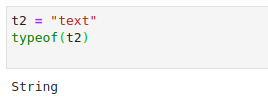
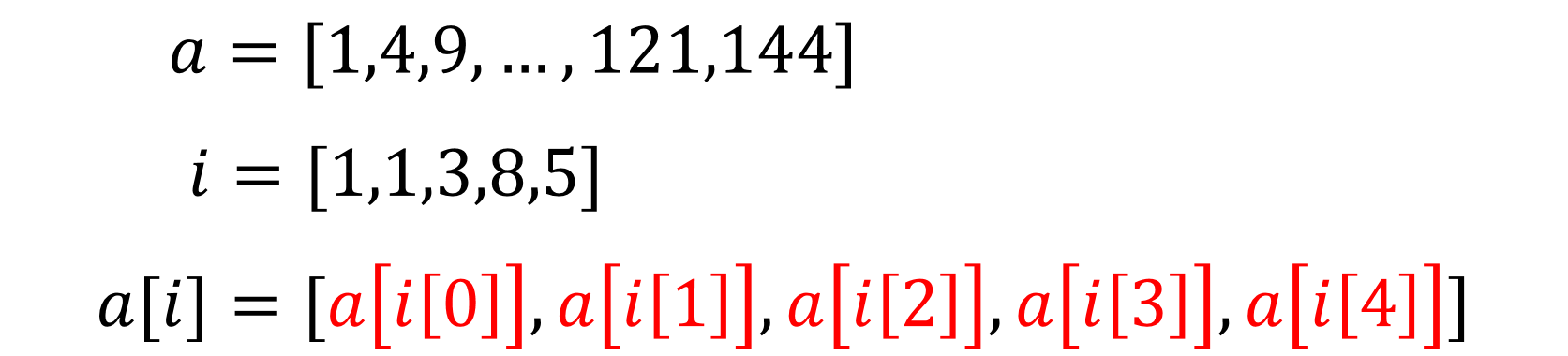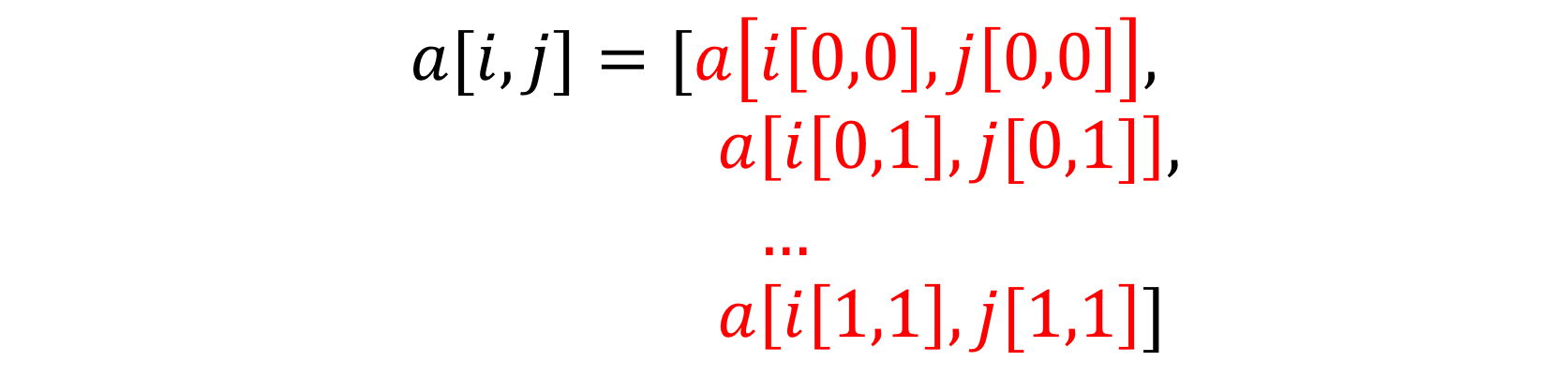RuntimeError: cuda runtime error (100) : no CUDA-capable device is detected at /opt/conda/conda-bld/pytorch_1591914855613/work/aten/src/THC/THCGeneral.cpp:47
importnumpyasnpTarray=np.arange(20).reshape(2,10)print(Tarray)num=int(input(": "))foriinrange(10):ifTarray[0,i]==num:print(f"founded data is placed Tarray[0,{i}] ")
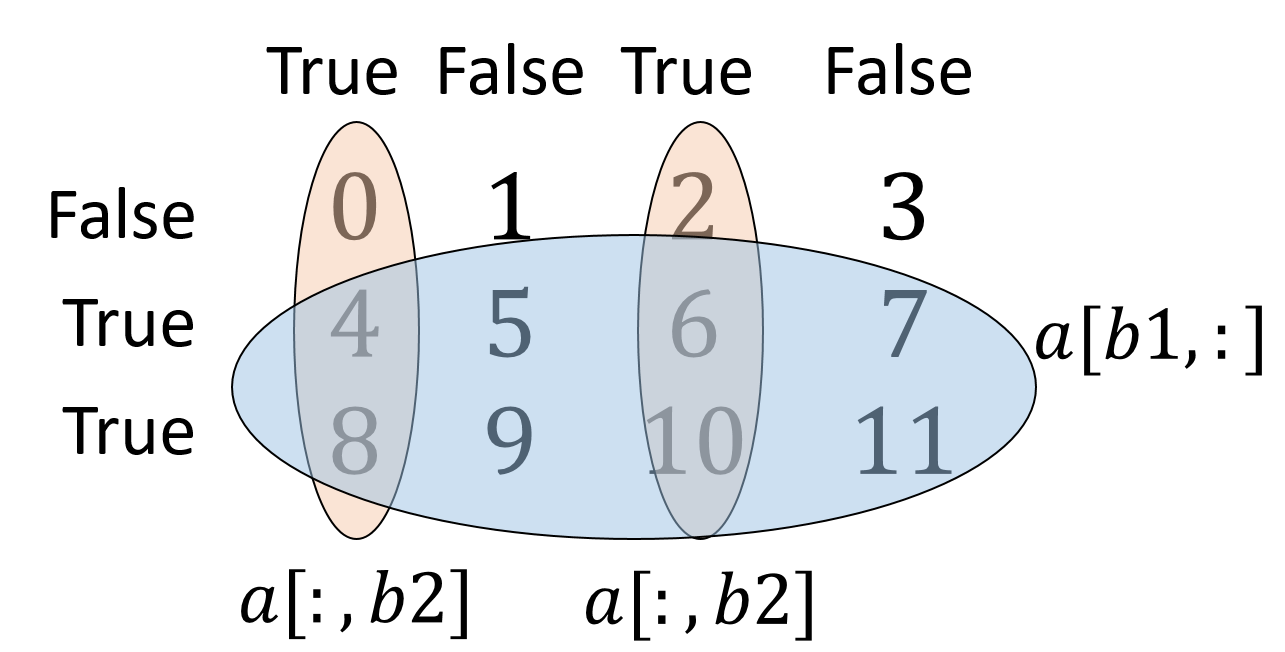
次は行をまたいで検索しましょう。
前述の Tarray[0,i] の 0 を変数に変えれば OK です。
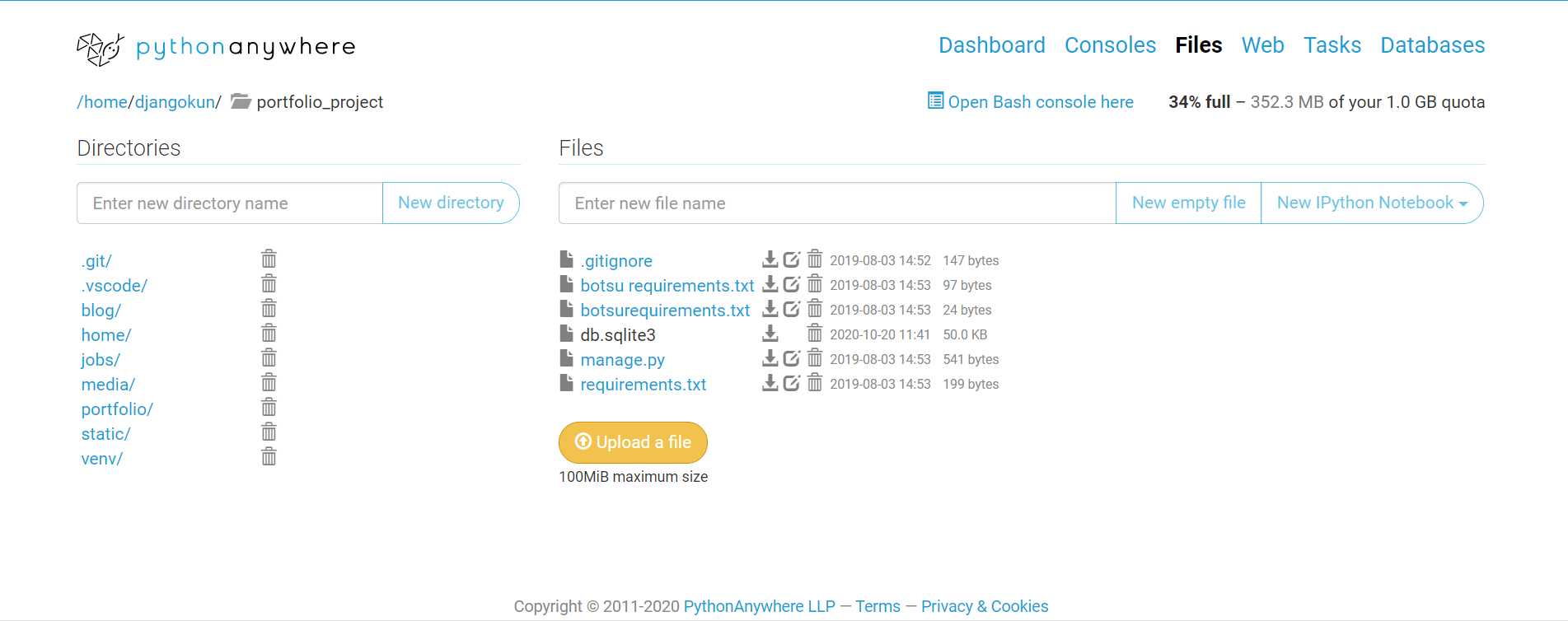
test.py
importnumpyasnpTarray=np.arange(20).reshape(2,10)print(Tarray)num=int(input(": "))forjinrange(2):foriinrange(10):ifTarray[j,i]==num:print(f"founded data is placed Tarray[{j},{i}] ")
importnumpyasnpM,N=map(int,input("enter M , N: ").split())atest=np.arange(M*N).reshape(M,N)print(atest)num=int(input("find value: "))foriinrange(M):forjinrange(N):ifatest[i,j]==num:print(f"found value is placed at [{i},{j}]")
importnumpyasnpM,N=map(int,input("enter M , N: ").split())atest=np.arange(M*N).reshape(M,N)print(atest)num=int(input("find value: "))foriinrange(M):forjinrange(N):ifatest[i,j]==num:print(f"found value is placed at [{i+1},{j+1}]")
parser=argparse.ArgumentParser()parser.add_argument("--n_epochs",type=int,default=200,help="number of epochs of training")parser.add_argument("--batch_size",type=int,default=64,help="size of the batches")parser.add_argument("--lr",type=float,default=0.0002,help="adam: learning rate")parser.add_argument("--b1",type=float,default=0.5,help="adam: decay of first order momentum of gradient")parser.add_argument("--b2",type=float,default=0.999,help="adam: decay of first order momentum of gradient")parser.add_argument("--n_cpu",type=int,default=8,help="number of cpu threads to use during batch generation")parser.add_argument("--latent_dim",type=int,default=100,help="dimensionality of the latent space")parser.add_argument("--img_size",type=int,default=32,help="size of each image dimension")parser.add_argument("--channels",type=int,default=1,help="number of image channels")parser.add_argument("--sample_interval",type=int,default=400,help="interval between image sampling")opt=parser.parse_args()print(opt)
usage: ipykernel_launcher.py [-h] [--n_epochs N_EPOCHS]
[--batch_size BATCH_SIZE] [--lr LR] [--b1 B1]
[--b2 B2] [--n_cpu N_CPU]
[--latent_dim LATENT_DIM] [--img_size IMG_SIZE]
[--channels CHANNELS]
[--sample_interval SAMPLE_INTERVAL]
ipykernel_launcher.py: error: unrecognized arguments: -f /root/.local/share/jupyter/runtime/kernel-ecf689bc-740f-4dea-8913-e0d8ac0b1761.json
An exception has occurred, use %tb to see the full traceback.
SystemExit: 2
/usr/local/lib/python3.6/dist-packages/IPython/core/interactiveshell.py:2890: UserWarning: To exit: use 'exit', 'quit', or Ctrl-D.
warn("To exit: use 'exit', 'quit', or Ctrl-D.", stacklevel=1)
Google Colabではopt = parser.parse_args()の行をopt = parser.parse_args(args=[])としてあげると無事通ります。
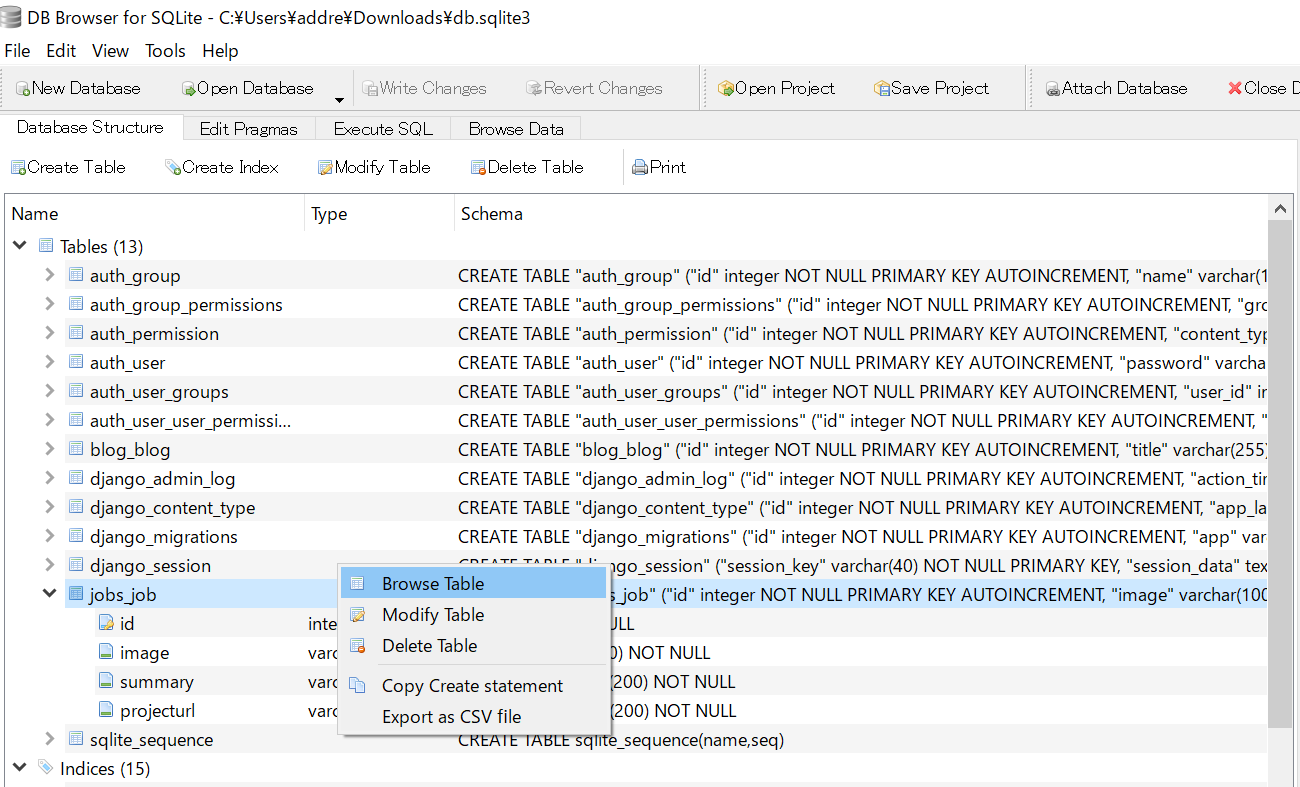
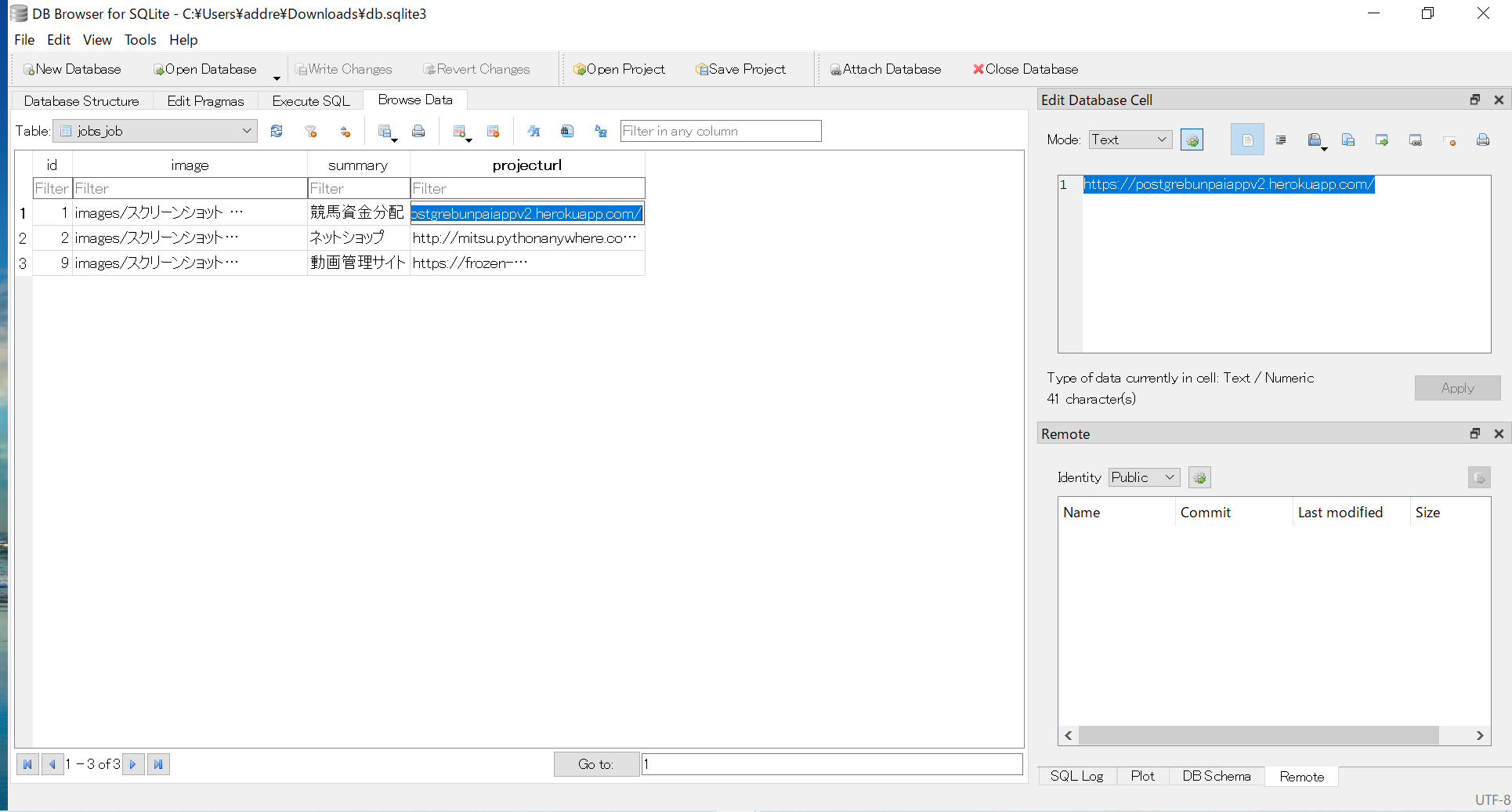
classDiscriminator(nn.Module):def__init__(self):super(Discriminator,self).__init__()defdiscriminator_block(in_filters,out_filters,bn=True):block=[nn.Conv2d(in_filters,out_filters,3,2,1),nn.LeakyReLU(0.2,inplace=True),nn.Dropout2d(0.25)]ifbn:block.append(nn.BatchNorm2d(out_filters,0.8))returnblockself.model=nn.Sequential(*discriminator_block(opt.channels,16,bn=False),*discriminator_block(16,32),*discriminator_block(32,64),*discriminator_block(64,128),)# The height and width of downsampled image
ds_size=opt.img_size//2**4self.adv_layer=nn.Sequential(nn.Linear(128*ds_size**2,1),nn.Sigmoid())defforward(self,img):out=self.model(img)out=out.view(out.shape[0],-1)validity=self.adv_layer(out)returnvalidity
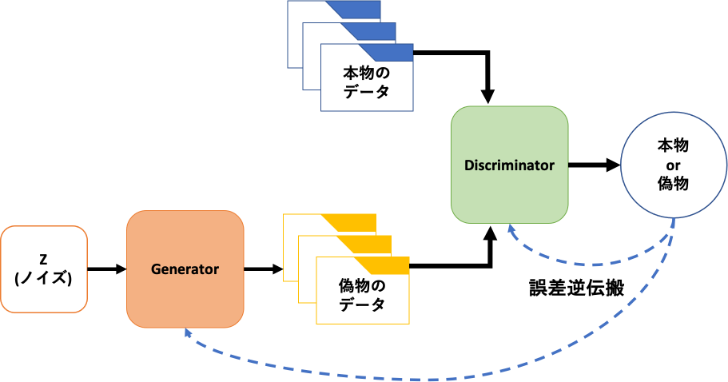
損失関数の設定とネットワーク周りの設定
# Loss function
adversarial_loss=torch.nn.BCELoss()# Initialize generator and discriminator
generator=Generator()discriminator=Discriminator()ifcuda:generator.cuda()discriminator.cuda()adversarial_loss.cuda()# Initialize weights
generator.apply(weights_init_normal)discriminator.apply(weights_init_normal)# Optimizers
optimizer_G=torch.optim.Adam(generator.parameters(),lr=opt.lr,betas=(opt.b1,opt.b2))optimizer_D=torch.optim.Adam(discriminator.parameters(),lr=opt.lr,betas=(opt.b1,opt.b2))Tensor=torch.cuda.FloatTensorifcudaelsetorch.FloatTensor
# Configure data loader
os.makedirs("./data/mnist",exist_ok=True)dataloader=torch.utils.data.DataLoader(datasets.MNIST("./data/mnist",train=True,download=True,transform=transforms.Compose([transforms.Resize(opt.img_size),transforms.ToTensor(),transforms.Normalize([0.5],[0.5])]),),batch_size=opt.batch_size,shuffle=True,)
Training
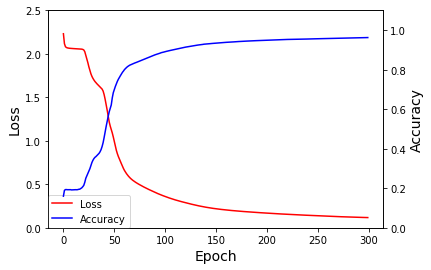
いざGANのTrainingを行っていきます。
# ----------
# Training
# ----------
forepochinrange(opt.n_epochs):fori,(imgs,_)inenumerate(dataloader):# Adversarial ground truths
valid=Tensor(imgs.shape[0],1).fill_(1.0)fake=Tensor(imgs.shape[0],1).fill_(0.0)# Configure input
real_imgs=imgs.type(Tensor)# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()# Sample noise as generator input
z=Tensor(np.random.normal(0,1,(imgs.shape[0],opt.latent_dim)))# Generate a batch of images
gen_imgs=generator(z)# Loss measures generator's ability to fool the discriminator
g_loss=adversarial_loss(discriminator(gen_imgs),valid)g_loss.backward()optimizer_G.step()# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()# Measure discriminator's ability to classify real from generated samples
real_loss=adversarial_loss(discriminator(real_imgs),valid)fake_loss=adversarial_loss(discriminator(gen_imgs.detach()),fake)d_loss=(real_loss+fake_loss)/2d_loss.backward()optimizer_D.step()print("[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"%(epoch,opt.n_epochs,i,len(dataloader),d_loss.item(),g_loss.item()))batches_done=epoch*len(dataloader)+iifbatches_done%opt.sample_interval==0:save_image(gen_imgs.data[:25],"images/%d.png"%batches_done,nrow=5,normalize=True)
私の実装は[4]とは以下の点でやや異なっています。
1. MNISTの画像データを2x2 average poolingしている。
2. optimizerは[4]で使用されたadamでなく単純な勾配降下法(それに伴い、学習率やEpoch数も調整)
1.については、オリジナルのサイズだと学習の難易度が高かったためです。縮約をとる際に行われるのは画素数分の行列のかけ算であり、かける行列の数が増えると出力値が発散 or 0収束しやすい、また勾配が消失しやすいなどのプラクティカルな難しさがあります。調整次第ではあると思うのですが今回は妥協しました。
また[5]では(ネットワーク構造やタスクがいくらか異なるためかもしれないですが)著者らもpoolingしています。
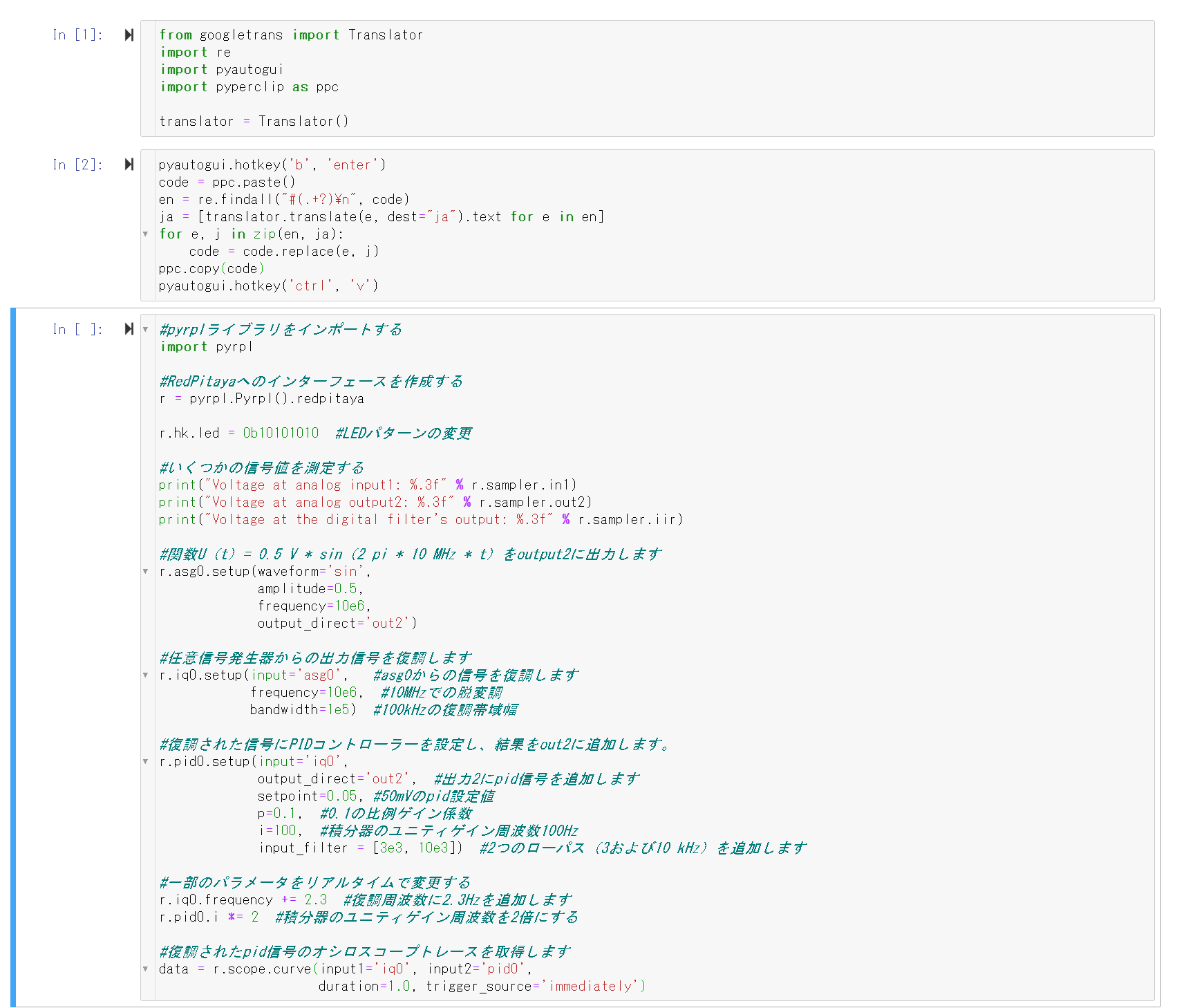
# import pyrpl library
importpyrpl# create an interface to the Red Pitaya
r=pyrpl.Pyrpl().redpitayar.hk.led=0b10101010# change led pattern
# measure a few signal values
print("Voltage at analog input1: %.3f"%r.sampler.in1)print("Voltage at analog output2: %.3f"%r.sampler.out2)print("Voltage at the digital filter's output: %.3f"%r.sampler.iir)# output a function U(t) = 0.5 V * sin(2 pi * 10 MHz * t) to output2
r.asg0.setup(waveform='sin',amplitude=0.5,frequency=10e6,output_direct='out2')# demodulate the output signal from the arbitrary signal generator
r.iq0.setup(input='asg0',# demodulate the signal from asg0
frequency=10e6,# demodulaltion at 10 MHz
bandwidth=1e5)# demodulation bandwidth of 100 kHz
# set up a PID controller on the demodulated signal and add result to out2
r.pid0.setup(input='iq0',output_direct='out2',# add pid signal to output 2
setpoint=0.05,# pid setpoint of 50 mV
p=0.1,# proportional gain factor of 0.1
i=100,# integrator unity-gain-frequency of 100 Hz
input_filter=[3e3,10e3])# add 2 low-passes (3 and 10 kHz)
# modify some parameters in real-time
r.iq0.frequency+=2.3# add 2.3 Hz to demodulation frequency
r.pid0.i*=2# double the integrator unity-gain-frequency
# take oscilloscope traces of the demodulated and pid signal
data=r.scope.curve(input1='iq0',input2='pid0',duration=1.0,trigger_source='immediately')