- 投稿日:2020-10-23T23:36:51+09:00
Chalice で Excel 向けの CP932 CSV ファイルを作成して返す
はじめに
Webアプリケーションの管理系の仕組みを作っていると「システムのデータをExcelで開けるCSVファイルにまとめてダウンロードできるようにして欲しい」というパターンに経験上結構遭遇する。
Python3系で何も考えずにCSVを作ると UTF-8 の文字エンコーディングになるので、Excel のデフォルトの設定だと文字化けしてしまう。 もちろん、Excelでちゃんと読み込みエンコーディングを指定すれば問題なく開けるのだが、「そんなの分からんから最初から文字化けないようにして」と言われることも多い。その場合、Windows用のエンコーディング (CP932, あるいは Shift_JIS, SJIS) でCSVファイルを作成する必要がある。今回は Chalice を使ってやっていたのだが、ドキュメントをよく見た結果ドはまりしたのでメモ。
version など
$ pipenv run chalice --version chalice 1.21.2, python 3.8.2, linux 5.4.0-52-genericドキュメントを読む
今回は Response で返したいので、Responseクラスの body に適切に値を入れればどうにかなると思っていた。 しかし、記事執筆(2020/10/23)時点のドキュメントにはこうある。
class Response(body, headers=None, status_code=200)
body: The HTTP response body to send back. This value must be a string.https://aws.github.io/chalice/api.html#response から引用・抜粋。 一部強調。
これを読んだときの思考。
「え…? CP932 にエンコードした文字列は bytes 型になるからここに渡せない…? 無理とするとファイルを作ってS3にアップロードして、これをダウンロードさせるか…」
が、body には bytes を入れても通る 。このドキュメントの
stringはstr型だけではなく、より広い文字列を意図しているのだそうだ。 改めて調べてみると、同じ疑問を持った人が質問してくれていた。実装例: 直接レスポンス
Chalice の
Response#bodyには bytes型も渡すことができる。 それを踏まえて実装するとこんな感じになる。 ブラウザで/にアクセスすると、CSVファイルとしてダウンロードされる。app.py#!/usr/bin/python # -*- coding: utf-8 -*- import csv import tempfile from chalice import Chalice, Response app = Chalice(app_name='csvtest') def csv_response(filename, encoding='utf8'): """ CSVファイルを返す方法1: 直接レスポンス """ with tempfile.TemporaryFile(mode='r+', encoding=encoding) as fh: # writer で書き込み writer = csv.writer(fh, lineterminator='\r\n') writer.writerow(['ユーザー名', 'ログイン日時']) writer.writerow(['user01', '2000/01/01 00:00:00']) # 書き込んだ全てのデータを data に読み込み fh.seek(0) data = fh.read() headers = {} headers['Content-Type'] = 'text/csv' headers['Content-Disposition'] = f'attachment;filename="{filename}"' return Response(body=data, status_code=200, headers=headers) @app.route('/') def index(): return csv_response('test.csv', encoding='cp932')別解: S3へのファイルアップロード
先の例では
tmpfileを使ってオンメモリにファイルを作成、さらにdataを読み込んでいる。 しかし、AWS Lambdaの場合はメモリ利用量が制限された環境での実行となるので、ファイルが大きくなってくる場合はメモリ利用量にかなりの影響を与えることが想像できる。 もちろんメモリ利用量の上限を上げることで回避できる問題だが、料金が倍となると躊躇することもあるだろう。
そういった場合は AWS Lambda で提供されている/tmp以下に一時的にファイルを作り、作成したファイルを S3 にアップロードするといった方法を用いればよい。
S3にアップロードした後はCloudFront - S3の通信経由で作成したファイルにアクセスさせたり、一時URLを作成・提供してユーザーにダウンロードをさせることができる。なお、
TempfileContextは AWS Lambda で用いた/tmp以下のファイルをエラーハンドリングなど考えずに消せるように準備したものであるので、コードの本質ではない。import os import csv import uuid import boto3 s3 = boto3.client('s3') class TempfileContext: """ 一時ファイルを作って消去するコンテキストを提供します """ def __init__(self): tmpfile = str(uuid.uuid4()) self.filename = f'/tmp/{tmpfile}' def __enter__(self): return self def __exit__(self, ex_type, ex_value, trace): try: if os.path.exists(self.filename): os.remove(self.filename) except Exception: pass def create_and_upload_csv(filename, encoding='utf8'): """ CSVファイルを返す方法2: CSVを作って S3にアップしておく """ with TempfileContext() as tmp: # 1. /tmp 領域に CSVファイルを作成 with open(tmp.filename, 'w', encoding=encoding) as fh: # writer で書き込み writer = csv.writer(fh, lineterminator='\n') writer.writerow(['ユーザー名', 'ログイン日時']) writer.writerow(['user01', '2000/01/01 00:00:00']) # 2. S3 にアップロード s3.upload_file(tmp.filename, BUCKETNAME, f'uploads/{filename}')
- 投稿日:2020-10-23T22:30:44+09:00
Lambda Layer と CloudFormation / sam-cli で楽ちん X-Ray
はじめに
こちらの Lambda Layer と X-Ray - Qiita という記事で、X-Ray を Lambda Layer で組み込む方法が紹介されています。複数の lambda をデプロイする場合に、個別に X-Ray を組み込まなくても一発で付け外しができるので、けっこういい感じです。
けっこういい感じなんですが、すこしコマンドを叩くのが手間なので、CloudFormation 化できないかな、と思っていたところ AWS SAM CLI で Lambda Layers が ビルドできるようになったよ - Qiita という記事を見つけました。
というわけで、2つの記事の内容をガッチャンコしたら、こんなかんじで
X-Ray の LambdaLayer を CloudFormation で作れて楽チン!
という記事です。
なお、 X-Ray は、AWS Lambda で使えるトレーシングツールです。X-Ray を使うことで、「Lambda のどの部分で時間がかかっているか?」「どこのリソース (DynamoDB, S3, etc) 呼び出しで時間をくっているか?」を下の図のような感じで確認できるようになります。
(図の参照元: AWS X-Ray コンソール: - AWS X-Ray)
X-Ray な Lambda Layer のテンプレート定義
用意するのは、template.yaml の他には xray-layer-src/requirements.txt だけ で OK です。
template.yaml
template.yamlAWSTemplateFormatVersion: "2010-09-09" Transform: AWS::Serverless-2016-10-31 Description: CloufFormation Template X-Ray lambda layer sample Resources: # X-Ray の Lambda Layer 定義 XRayLayer: Type: AWS::Serverless::LayerVersion Properties: Description: Lambda Layer for XRay ContentUri: xray-layer-src CompatibleRuntimes: - python3.8 # ここは利用している Python のランタイムを指定 Metadata: BuildMethod: python3.8 # sam-cli でビルド時に指定が必要 # XRayLayer を利用するラムダ定義の例 SomeFunction: Type: AWS::Serverless::Function Properties: CodeUri: lambda/src/ Handler: lambda_handler.lambda_handler Runtime: python3.8 Tracing: Active Layers: - !Ref XRayLayer # 作成した Layer の参照xray-layer-src/requirements.txt
xray-layer-src/requirements.txtaws-xray-sdkLambda Layer に入れるライブラリの指定で、ここでは aws-xray-sdk のみを指定すれば OK です。
これで、X-Ray Lambda Layer のリソースが作成できます。デプロイは通常の sam を使うときと同じです。
sam build sam deployX-Ray を利用する Lambda の例
X-Ray を利用するソースコードは、例えば次のようになります。
lambda-src/lamda_handler.pyimport ... # XRay SDK をインポート。公式ドキュメントにあるように最後にインポートする必要あり from aws_xray_sdk.core import patch_all # boto3 などの関連ライブラリにまとめて X-Ray のパッチをあてる patch_all() def lambda_handler(event, context): ...参考リンク


- 投稿日:2020-10-23T21:07:54+09:00
AWSの構成図からワンクリックでリソースを作成できるサービスを作ってみた
この記事について
AWSを学習しているときに構成図を見て、「この構成図にタグとかスペックを設定できて、ここから直接リソースを構築できたらいいのに!!」と思ったことがあるのは私だけでしょうか?
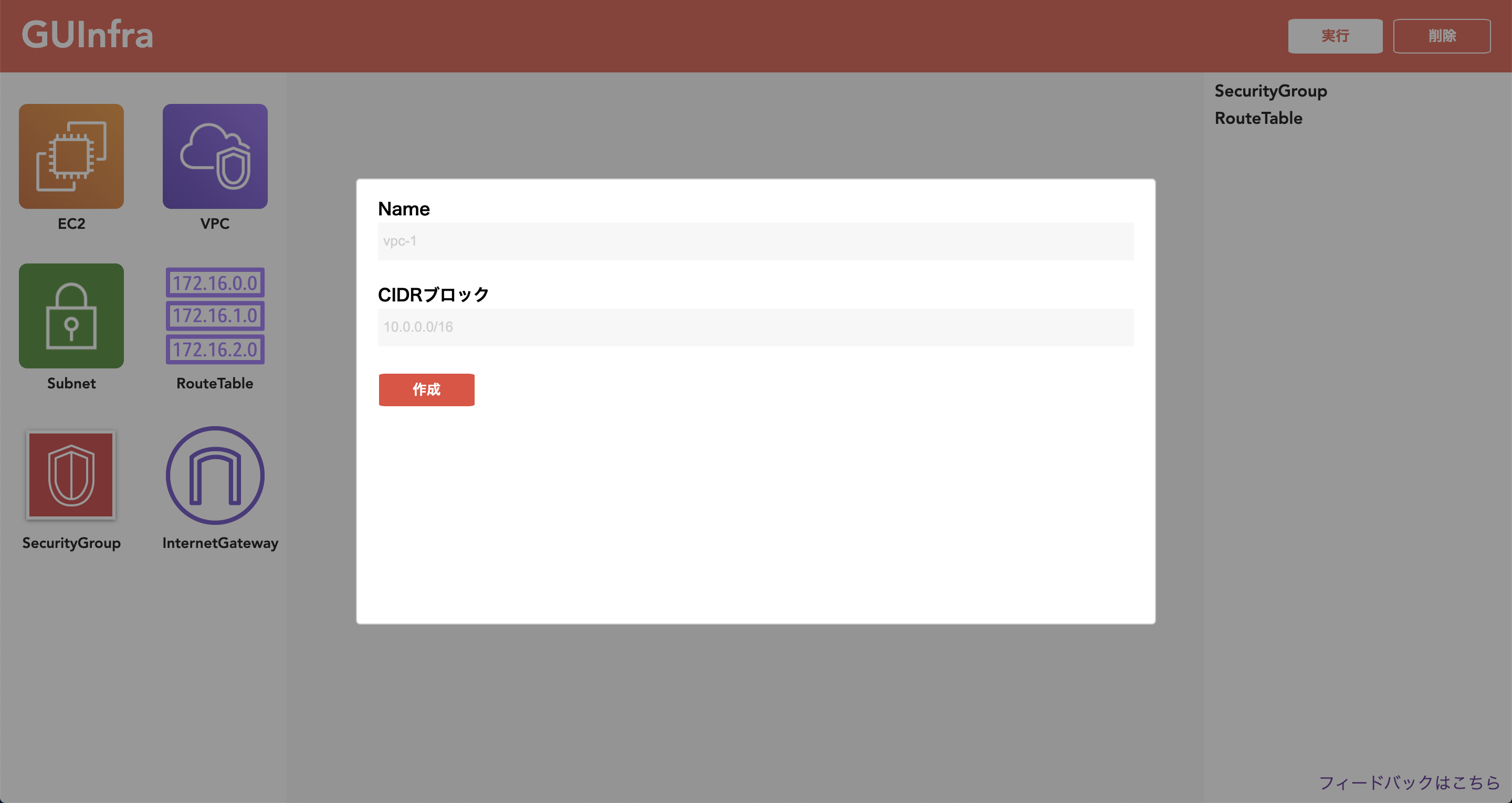
今回は、そんなサービスを作ったのでその紹介になります。URL: https://guinfra.app
フィードバック: https://forms.gle/iqHVrFQRjkNKWefA8(グラフ作成機能があったりキーの入力等の操作が必要だったりするので、PCからのアクセスを推奨しています!スマホからの方すみません?♂️)
自己紹介
鎌谷天馬と申します。N高等学校の3年生です。
2020年度の未踏ジュニアに採択していただき、今年の6月から「GUInfra」というクラウドインフラ学習サービスを開発してました。Twitter ← フォローしてください!
GUInfraとは
クラウドインフラについての現状と課題
昨今、AWSやGCPをはじめとするクラウドインフラが盛り上がっています。AWSが落ちたときはTwitterのトレンドにも上がったりと、ITについての知識の有無に関わらずとも最低限知っている単語の一つにもなっているようです。
クラウドインフラを学習することで、個人開発をしたサイトのデプロイができるようになったり、単純に雇用が増えたりと様々な利点が存在します。にもかかわらず、巷ではAWSなどのクラウドインフラは難しいといった意見が多いようです。そこで、私はこの原因を以下の二つに分析しました。
①VPCやIAMなどの、独自概念を理解するのが難しい
②コンソールが複雑。初学者にとって選ぶ必要のない選択肢も多数存在するGUInfraは、以上の課題を解決するサービスです。
どんなサービス?
GUInfraは、自作のグラフ作成ツールを提供してAWSの構成図を作成してもらい、実際にキーを入力してリソースの構築、破棄ができるようにしてそれを繰り返していただくことで、クラウドインフラ(現在はAWSのみに対応)の学習をサポートします。
また選択できるリソースやそのプロパティを初学者にとって学ぶのに必要な最小限のもののみに限定しているため、複雑なコンソールに悩むことなしにスムーズに学習を進めることができます。リソースは、「自力でネットワークを構築してEC2に静的なサイトをデプロイできる最低限のリソース」を意識して6つに選び抜きました。実装について
以下にコード公開しています。
https://github.com/tenmakamatani/GUInfra-webNext.js / TypeScriptで実装していて、デプロイはnowを利用しています。
グラフ作成の部分は、react-rndと言うライブラリを、そしてAWSとの通信はAWSが公式で出しているaws-sdkを利用しています。
デプロイに利用したnowはNext.jsにも対応していて、コマンド一発で簡単にデプロイできるだけでなく、Dev環境とProd環境を分けることができたり、Prod環境の方にドメインを設定できたりと、開発体験がめちゃくちゃ上がるのですごくおすすめです!今後の展望、課題
- リリースしたばかりなので、まずはユーザの生の声を聞きたいと思っています。使っていただけた方、是非右下のフィードバックフォームから感想を送っていただければと思います!!
- このバージョンではVPCやEC2などの基本的な知識については前提となっているため、本当に初学者の方に対する誘導はまだ存在しません。なので、各リソースへの説明や教科書的なものを実装したいと思っています。
作ってみて
グラフ作成機能やAWSとの通信機能など、シンプルなWebサービスとは違った独特な機能に開発が手こずったことはあったものの、私が求めていた機能を実現することができました。しかしまだ私の仮説を実現した段階であるため、様々な人からのフィードバックを得て、より良いサービスに進化させていきたいと思っています!
使っていただけた方、最初に貼ったフォームからフィードバックをくださるとめちゃくちゃ嬉しいです!!

- 投稿日:2020-10-23T21:02:46+09:00
Amplify with AppSyncのベタープラクティス
Amplify with AppSyncの開発に携わっていく中で見つけたプラクティスをまとめました。
皆さんの開発の助けになれば幸いです。前提
- Amplify上に展開しているアプリケーションはReact x TypeScriptで構成されていることを前提にしています。
- Amplify cliで運用するにあたってのプラクティス紹介が中心なので、AmplifyやAppSyncそのものの説明などはしていません。
- これらのプラクティスがどんなケースでも有効というわけではないので、プロジェクトに合わせて使えそうなものを採用してみてください。
- ここに載っているもの以外でみなさんが実践されている/ご存知の知見があれば、是非シェア頂けると助かります!
環境を分ける
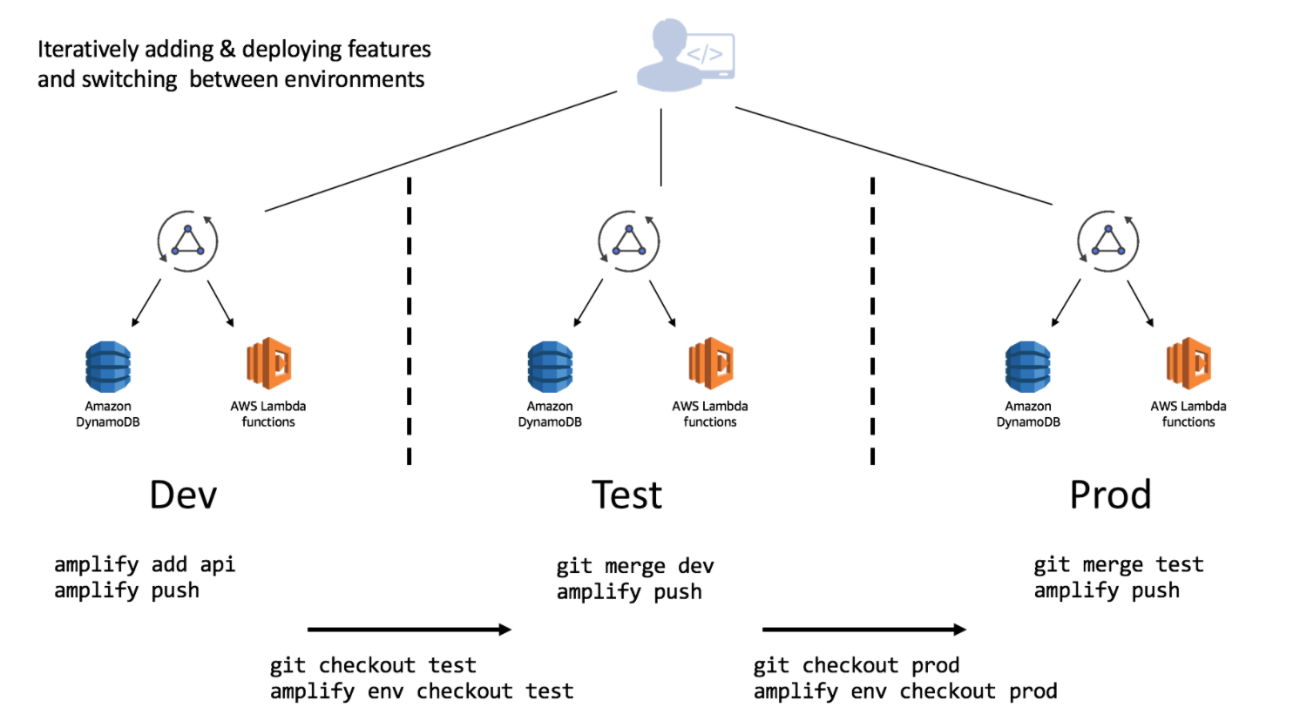
Amplifyには開発環境を分離できる機能が備わっています。
以下の図のように、開発環境や本番環境毎に切り替えることが出来るので、開発基盤を作る際にまずは環境を分けるのが良いと思います。
画像はAmplify Docs - Overviewより拝借具体的な方法はAmplify Docs - TEAM ENVIRONMENTSや、Amplify Multi Environment でチーム開発を整備するを参照ください。
Amplifyリソースのgitignoreは死守する
Amplify cliなどで最初のリソースを構築した際、gitignoreにはAmplify関連で以下のようなファイルが含まれていると思います。これらは何があってもignoreし続けましょう。
自分が携わっていたプロダクトでは初期の段階でignoreすべきリソースがgit管理されてしまっていたようで、誰かがamplify initなどする度に差分が大量にでて後始末が大変でした...。仕様をよく知らない人にとっては「そもそもこの大量の差分が出たファイルはgit管理しておくべきものなのか?」という判断がつかず、余計な確認コストが発生します(いやほんとマジで...)。
特にプロダクトの立ち上げ期の場合には動かすこと重視でこの辺のリソースが誤って紛れ込む事があるかもしれませんが、早い段階で掃除しておきましょう。
.gitignore#amplify amplify/\#current-cloud-backend amplify/.config/local-* amplify/mock-data amplify/backend/amplify-meta.json amplify/backend/awscloudformation build/ dist/ node_modules/ aws-exports.js awsconfiguration.json amplifyconfiguration.json amplify-build-config.json amplify-gradle-config.json amplifytools.xcconfigちなみに、何をignoreスべきかというのは時々ISSUEで議論されているので、覗いてみると新しい知見が得られるかもしれません。
参考: amplify/.config should be in .gitignore?バックエンド(AppSync)関連のリソースは出来る限りコード化しておく
AmplifyでAppSyncを使う場合、バックエンドのリソースの大部分をAWSのサービスを利用すると思います(DynamoDB, Lambda, etc.)。その際にどのGraphQLでどのようなVTL定義を使っているのか、どのリソースとどのリソースがどのように対応しているかなどはコードに落とし込んでおきたいところです。
そうしないと例えばある程度開発が進んだ段階で「見込み顧客にデモできる環境がほしいんだけど〜」みたいなケースが出てきた際に非常に厄介です。今ある環境の設定をAWSのwebコンソールから見ながら手動で新しい環境に設定を移植するのはさぞ辛いでしょう...。
逆に言うとこの辺りの設定をコードで落とし込んでさえ入れば、新しく環境を構築したい際には
amplify add envで環境を追加してamplify pushでAWS上に完全なリソースが構築されます(完璧にコード化できなかったとしても、手作業の割合を減らすことはできます)。具体的な方法は以下に書いてあるので、是非とも導入すると良いと思います。
デプロイは自動化しておく
速いうちからデプロイはすべて自動化しましょう....。開発が進むにつれて色々なリソースが追加されていき、デプロイ時の影響が幅広く発生してしまうかもしれません。さっさと自動化してしまいましょう。
フロントリソースをAmplifyへデプロイするのはAWSのwebコンソールでAmplifyを検索してやっていけますが、チョット面倒なのは
amplify pushです。開発環境では手元でamplify pushを実行して結果を確認したりデバッグしたりするかもしれませんが、他の環境では不要だと思いますので、そこは自動化するのが良いかと思います。Circle CIの例としては以下の感じでCircle CI上から
amplify pushが実行できます(実行するためにIAMの作成と権限付与が必要です)。production環境にPRを出してマージされた際に走るCIだと仮定して読んで頂けると良いかと思います。
*もっとスマートな案があれば教えて下さい!version: 2.1 executors: node-docker: working_directory: ~/repo docker: - image: circleci/node:latest jobs: amplify_push: executor: node-docker resource_class: small steps: - checkout - setup_aws_config - amplify_push commands: setup_aws_config: steps: - run: command: | set -x curl "https://s3.amazonaws.com/aws-cli/awscli-bundle.zip" -o "awscli-bundle.zip" unzip awscli-bundle.zip sudo ./awscli-bundle/install -i /usr/local/aws -b /usr/local/bin/aws aws configure set aws_access_key_id $AWS_ACCESS_KEY_ID aws configure set aws_secret_access_key $AWS_SECRET_ACCESS_KEY aws configure set default.region $AWS_DEFAULT_REGION amplify_push: steps: - run: command: | set -x sudo npm install -g @aws-amplify/cli # amplify envにproductionという環境がある前提 amplify init --amplify "{\"envName\":\"production\"}" --yes amplify push --yes workflows: exec: jobs: - amplify_push:VTLなどもテストする
フロントエンドそのものに対するテストは書くと思うのですが(書いてますよね?)、amplify-velocity-templateを使うとVTLなどに対してもテストが書けます。プロダクトの初期はVTLなどに対するテストなしでも良いかもしれませんが、開発が進むにつれて徐々にVTLにif文などを定義してトリッキーな実装になっていきます(マジでなります...)。その頃にはテスト出来るようになっていると安心感が得られると思います。
Amplify with AppSyncはフロントエンドで完結しない事項が非常に多いので、開発が進むにつれてこういったテストがないとデグレなどに気づきにくくなっていくので、速いうちに検討しておくと良いと思います。
詳細はEffective AppSync 〜 Serverless Framework を使用した AppSync の実践的な開発方法とテスト戦略 〜 VTL をテストするに非常に詳しく書いてありますので、そちらを参照ください。
serverless frameworkと連携する
serverless frameworkという、(文字通り)サーバーレス関連のプロダクトに対していろんな機能を提供してくれるフレームワークがあります。これはAWS純正のツールではないのですが、AWS LambdaやAppSyncに対して非常に便利な機能を提供してくれており、またpluginも多数存在します。自分はAWS Lambdaを使う際にはほぼ必ず使っています。
serverless framworkとAppSyncを連携させることで、テストやデプロイ周りでさらなる恩恵を受けられるポイントがたくさんあります。私の関わっているプロダクトでは既にある程度開発が進んでいるため、今の状態からserverless frameworkに土台を入れ替えるのは中々コストがつくので実践には躊躇していますが...、比較的初期段階であれば導入する価値は十分にあるかと思います。
参考
- serverless - AWS AppSync - The Ultimate Guide
- serverless - Serverless Appsync Plugin
- Effective AppSync 〜 Serverless Framework を使用した AppSync の実践的な開発方法とテスト戦略 〜
その他
AWS公式が出しているAmplify Framework Documentationに様々な色々情報が載っているので、こちらを覗いてみるとさらなる知見が得られるかもしれません。
- 投稿日:2020-10-23T20:09:55+09:00
AWS VPC作成の記録
はじめに
AWSのVPCを構成する要素とその作成方法。特にPublicサブネットの登録方法。そして、簡単にいくつかの設定値について記述します。
VPCを作成するぞ!
今回扱わないもの
私は、開発・検証環境を作ることが多いので毎日の料金負担が発生しそうなものは省略しています。
* Natゲートウェイ 設定するだけで料金がかかるようだ。
* Elastic IP 使用していると料金はかからないようだが、使わずにIPアドレスを占有していると料金がかかるようだ。VPC を俯瞰
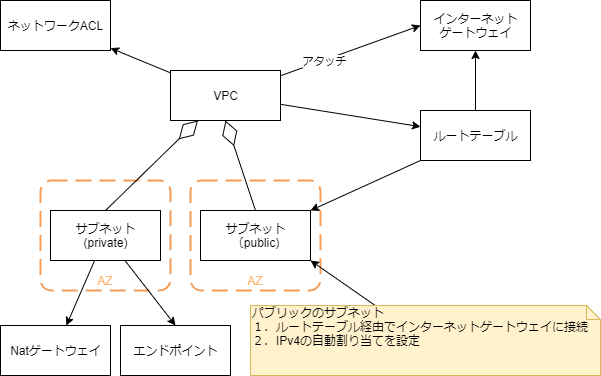
VPCの構成要素になります。ほかに「セキュリティグループ」もあります。
- VPC
- VPC本体
- ネットワークACL
- サブネットのファイアウォールのようなもの。セキュリティグループと使い分ける
- インターネットゲートウェイ
- インターネットへの接続を与える
- ルートテーブル
- ネットワークトラフィックの経路を与える
- サブネット
- インターネットへの接続有無でPublic、Privateのネットワークを構成
- Natゲートウェイ
- Privateサブネットがインターネットへ接続するために使う
- エンドポイント
- PrivateサブネットがS3などAWSのサービスにアクセスするために使う
作成と設定の順序
- VPC
- サブネット
- インターネットゲートウェイ
- ルートテーブル
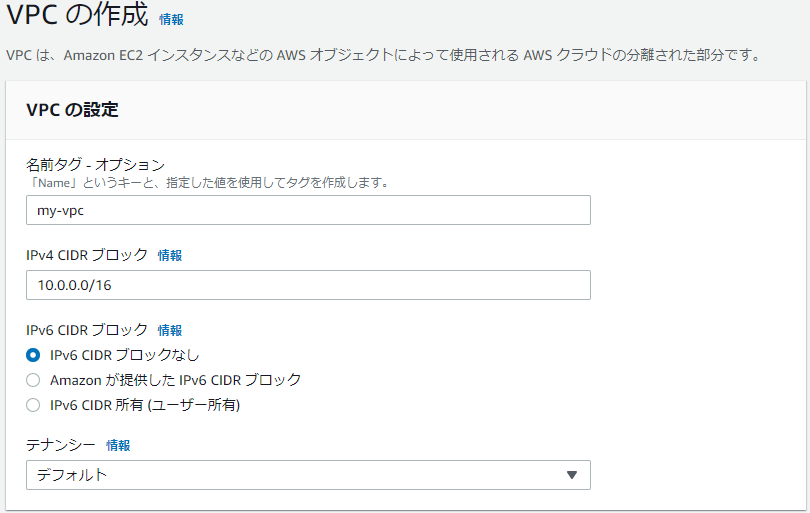
VPCを作成
- 名前タグ
- VPCに名前を付けます。
- IPv4 CIDR ブロック
- VPCのプレフィックス長は16にするようだ。サブネットのプレフィックス長は24
VPCを作成すると、ネットワークACLとルートテーブルが同時に作成される
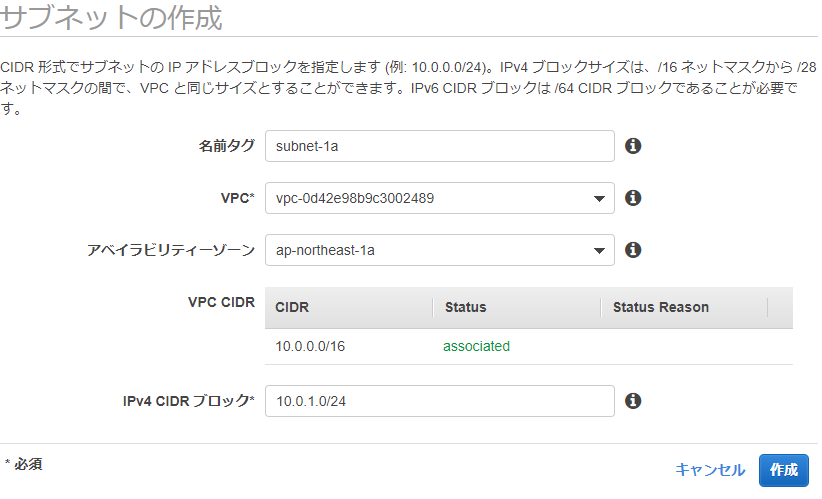
サブネットを作成
- 名前タグ
- サブネットの名前。Public,Privateやアベイラビリティゾーンがわかるように名前を工夫するとよい
- VPC
- 先に作成したVPCを選択
- アベイラビリティゾーン
- 選択
- IPv4 CIDR ブロック
- サブネットのプレフィックス長は24にするらしい
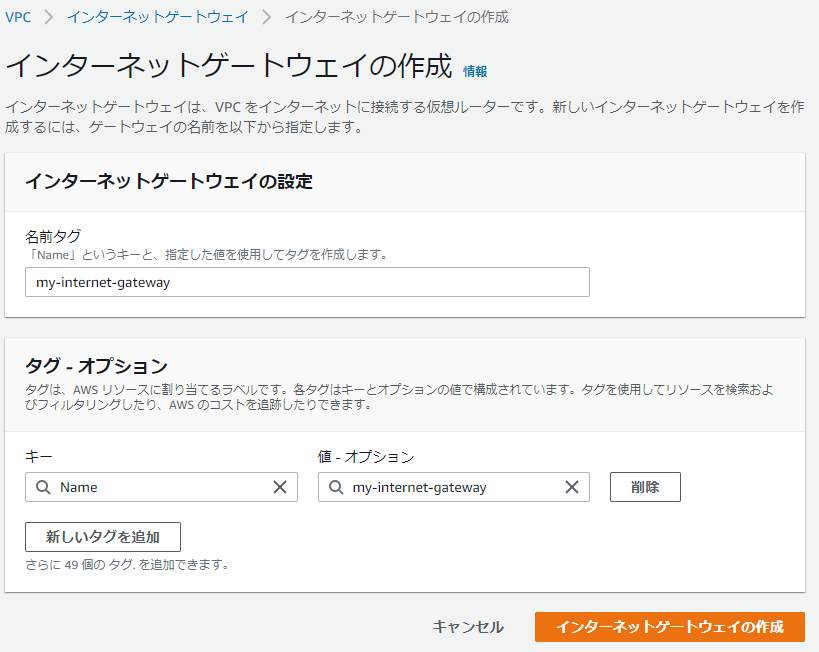
インターネットゲートウェイ
ここで行うこと
1. インターネットゲートウェイを作成
2. VPCにアタッチインタートゲートウェイを作成
- 名前タグ
- インターネットゲートウェイの名前を設定
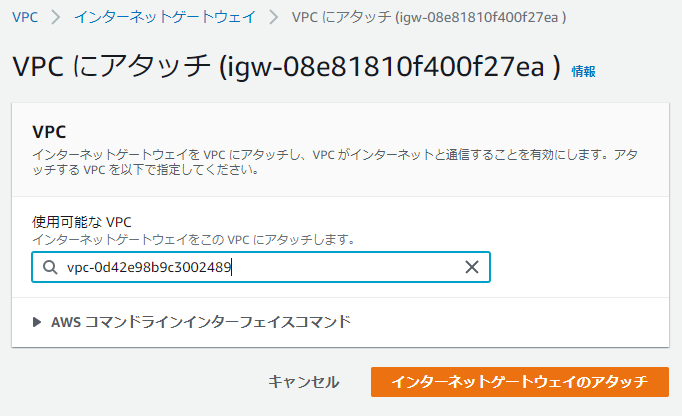
VPCにアタッチ
インターネットゲートウェイの詳細画面の「アクション」->「VPCにアタッチ」を選択
- 使用可能なVPC
- 先に作成したVPCを選択
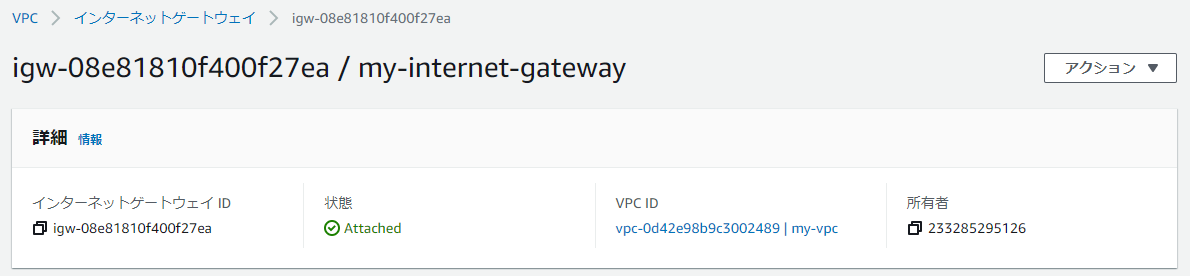
アタッチされます
ルートテーブル
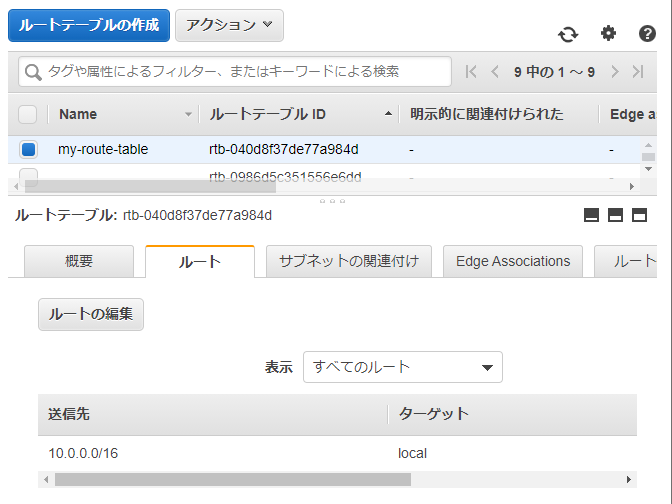
- ルートテーブルを作成します
- ルートテーブルとインターネットゲートウェイを関連付けます
- ルートテーブルにPublicサブネットを登録します。
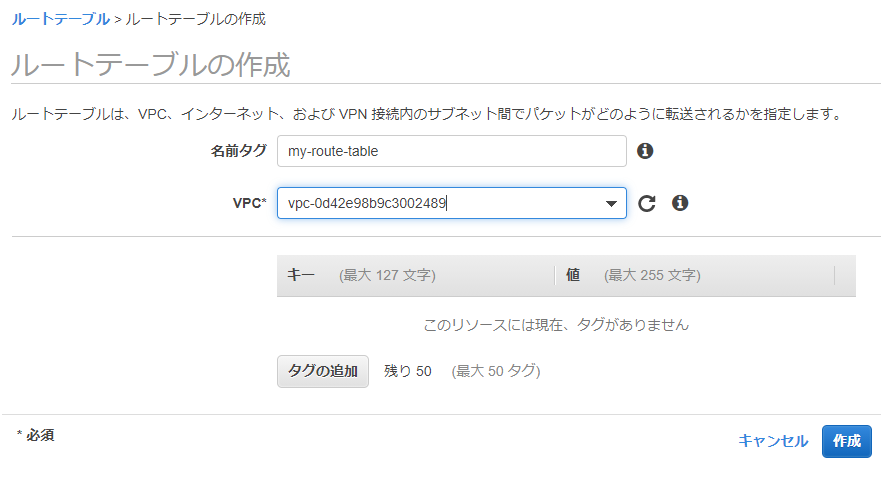
ルートテーブルの作成
- 名前タグ
- ルートテーブルの名前
- VPC
- 先に作成したVPC
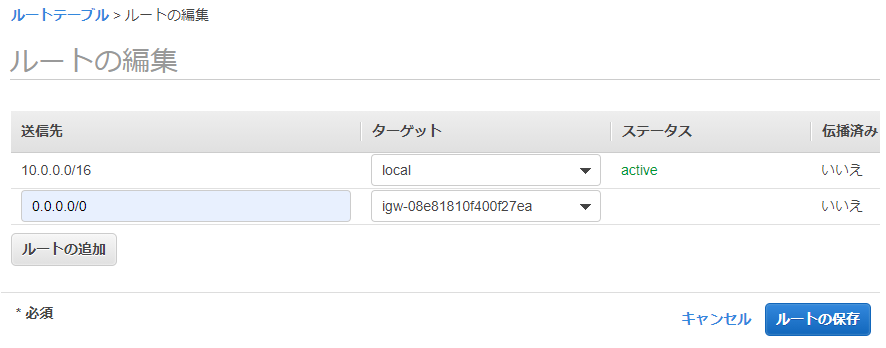
インターネットゲートウェイを関連付ける
作成したルートテーブルを選択します。下のルートタブにある「ルート編集」をクリックします。
- 「ルートの追加」をクリック
- 送信先に 「0.0.0.0/0」を入力
- ターゲットのドロップをクリックー>「internet Gateway」を選択ー>インターネットゲートウェイの一覧が表示されるー>先に作成したインターネットゲートウェイを選択
- 「ルートの保存」
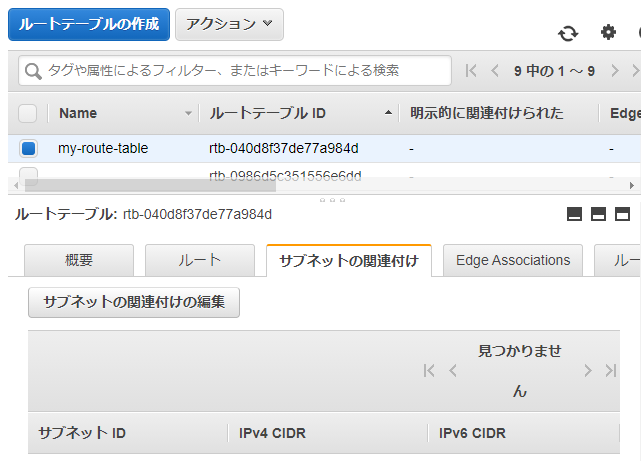
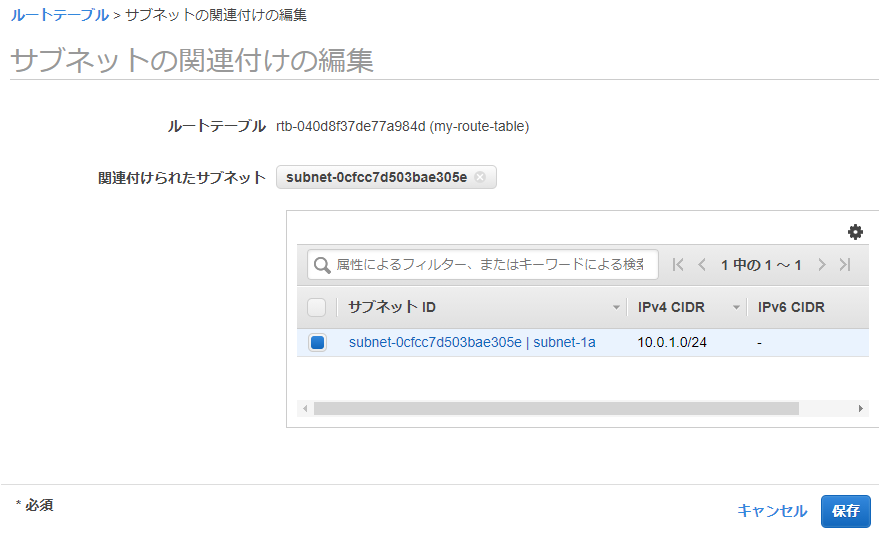
Publicサブネットを登録
作成したルートテーブルを選択します。下のサブネットの関連付けタブにある「サブネットの関連付けの編集」をクリックします。
- 関連付けるサブネットを選択
- 保存をクリック
Publicサブネット
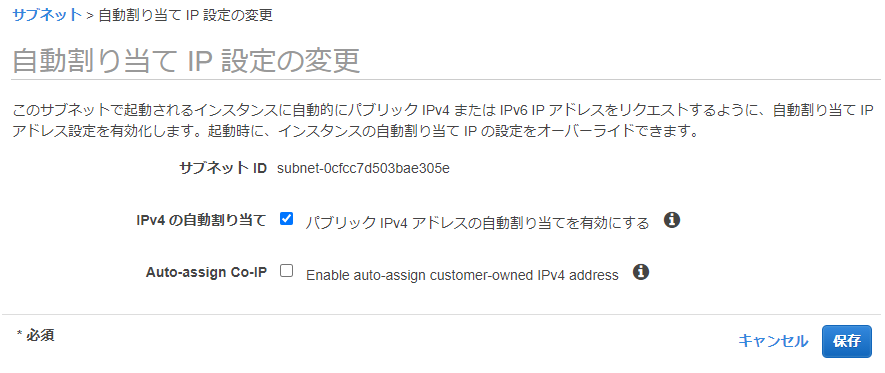
サブネットをPublicにするためには「パブリックIPv4 アドレスの自動割り当て」を「はい」にします。
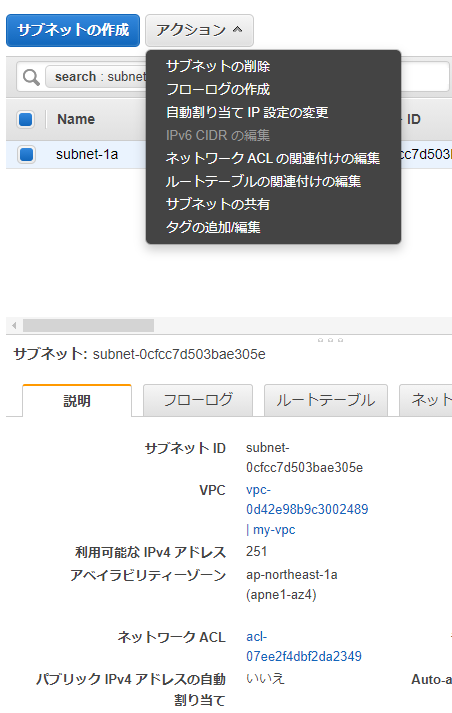
1. サブネットを選択
2. アクションから「自動割り当てIP設定の変更」を選択
- IPv4の自動割り当て 「パブリックIPv4アドレスの自動割り当てを有効にする」にチェックを入れる
- 保存をクリック
おわりの言葉
以上で、VPCを作成し、Publicサブネットを登録する方法を説明しました。
Privateサブネットは、インターネットゲートウェイのルートテーブルへの関連付けやアドレスの自動割り当ての設定を行いません。以上です。
- 投稿日:2020-10-23T19:49:08+09:00
Azure のバグ?致命的な仕様?を見つけた気がする(日本語をリソースグループ名で使えるが全体的にシステム動作不良?)
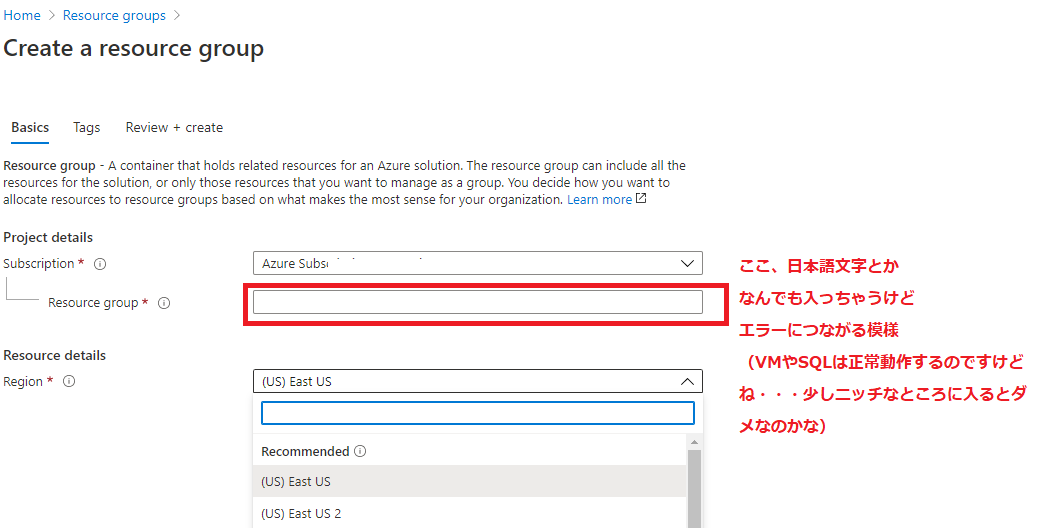
リソースグループ名で日本語を入力できるのだが・・・どうもおかしい
最近、VMやSQLなどオーソドックスで一般的に広く使われていそうではなさそうな機能を使い始めたのですが、どうも挙動がおかしい事態に遭遇。再現性100%の問題の迂回策を見つけた状況からするとリソースグループ名に日本語であれ何でも入っちゃう仕様に問題がある気がしてきました。オーソドックスな機能では問題なく動くのですが最近リリースまたは大幅改修が行われた機能が追い付いていない気がします。
(1)Log Analytics WorkspaceのAdvanced Settings画面。リソース名は日本語入らないのですけどね。Edgeは画面読み込み丸ごとNG、IEではなぜか正常表示、ChromeやFirefoxは中途半端に読み込めなかった事例(設定上のID、名前等は一部削除しています):
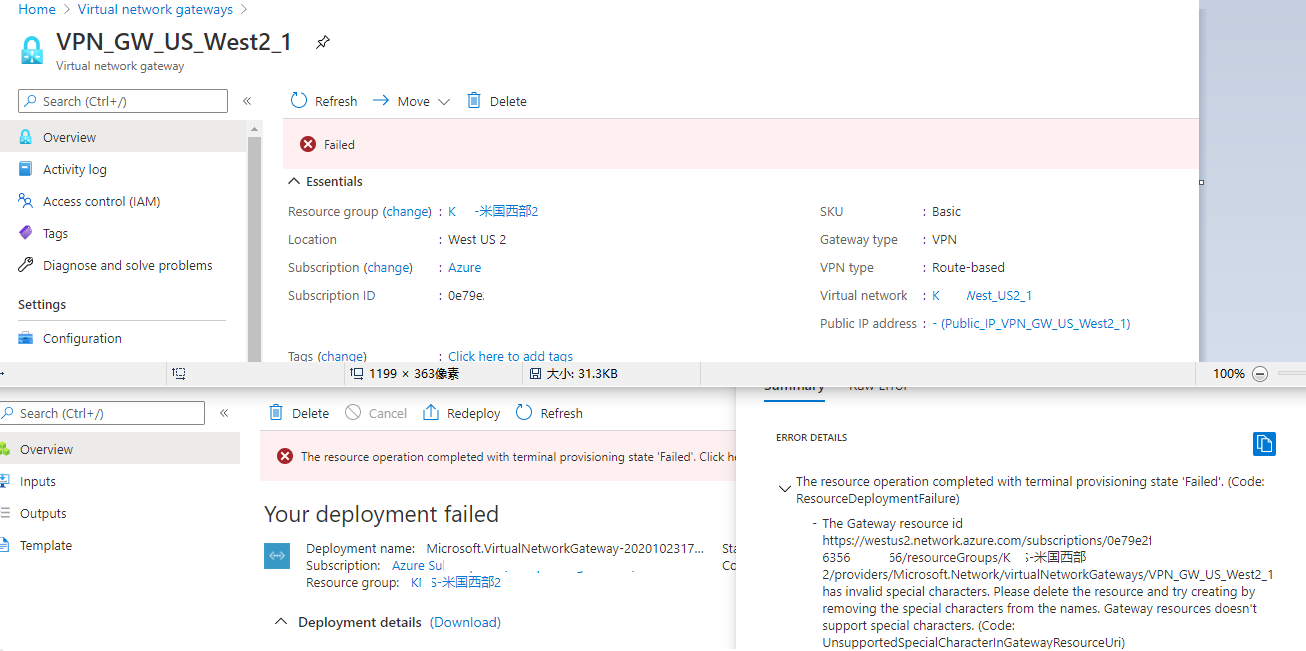
(2)VPN GWを何度構築しようとしてもエラーで止まり東日本リージョンは30分以上待たされて顕著なエラーメッセージはわからなかったが米国西部2リージョンでは直ぐにエラーとなりエラーログで特殊文字禁止の表示が(設定上のID、名前等は一部削除しています):
日本語はspecial characterというほど特殊文字なのかな・・・? リソース名に特殊文字は入っていないのですけどね。
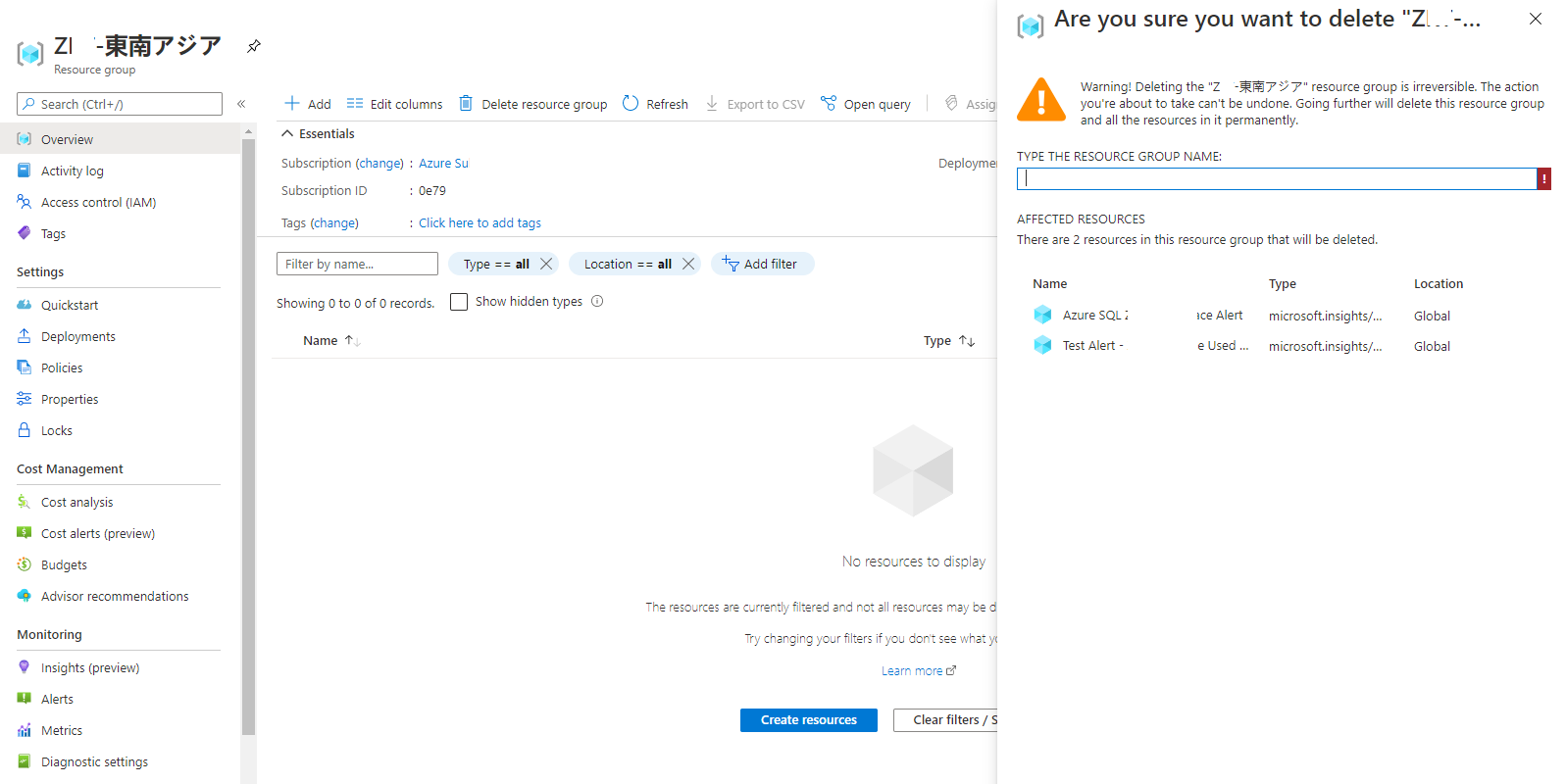
(3)リソースグループの中身の表示は空っぽだがリソースグループを削除しようとするとリソースがあるが消していいかの画面(設定上のID、名前等は一部削除しています):
Azure設定で日本語入力をすると多種多様な場所に悪影響しそうなことはわかった。
状況からするとURIの処理が上手く回っていないように見えるしURIが上手く回らないとセキュリティ的に何か問題がないのか気にはなる。
Microsoftのサポートでも頑張ってくれたと思うのですが時間がかかり直ぐに回答が来なかったので設定作業が私の方で滞っていた。別の作業をしようとしたら今度はそこが滞るようになりそれが原因で迂回策が分かった状況。アルファベットと特殊ではなさそうな記号オンリーのリソースグループを作成し時間をかけてこまめにリソースを移動。これでなんとか正常に動きそうだ。各種設定で日本語の入力はできてしまっても(!!)、普通にVMやSQLが動いても(!!)使用は控えよう。AWSで同じような問題ってあるのかな?
- 投稿日:2020-10-23T19:49:08+09:00
Azure のバグ?致命的な仕様?を見つけた気がする(日本語をリソースグループ名で使えるが全体的にシステム動作不良)
リソースグループ名で日本語を入力できるのだが・・・どうもおかしい
最近、VMやSQLなどオーソドックスで一般的に広く使われていそうではなさそうな機能を使い始めたのですが、どうも挙動がおかしい事態に遭遇。再現性100%の問題の迂回策を見つけた状況からするとリソースグループ名に日本語であれ何でも入っちゃう仕様に問題がある気がしてきました。オーソドックスな機能では問題なく動くのですが最近リリースまたは大幅改修が行われた機能が追い付いていない気がします。
(1)Log Analytics WorkspaceのAdvanced Settings画面。リソース名は日本語入らないのですけどね。Edgeは画面読み込み丸ごとNG、IEではなぜか正常表示、ChromeやFirefoxは中途半端に読み込めなかった事例(設定上のID、名前等は一部削除しています):
(2)VPN GWを何度構築しようとしてもエラーで止まり東日本リージョンは30分以上待たされて顕著なエラーメッセージはわからなかったが米国西部2リージョンでは直ぐにエラーとなりエラーログで特殊文字禁止の表示が(設定上のID、名前等は一部削除しています):
日本語はspecial characterというほど特殊文字なのかな・・・? リソース名に特殊文字は入っていないのですけどね。
(3)リソースグループの中身の表示は空っぽだがリソースグループを削除しようとするとリソースがあるが消していいかの画面(設定上のID、名前等は一部削除しています):
Azure設定で日本語入力をすると多種多様な場所に悪影響しそうなことはわかった。
状況からするとURIの処理が上手く回っていないように見えるしURIが上手く回らないとセキュリティ的に何か問題がないのか気にはなる。
Microsoftのサポートでも頑張ってくれたと思うのですが時間がかかり直ぐに回答が来なかったので設定作業が私の方で滞っていた。別の作業をしようとしたら今度はそこが滞るようになりそれが原因で迂回策が分かった状況。アルファベットと特殊ではなさそうな記号オンリーのリソースグループを作成し時間をかけてこまめにリソースを移動。これでなんとか正常に動きそうだ。各種設定で日本語の入力はできてしまっても(!!)、普通にVMやSQLが動いても(!!)使用は控えよう。AWSで同じような問題ってあるのかな?
- 投稿日:2020-10-23T19:49:08+09:00
Azure の致命的なバグか致命的な仕様を見つけた気がする(日本語をリソースグループ名で使えるが全体的にシステム動作不良)
リソースグループ名で日本語を入力できるのだが・・・どうもおかしい
最近、VMやSQLなどオーソドックスで一般的に広く使われていそうではなさそうな機能を使い始めたのですが、どうも挙動がおかしい事態に遭遇。再現性100%の問題の迂回策を見つけた状況からするとリソースグループ名に日本語であれ何でも入っちゃう仕様に問題がある気がしてきました。オーソドックスな機能では問題なく動くのですが最近リリースまたは大幅改修が行われた機能が追い付いていない気がします。
(1)Log Analytics WorkspaceのAdvanced Settings画面。リソース名は日本語入らないのですけどね。Edgeは画面読み込み丸ごとNG、IEではなぜか正常表示、ChromeやFirefoxは中途半端に読み込めなかった事例(設定上のID、名前等は一部削除しています):
(2)VPN GWを何度構築しようとしてもエラーで止まり東日本リージョンは30分以上待たされて顕著なエラーメッセージはわからなかったが米国西部2リージョンでは直ぐにエラーとなりエラーログで特殊文字禁止の表示が(設定上のID、名前等は一部削除しています):
日本語はspecial characterというほど特殊文字なのかな・・・? リソース名に特殊文字は入っていないのですけどね。
(3)リソースグループの中身の表示は空っぽだがリソースグループを削除しようとするとリソースがあるが消していいかの画面(設定上のID、名前等は一部削除しています):
Azure設定で日本語入力をすると多種多様な場所に悪影響しそうなことはわかった。
状況からするとURIの処理が上手く回っていないように見えるしURIが上手く回らないとセキュリティ的に何か問題がないのか気にはなる。
Microsoftのサポートでも頑張ってくれたと思うのですが時間がかかり直ぐに回答が来なかった、正確にはまだ来ていないので設定作業が私の方で滞っていた。別の作業をしようとしたら今度はそこが滞るようになりそれが原因で迂回策が分かった状況。アルファベットと特殊ではなさそうな記号オンリーのリソースグループを作成し時間をかけてこまめにリソースを移動。これでなんとか正常に動きそうだ。各種設定で日本語の入力はできてしまっても(!!)、普通にVMやSQLが動いても(!!)使用は控えよう。AWSで同じような問題ってあるのかな?一応「バグ」フィックスはしておいてと依頼はしておきました。
- 投稿日:2020-10-23T19:38:24+09:00
EMRをVisual Studio Codeから起動するスクリプト (コロナ禍対応)
Visual Studio CodeからEMRを使う方法として今はJupyterHubへの接続をしています。
毎回、EMR設定、立ち上げを行うのは面倒なので、スクリプトを書きました。
Security Groupの設定
昨今、毎回、IPが変わるようなシチュエーションも想定されるため、クライアントアドレスを自動的に送信して所望のアクセスを得ます。
sg_name=sg-hoge # delete existing security group sg=$(aws ec2 describe-security-groups --filters Name=vpc-id,Values=vpc-******* Name=group-name,Values=$sg_name --query 'SecurityGroups[*].[GroupId]' --profile prof) aws ec2 delete-security-group --group-id $sg --profile prof # create security group echo creating security group ... : $sg_name sg=$(aws ec2 create-security-group --group-name $sg_name --description "new security group" --vpc-id vpc-******** --profile prof) ip=$(curl https://checkip.amazonaws.com) echo security group id : $sg echo client IP address : $ip aws ec2 authorize-security-group-ingress --group-id $sg --protocol tcp --port 22 --cidr $ip/32 --profile prof # ssh aws ec2 authorize-security-group-ingress --group-id $sg --protocol tcp --port 9443 --cidr $ip/32 --profile prof # jupyter aws ec2 authorize-security-group-ingress --group-id $sg --protocol tcp --port 80 --cidr 10.0.0.0/16 --profile prof # http aws ec2 authorize-security-group-ingress --group-id $sg --protocol tcp --port 443 --cidr 10.0.0.0/16 --profile prof # https aws ec2 describe-security-groups --group-ids $sg --profile prof echo waiting security group ... aws ec2 wait security-group-exists --group-ids $sg --profile adspEMRクラスタの立ち上げ
こちらも、前回の同名クラスタがあれば削除するようにしています。
細かいクラスタ設定は --configurations に渡す設定ファイルに記載します。cluster_name = "hoge_cluster" # delete existing cluster active_cluster_id=$(aws emr list-clusters --query 'Clusters[?Name==`'"$cluster_name"'`]|[?contains(Status.State, `TERMINATED`) == `false`].[Id]' --profile prof) aws emr terminate-clusters --cluster-ids $active_cluster_id --profile prof aws emr wait cluster-terminated --cluster-ids $active_cluster_id --profile prof # create cluster numnodes=10 master_instance_type=m5.16xlarge cluster_ids=$( \ aws emr create-cluster \ --name $cluster_name \ --release-label emr-5.30.1 \ --applications Name=Hadoop Name=Spark Name=Livy Name=Hive Name=JupyterHub \ --instance-groups InstanceGroupType=MASTER,InstanceCount=1,InstanceType=$master_instance_type InstanceGroupType=CORE,InstanceCount=$numnodes,InstanceType=m4.large \ --log-uri s3n://aws-******/elasticmapreduce/ \ --service-role EMR_DefaultRole \ --auto-scaling-role EMR_AutoScaling_DefaultRole \ --ec2-attributes InstanceProfile=EMR_EC2_DefaultRole,SubnetId=subnet-01b77e396474dfba1,KeyName=masutani-ec2,EmrManagedMasterSecurityGroup=$sg,EmrManagedSlaveSecurityGroup=$sg \ --configurations file://./emr.json \ --profile prof) cluster_arn=$(cut -f 1 <<< ${cluster_ids}) cluster_id=$(cut -f 2 <<< ${cluster_ids}) echo Starting EMR clsuter ID : $cluster_id ... aws emr wait cluster-running --cluster-id $cluster_id --profile prof aws emr ssh --cluster-id $cluster_id --key-pair-file ~/.ssh/ec2.pem --profile prof master_dns=$(aws emr describe-cluster --cluster-id $cluster_id --output json --query 'Cluster.MasterPublicDnsName' --profile prof) echo Master DNS name : $master_dns echo jupyter URL: $master_dns:9443/Visual Studio Code タスク化
VSCodeで使うので、是非タスク化しましょう。
task.jsonに以下のようにスクリプトを指し示すように記述すれば大丈夫です。
ただ、起動するだけで、まだVSCodeのプラグインへの自動設定などの仕方がわかりません。orz{ "version": "2.0.0", "tasks": [ { "label": "emr: start cluster", "detail": "launch EMR Cluster", "type": "shell", "command": "/mnt/${workspaceFolder}/setupemr.sh", "windows": { "command": "/mnt/.../setupemr.sh" }, "presentation": { "reveal": "always", "panel": "new" } }, ] }
- 投稿日:2020-10-23T18:50:03+09:00
LINE Messaging API + AWS + GASでサーバーレスな体温管理
LINEベースで連絡をとっているサークルで、体温を毎日はかり各自Googleスプレッドシートに書き込んで管理していたのですが、回答率が悪く、またLINEでリマインドをすると他の連絡事項などのメッセージが流れていく、、ということが起こっていました。
そこで、LINEの公式アカウントを作り、そこで毎日体温のリマインドをし、そこに返信したらスプシに自動で書き込まれる、というシステムを今まで触れたことがなかったLINE Messaging APIやGASの勉強も兼ねて作ってみました。このソリューションのメリット
サークルに限らず会社や他のコミュニティでもそうだと思うのですが、COVID-19の感染が広がる中、メンバーの体温管理が必要な状況となっています。
体温を毎日測ってもらって、フォームで聞くかスプレッドシートに書き込んでもらうという手段が考えられるのですが、少しでもステップが多いと毎日行ってもらうのが厳しくなります。具体的に言うと、URLを送りそれに答えてもらうという形をとると回答率が一気に下がります。そして毎日リマインドをするのも大変で係の心理的負担にもなる上に大事な連絡事項が流れてしまいます。
そこで体温管理のソリューションに必要なことを2つに絞りました。
- 毎日リマインドのラインを個人宛に送る
- リマインドに対して画面を変えずに体温を送信できるようにする
そして個チャの中で送られたメッセージを処理してスプシに書き込むものを作れば、必要な要件を全て満たせているのではないかと言う考えです。
このソリューションのメリットは、LINEで1タップだけで体温登録でき自動でスプシに書き込んでくれること、そして毎日個人宛にLINEでリマインドを送信するためグループチャットでの連絡事項が流れないことです。
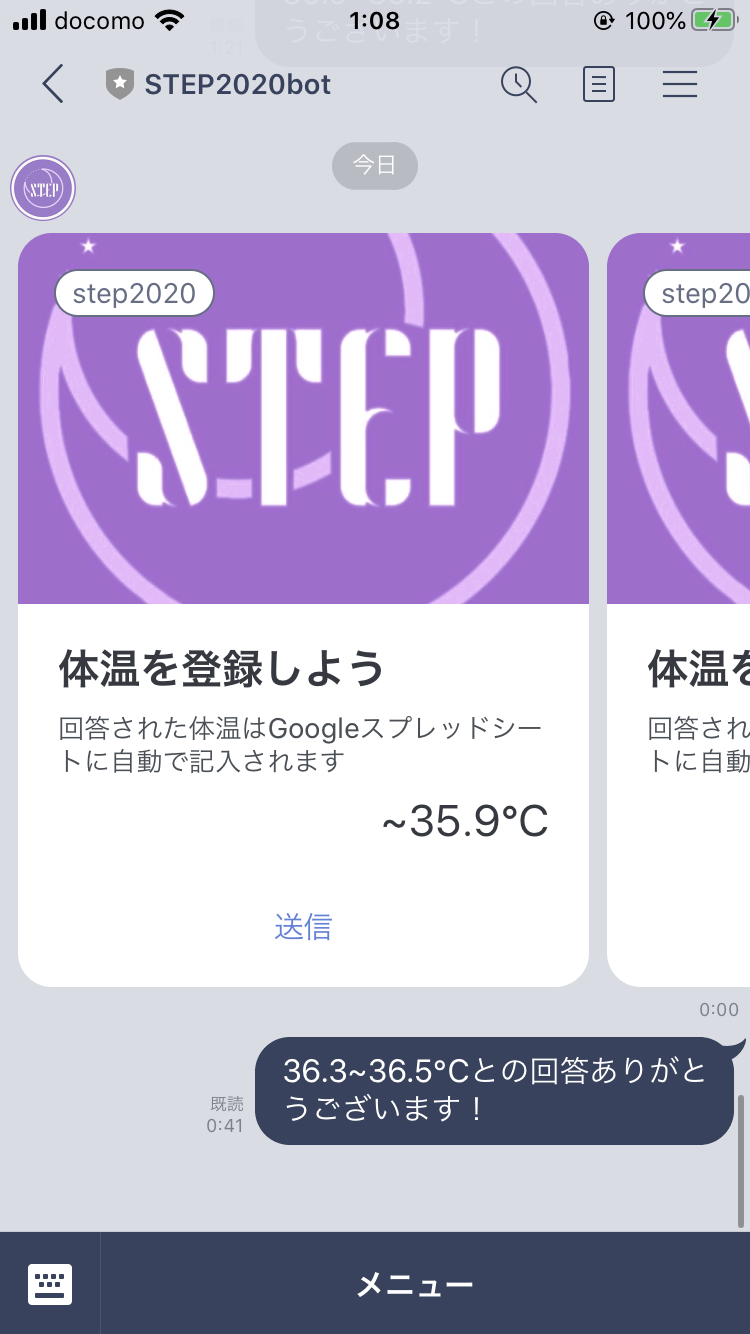
1タップで登録するというところの説明が足りていなかったので実際の画面をお見せします。
LINEの公式アカウントのメッセージタイプの中にカードタイプメッセージというものがあったので、それを使ってみました。自分の体温に該当するカードを選んでタップするだけで体温を送信することができます。ボタンクリックした時のアクションは残念ながらLINE Messaging APIでは送ってもらえなかったので、タップしたら「36.3~36.5℃との回答ありがとうございます!」というメッセージがユーザー側からされるように(ちょっと変な感じですが)したら無事Messaging APIにも拾ってもらえたのでそのような構成にしています。なんで0.1℃刻みにしていないのか、という質問については、カードタイプメッセージのカード枚数の上限が9枚だったからです、、今後増えると嬉しいなと思います。
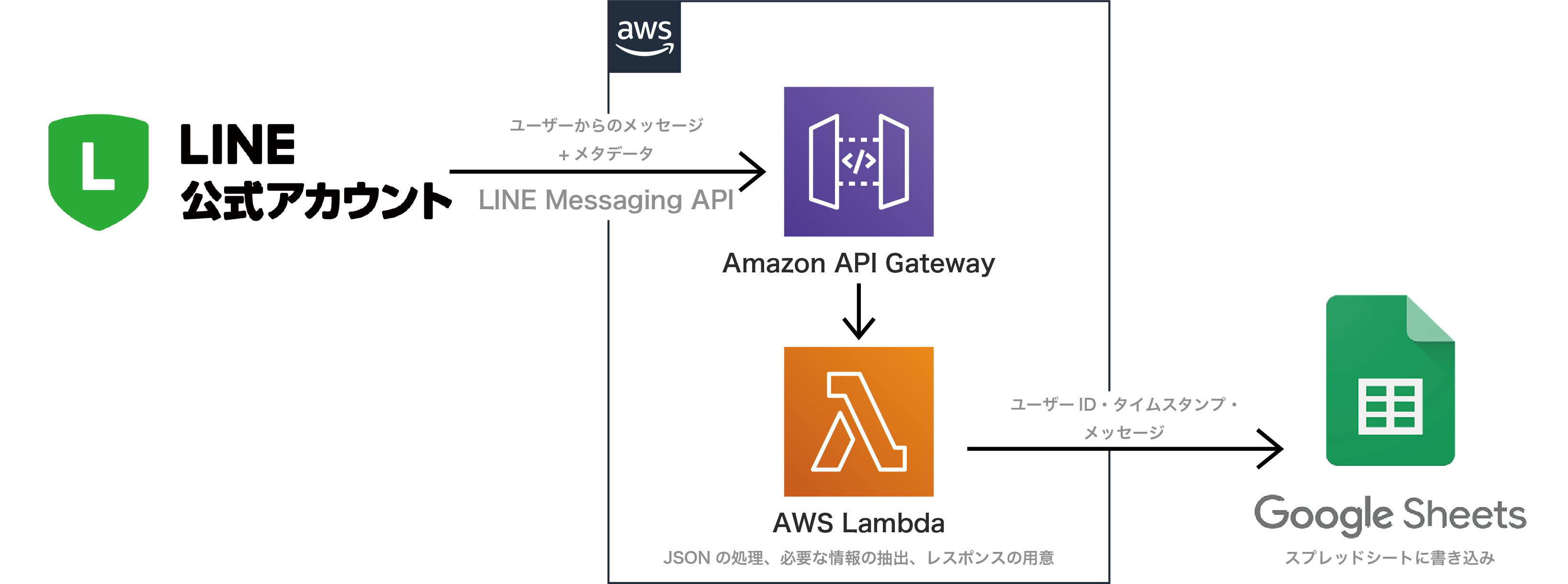
全体の構成
カードをタップした際に出力されるメッセージがLINE Messaging APIを通してAWS LamnbdaにJSONの形で届きます。LambdaでGASに送りたいデータだけを選んで整形して送り、最後にGASで簡単に処理をしてスプシに書き込むという流れです。
LINEからスプシに直接行ってもいいじゃないかという声もあるかもしれないのですが、LINE Messaging APIのWebhook URLを一つしか指定できないことから今後の拡張性を考えるとAWSで一つAPIを作ったほうがいいかなという判断です。
前置きはこのあたりにして実際の作り方に入っていこうと思います。
作り方
作り方はざっくり5つに分けることができます。
- LINE公式アカウントを作る
- AWSのAPI GatewayとLambdaを使ってAPIを作る
- 作ったAPIとLINEの公式アカウントを結びつける
- Lambdaからスプシにデータを送る
- 送られたデータをGASで処理してスプシに出力する
ひとつひとつ説明していこうと思うのですが、長くなりそうなのでわかりやすい参考記事を知っているものについてはそれを貼るなどして省略させていただきます。
LINE公式アカウント・カードタイプメッセージを作る
公式アカウントの作り方に関しては、こちらの公式ドキュメントがわかりやすいので是非ご参照下さい。
ドキュメントを読んで公式アカウントを作り、LINE Official Account Managerの ホーム/友だち追加 をクリックした時に出てくるQRコードをスキャンしてまずは自分の友達登録をしてみて下さい。
今後色々試す時に不便なので。ホーム/応答メッセージ で出てくるタイトルがDefaultのステータスはオフに切り替えておきましょう
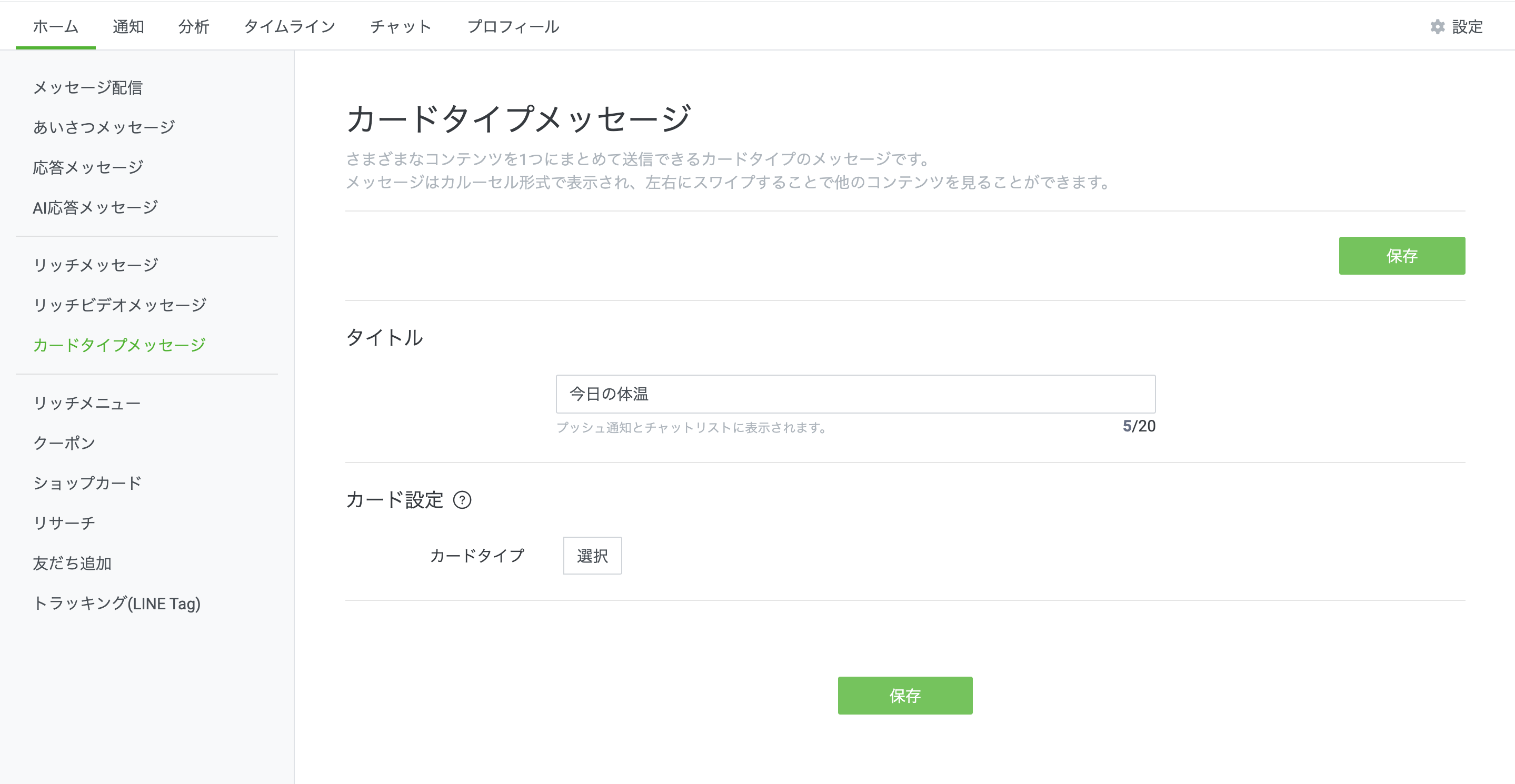
次に体温を聞くカードタイプメッセージを作っていこうと思います。LINE Official Account Managerの ホーム/カードタイプメッセージをクリックして下さい。
↓この画面になったら、作成をクリック
↓タイトルとカードタイプを聞かれます。タイトルは何でもいいのですが、カードタイプはプロダクトにします。
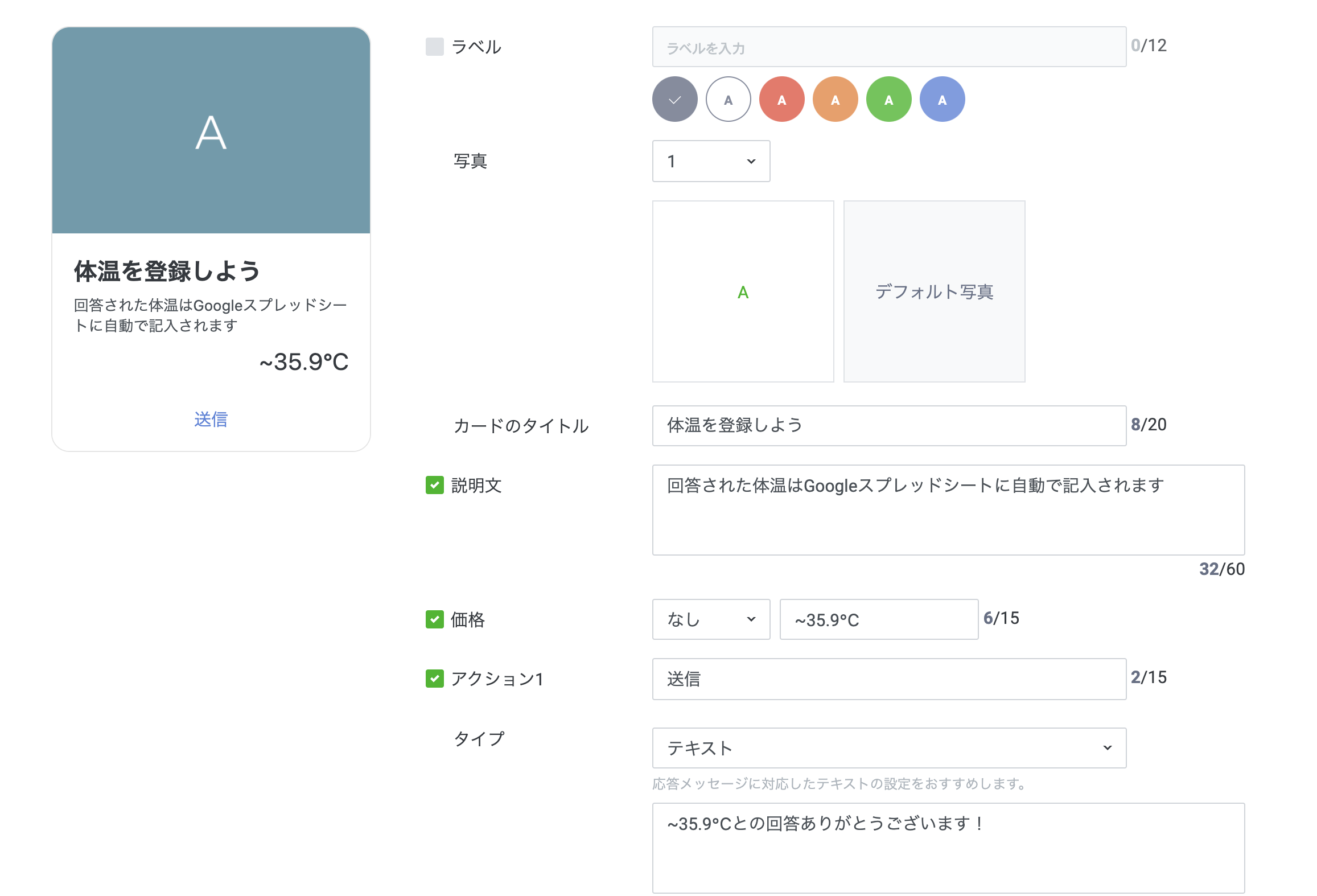
↓カードの設定は次のようにします。アクションタイプをテキストにして、〇〇℃との回答、ありがとうございます!とするようにして下さい。(℃が大事です、後で出てきます)
温度ごとに細かく分けてカードをたくさん作り(9枚まで)、保存します。↓保存したら、今度は ホーム/メッセージ配信を開いて下さい。作成をクリックです。
希望の配信日時、メッセージはカードタイプメッセージを選び、先ほど作ったものを選択して下さい。
それが配信され、カードをタップすると「〇〇℃との回答ありがとうございます!」というメッセージが見えたらセクション1は成功です。
AWSのAPI GatewayとLambdaを使ってAPIを作る
Webhookの設定上オープンAPIが必要です。API GatewayとLambdaを使って作っていきます。
まずAWSのアカウントを持っていない方は、こちらを参考にアカウントを開設して下さい。
※AWSマネジメントコンソールのUIは2020/10/23のものです
↓AWSのアカウントを作ったら、まずマネジメントコンソールでLambdaを検索してください。
↓左側のメニューで関数が選択されているのを確認し、「関数の作成」をクリック
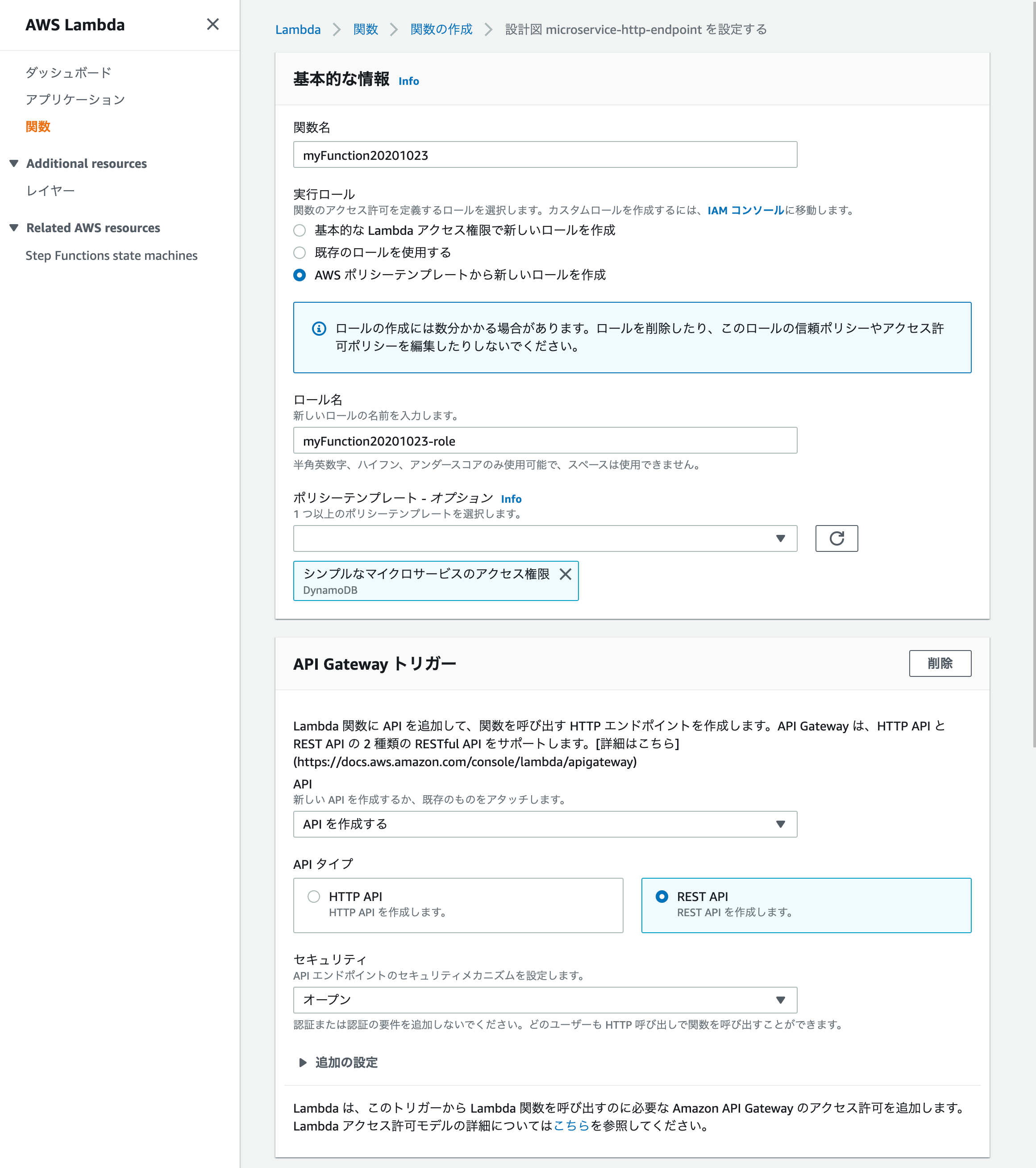
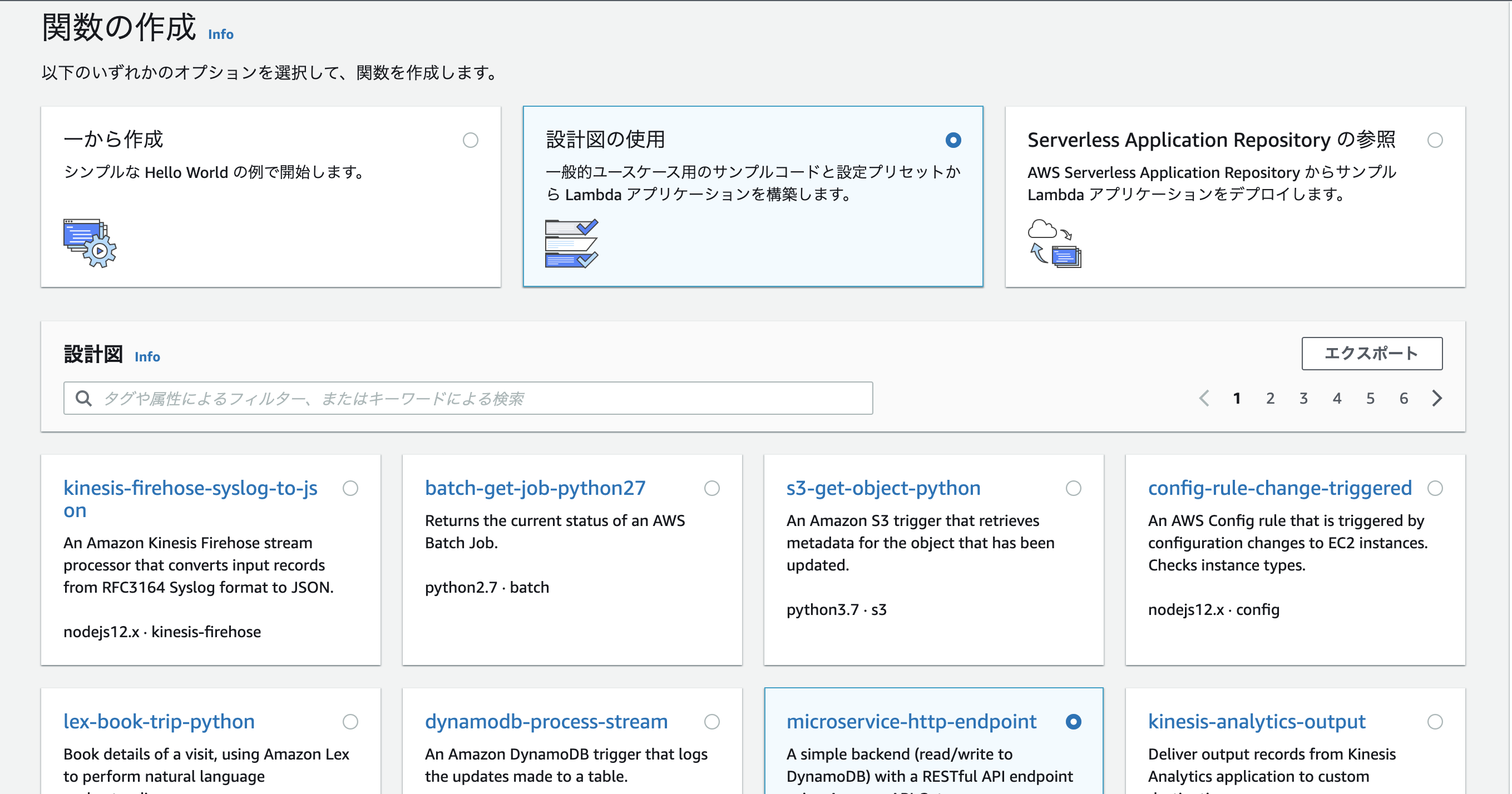
↓設計図の使用、microservice-http-endpointをクリック、右下の設定をクリックして下さい。
↓画面の様に設定をします。関数名・ロール名はご自由に設定して下さい。関数のコードはそのままにして、右下の関数の作成をクリック
Lambdaのデフォルトの関数コードをとりあえず以下の様に変えます(あとでもう一度変えます)
const AWS = require('aws-sdk'); exports.handler = (event, context) => { //console.log('Received event:', JSON.stringify(event, null, 2)); let body; let statusCode = '200'; const headers = { 'Content-Type': 'application/json', }; try { switch (event.httpMethod) { case 'DELETE': body = {"status":"delete success"}; break; case 'GET': body = {"status":"get success"}; break; case 'POST': body = {"status":"post success"}; break; case 'PUT': body = {"status":"put success"}; break; default: throw new Error(`Unsupported method "${event.httpMethod}"`); } } catch (err) { statusCode = '400'; body = err.message; } finally { body = JSON.stringify(body); } return { statusCode, body, headers, }; };今回はDynamoDBを使うことはないのでこの様に書き換えます。
Deployを押し忘れないようにして下さい。次にAPI Gatewayの設定をしていきます。
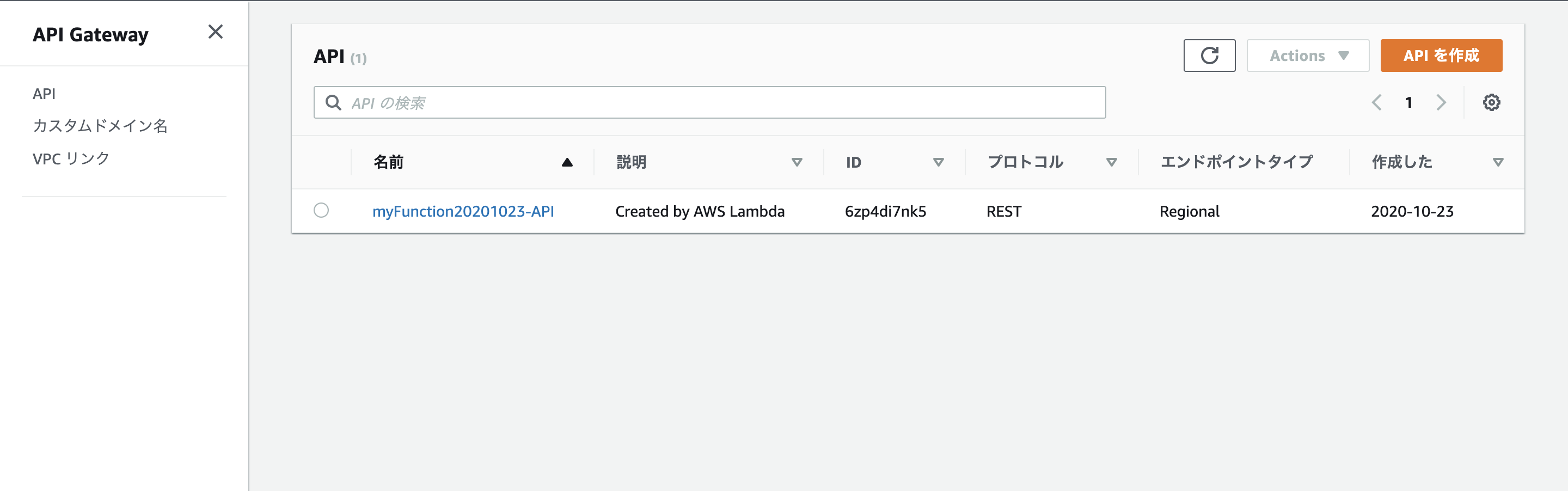
↓API Gatewayを開くと「先ほど作った関数-API」という名前のAPIが既にあることを確認できます。自分の作ったAPIをクリックして下さい。
↓するとこの様な画面になるはずです。真ん中のあたりにあるアクションをクリックして、APIのデプロイをして下さい。
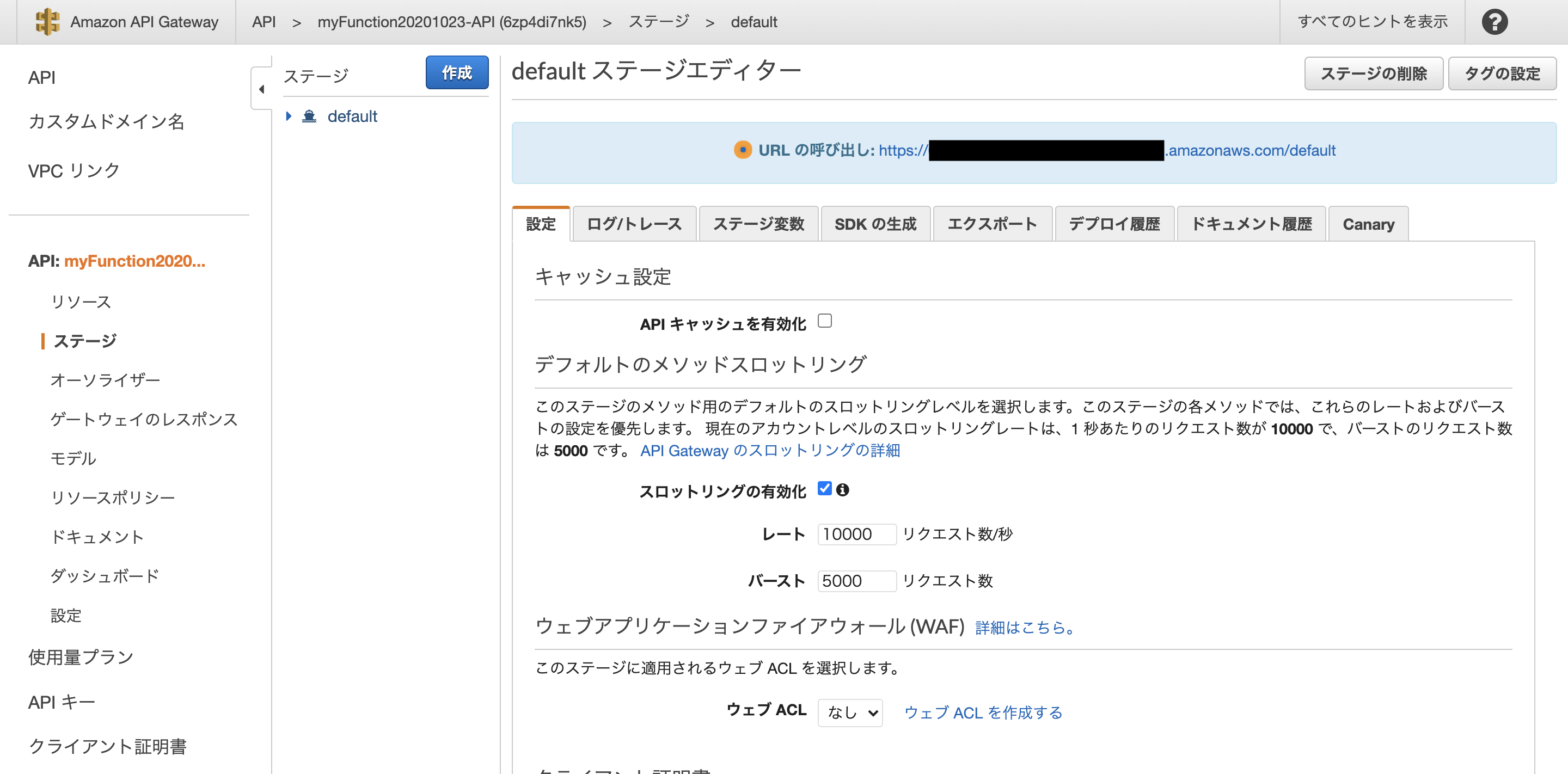
↓画面が変わった後のURLの呼び出しのところに書いてあるURLをコピーしてください。このように、~/defaultになっているはずです。この後に、リソースのところにあるメソッドの名前を入れてください。全体では、https://hogehoge.amazonaws.com/default/myFunction20201023 のようになっているはずです
これでLINE公式アカウントやスプレッドシートとやりとりするAPIが完成しました。
簡潔にするために、本当はもっと設定した方がいいところなど省略しているのですが、この通りにやっていただいたらとりあえず動くものはできます。
作ったAPIとLINEの公式アカウントを結びつける
こちらをみながらLINE Messaging APIのアクティベートをし、LINE Developersコンソールに登録していない場合は登録し、こちらを見て自分の公式アカウントに先ほどコピーしておいたURLをWebhook URLとして登録します。
↓公式アカウントを作った時にも閲覧したLINE Official Account Managerを開き、自分のアカウントを選択したら、右上にある「設定」をクリックして下さい。
左のメニューの中に「Messaging API」があるので、そこをクリックし、Messaging APIを有効にして下さい。Messaging APIのチャネルの設定は、LINE Developersコンソールで行います。 LINE Official Account Managerにログインするときに使っているLINEアカウントで、LINE Developersコンソールにログインします。チャネルができたらWebhook URLを設定していこうと思います。LINE Developersコンソールで自分の作ったチャネルを選択し、Messaging APIを選択して下さい。
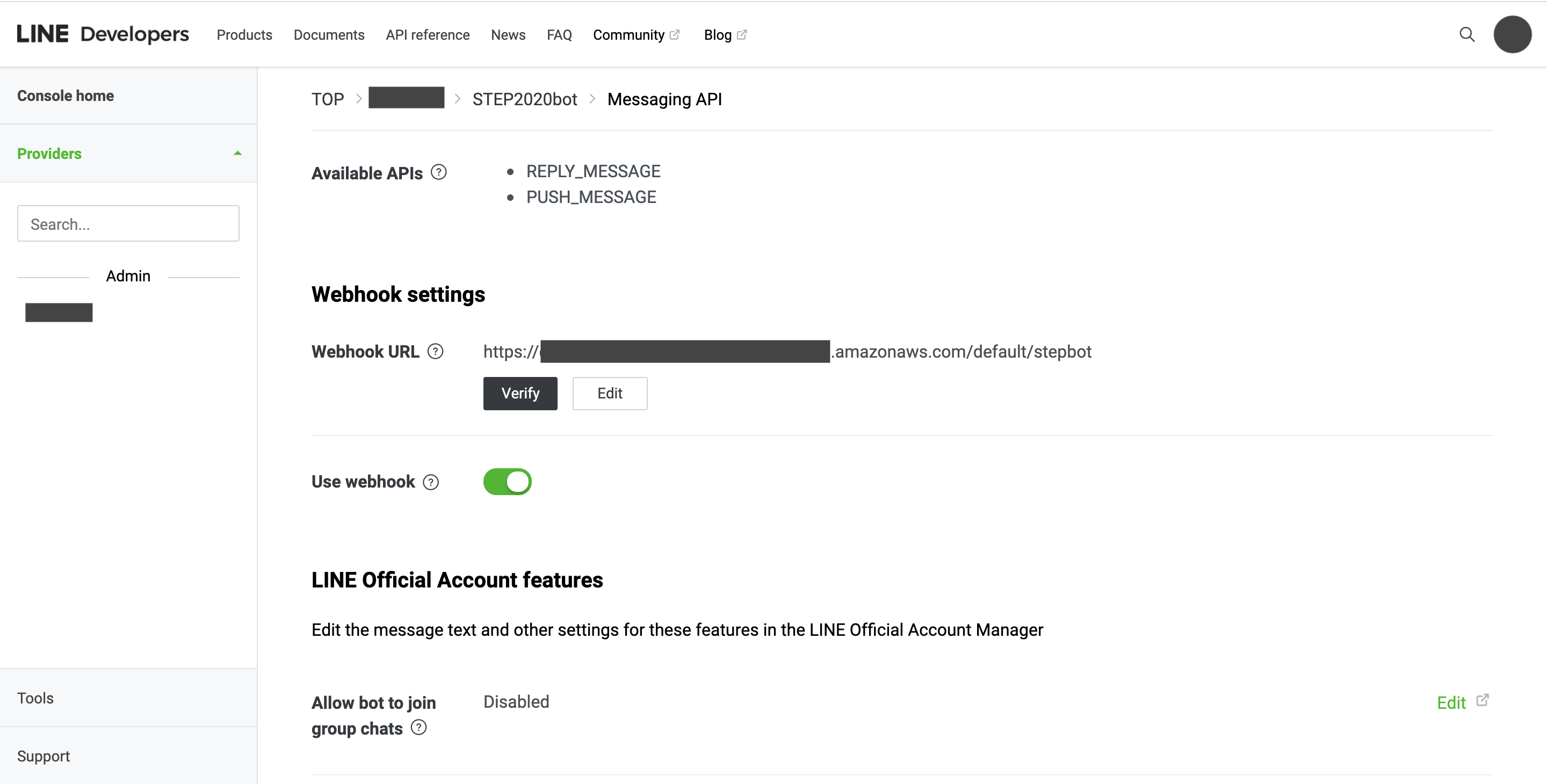
↓少し下にスクロールすると、このようにWebhookURLの下にEditという文字があるのでそれをクリックして下さい。
URLを入力するところがあるので、そこに先ほど用意してURLを入力します。/defaultの後にメソッド名を付け加えるのを忘れないようにして下さい。verifyを押し、200レスポンスが返ってくるのを確認して下さい。返ってこなかった時にはpostmanなどを使って原因を確認していきます。
Verifyのボタンを押した際に200レスポンスが返ってくることが確認できたらこのセクションは成功です。
ここまで設定したことで、LINEの公式アカウントでユーザーがメッセージを送ったり、新しく公式アカウントを追加した際にLambdaにJSONデータが送られるようになりました!この調子で次は必要なデータを抽出してスプシに送る用意をしましょう。
Lambdaからスプシにデータを送る
新しくスプシを作り、スクリプトエディタで簡単な関数を作り、Web APIとして公開し、Lambdaからデータを送るように設定します。
GASに関してはこの連載がとても丁寧で非常に助かったので初めてGASを触る方はこれを片っ端から進めていくのがおすすめです。まずはスプシを一枚作ってみて下さい。この時にある方はG Suiteアカウントで作成すると後の権限の設定が簡単になるのでそちらを使った方がいいと思います。
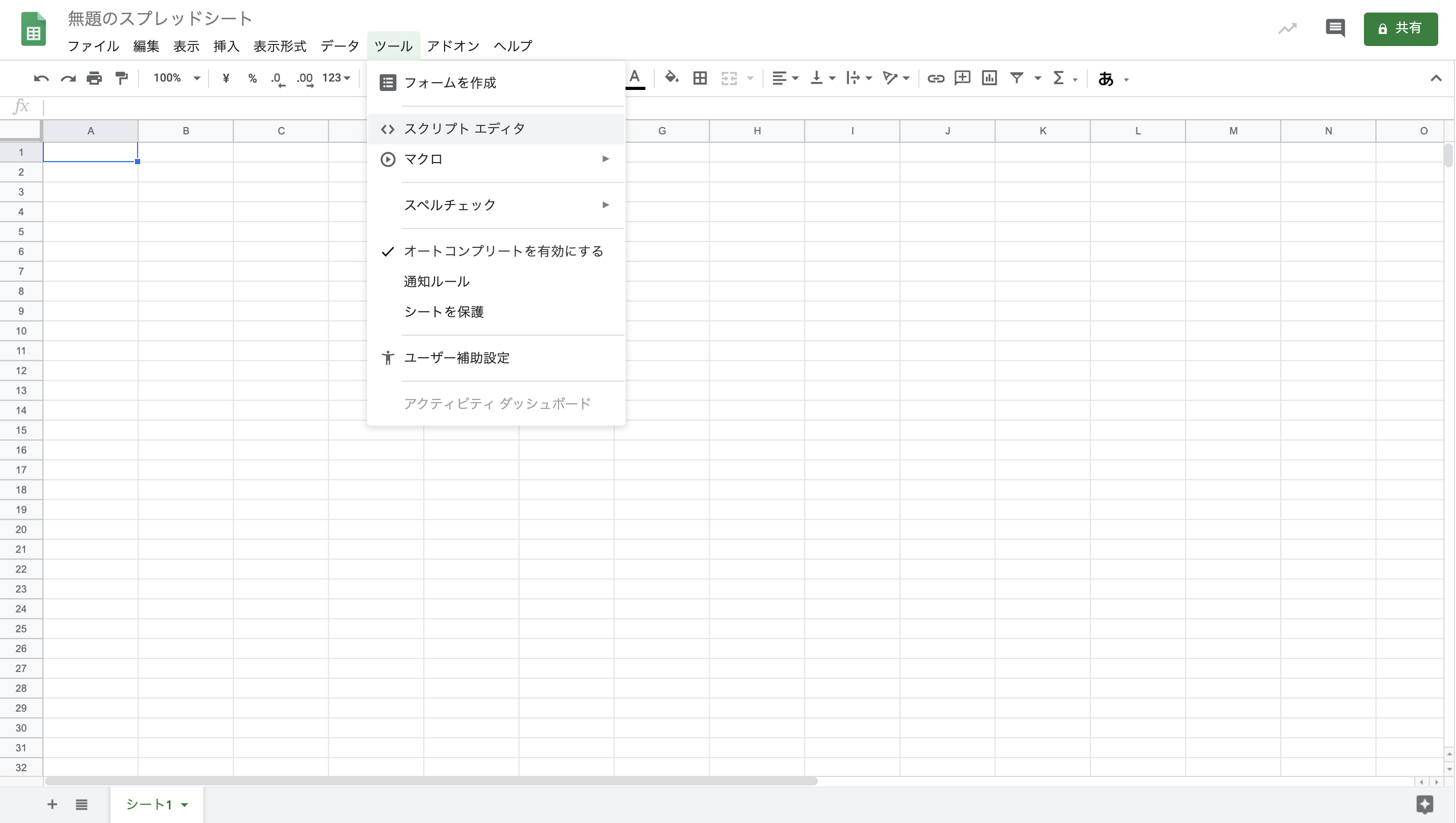
↓上のメニューの中の「ツール」をクリック、その中にある「スクリプトエディタ」をクリックして下さい。
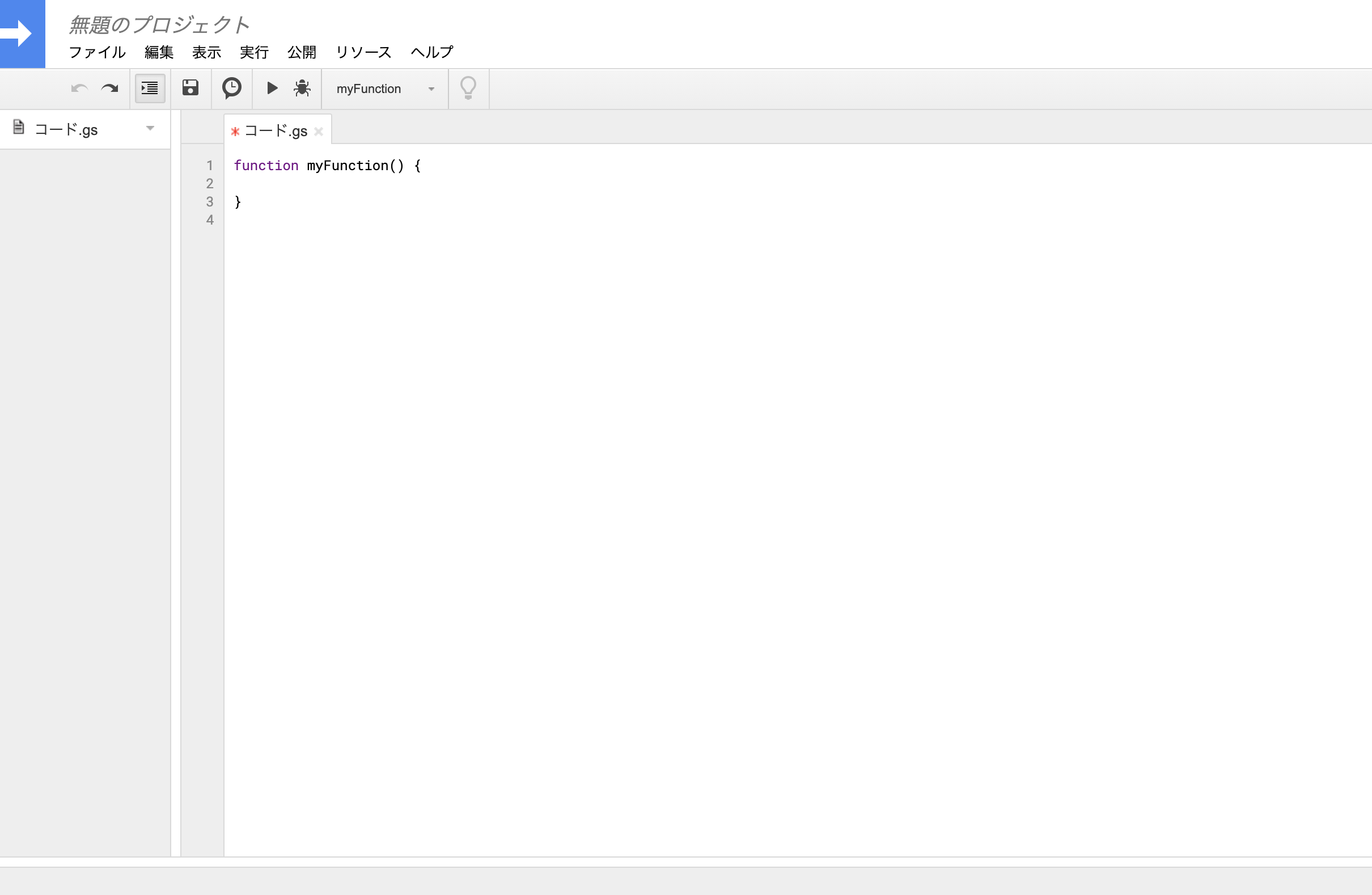
↓このようにエディタが開かれます。
ここに、
function doPost() { const ss = SpreadsheetApp.getActiveSpreadsheet(); const sheet = SpreadsheetApp.getActiveSheet(); const range = sheet.getRange(1,1); range.setValue("hello world"); }このようにコードを書きます。これはスプシのA1にhello worldと出力するコードです。cmd+sで保存、プロジェクト名を記入、cmd+rで実行です。許可を求められるのでG Suiteアカウントの方は許可を確認と押して下さい。無料アカウントの場合は、もう少し複雑です。この記事をご参照下さい。
A1にhello worldと書き込まれたのを確認できたら、次はこれをweb APIとして公開してみます。
↓公開→ウェブアプリケーションとして導入をクリックして下さい。
↓このようなモーダルが出てきたら、下のように設定し、Deployをクリック
URLが表示されるので大切に取っておきましょう。
次はLambdaの関数コードをもう一度いじっていきます。
AWSマネジメントコンソールに移動です。
先ほどいじったLambdaをもう一度開き、今度は次のようにコードを変更してみて下さい。const AWS = require('aws-sdk'); const https = require("https"); exports.handler = (event, context) => { console.log('Received event:', JSON.stringify(event, null, 2)); let body; let statusCode = '200'; const headers = { 'Content-Type': 'application/json', }; try { switch (event.httpMethod) { case 'DELETE': body = {"status":"delete success"}; break; case 'GET': body = {"status":"get success"}; break; case 'POST': body = {"status":"post success"}; //ここからスプシに投稿するコード const json = JSON.parse(event.body); var postMessage = { 'text': json.events[0].message.text, 'timestamp': json.events[0].timestamp, 'userId': json.events[0].source.userId } var postDataStr = JSON.stringify(postMessage); console.log("postData↓"); console.log(postDataStr); console.log("postData↑"); let options = { host: 'script.google.com', path: '/先ほどコピーしたURLのscript.google.com/と/execに挟まれている部分/exec', port: 443, method: 'POST', headers: { 'Content-Type': 'application/json', 'Content-Length': Buffer.byteLength(postDataStr) } }; var post_req = https.request(options, function(res) { console.log("https requested") res.setEncoding('utf8'); res.on('data', function (chunk) { console.log('Response: ' + chunk); context.succeed(); }); res.on('error', function (e) { console.log("Got error: " + e.message); context.done(null, 'FAILURE'); }); }); post_req.write(postDataStr); post_req.end(); //ここまでスプシに投稿するコード break; case 'PUT': body = {"status":"put success"}; break; default: throw new Error(`Unsupported method "${event.httpMethod}"`); } } catch (err) { statusCode = '400'; body = err.message; } finally { body = JSON.stringify(body); } return { statusCode, body, headers, }; };関数をDeployするのを忘れないようにして下さい。関数がDeployできたら、LINEで公式アカウントに何かメッセージを送ってみて、スプシにhello worldが書き込まれるのが確認できたらこのセクションは成功です。
送られたデータをGASで処理してスプシに出力する
スプシに送られたユーザーID、timestamp、メッセージをGASの中で処理して、スプシに出力していきます。
私の場合は既にスプシに名前の順番が決まっていて、それがラインの表示名とは違う名前での並びだったので、最初のメンバーの名前とLINEのユーザーIDの照らし合わせは手作業でやってしまったのですが、人数が多い場合は、こちらのようにプロフィール情報をゲットできるAPIがあるのでそれも組み合わせるとより効率的にできるのではないかと思います。先ほどのスプシのスクリプトエディタで、
function doPost(e) { const ss = SpreadsheetApp.getActiveSpreadsheet(); const sheet = SpreadsheetApp.getActiveSheet(); const member = {自分の団体の人数(わからない場合は大きめの値を入力するといいと思います)} var jsonString = e.postData.getDataAsString(); var data = JSON.parse(jsonString); var userId = data.userId; var time = data.timestamp+32400000; //日本時間に合わせています var dateRow = Math.floor(time/86400000)-18521(18521は適当な値に変更して下さい。); //epoch時間がミリセカンド単位になっていたので1日単位になるように割り、日時が希望する列に合うように1970年1月1日からの日数を計算して引きます。 var text = data.text; var temperature = text.split("℃"); //メッセージを℃の文字で分け、数字の部分だけがスプシに書き込まれるようにします。 const peopleRange = sheet.getRange(3, 3, member, 1);//UserIdを3列目、上から3行目から書き始めた場合です。 const peopleValues = peopleRange.getValues() var peopleArrayNumber; for(let i=1; i<member; i++){ if(String(peopleValues[i])===userId){ peopleArrayNumber = i+3 //上から3行目から始まっているためです。 } } const range = sheet.getRange(peopleArrayNumber,dateRow); if(text.match("℃")){ range.setValue(temperature); } }このように変更して、保存、公開をして下さい。
最初に作ったカードタイプメッセージを送信してタップし、このように書き込まれていったら成功です。
注意点としては、ユーザーIdで検索をかけているので、ユーザーIdだけは最初に用意しておかなければいけないです。今後改善していってその部分は直していこうと思います。
長い記事に最後までお付き合いいただきありがとうございました!このソリューションがより多くの方のお役に立てたら幸いです。



- 投稿日:2020-10-23T17:36:43+09:00
AWS Elemental Link 使ってみた!
発売日の朝に iPhone12 が届いた streampack 木村です。
早速、仕事しながらデータ移行などをやってますが、実はもうひとつ届いてたものがあります。
それがコレ
Elemental Link です
要は電源入れたら勝手に AWS にストリームを送ってくれるハードウェアエンコーダーボックスです。
AWS Elemental Link
https://aws.amazon.com/jp/medialive/features/link/リリースからちょっと時間経っちゃってますが、遅ればせながらオーダーしてみました。
注文
Elemental Link は AWS アカウントと紐付いている為、自身の AWS アカウントにログインした状態で、前述の Elemental Link のページ、もしくは MediaLive > Device > Purchase a device を辿ると注文ページに飛びます。
この後は、名前とか email とかお届け先住所とか region とか支払い方法などを埋めて行って最後にオーダー完了となります。
価格は1台 $995 です。
注意: 商品代金とは別に 輸入消費税 が別途かかります。
これは商品到着時に金額が判明し、支払う必要があります。
無事注文が完了すると、AWS から注文完了メールが飛んできます。
ちなみに私が注文したのは 2020/9/18 でした。
商品到着
そして 9/26。 我が家に配達されました。
注文から8日とは早いですね。輸入消費税は私の場合 10,800円でした。
なんで箱2つ?と思ったら、小さい箱には写真のビニールに入った電源ケーブルだけが入ってた。
大きい箱には本体と AC アダプター、ケーブルと説明書。
ケーブル2つも要らないのだが。。。
表面
電源ボタン等はありません。
ランプ類とスイッチが一つだけ。このスイッチを長押すると、デフォルトでは DHCP で IP アドレスを取得するところ、固定 IP に変更されます。
固定 IP アドレスは側面のシールに記載されています。裏面
- Ethernet
- 3G-SDI
- HDMI
- USB
- DC12V
の口があります。
配信
それではさっそく配信してみましょう!
AWS MediaLive 側
注文が完了すると、MediaLive > Devices に Elemental Link が表示されるようになります。
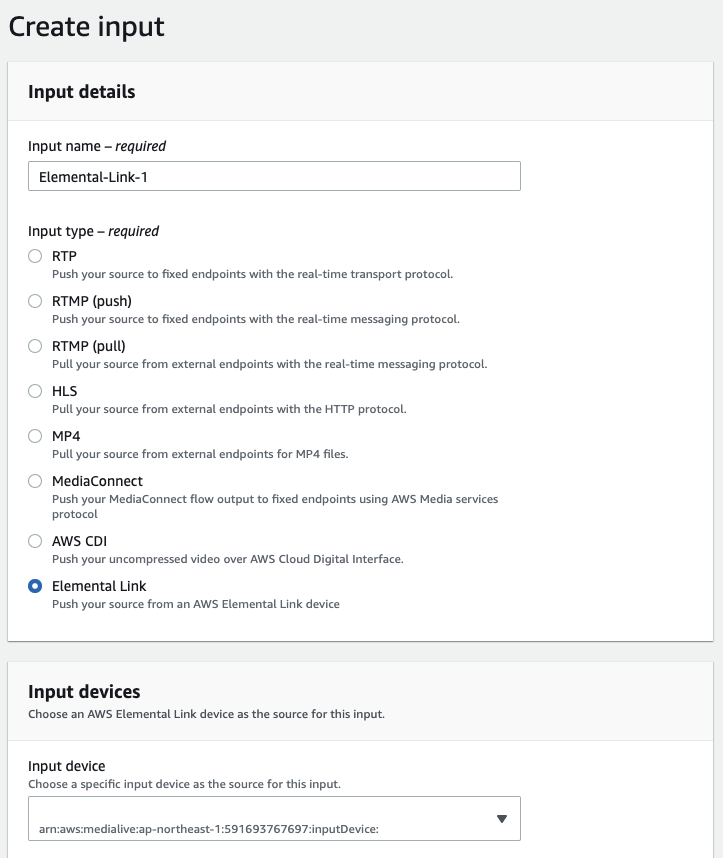
さて、こいつを Input としてまずは MediaLive Input を作成します。
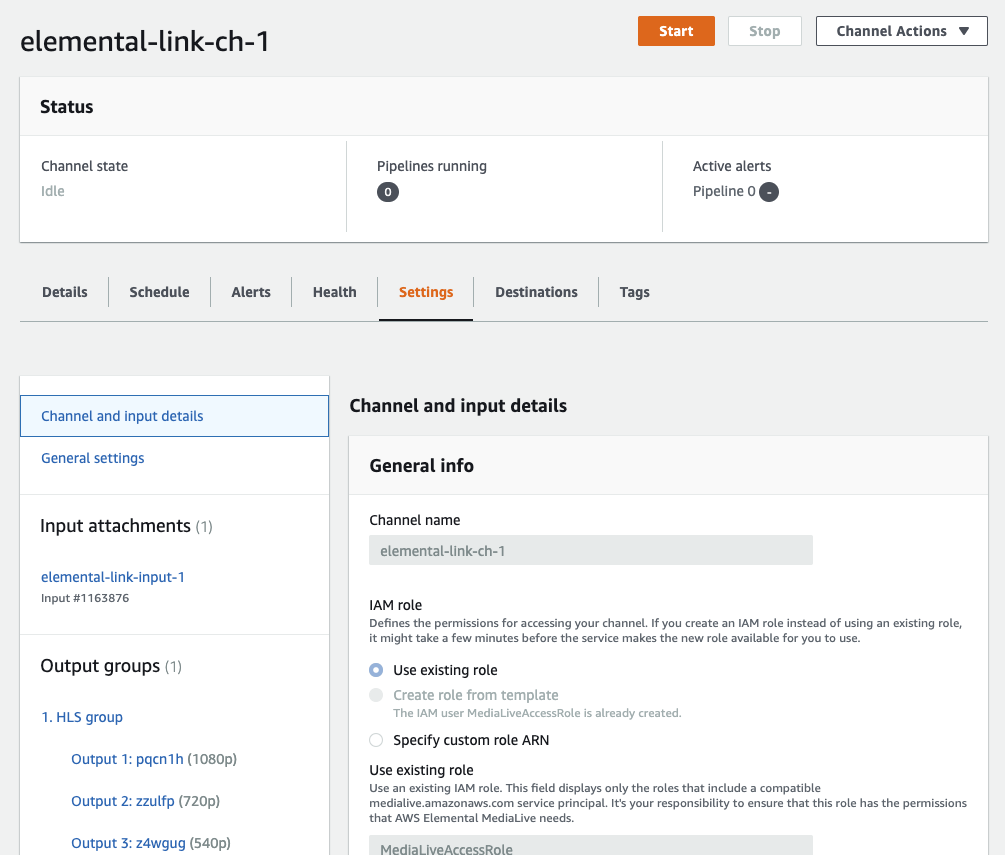
そして、この Input を使う MediaLive CH を作成します。(設定は適当に・・・)
当然、打ち上げは1本なので、SINGLE パイプラインとなります。
あとはチャンネルを開始するだけです。
Elemental Link 側
電源、lan線を挿してみます。
電源ケーブルを挿して暫くすると勝手に AWS と通信します。
正常に接続すると ONLINE と AWS LINK が青く点灯します。
カメラ接続
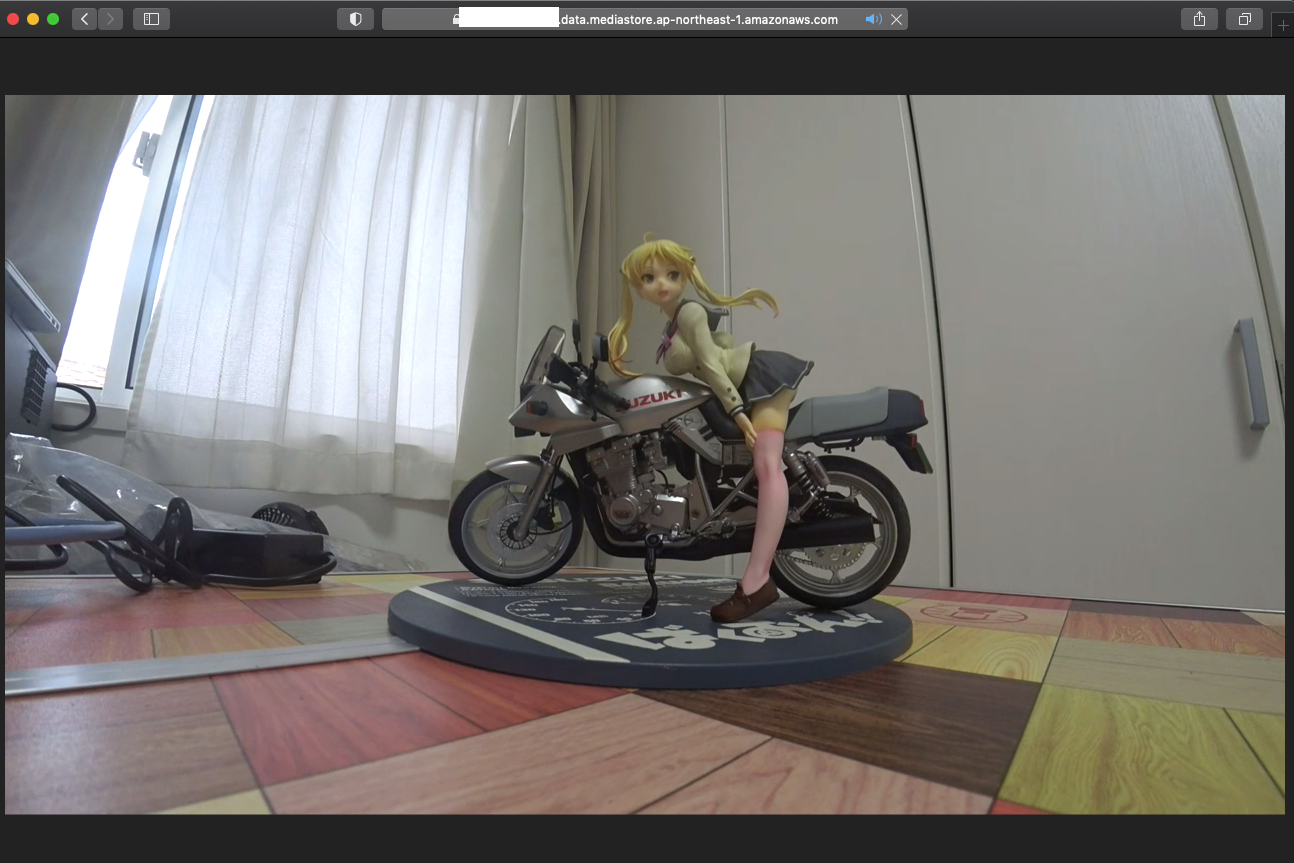
手持ちの SONY アクションカムを HDMI で接続。
暫くすると前面の STREAMING インジケーターが青く点灯します。
これで配信が開始された状態となります。
Elemental Link 側はホントに線をつなぐだけ・・・
こんな感じで凜ちゃんを撮影。
Mac Safari で視聴中。
当たり前ですがちゃんと見れてます。イジってみてわかったこと
気がついた点をリストしてみます。
Input Preview
Elemental Live にあって MediaLive に無いもの。
もう一生付かないと思っていたプレビューが Elemental Link で配信すると AWS コンソールで確認できます。これは Elemental Live と同様に5秒に一回くらいで静止画が更新されていく感じです。
出力ビットレート、フレームレート
Elemental Link 側ではエンコード設定をイジれないのですが、AWS コンソールでどの程度で打ち上げてるか確認できます。
デフォルト設定だとこんな感じ。
配信プロトコル
MediaLive Alert にこんな表示が。
どうやら UDP で打ち上げているようです。
設定変更
接続が完了すると、Devices から Elemental Link の設定確認、変更が可能になります。
写真のようにデフォルトでは 1920x1080 9Mbps 59.94fps で送出していることが確認できます。
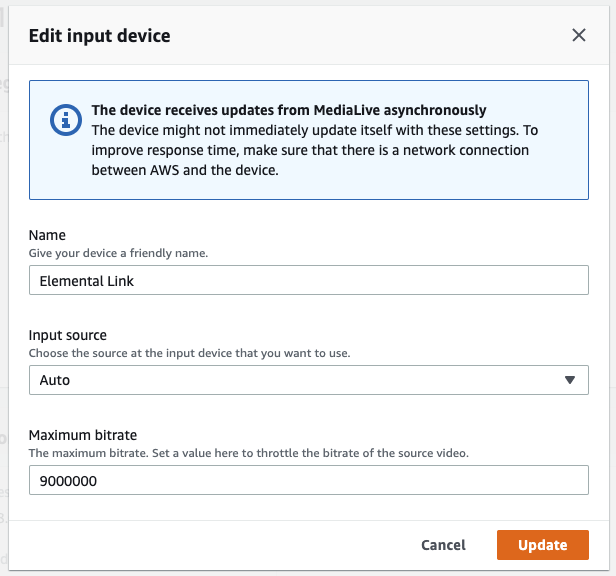
右上の Edit ボタンから設定変更が可能です。
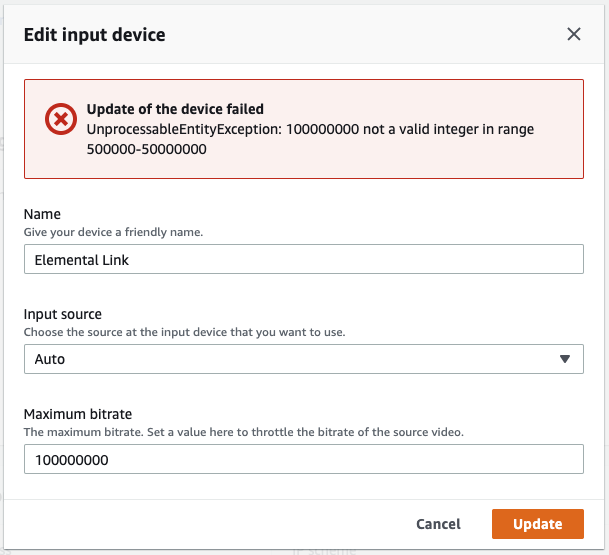
とは言っても変更できるのは下記の3つだけ。
調子こいてビットレートを 100Mbps にすると・・・
怒られました。
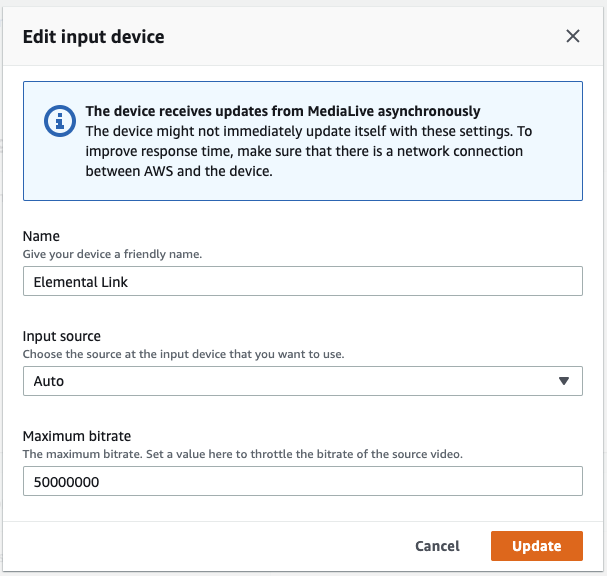
ならば 50Mbps にしてみます。
そうすると 50Mbps で投げるようになりました。
ビットレート変更は配信中でも可能です。
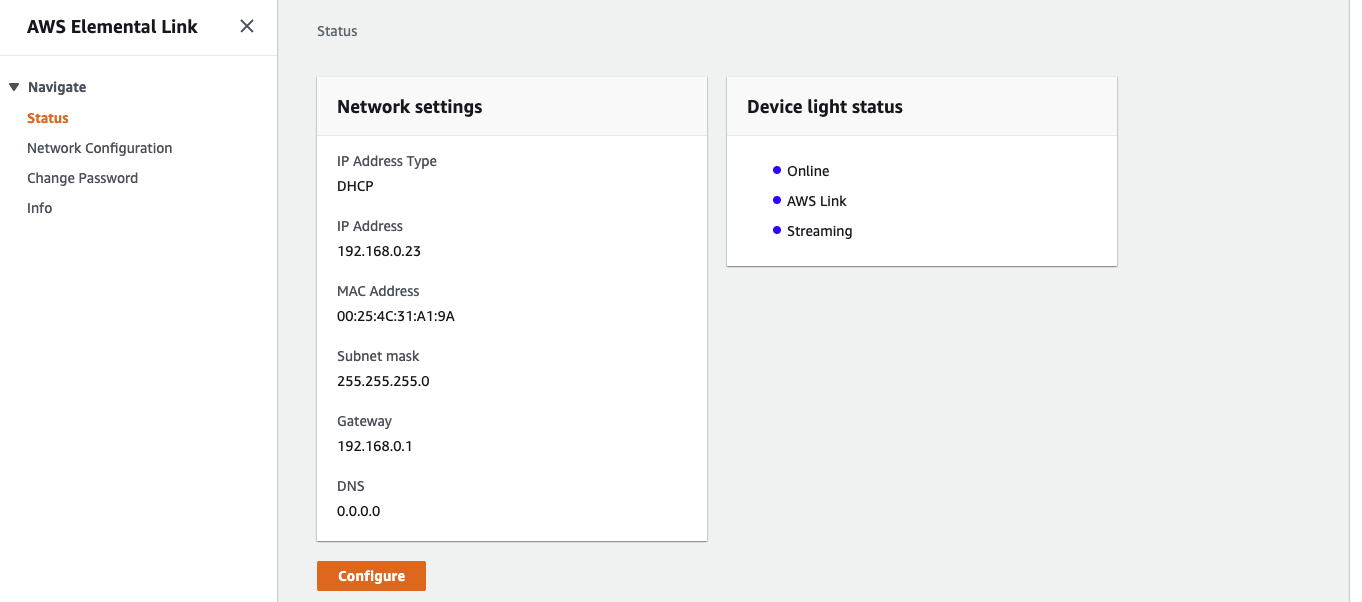
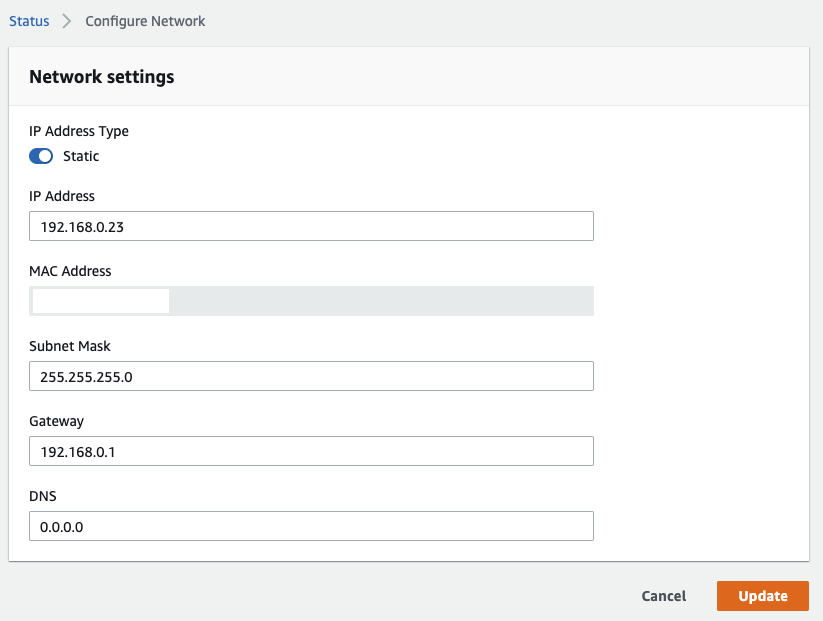
ネットワーク設定
Elemental Link のネットワーク設定は AWS コンソールではなく、本体にアクセスして変更することができます。
ブラウザーから
https://{Elemental Link の IP アドレス}にアクセスし、本体底面に記載のユーザー名/パスワードでログインします。
IP Address Type を Static にすることで任意のネットワーク設定が可能になります。
まとめ
実際にモノが届くまで、一体どういう仕組で配信するのか全く分からなかったのですが、何なら MediaLive も勝手に作られちゃう?? くらいに思ってたんですが、MediaLive 側は通常通りに設定する必要がありました。
対して Elemental Link 側はケーブル類をつなぐだけなので、配信の際には現場の人に、コレ繋いでね ♡
で済むのは結構楽になるんじゃないでしょうか。















- 投稿日:2020-10-23T16:51:47+09:00
Amazon Linuxでrbenvをインストール
依存ライブラリーをインストール
sudo yum -y install gcc sudo yum -y install make sudo yum -y install openssl sudo yum -y install openssl-devel sudo yum -y install gcc-c++ sudo yum install -y mysql-devel sudo yum install -y readline-devel sudo yum install -y libxml2-devel sudo yum install -y libxslt-devel sudo yum install -y bzip2gitをインストール
$ sudo yum -y install gitrbenvをインストール
$ git clone https://github.com/sstephenson/rbenv.git ~/.rbenv $ echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(rbenv init -)"' >> ~/.bash_profile $ exec $SHELL -lしかしこのままだとrbenv istallが出来ない。
$ rbenv install -v 2.6.2 rbenv: no such command `install'helpを見てみると、installコマンドが無いのが分かる。
$ rbenv -h Usage: rbenv <command> [<args>] Some useful rbenv commands are: commands List all available rbenv commands local Set or show the local application-specific Ruby version global Set or show the global Ruby version shell Set or show the shell-specific Ruby version rehash Rehash rbenv shims (run this after installing executables) version Show the current Ruby version and its origin versions List installed Ruby versions which Display the full path to an executable whence List all Ruby versions that contain the given executable解決方法
install するには
ruby-buildプラグインが必要となるのでインストールする。$ git clone https://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-buildhelpを見るとinstall(とuninstall)が追加されたのが分かる。
$ rbenv -h Usage: rbenv <command> [<args>] Some useful rbenv commands are: commands List all available rbenv commands local Set or show the local application-specific Ruby version global Set or show the global Ruby version shell Set or show the shell-specific Ruby version install Install a Ruby version using ruby-build uninstall Uninstall a specific Ruby version rehash Rehash rbenv shims (run this after installing executables) version Show the current Ruby version and its origin versions List installed Ruby versions which Display the full path to an executable whence List all Ruby versions that contain the given executable See `rbenv help <command>' for information on a specific command. For full documentation, see: https://github.com/rbenv/rbenv#readme
rbenv install -v 2.6.2するとインストールが始まる。
インストール終了後、rbenv versionsで確認できる。$ rbenv versions * system 2.6.2インストールLog
インストール時のlogファイルは
ruby-build.xxxxxxxxxxxxxxx.logというファイル名で
/tmp/配下に格納されている。
- 投稿日:2020-10-23T15:12:26+09:00
TimestreamにAWS CLIでクエリ
事前状態
- awscliを最新にする
- Timestreamでサンプルデータベース作っておく
ヘルプ
$ aws timestream-query helpTIMESTREAM-QUERY() TIMESTREAM-QUERY() NAME timestream-query - DESCRIPTION AVAILABLE COMMANDS o cancel-query o describe-endpoints o help o queryドキュメントはこちら
https://docs.aws.amazon.com/cli/latest/reference/timestream-query/query.html
CLIでクエリ
$ aws timestream-query query --query-string "SELECT * FROM testdb.IoT ORDER BY time DESC LIMIT 2" { "Rows": [ { "Data": [ { "ScalarValue": "Alpha" }, { "ScalarValue": "21135517" }, { "ScalarValue": "100" }, { "ScalarValue": "359" }, { "ScalarValue": "1000" }, { "ScalarValue": "Peterbilt" }, { "NullValue": true }, { "ScalarValue": "34.7465° N, 92.2896° W" }, { "ScalarValue": "location" }, { "ScalarValue": "2020-10-23 03:33:23.716000000" } ] }, { "Data": [ { "ScalarValue": "Alpha" }, { "ScalarValue": "8598979964" }, { "ScalarValue": "150" }, { "ScalarValue": "C-600" }, { "ScalarValue": "1000" }, { "ScalarValue": "Ford" }, { "ScalarValue": "14.0" }, { "NullValue": true }, { "ScalarValue": "speed" }, { "ScalarValue": "2020-10-23 03:33:15.708000000" } ] } ], "ColumnInfo": [ { "Name": "fleet", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "truck_id", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "fuel_capacity", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "model", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "load_capacity", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "make", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "measure_value::double", "Type": { "ScalarType": "DOUBLE" } }, { "Name": "measure_value::varchar", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "measure_name", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "time", "Type": { "ScalarType": "TIMESTAMP" } } ], "QueryId": "AEBQEAMXYYX46KAC5AWWAQMNHBHRRDECDAFOKKQ45N4PIVWTA3D5BVXELIKF4HA" }
- 投稿日:2020-10-23T11:57:15+09:00
AWS Lambda Powertoolsを触ってみた
はじめに
サーバレスのイベントで紹介されたAWS Lambda Powertoolsが便利そうだったので触ってみました。
(こちらのセッションでも詳しく紹介されています)AWS Lambda PowertoolsはLambda関数用のユーティリティ集で、
AWS X-Rayによるトレース、構造化ロギング、カスタムメトリックの出力が容易に実装できます。
また、SSM Parameter StoreやSecrets Managerからのパラメータ取得ができるユーティリティも付属しています。現在の対応ランタイムはAWS Lambda Powertools PythonとAWS Lambda Powertools Javaの2種類となっています。
Node.jsではDAZN Lambda Powertoolsがあります。触ってみる
構造化ロギング、カスタムメトリックの出力を試してみます。
LambdaのランタイムはPython3.8を使います。AWS Lambda Powertoolsの導入
インストールはPyPIまたはLambda Layerで行います。
今回はLambda Layerで導入してみます。Lambda Layerは複数のLambda関数でライブラリを共有する機能です。
AWS Lambda PowertoolsをLambda Layerとして作成し、
各Lambda関数にLayerを追加することでライブラリをimportできるようになります。Lambda Layerの作成
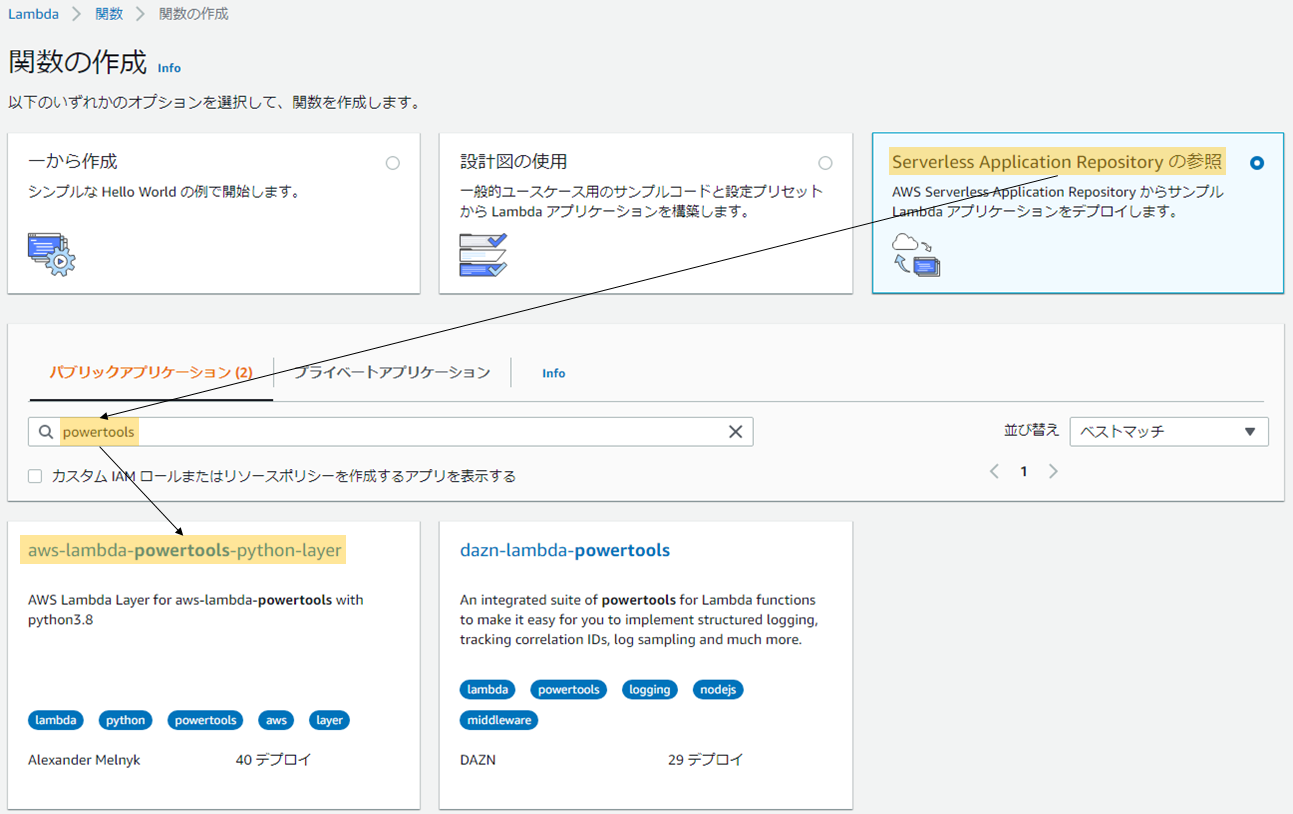
AWS Lambda PowertoolsのLambda Layerは
AWS Serverless Application Repositoryに公開されているAWS SAM テンプレートから数クリックで作成できます。Lambda関数の作成画面を開き「Serverless Application Repository の参照」を選択、
検索ウィンドウに「powertools」を入力して「aws-lambda-powertools-python-layer」をデプロイします。
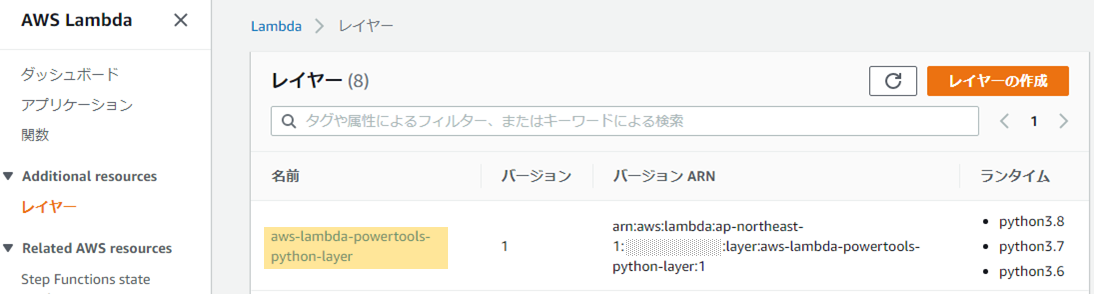
AWS Lambda PowertoolsのLambda Layerを作成するCloud Formationが実行され、
「aws-lambda-powertools-python-layer」という名前のLambda Layerが作成さます。
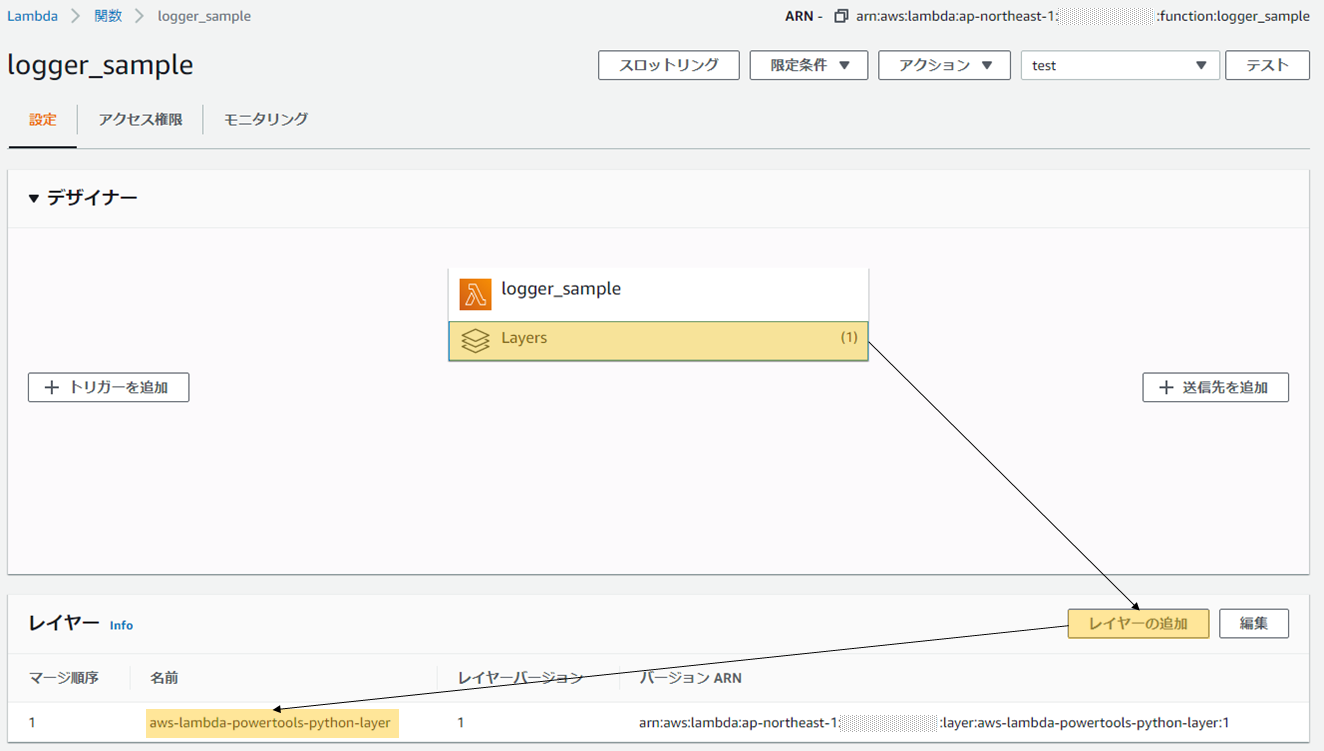
Lambda関数へLayerを追加
Lambda関数内のコードからAWS Lambda PowertoolsのライブラリをimportできるようにLambda Layerを追加します。
構造化ロギング
Loggerの実装
print文やPythonのLoggerを使ってログ出力をすることができますが、
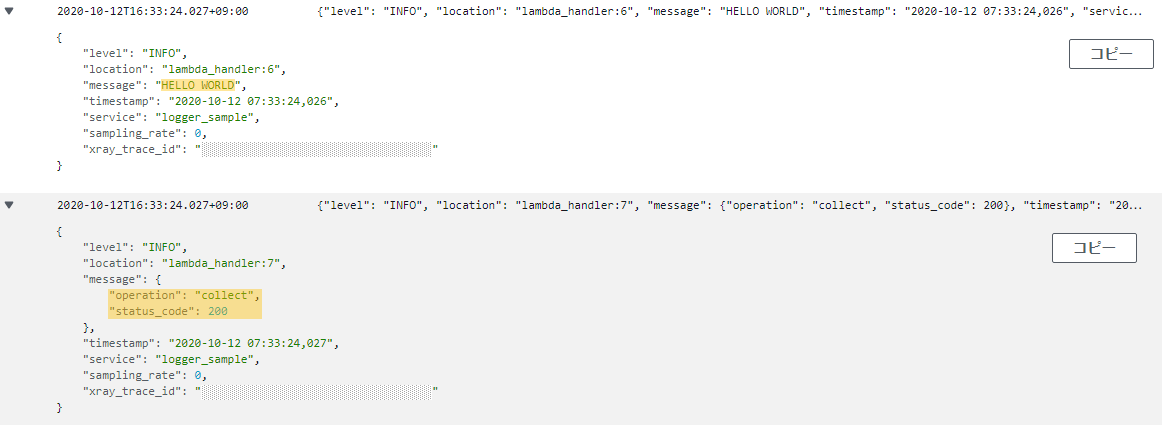
AWS Lambda Powertoolsを使うと、Jsonで構造化されたログを簡単に出力できます。AWS Lambda PowertoolsのLoggerをimportし、
INFOログと、ネストしたログを出力してみます。lambda_function.pyfrom aws_lambda_powertools import Logger logger = Logger(service="logger_sample") def lambda_handler(event, context): logger.info("HELLO WORLD") logger.info({ "operation": "collect", "status_code": 200 })他にもこのような便利な機能がありました。
デコレーターでLambdaのコンテキスト情報(cold_start:bool,memory_size:int)をログに含めたり
https://awslabs.github.io/aws-lambda-powertools-python/core/logger/#capturing-lambda-context-infoログに固定で出力する項目を追加したり
https://awslabs.github.io/aws-lambda-powertools-python/core/logger/#appending-additional-keys例外発生時にスタックトレースを出力したり
https://awslabs.github.io/aws-lambda-powertools-python/core/logger/#logging-exceptionsCloudWatch Logsに出力されたログの確認
先ほど出力したログをCloudWatch Logsで確認してみます。
ログがJSONで構造化されていることが確認できます。
CloudWatch Logs Insightsによるログ検索
Jsonで構造化されたログを出力すると、CloudWatch Logs Insightsは自動的にフィールドとして認識してくれます。
特定のフィールドに対してクエリで絞り込みや集計が行えるメリットがあります。
ネストされたJSONフィールドはドットで表記します。
カスタムメトリックの出力
boto3のCloudWatchでは、MetricDataをJSON構造で表記する必要がありました。
AWS Lambda Powertoolsを使うと、これが数ステップで実装できます。
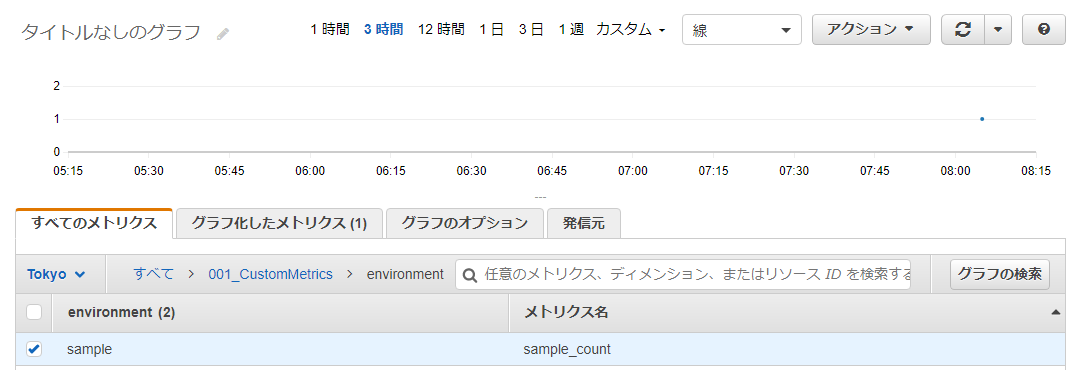
lambda_function.pyfrom aws_lambda_powertools import Metrics from aws_lambda_powertools.metrics import MetricUnit metrics = Metrics(namespace="001_CustomMetrics") @metrics.log_metrics def lambda_handler(event, context): metrics.add_dimension(name="environment", value="sample") metrics.add_metric(name="sample_count", unit=MetricUnit.Count, value=1)
最後に
AWS Lambda Powertoolsを使うと、可読性も高くシンプルに実装できとても便利ですね!
これからはLambdaでのコード開発で積極的に使ってみたいと思います。次はAWS Lambda Powertoolsを使ったAWS X-Rayトレースの実装も試してみます。
以上です。

- 投稿日:2020-10-23T10:51:01+09:00
【AWS】初心者が気にするべき請求
はじめに
AWSの請求って怖いですよね...
特にAWS始めたての頃なんか何にどれくらいの金額が発生するかわかりませんので頻繁にマイ請求ダッシュボードを見ていました。
今のところ、異常な額の請求は来ていませんが、今後何があるのかわかりませんからできる限りの対策を行いたいですよね。
「じゃあ異常な額の請求が来ないために何を気にすればいいの?」
「何がどうなったら高額請求がくるの?」を自分なりにまとめたので参考にしていただけると幸いです。
高額請求について
AWSの不本意な請求は大きく分けて以下の3パターンに分けられると思います。
- AWSアカウントの重要な情報流出による不正利用
- リソースの削除し忘れ
- アーキテクチャの設計ミス
それぞれがなぜ起きるのかを見てみます。
AWSアカウントの重要な情報流出による不正利用
最も高額になりやすいのがこのパターンです
ググったら約800万円の事例もありました。GCPですが。Qiitaにもいくつか記事があります。こういう記事を読んでいると胃が痛くなります。
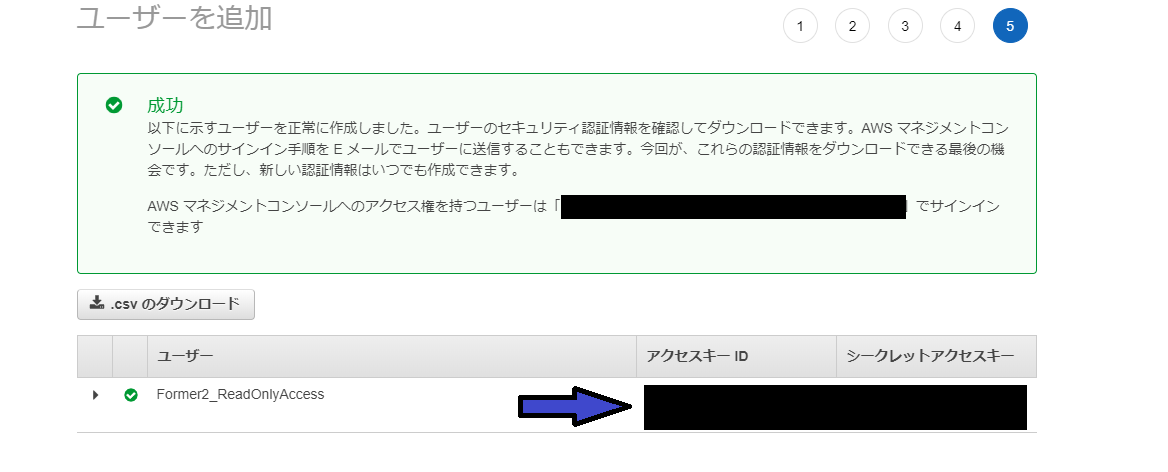
どの記事も根本的な原因が「アクセスキーIDとシークレットアクセスキーの流出」です。
IAMユーザを作成したときに出てくるこれのことです。
こちらのキーを使うと、このキーを持っているIAMユーザの権限を使うことができます。
そのため、もし仮に「EC2インスタンスの立ち上げ」が行えるユーザであった場合、その権限を利用され、高性能のインスタンスを立ち上げられ仮想通貨マイニングに利用されたりします。
なので絶対に流出しないように心がけてください
(というか、CLI,SDK,CDKあたりを使う予定がない方は作成しないほうが良いです。)より具体的な流出経路は以下の記事が参考になります。
怖すぎ!
幸い、FullAccess権限でもアクセスキーIDとシークレットアクセスキーだけではパスワードの変更は行えません。
マネジメントコンソールにログインはできるので慌てず適切に対処しましょう。上記記事でも紹介されていますが、git-secretsを導入すると、アクセスキーID,シークレットアクセスキーがcommit,pushするデータに含まれていた場合は教えてくれるみたいです。積極的に導入していきましょう。
参考
AWSで不正利用され80000ドルの請求が来た話
初心者がAWSでミスって不正利用されて$6,000請求、泣きそうになったお話。リソースの削除し忘れ
こちらが一番「あるある」だと思います。
勉強用にリソース立ち上げて削除し忘れ、放置していたら請求来てびっくりみたいな。私自身もデモで作ったNat Gatewayを消し忘れ、千円くらいの請求が来たことがあります。
これの対策は不要なリソースは削除を徹底することです。
CloudFormation等を用いてStackで管理すると消し忘れを少なくすることができます。ハンズオンなどをやる場合でも、どのリソースを作ったかなどは適宜メモを取りながら進めると消し忘れがなくていいと思います。
中でも注意すべき主要な時間課金リソースは以下です。
(料金はすべて東京リージョン価格です。)
EC2インスタンス(オンデマンド)
- EC2をStop状態にしてもEBSには料金が発生するため注意
- 試しに建てるなら絶対にt2.microを選択しましょう
ElasticIP
- ちょっと料金体系が複雑です。詳しくはコチラ。
NatGateway
- 1時間当たり0.062USD(+データ処理料金)
RDS
- 放置課金界の王。Auroraだとdb.t2.smallで1時間当たり0.063USD
ELB
- ALBは1時間当たり0.0243USD(+LCU料金)。詳しくはコチラ
アーキテクチャの設計ミス
最後なのですが、慣れてきたころにやりがちなのが「アーキテクチャの設計ミス」です。
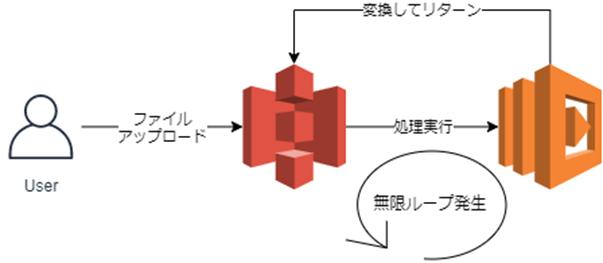
代表的なのが「Lambdaの無限ループ」ですね。S3にアップロードされたファイルをトリガーにして実行すると起こりやすいみたいです。
lambdaの料金
料金 リクエスト リクエスト100万件あたり0.20USD 実行時間 GB-秒あたり0.0000166667USD 公式も警告文を出していますね。
Lambda 関数で使用するバケットが、その関数をトリガーするのと同じバケットである場合、関数はループで実行される可能性があります。たとえば、オブジェクトがアップロードされるたびにバケットで関数をトリガーし、その関数によってオブジェクトがバケットにアップロードされると、その関数によって間接的にその関数自体がトリガーされます。これを回避するには、2 つのバケットを使用するか、受信オブジェクトで使用されるプレフィックスにのみ適用されるようにトリガーを設定します。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/with-s3.html#services-s3-runaway
Lambda関数の実行ログはCloudWatchlogsに出力されるので、デプロイしてすぐは異常な量のログが吐かれていないかを確認すべきです。
じゃあ結局初心者は何を気にすればいいの???
ここまで事例を交えて高額請求が来ないようにするには大雑把に以下の点に気を付ければ良いと思います。
リソース作成前にかかる料金を調べる
- 「AWS サービス名」で調べると公式のリソースページがヒットします。
最低でも「概要欄・料金」は必ず見ましょう。
不要になったリソースは即時削除する
「何のリソースを使っているか」を意識する
安易にキー等シークレットなものを上げない
定期的にマイ請求ダッシュボードを確認する
- ルートに入らなくともIAMユーザから確認できるようにも設定できます。
CloudWatchで請求情報のアラートを設定する
まとめ
AWSは従量課金制という特徴からコストが青天井なのが怖いところでもあり、便利なところでもあります。
設定や運用は注意して行いたいですね。また、AWSには設定額以上の請求がある際にアラームが鳴る機能があったり、インスタンスタイプなどの設定自体を定期的にチェックするConfigのカスタムルールなどがありますので、対策を行い高額請求されないようにしましょう。
- 投稿日:2020-10-23T09:46:45+09:00
AWS Certified Database - Specialty 合格しました
先日、AWS認定データベース専門知識の試験を受験し、合格しました!
その記録を残しておきます。AWSのデータベース関連の実務経歴としては、RDS PostgreSQLが直近1年ぐらいです。DMSは検証でちょっとだけ触りました。
AWS認定試験の履歴 (リンクは合格体験記)
- 2019年9月 AWS Certified Solutions Architect - Associate
- 2019年10月 AWS Certified Big Data - Specialty
- 2019年11月 AWS Certified Machine Learning – Specialty
- 2020年10月 AWS Certified Database - Specialty (今回)
勉強方法
AWSが公開しているYouTubeの動画を見ていました。
試験の1週間か2週間ぐらい前から動画を見てました。とはいっても自宅リモートワークでの仕事中ほとんどBGMでした。内容を把握しながら集中して見始めたのは試験の2日前からだったと思います。
集中して見るときは、2倍速再生にします。よくわからないところだけ1.25倍速ぐらいにします。動画を見ながらたまに重要そうなキーワードで検索してAWSのドキュメントを読みます。
見た動画は以下です。内容が古いものもあります。
- Database Migration オンデマンドセミナー | AWS
- この中に動画が8本あります
- AWS Black Belt Online Seminar
- AWS Japan Summit Online 2020
- この中のDB関連は少し見ました
勉強のために手を動かしたのは、Auroraを試しに起動したぐらいです。
以下の記事は、先人の知恵です。
- AWS Certified Database Specialty (DBS-C01) 試験のベータを受けてきてみた感想: ●○hinata_hisa○●
- AWS認定データベース専門知識(DBS)を、ほぼぶっつけ本番で取得したやったことまとめ - Qiita
- 【試験合格記】AWS 認定 データベース – 専門知識(DBS-C01) - Qiita
- AWS Certified Database – Specialty試験に合格しました - Qiita
- AWS Database資格に合格しました - Qiita
試験当日
諸事情で昨年受けてた会場とは別の会場で受験しました。
昨年利用した会場とは違って、リモート監視ではありませんでした。身分証明などの手続きも対面で、PCでは問題と最後のアンケートに答えるだけでした。ネットワーク、リモート監視用のカメラやスキャナの不具合に悩む必要がありません。会場を別にしてよかったです。
問題を解くインターフェースも昨年の会場とは違い、だいぶ使いやすくなってました。日本語英語の切り替えボタンもレスポンスよく機能します。システムが改善された可能性もありますが、リモート監視ではない会場ではもともと別システムのような気がします。
65問180分。時間にだいぶ余裕がありました。のんびり進めて、80分で1巡しました。60分で見直しフラグの付けた問題をひととおり見直しました。40分残りましたが、見直してもわからない問題はわからないし、あきらめて終了にしました。
日本語では意味がよくわからない問題がたまにありますので、そういう問題だけ英語の文章も読みました。
結果
スコア: 794 / 1000 (合格ライン 750)
所感
RDSが問題のほとんどを占めていた印象です。
細かいコマンドとかエラーメッセージとか、ちょっと勉強したぐらいでは絶対にわからないようなレベルの問題もちょくちょくありました。そういう問題はわからないので、適当に答えました。
- 勉強すべき主役のサービス
- RDS (主役中の主役)
- Aurora (主役中の主役中の主役)
- 一番だいじなサービス
- Serverlessも
- MySQL
- Auroraの次にだいじなDBエンジン その1
- PostgreSQL
- Auroraの次にだいじなDBエンジン その2
- Oracle
- SQL Server
- DynamoDB
- セカンダリインデックスがなんなのかぐらいの理解は必要
- ElastiCache
- Redis
- 移行やデプロイに関わる勉強すべきサービス
- DMS
- SCTも
- 業務で検証で少し触ったことはDMSのサービス概要を理解するうえで役に立ちました
- DMSに限らずマイグレーションの手法は抑えておくとよいです
- Snowball
- re:Invent 2019で実物を見たけど使ったことないぞ
- 概要がわかっていれば十分
- CloudFormation
- スタックセットというものは勉強して始めて知りました
- 前提としてどんなサービスなのかという理解は必要
- S3
- IAM
- VPC, Dicrect Connect, セキュリティグループなど
- あまりわかってなくても突破できそうなサービス
- QLDB
- Redshift
- Glue
- KMS
- Secrets Manager
- Systems Manager
- Trusted advisor
?

- 投稿日:2020-10-23T09:04:44+09:00
AWS S3 MacローカルディレクトリのファイルをS3に差分同期する
目的
- AWSのS3の任意のバケットにMacローカルのディレクトリの差分だけを同期する方法をまとめる
実施環境
- ハードウェア環境
項目 情報 OS macOS Catalina(10.15.5) ハードウェア MacBook Pro (13-inch, 2020, Four Thunderbolt 3 ports) プロセッサ 2 GHz クアッドコアIntel Core i5 メモリ 32 GB 3733 MHz LPDDR4 グラフィックス Intel Iris Plus Graphics 1536 MB
- S3
- 下記の方法でバケットを作成した。
前提条件
- 下記の方法でMacローカルのファイルを同期することがすでにできていること。
詳細
下記コマンドを実行してMacのローカルにディレクトリを作成する。
$ mkdir ~/test01下記コマンドを実行してMacのローカルにテキストファイルを作成する。
$ touch ~/test01/text01.txt下記コマンドを実行して既存のバケットの
test01ディレクトリにtext01.txtを同期する。$ aws s3 sync ~/test01 s3://同期先のバケット名/test01下記コマンドを実行してMacのローカルにtext02.txtを作成する。
$ touch ~/test01/text02.txt下記コマンドを実行して差分ファイルであるtest02.txtを既存のバケットの
test01ディレクトリにアップロードする。$ aws s3 sync ~/test01 s3://同期先のバケット名/test01
- 投稿日:2020-10-23T07:19:24+09:00
Amazon Web Services入門してみた (AWSの基礎)
はじめに
ITシステムやアプリケーション構築する際に「サーバーレス」というのが当たり前になっています。
クラウドの中で最もシェアが高く世界中で利用されているのが AWS です。
AWS には、サーバーレスアプリケーションの構築と実行に使用可能な、一連の完全マネージド型サービスが用意されています。サーバーレスアプリケーションでは、コンピューティング、データベース、ストレージ、ストリーム処理、メッセージキューイングなどのバックエンドコンポーネントのために、サーバーのプロビジョニングやメンテナンス、管理を行う必要がありません。また、アプリケーションの耐障害性や可用性を心配する必要もなくなりました。AWS の機能を基準にしてクラウドやオンプレミス環境との機能やコスト比較することがIT構築で必須となっているのが現在のIT業界の位置づけです。よって、AWS の知識があることがインフラエンジニアだけでなく、あらゆるプログラマーやSE、ITコンサルタントまでに至るまで必須となっています。
ドットインストール と本で AWS の知識を身につけたので、備忘録としてまとめます。
内容
Amazon Web Services入門
Amazonが提供する各種クラウドサービスについて簡単にまとめました。
※ 各種サービスの使い方についても別でまとめます。参考にした動画
ドットインストール Amazon Web Services入門
https://dotinstall.com/lessons/basic_aws
- AWSのアカウント作成から、EC2インスタンスの立ち上げ、RDSの立ち上げを把握します。
- EC2、RDS、S3での環境構築を実際できるように準備します。
ドットインストールの動画は少し古い情報であったので、最新の情報を確認して進めていきます。
参考にした本
- 図解即戦力 Amazon Web Servicesのしくみと技術がこれ1冊でしっかりわかる教科書
- Amazon Web Services 基礎からのネットワーク&サーバー構築
- ゼロからわかる Amazon Web Services超入門 はじめてのクラウド かんたんIT基礎講座
Amazon Web Services入門
Amazon Web Servicesについて、各種クラウドサービスを把握していきます。
01. Amazon Web Servicesとはなにか?
AWSの概要
AWS とは、Amazonが提供するクラウドサービスの総称です。Amazonが保有する膨大なコンピューターリソースを、使用量に応じた従量課金制で使用できます。オンプレミス(自社)サーバーのように多額の先行投資が必要なくなり、システムコストを下げることが可能です。また、多数のデータセンター(アベイラビリティーゾーン、AZ)で構成されており、AZも世界中の地域(リージョン)に分散して配置されています。このため、物理障害に強いシステムを構成することができます。
公式サイト
- AWSの公式サイトURL
必要となる知識
- Unixコマンド
必要となる準備
- AWSアカウント
AWS アカウントを作成すると、60以上のAWS製品を1年間無料で試せます。
また、AWSクラウドの世界中のリージョンで提供される、すべてのサービスを始めることができます。
用語について(EC2、RDS、S3)
EC2 (Elastic Compute Cloud)
多くのシステムの基盤となる、仮想マシンを実行できるサービスです。クラウド上でLinuxやWindowsなどの仮想マシンを起動して、その上でアプリケーションを実行することができます。RDS (Relational Database Service)
AWS上でRDBを利用できるサービスです。Amazon Aurora(MySQL互換DB)やOracle、SQL Server、PostgreSQL、MySQL、MariaDBといった主要なデータベースエンジンに対応しています。S3 (Simple Storage Service)
S3は、KVS(Key Value Store)に分類されるオンラインストレージサービスです。データ(オブジェクト)を、パケットと呼ばれるコンテナにキーと紐付けて保存します。オブジェクトを取得する際には、パケット名とキーを指定して取得するオブジェクトを特定します。RDB(リレーショナルデータベース)を使うまでもない、シンプルなデータモデルを扱う場合に適しています。料金について
料金の確認
AWSで新規にアカウントを取得すると、12ヶ月の無料利用枠が与えられます。これは、サービスごとに設定されている一定の利用条件内ならタダで使用できるというものです。中には、期限後にもそのまま無料で使えるサービスもあります。評価目的や学習目的のみならず、スモールスタートでの実運用にも活用できるでしょう。
非常に多くのサービスが対象になっており、ここでは書ききれないため、詳細はこちらのページをご覧ください。なお、AWSアカウントの登録にはクレジットカードが必要です。もちろん、無料枠内なら課金はされません。課金されたくない方は、無料枠を超えないように注意してください。
まとめ
Amazon Web Services(AWS)には非常に多くのサービスがあり、これからも増え続けていくと思います。しかし、一般的なアプリケーションに使われるサービスは限られています。ひとまず主要なサービスをおさえておき、それ以外のサービスは必要に応じて学んでいくと良いと感じました。無料利用枠を最大限に活用して、学習を進めていくことをおすすめします。
今後、EC2・RDS・S3の使い方で学んだことを備忘録としてまとめます。

- 投稿日:2020-10-23T07:19:24+09:00
Amazon Web Services入門 (AWSの基礎)
はじめに
ITシステムやアプリケーション構築する際に「サーバーレス」というのが当たり前になっています。
クラウドの中で最もシェアが高く世界中で利用されているのが AWS です。
AWS には、サーバーレスアプリケーションの構築と実行に使用可能な、一連の完全マネージド型サービスが用意されています。サーバーレスアプリケーションでは、コンピューティング、データベース、ストレージ、ストリーム処理、メッセージキューイングなどのバックエンドコンポーネントのために、サーバーのプロビジョニングやメンテナンス、管理を行う必要がありません。また、アプリケーションの耐障害性や可用性を心配する必要もなくなりました。AWS の機能を基準にしてクラウドやオンプレミス環境との機能やコスト比較することがIT構築で必須となっているのが現在のIT業界の位置づけです。よって、AWS の知識があることがインフラエンジニアだけでなく、あらゆるプログラマーやSE、ITコンサルタントまでに至るまで必須となっています。
ドットインストール と本で AWS の知識を身につけたので、備忘録としてまとめます。
内容
Amazon Web Services入門
Amazonが提供する各種クラウドサービスについて簡単にまとめました。
※ 各種サービスの使い方についても別でまとめます。参考にした動画
ドットインストール Amazon Web Services入門
https://dotinstall.com/lessons/basic_aws
- AWSのアカウント作成から、EC2インスタンスの立ち上げ、RDSの立ち上げを把握します。
- EC2、RDS、S3での環境構築を実際できるように準備します。
ドットインストールの動画は少し古い情報であったので、最新の情報を確認して進めていきます。
参考にした本
- 図解即戦力 Amazon Web Servicesのしくみと技術がこれ1冊でしっかりわかる教科書
- Amazon Web Services 基礎からのネットワーク&サーバー構築
- ゼロからわかる Amazon Web Services超入門 はじめてのクラウド かんたんIT基礎講座
Amazon Web Services入門
Amazon Web Servicesについて、各種クラウドサービスを把握していきます。
01. Amazon Web Servicesとはなにか?
AWSの概要
AWS とは、Amazonが提供するクラウドサービスの総称です。Amazonが保有する膨大なコンピューターリソースを、使用量に応じた従量課金制で使用できます。オンプレミス(自社)サーバーのように多額の先行投資が必要なくなり、システムコストを下げることが可能です。また、多数のデータセンター(アベイラビリティーゾーン、AZ)で構成されており、AZも世界中の地域(リージョン)に分散して配置されています。このため、物理障害に強いシステムを構成することができます。
公式サイト
- AWSの公式サイトURL
必要となる知識
- Unixコマンド
必要となる準備
- AWSアカウント
AWS アカウントを作成すると、60以上のAWS製品を1年間無料で試せます。
また、AWSクラウドの世界中のリージョンで提供される、すべてのサービスを始めることができます。
用語について(EC2、RDS、S3)
EC2 (Elastic Compute Cloud)
多くのシステムの基盤となる、仮想マシンを実行できるサービスです。クラウド上でLinuxやWindowsなどの仮想マシンを起動して、その上でアプリケーションを実行することができます。RDS (Relational Database Service)
AWS上でRDBを利用できるサービスです。Amazon Aurora(MySQL互換DB)やOracle、SQL Server、PostgreSQL、MySQL、MariaDBといった主要なデータベースエンジンに対応しています。S3 (Simple Storage Service)
S3は、KVS(Key Value Store)に分類されるオンラインストレージサービスです。データ(オブジェクト)を、パケットと呼ばれるコンテナにキーと紐付けて保存します。オブジェクトを取得する際には、パケット名とキーを指定して取得するオブジェクトを特定します。RDB(リレーショナルデータベース)を使うまでもない、シンプルなデータモデルを扱う場合に適しています。料金について
料金の確認
AWSで新規にアカウントを取得すると、12ヶ月の無料利用枠が与えられます。これは、サービスごとに設定されている一定の利用条件内ならタダで使用できるというものです。中には、期限後にもそのまま無料で使えるサービスもあります。評価目的や学習目的のみならず、スモールスタートでの実運用にも活用できるでしょう。
非常に多くのサービスが対象になっており、ここでは書ききれないため、詳細はこちらのページをご覧ください。なお、AWSアカウントの登録にはクレジットカードが必要です。もちろん、無料枠内なら課金はされません。課金されたくない方は、無料枠を超えないように注意してください。
まとめ
Amazon Web Services(AWS)には非常に多くのサービスがあり、これからも増え続けていくと思います。しかし、一般的なアプリケーションに使われるサービスは限られています。ひとまず主要なサービスをおさえておき、それ以外のサービスは必要に応じて学んでいくと良いと感じました。無料利用枠を最大限に活用して、学習を進めていくことをおすすめします。
今後、EC2・RDS・S3の使い方で学んだことを備忘録としてまとめます。
- 投稿日:2020-10-23T04:48:45+09:00
NginxでAWS ELBのHealth Checkログを出力させない方法
NginxでAWS ELBのHealth Checkをアクセスログとして出力させない方法を紹介します
環境

方法
コンフィグ
map $http_user_agent $loggable { ~ELB-HealthChecker 0; default 1; } access_log /var/log/nginx/access.log main if=$loggable;解説
mapとaccess_logに分けて少し解説していきます
map
map $first $second {...}とすると、$firstを{...}に沿って評価して返り値を$secondにマッピングします
今回の場合は$http_user_agent、つまりHTTPヘッダーに含まれるUser AgentがELB-HealthCheckerに部分一致するか評価して一致するなら0、一致しなければ1を$loggableにマッピングしますELB-HealthCheckerの前についている
~は正規表現を使うための記号です
~はcase-sensitiveで、~*はcase-insensitiveです[備考]
2020/10時点では正式なUser AgentはELB-HealthChecker/2.0でした
/以降はバージョンなので今後変更の可能性があるので、ELB-HealthCheckerが含まれているかだけチェックしましょうaccess_log
access_logには
ifというパラメータがあります
条件が0か空文字と評価されたらログ出力しなくなります
今回は$loggableのデフォルトが1で、ELB-HealthCheckerがUser Agentに含まれていたら0になるので、Health Checkのアクセスログが出力されなくなります。Reference

- 投稿日:2020-10-23T03:17:08+09:00
【挫折経験アリ】プログラミング未経験から独学10カ月でAWS,Laravel,Nuxt.js製webサービスをリリースするまで
プログラミング初心者こそ個人サービス作るべき
一度プログラミング学習に挫折したこともある僕ですが、学習を再度開始して半年ほど経ってから個人開発を始めました。
まず前提ですが、この記事は以下の方向けです。
- プログラミング頑張りたい初心者
- プログラミング学習継続してるのに中々成果が出ない方
- 個人開発でアプリケーションつくりたいから参考にしたい方
少しでも、プログラミング初学者の方の学習継続のヒントになれば幸いです。
まず初めに、一念発起して本気で個人開発したwebアプリがこちらです。
サービスの目的は3つあります。
1. オンラインイベントの開催にかかる負担を減らす。
2. 難しいイベント集客のサポートのため、出不精の人でも集客できるくらい、拡散されやすい仕組みを作る。
3. 来客者の期待値と主催者のイベント内容のミスマッチをなくす。まだまだ機能的に足りていませんが、サービスが目指す世界は以上の3つです。
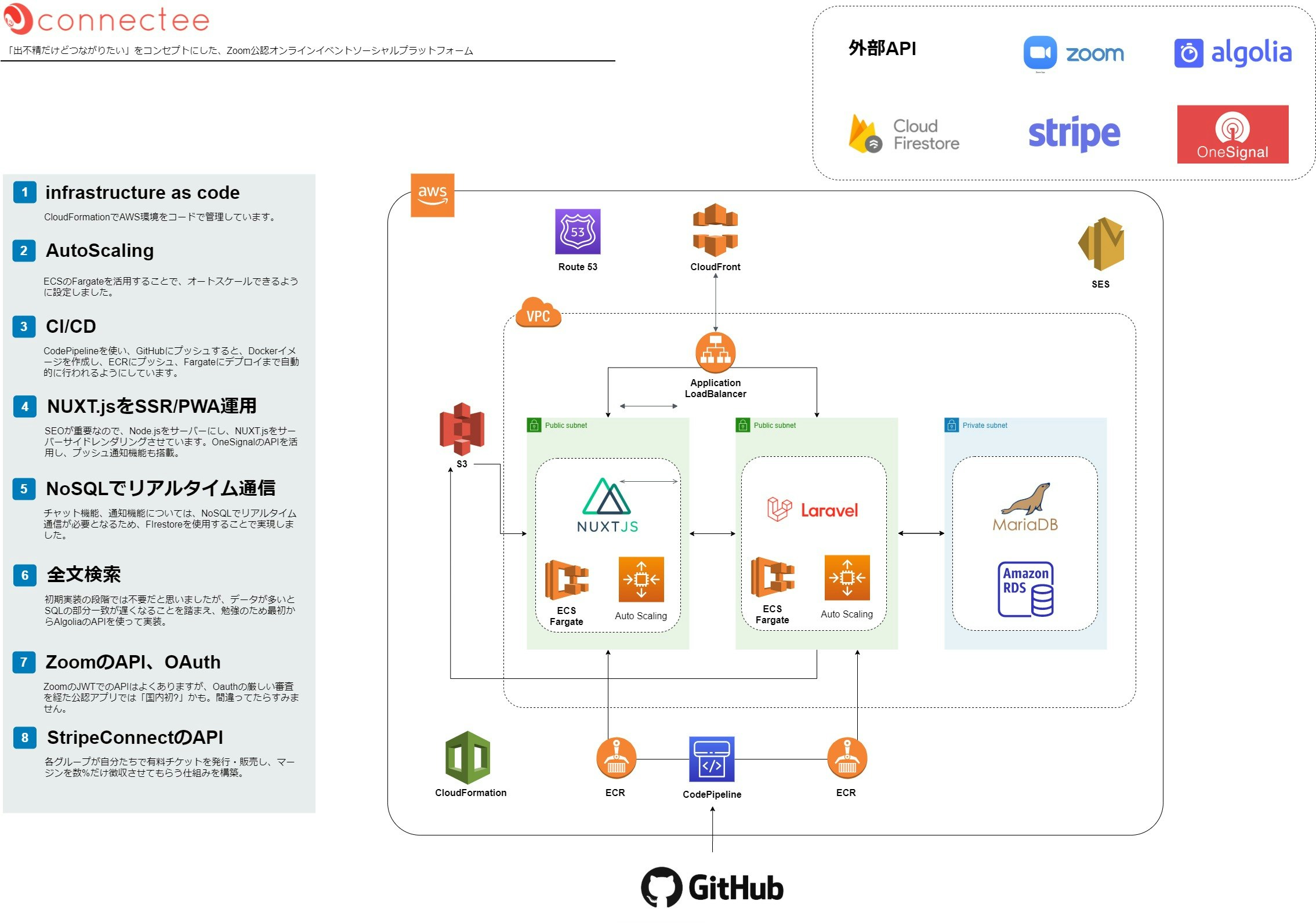
サービスの構成
ご覧のとおりの構成ですが、構成を決めた理由を以下に記していきます。
バックエンド
プログラミング始めてからの半年ほどはWordPressガチ勢でオリジナルテーマ開発とかやってたので、PHPで行こうと思い、Laravelを選択。
これは選択というより前提という感じでした。フロントエンド
SPAで開発したい!と思ったので、Laravel内のvueで作ろうかと思ったのですが、イベント紹介ページなどはSEOが重要なので、SSR対応は必須です。
そのためNuxt.jsを選択しました。インフラ



文献の豊富さからAWSにしました。割とポートフォリオだとHeroku使われるようですが、個人開発バンバンやっていきたいし、一人で全部できるエンジニアになりたかったので、インフラにも力を入れるため、Herokuなどは使いませんでした。
最初はふつうにEC2内にDocker入れて、、、と思ったんですが、拡張性、障害時の復旧、CI/CDとの相性など、評判の良いFargateを採用することに決めました。
また、割と頻繁にアップデートするだろうし、デプロイは自動化しておきたかったので、codepipelineを採用、AWSの管理画面で練習しているうちにごちゃごちゃしてくるし、別のサービスが入ったらどれがどれかがわかりにくくなるな、と思ったので、コードで管理できるcloud formationを使うようになりました。初めてのプログラミング学習は挫折
もともとはしがない塾講師です。
そんな僕がこのままではマズイ!と行動を起こしたのはAIが流行り出した2017年ごろ。
このまま塾講師やってたら仕事がなくなる、、、、と不安に駆られ、ITに関心を持ち始め、何かwebサービスやりたいと思うようになりました。プログラミングを自分で勉強して作るのは途方もないな、と思い、社内事業としてサービスを外注しながらスタートすることにしました。
このときの僕は、自分一人でやっていこうという覚悟もなければ、スキルもない、お金もない、会社に頼り切るしかない状態でした。
そんな情けない自分なのに、意気込みと努力は注ぎ込んでいたので、数年後に失敗する姿など微塵も想像していなかったのでした、、、恥そして、サービスを主導するリーダーのポジションをやるにあたり、マーケティングや事業運営、新規事業開発のやり方を勉強する合間を縫って、
自分でも少しは理解したほうがいいだろうということで、progateをやってみたのが最初のプログラミング学習。
HTMLはなんとなくわかり、JavaScriptあたりで忙しさと面倒臭さでいつの間にかやらなくなっていたのでした、、、これがはじめてのプログラミング学習の挫折でした。
プログラミングを本気でやろうという覚悟が全然できていなかったことが最大の失敗要因だと思います。
プログラミング学習再チャレンジのきっかけ
それから月日は流れ、前述のとおり、結果的にプロジェクトは失敗に終わりました。
このサービスの失敗の要因は様々あるのですが、最大の要因は自分が作れないことだと考えました。
自分で作れないからお金がかかる、正確な工数やイメージ通りのサービスになりにくい、、、
など、考えました。
とにかく会社や人に頼らないと何もできない自分に腹が立ち、自分でできる力をつけないとダメだ!!と強く思いました。もう失敗を経て精神的に追い詰められきっていたので、なんというか生存本能というと大袈裟かもしれませんが、完全にスイッチが入った感じがしました。
目標は会社に頼らず個人で生きていける力をつけること、でした。
このとき本気でやるぞ!と強く心に誓ったことが、学習を継続できた要因の最初の一つだと思います。プログラミング学習教材とかけたコスト
後ほど、めちゃくちゃよかった本はちょこちょこご紹介します。
- ドットインストール(無料のみ)
- Progate(1か月のみ、1000円)
- 10~15冊くらいの本(全部で3万円ほど)
- Qiita(本当にありがとうございます、運営のみなさん、投稿されてる先輩方、最高です)
だいたいこんな感じだったと思います。
基本的に本とGoogleがメインでして、
プログラミングスクールは頭をよぎることすらなかったです。
むしろランサーズとかで案件すぐ取ってたので、すぐにプラス出せて良かったです。最初はhtml、css、JavaScriptをprogateとドットインストールで
ここからは限界まで睡眠時間を削ってひたすら勉強です。
1週間ほどでHTMLとCSS、JavaScriptの基礎くらいまでをドットインストールとprogateを交互にやりました。
意識したのは実際に自分でもコーディングすることでした。ランサーズでランディングページ案件を初受注して勢いをつける
勉強を開始してからまだ1~2週間ほどですが、このタイミングでランディングページの案件獲得に挑戦しました。
まだ早いだろ!と躊躇する方も多いと思いますが、僕はぶっ込みました笑
というのも、ランサーズにはコンペ形式の募集案件があります。
これは、応募者がデザインカンプを制作して、発注者は応募があった制作物から選び、選ばれた応募者が正式に作業して納品する、という形式です。
この形式だと、ある程度発注者と受注者との間ですり合わせがされた状態からのスタートになるため、発注者にとってのハズレを引くリスクが少なく、受注初心者にとっても自分が対応できる完成予定物を事前に提示できるためリスクが少なくなります。僕の場合、ランディングページ制作に必要なイラレやフォトショ、XDなどの最低限のスキルはあったので、それほど苦労せず案件獲得することができました。
この早すぎるタイミングでの受注が結果的に学習のモチベーションを上げる最大の要因だったと思います。
勉強したことがお金になる瞬間を経験することで、もっと勉強したらもっと単価上がる!無駄にならない!とわかるので、難しいと感じても頑張れます。
こうして学習のスピードをさらに上げたのでした。次はPHPとWordpressの勉強をしながらWordpressオリジナルテーマ開発
[このWordpressの過程は、最初からWeb開発で転職目指す方などにはムダな過程だと思います。]
プログラミングを始めてから1ヶ月が経つ頃にはPHPとWordpressのprogateとドットインストールが完了して、wordpressのオリジナルテーマ開発を始めていました。
初めは、本などに載っているテーマを模倣し、そのソースを参考にしつつ、自分が思う機能を盛り込んだものを作っていく、というやり方です。今から思えばいわゆるコンポーネント志向で、
案件ごとに使い回しが効く自分専用テーマみたいなものを作っていきました。
案件受注するたびに既存のテーマなどをいじって納品する、という人もいるみたいですが、
- 自分の血肉にならないこと
- 細かい調整が入ったときに対応しづらいこと
の2点から、自分がゼロから理解しているフレームワーク的なものを作りました。
wordpressの情報はネットで溢れかえっているので、ある程度の機能は自分でも作れるし、この経験でPHPの理解が進んだと思います。
半年ほどweb制作に没頭
wordpressのオリジナルテーマができてからは、それを使ってコーポレートサイト、サービスサイト、ECサイトの構築を行っていました。
しかし、労力のわりに報酬が少ないweb制作1本でいくわけにもいかないので、いよいよLaravelの勉強を開始しました。Laravelの勉強を2週間で
本での勉強
https://www.amazon.co.jp/dp/B08625YD7Hネットでチュートリアル
https://www.hypertextcandy.com/laravel-tutorial-introductionをやりながら隙間時間でsqlの勉強も併せて行いました。
webサービスを構想
そんな中、コロナの猛威もあり、オフラインがすべてできなくなったことにより、オンラインイベントが成長していました。
この時点では、まだオンラインイベントの開催がやりやすいプラットフォームがなかったことから、
ポートフォリオがてら、webサービスを作ってみようと決心しました。まずはサービス設計
1.サービスの軸を決める
- ZoomのAPIを使って開催の手間を減らしたい
- SNSでイベント開催の呼びかけをするものの、なかなか反応がない、集まらないという課題感の解決
と考えました。
2.顧客を想定して機能の洗い出し
オンラインイベントプラットフォームを作るということは、マッチング型なので、
開催者と参加者の両方を集める必要があります。
どちらを優先するかというと、これはほぼ間違いなく開催者を優先すべきなので、
開催者ファーストでサービス設計を落とし込んで、機能を洗い出していきました。3. 画面設計
Adobe XD を使い、サービスのイメージを具現化する作業です。
CRUDに基づいて抜けがないように配慮しつつ頭の中のイメージを書き起こしていきました。
この過程で、非同期に画面遷移ができるSPA(シングルページアプリケーション)にしよう、と決断しました。4.テーブル設計
事前にリレーションの考え方や、正規化を勉強し、サンプルを複数見て、自分のサービスの設計を行いました。
https://engineers.weddingpark.co.jp/?p=662
このサイトが勉強になったことが印象強いです。5.フロントエンド側の技術選定
SPAだと、動的に画面が変わるため、SEOに弱いという欠点があります。
本サービスでは、SPAにしつつ、イベントサイトなのでSEOも重視しなければならないため、SSR対応は必須でした。
そのため、カンタンにSSR対応ができるNuxt.jsを選定しました。いよいよ開発スタート
バックエンド開発から
まずはバックエンドのLaravel側でAPIサーバーを開発していきました。
リレーショナルデータベースの場合、sqlで部分一致検索は重たいことを学び、その解決策として、「全文検索」という技術が使われていることを知りました。検索には力を入れるべきサービスなので、AlgoriaというサービスのAPIを導入しました。
また、イベントを開催するグループごとに決済権限を持たせたかったので、stripe connectの導入をすること、
それからオンラインイベントなのでメインとなるZoomAPI連携を実装する必要がありました。
特にstripe connectのAPIやZoomのAPIはドキュメントがすべて英語で、日本語の文献もほぼない状態だったので、このAPIを使うところが最も苦労したところです。
だいたいバックエンド開発に1か月ほどかかったように思います。開発環境の変更
また、開発環境として、それまでvagrantを使っていたのですが、遅すぎるし、環境要因のバグなども嫌だし、何せ遅いし、確実に使われなくなる技術だし、とにかく遅いので、Dockerでの環境構築のお勉強も隙間を縫って進めていたので、遅ればせながらdocker-composeで開発環境を構築しました。
フロントエンド開発へ
ある程度APIエンドポイントが出来たら、Nuxt.jsでのフロントエンド開発に移行しました。
PHPほどはjavascriptに慣れていなかったので、1.5カ月ほどかけてフロントエンドの実装を行いました。特に苦労したのは、オンラインイベント中に使うチャット機能の実装でした。リアルタイムに通信を行うため、FireStoreを利用することにしました。websocketを使う手もあったのですが、APIサーバーの負担を減らしたかったため一定まで無料利用できるFirebaseを選択しました。
また、web版のプッシュ通知をOneSignalのAPIで実装するのに併せてPWA化も行いました。ただ、NUXT.JS自体が簡単にPWA化できるので、この点は一切苦労しませんでした。
難しいイメージがつきまとうインフラ、AWSへの挑戦
ある程度できてきたら、いよいよ恐怖のインフラです。
AWSの勉強をする以前に、そもそもネットワークの基礎が理解できていなかったのですが、
この本はネットワークの基礎から書いてくれているので、とてもよかったです。
https://www.amazon.co.jp/dp/4296105442他にも動画や本で勉強しつつも、結局自分で動かさないと身につかないので、
実際にAWSを動かして理解を深めていきました。いろいろと勉強していく中で、ECS、kubernetesの存在を知り、この技術を使うことで、オートスケール、障害時の対応、環境依存をほぼなくせる、CI/CDとの相性など、総合的にメリットが多いことを知り、fargateでの環境構築を実際に管理画面からポチポチやってみることから始めました。
なんとか苦戦しながらも本番環境用のDockerfileをイチから書き直してfargateに乗っけることに成功し、
機能追加などをどんどんやるのに、デプロイの作業がとても面倒だったので、CI/CDツールの導入を検討しました。
CircleCIが有名どころですが、
管理上、AWS一本で統一しておきたかったため、Codepipelineで、GitHubのブランチにgit push するだけでデプロイするフローを作りました。さて、いろいろやっているうちに、AWSの管理画面での運用がやりづらいな、、と思うようになっていました。
というのも、一つのサービスでさえ、セキュリティグループなどゴチャゴチャしてくるので、複数サービスローンチしたら余計わかりにくいだろうな、、と思いました。
そこで、infrastructure as codeを導入することにしました。
こちらも、Terraformが有名どころかとは思いますが、
同じく管理上、AWS一本で統一しておきたかったため、Cloudformationを採用しました。いよいよ、デプロイ、ベータ版リリース!!と思ったらZoomの審査が厳しすぎた、、
リリースには欠かせないZoomのAPIですが、
JWTで認証してAPIを利用するパターンと、OAuthで認証してAPIを利用するパターンがあります。JWTだと社内利用などクローズドなシーンで使うことができるのですが、
今回はwebサービスとして不特定多数の方に公開するため、OAuthでの認証は欠かせません。申請に必要な事項を申請画面でポチポチ入力して、いざ提出ボタンを押して、返事を待つこと数日。
大量の提出書類とともに、「Need more information」と題したメールが来ました。
中身をGoogle翻訳で確認していくと
- 申請はすべて英語で行うこと
- 提出した写真にもっとZoomを使ってるっぽいところを使え
- 利用規約、サポートページ、特定商取引、プライバシーポリシーはすべて英語にしろ
- 30項目くらいあるセキュリティアンケートに英語で答えなさい
だいたいこんな感じでした、、、
大変すぎてやる気が出ません。。。
しかし、ここまで頑張って来て諦めるわけにはいきません。必死こいてGoogle翻訳を使いながら、なんとか作り上げ、サポートとの英語でのやり取りを経て提出。
すると数日経って「Need more information」のメール
足りない点を補ったり、セキュリティに必要な実装を追加回収など行って、再度提出。
すると数日経って「Need more information」のメール
足りない点を補って再度提出。
すると数日経って「Need more information」のメール
こんな感じで5回ほどのやり取りを経たころには1か月以上がたっていました
5カ月ほどの歳月を費やして、ようやくconnecteeをリリース
長い道のりでしたが、やっとここまで来ました。
感動です。
やっぱり人に頼って作ってもらうしかできなかったころと比べ、一人で設計から何からすべて作れるようになったことで、何より気持ちが楽になりました。
ポートフォリオ公開後、すぐに新規開発案件に参画
ポートフォリオ公開後、中規模のマッチングwebアプリの新規開発案件への参画が出来ました。
4名(フロント2、サーバー1、インフラ兼フロントのバックアップリーダー)体制でのチーム開発です。
僕はサーバーサイド兼管理画面を担当し、DBテーブル設計、APIエンドポイント設計、Laravelでのサーバーサイド開発、vue・Typescriptでの管理画面のwebフロント開発を担当しました。それまでの経験が活き、要件定義を見てDB設計から一人で行うことができました。
一人でやり切る力がついていたので、2カ月ほどを経て無事プロジェクトが完了しました。
ちなみにこのときにもwebsocketを導入したり、Dockerでの本番・検証環境構築、覚えたてのTypeScriptを使ったりと、さらなる成長ができました。webサービス開発、それから実務経験を終えて感じたこと
1.初心者は「思考停止」でプログラミングスクールには行くな
僕は今まで御覧いただいた通り、プログラミングスクールには行っていません。
とはいえ、塾講師としてのキャリアがあるので、プログラミングスクール側の立場も一定の理解があると思っています。
ここからはその前提での、個人的な意見です。ネットでいくらでも情報が出てくるこの時代、プログラミングスクールの価値っていうのは、
「教えてもらえること」ではなく、「モチベーション」だ
とか、
世の中には教えてもらわないと学べない人がいて、その人のためのサービスだ
とか、言われます。そして、80万円などの高額な学費にも関わらず、"とりあえず"プログラミングスクールに行く人は、「将来の自分への投資」だと。
正直、思考停止だと思います。
「エンジニアになるための勉強」をするのではなく、「エンジニアになってからも成長し続けるための勉強方法を身につける」必要があると思います。
エンジニアになってからは基本的にすべて独学になるので、独学のほうがエンジニアになってから苦労しないのでは???と思ってしまいます。ただし、第一言語の習得のための学習コストが最も大きいので、それを理解したうえで、一人で勉強する時間コストと天秤にかけての投資と考えて価値を見出せるような優秀な方なら、十分プログラミングスクールを有効活用できると思います。
ただ、思考停止でプログラミングスクール行くタイプの人の雰囲気を見ていると、エンジニアとして実務に入ってからも、先輩エンジニアに手取り足取り教えてもらってステップアップできると妄想を抱いている人がそれなりにいるように見えます。
会社の立場に立てば、そんな奴に給料払いたくないやろ、とわかるはずなんで、それがわかってない時点で厳しいのでは?と思ってしまいます、、、2.プログラミング学習の継続に最も重要なモチベーションの動機付け
僕の場合、一回目のプログラミング学習で挫折した時と、二回目でうまく学習を継続できた時との最大の違いは、
実際にプログラミングで報酬を得たかどうか、に尽きます。
早すぎるタイミングでしたが、身につけたスキルでわずかながらも稼いだという成功体験を味わったことがモチベーションへの大きな寄与を果たしていると思います。本当に自分が身につけることができて、お金になるかどうかが不安なまま膨大な学習を続ける不安は計り知れません。
その不安を早期に払拭できていたことが、その後の学習継続のモチベーション維持に間違いなく影響していたと思います。
大きな目標の前に小さな一歩一歩を積み重ねるほうがモチベーションは維持しやすいということです。正直、このおかげで、僕は心が折れそうになったことはほとんどなかったです。
強いて言うなら、ZoomのAPI申請のときくらい(笑)個人的には、プログラミングスクールにモチベーション管理を期待して通うよりはるかに有効な手段だと思うので、かなりおすすめの方法です!
3.自分で考えてwebサービスを作ることが成長への最短ルート
1年間の自分自身の成長曲線を考えると、connecteeの開発を始めたとき以降、それまでと比べて異常に伸びたと思います。
人が設計したものを作る受動的なときと、自分で設計からやる能動的なときとでは、吸収力が10倍と言ってもいいくらい違います。
また、自分で設計を経験し、インフラからフロントまで全ての工程を経験しておくと、自分の担当外のエンジニアがやりやすいかどうかまで配慮することができますし、絶対やっといたほうがいいな、と改めて思いました。
4.[最後に]プログラミングを楽しもう!!
僕はプログラミングが大好きです。
頭の中にあるイメージが実際に形を得て、思い通りに動くようになる瞬間がサイコーです。
初学者のうちはいっぱいいっぱいになりがちですが、モノづくりの喜びを楽しみながら勉強すると、継続しやすいと思います。少しでもこの記事がプログラミング初学者の参考になれば幸いです。


- 投稿日:2020-10-23T00:29:05+09:00
AWS運用改善サービスランキング【AWS Management Governance】
AWSを運用していると下記の様な悩みがでてきます。
- 便利さとセキュリティが両立できない。問題発生によりどんどん運用が面倒になる
- ソフトウェアバージョン管理ができていない(知らないうちに古いバージョンのまま使い続けていた)
- 同じような環境作成の依頼が何度も来る。(特にテスト環境など)
- コスト管理が面倒(組織や部署ごとに算出できていない)
- AWS運用改善案がでてこない(これは悩みではないかも)
私は大規模ECサイトの運用に1年ちょっと携わっています。
このECサイトは2015年に構築されたシステムであり、
今のベストプラクティスとはかけ離れていることから
上記のような悩みが出てきてしまいました。そこでAWS Management GovernanceのAWSサービスの中でAWS運用改善効果の高い順にランキングしました。
導入難易度も考慮に入れています。
この順序で導入を検討してみるのが良いのかなと思います。AWS Management Governance(旧 Management Tools)とは
Management ToolsからManagement & Governanceに名称変更が変更になりました。
ガバナンスとは企業自身が企業を管理することです。
要約するとルール違反や問題などを経営者に報告する機能が加わったと考えればよいと思います。AWS運用改善サービスランキング【AWS Management Governance】
1位 Amazon CloudWatch
導入しやすさ ★★★★★
運用改善効果 ★★★★★AWSの監視ツールです。簡単なジョブ実行やログ収集もできます。
デフォルトで利用できるので、とりあえず利用しましょう。
CloudWatch エージェントを入れることで監視可能な項目が増えます。2位 AWS Systems Manager
導入しやすさ ★★★★☆
運用改善効果 ★★★★★AWSを便利に使う管理ツールの集合体です。
SSMエージェントをインストールし、インターネットアクセス可能なら利用できます。
※Amazon Linuxや新しめのWindowsServer(2012以降など)ならデフォルトでエージェント導入済です。
自動OSパッチ適用やライセンス管理、サーバの自動起動、自動バックアップなどがプログラミングなしで実現できます。
エージェント不要で利用可能なパラメータストアはパスワードなどを安全に保管できるため、
パラメータストアだけでも利用価値があります。
これを利用して上述のCloudWatch エージェントを導入することもできます。
※機能豊富過ぎてまだ私も使いこなせていません。。3位 AWS CloudFormation
導入しやすさ ★★☆☆☆
運用改善効果 ★★★★★AWSのインフラをコードで管理するためのツールです。
インフラをコードのメリットは再現性(コピペで同様の環境を作れる)や変更点の管理(gitなどを利用)などです。
導入のハードルは少し高いですが、部分的でも良いので徐々にコード化していきましょう。IaC導入については下記の記事でも記載しましたので、良ければご覧下さい。(CloudFormationでなくCDK推しです)
4 AWS Well-Architected Tool
導入しやすさ -(導入不要)
運用改善効果 ★★★☆☆AWS利用の原則が分かります。
チェックツールを使うと自環境が原則とかけ離れていることが分かります。。
(5年前のベストプラクティスと今のベストプラクティスはかなり変っている模様)AWS Well-Architected 5本の柱を要約する(運用上の優秀性)
5位 AWS CloudTrail
導入しやすさ ★★★★★
運用改善効果 ★★☆☆☆デフォルトで利用可能です。
AWSリソースの操作について誰がいつ何をしたのか記録します。
インシデントが起こったとき、犯人捜しに効果を発揮します。5位 AWS Cost Explorer
導入しやすさ ★★★★★
運用改善効果 ★★☆☆☆デフォルトで利用可能です。
サービスや月ごとなどの単位で利用したAWS費用を確認できます。
タグ付けにより特定のリソースのみの費用を算出できます。(部署ごとなどでタグ付けして分割すると便利)6位 AWS Budgets
導入しやすさ ★★★★☆
運用改善効果 ★★☆☆☆
予算のしきい値を超えたときにアラートを発行するカスタム予算を設定。
予算超過アラートで知らずに起動したままになっていた無駄なインスタンスを検知できることがあるようです。評価中
AWS License Manager
ソフトウェアライセンスの使用状況を管理、検出、および報告するルールを設定
AWS Service Catalog
作成、整理、そして制御
AWS OpsWorks
Chef と Puppet を使って運用を自動化
AWS Config
AWS リソースの設定を記録して評価
AWS Marketplace
AWS で実行されるソフトウェアを発見、テスト、購入してデプロイする
AWS のコストと使用状況レポート
AWS のコストと使用状況をより詳しく見る
AWS X-Ray
本番環境や分散アプリケーションの分析とデバッグ
評価対象外
AWS Managed Services
すべてのエンタープライズカスタマーとパートナーに代わって AWS インフラストラクチャを運用
RDSやELBなども該当。広すぎるので対象外。
AWS Managed Services~Managed Servicesの概要~AWS Control Tower
新しいセキュアなマルチアカウント AWS 環境をセットアップおよび管理するための最も簡単な方法
⇒アカウント一つの環境のため今回は対象外。いずれ評価したい。AWS Organizations
AWS アカウント全体での一元的なガバナンスと管理
⇒アカウント一つの環境のため今回は対象外。いずれ評価したい。さいごに
週一回くらいのペースで評価中のサービスを調査していきます。
AWS初心者の方もできるところから徐々に運用改善していけたら良いと思いますので、参考になれば幸いです。