- 投稿日:2020-10-20T22:29:09+09:00
SAA-02 受験後感想
はじめに
30代未経験からエンジニアをめざすYNです。
先ほどソリューションアーキテクトアソシエイトを受験してきたので、感想をまとめます。
細かい結果はわからないですが、合格してバッジは貰えました。これでようやくAWS初心者は脱せたかもしれません。受験前対策
- Udemyの対策コースは5周ぐらい。問題文を読めば回答が浮かぶぐらいやった。
- web問題集も後半(80以降)は5周ぐらいやった。
- Blackbeltも一通りチェックした。
- ハンズオンはほぼやっていないが、
S3やLambdaやDaynamoDBなどを使ったwebアプリをつくった経験はある- AWS未経験、というかエンジニアですらないが、ゼロから初めて200時間ぐらいは勉強したと思う。
本番の感想
- 普通に難しいと感じた。自信を持って解けたと感じる問題は半分もなかったと思う。自分はめちゃくちゃ時間をかけて細かい部分まで勉強したと思っていたが、受験中はまったく自信がなかった。やはり対策は未熟だったと思う。
- 「これは分からんだろ」と諦めた問題が4問ぐらいあった
印象に残ったこと
SQSに関する問題が多かった。3~4問出たとおもう。自分はいつもSNSを使うか、SQSを使うか、それともSNS+SQSなのか、を迷うことが多かったので、そこら辺をもっと整理しておくべきだったと思う。FSxに関する問題が多かった。EFSと併せて5問ぐらい出たかもしれない。SBMとかWindowsといったワードが出たらFSxでしょ、ぐらいで記憶していたが、ActiveDirectoryとの統合に関してや、StorageGatewayとの連携に関する問題が複数でたので、その辺を組み合わせてしっかりと理解しておくべきだった。CloudFrontに関する問題も多かった。やはり4問ぐらいあったと思う。一般的なキャッシュに関する問題の他に、OAIを使ったS3へのアクセス制限に関する問題もあった。また、キャッシュで対応できる場合とできない場合を問う問題が複数あったと思う(ユーザごとにレスポンスが異なる場合はキャッシュで対応できない)。WAFに関する出題も2問ほどあったと思う。Lambda@Edgeに関する問題も出た。実際のユースケースについてうろ覚えだったのではっきりと確認しておくべきだった。- データ移行とSnowシリーズに関連する問題も複数出題された。
Snowball Edge1つで大体80TBぐらい、と単純に記憶していたが、データ移行にあたりデータの後処理と前処理をSnowballとどう連携させるか、という出題があって?となった。S3について、やはりストレージクラスについての問題が複数あった。基本は抑えたつもりでいたが、S3標準とS3標準IAで迷う問題があった。低頻度アクセスであることが明確に述べられておらず、このデータは低頻度なのではないかと推測させるようなケースがあり、やはり回答に迷った。また、S3とVPCエンドポイント接続に関する問題も複数出た。- 「最速のIOを実現するのは?」という問題で
EBSとインスタンスストアを比較する問題が出た。IOの速さだけなら後者なのだが、「10TBのデータを保存する場合」との記載もあり、インスタンスストアで10TBも行けるのか?と迷ってしまった。インスタンスストアの最大容量も確認しておくべきだった。また、「インスタンスストアのRAID0構成」という選択肢もあったが、それが可能なのかも迷ってしまった。最後に
何はともあれ合格してよかったです。
巷には、数時間の勉強で合格しただの、簡単だっただのという記事が溢れていますが、自分のようにめっちゃ勉強したつもりで挑んでも苦戦した人間もおり、今後受ける方はくれぐれも油断なさらぬよう。。。
- 投稿日:2020-10-20T22:18:25+09:00
全Lambdaからコードをzipダウンロードしてきて、zipのままキーワード検索する
これはなに?
全Lambdaからコードをzipダウンロードしてきて、zipのまま検索しました。
- ① 全Lambdaからコードをダウンロード
- ② zipのまま検索(zipgrep使用)
の2つの手順で行います。
利用ケース
リポジトリ管理していない直書Lambdaなどが大量に存在するカオスな検証アカウントで特定キーワードを含むLambdaがないか調査するときに使用。
カオスなアカウントが出来上がらないようにするのがいいとは思うのですが、古の闇に手を突っ込む機会に恵まれました。① 全Lambdaからコードをダウンロード
nemani/download_all_lambda_functions.sh
https://gist.github.com/nemani/defdde356b6678352bcd4af69b7fe529これを使います。
前提条件
・wgetが必要
・cliのアウトプットをtextにしておく
・bashつかわないとだめかも
・中でaws clilつかっているのでプロファイルなどは設定しておく使用中
・"Completed Downloading all the Lamdba Functions!"って出るけどバックグラウンドにタスク投げただけなので、全く終わってない
・数分またないとダウンロードが始まらないので数分待つ
・全てのバックグラウンドタスク終わったという合図がないのでダウンロードタスクが止まってzipの数が関数の数と一致したら完了と見做しました。使用例
# この辺はデフォルトプロファイルなど常に設定しているなら不要 export AWS_DEFAULT_PROFILE=xxxxx export AWS_DEFAULT_REGION=ap-northeast-1 export AWS_DEFAULT_OUTPUT=text # 実行 bash download_all_lambda_functions.sh出力結果
lambda_functions/* に関数ごとにzipが保存される
備考
リージョンごとにとってくるので、ちょっとめんどい。
他のリージョン指定でとってくるときフォルダは分けたほうがいいかも。for region in `aws ec2 describe-regions --query 'Regions[].RegionName' --region us-west-1 --output text` do 〜 doneで全リージョンをグルグル回してやっても良かったかも
② zipのまま検索(zipgrep使用)
使用例(HOGEHOGEを検索)
cd lambda_functions for file in *.zip; do res=`zipgrep -n HOGEHOGE $file` if [ -n "$res" ]; then echo "x:$file"; echo "$res"; else echo "o:$file"; fi doneボツ
最初は
find ./lambda_functions -name '*.zip' | xargs -I file zipgrep HOGEHOGE fileとかでやってたんですが、これだと、どのzipで検出したかわからなかったので前述のを流して確認しています。
出力結果例
キーワードに引っかかったlambdaを x:〜
引っかからなかったlambdaを o:〜
で出力しています。x:aaaa-checker.zip lambda_function.py:30: target = "HOGEHOGE", o:bbbb-deleter.zip o:cccc-notifier.zip x:dddd-test.zip lambda_function.py:21: print("HOGEHOGE")", ...備考
Lambda にライブラリや.env環境が同梱されているとgrepはけっこう時間がかかる。
- 投稿日:2020-10-20T21:40:01+09:00
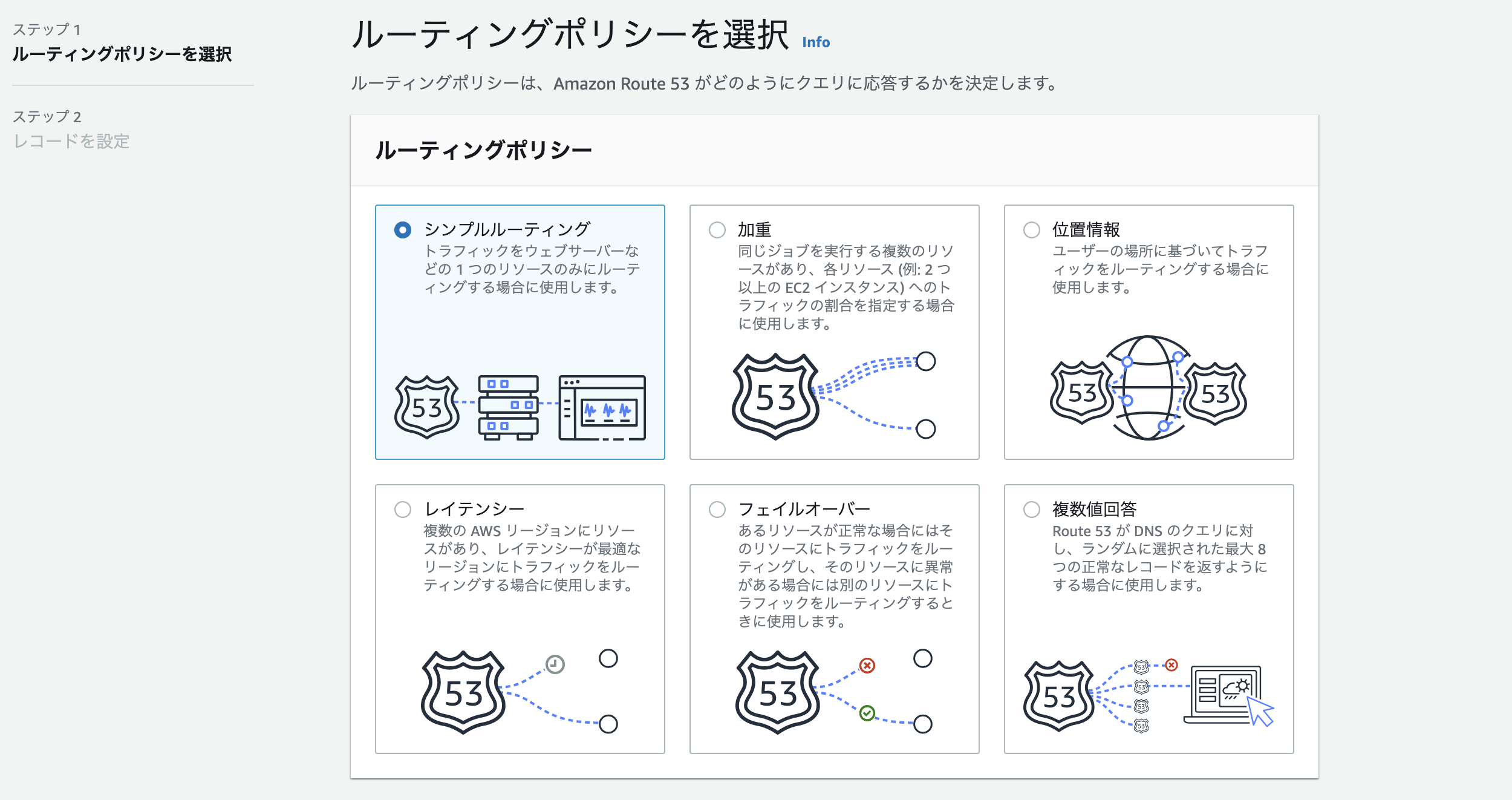
route53 最新版 レコード作成画面
現在ポートフォリオ等のために 初めてRoute53を
触る人用の設定案内です。あまり2020年10月現在の最新バージョンの
レコード作成画面を載せている人がいなくて とまどったので
誰かのために載せておきます。レコード作成画面
これは単純にシンプルルーティングでいいと思います。
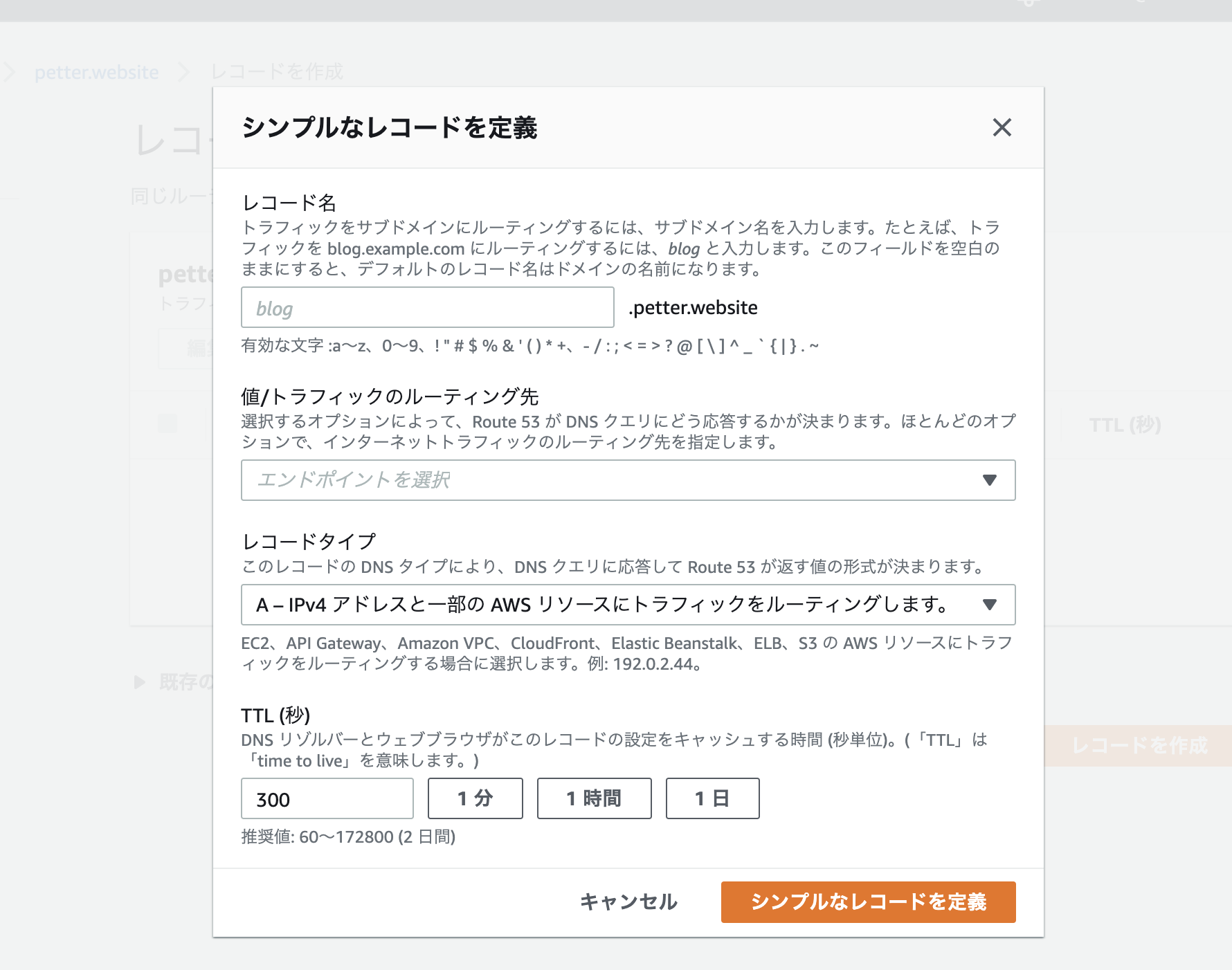
次に シンプルなレコードを作成 の画面
レコード名は お名前.com 等でドメインをとっている人は空白でいいと思います。
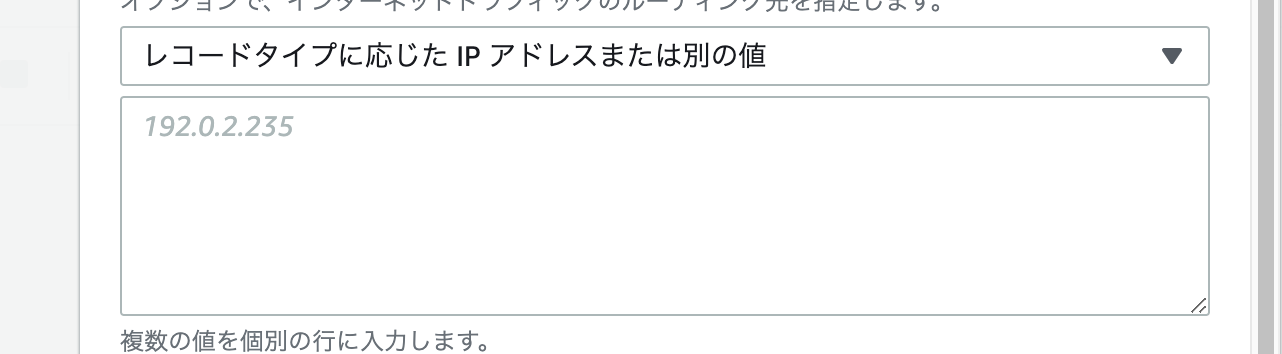
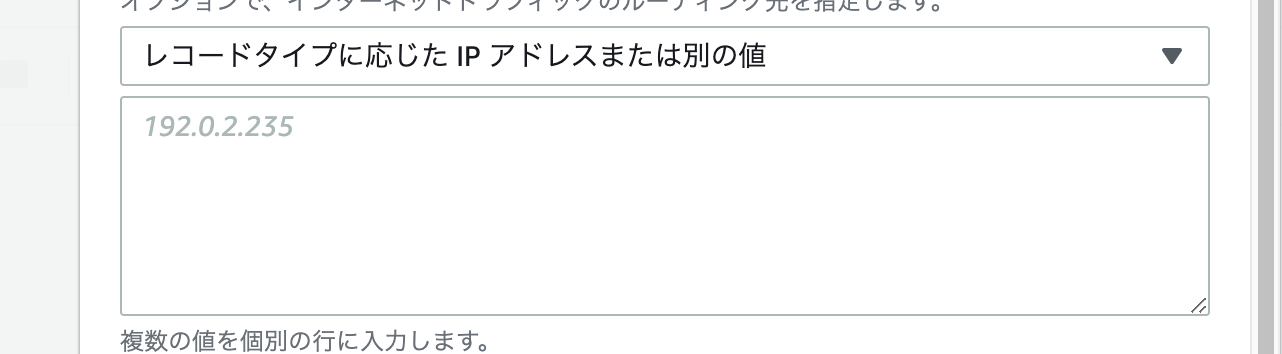
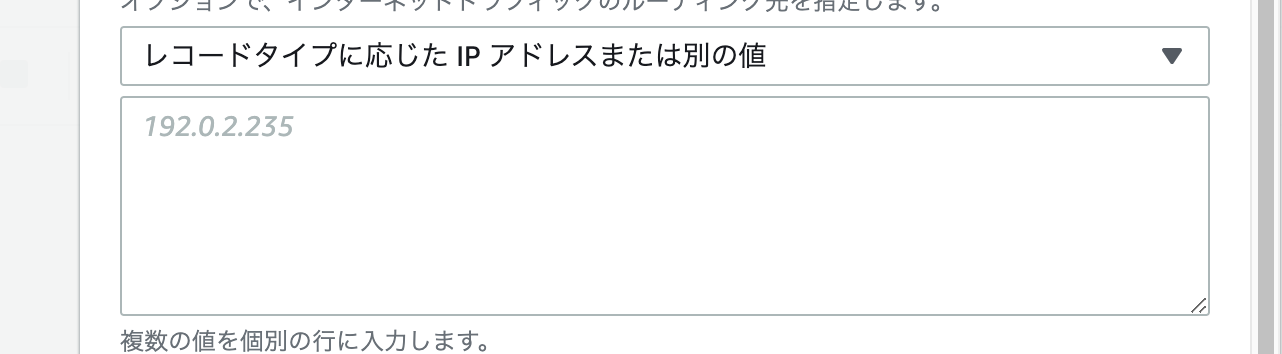
次に エンドポイントを選択 の部分は
レコードタイプに応じたIPアドレスまたはその別の値 を選択。
そのしたの空欄には EC2で割り当てた elasticIPを入力してください。
その後のTTLはデフォルトの300で大丈夫です。
かなり簡単な内容ですが、AWSに慣れてない方は戸惑うかもしれないので
参考になればと思います(もちろん私も戸惑いました)

- 投稿日:2020-10-20T21:06:15+09:00
AWS 認定 SysOps アドミニストレーターアソシエイトサンプル問題を解説します
こんにちは。今回は友人からの希望を受けて、 SysOps アドミニストレーターアソシエイトのサンプル問題解説です。
AWS 環境の管理や運用を担当するシステムアドミニストレーターな方向けの認定試験です。
AWS認定とは
AWS 認定は、クラウドの専門知識を検証し、専門家が需要の高いスキルを強調し、組織が AWS を使用してクラウドイニシアチブにおける効果的で革新的なチームを構築するのに役立ちます。個人やチームが独自の目標を達成できるように、役割と専門分野ごとに設計したさまざまな認定試験から選択します。
AWS 認定は領域やレベルごとに分けられ、本校執筆時点(2020/10)では12の認定資格が存在しています。
- レベル
- 基礎
- アソシエイト(中級ととらえてください)
- プロフェッショナル(上級ととらえてください)
- 専門知識(対象分野に特化した高度な認定)
- 領域
- 全般
- ソリューション
- 開発
- 運用
- DBや機械学習といった専門分野
表にまとめると以下の通りです。
# レベル 認定名 1 基礎 クラウドプラクティショナー 2 アソシエイト ソリューションアーキテクトアソシエイト 3 アソシエイト デベロッパー アソシエイト 4 アソシエイト SysOps アドミニストレーター アソシエイト 5 プロフェッショナル ソシューションアーキテクト プロフェッショナル 6 プロフェッショナル DevOps エンジニア プロフェッショナル 7 専門知識 高度なネットワーク 8 専門知識 Alexaスキルビルダー 9 専門知識 セキュリティ 10 専門知識 機械学習 11 専門知識 データ分析 12 専門知識 データベース AWS認定 SysOps アドミニストレーターアソシエイト
試験の概要や出題割合などは、以下の試験ガイドをご確認ください。
https://d1.awsstatic.com/ja_JP/training-and-certification/docs-sysops-associate/AWS-Certified-SysOps-Administrator-Associate_Exam-Guide.pdfサンプル問題を解いてみよう
それでは、サンプル問題を確認していきましょう。
※以降、Markdown記載に合わせて、サンプル問題のABCDを1234と置き換えています。
第1問
問題文
企業は単一のサーバーから Application Load Balancer (ALB) の背後にある複数の Amazon EC2 インスタンスにレガシーのウェブアプリケーションを移行しています。移行後、ユーザーがセッションの頻繁な切断、また再ログインを求められることを報告しています。
ユーザーから報告された問題を解決するために次のうちどの措置を講じる必要がありますか?
- ALB がマルチ AZ 構成になっていないかの確認
- ALB を基として Amazon CloudFront ディストリビューションの設定
- ALB の前に Network Load Balancer をデプロイする
- EC2 インスタンスのターゲットグループに対してスティッキーセッションの有効化。
回答
4
解説
ALB の利用やレガシーのウェブアプリケーションの移行、頻繁な切断や再ログインが求められるとの記載から考えていきます。
レガシーのウェブアプリケーションではセッション情報をサーバー内部で持つことが一般的でした。
通常、ALB は背後にいる Amazon EC2 インスタンスへバランスよくリクエストを振り分けます。インスタンスが2台いれば、A,B,A,B...のように。ログインを行うと前述の「A」のインスタンスでログインしセッション情報は「A」のインスタンス内部に格納されることになります。その後のリクエストで「B」のインスタンスへ振り分けられてしまうと、セッション情報が存在しない状態になります。そのため、問題文にあるような事象が発生してしまいます。
この事象を回避するには、セッション情報を Amazon DynamoDB や Amazon ElastiCache などに格納し、リクエストがあるたびにそれらサービスへセッション情報を確認するつくりにすることです。
ただし、レガシーなアプリケーションを移行してきた場合は、極力、アプリケーションコードに手を入れたくない、いれられないことも考えられます。
その場合は、選択肢の「4」にあるスティッキーセッションを有効化します。
スティッキーセッションを使うことで、セッション情報が生成されたインスタンスに対してリクエストが転送されるので、「A」のインスタンスでログインを行った場合に継続的に「A」への通信が行われることになります。よって、正答であると考えます。
- マルチ AZ 構成になっていることと ALB を使っていることで、セッションの切断や再ログインが求められることは要因の一つではありますが、「確認する」ことが解決のための手段ではないので回答としては不適当です。
- Amazon CloudFront ディストリビューションの設定をしても、セッション周りの動きはかわらないので、回答としては不適当です。
- ALB の前に Network Load Balancer (NLB)をデプロイしても、セッション周りの動きはかわらないので、回答としては不適当です。
- 前述の通り、スティッキーセッションを有効化する必要があるため、適当であると考えます。
第2問
問題文
運用チームは、毎週 AWS Personal Health ダッシュボードで、次の AWS ハードウェアメンテナンスイベントをチェックしています。最近、一人のスタッフが休暇中であったためチームはメンテナンスの予定を見落とし、その結果サービスが停止しました。ームはダッシュボードの確認を一人のスタッフに頼るのではなく、全員が次
のメンテナンスを周知できるような簡単な方法を求めています。これに対処する方法は次のうちどれですか?
- Personal Health ダッシュボードを監視する ウェブスクレーパーを構築する。新しいイベントが検出されたときに、チームで監視する Amazon SNS トピックに通知を送信する。
- AWS Health サービスに基づいて Amazon CloudWatch Events イベントを作成し、チームで監視する Amazon SNS トピックに通知を送信する。
- Personal Health ダッシュボードでメンテナンスの予定を表示するようチームにリマインドするために、チームで監視する Amazon SNS トピックに通知を送信し、Amazon CloudWatch Events を作成する。
- すべての EC2 インスタンスに対し継続的に ネットワーク接続確認を実行して正常性を確認するために AWS Lambda 関数を作成する。これに失敗した場合は、チームにアラートを送信する。
回答
2
解説
所謂、属人化が原因となった事象ですね。これを回避するには属人化を回避し、全員が即座に確認や対応といった初動に移れるように通知する仕組みが必要です。そして、できるだけ、機械化や自動化を取り入れて確認作業の漏れや抜けも防げるようにするとよいでしょう。
AWS Personal Health ダッシュボードの情報は、 AWS Health サービスで管理されています。イベントの発生や予告がされたことを契機に、Amazon CloudWatch Events のイベントが実行できます。そこから Amazon SQS や Amazon SNS などを通じて処理が行えます。
本件でいえば、次のメンテナンスの周知なので、運用担当者のメーリングリストや、MS Teams, Slackなどへ通知ができればよさそうなので、 Amazon SNS を使うのがよいでしょう。
- 前述の通り仕組みが用意されているのに、わざわざ ウェブスクレーパーを構築するのは、工数がもったいないです。画面構成や文字列が変わったら使えなくなってしまい、延々とメンテナンスを続けないとなりません。そのため、この回答は不適当であると考えます。
- 前述の通り、この選択肢が適当であると考えます。
- 良い線までいっているように見えますが、ダッシュボードを見に行く(表示する)をリマインドするために、Amazon SNS で通知するとあるので不適当であると考えます。
- 「ネットワーク接続確認」のみであればこの手法も悪くはなさそうですが、発生しうるインシデントはネットワーク問題だけではありません。また、要件としては、 AWS ハードウェアメンテナンスイベントが対象と記載があるため、要件を満たしていないため不適当です。
第3問
問題文
VPC で稼働されているアプリケーションは異なるアカウントによって所有され、かつ別のリージョンの VPC で稼働されているインスタンスにアクセスする必要があります。コンプライアンスの観点から、トラフィックはパブリックインターネットを通過してはなりません。
これらの要件を満たすために、管理者はネットワークルーティングをどのように構成すべきでしょうか?
- 各アカウント内に他のアカウントの仮想プライベートゲートウェイを示すルートを格納するカスタムルーティングテーブルを作成する。
- 各アカウント内にそれぞれの VPC のパブリックサブネットに NAT ゲートウェイを設定する。次に、NAT ゲートウェイからのパブリック IP アドレスを使用し、2 つの VPC 間のルーティングを有効にする。
- 1 つのアカウントで VPCs の間に VPN のサイト間の 接続を構成する。各アカウント内にリモート VPC のCIDR ブロックを示す VPC ルートテーブルにルートを追加する。
- 1 つのアカウントから VPC ピアリング要求を作成する。他のアカウントの管理者が要求を受け入れた後、ピアリングされた VPC の CIDR ブロックを示す各 VPC のルートテーブルにルートを追加する。
回答
4
解説
アプリケーションやインスタンスは VPC で稼働している、トラフィックはパブリックインターネットを通過してはならないという要件から、各 VPC を接続して トラフィックを AWS ネットワーク外に出さない VPC ピアリング接続や Transit Gateway で解決できそうです。
- 仮想プライベートゲートウェイ(VGW)はオンプレミスとの専用線接続(Direct Connect)や VPN との接続に使うものです。また、Direct Connect Gateway を利用していたとしても互いの VGW を介しての通信はできません。よって、不適当であると考えます。
- NAT ゲートウェイではパブリックインターネットに出てしまうため、不適当です。
- VPN とはいえ、パブリックインターネットを通過するので不適当です。
- VPC ピアリング接続の設定とルートテーブルの設定をしているため、この選択肢が適当であると考えます。
第4問
問題文
Amazon EC2 インスタンスで稼働されているアプリケーションは、Amazon DynamoDB テーブルに格納されているデータにアクセスする必要があります。
最も安全な方法でアプリケーションにテーブルへのアクセスを許可するソリューションは、次のうちどれですか?
- アプリケーションの IAM グループを作成し、必要な権限を持つアクセス許可ポリシーを添付する。EC2 インスタンスを IAM グループに追加する。
- Amazon EC2 に必要なアクセス許可を付与する DynamoDB テーブルの IAM リソースポリシーを作成する。
- DynamoDB テーブルへのアクセスに必要な権限を持つ IAM ロールを作成する。ロールを EC2 インスタンスにアサインする。
- アプリケーション用の IAM ユーザーを作成し、必要な権限を持つアクセス許可ポリシーを添付する。アクセスキーを生成し、そのキーをアプリケーションコードに埋め込む。
回答
3
解説
Amazon DynamoDB へ安全にアクセスするのが要件です。選択肢も併せて確認すると、IAM の設定の話のようです。
Amazon EC2 に設定ができる IAM の機能がわかり、アプリケーションから AWS サービスを利用する際のベストプラクティス、つまり安全なアクセス方法を知っていれば答えが導かれます。
- IAM グループに追加できるのは、IAM ユーザーのみです。Amazon EC2 インスタンスを追加することはできないので、不適当です。
- IAM リソースポリシーは Amazon EC2 でサポートされていません。そのため不適当です。
- IAM ロールを利用することで、Security Token Service(STS) の力により、一時的に利用可能なアクセスキーとシークレットアクセスキー、トークンが払い出されます。アプリケーションはこれらの情報を使うことで安全に AWS サービスへアクセスが行えます。よって、適当であると考えます。
- アクセスキー、シークレットアクセスキーをアプリケーションコードに埋め込むのはバッドノウハウです。何かのはずみでキーが漏れたり、キーを埋め込んだアプリケーションコードを Github などで公開してしまうと、権限を奪取されかねません。よって、安全に接続するという要件が満たせないため、不適当です。
第5問
問題文
サードパーティのサービスは毎晩 Amazon S3 にオブジェクトがアップロードしています。場合によってはサービスにより、誤ってフォーマットされたバージョンのオブジェクトがアップロードされることもあります。このような場合、SysOps Administrator は旧バージョンのオブジェクトを回復する必要があります。
リモートサービスからオブジェクトを取得せずにオブジェクトを回復する、最も効率的な方法は次のうちどれですか?
- 毎晩行われるオブジェクトのアップロードの前に S3 バケットをバックアップするための AWS Lambda 関数をトリガーする、Amazon CloudWatch Events スケジュールイベントを設定する。その際不良オブジェクトが検出された場合は、バックアップバージョンを復元する。
- オブジェクト作成時に、オブジェクトを Amazon Elasticsearch Service (Amazon ES) クラスターにコピーする S3 イベントを作成する。その際不良オブジェクトが検出された場合は、Amazon ES から以前のバージョンを取得する。
- 別のアカウントが所有する S3 バケットにオブジェクトをコピーする AWS Lambda 関数を作成します。S3 で新しいオブジェクトが作成されたときに関数をトリガーします。不良オブジェクトが検出された場合は、他のアカウントから以前のバージョンを取得します。
- S3 バケットのバージョン管理を有効にする。その際不良オブジェクトが検出された場合は、CLI または AWS 管理コンソールを使用して以前のバージョンにアクセスする。
回答
4
解説
Amazon S3 にアップロードされているオブジェクトをサードパーティのサービス(リモートのサービス)から取得せずに復旧するのが要件です。
Amazon S3 にはこういった際に使える機能として、バージョニングとレプリケーションが用意されています。
- バージョニング
- 格納したオブジェクトに対して更新(上書き)や削除を行うと、一意のバージョンIDを付与して、同じオブジェクト名だが、異なるバージョンIDをもつオブジェクトをその都度保持する機能
- 誤った削除や上書きをした際に、以前のバージョンを指定して復元が可能
- レプリケーション
- 異なるバケット間でオブジェクトを自動的に非同期コピーする機能
このことから、本問題の要件から、バージョニング機能を利用することが回答として正しそうです。
- Amazon S3 にはオブジェクトを格納したり削除したりといったアクションが実行された際、それをトリガに AWS Lambda の関数を実行する機能があります。また、前述の通りバージョニング機能があるため、わざわざ Amazon Cloudwatch Events のスケジュールイベントをトリガにバックアップするのは非効率であるため、不適当です。
- 執筆時点(2020年10月)では、 S3 イベントの送信先に指定できるのは、 Amazon SQS、Amazon SNS、AWS Lambda であるため不適当です。
- 別のバージョンへコピーする AWS Lambda 関数を作ったり、不良発生時のリカバリの際、専用の関数を使うのか、手作業でいったんダウンロードして再アップロードするのかはわかりませんが、効率が良い作業とは言えないため、不適当です。
- 前述の通り、バージョニング機能有効化し、選択肢にある通り、 AWS CLI や AWS 管理コンソール(マネージメントコンソール)から、戻したいバージョンを指定することで簡単に復元することができます。よって、適当であると考えます。
第6問
問題文
AWS 共有責任モデルによると、次の Amazon EC2 アクティビティのうち、AWS が責任を負うのはどれですか? (2つ選択)
- ネットワーク ACL の設定
- ネットワークインフラストラクチャのメンテナンス
- メモリ使用率の監視
- オペレーティングシステムへのパッチ適用
- ハイパーバイザーへのパッチ適用
回答
2、5
解説
責任共有モデルとは AWS と利用者で役割や責任の範囲を分けて対応し、全体的なセキュリティを確保しようという考え方です。ざっくりと役割や範囲をまとめると以下のような図になります。
これを踏まえて、正答だと考えられるものを選びます。
- ネットワーク ACL の設定は、上記参考リンクの図でいうところの「ネットワークトラフィック保護」に該当します。よって AWS の責任範囲ではないため不適当です。
- ネットワークインフラストラクチャは、上記参考リンクの図でいうところの「ネットワーキング」や「ハードウェア/AWSグローバルインフラストラクチャー」などに該当します。よって、AWSの責任範囲であるため、正解であると考えます。
- メモリ使用率の監視は、一般的には上記参考リンクの図でいうところの「オペレーティングシステム」に該当します。よって AWS の責任範囲ではないため不適当です。
- オペレーティングシステムへのパッチ適用は、一般的には上記参考リンクの図でいうところの「オペレーティングシステム」に該当します。よって AWS の責任範囲ではないため不適当です。
- ハイパーバイザーへのパッチ適用は、上記参考リンクの図でいうところの「ハードウェア/AWSグローバルインフラストラクチャー」に該当します。よって、AWSの責任範囲であるため、正解であると考えます。
第7問
問題文
セキュリティおよびコンプライアンスチームは、すべての Amazon EC2 ワークロードで承認済みの Amazon Machine Images (AMI) を使用する必要があります。SysOps Administrator は未承認の AMI から起動された EC2 インスタンスを検知するプロセスを実装しなければなりません。
これらの要件を満たすソリューションは次のうちどれですか?
- AWS Systems Manager インベントリを使用してカスタムレポートを作成し、未承認の AMI を識別する。
- 各 EC2 インスタンスで Amazon Inspector を実行し、未承認の AMI を使用している場合はインスタンスにフラグを立てる。
- AWS Config ルールを使用し、未承認の AMI を識別する。
- AWS Trusted Advisor を使用し、未承認の AMI を使用する EC2 ワークロードを識別する。
回答
3
解説
承認された AMI のみを使うように強制するには、 AWS Config の「approved-amis-by-id」や「approved-amis-by-tag」など AWS Config Managed Rule を利用することで効率よく検知することができます。検知後は、例えば、Amazon SNS を経由して自動的にメール通知などを行うといった運用が可能です。
これを踏まえて、正答だと考えられるものを選びます。
- AWS Systems Manager インベントリは、未承認の AMI を検知するサービスではないため、不適当です。さ
- Amazon Inspector はネットワークアクセシビリティや Amazon EC2 インスタンス上で動作するアプリケーションのセキュリティ状態をテストするサービスです。未承認の AMI を利用していることを検知するサービスではないため、不適当です。
- 上述の通り、 AWS Config のルールを使用し、設定することで、自動的に未承認の AMI を検知、識別することが可能です。よって正解と考えます。
- AWS Trusted Advisor はパフォーマンスやセキュリティ、コストといった観点でアドバイスをしてくれるサービスです。未承認の AMI を利用していることを検知するサービスではないため、不適当です。
第8問
問題文
SysOps Administrator は Application Load Balancer で大量の不正な HTTP リクエストを監視しています。そのリクエストはさまざまな IP アドレスから発信されています。それによりサーバーの負荷とコストが増加しています。
SysOps Administrator はこの不正なリクエストをブロックするために何を行う必要がありますか?
- 不正なリクエストをブロックするために、Amazon EC2 インスタンスに Amazon Inspector をインストールする。
- Amazon GuardDuty を使用し、ウェブサーバーをボットやスクレーパーから保護する。
- AWS Lambda を使用し、ウェブサーバーのログの分析及びボットトラフィックの検出を行い、セキュリティグループの IP アドレスをブロックする。
- AWS WAF レートベースのブラックリストを使用し、しきい値を超えたときにトラフィックをブロックする。
回答
4
解説
Application Load Balancer(ALB) を使っており、大量に発生している不正な HTTP リクエストをブロックするのが要件です。
これを達成するには、 AWS WAF を使うのが最適です。
AWS WAF では IP アドレスベースでアクセスを遮断したり、アクセス元の国や地域を基にした遮断をしたり、選択肢にある通りレートベースでの遮断といったことが可能です。そして、CloudFront や ALB と連携して、不正なリクエストをブロックすることができます。
- Amazon Inspector は、インターネットからリモートログインできるようになっていないか、セキュリティ脆弱性が無いかなどを自動的に判定するサービスであるため、回答としては不適当です。
- Amazon GuardDuty は AWS アカウント上のAWS CloudTrail イベントログ、Amazon VPC フローログ、および DNS ログなどの複数のイベントを解析し、脅威のあるイベントを検知するサービスのため、不適当です。
- リクエストは様々な IP アドレスから発信されているとあることから、すぐにセキュリティグループの上限値に抵触してしまうのが予想されること、 大量のアクセスとあることから AWS Lambda が大量に実行され、スロットリングになったり、処理時間が頭打ちになったりなど、結果的にコスト増大を引き起こします。よって、不適当です。
- 前述の通り、 AWS WAF のレートベースのブラックリストを使うことで、大量に発生している不正なリクエストを遮断することができるので、正解と考えます。
第9問
問題文
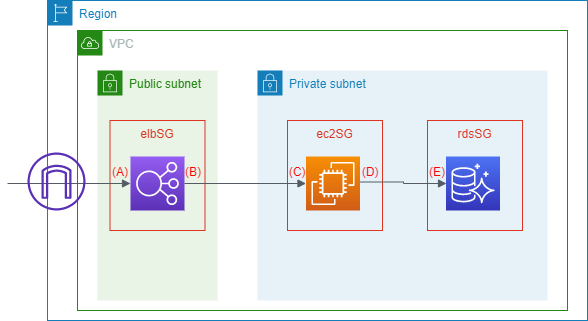
SysOps Administrator は AWS 上で運用されているウェブアプリケーションのセキュリティグループポリシーを設定しています。Elastic Load Balancer は Amazon EC2 インスタンスのフリートに接続します。各 Amazon EC2 インスタンスはポート 1521 を通じて Amazon RDS データベースに接続します。セキュリティグループの名称はそれぞれ elbSG、ec2SG、 rdsSG です。
これらのセキュリティグループをどのように設定すべきでしょうか?
- elbSG: 0.0.0.0/0 からポート 80 および 443 を許可する。
ec2SG: elbSG からポート 443 を許可する。
rdsSG: ec2SG からポート 1521 を許可する。- elbSG: 0.0.0.0/0 からポート 80 および 443 を許可する。
ec2SG: elbSG と rdsSG からポート 80 および 443 を許可する。
rdsSG: ec2SG からポート 1521 を許可する。- elbSG: ec2SG からポート 80 および 443 を許可する。
ec2SG: elbSG と rdsSG からポート 80 および 443 を許可する。
rdsSG: ec2SG からポート 1521 を許可する。- elbSG: ec2SG からポート 80 および 443 を許可する。
ec2SG: elbSG からポート 443 を許可する。
rdsSG: elbSG からポート 1521 を許可する。回答
1
解説
まず、問題文から類推される、使用するポートをまとめます。
- Elastic Load Balancer の 一般的な待ち受けポート: 80 や 443
- EC2(ウェブアプリケーションサーバ)の一般的な待ち受けポート: 80 や 443
- RDSの待ち受けポート(問題文中から): 1521
次に問題文から起こした想定される構成図は以下の通りです。
構成図内の (A) ~ (E) は各セキュリティグループのインバウンドとアウトバウンドを示します。
構成図と前述のポートをマッピングすると以下のようになります。
位置 送信元/送信先 ポート 補足 (A)elbSG インバウンド 0.0.0.0/0 80 および 443 443のみということも (B)elbSG アウトバウンド ec2SG 80 および 443 443 のみということも (C)ec2SG インバウンド elbSG 80 および 443 443 のみということも (D)ec2SG アウトバウンド rdsSG 1521 接続先の RDS の DB エンジンによる (E)rdsSG インバウンド ec2SG 1521 使用している RDS の DB エンジンによる 上の表で送信元や送信先に ec2SG などのようにセキュリティグループの名称が記載されていることにお気づきかと思います。
クラウドの場合、オンプレミスと異なり送信元や送信先の IP アドレスが常に変わる可能性があります。(AutoScaling でインスタンスが起動したり削除されたりするような環境など)
そのため、指定されたセキュリティグループが設定されている場合は通信が許可されるように設定が可能です。
- 構成図とポートのマッピングの表の通りの内容のため正解と考えます。
- ec2SGにある、RDS からは EC2 へ 80 や 443 での接続はしないため、不適当です。
- elbSGがインターネットからのアクセスが認めていない、elbSG にある ec2SG からの接続や ec2SG にある rdsSG からの接続はしないため、不適当です。
- elbSGがインターネットからのアクセスが認めていない、elbSG にある ec2SG からの接続や rdsSG にある elbSG からの接続はしないため、不適当です
第10問
問題文
E コマース関連企業は 1 日の売上を集計し、その結果を Amazon S3 に保存する夜間処理のコストを削減したいと考えています。その処理は複数のオンデマンドインスタンスで実行され、処理が完了するまでに 2 時間弱かかります。処理は夜間にいつでも実行できます。何らかの理由により処理が失敗した場合は、最初から処理を開始する必要があります。
この要件に基づいて、最もコスト効率の良いソリューションは次のうちどれですか?
- 予約インスタンスを購入する。
- スポットブロックのリクエストを作成する。
- すべてのスポットインスタンスのリクエストを作成する。
- オンデマンドインスタンスとスポットインスタンスを併用する。
回答
2
解説
処理時間は2時間弱で、複数のオンデマンドインスタンスで実行されている。いつ実行してもよい。処理失敗時は最初からやりなおす、つまり途中経過を管理したりリカバリするためのロールバックといったことは不要だが、何らかの要因でインスタンスが停止することが続くと、一向に処理が終わらないといったことも考えられる。こういった観点で、コスト効率が良いものを選ぶのが要件です。
- 2時間弱で終わる処理に対して ReservedInstance(予約インスタンス) を購入するのはやりすぎ(コスト高)なため、不適当です。
- スポットブロックは、スポットインスタンスの価格変動があっても一定の時間(60~360分)は起動し続けられるオプションです。よって要件を満たせるため、正解と考えます。
- スポットインスタンスですべてをまかなってしまうと、価格変動が頻繁に発生した場合、夜間に処理が完了しない恐れがあります。そのため、不適当です。
- たしかに、スポットインスタンスを併用するとオンデマンドインスタンスのみで実行している現在よりはコスト効率は上がりますが、選択肢の3のような事象に遭遇したりすると問題です。また、選択肢2と比較するとコスト効率の面でもよいとは言えなくなります。よって、不適当です。
サンプル問題以外の学習リソース
様々な学習リソースが用意されています。
以下はその一例です。
- AWS公式の模擬問題
- AWS 認定サイトから受験可能です。
- 認定準備ワークショップに参加
- AWS が定期的に開催しているワークショップに参加して学ぶことが可能です
- 試験対策テキスト
まとめ
SysOps アドミニストレーターアソシエイト試験は、既に AWS 上で稼働しているシステムに対して運用面での改善やインシデント対策に関する問題が多い傾向にあります。そのため、システム構築するには...という観点よりは、よりよくするにはどうしたらよいかで問題内容を把握し、最良の答えを選んでいっていただけたらと思います。
記載されている会社名、製品名、サービス名、ロゴ等は各社の商標または登録商標です。
- 投稿日:2020-10-20T20:32:27+09:00
スイッチロール先S3バケットポリシーの設定
AWSアカウント【1】のログインから、AWSアカウント【2】へスイッチロール後、AWSアカウント【2】のS3バケットへアクセスしたい場合の、S3バケットポリシーの記述方法
AWSアカウント【1】ログイン
↓
スイッチロール
↓
AWSアカウント【2】目的のS3バケットIAMロールIDを取得
スイッチロール先であるAWSアカウント【2】の認証情報で、AWSコマンドを実行
AWSコマンド$ aws iam get-role --role-name 【スイッチするロール名】実行結果例{ "Role": { "AssumeRolePolicyDocument": { "Version": "2012-10-17", "Statement": [ { "Action": "sts:AssumeRole", "Effect": "Allow", "Principal": { "Service": "s3.amazonaws.com" } } ] }, "MaxSessionDuration": 3600, "RoleId": "000000000000000000000", "CreateDate": "2020-10-20T20:10:20Z", "RoleName": "AWSaccount2SwitchRole", "Path": "/", "RoleLastUsed": {}, "Arn": "arn:aws:iam::999999999999:role/AWSaccount2SwitchRole" } }AWSアカウント【2】のIAMロールIDを取得
"RoleId": "000000000000000000000"バケットポリシーにロールIDを指定
"Principal"には何も指定せず、代わりに
"Condition": { "StringLike": { "aws:userid"へ
取得したIAMロールIDを記述!! ロールID末尾の
:*の記述漏れに注意 !!バケットポリシー例{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": "*", "Action": "s3:*", "Resource": [ "arn:aws:s3:::aws-account-2-bucket", "arn:aws:s3:::aws-account-2-bucket/*" ], "Condition": { "StringLike": { "aws:userid": "000000000000000000000:*" } } } ] }【参考】
https://dev.classmethod.jp/articles/s3-bucket-acces-to-a-specific-role/
https://qiita.com/n-ishida/items/33cef1d67adc0961625a/
- 投稿日:2020-10-20T20:28:55+09:00
AWSマネジメントコンソールにショートカットキーが欲しい!よし作ろう!
概要
AWSマネジメントコンソールで、S3を開いて、EC2開いて、VPC開いて、IAM開いて、次またEC2開いて、、、、
マウスの移動が煩わしい!!ショートカットキーが欲しい!!!!という切なる思いで作りました。3行まとめ
- Chrome拡張機能の「ScriptAutoRunner」を使ってます。
- 左Ctrl + m を押すと、左上の「サービス」をクリックするという挙動です。
- ただそれだけです。
手順
Chrome拡張を入れる
ScriptAutoRunnerをChromeにインストールします。
Chrome拡張にカミナリマークのアイコンができるので、それをクリックし、歯車をクリック
左上の
</>ボタンを押すと、入力フォームができます
タイトル入れます。
適当にshortcut keyとかにしておきます
このスクリプトを埋め込むターゲットのhostnameを入れます。
今回は、AWSのマネジメントコンソールの全ページに反映したいので、console.aws.amazon.comと入力します。
埋め込むスクリプトの挙動を考えます。
AWSマネージメントコンソールのサービスというボタンがクリックされると、メニューが展開されるのでこれをクリックできるような挙動にしたいと思います。
なんとなくですが、左Ctrl + mで開けるようにします(メニューだから m という安易な考え)
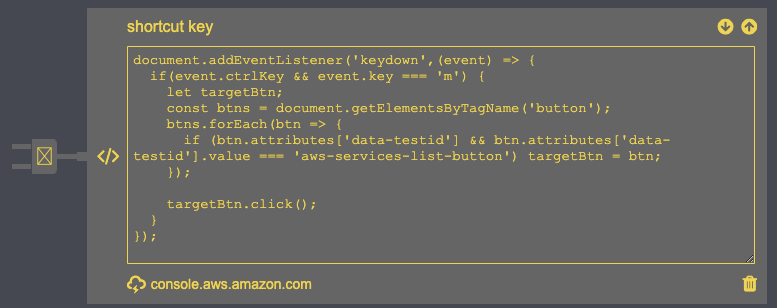
このbutton要素スクリプト書きます
document.addEventListener('keydown',(event) => { if(event.ctrlKey && event.key === 'm') { let targetBtn; const btns = document.getElementsByTagName('button'); btns.forEach(btn => { if (btn.attributes['data-testid'] && btn.attributes['data-testid'].value === 'aws-services-list-button') targetBtn = btn; }); targetBtn.click(); } });
8. 書けたら、テキストボックスの左のプラグのようになっている部分をクリックして、反映されるようにします。
このプラグのON/OFFは、Chromeの右上のアイコンからでも操作可能です。
通電された感じですね
9. AWSマネジメントコンソールを開いて動作確認
左Ctrl + mを押すことで、開閉ができるようになったと思います。
メニューを開くと、検索窓にフォーカスがあたっているので、そのまま入力し、矢印キーで選択後、ページ遷移できます。まとめ
AWSマネジメントコンソールにショートカットキーがなかったので、作ってみました。
個人的にはだいぶ便利になった!という感覚があります。
もしかしたらgithubのようにあるのかもしれませんが探せなかったです。あるよ!という方、教えていただけるととても喜びます。追記
マネコンはすぐUI変更されるので動かなくなるかもですが、その際は、Scriptを適宜変更してあげてください。


- 投稿日:2020-10-20T18:11:53+09:00
RDSにORM使ったけどモヤモヤが止まらないのでぜんぶ吐き出す!!!
転職活動でバックエンドも出来るぜ!アピールとしてポートフェリオぽいの作った方が良いかもね・・?という事で、こんなリポジトリ作ってたわけなんですけど、コード書いてて気づいた事つらつらと書きます。
何時もの奔放な個人開発じゃなく、気づき、ハマりのQiitaらしいアウトプットってことで。ちゃんと調べて書けーって怒られそうな気もするけどw
ORMの仕様とか親切で大惨事になるかも・・?
今回Goの代表的なORMであるgormを使いましたが、Delete投げる時に消す情報を先に取得しないまま、動かすとテーブル内のレコードすべてが消えるのが仕様らしいんです!
jsonData.Id = Ids DBMS.First(&jsonData) // この行無いと滅亡です! DBMS.Delete(&jsonData)今回一番作ってて?となったとこ。ありえん。
RDS?ORM?どっちが悪いでしょーか
RDSが一時的に不調っぽい時に動かすとダンマリでタイムアウトせず・・
DB, err := gorm.Open(DBTYPE, CONNECT) // ずーーっと接続中 if err != nil { fmt.Println("RDS access error!") panic(err.Error()) }せめてエラー応答して欲しかったなと。
Model定義の順番で構造が崩れる!?
type test struct { gorm.Model Number int `gorm:"primary_key"` }みたいに先にgorm.Modelを書いて、DB側のテーブルの最初にNumberが居るとgorm.Modelから取得した値がNumberに浸食してきます。
type test struct { Number int `gorm:"primary_key"` gorm.Model }こんなふうにDBスキーマにもよるけど最後に書いた方が無難。
残るモヤ
と、まあ学びを通じて残るモヤがまだまだありました。。
API書く練習して一通りORMからCRUDはまでは出来たけど、サービスがスケールする前提ってどうコードにするんだろ。APIサーバって"歩"のイメージで自身でスケール考慮しないような気がするが、、
— いもいもくん (@ma_anago) October 11, 2020手前にLBやKong入れる、バックエンドはマネージドでスケールするイメージなんすよね。
— いもいもくん (@ma_anago) October 11, 2020
API間でマルチキャストぽい通信して経路断も防ぐ、とかさあ。APIサーバー自身もマネージドサービスの方が良くね?という疑問
ORMの利点勉強しててやっぱ分からなかった。自動マイグレとか既に居るサービスには効果無いし。柔軟にDBからひっぱるなら、やっぱ生SQL流して変数に取り込んだ方が分かりやすくないー?って。むずいなチーム開発経験無いと変にズレてく気がして怖いわ
— いもいもくん (@ma_anago) October 11, 2020インジェクション食らうリスクは一旦おいといて、ORM無しと生SQLの処理速度って差があるんだろうか?
— いもいもくん (@ma_anago) October 11, 2020
Goみたいな軽量級でそこそこ差が出るならORMのメリットあんまないよねーにはなるようなORM以前からDB叩いてきたバックエンドエンジニアにはどう映ってるの?という疑問
gitのprivateリポジトリって草生えんのか!
— いもいもくん (@ma_anago) October 17, 2020
習慣的にコード書いてコミットしてるんでいつも通り生えて欲しいんです。昨日進めたっけな?とかわからんよな一行レベルでcommitし直ししたくて、git reset --hard HEAD~すると前回commitに戻ったうえにVSCodeが自動でホットリロードするの結構な嫌がらせ感ある。
— いもいもくん (@ma_anago) October 18, 2020VSCodeとかエコシステムが逆に足引っ張ってねーかい?という疑問
こういうアンチナレッジが残る事自体が学びなんでしょうけど、技術的な選定して舵を取るという意味でテックリードって大事なんやなと改めて思った。むしろテックリード不在の組織ってこういうのどうオトしてんだろ??
- 投稿日:2020-10-20T17:57:08+09:00
【0からAWSに挑戦】AmazonRDSとELBを導入する
背景
未経験から自社開発系企業の就職を目指します。良質なポートフォリオ作成のためAWSを勉強することにしました。
現状の知識レベルとしては、Ruby on railsを使って簡単なアプリケーション開発、gitを使ったバージョン管理、herokuを使ってデプロイできるレベルです。自分の忘備録かつ、同じくらいのレベルでこれからAWSに挑戦してみようと思っている方に向けて少しでも役に立てればと思います。
最終目標
既存のEC2・VPCのみで動いているアプリケーションをRDS(mysql)とELBを使って動かすこと。
↓↓↓↓関連記事はこちら↓↓↓↓
EC2とVPCを使ってRailsアプリをAWSにデプロイする part1
EC2とVPCを使ってRailsアプリをAWSにデプロイする part2
EC2とVPCを使ってRailsアプリをAWSにデプロイする part3
AmazonRDSとELBを導入する
ROUTE53を使ってドメイン設定 && ACMによるSSL化環境
・Ruby on Rails 6.0
・Ruby 2.6.6
・dbはmysqlを使用
・アプリケーションサーバはpumaを使用
・webサーバーはnginxを使用AmazonRDSとELBを導入する。
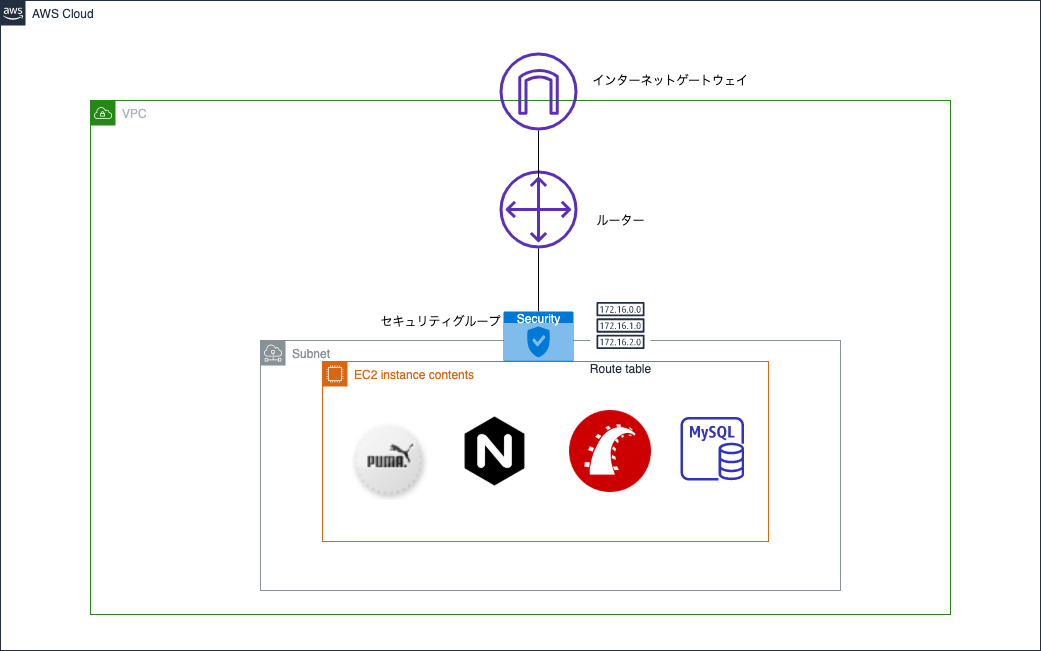
現状の構成
まず現状がどんな設定か確認します。図で表すと下記になります。(下手ですが許してください)
簡単に整理します。
- VPCの中に1つのサブネット
- サブネットのなかに1つのEC2インスタンスがあり、そのEC2内にDBやサーバーがすべて入っている
おそらくAWSでデプロイする時に考えられる最もシンプルな構成です。もちろんこの構成でも動くのですが、2つ問題点があります。まず1つがインターネットに接続できるサブネットにデーターベースがあることです。データーベースは個人情報などの大事な情報を扱うことが多いので、できればインターネットには繋げずにVPC内だけでやり取りするようにしたいです。もう一つはEC2サーバーが1つしかないということです。もしこのままだとアクセス集中して負荷が大きくなった時に対応できません。
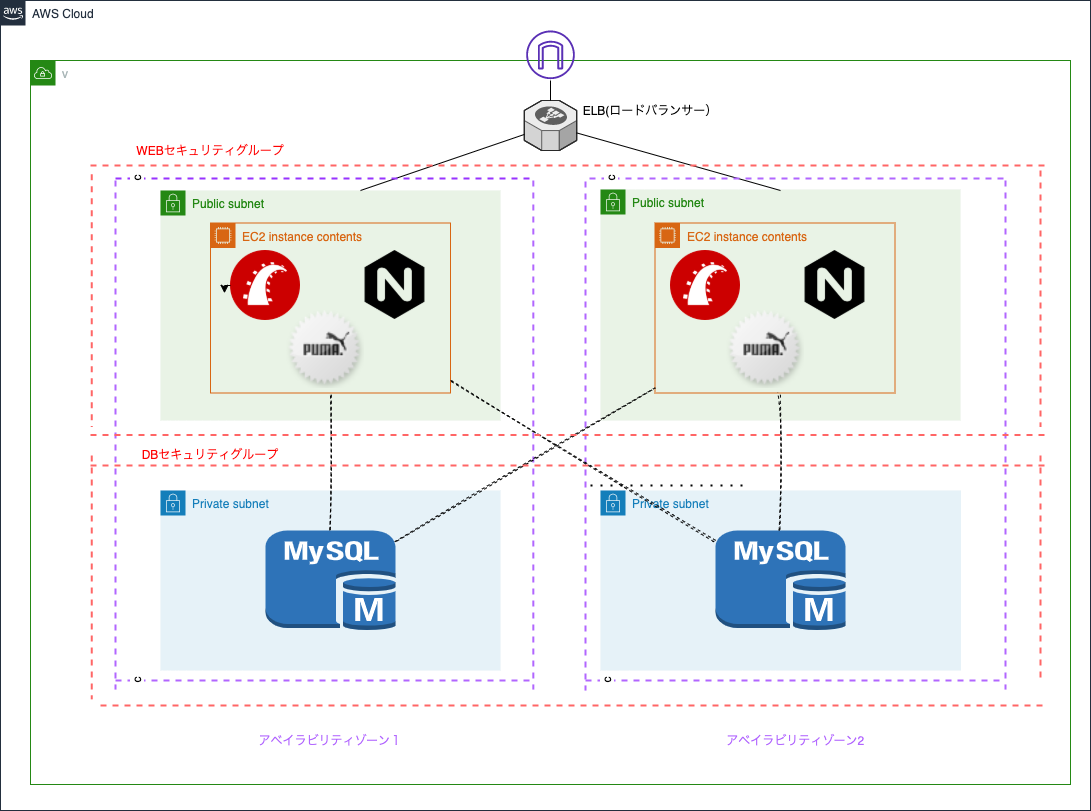
上記の問題点を解決するために、今回は「AmazonRDS」と「ELB」を導入します。この2つの説明はあとでしますが、この2つをいれることで、より安全で頑丈なシステムを構築します。完成イメージは下記になります。
※ルートテーブルやルーターは省略しています。
それでは構築していきましょう。RDSの導入
AmazonRDSとはなにか
AmazonRDSはマネージドリレーショナルデーターベースのことです。砕けた言い方をすると、Amazonが勝手にセットアップや管理をしてくれるデーターベースのことです。今まではEC2に自力でデータベースを入れて管理していましたが、データーベースのセキュリティ・バージョンの管理は非常に工数がかかります。そこでRDSサービスを使うことでそういった手間を省くことができます。またRDSはそれを1つのサーバーとして扱うのでVPCでのセキュリティの設定もしやすくなります。今回は安全性を考慮し、RDSのサーバーはインターネットに接続せず、VPCのプライベートネットワークだけで接続できるようにします。
RDSの設定
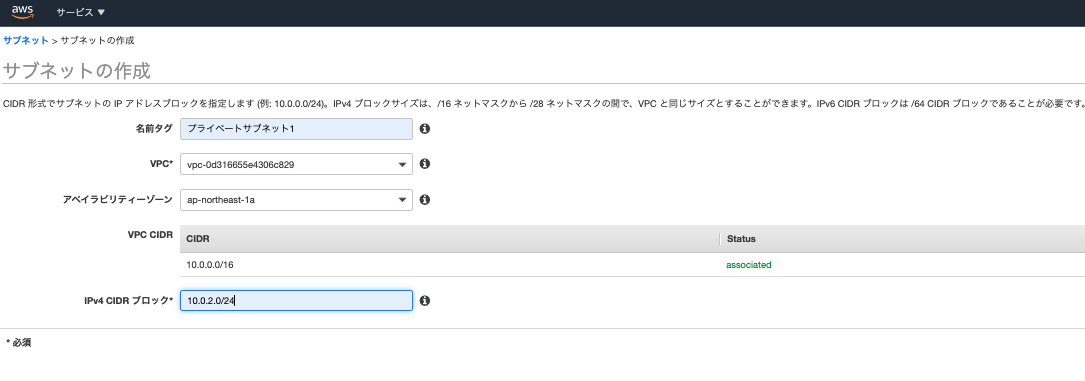
では早速RDSの作成に移りたいところですが、RDS作成には1つ注意点があります。それはRDSを作成するには2つ以上のアベイラビリティゾーンが必要です。なのであらかじめVPCメニューでサブネットを構築していきましょう。
前回の記事と基本同じですが、注意点が2つあります。1点目はアベイラビリティゾーンの選択です。今回はサブネットを2つ作りますが、1つは以前作ったサブネットと同じアベイラビリティゾーンを選択してください。もう一つは自由でOKです。というのも異なるアベイラビリティゾーンにデーターベースがあると少し接続が遅くなるからです。2点目はCIDRブロックです。前回の記事では「10.0.1.0/24」を選んだので、それ以外を指定します。CIDRブロックはVPC内の住所なので重複していたらおかしいですよね。今回は「10.0.3.0/24」と「10.0.4.0/24」にします。
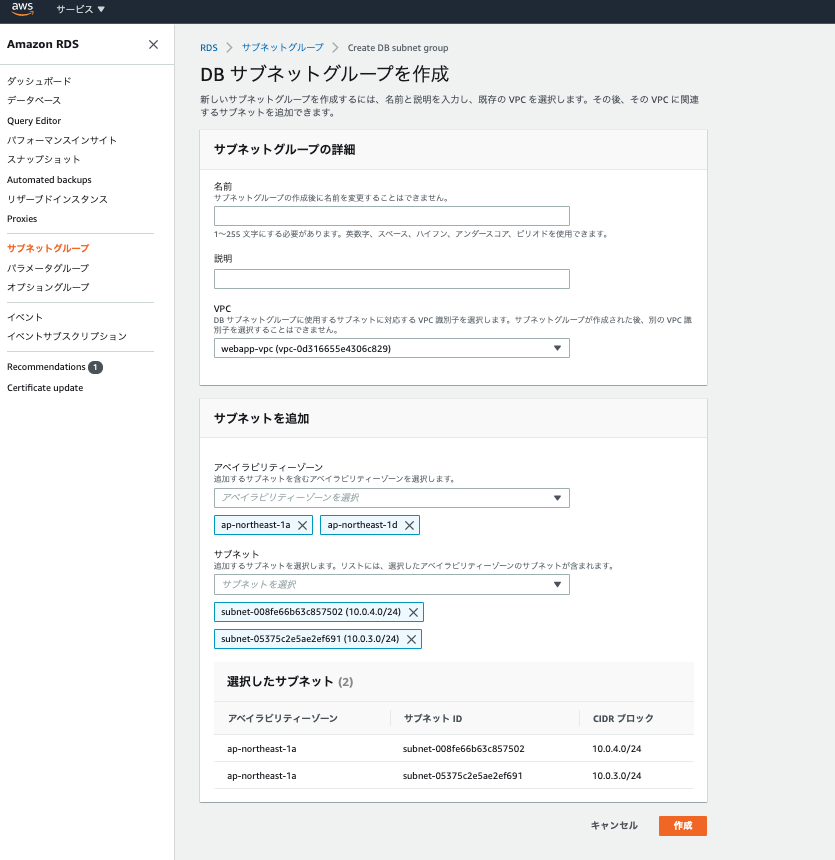
これで準備ができましたので、RDS作成していきましょう。Amazonのメニュー画面からRDSで検索しましょう。そうするとすぐ出てくるかと思います。まずはRDSのサイドメニューからサブネットグループを選択し、サブネットグループの作成をクリックします。ここではどこにRDSを置くかを設定します。
- 名前や説明はわかりやすいように設定してください
- VPCは現在使用中のVPCを選択しましょう。そうすると下メニューでサブネットとアベイラビリティゾーンが選択できるようになります。
- アベイラビリティゾーンとサブネットは先程作成したものを選んでください。
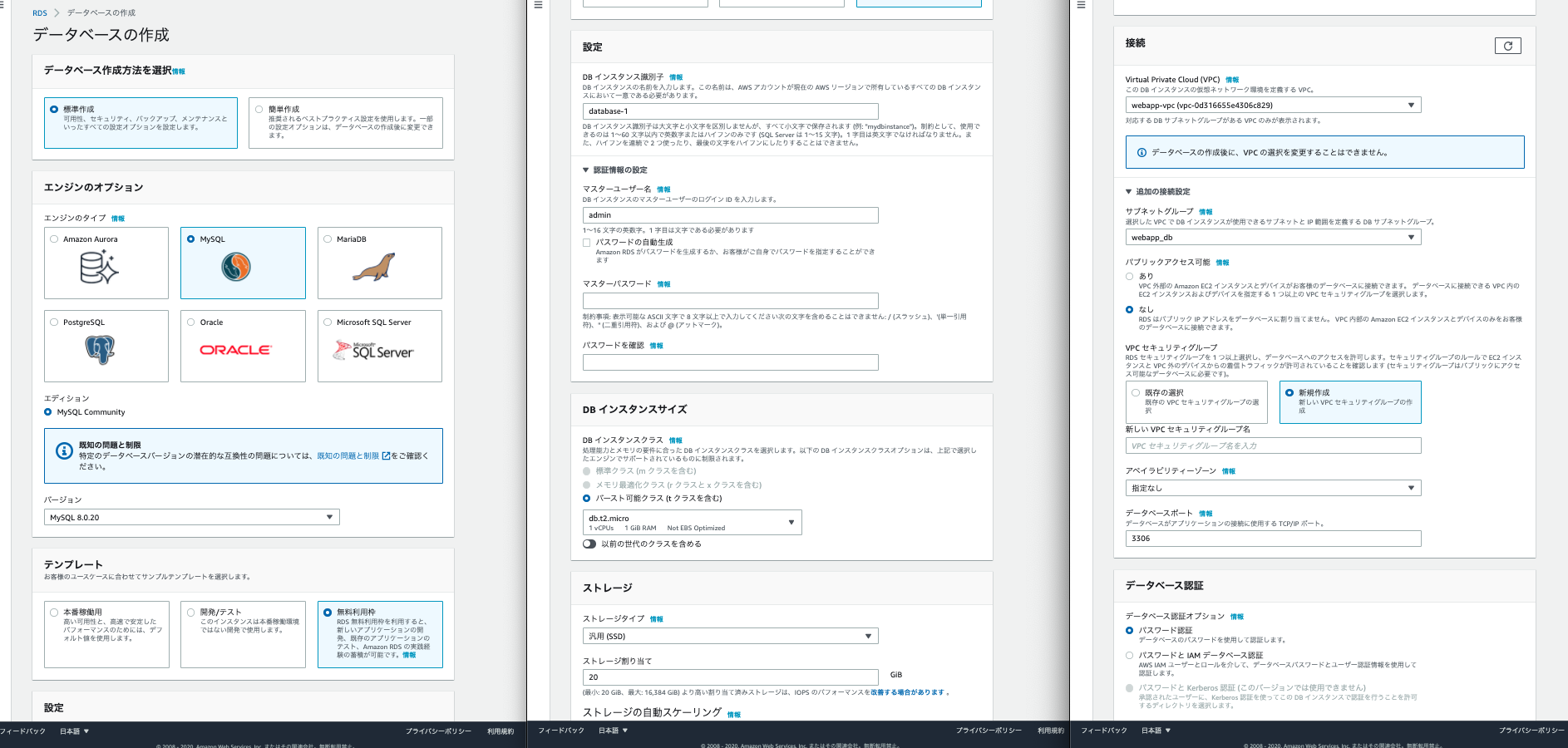
以上でサブネットグループの設定は完了です。続いて左のサイドメニューからデーターベース(もしくはダッシュボード)を選び、データーベースの作成をクリックします。そうすると下記画面がでてきます。
- エンジンのオプションは好きなDBを選びます今回はmysqlのversionは8でいきます
- テンプレートは無料利用枠を選択します。そうすると自動で無料枠で利用できる設定をAWSがしてくれます。
- 設定の項目はEC2でDBサーバーにアクセスするときに使います。任意のdb名・user名やパスワードを入力します。
- ストレージや可用性と耐久性はデフォルトのままでOKです。
- 接続の箇所は使用中のVPCで設定します。そして追加の接続設定で先程作ったサブネットグループを選択、パブリック接続はなし、VPCセキュリティグループはまだ作っていないので新規に作成します。アベイラビリティゾーンだけ指定すればOKです。(セキュリティグループは後ほど確認します)
- それより下の設定はデフォルトで問題ないです。
以上で完了です。作成ボタンを押します(作成までに5分くらい時間を要します)。
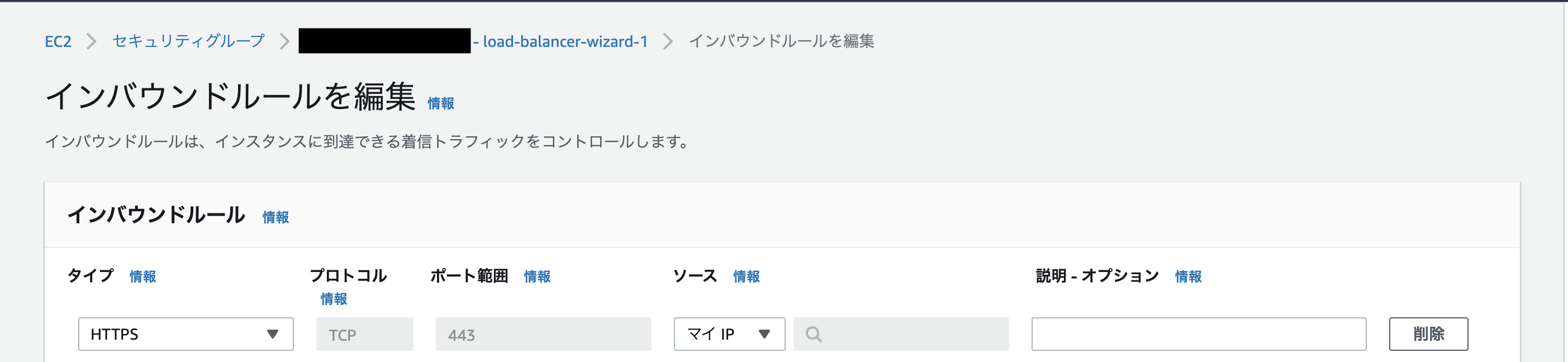
その間にDBのセキュリティグループを確認します。下記のようになっているはずです(※1行目のソースはマイIP)。HTTP通信を許可していないのでインターネットには直接接続されません。
以上でRDS自体の設定は終わりです。
EC2からRDSにアクセスする
まずRailsアプリケーションがある既存のEC2サーバーに接続します。ここは前回やったところなのですっ飛ばします。EC2サーバーからRDSにログインするには下記コマンドを入力してください。※補足ですがRDSを使用する場合でもEC2内にmysql,mysql-server等のインストールは必要です。
ec2サーバー内$ mysql -h {RDSのエンドポイント} -P 3306 -u admin -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 15 Server version: 5.7.22-log Source distribution Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>「mysql -h {RDSのエンドポイント} -P 3306 -u admin -p」のコマンドについて説明します。
- 「-h]がホストを指定するオプションで、今回はRDSのエンドポイントを指定します。エンドポイントはAWSで先程作成したRDSページに記載してあります。
- 「-u」はユーザー名の指定で、RDS作成時に使用した名前を入力します。今回はadminです。
- 「-p」はパスワード指定オプションで、このままエンター押すとパスワードが求められます。RDS作成時に登録したパスワードを入力してください。
最後に「mysql>」 と出てくれば成功です。接続が確認できたらexitで退出しましょう。
database.ymlの編集をする。
RDS用にデータベースを設定します。ただ直接RDSのパスワード等を書くのはセキュリティ上良くないので、環境変数を使います。以下の設定をまずしましょう。
ec2サーバー内(var/www/アプリケーション名/Gemfile) gem 'dotenv-rails' →記述したら「bundle install」を実行してください。 (var/www/アプリケーション名/) $ bundle exec rake secret $ vim .env説明します。
- 「dotenv-rails」はrailsで環境変数を管理するためのgemです。
- 「bundle exec rake secret」でシークレットキーを生成しています。シークレットキーは環境変数にアクセスするための鍵です。 - 環境変数の中身は「.env」内に記述します。
続いて「.env」ファイルに環境変数を記述します。
.envRDS_NAME=アプリケーション名_production RDS_USERNAME=admin RDS_PASSWORD={ RDSのパスワード } RDS_HOST={ RDSのエンドポイント }こちらは特に説明不要だと思います。変数名は好きな名前でOKです。
これで環境変数の設定は完了です。database.ymlを編集しましょう。database.ymlproduction: <<: *default database: <%= ENV['RDS_NAME'] %> username: <%= ENV['RDS_USERNAME'] %> password: <%= ENV['RDS_PASSWORD'] %> host: <%= ENV['RDS_HOST'] %>本番環境なのでproductionの中に記述します。そして最後にdatabaseを作成したら完了です。
ec2$ sudo service mysqld start $ bundle exec rake db:create RAILS_ENV=production $ bundle exec rake db:migrate RAILS_ENV=production少し長かったですがこれで本番環境にRDSが適用されました。
ELBの導入
ELBとはなにか
ELBとはAWSにあるロードバランサーです。ロードバランサーとはその名の通り、サーバーの負荷のバランスをとってくれるものです。例えばサーバーへのアクセスが増加した際に、1つのサーバーに負荷がかからないように複数のサーバーにアクセスを分散させてくれます。では早速ELBを導入してみましょう。
ELBの設定の準備
ELBの設定の前にELBを使うにはWEBサーバーが最低2つなければなりません。なので既存にあるものとは別に、EC2サーバーを立ち上げます。ただ1からEC2サーバーをつくり、もう一つのEC2サーバーと全く同じ設定をインストールするには時間がかかります。そこで既存のEC2を複製しましょう。
このEC2作成のやり方に関しては本記事では割愛します。下記記事に詳しく書いてあったので参照ください。
Amazon Web Services(AWS) のEC2でインスタンスをコピーする方法複製自体は簡単ですので、10分くらいあればできると思います。ただ少し注意点があるのでそちらだけ記載します。
- セキュリティグループは既存のEC2と同じものを使います。
- アベイラビリティゾーンは既存のものと異なるものを選びます。
- コピー後のファイルを確認する。その際に/etc/nginx/conf.d/{自分のアプリ名}.confにかいてあるIPアドレスが異なるので気をつけましょう。
- コピー後のファイルには権限が付与されていません。「sudo chmod ~」を使い権限を付与しましょう。
以上、コピーしたサーバーの方の動作チェックが済んだら準備完了です。
ELBの設定
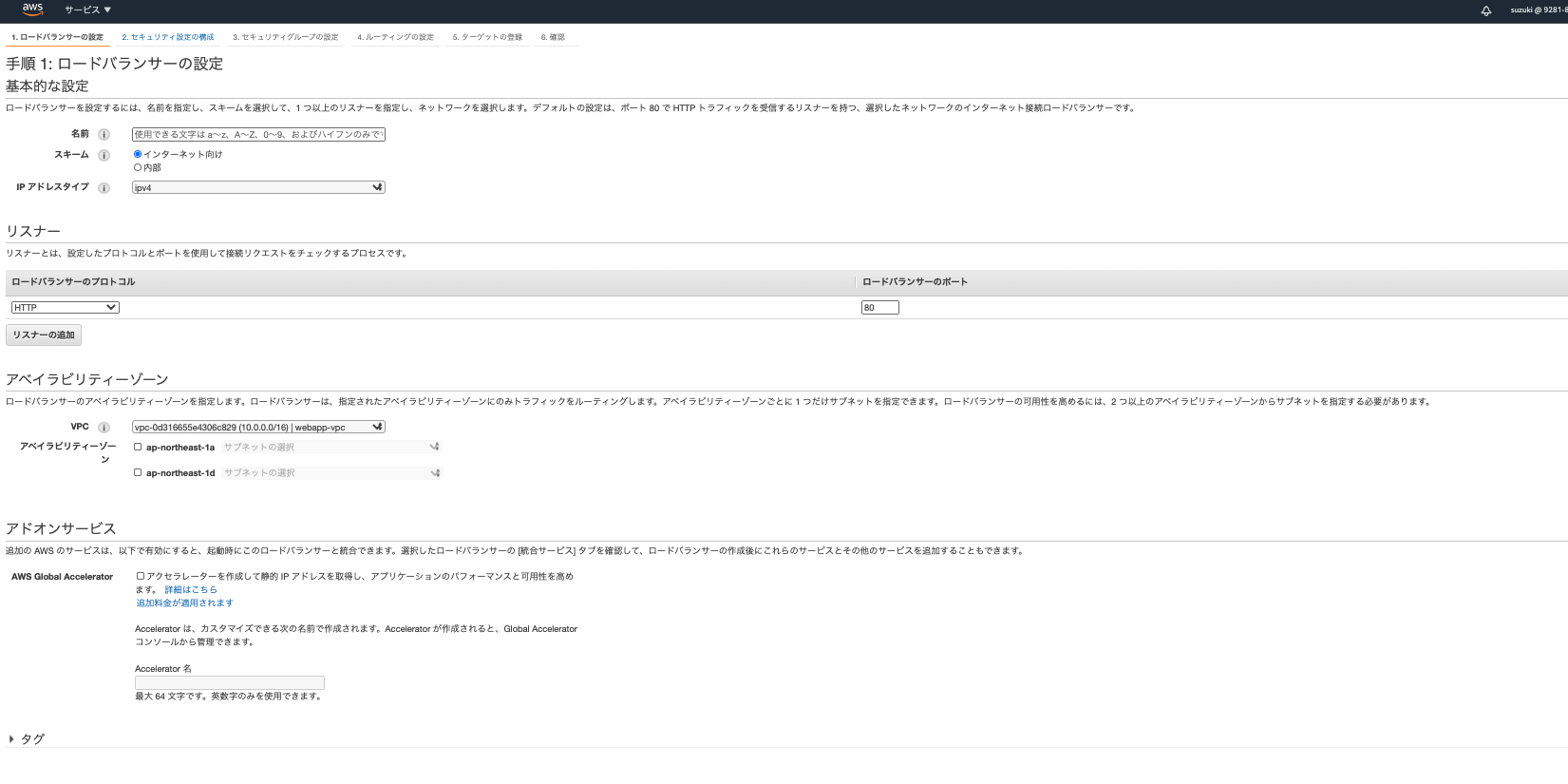
AWSのサービスからEC2を検索し、左のサイドメニューからロードバランサーを選択します。そしてロードバランサーの作成をクリックしましょう。そうすると下記画面に移ります。
今回は左にあるALBを選択します。3種類の違いについてはこちらに詳しく書いてありますが、基本的に最近アプリケーションをつくったのならば、ALBで問題ないかと思います。そして次からが設定画面です。
こちらも必要なところを説明します。
- 名前はわかりやすい名前を入力してください。
- アベイラビリティゾーンは使用中のVPCを選択して、アベイラビリティゾーンを2つ選択します。そしてそのアベイラビリティゾーンに属しているwebサーバーがあるサブネットを選択します。(この時アベイラビリティゾーンとサブネットはあ2つ以上なければエラーがでます)。ちなみにこのアベイラビリティゾーンの箇所でロードバランサーに接続するサブネットを設定を設定しています。
- タグの欄でキー「NAME」で値「{好きな値}」で後でわかりやすいように設定しておくとよいでしょう。
次の項目へ移動しましょう。次のセキュリティ設定の構成は飛ばして大丈夫です。
その次がセキュリティグループの設定です。こちらはWEBサーバーがあるEC2インスタンスに適用しているセキュリティグループを選択しましょう。こちらはそれで完了です。
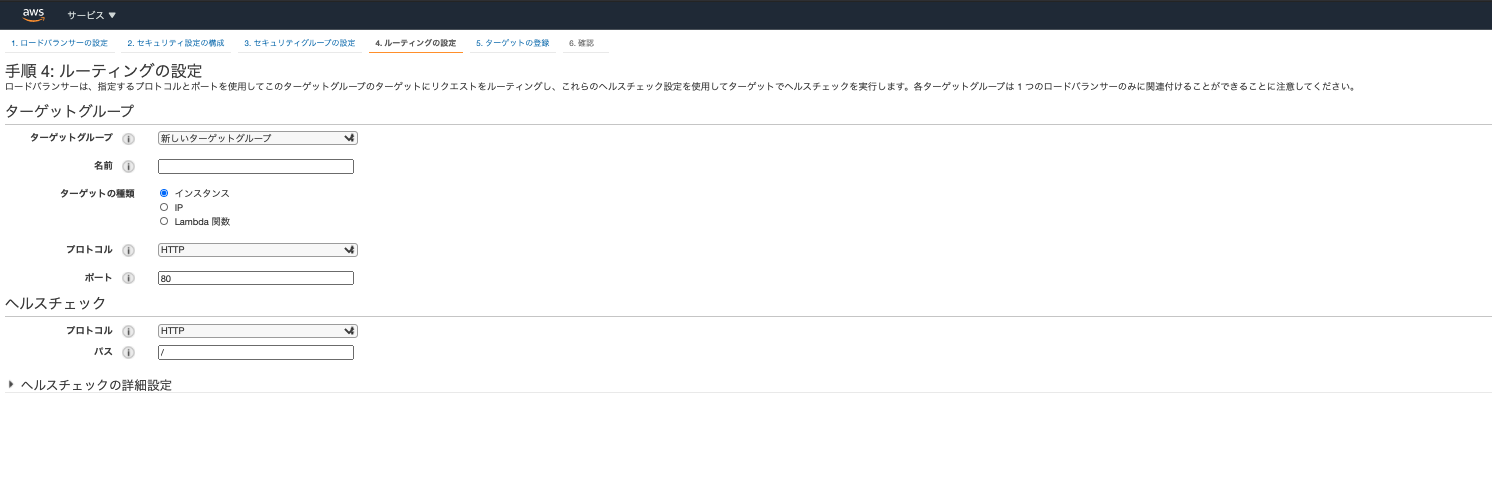
そしてその次がルーティングの設定です。下記のような画面が現れているはずです。
- ターゲットグループは「新しいターゲットグループ」で任意の名前をつけてください。
- 他はデフォルトのままでOKです
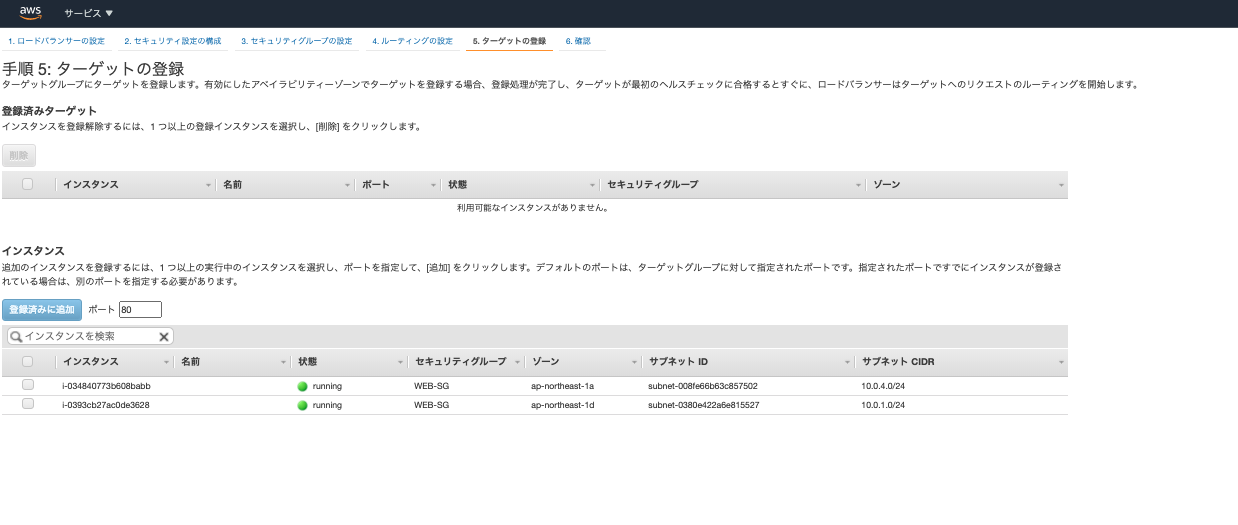
そして最後がターゲットの設定です。
- 「登録済みに追加」を押して、表示されているインスタンスをすべて選択してください。※こちらは先程指定したサブネットの中にあるインスタンスが表示されます。
※AWSではデータの送り先のことをターゲットといいます。
以上で完了です。設定も1つ1つみていけばそんなに難しい設定はしていません。
確認ページ後に作成ボタンをおしてELBを作成しましょう。また作成後にサイドメニューからロードバランサーを選択し、アクティブになっているか確認しましょう。アクティブになっていれば正常に動いています。
以上でRDSとELBの設定は完了です。ELBの方はSSLの設定のときにもでてくるので覚えておきましょう。
まとめ・感想
設定自体は簡単でしたが、全体の構成がどうするかというのは非常に難しいと感じました。作業している最中に、何をやっているかわからなくならないように、適宜構成図をつくりながら進めていきたいです。
参考
【画像付きで丁寧に解説】AWS(EC2)にRailsアプリをイチから上げる方法【その4〜Railsアプリの公開編〜】
→RDSの説明非常にわかりやすくて非常によかったです。「図解即戦力 Amazon Web Servicesのしくみと技術がこれ1冊でしっかりわかる教科書」
→AWSにどんな機能があるか、AWSの機能のおおまかな仕組みはどうなっているかなど非常に勉強になりました。


- 投稿日:2020-10-20T17:54:40+09:00
俺でもわかるALB Listener Rule HTTP Header:X-Forwarded-For判定
俺です。
特定IP(proxyなど)だけTarget-Bという次期リリースのBackend向けたい。
安全にリリースするために事前チェックしたい。というニーズがあるとおもいます。GETメインなウェッブサービスにおいてCDNを使うのはマナーかつ呼吸ってばっちゃが言ってましたが
以下のような構成のウェッブサービスがあったとき、User App-> CDN(CF) -> ALB -> Target
ALB Listener RuleのIP判定ではCDNなどを挟んでいると判定に使えないので、ドキュメント にもある通り http-headerを使えば世界平和という話です
実際に試すときはこんなかんじで、X-Fowarded-Forに特定IPが含まれている場合.
というルールを作ればよいです。[ { "Field": "http-header", "HttpHeaderConfig": { "HttpHeaderName": "X-Forwarded-For", "Values": ["*203.0.113.1*"] } } ]ではまた!
- 投稿日:2020-10-20T17:16:03+09:00
AWS 全リージョンの (ほぼ)全リソースのリストアップをするシェルスクリプト
リージョン一覧を取得し、その各リージョンにresourcegroupstaggingapi get-resourcesすることで、リソースの一覧を取得します。
スクリプト
get-resources.shfor region in `aws ec2 describe-regions --query 'Regions[].RegionName' --region us-west-1 --output text` do echo "region = ${region}" aws resourcegroupstaggingapi get-resources --region ${region} --query 'ResourceTagMappingList[].ResourceARN'; done
- describe-regionsでとってきた各regionに対してresourcegroupstaggingapi get-resources してます。
- 最初にdescribe-regionsするのはどのリージョンに対してでもOKだと思うので、とりあえずus-west-1にしています。
前提条件
- aws cli が入っていること
利用イメージ
実行
export AWS_PROFILE=xxxx # デフォルトプロファイルを常に設定しているなら不要 sh get-resources.sh出力
region = eu-north-1 [] region = ap-south-1 [] region = eu-west-3 [] region = eu-west-2 [] region = eu-west-1 [] region = ap-northeast-2 [] region = ap-northeast-1 [ "arn:aws:apigateway:ap-northeast-1::/restapis/〜/stages/devA", "arn:aws:apigateway:ap-northeast-1::/restapis/〜/stages/devB", 〜 "arn:aws:ec2:ap-northeast-1:111111111111:vpc/vpc-1111111a", "arn:aws:ec2:ap-northeast-1:111111111111:vpc/vpc-1111111b", 〜 "arn:aws:lambda:ap-northeast-1:111111111111:function:xxxx-checker", "arn:aws:lambda:ap-northeast-1:111111111111:function:xxxx-deleter", 〜 ...留意点
resourcegroupstaggingapiが対応していないサービスがもしあれば、それはリストアップされてこない。
参考
ec2/describe-regions
https://docs.aws.amazon.com/cli/latest/reference/ec2/describe-regions.html
リージョンのリストアップで利用resourcegroupstaggingapi/get-resources
https://docs.aws.amazon.com/cli/latest/reference/resourcegroupstaggingapi/get-resources.html
リソースのリストアップで利用
- 投稿日:2020-10-20T17:16:03+09:00
AWS 全リージョンの (ほぼ)全リソースをリストアップするシェルスクリプト
各リージョンの各サービスを個別に確認しなくても、全てのリソースをリストアップすることができます。
AWSアカウント解約時に、不要なアクティブリソースが残っていないかの確認にも役立つかもしれません。
AWS アカウントを解約したときに、アクティブなリソースがすべて自動的に終了されるとは限りません。アカウントを解約する前に、アクティブなリソースがあるかどうかを確認し、それらを終了することがベストプラクティスです。
スクリプト
get-resources.shfor region in `aws ec2 describe-regions --query 'Regions[].RegionName' --region us-west-1 --output text` do echo "region = ${region}" aws resourcegroupstaggingapi get-resources --region ${region} --query 'ResourceTagMappingList[].ResourceARN'; done
- describe-regionsでとってきた各regionに対してresourcegroupstaggingapi get-resources してます。
- 最初にdescribe-regionsするのはどのリージョンに対してでもOKだと思うので、とりあえずus-west-1にしています。
前提条件
- aws cli が入っていること
利用イメージ
実行
export AWS_PROFILE=xxxx # デフォルトプロファイルを常に設定しているなら不要 sh get-resources.sh出力
region = eu-north-1 [] region = ap-south-1 [] region = eu-west-3 [] region = eu-west-2 [] region = eu-west-1 [] region = ap-northeast-2 [] region = ap-northeast-1 [ "arn:aws:apigateway:ap-northeast-1::/restapis/〜/stages/devA", "arn:aws:apigateway:ap-northeast-1::/restapis/〜/stages/devB", 〜 "arn:aws:ec2:ap-northeast-1:111111111111:vpc/vpc-1111111a", "arn:aws:ec2:ap-northeast-1:111111111111:vpc/vpc-1111111b", 〜 "arn:aws:lambda:ap-northeast-1:111111111111:function:xxxx-checker", "arn:aws:lambda:ap-northeast-1:111111111111:function:xxxx-deleter", 〜 ...留意点
resourcegroupstaggingapiが対応していないサービスがもしあれば、それはリストアップされてこない。
参考
ec2/describe-regions
https://docs.aws.amazon.com/cli/latest/reference/ec2/describe-regions.html
リージョンのリストアップで利用resourcegroupstaggingapi/get-resources
https://docs.aws.amazon.com/cli/latest/reference/resourcegroupstaggingapi/get-resources.html
リソースのリストアップで利用
- 投稿日:2020-10-20T15:20:47+09:00
IPアドレスやEC2のアドレスではサイトに入れるのに、独自ドメインでは「応答時間が長すぎます。」となってしまう現象の解決。
環境
Mac
EC2
ELB
Route53
ACM(https化)
Amazon Linux2
unicorn
Nginx
Capistrano突然独自ドメインのサイトに入れなくなった!
発端
今まで普通に表示できていた開発中のhttps://<独自ドメイン>のサイトが突然表示されなくなり、応答時間が長すぎます。という画面で止まってしまう。
確認
まず原因がサーバーなのか、ドメインなのか、ブラウザなのかなど特定する必要があります。
①→サーバー(EC2)が起動しているか確認
AWS EC2のインスタンスに記載されているパブリック IPv4 アドレスやパブリック IPv4 DNSで表示できるか試したところここでは表示されるので、サーバーやブラウザの問題ではなく、ドメインの通し方だけが問題だとわかる。②→ターミナルで、% dig ○○.com(←独自ドメイン) あるいは % dig ns ○○.comを入れてANSERが返るか確認すると、ANSERが返ってきているので、ドメイン発行元は問題ない。
③→HTTPSがネットワーク中で何かうまくいっていないところがあるかもしれないので、ACMで証明書を当てている(https通信の発生元)ところはロードバランサー(ELB)になるのでそこを確認、通信を制限するのはセキュリティグループのインバウンドルール→httpsのソースがマイIPになっている※もしくはカスタムでIPアドレス指定になっている
解決
ロードバランサーのセキュリティグループが自宅のIPアドレスになっていたため、wifi接続場所を移動するとサイトにはいれなかった。ソースを「任意の場所」と変更すると0.0.0.0/0となるので、これで接続先を制限することなく、サイトの表示が可能になるということでした。
- 投稿日:2020-10-20T15:20:47+09:00
IPアドレスやEC2のアドレスでは入れるのに、独自ドメインでは「応答時間が長すぎます。」となってしまう現象の解決。
環境
Mac
EC2
ELB
Route53
ACM(https化)
Amazon Linux2
unicorn
Nginx
Capistrano突然独自ドメインのサイトに入れなくなった!
発端
今まで普通に表示できていた開発中のhttps://<独自ドメイン>のサイトが突然表示されなくなり、応答時間が長すぎます。という画面で止まってしまう。
確認
まず原因がサーバーなのか、ドメインなのか、ブラウザなのかなど特定する必要があります。
①→サーバー(EC2)が起動しているか確認
AWS EC2のインスタンスに記載されているパブリック IPv4 アドレスやパブリック IPv4 DNSで表示できるか試したところここでは表示されるので、サーバーやブラウザの問題ではなく、ドメインの通し方だけが問題だとわかる。②→ターミナルで、% dig ○○.com(←独自ドメイン) あるいは % dig ns ○○.comを入れてANSERが返るか確認すると帰ってきているので、ドメイン発行元は問題ない。
③→HTTPSがネットワーク中で何かうまくいっていないところがあるかもしれないので、ACMで証明書を当てている(https通信の発生元)ところはロードバランサー(ELB)になるのでそこを確認、通信を制限するのはセキュリティグループのインバウンドルール→httpsのソースがマイIPになっている※もしくはカスタムでIPアドレス指定になっている
解決
ロードバランサーのセキュリティグループが自宅のIPアドレスになっていたため、wifi接続場所を移動するとサイトにはいれなかった。ソースを「任意の場所」と変更すると0.0.0.0/0となるので、これで接続先を制限することなく、サイトの表示が可能になるということでした。
- 投稿日:2020-10-20T14:20:57+09:00
AWS single sign-on(SSO)でdatabricksにログインしたい
はじめに
本記事ではdatabricks on AWSにAWS single sign-on(SSO)を使用してログインする方法をご紹介いたします。
AWS SSOは無料でかつ簡単な設定で即座に利用できるSSOサービスとなっており、
セキュリティの観点からもぜひとも利用しておきたい機能です。前提条件
本記事内容はAWS SSOが有効になっているところからスタートします。
未完了の方は以下公式ドキュメントを参考に設定をお願いいたします。
https://docs.aws.amazon.com/ja_jp/singlesignon/index.html目次
- AWS側の設定
- databricks側の設定
- いざlogin!
本題
1. AWS側の設定
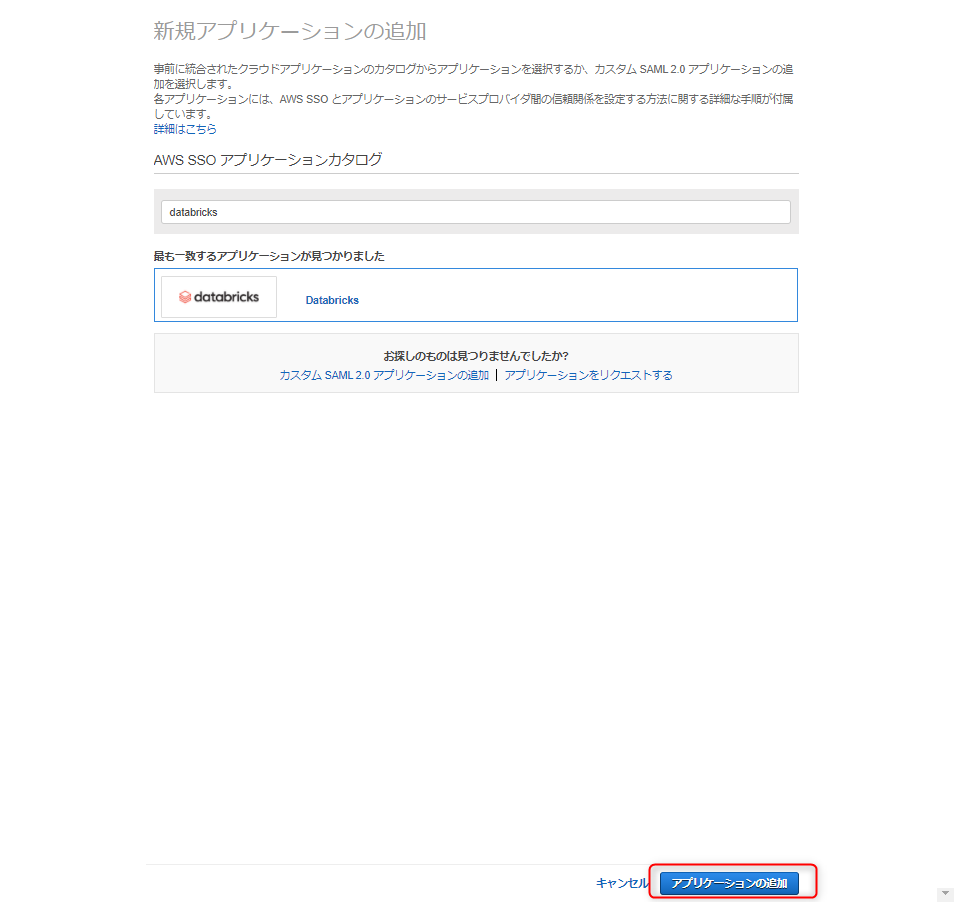
AWS SSOのサービス画面内の左上「アプリケーション」をクリック
「新規アプリケーションの追加」をクリック
ここでAWS SSO と連携するアプリケーションを選択します
画面中央の「アプリケーションの名前を入力します」の欄に"databricks"と記入
databricksが表示されたらそれをクリック
画面右下の「アプリケーションの追加」をクリックして追加の完了です
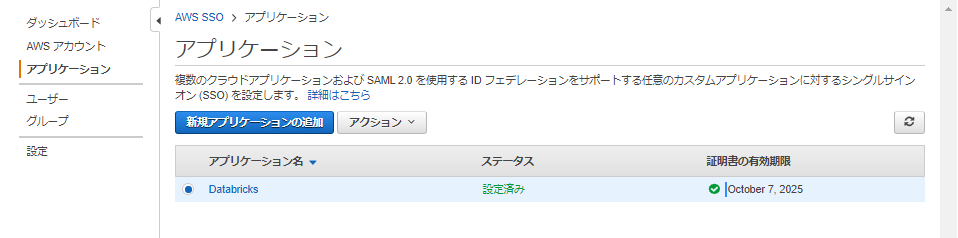
アプリケーションの画面に戻るとこのようにdatabricksが追加されていますので
クリックしてアプリケーション情報を確認しましょう
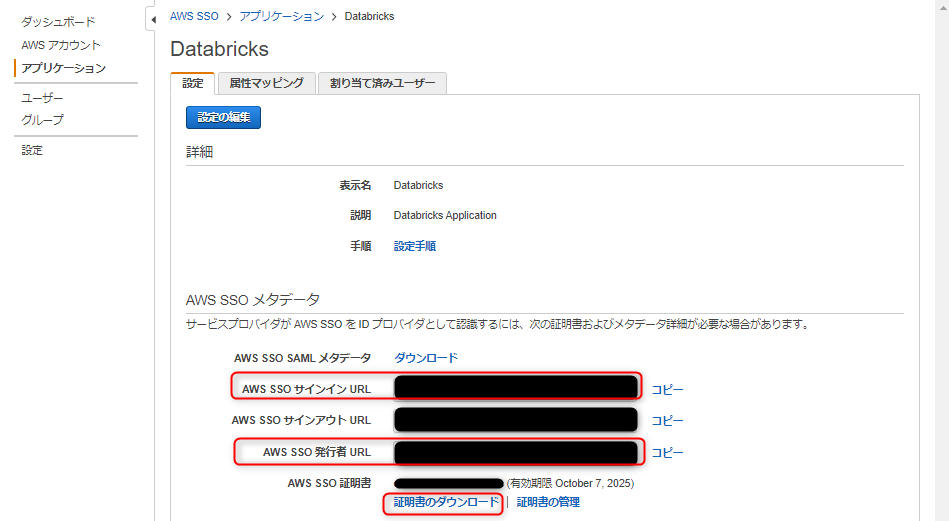
databricks側に登録する情報をコピー、ダウンロードします
「AWS SSOサインインURL」「AWS SSO 発行者URL」をコピーし
「AWS SSO証明書」をダウンロードしておきます
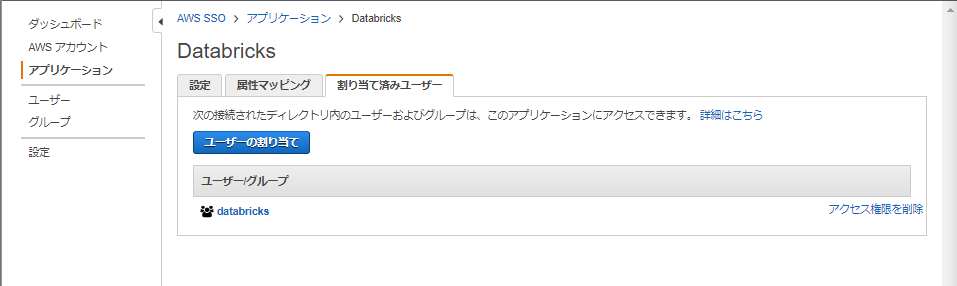
最後に、AWS SSOを使用してdatabricksにloginするユーザを割り当てます
「割り当て済みユーザ」タブ内の「ユーザの割り当て」から設定を行います
ユーザ個人を割り当てることもできますし、
databricksを使用するユーザが多数いる場合はグループを作成しておき、そのグループに割り当てるということも可能です
(この写真の例ではdatabricksという名前のグループに割り当てています)
2. databricks側の設定
databricksのコンソール画面にloginします
右上の人の形のアイコンから「admin console」に移動します
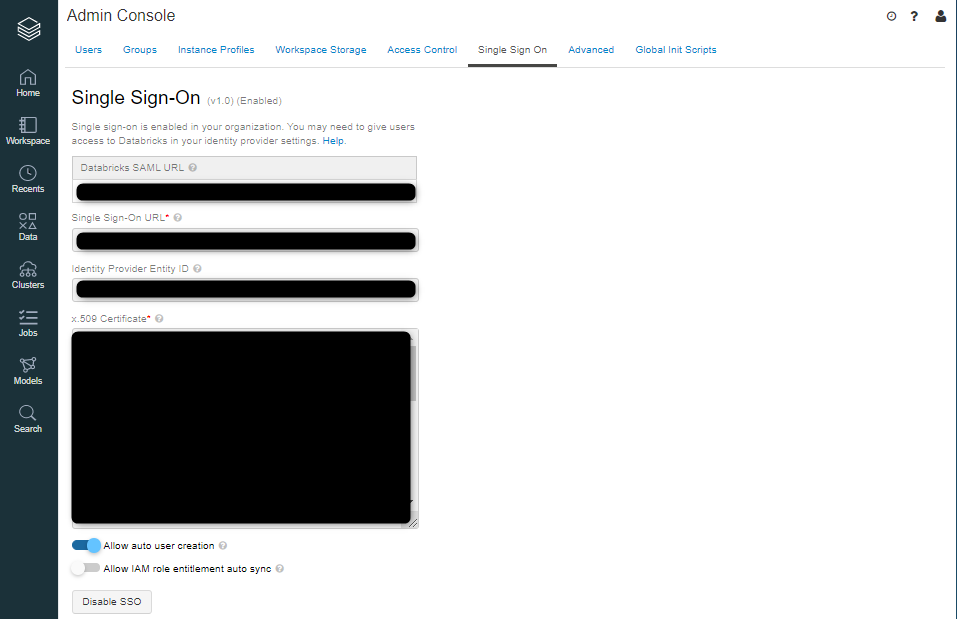
「Single Sign On」のタブをクリック
以下表をもとにAWS側の設定でコピー、ダウンロードした情報を貼り付けていきます
※2つのオプションについて(任意)
Allow auto user creation
→databricksのアカウントを持っていないユーザがAWS SSOでログインしたときに自動的にアカウントを作成するAllow IAM role entitlement auto sync
→IAM credential passthroughのためのSAML属性からの資格情報を同期する
(別途IAM credential passthroughの設定が必要なので本記事での説明は割愛します)「Enable SSO」をクリックして
この画面になったらdatabricks側のSSOの設定が完了です
3. いざlogin!
AWS Portalに入るとこのようにdatabricksアイコンが表示されているのでこのアイコンをクリックします
無事loginできました!
おわりに
今回はAWS SSOでdatabricksにログインする方法についてご紹介しました。
別記事で、databricks各種権限設定についてもご紹介する予定ですので、
そちらも併せてご覧いただければ幸いです。
最後までお読みいただきありがとうございました。




- 投稿日:2020-10-20T14:20:29+09:00
CognitoのAccessTokenを取得
背景
Cognitoでは、AccessToken、IDToken、RefreshTokenを取得できる。ここでサーバ側でAccessTokenの中身を使用してセッション管理に利用することができないか?
実装
Cognito User Poolでユーザを作成する。
作成画面については別途サーバで構築した管理画面で実施
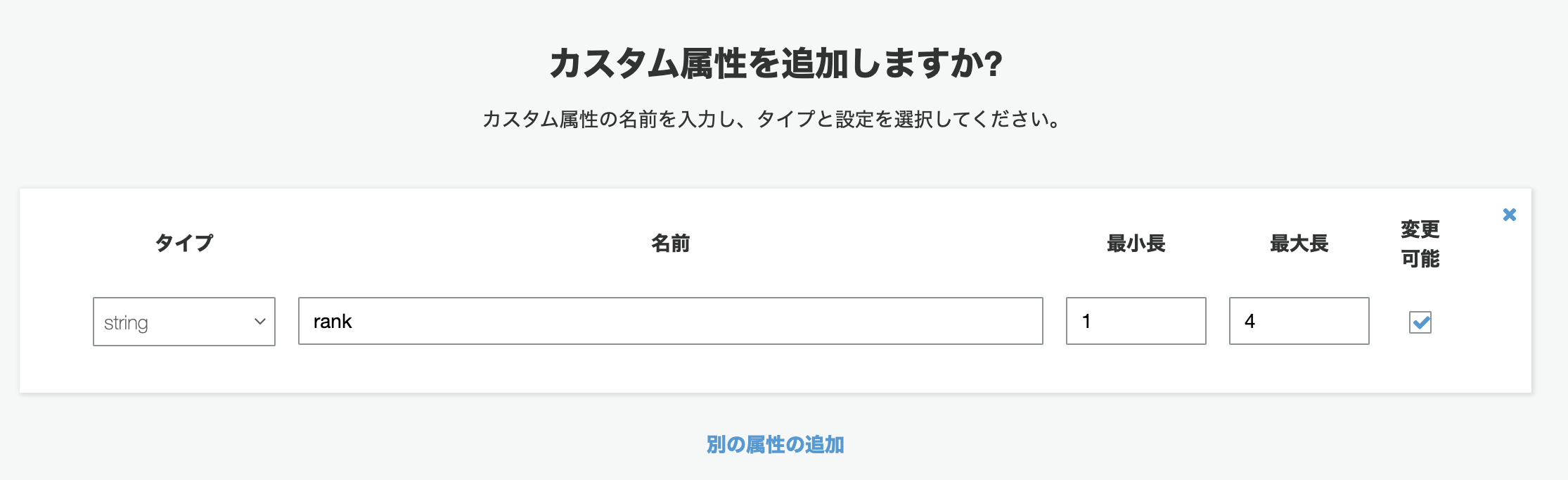
(APIGateway+Lambdaと S3に設置したViewでもOK:サーバレスで作成すると恐らく月額数円)UserPoolでランクの属性を追加
認証が行われると3つのトークンが払い出される。今回はIDトークンを使用してセッション管理を行う。
トークン名 内容 IDトークン name,emailなど認証されたユーザ情報が入る アクセストークン 認証されたリソースへのアクセスを付与 更新トークン 新しい ID またはアクセストークンの取得に必要な情報が含まれる IDトークンはJWTなので下記のようなトークンをクライアント側に返すので必要な要素をセッションやCookieに格納するなどの処理を行う。ここでカスタム属性を設定した場合は、下記の情報にカス
タム属性が付与される。
ちなみにJWTはbase64-encodedされたJSONこのあたりは次の「検証方法」に詳細な記載がある。{ "sub": "aaaaaaaa-bbbb-cccc-dddd-example", "aud": "xxxxxxxxxxxxexample", "email_verified": true, "token_use": "id", "auth_time": 1500009400, "iss": "https://cognito-idp.ap-southeast-2.amazonaws.com/ap-southeast-2_example", "cognito:username": "anaya", "exp": 1500013000, "given_name": "Anaya", "iat": 1500009400, "email": "anaya@example.com" }検証方法
- 投稿日:2020-10-20T13:23:25+09:00
Lambda コンソールで使う AWS SDK を最新にする
はじめに
Lambda を使って新しいサービスを使ってみたり、既存のサービスをちょっと試したいときに Lambda コンソールで実装をすることがあると思います。
しかし、Lambda コンソールで提供されている AWS SDK 実行環境は最新とは限らないため、そのままでは新しいサービスを使えないときがあります。ここでは、そのようなときに Lambda レイヤーをつかって Lambda コンソールの AWS SDK を最新にする方法を紹介します。事前準備
作業の途中で Docker を利用するので作業環境には Docker をインストールしておいてください。
Lambda 関数を用意する
現在と更新後の AWS SDK のバージョンを確認するために Lambda 関数を用意しておきます。
- Lambda コンソールを開き、"関数の作成" をクリックします。
- [関数名] に
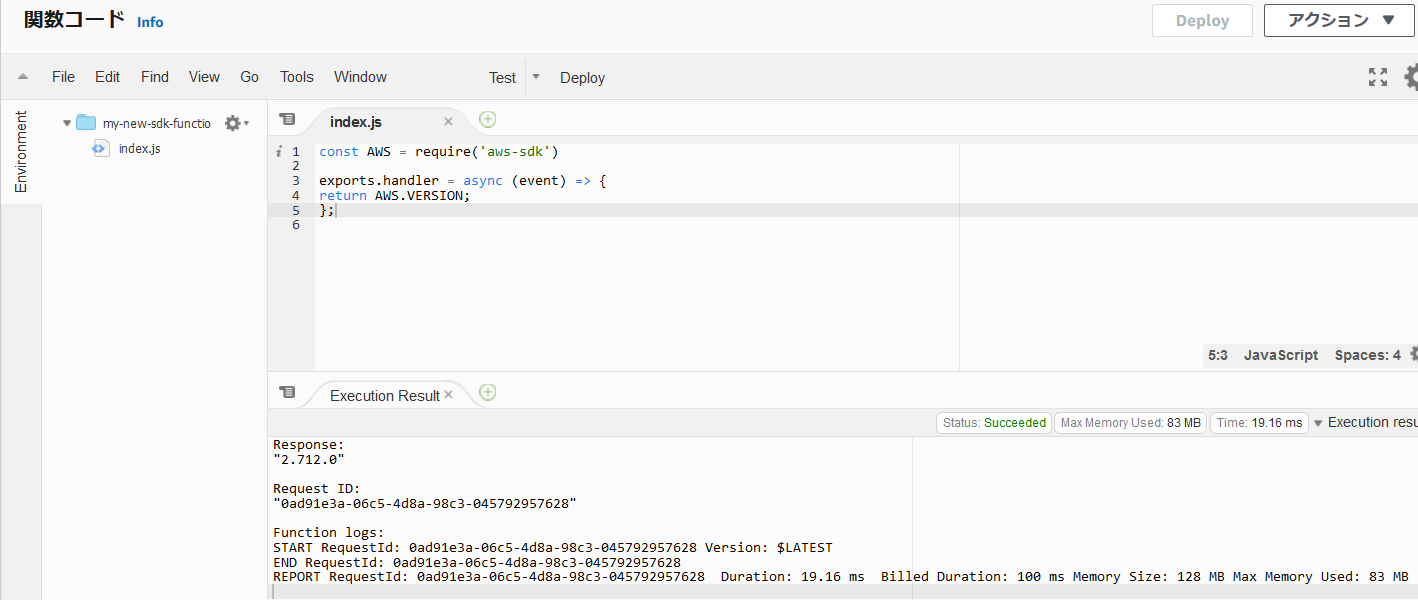
my-new-sdk-function、[ランタイム] にNode.js 12.xと入力し、他はデフォルト設定で "関数の作成" をクリックします。- できあがった my-new-sdk-function のコードを AWS SDK のバージョンを出力するようにします。関数コードペインでコードを以下のように変更します。変更後は "Deploy" をクリックしておきましょう。
+ const AWS = require('aws-sdk') exports.handler = async (event) => { - // TODO implement - const response = { - statusCode: 200, - body: JSON.stringify('Hello from Lambda!'), - }; - return response; + return AWS.VERSION; };現在の AWS SDK のバージョンを確認する
イベントを用意して、用意した Lambda 関数を呼び出します。
- Lambda コンソールの右上にある "テスト" をクリックします。
- "イベント名" に
MyNewSdkEventと名付け、他はデフォルトのまま "作成" をクリックします。- もう一度 "テスト" をクリックすると先ほど作成した Lambda 関数が実行されます。実行結果が関数コードペインに表示されます。執筆時点では 2.712.0 でした。
最新の AWS SDK バージョンをパッケージ化する
パッケージは Lambda 環境と互換性のあるオペレーティングシステムで作成することが勧められています。my-new-sdk-function を作成したときに選んだランタイム Node.js 12.x のオペレーティングシステム は "Amazon Linux 2" なので Amazon Linux 2 上でパッケージを作ります。
1.まず作業環境で作業ディレクトリを用意します。
mkdir -p my-new-sdk-layer2.作業ディレクトリに移動します。
cd aws-new-sdk-layer3.Docker で Amazon Linux 2 を起動します。
docker run \ -it \ --rm \ --name console \ --volume `pwd`:/tmp/my-new-sdk-layer \ --workdir /tmp/my-new-sdk-layer/nodejs \ amazonlinux bash4.以降の処理で使用するツールをインストールしておきます。
yum install -y tar gzip zip5.ノードバージョンマネージャー (nvm) をインストールします。
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.34.0/install.sh | bash6.コマンドラインで次のように入力して nvm を有効にします。
. ~/.nvm/nvm.sh7.nvm を使用して Node.js のバージョン 12 をインストールします。Node.js をインストールすると、Node Package Manager (npm) もインストールされます。
nvm install 128.AWS SDK の最新バージョンをインストールします。
npm install aws-sdk9.レイヤーにアップロードする .zip ファイルを作成します。
zip -r ../package.zip ../10.
exitして Amazon Linux 2 から抜けます。作業ディレクトリに package.zip があると思います。レイヤーを作成して関数に追加する
- Lambda コンソールのレイヤーページを開き、"レイヤーの作成" をクリックします。
レイヤー設定で以下の値を入力し、"作成" をクリックします。
- "名前" には
myNewSdkLayerを入力します。- [.zip ファイルをアップロード] を選択して、さきほど作成した zip ファイルをアップロードします。
- "互換性のあるランタイム - オプション" では
Node.js 12.xを選択します。レイヤーが作成されたら、Lambda コンソールの関数ページから、my-new-sdk-function を選択します。
デザイナーペインで、"Layers" を選択します。
レイヤーペインで、"レイヤーの追加" をクリックし、レイヤーを追加画面で以下の値を設定し、"追加" をクリックします。
- "レイヤーを選択" で
カスタムレイヤーを選択します。- "カスタムレイヤー" には先ほど作成した
myNewSdkLayerを選択します。- "バージョン" には
1を選択します。更新後の AWS SDK のバージョンを確認する
まえに用意した "MyNewSdkEvent" を再度、実行します。Lambda コンソールの右上にある "テスト" をクリックしてください。関数コードペインから実行結果を確認すると更新されたことが確認できると思います。今回は 2.773.0 になりました。
以上になります。

- 投稿日:2020-10-20T13:18:46+09:00
AWS CodeCommitをCloud9で使用する
AWS Cloud9からCodeCommitを使用する手順を紹介します。
CodeCommitはsshではなくhttps接続を使用します。https接続だと、当然ですが公開鍵の生成、登録が必要ありませんので、設定はその分容易です。
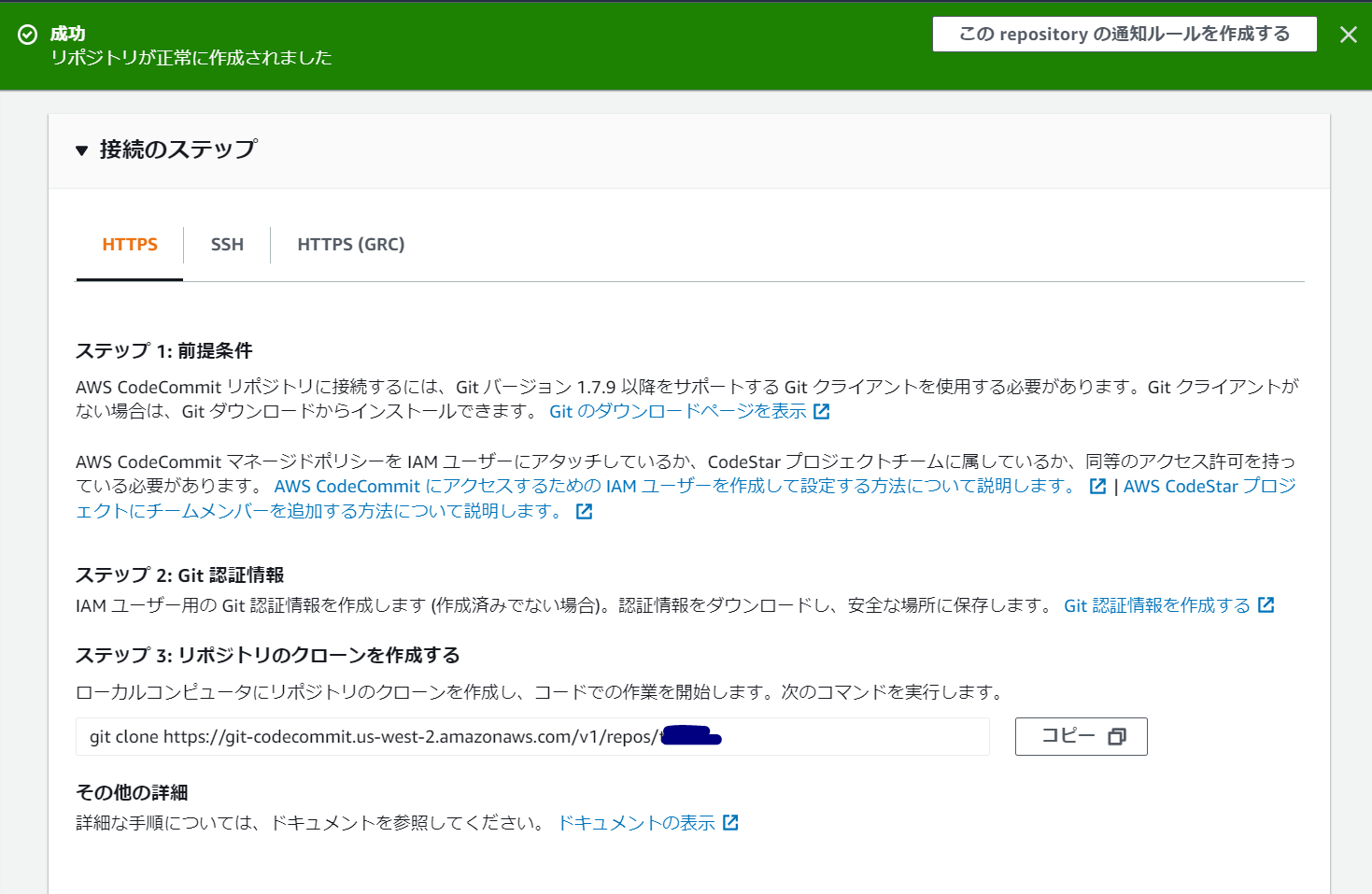
前提条件としてIAMユーザーに「AWSCodeCommitFullAccess」が割り当てられているものとします。1. CodeCommit上でリポジトリの作成
・「リポジトリを作成」からリモートリポジトリを作成
・リポジトリ名を指定して「作成」
これでAWS CodeCommit上にリポジトリが作成されました。2. Git認証情報の作成
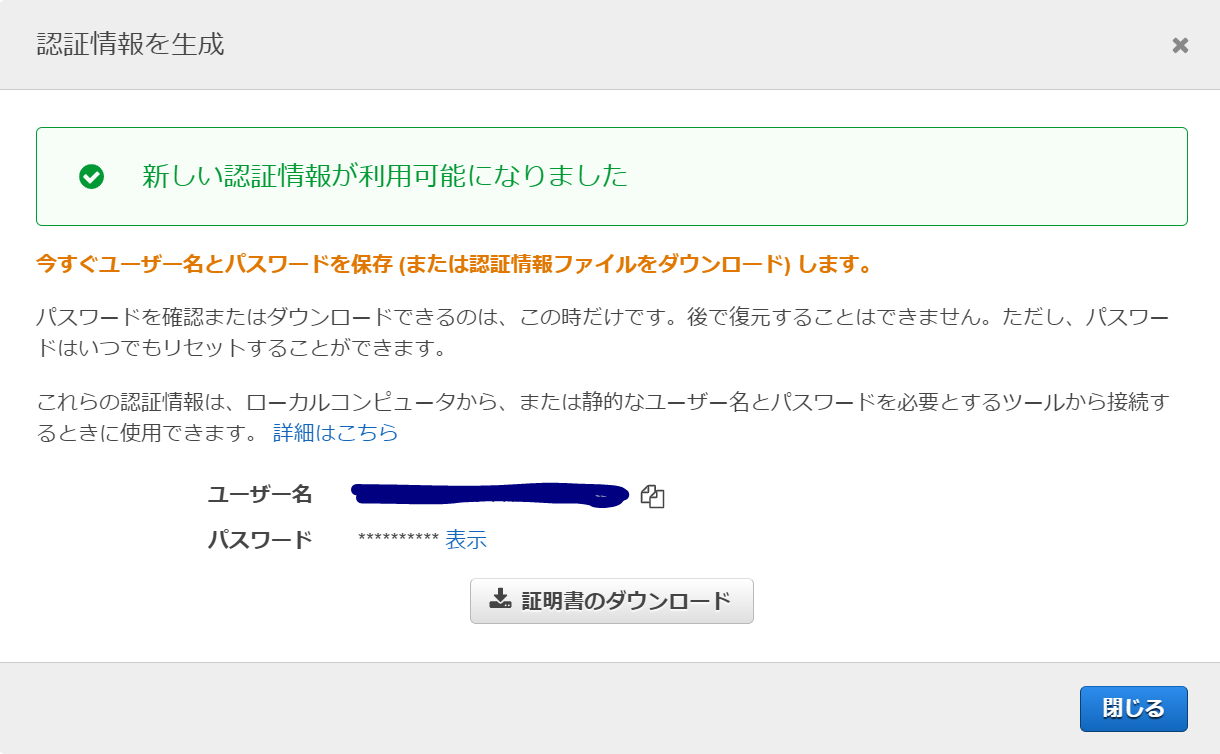
・IAM ダッシュボード→ユーザー→該当ユーザーを選択
・認証情報タブの「AWS CodeCommit の HTTPS Git 認証情報」で「認証情報を生成」
Git認証用のユーザー名とパスワードを控えておきます。証明書をダウンロードするとこれらの情報が記載されたCSVファイルがダウンロードされます。
3. Cloud9上での設定
3-1. ローカルリポジトリの作成
$ git init Initialized empty Git repository in /home/ec2-user/environment/.git/3-2. ユーザー設定
「USER_NAME」に「ユーザー名」を指定
「USER_EMAIL」に「メールアドレス」を指定$ git config --global user.name USER_NAME $ git config --global user.email USER_EMAIL3-3A. リモートリポジトリの追加
https以下URLはレポジトリの一覧からhttpsのボタンを押すとコピーされます。
$ git remote add origin https://git-codecommit.us-west-2.amazonaws.com/v1/repos/tst3-3B. クローンを作成を作成する場合
ディレクトリが作成されてクローンが作成されるのでカレントディレクトリに注意
$ git clone https://git-codecommit.us-west-2.amazonaws.com/v1/repos/tst Cloning into 'tst'... warning: You appear to have cloned an empty repository.3-4A. ステージに追加(ファイル指定)
$ git add run.py3-4B. ステージに追加(カレントフォルダ以下すべて)
$ git add .3-5. Commitからpush
$ git commit -m "first commit" [master (root-commit) 877da2a] first commit 1 file changed, 6 insertions(+) create mode 100644 run.py $ git push origin master Counting objects: 3, done. Compressing objects: 100% (2/2), done. Writing objects: 100% (3/3), 322 bytes | 322.00 KiB/s, done. Total 3 (delta 0), reused 0 (delta 0) To https://git-codecommit.us-west-2.amazonaws.com/v1/repos/tst * [new branch] master -> master4. Source Tree の使用
ファイル → 新規 → クローンの作成
URLにレポジトリのURL(3-3A)、保存パスの位置、名前を入力します。
IDとパスワードを聞かれますので、Git認証情報(2)で取得したものを設定します。以上
- 投稿日:2020-10-20T11:24:15+09:00
aws lightsail wordpress siteguardについて
ウェブサイトを立ち上げて間もない初心者です。
今回セキュリティー対策としてsiteguardというプラグインを導入しました。
新しいログインページをブックマークし、翌日開こうとしたところ、サイトは開けるのですがログインページにアクセスしません。
この場合どうしたらいいでしょうか、、、〇今回試したこと
wp-admin.phpやwp-login.phpで開こうとした
.htaccessから削除を試みたがlightsailには.htaccessがない?のでできなかった
wordpressの管理者画面からメールアドレスをチェックし、メールが来ているか確認したがきていなかった上記以外の方法でログインページに到達する方法があるのでしょうか、、
- 投稿日:2020-10-20T11:01:14+09:00
AWS WAFの導入手順
WAFを構成する要素
WAFを構成する要素として、「Web ACLs」「Rules」「Associated AWS resources」があります。これはIAMの考え方と似ていて、
- Web ACLs = IAM Group
- Rules = IAM Policy
- Associated AWS resources = IAM User
というイメージを持つとわかりやすいでしょう。
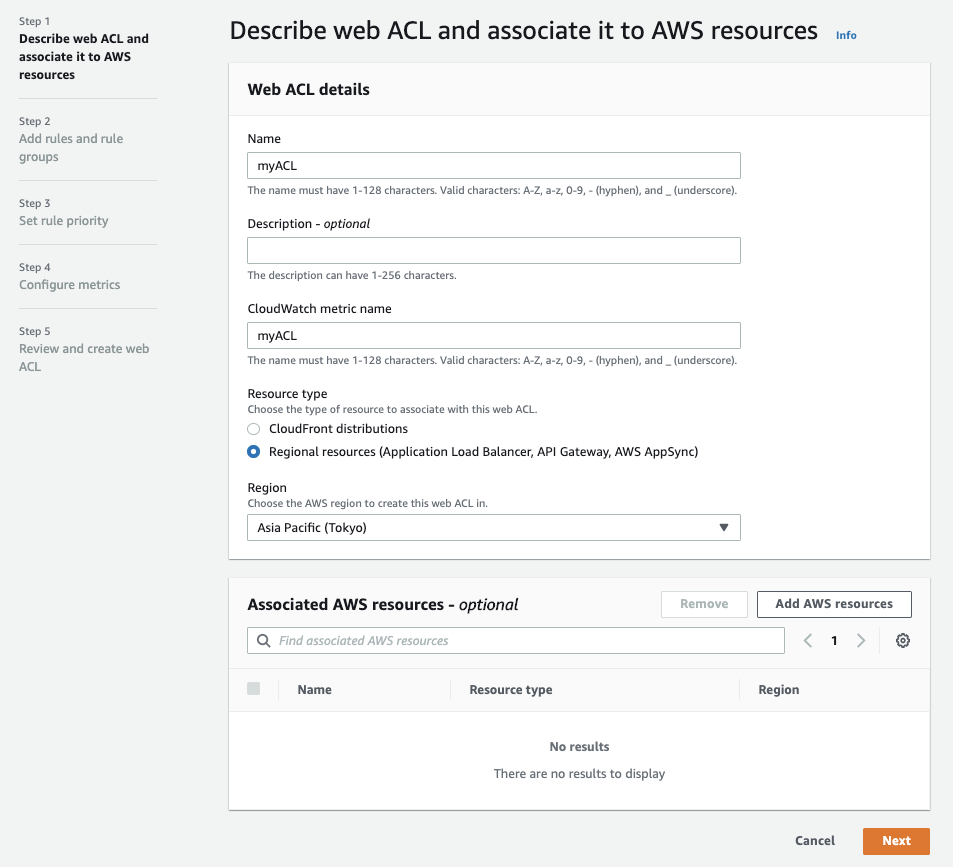
つまり「Web ACLs」という箱を作り、そこにアクセスの可否を制御する「Rules」を設定し、そこに対象となるAWSリソース(ALB or CloudFront)を紐付けることになります。Web ACLsの作成&リソースの関連付け(Describe web ACL and associate it to AWS resources)
それでは実際に作っていきます。
- AWSのコンソールから、「WAF&Shield」を選択
- 左サイドバーの「Web ACLs」を選択 > 「Create WebACL」を選択
Web ACL details
まずはルールやリソースを関連づけるための箱であるWeb ACLを作成します。
* 「Name」:ACLの名前を記入
* 「Resource type」:関連づけたいリソースの種類を選択(今回はALBなのでそのまま)
* 「Region」:リージョンを選択
Associated AWS resources
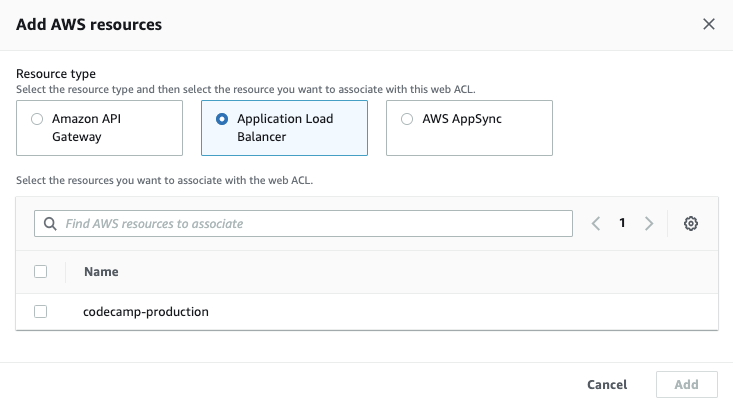
続いて、作成したWeb ACLにWAFの監視対象とするリソースを関連づけます。
- 「Add AWS Resources」を選択
- WAFを適用させたいリソースを選択して「Add」を選択
- 「Next」を選択
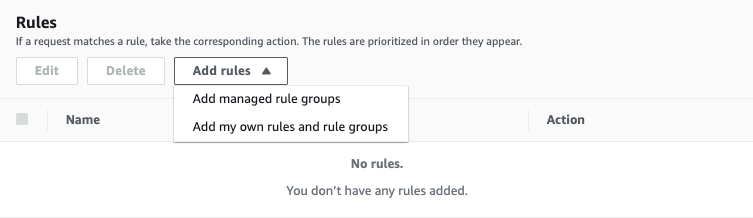
ルールの設定(Add rules and rule groups)
作成したWeb ACLにルールを適用していきましょう。WAFルールには、
- Managed Rule:AWSが提供しているルールセット
- My Own Rule:ユーザーが独自に定義するルール
の二種類あり、イメージとしてはIAM Policyでいうところの「AWS Managed Policy」と「Customer Managed Policy」の関係になります。
各Managed Ruleの詳細は公式ドキュメントにまとまっているので、ベースはManaged Ruleを使いつつ、追加で設定したいポリシーはMy Own Ruleとして定義するのが良いと思います。
今回はさくっと設定できる「Managed Rule」を設定することにします。
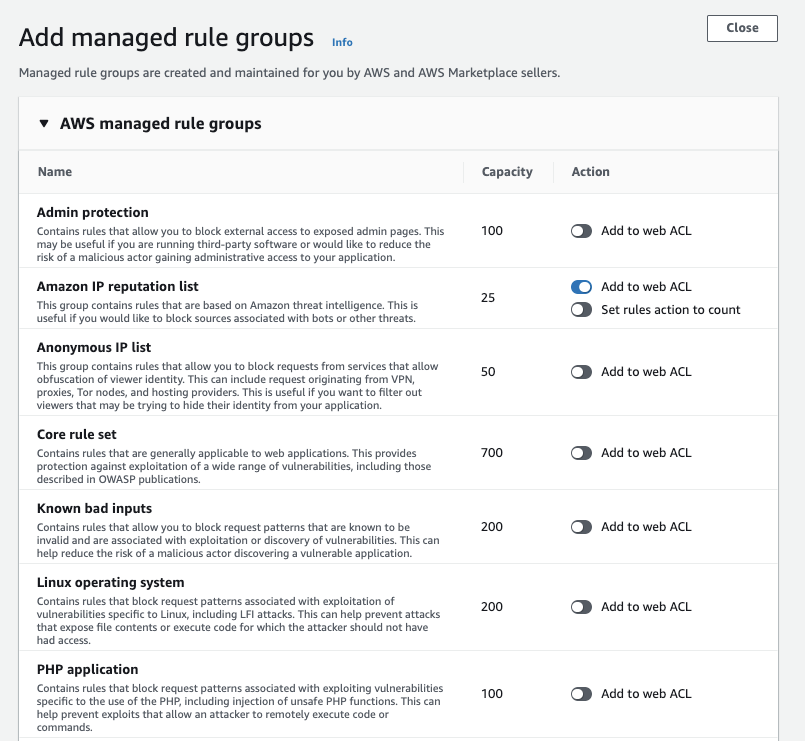
「Add rules」 > 「Add managed rule groups」を選択
適用するルールを選択肢して、「Add rules」を選択
今回は不審なIPからのアクセスをブロックする「Amazon IP reputation list」を追加します。
「Default action」は「Allow」のまま「Next」を選択
ルールの優先度(Set rule priority)
ルールの適用順序を設定する画面ですが、今回はこのまま「Next」を選択します。
メトリクスの設定(Configure metrics)
cloudwatchのメトリクスを設定する画面ですが、今回はこのまま「Next」を選択します。
確認画面(Review and create web ACL)
内容に問題なければこのまま「Create web ACL」を選択します。
確認
web ACLのoverviewでアクセスが確認できればOKです。
注意点
設定するルールによっては本来許可したいリクエストをブロックしてしまう可能性があります。
筆者の場合は一度テスト用のロードバランサを作成し、そこにWAFを紐づけた上で動作確認し、その後本番用のロードバランサへの切り替えを行いました。
- 投稿日:2020-10-20T11:01:14+09:00
AWS WAFを導入してみた
はじめに
WAFを構成する要素として、「Web ACLs」「Rules」「Associated AWS resources」があります。これはIAMの考え方と似ていて、
- Web ACLs = IAM Group
- Rules = IAM Policy
- Associated AWS resources = IAM User
というイメージを持つとわかりやすいでしょう。
つまり「Web ACLs」という箱を作り、そこにアクセスの可否を制御する「Rules」を設定し、そこに対象となるAWSリソース(ALB or CloudFront)を紐付けることになります。作成
それでは実際に作っていきます。
Web ACLsの作成&リソースの関連付け(Describe web ACL and associate it to AWS resources)
- AWSのコンソールから、「WAF&Shield」を選択
- 左サイドバーの「Web ACLs」を選択 > 「Create WebACL」を選択
Web ACL details
まずはルールやリソースを関連づけるための箱であるWeb ACLを作成します。
* 「Name」:ACLの名前を記入
* 「Resource type」:関連づけたいリソースの種類を選択(今回はALBなのでそのまま)
* 「Region」:リージョンを選択
Associated AWS resources
続いて、作成したWeb ACLにWAFの監視対象とするリソースを関連づけます。
- 「Add AWS Resources」を選択
- WAFを適用させたいリソースを選択して「Add」を選択
- 「Next」を選択
ルールの設定(Add rules and rule groups)
作成したWeb ACLにルールを適用していきましょう。WAFルールには、
- Managed Rule:AWSが提供しているルールセット
- My Own Rule:ユーザーが独自に定義するルール
の二種類あり、イメージとしてはIAM Policyでいうところの「AWS Managed Policy」と「Customer Managed Policy」の関係になります。
各Managed Ruleの詳細は公式ドキュメントにまとまっているので、ベースはManaged Ruleを使いつつ、追加で設定したいポリシーはMy Own Ruleとして定義するのが良いと思います。
今回はさくっと設定できる「Managed Rule」を設定することにします。
「Add rules」 > 「Add managed rule groups」を選択
適用するルールを選択肢して、「Add rules」を選択
今回は不審なIPからのアクセスをブロックする「Amazon IP reputation list」を追加します。
「Default action」は「Allow」のまま「Next」を選択
ルールの優先度(Set rule priority)
ルールの適用順序を設定する画面ですが、今回はこのまま「Next」を選択します。
メトリクスの設定(Configure metrics)
cloudwatchのメトリクスを設定する画面ですが、今回はこのまま「Next」を選択します。
確認画面(Review and create web ACL)
内容に問題なければこのまま「Create web ACL」を選択します。
確認
web ACLのoverviewでアクセスが確認できればOKです。
注意点
設定するルールによっては本来許可したいリクエストをブロックしてしまう可能性があります。
筆者の場合は一度テスト用のロードバランサを作成し、そこにWAFを紐づけた上で動作確認し、その後本番用のロードバランサへの切り替えを行いました。
- 投稿日:2020-10-20T09:47:13+09:00
取得したドメインをRoute53にて管理する方法
はじめに
取得したDomainをRoute53で管理する方法を記載します。
補足としてRoute53について簡単に説明。Route53は権威DNSです。
権威DNSって何?という方はググるともっと分かりやすい情報がでてくるかもしれませんが簡単に言うと、
保持しているドメインの名前解決をしてくれるDNSのことです。
そのため保持していないドメイン以外の名前解決は行ってくれないので、その場合にはキャッシュDNSを別に用意する必要があります。Domainの取得とRoute53への登録
どこでもいいんですが、ほとんど検証利用しかしないので1年以上使うことが私はないのでFreenomを使います。
Freenomとは、無料(1年間)でドメインを取得できる海外のサービスですので、検証利用などで有効活用できます。
Freenomeで勿論ドメイン管理することはできるのですが、あえてRoute53に管理させたいと思います。1) Freenomにアクセスし、アカウントを作成します。
2) アカウントを作成したら、Services → 登録をクリックします。
3) 新しい無料ドメインを探しますで、取得したいドメイン名を入れます。
4) 取得可能ドメイン一覧が表示されますが無料のやつから「今すぐ入手!」をクリックします。
5) カートに入ったらチェックアウトをクリックします。
6) 登録時に以下画面が表示されます。
・Use DNSを選択します。
・Periodには12Months @ Freeをプルダウンより選択します。
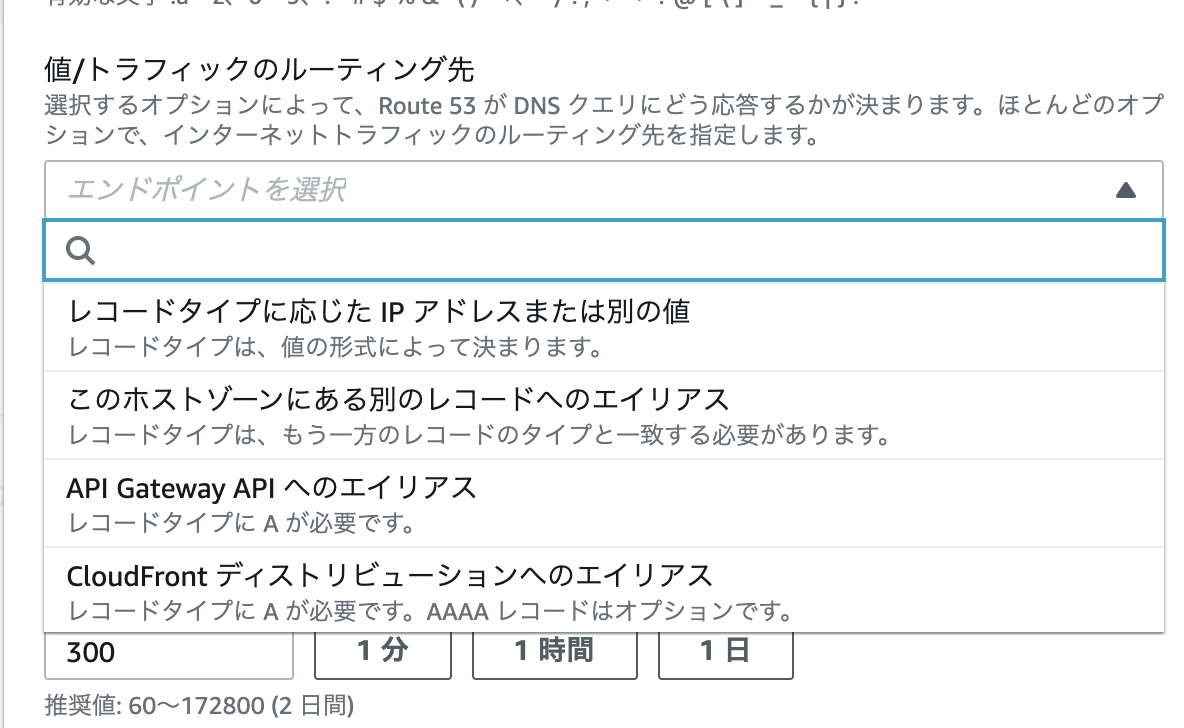
7) AWS ConsoleにログインしてRoute53にて本Domainのホストゾーンを作成します。
作成するとNSが作成されるので、値/トラフィックのルーティング先に書かれている内容をFreenomの画面(項番6の画面)のNameserverに記載します。
※NSには4つ表示されますが、そのうちの2つをまずは登録して下さい。
8) Nameserverに記載したらContinueをクリックします。
9) I have read and agree to the Terms & Conditionsにチェックを入れて、Complete Orderをクリックします。
10) 上部メニューのMy Domainsより、取得したドメインがあることを確認できれば登録は完了です。追加の設定
先程Route53のNSを2つ登録しましたが、残り2つあるので登録を行います。
上部メニューのMy Domainsより、登録したドメインの「Manage Domain」をクリックします。
画面が遷移するのでタブのManagement Toolsより、Nameserversをクリックします。
そうすると登録した2つが表示されていると思いますので、Nameserver3/Nameserver4に項番7で表示された残り2つを記載して、
「Change Nameservers」をクリックします。
再度Management Toolsより、Nameserversをクリックし残り2つが登録されていることを確認します。
最後に
今回はFreenomで実施しましたが、お名前.comなど取得したドメインも同じような形でRoute53で管理することができます。
もちろんRoute53にてドメインを購入することもできます。
またAWSサービスを使って展開している場合には各種AWSサービスとの連携もしやすいので、AWSにとって最適なDNSだと思ってます。余談ですが、最近全然投稿ができていないくて心がもやもやしてました。
最近忙しくて検証、勉強ができていないので、少しでも合間を見つけてやっていきたいと思います。




- 投稿日:2020-10-20T09:26:15+09:00
cliでs3を操作してみる(mac)
cliでs3を操作(バケットの作成やアップロード、ダウンロードなど)できるように設定をしていくつか実行してみます。
s3とは
s3とはamazon web serviceが提供してくれるオンラインストレージである。
dropboxに似ているものです。前提
- Homebrewをインストールしていること → こちらを参考にしました
- awsのアカウントを作成していること
まず、awscliをインストールする
$ brew install awscliを実行することでcliからawsを操作できるようになります。
次に、awsに接続する
$ aws configure AWS Access Key ID [None]: 'アクセスキー' AWS Secret Access Key [None]: 'シークレットキー' Default region name [None]: '設定したregion(東京だと"ap-northeast-1")' Default output format [None]: jsonとすることでawsへの接続ができるようになります。
ここまできたらcliでs3を操作できるようになります。いくつかやってみます。
いくつか操作をしてみよう
バケットを作る
s3ではバケットという大元を作らないといけません。こちらをcliで作ってみます。
$ aws s3 mb s3://(バケット名)とすることでバケットを作ることができます。やってみると
$ aws s3 mb s3://trainingtomosuke make_bucket: trainingtomosukeとなり、
trainingtomosukeというバケットができました。アップロードをする
バケットに以下のテキストをアップロードしたいとする。
'test.txt' test,test,test,test,testこのとき、このファイルがあるところのディレクトリに移って以下を実行します。
$ aws s3 cp (アップロードしたいファイル) s3://(バケット名)では、先ほど作ったバケットに
test.txtをアップロードしたいと思います。$ aws s3 cp test.txt s3://trainingtomosuke upload: ./test.txt to s3://trainingtomosuke/test.txtとなり、アップロードできました。
確認のためにaws s3 ls s3://trainingtomosuke/test.txtで見てみると$ aws s3 ls s3://trainingtomosuke 2020-10-19 20:39:59 29 test.txtと表示されており確かに、アップロードができています。
ダウンロードしてみる
$ aws s3 cp (アップロードしたいファイル) s3://(バケット名)のところを
$ aws s3 cp s3://(バケット名)/(ダウンロードしたいファイルのパス) (ダウンロードしたいディレクトリ)にするとダウンロードできます。大体、わかってきたと思いますが
aws s3と頭につけて実行すればs3の操作ができます。$ aws s3 cp s3://trainingtomosuke/test.txt ./ download: s3://trainingtomosuke/test.txt to ./test.txtとなってダウンロードできました。
まとめ
aws s3 [options] [ファイルまたはバケット] [ファイルまたはバケット]でs3の基本的な操作ができます。
皆さんも練習がてらにcliを触ってみてください。参考文献
- 投稿日:2020-10-20T08:35:24+09:00
DNSの仕組みとAWSのRoute53について簡単にまとめた
AWSのRoute53を触った時に、DNSについて改めてしっかり学びなおしたのでそのメモ。
参考にした記事は以下
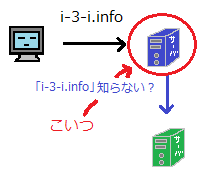
https://wa3.i-3-i.info/word1288.htmlDNSの構成要素
まずDNSサーバーは複数ある。
- フルサービスリゾルバ(DNSキャッシュサーバ)
- 権威サーバフルサービスリゾルバは、PCが問い合わせするサーバ。
なんとしてでもIPアドレスに関する情報を解決してくれるサーバである。
問い合わせた情報の結果はキャッシュで持ち、無駄な問い合わせを少なくするようにしてる。
権威サーバは、フルサービスリゾルバがアクセスする先のサーバ。
問い合わせに対する動作は以下の3つ
1. 自分の管理している情報にドメイン名とIPアドレスの対応が書いてあればそれを教えてあげる
2. 自分では管理していないけど委託していれば、委託先を教えてあげます
3. 全然分からない問い合わせであれば「知らない」と答えます。
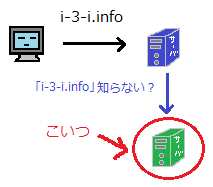
権威サーバの持つゾーンファイルについて
権威サーバは、DNSレコードを記載したゾーンファイル(AWSではルートテーブル)で情報の管理をしている。
DNSレコードの種類 説明 SOAレコード ゾーン(管理する範囲)に関する情報あれこれが書かれた行 NSレコード 管理を委託しているDNSサーバさんの名前が書かれた行 MXレコード そのドメイン宛のメールの配送先メールサーバが書かれた行 Aレコード ドメイン名に対応するIPアドレス(IPv4形式)が書かれた行 AAAAレコード ドメイン名に対応するIPアドレス(IPv6形式)が書かれた行 CNAMEレコード ドメイン名に付けた別名(あだ名)が書かれた行 CNAMEレコード ドメイン名に付けた別名(あだ名)が書かれた行 TXTレコード コメント等の、なんか適当な文章が書かれた行 AWSについて
Route53は、ゾーンファイルを管理するサービス。
ドメインごとにDNSレコードを管理できるようになっている。
最もシンプルなレコードでは以下を設定できる。
- DNSレコードの種類
- レコード名:home.example.comなど、どのURLに設定するか。
- 参照先IPアドレス・値などAWS上のAタグでは、以下のようにAWSリソースを指定することも可能。
設定できるのは
- S3
- API gateway
- ALB/NLB
- CloudFront
などなど。
- 投稿日:2020-10-20T02:57:47+09:00
ffmpeg-aws-lambda-layerでffmpegやffprobeを使う
ffmpeg-aws-lambda-layerでffmpegやffprobeを使う
はじめに
動画のフォーマットやサイズ変更、サムネイルの生成に便利な ffmpegの実行環境を AWS Lambda関数とレイヤーをつかって構築する手順を記載します。
ここでは、ffmpeg-aws-lambda-layerを使用します。Lambda関数とは別にffmpegやffprobeを含むAWS Lambda レイヤーを作成することで、これらのコマンドがLambda関数実行環境の /opt 以下に呼び出されます。デプロイパッケージにコマンド実行用のバイナリを含めることなくライブラリのように呼び出すことができます。Amazon Elastic Transcoderを使えば、動画のフォーマットやサイズ変更が簡単にできますが、費用が高いのでマシンパワーを必要とするような変換でなければLambdaで処理したほうが手軽で良いと思います。
以前書いた記事 (スマートホームカメラ ATOM Cam をセットアップ)で使用してるATOM Camの映像をNAS経由でS3に転送しAmazon Elastic Transcoderで動画フォーマットを変換する処理をつくったところ、あっというまに数千円消費してしまいました。こういう用途にはffmpegを使ったほうが良いようです。このサンプルでできること
ffmpeg-aws-lambda-layer に用意されているサンプルプロジェクトをデプロイすると、S3に ffmpeg-layer-example-uploadbucket-xxxx と ffmpeg-layer-example-resultbucket-xxxx (xxxxはランダムな文字列、以下同様)というバケットが生成され、Lambda関数との接続やIAM roleの設定が自動的に行われます。
ffmpeg-layer-example-uploadbucket-xxxx に動画ファイルがアップロードされると、自動的にffmpeg-layer-example-resultbucket-xxxx にサムネイル画像が生成さます。準備するもの
- ffmpeg-aws-lambda-layer に書かれているもの
- Unix Make environment - AWS command line utilities (just for deployment)今回は以下の環境で動作確認しました。
$ sw_vers ProductName: Mac OS X ProductVersion: 10.15.7 BuildVersion: 19H2$ aws --version aws-cli/2.0.57 Python/3.7.4 Darwin/19.6.0 exe/x86_64
- AWSアカウント
- Lambda, S3, CloudFormationを操作できるroleが必要です。Administrator権限があれば問題無し。
参考情報
- AWS LambdaでFFmpegを使って動画からサムネイルを作成する
- ffprobeで動画を解析する
- AWS Lambda(Node.js) + ffmpeg でエンコード
- カスタムAWS Lambdaランタイムで音声ファイルを生成・変換させてみる
準備
ffmpeg-aws-lambda-layer を git clone
git clone https://github.com/serverlesspub/ffmpeg-aws-lambda-layer.gitテンポラリ S3 バケットの準備
~/.aws/credentials の default profile に指定した region と同じリージョンにバケットを作成します。
サンプルプロジェクトををdeploy
DEPLOYMENT_BUCKET オプションの値に、テンポラリ S3 バケットのバケット名を指定します。
cd ffmpeg-aws-lambda-layer make deploy-example DEPLOYMENT_BUCKET=<BUCKET NAME>make コマンドを実行すると以下のようなログが流れます。
cd example && \ make deploy DEPLOYMENT_BUCKET=<BUCKET NAME> LAYER_STACK_NAME=ffmpeg-lambda-layer mkdir -p build aws cloudformation package --template-file template.yaml --output-template-file output.yaml --s3-bucket net.rev-system.nas Uploading to d5886731828e201e755325e950d28eab 1742 / 1742.0 (100.00%) Successfully packaged artifacts and wrote output template to file output.yaml. Execute the following command to deploy the packaged template aws cloudformation deploy --template-file /tmp/ffmpeg-aws-lambda-layer/example/output.yaml --stack-name <YOUR STACK NAME> aws cloudformation deploy --template-file output.yaml --stack-name ffmpeg-layer-example --capabilities CAPABILITY_IAM --parameter-overrides LambdaLayer=arn:aws:lambda:ap-northeast-1:************:layer:ffmpeg:1 Waiting for changeset to be created.. Waiting for stack create/update to complete Successfully created/updated stack - ffmpeg-layer-example aws cloudformation describe-stacks --stack-name ffmpeg-layer-example --query Stacks[].Outputs --output table -------------------------------------------------------------------------------------------- | DescribeStacks | +-------------------+----------------+-----------------------------------------------------+ | Description | OutputKey | OutputValue | +-------------------+----------------+-----------------------------------------------------+ | Upload S3 bucket | UploadBucket | ffmpeg-layer-example-uploadbucket-xxxxxxxxxxx | | Results S3 bucket| ResultsBucket | ffmpeg-layer-example-resultsbucket-yyyyyyyyyyyy | +-------------------+----------------+-----------------------------------------------------+ここで、以下のリソースが作成されます。
リソース種類 名称例 Lambda関数 ffmpeg-layer-example-ConvertFileFunction-nnnnnnnnnnnn Lambdaレイヤー ffmpeg S3 バケット(アップロード用) ffmpeg-layer-example-uploadbucket-xxxxxxxxxxx S3 バケット(変換済み) ffmpeg-layer-example-resultsbucket-yyyyyyyyyyyy CloudFrontスタック ffmpeg-layer-example IAMロール ffmpeg-layer-example-ConvertFileFunctionRole-zzzzzzzzzzzz サムネイルの生成
S3バケット ffmpeg-layer-example-uploadbucket-xxxxxxxxxxx に適当な動画ファイルをアップロードします。
しばらくすると ffmpeg-layer-example-resultsbucket-yyyyyyyyyyyy にサムネイル画像が出力されます。サムネイル以外の出力
動画を別フォーマットにしたり、ffprobeで動画ファイルのメタ情報を出力する場合は、
ffmpeg-aws-lambda-layer/example/src/index.jsを変更して再度デプロイすることでいろいろ試せます。Lambdaレイヤーのみ作成する
アップロード/変換済み用S3バケットやLambda関数はデプロイせず、Lambdaレイヤーのみデプロイする場合は以下のコマンドを実行します。
DEPLOYMENT_BUCKET オプションの値に、テンポラリ S3 バケットのバケット名を指定します。cd ffmpeg-aws-lambda-layer make deploy DEPLOYMENT_BUCKET=<BUCKET NAME>Lambdaレイヤーのみデプロイされるので、任意のLambda関数にこのレイヤーを追加することで使用できるようになります。
- 投稿日:2020-10-20T02:37:33+09:00
Aurora PostgreSQLの監査ログをAmazon ESに取り込んでみた
はじめに
本投稿は、Aurora PostgreSQLの監査ログをAmazon Elasticsearch Serviceに取り込んでみたという内容になっています。
利用環境
product version logstash (OSS版) 7.7.1 Java (Corretto) 11.0.8 OS(EC2) Amazon Linux2 (t3.small) AMI ID ami-03657b56516ab7912 Elasticsearch 7.7 (latest) PostgreSQL 11.6 Region us-east-2 ※投稿時点における最新版を採用しています。
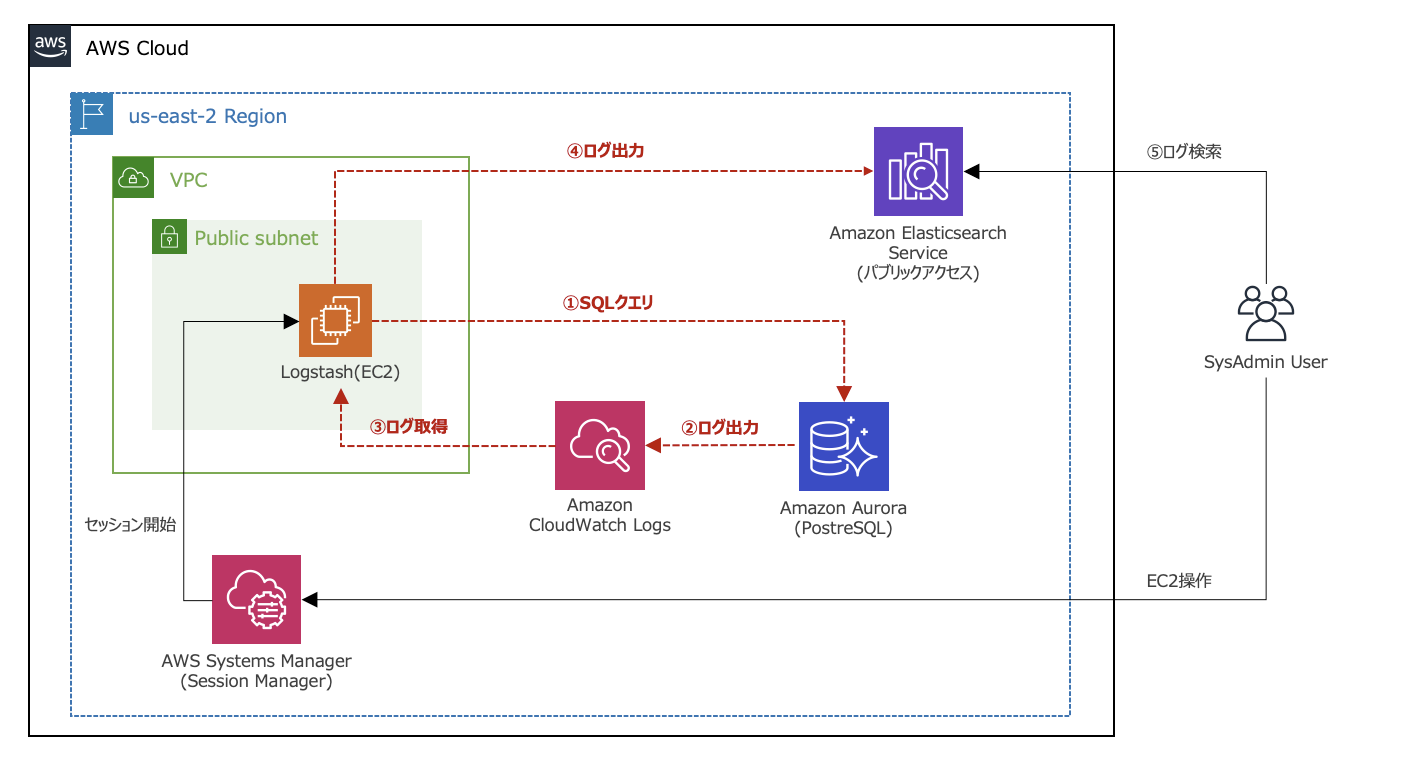
【構成図】
- CloudWatch Logsに出力したAurora PostgreSQLのログをLogstashがInputしています。
前提条件
- Aurora PostgreSQLのスロークエリログをAmazon ESに取り込んでみたで構築した環境を前提としています。
- 全てのDBコマンド処理は、Auraro PostgreSQLのマスターユーザで実行しています。
実施内容
- 監査ログ出力設定
- 監査ログの確認
- Logstashの設定
- Kibanaでの設定
1. 監査ログ出力設定
- まず、rds_pgauditという特定のデータベースロールを作成します。
- [Systems Manager] > [Session Manager]からLogstash用のEC2に接続します。
- EC2から以下のコマンド操作でDBに接続し、CREATE ROLEコマンドでrds_pgauditを作成します。
※ EC2からPostgreSQLにTCP5432で通信許可されている状態としています。$ psql -h [Auroraのエンドポイント] -U [マスターユーザ名] Password for user postgres: xxxxxxxxxxx(パスワード) psql (9.2.24, server 11.6) WARNING: psql version 9.2, server version 11.0. Some psql features might not work. SSL connection (cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256) Type "help" for help. postgres=> CREATE ROLE rds_pgaudit; CREATE ROLE postgres=> postgres=> \du List of roles Role name | Attributes | Member of ---------------------------+------------------------------------------------+-------------------------------------------------------------- pg_execute_server_program | Cannot login | {} pg_monitor | Cannot login | {pg_read_all_settings,pg_read_all_stats,pg_stat_scan_tables} pg_read_all_settings | Cannot login | {} pg_read_all_stats | Cannot login | {} pg_read_server_files | Cannot login | {} pg_signal_backend | Cannot login | {} pg_stat_scan_tables | Cannot login | {} pg_write_server_files | Cannot login | {} postgres | Create role, Create DB +| {rds_superuser} | Password valid until infinity | rds_ad | Cannot login | {} rds_iam | Cannot login | {} rds_password | Cannot login | {} rds_pgaudit | Cannot login | {} rds_replication | Cannot login | {} rds_superuser | Cannot login | {pg_monitor,pg_signal_backend,rds_replication,rds_password} rdsadmin | Superuser, Create role, Create DB, Replication+| {} | Password valid until infinity |
- 次にパラメータグループで設定を追加します。
- 監査ログの出力設定のためのパラメータグループとして、以下のものを利用します。
【パラメータグループの内容】
項目 値 パラメータグループファミリー aurora-postgresql11 タイプ DB Cluster Parameter Group グループ名 testpostgresql11-paramatergroup (任意) 説明 testpostgresql11 (任意) ※ DBクラスタパラメータグループとDBパラメータグループの関係性ですが、原則DBパラメータグループの設定が適用されます。DBパラメータグループがデフォルト値の場合、DBクラスタパラメータグループの設定が適用されます。
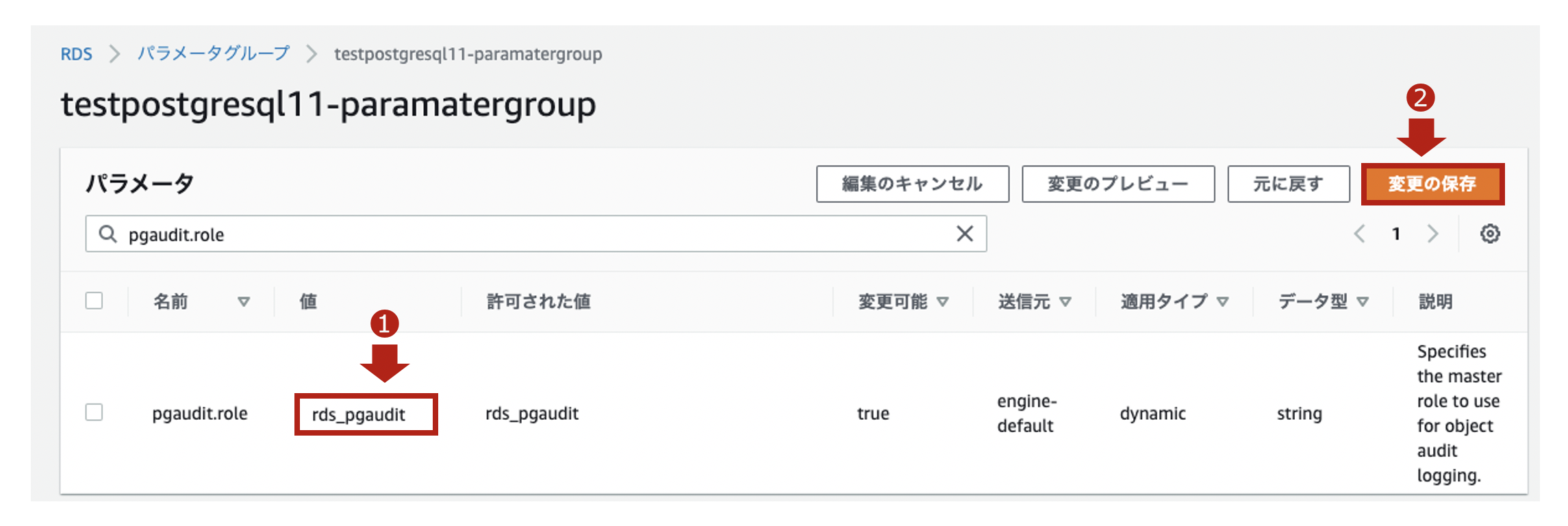
上記のパラメータグループにて、pgaudit.roleのパラメータを編集します。
コマンドで作成したロール(rds_pgaudit)を設定して、保存します。
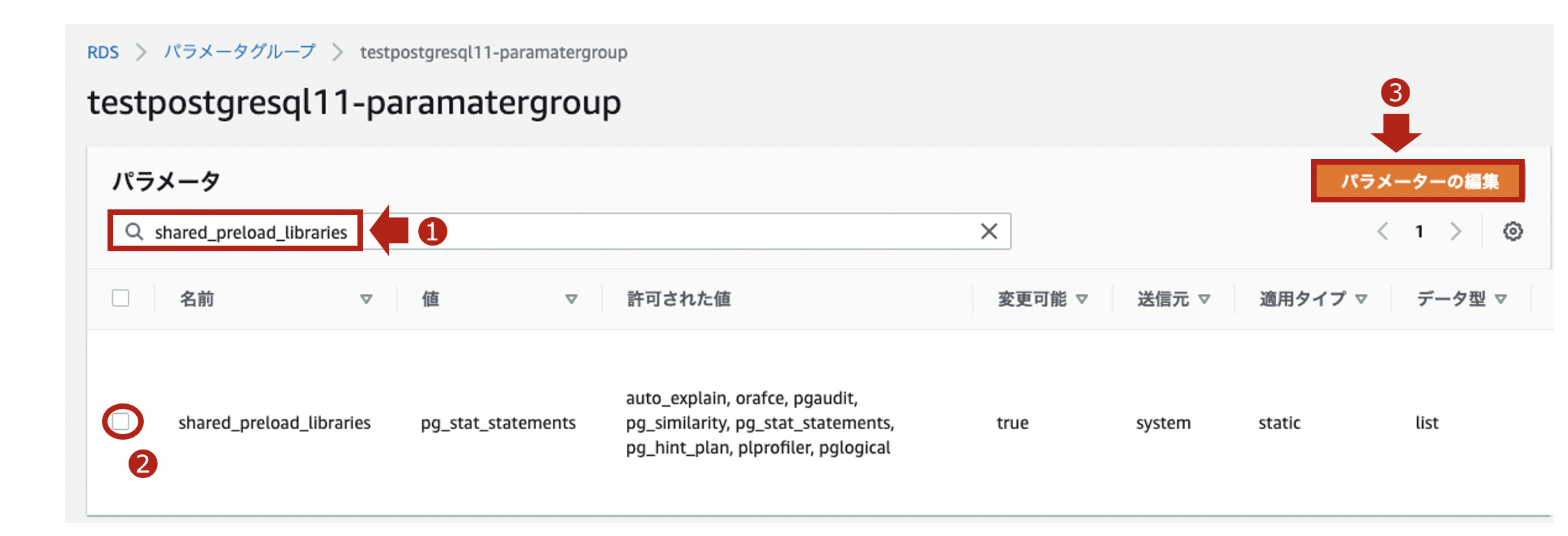
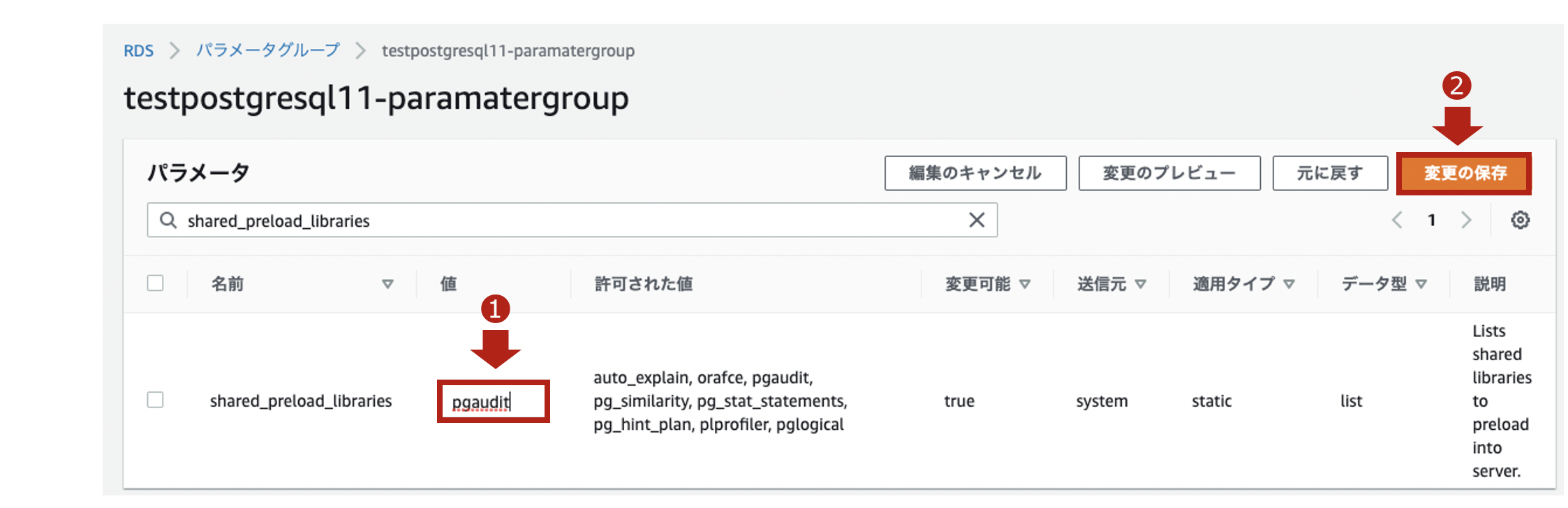
同じパラメータグループにて、次はshared_preload_librariesのパラメータを編集します。
pgauditを設定することでpgAuditのライブラリを、共有メモリにロードします。
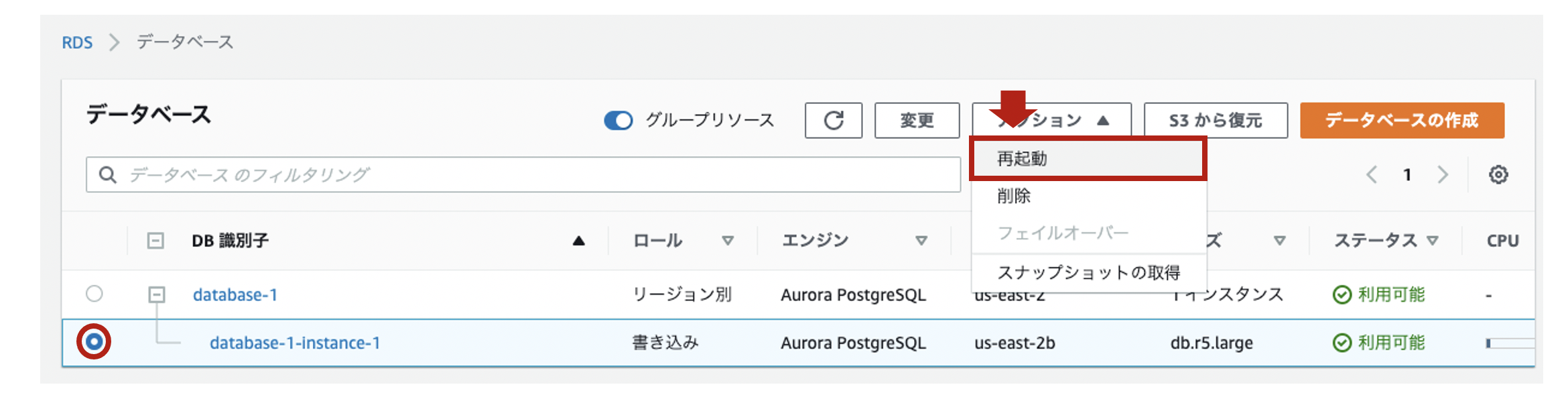
設定を反映させるため、DBインスタンスを再起動します。
再起動後、pgauditがちゃんとロードされていることを再接続して確認します。
$ psql -h [Auroraのエンドポイント] -U [マスターユーザ名] Password for user postgres: xxxxxxxxxxx(パスワード) psql (9.2.24, server 11.6) WARNING: psql version 9.2, server version 11.0. Some psql features might not work. SSL connection (cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256) Type "help" for help. postgres=> show shared_preload_libraries; shared_preload_libraries -------------------------- rdsutils,pgaudit (1 row)
- pgauditの拡張機能を有効にします。
postgres=> CREATE EXTENSION pgaudit; CREATE EXTENSION postgres=> \dx List of installed extensions Name | Version | Schema | Description ---------+---------+------------+--------------------------------- pgaudit | 1.3 | public | provides auditing functionality plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language (2 rows)
- 作成したロールに、pgauditがちゃんと紐付いていることを確認します。
postgres=> show pgaudit.role; pgaudit.role -------------- rds_pgaudit (1 row)【参考】
・pgaudit拡張機能の使用
・Auroraのパラメータグループの優先順位について実験してみた2. 監査ログの確認
- GRANTコマンドでクエリ監査対象とするテーブル(今回はtesttable)を指定します。
- testtableに対して、SELECTコマンドでSQLクエリを実行します。
$ psql -h [Auroraのエンドポイント] -U [マスターユーザ名] Password for user postgres: xxxxxxxxxxx(パスワード) psql (9.2.24, server 11.6) WARNING: psql version 9.2, server version 11.0. Some psql features might not work. SSL connection (cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256) Type "help" for help. postgres=> GRANT SELECT ON testtable TO rds_pgaudit; GRANT postgres=> SELECT * FROM testtable;
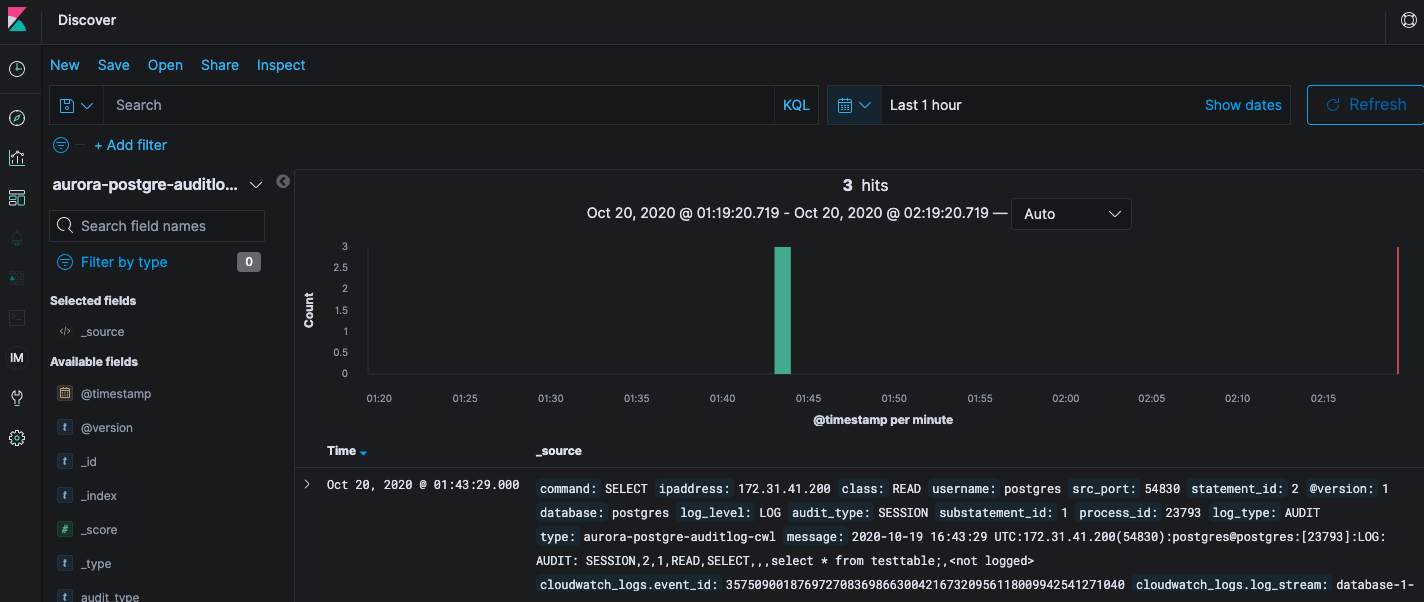
- [CloudWatch Logs]のロググループ配下のログストリームに以下のようなログが出力されます。(こちらが監査ログです。)
 log_format
log_format2020-10-19 10:49:24 UTC:172.31.41.200(44050):postgres@postgres:[27653]:LOG: AUDIT: OBJECT,1,1,READ,SELECT,TABLE,public.testtable,select name from testtable;,<not logged>余談ですが、デフォルトのログフォーマットは
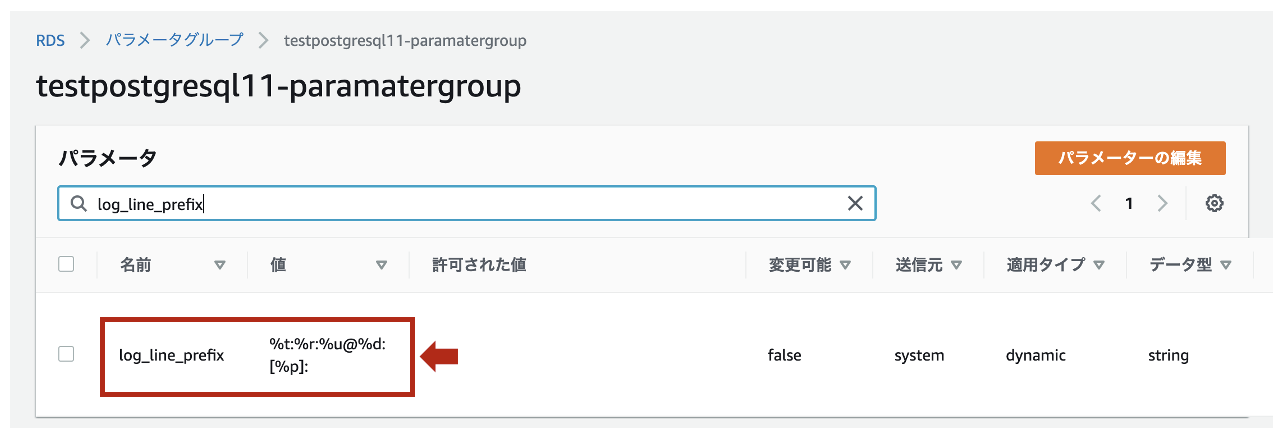
log_line_prefixで%t:%r:%u@%d:[%p]:と定義されています。
【参考】
・pgaudit拡張機能を使用する方法
・log_line_prefixの説明3. Logstashの設定
- 監査ログは、正規表現パターンを使って以下のようなフィールドと値にパースします。
フィールド 値(サンプル) データ型 タイムスタンプ 2020-10-19 10:49:24 日付型 タイムゾーン UTC 文字列型 (keyword) IPアドレス 172.31.41.200 IP型 ポート番号 44050 文字列型 (keyword) ユーザ名 postgres 文字列型 (keyword) データベース名 postgres 文字列型 (keyword) プロセスID 27653 文字列型 (keyword) ログレベル LOG 文字列型 (keyword) ログタイプ AUDIT 文字列型 (keyword) 認証タイプ OBJECT 文字列型 (keyword) ステートメントID 1 文字列型 (keyword) サブステートメントID 1 文字列型 (keyword) クラス READ 文字列型 (keyword) コマンド SELECT 文字列型 (keyword) オブジェクトタイプ TABLE 文字列型 (keyword) オブジェクト名 public.tessttable 文字列型 (keyword) クエリ文 select * from testtable; 文字列型 (text) パラメータ <not logged> 文字列型 (keyword)
- Grokパターン(
/etc/logstash/grok_patterns/aurora-postgresql-auditlog)を保存するディレクトリを作成します。
※ すでにgrok_patternsディレクトリが存在する場合、ファイルのみ作成してください。$ sudo mkdir /etc/logstash/grok_patterns $ sudo vi /etc/logstash/grok_patterns/aurora-postgresql-auditlog
- 下記の内容を上記のGrokパターンファイルに記述します。
aurora-postgresql-auditlog### PosgreSQL auditLog POSTGRESQL_AUDITLOG %{TIMESTAMP_ISO8601:timestamp} %{TZ:timezone}:%{IP:ipaddress}\(%{NUMBER:src_port}\):%{WORD:username}@%{WORD:database}:\[%{NUMBER:process_id}\]:%{WORD:log_level}:\s*%{WORD:log_type}: %{WORD:audit_type},%{NUMBER:statement_id},%{NUMBER:substatement_id},%{WORD:class},%{WORD:command},(?:|%{WORD:object_type}),(?:|%{DATA:object_name}),(?:%{DATA:statement}),%{GREEDYDATA:parameter}
- 下記のパイプライン構成ファイル(
/etc/logstash/conf.d/logstash.conf)を作成します。
(このタイミングではLogstashのプロセスは起動しません)$ sudo vi /etc/logstash/conf.d/logstash.conf
- 下記の内容を上記のパイプライン構成ファイルに記述します。
logstash.confinput { cloudwatch_logs { log_group => [ "/aws/rds/cluster/database-1/postgresql" ] region => "us-east-2" interval => 5 sincedb_path => "/etc/logstash/aurora-postgre-cwl_sincedb" } } filter { if "AUDIT:" in [message] { ### 読み込むGrok Patternファイルを"patterns_dir"で指定 grok { patterns_dir => [ "/etc/logstash/grok_patterns" ] match => { "message" => "%{POSTGRESQL_AUDITLOG}" } } ### dateフィールドから@timestampを抽出 date { match => [ "timestamp", "yyyy-MM-dd HH:mm:ss" ] timezone => "UTC" target => "@timestamp" } ### @timstampから日本時間を抽出 ruby { code => "event.set('[@metadata][local_time]',event.get('[@timestamp]').time.localtime.strftime('%Y-%m-%d'))" } ### document_idに利用する一意のIDを作成 fingerprint { source => "message" target => "[@metadata][fingerprint]" method => "MURMUR3" } ### デフォルトの型がstringのため、フィールド定義で定義した型に変換 mutate { ### typeフィールドを追加 add_field => { "type" => "aurora-postgre-auditlog-cwl" } ### 不要なフィールドを削除 remove_field => [ "timestamp", "timezone" ] } } } output { if [log_type] == "AUDIT" { ### 出力先のAmazonESのIndexを指定 elasticsearch { hosts => [ "https://search-test-es-xxxxxxxxxxxxxxxxxxxxxx.us-east-2.es.amazonaws.com:443" ] index => "%{type}-%{[@metadata][local_time]}" document_id => "%{[@metadata][fingerprint]}" ilm_enabled => false } } }【参考】
・pgAudit: PostgreSQL Audit Logging4. Kibanaでの設定
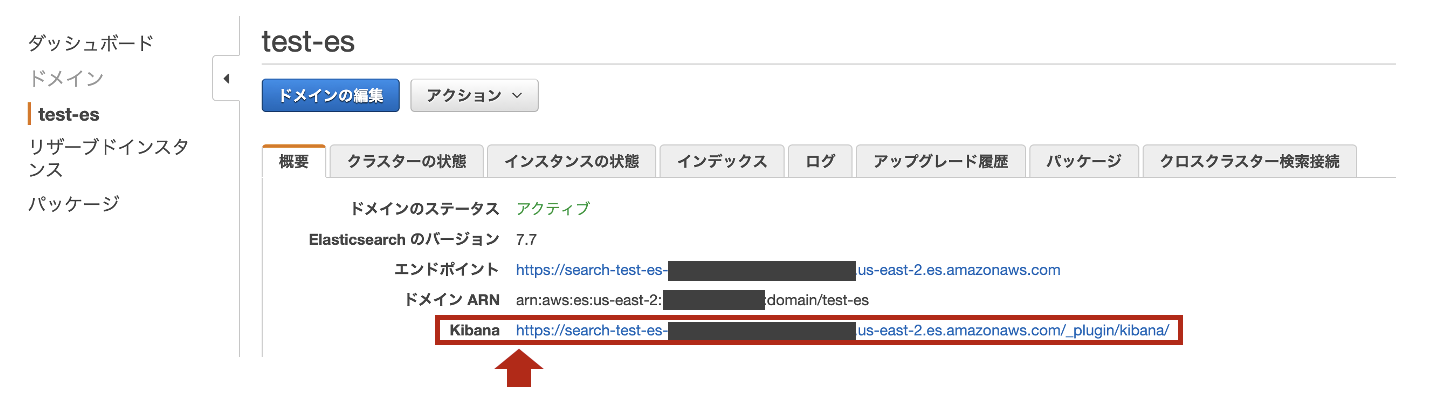
Amazon ESの
KibanaのURLをクリックします。
[Dev Tools]のConsoleからAurora PostgreSQLの監査ログのIndex Templateを追加します。
上記で張り付けたIndex Templateは以下の通りです。
index_templete_aurora-postgre-auditlog-cwlPUT _template/aurora-postgre-auditlog-cwl { "index_patterns": ["aurora-postgre-audit-cwl-*"], "settings": { "number_of_shards": 1, "number_of_replicas" : 1 }, "mappings": { "properties": { "@timestamp": { "type": "date" }, "@version" : { "type" : "keyword" }, "ipaddress" : { "type" : "ip" }, "src_port" : { "type" : "keyword" }, "username" : { "type" : "keyword" }, "database" : { "type" : "keyword" }, "process_id" : { "type" : "keyword" }, "log_level" : { "type" : "keyword" }, "log_type" : { "type" : "keyword" }, "audit_type" : { "type" : "keyword" }, "statement_id" : { "type" : "keyword" }, "substatement_id" : { "type" : "keyword" }, "class" : { "type" : "keyword" }, "command" : { "type" : "keyword" }, "object_type" : { "type" : "keyword" }, "object_name" : { "type" : "keyword" }, "statement" : { "type" : "text" }, "parameter" : { "type" : "keyword" }, "type" : { "type" : "keyword" }, "tags" : { "type" : "keyword" }, "message" : { "type" : "text" }, "cloudwatch_logs" : { "properties" : { "event_id" : { "type" : "keyword" }, "ingestion_time" : { "type" : "date" }, "log_group" : { "type" : "keyword" }, "log_stream" : { "type" : "keyword" } } } } } }
- Logstashを再起動します。
$ sudo systemctl restart logstash $ sudo systemctl status logstash
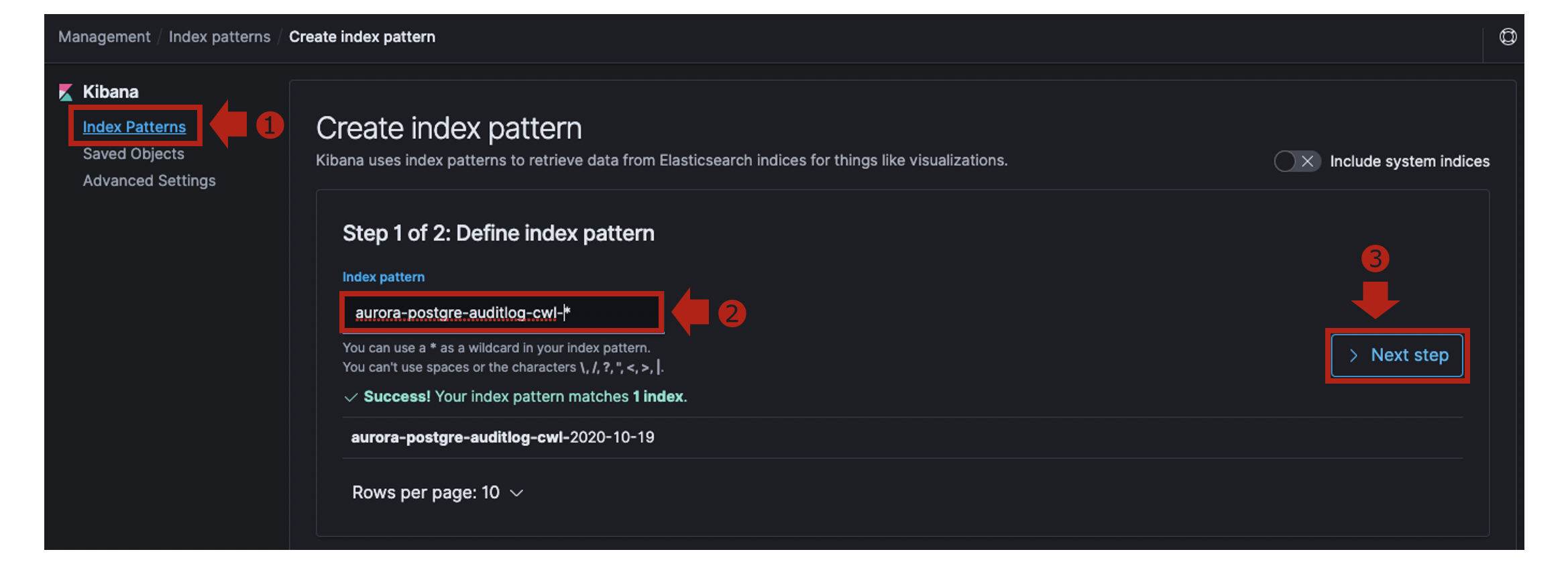
- Kibanaの [Management] > [Index Patterns]でCreate index patternをクリックします。
aurora-postgre-auditlog-cwl-*という名前でIndex Patternを作成します。
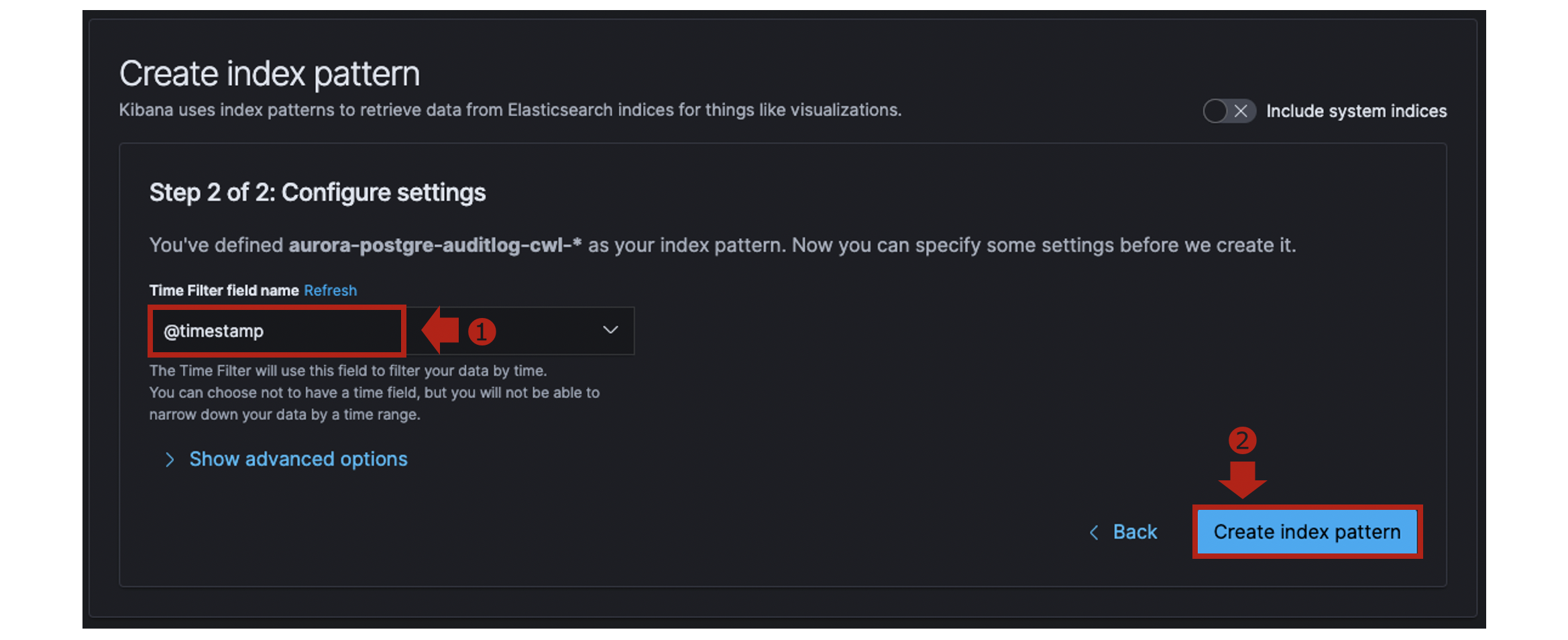
@timestampを指定します。
[Discover]を開き、Index Patternに
aurora-postgre-auditlog-cwl-*を指定します。デフォルトでは直近15分間のログが表示されます。表示されていればOKです。
取り込んだ監査ログは以下のようになっています。
aurora-postgre-auditlog_sample{ "_index": "aurora-postgre-auditlog-cwl-2020-10-19", "_type": "_doc", "_id": "2763317557", "_version": 1, "_score": null, "_source": { "command": "SELECT", "ipaddress": "172.31.41.200", "class": "READ", "username": "postgres", "src_port": "54830", "statement_id": "2", "@version": "1", "database": "postgres", "log_level": "LOG", "audit_type": "SESSION", "substatement_id": "1", "process_id": "23793", "log_type": "AUDIT", "type": "aurora-postgre-auditlog-cwl", "message": "2020-10-19 16:43:29 UTC:172.31.41.200(54830):postgres@postgres:[23793]:LOG: AUDIT: SESSION,2,1,READ,SELECT,,,select * from testtable;,<not logged>", "cloudwatch_logs": { "event_id": "35750900187697270836986630042167320956118009942541271040", "log_stream": "database-1-instance-1.0", "log_group": "/aws/rds/cluster/database-1/postgresql", "ingestion_time": "2020-10-19T16:43:30.109Z" }, "@timestamp": "2020-10-19T16:43:29.000Z", "statement": "select * from testtable;", "parameter": "<not logged>" }, "fields": { "cloudwatch_logs.ingestion_time": [ "2020-10-19T16:43:30.109Z" ], "@timestamp": [ "2020-10-19T16:43:29.000Z" ] }, "sort": [ 1603125809000 ] }まとめ
さて、いかがでしたでしょうか?
statementフィールド値にSQLクエリ文がそのまま含まれています。
データ型をtext型でスキーマ定義したので、クエリ文を全文検索することが可能になっています。
不正なSQLクエリが実行されていないか、DB監査ログから分析してみてはいかがでしょうか?


- 投稿日:2020-10-20T01:16:45+09:00
【AWS SAA合格体験記】資格習得の過程でAWSが少し好きになれた
はじめに
資格習得に向けて勉強するまでは、AWSはとても難しく扱いづらいものだという印象を持っていました。
私の作り出したAWSに対するイメージからIT業界歴1年半経ちますが、AWSと向き合うのを敬遠していました。
そんな私が、タイトルにもある通り資格習得の過程でAWSがもたらす利便性を知るにつれて少し好きになることが出来ました。
本記事は、AWSのSAA試験を合格するために行なった勉強法を中心に記載しております。資格を取ろうと思ったきっかけ
きっかけは大きく3つあります。
Youtuberのくろかわこうへいさんが投稿していたAWS関連の動画を見て、AWSについて深く勉強したいと思ったから
AWSのサービスを使用している現場が多く、ある程度基礎的な知識は身に付けておいたほうが良いと思ったから
Qiitaに投稿されているポートフォリオ関連の記事でAWSを使用するしている人が非常に多く、焦りから勉強しようと思った
勉強開始前の状態
- AWSを触ったことがなく、そもそもAWSって何?の状態
使用した教材 + レビュー
この1冊で合格-AWS認定ソリューションアーキテクト-アソシエイト-テキスト-問題集
AWSの主要サービスを丁寧に説明しており、AWS初心者が初めに勉強する教材としてはおススメかなと思います。
自分は、仕事場まで電車通勤なのでその時に読んでいました。これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)
AWS20サービス以上のハンズオン、3回の模擬テスト付き。
udemy教材で、セール期間中は千円台で購入可能。ハンズオンはすごく楽しく、勉強のモチベーションアップにつながった。【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)
SAA本番と同レベルの6回の模擬テストが付いている。
難易度は高いけど、良問揃いで使用した教材の中で一番おススメ!!!
こちらもudemy教材です。勉強のスケジュール
簡単にスケジュールと学習した内容を記載しました。
参考書を読む(2020年7月上旬~2020年7月上旬)
この1冊で合格-AWS認定ソリューションアーキテクト-アソシエイト-テキスト-問題集
上記参考書を1カ月、繰り返し読み込みました。読者の皆さんは、「参考書読むのに期間長すぎ!」と思った方もいると思います。私もそう思います。学習方法を振り返ったとき、一番の反省はこの時期でした。1、2周読んでも頭に内容が入ってこず、気づけば7週くらい読んでました。それでも内容の半分くらいしか理解できていませんでした(笑)
これからSAAを勉強する人に向けてアドバイスをするなら、インプットにあまり時間をかけないことが大事かなと思います。時間かけすぎるとだんだんやる気が落ちてきますし、アウトプットする中でAWSサービスを理解することが多かったです。AWSを実際に使ってみる(2020年8月上旬~2020年9月上旬)
ハンズオン形式の講義でAWSの利便性を肌で感じました!AWSの凄さを少し理解できるようになり、AWSを好きになり始めた時期。講義で使用する資料は、綺麗に整理されているので試験前もよく確認してました。3回分の模擬試験は本番に比べて難易度が割とやさしめな印象です。
問題集を解く(2020年9月中旬~2020年10月中旬)
初見のときは、難しすぎて試験合格は絶対無理だと思いました!一週目では正解率30~40%くらいでした。解説を丁寧に読み、理解できない単語があればBlackBeltやQiitaを使っていました。6回分の模擬試験がありますが、すべての回で正解率が90%以上出るまで繰り返し演習しました(4週かかりました)。
試験結果
778/1000でぎりぎり一発合格できました。見直ししてなかったら、多分落ちてました。1週解いた時点で残り60分ほどあり、じっくり見直しできたのが合格の要因かと思います。
まとめ
AWSの基礎知識を身に付いた思うので、次はアプリ開発でAWSサービスを使ってみようと思います。AWSをもっとすきになれるよう日々、勉強したいと思います。
長々と書いてしまいましたが、ここまで読んでいただきありがとうございました。
もしよろしければ、LGTM押していただけると幸いです。