- 投稿日:2020-10-24T19:49:39+09:00
画像を1ピクセルだけ変えて画像分類器を騙してみる
やりたいこと
色々調べていたらこんな論文がありました。
One Pixel Attack for Fooling Deep Neural
なんでも画像を1ピクセル変えるだけで、deep learningで作った画像分類器を騙せるらしい…(下図参照)。そこで本当に騙せるのか簡単なモデルで試してみました。
方法
原論文では色々難しい理屈に基づいてピクセルを変えているようです。しかしそれを実装するのは骨が折れるので、変更するピクセルをブルートフォース的に探索して、分類を最も間違えるようなピクセルの変え方を探します。
今回使うデータセットはfashion MNISTです。画像データにはファッションに関わる画像が含まれていて、それぞれの画像は靴やTシャツなど10種類のカテゴリーに分類されています。
tensorflowの画像分類のチュートリアルに従って、モデルを作ります。
チュートリアル通りに今回は全結合ネットワークでモデルを使用します。
(本当はCNNやもっと現代的なものを使いたいですが学習が大変なので…。)model = keras.Sequential([ keras.layers.Flatten(input_shape=(28, 28)), keras.layers.Dense(128, activation='relu'), keras.layers.Dense(10, activation='softmax') ])5 epoch 学習させると、訓練データに対してはaccuracy: 0.8920、テストデータに対してはaccuracy: 0.8757という精度が出ました。
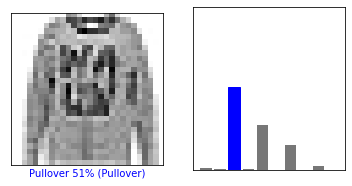
#訓練誤差 Train on 60000 samples Epoch 1/5 60000/60000 [==============================] - 2s 33us/sample - loss: 0.5018 - accuracy: 0.8234 Epoch 2/5 60000/60000 [==============================] - 2s 30us/sample - loss: 0.3709 - accuracy: 0.8658 Epoch 3/5 60000/60000 [==============================] - 2s 33us/sample - loss: 0.3344 - accuracy: 0.8791 Epoch 4/5 60000/60000 [==============================] - 2s 35us/sample - loss: 0.3113 - accuracy: 0.8848 Epoch 5/5 60000/60000 [==============================] - 2s 29us/sample - loss: 0.2923 - accuracy: 0.8920#テスト誤差 10000/10000 - 0s - loss: 0.3471 - accuracy: 0.8757 Test accuracy: 0.8757さて、1ピクセル変えた画像を作成して、分類の精度がどのぐらい下がるかを調べていきます。ターゲットとしたのはテストデータの500番目に入っていた"pull over"の画像です。下図で左はその画像データ、右はニューラルネットワークで計算された各カテゴリーに分類される確率です。ニューラルネットワークはこの画像は"pull over"であると正しく予想していますが、他の"Coat"や"Shirt"である確率もそれなりに高く予想されています。
この画像の"pull over"の予想確率が低くなるように、変更するピクセルの位置とそのピクセル値を全探索していきます。画像はたかだか28x28のサイズなので、全探索可能です。具体的には以下のようなコードを使いました。predictions = model.predict(test_images) score = predictions[500][2] #"pull over"である確率(ニューラルネットワークの予想) for i in range(28): for j in range(28): for val in np.arange(0.0, 1.0, 0.05): test_images_new = copy.deepcopy(test_images[500:501]) test_images_new[0][i][j] = val pred_new = model.predict(test_images_new) score_new = pred_new[0][2] if score_new < score: score = score_new print(i,j,val,score) val_0 = val ij = [i, j] img_save = test_images_new[0]結果
上記のコードを回すと、正解の予想確率を下げるようなピクセル変更がどんどん見つかりました。長くなるので、出力の最後の方だけコピペします。どうやら、画像の上の方に点を加えると分類の精度が落ちるようです。
# i j val prob 0 13 0.8500000000000001 0.41363287 0 13 0.9 0.40757006 0 13 0.9500000000000001 0.40149412 0 15 0.8500000000000001 0.40028474 0 15 0.9 0.3941359 0 15 0.9500000000000001 0.38800317実際に得られた画像と分類確率を下図に示します。画像の真ん中の上のあたりに黒い点が追加されています。分類確率を見ると、"pull over"である確率が下がって"Coat"である確率が最大になっています(差は小さいですが)。つまり、1ピクセル変えるだけでニューラルネットワークを騙すことに成功しています。
具体的にニューラルネットワークの予想を数値で見ると、以下のようになっていました。
'Pullover' 'Coat' 'Shirt' 'Bag' 元画像 51.1% 27.7 % 15.7 % 2.3 % 1ピクセル変えた画像 38.8 % 39.3 % 16.6 % 2.6 % 非常に簡単なモデル相手とはいえ1ピクセル変えるだけで本当に騙せるものなんですね…。