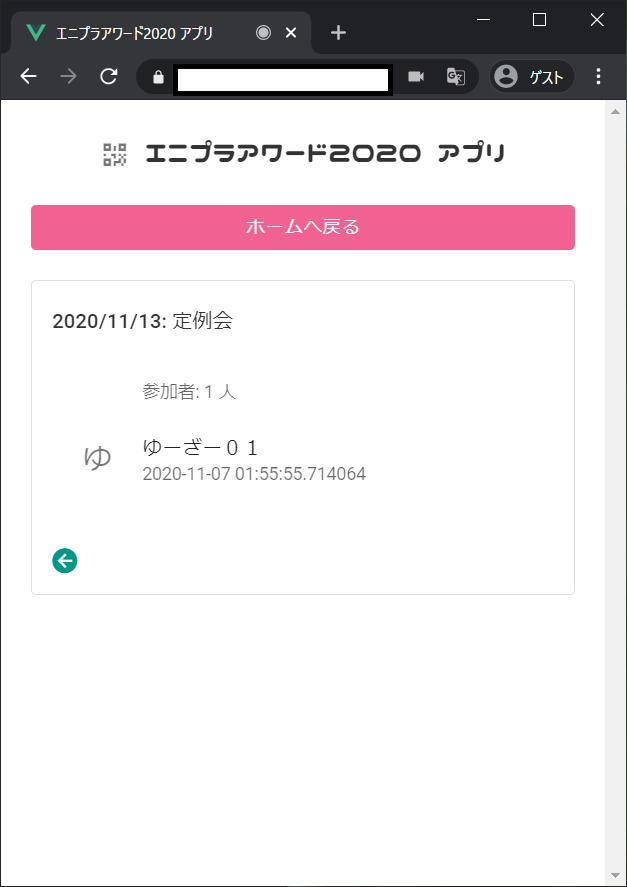
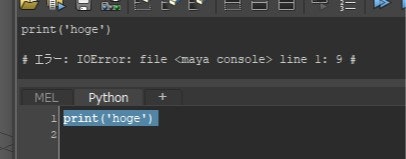
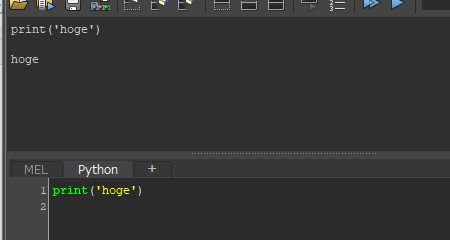
importrandomrandom.seed(1)''' n: 3通り
N = 1*(10**3)
N = 3*(10**3)
N = 5*(10**3)
'''tl=[]# list of tuples
foriinrange(N):l=random.randint(1,N)r=random.randint(1,N)tl.append((l,r,i))# 3 elements in tuple
'''
# 1. tuple同士の比較
for i in range(N):
for j in range(N):
res = tl[i] < tl[j]
# 2. tupleの要素同士の比較
for i in range(N):
for j in range(N):
res = tl[i][0] < tl[j][0]
'''
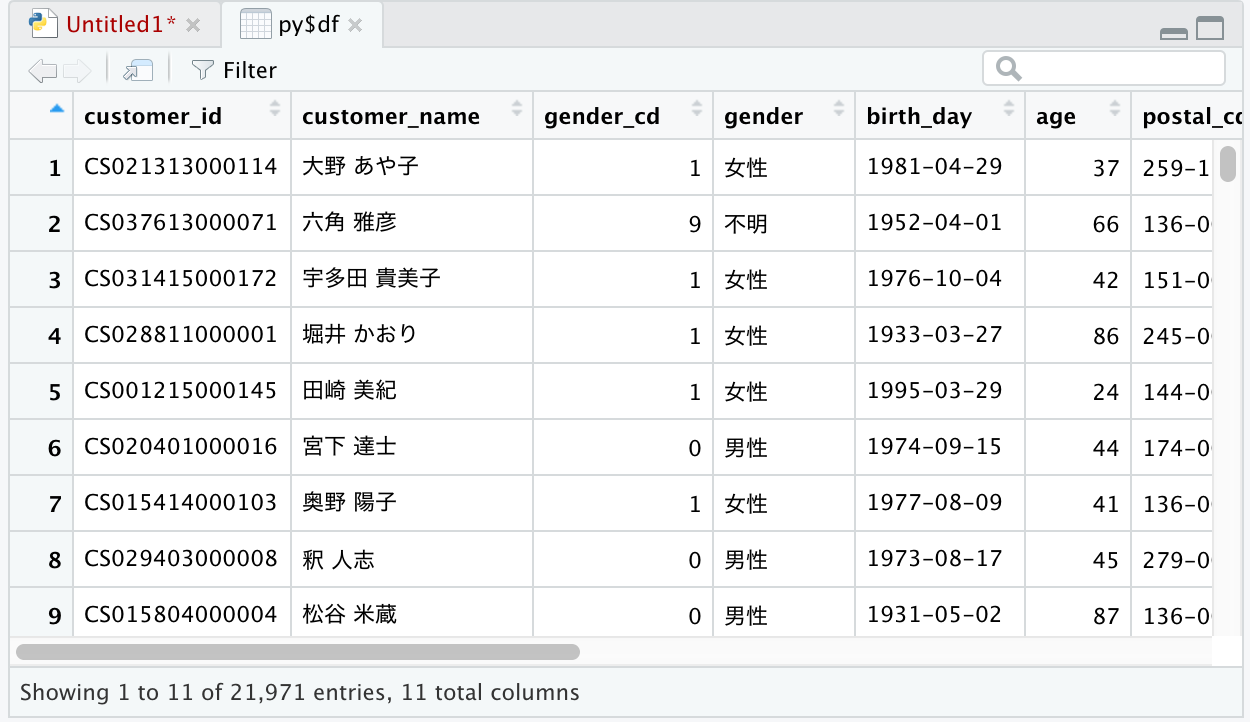
計測結果は以下です。
N
1. tuple同士
2. tupleの要素同士
$1*10^3$
78 ms
17 ms
$3*10^3$
672 ms
129 ms
$5*10^3$
1875 ms
368 ms
タプルの要素が3つなので「高々3倍程度の誤差か?」と思いきや、かなり大きな差が出ました。
怖い。
tuple配列のsort 「key指定なし」 vs. 「key指定あり」
importrandomrandom.seed(1)''' n: 3通り
N = 1*(10**5)
N = 3*(10**5)
N = 5*(10**5)
'''tl=[]# list of tuples
foriinrange(N):l=random.randint(1,N)r=random.randint(1,N)tl.append((l,r,i))# 3 elements in tuple
'''
3. tl.sort()
4. tl.sort(key=lambda x:x[0])
'''
以下のような命令によって到達することができます。"blue" AND "small"(より一般的なものからより特定のものへと階層を下降させる)、"blueeberry" IN COMMON "blueebell"(より特定のものからより一般的なものへと階層を上昇させる)、または "blueeberry" IGNORE "round"(同じく階層を上昇させる)という指示によって、概念{blue, small}に対応する新しいノードに到達することができる。
"""Localize objects in the local image.
Args:
path: The path to the local file.
"""
from google.cloud import vision
client = vision.ImageAnnotatorClient()
with open(uri, 'rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
objects = client.object_localization(
image=image).localized_object_annotations
print('Number of objects found: {}'.format(len(objects)))
for object_ in objects:
print('\n{} (confidence: {})'.format(object_.name, object_.score))
print('Normalized bounding polygon vertices: ')
for vertex in object_.bounding_poly.normalized_vertices:
print(' - ({}, {})'.format(vertex.x, vertex.y))
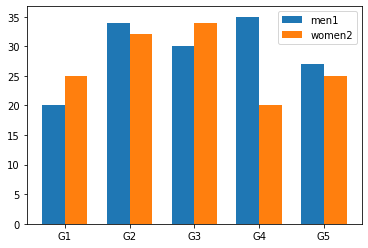
importnumpyasnpimportmatplotlib.pyplotasplt# 縦棒
defbarplot(ax,labels,datas):x=np.arange(len(labels))# the label locations
width=0.35# the width of the bars
rects1=ax.bar(x-width/2,datas[0]["val"],width,label=datas[0]["label"])rects2=ax.bar(x+width/2,datas[1]["val"],width,label=datas[1]["label"])# Add some text for labels, title and custom x-axis tick labels, etc.
ax.set_xticks(x)ax.set_xticklabels(labels)# 横棒
defbarhplot(ax,labels,datas):x=np.arange(len(labels))# the label locations
width=0.35# the width of the bars
rects1=ax.barh(x-width/2,datas[0]["val"],width,label=datas[0]["label"])rects2=ax.barh(x+width/2,datas[1]["val"],width,label=datas[1]["label"])# Add some text for labels, title and custom x-axis tick labels, etc.
ax.set_yticks(x)ax.set_yticklabels(labels)plt.gca().invert_yaxis()
$ pyenv versions
system
3.6.12
* 3.8.6 (set by /Users/kuryu/.pyenv/version)
3.8.6 で jupyter を起動して、 3.6.12 の kernel を動かすのを目指す。
まず jupyter を入れる
bash
$ python -V
Python 3.8.6
$ pip install jupyter
python のバージョンを変更する
bash
$ pyenv global 3.6.12
$ python -V
Python 3.6.12
必要なら venv を作成
pyenv 環境にそのまま構築することも可能だけど、今回は venv 作ります。
bash
$ python -m venv .venv
$ . .venv/bin/activate
(.venv)$ python -V
Python 3.6.12
(.venv)$ pip list
Package Version
-----------------
pip 18.1
setuptools 40.6.2
You are using pip version 18.1, however version 20.2.4 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
from flask import Flask, request
from flask import render_template
from flask import redirect
from flask_sqlalchemy import SQLAlchemy
import time
import statsd
ステップ2:Flaskアプリ、StatsdクライアントおよびDBを起動します-14〜23行目:
c = statsd.StatsClient('localhost',8125)
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///test.db'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
db = SQLAlchemy(app)