- 投稿日:2020-12-01T23:10:55+09:00
AWS Amplify フレームワークの使い方Part15〜SSR対応導入編〜
はじめに
ついにこの日がやってきました。
AmplifyがSSRに対応しました!!!パチパチパチ
しかもメチャクチャ簡単なんです。
実装方法
ほんの少しの設定とコード修正だけでOKなんです。
基本設定
設定は、今までのamplify設定ファイルに
ssr: trueを追加するだけです。plugins/amplify.jsimport Vue from 'vue' import Amplify, * as AmplifyModules from 'aws-amplify' import awsExports from '../aws-exports' Amplify.configure({ ...awsExports, ssr: true }) // これだけ Vue.use(AmplifyModules)たったこれだけで、SSRの設定完了です。
API/Auth/Storage
基本的にクライアントサイドでの実行については、一切コードを変更する必要はありません。(たぶん)
asyncDataやmiddlewareなどサーバーサイドで実行される関数についてのみ、withSSRContextを追加するだけです!Auth
// import { Auth } from 'aws-amplify' import { withSSRContext } from 'aws-amplify' export async function getServerSideProps(context) { const { Auth } = withSSRContext({ req: context.req }) const userInfo = await Auth.currentAuthenticatedUser() }API
// import { API, graphql } from 'aws-amplify' import { withSSRContext, graphql } from 'aws-amplify' import * as gqlQueries from '../graphql/queries' export async function getServerSideProps(context) { const { API } = withSSRContext(context) const userData = await API.graphql(gqlQueries.getUser, { id: 'taro'}); }Storage
おそらくほぼ同じ書き方だと思われますが、未調査&未検証なので、また追記します。
おわりに
こんな簡単に実装できるなんて本当に素晴らしいですね。
またデプロイの方法ですが、Next.jsであれば下記参考の公式ブログに簡単なデプロイ方法も掲載されていますが、Nuxtは自力で決める必要があります。
とりあえず、CloudFront+LambdaEgeをServerlessFramework使って構成するのが現時点でのベストプラクティスなのかなと思っていますが、どうやらAmplifyコンソールで、SSRに対応するとかしないとかの話が出ているようなので、こちらの今後にも期待です。Server-side rendering support / SSR #412
参考
- 投稿日:2020-12-01T22:36:11+09:00
AWS ソリューションアーキテクトアソシエイト 18
AWSにおけるコスト管理
AWSではアカウントごとにサービスを利用した分のコストが発生します。
通常、コストの支払い管理は、アカウントの管理者(たとえばIT部門など)が行います。しかし、どの程度利用しているかの詳細把握や、あらかじめ決められた予算を超過していないかの監視、利用部門へのコスト配賦など、コスト管理で行うべきことは多岐にわたります。【主なコスト管理のタスク】
タスク タスク概要 主なAWSサービス コストの請求・支払い 複数のAWSアカウントをまとめて支払い管理する Consolidated Billing(一括請求) コスト状況の詳細把握 コストとリソース使用量の詳細をレポート・分析する AWS Cost and Usage Report
(コストと使用状況レポート)コストの可視化・傾向分析 コストの可視化や深掘り分析、将来予測を行う AWS Cost ExpLorer 過剰利用の監視 予算策定や予算通過のアラートを管理する AWS Budgets(予算設定) コスト最適化の検討 コスト最適化の余地があるリソースを分析・改善する AWS Trusted Advisor AWSのBilling and Cost Management Dashboardから、上記に代表されるコスト・請求に関わるサービスにアクセスが可能です。
次に各AWSサービスの概要を説明します。Consolidated Billingによる支払い管理
Consolidated Billing(一括請求)は、複数のAWSアカウントに対する請求を1つに統合し、まとめて支払いできる機能です。「AWS Organizations」と呼ばれる、複数のAWSアカウントを一元管理するサービスの一機能として提供されています。
この機能で、次の利点が得られます。
- 複数のAWSアカウントのコストが1つの請求書に統合されることによる支払い義務の効率化
- 各AWSアカウント(たとえば業務部門・IT部門や開発環境・本番環境など)の使用状況を統合的に把握可能
- 複数のAWSアカウントの使用量を統合することで、ボリュームディスカウントによるコスト削減が可能
以下の図のように、請求先のマスターアカウント(Payer Account)に対し、メンバーアカウント(Linked Accont)の請求が統合できます。
【Consolidated Billing(一括請求)のイメージ】
マスターアカウント←全アカウントの費用がまとめて請求される
| ←合算された費用に対してボリュームディスカウントの適用が可能
|
|__メンバーアカウント
|__メンバーアカウントAWS Cost and Usage Reportによる詳細レポート・分析
AWS Cost and Usage Report(コストと使用状況レポート)では、AWSのサービスごとのリソース状況とコストを1時間ごとや日次で収集し、CSV形式でS3へ保存、またはRedshiftに格納したり、Amazon QuickSight(QuickSight)で分析・可視化したりできます。
Consolidated Billingを利用している場合は、マスターアカウントのレポートにメンバーアカウントの情報が表示されます。
たとえば、このレポートで取得可能な情報には以下のようなものがあります。
- bill/PayerAccountId:支払いアカウントのAWSアカウントID(Consolidated Billingの場合はマスターアカウントのID)
- product/ProductName:利用しているAWSサービスの名前
- product/region:AWSサービスのリージョン
- lineItem/UsageAmount:指定した期間に発生したリソース使用量
なお、このレポートではオンデマンドインスタンスだけでなくリザーブドインスタンスの利用状況や料金などの情報も取得できるため、定期的に監視・分析することでリザーブドインスタンスの見直しといったコスト最適化のための計画を検討することができます。
Cost Explorerによるコストの可視化と傾向分析
AWS Cost Explorer(Cost Explorer)は、先述のAWS Cost and Usage Reportのデータをグラフィカルに可視化したり検索したりできるサービスです。
たとえば、EC2のリソース使用量やコストを時系列にグラフ化し、詳細に分析したい場合はさまざまな条件(サービス別やタグ指定など)や期間を指定してフィルタリング・検索が可能です。
具体的には、以下の3つが提供されています。可視化
最大で過去12ヶ月分のコストデータをグラフ表示できます。あらかじめ以下のような可視化グラフが用意されており、簡単に切り替えて表示できます。
- Monthly costs by service:サービスごとの月次コスト推移
- Monthly costs by linked account:AWSアカウントごとのDaily costs
- Daily costs :日次コスト推移
- Monthly EC2 running costs and usage:月次EC2使用時間・コストの推移
- RI Utilization :リザーブドインスタンスのコスト推移やオンデマンドインスタンスの場合と比較したコスト削減額など
分析
サービス、AWSアカウント、リージョン、AZ、インスタンスタイプ、タグなどの条件でフィルタリング表示できます。
予測
可視化や分析だけでなく、過去の使用量のトレンドから今後3ヶ月間のコストを予測することができます。
予算設定による利用超過の監視
AWSでは、Billing and Cost Management DashboardのBudgetsから予算を作成することができます。
予算額やリソース使用量をあらかじめ設定し、現在どのくらい消費しているかを確認したり、超過時の通知方法を設定したりすることができます。予算額の設定
コストやリソース使用量など監視する対象を選び、月次や四半期などのタイミングを指定して監視する予算額や使用量を設定します。
通知の設定
設定した予算額を超過しそうな場合、または超過した場合にCloudWatchアラームやSNSトピック、メールなどによる通知が可能です。
超過の条件は予算額に対するパーセンテージや実際の消費量(金額)が大きい、小さい、等しいなどさまざまな設定が可能です。Trusted Advisorによるコスト最適化
ここまでは、コストの詳細把握・可視化と分析・予測・監視などに使えるAWSサービスを説明しました。
コスト管理に関連する最後のタスクはコスト最適化です。AWSでは、コスト最適化のヒントを推奨するサービスとして、AWS Trusted Advisor(Trusted Advisor)が提供されています。
Trusted Advisorは、AWSのベストプラクティスに基づいて、コスト最適化、セキュリティ、耐障害性、パフォーマンス、サービスの制限の5項目でユーザーのAWS利用状況をチェックし、改善すべき事項を推奨するサービスです。Trusted Advisorのコスト最適化機能では、たとえば以下の観点でコストの診断が行えます。
使用率の低いEC2インスタンス
少なくとも過去14日間、常に稼働しているEC2があり、1日のCPU使用率が10%以下、かつネットワークI/Oが5MB以下である日が4日以上ある場合にアラートします。
使用率が低いEC2インスタンスに対し、インスタンス数やインスタンスサイズを調整することでコスト削減が可能です。EC2リザーブドインスタンスの最適化
前月の1時間ごとのEC2使用量に基づいて、リザーブドインスタンスの最適数を推奨します。
推奨されたリザーブドインスタンス数を購入することで、少なくともEC2使用料金の10%を節約可能となります。関連付けられていないElastic IPアドレス(EIP)
稼働中のEC2インスタンスに関連づけられていないEIPをチェックします。
EIPに課金が発生するため、EC2インスタンスへ割り当てられていないEIPや、割り当てられていてもEC2インスタンスが停止中の場合には、使用していないEIPを解放することでコスト削減が可能です。これ以外にもELBやEBS、RDSなどのサービスについても、使用状況などからコスト最適化の診断を行うことができます。
- 投稿日:2020-12-01T22:35:52+09:00
AWS ソリューションアーキテクトアソシエイト 19
AWSにおける運用の考え方
ビジネスの変革が急速に進む現在、システム構築時やアプリケーション開発時だけでなく、その後のリリースや更新の早さや運用の品質向上・維持は重要な要素になっています。
システムの高い運用性を保つためにはできるだけ作業を自動化するとともに、構築した内容の文書化と動作確認のためのテストを定期的に実施する必要があります。
AWSには、クラウド上で高い運用性を実現するための以下のような設計原則があります。コードによるオペレーション実行
「コードを書いて実行する」というアプリケーションの考え方クラウドシステムのオペレーションに適用することにより、システムの運用を効率化します。
これまで手動で行っていた作業が自動化されることにより、作業ミスが少なくなります。
また、同じ作業であればコードを再利用することができます。定期的に、小規模で、元に戻すことができる変更を行う
システムは一度構築したら終わりではないため、定期的な更新を行う前提で設計することが重要です。
たとえば、システムを構成するコンポーネントを容易に変更できるようにあらかじめ設計しておきます。また、すでに稼働しているシステムに変更を加える場合は、システムは小さな範囲で変更します。
このような設計・運用をすることでメンテナンス性が上がります。万一、変更作業時に失敗が起きても影響を最小限に抑えることができ、変更前の状態に戻しやすくなります。運用手順を見直す
システムは定期的に変更されますが、システムだけが進化しても、それに見合った運用手順を確保しておかなければ、運用の品質向上・維持を果たすことができません。
障害発生を想定する
障害発生を想定したテストを行い、障害発生時の影響を性格に把握しておきます。また、発生した障害への対応手順もてすとし、手順が正しいかを確認して、運用チームが障害対応の内容を正しく理解しておくようにします。
運用の失敗をもとに改善する
運用上の作業や障害対応への経験をもとに、運用作業を改善します。また、経験から学んだ内容をチームなどに共有します。
次節からは、高い運用性をAWSで実現していくための考え方やサービスについて説明していきます。
- 投稿日:2020-12-01T22:35:20+09:00
AWS ソリューションアーキテクトアソシエイト 20
コードによるインフラストラクチャ構成管理
ハードウェアを自社で調達して行うインフラストラクチャ構築では、一般的にインフラストラクチャ担当のエンジニアが環境構築手順書を作成して、環境のセットアップを行います。
そのときの課題として、以下のようなことが挙げられます。
- 作業中にミスが発生する可能性がある
- 導入後に構成変更がることを考慮して、インフラストラクチャ管理(設計書やサーバーのパラメータなど)が必要
アプリケーション開発においても、以前はプログラムの変更やリリース作業で同様の問題が起きていました。しかし、現在は、サーバーへのデプロイ作業が自動化できるようになるなど、作業の効率化に有効な手段が一般化しています。
このようにアプリケーション開発で実践されているコード管理・作業自動化という手法をインフラストラクチャ構築にも導入して、インフラストラクチャ構築作業内容をコードで記述して管理できるようにしたInfrastructure as Code(IaC)という考え方があります。
AWSでは、定義ファイルをコーディングし、コードを実行することでリソースをプロビジョニングすることができます。インフラストラクチャ環境の運用をコードで管理しているため、まったく同じ作業であれば以前に実行したコードをそのまま流用できます。構築作業に変更が生じた場合は、該当箇所のみを修正してコードを実行することにより修正版のインフラストラクチャ環境を構築することができます。
これにより、従来は煩雑だったインフラストラクチャ構築手順のバージョン管理も容易になりました。CloudFormationのコード管理
AWSにおいてIaCを実現したのが、AWSリソースをプロビジョニングするサービスであるAWS CloudFormation(CloudFormation)です。
「テンプレート」と呼ばれるプロビジョニングのための定義ファイルを用意し実行することで、定義内容に従ってAWSリソースを構築することができます。AWSにおいてIaCを実現したのが、AWSをリソースをプロビジョニングするサービスであるAWS CloudFormation(CloudFormation)です。
- 投稿日:2020-12-01T21:08:31+09:00
AWSを予算内(無料枠)で使うために請求アラートを設定する
ご存知の方も多いと思いますが、AWSのアカウントは取得して12ヶ月は無料利用枠があります。
しかし、知らない間に12ヶ月を越えていたり無料枠から外れていたりして、気付いたら「請求額がとんでもねぇ…」という自体も考えられなくもありません。
(AWSの料金体系ってちょっぴり分かりづらくないですか?)そうならない為にも、AWSには請求額が一定額を越えそうな時にアラートメールを送ってくれる機能があるので設定していく。
AWSのUIはちょこちょこ変わっているみたいですが、この記事は2020年12月版のUIでの記事になります。AWSに関してはそこまで経験がない為、間違いやこうした方が良い等の意見があれば遠慮なくいただけると幸いです。
無料枠のアラートを設定する
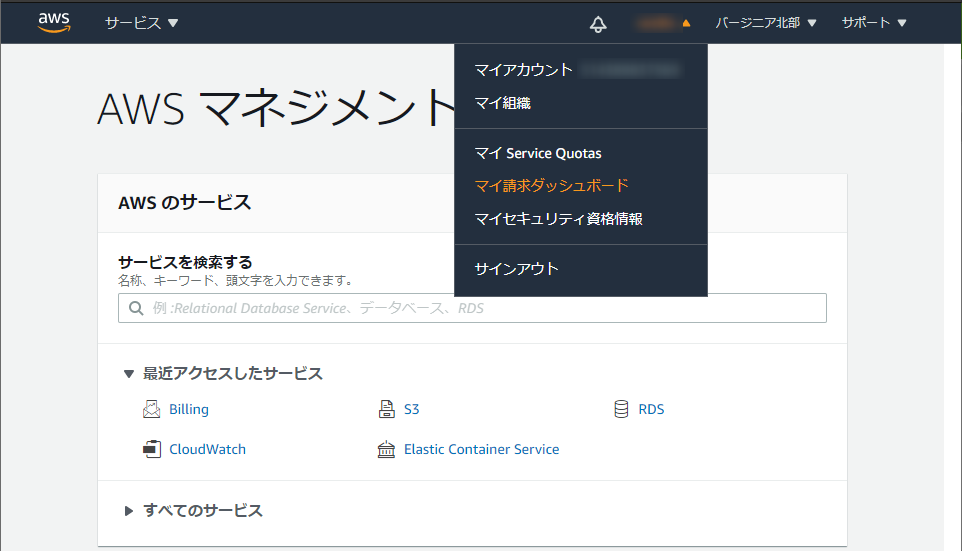
AWSマネジメントコンソールを開き、ユーザー名をクリック→「マイ請求ダッシュボード」を選択。
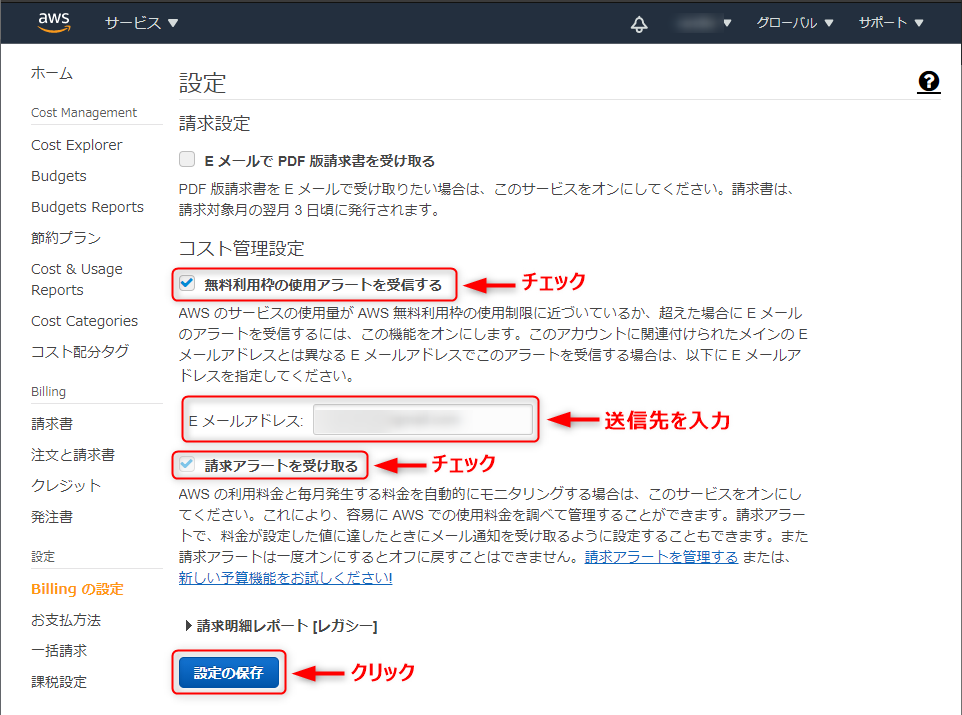
左から「Billingの設定」をクリック。
無料利用枠の使用アラートを受信する:チェック
Eメールアドレス:アラートの送信先アドレスを入力
請求アラートを受け取る:チェック
「設定の保存」をクリックして完了です。請求額のアラートを設定する
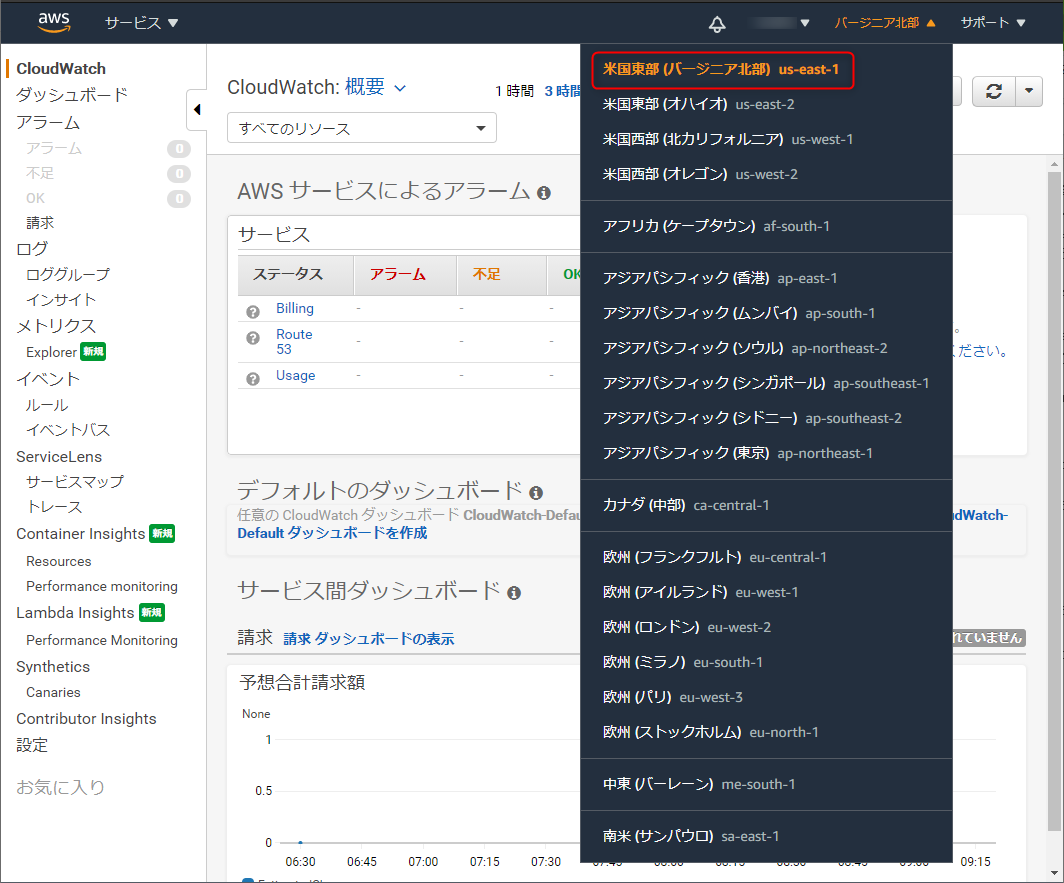
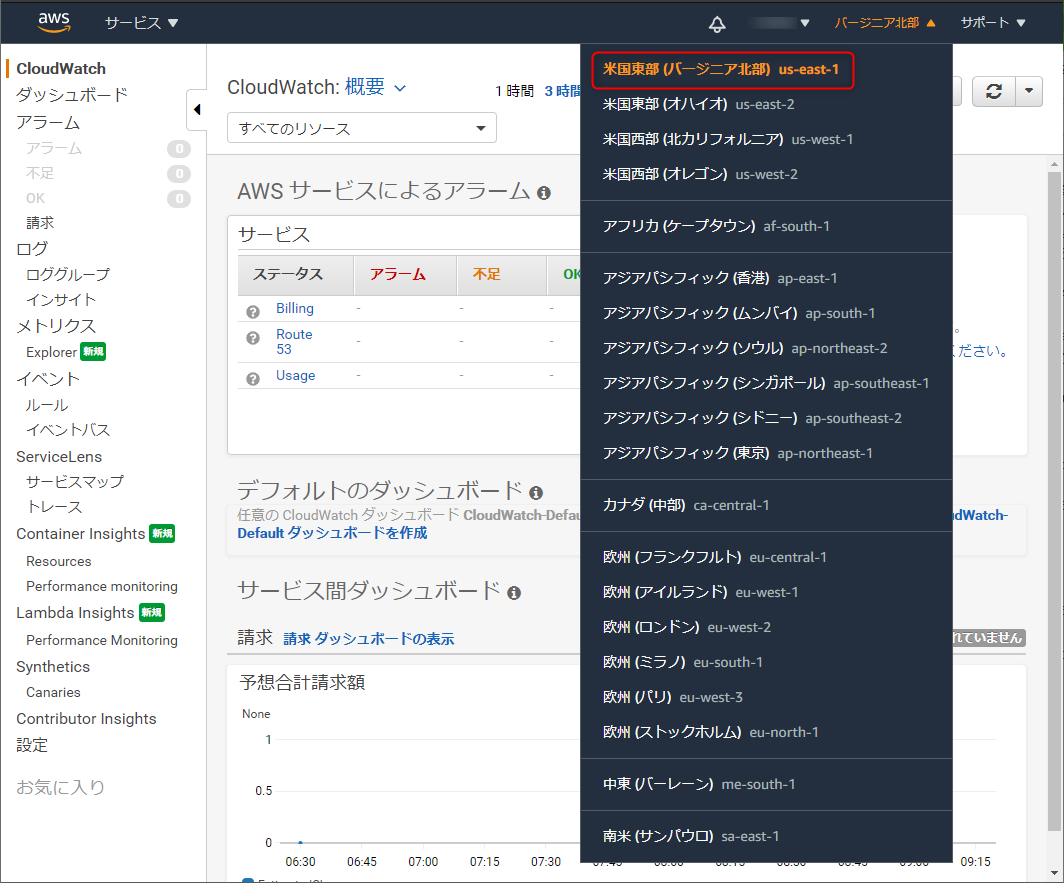
今度は、請求額が設定した値を超えた場合のアラートを「CloudWatch」を利用し設定します。
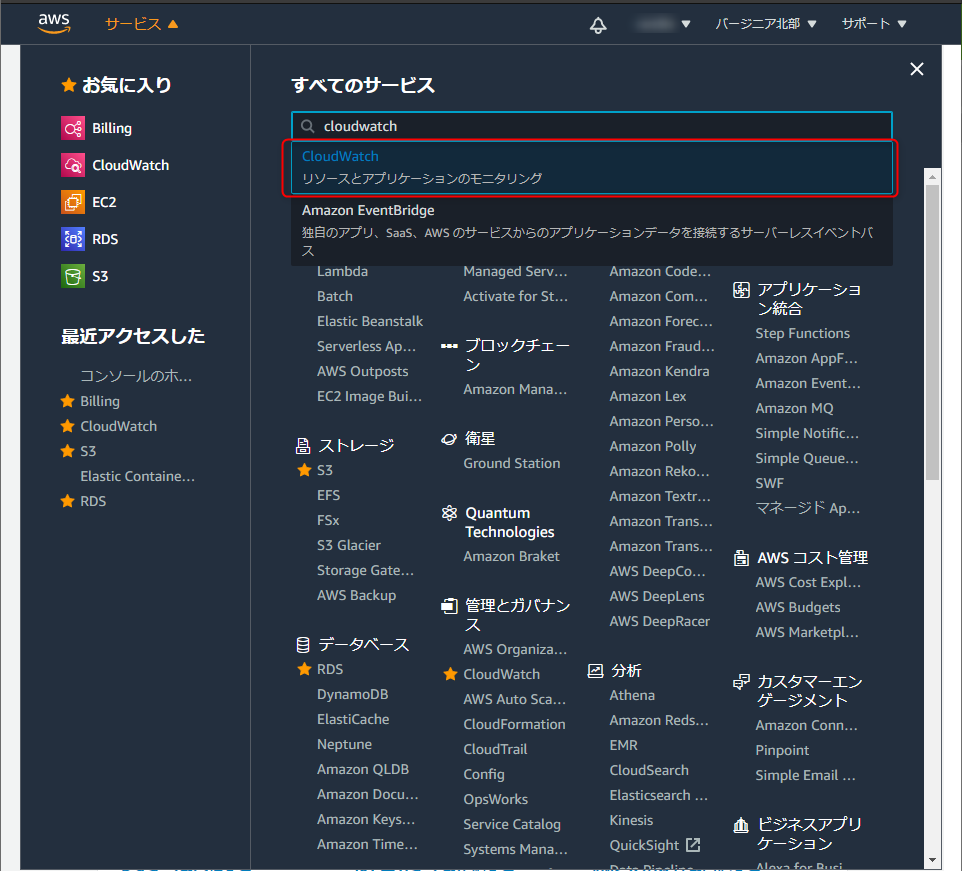
10個まで無料でアラームが設定でき、AWS無料利用枠が終わっても使えます。サービスから、「CloundWatch」と入力しクリック。
AWSのリージョンを「バージニア北部」に設定します。(なぜか東京にしていると設定ができない)
元から設定されている方はいいですが、変更した方は設定完了後リージョンを戻し忘れないように。
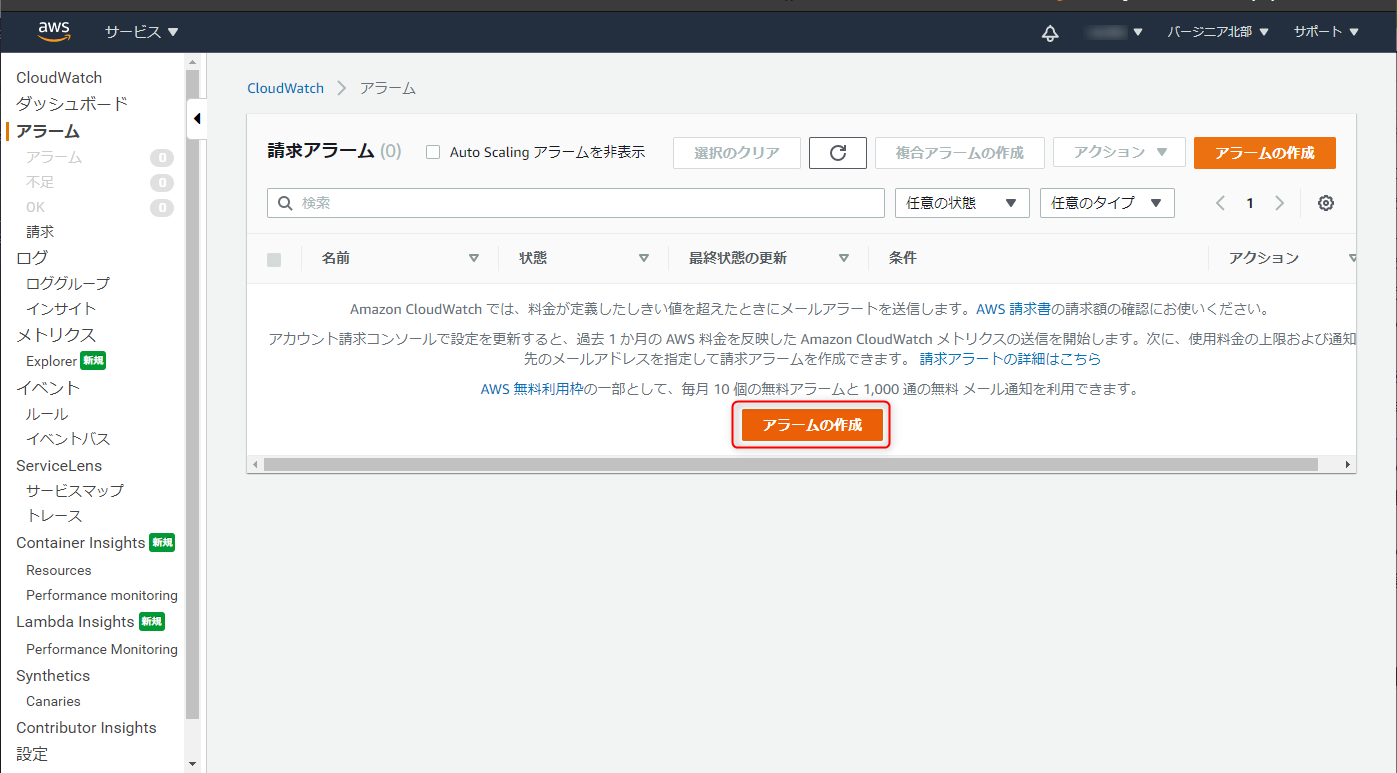
左から「請求」をクリックし、「アラームの作成」を選択。(真ん中のリンクの方が設定が早い)
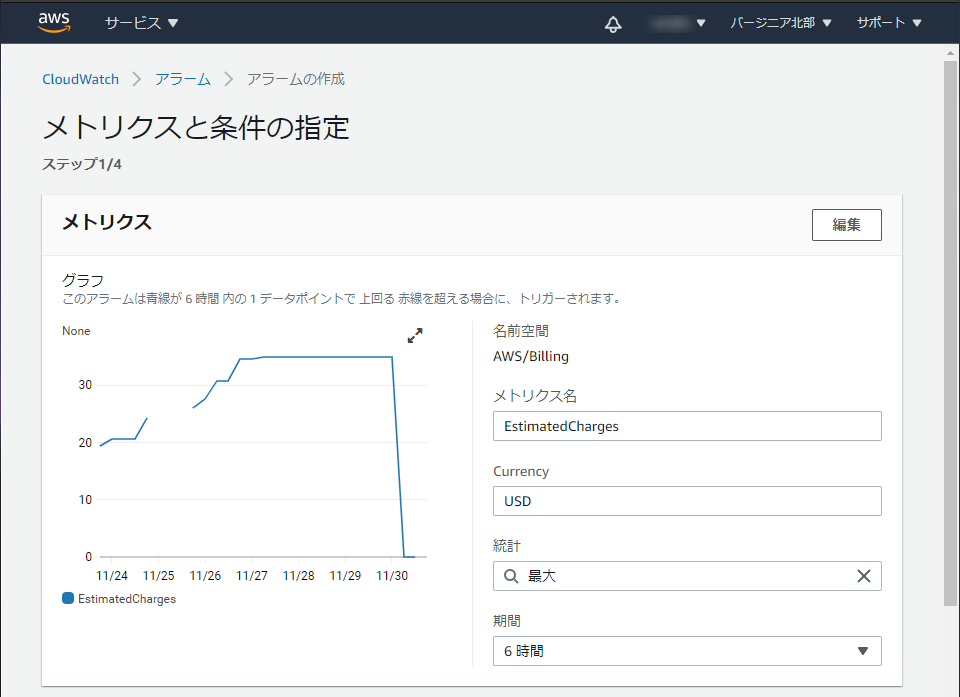
メトリクスを設定します(デフォルトでOK)
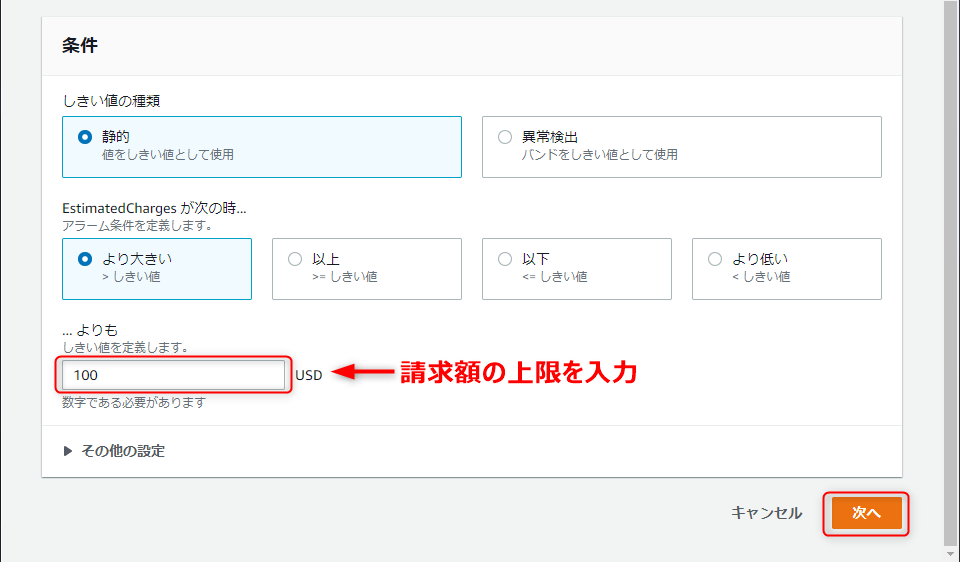
請求の条件を入力して、「次へ」をクリック。
今回は、100USDを超えた場合にアラートメールを飛ばすようにします。
※日本円ではなくドルなので、間違えないように。
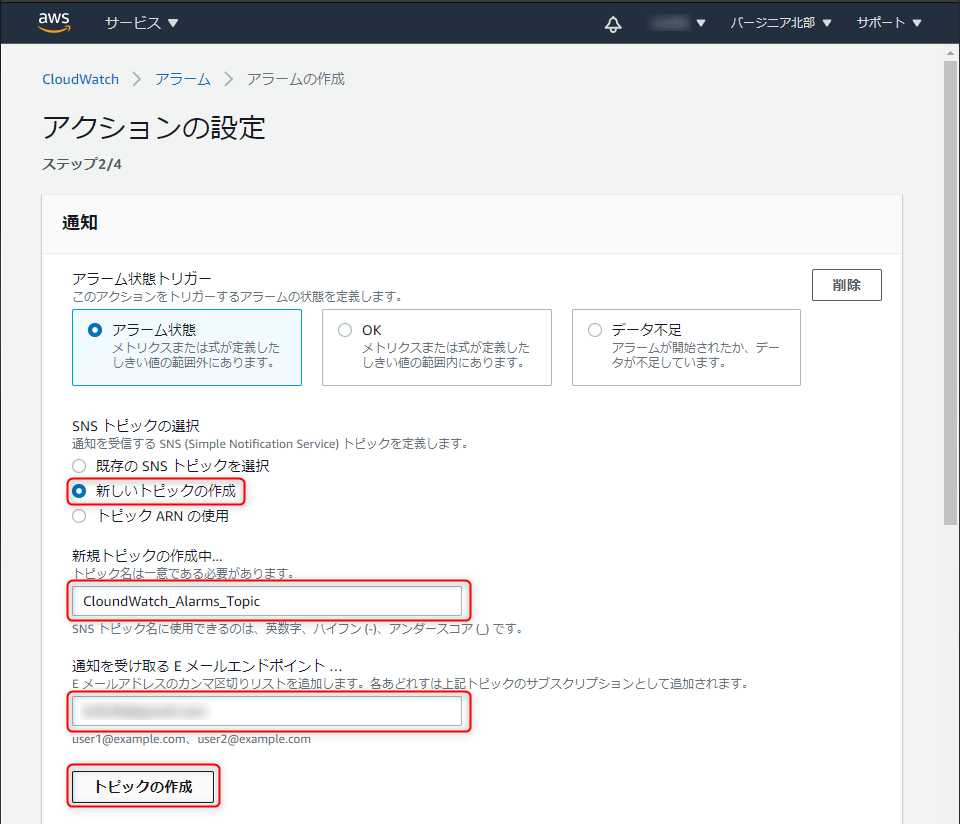
通知の設定をします。
新しいトピックの作成:チェック(既にトピックがある場合は既存のトピックでもOK)
新規トピックの作成:適当にトピック名を入力(デフォルトでOK)
通知を受け取るEメールエンドポイント:通知を受け取るメールアドレスを入力
「トピックの作成」をクリック。
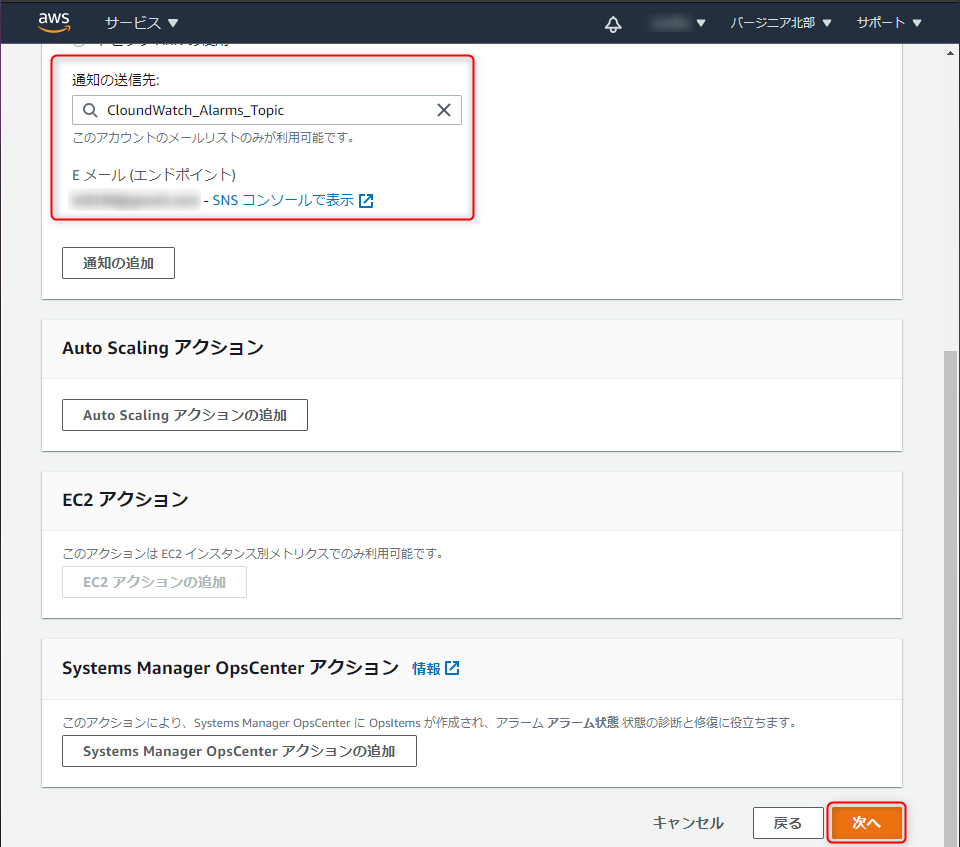
Eメール(エンドポイント)に通知先のメールアドレスが表示されていることを確認し、「次へ」をクリック。
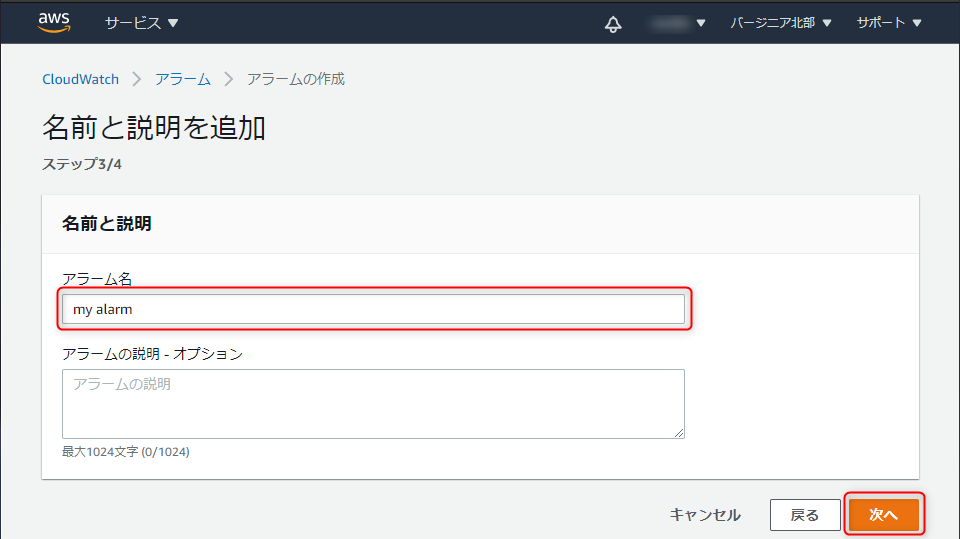
適当なアラーム名を入力し、「次へ」をクリック。
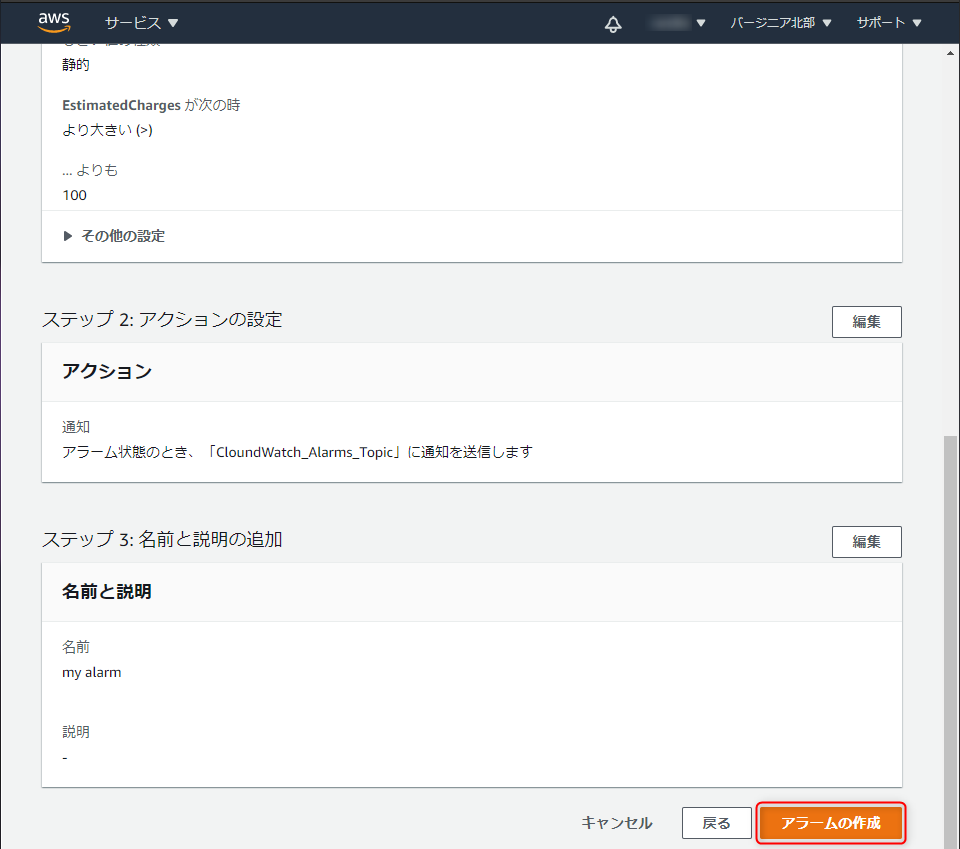
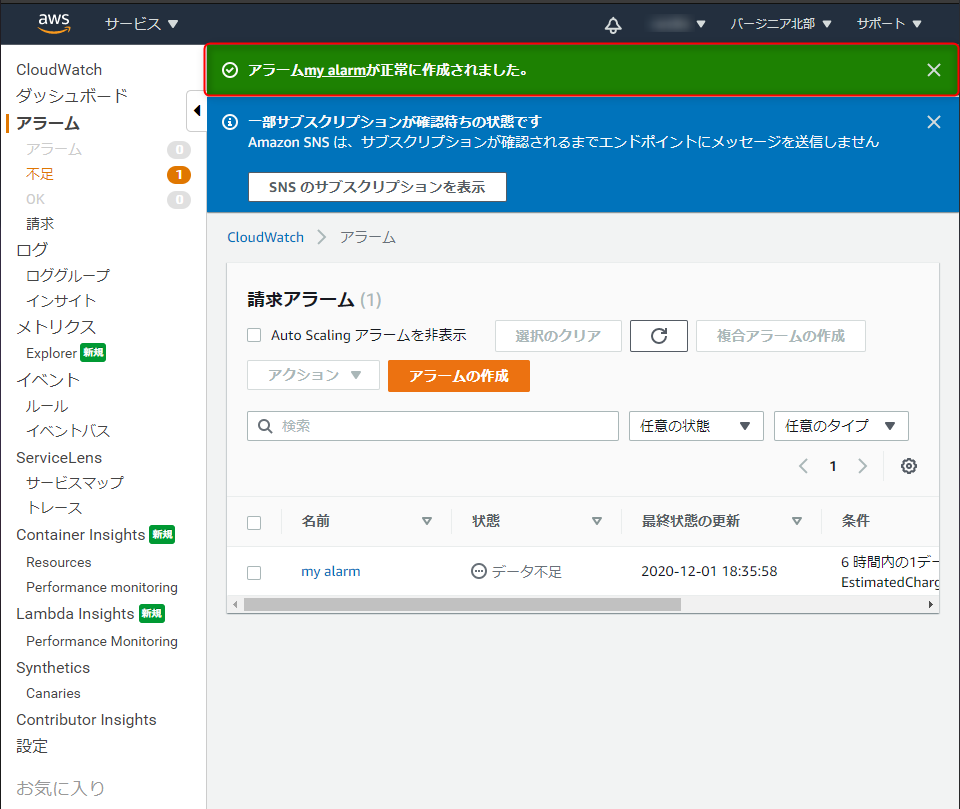
設定内容を確認し、「アラームの作成」をクリックします。
「アラーム○○が正常に作成されました」と表示されている事を確認し、メールアドレスの認証を行います。
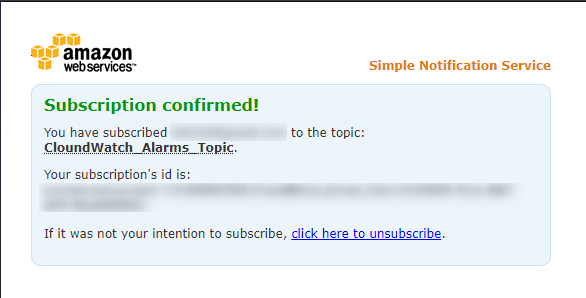
通知先に設定したメールアドレスにメールが届いているので、「Confirm subscription」をクリック。
正常にメールアドレスが認証されれば、下記のような画面が表示されます。
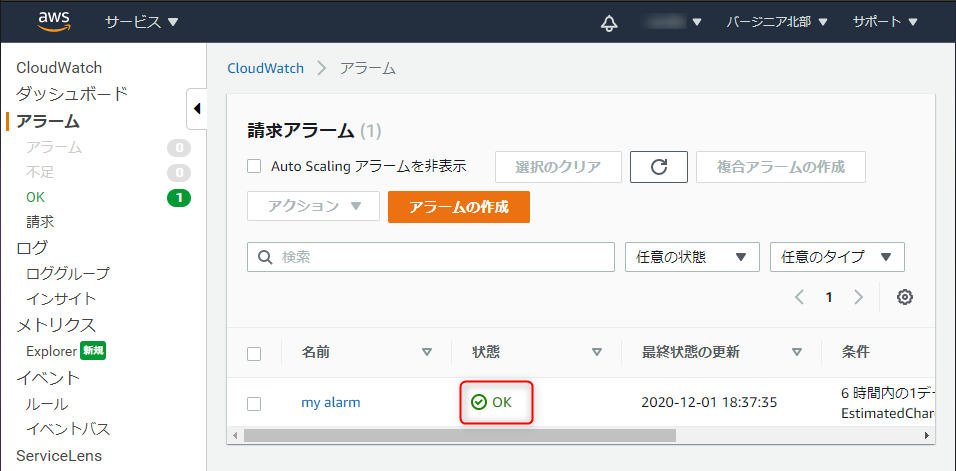
CloudWatchの画面を更新して、状態が「OK」となっていれば設定完了です。
終わりに
今回この記事で書いた内容はAWSの公式ドキュメントを見れば手順は書いてあるんだろうけど、どうも見づらくて読む気にならないので自分用に残した。
ちなみに請求アラートは10個まで作れるので、軽めのアラートと重要なアラートで分けて作っても良いですね。
これで予期しない請求に悩まなくて済みそうです。
- 投稿日:2020-12-01T19:19:30+09:00
【S3】Curlでファイルをアップロード時に所有者やバケットポリシーの問題
初めに
アドベントカレンダー記事の2発目です
最近、S3のObject OwnerShipがリリースしたので、所有者問題が解決されましたので、
簡単に使い方や、その前にアップロードしたオブジェクトの対応について書きます概要
外部からS3にアップロードしたデータの所有者はアップロードの人でしたが、
curlなどでアップロードすると、ゲストユーザー(?)になるので、ディフォルトでオブジェクトを公開することになります
バケットの所有者はオブジェクトの権限も持ってないので、IAMの権限があってもアクセスや削除などができませんこの記事は、S3のObject OwnerShipでアップロードされたものの所有者を強制的変更すると、
Object OwnerShipを設定する前に、アップロードされたオブジェクトの所有者を変更する方法を紹介しますS3のObject OwnerShipの設定手順
1. バケットの作成
コンソールで適当に作成します
方法は割愛します2. バケットポリシーの設定
- 特定のIPだけアクセス許可します
- PutObject時にACLを
bucket-owner-full-controlで設定してるリクエストだけ許可します
- オーナーはバケット所有者になるので、
Denyポリシーなくても公開はしないので不要です
- 需要次第に設定しても問題ありません
{ "Version": "2012-10-17", "Id": "test_policy", "Statement": [ { "Sid": "get", "Effect": "Allow", "Principal": "*", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::{バケット名}/*", "Condition": { "IpAddress": { "aws:SourceIp": [ "1.1.1.1/32" ] } } }, { "Sid": "put", "Effect": "Allow", "Principal": "*", "Action": [ "s3:PutObject", "s3:PutObjectAcl" ], "Resource": "arn:aws:s3:::{バケット名}/*", "Condition": { "StringEquals": { "s3:x-amz-acl": "bucket-owner-full-control" }, "IpAddress": { "aws:SourceIp": [ "1.1.1.1/32" ] } } } ] }3. S3 Object Ownershipの設定
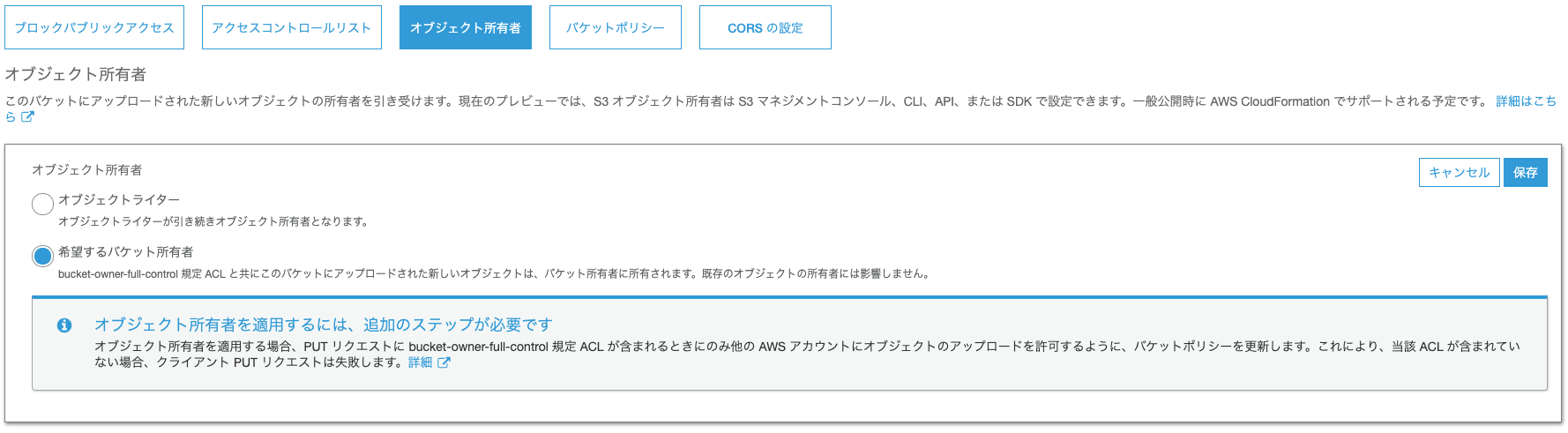
- S3 Object Ownershipの選択肢をオンにします
Curlでオブジェクトをアップロードする方法
$ curl -XPUT -H "x-amz-acl:bucket-owner-full-control" -T {ファイル名} https://{バケット名}.s3-ap-northeast-1.amazonaws.com/{ファイル名}検証
# curl -XPUT -T test.txt https://${バケット名}.s3-ap-northeast-1.amazonaws.com/test.txt <?xml version="1.0" encoding="UTF-8"?> <Error><Code>AccessDenied</Code><Message>Access Denied</Message><RequestId>829150681872CD3C</RequestId><HostId>W1sEi85Oa03yMlm8SSwFKvSv2RY7B1FhnhEQhspvsBX0VCPND0esPhg7hunsUpJoWiIHuik5r+k=</HostId></Error> 'bucket-owner-full-control' のヘッダーがないので、失敗 # curl -XPUT -H "x-amz-acl:bucket-owner-full-control" -T test.txt https://${バケット名}.s3-ap-northeast-1.amazonaws.com/test.txt エラーが出ないので、成功所有者
bucket-owner-full-controlがついていないままアップロードしたもの
bucket-owner-full-controlがついているアップロードしたもの
- ちゃんと所有者を変更してくれました
オブジェクトの所有者を変更する方法
1. バケットの全オブジェクトを取得
- 必要であれば、
--prefixをつけて、特定のプレフィックスを指定できます- 件数が多ければ、一回で全件表示出来ない場合があるので、
NextTokenを取得し、--starting-tokenをつけて続きを取得しましょうhttps://docs.aws.amazon.com/cli/latest/reference/s3api/list-objects-v2.html
# aws s3api list-objects-v2 --bucket ${バケット名} --query Contents[*].[Key] --output text >> /tmp/key.txt2. オブジェクトのACLを変更
1で取ったリストをもとに、オブジェクトのACLを変更します# cat key.txt | xargs -I KEY aws s3api put-object-acl --bucket ${バケット名} --key KEY --acl bucket-owner-full-control --no-sign-request3. オブジェクトの所有者を変更
1で取ったリストをもとに、オブジェクトの所有者を変更します# cat key.txt |xargs -I KEY aws s3 cp s3://${バケット名}/KEY s3://${バケット名}/KEY --metadata-directive REPLACE最後に
S3のObject OwnerShipがリリースしたことに、長年に悩まされたことを解消できました。
ありがとうございます!この記事もみんなさんの悩みを解決できたら嬉しいですね

- 投稿日:2020-12-01T18:10:54+09:00
【Athena】With句を使って一時テーブルを作成してSQLを簡略化させる
複雑なサブクエリ
AthenaでSQLを書いてデータを抽出しているとどうしても複雑なSQLになることが多いです。何度もつかうサブクエリに関してはviewテーブルを作成することも考えられますが、一時的に使うものまでviewテーブルを作成するのは面倒に感じられます。
With句を使って一時テーブルを作成する
With句のPrestodbのドキュメントはこちらです。
例えば以下のSQLを作成したとします。
SELECT t1.*, t2.* FROM (SELECT a, MAX(b) AS b FROM x GROUP BY a) as t1 INNER JOIN (SELECT a, AVG(d) AS d FROM y GROUP BY a) as t2 ON t1.a = t2.aサブクエリで取得しているテーブルをWith句で書くと処理がSQLスッキリします。
WITH t1 AS (SELECT a, MAX(b) AS b FROM x GROUP BY a), t2 AS (SELECT a, AVG(d) AS d FROM y GROUP BY a) SELECT t1.*, t2.* FROM t1 INNER JOIN t2 ON t1.a = t2.a;スッキリするだけでなく、複数回同じサブクエリが登場するときはそのまま使いまわしも可能、サブクエリの条件が変わったときもWith句の変更のみで済むため、変更漏れのリスクが避けられます。
With句は非常に便利なので使えることだけでも覚えておくと良いと思います。
- 投稿日:2020-12-01T17:46:58+09:00
脳死で出来る ECS (Fargate)でDocker環境のデプロイ
はじめに
前回の記事を書いていくと、今の流行はどうやらEC2ではなくECSであるそうなので、今回はそちらを勉強してみました。
備忘録として書いていますが、自分と同じくAWS初心者の方の手助けとなれば幸いです。対象読者
- AWSアカウント登録済み
- EC2やVPCなどの基礎的なAWSの知識は持っている
- 自分
全体構造
ECSとは
Amazon Elastic Container Serviceの略称で、EC2インスタンス(もしくはFargate)コンテナを複数操作することができるサービスです。また、他のAWSサービスとも連携することが容易です。
簡単にECSの全体構造を表してみました。
詳しくはまた作成するときに説明します。
一応こちらが公式です。
ECSを含めた構築の流れ
Dcoker イメージの作成
環境を揃えるため、今回使用するDocker イメージを作成します。
「自分の環境で試したいぜ」って方はこの章は無視してもらって構いません。
一応コードは、ここ に公開しています。
pullしてきたら、READMEにしたがってdocker build --tag 『今回のDockerイメージ名(任意)』 .を実行。
docker images REPOSITORY TAG IMAGE ID CREATED SIZE aws-example latest 05ad15c1ad82 About a minute ago 527MBで、イメージが作成できているか確認できます。
ちなみに、
docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 817ed89f61b7 aws-example "docker-entrypoint.s…" 32 seconds ago Exited (0) 25 seconds ago gracious_galois docker start 『上の CONTAINER ID』 docker exec -it 『上の CONTAINER ID』 shでコンテナの中に入ることができます。
ECRにpush
ECRとは、Amazon Elastic Container Registryの略称で、Dockerイメージを保管できるレジストリです。
AWS版のDocker Hubみたいな認識でいいです。では早速、DockerイメージをECRに
pushしていきます。AWSコンソールのサービスから『ECR』を選択。
『リポジトリを作成』を押下。
ECR上のリポジトリ名を記入。
『リポジトリを作成』を押下。
作成したリポジトリを押下。
『プッシュコマンドの表示』を押下。
以下に表示されるコマンドを順に実行。
※ AWS CLIをインストールしていない方は...
AWS公式のdockerイメージをインストール
docker run --rm -it amazon/aws-cli --version長いコマンドを
aws ~~~~みたいに打てるようにエイリアスする。alias aws='docker run --rm -ti -v ~/.aws:/root/.aws -v $(pwd):/aws amazon/aws-cli'以上でAWS CLIがコンテナ上で起動するようになります。
ブラウザをリロードして、以下のように表示されていればECRに
pushすることができています。
あとで必要なので、ついでに URI もコピーしておきます。
クラスターの作成
ECSメニューの『クラスター』から『今すぐ始める』を押下。
customの『設定』を押下。
今回のコンテナ名を決定。
『イメージ』に先ほどコピーしたECRの URI をペーストする。
『ポートマッピング』に今回開放している 3000番を記入。
『更新』を押下。
元の画面に戻ったら、『次』を押下。
『ロードバランサーの種類』は『Application Load Balancer』を選択。
『次』を押下。
『クラスター名』で、今回のクラスターの名前を決定。
『次』を押下。
確認して問題なければ、『作成』を押下。
以下の画面が表示されれば、ECSの作成は完了です。
念のため、デプロイできているか確認します。『サービスの表示』を押下。
『タスク』を選択。
作成されているタスクを押下。
パブリックIPをコピー。
http://『パブリックIP』:3000/でアクセスするとNuxtアプリが表示されます。ACMでSSL証明
ACMとは、AWS Certificate Managerの略称で SSL証明書などを無料で発行できるサービスです。
こちらを用いて、今回デプロイしたアプリを SSL証明していきます。また今回は、Route53で独自ドメインが紐づいたホストゾーンを既に作成しているものとします。
また本稿の前準備として、ロードバランサーのAレコードをホストゾーンに紐づけておいてください。AWSコンソールから、ACMもしくはCertificate Managerを選択。
『証明書のリクエスト』を押下。
自分で作成しているホストゾーンに紐づいているドメイン名を記入。
この際サブドメインを設定しても良い。(www.ecs-example.siteみたいにしても良い)
『次へ』を押下。
『DNSの検証』を選択。
『次へ』を押下。
『確認』を押下。
『確定とリクエスト』
『▼』を押下。
『Route 53でレコードの作成』を押下。
出てくるポップアップの内容を確認し、『作成』を押下。
『続行』を押下。
5分ほど待ち『発行済み』になればOK。
ドメイン設定
『クラスター』の『詳細』から、『ターゲットグループ名』にあるターゲットグループを押下。
『ロードバランサー』を押下。
『説明』タグが選択されていることを確認。
下にスクロールして自分の『セキュリティグループ』を押下。
『ELB Allowed Ports』と記されたセキュリティグループを選択。
『インバウンド』を選択。
『編集』を押下。
『ルールの追加』を押下。
『タイプ』に『HTTP』『HTTPS』を選択。(基本的に自動で『ポート番号』『ソース』が記入されますが、もしそうでない場合手動で記入してください。)
『保存』を押下。
左側のメニューから『ロードバランサー』を選択。
今回使用するVPCを選択。
『リスナーの追加』を押下。
『プロコトル:ポート』を『HTTPS』『443』に選択。
『アクションの追加』を押下。
『転送先...』を選択。
今回使用するターゲットグループを選択。
『デフォルトのSSl証明書』は『ACMから(推奨)』を選択して、先ほどACMで発行したSSL証明書を選択。
上と同様にロードバランサーのメニュー画面から『リスナーの追加』を押下。
『プロコトル:ポート』を『HTTPS』『80』に選択。
『アクションの追加』を押下。
『リダイレクト先...』を選択。
参考記事
Nuxt.jsでアプリ作成→Dockerfileを使ってイメージ作成→fargateでデプロイ→ドメイン設定・SSL化まで

































- 投稿日:2020-12-01T17:46:58+09:00
ECS (Fargate) + ACM + Route53 入門
はじめに
前回の記事を書いていくと、今の流行はどうやらEC2ではなくECSであるそうなので、今回はそちらを勉強してみました。
備忘録として書いていますが、自分と同じくAWS初心者の方の手助けとなれば幸いです。対象読者
- AWSアカウント登録済み
- EC2やVPCなどの基礎的なAWSの知識は持っている
- 自分
全体構造
ECSとは
Amazon Elastic Container Serviceの略称で、EC2インスタンス(もしくはFargate)コンテナを複数操作することができるサービスです。また、他のAWSサービスとも連携することが容易です。
簡単にECSの全体構造を表してみました。
詳しくはまた作成するときに説明します。
一応こちらが公式です。
ECSを含めた構築の流れ
Dcoker イメージの作成
環境を揃えるため、今回使用するDocker イメージを作成します。
「自分の環境で試したいぜ」って方はこの章は無視してもらって構いません。
一応コードは、ここ に公開しています。
pullしてきたら、READMEにしたがってdocker build --tag 『今回のDockerイメージ名(任意)』 .を実行。
docker images REPOSITORY TAG IMAGE ID CREATED SIZE aws-example latest 05ad15c1ad82 About a minute ago 527MBで、イメージが作成できているか確認できます。
ちなみに、
docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 817ed89f61b7 aws-example "docker-entrypoint.s…" 32 seconds ago Exited (0) 25 seconds ago gracious_galois docker start 『上の CONTAINER ID』 docker exec -it 『上の CONTAINER ID』 shでコンテナの中に入ることができます。
ECRにpush
ECRとは、Amazon Elastic Container Registryの略称で、Dockerイメージを保管できるレジストリです。
AWS版のDocker Hubみたいな認識でいいです。では早速、DockerイメージをECRに
pushしていきます。AWSコンソールのサービスから『ECR』を選択。
『リポジトリを作成』を押下。
ECR上のリポジトリ名を記入。
『リポジトリを作成』を押下。
作成したリポジトリを押下。
『プッシュコマンドの表示』を押下。
以下に表示されるコマンドを順に実行。
※ AWS CLIをインストールしていない方は...
AWS公式のdockerイメージをインストール
docker run --rm -it amazon/aws-cli --version長いコマンドを
aws ~~~~みたいに打てるようにエイリアスする。alias aws='docker run --rm -ti -v ~/.aws:/root/.aws -v $(pwd):/aws amazon/aws-cli'以上でAWS CLIがコンテナ上で起動するようになります。
ブラウザをリロードして、以下のように表示されていればECRに
pushすることができています。
あとで必要なので、ついでに URI もコピーしておきます。
クラスターの作成
ECSメニューの『クラスター』から『今すぐ始める』を押下。
customの『設定』を押下。
今回のコンテナ名を決定。
『イメージ』に先ほどコピーしたECRの URI をペーストする。
『ポートマッピング』に今回開放している 3000番を記入。
『更新』を押下。
元の画面に戻ったら、『次』を押下。
『ロードバランサーの種類』は『Application Load Balancer』を選択。
『次』を押下。
『クラスター名』で、今回のクラスターの名前を決定。
『次』を押下。
確認して問題なければ、『作成』を押下。
以下の画面が表示されれば、ECSの作成は完了です。
念のため、デプロイできているか確認します。『サービスの表示』を押下。
『タスク』を選択。
作成されているタスクを押下。
パブリックIPをコピー。
http://『パブリックIP』:3000/でアクセスするとNuxtアプリが表示されます。ACMでSSL証明
ACMとは、AWS Certificate Managerの略称で SSL証明書などを無料で発行できるサービスです。
こちらを用いて、今回デプロイしたアプリを SSL証明していきます。また今回は、Route53で独自ドメインが紐づいたホストゾーンを既に作成しているものとします。
また本稿の前準備として、ロードバランサーのAレコードをホストゾーンに紐づけておいてください。AWSコンソールから、ACMもしくはCertificate Managerを選択。
『証明書のリクエスト』を押下。
自分で作成しているホストゾーンに紐づいているドメイン名を記入。
この際サブドメインを設定しても良い。(www.ecs-example.siteみたいにしても良い)
『次へ』を押下。
『DNSの検証』を選択。
『次へ』を押下。
『確認』を押下。
『確定とリクエスト』
『▼』を押下。
『Route 53でレコードの作成』を押下。
出てくるポップアップの内容を確認し、『作成』を押下。
『続行』を押下。
5分ほど待ち『発行済み』になればOK。
ドメイン設定
『クラスター』の『詳細』から、『ターゲットグループ名』にあるターゲットグループを押下。
『ロードバランサー』を押下。
『説明』タグが選択されていることを確認。
下にスクロールして自分の『セキュリティグループ』を押下。
『ELB Allowed Ports』と記されたセキュリティグループを選択。
『インバウンド』を選択。
『編集』を押下。
『ルールの追加』を押下。
『タイプ』に『HTTP』『HTTPS』を選択。(基本的に自動で『ポート番号』『ソース』が記入されますが、もしそうでない場合手動で記入してください。)
『保存』を押下。
左側のメニューから『ロードバランサー』を選択。
今回使用するVPCを選択。
『リスナーの追加』を押下。
『プロコトル:ポート』を『HTTPS』『443』に選択。
『アクションの追加』を押下。
『転送先...』を選択。
今回使用するターゲットグループを選択。
『デフォルトのSSl証明書』は『ACMから(推奨)』を選択して、先ほどACMで発行したSSL証明書を選択。
上と同様にロードバランサーのメニュー画面から『リスナーの追加』を押下。
『プロコトル:ポート』を『HTTPS』『80』に選択。
『アクションの追加』を押下。
『リダイレクト先...』を選択。
参考記事
Nuxt.jsでアプリ作成→Dockerfileを使ってイメージ作成→fargateでデプロイ→ドメイン設定・SSL化まで

- 投稿日:2020-12-01T17:14:54+09:00
Amazon Forecast now supports accuracy measurements for individual items 翻訳まとめ
はじめに
今回は、2020年11月24日に Namita Das 氏、Christy Bergman 氏、Punit Jain 氏によって投稿された 「Amazon Forecast now supports accuracy measurements for individual items」の記事を翻訳し、まとめました。
本記事のリンクは下記 URL 参照■リンク
Amazon Forecast now supports accuracy measurements for individual itemsAmazon Forecast の新機能
この度、Amazon Forecast で個々のアイテムの予測精度を測ることができるようになりました。
これにより、特定のアイテムの予測精度を確認することが可能となります。各アイテムのバックテストと精度メトリクスから予測のエクスポート
この新機能を使う手順は以下です。
①Forecast のコンソール画面でデータセットグループを作成(今回は retail を選択)
②Target time series data のファイルをアップロード
③アップロード完了後、ダッシュボードの「Predictors」を選択し、「Train Predictor」をクリック
④予測トレーニングの入力項目に、以下の内容をそれぞれ入力
- 「forecast horizon」 で「24」を選択
- 「forecast frequency」で「hour」を選択
- 「Number of backtest windows」で「5」を選択
- 「Backtest window offset」で「24」を選択
- 「Forecast type」の3つある入力箇所に「mean」、「0.65」、「0.90」とそれぞれ入力
- 「Algorithm」で「Automatic」を選択
⑤予測のトレーニングが完了したら、「Predictors」ページでトレーニングが完了した予測子モデルを選択
⑥予測子モデルの詳細ページで「Predictor Metrics」にある「Export backtest results」を選択
⑦S3 に予測子モデルの csv ファイルをエクスポート
⑧S3 を確認すると、2つのフォルダにそれぞれ異なるファイルがあるのでそれを確認
- forecasted-values:各バックテストウィンドウからの予測を含んでいます
- accuracy-metrics-values:各バックテストウィンドウごとの各アイテムの精度メトリクスを含んでいます
accuracy-metrics-values のファイルには、wQL、WAPE、RMSE のメトリクスが提供されています。ファイルは出力されたデータの量に応じてファイルが複数ある場合があります。
■forecasted-values の csv データ
■accuracy-metrics-values の csv データ
- ダッシュボードの「Forecasts」を選択し、「Create a forecast」を選択
- 予測を実施する予測子モデルを選択
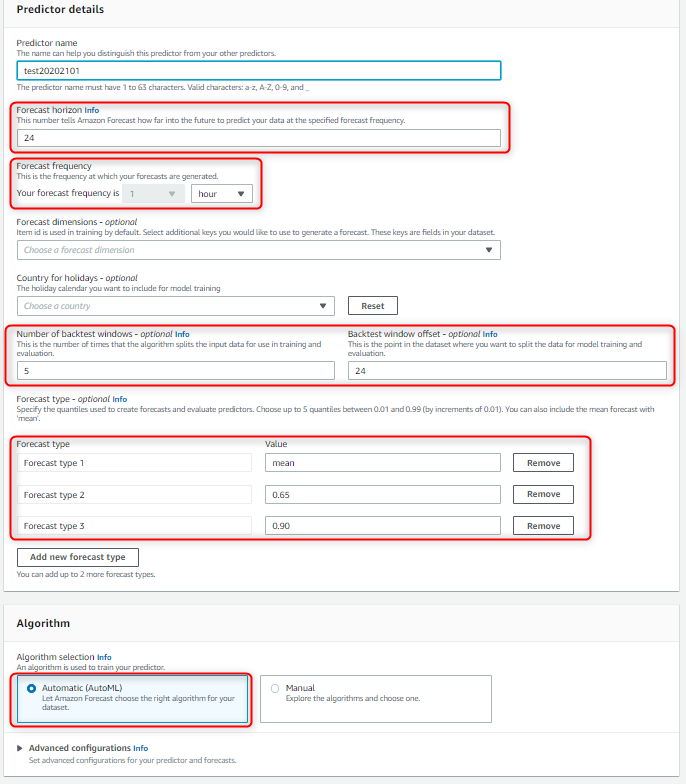
バックテスト予測とアイテム精度のメトリクスの可視化
バックテストの可視化を実施する場合は、 QuickSight を利用する必要があります。
QuickSIght を利用することでグラフの可視化が可能となり、精度の正確性がより視覚的にも分かりやすくなります。
おわりに
翻訳まとめは以上となります。
バックテストが可能となったことと、個々の予測の精度を見ることができるようになったため今まで以上に使いやすくなったかと思います。


- 投稿日:2020-12-01T16:37:28+09:00
Amazon EC2 Mac Instance を早速使ってみました
こんにちは。
本記事は、株式会社日立システムズのアドベントカレンダーの12/1の記事です。2020/12/1 に公開された、 Amazon EC2 Mac Instance を早速使ってみました。
https://aws.amazon.com/jp/blogs/aws/new-use-mac-instances-to-build-test-macos-ios-ipados-tvos-and-watchos-apps/本稿記載時点では、以下のリージョンでのみサポートされています。
また、一部のリージョンでは、起動制限数が0になっているため、制限解除が必要です。
- 米東(北バージニア)
- 米東(オハイオ)
- 米西(オレゴン)
- 欧州(アイルランド)
- アジア太平洋(シンガポール)
今回は、シンガポールリージョンで試してみました。
準備
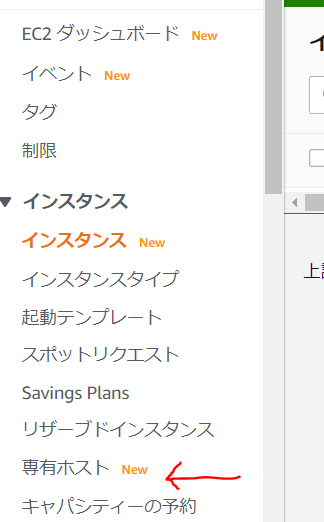
Dedicated Host を用意する
EC2 のコンソールへアクセスし、画面左側の「専有ホスト」をクリック
[専有ホストを割り当て]ボタンをクリック
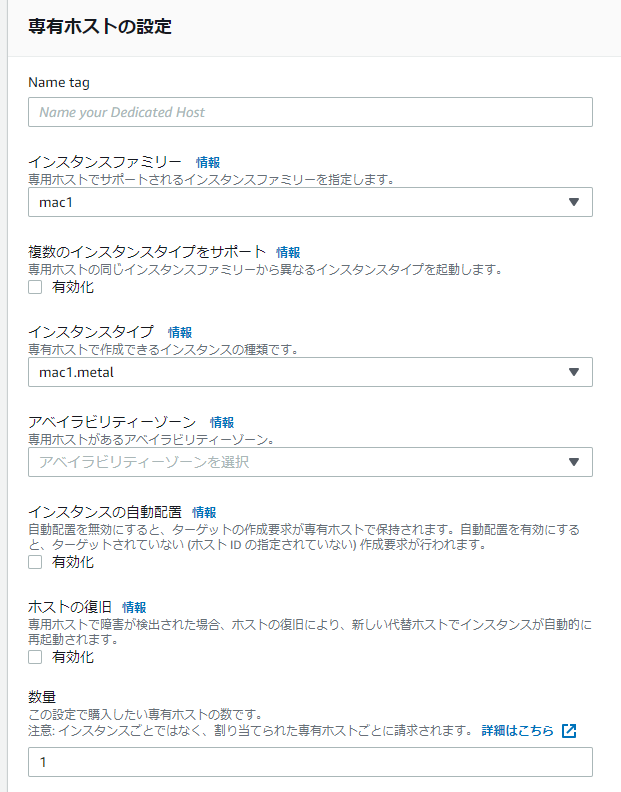
専有ホストの設定を適宜実施する。
設定例:
* Name tag: 専有ホストの名称を指定。(例:machost)
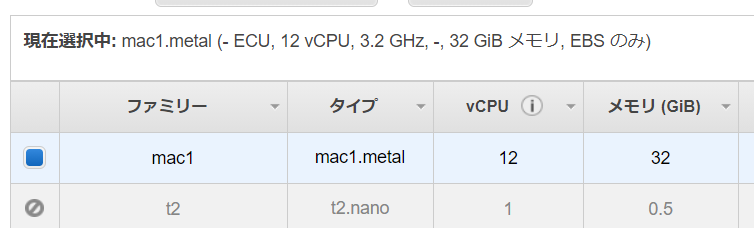
* インスタンスファミリー: mac1
* 複数のインスタンスタイプをサポート: 有効化のチェックを外す
* インスタンスタイプ: mac1.metal
* アベイラビリティゾーン: 任意のアベイラビリティゾーンを指定するその他の設定については、今回の検証では試していませんが、必要に応じて試してみてください。
設定が終わったら、スクロールし、[割り当て]ボタンをクリックする。
割り当てが終わると、以下のように表示されます。
注意点
mac1.metal 専有ホストは作成後少なくとも24時間は解放できません。
EC2 Instance を起動する
Dedicated Host(専有ホスト)の設定が終わったら、次に EC2 インスタンスを起動します。
EC2 のコンソールから「インスタンス」を選択する
画面右側の「インスタンスを起動」ボタンをクリック
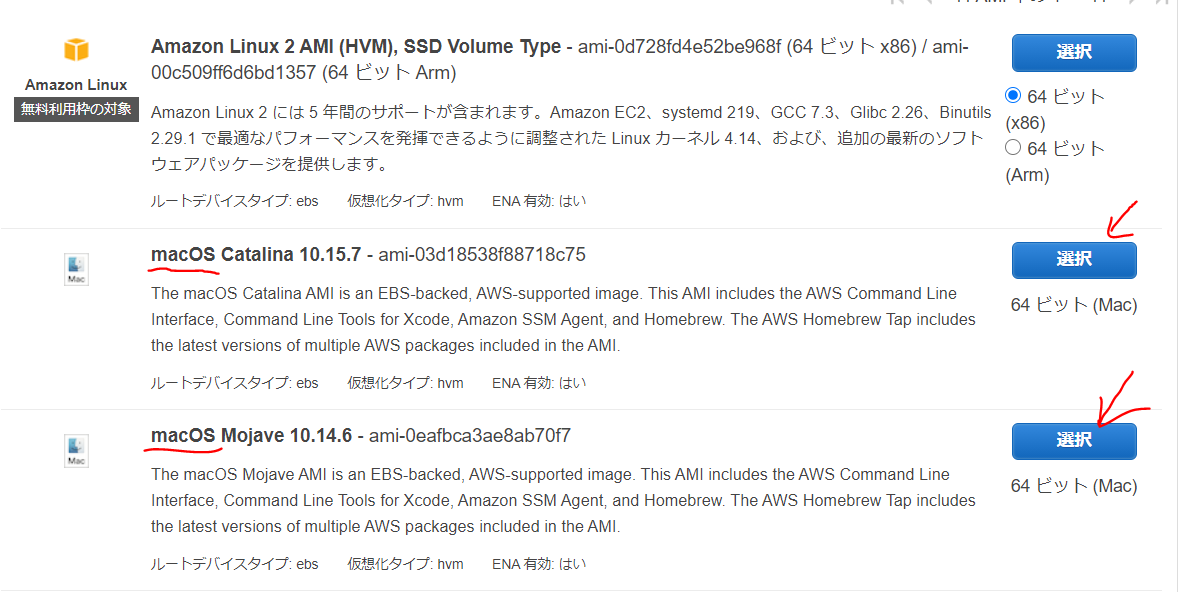
ステップ 1: Amazon マシンイメージ (AMI)
好みの macOS の AMI の右側にある、「選択」ボタンをクリック
ステップ 2: インスタンスタイプの選択
インスタンスタイプの選択はデフォルトで「mac1.metal」が選択されているので、そのままにして、画面右下の「次のステップ: インスタンスの詳細の設定」ボタンをクリック
ステップ 3: インスタンスの詳細の設定
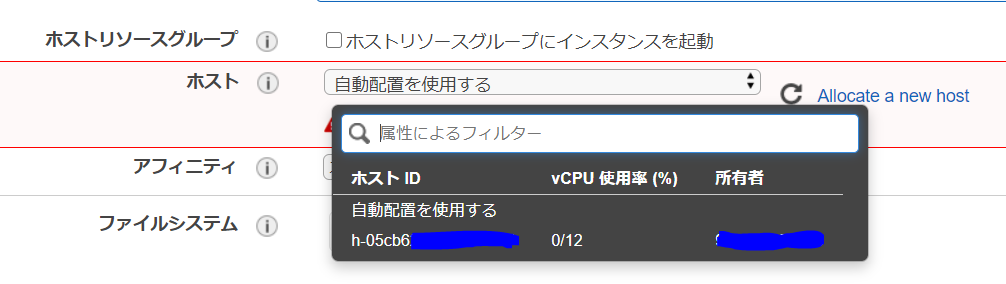
起動台数やアベイラビリティゾーンの設定は、Dedicated Host割り当て時に設定したものにする。
IAM ロールなどは適宜設定。画面スクロールし、真ん中あたりにある「ホスト」の箇所において、Dedicated Hostで割り当てを行ったホストを選択する。
ステップ 4: ストレージの追加
必要に応じて容量を増やしたり、個数を増やしたりする。
ステップ 5: タグの追加
必要に応じて Tag を設定する。
ステップ 6: セキュリティグループの設定
適宜、接続に使用するポートとアクセス元を指定する。
今回は、SSHを指定。GUI検証時に追加する予定。ステップ 7: インスタンス作成の確認
一覧を確認し問題がなければ、「起動」ボタンをクリックして EC2 インスタンスを起動させます。
これで Amazon EC2 Mac インスタンスの起動は完了です!
いざ接続!
SSH
Windows 10 環境で鍵を使って TeraTerm を使って試しました。
ログイン直後の表示
アップルマークアスキーアートの横に EC2 アスキーアートが並んでいます。
.:' __ :'__ __| __|_ ) .'` `-' ``. _| ( / : .-' ___|\___|___| : : : `-; Amazon EC2 `.__.-.__.' macOS Catalina 10.15.7 ec2-user@ip-172-31-25-*** ~ %uname コマンドの結果
uname -a を実行して結果を確認します。
ec2-user@ip-172-31-25-*** ~ % uname -a Darwin ip-172-31-25-***.ap-southeast-1.compute.internal 19.6.0 Darwin Kernel Version 19.6.0: Thu Oct 29 22:56:45 PDT 2020; root:xnu-6153.141.2.2~1/RELEASE_X86_64 x86_64sw_vers コマンドの結果
sw_vers を実行して結果を確認します。
ec2-user@ip-172-31-25-*** ~ % sw_vers ProductName: Mac OS X ProductVersion: 10.15.7 BuildVersion: 19H15brew コマンドの結果
brew list コマンドを実行して、何がインストールされているか確認します。
ec2-user@ip-172-31-25-*** ~ % brew list awscli python@3.9 ec2-macos-init readline ec2-macos-system-monitor sqlite gdbm xz openssl@1.1 amazon-ena-ethernet amazon-ssm-agentストレージの見え方を確認
df コマンドを実行して、ストレージの見え方を確認します。
ec2-user@ip-172-31-25-*** ~ % df -h Filesystem Size Used Avail Capacity iused ifree %iused Mounted on /dev/disk2s5 30Gi 10Gi 11Gi 48% 488252 312036148 0% / devfs 186Ki 186Ki 0Bi 100% 642 0 100% /dev /dev/disk2s1 30Gi 5.7Gi 11Gi 34% 151351 312373049 0% /System/Volumes/Data /dev/disk2s4 30Gi 2.0Gi 11Gi 16% 1 312524399 0% /private/var/vm map auto_home 0Bi 0Bi 0Bi 100% 0 0 100% /System/Volumes/Data/homeMacintosh HD ではないんですね。
プロセスの確認
ps -ef コマンドでプロセスを確認します
ちょっと多いので、折りたたんでいます。
詳細を開く
UID PID PPID C STIME TTY TIME CMD 0 1 0 0 6:08AM ?? 0:02.47 /sbin/launchd 0 40 1 0 6:10AM ?? 0:00.24 /usr/sbin/syslogd 0 41 1 0 6:10AM ?? 0:00.45 /usr/libexec/UserEventAgent (System) 0 44 1 0 6:10AM ?? 0:00.05 /System/Library/PrivateFrameworks/Uninstall.framework/Resources/uninstalld 0 45 1 0 6:10AM ?? 0:30.36 /usr/libexec/kextd 0 46 1 0 6:10AM ?? 0:00.32 /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/FSEvents.framework/Versions/A/Support/fseventsd 0 47 1 0 6:10AM ?? 0:00.17 /System/Library/PrivateFrameworks/MediaRemote.framework/Support/mediaremoted 0 51 1 0 6:10AM ?? 0:00.26 /usr/sbin/systemstats --daemon 0 52 1 0 6:10AM ?? 0:00.49 /usr/libexec/configd 0 54 1 0 6:10AM ?? 0:00.03 endpointsecurityd 0 55 1 0 6:10AM ?? 0:00.16 /System/Library/CoreServices/powerd.bundle/powerd 0 59 1 0 6:10AM ?? 0:02.74 /usr/libexec/logd 0 60 1 0 6:10AM ?? 0:00.02 /usr/libexec/keybagd -t 15 0 63 1 0 6:10AM ?? 0:00.05 /usr/libexec/watchdogd 0 66 1 0 6:10AM ?? 0:00.03 /usr/libexec/warmd 0 67 1 0 6:10AM ?? 8:41.31 /System/Library/Frameworks/CoreServices.framework/Frameworks/Metadata.framework/Support/mds 240 68 1 0 6:10AM ?? 0:00.11 /System/Library/CoreServices/iconservicesd 0 69 1 0 6:10AM ?? 0:00.35 /usr/libexec/diskarbitrationd 0 72 1 0 6:10AM ?? 0:00.27 /usr/libexec/coreduetd 0 75 1 0 6:10AM ?? 0:01.79 /usr/libexec/opendirectoryd 0 78 1 0 6:10AM ?? 0:00.22 /System/Library/CoreServices/launchservicesd 266 79 1 0 6:10AM ?? 0:00.05 /usr/libexec/timed 213 81 1 0 6:10AM ?? 0:00.05 /System/Library/PrivateFrameworks/MobileDevice.framework/Versions/A/Resources/usbmuxd -launchd 0 82 1 0 6:10AM ?? 0:01.23 /usr/sbin/securityd -i 0 83 1 0 6:10AM ?? 0:00.01 auditd -l 205 85 1 0 6:10AM ?? 0:00.17 /usr/libexec/locationd 0 89 1 0 6:10AM ?? 0:00.01 autofsd 244 90 1 0 6:10AM ?? 0:00.34 /usr/libexec/displaypolicyd -k 1 0 91 1 0 6:10AM ?? 0:00.27 /usr/libexec/dasd 0 94 1 0 6:10AM ?? 0:00.87 /usr/libexec/PerfPowerServices 0 97 1 0 6:10AM ?? 0:00.02 /System/Library/CoreServices/logind 0 98 1 0 6:10AM ?? 0:00.04 /System/Library/PrivateFrameworks/GenerationalStorage.framework/Versions/A/Support/revisiond 0 99 1 0 6:10AM ?? 0:00.01 /usr/sbin/KernelEventAgent 0 101 1 0 6:10AM ?? 0:00.14 /usr/sbin/bluetoothd 261 102 1 0 6:10AM ?? 0:00.06 /usr/libexec/hidd 0 103 1 0 6:10AM ?? 0:00.06 /usr/libexec/sandboxd 0 104 1 0 6:10AM ?? 0:00.96 /usr/libexec/corebrightnessd --launchd 0 105 1 0 6:10AM ?? 0:00.35 /usr/libexec/AirPlayXPCHelper 0 106 1 0 6:10AM ?? 0:00.40 /usr/sbin/notifyd 0 107 1 0 6:10AM ?? 0:18.01 /usr/libexec/syspolicyd 0 108 1 0 6:10AM ?? 0:00.06 /usr/libexec/taskgated 241 110 1 0 6:10AM ?? 0:00.09 /usr/sbin/distnoted daemon 0 113 1 0 6:10AM ?? 0:00.66 /usr/sbin/cfprefsd daemon 0 114 1 0 6:10AM ?? 0:00.71 /System/Library/CoreServices/loginwindow.app/Contents/MacOS/loginwindow console 263 116 1 0 6:10AM ?? 0:00.28 /System/Library/PrivateFrameworks/CoreAnalytics.framework/Support/analyticsd 0 117 1 0 6:10AM ?? 0:00.16 /System/Library/CoreServices/coreservicesd 0 118 1 0 6:10AM ?? 0:00.01 aslmanager 0 121 1 0 6:10AM ?? 0:00.40 /System/Library/Frameworks/Security.framework/Versions/A/XPCServices/authd.xpc/Contents/MacOS/authd 0 122 1 0 6:10AM ?? 0:00.15 /System/Library/PrivateFrameworks/TCC.framework/Resources/tccd system 0 132 1 0 6:10AM ?? 0:16.59 /usr/libexec/lsd runAsRoot 0 135 1 0 6:10AM ?? 0:00.27 /usr/libexec/nehelper 65 136 1 0 6:10AM ?? 0:00.17 /usr/sbin/mDNSResponder 0 140 1 0 6:10AM ?? 0:00.11 /usr/libexec/searchpartyd 0 150 1 0 6:10AM ?? 0:06.32 /usr/libexec/trustd 202 151 1 0 6:10AM ?? 0:00.29 /usr/sbin/coreaudiod 202 165 1 0 6:10AM ?? 0:00.03 /System/Library/Frameworks/CoreAudio.framework/Versions/A/XPCServices/com.apple.audio.DriverHelper.xpc/Contents/MacOS/com.apple.audio.DriverHelper 0 166 1 0 6:10AM ?? 0:00.26 /usr/libexec/mobileassetd 88 168 1 0 6:10AM ?? 0:03.71 /System/Library/PrivateFrameworks/SkyLight.framework/Resources/WindowServer -daemon 0 169 1 0 6:10AM ?? 0:00.00 /usr/libexec/smd 0 170 1 0 6:10AM ?? 0:00.29 /usr/libexec/diskmanagementd 0 171 1 0 6:10AM ?? 0:00.03 /System/Library/PrivateFrameworks/WirelessDiagnostics.framework/Support/awdd 0 172 1 0 6:10AM ?? 0:00.03 /System/Library/PrivateFrameworks/SystemAdministration.framework/XPCServices/writeconfig.xpc/Contents/MacOS/writeconfig 0 173 1 0 6:10AM ?? 0:00.14 /usr/libexec/airportd 242 174 1 0 6:10AM ?? 0:00.19 /usr/libexec/nsurlsessiond --privileged 0 175 1 0 6:10AM ?? 0:00.01 /usr/libexec/multiversed 0 176 1 0 6:10AM ?? 0:00.01 /System/Library/CryptoTokenKit/com.apple.ifdreader.slotd/Contents/MacOS/com.apple.ifdreader 0 177 1 0 6:10AM ?? 0:00.02 /usr/libexec/apfsd 0 178 1 0 6:10AM ?? 0:00.05 /usr/libexec/usbd 0 179 1 0 6:10AM ?? 0:00.01 /usr/libexec/firmwarecheckers/ethcheck/ethcheck --integrity-check-daemon 200 190 1 0 6:10AM ?? 0:00.01 /System/Library/PrivateFrameworks/BridgeOSSoftwareUpdate.framework/Support/bosUpdateProxy 0 191 1 0 6:10AM ?? 0:00.10 /System/Library/CoreServices/SubmitDiagInfo server-init 205 196 1 0 6:10AM ?? 0:01.57 /System/Library/PrivateFrameworks/GeoServices.framework/Versions/A/XPCServices/com.apple.geod.xpc/Contents/MacOS/com.apple.geod 205 197 1 0 6:10AM ?? 0:00.26 /usr/libexec/secinitd 205 198 1 0 6:10AM ?? 0:00.01 /usr/sbin/cfprefsd agent 205 200 1 0 6:10AM ?? 0:00.82 /usr/libexec/trustd --agent 0 268 1 0 6:10AM ?? 0:00.06 /usr/libexec/sysmond 0 269 51 0 6:10AM ?? 0:00.04 /usr/sbin/systemstats --logger-helper /private/var/db/systemstats 0 270 1 0 6:10AM ?? 0:01.74 /System/Library/PrivateFrameworks/XprotectFramework.framework/Versions/A/XPCServices/XprotectService.xpc/Contents/MacOS/XprotectService 0 271 1 0 6:10AM ?? 0:00.19 /System/Library/PrivateFrameworks/CoreDuetContext.framework/Resources/contextstored 0 276 1 0 6:10AM ?? 0:00.09 /usr/sbin/mDNSResponderHelper 0 277 1 0 6:10AM ?? 0:00.05 /usr/libexec/findmydeviced 24 278 1 0 6:10AM ?? 0:00.08 /usr/libexec/symptomsd 0 293 1 0 6:10AM ?? 0:00.30 /System/Library/PrivateFrameworks/ApplePushService.framework/apsd 0 295 1 0 6:10AM ?? 0:00.01 /System/Library/CoreServices/ReportCrash daemon 0 297 1 0 6:10AM ?? 0:00.01 /System/Library/Frameworks/PreferencePanes.framework/Versions/A/XPCServices/cacheAssistant.xpc/Contents/MacOS/cacheAssistant 0 298 1 0 6:10AM ?? 0:00.49 /usr/libexec/secinitd 0 341 1 0 6:11AM ?? 0:00.06 /usr/libexec/nesessionmanager 0 346 1 0 6:11AM ?? 0:00.06 /System/Library/Frameworks/SystemExtensions.framework/Versions/A/Helpers/sysextd 0 347 1 0 6:11AM ?? 0:00.05 /System/Library/Frameworks/Security.framework/Versions/A/XPCServices/com.apple.CodeSigningHelper.xpc/Contents/MacOS/com.apple.CodeSigningHelper 0 414 1 0 6:13AM ?? 0:00.10 /System/Library/CoreServices/backupd.bundle/Contents/Resources/backupd-helper -launchd 0 422 1 0 6:13AM ?? 0:00.03 /System/Library/Frameworks/AudioToolbox.framework/AudioComponentRegistrar -daemon 202 423 1 0 6:13AM ?? 0:00.01 /System/Library/Frameworks/AudioToolbox.framework/XPCServices/com.apple.audio.SandboxHelper.xpc/Contents/MacOS/com.apple.audio.SandboxHelper 270 424 1 0 6:13AM ?? 0:00.02 /System/Library/DriverExtensions/AppleUserHIDDrivers.dext/AppleUserHIDDrivers com.apple.driverkit.AppleUserUSBHostHIDDevice0 0x1000006cc 0 425 1 0 6:13AM ?? 0:00.01 /usr/libexec/thermald 270 426 1 0 6:13AM ?? 0:00.00 /System/Library/DriverExtensions/AppleUserHIDDrivers.dext/AppleUserHIDDrivers com.apple.driverkit.AppleUserHIDEventDriver 0x1000006fc 0 428 1 0 6:13AM ?? 0:00.04 /usr/libexec/runningboardd 0 429 1 0 6:13AM ?? 0:00.17 /System/Library/Frameworks/InputMethodKit.framework/Resources/imklaunchagent 0 430 1 0 6:13AM ?? 0:00.05 /usr/libexec/UserEventAgent (LoginWindow) 0 431 1 0 6:13AM ?? 0:00.05 /usr/sbin/universalaccessd launchd -s 0 432 1 0 6:13AM ?? 0:00.47 /usr/libexec/pkd 205 433 1 0 6:13AM ?? 0:00.02 /usr/sbin/distnoted agent 0 434 1 0 6:13AM ?? 4:34.75 /System/Library/Frameworks/CoreServices.framework/Frameworks/Metadata.framework/Versions/A/Support/mds_stores 89 448 1 0 6:13AM ?? 0:00.85 /usr/libexec/trustd --agent 88 451 1 0 6:13AM ?? 0:06.85 /System/Library/Frameworks/Metal.framework/Versions/A/XPCServices/MTLCompilerService.xpc/Contents/MacOS/MTLCompilerService 0 452 1 0 6:13AM ?? 0:00.01 /usr/local/Cellar/ec2-macos-system-monitor/1.1.0/libexec/bin/ec2monitoring-relayd 89 456 1 0 6:13AM ?? 0:00.02 /usr/sbin/distnoted agent 97 464 1 0 6:13AM ?? 0:00.52 /System/Library/Frameworks/ApplicationServices.framework/Frameworks/ATS.framework/Support/fontd 0 469 1 0 6:13AM ?? 0:00.01 /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/CVMServer 0 470 1 0 6:13AM ?? 0:00.01 /usr/libexec/colorsync.displayservices 0 471 1 0 6:13AM ?? 0:00.02 /usr/libexec/colorsyncd 0 472 1 0 6:13AM ?? 0:00.03 /System/Library/PrivateFrameworks/AmbientDisplay.framework/Versions/A/XPCServices/com.apple.AmbientDisplayAgent.xpc/Contents/MacOS/com.apple.AmbientDisplayAgent 55 473 1 0 6:13AM ?? 0:00.02 /System/Library/CoreServices/appleeventsd --server 0 476 1 0 6:13AM ?? 0:00.02 /System/Library/PrivateFrameworks/ViewBridge.framework/Versions/A/XPCServices/ViewBridgeAuxiliary.xpc/Contents/MacOS/ViewBridgeAuxiliary 0 477 1 0 6:13AM ?? 0:00.02 /usr/sbin/distnoted agent 0 478 1 0 6:13AM ?? 0:00.02 /usr/libexec/bootinstalld 0 479 1 0 6:13AM ?? 0:00.02 /System/Library/PrivateFrameworks/ViewBridge.framework/Versions/A/XPCServices/ViewBridgeAuxiliary.xpc/Contents/MacOS/ViewBridgeAuxiliary 92 480 1 0 6:13AM ?? 0:03.61 /System/Library/Frameworks/Security.framework/Versions/A/MachServices/SecurityAgent.bundle/Contents/MacOS/SecurityAgent 0 481 1 0 6:13AM ?? 0:00.03 /System/Library/CoreServices/ManagedClient.app/Contents/MacOS/ManagedClient 0 482 1 0 6:13AM ?? 0:00.01 /usr/libexec/corecaptured 0 483 1 0 6:13AM ?? 0:00.02 /usr/sbin/spindump 88 484 1 0 6:13AM ?? 0:00.24 /System/Library/Frameworks/Metal.framework/Versions/A/XPCServices/MTLCompilerService.xpc/Contents/MacOS/MTLCompilerService 92 485 1 0 6:13AM ?? 0:00.15 /System/Library/Frameworks/VideoToolbox.framework/Versions/A/XPCServices/VTDecoderXPCService.xpc/Contents/MacOS/VTDecoderXPCService 92 486 1 0 6:13AM ?? 0:00.10 /System/Library/Frameworks/Metal.framework/Versions/A/XPCServices/MTLCompilerService.xpc/Contents/MacOS/MTLCompilerService 0 491 1 0 6:13AM ?? 0:00.01 /System/Library/PrivateFrameworks/AccountPolicy.framework/XPCServices/com.apple.AccountPolicyHelper.xpc/Contents/MacOS/com.apple.AccountPolicyHelper 0 492 1 0 6:13AM ?? 0:00.02 /System/Library/Frameworks/LocalAuthentication.framework/Support/coreauthd 0 493 1 0 6:13AM ?? 0:00.02 /System/Library/Frameworks/CryptoTokenKit.framework/ctkahp.bundle/Contents/MacOS/ctkahp -d 0 495 1 0 6:13AM ?? 0:00.02 /System/Library/Frameworks/CryptoTokenKit.framework/ctkahp.bundle/Contents/MacOS/ctkahp 0 496 1 0 6:13AM ?? 0:00.03 /System/Library/Frameworks/CryptoTokenKit.framework/ctkd -tw 0 498 1 0 6:13AM ?? 0:00.02 /usr/sbin/systemsoundserverd 259 500 1 0 6:14AM ?? 0:00.02 /System/Library/Frameworks/CryptoTokenKit.framework/ctkd -s 501 514 1 0 6:14AM ?? 0:00.03 /usr/sbin/cfprefsd agent 501 515 1 0 6:14AM ?? 0:14.00 /usr/libexec/lsd 501 516 1 0 6:14AM ?? 0:01.21 /usr/libexec/trustd --agent 501 517 1 0 6:14AM ?? 0:00.02 /usr/sbin/distnoted agent 501 518 1 0 6:14AM ?? 0:00.07 /usr/libexec/secd 222 585 1 0 6:14AM ?? 0:00.08 /usr/sbin/netbiosd 0 588 1 0 6:14AM ?? 0:00.66 /opt/aws/ssm/bin/amazon-ssm-agent 0 674 1 0 6:14AM ?? 0:00.22 /System/Library/CoreServices/iconservicesagent runAsRoot 0 675 1 0 6:14AM ?? 0:00.07 /System/Library/Frameworks/Metal.framework/Versions/A/XPCServices/MTLCompilerService.xpc/Contents/MacOS/MTLCompilerService 0 676 1 0 6:14AM ?? 0:00.05 /System/Library/Frameworks/Metal.framework/Versions/A/XPCServices/MTLCompilerService.xpc/Contents/MacOS/MTLCompilerService 0 681 588 0 6:14AM ?? 0:01.27 /opt/aws/ssm/bin/ssm-agent-worker 0 697 1 0 6:14AM ?? 0:00.35 /System/Library/Frameworks/ApplicationServices.framework/Frameworks/SpeechSynthesis.framework/Resources/com.apple.speech.speechsynthesisd 0 698 1 0 6:14AM ?? 0:00.01 /System/Library/Frameworks/AudioToolbox.framework/XPCServices/com.apple.audio.SandboxHelper.xpc/Contents/MacOS/com.apple.audio.SandboxHelper 200 745 1 0 6:15AM ?? 0:05.63 /System/Library/CoreServices/Software Update.app/Contents/Resources/softwareupdated 0 747 1 0 6:15AM ?? 0:00.01 /System/Library/CoreServices/Software Update.app/Contents/Resources/suhelperd 0 748 1 0 6:15AM ?? 0:00.13 /usr/libexec/rtcreportingd 243 749 1 0 6:15AM ?? 0:00.15 /usr/libexec/nsurlstoraged --privileged 0 1712 1 0 6:34AM ?? 0:00.03 sshd: ec2-user [priv] 501 1719 1712 0 6:35AM ?? 0:00.01 sshd: ec2-user@ttys000 501 1720 1719 0 6:35AM ttys000 0:00.01 -zsh 0 1727 1720 0 6:36AM ttys000 0:00.00 ps -efVNC(GUI)接続
VNC 接続を行えるように、SSH 接続で Amazon EC2 Mac Instance に接続して以下の操作を行います。
また、AWSの発表記事にある通り、VNCにはセキュリティ脆弱性があるので、セキュリティグループの設定を厳しくしたり、記事中にあるとおり、SSH経由でVNCをトンネリングしたりすることも合わせてご検討ください。(検証用途として)ec2-user のパスワードをリセット(再設定)する
今回はとりあえず、VNC で接続できることを確認したいので、サクッと ec2-user のパスワードをリセット(再設定)してしまいます。
passwd コマンドでも構わないのですが、 macOS ではユーザー管理はディレクトリ構造となっており、 dscl コマンドで実行します。sudo dscl . -passwd /Users/ec2-user <Password文字列>VNC Server を起動する
以下のコマンドを実行する
sudo /System/Library/CoreServices/RemoteManagement/ARDAgent.app/Contents/Resources/kickstart -activate -configure -access -on -clientopts -setvnclegacy -vnclegacy yes -clientopts -setvncpw -vncpw <Password文字列> -restart -agent -privs -allVNC 接続をする
検証時は、自前の Macbook Pro(Big Sur)環境の画面共有(VNC)機能で行いました。
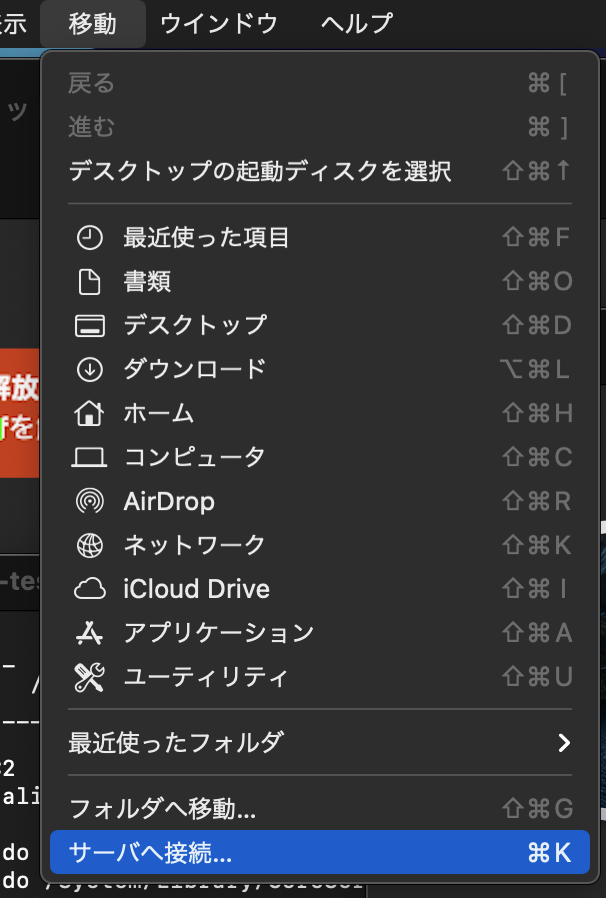
WindowsやLinuxなどの方は適宜、VNCアプリを使ってください。macOS のFinder の「移動」ー>[サーバへ接続]を選択する。
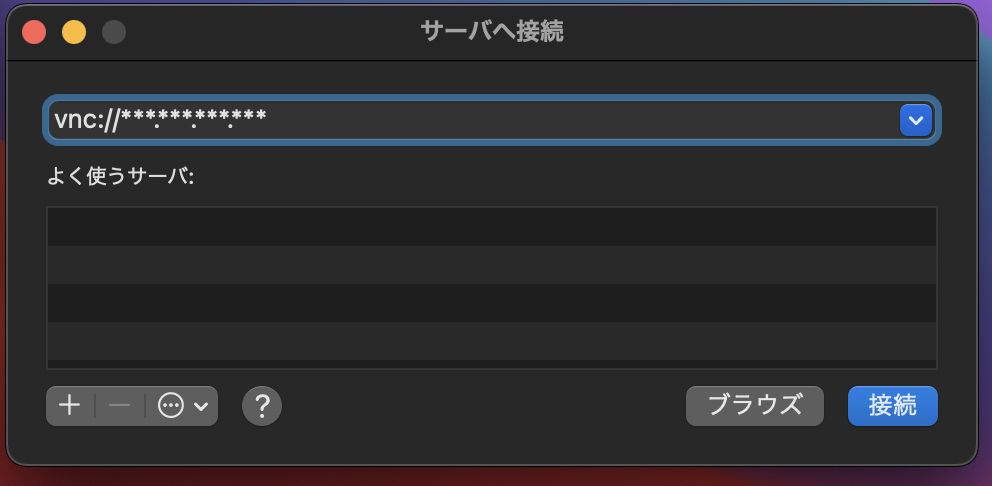
サーバへ接続のウィンドウが開いたら、Amazon EC2 Mac Instance のIPアドレス(今回はグローバルIPv4アドレス)を以下のように指定し、接続ボタンをクリックする。
vnc://...
ユーザ名とパスワードを指定するウィンドウが開くので以下のように指定し、サインインボタンをクリックする。
すると、macOS ログイン画面が表示されるので、パスワードを指定し、Enterキーを押下する。
ログインが行えれば、以下のように macOS のデスクトップ画面が表示されます。
おまけ
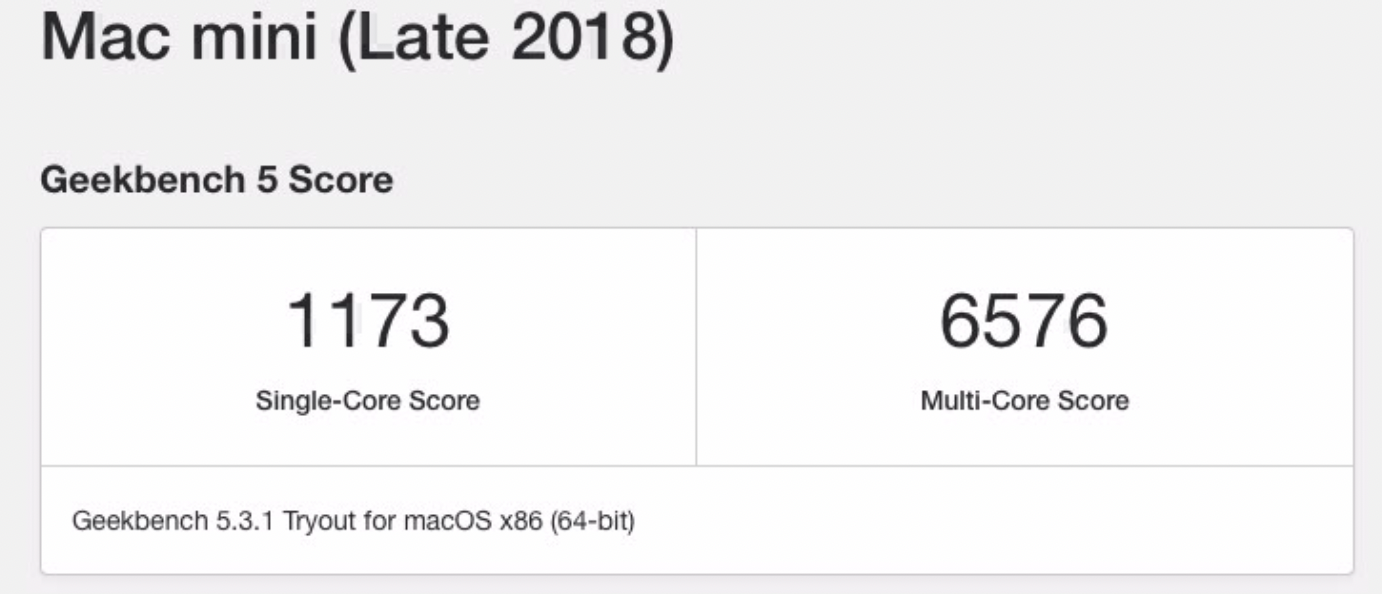
Geekbench 5 を使ってベンチマークをとってみました。
Mac mini(Late 2018)のようです。CPU ベンチの結果
Compute ベンチの結果
まとめ
macOS が Amazon EC2 インスタンスでサポートされたことで、シンクライアントから AWS 上の mac による開発環境へ接続して利用するといったことができるようになりました。
しかも、ほぼまっさらな状態で利用ができるためカスタム AMI を利用しての開発環境統一といったこともしやすそうですね。
さらに、各種記事にもありましたが、iOSアプリなどの開発環境を集約できるといったことも期待されています。
また、最近リリースされた M1 Chip 搭載モデルにも対応予定とのことで、これからとても楽しみなサービスアップデートでした。記載されている会社名、製品名、サービス名、ロゴ等は各社の商標または登録商標です。






- 投稿日:2020-12-01T16:02:16+09:00
AWSを勉強する - RDS
RDS(Relational Database Service)
AWSが提供するマネージドRDBサービス。
MySQL、MariaDB、PostgreSQL、Oracle、Microsoft SQL Serverなどから選択できる。
Amazon Auroraは、AWSが独自に開発した、クラウドのメリットを最大限に生かした新しいアーキテクチャのRDS。RDSは、複数のデータベースエンジンを利用できるが、それぞれのエンジンで提供されている機能のうち、RDSでは使用できない機能もあるので、機能制限をよく確かめる必要がある。
RDSで使えない機能が必要な場合は、EC2インスタンスにデータベースエンジンをインストールして使うなどの検討が必要。RDSで使えるストレージタイプ
RDSのデータ保存用ストレージには、EBSを利用。
EBSの中でもRDSで利用可能なストレージタイプは、下記の3つ
- 汎用SSD
- プロビジョンドIOPS SSD
- マグネティック
マグネティックは、過去に作成したDBインスタンスの下位互換性維持のために利用可能。
新しいDBインスタンスを作成する時は、基本的にSSDを選択。
プロビジョンドIOPSは、高いIOPSが求められている場合や、データ容量と比較してI/Oが多い場合に利用。ストレージの容量は、32TBまで拡張が可能。
拡張は、オンライン状態で実施可能だが、拡張中は、若干のパフォーマンス劣化が見られる。(利用頻度が比較的少ない時間帯に実施したほうがいい)RDSの特徴
RDSを利用することで、複雑になりがちなデータベースの運用を、シンプルかつ低コストに実現できる。運用の効率化を図れる。
マルチAZ構成
1つのリージョン内の2つのAZにDBインスタンスをそれぞれ配置し、障害発生時やメンテナンス時のダウンタイムを短くすることで高可用性を実現するサービス。
注意点
- 書き込み速度が遅くなる:2つのAZ間でデータを同期するため、シングルAZ構成よりも書き込みやこっミットにかかる時間が長くなる。
- フェイルオーバーには60~120秒かかる
リードレプリカ
通常のRDSとは別に、参照用のDBインスタンスを作成することができるサービス。
利用可能なデータベースエンジンは、Aurora、MySQL、MariaDB、PostgreSQLの4つ。リードレプリカを作成することで、マスターDBの負荷を抑えたり、読み込みが多いアプリケーションに置いてDBリソースのスケールアウトを容易に実現することが可能。
マスターとリードレプリカのデータ同期は、非同期レプリケーション方式。(リードレプリカを参照するタイミングによっては、マスター側で更新された情報が必ずしも反映されていない可能性がある)バックアップ/リストア
自動バックアップ
バックアップウィンドウと保持期間を指定することで、1日に1回自動的にバックアップ(DBスナップショット)を取得してくれるサービス。
バックアップの保持期間は最大35日。
バックアップからDBを復旧する場合は、取得したスナップショットを選択して新規RDSを作成する。
稼働中のRDSにバックアップのデータを戻すことはできない。手動スナップショット
任意のタイミングでRDBのバックアップ(DBスナップショット)を取得できるサービス。
手動スナップショットの取得数は、1リージョンあたり100個まで。データのリストア
RDSにデータをリストアする場合は、自動バックアップ及び手動で取得したスナップショットから新規のRDSを作成する。
ポイントインタイムリカバリー
直近5分前から最大35日前までの任意のタイミングの状態のRDSを新規に作成することができるサービス。
Amazon Aurora
Auroraでは、DBインスタンスを作成すると同時にDBクラスタが作成される。
DBクラスタは、1つ以上のDBインスタンスと、各DBインスタンスから参照するデータストレージで構成されている。
AuroraのデータストレージはSSDをベースとしたクラスタボリューム。
クラスタボリュームは、単一リージョン内の3つのAZにそれぞれ2つのデータコピーで構成され、各ストレージ間のデータは自動で気に動悸される。用語まとめ
フェイルオーバー
現用系コンピュータサーバ/システム/ネットワークで異常事態が発生したとき、自動的に冗長な待機系コンピュータサーバ/システム/ネットワークに切り替える機能。
スイッチオーバー
何らかの異常を察知して、人間が手動で切り替えを行うこと。
レプリケーション
あるコンピュータやソフトウェアの管理するデータ集合の複製を別のコンピュータ上に作成し、通信ネットワークを介してリアルタイムに更新を反映させて常に内容を同期すること。
- 投稿日:2020-12-01T15:57:42+09:00
Step FunctionsとAPI Gatewayの統合【前編】
はじめに
AWS Step FunctionsがAmazon API GatewayとインテグレーションされからAPI Gatewayを直接呼び出すことが可能になりました。
外部APIを呼び出しその結果を待って次の処理に移るようなワークフローを構築するときに便利です。従来のAPI Gatewayの呼び出し
従来はLambdaを呼び出して、Lambda関数から外部サービスをコールし、結果を待つように実装する必要がありました。
さらに結果待ちの間も課金が発生していました。
今回のアップデートによって外部待ちの部分はStep Functionsで組めるようになるため、Lambdaを利用する必要がなくなります。
結果として、よりシンプルかつコスト効率の高いワークフローを設計可能になります。
最小限のコードと組み込みのエラー処理でバックエンドオーケストレーションが可能です。API Gatewayとはどんなもの?
あらゆる規模のAPIを簡単に作成、公開、維持、監視、保護できるようにするフルマネージドサービスです。
これらのAPIを使用すると、アプリケーションはバックエンドサービスからデータ、ビジネスロジック、または機能にアクセスできます。Step Functionsはどんなもの?
AWS Lambda、Amazon SNS、AmazonDynamoDBなどのAWSサービスを使用して復元力のあるサーバーレスオーケストレーションワークフローを構築できます。
AWS Step Functionsは、多くのサービスとネイティブに統合されています。
Amazon States Language(ASL)を使用すると、タスクの状態から直接これらのサービスを調整できます。追加のリソースタイプについて
APIGatewayとの新しいStepFunctions統合は、StandardワークフローとExpressワークフローの両方で使用できます。
APIゲートウェイを簡単に呼び出すことができます。Request-Response:サービスを呼び出し、HTTP応答を受信した直後にStepFunctionsを次の状態に進めます。
このパターンは、標準ワークフローと高速ワークフローでサポートされています。
Wait-for-Callback:タスクトークンを使用してサービスを呼び出し、そのトークンがペイロードとともに返されるまでステップ関数を待機させます。
このパターンは、標準ワークフローでサポートされています。パラメータフィールド
以下のAmazon StatesLanguageパラメータフィールドで設定されます。
ApiEndpoint: APIルートエンドポイント。
パス:APIリソースパス。
メソッド:HTTPリクエストメソッド。
HTTPヘッダー:カスタムHTTPヘッダー。
RequestBody:APIリクエストの本文。
ステージ:APIゲートウェイのデプロイステージ。
AuthType:認証タイプ。チュートリアル
ステップ関数とのAPIGateway統合は、以下を使用して、もしくはAWSマネジメントコンソール内から構成できます。
- AWSサーバーレスアプリケーションモデル(AWS SAM)
- AWSコマンドラインインターフェイス(AWS CLI)
- AWS CloudFormation
AWSマネジメントコンソール編
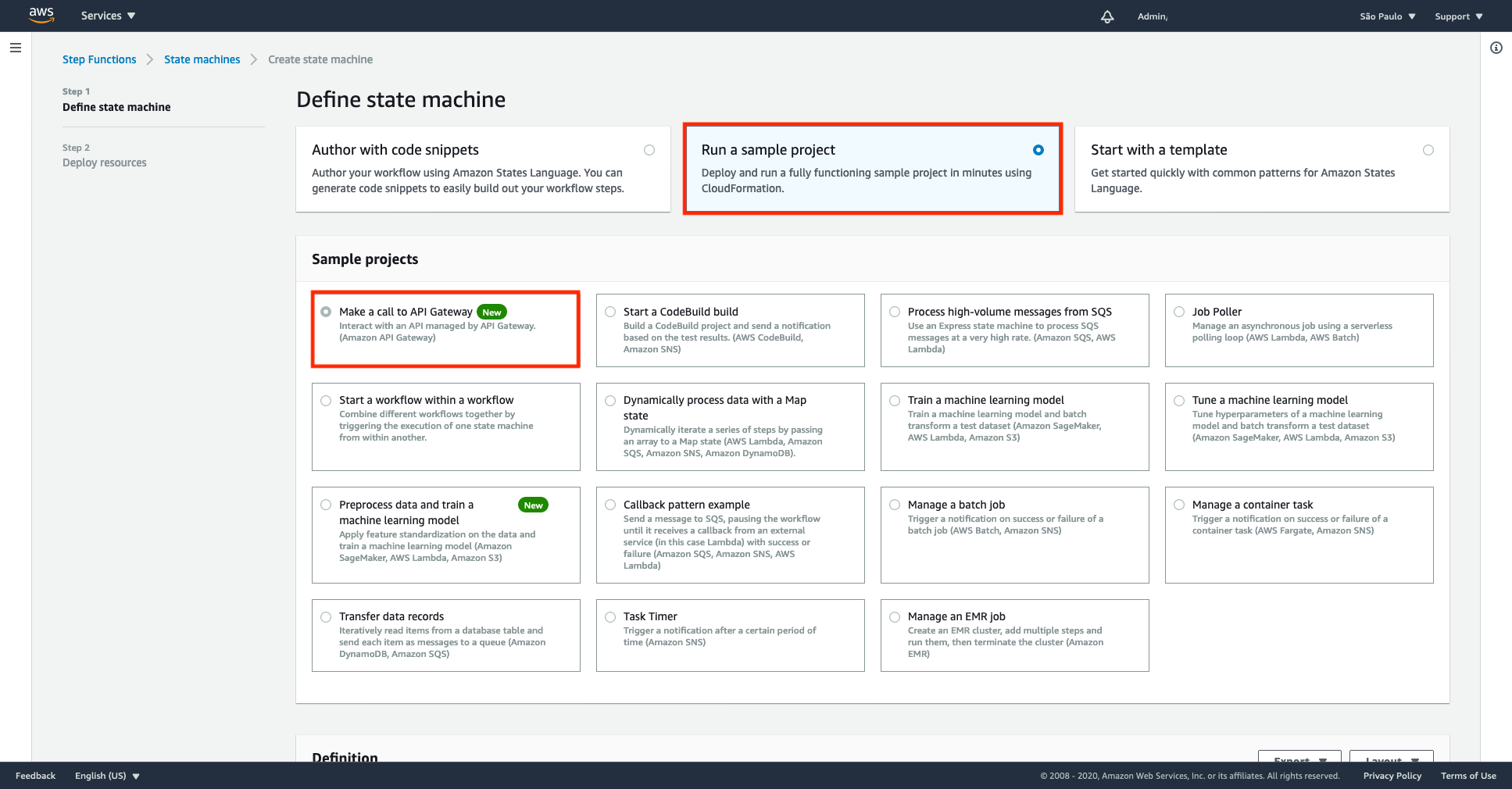
1.AWSマネジメントコンソールの[StepFunctions]ページに移動します。
2.[サンプルプロジェクトの実行]を選択し、[APIゲートウェイを呼び出す]を選択します。
定義セクションショー例のワークフローを構成するASL。
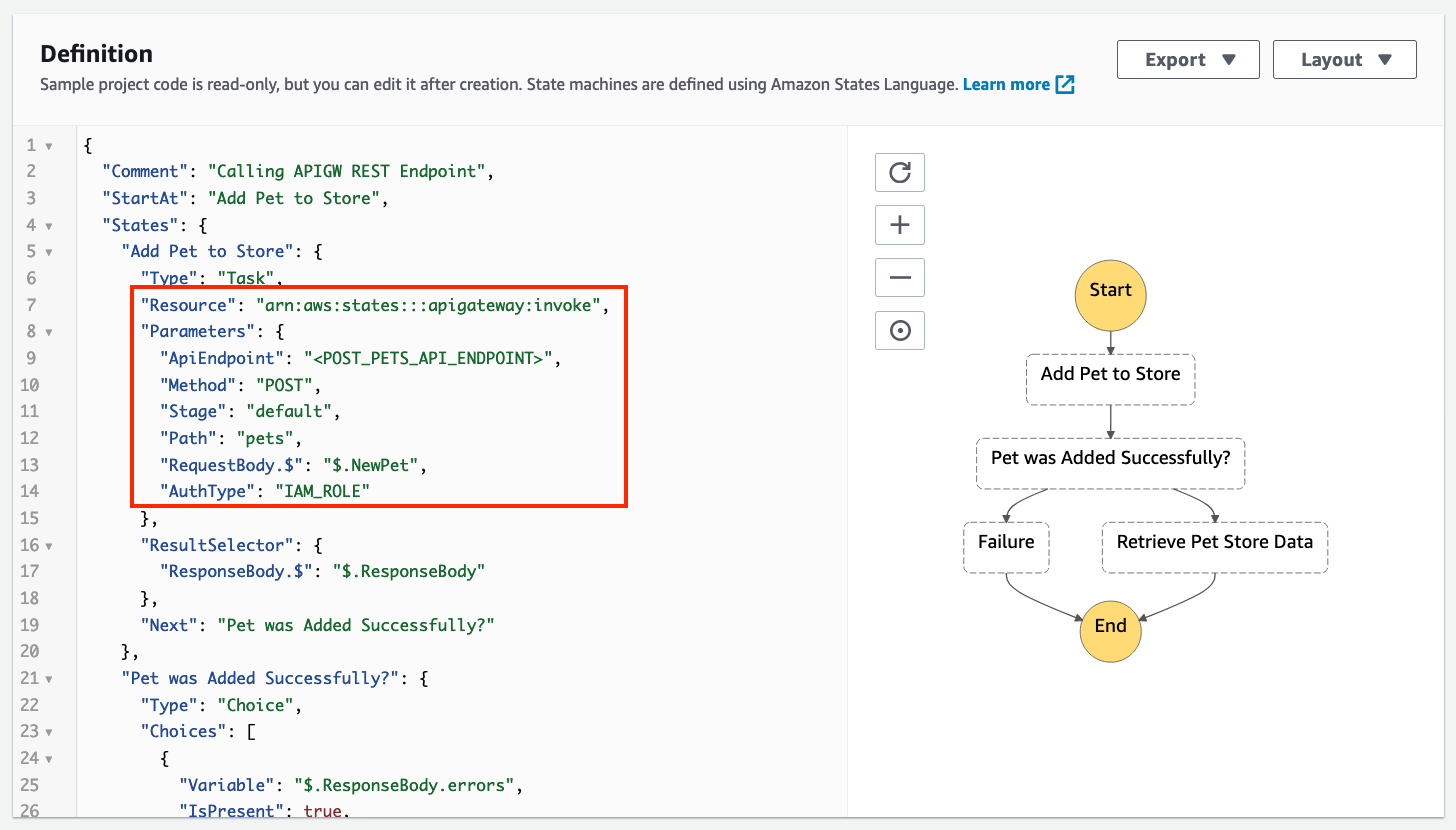
次の例は、新しいAPIGatewayリソースとそのパラメーターを示しています。
3.定義例を確認し、[次へ]を選択します。
4.「リソースのデプロイ」を選択します。これにより、ステップ関数の標準ワークフローと/pets、GETメソッドとPOSTメソッドを含むリソースを含むRESTAPIがデプロイされます。
また、ステップ関数からAPIエンドポイントを呼び出すために必要な権限を持つIAMロールをデプロイします。RequestBodyのフィールド
APIの要求入力をカスタマイズすることができます。
これは、ワークフローペイロードから取得した静的入力または動的入力の場合があります。ワークフローの実行
1.AWSマネジメントコンソールの[StepFunctions]ページから新しく作成されたステートマシンを選択します
2.[実行の開始]を選択します。
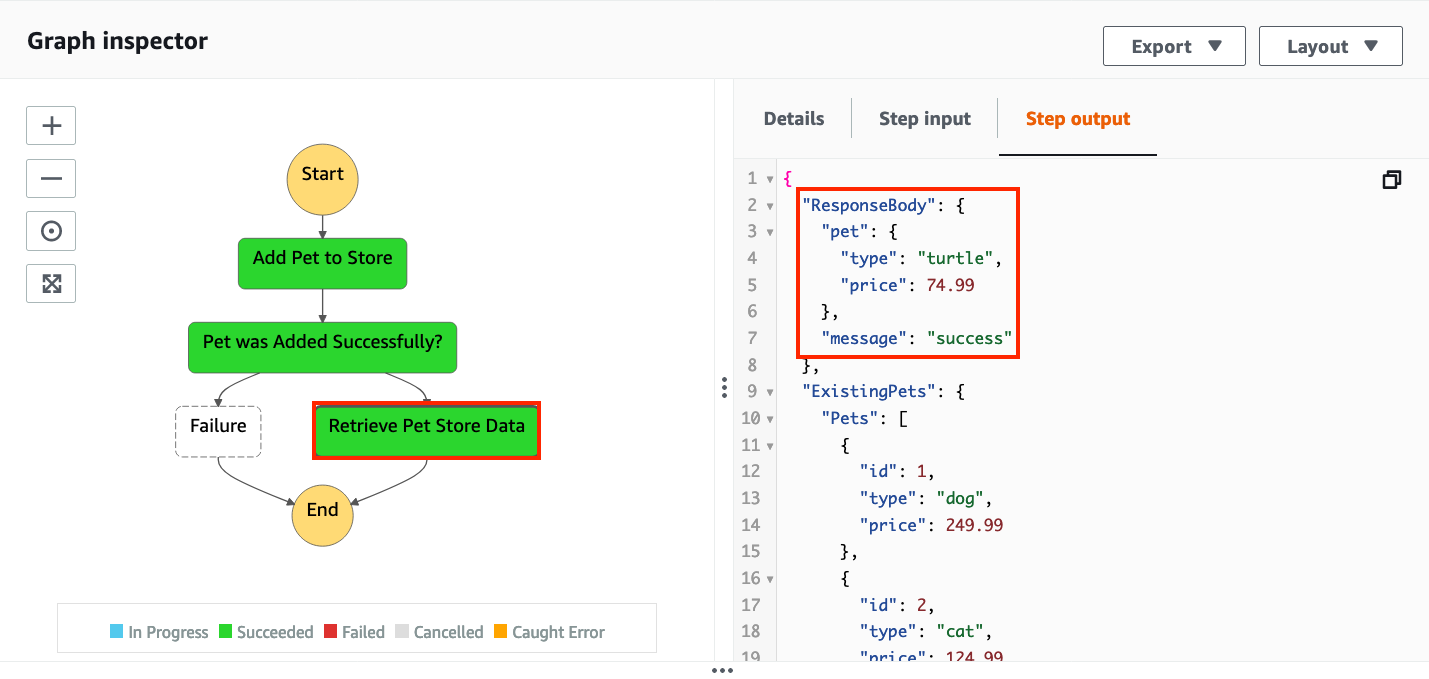
3.次のJSONを入力フィールドに貼り付けます。{ "NewPet": { "type": "turtle", "price": 74.99 } }4.[実行の開始]を選択します
5.「ペットショップデータの取得」ステップを選択してから、「ステップ出力」タブを選択します。
これは、「ペットショップに追加」POSTリクエストからの正常なresponseBody出力と、「ペットショップデータの取得」 GETリクエストからの応答を示しています。
アクセス制御
API Gateway統合は、AWS Identity and Access Management(IAM)の認証と承認をサポートします。
これには、IAMの役割、ポリシー、およびタグが含まれます。AWS IAMのロールとポリシー
API全体または個々のメソッドに適用できる柔軟で堅牢なアクセスコントロールを提供します。
これは、RESTAPIまたはHTTPAPIを作成、管理、または呼び出すことができるユーザーを制御します。タグベースのアクセス制御
タグベースのアクセス制御を使用すると、すべてのAPIGatewayリソースに対してよりきめ細かいアクセス制御を設定できます。
タグのキーと値のペアを指定して、API Gatewayリソースを目的、所有者、またはその他の基準で分類します。
これは、RESTAPIとHTTPAPIの両方のアクセスを管理するために使用できます。API Gatewayリソースポリシー
指定されたプリンシパル(通常はIAMユーザーまたはロール)がAPIを呼び出すことができるかどうかを制御するJSONポリシードキュメントです。
リソースポリシーを使用して、AWS StepFunctionsを介してRESTAPIへのアクセスを許可できます。
これは、別のAWSアカウントのユーザー、または指定された送信元IPアドレス範囲またはCIDRブロックのみの場合があります。AuthTypeパラメーター
API Gateway統合のアクセス制御を構成するには、AuthTypeパラメーターを次のいずれかに設定します。
{“AuthType””: “NO_AUTH”}許可なくAPIを直接呼び出します。これがデフォルト設定です。{“AuthType””: “IAM_ROLE”}ステップ関数は、ステートマシンの実行ロールを引き受け、署名バージョン4を使用して資格情報を使用して要求に署名します。{“AuthType””: “RESOURCE_POLICY”}ステップ関数は、サービスプリンシパルを使用してリクエストに署名し、APIエンドポイントを呼び出します。終わりに
ワンステップで構築が済んで、なおかつコストを下げれるようになるのは、どんな用途に対しても強いアプローチになりますね。
さらに後編に続きます。
APIGatewayを使用してステップ関数を使用してマイクロサービスをオーケストレーションしてAWSサービスにアクセスする方法について書いていきます。公式
- 投稿日:2020-12-01T15:28:26+09:00
AppDynamics Lambda Extension による Python 関数性能監視
この記事はシスコシステムズ有志による Cisco Systems Japan Advent Calendar 2020 (2枚目) の 3 日目として投稿しています。
2017年版: https://qiita.com/advent-calendar/2017/cisco
2018年版: https://qiita.com/advent-calendar/2018/cisco
2019年版: https://qiita.com/advent-calendar/2019/cisco
2020年版: https://qiita.com/advent-calendar/2020/cisco
2020年版(2枚目): https://qiita.com/advent-calendar/2020/cisco2はじめに
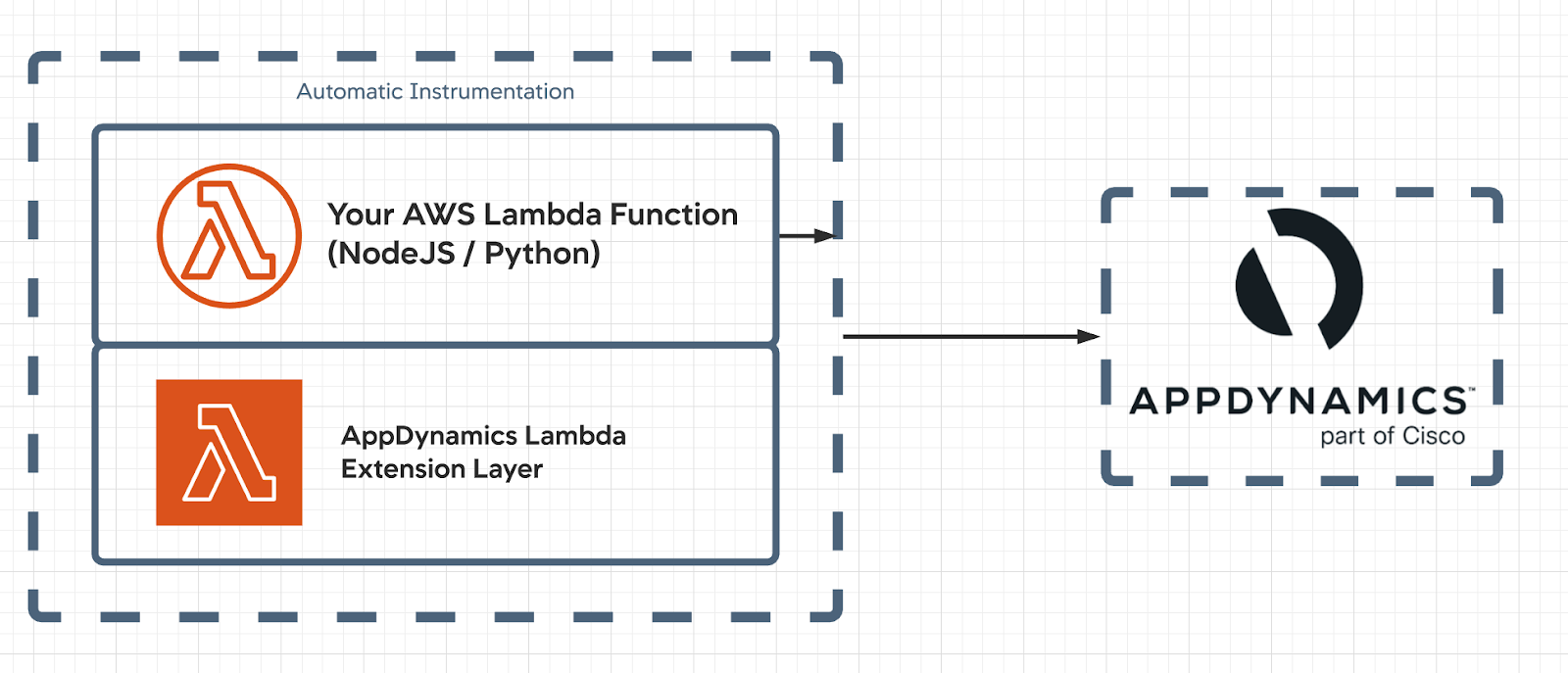
2020年10月にプレビューとなった AWS Lambda Extensions により,コード変更なしに Lamba 関数の AppDynamics での監視が可能となりました。
AWS Lambda Extensions(プレビュー)を構築する
Step-by-Step Guide: Enhancing Lambda Performance Monitoring with AppDynamics
これまでは,AppDynamics Tracer SDK を用いるため Lambda 関数のコード変更が必要でしたが, AppDynamics Extension Layer を追加することによりコード変更なしでモニタリング可能となりました。
本記事では,AWS SAM CLI を用いて Lambda 関数のテスト/デプロイ, AppDynamics による性能監視を試してみます。
AppDynamics Lambda Extention 利用前提条件
- Node.js 10+, Python 3.6+ で書かれた Lambda 関数がインストゥルメント可能
- Serverless APM for AWS Lambda subscription へサブスクライブ済み
- AppDynamics SaaS Controller : バージョン 4.5.11 以降が利用可能
利用可能な AWS リージョン
- ap-northeast-1 (東京)
- ap-northeast-2 (ソウル)
- ap-south-1
- ap-southeast-1
- ap-southeast-2
- eu-central-1
- eu-north-1
- eu-west-1
- eu-west-2
- eu-west-3
- ca-central-1
- sa-east-1
- us-east-1
- us-east-2
- us-west-1
インストゥルメント手順公式ドキュメント
2020年12月時点で英語版のみとなりますが,Extension を用いた Lambda 関数のインストゥルメント手順の公式ドキュメントはこちらになります。
Use the AppDynamics AWS Lambda Extension to Instrument Serverless APM at Runtime
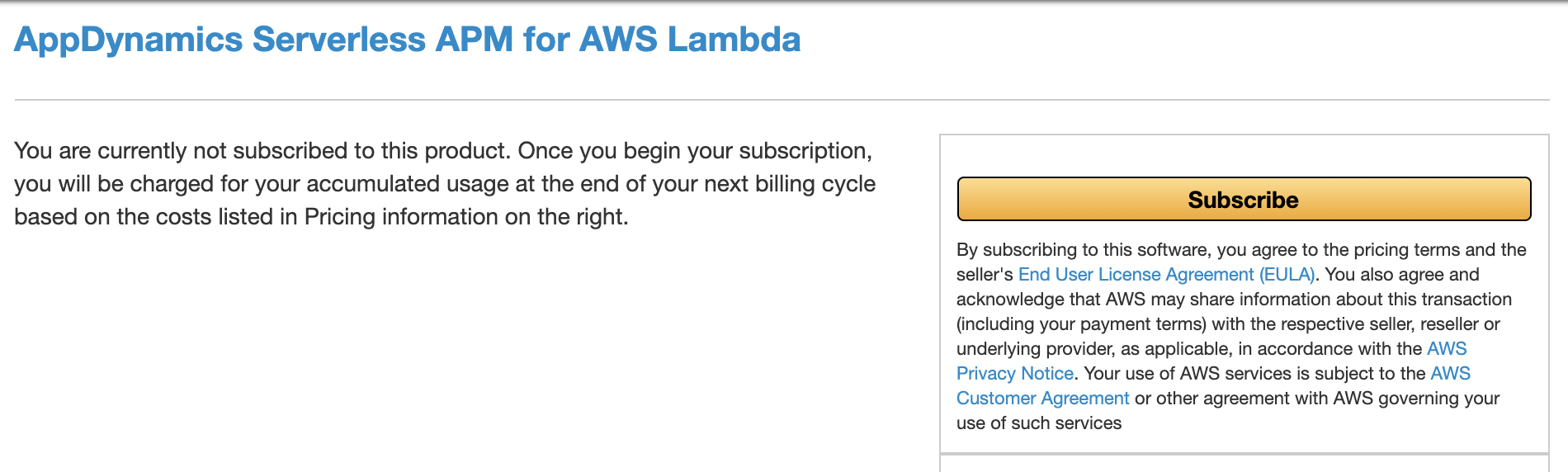
Serverless APM for AWS Lambda subscription へサブスクライブ
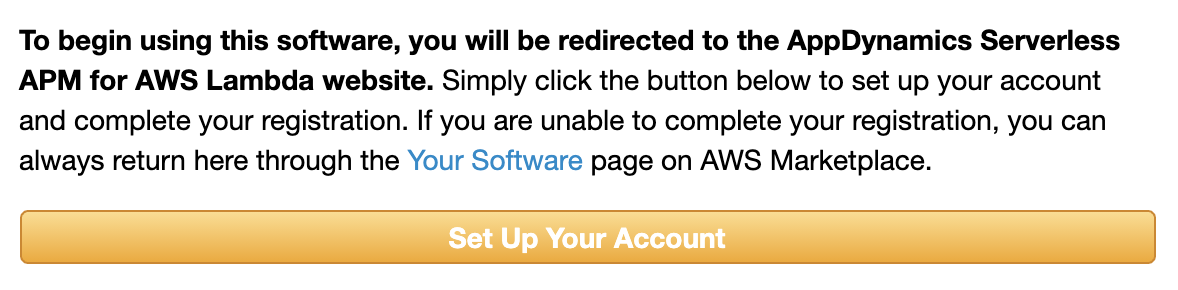
Serverless APM for AWS Lambda subscription から Continue to Subscribe をクリックし,
次の画面で Subscribe をクリック,
次に Set Up Your Account をクリックします。
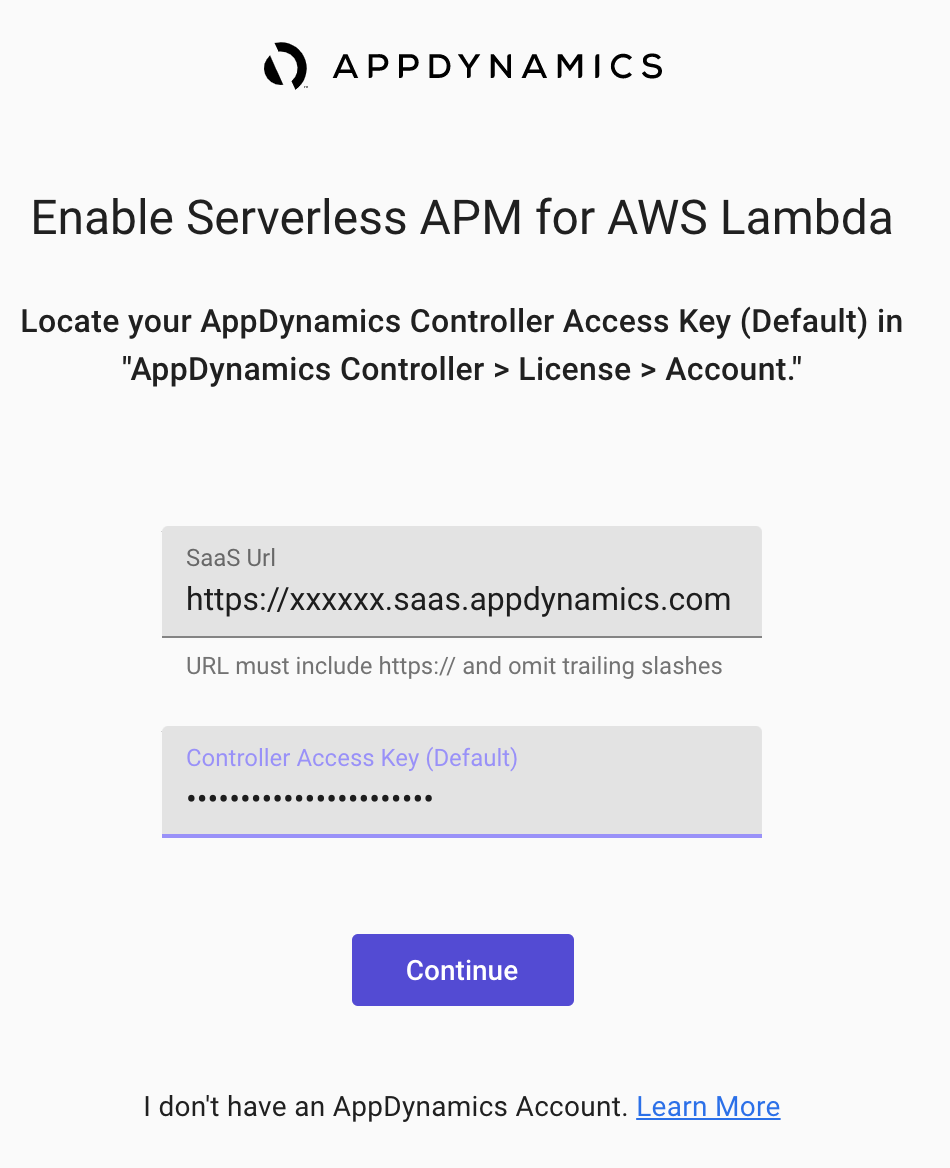
最後に AppDynamics SaaS コントローラURL, コントローラアクセスキーを入力します。
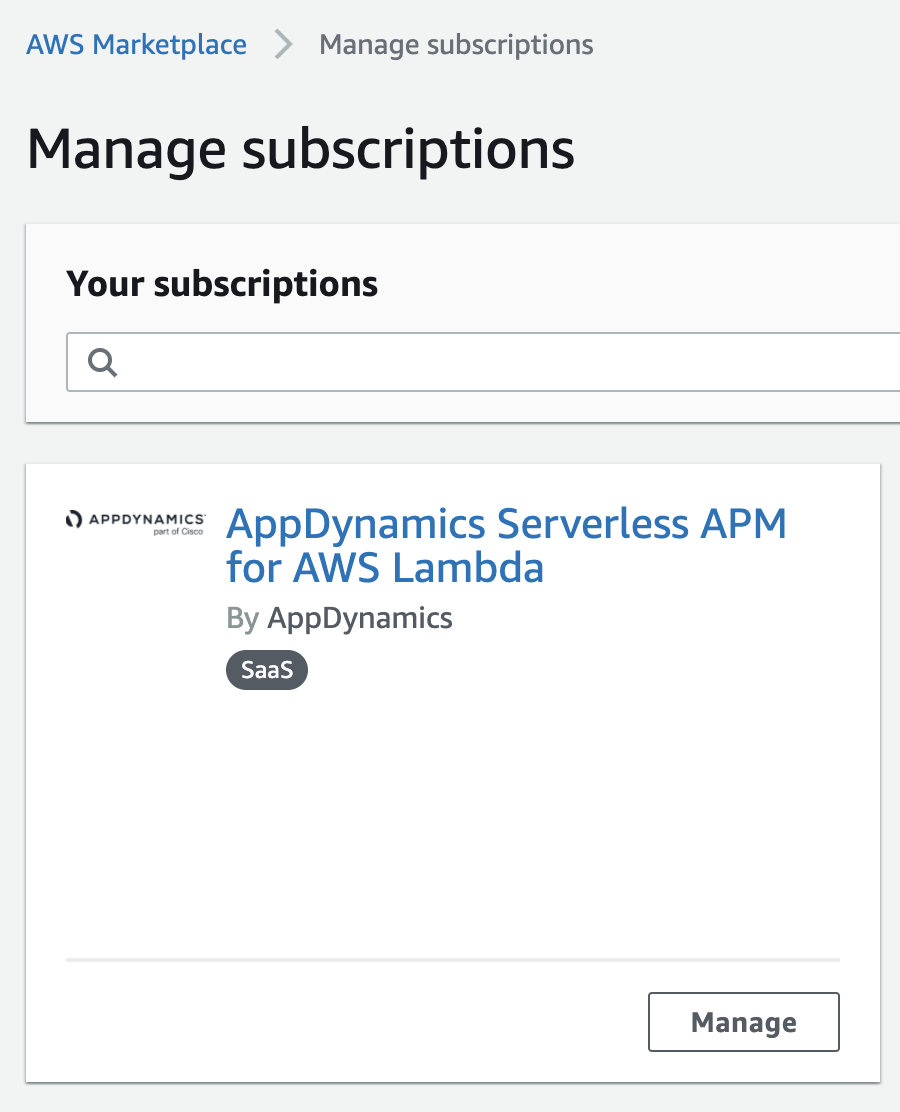
サブスクリプションの確認は AWS Marketplace > Manage subscriptions から行うことができます。
AWS SAM CLI による Lambda 関数のデプロイと AppDynamics Extension インストゥルメント
今回は AWS マネジメントコンソールを極力用いず,AWS SAM CLI を用いて監視対象の Lambda 関数のデプロイを行ってみます。AWS SAM CLI のインストールをされていない方は以下のリンクからご自分の利用環境に合わせてインストールを事前に行ってください。
template.yaml の編集
SAM のテンプレートを編集し,Layers に 以下のように ARN,
arn:aws:lambda:ap-northeast-1:716333212585:layer:appdynamics-lambda-extension:9を設定します(東京リージョンの場合)。利用リージョンが異なる場合は ap-northeast-1 を適宜変更してください。AWSTemplateFormatVersion: '2010-09-09' Transform: 'AWS::Serverless-2016-10-31' Description: AppDynamics Lambda extension Resources: Function: Type: 'AWS::Serverless::Function' Properties: Handler: lambda_function.lambda_handler Runtime: python3.8 CodeUri: code Handler: app.lambda_handler MemorySize: 128 Timeout: 3 Environment: Variables: APPDYNAMICS_CONTROLLER_HOST: your-account.saas.appdynamics.com APPDYNAMICS_SERVERLESS_API_ENDPOINT: 'https://syd-sls-agent-api.saas.appdynamics.com' APPDYNAMICS_ACCOUNT_NAME: your-account APPDYNAMICS_AGENT_ACCOUNT_ACCESS_KEY: your-access-key APPDYNAMICS_APPLICATION_NAME: your-application APPDYNAMICS_TIER_NAME: your-tier AWS_LAMBDA_EXEC_WRAPPER: /opt/appdynamics-extension-script Layers: - >- arn:aws:lambda:ap-northeast-1:716333212585:layer:appdynamics-lambda-extension:9各環境変数はご利用の AppDynamics コントローラへのアクセス情報,アプリケーション名,Tier名に適宜置き換えてください。なお,アクセスキーは SaaS コントローラ の右上の歯車アイコン - License - Account で確認することができます。
サンプル Python コード
今回は以下の非常にシンプルなサンプルコードを用います。ifconfig.io に GET リクエストを送り,グローバル IP アドレスを取得します。
import urllib.request def lambda_handler(event, context): url = 'https://ifconfig.io/' req = urllib.request.Request(url) req.add_header("User-Agent", 'curl') with urllib.request.urlopen(req) as res: body = res.read() return { 'statusCode': 200, 'body': body.decode().strip() }このスクリプトは
code/app.pyとして保存しておきます。ビルド
今回は Python 3.8 Runtime を用いますが,ローカル環境で 正常に SAM から Python 3.8 を実行できない場合は,
sam build -uでDocker コンテナを利用することにより抽象化/仮想化することができます。$ sam build -u Starting Build inside a container Building codeuri: code runtime: python3.8 metadata: {} functions: ['SampleFunction'] Fetching amazon/aws-sam-cli-build-image-python3.8 Docker container image...... Mounting /Users/foo/sample_app/code as /tmp/samcli/source:ro,delegated inside runtime container Build Succeeded Built Artifacts : .aws-sam/build Built Template : .aws-sam/build/template.yaml Commands you can use next ========================= [*] Invoke Function: sam local invoke [*] Deploy: sam deploy --guided Running PythonPipBuilder:ResolveDependencies Running PythonPipBuilder:CopySourceローカルテスト実行
sam local invokeでローカルテストを実行することができます。$ sam local invoke Invoking app.lambda_handler (python3.8) arn:aws:lambda:ap-northeast-1:716333212585:layer:appdynamics-lambda-extension:9 is already cached. Skipping download Skip pulling image and use local one: samcli/lambda:python3.8-f00964ae55accef74c51e9ff8. Mounting /Users/foo/sample_app/.aws-sam/build/SampleFunction as /var/task:ro,delegated inside runtime container [Appdynamics wrapper script] AWS_Execution_Env is [Appdynamics wrapper script] not supported, running lambda with default arguments START RequestId: db5cd0c4-3cf3-10a1-8fde-bf6711cc3df0 Version: $LATEST END RequestId: db5cd0c4-3cf3-10a1-8fde-bf6711cc3df0 REPORT RequestId: db5cd0c4-3cf3-10a1-8fde-bf6711cc3df0 Init Duration: 241.18 ms Duration: 371.69 ms Billed Duration: 400 ms Memory Size: 128 MB Max Memory Used: 27 MB {"statusCode":200,"body":"xx.xxx.xxx.xxx"}Lambda 関数,AppDynamics Extension Layer のデプロイ
正常にグローバル IP アドレスを取得可能なことが確認できたら,
sam deploy --guidedで自動デプロイを行うことができます。$ sam deploy --guided Configuring SAM deploy ====================== Looking for config file [samconfig.toml] : Found Reading default arguments : Success Setting default arguments for 'sam deploy' ========================================= Stack Name [Python]: AWS Region [ap-northeast-1]: #Shows you resources changes to be deployed and require a 'Y' to initiate deploy Confirm changes before deploy [Y/n]: y #SAM needs permission to be able to create roles to connect to the resources in your template Allow SAM CLI IAM role creation [Y/n]: y Save arguments to configuration file [Y/n]: y SAM configuration file [samconfig.toml]: SAM configuration environment [default]: Looking for resources needed for deployment: Found! Managed S3 bucket: aws-sam-cli-managed-default-samclisourcebucket-xxxxxxxxx A different default S3 bucket can be set in samconfig.toml Saved arguments to config file Running 'sam deploy' for future deployments will use the parameters saved above. The above parameters can be changed by modifying samconfig.toml Learn more about samconfig.toml syntax at https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/serverless-sam-cli-config.html Deploying with following values =============================== Stack name : Python Region : ap-northeast-1 Confirm changeset : True Deployment s3 bucket : aws-sam-cli-managed-default-samclisourcebucket-xxxxxxxxx Capabilities : ["CAPABILITY_IAM"] Parameter overrides : {} Signing Profiles : {} Initiating deployment ===================== Waiting for changeset to be created.. CloudFormation stack changeset ------------------------------------------------------------------------------------------------------------------------------------- Operation LogicalResourceId ResourceType Replacement ------------------------------------------------------------------------------------------------------------------------------------- + Add SampleFunctionRole AWS::IAM::Role N/A + Add SampleFunction AWS::Lambda::Function N/A ------------------------------------------------------------------------------------------------------------------------------------- Changeset created successfully. arn:aws:cloudformation:ap-northeast-1:679382613873:changeSet/samcli-deploy1606793756/cda913e6-946d-4713-b0b2-71c816716825 Previewing CloudFormation changeset before deployment ====================================================== Deploy this changeset? [y/N]: y 2020-12-01 12:36:12 - Waiting for stack create/update to complete CloudFormation events from changeset ------------------------------------------------------------------------------------------------------------------------------------- ResourceStatus ResourceType LogicalResourceId ResourceStatusReason ------------------------------------------------------------------------------------------------------------------------------------- CREATE_IN_PROGRESS AWS::IAM::Role SampleFunctionRole - CREATE_IN_PROGRESS AWS::IAM::Role SampleFunctionRole Resource creation Initiated CREATE_COMPLETE AWS::IAM::Role SampleFunctionRole - CREATE_IN_PROGRESS AWS::Lambda::Function SampleFunction - CREATE_IN_PROGRESS AWS::Lambda::Function SampleFunction Resource creation Initiated CREATE_COMPLETE AWS::Lambda::Function SampleFunction - CREATE_COMPLETE AWS::CloudFormation::Stack Python - ------------------------------------------------------------------------------------------------------------------------------------- Successfully created/updated stack - Python in ap-northeast-1AWS CLI によるLambda 関数の実行
aws lambda list-functions --query Functions[].FunctionNameを実行することにより,デプロイされている Lambda 関数のリストを取得することができます。$ aws lambda list-functions --query Functions[].FunctionName [ "Python-Function-123456ABCDEF" ]次に,以下のように
aws lambda invokeにより,コマンドラインから Lambda 関数を実行することが可能です。$ aws lambda invoke --function-name Python-Function-123456ABCDEF /dev/stdout {"statusCode": 200, "body": "\"Hello from Lambda!\""} "StatusCode": 200, "ExecutedVersion": "$LATEST" }ログの確認
sam logコマンドで Lambda 関数のログを確認します。sam logs -n Python-Function-123456ABCDEF ... 2020/12/01/[$LATEST]6e06e51410a146fab5b645091d7ce510 2020-12-01T04:28:41.708000 START RequestId: e0db5107-9048-45b6-a2d6-c9e586417891 Version: $LATEST 2020/12/01/[$LATEST]6e06e51410a146fab5b645091d7ce510 2020-12-01T04:28:41.715000 2020-12-01 04:28:41,715 AppDynamics - transaction_service.py [INFO]: Starting the business transaction. 2020/12/01/[$LATEST]6e06e51410a146fab5b645091d7ce510 2020-12-01T04:28:42.095000 2020-12-01 04:28:42,094 AppDynamics - transaction_service.py [INFO]: Stopping the business transaction. 2020/12/01/[$LATEST]6e06e51410a146fab5b645091d7ce510 2020-12-01T04:28:42.095000 2020-12-01 04:28:42,095 AppDynamics - event_service.py [INFO]: Total number of items in the events queue are 4 2020/12/01/[$LATEST]6e06e51410a146fab5b645091d7ce510 2020-12-01T04:28:42.095000 2020-12-01 04:28:42,095 AppDynamics - event_service.py [INFO]: Successfully scheduled the sending of events to downstream 2020/12/01/[$LATEST]6e06e51410a146fab5b645091d7ce510 2020-12-01T04:28:42.754000 2020-12-01 04:28:42,754 AppDynamics - http_service.py [INFO]: HTTP post request was successful for url https://syd-sls-agent-api.saas.appdynamics.com/v1/events 2020/12/01/[$LATEST]6e06e51410a146fab5b645091d7ce510 2020-12-01T04:28:42.756000 END RequestId: e0db5107-9048-45b6-a2d6-c9e586417891 2020/12/01/[$LATEST]6e06e51410a146fab5b645091d7ce510 2020-12-01T04:28:42.756000 REPORT RequestId: e0db5107-9048-45b6-a2d6-c9e586417891 Duration: 1041.72 ms Billed Duration: 1042 ms Memory Size: 128 MB Max Memory Used: 81 MB
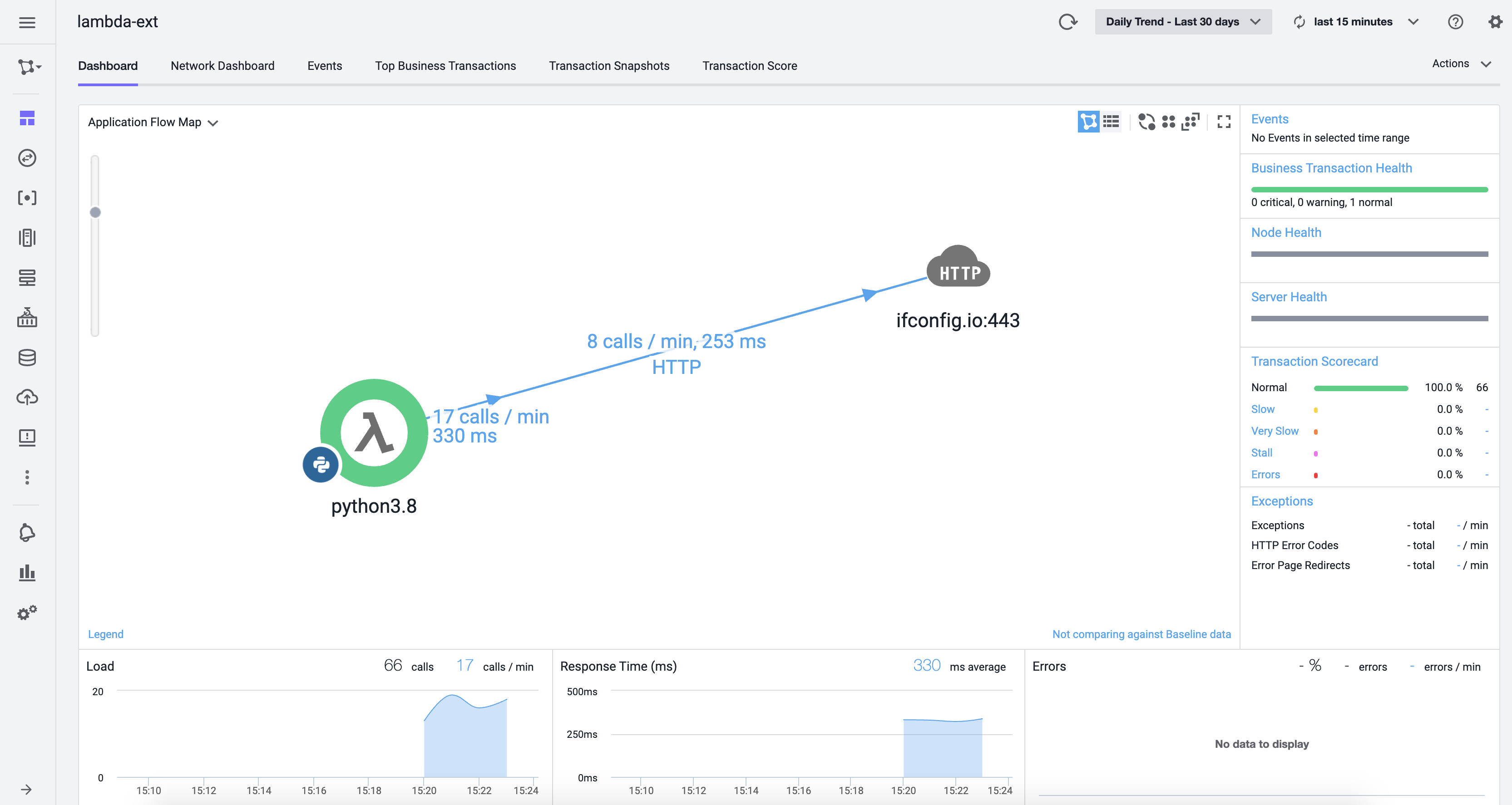
AppDynamics - http_service.py [INFO]: HTTP post request was successful for url https://syd-sls-agent-api.saas.appdynamics.com/v1/eventsを含む行が確認でき,正常にメトリックが AppDynamics SaaS プラットフォームに送信されていることが確認できます。Application Flow Map の確認
AppDynamics SaaS コントローラで template.yaml の APPDYNAMICS_APPLICATION_NAME で指定したアプリケーションの Application Flow Map を確認すると,以下のように Lambda 関数(Python) Tier からリモートサービスとして,ifconfig.io がコールされていることが確認できました。
Lambda 関数,S3 バケット, CloudFormation スタックの削除
以下のコマンドで SAM により作成した Lambda 関数,S3 バケット, CloudFormation スタックを削除することができます(Python: CloudFormation スタック名)。
aws cloudformation delete-stack --stack-name Pythonまとめ
今回は AWS SAM CLI を用い,2020年10月に導入された AppDynamics Lambda Extension で性能監視を行う Python で書かれた Lambda 関数のデプロイ,テストを実施しました。
Extension Layer により,従来必要であった Lambda 関数のコード変更が不要となり,より利便性が高くなったと考えます。

- 投稿日:2020-12-01T15:09:38+09:00
AWSのスイッチロールを使っている際に、KubernetesのRBAC認証設定について
初めに
またアドベントカレンダーの記事を書く時期、
アドベントカレンダー以外でも、記事を書く習慣を身につけたいですねw今回は
KubernetesのRBAC認証設定について書きました概要
Kubernetesは独自のRBAC認証があるので、IAMの権限があっても、RBACの設定を更新しない限り、EKSのクラスターに対して、
kubectlを叩くことができないhttps://aws.amazon.com/jp/premiumsupport/knowledge-center/amazon-eks-cluster-access/
AWS Identity and Access Management (IAM) エンティティが Amazon EKS クラスターのロールベースアクセス制御 (RBAC) 設定によって承認されていない場合、承認エラーが発生します
複数のAWSアカウントを管理するために、スイッチロールを利用しているのは一般的ですが、
スイッチロール先に個人ユーザーが存在しないため、ユーザー単位でKubernetesのRBACに登録することは出来ないので、
スイッチロール元のユーザーを登録する(別のAWSアカウントユーザーを登録する)方法を紹介しますRequirement
eksctlをインストールする
https://docs.aws.amazon.com/ja_jp/eks/latest/userguide/getting-started-eksctl.html
$ brew tap weaveworks/tap $ brew install weaveworks/tap/eksctl $ eksctl version
- windows
$ chocolatey install -y eksctl aws-iam-authenticator $ chocolatey upgrade -y eksctl aws-iam-authenticator $ eksctl versionAmazon EKS提供のkubectlをインストールする
RBAC認証設定
ロール登録やユーザー登録の方法も記載する
ロールを登録する手順
kubeconfigをAmazon EKS用に作成する
- ユーザーごとに各自作成する
aws-cliで自動作成
aws eks update-kubeconfigを使って、kubeconfigを自動作成することができる$ aws eks update-kubeconfig --name ${クラスター名} --profile ${プロファイル名} Added new context arn:aws:eks:ap-northeast-1:xxxxxxxxxxxx:cluster/ClusterName to ~/.kube/config
- 以下のように、クラスター情報やユーザー情報を
~/.kube/configに追加される(省略) users: - name: {cluster-arn} user: exec: apiVersion: client.authentication.k8s.io/v1alpha1 args: - --region - ap-northeast-1 - eks - get-token - --cluster-name - {クラスター名} command: aws env: - name: AWS_PROFILE value: {プロファイル名}現在のconfigmapを確認する
kubectl実行できる環境で実施してください
- 新規作成の場合は
configmap存在しない$ kubectl describe configmap -n kube-system aws-authconfigmapの修正
mapRolesを追加するaws-auth-cm.yamlapiVersion: v1 kind: ConfigMap metadata: name: aws-auth namespace: kube-system data: mapRoles: | - rolearn: arn:aws:iam::{スイッチロール先のアカウントID}:role/{ロール名} username: system:node:{{EC2PrivateDNSName}} groups: - system:bootstrappers - system:nodes - rolearn: arn:aws:iam::{スイッチロール先のアカウントID}:role/{スイッチロール時に使用するロール名} username: {ユーザー名 / スイッチロール時に使用するロール名} groups: - system:masters設定を反映する
kubectl実行できる環境で実施してください
- 新規作成の場合は、最初の一回だけ誰でも反映できるらしい
$ kubectl apply -f aws-auth-cm.yamlユーザを追加する手順
kubeconfigをAmazon EKS用に作成する
- ユーザーごとに各自作成する
aws-cliで自動作成
aws eks update-kubeconfigを使って、kubeconfigを自動作成することができる$ aws eks update-kubeconfig --name ${クラスター名} --profile ${プロファイル名} Added new context arn:aws:eks:ap-northeast-1:xxxxxxxxxxxx:cluster/ClusterName to ~/.kube/config
env部分のAWS_PROFILEは、自分のAWSクレディンシャル設定により変更 / コメントアウトする必要がある手動で作成
apiVersion: v1 clusters: - cluster: server: {endpoint-url} certificate-authority-data: {base64-encoded-ca-cert} name: {cluster-arn} contexts: - context: cluster: {cluster-arn} user: {cluster-arn} name: {cluster-arn} current-context: {cluster-arn} kind: Config preferences: {} users: - name: {cluster-arn} user: exec: apiVersion: client.authentication.k8s.io/v1alpha1 args: - --region - ap-northeast-1 - eks - get-token - --cluster-name - {クラスター名} command: aws # スイッチロール元のクレディンシャルの設定profile、defaultの場合は記入なしで大丈夫 #env: #- name: AWS_PROFILE # value: {プロファイル名}endpoint-url, base64-encoded-ca-cert, cluster-arn はコンソール画面で確認できる
現在のconfigmapを確認する
kubectl実行できる環境で実施してください
- 新規作成の場合は
configmap存在しない$ kubectl describe configmap -n kube-system aws-authconfigmapの修正
mapUsersを追加するaws-auth-cm.yamlapiVersion: v1 kind: ConfigMap metadata: name: aws-auth namespace: kube-system data: mapRoles: | - rolearn: arn:aws:iam::{スイッチロール先のアカウントID}:role/{ロール名} username: system:node:{{EC2PrivateDNSName}} groups: - system:bootstrappers - system:nodes mapUsers: | - userarn: arn:aws:iam::{スイッチロール元のアカウントID}:user/{ユーザー名} username: {ユーザー名} groups: - system:masters - userarn: arn:aws:iam::{スイッチロール元のアカウントID}:user/{ユーザー名} username: {ユーザー名} groups: - iam:base-users設定を反映する
kubectl実行できる環境で実施してください
- 新規作成の場合は、最初の一回だけ誰でも反映できるらしい
$ kubectl apply -f aws-auth-cm.yaml確認
kubectl get svc叩けるなら成功です# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 42m最後
ロールで認証するのが一般的だと思いますが、諸事情でロール認証を利用できない場合は、
ユーザーで認証する事もできます
- 投稿日:2020-12-01T14:54:15+09:00
CPUSurplusCreditBalanceの課金額は60クレジットで5円
CPUSurplusCreditBalanceの課金額の計算方法をAWSサポートに問い合わせてみた。
CPUSurplusCreditBalanceの課金額は約5円/時間
サポートに問い合わせた結果、「インスタンスタイプによらず、1時間あたり60クレジット」で「0.05USDが課金額」ということが分かった。
つまり、CPUSurplusCreditBalanceが60クレジットのインスタンスを即座に停止すると、下記の計算式で約5円が課金額になる。
60クレジットの超過 * 0.05 USD = 約5円上記の計算式は、Linux系のインスタンスを仮定している。Windowsの場合は0.096USDで計算することになる。
参考リンク
- 投稿日:2020-12-01T13:34:08+09:00
swagger-ui,swagger-editor環境構築(AWS/Docker)
前提条件
- AWS EC2インスタンス作成ができている
- EC2インスタンスにnginxインストール済
EC2にDockerをインストール
EC2インスタンスにSSH接続後、下記コマンドを入力
sudo amazon-linux-extras install dockerDocker起動
sudo systemctl start dockerDocker起動確認
sudo systemctl status docker
ActiveになっていればOK
swagger-editorのイメージをpull
sudo docker pull swaggerapi/swagger-editorswagger-uiのイメージをpull
sudo docker pull swaggerapi/swagger-uiswagger-editorを起動
sudo docker run -d -p 8000:8080 swaggerapi/swagger-editorswagger-uiを起動
sudo docker run -d -p 8001:8080 swaggerapi/swagger-uiコンテナ起動確認
sudo docker ps
swagger-editorとswagger-uiが表示されればOKnginx.confに追記
nginx.confを開く
sudo vim /etc/nginx/nginx.conf下記内容をnginx.confに追記
server{}内に必ず追記するようにしてください。location /swagger-editor/docker/ { proxy_pass http://localhost:8000/; proxy_redirect off; } location /swagger-ui/docker/ { proxy_pass http://localhost:8001/; proxy_redirect off; }nginxを再起動or再読み込み
再起動
sudo systemctl restart nginx再読み込み
sudo systemctl reload nginxすでに、docker上で動かしているコンテナがswagger系以外にもあるなら、再読み込みがおすすめ
再起動して失敗してしまうと、正常に動いていた機能も含めて全て利用不可になる可能性があるので。URLにアクセスして、swagger-editorの表示を確認
http://(IPv4アドレス)/swagger-editor/docker/下記のサイトが表示されればOK
URLにアクセスして、swagger-uiの表示を確認
http://(IPv4アドレス)/swagger-ui/docker/下記のサイトが表示されればOK
自動起動設定(nginx,docker編)
sudo systemctl enable nginxsudo systemctl enable docker自動起動設定(dockerコンテナ編)
コンテナ単体の自動起動設定をすることもできます。
コンテナ起動後に、下記コマンドを入力してください。sudo docker update --restart=always コンテナ名自動起動設定を無効化する場合は
sudo docker update --restart=no コンテナ名最後に
以上が、AWS/EC2とDockerを使ったswagger-ui,swagger-editorの環境構築手順です。
不明点、質問等があればコメント欄にお願い致します。




- 投稿日:2020-12-01T13:17:10+09:00
自然言語処理のサービスのAWS上での構成を考えてみる
目標
- AWSサービスを効率的に使って、自然言語処理に関するサービスを構築する。
- 可能な限りローコストを目指す(特にアクセスしていない時の料金を減らす)。
- もちろん高可用性構成。
- マルチテナント構成を取る
- BERTを使って類似文章検索を行う。
- 転置インデックスを使用した全文検索を行いたい(単語での検索など)。ElasticSearchは値段高いのでパス。
前提
今回は、構成の考察。検証済みの部分もあり、未検証部分もあり。
実際の製品がこの構成を取っている事を示すものでは無いです(まだ検証段階です)。
その為、この構成を取った事によって何か問題が発生するかもしれない事はご了承下さい。技術要件整理
データ
学習済み基本モデル
最近流行りの転移学習向けに、公開されている学習済みデータを使用する。サイズ的には1~数GBを想定。
ファインチューニング用コーパスデータ
転移学習でのファインチューニングをする為の言語データ。具体的には検索対象の全文章。サイズはテナントによるが、大きくて100MB程度。
最終文章ベクトルモデル
ファインチューニング後の学習モデル。これを使用して類似語、類似文章検索を行う。学習した後にpickleでシリアライズしておき、使用時にデシリアライズする。サイズ的には大きくて1GB程度を想定。
処理
最終文章ベクトルモデル作成
処理要素
- 学習済み基本モデルの読み込み
- 最終学習モデルの生成
- 最終学習モデルオブジェクトのpickleシリアライズファイル作成
特性
- 処理時間が長い(量やマシンパワーによるが1時間レベル)
- 扱うファイルがGBオーダー
- 瞬時の反映は要らないが、毎週、毎日、任意のタイミングでの処理をしたい。
類似文章検索
処理要素
- pickleシリアライズファイル読み込み
- 類似文章検索
- スコアリング処理
- 返信データ作成処理
特性
- ユーザーが入力&返答を待つ処理なので遅くて数秒
- pickleシリアライズファイルのメモリ展開に耐えられるメモリが必要
全文検索
処理要素
- 形態素解析ライブラリが必要(大きいサイズの言語データが必要)
- 転置インデックス作成処理(文書の登録更新時)
- 転置インデックスを読み込む
- スコアリング
- 結果返信
特性
- 形態素解析処理が必要
- 低レイテンシーが必要
技術ポイント
AWS Lambda
サーバーレス構成での鉄板サービス。以下の制限がある。
参考:AWS Lambda のクォータ
- 長くて15分の処理
- 一時ファイルは500MBまで
- メモリは最大で3GB(こちらの記事によると、10GBに拡張されたらしい)
- アップするzipファイルは依存ライブラリも含めて50 MBまで。展開後はレイヤー含めて250 MBまで
AWS LambdaLayer
Lambdaを使用する際、単純にやるとライブラリもまとめてソースをzipしてアップする。
多くのLambdaで共通ソースを使う場合、それを最大5つの層に分けて管理する事が出来る。
拙記事 LambdaLayer用zipをCodeBuildでお手軽に作ってみる。 で検証していたりします。AWS Lambda Container Support
Lambdaを使用する際、コンテナイメージを丸ごと指定できるというもの。
拙記事 LambdaでDockerコンテナイメージ使えるってマジですか?(Python3でやってみる) で検証していたりします。AWS EFS
EC2での使用が基本だが、LambdaやECSでも使える。テナント毎の情報保持して、各サービスでの高速ファイルアクセスに使用。
Amazon EFS を Lambda に使用する
Lambdaでの一時ファイル上限は500MB。大きいファイルは扱えない。またS3からダウンロードしてくるなどの事が必要になってしまう問題があった。機械学習のような大きいファイルを良く扱う処理をLambdaでやるには必須。
Amazon Elastic Container Service が Amazon EFS ファイルシステムをサポート開始
冗長化をする上で、永続層の共有化は必須。これが使えるようになったの2020年4月と最近なのね。
EFSにセットアップしたPythonライブラリをLambdaにimportする方法
拙記事 Lambda+EFSで自然言語処理ライブラリ(GiNZA)使ってみる で検証していたりします。
AWS SageMaker
機械学習プラットフォーム。機械学習エンジニア御用達ツールのJupyterNotebookの様に使える。
Amazon SageMaker ホスティングサービス
SageMakerで作成したモデルなどを使用した機械学習APIサービスとして提供する事が可能。
AWS ECS
AWS構成で高可用性を求める時、コンテナ技術が使われる。AutoScalingなどを効率よく使用できるサービス。
AWS Fargate
AWS ECS をベース(?)として、コンテナを起動して処理している間のみ料金がかかるサービス。
ある程度の時間がかかるが、一定のタイミングのみ行うような処理に向いている。AWS Batch
Fargeteと似ている感じだが、AWS Batch 資料及び QA 公開によると、以下の使い分けがあるらしい。説明ページのユースケース画像では、BigDataレベルの巨大な処理で使う事を想定しているらしい。今回は使わないと思うが、知識としては知っておいてよいかも。
AWS Batch では内部的に Amazon ECSを使用しつつ、キューイングされた計算処理を順次実行していくようなバッチコンピューティング環境に特化しております。そのため、このようなバッチ処理であれば AWS Batch をご利用いただき、それ以外のインタラクティブな処理を含む汎用的なワークロードではECS及びECSの機能の一部であるFargateをご利用いただければと思います。
Django
Python用フレームワーク(フロントにも使えるけど)。
EC2やコンテナ上で常駐型で展開するのが基本だと思うが、AWS LambdaでAPI開発するときのパターン集 によると、Lambdaにも組み込む事が可能らしい。
が、LambdaとDjangoの相性ってどうなの??によるとあまり推奨され無さそう。形態素解析
転置インデックスをする上でほぼ必須。各種ライブラリがあるが、言語データ部分のサイズが大きい。
GiNZA
形態素解析を始めとして各種自然言語処理が出来るpythonライブラリ。spaCyの機能をラップしてる(はず)なのでその機能は使える。
形態素解析エンジンにSudachiを使用したりもしている。BERT
最近流行っている言語処理技術。これをベースにして各種ライブラリや技術が派生している。
Sentense-BERT
BERTを基本(?)にした文章ベクトルライブラリ。日本語対応された方が後述記事でその紹介をしている。
【日本語モデル付き】2020年に自然言語処理をする人にお勧めしたい文ベクトルモデル考察
まず、アプリケーション部分の構成を考察し、それからビルドやモニタリング構成を考える。
CDN
CloudFrontを使用する。そこからweb静的リソースやAPIコールのオリジンへアクセスを分ける
フロントサイド
サーバーサイドレンダリングなどもあるが、今の時点ではVue.jsをビルドしたものを静的webリソースとして使用する。
サーバーサイド(API)
選択肢としては以下の構成が考えられる。
- APIGateway+Lambda
- ECSでAutoScaling(Djangoでサービス化)
- 自然言語処理部分だけSageMakerホスティングサービス
この部分が今回の記事のメイン。ネットの情報である程度の判断は出来るが、実際に検証してみないとその技術が使えると判断できない。
使用したいと思うライブラリが普通のPythonライブラリに比べて容量が大きい事は解っていた(辞書データがある)。いくつかの技術検証の元、APIGateway+Lambdaを使用する方向。LambdaLayer
拙記事LambdaLayer用zipをCodeBuildでお手軽に作ってみる。 で検証。記事ではnumpyを使っているが、本来使ってみたかったのは自然言語処理ライブラリのGiNZA。しかし、記事の手法でzip化してみたらLambdaクオータに引っかかる事が判明。もちろんアプリの共通ロジックには使える事は解った。しかし、LambdaをAPIとして使えるという判断にはならない。
Lambdaコンテナイメージ
拙記事LambdaでDockerコンテナイメージ使えるってマジですか?(Python3でやってみる) で検証。GiNZAの依存ライブラリ、Sudachiでsymlnkを使用している事から、コンテナ内とはいえLambdaで使えない事が判明。別の自然言語処理ライブラリを使うという選択肢もあれど、今後機能拡張の際にライブラリが縛られるのは避けたい。一度採用したライブラリが今後VerupなどでLambdaで使えないような事になったら大変なので採用は避けたい。
この時点までは、一旦Djangoでサービス起動できるコンテナを作成する方向で考えていた。Lambda+EFS
拙記事Lambda+EFSで自然言語処理ライブラリ(GiNZA)使ってみる で検証。
元々EFSはモデルデータなどの共有で使用予定だった。しかし、EFSをLambdaで使う事で大きなライブラリも普通に使える事を確認。
この検証を根拠に、Lambda+APIGatewayで対応する方向を考える事にした。サーバーサイド(バッチ処理)
主に自然言語処理のベクトル計算に使用する想定。ECSのFargeteで構成。
APIと共通部分は出てくると思うので、その共有化も課題。共通ストレージ
テナント毎の文書ベクトルファイルはAPI処理で素早くアクセスする必要がある。また、永続化してAutoScalingなどの複数API処理コンテナから共有される必要がある。ここはEFSの出番。
図にまとめてみる
CI/CDフェーズ
ビルド
モジュールとしての生成物はweb用(Vue)の静的リソース、ECS、Fargate用のコンテナイメージとなる。(Lambda使う場合にはLambda用コンテナイメージ)。これらをCodeBuildで行う。
デプロイ
CodeBuildを使って、githubで管理しているCloudFormationを展開。その際に使うコンテナイメージやS3リソースをビルドフェーズで生成する。イメージ図書いてみた(一方通行のフロー図は縦書きにしたいのは何でだろう)。
今後課題や残検証まとめ
- 今後の構成変更可能性を踏まえ、LambdaでもDjangoでも流用可能(プラットフォーム切り替えが可能な)様なソース構成
- API部分とFargete部分で共通処理は単一ソース管理
- モニタリング構成の検証
- DBのマルチテナント構成の検証
- ECSでのEFSのマウントの検証
- SageMakerのホスティングサービスの使い方検証(特に値段)
まとめ
全体設計を何もしないまま部分から作り始めるのも、全体設計を最初から細かく時間をかけるのもリスクがあると感じた。
前者は、いざ各部分をつなげようとすると繋がらなかったりする問題。後者は実際に実装を進めて行くと、解消できない問題に出会うかもしれない問題。もちろんこれは既存の上手く行っているシステムがあればそのリスクを回避できるので前例は探しておいた方が良い。
今回の考察でも、一旦Lambdaを使うのを諦めたのだが、最近提供された機能によりサーバーレスが実現できる見込みが立った。しかし実装を進めていくと別の問題で諦めなくてはならなくなるかもしれない。モジュールなどの機能群やレイヤーで分け、それの入れ替えを容易に出来るようにしておくのが一番重要な気がする。
それらを踏まえてまとめると、AWSに限らないと思うが、システム構成を考える時には以下の点が重要と思う(当たり前と言えば当たり前だが)
- 扱うデータのサイズ、更新頻度、要求レイテンシーレベルを明確にしておく
- ラフな全体図を描いた上で、主要ポイントは単体で技術テストをする(出来るっぽい、と思った事でも出来ない場合対応)
- 無駄なやり直しを防ぐ意味でも、各技術(主にAWS)のユースケースや制限を出来る限り事前調査
- 検証や実際に運用してみての問題が出てきた時の為に各モジュールは疎結合を意識する
- そして実際に構成の実装を進めつつ、問題点の洗い出し及び改善(場合によってはその部分設計しなおし)
その他
アドベントカレンダー用という事で、公開日の1ヵ月前ぐらいから書き始めていたが、2020年12月15日に下記記事が投稿された。
自分が今回の考察で漠然と感じていた事をより具体的に適切な図を使って説得力のある内容をふんだんに盛り込んだような記事。レベルの違いに衝撃を受ける。でも、自分のこの記事も状況に応じて技術を変える具体例の一つとして見てもらえると有り難い。
参考にさせて頂いたサイト
AWSオフィシャル
AWS Lambda のクォータ
AWS SageMaker皆さんの良記事
AWS LambdaでAPI開発するときのパターン集
LambdaとDjangoの相性ってどうなの??
AWS Lambda Layersでライブラリを共通化
[アップデート]Lambdaのメモリ上限が10G、vCPUの上限が6に拡張されました!! #reinvent
EFSにセットアップしたPythonライブラリをLambdaにimportする方法
【日本語モデル付き】2020年に自然言語処理をする人にお勧めしたい文ベクトルモデル
- 投稿日:2020-12-01T12:59:18+09:00
新しいシステム開発の地図帳
Ateam Group Manager & Specialist Advent Calendar 2020 の6日目は
株式会社エイチームフィナジー 金融メディア事業部の村上が担当します。
バックエンドの開発をメインでやっています。はじめに
今年の1月にエイチームフィナジーにジョインさせていただきました。
エイチームとしては新米ですが、業界歴としては長く今年で15年になります。
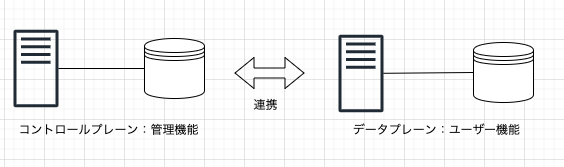
これだけ長くやっているといろんなシステム構築を行っており、それの経験をもとに、今後重要となってくるであろうシステムアーキテクチャについて少し書かせていただきたいと思います。コントロールプレーンとデータプレーン
いきなり難しい単語ですいません。。。
これは何かというとKubernetesのアーキテクチャーの一つです。
「Kubernetes使ってないから関係ないやん!!」とは思わないでください。簡単に説明していきます。
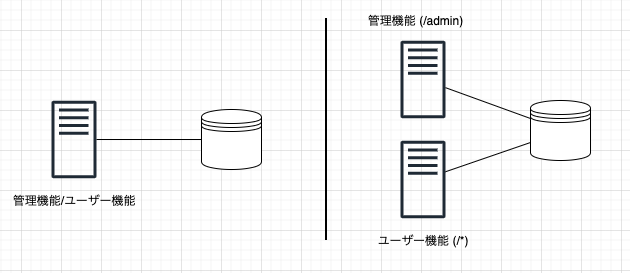
CMSを例に
「Contents Management System:コンテンツ・マネジメント・システム」を例にあげます。
ブログ・サイトやメディア系のサイトをイメージして見てください。機能として、
- 管理者が記事投稿する
- ユーザーが記事を閲覧する
- ユーザーの閲覧データを取得する
といった機能が挙げられると思います。これらは2つは簡単に「管理機能」と「ユーザー機能」に分けることができます。
この2つを別のサービスに分けて、管理しようというのが基本的な発想です。
- 管理機能:コントロールプレーン
- ユーザー機能:データプレーン
という感じです。
1つのアプリケーションに2つの機能(管理機能とユーザー機能)を実装して、サーバーやコンテナで動かしたり、1つのアプリケーションではあるけど、パス(/admin)とそれ以外でフォワードするサーバーを分けたりするということをすることがあると思います。
今回の場合は、アプリケーションを分けて、更に永続化層(DBなど)やリソースも分けるということまでします。
こうすることで得られるメリットに以下のようなことが挙げられます。
対障害性が高くなる
可用性を考慮して、サーバーを複数台にすることがありますが、DBなど、共有している部分が落ちてしまうとサービスが停止してしまします。
CMSを例にすると、閲覧などのユーザー機能では、記事データをHTMLで、S3のようなフルマネージドなオブジェクトストレージにあげておけば、DBサーバーがダウンしていても、ユーザー機能には影響なく、サービスが継続可能です。定期メンテナンスが容易
データベースはデータの読出し、書込みには非常に優れている反面、意外と手のかかるものです。
例えば、
- データバックアップ
- セキュリティパッチ
- バージョンアップ
など、上記作業のたびに、サービスを一時停止させざるを得ない場合もあります。
しかし、DB参照を管理機能のみに集中させていた場合、限定的なサービスの一時停止のみで容易にメンテナンスが実施可能になります。デメリット
デメリットももちろんあります。
- 分割しすぎると、ソースの管理が大変
- サービス分割は適切に
- サーバー側はコンテナ化していないと、管理が大変
- コンテナ化はほぼ必須です
- リソースは最適化していないと費用が大変
- DBをサービスごとに作成したりすると費用がかさむので、そのへんの最適化は必要です。
- しかし、統合してしまうと、分割している意味がなくなる
などです。
データベース以外の選択肢
上記でDBは運用保守にそれなりのコストがかかります。
データサイズが膨らめば膨らむほどそのコストが重くのしかかります。できれば、スケールが自動でメンテナンスコストがかからないフルマネージドなものを採用したいです。
そして、フルマネージドなものでユーザー機能を構成するとダウンタイムがないサービスが構築できます。データストアやストレージは以前よりも選択肢としてはかなり多くなっているので、用途別に簡単にまとめていきます。
Key-Valueデータベース
AWSでフルマネージドなKey-Valueデータベースと言えば「DynamoDB」です。
最近ではキャパシティを自動でスケールする「オンデマンドキャパシティ」があり、読込み/書込みリクエストを計算してキャパシティ設定する必要もなくなりました。
厳密なトランザクション管理を必要とせず、複雑なクエリー処理をしないものに向いています。
よくセッション管理などが例で挙げられたりします。また、DynamoDBは後述するストリーミングにも対応しています。
オブジェクトストレージ
AWSでいうS3です。
たぶん説明がいらないほどだと思いますが、一昔前はストレージサーバーを立てて、NFSでマウントというやり方でしたが、今はRestAPIでリソースが管理できるオブジェクトストレージが一般的です。
AWSのS3は耐久性はイレブンナイン(99.999999999%)なのは有名だと思います。HTMLファイルを上げれば、ホスティングも可能のため、コンテンツを見せるだけのWebサーバーとしても活用できます。
S3も後述するストリーミングにも対応しています。
データ連携は非同期処理
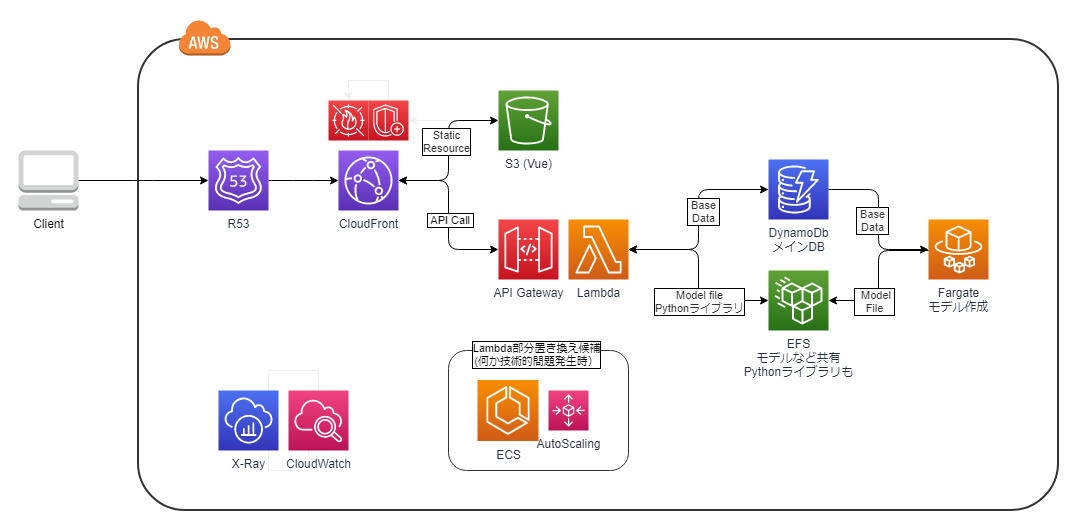
管理機能であるコントロールプレーンは、機能性を重視し、システムによるダウンタイムをある程度考慮した設計にする。
ユーザー機能である、データプレーンは、フルマネージドなサービスを組み合わせて、自動でスケールアウト/インする仕組みにしておき、ある程度、機能では制限が伴うここで問題になるのが、管理機能とユーザー機能でどうやってデータを同期させるかです。
管理機能で編集・保存された記事データ(DB)をユーザー機能側へ保存する(S3)必要があります。また、逆にユーザーが閲覧するサイトにタグのようなWebビーコンを設定している場合、大量のリクエストを受け付けて処理させるサーバーが必要になります。そして、そのデータを管理機能側へレポートデータとして同期させたりする必要もあると思います。
ユーザー機能側でAPIを作成して、それを実行するような機能も考えられなくはないですが、そうすると管理機能側でユーザー機能に依存した処理が混入してしまします。
せっかくサービスとして分離したので、できれば依存した処理を混入はしたくない
そういった場合には、処理するデータを一旦別のデータ領域に送信して、受け取る側がデータ領域を参照して処理をさせます。
以下のようなクラウドの仕組みを使いデータを非同期で処理させます。
メッセージキューイング(MQ)
非同期処理をするのに一般的なやりかたです。
APIのように直接データを渡すのではなく、MQを用意して、間接的にデータのやりとりを行います。
AWSではSQSになります。SQSのメッセージングをポーリングする必要がありましたが、最近ではLambdaと連携させてそのあたりの管理をしなくてもよくなりました。
完全マネージドで動作するし、並列処理にも向いています。
しかし、メッセージのデータサイズには制限があるので、メッセージが大きい場合はS3に保存するなど工夫が必要です。ストリーミング
大量のデータ(ストリーミングデータ)を処理したい場合には、それを処理できる基盤が必要になります。
AWSではKinesisになります。IoTのようなデバイスセンサーから送られてくるようなデータであったり、サイトに仕込んであるWebビーコンなどを処理させたい場合はこちらが向いています。
完全マネージドで、メッセージにサイズもSQSに比べると大きいです。
しかし、キューイングとは異なり、データは残り続けるので、どこまでデータを処理したかなどの状態を持っておく必要があります。
KCL(KinesisClientLibrary)やLambdaを使うとそのあたりは自動でやってくれます。もう1つの利点として、受信側を複数設定可能です。
SQSに関してはメッセージ処理するとキューから消えてしまいますが、Kinesisはデータを保持しているので複数の連携処理を設定できます。
Webビーコンのストリームデータを1つは管理機能のRDBへ、1つはアクセス解析する外部サービスへ連携などが容易に可能です。また、Kinesisだけではなく、DynamoDBやS3もストリーミング処理が可能です。
DynamoDBにデータが保存された時や、S3にファイルがアップロードされた時など、Lambdaで受け取り処理することが可能です。メッセージング
単純なメッセージング処理というのもあります。
AWSでいうSNSになります。
Lambdaと連携させることが可能です。
SQSやKinesisに比べて簡易ですが、データを保存する場所がないので、処理に失敗するとリトライが難しいのが難点です。データを非同期処理する際の注意点
データを非同期で反映させるにはいくつかの注意点があります。
1. データの順番に依存しないようにする
キューイングしたり、受信側を並列化したり、Kinesisでシャード数を増やすとデータを送信した順に受信はしなくなります。
順序制御したいときは別の仕組みで担保する必要があります。2. 重複実行の制御
非同期処理の場合、同じデータを2回処理してしまう場合もあります。
マネージドな部分もあり、こちらで制御するのが難しい場合もあるので、重複実行の制御をアプリ側で制御させる必要があります。
よく使われるものとして、「処理ID」と言われるUUIDなどを発行して、同じUUIDは実行しないなどの制御をします。3. エラー再試行とエクスポネンシャルバックオフ
非同期処理に限ったことではないですが、いろいろな処理をAPIや非同期処理が増えてくると、処理失敗することもあります。
一時的なエラーであれば、再実行する仕組みを作っておけば問題ないのですが、継続的なエラーの場合、即時に再実行されるとサーバー側の負荷が上がっていきます。
これを防ぐために、再実行時には適度な遅延間隔を設ける必要があります。
よく使われるのは「エクスポネンシャルバックオフアルゴリズム」です。
簡単に言うと、再実行の間隔を1秒後,2秒後,4秒後,8秒後とだんだん増やして行きます。
こうすることで適度に間隔があくので、受信側のサーバーの負荷が爆発的に上がることを抑えることができます。4. サーバーレスで
AWSだとLambdaを使用すればサーバーレスで連携部分を構築可能です。
サーバーレスは管理コストが下がるので非常に便利なものですが、運用には若干の工夫がいります。
Lambdaを多用すると、「どこで何が動いているかわからない」「どれとどれが連携しているかわからない」という状況に陥ります。
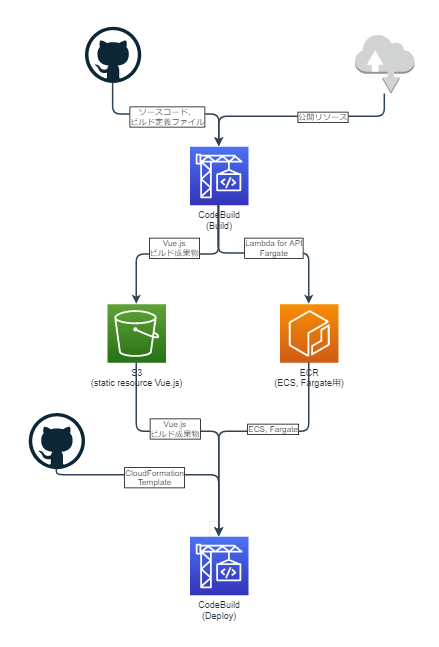
Lambdaでシステム構築するときは、コード管理はもちろん、連携するサービス(SQSやKinesis)も管理するのが良いと思います。まとめ
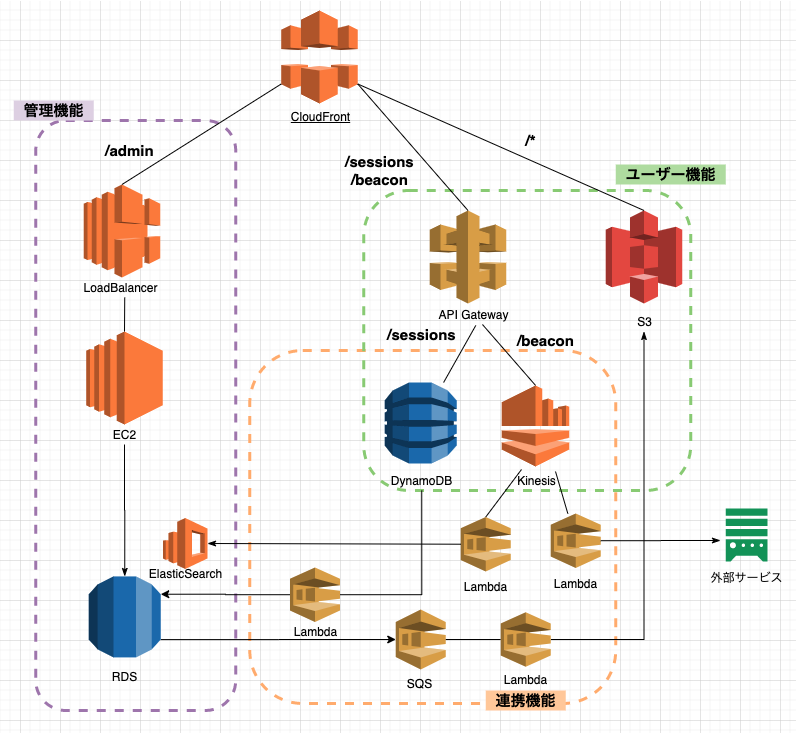
上記のことをまとめると下記のようなシステムアーキテクチャ図になります。
- 管理機能とユーザー機能で完全に永続下層まで分ける
- ユーザー機能部分はクラウドのフルマネージドのサービスで構築する
- データ連携はLambdaを使ったサーバーレスで構築する
がポイントになります。
もちろんこれにはデメリットもあります。
- 初期構築時にはある程度の工数が必要
- フルマネージドやサーバーレスで運用は楽になるかもしれませんが、構築コストはある程度増える
- 新しい技術を取り入れる時はある程度のバッファを考慮しておく必要がある
- 全体を管理する仕組みが必要
- 何度か触れましたが、いろいろなもので構築するので、その管理は雑になりやすい
- 導入・構築の際にはツールやルールを設けておく
- クラウドのマネージド・サービスに慣れる
- 権限関連でエラーを起こす
- ログが見にくい
- どこの連携が失敗しているかわからない
- などが起こるので、運用経験を積む必要がある
少し難しくとっつきにくい内容になったかもしれませんが、新しくアーキテクチャからシステムを開発することがあるのであれば、参考になれればと思いアドベントカレンダーに書かせていただきました。
- 投稿日:2020-12-01T12:17:19+09:00
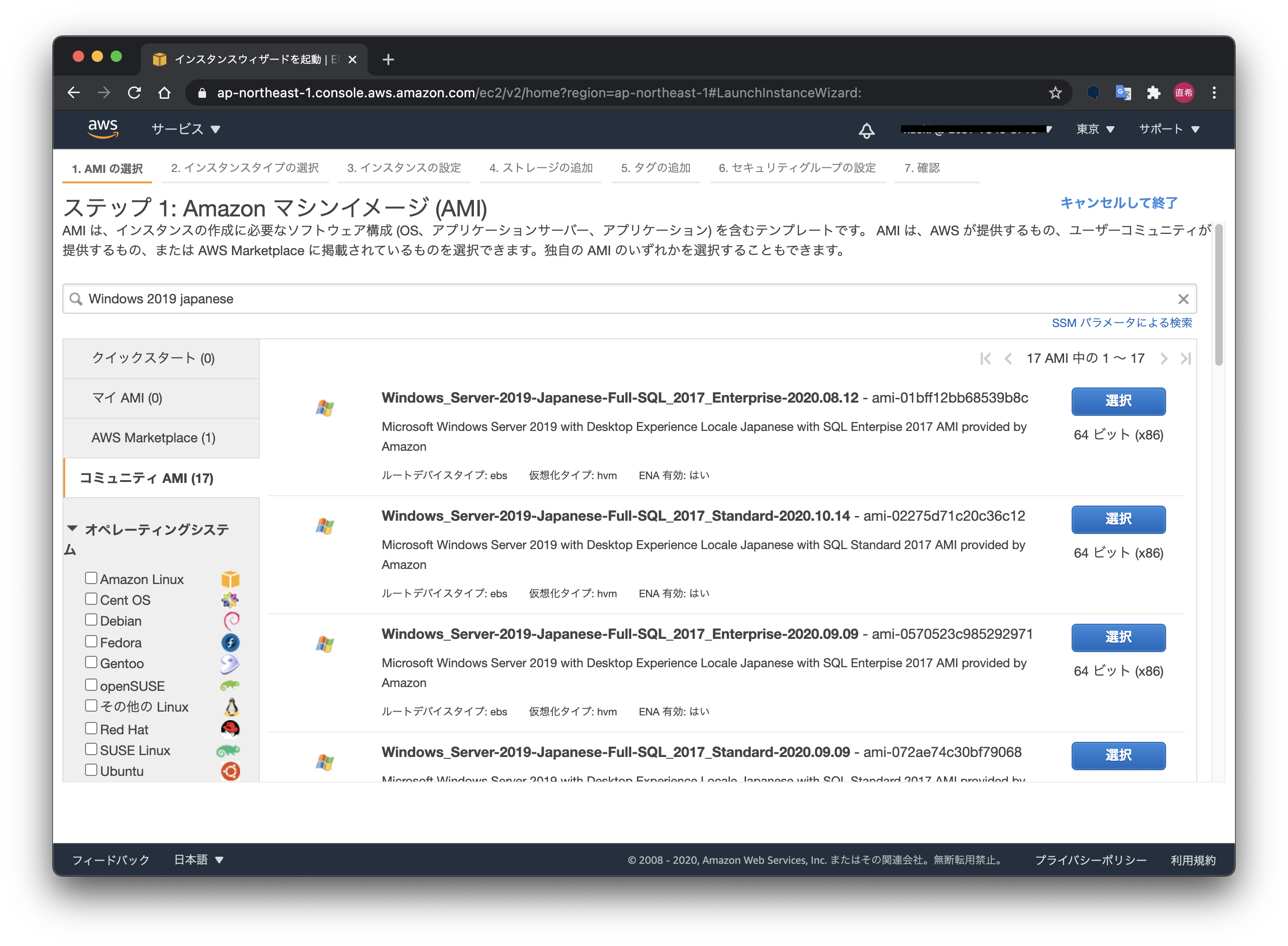
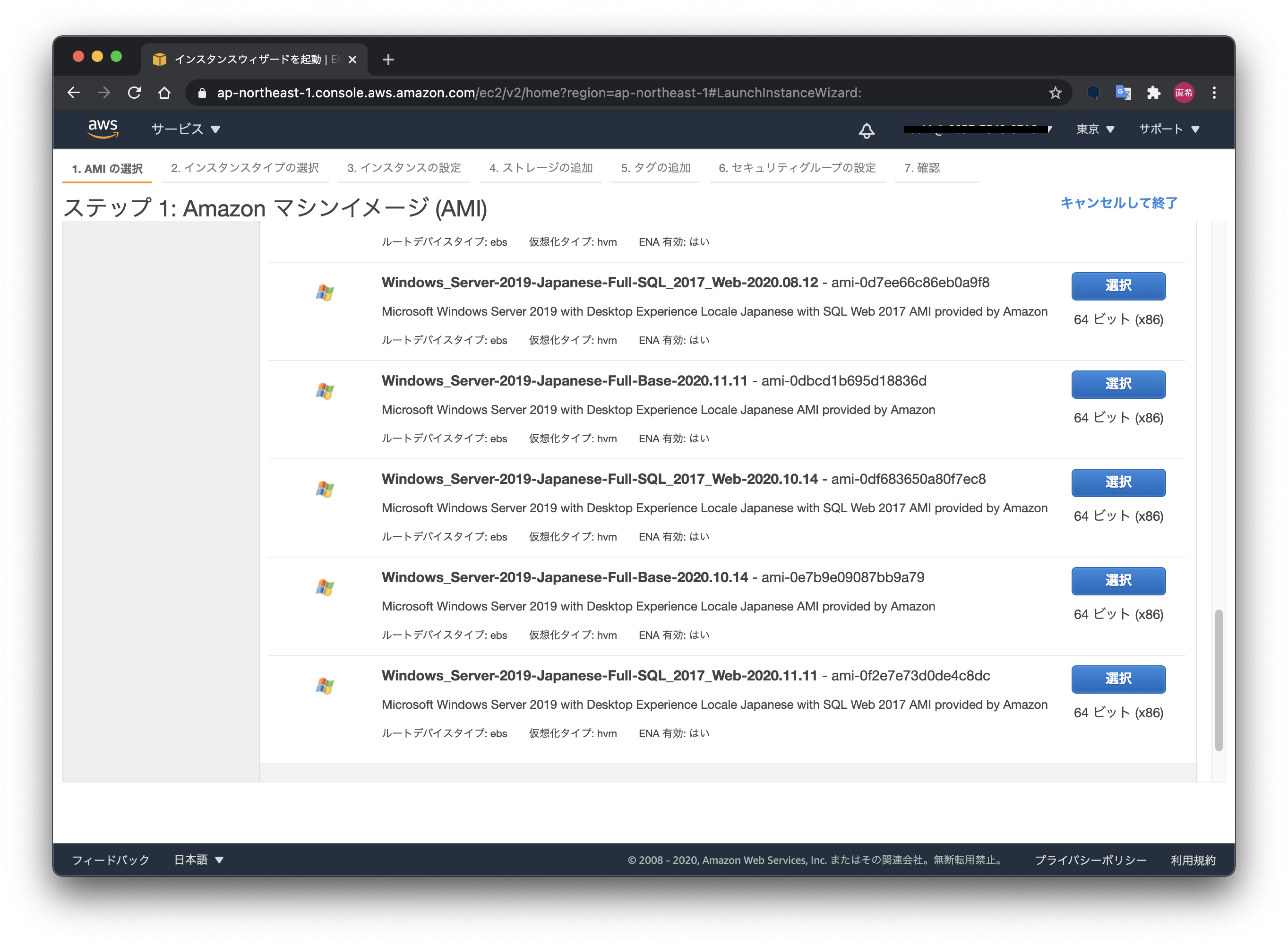
AWSで日本語化されたWindowsServerを作成する方法
インスタンス作成画面で、「コミュニティAMI」を選択し、検索ボックスに「Windows 20XX japanese」と入力します。
Amazonで用意されている日本語版AMIは17つもあるんですね。
その中には、「Full-Base」と「Full-SQL」がありまして・・・(慣れないと分かりづらい...)
Microsoft SQL Serverを使用しない場合は、「Full-Base」を選ぶと良いでしょう。
※毎回思いますが並び順は謎です...
ちなみに最後の日付はAMIの作成日時になります。新しいものを選んでおけば良いかなと。
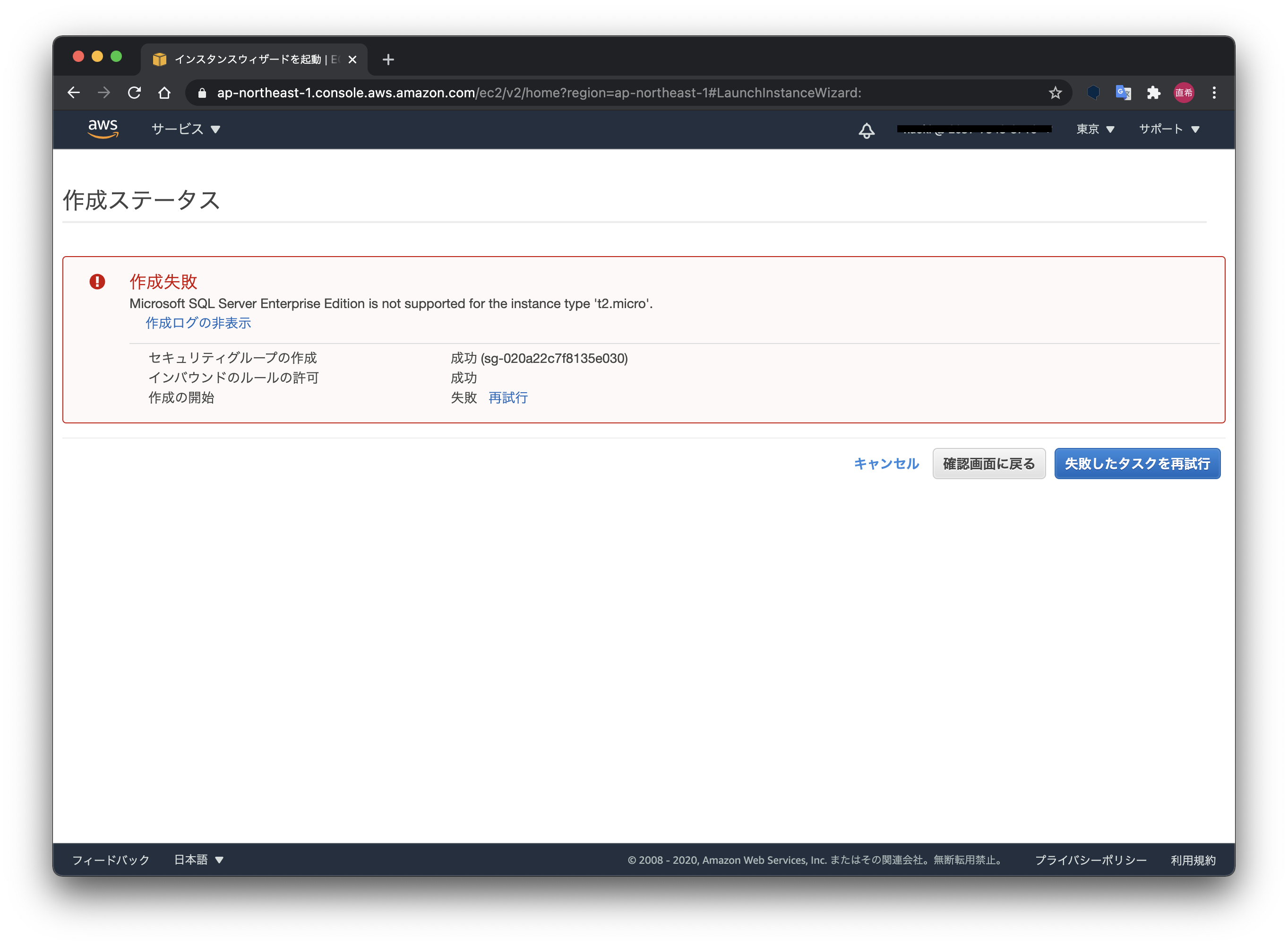
「Full-SQL」を選ぶと、無料利用枠の「t2.micro」では利用できないので注意が必要です。
以上になります。
- 投稿日:2020-12-01T10:36:19+09:00
GameLift FleetIQはわれわれの何を解決してくれるものなのか?
本ブログ記事はAWS & Game Advent Calendar 2020の12/1分の記事です。
2020/08/27にリリースされた、Amazon GameLift FleetIQをご存知でしょうか?そもそもGameLiftって何?と思われる方が多いかもしれません。
最近では、日本の各ゲーム会社からもどんどん新しいオンラインマルチのタイトルがリリースされていますが、そんなゲームを開発している方々に一度チェックしていただきたいサービスになります。
GameLift FleetIQは昔からあったGameLiftの一部の機能を切り出したものになりますが、今回はそのGameLift FleetIQにスコープをしぼってざっくりと解説します。
そもそもAmazon GameLiftとはどんなサービスなのか?
Amazon GameLiftは、AWSのサービスの一つでマルチプレイオンラインゲームに必要となる専用ゲームサーバーを管理するためにいろいろな機能を提供しているAWSの1サービスです。プレイヤー同士が対戦・協力するために一箇所に集まるための場を提供しているサーバーを専用ゲームサーバーと呼びます。このサーバー上で稼働するプロセスは、よくあるステートレスなWebアプリケーションとは異なり、ステートをサーバー内で保持(=ステートフル)し、複数のゲームクライアントからの永続的なネットワーク接続を直接受け付けます。専用ゲームサーバーではゲームクライアントに対し、プレイ可能なゲームプロセスに直接ネットワーク接続してもらうためのIPを伝える必要があります。そのためには、どのプロセスが利用可能なのか、そのプロセスが稼働しているゲームサーバーのIPアドレスやプロセスのポート番号など、ステータス情報などの管理が必要で、プレイヤーからのリクエストに応じて利用できるゲームプロセスをクライアントにレスポンスする必要があります。
AWSだとこの手の機能はコントロールプレーンとよばれ、もし自前する場合は専用ゲームサーバーとゲームクライアントに対するAPIやステータスを管理するためのDBなどを実装する必要がありますが、AWSのGameLiftではサービスとしてこれらの機能をマネージドとして提供しています。
また、プレイヤー数によってゲームサーバーをスケールさせる必要もあります。スケールアウトはシンプルにサーバーを追加するだけですが、スケールインはどうでしょう?ゲームプレイ中にさくっとインスタンスを削除するわけにはいかないので、そのような状況を避けるための安全な仕組みが必要になります。具体的には、削除予定のインスタンスに新しいプレイヤーを割り当てない、プレイ中のゲームが終了するまで待つ(ドレイニング)、そしてそもそも効率的にサーバを削除できるようになるべく特定のゲームサーバーにゲームを割り当てていく(いろんなゲームサーバーにゲームが散らばって配置されることでサーバーが削除しにくい状況になることを防ぐ)などの制御が必要になります。そしてこれらのスケールに関する機能もGameLiftが提供しています。
以上はGameLiftのフリート管理と呼ばれますが、それ以外にもマルチプレイオンラインゲームを提供するために必要なマッチメイキングなどの便利機能も用意されています。
ゲームの中でも特定のユースケースをターゲットとしている点で、GameLiftはAWSの中でユニークなサービスです。
そしてGameLift FleetIQとは?
本記事の本題となるGameLift FleetIQは、前述したAmazon GameLiftのフリート管理と一緒にまるごと独立して切り出したものです。
前述のGameLiftは専用ゲームサーバー上で動くプロセス(GameLiftではビルドと呼ぶ)はC++, C#, Node.js(リアルタイムサーバーという機能)のみをサポートしており、さらにGameLiftが提供するデプロイ機構を利用します。この仕様はUnreal EngineやUnityなどのゲームエンジンを利用してサーバー側のコードを開発する場合などでは充分ですが、最近だとサーバーはクライアントとは別のプログラム言語を利用したい!コンテナを利用したい!などの要件も多くなってきました。そのため、ゲームサーバー上で稼働するプロセスの言語や形態を問わず、ユーザ側が自由にプロセスのデプロイもできるように柔軟性を高めつつ、かつGameLiftのフリート管理のメリットであるマネージドなコントロールプレーンを提供するためにGameLift FleetIQが生まれました。
AgonesなどのOSSでもこのようなコントロールプレーンの機能を提供していたりしますが、さらにFleetIQにはAWSならではの価値を提供してくれるうれしい機能があります。それはスポットインスタンスの活用です。
スポットインスタントとは、使われていない余剰インスタンスを通常のオンデマンド価格に比べ最大90%も安く利用できるメニューです。価格が安いのは非常に魅力的ですが、余剰インスタンスを利用しているという性質上、インスタンスの需要が増えてくると稼働中に中断というイベントが発生し、2分後に停止されることがあります。この中断のリスク回避のために、複数のインスタンスタイプを設定して中断を局所化したり、中断したときに自動でリカバリできるようなテクニックが推奨されています。しかし、このテクニックでは中断したときに別のインスタンスタイプでスポットインスタンスとして起動するということはできますが、そもそも中断自体を防いだり、頻度を下げたりすることはできません。
クライアントから常時接続を受け付けているようなステートフルなゲームサーバーでスポットインスタンスを利用すると、この中断による割り込みによってプレイヤーがゲームプレイ中に強制的に追い出されてしまうなど深刻なユーザエクスペリエンスの低下につながる可能性があり、スポットインスタンスの利用は難しいという話を良く聞きます。中断までに2分間の猶予はありますが、ほとんどの場合は1ゲームあたり2分以上のプレイ時間であるため、その間にゲームを終わらせることも難しいです。
このように、ゲームサーバーのコストは下げたい、でもスポットを使うことは難しい、もうオンデマンド使うしかないか.....という状況をGameLift FleetIQは中断しにくいスポットインスタンスを選択するというユニークなアプローチで解決しています。
GameLiftではスポットインスタンスの中断率をヒューリスティックに予測するという機能が備わっており、あらかじめ設定したインスタンスタイプのリストの中から将来の中断発生率が低く、かつコストがインスタンスを起動してくれるというすぐれものです。新しいインスタンス起動時はもちろん、プレイヤーのリクエストをなるべく安全で安いインスタンスに誘導し、中断率が高そうなインスタンスはゲームの終了を待って削除、新しい安全なインスタンスを起動するというすぐれものです。このFleetIQによってゲームサーバーの平均コストを下げることができます。
どれくらいの中断発生率なのか?についてはこちらのブログ記事で実際のユーザの方からコメントいただいています。
同様に、PanzerdogのCEOであるAlexey Sazonov氏は、次のように述べています。“Amazon GameLiftとスポットインスタンスを併用することで、ゲーム「Tacticool」のローンチを加速させ、コストを削減することができました。私たちは1,800万回以上のゲームセッションの中、中断を経験したのはわずか 0.004% であり、専用サーバにおける優れたプレイヤー体験を維持ながら大幅なコスト削減を実現できました。”
ということで、GameLift FleetIQとは、専用ゲームサーバーのステータスなどの面倒な管理もやってくれて、加えてゲームサーバーで利用が難しいとされてきたスポットインスタンスも使えるすぐれものであると言えると思います。
専用ゲームサーバーの管理はAgonesなどでもやってくれると思いますが、そのサーバーのスケーリングやプレイヤーに対するゲームの割当もスポットインスタンスの落ちにくさと価格を見ながらよしなにやってくれるところがこのサービスの魅力だと思っています。
GameLift FleetIQのオペレーション
必要最低限のオペレーションをこちらに書いてみました。APIのコール元がそれぞれ異なることに注意してください。補足として、GameLift上ではゲームサーバー上で起動するゲームプロセスのことを"Game Server"と呼んでおり、API名にあるGameLiftのGameServerもプロセスのことを指しています。
環境準備:まず、専用ゲームサーバーをまとめて管理するゲームサーバーグループを作ります。通常はAdministrator(管理者)が操作を行います。ゲームサーバーグループはAWSのAuto Scaling Groupをラップしているものです。数を指定することで必要な数のゲームサーバーのインスタンスが起動します。
ゲームサーバーの起動:ゲームサーバーのインスタンスが起動によりゲームプロセスが起動、完了したらRegisterGameServer()をコールし、GameLiftに対してプレイヤーを受付可能な状態であることを通知します。このとき、ゲームサーバーのIPとプロセスがListenしているポートをコネクション情報として付与します。
ゲームプレイ開始時:ご自身のゲームのマッチメイキングなどの機能をもっている部分をゲームバックエンドとし、プレイヤーからのリクエストをもとに、ゲームプロセスをアサインするためのリクエストClaimGameServer()をコールします。GameLiftからは利用可能なゲームプロセスのIPとポートがレスポンスとして返答されます。
ゲームプレイ中:プレイヤーがゲームを開始したら、ゲームプロセスから自身が利用中であることを知らせるためにUpdateGameServer()をコールします。(その後1分以内ごとに定期的にステータスをアップデートする必要があります。)
ゲームプレイ終了時:ゲームプロセスは結果などを永続化したあと、DeregisterGameServer()をコールしてゲームサーバーのリストから自身を削除。もしプロセスをリサイクルする場合は再度RegisterGameServer()をコール。
上記以外にもAPIが用意されています。くわしくはこちら。
注意点
GameLift FleetIQを利用する前に知っておいていただきたい注意点となります。
- FleetIQによって中断率が低い安全なインスタンスを選択してくれますが、中断しないわけではありません。中断はするということ前提で、割り込みが発生したときにサーバーの情報を退避するとか、プレイヤーに通知するなどの処理は必要です。
- FleetIQはすべてのインスタンスタイプに対応しているわけではありません。現在対応しているインスタンスタイプは、GameLiftが対応しているc4, c5/c5a, r4, r5/r5a, m4, m5/m5aになります。
- GameLift FleetIQの操作はすべてCLIもしくはSDKからのみとなります。マネージメントコンソールには対応していません。。。
GameLiftやGameLift FleetIQとは別の選択肢
GameLiftやGameLift FleetIQとは別の選択肢を取ったほうがいいユースケースを考察してみます。
コンテナであれば、こちらのようにECS/Fargateを利用してそもそもコンテナを実行するインスタンスレイヤーを意識しない方法もありかと思います。ただし、ECSのTaskとして動作するゲームプロセスの管理はこちらの例のように自前で実装する必要があります。(ちょうど今日ブログが出てました)
Game Server Hosting on AWS Fargate
AWS Samples: Fargate Game ServersMMORPGのように1つのゲームプロセスでホストするプレイヤー数が多く、かつネットワーク接続時間も比較的長時間であるようなものはそもそもGameLiftは向いていません。MMORPGではサーバーをエリアごとに垂直分割するケースが多く、プレイヤーの行動によって接続するサーバーが変化することが多いでしょう。しかし、クエストなどで一時的に複数のプレイヤーが特定のゲーム部屋に集まるようなときには利用できそうです。
おすすめコンテンツ
GameLift FleetIQを利用する前にチェックいただきたいコンテンツを紹介します。
Game Tech Learning Path: Using GameLift FleetIQ for Game Servers(日本語版)
90分のトレーニングコンテンツです。非常に詳しく書かれているので、GameLift FleetIQの利用を検討されている方はまずこちらをご覧ください。無料です。公式ドキュメント:GameLift FleetIQガイド
GameLift FleetIQの細かい仕様はこちらで確認してください。GameLiftサンプル(五目ならべ)
五目並べを題材にしたGameLiftの実装サンプルです。ゲームバックエンドもAPI GatewayやLambdaを使ったサーバレス構成で、マルチプレイオンラインゲームのシステム全体について学習することができます。GameLiftサンプル(Unity)
Unityに特化したGameLiftの実装サンプルです。Unity Projectがそのまま利用できます。さいごに
いかがでしたでしょうか?最近良く聞かれるGameLift FleetIQの概要について専用ゲームサーバーのフリート管理という観点で解説してみました。詳しい実装などについてはお気軽にAWSのソリューションアーキテクトにお問い合わせください。
(免責) 本記事の内容はあくまでも個人の意見であり、所属する企業や団体は関係ございません。

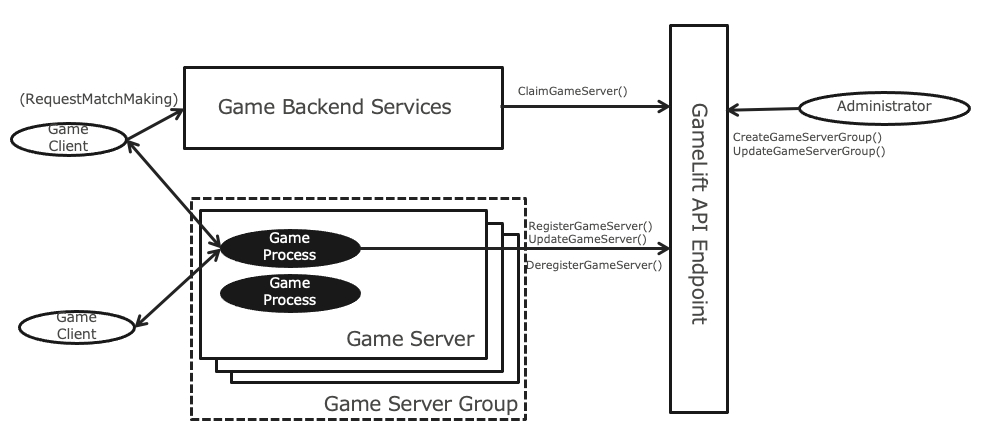
- 投稿日:2020-12-01T10:31:55+09:00
【初心者向け】AWS Lambda(Python) + API Gatewayで運行情報をお知らせしてくれるSlackAppを作るハンズオン!
はじめに
こんにちは!DMM WEBCAMPでメンターをしています@piyorです。
通学・出勤の時に電車が遅延しているかの確認をSlackで出来たら
チームメンバーなどで共有ができて便利ですよねという訳で、運行状況をPythonでスクレイピングしてその結果をSlackに送信するものを作成しました。
対象者
- サーバレス(AWS Lambda)に興味がある方
- Webスクレイピングに興味がある方
- SlackAppに興味がある方
※今回Pythonのコードについては基本的には説明しません
※スクレイピングとはなに?って方はこちらの記事などを参考にしてください
※スクレイピングを禁止しているサイトも存在します。こちらの記事などを参考にしましょう作るもの
?こんな感じに、遅延・運休してる路線を通知してくれます
?この画像の部分を引っ張って来て、それをSlackに通知をするという流れになります
目次
目次 構成 Lambda関数作成 API Gateway作成 SlackApp作成 Lambda関数の環境変数を設定する 朝の9時にSlackAppがPOSTしてくれるように設定する 終わりに 参考 構成
構成は、朝の通知以外にもSlackからコマンドを叩いたら結果が帰ってくるようにしました
Lambda関数作成
Lambdaはサーバレスでコードを実行するためのサービスです
今回は、スクレイピング処理・Slackにスクレイピングの結果を送信するために使用しますLambda関数を作成する
関数名:好きな関数名
ランタイム:Python3.8
他はデフォルト値で大丈夫です
外部ライブラリ・関数コードを用意する
使用ライブラリの説明
- os
- 標準ライブラリの1つでOS依存の機能使用するためのライブラリです
- 今回は環境変数を利用するために使用します
- requests
- HTTP通信のためのライブラリです
- Webページを取得するために使用します
- bs4 (beautifulsoup4)
- Webページから情報を取得するためのライブラリです
- スクレイピングを行うために使用します
- slackweb
- WebHookでSlackにPOSTするためのライブラリです
外部ライブラリ・関数コードの用意をする
Lambdaで外部ライブラリを使用する場合、別途用意する必要があります
詳細はAWS公式ドキュメントのPython の AWS Lambda デプロイパッケージなどを参考にしてください今回は、使用する外部ライブラリ・関数コードを用意しているので次のコマンドを実行してください
※githubからクローンし、クローンしたファイル群をzip化するものですコンソール$ git clone https://github.com/piyoraik/delay_bot.git $ cd delay_bot $ zip -r delay_bot.zip ./※コードだけ見たい方※
lambda_function.pyimport requests, bs4, slackweb, os # URL・トークンの定義 url = "https://transit.yahoo.co.jp/traininfo/area/6/" slack = slackweb.Slack(url=os.environ['SLACK_URL']) def lambda_handler(event, context): response = { 'statusCode': 200, 'isBase64Encoded': False, 'headers': {'Content-Type': 'application/json'}, 'body': 'done' } fetch_result = data_fetch(url) # 取得先のタイトルを取得 title = fetch_result.title.get_text() # 遅延情報の取得 delay_info = fetch_result.find(id='mdStatusTroubleLine').find_all('a') delay_info_text = '' for info in delay_info: delay_info_text += "\n" + info.get_text() + "\n" + info.get('href') slack_send(slack, title, delay_info_text) return response # slackに情報の送信 def slack_send(slack, title , text): attachments = [] attachment = { "color":"#D00000", "title": title, "text": text, "mrkdwn_in": ["text", "pretext"] } attachments.append(attachment) slack.notify(attachments=attachments) return # requestsでデータをスクレイピング def data_fetch(url): get_url = requests.get(url) bs4_obj = bs4.BeautifulSoup(get_url.text, 'html.parser') return bs4_objLambdaにアップロードする
.zipファイルを選択して、zipファイル化した
delay_bot.zipを選択しアップロードします
?アップロードをしてこのようになっていればOKです
※取得URLの変更を行う場合※
lambda_function.pyurl = "https://transit.yahoo.co.jp/traininfo/area/6/"現状では
lambda_function.py4行目のこの記述により
https://transit.yahoo.co.jp/traininfo/area/6/
このURLの情報を取得しています
例えば、関東エリアの運行情報を取得したい場合は、4行目の記述を以下のように修正しますlambda_function.pyurl = "https://transit.yahoo.co.jp/traininfo/area/4/"修正後に最新としてデプロイをクリックし、変更を反映させましょう
API Gateway作成
API GatewayはAPIの作成を行うサービスです
今回は、API Gatewayで作成したURLを呼び出すと先程作成したLambda関数を実行させるために使用しますAPI Gatewayの作成をする
APIタイプはREST APIで構築を行います
API名を入力しましょう、他はデフォルト値で問題ありません
メソッドを作成し設定を行う
アクションからメソッドの作成をクリックし、POSTを選択します
※メソッドについてはこちらの記事などを参考にしましょう選択後、セットアップを行います。
Lambdaプロキシ結合の使用とLambda関数を選択しましょう、選択後に保存をクリックします
APIのデプロイを行う
アクションからAPIのデプロイを選択しデプロイをしましょう
URLを確認する
デプロイをクリック後、URLが生成されます。
このURLは後で使用するのでいつでも確認できるようにしておきましょう
ここまでで作成したLambda関数を上のURLから呼び出す設定が完了しました
※今回POSTメソッドで作成しているのでブラウザでそのままURLを開いてもLambda関数は実行されません※SlackApp作成
SlackAppを作成する
まず、SlackAppを作成するために下記URLにアクセスします
https://api.slack.com/appsアクセスしたらCreate New Appをクリックします
SlackAppを作成するウィンドウが出てくるので、アプリ名とインストールをするワークスペースを選択します
選択後、Create Appをクリックし作成を行いましょう
Slash Commandsを作成する
SlackからAPI Gateway経由でLambda関数を呼び出すためにこちらを使用します
SlashCommandsからCreate New Commandを選択します
Slash Commandsを作成ページに遷移するのでコマンドの作成を行っていきましょう
次のように記述します
- Command: 呼び出すコマンドを入力
- RequestURL: API Gatewayのアドレスを入力
- Short Description: コマンドの説明を入力
- Usage Hint: 使い方のヒントを入力
入力が終わったらsaveをクリックし保存をしましょう
Incoming Webhooksの設定を行う
Incoming Webhooksのページに遷移し有効にしましょう
有効にしたらAdd New Webhook to Workspaceという項目が現れるのでここをクリックします
クリック後、SlackAppが投稿をするチャンネルを選択する画面が出てくるので選択し許可をします
選択後Webhook URLが発行されているので控えておきましょう、後で使用しますワークスペースにSlackAppにインストール
一通りの作業が終了したので、ワークスペースにSlackAppをインストールしていきます
黄色に表示されている部分をreinstall your appを選択し、インストールを行います
これでSlackAppの設定が完了です
Lambda関数の環境変数を設定する
環境変数の設定
Lambda関数からSlackに投稿するために環境変数の設定を行います
環境変数についてはこちらの記事などを参考にしてくださいlambda_function.pyslack = slackweb.Slack(url=os.environ['SLACK_URL'])PythonではLambda関数5行目の
os.environ['SLACK_URL']が環境変数の部分になりますLambdaの環境変数設定で設定を行います
次のように記述します
キー:「SLACK_URL」と入力
値:Webhook URLをペースト記述が出来たら保存を行います、これで環境変数の設定が完了です
動作確認
ここまで終わったらSLACKからLambda関数を呼び出すための設定が完了です!
実際にSlackから動作を確認してみましょうSlackから
/commandと入力すると次のように出てくるので選択して投稿してみましょう
POST後、このようにSlackAppから投稿されたら成功です!
朝の9時にSlackAppがPOSTしてくれるように設定する
SlackのSlash Commandから要求することは出来たので毎朝9時に投稿してくれるように設定をしていきます
Lambda関数を開きトリガーを追加をクリックします
クリックをすると、トリガー追加画面に遷移するのでEventBridge(CloudWatch Events)を選択します
今回はこのEventBridgeという機能を用いて毎朝9時に実行させますそれでは設定していきます、次のように入力しましょう
ルール:「新規ルールの作成」を選択
ルール名:ルール名を入力
ルールタイプ「スケジュール式」を選択
スケジュール式:cron(00 00 * * ? *)と入力スケジュール式のcronの設定は、AWSのページにも記載されていますがUTC時間で設定をします
設定はcron(分 時 日 月 曜日)という記載方法になります
cronの設定については、AWS公式ドキュメントのルールのスケジュール式を参考にしてください入力が出来たら追加をクリックしトリガーを有効化しましょう
これで毎朝9時にSlackAppが9時になると遅延情報をお知らせしてくれるようになります!終わりに
お疲れ様でした!
今回のハンズオンで少しでもAWSやPythonに興味を持っていただいたら幸いです!明日は@yoshimurayoshikiの番です!引き続き楽しんでいってください!
参考
Slackにincoming webhook経由でpythonからメッセージをPOSTする
Python Webスクレイピング 実践入門
API Gateway + LambdaでREST API開発を体験しよう [10分で完成編]
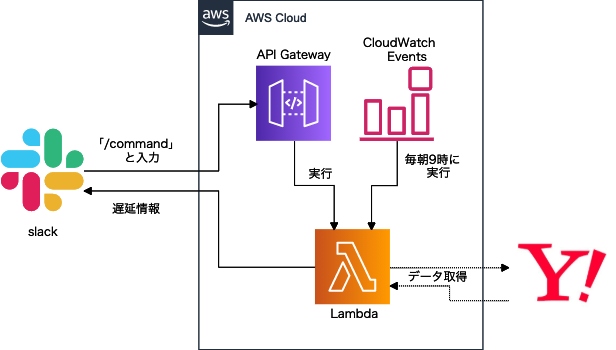
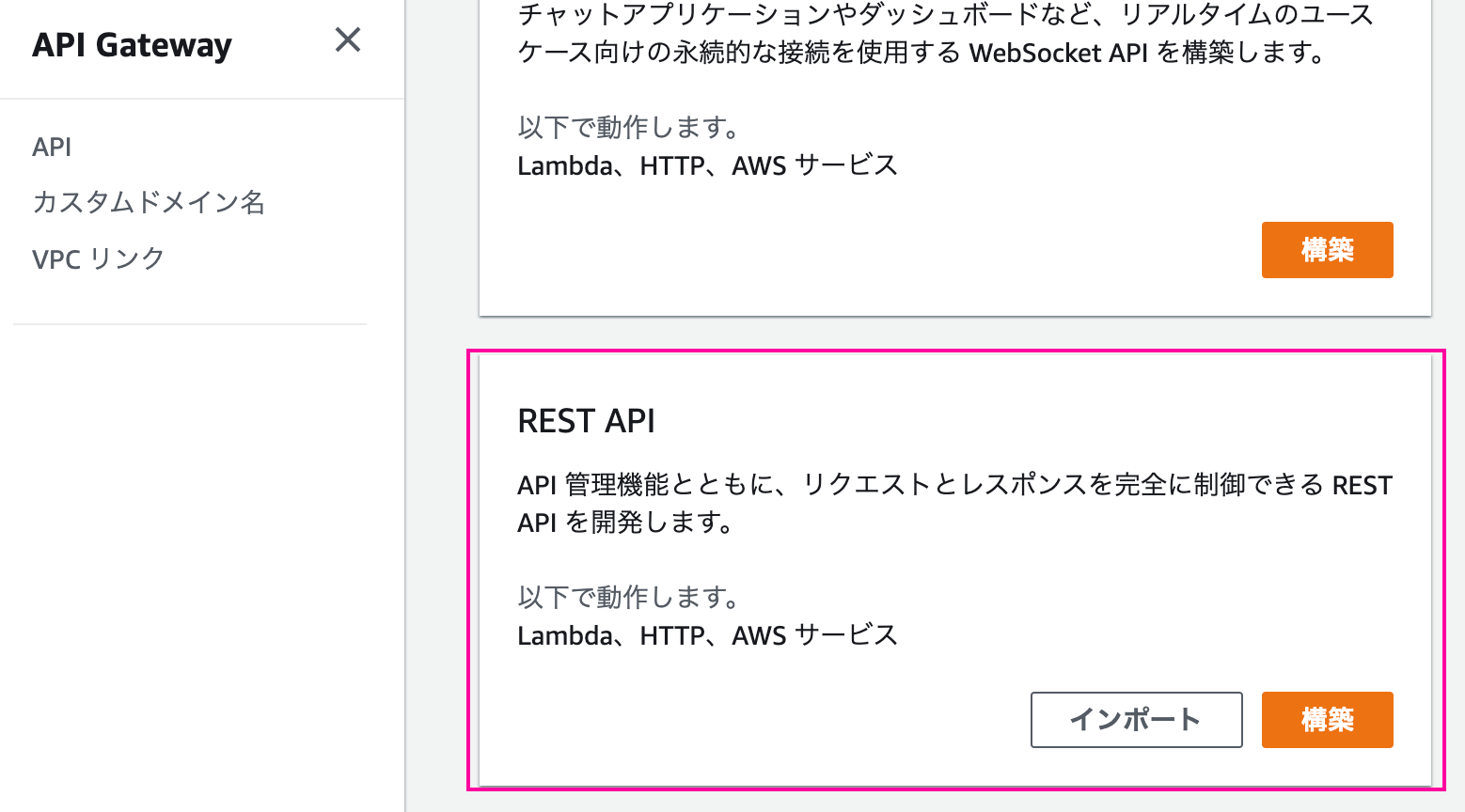
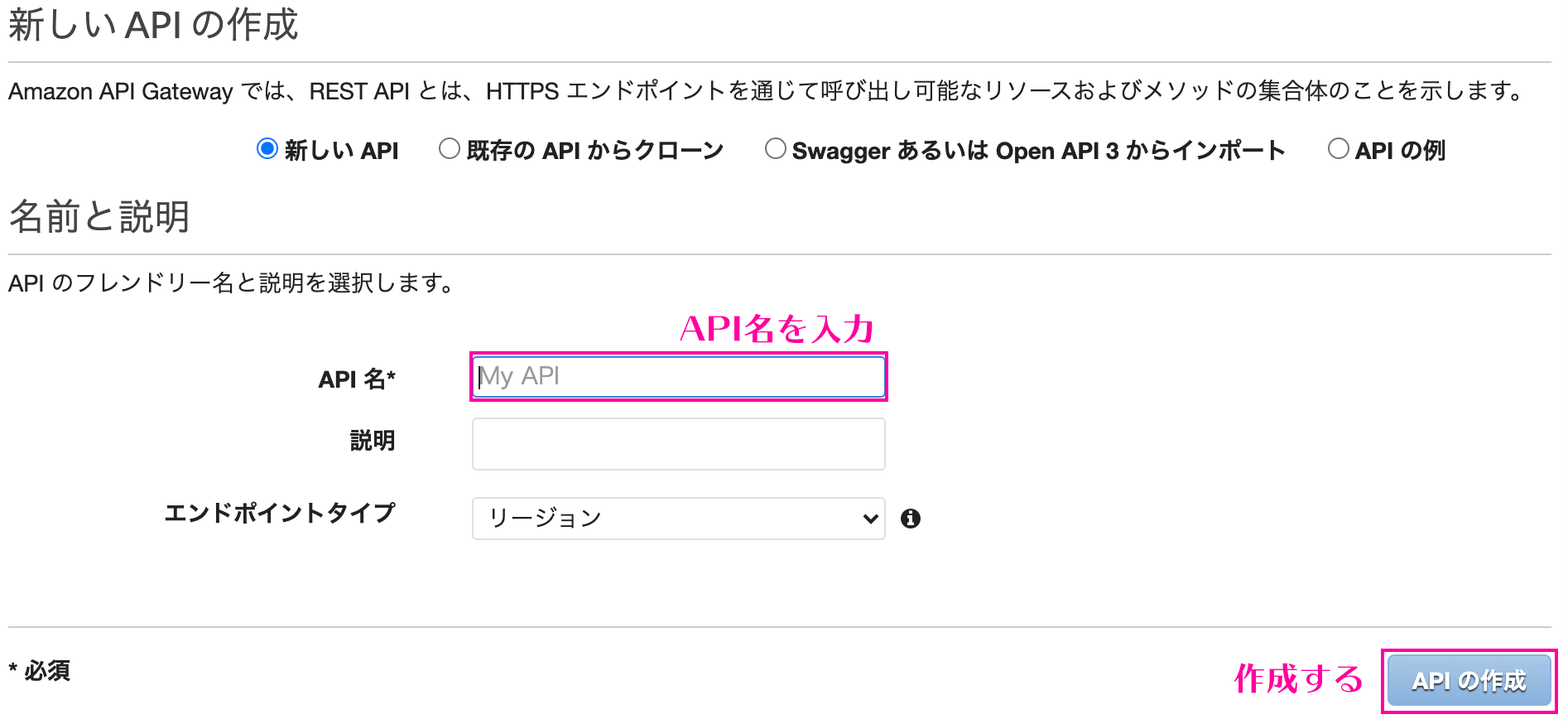
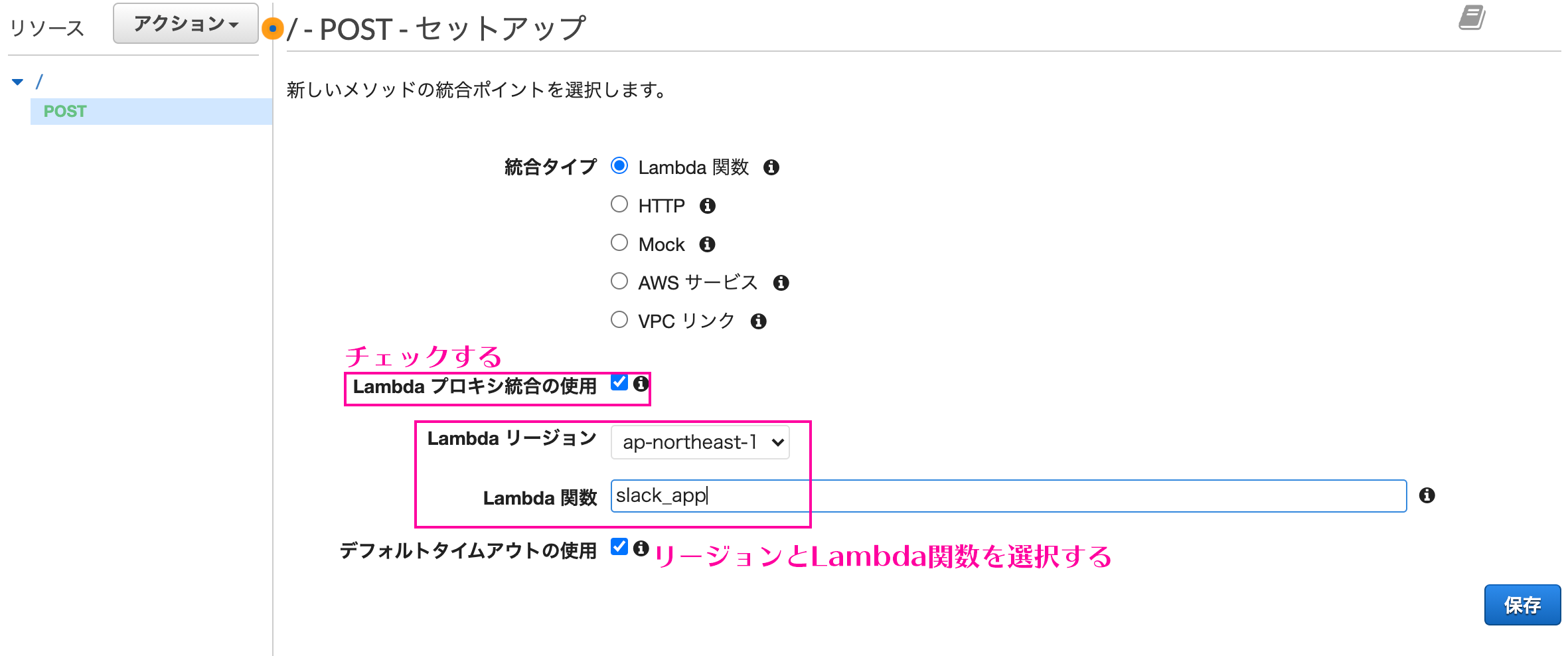
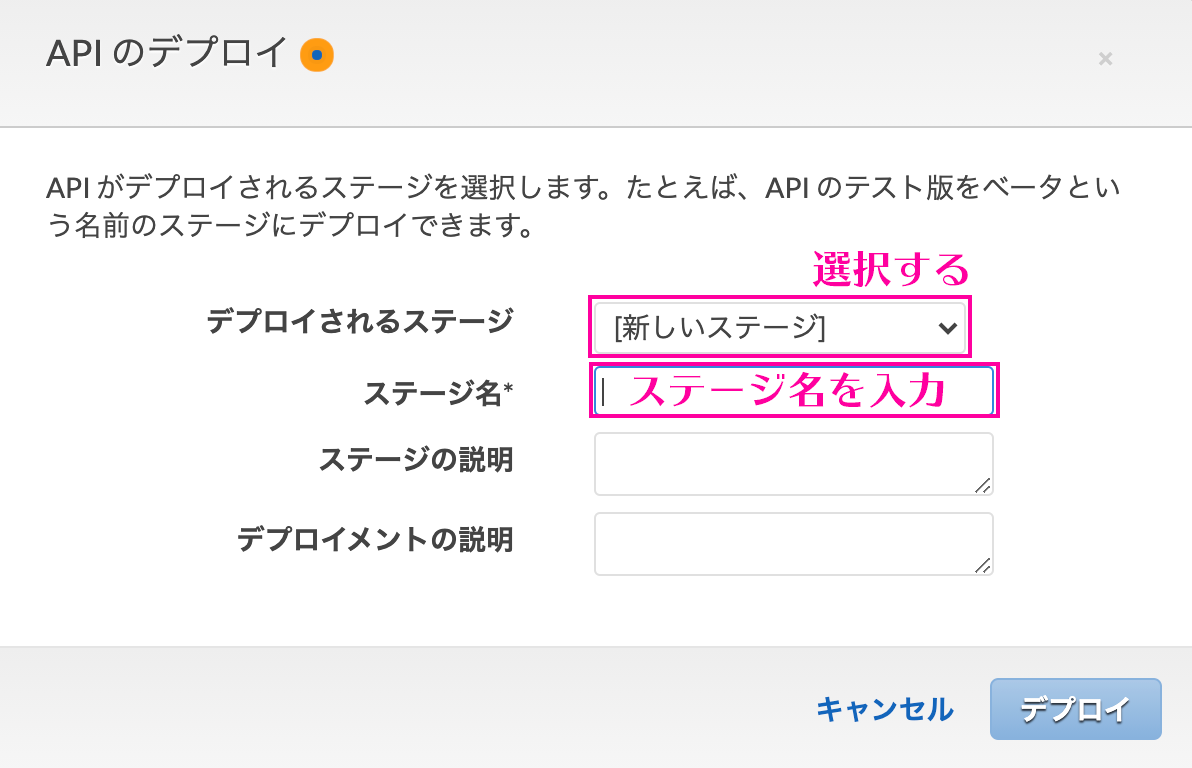
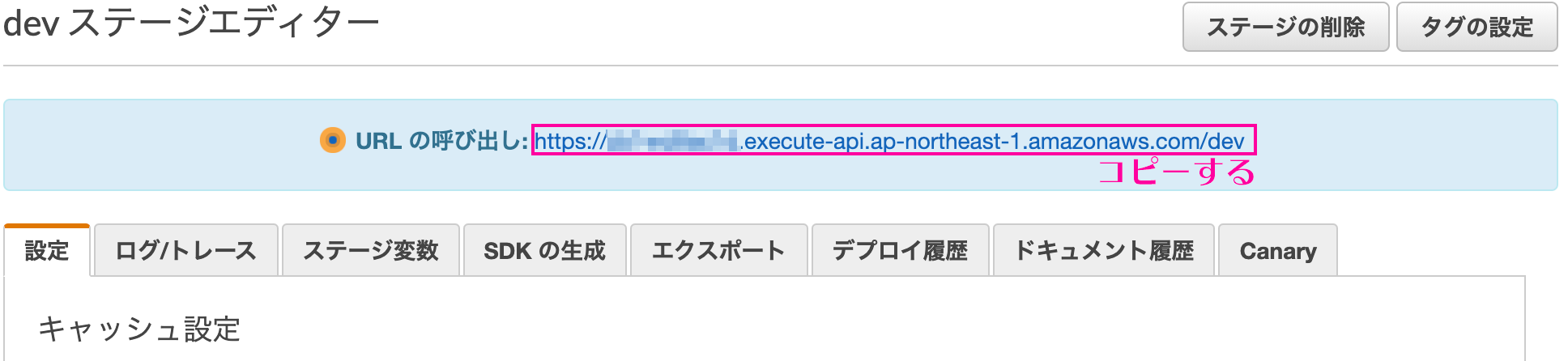
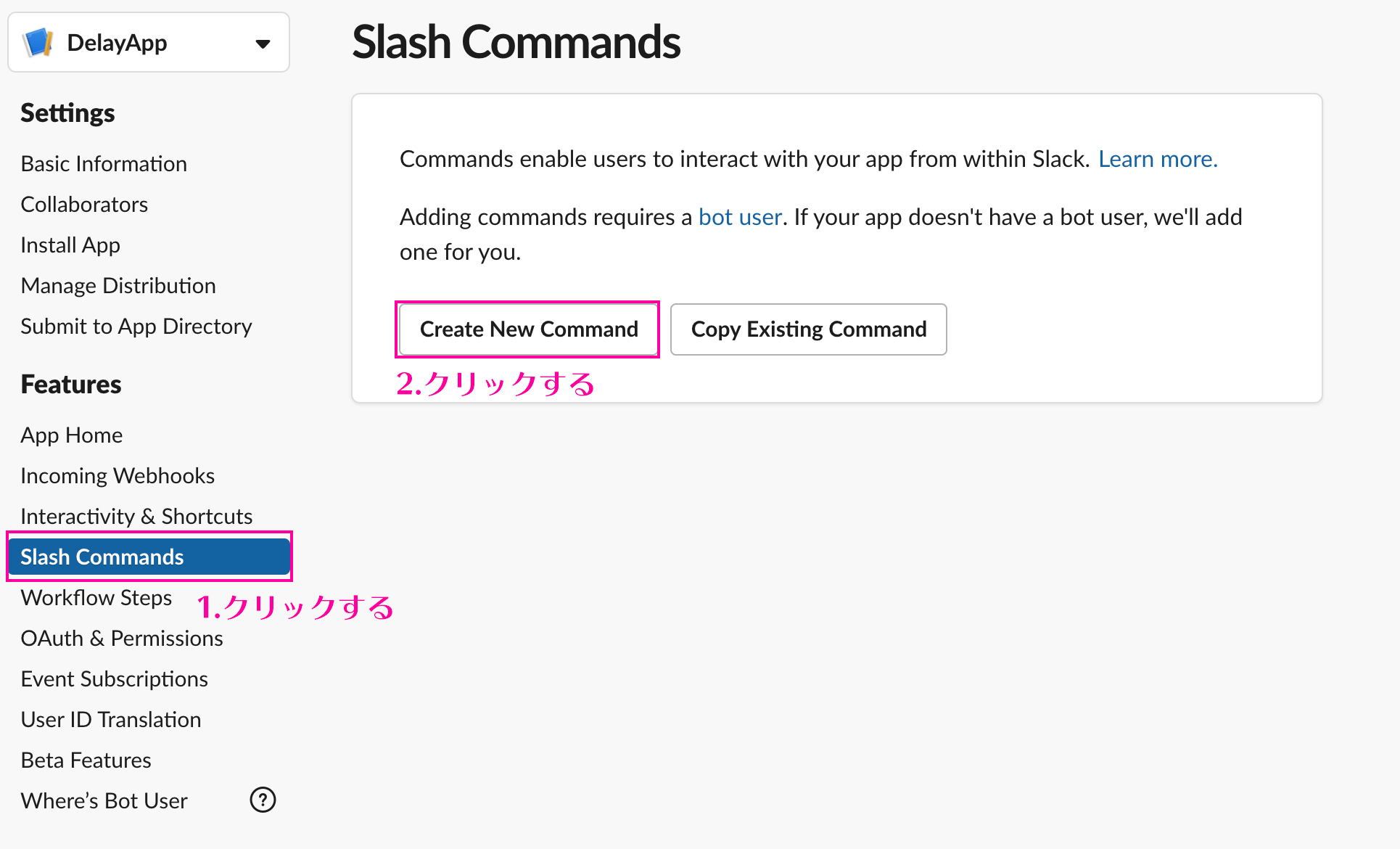
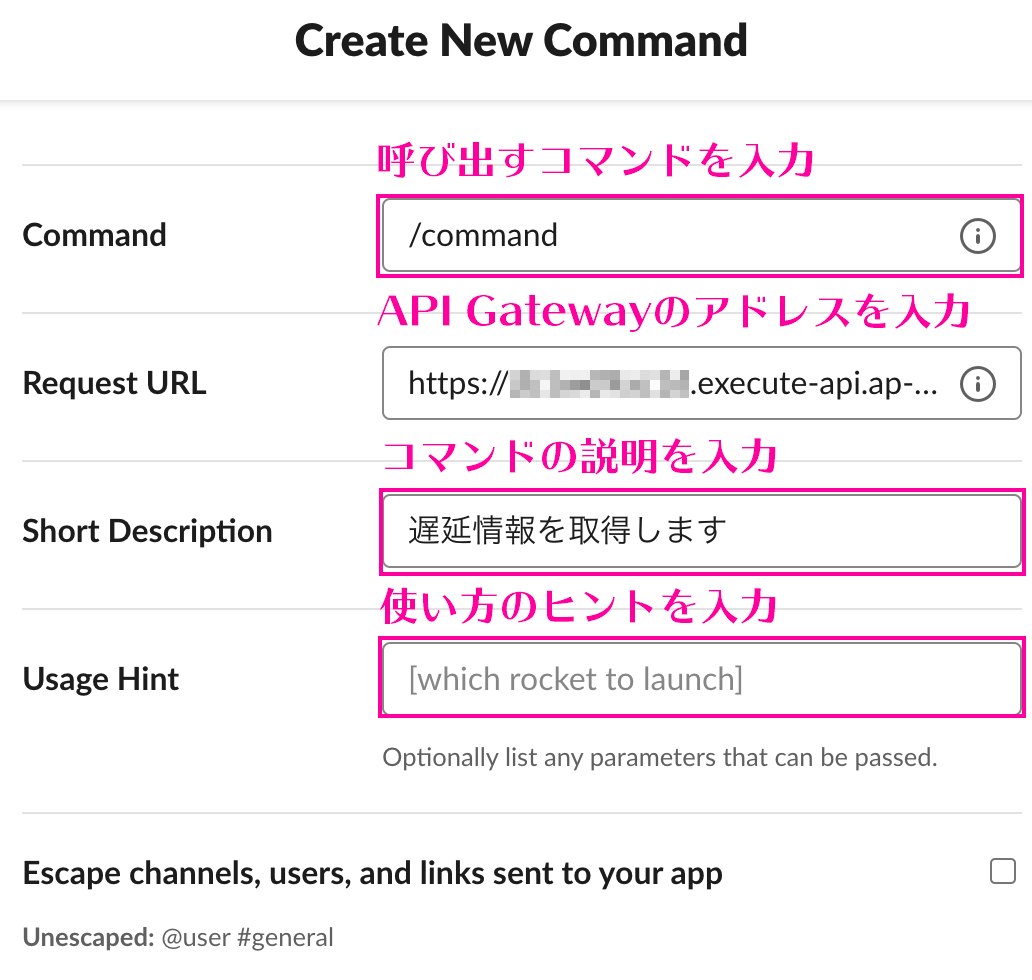
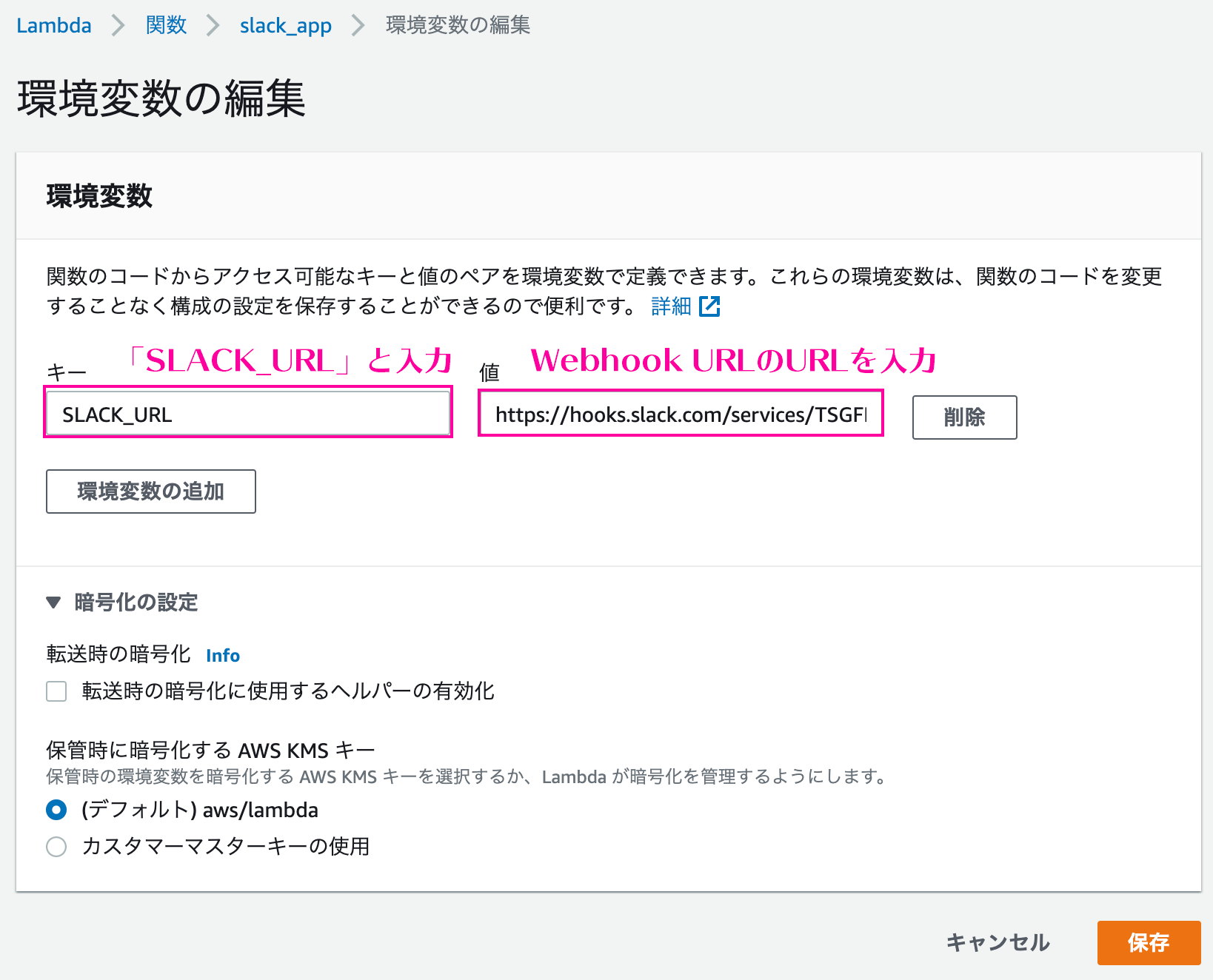
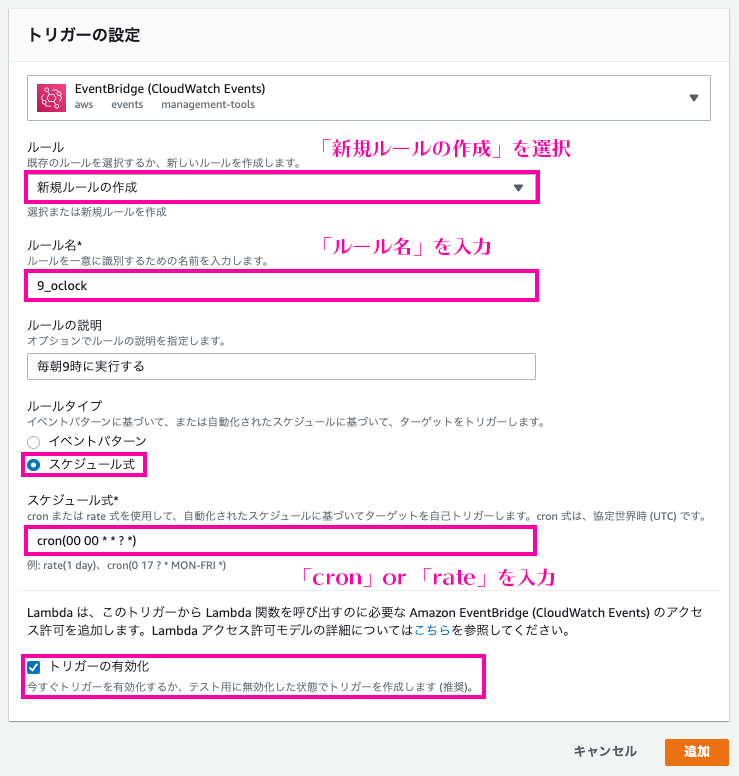
- 投稿日:2020-12-01T09:16:43+09:00
CDKで作成した踏み台サーバにAWS SSM Session Manager と AWS Instance Connect を利用してSSH接続する
TL;DR
- CDK を利用すると踏み台サーバが超簡単に作成できる
- CDK の踏み台サーバにはkeypair設定ができないが、EC2 Instance Connect を利用することで Session Manager 経由のSSH接続を実行できる
- 上記設定は
.ssh/configに記載し実行できるのですごく便利以下、一つずつ要素を説明していきます。
CDKにはEC2だけではなく、踏み台サーバ専用のConstructがある
CDKをちょっと触る始めようか、というところでとりあえずEC2の踏み台サーバくらいの、簡単なお題から作ってみようかなと思いドキュメントをあさっていたところ、なんと以下のようなConstructがあるのに気づきました
BastionHostLinux!! はい、そのものずばりの踏み台サーバです。
そして説明をよく見てみると、This creates a linux bastion host you can use to connect to other instances or services in your VPC.
The recommended way to connect to the bastion host is by using AWS Systems Manager Session Manager.
The operating system is Amazon Linux 2 with the latest SSM agent installed
You can also configure this bastion host to allow connections via SSHつまるところ、Session Manager周りの設定がすでにビルドインされたEC2インスタンスということです!これは必要十分ですね。というわけで以下のようにサクッとCDKで踏み台を建てることが出来ます。
export class CdkEc2SsmStack extends cdk.Stack { constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props); // VPCは既存のものを引っ張ってくる想定 const vpc = ec2.Vpc.fromLookup(this, "VPC", { vpcId: "your-vpc-id" }) const bastionSg = new ec2.SecurityGroup(this, "from-bastion", { securityGroupName: "from-bastion", vpc: vpc }); const allowFromBastionSg = new ec2.SecurityGroup(this, "allow-from-bastion", { securityGroupName: "allow-from-bastion", vpc: vpc }); allowFromBastionSg.addIngressRule( bastionSg, ec2.Port.tcp(22) ); const bastion = new ec2.BastionHostLinux(this, "bastion", { vpc: vpc, instanceName: "bastion", instanceType: new ec2.InstanceType("t3.micro"), securityGroup: bastionSg }); } }この設定だけで、AWS SSM Session Manager 経由でシェル接続が可能になります。素晴らしい!!
CDKの踏み台EC2にはKeyPair設定がない
さて、Session Managerへのシェル接続は実現できましたが、これはまだSSH接続ではありません。シェルでも大半の用途は可能ですが、例えばRDBへの接続への踏み台など、SSH接続が必要な場面は結構あります。また最近はVisual Studio Remote Developmentへの接続もありますしね。
というわけでKeypairも設定したいわけですが、ドキュメントを読んでもKeyPairを設定する方法の記載がありません。通常のEC2にはあるので、これは踏み台としての特性上あえて落としているんでしょう。
しかし、SSHするにはKeyPairは必須です。どうするべきか、と思っていれば公式のissueに対応案がありました。
あ、なるほど、Instance Connectね。
EC2 Instance Connect は、Session Managerとは別アプローチでSSH接続を行う仕組みです。コマンドを直接実行するには、EC2インスタンスに直接SSH接続できるような接続設定になっている必要があり、要はPrivate Subnetには踏み台を置けないなど、Session Manager と比べるとちょっと使いづらいのでこれまで使ってはいませんでした。
ただ、EC2 Instance Connect には面白い仕組みがあり、KeyPairを設定していないEC2にもSSH接続ができるんですよね。これはどういうことかというと、AWS CLIを経由して、ローカルの公開鍵をEC2に送りつけるAPIがあるのです。ちなみに送りつけたキーペアは短期間で無効になります。
そう、Instance Connect自体はちょっと使いづらいのですが、この「KeyPairの送信機能」をうまく使えば、現在の課題である、Session ManagerのKeyPair問題にうまく対処できるのです。
具体的には、まずは以下のようなSession Managerに対応したssh configを用意します。
Host %YOUR_SERVER_NAME% User ec2-user HostName %YOUR_INSTANCE_ID% Port 22 ProxyCommand sh -c "aws ssm start-session --target %h --document-name AWS-StartSSHSession --parameters 'portNumber=%p' --profile %YOUR_AWS_PROFILE%" IdentityFile "path/to/your/ssh/key"単純にこれを実行するだけでは、当然KeyPairエラーになりますが、ここで自分の公開鍵を以下のようにEC2に送りつけてやります。
aws ec2-instance-connect send-ssh-public-key \ --instance-id your-instance-id \ --availability-zone your-az-id \ --instance-os-user ec2-user \ --ssh-public-key file:///path/to/your/ssh/pub/key上記のコマンドを実行後にssh接続を行うことで、無事にKeyPairの登録なしにSSH接続が可能になります。
どうせなら1コマンドでやりたいよね
さて、これらのコマンドを1箇所に集めることはできそうでしょうか?具体的にはssh configに全部書きたいですね。やってみましょう。
と言っても難しいことは特になく、ProxyCommandの中でInstance ConnectのAPIを叩いてやればいいのです。
ちょっと長くなりますが、以下のようにしちゃえば大丈夫です。なお、キーペアはデフォルトで使われるid_rsaを利用する前提で、IdentityFileの記述も削除しています。Host %YOUR_SERVER_NAME% User ec2-user HostName %YOUR_INSTANCE_ID% Port 22 ProxyCommand sh -c "aws ec2-instance-connect send-ssh-public-key --instance-id %h --availability-zone your-az-id --instance-os-user ec2-user --ssh-public-key file://~/.ssh/id_rsa.pub && aws ssm start-session --target %h --document-name AWS-StartSSHSession --parameters 'portNumber=%p'"というわけで、これでMac/Linuxであれば、任意の環境への接続が以下の状況でできるようになります。
- Private Subnet下、ポート開放なし
- KeyPair設定無し
- SSM SessionManagerは導入済み(ただしCDKのデフォルトでOK)
Windowsはまた後ほど、、、
- 投稿日:2020-12-01T08:58:00+09:00
1億DAUの中華ゲームを支えるアーキテクチャ
前書き
「AWS & Game Advent Calendar 2020」二日目の記事になります。
近年日本では、アズールレーン、荒野行動、原神など中国制のゲームが多く進出されています。
最近では、「原神1ヶ月間251億円を稼いだ」や「王者栄耀のDAUが1億を超えた」などニュースにもなっています。私は中国出身のため、この1年の仕事中でも、関連の内容が聞かれたことは何回かありました。今回のAdvent Calendarをきっかけに、王者栄耀や荒野行動をはじめ、典型的な中華ゲームのアーキテクチャと日本のゲームの違いについて、説明したいと思います。
最後、AWS&Gameのカレンダーですが、ゲーム自体はAWSで動いていることとイコールになりません。実際この記事で触れたゲームの中、荒野行動のグローバルとアーチャー伝説だけがAWSの公開事例になります。また、この投稿は、個人の意見であり、所属する企業や団体は関係ありません。データは全部ネット上で集められたものです。
サーバ選択のシーンを見たことがありますか?
日本のモバイルゲームではあまり見かけない光景ですが、中国のゲームはサーバ選択式なものがそれなりにあります(中国本土のゲームは更に多いです)。例えば、アズレン や ライコスなど。
日本のモバイルゲームはブラウザゲームから発展したものが多く、LAMPベースのステートレスなアーキテクチャが多いです (図1)。一方中国のモバイルゲームはネットゲーム(MMO)から発展したものが多いため、MMOライクなステートフルなアーキテクチャが多いです(図2)。つまり、ユーザが接続するサーバが決まっているため、サーバ選択が必要になります。
もちろんゲームの仕様により、ステートフルじゃないと実現できないゲームがあるとと思いますが、どちらかというと、ステートフルとステートレスで両方ともできる場面なら、日本ゲームはステートレスの構成になりがちですが、中国は逆のパターン、ステートフルのケースが多いです。
ステートフルなゲームサーバの特徴
ステートフルの構成を採用した理由について、歴史的な原因はありますが、ソリューションアーキテクトの観点から見て、図2にはいくつかLAMP構成より優れているところもあります。
- 構成がシンプルで、拡張しやすい。LAMP構成は、データベースがボトルネックになりやすいです。特にユーザが大量に来るゲームでは、DBをシャーディングしないといけなくて、その作業を予めやらないと後が大変になります。またユーザの事前見積もりかなり重要であり、10万DAUベースで負荷試験を行い、100万DAUが来ましたら、リソースを増やすだけで解決できないケースが多く、shard数の修正、キャッシュの追加及びコードの修正も必要な場合はよく見られます。一方、図2の構成では、事前に1セット(ゲームサーバ+DB)あたり捌けるユーザ数を決めて、ユーザが多く来たら、同じようなセットを横に並べば大丈夫のため、簡単に増やせますし、DBのシャーディングも必要ありません。
- 単体サーバのパフォーマンスが良い。ゲームクライエントとサーバ間はSocket通信のため、httpのようなで都度接続のオーバーヘッドが無いです。また、構成がシンプルなため、負荷試験によりサーバ最大限のパフォーマンスを引き出せる可能性もあります。
アーキテクチャの観点以外、サーバサイドの作り方にも違いがあります。個人感覚になりますが、日本はDBにユーザの状態を管理することが多いことに対して、中国系のゲームはユーザの状態をサーバ側で管理し、DBはバックアップの役割を担うことが多いです。その理由について、中国で流行っているゲームフレームワークskynetからの記述を引用して解説致します。
簡単なwebアプリケーションなら、事前にデータフォーマットを定義し、リクエストを受けるたびに、DBからユーザの情報を読み取り、処理後DBに書き込みすることが一般的です。ネットゲームにおいて、強いコンテキストを持ち、ユーザ間の連携も多いです。もし同じモードを採用すると、DBの処理とロジックの処理の間、ボトルネックになりやすい、このボトルネックネックは通常キャッシュをレイヤーを追加するだけで解決できないことが多いです。
Skynetでゲームホストする場合は、同期的にデータをDBに保存することはおすすめしません、代わりにインメモリのDBに保存したほうが良い。サービス、アプリロジックやゲームデータは全部メモリで常駐します。もしDBはあなたのフレームワークの一部でしたら、殆どの場合バックアップとして使うべき。データの状態が変わったもしくは定期的にDBに保存します。アプリは直接メモリからデータを呼びます。
オリジンの英語文書
For simple web applications, it's more common to put user-related status or data (pre-defined data structure) in a database, after getting the client's request, the server application loads the user's data, process it and write it back to the database. For online game applications, there will be more context and interaction between data and services. If using the same model for these two types of applications, it's easy to have a bottleneck in database and feature modules, which cannot be resolved even by adding a layer of memory cache.
With Skynet as your game server, it's not recommended to synchronize your service data to the database, it's best to put it as a data structure in memory. Service, application logic code and game data are kept in the local memory. If a database is already a part of the game server framework, in most cases, it's used as a backup of game data. You can push your data into a database when state changes, or backup your data periodically. The application uses game data from memory directly.
このように、ユーザの状態を全部サーバ側で管理し、DBは定期的バックアップだけのため、リクエスト来るたびにDBにアクセスしなくなり、パフォーマンスも良くなります。特に中国製のモバイルゲームでは、ネットゲームに近い形なものが多く、複雑なロジックやユーザ連携も多いため、リクエストが来るたびにDBにアクセスすると、パフォーマンスどころか、ゲーム自体も成立しないこともありえます。なので、ゲームは自然的にこのような作りになりました。
余談ですが、ステートフルの構成が多いため、サーバサイドの評価指標として、1サーバあたりにどのぐらいユーザを捌けることはよく見られています。最初に紹介した1億のDAUのMOBAゲーム王者栄耀では、多くのゲームの中で優れたものであり、PVPサーバ単体だけで1.2万人のユーザを捌け、PVPでは無い部分は2万人を捌けることができます。
ステートフルなゲームサーバの課題
一方、もちろん全部良い話ではありません。ステートフルな構成では以下の課題があります。
可用性はLAMP構成より低い、DDoS攻撃にされやすい
ユーザはサーバに直接繋ぐため、そのサーバがダウンしたらユーザは一時的にプレイ不能になりますし、データロストの可能性もあります。また、ロードバランサーがなく、個々サーバのIPがpublicになっているため、攻撃されやすいです。サーバ跨いたユーザ連携はしにくい
本質はサーバシャドーイングので、DBのシャドーイングと似たような悩みがありました。コンテナやスポットインスタンスとの相性が悪い
ステートフルのため、コンテナにおける開発環境標準化のメリットやスポットインスタンスにおける90%コスト削減の恩恵を受けにくいです。進化し続けるアーキテクチャ
上記デメリットがあるため、最近ゲームでは更に進化し、下記のような三層構成になっています。実際王者栄耀や荒野行動もそのアーキテクチャの拡張の感じになります。
単一サーバからマイクロサービスに変換
ロジックに密に連携必要なところは同じところに固まりながら、ソーシャル、プレイステータスなど分割できそうなところは別のサービスとして分割します。こうして、分割された部分は高い可用性の構成も検討できますし、コストもサービスの特性にい応じて更に最適化することが可能です。荒野行動を作ったNetEeseさんは、チャットやProxyなどネットワークヘビーなワークロードにARMインスタンスを導入し、50%近くのコスト削減ができました。今年、第2世代のGraviton2のインスタンスもGAになり、さらなるコスト削減が期待できるかもしれません。Gateway及びproxyサーバの導入
個々サーバのIPを公開するのではなく、通信は全部単一IpのGateway経由で行うことにより、サーバが攻撃されたリスクを減らせます。個別通信が必要の場合も、クライエントから決めるではなくgatewayに問い合わせして、繋がるサーバを決め決めます。AWSサービスの中では、Amazon gameliftも似たような考え方です。事前に複数サーバを用意し、ユーザがゲームを加入するときだけ、Gameliftに問い合わせし、適切なサーバを案内します。そして、サーバが攻撃されリソースが足りなくなったら、自動スケールの仕組みで新しいサーバを起動し、ユーザを守ります。興味ある方は、こちらの記事 を参考していただければと思います。proxyサーバもDDoS攻撃から保護することができます。また異なるリクエストを適切なサーバに転送する役割もなっており、例えば、大型マップ間のシームレス移動とか、バトルしながらギルドチャットにメッセージを送るとか。
これでステートフルサーバの課題が多く解決されて、"理想"的なアーキテクチャとも言えますが、コンポーネントが多く、構成が複雑であり、運用コストが高いと思います。荒野行動や王者栄耀などDAUが膨大、ロジックが複雑なゲームでは採用を検討できるかもしれませんが、規模が小さいゲームやシンプルなカジュアルゲームはそこではやる必要はないと思います。近年、アーチャー伝説 を開発したHabbyを始め、一部の中国制ゲームは、極力運用コストを抑えたフルサーバレスのアーキテクチャの採用も見られます。
おまけ:1億DAUの王者栄耀で使うサーバ技術は?
先程アーキテクチャの話をしましたが、サーバ技術についてもう少し触れます。王者栄耀はMOBAゲームの中、少し特殊で、CS方(サーバ集中処理型)ではなく格ゲーでよく使われているキー入力同期の技術を利用しています。CS側は全部サーバで計算するため、チートがしにくいというメリットがありますが、プレイ感触が少し悪いです。事前予測や細かい調整を用いて、プレイヤー体験を最適化はできますが、開発コストがかかるため、キー入力同期を採用しました。サーバはUDPプロトコルを使って、送られてたフレームをまとめてクライエントに返します。毎回3フレーム冗長分を送信し、ネットワークが悪い時更に多めに送信しています。描画が60fpsまでできますが、操作は66ms単位で秒間15フレームで行っています。
キー入力同期は一番の課題は同期ズレであり、float利用を回避、ランダムシードの対策を入れても、バグや機種による同期ズレははやり発生します。自動化テスト、専用のテストサーバを用意や録画を全部アップロードなど施策で、継続改善した結果リリース時は2%ぐらいですが、その後色々改善した結果、2018年時点では約0.03%ぐらいになりました。最後
ここまで読んでいただいてありがとうございます。もし少しでもご参考になりましたら、ぜひLGTMやSNSでシェアをしていただければと思います。
この記事で利用した一部のデータと画像は以下の参考資料から取得したものになります。https://gameinstitute.qq.com/community/detail/115396
https://gameinstitute.qq.com/community/detail/118047
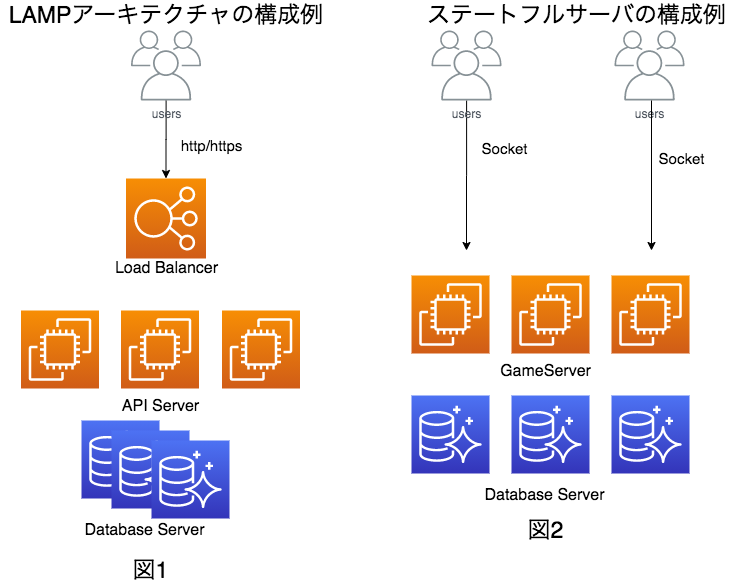
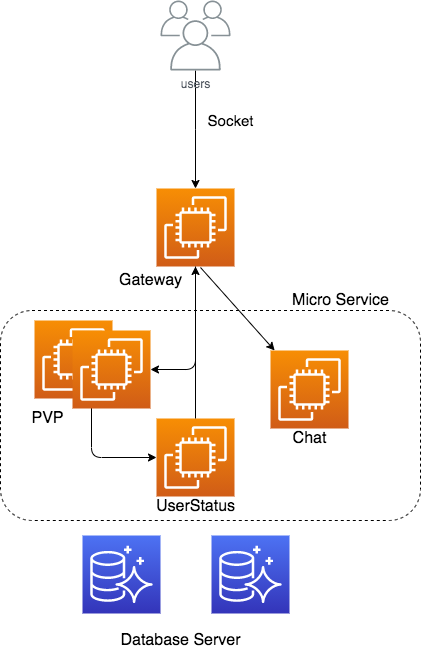

- 投稿日:2020-12-01T07:10:15+09:00
#データサイエンティスト育成を支える技術
なんでドコモがアドベントカレンダー?2020
お久しぶりです。@dcm_chidaです。
今年もアドベントカレンダーが始まりましたね。我々NTTドコモは2018年から毎年Qiitaアドベントカレンダーに取り組んでおります。
昨年のカレンダーではQiita民の皆様からたくさんの反響や応援の声をいただきました。おかげさまで今年もこうしてアドベントカレンダーに参加することが出来ます。圧倒的感謝!
QiitaZineでもピックアップしてもらいました!
特に今年はNTTドコモのR&D部署全体でアドベントカレンダーを立ち上げております。ドコモの技術や取り組みを紹介するような記事をたくさん投稿していこうと思うので、高評価&購読よろしくお願いします!
NTTドコモ R&D Advent Calendar 2020 - Qiita
NTTドコモ R&D 控え室 Advent Calendar 2020 - Qiita
Twitterやはてなもチェックしているのでコメントお待ちしております!
はじめに
さて、「データサイエンティスト育成」というテーマですが、みなさんデータサイエンススキルを身につける最も効果的な方法は一体なんだと思いますか?
私個人としては「機械学習コンペティションに参加すること」だと思ってます。
最近ではデータ分析に関する資格やプログラミングスクールがたくさんあります。もちろんそういった教科書的なお勉強は必要ですが、知識をインプットするだけでは実際の業務に応用できません。
より実践的にアウトプットする場が必要です。その選択肢の一つとして機械学習コンペティションが挙げられます。KaggleやSIGNATEなどが有名ですね。
我々NTTドコモR&Dではそうした機械学習コンペティションの一つであるKDD Cupに参加しています。
本記事ではNTTドコモR&Dにおける「KDD Cupを通したデータサイエンティスト育成」と「それを支える技術」について紹介していきたいと思います。
対象とする人
- R&D部門で機械学習コンペに取り組もうとしている
- データサイエンティスト育成に興味がある
主な内容
- NTTドコモR&DにおけるKDD Cupへの取り組み
- 機械学習コンペ用のAWS開発環境の運用ノウハウ
KDD Cup
KDD Cupとは?
KDD Cupとは権威ある国際学会KDD(Knowledge Discovery and Data mining)で開催される機械学習コンペティションのことです。
KDD Cup is the annual Data Mining and Knowledge Discovery competition organized by ACM Special Interest Group on Knowledge Discovery and Data Mining, the leading professional organization of data scientists.
1997年から毎年開催されており、今年で24回目となる歴史あるコンペティションです。世界中の研究機関や企業が数多く参加し、各々のデータ分析技術やプログラミング能力を競い合います。最近では特に中国企業や大学が多く参加していますね。
過去コンペはこちらにまとまっています。
KDD Cupは毎年どんなテーマが選ばれるかわかりません。最近はグラフ分析やAutoML、強化学習などチャレンジングなテーマが選ばれることが多いです。Kaggleでは好きなテーマに参加すれば良いですが、KDD Cupではこちらに選択権がありません。
そうなると当然専門外のお題になることがほとんどなので、毎年毎年地獄のような論文サーベイ?1から始まることになります。今年のテーマであるグラフニューラルネットでも論文やコードを大量に調べました。いやぁ大変だった。
ちなみに似たようなコンペはNeurIPSやRecSysなど他の国際学会でも開催されています。
NTT DOCOMO LABS
ドコモR&Dは2016年からKDD Cupに参加していますが、そのためにデータサイエンティスト有志が集まってチームを組みました。その名も「NTT DOCOMO LABS」です。
チームメンバーは画像処理、ネットワーク技術、セキュリティなど様々な分野から募っています。ガッツリ研究寄りの人からサービス開発専門の人まで様々です。年次も入社3年目の若手からオーバエイジ枠の選手2まで様々です。
結成当初は少数精鋭感がありましたが、最近では人材育成の意味合いも強くなってきています。昨年は若手社員が続々参戦し、20人以上の参加者が集まりました。来年はもっと増えると思います。
私個人としては2018年に初めて参加して今年で3回目でしたが、基本的なデータ分析スキルは全てKDD Cupで学んだと言っても過言ではありません。
データサイエンティスト育成計画
機械学習コンペで期待できるのは「個人としてのデータ分析スキルアップ」だけではありません。
普段と異なるチームで活動することによる「シナジー効果(相乗効果)」が期待できます。
通常のR&D組織でのあるあるを挙げてみましょう。
- ほぼ固定メンバーなので他のチームの業務内容は謎に包まれている
- 技術に特化したスペシャリストが身近にいない
- 本業務に関わる技術ばかり身についてしまう
- もしくは定型作業化してしまっている
- 若手社員にアピールの場がなかなか回ってこない
うぅ、何だか胃が痛くなってきますね…?
これに対して我々NTT DOCOMO LABSのような横断型組織では多くのメリットがあります。
- 担当や部署を跨いだコネが出来る(技術の貿易)
- データ分析が得意なスペシャリストとOJT的にチーム開発が出来る
- 最先端の技術を調査・取得し、時には本業務に応用することも可能
- 若手でもデータ分析力があれば重宝される
このように機械学習コンペ特殊部隊を組織することによって「データサイエンティストを育む土壌?」を形成しているわけです。
これまでの成績
我々は2016年からKDD Cupに参加していますが、これまでの結果を公開してみます。
Year Track Result Description 2020 ML Track1 (Task1) 7位 ? ECサイトのクリック予測 ML Track1 (Task2) 59位 ECサイトのバイアス除去 ML Track2 4位 ? Graph Adversarial Attack AutoML Track 15位 グラフデータのAutoML RL Track 3位 ? タクシー配車の最適化 2019 Regular Track1 Task1 114位 最適な交通経路の予測 Regular Track1 Task2 1位 ? 最適な交通経路の提案 AutoML Track Check Phase 敗退 テーブルデータのAutoML Humanity RL Track 29位 マラリア感染防止の方策 2018 Regular Track 16位 大気汚染の時系列予測 2017 Regular Track Task1 90位 交通渋滞時の移動時間予測 Regular Track Task2 70位 交通渋滞時の交通量予測 2016 Regular Track Finalist ? 論文の採択予測 これがこれまでの対戦記録です。報道発表などでは「良かった結果」ばかりが出ていますが、実際は「悪かった結果」もたくさんあります。
30日間毎日サブミットしたり…
メモリエラーで大爆死したり…
ポルナレフ状態でコンペが終了したり…
振り返れば、泥臭い努力を何年も積み重ねてきました。
個人的に一番思い入れが深いのが2019年のAutoMLTrackです。自分がリーダーを努めていたのですが、最終的にメモリエラー3で脱落してしまいました。そこそこ良い結果が狙えそうだっただけにショックが大きかったですね。辛すぎて有休を取ってひとり傷心温泉旅行に行きました。いい思い出です。
なんだか宣伝っぽくなってきてしまったので、今回はここまで?
今年のアドベントカレンダーでもKDD Cup関連のものが多く投稿されると思うので詳細はそちらをご覧ください。
データサイエンティスト育成を支える技術
さて、こんな感じでドコモR&DではKDD Cupに取り組んでいるのですが…
一体どうやって機械学習コンペ用の開発環境を用意するのか?
という問題が生じます。
個人PCでは流石にキツいです。
世界レベルのデータ分析コンペで戦うには高性能なGPUやメモリ盛り盛りのサーバが必要になってきます。当然AWSやオンプレサーバなどを利用することになりますが、そうなると様々な障壁が生じます。
- データサイエンス以外のスキル不足4(インフラ構築など)
- セキュリティ意識の統一
- 運用コストの管理
我々NTT DOCOMO LABSはこうした問題を解消するために、データ分析自己研鑽用のAWS環境を構築しました。
本章ではそうしたデータサイエンティスト育成を支える技術についてまとめたいと思います。
データ分析自己研鑽用のAWS環境
コンセプトはこんな感じです。
主な利用用途としては
- 機械学習コンペ用の開発環境
- (教科書レベルの)データ分析スキル向上
- 社内勉強会向けのアドホックな検証
などを想定しています。
基本的なネットワークやセキュリティ設定は社内でAWSに強い人を何人か引き込んで整備しました。データ分析に必要な環境は一通り揃えています。
特に毎年KDD Cupの期間は高性能のサーバがズラッと並びます。月間コストもぶっ飛んでいく5ので毎年ヒヤヒヤしますが、もはや恒例行事です。
以下、運用面でのTipsをいくつか紹介していきたいと思います。
Tips① 初回ログイン時にMFA設定を強制させる
AWS初心者の最初の関門は「IAMユーザとしてログインすること」です。
我々の環境ではまずはIAMユーザとしてログインして、MFAを設定するところからやってもらいます。MFAを設定しないと、(基本的な操作を除き)ほとんど全ての操作が制限されます。
IAMポリシーを一部抜粋するとこんな感じです。
IAMポリシー(一部抜粋){ "Version": "2012-10-17", "Statement": [ { "Sid": "LimitRegion", "Effect": "Deny", "Action": "*", "Resource": "*", "Condition": { "StringNotEquals": { "aws:RequestedRegion": [ "us-east-1", "ap-northeast-1" ] } } }, { "Sid": "BlockAnyAccessUnlessSignedInWithMFA", "Effect": "Deny", "NotAction": [ "iam:*", "s3:*", "codecommit:*", "sagemaker:*", "kms:Encrypt", "kms:Decrypt", "kms:ReEncrypt", "kms:GenerateDataKey", "kms:GenerateDataKeyWithoutPlaintext", "kms:DescribeKey" ], "Resource": "*", "Condition": { "BoolIfExists": { "aws:MultiFactorAuthPresent": "false" } } }, "以下、ゴリゴリにカスタマイズされたjsonが続く…" }AWSが本当に初めての人は「IAM」と言う概念を知りません。
そんな方々にはまず最初に「何でもかんでも自由にできると思ったら大間違いや!生殺与奪の権は管理者が握ってるんだぁ!」と言うことを実感してもらいます。
Tips② SageMakerを中心とした開発環境整備
次に関門となるのは「開発用のインスタンスの構築」です。
ここではSageMakerのノートブックインスタンス機能を利用します。
普通はEC2でインスタンスを構築して…SSHでログインして…ライブラリをインストールして…など面倒な作業が必要ですが、純粋にデータ分析だけやりたい人にとっては単なる重労働でしかありません。下手に設定をミスするとインスタンスの乗っ取りや暗号通貨のマイニングに使われてしまう可能性もあります。
単純にKDD Cupに参加するのが目的ならJupyter Notebook(もしくはJupyter Lab)が使えれば十分です。わざわざEC2インスタンスを作成して面倒な作業をする必要はありません。SageMakerのノートブックインスタンスではデフォルトでデータ分析に必要なライブラリ一式は揃っていますし、必要ならGPUも利用可能です。
設定も簡単です。VPCやSGなどは予め作っておいて、利用者にはそれを選択してもらうだけです。SSHログインも一切不要です。設定ミスや鍵紛失のリスクを最小限に抑えることができます。
このようにSageMakerを利用することで、データ分析者の負担を軽減しつつ、セキュアで高性能な環境構築をすることが可能になります。
Tips③ CodeCommitによるコード管理
趣味で参加する場合はGitHubやらGitLabでコードを管理すれば良いのですが、組織としてコンペに参加する場合は社内ルールなど少々面倒な事務手続き6が必要です。初心者が適当に公開リポジトリを作成して、アクセスキーが世界中にオープンになってしまったら情報漏洩になりかねません。
そこで導入するのがCodeCommitです。CodeCommitはAWS提供のコード管理サービスです。GitリポジトリをAWS環境にセキュアにホストすることが出来ます。
CodeCommitは前述のSageMakerのノートブックインスタンスにダイレクトにアタッチできるのが嬉しいところです。先程のJupyter Labのキャプチャ画面の左側を見ればわかりやすいと思います。
あまり多用すると意外とコストが高くつくのが難点ですが、コンペが終わったら消せば良いのでここは我慢します。
また.ipynb形式のファイルはコンソールからうまく表示できないのも難点です。ここはギリギリ我慢できませんが、どうせSageMakerで開くからなぁ…?
あと、シンタックスハイライトも結構雑なんだよなぁ…?
今後のアップデートに期待。
Tips④ GuardDutyを有効化する
セキュリティ周りは自動化しておきたいのでGuardDutyを有効化しておきます。
Amazon GuardDuty は、AWS アカウントとワークロードを保護するために悪意のある操作や不正な動作を継続的にモニタリングする脅威検出サービスです。アカウント侵害の可能性を示す異常な API コールや不正なデプロイなどのアクティビティをモニタリングします。インスタンスへの侵入の可能性や攻撃者による偵察も検出します。Amazon GuardDuty(インテリジェントな脅威検出) | AWSここら辺は説明不要ですね。
- ルートアカウントが使われた!
- 普段使わないsrcIPからコンソールにログインしてきた!
- IAMポリシーの権限が変更された!
このような自体が発生した場合、自動で検出してくれるのでとても便利です。ぜひ有効化しておきましょう。
デフォルト機能では結構見にくいので、うまくダッシュボード化するといいと思います。
Tips⑤ Billingを見てもらう
Billingは意図的に「参加者全員が見える状態」にしています。
AWS初心者が不安に思うこと第一位は「これを使うといくらくらいお金がかかるんだろうか?」だと思います。
- インスタンスタイプはどれを選べばいいの?
- メモリもっと増強して大丈夫かな?
- DeepLearningAMIってお金かかるの?
こういう恐怖心が成長を妨げます(多分)。クラウド破産を恐れていては自己研鑽が進みません!
- GPUのP3とP2では一時間で数百円も差がある!
- インスタンスを立ち上げっ放しにすると大変だー?
- Lambda関数…やっすい!サーバレスすげぇ!
こういうコスト感覚を身に付けてもらえるように、敢えて見えるようにしています。
デフォルト設定ではルートユーザしか見ることが出来ませんが、IAM権限によるアクセスを有効化してIAMポリシーをカスタマイズすれば見えるようになります。
{ "Sid": "ViewBilling", "Effect": "Allow", "Action": "aws-portal:ViewBilling", "Resource": "*" }IAM ユーザーに自分のアカウントの請求情報の表示を許可する
Slackなど利用できる場合は毎朝コスト通知するbotを設定しておくと、みんな見てくれるようになると思うのでオススメです。インスタンス立ち上げっぱなしやGPUフル稼働させていると見廻隊の誰かが気づいてくれます。月間予算を設定しておくのも大事ですね。
まとめ
本記事ではドコモR&DのKDD Cupへの取り組みとそれを支える技術について紹介しました。
私はどうかわかりませんが、きっと来年のKDD CupにもNTT DOCOMO LABSは参加すると思います。対戦希望の方々は是非参加してみてください。
それではみなさん、良い年末を…
じゃなくて、アドベントカレンダーはまだまだ続きますのでお楽しみに。参考

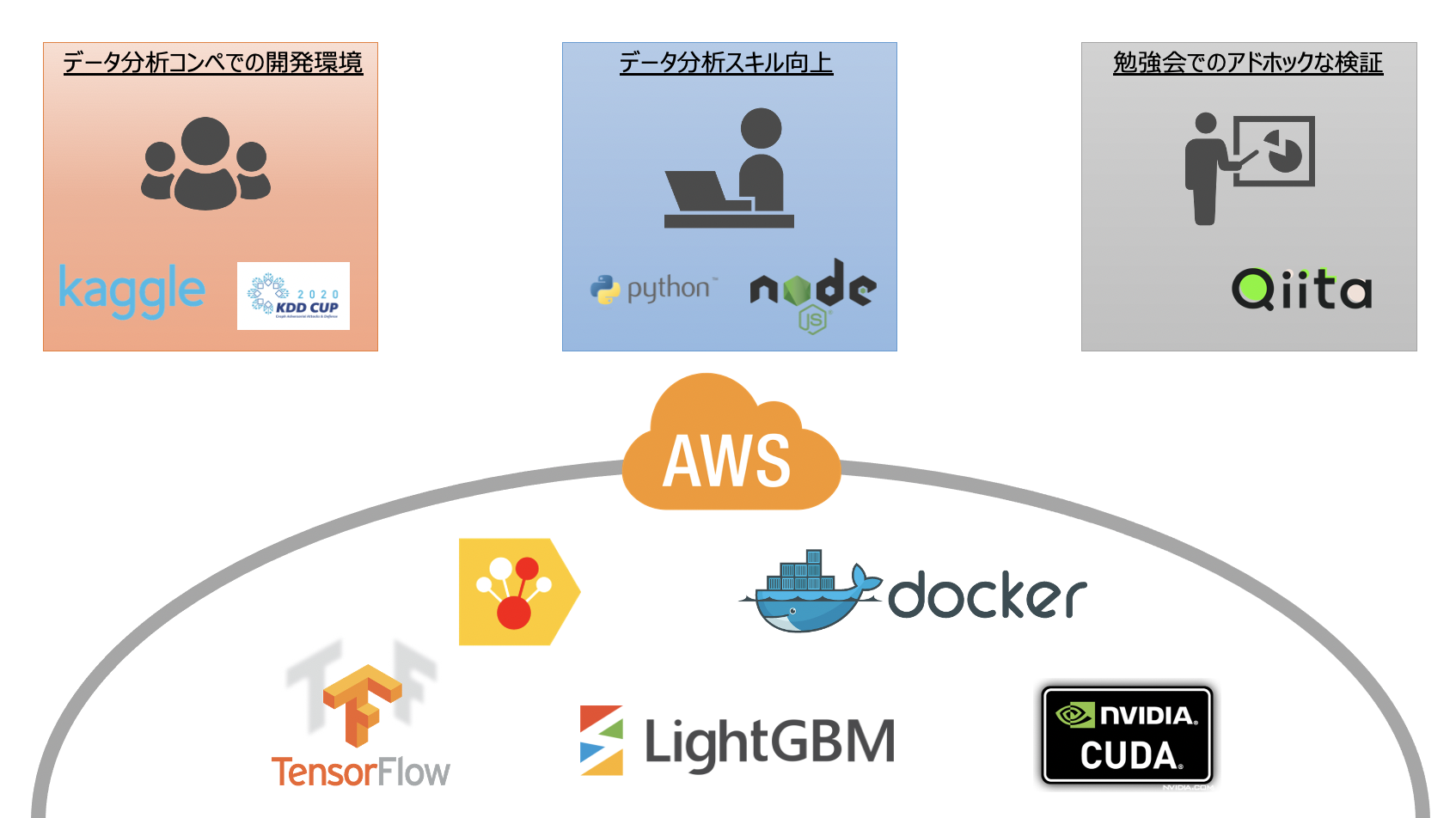

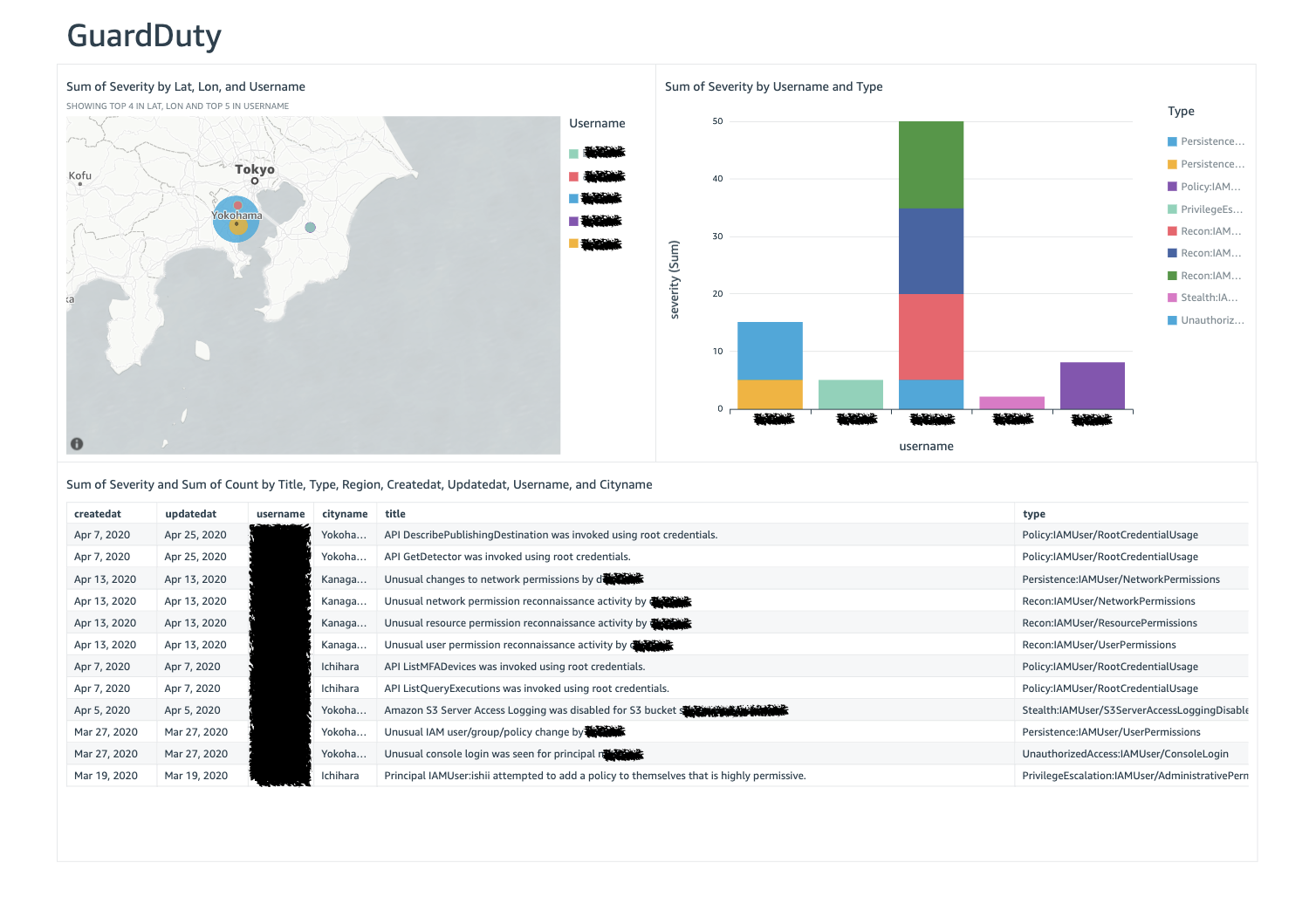
- 投稿日:2020-12-01T03:35:14+09:00
モバイルゲームのコンテキストで考える Lambda@Edge
AWS & Game Advent Calendar 2020 の 6 日目の記事です。
Lambda@Edge 使ってますか
Lambda@Edge (以下 L@E)を使用すると、サーバー管理を何も行わなくても、ウェブアプリケーションをグローバルに分散させ、パフォーマンスを向上させることができます。L@E は、Amazon CloudFront コンテンツ配信ネットワーク (CDN) によって生成されたイベントに対応してコードを実行します。コードを AWS Lambda にアップロードするだけで自動的にコードの実行やスケーリングが行われ、エンドユーザーに最も近い AWS ロケーションでの高可用性が実現します。
https://aws.amazon.com/jp/lambda/edge/ より引用
Amazon CloudFront (以下 CloudFront)のイベントをトリガーとインプットにして AWS Lambda (以下 Lambda)の Lambda Function を実行することができる機能です。
モバイルゲームでは通常、画像、動画、音声などの静的なアセットファイルのモバイル端末への配信に CDN がよく使われます。インストール後のアセット初回 DL で大量/大容量のファイルが端末に DL されるようになっておりゲームのリリース直後に激しいネットワーク通信が発生するケースがありますが、そういったときも CloudFront などの CDN を使っていれば安心です。 1 L@E を活用すると、ファイル DL というこの単純(だがスケーラブル)な機能にロジックを持たせたり、さらにそれに応じてリクエストやレスポンスの内容を書き換える、といったことがある程度可能になります。例えば、こちらの例(注:英語)では、レスポンスヘッダにセキュリティ関連のヘッダを動的に追加することでセキュリティを高める、といった使い方が紹介されています。
モバイルゲームのコンテキストで考える Lambda@Edge
この記事では、モバイルゲームのよくあるユースケースや要件に沿って L@E の利用シーンをいくつか列挙するかたちで紹介します。アーキテクチャや実装の詳細は割愛します。参考 URL をリンクしているものもあるので詳細はそちらを参照してください。
1.プレイヤーのプロフィール画像のサムネを動的に生成したい
え、サムネなんて、アップロードされたら自動で生成されるように Amazon S3 の Event を使っているよって?確かにそれで問題ありませんが、仕様というのは時間とともに変わるものです。必要なサムネのバリエーションが増えたりというのはよくあります。その際に既に存在する元画像全てに対して画像の変換を改めて実施するでももちろん問題ありません。実際にはもう何年も休眠しているプレイヤーの画像に対しては画像の変換と作成は不要かもしれません。L@E による動的な画像生成では、実際に使われる(アクセスのある)画像に対してのみ最初のリクエストで生成しておき以降はそのファイルが参照される、という柔軟な仕組みが可能です。2
L@E は、上図の(1)〜(4)に対応したポイントのいずれかを実行タイミングとして指定します。 (1):
Viewer request, (2):Origin request, (3):Origin response, (4):Viewer response。詳細は Lambda 関数をトリガーできる CloudFront イベント - Amazon CloudFront のドキュメントをどうぞ。
- クライアント端末から画像への HTTP リクエスト
- キャッシュがない場合、CloudFront のエッジがオリジンの S3 Bucket へリクエスト
- 該当のサムネ画像がオリジンにない場合、ステータスコード 400 となるがそれを条件にサムネの生成と S3 Bucket への Put を実行する。以降のアクセスでは、そのサムネに対するオリジンリクエストでは生成されたこのファイルが使用される。
- クライアント端末へ画像がレスポンスされるとともにキャッシュされる。
参考
2.バージョンが古いアプリにも対応するようにレスポンスするファイルを動的に変更したい
アプリをバージョンアップする際は後方互換性を意識したり、アプリ起動時にバージョンアップの強制をフックしたりなどはよく行われる実装かと思います。ただ、それだけではどうしても対応ができないこともあります。そうした際にクライアントアプリ側のバージョン情報に応じて自動的に一部ファイルを切り替えるようなことが可能です。例えば設定ファイルのようなものを対象とすれば、古いクライアントアプリにおいてのみ接続先やふるまいを変えるようなことを構成できます。
- クライアント端末から画像への HTTP リクエスト。クエリストリングや HTTP ヘッダにアプリのバージョン情報が入っている。その値に応じてリクエストする URL パスを書き換える。
- キャッシュがない場合、CloudFront のエッジがオリジンの S3 Bucket へリクエスト。Viewer Request で URL パスを書き換えている場合はこの Origin Request の URL パスも書き換わっている。
- 書き換えられた URL パスに応じた、そのアプリ・バージョンに合わせたファイルをレスポンス。
- 同じくアプリ・バージョンに合わせたファイルをクライアントにレスポンス。
参考
3.プレイヤー個別のアセットファイルを管理する
Application Server がプレイヤーに応じて異なるデータを返す場合に事前の認証・認可を必要とする構成は一般的です。静的なアセットにおいても同様のことをしたいときはないでしょうか?例えば、
- ある有料アイテムを課金したプレイヤー、あるいは特別なクエストを攻略したプレイヤー、など条件を満たしたプレイヤーにのみ見せても良い画像や音声のファイルがある。
- 各プレイヤーが独自にカスマイズやデコレーションした「名刺」や「プレミアムカード」のような画像を作成・DL できる機能があるが、毎回画像生成したくはない。かといってノーガードで CDN から配信し悪意のあるユーザが閲覧できてしまう可能性があるのでは困る。
といったようなユースケースです。こういうケースでは静的ファイルに対する認証・認可を L@E で構成すると便利です。
- 事前ステップ: クライアントは Amazon Cognito などで事前に認証(ログインなど)を行い、Json Web Token (JWT) などの認証トークンを予め受け取っておく。
- クライアント端末からファイルへの HTTP リクエスト。 JWT トークンを Authorization ヘッダや Cookie などに含めておき、 L@E がその正当性を検証し、リクエストされた URL のファイルをレスポンスしてもよいかを判定する。検証に失敗する場合は、キャッシュの有無に関わらず即座に 401 unauthorized をクライアントへレスポンスする。L@E ではレスポンスボディの動的な生成にも対応しています。
- Viewer request で適切に認証・認可されており、かつオリジンが CloudFront の該当ディストリビューション以外からは参照できないように適切に構成されているなら、ここでの特別な処理は不要です。
参考
- Authorization@Edge – How to Use Lambda@Edge and JSON Web Tokens to Enhance Web Application Security | Networking & Content Delivery (英語)
- Guest post: How Space Ape Games delivers secure WebApps using AWS | AWS Game Tech Blog (英語)
4.来週のイベント用の追加キャラの画像を UL しておきたいが、イベント開始前にすっぱ抜かれて公開されると困る
将来のイベント用のアセットを早めに用意しておくと、URL の規則性から見つけられてしまうことがあります。例えば既存のカードの URL が
- .../event/1/card/1.png
- .../event/1/card/2.png
- .../event/1/card/3.png
- ...
- .../event/2/card/1.png
- .../event/2/card/2.png
- .../event/2/card/3.png
- ...
のような Database の サロゲートキーや PK に依存している設計だと、まだ存在しない自然数のうち小さいものを狙えばいいのでけっこう単純です。あるいは以下のようなカード名になっていたり。
- .../card/Knight.png
- .../card/Lancer.png
- .../card/Witch.png
- ...
連番よりは推測しづらいですが、意味のある文字列ではあるのでそのゲームをよく遊んでいる人なら結局はあたりがつけやすかったりします。このような課題に対してよくある既存の解決方法と懸念は以下などです。
- イベント直前にファイル一式を UL する。
→ 直前作業は事故のもとですね。できれば早めに作業しておきたいところでしょう。- 各データのレコードそれぞれに、推測困難なランダム文字列などを登録しておきそれを URL パスに使用する。
→ 生成と登録の手間はまだしも、対応するファイルのアップロードが面倒なうえに、オリジン上のファイルパスやファイル名からどれが何のファイルなのかがぱっと見では内部の人にも分かりません。L@E を使うと上記2つのアプローチをどちらもより一歩改善するアプローチが可能です。
1.については、ファイルの UL 自体は事前に終えておきますが、該当の URL 範囲への Origin Request についてはイベント開始日時(の少し前)までは 404 Not Found を返すように L@E を実装します。該当のアセットの URL が
../event/3/*のように正規表現やワイルドカードなどをつかって L@E のコード上で指定しやすい場合により使いやすい方法です。
イベント開始後の適当なタイミングで、L@E 上の該当ロジックは削除するデプロイをしてもいいですし、さらに次のイベント用に同様のロジックを追加するときに前のイベントのロジックを削除してもよいです。前者のほうがより L@E の利用料金は抑えられます。
2.については、推測困難な文字列としてランダムな文字列を使用する代わりに、もとのデータを特定する値(PKやカード名など)をもとに変換や暗号化をすることで得られる文字列を使用します。その変換ロジックや共通鍵を L@E 上に持たせておき Origin Request で元の値に戻すように実装します。そうすることで、エンドユーザから見える URL は推測困難ながら、オリジン上では今までと同様に可読性のある URL を維持することが可能です。4
参考
まとめ
以上です。もっと色々ありそうですね。あったら教えて下さい。
CloudFront のクォータのドキュメントの確認と必要に応じた「クォータ引き上げのリクエスト」はお忘れなく。 ↩
また、ここではサムネを例にしていますが、プレイヤーがアップロードする画像の加工全般にあてはまるユースケースです。 ↩
この記事では、(1) Viewer request にもう1つ別の L@E を使用して、クライアントからの自由な画像サイズリクエストを対応可能なサイズバリエーションに落とし込むということが行われています。 ↩
共通鍵による暗号化・復号を含めて変換ロジックをエンドユーザが解明してしまう可能性は0ではありません。それを懸念する場合は、やはりランダムな文字列を使用し、それらと元の値のマッピングを DynamoDB などに保持しておき L@E から参照する、という方法も考えられます。 L@E はネットワーク経由で外部のリソースにアクセスすることも可能なのです。 ↩
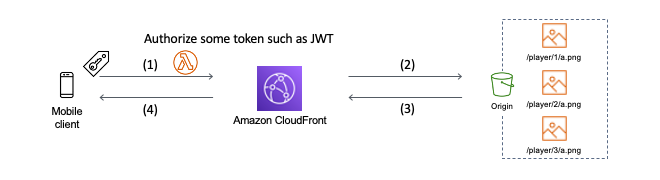
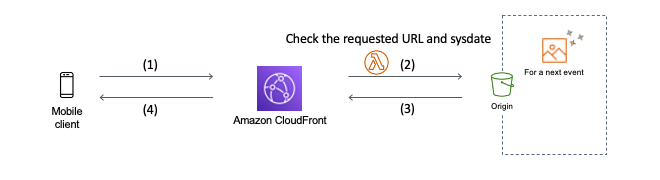
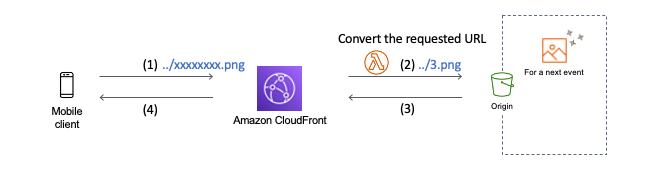
- 投稿日:2020-12-01T03:21:49+09:00
【知識0からのCloudFormation】LambdaをデプロイするCodePipelineを組む
CloudFormationについて知識ゼロ状態から、
APIGateway+Lambda関数をデプロイするCodePipleineを組めるようになるまでの道筋を書き残します。以下のステップで進めます。
(0) まず触ってみる : VPC作成を題材に
(1) Lambda作成
(2) IAMロール作成
(3) コードをS3に配置
(4) API Gateway作成
(5) Swaggerへ移行
(6) CICDパイプラインを作成
(7) Lambda関数のデプロイなお開始時点の理解状況はこんな感じ
- 登場する種々のリソースはコンソールで作成/利用したことはある。
- CloudFormationが何か自体は知ってるが使ったことが無い。
- Code3兄弟は使ったことがある。
(0) まず触ってみる。
以下の記事を参考にVPCを作成してみてCloudFormationmの書き方、スタック作成/削除を学ぶ。
CFnを使ってVPCを作ってみる● わかったこと
- template.ymlに書いた設定でリソースを作成できる。
- yamlファイルからスタックが作成され、作成するリソース郡はスタックごとに管理される。
- スタックを削除するとリソース本体も削除できる。
- スタックの作成時に設定する値はパラメータとしてymlに書いておき、CLI実行時にパラメータとして渡すことができる。
- 以下に種々のリソースを作成する時のお作法が載っている。
AWS_リソースおよびプロパティタイプのリファレンススタックの作成と削除# 作成 $ aws cloudformation deploy --stack-name test-vpc-stack \ --template-file template.yml \ --parameter-overrides \ VpcCIDR=10.0.0.0/16 # 削除 $ aws cloudformation delete-stack --stack-name test-vpc-stack(1) CloudFormationでLambdaを作ってみる。
arn:aws:iam::xxxxxxxxxxxx:role/fugafuga
IAM作成は今回のスコープでは無いのでLambda用のロールを事前にコンソールから作っておく。
ポリシーは空にして権限ゼロ状態。template.ymlAWSTemplateFormatVersion: "2010-09-09" Description: > Lambda template. Parameters: funcName: Type: String Description: > function name. Resources: # Lambda関数作成 Function: Type: AWS::Lambda::Function Properties: Code: ZipFile: > def lambda_handler(event, context): return { 'statusCode': 200, 'body': event } Description: > test cloudformation FunctionName: !Ref funcName # 実行時にパラメータで指定 Handler: index.lambda_handler Role: arn:aws:iam::xxxxxxxxxxxx:role/fugafuga Runtime: python3.8● わかったこと
Lambdaに載せるコードを指定する方法は2通り
- インラインで記述する。
- S3においての参照させる。
インラインでコードを記述する場合
ZipFileとつけてからコードを書く。- ファイル名はindexに固定されるようでHandlerに"index."を付さないといけない。
- nodeかpythonにしか対応していない。
(2) IAMロールも動的に生成してみる。
参照)
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/aws-resource-iam-role.html(1)で生成したLambdaを実行してもCloudWatchLogsにログを書き込む権限を持っていないのでロググループもログストリームも生成できない。
試しに実行結果からログへのリンクを踏んでも存在しないとしてエラーの文言が観察できる。
そこで、AWS管理ポリシーであるAWSLambdaBasicExecutionRoleをアタッチした関数名と同名のIAMロールを生成し、Lambda作成時にアタッチする。template.ymlAWSTemplateFormatVersion: "2010-09-09" Description: > Lambda template. Parameters: funcName: Type: String Description: > function name. Resources: # IAMロール作成 LambdaExecutionRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: "Allow" Principal: # 誰に権限を与えるのか Service: - "lambda.amazonaws.com" Action: # 何の権限を与えるのか - "sts:AssumeRole" # Lambdaに対して一時的な権限を発行する。 ManagedPolicyArns: - "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole" RoleName: !Ref funcName # 実行時に指定 # Lambda関数作成 Function: Type: AWS::Lambda::Function Properties: Code: ZipFile: > def lambda_handler(event, context): return { 'statusCode': 200, 'body': event } Description: > test cloudformation FunctionName: !Ref funcName # 実行時に指定 Handler: index.lambda_handler Role: !GetAtt LambdaExecutionRole.Arn # 上で作成したLambdaExecutionRoleのARNを取得して埋め込む Runtime: python3.8実行すると以下のエラーに遭遇した。
An error occurred (InsufficientCapabilitiesException) when calling the CreateChangeSet operation: Requires capabilities : [CAPABILITY_IAM]
AWS Identity and Access Management によるアクセスの制御
上記公式ドキュメントに従い、実行時にパラメータで--capabilities CAPABILITY_NAMED_IAMと指定する。
!Refの代わりに!Subを使うと文字列内に変数を埋め込むことができるらしい。
(2017年12月時点) 私的 CloudFormation ベストプラクティス(3) コードをS3に配置する。
CloudFormationのインフラ構築用のファイルにソースコードを直書きするのはひどすぎて見てられない。コード部分を分離し、zipしてS3に配置しよう。
S3Bucketでバケット名を指定し、S3Keyでzipファイル名を指定する(拡張子まで記述)。これによりファイル名のindex固定縛りもなくなった。
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/aws-properties-lambda-function-code.htmltemplate.yml抜粋# Lambda関数作成 Function: Type: AWS::Lambda::Function Properties: Code: S3Bucket: hogehoge S3Key: hogehoge.zip FunctionName: !Ref funcName Handler: hogehoge.lambda_handler Role: !GetAtt LambdaExecutionRole.Arn Runtime: python3.8(4) API Gatewayもつける。
サーバレスあるあるなAPI Gateway → Lambda構成を作ってみる。認証もかける。
コンソールからぽちぽちしていると気づかなかったが結構いろんなリソースを生成するためCloudFormationで書くとかなり行数が増える。
- POSTメソッドでRestAPIを作成
- リソースとメソッドの作成
- 使用量プランとAPIキーの生成
- Lambdaとの紐付け(権限付与)
- ステージの作成とデプロイ
参照)
Amazon API Gateway リソースタイプのリファレンスtemplate.yml追加リソースのみ抜粋# API Gateway RestAPI ApiGatewayRestApi: Type: "AWS::ApiGateway::RestApi" Properties: Name: !Sub "${funcName}Api" # API Gateway Deployment ApiGatewayDeployment: Type: "AWS::ApiGateway::Deployment" DependsOn: ApiGatewayMethod Properties: RestApiId: !Ref ApiGatewayRestApi # API Gateway Stage ApiGatewayStage: Type: "AWS::ApiGateway::Stage" Properties: StageName: "v1" RestApiId: !Ref ApiGatewayRestApi DeploymentId: !Ref ApiGatewayDeployment # API Gateway Resource ApiGatewayResource: Type: "AWS::ApiGateway::Resource" Properties: RestApiId: !Ref ApiGatewayRestApi ParentId: !GetAtt ApiGatewayRestApi.RootResourceId PathPart: !Ref funcName # API Gateway Method ApiGatewayMethod: Type: "AWS::ApiGateway::Method" Properties: RestApiId: !Ref ApiGatewayRestApi ResourceId: !Ref ApiGatewayResource ApiKeyRequired: True HttpMethod: "POST" AuthorizationType: "NONE" Integration: Type: "AWS" Uri: !Sub "arn:aws:apigateway:${AWS::Region}:lambda:path/2015-03-31/functions/arn:aws:lambda:${AWS::Region}:${AWS::AccountId}:function:${funcName}/invocations" IntegrationHttpMethod: "POST" IntegrationResponses: - StatusCode: 200 PassthroughBehavior: WHEN_NO_MATCH MethodResponses: - StatusCode: 200 ResponseModels: application/json: Empty # API Key ApiGatewayKey: Type: "AWS::ApiGateway::ApiKey" DependsOn: ApiGatewayDeployment Properties: Name: !Sub "${funcName}ApiKey" Enabled: True StageKeys: - RestApiId: !Ref ApiGatewayRestApi StageName: !Ref ApiGatewayStage # API Gateway UsagePlan ApiGatewayUsagePlan: Type: "AWS::ApiGateway::UsagePlan" Properties: ApiStages: - ApiId: !Ref ApiGatewayRestApi Stage: !Ref ApiGatewayStage Quota: Limit: 100 Period: DAY Throttle: BurstLimit: 10 RateLimit: 2 UsagePlanName: !Sub "${funcName}UsagePlan" # Connect ApiGatewayKey to UsagePlan UsagePlanKey: Type: AWS::ApiGateway::UsagePlanKey Properties: KeyId: !Ref ApiGatewayKey KeyType: "API_KEY" UsagePlanId: !Ref ApiGatewayUsagePlan # Lambda Permission LambdaPermission: Type: "AWS::Lambda::Permission" Properties: FunctionName: !GetAtt Function.Arn Action: "lambda:InvokeFunction" Principal: "apigateway.amazonaws.com"検証
$ curl -X POST https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/v1/fugafuga {"message":"Forbidden"}% $ curl -X POST -H 'x-api-key:scXwN5ZHmT5Ucn8tqRxF83U6BeFBdVWG2VHknQDk' https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/v1/fugafuga {"statusCode": 200, "body": {}}%参考
API Gateway + Lambda のCloudFormationテンプレート
https://github.com/ropupu/apigateway-lambda-cloudformation/blob/master/apigateway-lambda-cf.yml(5) API仕様をSwaggerに書き出す。
Lambda関数と同様にAPIの仕様は外出ししたい。
Swagger+APIGateway拡張形式でymlファイルにエクスポート(swagger.yml)しておきS3に置いて参照させることにする。
(ほんとはswagger.ymlも一から書けって話だが面倒なのでAPIGatewayコンソールから作ってエクスポートしいい感じに修正して使う)● わかったこと
- swagger.ymlで作れるのはAPIリソースまでで、ステージは生成されない。cfnのテンプレートファイルで
Stageを構成する必要がある。- 使用量プランやキーの生成には
Stageができたあとである必要があるのでDependsOn:で依存関係を指定する。AWS::Serverless::ApiやAWS::Serverless::FunctionはSAMのテンプレートなのでcfnの中では使えない。- swagger.ymlをzipにしてみたがエラーした。
template.yml抜粋Parameters: funcName: Type: String Default: fugafuga stage: Type: String Default: v1 s3Bucket: Type: String Default: hogehoge Resources: # API Gateway RestAPI ApiGatewayRestApi: Type: "AWS::ApiGateway::RestApi" Properties: Name: !Sub "${funcName}Api" Body: Fn::Transform: Name: AWS::Include Parameters: Location: !Sub s3://${s3Bucket}/swagger.yml # API Gateway Deployment ApiGatewayDeployment: Type: "AWS::ApiGateway::Deployment" Properties: RestApiId: !Ref ApiGatewayRestApi # API Gateway Stage ApiGatewayStage: Type: "AWS::ApiGateway::Stage" Properties: StageName: !Ref stage RestApiId: !Ref ApiGatewayRestApi DeploymentId: !Ref ApiGatewayDeployment # API Gateway Key ApiGatewayKey: Type: "AWS::ApiGateway::ApiKey" DependsOn: ApiGatewayStage Properties: Name: !Sub "${funcName}ApiKey" Enabled: True StageKeys: - RestApiId: !Ref ApiGatewayRestApi StageName: !Ref stage # API Gateway UsagePlan ApiGatewayUsagePlan: Type: "AWS::ApiGateway::UsagePlan" DependsOn: ApiGatewayStage Properties: ApiStages: - ApiId: !Ref ApiGatewayRestApi Stage: !Ref stage Quota: Limit: 100 Period: DAY Throttle: BurstLimit: 10 RateLimit: 2 UsagePlanName: !Sub "${funcName}UsagePlan" # Connect ApiGatewayKey to UsagePlan UsagePlanKey: Type: AWS::ApiGateway::UsagePlanKey DependsOn: ApiGatewayStage Properties: KeyId: !Ref ApiGatewayKey KeyType: "API_KEY" UsagePlanId: !Ref ApiGatewayUsagePlanswagger.yml--- swagger: "2.0" info: version: "1.0.0" title: Fn::Sub: "${funcName}Api" host: "ilgcfj40u7.execute-api.ap-northeast-1.amazonaws.com" basePath: Fn::Sub: "/${stage}" schemes: - "https" paths: /fugafuga: post: produces: - "application/json" responses: 200: description: "200 response" schema: $ref: "#/definitions/Empty" security: - api_key: [] x-amazon-apigateway-integration: uri: Fn::Sub: "arn:aws:apigateway:${AWS::Region}:lambda:path/2015-03-31/functions/arn:aws:lambda:${AWS::Region}:${AWS::AccountId}:function:${funcName}/invocations" responses: default: statusCode: "200" passthroughBehavior: "when_no_match" httpMethod: "POST" type: "aws" securityDefinitions: api_key: type: "apiKey" name: "x-api-key" in: "header" definitions: Empty: type: "object" title: "Empty Schema"参考
CloudFromationのAWS::Includeを利用してAWS SAMからインラインSwaggerを分離して管理する
CloudFormationでサイズの大きいSwaggerファイルを参照させる方法(6) CI/CDを見据える。
参照)
CodeBuild リソースタイプのリファレンス
CodePipeline リソースタイプのリファレンス現状だと手動でS3にファイルを置いてあげてから手動でデプロイコマンドを実行しないといけない。
CodeCommitへのGit Pushをトリガーにしてデプロイするように試みる(今回はCodeCommitリポジトリは事前にコンソールから用意した)。
リポジトリのファイル構成$ tree . pipe ├── README.md # 使用せず ├── hogehoge.py # 使用せず (※) └── pipeline_settings ├── buildspec.yml └── template.yml※ (1)~(5)で作成したtemplate.ymlでは独自に用意したS3バケットのhogehoge.zipを参照しているので現状では参照されていない。(7)で参照できるようにする。
まずはCodePipelineを通してデプロイできるようにCloudFormationでパイプラインを作成する。(参考記事のほぼコピペ)
pipeline.ymlAWSTemplateFormatVersion: "2010-09-09" Resources: ArtifactBucket: Type: AWS::S3::Bucket BuildProject: Type: AWS::CodeBuild::Project Properties: Name: 'testbuild' ServiceRole: !GetAtt CodeBuildRole.Arn Artifacts: Type: CODEPIPELINE Environment: Type: LINUX_CONTAINER ComputeType: BUILD_GENERAL1_SMALL Image: aws/codebuild/ubuntu-base:14.04 EnvironmentVariables: # buildspec.yml内で使用する環境変数。 - Name: PACKAGED_TEMPLATE_FILE_PATH Value: 'packaged.yml' - Name: S3_BUCKET Value: !Ref ArtifactBucket Source: Type: CODEPIPELINE BuildSpec: pipeline_settings/buildspec.yml # ルート直下にbuildspecがあるなら指定不要。 # デプロイ時のロール。面倒なので全てAdmin権限を与えておく。 PipelineDeployRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: 'Allow' Principal: Service: - 'cloudformation.amazonaws.com' Action: - 'sts:AssumeRole' ManagedPolicyArns: - 'arn:aws:iam::aws:policy/AdministratorAccess' RoleName: 'cfnrole' # パイプラインのロール。面倒なので全てAdmin権限を与えておく。 PipelineRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: 'Allow' Principal: Service: - 'codepipeline.amazonaws.com' Action: - 'sts:AssumeRole' ManagedPolicyArns: - 'arn:aws:iam::aws:policy/AdministratorAccess' RoleName: 'pipelinerole' # ビルド時のロール。面倒なので全てAdmin権限を与えておく。 CodeBuildRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: 'Allow' Principal: Service: - 'codebuild.amazonaws.com' Action: - 'sts:AssumeRole' ManagedPolicyArns: - 'arn:aws:iam::aws:policy/AdministratorAccess' RoleName: 'buildrole' Pipeline: Type: AWS::CodePipeline::Pipeline Properties: Name: 'testpipe' RoleArn: !GetAtt PipelineRole.Arn ArtifactStore: Type: S3 Location: !Ref ArtifactBucket Stages: - Name: Source Actions: - Name: DownloadSource ActionTypeId: Category: Source Owner: AWS Version: 1 Provider: CodeCommit Configuration: RepositoryName: 'pipe' BranchName: 'master' OutputArtifacts: - Name: SourceOutput - Name: Build Actions: - InputArtifacts: - Name: SourceOutput Name: Package ActionTypeId: Category: Build Provider: CodeBuild Owner: AWS Version: 1 OutputArtifacts: - Name: BuildOutput Configuration: ProjectName: !Ref BuildProject - Name: Deploy Actions: - Name: CreateChangeSet ActionTypeId: Category: Deploy Owner: AWS Provider: CloudFormation Version: '1' InputArtifacts: - Name: BuildOutput Configuration: ActionMode: CHANGE_SET_REPLACE RoleArn: !GetAtt PipelineDeployRole.Arn StackName: 'test-pipeline-stack' ChangeSetName: 'test-pipeline-stack-changeset' Capabilities: CAPABILITY_NAMED_IAM TemplatePath: 'BuildOutput::packaged.yml' RunOrder: '1' - Name: ExecuteChangeSet ActionTypeId: Category: Deploy Owner: AWS Provider: CloudFormation Version: '1' InputArtifacts: - Name: BuildOutput Configuration: ActionMode: CHANGE_SET_EXECUTE ChangeSetName: 'test-pipeline-stack-changeset' StackName: 'test-pipeline-stack' RunOrder: '2'buildspec.ymlversion: 0.2 phases: build: commands: - | aws cloudformation package \ --template-file pipeline_settings/template.yml \ --s3-bucket $S3_BUCKET \ --output-template-file $PACKAGED_TEMPLATE_FILE_PATH artifacts: files: - $PACKAGED_TEMPLATE_FILE_PATH - pipeline_settings/* - hogehoge.py discard-paths: yes実行$ aws cloudformation deploy --stack-name test-pipedeploy-stack \ --template-file pipeline.yml \ --capabilities CAPABILITY_NAMED_IAM Waiting for changeset to be created.. Waiting for stack create/update to complete Successfully created/updated stack - test-pipedeploy-stack
● わかったこと
- CodePipelineのデプロイフェーズにCloudFormationを利用できる。
- CreateChangeSetで以前のスタックとの差分を確認(新規スタックの場合は作成)し、ExecuteChangeSetでデプロイを実行する。
- pipelineのStackを先に削除するとデプロイしたStackを削除するロールが削除されるの削除の順に注意する必要あり。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/cloudformation-role-arn-error/ > role/{role-name} is invalid or cannot be assumed- pipelineを作成するorリポジトリにPushすると自動でパイプラインが回りだす。(ややラグがある)
- CodePipelineによりデプロイされたStackを削除する時、中身が空でないS3バケットがあると削除に失敗するので削除してから実行する。
参考
CloudFormationでLambdaの自動デプロイ環境を構築する
https://qiita.com/is_ryo/items/0382d183f514e0d06f4d(7) LambdaのコードをCICDパイプラインに乗せる。
詰まったのはLambdaのコードをどこから取ってくるかの指定方法。(6)ではS3のバケットを別で指定しているがCodeCommitのリポジトリにあるコードを参照してデプロイして欲しい。
CodeBuildの成果物(アーティファクト)はPipelineの中で自動生成したS3バケットに格納しているため、Pipelineの中で動的に取得する必要がある。
パラメータオーバーライドを使用することで実現できる。参考
* [aws-codepipeline] Parameter overrides cannot use Fn::GetArtifactAtt #1588
* CodePipeline パイプラインでのパラメーターオーバーライド関数の使用
* CloudFormationでCodeBuildの出力アーティファクトを使用するにはどうすればよいですか?
* CodePipeLineを使ってLambdaへの自動デプロイ
pipeline.ymlのデプロイステージにパラメータオーバーライドを指定する。pipeline.yml- Name: Deploy Actions: - Name: CreateChangeSet ActionTypeId: Category: Deploy Owner: AWS Provider: CloudFormation Version: '1' InputArtifacts: - Name: BuildOutPut Configuration: ActionMode: CHANGE_SET_REPLACE RoleArn: !GetAtt PipelineDeployRole.Arn StackName: 'test-pipeline-stack' ChangeSetName: 'test-pipeline-stack-changeset' Capabilities: CAPABILITY_NAMED_IAM TemplatePath: 'BuildOutPut::packaged.yml' ParameterOverrides: | { "s3Bucket": { "Fn::GetArtifactAtt" : [ "BuildOutPut", "BucketName" ] }, "s3Key": { "Fn::GetArtifactAtt" : [ "BuildOutPut", "ObjectKey" ] } } RunOrder: '1'Lambdaの設定の方も一部書き換わる。
template.yml#パラメータにs3Bucketとs3keyを受け取る口を用意。 Parameters: funcName: Type: String Default: fugafuga stage: Type: String Default: v1 s3Bucket: Type: String s3Key: Type: String # swagger.ymlもs3Bucketを参照してしまうので一旦はs3バケットのアドレス直書きに修正しておく Resources: # API Gateway RestAPI ApiGatewayRestApi: Type: "AWS::ApiGateway::RestApi" Properties: Name: !Sub "${funcName}Api" Body: Fn::Transform: Name: AWS::Include Parameters: Location: !Sub s3://hogehoge/swagger.yml # コードの参照先を変更。 Function: Type: "AWS::Lambda::Function" Properties: Code: S3Bucket: !Ref s3Bucket S3Key: !Ref s3Key FunctionName: !Ref funcName Handler: "hogehoge.lambda_handler" Role: !GetAtt LambdaExecutionRole.Arn Runtime: "python3.8"上記で指定するとスタックの更新時にパラメータとして設定することができる。
コンソールで確認すると以下に反映されている。
● わかったこと
- ObjectKeyに指定される値はzipファイルになるので中の1ファイルのみを指定してLambdaに乗せるとかはできなそう。 eg.) 以下はむり。
template.ymlFunction: Type: "AWS::Lambda::Function" Properties: Code: S3Bucket: !Ref s3Bucket S3Key: !Sub "${s3Key}/hogehoge.py" # これはムリ FunctionName: !Ref funcName Handler: "hogehoge.lambda_handler" Role: !GetAtt LambdaExecutionRole.Arn Runtime: "python3.8"
API Gatewayの方もS3を参照しているがこちらはCodeCommitからswagger.ymlを取ってくることも難しそう。出力アーティファクトはzipで固められてしまうのでswagger.ymlをtemplate.ymlにインラインで展開できない。なお、単に以下のようにS3の参照先をコメントアウトすると
pipeline_settings以下のファイルがLambda内に含まれていた。
pipelineのInputArtifactsで指定したBuildOutputの中が組み込まれるということなのだろうか?(調査していないため詳細不明)template.ymlFunction: Type: "AWS::Lambda::Function" Properties: # Code: # S3Bucket: !Ref s3Bucket # S3Key: "hogehoge.zip" FunctionName: !Ref funcName Handler: !Ref handler Role: !GetAtt LambdaExecutionRole.Arn Runtime: "python3.8"余談
Artifactに指定したフォルダ名が10文字までしか反映されていないようにうかがえる。
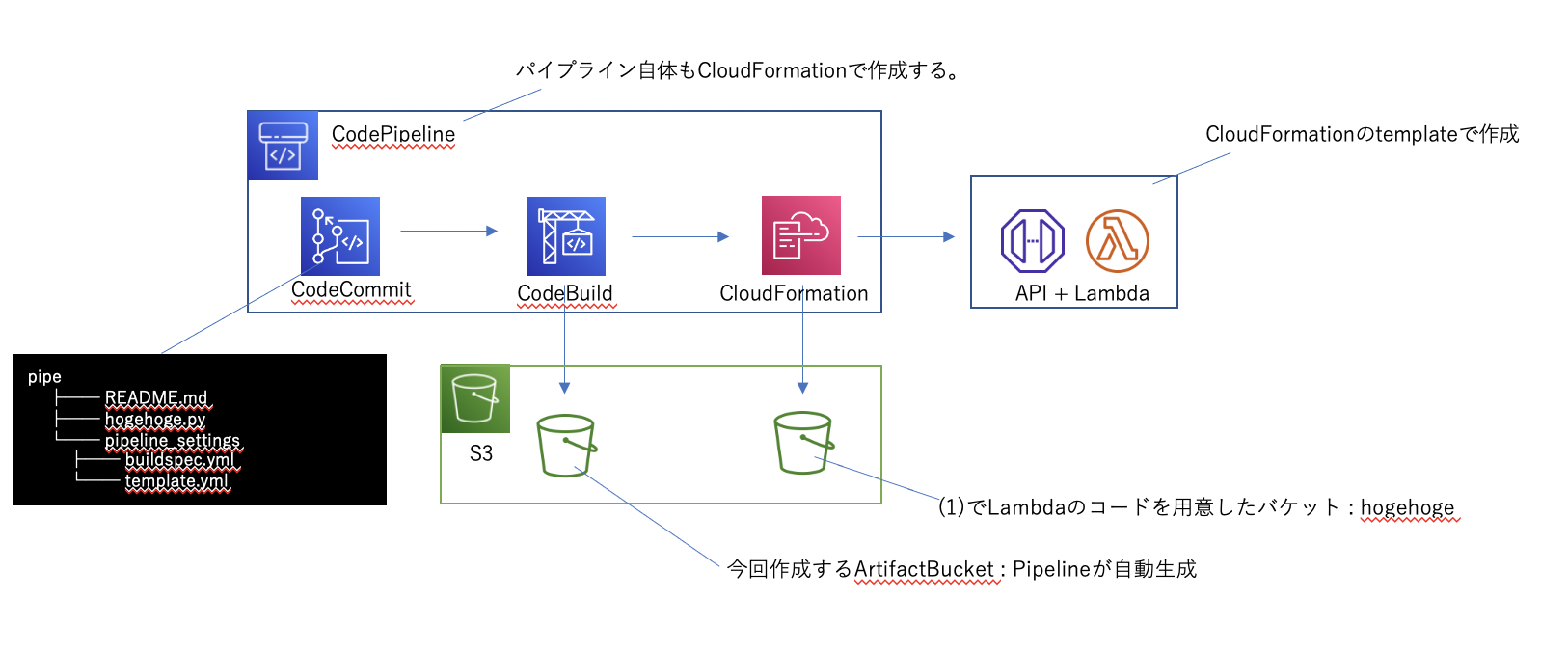
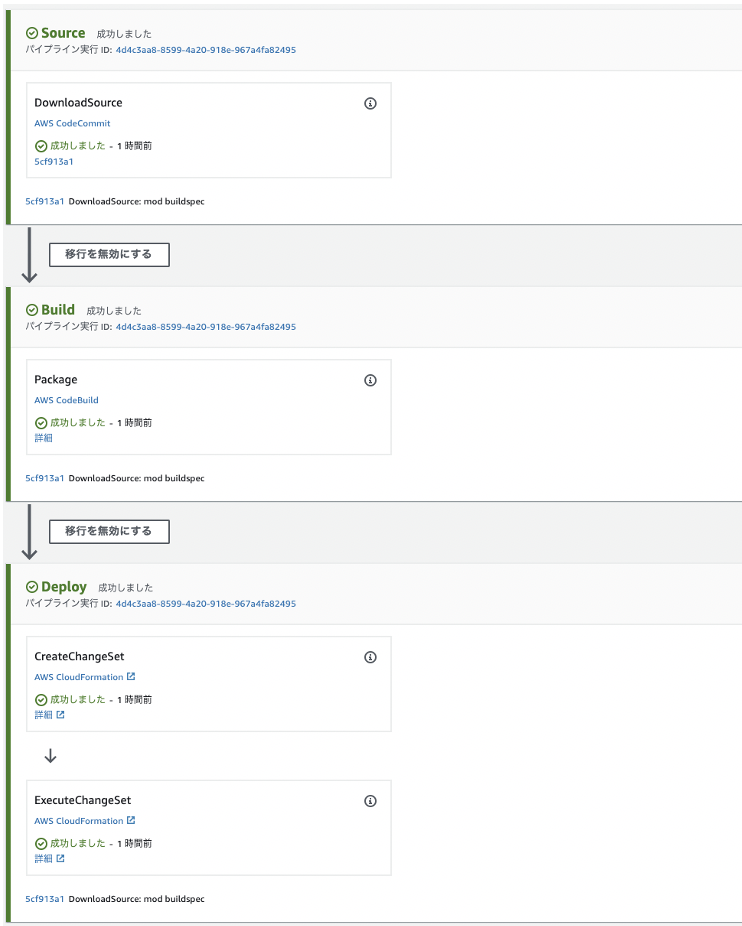
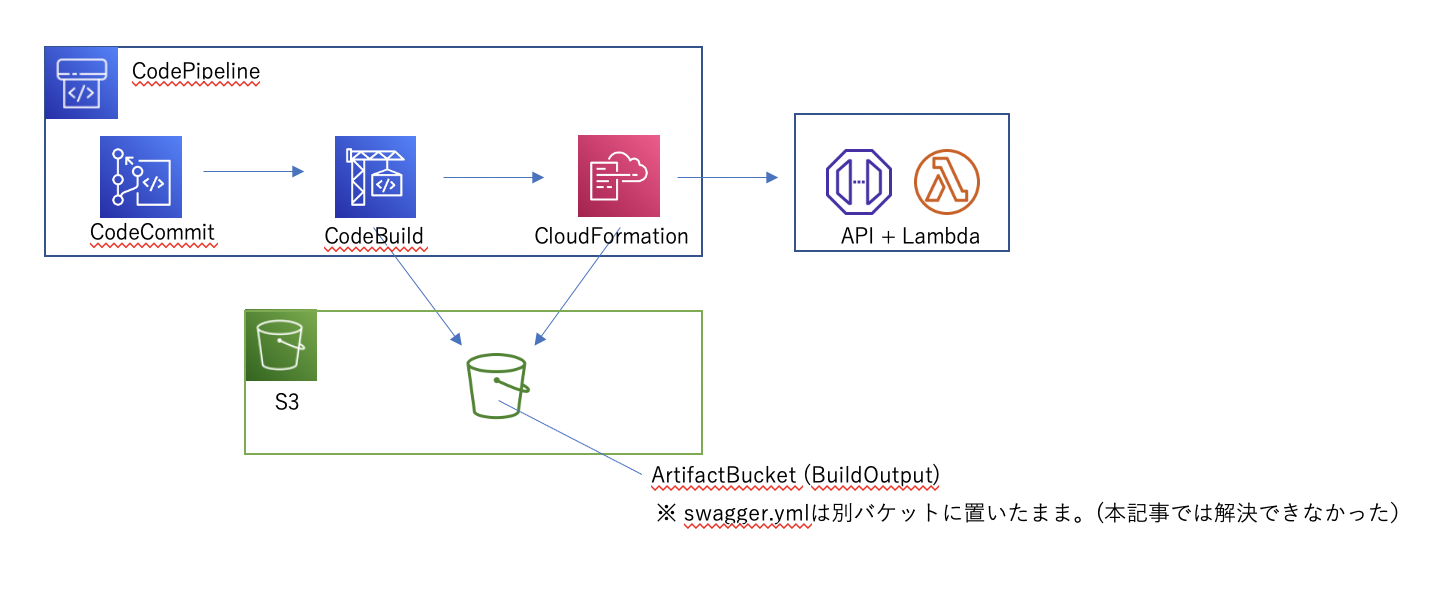
- 投稿日:2020-12-01T02:44:33+09:00
AWS Lightsail(BITNAME) でVirtualhostを作成しサブドメインでNginxで公開
はじめに
AWS Lightsailで初めてBITNAMEを使用した。
クセはないが設定ファイルの場所やsocketファイルの配置先が一般的ものとは違う、気を付けよう。設定方法
Virtualhostにwww.sample.comというサブドメインを紐づけます。
DNSだったりCDNだったりの設定は適宜よろしくです。ディレクトリ作成
雑にディレクトリを作成。
mkdir -p /opt/bitnami/nginx/html/www.sample.comNginxの設定ファイルを変更
以下がサンプル。
設定ファイルは/etc配下にないので注意。
ここから~ここまでを参考にしてください。/opt/bitnami/nginx/conf/nginx.conf# Based on https://www.nginx.com/resources/wiki/start/topics/examples/full/#nginx-conf user daemon daemon; worker_processes auto; error_log "/opt/bitnami/nginx/logs/error.log"; pid "/opt/bitnami/nginx/tmp/nginx.pid"; events { worker_connections 1024; } http { include mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user [$time_local] ' '"$request" $status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log "/opt/bitnami/nginx/logs/access.log"; add_header X-Frame-Options SAMEORIGIN; client_body_temp_path "/opt/bitnami/nginx/tmp/client_body" 1 2; proxy_temp_path "/opt/bitnami/nginx/tmp/proxy" 1 2; fastcgi_temp_path "/opt/bitnami/nginx/tmp/fastcgi" 1 2; scgi_temp_path "/opt/bitnami/nginx/tmp/scgi" 1 2; uwsgi_temp_path "/opt/bitnami/nginx/tmp/uwsgi" 1 2; sendfile on; tcp_nopush on; tcp_nodelay off; gzip on; gzip_http_version 1.0; gzip_comp_level 2; gzip_proxied any; gzip_types text/plain text/css application/javascript text/xml application/xml+rss; keepalive_timeout 65; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_ciphers HIGH:!aNULL:!MD5; client_max_body_size 80M; server_tokens off; include "/opt/bitnami/nginx/conf/server_blocks/*.conf"; # HTTP Server server { # Port to listen on, can also be set in IP:PORT format listen 80; include "/opt/bitnami/nginx/conf/bitnami/*.conf"; location /status { stub_status on; access_log off; allow 127.0.0.1; deny all; } } ## ここから ## server { listen 80; server_name www.sample.com; root /opt/bitnami/nginx/html/www.sample.com; location / { index index.html index.php; } location ~ \.php$ { fastcgi_pass unix:/opt/bitnami/php/var/run/www.sock; fastcgi_index index.php; fastcgi_param SCRIPT_FILENAME $document_root/$fastcgi_script_name; include fastcgi_params; } } ## ここまで ## }再起動
sudo /opt/bitnami/ctlscript.sh restartその他ハマり?ポイント
php-fmp関連
phpを使うために必要なphp-fmp君。
- 設定ファイルは/opt/bitnami/php/etc/php-fpm.d/www.confにある。
- socketファイルは/opt/bitnami/php/var/run/www.sock
- 投稿日:2020-12-01T01:57:40+09:00
Amazon DynamoDBでphpのセッションを管理する
はじめに
AWS DynamoDBでphpのセッションを管理します。
マルチAZの場合、複数のEC2でセッション情報を同期する必要があります。その場合、候補に上がるのが、 DynamoDBかElastiCacheになるはずです。
1. IAMポリシーの作成
EC2インスタンスにアタッチしているロールに、このポリシーを割り当てます。php-sessions{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "dynamodb:GetItem", "dynamodb:UpdateItem", "dynamodb:DeleteItem", "dynamodb:Scan", "dynamodb:BatchWriteItem" ], "Resource": "arn:aws:dynamodb:ap-northeast-1:{AWSのアカウントID}:table/{DynamoDBのテーブル名}" } ] }2. DynamoDBの作成
DynamoDBを作成します。
項目 値 テーブル名 任意 プライマリキー id (文字列) テーブル作成後、「概要->TTLの管理」から、 TTLを有効化にします。
項目 値 TTL属性 expired (任意) 3. EC2インスタンスにphpのSDKをインストールする
EC2インスタンスにcomposerを利用して、phpのSDKをインストールします。:スクリプト # composer設定 EXPECTED_SIGNATURE="$(wget -q -O - https://composer.github.io/installer.sig)" php -r "copy('https://getcomposer.org/installer', 'composer-setup.php');" ACTUAL_SIGNATURE="$(php -r "echo hash_file('sha384', 'composer-setup.php');")" if [ "$EXPECTED_SIGNATURE" != "$ACTUAL_SIGNATURE" ] then >&2 echo 'ERROR: Invalid installer signature' rm composer-setup.php exit 1 fi php composer-setup.php --quiet RESULT=$? rm composer-setup.php sudo mv composer.phar /usr/local/bin/composer sudo yum install -y --enablerepo=remi,remi-php70 php-xml sudo rm composer* composer require aws/aws-sdk-php4. phpからの利用方法
セッション管理用のクラスを作成します。
シングルトンパターンを利用します。SessionDynamoDB.php<?php # 任意のディレクトリに配置したautoload.phpを呼び出す require_once(dirname(__FILE__) . '/autoload.php'); use Aws\DynamoDb\DynamoDbClient; use Aws\DynamoDb\SessionHandler; use Aws\DynamoDb\Exception\DynamoDbException; interface SessionDynamoDBInterface { //インスタンスを生成する。 public static function getInstance(); //ハンドラーを登録する。 public function start(); } class SessionDynamoDB implements SessionDynamoDBInterface { private static $singleton; private $client; private $sessionHandler; /** * DynamoDBクライアント生成 */ private function __construct() { try { $this->client = DynamoDbClient::factory([ 'region' => 'ap-northeast-1', 'version' => 'latest', ]); $this->sessionHandler = SessionHandler::fromClient($this->client, [ 'table_name' => '{DynamoDBのテーブル名}', 'hash_key' => 'id', 'session_lifetime' => 3600, 'consistent_read' => true, 'locking' => false, 'batch_config' => [], 'max_lock_wait_time' => 10, 'min_lock_retry_microtime' => 5000, 'max_lock_retry_microtime' => 50000, ]); $this->sessionHandler->register(); // Start the session session_start(); // // Close the session (optional, but recommended) session_write_close(); } catch(DynamoDbException $e){ throw new DynamoDbException ($e->getMessage()); } } /** * インスタンスを生成する。 * * @return object self::$singleton */ public static function getInstance(): object { if (!isset(self::$singleton)) { self::$singleton = new SessionDynamoDB(); } return self::$singleton; } /** * このインスタンスの複製を許可しないようにする * * @throws RuntimeException */ public final function __clone() { throw new RuntimeException ('Clone is not allowed against ' . get_class($this)); } /** * ハンドラーを登録する。 * */ public function start(): void { $this->sessionHandler->register(); // Start the session session_start(); } }クラスからセッションを利用します。
php実行ファイル# 任意のディレクトリに配置したSessionDynamoDB.phpを呼び出す require_once(dirname(__FILE__) . '/SessionDynamoDB.php'); $session = SessionDynamoDB::getInstance(); $session->start(); # 冒頭に上記の記述をすれば、あとは普通に$_SESSIONを利用するだけです。 var_dump($_SESSION);
- 投稿日:2020-12-01T00:31:14+09:00
SessionManagerでPrivateなEC2にアクセスする
SessionManagerを利用してPrivateなEC2にアクセスする方法です。
NATGatewayかVPCエンドポイントを利用するかになりますが
基本的にはセキュリティ面、コスト面からVPCエンドポイントを利用したほうが
良いケースが多いと思います。SessionManager用VPCエンドポイントの作成
以下の3つのエンドポイントを作成します。
- com.amazonaws.[region].ssm
- com.amazonaws.[region].ec2messages
- com.amazonaws.[region].ssmmessages
それぞれインバウンドでHTTPS(443)を許可します。
基本はこれでSessionManagerの接続が行えるようになりますがS3へのログ保存等を
行う場合などは以下を追加するなど、あとは追加機能に応じて対応ください。
- com.amazonaws.ap-northeast-1.s3
詳細手順は以下公式ドキュメントに記載があります。
Systems Manager を使用してインターネットアクセスなしでプライベート EC2 インスタンスを管理できるように、VPC エンドポイントを作成するにはどうすればよいですか?
注意点
VPCエンドポイントは配置しているだけで課金されますので
テスト後不要になった場合は削除しましょう!!