っています(Dは双対:Dualの意味)。
(D) \ \ \max \ q(\lambda, \mu),\ \ {\rm s.t.}\ \ \mu \geq 0.⑥強双対定理
主問題の最適解を $x^{\ast}$ 、双対問題の最適解を $\lambda^{\ast}, \mu^{\ast}$ とします。
強双対定理とは 「主問題の最小値 $f(x^{\ast})$ と双対問題の最大値 $q(\lambda^{\ast}, \mu^{\ast})$ は一致する」 というものです。つまり、弱双対定理のときに考えた「この下界をどこまで実際の最小値に近づけることができるのか」に対する答えは、「完全に一致できる」となります。
f(x^{\ast}) = q(\lambda^{\ast}, \mu^{\ast})主問題と双対関数の目的関数の差は双対ギャップと呼ばれるので、強双対定理は 「最適解では双対ギャップは0である」 と言い換えることもできます。
今まで何となくラグランジュ関数を作って、ゴニョゴニョしてきたのも、全てはこの強双対定理を導くためです。感覚的には、こいつがラスボスです。
この定理の何がすごいかというと、
- 双対問題を解けば、主問題の最適値も求まる
- 双対ギャップを計算するだけで、その解が最適かどうか分かる
という点です。
そもそも不等式制約がついた最適化問題は解析が難しいので、この定理が無いと、最適解かどうかを見極めるだけで一苦労です。それがこの定理のおかげで(双対問題という謎の問題を1つ余分に解かなくてはいけませんが)2つの目的関数の差を計算するだけで最適解かどうかを判定することができます。
このように、今まで何となくラグランジュ関数やら双対問題やらを定義してきましたが、この定理でそれら全てが関連付けられます。
なお、この定理は常に成り立つわけではなく、主問題が制約想定(constraint qualification)と呼ばれる条件を満たしている必要が有ります。強双対定理を使うときは、主問題がこの制約想定が満たされているか確認する必要があるのですが、凸最適化問題の場合は大抵のケースで満たされているため、ここでは深く言及しません。
⑦KKT条件
強双対定理をベースに、主問題の1次最適性条件を書き出したのがKKT条件です。
\begin{aligned} \nabla f(x) + \sum_{i=1}^m \lambda_i \nabla g_i(x) + \sum_{i=1}^l \mu_i \nabla h_i(x)=0,\\ g(x) = 0,\\ h(x) \leq 0,\\ \mu_i \geq 0,\\ \mu_i h_i(x) = 0. \end{aligned} \tag{6}2~4本目の式は、主問題と双対問題の拘束条件から持ってきたもので、1と5本目の式は強双対定理を解析すると出てきます。
基本的にすべてのアルゴリズムは、この条件を満たす解を求めるのが目標なので、最低限このKKT条件の式の形だけ知っていればなんとかなります。
⑦-2 相補性条件
KKT条件の中で5本目の式は特に解釈が重要で、 「相補性条件」 と名前がついています。これは不等式制約の関数 $h(x)$ もしくは、その制約に対応する双対変数 $\mu$ のどちらかが0でなければならない、ということを意味しており、有効制約法の有効制約の判定などに用いられます。
後ほど説明する主双対内点法では、この相補性の右辺を大きな値から徐々に0に近づけて行くことによって最適解を見つけます。
アルゴリズム
用語の説明が終わったところで、実際の最適化アルゴリズムの説明に入ります。
主双対内点法の説明がメインですが、すべての内点法は「実行可能領域の内部で解を徐々に変化させて最適解を求める」という方針のため、極論その解の変化方向と変化量をどう決めるかという問題に帰着します。その違いを確認するためにも、ここでは 主内点法 の一種であるバリア法と、主双対内点法 の一種であるパス追従法について説明します。
バリア関数法(主内点法)
バリア関数法のほうが理解しやすいため、先に説明してしまいます。
バリア法は内点法の一種で、不等式制約をlog関数で近似して、ニュートン法でゴリ押しで解く方法です。非常に直感的で、ここに双対とかラグランジュといったワードは出てきません。(現在は主双対内点法が主流なのであまり使われていないようです。)
ここではまず、凸最適化問題の標準形(5)
\min_x f(x),\quad {\rm s.t.}\ g(x)=0,\ \ x \geq 0を、以下の形
\min_x f(x) - \nu \sum_{i=1}^l\log (x_i),\quad {\rm s.t.}\ g(x)=0.に近似します。等価な変形でないことに注意してください。変化点は、不等式制約が消えたことと、目的関数に以下の関数が追加されたこと。
- \nu \sum_{i=1}^l\log (x_i)これはバリア関数と呼ばれ、$x_i$ が正の方向から0に近づくに従って無限大に発散する関数で、$x_i\geq 0$ の制約の代わりとして近似的に使うことができます。
下の図がバリア関数ですが、$\nu$ が小さくなるに従って、壁が急になり、かつ $x>0$ の部分の値はほぼ$0$であることが分かります。 なので、 $\nu$ が小さい値であれば、殆どの領域でコスト関数に影響を及ぼさず、かつ $x>0$ の制約を取り込むことが可能です。
この時点で、問題から不等式制約が消えているので、ニュートン法を適用したら解くことができます。そして $\nu$ が十分小さい値であれば近似精度も良いはずです。ただし、問題が1つ。急すぎるバリア関数は $x=0$ に近づくと勾配がほぼ無限大になってしまうため、ニュートン法のような微分を使う計算がうまく回りません。
そこで、とりあえず大きな $\nu$ の値をとって、ニュートン法で解きます。その解を初期点として、$\nu$ を少し小さくした問題に対して、またニュートン法で解きます。このように徐々に $\nu$ を小さくして行きながら、本当の解に近づけていきます。こうすると、たとえ勾配が非常に大きな値でも、目標点が初期値のすぐ近くにあるため、計算が発散することはありません。
双対のような概念も現れず、直感的に分かりやすい方法ですが、バリアパラメータ $\nu$ のイテレーションとニュートン法のイテレーションの2種類の反復計算が行われるため、あまり効率の良い方法ではありません。
主双対内点法
主双対内点法は、主問題と双対問題をまとめて解くことによって、主問題の最適解を求める方法の総称です。
そもそも、本来求めたい解を得るためには双対問題は不要であり、無駄に次元を増やしているだけに感じますが、KKT条件を使って主問題と双対問題をまとめて解いたほうが高速と言うことが知られてから頻繁に使われるようになりました。なぜ主双対内点法が高速なのかについて(個人的な)考察は後ほど。
先程で述べた主内点法では $x_{k+1}=x_k+dx_k$ のように徐々に主問題の変数 $x$ を変化させて最適値を探しました。
一方で主双対内点法は、主問題の変数 $x$ と双対問題の変数 $\lambda,\ \mu$ の3変数を同時に変化させて最適値を探す方法です。\begin{aligned} x_{k+1}&=x_k+dx_k\\ \lambda_{k+1}&=\lambda_k+d\lambda_k\\ \mu_{k+1}&=\mu_k+d\mu_k \end{aligned}特徴としては、
- 変数、拘束条件の次元が大きい場合に有利
- 非線形最適化にも適用可能
が挙げられます。
主双対内点法にも勾配計算の違いによって、アフィンスケーリング法、パス追従法、ポテンシャル法などの種類がありますが、基本方針はどれも 「KKT条件を満たす解をニュートン法で求める」 です。
1つ理解してしまえば後は似た感じです。ここではイメージしやすい パス追従法 を取り上げて説明します。
例として、二次計画問題で確認してみます。二次計画問題の標準形は以下のようになります。
\min \ \frac{1}{2}x^TQx+c^Tx,\quad Ax=b,\ x\geq 0.この問題に対するKKT条件(6)は
\begin{aligned} &Ax = b,\ \ x \geq 0,\\ &A^T \lambda+ \mu=Qx+c,\ \ \mu \geq 0,\\ &x_i \mu_i=0 \end{aligned}となります。この式が $(x, \lambda, \mu)$ について解ければ万事解決なのですが、厄介な箇所が二点。
- $x\geq 0,\ \mu \geq 0$ の不等式制約の存在
- 相補性条件が非線形項 $x_i \mu_i$ を含む
この2点がクリアされれば、このKKT条件はただの線形連立方程式になるので解析的に解くことができます。
まず、1点目の不等式制約はとりあえず無視します(あとで対応する)。2点目の双線形は、適当な解の近傍で線形近似する、といった方針で進めます。
まずは不等式制約を無視しましょう。また、相補性条件 $x_i\mu_i$ も添字 $i$ がややこしいので、行列 $X$ を導入してベクトルで形式記述しておきます。 すると、解きたい方程式はこうなります。
\begin{aligned} &Ax = b,\\ &A^T \lambda+ \mu=Qx+c,\\ &X \mu=0.\\[6pt] & {\rm where}\ \ X={\rm diag}(x_1, \cdots, x_n) \end{aligned} \tag{7}次に線形近似について考えます。KKT条件の変数 $(x, \lambda, \mu)$ に対して、適当に初期値 $(x_0, \lambda_0, \mu_0)$ を取ってやります。ちなみにこの初期値は $e$ を単位ベクトルとして $x_0=10^5e,\ \lambda=0,\ \mu_0=10^5e$ のような値を選ぶことが多いそうです。
このとき、初期値 $(x_0, \lambda_0, \mu_0)$ を、
\begin{aligned} x_{k+1} \leftarrow x_k + dx\\ \lambda_{k+1} \leftarrow \lambda_k + d\lambda \\ \mu_{k+1} \leftarrow \mu_k + d\mu \end{aligned} \tag{8}と動かして(7)式を満たす解を求めることを考えます。記述が面倒なので、変数 $z=(x, \lambda, \mu)$ を導入して、この式を下のように書いておきます。
z_{k+1}\leftarrow z_k+dz移動後の解 $z_k+dz$ には方程式(7)を満たしていてほしいので、$z=z_k+dz$ を(7)に代入すると、
\begin{aligned} &A(x_k+dx) = b,\\ &A^T( \lambda+d \lambda)+( \mu_k+d \mu)=Q(x_k+dx)+c,\\ &(X_k+dX)( \mu_k+d \mu)=0 \end{aligned} \tag{9}となります。ここで$dz$が微小であるとして2次の変分量 $dXd\mu \simeq0$ と線形近似を施してやります。すると、(9)の3本目の相補性条件の式は
\begin{aligned} &(X_k+dX)( \mu_k+d \mu) \\[6pt] & \simeq X_{k} \mu_{k} + X_{k}d \mu + \mu_{k}dX = 0 \end{aligned}と近似されます。ここまでをまとめると、解くべき式は
\begin{aligned} &A(x_k+dx) = b,\\ &A^T( \lambda+d \lambda)+( \mu_k+d \mu)=Q(x_k+dx)+c,\\ &X_{k} \mu_{k} + X_{k}d \mu + \mu_{k}dX = 0 \end{aligned}となります。ここまででやっているのは、線形近似して変化量を求めるという、通常のニュートン法の考え方です。正直これをいきなり解いても良いのですが、この式をいきなり $dz$ について解くと、目的値が適当に取った初期値から離れすぎてしまい、線形近似で用いた $dz$ が微小という仮定が破綻してします。そのためパス追従法では「現在の相補性条件の左辺値 $(x_i\mu_i)$ を大きく変化させない範囲で $z$ を動かす」という方針を取ります。
今の解 $z_k$ におけるの $X_i\mu_i$ の平均値 $\nu_k$ を計算しましょう。(とりあえずここでは 相補性残差 と呼びます)
\nu_k= \frac{1}{N}\sum_i^N \left( x_i\mu_i \right)_kこの現在の相補性残差に近い値として、スケールを掛けた相補性残差 $\sigma \nu_k,\ \sigma \in [0, 1)$ を用いて計算を行います。なので結局、KKT条件はこんな感じで近似されます。
\begin{aligned} &A(x_k+dx) = b,\\ &A^T( \lambda+d \lambda)+( \mu_k+d \mu)=Q(x_k+dx)+c,\\ &X_{k} \mu_{k} + X_{k}d \mu + \mu_{k}dX=\sigma \nu_k \end{aligned} \tag{10}これを行列形式で書いたものがこちら。
\begin{aligned} &\begin{bmatrix} A & 0 & 0 \\ -Q & A^T & I\\ M_k & 0 & X_k \end{bmatrix} \begin{bmatrix} dx \\ d \lambda \\ d \mu \end{bmatrix} = \begin{bmatrix} b-Ax_k \\ Qx_k+c-A^T \lambda_k- \mu_k\\ \sigma\nu_k e - X_k \mu_k \end{bmatrix},\\[9pt] &X_k={\rm diag}(x_{k1}, \cdots, x_{kn}),\\ &M_k={\rm diag}(\mu_{k1},\cdots,\mu_{kl}),\quad e=[1,\cdots,1]^T. \end{aligned} \tag{11}この式の左辺はKKT行列などとも呼ばれます。この式はただの $(dx, d\lambda, d\mu)$ の一次連立方程式なので、数値計算で容易に解けます。この解 $dz$ をもとに本来求めたい解 $z$ を更新していきます。(実用上 $\sigma$ は0.1や0.01といった値が用いられるそうです。)
この更新のタイミングで、一番最初に無視した不等式条件を考慮します。
ここで、式(8)から求めた変化量を $dz_k$としましょう。このときの解の更新における方針は、スカラ係数 $\alpha$ を使って、不等式制約を壊さないように $\alpha$ の値を調節しながら、
z_{k+1} \leftarrow z_k + \alpha dz_kのように解の値を更新するというものです。そして、これは簡単な計算から、 $\alpha$ が以下の式を満たしていれば、更新によって不等式制約 $x\geq0,\ \mu\geq 0$ が破られることがないことが分かります。
\alpha = \min \left\{ \min_{dx_i<0} \left(-\frac{x_i}{dx_i}\right),\ \min_{d\mu_i<0} \left( -\frac{\mu_i}{d\mu_i}\right) ,1\right\}この更新によって求められた解を新たな初期値として、(11)式を解いて徐々に双対ギャップを下げていき、ある一定値以下になったところで計算をストップし、最適解を得ます。
解の収束性などの議論はすっ飛ばしましたが、これが大まかな主双対内点法の概要になります。
線形計画、二次計画に適用した場合は以下のような方針になります。
参考記事:
- 内点法 - wikipedia
- 主双対内点法 - 線形計画におけるパス追跡法
- 2次計画問題と内点法 - 東京工業大学 講義資料
- Primal-Dual Interior-Point Methods - CMU Lecture Notes
実装例:IPOPT
バリア法と主双対内点法の共通点(なぜ主双対内点法は高速なのか)
ここを読むと、主双対内点法がなぜ高速計算可能なのかのイメージが(少し)湧きます。(若干発展的な話なので読まなくても良いです。)
バリア関数法を二次計画問題に適用します。二次計画の標準形はこの形。
\min \ \frac{1}{2}x^TQx+c^Tx,\ \ {\rm s.t.}\ \ Ax=b,\ \ x \geq 0.これに対してバリア関数の近似を入れたのが、こんな形。
\min \ \frac{1}{2}x^TQx+c^Tx - \sum_{i}\nu_i \log(x_i) \,\ \ {\rm s.t.}\ \ Ax=b.この式は等式制約条件つきの最適化問題なので、ラグランジュの未定乗数法が適用できます。すると、以下の式が得られます。
\begin{aligned} &Ax=b,\\ &\nabla \left( \frac{1}{2} x^TQx+c^Tx - \sum_{i}\nu_i \log(x_i) \right) + \nabla\lambda^T (b-Ax)=0 \end{aligned}実際に勾配の計算をすると、こうなります。
\begin{aligned} &Ax=b,\\ &Qx+c- \frac{\nu}{x}-A^T\lambda=0, \quad \frac{\nu}{x}=\left[\frac{\nu_1}{x_1}, \cdots, \frac{\nu_n}{x_n} \right] \end{aligned} \tag{12}ラグランジュの未定乗数法から出てきた式なので、これを満たす $x, \lambda$ が見つかれば、それは最適解になっています。
ここで、$\nu/x$ の部分が見にくいので、新たな変数 $\mu$ を用いて
以下の式でまとめます。\frac{\nu}{x}=\mu \quad \quad (\ \Leftrightarrow \ x_i\mu_i=\nu_i)すると(12)式は
\begin{aligned} &Ax=b,\\ &Qx+c- \mu-A^T\lambda=0,\\ &x_i\mu_i=\nu_i \end{aligned}となります。変数が増えましたが、これを満たす $x, \lambda, \mu$ が見つかれば、それは最適解です。
よく見るとこの式は、主双対内点法の各ステップで解いていた方程式(10)と全く同じものになっています。つまり、主双対内点法で求めていた解は、バリア関数法の解と等価であり、相補性残差 $X\mu$ を徐々に小さくしながら解を求めていたのは、バリア関数の係数を徐々に小さくしていきながら最適化問題を解いていたのと同じことだったということです。
バリア関数法は「バリアパラメータ $\nu$のイテレーションとニュートン法のイテレーションの2種類の反復計算が行われるため、あまり効率の良い方法ではない」がデメリットでした。また、$\nu$ の更新の仕方によっては、勾配が急すぎて計算できない or 勾配が小さすぎて解が更新されない、といった問題も起こります。
一方で主双対内点法では「バリアパラメータなどの複数の変数を、相補性残差を0に近づけるという1つの方針に従って同時に最適化する」ことによって高速な計算を可能にしています。
(※ あくまで、ざっくりした個人的考察です。厳密に何で早いかという話は内点法の幾何学とかの論文を読めば書いてあるのかな?詳しい人がいたら教えていただけると嬉しいです。)
有効制約法
ここからは申し訳ない程度に、他のアルゴリズムを載せておきます。
有効制約法は線形計画における単体法を改良して、二次計画に適用したものです(QPの解法として普及した最初のアルゴリズムだそうです)。
手法の大雑把な説明としては、複数の制約条件の中から数個のみを取り出して、その制約条件が有効な場合の解をラグランジュの未定乗数法を用いて求める。相補性条件により、有効制約のラグランジュ定数が全て非負であれば、その解は最適解となる。すべて非負でない場合は、いい感じに制約を追加したり取り除いたりして、全て非負になるまで繰り返す。
という感じです。(言葉で書くより、この記事の冒頭に載せたgifを見ていただいたほうが分かりやすそうです。)
参考記事:
- 講義資料 - 有効制約法
- Algorithms for Quadratic Programming
- 大規模最適化問題へのアプローチ - 有効制約法、内点法、外点法
- 2次計画法 Pythonと機械学習 - Hatena Blog
実装例:qpOASES
交互方向乗数法(ADMM)
特殊な構造を持つ凸最適化問題に対して高速で問題を解くことができる手法です。
最近Oxford大学が公開したOSQPというQPソルバーがADMMをベースにしており、非常に高速だと巷で有名です。このアルゴリズムの解説もしたかったのですが、肝心の何で高速なの?が論文読んでもいまいちつかめなかったので、時間がある時にまとめようと思います。
実装例:OSQP
その他備考
凸関数で凸空間を表す
教授「凸空間は凸関数 $h(x)$ を用いて $h(x)\leq 0$ で表せるよ」と言われた時に、一瞬理解できなかった経験があるのでメモ。
凸関数を平面でカットしたときの下側の空間は凸空間になります。
例えば
・凸関数:$x^2+y^2-5$ を0でカットした下側の空間 $x^2+y^2\leq 5$ は円であり、これは凸空間です。
・2つの凸関数:$x^2+y^2-5$, $(x-1)^2+(y-1)^2-5$ を0でカットした下側の空間 $x^2+y^2\leq 5 \cap (x-1)^2+(y-1)^2\leq 5$ は凸空間です。
・1つの凸関数:$x^2+y^2-5$ と 1つの非凸関数 $-(x-1)^2-(y-1)^2+5$ を0でカットした下側の空間 $x^2+y^2\leq 5 \cap (x-1)^2+(y-1)^2\geq 5$ は凸空間ではありません。
制約想定
強双対性が成り立つための十分条件。(KKT条件も強双対性から来てるので、KKT条件が成り立つための条件でもある。)
なので、KKT条件を使う場合は、最適化問題がこの制約想定を満たしているか確認する必要がある。
制約想定の中にも、1次独立条件やSlater条件などの種類があり、どれか1つでも満たしていればok。
ちなみに凸最適で頻出の Slater条件 は、以下で表される「凸最適化問題」において、
\min \ f(x),\ \ {\rm s.t.} \ \ g(x)=0,\ \ h(x)\leq 0制約の内点に実行可能解を持つ、つまり
g(x)=0,\ \ h(x)< 0を満たす $x$ が1点でも存在する、という条件です。(※ $h(x)$ の制約から等号が消えていることに注意してください。)
KKT条件を線形計画問題で確認する
KKT条件を線形計画問題で確認します。
まず、線形計画法の標準形は下の形式で与えられます。
(P)\ \ \min_x c^T x, \quad {\rm s.t}. \ Ax=b,\ \ x \geq 0よって、ラグランジュ関数は
L(x, \lambda, \mu) = c^Tx + \lambda^T (b - Ax) + \mu^T (-x)となり、ラグランジュ双対関数は
\begin{aligned} q(\lambda, \mu) &= \inf_x \left[ c^Tx + \lambda^T (b - Ax) - \mu^T x \right] \\[5pt] &= \inf_x \left[ (c^T - \lambda^TA - \mu^T) x + \lambda^T b \right]\\[5pt] &= \begin{cases} -\infty \quad (c - A^T\lambda - \mu \neq 0)\\[3pt] \lambda^T b \quad \ (c - A^T\lambda - \mu = 0) \end{cases} \end{aligned}となります。 ($\infty$が出てきたのは線形計画だけのレアケースです。)
ここで、$q=-\infty$ の場合は双対問題に実行可能解が存在しない、という意味になります。上の説明では省きましたが、双対定理が成り立つためには実行可能解が存在することが条件として必要であるため、意味があるのは2つ目の $\lambda^Tb$ になります。よって、実行可能解が存在するための拘束条件を追加して双対問題を以下のように設定します。
(D) \ \ \max \ \lambda^Tb, \ \ {\rm s.t.}\ \ c - A^T\lambda - \mu = 0,\ \mu \geq 0.これに対して、双対定理を確認してみます。双対ギャップ(主問題と双対問題の目的関数の差)は、
c^Tx - \lambda~bです。この値を(P)と(D)の拘束条件を用いて変換すると、
\begin{aligned} c^Tx - \lambda^Tb &= c^Tx - b^T \lambda \\ &= c^Tx - (Ax)^T \lambda \\ &= c^Tx - x^TA^T\lambda \\ & = c^Tx - x^T (c - \mu) \\ &= x^T\mu \end{aligned}となります。拘束条件から $x \geq0,\ \mu \geq 0$ なので、$x^T \mu \geq 0 $ が成り立ちます。よって
c^Tx \geq b^T\lambdaが示せます。これは弱双対定理そのものですね。
対して強双対定理は、最適解において
c^Tx=b^T\lambda\ \ \Leftrightarrow \ \ x^T \mu =0が成り立つことです。これも先程の式変形から
x^T \mu =0と等価であることが分かります。これは相補性条件の式そのものを表しています。
最後に、この例題に対してKKT条件を書き下してみます。
\begin{aligned} \nabla f(x) + \sum_{i=1}^m \lambda_i &\nabla g_i(x) + \sum_{i=1}^l \mu_i \nabla h_i(x) \\ = \nabla(c^Tx) + \nabla &(b - Ax)^T \lambda + \nabla (-x)^T \mu \\ = c - \lambda^TA -\mu &= 0,\\[7pt] Ax&=b,\\ -x &\leq 0, \\ \mu &\geq 0,\\ x^T\mu&=0 \end{aligned}5つの式がありますが、1つ目は双対問題の可解性を満たすために導入した条件、2~4つ目は主・双対問題の拘束条件なので無条件で満たしています。5つ目は強双対定理から得られる式となっていて、 $(x,\ \mu)$ が最適解であればこの条件が満たされます。
したがって、主・双対問題の最適解においてKKT条件が満たされていること(KKT条件が最適解の必要条件であること)が分かります。
参考
- Convex Optimization – Boyd and Vandenberghe:凸最適で最も有名な本。著者曰く初心者向けらしいですが、基本的な情報は網羅されてる。書籍、講義ノートともに無料PDF公開されてる。
- Lecture 1 | Convex Optimization I (Stanford):上の本の著者によるスタンフォード大の講義シリーズ。
- CMU Lecture Note:CMUの講義ノート。これもたぶんBoydの本がベース。
- Wisconsin Univercity - NEOS guide:実際の最適化アルゴリズムについて良くまとまってる
- NTTデータ - Numerical Optimizerアルゴリズム解説:日本語の万能記事
- KKT conditions and Duality:KKT条件の分かりやすいスライド
- 投稿日:2020-12-01T22:35:52+09:00
Discord Botであそぼ
はじめに
この記事は東京高専プロコンゼミ Advent Calendar①1日目の記事です。
https://adventar.org/calendars/5509Discordとは?
ゲーマー向けの無料ボイスチャットアプリ。SlackやTeamsと同じように1つのサーバーと複数のチャンネルを使ったコミュニケーションツールです。
Discordのいいところを適当に箇条書きで挙げておきます。
- フレンドが今やっているゲームがわかる(マルチプレイに誘いやすい)
- 役職(ロール)という概念があり、かなり細かく権限の設定ができる(ネッ友とリア友が混ざってるサーバーだとすごく便利です)
- ユーザーが多い
- 無料で音声通話が25人まで、ビデオ通話が10人までできる
- Bot開発者にやさしい(Botについては次の章で詳しく説明します)
みんなDiscord、使おう!!(宣伝)
Discord Botとは?
Discordは色々なAPIを無料で提供しています。これを使ってbotを作ることで、音声通話で音楽を流したり、おみくじを作ったり、色々な機能を実現することができます。
APIの公式ドキュメントを1から見て自分でAPIを叩くのは面倒ですが、素晴らしいことに有志のユーザーがAPIのWrapperを作ってくれているので、botを作って動かすのはそう難しいことではありません。(プログラミングの基礎を知っていれば簡単に作れると思います)
現在メジャーなWrapperには、
・JavaScriptで実装されている discord.js
・Pythonで実装されている discord.py
の2つがあります。
この記事では discord.py を使って簡単なbotを実装し動かすところまでを説明していきたいと思います!簡単なbotを作ってみよう!!
というわけで、ようやく本題に入ります。今回は、じゃんけんができるbotを1から作っていきます。
準備
まずは、環境構築を済ませましょう。
今回は入れると長くなってしまうのでpythonとpipの環境構築は省いて、API Tokenの取得とサーバーへのbotの導入,discord.pyのダウンロードを説明します。tokenの取得
Discordにログインした状態で https://discord.com/developers/applications にアクセスします。すると、このような画面が出てくるので右上の"New Application"ボタンを押します。
出てきたポップアップのNAME欄にbotの名前を入力します.今回は"jyankenbot"と入力しました.これは読者の方が自由に変更しても大丈夫ですのでお好きな名前をつけてあげてください!
名前を入力したら"Create"ボタンを押します.
作成が終わると,この画面に遷移するので左のメニューにある"Bot"の部分をクリックしてください.
右上にある"Add Bot"ボタンを押してbotを追加します.
このようなポップアップが出てきますが,"Yes, do it!"を押してください.
作成に成功するとこのような表示がでてくるので,青い"Click to Reveal Token"をクリックしてください.Tokenが表示されます.
次の章ではプログラムにこのTokenを使うので,コピーするなりしてとっておいてください.(何度でも確認できるので個別に保存等はしなくて大丈夫です)
サーバーへのbotの導入
まずは新しくテスト用のサーバーを作りましょう!
サーバー名は適当で大丈夫ですし,アイコン画像もアップロードしなくてもサーバーを作ることができます.新規作成を押したらサーバーが作成されます!
次にbotの招待リンクを取得しましょう!
https://discord.com/developers/applications にアクセスして,先ほど作成したjyankenbotを選択したのち遷移されるページで,左のメニューの"OAuth2"の部分をクリックしてください.
クリックするとこのページに移るので,真ん中の"bot"のチェックボックスを選択してください.
少し下にスクロールすると"BOT PERMISSIONS"という欄があるので,"Administrator"を選択して下さい.これを選ぶとbotがサーバーに対してすべての行為を行えてしまうので,本当は良くないのですが今回はお試しで作るだけなので見逃してください.(ちゃんとしたbotを作るときはちゃんと権限を設定するようにしてください!!!!)
選択できたら画面中央にあるURLをコピーして,アクセスしてください.
アクセスするとbotをサーバーに追加する管理画面が表示されるので,先ほど作ったサーバーを選択して"はい"を押します.
認証ボタンを押す前にしっかり"管理者"にチェックがついていることを確認してください.
先ほど作ったサーバーのページに戻り,jyankenbotが追加されていれば成功です.お疲れさまでした.
discord.pyのダウンロード
ターミナルで以下のコマンドを実行するだけです、簡単!
$ pip install discord.pyプログラムを書く
環境構築が終わったら、さっそくコードを書いていきましょう!
まずはbot.pyファイルを作って,botのベースを書き込んでいきます。bot.pyfrom discord.ext import commands TOKEN = "ここにさっき取得したトークンを入れる" # botの初期化(command_prefixはコマンドの先頭につく文字を示している) bot = commands.Bot(command_prefix="/") # "/test"とメッセージが送られて来たらこの関数を実行する @bot.command() async def test(ctx): # 関数名がそのままコマンドになる # メッセージが送られたチャンネルに"hello world"と送る await ctx.send("hello world!!") # ctx.send()はctx.channel.send()のショートカット if __name__ == "__main__": # botを起動 bot.run(TOKEN)これは,チャットに"/test"と送られると"hello world!!"と返すbotです.
また,このコードではdiscord.pyのコマンドフレームワークというものを使っており,botのコマンド関連のコードをスマートに書くことができています.
次のようなコードでも同じ機能を実装できますが、明らかに前述のコードの方がコードの量が短くきれいですし、コマンドが10個、20個と増えたときもスパゲッティコードにならずに済む実装です。bot.pyimport discord TOKEN = "ここにさっき取得したトークンを入れる" bot = discord.Client() # メッセージが送られて来たらこの関数を実行する @bot.event async def on_message(message): # 文字列が"/"から始まっているかどうかを判定 if message.content.startswith("/"): # 文字列の1文字目を切り捨てる command = message.content[1:] if command == "test": # メッセージが送られたチャンネルに"hello world"と送る await message.channel.send("hello world!!") if __name__ == "__main__": # botを起動 bot.run(TOKEN)では実際にこのbotを動かしてテストしてみましょう!terminalでこのコマンドを実行してください.
$ python bot.pyこのように"/test"と入力して"hello world!!"と返ってきたら成功です!
これでbotの基本的な部分が完成しました!
次はじゃんけんコマンドを作ります!!bot.pyfrom discord.ext import commands from random import randint TOKEN = "ここにさっき取得したトークンを入れる" # botの初期化(command_prefixはコマンドの先頭につく文字を示している) bot = commands.Bot(command_prefix="/") # "/test"とメッセージが送られて来たらこの関数を実行する @bot.command() async def test(ctx): # 関数名がそのままコマンドになる # メッセージが送られたチャンネルに"hello world"と送る await ctx.send("hello world!!") # ctx.send()はctx.channel.send()のショートカット def hand_to_int(hand): """ グー: 0, チョキ: 1, パー: 2 とする handはカタカナ,ひらがな表記,数字に対応する """ hand_int = None if hand in ["グー", "ぐー", "0"]: hand_int = 0 elif hand in ["チョキ", "ちょき", "1"]: hand_int = 1 elif hand in ["パー", "ぱー", "2"]: hand_int = 2 return hand_int def get_player_result(player_hand, bot_hand): """ 勝利: 1, 敗北: 0, ひきわけ: 2 とする result_table[player_hand][bot_hand]で結果がわかるようにする """ result_table = [ [2, 1, 0], [0, 2, 1], [1, 0, 2] ] return result_table[player_hand][bot_hand] @bot.command() async def jyanken(ctx, hand): hand_emoji_list = [":fist:", ":v:", ":hand_splayed:"] player_hand = hand_to_int(hand) if player_hand is None: await ctx.send("不正な手です!もう一度やり直してください!!") return bot_hand = randint(0, 2) await ctx.send( f"あなた: {hand_emoji_list[player_hand]}\n" f"Bot: {hand_emoji_list[bot_hand]}" ) result = get_player_result(player_hand, bot_hand) if result == 0: await ctx.send("残念,あなたの負けです!!") elif result == 1: await ctx.send("おめでとうございます!!,あなたの勝ちです:tada:") else: await ctx.send("あいこ!") if __name__ == "__main__": # botを起動 bot.run(TOKEN)これでbotとじゃんけんができるようになりました!
これから上記のコードの解説をしていきます.まずこの部分ですが,コマンドフレームワークの恩恵でコマンド関数に引数を追加するだけで簡単に
/jyanken ぱーのようなコマンドの後ろの値を取得することができます!@bot.command() async def jyanken(ctx, hand):上の部分でとった手を表すテキストをプログラムで扱いやすいように,この関数を使って変換します.
handが手を表すテキストであれば対応する数字を返します.def hand_to_int(hand): """ グー: 0, チョキ: 1, パー: 2 とする handはカタカナ,ひらがな表記,数字に対応する """ hand_int = None if hand in ["グー", "ぐー", "0"]: hand_int = 0 elif hand in ["チョキ", "ちょき", "1"]: hand_int = 1 elif hand in ["パー", "ぱー", "2"]: hand_int = 2 return hand_int先ほどのように手を数字化したので,事前に勝ち負けを計算した表(2次元配列)を利用して,数字化されたじゃんけん結果を簡単に得ることができます.
def get_player_result(player_hand, bot_hand): """ 勝利: 1, 敗北: 0, ひきわけ: 2 とする result_table[player_hand][bot_hand]で結果がわかるようにする """ result_table = [ [2, 1, 0], [0, 2, 1], [1, 0, 2] ] return result_table[player_hand][bot_hand]最後に結果ごとにメッセージを送ります.
result = get_player_result(player_hand, bot_hand) if result == 0: await ctx.send("残念,あなたの負けです!!") elif result == 1: await ctx.send("おめでとうございます!!,あなたの勝ちです:tada:") else: await ctx.send("あいこ!")コードが書けたら実行して試してみましょう!!
先ほどと同じようにターミナルで以下のコマンドを実行するだけです!$ python bot.pyこのようにじゃんけんができれば成功です!!(僕は勝ててませんが,みなさんは勝てましたか?)
最後に
こんな感じでDiscord Botは簡単に作ることができます!今回はじゃんけんbotを作りましたが,Discord Botは本当に色々なことができるので是非皆さんもオリジナルbotを作って遊んでみてください!!
本当はもっとコードについて詳しく解説したり,botをクラウドにデプロイするところまで書きたかったのですが,さすがに
めんどくさい記事が長くなってしまうのでこのぐらいにしておきます.(デプロイに関してはカレンダーの担当日がもう一日あるので,もしかしたらそこで書くかも?)最後になりますが,拙い文章にここまでお付き合いいただきありがとうございました!!








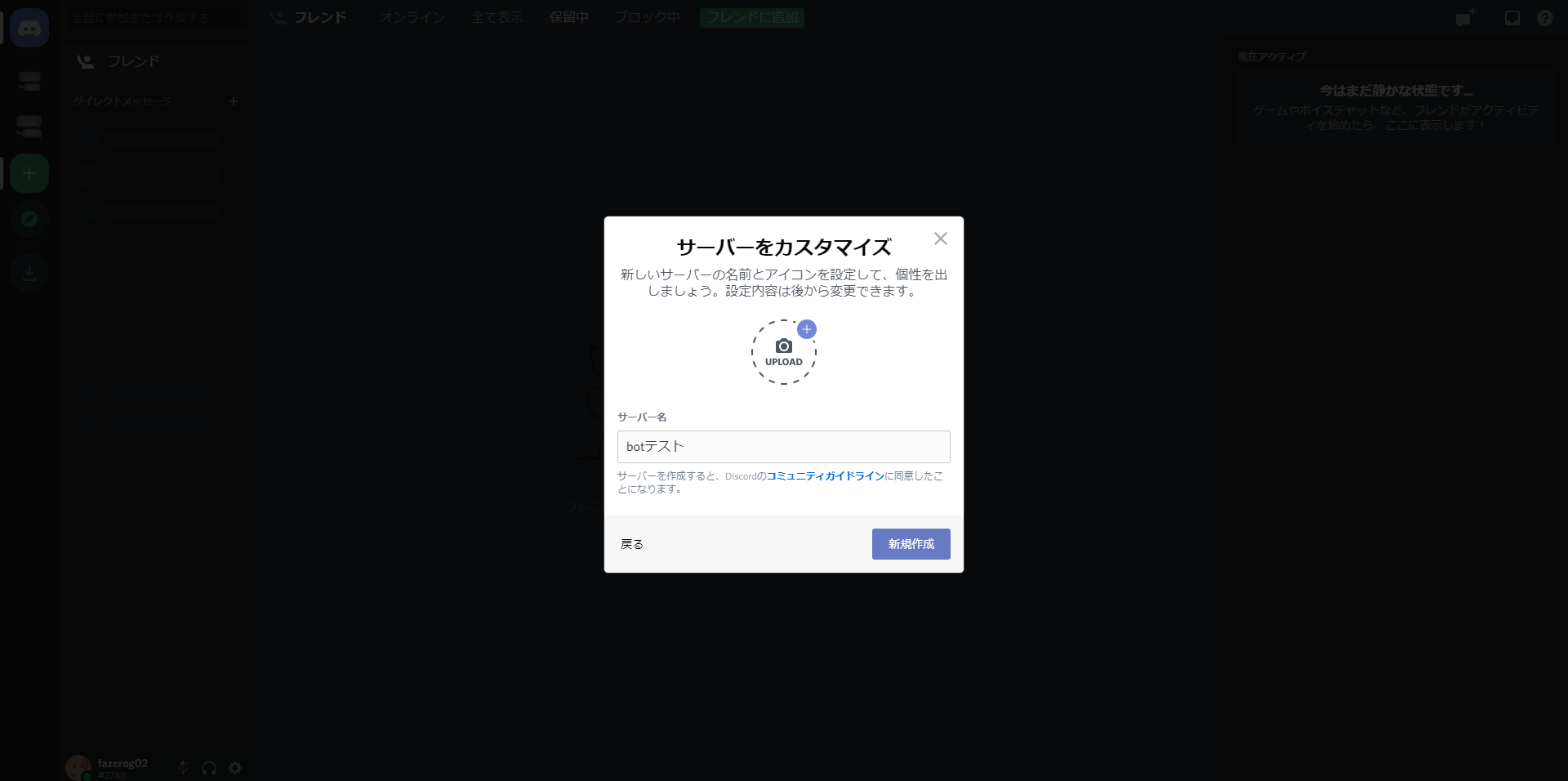







- 投稿日:2020-12-01T22:30:40+09:00
PythonでMCプロトコルを使用してPLCのデータを取り出す
三菱電機株式会社製のPLCからデータを読み出す, 書き込む際には,
MCプロトコルという通信プロトコルを通信フォーマットでデータのやり取りを行う必要があります.すでにQiitaにはMCプロトコルの説明や実装を紹介する記事を先駆者様たちが投稿されていましたが,
この度PythonのMCプロトコルライブラリpymcprotocolを作成いたしましたので紹介いたします.PyPI: https://pypi.org/project/pymcprotocol/
APIリファレンス: https://pymcprotocol.netlify.app/pymcprotocol.html
github: https://github.com/yohei250r/pymcprotocol対応PLC
Qシリーズ, Lシリーズ, iQシリーズに対応.
(QnAシリーズは3Eフレームについては互換とマニュアルにあるので多分通信可能です.
Aシリーズは3Eフレームには対応していないため, 現状は不可です.)対応通信フォーマット
MCプロトコル3Eタイプ(バイナリ形式, ASCII形式)を実装しています.
4Eタイプもそのうち実装します.対応コマンド
- 一括読み込み(ワード単位, ビット単位)
- 一括書き込み(ワード単位, ビット単位)
- ランダム読み込み
- ランダム書き込み(ワード単位, ビット単位)
に対応しています.
その他のコマンドですが, 実装が簡単で使用されそうなコマンドを優先して実装する予定です.インストール
pip install pymcprotocolPLCの設定
PLCのネットワーク設定でIPアドレス設定, MCプロトコル用のポート開放と, イーサネット通信形式の選択をしてください.
PythonからPLCへ接続
import pymcprotocol #Qシリーズがデフォルトです pymc3e = pymcprotocol.Type3E() #Lシリーズの場合はインスタンス化にplctypeを与えてください pymc3e = pymcprotocol.Type3E(plctype="L") #iQシリーズの場合はインスタンス化にplctypeを与えてください pymc3e = pymcprotocol.Type3E(plctype="iQ") #イーサネットの接続形式をASCIIにした場合はここで"ascii"を与えてください #もしMCプロトコルのアクセス経路をデフォルトから変更する場合もこのメソッドから可能です. pymc3e.setaccessopt(commtype="ascii") #PLCに設定したIPアドレス, MCプロトコル用ポートに接続 pymc3e.connect("192.168.1.2", 1025)コマンド発行
#D100からD110まで読み込み wordunits_values = pymc3e.batchread_wordunits(headdevice="D100", readsize=10) #X10からX20まで読み込み(ビットデバイスアクセス) bitunits_values = pymc3e.batchread_bitunits(headdevice="X10", readsize=10) #D10からD15まで与えた数値を書き込み pymc3e.batchread_wordunits(headdevice="D10", values=[0, 10, 20, 30, 40]) #Y10からY15まで与えた数値を書き込み(ビットデバイスアクセス) pymc3e.batchread_bitunits(headdevice="Y10", values=[0, 1, 0, 1, 0]) #"D1000", "D2000"をワード単位で読み込み #"D3000"をダブルワードで読み込み. (D3001が上位16ビットD3000が下位16ビット) word_values, dword_values = pymc3e.randomread(word_devices=["D1000", "D2000"], dword_devices=["D3000"]) #"D1000"に1000 "D2000"に2000を書き込み #"D3000"に655362を書き込み. (D3001が上位16ビットD3000が下位16ビット) pymc3e.randomwrite(word_devices=["D1000", "D1002"], word_value=[1000, 2000], dword_devices=["D1004"], dword_values=[655362]) #X0とX10にそれぞれ1と0を書き込み pymc3e.randomwrite_bitunits(bit_devices=["X0", "X10"], values=[1, 0]) #通信終了 pymc3e.close()まとめ
poetryでライブラリを作成すると本当に楽なのでおすすめです。
- 投稿日:2020-12-01T22:12:30+09:00
[python] yeo-johnson 変換をして歪度・尖度の減少量を見るメソッド
sklearn の PowerTransformer を使って yeo-johnson 変換を行うメソッドです。yeo-johnson 変換により分布が正規分布に近づきます。yeo-johnson変換を使用する際の参考にどうぞ。
yeo-johnson 変換による歪度・尖度の絶対値の減少量を表示する様にしてあります。歪度・尖度はどちらも正規分布で0になるので、yeo-johnson 変換によりどのくらい正規分布に近づいたかの指標になります。
yeo-johnson 変換を行う前に MinMaxScaler で正規化(最小値0、最大値1に変換)しています。これをしておかないと、
np.random.randn(30) / 100 + 10という様に、分散が小さく平均が大きい標本でRuntimeWarning: divide by zero encountered in logという warning が出ます。(結果が全て同じ値になってしまいます。) 参考:https://github.com/scikit-learn/scikit-learn/issues/14959#issuecomment-602090088import pandas as pd def yeojohnson(df): # 参照渡しされるので新規のものに変えておく df = df.copy() # 比較用に残しておく df_orig = df.copy() # yeo-johnson # 標準化は別にしても良い(standardize=Trueにしても良い) # mmなしだと、エラーが出たりするので先にやっておく # 参考:https://github.com/scikit-learn/scikit-learn/issues/14959#issuecomment-574253115 # 参考:https://github.com/scikit-learn/scikit-learn/issues/14959#issuecomment-602090088 from sklearn.preprocessing import MinMaxScaler, PowerTransformer mm = MinMaxScaler() pt = PowerTransformer(standardize=False) df[:] = mm.fit_transform(df[:]) df[:] = pt.fit_transform(df[:]) # 歪度・尖度を計算 # 歪度:負:左長裾、0:正規分布、正:右長裾 # 尖度:負:平、0:正規分布、正:凸 # なので絶対値の差を見る df_diff = pd.concat([ df_orig.skew(), df.skew(), df_orig.skew().abs() - df.skew().abs(), df_orig.kurtosis(), df.kurtosis(), df_orig.kurtosis().abs() - df.kurtosis().abs(), ], axis=1) df_diff.columns=[ 'skew (original)', 'skew (yeo-johnson)', 'skew abs decrease', 'kurtosis (original)', 'kurtosis (yeo-johnson)', 'kurtosis abs decrease', ] display(df_diff) return df # 使用例 from sklearn.datasets import load_iris iris = load_iris(as_frame=True)['data'] yeojohnson(iris)出力(歪度・尖度の減少量):

- 投稿日:2020-12-01T22:03:02+09:00
レーベンシュタイン距離でマジカルチェンジ!!
はじめに
COTOHA APIでマジカルバ・ナ・ナ!!に触発されて書きました。
レーベンシュタイン距離とは
レーベンシュタイン距離(Levenshtein distance)とは、二つの文字列がどれぐらい近いか(異なるか)を示すものです。
編集距離とも呼ばれます。一方の文字列をもう一方の文字列に変えるのに、
- 置換
- 削除
- 挿入
の操作を何回行うか、というのが定義になります。
図の引用元 https://id.fnshr.info/2011/11/29/damerau/上の図を例にすると、
- 「たいこ」と「たんすいこ」
レーベンシュタイン距離は2。「ん」と「す」を挿入- 「たいこ」と「たこ」
レーベンシュタイン距離は1。「い」を削除- 「たいこ」と「たばこ」
レーベンシュタイン距離は1。「い」を「ば」に置換といった具合になります。
この例からもわかるように、
レーベンシュタイン距離の値が小さい、つまり操作の回数が少ないほど2つの文字列は近く(似ている)、そうでない場合は文字列として遠い(異なる)
ということになります。詳細な使い方やPythonでの実装例は、こちらも参照下さい。
マジカルチェンジとは
90年代に放送されたテレビ番組「マジカル頭脳パワー」の1コーナー。
♪チェーンジ チェンジ♪
♪マジカルチェンジ♪
『つくしという字を1文字変えて?』
→『つくね』
『つくねという字を1文字変えて?』
→『つくえ』
︙といったように、文字を入れ替えて正しいコトバを作ることを繰り返すゲームです。
レーベンシュタイン流のコトバで言うと、
マジカルチェンジとは、編集距離1の置換を繰り返す操作である
と言うことができます(ほーん)。
今回は、レーベンシュタイン距離やMeCabを使用してこのゲームをPythonで実装してみました。
実装して、いろいろと遊んでみて下さい!
内容
環境
言語はPython、環境はGoogle Colaboratoryを使用しました。
ライブラリのインストール
まずはじめに、必要なライブラリをインストールします。
# 文字列同士の判定にレーベンシュタイン距離を使用 !pip install python-Levenshtein # 形態素解析エンジンMeCabと新語に強い辞書mecab-ipadic-NEologdのインストール !apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab > /dev/null !git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git > /dev/null !echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n > /dev/null 2>&1 !pip install mecab-python3 > /dev/null !ln -s /etc/mecabrc /usr/local/etc/mecabrc !echo `mecab-config --dicdir`"/mecab-ipadic-neologd" ★★MeCabとneologdの説明? # ひらがな・カタカナ変換にはpykakasiを使用 !pip install pykakasiGoogle ColabへのMeCabとNEologdのインストールについては、
Google ColabにMeCabとipadic-NEologdをインストールする
を参考にしました。コード
コード全体は以下です。
なお、mecab_list関数については、
PythonでMeCabの出力をリスト化するモジュール(mecab-python)
を参考にしました。from pykakasi import kakasi import Levenshtein as lv import MeCab path = "-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd" tagger = MeCab.Tagger(path) kakasi = kakasi() kakasi.setMode('K', 'H') # カタカナ→ひらがな conv = kakasi.getConverter() def mecab_list(text): node = tagger.parseToNode(text) word_class = [] while node: word = node.surface wclass = node.feature.split(',') if wclass[0] != u'BOS/EOS': if wclass[6] == None: word_class.append((word, wclass[0], wclass[1], wclass[2], "")) else: word_class.append((word, wclass[0], wclass[1], wclass[2], wclass[6])) node = node.next return word_class def magical_change(): answer_list = [] ng_list = [] #NGワードを設定 ng_list = [conv.do(i) for i in ng_list] question = input('最初のコトバを入れてね!(ひらがな or カタカナ)\n') question_hira = conv.do(question) answer_list.append(question_hira) answer = input( """ ################################# ♪チェーンジ チェンジ♪ ♪マジカルチェンジ♪ ################################# Q. 「{}」という字を一文字変えて? """.format(question)) while(True): answer_hira = conv.do(answer) question_hira = conv.do(question) info = lv.editops(question_hira, answer_hira) if answer_hira in answer_list: print('\nアウト!!\n※すでに出たコトバはダメ!') elif answer_hira in ng_list: print('\nアウト!!\n※そういうコトバはダメ!') elif len(info) != 1: print('\nアウト!!\n※変えていいのは1文字だけ!') elif info[0][0] != 'replace': print('\nアウト!!\n※文字の入れかえ以外やっちゃダメ!') elif len(mecab_list(answer)) != 1 or mecab_list(answer)[0][1] != '名詞': print('\nアウト!!\n※そんなコトバはないよ!') print('「{}」の形態素解析の結果は\n{}'.format(answer, mecab_list(answer))) else: answer_list.append(answer_hira) question = answer answer = input('\nQ. 「{}」という字を一文字変えて?\n'.format(question)) continue breakLet's マジカルチェンジ!!
magical_change()実際に遊んでみた様子です。
NG集
【その1】 既出のコトバを言った
回答例
Q. 「りんご」という字を一文字変えて? りんご アウト!! ※すでに出たコトバはダメ!カタカナも同様。
Q. 「りんご」という字を一文字変えて? リンゴ アウト!! ※すでに出たコトバはダメ!説明
リスト(answer_list)を用意し、答えたワードを追加していきます。
そして、答えたワードがリストに入っている場合には、既出のコトバなのでNGとします。
※この判定を入れないと、「りんご→さんご→りんご→さんご→りんご…」というつまらないゲームを生み出してしまいます。また、ひらがなとカタカナの区別をなくす(「りんご」と「リンゴ」は同じとみなす)ため、全てひらがなに統一しています(pykakashiを使用)。
これにより、「りんご」がすでに出た場合には、「リンゴ」と答えてもNGと判定しています。
※本来、マジカルチェンジは口頭で行うゲームなので、ひらがな・カタカナの区別はない。【その2】 NGワードを言った
回答例
Q. 「リンゴ」という字を一文字変えて? ビンゴ アウト!! ※そういうコトバはダメ!説明
言ってほしくないワードをNGと判定したい場合、NGリストに設定しておきます。
ng_list = ['ビンゴ', 'さんご'] #NGワードを設定答えたワードがNGリストに含まれている場合、NG判定をします。
上記のように、NGワードは複数設定可能です。【その3】 2文字以上の操作をしている
回答例
Q. 「りんご」という字を一文字変えて? たんす アウト!! ※変えていいのは1文字だけ!説明
editopsは、一方の文字列を他方の文字列に変換するのに必要な操作と操作の対象となる文字の位置を返します。
info = lv.editops('りんご', 'たんす') print(info) # [('replace', 0, 0), ('replace', 2, 2)] print(len(info)) # 2マジカルチェンジでOKなのは、1文字の置換のみです。
そのため、操作は1回である必要があります。
ここでは、lenでeditopsの要素数(つまり、操作の回数)をチェックして、1でなければNGとしています。【その4】 置換以外の操作をしている
回答例
# 挿入 Q. 「りんご」という字を一文字変えて? りんごす アウト!! ※文字の入れかえ以外やっちゃダメ! ------------------------------------------- # 削除 Q. 「りんご」という字を一文字変えて? りん アウト!! ※文字の入れかえ以外やっちゃダメ!説明
【その3】 2文字以上の操作をしている
をクリアしているので、1文字の操作にはなっていますが、置換ではなく挿入もしくは削除を行っている可能性があります。
マジカルチェンジでOKなのは、1文字の置換のみです。
ここでは、操作の種類をチェックして、replaceでない場合にはNGとしています。info = lv.editops('りんご', 'りんごす') print(info) # [('insert', 3, 3)] print(info[0][0]) # insert info = lv.editops('りんご', 'りん') print(info) # [('delete', 2, 2)] print(info[0][0]) # delete【その5】 コトバとして正しくない
回答例
Q. 「りんご」という字を一文字変えて? あんご アウト!! ※そんなコトバはないよ! 「あんご」の形態素解析の結果は [('あん', '動詞', '自立', '*', 'ある'), ('ご', '接頭詞', '名詞接続', '*', 'ご')]説明
ここまでのNG判定を通過してきたワードは問題なさそうな気が…。
しかし、「コトバとして正しくない」という可能性があります!
そこで、形態素解析および辞書を使用することで、コトバとして正しいかチェックを行っています。
ここでは、「1単語でかつ名詞」のみコトバとして正しいとしています。
ただし、NGとされて納得がいかない場合もあると思いますので、結果も合わせて表示しています。# OK word = 'りんご' print(mecab_list(word)) print(len(mecab_list(word))) print(mecab_list(word)[0][1]) # [('りんご', '名詞', '固有名詞', '人名', 'りんご')] # 1 # 名詞 # NG word = 'あんご' print(mecab_list(word)) print(len(mecab_list(word))) print(mecab_list(word)[0][1]) # [('あん', '動詞', '自立', '*', 'ある'), ('ご', '接頭詞', '名詞接続', '*', 'ご')] # 2 # 動詞ひらがなとカタカナで結果が異なることがあるのでご注意下さい。
word = 'たんご' print(mecab_list(word)) # [('たん', '名詞', '一般', '*', 'たん'), ('ご', '接頭詞', '名詞接続', '*', 'ご')] word = 'タンゴ' print(mecab_list(word)) # [('タンゴ', '名詞', '一般', '*', 'タンゴ')]おまけ
word = '鬼滅の刃' print(mecab_list(word)) # [('鬼滅の刃', '名詞', '固有名詞', '一般', '鬼滅の刃')]NEologdは新語にも対応。
まとめ
いかがだったでしょうか。
今回、Pythonを使ってマジカルチェンジを実装してみました。
レーベンシュタイン距離や形態素解析、辞書を組み合わせることで、こういうちょっとした遊びもできたりします。
是非、皆さんも実装して色々と遊んでみて下さい!


- 投稿日:2020-12-01T22:03:02+09:00
レーベンシュタイン距離でマジカルチ・ェ・ン・ジ!!
はじめに
COTOHA APIでマジカルバ・ナ・ナ!!に触発されて書きました。
レーベンシュタイン距離とは
レーベンシュタイン距離(Levenshtein distance)とは、二つの文字列がどれぐらい近いか(異なるか)を示すものです。
編集距離とも呼ばれます。一方の文字列をもう一方の文字列に変えるのに、
- 置換
- 削除
- 挿入
の操作を何回行うか、というのが定義になります。
図の引用元 https://id.fnshr.info/2011/11/29/damerau/上の図を例にすると、
- 「たいこ」と「たんすいこ」
レーベンシュタイン距離は2。「ん」と「す」を挿入- 「たいこ」と「たこ」
レーベンシュタイン距離は1。「い」を削除- 「たいこ」と「たばこ」
レーベンシュタイン距離は1。「い」を「ば」に置換といった具合になります。
この例からもわかるように、
レーベンシュタイン距離の値が小さい、つまり操作の回数が少ないほど2つの文字列は近く(似ている)、そうでない場合は文字列として遠い(異なる)
ということになります。詳細な使い方やPythonでの実装例は、こちらも参照下さい。
マジカルチェンジとは
90年代に放送されたテレビ番組「マジカル頭脳パワー」の1コーナー。
♪チェーンジ チェンジ♪
♪マジカルチェンジ♪
『つくしという字を1文字変えて?』
→『つくね』
『つくねという字を1文字変えて?』
→『つくえ』
︙といったように、文字を入れ替えて正しいコトバを作ることを繰り返すゲームです。
レーベンシュタイン流のコトバで言うと、
マジカルチェンジとは、編集距離1の置換を繰り返す操作である
と言うことができます(ほーん)。
今回は、レーベンシュタイン距離やMeCabを使用してこのゲームをPythonで実装してみました。
実装して、いろいろと遊んでみて下さい!
内容
環境
言語はPython、環境はGoogle Colaboratoryを使用しました。
ライブラリのインストール
まずはじめに、必要なライブラリをインストールします。
# 文字列同士の判定にレーベンシュタイン距離を使用 !pip install python-Levenshtein # 形態素解析エンジンMeCabと新語に強い辞書mecab-ipadic-NEologdのインストール !apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab > /dev/null !git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git > /dev/null !echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n > /dev/null 2>&1 !pip install mecab-python3 > /dev/null !ln -s /etc/mecabrc /usr/local/etc/mecabrc !echo `mecab-config --dicdir`"/mecab-ipadic-neologd" ★★MeCabとneologdの説明? # ひらがな・カタカナ変換にはpykakasiを使用 !pip install pykakasiGoogle ColabへのMeCabとNEologdのインストールについては、
Google ColabにMeCabとipadic-NEologdをインストールする
を参考にしました。コード
コード全体は以下です。
なお、mecab_list関数については、
PythonでMeCabの出力をリスト化するモジュール(mecab-python)
を参考にしました。from pykakasi import kakasi import Levenshtein as lv import MeCab path = "-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd" tagger = MeCab.Tagger(path) kakasi = kakasi() kakasi.setMode('K', 'H') # カタカナ→ひらがな conv = kakasi.getConverter() def mecab_list(text): node = tagger.parseToNode(text) word_class = [] while node: word = node.surface wclass = node.feature.split(',') if wclass[0] != u'BOS/EOS': if wclass[6] == None: word_class.append((word, wclass[0], wclass[1], wclass[2], "")) else: word_class.append((word, wclass[0], wclass[1], wclass[2], wclass[6])) node = node.next return word_class def magical_change(): answer_list = [] ng_list = [] #NGワードを設定 ng_list = [conv.do(i) for i in ng_list] question = input('最初のコトバを入れてね!(ひらがな or カタカナ)\n') question_hira = conv.do(question) answer_list.append(question_hira) answer = input( """ ################################# ♪チェーンジ チェンジ♪ ♪マジカルチェンジ♪ ################################# Q. 「{}」という字を一文字変えて? """.format(question)) while(True): answer_hira = conv.do(answer) question_hira = conv.do(question) info = lv.editops(question_hira, answer_hira) if answer_hira in answer_list: print('\nアウト!!\n※すでに出たコトバはダメ!') elif answer_hira in ng_list: print('\nアウト!!\n※そういうコトバはダメ!') elif len(info) != 1: print('\nアウト!!\n※変えていいのは1文字だけ!') elif info[0][0] != 'replace': print('\nアウト!!\n※文字の入れかえ以外やっちゃダメ!') elif len(mecab_list(answer)) != 1 or mecab_list(answer)[0][1] != '名詞': print('\nアウト!!\n※そんなコトバはないよ!') print('「{}」の形態素解析の結果は\n{}'.format(answer, mecab_list(answer))) else: answer_list.append(answer_hira) question = answer answer = input('\nQ. 「{}」という字を一文字変えて?\n'.format(question)) continue breakLet's マジカルチェンジ!!
magical_change()実際に遊んでみた様子です。
NG集
【その1】 既出のコトバを言った
回答例
Q. 「りんご」という字を一文字変えて? りんご アウト!! ※すでに出たコトバはダメ!カタカナも同様。
Q. 「りんご」という字を一文字変えて? リンゴ アウト!! ※すでに出たコトバはダメ!説明
リスト(answer_list)を用意し、答えたワードを追加していきます。
そして、答えたワードがリストに入っている場合には、既出のコトバなのでNGとします。
※この判定を入れないと、「りんご→さんご→りんご→さんご→りんご…」というつまらないゲームを生み出してしまいます。また、ひらがなとカタカナの区別をなくす(「りんご」と「リンゴ」は同じとみなす)ため、全てひらがなに統一しています(pykakashiを使用)。
これにより、「りんご」がすでに出た場合には、「リンゴ」と答えてもNGと判定しています。
※本来、マジカルチェンジは口頭で行うゲームなので、ひらがな・カタカナの区別はない。【その2】 NGワードを言った
回答例
Q. 「リンゴ」という字を一文字変えて? ビンゴ アウト!! ※そういうコトバはダメ!説明
言ってほしくないワードをNGと判定したい場合、NGリストに設定しておきます。
ng_list = ['ビンゴ', 'さんご'] #NGワードを設定答えたワードがNGリストに含まれている場合、NG判定をします。
上記のように、NGワードは複数設定可能です。【その3】 2文字以上の操作をしている
回答例
Q. 「りんご」という字を一文字変えて? たんす アウト!! ※変えていいのは1文字だけ!説明
editopsは、一方の文字列を他方の文字列に変換するのに必要な操作と操作の対象となる文字の位置を返します。
info = lv.editops('りんご', 'たんす') print(info) # [('replace', 0, 0), ('replace', 2, 2)] print(len(info)) # 2マジカルチェンジでOKなのは、1文字の置換のみです。
そのため、操作は1回である必要があります。
ここでは、lenでeditopsの要素数(つまり、操作の回数)をチェックして、1でなければNGとしています。【その4】 置換以外の操作をしている
回答例
# 挿入 Q. 「りんご」という字を一文字変えて? りんごす アウト!! ※文字の入れかえ以外やっちゃダメ! ------------------------------------------- # 削除 Q. 「りんご」という字を一文字変えて? りん アウト!! ※文字の入れかえ以外やっちゃダメ!説明
【その3】 2文字以上の操作をしている
をクリアしているので、1文字の操作にはなっていますが、置換ではなく挿入もしくは削除を行っている可能性があります。
マジカルチェンジでOKなのは、1文字の置換のみです。
ここでは、操作の種類をチェックして、replaceでない場合にはNGとしています。info = lv.editops('りんご', 'りんごす') print(info) # [('insert', 3, 3)] print(info[0][0]) # insert info = lv.editops('りんご', 'りん') print(info) # [('delete', 2, 2)] print(info[0][0]) # delete【その5】 コトバとして正しくない
回答例
Q. 「りんご」という字を一文字変えて? あんご アウト!! ※そんなコトバはないよ! 「あんご」の形態素解析の結果は [('あん', '動詞', '自立', '*', 'ある'), ('ご', '接頭詞', '名詞接続', '*', 'ご')]説明
ここまでのNG判定を通過してきたワードは問題なさそうな気が…。
しかし、「コトバとして正しくない」という可能性があります!
そこで、形態素解析および辞書を使用することで、コトバとして正しいかチェックを行っています。
ここでは、「1単語でかつ名詞」のみコトバとして正しいとしています。
ただし、NGとされて納得がいかない場合もあると思いますので、結果も合わせて表示しています。# OK word = 'りんご' print(mecab_list(word)) print(len(mecab_list(word))) print(mecab_list(word)[0][1]) # [('りんご', '名詞', '固有名詞', '人名', 'りんご')] # 1 # 名詞 # NG word = 'あんご' print(mecab_list(word)) print(len(mecab_list(word))) print(mecab_list(word)[0][1]) # [('あん', '動詞', '自立', '*', 'ある'), ('ご', '接頭詞', '名詞接続', '*', 'ご')] # 2 # 動詞ひらがなとカタカナで結果が異なることがあるのでご注意下さい。
word = 'たんご' print(mecab_list(word)) # [('たん', '名詞', '一般', '*', 'たん'), ('ご', '接頭詞', '名詞接続', '*', 'ご')] word = 'タンゴ' print(mecab_list(word)) # [('タンゴ', '名詞', '一般', '*', 'タンゴ')]おまけ
word = '鬼滅の刃' print(mecab_list(word)) # [('鬼滅の刃', '名詞', '固有名詞', '一般', '鬼滅の刃')]NEologdは新語にも対応。
まとめ
いかがだったでしょうか。
今回、Pythonを使ってマジカルチェンジを実装してみました。
レーベンシュタイン距離や形態素解析、辞書を組み合わせることで、こういうちょっとした遊びもできたりします。
是非、皆さんも実装して色々と遊んでみて下さい!
- 投稿日:2020-12-01T21:41:03+09:00
TensorFlowデベロッパー認定資格を受験体験記
この記事は、私が2020年9月にTensorflow Developer Certificateを受験した体験記についての投稿です。
TensorFlowディベロッパー認定資格について
この資格はGoogleよりリリースされたTensorFlowについての認定資格です。
2020年に始まったばかりの試験で、一般的に4択問題の認定資格が多い中で、コーディングが求められる試験です。手を動かしながら楽しみながら受験することができました。概要
試験内容:Pycharmを使ってTensorFlowの機械学習モデル構築(コーディング)。試験の中で、ローカルでモデルを作って学習します。
試験時間:5時間
費用:USD100
レベル:ビギナー向け(ディープラーニング協会のG資格よりは難しくE資格未満の知識+TensorFlowをコーディングできるスキル)
言語:英語(試験の公式ページやガイドブックには日本語版が準備されていますが、申し込み〜試験の実施はすべて英語でした。)TensorFlow デベロッパー認定資格の公式ページ
https://www.tensorflow.org/certificate?hl=ja
事前調査①:ユーザーコミュニティイベントに参加
2020年にローンチされたばかりの新しい試験であるため問題の内容や難易度が未知数でした。TensorFlow のユーザーコミュニティのTensorFlow User Group の主催イベントに参加し(ここから閲覧できます)、試験についていくつか知ることができました。
イベントの中でGoogle Khanh氏がプレゼンされた内容によると
"試験レベルに求められるレベルは"ジュニアの機械学習エンジニアのスキルセットを認定する試験(機械学習チームに入って即戦力になれるスキル)"ということのようです。
今後いくつかのレベルのリリースされる予定があることも言われていましたが、現時点でリリースされた試験はBeginner向けのようです。TFUG主催の動画で先人の方々がさまざまな経験を語っていただいているので、受験を検討されている肩には閲覧をオススメします。
事前準備②:公式ガイドブック
公式ページにある受験者向けのガイドブックが準備されています。日本語もあります。必要とされるスキルセットなどが記載されてます。このスキルセットが問題なく理解できると問題なく合格できると思います。
受験者向けガイドブック
https://www.tensorflow.org/extras/cert/TF_Certificate_Candidate_Handbook_ja.pdf?hl=ja勉強法
TFUGのイベントでも紹介された公式に推奨されているCourseraのオンライン講座を中心に勉強しました。動画で解説されている内容やコードを理解して、自分でも同じようにコーディングしながら、学習を進めました。
講座には16週のコースですが、私の場合は4週間ほどでコースの全カリキュラムを完了しました。
あとはTensorFlowのチュートリアルに記載されている内容を一通り確認しました。
ひたすらローレンス氏の解説を聞いて、手を動かすことを集中して行いました。
DeepLearning.AI テンソルフロー開発者 プロフェッショナル認定
https://www.coursera.org/professional-certificates/tensorflow-in-practiceTensorFlow Tutorial
https://www.tensorflow.org/tutorials?hl=ja申し込み
申し込みからは英語になります。申し込みが完了後、支払いが完了すると試験に向けた準備についてメールにて案内が送られてきます。
そこにPluginのインストール方法や使用するバージョンなどが書かれています。
英語で書かれていますが、Pycharmキャプチャ画像が貼られていますので、分かりやすいと思いました。試験申し込みサイト
https://app.trueability.com/google-certificates/tensorflow-developerいざ試験
5時間の制限時間内に、5つの機械学習モデルを構築します。実際の試験では、構築したモデルを提出することで採点がされます。
実際の試験は、Pycharmを立ち上げて、Pluginにしたがって進めていきます。環境の構築や問題のダウンロードもPluginがやってくれます。ローカル環境にてモデルを構築していくので、GPUの環境があると学習の進みが早いので、GPUがあった方がいいのです。何度も試行錯誤してさまざまなモデルを試せます。ただし必須では無いです。
私の場合は、Pycharmでモデルを構築しながら、他のアプローチについては、Google Colabなどでも並行して課題を違ったアプローチで学習させるなど、いくつかのモデルを並行して構築していきました。Google Colabで作ったモデルをダウンロードして提出を試みましたがエラーとなってしましました。
バージョンなどの不一致などによるものだと思ったのですが、試験の本質から外れてしまうので一旦横において他のモデルを試すくらいのアプローチでGoogle Colabを活用し、試験での提出モデルは、ローカル環境で学習させました。終わってみると5時間という時間はあっと言うまで、他の楽しみながら取り組むことができました。
構築したモデルはh5形式のファイルで保存し、Pycharm上のPluginを通して提出します。
しばらくするとその場で点数が表示されます。
提出回数に制限は無いようで、試験時間内であれば何度も提出ができます。モデルを提出する度に点数が表示されるので5つのモデルを提出し終わった時点では、点数が表示されています。
合格ラインが示されていないのでこれで合格できるか不安が残るのでひたすら高得点取得に向けてモデル構築を行いました。Pycharmを使ったことが無い方は、試験前に使い方などに慣れておいた方が、試験では戸惑いが無いかと思います。
Pycharm
https://www.jetbrains.com/ja-jp/pycharm/受けてみて
合否についてメールで来るのですが、いつまで経っても来ない、、、ということがあり、たまたま迷惑メールフォルダを確認したところ、メールがきておりました。
これから受けられる方はメールが迷惑メールフォルダに分類されてしまうことがあるのでお気をつけください。Beginner向けともコメントされていましたように、難易度は高くなく、基本的な理解や知識、またモデルとしてコーディングする際のスキルが問われた試験でした。
TensorFlowを使うような業務では、基本知識、スキルを扱った資格試験でしたので、合格することもそうですが、普段のスキルアップにもつながると思います。おまけ
今回は、Google主催のML Study Jams “Road to TF Certificate 2020”に登録して、試験を受けました。合格者への特典として、Googleが開発したAIで生成されたクッキーをGoogle様よりいただきました。
ほんのりジンジャーの香りがする硬めのクッキーでしたが非常に美味しかったです。
最後に
実際に事前に勉強するところから試験を受けるまでの流れから考えると、楽しかったという点と改めてTensorFlowの基本を学べてスキルアップできたと言うところに尽きます。
この記事を受けて、試験を受けてみたいと思っていただける方がいらっしゃると嬉しい限りです。
リンク
TensorFlow デベロッパー認定資格の公式ページ
https://www.tensorflow.org/certificate?hl=ja
受験者向けガイドブック
https://www.tensorflow.org/extras/cert/TF_Certificate_Candidate_Handbook_ja.pdf?hl=ja
(Coursera)DeepLearning.AI テンソルフロー開発者 プロフェッショナル認定
https://www.coursera.org/professional-certificates/tensorflow-in-practice
TensorFlow Tutorial
https://www.tensorflow.org/tutorials?hl=ja
TensorFlow User Group Meetup #11 - Road to TF Developer Certificate
https://www.youtube.com/watch?v=PjeAQX7fy6g



- 投稿日:2020-12-01T21:36:48+09:00
量子コンパイラを作る。 その2
概要
量子コンパイラを作る。
成果物
https://embed.plnkr.co/plunk/EFJWjGRw7484JzZE
投入したソース。
make 4 in 0 1 out 2 3 and 0 1 3 xor 0 1 2出力。
from blueqat import Circuit print (Circuit(4).h[ : 2].cx[0, 3].cx[1, 3].ccx[0, 1, 2].m[ : ].run(shots = 1000))実行結果
Counter({'0101': 272, '1110': 258, '1001': 249, '0000': 221})以上。
- 投稿日:2020-12-01T21:30:33+09:00
Watson Assistantの更新をPythonから行う(Watson Assistant API v1を使用)
はじめに
ここではPythonを用いてAPI経由で、IBM Cloud Watson Assistantの情報を更新する方法をメモとしてまとめておきたいと思います。(今回はSkillのNameとdescription, Intentを更新してみたいと思います。)
Watson Assistantの構成
今回、Watson Assistantを触るのは初めてだったので、まずはじめに構成からおさらいします。
Watson Assistantを使ってみて、わかったこととしては、構成として
大きく分けてIntent, Dialog, Entityという3つの要素があるようです。Intent: 質問の意図を定義するところ。
oooな質問がきたら、Aのグループに。
xxxな質問がきたら、Bのグループというように質問とそのグループを定義しているもの。Dialog: 主に回答と会話の流れを定義しているところ。
このグループの質問がきたら、この回答を返すと定義するところ。Entity:
同義語などを定義。ユーザーの入力を情報を表す。
公式サイトには以下と記載されていました。ユーザーが発言した入力テキストから抽出された意味付けされたキーワードが Entity です。
入力テキストから抽出された Entity は、ユーザーの「目的」の対象物を示したりします。公式サイト Watson Assistant (Watson Conversation) の使い方を学ぶ にWatson Assistantの使い方や構成についてわかりやすい記事があったので、これを見れば大まかにわかるはずです。
Watson Assistant APIを呼んでみる
v1, v2のAPI
現在Watson APIにはv1, v2と2つのAPIが存在するようです。
違いについてはこちらのQiitaにまとまっていたので参考にできるかと思いました。各バージョンで使用できるメソッドは公式サイトにまとめられていました。
今回は主にワークスペースの更新を行いたいためここではv1を使いたいと思います。
Skillの更新
SkillはWatson Assistant上のskillsタブを開いた際のこの一つ一つのSkillのことです。
Skillの中にはさきほどざっくり説明した、Intent, Dialog, Entityなど会話に必要な要素を定めることができます。
API経由でSkillのNameとDescriptionを更新する
今回は試しに、一番左の"テスト用"というSkillのスキル名(Name)とスキルの説明(description)をAPIから変更してみたいと思います。
まず現在の設定を確認しましょう。Skillの右上にあるRenameボタンを押すと、現在のスキル名(Name)とスキルの説明(description)を確認することができます。
ここではNameが"テスト用"、Descriptionが"テスト用のスキルです。"となってることが確認できました。公式には各言語でのAPIを呼ぶためのコードは掲載されています。
今回は、Pythonから呼んでみます。まず、ibm-watsonのSDKを環境にインストールする必要があります。
以下を実行してください。$ pip install ibm-watson更新するためのコードは以下になります。こちらは公式にも書いてあるものと同じになります。
(Skillという言葉とworkspaceという言葉がどちらも使われていますが、
以前はSkillではなくworkspaceという名前がついていて、v1のAPIを使用しているので
更新するための関数は公式の方で変更していないのかな・・・?と勝手におもっています。
ここでは公式が定めたAPIの関数以外はSkillという表記にします。)update_skill.pyimport json from ibm_watson import AssistantV1 from ibm_cloud_sdk_core.authenticators import IAMAuthenticator authenticator = IAMAuthenticator('{apikey}') assistant = AssistantV1( version='2020-04-01', authenticator = authenticator ) assistant.set_service_url('{url}') response=assistant.update_workspace( workspace_id='{skill_id}', name='テスト用スキルの更新テスト', # 更新したいスキル名にすること description='テスト用スキルの更新テスト用です。' # 変更したいスキルの説明文章にすること ).get_result() print(json.dumps(response, indent=2))またここに書かれている認証情報がのWatson Assistantのインスタンスのどこと対応しているかを解説します。
まずSkillの右上のView API Detailsを押してください。
このようなSkillの時詳細情報画面に遷移します。
コードとの対応は以下になります。
Skill ID: スキルを識別するためのIDです。
-> コードの {skill_id}に対応します。
Legacy v1 workspace URL: Watson APIを使用する際のエンドポイントです。
"https://api.地域名.assistant.watson.cloud.ibm.com" までを使用します。
-> コードの{url}に対応します。~.comまでを記載してください。
API key: Watson APIを使用する際の認証情報です。
-> {apikey}に対応します。コードの中のnameとdescriptionにはそれぞれ、
更新したいテキストを記載してください。更新後・・・再び先ほどのスキルのRenameを押して、以下の画面を開いて、
NameとDescriptionがさきほどコードの中で設定したテキストになっていれば更新成功です!
API経由でSkillのIntentを更新する
先ほどは一番わかりやすいNameとDescriptionの更新をやってみました。
Intentの更新についても軽く書いておきたいと思います。今回行うのはSkill更新の際に、いくつかIntentを作成し、そのIntentに紐づくテキストを定義することです。
例えば、"greeting"というIntentを作成し、そのカテゴリに分類したいテキスト、"おはよう"・"こんにちは"・"おやすみ"を定義するといった感じです。”カテゴリに分類したいテキスト”というのはWatson Assistant画面上でいうと、特定のIntentに紐づく
User Exampleの部分に対応します。
ではIntentの更新をコードから行ってみます。Intent名がgreetingで、
User examplesが"グッとモーニング、ハロー"をデータとしてセットし、
update_workspaceの引数にIntentをセットします。他のコードは先ほどと同様になります。update_skill.pyimport json from ibm_watson import AssistantV1 from ibm_cloud_sdk_core.authenticators import IAMAuthenticator authenticator = IAMAuthenticator('{apikey}') assistant = AssistantV1( version='2020-04-01', authenticator = authenticator ) assistant.set_service_url('{url}') # intentのデータは以下のように書く。今回はgreetingというintentを作成する let intents_list = [{ "intent": greeting, "examples": [{"text": "グットモーニング"}, {"text": "ハロー"}] }] response=assistant.update_workspace( workspace_id='{skill_id}', intents = intents_list, ).get_result() print(json.dumps(response, indent=2))実行し、Watson Assistantの画面でIntentを確認してみて、greetingというIntentに紐づくUser exampleの部分が変更されていれば成功です。
ちなみにこの更新は差分更新ではなく、workspaceごとの置き換えになるので注意してください。







- 投稿日:2020-12-01T21:28:34+09:00
Pythonでシンセサイザーを作って演奏する。
Pythonでシンセサイザーを作って演奏する。
Python実行環境
AWS cloud9 EC2 Ubuntu t2.small
Python 3.6.9ソースコード
MakeMusic.py
MakeMusic.pyimport numpy as np from scipy.io import wavfile import sys import re import os amp = 0.5 #音量 A = 440.0 #A=440Hz C = A * (2 ** (3 / 12)) #C=440*2^(3/12)H rate = 44100 #サンプリングレート bpm = 120 #BPM scoreWave = None filename = "" #main関数 def main(): readScore() saveWav() if __name__ is "__main__": main() #音の周波数を計算してsin波を生成する関数 def sinWave_from_key(k, o, s): """ parameters ---------- k : string key in scale o : int octave s : int seconds Returns ---------- wave : ndarray """ t = np.arange(0, s, 1 / rate) #時間パラメータ kArray = ['C', 'Cs', 'D', 'Ds', 'E', 'F', 'Fs', 'G', 'Gs', 'A', 'As', 'B'] wave = 0 * t if k in kArray: kNum = kArray.index(k) kFreq = C * (2 ** (kNum / 12)) * (2 ** (o - 4)) wave = amp * np.sin(2 * np.pi * kFreq * t) return wave #和音や長さからsin波を生成する def note(k, l): """ parameters ---------- k : string array key and scale [example-"C4, G5, ..."] l : string fraction """ numeratorBuff = l.split("/")[0] denominatorBuff = l.split("/")[1] numerator = int(numeratorBuff) denominator = int(denominatorBuff) fraction = numerator / denominator s = 60 / bpm * fraction * 4 #1/4音符4つで1小節 wave = None for key in k: keyName = re.search("[A-Za-z]*", key).group() keyOctave = int(re.search("\d", key).group()) if wave is None: wave = sinWave_from_key(keyName, keyOctave, s) else: wave += sinWave_from_key(keyName, keyOctave, s) global scoreWave if scoreWave is None: scoreWave = wave else: scoreWave = np.append(scoreWave, wave) #保存 def saveWav(): name = "" for s in filename: if s is ".": break name += s wavfile.write(name + ".wav", rate, scoreWave) #標準のisalnum等では不十分だったため半角英数のみのものを作った def checkAlnum(s): """ parameters ---------- s : string Returns ---------- result : bool """ alnum = re.compile(r'^[a-zA-Z0-9]+$') result = alnum.match(s) is not None return result #txt形式のスコアを読み込む def readScore(): global filename filename = sys.argv[1] if not filename.endswith(".txt"): print("!ERROR!---Please check the file extension.") return None with open(filename) as f: lines = f.readlines() for line in lines: if line.startswith("#"): #コメントアウト用 continue elif line.startswith("<") and (line.endswith(">") or line.endswith(">\n")): #BPM設定タグ用 global bpm bpm = int(re.search("\d+", line).group()) elif line.startswith("[") and (line.endswith("]") or line.endswith("]\n")): #音源ノート用 key = [] lineList = list(line) keyBuff = "" length = "" lengthBuff = "" mode = "" for l in lineList: #ノート内のキーと長さの要素に分ける if l is "[": mode = "note" elif checkAlnum(l) or l is "/": if mode is "note": keyBuff += l elif mode is "length": lengthBuff += l elif l is "+": key.append(keyBuff) keyBuff = "" elif l is ",": key.append(keyBuff) keyBuff = "" mode = "length" elif l is "]": length = lengthBuff note(key, length)sample.txt
sample.txt<bpm = 120> [C2, 1/4] [D2, 1/4] [E2, 1/4] [F2, 1/4] [G2, 1/4] [A2, 1/4] [B2, 1/4] [C3, 1/4]解説
MakeMusic.py
amp = 0.5 #音量 A = 440.0 #A=440Hz C = A * (2 ** (3 / 12)) #C=440*2^(3/12)H rate = 44100 #サンプリングレート bpm = 120 #BPM scoreWave = None filename = ""グローバル変数。書き出しに必要だったり定数だったり。BPMは定数じゃないけど、スコアファイルからも途中で変更できるようにグローバル変数にしました。
#main関数 def main(): readScore() saveWav() if __name__ is "__main__": main()今後の拡張性等を兼ねてmain関数とif文。今後拡張していくかはわかりませんが、オープンソースなので誰かやりたい人いたら笑。
#音の周波数を計算してsin波を生成する関数 def sinWave_from_key(k, o, s): """ parameters ---------- k : string key in scale o : int octave s : int seconds Returns ---------- wave : ndarray """ t = np.arange(0, s, 1 / rate) #時間パラメータ kArray = ['C', 'Cs', 'D', 'Ds', 'E', 'F', 'Fs', 'G', 'Gs', 'A', 'As', 'B'] wave = 0 * t if k in kArray: kNum = kArray.index(k) kFreq = C * (2 ** (kNum / 12)) * (2 ** (o - 4)) wave = amp * np.sin(2 * np.pi * kFreq * t) return wavesin波を引数をもとに生成し、ndarray型のwaveを返します。引数は(キー, オクターブ, 秒数)となっています。
#和音や長さからsin波を生成する def note(k, l): """ parameters ---------- k : string array key and scale [example-"C4, G5, ..."] l : string fraction """ numeratorBuff = l.split("/")[0] denominatorBuff = l.split("/")[1] numerator = int(numeratorBuff) denominator = int(denominatorBuff) fraction = numerator / denominator s = 60 / bpm * fraction * 4 #1/4音符4つで1小節 wave = None for key in k: keyName = re.search("[A-Za-z]*", key).group() keyOctave = int(re.search("\d", key).group()) if wave is None: wave = sinWave_from_key(keyName, keyOctave, s) else: wave += sinWave_from_key(keyName, keyOctave, s) global scoreWave if scoreWave is None: scoreWave = wave else: scoreWave = np.append(scoreWave, wave)スコアファイルから読み込んだノートをそれぞれ適切にsin波生成関数を用いて出力用の変数に格納していきます。やってることはコンパイラみたいなことです笑。
#保存 def saveWav(): name = "" for s in filename: if s is ".": break name += s wavfile.write(name + ".wav", rate, scoreWave)スコアファイルの名前をもとにwavファイルの名前を付け、書き出します。
#標準のisalnum等では不十分だったため半角英数のみのものを作った def checkAlnum(s): """ parameters ---------- s : string Returns ---------- result : bool """ alnum = re.compile(r'^[a-zA-Z0-9]+$') result = alnum.match(s) is not None return resultPython標準のisalnum等では","や全角文字も英数字として評価してしまって面倒だったので作りました。ほとんど完コピですが、参考にしたサイトがこちらです。私もまったく同じ状況にハマってしまって、試しにisalnumやisalpha等で色々な文字列を評価したところ、":"や";"まで英数字として評価されていたようでした・・・。これで小一時間悩まされました泣。
#txt形式のスコアを読み込む def readScore(): global filename filename = sys.argv[1] if not filename.endswith(".txt"): print("!ERROR!---Please check the file extension.") return None with open(filename) as f: lines = f.readlines() for line in lines: if line.startswith("#"): #コメントアウト用 continue elif line.startswith("<") and (line.endswith(">") or line.endswith(">\n")): #BPM設定タグ用 global bpm bpm = int(re.search("\d+", line).group()) elif line.startswith("[") and (line.endswith("]") or line.endswith("]\n")): #音源ノート用 key = [] lineList = list(line) keyBuff = "" length = "" lengthBuff = "" mode = "" for l in lineList: #ノート内のキーと長さの要素に分ける if l is "[": mode = "note" elif checkAlnum(l) or l is "/": if mode is "note": keyBuff += l elif mode is "length": lengthBuff += l elif l is "+": key.append(keyBuff) keyBuff = "" elif l is ",": key.append(keyBuff) keyBuff = "" mode = "length" elif l is "]": length = lengthBuff note(key, length)コマンドライン引数から読み込むファイルの名前を参照し、txt形式のスコアファイルから1行ずつ読み込んでBPMタグやnoteタグ等を割り振って処理しています。今後他のタグに対応させる時のために一応コメントアウト用のタグを明記してます。今のところは飾りなのでわざわざコメントタグを明記しなくても<>か[]でなければコメントとして扱われます。
使い方
sample.txtを例に解説します。
sample.txt<bpm = 120> [C2, 1/4] [D2, 1/4] [E2, 1/4] [F2, 1/4] [G2, 1/4] [A2, 1/4] [B2, 1/4] [C3, 1/4]BPMタグ
<bpm = 120>
<>で囲まれた文字列はBPMタグとして扱われます。
数値のみを参照しBPMとして処理しているため、<120> <bpm=120> <BPM120> <びーぴーえむ120>上記のどれでも半角で数値さえ入っていれば実行可能です。
noteタグ
[C2, 1/4] [D2, 1/4] [E2, 1/4] [F2, 1/4] [G2, 1/4] [A2, 1/4] [B2, 1/4] [C3, 1/4]
[]で囲まれた文字列はnoteタグとして扱われます。
noteタグでは["キー""オクターブ", "長さ"]のように記述する必要があります。
また、和音を鳴らしたい場合、["キー1""オクターブ1"+"キー2""オクターブ2"+"キー3""オクターブ3", "長さ"]のように音を+で重ねることができますが、長さは1つのみになります。例として、[C2+E2+G2, 1/4]これで四分音符の長さで
C2E2G2(ドミソ)の和音が生成されます。
また、[C2, 1/4] [C2+E2, 1/4] [C2+E2+G2, 1/4] [C2+E2+G2+C3, 1/4]こうすることで順に音を重ねていくことも可能です。
また、休符の設定も可能で、[R0, 1/4] [R1, 1/4]このように
["キー以外の半角英字""オクターブ", "長さ"]と入力することで休符を設定できます。R以外でも問題はありませんが、Rを使った方が分かりやすいかと思います。オクターブも整数であればどうせ休符なので100でも可能です。コメントタグ
#コメントタグです。
#で開始した文字列は改行までコメントとして扱われます。上記のタグ以外の文字列であればコメントとして扱われますが、今後機能の拡張等を考え、#を予約しておきました。まとめ
Pythonをあまり使ってこなかったのですが、やはり楽でいいですね。普段はC#やJavaを使うので定数がないことやクラス関数周りで不思議に思うことがいくつもあって面白かったです。
GUIで多機能な無料DAW等もありますが、CUIでシンセサイザーを動かして曲を作るのも独特で面白いので、今後これで曲を作ってみようと思います。
他にもmatplotlib等入れて楽曲のsin波をグラフ化したり様々な音源を重ね合わせで再現したり、もしくは人工音声で歌詞を入れて歌わせたりできると思いますので、ぜひコピペでもして使ってみてください。
- 投稿日:2020-12-01T21:26:32+09:00
[Python]優先度付きキュー(heapq) ABC141D
優先度付きキューについて
優先度付きキュー (Priority queue) はデータ型の一つで、具体的には
- 値の追加 $O(\log{N})$
- 値の削除 $O(\log{N})$
- 最小値(最大値)の取得 $O(1)$
通常のリストだとそれぞれ $O(N)$ です。
最小値(最大値)のみを得たい、のみに処理したい、を何回も繰り返すときに使います。Pythonでの使い方
Pythonでは優先度付きキューは heapq として標準ライブラリに用意されています。使いたいときはimportしましょう。
各メソッドについて
頻繁に使うメソッドは3つです。
heapq.heapify(リスト)でリストを優先度付きキューに変換。heapq.heappop(優先度付きキュー (=リスト) )で優先度付きキューから最小値を取り出す。heapq.heappush(優先度付きキュー (=リスト) , 挿入したい要素)で優先度付きキューに要素を挿入。※ Pythonではheap化されたリストのクラスもリストであるためこのような書き方をしています。↓参考
import heapq a = [1, 6, 8, 0, -1] print(type(a)) # <class 'list'> heapq.heapify(a) print(type(a)) # <class 'list'>では、各メソッドの使い方について見ていきましょう。
import heapq # heapqライブラリのimport a = [1, 6, 8, 0, -1] heapq.heapify(a) # リストを優先度付きキューへ print(a) # 出力: [-1, 0, 8, 1, 6] (優先度付きキューとなった a) print(heapq.heappop(a)) # 最小値の取り出し # 出力: -1 (a の最小値) print(a) # 出力: [0, 1, 8, 6] (最小値を取り出した後の a) heapq.heappush(a, -2) # 要素の挿入 print(a) # 出力: [-2, 0, 1, 8, 6] (-2 を挿入後の a)なお、もちろんリストのheap化は行わなくても
heappop()とheappush()は使用できます。しかしheappop()ではリストの先頭の要素が取り出される仕様になっているため、初回のheappop()を行う際は気をつけましょう。最初のリストが空のリスト[]であるような場合にはheapifyを行う必要がないので以下の通りで問題ありません。import heapq # heapqライブラリのimport a = [1, 6, 8, 0, -1] # heapq.heapify(a) print(heapq.heappop(a)) # 先頭の要素 (1) が取り出される!!!! print(a) # [-1, 6, 8, 0] heapq.heappush(a, -2) # 要素の挿入 print(a) # [-2, -1, 8, 0, 6] print(heapq.heappop(a)) # 最小値の取り出し print(a) # [-1, 0, 8, 6]最大値の取り出し
デフォルトのheapqは最小値を想定しています。最大値の時は、各要素に-1をかけた上で最小値を取り出し、-1をかけて最大値を復元します。以下のコードでは
map関数で各要素を-1倍していますが、実際に問題を解く際には入力時に-1した方が高速です。import heapq a = [1, 6, 8, 0, -1] a = list(map(lambda x: x*(-1), a)) # 各要素を-1倍 print(a) heapq.heapify(a) print(heapq.heappop(a)*(-1)) # 最大値の取り出し print(a)出力[-8, -6, -1, 0, 1] 8 [-6, 0, -1, 1]ABC177D
この問題は 最大値を1/2することをM回繰り返す だけでよいのですが、通常のリストを使うと、最大値の選定に $O(N)$ 、それをM回のため計算量が $O(NM)$ で間に合いません。
そこでheapqの出番です。heapqでは最大値の選定に $O(\log{N})$ 、それをM回のため計算量が $O(M \log {N})$ となり間に合います。以下が実装です。ABC141D.pyimport heapq n, m = map(int, input().split()) a = list(map(lambda x: int(x)*(-1), input().split())) heapq.heapify(a) # aを優先度付きキューに for _ in range(m): tmp_min = heapq.heappop(a) heapq.heappush(a, (-1)*(-tmp_min//2)) # 負数の剰余演算を避けるため一時的に0以上の整数にしています print(-sum(a))
当内容は、次を参考にした。
【Python】優先度付きキューの使い方【heapq】【ABC141 D】
- 投稿日:2020-12-01T19:59:13+09:00
スタジオジブリ作品の場面写真を楽に全部ダウンロードしたい【Python】
はじめに
2020/09/18,2020/11/20にスタジオジブリ作品の場面写真が常識の範囲でご自由にお使いくださいということで提供されましたね
- 「思い出のマーニー,かぐや姫の物語,風立ちぬ,コクリコ坂から,借りぐらしのアリエッティ,崖の上のポニョ,ゲド戦記,千と千尋の神隠し」
http://www.ghibli.jp/info/013344/- 「平成狸合戦ぽんぽこ,海が聞こえる,紅の豚,魔女の宅急便,となりのトトロ」
http://www.ghibli.jp/info/013381/それぞれ400枚,250枚あるので全部ダウンロードしたい場合,大変だと感じました
そこで,作品ごとにフォルダを分けて自動で保存できるようにPythonのプログラムを用意しました
動作環境
Python 3.8.6
コード
import os import urllib.error import urllib.request def download_file(url, dst_path): try: with urllib.request.urlopen(url) as web_file, open(dst_path, 'wb') as local_file: local_file.write(web_file.read()) except urllib.error.URLError as e: print(e) def download_file_to_dir(url, dst_dir): download_file(url, os.path.join(dst_dir, os.path.basename(url))) os.mkdir('ghibli_data') name = ['marnie','kaguyahime','kazetachinu','kokurikozaka','karigurashi','ponyo','ged','chihiro','tanuki','umi','porco','majo','totoro'] for i in range(len(name)): os.mkdir('ghibli_data/'+ name[i]) for j in range(1,51): url = 'http://www.ghibli.jp/gallery/'+name[i]+'{0:03d}'.format(j)+'.jpg' print(url) dst_dir = 'ghibli_data/'+name[i]+'/' download_file_to_dir(url, dst_dir)おわりに
このプログラムが誰かの役に立つといいな
- 投稿日:2020-12-01T19:39:12+09:00
RaspberryPi 4BでAI、RaspberryPi 4BでIoT(まえがき)
はじめに
プログラミングの学習を始めてから4ヶ月。pythonを使い、ラズベリーパイで高齢者見守りシステムを作ってみました。
制作の過程を、数回に分けてまとめていきます。システム機能
- 対象者の起床を見守ります。予定の時刻までに起床が確認できないときは、あらかじめ登録している家族にLINEで連絡します。
- 対象者の活動量を見守ります。対象者が動かない状態が長く続いたときは、声をかけてみます。それでも反応がない場合、あらかじめ登録している家族にLINEで連絡します。
- 対象者の所在が確認できない状態が長く続いたときは、あらかじめ登録している家族にLINEで連絡します。ただし、googleカレンダーに登録されている外出予定期間は、装置が見守り対象者を認識できなくても、所在が確認できていると見做します。
- 複数台の装置が連携することで、広い範囲をカバーして対象者を見守ります。
記事内容
- システム概要
環境構築 (投稿予定)
- RaspberryPi初期設定
- 開発ツールインストール
ソフトウエア制作 (投稿予定)
- マルチプロセッシング・マルチスレッディング
- スレッド間同期
- 顔認識
- 物体認識
- 物体追跡
- google calendarスケジュール取得
- LINE通知
- 音声合成
- 装置間通信(FireStore)
ハードウエア制作 (投稿予定)
おわりに
プログラミング初心者のため、誤りが多々あると思います。アドバイス、励ましのコメントなどいただけると嬉しいです。
- 投稿日:2020-12-01T19:17:15+09:00
~/.python_history に空白文字が正しく記録されない
この記事は、上智大学エレクトロニクス研究部Advent Calendar第4日目の記事です。
エレラボでは、Pythonユーザーが多く、僕のそのうちの一人です。そんな愛してやまないPythonですが、最近
~/.python_historyの形式がおかしくなってしまっていることに気が付きました。これは一大事です。なんとかして解決しないと…!事象
MacOS Catalinaで
~/.python_historyファイルの空白文字が\040に、\が\134に、 水平タブ が\011置き換わってしまう。
また、~/.python_historyの先頭に_HiStOrY_V2_という謎のおまじないが書き込まれる。❯ head -n 5 ~/.python_history _HiStOrY_V2_ import\040secrets [secrets.token_urlsafe(16)\040for\040_\040in\040range(10)] [secrets.token_urlsafe(12)\040for\040_\040in\040range(10)] [secrets.token_urlsafe(8)\040for\040_\040in\040range(10)]対処方法
GNU版の
readlineをリンクできるように設定した状態で Pythonのビルドを行う。export CFLAGS="-I$(brew --prefix readline)/include -I$(brew --prefix openssl)/include -I$(xcrun --show-sdk-path)/usr/include" export LDFLAGS="-L$(brew --prefix readline)/lib -L$(brew --prefix openssl)/lib" # Pythonのビルド(上記は
Homebrewを用いて GNU版の(以下純正と表記)readlineをインストールした場合)書き換わってしまった
~/.python_historyは、以下のように行頭を削除し、 エスケープされた文字を元の文字に置き換える。cp ~/.python_history ~/.python_history.bak && cat ~/.python_history.bak | sed -e '1d' | unvis > ~/.python_historyただし、行頭の
_HiStOrY_V2_を消すと、原因となっているPythonインタプリタを実行し、終了した時点ですべての履歴を消される。原因となっているPythonインタプリタとreadlineがリンクされたPythonインタプリタを共存して使いたい場合、行頭を残すために以下のように編集すると良いだろう。cp ~/.python_history ~/.python_history.bak && cat ~/.python_history.bak | unvis > ~/.python_history
/usr/bin/python3を使わないようにする
xcode-select --installによってインストールされるPythonには、libeditがリンクされている。readlineがリンクされているPythonインタプリタを常用する場合、/usr/bin/python3を使わないことをおすすめする。再現手順
以下のように、
LDFLAGSを設定せずにPythonのビルドを行うと、 XCode SDKに含まれるreadlineのフリをしたlibeditがPythonのreadlineモジュールとしてリンクされてしまう。wget https://www.python.org/ftp/python/3.8.1/Python-3.8.1.tgz tar -xvzof Python-3.8.1.tgz mv Python-3.8.1 Python-3.8.1.tgz ~/Downloads cd Python-3.8.1 ./configure --enable-optimizations --prefix=$HOME/Downloads make make test # この時点で `~/.python_history` が書き換わる ./python.exe >>> import secrets >>> [secrets.token_urlsafe(8) for _ in range(10)]このように
libeditがリンクされたPythonを開き、コマンドを実行すると、 空白文字が\040に置き換わってしまうことがわかる。❯ tail -n 2 ~/.python_history import\040secrets [secrets.token_urlsafe(8)\040for\040_\040in\040range(10)]原因
そもそも、なぜ
XCode SDKに純正のreadlineが入っていないのか?それは、readlineがGPLライセンスで、libeditがBSDライセンスだからだと言われている。Appleとしても自社のコードを守るためにGPLライセンスのものを極力同梱したくないだろう。そんな理由で使われているlibeditは上記の通りreadlineと互換性がなく、このような問題を引き起こしている。
それを回避するためには、純正のreadlineをhomebrewでインストールし、冒頭の通りライブラリのパスさえしっかりと設定する。この設定を行えば問題は解消する。export CFLAGS="-I$(brew --prefix readline)/include -I$(brew --prefix openssl)/include -I$(xcrun --show-sdk-path)/usr/include" export LDFLAGS="-L$(brew --prefix readline)/lib -L$(brew --prefix openssl)/lib" # Pythonのビルドちなみに、
Homebrewでreadlineをインストールした場合、caveatsにreadlineを使いたいならLDFLAGS,CFLAGSをいじるように警告が出るようになっている。readline is keg-only, which means it was not symlinked into /usr/local, because macOS provides the BSD libedit library, which shadows libreadline. In order to prevent conflicts when programs look for libreadline we are defaulting this GNU Readline installation to keg-only. For compilers to find readline you may need to set: export LDFLAGS="-L/usr/local/opt/readline/lib" export CPPFLAGS="-I/usr/local/opt/readline/include"そもそも
readlineって何??この記事はアドベントカレンダーのものなので続きは別の日に公開します。
readlineとlibeditの解説記事を 明日(12/5)に公開予定します。ぜひご購読お願いします!!他にもネタが思いつく限りどんどん投稿していこうと思います。他の部員も面白い投稿をたくさんしてくれているので、ぜひいいね/購読よろしくお願いします!
上智大学エレクトロニクス研究部Advent Calendar
上智大学エレクトロニクス研究部の公式サイト参考文献
- 投稿日:2020-12-01T19:16:41+09:00
ご注文はPyTorchですか? ~Tensorを知っTensor~
はじめに
皆さん、ディープラーニングしてますか?私はテスト勉強で過学習をして死にました。
それはともかく、最近はディープラーニング初心者でも耳にするPyTorch。同じディープラーニング用のフレームワークKerasと比べると難しく感じるものの、慣れてしまえばKerasの方が難しく感じてくる場面に出くわします。目次
PyTorchとは
PyTorch は、Facebookが開発・公開するディープラーニング用ライブラリです。
筆者はFacebookアカウントが大統領選のBAN祭りでやられたので、いろいろな連携サービスが使えなくなってしまいました。
PyTorchの公式ページではドキュメントが英語で書かれています。英語ツヨツヨになりたい。
ドキュメントの中では見やすい部類なので、Google翻訳レベルでも見ることができるのではないでしょうか。DeepL使いましょう。PyTorchのインストール
PyTorchのインストール方法は、公式サイトに実行すべきコマンドが載っています。
下の画像のように、自分が使う環境をクリックしたら、その下に実行するコマンドが出てくるので、これをコピーしてターミナルやプロンプトにペーストして実行します。
CUDAを使用したい場合は、別途CUDAをインストールする必要があるかもしれません。(あんまりよく覚えていない)
筆者はWindows10にPython3.8をインストールして、venvからpipでインストールしています。
そもそもPythonをインストールしていない人は、Pythonインストールに関する記事を探してください。
できればMatplotlibやJupyterをインストールしておくといいでしょう。PyTorchのインポート
PyTorchがインストールできたらPyTorchをインポートして使ってみましょう。
ターミナルからPythonを起動して、以下を実行してみてください。import torch print(torch.device('cuda' if torch.cuda.is_available() else 'cpu'))NVIDIA製グラフィックボードを利用していて、CUDAがきちんと利用できていれば
cudaと表示されます。
NVIDIA製グラフィックを利用していなかったり、CUDAが利用できていない場合はcpuと表示されます。
インストールできていない場合はエラーが出ます。まとめ
今回はPyTorchの紹介からインポートまでを行いました。
次回は線形代数に少し触れながらPyTorchを使っていきたいと思います。

- 投稿日:2020-12-01T18:22:36+09:00
気象予報値(MSM-GPV)をpythonで音にしてみたい。
[Something went wrong]()
はじめに
R&Dアドベントカレンダーの6日目を担当します、NTTドコモクロステック開発部3年目社員の角谷昌恭です。
普段の業務では再生可能エネルギーやら電力やら、、通信会社では珍しい分野の研究・開発をしてますので、
本記事では普段の業務の中で目にすることが多い気象関係のデータの中から、特に気象予報値にフォーカスした記事を作成したいと思います。そこで本記事では、MSM-GPVという気象庁作成の気象予報値の入手方法や使用ルール、データ構造に関する内容をメインに記載しますが、
ただ、それだとあまり面白い記事になりそうにないので、本データの活用方法の例を一つ記載したいと思います。その活用方法の例というのがタイトルの通り、気象予報値を音にするってものなのですが、
これだけを聞くと何を言ってるんだ君は?って話だと思いますので、何故こんなことをしたいのかというお気持ちを簡単にイメージ図にしました。
イメージ通りのことができる様になった暁には、おもむろに電子音を聞いて、
「この音、、雨が来るな、、」
みたいな一発芸ができそう✌️
飲み会とかでヒーローになれそう✌️✌️という妄想が膨らみ、本記事ではデータの活用例として、気象予報値(MSM-GPV)の音声化に取り組みます。
気象予報値(MSM-GPV)とは?
本章では気象予報値とは何ぞや?MSM-GPVとは何ぞや?といったことを少し真面目に記載していきます。
気象予報値とはその名の通り、実際に観測装置等を用いて測定したリアルタイムの気象情報ではなく、何らかの手法(衛生画像を用いた予測や、ゴリゴリの物理演算による予測など様々)により将来の気象情報を予測したデータのことを指します。
使用用途としては、例えば各地の時間別の天気予報を作成したり、太陽光パネルの発電量の予測を行う際の説明変数として用いられています。
今回はその気象予報値の中でも、過去データがアーカイブされ、公開されている「MSM-GPV」を取り上げたいと思います。まずは「MSM-GPV」とは何ぞや?について簡単に説明します。
正式名称は「メソ数値予報モデルGPV(Grid Point Value)」で、気象庁がゴリゴリの物理演算で算出している気象予報値です。笑
基本的にリアルタイムの予報値を提供するサービスであり、本データは「一般財団法人 気象業務支援センター」が有料にて提供してますので、参考までに以下にURLを記載します。「一般財団法人 気象業務支援センター」 -> http://www.jmbsc.or.jp/jp/online/file/f-online10200.htm
過去データについては後ほど説明致しますので、まずはリアルタイムに取得した場合のデータの概要について説明します。
データの種類には、39時間先まで予測したデータと、51時間先まで予測したデータの2種類あり(過去データに関しては15時間と33時間だったりします)、それぞれ以下のタイミングで計算が開始されおよそ2時間半で計算が終了します。39時間先 : 03、06、09、15、18、21UTC (1日6回)
51時間先 : 00、12UTC (1日2回)ちなみにUTCとは協定世界時のことで日本との時差は+9時間あります。
なので03UTCで計算されたデータを日本で取得する時刻は以下の様になります。3(UTC) + 9(時差) + 2.5(計算時間) = 14.5(日本時間)
提供しているデータは上のURLにも記載されていますが以下の様な内容となっております。
データ形式 : 国際気象通報式FM92 GRIB 二進形式格子点資料気象通報式(第2版) *通称GRIB2、後ほど説明致します。
配信領域 : 北緯 22.4度~47.6度、東経 120度~150度の区間を5kmメッシュ
予報時間 : 地上は1時間毎、気圧面は3時間毎
要素 : 海面更正気圧、地上気圧、風(東西成分と南北成分)、気温、相対湿度、時間降水量、雲量(全雲量、上層雲、中層雲、下層雲)、日射量リアルタイム版は有料となっておりますが、過去データであれば「DIAS」というデータ統合・解析システムにより公開されております。
URLは以下の通りで、実際には東京大学生産技術研究所喜連川研究室が運営しているサイトにてダウンロードすることが可能です。
*ただし本データの公開は「非商業的な研究及び教育用途のために提供している」ため、その利用については確認の後、自己責任でお願いします。
また、DIASに掲載されているデータの使用についての注意書きもURL先のサイトにて確認できますので、必ずよく読んでからご使用ください。「DIAS」 -> https://diasjp.net/
「GPV Data Archive」 -> http://apps.diasjp.net/gpv/また、「GPV Data Archive」にてダウンロードする際に複数のファイルが存在し、どれを選択して良いか迷う可能性がありますので、その際は以下のファイル名の作成ルールをご参考ください。(個人の解釈によるものなので間違ってたらごめんなさい、、笑)
Z_C_RJTDYYYYMMDD030000_MSM_GPV_Rjp_Lsurf_FH00-15_grib2.bin
記号 意味 YYYY 西暦 MM 月 DD 日 03 UTC Lsurf 地上:Lsurf、気圧面:L-pall FH00-15 予測時間先情報、先の場合00-15、過去データは上述の予測時間の間隔とは異なる可能性があるので要注意 簡単なデータ構造の説明
前述した様にMSM-GPVは「国際気象通報式FM92 GRIB 二進形式格子点資料気象通報式(第2版) *通称GRIB2」という、WMO(世界気象機関)が定めるバイナリ通報式を採用しております。
何ぞや?と思う方が大半だと思いますが、公式のドキュメントを読む限りですと、GRIB2表を参照し、要素の情報をGRIB2データ中で記述する⾃⼰記述型のデータ形式のことの様です。
平たく言ってしまえば、バイナリデータとしてファイルフォーマット化し伝送する⽅式を採用しており、それを人語に翻訳するためにはGRIB2表を参照してくれってことだと思います。
以下に公式のドキュメントのURLを記載致しますので、興味のある方は確認してみてください。「国際気象通報式」 -> https://www.jma.go.jp/jma/kishou/books/tsuhoshiki/kokusaibet/kokusaibet_22.pdf
本形式のバイナリデータを可視化するツールとして例えば「Wgrib2」「ecCodes」などもありますが、本記事ではpythonの「pygrib」というライブラリを使用して可視化する方法についてご紹介します。
pygribが何ものかについては本記事では割愛致しますので興味のある方は下記のURLで確認してみてください。「Module pygrib」 -> https://jswhit.github.io/pygrib/docs/pygrib-module.html
では早速pygribの使用方法ですが、まずはconda等を使用して実行したい環境にライブラリをインストールして下さい。
*可能であればdockerを使用すると良いです。というのもこのpygrib、インストールしimportするまでに環境によっては色々とエラーがでる可能性がありますので、融通が効きやすいdockerでの環境構築をお勧めします。以下のQiita記事にpygribを含んだdockerfileについて記載してある記事を見つけたので是非参考にしてみて下さい。「pythonでgrib2フォーマットのファイルを触れる環境を用意する(Docker編)」 -> https://qiita.com/mhangyo/items/8494a8039973ba220ce5#fnref1
インストールが完了致しましたら早速MSM-GPVのデータ構造をざっくり見ていきましょう。
まずは「open」を使用してバイナリデータを開封します。(例では2018年2月5日の地上、予測時間先00-15時間先を使用しております)sample.pyimport pygrib gpv = pygrib.open\ ('input/msmgpv_raw/Z__C_RJTD_20180205150000_MSM_GPV_Rjp_Lsurf_FH00-15_grib2.bin') gpv_list = gpv.select(forecastTime=0, name='Surface pressure') print(type(gpv_list)) gpv_message = gpv.select(forecastTime=0, name='Surface pressure')[0] print(type(gpv_message)) print(gpv_message)実行結果
sample.py<class 'list'> <class 'pygrib.gribmessage'> 2:Surface pressure:Pa (instant):regular_ll:surface:level 0:fcst time 0 hrs:from 201802051500ここで行っている作業を簡単に説明しますと、pygrib.openクラスを使ってファイルとのインターフェースを作成し、selectメソッドを使用し条件に合致するpygrib.gribmessageのリストを取得、取得したリストからpygrib.gribmessageを取得しています。
forecastTimeで指定できるのは予測時間先情報、例で使用しているデータでは0-15の範囲、nameで使用できるのはデータの要素になります。参考までにnameで指定できる変数名とその意味について簡単に記載します。
id 変数名 意味 0 Pressure reduced to MSL 海面更正気圧 1 Surface pressure 気圧 2 10 metre U wind component 風の東西成分 3 10 metre V wind component 風の南北成分 4 Temperature 気温 5 Relative humidity 湿度 6 Low cloud cover 低層の雲量 7 Medium cloud cover 中層の雲量 8 High cloud cover 上層の雲量 9 Total cloud cover 全雲量 10 Total precipitation 積算降水量 11 Downward short-wave radiation flux 日射量 *selectで指定できる検索条件についてはいくつかあるみたいですが、自分はforecastTimeとname以外使用したことがありませんのでもし他の検索条件をご存知な方がいらっしゃったら教えて頂けると助かります。笑
現在の状態は選択した予測時間先の選択したデータ項目の全メッシュのデータが含まれている状態です。
ですので次は、必要な区間(緯度経度で指定)のデータだけを抽出したいと思います。
まずはlatolonsメソッドを使用すると、メッシュの緯度・経度を羅列したデータが確認できますので見てみましょう。sample.pylats, lons = gpv_message.latlons() print(lats) print(lons)出力結果
sample.py[[47.6 47.6 47.6 ... 47.6 47.6 47.6 ] [47.55 47.55 47.55 ... 47.55 47.55 47.55] [47.5 47.5 47.5 ... 47.5 47.5 47.5 ] ... [22.5 22.5 22.5 ... 22.5 22.5 22.5 ] [22.45 22.45 22.45 ... 22.45 22.45 22.45] [22.4 22.4 22.4 ... 22.4 22.4 22.4 ]] [[120. 120.0625 120.125 ... 149.875 149.9375 150. ] [120. 120.0625 120.125 ... 149.875 149.9375 150. ] [120. 120.0625 120.125 ... 149.875 149.9375 150. ] ... [120. 120.0625 120.125 ... 149.875 149.9375 150. ] [120. 120.0625 120.125 ... 149.875 149.9375 150. ] [120. 120.0625 120.125 ... 149.875 149.9375 150. ]]latsとlonsで格納形式が異なりますが、行列として表記した場合と地図上に表示した場合が視覚的に一致するようにこのような順番になっているのでは、、と思いますが真相はよくわかりませんので知っている方いらっしゃったら教えてください。笑
次にdataメソッドを使用して、指定した緯度・経度と最も近いメッシュ上のデータを取得してみます。
引数はlat1(緯度最小)、lat2(緯度最大)、lon1(経度最小)、lon2(経度最大)を指定します。
ただし、dataメソッドはメッシュ上に存在するlatとlonを指定する必要がありますので、少し工夫します。sample.pyimport numpy as np def getNearestLatLon(lat, lon, message): """ 概要: 指定した緯度経度から最も近いメッシュ上の緯度経度を算出する @param lat: 対象の緯度 @param lon: 対象の経度 @param message: 対象のpygrib.gribmessage @return 対象値に最も近いメッシュ状のlat,lon """ # メッシュ上のlatとlonのリストを作成 lats, lons = message.latlons() lat_list = [] for n in range(0, len(lats)): tmp = lats[n][0] lat_list.append(float(tmp)) lon_list = lons[0] # リスト要素と対象値の差分を計算し最小値の値を取得 lat_near = lat_list[np.abs(np.asarray(lat_list) - lat).argmin()] lon_near = lon_list[np.abs(np.asarray(lon_list) - lon).argmin()] return lat_near, lon_near # 対象としたいlat、lon lat = 35.0 lon = 139.0 lat_near, lon_near = getNearestLatLon(lat, lon, gpv_message) print("lat_near : {} \nlon_near : {}".format(lat_near, lon_near)) # dataメソッドによる抽出 print(gpv_message.data(lat1=lat_near, lat2=lat_near, lon1=lon_near, lon2=lon_near))出力結果
sample.pylat_near : 35.00000000000072 lon_near : 139.0 (array([[98104.17480469]]), array([[35.]]), array([[139.]]))lat1とlat2、lon1とlon2に同じ値を指定することで指定したlatとlonに近いメッシュ上の点を取得することができました。
音にしてみよう!
MSM-GPVのダウンロードと大まかなデータ構造がわかったところで、早速音で気象予報値を表現してみたいと思います!
やりたいこととしては、MSM-GPVデータで取得可能な気象予報値に対して楽器を割り当て、その値の変動に応じて音階を変化させるというものです。
音の雰囲気から穏やかな1日なのか、慌ただしく天候が変化するかなどがわかるんじゃないかなと思ってます。(小並感)sample.py# 基本ライブラリ import numpy as np import pandas as pd # pygrib import pygrib # pretty_midi import pretty_midi def getNearestLatLon(lat, lon, message): """ 概要: 指定した緯度経度から最も近いメッシュ上の緯度経度を算出する @param lat: 対象の緯度 @param lon: 対象の経度 @param message: 対象のpygrib.gribmessage @return 対象値に最も近いメッシュ上のlat,lon """ # メッシュ上のlatとlonのリストを作成 lats, lons = message.latlons() lat_list = [] for n in range(0, len(lats)): tmp = lats[n][0] lat_list.append(float(tmp)) lon_list = lons[0] # リスト要素と対象値の差分を計算し最小値の値を取得 lat_near = lat_list[np.abs(np.asarray(lat_list) - lat).argmin()] lon_near = lon_list[np.abs(np.asarray(lon_list) - lon).argmin()] return lat_near, lon_near def getGpvDf(lat, lon, gpv, max_time = 15): """ 概要: 指定した緯度経度から最も近いメッシュ上の緯度経度のGPVデータを抽出する @param lat: 対象の緯度 @param lon: 対象の経度 @param gpv: 対象日時のmsm-gpv @param max_time: 予測時間の最大値 @return 対象値に最も近いメッシュ上のGPVデータをdataframeにて返す (index=変数、columns=予測時間の形式) """ # 予測時間の範囲に応じて抽出するデータの範囲を変更 if max_time == 15: for t in range(0, 15, 1): gpv_message = gpv.select(forecastTime=t) gpv_var_list = [] for x in range(0, 11, 1): gpv_message_var = gpv_message[x] lat_near, lon_near = getNearestLatLon(lat, lon, gpv_message_var) gpv_data_var = gpv_message_var.data\ (lat1=lat_near, lat2=lat_near, lon1=lon_near, lon2=lon_near) gpv_var_list.append(gpv_data_var[0][0]) if t == 0: gpv_df = pd.DataFrame(gpv_var_list) else: gpv_df = pd.concat([gpv_df, pd.DataFrame(gpv_var_list)], axis=1) else: for t in range(16, 33, 1): gpv_message = gpv.select(forecastTime=t) gpv_var_list = [] for x in range(0, 11, 1): gpv_message_var = gpv_message[x] lat_near, lon_near = getNearestLatLon(lat, lon, gpv_message_var) gpv_data_var = gpv_message_var.data\ (lat1=lat_near, lat2=lat_near, lon1=lon_near, lon2=lon_near) gpv_var_list.append(gpv_data_var[0][0]) if t == 16: gpv_df = pd.DataFrame(gpv_var_list) else: gpv_df = pd.concat([gpv_df, pd.DataFrame(gpv_var_list)], axis=1) return gpv_df def getMelody(gpv_df): """ 概要: GPVデータのデータフレームから、各変数の変化を表現する音声ファイルを作成する @param gpv_df: 対象値に最も近いメッシュ上のGPVデータのdataframe @return GPVデータから作成したmidiファイル """ #pretty_midiオブジェクトの作成 pm = pretty_midi.PrettyMIDI(resolution=960, initial_tempo=120) # 各変数に楽器を割り当て、奏でる音階を値の変化から決定する for n in range(0, len(gpv_df.index), 1): # 楽器の割り当て、listは楽器の種別が重なりにくくするための工夫です instrument_list = [x*5 for x in range(0, 11, 1)] instrument = pretty_midi.Instrument(instrument_list[n]) # 最小値0,最大値1にMin-Max Normalization gpv_df_norm = gpv_df.apply(lambda x : ((x - x.min())/(x.max()-x.min())),axis=1) for t in range(0, len(gpv_df), 1): tmp = gpv_df_norm.iloc[n,t] if 0<=tmp and tmp<=1/8: note_number = pretty_midi.note_name_to_number('C4') elif 1/8<tmp and tmp<=2/8: note_number = pretty_midi.note_name_to_number('D4') elif 2/8<tmp and tmp<=3/8: note_number = pretty_midi.note_name_to_number('E4') elif 3/8<tmp and tmp<=4/8: note_number = pretty_midi.note_name_to_number('F4') elif 4/8<tmp and tmp<=5/8: note_number = pretty_midi.note_name_to_number('G4') elif 5/8<tmp and tmp<=6/8: note_number = pretty_midi.note_name_to_number('A4') elif 6/8<tmp and tmp<=7/8: note_number = pretty_midi.note_name_to_number('B4') elif 7/8<tmp and tmp<=1: note_number = pretty_midi.note_name_to_number('C5') else: # 全ての値が0の場合適当な音を代入(正規化でNaNとなるため) note_number = pretty_midi.note_name_to_number('C5') note = pretty_midi.Note(velocity=100, pitch=note_number, start=t, end=t+1) instrument.notes.append(note) pm.instruments.append(instrument) pm.write('output/midi/test.mid') #midiファイルを書き込みます。 # 対象としたいlat、lon lat = 35.0 lon = 139.0 # 対象としたい日時のMSM-GPVデータ gpv = pygrib.open\ ('input/msmgpv_raw/Z__C_RJTD_20180205150000_MSM_GPV_Rjp_Lsurf_FH00-15_grib2.bin') gpv_df = getGpvDf(lat, lon, gpv, max_time = 15) getMelody(gpv_df)出力結果
以下のURLのoutputの中に、作成したmidiファイルとmp3ファイルを格納しましたので聞いてみてください。「msmgpv_getmelody git」 -> https://github.com/sumiya-masayasu/msmgpv_getmelody
作成元となるMSM-GPVデータを変更することで音がしっかりと変わっていることはわかりますね。
おわりに
やりたいことの主軸はできたので筆者的には満足しています。
ただ、これだけでは到底一発芸への昇華は不可能ですので、今後取り組みたい改善点について以下に記載致します。
- 予測期間の中での変動を音で表現しているが、過去数年分データから抽出した最大値、最初値で正規化した方が良さそう
- 楽器をランダムに設定しているが、楽器にも相性があると思うのでちゃんと選んだ方が良さそう。
- 数値によって音階を設定しているが、音の強弱や音階の幅なども細かく表現できた方が表現に幅ができて良さそう
- 気象状況のイメージと音のイメージがリンクすると、もっと聴きやすくなりそう(雨の時に不協和音が流れるなど)
これら改善点を解決した暁には、実際に自身の体で本当に音を聞くだけで気象予報が理解できる人間になれるのかを検証してみたいと思います。笑
進展があれば以上の内容について追記できたらなと思いますが、一旦は本内容にてR&Dアドベントカレンダーの6日目を終了したいと思います。
最後まで読んでいただき、ありがとうございました!


- 投稿日:2020-12-01T18:13:32+09:00
Airtestを使ったAndroidアプリの自動操作
はじめに
ソフトウェアテストの業界向けに役に立つ話、第一回目です。
Airtest IDEというUI自動化ソフトウェアを使用して、Androidアプリのかんたんな自動化をしてみました。
1. Airtestをダウンロード
Airtest Projects
https://airtest.netease.com/公式サイトからソフトウェアをダウンロードし、インストールします。
2. 起動
ソフトウェアを起動すると、ログインを求められますが「Skip」しても問題ないようです。3. 新規作成
メニューバーから「File」>「New」>「.air Airtest Project」を選択し、新規のプロジェクトを作成します。
4. スマホの接続
スマホをPCと接続し、右側の「Devices」にある「refresh ADB」を押します。すると、デバイス名が表示されますので、「connect」ボタンを押して接続します。接続の際に以下の操作が事前に必要です。
- Android開発者向けオプションが「ON」になっている
- USBデバッグが「ON」になっている
5. テストアプリをインストールする
https://github.com/AirtestProject/Airtest/tree/master/playground/blackjack_example
今回はAirtestのGitHubにあるブラックジャックのサンプルアプリ「blackjack-release-signed.apk」をインストールしてみました。
6. タッチしたい箇所を選択する
ツールボックスにある「touch」のボタンを押し、タッチしたい箇所をドラッグして切り取ります。すると、コードが自動的に生成されます。7. 一連の操作を書く
コードはPythonで記述するようです。今回は以下のような一連の操作を書きました。
- スタートボタンを押す
- 掛け金をベットする
- ブラックジャックを開始する
- カードを交換しない
- 勝利だったら、タイトル画面へ それ以外はもう一度プレイする
結果
勝利するまで、ゲームを自動で続けてくれました。さいごに
スマートフォンのアプリゲームでは、バトルがオートで行えることが多いのでさまざまなタイトルで活用できるかと思います。自社開発したアプリゲームのテストなどで参考にしていただければと思います。




- 投稿日:2020-12-01T18:13:28+09:00
競プロのライブラリ整理~二分探索と三分探索~
前書き
前提
全順序集合として整数または実数の時のみしか想定していません。
(1)アルゴリズムの説明
①二分探索とは
全順序集合上で単調増加(or単調減少)関数$f$が定義されている時に$f(y)=x$となる最小(or最大)の$y$を求める探索アルゴリズムのこと。探索区間の長さを$n$とした時、探索を行うごとにその長さが$\frac{1}{2}$になるので、一回の探索でかかる時間計算量を$O(X)$とした時に$O(X \log{n})$で探索を行うことができる。また、線形探索を行う場合は時間計算量は$O(X n)$である。
②三分探索とは
全順序集合上で狭義凸(or狭義凹)関数$f$が定義されている時に$f(y)$が極小値(or極大値)を取る$y$を求める探索アルゴリズムのこと。探索区間の長さを$n$とした時、探索を行うごとにその長さが$\frac{2}{3}$になるので、一回の探索でかかる時間計算量を$O(X)$とした時に$O(X \log{n})$で探索を行うことができる。また、線形探索を行う場合は時間計算量は$O(X n)$である。
(2)抽象化の説明
①二分探索の抽象化
先程の二分探索で「$f(y)=x$となる最小(or最大)の$y$を求める」と書きましたが、「$f(y)=x$となる最小(or最大)の$y$」が存在しない可能性を考慮すれば「$f(y) \leqq x$となる最小(or最大)の$y$を求める」及び「$f(y) \geqq x$となる最小(or最大)の$y$を求める」とする二分探索を使うべきです。
この場合を含む時はめぐる式二分探索と呼ばれる実装を行うと良いです。この二分探索の実装ではある値を境にFalse,Trueが切り替わるとして考えています。こちらのめぐる式二分探索を理解しておかないと以降の議論が理解できないと思うので、けんちょんさんの記事を参考に理解してください。
いずれにせよ、めぐる式二分探索によりある値を境にTrue,FalseまたはFalse,Trueとして切り替わる場合を考えます。この時、前者ではTrueの中での最大値を求め、後者ではTrueの中での最小値を求めます。このような抽象化を行うことで任意の場合について二分探索を行うことができます。従って、True,Falseを適切に返す関数を与えてやれば抽象化することができます。
②三分探索の抽象化
アルゴリズムの挙動としては二分探索より難しい三分探索ですが、抽象化する際にはそこまで難しくないと思います。先程はTrue,Falseを適切に返す関数を与えましたが、三分探索ではその代わりに極小値(or極大値)を返す関数を与えレバ良いだけです。
(3)抽象化ライブラリの実装
①二分探索のライブラリ
コードの説明
まず、整数か実数での場合分け,「True,False」または「False,True」での場合分けが必要です。この場合分け及びboolを与える関数が$f$で単調性が必要なことはここでは既知のものとします。
このもとで探索範囲及び誤差を指定する必要があります。探索範囲については題意に合わせて設定する必要がありますが、$l,r$はsearchtypeの条件より$searchtype=0$の時は$l$でTrue,$r$でFalseの条件を満たし、$searchtype=1$の時は$r$でTrue,$l$でFalseの条件を満たす必要があります。また、誤差についてですが、整数は探索範囲が1になるまでは正確に二分でき、実数は指定された誤差まで分割すれば十分です。
実は、この誤差の指定による方法だとループが終了しない可能性があるので次の章で説明をします。
また、コンストラクタの引数に与えるのは以上の変数なのですが、さらにop1,op2として演算子が二つ定義されます。op1については整数か実数かで割り算で異なる演算子を使うためですが、op2は説明が必要だと思うのでcalc関数の説明で書きます。また、valueはcalcで求めた解を格納する変数です。
次にcalc関数の中を見ます。この時、一般的なめぐる式全探索を知っている人であれば$searchtype=1$の時を想像しながら考えることで理解できると思います。(以下の説明は$searchtype=1$のものです。op2の関係が反対になることを考えれば$searchtype=0$の時でも理解できると思います。)
まず、while文の条件式については誤差の範囲より大きい時は探索を続けるだけなので難しくないと思います。そして、diffについては二等分した時の二等分点との差になります。bisectionについては二等分点です。この二等分点でTrueの時は$r$を二等分点にセットすれば良いです。なぜなら、$searchtype=1$の条件を見ればわかるように$f(r)$はTrueであるからです。この分割を順に行っていけば常に$f(r)$はTrueである条件を満たしながら二分することができるので、最終的に返すべきは$r$になります。
コード
binary_search.pyfrom operator import floordiv,truediv,truth,not_ ''' domain:= 定義域が整数(0)or実数(1) searchtype:= T→Fで最大値(0)かF→Tで最小値(1)か f:= boolを返す関数(単調性が必要)(答えでtrueを返すように) l,r:= 探索範囲(l,rはsearchtypeの条件を満たすように) eps:= 誤差(整数なら1,実数なら誤差指定による) ''' #答えはvalueに格納 class binary_search: def __init__(self,domain,searchtype,f,l,r,eps): self.domain=domain self.searchtype=searchtype self.f=f self.l,self.r=l,r self.eps=eps self.op1=[floordiv,truediv][domain] self.op2=[not_,truth][searchtype] self.value=self.calc() def calc(self): while self.r-self.l>self.eps: diff=self.op1(self.r-self.l,2) bisection=self.l+diff if self.op2(self.f(bisection)): self.r=bisection else: self.l=bisection return [self.l,self.r][self.searchtype]②三分探索のライブラリ
コードの説明
まだ
コード
ternary_search.py#狭義に凸or凹の関数に対して極値(最小値or最大値)を求める #広義に凸or凹であっても求まることはある(傾き0の区間が小さければ) from operator import floordiv,truediv,gt,lt ''' domain:= 定義域が整数(0)or実数(1) searchtype:= 狭義に凸で最大値を求めたい(0)or狭義に凹で最小値を求めたい(1) f:= 最大or最小にしたい値を返す l,r:= 探索範囲 eps:= 誤差(整数なら2,実数なら誤差指定による) ''' #インスタンス変数を増やせばfの引数が増えても対応できます #答えはvalueに格納 class ternary_search: def __init__(self,domain,searchtype,f,l,r,eps): self.domain=domain self.searchtype=searchtype self.f=f self.l,self.r=l,r self.eps=eps self.op1=[floordiv,truediv][domain] self.op2=[gt,lt][searchtype] self.value=self.calc() def calc(self): while self.r-self.l>self.eps: diff=self.op1(self.r-self.l,3) trisection1=self.l+diff trisection2=self.r-diff if self.op2(self.f(trisection1),self.f(trisection2)): self.r=trisection2 else: self.l=trisection1 return self.l+1-self.op2(self.f(self.l),self.f(self.l+1))(4)精度を考慮した抽象化ライブラリ
回数の決めうちをしないと精度の問題で落とされる可能性があります。概念として難しいものではないと思うので、えびさんの記事を読めばわかると思います。
①二分探索のライブラリ
コード
binary_search_iter.py#二分探索 from operator import floordiv,truediv,truth,not_ from math import log ''' domain:= 定義域が整数(0)or実数(1) searchtype:= T→Fで最大値(0)かF→Tで最小値(1)か f:= boolを返す関数(単調性が必要)(答えでtrueを返すように) l,r:= 探索範囲(l,rはsearchtypeの条件を満たすように) eps:= 誤差(整数なら1,実数なら誤差指定による) ''' #答えはvalueに格納 class binary_search: def __init__(self,domain,searchtype,f,l,r,eps): self.domain=domain self.searchtype=searchtype self.f=f self.l,self.r=l,r self.iter=int(log((r-l)/eps,2.0))+2 self.op1=[floordiv,truediv][domain] self.op2=[not_,truth][searchtype] self.value=self.calc() def calc(self): for _ in range(self.iter): diff=self.op1(self.r-self.l,2) bisection=self.l+diff if self.op2(self.f(bisection)): self.r=bisection else: self.l=bisection return [self.l,self.r][self.searchtype]②三分探索のライブラリ
コード
ternary_search_iter.py#三分探索 #狭義に凸or凹の関数に対して極値(最小値or最大値)を求める #広義に凸or凹であっても求まることはある(傾き0の区間が小さければ) from operator import floordiv,truediv,gt,lt from math import log ''' domain:= 定義域が整数(0)or実数(1) searchtype:= 狭義に凸で最大値を求めたい(0)or狭義に凹で最小値を求めたい(1) f:= 最大or最小にしたい値を返す l,r:= 探索範囲 eps:= 誤差(整数なら2,実数なら誤差指定による) ''' #インスタンス変数を増やせばfの引数が増えても対応できます #答えはvalueに格納 class ternary_search: def __init__(self,domain,searchtype,f,l,r,eps): self.domain=domain self.searchtype=searchtype self.f=f self.l,self.r=l,r self.iter=int(log((r-l)/eps,1.5))+2 self.op1=[floordiv,truediv][domain] self.op2=[gt,lt][searchtype] self.value=self.calc() def calc(self): for _ in range(self.iter): diff=self.op1(self.r-self.l,3) trisection1=self.l+diff trisection2=self.r-diff if self.op2(self.f(trisection1),self.f(trisection2)): self.r=trisection2 else: self.l=trisection1 return self.l+1-self.op2(self.f(self.l),self.f(self.l+1))
- 投稿日:2020-12-01T17:43:48+09:00
vscodeでオリジナルのショートカット(スニペット)を登録して,人生の無駄を削減する.
はじめに
背景
近年,私のアルバイト先で私がポンコツなせいで,変数の中身を確認したい時がよくあります.
import pdb; pdb.set_trace()という方法を知りました.大変便利でお世話になるのですが,毎回import pdb; pdb.set_trace()と入力するのがだんだん面倒になってきました.目的
そこで,頻繁に入力する決まった表現を短いタイピングで実現することを目標にします.
意義
人生の時間が増える.
方法
コード > 基本設定 > ユーザースニペット を押します.
登録したい言語を入力します.
コメントアウトを外し,以下を入力します.
- スニペットの名前
- 入力する短縮キーワード(prefix)
- 実際に入力されるコード(body)
- 説明(description)

prefixを入力すると,候補として上がってきます.
おわりに
人生から無駄な時間が減ります.



- 投稿日:2020-12-01T17:42:09+09:00
初めての投稿
今回が初めての投稿です。
筑波大学情報学郡情報科学類、現在3年の学生です。得意な言語はPython, Java, C, Matlab, Rなどです。
今後、個人的な備忘録として、また共有したい知識についての記事を投稿していきたいと思います。
- 投稿日:2020-12-01T17:25:53+09:00
卒論のために,オリジナルのNN(ニューラルネットワーク)をいい感じに可視化する.
卒論のために,オリジナルのNN(ニューラルネットワーク)をいい感じに可視化する.
これ
http://alexlenail.me/NN-SVG/LeNet.html
こんなんとか↓
こんなんとか↓
こんなんとか↓
が自由自在.でも,ちょっと作るのは大変.
大学の先生がTwitterで教えてくれました.



- 投稿日:2020-12-01T17:00:50+09:00
Human In The Loop実装してみた ― Part② 検証ツール ―
Human In The Loop実装してみた ― Part① ダッシュボード ―
の続きです。Part①では、目標設定、使用データ紹介、モニタリング用ダッシュボードの実装を行いました。前提条件や目標、利用技術などの詳細は前回のPart①をご確認下さい。
<HITL実装目次>
Part① ダッシュボード ← 前回
Part② 検証ツール ← 今回
Part③ HITL(①と②+モデル再学習の仕組み)■ ダッシュボード実装結果(前回)
■ 検証ツール実装結果(今回)
Part②で何をやるか
Part①ではモニタリングで使用することを想定したダッシュボードを実装しました。
今回はモニタリングで不自然な振る舞いを発見した際、それが異常かを有識者が判定する作業を効率化するための検証ツールを実装します(以下「イメージ」の有識者判定部分)。本記事の検証ツールは、アノテーションツールをベースとします。実装に入る前に、アノテーションについて簡単に説明し、どういうものを作ろうとしているかを整理します。
アノテーションとは
アノテーションとは、「特定のデータに対して情報タグ(メタデータ)を付加する」[参考1] ことを意味します。
本来、画像や自然言語など非構造化データにラベルを付与し、教師データとして学習を方向付けたり、効率化したりすることが多いのですが、今回はテーブルデータという構造化データに対して、モデルの再学習用に異常か正常かのラベルを付与することを考えます。
ちなみに、大量のアノテーションは手間のかかる作業であることが多く、外注するのにもコストがかかるため、限られた有識者のリソースを効率的に活かすためにも、今回のような検証ツールは必要だと考えます。実装
以下に分けて実装していきます。
1. ダッシュボード
2. 検証ツール ← 今回
3. HITL(①と②+モデル再学習の仕組み)2. 検証ツール
■ 実装内容
- 目標:構造化データにラベルを付与するツール
- 入力:テーブルデータ(csvファイル)
- 出力:入力+検証結果
- ファイルの入力方法:選択とdrag & dropどちらも
- 基本機能:読み取り、表示、更新、削除
- オプション:初期化、sort、filter、export
■ 実装イメージ ※IDは本件では時間(Time)
■ 実装結果
Dashを使用した感想
このシリーズにおけるHuman In The Loop実装に必要なウェブアプリの実装箇所は今回で全てなので、メインで使用したDashというフレームワーク[参考4]について感想を述べたいと思います。
Dashを使ってみた感想
- flaskをベースとしているだけあって軽量
- 簡易的なツール作成用という印象
- 特にcallback関数がIDと一対一でないとエラーがでるなどは課題有
- デフォルトだと自動コールバックがかかるので注意
- DataTableなど、不適切な引数を入れてしまうと表示されないものがあるので注意
- DataTable表示のための関数はdashチュートリアルのものをコピーが簡単
- (csvとxlsファイルをutf-8にデコードしてpandas DataFrameにしてくれる)
- bootstrapでレイアウトを決めても適切にstyle指定をしないと、はみ出したり背景色がおかしくなったりする
まとめ
今回はHuman In The Loopにおける有識者検証時に使用する、検証ツールを実装しました。
検証ツールによって、検証対象データの取得、表示、確認、結果出力の流れがスムーズになり、手作業に比べ作業が効率化することが分かりました。また、今回はテーブルデータを表示しましたが、表示するものを文章にしたり画像にしたりすることで、典型的なアノテーションツールとしても利用できると感じました。
次回は今まで作成したダッシュボードと検証ツールに、モデルを再学習する仕組みを追加することで、Human In The Loopを実演したいと思います。改善点やご質問などあれば、コメントいただければ幸いです。
参考
アノテーションという言葉の意味
https://www.weblio.jp/content/アノテーション
(参考)アノテーションの種類:https://japan.zdnet.com/article/35134024/Dashで機械学習ができるWebアプリを作る [Step1]
https://wimper-1996.hatenablog.com/entry/2019/10/28/dash_machine_learning1
※ Dashのテーブルデータ処理などで参考にさせていただきましたコード公開済み
http://github.com/utmotoplotly
https://plotly.com/




