- 投稿日:2020-10-24T23:44:33+09:00
【python】for文エラー
TypeError: 'int' object is not iterable
のエラーが生じたときの対処法for文の使い方
以下のように in の後には範囲を指定する。
for i in range(0:4): print(i) #0 1 2 3上の例では in の後に0から3を指定している。
エラーが出る使い方
以下のように in の後に数字のみを入れるとエラーが起きる。
for i in 4: print(i) #TypeError: 'int' object is not iterable以上の例は in の後に数字が入っているため、for文を何回したらよいかわからないというエラーが出ている。
- 投稿日:2020-10-24T23:32:09+09:00
FastAPI + SQLAlchemy(postgresql)でAPI実装してみた(Dockerやミドルウェア, テストコードなども含む)
アーキテクチャ
python: v3.8.5 postgresql: v12.4 fastapi: v0.60.2 SQLAlchemy: v1.3.18マイグレーションツール
alembic: v1.4.2FastAPIとは
詳細は既にQiitaにチョコチョコ記事あるので割愛します。
ドキュメントが豊富(読みきれてない)で、Swaggerと互換性あるのがとても素晴らしいです。
(パフォーマンスも良いらしいがベンチマーク測ったことないので断言できない、でも多分速い。)
しっかり触ったことのあるフレームワークはDjangoだけなのでミドルウェアやテストコード周り苦労した・・・。
(Djangoはフルスタックフレームワークだからミドルウェアとかあまり気にしたことない)Python3.8.5の仮装環境作成
pyenv, virtualenvが入ってない場合は下記を参考に入れてください。
・Mac
・Windows$ pyenv virtualenv 3.8.5 env_fastapi_sample仮装環境を適用
プロジェクトルートを作成
$ mkdir fastapi_sampleプロジェクトルートにcd
$ cd fastapi_sample仮装環境を適用
$ pyenv local env_fastapi_samplerequirements.txt作成/インストール
$ touch requirements.txtrequirements.txtにfastapiを追記
fastapi_sample/requirements.txtfastapi==0.60.2 uvicorn==0.11.8仮装環境にインストール
$ pip3 install -r requirements.txtエントリーポイント(main.py)を作成して、Swagger-UIを表示してみる
エントリーポイント(main.py)作成
$ touch main.pymain.pyを編集
fastapi_sample/main.pyfrom fastapi import FastAPI app = FastAPI() @app.get("/") async def root(): return {"message": "Hello World"}Swagger-UI表示
$ uvicorn main:app --reloadブラウザから「http://127.0.0.1:8000」にアクセスして
{"message":"Hello World"}が表示されていれば完了です。Docker化
Nginxのリバースプロキシによってアプリケーションをhttpsで公開するようにします。
ベースのdocker-compose.yml
fastapi_sample/docker-compose.ymlversion: '3' services: # Nginxコンテナ nginx: container_name: nginx_fastapi_sample image: nginx:alpine depends_on: - app - db environment: TZ: "Asia/Tokyo" ports: - "80:80" - "443:443" volumes: - ./docker/nginx/conf.d:/etc/nginx/conf.d - ./docker/nginx/ssl:/etc/nginx/ssl # アプリケーションコンテナ app: build: context: . dockerfile: Dockerfile container_name: app_fastapi_sample volumes: - '.:/fastapi_sample/' environment: - LC_ALL=ja_JP.UTF-8 expose: - 8000 depends_on: - db entrypoint: /fastapi_sample/docker/wait-for-it.sh db 5432 postgres postgres db_fastapi_sample command: bash /fastapi_sample/docker/rundevserver.sh restart: always tty: true # DBコンテナ db: image: postgres:12.4-alpine container_name: db_fastapi_sample environment: - POSTGRES_USER=postgres - POSTGRES_PASSWORD=postgres - POSTGRES_DB=db_fastapi_sample - POSTGRES_INITDB_ARGS=--encoding=UTF-8 --locale=C volumes: - db_data:/var/lib/postgresql/data ports: - '5432:5432' volumes: db_data: driver: localNginxコンテナの設定
confファイルを用意する
$ mkdir -p nginx/conf.d $ touch nginx/conf.d/app.conffastapi_sample/docker/nginx/conf.d/app.confupstream backend { server app:8000; # appはdocker-compose.ymlの「app」 } # 80番ポートへのアクセスは443番ポートへのアクセスに強制する server { listen 80; return 301 https://$host$request_uri; } server { listen 443 ssl; ssl_certificate /etc/nginx/ssl/server.crt; ssl_certificate_key /etc/nginx/ssl/server.key; ssl_protocols TLSv1.2 TLSv1.3; location / { proxy_set_header Host $http_host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-Host $http_host; proxy_set_header X-Forwarded-Server $http_host; proxy_set_header X-Forwarded-Server $host; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; proxy_redirect http:// https://; proxy_pass http://backend; } # ログを出力したい場合はコメントアウト外してください # access_log /var/log/nginx/access.log; # error_log /var/log/nginx/error.log; } server_tokens off;NginxのSSL化に必要なファイルを用意
$ mkdir -p nginx/conf.d nginx/sslOpenSSLを使って秘密鍵(server.key)を生成する
# ディレクトリ移動 $ cd nginx/conf.d # 秘密鍵生成 $ openssl genrsa 2024 > server.key # 確認 $ ls -ll total 8 -rw-r--r-- 1 user staff 1647 10 24 13:23 server.key証明書署名要求(server.csr)を生成
$ openssl req -new -key server.key > server.csr$ openssl req -new -key server.key > server.csr ... .. . Country Name (2 letter code) [AU]:JP # 国を示す2文字のISO略語 State or Province Name (full name) [Some-State]:Tokyo # 会社が置かれている都道府県 Locality Name (eg, city) []:Chiyodaku # 会社が置かれている市区町村 Organization Name (eg, company) [Internet Widgits Pty Ltd]:fabeee # 会社名 Organizational Unit Name (eg, section) []:- # 部署名(ハイフンにしました。) Common Name (e.g. server FQDN or YOUR name) []:localhost(ウェブサーバのFQDN。一応localhostにした) Email Address []: # 未入力でエンター Please enter the following 'extra' attributes to be sent with your certificate request A challenge password []: # 未入力でエンター An optional company name []: # 未入力でエンター ... .. . $ ls -ll total 16 -rw-r--r-- 1 user staff 980 10 24 13:27 server.csr # 証明書署名要求ができた -rw-r--r-- 1 user staff 1647 10 24 13:23 server.keyサーバ証明書(server.crt)を生成
openssl x509 -req -days 3650 -signkey server.key < server.csr > server.crt % ls -ll total 24 -rw-r--r-- 1 tabata staff 1115 10 24 13:40 server.crt # サーバ証明書ができた -rw-r--r-- 1 tabata staff 948 10 24 13:29 server.csr -rw-r--r-- 1 tabata staff 1647 10 24 13:23 server.keyサーバ証明書を信頼する
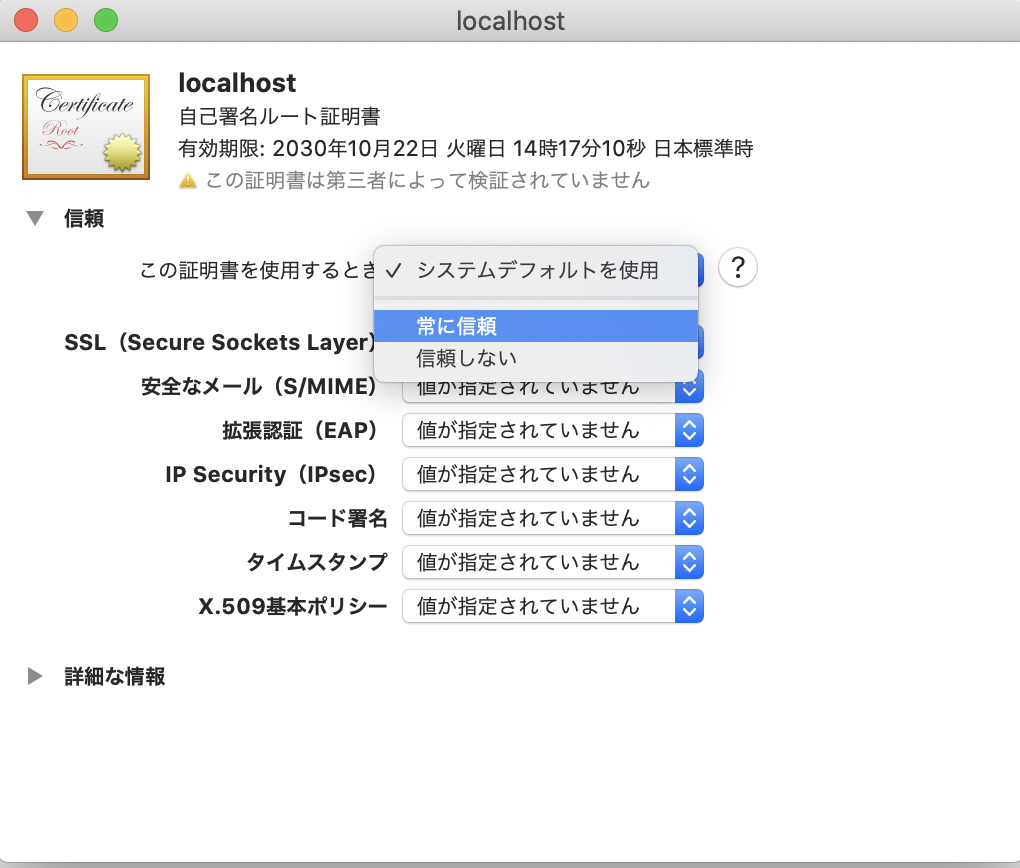
server.crtをダブルクリック
「この証明書を使用するとき」のプルダウンから「常に信頼する」を選択する
最終的にこうなっていればNginxの設定は完了です
fastapi_sample ├── docker │ └── nginx │ ├── conf.d │ │ └── app.conf │ └── ssl │ ├── server.crt │ ├── server.csr │ └── server.key ├── docker-compose.yml ├── main.py └── requirements.txtapp(FastAPI)コンテナの設定
Dockerfile
イメージはubuntu20.04です。
・pyenvでコンテナ内のpythonバージョンをv3.8.5にしている
・apt installで必要なモジュールをインストール(不要なものは削ってもらって構いません)
・pip3 install -r requirements.txtでpythonモジュールをコンテナ内にインストールFROM ubuntu:20.04 ENV DEBIAN_FRONTEND=noninteractive ENV HOME /root ENV PYTHONPATH /fastapi_sample/ ENV PYTHON_VERSION 3.8.5 ENV PYTHON_ROOT $HOME/local/python-$PYTHON_VERSION ENV PATH $PYTHON_ROOT/bin:$PATH ENV PYENV_ROOT $HOME/.pyenv RUN mkdir /fastapi_sample \ && rm -rf /var/lib/apt/lists/* RUN apt update && apt install -y git curl locales python3-pip python3-dev python3-passlib python3-jwt \ libssl-dev libffi-dev zlib1g-dev libpq-dev postgresql RUN echo "ja_JP UTF-8" > /etc/locale.gen \ && locale-gen RUN git clone https://github.com/pyenv/pyenv.git $PYENV_ROOT \ && $PYENV_ROOT/plugins/python-build/install.sh \ && /usr/local/bin/python-build -v $PYTHON_VERSION $PYTHON_ROOT WORKDIR /fastapi_sample ADD . /fastapi_sample/ RUN LC_ALL=ja_JP.UTF-8 \ && pip3 install -r requirements.txtwait-for.it.sh
データベースが立ち上がるのを待ってからappコンテナを起動するようにするためのシェルスクリプトです。
docker-componseに記載しているdepends_onでコンテナの起動順は制御できますが、
データベースが立ち上がっていない場合、appコンテナでエラーが発生することがあります。
(appコンテナ起動時にDB操作をするようなコマンドを実行しようとした場合、データベースが立ち上がっていないためにエラー、とか)fastapi_sample/docker/wait-for-it.sh#!/bin/sh set -e # 引数はdocker-compose.ymlで指定している。 # app: # ... # .. # . # entrypoint: /fastapi_sample/docker/wait-for-it.sh db 5432 postgres postgres db_fastapi_sample # ココ # ... host="$1" shift port="$1" shift user="$1" shift password="$1" shift database="$1" shift cmd="$@" echo "Waiting for postgresql" until pg_isready -h"$host" -U"$user" -p"$port" -d"$database" do echo -n "." sleep 1 done >&2 echo "PostgreSQL is up - executing command" exec $cmdrundevserver.sh
uvicornを起動してアプリケーションを起動するためのシェルスクリプトファイルです。
・docker-compose up時に毎回requirements.txtのモジュールを読み込む
・uvicornでアプリケーションを起動する
・--reloadでホットリロード(pythonファイルを変更すると即反映してくれる)
・--portを8000から変える場合はnginxのapp.conf内の8000も変える必要があるpip3 install -r requirements.txt uvicorn main:app\ --reload\ --port 8000\ --host 0.0.0.0\ --log-level debug最終的なディレクトリ構成
fastapi_sample ├── Dockerfile ├── docker │ ├── nginx │ │ ├── conf.d │ │ │ └── app.conf │ │ └── ssl │ │ ├── server.crt │ │ ├── server.csr │ │ └── server.key │ ├── rundevserver.sh │ └── wait-for-it.sh ├── docker-compose.yml ├── main.py └── requirements.txtコンテナ起動
$ docker-compose up -dこんなエラーが出た場合は、Dockerイメージがディスクを逼迫している可能性があるので、
docker image pruneで不要なイメージを削除してください。(僕はこれで40GB分ディスクに空きができました?). .. ... Get:1 http://security.debian.org/debian-security buster/updates InRelease [65.4 kB] Get:2 http://deb.debian.org/debian buster InRelease [122 kB] Get:3 http://deb.debian.org/debian buster-updates InRelease [49.3 kB] Err:1 http://security.debian.org/debian-security buster/updates InRelease At least one invalid signature was encountered. Err:2 http://deb.debian.org/debian buster InRelease At least one invalid signature was encountered. Err:3 http://deb.debian.org/debian buster-updates InRelease At least one invalid signature was encountered. Reading package lists... W: GPG error: http://security.debian.org/debian-security buster/updates InRelease: At least one invalid signature was encountered. E: The repository 'http://security.debian.org/debian-security buster/updates InRelease' is not signed. W: GPG error: http://deb.debian.org/debian buster InRelease: At least one invalid signature was encountered. E: The repository 'http://deb.debian.org/debian buster InRelease' is not signed. W: GPG error: http://deb.debian.org/debian buster-updates InRelease: At least one invalid signature was encountered. E: The repository 'http://deb.debian.org/debian buster-updates InRelease' is not signed. ... .. .ブラウザからアクセス
コンテナの起動が完了したか確認します。
STATUS列が"Up..."となっていればOKです。$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES b77fa2465fb1 nginx:alpine "/docker-entrypoint.…" About a minute ago Up About a minute 0.0.0.0:80->80/tcp, 0.0.0.0:443->443/tcp nginx_fastapi_sample eb18438efd2c fastapi_sample_app "/fastapi_sample/doc…" About a minute ago Up About a minute 8000/tcp app_fastapi_sample 383b0e46af68 postgres:12.4-alpine "docker-entrypoint.s…" About a minute ago Up About a minute 0.0.0.0:5432->5432/tcp db_fastapi_samplehttps://localhostにアクセスして、
{"message":"Hello World"}が表示されれば完了です。ライブラリ「pydantic」を使用して環境変数(.env)を扱う
.envファイル作成$ touch .envfastapi_sample/.envDEBUG=True DATABASE_URL=postgresql://postgres:postgres@db:5432/db_fastapi_sample「pydatic」を使って環境変数を読み込む設定ファイルを作成
ライブラリ「pydantic」を使うと、.env から値を読み込む処理を簡単に実装できます。
また型に合わせてキャストしてくれたりするので超便利。
os.getenv('DEBUG') == 'True'みたいな気持ち悪い条件式を書かなくてよくなります。(distutils.util.strtobool使えって話ですが、、、)pydanticをインストール
fastapi_sample/requirements.txtpydantic[email]==1.6.1 # 追記したらpip3 installフォルダ「core」を作成、その直下に「config.py」を作成
$ mkdir core $ touch core/config.pyfastapi_sample/core/config.pyimport os from functools import lru_cache from pydantic import BaseSettings PROJECT_ROOT = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) class Environment(BaseSettings): """ 環境変数を読み込むファイル """ debug: bool # .envから読み込んだ値をbool型にキャッシュ database_url: str class Config: env_file = os.path.join(PROJECT_ROOT, '.env') @lru_cache def get_env(): """ 「@lru_cache」でディスクから読み込んだ.envの結果をキャッシュする """ return Environment()alembic(マイグレーションツール)環境の用意 と モデルを用意
何はともあれインストール
requirements.txtに alembic と sqlalchemy 追記してから
pip3 install -r requirements.txtでインストール
(Dockerの手順を踏んでいる人はdocker-compose restart appまたはdocker-compose exec app pip3 install -r requiements.txt)fastapi_samepl/requirements.txtalembic==1.4.2 # 追記 . .. ... psycopg2==2.8.6 # 追記 . .. ... SQLAlchemy==1.3.18 # 追記 SQLAlchemy-Utils==0.36.8 # 追記プロジェクトルート直下にalembic環境を作成する
$ alembic init migrations # Dockerの手順を踏んだ人はdocker-compose exec app alembic init migrationsプロジェクトルートにalembicテンプレートが作成されます。(alembic.ini, migrationsフォルダ)
fastapi_sample(プロジェクトルート) ├── ... ├── .. ├── . ├── alembic.ini ├── migrations │ ├── README │ ├── env.py │ ├── script.py.mako │ └── versions └── ...ベースモデルを用意
modelsフォルダを作成し、まずはベースモデルを実装します。mkdir models touch models/base.pyfastapi_sample/migrations/models/base.pyfrom sqlalchemy import Column from sqlalchemy.dialects.postgresql import INTEGER, TIMESTAMP from sqlalchemy.ext.declarative import declarative_base, declared_attr from sqlalchemy.sql.functions import current_timestamp Base = declarative_base() class BaseModel(Base): """ ベースモデル """ __abstract__ = True id = Column( INTEGER, primary_key=True, autoincrement=True, ) created_at = Column( 'created_at', TIMESTAMP(timezone=True), server_default=current_timestamp(), nullable=False, comment='登録日時', ) updated_at = Column( 'updated_at', TIMESTAMP(timezone=True), onupdate=current_timestamp(), comment='最終更新日時', ) @declared_attr def __mapper_args__(cls): """ デフォルトのオーダリングは主キーの昇順 降順にしたい場合 from sqlalchemy import desc # return {'order_by': desc('id')} """ return {'order_by': 'id'}ユーザーモデルを用意
モデルはなんでもいいですが、認証編を書くときに使えそうなのでユーザーモデルを作成します。
fastapi_sample/migrations/models/user.pyfrom migrations.models.base import BaseModel from sqlalchemy import ( BOOLEAN, VARCHAR, Column, ) class User(BaseModel): __tablename__ = 'users' email = Column(VARCHAR(254), unique=True, nullable=False) password = Column(VARCHAR(128), nullable=False) last_name = Column(VARCHAR(100), nullable=False) first_name = Column(VARCHAR(100), nullable=False) is_admin = Column(BOOLEAN, nullable=False, default=False) is_active = Column(BOOLEAN, nullable=False, default=True)ユーザーモデルがマイグレーション対象にする
__init__.pyを作成touch models/__init__.pyfastapi_sample/migrations/models/__init__.pyfrom migrations.models import user # これだけ追記 # from migrations.models import school # モデルが増えた場合はこのファイルにインポート文を忘れずに追加する # インポート文を大量に書きたくない人は動的インポートをお試しあれ(こっちにする場合は、上のインポート文は消してください) # import importlib # import os # IGNORE_FILE_NAMES = ['__init__.py', '__pycache__'] # MODEL_FILES = os.listdir(os.path.dirname(__file__)) # [ # importlib.import_module( # f'migrations.models.{model_file.replace(".py", "")}', # ) # for model_file in MODEL_FILES # if model_file not in IGNORE_FILE_NAMES # ]env.pyを編集する
fastapi_sample/migrations/env.pyfrom migrations import models # __init__.pyをロード ... .. . target_metadata = models.base.Base.metadata # メタデータをセット ... .. .DBの接続先を変更
モデルを実装したところで、早速マイグレーションを行いたいところです。
が、alembicがプロジェクトテンプレートのままなのでalembic.iniのなかのデータベースURLもテンプレートのままです。fastapi_sample/alembic.ini. .. ... sqlalchemy.url = driver://user:pass@localhost/dbname ... .. .なので勿論alembicのマイグレーションファイル生成コマンドなどは失敗してしまいます。
$ docker-compose exec app alembic revision --autogenerate Traceback (most recent call last): File "/root/local/python-3.8.5/bin/alembic", line 8, in <module> sys.exit(main()) ... (長いので省略) . cls = registry.load(name) File "/root/local/python-3.8.5/lib/python3.8/site-packages/sqlalchemy/util/langhelpers.py", line 267, in load raise exc.NoSuchModuleError( sqlalchemy.exc.NoSuchModuleError: Can't load plugin: sqlalchemy.dialects:driveralembic.iniを直接書き換えるのもいいですが、開発環境やステージング、本番環境でそれぞれ異なるalembic.iniファイルができてしまい気持ち悪いです。
なので、マイグレーションファイル生成時やマイグレート実行時は、alembic.iniのデータベースURLを一時的に.envのDATABASE_URLで書き換えるようにしてみます。
python-dotenvをインストールfastapi_sample/requirements.txtpython-dotenv==0.14.0 # 追記したらインストールする
env.pyを修正fastapi_sample/migrations/env.pyimport os from core.config import PROJECT_ROOT from dotenv import load_dotenv . .. ... # other values from the config, defined by the needs of env.py, # can be acquired: # my_important_option = config.get_main_option("my_important_option") # ... etc. # alembic.iniの'sqlalchemy.url'を.envのDATABASE_URLで書き換える load_dotenv(dotenv_path=os.path.join(PROJECT_ROOT, '.env')) config.set_main_option('sqlalchemy.url', os.getenv('DATABASE_URL')) def run_migrations_offline(): ... .. .再度マイグレーションファイル生成コマンド実行
% docker-compose exec app alembic revision --autogenerate None /fastapi_sample INFO [alembic.runtime.migration] Context impl PostgresqlImpl. INFO [alembic.runtime.migration] Will assume transactional DDL. INFO [alembic.autogenerate.compare] Detected added table 'users' Generating /fastapi_sample/migrations/versions/2bc0a23e563c_.py ... doneマイグレーションファイルを生成できました。
migrations ├── ... ├── ... ├── models └── versions └── 2bc0a23e563c_.py # マイグレーションファイルができた。ただ、今のままだとマイグレーションファイルの生成順がパッと見でわからないのと、マイグレーションファイル内に記載してある生成日時(Create Date)がUTCのままなので日本時間に変えたいです。
alembic.iniを修正します。
fastapi_sample/alembic.ini. .. ... [alembic] # path to migration scripts script_location = migrations # ファイルの接頭に「YYYYMMDD_HHMMSS_」がつくようにする # template used to generate migration files file_template = %%(year)d%%(month).2d%%(day).2d_%%(hour).2d%%(minute).2d%%(second).2d_%%(rev)s_%%(slug)s # タイムゾーンを日本時間に # timezone to use when rendering the date # within the migration file as well as the filename. # string value is passed to dateutil.tz.gettz() # leave blank for localtime timezone = Asia/Tokyo ... .. .先ほど生成したマイグレーションファイルを消して、再度マイグレーションファイルを生成します。
migrations ├── ... ├── ... ├── models └── versions └── 20201024_200033_8a19c4c579bf_.py # ファイル内のCreate Dateも日本時間になっているマイグレート実行
$ alembic upgrade head # Dockerの手順を踏んだ人はdocker-compose exec app alembic upgrade headちゃんとユーザーテーブルが作成されています。
(alembic_versionはalembicがバージョン管理に使用するテーブルで、自動生成されます)
データアクセスクラス作成
ベースのデータアクセスクラスを作成
単純な全件取得や1件取得、登録、更新、削除などを記載します。
base.pyに記載しているget_db_session()は後述するリクエストミドルウェアやテストコード実行時などで大変重要な役割を果たします、今は気にしなくて良いです。mkdir crud touch crud/base.pyfastapi_sample/crud/base.pyfrom core.config import get_env from migrations.models.base import Base from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker, scoped_session, query from typing import List, TypeVar ModelType = TypeVar("ModelType", bound=Base) connection = create_engine( get_env().database_url, echo=get_env().debug, encoding='utf-8', ) Session = scoped_session(sessionmaker(connection)) def get_db_session() -> scoped_session: yield Session class BaseCRUD: """ データアクセスクラスのベース """ model: ModelType = None def __init__(self, db_session: scoped_session) -> None: self.db_session = db_session self.model.query = self.db_session.query_property() def get_query(self) -> query.Query: """ ベースのクエリ取得 """ return self.model.query def gets(self) -> List[ModelType]: """ 全件取得 """ return self.get_query().all() def get_by_id(self, id: int) -> ModelType: """ 主キーで取得 """ return self.get_query().filter_by(id=id).first() def create(self, data: dict = {}) -> ModelType: """ 新規登録 """ obj = self.model() for key, value in data.items(): if hasattr(obj, key): setattr(obj, key, value) self.db_session.add(obj) self.db_session.flush() self.db_session.refresh(obj) return obj def update(self, obj: ModelType, data: dict = {}) -> ModelType: """ 更新 """ for key, value in data.items(): if hasattr(obj, key): setattr(obj, key, value) self.db_session.flush() self.db_session.refresh(obj) return obj def delete_by_id(self, id: int) -> None: """ 主キーで削除 """ obj = self.get_by_id(id) if obj: obj.delete() self.db_session.flush() return Noneユーザーデータアクセスクラスを作成
touch crud/crud_user.pyfastapi_sample/crud/crud_user.pyfrom crud.base import BaseCRUD from migrations.models.user import User class CRUDUser(BaseCRUD): """ ユーザーデータアクセスクラスのベース """ model = UserAPI実装
お待たせしました、ようやくAPI実装編です。
API実装前準備
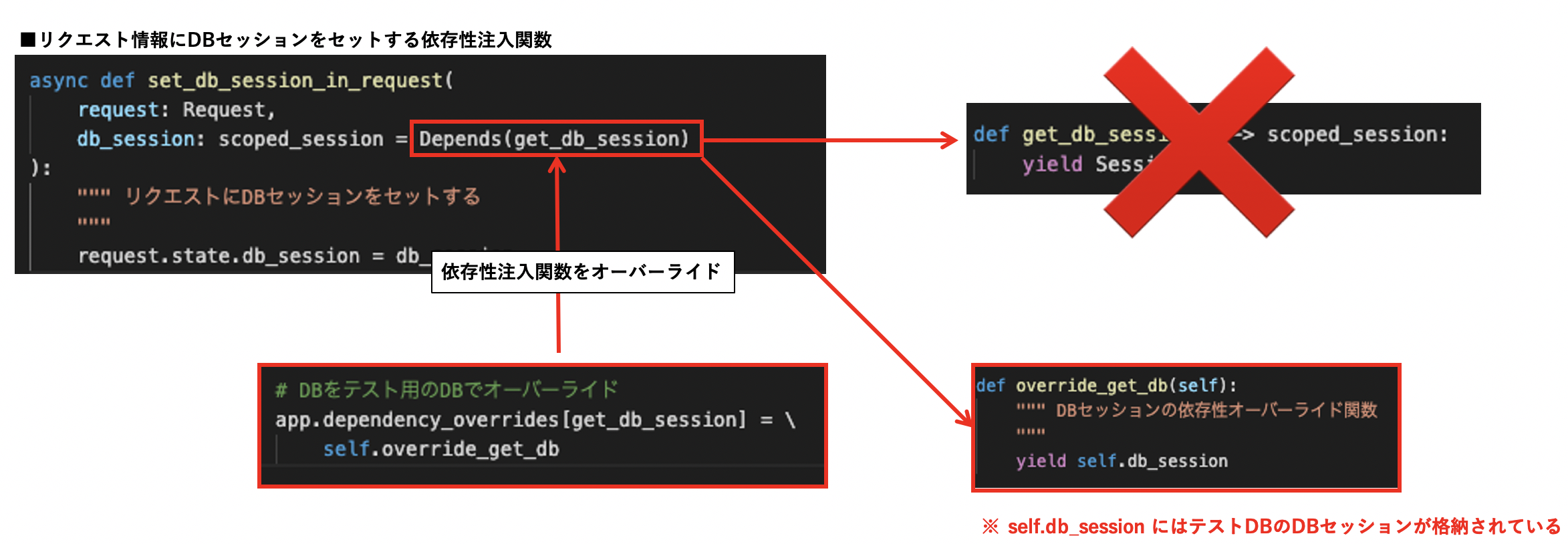
リクエスト情報にDBセッションを格納する依存性注入用(Depends)の関数を実装します。
このFastAPIの依存性注入システムがとても強力で、パラメーターをまとめたりもすることができます。
完全に理解しているわけではないので、申し訳ないのですが詳細は公式ドキュメントを参照してください。mkdir dependencies touch dependencies/__init__.pydependencies/__init__.pyfrom fastapi import Depends, Request from crud.base import get_db_session from sqlalchemy.orm import scoped_session async def set_db_session_in_request( request: Request, db_session: scoped_session = Depends(get_db_session) ): """ リクエストにDBセッションをセットする """ request.state.db_session = db_sessionAPIを実装していくフォルダ作成
mkdir -p api/v1ユーザーの一覧取得API実装
touch api/v1/user.pyfastapi_sample/api/v1/user.pyfrom crud.base import Session from crud.crud_user import CRUDUser from fastapi import Request from fastapi.encoders import jsonable_encoder class UserAPI: """ ユーザーに関するAPI """ @classmethod def gets(cls, request: Request): """ 一覧取得 """ # 依存性注入システムを用いて、リクエスト情報にDBセッションをセットしたので、 # ここで「request.state.db_session」を使用することができる return jsonable_encoder(CRUDUser(request.state.db_session).gets())APIルーター実装
ルーターの
dependencies=[Depends(set_db_session_in_request)]が今後重要な機能を果たしてくれますmkdir -p api/endpoints/v1 touch api/endpoints/v1/user.pyfastapi_sample/api/endpoints/v1/user.pyfrom api.v1.user import UserAPI from dependencies import set_db_session_in_request from fastapi import APIRouter, Depends, Request router = APIRouter() @router.get( '/', dependencies=[Depends(set_db_session_in_request)]) async def gets(request: Request): return UserAPI.gets(request)ルーターをエントリーポイントに登録する
APIルーターを作成
touch api/endpoints/v1/__init__.pyfastapi_sample/api/endpoints/v1/__init__.pyfrom fastapi import APIRouter from api.endpoints.v1 import user api_v1_router = APIRouter() api_v1_router.include_router( user.router, prefix='users', tags=['users'])main.pyを編集
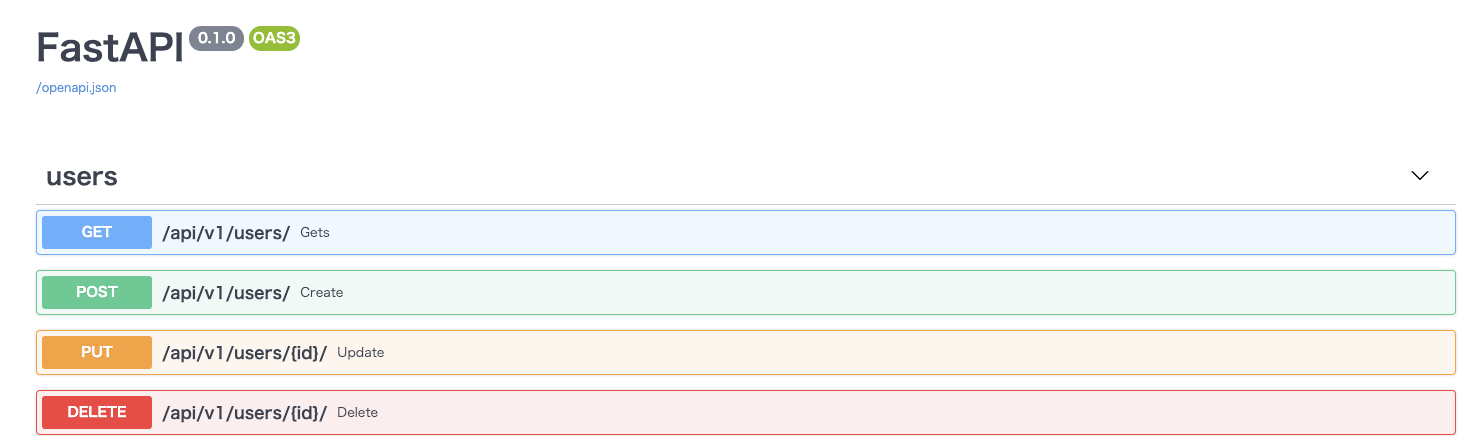
fastapi_sample/main.pyfrom api.endpoints.v1 import api_v1_router # 追記 from fastapi import FastAPI app = FastAPI() app.include_router(api_v1_router, prefix='/api/v1') # 追記 @app.get("/") async def root(): return {"message": "Hello World"}ブラウザからhttps://localhost/docsアクセスすると実装したAPIが表示されているはずです。
登録/更新用にスキーマ(フォーム?)を定義する
mkdir api/schemas touch api/schemas/user.pyfastapi_sample/api/schemas/user.pyfrom pydantic import BaseModel, EmailStr from typing import Optional class BaseUser(BaseModel): email: EmailStr last_name: str first_name: str is_admin: bool class CreateUser(BaseUser): password: str class UpdateUser(BaseUser): password: Optional[str] last_name: Optional[str] first_name: Optional[str] is_admin: bool class UserInDB(BaseUser): class Config: orm_mode = Trueユーザーの登録/更新/削除のAPIを追加
fastapi_sample/api/v1/user.pyfrom api.schemas.user import CreateUser, UpdateUser, UserInDB from crud.crud_user import CRUDUser from fastapi import Request # from fastapi.encoders import jsonable_encoder # 削除 from typing import List class UserAPI: """ ユーザーに関するAPI """ @classmethod def gets(cls, request: Request) -> List[UserInDB]: """ 一覧取得 """ return CRUDUser(request.state.db_session).gets() # jsonable_encoderは使わない @classmethod def create( cls, request: Request, schema: CreateUser ) -> UserInDB: """ 新規登録 """ return CRUDUser(request.state.db_session).create(schema.dict()) @classmethod def update( cls, request: Request, id: int, schema: UpdateUser ) -> UserInDB: """ 更新 """ crud = CRUDUser(request.state.db_session) obj = crud.get_by_id(id) return CRUDUser(request.state.db_session).update(obj, schema.dict()) @classmethod def delete(cls, request: Request, id: int) -> None: """ 削除 """ return CRUDUser(request.state.db_session).delete_by_id(id)ユーザーのAPIルーターを編集
fastapi_sample/api/endpoints/v1/user.pyfrom api.schemas.user import CreateUser, UpdateUser, UserInDB from api.v1.user import UserAPI from dependencies import set_db_session_in_request from fastapi import APIRouter, Depends, Request from typing import List router = APIRouter() @router.get( '/', response_model=List[UserInDB], # response_modelを追加 dependencies=[Depends(set_db_session_in_request)]) def gets(request: Request) -> List[UserInDB]: """ 一覧取得 """ return UserAPI.gets(request) @router.post( '/', response_model=UserInDB, dependencies=[Depends(set_db_session_in_request)]) def create(request: Request, schema: CreateUser) -> UserInDB: """ 新規登録 """ return UserAPI.create(request, schema) @router.put( '/{id}/', response_model=UserInDB, dependencies=[Depends(set_db_session_in_request)]) def update(request: Request, id: int, schema: UpdateUser) -> UserInDB: """ 更新 """ return UserAPI.update(request, id, schema) @router.delete( '/{id}/', dependencies=[Depends(set_db_session_in_request)]) def delete(request: Request, id: int) -> None: """ 削除 """ return UserAPI.delete(request, id)ブラウザからアクセスして確認
CRUDのAPIを無事実装できました。
routerに
response_modelを指定すると、DBから取得したオブジェクトのJSONシリアライズを開発者が明示的に実装する必要がなくなります。(jsonable_encoder()を使わなくて良くなったのはこれのおかげ)
また、swagger-UI上にも反映してくれます。
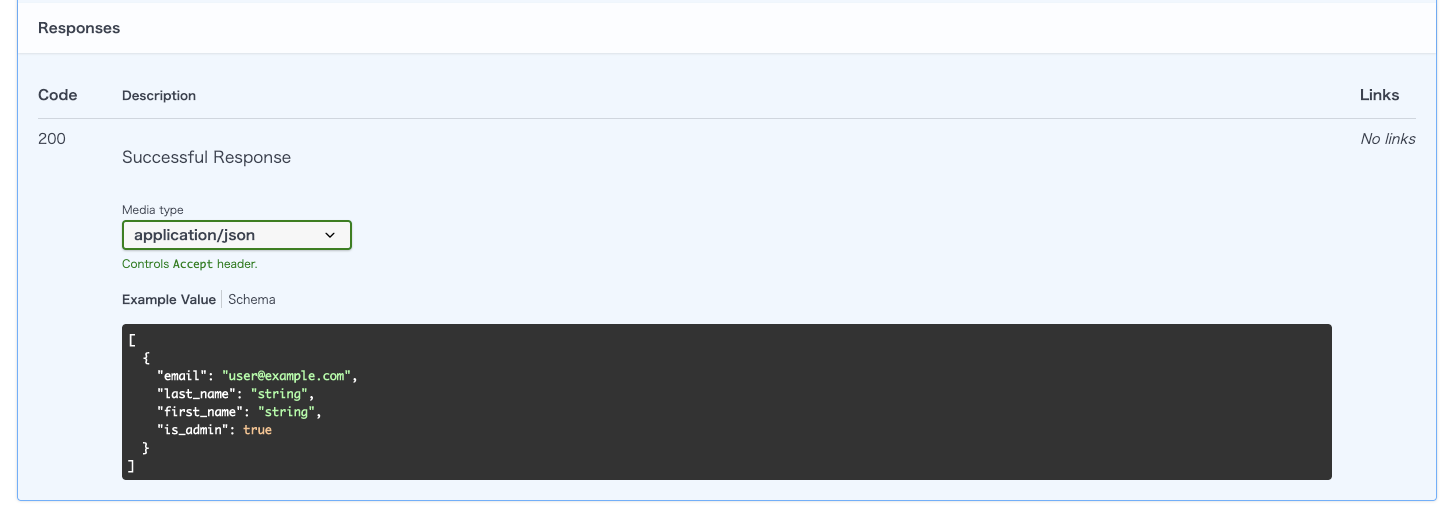
※一覧取得のレスポンス
リクエストミドルウェアを実装する
さて、APIは実行できましたが、DBセッションのコミット実行していないので登録/更新/削除を実行してもDBが変更されません。
変更をDBに反映させるため、以下のようなリクエストミドルウェアを実装して適用します。
・リクエストが完了したらDBセッションコミットしてからDBセッション破棄
・エラー発生時はロールバックしてからDBセッション破棄mkdir middleware touch middleware/__init__.pyfastapi_sample/middleware/__init__.pyfrom fastapi import Request, Response from starlette.middleware.base import BaseHTTPMiddleware class HttpRequestMiddleware(BaseHTTPMiddleware): async def dispatch(self, request: Request, call_next) -> Response: try: response = await call_next(request) # 予期せぬ例外 except Exception as e: print(e) request.state.db_session.rollback() raise e # 正常終了時 else: request.state.db_session.commit() return response # DBセッションの破棄は必ず行う finally: request.state.db_session.remove()エントリーポイントにミドルウェアを適用する
fastapi_sample/main.pyfrom api.endpoints.v1 import api_v1_router from fastapi import FastAPI from middleware import HttpRequestMiddleware # 追加 app = FastAPI() app.include_router(api_v1_router, prefix='/api/v1') # ミドルウェアの設定 app.add_middleware(HttpRequestMiddleware) # 追加 @app.get("/") async def root(): return {"message": "Hello World"}CRUD実行で確認
無事DBに反映されるようになりました。
テストコード実装編
CRUDを実装できたので、次はテストコードを実装していきます。
とはいえ、単純にテストコードからAPIを実行してしまうと、DBに登録・更新・削除が実行されるため、テスト実行ごとに結果が変わってしまう可能性があります。
それを防ぐため、テスト関数ごとにクリーンなDBを作成し、そのDBを使用してテストするようにしたいと思います。pytestをインストール
fastapi_sample/requirements.txtpytest==6.1.0 # 追記したらrequirements.txtをインストールし直すのを忘れずにテスト用のDB接続情報を環境変数に追加
fastapi_sample/.envDEBUG=True DATABASE_URL=postgresql://postgres:postgres@db:5432/db_fastapi_sample TEST_DATABASE_URL=postgresql://postgres:postgres@db:5432/test_db_fastapi_sample # 追加fastapi_sample/core/config.pyclass Environment(BaseSettings): """ 環境変数を読み込むファイル """ debug: bool database_url: str test_database_url: str # 追加テストコード実装用のフォルダ作成
mkdir testsAPIのベーステストクラスを作成
touch tests/base.pyfastapi_sample/tests/base.pyimport psycopg2 from core.config import get_env from crud.base import Base, get_db_session from fastapi.testclient import TestClient from main import app from psycopg2.extensions import ISOLATION_LEVEL_AUTOCOMMIT from sqlalchemy import create_engine from sqlalchemy.orm import scoped_session, sessionmaker from sqlalchemy_utils import database_exists, drop_database test_db_connection = create_engine( get_env().test_database_url, encoding='utf8', pool_pre_ping=True, ) class BaseTestCase: def setup_method(self, method): """ 前処理 """ # テストDB作成 self.__create_test_database() self.db_session = self.get_test_db_session() # APIクライアントの設定 self.client = TestClient(app, base_url='https://localhost',) # DBをテスト用のDBでオーバーライド app.dependency_overrides[get_db_session] = \ self.override_get_db def teardown_method(self, method): """ 後処理 """ # テストDB削除 self.__drop_test_database() # オーバーライドしたDBを元に戻す app.dependency_overrides[self.override_get_db] = \ get_db_session def override_get_db(self): """ DBセッションの依存性オーバーライド関数 """ yield self.db_session def get_test_db_session(self): """ テストDBセッションを返す """ return scoped_session(sessionmaker(bind=test_db_connection)) def __create_test_database(self): """ テストDB作成 """ # テストDBが削除されずに残ってしまっている場合は削除 if database_exists(get_env().test_database_url): drop_database(get_env().test_database_url) # テストDB作成 _con = \ psycopg2.connect('host=db user=postgres password=postgres') _con.set_isolation_level(ISOLATION_LEVEL_AUTOCOMMIT) _cursor = _con.cursor() _cursor.execute('CREATE DATABASE test_db_fastapi_sample') # テストDBにExtension追加 _test_db_con = psycopg2.connect( 'host=db dbname=test_db_fastapi_sample user=postgres password=postgres' ) _test_db_con.set_isolation_level(ISOLATION_LEVEL_AUTOCOMMIT) # テストDBにテーブル追加 Base.metadata.create_all(bind=test_db_connection) def __drop_test_database(self): """ テストDB削除 """ drop_database(get_env().test_database_url)ポイントはこのDBオーバーライド部分です。
アプリケーションが参照するDBをテストDBに切り替えています。# DBをテスト用のDBでオーバーライド app.dependency_overrides[get_db_session] = self.override_get_db
こうすることで、APIやミドルウェアで使用している「request.state.db_session」もテストDBに切り替えることができます。
一覧取得のテストコードを実装してみる
requirements.txtrequests==2.24.0 # 追記したら必ずrequirements.txtをインストールmkdir -p tests/api/v1 touch tests/api/v1/test_user.py # "test_"を接頭に付けないとpytest実行時にスルーされてしまうので必ずつけるfastapi_sample/tests/api/v1/test_user.pyimport json from crud.crud_user import CRUDUser from fastapi import status from tests.base import BaseTestCase class TestUserAPI(BaseTestCase): """ ユーザーAPIのテストクラス """ TEST_URL = '/api/v1/users/' def test_gets(self): """ 一覧取得のテスト """ # テストユーザー登録 test_data = [ { 'email': 'test1@example.com', 'password': 'password', 'last_name': 'last_name', 'first_name': 'first_name', 'is_admin': False }, { 'email': 'test2@example.com', 'password': 'password', 'last_name': 'last_name', 'first_name': 'first_name', 'is_admin': True }, { 'email': 'test3@example.com', 'password': 'password', 'last_name': 'last_name', 'first_name': 'first_name', 'is_admin': False }, ] for data in test_data: CRUDUser(self.db_session).create(data) self.db_session.commit() response = self.client.get(self.TEST_URL) # ステータスコードの検証 assert response.status_code == status.HTTP_200_OK # 取得した件数の検証 response_data = json.loads(response._content) assert len(response_data) == len(test_data) # レスポンスの内容を検証 expected_data = [{ 'email': item['email'], 'last_name': item['last_name'], 'first_name': item['first_name'], 'is_admin': item['is_admin'], } for i, item in enumerate(test_data, 1)] assert response_data == expected_dataテスト実行
pytest # Dockerの手順を踏んだ方は、docker-compose exec app pytest # print()文の出力を確認したい場合は、pytest -v --capture=no% docker-compose exec app pytest -v --capture=no ================================================================================================== test session starts =================================================================================================== platform linux -- Python 3.8.5, pytest-6.1.0, py-1.9.0, pluggy-0.13.1 -- /root/local/python-3.8.5/bin/python3.8 cachedir: .pytest_cache rootdir: /fastapi_sample collected 1 item tests/api/v1/test_user.py::TestUserAPI::test_gets PASSED # 成功 ==================================================================================================== warnings summary ==================================================================================================== <string>:2 <string>:2: SADeprecationWarning: The mapper.order_by parameter is deprecated, and will be removed in a future release. Use Query.order_by() to determine the ordering of a result set. -- Docs: https://docs.pytest.org/en/stable/warnings.htmlテストも無事成功しました。
データベースを確認してみましょう。
API実装時に試しに登録したデータしかありません。
テスト用のDBに切り替えてのテスト実行は成功したようです!
ローカルDBを汚さず、かつ テストケースごとのテストデータも干渉することなくテストコードを実行することができるようになりました。
やったね。リクエストミドルウェア実装後、swagger-UI表示時「Internal Server Error」になる
swagger-UI表示時、「request.state」に「db_session」が存在しないため、Key Errorで「Internal Server Error」となります。
手取り早く直したい場合
リクエストミドルウェアの「request.state.db_session」を以下のように書き換えます。
fastapi_sample/middleware/__init__.pyfrom crud.base import Session # 追加 from fastapi import Request, Response from starlette.middleware.base import BaseHTTPMiddleware class HttpRequestMiddleware(BaseHTTPMiddleware): async def dispatch(self, request: Request, call_next) -> Response: try: response = await call_next(request) # 予期せぬ例外 except Exception as e: print(e) getattr(request.state, 'db_session', Session).rollback() # これに書き換え raise e # 正常終了時 else: getattr(request.state, 'db_session', Session).commit() # これに書き換え return response # DBセッションの破棄は必ず行う finally: getattr(request.state, 'db_session', Session).remove() # これに書き換えリクエストミドルウェアは触りたくない場合
swagger-uiで表示するエンドポイントを全てオーバーライドするしかありません。
FastAPIクラスをオーバーライド
touch core/fastapi.pyfastapi_sample/core/fastapi.pyimport fastapi from fastapi import Request from fastapi.exceptions import RequestValidationError from fastapi.exception_handlers import ( http_exception_handler, request_validation_exception_handler, ) from fastapi.openapi.docs import ( get_redoc_html, get_swagger_ui_html, get_swagger_ui_oauth2_redirect_html, ) from fastapi.responses import JSONResponse, HTMLResponse from starlette.exceptions import HTTPException class FastAPI(fastapi.FastAPI): def setup(self) -> None: if self.openapi_url: urls = (server_data.get("url") for server_data in self.servers) server_urls = {url for url in urls if url} async def openapi(req: Request) -> JSONResponse: root_path = req.scope.get("root_path", "").rstrip("/") if root_path not in server_urls: if root_path and self.root_path_in_servers: self.servers.insert(0, {"url": root_path}) server_urls.add(root_path) return JSONResponse(self.openapi(self, req)) # 書き換えているのはこの部分だけ self.add_route(self.openapi_url, openapi, include_in_schema=False) if self.openapi_url and self.docs_url: async def swagger_ui_html(req: Request) -> HTMLResponse: root_path = req.scope.get("root_path", "").rstrip("/") openapi_url = root_path + self.openapi_url oauth2_redirect_url = self.swagger_ui_oauth2_redirect_url if oauth2_redirect_url: oauth2_redirect_url = root_path + oauth2_redirect_url return get_swagger_ui_html( openapi_url=openapi_url, title=self.title + " - Swagger UI", oauth2_redirect_url=oauth2_redirect_url, init_oauth=self.swagger_ui_init_oauth, ) self.add_route( self.docs_url, swagger_ui_html, include_in_schema=False ) if self.swagger_ui_oauth2_redirect_url: async def swagger_ui_redirect(req: Request) -> HTMLResponse: return get_swagger_ui_oauth2_redirect_html() self.add_route( self.swagger_ui_oauth2_redirect_url, swagger_ui_redirect, include_in_schema=False, ) if self.openapi_url and self.redoc_url: async def redoc_html(req: Request) -> HTMLResponse: root_path = req.scope.get("root_path", "").rstrip("/") openapi_url = root_path + self.openapi_url return get_redoc_html( openapi_url=openapi_url, title=self.title + " - ReDoc" ) self.add_route(self.redoc_url, redoc_html, include_in_schema=False) self.add_exception_handler(HTTPException, http_exception_handler) self.add_exception_handler( RequestValidationError, request_validation_exception_handler )swagger-ui用のルーターを用意
touch api/endpoints/swagger_ui.pyfastapi_sample/api/endpoints/swagger_ui.pyfrom core.fastapi import FastAPI from crud.base import Session from dependencies import set_db_session_in_request from fastapi import APIRouter, Depends, Request from fastapi.openapi.docs import get_redoc_html, get_swagger_ui_html from fastapi.openapi.utils import get_openapi swagger_ui_router = APIRouter() @swagger_ui_router.get( '/docs', include_in_schema=False, dependencies=[Depends(set_db_session_in_request)]) async def swagger_ui_html(request: Request): return get_swagger_ui_html( openapi_url=FastAPI().openapi_url, title=FastAPI().title, oauth2_redirect_url=FastAPI().swagger_ui_oauth2_redirect_url, ) @swagger_ui_router.get( '/redoc', include_in_schema=False, dependencies=[Depends(set_db_session_in_request)]) async def redoc_html(request: Request): return get_redoc_html( openapi_url=FastAPI().openapi_url, title=FastAPI().title + " - ReDoc", ) def openapi(app: FastAPI, request: Request): request.state.db_session = Session if app.openapi_schema: return app.openapi_schema openapi_schema = get_openapi( title="FastAPI", version="0.1.0", routes=app.routes, ) app.openapi_schema = openapi_schema return app.openapi_schemaエントリーポイント修正
fastapi_sample/main.pyfrom api.endpoints.swagger_ui import openapi, swagger_ui_router from api.endpoints.v1 import api_v1_router from core.config import get_env # from fastapi import FastAPI from core.fastapi import FastAPI # オーバーライドしたFastAPIクラスを使用する from middleware import HttpRequestMiddleware app = FastAPI( docs_url=None, # Noneを設定しないとswagger-uiのルーターで定義したものに変わらない redoc_url=None, # Noneを設定しないとswagger-uiのルーターで定義したものに変わらない ) app.include_router(api_v1_router, prefix='/api/v1') # ミドルウェアの設定 app.add_middleware(HttpRequestMiddleware) # @app.get("/") # async def root(): # return {"message": "Hello World"} # swagger-uiは開発時のみ表示されるようにする if get_env().debug: app.include_router(swagger_ui_router) app.openapi = openapi無事swagger-uiのエラーが解消され、表示されるようになりました。
終わり
FastAPIでCRUDを実装してみました。
フルスタックフレームワークのDjango(RestはDRF)ばかり使っていたせいで、初め「なんだこの使いづらいフレームワークは・・・」とか思っていましたが、今ではもうDjangoよりFastAPI派になってしまいました。
ガシガシ環境周りのコードを自分で実装できて楽しいですし、何より成長に繋がりました。
公式ドキュメントを読みきれていないので、他にもいい方法はあるかと思いますので、
コメントでこっそり教えてもらえると嬉しいです( ´ノω`)
私が所属しているFabeee株式会社はお仕事 と 一緒に働くお仲間を随時募集しております!!!!(宣伝)




- 投稿日:2020-10-24T23:32:09+09:00
FastAPI + SQLAlchemy(postgresql)でCRUD APIを実装してみた(Dockerやミドルウェア, テストコードなども含む)
アーキテクチャ
python: v3.8.5 postgresql: v12.4 fastapi: v0.60.2 SQLAlchemy: v1.3.18マイグレーションツール
alembic: v1.4.2FastAPIとは
詳細は既にQiitaにチョコチョコ記事あるので割愛します。
ドキュメントが豊富(読みきれてない)で、Swaggerと互換性あるのがとても素晴らしいです。
(パフォーマンスも良いらしいがベンチマーク測ったことないので断言できない、でも多分速い。)
しっかり触ったことのあるフレームワークはDjangoだけなのでミドルウェアやテストコード周り苦労した・・・。
(Djangoはフルスタックフレームワークで、勝手にいろいろやってくれるからミドルウェアとかテストの実装環境とかあまり気にしたことない)Python3.8.5の仮装環境作成
pyenv, virtualenvが入ってない場合は下記を参考に入れてください。
・Mac
・Windows$ pyenv virtualenv 3.8.5 env_fastapi_sample仮装環境を適用
プロジェクトルートを作成
$ mkdir fastapi_sampleプロジェクトルートにcd
$ cd fastapi_sample仮装環境を適用
$ pyenv local env_fastapi_samplerequirements.txt作成/インストール
$ touch requirements.txtrequirements.txtにfastapiを追記
fastapi_sample/requirements.txtfastapi==0.60.2 uvicorn==0.11.8仮装環境にインストール
$ pip3 install -r requirements.txtエントリーポイント(main.py)を作成して、Swagger-UIを表示してみる
エントリーポイント(main.py)作成
$ touch main.pymain.pyを編集
fastapi_sample/main.pyfrom fastapi import FastAPI app = FastAPI() @app.get("/") async def root(): return {"message": "Hello World"}Swagger-UI表示
$ uvicorn main:app --reloadブラウザから「http://127.0.0.1:8000」にアクセスして
{"message":"Hello World"}が表示されていれば完了です。Docker化
Nginxのリバースプロキシによってアプリケーションをhttpsで公開するようにします。
ベースのdocker-compose.yml
fastapi_sample/docker-compose.ymlversion: '3' services: # Nginxコンテナ nginx: container_name: nginx_fastapi_sample image: nginx:alpine depends_on: - app - db environment: TZ: "Asia/Tokyo" ports: - "80:80" - "443:443" volumes: - ./docker/nginx/conf.d:/etc/nginx/conf.d - ./docker/nginx/ssl:/etc/nginx/ssl # アプリケーションコンテナ app: build: context: . dockerfile: Dockerfile container_name: app_fastapi_sample volumes: - '.:/fastapi_sample/' environment: - LC_ALL=ja_JP.UTF-8 expose: - 8000 depends_on: - db entrypoint: /fastapi_sample/docker/wait-for-it.sh db 5432 postgres postgres db_fastapi_sample command: bash /fastapi_sample/docker/rundevserver.sh restart: always tty: true # DBコンテナ db: image: postgres:12.4-alpine container_name: db_fastapi_sample environment: - POSTGRES_USER=postgres - POSTGRES_PASSWORD=postgres - POSTGRES_DB=db_fastapi_sample - POSTGRES_INITDB_ARGS=--encoding=UTF-8 --locale=C volumes: - db_data:/var/lib/postgresql/data ports: - '5432:5432' volumes: db_data: driver: localNginxコンテナの設定
confファイルを用意する
$ mkdir -p nginx/conf.d $ touch nginx/conf.d/app.conffastapi_sample/docker/nginx/conf.d/app.confupstream backend { server app:8000; # appはdocker-compose.ymlの「app」 } # 80番ポートへのアクセスは443番ポートへのアクセスに強制する server { listen 80; return 301 https://$host$request_uri; } server { listen 443 ssl; ssl_certificate /etc/nginx/ssl/server.crt; ssl_certificate_key /etc/nginx/ssl/server.key; ssl_protocols TLSv1.2 TLSv1.3; location / { proxy_set_header Host $http_host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-Host $http_host; proxy_set_header X-Forwarded-Server $http_host; proxy_set_header X-Forwarded-Server $host; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; proxy_redirect http:// https://; proxy_pass http://backend; } # ログを出力したい場合はコメントアウト外してください # access_log /var/log/nginx/access.log; # error_log /var/log/nginx/error.log; } server_tokens off;NginxのSSL化に必要なファイルを用意
$ mkdir -p nginx/conf.d nginx/sslOpenSSLを使って秘密鍵(server.key)を生成する
# ディレクトリ移動 $ cd nginx/conf.d # 秘密鍵生成 $ openssl genrsa 2024 > server.key # 確認 $ ls -ll total 8 -rw-r--r-- 1 user staff 1647 10 24 13:23 server.key証明書署名要求(server.csr)を生成
$ openssl req -new -key server.key > server.csr$ openssl req -new -key server.key > server.csr ... .. . Country Name (2 letter code) [AU]:JP # 国を示す2文字のISO略語 State or Province Name (full name) [Some-State]:Tokyo # 会社が置かれている都道府県 Locality Name (eg, city) []:Chiyodaku # 会社が置かれている市区町村 Organization Name (eg, company) [Internet Widgits Pty Ltd]:fabeee # 会社名 Organizational Unit Name (eg, section) []:- # 部署名(ハイフンにしました。) Common Name (e.g. server FQDN or YOUR name) []:localhost(ウェブサーバのFQDN。一応localhostにした) Email Address []: # 未入力でエンター Please enter the following 'extra' attributes to be sent with your certificate request A challenge password []: # 未入力でエンター An optional company name []: # 未入力でエンター ... .. . $ ls -ll total 16 -rw-r--r-- 1 user staff 980 10 24 13:27 server.csr # 証明書署名要求ができた -rw-r--r-- 1 user staff 1647 10 24 13:23 server.keyサーバ証明書(server.crt)を生成
openssl x509 -req -days 3650 -signkey server.key < server.csr > server.crt % ls -ll total 24 -rw-r--r-- 1 tabata staff 1115 10 24 13:40 server.crt # サーバ証明書ができた -rw-r--r-- 1 tabata staff 948 10 24 13:29 server.csr -rw-r--r-- 1 tabata staff 1647 10 24 13:23 server.keyサーバ証明書を信頼する
server.crtをダブルクリック
「この証明書を使用するとき」のプルダウンから「常に信頼する」を選択する
最終的にこうなっていればNginxの設定は完了です
fastapi_sample ├── docker │ └── nginx │ ├── conf.d │ │ └── app.conf │ └── ssl │ ├── server.crt │ ├── server.csr │ └── server.key ├── docker-compose.yml ├── main.py └── requirements.txtapp(FastAPI)コンテナの設定
Dockerfile
イメージはubuntu20.04です。
・pyenvでコンテナ内のpythonバージョンをv3.8.5にしている
・apt installで必要なモジュールをインストール(不要なものは削ってもらって構いません)
・pip3 install -r requirements.txtでpythonモジュールをコンテナ内にインストールFROM ubuntu:20.04 ENV DEBIAN_FRONTEND=noninteractive ENV HOME /root ENV PYTHONPATH /fastapi_sample/ ENV PYTHON_VERSION 3.8.5 ENV PYTHON_ROOT $HOME/local/python-$PYTHON_VERSION ENV PATH $PYTHON_ROOT/bin:$PATH ENV PYENV_ROOT $HOME/.pyenv RUN mkdir /fastapi_sample \ && rm -rf /var/lib/apt/lists/* RUN apt update && apt install -y git curl locales python3-pip python3-dev python3-passlib python3-jwt \ libssl-dev libffi-dev zlib1g-dev libpq-dev postgresql RUN echo "ja_JP UTF-8" > /etc/locale.gen \ && locale-gen RUN git clone https://github.com/pyenv/pyenv.git $PYENV_ROOT \ && $PYENV_ROOT/plugins/python-build/install.sh \ && /usr/local/bin/python-build -v $PYTHON_VERSION $PYTHON_ROOT WORKDIR /fastapi_sample ADD . /fastapi_sample/ RUN LC_ALL=ja_JP.UTF-8 \ && pip3 install -r requirements.txtwait-for-it.sh
データベースが立ち上がるのを待ってからappコンテナを起動するようにするためのシェルスクリプトです。
docker-componseに記載しているdepends_onでコンテナの起動順は制御できますが、
データベースが立ち上がっていない場合、appコンテナでエラーが発生することがあります。
(appコンテナ起動時にDB操作をするようなコマンドを実行しようとした場合、データベースが立ち上がっていないためにエラー、とか)fastapi_sample/docker/wait-for-it.sh#!/bin/sh set -e # 引数はdocker-compose.ymlで指定している。 # app: # ... # .. # . # entrypoint: /fastapi_sample/docker/wait-for-it.sh db 5432 postgres postgres db_fastapi_sample # ココ # ... host="$1" shift port="$1" shift user="$1" shift password="$1" shift database="$1" shift cmd="$@" echo "Waiting for postgresql" until pg_isready -h"$host" -U"$user" -p"$port" -d"$database" do echo -n "." sleep 1 done >&2 echo "PostgreSQL is up - executing command" exec $cmd # 僕は優しいのでMySQL用も書いてあげるのだ #!/bin/sh # set -e # host="$1" # shift # user="$1" # shift # password="$1" # shift # cmd="$@" # echo "Waiting for mysql" # until mysqladmin ping -h "$host" --silent # do # echo -n "." # sleep 1 # done # >&2 echo "MySQL is up - executing command" # exec $cmdrundevserver.sh
uvicornを起動してアプリケーションを起動するためのシェルスクリプトファイルです。
・docker-compose up時に毎回requirements.txtのモジュールを読み込む
・uvicornでアプリケーションを起動する
・--reloadでホットリロード(pythonファイルを変更すると即反映してくれる)
・--portを8000から変える場合はnginxのapp.conf内の8000も変える必要があるpip3 install -r requirements.txt uvicorn main:app\ --reload\ --port 8000\ --host 0.0.0.0\ --log-level debug最終的なディレクトリ構成
fastapi_sample ├── Dockerfile ├── docker │ ├── nginx │ │ ├── conf.d │ │ │ └── app.conf │ │ └── ssl │ │ ├── server.crt │ │ ├── server.csr │ │ └── server.key │ ├── rundevserver.sh │ └── wait-for-it.sh ├── docker-compose.yml ├── main.py └── requirements.txtコンテナ起動
$ docker-compose up -dこんなエラーが出た場合は、Dockerイメージがディスクを逼迫している可能性があるので、
docker image pruneで不要なイメージを削除してください。(僕はこれで40GB分ディスクに空きができました?). .. ... Get:1 http://security.debian.org/debian-security buster/updates InRelease [65.4 kB] Get:2 http://deb.debian.org/debian buster InRelease [122 kB] Get:3 http://deb.debian.org/debian buster-updates InRelease [49.3 kB] Err:1 http://security.debian.org/debian-security buster/updates InRelease At least one invalid signature was encountered. Err:2 http://deb.debian.org/debian buster InRelease At least one invalid signature was encountered. Err:3 http://deb.debian.org/debian buster-updates InRelease At least one invalid signature was encountered. Reading package lists... W: GPG error: http://security.debian.org/debian-security buster/updates InRelease: At least one invalid signature was encountered. E: The repository 'http://security.debian.org/debian-security buster/updates InRelease' is not signed. W: GPG error: http://deb.debian.org/debian buster InRelease: At least one invalid signature was encountered. E: The repository 'http://deb.debian.org/debian buster InRelease' is not signed. W: GPG error: http://deb.debian.org/debian buster-updates InRelease: At least one invalid signature was encountered. E: The repository 'http://deb.debian.org/debian buster-updates InRelease' is not signed. ... .. .ブラウザからアクセス
コンテナの起動が完了したか確認します。
STATUS列が"Up..."となっていればOKです。$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES b77fa2465fb1 nginx:alpine "/docker-entrypoint.…" About a minute ago Up About a minute 0.0.0.0:80->80/tcp, 0.0.0.0:443->443/tcp nginx_fastapi_sample eb18438efd2c fastapi_sample_app "/fastapi_sample/doc…" About a minute ago Up About a minute 8000/tcp app_fastapi_sample 383b0e46af68 postgres:12.4-alpine "docker-entrypoint.s…" About a minute ago Up About a minute 0.0.0.0:5432->5432/tcp db_fastapi_samplehttps://localhostにアクセスして、
{"message":"Hello World"}が表示されれば完了です。ライブラリ「pydantic」を使用して環境変数(.env)を扱う
.envファイル作成$ touch .envfastapi_sample/.envDEBUG=True DATABASE_URL=postgresql://postgres:postgres@db:5432/db_fastapi_sample「pydatic」を使って環境変数を読み込む設定ファイルを作成
ライブラリ「pydantic」を使うと、.env から値を読み込む処理を簡単に実装できます。
また型に合わせてキャストしてくれたりするので超便利。
os.getenv('DEBUG') == 'True'みたいな気持ち悪い条件式を書かなくてよくなります。(distutils.util.strtobool使えって話ですが、、、)pydanticをインストール
fastapi_sample/requirements.txtpydantic[email]==1.6.1 # 追記したらpip3 installフォルダ「core」を作成、その直下に「config.py」を作成
$ mkdir core $ touch core/config.pyfastapi_sample/core/config.pyimport os from functools import lru_cache from pydantic import BaseSettings PROJECT_ROOT = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) class Environment(BaseSettings): """ 環境変数を読み込むファイル """ debug: bool # .envから読み込んだ値をbool型にキャッシュ database_url: str class Config: env_file = os.path.join(PROJECT_ROOT, '.env') @lru_cache def get_env(): """ 「@lru_cache」でディスクから読み込んだ.envの結果をキャッシュする """ return Environment()alembic(マイグレーションツール)環境の用意 と モデルを用意
何はともあれインストール
requirements.txtに alembic と sqlalchemy 追記してから
pip3 install -r requirements.txtでインストール
(Dockerの手順を踏んでいる人はdocker-compose restart appまたはdocker-compose exec app pip3 install -r requiements.txt)fastapi_samepl/requirements.txtalembic==1.4.2 # 追記 . .. ... psycopg2==2.8.6 # 追記 . .. ... SQLAlchemy==1.3.18 # 追記 SQLAlchemy-Utils==0.36.8 # 追記プロジェクトルート直下にalembic環境を作成する
$ alembic init migrations # Dockerの手順を踏んだ人はdocker-compose exec app alembic init migrationsプロジェクトルートにalembicテンプレートが作成されます。(alembic.ini, migrationsフォルダ)
fastapi_sample(プロジェクトルート) ├── ... ├── .. ├── . ├── alembic.ini ├── migrations │ ├── README │ ├── env.py │ ├── script.py.mako │ └── versions └── ...ベースモデルを用意
まずはベースモデルを実装します。
touch models.pyfastapi_sample/migrations/models.pyfrom sqlalchemy import Column from sqlalchemy.dialects.postgresql import INTEGER, TIMESTAMP from sqlalchemy.ext.declarative import declarative_base, declared_attr from sqlalchemy.sql.functions import current_timestamp Base = declarative_base() class BaseModel(Base): """ ベースモデル """ __abstract__ = True id = Column( INTEGER, primary_key=True, autoincrement=True, ) created_at = Column( 'created_at', TIMESTAMP(timezone=True), server_default=current_timestamp(), nullable=False, comment='登録日時', ) updated_at = Column( 'updated_at', TIMESTAMP(timezone=True), onupdate=current_timestamp(), comment='最終更新日時', ) @declared_attr def __mapper_args__(cls): """ デフォルトのオーダリングは主キーの昇順 降順にしたい場合 from sqlalchemy import desc # return {'order_by': desc('id')} """ return {'order_by': 'id'}ユーザーモデルを用意
モデルはなんでもいいですが、認証編を書くときに使えそうなのでユーザーモデルを作成します。
モジュール分割はあえてしていません。(マイグレーションファイル生成時などで不都合発生して手間なので、しない方がいいかも?)fastapi_sample/migrations/models.pyfrom sqlalchemy import ( BOOLEAN, # 追加 Column INTEGER, TIMESTAMP, VARCHAR, # 追加 ) from sqlalchemy.ext.declarative import declarative_base, declared_attr from sqlalchemy.sql.functions import current_timestamp Base = declarative_base() class BaseModel(Base): ... .. . class User(BaseModel): __tablename__ = 'users' email = Column(VARCHAR(254), unique=True, nullable=False) password = Column(VARCHAR(128), nullable=False) last_name = Column(VARCHAR(100), nullable=False) first_name = Column(VARCHAR(100), nullable=False) is_admin = Column(BOOLEAN, nullable=False, default=False) is_active = Column(BOOLEAN, nullable=False, default=True)env.pyを編集する
fastapi_sample/migrations/env.pyfrom migrations.models import Base # 追加 ... .. . target_metadata = Base.metadata # メタデータをセット ... .. .DBの接続先を変更
モデルを実装したところで、早速マイグレーションを行いたいところです。
が、alembicがプロジェクトテンプレートのままなのでalembic.iniのなかのデータベースURLもテンプレートのままです。fastapi_sample/alembic.ini. .. ... sqlalchemy.url = driver://user:pass@localhost/dbname ... .. .なので勿論alembicのマイグレーションファイル生成コマンドなどは失敗してしまいます。
$ docker-compose exec app alembic revision --autogenerate Traceback (most recent call last): File "/root/local/python-3.8.5/bin/alembic", line 8, in <module> sys.exit(main()) ... (長いので省略) . cls = registry.load(name) File "/root/local/python-3.8.5/lib/python3.8/site-packages/sqlalchemy/util/langhelpers.py", line 267, in load raise exc.NoSuchModuleError( sqlalchemy.exc.NoSuchModuleError: Can't load plugin: sqlalchemy.dialects:driveralembic.iniを直接書き換えるのもいいですが、開発環境やステージング、本番環境でそれぞれ異なるalembic.iniファイルができてしまい気持ち悪いです。
なので、マイグレーションファイル生成時やマイグレート実行時は、alembic.iniのデータベースURLを一時的に.envのDATABASE_URLで書き換えるようにしてみます。
python-dotenvをインストールfastapi_sample/requirements.txtpython-dotenv==0.14.0 # 追記したらインストールする
env.pyを修正fastapi_sample/migrations/env.pyimport os from core.config import PROJECT_ROOT from dotenv import load_dotenv . .. ... # other values from the config, defined by the needs of env.py, # can be acquired: # my_important_option = config.get_main_option("my_important_option") # ... etc. # alembic.iniの'sqlalchemy.url'を.envのDATABASE_URLで書き換える load_dotenv(dotenv_path=os.path.join(PROJECT_ROOT, '.env')) config.set_main_option('sqlalchemy.url', os.getenv('DATABASE_URL')) def run_migrations_offline(): ... .. .再度マイグレーションファイル生成コマンド実行
% docker-compose exec app alembic revision --autogenerate None /fastapi_sample INFO [alembic.runtime.migration] Context impl PostgresqlImpl. INFO [alembic.runtime.migration] Will assume transactional DDL. INFO [alembic.autogenerate.compare] Detected added table 'users' Generating /fastapi_sample/migrations/versions/2bc0a23e563c_.py ... doneマイグレーションファイルを生成できました。
migrations ├── ... ├── ... ├── models.py └── versions └── 2bc0a23e563c_.py # マイグレーションファイルができた。ただ、今のままだとマイグレーションファイルの生成順がパッと見でわからないのと、マイグレーションファイル内に記載してある生成日時(Create Date)がUTCのままなので日本時間に変えたいです。
alembic.iniを修正します。
fastapi_sample/alembic.ini. .. ... [alembic] # path to migration scripts script_location = migrations # ファイルの接頭に「YYYYMMDD_HHMMSS_」がつくようにする # template used to generate migration files file_template = %%(year)d%%(month).2d%%(day).2d_%%(hour).2d%%(minute).2d%%(second).2d_%%(rev)s_%%(slug)s # タイムゾーンを日本時間に # timezone to use when rendering the date # within the migration file as well as the filename. # string value is passed to dateutil.tz.gettz() # leave blank for localtime timezone = Asia/Tokyo ... .. .先ほど生成したマイグレーションファイルを消して、再度マイグレーションファイルを生成します。
migrations ├── ... ├── ... ├── models.py └── versions └── 20201024_200033_8a19c4c579bf_.py # ファイル内のCreate Dateも日本時間になっているマイグレート実行
$ alembic upgrade head # Dockerの手順を踏んだ人はdocker-compose exec app alembic upgrade headちゃんとユーザーテーブルが作成されています。
(alembic_versionはalembicがバージョン管理に使用するテーブルで、自動生成されます)
コンテナ起動時にマイグレートが実行されるようにする
これでコンテナを起動するたびにマイグレートが実行されるようになります。
fastapi_sample/docker/rundevserver.shpip3 install -r requirements.txt alembic upgrade head # 追記 uvicorn main:app\ --reload\ --port 8000\ --host 0.0.0.0\ --log-level debugデータアクセスクラス作成
ベースのデータアクセスクラスを作成
単純な全件取得や1件取得、登録、更新、削除などを記載します。
base.pyに記載しているget_db_session()は後述するリクエストミドルウェアやテストコード実行時などで大変重要な役割を果たします、今は気にしなくて良いです。mkdir crud touch crud/base.pyfastapi_sample/crud/base.pyfrom core.config import get_env from migrations.models import Base from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker, scoped_session, query from typing import List, TypeVar ModelType = TypeVar("ModelType", bound=Base) connection = create_engine( get_env().database_url, echo=get_env().debug, encoding='utf-8', ) Session = scoped_session(sessionmaker(connection)) def get_db_session() -> scoped_session: yield Session class BaseCRUD: """ データアクセスクラスのベース """ model: ModelType = None def __init__(self, db_session: scoped_session) -> None: self.db_session = db_session self.model.query = self.db_session.query_property() def get_query(self) -> query.Query: """ ベースのクエリ取得 """ return self.model.query def gets(self) -> List[ModelType]: """ 全件取得 """ return self.get_query().all() def get_by_id(self, id: int) -> ModelType: """ 主キーで取得 """ return self.get_query().filter_by(id=id).first() def create(self, data: dict = {}) -> ModelType: """ 新規登録 """ obj = self.model() for key, value in data.items(): if hasattr(obj, key): setattr(obj, key, value) self.db_session.add(obj) self.db_session.flush() self.db_session.refresh(obj) return obj def update(self, obj: ModelType, data: dict = {}) -> ModelType: """ 更新 """ for key, value in data.items(): if hasattr(obj, key): setattr(obj, key, value) self.db_session.flush() self.db_session.refresh(obj) return obj def delete_by_id(self, id: int) -> None: """ 主キーで削除 """ obj = self.get_by_id(id) if obj: obj.delete() self.db_session.flush() return Noneユーザーデータアクセスクラスを作成
touch crud/crud_user.pyfastapi_sample/crud/crud_user.pyfrom crud.base import BaseCRUD from migrations.models import User class CRUDUser(BaseCRUD): """ ユーザーデータアクセスクラスのベース """ model = UserAPI実装
お待たせしました、ようやくAPI実装編です。
API実装前準備
リクエスト情報にDBセッションを格納する依存性注入用(Depends)の関数を実装します。
このFastAPIの依存性注入システムがとても強力で、パラメーターをまとめたりもすることができます。
完全に理解しているわけではないので、申し訳ないのですが詳細は公式ドキュメントを参照してください。mkdir dependencies touch dependencies/__init__.pydependencies/__init__.pyfrom fastapi import Depends, Request from crud.base import get_db_session from sqlalchemy.orm import scoped_session async def set_db_session_in_request( request: Request, db_session: scoped_session = Depends(get_db_session) ): """ リクエストにDBセッションをセットする """ request.state.db_session = db_sessionAPIを実装していくフォルダ作成
mkdir -p api/v1ユーザーの一覧取得API実装
touch api/v1/user.pyfastapi_sample/api/v1/user.pyfrom crud.base import Session from crud.crud_user import CRUDUser from fastapi import Request from fastapi.encoders import jsonable_encoder class UserAPI: """ ユーザーに関するAPI """ @classmethod def gets(cls, request: Request): """ 一覧取得 """ # 依存性注入システムを用いて、リクエスト情報にDBセッションをセットしたので、 # ここで「request.state.db_session」を使用することができる return jsonable_encoder(CRUDUser(request.state.db_session).gets())APIルーター実装
ルーターの
dependencies=[Depends(set_db_session_in_request)]が今後重要な機能を果たしてくれますmkdir -p api/endpoints/v1 touch api/endpoints/v1/user.pyfastapi_sample/api/endpoints/v1/user.pyfrom api.v1.user import UserAPI from dependencies import set_db_session_in_request from fastapi import APIRouter, Depends, Request router = APIRouter() @router.get( '/', dependencies=[Depends(set_db_session_in_request)]) async def gets(request: Request): return UserAPI.gets(request)ルーターをエントリーポイントに登録する
APIルーターを作成
touch api/endpoints/v1/__init__.pyfastapi_sample/api/endpoints/v1/__init__.pyfrom fastapi import APIRouter from api.endpoints.v1 import user api_v1_router = APIRouter() api_v1_router.include_router( user.router, prefix='users', tags=['users'])main.pyを編集
fastapi_sample/main.pyfrom api.endpoints.v1 import api_v1_router # 追記 from fastapi import FastAPI app = FastAPI() app.include_router(api_v1_router, prefix='/api/v1') # 追記 @app.get("/") async def root(): return {"message": "Hello World"}ブラウザからhttps://localhost/docsアクセスすると実装したAPIが表示されているはずです。
登録/更新用にスキーマ(フォーム?)を定義する
mkdir api/schemas touch api/schemas/user.pyfastapi_sample/api/schemas/user.pyfrom pydantic import BaseModel, EmailStr from typing import Optional class BaseUser(BaseModel): email: EmailStr last_name: str first_name: str is_admin: bool class CreateUser(BaseUser): password: str class UpdateUser(BaseUser): password: Optional[str] last_name: Optional[str] first_name: Optional[str] is_admin: bool class UserInDB(BaseUser): class Config: orm_mode = Trueユーザーの登録/更新/削除のAPIを追加
fastapi_sample/api/v1/user.pyfrom api.schemas.user import CreateUser, UpdateUser, UserInDB from crud.crud_user import CRUDUser from fastapi import Request # from fastapi.encoders import jsonable_encoder # 削除 from typing import List class UserAPI: """ ユーザーに関するAPI """ @classmethod def gets(cls, request: Request) -> List[UserInDB]: """ 一覧取得 """ return CRUDUser(request.state.db_session).gets() # jsonable_encoderは使わない @classmethod def create( cls, request: Request, schema: CreateUser ) -> UserInDB: """ 新規登録 """ return CRUDUser(request.state.db_session).create(schema.dict()) @classmethod def update( cls, request: Request, id: int, schema: UpdateUser ) -> UserInDB: """ 更新 """ crud = CRUDUser(request.state.db_session) obj = crud.get_by_id(id) return CRUDUser(request.state.db_session).update(obj, schema.dict()) @classmethod def delete(cls, request: Request, id: int) -> None: """ 削除 """ return CRUDUser(request.state.db_session).delete_by_id(id)ユーザーのAPIルーターを編集
fastapi_sample/api/endpoints/v1/user.pyfrom api.schemas.user import CreateUser, UpdateUser, UserInDB from api.v1.user import UserAPI from dependencies import set_db_session_in_request from fastapi import APIRouter, Depends, Request from typing import List router = APIRouter() @router.get( '/', response_model=List[UserInDB], # response_modelを追加 dependencies=[Depends(set_db_session_in_request)]) def gets(request: Request) -> List[UserInDB]: """ 一覧取得 """ return UserAPI.gets(request) @router.post( '/', response_model=UserInDB, dependencies=[Depends(set_db_session_in_request)]) def create(request: Request, schema: CreateUser) -> UserInDB: """ 新規登録 """ return UserAPI.create(request, schema) @router.put( '/{id}/', response_model=UserInDB, dependencies=[Depends(set_db_session_in_request)]) def update(request: Request, id: int, schema: UpdateUser) -> UserInDB: """ 更新 """ return UserAPI.update(request, id, schema) @router.delete( '/{id}/', dependencies=[Depends(set_db_session_in_request)]) def delete(request: Request, id: int) -> None: """ 削除 """ return UserAPI.delete(request, id)ブラウザからアクセスして確認
CRUDのAPIを無事実装できました。
routerに
response_modelを指定すると、DBから取得したオブジェクトのJSONシリアライズを開発者が明示的に実装する必要がなくなります。(jsonable_encoder()を使わなくて良くなったのはこれのおかげ)
また、swagger-UI上にも反映してくれます。
※一覧取得のレスポンス
リクエストミドルウェアを実装する
さて、APIは実行できましたが、DBセッションのコミット実行していないので登録/更新/削除を実行してもDBが変更されません。
変更をDBに反映させるため、以下のようなリクエストミドルウェアを実装して適用します。
・リクエストが完了したらDBセッションコミットしてからDBセッション破棄
・エラー発生時はロールバックしてからDBセッション破棄mkdir middleware touch middleware/__init__.pyfastapi_sample/middleware/__init__.pyfrom fastapi import Request, Response from starlette.middleware.base import BaseHTTPMiddleware class HttpRequestMiddleware(BaseHTTPMiddleware): async def dispatch(self, request: Request, call_next) -> Response: try: response = await call_next(request) # 予期せぬ例外 except Exception as e: print(e) request.state.db_session.rollback() raise e # 正常終了時 else: request.state.db_session.commit() return response # DBセッションの破棄は必ず行う finally: request.state.db_session.remove()エントリーポイントにミドルウェアを適用する
fastapi_sample/main.pyfrom api.endpoints.v1 import api_v1_router from fastapi import FastAPI from middleware import HttpRequestMiddleware # 追加 app = FastAPI() app.include_router(api_v1_router, prefix='/api/v1') # ミドルウェアの設定 app.add_middleware(HttpRequestMiddleware) # 追加 @app.get("/") async def root(): return {"message": "Hello World"}CRUD実行で確認
無事DBに反映されるようになりました。
テストコード実装編
CRUDを実装できたので、次はテストコードを実装していきます。
とはいえ、単純にテストコードからAPIを実行してしまうと、DBに登録・更新・削除が実行されるため、テスト実行ごとに結果が変わってしまう可能性があります。
それを防ぐため、テスト関数ごとにクリーンなDBを作成し、そのDBを使用してテストするようにしたいと思います。pytestをインストール
fastapi_sample/requirements.txtpytest==6.1.0 # 追記したらrequirements.txtをインストールし直すのを忘れずにテスト用のDB接続情報を環境変数に追加
fastapi_sample/.envDEBUG=True DATABASE_URL=postgresql://postgres:postgres@db:5432/db_fastapi_sample TEST_DATABASE_URL=postgresql://postgres:postgres@db:5432/test_db_fastapi_sample # 追加fastapi_sample/core/config.pyclass Environment(BaseSettings): """ 環境変数を読み込むファイル """ debug: bool database_url: str test_database_url: str # 追加テストコード実装用のフォルダ作成
mkdir testsAPIのベーステストクラスを作成
touch tests/base.pyfastapi_sample/tests/base.pyimport psycopg2 from core.config import get_env from crud.base import get_db_session from fastapi.testclient import TestClient from main import app from migrations.models import Base from psycopg2.extensions import ISOLATION_LEVEL_AUTOCOMMIT from sqlalchemy import create_engine from sqlalchemy.orm import scoped_session, sessionmaker from sqlalchemy_utils import database_exists, drop_database test_db_connection = create_engine( get_env().test_database_url, encoding='utf8', pool_pre_ping=True, ) class BaseTestCase: def setup_method(self, method): """ 前処理 """ # テストDB作成 self.__create_test_database() self.db_session = self.get_test_db_session() # APIクライアントの設定 self.client = TestClient(app, base_url='https://localhost',) # DBをテスト用のDBでオーバーライド app.dependency_overrides[get_db_session] = \ self.override_get_db def teardown_method(self, method): """ 後処理 """ # テストDB削除 self.__drop_test_database() # オーバーライドしたDBを元に戻す app.dependency_overrides[self.override_get_db] = \ get_db_session def override_get_db(self): """ DBセッションの依存性オーバーライド関数 """ yield self.db_session def get_test_db_session(self): """ テストDBセッションを返す """ return scoped_session(sessionmaker(bind=test_db_connection)) def __create_test_database(self): """ テストDB作成 """ # テストDBが削除されずに残ってしまっている場合は削除 if database_exists(get_env().test_database_url): drop_database(get_env().test_database_url) # テストDB作成 _con = \ psycopg2.connect('host=db user=postgres password=postgres') _con.set_isolation_level(ISOLATION_LEVEL_AUTOCOMMIT) _cursor = _con.cursor() _cursor.execute('CREATE DATABASE test_db_fastapi_sample') # テストDBにExtension追加 _test_db_con = psycopg2.connect( 'host=db dbname=test_db_fastapi_sample user=postgres password=postgres' ) _test_db_con.set_isolation_level(ISOLATION_LEVEL_AUTOCOMMIT) # テストDBにテーブル追加 Base.metadata.create_all(bind=test_db_connection) def __drop_test_database(self): """ テストDB削除 """ drop_database(get_env().test_database_url)ポイントはこのDBオーバーライド部分です。
アプリケーションが参照するDBをテストDBに切り替えています。# DBをテスト用のDBでオーバーライド app.dependency_overrides[get_db_session] = self.override_get_db
こうすることで、APIやミドルウェアで使用している「request.state.db_session」もテストDBに切り替えることができます。
一覧取得のテストコードを実装してみる
requirements.txtrequests==2.24.0 # 追記したら必ずrequirements.txtをインストールmkdir -p tests/api/v1 touch tests/api/v1/test_user.py # "test_"を接頭に付けないとpytest実行時にスルーされてしまうので必ずつけるfastapi_sample/tests/api/v1/test_user.pyimport json from crud.crud_user import CRUDUser from fastapi import status from tests.base import BaseTestCase class TestUserAPI(BaseTestCase): """ ユーザーAPIのテストクラス """ TEST_URL = '/api/v1/users/' def test_gets(self): """ 一覧取得のテスト """ # テストユーザー登録 test_data = [ { 'email': 'test1@example.com', 'password': 'password', 'last_name': 'last_name', 'first_name': 'first_name', 'is_admin': False }, { 'email': 'test2@example.com', 'password': 'password', 'last_name': 'last_name', 'first_name': 'first_name', 'is_admin': True }, { 'email': 'test3@example.com', 'password': 'password', 'last_name': 'last_name', 'first_name': 'first_name', 'is_admin': False }, ] for data in test_data: CRUDUser(self.db_session).create(data) self.db_session.commit() response = self.client.get(self.TEST_URL) # ステータスコードの検証 assert response.status_code == status.HTTP_200_OK # 取得した件数の検証 response_data = json.loads(response._content) assert len(response_data) == len(test_data) # レスポンスの内容を検証 expected_data = [{ 'email': item['email'], 'last_name': item['last_name'], 'first_name': item['first_name'], 'is_admin': item['is_admin'], } for i, item in enumerate(test_data, 1)] assert response_data == expected_dataテスト実行
pytest # Dockerの手順を踏んだ方は、docker-compose exec app pytest # print()文の出力を確認したい場合は、pytest -v --capture=no% docker-compose exec app pytest -v --capture=no ================================================================================================== test session starts =================================================================================================== platform linux -- Python 3.8.5, pytest-6.1.0, py-1.9.0, pluggy-0.13.1 -- /root/local/python-3.8.5/bin/python3.8 cachedir: .pytest_cache rootdir: /fastapi_sample collected 1 item tests/api/v1/test_user.py::TestUserAPI::test_gets PASSED # 成功 ==================================================================================================== warnings summary ==================================================================================================== <string>:2 <string>:2: SADeprecationWarning: The mapper.order_by parameter is deprecated, and will be removed in a future release. Use Query.order_by() to determine the ordering of a result set. -- Docs: https://docs.pytest.org/en/stable/warnings.htmlテストも無事成功しました。
データベースを確認してみましょう。
API実装時に試しに登録したデータしかありません。
テスト用のDBに切り替えてのテスト実行は成功したようです!
ローカルDBを汚さず、かつ テストケースごとのテストデータも干渉することなくテストコードを実行することができるようになりました。
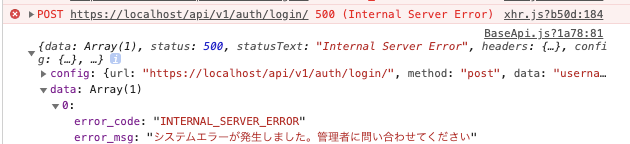
やったね。リクエストミドルウェア実装後、swagger-UI表示時「Internal Server Error」になる
swagger-UI表示時、「request.state」に「db_session」が存在しないため、Key Errorで「Internal Server Error」となります。
手取り早く直したい場合
リクエストミドルウェアの「request.state.db_session」を以下のように書き換えます。
fastapi_sample/middleware/__init__.pyfrom crud.base import Session # 追加 from fastapi import Request, Response from starlette.middleware.base import BaseHTTPMiddleware class HttpRequestMiddleware(BaseHTTPMiddleware): async def dispatch(self, request: Request, call_next) -> Response: try: response = await call_next(request) # 予期せぬ例外 except Exception as e: print(e) getattr(request.state, 'db_session', Session).rollback() # これに書き換え raise e # 正常終了時 else: getattr(request.state, 'db_session', Session).commit() # これに書き換え return response # DBセッションの破棄は必ず行う finally: getattr(request.state, 'db_session', Session).remove() # これに書き換えリクエストミドルウェアは触りたくない場合
swagger-uiで表示するエンドポイントを全てオーバーライドするしかありません。
FastAPIクラスをオーバーライド
touch core/fastapi.pyfastapi_sample/core/fastapi.pyimport fastapi from fastapi import Request from fastapi.exceptions import RequestValidationError from fastapi.exception_handlers import ( http_exception_handler, request_validation_exception_handler, ) from fastapi.openapi.docs import ( get_redoc_html, get_swagger_ui_html, get_swagger_ui_oauth2_redirect_html, ) from fastapi.responses import JSONResponse, HTMLResponse from starlette.exceptions import HTTPException class FastAPI(fastapi.FastAPI): def setup(self) -> None: if self.openapi_url: urls = (server_data.get("url") for server_data in self.servers) server_urls = {url for url in urls if url} async def openapi(req: Request) -> JSONResponse: root_path = req.scope.get("root_path", "").rstrip("/") if root_path not in server_urls: if root_path and self.root_path_in_servers: self.servers.insert(0, {"url": root_path}) server_urls.add(root_path) return JSONResponse(self.openapi(self, req)) # 書き換えているのはこの部分だけ self.add_route(self.openapi_url, openapi, include_in_schema=False) if self.openapi_url and self.docs_url: async def swagger_ui_html(req: Request) -> HTMLResponse: root_path = req.scope.get("root_path", "").rstrip("/") openapi_url = root_path + self.openapi_url oauth2_redirect_url = self.swagger_ui_oauth2_redirect_url if oauth2_redirect_url: oauth2_redirect_url = root_path + oauth2_redirect_url return get_swagger_ui_html( openapi_url=openapi_url, title=self.title + " - Swagger UI", oauth2_redirect_url=oauth2_redirect_url, init_oauth=self.swagger_ui_init_oauth, ) self.add_route( self.docs_url, swagger_ui_html, include_in_schema=False ) if self.swagger_ui_oauth2_redirect_url: async def swagger_ui_redirect(req: Request) -> HTMLResponse: return get_swagger_ui_oauth2_redirect_html() self.add_route( self.swagger_ui_oauth2_redirect_url, swagger_ui_redirect, include_in_schema=False, ) if self.openapi_url and self.redoc_url: async def redoc_html(req: Request) -> HTMLResponse: root_path = req.scope.get("root_path", "").rstrip("/") openapi_url = root_path + self.openapi_url return get_redoc_html( openapi_url=openapi_url, title=self.title + " - ReDoc" ) self.add_route(self.redoc_url, redoc_html, include_in_schema=False) self.add_exception_handler(HTTPException, http_exception_handler) self.add_exception_handler( RequestValidationError, request_validation_exception_handler )swagger-ui用のルーターを用意
touch api/endpoints/swagger_ui.pyfastapi_sample/api/endpoints/swagger_ui.pyfrom core.fastapi import FastAPI from crud.base import Session from dependencies import set_db_session_in_request from fastapi import APIRouter, Depends, Request from fastapi.openapi.docs import get_redoc_html, get_swagger_ui_html from fastapi.openapi.utils import get_openapi swagger_ui_router = APIRouter() @swagger_ui_router.get( '/docs', include_in_schema=False, dependencies=[Depends(set_db_session_in_request)]) async def swagger_ui_html(request: Request): return get_swagger_ui_html( openapi_url=FastAPI().openapi_url, title=FastAPI().title, oauth2_redirect_url=FastAPI().swagger_ui_oauth2_redirect_url, ) @swagger_ui_router.get( '/redoc', include_in_schema=False, dependencies=[Depends(set_db_session_in_request)]) async def redoc_html(request: Request): return get_redoc_html( openapi_url=FastAPI().openapi_url, title=FastAPI().title + " - ReDoc", ) def openapi(app: FastAPI, request: Request): request.state.db_session = Session if app.openapi_schema: return app.openapi_schema openapi_schema = get_openapi( title="FastAPI", version="0.1.0", routes=app.routes, ) app.openapi_schema = openapi_schema return app.openapi_schemaエントリーポイント修正
fastapi_sample/main.pyfrom api.endpoints.swagger_ui import openapi, swagger_ui_router from api.endpoints.v1 import api_v1_router from core.config import get_env # from fastapi import FastAPI from core.fastapi import FastAPI # オーバーライドしたFastAPIクラスを使用する from middleware import HttpRequestMiddleware app = FastAPI( docs_url=None, # Noneを設定しないとswagger-uiのルーターで定義したものに変わらない redoc_url=None, # Noneを設定しないとswagger-uiのルーターで定義したものに変わらない ) app.include_router(api_v1_router, prefix='/api/v1') # ミドルウェアの設定 app.add_middleware(HttpRequestMiddleware) # @app.get("/") # async def root(): # return {"message": "Hello World"} # swagger-uiは開発時のみ表示されるようにする if get_env().debug: app.include_router(swagger_ui_router) app.openapi = openapi無事swagger-uiのエラーが解消され、表示されるようになりました。
【オマケ①】CORS問題を回避
このままだと、フロントエンドからのAPI呼び出し時にCORSエラー発生してしまいます。
この問題を回避するため、CORSミドルウェアを実装します。
.envと環境変数を扱うクラスを編集fastapi_sample/.envALLOW_HEADERS='["*"]' # 追加 ALLOW_ORIGINS='["*"]' # 追加 DEBUG=True DATABASE_URL=postgresql://postgres:postgres@db:5432/db_fastapi_sample TEST_DATABASE_URL=postgresql://postgres:postgres@db:5432/test_db_fastapi_samplefastapi_sample/core/config.pyclass Environment(BaseSettings): """ 環境変数を読み込むファイル """ allow_headers: list # 追加 allow_origins: list # 追加 ... .. .CORSミドルウェアを実装・エントリポイントに適用
fastapi_sample/middleware/__init__.pyfrom core.config import get_env # 追加 from crud.base import Session from fastapi import Request, Response from starlette.middleware import cors # 追加 from starlette.middleware.base import BaseHTTPMiddleware from starlette.types import ASGIApp # 追加 class CORSMiddleware(cors.CORSMiddleware): """ CORS問題を回避するためのミドルウェア """ def __init__(self, app: ASGIApp) -> None: super().__init__( app, allow_origins=get_env().allow_origins, allow_methods=cors.ALL_METHODS, allow_headers=get_env().allow_headers, allow_credentials=True, ) class HttpRequestMiddleware(BaseHTTPMiddleware): ... .. .fastapi_sample/main.pyfrom api.endpoints.swagger_ui import openapi, swagger_ui_router from api.endpoints.v1 import api_v1_router from core.config import get_env from core.fastapi import FastAPI from middleware import ( CORSMiddleware, # 追加 HttpRequestMiddleware ) ... .. . # ミドルウェアの設定 # ・ミドルウェアは 後 に追加したものが先に実行される # ・CORSMiddlewareは必ず一番 後 に追加すること # ・ミドルウェアを追加する場合はCORSMiddleware と ProcessRequestMiddlewareより 前 に追加すること app.add_middleware(HttpRequestMiddleware) app.add_middleware(CORSMiddleware) # 追加 ... .. .ポイントはミドルウェアを追加する順番です。
後に書いたミドルウェアが先に実行されるので、CORSミドルウェアは一番最後に書きましょう。
無事、フロントエンドのCORSエラーは回避することができるようになりました。
(文字列"ログイン成功"を返すだけのAPIを作成してフロントエンドから実行)
【オマケ②】カスタム例外
HTTPExceptionを継承してカスタム例外を作成してみます。
エラーレスポンスはこんな感じで、エラーコードとエラーメッセージを複数返せるような形式します。detail: [ { error_code: 'エラーコード', error_message: 'エラーメッセージ' }, { error_code: 'エラーコード', error_message: 'エラーメッセージ' }, { ... }, { ... }, ]メッセージを管理するiniファイルを作成
touch core/error_messages.inifastapi_sample/core/error_messages.ini[messages] INTERNAL_SERVER_ERROR=システムエラーが発生しました。管理者に問い合わせてください FAILURE_LOGIN=ログイン失敗カスタム例外を実装するフォルダ作成
mkdir exception touch exception/__init__.py touch exception/error_messages.pyエラーコードとエラーメッセージの管理クラス
fastapi_sample/exception/error_messages.pyimport os from configparser import ConfigParser from core.config import PROJECT_ROOT from functools import lru_cache MESSAGES_INI = ConfigParser() MESSAGES_INI.read( os.path.join(PROJECT_ROOT, 'core/error_messages.ini'), 'utf-8' ) @lru_cache def get(key: str, *args): return MESSAGES_INI.get('messages', key).format(*args) INTERNAL_SERVER_ERROR = 'INTERNAL_SERVER_ERROR' FAILURE_LOGIN = 'FAILURE_LOGIN'fastapi_sample/exception/__init__.pyfrom fastapi import status, HTTPException from exception import error_messages class ApiException(HTTPException): """ API例外 """ default_status_code = status.HTTP_400_BAD_REQUEST def __init__( self, *errors, status_code: int = default_status_code ) -> None: self.status_code = status_code self.detail = [ { 'error_code': error['error_code'], 'error_msg': error_messages.get( error['error_code'], *error['msg_params']), } for error in list(errors) ] super().__init__(self.status_code, self.detail) def create_error(error_code: str, *msg_params) -> dict: """ エラー生成 """ return { 'error_code': error_code, 'msg_params': msg_params, }カスタム例外をスローする
fastapi_sample/api/v1/auth.pyfrom fastapi import Request from exception import ( ApiException, create_error, error_messages, ) class AuthAPI: """ 認証に関するAPI """ @classmethod def login(cls, request: Request): """ ログインAPI """ # カスタム例外をスロー raise ApiException( create_error(error_messages.FAILURE_LOGIN) ) return 'ログイン成功'リクエストミドルウェアを修正する
fastapi_sample/middleware/__init__.pyfrom exception import ApiException # 追加 from fastapi import Request, Response from starlette.middleware.base import BaseHTTPMiddleware class HttpRequestMiddleware(BaseHTTPMiddleware): async def dispatch(self, request: Request, call_next) -> Response: try: response = await call_next(request) # アプリケーション例外 except ApiException as ae: # 追加 request.state.db_session.rollback() raise ae # 追加 except Exception as e: request.state.db_session.rollback() raise e else: request.state.db_session.commit() return response finally: request.state.db_session.remove()▼フロント側(エラーレスポンスを確認したいだけなのでスルーでOKです)
sample.jsaxios.interceptors.response.use( response => { return response; }, error => { // エラーレスポンスをコンソール表示 console.log(error.response); ... .. .カスタム例外がスローされ、フロント側でエラーレスポンスを確認することができました。
システムエラーについて
アプリが意図的に返す例外は問題ないですが、意図せぬ例外(システムエラー)はどうでしょうか。
fastapi_sample/api/v1/auth.pyfrom fastapi import Request class AuthAPI: """ 認証に関するAPI """ @classmethod def login(cls, request: Request): """ ログインAPI """ result = 1 / 0 # 0除算でエラー return result
結果はCORSエラーが返却された上に、エラーレスポンス(error.response)の中身がundefinedです。
(CORSエラーは多分エラーの形式が不正だから・・・??)
システム例外用のカスタムExceptionを作成
fastapi_sample/exception/__init__.pyimport traceback # 追加 from fastapi import status, HTTPException from exception import error_messages class ApiException(HTTPException): ... .. . class SystemException(HTTPException): """ システム例外 """ def __init__(self, e: Exception) -> None: self.exc = e self.stack_trace = traceback.format_exc() self.status_code = status.HTTP_500_INTERNAL_SERVER_ERROR self.detail = [ { 'error_code': error_messages.INTERNAL_SERVER_ERROR, 'error_msg': error_messages.get( error_messages.INTERNAL_SERVER_ERROR) } ] super().__init__(self.status_code, self.detail)リクエストミドルウェアを修正
fastapi_sample/middleware/__init__.pyfrom exception import ( ApiException, SystemException, # 追加 ) from fastapi import Request, Response from fastapi.responses import JSONResponse # 追加 from starlette.middleware.base import BaseHTTPMiddleware class HttpRequestMiddleware(BaseHTTPMiddleware): async def dispatch(self, request: Request, call_next) -> Response: try: response = await call_next(request) except ApiException as ae: request.state.db_session.rollback() # アプリケーション例外もシステム例外に合わせてResponseを返却する形式に変える return JSONResponse( se.detail, status_code=se.status_code) except Exception as e: request.state.db_session.rollback() se = SystemException(e) # カスタムシステム例外に変換 # raise seとしても、フロント側のエラーレスポンスはなぜか"undefined"のままなのでResponseを返却する # API例外と同じくHTTPExceptionを継承しているのに何故・・・∑(゚Д゚) # raise se return JSONResponse( se.detail, status_code=se.status_code) else: request.state.db_session.commit() return response finally: request.state.db_session.remove()フロント側でシステムエラーのエラーレスポンスを受け取ることができました。
終わり
FastAPIでCRUDを実装してみました。
フルスタックフレームワークのDjango(RestはDRF)ばかり使っていたせいで、初め「なんだこの使いづらいフレームワークは・・・」とか思っていましたが、今ではもうDjangoよりFastAPI派になってしまいました。
ガシガシ環境周りのコードを自分で実装できて楽しいですし、何より成長に繋がりました。
公式ドキュメントを読みきれていないので、他にもいい方法はあるかと思いますので、
コメントでこっそり教えてもらえると嬉しいです( ´ノω`)
私が所属しているFabeee株式会社はお仕事 と 一緒に働くお仲間を随時募集しております!!!!(宣伝)




- 投稿日:2020-10-24T22:12:37+09:00
Pythonで型を極める【Python 3.9対応】
はじめに
みなさん。Pythonで型書いてますか?最近は型の重要性を再認識しているので、皆さんにもぜひPythonで型を書いて頂きたと思ってこの記事を書きました。
注意事項として今回の記事では下記の事項については言及しません。
- 型チェックツールの導入方法(mypy,pyrightなど)
今回の内容は以前の書いた記事の補足内容となっていますので、以前の記事ももしよければ参照ください。
そもそもPythonでなぜ型を書くのか?
Pythonは動的型付き言語なので、型を書かなくてもプログラムは動きます。型を書かないことで、コードの量は少なくなりますし、初学者にとっても習得しやすい言語となっていることはメリットかと思います。
ただし、ある程度の行数のコードを書く場合、プログラムを複数人でメンテナンスする場合、型がないと以下の様な問題が発生する。
- 関数を見ただけでは、返り値がどのようなものか分からない
- 変数に想定外の値が代入されていても分からない
なので、プログラムを長期にわたって保守するという観点からみると、型がある方が優位性があると思います。
例えば、以下のような関数がある場合を考えます。
def add(a, b): """引数を足した結果を返す""" return a + b def add_type(a: int, b: int) -> int: """引数を足した結果を返す""" return a + b同じ内容の関数ですが、片方は型があり、もう片方は型がありません。
実際に以下のように使うことができますが、関数の作成者は文字列が入ることを想定していなかった場合、型があるadd_type関数の方ではエディタでエラーが表示されます。print(add('1', '2')) print(add_type('1', '2'))
関数の作成者と利用者が必ずしも同じとは限りませんし、自分で作成した関数でも時間がたてば内容を忘れます。型をつけることで自分が想定したとおりに関数を利用してもらうことが期待できます。
型入門
組み込み型(list,dict,tuple)
listなどについてはPython3.8までと3.9で書き方が異なります。従来のtypingを使う方法が非推奨になり、組み込み型を利用する方法が推奨になっています。
Python3.8の場合
from typing import Dict, List, Tuple val_e: Dict[str, int] = {'size': 12, 'age': 24} val_f: List[str] = ['taro', 'jiro'] val_g: Tuple[str, int] = ('name', 12)Python3.9の場合
val_e: dict[str, int] = {'size': 12, 'age': 24} val_f: list[str] = ['taro', 'jiro'] val_g: tuple[str, int] = ('name', 12)Finalについて
Python3.8からFinalがデフォルトで使用できるようになってます。定数(再代入不可)を定義することで、再代入されないようにすることができます。
from typing import Final TABLE_NAME: Final[str] = 'sample'再代入しようとするとエラーが表示されます。
定数にはtupleを積極的に使う
listとtupleは同じような機能があるので、ついついlistを使いがちですが、tupleの方がメリットが多い場合があるので紹介します。
listの場合、内部の情報を書き換えることが可能ですが、定数として定義するものは、内部の情報を書き換えられることを望まないことがほとんどです。そのような場合はtupleで定義すると内部情報が変更される心配がありません。Python3.8の場合
from typing import Final, Tuple, List # tupleなので変更不可 NAME_TUPLE: Final[Tuple[str, str]] = ('taro', 'jiro') # listは変更可能 NAME_LIST: Final[List[str]] = ['taro', 'jiro'] NAME_LIST[0] = 'saburo'Python3.9の場合
from typing import Final # tupleなので変更不可 NAME_TUPLE: Final[tuple[str, str]] = ('taro', 'jiro') # listは変更可能 NAME_LIST: Final[list[str]] = ['taro', 'jiro'] NAME_LIST[0] = 'saburo'定数にはnamedtupleを積極的に使う
定数にdictを使う場合もあるかと思います。その場合namedtupleを使うと内部情報が変更されないので安心です。
from typing import NamedTuple, TypedDict class StudentInfoTuple(NamedTuple): name: str age: int class StudentInfoDict(TypedDict): name: str age: int # namedtupleの場合、内部情報を書き換えることができない TARO: Final[StudentInfoTuple] = StudentInfoTuple('taro', 12) # 下記行はエラーになる # TARO.name = 'taro2' # dictの場合内部情報を書き換えることができる JIRO: Final[StudentInfoDict] = {'name': 'jiro', 'age': 9} JIRO['name'] = 'jiro2'TypedDictのオプショナルな引数について
まず、TypedDictには2通りの書き方があります。
以下の例の場合、MovieAとMovieBは同じ意味の型として利用できます。from typing import TypedDict MovieA = TypedDict('MovieA', {'name': str, 'year': int}) class MovieB(TypedDict): name: str year: int cat: MovieA = {'name': 'cat', 'year': 1993} dog: MovieB = {'name': 'dog', 'year': 2000}では、Movieという型にauthorという属性がある場合とない場合がある場合を考慮したい場合はどうしたらいいでしょうか?
その場合は以下のように書きます。from typing import TypedDict class MovieRequiredType(TypedDict): name: str year: int class MovieOptionalType(TypedDict, total=False): author: str class MovieType(MovieRequiredType, MovieOptionalType): pass # MovieTypeはauthor属性があってもなくても良い rabbit: MovieType = {'name': 'rabbit', 'year': 2002} deer: MovieType = {'name': 'deer', 'year': 2006, 'author': 'jack'}もちろん、必須属性であるnameとyearがなければエディタ上でエラーとなります。
TypedDictに関しては2通りの書き方がありますが、多重継承できるという点でclassスタイルの方がメリットがあります。なので、こちらを積極的に利用する方が多いかと思います。
最後に
Pythonにおける型の重要性について理解いただけたのではないでしょうか。型を書くことはめんどくさいと思われるかもしれませんが、複雑なコードになればなるほど、型のありがたさが理解できるのではないかと思います。
最後に少し注意点ですが、Python3.9の記法は一部のツール(mypyなど)で対応されていないので、ご利用の際はご注意ください。(2020年10月時点)



- 投稿日:2020-10-24T21:42:01+09:00
最短コースで機械学習を学べる 書籍「Pythonで儲かるAIをつくる」紹介
はじめに
書籍「Pythonで儲かるAIをつくる」の著者です。当記事でこの本の特徴をご紹介します。
Amazonリンク(単行本)
https://www.amazon.co.jp/dp/4296106961Amazonリンク(Kindle)
https://www.amazon.co.jp/dp/B08F9P726T本書サポートサイト (Github)
https://github.com/makaishi2/profitable_ai_book_info/blob/master/README.mdまずは、下記の目次をご覧下さい。
タイトルで誤解を受けることが多いのですが、目次を見ていただければわかるとおりいたって真面目な書籍です。「AIを使ってFXや株で大儲けをしよう」という本ではありませんので、誤解なきようお願いします。
主な対象読者
本書は、主に次の2つの読者層を想定しています。
業務専門家
IT部門でなく、実業務を担当しているリーダークラスの責任者。これから自分の業務のAI化を進めたいが、どこから手をつけたらいいかわからない人。
この場合、本書の1章、2章、3章を読んだ後、自分の業務に適用できそうな処理パターンにあたりをつけて、5章の該当節を読み進めて下さい。4章はオプションになりますが、4.1節、4.4節はできるだけ読んでほしいです。6章は重要なので是非読んで下さい。データサイエンティスト志望者
元々プログラミングが得意で、これからデータサイエンティストとしてのスキルを伸ばしていきたい人。
この場合は、飛ばさずに最初から全部読み進めて下さい。
本書の本文のサンプルコーディングは、Python、Pandas、matplotlibといった言語、ライブラリはある程度理解している前提で書かれています。このあたりの知識が不十分な場合は、本書巻末の「講座2 機械学習のためのPython入門」にこれらのライブラリの簡潔な解説があるので、そちらから先に読んで下さい。本書のコーディングで出て来る必要最小限の機能を最短コースで説明しています。
ライブラリ以前にPythonの経験もない方もいるかもしれませんが、心配は無用です。こういう人向けには本書のサポートページ(Github)上にPython入門を公開しました。こちらも書籍の実習で出てくる必要最小限の文法に絞り込んだ最短コースのPython入門になっています。書籍の特徴
業務専門家にとって
今までAIと接点がなかった業務専門家にとってAIとは「なんだか得体の知れないもの」あるいは「何でもできるすごいもの」といったイメージを持ちがちです。実は、現在のAI技術でできることはかなり限定されています。
本書を通読することで、AIでできることがなんであるか理解できます。本書の中で「処理パターン」と呼んでいる、「分類」「回帰」「クラスタリング」といった、AIでできることと、自分の業務の対応付けができるようになります。このことこそが、AI化を推進する第一歩になります。下の図は、本書5章でまとめている処理パターン一覧です。
1行1行のコーディングの意味は必ずしも理解できなくて構わないので、5章のうち、自分が業務で適用してみたい処理パターンについては、必ずPython実習も流してみるようにして下さい。処理の流れをPythonコードを通じて理解することで、機械学習モデルの適用パターンをより具体的にイメージすることができます。
例えば、下の図は、5.2節の例題(回帰)の実習中に出てくるモデルの予測結果と正解を重ねがきしたグラフになります。
また、6章ではAI化を進めるにあたって陥りがちな落とし穴についても解説があります。ここに書かれていることを十分に理解することで、初めて実業務適用が可能なPoC(Proof of Conceptの略。AI化を着手するにあたった最初に行う技術検証のこと)を間違いなく選択できるようになります。具体的な6章の内容は以下の通りです。
データサイエンティスト志望者にとって
データサイエンティスト志望者にとっての本書の最大の特徴は、機械学習モデルをPythonで構築するために何をしたらいいかが最短コースで理解できる点にあります(この点を指してSNS上で「超爆速カリキュラム」と評していただいた読者もいます)。
この目的を実現するため、従来の機械学習の解説書で多くのページを割きがちであったアルゴリズムの数学的説明は、図を多用したイメージによる最小限のものに限定し、数式は加減乗除のみとしました。そして、具体的にどうしたら機械学習モデルを作れるかという点に力点を置きました。こうすることで、従来の機械学習・データサイエンス本にありがちだった、数学的なハードルが低くなりました。
難しい数学の話は省略した一方で、教師あり機械学習で重要な評価については、1節(4.4節)を割いて、かなり詳しく解説しました(具体的には精度(Accuracy)と適合率(Precision)、再現率(Recall)をどのように使い分けるかなど)。数式としては分数式だけで理解できる節なので、是非、この節は完全に理解するようにして下さい。
データサイエンティスト・プログラマー向けの従来の入門書では、モデルの技術的説明と実装コードで話が終わってしまい、業務観点の解説が少ない傾向があったかと思います。
本書の5章では、必ず冒頭に「この処理パターンはこのような業務のこのような箇所で使える」という点を説明するようにしています。データサイエンティスト志望者は、章の冒頭のこの説明を念頭において実装コードを読み進めることで、「処理パターンと業務の対応付け」を含めて理解することができるようになります。その他の特徴
その他、本書の特徴として次のようなことがあります。
実習コードはGoogle Colab前提
Google Colabとは、Gmailのアカウントさえ持っていれば、セットアップ手順なしにすぐに使えるクラウド上のPython(Jupyter Notebook)環境です。実習コードそのものもすべてインターネット(Github)に公開されているので、今までPython、Jupyter Notebookの導入が手間が大変で書籍の実習ができなかった読者も、すぐに実習コードを動かすことができます。
具体的な手順については、qiitaに別記事を記載していますので、そちらを参照されて下さい。
Google Colaboratoryで書籍「Pythonで儲かるAIをつくる」の実習コードを動かす方法最新技術の採用
5.2の回帰でXGboostを使ったり、5.3の時系列分析でProphetを使ったり、機械学習の最新技術も取り入れています。この場合も高度な利用方法には踏み込まず、あまり利用経験のないユーザーがすぐに使えるレベルにとどめているので、「最新技術なので難しいのでは」という心配はありません。アソシエーション分析も事例化
マーケティング分析で多用されるアソシエーション分析(教師なし学習の一種)は、Python機械学習のデファクトスタンダードであるscikit-learnにライブラリがないことから、従来あまりPythonで実習ガイドがなかった領域です(R言語が用いられることが多かった)。本書ではscikit-learnと別のライブラリであるmlextendを利用することで、この領域の実習も実現しています。その概要については、qiitaで別記事を記載しましたので、関心がある方は参照して下さい。
Pythonでアソシエーション分析更に詳しく知りたい方は
本書のサポートページに、5章と同じ書きぶりの追加事例と、Python文法の解説であるPython入門を公開しています。こちらを読んでいただくと、より本書のイメージがよりつかめるかと思います。







- 投稿日:2020-10-24T20:38:40+09:00
【自然言語処理】科研費データベースからMeCab-ipadic-neologdとtermextractでキーワードを抽出する
科研費申請書を書いている研究者のみなさま、お疲れ様です。
ご存知の通り、過去に採択された研究は科研費データベースに載っています。が、全部見るのはなかなか大変です。
過去の傾向をざっくり把握してみよう! ということで、今回は科研費データベースの研究の概要から自然言語処理でキーワードを抽出してみました。形態素解析パッケージMeCabと専門用語抽出ツールのtermextractを使っています。環境構築
PythonとJupyter Notebookを使います。
OSなど
- MacOS Mojave 10.14.5
- Anaconda 2020.02
- Python 3.7.6
- Jupyter Notebook 6.0.3
MeCab
こちらを参考に、形態素解析のためにMeCabとmecab-python3をインストールし、neologdを標準辞書に設定します。
インストールできたらbashで試してみましょう。標準辞書ipadic(MeCabのデフォルト)
bashecho "真核生物" | mecab 真 接頭詞,名詞接続,*,*,*,*,真,マ,マ 核 名詞,一般,*,*,*,*,核,カク,カク 生物 名詞,一般,*,*,*,*,生物,セイブツ,セイブツ EOSデフォルトのipadicでは「真核生物」が認識されません。
bashecho "科学研究費補助金" | mecab 科学 名詞,一般,*,*,*,*,科学,カガク,カガク 研究 名詞,サ変接続,*,*,*,*,研究,ケンキュウ,ケンキュー 費 名詞,接尾,一般,*,*,*,費,ヒ,ヒ 補助 名詞,サ変接続,*,*,*,*,補助,ホジョ,ホジョ 金 名詞,接尾,一般,*,*,*,金,キン,キン EOS「科学研究費補助金」も認識してくれませんでした。
標準辞書neologd
bashecho "真核生物" | mecab 真核生物 名詞,固有名詞,一般,*,*,*,真核生物,シンカクセイブツ,シンカクセイブツ EOSneologdは「真核生物」を認識してくれました! これならキーワード抽出に少し期待が持てるかな。
bashecho "科学研究費補助金" | mecab 科学 名詞,一般,*,*,*,*,科学,カガク,カガク 研究 名詞,サ変接続,*,*,*,*,研究,ケンキュウ,ケンキュー 費 名詞,接尾,一般,*,*,*,費,ヒ,ヒ 補助金 名詞,固有名詞,一般,*,*,*,補助金,ホジョキン,ホジョキン EOS「科学研究費補助金」は1語として認識してくれないようです。
mecab-python
PythonでMeCabを試してみましょう。テスト用に後述のデータの1文目をお借りしました。
pythonimport sys import MeCab tagger = MeCab.Tagger ("mecabrc") print(tagger.parse ("真核生物はユニコンタとバイコンタに大別できる。"))出力結果真核生物 名詞,固有名詞,一般,*,*,*,真核生物,シンカクセイブツ,シンカクセイブツ は 助詞,係助詞,*,*,*,*,は,ハ,ワ ユニコンタ 名詞,固有名詞,一般,*,*,*,ユニコンタ,ユニコンタ,ユニコンタ と 助詞,並立助詞,*,*,*,*,と,ト,ト バイコンタ 名詞,固有名詞,一般,*,*,*,バイコンタ,バイコンタ,バイコンタ に 助詞,格助詞,一般,*,*,*,に,ニ,ニ 大別 名詞,サ変接続,*,*,*,*,大別,タイベツ,タイベツ できる 動詞,自立,*,*,一段,基本形,できる,デキル,デキル 。 記号,句点,*,*,*,*,。,。,。 EOSPythonから形態素解析できました。
termextract
termextractは専門語抽出をしてくれるパッケージです。MeCabの解析結果の形式でデータを渡す必要があります。
こちらを参考にインストールしました。科研費データベースからcsvデータをダウンロード
いよいよ科研費データを扱っていきます。
当初Pythonでスクレイピングしようかと思ってスクレイピング禁止だーとかいろいろ調べていたのですが、csvでダウンロードできることに気づき、ことなきを得ました。
検索ワード「クラミドモナス」で全件ダウンロードしてみます。
クラミドモナスに馴染みのない人はこちらを見てみてください。pandasでデータ読み込み・整形
pandasでデータを読み込んで確認します。encodingを指定するのを忘れましたが、エラーが出ずに読み込めました。
pythonimport pandas as pd kaken = pd.read_csv('kaken.nii.ac.jp_2020-10-23_22-31-59.csv')
kaken.head()でデータの最初の部分を確認します。NaNが多そうです。
kaken.info()でデータ全体を確認します。出力結果<class 'pandas.core.frame.DataFrame'> RangeIndex: 528 entries, 0 to 527 Data columns (total 40 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 研究課題名 528 non-null object 1 研究課題名 (英文) 269 non-null object 2 研究課題/領域番号 528 non-null object 3 研究期間 (年度) 528 non-null object 4 研究代表者 471 non-null object 5 研究分担者 160 non-null object 6 連携研究者 31 non-null object 7 研究協力者 20 non-null object 8 特別研究員 53 non-null object 9 外国人特別研究員 4 non-null object 10 受入研究者 4 non-null object 11 キーワード 505 non-null object 12 研究分野 380 non-null object 13 審査区分 102 non-null object 14 研究種目 528 non-null object 15 研究機関 528 non-null object 16 応募区分 212 non-null object 17 総配分額 526 non-null float64 18 総配分額 (直接経費) 526 non-null float64 19 総配分額 (間接経費) 249 non-null float64 20 各年度配分額 526 non-null object 21 各年度配分額 (直接経費) 526 non-null object 22 各年度配分額 (間接経費) 526 non-null object 23 現在までの達成度 (区分コード) 46 non-null float64 24 現在までの達成度 (区分) 46 non-null object 25 理由 46 non-null object 26 研究開始時の研究の概要 14 non-null object 27 研究概要 323 non-null object 28 研究概要 (英文) 156 non-null object 29 研究成果の概要 85 non-null object 30 研究成果の概要 (英文) 85 non-null object 31 研究実績の概要 84 non-null object 32 現在までの達成度 (段落) 90 non-null object 33 今後の研究の推進方策 94 non-null object 34 次年度の研究費の使用計画 0 non-null float64 35 次年度使用額が生じた理由 0 non-null float64 36 次年度使用額の使用計画 0 non-null float64 37 自由記述の分野 0 non-null float64 38 評価記号 3 non-null object 39 備考 0 non-null float64 dtypes: float64(9), object(31) memory usage: 165.1+ KB「研究開始時の研究の概要」「研究概要」「研究成果の概要」「研究実績の概要」に文章が入っていそうです。「キーワード」もありますが、今回はあくまで文章からキーワード抽出したいので、無視します。
おそらく年度ごとに執筆すべき項目が変わった影響で、NaNが多くて文章の入っている行が揃っていません。文章だけデータフレームから出してリストを作ってしまうことにします。pythoncolumn_list = ['研究開始時の研究の概要', '研究概要', '研究成果の概要', '研究実績の概要'] abstracts = [] for column in column_list: abstracts.extend(kaken[column].dropna().tolist())
形態素解析の準備ができました。このリストの各要素に対して形態素解析をかけていきましょう。MeCabで形態素解析
こちらを参考に、MeCabで形態素解析した結果の語のリストを返す関数を定義しました。
デフォルトでは名詞・動詞・形容詞のみ抽出し、動詞と形容詞は原型に戻します。pythontagger = MeCab.Tagger('') tagger.parse('') def wakati_text(text, word_class = ['動詞', '形容詞', '名詞']): # 分けてノードごとにする node = tagger.parseToNode(text) terms = [] while node: # 単語 term = node.surface # 品詞 pos = node.feature.split(',')[0] # もし品詞が条件と一致していたら if pos in word_class: if pos == '名詞': terms.append(term) #文中の形 else: terms.append(node.feature.split(",")[6]) # 原型で入れる node = node.next return termsさきほど抽出したデータの一部を使ってテストしてみます。
名詞・動詞・形容詞のみ抽出できています。(「9+2構造」は抽出できませんね……)
リストabstracts全体に関数wakati_textを適用して名詞・動詞・形容詞のリストを得ます。pythonwakati_abstracts = [] for abstract in abstracts: wakati_abstracts.extend(wakati_text(abstract))名詞・動詞・形容詞のリストができました。
可視化
リスト
wakati_abstractsの要素を数え、数が多い方から50位まで棒グラフにしてみます。pythonimport collections import matplotlib.pyplot as plt import matplotlib as mpl words, counts = zip(*collections.Counter(wakati_abstracts).most_common()) mpl.rcParams['font.family'] = 'Noto Sans JP Regular' plt.figure(figsize=[12, 6]) plt.bar(words[0:50], counts[0:50]) plt.xticks(rotation =90) plt.ylabel('freq') plt.savefig('kaken_bar.png', dpi=200, bbox_inches="tight")
ストップワード除去をしなかったため、「する」「こと」「れる」「いる」「的」などが上位に来ています。
検索ワードである「クラミドモナス」のほか、「遺伝子」「光」「細胞」「鞭毛」「タンパク質」「ダイニン」など、クラミドモナス関係者なら見覚えのある単語が並んでいます。
動詞と形容詞はいらなかったのでは? と思われる結果になっています。名詞のみの抽出
上記と同様の手順で名詞のみを抽出してみました。
関数wakati_abstractの第2引数を['名詞']とするだけです。pythonnoun_abstracts = [] for abstract in abstracts: noun_abstracts.extend(wakati_text(abstract, ['名詞']))途中のコードは上と同じなので省略して、可視化の結果を示します。
「こと」が1位に来ていたり、数字の「1」「2」「3」が入っているのが気になりますが、先ほどよりも若干キーワードっぽい結果になっています。termextractを使った専門用語抽出
次に、termextractを使って専門用語を抽出してみます。
こちらを参考に、形態素解析方式をやってみました。データ整形
termextractの入力形式はMeCabの形態素解析の出力結果です。
リストabstractsをMeCabで解析し、各要素の解析結果を連結して改行で区切った形式にします。python# mecabの形式で渡す mecab_abstracts = [] for abstract in abstracts: mecab_abstracts.append(tagger.parse(abstract)) input_text = '/n'.join(mecab_abstracts)
termextractで解析
コードはほぼ全面的にこちらのものです。
pythonimport termextract.mecab import termextract.core word_list = [] value_list = [] frequency = termextract.mecab.cmp_noun_dict(input_text) LR = termextract.core.score_lr(frequency, ignore_words=termextract.mecab.IGNORE_WORDS, lr_mode=1, average_rate=1 ) term_imp = termextract.core.term_importance(frequency, LR) # 重要度が高い順に並べ替えて出力 data_collection = collections.Counter(term_imp) for cmp_noun, value in data_collection.most_common(): word = termextract.core.modify_agglutinative_lang(cmp_noun) word_list.append(word) value_list.append(value) print(word, value, sep="\t")
スコアが何を意味しているのかはよく理解していませんが、それらしき語が表示されています。
これも可視化してみます。可視化
コードは上と同じなので省略します。
「光化学系II」「形質転換体」「鞭毛運動」「遺伝子群」など、よりそれらしい単語がとれています。
「クラミドモナス」と「緑藻クラミドモナス」、「ダイニン」と「軸糸ダイニン」が異なる項目になっているのは、まあしかたないですかね。まとめ
科研費データベースの検索結果からキーワード抽出しました。MeCabで形態素解析のみした結果より、termextractの方がよりキーワードらしい単語抽出ができました。
おまけ:GiNZA
ついでにGiNZAの固有表現抽出も試してみました。
pythonimport spacy from spacy import displacy nlp = spacy.load('ja_ginza') doc = nlp(abstracts[0]) #固有表現抽出の結果の描画 displacy.render(doc, style="ent", jupyter=True)
固有表現じゃないのでしかたないですが、「ユニコンタ」「バイコンタ」「繊毛」「クラミドモナス」など、とってほしい表現がとれてないですね。そしてやっぱり「9+2構造」はとれない。
参考










- 投稿日:2020-10-24T18:50:02+09:00
駐車場の満空情報の識別をWebカメラとラズパイで入手した画像と深層学習を利用して実現してみようと思った話。
はじめに
事務所の窓から正面にある駐車場の映像を5分ごとに撮影して動画を作って遊んでいました。
はじめの頃はそれだけで面白かったのですが、だんだんとつまらくなってきて「何か他にできることないかな〜」って考えていたら表題のようなことを思いつきました。
この結果をWebサイトで常に確認できるようにしてみました。
上述にもあるとおり、写真は5分周期で更新されます。準備
まず、以下のフォルダを作成。
img 0-多い 1-少ない 2-ガラガラ models次に、img以下のそれぞれのフォルダに分類したい画像を保存。
学習
# ライブラリ読込 import glob import cv2 from matplotlib import pyplot as plt import numpy as np import keras import tensorflow as tf from sklearn import model_selection from keras.utils.np_utils import to_categorical from keras.layers import Activation, Conv2D, Dense, Flatten, MaxPooling2D, Dropout from keras.models import Sequential import random # ラベルデータ作成 labels = [] for i in range(3): labels.append("{}-".format(i)) # 画像ファイル数の取得 n = [] for l in labels: files = glob.glob("img/{}*/*.jpg".format(l)) print("{} : {}".format(l, len(files))) n.append(len(files)) # 画像ファイル読込 imgX = [] y = [] k = 0 for l in labels: print(l) files = glob.glob("img/{}*/*.jpg".format(l)) files.sort() print(len(files), end=" -> ") j = int(min(n) * 1.5) if j > len(files): j = len(files) files = random.sample(files, j) print(len(files)) i = 0 for f in files: img = cv2.imread(f) h, w, c = img.shape img = img[int(h/2):h, :] img = cv2.resize(img, (100, 100)) imgX.append(img) y.append(k) print("\r{}".format(i), end="") i += 1 print() k += 1 # 画像データを配列データに変換 X = np.array(imgX) X = X / 255 # 学習・検証用データに分割 test_size = 0.2 X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=test_size, random_state=42) X_valid, X_test, y_valid, y_test = model_selection.train_test_split(X_test, y_test, test_size=.5, random_state=42) y_train = to_categorical(y_train) y_valid = to_categorical(y_valid) y_test = to_categorical(y_test) # 学習モデルの作成 input_shape = X[0].shape model = Sequential() model.add(Conv2D( input_shape=input_shape, filters=64, kernel_size=(5, 5), strides=(1, 1), padding="same", activation='relu')) model.add(MaxPooling2D(pool_size=(4, 4))) model.add(Conv2D( filters=32, kernel_size=(5, 5), strides=(1, 1), padding="same", activation='relu')) model.add(Conv2D( filters=32, kernel_size=(5, 5), strides=(1, 1), padding="same", activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Conv2D( filters=16, kernel_size=(5, 5), strides=(1, 1), padding="same", activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten()) model.add(Dense(1024, activation='sigmoid')) model.add(Dense(2048, activation='sigmoid')) model.add(Dense(len(labels), activation='softmax')) model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) # 学習 history = model.fit( X_train, y_train, batch_size=400, epochs=200, verbose=1, shuffle=True, validation_data=(X_valid, y_valid)) score = model.evaluate(X_test, y_test, batch_size=32, verbose=0) print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score)) # 学習済みモデルの保存 mdlname = "models/mdl_parking_status.h5" model.save(mdlname)途中の出力は割愛して、学習結果は以下のとおり。
validation loss:0.15308915078639984 validation accuracy:0.9653465151786804学習の過程をグラフで確認すると以下のとおり。
なんとなく学習できてそう。
識別
以下のスクリプトで識別。
# ライブラリ読込 import glob import cv2 from matplotlib import pyplot as plt import numpy as np import requests import keras # 学習済みモデルの読込 mdlname = "models/mdl_parking_status.h5" model = keras.models.load_model(mdlname) # ラベルデータの作成 labels = [] for lbl in glob.glob("img/*"): labels.append(lbl.split("/")[-1]) labels.sort() # 画像読込 imgX = [] img_url = "http://160.16.98.190/parking" req = requests.get(img_url) img_org = np.fromstring(req.content, dtype='uint8') img_org = cv2.imdecode(img_org, 1) h, w, c = img_org.shape img = img_org[int(h/2):h, :] img = cv2.resize(img, (100, 100)) imgX.append(img) X = np.array(imgX) X = X / 255 # 識別 pred = model.predict(X, batch_size=32) m = np.argmax(pred[0]) # 結果表示 print(pred) print(labels[m])取得した画像はこちら。
識別結果は以下のとおり。
[[9.2753559e-01 7.2361618e-02 1.0272356e-04]] 0-多い...多分できた!


- 投稿日:2020-10-24T18:33:38+09:00
numpyのint64をpythonのintに変換する
- 投稿日:2020-10-24T17:40:18+09:00
tweepy のapi.search て完璧じゃないの!?
はじめに
僕の生きる糧である女優の松岡茉優さんの最新画像を自動取得すべく、LINE Bot の作りました。
もしよかったらQRコードで追加してやってください。僕が喜びます。
詳しいコードは以下の記事もしくは GitHub をご覧ください。
[毎日定時に推し画像が送られてくるLINE Bot を作った]
https://qiita.com/soma_sekimoto/items/4c01d0ab890024d6f87cGitHub
https://github.com/SomaSekimoto/MayuDeliveryこの画像送信bot の画像取得元が、twitter になっています。(なぜなら情報が早いから。つまり最新の画像も出るのが早い。)
tweepy を使って実装して、つい今日まで満足していました。tweepy 神だなぁと思っていました。
あ、ちなみにもうお気づきかもしれませんが、これは技術的なことあんまり書かないです。
tweepy で api.search 使っていたのだが何かおかしい。。。
最近ふと思いついて、
コード内で記述している 検索ワードを、実際の twitter の検索窓にも入力して全く同じ検索部分のコード
q = f"#松岡茉優 OR 松岡茉優 -'松岡茉優似' filter:media exclude:retweets min_faves:10 since:{yesterday}" tweets = tweepy.Cursor( api.search, q=q, tweet_mode='extended', include_entities=True).items(20)ドキュメント読んでみたらちゃんと書いてあった。
https://github.com/tweepy/tweepy/blob/master/docs/api.rst
Please note that Twitter's search service and, by extension, the Search API is not meant to be an exhaustive source of Tweets. Not all Tweets will be indexed or made available via the search interface.
要は、
「Search メソッドで全部のツイートを取得するわけではないですよ!!」
ってことだと僕は解釈しました。
そもそもの tweepy の仕様だったのか。。。。
でもどのツイートが取得できてどれができないのか知りたい。知りたい。
result_type="mixed" で取りたかったツイートを取得できた。
取得したかったツイートが取得できた。
修正前
q = f"#松岡茉優 OR 松岡茉優 -'松岡茉優似' filter:media exclude:retweets min_faves:10 since:{yesterday}" tweets = tweepy.Cursor( api.search, q=q, tweet_mode='extended', include_entities=True).items(20)修正後
q = f"#松岡茉優 OR 松岡茉優 -'松岡茉優似' filter:media exclude:retweets min_faves:10 since:{yesterday}" tweets = tweepy.Cursor( api.search, q=q, tweet_mode='extended', result_type="mixed", include_entities=True).items(20)result_type で設定できる値は、三種類あって
"recent": 時系列で最新のツイートを検索
"popular": 人気のあるツイートを検索(何を基準に人気か判断しているかは不明)
"mixed": 上記を混ぜたもの。
となっている。さらに、調べていくと、デフォルトだと "recent" が設定されていることがわかった。
以下記事参照
https://note.com/katomaru0510/n/n8797618a68ce
https://qiita.com/mima_ita/items/ba59a18440790b12d97eおわりに
完全に自分のやらかしでした。
もちろん result_type の存在も知っていましたが、デフォルトだと そういったツイートの種類にかかわらず全部取得してきてくれるものだと勘違いしていました。
とりあえず今回は解決しましたが、根本的にtweepy の api.search について解明できたわけではないので、これからも tweepy 使いながら理解を深めていきます。


- 投稿日:2020-10-24T16:54:57+09:00
PythonのWebスクレイピングで卓球世界ランカーを抽出してみた
記録用アウトプット
初めて、PythonのWebスクレイピングを使ってみた。
卓球王国WEBのページから2020/10/24現在の世界ランキングを抽出してみた。プログラム
Webページに記載されている世界ランク、氏名、国籍を全員分出力する。
また、日本人のみ抽出して、別ファイルに出力する。tabletenissWorldRank.pyimport requests from bs4 import BeautifulSoup # URL url = 'https://world-tt.com/ps_player/worldrank.php' # responseオブジェクト作成 response = requests.get(url) # 文字化け防止 response.encoding = response.apparent_encoding # BeautifulSoupオブジェクトの作成 soup = BeautifulSoup(response.text, 'html.parser') # divタグを取得 ranks = soup.find_all('div', class_='Position Entry') names = soup.find_all('div', class_='Name Entry') countries = soup.find_all('div', class_='Country Entry') # テキストファイルに出力 i = 0 with open('ranks.txt', 'w') as file_ranks: with open('japanese.txt', 'w') as file_japanese: while i < len(ranks): # print(i) # print(ranks[i].text) if i == 0: file_ranks.write('男子\n') file_japanese.write('男子\n') if i == len(ranks) / 2: file_ranks.write('\n女子\n') file_japanese.write('\n女子\n') if countries[i].text == "日本": file_japanese.write(ranks[i].text + ' ' + names[i].text + '\n') file_ranks.write(ranks[i].text + ' ' + names[i].text + ' ' + countries[i].text + '\n') i += 1出力結果
ranks.textの出力結果は長くなるため、省略する。
japanese.text男子 4位 張本智和 13位 丹羽孝希 17位 水谷隼 35位 宇田幸矢 45位 神巧也 48位 森薗政崇 女子 2位 伊藤美誠 9位 石川佳純 11位 平野美宇 17位 佐藤瞳 22位 加藤美優 29位 早田ひな 36位 橋本帆乃香 37位 芝田沙季 49位 木原美悠感想
Webページのレイアウト頼りになっているから、レイアウトが変わったら抽出が難しくなる。
テキストファイルに出力する際の、条件分岐はもっといい方法があるのだろう。
- 投稿日:2020-10-24T15:50:03+09:00
Python 3.10 からは inspect.signature() が返す形が typing.get_type_hints() ベースになる模様です
今日気づいたのですが、Python 3.10 の inspect モジュールでは
typing.get_type_hints()を使って型を解釈するようになりました。該当のコミットはこちらです。これは Python 3.10 からデフォルトで有効になるアノテーションの遅延評価に関連する修正のようです。
obj.__annotations__に詰まっている型アノテーション情報が文字列となるので、typing.get_type_hints()に任せるのが適当であるという判断でしょう。
この変更により、単にobj.__annotations__を参照していたinspect.signature()の型情報が、もう一歩踏み込んだ解析結果に切り替わるということになります。たとえば、Python 3.9 では次の
hello()関数の引数nameはstr型と扱われています。$ python3.9 Python 3.9.0 (default, Oct 24 2020, 15:41:29) [Clang 11.0.3 (clang-1103.0.32.59)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> def hello(name: str = None): ... print("Hello ", name) ... >>> import inspect >>> inspect.signature(hello) <Signature (name: str = None)>一方、Python 3.10 (開発中)では
Optional[str]型とみなされます。デフォルト引数がNoneであることを見て、より適した型を返すようになっているわけです。$ python3.10 Python 3.10.0a1+ (heads/master:805ef73, Oct 24 2020, 15:07:19) [Clang 11.0.3 (clang-1103.0.32.59)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> def hello(name: str = None): ... print("Hello ", name) ... >>> import inspect >>> inspect.signature(hello) <Signature (name: Optional[str] = None)>ちなみに、実行時に名前解決ができない場合(
typing.TYPE_CHECKINGで実行時は import していない場合など) はこれまで通りobj.__signature__を参照するため、アノテーションによっては解釈結果が変化します。$ python3.10 Python 3.10.0a1+ (heads/master:805ef73, Oct 24 2020, 15:07:19) [Clang 11.0.3 (clang-1103.0.32.59)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> def hello(name: Unknown, age: int = None): pass ... >>> import inspect >>> inspect.signature(hello) <Signature (name: 'Unknown', age: 'int' = None)>このケースでは
Unknown型が解決できないため、引数ageの型はOptional[int]ではなく、単なるintになります。
- 投稿日:2020-10-24T14:18:56+09:00
SQLのLIKE句を、pandas(python)のqueryメソッドのstr.contains()を使って合致するデータの抽出を行って見た
はじめに
最近、プライベートでデータ分析のツールを作成している関係でpandasというpython外部ライブラリを活用している。が、いざ使って見ると、「pandas?なにそれかわいいの?」と動物のパンダ?を連想させるヤバい思考に行きつつある状況になる。
これはまずいと感じ、投稿者はpandasを探し求める旅に出る。
この記事は、pandasを飼いならすためにpandasをSQLっぽく考えるというデータサイエンス初学者に向けた記事となります。そもそもpandasとは何か
pandasとは、構造化された(表形式、多次元、潜在的に不均質)データと時系列データを簡単かつ直感的に操作できるように設計された高速で柔軟な表現力のあるデータ構造を提供するPythonパッケージで、実際的な実世界のデータ分析を行うための基本的な高レベルのビルドを行う事が可能なツールです。
要は、表データをpythonを使っていい感じに処理して目的のデータ抽出するツールです。実践
準備
今回は下記の表データ【store】を用いてpandas攻略を行います。(表データはCSV形式)
※データは長いので冒頭部分のみ表示
参考データ:データサイエンス100本ノック
https://github.com/The-Japan-DataScientist-Society/100knocks-preprocessまた、今回はpandasを使用するため、コードは下記のように予め準備しておきます。
pythonimport pandas as pd df_store = pd.read_sql('storeのCSVファイルのパス', sep=',')本題
タイトルにある通り、今回はSQLのLIKE句をpandasを使って再現します
問題:店舗データフレーム(df_store)から横浜市の店舗(address)だけ全項目表示せよ。
目的:条件に一致する対象行のデータ抽出する事
解答
解答を記述するとこんな感じになります。
pandas(python)df_store.query("address.str.contains('横浜市')", engine='python')そして、図に表すとこんな感じになります。
これをSQL文で表すとこんな感じになります。
SQLselect * from store where address LIKE '%横浜市%';解説
それでは、ここから解説していきます。
- pandasのqueryメソッドを活用する
まず、pandasのqueryメソッドを用いてSQLに当たるWHERE文を定義します※補足:pandasのqueryメソッドに関する詳細の記事は下記を参考にしてみて下さい。
https://qiita.com/syuki-read/items/9a57b78f6a577c2fbefe形式を表現するとこんな感じです。
pandas(python)df_store.query('指定したい条件内容')これをSQLで考えると、こんな感じになります。
SQLselect * from store where '条件内容';FROM句:データベース内の指定する表を選択する
SELECT文:指定した表から抽出すべき列を選択する
- SQLのLIKE句を、str.contains()で表現する
そしてここから、pandasのqueryメソッドのstr.contains()を用いて、(SQLのLIKE句のように)対象の列(address)から条件に合致するカラムの選択を行います。str.contains()の内容を説明すると、これは()内に含まれる文字列を抽出する事を意味します。実際に書いてみるとこんな感じになります。
pandas(python)df_store.query("address.str.contains('横浜市')", engine='python')ここでは、storeテーブルのaddress列の文字列の中に「横浜市」が含まれているカラムを抽出するという事を指します。また、後ろに書いてある「engine='python'」は文字列型(str型)のメソッドではお約束事して、必要となるためこちらも忘れずに付ける事に注意しましょう。
これをSQLで考えるとこんな感じになります。
SQLselect * from store where address LIKE '%横浜市%';そして、図を表すとこんな感じになります。
- 全体図
全体をまとめると、こんな感じになります。
コラム
今回はstr.contains()でデータ抽出を行いましたが、文字列(str型)のデータ抽出は他にもこんなのあったりします。
- str.contains(): 特定の文字列を含む
- str.endswith(): 特定の文字列で終わる
- str.startswith(): 特定の文字列で始まる
- str.match(): 正規表現のパターンに一致する
データ抽出は状況によって変化するため、柔軟に使い分けていく事が大事です。
まとめ
今回はpandasを使って、SQLのLIKE句の表現を行いました。pandasはデータベース及びSQLを意識したpythonライブラリなため、普段からSQLを意識するとかなり使いやすいツールだと改めて感じます。また、特定の命令文を指示する時、SQLがいくつものパターンがあるように、pandasにも多様なパターンが存在すると、pandasを活用して日々実感を持ちます。
終わりに
今回、利活用したデータはデータサイエンス協会(DS協会)の「データサイエンス100本ノック」を参考にしております。こちらはJupyter notebookを使用しているので、より見やすいデータが抽出されます。
この記事を読んで、「実際に実装してみたい!!」という方がおりましたら、下記にその実装に関する記事を上げているので、良かったそちらの記事を参考に是非実装してみて下さい。データサイエンス初学者にむけた、データサイエンス100本ノックを実装する方法:
https://qiita.com/syuki-read/items/714fe66bf5c16b8a7407




- 投稿日:2020-10-24T14:18:56+09:00
SQLのLIKE句を、pandas(python)のqueryメソッドのstr.contains()を使って合致するデータ抽出を行って見た
はじめに
最近、プライベートでデータ分析のツールを作成している関係でpandasというpython外部ライブラリを活用している。が、いざ使って見ると、「pandas?なにそれかわいいの?」と動物のパンダ?を連想させるヤバい思考に行きつつある状況になる。
これはまずいと感じ、投稿者はpandasを探し求める旅に出る。
この記事は、pandasを飼いならすためにpandasをSQLっぽく考えるというデータサイエンス初学者に向けた記事となります。そもそもpandasとは何か
pandasとは、構造化された(表形式、多次元、潜在的に不均質)データと時系列データを簡単かつ直感的に操作できるように設計された高速で柔軟な表現力のあるデータ構造を提供するPythonパッケージで、実際的な実世界のデータ分析を行うための基本的な高レベルのビルドを行う事が可能なツールです。
要は、表データをpythonを使っていい感じに処理して目的のデータ抽出するツールです。実践
準備
今回は下記の表データ【store】を用いてpandas攻略を行います。(表データはCSV形式)
※データは長いので冒頭部分のみ表示
参考データ:データサイエンス100本ノック
https://github.com/The-Japan-DataScientist-Society/100knocks-preprocessまた、今回はpandasを使用するため、コードは下記のように予め準備しておきます。
pythonimport pandas as pd df_store = pd.read_sql('storeのCSVファイルのパス', sep=',')本題
タイトルにある通り、今回はSQLのLIKE句をpandasを使って再現します
問題:店舗データフレーム(df_store)から横浜市の店舗(address)だけ全項目表示せよ。
目的:条件に一致する対象行のデータ抽出する事
解答
解答を記述するとこんな感じになります。
pandas(python)df_store.query("address.str.contains('横浜市')", engine='python')そして、図に表すとこんな感じになります。
これをSQL文で表すとこんな感じになります。
SQLselect * from store where address LIKE '%横浜市%';解説
それでは、ここから解説していきます。
- pandasのqueryメソッドを活用する
まず、pandasのqueryメソッドを用いてSQLに当たるWHERE文を定義します※補足:pandasのqueryメソッドに関する詳細の記事は下記を参考にしてみて下さい。
https://qiita.com/syuki-read/items/9a57b78f6a577c2fbefe形式を表現するとこんな感じです。
pandas(python)df_store.query('指定したい条件内容')これをSQLで考えると、こんな感じになります。
SQLselect * from store where '条件内容';FROM句:データベース内の指定する表を選択する
SELECT文:指定した表から抽出すべき列を選択する
- SQLのLIKE句を、str.contains()で表現する
そしてここから、pandasのqueryメソッドのstr.contains()を用いて、(SQLのLIKE句のように)対象の列(address)から条件に合致するカラムの選択を行います。str.contains()の内容を説明すると、これは()内に含まれる文字列を抽出する事を意味します。実際に書いてみるとこんな感じになります。
pandas(python)df_store.query("address.str.contains('横浜市')", engine='python')ここでは、storeテーブルのaddress列の文字列の中に「横浜市」が含まれているカラムを抽出するという事を指します。また、後ろに書いてある「engine='python'」は文字列型(str型)のメソッドではお約束事して、必要となるためこちらも忘れずに付ける事に注意しましょう。
これをSQLで考えるとこんな感じになります。
SQLselect * from store where address LIKE '%横浜市%';そして、図を表すとこんな感じになります。
- 全体図
全体をまとめると、こんな感じになります。
コラム
今回はstr.contains()でデータ抽出を行いましたが、文字列(str型)のデータ抽出は他にもこんなのあったりします。
- str.contains(): 特定の文字列を含む
- str.endswith(): 特定の文字列で終わる
- str.startswith(): 特定の文字列で始まる
- str.match(): 正規表現のパターンに一致する
データ抽出は状況によって変化するため、柔軟に使い分けていく事が大事です。
まとめ
今回はpandasを使って、SQLのLIKE句の表現を行いました。pandasはデータベース及びSQLを意識したpythonライブラリなため、普段からSQLを意識するとかなり使いやすいツールだと改めて感じます。また、特定の命令文を指示する時、SQLがいくつものパターンがあるように、pandasにも多様なパターンが存在すると、pandasを活用して日々実感を持ちます。
終わりに
今回、利活用したデータはデータサイエンス協会(DS協会)の「データサイエンス100本ノック」を参考にしております。こちらはJupyter notebookを使用しているので、より見やすいデータが抽出されます。
この記事を読んで、「実際に実装してみたい!!」という方がおりましたら、下記にその実装に関する記事を上げているので、良かったそちらの記事を参考に是非実装してみて下さい。データサイエンス初学者にむけた、データサイエンス100本ノックを実装する方法:
https://qiita.com/syuki-read/items/714fe66bf5c16b8a7407

- 投稿日:2020-10-24T11:55:21+09:00
Django UUIDFieldのdefaultはuuid.uuid4()ではなく、uuid.uuid4と表記する
結論?
タイトル通りです。
Django UUIDFieldのdefaultはuuid.uuid4()ではなく、uuid.uuid4と表記しましょう。
ハマります。困りごと?
Djangoで画面側Formからのデータ登録です。
一回目は、登録がうまくいく。
二回目以降は、登録時にエラーが出てしまう。
runserverでサーバを動かし直すと、登録できた。
今考えるとこれが大ヒントだった。エラー内容⚡
エラーは以下です。
「
created_atがNULL制約に違反しているYo!」
...まぁ、エラーの内容は全く関係なかったんですが。django.db.utils.IntegrityError: NOT NULL constraint failed: iine_room.created_atテーブル定義?
「
created_atがNULL制約に違反しているYo!」
テーブル定義は以下。
created_at = models.DateTimeField(auto_now_add=True)にしているから、自動で更新されるはずなんだけど。。models.pyclass Room(models.Model): id = models.UUIDField('部屋ID', primary_key=True, default=uuid.uuid4()) name = models.CharField('部屋名', max_length=100) start_at = models.DateTimeField('開始時刻', default=None, blank=True, null=True) end_at = models.DateTimeField('終了時刻', default=None, blank=True, null=True) created_at = models.DateTimeField(auto_now_add=True) # 指定している。 updated_at = models.DateTimeField(auto_now=True)デバッグしていく??
デバッグして中身を追っていくYo
views.pydef post(self, request, *args, **kwargs): self.object = None form = self.get_form() if form.is_valid(): self.form_valid(form)
self.form_valid(form)を追うよedit.pydef form_valid(self, form): """If the form is valid, save the associated model.""" self.object = form.save() return super().form_valid(form)
self.object = form.save()を追うよforms\models.pydef save(self, commit=True): """ Save this form's self.instance object if commit=True. Otherwise, add a save_m2m() method to the form which can be called after the instance is saved manually at a later time. Return the model instance. """ if self.errors: raise ValueError( "The %s could not be %s because the data didn't validate." % ( self.instance._meta.object_name, 'created' if self.instance._state.adding else 'changed', ) ) if commit: # If committing, save the instance and the m2m data immediately. self.instance.save() self._save_m2m() else: # If not committing, add a method to the form to allow deferred # saving of m2m data. self.save_m2m = self._save_m2m return self.instance (↓省略)
self.instance.save()を追うよmodels\base.pydef _save_table(self, raw=False, cls=None, force_insert=False, force_update=False, using=None, update_fields=None): """ Do the heavy-lifting involved in saving. Update or insert the data for a single table. """ meta = cls._meta non_pks = [f for f in meta.local_concrete_fields if not f.primary_key] if update_fields: non_pks = [f for f in non_pks if f.name in update_fields or f.attname in update_fields] pk_val = self._get_pk_val(meta) if pk_val is None: pk_val = meta.pk.get_pk_value_on_save(self) setattr(self, meta.pk.attname, pk_val) pk_set = pk_val is not None (↓省略)
pk_val = self._get_pk_val(meta)pk_valは付与されているよな?(確認)
pk_val = 18d19958-3e11-4444-ac51-3707ba366440付与されているね。
あれ、もしかして。
主キーが既存のものと、かぶってたりしてない?
調査してみる。>>> Room.objects.filter(pk='18d19958-3e11-4444-ac51-3707ba366440') <QuerySet [<Room: 10/24 11:26:09: <te> 18d19958-3e11-4444-ac51-3707ba366440>]>すでにおるやんけ。
見事に被ってる。
UUIDが被るという奇跡を起こしてしまったか!?ちなみにUUIDが衝突する確率は?
たとえば、UUID を 3×10173×1017 回くらいつくると、1 % (p=0.01p=0.01) の確率で衝突するってことですね。
https://qiita.com/kiririmode/items/9ddf7f2aec6e8ba4dc7fいや、ありえないやん。
解決へ✅
UUIDが起動時にしか生成されていない?
もう一回モデルを見てみる。models.pyclass Room(models.Model): id = models.UUIDField('部屋ID', primary_key=True, default=uuid.uuid4()) name = models.CharField('部屋名', max_length=100) start_at = models.DateTimeField('開始時刻', default=None, blank=True, null=True) end_at = models.DateTimeField('終了時刻', default=None, blank=True, null=True) created_at = models.DateTimeField(auto_now_add=True) updated_at = models.DateTimeField(auto_now=True)
default=uuid.uuid4()。
しっかりと表記してる。(と思い込んでいる)
一旦django default=uuid.uuid4()でぐぐってみる。...
default=uuid.uuid4と書いてある。
コード内の表記はdefault=uuid.uuid4()
あ、カッコが不要やん。
起動時に実行されてdefault='18d19958-3e11-4444-ac51-3707ba366440'のような形になっていたようだ。結論?
Django UUIDFieldのdefaultは
uuid.uuid4()ではなく、uuid.uuid4と表記しましょう。関数のカッコには気をつけましょう。
関数によって毎回値が変わるものにはカッコはつけない!エラー内容だけを頼りにするとその内容が正しくなかったときにハマります。
エラー内容は鵜呑みにしない!
- 投稿日:2020-10-24T11:36:35+09:00
Pythonで解く【初中級者が解くべき過去問精選 100 問】(056 - 059 最短経路問題:ダイクストラ法)
1. 目的
初中級者が解くべき過去問精選 100 問をPythonで解きます。
すべて解き終わるころに水色になっていることが目標です。本記事は「056 - 059 最短経路問題:ダイクストラ法」です。
2. 総括
ダイクストラ法とワーシャルフロイド法についてはYouTubeのAbdul Bariのチャンネルを見て理解しました。
とても分かりやすく、動画を見てアルゴリズムを理解してから問題を解いたのでスムーズに進めることができました。3. 本編
056 - 059 最短経路問題:ダイクストラ法
056. GRL_1_A - 単一始点最短経路
回答
import heapq #--------------------------------------[入力受取]--------------------------------------# INF = float('inf') V, E, r = map(int, input().split()) graph = [[] for _ in range(V)] for _ in range(E): s, t, d = map(int, input().split()) graph[s].append((t, d)) #--------------------------------------[初期値]--------------------------------------# dp = [INF] * V visited = [-1] * V dp[r] = 0 h = [(0, r)] #--------------------------------------[探索開始]--------------------------------------# while h: d, s = heapq.heappop(h) # costが小さい順に取り出す if visited[s] == 1: continue visited[s] = 1 targets = graph[s] for target in targets: t, d = target if dp[t] > dp[s] + d: dp[t] = dp[s] + d heapq.heappush(h, (dp[t], t)) #--------------------------------------[回答]--------------------------------------# for answer in dp: if answer == INF: print('INF') else: print(answer)ヒープで小さい順から取り出します。
アルゴリズムは3.6 Dijkstra Algorithm - Single Source Shortest Path - Greedy Methodがわかりやすいです。
この動画で解説されている通りコードに落としてやると回答となります。
057. JOI 2008 予選 6 - 船旅
回答
import heapq def cal_cost(graph, n, start, end): #--------------------------------------[初期値]--------------------------------------# dp = [INF] * (n + 1) visited = [-1] * (n + 1) dp[start] = 0 h = [(0, start)] #--------------------------------------[探索開始]--------------------------------------# while h: _, s = heapq.heappop(h) # sはstart, eはend if visited[s] == 1: continue visited[s] = 1 targets = graph[s] for target in targets: cost, e = target if dp[e] > dp[s] + cost: dp[e] = dp[s] + cost heapq.heappush(h, (dp[e], e)) return dp[end] if __name__ == "__main__": INF = float('inf') n, k = map(int, input().split()) # nは島の数、kは以下の入力の行数 graph = [[] for _ in range(n+1)] # 1インデックス answer_list = [] for _ in range(k): info_list = list(map(int, input().split())) if info_list[0] == 1: island_1, island_2, cost = info_list[1], info_list[2], info_list[3] graph[island_1].append((cost, island_2)) graph[island_2].append((cost, island_1)) else: start, end = info_list[1], info_list[2] answer = cal_cost(graph, n, start, end) answer_list.append(answer) for answer in answer_list: if answer == INF: print(-1) else: print(answer)問題56を少しだけ変えた問題ですが、基本的には行っていることは同じです。
とくにcal_cost()の中身はほぼ同じなので、入力の受け取りだけ、気を付けてやれば解けます。
058. JOI 2016 予選 5 - ゾンビ島
回答
from collections import deque import heapq #--------------------------------------[初期値]--------------------------------------# INF = float('inf') N, M, K, S = map(int, input().split()) # N個の町、M本の道路、K個がゾンビに支配、ゾンビからS本以内は危険な町 P, Q = map(int, input().split()) # 危険じゃない場合はP円、危険な場合はQ円 zombie_towns = [int(input()) for _ in range(K)] graph = [[] for _ in range(N+1)] for _ in range(M): townA, townB = map(int, input().split()) graph[townA].append((INF, townB)) graph[townB].append((INF, townA)) #--------------------------------------[BFSでゾンビ町からの距離を探索]--------------------------------------# # zombie_townsからS本以内の危険な町を探すためのBFS visited = [INF] * (N+1) q = deque() for zombie_town in zombie_towns: q.append(zombie_town) visited[zombie_town] = 0 while q: start_town = q.popleft() for target in graph[start_town]: _, end_town = target if visited[end_town] != INF: continue q.append(end_town) visited[end_town] = visited[start_town] + 1 # zombie_townsからS本以内の危険な町についてsetとして記録しておく cost_Q = set() for i in range(1, N+1): if visited[i] <= S: cost_Q.add(i) #--------------------------------------[heapqで最短距離を探索]]--------------------------------------# # heapをまわす dp = [INF] * (N+1) visited2 = [-1] * (N+1) dp[1] = 0 h = [(0, 1)] answer = 0 while h: cost, s = heapq.heappop(h) # sはstart, eはend if visited2[s] == 1: continue if s in zombie_towns: # ゾンビがいる町は行かない continue visited2[s] = 1 targets = graph[s] for target in targets: _, e = target if e in cost_Q: # zombie_townsからS本以内の危険な町はQ, それ以外はP cost = Q else: cost = P if dp[e] > dp[s] + cost: dp[e] = dp[s] + cost heapq.heappush(h, (dp[e], e)) if e == N: # 目的地がでてきたらそこでbreak answer = dp[s] # 答えは目的地の一つ前で記録したコスト break if answer != 0: break print(answer)実装が重いです。
ただ、やることを分解してやると、いままで解いてきた問題の組み合わせなので、理解はしやすいです。
問題は大きく二つに分けることができ、「ゾンビの町からの距離を求める」という問題と「最小コストの道のりを求める」という問題です。「ゾンビの町からの距離を求める」ためには
BFSでゾンビからの最短距離を求めればよいです。
「最小コストの道のりを求める」ためには、heapqを使ってダイクストラ法を使えばよいです。
059. JOI 2014 予選 5 - タクシー
回答(TLE (pypyだとMLE))
from collections import deque import heapq #------------------[BFSで各点からそれぞれの目的地までの距離を求める]----------------------# def bfs(start, graph): visited = [-1] * N q = deque() q.append(start) visited[start] = 0 while q: s = q.popleft() targets = graph[s] for e in targets: if visited[e] != -1: continue visited[e] = visited[s] + 1 q.append(e) return visited if __name__ == "__main__": #------------------[入力]----------------------# INF = float('inf') N, K = map(int, input().split()) # N個の町、K本の道路 costs = [INF] * N counts = [0] * N for i in range(N): C, R = map(int, input().split()) costs[i] = C counts[i] = R graph = [[] for _ in range(N)] for _ in range(K): A, B = map(int, input().split()) A -= 1 B -= 1 graph[A].append(B) graph[B].append(A) #------------------[graphの再構築]]----------------------# graph2 = [[] for _ in range(N)] for start in range(N): end_list = bfs(start, graph) for end, count in enumerate(end_list): if counts[start] < count: continue if start == end: continue graph2[start].append((costs[start], end)) #回数制限内にいける箇所のみgraphに追加 #------------------[heapqで最短距離]]----------------------# dp = [INF] * N visited = [-1] * N dp[0] = 0 h = [(0, 0)] while h: _, s = heapq.heappop(h) if visited[s] == 1: continue visited[s] = 1 targets = graph2[s] for target in targets: cost, e = target if dp[e] > dp[s] + cost: dp[e] = dp[s] + cost heapq.heappush(h, (dp[e], e)) print(dp[N-1])上記コードだと、5ケースのうち2つが
TLEになります。pypyで提出すると5ケースのうち1つだけMLEとなります。大きな考え方は問題58と似ていて、
BFSを行ってからダイクストラ法を行います。方針を書くと、
1. すべての町を始点として、graphをもとにそれぞれの町に何手で行けるかをbfsで算定
2. この手数のリストをend_listに入れておく
3.end_listと入力値Rを記録したcountsを使ってgraph2を作成します
4.graph2を作れれば、あとはダイクストラ法を行うだけです。
問題文であたえられる
graphはbfsに使い、
再構築したgraph2はダイクストラ法で使う、
という点が、この問題の面白いところでしょうか。








- 投稿日:2020-10-24T11:34:09+09:00
Pythonで解く【初中級者が解くべき過去問精選 100 問】(053 - 055 動的計画法:その他)
1. 目的
初中級者が解くべき過去問精選 100 問をPythonで解きます。
すべて解き終わるころに水色になっていることが目標です。本記事は「053 - 055 動的計画法:その他」です。
2. 総括
「その他」とあるようにこの3問は今までの
dpとは少し志向(嗜好?)が違い、dpらしくないdpであると感じました。3. 本編
053 - 055 動的計画法:その他
053. DPL_1_D - 最長増加部分列
回答
import bisect n = int(input()) A = [int(input()) for _ in range(n)] dp = [A[0]] for i in range(1, n): if A[i] > dp[-1]: dp.append(A[i]) else: ind = bisect.bisect_left(dp, A[i]) dp[ind] = A[i] print(len(dp))二分探索とDPで解きます。
dpに昇順にAの要素を順に追加していきます。
具体的には、
- すべての
Aの要素A[i]についてdpの最後の要素より大きいものはdpに追加し- 大きくない場合は
dpの中にA[i]以上の数字が存在するので、A[i]で置き換える- できあがった
dpの長さが答え です。
054. AtCoder Beginner Contest 006 D - トランプ挿入ソート
回答
import bisect N = int(input()) C = [int(input()) for _ in range(N)] dp = [C[0]] # 初期値 for i in range(1, N): if C[i] > dp[-1]: dp.append(C[i]) else: ind = bisect.bisect_left(dp, C[i]) dp[ind] = C[i] print(N - len(dp))
- DPL_1_D - 最長増加部分列とほぼ同じです。 違いは最後の
print(N - len(dp))。 トランプを挿入する必要回数は、トランプの数から最長増加部分列の長さを引いた数になります。
055. AtCoder Beginner Contest 134 E - Sequence Decomposing
回答
import bisect from collections import deque N = int(input()) A = [int(input()) for _ in range(N)] dp = deque() dp.append(A[0]) for i in range(1, N): ind = bisect.bisect_left(dp, A[i]) if ind == 0: dp.appendleft(A[i]) else: dp[ind-1] = A[i] print(len(dp))上記2つの問題から少しだけ考え方をかえます。
上記2つの問題では、dpの最大値以上の要素をappendしていましたが、
今回は最小値以下の要素をappendleftしていきます。



- 投稿日:2020-10-24T11:18:29+09:00
Djangoの開発サーバーにブラウザからアクセス
Djangoとは??
よくある Web 開発タスクを迅速かつ簡単化するように設計されたフレームワーク
インストール
仮想環境作成し、アクティベート
仮想環境名はlesson1としました。$ conda create -n lesson1 $ source activate lesson1 $ conda install django対話モードでdjangoが入っているか確認
$ python >>> import django >>> print(django.get_version()) 3.1.2プロジェクト作成
djangoがインストールされていることが確認できたので早速プロジェクトを作っていきます。
プロジェクトとは??
プロジェクトとは、データベースの設定やDjango固有のオプション、アプリケーション固有の設定などといった、個々のDjangoインスタンスの設定を集めたものです。
早速startprojectで作っていきます。
$ django-admin startproject プロジェクト名$ django-admin startproject applsコマンドで中身を確認
manage.py appcdコマンドでappの中に入っていくと
以下のような構成になっていることがわかります。
- app
- init.py
- asgi.py
- settings.py
- urls.py
- wsgi.py
- manage.py
__init__.py asgi.py settings.py urls.py wsgi.py開発サーバーを起動
app に戻り簡易的な開発サーバーを起動します。
$ python manage.py runserver(lesson1) KiyoshinoMacBook-Pro:myblogapp kirinboy96$ python manage.py runserver Watching for file changes with StatReloader Performing system checks... System check identified no issues (0 silenced). You have 18 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions. Run 'python manage.py migrate' to apply them. October 24, 2020 - 01:28:39 Django version 3.1.2, using settings 'app.settings' Starting development server at http://127.0.0.1:8000/ Quit the server with CONTROL-C. [24/Oct/2020 01:29:10] "GET / HTTP/1.1" 200 16351 [24/Oct/2020 01:29:10] "GET /static/admin/css/fonts.css HTTP/1.1" 200 423 [24/Oct/2020 01:29:10] "GET /static/admin/fonts/Roboto-Light-webfont.woff HTTP/1.1" 200 85692 [24/Oct/2020 01:29:10] "GET /static/admin/fonts/Roboto-Regular-webfont.woff HTTP/1.1" 200 85876 [24/Oct/2020 01:29:10] "GET /static/admin/fonts/Roboto-Bold-webfont.woff HTTP/1.1" 200 86184 Not Found: /favicon.ico [24/Oct/2020 01:29:10] "GET /favicon.ico HTTP/1.1" 404 1975localhost:8000をブラウジングすると
DBのマイグレーション
マイグレーションでエラーが出ているので
一度コントロール+Cでサーバを止めます。
$ python manage.py migrate^C(lesson1) KiyoshinoMacBook-Pro:gapp kirinboy96$ python manage.py migrate Operations to perform: Apply all migrations: admin, auth, contenttypes, sessions Running migrations: Applying contenttypes.0001_initial... OK Applying auth.0001_initial... OK Applying admin.0001_initial... OK Applying admin.0002_logentry_remove_auto_add... OK Applying admin.0003_logentry_add_action_flag_choices... OK Applying contenttypes.0002_remove_content_type_name... OK Applying auth.0002_alter_permission_name_max_length... OK Applying auth.0003_alter_user_email_max_length... OK Applying auth.0004_alter_user_username_opts... OK Applying auth.0005_alter_user_last_login_null... OK Applying auth.0006_require_contenttypes_0002... OK Applying auth.0007_alter_validators_add_error_messages... OK Applying auth.0008_alter_user_username_max_length... OK Applying auth.0009_alter_user_last_name_max_length... OK Applying auth.0010_alter_group_name_max_length... OK Applying auth.0011_update_proxy_permissions... OK Applying auth.0012_alter_user_first_name_max_length... OK Applying sessions.0001_initial... OK再度開発用サーバーを起動
エラーが治ったのが確認できました。(lesson1) KiyoshinoMacBook-Pro:myblogapp kirinboy96$ python manage.py runserver Watching for file changes with StatReloader Performing system checks... System check identified no issues (0 silenced). October 24, 2020 - 01:37:07 Django version 3.1.2, using settings 'app.settings' Starting development server at http://127.0.0.1:8000/ Quit the server with CONTROL-C. [24/Oct/2020 01:37:10] "GET / HTTP/1.1" 200 16351日本語化
finderからsetting.pyを開きます。
106行目ぐらいにある言語と時間設定を日本語、日本標準時に書き換えておく。# LANGUAGE_CODE = 'en-us' LANGUAGE_CODE = 'ja' # TIME_ZONE = 'UTC' TIME_ZONE = 'Asia/tokyo'タイムゾーンと言語設定を変えて再度サーバーを起動すると
日本語に変わっているのが確認できました。


- 投稿日:2020-10-24T10:06:51+09:00
Django Todoリストで定期的に発生するものを予約する機能を実装する
・年末はクリスマスのお知らせを作成する
・お年玉の準備
・決算書作成
・給与処理
・不燃物のゴミ出し定期的(毎日・第2週の水曜日・○月○日)に発生するタスクをPlanとして登録し、作成処理を実施することでタスクを作成できる機能を作っています。
今は、マスタに登録したらタスクができるところまで作成しました。
マスタ登録画面は、色々入力制御を入れる必要がありそうなので後回しにしました(笑)modelsとviewsはこんな感じです。
models.pyfrom django.db import models from shisetsu.models import * from accounts.models import * from django.contrib.auth.models import User from django.db.models.signals import post_save from django.dispatch import receiver from django_currentuser.db.models import CurrentUserField from django_currentuser.middleware import ( get_current_user, get_current_authenticated_user) from django.core.validators import MaxValueValidator, MinValueValidator # ProxyModelを作って、__str__()をoverride class MyUser(User): def __str__(self): return '%s %s' % (self.last_name, self.first_name) class Meta: proxy = True # Create your models here. class TodoModel(models.Model): title = models.CharField(verbose_name='タイトル', max_length=100, null=True) memo = models.TextField(verbose_name='内容', null=True) priority = models.CharField( verbose_name='優先度', max_length=50, choices=(('danger','高'),('warning','中'),('Light','低')), ) shisetsu_name = models.ForeignKey(Shisetsu, verbose_name='施設',on_delete=models.SET_NULL,blank=True, null=True) user = models.ForeignKey(MyUser, on_delete=models.CASCADE, verbose_name='担当者',blank=True, null=True) plants_startdate = models.DateField(verbose_name='開始予定日', blank=True, null=True) plants_enddate = models.DateField(verbose_name='終了予定日', blank=True, null=True) enddate = models.DateField(verbose_name='終了日', blank=True, null=True) create_date = models.DateTimeField(verbose_name='登録日時', auto_now_add=True) create_user = CurrentUserField(verbose_name='登録者', editable=False, related_name='todo_create_articles') update_date = models.DateTimeField(verbose_name='更新日時', auto_now=True) update_user = CurrentUserField(verbose_name='更新者', editable=False, related_name='todo_update_articles') def __str__(self): return self.title class Todo_PlanModel(models.Model): title = models.CharField(verbose_name='タイトル', max_length=100, null=True) memo = models.TextField(verbose_name='内容', null=True) priority = models.CharField( verbose_name='優先度', max_length=50, choices=(('danger','高'),('warning','中'),('Light','低')), ) shisetsu_name = models.ForeignKey(Shisetsu, verbose_name='施設',on_delete=models.SET_NULL,blank=True, null=True) user = models.ForeignKey(MyUser, on_delete=models.CASCADE, verbose_name='担当者',blank=True, null=True) hyoujijyun = models.IntegerField(verbose_name='表示順',unique=True) cycle = models.CharField( verbose_name='周期', max_length=50, choices=(('daily','毎日'),('everyweek','毎週'),('monthly','毎月'),('day','月日'),('week','週曜日')), ) youbi = models.CharField( verbose_name='曜日', max_length=10, blank=True, null=True, choices=( ('0','月'), ('1','火'), ('2','水'), ('3','木'), ('4','金'), ('5','土'), ('6','日') ), ) month = models.CharField( verbose_name='月', max_length=10, blank=True, null=True, choices=( ('1','1月'), ('2','2月'), ('3','3月'), ('4','4月'), ('5','5月'), ('6','6月'), ('7','7月'), ('8','8月'), ('9','9月'), ('10','10月'), ('11','11月'), ('12','12月') ), ) week = models.IntegerField(verbose_name='何週目', blank=True, null=True, validators=[MaxValueValidator(5), MinValueValidator(1)]) day = models.IntegerField(verbose_name='日付', blank=True, null=True, validators=[MaxValueValidator(31), MinValueValidator(1)]) create_date = models.DateTimeField(verbose_name='登録日時', auto_now_add=True) create_user = CurrentUserField(verbose_name='登録者', editable=False, related_name='todo_plan_create_articles') update_date = models.DateTimeField(verbose_name='更新日時', auto_now=True) update_user = CurrentUserField(verbose_name='更新者', editable=False, related_name='todo_plan_update_articles') def __str__(self): return self.titleviews.pydef todoplancreatefunc(request): if request.method == 'GET': return render(request,'todo/todoplancreate.html') else: yearmonth = request.POST['yearmonth'] year = int(yearmonth[0:4]) month= int(yearmonth[5:7]) lastday = calendar.monthrange(year, month)[1] #毎日設定分を処理する todo_plan = Todo_PlanModel.objects.filter(cycle="daily").order_by("hyoujijyun") for todoplan in todo_plan: for i in range(lastday): sakuseiday = datetime.date(year,month,i + 1) new_object = TodoModel( title = todoplan.title, memo = todoplan.memo, priority = todoplan.priority, shisetsu_name = todoplan.shisetsu_name, user = todoplan.user, plants_startdate = sakuseiday, plants_enddate = sakuseiday, ) new_object.save() #毎週を処理する todo_plan = Todo_PlanModel.objects.filter(cycle="everyweek").order_by("hyoujijyun") for todoplan in todo_plan: for i in range(5): day = get_day_of_nth_dow(year, month, i + 1, int(todoplan.youbi)) if day != None: sakuseiday = datetime.date(year, month, day) new_object = TodoModel( title = todoplan.title, memo = todoplan.memo, priority = todoplan.priority, shisetsu_name = todoplan.shisetsu_name, user = todoplan.user, plants_startdate = sakuseiday, plants_enddate = sakuseiday, ) new_object.save() #毎月を処理する todo_plan = Todo_PlanModel.objects.filter(cycle="monthly").order_by("hyoujijyun") for todoplan in todo_plan: #対象月の月末を取得 lastday = calendar.monthrange(year, month)[1] #月末の日付より指定された日付が大きかったら置き換える if todoplan.day > lastday: day = lastday else: day = todoplan.day sakuseiday = datetime.date(year, month, day) new_object = TodoModel( title = todoplan.title, memo = todoplan.memo, priority = todoplan.priority, shisetsu_name = todoplan.shisetsu_name, user = todoplan.user, plants_startdate = sakuseiday, plants_enddate = sakuseiday, ) new_object.save() #月日付指定を処理する todo_plan = Todo_PlanModel.objects.filter(cycle="day").order_by("hyoujijyun") for todoplan in todo_plan: #対象月の月末を取得 lastday = calendar.monthrange(year, int(todoplan.month))[1] #月末の日付より指定された日付が大きかったら置き換える if todoplan.day > lastday: day = lastday else: day = todoplan.day sakuseiday = datetime.date(year, int(todoplan.month), day) print(sakuseiday) new_object = TodoModel( title = todoplan.title, memo = todoplan.memo, priority = todoplan.priority, shisetsu_name = todoplan.shisetsu_name, user = todoplan.user, plants_startdate = sakuseiday, plants_enddate = sakuseiday, ) new_object.save() #週曜日指定 todo_plan = Todo_PlanModel.objects.filter(cycle="week").order_by("hyoujijyun") for todoplan in todo_plan: day = get_day_of_nth_dow(year, month, todoplan.week, int(todoplan.youbi)) if day == None: day = lastday = calendar.monthrange(year, month)[1] sakuseiday = datetime.date(year, month, day) new_object = TodoModel( title = todoplan.title, memo = todoplan.memo, priority = todoplan.priority, shisetsu_name = todoplan.shisetsu_name, user = todoplan.user, plants_startdate = sakuseiday, plants_enddate = sakuseiday, ) new_object.save() messages = '処理が終了しました' context = { 'messages': messages, } return render(request,'todo/todoplancreate.html', context)これだと、データベースにすごくアクセスしてしまうので、改善していきたいと思いますが、動くものを改変するのには少し抵抗があります。ひとつひとつ処理が正しく動くをみながら作ったのが原因ですが…
まずは、毎日がうまくいくかなって感じで作ったのでひとつひとつで考えた結果でございます(笑)まずは、最初にPlanテーブルからすべてを取得したものを順番に処理する形に変えて、できればオブジェクトに追加していって最後に一気にSaveするといった形が理想なのかなって思っています。
マスタを登録します。
定期タスクを作成する前
レコードをすべて削除したので何も残っていないです
作成画面で処理を実行します
11月の第2週の木曜日としてタスクが作成されました!





- 投稿日:2020-10-24T08:22:30+09:00
【自動化】PythonでOutlookの予定を抜き出す
Outlookで予定と実績を管理しているけれど…
私の会社はメール文化なので、Outlookでメールをやり取りし、仕事や会議の予定もOutlookで管理しています。
また、日報や週報での実績報告のために、いつ何をどこまでやったかもOutlookの予定に記録しています。結果として、Outlookの予定表は予定と実績記録だらけで、目視で管理するのが面倒な状態になります。
週報にその日の業務実績を書く場合も、Outlookの予定表を書き写さないといけません。
私の業務はかなりマルチタスクで1日の予定の数がすごいことになっているので、手作業で確認して書き写すのがとても面倒です。Pythonを使うとOutlookから予定表をまとめて抜き出すことができるので、あとはテキストファイルなりExcelなりに整形して、日報などにそのまま貼り付けることができます。
本記事ではMicrosoft Outlookのクライアントソフトから、Pythonで予定を抜き出す方法をご紹介します。
PythonでOutlookの予定表を抜き出す
outlookを操作するためにはwin32com.clientをimportする必要があります。
私はAnacondaを使っていますが、特に追加でインストールしなくてもimportできました。pythonimport win32com.client次にOutlookのオブジェクトを作成し、予定表と取り出します。
pythonoutlook = win32com.client.Dispatch("Outlook.Application").GetNamespace("MAPI") calender = outlook.GetDefaultFolder(9) # 「9」というのがOutlookの予定表のことこのcalenderというのが予定表です。
では早速、期間を指定して予定を抜き出してみましょう。
ここでは【2020-10-19~2020-10-23】の予定を抜き出してみます。
※例として、この期間には2つだけ予定を登録しています。pythonimport datetime items = calender.Items # このitemsが一つ一つの「予定」 select_items = [] # 指定した期間内の予定を入れるリスト # 予定を抜き出したい期間を指定 start_date = datetime.date(2020, 10, 19) # 2020-10-19 end_date = datetime.date(2020, 10, 23) # 2020-10-23 for item in items: if start_date <= item.start.date() <= end_date: select_items.append(item) # 抜き出した予定の詳細を表示 for select_item in select_items: print("件名:", select_item.subject) print("場所:", select_item.location) print("開始時刻:", select_item.start) print("終了時刻:", select_item.end) print("本文:", select_item.body) print("----")実行結果件名: 不具合調査 場所: 実験室1 開始時刻: 2020-10-20 10:00:00+00:00 終了時刻: 2020-10-20 11:30:00+00:00 本文: ハングする不具合の調査をAさんと行う。 ---- 件名: コードレビュー 場所: 会議室3 開始時刻: 2020-10-22 14:00:00+00:00 終了時刻: 2020-10-22 15:00:00+00:00 本文: Bさん、Cさんとと案件1234のコードレビューを行う。 ---- 予定を抜き出せていますね!
日報などの形式に合わせてprint文を工夫すれば、出力結果をそのままコピペできるはずです。コードまとめ
最後にコードをまとめて載せておきます。
pythonimport win32com.client import datetime outlook = win32com.client.Dispatch("Outlook.Application").GetNamespace("MAPI") calender = outlook.GetDefaultFolder(9) items = calender.Items # このitemsが一つ一つの「予定」 select_items = [] # 指定した期間内の予定を入れるリスト # 予定を抜き出したい期間を指定 start_date = datetime.date(2020, 10, 19) # 2020-10-19 end_date = datetime.date(2020, 10, 23) # 2020-10-23 for item in items: if start_date <= item.start.date() <= end_date: select_items.append(item) # 抜き出した予定の詳細を表示 for select_item in select_items: print("件名:", select_item.subject) print("場所:", select_item.location) print("開始時刻:", select_item.start) print("終了時刻:", select_item.end) print("本文:", select_item.body) print("----")Microsoft Office関連の自動化
Microsoft Officeに関連する他の自動化シリーズはこちらです。ご興味があればどうぞ!
【自動化】PythonでOutlookメールを送信する
https://qiita.com/konitech913/items/51867dbe24a2a4272bb6【自動化】PythonでOutlookのメールを読み込む
https://qiita.com/konitech913/items/8a285522b0c118d5f905【自動化】Pythonでメール(msgファイル)を読み込む
https://qiita.com/konitech913/items/fa0cf66aad27d16258c0【自動化】PythonでWordの文書を読み取る
https://qiita.com/konitech913/items/c30236bdf47775535e2f
- 投稿日:2020-10-24T05:56:53+09:00
FastAPI vs Vert.x ベンチマークとか感想とか
AIをAPIにするためにPythonのFWを探していたが、FastAPIに出会って触ってみたらめっちゃ速いし良さそうだったのでプロジェクトでVertxをすでに技術選択していた自分にアチャーってなってる
ベンチマーク
Rails6が100同時で250req/secぐらいでるサーバーで確認
Requests per second: 245.42 [#/sec] (mean) Time per request: 407.472 [ms] (mean) Time per request: 4.075 [ms] (mean, across all concurrent requests)OKってテキスト返すだけのサンプルプログラムベンチマーク
FastAPIはgunicorn -> uvicornx4で起動100同時
Vert.x - Kotlin
Requests per second: 3207.38 [#/sec] (mean) Time per request: 31.178 [ms] (mean) Time per request: 0.312 [ms] (mean, across all concurrent requests)FastAPI
Requests per second: 2703.43 [#/sec] (mean) Time per request: 36.990 [ms] (mean) Time per request: 0.370 [ms] (mean, across all concurrent requests)1000同時
Vert.x - Kotlin
Requests per second: 3777.86 [#/sec] (mean) Time per request: 264.700 [ms] (mean) Time per request: 0.265 [ms] (mean, across all concurrent requests) Transfer rate: 1080.97 [Kbytes/sec] receivedFastAPI
Requests per second: 2746.82 [#/sec] (mean) Time per request: 364.058 [ms] (mean) Time per request: 0.364 [ms] (mean, across all concurrent requests) Transfer rate: 413.10 [Kbytes/sec] received10000同時
Vert.x - Kotlin
Requests per second: 3736.25 [#/sec] (mean) Time per request: 2676.477 [ms] (mean) Time per request: 0.268 [ms] (mean, across all concurrent requests) Transfer rate: 1069.07 [Kbytes/sec] receivedFastAPI
Requests per second: 3524.81 [#/sec] (mean) Time per request: 2837.034 [ms] (mean) Time per request: 0.284 [ms] (mean, across all concurrent requests) Transfer rate: 218.69 [Kbytes/sec] received感想
FastAPI良い。。。
* 普通に使う分にはvertxとFastAPIは同程度の速度でしょう。FastAPIくそ速い
* FastAPIはソースコードの量少なくてすむ、すぐかける
* パフォーマンスは実用なら誤差範囲。FWというより使う言語の好みの問題に収束しそう
私はVertxが好き。
* 動かすまでにIDEがミスをかなり詳しく検知してくれる(静的型付け)
* ディレクトリ構造気にせず作業できる
* プロジェクトの構造を構築しやすい
* Vertxはeventbusとか夢もある技術選択してしまったポジショントークでVertxを擁護したいけど、FastAPIの良さにはもう文句でない。FastAPIは流行るでしょう。もう流行ってる。VertxはいつまでもマイナーFWです。。
FastAPI
- APIドキュメントを自動リアルタイム生成
- 開発中はリアルタイムにリロードしてくれるので楽
- webの記事がvertxより充実している印象
- 比べると圧倒的にシンプルでとっつきやすい
- AIとつなぎ込みが簡単(のはず?)なのでPythonでバックエンドは完結できそうな感じある
- だれが書いても同じような見通しの良さのコードになりそう→超重要
- サーバーサイドを薄く、軽く、速く、という最近の流れにマッチしてる感じある
- Docker使えばこちらもデプロイ簡単らしい。
- C10K大丈夫
- sessionは標準では無いっぽいのがAPI特化故か。issueは立ってる
Vertx
- (Kotlinなら)静的型付けの楽さ。起動しなくてもタイポとか指摘してくれる
- IDEの恩恵をフルに得られる。補完とかリファクタはIDEがある分一日の長の感じある
- fat-jarつかえばデプロイかんたん(Javaいれたらサーバー構築完了の楽さ好き)
- (私は)Kotlin書いてて楽しい
- (OpenAPIのライブラリつかって開発)APIドキュメントはこちらも自動生成っぽいことにはなる
- OpenAPI読み込めるの最高→重要
- ロギングとかのJVM資産ある(これは私がPythonよく知らないだけなのかも。でもlog4jとか便利よね)
- eventbusという夢
- C10K大丈夫
- 実はいろいろ揃っていて他に何も要らない感じはある。sessionとかあるので旧来風にsession cookieで認証維持とかできて楽
- やろうとおもえばSpringすればDIもできる。なんでもできる
他のフレームワークとの比較
JVM言語とPythonなのでactixとかとくらべてエンジニアは集めやすそう。業務系なら鉄板SpringBootとか.Net MVCが情報量多くて良さそう。
- 投稿日:2020-10-24T03:17:39+09:00
Django Signalsの種類と使い方
概要
Signalsとは
データが更新されたり、リクエストが起きた時が起きた時に処理を走らせることができる。
例えば、データが作成されたことをお知らせしたい時や他のデータもついでに作成したい時なんかに便利どこに書けばいいの?
公式サイトよると
Strictly speaking, signal handling and registration code can live anywhere you like, although it's recommended >to avoid the application's root module and its models module to minimize side-effects of importing code.
In practice, signal handlers are usually defined in a signals submodule of the application they relate to. >Signal receivers are connected in the ready() method of your application configuration class. If you're using >the receiver() decorator, import the signals submodule inside ready().
全く意味は分かりませんが、どうやらサブモジュールに定義するといいらしい。
ってことでsignals.pyを作った!種類
何ができるんだろう
名前 意味 pre_init モデルをインスタンス化した最初 post_init モデルをインスタンス化した最後 pre_save モデルのsave()メソッドの最初 post_save モデルのsave()メソッドの最後 m2m_changed 中間テーブルの変更 pre_migrate migrateを実行する前 post_migrate migrateを実行した後 request_started HTTPリクエストを応答した最初 request_finished HTTPリクエストを応答した最後 got_request_exception HTTPリクエスト中に例外が発生したら connection_created DBの接続が開始されたら Django 公式サイトにはまだいくつか種類があったけど眠い。(現在 AM 2:38)??
使い方
Djangoに
receiverを認識しもらうために下準備が必要。
ちなみに今回のアプリケーションの名前はbookという謎な名前です???AppConfigに準備
settings.pyにAppConfigを参照しておく??
settings.pyDJANGO_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ] THIRD_PARTY_APPS = [ 'rest_framework', 'django_filters', ] LOCAL_APPS = [ 'common.apps.CommonConfig', 'book.apps.BookConfig', # <- こいつ ] INSTALLED_APPS = DJANGO_APPS + THIRD_PARTY_APPS + LOCAL_APPSapp.pyに
signals.pyをimportする必要がある???book/apps.pyfrom django.apps import AppConfig from django.utils.translation import ugettext_lazy as _ class BookConfig(AppConfig): name = 'book' verbose_name = _('Book') def ready(self): try: import book.signals except ImportError: passってことで下準備が終わったので、
signals.pyに
どんどん書いていこう~????receiverを書く
@receiverデコレータを書いて基本的なのは実行ができる☺️☺️ってことでサンプルに、
pre_saveの書きかた!!!!book/signals.pyfrom django.db.models.signals import pre_save from django.dispatch import receiver from .models import Book @receiver(pre_save, sender=Book) def sample(sender, *args, **kwargs): print(sender, args, kwargs)これでviews.pyとかでモデルオブジェクトを
save()した最後には
sample()が実行される。book/views.pyclass ListBook(APIView): def get(self, request): b = Book(# ゴニョゴニョいれる) b.save() return Response('success')ってことで以上になります☺️☺️☺️☺️
- 投稿日:2020-10-24T02:50:19+09:00
Chainerによる機械学習のためのPython学習メモ 13章 ニューラルネットワークの基礎
What
Chainerを利用して機械学習を学ぶにあたり、私自身が、気がついた点、リサーチした内容をまとめる記事になります。今回は、ニューラルネットワークの基礎を勉強します。
私の理解に基づいて記述しているため、間違っている場合があります。間違いは都度修正するつもりです、ご容赦ください。
Content
ニューラルネットワークとは
ニューラルネットワークは、微分可能な変換を繋げて作られた計算グラフ (computational graph) を指す。
ここでは、他にセットで知っておくべき用語を紹介する。
ノード・・・入力または(最終)出力 途中途中の演算結果もノードになる(と思われる)
エッジ・・・ノード間を結ぶ線。状態遷移をみやすくするだけ?
このノードが非常に多いニューラルネットワークを用いた機械学習をディープラーニングというらしい。(やっと出てきました)Layer
入力層→中間層or隠れ層(演算過程)→出力層のことを指す。
構造
中間層のノード数は任意性がある。設計者のセンスが問われる。自分で決めるパラメータをハイパーパラメータという。ニューラルネットワークにはいくつか種類がある。(全結合、畳み込み、再帰型など)
ニューラルネットワークの計算
入力が与えられたとき、ニューラルネットワークの各層を順番に計算していき、出力まで計算を行うことを、順伝播 (forward propagation) と言います。
線形変換
入出力の関係式を行列を用いて表現できる場合、線形変換可能
非線形変換
非線形な入出力も扱いたい場合、線形変換した結果を非線形変換する過程を一個挟むことでニューラルネットワークを非線形なものとして取り扱う。線形→非線形化する関数を活性化関数という。活性化関数はいろいろあるよう。
今回はここまで、次回続きをやります
Comment
よく実験系、理論系と区別することがありますが、そう遠くない未来に両方理解できる人が絶対必要になると思うから
機械学習独自に勉強して使いこなすと言ってみたら、応援してもらえました。
頑張ろう
- 投稿日:2020-10-24T02:04:47+09:00
Twitter Botで引用RTをするときにつまづいたメモ
はじめに
今回が人生初、Qiita投稿となります。
仏のような心をもってこの記事を読んでください。
間違っていたところがあれば指摘していただけると嬉しいです。何が起こった?
学校にて、そのあまりにもの授業の面倒くささから午後だけ休み、プログラムを書いてやろうと思い、工業力学と英語の授業にバイバイしました。
そこで前々から作りたかった「自分がその日コミットしていなかったら#contributter_reportの自動ツイートを利用して自分を煽り散らすTwitter Bot」を作ることにし、その中で引用RTをしたいと思い、調べてみましたが公式のドキュメントにもググってもなかなか出てきません。
そこでやっと見つけたので、僕と同じような人がいたらググって検索結果に出てきやすいようにQiitaの記事を書くことにしました。引用RTをする方法
これは周知の事実で僕だけが知らなかったとしたら非常に恥ずかしいのですが、
引用RTは 引用RTにそえる文字と同時に引用元のツイートのURLをツイートするだけでできます。例として下のツイートを引用RTとすると、このツイートのURLをコピーし
引用RTするテキストと一緒に引用元のツイートのURLを貼り付けてツイートするだけで、
この様に引用RTすることができます。
サンプルコード
別ファイルのkey.pyにAPIkeyやアクセストークンを設定していて最初にimportしています。
import tweepy from key import CONSUMER_KEY, CONSUMER_SECRET, ACCESS_TOKEN_KEY, ACCESS_TOKEN_SECRET auth = tweepy.OAuthHandler(CONSUMER_KEY,CONSUMER_SECRET) auth.set_access_token(ACCESS_TOKEN_KEY,ACCESS_TOKEN_SECRET) api = tweepy.API(auth) tmp = 'https://twitter.com/genshi0916/status/' for tweet in tweepy.Cursor(api.search, q='genshi0916 contribution 0').items(1): text = tweet.text id = tweet.id try: print(text) print("contribution数:0ってどういうことですか?????????????進捗出してください\n" + tmp + str(id)) api.update_status("contribution数:0ってどういうことですか?????????????進捗出してください\n" + tmp + str(id)) except: print('error')tweet.idでツイートのidを取得し、tmpにツイートID以外の部分(今回はgenshi0916のツイートのみに反応するbotなので'https://twitter.com/genshi0916/status/' となっています。)
ユーザー名はこのソースのままでいくと、
user_name = tweet.user.screen_nameなど追加しその次の行にtmpを移動させ下のようにすると良いと思います。
tmp = 'https://twitter.com/'+user_name+'/status/'まとめ
引用RTは文字と引用元のツイートのURLをツイート!!!!!!
この記事が誰かの助けになってくれたら嬉しいです。
Twitter BotでよきTwitterライフを!!!ソースはGithubで公開しているのでurlを貼っておきます。
https://github.com/Genshi0916/genshi-contribution-check参考文献



- 投稿日:2020-10-24T00:15:25+09:00
yukicoder contest 271 参戦記
yukicoder contest 271 参戦記
A 1264 010
010 は 010 → 101 と1回操作ができ、0100 は 0100 → 1010 → 1101 と2回操作ができ、01000 は 01000 → 10100 → 11010 → 11101 と3回操作できの辺りで答えが分かる.
N = int(input()) print('01' + '0' * N)B 1265 Balloon Survival
N≦1000なのでO(N2logN)でもギリギリなんとかなるので、全組み合わせの距離を出して、小さい順に並べて消滅をシミュレートしていけばいい. 既に消滅した風船は記録しておいて、それの衝突が来たらスキップ. 1番目の風船と衝突する風船の数が答え.
N = int(input()) xy = [tuple(map(int, input().split())) for _ in range(N)] a = [] for i in range(N - 1): for j in range(i + 1, N): d = (xy[i][0] - xy[j][0]) * (xy[i][0] - xy[j][0]) + (xy[i][1] - xy[j][1]) * (xy[i][1] - xy[j][1]) a.append((d, i, j)) a.sort() result = 0 t = set() for _, i, j in a: if i in t or j in t: continue if i == 0: result += 1 t.add(j) else: t.add(i) t.add(j) print(result)