- 投稿日:2020-11-25T23:47:26+09:00
【保存版】Flaskで画像を操作したいと思ったときの6パターンについて書き分ける
Flask上で画像を操作する場合、ソースコードのパターンとして画像の生成元をどうするかというもので3パターン、画像の最終的な処理方法をどうするかというもので2パターンで組み合わせで合計6パターンがあると思います。この6パターンについてソースコードを書き分ける必要がありますのでそれについて記載します。
画像の生成元の3つとは
- HTMLからFlaskで立てたURLへ直接画像がアップロードされる場合、
- Flaskの関数の中でmatplotlibなどで生成する場合、
- クラウドないしはローカルフォルダなどに保存されている画像を読み込んでくる場合
の3つです。
最終的な処理方法として2つあるというのは、
- 画像をクラウドないしはローカルフォルダなどに保存する場合と
- クライアント側へ画像をreturnする場合
の2つです。画像から例えばOCRで情報を抽出して文字列で返す場合もあると思いますが、これはJSONなどでリターンすればOKなので6パターンに中で対応できると思います。
したがって、Flaskで画像を操作したいと思うと、この6パターンについてソースコードを書き分ける必要があり、かなり大変です。
しかし、幸いなことに、この6パターンのうち画像をどこかに保存する場合とクライアント側へ返す場合については、画像をメモリ上でBlob形式で保持することができれば同時に対応できますので、事実上かき分けなければならないのは3パターンとなります。この3パターンについてサンプルのソースコードを整理したいと思います。ここでは、画像の保存先としてGoogle Cloud Storageを利用した例で説明します。適宜AWSのS3、ローカルのフォルダの場所などと読み替えて下さい。今回記載するサンプルコードは下記の3つです。
1. 画像をFlaskの関数内で生成し、メモリ上でBlob形式で保持したのちにGCSへ保存しクラウアント側へ返す
2. 画像をクラウアントから受け取り、メモリ上でBlob形式で保持したのちにGCSへ保存しクラウアント側へ返す
3. 画像をGSCから読み取り、メモリ上でBlob形式で保持したのちにGCSへ保存しクラウアント側へ返す画像をFlaskの関数内で生成し、メモリ上でBlob形式で保持したのちにGCSへ保存とクラウアント側へ返す
main.py# -*- coding: utf-8 -*- import io import numpy as np import matplotlib import matplotlib.pyplot as plt matplotlib.use('Agg') from flask import Flask, send_file app = Flask(__name__) @app.route('/') def hello(): buf = io.BytesIO() x = np.linspace(0, 10) y = np.sin(x) plt.plot(x, y) plt.savefig(buf, format='png') buf.seek(0) os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = './path/to/your/credential_goole.json' storage_client = storage.Client() bucket = storage_client.get_bucket('your_backetname.com') blob = Blob(filename, bucket) blob.upload_from_string(data=buf.getvalue(), content_type=content_type) return send_file( buf,attachment_filename=filename,as_attachment=True ) if __name__ == "__main__": app.run(debug=True)ポイントは2つあって、一つはmatplotlib.use('Agg')という部分でGUIに対応していないFlaskで動作するようにしていることと、二つ目はsavefigの部分でメモリ上でファイルを書き出していることです。ローカルで動かす場合は、普通にHDD(SSD?)にjpgなどで書き出しても問題ないと思いますが、クラウドなどだとローカルへのアクセスが禁止されていることが往々にしてあります。この場合に備えて、メモリ上でファイルの読み書きを行うioモジュールを使って、ローカルに書き出すことなく画像を出力します。
画像をGSCから読み取り、メモリ上でBlob形式で保持したのちにGCSへ保存とクラウアント側へ返す
次はクラウドからデータを持ってくる場合です。
main.py# coding: utf-8 import os import io import time import string import random import datetime import numpy as np from PIL import Image import cv2 from flask import Flask, render_template, request, redirect, url_for, send_from_directory,send_file from google.cloud import storage from google.cloud.storage import Blob import inspect import numpy as np import cv2 app = Flask(__name__) @app.route("/", methods=["GET", "POST"]) def hello(): os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = './path/to/your/credential_goole.json' storage_client = storage.Client() bucket = storage_client.get_bucket('your_backetname.com') source_blob_name = "path/to/your/file_on_gcs.jpg" #検索する場合はここを使う """ blobs = bucket.list_blobs(prefix="") for blob in blobs: print(blob.name) print(dir(blob)) print(blob.content_type) source_blob_name = blob.name content_type = blob.content_type print(inspect.getfullargspec(bucket.list_blobs)) """ blob = bucket.get_blob(source_blob_name) buf = io.BytesIO() blob.download_to_file(buf) buf.seek(0) destination_blob_name = "path/to/your/file_on_gcs.jpg" blob = Blob(destination_blob_name, bucket) blob.upload_from_string(data=buf.getvalue(), content_type=content_type) return send_file( buf,attachment_filename=source_blob_name,as_attachment=True ) if __name__ == "__main__": app.run()上記ファイルを実行しFlaskサーバが立てたあと、こちらについてはブラウザなどで直接叩いたいただければ問題ありません。
画像をクラウアントから受け取り、メモリ上でBlob形式で保持したのちにGCSへ保存とクラウアント側へ返す
最後のパターンです。
main.py# coding: utf-8 import os import io import time import string import random import datetime import numpy as np from PIL import Image import cv2 from flask import Flask, render_template, request, redirect, url_for, send_from_directory,send_file from google.cloud import storage from google.cloud.storage import Blob import inspect import numpy as np import cv2 app = Flask(__name__) @app.route("/", methods=["GET", "POST"]) def hello(): if request.files['image']: filename = request.files['image'].filename content_type = request.files['image'].content_type # 画像として読み込み stream = request.files['image'].stream img_array = np.asarray(bytearray(stream.read()), dtype=np.uint8) img = cv2.imdecode(img_array, 1) is_success, buffer = cv2.imencode(".jpg", img) buf = io.BytesIO(buffer) #buf = io.BytesIO() buf.seek(0) os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = './path/to/your/credential_goole.json' storage_client = storage.Client() bucket = storage_client.get_bucket('your_backetname.com') blob = Blob(filename, bucket) blob.upload_from_string(data=buf.getvalue(), content_type=content_type) return send_file( buf,attachment_filename=filename,as_attachment=True ) if __name__ == "__main__": app.run()上記ファイルを実行しFlaskサーバが立てたあと、こちらについては画像をHTMLからアップロードする必要があります。
APIを叩いてcanvas要素に描写するHTMLも載せておきますので、こちらを参考にしてください。buf変数に読み込んだものをOpenCVなどで操作すれば簡単な画像処理ソフトになると思います。index.html<!doctype html> <html lang="ja"> <head> <!-- Required meta tags --> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <!-- Bootstrap CSS --> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css" integrity="sha384-ggOyR0iXCbMQv3Xipma34MD+dH/1fQ784/j6cY/iJTQUOhcWr7x9JvoRxT2MZw1T" crossorigin="anonymous"> <script src="https://code.jquery.com/jquery-3.3.1.min.js" crossorigin="anonymous"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.7/umd/popper.min.js" integrity="sha384-UO2eT0CpHqdSJQ6hJty5KVphtPhzWj9WO1clHTMGa3JDZwrnQq4sF86dIHNDz0W1" crossorigin="anonymous"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/js/bootstrap.min.js" integrity="sha384-JjSmVgyd0p3pXB1rRibZUAYoIIy6OrQ6VrjIEaFf/nJGzIxFDsf4x0xIM+B07jRM" crossorigin="anonymous"></script> <title>bootstrapとjquery</title> </head> <body> <main> <article> <section> <input type="button" value="Start" onclick="main();"/> <canvas style="height: 30vw;width:50vh"></canvas> </section> </article> </main> <script language="javascript" type="text/javascript"> function main(){ var canvas = document.getElementsByTagName('canvas'); var ctx = canvas[0].getContext('2d'); var img = new Image(); img.src = 'http://0.0.0.0:5000';//FlaskでホスティングしたURL img.onload = function() { img.style.display = 'none'; // ようわからん console.log('WxH: ' + img.width + 'x' + img.height) ctx.drawImage(img, 0, 0); var imageData = ctx.getImageData(0, 0, img.width*2, img.height*2) for(x = 0 ; x < 1000 ; x += 10) { for(y = 0 ; y < 1000 ; y += 10) { ctx.putImageData(imageData, x, y); } } }; } </script> </body> </html>curlコマンドでForm送信は代替できます。
HTML側はcurlコマンドで代替する方法はこちらFlaskで画像を処理場合のソースコードはパターンごとに書き分ける必要があり、普段は目の前のタスクを終わらせて終わりがちですが、今回は6つのパターンについてまとめました。AWSのS3を使う場合やローカルで完結させる場合も同様に処理できると思いますので、ぜひ参考にしていただけるとうれしいです。
この記事が役に立ったと思ったらLGTMお願いいたします
- 投稿日:2020-11-25T23:07:34+09:00
DPさん、お手柔らかに
こんばんは(;´・ω・)
前回、ここ で最後に DP に触れてみましたが、
今一 ピンと来なかったので、もうちょっとカジってみます(*´з`)9初心者なので、早速ググってみると
"分からない"、
"壁"、
"登竜門"
とか色々、一緒に出てきました。
やっぱり皆、一度はハマるんですね。取りあえず、やってみましょう。
初級問題:与えられた要素を任意に組み合わせて最大値を求めてみます。Combination_DP.pyN = 3 # 要素数 A = [7,-6,9] #要素 memo = [0]*(N+1) # 要素数 + 1 のメモを 1 行(all 0)を用意 for i in range(N): memo[i+1]=max(memo[i],memo[i]+A[i]) print(memo[N])#回答の表示for 文は何をしているのでしょうか?
一個ずつ追って見ましょう。i = 0 のとき
memo[0] には 0 が格納されていますが、
memo[0] + A[0] = 0 + 7 と比べると何方が大きいでしょうか?
勿論、後者ですよね。
計算結果は memo[1] に 7 を格納します。
i = 1 のとき
memo[1] にある 7 と
memo[1]+A[1] の 1 とでは、どちらが大きいでしょうか?
前者ですよね?
この結果は memo[2] に格納します。
i = 2 のとき
memo[2] にある 7 と
memo[2] + A[2] の 16 はどちらが大きいですか?
はい、結果を格納します。
最後に memo[3] を表示すれば回答にたどり着けます。
御覧の通り、計算結果を次のセルに渡すので、最終的には
計算したい要素数 + 1 のメモが必要です。
個人的には、以下のような書き方もあると思います。Combination_DP.pyN = 3 A = [7,-6,9] memo = [0]*(N) memo[0] = A[0] for i in range(1,N,1): memo[i]=max(memo[i-1],memo[i-1]+A[i]) print(memo[N-1])上記は memo[0] に初期値を入れて、
for 文をmemo[1]から始めています。
こうすることで、ひとつ前の値(= i-1)を参考に、
今の値(= i ) を算出することが出来ます。へー( ゚Д゚)
っとなったところでググって次なる問題を探した所、
こちらに出会いました。
分かり易くて感謝のコメントを思わず捧げてしまいました。早速、カエル問題にチャレンジしました。
min_cost.pya = [2,9,4,5,1,6,10] N = len(a) memo = [0]*(N) for i in range(1,N,1): memo[i]=memo[i-1]+abs(a[i-1]-a[i]) if i > 1 : memo[i] = min(memo[i],memo[i-2]+abs(a[i-2]-a[i])) print(memo[N-1])有識者の皆様は初期化する意味で、INF を全セルに代入し、
+1 で移動するときのコストと比較して小さい方を上書き。
そのあとに +2 で移動するときのコストを比較して、
小さければ上書きし最終セルを出力されています。個人的には、All 0 初期値とし、
+1 のコストをいきなり上書きしても問題ないと思います。
なぜなら、最初に必ず+1 で移動した場合のコストを埋めてから、
+2 の移動コストと比較しないと問題が解けないからです(笑)
もう一つの書き方も試しました。Combination_DP.pya = [2,9,4,5,1,6,10] N = len(a) memo = [0]*(N) for i in range(N-1): memo[i+1]=memo[i]+abs(a[i+1]-a[i]) if i >= 1 : memo[i+1] = min(memo[i+1],memo[i-1]+abs(a[i+1]-a[i-1])) print(memo[N-1])私は冒頭にあるメモの概念と、
以下のアプローチをイメージ出来たら理解した気分になれました(笑)Step 1. +1 のコストを最初に memo
Step 2. +2 のコストと Step 1 で求めた memo を比較して小さい方の値を上書きまだまだ、足を踏み入れたばかりなので、
もう少し違う問題も挑戦しようと思います。



- 投稿日:2020-11-25T23:07:05+09:00
pythonエンジニア認定基礎試験に合格した
python認定エンジニア試験を受験しようと思ったきっかけ
面接でpythonを使ってアンケートを分析したことがあると言った際に、面接官の方から「python認定エンジニア試験を受験してみたら?」と勧められたので。
勉強を始める前のレベル
PyQと言うpythonを学べるサイトでpythonの文法やデータ分析について一通り学んでおり、基礎的な知識は身に付いている程度。ただ、文法は自信がないものの、pythonを使っての分析は実際に使えるレベル。
勉強方法
pythonチュートリアルを読みながら、理解できないコードを実際に動かしながらやってました。テキストにあるコードを頭の中でどのような処理がされるのか、を自分で理解するまで動かしました。デバック機能を使いまくり、とにかく納得するまでやるのが良いかなと思います。
一通りテキストを読んで、コードを動かしたあとは公式ホームページにある模擬テストを一日一回やってました。間違えた問題をどこが間違っているのか、なんで正解したのかを徹底的に分析したのが重要だと思います。あと、問題は必ずテキストを基に作られているので、間違えた問題を参考にテキストにマーカーを引いて、後日見直しをしました。実際に受験して
1000点中の900点でした。残りの100点、何を間違えてたんだ。時間は60分ありますが、見直ししても30分ほど余裕がありました。すぐに結果がわかるので、終了のタイミングを伸ばし伸ばしにしてしまいます笑
受験日は会場によってはほぼ毎日受けられるところもあるので要確認です。一番最初に受験日を決めて勉強するのが良いと思います。
- 投稿日:2020-11-25T23:05:31+09:00
Window環境でなるべく汚さずPython環境を乱立させる。
0. はじめに
0-1. やること
Windowsで出来る限り環境を汚さず、Python環境を乱立させます。
0-2. 動作検証環境
Window 10 Pro Ver 1909 (Build 18363.1198)
1. 手順
1-1. 作業フォルダの作成
お好みでフォルダを作成する。
C:\Python ├ env ←Python格納フォルダ └ project ←スクリプトファイル(*.py)格納フォルダ1-2. Pythonのダウンロード
以下のURLより、使用したいバージョンの「embeddable zip file」をダウンロードする。
例:python-3.8.6-embed-amd64.zip
https://www.python.org/downloads/windows/
1-3. 資材の格納
ダウンロードしたzipファイルを解凍し、envフォルダ配下に格納する。
env直下にpython.exe等を配置するのではなく、お好みの環境名称のサブフォルダを切って格納してください。
以下の例では、「python-3.8.6」という名称のフォルダ配下に個々のファイルがあるイメージです。C:\Python ├ env │ └ python-3.8.6 ←例えば、「python-3.8.6」という名称のフォルダにして格納する。 └ project1-4. 起動用batの作成
デスクトップ等、起動しやすい場所に以下を作成する。
1-3で作成した環境名(フォルダ名)をbatファイル名にしてください。python-3.8.6.bat@echo off cls set envname=%~n0 set work_dir=C:\Python\project set python_dir=C:\Python\env\%envname% set script_dir=C:\Python\env\%envname%\Scripts set PATH=%python_dir%;%script_dir%;%PATH% cd /d %work_dir% cmd /k title %envname%1-5. pipのインストール
1-5-1. get-pip.pyの取得
以下のURLよりget-pip.pyをダウンロードし、projectフォルダに格納する。
https://bootstrap.pypa.io/get-pip.pyC:\Python ├ env │ └ python-3.8.6 └ project └ get-pip.py1-5-2. コンフィグ修正
C:\Python\env\python-3.8.6\python38.pthをテキストエディタで開き、5行目のコメントアウトを解除(#を削除)する。
フォルダ名・環境名は適宜読み替えてください。
python**.pthの*はPythonのバージョンにより異なります。
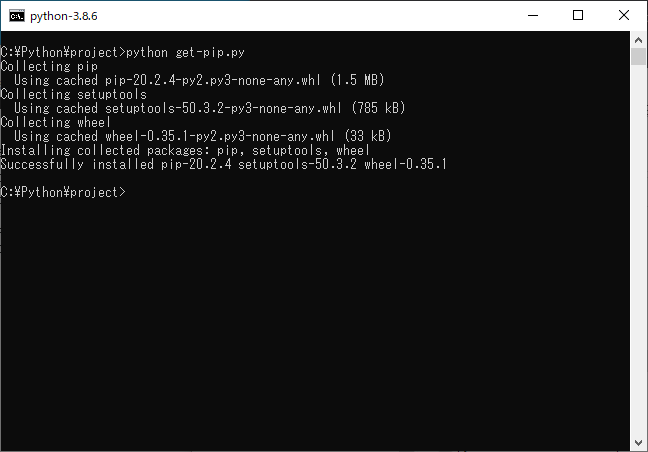
(Python 3.8.ならpython38.pth、Python 3.9.*ならpython39.pth)1-5-3. get-pip.pyの実行
で作成したbatを起動し、pipをインストールする。
> python get-pip.py
1-6. 環境を乱立させる!
同様の手順でenv配下にお好きな環境を作成する。
削除したければフォルダ削除でOK。
環境の起動(切り替え?)は1-4で作成するbatの選択を変えるだけ。
(batのフォルダ名とenv配下のフォルダ名を合わせるだけ)C:\Python ├ env │ ├ python-3.8.6 │ ├ python-3.7.9 │ ├ myenv1 │ ├ myenv2 │ └ myenv3 └ project └ get-pip.py2. ポイント
- embeddable版にはインストール版と異なる制約もありますが、ちょっと触ってみるくらいであれば問題なさそうです。
- python資材そのものを分けて使用する為、venv等の仮想機能は使用しません(できません)。その代わり、バージョン自体を混在させる(Python 3.7とPython 3.8等)ことは容易です。
- 資材を置くだけなので本来はフルパスで呼び出すかパスを通さないと実行できません。この手順内ではbatで環境変数をいじっていますが、同プロンプト内でしか有効になりません。(故に環境を汚しません)
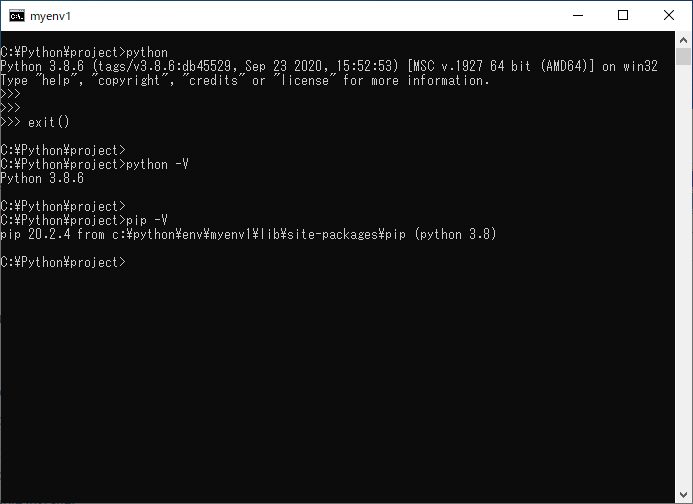
- 意図した環境が動いているか自信がない場合には、pip -Vコマンドを実行すればインストール先フォルダパスも表示されるので確認できます。(一応コマンドプロンプトの枠にも表示しています。)
- 環境名(フォルダ名)を変更した場合には、pipを再インストール(get-pip.pyを再実行してください。
- project配下に自作のスクリプトを格納していくイメージです。同フォルダ内の別スクリプトファイルをimportする場合には、適切にパスを追加するか、各環境のフォルダ直下に以下のpthファイル(ファイル名は任意)を作成しておけば解消できるようです。
current.pthimport sys; sys.path.append('')
3. 参考
Windowsで環境を極力汚さずにPythonを動かす方法 (Python embeddable版)
https://qiita.com/rhene/items/68941aced93ccc9c3071
超軽量、超高速な配布用Python「embeddable python」
https://qiita.com/mm_sys/items/1fd3a50a930dac3db299

- 投稿日:2020-11-25T23:05:24+09:00
Flaskで作るSNS Flask(Template)編
初めに
Udemyの下記講座の受講記録
Python+FlaskでのWebアプリケーション開発講座!!~0からFlaskをマスターしてSNSを作成する~
https://www.udemy.com/course/flaskpythonweb/この記事ではFlaskのView側(Template側)について記載する。
Flaskとは
- PythonのWebフレームワーク
MVT(モデル・ビュー・テンプレート)
Model:データ挿入、更新、削除など、データベースにアクセスする処理を実行する。
View:ユーザーの入力を受け付け、処理に必要なモデルを呼び出し、その結果をTemplateに渡す。
Template:Viewから渡されたデータをもとに動的にページを作成してユーザーに結果を表示する。
Tutorial
from flask import Flask app = Flask(__name__) @app.route('/') def index(): return '<h1>Hello World!</h1>' if __name__ == '__main__': app.run(host='0.0.0.0', port=5000, debug=True)
hostには’0.0.0.0'を指定する。ただし、'0.0.0.0'はどんな接続でも受け入れる状態のことで、厳密には有効なアドレスではないらしい。
'0.0.0.0'と同様に、'127.0.0.1'というhostもよく利用される。
'127.0.0.1'は、自分自身を指すIPアドレスである。そのため、自分自身のサービスが動作しているかどうかを確認したり、自分自身のコンピュータ上で動作しているサービスへ接続する場合に利用したりできる。どちらのhostアドレスもURL上'localhost'に置き換えて接続できる。
debug=True によるデバッグ
app.run()にデバッグオプション"debug=True"を設定することで、エラーが発生した時にブラウザにエラーの詳細が表示されるようになる。
水色の行にカーソルを当てると、右端にコンソールのアイコンが表示される。
このアイコンを選択して表示される画面に、コンソールに表示されているPINを入力すると、ブラウザ上でコンソール入力によるデバッグが可能となる。・Browser
・Console
・Debug
ルーティング
#1つのメソッドにルーティングを複数指定することも可能 @app.route('/') @app.route('/hello') def index(): return '<h1>Hello World!</h1>' #URLのパラメータに応じて表示を変更する @app.route('/post_name/<post_name>') def show_post_name(post_name): print(type(post_name)) return '<h1>{}</h1>'.format(post_name) #パラメータのデータ型をして可能(デフォルトはstring) #指定したデータ型以外が渡された場合はNotFoundになる。 @app.route('/post_id/<int:post_id>') def show_post_id(post_id): print(type(post_id)) return '<h1>{}</h1>'.format(post_id) #ルーティングで複数のパラメータを取得することも可能 @app.route('/post_data/<int:post_id>/<post_name>') def show_post_data(post_id, post_name): return '<h1>{}`s id = {}</h1>'.format(post_name, post_id)テンプレート
- Flaskで利用するHTMLファイル。
- Jinjaというライブラリを使用している。
- Templatesフォルダ配下に格納する。
- "render_template()"メソッドで処理で使用するテンプレートファイルを指定する。
@app.route('/') def index(): return render_template('index.html')
- テンプレートを格納するフォルダ名は基本的に”Templates"だが、別名に変更したい場合は、appにFlaskを代入する際に変更後のフォルダを指定する。
#テンプレートを格納するフォルダを'Template_2'に変更する例 app = Flask(__name__, template_folder='Template_2'テンプレートへの引数の受け渡し
- Template側では、受け取った変数を表示する箇所を"{{ 変数名 }}"と記入する。
- スクリプト側では、render_template()でテンプレートの後にカンマ区切りで"テンプレート側変数名=スクリプト側変数名"の形式で記入する。
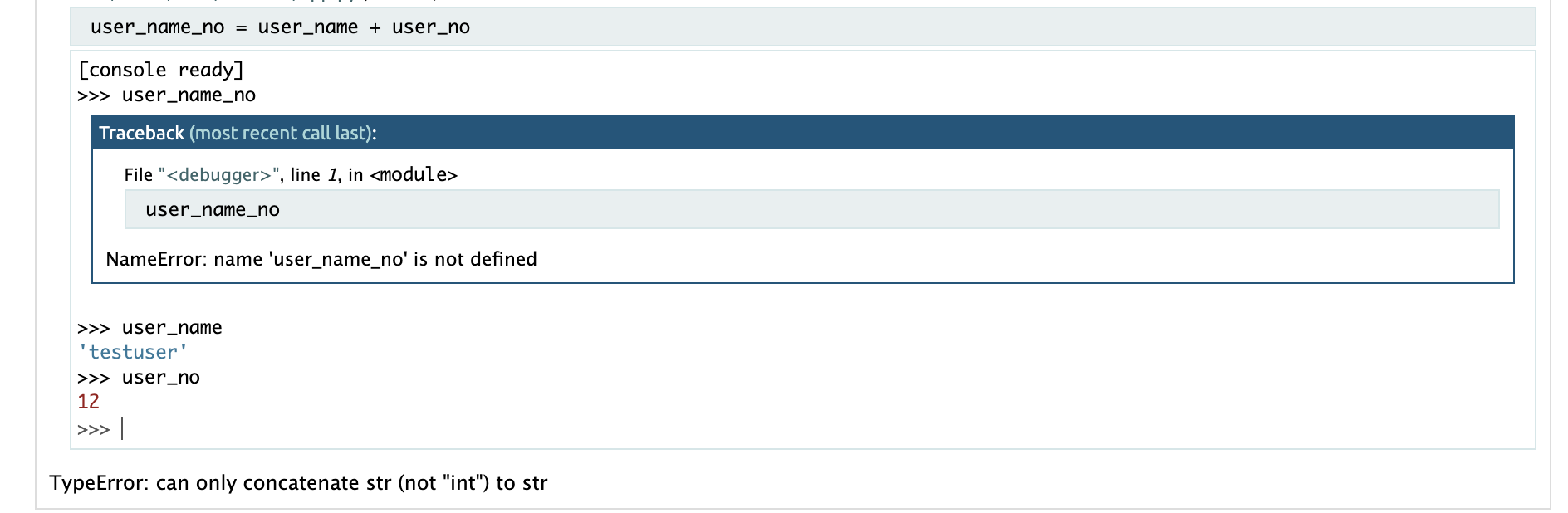
@app.route('/home/<string:user_name>') def home(user_name): login_user = user_name return render_template('home.html', user_name = login_user)辞書型変数を使用する場合
@app.route('/home/<string:user_name>/<int:age>') def home(user_name, age): login_user ={ 'name': user_name ,'age': age } return render_template('home.html', user_info = login_user)<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Flask Page</title> </head> <body> <h1>{{user_info.name}}({{user_info['age']}})さんがログインしました</h1> </body> </html>辞書型変数から特定の要素を取得する場合は、以下どちらの形式でも良い。
- 辞書変数名.キー
- 辞書変数名[キー]
テンプレート内への制御構文埋め込み
- {% %} : if,forなどの制御構文埋め込み
- {{ }} : 変数の埋め込み
- {# #} : コメント
def user_list(): users = ['Taro2','Jiro','Sabro','Shiro'] is_login = True return render_template('userlist.html', users = users, is_login = is_login)<body> <ul> {% for user in users %} <li>{{ user }}</li> {% endfor %} </ul> {# 制御構文に終了タグが必要になる。(endfor, endifなど) #} {% if is_login %} <p>ログイン済みです</p> {% else %} <p>ログインしていません</p> {% endif %} {% if 'Taro' in users %} <p>Taro is Exist.</p> {% endif %} </body>テンプレートの継承
- 継承元テンプレートに"{% block content %} --- {% end block %}"
- 継承先テンプレートに"{% extend '継承先テンプレート' %} --- {% block content %} --- {% end block %}"
- "content"はブロックごとに異なる名称を設定する。継承元に定義されているブロックと同じ名称が設定されている継承先のブロックが反映される。
- 継承元の要素利用したい(例えば、継承元の"title"タグに記載されている内容を継承先でも行事したい場合)は、"{{ super() }}"タグを利用する。
#base.html <!-- 継承元 --> <html> <head> <!-- 継承元の要素を利用したい場合は、"{{ super() }}"を使用する。 --> {% block title %}{% page_title %}{{ super() }} {% endblock %} </head> <body> {% block content %} ここに継承先ファイルの内容が埋め込まれる {% endblock %} </body> </html> #sub.html <!-- 継承先 --> {% extends "template.html" %} {% block content %} ここに継承先ファイルに埋め込む内容を記入する {% endblock %} {% block subcontent %} 複数ブロック存在する場合は異なるブロック名称を設定する。 {% endblock %}継承元
<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>{% block title %}MyPage{% endblock %}</title> </head> <body> {% block content %} {% endblock %} </body> </html>継承先
{% extends 'base.html' %} {% block title %}Index {{ super() }}{% endblock %} {% block content %} <h1>Hello From Flask, HTML</h1> {% endblock %}結果
赤枠内でsuper()を使用することで継承先で指定した文字だけでなく継承元の要素であるもじもはんえいされていることが確認できる。フィルター
- "{% 変数 | フィルター %}"の形式で記載することで、変数そのものは変更せずに、表示だけフィルターで処理した結果を表示することが可能。
- "{% filter filter名%} {% block contetnt %}~{%endblock%} {% endfilter %}"とすることで、ブロック全体にフィルターの効果を反映することができる。
{# ブロック単位でフィルターを適用する場合 #} {# {% filter upper %} #} {% block content %} {# 個別にフィルターを適用する場合 #} <h1>Hello From Flask, HTML</h1> <!-- 大文字 --> <h1>{{ "Hello From Flask, HTML on filter-upper" | upper}}</h1> <!-- 文頭のみ大文字 --> <h1>{{ "Hello From Flask, HTML on filter-capitalize" | capitalize}}</h1> <!-- 単語の先頭のみ大文字 --> <h1>{{ "Hello From Flask, HTML on filter-title" | title}}</h1> <!-- 小文字 --> <h1>{{ "Hello From Flask, HTML on filter-lower" | lower}}</h1> <!-- 変数に値が設定されていない場合のデフォルト値 --> <p>{{ user|default("valiable user does not Exist") }}</p> <!-- urlのリンク化。(target="_blak")追加で新規タブで開く --> <p>{{ 'jinja : https://jinja.palletsprojects.com/en/2.11.x/' | urlize(target="_blank")}}</p> {% endblock %} {# {% endfilter %} #}{% block content %} <h1>先頭の人:{{users | first}}</h1> <h1>最後の人:{{users | last}}</h1> <h1>ソートして先頭の人:{{users | sort | first}}</h1> <h1>ランダム:{{users | random}}</h1> <ul> {# フィルタで逆順にソートしてセットする #} {% for user in users | reverse %} {# userの"Ta"を"Go"に置換 #} <li>{{ user | replace('Ta', 'Go')}}</li> {% endfor %} </ul> {# 制御構文に終了タグが必要になる。(endfor, endifなど) #} {% if is_login %} <p>ログイン済みです</p> {% else %} <p>ログインしていません</p> {% endif %} {% if 'Taro' in users %} <p>Taro is Exist.</p> {% endif %} {% endblock %}カスタムフィルター
独自のフィルターを作成する事ができる。
作成したフィルタの使用方法は組み込みフィルタと同様。from datetime import datetime #文字列を反転させるフィルタ @app.template_filter('reverse_name') def reverse(name): return name[-1::-1] @app.template_filter('birth_year') def calc_birth_year(age): now_timestamp = datetime.now() return str(now_timestamp.year - int(age)) + '年'<!-- 誕生年を表示する(birth_year) --> {% for user in users %} <li>{{user.name}} {{user.age}} born at {{user.age | birth_year}}</li> {% endfor %} {% for user in users | reverse %} <!-- userの"Ta"を"Go"に置換 --> <li>{{ user | reverse | replace('Ta', 'Go')}}</li> {% endfor %}画面遷移・エラーハンドリング
指定した関数のページに遷移 <a href="{{ url_for('index')}}">New page </a> <!-- app.pyの下記関数のこと @app.route('/') def index(): return render_template('index.html') --> 画像ファイルを表示(静的ファイルを読み込む場合は第1引数は'static'とする) <img src="{{ url_for('static', filename=ファイルパス}}">from flask import Flask, render_template, redirect, url_for, abort #リダイレクト return redirect(url_for('info', variable='man')) #指定したエラーを発生させるメソッド #設定したメッセージはエラーハンドラーで"error.description"とすることで取得可能 abort(エラー番号, メッセージ) #エラーハンドラー(エラー発生時に関数を呼び出す) #関数の引数にはエラーオブジェクトを渡すことが必須。(引数名は任意) #’エラー番号'にはコンソールに表示されているエラー番号を設定する。 @app.errorhandler(エラー番号) def page_not_found(e): return render_template('not_found.html')[,サーバーに返すエラー番号(ステータスコード)]例1
@app.route('/user/<string:user_name>/<int:age>') def user(user_name, age): if user_name in ['Taro','Jiro','Saburo']: #homeメソッドのurlにリダイレクトする return redirect(url_for('home', user_name=user_name, age=age)) else: #特定のエラーを発生させる abort(500, 'リダイレクト不可のユーザー') @app.errorhandler(500) def system_error(error): #上記abortメソッドで設定したメッセージを取得する。 error_description = error.description return render_template('system_error.html', error_description=error_description), 500例2
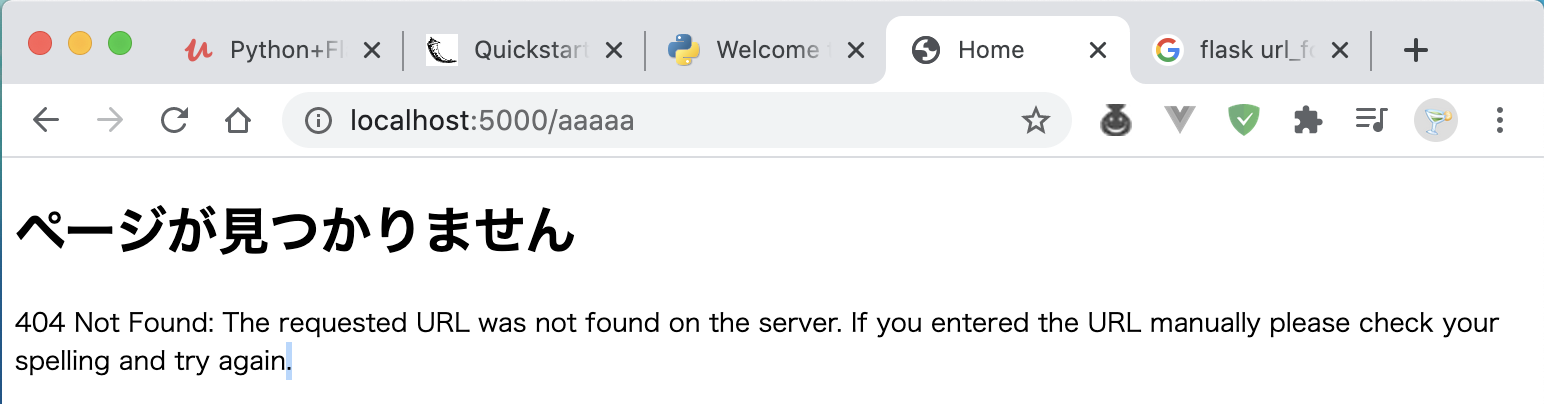
@app.errorhandler(404) #引数にerrorオブジェクトは必須 def page_not_found(e): #404エラー発生時に以下のテンプレートページを開く。戻り値として404を返す。 return render_template('page_not_found.html', error=e), 404{% extends 'base.html' %} {% block title %}Not Found{% endblock %} {% block content %} <h1>ページが見つかりません</h1> <p>{{ error }}</p> {% endblock %}結果
Form
Templateに作成している入力フォームから送信されたリクエストを取得する。
#リクエストデータを取得するモジュール from flask import request #GETリクエスト var = request.args.get('フォーム名') #POSTリクエスト var = rwquest.form.get('フォーム名') #リクエストのタイプを確認する(GETかPOSTか) request.method #関数が受け付けるリクエストのタイプを指定する(デフォルトは'GET') @app.route('/',methods=['GET','POST']例
@app.route('/home') _def home(): print(request.full_path) print(request.method) print(request.args) return render_template('home.html')実行結果
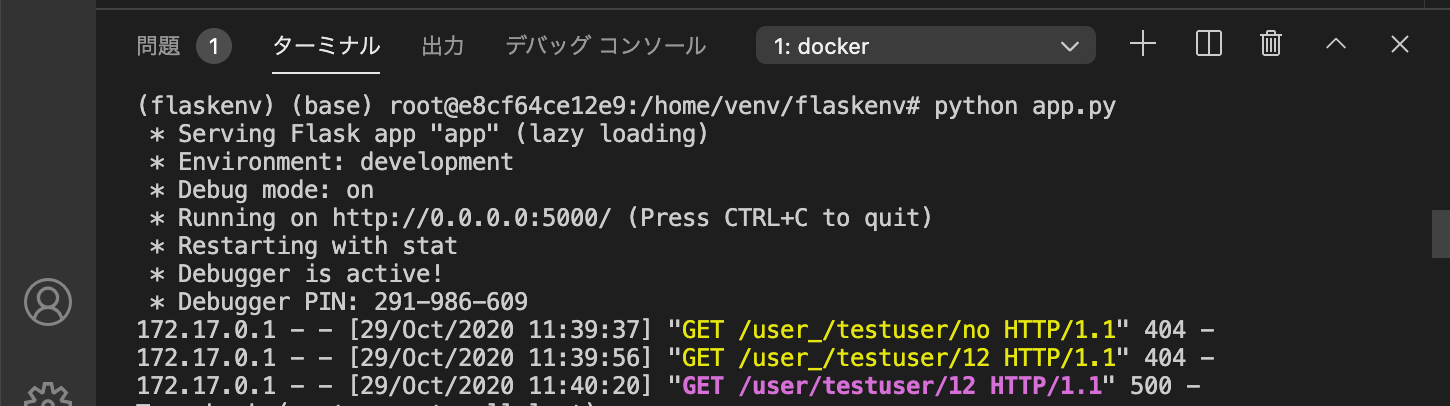
#request.full_path 172.17.0.1 - - [08/Nov/2020 14:33:58] "GET / HTTP/1.1" 200 - /home?last_name=yamada&first_name=taro&job=%E5%85%AC%E5%8B%99%E5%93%A1&gender=%E7%94%B7%E6%80%A7&message=this+is+a+pen. #request.method GET #request.args ImmutableMultiDict([('last_name', 'yamada'), ('first_name', 'taro'), ('job', '公務員'), ('gender', '男性'), ('message', 'this is a pen.')]) 172.17.0.1 - - [08/Nov/2020 14:34:24] "GET /home?last_name=yamada&first_name=taro&job=公務員&gender=男性&message=this+is+a+pen. HTTP/1.1" 200 -POSTメソッドにしたい場合
requestをPOSTにしたい場合は、formタグのmethod属性に’POST'を指定する。{% extends 'base.html' %} {% block content %} <h1>サインアップページ</h1> <form action='{{ url_for("home") }}' method='POST'> ・・・#'method'ではなく'methods'。's'を忘れない。 #'[]'も必須。 #デフォルト(省略時)は'GET' @app.route('/home', methods=['GET','POST']) def home():結果(コンソールで確認)
172.17.0.1 - - [08/Nov/2020 15:31:30] "GET / HTTP/1.1" 200 - /home? POST ImmutableMultiDict([])ファイルアップロード
secure_filename(ファイル名)
'werkzeug'というWSGIライブラリのメソッド。(Flaskをインストールすると一緒についてくる。)
ファイル名を安全な形に変換する処理。ただし、日本語には対応していないため、日本語名称が設定されているファイルがアップロード対象になる可能性がある場合は、別のライブラリで事前に対処しておく必要がある。
→pykakasipykakasi
漢字や平仮名など、日本語を指定した文字に変換してくれるライブラリ。import pykakasi kakasi = pykakasi.kakasi() kakasi.setMode('H','a') #ひらがなをアルファベット小文字に変換 kakasi.setMode('K','a') #カナ文字をアルファベット小文字に変換 kakasi.setMode('J','a') #漢字をアルファベット小文字に変換 conv = kakasi.getConverter() conv.do('テスト') >'tesuto' conv.do('案山子') >'kakashi'HTML側
<form method='POST' enctype='multipart/form-data'> <input type="file" name='file'> <input type="submit" value='アップロード'> </form>Python側
from werkzeug.utils import secure_filename import pykakasi class Kakasi: kakasi = pykakasi.kakasi() kakasi.setMode('H', 'a') kakasi.setMode('K', 'a') kakasi.setMode('J', 'a') conv = kakasi.getConverter() ### 省略 ### @app.route('/upload', methods=['GET','POST']) def upload(): if request.method == 'GET': return render_template('upload.html') elif request.method == 'POST': #requestからファイルアップロード情報を取得 file = request.files['file'] #日本語ファイル名をascii表記に変換する。 convert_file_name = Kakasi.japanese_to_ascii(file.filename) #ファイル名を安全な内容に変換 save_filename = secure_filename(convert_file_name) #osモジュールのjoin処理で保存するファイルパスを作成し、saveで保存 file.save(os.path.join('./static/images', save_filename))wtforms
フォームの実装簡略化、XSSなどのセキュリティ対策として有効なライブラリ
https://wtforms.readthedocs.io/en/2.3.x/fields/例えば以下のタグが、
<form method='POST'> <label for='name'>名前</label> <input type='text' name='name'> </form>wtforms.Formを使えば、以下のように記述できる
<form method='POST'> {{ form.name.label }} {{form.name()} </form>pythonのスクリプトは下記の通り(一部省略)
from flask import Flask, render_template, request from wtforms import StringField, SubmitField,IntegerField from wtforms.form import Form class UserForm(Form): name = StringField('名前') return render_template('index.html', form=form, name=name)'form.name.label' には、スクリプト側で「〜Field」として定義した時に指定した名称が表示される。
csrf対策
<form action="" method='POST'> <!--フォームの先頭に記述する --> {{ form.csrf_token }} {{ form.name.label }}{{ form.name() }} {{ form.age.label }}{{ form.age() }} {{ form.submit()}} </form>template関数とセッション
template関数とは、ビューヘルパーのこと。
複数のTemplateで共通的に使用したい部分を別ファイルに切り出しておいて、使いたい時にインポートして使用することができる。
- template関数の宣言は"macro func_name(arg)"
- xxx | safe : エスケープ処理を行わない
Template関数
{% macro render_field(field) %} <dt>{{ field.label }}</dt> <dd>{{ field(**kwargs) | safe}}</dd> {% if field.errors %} <ul class="error"> {% for error in field.errors %} <li>{{ error }}</li> {% endfor %} </ul> {% endif %} {% endmacro %}Template
{% extends 'base.html' %} <!-- template関数(ヘルパー)をインポートする --> {% from '_formhelpers.html' import render_field %} {% block content %} <form method="POST"> {{ form.csrf_token }} <!-- temlate関数の処理が適用される。 --> {{ render_field(form.name) }} {{ form.submit }} </form> {% endblock %}スクリプト
class UserForm(Form): name = StringField('名前:') age = IntegerField('年齢:') password = PasswordField('パスワード:') birthday = DateField('誕生日:', format='%Y/%m/%d') gender = RadioField('性別:', choices=[('man', '男性'), ('woman', '女性')]) major = SelectField( '専攻', choices=[('bungaku', '文学部'), ('hougaku', '法学部'), ('rigaku', '理学部')]) is_japanese = BooleanField('日本人?:') message = TextAreaField('メッセージ:') submit = SubmitField('送信') @app.route('/', methods=['GET', 'POST']) def index(): form = UserForm(request.form) # POSTされたデータをセッションに格納する。 if request.method == 'POST' and form.validate(): session['name'] = form.name.data session['age'] = form.age.data session['password'] = form.password.data session['birthday'] = form.birthday.data session['gender'] = form.gender.data session['major'] = form.major.data session['nationality'] = '日本人' if form.is_japanese.data else '外国人' session['message'] = form.message.data return redirect(url_for('show_user')) return render_template('user_regist.html', form=form)Fieldのいろいろ
<!-- formのサイズ(幅)を指定する --> <form method="POST"> {{ form.csrf_token }} {# temlate関数の処理がそれぞれに適用される。 #} {{ render_field(form.name, size=100) }} <!-- template関数(render_field)を使用しない場合 --> <!-- {{ form.age(size=200)}} -->from wtforms import Form, widgets class UserForm(Form): #デフォルト値設定 name = StringField('名前:', default='山田花子') #placeholder設定(render_kwに辞書型として設定する) birthday = DateField('誕生日:', format='%Y/%m/%d',render_kw={'placeholder': 'yyy/mm/dd'}) #formをTextAreaタイプに変更する name = StringField('名前:', widget=widgets.TextArea())<!-- 初期値(チェックボックス) --> {{ render_field(form.is_japanese,checked=true) }} <!-- タグのクラス属性を追加 --> {{ render_field(form.age, class='age-class') }}バリデーション
組み込みバリデーション
Flaskにもともと定義されているバリデーション。from wtforms.validators import DataRequired, EqualTo, Length, NumberRange, ValidationError class UserForm(Form): name = StringField('名前:', widget=widgets.TextArea(), validators=[ DataRequired('データを入力してください')], default='山田花子') age = IntegerField('年齢:', validators=[NumberRange(0, 100, '入力値が不正です')]) password = PasswordField('パスワード:', validators=[ Length(4, 10, '4文字以上10文字以下'), EqualTo('confirm_password', 'パスワード不一致')]) confirm_password = PasswordField('再入力', validators=[])https://wtforms.readthedocs.io/en/2.3.x/validators/#custom-validators
自作バリデーション
独自のバリデーションを作成したい場合に、関数とおなじように作成することが可能。クラス内でバリデーションを定義する場合
#フォーマット def validate_<対象フォーム名>(form, field): <処理> raise ValidattionError('エラーメッセージ')#作成例 class UserForm(Form): name = StringField('名前:', widget=widgets.TextArea(), default='山田花子') # 自作バリデーション def validate_name(form, field): if field.data == 'nanashi': raise ValidationError('この名前は使用できません。')クラスの外でバリデーションを定義する場合
def validate_<対象フォーム名>(form, field): <処理> raise ValidationError('エラーメッセージ')def validate_name(form, field): if field.data == 'nanashi2': raise ValidationError('その名前も使用できません') class UserForm(Form): name = StringField('名前:', widget=widgets.TextArea(), validators=[validate_name,DataRequired('データを入力してください')], default='山田花子')


- 投稿日:2020-11-25T22:52:32+09:00
Pandas DataFrameのすべてのメソッドとそれぞれに渡せる引数を調べた
Pandas DataFrameのすべてのメソッドとそれぞれに渡せる引数について調べました。
知っているメソッドしか使わないので、他のメソッドも調べて積極的に使っていきたいと思います。以下、方法と結果です。
方法
下記ファイルを実行するとinspectモジュールを使って自動で調べてくれます。
main.py# coding: utf-8 import inspect import pandas as pd def main(): print(123) df = pd.DataFrame({ "col1":[i for i in range(10)], "col2":[i*2 for i in range(10)], }) print(df) print(dir(df)) df_methods = dir(df) print(len(dir(df)),dir(df)) n = 1 for i,method in enumerate(df_methods): if not '_' in method and method != 'T': try: exec("inspect.getfullargspec(df.%s)"%(method)) print("%s番目のメソッド: %s"%(n,method)) exec("print(' df.'+method+'の受け取れる引数:',inspect.getfullargspec(df.%s))"%(method)) n += 1 except: pass print("") return "Hello World!" if __name__ == "__main__": main()https://docs.python.org/3/library/inspect.html
結果
1番目のメソッド: abs df.absの受け取れる引数: FullArgSpec(args=['self'], varargs=None, varkw=None, defaults=None, kwonlyargs=[], kwonlydefaults=None, annotations={'return': ~FrameOrSeries, 'self': ~FrameOrSeries}) 2番目のメソッド: add df.addの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level', 'fill_value'], varargs=None, varkw=None, defaults=('columns', None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 3番目のメソッド: agg df.aggの受け取れる引数: FullArgSpec(args=['self', 'func', 'axis'], varargs='args', varkw='kwargs', defaults=(None, 0), kwonlyargs=[], kwonlydefaults=None, annotations={}) 4番目のメソッド: aggregate df.aggregateの受け取れる引数: FullArgSpec(args=['self', 'func', 'axis'], varargs='args', varkw='kwargs', defaults=(None, 0), kwonlyargs=[], kwonlydefaults=None, annotations={}) 5番目のメソッド: align df.alignの受け取れる引数: FullArgSpec(args=['self', 'other', 'join', 'axis', 'level', 'copy', 'fill_value', 'method', 'limit', 'fill_axis', 'broadcast_axis'], varargs=None, varkw=None, defaults=('outer', None, None, True, None, None, None, 0, None), kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame'}) 6番目のメソッド: all df.allの受け取れる引数: FullArgSpec(args=['self', 'axis', 'bool_only', 'skipna', 'level'], varargs=None, varkw='kwargs', defaults=(0, None, True, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 7番目のメソッド: any df.anyの受け取れる引数: FullArgSpec(args=['self', 'axis', 'bool_only', 'skipna', 'level'], varargs=None, varkw='kwargs', defaults=(0, None, True, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 8番目のメソッド: append df.appendの受け取れる引数: FullArgSpec(args=['self', 'other', 'ignore_index', 'verify_integrity', 'sort'], varargs=None, varkw=None, defaults=(False, False, False), kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame'}) 9番目のメソッド: apply df.applyの受け取れる引数: FullArgSpec(args=['self', 'func', 'axis', 'raw', 'result_type', 'args'], varargs=None, varkw='kwds', defaults=(0, False, None, ()), kwonlyargs=[], kwonlydefaults=None, annotations={}) 10番目のメソッド: applymap df.applymapの受け取れる引数: FullArgSpec(args=['self', 'func'], varargs=None, varkw=None, defaults=None, kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame'}) 11番目のメソッド: asfreq df.asfreqの受け取れる引数: FullArgSpec(args=['self', 'freq', 'method', 'how', 'normalize', 'fill_value'], varargs=None, varkw=None, defaults=(None, None, False, None), kwonlyargs=[], kwonlydefaults=None, annotations={'return': ~FrameOrSeries, 'self': ~FrameOrSeries, 'how': typing.Union[str, NoneType], 'normalize': <class 'bool'>}) 12番目のメソッド: asof df.asofの受け取れる引数: FullArgSpec(args=['self', 'where', 'subset'], varargs=None, varkw=None, defaults=(None,), kwonlyargs=[], kwonlydefaults=None, annotations={}) 13番目のメソッド: assign df.assignの受け取れる引数: FullArgSpec(args=['self'], varargs=None, varkw='kwargs', defaults=None, kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame'}) 14番目のメソッド: astype df.astypeの受け取れる引数: FullArgSpec(args=['self', 'dtype', 'copy', 'errors'], varargs=None, varkw=None, defaults=(True, 'raise'), kwonlyargs=[], kwonlydefaults=None, annotations={'return': ~FrameOrSeries, 'self': ~FrameOrSeries, 'copy': <class 'bool'>, 'errors': <class 'str'>}) 15番目のメソッド: backfill df.backfillの受け取れる引数: FullArgSpec(args=['self', 'axis', 'inplace', 'limit', 'downcast'], varargs=None, varkw=None, defaults=(None, False, None, None), kwonlyargs=[], kwonlydefaults=None, annotations={'return': typing.Union[~FrameOrSeries, NoneType], 'self': ~FrameOrSeries, 'inplace': <class 'bool'>}) 16番目のメソッド: bfill df.bfillの受け取れる引数: FullArgSpec(args=['self', 'axis', 'inplace', 'limit', 'downcast'], varargs=None, varkw=None, defaults=(None, False, None, None), kwonlyargs=[], kwonlydefaults=None, annotations={'return': typing.Union[~FrameOrSeries, NoneType], 'self': ~FrameOrSeries, 'inplace': <class 'bool'>}) 17番目のメソッド: bool df.boolの受け取れる引数: FullArgSpec(args=['self'], varargs=None, varkw=None, defaults=None, kwonlyargs=[], kwonlydefaults=None, annotations={}) 18番目のメソッド: boxplot df.boxplotの受け取れる引数: FullArgSpec(args=['self', 'column', 'by', 'ax', 'fontsize', 'rot', 'grid', 'figsize', 'layout', 'return_type', 'backend'], varargs=None, varkw='kwargs', defaults=(None, None, None, None, 0, True, None, None, None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 19番目のメソッド: clip df.clipの受け取れる引数: FullArgSpec(args=['self', 'lower', 'upper', 'axis', 'inplace'], varargs='args', varkw='kwargs', defaults=(None, None, None, False), kwonlyargs=[], kwonlydefaults=None, annotations={'return': ~FrameOrSeries, 'self': ~FrameOrSeries, 'inplace': <class 'bool'>}) 20番目のメソッド: combine df.combineの受け取れる引数: FullArgSpec(args=['self', 'other', 'func', 'fill_value', 'overwrite'], varargs=None, varkw=None, defaults=(None, True), kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame', 'other': 'DataFrame'}) 21番目のメソッド: compare df.compareの受け取れる引数: FullArgSpec(args=['self', 'other', 'align_axis', 'keep_shape', 'keep_equal'], varargs=None, varkw=None, defaults=(1, False, False), kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame', 'other': 'DataFrame', 'align_axis': typing.Union[str, int], 'keep_shape': <class 'bool'>, 'keep_equal': <class 'bool'>}) 22番目のメソッド: copy df.copyの受け取れる引数: FullArgSpec(args=['self', 'deep'], varargs=None, varkw=None, defaults=(True,), kwonlyargs=[], kwonlydefaults=None, annotations={'return': ~FrameOrSeries, 'self': ~FrameOrSeries, 'deep': <class 'bool'>}) 23番目のメソッド: corr df.corrの受け取れる引数: FullArgSpec(args=['self', 'method', 'min_periods'], varargs=None, varkw=None, defaults=('pearson', 1), kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame'}) 24番目のメソッド: corrwith df.corrwithの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'drop', 'method'], varargs=None, varkw=None, defaults=(0, False, 'pearson'), kwonlyargs=[], kwonlydefaults=None, annotations={'return': <class 'pandas.core.series.Series'>}) 25番目のメソッド: count df.countの受け取れる引数: FullArgSpec(args=['self', 'axis', 'level', 'numeric_only'], varargs=None, varkw=None, defaults=(0, None, False), kwonlyargs=[], kwonlydefaults=None, annotations={}) 26番目のメソッド: cov df.covの受け取れる引数: FullArgSpec(args=['self', 'min_periods', 'ddof'], varargs=None, varkw=None, defaults=(None, 1), kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame', 'min_periods': typing.Union[int, NoneType], 'ddof': typing.Union[int, NoneType]}) 27番目のメソッド: cummax df.cummaxの受け取れる引数: FullArgSpec(args=['self', 'axis', 'skipna'], varargs='args', varkw='kwargs', defaults=(None, True), kwonlyargs=[], kwonlydefaults=None, annotations={}) 28番目のメソッド: cummin df.cumminの受け取れる引数: FullArgSpec(args=['self', 'axis', 'skipna'], varargs='args', varkw='kwargs', defaults=(None, True), kwonlyargs=[], kwonlydefaults=None, annotations={}) 29番目のメソッド: cumprod df.cumprodの受け取れる引数: FullArgSpec(args=['self', 'axis', 'skipna'], varargs='args', varkw='kwargs', defaults=(None, True), kwonlyargs=[], kwonlydefaults=None, annotations={}) 30番目のメソッド: cumsum df.cumsumの受け取れる引数: FullArgSpec(args=['self', 'axis', 'skipna'], varargs='args', varkw='kwargs', defaults=(None, True), kwonlyargs=[], kwonlydefaults=None, annotations={}) 31番目のメソッド: describe df.describeの受け取れる引数: FullArgSpec(args=['self', 'percentiles', 'include', 'exclude', 'datetime_is_numeric'], varargs=None, varkw=None, defaults=(None, None, None, False), kwonlyargs=[], kwonlydefaults=None, annotations={'return': ~FrameOrSeries, 'self': ~FrameOrSeries}) 32番目のメソッド: diff df.diffの受け取れる引数: FullArgSpec(args=['self', 'periods', 'axis'], varargs=None, varkw=None, defaults=(1, 0), kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame', 'periods': <class 'int'>, 'axis': typing.Union[str, int]}) 33番目のメソッド: div df.divの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level', 'fill_value'], varargs=None, varkw=None, defaults=('columns', None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 34番目のメソッド: divide df.divideの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level', 'fill_value'], varargs=None, varkw=None, defaults=('columns', None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 35番目のメソッド: dot df.dotの受け取れる引数: FullArgSpec(args=['self', 'other'], varargs=None, varkw=None, defaults=None, kwonlyargs=[], kwonlydefaults=None, annotations={}) 36番目のメソッド: drop df.dropの受け取れる引数: FullArgSpec(args=['self', 'labels', 'axis', 'index', 'columns', 'level', 'inplace', 'errors'], varargs=None, varkw=None, defaults=(None, 0, None, None, None, False, 'raise'), kwonlyargs=[], kwonlydefaults=None, annotations={}) 37番目のメソッド: droplevel df.droplevelの受け取れる引数: FullArgSpec(args=['self', 'level', 'axis'], varargs=None, varkw=None, defaults=(0,), kwonlyargs=[], kwonlydefaults=None, annotations={'return': ~FrameOrSeries, 'self': ~FrameOrSeries}) 38番目のメソッド: dropna df.dropnaの受け取れる引数: FullArgSpec(args=['self', 'axis', 'how', 'thresh', 'subset', 'inplace'], varargs=None, varkw=None, defaults=(0, 'any', None, None, False), kwonlyargs=[], kwonlydefaults=None, annotations={}) 39番目のメソッド: duplicated df.duplicatedの受け取れる引数: FullArgSpec(args=['self', 'subset', 'keep'], varargs=None, varkw=None, defaults=(None, 'first'), kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'Series', 'subset': typing.Union[typing.Hashable, typing.Sequence[typing.Hashable], NoneType], 'keep': typing.Union[str, bool]}) 40番目のメソッド: eq df.eqの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level'], varargs=None, varkw=None, defaults=('columns', None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 41番目のメソッド: equals df.equalsの受け取れる引数: FullArgSpec(args=['self', 'other'], varargs=None, varkw=None, defaults=None, kwonlyargs=[], kwonlydefaults=None, annotations={}) 42番目のメソッド: eval df.evalの受け取れる引数: FullArgSpec(args=['self', 'expr', 'inplace'], varargs=None, varkw='kwargs', defaults=(False,), kwonlyargs=[], kwonlydefaults=None, annotations={}) 43番目のメソッド: ewm df.ewmの受け取れる引数: FullArgSpec(args=['self', 'com', 'span', 'halflife', 'alpha', 'min_periods', 'adjust', 'ignore_na', 'axis', 'times'], varargs=None, varkw=None, defaults=(None, None, None, None, 0, True, False, 0, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 44番目のメソッド: expanding df.expandingの受け取れる引数: FullArgSpec(args=['self', 'min_periods', 'center', 'axis'], varargs=None, varkw=None, defaults=(1, None, 0), kwonlyargs=[], kwonlydefaults=None, annotations={}) 45番目のメソッド: explode df.explodeの受け取れる引数: FullArgSpec(args=['self', 'column', 'ignore_index'], varargs=None, varkw=None, defaults=(False,), kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame', 'column': typing.Union[str, typing.Tuple], 'ignore_index': <class 'bool'>}) 46番目のメソッド: ffill df.ffillの受け取れる引数: FullArgSpec(args=['self', 'axis', 'inplace', 'limit', 'downcast'], varargs=None, varkw=None, defaults=(None, False, None, None), kwonlyargs=[], kwonlydefaults=None, annotations={'return': typing.Union[~FrameOrSeries, NoneType], 'self': ~FrameOrSeries, 'inplace': <class 'bool'>}) 47番目のメソッド: fillna df.fillnaの受け取れる引数: FullArgSpec(args=['self', 'value', 'method', 'axis', 'inplace', 'limit', 'downcast'], varargs=None, varkw=None, defaults=(None, None, None, False, None, None), kwonlyargs=[], kwonlydefaults=None, annotations={'return': typing.Union[ForwardRef('DataFrame'), NoneType]}) 48番目のメソッド: filter df.filterの受け取れる引数: FullArgSpec(args=['self', 'items', 'like', 'regex', 'axis'], varargs=None, varkw=None, defaults=(None, None, None, None), kwonlyargs=[], kwonlydefaults=None, annotations={'return': ~FrameOrSeries, 'self': ~FrameOrSeries, 'like': typing.Union[str, NoneType], 'regex': typing.Union[str, NoneType]}) 49番目のメソッド: first df.firstの受け取れる引数: FullArgSpec(args=['self', 'offset'], varargs=None, varkw=None, defaults=None, kwonlyargs=[], kwonlydefaults=None, annotations={'return': ~FrameOrSeries, 'self': ~FrameOrSeries}) 50番目のメソッド: floordiv df.floordivの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level', 'fill_value'], varargs=None, varkw=None, defaults=('columns', None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 51番目のメソッド: ge df.geの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level'], varargs=None, varkw=None, defaults=('columns', None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 52番目のメソッド: get df.getの受け取れる引数: FullArgSpec(args=['self', 'key', 'default'], varargs=None, varkw=None, defaults=(None,), kwonlyargs=[], kwonlydefaults=None, annotations={}) 53番目のメソッド: groupby df.groupbyの受け取れる引数: FullArgSpec(args=['self', 'by', 'axis', 'level', 'as_index', 'sort', 'group_keys', 'squeeze', 'observed', 'dropna'], varargs=None, varkw=None, defaults=(None, 0, None, True, True, True, <object object at 0x10f5df5c0>, False, True), kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrameGroupBy', 'as_index': <class 'bool'>, 'sort': <class 'bool'>, 'group_keys': <class 'bool'>, 'squeeze': <class 'bool'>, 'observed': <class 'bool'>, 'dropna': <class 'bool'>}) 54番目のメソッド: gt df.gtの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level'], varargs=None, varkw=None, defaults=('columns', None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 55番目のメソッド: head df.headの受け取れる引数: FullArgSpec(args=['self', 'n'], varargs=None, varkw=None, defaults=(5,), kwonlyargs=[], kwonlydefaults=None, annotations={'return': ~FrameOrSeries, 'self': ~FrameOrSeries, 'n': <class 'int'>}) 56番目のメソッド: hist df.histの受け取れる引数: FullArgSpec(args=['data', 'column', 'by', 'grid', 'xlabelsize', 'xrot', 'ylabelsize', 'yrot', 'ax', 'sharex', 'sharey', 'figsize', 'layout', 'bins', 'backend', 'legend'], varargs=None, varkw='kwargs', defaults=(None, None, True, None, None, None, None, None, False, False, None, None, 10, None, False), kwonlyargs=[], kwonlydefaults=None, annotations={'data': 'DataFrame', 'column': typing.Union[typing.Hashable, NoneType, typing.Sequence[typing.Union[typing.Hashable, NoneType]]], 'grid': <class 'bool'>, 'xlabelsize': typing.Union[int, NoneType], 'xrot': typing.Union[float, NoneType], 'ylabelsize': typing.Union[int, NoneType], 'yrot': typing.Union[float, NoneType], 'sharex': <class 'bool'>, 'sharey': <class 'bool'>, 'figsize': typing.Union[typing.Tuple[int, int], NoneType], 'layout': typing.Union[typing.Tuple[int, int], NoneType], 'bins': typing.Union[int, typing.Sequence[int]], 'backend': typing.Union[str, NoneType], 'legend': <class 'bool'>}) 57番目のメソッド: idxmax df.idxmaxの受け取れる引数: FullArgSpec(args=['self', 'axis', 'skipna'], varargs=None, varkw=None, defaults=(0, True), kwonlyargs=[], kwonlydefaults=None, annotations={'return': <class 'pandas.core.series.Series'>}) 58番目のメソッド: idxmin df.idxminの受け取れる引数: FullArgSpec(args=['self', 'axis', 'skipna'], varargs=None, varkw=None, defaults=(0, True), kwonlyargs=[], kwonlydefaults=None, annotations={'return': <class 'pandas.core.series.Series'>}) 59番目のメソッド: iloc df.ilocの受け取れる引数: FullArgSpec(args=['self', 'axis'], varargs=None, varkw=None, defaults=(None,), kwonlyargs=[], kwonlydefaults=None, annotations={}) 60番目のメソッド: info df.infoの受け取れる引数: FullArgSpec(args=['self', 'verbose', 'buf', 'max_cols', 'memory_usage', 'null_counts'], varargs=None, varkw=None, defaults=(None, None, None, None, None), kwonlyargs=[], kwonlydefaults=None, annotations={'return': None, 'verbose': typing.Union[bool, NoneType], 'buf': typing.Union[typing.IO[str], NoneType], 'max_cols': typing.Union[int, NoneType], 'memory_usage': typing.Union[bool, str, NoneType], 'null_counts': typing.Union[bool, NoneType]}) 61番目のメソッド: insert df.insertの受け取れる引数: FullArgSpec(args=['self', 'loc', 'column', 'value', 'allow_duplicates'], varargs=None, varkw=None, defaults=(False,), kwonlyargs=[], kwonlydefaults=None, annotations={'return': None}) 62番目のメソッド: interpolate df.interpolateの受け取れる引数: FullArgSpec(args=['self', 'method', 'axis', 'limit', 'inplace', 'limit_direction', 'limit_area', 'downcast'], varargs=None, varkw='kwargs', defaults=('linear', 0, None, False, None, None, None), kwonlyargs=[], kwonlydefaults=None, annotations={'return': typing.Union[~FrameOrSeries, NoneType], 'self': ~FrameOrSeries, 'method': <class 'str'>, 'axis': typing.Union[str, int], 'limit': typing.Union[int, NoneType], 'inplace': <class 'bool'>, 'limit_direction': typing.Union[str, NoneType], 'limit_area': typing.Union[str, NoneType], 'downcast': typing.Union[str, NoneType]}) 63番目のメソッド: isin df.isinの受け取れる引数: FullArgSpec(args=['self', 'values'], varargs=None, varkw=None, defaults=None, kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame'}) 64番目のメソッド: isna df.isnaの受け取れる引数: FullArgSpec(args=['self'], varargs=None, varkw=None, defaults=None, kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame'}) 65番目のメソッド: isnull df.isnullの受け取れる引数: FullArgSpec(args=['self'], varargs=None, varkw=None, defaults=None, kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame'}) 66番目のメソッド: items df.itemsの受け取れる引数: FullArgSpec(args=['self'], varargs=None, varkw=None, defaults=None, kwonlyargs=[], kwonlydefaults=None, annotations={'return': typing.Iterable[typing.Tuple[typing.Union[typing.Hashable, NoneType], pandas.core.series.Series]]}) 67番目のメソッド: iteritems df.iteritemsの受け取れる引数: FullArgSpec(args=['self'], varargs=None, varkw=None, defaults=None, kwonlyargs=[], kwonlydefaults=None, annotations={'return': typing.Iterable[typing.Tuple[typing.Union[typing.Hashable, NoneType], pandas.core.series.Series]]}) 68番目のメソッド: iterrows df.iterrowsの受け取れる引数: FullArgSpec(args=['self'], varargs=None, varkw=None, defaults=None, kwonlyargs=[], kwonlydefaults=None, annotations={'return': typing.Iterable[typing.Tuple[typing.Union[typing.Hashable, NoneType], pandas.core.series.Series]]}) 69番目のメソッド: itertuples df.itertuplesの受け取れる引数: FullArgSpec(args=['self', 'index', 'name'], varargs=None, varkw=None, defaults=(True, 'Pandas'), kwonlyargs=[], kwonlydefaults=None, annotations={}) 70番目のメソッド: join df.joinの受け取れる引数: FullArgSpec(args=['self', 'other', 'on', 'how', 'lsuffix', 'rsuffix', 'sort'], varargs=None, varkw=None, defaults=(None, 'left', '', '', False), kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame'}) 71番目のメソッド: keys df.keysの受け取れる引数: FullArgSpec(args=['self'], varargs=None, varkw=None, defaults=None, kwonlyargs=[], kwonlydefaults=None, annotations={}) 72番目のメソッド: kurt df.kurtの受け取れる引数: FullArgSpec(args=['self', 'axis', 'skipna', 'level', 'numeric_only'], varargs=None, varkw='kwargs', defaults=(None, None, None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 73番目のメソッド: kurtosis df.kurtosisの受け取れる引数: FullArgSpec(args=['self', 'axis', 'skipna', 'level', 'numeric_only'], varargs=None, varkw='kwargs', defaults=(None, None, None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 74番目のメソッド: last df.lastの受け取れる引数: FullArgSpec(args=['self', 'offset'], varargs=None, varkw=None, defaults=None, kwonlyargs=[], kwonlydefaults=None, annotations={'return': ~FrameOrSeries, 'self': ~FrameOrSeries}) 75番目のメソッド: le df.leの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level'], varargs=None, varkw=None, defaults=('columns', None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 76番目のメソッド: loc df.locの受け取れる引数: FullArgSpec(args=['self', 'axis'], varargs=None, varkw=None, defaults=(None,), kwonlyargs=[], kwonlydefaults=None, annotations={}) 77番目のメソッド: lookup df.lookupの受け取れる引数: FullArgSpec(args=['self', 'row_labels', 'col_labels'], varargs=None, varkw=None, defaults=None, kwonlyargs=[], kwonlydefaults=None, annotations={'return': <class 'numpy.ndarray'>}) 78番目のメソッド: lt df.ltの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level'], varargs=None, varkw=None, defaults=('columns', None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 79番目のメソッド: mad df.madの受け取れる引数: FullArgSpec(args=['self', 'axis', 'skipna', 'level'], varargs=None, varkw=None, defaults=(None, None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 80番目のメソッド: mask df.maskの受け取れる引数: FullArgSpec(args=['self', 'cond', 'other', 'inplace', 'axis', 'level', 'errors', 'try_cast'], varargs=None, varkw=None, defaults=(nan, False, None, None, 'raise', False), kwonlyargs=[], kwonlydefaults=None, annotations={}) 81番目のメソッド: max df.maxの受け取れる引数: FullArgSpec(args=['self', 'axis', 'skipna', 'level', 'numeric_only'], varargs=None, varkw='kwargs', defaults=(None, None, None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 82番目のメソッド: mean df.meanの受け取れる引数: FullArgSpec(args=['self', 'axis', 'skipna', 'level', 'numeric_only'], varargs=None, varkw='kwargs', defaults=(None, None, None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 83番目のメソッド: median df.medianの受け取れる引数: FullArgSpec(args=['self', 'axis', 'skipna', 'level', 'numeric_only'], varargs=None, varkw='kwargs', defaults=(None, None, None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 84番目のメソッド: melt df.meltの受け取れる引数: FullArgSpec(args=['self', 'id_vars', 'value_vars', 'var_name', 'value_name', 'col_level', 'ignore_index'], varargs=None, varkw=None, defaults=(None, None, None, 'value', None, True), kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame'}) 85番目のメソッド: merge df.mergeの受け取れる引数: FullArgSpec(args=['self', 'right', 'how', 'on', 'left_on', 'right_on', 'left_index', 'right_index', 'sort', 'suffixes', 'copy', 'indicator', 'validate'], varargs=None, varkw=None, defaults=('inner', None, None, None, False, False, False, ('_x', '_y'), True, False, None), kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame'}) 86番目のメソッド: min df.minの受け取れる引数: FullArgSpec(args=['self', 'axis', 'skipna', 'level', 'numeric_only'], varargs=None, varkw='kwargs', defaults=(None, None, None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 87番目のメソッド: mod df.modの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level', 'fill_value'], varargs=None, varkw=None, defaults=('columns', None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 88番目のメソッド: mode df.modeの受け取れる引数: FullArgSpec(args=['self', 'axis', 'numeric_only', 'dropna'], varargs=None, varkw=None, defaults=(0, False, True), kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame'}) 89番目のメソッド: mul df.mulの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level', 'fill_value'], varargs=None, varkw=None, defaults=('columns', None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 90番目のメソッド: multiply df.multiplyの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level', 'fill_value'], varargs=None, varkw=None, defaults=('columns', None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 91番目のメソッド: ne df.neの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level'], varargs=None, varkw=None, defaults=('columns', None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 92番目のメソッド: nlargest df.nlargestの受け取れる引数: FullArgSpec(args=['self', 'n', 'columns', 'keep'], varargs=None, varkw=None, defaults=('first',), kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame'}) 93番目のメソッド: notna df.notnaの受け取れる引数: FullArgSpec(args=['self'], varargs=None, varkw=None, defaults=None, kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame'}) 94番目のメソッド: notnull df.notnullの受け取れる引数: FullArgSpec(args=['self'], varargs=None, varkw=None, defaults=None, kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame'}) 95番目のメソッド: nsmallest df.nsmallestの受け取れる引数: FullArgSpec(args=['self', 'n', 'columns', 'keep'], varargs=None, varkw=None, defaults=('first',), kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame'}) 96番目のメソッド: nunique df.nuniqueの受け取れる引数: FullArgSpec(args=['self', 'axis', 'dropna'], varargs=None, varkw=None, defaults=(0, True), kwonlyargs=[], kwonlydefaults=None, annotations={'return': <class 'pandas.core.series.Series'>}) 97番目のメソッド: pad df.padの受け取れる引数: FullArgSpec(args=['self', 'axis', 'inplace', 'limit', 'downcast'], varargs=None, varkw=None, defaults=(None, False, None, None), kwonlyargs=[], kwonlydefaults=None, annotations={'return': typing.Union[~FrameOrSeries, NoneType], 'self': ~FrameOrSeries, 'inplace': <class 'bool'>}) 98番目のメソッド: pipe df.pipeの受け取れる引数: FullArgSpec(args=['self', 'func'], varargs='args', varkw='kwargs', defaults=None, kwonlyargs=[], kwonlydefaults=None, annotations={}) 99番目のメソッド: pivot df.pivotの受け取れる引数: FullArgSpec(args=['self', 'index', 'columns', 'values'], varargs=None, varkw=None, defaults=(None, None, None), kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame'}) 100番目のメソッド: plot df.plotの受け取れる引数: FullArgSpec(args=['self'], varargs='args', varkw='kwargs', defaults=None, kwonlyargs=[], kwonlydefaults=None, annotations={}) 101番目のメソッド: pop df.popの受け取れる引数: FullArgSpec(args=['self', 'item'], varargs=None, varkw=None, defaults=None, kwonlyargs=[], kwonlydefaults=None, annotations={'return': <class 'pandas.core.series.Series'>, 'item': typing.Union[typing.Hashable, NoneType]}) 102番目のメソッド: pow df.powの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level', 'fill_value'], varargs=None, varkw=None, defaults=('columns', None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 103番目のメソッド: prod df.prodの受け取れる引数: FullArgSpec(args=['self', 'axis', 'skipna', 'level', 'numeric_only', 'min_count'], varargs=None, varkw='kwargs', defaults=(None, None, None, None, 0), kwonlyargs=[], kwonlydefaults=None, annotations={}) 104番目のメソッド: product df.productの受け取れる引数: FullArgSpec(args=['self', 'axis', 'skipna', 'level', 'numeric_only', 'min_count'], varargs=None, varkw='kwargs', defaults=(None, None, None, None, 0), kwonlyargs=[], kwonlydefaults=None, annotations={}) 105番目のメソッド: quantile df.quantileの受け取れる引数: FullArgSpec(args=['self', 'q', 'axis', 'numeric_only', 'interpolation'], varargs=None, varkw=None, defaults=(0.5, 0, True, 'linear'), kwonlyargs=[], kwonlydefaults=None, annotations={}) 106番目のメソッド: query df.queryの受け取れる引数: FullArgSpec(args=['self', 'expr', 'inplace'], varargs=None, varkw='kwargs', defaults=(False,), kwonlyargs=[], kwonlydefaults=None, annotations={}) 107番目のメソッド: radd df.raddの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level', 'fill_value'], varargs=None, varkw=None, defaults=('columns', None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 108番目のメソッド: rank df.rankの受け取れる引数: FullArgSpec(args=['self', 'axis', 'method', 'numeric_only', 'na_option', 'ascending', 'pct'], varargs=None, varkw=None, defaults=(0, 'average', None, 'keep', True, False), kwonlyargs=[], kwonlydefaults=None, annotations={'return': ~FrameOrSeries, 'self': ~FrameOrSeries, 'method': <class 'str'>, 'numeric_only': typing.Union[bool, NoneType], 'na_option': <class 'str'>, 'ascending': <class 'bool'>, 'pct': <class 'bool'>}) 109番目のメソッド: rdiv df.rdivの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level', 'fill_value'], varargs=None, varkw=None, defaults=('columns', None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 110番目のメソッド: reindex df.reindexの受け取れる引数: FullArgSpec(args=[], varargs='args', varkw='kwargs', defaults=None, kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame'}) 111番目のメソッド: rename df.renameの受け取れる引数: FullArgSpec(args=[], varargs='args', varkw='kwargs', defaults=None, kwonlyargs=[], kwonlydefaults=None, annotations={'return': typing.Union[ForwardRef('DataFrame'), NoneType]}) 112番目のメソッド: replace df.replaceの受け取れる引数: FullArgSpec(args=['self', 'to_replace', 'value', 'inplace', 'limit', 'regex', 'method'], varargs=None, varkw=None, defaults=(None, None, False, None, False, 'pad'), kwonlyargs=[], kwonlydefaults=None, annotations={}) 113番目のメソッド: resample df.resampleの受け取れる引数: FullArgSpec(args=['self', 'rule', 'axis', 'closed', 'label', 'convention', 'kind', 'loffset', 'base', 'on', 'level', 'origin', 'offset'], varargs=None, varkw=None, defaults=(0, None, None, 'start', None, None, None, None, None, 'start_day', None), kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'Resampler', 'closed': typing.Union[str, NoneType], 'label': typing.Union[str, NoneType], 'convention': <class 'str'>, 'kind': typing.Union[str, NoneType], 'base': typing.Union[int, NoneType], 'origin': typing.Union[str, ForwardRef('Timestamp'), datetime.datetime, numpy.datetime64, int, numpy.int64, float], 'offset': typing.Union[ForwardRef('Timedelta'), datetime.timedelta, numpy.timedelta64, int, numpy.int64, float, str, NoneType]}) 114番目のメソッド: rfloordiv df.rfloordivの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level', 'fill_value'], varargs=None, varkw=None, defaults=('columns', None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 115番目のメソッド: rmod df.rmodの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level', 'fill_value'], varargs=None, varkw=None, defaults=('columns', None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 116番目のメソッド: rmul df.rmulの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level', 'fill_value'], varargs=None, varkw=None, defaults=('columns', None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 117番目のメソッド: rolling df.rollingの受け取れる引数: FullArgSpec(args=['self', 'window', 'min_periods', 'center', 'win_type', 'on', 'axis', 'closed'], varargs=None, varkw=None, defaults=(None, False, None, None, 0, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 118番目のメソッド: round df.roundの受け取れる引数: FullArgSpec(args=['self', 'decimals'], varargs='args', varkw='kwargs', defaults=(0,), kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame'}) 119番目のメソッド: rpow df.rpowの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level', 'fill_value'], varargs=None, varkw=None, defaults=('columns', None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 120番目のメソッド: rsub df.rsubの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level', 'fill_value'], varargs=None, varkw=None, defaults=('columns', None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 121番目のメソッド: rtruediv df.rtruedivの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level', 'fill_value'], varargs=None, varkw=None, defaults=('columns', None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 122番目のメソッド: sample df.sampleの受け取れる引数: FullArgSpec(args=['self', 'n', 'frac', 'replace', 'weights', 'random_state', 'axis'], varargs=None, varkw=None, defaults=(None, None, False, None, None, None), kwonlyargs=[], kwonlydefaults=None, annotations={'return': ~FrameOrSeries, 'self': ~FrameOrSeries}) 123番目のメソッド: sem df.semの受け取れる引数: FullArgSpec(args=['self', 'axis', 'skipna', 'level', 'ddof', 'numeric_only'], varargs=None, varkw='kwargs', defaults=(None, None, None, 1, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 124番目のメソッド: shift df.shiftの受け取れる引数: FullArgSpec(args=['self', 'periods', 'freq', 'axis', 'fill_value'], varargs=None, varkw=None, defaults=(1, None, 0, None), kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame'}) 125番目のメソッド: skew df.skewの受け取れる引数: FullArgSpec(args=['self', 'axis', 'skipna', 'level', 'numeric_only'], varargs=None, varkw='kwargs', defaults=(None, None, None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 126番目のメソッド: squeeze df.squeezeの受け取れる引数: FullArgSpec(args=['self', 'axis'], varargs=None, varkw=None, defaults=(None,), kwonlyargs=[], kwonlydefaults=None, annotations={}) 127番目のメソッド: stack df.stackの受け取れる引数: FullArgSpec(args=['self', 'level', 'dropna'], varargs=None, varkw=None, defaults=(-1, True), kwonlyargs=[], kwonlydefaults=None, annotations={}) 128番目のメソッド: std df.stdの受け取れる引数: FullArgSpec(args=['self', 'axis', 'skipna', 'level', 'ddof', 'numeric_only'], varargs=None, varkw='kwargs', defaults=(None, None, None, 1, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 129番目のメソッド: sub df.subの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level', 'fill_value'], varargs=None, varkw=None, defaults=('columns', None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 130番目のメソッド: subtract df.subtractの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level', 'fill_value'], varargs=None, varkw=None, defaults=('columns', None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 131番目のメソッド: sum df.sumの受け取れる引数: FullArgSpec(args=['self', 'axis', 'skipna', 'level', 'numeric_only', 'min_count'], varargs=None, varkw='kwargs', defaults=(None, None, None, None, 0), kwonlyargs=[], kwonlydefaults=None, annotations={}) 132番目のメソッド: swapaxes df.swapaxesの受け取れる引数: FullArgSpec(args=['self', 'axis1', 'axis2', 'copy'], varargs=None, varkw=None, defaults=(True,), kwonlyargs=[], kwonlydefaults=None, annotations={'return': ~FrameOrSeries, 'self': ~FrameOrSeries}) 133番目のメソッド: swaplevel df.swaplevelの受け取れる引数: FullArgSpec(args=['self', 'i', 'j', 'axis'], varargs=None, varkw=None, defaults=(-2, -1, 0), kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame'}) 134番目のメソッド: tail df.tailの受け取れる引数: FullArgSpec(args=['self', 'n'], varargs=None, varkw=None, defaults=(5,), kwonlyargs=[], kwonlydefaults=None, annotations={'return': ~FrameOrSeries, 'self': ~FrameOrSeries, 'n': <class 'int'>}) 135番目のメソッド: take df.takeの受け取れる引数: FullArgSpec(args=['self', 'indices', 'axis', 'is_copy'], varargs=None, varkw='kwargs', defaults=(0, None), kwonlyargs=[], kwonlydefaults=None, annotations={'return': ~FrameOrSeries, 'self': ~FrameOrSeries, 'is_copy': typing.Union[bool, NoneType]}) 136番目のメソッド: transform df.transformの受け取れる引数: FullArgSpec(args=['self', 'func', 'axis'], varargs='args', varkw='kwargs', defaults=(0,), kwonlyargs=[], kwonlydefaults=None, annotations={'return': 'DataFrame'}) 137番目のメソッド: transpose df.transposeの受け取れる引数: FullArgSpec(args=['self'], varargs='args', varkw=None, defaults=None, kwonlyargs=['copy'], kwonlydefaults={'copy': False}, annotations={'return': 'DataFrame', 'copy': <class 'bool'>}) 138番目のメソッド: truediv df.truedivの受け取れる引数: FullArgSpec(args=['self', 'other', 'axis', 'level', 'fill_value'], varargs=None, varkw=None, defaults=('columns', None, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 139番目のメソッド: truncate df.truncateの受け取れる引数: FullArgSpec(args=['self', 'before', 'after', 'axis', 'copy'], varargs=None, varkw=None, defaults=(None, None, None, True), kwonlyargs=[], kwonlydefaults=None, annotations={'return': ~FrameOrSeries, 'self': ~FrameOrSeries, 'copy': <class 'bool'>}) 140番目のメソッド: unstack df.unstackの受け取れる引数: FullArgSpec(args=['self', 'level', 'fill_value'], varargs=None, varkw=None, defaults=(-1, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 141番目のメソッド: update df.updateの受け取れる引数: FullArgSpec(args=['self', 'other', 'join', 'overwrite', 'filter_func', 'errors'], varargs=None, varkw=None, defaults=('left', True, None, 'ignore'), kwonlyargs=[], kwonlydefaults=None, annotations={'return': None}) 142番目のメソッド: var df.varの受け取れる引数: FullArgSpec(args=['self', 'axis', 'skipna', 'level', 'ddof', 'numeric_only'], varargs=None, varkw='kwargs', defaults=(None, None, None, 1, None), kwonlyargs=[], kwonlydefaults=None, annotations={}) 143番目のメソッド: where df.whereの受け取れる引数: FullArgSpec(args=['self', 'cond', 'other', 'inplace', 'axis', 'level', 'errors', 'try_cast'], varargs=None, varkw=None, defaults=(nan, False, None, None, 'raise', False), kwonlyargs=[], kwonlydefaults=None, annotations={}) 144番目のメソッド: xs df.xsの受け取れる引数: FullArgSpec(args=['self', 'key', 'axis', 'level', 'drop_level'], varargs=None, varkw=None, defaults=(0, None, True), kwonlyargs=[], kwonlydefaults=None, annotations={'drop_level': <class 'bool'>})結構知らないのある。
この記事が役に立ったと思ったらLGTMお願いいたします
- 投稿日:2020-11-25T22:48:29+09:00
gdstkでPython最速のGDSII layout制作環境を作る
はじめに
この記事は、過去記事”PythonでGDSII formatを扱う”および”gdspyを使って、PythonではじめてのGDSIIファイルを作る”の続きである。これらの記事では、Python上でGDSII layoutを扱うためのライブラリ"gdspy"について説明してきたが、これはPythonネイティブで動作するため遅すぎた。そのため作者である@heitzmannはver.1.6系を最後にgdspyの継続をあきらめ、新規プロジェクト"gdstk"(GDSII Tool Kit)に現在注力している。gdstkは、C++で書かれたGDSIIファイルI/Oと、そのPythonラッパーで構成される。したがって我々ユーザの立場からは、Pythonの高い可読性と機能性とを維持したまま、C++に由来する高速性を発揮してGDSII layoutファイルを取り扱うことができる1。高速化の寄与は驚異的で、gdspyその他PythonによるGDSII関係ライブラリに比べて10倍~20倍は当たり前である2。本稿執筆現在、ver0.2.0までが公開されている。本記事では、まずgdstkを利用するための環境構築について述べ、次にgdstkを利用した簡単なGDSIIファイル作成について述べる。
GDSTKの環境構築
gdstkはconda-forgeおよびpipパッケージに収録されているため、そのインストールはとっても簡単3である。
> conda install -c conda-forge gdstk
または
> pip install gdstk
でインストールできる。そのほか、Anaconda3などを用いれば、GUIで簡単にインストールできる。Anaconda等でgdstk用仮想環境を作成の上インストールすることをお勧めする。GDSTKの歩き方
更新など最新情報はGitHubで、APIリファレンス含む完全なドキュメントはこちらで公開されている。英語力に自信のある向きはこんな記事読んでないでこれら公式を読むべきである。GitHubでウォッチしてメーリングリストを購読すると、細かいノウハウに関する情報共有ができるのでお勧めである。またプロジェクト継続のためぜひ作者である@heitzmannに寄付をお願いしたい。
GDSTKではじめてのGDSIIファイルを出力する
次のコードを実行してみよう。
first.pyimport gdstk lib = gdstk.Library() #特に指定しなければ単位はum topcell = lib.new_cell("Top") #Topセルを作成 subcell = lib.new_cell("subcell") #サブセルを作成 box = gdstk.rectangle((0,0), (1,2)) #左下(0,0),右上(1,2)の四角形を作成 subcell.add(box) #四角形をサブセルに追加 ref = gdstk.Reference(subcell, origin=(0,0), columns =3, rows =2, spacing = (5,5)) #サブセルへの配列リファレンスを原点(0,0)に挿入。3行2列で、間隔は(5,5) topcell.add(ref) #サブセルへのリファレンスをTopセルに挿入。 text = gdstk.text('First GDS',2, (0,10)) #高さ2のテキストを位置(0,10)に挿入。 topcell.add(*text) #gdstk.textは1文字ずつのPolygonのリストを返すので、*textでリストをunpackしてadd()に渡す。 lib.write_gds('output.gds') #gdsファイル出力 topcell.write_svg('output.svg') #svgファイル出力
output.gdsとoutput.svgの2つのファイルが出力される。output.svgの中身はこんな感じ。
output.gdsは、KLayout等で閲覧できる。OASIS形式でファイルを出力する
OASIS形式はGDSIIの後継となるレイアウトフォーマットである。非矩形配列、Parametric cell、ファイル内部でのzlib圧縮などをサポートしているためGDSIIに比べファイルサイズを1/10程度にできる。KLayoutをインストールしていれば、それと同じフォルダにstrm2oas.exeが入っているはずである4。これはコマンドラインでKLayoutを呼び出してGDSIIをOASIS形式に変換してくれる。下記をfirst.pyに追記して実行すればOASISファイルを出力できる。これはWindowsの場合であるが、strm2oasのパスは適宜読み替えてほしい。
first.pyimport subprocess del lib #ファイルを出力したのでメモリ確保のためgdsライブラリを破棄する。 subprocess.call('C:\\Users\\<username>\\AppData\\Roaming\\KLayout\\strm2oas.exe output.gds output.oas')

- 投稿日:2020-11-25T22:46:48+09:00
【VSCode tips】VSCode の Python Extension のエラーを修正する 【#3】
現象
Windows 10 にて Visual Studio CodeのPython拡張機能をインストール・有効化すると、
C:\Users\ユーザー名\AppData\Local\Microsoft\WindowsApps\python3.exeというログが出力される。原因
Windows 10 の機能である
アプリ実行エイリアスにて、上記パスを参照しているが、python3.exeは存在しない(実行ファイルでない)ため、エラーが出力されている。対処
アプリ実行エイリアスから python を参照している、該当すエントリーを削除する- Visual Studio Codeを再起動する
- 投稿日:2020-11-25T22:35:13+09:00
Flaskのrequestsモジュールについて、すべてのメソッドを実行してしっかり理解する
PythonのFlaskでweb APIを作成することがあるのですが、クエリパラメータの読み込みなどちゃんと理解せずに使ってしまっているので、ここでは、http://127.0.0.1:5000 というURLをFlaskで立てて、そこにPOST通信とGET通信を試みた際の挙動について、requetstsモジュールのすべてのメソッドを実行して調べます。
方法
検証用のflaskの関数とcurlコマンドについて説明します。
Flaskの関数
URLが叩かれたときのrequestモジュールをすべて実行するためのFlaskの関数はこちらです。
main.py# coding: utf-8 from flask import Flask, request app = Flask(__name__) @app.route("/", methods=["GET", "POST"]) def hello(): request_methods = dir(request) print(len(dir(request)),dir(request)) for i,method in enumerate(request_methods): print("%s番目のメソッド:\n %s"%(i+1,method)) exec("print(' request.'+method+'の実行結果:',request.%s)"%(method)) print("") return "Hello World!" if __name__ == "__main__": app.run()Pythonでは、dir()ですべてのメソッドを非再帰的ですが求められますので、これをrequest_methods という変数にリスト形式で保存したあと、文字列をプログラムに変換するexecコマンドを使ってループの中で実行しています。
curlコマンドについて
この関数で立てたURLに対してcurlでGet通信とPost通信を行います。
curl -H 'Host:some_destination.com.' -H 'Authorization:something' -X GET "http://127.0.0.1:5000?arg1=myarg1&arg2=myarg2" --insecureGet通信の場合、基本的には、 http://127.0.0.1:5000?arg1=myarg1&arg2=myarg2 と言う形でクエリパラメータを付与した場合の挙動を調べるようにしています。
curl -X POST -H 'Host:some_destination.com.' -H 'Authorization:something' -F 'image=@./na18_1920x1080_221804.jpg' -F "arg1=myarg1" -F "arg2=myarg2" http://127.0.0.1:5000/ --insecurePost通信の場合、クエリパラメータを同様に付与することに加えて、HTMLのformから画像をsubmitした場合のrequestモジュールの挙動を調べます。今回は、curlコマンドを打つターミナルの場所にna18_1920x1080_221804.jpgと言う画像ファイルを置いて、それをformからSubmitしています。
以下、Get通信とPost通信をした結果ですが、Requestsモジュールは下記の116個のメソッドも持つため結構長くなります。ご了承ください。
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__enter__', '__eq__', '__exit__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_cached_json', '_get_data_for_json', '_get_file_stream', '_get_stream_for_parsing', '_load_form_data', '_parse_content_type', 'accept_charsets', 'accept_encodings', 'accept_languages', 'accept_mimetypes', 'access_control_request_headers', 'access_control_request_method', 'access_route', 'application', 'args', 'authorization', 'base_url', 'blueprint', 'cache_control', 'charset', 'close', 'content_encoding', 'content_length', 'content_md5', 'content_type', 'cookies', 'data', 'date', 'dict_storage_class', 'disable_data_descriptor', 'encoding_errors', 'endpoint', 'environ', 'files', 'form', 'form_data_parser_class', 'from_values', 'full_path', 'get_data', 'get_json', 'headers', 'host', 'host_url', 'if_match', 'if_modified_since', 'if_none_match', 'if_range', 'if_unmodified_since', 'input_stream', 'is_json', 'is_multiprocess', 'is_multithread', 'is_run_once', 'is_secure', 'json', 'json_module', 'list_storage_class', 'make_form_data_parser', 'max_content_length', 'max_form_memory_size', 'max_forwards', 'method', 'mimetype', 'mimetype_params', 'on_json_loading_failed', 'origin', 'parameter_storage_class', 'path', 'pragma', 'query_string', 'range', 'referrer', 'remote_addr', 'remote_user', 'routing_exception', 'scheme', 'script_root', 'shallow', 'stream', 'trusted_hosts', 'url', 'url_charset', 'url_root', 'url_rule', 'user_agent', 'values', 'view_args', 'want_form_data_parsed']結果
Get通信の場合
基本的には43番目のargs、45番目のbase_url66番目のfull_path、68番目のget_json、69番目のheaders,90番目のmethod,98番目のquery_string、109番目のurl,111番目のurl_rootあたりがGet通信では見ておけば良さそうです。
1番目のメソッド: __class__ request.__class__の実行結果: <class 'werkzeug.local.LocalProxy'> 2番目のメソッド: __delattr__ request.__delattr__の実行結果: <bound method LocalProxy.<lambda> of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 3番目のメソッド: __dict__ request.__dict__の実行結果: {'environ': {'wsgi.version': (1, 0), 'wsgi.url_scheme': 'http', 'wsgi.input': <_io.BufferedReader name=7>, 'wsgi.errors': <_io.TextIOWrapper name='<stderr>' mode='w' encoding='UTF-8'>, 'wsgi.multithread': True, 'wsgi.multiprocess': False, 'wsgi.run_once': False, 'werkzeug.server.shutdown': <function WSGIRequestHandler.make_environ.<locals>.shutdown_server at 0x10a496840>, 'SERVER_SOFTWARE': 'Werkzeug/1.0.1', 'REQUEST_METHOD': 'GET', 'SCRIPT_NAME': '', 'PATH_INFO': '/', 'QUERY_STRING': 'arg1=myarg1&arg2=myarg2', 'REQUEST_URI': '/?arg1=myarg1&arg2=myarg2', 'RAW_URI': '/?arg1=myarg1&arg2=myarg2', 'REMOTE_ADDR': '127.0.0.1', 'REMOTE_PORT': 56805, 'SERVER_NAME': '127.0.0.1', 'SERVER_PORT': '5000', 'SERVER_PROTOCOL': 'HTTP/1.1', 'HTTP_HOST': 'some_destination.com.', 'HTTP_USER_AGENT': 'curl/7.64.1', 'HTTP_ACCEPT': '*/*', 'HTTP_AUTHORIZATION': 'something', 'werkzeug.request': <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>}, 'shallow': False, 'url_rule': <Rule '/' (GET, HEAD, POST, OPTIONS) -> hello>, 'view_args': {}, 'url': 'http://some_destination.com./?arg1=myarg1&arg2=myarg2'} 4番目のメソッド: __dir__ request.__dir__の実行結果: <bound method LocalProxy.__dir__ of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 5番目のメソッド: __doc__ request.__doc__の実行結果: Acts as a proxy for a werkzeug local. Forwards all operations to a proxied object. The only operations not supported for forwarding are right handed operands and any kind of assignment. Example usage:: from werkzeug.local import Local l = Local() # these are proxies request = l('request') user = l('user') from werkzeug.local import LocalStack _response_local = LocalStack() # this is a proxy response = _response_local() Whenever something is bound to l.user / l.request the proxy objects will forward all operations. If no object is bound a :exc:`RuntimeError` will be raised. To create proxies to :class:`Local` or :class:`LocalStack` objects, call the object as shown above. If you want to have a proxy to an object looked up by a function, you can (as of Werkzeug 0.6.1) pass a function to the :class:`LocalProxy` constructor:: session = LocalProxy(lambda: get_current_request().session) .. versionchanged:: 0.6.1 The class can be instantiated with a callable as well now. 6番目のメソッド: __enter__ request.__enter__の実行結果: <bound method LocalProxy.<lambda> of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 7番目のメソッド: __eq__ request.__eq__の実行結果: <bound method LocalProxy.<lambda> of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 8番目のメソッド: __exit__ request.__exit__の実行結果: <bound method LocalProxy.<lambda> of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 9番目のメソッド: __format__ request.__format__の実行結果: <built-in method __format__ of LocalProxy object at 0x10a5d02d0> 10番目のメソッド: __ge__ request.__ge__の実行結果: <bound method LocalProxy.<lambda> of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 11番目のメソッド: __getattribute__ request.__getattribute__の実行結果: <method-wrapper '__getattribute__' of LocalProxy object at 0x10a5d02d0> 12番目のメソッド: __gt__ request.__gt__の実行結果: <bound method LocalProxy.<lambda> of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 13番目のメソッド: __hash__ request.__hash__の実行結果: <bound method LocalProxy.<lambda> of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 14番目のメソッド: __init__ request.__init__の実行結果: <bound method LocalProxy.__init__ of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 15番目のメソッド: __init_subclass__ request.__init_subclass__の実行結果: <built-in method __init_subclass__ of type object at 0x7feb3d122e18> 16番目のメソッド: __le__ request.__le__の実行結果: <bound method LocalProxy.<lambda> of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 17番目のメソッド: __lt__ request.__lt__の実行結果: <bound method LocalProxy.<lambda> of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 18番目のメソッド: __module__ request.__module__の実行結果: werkzeug.local 19番目のメソッド: __ne__ request.__ne__の実行結果: <bound method LocalProxy.<lambda> of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 20番目のメソッド: __new__ request.__new__の実行結果: <built-in method __new__ of type object at 0x109498d30> 21番目のメソッド: __reduce__ request.__reduce__の実行結果: <built-in method __reduce__ of LocalProxy object at 0x10a5d02d0> 22番目のメソッド: __reduce_ex__ request.__reduce_ex__の実行結果: <built-in method __reduce_ex__ of LocalProxy object at 0x10a5d02d0> 23番目のメソッド: __repr__ request.__repr__の実行結果: <bound method LocalProxy.__repr__ of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 24番目のメソッド: __setattr__ request.__setattr__の実行結果: <bound method LocalProxy.<lambda> of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 25番目のメソッド: __sizeof__ request.__sizeof__の実行結果: <built-in method __sizeof__ of LocalProxy object at 0x10a5d02d0> 26番目のメソッド: __str__ request.__str__の実行結果: <bound method LocalProxy.<lambda> of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 27番目のメソッド: __subclasshook__ request.__subclasshook__の実行結果: <built-in method __subclasshook__ of type object at 0x7feb3d122e18> 28番目のメソッド: __weakref__ request.__weakref__の実行結果: None 29番目のメソッド: _cached_json request._cached_jsonの実行結果: (Ellipsis, Ellipsis) 30番目のメソッド: _get_data_for_json request._get_data_for_jsonの実行結果: <bound method JSONMixin._get_data_for_json of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 31番目のメソッド: _get_file_stream request._get_file_streamの実行結果: <bound method BaseRequest._get_file_stream of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 32番目のメソッド: _get_stream_for_parsing request._get_stream_for_parsingの実行結果: <bound method BaseRequest._get_stream_for_parsing of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 33番目のメソッド: _load_form_data request._load_form_dataの実行結果: <bound method Request._load_form_data of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 34番目のメソッド: _parse_content_type request._parse_content_typeの実行結果: <bound method CommonRequestDescriptorsMixin._parse_content_type of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 35番目のメソッド: accept_charsets request.accept_charsetsの実行結果: 36番目のメソッド: accept_encodings request.accept_encodingsの実行結果: 37番目のメソッド: accept_languages request.accept_languagesの実行結果: 38番目のメソッド: accept_mimetypes request.accept_mimetypesの実行結果: */* 39番目のメソッド: access_control_request_headers request.access_control_request_headersの実行結果: None 40番目のメソッド: access_control_request_method request.access_control_request_methodの実行結果: None 41番目のメソッド: access_route request.access_routeの実行結果: ImmutableList(['127.0.0.1']) 42番目のメソッド: application request.applicationの実行結果: <bound method BaseRequest.application of <class 'flask.wrappers.Request'>> 43番目のメソッド: args request.argsの実行結果: ImmutableMultiDict([('arg1', 'myarg1'), ('arg2', 'myarg2')]) 44番目のメソッド: authorization request.authorizationの実行結果: None 45番目のメソッド: base_url request.base_urlの実行結果: http://some_destination.com./ 46番目のメソッド: blueprint request.blueprintの実行結果: None 47番目のメソッド: cache_control request.cache_controlの実行結果: 48番目のメソッド: charset request.charsetの実行結果: utf-8 49番目のメソッド: close request.closeの実行結果: <bound method BaseRequest.close of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 50番目のメソッド: content_encoding request.content_encodingの実行結果: None 51番目のメソッド: content_length request.content_lengthの実行結果: None 52番目のメソッド: content_md5 request.content_md5の実行結果: None 53番目のメソッド: content_type request.content_typeの実行結果: None 54番目のメソッド: cookies request.cookiesの実行結果: ImmutableMultiDict([]) 55番目のメソッド: data request.dataの実行結果: b'' 56番目のメソッド: date request.dateの実行結果: None 57番目のメソッド: dict_storage_class request.dict_storage_classの実行結果: <class 'werkzeug.datastructures.ImmutableMultiDict'> 58番目のメソッド: disable_data_descriptor request.disable_data_descriptorの実行結果: False 59番目のメソッド: encoding_errors request.encoding_errorsの実行結果: replace 60番目のメソッド: endpoint request.endpointの実行結果: hello 61番目のメソッド: environ request.environの実行結果: {'wsgi.version': (1, 0), 'wsgi.url_scheme': 'http', 'wsgi.input': <_io.BufferedReader name=7>, 'wsgi.errors': <_io.TextIOWrapper name='<stderr>' mode='w' encoding='UTF-8'>, 'wsgi.multithread': True, 'wsgi.multiprocess': False, 'wsgi.run_once': False, 'werkzeug.server.shutdown': <function WSGIRequestHandler.make_environ.<locals>.shutdown_server at 0x10a496840>, 'SERVER_SOFTWARE': 'Werkzeug/1.0.1', 'REQUEST_METHOD': 'GET', 'SCRIPT_NAME': '', 'PATH_INFO': '/', 'QUERY_STRING': 'arg1=myarg1&arg2=myarg2', 'REQUEST_URI': '/?arg1=myarg1&arg2=myarg2', 'RAW_URI': '/?arg1=myarg1&arg2=myarg2', 'REMOTE_ADDR': '127.0.0.1', 'REMOTE_PORT': 56805, 'SERVER_NAME': '127.0.0.1', 'SERVER_PORT': '5000', 'SERVER_PROTOCOL': 'HTTP/1.1', 'HTTP_HOST': 'some_destination.com.', 'HTTP_USER_AGENT': 'curl/7.64.1', 'HTTP_ACCEPT': '*/*', 'HTTP_AUTHORIZATION': 'something', 'werkzeug.request': <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>} 62番目のメソッド: files request.filesの実行結果: ImmutableMultiDict([]) 63番目のメソッド: form request.formの実行結果: ImmutableMultiDict([]) 64番目のメソッド: form_data_parser_class request.form_data_parser_classの実行結果: <class 'werkzeug.formparser.FormDataParser'> 65番目のメソッド: from_values request.from_valuesの実行結果: <bound method BaseRequest.from_values of <class 'flask.wrappers.Request'>> 66番目のメソッド: full_path request.full_pathの実行結果: /?arg1=myarg1&arg2=myarg2 67番目のメソッド: get_data request.get_dataの実行結果: <bound method BaseRequest.get_data of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 68番目のメソッド: get_json request.get_jsonの実行結果: <bound method JSONMixin.get_json of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 69番目のメソッド: headers request.headersの実行結果: Host: some_destination.com. User-Agent: curl/7.64.1 Accept: */* Authorization: something 70番目のメソッド: host request.hostの実行結果: some_destination.com. 71番目のメソッド: host_url request.host_urlの実行結果: http://some_destination.com./ 72番目のメソッド: if_match request.if_matchの実行結果: 73番目のメソッド: if_modified_since request.if_modified_sinceの実行結果: None 74番目のメソッド: if_none_match request.if_none_matchの実行結果: 75番目のメソッド: if_range request.if_rangeの実行結果: 76番目のメソッド: if_unmodified_since request.if_unmodified_sinceの実行結果: None 77番目のメソッド: input_stream request.input_streamの実行結果: <_io.BufferedReader name=7> 78番目のメソッド: is_json request.is_jsonの実行結果: False 79番目のメソッド: is_multiprocess request.is_multiprocessの実行結果: False 80番目のメソッド: is_multithread request.is_multithreadの実行結果: True 81番目のメソッド: is_run_once request.is_run_onceの実行結果: False 82番目のメソッド: is_secure request.is_secureの実行結果: False 83番目のメソッド: json request.jsonの実行結果: None 84番目のメソッド: json_module request.json_moduleの実行結果: <module 'flask.json' from '/Library/Python/3.7/site-packages/flask/json/__init__.py'> 85番目のメソッド: list_storage_class request.list_storage_classの実行結果: <class 'werkzeug.datastructures.ImmutableList'> 86番目のメソッド: make_form_data_parser request.make_form_data_parserの実行結果: <bound method BaseRequest.make_form_data_parser of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 87番目のメソッド: max_content_length request.max_content_lengthの実行結果: None 88番目のメソッド: max_form_memory_size request.max_form_memory_sizeの実行結果: None 89番目のメソッド: max_forwards request.max_forwardsの実行結果: None 90番目のメソッド: method request.methodの実行結果: GET 91番目のメソッド: mimetype request.mimetypeの実行結果: 92番目のメソッド: mimetype_params request.mimetype_paramsの実行結果: {} 93番目のメソッド: on_json_loading_failed request.on_json_loading_failedの実行結果: <bound method JSONMixin.on_json_loading_failed of <Request 'http://some_destination.com./?arg1=myarg1&arg2=myarg2' [GET]>> 94番目のメソッド: origin request.originの実行結果: None 95番目のメソッド: parameter_storage_class request.parameter_storage_classの実行結果: <class 'werkzeug.datastructures.ImmutableMultiDict'> 96番目のメソッド: path request.pathの実行結果: / 97番目のメソッド: pragma request.pragmaの実行結果: 98番目のメソッド: query_string request.query_stringの実行結果: b'arg1=myarg1&arg2=myarg2' 99番目のメソッド: range request.rangeの実行結果: None 100番目のメソッド: referrer request.referrerの実行結果: None 101番目のメソッド: remote_addr request.remote_addrの実行結果: 127.0.0.1 102番目のメソッド: remote_user request.remote_userの実行結果: None 103番目のメソッド: routing_exception request.routing_exceptionの実行結果: None 104番目のメソッド: scheme request.schemeの実行結果: http 105番目のメソッド: script_root request.script_rootの実行結果: 106番目のメソッド: shallow request.shallowの実行結果: False 107番目のメソッド: stream request.streamの実行結果: <_io.BytesIO object at 0x10a592c50> 108番目のメソッド: trusted_hosts request.trusted_hostsの実行結果: None 109番目のメソッド: url request.urlの実行結果: http://some_destination.com./?arg1=myarg1&arg2=myarg2 110番目のメソッド: url_charset request.url_charsetの実行結果: utf-8 111番目のメソッド: url_root request.url_rootの実行結果: http://some_destination.com./ 112番目のメソッド: url_rule request.url_ruleの実行結果: / 113番目のメソッド: user_agent request.user_agentの実行結果: curl/7.64.1 114番目のメソッド: values request.valuesの実行結果: CombinedMultiDict([ImmutableMultiDict([('arg1', 'myarg1'), ('arg2', 'myarg2')]), ImmutableMultiDict([])]) 115番目のメソッド: view_args request.view_argsの実行結果: {} 116番目のメソッド: want_form_data_parsed request.want_form_data_parsedの実行結果: FalsePost通信の場合
基本的には43番目のargs、44番目のauthorization、45番目のbase_url,62番目のfiles、63番目のform、69番目のheaders,90番目のmethod,114番目のvaluesあたりがPost通信では見ておけば良さそうです。
1番目のメソッド: __class__ request.__class__の実行結果: <class 'werkzeug.local.LocalProxy'> 2番目のメソッド: __delattr__ request.__delattr__の実行結果: <bound method LocalProxy.<lambda> of <Request 'http://some_destination.com./' [POST]>> 3番目のメソッド: __dict__ request.__dict__の実行結果: {'environ': {'wsgi.version': (1, 0), 'wsgi.url_scheme': 'http', 'wsgi.input': <_io.BufferedReader name=5>, 'wsgi.errors': <_io.TextIOWrapper name='<stderr>' mode='w' encoding='UTF-8'>, 'wsgi.multithread': True, 'wsgi.multiprocess': False, 'wsgi.run_once': False, 'werkzeug.server.shutdown': <function WSGIRequestHandler.make_environ.<locals>.shutdown_server at 0x10a496840>, 'SERVER_SOFTWARE': 'Werkzeug/1.0.1', 'REQUEST_METHOD': 'POST', 'SCRIPT_NAME': '', 'PATH_INFO': '/', 'QUERY_STRING': '', 'REQUEST_URI': '/', 'RAW_URI': '/', 'REMOTE_ADDR': '127.0.0.1', 'REMOTE_PORT': 56815, 'SERVER_NAME': '127.0.0.1', 'SERVER_PORT': '5000', 'SERVER_PROTOCOL': 'HTTP/1.1', 'HTTP_HOST': 'some_destination.com.', 'HTTP_USER_AGENT': 'curl/7.64.1', 'HTTP_ACCEPT': '*/*', 'HTTP_AUTHORIZATION': 'something', 'CONTENT_LENGTH': '1142200', 'CONTENT_TYPE': 'multipart/form-data; boundary=------------------------f915de6b8767f310', 'HTTP_EXPECT': '100-continue', 'werkzeug.request': <Request 'http://some_destination.com./' [POST]>}, 'shallow': False, 'url_rule': <Rule '/' (GET, HEAD, POST, OPTIONS) -> hello>, 'view_args': {}, 'url': 'http://some_destination.com./'} 4番目のメソッド: __dir__ request.__dir__の実行結果: <bound method LocalProxy.__dir__ of <Request 'http://some_destination.com./' [POST]>> 5番目のメソッド: __doc__ request.__doc__の実行結果: Acts as a proxy for a werkzeug local. Forwards all operations to a proxied object. The only operations not supported for forwarding are right handed operands and any kind of assignment. Example usage:: from werkzeug.local import Local l = Local() # these are proxies request = l('request') user = l('user') from werkzeug.local import LocalStack _response_local = LocalStack() # this is a proxy response = _response_local() Whenever something is bound to l.user / l.request the proxy objects will forward all operations. If no object is bound a :exc:`RuntimeError` will be raised. To create proxies to :class:`Local` or :class:`LocalStack` objects, call the object as shown above. If you want to have a proxy to an object looked up by a function, you can (as of Werkzeug 0.6.1) pass a function to the :class:`LocalProxy` constructor:: session = LocalProxy(lambda: get_current_request().session) .. versionchanged:: 0.6.1 The class can be instantiated with a callable as well now. 6番目のメソッド: __enter__ request.__enter__の実行結果: <bound method LocalProxy.<lambda> of <Request 'http://some_destination.com./' [POST]>> 7番目のメソッド: __eq__ request.__eq__の実行結果: <bound method LocalProxy.<lambda> of <Request 'http://some_destination.com./' [POST]>> 8番目のメソッド: __exit__ request.__exit__の実行結果: <bound method LocalProxy.<lambda> of <Request 'http://some_destination.com./' [POST]>> 9番目のメソッド: __format__ request.__format__の実行結果: <built-in method __format__ of LocalProxy object at 0x10a5d02d0> 10番目のメソッド: __ge__ request.__ge__の実行結果: <bound method LocalProxy.<lambda> of <Request 'http://some_destination.com./' [POST]>> 11番目のメソッド: __getattribute__ request.__getattribute__の実行結果: <method-wrapper '__getattribute__' of LocalProxy object at 0x10a5d02d0> 12番目のメソッド: __gt__ request.__gt__の実行結果: <bound method LocalProxy.<lambda> of <Request 'http://some_destination.com./' [POST]>> 13番目のメソッド: __hash__ request.__hash__の実行結果: <bound method LocalProxy.<lambda> of <Request 'http://some_destination.com./' [POST]>> 14番目のメソッド: __init__ request.__init__の実行結果: <bound method LocalProxy.__init__ of <Request 'http://some_destination.com./' [POST]>> 15番目のメソッド: __init_subclass__ request.__init_subclass__の実行結果: <built-in method __init_subclass__ of type object at 0x7feb3d122e18> 16番目のメソッド: __le__ request.__le__の実行結果: <bound method LocalProxy.<lambda> of <Request 'http://some_destination.com./' [POST]>> 17番目のメソッド: __lt__ request.__lt__の実行結果: <bound method LocalProxy.<lambda> of <Request 'http://some_destination.com./' [POST]>> 18番目のメソッド: __module__ request.__module__の実行結果: werkzeug.local 19番目のメソッド: __ne__ request.__ne__の実行結果: <bound method LocalProxy.<lambda> of <Request 'http://some_destination.com./' [POST]>> 20番目のメソッド: __new__ request.__new__の実行結果: <built-in method __new__ of type object at 0x109498d30> 21番目のメソッド: __reduce__ request.__reduce__の実行結果: <built-in method __reduce__ of LocalProxy object at 0x10a5d02d0> 22番目のメソッド: __reduce_ex__ request.__reduce_ex__の実行結果: <built-in method __reduce_ex__ of LocalProxy object at 0x10a5d02d0> 23番目のメソッド: __repr__ request.__repr__の実行結果: <bound method LocalProxy.__repr__ of <Request 'http://some_destination.com./' [POST]>> 24番目のメソッド: __setattr__ request.__setattr__の実行結果: <bound method LocalProxy.<lambda> of <Request 'http://some_destination.com./' [POST]>> 25番目のメソッド: __sizeof__ request.__sizeof__の実行結果: <built-in method __sizeof__ of LocalProxy object at 0x10a5d02d0> 26番目のメソッド: __str__ request.__str__の実行結果: <bound method LocalProxy.<lambda> of <Request 'http://some_destination.com./' [POST]>> 27番目のメソッド: __subclasshook__ request.__subclasshook__の実行結果: <built-in method __subclasshook__ of type object at 0x7feb3d122e18> 28番目のメソッド: __weakref__ request.__weakref__の実行結果: None 29番目のメソッド: _cached_json request._cached_jsonの実行結果: (Ellipsis, Ellipsis) 30番目のメソッド: _get_data_for_json request._get_data_for_jsonの実行結果: <bound method JSONMixin._get_data_for_json of <Request 'http://some_destination.com./' [POST]>> 31番目のメソッド: _get_file_stream request._get_file_streamの実行結果: <bound method BaseRequest._get_file_stream of <Request 'http://some_destination.com./' [POST]>> 32番目のメソッド: _get_stream_for_parsing request._get_stream_for_parsingの実行結果: <bound method BaseRequest._get_stream_for_parsing of <Request 'http://some_destination.com./' [POST]>> 33番目のメソッド: _load_form_data request._load_form_dataの実行結果: <bound method Request._load_form_data of <Request 'http://some_destination.com./' [POST]>> 34番目のメソッド: _parse_content_type request._parse_content_typeの実行結果: <bound method CommonRequestDescriptorsMixin._parse_content_type of <Request 'http://some_destination.com./' [POST]>> 35番目のメソッド: accept_charsets request.accept_charsetsの実行結果: 36番目のメソッド: accept_encodings request.accept_encodingsの実行結果: 37番目のメソッド: accept_languages request.accept_languagesの実行結果: 38番目のメソッド: accept_mimetypes request.accept_mimetypesの実行結果: */* 39番目のメソッド: access_control_request_headers request.access_control_request_headersの実行結果: None 40番目のメソッド: access_control_request_method request.access_control_request_methodの実行結果: None 41番目のメソッド: access_route request.access_routeの実行結果: ImmutableList(['127.0.0.1']) 42番目のメソッド: application request.applicationの実行結果: <bound method BaseRequest.application of <class 'flask.wrappers.Request'>> 43番目のメソッド: args request.argsの実行結果: ImmutableMultiDict([]) 44番目のメソッド: authorization request.authorizationの実行結果: None 45番目のメソッド: base_url request.base_urlの実行結果: http://some_destination.com./ 46番目のメソッド: blueprint request.blueprintの実行結果: None 47番目のメソッド: cache_control request.cache_controlの実行結果: 48番目のメソッド: charset request.charsetの実行結果: utf-8 49番目のメソッド: close request.closeの実行結果: <bound method BaseRequest.close of <Request 'http://some_destination.com./' [POST]>> 50番目のメソッド: content_encoding request.content_encodingの実行結果: None 51番目のメソッド: content_length request.content_lengthの実行結果: 1142200 52番目のメソッド: content_md5 request.content_md5の実行結果: None 53番目のメソッド: content_type request.content_typeの実行結果: multipart/form-data; boundary=------------------------f915de6b8767f310 54番目のメソッド: cookies request.cookiesの実行結果: ImmutableMultiDict([]) 55番目のメソッド: data request.dataの実行結果: b'' 56番目のメソッド: date request.dateの実行結果: None 57番目のメソッド: dict_storage_class request.dict_storage_classの実行結果: <class 'werkzeug.datastructures.ImmutableMultiDict'> 58番目のメソッド: disable_data_descriptor request.disable_data_descriptorの実行結果: False 59番目のメソッド: encoding_errors request.encoding_errorsの実行結果: replace 60番目のメソッド: endpoint request.endpointの実行結果: hello 61番目のメソッド: environ request.environの実行結果: {'wsgi.version': (1, 0), 'wsgi.url_scheme': 'http', 'wsgi.input': <_io.BufferedReader name=5>, 'wsgi.errors': <_io.TextIOWrapper name='<stderr>' mode='w' encoding='UTF-8'>, 'wsgi.multithread': True, 'wsgi.multiprocess': False, 'wsgi.run_once': False, 'werkzeug.server.shutdown': <function WSGIRequestHandler.make_environ.<locals>.shutdown_server at 0x10a496840>, 'SERVER_SOFTWARE': 'Werkzeug/1.0.1', 'REQUEST_METHOD': 'POST', 'SCRIPT_NAME': '', 'PATH_INFO': '/', 'QUERY_STRING': '', 'REQUEST_URI': '/', 'RAW_URI': '/', 'REMOTE_ADDR': '127.0.0.1', 'REMOTE_PORT': 56815, 'SERVER_NAME': '127.0.0.1', 'SERVER_PORT': '5000', 'SERVER_PROTOCOL': 'HTTP/1.1', 'HTTP_HOST': 'some_destination.com.', 'HTTP_USER_AGENT': 'curl/7.64.1', 'HTTP_ACCEPT': '*/*', 'HTTP_AUTHORIZATION': 'something', 'CONTENT_LENGTH': '1142200', 'CONTENT_TYPE': 'multipart/form-data; boundary=------------------------f915de6b8767f310', 'HTTP_EXPECT': '100-continue', 'werkzeug.request': <Request 'http://some_destination.com./' [POST]>} 62番目のメソッド: files request.filesの実行結果: ImmutableMultiDict([('image', <FileStorage: 'na18_1920x1080_221804.jpg' ('image/jpeg')>)]) 63番目のメソッド: form request.formの実行結果: ImmutableMultiDict([('arg1', 'myarg1'), ('arg2', 'myarg2')]) 64番目のメソッド: form_data_parser_class request.form_data_parser_classの実行結果: <class 'werkzeug.formparser.FormDataParser'> 65番目のメソッド: from_values request.from_valuesの実行結果: <bound method BaseRequest.from_values of <class 'flask.wrappers.Request'>> 66番目のメソッド: full_path request.full_pathの実行結果: /? 67番目のメソッド: get_data request.get_dataの実行結果: <bound method BaseRequest.get_data of <Request 'http://some_destination.com./' [POST]>> 68番目のメソッド: get_json request.get_jsonの実行結果: <bound method JSONMixin.get_json of <Request 'http://some_destination.com./' [POST]>> 69番目のメソッド: headers request.headersの実行結果: Host: some_destination.com. User-Agent: curl/7.64.1 Accept: */* Authorization: something Content-Length: 1142200 Content-Type: multipart/form-data; boundary=------------------------f915de6b8767f310 Expect: 100-continue 70番目のメソッド: host request.hostの実行結果: some_destination.com. 71番目のメソッド: host_url request.host_urlの実行結果: http://some_destination.com./ 72番目のメソッド: if_match request.if_matchの実行結果: 73番目のメソッド: if_modified_since request.if_modified_sinceの実行結果: None 74番目のメソッド: if_none_match request.if_none_matchの実行結果: 75番目のメソッド: if_range request.if_rangeの実行結果: 76番目のメソッド: if_unmodified_since request.if_unmodified_sinceの実行結果: None 77番目のメソッド: input_stream request.input_streamの実行結果: <_io.BufferedReader name=5> 78番目のメソッド: is_json request.is_jsonの実行結果: False 79番目のメソッド: is_multiprocess request.is_multiprocessの実行結果: False 80番目のメソッド: is_multithread request.is_multithreadの実行結果: True 81番目のメソッド: is_run_once request.is_run_onceの実行結果: False 82番目のメソッド: is_secure request.is_secureの実行結果: False 83番目のメソッド: json request.jsonの実行結果: None 84番目のメソッド: json_module request.json_moduleの実行結果: <module 'flask.json' from '/Library/Python/3.7/site-packages/flask/json/__init__.py'> 85番目のメソッド: list_storage_class request.list_storage_classの実行結果: <class 'werkzeug.datastructures.ImmutableList'> 86番目のメソッド: make_form_data_parser request.make_form_data_parserの実行結果: <bound method BaseRequest.make_form_data_parser of <Request 'http://some_destination.com./' [POST]>> 87番目のメソッド: max_content_length request.max_content_lengthの実行結果: None 88番目のメソッド: max_form_memory_size request.max_form_memory_sizeの実行結果: None 89番目のメソッド: max_forwards request.max_forwardsの実行結果: None 90番目のメソッド: method request.methodの実行結果: POST 91番目のメソッド: mimetype request.mimetypeの実行結果: multipart/form-data 92番目のメソッド: mimetype_params request.mimetype_paramsの実行結果: {'boundary': '------------------------f915de6b8767f310'} 93番目のメソッド: on_json_loading_failed request.on_json_loading_failedの実行結果: <bound method JSONMixin.on_json_loading_failed of <Request 'http://some_destination.com./' [POST]>> 94番目のメソッド: origin request.originの実行結果: None 95番目のメソッド: parameter_storage_class request.parameter_storage_classの実行結果: <class 'werkzeug.datastructures.ImmutableMultiDict'> 96番目のメソッド: path request.pathの実行結果: / 97番目のメソッド: pragma request.pragmaの実行結果: 98番目のメソッド: query_string request.query_stringの実行結果: b'' 99番目のメソッド: range request.rangeの実行結果: None 100番目のメソッド: referrer request.referrerの実行結果: None 101番目のメソッド: remote_addr request.remote_addrの実行結果: 127.0.0.1 102番目のメソッド: remote_user request.remote_userの実行結果: None 103番目のメソッド: routing_exception request.routing_exceptionの実行結果: None 104番目のメソッド: scheme request.schemeの実行結果: http 105番目のメソッド: script_root request.script_rootの実行結果: 106番目のメソッド: shallow request.shallowの実行結果: False 107番目のメソッド: stream request.streamの実行結果: <werkzeug.wsgi.LimitedStream object at 0x10a593e48> 108番目のメソッド: trusted_hosts request.trusted_hostsの実行結果: None 109番目のメソッド: url request.urlの実行結果: http://some_destination.com./ 110番目のメソッド: url_charset request.url_charsetの実行結果: utf-8 111番目のメソッド: url_root request.url_rootの実行結果: http://some_destination.com./ 112番目のメソッド: url_rule request.url_ruleの実行結果: / 113番目のメソッド: user_agent request.user_agentの実行結果: curl/7.64.1 114番目のメソッド: values request.valuesの実行結果: CombinedMultiDict([ImmutableMultiDict([]), ImmutableMultiDict([('arg1', 'myarg1'), ('arg2', 'myarg2')])]) 115番目のメソッド: view_args request.view_argsの実行結果: {} 116番目のメソッド: want_form_data_parsed request.want_form_data_parsedの実行結果: Trueこれで次以降ちゃんとできるはず・・・!!
この記事が役に立ったと思ったらLGTMお願いいたします
最後に自分用のメモ。
GCFで検証する場合、pythonファイルは下記。main.py# coding: utf-8 from flask import Flask, request app = Flask(__name__) @app.route("/", methods=["GET", "POST"]) def hello(request): request_methods = dir(request) print(len(dir(request)),dir(request)) for i,method in enumerate(request_methods): print("%s番目のメソッド:\n %s"%(i+1,method)) exec("print(' request.'+method+'の実行結果:',request.%s)"%(method)) print("") return "Hello World!"
- 投稿日:2020-11-25T22:20:29+09:00
Huggingface Transformersを使って10行で桃太郎の続きを生成する
動作環境
- Google Colaboratory
- Huggingface Transformers 2.5.1
- Pytorch 1.5.0
実装内容
- 「桃太郎」でおばあさんが桃を割ったところまでの文章を入力し、その続きを日本語版BERTに予測させる。
ソースコード
generate_ja_sentence.ipynb!pip install torch torchvision -f https://download.pytorch.org/whl/torch_stable.html !pip install transformers !pip install fugashi !pip install ipadic import torch from transformers import AutoModelWithLMHead, AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese-whole-word-masking") model = AutoModelWithLMHead.from_pretrained("cl-tohoku/bert-base-japanese-whole-word-masking") prompt = "昔々、あるところにおじいさんとおばあさんが住んでいました。おじいさんは山へ芝刈りに、おばあさんは川で洗濯にいきました。おばあさんが川で洗濯をしていると、大きな桃が流れてきました。おばあさんは大きな桃を拾いあげて家に持ち帰りました。そしておじいさんとおばあさんが桃を食べようと桃を切ってみると、" inputs = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt") prompt_length = len(tokenizer.decode(inputs[0], skip_special_tokens=True, clean_up_tokenization_spaces=True)) outputs = model.generate(inputs, max_length=150, do_sample=True, top_k=60, top_p=0.98) generated = tokenizer.decode(outputs[0])[prompt_length:].replace(" ", "") print(prompt + generated)生成した文章はこのようになりました。
昔々、あるところにおじいさんとおばあさんが住んでいました。おじいさんは山へ芝刈りに、おばあさんは川で洗濯にいきました。おばあさんが川で洗濯をしていると、大きな桃が流れてきました。おばあさんは大きな桃を拾いあげて家に持ち帰りました。そしておじいさんとおばあさんが桃を食べようと桃を切ってみると、偶然みてまたこの桃が降りてくる。すると、桃が降りてくる。するとまた桃が割れる。すると、桃が割れてしまうので、もう一度少しずつ割れ続ける。すると、おばあさんが言う
めちゃくちゃホラー展開になってしまいました。
まとめ
上手く生成できたとは言い難いですが、実質数行で文章生成が出来てしまいました。
まだまだ勉強不足なので、この数行の中身を理解するまでは時間がかかりそうです
ここまで読んでいただきありがとうございました。参考リンク
- 投稿日:2020-11-25T21:24:42+09:00
MatplotlibをFlaskで拡張して、誰でもPythonで作成したグラフを見られるようにする
製造業やWeb制作会社だとPythonをインストールしているのが自分のPCだけだったりします。そんな時、PythonをインストールしていないPCでもMatplotlibでグラフを生成し、ブラウザを介して画像としてダウンロードする方法をメモします。
これにより、
- 誰にでもMatplotlibで生成したグラフにアクセスしてもらえる環境を構築する
- 自分のPCが非力な時、性能の良いサーバで画像を生成して効率化を図る
- めちゃめちゃ重いデータをあらかじめグラフ作成しておいてすぐ提供できるようにする
ことができるようになります。
方法と項目
方法は下記のとおりです。
- WebAPIを作成し、あるURLを叩いたらPythonの関数が走るようにする
- その関数の中でMatplotlibで画像を生成し、returnする
この記事ではそれぞれについて説明した後、さらに
- 本番環境でも耐えられるようにクラウドサービスの一つであるGCFにデプロイする方法と、
- そのAPIを叩いてcanvas要素に描写するHTMLのサンプル作成
までまとめます。
実際のところ、グラフの生成はユーザー側でJavaScriptで描写することの方が望ましいとは思いますが、Matplotlibで凝ったグラフを作るとこういうことやりたくなると思いますので、Geekな気分の時にお役立ていただけるとうれしいです。FlaskでWebAPIを作成し、あるURLを叩いたらPythonの関数が走るようにする
これはFlaskの基本的な使い方なので簡単に説明します。とりあえず自分だけに公開します。
main.py# -*- coding: utf-8 -*- from flask import Flask app = Flask(__name__) @app.route('/') def hello(): name = "Hello World" return name if __name__ == "__main__": app.run(debug=True)これを実行するとこうなります。
* Serving Flask app "main" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: on * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) * Restarting with fsevents reloader * Debugger is active! * Debugger PIN: 280-448-684http://127.0.0.1:5000 にアクセスするとこう表示されます。
もし同一ネットワーク内の他のPCからも見られるようにしたいなら、最後の部分をこうします。
main.pyapp.run(debug=False, host='0.0.0.0', port=5000)host=''0.0.0.0'をしていることで可能になります。あとはネットワーク内の自身のIPを調べて、http://xx.xx.xx.xx:5000でアクセスできるようになります。
以上がFlaskでの簡単のWebAPIの作成です。これについてはQiitaにたくさん記事あると思いますので関数の中でグラフを作成する部分に行きます。
関数の中でMatplotlibで画像を生成し、returnする
先ほどの関数の中でグラフを生成して、文字列の代わりにグラフをリターンすることにします。
main.py# -*- coding: utf-8 -*- import io import numpy as np import matplotlib import matplotlib.pyplot as plt matplotlib.use('Agg') from flask import Flask, send_file app = Flask(__name__) @app.route('/') def hello(): image = io.BytesIO() x = np.linspace(0, 10) y = np.sin(x) plt.plot(x, y) plt.savefig(image, format='png') image.seek(0) return send_file(image, attachment_filename="image.png", as_attachment=True) if __name__ == "__main__": app.run(debug=True)ポイントは2つあって、一つはmatplotlib.use('Agg')という部分と、二つ目はsavefigの部分でメモリ上でファイルを書き出していることです。
matplotlib.use('Agg')
FlaskはGUIをサポートしていないので、Aggがないとエラーで落ちます。
ioモジュールを使ってメモリ上でファイルを書き出し
ローカルで動かす場合は、普通にHDD(SSD?)にjpgなどで書き出しても問題ないと思いますが、クラウドなどだとローカルへのアクセスが禁止されていることが往々にしてあります。この場合に備えて、メモリ上でファイルの読み書きを行うioモジュールを使って、ローカルに書き出すことなく画像を出力します。
これを実行してhttp://127.0.0.1:5000 にアクセスすると勝手にファイルをダウンロードしてくれます。
開くとちゃんと画像になってます。
以上でとりあえず動作するようになりましたが、下記の2つの問題があります。
- Flaskの簡易サーバで実行していること
- 通信は暗号化されていないこと
の2点です。Flaskの簡易サーバで運用することは元々推奨されていないですし、httpsではなくhttpでアクセスしていることからわかるように通信は暗号化されていません。これでは実用に耐えられるものではありません。
そこで、この辺の本番環境への移行を簡単にしてくれるサービスとして、AWS,Herokuなどのクラウドサービスが登場するわけですが、今回はGoogle Cloud PlaftformのCloudFunctionsでデプロイします。勝手にSSL化もしてくれます。AWSならlambdaがGCFに相当します。
GCPのCloud Functionsでホスティングする
Cloud Functionsでホスティングするには、GCPを契約した後、SDKをダウンロードして、GCFの設定を完了する必要があります。最初は訳分からなくて少し大変でしたがクラウドは応用範囲広いので頑張りたいところです(自分に言ってる)。
GCFについてはこちら
https://cloud.google.com/functions/docs/quickstart-consoleGCFですが、欠点としてデプロイに時間がかかることがあります。したがって、開発時は自分のローカル環境でエミュレート(クラウドの環境を再現)して開発し、うまく行ったらデプロイする流れになります。エミュレートしないと開発効率が非常に落ちました。
ローカルでエミュレートする
ローカルでエミュレートするには、少し特殊な設定が必要です。SDKに加えて、pipでfunctions-frameworkというものをインストールします。
pip install functions-framework
デプロイしたいファイルを用意します。GCFの場合、必ずmain.pyという名前で作成する必要があります。
main.py# -*- coding: utf-8 -*- import matplotlib.pyplot as plt import io import json import numpy as np import matplotlib matplotlib.use('Agg') from flask import Flask, send_file def hello(request): headers = { 'Access-Control-Allow-Origin': '*', #'Access-Control-Allow-Origin': 'http://localhost:8080', } image = io.BytesIO() x = np.linspace(0, 10) y = np.sin(x) plt.plot(x, y) plt.savefig(image, format='png') image.seek(0) return send_file(image, attachment_filename="image.png", as_attachment=True) #return (json.dumps({'rtrn1':'rtrn1'}))main.pyのファイルのあるフォルダでターミナルを開いて、下記を打ち込むとエミュレートしてくれます。
functions-framework --target=hello --port=8080あとはhttp://localhost:8080/にアクセスするだけです。
なお、WindowsでAnacondaの場合は、anaconda prompt経由でcdで移動してコマンド打つ必要があります。また、 http://0.0.0.0:8080/ではなく localhost:8080/でアクセスします。詳しくはこちら。
https://github.com/GoogleCloudPlatform/functions-framework-pythonいよいよ本番環境へデプロイします。
本番環境へデプロイする
本番環境でデプロイする場合、ファイルの存在するフォルダで下記を実行します。もし標準モジュール以外のものを使う場合、同じ階層にrequirements.txtというテキストファイルを作成し、使用するライブラリを一つずつ記載する必要があります。今回で言うとmatplotlibとnumpy、Flaskの記載が必要です。
requirements.txtFlask==1.1.2 matpolotlib==3.3.2 numpy1.19.2基本的には、pip listで表示した自分の使ったライブラリのバージョンを記載すればOKですが、ランタイム環境が開発とデプロイ先で異なる場合は注意が必要です。例えば自分はPython3.6で開発していて標準のランタイムであるPython3.7にデプロイする場合、使っていたライブラリのバージョンがデプロイ先のランタイムではサポートされていないことがあります。この場合、意味不明のエラーでデプロイできませんので注意してください。特にnumpyとか注意。
その他はまった点
gcfから他のサービスと連携する際、認証はいらないです。
gcf上でローカルにファイルを書き出すようなプログラムをかくと意味不明なエラーでcrashする
ioモジュールでメモリに書き出す必要があります
諸々準備したら、下記のコマンドでデプロイします。
gcloud functions deploy hello --runtime python37 --trigger-http --allow-unauthenticatedあとはコンソールにデプロイ先のURLが表示されるので環境です。httpsでアクセスできるようになって、SSL化もバッチリです。
最後にHTML側のコードの紹介です。
APIを叩いてcanvas要素に描写する
これまではURLを直接叩いてましたが、APIを叩いてcanvas要素に描写するHTMLも載せておきます。
index.html<!doctype html> <html lang="ja"> <head> <!-- Required meta tags --> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <!-- Bootstrap CSS --> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css" integrity="sha384-ggOyR0iXCbMQv3Xipma34MD+dH/1fQ784/j6cY/iJTQUOhcWr7x9JvoRxT2MZw1T" crossorigin="anonymous"> <script src="https://code.jquery.com/jquery-3.3.1.min.js" crossorigin="anonymous"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.7/umd/popper.min.js" integrity="sha384-UO2eT0CpHqdSJQ6hJty5KVphtPhzWj9WO1clHTMGa3JDZwrnQq4sF86dIHNDz0W1" crossorigin="anonymous"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/js/bootstrap.min.js" integrity="sha384-JjSmVgyd0p3pXB1rRibZUAYoIIy6OrQ6VrjIEaFf/nJGzIxFDsf4x0xIM+B07jRM" crossorigin="anonymous"></script> <title>bootstrapとjquery</title> </head> <body> <main> <article> <section> <input type="button" value="Start" onclick="main();"/> <canvas style="height: 30vw;width:50vh"></canvas> </section> </article> </main> <script language="javascript" type="text/javascript"> function main(){ var canvas = document.getElementsByTagName('canvas'); var ctx = canvas[0].getContext('2d'); var img = new Image(); img.src = 'http://0.0.0.0:5000';//FlaskでホスティングしたURL img.onload = function() { img.style.display = 'none'; // ようわからん console.log('WxH: ' + img.width + 'x' + img.height) ctx.drawImage(img, 0, 0); var imageData = ctx.getImageData(0, 0, img.width*2, img.height*2) for(x = 0 ; x < 1000 ; x += 10) { for(y = 0 ; y < 1000 ; y += 10) { ctx.putImageData(imageData, x, y); } } }; } </script> </body> </html>ボタンを押したらURLを叩いて、canvas要素へ描写してくれます。
最後に
実際のところ、Flaskで返すのはデータにして、ユーザー側でJavaScriptのChart.jsで描写することの方が望ましいとは思います。でも、結構Matplotlibで凝ったグラフを作るとこういうことやりたくなりますよね。Geekな気分の時にお役に立てるとうれしいです。
この記事が役に立ったと思ったらLGTMお願いいたします

- 投稿日:2020-11-25T21:19:10+09:00
PythonでReading Trackerを実装してみた
はじめに
Reading Trackerというものをご存知でしょうか? 私は、本を読むときに読んでいるつもりで、視線は移動しているのに内容がなかなか入っていかないことがあり、そのときにこのReading Trackerが役に立ちます。
Reading Trackerとは、栞のような形状をしていて、本のちょうど一行分だけを見えるようにして周りの行を覆い隠すものです。
実際に見た方が早いと思うので、amazonのリンクを貼っておきます。
前にTwitterで紹介されている方もいました。
https://twitter.com/cbydbbmpg/status/1272843665593913346私もこのツイートでReading Trackerの存在を知りました。
作ったもの
Qiitaの難しい記事を見ているときや、ブログ、論文を見ているときに使える、パソコン上でのReading Trackerを作りました。
実装
from tkinter import ttk import tkinter import os root = tkinter.Tk() root.wm_attributes("-transparent", True) root.geometry("+300+300") #覆い隠す部分の大きさを変える際はframe_1とframe_2のwidthとheightを変更してください frame_1 = tkinter.Frame(width=800, height=150, bg="sky blue") frame_1.pack() f = tkinter.Frame(root, width=800, height=15)#ここのheightの部分を大きくすれば透ける部分が広くなります f.configure(bg="systemTransparent") f.pack() frame_2 = tkinter.Frame(width=800, height=180, bg="sky blue") frame_2.pack() root.mainloop()完成品
- 投稿日:2020-11-25T21:09:46+09:00
gunicornで起動するworkerに連番を割り振る
複数の Worker を起動するアプリケーションにおいて、各 Worker に一意な連番を割り振りたい場面があったのでメモ。
設定ファイルの
Server Hooksを使えばワーカーの起動時に呼ばれる処理を定義できるため、ここでワーカープロセス毎に環境変数を設定する。実装
FastAPI + gunicorn の例
pre_forkイベントを利用するgunicorn.config.pyimport os workers = 4 def pre_fork(server, worker): print('## called pre_fork') os.environ['WORKER_ID'] = str(server.worker_age - 1)main.pyimport os from fastapi import FastAPI app = FastAPI() worker_id = os.getenv('WORKER_ID') print('## WORKER_ID:', worker_id) @app.get('/') def index(): return {'msg': 'hello!'}起動コマンドと出力
$ gunicorn main:app -c gunicorn.config.py[2020-11-25 21:07:32 +0900] [18136] [INFO] Starting gunicorn 20.0.4 [2020-11-25 21:07:32 +0900] [18136] [INFO] Listening at: http://127.0.0.1:8000 (18136) [2020-11-25 21:07:32 +0900] [18136] [INFO] Using worker: sync ## called pre_fork [2020-11-25 21:07:32 +0900] [18139] [INFO] Booting worker with pid: 18139 ## called pre_fork [2020-11-25 21:07:32 +0900] [18140] [INFO] Booting worker with pid: 18140 ## called pre_fork ## WORKER_ID: 0 [2020-11-25 21:07:32 +0900] [18141] [INFO] Booting worker with pid: 18141 ## WORKER_ID: 1 ## called pre_fork [2020-11-25 21:07:32 +0900] [18142] [INFO] Booting worker with pid: 18142 ## WORKER_ID: 2 ## WORKER_ID: 3
pre_forkが4回呼び出され、ワーカー毎に0~3の番号が環境変数にセットされた
- 投稿日:2020-11-25T21:00:17+09:00
【AI】LobeからExportしたモデルの使い方
➊はじめに
前回は『
【AI】LobeでMNISTをやってみた』にて、AI側については一切プログラミングすることなく、推論エンジンをローカルPCにデプロイしました。また、Local APIを介してアプリと推論エンジンの通信を行いました。
➋今回やること
Lobeから
TensorFlow(saved_model)形式でエクスポートし、そのモデルを利用できるか確認してみたいと思います。今回はLobeが用意した➎Lobe-APIを使用する方法と、➏tensorflowライブラリを使用する方法の2種類を検証したいと思います。
➌Lobeからエクスポート
■エクスポート形式
Lobeからのエクスポート形式は、以下4つに対応しています。
今回は「TensorFlow 1.15 SavedModel」を検証します。
Export 説明 TensorFlow 1.15 SavedModel TensorFlowのSavedModelは、TensorFlow 1.xを実行するPythonアプリケーションで使用される標準形式であり、TensorFlow Webサービスにデプロイして、APIとしてクラウド上で推論を実行できます。 AndroidまたはRaspberryPi モデルをTensorFlowLiteとしてエクスポートして、モバイルおよびIoTアプリケーションで使用します。 Apple iOS モデルをCoreMLとしてエクスポートして、iOS、iPad、およびMacアプリを開発します。 ローカルAPI LobeはローカルAPIをホストして、RESTエンドポイントを介してモデルを呼び出します。このオプションを使用して、アプリの開発中に予測を実行するサービスをモックします。 ■エクスポート実施
■Lobeから対象PJを開いて、[
Export]を押下します。
■[
TensorFlow]を押下します。
■書き出しフォルダを選択するとExportが始まります。
■エクスポート結果
SavedModel形式については、TensorFlow:「SavedModel形式の使用」等をご参考ください。export model │ ├─example │ │ │ ├─README.md │ ├─requirements.txt │ └─tf_example.py │ ├─variables │ │ │ ├─variables.data-00000-of-00001 │ └─variables.index │ ├─saved_model.pb └─signature.json➍Lobe-APIとは
Lobeは、Exportしたモデルを簡単に読み込むためのライブラリ
Lobe-APIを用意しています。このLobe-APIを使うと以下の通りイメージファイル、URL、画像データから直接推論が可能となります。ただし、Lobe-APIをインストールするとtensorflowのバージョンが1.15にデグレードされてしまうので注意が必要です。詳細はここ → Lobe-API:https://github.com/lobe/lobe-python
OPTION 1:イメージファイルから推論する場合from lobe import ImageModel model = ImageModel.load('path/to/ExportFolder') result = model.predict_from_file('path/to/file.png')
OPTION 2:URLから推論する場合from lobe import ImageModel model = ImageModel.load('path/to/ExportFolder') result = model.predict_from_url('http://path/to/file.png')
OPTION 3:Pillow imageから推論する場合from lobe import ImageModel from PIL import Image model = ImageModel.load('path/to/ExportFolder') img = Image.open('path/to/file.png') result = model.predict(img)➎【使い方1】Lobe-APIを使用
では、早速
Lobe-APIを使って推論を実施させたいと思います。■python仮想環境構築
まず、anacondaのcondaコマンドを使用して、python仮想環境[
lober1]を作ります。
Lobe-APIはpython=3.7以上でないと動かないため以下のように設定します。2020/11現在、Google ColabのPythonバージョンは3.6.9なので、Google ColabではLobe-APIは使えませんでした。
仮想環境[lober1]構築C:\Lobe test>conda create -n lober1 python=3.7 C:\Lobe test>conda activate lober1■Lobe-APIのインストール
依存関係にあるライブラリも合わせて自動でインストールされます。
Lobe-APIインストール(lober1) C:\Lobe test>pip install git+https://github.com/lobe/lobe-python■Lobe-APIが返却する推論結果数を変更
Lobe-APIのデフォルトでは、推論結果を「認識率ベスト5までのクラスをソート」して返却してきます。
推論結果をどの様に使うかによりますが、今回は全クラス返却するように変更します。
仮想環境[lober1]下にインストールされたライブラリを修正します。C:\Users\[username]\anaconda3\envs\lober1\Lib\site-packages\lobe_results.py
「_results.py」のLine20を以下の様に修正します。_results.py20: top_predictions = confidences.argsort()[-5:][::-1] ← ベスト5のみに絞っている ↓↓↓↓ 20: top_predictions = confidences.argsort()[:][::-1] ← 全クラスに変更■サンプルプログラム
src01.py############################################################ # Lobeで作ったモデルを使う方法 1 ############################################################ import tensorflow as tf from lobe import ImageModel print("tensorflow : ", tf.__version__) ############################################################ # Export Model読込 ############################################################ model = ImageModel.load('export model') #----------------------------------------------------- # OPTION 1: イメージファイルから推論する場合 #----------------------------------------------------- print('■OPTION 1: Predict from an image file') result = model.predict_from_file('sample.png') pred = result.prediction sorted_labels = sorted(result.labels) conf = sorted_labels[int(result.prediction)][1] print('predict :', pred) print('confidence: {:1.010f}'.format(conf)) for label, conf in (sorted(result.labels)): print(label, '{:1.030f}'.format(conf)) print() #----------------------------------------------------- # OPTION 2: URLから推論する場合 #----------------------------------------------------- print('■OPTION 2: Predict from an image url') result = model.predict_from_url('https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/405376/4f9c554d-f3f5-fc8d-2e08-30e8eb6079a4.png') pred = result.prediction sorted_labels = sorted(result.labels) conf = sorted_labels[int(result.prediction)][1] print('predict :', pred) print('confidence: {:1.010f}'.format(conf)) for label, conf in (sorted(result.labels)): print(label, '{:1.030f}'.format(conf)) print() #----------------------------------------------------- # OPTION 3: Pillow imageから推論する場合 #----------------------------------------------------- print('■OPTION 3: Predict from Pillow image') from PIL import Image img = Image.open('sample.png') result = model.predict(img) pred = result.prediction sorted_labels = sorted(result.labels) conf = sorted_labels[int(result.prediction)][1] print('predict :', pred) print('confidence: {:1.010f}'.format(conf)) for label, conf in (sorted(result.labels)): print(label, '{:1.030f}'.format(conf)) print()■サンプルデータ
以下のサンプルデータを「sample.png」として「src01.py」と同じフォルダに保存してください。
サンプルデータ:sample.png
サンプル画像URL:https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/405376/4f9c554d-f3f5-fc8d-2e08-30e8eb6079a4.png
■プログラミング実行結果
src01.py実行結果(lober1) C:\Lobe test>python src01.py tensorflow : 1.15.4 ■OPTION 1: Predict from an image file predict : 9 confidence: 0.9999991655 0 0.000000000000000000004691450972 1 0.000000000000000000000000000000 2 0.000000000000000000204086976737 3 0.000000000000000000000101685206 4 0.000000000000000012389047993676 5 0.000000000000000000010694401651 6 0.000000000000000000000000045193 7 0.000000881124378793174400925636 8 0.000000000000000404111716429163 9 0.999999165534973144531250000000 ■OPTION 2: Predict from an image url predict : 9 confidence: 0.9999991655 0 0.000000000000000000004691450972 1 0.000000000000000000000000000000 2 0.000000000000000000204086976737 3 0.000000000000000000000101685206 4 0.000000000000000012389047993676 5 0.000000000000000000010694401651 6 0.000000000000000000000000045193 7 0.000000881124378793174400925636 8 0.000000000000000404111716429163 9 0.999999165534973144531250000000 ■OPTION 3: Predict from Pillow image predict : 9 confidence: 0.9999991655 0 0.000000000000000000004691450972 1 0.000000000000000000000000000000 2 0.000000000000000000204086976737 3 0.000000000000000000000101685206 4 0.000000000000000012389047993676 5 0.000000000000000000010694401651 6 0.000000000000000000000000045193 7 0.000000881124378793174400925636 8 0.000000000000000404111716429163 9 0.999999165534973144531250000000➏【使い方2】TensorFlowライブラリを使用
Lobe-APIを使用せずに、tensorflowライブラリを使って推論する方法です。■python仮想環境構築
anacondaを利用してpython仮想環境[
lober2]を作ります。仮想環境[lober2]構築(lober1) C:\Lobe test>conda deactivate C:\Lobe test>conda create -n lober2 python=3.7 C:\Lobe test>conda activate lober2 (lober2) C:\Lobe test>conda install tensorflow pillow■サンプルプログラム
src02.py############################################################ # Lobeで作ったモデルを使う方法 2 ############################################################ import json import numpy as np import tensorflow as tf from PIL import Image from tensorflow.keras.preprocessing.image import img_to_array print("tensorflow : ", tf.__version__) export_holder = 'export model/' ############################################################ # Export Model読込 ############################################################ # https://www.tensorflow.org/guide/saved_model # signature読込 sig_holder = export_holder + 'signature.json' with open(sig_holder, 'r') as f: signature = json.load(f) inputs = signature.get('inputs') outputs = signature.get('outputs') # モデルの学習画像サイズを取得 input_width, input_height = inputs['Image']['shape'][1:3] # model読込 model = tf.saved_model.load(export_holder) infer = model.signatures['serving_default'] ############################################################ # 画像データ読込 ############################################################ imgPIL = Image.open('sample.png') imgPIL = imgPIL.convert('RGB') imgPIL = imgPIL.resize((input_width, input_height)) x = img_to_array(imgPIL) / 255 x = x[None, ...] ############################################################ # 推論 ############################################################ predict = infer(tf.constant(x)) # 推論結果 predict = infer(tf.constant(x))['Prediction'][0] print('predict :', predict.numpy().decode()) # 確率 confidence = infer(tf.constant(x))['Confidences'][0] confidence = confidence.numpy() print('confidence: {:1.010f}'.format(confidence[int(predict)])) print() for i, conf in enumerate(confidence): print(i, '{:1.030f}'.format(conf)) print()■サンプルデータ
以下のサンプルデータを「sample.png」として「src02.py」と同じフォルダに保存してください。
サンプルデータ:sample.png
■プログラミング実行結果
src02.py実行結果(lober1) C:\Lobe test>python src02.py tensorflow : 2.1.0 predict : 9 confidence: 0.9999991655 0 0.000000000000000000004691540637 1 0.000000000000000000000000000000 2 0.000000000000000000204095532887 3 0.000000000000000000000101689472 4 0.000000000000000012389331716626 5 0.000000000000000000010694728000 6 0.000000000000000000000000045193 7 0.000000881154619492008350789547 8 0.000000000000000404117883887810 9 0.999999165534973144531250000000➐手書きアプリケーション
せっかくなので、いつもの手書きwebツールの
mnisterをTensorflowモデルを読み込めるように改造してみました。こちらは【使い方2】のTensorFlowライブラリを使用する方法でモデルを利用しています。ダウンロードは以下から取得可能となっていますので、ぜひご参考ください。※「mnister_for_tensorflow」アプリケーションを動作させる場合は、LobeのTensorFlow Exportモデルを各自用意する必要があります。モデルの作り方は『
【AI】LobeでMNISTをやってみた』と『本項➌』を参考にすれば簡単に実行できます。■システム図
■ダウンロード
mnister_for_Tensorflowを格納するディレクトリに移動後、以下のgit cloneコマンドを打ち込んでmnister_for_TensorflowツールをGETしてください。実行方法などはREADME.mdをご参照ください。
commandgit clone https://github.com/PoodleMaster/mnister_for_tensorflow
Github : https://github.com/PoodleMaster/mnister_for_tensorflow➑以上
LobeからエクスポートしたTensorFlowモデルは、APIなども用意されており、問題なく簡単に利用することができました。
microsoftの『
Lobe』やGoogleの『Teachable Machine』など、AIプログラミングすることなく、誰でも簡単にモデルを構築できたり、推論結果からモデルの更新ができるようになってきました。これからは、益々AIでどんなサービスができるかが重要視される時代になっていくんでしょうね…お疲れ様でした。
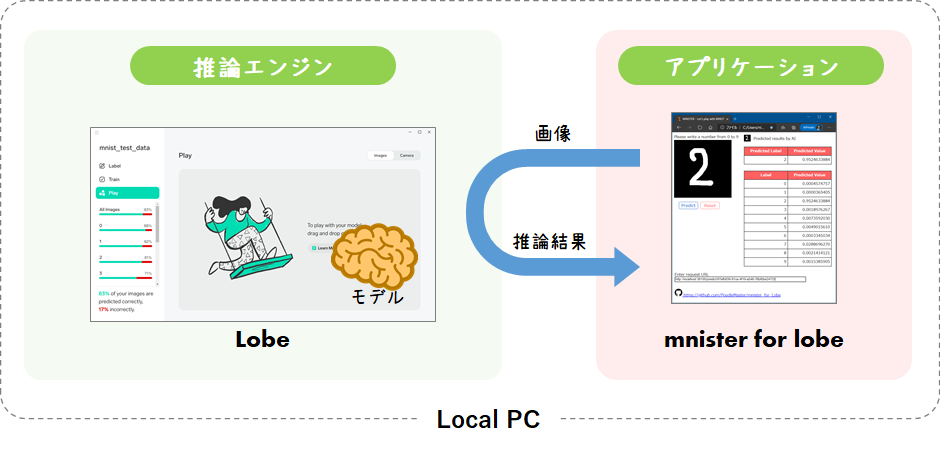
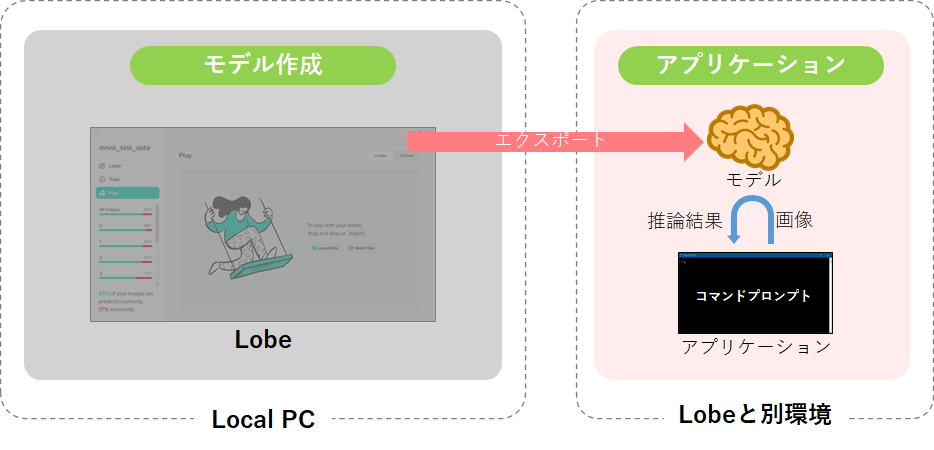
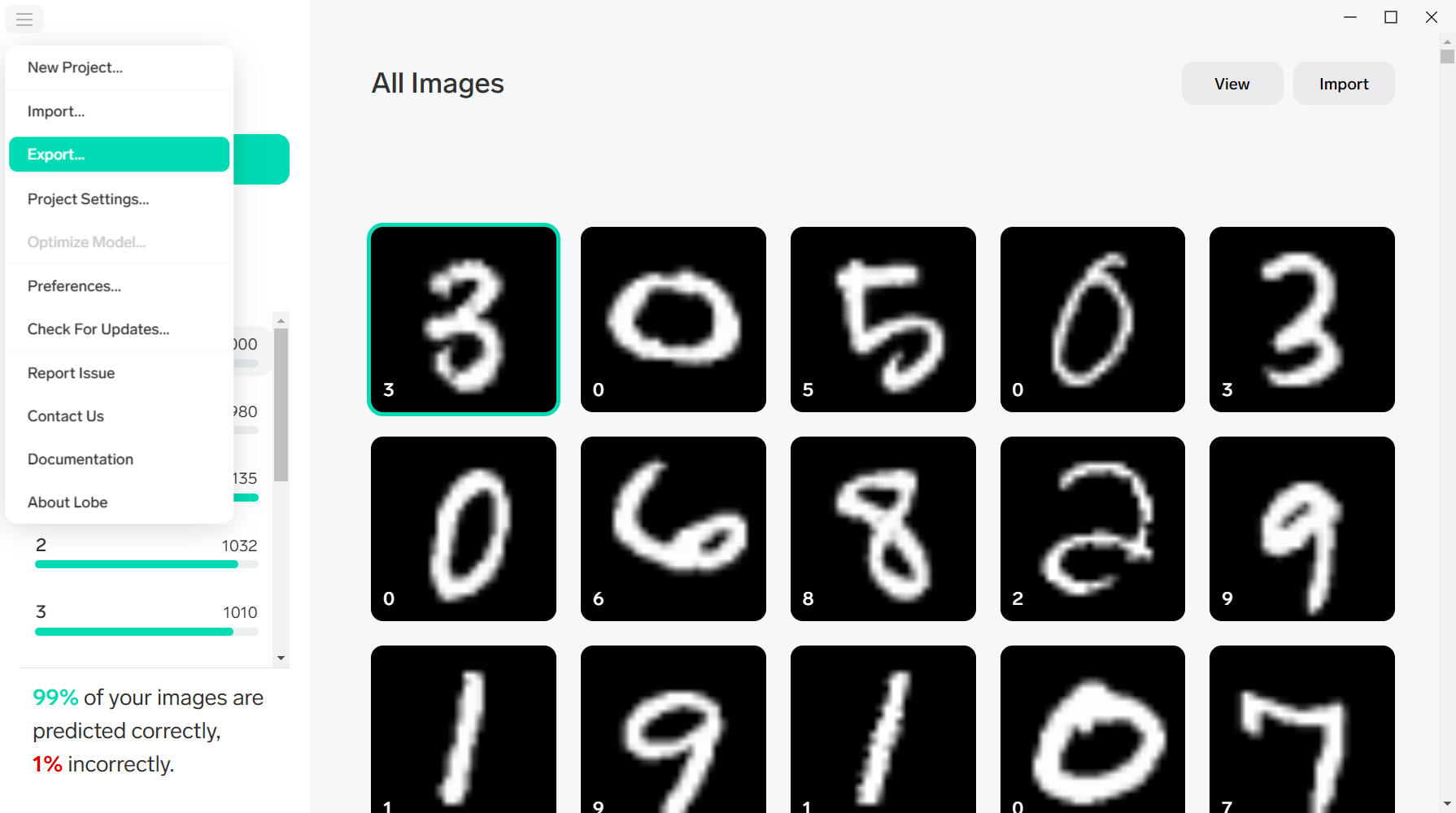
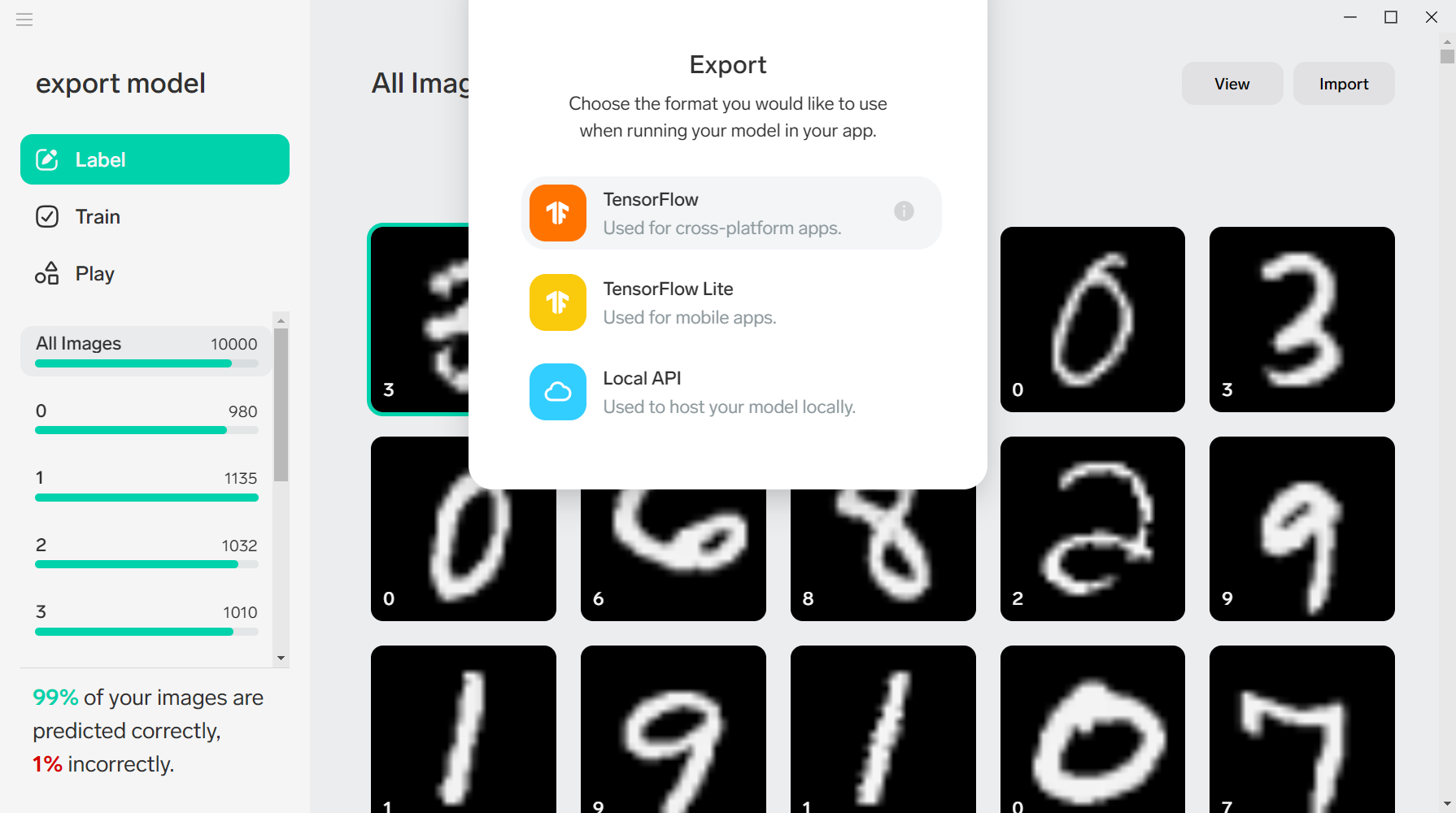



- 投稿日:2020-11-25T20:44:44+09:00
Azure Functions上のpythonプログラムから、毎朝6時にその日の1時間ごとの天気予報をslackに通知する
はじめに
朝起きた時の晴れ空で、洗濯しようと決意する人は多いはず。ただ、急な雨で後悔をした人も同じくらい多いはず。
かといっていちいち天気予報をググるのも面倒だし、テレビでは時間が合わずちょうどいまって時に教えてくれない。毎朝、いい感じのタイミングに天気予報をスマホに通知してくれないかなぁ、、
そんな希望に応えるために、表題のようなコードを書いてみました。
「「そういうアプリあるでしょう??」」それを言ったらおしまいです。忘れましょう。やってみたこと
1.TimerTriggerを持つAzure Funcitionsを準備する
2.OpenWeatherMapのAPIをたたき、東京都の1時間ごとの天気予報データをslackに投稿するpythonコードを書く環境・使用ツール
・windows10
・python3.7.2
・OpenWeatherMap
・Azure Functions
・Visual Studio CodeAzure Functionsを準備する
ざっくりこんな感じ。ぶっちゃけこれ以上語ることはない。。
強いて言うなら、「Select a template for your project's first function」のところで、HTTP triggerではなくTimer triggerを選んだくらい。
私の私による私のための備忘録なので許してください。
Visual Studio Codeから見えるフォルダの階層関係は、下のような感じになります。
TimerTriggerに加えてHttpTriggerを二つ作っていますが、気にしない。私の本命はTimerTriggerですが、どれか一つあればいいです。OpenWeatherMap APIをたたくpythonコードをAzure Functionsに追加する
Azure Functionsでは、TimerTrigger配下にある__init__.pyファイルをいじります。以下の写真は、こちらからの抜粋です。
何の手も加えていない状態の__init.py__ファイルには、関数はmainしかありません。さらに関数を追加する場合には、以下のような追記をしてみましょう。
具体的には、新たに関数を一つ作成し(pi_digits_Python)、返り値を得ます(output)。そして、その関数をmain関数の中で実行し、変数に返り値を代入しています。その変数をmain関数の中で活用していますね。
私もこの書き方を参考にし、TimerTriggerの__init.py__に新たな関数を追加しました。__init__.pyimport datetime import logging import requests import json import slackweb import azure.functions as func def weathercast(): apikey = "xxxxxxxxxxxxxx" api = "https://api.openweathermap.org/data/2.5/onecall?lat={lat}&lon={lon}&exclude={part}&appid={key}" latitude = xx longitude = xx exclude = "current" output = "" url = api.format(lat = latitude, lon = longitude, part = exclude, key = apikey) r = requests.get(url) data = r.json() data = json.loads(r.text) for i in range(8): weather = data["hourly"][i]["weather"][0]["main"] weather_detail = data["hourly"][i]["weather"][0]["description"] k = lambda x : x - 273.15 l = k(data["hourly"][i]["temp"]) temp = round(l,1) output += "天気:" + weather + ("\n") + "天気詳細:" + weather_detail + ("\n") + "気温:" + str(temp) + ("\n") + ("\n") output += "zura" return output def main(mytimer: func.TimerRequest) -> None: utc_timestamp = datetime.datetime.utcnow().replace( tzinfo=datetime.timezone.utc).isoformat() if mytimer.past_due: logging.info('The timer is past due!') logging.info('Python timer trigger function ran at %s', utc_timestamp) weathercast_zura = weathercast() slack = slackweb.Slack(url="xxx") slack.notify(text=weathercast_zura, urfurl_links = 'true')必要なモジュールをimportし、新たにweathercastという関数を追加、この関数から得た返り値outputをmain関数に追加しています。それをそのままslackに投げています。
weathercast関数の中身は、これとかこれとかを参考に。まあ基本はOpenWeatherMap APIのドキュメントを読みました。slackに飛ばすのは、こちらの記事を参考に。
その他注意事項
importするモジュールは、「requirement.txt」にバージョン情報と共に記述する必要があります。こんな感じ。今回は、requestモジュールとjsonモジュールを追加でimportしているので、importしたいバージョンと共に記載してあげましょう。
ちなみに、import datetimeとimport loggingは__init__.pyにもともと記載されていたものなので、気にしない。azure-functions slackweb==1.0.5 requests==2.22.0余談
lambdaに初めて触った
lambdaってなんだかおもしろい形ですね。
lambda 引数:返り値を基本形として、ここから得られた返り値を別の変数に代入してあげるのかな。
k = lambda x : x - 273.15 l = k(293.15)とかってやったら、変数lには20が入っているはず。いちいちdefで関数を作成するより楽ですね。参考にしたのはこちら。
時差を考慮して
TimerTrigger配下のfunction.jsonでは、TimerTriggerが発動する時間が設定されております。基本的には冒頭の「Azure Functionsを準備する」のフェーズで設定しますが、後々変更したいときはこのファイルをいじります。
__init__.pyを見ている感じ、timezoneがutcのように見受けられるので、時差を意識した記述としています。{ "scriptFile": "__init__.py", "bindings": [ { "name": "mytimer", "type": "timerTrigger", "direction": "in", "schedule": "0 0 21 * * 0-6" } ] }とてつもない反省
このページのようにcmdをたたかないと、コードは動きませんよね。。
Azure Functionsに乗っける前に普通にローカルで確認していましたが、__init__.pyとしか打っておらず「全然動かねぇ!!!」ってなっていました。もう二度と間違えん。衆目に晒すのは恥でしかありませんが、まぁ備忘録なので。
結果
想定通り、翌朝6時に写真のように時間ごとの天気予報、ついでに気温がslackに届きました。
最後に
ここから派生して、slackに「東京」と打ち込んだら東京の1日の天気を返してくれるようなBotを作りたいのですが、大体の記事が一バージョン前??のやつっぽくてよくわからないですね、、、
ぼちぼち試してみますが、知見のある方の記事を待つ、です。参考
・OpenWeatherMap
・Azure Functions
・クイック スタート:Visual Studio Code を使用して Azure で関数を作成する
・6: 2 つ目の Python 関数を Azure Functions に追加する
・無料天気予報APIのOpenWeatherMapを使ってみる
・pythonでopenweathermapのAPIを叩こう
・Weather API
・Python3でslackに投稿する
・Pythonのlambdaって分かりやすい

- 投稿日:2020-11-25T20:42:04+09:00
メルアイコン変換器を作った話
はじめに
「メルアイコン」と呼ばれる、Melvilleさんの描くアイコンはその独特な作風から大勢から人気を集めています。
上はMelvilleさんのアイコンです。
特にこの方へアイコンの作成を依頼し、それをtwitterアイコンとしている人がとても多いことで知られています。
代表的なメルアイコンの例


(左から順にゆかたゆさん、みなぎさん、しゅんしゅんさんのものです (2020/12/1現在))
自分もこんな感じのメルアイコンが欲しい!!!!!!ということで機械学習でメルアイコン生成器を実装しました!!!!!.......というのが前回の大まかなあらすじです。
今回は別の手法を使って、キャラの画像をメルアイコンに変換するモデルを実装しました。例えばこんな感じで変換できます。

本記事ではこれに用いた手法を紹介していきます。
GANとは
画像の変換にあたってはUGATITという手法を使っています。これはGAN(Generative adversarial networks、敵対的生成ネットワーク)という手法をベースにしたもので、GANは以下のような構成をとっています。
この手法では、画像を生成するニューラルネットワーク(Generator)と、画像を識別するニューラルネットワーク(Discriminator)の2つを組み合わせます。
Generatorは画像を生成し(偽画像と呼ぶことにします)、それによってDiscriminatorに本物画像だと誤認させることを目指して学習を進めます。一方でDiscriminatorはGeneratorに騙されないよう、より正確に画像を識別しようと学習します。
二つのニューラルネットワークがお互いに鍛え合うことで、Generatorは学習データに近い画像を生成できるようになっていく、というわけです。
要するにGenerator VS Discriminatorです。UGATIT
今回、キャラの画像⇄メルアイコンの変換にはUGATITというものを用いました。
これはGenerator VS Discriminatorによって学習を進めていくGANを基とした方式で、大まかな全体図は以下の図のようになっています。UGATITではGeneratorを2種類、Discriminatorを2種類用います。
まず「GeneratorA2B」を用意します。これはドメインA(図ではキャラの画像)に属する画像を入力に取り、ドメインB(図ではメルアイコン)に属する画像に変換するGeneratorです。またそれとは別に、「DiscriminatorB」を作ります。これは入力されたメルアイコンが本物なのか偽物なのかを識別します。
「ドメインA→ドメインB」の学習
DiscriminatorBは、本物のメルアイコンもしくはGeneratorA2Bによって生成された偽物のメルアイコンを入力に取り、それらが本物か偽物かを正しく識別できるように学習します。一方、GeneratorA2Bはキャラの画像を入力に取り、それを元に画像を生成し、DiscriminatorBを本物だと騙せるよう学習します。GeneratorA2BとDiscriminatorBが相互に鍛え合うことで、GeneratorA2Bはメルアイコンっぽい画像を生成できるようになっていきます。「ドメインA→ドメインB→ドメインA」の学習
さらにこれだけではなく、逆にドメインBをAに変換する「GeneratorB2A」と、ドメインAに属する画像を識別する「DiscriminatorA」を準備します。
先ほどGeneratorA2Bによって出力されたメルアイコンをGeneratorB2Aに入力します。つまり「ドメインA→ドメインB→ドメインA」という変換を施します。Discriminatorを騙すだけでなく、変換前のドメインAと、2回変換されて出てきたドメインAの画像が一致するようにも目指し学習を進めます。こうすることで生成結果に多様性を持たせ、モード崩壊の問題を軽減します。また、「ドメインA→ドメインB」と「ドメインA→ドメインB→ドメインA」に関して説明しましたが、AとB逆バージョン「ドメインB→ドメインA」と「ドメインB→ドメインA→ドメインB」についても同様の学習を進めます。
データセットの用意
Generatorがキャラの画像→メルアイコンの変換ができるようになったり、Discriminatorが画像を本物か偽物か識別できるようになったりするためには、すでに存在するキャラの画像やメルアイコンをできるだけ大量に持ってきてデータセットを作り、これを学習に用いる必要があります。
キャラの画像の用意
まずキャラの画像を集めます。
lbpcascade_animefaceという画像内からキャラの顔を抽出してくれるソースコードがgithubにあったのでこれを使います。これを実行すると例えば下の画像のように、キャラの画像を入力に取り、顔の部分を赤く囲ったものを出力できます。
このソースコードを改造してgoogle画像検索やtwitterのメディア欄からキャラの画像を自動抽出、45°傾けて保存しまくるものを作りました。退屈なことはpythonにやらせましょう。
これを使って約900枚ほどの、45°傾いたキャラの顔の画像が集まりました。これらをデータセットに用います。
メルアイコンの用意
メルアイコン側のデータセットに関しては、Melvilleさんから頂いた約640枚の本家メルアイコンを使います。また、メルアイコン生成器 version2から約260枚ほど生成しこれらも一緒に使います。

例えばこんな感じの画像を生成しておきます。
これら合計で900枚ほどのメルアイコンをデータセットに用います。
Discriminatorの作成
Discriminatorの役割は、入力された画像が本物のメルアイコンなのか、Generatorによって作成された偽画像なのかを判定することです。Generatorに騙されないように精度を上げていくことを目標に学習します。
Discriminatorは、おおざっぱには下の図のような構成になっています。
最初に入力された、本物または偽物のメルアイコン(チャネル数3(RGBの3つ)、縦横256×256pixelの画像)をEncoderと呼ばれる箇所に入力します。Encoder内では畳み込みを数回行うことでFeature mapを出力します。メルアイコンをメルアイコンたらしめている特徴を、入力画像から抽出し出力しているようなイメージです。
次にこのFeature mapを、後述するCAMという機能を用いてAttention Feature mapというものに変換します。メルアイコンの数ある特徴のうち、どういった特徴を集中的に見ると良いかという情報を付加しているようなイメージです。
このAttention Feature mapを次の層に渡し、さらに数回畳み込みを繰り返します(図の「conv」)。最終的に、入力された画像がどれだけ本物のメルアイコンっぽいかを表す値(本物っぽいほど大きな値になるよう学習します)を出力します。
CAMとは
CAM(Class Activation Map)とは、画像を識別するニューラルネットが、どのようにしてそう識別したかという情報を可視化する機能です。
図の引用元例えば上の画像では、ニューラルネットが犬を膝にのせた人間の画像を入力にとり、その画像がAustralian terrier(オーストラリアン・テリアという犬種)だと判定しています。
CAMを用いるとニューラルネットでただ画像を判定するだけでなく、判断に用いた根拠を可視化できるようになります。その結果が上の図の一番右下の「ヒートマップ」と呼ばれるものです。
この例では犬の顔を一番重要な判断材料、胴体を次に重要な判断材料としていることがわかります。
このヒートマップをメルアイコン変換器のDiscriminatorに用いることで、偽物か本物かをただ判断するだけでなく、画像のどこに注意を向けて判定すべきかという情報も一緒に学習できるようにします。ヒートマップの計算方法
ではヒートマップは具体的にどうやって作成するのでしょうか。
上の図のニューラルネットの、最後のこの部分を見てみます。
畳み込みを繰り返すことによって数枚のFeature mapを得て、その1つ1つに対しGAP(Global Average Pooling、縦横全ピクセルに対して平均値を求める操作)を施します。さらに得られた値を全結合層に入力し、各クラスについて具体的なスコアを得ます。例えばオーストラリアン・テリアというクラスのスコアが一番高ければ最終的な判断結果はオーストラリアン・テリアとします。この操作を式に起こしてみます。
上の図の一番左側のようにcチャネル分Feature mapがあります(図の例ではc=3)。この各Feature mapを$f_k(x,y)$と表現することにします。例えば2枚目のFeature mapの(33,4)ピクセル目に位置する値は$f_2(33,4)$と表せます。
このc個のFeature mapについて、各々に対し平均をとり$\sum_{x,y} f_k(x,y)$を得ます。
さらに、得られたc個の平均値を全結合層に入力し最終的なスコア$S = \sum_{k}w_k\sum_{x,y} f_k(x,y)$を得ます。ここで、得られたスコア$S$は$\sum$の位置を入れ替えることで
$$S = \sum_{k}w_k\sum_{x,y} f_k(x,y) = \sum_{x,y}\sum_{k}w_kf_k(x,y)$$
のように式変形できます。
この$S = \sum_{x,y}\sum_{k}w_kf_k(x,y)$のうち、$(x,y)$について足し合わせる前の値
$$\sum_{k}w_kf_k(x,y)$$
に注目します。
各$w$が、各々の特徴マップ$f_k(x,y)$に対応する重みをつけることによってスコアを算出していると分かります。つまり、$w$を見ればどの特徴に注意を向けた結果オーストラリアン・テリアのスコアが高くなったのかが分かるということになります。
さらに、$(x,y)$について足し合わせる前の値であるため、位置の情報が残っています。つまり、どの特徴に注意を向けたかという情報だけでなく、具体的に画像のどの位置に注意を向けたか、という情報まで保持していることになります。この$\sum_{k}w_kf_k(x,y)$が目的のヒートマップです。まさに下の図の一番右下そのものというわけです。
CAMの導入
DiscriminatorにこのCAMの機能を導入することで、判定の際に画像のどこに注意を向けるべきかという情報を学習できるようにします。
まずDecoderから出力されたFeature mapに対し、それぞれGAPをとります。さらにそれをFC(Full connection(全結合層))に入力し、どれだけ入力画像が本物に近いかを示す値(図の「本物or偽物」のところ)を得ます。入力画像が本物に近いほどこの値が大きくなるよう学習します。
学習の過程で、判断に重要となるFeature mapに対応する$w_k$ほど大きな値を持つようになり、反対に重要度の低いFeature mapに対応する$w_k$ほど小さな値を持つようになります。この各$w_k$を用いてFeature mapに重み付けをすることでヒートマップ(図ではAttention Feature map)を計算します。
また、UGATITにおいてはCAMの計算途中でGAPを計算していますが、これに加えてGMP(Global Max Pooling)を使用するバージョンのCAMも一緒に使います。縦横全ピクセルに対して平均を計算するGAPに対し、GMPでは平均ではなく最大値を計算します。2種類のCAMを使用することで片方だけの場合と比べてより良い結果が期待できます。
こうしてできあがったAttention Feature mapを次以降の畳み込み層へと渡し、最終的な判断結果を得ます。
Discriminatorの全体像
以上のようにしてDiscriminatorを構成します。全体像は以下のようになります。
入力された画像がどれだけ本物のメルアイコンに近いかを示す値を合わせて3種類出力していますが、このうちCAMの機能によって出力される分(上の図の、上側の2つの「本物or偽物」)は判定において補助的な機能(Attention Feature mapの作成)を果たします。メインは下側の「本物or偽物」です。また、メルアイコンを識別するDiscriminatorについて紹介しましたが、キャラの画像を識別するDiscriminatorも入力する画像の種類が違うだけで同様の構成をしています。
Generatorの作成
Generatorの役割は、入力されたキャラの画像(チャネル数3、縦横256×256pixel)をできるだけメルアイコンっぽく変換し、それを用いてDiscriminatorを本物のメルアイコンだと誤認させることです。うまく騙せるよう精度を上げることを目指して学習を進めます。
※Decoderの前にあるFC(全結合層),${\gamma}$,${\beta}$については後述します。入力画像をAttention Feature mapに変換するところまではDiscriminatorと似ています。Generatorにおいて、CAMの仕組みは「キャラの画像とメルアイコン両者において、明確に違うのはどういった特徴か」を学習するのに役立ちます。とてもアバウトなイメージですが、例えばGeneratorが「もしかしたら目のパーツが両者において明確に違うのでは?」ということを学習したとすると、入力画像に対してそこを重点的に変換することでよりDiscriminatorを騙しやすい画像を作成できます。
Attention Feature mapに対し畳み込みを実行し、さらにそれをDecoderと呼ばれる箇所に入力します。この部位で畳み込みとUpsamplingを繰り返し、最終的にチャネル数3、縦横256×256pixelの画像を生成します。
また、このDecoder内ではAdaILNという正規化をします。AdaILN
ニューラルネットにおいて、畳み込みなどをするたびに「正規化」という操作を施すことがよくあります。
層と層の中間を流れるデータに対して正規化をかけると平均と分散を揃えることができ、学習の効率を改善できます。正規化にはいろいろな種類がありますが、Generator内のDecoderにおいてはAdaILNという正規化を実行します。
これはやってきたデータに対し、Instance Normalizationをかけたもの$\widehat{a_I}$と、Layer Normalizationをかけたもの$\widehat{a_L}$の2つを比率${\rho}$で混ぜ合わせる正規化の手法です。${\rho}$は0以上1以下のパラメーターとし、AdaILN内で学習によって決定します。
※${\gamma}$,${\beta}$については後述します。Instance Normalizationは各チャネルごとに正規化をかけるというもので、(各特徴ごとに正規化をかけているようなイメージ)、入力データの細かな特徴を保持するのが得意です。しかし、画像全体にまたがる大局的な特徴を捉えるのは不得意です。
一方反対に、Layer Normalizationはやってきたデータ全部に対し一度に正規化をかける手法で、大局的な特徴を捉えるのは得意ですが局所的な特徴が失われやすいという欠点を持ちます。このようにInstance NormalizationとLayer Normalizationはこの点では正反対の特徴を持っています。
この2つを最適な比率で混ぜ合わせることで、双方の良いとこ取りを目指し、さらなる変換精度の向上を狙います。Generatorの全体像
このAdaILNをDecoderへと導入します。
Generator内のCAMによって出力されたAttention Feature mapに対し畳み込みを実行し、さらにこれをFC(全結合層)へと入力し${\gamma}$,${\beta}$を得ます。これをDecoder内のAdaILNに入力します。
また、上では「キャラの画像→メルアイコン」の変換を実行するGeneratorについて紹介しましたが、逆の「メルアイコン→キャラの画像」を行うGeneratorに関しても全く同様の構成です。入力する画像の種類と出力する画像の種類がそれぞれ逆なだけです。
学習方法・誤差関数
UGATITでは次に解説する4種類の誤差関数を用います。
Adversarial loss
$$L_{lsgan}^{s→t} = E_{x\in X_t}[(D_t(x))^{2}] + E_{x\in X_s}[(1-D_t(G_{s→t}(x)))^{2}]$$Cycle loss
$$L_{cycle}^{s→t} = E_{x\in X_s}[|x-G_{t→s}(G_{s→t}(x))|_
{1}]$$Identity loss
$$L_{identity}^{s→t} = E_{x\in X_t}[|x-G_{s→t}(x)|_
{1}]$$CAM loss
$$L_{cam}^{s→t} = -(E_{x\in X_s}[log({\eta_{s}}(x))] + E_{x\in X_t}[log(1-{\eta_{s}}(x))])$$
$$L_{cam}^{D_{t}} = E_{x\in X_t}[({\eta_{D_{t}}}(x))^{2}] + E_{x\in X_s}[(1-{\eta_{D_{t}}}(G_{s→t}(x))^{2}]$$ただし変換元ドメインの画像の集合を$X_{s}$(source),変換先ドメインの画像の集合を$X_{t}$(target)とします。$E$はミニバッチごとに平均をとる操作です。
これらについて順番に解説していきます。以下では変換元ドメイン$X_{s}$(source)をキャラの画像、変換先ドメイン$X_{t}$(target)をメルアイコンとして説明しますが、変換元と変換先逆バージョンについても同様のことをします。
Adversarial loss
$$L_{lsgan}^{s→t} = E_{x\in X_t}[(D_t(x))^{2}] + E_{x\in X_s}[(1-D_t(G_{s→t}(x)))^{2}]$$
DiscriminatorはこのAdversarial lossを最大化するよう目指すことで、本物のメルアイコンほど1に近い値を出力し、Generatorによって生成された偽のメルアイコンほど0に近い値を出力できるよう学習します。Generatorに騙されないよう精度をあげるよう学習を進めます。
一方でGeneratorはこれを最小化するよう目指し、生成したメルアイコンでDiscriminatorを本物だと騙せるよう学習します。
Cycle loss
$$L_{cycle}^{s→t} = E_{x\in X_s}[|x-G_{t→s}(G_{s→t}(x))|_
{1}]$$
Cycle lossは「キャラの画像→メルアイコン→キャラの画像」と2回変換をかけたときに、ちゃんと元の画像に戻ってこれるようにするための項です。元のキャラの画像と、2回変換をかけたあとのキャラの画像のL1ノルムを最小化するよう目指すことでモード崩壊の問題を軽減します。
Identity loss
$$L_{identity}^{s→t} = E_{x\in X_t}[|x-G_{s→t}(x)|_
{1}]$$
変換先ドメインに属する画像をGeneratorに入力、出力画像との距離を最小化します。(図のように、変換先ドメインに属する画像をGeneratorに入力した時、入力と出力が一致するのを目指す)
UGATITの論文中ではGeneratorはこの項$L_{identity}^{s→t}$を最小化することによって、入力画像と出力画像の色分布を似たものにできると言及されています。
自分的な解釈ですがおそらく「キャラの画像→メルアイコン」で、入力と出力を似たような画像にするための項です。CAM loss
$$L_{cam}^{s→t} = -(E_{x\in X_s}[log({\eta_{s}}(x))] + E_{x\in X_t}[log(1-{\eta_{s}}(x))])$$
$$L_{cam}^{D_{t}} = E_{x\in X_t}[({\eta_{D_{t}}}(x))^{2}] + E_{x\in X_s}[(1-{\eta_{D_{t}}}(G_{s→t}(x))^{2}]$$
この項によって、先ほど解説したCAMの部分が画像を正しく分類できるようになるのを目指し、CAMでうまくヒートマップを作れるようにします。
誤差関数の全体像
以上で紹介した$L_{lsgan}^{s→t}$,$L_{cycle}^{s→t}$,$L_{identity}^{s→t}$,$L_{cam}^{s→t}$を用いて、誤差関数は全体では以下のように表せます。
$$\min_{G_{s→t},G_{t→s},\eta_{s},\eta_{t}}\max_{D_{s},D_{t},\eta_{D_{s}},\eta_{D_{t}}} \lambda_{1}L_{lsgan} + \lambda_{2}L_{cycle} + \lambda_{3}L_{identity} + \lambda_{4}L_{cam}$$
ただし$L_{lsgan} = L_{lsgan}^{s→t} + L_{lsgan}^{t→s}$で、他の項($L_{cycle}$,$L_{identity}$,$L_{cam}$)も似たように定義します。係数はそれぞれ$\lambda_{1}=1$,$\lambda_{2}=10$,$\lambda_{3}=10$,$\lambda_{4}=1000$です。
学習方法
ミニバッチサイズ$M$は1とし、epoch数は40としました。誤差伝搬の最適化手法にはAdamを使い、学習率0.0001、Adamの一次モーメントと二次モーメント(モーメント推定に使う指数減衰率)はそれぞれ0.5と0.999に設定しました。
また、ある程度学習が進んだ段階から学習率を徐々に下げる処理を入れています。こうすることで汎化性能の向上が狙えるようです。(参考)全体像
上でも紹介した画像の再掲ですが、先ほど作成したGeneratorとDiscriminatorを組み合わせ、UGATITを構成します。
いざ生成
用意したデータセットを用いて学習を行い、Generatorで「キャラの画像→メルアイコン」の変換を実行します。
UGATITすげえ!!!!!!!!!!!!
かなりうまく変換できているのではないでしょうか!?個人的にはめちゃめちゃ感動しました。学習途中における出力は下のようになりました。
epoch1
epoch8
epoch20
epoch30
epoch40(最終的な出力)
徐々に学習が進められているのがわかります。
まとめ
UGATITによってキャラの画像からメルアイコンを生成できるようになりました。
機械学習で画像変換をする手法はUGATIT以外にもpix2pix,CycleGAN,StarGAN,ACGANなど他にも様々なものがあり、新しい手法もどんどん開拓されています。皆さんも是非GANでガンガン画像変換しましょう。ソースコード
書いたコードはこのリポジトリにあります。
https://github.com/zassou65535/image_converter前作
参考
U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation
U-GAT-IT — Official PyTorch Implementation
2019年までのCAM(Class Activation Map)まとめ
【論文紹介】U-GAT-IT
lbpcascade_animeface
学習率減衰/バッチサイズ増大とEarlyStoppingの併用で汎化性能を上げる@tensorflow2.0



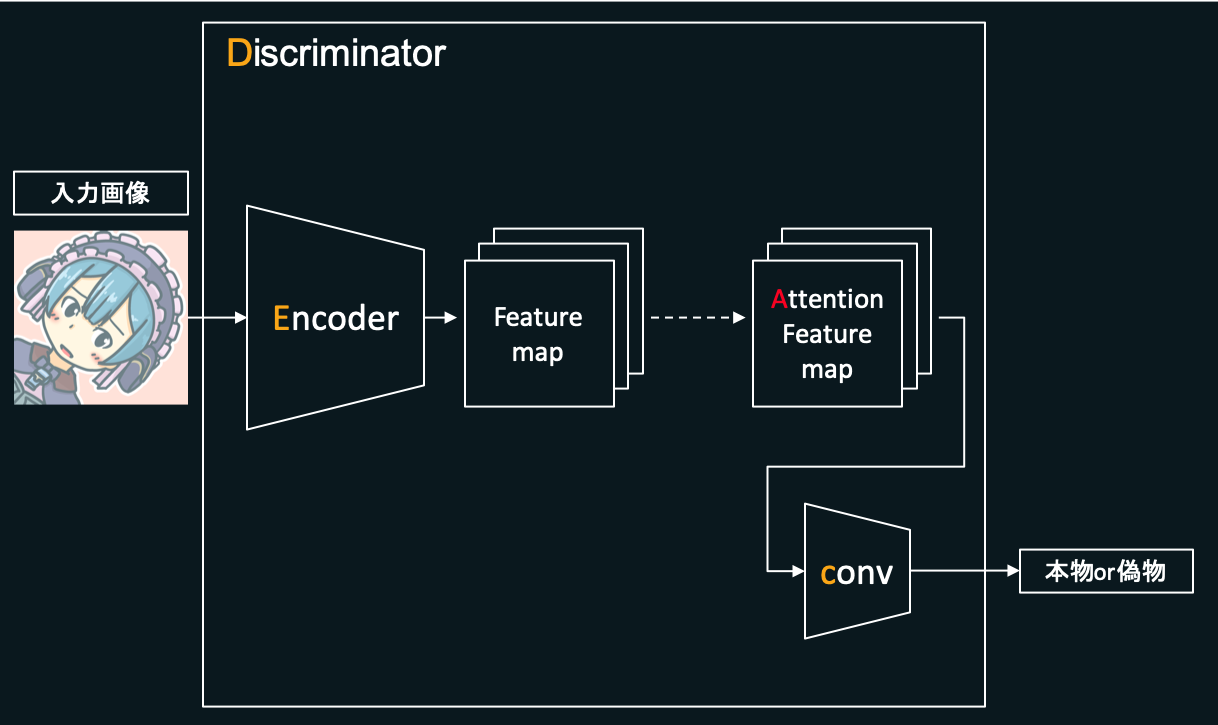
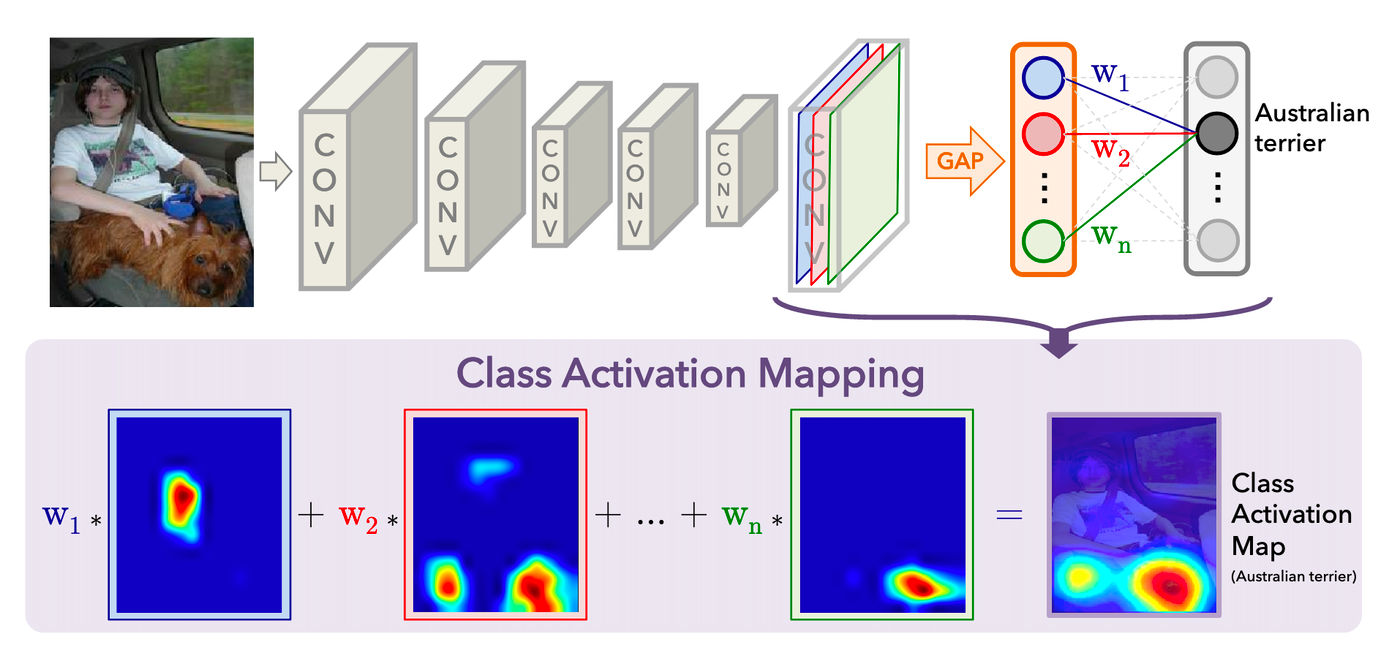
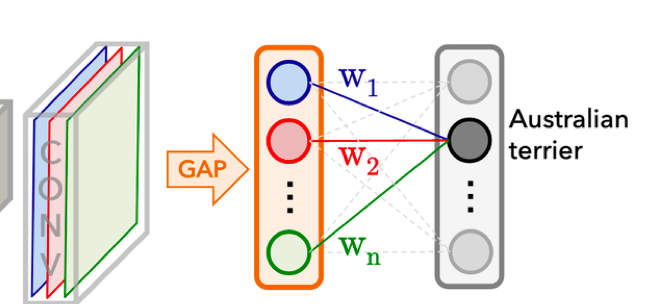

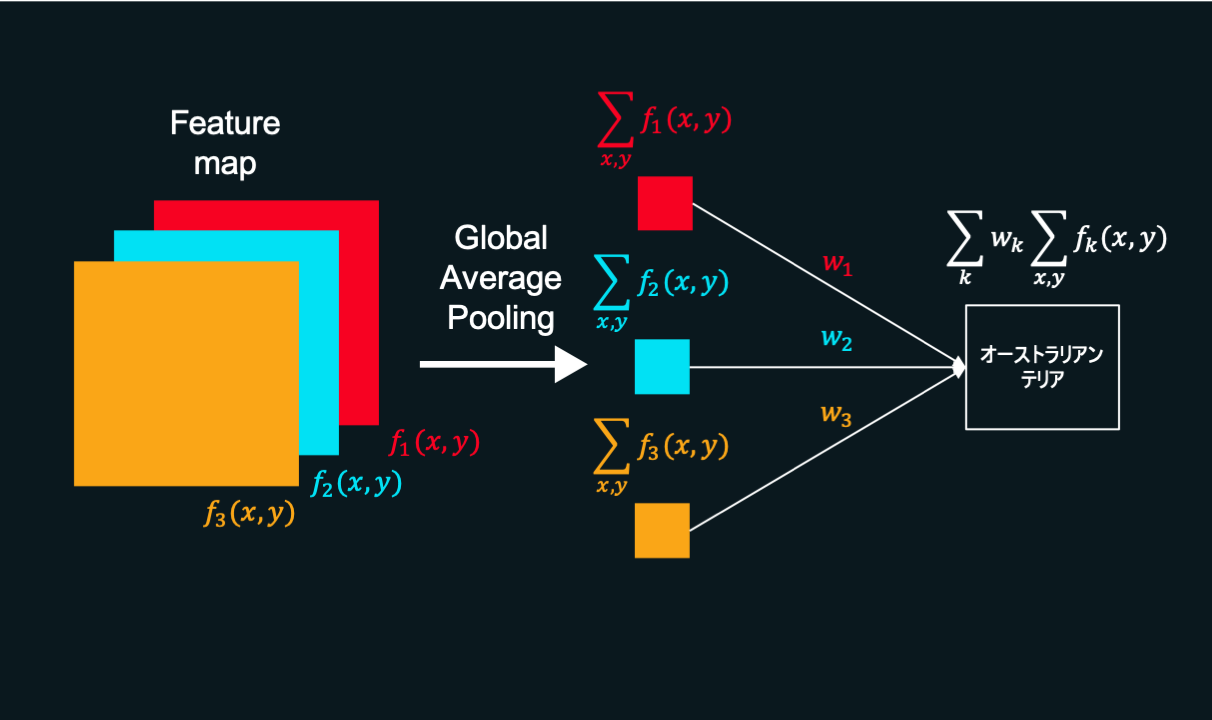
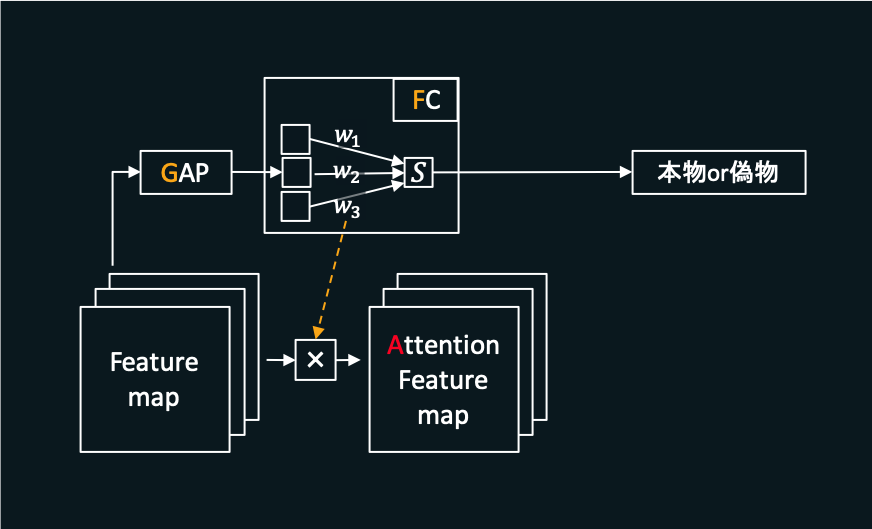
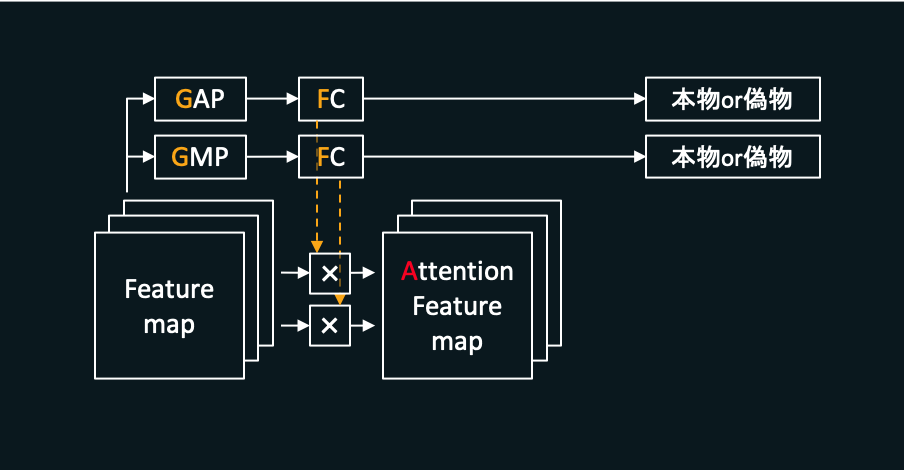
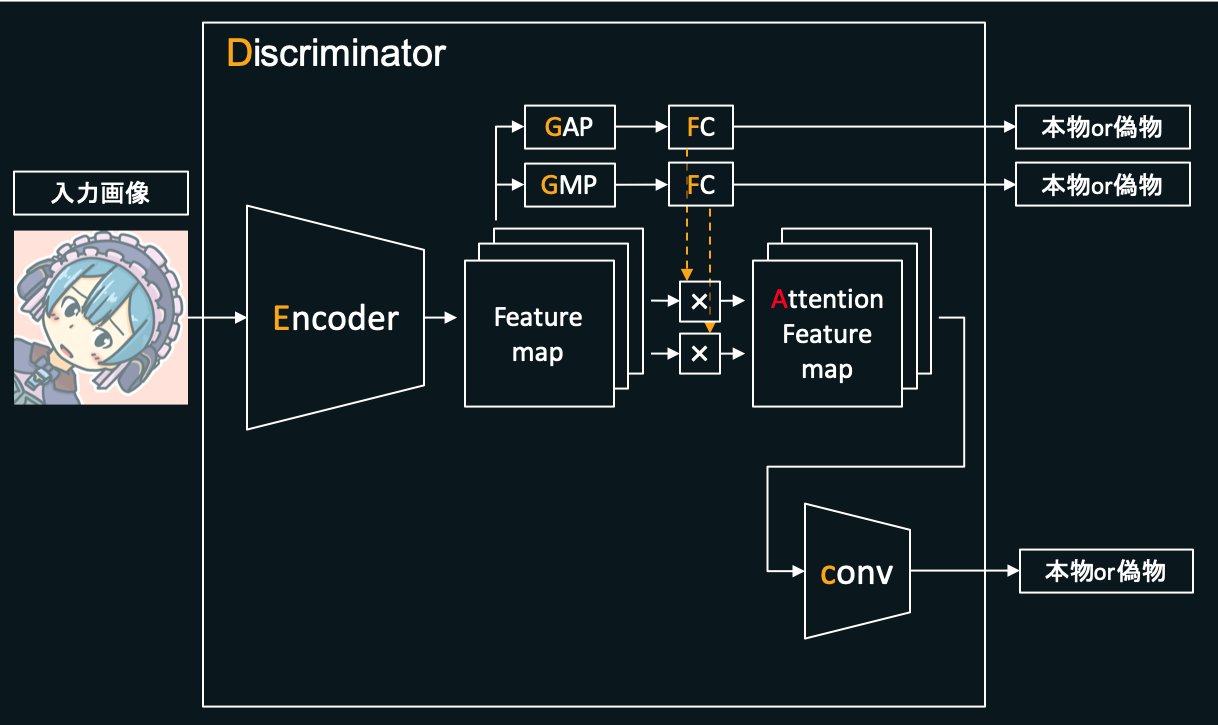
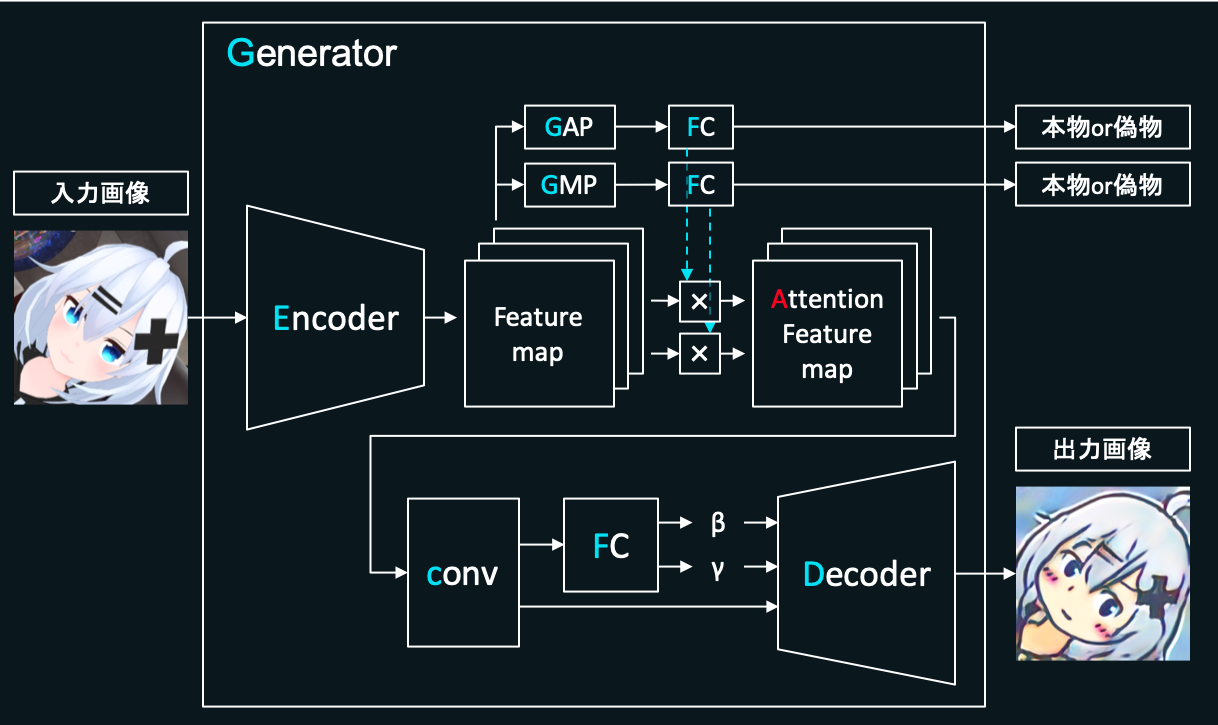
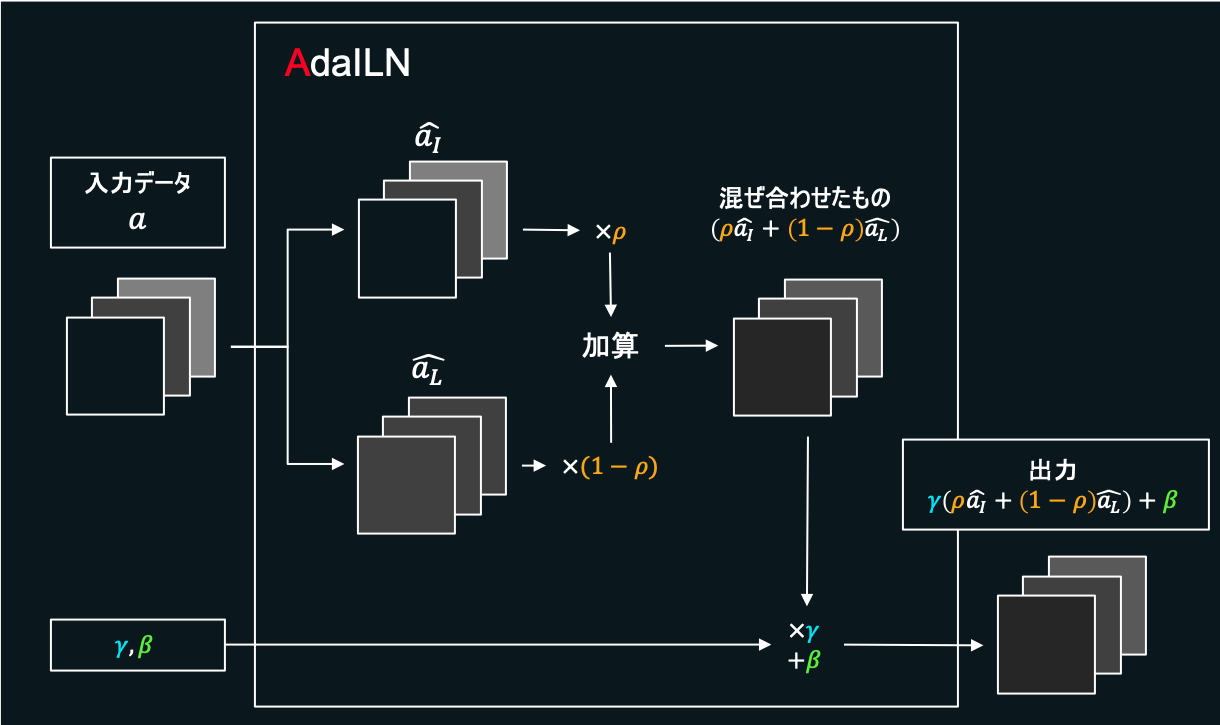
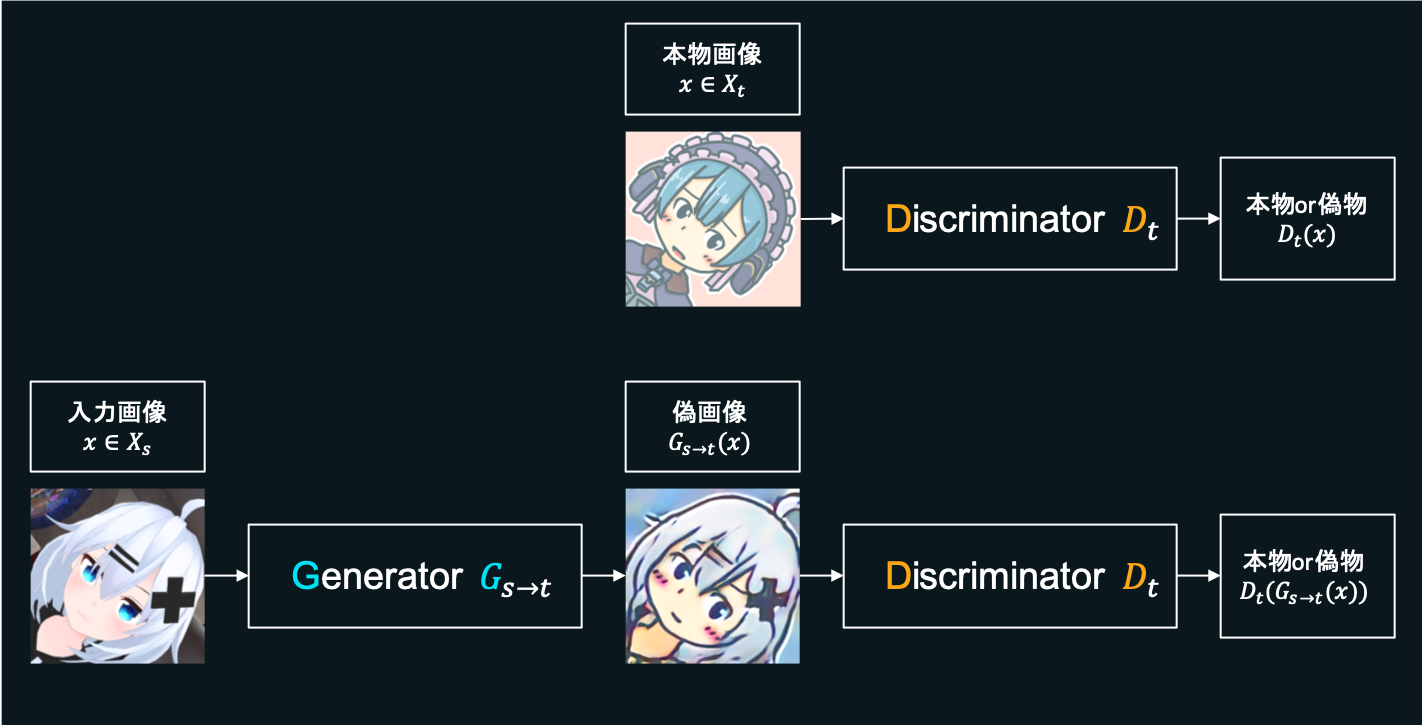
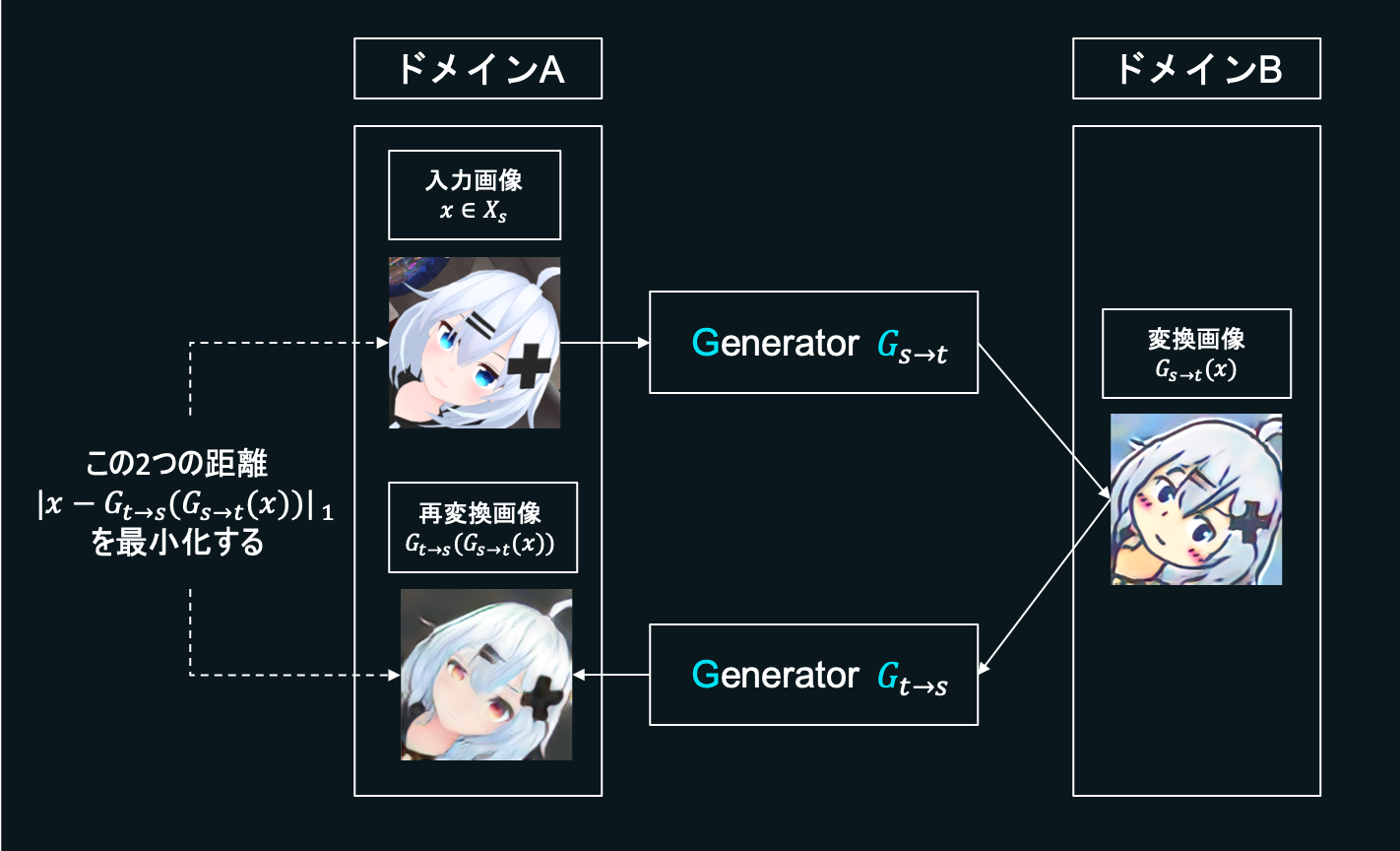

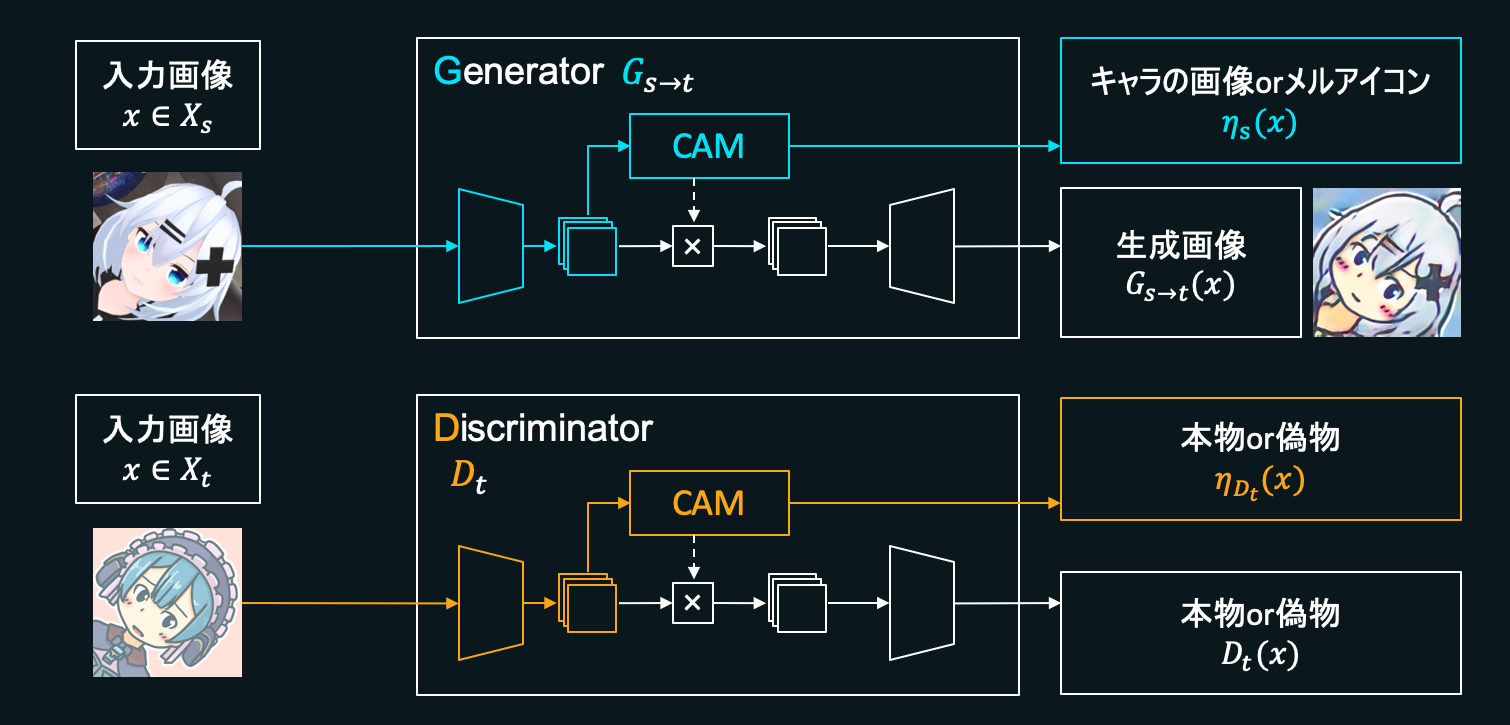





- 投稿日:2020-11-25T20:36:01+09:00
Python関数(備忘録)
Pythonの関数周りの備忘録です。
随時追加・修正を行っていきます。引数
# 引数なし def say(): print('hello') say() # hello # 引数あり def sub(a, b): return a - b result = add(3, 2) # 1 # 引数と返り値の型宣言 def add(a: int, b: int) -> int: return a + b result = add(2, 3) print(result) # 5 result = add('AAA', 'BBB') print(result) # AAABBB(型宣言をしても実行は出来るのでこうなってしまう) # 引数の指定の仕方 def dinner(main, side, dessert='pudding'): print('main =', main) print('side =', side) print('dessert =', dessert) # 位置引数 dinner('beef', 'salad', 'ice') # dinner関数が受け取る引数の順番の通り渡す # キーワード引数 dinner(dessert='cake', main='fish', side='soup') # dinner関数が受け取る引数の名前を指定して渡す # 位置引数とキーワード引数を混ぜて使う dinner('fish', dessert='cake', side='soup') # 順序に注意 # デフォルト引数 dinner('beef', 'salad') # dessertを指定していないのでデフォルト値のpudding # リストや辞書は参照渡しなのでデフォルト引数に空のリストは指定しない def append(x, list=None) if list is None: list = [] list.append(x) return list # 位置引数のタプル化 def cooking(taste, **args): print('taste = ', taste) print(args) # ('beef', 'pork') cooking('salt', 'beef', 'pork') # キーワード引数の辞書化 def cooking(taste, **args, **kwargs): print('taste = ', taste) print(args) # ('beef', 'pork') print(kwargs) # {drink='juice', dessert='ice'} cooking('soy sauce', 'beef', 'pork', drink='juice', dessert='ice'):Docstrings
def sub(a, b): """関数subに関する説明 Args: param1 (int): XXXXXXXXXX param2 (int): XXXXXXXXXX Returns: int: XXXXXXXX """ return a - b # 以下の方法でDocstringsに記述した関数のhelpを参照出来る help(sub) sub.__doc__関数内関数
def outer_func(a, b): # 他の関数から呼ばれない関数としてouter_func内で関数を定義 def inner_func(c, d): return 2c + d result1 = inner_func(a, b) # 2*2+3=7 result2 = inner_func(b, a) # 2*3+2=8 outer_func(2, 3) # 7+8=15クロージャー
def circle_area(pi): def calc(radius): return pi * radius * radius return calc circle_area1 = circle_area(3.14) circle_area2 = circle_area(3) print('計算結果') # 引数を渡した関数を定義しておいて後から実行できる print(circle_area1(10)) # 314.0 print(circle_area2(10)) # 300デコレーター
# メインの処理の前に====BEFORE====を出力する機能を持つデコレーター def print_before(func): def wrapper(*args, **kwargs): print('====BEFORE====') result = func(*args, **kwargs) return result return wrapper # メインの処理の後に====AFTER====を出力する機能を持つデコレーター def print_after(func): def wrapper(*args, **kwargs): result = func(*args, **kwargs) print('====AFTER====') return result return wrapper @print_before # デコーレーターの指定 @print_after # 上から順番に実行される def say(): print('hello') # ====BEFORE==== hello ====AFTER====ラムダ
weeks = ['Mon', 'TUE', 'wed', 'Thu', 'fri', 'SAT', 'SUN'] def conversion(words, func): for word in words: print(func(word)) # weeks内のwordを1つずつcapitalizeした文字列を順に出力する conversion(weeks, lambda word: word.capitalize()) # weeks内のwordを1つずつlowerした文字列を順に出力する conversion(weeks, lambda word: word.lower()) # weeks内のwordを1つずつupperした文字列を順に出力する conversion(weeks, lambda word: word.upper())ジェネレーター
def meal(): # 朝食の前に必要な処理を書ける yield 'Breakfast' # 昼食の前に必要な処理を書ける yield 'Lunch' # 夕食の前に必要な処理を書ける yield 'Dinner' m = meal() # next(m)が実行される度にyieldが順番に返却される print('Wake UP') print(next(m)) # Breakfast print('Working') print(next(m)) # Lunch print('Working') print('Go home') print(next(m)) # Dinner print('Good night')
- 投稿日:2020-11-25T19:34:43+09:00
Django 夜間勤務者対応
施設によって、22時~6時までは二人勤務が必須になっている施設があり、シフトを作成するときに、チェックするのが大変ということを聞いていました。
今回ではあれば、2つの施設が対象です。
今後も増えることもあるかもしれないので、Shisetsuマスタと、Shiftマスタに夜間勤務者数をカウントできるようにしました。schedule/models.pyclass Shift(models.Model): id = models.AutoField(verbose_name='シフトID',primary_key=True) name = models.CharField(verbose_name='シフト名', max_length=1, unique=True) start_time = models.TimeField(verbose_name="開始時間") end_time = models.TimeField(verbose_name="終了時間") wrok_time = models.IntegerField(verbose_name='勤務時間',default=0,) yakan = models.IntegerField(verbose_name='夜間勤務',default=0,)shisetsu/models.pyclass Shisetsu(models.Model): id = models.IntegerField(verbose_name='施設ID',primary_key=True) name = models.CharField(verbose_name='施設名', max_length=50) adress = models.CharField(verbose_name='住所', max_length=100) tel = models.CharField(verbose_name='電話番号', max_length=20) fax = models.CharField(verbose_name='FAX番号', max_length=20) color = ColorField(verbose_name='表示色', default='#FF0000') yakan_kinmu = models.IntegerField(verbose_name='夜間必要者数', default=0) def __str__(self): return self.nameもし、夜間の時間で途中交代があったりすると対応ができませんが、今のところそういうことはないということなので、この形にしました。
人数といいながら、数値なので、10としてシフトよって2や3ってするとトータルでのチェックには使えます
Viewsはこちら
views.pydef yakincheckfunc(request,year_num,month_num): year, month = int(year_num), int(month_num) #対象の施設を取得 shisetsu_object = Shisetsu.objects.filter(yakan_kinmu__gt=0) shisetsu_list = list(shisetsu_object) #シフト範囲の日数を取得する enddate = datetime.date(year,month,20) startdate = enddate + relativedelta(months=-1) kaisu = enddate - startdate kaisu = int(kaisu.days) kikan = str(startdate) +"~"+ str(enddate) count = 0 message = [] #対象の施設を含んだスケジュールトランデータを取得 for shisetsu in shisetsu_object: #夜間勤務必要者数 shisetsu_yakan = shisetsu.yakan_kinmu for i in range(kaisu): startdate1 = startdate + timedelta(days=i) #スケジュールを取得 schedule_object = Schedule.objects.filter(shisetsu_name_1_id = shisetsu.id, year = year, month = month, date = startdate1).all() #夜間トータル変数 yakan_total = 0 for schedule in schedule_object: if schedule.shift_name_1.yakan is not None: yakan_total = yakan_total + schedule.shift_name_1.yakan if schedule.shift_name_2 is not None: yakan_total = yakan_total + schedule.shift_name_2.yakan if schedule.shift_name_3 is not None: yakan_total = yakan_total + schedule.shift_name_3.yakan if schedule.shift_name_4 is not None: yakan_total = yakan_total + schedule.shift_name_4.yakan #施設夜間時間よりスケジュールの夜間トータルが少なかったらエラーとする if shisetsu_yakan - yakan_total > 0: new_lecord = {'shisetsu' : shisetsu.name, 'date' : startdate1} message.append(new_lecord) count = count + 1 context = { 'year': year, 'month': month, 'message': message, } return render(request,'schedule/yakancheckkekka.html', context)こちらのコードを書くのに、4時間ぐらい!
最初のころに比べたら早くなったように思います(⌒∇⌒)Htmlはこちら
schedule.yakancheckkekka.html{% extends 'accounts/base.html' %} {% load static %} {% block customcss %} <link rel="stylesheet" href="{% static 'schedule/month.css' %}"> <link rel="stylesheet" type="text/css" media="print" href="{% static 'schedule/monthprint.css' %}"> <style type="text/css"> @page { size:landscape; } </style> {% endblock customcss %} {% block header %} チェック結果 {{year}}年{{month}}月 {% endblock header %} {% block content %} <table class="table table-striped table-bordered"> <div class='container'> <thead> <th>施設</th> <th>日付</th> </thead> <tbody> {% for mess in message %} <tr> <td >{{ mess.shisetsu }}</td> <td >{{ mess.date }}</td> </tr> {% endfor %} </tbody> </div> </table> {% endblock content %}簡単な表示で出力するようにしました。
出力結果がこちら
本当は、シフト画面でモーダルウィンドウで表示したかったのですが、まだまだそこは実力不足だったので、別タブで表示する形の工夫をしました。

- 投稿日:2020-11-25T19:03:59+09:00
DjangoでDBのデータを更新&取得してD3.jsのグラフにする
はじめに
現在,深層学習でリアルタイムに予測したPython(Django)での数値データを,グラフで描画するWebアプリを作っています。
グラフの描画は,matplotlibを用いて画像をHTMLファイルに貼り付けてもいいのですが,そのうちグラフにインタラクティブ性を持たせたかったため,D3.jsを用いてグラフ描画を行います。
D3.jsはJavaScriptのデータから,SVGデータを出力できるライブラリです。今回作っているアプリでは,1分間に1度,リアルタイムに予測された数値をデータベースに保存し,それらのデータを時系列データとして,折れ線グラフで表示することを行います。
サンプルプログラム
ファイル構造
「system」というプロジェクトを作成
「template」の中のindex.htmlを最終的に作ります(今回はtemplateの機能は使っていませんが...). ├── mysite │ ├── .... │ ├── .... │ └── setting.py * │ ├── templates │ └── index.html * │ ├── system <-プロジェクト名 │ ├── views.py * │ └── urls.py * │ ├── manage.py └── ◯◯◯◯.db <-データが保存されるDBこの中で,*が付いているものを説明していきます。
データベースの設定・構造
深層学習のモデルから得られた出力(0から1の小数)をpredとしてDBに保存するため,そのためのDB設定を行います。
設定
setting.pyでSQLiteのdbファイルを設定します
mysite/setting.py... DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, '◯◯◯◯.sqlite3'), } } ...DBの構造
カラム名 id pred 型 int real 説明 データのID 予測値 実際にテーブルを作るSQLを書くとしたらこんな感じ↓(Djangoなので,実際にはコマンドを叩くことはないです)
テーブル名は{プロジェクト名}_{テーブルのモデル名}になる。CREATE TABLE "system_preddata" ( "id" integer NOT NULL, "pred" real NOT NULL, PRIMARY KEY("id" AUTOINCREMENT) );Python側の処理
pred_func()は深層学習モデルがある値の出力をする,架空の関数です。
system/views.pyfrom django.db import models # テーブルのモデルを指定 class PredData(models.Model): pred = models.FloatField() def __str__(self): return '<pred:'+str(self.pred)+'>' # 新しいデータを加える def data_insert(insert_data): d = insert_data t = PredData(pred = d[0]) t.save() # 予測されたデータをDBに加えて,データを全て取得し,index.htmlに返す def main(request): red = pred_func() #予測する関数 insert_data = [pred] data_insert(insert_data) #データを追加する d = {'pred_data': PredData.objects.all()} #データを全て取得する return render(request, 'index.html', d)system/url.pyfrom django.conf.urls import url from . import views # views.pred_systemの関数を呼び出す urlpatterns = [ ... url(r'^$', views. main, name='main'), ]HTML側の処理
/system/index.htmlの中身です。
D3.jsの部分は,こちらのサイトを参考にしました
https://wizardace.com/d3-linechart-base/グラフでの
templates/index.html<!DOCTYPE html> <html> <head lang="ja"> <meta charset="UTF-8"> <!-- 60秒後に更新 --> <meta http-equiv="refresh" content="60"> <!-- D3.jsの読み込み --> <script src="https://d3js.org/d3.v5.min.js"></script> <title></title> </head> <body> <script src="https://code.jquery.com/jquery-3.3.1.slim.min.js" integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo" crossorigin="anonymous"></script> <script type="text/javascript"> // データセットをつくる var data = [] //深層学習による予測値 var minutes_len = 0 //データの個数をカウント {% for d in pred_data %} data.push(["{{ d.id }}"-1,"{{ d.pred }}"]); minutes_len ++; {% endfor %} console.log(data); console.log(minutes_len); var width = 800; // グラフの幅 var height = 400; // グラフの高さ var margin = { "top": 30, "bottom": 60, "right": 30, "left": 60 }; // SVG領域の設定 var svg = d3.select("body").append("svg").attr("width", width).attr("height", height); // 軸の長さ var xScale = d3.scaleLinear() .domain([0, minutes_len]) // x軸はデータの数によって決める .range([margin.left, width - margin.right]); var yScale = d3.scaleLinear() .domain([0,1]) //0<予測値<1 .range([height - margin.bottom, margin.top]); // 軸の表示 var axisx = d3.axisBottom(xScale).ticks(minutes_len); var axisy = d3.axisLeft(yScale).ticks(5); svg.append("g") .attr("transform", "translate(" + 0 + "," + (height - margin.bottom) + ")") .call(axisx) .append("text") .attr("fill", "black") .attr("x", (width - margin.left - margin.right) / 2 + margin.left) .attr("y", 35) .attr("text-anchor", "middle") .attr("font-size", "10pt") .attr("font-weight", "bold") .text("X Label"); svg.append("g") .attr("transform", "translate(" + margin.left + "," + 0 + ")") .call(axisy) .append("text") .attr("fill", "black") .attr("text-anchor", "middle") .attr("x", -(height - margin.top - margin.bottom) / 2 - margin.top) .attr("y", -35) .attr("transform", "rotate(-90)") .attr("font-weight", "bold") .attr("font-size", "10pt") .text("Y Label"); // グラフのラインを表示 svg.append("path") .datum(data) .attr("fill", "none") .attr("stroke", "blue") .attr("stroke-width", 3) .attr("d", d3.line() .x(function(d) { return xScale(d[0]); }) .y(function(d) { return yScale(d[1]); })); </script> <br> <!-- 実際の値をテーブルで表示をして確認 --> <table border="1"> <thead> <tr> <th>id</th> <th>pred</th> </tr> </thead> <tbody> {% for d in pred_data %} <tr> <td>{{ d.id }}</td> <td>{{ d.pred }}</td> </tr> {% endfor %} </tbody> </table> </body> </html>グラフはこのようになります↓
まとめ
D3.jsとDjangoを連携する方法について書きました。
これから,インタラクティブなグラフになる仕組みを作っていけたらと思います。
- 投稿日:2020-11-25T18:24:51+09:00
[OpenCV+dlib] 顔認識の実験
1.はじめに
OpenCVとdlibで顔認識を実験してみました。
2. Face Detector()
まず、顔を検出します。
顔の検出というのは、「画像の中から、人の顔を認識し、その位置を特定する」ことを意味します。
dlibのget_frontal_face_detector()を利用します。import dlib #dlibのget_frontal_face_detectorのインスタンスを立てる。 detector = dlib.get_frontal_face_detector() #imagesで顔を検出し、それをfacesに保存する。 faces = detector(images)上記のコードのfacesに保存された情報を元に、検出された顔に四角い枠を表示します。
実行結果を示します。二人の女性を顔を検出し、白い枠で表示されていることが分かります。
3. Facial Landmark Detection
顔の中の各パーツの位置関係、寸法を元に、識別可能な情報の抽出を行います。
この情報をFacial Landmarkといいます。
dlibでは、顔から68個のポイントの情報を取得します。実際の顔の識別には、Landmark pointのユークリッド距離が使われます。基準となる顔のLandmark pointと新しく認識された顔のLandmark pointとのユークリッド距離を計算し、その値が閾値より小さいと同じ顔であると認識します。Google Photosやスマホの写真フォルダー、このような顔認識のアルゴリズムが採用されています。
先ほどの女性の顔よりLandmark pointを取得します。2段階に分けて行われます。
import dlib #--------------------------- #Step 1. Faceを認識する。 #--------------------------- #dlibのget_frontal_face_detectorのインスタンスを立てる。 detector = dlib.get_frontal_face_detector() #imagesで顔を検出し、それをfacesに保存する。 faces = detector(images) #-------------------------- #Step 2. FaceよりLandmark pointを抽出する。 #--------------------------- for face in faces: dlib_shape = landmark_predictor(imgage,face) shape_2d = np.array([[p.x, p.y] for p in dlib_shape.parts()])取得されたshape_2dのshapeを確認するとtupleとして(68,2)となっています。(68=landmark point 68 points, 2= x,y 座標)
この情報を元に、顔の周辺にLandmark pointsを描画します。
for s in shape_2d: cv2.circle(image, center=tuple(s), radius=1, color=(255, 255, 255), thickness=2, lineType=cv2.LINE_AA)
まとめ
- dlibライブラリのFace DetectionとLandmark Points取得の機能を利用し、顔認識の実効性を確認しました。
参考資料
1.Dlib Main Page
2.Github Davis King's Page実行コード
1.7行目の
'model/shape_predictor_68_face_landmarks.dat'は、ここのリンクでダウンロードしてください
2. 9行目のload videoは、動画のmp4ファイル、あるいはWebCAMを使用してください。自分の顔でやるとなかなか面白いです。import cv2 import dlib import sys import numpy as np scaler = 0.5 #Initialize face detector and shape predictor detector = dlib.get_frontal_face_detector() landmark_predictor = dlib.shape_predictor('model/shape_predictor_68_face_landmarks.dat') #load video cap = cv2.VideoCapture('samples/girls3.mp4') #cap = cv2.VideoCapture(0) #内臓カメラ #cap = cv2.VideoCapture(1) #USBカメラ #Face recognition while True: # read frame buffer from video ret, img = cap.read() if not ret: cap.set(cv2.CAP_PROP_POS_FRAMES,0) continue # resize frame img = cv2.resize(img, (int(img.shape[1] * scaler), int(img.shape[0] * scaler))) ori = img.copy() # detect faces faces = detector(img) #例外処理 顔が検出されなかった時 if len(faces) == 0: print('no faces') img_rec = img for face in faces: # rectangle visualize img_rec = cv2.rectangle(img, pt1=(face.left(), face.top()), pt2=(face.right(), face.bottom()), color=(255, 255, 255), lineType=cv2.LINE_AA, thickness=2) # landmark dlib_shape = landmark_predictor(img,face) shape_2d = np.array([[p.x, p.y] for p in dlib_shape.parts()]) print(shape_2d.shape) for s in shape_2d: cv2.circle(img, center=tuple(s), radius=1, color=(255, 255, 255), thickness=2, lineType=cv2.LINE_AA) cv2.imshow('original', ori) cv2.imshow('img_rec', img_rec) if cv2.waitKey(1) == ord('q'): sys.exit(1)

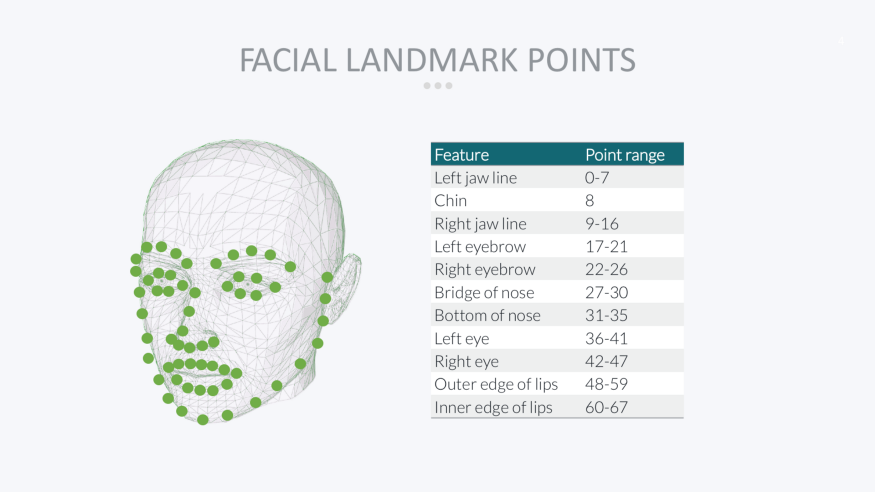

- 投稿日:2020-11-25T18:21:57+09:00
discord.py commandsフレームワークの小ネタ: クールダウン
皆さんこんにちは、daima3629と申します。
DiscordBotのTipsということで、8日目はDiscordAPIのPython用ラッパーライブラリであるdiscord.pyのcommandsフレームワークの小ネタを紹介していきたいと思います。
あれ...?8日目...?なにかおかしいnおっと誰か来たようだ
今回ご紹介致しますのは、その名も「クールダウン」!(商品紹介風)クールダウンとは?
「一定時間内に指定した回数以上コマンドを入力するとそれ以上のコマンドは受け付けなくなる」です。
まあ言葉で書き連ねてもよくわかんないと思うので、GIF画像をご用意したのでどういう挙動をするのかご覧ください。
こんな感じです。
なんとなくわかったとこで実際にどのようなコードを書けばいいのかお教えしましょう!今回使用するコード
# コマンドの実装部分のみ書いてあり、その他の部分は省略してあります @bot.command() @commands.cooldown(2, 10, type=discord.BucketType.user) async def hello(ctx): await ctx.send("hello!") @bot.event async def on_command_error(ctx, err): if isinstance(err, commands.CommandOnCooldown): return await ctx.send("クールダウン中だよ!")とりあえずクールダウンに直接関わる部分
とりあえずコードを2つのブロックに分けて、1つ目を見ていきましょう!
@bot.command() @commands.cooldown(2, 10, type=discord.BucketType.user) async def hello(ctx): await ctx.send("hello!")commands.cooldown
今回の記事の本命です。
@commands.cooldown(rate, per, type)このようにして使います。
引数名の説明は以下の通り。
引数名 説明 rate 一定時間内に何回コマンドを打ったら
クールダウンに入るのか数字で指定per 一定時間を指定 type クールダウンタイプを指定
type引数に指定するものはちょっと変わったものです。
これはリファレンスを見たほうがわかりやすいかもしれません。
今回のコード例ではBucketType.userを使用しているのでユーザーごとのクールダウンとなります。これをもとに今回のクールダウンを見てみると、「10秒間の間に2回以上はコマンドを受け付けないユーザーごとのクールダウン」と読み取れますね!
on_command_error
もう一つ残っているコードを見てみましょう。
@bot.event async def on_command_error(ctx, err): if isinstance(err, commands.CommandOnCooldown): return await ctx.send("クールダウン中だよ!")ここで出ました
on_command_error。
早速見ていきましょう。クールダウン時はエラーが出る
クールダウンのときコマンドを実行すると
CommandOnCooldownというエラー(例外)が発生します。
これを利用して、コードではクールダウン時にメッセージを発するようにしています。
on_command_errorは他にもコマンドが存在しないときのエラーもキャッチできますよね。
割と使う要素です。エラーはオブジェクトの一種
Python自体の知識ですが、エラーは
discord.Userとかと同じオブジェクトの一種です。
つまり、なにかしら情報が入っていると。
ではリファレンスを見てみましょう。
要素名 説明 retry_after 再びコマンドが使えるようになるまでにかかる秒数(float型) cooldown クールダウンオブジェクト
retry_afterは整数(int型)ではなく小数(float型)であることに注意です。
またcooldownはcooldown.rateのようにアクセスすることでデコレータで指定した情報を取得するために用意されています。クールダウン応用編
これまで学んできたことを生かして、少し応用を効かせたコードを書いてみましょう!
クールダウンが終わるまでどのくらいかかるか表示する!
クールダウンの残り時間がわからないほどイライラすることはありません。
ユーザーのイライラを解消するためにも残り時間を表示してあげましょう。小数点以下を切り捨てる
retry_afterを使うわけですが、先程も言ったようにこれは小数なので、そのまま表示すると「あと3.1548秒待ってね!」のように表示されてしまうので、切り捨てが必要です。
今回はint型に変換することで切り捨てます。実装してみよう
今回は秒数が大きくなる可能性も考慮して、「~分…秒」の形で表示させることにします。
@bot.event async def on_command_error(ctx, err): if isinstance(err, commands.CommandOnCooldown): retry_after_int = int(err.retry_after) retry_minute = retry_after_int // 60 retry_second = retry_after_int % 60 return await ctx.send(f"クールダウン中だよ!あと{retry_minute}分{retry_second}秒待ってね!")今回のポイントは先程説明した小数点切り捨てに加え、2つの演算子、
//と%です。
//は割り算したとき小数になった場合に小数点以下を切り捨てた数値を返す演算子で、
%は割り算したときの余りを返す演算子です。
これを組み合わせることで「~秒」を「~分...秒」の形にしています。おまけ: Cogに組み込んでみる
もちろんクールダウンはCogの中のコマンドにも組み込めます。
使用例だけ記しておきます。
細かい解説は省きます。class CooldownCog(commands.Cog): def __init__(self, bot): self.bot = bot @commands.command() @commands.cooldown(2, 10, type=discord.BucketType.user) async def hello(ctx): await ctx.send("hello!") @commands.Cog.listner() async def on_command_error(self, ctx, err): if isinstance(err, commands.CommandOnCooldown): return await ctx.send("クールダウン中だよ!") await self.bot.on_command_error(ctx, err)まとめ
commands.cooldownを使うことでコマンドにクールダウンを実装させることができる!on_command_errorを使うことでクールダウンに応じて文章を送ることができる!というわけで、みなさんもクールダウンを使って一歩先のBot開発者になりませんか!?
この記事が役に立ったのなら幸いです。

- 投稿日:2020-11-25T17:58:57+09:00
JupyterNotebookあれこれ
JupyterNotebookをPythonの学習で使うにあたって使いこなしたいテクニックについてまとめていく。
セルについて
JupyterNotebookは一般的なテキストエディタ、コードエディタとは違い、セルによって区切ることができ、セル単位でコードの実行ができることが特徴。
出力もセル直下にそれぞれ表示されるため、コードと実行結果の対応がわかりやすい。
JupyterNotebookと同じくAnacondaに標準で入っているVisualStudioCode(VScode)との比較
上記のように、区切ったセルごとにMarkDown形式で説明やコメントをつけることができる点で、学習に使うツールとしてVSCodeよりJupyterNotebookが優れているといえる。
また、LaTeX(TeX)という形式で数式を入力することができる。
開発などで大量のコードを書く場合には
JupyterNotebookでコード単位の単体テスト
↓
VSCodeでコードをまとめて全体のテスト
という風に使い分けている。CommandModeとEditMode
JupyterNotebookのセルにはCommandModeとEditModeという2つのモードがある
上記画像のように左の線が水色になっているのがCommandMode
上記画像のように左の線が緑色になっているのがEditModeCommandMode → EditMode は
Enter
EditMode → CommandMode はEscape
で移行できる。CommandModeで使えるテクニックまとめ
Hを押すとショートカット一覧が出る
新規セルを挿入
Aで現在のセルの上(Above)、Bで現在のセルの下(Below)に新しいセルを挿入することができるCodeモードとMarkdownモードを切り替える
Pythonのプログラムを書いて実行するために使うセルはCodeモードで使い、説明やコメントをつけるときにはMarkdownモードで使う。
YでCodeモードへ、MでMarkdownモードへと移行できる。
新規セルを挿入したときにはデフォルトでCodeモードになっているので、MarkDownモードで入力したいときには
Esc→M→Enter→入力
をクセづけるとスムーズに
Xでセルの切り取り、Cでコピー、Vで貼り付け
よく使うCtrl+Cと同じ。
切り取った後貼り付けなければ実質削除なのでよくXを削除として使う。
(ちなみに本当の削除コマンドはD2連打)EditModeで使えるテクニックまとめ
コード実行
Ctrl+Enterでコード実行
Shift+Enterだと、下にセルがある場合は下のセルに移動、下にセルがない場合はセルが追加された上で次のセルに移動
末尾セルで入力していき、実行しながらどんどん書いていきたい場合にはShift+Enterを自分の中でデフォルトにしておくといいかも
Shiftで入力補完
入力途中でShiftを押すと候補を提示してくれる。
ライブラリ名やメソッド名が長いときや思い出せないときに便利


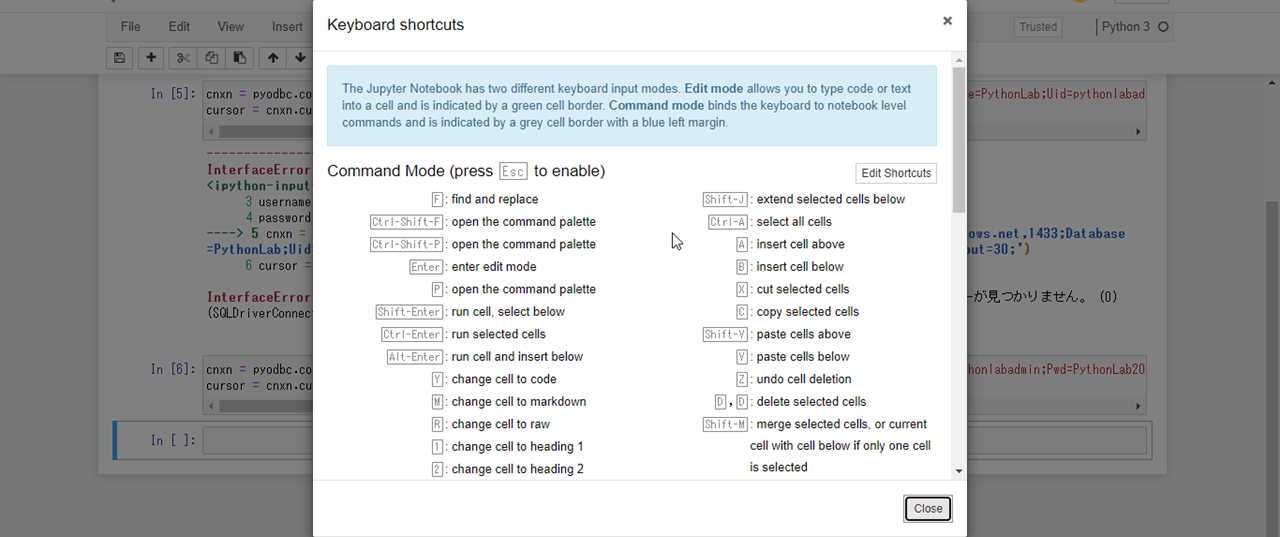

- 投稿日:2020-11-25T17:55:53+09:00
取得したツイートをCSVファイルに記録する
環境・バージョン OS:Windows10 言語:python 3..8.3 パッケージ:tweepy3.9.0, pndas1.0.5 はじめに 前回の記事でツイートを取得する方法を紹介したので、今回はそれをcsvファイルとして記録する方法についてまとめます。ファイルへの書き込み/読み込みをするだけなら標準ライブラリのcsvモジュールを使ってもできますが、応用することを考えてpandasパッケージを利用します。予めインストールしておいてください。 pip install pandas 参考:pandas公式ドキュメント csvとは csv(Comma Separated Value)とは、「テキストデータをカンマで区切ったデータ形式」です。例えば、以下はcsvファイルです。 a.csv 1,あ hoge,23 csvファイルへの書き込み csvファイルへの書き込みは以下の手順でできます。 1. データフレームの作成 2. to_csvメソッドで書き込み データフレームとは二次元構造のデータです。例えば数学における行列はデータフレームです。 #pandasをインポート(以降省略) import pandas as pd #データフレームの作成 #定義:df = pd.DataFrame(data = 格納するデータ, index = 行名, columns = 列名) b = pd.DataFrame( data=[[3,4],[5,6]], index=["1行目","2行目"], columns=["1列目","2列目"] ) #csvファイルへの書き込み #df.to_csv("ファイルへのパス") #ファイル名のみの場合はカレントディレクトリに作成される。 b.to_csv("b.csv") b.csv ,1列目,2列目 1行目,3,4 2行目,5,6 pd.DateFrameのindexとcolumnsは省略可能です。その場合、行も列も0始まりの連番が付けられます。 また、indexとcolumnsはそれぞれ削除してcsvファイルに出力することもできます。 #indexとcolumnsを省略 c = pd.DataFrame( data=[[3,4],[5,6]] ) #indexとcolumnsを削除して出力 c.to_csv("c.csv",index=False,header=False) c.csv 3,4 5,6 csvファイルの読み込み csvファイルを読み込むにはread_csvメソッドを使います。先ほどのb.csvを読み込んでみます。 #b.csvを読み込む d = pd.read_csv("b.csv") #確認 print(d) Unnamed: 0 1列目 2列目 0 1行目 3 4 1 2行目 5 6 一応読み込むことはできましたが、「1行目」「2行目」が行名として認識されず、おかしなことになってしまいました。 これを回避するにはオプション「index_col=0」を追加します。 #b.csvを読み込む e = pd.read_csv("b.csv",index_col=0) #確認 print(e) 1列目 2列目 1行目 3 4 2行目 5 6 正しく読み込めました。データフレームの特定の行や列を抽出したい場合は以下のようにします。 print(e["1列目"]) print("-------------------") print(e.loc["1行目"]) print("-------------------") print(e.at["1行目","1列目"]) 1行目 3 2行目 5 Name: 1列目, dtype: int64 ------------------- 1列目 3 2列目 4 Name: 1行目, dtype: int64 ------------------- 3 初めから特定の列だけ読み込む場合は以下のようにします。 f=pd.read_csv("b.csv",usecols=["1列目"]) #確認 print(f) 1列目 0 3 1 5 取得したツイートをcsvファイルへ保存してから取り出す 本題に入ります。前回のtweepyと今回のpandasを組み合わせて、ツイートを取得してcsvファイルに保存し、さらに特定のデータだけ抽出してみます。 取得するツイートは以下のTLとします。 長くなりますがプログラムを一気に書きます。 #tweepyとpandasをインポート import tweepy import pandas as pd #OAuth認証 consumer_key = "" consumer_secret = "" access_token = "" access_token_secret = "" auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_token_secret) #APIクラスをインスタンス化 api = tweepy.API(auth) #TLのツイートを取得する #全文取得したいのでtweet_mode = "extended"を付ける TL_tweets = api.home_timeline(tweet_mode = "extended") #データフレームを作成する #「ツイート日時」、「ユーザーネーム」、「本文」の順に保存する TL_tweets_df_data = [[i.created_at,i.user.name,i._json["full_text"]] for i in TL_tweets] TL_tweets_df_columns = ["ツイート日時","ユーザーネーム","本文"] TL_tweets_df = pd.DataFrame( data = TL_tweets_df_data, columns = TL_tweets_df_columns ) #csvファイルに書き込む TL_tweets_df.to_csv("TL.csv") #ツイート本文だけ取り出す TL_tweets_text = pd.read_csv("TL.csv",usecols=["本文"]) #データフレームの表示幅を変更 #これがないと途中までしか表示されない pd.options.display.max_colwidth = 300 #確認 print(TL_tweets_text) 本文 0 こんにちは? 1 あいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえおあいうえお https://t.co/BrX4mQVv21 2 テスト 最後に 今回はpandasを使って取得したツイートをcsvファイルに保存しました。 次回は一定時間自動的にsearchメソッドでツイートを取得し、csvファイルに追記していくプログラムを作ります。その際、スパムを取り除いたり、重複なく取得する工夫や特殊な文字に対する処理が課題になると思います。 参考 pandas.DataFrame pandas.DataFrame.to_csv pandas.read_csv
- 投稿日:2020-11-25T17:47:29+09:00
TensorFlow.kerasのModel.fit()実行時におけるsteps_per_epoch
概要
TensorFlow.keras(以下tf.keras)ではModel.fit()を実行してモデルの訓練を行います。
そのModel.fit()の引数にsteps_per_epochという項目があり、これにどんな値を与えれば良いのかを確認します。データ拡張などでImageDataGeneratorを使用することを前提としています。ImageDataGenerator
tf.keras内のデータ拡張を簡単に行うことができるクラスです。ImageDataGeneratorは指定したバッチサイズ・画像の加工内容で無限にバッチを生成することができます。このバッチ生成は訓練時に行われるため、大規模データセットや比較的大きなバッチサイズでも使用するメモリを少なくし訓練を可能にします。
train.py# インスタンスの作成 (画像の加工内容の指定) train_datagen = ImageDataGenerator( rescale=1./255, rotation_range=30, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.1, zoom_range=0.2, horizontal_flip=True, fill_mode='nearest' ) train_generator = train_datagen.flow_from_directory( TRAIN_DATA_DIR, # データセットがあるディレクトリ target_size=(IMG_WIDTH, IMG_HEIGHT), color_mode='rgb', classes=CLASSES, # クラスの配列 ['dog', 'cat']など class_mode='categorical', batch_size=BATCH_SIZE # 1回のバッチ生成で作る画像数 )ImageDataGeneratorはこのように使われます。classesは与えなくても自動的にディレクトリの構成で判断してくれる機能も備わっています。また、訓練データに対するgeneratorと検証データに対するgeneratorをそれぞれ用意することが一般的です。
ImageDataGeneratorを使用したfit()
ここからが本題です。以下はModel.fit()の実行例です。
train.py# modelは作成したModelクラスのインスタンス (省略) history = model.fit_generator( train_generator, steps_per_epoch=STEPS_PER_EPOCH, # ? epochs=EPOCHS, validation_data=validation_generator, validation_steps=VALIDATION_STEPS # ? )第一引数には訓練データのgeneratorを指定します。その他で意味がわかりくいのはsteps_per_epochとvalidation_stepなどだと思います。
steps_per_epoch
各エポックのイテレーション回数を指定します。イテレーションは簡単に言うと各エポックで重みを更新する回数です。通常バッチごとに重みが更新されるので、各エポックでバッチを生成する回数に等しいです。steps_per_epochの値は1以上のint型であればどんな値でもエラーは出ないと思われます。デフォルトの値(None)は、画像数 ÷ バッチサイズで与えられます。
例を示すと以下になります。
1000(訓練用画像数) ÷ 10(バッチサイズ) = 100(steps_per_epoch)簡単な計算ですが注意があります。
もし、「データ拡張を使用して画像数を3倍にした」と解説を添えた場合に、上の計算の総画像数はどうなるでしょうか?これを1000と3000のどちらに定義するのかが曖昧なのです。
色々な解説記事を見てみると、記事によってまちまちだと感じます。
なので、自分が実験で何を比較したいかなどを考えてから設定すべきなのかなーとも思います。それとも、デフォルトの値が生の訓練用画像数を用いて計算していることから「画像数を○倍にした」という解説自体がナンセンスなんでしょうか?自分には答えは出せません...。どちらにしろ理解していることが重要だと思うので今回記事にさせていただきました。
ぼやき:研究で作成した小さなデータセットでデフォルトの値だと学習曲線がガタガタで何が起きているかわからない...
validation_steps
Model.fit()実行時に各epochの終了時点で検証データに対するlossとaccuracyが計算されます。その際に何回バッチを生成して値を求めるかをvalidation_stepsに与えます。デフォルト(None)ではsteps_per_epochと同様にデータセットの検証データの画像を全て使いきるような値に設定されます。( 検証用画像数 ÷ バッチサイズ )。検証用データには画像加工などを施さないことが一般的なので、こちらはNoneを指定して問題ないと思います。
補足
以前はImageDataGeneratorのデータ拡張を使用した際の訓練はModel.fit_generator()が使用されていましたが、現在はModel.fit()もgeneratorを使用した訓練のサポートがされているため、そちらを使おうという方針になっています。(2020/11/25)
※記事に誤りがあった場合は修正または削除で対応します※
参考

- 投稿日:2020-11-25T17:33:09+09:00
Matplotlibのグラフを直接LINE Notifyに送信する
やりたいこと
Matplotlibで生成したグラフを、ファイルに保存せずに直接LINE Notifyに送信したい。
コード
import numpy as np import numpy.random as random import matplotlib.pyplot as plt import io import requests #適当にグラフを作る random.seed(10) x = np.arange(1, 101, 1) y = random.randn(100) y.sort() plt.plot(x, y) #メモリに画像を保存 buf = io.BytesIO() plt.savefig(buf, format='png') #グラフを表示しない plt.close() line_notify_token = 'LINE Notifyのトークン' line_notify_api = 'https://notify-api.line.me/api/notify' headers = {'Authorization': f'Bearer {line_notify_token}'} data = {'message': 'matplotlib test'} files = {'imageFile': buf.getvalue()} result = requests.post(line_notify_api, headers = headers, data = data, files = files)結果
参考文献
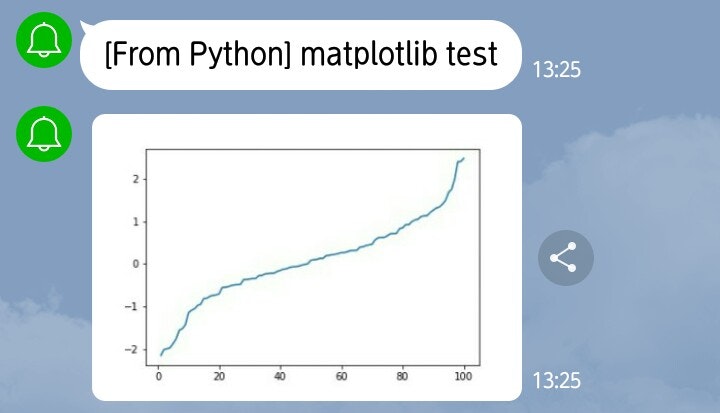
- 投稿日:2020-11-25T17:32:09+09:00
【Python】生物実験データを用いて棒グラフ描いてみた【初心者】
僕が普段行っている実験データを利用して棒グラフを描いてみました。
以前記事にした実験データの自動データ処理プログラムを作ってみた【R】のPython版です。インポート
%matplotlib inline import matplotlib.pyplot as plt import pandas as pd import seaborn as sns import numpy as npデータの読み込み
am = pd.read_csv('./sa_am_2.csv',names=("blank","control","c1","c10","c100"))列に名前がないデータなので、namesで列名を付けた。
今回使うデータはこれ。平均、controlとの相対値、標準偏差をそれぞれ求める
#各列の平均を求める mean_blank_am=am["blank"].mean() mean_control_am=am["control"].mean() mean_c1_am=am["c1"].mean() mean_c10_am=am["c10"].mean() mean_c100_am=am["c100"].mean() #blankを引く blank_control_am=mean_control_am-mean_blank_am blank_c1_am=mean_c1_am-mean_blank_am blank_c10_am=mean_c10_am-mean_blank_am blank_c100_am=mean_c100_am-mean_blank_am #dmsoとの相対値を求める control100_am=blank_control_am/blank_control_am*100 control_c1_am=blank_c1_am/blank_control_am*100 control_c10_am=blank_c10_am/blank_control_am*100 control_c100_am=blank_c100_am/blank_control_am*100 #標準偏差を求める sd_control_am = am["control"].std()*100 sd_c1_am=am["c1"].std()*100 sd_c10_am=am["c10"].std()*100 sd_c100_am=am["c100"].std()*100グラフの作成(棒グラフ)
#グラフの作成 x_am = np.array(["control","1µM","10µM","100µM"]) y_am = np.array([control100_am,control_c1_am,control_c10_am,control_c100_am]) e_am = np.array([sd_control_am,sd_c1_am,sd_c10_am,sd_c100_am]) plot_am = plt.figure() ee_am = plot_am.add_subplot(1, 1, 1) ee_bar=ee_am.bar(x_am,y_am,yerr=e_am,tick_label=x_am,error_kw=dict(lw = 1, capthick = 1, capsize = 5)) ee_bar[0].set_color("black") ee_am.set_title("barplot") ee_am.set_xlabel("x_test") ee_am.set_ylabel("y_test") plt.savefig("barplot_am.png")
グラフの作成(並列棒グラフ)
#グラフの作成(並列棒グラフ) x = np.array(["control","1µM","10µM","100µM"]) x_length = np.arange(len(x)) y_am = np.array([control100_am,control_c1_am,control_c10_am,control_c100_am]) e_am = np.array([sd_control_am,sd_c1_am,sd_c10_am,sd_c100_am]) y = np.array([control100,control_c1,control_c10,control_c100]) e = np.array([sd_control,sd_c1,sd_c10,sd_c100]) plot_mix = plt.figure() mix = plot_mix.add_subplot(1, 1, 1) mixbar_am=mix.bar(x_length,y_am,yerr=e_am,tick_label=x,error_kw=dict(lw = 3, capthick = 2, capsize = 10),width=0.4, label='am') mixbar_cv=mix.bar(x_length+0.4,y,yerr=e,tick_label=x,error_kw=dict(lw = 5, capthick = 3, capsize = 5),width=0.4, label='cv') mix.legend() mixbar_am[0].set_color("green") mixbar_cv[3].set_color("red") mix.set_xticks(x_length + 0.2) mix.set_xticklabels(x) mix.set_title("barplot") mix.set_xlabel("x_test") mix.set_ylabel("y_test") plt.savefig("barplot_mix.png")
新たに加えたデータは省略(平均とか求める処理は同じ)。コードの説明(自分用メモ)
add_subplot→グラフの枠組みを描く
yerr→エラーバーを付ける。
error_kw→エラーバーのオプションを付ける(オプションはdict(lw = , capthick = , capsize = )で太さや傘の長さを変えられる)。
label→凡例名
mix.legend()→凡例を付ける。何も指定しないと自動でベストな位置に付けてくれる。
set_color→棒グラフの色を変える。参考ウェブサイト
棒グラフ作成の大まかな流れは棒グラフ|Python (matplotlib/seaborn) を利用した棒グラフの作成方法を参照。
凡例の詳細はmatplotlib の legend(凡例) の 位置を調整するを参照。
色の詳細はmatplotlib で指定可能な色の名前と一覧を参照。
- 投稿日:2020-11-25T17:27:27+09:00
小学生に馬鹿にされないように、約36万行の7年目のPython2系プロジェクトを3系移行させた話
皆さんご存じの通りPython2系は2020年の1月ごろを持ってサポートが切れてEoLとなりました。
一方で、弊社のプロジェクトではファーストコミットから7年目・現在残存するPythonコードだけで36万行(docstring・テストを含む)のPython2が使われていたプロジェクトが残っていました。
Python2系を使っていると小学生にも馬鹿にされてしまう世知辛いこのご時世(※参考 : エンジニア一同衝撃 Python子ども向けワークショップにやってきた小2開発者のさりげない一言)。
これは、突然2系のプロジェクト担当になったエンジニアがたくさんのコードを頑張って3系移行するまでの泥臭い作業ログの記録です。
2系を使っているとディスられてしまう一方で、それなりの規模のプロジェクトでの移行関係の情報が表に出てこないので書きました(もうほとんどの方が3系だと思いますので、需要はほぼ無さそうですが・・・)。
※恐らく記事内に結構ポエム成分を含みます。
※2系環境から3系移行というよりかは、頑張ってレガシープロジェクトを改善していくという側面が強い記事かもしれません。
※執筆に関しては上長からは許可をいただいています。TL;DR
- テストが無いプロジェクトコードを部分的にリプレイスしつつ全体的にテストを追加していく作業が必要日数のほとんどの割合を占めた。
- テストやLintなどが整った後はコード量が膨大でも2系/3系互換コード化などは短期間で対応ができた。テストは偉大。
スタート時点の状態・条件など
Python2系を使っていたプロジェクトを引き継いだのは3年前くらいです。
その前段階から3系でお仕事をしていたため、2系のプロジェクトと聞いて当時抵抗感が強く出た記憶があります(また、残りのサポート期間的に移行を何とかしないという認識も)。
プロジェクト自体は社内用のweb上のツールだったため人がほとど割かれておらず、Python2系というだけでなく以下のような問題を抱えていました。
- テストが書かれていなかった。
- 保守されている仕様書が無い / 正確な仕様を完全に把握している人が社内に残っていない / ヒアリングした内容と実際の実装が乖離している。
- 保守されているDB関係などのドキュメントが無い。
- docstringが皆無。
- 前任の方がチームに残っていない(担当が今は増えましたが当時は自分一人)。
- ifやforなどでの意味のあるインデントがものすごい深くなっており(ネスト10個以上など)ものすごい認知的複雑度が高いコードがたくさんある。
- パフォーマンスが遅く、コードの内容把握のために動かそうとしても1つの関数で20分などかかったりしていた。
- 既存の機能で正常に動いていない箇所が結構あった / 計算ミスが多かった。
- メモリリークしていた。
- 密結合になっていて、アップデートすると予期せぬところがデグレしたりする。
- 担当になった私の方が、プロジェクトで利用されていたDjangoやLinux、AWSなどに精通していなかった(それまでは長いことデザイナーやゲームのクライアントエンジニアで演出寄りな仕事をしていた)。
改めて書き出してみると中々つらみに溢れている感じですね…。
一方で、
- 技術的な選択などの裁量はしっかり与えていただいた。
- レガシーコード改善系だったり使ったことの無い技術(大半は使ったことが無いものばかりでしたが)に対する大量の書籍などは会社側が一通り負担してくれて(購入に制限は特に無く)、且つ業務時間中の技術のキャッチアップもできていた(かなり勉強になった)。
- スケジュールに追われることはほぼなく、残業が0に近い点や休みの多さ・有給消化率的に労働環境はとてもホワイト環境だった 。
- 口頭コミュニケーションなども少なく作業に没頭できる時間か多かった。
といったポジティブな面も色々ありました。
3系にしたいけれども・・・
プロジェクトを引き継いだ時点で「2系のままだとアカン・・・」ということは考えていました。ただし結局今年になるまで移行に手を出しませんでした。
何故ここまで遅れた(遅らせた)のかは色々理由があるのですが、ぱっと思いつくところで大きなところだと以下の点が挙げられます。
そもそもツールの利用率がこのままだと下がっていってしまって、3系移行などをしている間にプロジェクト終了もありえるのでは?という感覚が強かった
社内のユーザー向けとはいえ、バグが多い・UIが分かりにくい・パフォーマンスが悪い…といった具合に、お世辞にもUXが良いとは言えませんでした。
これでは頑張って3系に移行しても、利用ユーザーがろくに居なくなってしまっていたらプロジェクト終了という会社の選択も起こり得ます。
そのため移行云々よりもまずはバグを減らす・分かりやすく見栄えるデザインのUIにする(元デザイナーとしてどうしても直したかったり等)・パフォーマンスを良くするといったUX改善を先に注力しました。
ここまで問題を抱えていると、プロジェクト終了してSaaSとかで妥協するのも(人件費などの面的にも)アリなのでは・・・という考えが何度も頭をよぎりましたが、当時の上司の方がこのプロジェクトを熱く推していらっしゃったので、継続して改善頑張っていくかと判断しています。
一般ユーザーは使わず、社内の限られた環境でのみ使われるものなので多少はEoLの期限を超えても致命的ではないと判断した
利用は社内のみで、外部からは繋がらない社内プロジェクトではあったため、なるべく早めに3系移行はしたいとは考えつつも多少は2系のEoLを超えてしまっても一応は致命傷ではない・・・と判断しました(正直言ってEoLの期限までに人的リソースが足りなかった・・・)。
それよりも先に、後述するように機能全体的なテストカバレッジの確保などを優先しました。
テストの拡充を優先した
プロジェクト担当前はPython3系でお仕事していたので、2系/3系で大分書き方が違うなとは感じていました。
実際に2系と3系の差異をまとめられている方もいらっしゃって、大分参考にさせていただきましたが、記事を見てみるとその差異の多さに結構圧倒されます(且つ、実際に移行をしてみたら記事で触れられている点以外も引っかかったりなどしています)。
参考 : Python のバージョン毎の違いとその吸収方法について
スタートしたばかりのような小規模なプロジェクトであればそのままアップデートという選択肢も取れますが、今回のプロジェクトは結構長寿なプロジェクトということもあり、これだけ2系と3系で書き方や挙動が違うとテストが無いと悪影響を抑えつつ移行するのが現実的ではありません。
上記を鑑みてテストでほとんどの部分のカバレッジが確保するという点を3系移行よりも先に対応しました。
テストを追加し始めてからしばらくしてから、3系移行関係の記事でもテストのことが触れられており、この選択は合ってはいたかなとは思っています。実際に普段の業務でテストに救われた数はとても多いですし、3系移行の時でもテストで事前に色々問題を検知できています。
テストコード(とドキュメント)が欠如していることで、Python 3への移行が進まないプロジェクトは数多い。十分な量のテストコードがなければ、自分たちが正しいことをしていることを確信できない以上、そうなるのは当然だ。そうしたプロジェクトをPython 3に移行するには、テストコードを書くところから始める必要がある。
今がPython 2からPython 3へ移行するのにベストなタイミング:トークセッションレポートテストに関してはDjangoプロジェクトだったというのもあり、Test-Driven Development with Python(私が読んだのは初版ですが)などを(他の古典的なレガシーコード改善系の名著も含め)何冊か買って読んでいきました。
立ちはだかる途中からテスト追加するの難しい問題
先にテストを拡充していこうと決めたはいいものの、やったことがある方は分かると思いますが他の方が書いたテストの無いコードにテストを加えるというのはなかなかにハードです。以下のような壁が立ちはだかります。
- 他人のコードに対して自分が精通していないので、そもそもどんな処理なのかが曖昧でテストが書くのが難しい(docstringなどがあれば楽ではありますがそのあたりも無いため)。
- 認知的複雑度などが高く、巨大な関数やメソッドなどが多く読みづらいだけでなくテストを書き足すのがとても難しい。
- パフォーマンスなどの面でテストを頑張って追加してもテスト時間が問題になりがちになる(単体テストはなるべく速くしたい)。
全部作り直したい症候群に襲われるものの・・・
こうなってくるとプロジェクトはじめから作り直した方がいいのでは?という感覚に大分襲われてきます。フルに作り直すのが正解なこともぼちぼちあるとは思いますが、今回はそこまではやりませんでした(他人の理解が難しいコードだからそう思ってしまうという感情面が強かった気がするため、フルの作り直しはしないようにそこはぐっと抑えつつ)。
ほとんどの場合は、漸進的に今のプログラムを修正・改良していった方が得策なのだ。
スクラッチから書き直したくなるプログラマは、書き直したプログラムもまたスクラッチから書き直したくなる。全部書き直しにするのはリスクが高くやるべきではないものの、開発体験(DX)が正直良くないのも確かです。そのため、以下のように今回のプロジェクトでバランスが取れるかなと思える形で進めていきました。
- 全て1から書き直すことはせず、既存ユーザーが既存のものを継続して利用できる状態は保つ。
- ただしUIの改善・コード内容の把握度・docstringやテストの追加・パフォーマンスの改善・テストがしやすくなるように関数などを小さくしていくなどの面が既存コードのままだと厳しいので、機能単位で細かくコードのリプレイスは進めていく。
- 細かいリプレイスは進めつつも既存のものも並行して動かし続ける(古いコードはすぐに切り落としはせずにユーザーが利用できる状態にする)。
- 新しいコードではdocstringやらテストやらは一通り追加する方向で進めていく。
- UI上の告知で、新バージョンへ移行している旨を表示し新バージョンの利用ができるリンクを貼っておく。
- 新バージョンについてユーザーに触ってもらってフィードバックを得る。
- しばらく期間を置いたりフィードバックの改善を新バージョン側に反映したのち、ユーザーのメインの(メニューなどによる)UIの導線を新バージョンに切り替え、ユーザーのメインの利用が新バージョンのコードやUIのものになるようにする。
- ただししばらく旧バージョンのものはユーザーから利用できるようにはリンクなどは残しておく。
- しばらくの期間そのまま放置し、特にお問い合わせなども無くなって来たり、利用ログなどを見て旧バージョンがほぼ使われなくなってきたのを確認したのちに旧バージョンのものを切り落とし、古いコードも削除する。
- 上記のようなイテレーションを何度も細かく繰り返し、最終的に機能全体的なコードのリプレイス(古いコードの削除)と全体的なテストやdocstringなどのカバレッジを確保する。
ストラングラーパターンとかがちょっと近いでしょうか。
「ストラングラーパターン」は、既存のシステムを段階的に新規システムに置き換えていく手法のことです。マーティン・ファウラーが2004年の記事「StranglerApplication」で名付けました。
ストラングラーパターン:段階的なシステム移行このパターンは、移行によるリスクを最小化し、長期にわたって開発を分散させるのに役立ちます。
...
時間の経過とともに、機能が新しいシステムに移行されると、レガシ システムは最終的に "抑圧" されて、必要なくなります。 このプロセスが完了すると、レガシ システムを安全に廃止できます。
ストラングラー パターン - Microsoft DocsAWSのwebコンソールや、Googleやマイクソフトのサービスなどでもちらほら見かけたりしますね。
一気に全てリプレイスするよりかは、小さい単位でリプレイスを進めて頻繁にデプロイしていくので、一気に全部書き直したものでリプレイス・・・とするよりかはリスクが少なくて済むというメリットがあります。
全ての古いコードのリプレイスと全体的なテストの拡充が終わるまではかなりの長期戦となった
ある程度覚悟していたものではありますが、全ての機能の段階的な移行・切り落とし・テストカバレッジの確保が終わるまではものすごい長期戦になりました。
スタートしてから一通り終わるまで約2年半くらいかかっています。その段階でコミット数9000程度、残存するPythonコードも30万行を超えるくらいにはなっていました。
最近でこそ人数を増やしていただけましたが、1人で全てやらないといけなかったので、こういったリプレイスに全リソースを割くこともできないというのも大きかったように思えます。
例えば社内の方から3人日くらいのライトな要望をいただいたとして、チームが自分一人なのでそうすると3日間はそのタスクだけでチームの人的リソース使用率が100%になってしまいます。社内ツールといえども全社的に横断的に使われているので、3桁人数の方がユーザーになりうるので、要望や質問対応なども含め自分で対応しないといけません。障害が出ればそちらも対応は全て自分で頑張る必要はあります。
そうこうしているうちに、リプレイスが終わって古いコードの切り落としが完了するまでの2年半は正直あっという間でした。
個別の機能のリプレイスが進んでUXもじわりじわりと改善していったところ、利用者もじわりじわりと色々な方が使う形になってきました。機能が改善し会社から少しは評価されたのか、社内でベテランの凄腕エンジニアさんをメンバー(平均年齢の低い若い会社なので自分も社内だと古参エンジニアに該当しますが・・・)に迎えることなどもでき人的リソースもかなり余裕ができました。
ベテランエンジニアさんのプロジェクト参加によってリソースの余裕ができたことによって、より一層改善のペースが上がりました。ポジティブなサイクルに入ったとも言えます。
テストのカバレッジが確保できてからはとても開発体験が良くなった
全体的にテストカバレッジが確保(※カバレッジ100%は目指してはいません)できてからは、かなり開発体験が良くなったように感じます。
プロジェクトを引き継いだ直後だと2週間に1回程度のデプロイ・且つデグレしてお問い合わせが来ることが多い・・・みたいな状態でしたが、現状では1日平均3回程度のデプロイ・ほぼデグレのお問い合わせが来なくなり(稀には来るので0ではないですが)、とても平和な感じになりました。まるでテストという守護神に守られているような感覚です(テストは偉大・・・)。
もちろんテストでカバーできない障害なども稀に発生します(単体テストでは問題無かった一方で、本番で悪影響が出てくるケースなど)。とはいってもそういったケースは今のところ半年に1回程度ですし、8~9割程度はテストで事前に問題を検知できている気はするので大分助かっています。
また、頻繁に(気軽に)デプロイできるようになったことで、結構攻めの改善などにも手が出せるようになってきました。元々の目的であったPythonの2系から3系移行に関しても同様です。
Lintやdocstringも拡充させた
後で触れますが、3系移行をする際の調整などでコードを全体的に読む必要が出てくるため、なるべく瞬時に各コードを理解できるようにするため、テストを整備したのと同様にLintやdocstring関係を整備しました。
まずはコーディング規約は基本的にPEP8に合わせる形としました(コードに一貫性を持たせたかったのでコーディング規約を設けたかったのと、自前のルールではなくPEP8だとLintなどのライブラリやエディタ拡張機能なども充実しているため)。LintとしてはPEP8準拠で楽をするためにisort・autoflake・autopep8・flake8の4つを利用しています。CI的にコードレビューやデプロイ前には各Lintを通してある状態にしています。
参考 : [Pythonコーディング規約]PEP8を読み解く
ルールに準じることで各コードの雰囲気が似たような形となり、読む際の負担が減ったように感じます(人による癖などが)。
docstringにはNumPyスタイルで統一し、基本的に新しいコードには必ず追加する・古いコードに関してもだんだんと追加していくといった形で進めました。
参考 : [Python]可読性を上げるための、docstringの書き方を学ぶ(NumPyスタイル)
また、気を付けていても追加し忘れてしまったり、頻繁にアップデートでコードを変えたりしていると引数内容がずれている・・・みたいなことが発生しがちです。
そういったケースを避けるためにもこの辺りのチェックは自前でライブラリを書いてPyPI(pip)に登録して、こちらもLintとしてコードレビューや本番デプロイ前にチェックが走るようにしていきました。参考 : NumPyスタイルのdocstringをチェックしてくれるLintを作りました。
この記事を書いている時点で、プロジェクトで残存するPythonモジュール数が約1250・36万行くらいにはなっていますが、じわりじわりとLintのチェック対象となっているモジュールのカバレッジは増えていき、現在各Lintで96%~100%のカバレッジとなっているようです。
Lintは段階的に導入・反映していった
Lintが無いプロジェクトに対して途中からLintを追加していったわけですが、一気に全てのモジュールに対してLintを反映・本番反映・・・とすると、この規模のコード量だと更新されるモジュールが膨大になってしまいます。基本的にはLintを反映しても悪影響が出ないことが大半ですが、稀に悪影響が出るところもあったりするので、一気に全てのモジュールに対して反映はせずにテストが追加済みのモジュールに対して少しずつLint対象に追加としていきました。
基本的にはLintを通してもテストを通ることを確認するため、テストの整備と同時並行でLint関係もじわりじわりと整備していきました。
Lintもなるべく速く終わるように改善
テストなども含め、デプロイまでに必要な処理にかかる時間が長くなってくるとちょっと開発体験が悪くなってきます。Lintの処理時間も同様です。コード量が多いと、全体に複数のLintを流すのが結構時間がかかるようになってきました。
また、後で触れますが2系/3系変換用のものもLint的に組み込んでいったので、作業中何度も何度も流していくことになります。
頻繁にLintを流した方がいい一方で、遅くなってきて待ち時間などが目立ってくると少し辛いものがあります。
そこで、テストの並列化といったようなスローテスト問題の解決と同様に以下のようにLintの処理時間を短くするために以下のような調整を入れていきました。
- 対象とするモジュール単位でのLintの並列化
- Lintの最終実行日時とモジュール更新日時を加味し、更新がされていないモジュールをLint対象から除外する判定の追加(すでにLint反映済みのものに対するチェックのスキップ)
- flake8やnumdoclintなどに関しては、前回チェックしてから更新されていない・且つ前回もチェックで引っかかっていないモジュールは対象外にするように調整
これで大体プロジェクト全体に各Lintを一通り流しても20秒くらいでLintが流れるようになり、大分快適且つ気軽な実行ができるようになりました。
3系移行の作業を進める
ここまででリプレイス、ドキュメント・docstring・テスト・Lintの追加・・・と色々触れてきましたが、これでやっと3系に移行を踏み切っていい感じになってきました(なお、期間的にもここまでが日数のほとんどで、実は3系移行自体の作業は少ない日数で対応が終わったりしています)。
この節からついに3系移行関係が中心とした内容となります。
移行作業は2系と3系両方で動く形のコードにしていく方向性を選択
移行する際には一気に3系に切り替える方法(2系では動かないコードに変換)と、まずは2系と3系両方で動く形にコードをしてから3系に環境を移し、しばらくしてから問題なさそうであれば古い2系環境を切り捨てる・・・といった2つの選択肢があります。
基本的には前者の方が作業自体は少なく、後者の方は段階的に移行していけるのと、3系に切り替えた後に問題が出てきた場合に一旦2系に切り戻したり・・・といった対応が取れるというメリットがあります。
今回のプロジェクトでは以下の理由から後者を選択しました。
- 残存するコード量が多く、並行して機能開発などのアップデートもかけていきたかったので段階的に移行したい。
- テストは通ったとしても、不測の事態が発生する可能性は高いと踏んでいたので、なるべくユーザーに迷惑がかからないようにすぐに2系に戻せるようにしておきたい。
移行の4本柱 six・future・builtins・modernizeパッケージ
2系互換を考えなければ2to3などの便利なものも用意されています。
2to3 - Python 2 から 3 への自動コード変換
ただし今回のプロジェクトでは2系互換を保ったまま進めようと決めたので、2to3は使わずに以下の4つのパッケージを主に使っていきました。
six
2系と3系の書き方の差異などを吸収する形のコードを書くことができるようにするパッケージです。
例えば文字列の型判定が、2系だと
if isinstance(str_value, basestring): ...な一方で、3系だとbasestringか存在しないため
if isinstance(str_value, str): ...といった書き方になります。これをsixを使うことで
if isinstance(str_value, six.string_types): ...といった2系でも3系でも動くコードにできます。そのほかにもリクエスト関係でのパッケージ構成が2系と3系で変わっているものやrangeの挙動の違いを吸収したりと、色々なラッパー的な2系と3系の互換性のための機能が含まれています。
future
futureパッケージのものを対象のモジュールでimportすることで、そのモジュールで将来のPythonバージョンと同じ書き方ができるようになります。
例えばprint関数は2系だと
print 'cat'としますが、3系だと
print('cat')といった形で関数呼び出し的に
()の括弧が必要になります。そこでモジュール内で
from __future__ import print_functionといったようにfutureパッケージから必要なものをimportすると、2系でも3系と同じ書き方でprint関数を書くことができるようになります。ただし、注意点として私が使っていたisortのバージョンの影響かもしれませんが、future関係のimportがあるとisortと挙動がおかしくなる・・・といったケースがたまに発生しました(同じモジュールに再度Lintを流せば大丈夫にはなる)。
そのあたりはコミットの際やテストなどで検知ができていましたが、テストが無いとやはりこの辺りの影響が怖いなという印象を受けました。
builtins
builtinsパッケージもfutureパッケージに似たような挙動をします。特定のものをimportすることで、2系と3系で挙動を合わせるといったことが可能になります。
たとえば2系だと整数の型がintとlongと分かれています。64bitなどの大きさの整数だとintではなくlongが必要になってきます。
一方で3系だとintのみです。小さい整数でも大きい整数でもintだけで扱うことができます(大きい整数では自動でサイズが大きくなります)。
そこで、futureパッケージと同じように
from builtins import intといったようにbuiltinsモジュールのものをimportしておくことで、intの挙動が2系でも3系と同じようになります。longは3系では使えないので、builtinsパッケージのものを使うことで2系と3系で同じコードで動く形にすることができます。modernize
modernizeはPythonのコードを2系と3系の互換のある形に変換してくれるライブラリです。前述までのsixやfutureなどを使った書き方に変換してくれます。
サードパーティーのライブラリとなるので、pipなどでインストールする必要があります。
また、コマンドの実行自体はPython3系が必要です。
sixなどは便利な一方で、機能はたくさんあり最初は中々どう書けばいいのか悩みますが、modernizeを使うことでライブラリに任せる形でsixなどを使ったコードに変換できます。どのように変換されるのかのdiffを見たりしても、sixなどの使い方の勉強になりますし、modernizeを通して初めて「〇〇も2系と3系で挙動が違うのか・・・」といった気づきも結構ありました。
手動で全部やると結構辛かったり、対応漏れなども起こりがちなのでライブラリでやってくれるところはライブラリに頼っていきました。
Docker移行
ファーストコミットから7年ものの古いプロジェクトでもあり、且つ私を含めてメンバーが元デザイナーや元ゲームのクライアントエンジニアといった経歴でインフラ関係にも強く無かったので、昔からのままでVirtualBoxとVMWareを使っていました(web業界と異なって、ゲームエンジンやらAdobeツールなどに詳しくてもDockerを使う機会が無かったというのも大きい気がします)。
しかし3系移行をするに伴って3系の環境を新たに作ったり、メンバー間で開発環境を頻繁にやりとりしたりが発生していく気配がしていたのと、元々新しい方の環境作るのが面倒だったのと、2系と3系環境を両方同時に動かしたりは必要になりそうなもののVirtualBoxなどで2つ同時に起動するのは負荷的にきつい・・・といった状態だったのでDocker対応を進めました。それにもう世の中ではDockerを使うのが当たり前・・・となっている気がするので、キャッチアップしておこうという側面も強かったかもしれません。
まずはDockerのことが良く分かっていなかったので、Docker Deep Dive: Zero to Docker in a single bookという本を買って勉強しました。
当時の記事 : [Docker入門]勉強して得られたDockerの知見を色々まとめてみた
古いものも使っていますし、Dockerのベテランもチームにいないので、開発環境のDocker対応結構難航するかな・・・?と思っていましたが実際にやってみたら案外スムーズに対応が進みました(移行が楽だったのでもっと早めに移行しても良かったなと)。
まずは2系の既存の開発環境をDocker対応し、次いで3系環境も用意し、3系で大分動くようになってきてからメンバーに3系環境を共有しました。
共有ディレクトリを設定して、2系と3系のDocker開発環境それぞれで同じコードを参照するようにした
Dockerにそこまで詳しくないのでこれが正解なのかよく分かっていませんが、開発環境のコードはローカルのWindowsで開発していたのでホスト側に置いて、共有ディレクトリ設定をそれぞれDockerの2系と3系の開発環境のLinuxで行う形にしました。
基本的に2系/3系互換のコードにしていく作業の都合2系と3系環境の同時起動が必要になるので、頻繁にLint反映やテストを流したりするためモジュールファイルを更新したら2系と3系環境両方に即時で反映されるようにしました。
ライブラリ関係の調整
3系環境の対応を進めていて、一部ライブラリの調整が必要になりました。
まずはいい機会なので使われていないライブラリを削除していきました(テストもこの時点では大部分がカバーできていたので攻める形で)。
pipでインストールされるライブラリが90強程度あり、引き継ぐ前からインストールされていたものが使っているのか使われていないのかいまいち分からずそのままにしてあったのですが、1つ1つ精査して使われていないと思われて、且つ切り落とした状態のDockerイメージでテストを流してみても引っかからないといったものを順番に切り落としていきました。
最終的には90件程度あったライブラリが60件程度まで少なくなりました。
続いて残ったライブラリで3系でインストールがうまくいかないものがあったので調整していきました。
具体的には、保守が止まっているライブラリが1つ、アップデートが必要になったライブラリが2つといったところです。
保守が止まっていたライブラリ(3系でインストールができない)ものは他の方がforkして3系対応したものがPyPIにも登録されていたのでそちらに切り替えることで解決できました。
他のアップデートが必要になったライブラリに関しては「Python3.xだったらこのバージョンに対応しているよ」といった互換性的なところの影響でアップデートをせざるを得ないライブラリが存在しました。逆に2系環境ではそのライブラリバージョンがインストールできないといったケースも発生し、仕方無いので2系と3系の環境で一部だけそれぞれ別のライブラリバージョンを使う形で進めました。
ライブラリバージョンの差異によってどちらか片方の環境でテストが引っかかった箇所などは、都度2系と3系両方で動作するようにラッパーなどを設けてそちらを利用する形に書き換えていきました(自前のsixみたいな対応ですね)。
全体としては影響が出たのが3つのライブラリといった程度で、作業を始めるまでは「もっと色々ライブラリが動かなくて詰んだりしないだろうか・・・」と懸念していましたが、この辺りはとてもスムーズで、OSSライブラリでちゃんと3系対応などで保守してくださっていたContributorの皆様には感謝しかありません・・・
3系環境でDjangoのコマンドなどが通る最低限のコードやライブラリの対応を進めていく
Lintの反映(手動・自動共に)はプロジェクトで使っていたDjangoのコマンドを利用していました。
しかしながらmodernizeは3系環境でしか動いてくれない(他の環境のPythonとか使ってしまうのも手ではありますが)ので、まずはDjangoのコマンドが3系環境で最低限実行できるところまで手動で対応して持っていきました。
警告も結構発生していたりテストも通していないような状態ではありましが、3系環境でコマンドが実行できるようになるまでのコードの調整は大した量ではない印象で完了しました(1.5人日くらい?)。
各モジュールにmodernizeを反映していく
3系環境でDjangoのコマンドが実行できるようになったので、約1250個の各Pythonモジュール(
__init__.pyなどを除く)にmodernizeを反映していきました。流れとしては他のLintと同じように組み込み、少しずつLintのカバレッジを上げていく・・・としていきました。
一定数(20個ずつなど)のモジュールに対してmodernizeを反映 → 変更された内容を目で確認して、問題がありそうなら手動で調整する → modernize以外のLintを反映する → 2系環境でテストを流し、引っかかれば修正する → 諸々問題なさそうであれば本番にデプロイしていく・・・といった作業をひたすらに繰り返していきました。
modernize反映後のコードは、挙動が変わっていたりがテストで検知されたりは結構ありましたし、テストパターンで検知できない更新があったり(例えば、初期値が小さい値でコード内で値が大きくなるような箇所でlongがそのままintに変換されたもののbuiltinsパッケージのものがimportされない等)、前述のfutureとisortでの変な挙動などの件もありましたので、目視での確認なども挟んで進めました。modernizeがどのように更新していくのかに興味があったというのもあります。
また、modernize反映後のコードはPEP8などが加味されていない形となるので、前述のisortやautoflake、autopep8などの他のLintを通すことも必要になりました。
ひたすら繰り返しの作業ではありますが、思っていたほどこの作業は時間がかかりませんでした
。5人日弱といったところでしょうか。テストカバレッジを上げるための作業などと比べると大分さくっと終わった印象を受けました。なお、この時点ではまだ3系でテストが一通り通るといった状態にはまだなっていません(3系環境で一通りのモジュールimportなどはできたり、起動等はできるようにはなっています)。
3系環境で一通りテストが通るようにする
modernizeを通しきったおかげで一通りのモジュールのimportやDjango関係の起動などができるようになったので、今度は3系環境で一通りのテストが通るように調整していきます。
案外modernizeを通し、2系環境ですでにテストが通っているコードでも3系環境でテストを流してみるとテストに引っかかったりして、新しく「2系と3系でそんな挙動の違いがあるのか・・・」と気づくような内容であったり、ライブラリバージョンが同じでも2系と3系で挙動が異なっていてテストに引っかかるといったケースが結構出てきました。テストが無かった状態で進めるとするとこの辺りはまず本番デプロイ前に気づくのが難しいので、改めてテスト周りを先に整備しておいて良かったと感じます。
ここもmodernize同様、そこまで工数がかかるといったものでもなく、テストの関数の件数ベースで3000強程度のテストで5人日程度で対応が完了しました。
チームに3系環境を展開する
ここまで来ると、まだ細かい点で直す必要がある点はちらほらあるものの大分2系環境同様に動くようになってきました。
3系環境のイメージをチームに展開したのもこのあたり(実際にはもう少し前でしたが)のタイミングです。
また、このタイミングからは今後のアップデートは2系と3系両方でテストを通してからデプロイする形にしてあります。Lintに関しても3系環境でmodernizeも含め1つのコマンドで一通り実行できる段階になっています(前述の通り、手動でLintを通す場合でも共有ディレクトリのおかげで1回流せば2系環境にも反映されるようになっています)。
発生していた警告をつぶしていった
3系環境を中心に、Python自体やライブラリのDeprecatedWarningやFutureWarningなどが結構発生していました(3系環境で一部ライブラリをアップデートしたのも絡み)。
これらに関しても3系に切り替える前に警告系を一通りつぶしておきたかったので、開発環境ではテストで警告が出ていても通ってしまっていてもテスト失敗にはしていなかったところを警告でも失敗するようにテストランナーを調整したり、開発環境のViewで警告が出ていたらエラーになるようにDjango関係で調整したりして警告を一通りつぶしていきました(これらも小さく分割して、少しずつまめにデプロイしていきました)。
作業自体は約3人日といったところでしょうか。
いざ、本番環境の切り替えへ
幸い社内用のwebのツールということもあり、土日などは利用者がほとんどいません。そのため切り替え作業や検証作業などは土日に休出・代休を平日に取らせていただく形で(何かトラブルが発生しても時間的な余裕がある状態で)進めることができました(作業自体は土曜で完了・日曜はほぼ経過観測で大体他の作業を行っているといった具合でした)。
また、「事前にやれることは色々やりましたがきっとどこかしら影響は出ます」「トラブルなどで2日で終わらなかったら一旦2系に戻して来週の土日にまた作業します」みたいなものはお知らせなどは事前に展開したりして、ゆっくりと落ち着いて作業ができる状況を作り、トラブルがあっても切り戻しがしやすいようにはしておきました。
そのあたりを考慮していても「移行で死ぬときは死ぬ」とはチームのチャットには流していた(良く聞くフェイルオーバーがうまく動いていないとか、ロールバック自体が失敗するとか)ので、「何らか思いっきり失敗しても休日でユーザーがいないのだからゆっくり対応はできる」といった状況は大変助かりました(主に精神的に)。
結果的には本番環境の3系切り替えで大きな障害などは無く(少なくともユーザーに大きな影響の出るものは無く)、無事移行が終わりました。
ただし本番環境でテストを通した時に、開発環境で事前に再現できていなかった条件でテストで引っかかったところが一部見つかりました(環境特有のもの)。そちらもユーザーの利用開始前に修正は終わりましたので、やはりテストがしっかりしていると安心感があるなと(多くのところをユーザーから指摘される前に検知して直せるなど)感じました。
余談 : マイクロサービス化はしなかったの?
今回のプロジェクトではマイクロサービス化はしませんでした。Building Microservices: Designing Fine-Grained Systemsなどの本は買っていただいているのですが、まだ未読でマイクロサービスに詳しくないので判断ができなかったとも言えます(メンバーがインフラとかに強くないというのもあります)。
疎結合感が増えたりでメリットも大きそうで結構使うか使わないか悩んだのですが、チームが1人か2人で回してきている(会社の都合ではあるので、内製なら最低3人・・・といった突っ込みはさておき)ので、チーム人数の多さに起因するコミュニケーションコストは抑えられていますし、1日平均3回くらいのデプロイはできているのでマイクロサービス化までは今回は手を出さなくてもいいかな?という所感に落ち着きました。
将来書籍をしっかり読んで知見が得られたら意見が変わって「やっぱりマイクロサービス化しよう」という判断にはなるかもしれません。ただし、Twitterなどでもちらほらマイクロサービス化による煩雑さというか、つらみを何度か見かけてはいるので「流行っているからマイクロサービス化する」とはしない形にはなると思います(しっかり本を消化してメリットがデメリットよりも大きそうであれば利用していこうかなと)。
今後の展望
今後は段々と、こまめにプログラム言語やライブラリバージョンをアップデートしていきたい
今まではテストやらLintやらDockerやらが整備されていなかったので、Pythonやライブラリのアップデートは慎重に行う必要がありましたが、今回の移行作業で大分整ったので、今後は攻める形でまめにアップデートをかけていけたらいいなと考えています。
まめにバージョンアップすることで影響を小さく1回の対応の工数も下げれますし、一気にバージョンを上げてエラーになるのではなくDeprecatedWarningなども検知小さなバージョンアップで検知しやすくなります。まめにアップデートすることで、アップデート作業自体の訓練にもなります。
それに今回のような大きなバージョンアップだとどうしても気が重くなりがちでアップデートせずに放置しがちで余計に良くないと考えています。
なにかのスライドで見かけた「テストなどが通ることが確認できたら自動でアップデートする」みたいなことをしてもいいかもしれませんね(VS Codeで起動したらいつの間にか自動でアップデートされているような形で)。
型アノテーション関係を充実させていきたい
Python3系にして個人的に特にありがたいのが型アノテーション周りです(2系の文字列などの煩雑さから開放されるといったものも大きいですが)。
2系環境でもインラインコメントをする形で使えたり(実際にある程度便利に使っていたり)、Pylanceなども快適に使えていましたが、やはり3系の書き方だと色々快適です(エディタや拡張機能なども加味し)。
最近のPython3.9や3.10などでも色々便利そうな型アノテーション周りのアップデートが入ってきています。プライベートでは新しいPythonバージョンを使ったりしていて便利さやミスの減り具合は身に染みていたので、今後積極的にこのあたりは折角3系環境になったのですから導入したりPyrightなどをCI的に整備したりもしていきたいと考えています。
新しいライブラリを導入して機能追加などに役立てていきたい
昔からあったライブラリなどであれば、新しいバージョンにアップデートはできなくなったりはして来ている一方で、少しバージョンを最新から下げたりすればまだ結構使える状態です。
しかしながら新しく生まれてきているライブラリなどは2系はそもそも対応されていなかったりというケースが大半になってきました。
今までは「2系だから便利そうだけどこれは使えない・・・」といったケースも結構あったので、それらが解決して選択肢が増えるのは楽しみですし、新しいものも積極的に試したり導入したりしていきたいなと考えています。
参考サイト・参考文献
- 投稿日:2020-11-25T17:09:57+09:00
Jupyter notebookの出力セルの大きさを無限にする
以下のマジックコマンドをセルに入れて実行。
%%javascript IPython.OutputArea.auto_scroll_threshold = 9999;
- 投稿日:2020-11-25T16:16:53+09:00
Pythonで文字列からUnicode変換「u''」と「.decode('utf-8')」
[\u30d7\u30ed\u30c0\u30af\u30c8\u30c7\u30b6\u30a4\u30f3]このコードは、Unicode文字のエスケープシーケンスというらしいです。
(情報源:https://blog.xin9le.net/entry/2015/02/08/212947)python 2.x(3の前のいろいろ)バージョンでは、日本語をこの状態に変換しないといけません。
そのために、文字の前に「u」をつけてください。するとunicode変換されます。u'プロダクトデザイン'ですが、もしここに変数を入れようと思った場合、「u」をつけても、新しい変数の名前になってしまいます。
これでは何もできません。test.pytest = 'プロダクトデザイン' nanika(utest) # nanikaは適当です。なので、.decode('utf-8')を使います。以上!
(情報源:https://qiita.com/yubessy/items/9e13af05a295bbb59c25)test.pytest = 'プロダクトデザイン' nanika(test.decode('utf-8')) # nanikaは適当です。あと補足ですが、文字列とunicode文字エスケープシーケンスなどをwebサイト上で変換することができるサイトがあります。
こちら。どうぞ。
http://0xcc.net/jsescape/あと、unicode文字エスケープシーケンスを普通の文字列にjavascriptで変換しやすいように関数を作った方がいます。
素晴らしすぎる..。感謝しかないです。
https://shanabrian.com/web/javascript/unicode-unescape.phpvar unicodeUnescape = function(str) { var result = '', strs = str.match(/\\u.{4}/ig); if (!strs) return ''; for (var i = 0, len = strs.length; i < len; i++) { result += String.fromCharCode(strs[i].replace('\\u', '0x')); } return result; };var result = unicodeUnescape('abc123\\u3042\\u3044\\u3046\\u3048\\u304a'); console.log(result);
- 投稿日:2020-11-25T15:46:42+09:00
ドーキンスのイタチプログラム
R.ドーキンスは、生物が遺伝子の突然変異と選択による「進化」により環境に適応してきたことを説明するため、単純なランダムな変化と蓄積淘汰を比べる「イタチプログラム」を提唱しました。蓄積淘汰とは、環境により適応した子どもが生き残りやすくなるというメカニズムです。イタチプログラムは以下のようなアルゴリズムです。
1.ランダムな28文字の文字列を用意する。
2.一定数(100など)のコピーを作る、ただし、各文字のコピー時に一定確率(5%など)でランダムな文字に変異する。
3.ターゲットの文字列"METHINKS IT IS LIKE A WEASEL"とできた各コピーを比べ、合致した文字数に応じたスコアを算出し、最も高いスコアの文字列で更新し、2に戻る。
4.ターゲットと合致すればそこで終了する。"Methinks it is like a weasel."はハムレットの一節だそうです。現代語では"To me it looks like a weasel."
イタチプログラムをPythonで書いてみました。
weasel.pyimport random target_string = "METHINKS IT IS LIKE A WEASEL" char_list = ["A","B","C","D","E","F","G","H","I","J","K","L","M","N","O","P","Q","R","S","T","V","W","X","Y","Z"," "] child_per_generation = 100 mutation_chance = 5 length = len(target_string) def check_string(character): score = 0 for i in range(length): if character[i] == target_string[i]: score += 1 return score #マッチした文字数=スコア を返す def make_child(parent): child = "" for char in parent: if random.random() < mutation_chance * 0.01: child += random.choice(char_list) #突然変異 else: child += char #そのまま遺伝 return child def main(): generation = 0 best_score = 0 best_child = "" first_char = "" for n in range(length): first_char += random.choice(char_list) #ここまで初期化と最初の文字列の生成 while True: for j in range(child_per_generation): if best_child == "": best_child = first_char #最初はランダムな文字列で開始 new_child = make_child(best_child) new_score = check_string(new_child) if new_score > best_score: best_score = new_score best_child = new_child #世代の最良の文字列で更新する print(str(generation) + " " + best_child + " --score:" + str(best_score)) if best_score == length: break #合致すれば終了 generation += 1 main()実行結果のサンプルです。
% python weasel.py 0 VCTHJWRBDCZJXGVZQO CVFKA YFL --score:3 1 VCTHJWRBCCZ XGVZQH VFWA YFL --score:6 2 VETHJWCBCCZ XGVLQH VFWA YFL --score:8 3 METHJWCB CT XSVLLHX VFWAAYOL --score:13 4 METHJWCB CT XSVLLHX VFWAAYOL --score:13 5 METHJWCB CT XSVLLHX VFWAAYEL --score:14 6 METHJWCB CT XSVLLHX VFWAAYEL --score:14 7 METHJWEB CT XSVLLVE AFWAAYEL --score:16 8 METHJWEB CT XSVLLVE AFWAAYEL --score:16 9 METHIWEB CT XSVLKVE AFWAAYEL --score:17 10 METHIWEB CT ISVLKVE AFWAAVEL --score:18 11 METHIWKB CT ISVLKVE A WAAVEL --score:20 12 METHIWKB CT ISVLKVE A WAAVEL --score:20 13 METHIWKB IT ISVLKVE A WAAVEL --score:21 14 METHINKB IT ISVLKVE A WAAVEL --score:22 15 METHINKB IT ISVLKVE A WEAVEL --score:23 16 METHINKB IT ISVLKVE A WEAVEL --score:23 17 METHINKB IT ISVLKVE A WEAVEL --score:23 18 METHINKB IT ISVLKVE A WEAVEL --score:23 19 METHINKB IT ISVLKVE A WEASEL --score:24 20 METHINKB IT IS LKVE A WEASEL --score:25 21 METHINKB IT IS LKVE A WEASEL --score:25 22 METHINKB IT IS LKVE A WEASEL --score:25 23 METHINKB IT IS LKVE A WEASEL --score:25 24 METHINKB IT IS LKVE A WEASEL --score:25 25 METHINKB IT IS LKVE A WEASEL --score:25 26 METHINKB IT IS LKVE A WEASEL --score:25 27 METHINKB IT IS LKVE A WEASEL --score:25 28 METHINKB IT IS LKVE A WEASEL --score:25 29 METHINKB IT IS LKVE A WEASEL --score:25 30 METHINKB IT IS LKVE A WEASEL --score:25 31 METHINKB IT IS LIVE A WEASEL --score:26 32 METHINKB IT IS LIVE A WEASEL --score:26 33 METHINKB IT IS LIVE A WEASEL --score:26 34 METHINKB IT IS LIVE A WEASEL --score:26 35 METHINKS IT IS LIVE A WEASEL --score:27 36 METHINKS IT IS LIVE A WEASEL --score:27 37 METHINKS IT IS LIKE A WEASEL --score:28確かに比較的短期で正解へ収束しています。これを完全にランダムな変異で実現しようとすると、途方もない時間がかかるでしょう。
参考:
Weasel program
https://en.wikipedia.org/wiki/Weasel_program